typora-root-url: D:\机构文档\os图片
QEMU有两种运行模式: User mode 模式,即用户态模拟,如 qemu-riscv64 程序,能够模拟不同处理器的用户态指令的执行,并可以直接解析ELF可执行文件,加载运行那些为不同处理器编译的用户级Linux应用程序(ELF可执行文件);在翻译并执行不同应用程序中的不同处理器的指令时,如果碰到是系统调用相关的汇编指令,它会把不同处理器(如RISC-V)的Linux系统调用转换为本机处理器(如x86-64)上的Linux系统调用,这样就可以让本机Linux完成系统调用,并返回结果(再转换成RISC-V能识别的数据)给这些应用。 System mode 模式,即系统态模式,如 qemu-system-riscv64 程序,能够模拟一个完整的基于不同CPU的硬件系统,包括处理器、内存及其他外部设备,支持运行完整的操作系统。
// os/src/main.rs
#![feature(llvm_asm)]
const SYSCALL_EXIT: usize = 93;
fn syscall(id: usize, args: [usize; 3]) -> isize {
let mut ret: isize;
unsafe {
llvm_asm!("ecall"
: "={x10}" (ret)
: "{x10}" (args[0]), "{x11}" (args[1]), "{x12}" (args[2]), "{x17}" (id)
: "memory"
: "volatile"
);
}
ret
}
pub fn sys_exit(xstate: i32) -> isize {
syscall(SYSCALL_EXIT, [xstate as usize, 0, 0])
}
#[no_mangle]
extern "C" fn _start() {
sys_exit(9);
}
- 一条运行os代码的指令
cargo build --target riscv64gc-unknown-none-elf
首先封装一下对 SYSCALL_WRITE 系统调用。这个是 Linux 操作系统内核提供的系统调用,其 ID 就是 SYSCALL_WRITE。
const SYSCALL_WRITE: usize = 64;
pub fn sys_write(fd: usize, buffer: &[u8]) -> isize {
syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()])
}然后实现基于 Write Trait 的数据结构,并完成 Write Trait 所需要的 write_str 函数,并用 print 函数进行包装。
- 启动OS:硬件启动后,会有一段代码(一般统称为bootloader)对硬件进行初始化,让包括内核在内的系统软件得以运行;
- OS准备好应用程序执行的环境:要运行该应用程序的时候,内核分配相应资源,将程序代码和数据载入内存,并赋予 CPU 使用权,由此应用程序可以运行;
- 应用程序开始执行:程序员编写的代码是应用程序的一部分,它需要标准库/核心库进行一些初始化工作后才能运行。
在QEMU模拟的硬件中,物理内存和外设都是通过对内存读写的方式来进行访问,下面列出了QEMU模拟的物理内存空间。
// qemu/hw/riscv/virt.c
static const struct MemmapEntry {
hwaddr base;
hwaddr size;
} virt_memmap[] = {
[VIRT_DEBUG] = { 0x0, 0x100 },
[VIRT_MROM] = { 0x1000, 0xf000 },
[VIRT_TEST] = { 0x100000, 0x1000 },
[VIRT_RTC] = { 0x101000, 0x1000 },
[VIRT_CLINT] = { 0x2000000, 0x10000 },
[VIRT_PCIE_PIO] = { 0x3000000, 0x10000 },
[VIRT_PLIC] = { 0xc000000, VIRT_PLIC_SIZE(VIRT_CPUS_MAX * 2) },
[VIRT_UART0] = { 0x10000000, 0x100 },
[VIRT_VIRTIO] = { 0x10001000, 0x1000 },
[VIRT_FLASH] = { 0x20000000, 0x4000000 },
[VIRT_PCIE_ECAM] = { 0x30000000, 0x10000000 },
[VIRT_PCIE_MMIO] = { 0x40000000, 0x40000000 },
[VIRT_DRAM] = { 0x80000000, 0x0 },
};VIRT_DRAM:DRAM的内存起始地址是 0x80000000 ,缺省大小为128MB。在本书中一般限制为8MB。
VIRT_UART0:串口相关的寄存器起始地址是 0x10000000 ,范围是 0x100 ,我们通过访问这段特殊的区域来实现字符输入输出的管理与控制。
在RISC-V64计算机启动执行前,先在其模拟的内存中放置好BootLoader程序和操作系统的二进制代码
-bios $(BOOTLOADER)这个参数意味着硬件内存中的固定位置0x80000000处放置了一个BootLoader程序–RustSBI(戳 附录 C:深入机器模式:RustSBI 可以进一步了解RustSBI。)。-device loader,file=$(KERNEL_BIN),addr=$(KERNEL_ENTRY_PA)这个参数表示硬件内存中的特定位置$(KERNEL_ENTRY_PA)放置了操作系统的二进制代码$(KERNEL_BIN)。$(KERNEL_ENTRY_PA)的值是0x80200000
当我们执行包含上次参数的qemu-system-riscv64软件,就意味给这台虚拟的RISC-V64计算机加电了。此时,CPU的其它通用寄存器清零, 而PC寄存器会指向 0x1000 的位置。 这个 0x1000 位置上是CPU加电后执行的第一条指令(固化在硬件中的一小段引导代码),它会很快跳转到 0x80000000 处, 即RustSBI的第一条指令。RustSBI完成基本的硬件初始化后, 会跳转操作系统的二进制代码 $(KERNEL_BIN) 所在内存位置 0x80200000 ,执行操作系统的第一条指令。 这时我们的编写的操作系统才开始正式工作。
os代码的执行指令(模板)
# 编译生成ELF格式的执行文件
$ cargo build --release
Compiling os v0.1.0 (/media/chyyuu/ca8c7ba6-51b7-41fc-8430-e29e31e5328f/thecode/rust/os_kernel_lab/os)
Finished release [optimized] target(s) in 0.15s
# 把ELF执行文件转成bianary文件
$ rust-objcopy --binary-architecture=riscv64 target/riscv64gc-unknown-none-elf/release/os --strip-all -O binary target/riscv64gc-unknown-none-elf/release/os.bin
#加载运行
$ qemu-system-riscv64 -machine virt -nographic -bios ../bootloader/rustsbi-qemu.bin -device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000
# 无法退出,风扇狂转,感觉碰到死循环我们可以通过 链接脚本 (Linker Script) 调整链接器的行为,使得最终生成的可执行文件的内存布局符合我们的预期。 我们修改 Cargo 的配置文件来使用我们自己的链接脚本 os/src/linker.ld 而非使用默认的内存布局:
// os/.cargo/config
[build]
target = "riscv64gc-unknown-none-elf"
[target.riscv64gc-unknown-none-elf]
rustflags = [
"-Clink-arg=-Tsrc/linker.ld", "-Cforce-frame-pointers=yes"
]具体的链接脚本 os/src/linker.ld 如下:
OUTPUT_ARCH(riscv)
ENTRY(_start)
BASE_ADDRESS = 0x80200000;
SECTIONS
{
. = BASE_ADDRESS;
skernel = .;
stext = .;
.text : {
*(.text.entry)
*(.text .text.*)
}
. = ALIGN(4K);
etext = .;
srodata = .;
.rodata : {
*(.rodata .rodata.*)
*(.srodata .srodata.*)
}
. = ALIGN(4K);
erodata = .;
sdata = .;
.data : {
*(.data .data.*)
*(.sdata .sdata.*)
}
. = ALIGN(4K);
edata = .;
.bss : {
*(.bss.stack)
sbss = .;
*(.bss .bss.*)
*(.sbss .sbss.*)
}
. = ALIGN(4K);
ebss = .;
ekernel = .;
/DISCARD/ : {
*(.eh_frame)
}
}冒号前面表示最终生成的可执行文件的一个段的名字,花括号内按照放置顺序描述将所有输入目标文件的哪些段放在这个段中,每一行格式为 <ObjectFile>(SectionName),表示目标文件 ObjectFile 的名为 SectionName 的段需要被放进去。我们也可以 使用通配符来书写 <ObjectFile> 和 <SectionName> 分别表示可能的输入目标文件和段名。因此,最终的合并结果是,在最终可执行文件 中各个常见的段 .text, .rodata .data, .bss 从低地址到高地址按顺序放置,每个段里面都包括了所有输入目标文件的同名段, 且每个段都有两个全局符号给出了它的开始和结束地址(比如 .text 段的开始和结束地址分别是 stext 和 etext )。
如何做到执行环境的初始化代码被放在内存上以 0x80200000 开头的区域上?
在链接脚本第 7 行,我们将当前地址设置为
BASE_ADDRESS也即0x80200000,然后从这里开始往高地址放置各个段。第一个被放置的 是.text,而里面第一个被放置的又是来自entry.asm中的段.text.entry,这个段恰恰是含有两条指令的执行环境初始化代码, 它在所有段中最早被放置在我们期望的0x80200000处。
关于rust运行和gdb调试的指令
# 在一个终端执行如下命令:
$ qemu-system-riscv64 -machine virt -nographic -bios ../bootloader/rustsbi-qemu.bin -device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000 -S -s
# 在另外一个终端执行如下命令:
$ rust-gdb target/riscv64gc-unknown-none-elf/release/os
(gdb) target remote :1234
(gdb) break *0x80200000
(gdb) x /16i 0x80200000
(gdb) si需要有一段正确配置栈空间布局
为了说明如何实现正确的栈,我们需要讨论这样一个问题:应用函数调用所需的栈放在哪里?
需要有一段代码来分配并栈空间,并把
sp寄存器指向栈空间的起始位置(注意:栈空间是从上向下push数据的)。 所以,我们要写一小段汇编代码entry.asm来帮助建立好栈空间。 从链接脚本第 32 行开始,我们可以看出entry.asm中分配的栈空间对应的段.bss.stack被放入到可执行文件中的.bss段中的低地址中。在后面虽然有一个通配符.bss.*,但是由于链接脚本的优先匹配规则它并不会被匹配到后面去。 这里需要注意的是地址区间 [sbss,ebss) 并不包括栈空间,其原因后面再进行说明。代码来分配并栈空间,并把sp寄存器指向栈空间的起始位置(注意:栈空间是从上向下push数据的)。 所以,我们要写一小段汇编代码entry.asm来帮助建立好栈空间。 从链接脚本第 32 行开始,我们可以看出entry.asm中分配的栈空间对应的段.bss.stack被放入到可执行文件中的.bss段中的低地址中。在后面虽然有一个通配符.bss.*,但是由于链接脚本的优先匹配规则它并不会被匹配到后面去。 这里需要注意的是地址区间 [sbss,ebss) 并不包括栈空间,其原因后面再进行说明。
.section .text.entry
.globl _start
_start:
la sp,boot_stack_top
call rust_main
.section .bss.stack
globl boot_stack
boot_stack:
.space 4096*16
.globl boot_stack_top
boot_stack_top:
由于一般应用程序的 .bss 段在程序正式开始运行之前会被执环境(系统库或操作系统内核)固定初始化为零,因此在 ELF 文件中,为了节省磁盘空间,只会记录 .bss 段的位置,且应用程序的假定在它执行前,其 .bss段 的数据内容都已是 全0 。 如果这块区域不是全零,且执行环境也没提前清零,那么会与应用的假定矛盾,导致程序出错。
const SBI_CONSOLE_PUTCHAR: usize = 1;
pub fn console_putchar(c: usize) {
syscall(SBI_CONSOLE_PUTCHAR, [c, 0, 0]);
}
impl Write for Stdout {
fn write_str(&mut self, s: &str) -> fmt::Result {
//sys_write(STDOUT, s.as_bytes());
for c in s.chars() {
console_putchar(c as usize);
}
Ok(())
}
}把系统调用转变成为rust sbi调用
错误处理函数的更新
// os/src/main.rs
#![feature(panic_info_message)]
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
if let Some(location) = info.location() {
println!("Panicked at {}:{} {}", location.file(), location.line(), info.message().unwrap());
} else {
println!("Panicked: {}", info.message().unwrap());
}
shutdown()
}

RISC-V 指令各部分含义
在大多数只与通用寄存器打交道的指令中, rs 表示 源寄存器 (Source Register), imm 表示 立即数 (Immediate), 是一个常数,二者构成了指令的输入部分;而 rd 表示 目标寄存器 (Destination Register),它是指令的输出部分。rs 和 rd 可以在 32 个通用寄存器 x0~x31 中选取。但是这三个部分都不是必须的,某些指令只有一种输入类型,另一些指令则没有输出部分
ret指令的解析 ra(x1)(寄存器存储跳转后的下一条指令地址)
事实上在函数返回的时候我们常常使用一条 伪指令 (Pseudo Instruction) 跳转回调用之前的位置: ret 。它会被汇编器翻译为 jalr x0, 0(x1),含义为跳转到寄存器 ra 保存的物理地址,由于 x0 是一个恒为 0 的寄存器,在 rd 中保存这一步被省略。
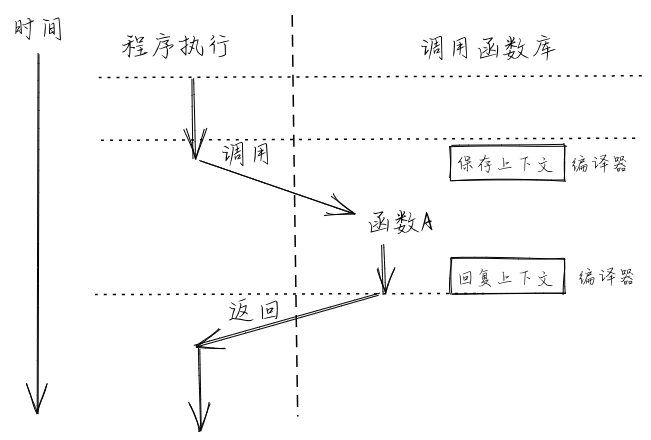
函数调用上下文
在一个函数调用子函数的前后,ra 寄存器的值不能发生变化。但实际上, 这并不仅仅局限于 ra 一个寄存器,而是作用于所有的通用寄存器。这是因为,编译器是独立编译每个函数的,因此一个函数并不能知道它所调用的 子函数修改了哪些寄存器。而站在一个函数的视角,在调用子函数的过程中某些寄存器的值被覆盖的确会对它接下来的执行产生影响。因此这是必要的。 我们将由于函数调用,在控制流转移前后需要保持不变的寄存器集合称之为 函数调用上下文 (Context) 或称 活动记录 (Activation Record),利用这一概念 ,则在函数调用前后需要保持不变的寄存器集合被称为函数调用上下文。
RISC-V 架构上的 C 语言调用规范
RISC-V 架构上的 C 语言调用规范可以在 这里 找到。 它对通用寄存器的使用做出了如下约定:
| 寄存器组 | 保存者 | 功能 |
|---|---|---|
| a0~a7 | 调用者保存 | 用来传递输入参数。特别的 a0 和 a1 用来保存返回值。 |
| t0~t6 | 调用者保存 | 作为临时寄存器使用,在函数中可以随意使用无需保存。 |
| s0~s11 | 被调用者保存 | 作为临时寄存器使用,保存后才能在函数中使用。 |
剩下的 5 个通用寄存器情况如下:
- zero(x0) 之前提到过,它恒为零,函数调用不会对它产生影响;
- ra(x1) 是调用者保存的,不过它并不会在每次调用子函数的时候都保存一次,而是在函数的开头和结尾保存/恢复即可,因为在执行期间即使被 覆盖也没有关系。看上去和被调用者保存寄存器保存的位置一样,但是它确实是调用者保存的。
- sp(x2) 是被调用者保存的。这个之后就会提到。
- gp(x3) 和 tp(x4) 在一个程序运行期间都不会变化,因此不必放在函数调用上下文中。它们的用途在后面的章节会提到。
更加详细的内容可以参考 Cornell 的 课件 。
函数调用上下文的保存/恢复时机以及寄存器的选择,但我们并没有详细说明这些寄存器保存在哪里,只是用“内存中的一块区域”草草带过。实际上, 它更确切的名字是 栈 (Stack) 。 sp(x2) 常用来保存 栈指针 (Stack Pointer),它是一个指向了内存中已经用过的位置的一个地址。在 RISC-V 架构中,栈是从高地址到低地址增长的。在一个函数中,作为起始的开场白负责分配一块新的栈空间,其实它只需要知道需要空间的大小,然后将 sp 的值减小相应的字节数即可,于是物理地址区间 新旧[新sp,旧sp) 对应的物理内存便可以被这个函数用来函数调用上下文的保存/恢复 以及其他工作,这块物理内存被称为这个函数的 栈帧 (Stackframe)。同理,函数中作为结尾的收场白负责将开场白分配的栈帧回收,这也仅仅需要 将 sp 的值增加相同的字节数回到分配之前的状态。这也可以解释为什么 sp 是一个被调用者保存寄存器。

它的开头和结尾分别在 sp(x2) 和 fp(s0) 所指向的地址。按照地址从高到低分别有以下内容,它们都是通过 sp 加上一个偏移量来访问的:
- ra 寄存器保存其返回之后的跳转地址,是一个调用者保存寄存器;
- 父亲栈帧的结束地址 fp,是一个被调用者保存寄存器;
- 其他被调用者保存寄存器 s1~s11;
- 函数所使用到的局部变量。

- 已初始化数据段保存程序中那些已初始化的全局数据,分为
.rodata和.data两部分。前者存放只读的全局数据,通常是一些常数或者是 常量字符串等;而后者存放可修改的全局数据。 - 未初始化数据段
.bss保存程序中那些未初始化的全局数据,通常由程序的加载者代为进行零初始化,也即将这块区域逐字节清零; - 堆 (heap) 区域用来存放程序运行时动态分配的数据,如 C/C++ 中的 malloc/new 分配到的数据本体就放在堆区域,它向高地址增长;
- 栈区域 stack 不仅用作函数调用上下文的保存与恢复,每个函数作用域内的局部变量也被编译器放在它的栈帧内。它向低地址增长。
在一个函数的视角中,它能够访问的变量包括以下几种:
- 函数的输入参数和局部变量:保存在一些寄存器或是该函数的栈帧里面,如果是在栈帧里面的话是基于当前 sp 加上一个偏移量来访问的;
- 全局变量:保存在数据段
.data和.bss中,某些情况下 gp(x3) 寄存器保存两个数据段中间的一个位置,于是全局变量是基于 gp 加上一个偏移量来访问的。
局部变量与全局变量
在一个函数的视角中,它能够访问的变量包括以下几种:
- 函数的输入参数和局部变量:保存在一些寄存器或是该函数的栈帧里面,如果是在栈帧里面的话是基于当前 sp 加上一个偏移量来访问的;
- 全局变量:保存在数据段
.data和.bss中,某些情况下 gp(x3) 寄存器保存两个数据段中间的一个位置,于是全局变量是基于 gp 加上一个偏移量来访问的。 - 堆上的动态变量:本体被保存在堆上,大小在运行时才能确定。而我们只能 直接 访问栈上或者全局数据段中的 编译期确定大小 的变量。 因此我们需要通过一个运行时分配内存得到的一个指向堆上数据的指针来访问它,指针的位宽确实在编译期就能够确定。该指针即可以作为局部变量 放在栈帧里面,也可以作为全局变量放在全局数据段中。
我们可以将常说的编译流程细化为多个阶段(虽然输入一条命令便可将它们全部完成):
- 编译器 (Compiler) 将每个源文件从某门高级编程语言转化为汇编语言,注意此时源文件仍然是一个 ASCII 或其他编码的文本文件;
- 汇编器 (Assembler) 将上一步的每个源文件中的文本格式的指令转化为机器码,得到一个二进制的 目标文件 (Object File);
- 链接器 (Linker) 将上一步得到的所有目标文件以及一些可能的外部目标文件链接在一起形成一个完整的可执行文件。
每个目标文件都有着自己局部的内存布局,里面含有若干个段。在链接的时候,链接器会将这些内存布局合并起来形成一个整体的内存布局。此外,每个目标文件 都有一个符号表,里面记录着它需要从其他文件中寻找的外部符号和能够提供给其他文件的符号,通常是一些函数和全局变量等。在链接的时候汇编器会将 外部符号替换为实际的地址。
批处理系统 (Batch System) 应运而生。它的核心思想是:将多个程序打包到一起输入计算机。而当一个程序运行结束后,计算机会 自动 加载下一个程序到内存并开始执行。这便是最早的真正意义上的操作系统。
确保操作系统的安全,对应用程序而言,需要限制的主要有两个方面: - 应用程序不能访问任意的地址空间(这个在第四章会进一步讲解,本章不会讲解) - 应用程序不能执行某些可能破会计算机系统的指令(本章的重点)
为了让应用程序获得操作系统的函数服务,采用传统的函数调用方式(即通常的 call 和 ret 指令或指令组合)将会直接绕过硬件的特权级保护检查。所以要设计新的指令:执行环境调用(Execution Environment Call,简称 ecall )和执行环境返回(Execution Environment Return,简称 eret )):
ecall:具有用户态到内核态的执行环境切换能力的函数调用指令(RISC-V中就有这条指令)eret:具有内核态到用户态的执行环境切换能力的函数返回指令(RISC-V中有类似的sret指令)
但硬件具有了这样的机制后,还需要操作系统的配合才能最终完成对操作系统自己的保护。首先,操作系统需要提供相应的控制流,能在执行 eret 前准备和恢复用户态执行应用程序的上下文。其次,在应用程序调用 ecall 指令后,能够保存用户态执行应用程序的上下文,便于后续的恢复;且还要坚持应用程序发出的服务请求是安全的。
RISC-V 架构中一共定义了 4 种特权级:
| 级别 | 编码 | 名称 |
|---|---|---|
| 0 | 00 | 用户/应用模式 (U, User/Application) |
| 1 | 01 | 监督模式 (S, Supervisor) |
| 2 | 10 | H, Hypervisor |
| 3 | 11 | 机器模式 (M, Machine) |

下表中我们给出了 RISC-V 特权级定义的会导致从低特权级到高特权级的各种 异常:
| Interrupt | Exception Code | Description |
|---|---|---|
| 0 | 0 | Instruction address misaligned |
| 0 | 1 | Instruction access fault |
| 0 | 2 | Illegal instruction |
| 0 | 3 | Breakpoint |
| 0 | 4 | Load address misaligned |
| 0 | 5 | Load access fault |
| 0 | 6 | Store/AMO address misaligned |
| 0 | 7 | Store/AMO access fault |
| 0 | 8 | Environment call from U-mode |
| 0 | 9 | Environment call from S-mode |
| 0 | 11 | Environment call from M-mode |
| 0 | 12 | Instruction page fault |
| 0 | 13 | Load page fault |
| 0 | 15 | Store/AMO page fault |
与特权级无关的一般的指令和通用寄存器 x0~x31 在任何特权级都可以任意执行。而每个特权级都对应一些特殊指令和 控制状态寄存器 (CSR, Control and Status Register) ,来控制该特权级的某些行为并描述其状态。当然特权指令不只是具有有读写 CSR 的指令,还有其他功能的特权指令。
如果低优先级下的处理器执行了高优先级的指令,会产生非法指令错误的异常,于是位于高特权级的执行环境能够得知低优先级的软件出现了该错误,这个错误一般是不可恢复的,此时一般它会将上层的低特权级软件终止。这在某种程度上体现了特权级保护机制的作用。
在RISC-V中,会有两类低优先级U模式下运行高优先级S模式的指令:
- 指令本身属于高特权级的指令,如
sret指令(表示从S模式返回到U模式)。 - 指令访问了 S模式特权级下才能访问的寄存器 或内存,如表示S模式系统状态的 控制状态寄存器
sstatus等。
| 指令 | 含义 |
|---|---|
| sret | 从S模式返回U模式。在U模式下执行会产生非法指令异常 |
| wfi | 处理器在空闲时进入低功耗状态等待中断。在U模式下执行会尝试非法指令异常 |
| sfence.vma | 刷新TLB缓存。在U模式下执行会尝试非法指令异常 |
| 访问S模式CSR的指令 | 通过访问 sepc/stvec/scause/sscartch/stval/sstatus/satp等CSR 来改变系统状态。在U模式下执行会尝试非法指令异常 |
在下一节中,我们将看到 在U模式下的用户态应用程序 ,如果执行上述S模式特权指令指令,将会产生非法指令异常,从而看出RISC-V的特权模式设计在一定程度上提供了对操作系统的保护。
-
sfence.vma:刷新TLB缓存。在U模式下执行会尝试非法指令异常
-
访问S模式CSR的指令:通过访问 sepc/stvec/scause/sscartch/stval/sstatus/satp等CSR 来改变系统状态。在U模式下执行会尝试非法指令异常
代码中尝试引入了外部库:
#[macro_use]
extern crate user_lib;
这个外部库其实就是 user 目录下的 lib.rs 以及它引用的若干子模块中。至于这个外部库为何叫 user_lib 而不叫 lib.rs 所在的目录的名字 user ,是因为在 user/Cargo.toml 中我们对于库的名字进行了设置: name = "user_lib" 。它作为 bin 目录下的源程序所依赖的用户库,等价于其他编程语言提供的标准库。
在 user/.cargo/config 中,我们和第一章一样设置链接时使用链接脚本 user/src/linker.ld 。在其中我们做的重要的事情是:
- 将程序的起始物理地址调整为
0x80400000,三个应用程序都会被加载到这个物理地址上运行; - 将
_start所在的.text.entry放在整个程序的开头,也就是说批处理系统只要在加载之后跳转到0x80400000就已经进入了 用户库的入口点,并会在初始化之后跳转到应用程序主逻辑; - 提供了最终生成可执行文件的
.bss段的起始和终止地址,方便clear_bss函数使用。
write和exit系统调用
/// 功能:将内存中缓冲区中的数据写入文件。
/// 参数:`fd` 表示待写入文件的文件描述符;
/// `buf` 表示内存中缓冲区的起始地址;
/// `len` 表示内存中缓冲区的长度。
/// 返回值:返回成功写入的长度。
/// syscall ID:64
fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize;
/// 功能:退出应用程序并将返回值告知批处理系统。
/// 参数:`xstate` 表示应用程序的返回值。
/// 返回值:该系统调用不应该返回。
/// syscall ID:93
fn sys_exit(xstate: usize) -> !;Rust 中的 llvm_asm! 宏的完整格式如下:
llvm_asm!(assembly template
: output operands
: input operands
: clobbers
: options
);const SYSCALL_WRITE: usize = 64;
const SYSCALL_EXIT: usize = 93;
fn syscall(id: usize, args: [usize; 3]) -> isize {
let mut ret: isize; //ret必须是可变绑定,将他和x10寄存器进行绑定,便可以拿到返回值
unsafe {
llvm_asm!("ecall"
: "={x10}" (ret)
: "{x10}" (args[0]), "{x11}" (args[1]), "{x12}" (args[2]), "{x17}" (id)
: "memory"
: "volatile"
);
}
ret
}下面逐行进行说明。
第 7 行指定输出操作数。这里由于我们的系统调用返回值只有一个 isize ,根据调用规范它会被保存在 a0 寄存器中。在双引号内,我们 可以对于使用的操作数进行限制,由于是输出部分,限制的开头必须是一个 = 。我们可以在限制内使用一对花括号再加上一个寄存器的名字告诉 编译器汇编的输出结果会保存在这个寄存器中。我们将声明出来用来保存系统调用返回值的变量 ret 包在一对普通括号里面放在操作数限制的 后面,这样可以把变量和寄存器建立联系。于是,在系统调用返回之后我们就能在变量 ret 中看到返回值了。注意,变量 ret 必须为可变 绑定,否则无法通过编译,这也说明在 unsafe 块内编译器还是会进行力所能及的安全检查。
第 8 行指定输入操作数。由于是输入部分,限制的开头不用加上 = 。同时在限制中设置使用寄存器 a0~a2 来保存系统调用的参数,以及 寄存器 a7 保存 syscall ID ,而它们分别 syscall 的参数变量 args 和 id 绑定。
第 9 行用于告知编译器插入的汇编代码会造成的一些影响以防止编译器在不知情的情况下误优化。常用的使用方法是告知编译器某个寄存器在执行嵌入 的汇编代码中的过程中会发生变化。我们这里则是告诉编译器:程序在执行嵌入汇编代码中指令的时候会修改内存。这能给编译器提供更多信息以生成正确的代码。
第 10 行用于告知编译器将我们在程序中给出的嵌入汇编代码保持原样放到最终构建的可执行文件中。如果不这样做的话,编译器可能会把它和其他代码 一视同仁并放在一起进行一些我们期望之外的优化。为了保证语义的正确性,一些比较关键的汇编代码需要加上该选项。
于是 sys_write 和 sys_exit 只需将 syscall 进行包装:
1// user/src/syscall.rs
2
3const SYSCALL_WRITE: usize = 64;
4const SYSCALL_EXIT: usize = 93;
5
6pub fn sys_write(fd: usize, buffer: &[u8]) -> isize {
7 syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()])
8}
9
10pub fn sys_exit(xstate: i32) -> isize {
11 syscall(SYSCALL_EXIT, [xstate as usize, 0, 0])
12}
在 os/src/main.rs 中能够找到这样一行:
global_asm!(include_str!("link_app.S"));
这里我们引入了一段汇编代码 link_app.S ,它一开始并不存在,而是在构建的时候自动生成的。当我们使用 make run 让系统成功运行起来 之后,我们可以先来看一看里面的内容:
1# os/src/link_app.S
2
3 .align 3
4 .section .data
5 .global _num_app
6_num_app:
7 .quad 3
8 .quad app_0_start
9 .quad app_1_start
10 .quad app_2_start
11 .quad app_2_end
12
13 .section .data
14 .global app_0_start
15 .global app_0_end
16app_0_start:
17 .incbin "../user/target/riscv64gc-unknown-none-elf/release/00hello_world.bin"
18app_0_end:
19
20 .section .data
21 .global app_1_start
22 .global app_1_end
23app_1_start:
24 .incbin "../user/target/riscv64gc-unknown-none-elf/release/01store_fault.bin"
25app_1_end:
26
27 .section .data
28 .global app_2_start
29 .global app_2_end
30app_2_start:
31 .incbin "../user/target/riscv64gc-unknown-none-elf/release/02power.bin"
32app_2_end:
可以看到第 13 行开始的三个数据段分别插入了三个应用程序的二进制镜像,并且各自有一对全局符号 app_*_start, app_*_end 指示它们的 开始和结束位置。而第 3 行开始的另一个数据段相当于一个 64 位整数数组。数组中的第一个元素表示应用程序的数量,后面则按照顺序放置每个应用 程序的起始地址,最后一个元素放置最后一个应用程序的结束位置。这样每个应用程序的位置都能从该数组中相邻两个元素中得知。这个数组所在的位置 同样也由全局符号 _num_app 所指示。
这个文件是在 cargo build 的时候,由脚本 os/build.rs 控制生成的。
应用管理器 AppManager 结构体定义 如下:
struct AppManager {
inner: RefCell<AppManagerInner>,
}
struct AppManagerInner {
num_app: usize,
current_app: usize,
app_start: [usize; MAX_APP_NUM + 1],
}
unsafe impl Sync for AppManager {}current_app 字段表示当前执行到了第几个应用,它会在系统运行期间发生变化。因此在声明全局变量 的时候一种自然的方法是利用 static mut。但是在 Rust 中,任何对于 static mut 变量的访问都是 unsafe 的,而我们要尽可能 减少 unsafe 的使用来更多的让编译器负责安全性检查。
此外,为了让 AppManager 能被直接全局实例化,我们需要将其标记为 Sync 。
于是,我们利用 RefCell 来提供 内部可变性 (Interior Mutability), 所谓的内部可变性就是指在我们只能拿到 AppManager 的不可变借用,意味着同样也只能 拿到 AppManagerInner 的不可变借用的情况下依然可以修改 AppManagerInner 里面的字段。 使用 RefCell::borrow/RefCell::borrow_mut 分别可以拿到 RefCell 里面内容的不可变借用/可变借用, RefCell 会在运行时维护当前它管理的对象的已有借用状态,并在访问对象时进行借用检查。于是 RefCell::borrow_mut 就是我们实现内部可变性的关键。
lazy_static! 宏提供了全局变量的运行时初始化功能。一般情况下,全局变量必须在编译期设置一个初始值,但是有些全局变量依赖于运行期间 才能得到的数据作为初始值。这导致这些全局变量需要在运行时发生变化,也即重新设置初始值之后才能使用。如果我们手动实现的话有诸多不便之处, 比如需要把这种全局变量声明为 static mut 并衍生出很多 unsafe code。这种情况下我们可以使用 lazy_static! 宏来帮助我们解决 这个问题。这里我们借助 lazy_static! 声明了一个 AppManager 结构的名为 APP_MANAGER 的全局实例,且只有在它第一次被使用到 的时候才会进行实际的初始化工作。
因此,借助 Rust 核心库提供的 RefCell 和外部库 lazy_static!,我们就能在避免 static mut 声明的情况下以更加优雅的Rust风格使用全局变量。
在APP_MANAGER中load_app负责将参数 app_id 对应的应用程序的二进制镜像加载到物理内存以 0x80400000 开头的位置,这个位置是批处理操作系统和应用程序 之间约定的常数地址,回忆上一小节中,我们也调整应用程序的内存布局以同一个地址开头。第 8 行开始,我们首先将一块内存清空,然后找到待加载应用 二进制镜像的位置,并将它复制到正确的位置。它本质上是把数据从一块内存复制到另一块内存,从批处理操作系统的角度来看是将它数据段的一部分复制到了它 程序之外未知的地方。在这一点上也体现了冯诺依曼计算机的 代码即数据 的特征。
注意第 7 行我们插入了一条奇怪的汇编指令 fence.i ,它是用来清理 i-cache 的。我们知道缓存是存储层级结构中提高访存速度的很重要一环。 而 CPU 对物理内存所做的缓存又分成 数据缓存 (d-cache) 和 指令缓存 (i-cache) 两部分,分别在 CPU 访存和取指的时候使用。在取指 的时候,对于一个指令地址, CPU 会先去 i-cache 里面看一下它是否在某个已缓存的缓存行内,如果在的话它就会直接从高速缓存中拿到指令而不是通过 总线和内存通信。通常情况下, CPU 会认为程序的代码段不会发生变化,因此 i-cache 是一种只读缓存。但在这里,我们会修改会被 CPU 取指的内存 区域,这会使得 i-cache 中含有与内存中不一致的内容。因此我们这里必须使用 fence.i 指令手动清空 i-cache ,让里面所有的内容全部失效, 才能够保证正确性
- 当启动应用程序的时候,需要初始化应用程序的用户态上下文,并能切换到用户态执行应用程序;
- 当应用程序发起系统调用(即发出Trap )之后,需要到批处理操作系统中进行处理;
- 当应用程序执行出错的时候,需要到批处理操作系统中杀死该应用并加载运行下一个应用;
- 当应用程序执行结束的时候,需要到批处理操作系统中加载运行下一个应用(实际上也是通过系统调用
sys_exit来实现的)。
RISC-V 架构中,关于 Trap 有一条重要的规则:在 Trap 前的特权级不会高于Trap后的特权级。因此如果触发 Trap 之后切换到 S 特权级(下称 Trap 到 S), 说明 Trap 发生之前 CPU 只能运行在 S/U 特权级。但无论如何,只要是 Trap 到 S 特权级,操作系统就会使用 S 特权级中与 Trap 相关的 控制状态寄存器 (CSR, Control and Status Register) 来辅助 Trap 处理。我们在编写运行在 S 特权级的批处理操作系统中的 Trap 处理相关代码的时候,就需要使用如下所示的S模式的CSR寄存器。
| CSR 名 | 该 CSR 与 Trap 相关的功能 |
|---|---|
| sstatus | SPP 等字段给出 Trap 发生之前 CPU 处在哪个特权级(S/U)等信息 |
| sepc | 当 Trap 是一个异常的时候,记录 Trap 发生之前执行的最后一条指令的地址 |
| scause | 描述 Trap 的原因 |
| stval | 给出 Trap 附加信息 |
| stvec | 控制 Trap 处理代码的入口地址 |
S模式下最重要的 sstatus 寄存器
注意 sstatus 是 S 特权级最重要的 CSR,可以从很多方面控制 S 特权级的CPU行为和执行状态
当 CPU 执行完一条指令并准备从用户特权级 Trap 到 S 特权级的时候,硬件会自动帮我们做这些事情:
sstatus的SPP字段会被修改为 CPU 当前的特权级(U/S)。sepc会被修改为 Trap 回来之后默认会执行的下一条指令的地址。当 Trap 是一个异常的时候,它实际会被修改成 Trap 之前执行的最后一条 指令的地址。scause/stval分别会被修改成这次 Trap 的原因以及相关的附加信息。- CPU 会跳转到
stvec所设置的 Trap 处理入口地址,并将当前特权级设置为 S ,然后开始向下执行。
stvec 相关细节
在 RV64 中, stvec 是一个 64 位的 CSR,在中断使能的情况下,保存了中断处理的入口地址。它有两个字段:
- MODE 位于 [1:0],长度为 2 bits;
- BASE 位于 [63:2],长度为 62 bits。
当 MODE 字段为 0 的时候, stvec 被设置为 Direct 模式,此时进入 S 模式的 Trap 无论原因如何,处理 Trap 的入口地址都是 BASE<<2 , CPU 会跳转到这个地方进行异常处理。本书中我们只会将 stvec 设置为 Direct 模式。而 stvec 还可以被设置为 Vectored 模式
而当 CPU 完成 Trap 处理准备返回的时候,需要通过一条 S 特权级的特权指令 sret 来完成,这一条指令具体完成以下功能:
- CPU 会将当前的特权级按照
sstatus的SPP字段设置为 U 或者 S ; - CPU 会跳转到
sepc寄存器指向的那条指令,然后开始向下执行。
从上面可以看出硬件主要负责特权级切换、跳转到异常处理入口地址(要在使能异常/中断前设置好)以及在 CSR 中保存一些只有硬件才方便探测到的硬件内的 Trap 相关信息。这基本上都是硬件不得不完成的事情,剩下的工作都交给软件,让软件能有更大的灵活性。
在 Trap 发生时需要保存的物理资源内容,并将其一起放在一个名为 TrapContext 的类型中,定义如下:
#[repr(C)]
pub struct TrapContext {
pub x: [usize; 32],
pub sstatus: Sstatus,
pub sepc: usize,
}可以看到里面包含所有的通用寄存器 x0~x31 ,还有 sstatus 和 sepc 。那么为什么需要保存它们呢?
