diff --git a/.github/workflows/deploy-preview.yml b/.github/workflows/deploy-preview.yml
new file mode 100644
index 00000000..6ccba677
--- /dev/null
+++ b/.github/workflows/deploy-preview.yml
@@ -0,0 +1,27 @@
+
+name: Dispatch Preview Update
+on:
+ push:
+ branches: [development]
+
+jobs:
+ dispatch:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Setup SSH Keys and known_hosts
+ uses: webfactory/ssh-agent@v0.5.3
+ with:
+ ssh-private-key: ${{ secrets.DEPLOY_KEY }}
+
+
+ - name: Pull new posts
+ run: |
+ git clone --recursive git@github.com:CHTC/article-preview.git
+ cd article-preview
+ git config user.name "GitHub Actions"
+ git config user.email "actions@github.com"
+ git submodule update --remote
+ git add _posts
+ git remote -v
+ git commit -m "Article Submodule Updated"
+ git push git@github.com:CHTC/article-preview.git
diff --git a/2022-06-30-Opotowsky.md b/2022-06-30-Opotowsky.md
new file mode 100644
index 00000000..8d8ca394
--- /dev/null
+++ b/2022-06-30-Opotowsky.md
@@ -0,0 +1,65 @@
+---
+title: "Expediting Nuclear Forensics and Security Using High Through Computing"
+
+author: Hannah Cheren
+
+publish_on:
+ - htcondor
+ - path
+ - chtc
+
+type: user
+
+canonical_url: https://osg-htc.org/spotlights/Opotowsky.html
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Opotowsky-card.jpeg"
+ alt: Photo by Dan Myers on Unsplash
+
+description: Arrielle C. Opotowsky, a 2021 Ph.D. graduate from the University of Wisconsin-Madison's Department of Engineering Physics, describes how she utilized high throughput computing to expedite nuclear forensics investigations.
+excerpt: Arrielle C. Opotowsky, a 2021 Ph.D. graduate from the University of Wisconsin-Madison's Department of Engineering Physics, describes how she utilized high throughput computing to expedite nuclear forensics investigations.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Opotowsky-card.jpeg"
+card_alt: Arrielle C. Opotowsky, a 2021 Ph.D. graduate from the University of Wisconsin-Madison's Department of Engineering Physics, describes how she utilized high throughput computing to expedite nuclear forensics investigations.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Opotowsky-card.jpeg"
+banner_alt: Arrielle C. Opotowsky, a 2021 Ph.D. graduate from the University of Wisconsin-Madison's Department of Engineering Physics, describes how she utilized high throughput computing to expedite nuclear forensics investigations.
+---
+ ***Arrielle C. Opotowsky, a 2021 Ph.D. graduate from the University of Wisconsin-Madison's Department of Engineering Physics, describes how she utilized high throughput computing to expedite nuclear forensics investigations.***
+
+
+
+ Photo by Dan Myers on Unsplash.
+
+
+
+
+ Arrielle C. Opotowsky, 2021 Ph.D. graduate from the University of Wisconsin-Madison's Department of Engineering Physics
+
+
+ "Each year, there can be from two to twenty incidents related to the malicious use of nuclear materials,” including theft, sabotage, illegal transfer, and even terrorism, [Arrielle C. Opotowsky](http://scifun.org/Thesis_Awards/opotowsky.html) direly warned. Opotowsky, a 2021 Ph.D. graduate from the University of Wisconsin-Madison's Department of Engineering Physics, immediately grabbed the audience’s attention at [HTCondor Week 2022](https://agenda.hep.wisc.edu/event/1733/timetable/?view=standard).
+
+ Opotowsky's work focuses on nuclear forensics. Preventing nuclear terrorism is the primary concern of nuclear security, and nuclear forensics is “the *response* side to a nuclear event occurring,” Opotowsky explains. Typically in a nuclear forensics investigation, specific measurements need to be processed; unfortunately, some of these measurements can take months to process. Opotowsky calls this “slow measure” general mass spectrometry. Although this measurement can help point investigators in the right direction, they wouldn’t be able to do until long after the incident has occurred.
+
+ In trying to learn how she could expedite a nuclear forensics investigation, Opotowsky wanted to see if Gamma Spectroscopy, a “fast measurement,” could be the solution. This measure can potentially point investigators in the right direction, but in days rather than months.
+
+ To test whether this “fast measurement” could expedite a nuclear forensics investigation compared to a “slow measurement,” Opotowsky created a workflow and compared the two measurements.
+
+ While Opotowsky was a graduate student working on this problem, the workflow she created was running on her personal computer and suddenly stopped working. In a panic, she went to her advisor, [Paul Wilson](https://directory.engr.wisc.edu/ep/faculty/wilson_paul), for help, and he pointed her to the UW-Madison Center for High Throughput Computing (CHTC).
+
+ CHTC Research Computing Facilitators came to her aid, and “the support was phenomenal – there was a one-on-one introduction and a tutorial and incredible help via emails and office hours…I had a ton of help along the way.”
+
+ She needed capacity from the CHTC because she used a machine-learning workflow and 10s of case variations. She had a relatively large training database because she used several algorithms and hyperparameter variations and wanted to predict several labels. The sheer magnitude of these training databases is the leading reason why Opotowsky needed the services of the CHTC.
+
+ She used two computation categories, the second of which required a specific capability offered by the CHTC - the ability to scale out a large problem into an ensemble of smaller jobs running in parallel. With 500,000 total entries in the databases and a limit of 10,000 jobs per case submission, Opotowsky split the computations into fifty calculations per job. This method resulted in lower memory needs per job, each taking only a few minutes to run.
+
+ “I don’t think my research would have been possible” without HTC, Opotowsky noted as she reflected on how the CHTC impacted her research. “The main component of my research driving my need [for the CHTC] was the size of my database. It would’ve had to be smaller, have fewer parameter variations, and that ‘fast’ measurement was like a ‘real-world’ scenario; I wouldn’t have been able to have that.”
+
+ Little did Opotowsky know that her experience using HTC would also benefit her professionally. Having HTC experience has helped Opotowsky in job interviews and securing her current position in nuclear security. As a nuclear methods software engineer, “knowledge of designing code and interacting with job submission systems is something I use all the time,” she comments, “[learning HTC] was a wonderful experience to gain” from both a researcher and professional point of view.
+
+
+...
+
+ *Watch a video recording of Arrielle C. Opotowsky’s talk at HTCondor Week 2022, and browse her [slides](https://agenda.hep.wisc.edu/event/1733/contributions/25511/attachments/8299/9577/HTCondorWeek_AOpotowsky.pdf).*
+
+
diff --git a/2022-07-06-Wilcots.md b/2022-07-06-Wilcots.md
new file mode 100644
index 00000000..19e0fe36
--- /dev/null
+++ b/2022-07-06-Wilcots.md
@@ -0,0 +1,124 @@
+---
+title: "Keynote Address: The Future of Radio Astronomy Using High Throughput Computing"
+
+author: Hannah Cheren
+
+publish_on:
+ - htcondor
+ - path
+ - chtc
+
+type: user
+
+canonical_url: https://htcondor.org/featured-users/2022-07-06-Wilcots.html
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Wilcots-card.png"
+ alt: Image of the black hole in the center of our Milky Way galaxy.
+
+description: Eric Wilcots, UW-Madison dean of the College of Letters & Science and the Mary C. Jacoby Professor of Astronomy, dazzles the HTCondor Week 2022 audience.
+excerpt: Eric Wilcots, UW-Madison dean of the College of Letters & Science and the Mary C. Jacoby Professor of Astronomy, dazzles the HTCondor Week 2022 audience.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Wilcots-card.png"
+card_alt: Eric Wilcots, UW-Madison dean of the College of Letters & Science and the Mary C. Jacoby Professor of Astronomy, dazzles the HTCondor Week 2022 audience.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Wilcots-card.png"
+banner_alt: Eric Wilcots, UW-Madison dean of the College of Letters & Science and the Mary C. Jacoby Professor of Astronomy, dazzles the HTCondor Week 2022 audience.
+---
+ ***Eric Wilcots, UW-Madison dean of the College of Letters & Science and the Mary C. Jacoby Professor of Astronomy, dazzles the HTCondor Week 2022 audience.***
+
+
+
+ Image of the black hole in the center of our Milky Way galaxy.
+
+
+
+
+ Eric Wilcots
+
+
+ “My job here is to…inspire you all with a sense of the discoveries to come that will need to be enabled by,” high throughput computing (HTC), Eric Wilcots opened his keynote for HTCondor Week 2022. Wilcots is the UW-Madison dean of the College of Letters & Science and the Mary C. Jacoby Professor of Astronomy.
+
+ Wilcots points out that the black hole image (shown above) is a remarkable feat in the world of astronomy. “Only the third such black hole imaged in this way by the Event Horizon Telescope,” and it was made possible with the help of the HTCondor Software Suite (HTCSS).
+
+ **Beginning to build the future**
+
+ Wilcots described how in the 1940s, a group of universities recognized that no single university could build a radio telescope necessary to advance science. To access these kinds of telescopes, the universities would need to have the national government involved, as it was the only one with this capability at that time. In 1946, these universities created Associated Universities Incorporated (AUI), which eventually became the management agency for the National Radio Astronomy Observatory (NRAO).
+
+ Advances in radio astronomy rely on current technology available to experts in this field. Wilcots explained that “the science demands more sensitivity, more resolution, and the ability to map large chunks of the sky simultaneously.” New and emerging technologies must continue pushing forward to discover the next big thing in radio astronomy.
+
+ This next generation of science requires more sensitive technology with higher spectra resolution than the Karl G. Jansky Very Large Array (JVLA) can provide. It also requires sensitivity in a particular chunk of the spectrum that neither the JVLA nor Atacama Large Millimeter/submillimeter Array (ALMA) can achieve. Wilcots described just what piece of technology astronomers and engineers need to create to reach this level of sensitivity. “We’re looking to build the Next Generation Very Large Array (ngVLA)...an instrument that will cover a huge chunk of spectrum from 1 GHz to 116 GHz.”
+
+ **The fundamentals of the ngVLA**
+
+ “The unique and wonderful thing about interferometry, or the basis of radio astronomy,” Wilcots discussed, “is the ability to have many individual detectors or dishes to form a telescope.” Each dish collects signals, creating an image or spectrum of the sky when combined. Because of this capability, engineers working on these detectors can begin to collect signals right away, and as more dishes get added, the telescope grows larger and larger.
+
+ Many individual detectors also mean lots of flexibility in the telescope arrays built, Wilcots explained. Here, the idea is to do several different arrays to make up one telescope. A particular scientific case drives each of these arrays:
+ - Main Array: a dish that you can control and point accurately but is also robust; it’ll be the workhorse of the ngVLA, simultaneously capable of high sensitivity and high-resolution observations.
+ - Short Baseline Array: dishes that are very close together, which allows you to have a large field of view of the sky.
+ - Long Baseline Array: spread out across the continental United States. The idea here is the longer the baseline, the higher the resolution. Dishes that are well separated allow the user to get spectacular spatial resolution of the sky. For example, the Event Horizon Telescope that took the image of the black hole is a telescope that spans the globe, which is the longest baseline we can get without putting it into orbit.
+
+
+
+ The ngVLA will be spread out over the southwest United States and Mexico.
+
+
+ A consensus study report called Pathways to Discovery in Astronomy and Astrophysics for the 2020s (Astro2020) identified the ngVLA as a high priority. The construction of this telescope should begin this decade and be completed by the middle of the 2020s.
+
+ **Future of radio astronomy: planet formation**
+
+ An area of research that radio astronomers are interested in examining in the future is imaging the formation of planets, Wilcot notes. Right now, astronomers can detect a planet’s presence and deduce specific characteristics, but being able to detect a planet directly is the next huge priority.
+
+
+
+ A planetary system forming
+
+
+ One place astronomers might be able to do this with something like the ngVLA is in the early phases of planet formation within a planetary system. The thermal emissions from this process are bright enough to be detected by a telescope like the ngVLA. So the idea is to use this telescope to map an image of nearby planetary systems and begin to image the early stages of planet formation directly. A catalog of these planets forming will allow astronomers to understand what happens when planetary systems, like our own, form.
+
+ **Future of radio astronomy: molecular systems**
+
+ Wilcots explains that radio astronomers have discovered the spectral signature of innumerable molecules within the past fifty years. The ngVLA is being designed to probe, detect, catalog, and understand the origin of complex molecules and what they might tell us about star and planet formation. Wilcots comments in his talk that “this type of work is spawning a new type of science…a remarkable new discipline of astrobiology is emerging from our ability to identify and trace complex organic molecules.”
+
+ **Future of radio astronomy: galaxy completion**
+
+ Next, Wilcots discusses that radio astronomers want to understand how stars form in the first place and the processes that drive the collapse of clouds of gas into regions of star formations.
+
+
+
+ An image of a blue spiral from the VLA of a nearby spiral galaxy is on the left. On the right an optical extent of the galaxy.
+
+
+ The gas in a galaxy tends to extend well beyond the visible part of the galaxy, and this enormous gas reservoir is how the galaxy can make stars.
+
+ Astronomers like Wilcots want to know where the gas is, what drives that process of converting the gas into stars, what role the environment might play, and finally, what makes a galaxy stop creating stars.
+
+ ngVLA will be able to answer these questions as it combines the sensitivity and spatial resolution needed to take images of gas clouds in nearby galaxies while also capturing the full extent of that gas.
+
+ **Future of radio astronomy: black holes**
+
+ Wilcots’ look into the future of radio astronomy finishes with the idea and understanding of black holes.
+
+ Multi-messenger astrophysics helps experts recognize that information about the universe is not simply electromagnetic, as it is known best; there is more than one way astronomers can look at the universe.
+
+ More recently, astronomers have been looking at gravitational waves. In particular, they’ve been looking at how they can find a way to detect the gravitational waves produced by two black holes orbiting around one another to determine each black hole’s mass and learn something about them. As the recent EHT images show, we need radio telescopes' high resolution and sensitivity to understand the nature of black holes fully.
+
+ **A look toward the future**
+
+ The next step is for the NRAO to create a prototype of the dishes they want to install for the telescope. Then, it’s just a question of whether or not they can build and install enough dishes to deliver this instrument to its full capacity. Wilcots elaborates, “we hope to transition to full scientific operations by the middle of next decade (the 2030s).”
+
+ The distinguished administrator expressed that “something that’s haunted radio astronomy for a while is that to do the imaging, you have to ‘be in the club,’ ” meaning that not just anyone can access the science coming out of these telescopes. The goal of the NRAO moving forward is to create science-ready data products so that this information can be more widely available to anyone, not just those with intimate knowledge of the subject.
+
+ This effort to make this science more accessible has been part of a budding collaboration between UW-Madison, the NRAO, and a consortium of Historically Black Colleges and Universities and other Minority Serving Institutions in what is called Project RADIAL.
+
+ “The idea behind RADIAL is to broaden the community; not just of individuals engaged in radio astronomy, but also of individuals engaged in the computing that goes into doing the great kind of science we have,” Wilcots explains.
+
+ On the UW-Madison campus in the Summer of 2022, half a dozen undergraduate students from the RADIAL consortium will be on campus doing summer research. The goal is to broaden awareness and increase the participation of communities not typically involved in these discussions in the kind of research in the radial astronomy field.
+
+ “We laid the groundwork for a partnership with a number of these institutions, and that partnership is alive and well,” Wilcots remarks, “so stay tuned for more of that, and we will be advancing that in the upcoming years.”
+
+...
+
+ *Watch a video recording of Eric Wilcots’ talk at HTCondor Week 2022.*
+
+
diff --git a/2022-07-18-EOL-OSG.md b/2022-07-18-EOL-OSG.md
new file mode 100644
index 00000000..5d1f00a6
--- /dev/null
+++ b/2022-07-18-EOL-OSG.md
@@ -0,0 +1,47 @@
+---
+title: "Retirements and New Beginnings: The Transition to Tokens"
+
+author: Hannah Cheren
+
+publish_on:
+ - osg
+ - path
+ - htcondor
+
+type: news
+
+canonical_url: https://osg-htc.org/spotlights/EOL-OSG.html
+
+image:
+ path:
+ alt:
+
+description: May 1, 2022, officially marked the retirement of OSG 3.5, GridFTP, and GSI dependencies. OSG 3.6, up and running since February of 2021, is prepared for usage and took its place, relying on WebDAV and bearer tokens.
+excerpt: May 1, 2022, officially marked the retirement of OSG 3.5, GridFTP, and GSI dependencies. OSG 3.6, up and running since February of 2021, is prepared for usage and took its place, relying on WebDAV and bearer tokens.
+
+card_src:
+card_alt:
+
+banner_src:
+banner_alt:
+---
+
+ ***May 1, 2022, officially marked the retirement of OSG 3.5, GridFTP, and GSI dependencies. OSG 3.6, up and running since February of 2021, is prepared for usage and took its place, relying on WebDAV and bearer tokens.***
+
+ In December of 2019, OSG announced its plan to transition towards bearer tokens and WebDAV-based file transfer, which would ultimately culminate in the retirement of OSG 3.5. Nearly two and a half years later, after significant development and work with collaborators on the transition, OSG marked the end of support for OSG 3.5.
+
+ OSG celebrated the successful and long-planned OSG 3.5 retirement and transition to OSG 3.6, the first version of the OSG Software Stack without any Globus dependencies. Instead, it relies on WebDAV (an extension to HTTP/S allowing for distributed authoring and versioning of files) and bearer tokens.
+
+ Jeff Dost, OSG Coordinator of Operations, reports that the transition “was a big success!” Ultimately, OSG made the May 1st deadline without having to backtrack and put out new fires. Dost notes, however, that “the transition was one of the most difficult ones I can remember in the ten plus years of working with OSG, due to all the coordination needed.”
+
+ Looking back, for nearly fifteen years, communications in OSG were secured with X.509 certificates and proxies via Globus Security Infrastructure (GSI) as an Authentication and Authorization Infrastructure (AAI).
+
+ Then, in June of 2017, Globus announced the end of support for its open-source Toolkit that the OSG depended on. In October, they established the Grid Community Forum (GCF) to continue supporting the Toolkit to ensure that research could continue uninterrupted.
+
+ While the OSG continued contributing to the GCT, the long-term goal was to transition the research community from these approaches to token-based pilot job authentication instead of X.509 proxy authentication.
+
+ A more detailed document of the OSG-LHC GridFTP and GSI migration plans can be found in [this document](https://docs.google.com/document/d/1DAFeAaUmHHVcJGZMTIDUtLs9koCruQRDY1sJq1opeNs/edit#heading=h.6f8tit251wrg). Please visit the GridFTP and GSI Migration [FAQ page](https://osg-htc.org/technology/policy/gridftp-gsi-migration/index.html) if you have any questions. For more information and news about OSG 3.6, please visit the [OSG 3.6 News](https://osg-htc.org/docs/release/osg-36/) release documentation page.
+
+...
+
+ *If you have any questions about the retirement of OSG 3.5 or the implementation of OSG 3.6, please contact help@opensciencegrid.org.*
diff --git a/2022-07-18-Messick.md b/2022-07-18-Messick.md
new file mode 100644
index 00000000..81219e5d
--- /dev/null
+++ b/2022-07-18-Messick.md
@@ -0,0 +1,65 @@
+---
+title: "LIGO's Search for Gravitational Waves Signals Using HTCondor"
+
+author: Hannah Cheren
+
+publish_on:
+ - htcondor
+ - path
+ - chtc
+
+type: user
+
+canonical_url: https://htcondor.org/featured-users/2022-07-06-Messick.html
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Messick-card.png"
+ alt: Image of two black holes from Cody Messick’s presentation slides.
+
+description: Cody Messick, a Postdoc at the Massachusetts Institute of Technology (MIT) working for the LIGO lab, describes LIGO's use of HTCondor to search for new gravitational wave sources.
+excerpt: Cody Messick, a Postdoc at the Massachusetts Institute of Technology (MIT) working for the LIGO lab, describes LIGO's use of HTCondor to search for new gravitational wave sources.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Messick-card.png"
+card_alt: Image of two black holes from Cody Messick’s presentation slides.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Messick-card.png"
+banner_alt: Image of two black holes from Cody Messick’s presentation slides.
+---
+ ***Cody Messick, a Postdoc at the Massachusetts Institute of Technology (MIT) working for the LIGO lab, describes LIGO's use of HTCondor to search for new gravitational wave sources.***
+
+
+
+ Image of two black holes. Photo credit: Cody Messick’s presentation slides.
+
+
+ High-throughput computing (HTC) is critical to astronomy, from black hole research to radial astronomy and beyond. At the [2022 HTCondor Week](https://agenda.hep.wisc.edu/event/1733/timetable/?view=standard), another area of astronomy was put in the spotlight by [Cody Messick](https://space.mit.edu/people/messick-cody/), a researcher working for the [LIGO](https://space.mit.edu/instrumentation/ligo/) lab and a Postdoc at the Massachusetts Institute of Technology (MIT). His work focuses on a gravitational-wave analysis that he’s been running with the help of HTCondor to search for new gravitational wave signals.
+
+ Starting with general relativity and why it’s crucial to his work, Messick explains that “it tells us two things; first, space and time are not separate entities but are instead part of a four-dimensional object called space-time. Second, space-time is warped by mass and energy, and it’s these changes to the geometry of space-time that we experience as gravity.”
+
+ Messick notes that general relativity is important to his work because it predicts the existence of gravitational waves. These waves are tiny ripples in the curvature of space-time that travel at the speed of light and stretch and compress space. Accelerating non-spherically symmetric masses generate these waves.
+
+ Generating ripples in the curvature of space-time large enough to be detectable using modern ground-based gravitational-wave observatories takes an enormous amount of energy; the observations made thus far have come from the mergers of compact binaries, pairs of extraordinarily dense yet relatively small astronomical objects that spiral into each other at speeds approaching the speed of light. Black holes and neutron stars are examples of these so-called compact objects, both of which are or almost are perfectly spherical.
+
+ Messick and his team first detected two black holes going two-thirds the speed of light right before they collided. “It’s these fantastic amounts of energy in a collision that moves our detectors by less than the radius of a proton, so we need extremely energetic explosions of collisions to detect these things.”
+
+ Messick looks for specific gravitational waveforms during the data analysis. “We don’t know which ones we’re going to look for or see in advance, so we look for about a million different ones.” They then use match filtering to find the probability that the random noise in the detectors would generate something that looks like a gravitational-wave; the first gravitational-wave observation had less than a 1 in 3.5 billion chance of coming from noise and matched theoretical predictions from general relativity extremely well.
+
+ Messick's work with external collaborators outside the LIGO-Virgo-KAGRA collaboration looks for systems their normal analyses are not sensitive to. Scientists use the parameter kappa to characterize the ability of a nearly spherical object to distort when spinning rapidly or, in simple terms, how squished a sphere will become when spinning quickly.
+
+ LIGO searches are insensitive to any signal with a kappa greater than approximately ten. “There could be [signals] hiding in the data that we can’t see because we’re not looking with the right waveforms,” Messick explains. His analysis has been working on this problem.
+
+ Messick uses HTCondor DAGs to model his workflows, which he modified to make integration with OSG easier. The first job checks the frequency spectrum of the noise. These workflows go into an aggregation of the frequency spectrum, decomposition (labeled by color by type of detector), and finally, the filtering process occurs.
+
+
+
+ A section of Messick’s DAG workflow.
+
+
+Although Messick’s work is more physics-heavy than computationally driven, he remarks that “HTCondor is extremely useful to us… it can fit the work we’ve been doing very, very naturally.”
+
+...
+
+ *Watch a video recording of Cody Messick’s talk at HTCondor Week 2022, and browse his [slides](https://agenda.hep.wisc.edu/event/1733/contributions/25501/attachments/8303/9586/How%20LIGO%20Analysis%20is%20using%20HTCondor.pdf).*
+
+
+
diff --git a/2022-09-27-DoIt-Article-Summary.md b/2022-09-27-DoIt-Article-Summary.md
index 6b09f13e..984389f2 100644
--- a/2022-09-27-DoIt-Article-Summary.md
+++ b/2022-09-27-DoIt-Article-Summary.md
@@ -1,5 +1,5 @@
---
-title: "Solving for the future: Investment, new coalition levels up research computing infrastructure at UW–Madison"
+title: Summary of "Solving for the future; Investment, new coalition levels up research computing infrastructure at UW–Madison"
author: Hannah Cheren
diff --git a/2022-11-03-ucsd-external-release.md b/2022-11-03-ucsd-external-release.md
new file mode 100644
index 00000000..d0ce2a77
--- /dev/null
+++ b/2022-11-03-ucsd-external-release.md
@@ -0,0 +1,49 @@
+---
+title: PATh Extends Access to Diverse Set of High Throughout Computing Research Programs
+
+author: Cannon Lock
+
+publish_on:
+- path
+
+type: news
+
+canonical_url: "https://path-cc.io/news/2022-11-03-ucsd-external-release"
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/ucsd-public-relations.png"
+ alt: The colors on the chart correspond to the total number of core hours – nearly 884,000 – utilized by researchers at participating universities on PATh Facility hardware located at SDSC.
+
+description: |
+ UCSD announces the new PATh Facility and discusses its impact on science.
+excerpt: |
+ UCSD announces the new PATh Facility and discusses its impact on science.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/ucsd-public-relations.png"
+card_alt: The colors on the chart correspond to the total number of core hours – nearly 884,000 – utilized by researchers at participating universities on PATh Facility hardware located at SDSC.
+---
+
+Finding the right road to research results is easier when there is a clear PATh to follow. The Partnership to Advance Throughput Computing ([PATh](https://path-cc.io/))—a partnership between the [OSG Consortium](https://osg-htc.org/) and the University of Wisconsin-Madison’s Center for High Throughput Computing ([CHTC](https://chtc.cs.wisc.edu/)) supported by the National Science Foundation (NSF)—has cleared the way for science and engineering researchers for years with its commitment to advancing distributed high throughput computing (dHTC) technologies and methods.
+
+HTC involves running a large number of independent computational tasks over long periods of time—from hours and days to week or months. dHTC tools leverage automation and build on distributed computing principles to save researchers with large ensembles incredible amounts of time by harnessing the computing capacity of thousands of computers in a network—a feat that with conventional computing could take years to complete.
+
+Recently PATh launched the [PATh Facility](https://path-cc.io/facility/index.html), a dHTC service meant to handle HTC workloads in support and advancement of NSF-funded open science. It was announced earlier this year via a [Dear Colleague Letter](https://www.nsf.gov/pubs/2022/nsf22051/nsf22051.jsp) issued by the NSF and identified a diverse set of [eligible research programs](https://www.nsf.gov/pubs/2022/nsf22051/nsf22051.jsp) that range across 14 domain science areas including geoinformatics, computational methods in chemistry, cyberinfrastructure, bioinformatics, astronomy, arctic research and more. Through this 2022-2023 fiscal year pilot project, the NSF awards credits for access to the PATh Facility, and researchers can request computing credits associated with their NSF awards. There are two ways to request credit: 1) within new proposals or 2) with existing awards via an email request for additional credits to participating program officers.
+
+“It is a remarkable program because it spans almost the entirety of the NSF’s directorates and offices,” said San Diego Supercomputer Center ([SDSC](https://www.sdsc.edu/)) Director Frank Würthwein, who also serves as executive director of the OSG Consortium.
+
+Access to the PATh Facility offers researchers approximately 35,000 modern cores and up to 44 A100 GPUs. Recently SDSC, located at [UC San Diego](https://ucsd.edu/), added PATh Facility hardware on its [Expanse](https://www.sdsc.edu/services/hpc/expanse/) supercomputer for use by researchers with PATh credits. According to SDSC Deputy Director Shawn Strande: “Within the first two weeks of operations, we saw researchers from 10 different institutions, including one minority serving institution, across nearly every field of science. The beauty of the PATh model of system integration is that researchers have access as soon as the resource is available via OSG. PATh democratizes access by lowering barriers to doing research on advanced computing resources.”
+
+While the PATh credit ecosystem is still growing, any PATh Facility capacity not used for credit will be available to the Open Science Pool ([OSPool](https://osg-htc.org/services/open_science_pool.html)) to benefit all open science under a Fair-Share allocation policy. “For researchers familiar with the OSPool, running HTC workloads on the PATh Facility should feel like second-nature” said Christina Koch, PATh’s research computing facilitator.
+
+“Like the OSPool, the PATh Facility is nationally spanning, geographically distributed and ideal for HTC workloads. But while resources on the OSPool belong to a diverse range of campuses and organizations that have generously donated their resources to open science, the allocation of capacity in the PATh Facility is managed by the PATh project itself,” said Koch.
+
+PATh will eventually reach over six national sites: SDSC at UC San Diego, CHTC at the University of Wisconsin-Madison, the Holland Computing Center at the University of Nebraska-Lincoln, Syracuse University’s Research Computing group, the Texas Advanced Computing Center at the University of Texas at Austin and Florida International University’s AMPATH network in Miami.
+
+PIs may contact [credit-accounts@path-cc.io](mailto:credit-accounts@path-cc.io) with questions about PATh resources, using HTC, or estimating credit needs. More details also are available on the [PATh credit accounts](https://path-cc.io/services/credit-accounts/) web page.
