

Hearing impaired often face difficulties in communicating effectively with non-disabled individuals, leading to discrimination in various aspects of society such as education and employment.
Hearing impaired learn pronunciation to ultimately communicate seamlessly with non-disabled individuals without relying on anyone else's assistance.
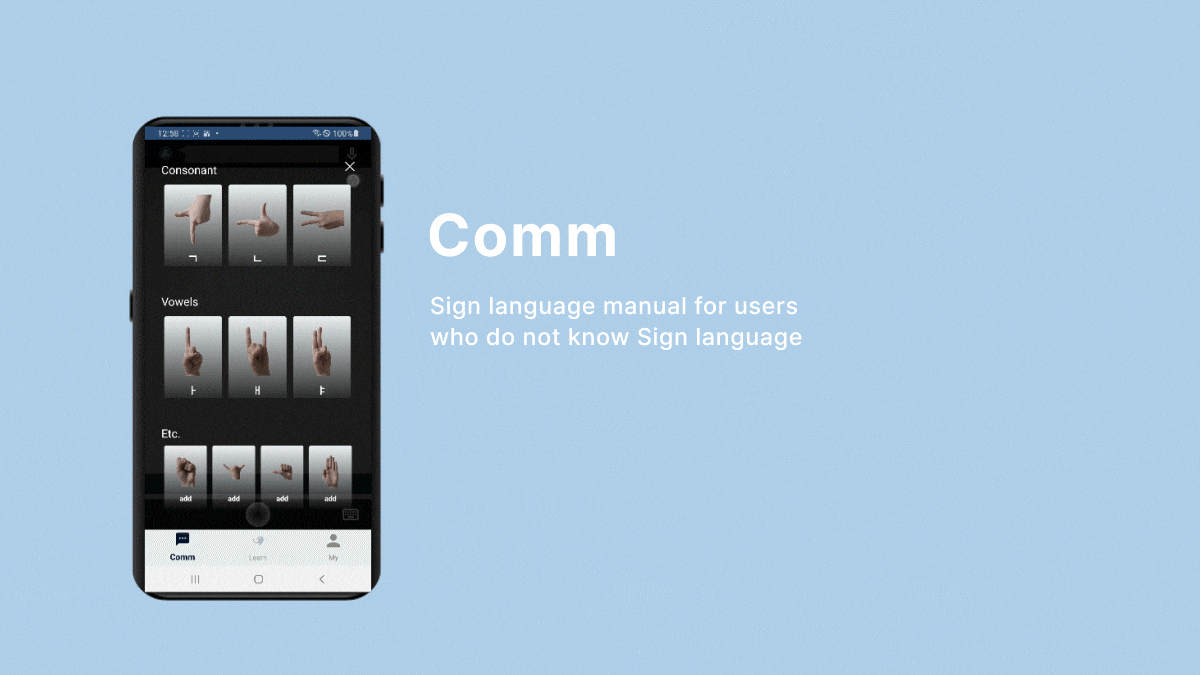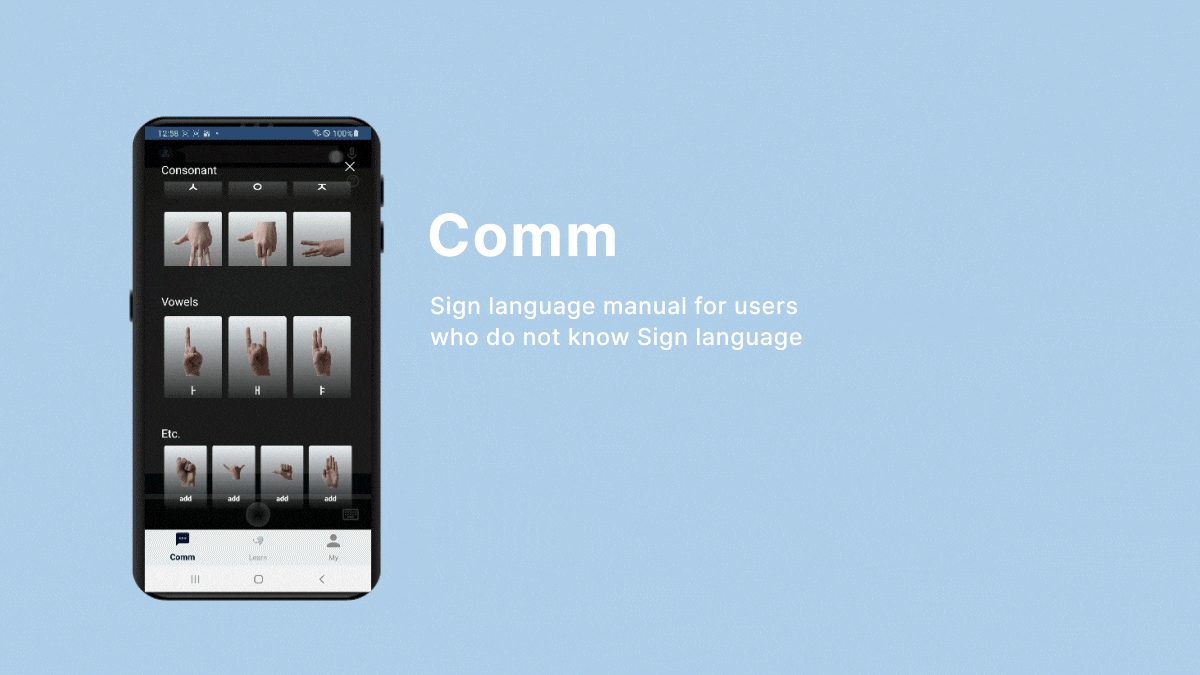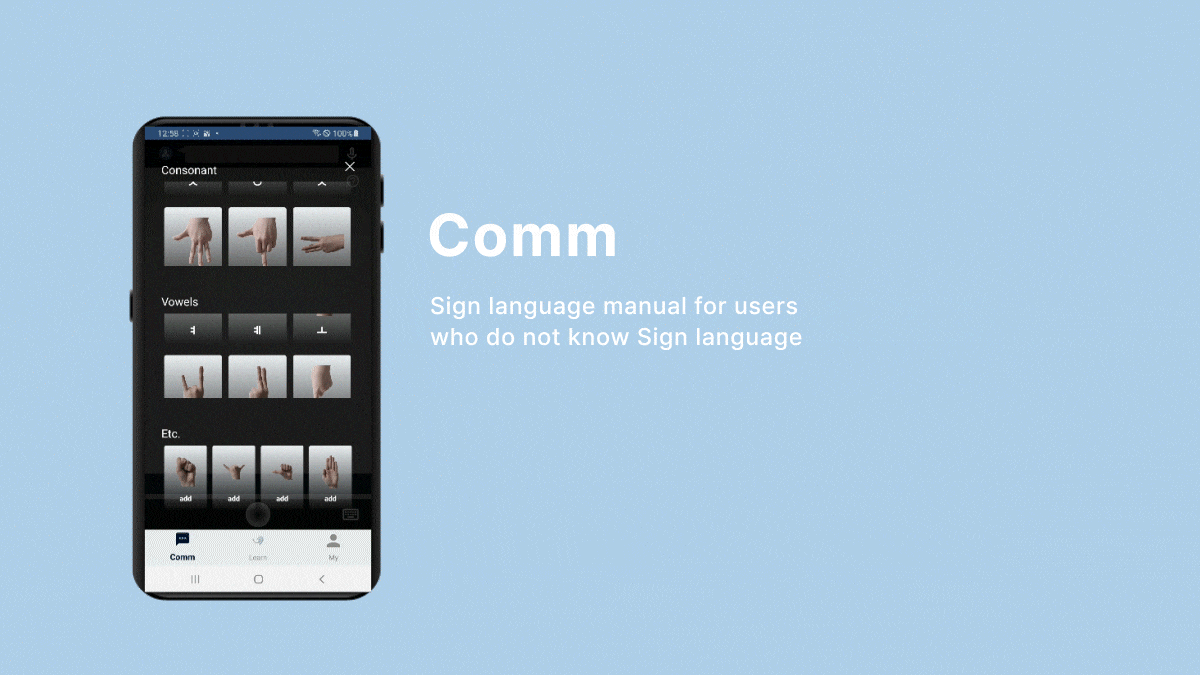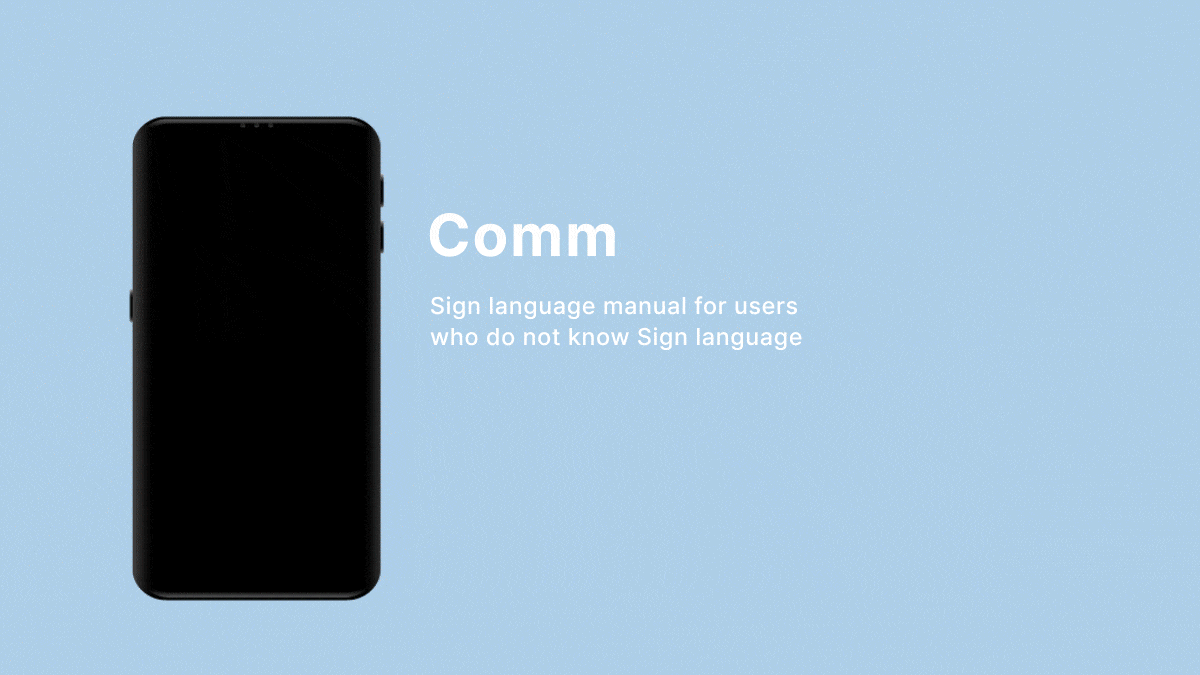
Even without pronunciation training and correction, real-time communication with non-disabled individuals is facilitated through sign language or text.









- Java 17
- Springboot, Spring Security
- Spring Data JPA
- MySQL
- Redis
- Docker, Docker-compose
- GCP Compute Engine
- I built a Docker image for our Spring Boot project using a Dockerfile and pushed it to Dockerhub.
- Next, I used the Vim text editor within a GCP Compute Engine instance to write the docker-compose.yml.
- After that, I pulled the Spring Boot image, along with MySQL and Redis images.
- Running 'docker-compose up -d' created the necessary containers.
- Subsequently, I utilized a Docker MySQL container to create a user, schema, and database.
- Backend communicated with the frontend using the server container we created.
- To connect to an external API for pronunciation testing, the frontend sent recorded audio files to the server using Multipart.
- The server then handled the encoding to Base64 and sent the encoded values to the external API.
- The external API processed the audio, returned the pronunciation scores to the server, which in turn forwarded them to the frontend.
- Additionally, we stored Refresh Tokens in the Redis container for user authentication and authorization.
- Furthermore, to play pronunciation practice videos, the backend sends the string that needs to be pronounced to an AI server. The AI server then separates the consonants and vowels in the string.