- 对于通用寄存器而言,两条执行流运行在不同的特权级,所属的软件也可能由不同的编程语言编写,虽然在 Trap 控制流中只是会执行 Trap 处理 相关的代码,但依然可能直接或间接调用很多模块,因此很难甚至不可能找出哪些寄存器无需保存。既然如此我们就只能全部保存了。但这里也有一些例外, 如
x0被硬编码为 0 ,它自然不会有变化;还有tp(x4)除非我们手动出于一些特殊用途使用它,否则一般也不会被用到。它们无需保存, 但我们仍然在TrapContext中为它们预留空间,主要是为了后续的实现方便。 - 对于 CSR 而言,我们知道进入 Trap 的时候,硬件会立即覆盖掉
scause/stval/sstatus/sepc的全部或是其中一部分。scause/stval的情况是:它总是在 Trap 处理的第一时间就被使用或者是在其他地方保存下来了,因此它没有被修改并造成不良影响的风险。 而对于sstatus/sepc而言,它们会在 Trap 处理的全程有意义(在 Trap 执行流最后sret的时候还用到了它们),而且确实会出现 Trap 嵌套的情况使得它们的值被覆盖掉。所以我们需要将它们也一起保存下来,并在sret之前恢复原样。
特权级切换的核心是对Trap的管理。这主要涉及到如下一下内容:
- 应用程序通过
ecall进入到内核状态时,操作系统保存被打断的应用程序的Trap 上下文。 - 操作系统根据与Trap相关的CSR寄存器内容,完成系统调用服务的分发与处理。
- 操作系统完成系统调用服务后,需要恢复被打断的应用程序的Trap 上下文,并通
sret让应用程序继续执行。
首先是保存 Trap 上下文的 __alltraps 的实现:
.altmacro
.macro SAVE_GP n
sd x\n, \n*8(sp)
.endm
.macro LOAD_GP n
ld x\n, \n*8(sp)
.endm
.section .text
.globl __alltraps
.globl __restore
.align 2
__alltraps:
csrrw sp, sscratch, sp
# now sp->kernel stack, sscratch->user stack
# allocate a TrapContext on kernel stack
addi sp, sp, -34*8
# save general-purpose registers
sd x1, 1*8(sp)
# skip sp(x2), we will save it later
sd x3, 3*8(sp)
# skip tp(x4), application does not use it
# save x5~x31
.set n, 5
.rept 27
SAVE_GP %n
.set n, n+1
.endr
# we can use t0/t1/t2 freely, because they were saved on kernel stack
csrr t0, sstatus
csrr t1, sepc
sd t0, 32*8(sp)
sd t1, 33*8(sp)
# read user stack from sscratch and save it on the kernel stack
csrr t2, sscratch
sd t2, 2*8(sp)
# set input argument of trap_handler(cx: &mut TrapContext)
mv a0, sp
call trap_handler
-
第 7 行我们使用
.align将__alltraps的地址 4 字节对齐,这是 RISC-V 特权级规范的要求; -
第 8 行的
csrrw原型是 csrrw rd, csr, rs 可以将 CSR 当前的值读到通用寄存器 rd 中,然后将 通用寄存器 rs 的值写入该 CSR 。因此这里起到的是交换 sscratch 和 sp 的效果。在这一行之前 sp 指向用户栈, sscratch 指向内核栈(原因稍后说明),现在 sp 指向内核栈, sscratch 指向用户栈。 -
第 12 行,我们准备在内核栈上保存 Trap 上下文,于是预先分配 34×8 字节的栈帧,这里改动的是 sp ,说明确实是在内核栈上。
-
第 13
24 行,保存 Trap 上下文的通用寄存器 x0x31,跳过 x0 和 tp(x4),原因之前已经说明。我们在这里也不保存 sp(x2),因为我们要基于 它来找到每个寄存器应该被保存到的正确的位置。实际上,在栈帧分配之后,我们可用于保存 Trap 上下文的地址区间为 [sp,sp+8×34) ,按照
TrapContext结构体的内存布局,它从低地址到高地址分别按顺序放置 x0~x31,最后是 sstatus 和 sepc 。因此通用寄存器 xn 应该被保存在地址区间 [sp+8n,sp+8(n+1)) 。 在这里我们正是这样基于 sp 来保存这些通用寄存器的。为了简化代码,x5~x31 这 27 个通用寄存器我们通过类似循环的
.rept每次使用SAVE_GP宏来保存,其实质是相同的。注意我们需要在Trap.S开头加上.altmacro才能正常使用.rept命令。 -
第 25~28 行,我们将 CSR sstatus 和 sepc 的值分别读到寄存器 t0 和 t1 中然后保存到内核栈对应的位置上。指令 csrr rd, csr 的功能就是将 CSR 的值读到寄存器 rd 中。这里我们不用担心 t0 和 t1 被覆盖, 因为它们刚刚已经被保存了。
-
第 30~31 行专门处理 sp 的问题。首先将 sscratch 的值读到寄存器 t2 并保存到内核栈上,注意它里面是进入 Trap 之前的 sp 的值,指向 用户栈。而现在的 sp 则指向内核栈。
-
第 33 行令 a0←sp,让寄存器 a0 指向内核栈的栈指针也就是我们刚刚保存的 Trap 上下文的地址, 这是由于我们接下来要调用
trap_handler进行 Trap 处理,它的第一个参数cx由调用规范要从 a0 中获取。而 Trap 处理函数trap_handler需要 Trap 上下文的原因在于:它需要知道其中某些寄存器的值,比如在系统调用的时候应用程序传过来的 syscall ID 和 对应参数。我们不能直接使用这些寄存器现在的值,因为它们可能已经被修改了,因此要去内核栈上找已经被保存下来的值。
当 trap_handler 返回之后会从调用 trap_handler 的下一条指令开始执行,也就是从栈上的 Trap 上下文恢复的 __restore :
__restore:
# case1: start running app by __restore
# case2: back to U after handling trap
mv sp, a0
# now sp->kernel stack(after allocated), sscratch->user stack
# restore sstatus/sepc
ld t0, 32*8(sp)
ld t1, 33*8(sp)
ld t2, 2*8(sp)
csrw sstatus, t0
csrw sepc, t1
csrw sscratch, t2
# restore general-purpuse registers except sp/tp
ld x1, 1*8(sp)
ld x3, 3*8(sp)
.set n, 5
.rept 27
LOAD_GP %n
.set n, n+1
.endr
# release TrapContext on kernel stack
addi sp, sp, 34*8
# now sp->kernel stack, sscratch->user stack
csrrw sp, sscratch, sp
sret- 第 8 行比较奇怪我们暂且不管,假设它从未发生,那么 sp 仍然指向内核栈的栈顶。
- 第 11~24 行负责从内核栈顶的 Trap 上下文恢复通用寄存器和 CSR 。注意我们要先恢复 CSR 再恢复通用寄存器,这样我们使用的三个临时寄存器 才能被正确恢复。
- 在第 26 行之前,sp 指向保存了 Trap 上下文之后的内核栈栈顶, sscratch 指向用户栈栈顶。我们在第 26 行在内核栈上回收 Trap 上下文所 占用的内存,回归进入 Trap 之前的内核栈栈顶。第 27 行,再次交换 sscratch 和 sp,现在 sp 重新指向用户栈栈顶,sscratch 也依然保存 进入 Trap 之前的状态并指向内核栈栈顶。
- 在应用程序执行流状态被还原之后,第 28 行我们使用
sret指令回到 U 特权级继续运行应用程序执行流。
sscratch CSR 的用途
在特权级切换的时候,我们需要将 Trap 上下文保存在内核栈上,因此需要一个寄存器暂存内核栈地址,并以它作为基地址来依次保存 Trap 上下文 的内容。但是所有的通用寄存器都不能够用来暂存,因为它们都需要被保存,如果覆盖掉它们会影响应用执行流的执行。
事实上我们缺少了一个重要的中转寄存器,而 sscratch CSR 正是为此而生。从上面的汇编代码中可以看出,在保存 Trap 上下文的时候,它 起到了两个作用:首先是保存了内核栈的地址,其次它作为一个中转站让 sp 目前指向的用户栈的地址可以暂时保存下来。于是,我们仅需一条 csrrw 指令就完成了从用户栈到内核栈的切换,这是一种极其精巧的实现。
Trap 在使用 Rust 实现的 trap_handler 函数中完成分发和处理:
1// os/src/trap/mod.rs
2
3#[no_mangle]
4pub fn trap_handler(cx: &mut TrapContext) -> &mut TrapContext {
5 let scause = scause::read();
6 let stval = stval::read();
7 match scause.cause() {
8 Trap::Exception(Exception::UserEnvCall) => {
9 cx.sepc += 4;
10 cx.x[10] = syscall(cx.x[17], [cx.x[10], cx.x[11], cx.x[12]]) as usize;
11 }
12 Trap::Exception(Exception::StoreFault) |
13 Trap::Exception(Exception::StorePageFault) => {
14 println!("[kernel] PageFault in application, core dumped.");
15 run_next_app();
16 }
17 Trap::Exception(Exception::IllegalInstruction) => {
18 println!("[kernel] IllegalInstruction in application, core dumped.");
19 run_next_app();
20 }
21 _ => {
22 panic!("Unsupported trap {:?}, stval = {:#x}!", scause.cause(), stval);
23 }
24 }
25 cx
26}
-
第 4 行声明返回值为
&mut TrapContext并在第 25 行实际将传入的cx原样返回,因此在__restore的时候 a0 在调用trap_handler前后并没有发生变化,仍然指向分配 Trap 上下文之后的内核栈栈顶,和此时 sp 的值相同,我们 sp←a0 并不会有问题; -
第 7 行根据 scause 寄存器所保存的 Trap 的原因进行分发处理。这里我们无需手动操作这些 CSR ,而是使用 Rust 的 riscv 库来更加方便的 做这些事情。要引入 riscv 库,我们需要:
# os/Cargo.toml [dependencies] riscv = { git = "https://github.com/rcore-os/riscv", features = ["inline-asm"] } -
第 8~11 行,发现 Trap 的原因是来自 U 特权级的 Environment Call,也就是系统调用。这里我们首先修改保存在内核栈上的 Trap 上下文里面 sepc,让其增加 4。这是因为我们知道这是一个由
ecall指令触发的系统调用,在进入 Trap 的时候,硬件会将 sepc 设置为这条ecall指令所在的地址(因为它是进入 Trap 之前最后一条执行的指令)。而在 Trap 返回之后,我们希望应用程序执行流从ecall的下一条指令 开始执行。因此我们只需修改 Trap 上下文里面的 sepc,让它增加ecall指令的码长,也即 4 字节。这样在__restore的时候 sepc 在恢复之后就会指向ecall的下一条指令,并在sret之后从那里开始执行。这属于我们之前提到过的——用户程序能够预知到的执行流 状态所发生的变化。用来保存系统调用返回值的 a0 寄存器也会同样发生变化。我们从 Trap 上下文取出作为 syscall ID 的 a7 和系统调用的三个参数 a0~a2 传给
syscall函数并获取返回值。syscall函数是在syscall子模块中实现的。 -
第 12~20 行,分别处理应用程序出现访存错误和非法指令错误的情形。此时需要打印错误信息并调用
run_next_app直接切换并运行下一个 应用程序。 -
第 21 行开始,当遇到目前还不支持的 Trap 类型的时候,我们的批处理操作系统整个 panic 报错退出。
当批处理操作系统初始化完成,或者是某个应用程序运行结束或出错的时候,我们要调用 run_next_app 函数切换到下一个应用程序。此时 CPU 运行在 S 特权级,而它希望能够切换到 U 特权级。在 RISC-V 架构中,唯一一种能够使得 CPU 特权级下降的方法就是通过 Trap 返回系列指令,比如 sret 。事实上,在运行应用程序之前要完成如下这些工作:
- 跳转到应用程序入口点
0x80400000。 - 将使用的栈切换到用户栈。
- 在
__alltraps时我们要求sscratch指向内核栈,这个也需要在此时完成。 - 从 S 特权级切换到 U 特权级。
它们可以通过复用 __restore 的代码更容易的实现。我们只需要在内核栈上压入一个相应构造的 Trap 上下文,再通过 __restore ,就能 让这些寄存器到达我们希望的状态。
impl TrapContext {
pub fn set_sp(&mut self, sp: usize) { //设置x[2]为用户栈的栈顶,x[2]保存的事sscratch这个寄存器
self.x[2] = sp; //在上下文push在内核栈,返回后刚好能回到用户栈
}
pub fn app_init_context(entry: usize, sp: usize) -> Self {
let mut sstatus = sstatus::read(); //设置第一次应用压入时的状态
sstatus.set_spp(SPP::User);
let mut cx = Self {
x: [0; 32],
sstatus,
sepc: entry,
};
cx.set_sp(sp); //设置sscratch这个寄存器 也就是用户栈顶位置
cx
}
}为 TrapContext 实现 app_init_context 方法,修改其中的 sepc 寄存器为应用程序入口点 entry, sp 寄存器为我们设定的 一个栈指针,并将 sstatus 寄存器的 SPP 字段设置为 User 。
在 run_next_app 函数中我们能够看到:
1// os/src/batch.rs
2
3pub fn run_next_app() -> ! {
4 let current_app = APP_MANAGER.inner.borrow().get_current_app();
5 unsafe {
6 APP_MANAGER.inner.borrow().load_app(current_app);
7 }
8 APP_MANAGER.inner.borrow_mut().move_to_next_app();
9 extern "C" { fn __restore(cx_addr: usize); }
10 unsafe {
11 __restore(KERNEL_STACK.push_context(
12 TrapContext::app_init_context(APP_BASE_ADDRESS, USER_STACK.get_sp())
13 ) as *const _ as usize); //
14 }
15 panic!("Unreachable in batch::run_current_app!");
16}
pub fn push_context(&self, cx: TrapContext) -> &'static mut TrapContext {
let cx_ptr = (self.get_sp() - core::mem::size_of::<TrapContext>()) as *mut TrapContext;
unsafe {
*cx_ptr = cx;
}
unsafe{
cx_ptr.as_mut().unwrap()
}
}在高亮行所做的事情是在内核栈上压入一个 Trap 上下文,其 sepc 是应用程序入口地址 0x80400000 ,其 sp 寄存器指向用户栈,其 sstatus 的 SPP 字段被设置为 User 。push_context 的返回值是内核栈压入 Trap 上下文之后的栈顶,它会被作为 __restore 的参数( 回看 __restore 代码 ,这时我们可以理解为何 __restore 的开头会做 sp←a0 )使得在 __restore 中 sp 仍然可以指向内核栈的栈顶。这之后,就和一次普通的 __restore 一样了。push_context直接从用户栈顶拿到上下文并push到内核栈。
- 通过提前加载应用程序到内存,减少应用程序切换开销
- 通过协作机制支持程序主动放弃处理器,提高系统执行效率
- 通抢占机制支持程序被动放弃处理器,提高不同程序对处理器资源使用的公平性,也进一步提高了应用对I/O事件的响应效率
早期的计算机系统大部分是单处理器计算机系统。当处理器进一步发展后,它与IO的速度差距也进一步拉大。这时计算机科学家发现,在 多道程序 运行方式下,一个程序如果不让出处理器,其他程序是无法执行的。如果一个应用由于IO操作让处理器空闲下来或让处理器忙等,那其他需要处理器资源进行计算的应用还是没法使用空闲的处理器资源。于是就想到,让应用在执行IO操作时,可以主动 释放处理器 ,让其他应用继续执行。当然执行 放弃处理器 的操作算是一种对处理器资源的直接管理,所以应用程序可以发出这样的系统调用,让操作系统来具体完成。这样的操作系统就是支持 多道程序 协作式操作系统。
计算机科学家很快发现,编写应用程序的科学家(简称应用程序员)来自不同的领域,他们不一定有友好互助的意识,也不了解其他程序的执行情况,很难(也没必要)有提高整个系统利用率上的大局观。在他们的脑海里,整个计算机就应该是为他们自己的应用准备的,不用考虑其他程序的运行。这导致应用程序员在编写程序时,无法做到在程序的合适位置放置 放弃处理器的系统调用请求 ,这样系统的整体利用率还是无法提高。
所以,站在系统的层面,还是需要有一种办法能强制打断应用程序的执行,来提高整个系统的效率,让在整个系统中执行的多个程序之间占用计算机资源的情况相对公平一些。根据计算机系统的硬件设计,为提高I/O效率,外设可以通过硬件中断机制来与处理机进行I/O交互操作。这种硬件中断机制·可随时打断应用程序的执行,并让操作系统来完成对外设的I/O响应。
而操作系统可进一步利用某种以固定时长为时间间隔的外设中断(比如时钟中断)来强制打断一个程序的执行,这样一个程序只能运行一段时间(可以简称为一个时间片, Time Slice)就一定会让出处理器,且操作系统可以在处理外设的I/O响应后,让不同应用程序分时占用处理器执行,并可通过程序占用处理器的总执行时间来评估运行的程序对处理器资源的消耗。
我们可以把一个程序在一个时间片上占用处理器执行的过程称为一个 任务 (Task),让操作系统对不同程序的 任务 进行管理。通过平衡各个程序在整个时间段上的任务数,就达到一定程度的系统公平和高效的系统效率。在一个包含多个时间片的时间段上,会有属于不同程序的多个任务在轮流占用处理器执行,这样的操作系统就是支持 分时多任务 的抢占式操作系统。
本章所介绍的多道程序和分时多任务系统都有一些共同的特点:在内存中同一时间可以驻留多个应用。所有的应用都是在系统启动的时候分别加载到内存的不同区域中。由于目前计算机系统中只有一个处理器,则同一时间最多只有一个应用在执行,剩下的应用则处于就绪状态,需要内核将处理器分配给它们才能开始执行。一旦应用开始执行,它就处于运行状态了。
本章主要是设计和实现建立支持 多道程序 的二叠纪“锯齿螈”初级操作系统、支持多道程序的三叠纪“始初龙”协作式操作系统和支持 分时多任务 的三叠纪“腔骨龙”抢占式操作系统,从而对可支持运行一批应用程序的多种执行环境有一个全面和深入的理解,并可归纳抽象出 任务 , 任务切换 等操作系统的概念。
由于每个应用被加载到的位置都不同,也就导致它们的链接脚本 linker.ld 中的 BASE_ADDRESS 都是不同的。实际上, 我们写了一个脚本 build.py 而不是直接用 cargo build 构建应用的链接脚本:
import os
base_address = 0x80400000
step = 0x20000
linker = 'src/linker.ld'
app_id = 0
apps = os.listdir('src/bin')
apps.sort()
for app in apps:
app = app[:app.find('.')]