+
+
+
+
+ A diverse set of PATh national and international users benefit from the resource, and the recent launch of the PATh Facility further supports HTC workloads in an effort to advance NSF-funded open science. The colors on the chart correspond to the total number of core hours – nearly 884,000 – utilized by researchers at participating universities on PATh Facility hardware located at SDSC. Credit: Ben Tolo, SDSC
+
+
\ No newline at end of file
diff --git a/2022-11-09-CHTC-pool-record.md b/2022-11-09-CHTC-pool-record.md
new file mode 100644
index 00000000..4140f541
--- /dev/null
+++ b/2022-11-09-CHTC-pool-record.md
@@ -0,0 +1,65 @@
+---
+title: CHTCPool Hits Record Number of Core Hours
+
+author: Shirley Obih
+
+publish_on:
+ - htcondor
+ - path
+ - chtc
+
+type: news
+
+canonical_url: https://chtc.cs.wisc.edu/CHTC-pool-record.html
+
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/Pool-Record-Image.jpg
+ alt: Pool Record Banner
+
+description: CHTC smashes record
+excerpt: CHTC smashes record
+
+card_src: https://raw.githubusercontent.com/CHTC/Articles/main/images/Pool-Record-Image.jpg
+card_alt: Pool Record Banner
+
+banner_src: https://raw.githubusercontent.com/CHTC/Articles/main/images/Pool-Record-Image.jpg
+banner_alt: Pool Record Banner
+---
+
+CHTC users recorded the most ever usage in the CHTC Pool on October 18th this year - utilizing
+over 700,000 core hours - only to have that record broken again a mere two days later on Oct 20th,
+with a total of 710,796 core hours reached.
+
+The Center for High Throughput (CHTC) users are hard at work smashing records with two almost consecutive record numbers of core hour usage.
+October 20th was the highest daily core hour in the CHTC Pool with 710,796 hours utilized, a feat attained
+just two days after the October 18th record break of 705,801 core hours.
+
+What is contributing to these records? One factor likely is UW’s investment in new hardware.
+UW-Madison’s research computing hardware recently underwent a [substantial hardware refresh](https://chtc.cs.wisc.edu/DoIt-Article-Summary.html),
+adding 207 new servers representing over 40,000 “batch slots” of computing capacity.
+
+However, additional capacity requires researchers ready and capable to use it.
+The efforts of the CHTC facilitation team, led by Christina Koch, contributed to
+this readiness. Since September 1, CHTC's Research Computing Facilitators have met
+with 70 new users for an introductory consultation, and there have been over 80
+visits to the twice-weekly drop-in office hours hosted by the facilitation team.
+Koch notes that "using large-scale computing can require skills and concepts that
+are new to most researchers - we are here to help bridge that gap."
+
+Finally, the hard work of the researchers themselves is another linchpin to these records.
+Over 80 users that span many fields of science contributed to this success, including
+these users with substantial usage:
+
+- [Ice Cube Neutrino Observatory](https://icecube.wisc.edu): an observatory operated by University of Madison, designed to observe the cosmos from deep within the South Pole ice.
+- [ECE_miguel](https://www.ece.uw.edu/people/miguel-a-ortega-vazquez/): In the Department of Electrical and Computer Engineering, Joshua San Miguel’s group explores new paradigms in computer architecture.
+- [MSE_Szlufarska](https://directory.engr.wisc.edu/mse/Faculty/Szlufarska_Izabela/): Isabel Szlufarska’s lab focuses on computational materials science, mechanical behavior at the nanoscale using atomic scale modeling to understand and design new materials.
+- [Genetics_Payseur](https://payseur.genetics.wisc.edu): Genetics professor Bret Payseur’s lab uses genetics and genomics to understand mechanisms of evolution.
+- [Pharmacy_Jiang](https://apps.pharmacy.wisc.edu/sopdir/jiaoyang_jiang/index.php): Pharmacy professor Jiaoyang Jiang’s interests span the gap between biology and chemistry by focusing on identifying the roles of protein post-translational modifications in regulating human physiological and pathological processes.
+- [EngrPhys_Franck](https://www.franck.engr.wisc.edu): Jennifer Franck’s group specializes in the development of new experimental techniques at the micro and nano scales with the goal of providing unprecedented full-field 3D access to real-time imaging and deformation measurements in complex soft matter and cellular systems.
+- [BMI_Gitter](https://www.biostat.wisc.edu/~gitter/): In Biostatistics and Computer Sciences, Anthony Gitter’s lab conducts computational biology research that brings together machine learning techniques and problems in biology
+- [DairyScience_Dorea](https://andysci.wisc.edu/directory/joao-ricardo-reboucas-dorea/): Joao Dorea’s Animal and Dairy Science group focuses on the development of high-throughput phenotyping technologies.
+
+Any UW student or researcher who wants to utilize high throughput of computing resources
+towards a given problem can harness the capacity of CHTC Pool.
+
+[Users can sign up here](https://chtc.cs.wisc.edu/uw-research-computing/get-started.html)
diff --git a/2022-12-05-htcondor-week-2023.md b/2022-12-05-htcondor-week-2023.md
new file mode 100644
index 00000000..dd76259a
--- /dev/null
+++ b/2022-12-05-htcondor-week-2023.md
@@ -0,0 +1,48 @@
+---
+title: "Save the Date! HTCondor Week 2023, June 5-8"
+
+author: Hannah Cheren
+
+publish_on:
+ - htcondor
+
+type: news
+
+canonical_url: http://htcondor.org/HTCondorWeek2023
+
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/HTCondor_Banner.jpeg
+ alt: HTCondor Week 2023
+
+description: "Save the Date! HTCondor Week 2023, June 5-8"
+excerpt: "Save the Date! HTCondor Week 2023, June 5-8"
+
+card_src: https://raw.githubusercontent.com/CHTC/Articles/main/images/HTCondor_Banner.jpeg
+card_alt: HTCondor Week 2023
+
+banner_src: https://raw.githubusercontent.com/CHTC/Articles/main/images/HTCondor_Banner.jpeg
+banner_alt: HTCondor Week 2023
+---
+
+
Save the Date for HTCondor Week May 23 - 26!
+
+
+Hello HTCondor Users and Collaborators!
+
+We want to invite you to HTCondor Week 2023, our annual HTCondor user conference, from June 5-8, 2023 at the Fluno Center at the Univeristy of Wisconsin-Madison!
+
+More information about registration coming soon.
+
+We will have a variety of in-depth tutorials and talks where you can learn more about HTCondor and how other people are using and deploying HTCondor. Best of all, you can establish contacts and learn best practices from people in industry, government, and academia who are using HTCondor to solve hard problems, many of which may be similar to those you are facing.
+
+And make sure you check out these articles written on presentations from last year's HTCondor Week!
+- [Using high throughput computing to investigate the role of neural oscillations in visual working memory](https://path-cc.io/news/2022-07-06-Fulvio/)
+- [Using HTC and HPC Applications to Track the Dispersal of Spruce Budworm Moths](https://path-cc.io/news/2022-07-06-Garcia/)
+- [Testing GPU/ML Framework Compatibility](https://path-cc.io/news/2022-07-06-Hiemstra/)
+- [Expediting Nuclear Forensics and Security Using High Throughput Computing](https://path-cc.io/news/2022-07-06-Opotowsky/)
+- [The Future of Radio Astronomy Using High Throughput Computing](https://path-cc.io/news/2022-07-12-Wilcots/)
+- [LIGO's Search for Gravitational Waves Signals Using HTCondor](https://path-cc.io/news/2022-07-21-Messick/)
+
+Hope to see you there,
+
+\- The Center for High Throughput Computing
diff --git a/2022-12-14-CHTC-Facilitation.md b/2022-12-14-CHTC-Facilitation.md
new file mode 100644
index 00000000..ccb12697
--- /dev/null
+++ b/2022-12-14-CHTC-Facilitation.md
@@ -0,0 +1,71 @@
+---
+title: CHTC Facilitation Innovations for Research Computing
+
+author: Hannah Cheren
+
+publish_on:
+- chtc
+- path
+- htcondor
+- osg
+
+type: news
+
+canonical_url: "https://chtc.cs.wisc.edu/chtc-facilitation.html"
+
+image:
+path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Facilitation-cover.jpeg"
+alt: Research Computing Facilitator Christina Koch with a researcher.
+
+description: |
+ After adding Research Computing Facilitators in 2013-2014, CHTC has expanded its reach to support researchers in all disciplines interested in using large-scale computing to support their research through the shared computing capacity offered by the CHTC.
+excerpt: |
+ After adding Research Computing Facilitators in 2013-2014, CHTC has expanded its reach to support researchers in all disciplines interested in using large-scale computing to support their research through the shared computing capacity offered by the CHTC.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Facilitation-cover.jpeg"
+card_alt: Research Computing Facilitator Christina Koch with a researcher.
+---
+ ***After adding Research Computing Facilitators in 2013-2014, CHTC has expanded its reach to support researchers in all disciplines interested in using large-scale computing to support their research through the shared computing capacity offered by the CHTC.***
+
+
+
+ Research Computing Facilitator Christina Koch with a researcher.
+
+
+ As the core research computing center at the University of Wisconsin-Madison and the leading high throughput computing (HTC) force nationally, the Center for High Throughput Computing (CHTC), formed in 2014, has always had one simple goal: to help researchers in all fields use HTC to advance their work.
+
+ Soon after its founding, CHTC learned that computing capacity alone was not enough; there needed to be more communication between researchers who used computing and the computer scientists who wanted to help them. To address this gap, the CHTC needed a new, two-way communication model that better understood and advocated for the needs of researchers and helped them understand how to apply computing to transform their research. In 2013, CHTC hired its first Research Computing Facilitator (RCF), Lauren Michael, to implement this new model and provide staff experience in domain research, research computing, and communication/teaching skills. Since then, the team has expanded to include additional facilitators, which today include Christina Koch, now leading the team, Rachel Lombardi, and a new team member CHTC is actively hiring.
+
+
+## What is an RCF?
+ An RCF’s job is to understand a new user's research goals and provide computing options that fit their needs. “As a Research Computing Facilitator, we want to facilitate the researcher’s use of computing,” explains Koch. “They can come to us with problems with their research, and we can advise them on different computing possibilities.”
+
+ Computing facilitators know how to work with researchers and understand research enough to guide the customizations researchers need. More importantly, RCFs are passionate about helping people and solving problems.
+
+ In the early days of CHTC, it was a relatively new idea to hire people with communication and problem-solving skills and apply those talents to computational research. Having facilitators with these skills bridge the gap between research computing organizations and researchers was what was unique to CHTC; in fact, the term “Research Computing Facilitator” was coined at UW-Madison.
+
+## RCF as a part of the CHTC model
+ Research computing facilitators have become an integral part of the CHTC and are a unique part of the model for this center. Koch elaborates that “...what’s unique at the CHTC is having a dedicated role – that we’re not just ‘user support’ responding to people’s questions, but we’re taking this more proactive, collaborative stance with researchers.” Research Computing Facilitators strengthen the CHTC and allow a more diverse range of computing dimensions to be supported. This support gives these researchers a competitive edge that others may not necessarily have.
+
+ The uniqueness of the RFC role allows for customized solutions for researchers and their projects. They meet with every researcher who [requests an account](https://chtc.cs.wisc.edu/uw-research-computing/form.html) to use [CHTC computing resources](https://chtc.cs.wisc.edu/uw-research-computing/index.html). These individual meetings allow RCFs to have strategic conversations to provide personal recommendations and discuss long-term goals.
+
+ Meetings between the facilitators and researchers also get researchers thinking about what they could do if they could do things faster, at a grander scale, and with less time and effort investment for each project. “We want to understand what their research project is, the goals of that project, and the limitations they’re concerned with to see if using CHTC resources could aid them,” Lombardi explains. “We’re always willing to push the boundaries of our services to try to accommodate to researchers' needs.” The RCFs must know enough about the researchers’ work to talk to the researchers about the dimensions of their computing requirements in terms they understand.
+
+ Although RCFs are integral to CHTC’s model, that doesn’t mean it doesn’t come without challenges. One hurdle is that they are facilitators, which means they’re ultimately not the ones to make choices for the researchers they support. They present solutions given each researcher’s unique circumstances, and it’s up to researchers to decide what to do. Koch explains that“it’s about finding the balance between helping them make those decisions while still having them do the actual work, even if it’s sometimes hard, because they understand that it will pay off in the long run.”
+
+ Supporting research computing across domains is also a significant CHTC facilitation accomplishment. Researchers used to need a programming background to apply computing to their analyses, which meant the physical sciences typically dominated large-scale computational analyses. Over the years, computing has become a lot more accessible. More researchers in the life sciences, social sciences, and humanities, have access to community software tools they can apply to their research problems. “It’s not about a user’s level of technical skill or what kind of science they do,” Koch says. It’s about asking, “are you using computing, and do you need help expanding?” CHTC’s ability to pull in researchers across new disciplines has been rewarding and beneficial. “When new disciplines start using computing to tackle their problems, they can do some new, interesting research to contribute to their fields,” Koch notes.
+
+## Democratizing Access
+ CHTC’s success can inspire other campuses to rethink their research computing operations to support their researchers better and innovate. Recognized nationally and internationally as an expert in HTC and facilitation, CHTC’s approach has started to make its way onto other campus computing centers.
+
+ CHTC efforts aim to bring broader access to HTC systems. “CHTC has enabled access to computing to a broad spectrum of researchers on campus,” Lombardi explains, “and we strive to help researchers and organizations implement throughput computing capacity.” CHTC is part of national and international efforts to bring that level of computing to other communities through partnerships with organizations, such as the [Campus Cyberinfrastructure (CC*) NSF program](https://beta.nsf.gov/funding/opportunities/campus-cyberinfrastructure-cc).
+
+ The CC* program supports campuses across the country that wish to contribute computing capacity to the [Open Science Pool (OSPool)](https://osg-htc.org/services/open_science_pool.html). These institutions are awarded a grant, and in turn, they agree to donate resources to the OSPool, a mutually beneficial system to democratize computing and make it more accessible to researchers who might not have access to such capacity otherwise.
+
+ The RCF team meets with researchers weekly from around the world (including Africa, Europe, and Asia). They hold OSG Office Hours twice a week for one-on-one support and provide training at least twice a month for new users and on special topics.
+
+ For other campuses to follow in CHTC’s footsteps, they can start implementing facilitation first, even before a campus has any computing systems. In some cases, such as on smaller campuses, they might not even have or need to have a computing center. Having facilitators is crucial to providing researchers with individualized support for their projects.
+
+ The next step would be for campuses to look at how they currently support their researchers, including examining what they’re currently doing and if there’s anything they’d want to do differently to communicate this ethic of supporting researchers.
+
+ Apart from the impact that research computing facilitators have had on the research community, Koch notes what this job means to her, “[w]orking for a more mission-driven organization where I feel like I’m enabling other people’s research success is so motivating.” Now, almost ten years later, the CHTC has gone from having roughly one hundred research groups using the capacity it provides to having several hundred research groups and thousands of users per year. “Facilitation will continue to advise and support these projects to advance the big picture,” Lombardi notes, “we’ll always be available to researchers who want to talk to someone about how CHTC resources can advance their work!”
diff --git a/2022-12-19-Lightning-Talks.md b/2022-12-19-Lightning-Talks.md
new file mode 100644
index 00000000..7176f3a7
--- /dev/null
+++ b/2022-12-19-Lightning-Talks.md
@@ -0,0 +1,172 @@
+---
+title: "Student Lightning Talks from the OSG User School 2022"
+
+author: Hannah Cheren
+
+publish_on:
+ - osg
+ - path
+ - chtc
+ - htcondor
+
+type: news
+
+canonical_url: https://osg-htc.org/spotlights/Lightning-Talks.html
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Lightning-Talks-card.jpeg"
+ alt: Staff and attendees from the OSG User School 2022.
+
+description: The OSG User School student lightning talks showcased their research, inspiring all the event participants.
+excerpt: The OSG User School student lightning talks showcased their research, inspiring all the event participants.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Lightning-Talks-card.jpeg"
+card_alt: Staff and attendees from the OSG User School 2022.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Lightning-Talks-card.jpeg"
+banner_alt: Staff and attendees from the OSG User School 2022.
+---
+ ***The OSG User School student lightning talks showcased their research, inspiring all the event participants.***
+
+
+
+ Staff and attendees from the OSG User School 2022.
+
+
+ Each summer, the OSG Consortium offers a [week-long summer school](https://osg-htc.org/user-school-2022/) for researchers who want to learn how to use [high-throughput computing](https://htcondor.org/htc.html) (HTC) methods and services to handle large-scale computing applications at the heart of today’s cutting-edge science. This past summer the school was back in-person on the University of Wisconsin–Madison campus, attended by 57 students and over a dozen staff.
+
+ Participants from Mali and Uganda, Africa, to campuses across the United States learned through lectures, discussions, and hands-on activities how to apply HTC approaches to handle large ensembles of jobs and large datasets in support of their research work.
+“It's truly humbling to see how much cool work is being done with computing on @CHTC_UW and @opensciencegrid!!” research facilitator Christina Koch tweeted regarding the School.
+
+ One highlight of the School is the closing participants’ lightning talks, where the researchers present their work and plans to integrate HTC, expanding the scope and goals of their research.
+The lightning talks given at this year’s OSG User School illustrate the diversity of students’ research and its expanding scope enabled by the power of HTC and the School.
+
+ *Note: Applications to attend the School typically open in March. Check the [OSG website](https://osg-htc.org/) for this announcement.*
+
+
+
+ Devin Bayly
+
+
+ [Devin Bayly](https://sxsw.arizona.edu/person/devin-bayly), a data and visualization consultant at the University of Arizona's Research Technologies department, presented “*OSG for Vulkan StarForge Renders.*” Devin has been working on a multimedia project called Stellarscape, which combines astronomy data with the fine arts. The project aims to pair the human’s journey with a star’s journey from birth to death.
+
+ His goal has been to find a way to support connections with the fine arts, a rarity in the HTC community. After attending the User School, Devin intends to use the techniques he learned to break up his data and entire simulation into tiles and use a low-level graphics API called Vulkan to target and render the data on CPU/GPU capacity. He then intends to combine the tiles into individual frames and assemble them into a video.
+
+
+
+ Rendering of the Starforge simulation gas position data.
+
+
+ Starforge Anvil of Creation: *Grudi'c, Michael Y. et al. “STARFORGE: Toward a comprehensive numerical model of star cluster formation and feedback.” arXiv: Instrumentation and Methods for Astrophysics (2020): n. pag. [https://arxiv.org/abs/2010.11254](https://arxiv.org/abs/2010.11254)*
+
+
+
+ Mike Nsubuga
+
+
+ [Mike Nsubuga](https://miken.netlify.app/), a Bioinformatics Research fellow at the African Center of Excellence in Bioinformatics and Data-Intensive Sciences ([ACE](https://ace.ac.ug/)) within the Infectious Disease Institute ([IDI](https://idi.mak.ac.ug/)) at Makerere University in Uganda, presented “*End-to-End AI data systems for targeted surveillance and management of COVID-19 and future pandemics affecting Uganda.*”
+
+ Nsubuga noted that in the United States, there are two physicians for every 1000 people; in Uganda, there is only one physician per 25,000 people. Research shows that AI, automation, and data science can support overburdened health systems and health workers when deployed responsibly.
+Nsubuga and a team of Researchers at ACE are working on creating AI chatbots for automated and personalized symptom assessments in English and Luganda, one of the major languages of Uganda. He's training the AI models using data from the public and healthcare workers to communicate with COVID-19 patients and the general public.
+
+ While at the School, Nsubuga learned how to containerize his data into a Docker image, and from that, he built an Apptainer (formerly Singularity) container image. He then deployed this to the [Open Science Pool](https://osg-htc.org/services/open_science_pool.html) (OSPool) to determine how to mimic the traditional conversation assistant workflow model in the context of COVID-19. The capacity offered by the OSPool significantly reduced the time it takes to train the AI model by eight times.
+
+
+
+ Jem Guhit
+
+
+ Jem Guhit, a Physics Ph.D. candidate from the University of Michigan, presented “*Search for Di-Higgs production in the LHC with the ATLAS Experiment in the bbtautau Final State.*” The Higgs boson was discovered in 2012 and is known for the Electroweak Symmetry Breaking (EWSB) phenomenon, which explains how other particles get mass. Since then, the focus of the LHC has been to investigate the properties of the Higgs boson, and one can get more insight into how the EWSB Mechanism works by searching for two Higgs bosons using the ATLAS Detector. The particle detectors capture the resultant particles from proton-proton collisions and use this as data to look for two Higgs bosons.
+
+ DiHiggs searches pose a challenge because the rate at which a particle process occurs for two Higgs bosons is 30x smaller than for a single Higgs boson. Furthermore, the particles the Higgs can decay to have similar particle trajectories to other particles produced in the collisions unrelated to the Higgs boson. Her strategy is to use a machine learning (ML) method powerful enough to handle complex patterns to determine whether the decay products come from a Higgs boson. She plans to use what she’s learned at the User School to show improvements in her machine-learning techniques and optimizations. With these new skills, she has been running jobs on the University of Michigan's [HTCondor](https://htcondor.com/) system utilizing GPU and CPUs to run ML jobs efficiently and plans to use the [OSPool](https://osg-htc.org/services/open_science_pool.html) computing cluster to run complex jobs.
+
+
+
+ Peder Engelstad
+
+
+ [Peder Engelstad](https://www.nrel.colostate.edu/ra-highlights-meet-peder-engelstad/), a spatial ecologist and research associate in the Natural Resource Ecology Laboratory at Colorado State University (and 2006 University of Wisconsin-Madison alumni), presented a talk on “*Spatial Ecology & Invasive Species.*” Engelstad’s work focuses on the ecological importance of natural spatial patterns of invasive species.
+
+ He uses modeling and mapping techniques to explore the spatial distribution of suitable habitats for invasive species. The models he uses combine locations of species with remotely-sensed data, using ML and spatial libraries in R. Recently. he’s taken on the massive task of creating thousands of suitability maps. To do this sequentially would take over three years, but he anticipates HTC methods can help drastically reduce this timeframe to a matter of days.
+
+ Engelstad said it’s been exciting to see the approaches he can use to tackle this problem using what he’s learned about HTC, including determining how to structure his data and break it into smaller chunks. He notes that the nice thing about using geospatial data is that they are often in a 2-D grid system, making it easy to index them spatially and designate georeferenced tiles to work on. Engelstad says that an additional benefit of incorporating HTC methods will be to free up time to work on other scientific questions.
+
+
+
+ Zachary Baldwin
+
+
+ [Zachary Baldwin](https://zabaldwin.github.io/), a Ph.D. candidate in Nuclear and Particle Physics at Carnegie Mellon University, works for the [GlueX Collaboration](http://www.gluex.org/), a particle physics experiment at the Thomas Jefferson National Lab that searches for and studies exotic hybrid mesons. Baldwin presented a talk on “*Analyzing hadronic systems in the search for exotic hybrid mesons at GlueX.*”
+
+ His thesis looks at data collected from the GlueX experiment to possibly discover forbidden quantum numbers found within subatomic particle systems to determine if they exist within our universe. Baldwin's experiment takes a beam of electrons, speeds them up to high energies, and then collides them with a thin diamond wafer. These electrons then slow down, producing linearly polarized photons. These photons will then collide with a container of liquid hydrogen (protons) within the center of his experiment. Baldwin studies the resulting systems produced within these photon-proton collisions.
+
+ The collision creates billions of particles, leaving Baldwin with many petabytes of data. Baldwin remarks that too much time gets wasted looping through all the data points, and massive processes run out of memory before he can compute results, which is one aspect where HTC comes into play. Through the User School, another major area he's been working on is simulating Monte Carlo particle reactions using [OSPool](https://osg-htc.org/services/open_science_pool.html)'s containers which he pushes into the OSPool using HTCondor to simulate events that he believes would happen in the real world.
+
+
+
+ Olaitan Awe
+
+
+ Olaitan Awe, a systems analyst in the Information Technology department at the Jackson Laboratory (JAX), presented “*Newborn Screening (NBS) of Inborn Errors of Metabolism (IEM).*” The goal of newborn screening is that, when a baby is born, it detects early what diseases they might have.
+
+ Genomic Newborn Screenings (gNBS) are generally cheap, detect many diseases, and have a quick turnaround time. The gNBS takes a child’s genome and compares it to a reference genome to check for variations. The computing challenge lies in looking for all variations, determining which are pathogenic, and seeing which diseases they align with.
+
+ After attending the User School, Awe intends to tackle this problem by writing [DAGMan](https://htcondor.org/dagman/dagman.html) scripts to implement parent-child relations in a pipeline he created. He then plans to build custom containers to run the pipeline on the [OSPool](https://osg-htc.org/services/open_science_pool.html) and stage big data shared across parent-child processes. The long-term goal is to develop a validated, reproducible gNBS pipeline for routine clinical practice and apply it to African populations.
+
+
+
+ Max Bareiss
+
+
+ [Max Bareiss](https://safetyimpact.beam.vt.edu/news/2021Abstracts/BareissAAAM20211.html), a Ph.D. Candidate at the Virginia Tech Center for Injury Biomechanics presented “*Detection of Camera Movement in Virginia Traffic Camera Video on OSG.*” Bareiss used a data set of 1263 traffic cameras in Virginia for his project. His goal was to determine how to document the crash, near-crashes, and normal driving recorded by traffic cameras using his video analysis pipeline. This work would ultimately allow him to detect vehicles and pedestrians and determine their trajectories.
+
+ The three areas he wanted to tackle and obtain help with at the User School were data movement, code movement, and using GPUs for other tasks. For data movement, he used MinIO, a high-performance object storage, so that the execution points could directly copy the videos from Virginia Tech. For code movement, Bareiss used Alpine Linux and multi-stage build, which he learned to implement throughout the week. He learned about using GPUs at the [Center for High Throughput Computing](https://chtc.cs.wisc.edu/) (CHTC) and in the [OSPool](https://osg-htc.org/services/open_science_pool.html).
+
+ Additionally, he learned about [DAGMan](https://htcondor.org/dagman/dagman.html), which he noted was “very exciting” since his pipeline was already a directed acyclic graph (DAG).
+
+
+
+ Matthew Dorsey
+
+
+ [Matthew Dorsey](https://www.linkedin.com/in/matthewadorsey/), a Ph.D. candidate in the Chemical and Biomolecular Engineering Department at North Carolina State University, presented on “*Computational Studies of the Structural Properties of Dipolar Square Colloids.*”
+
+ Dorsey is studying a colloidal particle developed in a research lab at NC State University in the Biomolecular Engineering Department. His research focuses on using computer models to discover what these particles can do. The computer models he has developed explore how different parameters (like the system’s temperature, particle density, and the strength of an applied external field) affect the particle’s self-assembly.
+
+ Dorsey recently discovered how the magnetic dipoles embedded in the squares lead to structures with different material properties. He intends to use the [HTCondor Software Suite](https://htcondor.com/htcondor/overview/) (HTCSS) to investigate the applied external fields that change with respect to time. “The HTCondor system allows me to rapidly investigate how different combinations of many different parameters affect the colloids' self-assembly,” Dorsey says.
+
+
+
+ Ananya Bandopadhyay
+
+
+ [Ananya Bandopadhyay](https://thecollege.syr.edu/people/graduate-students/ananya-bandopadhyay/), a graduate student from the Physics Department at Syracuse University, presented “*Using HTCondor to Study Gravitational Waves from Binary Neutron Star Mergers.*”
+
+ Gravitational waves are created when black holes or neutron stars crash into each other. Analyzing these waves helps us to learn about the objects that created them and their properties.
+
+ Bandopadhyay's project focuses on [LIGO](https://www.ligo.caltech.edu/)'s ability to detect gravitational wave signals coming from binary neutron star mergers involving sub-solar mass component stars, which she determines from a graph which shows the detectability of the signals as a function of the component masses comprising the binary system.
+
+ The fitting factors for the signals would have initially taken her laptop a little less than a year to run. She learned how to use [OSPool](https://osg-htc.org/services/open_science_pool.html) capacity from the School, where it takes her jobs only 2-3 days to run. Other lessons that Bandopadhyay hopes to apply are data organization and management as she scales up the number of jobs. Additionally, she intends to implement [containers](https://htcondor.readthedocs.io/en/latest/users-manual/container-universe-jobs.html) to help collaborate with and build upon the work of researchers in related areas.
+
+
+
+ Meng Luo
+
+
+ [Meng Luo](https://www.researchgate.net/profile/Meng-Luo-8), a Ph.D. student from the Department of Forest and Wildlife Ecology at the University of Wisconsin–Madison, presented “*Harnessing OSG to project the impact of future forest productivity change on land use change.*” Luo is interested in learning how forest productivity increases or decreases over time.
+
+ Luo built a single forest productivity model using three sets of remote sensing data to predict this productivity, coupling it with a global change analysis model to project possible futures.