- Kotlin plugin version 1.9.0
- We used Kotlin and XML to develop the Android app. We implemented Google OAuth within Android Studio to allow users to use the app after signing in with Google.
- We also used Google's built-in Speech Recognizer and Text to Speech feature as speed is important for the real-time communication menu.
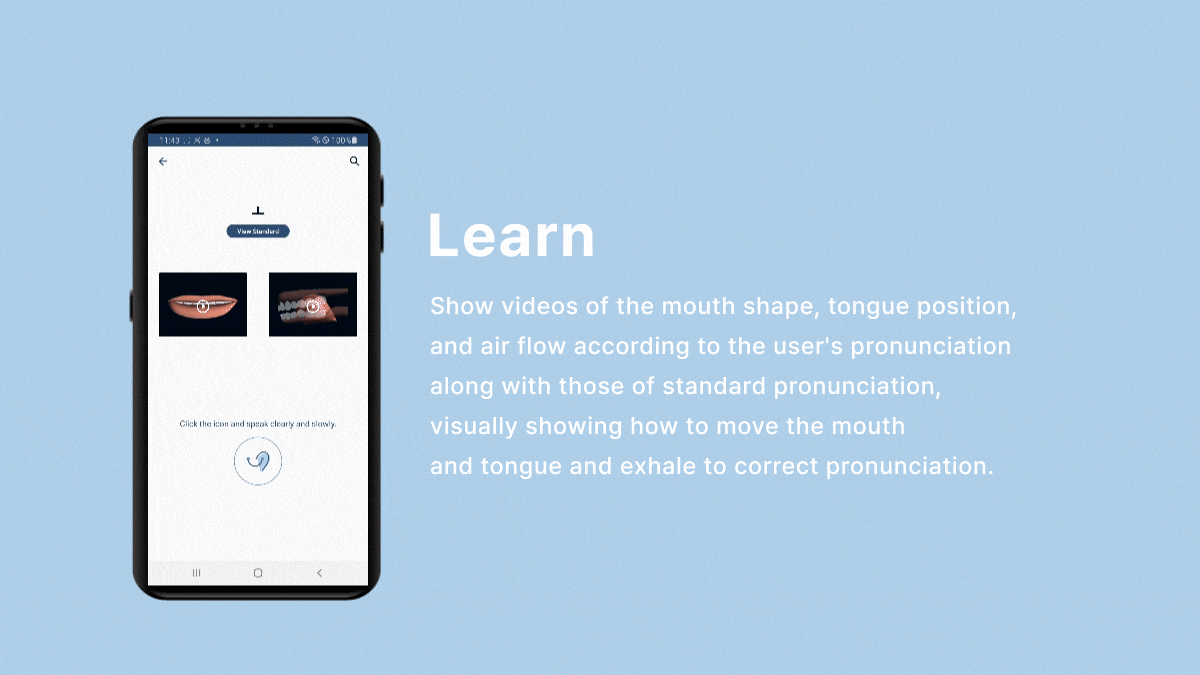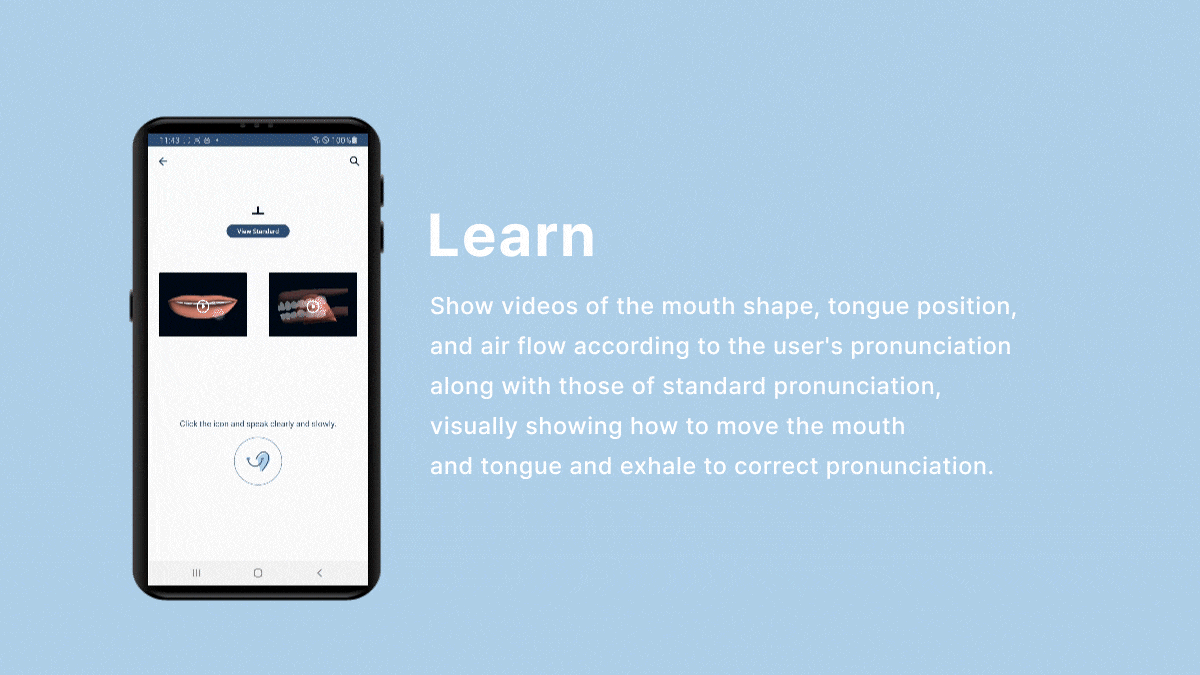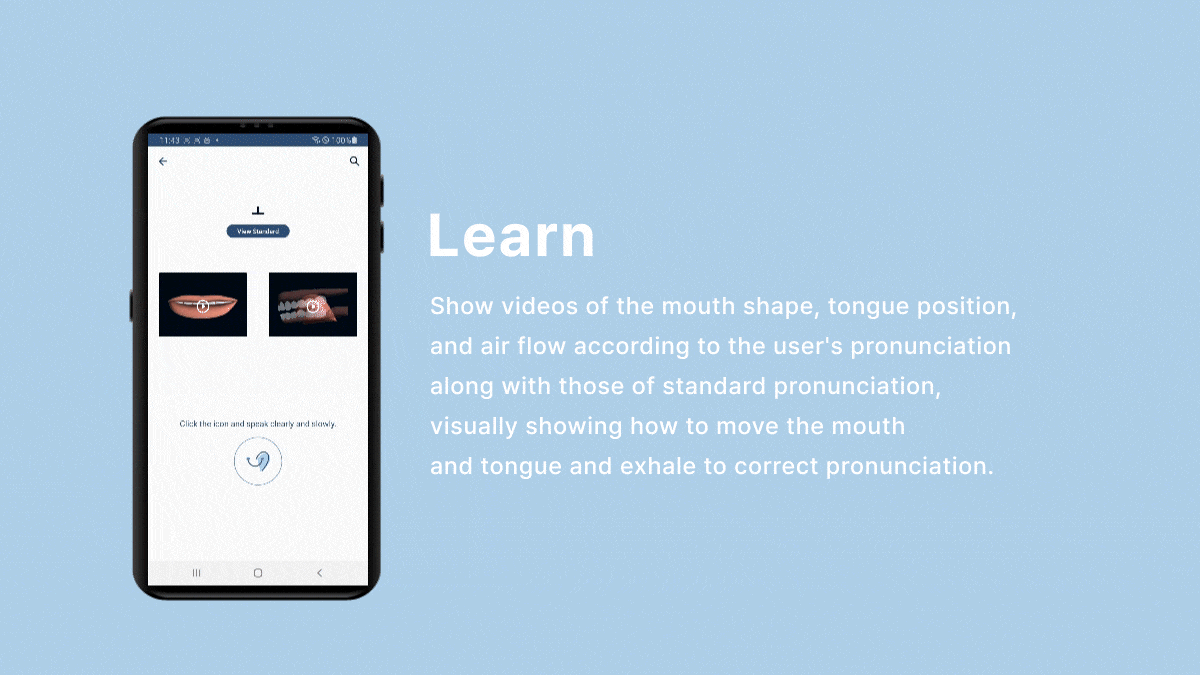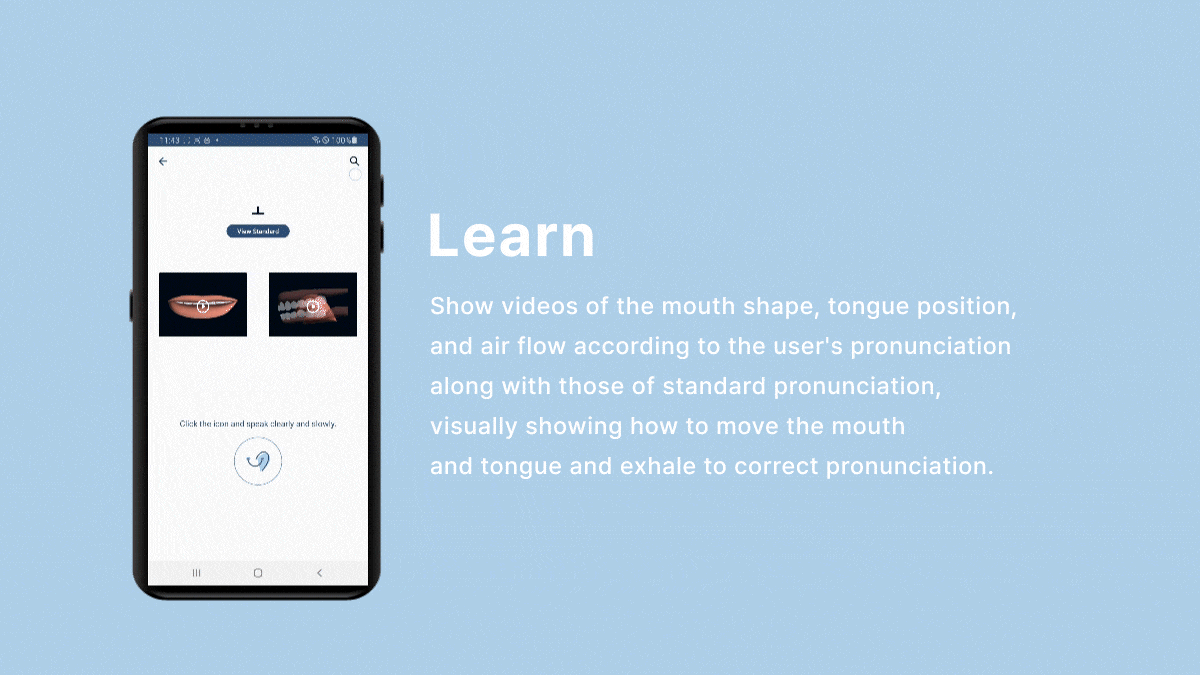
- We imported the mouth shape and tongue position images for the learning menu from Google Cloud Storage.
- ffmpeg 6.1.1
- fastapi 0.109.0
- uvicorn 0.26.0
- gunicorn 21.2.0
- python-multipart 0.0.6
- audiosegment 0.23.0
- google-cloud-speech 2.23.0
- pydub 0.25.1
- librosa 0.10.1
- soundfile 0.12.1
- To implement the communication function, I used Colab to train Google MediaPipe's Gesture Recognizer model through manually collected sign language images, and then saved them as task files and handed them over to Android.
- In order to learn how the user's pronunciation differs from the standard pronunciation by syllable, we used libraries such as FFmpeg and librosa to cut the voice file delivered by Android through the server into syllables, and then passed it to the Google Cloud Speech API to get the syllable-by-syllable pronunciation.
- I converted all functions to FastAPI, and then dockerized them, and pushed them to Docker Hub. After that, we deployed the server by pulling the docker image to the Virtual Machine inside Google's Compute Engine and deployed the server to communicate with Android.
| Member | 이서현 (Lee Seohyun) | 노수진 (Sujin Roh) | 김하연 (Kim Hayeon) | 김예솔 (Kim Yesol) |
|---|---|---|---|---|
| Role | PM / AI Developer | Backend Developer | Frontend Developer | UX-UI Designer |
| Profile |  |
 |
 |
 |