lines = []
lines_before = []
with open(linker, 'r') as f:
for line in f.readlines():
lines_before.append(line)
line = line.replace(hex(base_address), hex(base_address+step*app_id))
lines.append(line)
with open(linker, 'w+') as f:
f.writelines(lines)
os.system('cargo build --bin %s --release' % app)
print('[build.py] application %s start with address %s' %(app, hex(base_address+step*app_id)))
with open(linker, 'w+') as f:
f.writelines(lines_before)
app_id = app_id + 1
它的思路很简单,在遍历 app 的大循环里面只做了这样几件事情:
- 第 16~22 行,找到
src/linker.ld中的BASE_ADDRESS = 0x80400000;这一行,并将后面的地址 替换为和当前应用对应的一个地址; - 第 23 行,使用
cargo build构建当前的应用,注意我们可以使用--bin参数来只构建某一个应用; - 第 25~26 行,将
src/linker.ld还原。
应用的加载方式也和上一章的有所不同。上一章中讲解的加载方法是让所有应用都共享同一个固定的加载物理地址。也是因为这个原因,内存中同时最多只能驻留一个应用,当它运行完毕或者出错退出的时候由操作系统的 batch 子模块加载一个新的应用来替换掉它。本章中,所有的应用在内核初始化的时候就一并被加载到内存中。为了避免覆盖,它们自然需要被加载到不同的物理地址。这是通过调用 loader 子模块的 load_apps 函数实现的:
pub fn load_apps(){
extern "C"{
fn _num_app(); //加载汇编程序
}
let num_app_ptr=_num_app as usize as *const usize; //获得num_app存在的位置
let num_app=get_num_app(); //从data段中拿到一些数据
let app_start=unsafe{
core::slice::from_raw_parts(num_app_ptr.add(1), num_app+1)
};
unsafe {
llvm_asm!("fence.i"::::"volatile");
}
for i in 0..num_app{
let base_i=get_base_i(i); //从0x0840000开始存放
(base_i..base_i+APP_SIZE_LIMIT).for_each(|addr|unsafe{
(addr as *mut u8).write_volatile(0)
});
let src = unsafe{
core::slice::from_raw_parts(app_start[i] as *const u8, app_start[i+1]-app_start[i])
};
let dst = unsafe {
core::slice::from_raw_parts_mut(base_i as *mut u8, src.len())
};
dst.copy_from_slice(src);
}
}可以看出,第 i 个应用被加载到以物理地址 base_i 开头的一段物理内存上,而 base_i 的计算方式如下:
1 // os/src/loader.rs
2
3 fn get_base_i(app_id: usize) -> usize {
4 APP_BASE_ADDRESS + app_id * APP_SIZE_LIMIT
5 }我们可以在 config 子模块中找到这两个常数。从这一章开始, config 子模块用来存放内核中所有的常数。看到 APP_BASE_ADDRESS 被设置为 0x80400000 ,而 APP_SIZE_LIMIT 和上一章一样被设置为 0x20000 ,也就是每个应用二进制镜像的大小限制。因此,应用的内存布局就很明朗了——就是从 APP_BASE_ADDRESS 开始依次为每个应用预留一段空间。
这样,我们就说明了多个应用是如何被构建和加载的。
当多道程序的初始化放置工作完成,或者是某个应用程序运行结束或出错的时候,我们要调用 run_next_app 函数切换到下一个应用程序。此时 CPU 运行在 S 特权级的操作系统中,而操作系统希望能够切换到 U 特权级去运行应用程序。这一过程与上章的 执行应用程序 一节的描述类似。相对不同的是,操作系统知道每个应用程序预先加载在内存中的位置,这就需要设置应用程序返回的不同 Trap 上下文(Trap上下文中保存了 放置程序起始地址的epc 寄存器内容):
- 跳转到应用程序(编号 i )的入口点 entryi
- 将使用的栈切换到用户栈
本节的重点是操作系统的核心机制—— 任务切换 。 任务切换支持的场景是:一个应用在运行途中便会主动交出 CPU 的使用权,此时它只能暂停执行,等到内核重新给它分配处理器资源之后才能恢复并继续执行。
我们又看到了熟悉的“暂停-继续”组合。一旦一条执行流需要支持“暂停-继续”,就需要提供一种执行流切换的机制,而且需要保证执行流被切换出去之前和切换回来之后,它的状态,也就是在执行过程中同步变化的资源(如寄存器、栈等)需要保持不变,或者变化在它的预期之内。而不是所有的资源都需要被保存,事实上只有那些对于执行流接下来的进行仍然有用,且在它被切换出去的时候有被覆盖的风险的那些资源才有被保存的价值。这些物理资源被称为 任务上下文 (Task Context)
本节的任务切换的执行过程是第二章的 Trap 之后的另一种异常控制流,都是描述两条执行流之间的切换,如果将它和 Trap 切换进行比较,会有如下异同:
- 与 Trap 切换不同,它不涉及特权级切换;
- 与 Trap 切换不同,它的一部分是由编译器帮忙完成的;
- 与 Trap 切换相同,它对应用是透明的。

事实上,它是来自两个不同应用的 Trap 执行流之间的切换。当一个应用 Trap 到 S 模式的操作系统中进行进一步处理(即进入了操作系统的Trap执行流)的时候,其 Trap 执行流可以调用一个特殊的 __switch 函数。这个函数表面上就是一个普通的函数调用:在 __switch 返回之后,将继续从调用该函数的位置继续向下执行。但是其间却隐藏着复杂的执行流切换过程。具体来说,调用 __switch 之后直到它返回前的这段时间,原 Trap 执行流会先被暂停并被切换出去, CPU 转而运行另一个应用的 Trap 执行流。之后在时机合适的时候,原 Trap 执行流才会从某一条 Trap 执行流(很有可能不是它之前切换到的那一条)切换回来继续执行并最终返回。不过,从实现的角度讲, __switch 和一个普通的函数之间的差别仅仅是它会换栈。
当 Trap 执行流准备调用 __switch 函数并进入暂停状态的时候,让我们考察一下它内核栈上的情况。如上图所示,在准备调用 __switch 函数之前,内核栈上从栈底到栈顶分别是保存了应用执行状态的 Trap 上下文以及内核在对 Trap 处理的过程中留下的调用栈信息。由于之后还要恢复回来执行,我们必须保存 CPU 当前的某些寄存器,我们称它们为 任务上下文 (Task Context)。我们会在稍后介绍里面需要包含哪些寄存器。至于保存的位置,我们将任务上下文直接压入内核栈的栈顶,从这一点上来说它和函数调用一样。
这样需要保存的信息就已经确实的保存在内核栈上了,而恢复的时候我们要从任务上下文的位置——也就是这一时刻内核栈栈顶的位置找到被保存的寄存器快照进行恢复,这个位置也需要被保存下来。对于每一条被暂停的 Trap 执行流,我们都用一个名为 task_cx_ptr 的变量来保存它栈顶的任务上下文的地址


下面我们给出 __switch 的实现:
1# os/src/task/switch.S
2
3.altmacro
4.macro SAVE_SN n
5 sd s\n, (\n+1)*8(sp)
6.endm
7.macro LOAD_SN n
8 ld s\n, (\n+1)*8(sp)
9.endm
10 .section .text
11 .globl __switch
12__switch:
13 # __switch(
14 # current_task_cx_ptr2: &*const TaskContext,
15 # next_task_cx_ptr2: &*const TaskContext
16 # )
17 # push TaskContext to current sp and save its address to where a0 points to
18 addi sp, sp, -13*8
19 sd sp, 0(a0)
20 # fill TaskContext with ra & s0-s11
21 sd ra, 0(sp)
22 .set n, 0
23 .rept 12
24 SAVE_SN %n
25 .set n, n + 1
26 .endr
27 # ready for loading TaskContext a1 points to
28 ld sp, 0(a1)
29 # load registers in the TaskContext
30 ld ra, 0(sp)
31 .set n, 0
32 .rept 12
33 LOAD_SN %n
34 .set n, n + 1
35 .endr
36 # pop TaskContext
37 addi sp, sp, 13*8
38 ret我们手写汇编代码来实现 __switch 。可以看到它的函数原型中的两个参数分别是当前 Trap 执行流和即将被切换到的 Trap 执行流的 task_cx_ptr2 ,从 RISC-V 调用规范 可以知道它们分别通过寄存器 a0/a1 传入。
阶段 [2] 体现在第 18~26 行。第 18 行在 A 的内核栈上预留任务上下文的空间,然后将当前的栈顶位置保存下来。接下来就是逐个对寄存器进行保存,从中我们也能够看出 TaskContext 里面究竟包含哪些寄存器:
1// os/src/task/context.rs
2
3#[repr(C)]
4pub struct TaskContext {
5 ra: usize,
6 s: [usize; 12],
7}这里面只保存了 ra 和被调用者保存的 s0~s11 。ra 的保存很重要,它记录了 __switch 返回之后应该到哪里继续执行,从而在切换回来并 ret 之后能到正确的位置。而保存调用者保存的寄存器是因为,调用者保存的寄存器可以由编译器帮我们自动保存。我们会将这段汇编代码中的全局符号 __switch 解释为一个 Rust 函数:
1// os/src/task/switch.rs
2
3global_asm!(include_str!("switch.S"));
4
5extern "C" {
6 pub fn __switch(
7 current_task_cx_ptr2: *const usize,
8 next_task_cx_ptr2: *const usize
9 );
10}我们会调用该函数来完成切换功能而不是直接跳转到符号 __switch 的地址。因此在调用前后 Rust 编译器会自动帮助我们插入保存/恢复调用者保存寄存器的汇编代码。
仔细观察的话可以发现 TaskContext 很像一个普通函数栈帧中的内容。正如之前所说, __switch 的实现除了换栈之外几乎就是一个普通函数,也能在这里得到体现。尽管如此,二者的内涵却有着很大的不同。
剩下的汇编代码就比较简单了。读者可以自行对照注释看看图示中的后面几个阶段各是如何实现的。另外,后面会出现传给 __switch 的两个参数相同,也就是某个 Trap 执行流自己切换到自己的情形,请读者对照图示思考目前的实现能否对它进行正确处理。
本节的一个重点是展示进一步增强的操作系统管理能力的和对处理器资源的相对高效利用。为此,对 任务 的概念进行进一步扩展和延伸:形成了
- 任务运行状态:任务从开始到结束执行过程中所处的不同运行状态:未初始化、准备执行、正在执行、已退出
- 任务控制块:管理程序的执行过程的任务上下文,控制程序的执行与暂停
- 任务相关系统调用:应用程序和操作系统直接的接口,用于程序主动暂停
sys_yield和主动退出sys_exit
我们给出 sys_yield 的标准接口:
第三章新增系统调用(一)
/// 功能:应用主动交出 CPU 所有权并切换到其他应用。
/// 返回值:总是返回 0。
/// syscall ID:124
fn sys_yield() -> isize;
然后是用户库对应的实现和封装:
// user/src/syscall.rs
pub fn sys_yield() -> isize {
syscall(SYSCALL_YIELD, [0, 0, 0])
}
// user/src/lib.rs
pub fn yield_() -> isize { sys_yield() }注意 yield 是 Rust 的关键字,因此我们只能将应用直接调用的接口命名为 yield_ 。rust任务控制块与任务运行状态
#[derive(Copy, Clone, PartialEq)]
pub enum TaskStatus {
UnInit,
Ready,
Running,
Exited,
}注解
Rust 语法卡片:#[derive]
通过 #[derive(...)] 可以让编译器为你的类型提供一些 Trait 的默认实现。
- 实现了
CloneTrait 之后就可以调用clone函数完成拷贝; - 实现了
PartialEqTrait 之后就可以使用==运算符比较该类型的两个实例,从逻辑上说只有 两个相等的应用执行状态才会被判为相等,而事实上也确实如此。 Copy是一个标记 Trait,决定该类型在按值传参/赋值的时候取移动语义还是复制语义。
仅仅有这个是不够的,内核还需要保存一个应用的更多信息,我们将它们都保存在一个名为 任务控制块 (Task Control Block) 的数据结构中:
pub struct TaskControlBlock {
pub task_cx_ptr: usize,
pub task_status: TaskStatus,
}
impl TaskControlBlock {
pub fn get_task_cx_ptr2(&self) -> *const usize {
&self.task_cx_ptr as *const usize
}
}可以看到我们还在 task_cx_ptr 字段中维护了一个上一小节中提到的指向应用被切换出去的时候,它内核栈栈顶的任务上下文的指针。而在任务切换函数 __switch 中我们需要用这个 task_cx_ptr 的指针作为参数并代表这个应用,于是 TaskControlBlock 还提供了获取这个指针的指针 task_cx_ptr2 的方法 get_task_cx_ptr2 。
任务控制块非常重要。在内核中,它就是应用的管理单位。在后面的章节我们还会不断向里面添加更多内容。
我们还需要一个全局的任务管理器来管理这些用任务控制块描述的应用:
// os/src/task/mod.rs
pub struct TaskManager {
num_app: usize,
inner: RefCell<TaskManagerInner>,
}
struct TaskManagerInner {
tasks: [TaskControlBlock; MAX_APP_NUM],
current_task: usize,
}
unsafe impl Sync for TaskManager {}
其中仍然使用到了变量与常量分离的编程风格:字段 num_app 仍然表示任务管理器管理的应用的数目,它在 TaskManager 初始化之后就不会发生变化;而包裹在 TaskManagerInner 内的任务控制块数组 tasks 以及表示 CPU 正在执行的应用编号 current_task 会在执行应用的过程中发生变化: 每个应用的运行状态都会发生变化,而 CPU 执行的应用也在不断切换。
再次强调,这里的 current_task 与第二章批处理系统中的含义不同。在批处理系统中,它表示一个既定的应用序列中的执行进度,隐含着在该应用之前的都已经执行完毕,之后都没有执行;而在这里我们只能通过它知道 CPU 正在执行哪个应用,而不能获得其他应用的任何信息。
lazy_static!{ //一些很简单的初始化工作
pub static ref TASK_MANAGER:TaskManager={
let num_app=get_num_app(); //获取当前app的数量
let mut tasks=[
TaskControlBlock{
task_cx_ptr:0,
task_status:TaskStatus::Running,
};
MAX_APP_NUM
];
for i in 0..num_app{
tasks[i].task_cx_ptr=init_app_cx(i) as *const _ as usize;
tasks[i].task_status=TaskStatus::Ready;
}
TaskManager{
num_app,
inner:RefCell::new(TaskManagerInner{
tasks,
current_task:0,
}),
}
};
}构建一个TASK_MANAGER的全局构造器 同样是需要 具有内部可变性
sys_yield 的实现用到了 task 子模块提供的 suspend_current_and_run_next 接口:
// os/src/syscall/process.rs
use crate::task::suspend_current_and_run_next;
pub fn sys_yield() -> isize {
suspend_current_and_run_next();
0
}
这个接口如字面含义,就是暂停当前的应用并切换到下个应用。
同样, sys_exit 也改成基于 task 子模块提供的 exit_current_and_run_next 接口:
// os/src/syscall/process.rs
use crate::task::exit_current_and_run_next;
pub fn sys_exit(exit_code: i32) -> ! {
println!("[kernel] Application exited with code {}", exit_code);
exit_current_and_run_next();
panic!("Unreachable in sys_exit!");
}
它的含义是退出当前的应用并切换到下个应用。在调用它之前我们打印应用的退出信息并输出它的退出码。如果是应用出错也应该调用该接口,不过我们这里并没有实现,有兴趣的读者可以尝试。
suspend_current_and_run_next();exit_current_and_run_next(); 实现方法 主要体现在run_next_app,所以只会重点讲述run_next_task
接下来看看 run_next_task 的实现:
1// os/src/task/mod.rs
2
3fn run_next_task() {
4 TASK_MANAGER.run_next_task();
5}
6
7impl TaskManager {
8 fn run_next_task(&self) {
9 if let Some(next) = self.find_next_task() {
10 let mut inner = self.inner.borrow_mut();
11 let current = inner.current_task;
12 inner.tasks[next].task_status = TaskStatus::Running;
13 inner.current_task = next;
14 let current_task_cx_ptr2 = inner.tasks[current].get_task_cx_ptr2();
15 let next_task_cx_ptr2 = inner.tasks[next].get_task_cx_ptr2();
16 core::mem::drop(inner);
17 unsafe {
18 __switch(
19 current_task_cx_ptr2,
20 next_task_cx_ptr2,
21 );
22 }
23 } else {
24 panic!("All applications completed!");
25 }
26 }
27}
run_next_task 使用任务管理器的全局实例 TASK_MANAGER 的 run_next_task 方法。它会调用 find_next_task 方法尝试寻找一个运行状态为 Ready 的应用并返回其 ID 。注意到其返回的类型是 Option<usize> ,也就是说不一定能够找到,当所有的应用都退出并将自身状态修改为 Exited 就会出现这种情况,此时 find_next_task 应该返回 None 。如果能够找到下一个可运行的应用的话,我们就可以分别拿到当前应用 current 和即将被切换到的应用 next 的 task_cx_ptr2 ,然后调用 __switch 接口进行切换。如果找不到的话,说明所有的应用都运行完毕了,我们可以直接 panic 退出内核。
注意在实际切换之前我们需要手动 drop 掉我们获取到的 TaskManagerInner 的可变引用。因为一般情况下它是在函数退出之后才会被自动释放,从而 TASK_MANAGER 的 inner 字段得以回归到未被借用的状态,之后可以再借用。如果不手动 drop 的话,编译器会在 __switch 返回,也就是当前应用被切换回来的时候才 drop,这期间我们都不能修改 TaskManagerInner ,甚至不能读(因为之前是可变借用)。正因如此,我们需要在 __switch 前提早手动 drop 掉 inner 。
于是 find_next_task 又是如何实现的呢?
1// os/src/task/mod.rs
2
3impl TaskManager {
4 fn find_next_task(&self) -> Option<usize> {
5 let inner = self.inner.borrow();
6 let current = inner.current_task;
7 (current + 1..current + self.num_app + 1)
8 .map(|id| id % self.num_app)
9 .find(|id| {
10 inner.tasks[*id].task_status == TaskStatus::Ready
11 })
12 }
13}
TaskManagerInner 的 tasks 是一个固定的任务控制块组成的表,长度为 num_app ,可以用下标 0~num_app-1 来访问得到每个应用的控制状态。我们的任务就是找到 current_task 后面第一个状态为 Ready 的应用。因此从 current_task + 1 开始循环一圈,需要首先对 num_app 取模得到实际的下标,然后检查它的运行状态。
注解
Rust 语法卡片:迭代器
a..b 实际上表示左闭右开区间 [a,b) ,在 Rust 中,它会被表示为类型 core::ops::Range ,标准库中为它实现好了 Iterator trait,因此它也是一个迭代器。
关于迭代器的使用方法如 map/find 等,请参考 Rust 官方文档。

- 在应用真正跑起来之前,需要 CPU 第一次从内核态进入用户态。我们在第二章批处理系统中也介绍过实现方法,只需在内核栈上压入构造好的 Trap 上下文,然后
__restore即可。本章的思路大致相同,但是有一些变化。 - 当一个应用即将被运行的时候,它会被
__switch过来。如果它是之前被切换出去的话,那么此时它的内核栈上应该有 Trap 上下文和任务上下文,切换机制可以正常工作。但是如果它是第一次被执行怎么办呢?这就需要它的内核栈上也有类似结构的内容。我们是在创建TaskManager的全局实例TASK_MANAGER的时候来进行这个初始化的。
当时我们进行了这样的操作。 init_app_cx 是在 loader 子模块中定义的:
// os/src/loader.rs
pub fn init_app_cx(app_id: usize) -> &'static TaskContext {
KERNEL_STACK[app_id].push_context(
TrapContext::app_init_context(get_base_i(app_id), USER_STACK[app_id].get_sp()),
TaskContext::goto_restore(),
)
}
impl KernelStack {
fn get_sp(&self) -> usize {
self.data.as_ptr() as usize + KERNEL_STACK_SIZE
}
pub fn push_context(&self, trap_cx: TrapContext, task_cx: TaskContext) -> &'static mut TaskContext {
unsafe {
let trap_cx_ptr = (self.get_sp() - core::mem::size_of::<TrapContext>()) as *mut TrapContext;
*trap_cx_ptr = trap_cx;
let task_cx_ptr = (trap_cx_ptr as usize - core::mem::size_of::<TaskContext>()) as *mut TaskContext;
*task_cx_ptr = task_cx;
task_cx_ptr.as_mut().unwrap()
}
}
}这里 KernelStack 的 push_context 方法先压入一个和之前相同的 Trap 上下文,再在它上面压入一个任务上下文,然后返回任务上下文的地址。这个任务上下文是我们通过 TaskContext::goto_restore 构造的:
// os/src/task/context.rs
impl TaskContext {
pub fn goto_restore() -> Self {
extern "C" { fn __restore(); }
Self {
ra: __restore as usize,
s: [0; 12],
}
}
}它只是将任务上下文的 ra 寄存器设置为 __restore 的入口地址。这样,在 __switch 从它上面恢复并返回之后就会直接跳转到 __restore ,此时栈顶是一个我们构造出来第一次进入用户态执行的 Trap 上下文,就和第二章的情况一样了。
当时我们进行了这样的操作。 init_app_cx 是在 loader 子模块中定义的:
// os/src/loader.rs
pub fn init_app_cx(app_id: usize) -> &'static TaskContext {
KERNEL_STACK[app_id].push_context(
TrapContext::app_init_context(get_base_i(app_id), USER_STACK[app_id].get_sp()),
TaskContext::goto_restore(),
)
}
impl KernelStack {
fn get_sp(&self) -> usize {
self.data.as_ptr() as usize + KERNEL_STACK_SIZE
}
pub fn push_context(&self, trap_cx: TrapContext, task_cx: TaskContext) -> &'static mut TaskContext {
unsafe {
let trap_cx_ptr = (self.get_sp() - core::mem::size_of::<TrapContext>()) as *mut TrapContext;
*trap_cx_ptr = trap_cx;
let task_cx_ptr = (trap_cx_ptr as usize - core::mem::size_of::<TaskContext>()) as *mut TaskContext;
*task_cx_ptr = task_cx;
task_cx_ptr.as_mut().unwrap()
}
}
}
这里 KernelStack 的 push_context 方法先压入一个和之前相同的 Trap 上下文,再在它上面压入一个任务上下文,然后返回任务上下文的地址。这个任务上下文是我们通过 TaskContext::goto_restore 构造的:
// os/src/task/context.rs
impl TaskContext {
pub fn goto_restore() -> Self {
extern "C" { fn __restore(); }
Self {
ra: __restore as usize,
s: [0; 12],
}
}
}
它只是将任务上下文的 ra 寄存器设置为 __restore 的入口地址。这样,在 __switch 从它上面恢复并返回之后就会直接跳转到 __restore ,此时栈顶是一个我们构造出来第一次进入用户态执行的 Trap 上下文,就和第二章的情况一样了。
需要注意的是, __restore 的实现需要做出变化:它 不再需要 在开头 mv sp, a0 了。因为在 __switch 之后,sp 就已经正确指向了我们需要的 Trap 上下文地址。
在 rust_main 中我们调用 task::run_first_task 来开始应用的执行:
1// os/src/task/mod.rs
2
3impl TaskManager {
4 fn run_first_task(&self) {
5 self.inner.borrow_mut().tasks[0].task_status = TaskStatus::Running;
6 let next_task_cx_ptr2 = self.inner.borrow().tasks[0].get_task_cx_ptr2();
7 let _unused: usize = 0;
8 unsafe {
9 __switch(
10 &_unused as *const _,
11 next_task_cx_ptr2,
12 );
13 }
14 }
15}
16
17pub fn run_first_task() {
18 TASK_MANAGER.run_first_task();
19}这里我们取出即将最先执行的编号为 0 的应用的 task_cx_ptr2 并希望能够切换过去。注意 __switch 有两个参数分别表示当前应用和即将切换到的应用的
task_cx_ptr2 ,其第一个参数存在的意义是记录当前应用的任务上下文被保存在哪里,也就是当前应用内核栈的栈顶,这样之后才能继续执行该应用。但在 run_first_task 的时候,我们并没有执行任何应用, __switch 前半部分的保存仅仅是在启动栈上保存了一些之后不会用到的数据,自然也无需记录启动栈栈顶的位置。
因此,我们显式声明了一个 _unused 变量,并将它的地址作为第一个参数传给 __switch ,这样保存一些寄存器之后的启动栈栈顶的位置将会保存在此变量中。然而无论是此变量还是启动栈我们之后均不会涉及到,一旦应用开始运行,我们就开始在应用的用户栈和内核栈之间开始切换了。这里声明此变量的意义仅仅是为了避免覆盖到其他数据。
如果应用自己很少 yield ,内核就要开始收回之前下放的权力,由它自己对 CPU 资源进行集中管理并合理分配给各应用,这就是内核需要提供的任务调度能力。我们可以将多道程序的调度机制分类成 协作式调度 (Cooperative Scheduling) ,因为它的特征是:只要一个应用不主动 yield 交出 CPU 使用权,它就会一直执行下去。与之相对, 抢占式调度 (Preemptive Scheduling) 则是应用 随时 都有被内核切换出去的可能。
现代的任务调度算法基本都是抢占式的,它要求每个应用只能连续执行一段时间,然后内核就会将它强制性切换出去。一般将 时间片 (Time Slice) 作为应用连续执行时长的度量单位,每个时间片可能在毫秒量级。调度算法需要考虑:每次在换出之前给一个应用多少时间片去执行,以及要换入哪个应用。可以从性能和 公平性 (Fairness) 两个维度来评价调度算法,后者要求多个应用分到的时间片占比不应差距过
以内核所在的 S 特权级为例,中断屏蔽相应的 CSR 有 sstatus 和 sie 。sstatus 的 sie 为 S 特权级的中断使能,能够同时控制三种中断,如果将其清零则会将它们全部屏蔽。即使 sstatus.sie 置 1 ,还要看 sie 这个 CSR,它的三个字段 ssie/stie/seie 分别控制 S 特权级的软件中断、时钟中断和外部中断的中断使能。比如对于 S 态时钟中断来说,如果 CPU 不高于 S 特权级,需要 sstatus.sie 和 sie.stie 均为 1 该中断才不会被屏蔽;如果 CPU 当前特权级高于 S 特权级,则该中断一定会被屏蔽
在正文中我们只需要了解:
- 包括系统调用(即来自 U 特权级的环境调用)在内的所有异常都会 Trap 到 S 特权级处理;
- 只需考虑 S 特权级的时钟/软件/外部中断,且它们都会被 Trap 到 S 特权级处理。
默认情况下,当 Trap 进入某个特权级之后,在 Trap 处理的过程中同特权级的中断都会被屏蔽。这里我们还需要对第二章介绍的 Trap 发生时的硬件机制做一下补充,同样以 Trap 到 S 特权级为例:
- 当 Trap 发生时,
sstatus.sie会被保存在sstatus.spie字段中,同时sstatus.sie置零,这也就在 Trap 处理的过程中屏蔽了所有 S 特权级的中断; - 当 Trap 处理完毕
sret的时候,sstatus.sie会恢复到sstatus.spie内的值。
也就是说,如果不去手动设置 sstatus CSR ,在只考虑 S 特权级中断的情况下,是不会出现 嵌套中断 (Nested Interrupt) 的。嵌套中断是指在处理一个中断的过程中再一次触发了中断从而通过 Trap 来处理。由于默认情况下一旦进入 Trap 硬件就自动禁用所有同特权级中断,自然也就不会再次触发中断导致嵌套中断了。
一个计数器统计处理器自上电以来经过了多少个内置时钟的时钟周期,计数器保存在一个 64 位的 CSR mtime 中,我们无需担心它的溢出问题,在内核运行全程可以认为它是一直递增的。
另外一个 64 位的 CSR mtimecmp 的作用是:一旦计数器 mtime 的值超过了 mtimecmp,就会触发一次时钟中断。这使得我们可以方便的通过设置 mtimecmp 的值来决定下一次时钟中断何时触发。
总结两个计数器:分别记录mtime ,mtimecmp
mtime: 记录当前的总共的时钟周期
了避免 S 特权级时钟中断被屏蔽,我们需要在执行第一个应用之前进行一些初始化设置:
#[no_mangle]
pub fn rust_main() -> ! {
clear_bss();
println!("[kernel] Hello, world!");
trap::init(); //init在这个时候调用---------设置trap函数入口地址
loader::load_apps(); //加载APP进入内存,通过(data段)link_app.s的设置
trap::enable_timer_interrupt(); //第 9 行设置了 sie.stie 使得 S 特权级时钟中断不会被屏蔽;
timer::set_next_trigger(); //设置时间片 10ms 的计时器
task::run_first_task(); // 开启任务的执行
panic!("Unreachable in rust_main!");
}
pub fn enable_timer_interrupt() {
unsafe{
sie::set_stimer(); //设置了 sie.stie 使得 S 特权级时钟中断不会被屏蔽;
}
}- 第 9 行设置了
sie.stie使得 S 特权级时钟中断不会被屏蔽; - 第 10 行则是设置第一个 10ms 的计时器。
这样,当一个应用运行了 10ms 之后,一个 S 特权级时钟中断就会被触发。由于应用运行在 U 特权级,且 sie 寄存器被正确设置,该中断不会被屏蔽,而是 Trap 到 S 特权级内的我们的 trap_handler 里面进行处理,并顺利切换到下一个应用。这便是我们所期望的抢占式调度机制。从应用运行的结果也可以看出,三个 power 系列应用并没有进行 yield ,而是由内核负责公平分配它们执行的时间片。
这里我们先通过 yield 来优化 轮询 (Busy Loop) 过程带来的 CPU 资源浪费。在 03sleep 这个应用中:
// user/src/bin/03sleep.rs
#[no_mangle]
fn main() -> i32 {
let current_timer = get_time();
let wait_for = current_timer + 3000;
while get_time() < wait_for {
yield_();
}
println!("Test sleep OK!");
0
}它的功能是等待 3000ms 然后退出。可以看出,我们会在循环里面 yield_ 来主动交出 CPU 而不是无意义的忙等。尽管我们不这样做
,已有的抢占式调度还是会在它循环 10ms 之后切换到其他应用,但是这样能让内核给其他应用分配更多的 CPU 资源并让它们更早运行结束。
如果要实现动态内存分配的能力,需要操作系统需要有如下功能:
- 初始时能提供一块大内存空间作为初始的“堆”。在没有分页机制情况下,这块空间是物理内存空间,否则就是虚拟内存空间。
- 提供在堆上分配一块内存的函数接口。这样函数调用方就能够得到一块地址连续的空闲内存块进行读写。
- 提供释放内存的函数接口。能够回收内存,以备后续的内存分配请求。
- 提供空闲空间管理的连续内存分配算法。能够有效地管理空闲快,这样就能够动态地维护一系列空闲和已分配的内存块。
- (可选)提供建立在堆上的数据结构和操作。有了上述基本的内存分配与释放函数接口,就可以实现类似动态数组,动态字典等空间灵活可变的堆数据结构,提高编程的灵活性。
动态缺点:它背后运行着连续内存分配算法,相比静态分配会带来一些额外的开销。如果动态分配非常频繁,可能会产生很多无法使用的空闲空间碎片,甚至可能会成为应用的性能瓶颈。
静态缺点:它在编译期间确定大小,分配时候可能会由于文件大小不确定导致内存不够或者内存过大,导致应用效率降低
- 裸指针
*const T/*mut T基本等价于 C/C++ 里面的普通指针T*,它自身的内容仅仅是一个地址。它最为灵活, 但是也最不安全。编译器只能对它进行最基本的可变性检查, 第一章 曾经提到,对于裸指针 解引用访问它指向的那块数据是 unsafe 行为,需要被包裹在 unsafe 块中。 - 引用
&T/&mut T自身的内容也仅仅是一个地址,但是 Rust 编译器会在编译的时候进行比较严格的 借用检查 (Borrow Check) ,要求引用的生命周期必须在被借用的变量的生命周期之内,同时可变借用和不可变借用不能共存,一个 变量可以同时存在多个不可变借用,而可变借用同时最多只能存在一个。这能在编译期就解决掉很多内存不安全问题。 - 智能指针不仅包含它指向的区域的地址,还含有一些额外的信息,因此这个类型的字节大小大于平台的位宽,属于一种胖指针。 从用途上看,它不仅可以作为一个媒介来访问它指向的数据,还能在这个过程中起到一些管理和控制的功能。
在 Rust 中,与动态内存分配相关的智能指针有如下这些:
-
Box<T>在创建时会在堆上分配一个类型为T的变量,它自身也只保存在堆上的那个变量的位置。而和裸指针或引用 不同的是,当Box<T>被回收的时候,它指向的——也就是在堆上被动态分配的那个变量也会被回收。 -
Rc<T>是一个单线程上使用的引用计数类型,Arc<T>与其功能相同,只是它可以在多线程上使用。它提供了 多所有权,也即地址空间中同时可以存在指向同一个堆上变量的Rc<T>,它们都可以拿到指向变量的不可变引用来 访问这同一个变量。而它同时也是一个引用计数,事实上在堆上的另一个位置维护了堆上这个变量目前被引用了多少次, 也就是存在多少个Rc<T>。这个计数会随着Rc<T>的创建或复制而增加,并当Rc<T>生命周期结束 被回收时减少。当这个计数变为零之后,这个计数变量本身以及被引用的变量都会从堆上被回收。 -
Mutex<T>是一个互斥锁,在多线程中使用,它可以保护里层被动态分配到堆上的变量同一时间只有一个线程能对它 进行操作,从而避免数据竞争,这是并发安全的问题,会在后面详细说明。同时,它能够提供 内部可变性 。Mutex<T>时常和Arc<T>配套使用,因为它是用来 保护多个线程可能同时访问的数据,其前提就是多个线程都拿到指向同一块堆上数据的Mutex<T>。于是,要么就是 这个Mutex<T>作为全局变量被分配到数据段上,要么就是我们需要将Mutex<T>包裹上一层多所有权变成Arc<Mutex<T>>,让它可以在线程间进行传递。请记住Arc<Mutex<T>>这个经典组合,我们后面会经常用到。之前我们通过
RefCell<T>来获得内部可变性。可以将Mutex<T>看成RefCell<T>的多线程版本, 因为RefCell<T>是只能在单线程上使用的。而且RefCell<T>并不会在堆上分配内存,它仅用到静态内存 分配。
随后,是一些 集合 (Collection) 或称 容器 (Container) 类型,它们负责管理一组数目可变的元素,这些元素 的类型相同或是有着一些同样的特征。在 C++/Python/Java 等高级语言中我们已经对它们的使用方法非常熟悉了,对于 Rust 而言,我们则可以直接使用以下容器:
- 向量
Vec<T>类似于 C++ 中的std::vector; - 键值对容器
BTreeMap<K, V>类似于 C++ 中的std::map; - 有序集合
BTreeSet<T>类似于 C++ 中的std::set; - 链表
LinkedList<T>类似于 C++ 中的std::list; - 双端队列
VecDeque<T>类似于 C++ 中的std::deque。 - 变长字符串
String类似于 C++ 中的std::string。
- C 语言仅支持
malloc/free这一对操作,它们必须恰好成对使用,否则就会出现错误。比如分配了之后没有回收,则会导致 内存溢出;回收之后再次 free 相同的指针,则会造成 Double-Free 问题;又如回收之后再尝试通过指针访问它指向的区域,这 属于 Use-After-Free 问题。总之,这样的内存安全问题层出不穷,毕竟人总是会犯错的。 - Python/Java 通过 引用计数 (Reference Counting) 对所有的对象进行运行时的动态管理,一套 垃圾回收 (GC, Garbage Collection) 机制会被自动定期触发,每次都会检查所有的对象,如果其引用计数为零则可以将该对象占用的内存 从堆上回收以待后续其他的对象使用。这样做完全杜绝了内存安全问题,但是性能开销则很大,而且 GC 触发的时机和每次 GC 的 耗时都是无法预测的,还使得性能不够稳定。
C++ 的 资源获取即初始化 (RAII, Resource Acquisition Is Initialization) 风格则致力于解决上述问题。 RAII 的含义是说,将一个使用前必须获取的资源的生命周期绑定到一个变量上。以 Box<T> 为例,在它被 创建的时候,会在堆上分配一块空间保存它指向的数据;而在 Box<T> 生命周期结束被回收的时候,堆上的那块空间也会 立即被一并回收。这也就是说,我们无需手动回收资源,它会和绑定到的变量同步由编译器自动回收,我们既不用担心忘记回收更不 可能回收多次;同时,由于我们很清楚一个变量的生命周期,则该资源何时被回收也是完全可预测的,我们也明确知道这次回收 操作的开销。在 Rust 中,不限于堆内存,将某种资源的生命周期与一个变量绑定的这种 RAII 的思想无处不见,甚至这种资源 可能只是另外一种类型的变量。
alloc 库需要我们提供给它一个 全局的动态内存分配器 ,它会利用该分配器来管理堆空间,从而使得它提供的堆数据结构可以正常 工作。具体而言,我们的动态内存分配器需要实现它提供的 GlobalAlloc Trait,这个 Trait 有两个必须实现的抽象接口:
// alloc::alloc::GlobalAlloc
pub unsafe fn alloc(&self, layout: Layout) -> *mut u8;
pub unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);可以看到,它们类似 C 语言中的 malloc/free ,分别代表堆空间的分配和回收,也同样使用一个裸指针(也就是地址) 作为分配的返回值和回收的参数。两个接口中都有一个 alloc::alloc::Layout 类型的参数, 它指出了分配的需求,分为两部分,分别是所需空间的大小 size ,以及返回地址的对齐要求 align 。这个对齐要求 必须是一个 2 的幂次,单位为字节数,限制返回的地址必须是 align 的倍数。
为何 C 语言 malloc 的时候不需要提供对齐需求?
在 C 语言中,所有对齐要求的最大值是一个平台有关的很小的常数(比如8 bytes),消耗少量内存即可使得每一次分配都符合这个最大 的对齐要求。因此也就不需要区分不同分配的对齐要求了。而在 Rust 中,某些分配的对齐要求可能很大,就只能采用更 加复杂的方法。
之后,只需将我们的动态内存分配器类型实例化为一个全局变量,并使用 #[global_allocator] 语义项标记即可。由于该 分配器的实现比较复杂,我们这里直接使用一个已有的伙伴分配器实现。首先添加 crate 依赖:
# os/Cargo.toml
buddy_system_allocator = "0.6"接着,需要引入 alloc 库的依赖,由于它算是 Rust 内置的 crate ,我们并不是在 Cargo.toml 中进行引入,而是在 main.rs 中声明即可:
// os/src/main.rs
extern crate alloc;// as_ref和Borrow的区别 ?
// as_ref 是转引用函数, 将具有所有权对象转换成引用对象,
// 不改变被转换对象的基础上产生一个引用对象.
// as_ref 并不是所有类型都默认支持, 很多时候都需要自己去声明.
// as_ref 是AsRef trait 的公共接口方法.
// 只有那些实现了 as_ref 公共接口方法的类型才能使用as_ref.
// 目前: Option, Box, Result 这三种类型默认提供支持as_ref.
// as_ref 和 Borrow 的区别是:
// 基础数据类型引用:
// Borrow 可以直接在 int, &str, String, vec, [], struct, enum 这种类型上直接指定&来引用.
// as_ref 则不行, 它需要声明泛型T: AsRef<int>, T: AsRef<str>, T: AsRef<struct name> 来支持.
// 嵌套数据类型引用: Some(&int) , Box(&int) ,
// Borrow 必须在定义结构时声明 Some<&int> , Box<&int> 才是引用.
// as_ref 则直接可以在这些嵌套结构上使用as_ref.