+
+ Using her computer would take her two years to finish this work. During the User School, Luo learned she could use [Apptainer](https://portal.osg-htc.org/documentation/htc_workloads/using_software/containers-singularity/) to run her model and multiple events simultaneously. She also learned to use the [DAGMan workflow](https://htcondor.readthedocs.io/en/latest/users-manual/dagman-workflows.html) to organize the process better. With all this knowledge, she ran a scenario, which used to take a week to complete but only took a couple of hours with the help of [OSPool](https://osg-htc.org/services/open_science_pool.html) capacity.
+
+ Tinghua Chen from Wichita State University presented a talk on “*Applying HTC to Higgs Boson Production Simulations.*” Ten years ago, the [ATLAS](https://atlas.cern/) and [CMS](https://cms.cern/) experiments at [CERN](https://home.web.cern.ch/) announced the discovery of the Higgs boson. CERN is a research center that operates the world's largest particle physics laboratory. The ATLAS and CMS experiments are general-purpose detectors at the Large Hadron Collider (LHC) that both study the Higgs boson.
+
+ For his work, Chen uses a Monte Carlo event generator, Herwig 7, to simulate the production of the Higgs boson in vector boson fusion (VBF). He uses the event generator to predict hadronic cross sections, which could be useful for the experimentalist to study the Standard Model Higgs boson. Based on the central limit theorem, the more events Chen can generate, the more accurate the prediction.
+
+ Chen can run ten thousand events on his laptop, but the predictions could be more accurate. Ideally, he'd like to run five billion events for more precision. Running all these events would be impossible on his laptop; his solution is to run the event generators using the HTC services provided by the OSG consortium.
+
+ Using a workflow he built, he can set up the event generator using parallel integration steps and event generation. He can then use the Herwig 7 event generator to build, integrate, and run the events.
+
+...
+
+Thank you to all the researchers who presented their work in the Student Lightning Talks portion of the OSG User School 2022!
diff --git a/2022-12-19-ML-Demo.md b/2022-12-19-ML-Demo.md
new file mode 100644
index 00000000..5a3f04ee
--- /dev/null
+++ b/2022-12-19-ML-Demo.md
@@ -0,0 +1,107 @@
+---
+title: "CHTC Hosts Machine Learning Demo and Q+A session"
+
+author: Shirley Obih
+
+publish_on:
+ - chtc
+
+type: user
+
+canonical_url: https://chtc.cs.wisc.edu/mldemo.html
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/firstmldemoimage.png"
+ alt: A broad lens image of some students present at the demo.
+
+description: Over 60 students and researchers attended the Center for High Throughput Computing (CHTC) machine learning and GPU demonstration on November 16th.
+excerpt: Eric Wilcots, UW-Madison dean of the College of Letters & Science and the Mary C. Jacoby Professor of Astronomy, dazzles the HTCondor Week 2022 audience.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/firstmldemoimage.png"
+card_alt: Koch and Gitter presenting at the demo
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/ML_1.jpeg"
+banner_alt: Koch and Gitter presenting at the demo
+---
+***Over 60 students and researchers attended the Center for High Throughput Computing (CHTC) machine learning and GPU demonstration on November 16th. UW Madison Associate Professor of Biostatistics and Medical Informatics Anthony Gitter and CHTC Lead Research Computing Facilitator Christina Koch led the demonstration and fielded many questions from the engaged audience.***
+
+
+
+ Koch and Gitter presenting at the demo.
+
+
+[CHTC services](https://chtc.cs.wisc.edu/uw-research-computing/) include a free large scale computing systems solution for campus researchers who have encountered computing issues and outgrown their resources, often a laptop, Koch began. One of the services CHTC provides is the [GPU Lab](https://chtc.cs.wisc.edu/uw-research-computing/gpu-lab.html), a resource within the HTC system of CHTC.
+
+The GPU Lab supports up to dozens of concurrent jobs per user, a variety of GPU types including 40GB and 80GB A100s, runtimes from a few hours up to seven days, significant RAM needs, and space for large data sets.
+
+Researchers are not waiting to take advantage of these CHTC GPU resources. Over the past two months, 52 researchers ran over 17,000 jobs on GPU hardware. Additionally, the UW-Madison [IceCube project](https://icecube.wisc.edu) alone ran over 70K jobs.
+
+Even more capacity is available. The recent [$4.3 million investment from the Wisconsin Alumni Research Foundation (WARF) in UW-Madison’s research computing hardware](https://chtc.cs.wisc.edu/DoIt-Article-Summary.html) is a significant contributor to this abundance of resources, Gitter noted.
+
+There are two main ways to know what GPUs are available and the number of GPUs users may request per job:
+The first is through the CHTC website - which offers up-to-date information. To access this information, go to the [CHTC website](https://chtc.cs.wisc.edu) and enter ‘gpu’ in the search bar. The first result will be the [‘Jobs that Use GPU Overview’](https://chtc.cs.wisc.edu/uw-research-computing/gpu-jobs.html) which is the main guide on using GPUs in CHTC. At the very top of this guide is a table that contains information about the kinds of GPUs, the number of servers, and the number of GPUs per server, which limits how many GPUs can be requested per job. Also listed is the GPU memory, which shows the amount of GPU memory and the attribute you would use in the ‘required_gpu’ statement when submitting a job.
+
+A second way is to use the ‘condor_status’ command. To use this command, make sure to set a constraint of ‘Gpus > 0’ to prevent printing out information on every single server we have in the system: condor_status -constraint ‘Gpus > 0’. This gives the names of servers in the pool and their availability status - idle or busy. Users may also add an auto format flag attribute ‘-af’ to print out any desired attribute of the machine. For instance, to access the attributes like those listed in the table of the CHTC guide, users must include the GPUs prefix followed by an underscore and then the name of the column to access.
+
+The GPU Lab, due to its expansive potential, can be used in many scenarios. Koch explained this using real-world examples. Researchers might want to seek the CHTC GPU Lab when:
+Running into the time limit of an existing GPU while trying to develop and run a machine learning algorithm.
+Working with models that require more memory than what is available with a current GPU in use.
+Trying to benchmark the performance of a new machine algorithm and realizing that the computing resources available are time-consuming and not equipped for multitasking.
+
+While GPU Lab users routinely submit many jobs that need a single GPU without issue, users may need to work collaboratively with the CHTC team on extra testing and configuration when handling larger data sets and models and benchmark precise timing. Koch presented a slide outlining what is easy to more challenging on CHTC GPU resources, stressing that, when in doubt about what is feasible, to contact CHTC:
+
+
+
+ Slide showing what is possible with GPU Lab.
+
+
+Work that is done in CHTC is run through a job submission. Koch presented a flowchart demonstration on how this works:
+
+
+ How to run work via job submission.
+
+
+
+
+She demonstrated the three-step process of
+1. login and file upload
+2. submission to queue, and
+3. job-run execution by HTCondor job scheduler.
+This process, she displayed, involves writing up a submit file and utilizing command line syntax to be submitted to the queue. Below are some commands that can be used to submit a file:
+
+
+ Commands to use when submitting jobs.
+
+
+
+The next part of the demo was led by Gitter. To demonstrate what commands would be needed for specific kinds of job submissions, he explained what a job submit file should look like, some necessary commands, and the importance of listing out commands sequentially.
+
+
+ How a job submit file should look.
+
+
+Gitter also demonstrated how to run jobs using the example GitHub repository with the following steps:
+Connecting a personal user account to a submit server in CHTC
+Utilizing the ‘ls’ command to inspect the home directory
+Cloning the pre existing template repository with runnable GPU examples
+Including a “‘condor_submit*insert-file-name*.sub’” command line to define the job the user wants to run
+Applying the ‘condor_q’command to monitor the job that has been submitted
+
+Users are able to choose GPU related submit file options. Gitter demonstrated ways to access the different options that are needed in the HTCondor submit file in order to access the GPUs in CHTC GPU Lab and beyond. These include:
+‘Request_gpus’ to enable GPU use
+‘+WantGPULab’ to indicate whether or not to use CHTC’s shared use GPUs
++GPUJobLength’ to indicate which job type the user would like to submit
+‘Require_gpus’ to request specific GPU attributes or CUDA functionality
+
+He outlined some other commands for running PyTorch jobs and for exploring available GPUs. All commands from the demo can be accessed [here](https://docs.google.com/presentation/d/1pdE3oT539iOjxuIRvGeUjQ_GcaiD00r4iCOdp65PPME/edit#slide=id.p).
+
+The event concluded with a Q&A session for audience members. Some of these questions prompted a discussion on the availability of default repositories and tools that are able to track the resources a job is using. In addition to interactive monitoring, HTCondor has a log file that provides information about when a job was started, a summary of what was requested – disk, memory, GPUs and CPUs as well as what was allocated and estimated to be used.
+
+Currently, there is a template GitHub repository that can be cloned and used as a starting point. These PyTorch and TensorFlow examples can be useful to you as a starting point. However, nearly every user is using a slightly different combination of packages for their work. For this reason, users will most likely need to make some manual modifications to either adjust versions, change scripts, attribute different names to your data file, etc.
+
+These resources will be helpful when getting started:
+- [Request an account with CHTC](https://chtc.cs.wisc.edu/uw-research-computing/form.html)
+- [Access the event slides (including demo commands)](https://docs.google.com/presentation/d/1pdE3oT539iOjxuIRvGeUjQ_GcaiD00r4iCOdp65PPME/edit#slide=id.p)
+- [Access a guide to assist with all your computing needs](https://chtc.cs.wisc.edu/uw-research-computing/guides)
+- [Access to GPU templates](https://github.com/CHTC/templates-GPUs)
+- [Contact CHTC](https://chtc.cs.wisc.edu/uw-research-computing/get-help.html) for assistance
diff --git a/2023-01-20-chtc-demo.md b/2023-01-20-chtc-demo.md
new file mode 100644
index 00000000..03c6b639
--- /dev/null
+++ b/2023-01-20-chtc-demo.md
@@ -0,0 +1,65 @@
+---
+title: CHTC Leads High-Throughput Computing Demonstrations
+
+author: Shirley Obih
+
+publish_on:
+ - htcondor
+ - path
+ - chtc
+
+type: news
+
+canonical_url: (https://chtc.cs.wisc.edu/chtc-demo.html)
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/classroomimage.jpeg"
+ alt: Christina Koch presenting to Kaiping Chen's class.
+
+description: Students and researchers acquire high-throughput computing knowhow from CHTC led demonstrations.
+excerpt: Students and researchers acquire high-throughput computing knowhow from CHTC led demonstrations.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/classroomimage.jpeg"
+card_alt: Christina Koch presenting to Kaiping Chen's class
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/classimage.png"
+banner_alt: Christina Koch presenting to Kaiping Chen's class
+
+---
+
+***UW-Madison Assistant Professor [Kaiping Chen](https://lsc.wisc.edu/facstaff/chen-kaiping/) is taking her [life sciences](https://lsc.wisc.edu) course (LSC660) to the next level by incorporating high throughput computing (HTC) into her class. Data Science for understanding science communication involves learning to use statistical methods (e.g., chi-square, analysis of variance, correlation and regression analysis, nonparametric tests) and computational methods (e.g., automated text analysis, computer vision) – all of which sometimes requires complex, time-consuming computing that surpasses the capacity of the everyday computer.***
+
+
+
+ Kaiping Chen, Assistant Professor of Life Science Communication.
+
+
+To meet this computing challenge, Chen enlisted the help of [CHTC](https://chtc.cs.wisc.edu) Lead Research Computing Facilitator Christina Koch in November 2022 for a demonstration for her class. Chen wanted students to:
+Acquire knowledge about the basic approaches for large scale computing
+Understand the different scenarios regarding why they may need to use high throughput computing in research.
+Be able to distinguish between independent and sequential tasks.
+Be able to submit script jobs onto the campus computer cluster of CHTC
+Obtain a basic understanding of the parallel computing implementation in R.
+
+Koch achieved these goals by presenting the uses of HTC for large scale computing and leading a hands-on demonstration with Kaiping to teach students how to submit and run R programming scripts to perform topic modeling on social media data using HTC.
+
+This learning, Chen noted, served as a tool to aid students to convert theoretical, class-based knowledge into more practical abilities, including learning how to approach computational tasks that could be useful in future work. Two examples of such complex computational tasks include structure topic models (STMs) and regression models. STM uses unsupervised machine learning to identify keywords and major themes across large corpus that could be interpreted into human-readable formats for data analysis. It is also useful in comparing social media influencer versus non-influencer perspectives on science issues through STM.
+
+The majority of the students in the class, while new to CHTC resources, found the class to be a good introduction to HTC. Ph.D student Ashley Cate from [LSC](https://lsc.wisc.edu) was a prime example.
+“I am still an extreme novice when it comes to understanding all the options CHTC has to offer. However, one thing that Christina Koch made very clear is that you’re not alone in your endeavor of utilizing HTC to meet your research needs, and I feel very confident that the professionals would be able to work me through how CHTC could help me.” Master’s student of Life Sciences Communication Jocelyn Cao reported that “I do think I will be utilizing CHTC in my future work because I am interested in doing work with social media.”
+
+
+Other campus groups have also reached out to Koch to learn about CHTC services for their research. Lindley's research group; a group of undergraduate students, M.S., Ph.D and postdocs candidates involved in nuclear reactor physics, advanced reactor design and integrated energy systems wanted to understand how to harness the power of HPC/HTC in their research.
+
+[Ben Lindley](https://directory.engr.wisc.edu/ep/Faculty/Lindley_Benjamin/), UW Madison Engineering Physics assistant professor has utilized CHTC in his previous work to build software. Wth the assistance of post-doc Una Baker, Lindley Lindley sought the help of CHTC.. “One of the beauties of the high throughput computing resources is that we can analyze dozens or hundreds of cases in parallel,” Lindley said. These cases represent scenarios where certain design features of nuclear reactors are modified and observed for change. “Without HTC, the scope of research could be very limited. Computers could crash and tasks could take too long to complete.”
+
+
+
+ Ben Lindley, Assistant Professor of Engineering Physics
+
+
+
+
+In-person demonstrations with classrooms and research groups are always available at CHTC to UW-Madison researchers looking to expand computing beyond local resources. Koch noted that “we are always happy to meet with course instructors who are interested in including large scale computing in their courses, to share different ways we can support our goals.”
+
+Contact CHTC [here](https://chtc.cs.wisc.edu/uw-research-computing/get-help.html).
diff --git a/2023-01-20-materials-science.md b/2023-01-20-materials-science.md
new file mode 100644
index 00000000..2b2628b1
--- /dev/null
+++ b/2023-01-20-materials-science.md
@@ -0,0 +1,48 @@
+---
+title: Empowering Computational Materials Science Research using HTC
+
+author: Hannah Cheren
+
+publish_on:
+- chtc
+- path
+- htcondor
+
+type: user
+
+canonical_url: "https://chtc.cs.wisc.edu/materials-science.html"
+
+image:
+path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/materials-science.jpg"
+alt: Computer screen with lines of code. Uploaded by AltumCode on Unsplash.
+
+description: |
+ Ajay Annamareddy, a research scientist at the University of Wisconsin-Madison, describes how he utilizes high-throughput computing in computational materials science.
+excerpt: |
+ Ajay Annamareddy, a research scientist at the University of Wisconsin-Madison, describes how he utilizes high-throughput computing in computational materials science.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/materials-science.jpg"
+card_alt: Computer screen with lines of code. Uploaded by AltumCode on Unsplash.
+---
+ ***Ajay Annamareddy, a research scientist at the University of Wisconsin-Madison, describes how he utilizes high-throughput computing in computational materials science.***
+
+
+
+ Computer screen with lines of code. Uploaded by AltumCode on Unsplash
+
+
+ Groundbreaking research is in the works for the [Computational Materials Group (CMG)](https://matmodel.engr.wisc.edu/) at the University of Wisconsin-Madison (UW-Madison). [Ajay Annamareddy](https://matmodel.engr.wisc.edu/members/), a research scientist within CMG, has been a leading user of GPU hours with the [Center for High Throughput Computing](https://chtc.cs.wisc.edu/) (CHTC). He utilizes this capacity to run machine learning (ML) simulations as applied to material science problems that have gained tremendous interest in the past decade. CHTC resources have allowed him to study hugely data-driven problems that are practically impossible to deal with using regular resources.
+
+ Before coming to UW-Madison, Annamareddy received his Ph.D. in Nuclear Engineering from North Carolina State University. He was introduced to modeling and simulation work there, but he started using high-throughput computing (HTC) and CHTC services when he came to UW-Madison to work as a PostDoc with [Prof. Dane Morgan in the Materials Science and Engineering department](https://energy.wisc.edu/about/energy-experts/dane-morgan). He now works for CMG as a Research Scientist, where he’s been racking up GPU hours for over a year.
+
+ Working in the field of computational materials, Annamareddy and his group use computers to determine the properties of materials. So rather than preparing material and measuring it in experiments, they use a computer, which is less expensive and more time efficient. Annamareddy studies metallic glasses. These materials have many valuable properties and applications, but are not easy to make. Instead, he uses computer simulations of these materials to analyze and understand their fundamental properties.
+
+ Annamareddy’s group utilizes HTC and high-performance computing (HPC) for their work, so his project lead asked him to contact CHTC and set up an account. Christina Koch, the lead research computing facilitator, responded. “She helped me set up the account and determine how many resources we needed,” Annamareddy explained. “She was very generous in that whenever I exceeded my limits, she would increase them a bit more!”
+
+ CHTC resources have become critical for Annamareddy’s work. One of the projects involves running ML simulations, which he notes would be “difficult to complete” without the support of CHTC. Annamareddy uses graph neural networks (GNN), a powerful yet slightly inefficient deep learning technique. The upside to using GNN is that as long as there is some physics component in the underlying research problem, this technique can analyze just about anything. “The caveat is you need to provide lots of data for this technique to figure out a solution.”
+
+ Meeting this data challenge, Annamareddy put the input data he generates using high-performance computing (HPC) on the HTC staging location, which gets transferred to a local machine before the ML job starts running. “I use close to twenty gigabytes of data for my simulation, so this would be extremely inefficient to run without staging,” he explains. The CHTC provides Annamareddy with the storage and organization he needs to perform these potentially ground-breaking ML simulations.
+
+ Researchers often study materials in traditional atomistic simulations at different timescales, ranging from picoseconds to microseconds. Annamareddy’s goal with his work is to extend the time scales of these conventional simulations by using ML, which he found is well supported by HTC resources. “We have yet to reach it, but we hope we can use ML to extend the time scale of atomistic simulations by a few orders of magnitude. This would be extremely valuable when modeling systems like glass-forming materials where we should be able to obtain properties, like density and diffusion coefficients, much closer to experiments than currently possible with atomistic simulations,” Annamareddy elaborates. This is something that has never been done before in the field.
+
+ This project can potentially extend the time scales possible for conventional molecular dynamic simulations, allowing researchers in this field to predict how materials will behave over more extended periods of time. “It's ambitious – but I’ve been working on it for more than a year, and we’ve made a lot of progress…I enjoy the challenge immensely and am happy I’m working on this problem!”
diff --git a/2023-03-01-Google-HTCondor.md b/2023-03-01-Google-HTCondor.md
new file mode 100644
index 00000000..b6aea2ec
--- /dev/null
+++ b/2023-03-01-Google-HTCondor.md
@@ -0,0 +1,55 @@
+---
+title: HTCondor and Google Quantum Computing
+
+author: Hannah Cheren
+
+publish_on:
+- chtc
+- path
+- htcondor
+
+type: user
+
+canonical_url: "https://chtc.cs.wisc.edu/htcondor-google-qvm.html"
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/google-qvm.jpg"
+ alt: Quantum AI Logo. Image from Quantum AI Product Manager Catherine Vollgraff Heidweiller’s research blog post.
+
+description: |
+ Google's launch of a Quantum Virtual Machine emulates the experience and results of programming one of Google's quantum computers, managed by an HTCondor system running in Google Cloud.
+excerpt: |
+ Google's launch of a Quantum Virtual Machine emulates the experience and results of programming one of Google's quantum computers, managed by an HTCondor system running in Google Cloud.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/google-qvm.jpg"
+card_alt: Quantum AI Logo. Image from Quantum AI Product Manager Catherine Vollgraff Heidweiller’s research blog post.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/google-qvm.jpg"
+banner_alt: Quantum AI Logo. Image from Quantum AI Product Manager Catherine Vollgraff Heidweiller’s research blog post.
+---
+ ***Google's launch of a Quantum Virtual Machine emulates the experience and results of programming one of Google's quantum computers, managed by an HTCondor system running in Google Cloud.***
+
+
+
+ Quantum AI Logo. Image from Quantum AI Product Manager Catherine Vollgraff Heidweiller’s research blog post.
+
+
+ The CEO of Google and Alphabet, Sudar Pichai, tweeted out some thrilling news:
+
+ “Excited to launch a Quantum Virtual Machine (QVM) which emulates the experience and results of programming one of our quantum computers. It will make it easier for researchers to prototype new algorithms and help students learn how to program a quantum computer.” – [Tweet](https://twitter.com/sundarpichai/status/1549448858282774528).
+
+ Today’s “classical” computing systems, from laptops to large supercomputers, are built using circuit behavior defined by classical physics. Quantum computer circuity, still in the early phases of development, harnesses the laws of quantum mechanics to solve computing problems in new ways. Quantum computers offer exponential speedups – over 100 million times faster for specific issues – to produce groundbreaking results. However, quantum computing will require scientists and engineers to revisit many classical algorithms and develop new ones tailored to exploit the benefits of quantum processors. Therefore, the QVM is a helpful tool for quantum algorithms research.
+
+ “The QVM is, in essence, a realistic simulation of a grid on our quantum hardware using classical computers,” Tom Downes, a consultant for High-Performance Computing (HPC) at Google Cloud, explains. Simulating a grid of qubits, the basic unit of quantum information, on a quantum processor requires many trajectory simulations of quantum noise. Downes explains, “quantum computers are noisy, so it is important to test and adjust your quantum circuits in realistic conditions so they can perform well and output the data you are looking for in your research problem. To virtualize a processor, the QVM uses the noise data and topology of Google's real hardware.” This grid size determines whether a researcher can use their laptop or require a setup utilizing many classical computers to power the simulation. Essentially, research on the QVM is "proof of concept" research.
+
+ To enable researchers to test their algorithms on a larger grid of qubits, Google utilized the [HTCondor Software Suite](https://htcondor.org) (HTCSS) to organize the capacity of many classical computers to run multiple simulations of a quantum circuit simultaneously. The HTCondor Software Suite enables researchers to easily harness the collective computing power of many classical computers and submit and manage large numbers of computing jobs. Today, HTCSS is used at universities, government labs, and commercial organizations worldwide, including within Google’s own Google Cloud Platform, to power QVM. Downes details, “this ability to test on a 32-qubit grid can extrapolate its performance to a non-simulatable grid more feasible.”
+
+ The new [Google Quantum AI tutorial](https://quantumai.google/qsim/tutorials/multinode) shows users how to use the Cloud HPC Toolkit, which makes it easy for new users to deploy HTCondor pools in Google Cloud. Downes describes that the tutorial “provides the basic elements of an HTCondor pool: a central manager, an access point, and a pool of execute points that scale in size to work through the job queue.”
+
+ The tutorial by Google describes how to:
+- Use terraform to deploy an HTCondor cluster in the Google Cloud
+- Run a multi-node quantum computing simulation using HTCondor
+- Query cluster information and monitor running jobs in HTCondor
+- Use terraform to destroy the cluster
+
+ Please visit [this website](https://blog.google/technology/research/our-new-quantum-virtual-machine-will-accelerate-research-and-help-people-learn-quantum-computing/) for more information about the Quantum Virtual Machine and [how researchers can use HTCondor for multinode quantum simulations](https://quantumai.google/qsim/tutorials/multinode).
diff --git a/2023-04-10-ospool-computation.md b/2023-04-10-ospool-computation.md
new file mode 100644
index 00000000..10fe848b
--- /dev/null
+++ b/2023-04-10-ospool-computation.md
@@ -0,0 +1,60 @@
+---
+title: OSPool As a Tool for Advancing Research in Computational Chemistry
+
+author: Shirley Obih
+
+publish_on:
+- osg
+- path
+- htcondor
+
+type: news
+
+canonical_url: https://osg-htc.org/spotlights/2023-04-10-ospool-computation.html
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/ospool-comp.jpg
+ alt: Microscope beside computer by Tima Miroshnichenko from Pexels.
+
+description: Assistant Professor Eric Jonas uses OSG resources to understand the structure of molecules based on their measurements and derived properties.
+excerpt: Assistant Professor Eric Jonas uses OSG resources to understand the structure of molecules based on their measurements and derived properties.
+
+card_src: https://raw.githubusercontent.com/CHTC/Articles/main/images/ospool-comp.jpg
+card_alt: Microscope beside computer by Tima Miroshnichenko from Pexels.
+
+banner_src: https://raw.githubusercontent.com/CHTC/Articles/main/images/ospool-comp.jpg
+banner_alt: Microscope beside computer by Tima Miroshnichenko from Pexels.
+---
+
+**Assistant Professor Eric Jonas uses OSG resources to understand the structure of molecules based on their measurements and derived properties.**
+
+
+ Microscope beside computer by Tima Miroshnichenko from Pexels.
+
+
+
+
+ Eric Jonas, Assistant professor at Uchicago
+
+
+Picture this: You have just developed a model that predicts the properties of some molecules and plan to include this model in a section of a research paper. However, just a few days before the paper is to be published on your professional website, you discover an error in the data generation process, which requires you to compute your work again and quickly!
+This scenario was the case with Assistant Professor [Eric Jonas](https://jonaslab.uchicago.edu), who works in the Department of Computer Science at the University of Chicago (UChicago).
+While this process is normally tedious, he noted how the OSPool helped streamline the steps needed to regenerate results: “The OSPool made it easy to go back and regenerate the data set with about 70 million new molecules in just a matter of days.”
+
+Although this was a fairly recent incident for Jonas, he is not new to high throughput computing or the OSPool. With usage reaching as far back as his graduate school days, Jonas has utilized resources ranging from cloud computing infrastructures like Amazon Web Services to the National Supercomputing Center for his work with biological signal acquisition, molecular inverse problems, machine learning, and other ways of exploiting scalable computation.
+
+He soon realized, though, that although these other resources could run large amounts of data in a relatively short time, they required a long, drawn-out sequence of actions to provide results – creating an application, waiting for it to be accepted, and then waiting in line for long periods for a job to run. Faced with this problem in 2021, Jonas found a solution with the [OSG Consortium](https://osg-htc.org) and its OSPool, OSG’s distributed pool of computing resources for running high-throughput jobs.
+
+In April of 2021, he enlisted the help of [HTCondor](https://htcondor.com) and the OSPool to run pre-exising computations that allow for the generation of training data and the development of new machine learning techniques to determine molecular structures in mixtures, chemical structures in new plant species, and other related queries.
+
+Jonas’ decision to transition to the OSPool boiled down to three simple reasons:
+Less red tape involved in getting started.
+Better communication and assistance from staff.
+Greater flexibility with running other people’s software to generate data for his specific research, which, in his words, are a much better fit for his specific research which would otherwise have been too computationally bulky to handle alone.
+
+In terms of challenges with OSPool utilization, Jonas’ only point of concern is the amount of time it takes for code that has been uploaded to reach the OSPool. “It takes between 8 and 12 hours for that code to get to OSG. The time-consuming containerization process means that any bug in code that prevents it from running isn't discovered and resolved as quickly, and takes quite a while, sometimes overnight.”
+
+He and his research team have since continued to utilize OSPool to generate output and share data with other users. They have even become advocates for the resource: “After we build our models, as a next step, we’re like, let’s run our model on the OSPool to allow the community (which constitutes the entirety of OSPool users) also to generate their datasets. I guess my goal, in a way, is to help OSG grow any way I can, whether that involves sharing my output with others or encouraging people to look into it more.”
+
+Jonas spoke about how he hopes more people would take advantage of OSPool:
+“We’re already working on expanding our use of it at UChicago, but I want even more people to know that OSPool is out there and to know what kind of jobs it's a good fit for because if it fits the kind of work you’re doing, it’s like having a superpower!”
+
diff --git a/2023-04-18-ASP.md b/2023-04-18-ASP.md
new file mode 100644
index 00000000..99d8b89b
--- /dev/null
+++ b/2023-04-18-ASP.md
@@ -0,0 +1,66 @@
+---
+title: Distributed Computing at the African School of Physics 2022 Workshop
+
+author: Hannah Cheren
+
+publish_on:
+- chtc
+- path
+- osg
+- htcondor
+
+type: user
+
+canonical_url: "https://osg-htc.org/spotlights/asp.html"
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/asp-banner.jpeg"
+ alt: Image obtained from the official ASP2022 page on the African School of Physics website.
+
+description: |
+ Over 50 students chose to participate in a distributed computing workshop from the 7th biennial African School of Physics (ASP) 2022 at Nelson Mandela University in Gqeberha, South Africa.
+excerpt: |
+ Over 50 students chose to participate in a distributed computing workshop from the 7th biennial African School of Physics (ASP) 2022 at Nelson Mandela University in Gqeberha, South Africa.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/asp-banner.jpeg"
+card_alt: Image obtained from the official ASP2022 page on the African School of Physics website.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/asp-banner.jpeg"
+banner_alt: Image obtained from the official ASP2022 page on the African School of Physics website.