// 引用的引用
// Borrow 引用的引用的表现形式是: &str -> &&str
// as_ref 引用的引用的表现形式是: &str -> &str最终,到目前为止仍被操作系统内核广泛使用的抽象被称为 地址空间 (Address Space) 。某种程度上讲,可以将它看成一块 巨大但并不一定真实存在的内存。在每个应用程序的视角里,操作系统分配给应用程序一个范围有限(但其实很大),独占的连续地址空间(其中有些地方被操作系统限制不能访问,如内核本身占用的虚地址空间等),因此应用程序可以在划分给它的地址空间中随意规划内存布局,它的 各个段也就可以分别放置在地址空间中它希望的位置(当然是操作系统允许应用访问的地址)。应用同样可以使用一个地址作为索引来读写自己地址空间的数据,就像用物理地址 作为索引来读写物理内存上的数据一样。这种地址被称为 虚拟地址 (Virtual Address) 。当然,操作系统要达到 地址空间 抽象的设计目标,需要有计算机硬件的支持,这就是计算机组成原理课上讲到的 MMU 和 TLB 等硬件机制。
从此,应用能够直接看到并访问的内存就只有操作系统提供的地址空间,且它的任何一次访存使用的地址都是虚拟地址,无论取指令来执行还是读写 栈、堆或是全局数据段都是如此。事实上,特权级机制被拓展,使得应用不再具有通过物理地址直接访问物理内存的能力。应用所处的执行环境在安全方面被进一步强化,形成了用户态特权级和地址空间的二维安全措施。
由于每个应用独占一个地址空间,里面只含有自己的各个段,于是它可以随意规划 各个段的分布而无需考虑和其他应用冲突;同时,它完全无法窃取或者破坏其他应用的数据,毕竟那些段在其他应用的地址空间 内,鉴于应用只能通过虚拟地址读写它自己的地址空间,这是它没有能力去访问的。这是 地址空间 抽象对应用程序执行的安全性和稳定性的一种保障。
开始回顾一下 计算机组成原理 课。如上图所示,当应用取指或者执行 一条访存指令的时候,它都是在以虚拟地址为索引读写自己的地址空间。此时,CPU 中的 内存管理单元 (MMU, Memory Management Unit) 自动将这个虚拟地址进行 地址转换 (Address Translation) 变为一个物理地址, 也就是物理内存上这个应用的数据真实被存放的位置。也就是说,在 MMU 的帮助下,应用对自己地址空间的读写才能被实际转化为 对于物理内存的访问。
事实上,每个应用的地址空间都可以看成一个从虚拟地址到物理地址的映射。可以想象对于不同的应用来说,该映射可能是不同的, 即 MMU 可能会将来自不同两个应用地址空间的相同虚拟地址翻译成不同的物理地址。要做到这一点,就需要硬件提供一些寄存器 ,软件可以对它进行设置来控制 MMU 按照哪个应用的地址空间进行地址转换。于是,将应用的数据放到物理内存并进行管理,而 在任务切换的时候需要将控制 MMU 选用哪个应用的地址空间进行映射的那些寄存器也一并进行切换,则是作为软件部分的内核需 要完成的工作。
地址空间只是一层抽象接口,它有很多种具体的实现策略。对于不同的实现策略来说,操作系统内核如何规划应用数据放在物理内存的位置, 而 MMU 又如何进行地址转换也都是不同的。下面我们简要介绍几种曾经被使用的策略,并探讨它们的优劣。
注意:
为了方便实现虚拟页面到物理页帧的地址转换,我们给每个虚拟页面和物理页帧一个编号,分别称为 虚拟页号 (VPN, Virtual Page Number) 和 物理页号 (PPN, Physical Page Number) 。每个应用都有一个不同的 页表 (Page Table)
虚拟地址到物理地址的转换过程:
当 MMU 进行地址转换的时候,它首先找到给定的虚拟地址所在的虚拟页面的页号,然后查当前应用的页表根据虚拟页号 找到物理页号,最后按照虚拟地址在它所在的虚拟页面中的相对位置相应给物理页号对应的物理页帧的起始地址加上一个偏移量, 这就得到了实际访问的物理地址。
这种思想在计算机科学中得到了广泛应用:为了方便接下来的说明,我们可以举一道数据结构的题目作为例子。设想我们要维护 一个字符串的多重集,集合中所有的字符串的字符集均为 α={a,b,c} ,长度均为一个给定的常数 n 。该字符串集合一开始为空集。我们要支持两种操作,第一种是将一个字符串插入集合,第二种是查询一个字符串在当前 的集合中出现了多少次。
简单起见,假设 n=3 。那么我们可能会建立这样一颗 字典树 (Trie)
字典树由若干个节点(图中用椭圆形来表示)组成,从逻辑上而言每个节点代表一个可能的字符串前缀。每个节点的存储内容 都只有三个指针,对于蓝色的非叶节点来说,它的三个指针各自指向一个子节点;而对于绿色的叶子节点来说,它的三个指针不再指向 任何节点,而是具体保存一种可能的长度为 n 的字符串的计数。这样,对于题目要求的两种操作,我们只需根据输入的 字符串中的每个字符在字典树上自上而下对应走出一步,最终就能够找到字典树中维护的它的计数。之后我们可以将其直接返回或者 加一。
注意到如果某些字符串自始至终没有被插入,那么一些节点没有存在的必要。反过来说一些节点是由于我们插入了一个以它对应的字符串 为前缀的字符串才被分配出来的。如下图所示:
一开始仅存在一个根节点。在我们插入字符串 acb 的过程中,我们只需要分配 a 和 ac 两个节点。 注意 ac 是一个叶节点,它的 b 指针不再指向另外一个节点而是保存字符串 acb 的计数。 此时我们无法访问到其他未分配的节点,如根节点的 b/c 或是 a 节点的 a/b 均为空指针。 如果后续再插入一个字符串,那么 至多分配两个新节点 ,因为如果走的路径上有节点已经存在,就无需重复分配了。 这可以说明,字典树中节点的数目(或者说字典树消耗的内存)是随着插入字符串的数目逐渐线性增加的。
读者可能很好奇,为何在这里要用相当一部分篇幅来介绍字典树呢?事实上 SV39 分页机制等价于一颗字典树。 27 位的 虚拟页号可以看成一个长度 n=3 的字符串,字符集为 α={0,1,2,...,511} ,因为每一位字符都 由 9 个比特组成。而我们也不再维护所谓字符串的计数,而是要找到字符串(虚拟页号)对应的页表项。 因此,每个叶节点都需要保存 512 个 8 字节的页表项,一共正好 4KiB , 可以直接放在一个物理页帧内。而对于非叶节点来说,从功能上它只需要保存 512 个指向下级节点的指针即可, 不过我们就像叶节点那样也保存 512 个页表项,这样所有的节点都可以被放在一个物理页帧内,它们的位置可以用一个 物理页号来代替。当想从一个非叶节点向下走时,只需找到当前字符对应的页表项的物理页号字段,它就指向了下一级节点的位置, 这样非叶节点中转的功能也就实现了。每个节点的内部是一个线性表,也就是将这个节点起始物理地址加上字符对应的偏移量就找到了 指向下一级节点的页表项(对于非叶节点)或是能够直接用来地址转换的页表项(对于叶节点)。
这种页表实现被称为 多级页表 (Multi-Level Page-Table) 。由于 SV39 中虚拟页号被分为三级 页索引 (Page Index) ,因此这是一种三级页表。
非叶节点的页表项标志位含义和叶节点相比有一些不同:
- 当 V 为 0 的时候,代表当前指针是一个空指针,无法走向下一级节点,即该页表项对应的虚拟地址范围是无效的;
- 只有当V 为1 且 R/W/X 均为 0 时,表示是一个合法的页目录表项,其包含的指针会指向下一级的页表。
- 注意: 当V 为1 且 R/W/X 不全为 0 时,表示是一个合法的页表项,其包含了虚地址对应的物理页号。
在这里我们给出 SV39 中的 R/W/X 组合的含义:
这里总结一下之前的内存的各个段都干什么了
- 0x80200000:物理内存的 起始物理地址。该处开始存放各个数据段的布局,例如rodata,bss,data,还有处于.bss段的栈
- 0x80400000:该处开始存放内核段代码,例如各个应用的代码
- 0x80800000:硬编码整块物理内存的终止物理地址
这意味着我们总共能使用的内存是8mb
我们用一个左闭右开的物理页号区间来表示 可用的物理内存,则:
- 区间的左端点应该是
ekernel的物理地址以上取整方式转化成的物理页号; - 区间的右端点应该是
MEMORY_END以下取整方式转化成的物理页号。
初始化非常简单。在通过 FrameAllocator 的 new 方法创建实例的时候,只需将区间两端均设为 0 , 然后创建一个新的向量;而在它真正被使用起来之前,需要调用 init 方法将自身的 [current,end) 初始化为可用物理页号区间:
// os/src/mm/frame_allocator.rs
impl FrameAllocator for StackFrameAllocator {
fn new() -> Self {
Self {
current: 0,
end: 0,
recycled: Vec::new(),
}
}
}
impl StackFrameAllocator {
pub fn init(&mut self, l: PhysPageNum, r: PhysPageNum) {
self.current = l.0;
self.end = r.0;
}
}
接下来我们来看核心的物理页帧分配和回收如何实现:
// os/src/mm/frame_allocator.rs
impl FrameAllocator for StackFrameAllocator {
fn alloc(&mut self) -> Option<PhysPageNum> {
if let Some(ppn) = self.recycled.pop() {
Some(ppn.into())
} else {
if self.current == self.end {
None
} else {
self.current += 1;
Some((self.current - 1).into())
}
}
}
fn dealloc(&mut self, ppn: PhysPageNum) {
let ppn = ppn.0;
// validity check
if ppn >= self.current || self.recycled
.iter()
.find(|&v| {*v == ppn})
.is_some() {
panic!("Frame ppn={:#x} has not been allocated!", ppn);
}
// recycle
self.recycled.push(ppn);
}
}
-
在分配
alloc的时候,首先会检查栈recycled内有没有之前回收的物理页号,如果有的话直接弹出栈顶并返回; 否则的话我们只能从之前从未分配过的物理页号区间 [current,end) 上进行分配,我们分配它的 左端点current,同时将管理器内部维护的current加一代表current此前已经被分配过了。在即将返回 的时候,我们使用into方法将 usize 转换成了物理页号PhysPageNum。注意极端情况下可能出现内存耗尽分配失败的情况:即
recycled为空且 current==end 。 为了涵盖这种情况,alloc的返回值被Option包裹,我们返回None即可。 -
在回收
dealloc的时候,我们需要检查回收页面的合法性,然后将其压入recycled栈中。回收页面合法有两个 条件:- 该页面之前一定被分配出去过,因此它的物理页号一定 <current ;
- 该页面没有正处在回收状态,即它的物理页号不能在栈
recycled中找到。
我们通过
recycled.iter()获取栈上内容的迭代器,然后通过迭代器的find方法试图 寻找一个与输入物理页号相同的元素。其返回值是一个Option,如果找到了就会是一个Option::Some, 这种情况说明我们内核其他部分实现有误,直接报错退出。
下面我们来创建 StackFrameAllocator 的全局实例 FRAME_ALLOCATOR :
// os/src/mm/frame_allocator.rs
use spin::Mutex;
type FrameAllocatorImpl = StackFrameAllocator;
lazy_static! {
pub static ref FRAME_ALLOCATOR: Mutex<FrameAllocatorImpl> =
Mutex::new(FrameAllocatorImpl::new());
}
这里我们使用互斥锁 Mutex<T> 来包裹栈式物理页帧分配器。每次对该分配器进行操作之前,我们都需要先通过 FRAME_ALLOCATOR.lock() 拿到分配器的可变借用。注意 alloc 中并没有提供 Mutex<T> ,它 来自于一个我们在 no_std 的裸机环境下经常使用的名为 spin 的 crate ,它仅依赖 Rust 核心库 core 提供一些可跨平台使用的同步原语,如互斥锁 Mutex<T> 和读写锁 RwLock<T> 等。
注解
Rust 语法卡片:在单核环境下使用 Mutex 的原因
在编写一个多线程的应用时,加锁的目的是为了避免数据竞争,使得里层的共享数据结构同一时间只有一个线程 在对它进行访问。然而,目前我们的内核运行在单 CPU 上,且 Trap 进入内核之后并没有手动打开中断,这也就 使得同一时间最多只有一条 Trap 执行流并发访问内核的各数据结构,此时应该是并没有任何数据竞争风险的。那么 加锁的原因其实有两点:
-
在不触及
unsafe的情况下实现static mut语义。如果读者还有印象, 前面章节 我们使用RefCell<T>提供了内部可变性去掉了 声明中的mut,然而麻烦的在于static,在 Rust 中一个类型想被实例化为一个全局变量,则 该类型必须先告知编译器自己某种意义上是线程安全的,这个过程本身是unsafe的。因此我们直接使用
Mutex<T>,它既通过lock方法提供了内部可变性,又已经在模块内部告知了 编译器它的线程安全性。这样unsafe就被隐藏在了spincrate 之内,我们无需关心。这种风格 是 Rust 所推荐的。 -
方便后续拓展到真正存在数据竞争风险的多核环境下运行。
这里引入了一些新概念,比如什么是线程,又如何定义线程安全?读者可以先不必深究,暂时有一个初步的概念即可。
可以发现, frame_alloc 的返回值类型并不是 FrameAllocator 要求的物理页号 PhysPageNum ,而是将其 进一步包装为一个 FrameTracker 。这里借用了 RAII 的思想,将一个物理页帧的生命周期绑定到一个 FrameTracker 变量上,当一个 FrameTracker 被创建的时候,我们需要从 FRAME_ALLOCATOR 中分配一个物理页帧:
Rust 语法卡片:Drop Trait
Rust 中的 Drop Trait 是它的 RAII 内存管理风格可以被有效实践的关键。之前介绍的多种在堆上分配的 Rust 数据结构便都是通过实现 Drop Trait 来进行被绑定资源的自动回收的。例如:
Box<T>的drop方法会回收它控制的分配在堆上的那个变量;Rc<T>的drop方法会减少分配在堆上的那个引用计数,一旦变为零则分配在堆上的那个被计数的变量自身 也会被回收;Mutex<T>的lock方法会获取互斥锁并返回一个MutexGuard<'a, T>,它可以被当做一个&mut T来使用;而MutexGuard<'a, T>的drop方法会将锁释放,从而允许其他线程获取锁并开始访问里层的 数据结构。锁的实现原理我们先不介绍。
FrameTracker 的设计也是基于同样的思想,有了它之后我们就不必手动回收物理页帧了,这在编译期就解决了很多 潜在的问题。
我们知道,SV39 多级页表是以节点为单位进行管理的。每个节点恰好存储在一个物理页帧中,它的位置可以用一个物理页号来 表示。
1// os/src/mm/page_table.rs
2
3pub struct PageTable {
4 root_ppn: PhysPageNum,
5 frames: Vec<FrameTracker>,
6}
7
8impl PageTable {
9 pub fn new() -> Self {
10 let frame = frame_alloc().unwrap();
11 PageTable {
12 root_ppn: frame.ppn,
13 frames: vec![frame],
14 }
15 }
16}
每个应用的地址空间都对应一个不同的多级页表,这也就意味这不同页表的起始地址(即页表根节点的地址)是不一样的。因此 PageTable 要保存它根节点的物理页号 root_ppn 作为页表唯一的区分标志。此外, 向量 frames 以 FrameTracker 的形式保存了页表所有的节点(包括根节点)所在的物理页帧。这与物理页帧管理模块 的测试程序是一个思路,即将这些 FrameTracker 的生命周期进一步绑定到 PageTable 下面。当 PageTable 生命周期结束后,向量 frames 里面的那些 FrameTracker 也会被回收,也就意味着存放多级页表节点的那些物理页帧 被回收了。
当我们通过 new 方法新建一个 PageTable 的时候,它只需有一个根节点。为此我们需要分配一个物理页帧 FrameTracker 并挂在向量 frames 下,然后更新根节点的物理页号 root_ppn 。
多级页表并不是被创建出来之后就不再变化的,为了 MMU 能够通过地址转换正确找到应用地址空间中的数据实际被内核放在内存中 位置,操作系统需要动态维护一个虚拟页号到页表项的映射,支持插入/删除键值对,其方法签名如下:
// os/src/mm/page_table.rs
impl PageTable {
pub fn map(&mut self, vpn: VirtPageNum, ppn: PhysPageNum, flags: PTEFlags);
pub fn unmap(&mut self, vpn: VirtPageNum);
}
- 我们通过
map方法来在多级页表中插入一个键值对,注意这里我们将物理页号ppn和页表项标志位flags作为 不同的参数传入而不是整合为一个页表项; - 相对的,我们通过
unmap方法来删除一个键值对,在调用时仅需给出作为索引的虚拟页号即可。
在这些操作的过程中我们自然需要访问或修改多级页表节点的内容。每个节点都被保存在一个物理页帧中,在多级页表的架构中我们是以 一个节点被存放在的物理页帧的物理页号作为指针指向该节点,这意味着,对于每个节点来说,一旦我们知道了指向它的物理页号,我们 就需要能够修改这个节点的内容。前面我们在使用 frame_alloc 分配一个物理页帧之后便立即将它上面的数据清零其实也是一样 的需求。总结一下也就是说,至少在操作某个多级页表或是管理物理页帧的时候,我们要能够自由的读写与一个给定的物理页号对应的 物理页帧上的数据。
在尚未启用分页模式之前,内核和应用的代码都可以通过物理地址直接访问内存。而在打开分页模式之后,分别运行在 S 特权级 和 U 特权级的内核和应用的访存行为都会受到影响,它们的访存地址会被视为一个当前地址空间( satp CSR 给出当前 多级页表根节点的物理页号)中的一个虚拟地址,需要 MMU 查相应的多级页表完成地址转换变为物理地址,也就是地址空间中虚拟地址指向的数据真正被内核放在的物理内存中的位置,然后 才能访问相应的数据。此时,如果想要访问一个特定的物理地址 pa 所指向的内存上的数据,就需要对应 构造 一个虚拟地址 va ,使得当前地址空间的页表存在映射 va→pa ,且页表项中的保护位允许这种 访问方式。于是,在代码中我们只需访问地址 va ,它便会被 MMU 通过地址转换变成 pa ,这样我们就做到了在启用 分页模式的情况下也能从某种意义上直接访问内存。
这就需要我们提前扩充多级页表维护的映射,使得对于每
它的 vpn 。这里我们采用一种最 简单的 恒等映射 (Identical Mapping) ,也就是说对于物理内存上的每个物理页帧,我们都在多级页表中用一个与其 物理页号相等的虚拟页号映射到它。当我们想针对物理页号构造一个能映射到它的虚拟页号的时候,也只需使用一个和该物理页号 相等的虚拟页号即可。
注解
其他的映射方式
为了达到这一目的还存在其他不同的映射方式,例如比较著名的 页表自映射 (Recursive Mapping) 等。有兴趣的同学 可以进一步参考 BlogOS 中的相关介绍 。
这里需要说明的是,在下一节中我们可以看到,应用和内核的地址空间是隔离的。而直接访问物理页帧的操作只会在内核中进行, 应用无法看到物理页帧管理器和多级页表等内核数据结构。因此,上述的恒等映射只需被附加到内核地址空间即可。
于是,我们来看看在内核中应如何访问一个特定的物理页帧:
// os/src/mm/address.rs
impl PhysPageNum {
pub fn get_pte_array(&self) -> &'static mut [PageTableEntry] {
let pa: PhysAddr = self.clone().into();
unsafe {
core::slice::from_raw_parts_mut(pa.0 as *mut PageTableEntry, 512)
}
}
pub fn get_bytes_array(&self) -> &'static mut [u8] {
let pa: PhysAddr = self.clone().into();
unsafe {
core::slice::from_raw_parts_mut(pa.0 as *mut u8, 4096)
}
}
pub fn get_mut<T>(&self) -> &'static mut T {
let pa: PhysAddr = self.clone().into();
unsafe {
(pa.0 as *mut T).as_mut().unwrap()
}
}
}
我们构造可变引用来直接访问一个物理页号 PhysPageNum 对应的物理页帧,不同的引用类型对应于物理页帧上的一种不同的 内存布局,如 get_pte_array 返回的是一个页表项定长数组的可变引用,可以用来修改多级页表中的一个节点;而 get_bytes_array 返回的是一个字节数组的可变引用,可以以字节为粒度对物理页帧上的数据进行访问,前面进行数据清零 就用到了这个方法; get_mut 是个泛型函数,可以获取一个恰好放在一个物理页帧开头的类型为 T 的数据的可变引用。
在实现方面,都是先把物理页号转为物理地址 PhysAddr ,然后再转成 usize 形式的物理地址。接着,我们直接将它 转为裸指针用来访问物理地址指向的物理内存。在分页机制开启前,这样做自然成立;而开启之后,虽然裸指针被视为一个虚拟地址, 但是上面已经提到这种情况下虚拟地址会映射到一个相同的物理地址,因此在这种情况下也成立。注意,我们在返回值类型上附加了 静态生命周期泛型 'static ,这是为了绕过 Rust 编译器的借用检查,实质上可以将返回的类型也看成一个裸指针,因为 它也只是标识数据存放的位置以及类型。但与裸指针不同的是,无需通过 unsafe 的解引用访问它指向的数据,而是可以像一个 正常的可变引用一样直接访问。
注解
unsafe 真的就是“不安全”吗?
下面是笔者关于 unsafe 一点可能不太正确的理解,不感兴趣的读者可以跳过。
当我们在 Rust 中使用 unsafe 的时候,并不仅仅是为了绕过编译器检查,更是为了告知编译器和其他看到这段代码的程序员: “ 我保证这样做是安全的 ” 。尽管,严格的 Rust 编译器暂时还不能确信这一点。从规范 Rust 代码编写的角度, 我们需要尽可能绕过 unsafe ,因为如果 Rust 编译器或者一些已有的接口就可以提供安全性,我们当然倾向于利用它们让我们 实现的功能仍然是安全的,可以避免一些无谓的心智负担;反之,就只能使用 unsafe ,同时最好说明如何保证这项功能是安全的。
这里简要从内存安全的角度来分析一下 PhysPageNum 的 get_* 系列方法的实现中 unsafe 的使用。为了方便 解释,我们可以将 PhysPageNum 也看成一种 RAII 的风格,即它控制着一个物理页帧资源的访问。首先,这不会导致 use-after-free 的问题,因为在内核运行全期整块物理内存都是可以访问的,它不存在被释放后无法访问的可能性;其次, 也不会导致并发冲突。注意这不是在 PhysPageNum 这一层解决的,而是 PhysPageNum 的使用层要保证任意两个线程 不会同时对一个 PhysPageNum 进行操作。读者也应该可以感觉出这并不能算是一种好的设计,因为这种约束从代码层面是很 难直接保证的,而是需要系统内部的某种一致性。虽然如此,它对于我们这个极简的内核而言算是很合适了。
我们以逻辑段 MapArea 为单位描述一段连续地址的虚拟内存。所谓逻辑段,就是指地址区间中的一段实际可用(即 MMU 通过查多级页表 可以正确完成地址转换)的地址连续的虚拟地址区间,该区间内包含的所有虚拟页面都以一种相同的方式映射到物理页帧,具有可读/可写/可执行等属性。
// os/src/mm/memory_set.rs
pub struct MapArea {
vpn_range: VPNRange,
data_frames: BTreeMap<VirtPageNum, FrameTracker>,
map_type: MapType,
map_perm: MapPermission,
}
其中 VPNRange 描述一段虚拟页号的连续区间,表示该逻辑段在地址区间中的位置和长度。它是一个迭代器,可以使用 Rust 的语法糖 for-loop 进行迭代。有兴趣的读者可以参考 os/src/mm/address.rs 中它的实现。
注解
Rust 语法卡片:迭代器 Iterator
Rust编程的迭代器模式允许你对一个序列的项进行某些处理。迭代器(iterator)是负责遍历序列中的每一项和决定序列何时结束的控制逻辑。对于如何使用迭代器处理元素序列和如何实现 Iterator trait 来创建自定义迭代器的内容,可以参考 Rust 程序设计语言-中文版第十三章第二节
MapType 描述该逻辑段内的所有虚拟页面映射到物理页帧的同一种方式,它是一个枚举类型,在内核当前的实现中支持两种方式:
// os/src/mm/memory_set.rs
#[derive(Copy, Clone, PartialEq, Debug)]
pub enum MapType {
Identical,
Framed,
}
其中 Identical 表示之前也有提到的恒等映射,用于在启用多级页表之后仍能够访问一个特定的物理地址指向的物理内存;而 Framed 则表示对于每个虚拟页面都需要映射到一个新分配的物理页帧。
当逻辑段采用 MapType::Framed 方式映射到物理内存的时候, data_frames 是一个保存了该逻辑段内的每个虚拟页面 和它被映射到的物理页帧 FrameTracker 的一个键值对容器 BTreeMap 中,这些物理页帧被用来存放实际内存数据而不是 作为多级页表中的中间节点。和之前的 PageTable 一样,这也用到了 RAII 的思想,将这些物理页帧的生命周期绑定到它所在的逻辑段 MapArea 下,当逻辑段被回收之后这些之前分配的物理页帧也会自动地同时被回收。
MapPermission 表示控制该逻辑段的访问方式,它是页表项标志位 PTEFlags 的一个子集,仅保留 U/R/W/X 四个标志位,因为其他的标志位仅与硬件的地址转换机制细节相关,这样的设计能避免引入错误的标志位。
// os/src/mm/memory_set.rs
bitflags! {
pub struct MapPermission: u8 {
const R = 1 << 1;
const W = 1 << 2;
const X = 1 << 3;
const U = 1 << 4;
}
}
地址空间是一系列有关联的逻辑段,这种关联一般是指这些逻辑段属于一个运行的程序(目前把一个运行的程序称为任务,后续会称为进程)。用来表明正在运行的应用所在执行环境中的可访问内存空间,在这个内存空间中,包含了一系列的不一定连续的逻辑段。这样我们就有任务的地址空间,内核的地址空间等说法了。地址空间使用 MemorySet 类型来表示:
// os/src/mm/memory_set.rs
pub struct MemorySet {
page_table: PageTable,
areas: Vec<MapArea>,
}
它包含了该地址空间的多级页表 page_table 和一个逻辑段 MapArea 的向量 areas 。注意 PageTable 下 挂着所有多级页表的节点所在的物理页帧,而每个 MapArea 下则挂着对应逻辑段中的数据所在的物理页帧,这两部分 合在一起构成了一个地址空间所需的所有物理页帧。这同样是一种 RAII 风格,当一个地址空间 MemorySet 生命周期结束后, 这些物理页帧都会被回收。
在本章之前,内核和应用代码的访存地址都被视为一个物理地址直接访问物理内存,而在分页模式开启之后,它们都需要通过 MMU 的 地址转换变成物理地址再交给 CPU 的访存单元去访问物理内存。地址空间抽象的重要意义在于 隔离 (Isolation) ,当我们 在执行每个应用的代码的时候,内核需要控制 MMU 使用这个应用地址空间的多级页表进行地址转换。由于每个应用地址空间在创建 的时候也顺带设置好了多级页表使得只有那些存放了它的数据的物理页帧能够通过该多级页表被映射到,这样它就只能访问自己的数据 而无法触及其他应用或是内核的数据。
启用分页模式下,内核代码的访存地址也会被视为一个虚拟地址并需要经过 MMU 的地址转换,因此我们也需要为内核对应构造一个 地址空间,它除了仍然需要允许内核的各数据段能够被正常访问之后,还需要包含所有应用的内核栈以及一个 跳板 (Trampoline) 。我们会在本章的最后一节再深入介绍跳板的机制。
下图是软件看到的 64 位地址空间在 SV39 分页模式下实际可能通过 MMU 检查的最高 256GiB (之前在 这里 中解释过最高和最低 256GiB 的问题):
注意相邻两个内核栈之间会预留一个 保护页面 (Guard Page) ,它是内核地址空间中的空洞,多级页表中并不存在与它相关的映射。 它的意义在于当内核栈空间不足(如调用层数过多或死递归)的时候,代码会尝试访问 空洞区域内的虚拟地址,然而它无法在多级页表中找到映射,便会触发异常,此时控制权会交给 trap handler 对这种情况进行 处理。由于编译器会对访存顺序和局部变量在栈帧中的位置进行优化,我们难以确定一个已经溢出的栈帧中的哪些位置会先被访问, 但总的来说,空洞区域被设置的越大,我们就能越早捕获到这一错误并避免它覆盖其他重要数据。由于我们的内核非常简单且内核栈 的大小设置比较宽裕,在当前的设计中我们仅将空洞区域的大小设置为单个页面。
下面则给出了内核地址空间的低 256GiB 的布局:
四个逻辑段 .text/.rodata/.data/.bss 被恒等映射到物理内存,这使得我们在无需调整内核内存布局 os/src/linker.ld 的情况下就仍能和启用页表机制之前那样访问内核的各数据段。注意我们借用页表机制对这些逻辑段的访问方式做出了限制,这都是为了 在硬件的帮助下能够尽可能发现内核中的 bug ,在这里:
- 四个逻辑段的 U 标志位均未被设置,使得 CPU 只能在处于 S 特权级(或以上)时访问它们;
- 代码段
.text不允许被修改; - 只读数据段
.rodata不允许被修改,也不允许从它上面取指; .data/.bss均允许被读写,但是不允许从它上面取指。
此外, 之前 提到过内核地址空间中需要存在一个恒等映射到内核数据段之外的可用物理 页帧的逻辑段,这样才能在启用页表机制之后,内核仍能以纯软件的方式读写这些物理页帧。它们的标志位仅包含 rw ,意味着该 逻辑段只能在 S 特权级以上访问,并且只能读写。
1// os/src/mm/memory_set.rs
2
3extern "C" {
4 fn stext();
5 fn etext();
6 fn srodata();
7 fn erodata();
8 fn sdata();
9 fn edata();
10 fn sbss_with_stack();
11 fn ebss();
12 fn ekernel();
13 fn strampoline();
14}
15
16impl MemorySet {
17 /// Without kernel stacks.
18 pub fn new_kernel() -> Self {
19 let mut memory_set = Self::new_bare();
20 // map trampoline
21 memory_set.map_trampoline();
22 // map kernel sections
23 println!(".text [{:#x}, {:#x})", stext as usize, etext as usize);
24 println!(".rodata [{:#x}, {:#x})", srodata as usize, erodata as usize);
25 println!(".data [{:#x}, {:#x})", sdata as usize, edata as usize);
26 println!(".bss [{:#x}, {:#x})", sbss_with_stack as usize, ebss as usize);
27 println!("mapping .text section");
28 memory_set.push(MapArea::new(
29 (stext as usize).into(),
30 (etext as usize).into(),
31 MapType::Identical,
32 MapPermission::R | MapPermission::X,
33 ), None);
34 println!("mapping .rodata section");
35 memory_set.push(MapArea::new(
36 (srodata as usize).into(),
37 (erodata as usize).into(),
38 MapType::Identical,
39 MapPermission::R,
40 ), None);
41 println!("mapping .data section");
42 memory_set.push(MapArea::new(
43 (sdata as usize).into(),
44 (edata as usize).into(),
45 MapType::Identical,
46 MapPermission::R | MapPermission::W,
47 ), None);
48 println!("mapping .bss section");
49 memory_set.push(MapArea::new(
50 (sbss_with_stack as usize).into(),
51 (ebss as usize).into(),
52 MapType::Identical,
53 MapPermission::R | MapPermission::W,
54 ), None);
55 println!("mapping physical memory");
56 memory_set.push(MapArea::new(
57 (ekernel as usize).into(),
58 MEMORY_END.into(),
59 MapType::Identical,
60 MapPermission::R | MapPermission::W,
61 ), None);
62 memory_set
63 }
64}
new_kernel 将映射跳板和地址空间中最低 256GiB 中的所有的逻辑段。第 3 行开始,我们从 os/src/linker.ld 中引用了很多表示了各个段位置的符号,而后在 new_kernel 中,我们从低地址到高地址 依次创建 5 个逻辑段并通过 push 方法将它们插入到内核地址空间中,上面我们已经详细介绍过这 5 个逻辑段。跳板 是通过 map_trampoline 方法来映射的,我们也将在本章最后一节进行讲解。
现在我们来介绍如何创建应用的地址空间。在前面的章节中,我们直接将丢弃所有符号的应用二进制镜像链接到内核,在初始化的时候 内核仅需将他们加载到正确的初始物理地址就能使它们正确执行。但本章中,我们希望效仿内核地址空间的设计,同样借助页表机制 使得应用地址空间的各个逻辑段也可以有不同的访问方式限制,这样可以提早检测出应用的错误并及时将其终止以最小化它对系统带来的 恶劣影响。
在第三章中,每个应用链接脚本中的起始地址被要求是不同的,这样它们的代码和数据存放的位置才不会产生冲突。但是这是一种对于应用开发者 极其不友好的设计。现在,借助地址空间的抽象,我们终于可以让所有应用程序都使用同样的起始地址,这也意味着所有应用可以使用同一个链接脚本了:
1/* user/src/linker.ld */
2
3OUTPUT_ARCH(riscv)
4ENTRY(_start)
5
6BASE_ADDRESS = 0x0;
7
8SECTIONS
9{
10 . = BASE_ADDRESS;
11 .text : {
12 *(.text.entry)
13 *(.text .text.*)
14 }
15 . = ALIGN(4K);
16 .rodata : {
17 *(.rodata .rodata.*)
18 }
19 . = ALIGN(4K);
20 .data : {
21 *(.data .data.*)
22 }
23 .bss : {
24 *(.bss .bss.*)
25 }
26 /DISCARD/ : {
27 *(.eh_frame)
28 *(.debug*)
29 }
30}
我们将起始地址 BASE_ADDRESS 设置为 0x0 ,显然它只能是一个地址空间中的虚拟地址而非物理地址。 事实上由于我们将入口汇编代码段放在最低的地方,这也是整个应用的入口点。 我们只需清楚这一事实即可,而无需像之前一样将其硬编码到代码中。此外,在 .text 和 .rodata 中间以及 .rodata 和 .data 中间我们进行了页面对齐,因为前后两个逻辑段的访问方式限制是不同的,由于我们只能以页为单位对这个限制进行设置, 因此就只能将下一个逻辑段对齐到下一个页面开始放置。相对的, .data 和 .bss 两个逻辑段由于限制相同,它们中间 则无需进行页面对齐。
它仅需要提供两个函数: get_num_app 获取链接到内核内的应用的数目,而 get_app_data 则根据传入的应用编号 取出对应应用的 ELF 格式可执行文件数据。它们和之前一样仍是基于 build.rs 生成的 link_app.S 给出的符号来 确定其位置,并实际放在内核的数据段中。 loader 模块中原有的内核和用户栈则分别作为逻辑段放在内核和用户地址空间中,我们无需再去专门为其定义一种类型。
在阅读下面代码的时候请结合这段话
我们可以通过二进制工具 rust-readobj 来看看 ELF 文件中究竟包含什么内容,输入命令:
$ rust-readobj -all target/debug/os
首先可以看到一个 ELF header,它位于 ELF 文件的开头:
1File: target/debug/os
2Format: elf64-x86-64
3Arch: x86_64
4AddressSize: 64bit
5LoadName:
6ElfHeader {
7Ident {
8 Magic: (7F 45 4C 46)
9 Class: 64-bit (0x2)
10 DataEncoding: LittleEndian (0x1)
11 FileVersion: 1
12 OS/ABI: SystemV (0x0)
13 ABIVersion: 0
14 Unused: (00 00 00 00 00 00 00)
15}
16Type: SharedObject (0x3)
17Machine: EM_X86_64 (0x3E)
18Version: 1
19Entry: 0x5070
20ProgramHeaderOffset: 0x40
21SectionHeaderOffset: 0x32D8D0
22Flags [ (0x0)
23]
24HeaderSize: 64
25ProgramHeaderEntrySize: 56
26ProgramHeaderCount: 12
27SectionHeaderEntrySize: 64
28SectionHeaderCount: 42
29StringTableSectionIndex: 41
30}
31......
- 第 8 行是一个称之为 魔数 (Magic) 独特的常数,存放在 ELF header 的一个固定位置。当加载器将 ELF 文件加载到内存之前,通常会查看 该位置的值是否正确,来快速确认被加载的文件是不是一个 ELF 。
- 第 19 行给出了可执行文件的入口点为
0x5070。 - 从 20-21 行中,我们可以知道除了 ELF header 之外,还有另外两种不同的 header,分别称为 program header 和 section header, 它们都有多个。ELF header 中给出了其他两种header 的大小、在文件中的位置以及数目。
- 从 24-27 行中,可以看到有 12 个不同的 program header,它们从文件的 0x40 字节偏移处开始,每个 56 字节; 有64个section header,它们从文件的 0x2D8D0 字节偏移处开始,每个 64 字节;
有多个不同的 section header,下面是个具体的例子:
......
Section {
Index: 14
Name: .text (157)
Type: SHT_PROGBITS (0x1)
Flags [ (0x6)
SHF_ALLOC (0x2)
SHF_EXECINSTR (0x4)
]
Address: 0x5070
Offset: 0x5070
Size: 208067
Link: 0
Info: 0
AddressAlignment: 16
EntrySize: 0
}
每个 section header 则描述一个段的元数据。
其中,我们看到了代码段 .text 需要被加载到地址 0x5070 ,大小 208067 字节,。 它们分别由元数据的字段 Offset、 Size 和 Address 给出。。
我们还能够看到程序中的符号表:
Symbol {
Name: _start (37994)
Value: 0x5070
Size: 47
Binding: Global (0x1)
Type: Function (0x2)
Other: 0
Section: .text (0xE)
}
Symbol {
Name: main (38021)
Value: 0x51A0
Size: 47
Binding: Global (0x1)
Type: Function (0x2)
Other: 0
Section: .text (0xE)
}
里面包括了我们写的 main 函数的地址以及用户态执行环境的起始地址 _start 函数的地址。
因此,从 ELF header 中可以看出,ELF 中的内容按顺序应该是:
- ELF header
- 若干个 program header
- 程序各个段的实际数据
- 若干的 section header
在创建应用地址空间的时候,我们需要对 get_app_data 得到的 ELF 格式数据进行解析,找到各个逻辑段所在位置和访问 限制并插入进来,最终得到一个完整的应用地址空间:
1// os/src/mm/memory_set.rs
2
3impl MemorySet {
4 /// Include sections in elf and trampoline and TrapContext and user stack,
5 /// also returns user_sp and entry point.
6 pub fn from_elf(elf_data: &[u8]) -> (Self, usize, usize) {
7 let mut memory_set = Self::new_bare();
8 // map trampoline
9 memory_set.map_trampoline();
10 // map program headers of elf, with U flag
11 let elf = xmas_elf::ElfFile::new(elf_data).unwrap();
12 let elf_header = elf.header;
13 let magic = elf_header.pt1.magic;
14 assert_eq!(magic, [0x7f, 0x45, 0x4c, 0x46], "invalid elf!");
15 let ph_count = elf_header.pt2.ph_count();
16 let mut max_end_vpn = VirtPageNum(0);
17 for i in 0..ph_count {
18 let ph = elf.program_header(i).unwrap();
19 if ph.get_type().unwrap() == xmas_elf::program::Type::Load {
20 let start_va: VirtAddr = (ph.virtual_addr() as usize).into();
21 let end_va: VirtAddr = ((ph.virtual_addr() + ph.mem_size()) as usize).into();
22 let mut map_perm = MapPermission::U;
23 let ph_flags = ph.flags();
24 if ph_flags.is_read() { map_perm |= MapPermission::R; }
25 if ph_flags.is_write() { map_perm |= MapPermission::W; }
26 if ph_flags.is_execute() { map_perm |= MapPermission::X; }
27 let map_area = MapArea::new(
28 start_va,
29 end_va,
30 MapType::Framed,
31 map_perm,
32 );
33 max_end_vpn = map_area.vpn_range.get_end();
34 memory_set.push(
35 map_area,
36 Some(&elf.input[ph.offset() as usize..(ph.offset() + ph.file_size()) as usize])
37 );
38 }
39 }
40 // map user stack with U flags
41 let max_end_va: VirtAddr = max_end_vpn.into();
42 let mut user_stack_bottom: usize = max_end_va.into();
43 // guard page
44 user_stack_bottom += PAGE_SIZE;
45 let user_stack_top = user_stack_bottom + USER_STACK_SIZE;
46 memory_set.push(MapArea::new(
47 user_stack_bottom.into(),
48 user_stack_top.into(),
49 MapType::Framed,
50 MapPermission::R | MapPermission::W | MapPermission::U,
51 ), None);
52 // map TrapContext
53 memory_set.push(MapArea::new(
54 TRAP_CONTEXT.into(),
55 TRAMPOLINE.into(),
56 MapType::Framed,
57 MapPermission::R | MapPermission::W,
58 ), None);
59 (memory_set, user_stack_top, elf.header.pt2.entry_point() as usize)
60 }
61}
-
第 9 行,我们将跳板插入到应用地址空间;
-
第 11 行,我们使用外部 crate
xmas_elf来解析传入的应用 ELF 数据并可以轻松取出各个部分。 此前 我们简要介绍过 ELF 格式的布局。第 14 行,我们取出 ELF 的魔数来判断 它是不是一个合法的 ELF 。第 15 行,我们可以直接得到 program header 的数目,然后遍历所有的 program header 并将合适的区域加入 到应用地址空间中。这一过程的主体在第 17~39 行之间。第 19 行我们确认 program header 的类型是
LOAD, 这表明它有被内核加载的必要,此时不必理会其他类型的 program header 。接着通过ph.virtual_addr()和ph.mem_size()来计算这一区域在应用地址空间中的位置,通过ph.flags()来确认这一区域访问方式的 限制并将其转换为MapPermission类型(注意它默认包含 U 标志位)。最后我们在第 27 行创建逻辑段map_area并在第 34 行push到应用地址空间。在push的时候我们需要完成数据拷贝,当前 program header 数据被存放的位置可以通过ph.offset()和ph.file_size()来找到。 注意当 存在一部分零初始化的时候,ph.file_size()将会小于ph.mem_size(),因为这些零出于缩减可执行 文件大小的原因不应该实际出现在 ELF 数据中。 -
我们从第 40 行开始处理用户栈。注意在前面加载各个 program header 的时候,我们就已经维护了
max_end_vpn记录目前涉及到的最大的虚拟页号,只需紧接着在它上面再放置一个保护页面和用户栈即可。 -
第 53 行则在应用地址空间中映射次高页面来存放 Trap 上下文。
-
第 59 行返回的时候,我们不仅返回应用地址空间
memory_set,也同时返回用户栈虚拟地址user_stack_top以及从解析 ELF 得到的该应用入口点地址,它们将被我们用来创建应用的任务控制块。
我们调用 MemorySet::activate :
1// os/src/mm/page_table.rs 2 3pub fn token(&self) -> usize { 4 8usize << 60 | self.root_ppn.0 5} 6 7// os/src/mm/memory_set.rs 8 9impl MemorySet { 10 pub fn activate(&self) { 11 let satp = self.page_table.token(); 12 unsafe { 13 satp::write(satp); 14 llvm_asm!("sfence.vma" :::: "volatile"); 15 } 16 } 17}
PageTable::token 会按照 satp CSR 格式要求 构造一个无符号 64 位无符号整数,使得其 分页模式为 SV39 ,且将当前多级页表的根节点所在的物理页号填充进去。在 activate 中,我们将这个值写入当前 CPU 的 satp CSR ,从这一刻开始 SV39 分页模式就被启用了,而且 MMU 会使用内核地址空间的多级页表进行地址转换。
我们必须注意切换 satp CSR 是否是一个 平滑 的过渡:其含义是指,切换 satp 的指令及其下一条指令这两条相邻的指令的 虚拟地址是相邻的(由于切换 satp 的指令并不是一条跳转指令, pc 只是简单的自增当前指令的字长), 而它们所在的物理地址一般情况下也是相邻的,但是它们所经过的地址转换流程却是不同的——切换 satp 导致 MMU 查的多级页表 是不同的**。这就要求前后两个地址空间在切换 satp 的指令 附近 的映射满足某种意义上的连续性。**
幸运的是,我们做到了这一点。这条写入 satp 的指令及其下一条指令都在内核内存布局的代码段中,在切换之后是一个恒等映射, 而在切换之前是视为物理地址直接取指,也可以将其看成一个恒等映射。这完全符合我们的期待:即使切换了地址空间,指令仍应该 能够被连续的执行。
注意到在 activate 的最后,我们插入了一条汇编指令 sfence.vma ,它又起到什么作用呢?(刷新TLB)
让我们再来回顾一下多级页表:它相比线性表虽然大量节约了内存占用,但是却需要 MMU 进行更多的隐式访存。如果是一个线性表, MMU 仅需单次访存就能找到页表项并完成地址转换,而多级页表(以 SV39 为例,不考虑大页)最顺利的情况下也需要三次访存。这些 额外的访存和真正访问数据的那些访存在空间上并不相邻,加大了多级缓存的压力,一旦缓存缺失将带来巨大的性能惩罚。如果采用 多级页表实现,这个问题会变得更为严重,使得地址空间抽象的性能开销过大。
为了解决性能问题,一种常见的做法是在 CPU 中利用部分硬件资源额外加入一个 快表 (TLB, Translation Lookaside Buffer) , 它维护了部分虚拟页号到页表项的键值对。当 MMU 进行地址转换的时候,首先 会到快表中看看是否匹配,如果匹配的话直接取出页表项完成地址转换而无需访存;否则再去查页表并将键值对保存在快表中。一旦 我们修改了 satp 切换了地址空间,快表中的键值对就会失效,因为它还表示着上个地址空间的映射关系。为了 MMU 的地址转换 能够及时与 satp 的修改同步,我们可以选择立即使用 sfence.vma 指令将快表清空,这样 MMU 就不会看到快表中已经 过期的键值对了。
注解
sfence.vma 是一个屏障
对于一种仅含有快表的 RISC-V CPU 实现来说,我们可以认为 sfence.vma 的作用就是清空快表。事实上它在特权级 规范中被定义为一种含义更加丰富的内存屏障,具体来说: sfence.vma 可以使得所有发生在它后面的地址转换都能够 看到所有排在它前面的写入操作,在不同的平台上这条指令要做的事情也都是不同的。这条指令还可以被精细配置来减少同步开销, 详情请参考 RISC-V 特权级规范。
现在可以说明我们在创建用户/内核地址空间中用到的 map_trampoline 是如何实现的了:
1// os/src/config.rs
2
3pub const TRAMPOLINE: usize = usize::MAX - PAGE_SIZE + 1;
4
5// os/src/mm/memory_set.rs
6
7impl MemorySet {
8 /// Mention that trampoline is not collected by areas.
9 fn map_trampoline(&mut self) {
10 self.page_table.map(
11 VirtAddr::from(TRAMPOLINE).into(),
12 PhysAddr::from(strampoline as usize).into(),
13 PTEFlags::R | PTEFlags::X,
14 );
15 }
16}
这里我们为了实现方便并没有新增逻辑段 MemoryArea 而是直接在多级页表中插入一个从地址空间的最高虚拟页面映射到 跳板汇编代码所在的物理页帧的键值对,访问方式限制与代码段相同,即 RX 。
最后可以解释为何我们在 __alltraps 中需要借助寄存器 jr 而不能直接 call trap_handler 了。因为在 内存布局中,这条 .text.trampoline 段中的跳转指令和 trap_handler 都在代码段之内,汇编器(Assembler)和链接器(Linker)会根据 linker-qemu/k210.ld 的地址布局描述,设定电子指令的地址,并计算二者地址偏移量 并让跳转指令的实际效果为当前 pc 自增这个偏移量。但实际上我们知道由于我们设计的缘故,这条跳转指令在被执行的时候, 它的虚拟地址被操作系统内核设置在地址空间中的最高页面之内,加上这个偏移量并不能正确的得到 trap_handler 的入口地址。
问题的本质可以概括为:跳转指令实际被执行时的虚拟地址和在编译器/汇编器/链接器进行后端代码生成和链接形成最终机器码时设置此指令的地址是不同的。
为了让应用在运行时有一个安全隔离且符合编译器给应用设定的地址空间布局的虚拟地址空间,操作系统需要对任务进行更多的管理,所以任务控制块相比第三章也包含了更多内容:
1// os/src/task/task.rs
2
3pub struct TaskControlBlock {
4 pub task_cx_ptr: usize,
5 pub task_status: TaskStatus,
6 pub memory_set: MemorySet,
7 pub trap_cx_ppn: PhysPageNum,
8 pub base_size: usize,
9}
除了应用的地址空间 memory_set 之外,还有位于应用地址空间次高页的 Trap 上下文被实际存放在物理页帧的物理页号 trap_cx_ppn ,它能够方便我们对于 Trap 上下文进行访问。此外, base_size 统计了应用数据的大小,也就是 在应用地址空间中从 0x0 开始到用户栈结束一共包含多少字节。它后续还应该包含用于应用动态内存分配的 堆空间的大小,但我们暂不支持。
-
创建了内核地址空间的全局实例
-
内存子系统的初始化
-
pub use memory_set::KERNEL_SPACE; pub fn init() { heap_allocator::init_heap(); //初始化堆 frame_allocator::init_frame_allocator();//初始化帧分配器 KERNEL_SPACE.lock().activate(); //开启分页,将内核地址空间的根页表的地址给satp 然后刷新TLB sfence.vma }
问题一:为何把trap上下文保存在用户地址空间而不是内核栈中?
答:**假如我们将其放在内核栈 中,在保存 Trap 上下文之前我们必须先切换到内核地址空间,这就需要我们将内核地址空间的 token 写入 satp 寄存器,之后我们 还需要有一个通用寄存器保存内核栈栈顶的位置,这样才能以它为基址保存 Trap 上下文。在保存 Trap 上下文之前我们必须完成这 两项工作。然而,我们无法在不破坏任何一个通用寄存器的情况下做到这一点,**因为事实上我们需要用到内核的两条信息:内核地址空间 的 token 还有应用内核栈顶的位置,硬件却只提供一个 sscratch 可以用来进行周转。所以,我们不得不将 Trap 上下文保存在 应用地址空间的一个虚拟页面中以避免切换到内核地址空间才能保存。
-
扩展Trap上下文
pub struct TrapContext { pub x: [usize; 32], pub sstatus: Sstatus, pub sepc: usize, pub kernel_satp: usize, pub kernel_sp: usize, pub trap_handler: usize, }
kernel_satp表示内核地址空间的 token ;kernel_sp表示当前应用在内核地址空间中的内核栈栈顶的虚拟地址;trap_handler表示内核中 trap handler 入口点的虚拟地址。
5.__alltraps
和__restored 的更改- 在alltraps中增加了trapcontext的新增字段
- 增加了地址切换
6.加载和执行应用程序
- 任务控制块的创建代码是个核心
7.然后进行全局应该管理器是实例化
1// os/src/task/mod.rs
2
3struct TaskManagerInner {
4 tasks: Vec<TaskControlBlock>,
5 current_task: usize,
6}
7
8lazy_static! {
9 pub static ref TASK_MANAGER: TaskManager = {
10 println!("init TASK_MANAGER");
11 let num_app = get_num_app();
12 println!("num_app = {}", num_app);
13 let mut tasks: Vec<TaskControlBlock> = Vec::new();
14 for i in 0..num_app {
15 tasks.push(TaskControlBlock::new(
16 get_app_data(i),
17 i,
18 ));
19 }
20 TaskManager {
21 num_app,
22 inner: RefCell::new(TaskManagerInner {
23 tasks,
24 current_task: 0,
25 }),
26 }
27 };
28}8.每个应用的二进制文件的改动
- 首先,我们在
.incbin中不再插入清除全部符号的应用二进制镜像*.bin,而是将构建得到的 ELF 格式文件直接链接进来; - 其次,在链接每个 ELF 格式文件之前我们都加入一行
.align 3来确保它们对齐到 8 字节,这是由于如果不这样做,xmas-elfcrate 可能会在解析 ELF 的时候进行不对齐的内存读写,例如使用ld指令从内存的一个没有对齐到 8 字节的地址加载一个 64 位的值到一个通用寄存器。而在 k210 平台上,由于其硬件限制,这会触发一个内存读写不对齐的异常,导致解析无法正常完成。
9.改进Trap处理的实现 (当有s-s的trap的时候直接panic)
10.trap_return 开头写了set_user_trap_entry(); 设置下次trap进来的时候跳到什么地方去执行
为了在用户态就可以借助操作系统的服务动态灵活地管理和控制应用的执行,我们需要在已有的 任务 抽象的基础上进一步扩展,形成新的抽象: 进程 ,并实现若干基于 进程 的强大系统调用。
- 创建 (Create):操作系统需要提供一些创建新进程的服务。用户在shell中键入命令或用鼠标双击应用程序图标(这需要GUI界面,目前我们还没有实现)时,会调用操作系统服务来创建新进程,运行指定的程序。
- 销毁 (Destroy):操作系统还需提供退出并销毁进程的服务。进程会在运行完成后可自行退出,但还需要其他进程(如创建这些进程的父进程)来回收这些进程最后的资源并销毁这些进程。
- 等待 (Wait):操作系统提供等待进程停止运行是很有用的,比如上面提到的退出信息的收集。
- 信息 (Info):操作系统也可提供有关进程的身份和状态等进程信息,例如进程的ID,进程的运行状态,进程的优先级等。
- 其他控制:操作系统还可有其他的进程控制服务。例如,让一个进程能够杀死另外一个进程,暂停进程(停止运行一段时间),恢复进程(继续运行)等。
注解
任务和进程的关系与区别
第三章提到的 任务 和这里提到的 进程 有何关系和区别? 这需要从二者对资源的占用和执行的过程这两个方面来进行分析。
任务和进程都是一个程序的执行过程,或表示了一个运行的程序;都是能够被操作系统打断并通过切换来分时占用CPU资源;都需要 地址空间 来放置代码和数据;都有从开始运行到结束运行这样的生命周期。
第三章提到的 任务 是这里提到的 进程 的初级阶段,还没进化到拥有更强大的动态变化的功能:进程可以在运行的过程中,创建 子进程 、 用新的 程序 内容覆盖已有的 程序 内容、可管理更多的 物理或虚拟的 资源 。
因此,进程就是选取某个可执行文件并对其进行一次动态执行的过程。相比可执行文件,它的动态性主要体现在:
- 它是一个过程,从时间上来看有开始也有结束;
- 在该过程中对于可执行文件中给出的需求要相应对 硬件资源 进行 动态绑定 。
- 这个进程模型有三个运行状态:就绪态、运行态和等待态;
- 有基于独立的页表的地址空间;
- 可被操作系统调度来分时占用CPU执行;
- 可以动态创建和退出;
- 可通过系统调用获得操作系统的服务。
/// 功能:当前进程 fork 出来一个子进程。
/// 返回值:对于子进程返回 0,对于当前进程则返回子进程的 PID 。
/// syscall ID:220
pub fn sys_fork() -> isize;进程A调用 fork 系统调用之后,内核会创建一个新进程B,这个进程B和调用 fork 的进程A在返回用户态那一瞬间几乎处于相同的状态:这意味着它们包含的
用户态的代码段、堆栈段及其他数据段的内容完全相同,但是它们是被放在两个独立的地址空间中的。因此新进程的地址空间需要从原有进程的地址空间完整拷贝一份。两个进程通用寄存器也几乎完全相同。例如, pc 相同意味着两个进程会从同一位置的一条相同指令(我们知道其上一条指令一定是用于系统调用的 ecall 指令)开始向下执行, sp 相同则意味着两个进程的用户栈在各自的地址空间中的位置相同。其余的寄存器相同则确保了二者回到了相同的执行流状态。
但是唯有用来保存 fork 系统调用返回值的 a0 寄存器(这是 RV64 函数调用规范规定的函数返回值所用的寄存器)的值是不同的。这区分了两个进程:原进程的返回值为新创建进程的 PID ,而新创建进程的返回值为 0 。由于新的进程是原进程主动调用 fork 衍生出来的,我们称新进程为原进程的 子进程 (Child Process) ,相对的原进程则被称为新进程的 父进程 (Parent Process) 。这样二者就建立了一种父子关系。注意到每个进程可能有多个子进程,但最多只能有一个父进程,于是所有进程可以被组织成一颗有根树,其根节点正是代表用户初始程序-initproc的第一个用户态的初始进程。
相比创建一个进程, fork 更重要的功能是建立一对新的父子关系。在我们的进程模型中,父进程和子进程之间的联系更为紧密,它们更容易进行合作或通信,而且一些重要的机制也需要在它们之间才能展开
/// 功能:当前进程等待一个子进程变为僵尸进程,回收其全部资源并收集其返回值。
/// 参数:pid 表示要等待的子进程的进程 ID,如果为 -1 的话表示等待任意一个子进程;
/// exit_code 表示保存子进程返回值的地址,如果这个地址为 0 的话表示不必保存。
/// 返回值:如果要等待的子进程不存在则返回 -1;否则如果要等待的子进程均未结束则返回 -2;
/// 否则返回结束的子进程的进程 ID。
/// syscall ID:260
pub fn sys_waitpid(pid: isize, exit_code: *mut i32) -> isize;当一个进程通过 exit 系统调用退出之后,它所占用的资源并不能够立即全部回收。比如该进程的内核栈目前就正用来进行系统调用处理,如果将放置它的物理页帧回收的话,可能会导致系统调用不能正常处理。对于这种问题,一种典型的做法是当进程退出的时候内核立即回收一部分资源并将该进程标记为 僵尸进程 (Zombie Process) 。之后,由该进程的父进程通过一个名为 waitpid 的系统调用来收集该进程的返回状态并回收掉它所占据的全部资源,这样这个进程才被彻底销毁。系统调用 waitpid 的原型如下:
一般情况下一个进程要负责通过 waitpid 系统调用来等待所有它 fork 出来的子进程结束并回收掉它们占据的资源,这也是父子进程间的一种同步手段。但这并不是必须的:如果一个进程先于它的子进程结束,在它退出的时候,它的所有子进程将成为进程树的根节点——用户初始进程的子进程,同时这些子进程的父进程也会变成用户初始进程。这之后,这些子进程的资源就由用户初始进程负责回收了,这也是用户初始进程很重要的一个用途。后面我们会介绍用户初始进程是如何实现的
如果仅有 fork 的话,那么所有的进程都只能和用户初始进程一样执行同样的代码段,这显然是远远不够的。于是我们还需要引入 exec 系统调用来执行不同的可执行文件:
/// 功能:将当前进程的地址空间清空并加载一个特定的可执行文件,返回用户态后开始它的执行。
/// 参数:path 给出了要加载的可执行文件的名字;
/// 返回值:如果出错的话(如找不到名字相符的可执行文件)则返回 -1,否则不应该返回。
/// syscall ID:221
pub fn sys_exec(path: &str) -> isize;注意,我们知道 path 作为 &str 类型是一个胖指针,既有起始地址又包含长度信息。在实际进行系统调用的时候,我们只会将起始地址传给内核(对标 C 语言仅会传入一个 char* )。这就需要应用负责在传入的字符串的末尾加上一个 \0 ,这样内核才能知道字符串的长度。下面给出了用户库 user_lib 中的调用方式:
我们刚刚介绍了 fork/waitpid/exec 三个重要系统调用,借助它们我们可以开发功能更为强大的应用程序。下面我们通过描述两个重要的应用程序: 用户初始程序-init 和 shell程序-user_shell 的开发过程,来展示这些重要系统调用的使用方法。
读者可以在 user/src/syscall.rs 中看到以 sys_* 开头的系统调用的函数原型,它们后续还会在 user/src/lib.rs 中被封装成方便应用程序使用的形式。如 sys_fork 被封装成 fork ,而 sys_exec 被封装成 exec 。这里值得一提的是 sys_waitpid 被封装成两个不同的 API :
1// user/src/lib.rs
2
3pub fn wait(exit_code: &mut i32) -> isize {
4 loop {
5 match sys_waitpid(-1, exit_code as *mut _) {
6 -2 => { yield_(); }
7 // -1 or a real pid
8 exit_pid => return exit_pid,
9 }
10 }
11}
12
13pub fn waitpid(pid: usize, exit_code: &mut i32) -> isize {
14 loop {
15 match sys_waitpid(pid as isize, exit_code as *mut _) {
16 -2 => { yield_(); }
17 // -1 or a real pid
18 exit_pid => return exit_pid,
19 }
20 }
21}其中 wait 表示等待任意一个子进程结束,根据 sys_waitpid 的约定它需要传的 pid 参数为 -1 ;而 waitpid 则等待一个 PID 固定的子进程结束。在具体实现方面,我们看到当 sys_waitpid 返回值为 -2 ,即要等待的子进程存在但它却尚未退出的时候,我们调用 yield_ 主动交出 CPU 使用权,待下次 CPU 使用权被内核交还给它的时候再次调用 sys_waitpid 查看要等待的子进程是否退出。这样做可以减小 CPU 资源的浪费。
目前的实现风格是尽可能简化内核,因此 sys_waitpid 是立即返回的,即它的返回值只能给出返回这一时刻的状态。如果这一时刻要等待的子进程还尚未结束,那么也只能如实向应用报告这一结果。于是用户库 user_lib 就需要负责对返回状态进行持续的监控,因此它里面便需要进行循环检查。在后面的实现中,我们会将 sys_waitpid 的内核实现设计为 阻塞 的,也即直到得到一个确切的结果位置都停在内核内,也就意味着内核返回给应用的结果可以直接使用。那是 wait 和 waitpid 两个 API 的实现便会更加简单。
由于shell程序-user_shell需要捕获我们的输入并进行解析处理,我们需要加入一个新的用于输入的系统调用:
/// 功能:从文件中读取一段内容到缓冲区。
/// 参数:fd 是待读取文件的文件描述符,切片 buffer 则给出缓冲区。
/// 返回值:如果出现了错误则返回 -1,否则返回实际读到的字节数。
/// syscall ID:63
pub fn sys_read(fd: usize, buffer: &mut [u8]) -> isize;
在实际调用的时候我们必须要同时向内核提供缓冲区的起始地址及长度:
// user/src/syscall.rs
pub fn sys_read(fd: usize, buffer: &mut [u8]) -> isize {
syscall(SYSCALL_READ, [fd, buffer.as_mut_ptr() as usize, buffer.len()])
}
我们在用户库中将其进一步封装成每次能够从 标准输入 中获取一个字符的 getchar 函数:
// user/src/lib.rs
pub fn read(fd: usize, buf: &mut [u8]) -> isize { sys_read(fd, buf) }
// user/src/console.rs
const STDIN: usize = 0;
pub fn getchar() -> u8 {
let mut c = [0u8; 1];
read(STDIN, &mut c);
c[0]
}
其中,我们每次临时声明一个长度为 1 的缓冲区。
接下来就可以介绍shell程序- user_shell 是如何实现的了:
1// user/src/bin/user_shell.rs
2
3#![no_std]
4#![no_main]
5
6extern crate alloc;
7
8#[macro_use]
9extern crate user_lib;
10
11const LF: u8 = 0x0au8;
12const CR: u8 = 0x0du8;
13const DL: u8 = 0x7fu8;
14const BS: u8 = 0x08u8;
15
16use alloc::string::String;
17use user_lib::{fork, exec, waitpid, yield_};
18use user_lib::console::getchar;
19
20#[no_mangle]
21pub fn main() -> i32 {
22 println!("Rust user shell");
23 let mut line: String = String::new();
24 print!(">> ");
25 loop {
26 let c = getchar();
27 match c {
28 LF | CR => {
29 println!("");
30 if !line.is_empty() {
31 line.push('\0');
32 let pid = fork();
33 if pid == 0 {
34 // child process
35 if exec(line.as_str()) == -1 {
36 println!("Error when executing!");
37 return -4;
38 }
39 unreachable!();
40 } else {
41 let mut exit_code: i32 = 0;
42 let exit_pid = waitpid(pid as usize, &mut exit_code);
43 assert_eq!(pid, exit_pid);
44 println!(
45 "Shell: Process {} exited with code {}",
46 pid, exit_code
47 );
48 }
49 line.clear();
50 }
51 print!(">> ");
52 }
53 BS | DL => {
54 if !line.is_empty() {
55 print!("{}", BS as char);
56 print!(" ");
57 print!("{}", BS as char);
58 line.pop();
59 }
60 }
61 _ => {
62 print!("{}", c as char);
63 line.push(c as char);
64 }
65 }
66 }
67}
可以看到,在以第 25 行开头的主循环中,每次都是调用 getchar 获取一个用户输入的字符,并根据它相应进行一些动作。第 23 行声明的字符串 line 则维护着用户当前输入的命令内容,它也在不断发生变化。
为了更好实现进程管理,同时也使得操作系统整体架构更加灵活,能够满足后续的一些需求,我们需要重新设计一些数据结构包含的内容及接口。本节将按照如下顺序来进行介绍:
- 基于应用名的应用链接/加载器
- 进程标识符
PidHandle以及内核栈KernelStack - 任务控制块
TaskControlBlock - 任务管理器
TaskManager - 处理器管理结构
Processor
在实现 exec 系统调用的时候,我们需要根据应用的名字而不仅仅是一个编号来获取应用的 ELF 格式数据。因此原有的链接和加载接口需要做出如下变更:
在链接器 os/build.rs 中,我们需要按顺序保存链接进来的每个应用的名字:
1 // os/build.rs
2
3 for i in 0..apps.len() {
4 writeln!(f, r#" .quad app_{}_start"#, i)?;
5 }
6 writeln!(f, r#" .quad app_{}_end"#, apps.len() - 1)?;
7
8 writeln!(f, r#"
9 .global _app_names
10_app_names:"#)?;
11 for app in apps.iter() {
12 writeln!(f, r#" .string "{}""#, app)?;
13 }
14
15 for (idx, app) in apps.iter().enumerate() {
16 ...