+---
+ ***Over 50 students chose to participate in a distributed computing workshop from the 7th biennial African School of Physics (ASP) 2022 at Nelson Mandela University in Gqeberha, South Africa.***
+
+
+
+ Image obtained from the official ASP2022 page on the African School of Physics website.
+
+
+
+
+ Dr. Severini helping a student during ASP2022.
+
+
+Almost 200 students from 41 countries were selected to participate in the [7th ASP 2022](https://www.africanschoolofphysics.org/asp2022/) at [Nelson Mandela University in Gqeberha, South Africa](https://science.mandela.ac.za/ASP-2022). With the school being shortened to two weeks, a parallel learning system was implemented, where participants could choose lectures to attend to improve their educational growth. [Dr. Horst Severini](https://www.nhn.ou.edu/~hs/) is a Research Scientist and Adjunct Professor in [High Energy Physics](http://www-hep.nhn.ou.edu/) and [Information Technology](http://it.ou.edu/) from the University of Oklahoma (OU) and a co-leader of the high-performance computing workshop. He anticipated maybe 25 students attending on his track, “...we had about that many laptops,” he remarked, “and then we ended up with over 50 students!”
+
+Severini was first introduced to distributed computing during his postdoc at OU. Then in the spring of 2012, Severini was introduced to [Kétévi Assamagan](https://www.aasciences.africa/fellow/ketevi-assamagan), one of the founders of the ASP. Assamagan met with Severini and invited him and his colleagues to participate, leading to a scramble to create a curriculum for this new lecture series. They were eager to show students how distributed computing could help with their work.
+
+After a few years of fine-tuning the high throughput classes, Severini has the workshop ironed out. After receiving an introduction to basic commands in Linux, the students started with a basic overview of high-energy physics, why computing is important to high-energy physics, and then some [HTCondor basics](https://htcondor.com/). “The goal, really, is to teach students the basics of HTCondor, and then let them go off and see what they can do with it,” Severini explained. The workshop was so successful that students worked through coffee breaks and even stuck around at the end to obtain [OSG accounts](https://portal.osg-htc.org/application) to continue their work.
+
+A significant improvement for the 2022 high-performance computing workshop was the move from using [OSG Connect](https://connect.osg-htc.org/) for training sessions to Jupyter Notebooks. The switch to Jupyter Notebooks for training developed during the middle of 2022. “Jupyter allows people to ‘test drive’ submitting jobs on an HTCondor system without needing to create a full [OSPool account](https://portal.osg-htc.org/application),” [OSG](https://osg-htc.org/) [Research Computing Facilitator](https://chtc.cs.wisc.edu/CHTC-Facilitation.html) [Christina Koch](https://wid.wisc.edu/people/christina-koch/) clarified. “Moving forward, we hope people can keep using the Jupyter Notebook interface once they get a full OSPool account so that they can move seamlessly from the training experience to all of the OSPool.”
+
+
+
+ Students working together and listening to a lecture during ASP2022.
+
+
+“[Jupyter Notebooks] worked quite well,” Severini said, noting that the only issue was that a few people lost their home directories overnight. However, these “beginning glitches” didn’t slow participants down whatsoever. “People enjoyed [the workshop] and showed it by not wanting to leave during breaks; they just wanted to keep working!”
+
+Severini’s main goal for the high-performance computing workshop is to migrate the material into Jupyter Notebooks. “I’ve always been most familiar with shell scripts, so I always do anything I can in there because I know it's repeatable…but I’ll adapt, so we'll work on that for the next one,” he explains.
+
+Overall, “everything’s been working well, and the students enjoy it; we’ll keep adjusting and going with the times!”
+
+...
+
+*More information about [scheduling](https://osg-htc.org/dosar/ASP2022/ASP2022_Schedule/) and [materials](https://osg-htc.org/dosar/ASP2022/ASP2022_Materials/) from the 7th ASP 2022. The 8th ASP 2024 will take place in Morocco, Africa. Check [this site](https://www.africanschoolofphysics.org/) for more information as it comes out.*
+
+*For more information or questions about the switch to Jupyter Notebooks, please email [chtc@cs.wisc.edu.](mailto:chtc@cs.wisc.edu)*
diff --git a/2023-04-18-CHTC-Philosophy.md b/2023-04-18-CHTC-Philosophy.md
new file mode 100644
index 00000000..6ec25c35
--- /dev/null
+++ b/2023-04-18-CHTC-Philosophy.md
@@ -0,0 +1,74 @@
+---
+title: The CHTC Philosophy of High Throughput Computing – A Talk by Greg Thain
+
+author: Hannah Cheren
+
+publish_on:
+- chtc
+- path
+- htcondor
+- osg
+
+type: news
+
+canonical_url: "https://chtc.cs.wisc.edu/chtc-philosophy.html"
+
+image:
+path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/chtc-philosophy-banner.jpg"
+alt: Image from Greg Thain’s CHTC Philosophy of High Throughput Computing slideshow.
+
+description: |
+ HTCondor Core Developer Greg Thain spoke to UW faculty and researchers about research computing and the missions and goals of the Center for High Throughput Computing (CHTC).
+excerpt: |
+ HTCondor Core Developer Greg Thain spoke to UW faculty and researchers about research computing and the missions and goals of the Center for High Throughput Computing (CHTC).
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/chtc-philosophy-banner.png"
+card_alt: Image from Greg Thain’s CHTC Philosophy of High Throughput Computing slideshow.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/chtc-philosophy-banner.png"
+banner_alt: Image from Greg Thain’s CHTC Philosophy of High Throughput Computing slideshow.
+---
+ ***HTCondor Core Developer Greg Thain spoke to UW faculty and researchers about research computing and the missions and goals of the Center for High Throughput Computing (CHTC).***
+
+
+
+ Photo credits: Greg Thain’s CHTC Philosophy of High Throughput Computing slideshow.
+
+
+[The Center for High Throughput Computing](https://chtc.cs.wisc.edu/) (CHTC) is proud to be home to a breadth of research on campus, with over 300 projects and 20 million core hours used by departments on the University of Wisconsin-Madison campus, ranging from the College of Agriculture and Life Sciences (CALS) to the School of Education, School of Pharmacy, and many more. “The CHTC is known best for being a place to run lots of fast jobs for free, to which we hope to continue democratizing computing across the campus,” Greg Thain began in his talks to UW-Madison researchers and staff on March 9 and 17, organized by UW-Madison Chief Technology Officer Todd Shechter.
+
+“We like to think of the CHTC like the UW Hospital,” Thain explained, “like the hospital’s main purpose is to train the next generation of health professionals and conduct medical research. In the same way, the CHTC is our research laboratory and is where others can come and conduct their research; we do both research and provide a service.”
+
+The main asset leveraged by the CHTC is research computing. “Research computing consists of research that happens to use computing and research about computing,” Thain explained, “both of which start and end with people.” Thain then described the two phases researchers go through when they approach the CHTC for help; “first, they seek assistance and guidance on a problem they’re currently facing. Second, they realize they can do something revolutionary with high throughput computing (HTC).”
+
+A component of research computing using the CHTC tailored to scientists and researchers is that they don’t have to spend time supervising their programs running. Users can configure an [HTCondor Access Point](https://osg-htc.org/docs/submit/osg-flock/) to manage all their work, allowing them to essentially “submit it and forget it.” This compute system is similar to others in that any user can understand it and have it be reliable, “except ours has the extra touch of being a ‘submit it and forget it’ system,” Thain clarified.
+
+Similarly, the CHTC also created software for where the work runs, called an HTCondor Execution Point (EP). These Execution Points may be machines owned by other researcher providers and have different policies.
+
+Both researchers and research providers may have constraints; the goal then of HTCondor is to “manage and maintain these restraints; there are many users and researcher providers in the real world, and the CHTC is currently working on optimizing these individuals' wants and needs.”
+
+“This is a distributed problem,” Thain continued, “not because of the machines; it’s distributed because of the people.” Having distributed authority as opposed to distributed machines means that tools and policies are distributed.
+
+The implicit assumption is that all work can be divided into smaller, mostly independent jobs. In this way, “the goal is to optimize the time to finish running these jobs instead of the time to run a single one; to do this, we want to break up the jobs as much as possible so they can run in parallel,” Thain explained. The implication of this is there are a lot of different jobs, and how difficult it is to break them up varies.
+
+
+
+ Research Computing Facilitator Christina Koch with a researcher.
+
+
+To mitigate this, [research computing facilitators](https://chtc.cs.wisc.edu/CHTC-Facilitation.html) (RCFs) work with users and researchers to overcome their specific problems. RCFs are different from a traditional “help desk;” their role is to interface with graduate students, PIs, and other researchers and guide them to find the best-fit solution for their projects. RCFs must have a broad understanding of the basic sciences to communicate with the researchers, understand their work, and give them useful and reasonable recommendations and other technological approaches.
+
+“The CHTC’s top priority is always reliability, but with all this work going on, the dream for us is scalability,” Thain described. Ideally, more loads would increase performance; in reality, it boosts performance a little, and then it plateaus. To compensate for this, the CHTC goes out of its way to make access points more reliable. “Adding access points helps to scale and allows submission near the user.” Thain notes the mantra: “submit locally, run globally.”
+
+As the CHTC is our on-campus laboratory for experimenting with distributing computing, the [Open Science Pool](https://osg-htc.org/services/open_science_pool.html) (OSPool) is a bolder experiment expanding these idea onto a national scale of interconnected campuses.
+
+
+
+ Map of campuses using OSPool computing resources.
+
+
+The OSG and subsequent OSPool provide computing access on a national level in the same way that someone can access an available machine locally. For example, if the machines on campus are unavailable or all being used, users can access machines in the greater OSG Consortium. “But at the end of the day, all this computing, storage and networking research is in service to the needs of people who rely on high throughput computing to accomplish their research,” Thain maintains. “We hope the OSPool will be an accelerator for a broad swath of researchers in all kinds of disciplines, from all over the United States.”
+
+...
+
+*The full slideshow can be found [here](https://github.com/GregThain/talks/blob/master/2023misc/CHTC%20for%20Research%20Computing.pptx). Please click [here](https://chtc.cs.wisc.edu/uw-research-computing/index.html) for more information about researching computing within the CHTC, or visit [this page](https://chtc.cs.wisc.edu/uw-research-computing/get-help.html) to contact our RCFs for any questions.*
diff --git a/2023-04-24-hannah.md b/2023-04-24-hannah.md
new file mode 100644
index 00000000..9a840074
--- /dev/null
+++ b/2023-04-24-hannah.md
@@ -0,0 +1,130 @@
+---
+title: Get To Know Student Communications Specialist Hannah Cheren
+
+author: Shirley Obih
+
+publish_on:
+- chtc
+- path
+- htcondor
+- osg
+
+type: spotlight
+
+canonical_url: https://path-cc.io/news/2023-04-24-hannah/
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/hannaheadshot.jpg
+ alt: Headshot of Hannah Cheren
+
+description: During her two year tenure with the Morgridge Institute for Research - Research Computing lab, Hannah Cheren made significant science writing contributions and along the way changed the direction of her life.
+
+card_src: https://raw.githubusercontent.com/CHTC/Articles/main/images/hannaheadshot.jpg
+card_alt: Headshot of Hannah Cheren
+
+banner_src: https://raw.githubusercontent.com/CHTC/Articles/main/images/hannaheadshot.jpg
+banner_alt: Headshot of Hannah Cheren
+---
+
+**During her two year tenure with the Morgridge Institute for Research - Research Computing lab, Hannah Cheren made significant science writing contributions and along the way changed the direction of her life.**
+
+
+ Hannah Cheren, Student Writer.
+
+
+During her two year tenure with the Morgridge Institute for Research - Research Computing lab, Hannah Cheren made significant science writing contributions and along the way changed the direction of her life.
+
+Hannah is a senior undergraduate student in Life Sciences Communications and Statistics, simultaneously working towards a certificate in Data Science. She is a contributing writer for the Center for High Throughput Computing (CHTC) and the National Science Foundation funded PATh project, publishing 19 science and research computing articles describing high-throughput research computing and highlighting the researchers who utilize these organizations’ services. After her graduation this May, Hannah will be joining a public relations and communications consulting group for the life sciences as an Account Coordinator.
+
+Hannah takes her well-earned center-stage to share a bit about herself, experiences and professional trajectory so far, as well as her plans after graduation.
+
+**What piqued your interest in life sciences communication?**
+I came to college intending to be a computer science major, but I immediately realized it wasn’t for me. I had a bit of a freak-out moment, but eventually made my way to the career advising office, where I was given a list of all the majors offered by the university so I could see all my options at a glance.
+
+Life Sciences Communication (LSC) stood out to me as an interesting route because I have always had an interest in writing and communications. I still felt like I didn't know much about LSC, so I reached out to Tera Wagner, the former Life Sciences Communication advisor, who really sold it to me.
+
+
+
+ Hannah Cheren and former LSC advisor, Tera Wagner.
+
+
+What drew me in was how different it is from journalism and other communications-based majors in the sense that you’re taught to take complex scientific information and translate it to a more easily digestible version that just about anybody can understand!
+
+How did you hear about / get started as a writer with the OSG/PAth communications team at Morgridge?
+I learned about the job position from the advisor I just spoke about, Tera Wagner. She thought it
+might be a good fit for me, and it turns out it was!
+
+**Why this position in particular?**
+ The job description captured my attention, and the interview process reinforced my interest, for sure. I remember being asked how well I could handle criticism, and while I was a bit stunned by the question, I knew I would be challenged and learn a lot in this role. As a writer, half the job is having people critique and edit your work. I knew this was the field I’d eventually like to go into, so learning to handle criticism this early in my career was a skill that I wanted to learn sooner rather than later.
+
+**How would you describe your experience so far working with the rest of the team?**
+This job, in general, has been life-changing; it’s set me up for success in more ways than I expected. I remember the first couple of months were really challenging for me - this was my first “real” job, and even starting out, I felt like I had been thrown to the wolves. The summer of 2022 was a big turning point; I had more time to fully immerse myself and learn all I could, and started feeling a lot more confident. We had recently wrapped up HTCondor Week 2022, and within a couple of months, I had written and published seven articles about researchers from the event. It was a lot, but I became accustomed to how fast-paced this job could get, and it helped improve my efficiency, which I would say has really helped set me up for the real world.
+In terms of ‘lows,’ I’m not sure what I would classify as a low. Honestly, it has all been a great learning experience. Even when things go wrong, I take it all in good stride.
+
+**Favorite story you’ve written to date and why?**
+The Lightning Talks article was the one that I (not to be dramatic) felt like I put in my blood, sweat, and tears into. It was pretty intense because it involved interviewing and writing about work from 11 different researchers. The article ended up being really cool, and I'm very proud of it!
+What kind of writer did you hope you’d become prior to starting and how has that changed in the time you’ve been here?
+When I was younger, I was really into writing and reading. My dream job at the time was to be a novelist. I used to write all the time, from elementary school all the way to high school, so it has always been in the picture.
+As I got older, I began to skew away from writing because I wasn’t sure how I could make a career out of it and it didn't seem to be a highly sought-after professional path, or so I thought.
+But this experience has felt really full circle. I feel like this job has allowed me to find my “writing voice” again - while still maintaining the scientific theme - which has been exhilarating and inspiring for me.
+ I feel I have been able to come into my own as a science writer for PATh and I learned what was expected of me in this position. Writing, coupled with video editing and scheduling Tweets , helped me feel more comfortable with the organization and further hone in on technical and soft skills.
+
+**How would you say this position has helped you learn about High Throughput Computing (HTC)?**
+It has helped a ton! I went from having no knowledge about HTC to enrolling in a class that teaches HTC because I have grown so much in my confidence.
+
+**Why do you think communication is important for the PATh project?**
+The research that occurs within the PATh project is not only interesting, but so incredibly important within each field. Not only that, I think it’s important to communicate about this work in a way that people who aren’t in the field can understand it. By doing this, I hope to show researchers in all stages of their career or students who are interested in this type of work that it’s not all scary and complicated. Communicating about the PATh project, hopefully, motivates people who are already using HTC to stick with it and can encourage those who think it might be a good fit for their research to try it out.
+
+**What would you miss about your job when you leave?**
+Oh my gosh, everything! I’ll, of course, miss the people I work with; I will miss my little cubicle where I can see everyone passing by and be near the people I work closest with. I will also miss the work - it’s true what they say; if you do what you love, you’ll never work a day in your life. I honestly get so excited to go to work because I just think what we do is so incredible. I’ll also miss the researchers - it’s been so great to be able to interview and interact with so many different kinds of people and learn about topics and research they’re passionate about. I’m so grateful for my time here and I’m excited about what else I get to do in between now and when I graduate!
+
+**What would be your advice to upcoming writers who also aspire to work in life science communications?**
+This field is often fast-paced and can sometimes feel overwhelming. My advice is not to get discouraged by it; eventually, you’ll get used to it, and it’ll be part of your routine. Also, I think something that a lot of science writers experience in the beginning of their careers is “losing their voice.” Science writing can be very technical, and as a writer, it can sometimes be disheartening to sacrifice writing with your style to writing with more jargon to a specific audience. After a while, you’ll find your “science writing voice;” practice truly does make perfect, and with a little time (and lots of editing), you’ll begin to produce writing that sounds like you but still delivers on that science aspect. Speaking of editing, your writings may go through many fine-tuning rounds before publication. Try not to take it personally, and be confident in your writing! Take every piece of criticism as a learning opportunity and make the best out of it.
+
+**What is your hope for our industry?**
+I hope to keep seeing a wide variety of people with different backgrounds and interests find LSC. I think many people see science communication and think they need a background in science and have to write all day, which couldn’t be farther from the truth. While I write a lot, I do it because I love it! However, people can go so many other avenues; from social media consulting to marketing, videography, lab work, genetics, social science research, and so many more; I can’t even name them all! For example, I’m currently conducting research using TikTok as my data source, which I didn’t even know would be a thing. I hope to continue to see this field continue to branch out and break down boundaries on what can be studied.
+
+**I’m curious about your research on Tiktok. Can you talk more about that?**
+Yes! I’m currently writing a thesis on how Tiktok has become a platform for psychological polarization - political polarization, in particular. We’re seeing an app that was originally intended to be an entertainment platform become a hub for information, including science communication. This new type of content “blew up” during the height of the pandemic in 2020, when scientists and doctors discovered that creating short videos on TikTok was a great way to reach a wide variety of audiences. However, as COVID-19 became politicized in the media, it did the same on TikTok. What’s even crazier than this is these videos about COVID-19 and the vaccine seem to have polarized its users to an extent unlike anything we’ve seen before. I think that’s super interesting and extremely important to study.
+This thesis was inspired by a book I read called Frenemies by Jaime E. Settle. She essentially studied the same thing I described but on Facebook. I thought Settle’s train of thought and reasoning were so interesting, but I remember finishing it and thinking, “too bad this isn’t going to matter in a couple of decades.” While this book really opened the door to this bigger conversation, Facebook is not a platform younger generations use. So, using her line of thinking, I wanted to conduct similar research using TikTok, an app that’s wildly more popular among my generation and younger and has users that regularly communicate about scientific issues. Saying that I do research on TikTok sounds a little silly, but I really do think that my work will be important for studying political polarization in the future!
+
+
+**What do you think you have accomplished for PATh?**
+I would like to think my work has given researchers something tangible to share with their families, friends, and peers about the details of their research. Everyone I’ve interviewed so far is doing such fascinating work, and my goal when I’m writing about it is to shine as big as a light on them and all their hard work as much as possible. With each article, I hope these researchers can read through my eyes how amazing all their accomplishments are and have a space where they can brag about it because they deserve to!
+On the flip side, I hope that I show researchers who may think that HTC can advance their work that it’s possible to get started. You don’t need to be a rocket scientist or even a computer scientist to use these resources; anyone who can benefit from using HTC to make their lives just a little easier should absolutely try it.
+
+**How has your work here impacted how you think about your future and your goals?**
+First and foremost, it has impacted how I think about science writing as not only an interest, but a possible career. I have learned so much and gained so much valuable experience and people seem genuinely curious about what it is I do.
+The jobs I have applied to post-graduation are more science writing and market research-type jobs at life sciences companies – which even a couple of years ago isn’t the trajectory I thought I would follow. That being said, I couldn’t be happier in discovering my passion for this type of work - I love my job so much, and I definitely see myself doing something like this for a very long time!
+
+**Hannah outside of work:**
+
+
+ Hannah Cheren’s dog.
+
+
+**When do you feel most like yourself?**
+I love Madison, but I’m an east coast girl at heart; I’m from New Jersey, and spending time with my family there is so important to me. We have a very active seven-year-old dog and I love taking her on walks with my two younger sisters, who have always been my best friends! They’re both at school as well, and I love spending as much time as I can with them and my parents!
+
+**If you could have dinner with, interview, and write about one person, alive or dead, who would it be and why?**
+Katherine Johnson. She was a mathematician at NASA and calculated trajectories that led Apollo 11 to the moon. She was also one of the first African American women to work at NASA.
+
+I was in highschool when the movie Hidden Figures came out. This movie tells the story of three young African American women working at NASA, including Katherine Johnson. I was in complete awe of Taraji P. Henson’s portrayal of Johnson, and I instantly became fascinated by her and her story. This movie was so inspiring as a young girl interested in pursuing studying in a STEM-related field, and Katherine Johnson, in particular, was a character who really stuck out to me. She passed away a couple of years ago, but I would’ve loved nothing more than to speak with her and express to her how much she had an impact on me as a girl in STEM!
+
+**If you had to describe your personality in a song, what would be the title?**
+Bubbly! I’m a big optimist.
+
+
+
+ Hannah and her sisters at an event.
+
+
+**What animal intrigues you the most and why?**
+Cows. We don’t see a lot of cows in New Jersey…so coming to Wisconsin and seeing them in fields every five minutes was so funny to me. I’ve had a running joke ever since that they’re my favorite animal, but now I think I tricked myself into actually believing it, so they intrigue me the most for sure!
+
+**Quick-fire questions**:
+- Vacation or staycation? Vacation. I love to travel! I’m going to Italy to visit my sister abroad and Israel during the summer with my sisters and cousin for birthright, and I couldn’t be more excited.
+- Tiktok or instagram? Tiktok.
+- Rom-com, action, supernatural or horror movies? Action; my friends from home got me on a Marvel binge recently!
+- Fine dining or casual? Casual.
+- Favorite decade for music? This is going to be so boring, but I don’t think I have a favorite decade of music. Most of what I listen to is from this decade, though. My favorite artist currently is Quinn XCII.
+- Thrifting or high street? Thrifting, for sure!
diff --git a/2023-04-27-CDIS-bldg.md b/2023-04-27-CDIS-bldg.md
new file mode 100644
index 00000000..571cd310
--- /dev/null
+++ b/2023-04-27-CDIS-bldg.md
@@ -0,0 +1,33 @@
+---
+title: Construction Commences on CHTC's Future Home in New CDIS Building
+
+author: Shirley Obih
+
+publish_on:
+ - chtc
+ - htcondor
+ - path
+
+type: news
+
+canonical_url: https://chtc.cs.wisc.edu/CDIS-bldg.html
+
+image:
+
+description: Breaking ground on new CDIS building
+excerpt:
+
+card_src:
+card_alt:
+
+banner_src:
+banner_alt:
+---
+
+Breaking ground is as symbolic as it is exciting – a metaphorical act of consecrating a new location and the start of something new. On April 25th, UW-Madison broke ground on 1240 W. Johnson St., Madison WI; a location that will become the new building for the School of Computer, Data & Information Sciences and the new home for the Center for High Throughput Computing (CHTC) in 2025.
+
+“The new CDIS building is the latest crest in a wave of expansion and renewal enhancing the campus landscape to meet the needs of current and future Badgers,” [the university reports](https://news.wisc.edu/governor-chancellor-to-break-ground-on-new-home-for-uws-newest-school/). This building, expected to be nearly 350000 square feet, will be the most sustainable facility on campus and will create a new center of activity for UW, enabling important connections and establishing a tech corridor from Physics and Chemistry to the Discovery Building to the College of Engineering.
+
+CHTC Technical Lead Todd Tannenbaum wryly remarks that "while the 1960's charm of our current old building is endearing at times (isn't cinder block making a comeback?), I am inspired by the opportunity to work every day in a new and modern building. I am also especially excited by how this will open up new possibilities for collaboration across not only Comp Sci, but also the community of faculty and researchers in the Information School, Statistics, and Data Sciences."
+
+Read more about the extensive construction plans ahead, the budget, and how the project is being funded [here](https://news.wisc.edu/governor-chancellor-to-break-ground-on-new-home-for-uws-newest-school/). Launch a virtual tour of the building [here](https://cdis.wisc.edu/building/tour/).
diff --git a/2023-10-24-GPARGO-CC*.md b/2023-10-24-GPARGO-CC*.md
new file mode 100644
index 00000000..02e99dda
--- /dev/null
+++ b/2023-10-24-GPARGO-CC*.md
@@ -0,0 +1,104 @@
+---
+title: Great Plains Regional CyberTeam Granted CC* Award
+
+author: Hannah Cheren
+
+publish_on:
+ - osg
+ - path
+ - chtc
+
+type: user
+
+canonical_url: https://path-cc.io/news/2023-10-24-great-plains-regional-cyber-team-granted-cc-award/ https://osg-htc.org/spotlights/great-plains-regional-cyber-team-granted-cc-award.html
+
+
+image:
+ path:
+
+ Group photo of those involved with the 2023 HTCondor European Workshop
+
+
+The ninth [2023 HTCondor European Workshop](https://indico.cern.ch/event/1274213/) took place September 19–22
+at [IJCLab](https://www.ijclab.in2p3.fr/en/home/) in Orsay, France, to join communities of high-throughput computing
+(HTC) users together. Attendees and HTCondor users have the opportunity to learn from developers and vice versa,
+HTCondor Core Developer Greg Thain says. During the workshops, “[I]nformation [is] going in all directions — developers
+to users, users to users, and users back up to developers,” Thain elaborates. Attendees discuss aspects of
+[HTCondor Software Suite (HTCSS)](https://htcondor.org/) and HTC that they like and areas that could undergo potential development.
+
+
+
+This year, one featured talk was from the [European Weather Cloud (EWC)](https://www.europeanweather.cloud/),
+part of the meteorological community, which just started using HTCondor, Thain mentions. In their presentation,
+Francesco Murdaca and Mike Grant discussed their challenges and current uses of HTC. Other HTCondor users like
+[DESY](https://www.desy.de/index_eng.html) and [CERN](https://home.cern/science/physics) also provided updates,
+challenges, and the scope of their current HTC uses.
+
+
+
+Another highlight was this year’s “Lightning Talks” sessions, which gave individual attention to users as a way
+for them to highlight what works, what doesn’t, and what they’re trying to accomplish, HTCondor Technical Lead
+Todd Tannenbaum says. These lightning talks spurred spontaneous discussion. Also included in this year’s programming
+was a discussion of [Pelican](https://pelicanplatform.org/), a new system for sharing data, Thain reveals.
+
+
+
+HTCSS provides distributed high-throughput computing (dHTC) resources to users in academic, government, and commercial
+organizations across the globe. High energy physics is a leading group of dHTC use, of which CERN in Geneva, Switzerland,
+is a major player. For high-energy physics, Thain explains that more computation needs to be done than can be accomplished
+in one physical area, so physics communities and member nations affiliated with CERN share resources with each other.
+However, HTCondor’s resources are not restricted to just these organizations — a broad range of scientific and research
+disciplines tap into its resources. “About 50% of the participants were regular participants — we’ve seen their faces at
+a lot of these workshops in Europe — but happily about 50% of the faces were new. So that was an encouraging sign, and
+we are making plans to have another one,” Tannenbaum says. “The audience has widened a bit from just the system administrators
+at these national labs that are doing the [LHC computing](https://home.cern/science/computing/grid) to include a couple of
+commercial companies and other universities.”
+
+
+
+The topics of discussion vary by year, Thain explains, depending on new developments or changes in the computing landscape,
+but are mainly driven by the Europeans. “One of the things we do in the year before is try and take the pulse of what’s new,
+what’s concerning, or what’s difficult and try to make sure that we have a workshop that addresses that,” Thain explains.
+“We’ve talked about the new tokens the last couple of years, and there’s been a lot of concern about electrical power, especially
+in terms of global events.” With the war in Ukraine and energy embargoes from Russia, electric prices have been less stable,
+Tannenbaum says, which is a big concern of European data centers. Security, energy management, and power-saving were big
+themes of this year’s workshops.
+
+
+
+One of the popular workshops — and one that Tannenbaum looks forward to — is the “Show Us Your Toolbox” session. During this
+session, “...folks from all the different national labs [show] how they solve problems like monitoring their cluster, managing
+data, and interactive work. Just talking about what challenges they have at their site and their solutions to date inspires
+good discussion amongst the participants,” Tannenbaum shares. Other topics up for discussion included how German sites were
+deploying HTCSS, ways to improve upon the current HTCSS, and the money and resources users saved with HTCSS.