17 }
第 8~13 行,我们按照顺序将各个应用的名字通过 .string 伪指令放到数据段中,注意链接器会自动在每个字符串的结尾加入分隔符 \0 ,它们的位置则由全局符号 _app_names 指出。
而在加载器 loader.rs 中,我们用一个全局可见的 只读 向量 APP_NAMES 来按照顺序将所有应用的名字保存在内存中:
// os/src/loader.rs
lazy_static! {
static ref APP_NAMES: Vec<&'static str> = {
let num_app = get_num_app();
extern "C" { fn _app_names(); }
let mut start = _app_names as usize as *const u8;
let mut v = Vec::new();
unsafe {
for _ in 0..num_app {
let mut end = start;
while end.read_volatile() != '\0' as u8 {
end = end.add(1);
}
let slice = core::slice::from_raw_parts(start, end as usize - start as usize);
let str = core::str::from_utf8(slice).unwrap();
v.push(str);
start = end.add(1);
}
}
v
};
}
使用 get_app_data_by_name 可以按照应用的名字来查找获得应用的 ELF 数据,而 list_apps 在内核初始化时被调用,它可以打印出所有可用的应用的名字。
// os/src/loader.rs
pub fn get_app_data_by_name(name: &str) -> Option<&'static [u8]> {
let num_app = get_num_app();
(0..num_app)
.find(|&i| APP_NAMES[i] == name)
.map(|i| get_app_data(i))
}
pub fn list_apps() {
println!("/**** APPS ****");
for app in APP_NAMES.iter() {
println!("{}", app);
}
println!("**************/")
}
同一时间存在的所有进程都有一个自己的进程标识符,它们是互不相同的整数。这里我们使用 RAII 的思想,将其抽象为一个 PidHandle 类型,当它的生命周期结束后对应的整数会被编译器自动回收:
// os/src/task/pid.rs
pub struct PidHandle(pub usize);
类似之前的物理页帧分配器 FrameAllocator ,我们实现一个同样使用简单栈式分配策略的进程标识符分配器 PidAllocator ,并将其全局实例化为 PID_ALLOCATOR :
// os/src/task/pid.rs
struct PidAllocator {
current: usize,
recycled: Vec<usize>,
}
impl PidAllocator {
pub fn new() -> Self {
PidAllocator {
current: 0,
recycled: Vec::new(),
}
}
pub fn alloc(&mut self) -> PidHandle {
if let Some(pid) = self.recycled.pop() {
PidHandle(pid)
} else {
self.current += 1;
PidHandle(self.current - 1)
}
}
pub fn dealloc(&mut self, pid: usize) {
assert!(pid < self.current);
assert!(
self.recycled.iter().find(|ppid| **ppid == pid).is_none(),
"pid {} has been deallocated!", pid
);
self.recycled.push(pid);
}
}
lazy_static! {
static ref PID_ALLOCATOR : Mutex<PidAllocator> = Mutex::new(PidAllocator::new());
}
PidAllocator::alloc 将会分配出去一个将 usize 包装之后的 PidHandle 。我们将其包装为一个全局分配进程标识符的接口 pid_alloc 提供给内核的其他子模块:
// os/src/task/pid.rs
pub fn pid_alloc() -> PidHandle {
PID_ALLOCATOR.lock().alloc()
}
同时我们也需要为 PidHandle 实现 Drop Trait 来允许编译器进行自动的资源回收:
// os/src/task/pid.rs
impl Drop for PidHandle {
fn drop(&mut self) {
PID_ALLOCATOR.lock().dealloc(self.0);
}
}
在内核中,每个进程的执行状态、资源控制等元数据均保存在一个被称为 进程控制块 (PCB, Process Control Block) 的结构中,它是内核对进程进行管理的单位,故而是一种极其关键的内核数据结构。在内核看来,它就等价于一个进程。
承接前面的章节,我们仅需对任务控制块 TaskControlBlock 进行若干改动并让它直接承担进程控制块的功能:
1// os/src/task/task.rs
2
3pub struct TaskControlBlock {
4 // immutable
5 pub pid: PidHandle,
6 pub kernel_stack: KernelStack,
7 // mutable
8 inner: Mutex<TaskControlBlockInner>,
9}
10
11pub struct TaskControlBlockInner {
12 pub trap_cx_ppn: PhysPageNum,
13 pub base_size: usize,
14 pub task_cx_ptr: usize,
15 pub task_status: TaskStatus,
16 pub memory_set: MemorySet,
17 pub parent: Option<Weak<TaskControlBlock>>,
18 pub children: Vec<Arc<TaskControlBlock>>,
19 pub exit_code: i32,
20}
任务控制块中包含两部分:
- 在初始化之后就不再变化的作为一个字段直接放在任务控制块中。这里将进程标识符
PidHandle和内核栈KernelStack放在其中; - 在运行过程中可能发生变化的则放在
TaskControlBlockInner中,将它再包裹上一层互斥锁Mutex<T>放在任务控制块中。这是因为在我们的设计中外层只能获取任务控制块的不可变引用,若想修改里面的部分内容的话这需要Mutex<T>所提供的内部可变性。另外,当后续真正可能有多核同时修改同一个任务控制块中的内容时,Mutex<T>可以提供互斥从而避免数据竞争。
TaskControlBlockInner 中则包含下面这些内容:
-
trap_cx_ppn指出了应用地址空间中的 Trap 上下文(详见第四章)被放在的物理页帧的物理页号。 -
base_size的含义是:应用数据仅有可能出现在应用地址空间低于base_size字节的区域中。借助它我们可以清楚的知道应用有多少数据驻留在内存中。 -
task_cx_ptr指出一个暂停的任务的任务上下文在内核地址空间(更确切的说是在自身内核栈)中的位置,用于任务切换。 -
task_status维护当前进程的执行状态。 -
memory_set表示应用地址空间。 -
parent指向当前进程的父进程(如果存在的话)。注意我们使用Weak而非Arc来包裹另一个任务控制块,因此这个智能指针将不会影响父进程的引用计数。 -
children则将当前进程的所有子进程的任务控制块以Arc智能指针的形式保存在一个向量中,这样才能够更方便的找到它们。 -
当进程调用 exit 系统调用主动退出或者执行出错由内核终止的时候,它的退出码
exit_code会被内核保存在它的任务控制块中,并等待它的父进程通过 waitpid 回收它的资源的同时也收集它的 PID 以及退出码。进程控制块在内核中,每个进程的执行状态、资源控制等元数据均保存在一个被称为 进程控制块 (PCB, Process Control Block) 的结构中,它是内核对进程进行管理的单位,故而是一种极其关键的内核数据结构。在内核看来,它就等价于一个进程。
承接前面的章节,我们仅需对任务控制块
TaskControlBlock进行若干改动并让它直接承担进程控制块的功能:1// os/src/task/task.rs 2 3pub struct TaskControlBlock { 4 // immutable 5 pub pid: PidHandle, 6 pub kernel_stack: KernelStack, 7 // mutable 8 inner: Mutex<TaskControlBlockInner>, 9} 10 11pub struct TaskControlBlockInner { 12 pub trap_cx_ppn: PhysPageNum, 13 pub base_size: usize, 14 pub task_cx_ptr: usize, 15 pub task_status: TaskStatus, 16 pub memory_set: MemorySet, 17 pub parent: Option<Weak<TaskControlBlock>>, 18 pub children: Vec<Arc<TaskControlBlock>>, 19 pub exit_code: i32, 20}任务控制块中包含两部分:
- 在初始化之后就不再变化的作为一个字段直接放在任务控制块中。这里将进程标识符
PidHandle和内核栈KernelStack放在其中; - 在运行过程中可能发生变化的则放在
TaskControlBlockInner中,将它再包裹上一层互斥锁Mutex<T>放在任务控制块中。这是因为在我们的设计中外层只能获取任务控制块的不可变引用,若想修改里面的部分内容的话这需要Mutex<T>所提供的内部可变性。另外,当后续真正可能有多核同时修改同一个任务控制块中的内容时,Mutex<T>可以提供互斥从而避免数据竞争。
TaskControlBlockInner中则包含下面这些内容:trap_cx_ppn指出了应用地址空间中的 Trap 上下文(详见第四章)被放在的物理页帧的物理页号。base_size的含义是:应用数据仅有可能出现在应用地址空间低于base_size字节的区域中。借助它我们可以清楚的知道应用有多少数据驻留在内存中。task_cx_ptr指出一个暂停的任务的任务上下文在内核地址空间(更确切的说是在自身内核栈)中的位置,用于任务切换。task_status维护当前进程的执行状态。memory_set表示应用地址空间。parent指向当前进程的父进程(如果存在的话)。注意我们使用Weak而非Arc来包裹另一个任务控制块,因此这个智能指针将不会影响父进程的引用计数。children则将当前进程的所有子进程的任务控制块以Arc智能指针的形式保存在一个向量中,这样才能够更方便的找到它们。- 当进程调用 exit 系统调用主动退出或者执行出错由内核终止的时候,它的退出码
exit_code会被内核保存在它的任务控制块中,并等待它的父进程通过 waitpid 回收它的资源的同时也收集它的 PID 以及退出码。
- 在初始化之后就不再变化的作为一个字段直接放在任务控制块中。这里将进程标识符
注意我们在维护父子进程关系的时候大量用到了引用计数 Arc/Weak 。子进程的进程控制块并不会被直接放到父进程控制块下面,因为子进程完全有可能在父进程退出后仍然存在。因此进程控制块的本体是被放到内核堆上面的,对于它的一切访问都是通过智能指针 Arc/Weak 来进行的。当且仅当它的引用计数变为 0 的时候,进程控制块以及被绑定到它上面的各类资源才会被回收。
在前面的章节中,任务管理器 TaskManager 不仅负责管理所有的任务,还维护着 CPU 当前在执行哪个任务。由于这种设计不够灵活,不能拓展到后续的多核环境,我们需要将任务管理器对于 CPU 的监控职能拆分到下面即将介绍的处理器管理结构 Processor 中去,任务管理器自身仅负责管理所有任务。在这里,任务指的就是进程。
1// os/src/task/manager.rs
2
3pub struct TaskManager {
4 ready_queue: VecDeque<Arc<TaskControlBlock>>,
5}
6
7/// A simple FIFO scheduler.
8impl TaskManager {
9 pub fn new() -> Self {
10 Self { ready_queue: VecDeque::new(), }
11 }
12 pub fn add(&mut self, task: Arc<TaskControlBlock>) {
13 self.ready_queue.push_back(task);
14 }
15 pub fn fetch(&mut self) -> Option<Arc<TaskControlBlock>> {
16 self.ready_queue.pop_front()
17 }
18}
19
20lazy_static! {
21 pub static ref TASK_MANAGER: Mutex<TaskManager> = Mutex::new(TaskManager::new());
22}
23
24pub fn add_task(task: Arc<TaskControlBlock>) {
25 TASK_MANAGER.lock().add(task);
26}
27
28pub fn fetch_task() -> Option<Arc<TaskControlBlock>> {
29 TASK_MANAGER.lock().fetch()
30}
TaskManager 将所有的任务控制块用引用计数 Arc 智能指针包裹后放在一个双端队列 VecDeque 中。正如之前介绍的那样,我们并不直接将任务控制块放到 TaskManager 里面,而是将它们放在内核堆上,在任务管理器中仅存放他们的引用计数智能指针,这也是任务管理器的操作单位。这样做的原因在于,任务控制块经常需要被放入/取出,如果直接移动任务控制块自身将会带来大量的数据拷贝开销,而对于智能指针进行移动则没有多少开销。其次,允许任务控制块的共享引用在某些情况下能够让我们的实现更加方便。
TaskManager 提供 add/fetch 两个操作,前者表示将一个任务加入队尾,后者则表示从队头中取出一个任务来执行。从调度算法来看,这里用到的就是最简单的 先到先得 算法。全局实例 TASK_MANAGER 则提供给内核的其他子模块 add_task/fetch_task 两个函数。
每个 Processor 都有一个不同的 idle 执行流,它们运行在每个核各自的启动栈上,功能是尝试从任务管理器中选出一个任务来在当前核上执行。在内核初始化完毕之后,每个核都会通过调用 run_tasks 函数来进入 idle 执行流:
1// os/src/task/processor.rs
2
3impl Processor {
4 fn get_idle_task_cx_ptr2(&self) -> *const usize {
5 let inner = self.inner.borrow();
6 &inner.idle_task_cx_ptr as *const usize
7 }
8 pub fn run(&self) {
9 loop {
10 if let Some(task) = fetch_task() {
11 let idle_task_cx_ptr2 = self.get_idle_task_cx_ptr2();
12 // acquire
13 let mut task_inner = task.acquire_inner_lock();
14 let next_task_cx_ptr2 = task_inner.get_task_cx_ptr2();
15 task_inner.task_status = TaskStatus::Running;
16 drop(task_inner);
17 // release
18 self.inner.borrow_mut().current = Some(task);
19 unsafe {
20 __switch(
21 idle_task_cx_ptr2,
22 next_task_cx_ptr2,
23 );
24 }
25 }
26 }
27 }
28}
29
30pub fn run_tasks() {
31 PROCESSOR.run();
32}
可以看到,调度功能的主体在第 8 行的 Processor::run 中实现。它循环调用 fetch_task 直到顺利从任务管理器中取出一个任务,随后便准备通过任务切换的方式来执行:
- 第 11 行得到
__switch的第一个参数,也就是当前 idle 执行流的 task_cx_ptr2,这调用了第 4 行的get_idle_task_cx_ptr2方法。 - 第 13~16 行需要先获取从任务管理器中取出的任务的互斥锁再对对应的任务控制块进行操作,因为在多核环境下有可能会产生并发冲突。在里面我们获取任务的 task_cx_ptr2 作为
__switch的第二个参数并修改任务的状态。第 16 行我们需要手动释放互斥锁,这样才能划分出更加精确的临界区。如果依赖编译器在循环的末尾自动释放的话,相当于扩大了临界区,有可能会导致死锁。 - 第 18 行我们修改当前
Processor正在执行的任务为我们取出的任务。注意这里相当于Arc<TaskControlBlock>形式的任务从任务管理器流动到了处理器管理结构中。也就是说,在稳定的情况下,每个尚未结束的进程的任务控制块都只能被引用一次,要么在任务管理器中,要么则是在某个处理器的Processor中。 - 第 20 行我们调用
__switch来从当前的 idle 执行流切换到接下来要执行的任务。
上面介绍了从 idle 执行流通过任务调度切换到某个任务开始执行的过程。而反过来,当一个应用用尽了内核本轮分配给它的时间片或者它主动调用 yield 系统调用交出 CPU 使用权之后,进入内核后它会调用 schedule 函数来切换到 idle 执行流并开启新一轮的任务调度。
// os/src/task/processor.rs
pub fn schedule(switched_task_cx_ptr2: *const usize) {
let idle_task_cx_ptr2 = PROCESSOR.get_idle_task_cx_ptr2();
unsafe {
__switch(
switched_task_cx_ptr2,
idle_task_cx_ptr2,
);
}
}这里,我们需要传入即将被切换出去的任务的 task_cx_ptr2 来在合适的位置保存任务上下文,之后就可以通过 __switch 来切换到 idle 执行流。切换回去之后,从源代码级来看,我们将跳转到 Processor::run 中 __switch 返回之后的位置,也即开启了下一轮循环。
在procceror 中在增加idle_task_cx_ptr2的目的
这样做的主要目的是使得换入/换出进程和调度执行流在内核层各自执行在不同的内核栈上,分别是进程自身的内核栈和内核初始化时使用的启动栈。这样的话,调度相关的数据不会出现在进程内核栈上,也使得调度机制对于换出进程的Trap执行流是不可见的,它在决定换出的时候只需调用schedule而无需操心调度的事情。从而各执行流的分工更加明确了,虽然带来了更大的开销。
pub fn fork(self: &Arc<TaskControlBlock>) -> Arc<TaskControlBlock> {
// ---- hold parent PCB lock
let mut parent_inner = self.acquire_inner_lock();
// copy user space(include trap context)
let memory_set = MemorySet::from_existed_user(
&parent_inner.memory_set
);//copy父进程的地址空间 但是对应实际的物理帧率缺不相同
let trap_cx_ppn = memory_set
.translate(VirtAddr::from(TRAP_CONTEXT).into())
.unwrap()
.ppn(); //父进程的trapcontext在from_elf时候映射并分配物理页帧率,在newTCB的时候初始化
//在fork的时候 在from_existed_user的时候就已经分配新的物理页帧和copy数据
// alloc a pid and a kernel stack in kernel space
let pid_handle = pid_alloc();
let kernel_stack = KernelStack::new(&pid_handle);
let kernel_stack_top = kernel_stack.get_top();
// push a goto_trap_return task_cx on the top of kernel stack
let task_cx_ptr = kernel_stack.push_on_top(TaskContext::goto_trap_return());
//由于内核栈不是应用地址空间的内容,在TCB只需知道内核在真实内存的地址就行
let task_control_block = Arc::new(TaskControlBlock {
pid: pid_handle,
kernel_stack,
inner: Mutex::new(TaskControlBlockInner {
trap_cx_ppn,
base_size: parent_inner.base_size,
task_cx_ptr: task_cx_ptr as usize,
task_status: TaskStatus::Ready,
memory_set,
parent: Some(Arc::downgrade(self)), //Arc::downgrade()是父进程的弱引用计数
children: Vec::new(),
exit_code: 0,
}),
});
// add child
parent_inner.children.push(task_control_block.clone());
// modify kernel_sp in trap_cx
// **** acquire child PCB lock
let trap_cx = task_control_block.acquire_inner_lock().get_trap_cx();
// **** release child PCB lock
trap_cx.kernel_sp = kernel_stack_top;
// return
task_control_block
// ---- release parent PCB lock
} //进程frok的时候仅仅修改应用地址空间的trapcontext中的内核栈顶的位置,
//然后再内核栈中压入taskcontext使它第一次进入内核后可以跳转到trap_teturn中,可以进入用户态在具体实现 sys_fork 的时候,我们需要特别注意如何体现父子进程的差异:
1// os/src/syscall/process.rs
2
3pub fn sys_fork() -> isize {
4 let current_task = current_task().unwrap();
5 let new_task = current_task.fork();
6 let new_pid = new_task.pid.0;
7 // modify trap context of new_task, because it returns immediately after switching
8 let trap_cx = new_task.acquire_inner_lock().get_trap_cx();
9 // we do not have to move to next instruction since we have done it before
10 // for child process, fork returns 0
11 trap_cx.x[10] = 0;
12 // add new task to scheduler
13 add_task(new_task);
14 new_pid as isize
15}
在调用 syscall 进行系统调用分发并具体调用 sys_fork 之前,我们已经将当前进程 Trap 上下文中的 sepc 向后移动了 4 字节使得它回到用户态之后会从 ecall 的下一条指令开始执行。之后当我们复制地址空间的时候,子进程地址空间 Trap 上下文的 sepc 也是移动之后的值,我们无需再进行修改。
父子进程回到用户态的瞬间都处于刚刚从一次系统调用返回的状态,但二者的返回值不同。第 8~11 行我们将子进程的 Trap 上下文用来存放系统调用返回值的 a0 寄存器修改为 0 ,而父进程系统调用的返回值会在 trap_handler 中 syscall 返回之后再设置为 sys_fork 的返回值,这里我们返回子进程的 PID 。这就做到了父进程 fork 的返回值为子进程的 PID ,而子进程的返回值则为 0 。通过返回值是否为 0 可以区分父子进程。
另外,不要忘记在第 13 行,我们将生成的子进程通过 add_task 加入到任务管理器中。
exec 系统调用使得一个进程能够加载一个新的 ELF 可执行文件替换原有的应用地址空间并开始执行。我们先从进程控制块的层面进行修改:
pub fn exec(&self, elf_data: &[u8]) {
// memory_set with elf program headers/trampoline/trap context/user stack
let (memory_set, user_sp, entry_point) = MemorySet::from_elf(elf_data); //在这里又创建了应用的地址空间
let trap_cx_ppn = memory_set
.translate(VirtAddr::from(TRAP_CONTEXT).into())
.unwrap()
.ppn();
// **** hold current PCB lock
let mut inner = self.acquire_inner_lock();
// substitute memory_set
inner.memory_set = memory_set;
// update trap_cx ppn
inner.trap_cx_ppn = trap_cx_ppn;
// initialize trap_cx
let trap_cx = inner.get_trap_cx();
*trap_cx = TrapContext::app_init_context(
entry_point,
user_sp,
KERNEL_SPACE.lock().token(),
self.kernel_stack.get_top(),
trap_handler as usize,
);
// **** release current PCB lock
}它在解析传入的 ELF 格式数据之后只做了两件事情:
- 首先是从 ELF 生成一个全新的地址空间并直接替换进来(第 15 行),这将导致原有的地址空间生命周期结束,里面包含的全部物理页帧都会被回收;
- 然后是修改新的地址空间中的 Trap 上下文,将解析得到的应用入口点、用户栈位置以及一些内核的信息进行初始化,这样才能正常实现 Trap 机制。
这里无需对任务上下文进行处理,因为这个进程本身已经在执行了,而只有被暂停的应用才需要在内核栈上保留一个任务上下文。
总感觉exec和fork创建了应用空间,而fork出来的会copy父进程的,exec会重新创建,感觉在这里会浪费内存,感觉这可能更加的灵活,但如果在大量应用fork的时候就不太好,听说有一种新的实现-----spawn后续可以学习一手
借助它 sys_exec 就很容易实现了:
pub fn translated_str(token: usize, ptr: *const u8) -> String {
let page_table = PageTable::from_token(token); //地址空间的变换
let mut string = String::new();
let mut va = ptr as usize;
loop {
let ch: u8 = *(page_table.translate_va(VirtAddr::from(va)).unwrap().get_mut());
if ch == 0 {
break;
} else {
string.push(ch as char);
va += 1;
}
}//一个字节一个字节的取
string
}
pub fn sys_exec(path: *const u8) -> isize {
let token = current_user_token(); //拿到当前地址空间的token
let path = translated_str(token, path);
if let Some(data) = get_app_data_by_name(path.as_str()) {
let task = current_task().unwrap();
task.exec(data); //构建PATH的TCB , 实际上替换地址空间
0 //成功就返回0
} else {
-1 //没有找到的话就不做任何事情并返回 -1,在shell程序-user_shell中我们也正是通过这个返回值来判断要执行的应用是否存在
}
}应用在 sys_exec 系统调用中传递给内核的只有一个要执行的应用名字符串在当前应用地址空间中的起始地址,如果想在内核中具体获得字符串的话就需要手动查页表。第 3 行的 translated_str 便可以从内核地址空间之外的某个地址空间中拿到一个字符串,其原理就是逐字节查页表直到发现一个 \0 为止。
回到 sys_exec 的实现,它调用 translated_str 找到要执行的应用名并试图在应用加载器提供的 get_app_data_by_name 接口中找到对应的 ELF 数据。如果找到的话就调用 TaskControlBlock::exec 替换掉地址空间并返回 0。这个返回值其实并没有意义,因为我们在替换地址空间的时候本来就对 Trap 上下文重新进行了初始化。如果没有找到的话就不做任何事情并返回 -1,在shell程序-user_shell中我们也正是通过这个返回值来判断要执行的应用是否存在。
原来在 trap_handler 中我们是这样处理系统调用的:
// os/src/trap/mod.rs
#[no_mangle]
pub fn trap_handler() -> ! {
set_kernel_trap_entry();
let cx = current_trap_cx();
let scause = scause::read();
let stval = stval::read();
match scause.cause() {
Trap::Exception(Exception::UserEnvCall) => {
cx.sepc += 4;
cx.x[10] = syscall(cx.x[17], [cx.x[10], cx.x[11], cx.x[12]]) as usize;
}
...
}
trap_return();
}这里的 cx 是当前应用的 Trap 上下文的可变引用,我们需要通过查页表找到它具体被放在哪个物理页帧上,并构造相同的虚拟地址来在内核中访问它。对于系统调用 sys_exec 来说,一旦调用它之后,我们会发现 trap_handler 原来上下文中的 cx 失效了——因为它是用来访问之前地址空间中 Trap 上下文被保存在的那个物理页帧的,而现在它已经被回收掉了。因此,为了能够处理类似的这种情况,我们在 syscall 分发函数返回之后需要重新获取 cx ,目前的实现如下:
// os/src/trap/mod.rs
#[no_mangle]
pub fn trap_handler() -> ! {
set_kernel_trap_entry();
let scause = scause::read();
let stval = stval::read();
match scause.cause() {
Trap::Exception(Exception::UserEnvCall) => {
// jump to next instruction anyway
let mut cx = current_trap_cx();
cx.sepc += 4;
// get system call return value
let result = syscall(cx.x[17], [cx.x[10], cx.x[11], cx.x[12]]);
// cx is changed during sys_exec, so we have to call it again
cx = current_trap_cx();
cx.x[10] = result as usize;
}
...
}
trap_return();
}为了实现shell程序-user_shell的输入机制,我们需要实现 sys_read 系统调用使得应用能够取得用户的键盘输入。
// os/src/syscall/fs.rs
use crate::sbi::console_getchar;
const FD_STDIN: usize = 0;
pub fn sys_read(fd: usize, buf: *const u8, len: usize) -> isize {
match fd {
FD_STDIN => {
assert_eq!(len, 1, "Only support len = 1 in sys_read!");
let mut c: usize;
loop {
c = console_getchar();
if c == 0 {
suspend_current_and_run_next();
continue;
} else {
break;
}
}
let ch = c as u8;
let mut buffers = translated_byte_buffer(current_user_token(), buf, len); //这里功能只写入一个字符却翻译了len长度,可能会影响性能
unsafe { buffers[0].as_mut_ptr().write_volatile(ch); }
1
}
_ => {
panic!("Unsupported fd in sys_read!");
}
}
}目前我们仅支持从标准输入 FD_STDIN 即文件描述符 0 读入,且单次读入的长度限制为 1,即每次只能读入一个字符。我们调用 sbi 子模块提供的从键盘获取输入的接口 console_getchar ,如果返回 0 的话说明还没有输入,我们调用 suspend_current_and_run_next 暂时切换到其他进程,等下次切换回来的时候再看看是否有输入了。获取到输入之后,我们退出循环并手动查页表将输入的字符正确的写入到应用地址空间。
当应用调用 sys_exit 系统调用主动退出或者出错由内核终止之后,会在内核中调用 exit_current_and_run_next 函数退出当前任务并切换到下一个。使用方法如下:
1// os/src/syscall/process.rs
2
3pub fn sys_exit(exit_code: i32) -> ! {
4 exit_current_and_run_next(exit_code);
5 panic!("Unreachable in sys_exit!");
6}
7
8// os/src/trap/mod.rs
9
10#[no_mangle]
11pub fn trap_handler() -> ! {
12 set_kernel_trap_entry();
13 let scause = scause::read();
14 let stval = stval::read();
15 match scause.cause() {
16 Trap::Exception(Exception::StoreFault) |
17 Trap::Exception(Exception::StorePageFault) |
18 Trap::Exception(Exception::InstructionFault) |
19 Trap::Exception(Exception::InstructionPageFault) |
20 Trap::Exception(Exception::LoadFault) |
21 Trap::Exception(Exception::LoadPageFault) => {
22 println!(
23 "[kernel] {:?} in application, bad addr = {:#x}, bad instruction = {:#x}, core dumped.",
24 scause.cause(),
25 stval,
26 current_trap_cx().sepc,
27 );
28 // page fault exit code
29 exit_current_and_run_next(-2);
30 }
31 Trap::Exception(Exception::IllegalInstruction) => {
32 println!("[kernel] IllegalInstruction in application, core dumped.");
33 // illegal instruction exit code
34 exit_current_and_run_next(-3);
35 }
36 ...
37 }
38 trap_return();
39}
相比前面的章节, exit_current_and_run_next 带有一个退出码作为参数。当在 sys_exit 正常退出的时候,退出码由应用传到内核中;而出错退出的情况(如第 29 行的访存错误或第 34 行的非法指令异常)则是由内核指定一个特定的退出码。这个退出码会在 exit_current_and_run_next 写入当前进程的进程控制块中:
// os/src/mm/memory_set.rs
pub fn recycle_data_pages(&mut self) {
//*self = Self::new_bare();
self.areas.clear();
}
pub struct MapArea {
vpn_range: VPNRange,
data_frames: BTreeMap<VirtPageNum, FrameTracker>, //当清空地址空间中的逻辑段集合的时候,这里的FrameTracker也会被回收
map_type: MapType,
map_perm: MapPermission,
}
pub fn exit_current_and_run_next(exit_code: i32) {
// take from Processor
let task = take_current_task().unwrap(); //为了正确维护进程控制块的引用计数
// **** hold current PCB lock
let mut inner = task.acquire_inner_lock();
// Change status to Zombie
inner.task_status = TaskStatus::Zombie; //修改当前进程为僵尸进程,这样它后续才能被父进程在 waitpid 系统调用的时候回收
// Record exit code
inner.exit_code = exit_code;
// do not move to its parent but under initproc
// ++++++ hold initproc PCB lock here
{
let mut initproc_inner = INITPROC.acquire_inner_lock();
for child in inner.children.iter() {
child.acquire_inner_lock().parent = Some(Arc::downgrade(&INITPROC));
initproc_inner.children.push(child.clone());
} //把该进程下的子进程全部都挂在到inintproc下面去
}
// ++++++ release parent PCB lock here
inner.children.clear();
// deallocate user space
inner.memory_set.recycle_data_pages(); //self.areas.clear();这里直接是把地址空间中的Vec!清空
//这将导致应用地址空间的所有数据被存放在的物理页帧被回收,而用来存放页表的那些物理页帧此时则不会被回收,这是rell思想
drop(inner);
// **** release current PCB lock
// drop task manually to maintain rc correctly
drop(task);
// we do not have to save task context
let _unused: usize = 0;
schedule(&_unused as *const _);
}- 第 13 行我们调用
take_current_task来将当前进程控制块从处理器监控PROCESSOR中取出而不是得到一份拷贝,这是为了正确维护进程控制块的引用计数; - 第 17 行我们将进程控制块中的状态修改为
TaskStatus::Zombie即僵尸进程,这样它后续才能被父进程在waitpid系统调用的时候回收; - 第 19 行我们将传入的退出码
exit_code写入进程控制块中,后续父进程在waitpid的时候可以收集; - 第 24~26 行所做的事情是将当前进程的所有子进程挂在初始进程
initproc下面,其做法是遍历每个子进程,修改其父进程为初始进程,并加入初始进程的孩子向量中。第 32 行将当前进程的孩子向量清空。 - 第 34 行对于当前进程占用的资源进行早期回收。在第 4 行可以看出,
MemorySet::recycle_data_pages只是将地址空间中的逻辑段列表areas清空,这将导致应用地址空间的所有数据被存放在的物理页帧被回收,而用来存放页表的那些物理页帧此时则不会被回收。 - 最后在第 41 行我们调用
schedule触发调度及任务切换,由于我们再也不会回到该进程的执行过程中,因此无需关心任务上下文的保存。
父进程通过 sys_waitpid 系统调用来回收子进程的资源并收集它的一些信息:
pub fn sys_waitpid(pid: isize, exit_code_ptr: *mut i32) -> isize {
let task = current_task().unwrap();
// find a child process
// ---- hold current PCB lock
let mut inner = task.acquire_inner_lock();
if inner.children
.iter()
.find(|p| {pid == -1 || pid as usize == p.getpid()})
.is_none() {
return -1;
// ---- release current PCB lock
}
let pair = inner.children
.iter()
.enumerate()
.find(|(_, p)| {
// ++++ temporarily hold child PCB lock
p.acquire_inner_lock().is_zombie() && (pid == -1 || pid as usize == p.getpid())
// ++++ release child PCB lock
});
//找到一个pid相同的子进程,并且是僵尸进程 ,这一段和上一段可以使用编程技巧写的更好一些
if let Some((idx, _)) = pair {
let child = inner.children.remove(idx);
// confirm that child will be deallocated after removing from children list
assert_eq!(Arc::strong_count(&child), 1);//确认这是对于该子进程控制块的唯一一次强引用
let found_pid = child.getpid();
// ++++ temporarily hold child lock
let exit_code = child.acquire_inner_lock().exit_code; //取出孩子进程的退出码
// ++++ release child PCB lock
*translated_refmut(inner.memory_set.token(), exit_code_ptr) = exit_code; //通过传进来的地址,进行exit_code的写入
found_pid as isize //返回退出自进程的Pid
} else {
-2 //如果找到该进程,但该进程却没有僵尸子进程 则yield()过一会再看
}
// ---- release current PCB lock automatically
} 1// os/src/syscall/process.rs
2
3/// If there is not a child process whose pid is same as given, return -1.