+
+
+
+Another opportunity for users was participating in office hours, where they could take their computing issues to developers
+who work on HTCondor. For Tannenbaum, this is instructive because it helps him determine where people run into problems that
+he might not experience and understand which parts of HTCSS may need refining.
+
+
+
+Planning for the 2024 HTCondor European Workshop is already underway, with the venue set for [Nikhef](https://www.nikhef.nl/en/),
+the Dutch National Institute for Subatomic Physics, in Amsterdam, Tannenbaum reveals. Feedback from the attendees of this year’s
+workshop provided insightful information planners will take into account when they meet in a few months to discuss next year’s
+workshop. “Looking at the feedback from the user surveys, we felt that this was the proof of the importance of in-person workshops,”
+Tannenbaum says. Restricting the workshops to Zoom or other online formats, like what occurred in 2020, causes the workshops to
+become less participatory and more reliant on passive listening. “It was much more a series of lectures. [The format was like] slide
+show, next slide show, next slide show, which is useful to people, but it doesn't have that give and take and that everybody is
+sharing and thinking together,” Tannenbaum says of the online workshops.
+
+
+
+Across the globe, similar workshops have popped up or are in the beginnings of development in places like India and Southeast Asia,
+which the European workshops have had a part in spearheading, Tannenbaum says. “[T]here’s a lot of opportunities to
+network with people and share good ideas. If people are in Europe, we’d love to see them next year in Amsterdam. It’s a great
+opportunity to have high-level conversations with other users. These last 10 years of meetings have come out of the work that
+was done almost 30 years ago,” Thain states.
diff --git a/2023-11-10-chtc-workshop.md b/2023-11-10-chtc-workshop.md
new file mode 100644
index 00000000..797fbf51
--- /dev/null
+++ b/2023-11-10-chtc-workshop.md
@@ -0,0 +1,32 @@
+---
+title: CHTC Launches First Introductory Workshop on HTC and HPC
+
+author: Malia Bicoy
+
+publish_on:
+ - htcondor
+ - path
+ - chtc
+
+type: news
+
+canonical_url: https://chtc.cs.wisc.edu/chtc-workshop.html
+
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/CHTC_Workshop.jpg
+ alt: facilitation team introducing htc to students
+
+excerpt: On November 8, CHTC hosted a hands-on workshop for researchers new to high throughput computing (HTC) or high performance computing (HPC).
+
+---
+
+### On November 8, CHTC hosted a hands-on workshop for researchers new to high throughput or high performance computing
+
+The Center for High Throughput Computing (CHTC) facilitation team spent the morning of November 8 with over 50 students, researchers and faculty interested in learning high performance computing (HPC) and high throughput computing (HTC). Lead Research Computing Facilitator, Christina Koch, began by asking everyone in the room who had run into problems with computing on a single computer to raise their hand. Over half the room did so. Participants reported bottlenecks such as month-long run times or loops with millions of iterations. The facilitation team then delved into why these problems were happening and how CHTC could help.
+
+The workshop focused on identifying and practicing the steps needed to use a large-scale computing system at CHTC. Students were provided with detailed workflows and tools to improve their usage of high throughput computing or high performance computing. Hands-on examples were also incorporated, where attendees did the work themselves. Participants then got to “meet a server” and see what happens behind the scenes when they use CHTC resources.
+
+Given the attendance and high level of interest in this workshop, it certainly will not be the last. The CHTC facilitation team is planning to host additional large-scale computing workshops in the future for those that missed this opportunity.
+
+
+
diff --git a/2023-11-10-rachel-lombardi-feature.md b/2023-11-10-rachel-lombardi-feature.md
new file mode 100644
index 00000000..df0f8c2a
--- /dev/null
+++ b/2023-11-10-rachel-lombardi-feature.md
@@ -0,0 +1,106 @@
+---
+title: Get to Know CHTC Research Computing Facilitator Rachel Lombardi
+
+author: Sarah Matysiak
+
+publish_on:
+ - htcondor
+ - path
+ - osg
+ - chtc
+
+type: news
+
+canonical_url: https://chtc.cs.wisc.edu/get-to-know-rachel-lombardi.html
+
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/lombardihiking.png
+ alt: Rachel Lombardi hiking at Yosemite National Park during grad school at UC Davis
+
+excerpt: Staff profile of Research Computing Facilitator Rachel Lombardi
+
+---
+**Lombardi’s journey to computational research wasn’t linear, but she’s glad to have found her way to the CHTC**
+
+
+
+**Did you always know you would end up in computational research?**
+I always knew that I wanted to go into something science-related, but not necessarily with a computational focus. When I was in high school, I knew I didn't want to do medicine because my family was very medicine-focused, so I explored the concept of food science. I interned with Kellogg and loved food science — the process of product development, the scientific side of food, and the quick production aspect of it. But, I had already committed to the University of Michigan, which did not have a food science program, and decided to do four years there to get a B.S. in Biochemistry. When I graduated, I was still interested in exploring the food science route, so I did a Ph.D. at the University of California, Davis, in food science. As a part of that Ph.D., I did a lot of computational research involving sequencing, transcriptomics, proteomics, and metabolomics. My research was focused on understanding the plant response to a deadly citrus disease.
+
+Exploring the computational side of my research ended up being more enjoyable than the actual food science side, but since my background was in the life sciences, I struggled with the computational side. It was a fun relationship, but also very stressful trying to learn all this by myself. I ended up finding some amazing mentors outside of my lab and becoming a part of this computational research community that helped teach me skills to do my work. In the end, I appreciated them so much and I loved what they had done. I knew this was what I wanted to do — help other people do their research.
+
+
+
+
+**What was your path to becoming a research computing facilitator?**
+One of the communities that I was exposed to in grad school while trying to complete my research was called The Carpentries. The Carpentries provides a lot of resources for teaching computational tools, and I loved the community so much that I became an instructor for them. As a part of being an instructor, you’re also put on their mailing lists, and it was the facilitators here [the UW-Madison Center for High Throughput Computing (CHTC)] who posted this job to that mailing list. It was not even a question for me; I knew this was the job for me. I had never been to Wisconsin, never been to Madison, and it was during the pandemic, but I was like “This is what I want to do, and if they'll have me, I will go.”
+
+
+
+
+**Has coming from a biochemistry and food science background to computational research been a learning curve?**
+Absolutely. It’s a challenge not being able to fully understand the details of what's going on with our various high throughput and high performance computation resources. But there’s such a breadth of what we do that even a computer scientist on the team likely does not understand every component. However, I also think this makes me much better at doing my job. It can be challenging for a computer scientist to talk to someone from biology or a different discipline when they have not carried out bench-top or field research before. It's really important to have a facilitator who can serve as the middleman, where I can communicate with the computer scientist but can also distill it for an individual researcher and see how that's going to apply to their research projects. Ultimately, this makes me better at my job.
+
+
+
+
+**What are some of your tasks and favorite parts of your role?**
+My favorite part is working with other CHTC staff members. The CHTC team is very collaborative and so much fun to work with. I also enjoy the creative exchange of ideas.
+
+As a facilitator, my role requires interdisciplinary and multi-tasking components of my job. I like to be able to spend part of my day learning about a tool to help a researcher and another part of my day planning a training event that's coming up — I'm not restricted to just one science domain. That hustle and bustle, interdisciplinary aspect makes every day different
+
+I also love working with researchers and hearing about what a grad student or a lab is going to be diving into over the next few years as they plan future analyses, or helping them identify solutions for computational problems they are currently tackling. It's fun to be able to see what science is underway, what their results could show, and how it could help others.
+
+
+
+
+**What are some challenges and triumphs you have faced while on the job?**
+Let's start with challenges. This job requires an incredible amount of flexibility and multitasking skills. Things could change in a minute: your plans for the day, your plans for the week, your plans for the month. That’s constantly happening with this job, so I need to be able to reassess priorities and help facilitate two or three different computing systems. It also requires keeping on top of what has changed with one system that hasn't changed for another. Because my background is not computer science, it’s not something that comes easily.
+
+As far as the triumphs, my triumphs are when we help make computing click for researchers. It's an exciting moment when you see that they understand what they're doing and that they understand how to apply these resources to make their research better. It’s so rewarding to see that happen and to see them meet their goals of going to a conference, getting published, or even graduating. It's rewarding because I know how hard they've worked, and I'm happy that we were there to support them.
+
+
+
+
+**What impact do you hope to have?**
+I want to help advance research in whatever way that I can. I am inspired by researchers of different domains, what it [high-throughput computing] can do for people today and in the future, and how it can be all interconnected. Anything that I can do to help a researcher get their work done is my goal at the end of the day, and if that’s using our computing resources, great; I will help you use them. If that means not using our computing resources and telling somebody else that this is not the best way for them to get their research done, we will also be very upfront with that as well. Research can be a very isolating experience. To have that researcher know that they are being supported and that someone’s on their team as much as we can be is a goal of mine.
+
+
+
+
+**Can you tell me about your involvement with the NIAID?**
+The [OSG] has many collaborations with different government, academic, and nonprofit entities, one of them being the [National Institute of Allergy and Infectious Diseases] (NIAID). As a part of that collaboration, I was able to travel to Uganda, which was an incredible experience for so many reasons.
+
+
+
+ Rachel Lombardi (left) and OSG Executive Director Frank Wuerthwein (right) in Uganda.
+
+
+In Uganda, I led a workshop for researchers who were part of the African Centers of Excellence (ACE) in the bioinformatics program. I worked with the researchers there to show them how their research could benefit from using OSPool resources.
+
+Being able to meet with researchers in person at Makerere University was just incredible — there are so many things that are hard to grasp until you're there. They have a high-performance computing system over there that, in theory, they can use, but they don't have stable power. I would be sitting in a meeting with important leaders from universities and different U.S. computing centers, and the power shuts off. Things like that are hard to comprehend until you're there, and I grew so much from that experience. I began to understand what their challenges were and what we could do to address them.
+
+One of the questions that I still think about so much is that I was mentioning office hours in my talk as a form of support and just kept saying “Don't worry, you're not alone. We have office hours.” About midway through my talk, somebody raised their hand and asked what office hours were. That cultural difference made me reevaluate how we can provide better support for communities in the U.S. and our collaborators abroad. It also made me realize that researchers can have vast differences in their backgrounds.
+
+Some ACE students also attended the last two OSG Schools. I was able to once again work with them for a week. We’re starting to see a lot of fruition in their research and it's exciting.
+
+
+
+
+**How do you spend your time outside of work?**
+I travel a fair amount for work and fun. I'm really lucky my family is around the United States, so I almost always have some place that I can go.
+
+I enjoy the Madison art scene with friends. There's a craft fair you can almost certainly find me at.
+
+I'm getting into home improvement projects, and my apartment makes a great test bed. I've been getting fairly comfortable with power tools like saws, table saws, and miter saws.
+
+
+
+ Hiking at Yosemite National Park during grad school at UC Davis
+
+
+
+
+
+**What’s your favorite place you’ve traveled to?**
+My favorite place is probably Mackinac Island in northern Michigan. It was a place that my family would go on trips to growing up, and there’s no cars allowed on the very small island — it’s just horse-drawn carriages or bikes. All day, you just eat fudge because there are a lot of fudge-making places. I just have a lot of good and happy memories there.
diff --git a/2023-11-10-spalding-lab.md b/2023-11-10-spalding-lab.md
new file mode 100644
index 00000000..b37ccb7f
--- /dev/null
+++ b/2023-11-10-spalding-lab.md
@@ -0,0 +1,62 @@
+---
+title: Plant physiology researchers used high throughput computing to remedy research “bottleneck”
+
+author: Sarah Matysiak
+
+publish_on:
+ - htcondor
+ - path
+ - osg
+ - chtc
+
+type: user
+
+canonical_url: https://chtc.cs.wisc.edu/spalding-lab.html
+
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/spaldinglab.jpg
+ alt: Members of the Spalding Research Lab
+
+excerpt: The Spalding lab uses high-throughput computing to study plant physiology
+
+---
+
+**Once they began using HTC resources, the Spalding Lab was able to increase their efficiency in data collection and analysis and develop new methodologies.**
+
+
+
+Enhancing his research with high throughput computing was a pivotal moment for University of Wisconsin–Madison molecular plant physiologist Edgar Spalding when his [research group](https://spalding.botany.wisc.edu/) started using it in 2006. Over the past five years, the research group has used approximately 200,000 computing hours, including as a way to "develop the measurement algorithm and to process the tens-of-thousands of images automatically" of maize seedling root growth when rotated horizontally, Spalding says.
+
+
+
+ Data on the average gravitropic response of each of the maize gathered from using HTC types
+
+
+
+Spalding’s research group was studying Arabidopsis plant populations with genetically diverse members and tracking their response to light or gravity due to a mutation — one seedling at a time. Since Arabidopsis seedlings are only a few millimeters tall, Spalding says his research group found that obtaining high-resolution digital images was the best approach to measure the direction of their growth. A computer collected images every few minutes as the seedlings grew. “If we could characterize this whole genetically diverse population, we could use the powerful techniques of statistical genetics to track down the genes affecting the process. That meant we now had thousands and thousands of images to measure,” Spalding explains.
+
+
+
+The thousands of digital images to measure created a bottleneck in Spalding’s research. That was before he led an effort with [Center for High Throughput Computing (CHTC)](https://chtc.cs.wisc.edu/) Director Miron Livny, other plant biologists, and computer scientists to develop a proposal for a competitive National Science Foundation grant that would produce cyberinfrastructure to support plant biology research. Though the application wasn’t successful, the connections Spalding made from that meeting were meaningful nonetheless.
+
+
+
+Speaking with Livny at the meeting — from whom he learned about high throughput computing — helped Spalding realize the inefficiencies of his group in analyzing thousands of seedlings. “[O]ur research up until that point had been focused on one seedling at a time. Faced with large numbers of seedlings to do a broader scale of investigation meant that we had to find computing methodologies that matched our new data type, which was tens of thousands of images instead of a couple of dozen. That drove our need for a different way of computing,” Spalding describes.
+
+
+
+When asked about which accomplishment using high throughput computing (HTC) was most impactful, Spalding said “The way we measure yield-related features from maize ears and several thousand kernels has had a large impact.” The Spalding Lab had others from around the world asking for their help in making these measurements. “In many cases, we can use our workflow [algorithms] running on CHTC to process their images of maize ears and kernels and return data that helps them answer their scientific or crop breeding questions,” Spalding says.
+
+
+
+The Spalding Lab did not need to adjust the type of data they collected. Rather, using HTC changed the way they created tools to analyze the data. Today, Spalding says his research group continues to use HTC in three ways: “from tool development to extracting the features from the images with the tool that you developed to applying it in the challenge of statistically matching it to elements of the results to elements of the genome.” As his team became more experienced in writing new algorithms to make measurements, they realized that HTC was useful in developing new methodologies; it was more than just increased computing capacity.
+
+
+
+In other words, HTC is useful as both a development resource and a production resource. Making measurements on seedlings and then matching processes to the genome elements that control those processes involved a lot of computation. “We realized that statistical modeling of the measurements from the biology to the genetic information in the population also benefited from high throughput computing.” HTC in all these cases, Spalding elaborates, “was beneficial and changed the way we work. It changed the nature of the questions we asked.” In addition to these uses of HTC, the research group’s uses of machine learning (ML) also continue to become a bigger part of the tool development stage and in driving the methods to train a model to recognize a feature in a seedling.
+
+
+
+Spalding has also spoken at the [OSG School](https://osg-htc.org/user-school-2023/) in the past. Spalding emphasizes that students “should not do something because they think computing will be a bottleneck. There are ways to bring the computing they need to their problem and they should not shy away from a question just because they think it might be difficult to compute. There are people like the CHTC staff that can remove that bottleneck if the person’s willing to learn about it.”
+
+
diff --git a/2023-11-17-hanna-lab.md b/2023-11-17-hanna-lab.md
new file mode 100644
index 00000000..0c66f140
--- /dev/null
+++ b/2023-11-17-hanna-lab.md
@@ -0,0 +1,124 @@
+---
+title: Training a dog and training a robot aren’t so different
+
+author: Sarah Matysiak
+
+publish_on:
+ - path
+ - chtc
+ - osg
+ - htcondor
+
+type: user
+
+canonical_url: https://chtc.cs.wisc.edu/hanna-lab.html
+
+
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/hannalab.png
+ alt: Group photo of members of the Hanna Lab
+
+excerpt: In the Hanna Lab, researchers use high throughput computing as a critical tool for training robots with reinforcement learning.
+
+---
+
+**For AI and robotics researcher Josiah Hanna and his lab, high throughput computing is a critical tool in reinforcement learning.**
+
+
+
+
+Artificial intelligence (AI) robotics expert [Josiah Hanna](https://pages.cs.wisc.edu/~jphanna/)’s research has a lot in common with training dogs: Both robotics training and dog
+training use a type of reinforcement learning to encourage the desired behavior. With computers or robots, however, this type of reinforcement learning is a branch of machine learning (ML) that models an intelligent agent interacting with a task environment.
+
+
+
+
+Comparing robotic reinforcement learning to training a dog how to sit, Hanna explains that “you don’t explicitly tell the dog how to sit, but you coax the dog into sitting, and when it
+shows that behavior, you reward that. Over time, the robot dog learns these are the actions that lead to getting the reward, and it learns to avoid actions that don’t lead to the reward.
+We want to give computers and robots the ability to learn through experience, by seeing what works and what leads to them achieving the goals we set for them. Then, when they see the
+actions that lead to reaching their goals, they know that they should do that again in the future.”
+
+
+
+In other words, Hanna’s research specifically seeks to develop algorithms that enable computers to learn goal-oriented behavior in order to better accomplish their goals. Unlike a dog,
+robots aren’t necessarily rewarded but instead learn from past mistakes and take that information to determine what a successful action is. Through trial and error, the agent learns
+which actions it needs to take to achieve its goals. “It’s critical that they’re [computers] able to learn through their experience. That's what my research and the whole field of
+reinforcement learning studies — the kinds of algorithms which will enable this to happen,” Hanna elaborates.
+
+
+
+Another way that UW–Madison Computer Sciences Ph.D. student [Nicholas Corrado](https://nicholascorrado.github.io/) describes it is like teaching a robot how to walk. Initially, the
+robot moves its legs randomly and likely falls over. Through trial and error, however, the robot eventually discovers that it can make forward progress by moving its legs to take
+only a single step forward. Wanting to maximize its forward progress, the robot then increases the probability of executing this stepping behavior and eventually learns how to walk.
+“It requires a lot of computing to do this because starting from random movements, and getting to walking behavior is not super straightforward,” Corrado elaborates.
+
+
+
+Unlike other types of ML that are classification-based, a lot of reinforcement learning relies on simulations because it’s based on modeling agents performing some task. The difference
+between other areas of ML and reinforcement learning, Corrado explains, is that with reinforcement learning, “You have this multi-step decision-making process that you must learn how
+to solve optimally. It’s so much harder because the agent needs to learn how its action right now affects its performance way down the road, so reinforcement learning feels like a much
+harder problem to focus on than what we call supervised learning methods.”
+
+
+
+Since learning on physical robots is difficult, Hanna’s lab will sometimes use simulations as a “surrogate” for physical robots. This is where high throughput computing (HTC) becomes
+a valuable tool. Hanna shares that “it’s really useful to have high throughput computing so you can run your simulation or learning algorithm for many different processes. You can see
+how different learning algorithms or different parameters for learning algorithms affect the ability of an algorithm to produce robust behavior or high-performing behavior.” In this
+sense, the [Center for High Throughput Computing (CHTC)](https://chtc.github.io/) is a “huge resource” for Hanna’s students who evaluate a wide variety of different algorithms they
+think might work better than previous ones. It’s a great enabler of increasing experimentation bandwidth, or how many experiments they can run. In fact, for the Hanna Lab, its CHTC
+usage is nearly 5.7 million hours.
+
+
+
+One project the Hanna lab is working on is enabling robots to learn to play soccer, Corrado says. With reinforcement learning, researchers programmed robots to play soccer and then
+entered an annual [international competition](https://www.robocup.org/) where they placed third despite it being their first time participating, “greatly exceeding our expectations,”
+Corrado highlights. The end goal isn’t necessarily to train robots how to play soccer but rather “develop reinforcement learning techniques that enable us to train agents to work
+cooperatively” and “develop techniques that improve the data efficiency of reinforcement learning. If we can reduce the data requirement, reinforcement learning is going to be much,
+much more practical for industrial applications.”
+
+
+
+
+ From the annual RoboCup Standard Platform League (SPL) competition, a research competition that aims to advance the capabilities of robotics
+in challenging, real-time domains.
+
+
+
+
+
+ Even before Hanna came to UW–Madison, he had experience with [HTCondor Software Suite (HTCSS)](https://htcondor.org/) from graduate school. It was a “critical resource” for Hanna then
+and remains as such today in his role as a researcher and professor at UW–Madison. “One of the first things I did when I got here [UW–Madison] was tap into HTC resources,” Hanna recalls.
+As a new principal investigator (PI), Hanna also had a meeting with a CHTC facilitator to learn how to obtain access and what resources it provides.
+
+
+
+Since he found the tool so valuable while he was a graduate student, Hanna also tries to set up his students with the CHTC early on instead of running experiments locally on their
+computers. Hanna shares “It's a great resource we have to leverage that helps speed things up.” For the research group, running a high volume of simulations and experiments is a
+key enabler of progress. This means Hanna encourages his students to run experiments whenever they reach uncertainties, which can help provide clarity. “Oftentimes it's just easier
+to run the experiment. Something I try to guide the students on is knowing when some experiments just need to be run to understand some aspect of designing reinforcement learning
+algorithms.” His students are developing their own pipelines with CHTC, learning how to work more efficiently with it, and writing scripts to launch experiments with it.
+
+
+
+To put into context exactly how many experiments reinforcement learning requires, Corrado says, “Benchmarks contain anywhere from 5–10 tasks, and maybe you need to compare four
+different algorithms and run 20 independent runs of each algorithm on each task. At that point, you’re running hundreds of experiments. I’ve even had to run thousands of experiments.”
+In fact, for a paper currently under review, through performing a hyperparameter sweep of an algorithm — which determines the hyperparameter combination that performs best out of
+many combinations — Corrado had submitted enough jobs to hit the default CHTC limit of a 10,000-job submission. This was something he definitely could not have accomplished on his
+personal laptop or with a lab-specific server.
+
+
+
+Hanna says he is also seeing a shift toward more high-performance computing with GPUs in his lab, which CHTC has helped enable. “Up until recently, reinforcement learning was
+separate from other forms of deep learning that were going on, and you really couldn't benefit that much from a GPU unless you had a lot of CPUs as well, which is what high
+throughput computing is really good for,” Hanna explains.
+
+
+
+When asked about the future use of CHTC in his lab, Hanna imagines spending more time with multi-processing and networking several CPUs together, both of which reinforcement
+learning experiments could benefit from. As CHTC continues increasing its GPU capacity, Hanna says he plans to use that more in their work as well.
+
+
+
+Without the CHTC, the type of large-scale experimentation the Hanna Lab uses would be impractical, Corrado says. For this type of work, HTC is almost always necessary and continues
+to expand the horizons of the lab.
diff --git a/2023-11-27-adjacent-tissues-paper.md b/2023-11-27-adjacent-tissues-paper.md
new file mode 100644
index 00000000..825af746
--- /dev/null
+++ b/2023-11-27-adjacent-tissues-paper.md
@@ -0,0 +1,85 @@
+---
+title: Using HTC expanded scale of research using noninvasive measurements of tendons and ligaments
+
+author: Sarah Matysiak
+
+publish_on:
+ - htcondor
+ - path
+ - osg
+ - chtc
+
+type: user
+
+canonical_url: https://chtc.cs.wisc.edu/adjacent-tissues-paper.html
+
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/jonblank.jpg
+ alt: Jonathon Blank, a co-author of the paper
+
+excerpt: With this technique and the computing power of high throughput computing (HTC) combined, researchers can obtain thousands of simulations to study the pathology of tendons and ligaments.
+
+---
+**With this technique and the computing power of high throughput computing (HTC) combined, researchers can obtain thousands of simulations to study the pathology of tendons
+and ligaments.**
+
+
+
+A recent paper published in the [Journal of the Mechanical Behavior of Biomedical Materials](https://www.sciencedirect.com/science/article/abs/pii/S1751616123004915) by former Ph.D.
+student in the Department of Mechanical Engineering (and current post-doctoral researcher at the University of Pennsylvania)
+[Jonathon Blank](https://www.med.upenn.edu/orl/personnel/jonathon-blank-ph-d.html) and John Bollinger Chair of Mechanical Engineering
+[Darryl Thelen](https://directory.engr.wisc.edu/me/faculty/thelen_darryl/) used the [Center for High Throughput Computing (CHTC)](https://chtc.github.io/) to obtain their results.
+Results that, Blank says, would not have been obtained at the same scale without HTC. “[This project], and a number of other projects, would have had a very small snapshot of the
+problem at hand, which would not have allowed me to obtain the understanding of shear waves that I did. Throughout my time at UW, I ran tens of thousands of simulations — probably
+even hundreds of thousands.”
+
+
+
+ Post-doctoral researcher at the University of Pennsylvania Jonathon Blank.
+
+
+Using noninvasive sensors called shear wave tensiometers, researchers on this project applied HTC to study tendon structure and function. Currently, research in this field is hard
+to translate because most assessments of tendon and ligament structure-function relationships are performed on the benchtop in a lab, Blank explains. To translate the benchtop
+experiments into studying tendons in humans, the researchers use tensiometers as a measurement tool, and this study developed from trying to better understand these measurements
+and how they can be applied to humans. “Tendons are very complex materials from an engineering perspective. When stretched, they can bear loads far exceeding your body weight, and
+interestingly, even though they serve their roles in transmitting force from muscle to bone really well, the mechanisms that give rise to injury and pathology in these tissues aren’t
+well understood.”
+
+
+
+ John Bollinger Chair of Mechanical Engineering Darryl Thelen.
+
+
+In living organisms, researchers have used tensiometers to study the loading of muscles and tendons, including the triceps surae, which connects to the Achilles tendon, Blank notes.
+Since humans are variable regarding the size, stiffness, composition, and length of their tendons or ligaments, it’s “challenging to use a model to accurately represent a parameter
+space of human biomechanics in the real world. High throughput computing is particularly useful for our field just because we can readily express that variability at a large scale”
+through HTC. With Thelen and Orthopedics and Rehabilitation assistant professor [Josh Roth](https://directory.engr.wisc.edu/me/Faculty/Roth_Josh/), Blank developed a pipeline for
+simulating shear wave propagation in tendons and ligaments with HTC, which Blank and Thelen used in the paper.
+
+
+
+With HTC, the researchers of this paper were able to further explore the mechanistic causes of changes in wave speed. “The advantage of this technique is being able to fully explore
+an input space of different stiffnesses, geometries, microstructures, and applied forces. The advantage of the capabilities offered by the CHTC is that we can fill the entire input
+space, not just between two data points, and thereby study changes in shear wave speed due to physiological factors and the mechanical underpinning driving those changes,” Blank
+elaborates.
+
+
+
+It wasn’t challenging to implement, Blank states, since facilitators were readily available to help and meet with him. When he first started using HTC, Blank attended the CHTC
+office hours to get answers to his questions, even during COVID-19; during this time, there were also numerous one-on-one meetings. Having this backbone of support from the CHTC
+research facilitators propelled Blank’s research and made it much easier. “For a lot of modeling studies, you'll have this sparse input space where you change a couple of parameters
+and investigate the sensitivity of your model that way. But it’s hard to interpret what goes on in between, so the CHTC quite literally saved me a lot of time. There were some
+1,000 simulations in the paper, and HTC by scaling out the workload turned a couple thousand hours of simulation time into two or three hours of wall clock time. It’s a unique tool
+for this kind of research.”
+
+
+
+The next step from this paper’s findings, Blank describes, is providing subject-specific measurements of wave speeds. This involves “understanding if when we use a tensiometer on
+someone’s Achilles tendon, for example, can we account for the tendon's shape, size, injury status, etcetera — all of these variables matter when measuring shear wave speeds.”
+Researchers from the lab can then use wearable tensiometers to measure tension in the Achilles and other tendons to study human movement in the real world.
+
+
+
+From his CHTC-supported studies, Blank learned how to design computational research, diagnose different parameter spaces, and manage data. “For my field, it [HTC] is very important
+because people are extremely variable — so our models should be too. The automation and capacity enabled by HTC makes it easy to understand whether our models are useful, and if
+they are, how best to tune them to inform human biomechanics,” Blank says.
diff --git a/2023-12-12-osgschool.md b/2023-12-12-osgschool.md
new file mode 100644
index 00000000..c914ae41
--- /dev/null
+++ b/2023-12-12-osgschool.md
@@ -0,0 +1,56 @@
+---
+title: "OSG School mission: Don’t let computing be a barrier to research"
+
+author: Malia Bicoy
+
+publish_on:
+ - chtc
+ - osg
+ - htcondor
+ - path
+
+type: news
+
+canonical_url: "https://chtc.cs.wisc.edu/osgschool.html"
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/OSG-User-School.jpg"
+ alt: The OSG School 2023 attendees
+
+excerpt: |
+ The OSG Consortium hosted its annual OSG School in August 2023,
+ assisting participants from a wide range of campuses and areas of research through HTC learning.