4/// Else if there is a child process but it is still running, return -2.
5pub fn sys_waitpid(pid: isize, exit_code_ptr: *mut i32) -> isize {
6 let task = current_task().unwrap();
7 // find a child process
8
9 // ---- hold current PCB lock
10 let mut inner = task.acquire_inner_lock();
11 if inner.children
12 .iter()
13 .find(|p| {pid == -1 || pid as usize == p.getpid()})
14 .is_none() {
15 return -1;
16 // ---- release current PCB lock
17 }
18 let pair = inner.children
19 .iter()
20 .enumerate()
21 .find(|(_, p)| {
22 // ++++ temporarily hold child PCB lock
23 p.acquire_inner_lock().is_zombie() &&
24 (pid == -1 || pid as usize == p.getpid())
25 // ++++ release child PCB lock
26 });
27 if let Some((idx, _)) = pair {
28 let child = inner.children.remove(idx);
29 // confirm that child will be deallocated after removing from children list
30 assert_eq!(Arc::strong_count(&child), 1);
31 let found_pid = child.getpid();
32 // ++++ temporarily hold child lock
33 let exit_code = child.acquire_inner_lock().exit_code;
34 // ++++ release child PCB lock
35 *translated_refmut(inner.memory_set.token(), exit_code_ptr) = exit_code;
36 found_pid as isize
37 } else {
38 -2
39 }
40 // ---- release current PCB lock automatically
41}sys_waitpid 是一个立即返回的系统调用,它的返回值语义是:如果当前的进程不存在一个符合要求的子进程,则返回 -1;如果至少存在一个,但是其中没有僵尸进程(也即仍未退出)则返回 -2;如果都不是的话则可以正常回收并返回回收子进程的 pid 。但在编写应用的开发者看来, wait/waitpid 两个辅助函数都必定能够返回一个有意义的结果,要么是 -1,要么是一个正数 PID ,是不存在 -2 这种通过等待即可消除的中间结果的。这等待的过程正是在用户库 user_lib 中完成。
第 11~17 行判断 sys_waitpid 是否会返回 -1 ,这取决于当前进程是否有一个符合要求的子进程。当传入的 pid 为 -1 的时候,任何一个子进程都算是符合要求;但 pid 不为 -1 的时候,则只有 PID 恰好与 pid 相同的子进程才算符合条件。我们简单通过迭代器即可完成判断。
第 1826 行判断符合要求的子进程中是否有僵尸进程,如果有的话还需要同时找出它在当前进程控制块子进程向量中的下标。如果找不到的话直接返回 36 行的处理:-2 ,否则进入第 28
- 第 28 行我们将子进程从向量中移除并置于当前上下文中,此时可以确认这是对于该子进程控制块的唯一一次强引用,即它不会出现在某个进程的子进程向量中,更不会出现在处理器监控器或者任务管理器中。当它所在的代码块结束,这次引用变量的生命周期结束,将导致该子进程进程控制块的引用计数变为 0 ,彻底回收掉它占用的所有资源,包括:内核栈和它的 PID 还有它的应用地址空间存放页表的那些物理页帧等等。
- 剩下主要是将收集的子进程信息返回回去。第 31 行得到了子进程的 PID 并会在最终返回;第 33 行得到了子进程的退出码并于第 35 行写入到当前进程的应用地址空间中。由于应用传递给内核的仅仅是一个指向应用地址空间中保存子进程返回值的内存区域的指针,我们还需要在
translated_refmut中手动查页表找到应该写入到物理内存中的哪个位置。其实现可以在os/src/mm/page_table.rs中找到,比较简单,在这里不再赘述。
其实我们在第二章就对应用程序引入了基于 文件 的标准输出接口 sys_write ,在第五章引入了基于 文件 的标准输入接口 sys_read 。虽然之前还没有文件描述符表,我们提前把标准输出设备在文件描述符表中的文件描述符的值规定为 1 ,用 Stdout 表示;把标准输入设备在文件描述符表中的文件描述符的值规定为 0,用 Stdin 表示 。现在,我们可以重构操作系统,为标准输入和标准输出实现 File Trait,使得进程可以按文件接口与I/O外设进行交互:
1// os/src/fs/stdio.rs
2
3pub struct Stdin;
4
5pub struct Stdout;
6
7impl File for Stdin {
8 fn read(&self, mut user_buf: UserBuffer) -> usize {
9 assert_eq!(user_buf.len(), 1);
10 // busy loop
11 let mut c: usize;
12 loop {
13 c = console_getchar();
14 if c == 0 {
15 suspend_current_and_run_next();
16 continue;
17 } else {
18 break;
19 }
20 }
21 let ch = c as u8;
22 unsafe { user_buf.buffers[0].as_mut_ptr().write_volatile(ch); }
23 1
24 }
25 fn write(&self, _user_buf: UserBuffer) -> usize {
26 panic!("Cannot write to stdin!");
27 }
28}
29
30impl File for Stdout {
31 fn read(&self, _user_buf: UserBuffer) -> usize{
32 panic!("Cannot read from stdout!");
33 }
34 fn write(&self, user_buf: UserBuffer) -> usize {
35 for buffer in user_buf.buffers.iter() {
36 print!("{}", core::str::from_utf8(*buffer).unwrap());
37 }
38 user_buf.len()
39 }
40}
可以看到,标准输入文件 Stdin 是只读文件,只允许进程通过 read 从里面读入,目前每次仅支持读入一个字符,其实现与之前的 sys_read 基本相同,只是需要通过 UserBuffer 来获取具体将字节写入的位置。相反,标准输出文件 Stdout 是只写文件,只允许进程通过 write 写入到里面,实现方法是遍历每个切片,将其转化为字符串通过 print! 宏来输出。值得注意的是,如果有多核同时使用 print! 宏,将会导致两个不同的输出交错到一起造成输出混乱,后续我们还会对它做一些改进。
这样,应用程序如果要基于文件进行I/O访问,大致就会涉及如下几个操作:
- 打开(open):应用只有打开文件,操作系统才能返回一个可进行读写的文件描述符给应用,应用才能基于这个值来进行对应文件的读写;
- 关闭(close):应用基于文件描述符关闭文件后,就不能再对文件进行读写操作了,这样可以在一定程度上保证对文件的合法访问;
- 读(read):应用可以基于文件描述符来读文件内容到相应内存中;
- 写(write):应用可以基于文件描述符来把相应内存内容写到文件中;
在本节中,还不会涉及创建文件。当一个进程被创建的时候,内核会默认为其打开三个缺省就存在的文件:
- 文件描述符为 0 的标准输入;
- 文件描述符为 1 的标准输出;
- 文件描述符为 2 的标准错误输出。
在我们的实现中并不区分标准输出和标准错误输出,而是会将文件描述符 1 和 2 均对应到标准输出。实际上,在本章中,标准输出文件就是串口输出,标准输入文件就是串口输入。
这里隐含着有关文件描述符的一条重要的规则:即进程打开一个文件的时候,内核总是会将文件分配到该进程文件描述符表中 最小的 空闲位置。比如,当一个进程被创建以后立即打开一个文件,则内核总是会返回文件描述符 3 。当我们关闭一个打开的文件之后,它对应的文件描述符将会变得空闲并在后面可以被分配出去。
我们需要在进程控制块中加入文件描述符表的相应字段:
1// os/src/task/task.rs
2
3pub struct TaskControlBlockInner {
4 pub trap_cx_ppn: PhysPageNum,
5 pub base_size: usize,
6 pub task_cx_ptr: usize,
7 pub task_status: TaskStatus,
8 pub memory_set: MemorySet,
9 pub parent: Option<Weak<TaskControlBlock>>,
10 pub children: Vec<Arc<TaskControlBlock>>,
11 pub exit_code: i32,
12 pub fd_table: Vec<Option<Arc<dyn File + Send + Sync>>>,
13}
可以看到 fd_table 的类型包含多层嵌套,我们从外到里分别说明:
Vec的动态长度特性使得我们无需设置一个固定的文件描述符数量上限,我们可以更加灵活的使用内存,而不必操心内存管理问题;Option使得我们可以区分一个文件描述符当前是否空闲,当它是None的时候是空闲的,而Some则代表它已被占用;Arc首先提供了共享引用能力。后面我们会提到,可能会有多个进程共享同一个文件对它进行读写。此外被它包裹的内容会被放到内核堆而不是栈上,于是它便不需要在编译期有着确定的大小;dyn关键字表明Arc里面的类型实现了File/Send/Sync三个 Trait ,但是编译期无法知道它具体是哪个类型(可能是任何实现了FileTrait 的类型如Stdin/Stdout,故而它所占的空间大小自然也无法确定),需要等到运行时才能知道它的具体类型,对于一些抽象方法的调用也是在那个时候才能找到该类型实现的版本的地址并跳转过去。
Rust 语法卡片:Rust 中的多态
在编程语言中, 多态 (Polymorphism) 指的是在同一段代码中可以隐含多种不同类型的特征。在 Rust 中主要通过泛型和 Trait 来实现多态。
泛型是一种 编译期多态 (Static Polymorphism),在编译一个泛型函数的时候,编译器会对于所有可能用到的类型进行实例化并对应生成一个版本的汇编代码,在编译期就能知道选取哪个版本并确定函数地址,这可能会导致生成的二进制文件体积较大;而 Trait 对象(也即上面提到的 dyn 语法)是一种 运行时多态 (Dynamic Polymorphism),需要在运行时查一种类似于 C++ 中的 虚表 (Virtual Table) 才能找到实际类型对于抽象接口实现的函数地址并进行调用,这样会带来一定的运行时开销,但是更为灵活。
首先来介绍什么是 管道 (Pipe) 。管道是一种进程间通信机制,由操作系统提供,并可通过直接编程或在shell程序的帮助下轻松地把不同进程(目前是父子进程之间或子子进程之间)的输入和输出对接起来。我们也可以将管道看成一个有一定缓冲区大小的字节队列,它分为读和写两端,需要通过不同的文件描述符来访问。读端只能用来从管道中读取,而写端只能用来将数据写入管道。由于管道是一个队列,读取的时候会从队头读取并弹出,而写入的时候则会写入到队列的队尾。同时,管道的缓冲区大小是有限的,一旦整个缓冲区都被填满就不能再继续写入,需要等到读端读取并从队列中弹出一些字符之后才能继续写入。当缓冲区为空的时候自然也不能继续从里面读取,需要等到写端写入了一些数据之后才能继续读取。
/// 功能:为当前进程打开一个管道。
/// 参数:pipe 表示应用地址空间中的一个长度为 2 的 usize 数组的起始地址,内核需要按顺序将管道读端
/// 和写端的文件描述符写入到数组中。
/// 返回值:如果出现了错误则返回 -1,否则返回 0 。可能的错误原因是:传入的地址不合法。
/// syscall ID:59
pub fn sys_pipe(pipe: *mut usize) -> isize;在用户库中会将其包装为 pipe 函数:
// user/src/syscall.rs
const SYSCALL_PIPE: usize = 59;
pub fn sys_pipe(pipe: &mut [usize]) -> isize {
syscall(SYSCALL_PIPE, [pipe.as_mut_ptr() as usize, 0, 0])
}
// user/src/lib.rs
pub fn pipe(pipe_fd: &mut [usize]) -> isize {
sys_pipe(pipe_fd)
}关闭文件的系统调用 sys_close 实现非常简单,我们只需将进程控制块中的文件描述符表对应的一项改为 None 代表它已经空闲即可,同时这也会导致内层的引用计数类型 Arc 被销毁,会减少一个文件的引用计数,当引用计数减少到 0 之后文件所占用的资源就会被自动回收。
// os/src/syscall/fs.rs
pub fn sys_close(fd: usize) -> isize {
let task = current_task().unwrap();
let mut inner = task.acquire_inner_lock();
if fd >= inner.fd_table.len() {
return -1;
}
if inner.fd_table[fd].is_none() {
return -1;
}
inner.fd_table[fd].take();
0
}
我们将管道的一端(读端或写端)抽象为 Pipe 类型:
// os/src/fs/pipe.rs
pub struct Pipe {
readable: bool,
writable: bool,
buffer: Arc<Mutex<PipeRingBuffer>>,
}
readable 和 writable 分别指出该管道端可否支持读取/写入,通过 buffer 字段还可以找到该管道端所在的管道自身。后续我们将为它实现 File Trait ,之后它便可以通过文件描述符来访问。
而管道自身,也就是那个带有一定大小缓冲区的字节队列,我们抽象为 PipeRingBuffer 类型:
// os/src/fs/pipe.rs
const RING_BUFFER_SIZE: usize = 32;
#[derive(Copy, Clone, PartialEq)]
enum RingBufferStatus {
FULL,
EMPTY,
NORMAL,
}
pub struct PipeRingBuffer {
arr: [u8; RING_BUFFER_SIZE],
head: usize,
tail: usize,
status: RingBufferStatus,
write_end: Option<Weak<Pipe>>,
}
RingBufferStatus记录了缓冲区目前的状态:FULL表示缓冲区已满不能再继续写入;EMPTY表示缓冲区为空无法从里面读取;而NORMAL则表示除了FULL和EMPTY之外的其他状态。PipeRingBuffer的arr/head/tail三个字段用来维护一个循环队列,其中arr为存放数据的数组,head为循环队列队头的下标,tail为循环队列队尾的下标。PipeRingBuffer的write_end字段还保存了它的写端的一个弱引用计数,这是由于在某些情况下需要确认该管道所有的写端是否都已经被关闭了,通过这个字段很容易确认这一点。
从内存管理的角度,每个读端或写端中都保存着所属管道自身的强引用计数,且我们确保这些引用计数只会出现在管道端口 Pipe 结构体中。于是,一旦一个管道所有的读端和写端均被关闭,便会导致它们所属管道的引用计数变为 0 ,循环队列缓冲区所占用的资源被自动回收。虽然 PipeRingBuffer 中保存了一个指向写端的引用计数,但是它是一个弱引用,也就不会出现循环引用的情况导致内存泄露。
通过 PipeRingBuffer::new 可以创建一个新的管道:
// os/src/fs/pipe.rs
impl PipeRingBuffer {
pub fn new() -> Self {
Self {
arr: [0; RING_BUFFER_SIZE],
head: 0,
tail: 0,
status: RingBufferStatus::EMPTY,
write_end: None,
}
}
}
Pipe 的 read/write_end_with_buffer 方法可以分别从一个已有的管道创建它的读端和写端:
// os/src/fs/pipe.rs
impl Pipe {
pub fn read_end_with_buffer(buffer: Arc<Mutex<PipeRingBuffer>>) -> Self {
Self {
readable: true,
writable: false,
buffer,
}
}
pub fn write_end_with_buffer(buffer: Arc<Mutex<PipeRingBuffer>>) -> Self {
Self {
readable: false,
writable: true,
buffer,
}
}
}
可以看到,读端和写端的访问权限进行了相应设置:不允许向读端写入,也不允许从写端读取。
通过 make_pipe 方法可以创建一个管道并返回它的读端和写端:
// os/src/fs/pipe.rs
impl PipeRingBuffer {
pub fn set_write_end(&mut self, write_end: &Arc<Pipe>) {
self.write_end = Some(Arc::downgrade(write_end));
}
}
/// Return (read_end, write_end)
pub fn make_pipe() -> (Arc<Pipe>, Arc<Pipe>) {
let buffer = Arc::new(Mutex::new(PipeRingBuffer::new()));
let read_end = Arc::new(
Pipe::read_end_with_buffer(buffer.clone())
);
let write_end = Arc::new(
Pipe::write_end_with_buffer(buffer.clone())
);
buffer.lock().set_write_end(&write_end);
(read_end, write_end)
}
注意,我们调用 PipeRingBuffer::set_write_end 在管道中保留它的写端的弱引用计数。
首先来看如何为 Pipe 实现 File Trait 的 read 方法,即从管道的读端读取数据。在此之前,我们需要对于管道循环队列进行封装来让它更易于使用:
1// os/src/fs/pipe.rs
2
3impl PipeRingBuffer {
4 pub fn read_byte(&mut self) -> u8 {
5 self.status = RingBufferStatus::NORMAL;
6 let c = self.arr[self.head];
7 self.head = (self.head + 1) % RING_BUFFER_SIZE;
8 if self.head == self.tail {
9 self.status = RingBufferStatus::EMPTY;
10 }
11 c
12 }
13 pub fn available_read(&self) -> usize {
14 if self.status == RingBufferStatus::EMPTY {
15 0
16 } else {
17 if self.tail > self.head {
18 self.tail - self.head
19 } else {
20 self.tail + RING_BUFFER_SIZE - self.head
21 }
22 }
23 }
24 pub fn all_write_ends_closed(&self) -> bool {
25 self.write_end.as_ref().unwrap().upgrade().is_none()
26 }
27}
PipeRingBuffer::read_byte 方法可以从管道中读取一个字节,注意在调用它之前需要确保管道缓冲区中不是空的。它会更新循环队列队头的位置,并比较队头和队尾是否相同,如果相同的话则说明管道的状态变为空 EMPTY 。仅仅通过比较队头和队尾是否相同不能确定循环队列是否为空,因为它既有可能表示队列为空,也有可能表示队列已满。因此我们需要在 read_byte 的同时进行状态更新。
PipeRingBuffer::available_read 可以计算管道中还有多少个字符可以读取。我们首先需要需要判断队列是否为空,因为队头和队尾相等可能表示队列为空或队列已满,两种情况 available_read 的返回值截然不同。如果队列为空的话直接返回 0,否则根据队头和队尾的相对位置进行计算。
PipeRingBuffer::all_write_ends_closed 可以判断管道的所有写端是否都被关闭了,这是通过尝试将管道中保存的写端的弱引用计数升级为强引用计数来实现的。如果升级失败的话,说明管道写端的强引用计数为 0 ,也就意味着管道所有写端都被关闭了,从而管道中的数据不会再得到补充,待管道中仅剩的数据被读取完毕之后,管道就可以被销毁了。
下面是 Pipe 的 read 方法的实现:
1// os/src/fs/pipe.rs
2
3impl File for Pipe {
4 fn read(&self, buf: UserBuffer) -> usize {
5 assert_eq!(self.readable, true);
6 let mut buf_iter = buf.into_iter();
7 let mut read_size = 0usize;
8 loop {
9 let mut ring_buffer = self.buffer.lock();
10 let loop_read = ring_buffer.available_read();
11 if loop_read == 0 {
12 if ring_buffer.all_write_ends_closed() {
13 return read_size;
14 }
15 drop(ring_buffer);
16 suspend_current_and_run_next();
17 continue;
18 }
19 // read at most loop_read bytes
20 for _ in 0..loop_read {
21 if let Some(byte_ref) = buf_iter.next() {
22 unsafe { *byte_ref = ring_buffer.read_byte(); }
23 read_size += 1;
24 } else {
25 return read_size;
26 }
27 }
28 }
29 }
30}
-
第 6 行的
buf_iter将传入的应用缓冲区buf转化为一个能够逐字节对于缓冲区进行访问的迭代器,每次调用buf_iter.next()即可按顺序取出用于访问缓冲区中一个字节的裸指针。 -
第 7 行的
read_size用来维护实际有多少字节从管道读入应用的缓冲区。 -
File::read的语义是要从文件中最多读取应用缓冲区大小那么多字符。这可能超出了循环队列的大小,或者由于尚未有进程从管道的写端写入足够的字符,因此我们需要将整个读取的过程放在一个循环中,当循环队列中不存在足够字符的时候暂时进行任务切换,等待循环队列中的字符得到补充之后再继续读取。这个循环从第 8 行开始,第 10 行我们用
loop_read来保存循环这一轮次中可以从管道循环队列中读取多少字符。如果管道为空则会检查管道的所有写端是否都已经被关闭,如果是的话,说明我们已经没有任何字符可以读取了,这时可以直接返回;否则我们需要等管道的字符得到填充之后再继续读取,因此我们调用suspend_current_and_run_next切换到其他任务,等到切换回来之后回到循环开头再看一下管道中是否有字符了。在调用之前我们需要手动释放管道自身的锁,因为切换任务时候的__switch并不是一个正常的函数调用。如果
loop_read不为 0 ,在这一轮次中管道中就有loop_read个字节可以读取。我们可以迭代应用缓冲区中的每个字节指针并调用PipeRingBuffer::read_byte方法来从管道中进行读取。如果这loop_read个字节均被读取之后还没有填满应用缓冲区就需要进入循环的下一个轮次,否则就可以直接返回了。
简要介绍一下在内核中添加文件系统的大致开发过程
-
第一步是能够写出与文件访问相关的应用:在用户态我们只需要遵从相关系统调用的接口约定,在用户库里完成对应的封装即可
-
第二步就是要实现 easyfs 文件系统了:我们可以在用户态实现 easyfs 文件系统,并在用户态完成文件系统功能的基本测试并基本验证其实现正确性之后,就可以放心的将该模块嵌入到操作系统内核中。当然,有了文件系统的具体实现,还需要对上一章的操作系统内核进行扩展,实现与 easyfs 文件系统对接的接口,这样才可以让操作系统拥有一个简单可用的文件系统。从而,内核可以支持允许文件读写功能的更复杂的应用,在命令行参数机制的加持下,可以进一步提升整个系统的灵活性,让应用的开发和调试变得更为轻松。
-
第三步,我们需要把easyfs文件系统加入到我们的操作系统内核中。这还需要做两件事情,第一件是在Qemu模拟的
virtio块设备上实现块设备驱动程序os/src/drivers/block/virtio_blk.rs。由于我们可以直接使用virtio-driverscrate中的块设备驱动,所以只要提供这个块设备驱动所需要的内存申请与释放以及虚实地址转换的4个函数就可以了。而我们之前操作系统中的虚存管理实现中,以及有这些函数,导致块设备驱动程序很简单,具体实现细节都被virtio-driverscrate封装好了。- 第二件事情是把文件访问相关的系统调用与easyfs文件系统连接起来。在easfs文件系统中是没有进程的概念的。而进程是程序运行过程中访问资源的管理实体,这就要对
easy-fscrate 提供的Inode结构进一步封装,形成OSInode结构,以表示进程中一个打开的常规文件,对于应用程序而言,它理解的磁盘数据是常规的文件和目录,不是OSInode这样相对复杂的结构。其实常规文件对应的 OSInode 是文件在操作系统内核中的内部表示,因此需要为它实现 File Trait 从而能够可以将它放入到进程文件描述符表中,并通过 sys_read/write 系统调用进行读写。这样就建立了文件与OSInode的对应关系,并通过上面描述的三个步骤完成了包含文件系统的操作系统内核,并能给应用提供基于文件的系统调用服务
- 第二件事情是把文件访问相关的系统调用与easyfs文件系统连接起来。在easfs文件系统中是没有进程的概念的。而进程是程序运行过程中访问资源的管理实体,这就要对
我们提到了把标准输出设备在文件描述符表中的文件描述符的值规定为 1 ,用 Stdin 表示;把标准输入设备在文件描述符表中的文件描述符的值规定为 0,用 stdout 表示 。另外,还有一条文件描述符相关的重要规则:即进程打开一个文件的时候,内核总是会将文件分配到该进程文件描述符表中编号 最小的 空闲位置。利用这些约定,只实现新的系统调用 sys_dup 完成对文件描述符的复制,就可以巧妙地实现标准 I/O 重定向功能了。
具体思路是,在某应用进程执行之前,父进程(比如 user_shell进程)要对子应用进程的文件描述符表进行某种替换。以输出为例,父进程在创建子进程前,提前打开一个常规文件 A,然后 fork 子进程,在子进程的最初执行中,通过 sys_close 关闭 Stdout 文件描述符,用 sys_dup 复制常规文件 A 的文件描述符,这样 Stdout 文件描述符实际上指向的就是常规文件A了,这时再通过 sys_close 关闭常规文件 A 的文件描述符。至此,常规文件 A 替换掉了应用文件描述符表位置 1 处的标准输出文件,这就完成了所谓的 重定向 ,即完成了执行新应用前的准备工作。
-
第五层:它的最底层就是对块设备的访问操作接口-----在
easy-fs/src/block_dev.rs中,可以看到BlockDevicetrait 代表了一个抽象块设备,该 trait 仅需求两个函数read_block和write_block(为每个看到的块设备实现BlockDevicetrait) 并提供给 easy-fs 库的上层 -
第四层:块缓存层。在
easy-fs/src/block_cache.rs中,BlockCache代表一个被我们管理起来的块的缓冲区,它带有缓冲区本体以及块的编号等信息。当它被创建的时候,将触发一次read_block将数据从块设备读到它的缓冲区中。接下来只要它驻留在内存中,便可保证对于同一个块的所有操作都会直接在它的缓冲区中进行而无需额外的read_block----(块缓存管理器BlockManager在内存中管理有限个BlockCache并实现了类似 FIFO 的缓存替换算法,当一个块缓存被换出的时候视情况可能调用write_block将缓冲区数据写回块设备。总之,块缓存层对上提供get_block_cache接口来屏蔽掉相关细节,从而可以透明的读写一个块) -
第三层:文件系统的磁盘数据结构。包括了管理这个文件系统的 超级块 (Super Block),管理空闲磁盘块的 索引节点位图区 和 数据块位图区 ,以及管理文件的 索引节点区 和 放置文件数据的 数据块区 组成。
-
第二层: 磁盘块管理器 其核心是
EasyFileSystem数据结构及其关键成员函数:- EasyFileSystem.create:创建文件系统
- EasyFileSystem.open:打开文件系统
- EasyFileSystem.alloc_inode:分配inode (dealloc_inode未实现,所以还不能删除文件)
- EasyFileSystem.alloc_data:分配数据块
- EasyFileSystem.dealloc_data:回收数据块
-
第一层:对于单个文件的管理和读写的控制逻辑主要是 索引节点 来完成,其核心是
Inode数据结构及其关键成员函数:- Inode.new:在磁盘上的文件系统中创建一个inode
- Inode.find:根据文件名查找对应的磁盘上的inode
- Inode.create:在根目录下创建一个文件
- Inode.read_at:根据inode找到文件数据所在的磁盘数据块,并读到内存中
- Inode.write_at:根据inode找到文件数据所在的磁盘数据块,把内存中数据写入到磁盘数据块中
每个常规文件都有一个 文件名 (Filename) ,用户需要通过它来区分不同的常规文件。方便起见,在下面的描述中,“文件”有可能指的是常规文件、目录,也可能是之前提到的若干种进程可以读写的 标准输出、标准输入、管道等I/O 资源
在 Linux 系统上, stat 工具可以获取文件的一些信息。下面以我们项目中的一个源代码文件 os/src/main.rs 为例:
$ cd os/src/
$ stat main.rs
File: main.rs
Size: 940 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 4975 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ oslab) Gid: ( 1000/ oslab)
Access: 2021-02-28 23:32:50.289925450 +0800
Modify: 2021-02-28 23:32:50.133927136 +0800
Change: 2021-02-28 23:32:50.133927136 +0800
Birth: -
stat 工具展示了 main.rs 的如下信息:
- File 表明它的文件名为
main.rs。 - Size 表明它的字节大小为 940 字节。
- Blocks 表明它占据 8 个 块 (Block) 来存储。在文件系统中,文件的数据以块为单位进行存储,在 IO Block 可以看出在 Ubuntu 系统中每个块的大小为 4096 字节。
- regular file 表明这个文件是一个常规文件。事实上,其他类型的文件也可以通过文件名来进行访问。
- 当文件是一个特殊文件(如块设备文件或者字符设备文件的时候),Device 将指出该特殊文件的 major/minor ID 。对于一个常规文件,我们无需关心它。
- Inode 表示文件的底层编号。在文件系统的底层实现中,并不是直接通过文件名来索引文件,而是首先需要将文件名转化为文件的底层编号,再根据这个编号去索引文件。然而,用户无需关心这一信息。
- Links 给出文件的硬链接数。同一个文件系统中如果两个文件(目录也是文件)具有相同的inode号码,那么就称它们是“硬链接”关系。这样links的值其实是一个文件的不同文件名的数量。(本章的练习需要你在文件系统中实现硬链接!)