+
+---
+
+Most applicants to the annual OSG School share a common challenge: obstacles within their research that they would like to overcome. Answering this need, the [OSG Consortium](https://osg-htc.org/) holds an annual weeklong School each summer for researchers and facilitators to expand their adoption of high throughput computing (HTC) methodologies. Instructors teach students through a combination of lectures and hands-on activities, starting out with the basics to accommodate all experience levels.
+
+This year the 11th OSG School took place in August, with over 50 participants from across the nation as well as 5 attendees from Uganda and Mali, representing over 30 campuses or institutions and 35 research domains.
+
+Online applications to attend the School open in March. Applicants are considered based on how large-scale computing could benefit their research. Over 100 applications are submitted each year, with around 60 being admitted. All of the participants' travel and accommodation expenses are covered with funding from the [Partnership to Advance Throughput Computing](https://path-cc.io/) (PATh) NSF award.
+
+The OSG School Director [Tim Cartwright](https://www.cs.wisc.edu/staff/cartwright-tim-2/) believes this year’s participants had as diverse computing experiences as they do backgrounds. “Some had never heard about large-scale computing until they saw the School announcements,” he said, “and others had been using it and recognized they were not getting as much out of it as they could.”
+
+The obstacles researchers encountered that motivated their application to the School varied. Political Methodology Ph.D. candidate at the University of Wisconsin–Madison [Saloni Bhogale](https://polisci.wisc.edu/staff/bhogale-saloni/) attended this year’s School after applying HTC methods to her research for almost a year. Her research — which analyzes factors affecting access to justice in India — requires computation over millions of court cases and complaints. Bhogale found that her jobs kept abruptly halting throughout the year, and she was puzzled about how to resolve the problem and how the HTC services were operating. “There were too many hiccups I was constantly running into,” Bhogale said, “I felt like I was more confused than I should be.” When she saw a flier for the OSG School, she decided some extra help was in order.
+
+Assistant Professor [Xiaoyuan (Sue) Suo](http://mercury.webster.edu/xiaoyuansuo/) works in the Department of Math and Computer Science at Webster University and decided to attend the OSG School because she wanted to know more about HTC and its applications. “I never had systematic training,” she explained, “I felt training would be beneficial to me.”
+
+Another participant at this year’s user school was [Paulina Grekov](https://edpsych.education.wisc.edu/staff/grekov-paulina/), a doctoral student in Educational Psychology at the University of Wisconsin–Madison. She works in the quantitative methods program and runs complex statistical models of educational studies. Grekov originally tried to run computations without HTC, but it was taking a toll on her personal computer. “Some of the modeling I was doing, specifically statistical modeling, was just frying my computer. The battery was slowly breaking — it was a disaster — my computer was constantly on overdrive,” Grekov recalled.
+
+During the School, participants were taught the basics of HTC. They were guided through step-by-step instructions and lectures, discussing everything from [HTCondor](https://htcondor.org/) job execution to troubleshooting. Each topic was accompanied by hands-on exercises that allowed attendees to experience the power of HTC. The School also delved into extra topics that could be useful to students, like workflows with [DAGMan](https://htcondor.org/dagman/dagman.html) and GPUs.
+
+Bhogale recalls that she appreciated the time participants were given to work on their own science applications and the ease of finding an expert to answer her questions. “I was running a pilot of the processes that I would want to do during the School — everyone was right there. So if I ran into an issue, I could just talk to someone,” she said.
+
+On the last day of the School, the students had an opportunity to showcase what they learned during the week by presenting lightning talks on how they plan to apply HTC in their research. From tracing the evolution of binary black holes to estimating the effect of macroeconomic policies on the economy, ten participants presented ways in which their work could benefit from HTC.
+
+Postdoctoral Ecologist Researcher [Kristin Davis](https://fwce.nmsu.edu/faculty-staff/professional-staff.html) from New Mexico State University gave a lightning talk on how she would utilize HTC to run her large environmental datasets concerning the American Kestrel faster. [Yujie Wan](https://astro.illinois.edu/directory/profile/yujiew2) from the astronomy department at the University of Illinois Urbana-Champaign talked about how HTC could help her create astronomical maps using a submit file for each observation. Wan said she could then make a DAG file that combines her submit files and have all her maps in just two hours. [Cyril Versoza](https://search.asu.edu/profile/3419308), a graduate research assistant for the Pfeifer Lab at Arizona State University, discussed how the OSG would be a suitable system to implement a mutational spectrum pipeline for his work in evolutionary biology.
+
+Lightning presentations like these open the door for researchers to hear from those outside of their fields. Participants also had the opportunity to hear from researchers who have already made progress in their research applying HTC. “I remember coming back almost every day and talking to my friends and saying there’s fascinating research happening,” Bhogale said.
+
+The 2023 OSG School also marked the second year that the School collaborated with the [African Centers of Excellence in Bioinformatics and Data-Intensive Science (ACE) Program](https://www.niaid.nih.gov/research/african-centers-excellence) facilitated by the [National Institute of Allergies and Infectious Diseases (NIAID)](https://www.niaid.nih.gov/). ACE aims to bring large-scale computing to Africa. Joint NIAID and PATh support enabled five ACE students from Mali and Uganda as well as two staff members from NIAID to come to the School. “To work with the students and work with the staff from NIAID, it makes things feel more complete,” Cartwright said.
+
+After the school ended, some of this year’s attendees provided advice for prospective OSG School students. Grekov recommended that those who attend come in with a goal and a research question in mind. She believes it would lead students to ask the right questions and focus on particular aspects. “Come with an idea you want to solve,” she said. Bhogale recommended any potential student who is concerned about the difficulty of the School to simply “go all in.” She hopes to see more of the social science crowd, like herself, incorporating HTC into their research.
+
+The 2023 OSG School was one event among a variety of activities that have furthered the spread of large-scale computing in the research world. Tim Cartwright says the goal of the School goes beyond selective expansion, however. “The big picture is always focused on the democratization of access to computing for research,” he said. “We’re trying to make it available to everyone in higher education, regardless of the scale of their computational needs.”
+
+****
diff --git a/2023-12-13-GLUE-lab.md b/2023-12-13-GLUE-lab.md
new file mode 100644
index 00000000..1b3a8b41
--- /dev/null
+++ b/2023-12-13-GLUE-lab.md
@@ -0,0 +1,114 @@
+---
+title: How the GLUE Lab is bringing the potential of HTC to track the movement of cattle and land use change
+
+author: Sarah Matysiak
+
+publish_on:
+ -
+
+ Cattle grazing grass on the Cerrado in rural Mato Grosso, Brazil.
+
+
+
+
+
+
+It was during a [Data Science Research Bazaar](https://datascience.wisc.edu/2023/10/12/share-your-work-at-the-2024-research-bazaar/) presentation led by OSG Research Facilitation
+Lead Christina Koch in early 2023 when [Matthew Christie](https://gibbs-lab.wisc.edu/matt-christie.html), the Technical Lead of the [Global Land Use and Environment Lab (GLUE)](https://gibbs-lab.wisc.edu/)
+based in Madison, Wisconsin, says the GLUE Lab became more familiar with the [Center for High Throughput Computing (CHTC)](https://chtc.github.io/). “That planted the seed for what
+the center [CHTC] could offer us,” Christie says.
+
+
+
+ GLUE Lab technical lead Matthew Christie.
+
+
+
+
+
+
+
+The GLUE Lab studies how land across the world is being used for agriculture and the systems responsible for land use change. Christie — who researches land use in Brazil with a
+focus on how the Amazon and Cerrado biomes are changing as natural vegetation recedes — takes data describing the cattle supply chain in Brazil and integrates it into a single
+database the GLUE Lab can use for research. With this data, the lab also aims to inform policy decisions by the Brazilian government and international companies.
+
+
+
+In the Amazon, Christie says, one of the main systems causing land use change is in the cattle sector, or the production of cattle. “One of the motivating facts of our research
+is that 80% of forest cleared in the Amazon is cleared in order to raise cattle. And so we're interested in understanding the cattle supply chain, how it operates, and what it
+looks like.” The lab gets its data from the Rural Environmental Registry (CAR), which is a public property boundary registry data from Brazil, and the Guide to Animal Transport
+(GTA), which records animal movement and sales in Brazil.
+
+
+
+The possibilities of utilizing high throughput computing (HTC) for the lab's research intrigued Christie, who had some awareness of HTC from the research bazaar and had even started refactoring some of the lab’s
+data pipeline before attending, but he wanted to learn more besides what he gained from watching introductory tutorials. Christie was accepted and attended the [OSG School](https://osg-htc.org/user-school-2023/)
+in the summer of 2023. He and other lab members believed their work could benefit from the school training with [HTCondor](https://htcondor.org/), the workload management application developed by the CHTC for HTC, and the associated big data sets
+with a large number of jobs.
+
+
+
+Upon realizing the lab’s work could greatly benefit from the OSG School, Christie used a “test case” project that resembled a standard research project to model a task with many
+independent trials, finding how — for the first time — HTC could prove itself resourceful for GLUE Lab research. The specific project Christie worked
+on during the School using HTC was to compute simulated journeys of cows through properties in Brazil's cattle supply chain. By the end of the week-long School, Christie says
+using HTC scaled up the modeling project by a factor of 10. In this sense, HTC is the “grease that makes our research run more smoothly.”
+
+
+
+Since attending the School, witnessing the test case’s success with HTC, and discovering ways its other research projects could benefit, the GLUE Lab has begun shifting to applying
+HTC. However, this process requires pipeline changes lab members are currently working through. “We have been in the process of working through some of our big projects that we
+think really could benefit from these resources, but that in itself has a cost. Currently, we’re still in the process of writing or refactoring our pipelines to use HTC,” Christie
+elaborates.
+
+
+
+For a current project, Christie mentions he and other GLUE Lab members are looking at how to adapt their code to HTC without having to rewrite all of it. With the parallelism that
+HTC offers compared to the single computing environment the lab used before to run its data pipeline, each job now has its own environment. But it’s complex “leveraging the
+parallelism in our database build pipeline. Working on that is an exercise, but with handling data, there are many dependencies, and you have to figure out how to model them.”
+Christie says lab members are working on adjusting the workflow to ensure each job has the data it needs before it can run. While this can sometimes be straightforward,
+“sometimes a step in the pipeline has special inputs that are unique to it. With many steps in the pipeline, properly tracking and preparing all this data has been the main source
+of work to get the pipeline to run fully using HTC.”
+
+
+
+For now, Christie says cutting down the two-day run time of their database build pipeline to just a matter of hours with HTC “would be a wonderful improvement that would accelerate
+deployment and testing of this database. It would let us introduce new features and catch bugs faster.”
+
+
+
+
+ Smoke rising over recently burned pastures in Alto Boa Vista, Brazil.
+
+
+
+
+
+
+Christie recognizes the strength of the CHTC comes from not only its limitless computation power but also the humans who are running it behind the screen and that it’s free for
+researchers at UW–Madison, distinguishing it from other platforms and drastically lowering the entry barrier for researchers who want to scale up their research projects —
+“Instead of waiting months or years to receive funding for cloud resources, they can [request an account](https://uwmadison.co1.qualtrics.com/jfe/form/SV_8f6nTgaaVhefdmS) and get
+started in a matter of weeks,” Christie says.
+
+
+
+Christie values the unique opportunity to attend office hours and meet with facilitators, which makes his experience special. “I would definitely recommend that people look at this
+invaluable resource that we have on campus. Whether your work is with high throughput or high performance computing, there are offerings for both that researchers should consider,"
+Christie says.
diff --git a/2023-12-13-rachel-lombardi-feature.md b/2023-12-13-rachel-lombardi-feature.md
new file mode 100644
index 00000000..af869483
--- /dev/null
+++ b/2023-12-13-rachel-lombardi-feature.md
@@ -0,0 +1,157 @@
+---
+title: Get to Know CHTC Research Computing Facilitator Rachel Lombardi
+
+author: Sarah Matysiak
+
+publish_on:
+ - htcondor
+ - path
+ - osg
+ - chtc
+ - pelican
+
+type: user
+
+canonical_url: https://chtc.cs.wisc.edu/rachel-lombardi-feature.html
+
+tag:
+- chtc_featured_article
+
+image:
+ path: https://raw.githubusercontent.com/CHTC/Articles/main/images/rachellombardi.jpg
+ alt: CHTC Research Computing Facilitator Rachel Lombardi
+
+excerpt: Lombardi’s journey to computational research wasn’t a direct route, but she’s glad to have found her way to the CHTC
+
+---
+
+**Lombardi’s journey to computational research wasn’t a direct route, but she’s glad to have found her way to the CHTC.**
+
+
+
+ CHTC Research Computing Facilitator Rachel Lombardi.
+
+
+
+**Did you always know you would end up in computational research?**
+
+I always knew that I wanted to go into something science-related, but not necessarily with a computational focus. When I was in high school, I knew I didn't want to do medicine
+because my family was very medicine-focused, so I explored the concept of food science. But I had already committed to the University of Michigan, which did not have a food
+science program, and decided to do four years there to get a B.S. in Biochemistry. When I graduated, I was still interested in exploring the food science route, so I did a Ph.D.
+at the University of California, Davis, in food science.
+
+
+
+Exploring the computational side of my research ended up being more enjoyable than the actual food science side, but since my background was in the life sciences, I struggled
+with the computational side. I ended up finding some amazing mentors outside of my lab and becoming a part of this computational research community that helped teach me skills
+to do my work. In the end, I appreciated them so much and I loved what they had done. I knew this was what I wanted to do — help other people do their research.
+
+
+
+
+**What was your path to becoming a research computing facilitator?**
+
+One of the communities that I was exposed to in grad school while trying to complete my research was called The Carpentries. The Carpentries provides a lot of resources for
+teaching computational tools, and I loved the community so much that I became an instructor for them. As a part of being an instructor, you’re also put on their mailing lists,
+and it was the facilitators here [the UW-Madison Center for High Throughput Computing (CHTC)] who posted this job to that mailing list. It was not even a question for me; I
+knew this was the job for me.
+
+
+
+
+**Has coming from a biochemistry and food science background to computational research been a learning curve?**
+
+Absolutely. It’s a challenge not being able to fully understand the details of what's going on with our various high throughput and high performance computation resources. But
+there’s such a breadth of what we do that even a computer scientist on the team likely does not understand every component. However, I also think this makes me much better at
+doing my job. It can be challenging for a computer scientist to talk to someone from biology or a different discipline when they have not carried out bench-top or field research
+before. It's really important to have a facilitator who can serve as the middleman, where I can communicate with the computer scientist but can also distill it for an individual
+researcher and see how that's going to apply to their research projects.
+
+
+
+
+**What are some of your tasks and favorite parts of your role?**
+
+My favorite part is working with other CHTC staff members. The CHTC team is very collaborative and so much fun to work with. I also enjoy the creative exchange of ideas.
+
+
+
+As a facilitator, my role requires interdisciplinary and multi-tasking components of my job. I like to be able to spend part of my day learning about a tool to help a researcher and
+another part of my day planning a training event that's coming up — I'm not restricted to just one science domain.
+
+
+
+I also love working with researchers and hearing about what a grad student or a lab is going to be diving into over the next few years as they plan future analyses, or helping them
+identify solutions for computational problems they are currently tackling. It's fun to be able to see what science is underway, what their results could show, and how it could help
+others.
+
+
+
+
+
+
+**What are some challenges and triumphs you have faced while on the job?**
+
+Let's start with challenges. This job requires an incredible amount of flexibility and multitasking skills. Things could change in a minute, so I need to be able to reassess
+priorities and help facilitate two or three different computing systems. Because my background is not computer science, it’s not something that comes easily.
+
+
+
+As far as the triumphs, my triumphs are when we help make computing click for researchers. It's an exciting moment when you see that they understand what they're doing and that
+they understand how to apply these resources to make their research better.
+
+
+
+**What impact do you hope to have?**
+
+I want to help advance research in whatever way that I can. I am inspired by researchers of different domains, what it [high throughput computing] can do for people today and in
+the future, and how it can be all interconnected. Research can be a very isolating experience. To have that researcher know that they are being supported and that someone’s on
+their team as much as we can be is a goal of mine.
+
+
+
+
+**Can you tell me about your involvement with the NIAID?**
+
+The [OSG] has many collaborations with different government, academic, and nonprofit entities, one of them being the [National Institute of Allergy and Infectious Diseases (NIAID)].
+As a part of that collaboration, I was able to travel to Uganda.
+
+
+
+In Uganda, I led a workshop for researchers who were part of the African Centers of Excellence (ACE) in the bioinformatics program. I worked with the researchers there to show
+them how their research could benefit from using OSPool resources.
+
+
+
+Being able to meet with researchers in person at Makerere University was just incredible — there are so many things that are hard to grasp until you're there. They have a
+high-performance computing system over there that, in theory, they can use, but they don't have stable power. I would be sitting in a meeting with important leaders from universities
+and different U.S. computing centers, and the power shuts off. I began to understand what their challenges were and what we could do to address them.
+
+
+
+One of the questions that I still think about so much is that I was mentioning office hours in my talk as a form of support and just kept saying “Don't worry, you're not alone.
+We have office hours.” About midway through my talk, somebody raised their hand and asked what office hours were. That cultural difference made me reevaluate how we can provide
+better support for communities in the U.S. and our collaborators abroad. It also made me realize that researchers can have vast differences in their backgrounds.
+
+
+
+
+ Rachel Lombardi (left) and OSG Executive Director Frank Wuerthwein (right) in Uganda.
+
+
+
+
+
+**How do you spend your time outside of work?**
+
+I travel a fair amount for work and fun. I'm really lucky my family is around the United States, so I almost always have some place that I can go.
+
+
+
+I enjoy the Madison art scene with friends. There's a craft fair you can almost certainly find me at.
+
+
+
+ Lombardi hiking at Yosemite National Park during grad school at UC Davis.
+
+
diff --git a/2023-12-15-AMNH-workshops.md b/2023-12-15-AMNH-workshops.md
new file mode 100644
index 00000000..ed63aa69
--- /dev/null
+++ b/2023-12-15-AMNH-workshops.md
@@ -0,0 +1,98 @@
+---
+title: The American Museum of Natural History Ramps Up Education on Research Computing
+
+author: Sarah Matysiak
+
+publish_on:
+ - htcondor
+ - path
+ - osg
+ - chtc
+
+type: news
+
+canonical_url: "https://osg-htc.org/spotlights/AMNH-workshops.html"
+
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/amnhgroup.jpeg"
+ alt: From left to right, Senior Bioinformaticist of the Institute for Comparative Genomics Apurva Narechania, Research Computing Facilitator Rachel Lombardi, and Bioinformatics Specialist Dean Bobo at the AMNH.
+
+excerpt: With a multi-day workshop, the museum strives to expand the scale of its educational and training services by bringing additional computing capacity resources to New York-area researchers and tapping into the power of high throughput computing (HTC).
+---
+
+**With a multi-day workshop, the museum strives to expand the scale of its educational and training services by bringing additional computing capacity resources to
+New York-area researchers and tapping into the power of high throughput computing (HTC).**
+
+
+
+
+After “falling in love with the system” during the [2023 OSG School](https://osg-htc.org/user-school-2023/%20/h), [American Museum of Natural History Museum (AMNH)](https://www.amnh.org/%20/h)
+bioinformatics specialist [Dean Bobo](https://www.amnh.org/research/staff-directory/dean-bobo%20/h) wondered if he could jump on an offer to bring New York institutions’ and
+researchers’ attention to the [OSPool](https://osg-htc.org/services/open_science_pool.html%20/h), a pool of computing capacity freely available to U.S.-affiliated institution
+researchers. Research Facilitation Lead Christina Koch mentioned the capacity of the National Science Foundation (NSF)-funded [Partnership to Advance Throughput Computing](https://path-cc.io/) (PATh)
+project to help institutions put on local trainings. So he reached out to Koch — and indeed the offer did stand!
+
+The PATh project is committed to advancing the state of the art and adoption of high throughput computing (HTC). As part of this commitment, the project annually offers the OSG
+School at UW–Madison, which is open to participants who want to transform their research and scale out utilizing HTC. AMNH wanted to host a shortened version of the OSG School
+for their researchers with the help of the PATh team.
+
+**A Successful Workshop**
+
+Through Koch, Bobo connected with Research Computing Facilitator Rachel Lombardi who helped him plan the OSPool workshop on the second day of the museum’s multi-day workshop.
+“It was for our own museum community, but for other outside institutions as well,” Bobo says. So, Bobo arranged a computational skills training on November 3 and 6 at the AMNH in
+New York, New York. This was the first time the museum arranged a multi-day workshop with one day centered around OSPool resources.
+
+The first day of the two-day training included a workshop teaching basic computational skills to an audience of students from the museum’s graduate program and graduate students,
+as well as researchers from various institutions around New York City. About 20 people chose to attend the second day, which involved training on OSPool resources. That day, Lombardi
+led a workshop likened to an OSG School crash course, with lectures covering the topics of software and container basics, principles of job submission, troubleshooting, learning about
+the jobs a user is running, and information for the next steps researchers could take.
+
+
+
+
+
+ Rachel Lombardi during her presentation.
+
+
+
+
+
+The workshop garnered great success, which Bobo measured through the number of eyes it opened, including “folks who are completely new to HTC but also people who are more experienced
+with high performance computing on our local HPCs. They realized the utility and the capabilities of the OSPool and the resources therein. Some folks after the workshop said that
+they would give it a shot, which is great for me to hear. I feel like all this work was worth it because there are going to be attempts to get their software and pipelines lifted
+over to the OSPool.”
+
+**Empowering the HTC Community**
+
+The AMNH is looking to start hosting more OSPool events, bringing an event inspired by the OSG School locally to New York, and this workshop was the first step toward future OSPool
+workshops. From leading a section of the workshop, Lombardi learned “what resources [the AMNH] would need from PATh facilitators to run its own OSPool trainings.” The goal is to
+“empower them to do these things [conduct training] without necessarily waiting for the annual OSG School,” notes Lombardi. Bobo also picked up a few valuable lessons too. He gained
+insights about community outreach and a better understanding of instructing on HTC and utilizing OSPool capacity.
+
+In this sense, the workshops the AMNH hosted — with support from PATh — reflected the ideal of “training the trainers” to scale out the facilitation effort and share computing
+capacity. “It won’t be sustainable to come in person and support a training for everyone who asks, so we’re thinking about how to develop and publish easy-to-use training materials
+that people could use on their own, a formal process of (remote) coaching and support, and even a ‘train the trainers’ program where we could build community among people who want
+to run an OSPool training,” Koch explains.
+
+**A Continuing Partnership**
+
+Even before arranging the two-day workshop, the AMNH already had a strong partnership with the PATh and the [OSG Consortium,](https://osg-htc.org/) which provides distributed HTC
+services to the research community, Bobo says. The museum contributes its spare CPU power to the OSPool, and museum staff as well as PATh system administrators and facilitators
+communicate regularly. So far the museum has contributed over 15.5 million core hours to the OSPool.
+
+One way the museum wants to utilize the OSPool capacity is for a genomic surveillance tool that surveys the population dynamics of diseases like COVID-19, RSV, influenza, or other
+emerging diseases. “We've been using this method of diversity called K Hill. We're looking to port that software into the OSPool because it's computationally expensive to do this
+every day, but that becomes feasible with the OSPool. We would like to make this tool a public resource, but we would have to work with the PATh facilitators to figure out if this
+is logistically possible. We want to make our tools ported to the OSPool so that you don't need your own dedicated cluster to run an analysis,” Bobo explains.
+
+**Future Directions**
+
+When asked what’s in store for the future of this partnership, Bobo says he wants it to grow by putting on workshops that mirror the OSG School as a means of generating proximity and
+convenience for investigators in New York for whom the school may be out of reach. “We are so enthusiastic about building and continuing our relationship with the PATh project. I'm
+looking forward to developing a workshop that we run here at the museum. In our first year, getting help from the facilitators whom I'm familiar with would be really helpful, and
+this is something that I'm looking forward to doing subsequent to our first workshop to get there. There's definitely more coming from our collaboration,” Bobo elaborates.
+
+The PATh facilitators aim to give community members the resources they need to learn about the OSPool and control workload placement at the Access Points, Lombardi explains.
+Attending and arranging trainings at this workshop with the AMNH was one of the ways they upheld this goal. “I feel like we hit the nail on the head with this event set up in that
+we provided OSPool as a resource and they provided a lot of valuable input and feedback; it’s like a two-way street.”
diff --git a/2024-01-16-tribalcollege.md b/2024-01-16-tribalcollege.md
new file mode 100644
index 00000000..3c8c22a4
--- /dev/null
+++ b/2024-01-16-tribalcollege.md
@@ -0,0 +1,78 @@
+---
+title: Tribal College and CHTC pursue opportunities to expand computing education and infrastructure
+
+author: Malia Bicoy
+
+publish_on:
+ - htcondor
+ - path
+ - osg
+ - chtc
+
+type: news
+
+canonical_url: "https://chtc.cs.wisc.edu/tribalcollege.html"
+
+tag:
+- chtc_featured_article
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/IMG_4839.JPG"
+ alt: Salish Kootenai College in Montana
+
+excerpt: Salish Kootenai College and CHTC take steps toward bringing underrepresented communities to cyberinfrastructure.
+---
+
+### Salish Kootenai College and CHTC take steps toward bringing underrepresented communities to cyberinfrastructure.
+
+Access to cyberinfrastructure (CI) is the bedrock foundation essential for students and researchers determined to contribute to science.
+That’s why [Lee Slater](https://directory.skc.edu/DirectoryPages/Details?id=CfDJ8O8zyTaRItpCg8XGaUCJkB651OAonuZDx4jdp7IDCfnSKU5aR_WtC8v2P9cipIB_U0SOxhKAJF-Pj2fFJQiycx2Ayov_77GVH_8r-hIxr4FWxC6YHGvIdmWgP4HTpBH6EA),
+the Cyberinfrastructure Facilitator at [Salish Kootenai College](https://www.skc.edu/) (SKC), a tribal community college in northwest Montana, first brought
+up the “missing millions.” The term was coined after the [National Science Foundation](https://www.nsf.gov/) (NSF) [reported](https://www.nsf.gov/nsb/news/news_summ.jsp?cntn_id=308617&org=NSB&from=news)
+that users and providers of the CI as a whole do not accurately represent society. Underrepresented racial and gender demographics were largely missing from
+the field. “[The missing millions] just don’t have access to high performance computing platforms and so they’re not contributing greatly to the scientific
+body of knowledge that other privileged students have access to,” Slater explained. “It’s a real serious deficit for these students. One of the goals we’re
+trying to get accomplished is to bring these educational and research platforms to students and faculty to really enrich the experience they have as students.”
+
+SKC inhabits an indigenous reserve known as the Flathead Reservation, which includes territory in four western states. Established in 1855, the reservation
+is home to the [Confederated Salish and Kootenai Tribes](https://csktribes.org/index.php/history-culture). SKC — with just over 600 students — makes up a
+small, but vital portion of the much larger reservation. The college consists largely of tribal descendents or members, making up almost 80 percent of the
+school population.
+
+
+
+ TCU Salish Kootenai College in Montana.
+
+
+
+The [Center for High Throughput Computing](https://chtc.cs.wisc.edu/) (CHTC) Director [Miron Livny](https://wid.wisc.edu/people/miron-livny/) traveled
+to Montana this past October to meet with Salish Kootenai College faculty and staff. The four-day trip was coordinated by International Networking
+Coordinator [Dale Smith](https://nsrc.org/bios/DaleSmith.html) from the University of Oregon, who also works for the [American Indian Higher Education Consortium](https://www.aihec.org/).
+The visit was meant for Livny to experience one of the nation’s tribal colleges and universities (TCUs) and to further the discourse between CHTC and SKC.
+“The main goal was for him to see our infrastructure, meet the faculty and see research opportunities,” Slater recalled.
+
+SKC’s biggest and most immediate computing goal is to provide the access and training to utilize a web platform for JupyterHub that would be available
+for faculty and student use. The Jupyter Notebook connects with an OSPool Access Point, where students can place their workloads and data and which
+automates the execution of jobs and data movement across associated resources. Slater believes this would be beneficial, as many SKC faculty members do
+computing and data analysis within their specialties. “The fact that we could have a web platform with JupyterHub that students could access and faculty
+could access would really be a great facilitation,” Slater explained.
+
+Slater would also like to collaborate with other TCUs, train faculty in computing software and overall increase their cyberinfrastructure capabilities.
+SKC Chief Information Officer (CIO) [Al Anderson](https://directory.skc.edu/DirectoryPages/Details?id=CfDJ8O8zyTaRItpCg8XGaUCJkB7b0ZSBgHaupnK8YvzZyYHHntJZx4CTkdZ7cOjYBddlHqQVWhD53ZLZ8U0KKZj0EFXJHjb_SReT3j_LA9st4EWwh2YWiuubKNif4oP8YSnaOw) would
+like to leverage storage capacity for a faculty researcher who is examining the novel behavior of elk on the National Bison Range. This work requires taking a
+vast amount of photographs that then must be processed and stored. “We found that we have this storage issue — right now they’re using portable hard drives
+and it’s just a mess,” Anderson said.
+
+Engagements like this are an early, but important step in bringing underserved communities to cyberinfrastructure and thus to science and research.
+The [NSF “Missing Millions” report](https://www.rti.org/publication/missing-millions/fulltext.pdf) focused on the need for democratizing access to
+computing and showed a deficiency of engagement with institutions created for marginalized groups. Institutions like historically black colleges and universities (HBCUs)
+and TCUs tend to lack cyberinfrastructure capabilities that can be hard to implement without engagement from outside institutions.
+SKC’s engagement with CHTC is an example of steps both are taking in addressing this deficiency.
+
+Longer term goals for the college are largely educational-focused. “We’re a small school, traditionally we have more educational needs than really heavy
+research needs,” Slater said. Anderson agreed stating, “I think a lot of our focus is the educational side of computing and how to get people hooked into
+those things.”
+
+Anderson and Slater are also focused on relationship-building with faculty and discovering what they need to educate their students.
+They believe hearing from the SKC community should be first and foremost. “We’re still in that formative stage of asking, what do we need to support?”
+Anderson explained, “Through these conversations we’re slowly discovering.”
diff --git a/2024-02-02-gis-story.md b/2024-02-02-gis-story.md
new file mode 100644
index 00000000..1419ec2e
--- /dev/null
+++ b/2024-02-02-gis-story.md
@@ -0,0 +1,56 @@
+---
+title: Preserving Historic Wisconsin aerial photos with a little help from CHTC
+
+author: Malia Bicoy
+
+publish_on:
+ - htcondor
+ - path
+ - osg
+ - chtc
+
+type: user
+
+canonical_url: "https://chtc.cs.wisc.edu/gis-story.html"
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/Central-Campus-Madison.jpg"
+ alt: 1937 aerial photo of central UW Madison campus
+
+excerpt: Associate State Cartographer Jim Lacy works with CHTC to digitize and preserve historical aerial photography for the public.
+
+---
+### Associate State Cartographer Jim Lacy works with CHTC to digitize and preserve historical aerial photography for the public.
+
+
+
+ Two aerial photos of Madison, Wisconsin in 1937 available on WHAIFinder.
+
+
+Right now, hundreds of thousands of historic aerial photos from around Wisconsin are gradually aging in file cabinets on the University of Wisconsin-Madison campus, with some of the photos approaching 100 years old. Although historical photography is a captivating and well-trodden method to study the past, without intervention, this opportunity will be lost as the photos get older and begin to decay.
+
+Addressing this challenge is the [State Cartographer’s Office](https://www.sco.wisc.edu/) (SCO) and the [Arthur H. Robinson Map Library](https://geography.wisc.edu/maplibrary/) (RML), units within the [Department of Geography](https://geography.wisc.edu/) at the University of Wisconsin-Madison, who are working to digitally preserve Wisconsin aerial photography from the twentieth century. The SCO and RML team created a free digital tool in 2011 called the [Wisconsin Historic Aerial Image Finder](https://maps.sco.wisc.edu/WHAIFinder/) (WHAIFinder), where the public can view and download digital versions of the air-photos at any time. The platform currently provides almost 40,000 Wisconsin aerial images, ranging from 1937-1941.
+
+SCO’s Associate State Cartographer [Jim Lacy](https://www.sco.wisc.edu/staff/jim-lacy/) continues the effort of digitizing Wisconsin air-photos from other decades alongside Map & Geospatial Data Librarian [Jaime Martindale](https://geography.wisc.edu/maplibrary/staff/) from the RML. “We really want to work hard to digitally preserve all of that photography. That way it's available forever,” Lacy said.
+
+
+
+ Associate State Cartographer Jim Lacy
+
+
+One of the steps necessary when digitizing the photography is to convert the images to Cloud Optimized GeoTIFF (COG) format and generate jpegs. This caused a computing bottleneck for Lacy, who experimented with his local PC and found that about 100,000 images in need of converting would take over a month to process. “What we’re doing with the COG conversion frankly is not that complicated.” Lacy said, “It’s basically reformatting data, but it’s still fairly compute intensive.”
+
+Asking himself if there was a better way, Lacy went in search of a [solution](https://www.linkedin.com/feed/update/urn:li:activity:7143673958825885696/) and looked to the [Center for High Throughput Computing](https://chtc.cs.wisc.edu/) (CHTC) last November for a more efficient computing option. Specializing in high throughput computing (HTC), CHTC allows for users like Lacy to split their work up into a large amount of smaller-scale jobs that can be processed in parallel. He attended a CHTC workshop and worked in close collaboration with the CHTC facilitation team to find the right computing techniques.
+
+“The facilitators were extremely helpful in giving me pushes in the right direction,” Lacy remarked. He found that using the [HTCondor](https://htcondor.org/) Software Suite (HTCSS) was a “learning curve,” despite his previous experience with necessary user elements like shell scripting and UNIX. “It took some learning, patience, and a lot of trial and error.”
+
+The impact of using CHTC services and capacity was noteworthy. Running his own case study using input files from the [National Agriculture Imagery Program](https://naip-usdaonline.hub.arcgis.com/) (NAIP) for Dane County, Lacy found that what took his local PC 93 minutes to run took five minutes when done through CHTC. “It’s been a huge time saver,” Lacy stated. He also found that utilizing CHTC allowed room for mistakes and experimentation. “If we were to use a desktop PC it would take a week each time. For us, the option of repeatability is really important.”
+
+
+
+ A snapshot of Lacy's presentation analyzing the differences between using CHTC versus a local PC.
+
+
+One issue Lacy had while using CHTC pertained to the data transfer time, despite the entire process taking less time than his local PC. In his case study, the total data transfer overhead came out to around 21 hours. That was 14 times longer than the amount of time it took to process the data. Lacy recently met with CHTC, including members of the facilitation team and the [Pelican](https://pelicanplatform.org/) project to discuss possible improvements to data transferring, as well as making the entire process less hands-on.
+
+Utilizing open capacity from a research computing center, Lacy views his work with the SCO to be atypical to the research world. “We do some research, but our main focus is outreach and connecting people to mapping related resources. We’re all about the Wisconsin Idea,” Lacy remarked. “The goal of the Wisconsin Idea is to share our knowledge and help other folks solve problems. ”
diff --git a/2024-02-26-california-megafires.md b/2024-02-26-california-megafires.md
new file mode 100644
index 00000000..9c6f34b5
--- /dev/null
+++ b/2024-02-26-california-megafires.md
@@ -0,0 +1,75 @@
+---
+title: Ecologists utilizing HTC to examine the effects of megafires on wildlife
+
+author: Bryna Goeking
+
+publish_on:
+ - osg
+ - path
+ - htcondor
+ - chtc
+
+type: user
+
+canonical_url: "https://osg-htc.org/spotlights/california-wildfires.html"
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/California_wildfire.jpg"
+ alt: Photo of California wildfires, 2021
+
+excerpt: Studying the impact of two high-fire years in California on over 600 species, ecologists enlist help from CHTC.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/California_wildfire.jpg"
+banner_alt: Photo of California wildfires, 2021
+
+---
+
+**Studying the impact of two high-fire years in California on over 600 species, ecologists enlist help from CHTC.**
+
+
+The western United States is seeing an unprecedented increase in wildfires. Researcher
+[Jessalyn Ayars](https://www.fs.usda.gov/research/about/people/jessalyn.ayars) and her
+team examined how severe wildfires impact the habitats of over 600 species across two megafire
+years in California. Ayars, a former Post-Baccalaureate Research Fellow at the Rocky Mountain
+Research Station located in Colorado, investigated this impact on wildlife with Dr. [Gavin Jones](https://www.fs.usda.gov/research/about/people/gavin.jones)
+and Dr. [Anu Kramer](https://peery.russell.wisc.edu/anu-kramer/) of the University of Wisconsin—Madison. T
+heir research was enabled by capacity provided by the [Center for High Throughput Computing (CHTC)](https://chtc.cs.wisc.edu/)
+and [published](https://www.pnas.org/doi/10.1073/pnas.2312909120#sec-3) in the Proceedings of the National Academy of Sciences.
+
+“Megafires are extremely large, high-severity fires. They are increasing worldwide, especially in the western U.S.”
+Ayars explained. “In 2020 and 2021 California experienced a severe fire season.” California was also favorable for
+the team to study due to its extensive maps showing the habitat suitability for all vertebrate species. Typically,
+ecologists will study the effects of one species or a small number of species after wildfire — Ayars’ research is
+novel in that it surveys a wide range of species.
+
+Surveying a wide range of species across a state led to a bottleneck of data to analyze: “Each species was a gigantic
+math problem across the state of California. We were dealing with 608 vertebrae species, each with a suitability map
+the size of California at a 30-meter resolution. To get our results we needed to overlay the fire maps [with] the
+habitat suitability maps to see how much area burned, and in what severity.”
+
+
+
+ Jessalyn Ayars posing in front of mountains
+
+
+Very quickly, Ayars knew that doing this hundreds of times by hand was impractical. “That’s just so much data —
+it wasn’t possible to do it all on a desktop computer,” she said. Ayars learned about the CHTC from her advisor
+at the Rocky Mountain Research Station, Dr. Gavin Jones, who received his Ph.D. from UW-Madison and had connections
+with CHTC from earlier research.
+
+The CHTC Research Computing Facilitators (RCF) helped Ayars and her team break down large chunks of data into smaller
+jobs that could scale-out to run simultaneously using capacity provided by [the NSF funded OSPool](https://osg-htc.org/services/open_science_pool.html).
+“The folks at CHTC were super helpful in setting me up for all the processing, breaking down that giant problem
+into one species and one fire severity at a time so they could run in parallel" across the more than 50 sites that
+contribute capacity to the OSPool, she said.
+
+“I would recommend anyone interested in using HTC [high throughput computing] or just curious about whether or
+not it would be helpful for their work to reach out to CHTC,” she said. “It’s a great resource and they’re great
+at teaching you.” Ayars gave a special shout-out to [Rachel Lombardi](https://www.cs.wisc.edu/staff/lombardi-rachel/)
+and [Christina Koch,](https://www.cs.wisc.edu/staff/koch-christina/) two RCFs at CHTC. Research computing facilitators
+help new or potential users of CHTC services understand what computing resources are available on and off the UW-Madison
+campus and provide support for adapting workloads to harness HTC.
+
+Ayars hopes that her team’s work will be a “call to action” for other wildlife ecologists studying the impact of wildfires
+on species. “These conditions are so different from what wildlife evolved in, and from what researchers have studied wildfire
+in. It’s hard to say how wildlife will respond to these wildfires going forward.”
diff --git a/2024-02-27-cole-story.md b/2024-02-27-cole-story.md
new file mode 100644
index 00000000..88c88c63
--- /dev/null
+++ b/2024-02-27-cole-story.md
@@ -0,0 +1,195 @@
+---
+title: Get to Know HTCondor Core Developer Cole Bollig
+
+author: Malia Bicoy
+
+publish_on:
+ - htcondor
+ - osg
+ - chtc
+
+type: news
+
+canonical_url: "https://chtc.cs.wisc.edu/cole-story.html"
+
+image:
+ path: "
+
+
+
+**What kind of work do you do for CHTC?**
+
+I’m one of the core developers for the HTCondor Software Suite (HTCSS).
+It’s a lot of coding, development and bug fixes. I also participate in
+meetings for various collaborations like the LIGO organization and FermiLab.
+The bulk of my work, however, is developing the HTCondor software. I have a
+specific focus on DAGMan, as I’m the quote-on-quote “DAGMan expert”.
+
+**How would you define DAGMan?**
+
+DAGMan is a HTCSS tool, which assists users in automatically managing workflows
+of HTCondor jobs. In the complex, modern world of computation, it makes sense to
+break complex workloads into smaller organized steps where a user has a job that
+requires the output of another as input. Theoretically, a user could sit on a
+computer, submit the first job, and wait for said job to finish before running
+the next job in the process to achieve a bigger task like sequencing genomes or
+analyzing gravitational waves, but why not let HTCondor take care of that? Enter
+DAGMan, DAGMan allows a user to describe the steps/jobs in a workflow as nodes and
+create execution dependencies between them via edges so a job is not executed until
+all of the other nodes it depends on complete successfully. Describing these nodes and
+edges is what creates the technical computer science jargony concept of the directed
+acyclic graph (DAG) the tool manages. Meaning DAGMan is a DAG Manager. While the base
+concept of DAGMan is to automatically manage a workflow for the user, DAGMan is also
+equipped with many useful features to assist the user in their research.
+
+**Why did you want to join the CHTC team?**
+
+I graduated college and had been applying to a lot of places. This position seemed
+well-fitting because it had a C++ focus, which I prefer to program with. The job
+was also affiliated with UW-Madison — a trusted place — and I fit the requirements.
+I was really ecstatic to even get an interview, to be honest. Getting a job in the
+computer science field can be a bit rough as a fresh graduate. I will say, after
+two years of working here, it’s been great. I’m all for CHTC.
+
+
+
+
+
+**What’s your favorite part about working at CHTC?**
+
+I don’t know if I could single it down to one thing. For one, it’s a really cool group
+of people that I work with. Whether it’s directly on the team at CHTC or indirectly
+through an organization, they’re all awesome and do great things. It’s a very nurturing
+environment. As for HTCondor, it’s crazy to think about distributed high throughput computing
+software as a nerd myself. I’m very appreciative to work on something so cool and nerdy. The
+top aspect I enjoy, however, would probably be the gratification I get from the work we do.
+As a software engineer I could be working at Facebook or Google to create a new obscure feature
+that a few people interact with and feed the pockets of Mark Zuckerburg. Instead, I’m helping
+the scientific community. It is very gratifying to know that me clicking away at my keyboard
+all day is actually directly impacting science.
+
+**What is the most challenging part of your job?**
+
+The unknown. We’re actively developing the software. We don’t know where things are going
+to be tomorrow. We can plan as best as we can, but it’s a lot of learning as we go. Another
+challenging part is the code is a bit archaic at parts. It’s challenging to figure out what
+the code is doing and how it can improve. Even in the improvement sense, we don’t know what
+the research of tomorrow will need until it’s today.
+
+**What do you think is the most exciting development happening right now?**
+
+For me personally, it’s delving into the DAGMan code. I am the expert. It was pretty
+stable when I got here, but I keep looking at the code and thinking about new ways it
+can be improved or bringing it up to more modern standards. Another focus is DAGMan
+handling various authentication methods — especially tokens — based technology. It’s a
+bit of an issue right now, but over the next year or so, I hope we can iron out the details.
+
+**I heard through the grapevine you go by “Dag Boy” here at CHTC, what’s the story behind the name?**
+
+The name comes from my fellow core developer [Greg Thain](https://chtc.cs.wisc.edu/people.html).
+My first day here, one of my previous office neighbors came over and said, “Did anyone mention
+I’m leaving and you're taking over all my responsibilities?” Which I, of course, had no idea was
+happening, but he quickly got me up to date with the basics of DAGMan. I was young, and newly in
+charge of DAGMan — I couldn’t have been an expert by that point. Greg started calling me “Dag Boy”
+because I still had to grow up, and it stuck.
+
+**What social event with work friends have you enjoyed the most?**
+
+There’s a lot. We have a HTC week every year, for one. I get to directly interact with users and
+admins of the HTCondor software. On a smaller scale, we have Condor Fun Day. It’s just CHTC people
+hanging out, cooking food, and drinking a little. There’s also daily things. Some of us go to Big 10
+for lunch every Tuesday. They have three dollar sloppy joes. On Fridays at lunch, we have a little
+group that plays Sheepshead in the conference room. There is never truly a dull day.
+
+**HTC24 will be coming up this summer. Can you tell me about that and what you like or don’t like about it?**
+
+A dislike is that it’s a lot of setup. Putting together a conference that people from all
+over the country come to is never easy. At the end of the day — end of the week actually —
+it’s a great experience. The effort is truly worth it. Meeting all those people and doing all
+the social stuff afterwards is great. Last year, a group of us went out kayaking and
+paddleboarding on Lake Wingra. We just got to socialize and have fun. You can learn a lot too.
+It’s not just about the social aspect, there’s also the technical aspect. We get to tell our
+users about all the cool stuff we made, and they get to tell us about all the cool stuff they
+did with our cool stuff. It’s a nice cycle.
+
+**I hear you are involved in the CHTC Fellows Program. What is that about?**
+
+It’s a new thing we’re trying out this year, and we hope to continue it in future years.
+It’s a step up from a standard internship. We took the setup from the Google Summer of Code.
+We’re trying to get students who want to learn in our environment and develop specific projects
+that they want to work on. It’s a chance for them to get experience in a distributed high
+throughput computing environment, and we can test features out that we might not otherwise
+have had time for.
+
+**What’s changed since you began working for CHTC?**
+
+The biggest change — other than moving to another building in the future (does happy dance) —
+is the code. We’re actively adding new features, but my favorite pastime is helping to update
+HTCondor to modern C++ standards. The code has been around a long time and some parts predate
+the C++ standard library. We’ve been slowly updating HTCondor throughout the millions of
+lines of code.
+
+
+
+
+
+**You received a Bachelor’s in Media Arts and Game Development from UW-Whitewater, do you create or play video games in your spare time? Tell me a little about that.**
+
+Yes, I am a gamer. I have three Xboxes, a Game Boy Color and a NES.
+I grew up with a bunch of other game systems that no longer exist in my hands —
+which is very unfortunate. Retro games cost so much now. Anyway, my discovery of
+computer science in high school plus me being a gamer is what put me towards the
+career path of game development originally. I went to UW-Whitewater and got a degree
+with an overly complicated name. It was Media Arts and Game Development with a technical
+emphasis — a mouthful. Then I ended up here, and I’m not disappointed. It’s a great place
+to work. I do wish I would find some motivation to do game development, because I have
+all of these ideas stuck in my head. I should make them come to fruition, but in the
+meantime I’ll just play some more video games.
+
+**A video game that is on your list these days.**
+
+The main video game I’ve been playing recently is Minecraft, which is a masterpiece in
+my opinion. There are a few of us on the team here that will occasionally talk about
+Minecraft. It’s a fun time, talking about the technical details. The other series I’ve
+been playing is the Borderlands series. I’m a very big fan, and I have invested a lot
+of time into it. A lot of time.
+
+**Favorite things to do in Madison on the weekends.**
+
+I come from the outskirts of Cross Plains, but whenever I come into Madison I enjoy going
+to the Terrace. I also like to just roam around the isthmus. I’ve recently gotten into
+going to concerts as well. Luckily we have a couple decent concert places around here, and
+they get some fun artists. One of the best things about Madison, though, is it’s a stone's
+throw away from a good hike. It’s not a very far drive. I’m also a big food advocate,
+and Madison has good food.
+
+
+
+
+
+**Do you know any good programming puns?**
+
+Really bashing my brain with this one. That was the pun by the way. The team loves it when
+I make bad puns. I have more. If you want to eat data, you can either do it bit by bit or
+in one big byte! This one is also good: there are 10 types of people in the world. Those who
+understand binary and those who don’t. I could keep going.
+
+**What would you tell your younger self when you first started here at CHTC?**
+
+That’s a difficult question because I am so young. One of my favorite pastimes is making my
+coworkers feel old, but don’t tell them I said that. Anyway, one piece of advice I’d give to my
+younger self would be that you will always keep learning. Whether that means learning to become a
+better developer, figuring out new technologies to apply to the code-base, or even discovering weird
+obscure things. You never truly stop learning. I feel like pushing that towards my younger self would
+probably be good for him.
+
+**Is there something you wish to add?**
+
+I’m actually applying to UW-Madison’s professional masters program for computer science, which would
+be pretty cool to get into.
diff --git a/2024-04-03-campus-onboarding.md b/2024-04-03-campus-onboarding.md
new file mode 100644
index 00000000..1c932183
--- /dev/null
+++ b/2024-04-03-campus-onboarding.md
@@ -0,0 +1,117 @@
+---
+title: “Becoming part of something bigger” motivates campus contributions to the OSPool
+
+author: Bryna Goeking
+
+publish_on:
+ - osg
+ - path
+ - htcondor
+ - chtc
+
+type: user
+
+canonical_url: "https://osg-htc.org/spotlights/campus-onboarding.html"
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/ospool-con-map.png"
+ alt: Map of institutions contributing to the Open Science Pool (OSPool).
+
+excerpt: A spotlight on two newer contributors to the OSPool and the onboarding process.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/ospool-con-map.png"
+banner_alt: Map of institutions contributing to the Open Science Pool (OSPool).
+
+---
+
+*A spotlight on two newer contributors to the OSPool and the onboarding process.*
+
+A campus’ motivation to contribute computing capacity to the [Open Science Pool](https://osg-htc.org/services/open_science_pool.html) (OSPool),
+an internationally recognized resource supporting scientific research, can be distilled down to the desire to "become part of something bigger,"
+says OSG Campus Coordinator [Tim Cartwright](https://www.cs.wisc.edu/staff/cartwright-tim-2/). The “something bigger” refers to national cyberinfrastructure.
+By sharing idle, unused capacity with institutions nationwide, contributors enhance the OSPool and contribute to the science executed by researchers
+utilizing this pool.
+
+
+
+ Tim Cartwright.
+
+
+Approximately 80% of OSPool member schools donate capacity to the OSPool after receiving a Campus Cyberinfrastructure (CC*) grant from the
+[National Science Foundation](https://new.nsf.gov/funding/opportunities/campus-cyberinfrastructure-cc) (NSF), which requires dedicating 20% of
+computing capacity to a larger entity like the OSPool. Campuses choose the OSPool to provide this capacity, in part, because it is a readily implemented
+approach to meet this requirement without impeding research happening on-campus. Leading the onboarding efforts, Cartwright and OSG staff have developed
+a straightforward, fairly easy-to-implement approach for campuses who wish to contribute capacity. Cartwright describes the growth of the OSPool as “an
+incredible boom” since 2020. In the past year, about [70 institutions](https://osg-htc.org/services/open_science_pool/institutions) have contributed to the OSPool.
+
+A closer look at the journey of two new OSPool members, [Montana State University](https://www.montana.edu/) and [The University of Michigan-Ann Arbor](https://umich.edu/)
+illustrates the motivations and experiences of campuses when integrating some of their capacity into the OSPool.
+
+**Montana State University**
+
+[Coltran Hophan-Nichols](https://www.montana.edu/uit/rci/people/), Director of Systems and Research Computing at Montana State, approached the OSG Consortium before
+applying for a Campus Cyberinfrastructure (CC*) grant. Familiar with the OSPool, he knew it would be a logical choice to fulfill the 20% requirement.
+
+Along with growing student interest in HPC and HTC, Montana State needed to provide new computational resources for fields such as quantum science, artificial
+intelligence and precision agriculture that were expanding rapidly. Hophan-Nichols knew that the OSPool could augment these much-needed resources for researchers
+while allowing Montana State to give back capacity that would otherwise sit idle. “We pursued the OSPool because it provides national-level access while being flexible
+[with allocations],” Hophan-Nichols said. “We’re able to contribute significant capacity without impacting what researchers here can do.”
+
+“The integration itself is a relatively simple process,” Cartwright said, consisting of two meetings with the campus staff and Cartwright, plus OSG Operations team
+members. The first meeting is a “kickoff,” where Cartwright and the campus staff talk through the technical aspects of integration. Much of the work occurs between
+the two meetings, with campus staff setting up access to their cluster and OSG staff preparing connection and service configuration. The second meeting is the actual
+integration to the OSPool, which involves setting up new OSG services to connect the site and manually verifying correct operations.
+
+During the integration meeting, the OSG team verifies that access to the site works as expected, that manual tests succeed and that the end-to-end automated
+processes function. To alleviate safety concerns, Cartwright explains that connections into the campus system are limited to one common service (SSH) and even
+then, only to one computer within the campus. All other networks are established from within the campus to external systems. “We have tried to make it as
+minimally intrusive as we possibly can to work with individual campuses and what their security teams are comfortable with,” he said.
+
+Regardless of how much is done to prepare, some hiccups occur. Montana State “had to make minor tweaks to configuration changes, which ultimately sped up transfer
+for OSPool and local transfers,” Hophan-Nichols said. The OSG Operations team and Cartwright also try to identify common issues and troubleshoot them before the integration.
+
+After making sure that connections were working and jobs were starting to run, Montana State kept its contributed capacity small to ensure everything was
+working properly. Since then, Hophan-Nichols has worked with Cartwright to scale up availability. When they first joined, they were contributing fewer
+[than 1,000 jobs](https://gracc.opensciencegrid.org/d/uZoiT7FVz/open-science-pool?from=now-90d&to=now&var-interval=$__auto_interval_interval&var-project=All&var-institution=All&var-Filter=OIM_Facility%7C!%3D%7CLangston%20University&var-Filter=OIM_Facility%7C%3D%7CMontana%20State%20University)
+per day. Now, they are contributing up to 181,000 jobs per day and over 2.53 million jobs in total from January through March.
+
+“It’s been mutually beneficial,” Hophan-Nichols said. “There is next to no impact on the availability of capacity for local researchers and we still
+have a significant chunk of resources we’re able to contribute to the OSPool.”
+
+**The Michigan HORUS Project**
+
+The [HORUS](https://horus-ci.org/) Project, a joint effort among the University of Michigan-Ann Arbor (U-M), [Merit Networks](https://www.merit.edu/),
+[Michigan State University](https://msu.edu/) and [Wayne State University](https://wayne.edu/) (WSU), integrated some of their computing capacity into
+the OSPool in January 2024. The HORUS regional compute project, building upon the previous [OSiRIS](https://www.osris.org/) project, exists to grow statewide
+computing and storage capacity, as well as contribute to open capacity. [Shawn McKee](https://micde.umich.edu/member/shawn-mckee/), a Research Scientist at U-M,
+and his colleagues at Merit and WSU secured a CC* grant to create HORUS and begin contributing capacity to the OSPool. “We had been planning to join for a while,
+but we managed to get everything operational earlier this year,” he said.
+
+
+
+ HORUS logo, inspired by the Egyptian god Horus. Created by Michelle David of Michigan State University, courtesy of HORUS website.
+
+
+HORUS project team members faced unique technical challenges trying to combine their existing statewide system with the broader OSPool. Between the initial meeting
+and the onboarding, McKee and his colleagues established a secure transfer node for the OSG Consortium to use. Similar to Montana State, the HORUS project engineers
+have a strong background in research computing which made the integration straightforward. In the end, connecting via SSH jump hosts and routing jobs to all three
+campuses only took 40 minutes. “Pretty quickly, ‘Hello World!’ worked right away and users could start using it,” McKee recalled.
+
+McKee also values the OSPool for its ability to smoothly fulfill the 20% requirement for their CC* grant. Beyond this, the OSPool offers more capacity to researchers
+and accesses capacity from the HORUS project that would otherwise sit idle. “It was great to have the OSG Consortium come in and start utilizing large memory and
+compute nodes that were only lightly loaded,” McKee said. “There was significant idle time that now the OSPool can use.”
+
+Across the HORUS project, McKee identified at least four researchers interested in using idle resources in the OSPool and is excited to keep growing campus involvement.
+At U-M, [PI Keith Riles](https://osg-htc.org/projects.html?project=Michigan_Riles) uses the OSPool for work in gravitational physics. Through the OSPool, Riles has
+run over 200,000 jobs across 52 facilities. At WSU, [PI Chun Shen](https://osg-htc.org/projects.html?project=WSU_3DHydro) uses the OSPool for work in nuclear physics,
+utilizing its capacity to run over 13 million jobs across 41 facilities.
+
+Once campuses are onboarded, OSG staff continue to collaborate with campus personnel. Beginning in February, they introduced OSG Campus Meet-Ups, a weekly
+campus-focused video conference where campus staff can talk and learn from each other or OSG staff. [Throughput Computing](https://chtc.cs.wisc.edu/events/2024/01/throughput-computing-2024)
+and [OSG School](https://osg-htc.org/school-2024/), two events in the summer, also offer in-person opportunities for campus staff to visit OSG staff and other campuses on the University of Wisconsin–Madison campus.
+
+**Prospective Campuses**
+
+The NSF CC* program provides unique access to resources and funding to improve campus research. CC* applicants can receive a letter of collaboration from one
+of the [PATh](https://path-cc.io/) PIs for submission. For more information,
+visit the [PATh website instructions](https://path-cc.io/services/research-computing/#let-the-path-team-help-with-your-proposal).
diff --git a/2024-04-04-nrao.md b/2024-04-04-nrao.md
new file mode 100644
index 00000000..74d193ed
--- /dev/null
+++ b/2024-04-04-nrao.md
@@ -0,0 +1,121 @@
+---
+title: Through the use of high throughput computing, NRAO delivers one of the deepest radio images of space
+
+author: Bryna Goeking
+
+publish_on:
+ - chtc
+ - osg
+ - pelican
+ - htcondor
+
+type: user
+
+canonical_url: https://chtc.cs.wisc.edu/nrao-story.html
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/nrao-vla.png"
+ alt: Radio image of space.
+
+excerpt: "The National Radio Astronomy Observatory’s collaboration with the NSF-funded Partnership to Advance
+Throughput Computing (PATh; NSF grant #2030508) and the Pelican Project (NSF grant #2331480) leads to successfully
+imaged deep space and creates a first-of-its-kind nationally distributed workflow model for data-intensive scientific investigations."
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/nrao-vla.png"
+banner_alt: Radio Image of Space
+
+---
+
+*The National Radio Astronomy Observatory’s collaboration with the NSF-funded Partnership to Advance Throughput Computing
+([PATh](https://path-cc.io/); NSF grant #2030508) and the Pelican Project (NSF grant #2331480) leads to successfully imaged deep
+space and creates a first-of-its-kind nationally distributed workflow model for data-intensive scientific investigations.*
+
+
+Ten years ago, the [National Radio Astronomy Observatory](https://public.nrao.edu/) (NRAO) pointed its
+[Very Large Array](https://public.nrao.edu/telescopes/vla/) (VLA) telescopes toward a well-studied portion of the sky, searching for the
+oldest view of the universe. Deeper structures reflect older structures in space, as their light takes longer to travel through space
+and be picked up by telescopes. Radio astronomy can go even further, detecting structures beyond visible light. The VLA
+telescopes generated enough data that a single image of a portion of the sky resulted in two terabytes of data. Without the
+computing capacity to image the complete data set, it sat largely unprocessed — until now.
+
+
+The high sensitivity of radio images requires a vast amount of computing to reach a final product, noted Felipe Madsen, an
+NRAO software engineer. The VLA telescopes are interferometers, meaning they point two antennas at the same portion of the
+sky; the differences in what these antennas provide eventually result in an image, Madsen explains. NRAO models and re-models
+the data to decrease the noise level until the noise is indistinguishable from structures in space. “This project is a lot
+more data-intensive than most other projects,” Madsen said. The final image turned nine terabytes of data into a single
+product of one gigabyte. A previous computing run in 2016 using only a subset of this data took nearly two weeks of active
+processing — researchers at NRAO knew that attempting to process this entire data set in-house was impractical.
+
+Curious about how high-throughput computing (HTC) could enhance its capacity to process data from the VLA, NRAO joined
+forces with the [Center for High Throughput Computing](https://chtc.cs.wisc.edu/) (CHTC) in 2018. After learning about
+what HTC could accomplish, NRAO began executing trial runs in 2019, experimenting with HTC. “Four years ago, we were
+beginning to use GPU software to process our data,” Madsen explained. “From the beginning, we understood that to be
+compatible with HTC we needed to make changes to our systems.”
+
+
+Each team learned from and made improvements based on insights from each other. [Greg Thain](https://www.cs.wisc.edu/staff/thain-gregory/),
+an [HTCondor](https://htcondor.org/) Core Developer for the CHTC, met with NRAO weekly to discuss HTC and changes both parties
+could make. These weekly meetings resulted in the HTCondor team making changes to the software, eventually improving the
+experience of other users, he said. OSG Software Area Coordinator of CHTC [Brian Lin](https://www.cs.wisc.edu/staff/lin-brian/)
+helped NRAO manage their distributed infrastructure of resources across the country and transition workflows from CPUs to GPUs
+to make their workflows more compatible with HTC. Through distributed HTC, NRAO was able to run workflows across the country through the
+[Open Science Pool](https://osg-htc.org/services/open_science_pool.html) (OSPool) and
+[PATh Facility](https://path-cc.io/facility/index.html).
+
+
+At NRAO, Madsen developed the software to interface the scientific software in the [LibRA package](https://github.com/ardg-nrao/libra)
+developed by NRAO Algorithms Research & Development Group with the CHTC infrastructure software. This separation of software
+allowed the two teams to solve problems that arose in real-time as the data began to transfer across sites nationwide.
+
+
+By December 2023, both parties were ready to tackle the VLA telescope deep sky data using HTC. Transitioning workflows to
+nationwide resources led to data movement issues, struggling to move efficiently from distributed resources. The December
+2023 image processing run relied upon resources from the [Open Science Data Federation](https://osg-htc.org/services/osdf.html)
+(OSDF) and the recently funded [Pelican Project](https://chtc.cs.wisc.edu/the-pelican-project.html) to speed up data
+transfers across sites. [Brian Bockelman](https://morgridge.org/profile/brian-bockelman/), PI of the
+[Pelican Project](https://pelicanplatform.org/), and his team helped NRAO improve data movement using the OSDF. “Both teams
+were working to solve problems as they were happening,” Madsen recounted. “That made for a very successful collaboration
+in this process.”
+
+
+
+
+ The final product, looking into deep space.
+
+
+
+Ultimately, the imaging process was 300 times faster than without using HTC, NRAO reported in
+a [press release](https://public.nrao.edu/news/astronomers-study-the-universe-300-times-faster/) describing
+the project. What had previously taken two weeks now took only two hours to create the final result. By
+the end, the collaboration resulted in one of the earliest radio images of the
+[Hubble Ultra Deep Field](https://esahubble.org/images/heic0611b/).
+
+
+The collaboration that led to this imaging is even bigger than NRAO and CHTC.
+The [OSPool](https://osg-htc.org/services/open_science_pool), which provided some of the computing capacity for the project,
+is supported by campuses and institutions across the country that share their excess capacity with the pool
+that NRAO utilized. For this project, 13 campuses contributed computing capacity, from small institutions
+like [Emporia State University](https://www.emporia.edu/) to larger ones like [San Diego State University](https://www.sdsu.edu/).
+
+
+
+
+ A map of contributors across the OSPool and PATh Facility. Image courtesy of S. Dagnello, NRAO/AUI/NSF
+
+
+
+
+The December 2023 run and the working relationship between CHTC and NRAO revolutionized information available to astronomers
+and proved that HTC is a viable option for the field. “It’s useful to do this run once. What’s exciting is doing it
+30,000 times for the entire sky,” Bockelman said. Although previous radio astronomy imaging workflows utilized HTC,
+this run was the first to image data on a distributed workflow nationwide from start to finish. Moving forward, NRAO
+and CHTC will continue covering the entire area of the sky seen by the VLA telescopes.
+
+
+Madsen is enthusiastic about continuing this project, and how the use of HTC is revolutionizing astronomy, “I’ve always felt
+like, in this project, we are at the cutting edge of the current knowledge for making this kind of imaging.
+On the astronomy side, we can access a lot of new information with this image,” he said. “We have also imaged a data set that was
+previously impractical to image.”
diff --git a/2024-04-18-euro-htc.md b/2024-04-18-euro-htc.md
new file mode 100644
index 00000000..3ce7253b
--- /dev/null
+++ b/2024-04-18-euro-htc.md
@@ -0,0 +1,50 @@
+---
+
+title: Save The Date - 2024 European HTCondor Workshop
+
+author:
+
+publish_on:
+ - chtc
+ - osg
+ - path
+ - htcondor
+
+type: events
+
+canonical_url: "https://chtc.cs.wisc.edu/euro-htcondor.html"
+
+image:
+ path: "https://raw.githubusercontent.com/CHTC/Articles/main/images/HTCondor_Bird.png"
+ alt: Text Description of image
+
+description: This year's European HTCondor Workshop will held from September 24-27 in Amsterdam.
+excerpt: This year's European HTCondor Workshop will held from September 24-27 in Amsterdam.
+
+card_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/HTCondor_Bird.png"
+card_alt: HTCondor Software Suite Logo.
+
+banner_src: "https://raw.githubusercontent.com/CHTC/Articles/main/images/HTCondor_Bird.png"
+banner_alt: HTCondor Software Suite Logo.
+
+---
+
+**Save The Date: 2024 European HTCondor Workshop**
+
+This year’s European HTCondor Workshop will be held from September 24 to 27th hosted by NIKHEF-Amsterdam, the Dutch National Institute
+for Subatomic Physics, in the beautiful Dutch capital city of Amsterdam.
+
+The workshop will be an excellent occasion for learning from the sources (the developers!) about HTCondor, exchanging with your colleagues
+about experiences and plans and providing your feedback to the experts. The HTCondor Compute Entry point (CE) will be covered as well.
+Participation is open to all organizations (including companies) and persons interested in HTCondor (and by no means restricted to particle
+physics and/or academia!) If you know potentially interested persons, don't hesitate to make them aware of this opportunity.
+
+The workshop will cover both using and administering HTCondor; topics will be chosen to best match participants' interests. We would very much
+like to know about your use of HTCondor, in your project, your experience and your plans. You are warmly encouraged to propose a short presentation.
+
+There will also time and space for short, maybe spontaneous interactive participation ("show us your toolbox sessions") which proved to
+be very popular in previous meetings.
+
+Registration and abstract submission will be opened in due course.
+
+To ease travel, the workshop will begin Tuesday morning and end around Friday lunchtime.
diff --git a/HTC23_David_Swanson_Awardees b/HTC23_David_Swanson_Awardees
new file mode 100644
index 00000000..2a381a83
--- /dev/null
+++ b/HTC23_David_Swanson_Awardees
@@ -0,0 +1,68 @@
+---
+title: OSG David Swanson Awardees Honored at HTC23
+
+author: Sarah Matysiak
+
+publish_on:
+ - osg
+ - path
+ - CHTC
+
+
+
+type: user
+
+image:
+ path: CANNON TO ADD
+ alt: GP-ARGO node locations
+
+excerpt: Jimena González Lozano and Aashish Tripathee are 2023’s recipients of the David Swanson award for their research advancements with strategic use of high-throughput computing (HTC).
+
+
+---
+
+OSG leadership created the [OSG David Swanson Award](https://osg-htc.org/outreach/swanson-award/) in memoriam of Swanson, who championed throughout his life for both the success of his students and the expansion of OSG and research computing. David Swanson, who passed away unexpectedly in 2019, was a computer science and engineering research professor at the University of Nebraska-Lincoln. The award reflects Swanson’s and [OSG School’s](https://osg-htc.org/user-school-2023/) emphasis on helping people develop their skills in technology and advancing science with large-scale computing, OSG research facilitation lead Christina Koch says. Researchers — like [Jimena González Lozano](https://www.physics.wisc.edu/directory/gonzalez-lozano-jimena/) and [Aashish Tripathee](https://lsa.umich.edu/physics/people/research-fellows/aashisht.html) who sought the OSG School’s high-throughput computing (HTC) resources to solve complex computational challenges, and in turn, were able to evolve their research projects — have been honored with the award since its establishment in 2019. González is a Department of Physics observational cosmology Ph.D. student at the University of Wisconsin-Madison, and Tripathee is a University of Michigan Physics post-doctoral research fellow.
+
+Awardees are provided the opportunity to share their research at the OSG All-Hands Meeting, which is part of the annual [2023 Throughput Computing (HTC23) conference](https://agenda.hep.wisc.edu/event/2014/contributions/), held in Madison, Wisconsin. “To have it in the context of recognizing a wonderful person like David is really meaningful. It’s like ‘Oh yes, this is why we’re doing what we’re doing,’ and it’s rewarding,” Koch reflects.
+
+
+As a David Swanson awardee, it’s an honor to be an example of how HTC and the OSG School transformed her research, González elaborates. “I couldn’t even explore new ideas [because it could take weeks to run one simulation], and it was around that time that I was reading all my emails carefully, and I saw the OSG User School [application] announcement,” González remembers. “They did a really good job at describing what you would learn and what high-throughput computing is. From that description, I thought that it was perfect for me. I applied, and then during the summer of 2021, I learned how to implement it, and it was very quick. After the first day, I already knew how to submit a job.”
+
+
+[Gonàzlez’s research](https://www.youtube.com/watch?v=LzzBHMr_WRA) on strong gravitational lenses in the dark energy survey implements HTC and machine learning. Strong gravitational lenses can image stars from which González can extract the position of the source and the magnification between the images. From the images, González creates thousands of simulations composed of millions of images while constraining the quality of the images. Because of the volume of simulations she needs to train, González could be left waiting for up to weeks using machine learning — and the tighter constraints, the greater the waiting time. This put its own constraints on which properties she could experiment with. Some ideas, Gonzàlez says, were impossible to do because she couldn’t do them quickly. Implementing HTC shortened the waiting time from *days to hours*. The OSG school also impacted other areas of González’s research, including training the machine and performing a complete search — each was reduced from long wait times spanning days to years to much more manageable wait times of as little as three hours.
+
+
+[Tripathee uses HTC](https://www.youtube.com/watch?v=hKA8H7TtMAg) for solving a big data challenge too. For one project on continuous gravitational waves, the data he collected spans a year and the entire sky, as well as the polarization over 24 times, resulting in 80 quadrillion templates. The solution, Tripathee said at HTC23, is looking at 500 billion templates per job. The answer for computing templates at a magnitude of a quadrillion is to use HTC, which helps with efficiency when running the numbers and makes the project possible. Without HTC, Tripathee’s jobs would’ve taken on average more than 10 hours for some or more than 24 hours for others. Through the OSG, Tripathee uses 22 million core hours, 1.4 million hours per month, and 47,000 hours per day.
+
+
+Tripathee’s mentor and OSG Deputy Executive Director Tim Cartwright encouraged Tripathee to self-nominate for the award. Upon learning he was chosen to receive the award, “It felt like a nice validation and a recognition of having used the [OSG] to perform research,” Tripathee says about receiving the award. Attending HTC23 event in Madison to receive the award was rewarding. “I also got to meet a lot of people… like the OSG faculty, Tim Cartwright in particular, and Christina [Koch]. There was a really nice opportunity and an honor to come to Madison, attend the event, and receive the award but also meet [David Swanson’s widow,] Ronda.”
+
+
+Acknowledging the great success of this regional network organization, the National Science Foundation (NSF)
+supports it. First, CyberTeam received a CC* award, and later, the entire GP-ARGO network received one — something that
+no one has done before. “Applying as a network rather than a single institution made sense,” Andresen explained, “this
+emphasizes this is a regional effort rather than an individual, institutional effort.”
+
+GP-ARGO has truly set the curve in taking on a project of this scale and magnitude and doing it successfully. Reflecting
+on what went well, Andresen gleamed, “I mean, we did it! We’ve got it working; we’re among the top five OSG entry points,
+we’ve contributed 13 million CPU hours of science, and we have people who are excited and involved, which has been incredibly
+fun and exciting.”
+
+Furthermore, the team has ensured the sustainability of this operation. “Most of the institutions we're working with don't
+have the expertise or the full-time employees to spare,” Andresen explained. Central administration by OSG has been instrumental
+in this regard, especially recently, regarding restructuring administration roles with the leaving of Kyle Hudson. “If
+something happens to whoever is the administrator, like leaving for another institution,” Hudson jokingly remarked, “we
+have four people across four different institutions that all have administrative rights. I was a primary person doing that,
+but I was not the only person who could do this, so somebody else can take over.”
+
+Part of GP-ARGO’s appeal lies in their determination and dedication to helping other consortiums and networks aiming to achieve
+similar goals. They provide a Git repository with all their code and emphasize the importance of both social and technical networks.
+“Building trust and familiarity is crucial,” Andresen advised. “Get involved with the OSG and get to know people; having Derek
+[Weitzel] available as the interface has been invaluable. Knowing the context and the people is much easier than starting from scratch.”
+
+Despite the immense undertaking, Andresen commented on how fun and exciting the project has been, with the OSG playing a pivotal
+role. “This program only builds stronger connections within the region between all these different professionals,” Weitzel
+reflected. “It’s allowed us to reach out to different types of people, creating new opportunities that build on each other.”
+
+Echoing this sentiment, Hudson highlighted the project's impact in involving previously less-engaged institutions within GPN with the network's recent expansion from 18 to 19 campuses. “Cameron University heard about some of the things we're doing
+through their state network, had a spare box, and asked if they could get involved!” Hudson explained.
diff --git a/images/HTCondor_Banner.jpeg b/images/HTCondor_Banner.jpeg
new file mode 100644
index 00000000..c6eca8be
Binary files /dev/null and b/images/HTCondor_Banner.jpeg differ
diff --git a/images/NIAID-banner.jpg b/images/NIAID-banner.jpg
new file mode 100644
index 00000000..4b8ab10f
Binary files /dev/null and b/images/NIAID-banner.jpg differ
diff --git a/images/NIAID-card.jpg b/images/NIAID-card.jpg
new file mode 100644
index 00000000..29755f70
Binary files /dev/null and b/images/NIAID-card.jpg differ
diff --git a/images/cartwright-headshot.jpeg b/images/cartwright-headshot.jpeg
new file mode 100644
index 00000000..5a6ac61b
Binary files /dev/null and b/images/cartwright-headshot.jpeg differ
diff --git a/images/cole_terrace.jpg b/images/cole_terrace.jpg
new file mode 100644
index 00000000..aed60ab6
Binary files /dev/null and b/images/cole_terrace.jpg differ
diff --git a/images/horus-logo.png b/images/horus-logo.png
new file mode 100644
index 00000000..bc7c4185
Binary files /dev/null and b/images/horus-logo.png differ
diff --git a/images/ospool-con-map.png b/images/ospool-con-map.png
new file mode 100644
index 00000000..7ef0923f
Binary files /dev/null and b/images/ospool-con-map.png differ
diff --git a/images/ucsd-public-relations.png b/images/ucsd-public-relations.png
new file mode 100644
index 00000000..e76d80ca
Binary files /dev/null and b/images/ucsd-public-relations.png differ
 +
+  +
+ 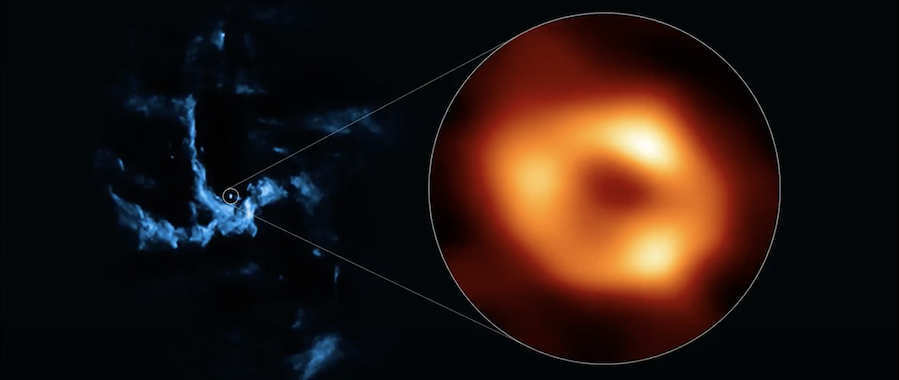 +
+  +
+ 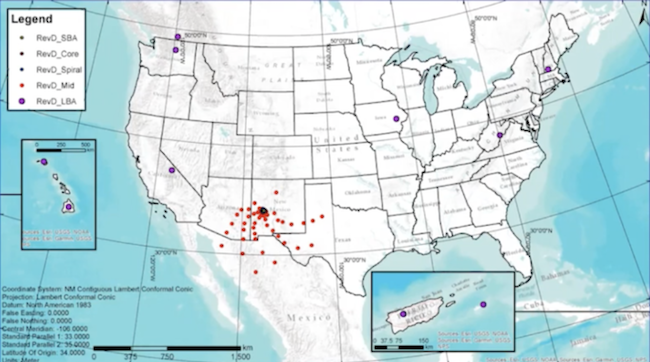 +
+ 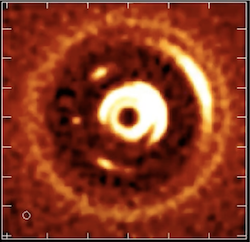 +
+ 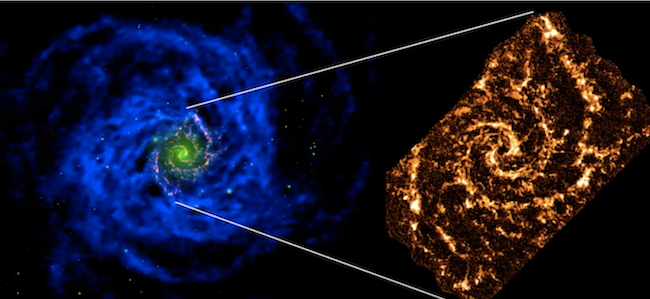 +
+  +
+  +
+ 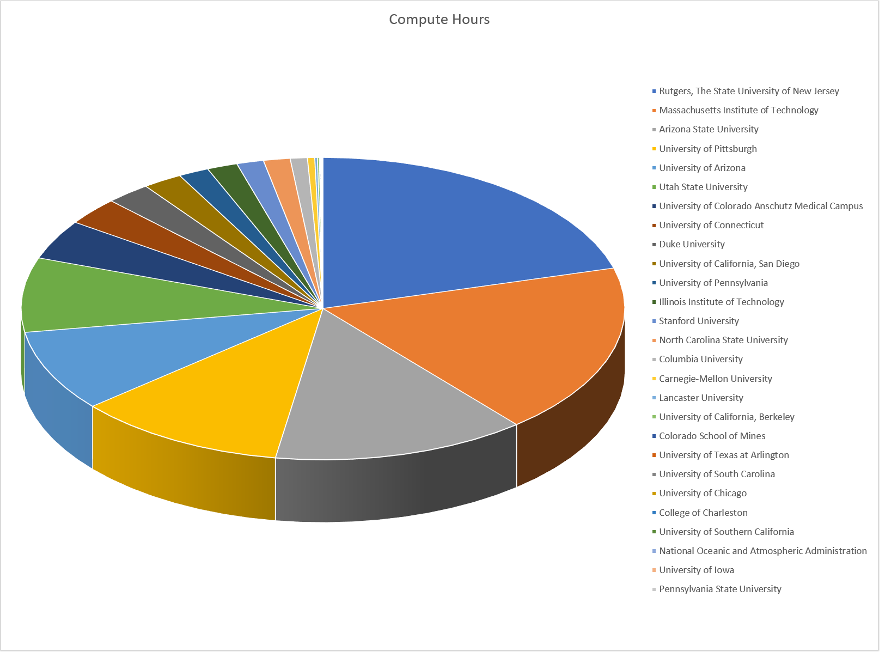 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ 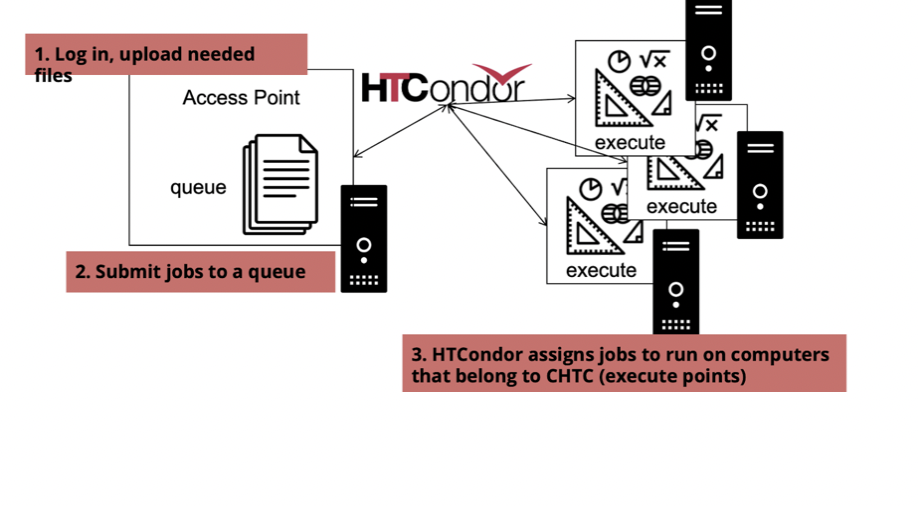 +
+  +
+ 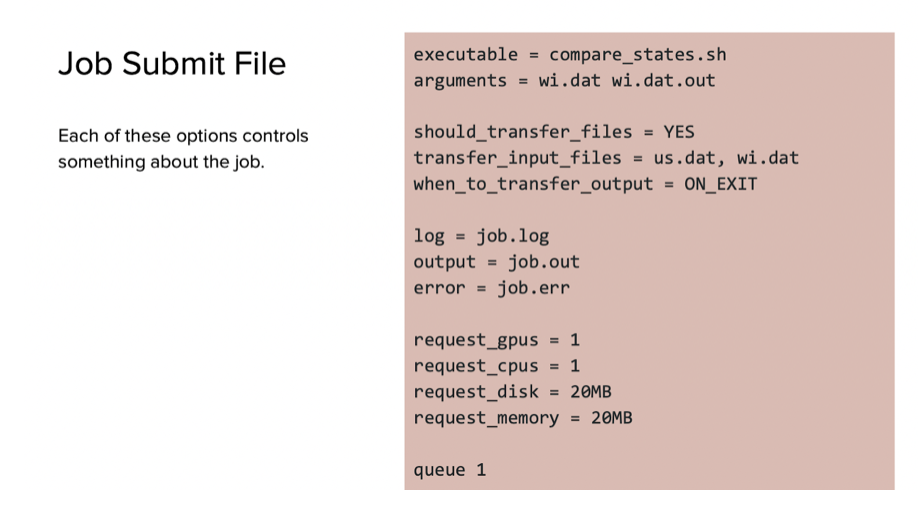 +
+  +
+  +
+ .](https://raw.githubusercontent.com/CHTC/Articles/main/images/materials-science.jpg) +
+  +
+  +
+  +
+  on the African School of Physics website.](https://raw.githubusercontent.com/CHTC/Articles/main/images/asp-banner.jpeg) +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+
+**What kind of work do you do for CHTC?**
+
+I’m one of the core developers for the HTCondor Software Suite (HTCSS).
+It’s a lot of coding, development and bug fixes. I also participate in
+meetings for various collaborations like the LIGO organization and FermiLab.
+The bulk of my work, however, is developing the HTCondor software. I have a
+specific focus on DAGMan, as I’m the quote-on-quote “DAGMan expert”.
+
+**How would you define DAGMan?**
+
+DAGMan is a HTCSS tool, which assists users in automatically managing workflows
+of HTCondor jobs. In the complex, modern world of computation, it makes sense to
+break complex workloads into smaller organized steps where a user has a job that
+requires the output of another as input. Theoretically, a user could sit on a
+computer, submit the first job, and wait for said job to finish before running
+the next job in the process to achieve a bigger task like sequencing genomes or
+analyzing gravitational waves, but why not let HTCondor take care of that? Enter
+DAGMan, DAGMan allows a user to describe the steps/jobs in a workflow as nodes and
+create execution dependencies between them via edges so a job is not executed until
+all of the other nodes it depends on complete successfully. Describing these nodes and
+edges is what creates the technical computer science jargony concept of the directed
+acyclic graph (DAG) the tool manages. Meaning DAGMan is a DAG Manager. While the base
+concept of DAGMan is to automatically manage a workflow for the user, DAGMan is also
+equipped with many useful features to assist the user in their research.
+
+**Why did you want to join the CHTC team?**
+
+I graduated college and had been applying to a lot of places. This position seemed
+well-fitting because it had a C++ focus, which I prefer to program with. The job
+was also affiliated with UW-Madison — a trusted place — and I fit the requirements.
+I was really ecstatic to even get an interview, to be honest. Getting a job in the
+computer science field can be a bit rough as a fresh graduate. I will say, after
+two years of working here, it’s been great. I’m all for CHTC.
+
+
+
+
+**What kind of work do you do for CHTC?**
+
+I’m one of the core developers for the HTCondor Software Suite (HTCSS).
+It’s a lot of coding, development and bug fixes. I also participate in
+meetings for various collaborations like the LIGO organization and FermiLab.
+The bulk of my work, however, is developing the HTCondor software. I have a
+specific focus on DAGMan, as I’m the quote-on-quote “DAGMan expert”.
+
+**How would you define DAGMan?**
+
+DAGMan is a HTCSS tool, which assists users in automatically managing workflows
+of HTCondor jobs. In the complex, modern world of computation, it makes sense to
+break complex workloads into smaller organized steps where a user has a job that
+requires the output of another as input. Theoretically, a user could sit on a
+computer, submit the first job, and wait for said job to finish before running
+the next job in the process to achieve a bigger task like sequencing genomes or
+analyzing gravitational waves, but why not let HTCondor take care of that? Enter
+DAGMan, DAGMan allows a user to describe the steps/jobs in a workflow as nodes and
+create execution dependencies between them via edges so a job is not executed until
+all of the other nodes it depends on complete successfully. Describing these nodes and
+edges is what creates the technical computer science jargony concept of the directed
+acyclic graph (DAG) the tool manages. Meaning DAGMan is a DAG Manager. While the base
+concept of DAGMan is to automatically manage a workflow for the user, DAGMan is also
+equipped with many useful features to assist the user in their research.
+
+**Why did you want to join the CHTC team?**
+
+I graduated college and had been applying to a lot of places. This position seemed
+well-fitting because it had a C++ focus, which I prefer to program with. The job
+was also affiliated with UW-Madison — a trusted place — and I fit the requirements.
+I was really ecstatic to even get an interview, to be honest. Getting a job in the
+computer science field can be a bit rough as a fresh graduate. I will say, after
+two years of working here, it’s been great. I’m all for CHTC.
+
+ +
+ +
+ +
+ +
+  +
+  +
+