- Uid 给出该文件的所属的用户 ID , Gid 给出该文件所属的用户组 ID 。Access 的其中一种表示是一个长度为 10 的字符串(这里是
-rw-r--r--),其中第 1 位给出该文件的类型,这个文件是一个常规文件,因此这第 1 位为-。后面的 9 位可以分为三组,分别表示该文件的所有者/在该文件所属的用户组内的其他用户以及剩下的所有用户能够读取/写入/将该文件作为一个可执行文件来执行。 - Access/Modify 分别给出该文件的最近一次访问/最近一次修改时间。
常规文件和目录都是实际保存在持久存储设备中的。持久存储设备仅支持以扇区为单位的随机读写,这和上面介绍的通过路径即可索引到文件并进行读写的用户视角有很大的不同。负责中间转换的便是 文件系统 (File System) 。具体而言,文件系统负责将逻辑上的目录树结构(包括其中每个文件或目录的数据和其他信息)映射到持久存储设备上,决定设备上的每个扇区各应存储哪些内容。反过来,文件系统也可以从持久存储设备还原出逻辑上的目录树结构。
文件系统有很多种不同的实现,每一种都能将同一个逻辑上目录树结构转化为一个不同的持久存储设备上的扇区布局。最著名的文件系统有 Windows 上的 FAT/NTFS 和 Linux 上的 ext3/ext4 等。
在一个计算机系统中,可以同时包含多个持久存储设备,它们上面的数据可能是以不同文件系统格式存储的。为了能够对它们进行统一管理,在内核中有一层 虚拟文件系统 (VFS, Virtual File System) ,它规定了逻辑上目录树结构的通用格式及相关操作的抽象接口,只要不同的底层文件系统均实现虚拟文件系统要求的那些抽象接口,再加上 挂载 (Mount) 等方式,这些持久存储设备上的不同文件系统便可以用一个统一的逻辑目录树结构一并进行管理。
- 扁平化:仅存在根目录
/一个目录,剩下所有的文件都放在根目录内。在索引一个文件的时候,我们直接使用文件的文件名而不是它含有/的绝对路径。 - 权限控制:我们不设置用户和用户组概念,全程只有单用户。同时根目录和其他文件也都没有权限控制位,即完全不限制文件的访问方式,不会区分文件是否可执行。
- 不记录文件访问/修改的任何时间戳。
- 不支持软硬链接。
- 除了下面即将介绍的系统调用之外,其他的很多文件系统相关系统调用均未实现。
在读写一个常规文件之前,应用首先需要通过内核提供的 sys_open 系统调用让该文件在进程的文件描述符表中占一项,并得到操作系统的返回值–文件描述符,即文件关联的表项在文件描述表中的索引值:
/// 功能:打开一个常规文件,并返回可以访问它的文件描述符。
/// 参数:path 描述要打开的文件的文件名(简单起见,文件系统不需要支持目录,所有的文件都放在根目录 / 下),
/// flags 描述打开文件的标志,具体含义下面给出。
/// 返回值:如果出现了错误则返回 -1,否则返回打开常规文件的文件描述符。可能的错误原因是:文件不存在。
/// syscall ID:56
pub fn sys_open(path: *const u8, flags: u32) -> isize;
目前我们的内核支持以下几种标志(多种不同标志可能共存):
- 如果
flags为 0,则表示以只读模式 RDONLY 打开; - 如果
flags第 0 位被设置(0x001),表示以只写模式 WRONLY 打开; - 如果
flags第 1 位被设置(0x002),表示既可读又可写 RDWR ; - 如果
flags第 9 位被设置(0x200),表示允许创建文件 CREATE ,在找不到该文件的时候应创建文件;如果该文件已经存在则应该将该文件的大小归零; - 如果
flags第 10 位被设置(0x400),则在打开文件的时候应该清空文件的内容并将该文件的大小归零,也即 TRUNC 。
注意 flags 里面的权限设置只能控制进程对本次打开的文件的访问。一般情况下,在打开文件的时候首先需要经过文件系统的权限检查,比如一个文件自身不允许写入,那么进程自然也就不能以 WRONLY 或 RDWR 标志打开文件。但在我们简化版的文件系统中文件不进行权限设置,这一步就可以绕过。
在用户库 user_lib 中,我们将该系统调用封装为 open 接口:
// user/src/lib.rs
bitflags! {
pub struct OpenFlags: u32 {
const RDONLY = 0;
const WRONLY = 1 << 0;
const RDWR = 1 << 1;
const CREATE = 1 << 9;
const TRUNC = 1 << 10;
}
}
pub fn open(path: &str, flags: OpenFlags) -> isize {
sys_open(path, flags.bits)
}
借助 bitflags! 宏我们将一个 u32 的 flags 包装为一个 OpenFlags 结构体更易使用,它的 bits 字段可以将自身转回 u32 ,它也会被传给 sys_open :
// user/src/syscall.rs
const SYSCALL_OPEN: usize = 56;
pub fn sys_open(path: &str, flags: u32) -> isize {
syscall(SYSCALL_OPEN, [path.as_ptr() as usize, flags as usize, 0])
}
我们在 sys_open 传给内核的两个参数只有待打开文件的文件名字符串的起始地址(和之前一样,我们需要保证该字符串以 \0 结尾)还有标志位。由于每个通用寄存器为 64 位,我们需要先将 u32 的 flags 转换为 usize 。
在打开一个文件之后,我们就可以用之前的 sys_read/sys_write 两个系统调用来对它进行读写了。需要注意的是,常规文件的读写模式和之前介绍过的几种文件有所不同。标准输入输出和匿名管道都属于一种流式读写,而常规文件则是顺序读写和随机读写的结合。由于常规文件可以看成一段字节序列,我们应该能够随意读写它的任一段区间的数据,即随机读写。然而用户仅仅通过 sys_read/sys_write 两个系统调用不能做到这一点。
事实上,进程为每个它打开的常规文件维护了一个偏移量,在刚打开时初始值一般为 0 字节。当 sys_read/sys_write 的时候,将会从文件字节序列偏移量的位置开始 顺序 把数据读到应用缓冲区/从应用缓冲区写入数据。操作完成之后,偏移量向后移动读取/写入的实际字节数。这意味着,下次 sys_read/sys_write 将会从刚刚读取/写入之后的位置继续。如果仅使用 sys_read/sys_write 的话,则只能从头到尾顺序对文件进行读写。当我们需要从头开始重新写入或读取的话,只能通过 sys_close 关闭并重新打开文件来将偏移量重置为 0。为了解决这种问题,有另一个系统调用 sys_lseek 可以调整进程打开的一个常规文件的偏移量,这样便能对文件进行随机读写。在本教程中并未实现这个系统调用,因为顺序文件读写就已经足够了。顺带一提,在文件系统的底层实现中都是对文件进行随机读写的。
下面我们从本章的测试用例 filetest_simple 来介绍文件系统接口的使用方法:
#![no_std]
#![no_main]
#[macro_use]
extern crate user_lib;
use user_lib::{
open,
close,
read,
write,
OpenFlags,
};
#[no_mangle]
pub fn main() -> i32 {
let test_str = "Hello, world!";
let filea = "filea\0";
let fd = open(filea, OpenFlags::CREATE | OpenFlags::WRONLY);
assert!(fd > 0);
let fd = fd as usize;
write(fd, test_str.as_bytes());
close(fd);
let fd = open(filea, OpenFlags::RDONLY);
assert!(fd > 0);
let fd = fd as usize;
let mut buffer = [0u8; 100];
let read_len = read(fd, &mut buffer) as usize;
close(fd);
assert_eq!(
test_str,
core::str::from_utf8(&buffer[..read_len]).unwrap(),
);
println!("file_test passed!");
0
}- 第 20~25 行,我们打开文件
filea,向其中写入字符串Hello, world!而后关闭文件。这里需要注意的是我们需要为字符串字面量手动加上\0作为结尾。在打开文件时 CREATE 标志使得如果filea原本不存在,文件系统会自动创建一个同名文件,如果已经存在的话则会清空它的内容。而 WRONLY 使得此次只能写入该文件而不能读取。 - 第 27~32 行,我们以只读 RDONLY 的方式将文件
filea的内容读取到缓冲区buffer中。注意我们很清楚filea的总大小不超过缓冲区的大小,因此通过单次read即可将filea的内容全部读取出来。而更常见的情况是需要进行多次read直到它的返回值为 0 才能确认文件的内容已被读取完毕了。 - 最后的第 34~38 行我们确认从
filea读取到的内容和之前写入的一致,则测试通过。
本节我们介绍一个简易文件系统实现 easy-fs。作为一个文件系统而言,它的磁盘布局(为了叙述方便,我们用磁盘来指代一系列持久存储设备)体现在磁盘上各扇区的内容上,而它解析磁盘布局得到的逻辑目录树结构则是通过内存上的数据结构来访问的,这意味着它要同时涉及到对磁盘和对内存的访问。它们的访问方式是不同的,对于内存直接通过一条指令即可直接读写内存相应的位置,而磁盘的话需要用软件的方式向磁盘发出请求来间接进行读写。因此,我们也要特别注意哪些数据结构是存储在磁盘上,哪些数据结构是存储在内存中的,这样在实现的时候才不会引起混乱。
大家可以看到,内核的功能越来越多,代码量也越来越大(是Linux的万分之一)。为了减少同学学习内核的分析理解成本,我们需要让内核的各个部分之间尽量松耦合,所以easy-fs 被从内核中分离出来,它的实现分成两个不同的 crate :
easy-fs为简易文件系统的本体,它是一个库形式 crate,实现一种简单的文件系统磁盘布局;easy-fs-fuse是一个能在开发环境(如 Ubuntu)中运行的应用程序,它可以对easy-fs进行测试,或者将为我们内核开发的应用打包为一个 easy-fs 格式的文件系统镜像。
这样,整个easy-fs文件系统的设计开发可以按照应用程序库的开发过程来完成。而且在开发完毕后,可直接放到内核中,形成有文件系统支持的新内核。
能做到这一点,是由于我们在easy-fs设计上,采用了松耦合模块化设计思路。easy-fs与底层设备驱动之间通过抽象接口 BlockDevice 来连接,避免了与设备驱动的绑定。easy-fs通过Rust提供的alloc crate来隔离了操作系统内核的内存管理,避免了直接调用内存管理的内核函数。在底层驱动上,采用的是轮询的方式访问 virtio_blk 虚拟磁盘设备,从而避免了访问外设中断的相关内核函数。easy-fs在设计中避免了直接访问进程相关的数据和函数,从而隔离了操作系统内核的进程管理。
同时,easy-fs本身也划分成不同的层次,形成层次化模块的设计架构。easy-fs crate 自下而上大致可以分成五个不同的层次:
- 磁盘块设备接口层:定义了以块大小为单位对磁盘块设备进行读写的trait接口
- 块缓存层:在内存中缓存磁盘块的数据,避免频繁读写磁盘
- 磁盘数据结构层:磁盘上的超级块、位图、索引节点、数据块、目录项等核心数据结构和相关处理
- 磁盘块管理器层:合并了上述核心数据结构和磁盘布局所形成的磁盘文件系统数据结构,以及创建/打开文件系统的相关处理和磁盘块的分配和回收处理
- 索引节点层:管理索引节点(即文件控制块)数据结构,并实现文件创建/文件打开/文件读写等成员函数来向上支持文件操作相关的系统调用的处理
大家也许觉得有五层架构的文件系统是一个很复杂的软件。其实,相对于面向Qemu模拟器的操作系统内核源码所占的2400行左右代码,它只有900行左右的代码,占总代码量的27%。且由于其代码逻辑其实是一种自上而下的线性思维,属于传统的常规编程。相对于异常/中断/系统调用的特权级切换,进程管理中的进程上下文切换,内存管理中的页表地址映射等非常规编程,其实更容易理解。
定义设备驱动需要实现的块读写trai接口的块设备接口层的代码在 block_dev.rs 中。
在 easy-fs 库的最底层声明了一个块设备的抽象接口 BlockDevice :
// easy-fs/src/block_dev.rs
pub trait BlockDevice : Send + Sync + Any {
fn read_block(&self, block_id: usize, buf: &mut [u8]);
fn write_block(&self, block_id: usize, buf: &[u8]);
}
它需要实现两个抽象方法:
read_block可以将编号为block_id的块从磁盘读入内存中的缓冲区buf;write_block可以内存中的缓冲区buf中的数据写入磁盘编号为block_id的块。
这是因为块设备仅支持以块为单位进行随机读写,由此才有了这两个抽象方法。但这是由具体的块设备驱动要实现的方法,在 easy-fs 中并没有一个实现了 BlockDevice Trait 的具体类型。实际上这是需要由文件系统的使用者(比如操作系统内核或直接测试 easy-fs 文件系统的 easy-fs-fuse 应用程序)提供并接入到 easy-fs 库的。 easy-fs 库的块缓存层会调用这两个方法,进行块缓存的管理。这也体现了 easy-fs 的泛用性:它可以用于管理任何实现了 BlockDevice Trait 的块设备。
注解
块与扇区
实际上,块和扇区是两个不同的概念。 扇区 (Sector) 是块设备随机读写的大小单位,通常每个扇区为 512 字节。而块是文件系统存储文件时的大小单位,每个块的大小等同于一个或多个扇区。之前提到过 Linux 默认文件系统的单个块大小为 4096 字节。在我们的 easy-fs 实现中一个块的大小和扇区相同为 512 字节,因此在后面的讲解中我们不再区分扇区和块的概念。
实现磁盘块缓存功能的块缓存层的代码在 block_cache.rs 中。
由于操作系统频繁读写磁盘块会极大降低系统性能,因此常见的手段是先通过 read_block 将一个块上的数据从磁盘读到内存中的一个缓冲区中,这个缓冲区中的内容是可以直接读写的,那么后续对这个数据块的大部分访问就可以在内存中完成了。如果对于缓冲区中的内容进行了修改,那么后续还需要通过 write_block 将缓冲区中的内容写回到磁盘块中。
事实上,无论站在代码实现鲁棒性还是性能的角度,将这些缓冲区合理的管理起来都是很有必要的。一种完全不进行任何管理的模式可能是:每当要对一个磁盘块进行读写的时候,都通过 read_block 将块数据读取到一个 临时 创建的缓冲区,并在进行一些操作之后(可选地)将缓冲区的内容写回到磁盘块。从性能上考虑,我们需要尽可能降低实际块读写(即 read/write_block )的次数,因为每一次调用它们都会产生大量开销。要做到这一点,关键就在于对于块读写操作进行 合并 。例如,如果一个块已经被读到缓冲区中了,那么我们就没有必要再读一遍,直接用已有的缓冲区就行了;同时,对于同一个块的缓冲区的多次修改没有必要每次都写回磁盘,只需等所有的修改都结束之后统一写回磁盘即可。
但是,当磁盘上的数据结构比较复杂的时候,在编程的时候我们很难手动正确的规划块读取/写入的时机。这不仅可能涉及到复杂的参数传递,稍有不慎还有可能引入同步性问题(目前可以暂时忽略):即对于一个块缓冲区的修改在对于同一个块进行后续操作的时候不可见。它很致命但又难以调试。
因此,我们的做法是将缓冲区统一管理起来。当我们要读写一个块的时候,首先就是去全局管理器中查看这个块是否已被缓存到内存中的缓冲区中。这样,在一段连续时间内对于一个块进行的所有操作均是在同一个固定的缓冲区中进行的,这解决了同步性问题。此外,通过 read/write_block 进行块实际读写的时机完全交给全局管理器处理,我们在编程时无需操心。全局管理器会尽可能将更多的块操作合并起来,并在必要的时机发起真正的块的实际读写。
块缓存 BlockCache 的声明如下:
// easy-fs/src/lib.rs
pub const BLOCK_SZ: usize = 512;
// easy-fs/src/block_cache.rs
pub struct BlockCache {
cache: [u8; BLOCK_SZ],
block_id: usize,
block_device: Arc<dyn BlockDevice>,
modified: bool,
}
其中:
cache是一个 512 字节的数组,表示位于内存中的缓冲区;block_id记录了这个块缓存来自于磁盘中的块的编号;block_device保留一个底层块设备的引用使得可以和它打交道;modified记录自从这个块缓存从磁盘载入内存之后,它有没有被修改过。
当我们创建一个 BlockCache 的时候,这将触发一次 read_block 将一个块上的数据从磁盘读到缓冲区 cache :
// easy-fs/src/block_cache.rs
impl BlockCache {
/// Load a new BlockCache from disk.
pub fn new(
block_id: usize,
block_device: Arc<dyn BlockDevice>
) -> Self {
let mut cache = [0u8; BLOCK_SZ];
block_device.read_block(block_id, &mut cache);
Self {
cache,
block_id,
block_device,
modified: false,
}
}
}
一旦缓冲区已经存在于内存中,CPU 就可以直接访问存储在它上面的磁盘数据结构:
1// easy-fs/src/block_cache.rs
2
3impl BlockCache {
4 fn addr_of_offset(&self, offset: usize) -> usize {
5 &self.cache[offset] as *const _ as usize
6 }
7
8 pub fn get_ref<T>(&self, offset: usize) -> &T where T: Sized {
9 let type_size = core::mem::size_of::<T>();
10 assert!(offset + type_size <= BLOCK_SZ);
11 let addr = self.addr_of_offset(offset);
12 unsafe { &*(addr as *const T) }
13 }
14
15 pub fn get_mut<T>(&mut self, offset: usize) -> &mut T where T: Sized {
16 let type_size = core::mem::size_of::<T>();
17 assert!(offset + type_size <= BLOCK_SZ);
18 self.modified = true;
19 let addr = self.addr_of_offset(offset);
20 unsafe { &mut *(addr as *mut T) }
21 }
22}
addr_of_offset可以得到一个BlockCache内部的缓冲区中指定偏移量offset的字节地址;get_ref是一个泛型方法,它可以获取缓冲区中的位于偏移量offset的一个类型为T的磁盘上数据结构的不可变引用。该泛型方法的 Trait Bound 限制类型T必须是一个编译时已知大小的类型,我们通过core::mem::size_of::<T>()在编译时获取类型T的大小并确认该数据结构被整个包含在磁盘块及其缓冲区之内。这里编译器会自动进行生命周期标注,约束返回的引用的生命周期不超过BlockCache自身,在使用的时候我们会保证这一点。get_mut与get_ref的不同之处在于它会获取磁盘上数据结构的可变引用,由此可以对数据结构进行修改。由于这些数据结构目前位于内存中的缓冲区中,我们需要将BlockCache的modified标记为 true 表示该缓冲区已经被修改,之后需要将数据写回磁盘块才能真正将修改同步到磁盘。
BlockCache 的设计也体现了 RAII 思想, 它管理着一个缓冲区的生命周期。当 BlockCache 的生命周期结束之后缓冲区也会被从内存中回收,这个时候 modified 标记将会决定数据是否需要写回磁盘:
// easy-fs/src/block_cache.rs
impl BlockCache {
pub fn sync(&mut self) {
if self.modified {
self.modified = false;
self.block_device.write_block(self.block_id, &self.cache);
}
}
}
impl Drop for BlockCache {
fn drop(&mut self) {
self.sync()
}
}
在 BlockCache 被 drop 的时候,它会首先调用 sync 方法,如果自身确实被修改过的话才会将缓冲区的内容写回磁盘。事实上, sync 并不是只有在 drop 的时候才会被调用。在 Linux 中,通常有一个后台进程负责定期将内存中缓冲区的内容写回磁盘。另外有一个 sys_fsync 系统调用可以手动通知内核将一个文件的修改同步回磁盘。由于我们的实现比较简单, sync 仅会在 BlockCache 被 drop 时才会被调用。
我们可以将 get_ref/get_mut 进一步封装为更为易用的形式:
// easy-fs/src/block_cache.rs
impl BlockCache {
pub fn read<T, V>(&self, offset: usize, f: impl FnOnce(&T) -> V) -> V {
f(self.get_ref(offset))
}
pub fn modify<T, V>(&mut self, offset:usize, f: impl FnOnce(&mut T) -> V) -> V {
f(self.get_mut(offset))
}
}
它们的含义是:在 BlockCache 缓冲区偏移量为 offset 的位置获取一个类型为 T 的磁盘上数据结构的不可变/可变引用(分别对应 read/modify ),并让它进行传入的闭包 f 中所定义的操作。注意 read/modify 的返回值是和传入闭包的返回值相同的,因此相当于 read/modify 构成了传入闭包 f 的一层执行环境,让它能够绑定到一个缓冲区上执行。
这里我们传入闭包的类型为 FnOnce ,这是因为闭包里面的变量被捕获的方式涵盖了不可变引用/可变引用/和 move 三种可能性,故而我们需要选取范围最广的 FnOnce 。参数中的 impl 关键字体现了一种类似泛型的静态分发功能。
我们很快将展示 read/modify 接口如何在后续的开发中提供便利。
为了避免在块缓存上浪费过多内存,我们希望内存中同时只能驻留有限个磁盘块的缓冲区:
// easy-fs/src/block_cache.rs
const BLOCK_CACHE_SIZE: usize = 16;
块缓存全局管理器的功能是:当我们要对一个磁盘块进行读写从而需要获取它的缓冲区的时候,首先看它是否已经被载入到内存中了,如果已经被载入的话则直接返回,否则需要读取磁盘块的数据到内存中。此时,如果内存中驻留的磁盘块缓冲区的数量已满,则需要遵循某种缓存替换算法将某个块的缓冲区从内存中移除,再将刚刚请求的块的缓冲区加入到内存中。我们这里使用一种类 FIFO 的简单缓存替换算法,因此在管理器中只需维护一个队列:
// easy-fs/src/block_cache.rs
use alloc::collections::VecDeque;
pub struct BlockCacheManager {
queue: VecDeque<(usize, Arc<Mutex<BlockCache>>)>,
}
impl BlockCacheManager {
pub fn new() -> Self {
Self { queue: VecDeque::new() }
}
}
队列 queue 中管理的是块编号和块缓存的二元组。块编号的类型为 usize ,而块缓存的类型则是一个 Arc<Mutex<BlockCache>> 。这是一个此前频频提及到的 Rust 中的经典组合,它可以同时提供共享引用和互斥访问。这里的共享引用意义在于块缓存既需要在管理器 BlockCacheManager 保留一个引用,还需要以引用的形式返回给块缓存的请求者让它可以对块缓存进行访问。而互斥访问在单核上的意义在于提供内部可变性通过编译,在多核环境下则可以帮助我们避免可能的并发冲突。事实上,一般情况下我们需要在更上层提供保护措施避免两个线程同时对一个块缓存进行读写,因此这里只是比较谨慎的留下一层保险。
警告
Rust Pattern卡片: Arc<Mutex<?>>
先看下Arc和Mutex的正确配合可以达到支持多线程安全读写数据对象。如果需要多线程共享所有权的数据对象,则只用Arc即可。如果需要修改 T 类型中某些成员变量 member ,那直接采用 Arc<Mutex<T>> ,并在修改的时候通过 obj.lock().unwrap().member = xxx 的方式是可行的,但这样的编程模式的同步互斥的粒度太大,可能对互斥性能的影响比较大。为了减少互斥性能开销,其实只需要在 T 类型中的需要被修改的成员变量上加 Mutex<_> 即可。如果成员变量也是一个数据结构,还包含更深层次的成员变量,那应该继续下推到最终需要修改的成员变量上去添加 Mutex 。
get_block_cache 方法尝试从块缓存管理器中获取一个编号为 block_id 的块的块缓存,如果找不到的话会从磁盘读取到内存中,还有可能会发生缓存替换:
1// easy-fs/src/block_cache.rs
2
3impl BlockCacheManager {
4 pub fn get_block_cache(
5 &mut self,
6 block_id: usize,
7 block_device: Arc<dyn BlockDevice>,
8 ) -> Arc<Mutex<BlockCache>> {
9 if let Some(pair) = self.queue
10 .iter()
11 .find(|pair| pair.0 == block_id) {
12 Arc::clone(&pair.1)
13 } else {
14 // substitute
15 if self.queue.len() == BLOCK_CACHE_SIZE {
16 // from front to tail
17 if let Some((idx, _)) = self.queue
18 .iter()
19 .enumerate()
20 .find(|(_, pair)| Arc::strong_count(&pair.1) == 1) {
21 self.queue.drain(idx..=idx);
22 } else {
23 panic!("Run out of BlockCache!");
24 }
25 }
26 // load block into mem and push back
27 let block_cache = Arc::new(Mutex::new(
28 BlockCache::new(block_id, Arc::clone(&block_device))
29 ));
30 self.queue.push_back((block_id, Arc::clone(&block_cache)));
31 block_cache
32 }
33 }
34}
-
第 9 行会遍历整个队列试图找到一个编号相同的块缓存,如果找到了话会将块缓存管理器中保存的块缓存的引用复制一份并返回;
-
第 13 行对应找不到的情况,此时必须将块从磁盘读入内存中的缓冲区。在实际读取之前需要判断管理器保存的块缓存数量是否已经达到了上限。如果达到了上限(第 15 行)才需要执行缓存替换算法丢掉某个块的缓存空出一个空位。这里使用一种类 FIFO 算法,如果是 FIFO 算法的话,每次加入一个缓存的时候需要从队尾加入,需要替换的时候则从队头弹出。但是此时队头对应的块缓存可能仍在使用:判断的标志是其强引用计数 ≥2 ,即除了块缓存管理器保留的一份副本之外,在外面还有若干份副本正在使用。因此,我们的做法是从队头遍历到队尾找到第一个强引用计数恰好为 1 的块缓存并将其替换出去。
那么是否有可能出现队列已满且其中所有的块缓存都正在使用的情形呢?事实上,只要我们的上限
BLOCK_CACHE_SIZE设置的足够大,超过所有线程同时访问的块总数上限,那么这种情况永远不会发生。但是,如果我们的上限设置不足,这里我们就只能 panic 。 -
第 27 行开始我们创建一个新的块缓存(会触发
read_block进行块读取)并加入到队尾,最后返回给请求者。
接下来需要创建 BlockCacheManager 的全局实例:
// easy-fs/src/block_cache.rs
lazy_static! {
pub static ref BLOCK_CACHE_MANAGER: Mutex<BlockCacheManager> = Mutex::new(
BlockCacheManager::new()
);
}
pub fn get_block_cache(
block_id: usize,
block_device: Arc<dyn BlockDevice>
) -> Arc<Mutex<BlockCache>> {
BLOCK_CACHE_MANAGER.lock().get_block_cache(block_id, block_device)
}
之后,对于其他模块而言就可以直接通过 get_block_cache 方法来请求块缓存了。这里需要指出的是,它返回的是一个 Arc<Mutex<BlockCache>> ,调用者需要通过 .lock() 获取里层互斥锁 Mutex 才能对最里面的 BlockCache 进行操作,比如通过 read/modify 访问缓冲区里面的磁盘数据结构。
磁盘数据结构层的代码在 layout.rs 和 bitmap.rs 中。
对于一个文件系统而言,最重要的功能是如何将一个逻辑上的文件目录树结构映射到磁盘上,决定磁盘上的每个块应该存储文件相关的哪些数据。为了更容易进行管理和更新,我们需要将磁盘上的数据组织为若干种不同的磁盘上数据结构,并合理安排它们在磁盘中的位置。
在 easy-fs 磁盘布局中,按照块编号从小到大顺序地分成 5 个不同属性的连续区域:
- 最开始的区域的长度为一个块,其内容是 easy-fs 超级块 (Super Block),超级块内以魔数的形式提供了文件系统合法性检查功能,同时还可以定位其他连续区域的位置。
- 第二个区域是一个索引节点位图,长度为若干个块。它记录了后面的索引节点区域中有哪些索引节点已经被分配出去使用了,而哪些还尚未被分配出去。
- 第三个区域是索引节点区域,长度为若干个块。其中的每个块都存储了若干个索引节点。
- 第四个区域是一个数据块位图,长度为若干个块。它记录了后面的数据块区域中有哪些数据块已经被分配出去使用了,而哪些还尚未被分配出去。
- 最后的区域则是数据块区域,顾名思义,其中的每一个已经分配出去的块保存了文件或目录中的具体数据内容。
索引节点 (Inode, Index Node) 是文件系统中的一种重要数据结构。逻辑目录树结构中的每个文件和目录都对应一个 inode ,我们前面提到的在文件系统实现中文件/目录的底层编号实际上就是指 inode 编号。在 inode 中不仅包含了我们通过 stat 工具能够看到的文件/目录的元数据(大小/访问权限/类型等信息),还包含实际保存对应文件/目录数据的数据块(位于最后的数据块区域中)的索引信息,从而能够找到文件/目录的数据被保存在磁盘的哪些块中。从索引方式上看,同时支持直接索引和间接索引。
每个区域中均存储着不同的磁盘数据结构, easy-fs 文件系统能够对磁盘中的数据进行解释并将其结构化。下面我们分别对它们进行介绍。
超级块 SuperBlock 的内容如下:
// easy-fs/src/layout.rs
#[repr(C)]
pub struct SuperBlock {
magic: u32,
pub total_blocks: u32,
pub inode_bitmap_blocks: u32,
pub inode_area_blocks: u32,
pub data_bitmap_blocks: u32,
pub data_area_blocks: u32,
}
其中, magic 是一个用于文件系统合法性验证的魔数, total_block 给出文件系统的总块数。注意这并不等同于所在磁盘的总块数,因为文件系统很可能并没有占据整个磁盘。后面的四个字段则分别给出 easy-fs 布局中后四个连续区域的长度各为多少个块。
下面是它实现的方法:
// easy-fs/src/layout.rs
impl SuperBlock {
pub fn initialize(
&mut self,
total_blocks: u32,
inode_bitmap_blocks: u32,
inode_area_blocks: u32,
data_bitmap_blocks: u32,
data_area_blocks: u32,
) {
*self = Self {
magic: EFS_MAGIC,
total_blocks,
inode_bitmap_blocks,
inode_area_blocks,
data_bitmap_blocks,
data_area_blocks,
}
}
pub fn is_valid(&self) -> bool {
self.magic == EFS_MAGIC
}
}
initialize可以在创建一个 easy-fs 的时候对超级块进行初始化,注意各个区域的块数是以参数的形式传入进来的,它们的划分是更上层的磁盘块管理器需要完成的工作。is_valid则可以通过魔数判断超级块所在的文件系统是否合法。
SuperBlock 是一个磁盘上数据结构,它就存放在磁盘上编号为 0 的块的开头。
在 easy-fs 布局中存在两类不同的位图,分别对索引节点和数据块进行管理。每个位图都由若干个块组成,每个块大小为 512 bytes,即 4096 bits。每个 bit 都代表一个索引节点/数据块的分配状态, 0 意味着未分配,而 1 则意味着已经分配出去。位图所要做的事情是通过基于 bit 为单位的分配(寻找一个为 0 的bit位并设置为 1)和回收(将bit位清零)来进行索引节点/数据块的分配和回收。
// easy-fs/src/bitmap.rs
pub struct Bitmap {
start_block_id: usize,
blocks: usize,
}
impl Bitmap {
pub fn new(start_block_id: usize, blocks: usize) -> Self {
Self {
start_block_id,
blocks,
}
}
}
位图 Bitmap 中仅保存了它所在区域的起始块编号以及区域的长度为多少个块。通过 new 方法可以新建一个位图。注意 Bitmap 自身是驻留在内存中的,但是它能够表示索引节点/数据块区域中的那些磁盘块的分配情况。磁盘块上位图区域的数据则是要以磁盘数据结构 BitmapBlock 的格式进行操作:
// easy-fs/src/bitmap.rs
type BitmapBlock = [u64; 64];
BitmapBlock 是一个磁盘数据结构,它将位图区域中的一个磁盘块解释为长度为 64 的一个 u64 数组, 每个 u64 打包了一组 64 bits,于是整个数组包含 64×64=4096 bits,且可以以组为单位进行操作。
首先来看 Bitmap 如何分配一个bit:
1// easy-fs/src/bitmap.rs
2
3const BLOCK_BITS: usize = BLOCK_SZ * 8;
4
5impl Bitmap {
6 pub fn alloc(&self, block_device: &Arc<dyn BlockDevice>) -> Option<usize> {
7 for block_id in 0..self.blocks {
8 let pos = get_block_cache(
9 block_id + self.start_block_id as usize,
10 Arc::clone(block_device),
11 )
12 .lock()
13 .modify(0, |bitmap_block: &mut BitmapBlock| {
14 if let Some((bits64_pos, inner_pos)) = bitmap_block
15 .iter()
16 .enumerate()
17 .find(|(_, bits64)| **bits64 != u64::MAX)
18 .map(|(bits64_pos, bits64)| {
19 (bits64_pos, bits64.trailing_ones() as usize)
20 }) {
21 // modify cache
22 bitmap_block[bits64_pos] |= 1u64 << inner_pos;
23 Some(block_id * BLOCK_BITS + bits64_pos * 64 + inner_pos as usize)
24 } else {
25 None
26 }
27 });
28 if pos.is_some() {
29 return pos;
30 }
31 }
32 None
33 }
34}
其主要思路是遍历区域中的每个块,再在每个块中以bit组(每组 64 bits)为单位进行遍历,找到一个尚未被全部分配出去的组,最后在里面分配一个bit。它将会返回分配的bit所在的位置,等同于索引节点/数据块的编号。如果所有bit均已经被分配出去了,则返回 None 。
第 7 行枚举区域中的每个块(编号为 block_id ),在循环内部我们需要读写这个块,在块内尝试找到一个空闲的bit并置 1 。一旦涉及到块的读写,就需要用到块缓存层提供的接口:
-
第 8 行我们调用
get_block_cache获取块缓存,注意我们传入的块编号是区域起始块编号start_block_id加上区域内的块编号block_id得到的块设备上的块编号。 -
第 12 行我们通过
.lock()获取块缓存的互斥锁从而可以对块缓存进行访问。 -
第 13 行我们使用到了
BlockCache::modify接口。它传入的偏移量offset为 0,这是因为整个块上只有一个BitmapBlock,它的大小恰好为 512 字节。因此我们需要从块的开头开始才能访问到完整的BitmapBlock。同时,传给它的闭包需要显式声明参数类型为&mut BitmapBlock,不然的话,BlockCache的泛型方法modify/get_mut无法得知应该用哪个类型来解析块上的数据。在声明之后,编译器才能在这里将两个方法中的泛型T实例化为具体类型BitmapBlock。总结一下,这里
modify的含义就是:从缓冲区偏移量为 0 的位置开始将一段连续的数据(数据的长度随具体类型而定)解析为一个BitmapBlock并要对该数据结构进行修改。在闭包内部,我们可以使用这个BitmapBlock的可变引用bitmap_block对它进行访问。read/get_ref的用法完全相同,后面将不再赘述。 -
闭包的主体位于第 14~26 行。它尝试在
bitmap_block中找到一个空闲的bit并返回其位置,如果不存在的话则返回None。它的思路是,遍历每 64 bits构成的组(一个u64),如果它并没有达到u64::MAX(即 264−1 ),则通过u64::trailing_ones找到最低的一个 0 并置为 1 。如果能够找到的话,bit组的编号将保存在变量bits64_pos中,而分配的bit在组内的位置将保存在变量inner_pos中。在返回分配的bit编号的时候,它的计算方式是block_id*BLOCK_BITS+bits64_pos*64+inner_pos。注意闭包中的block_id并不在闭包的参数列表中,因此它是从外部环境(即自增block_id的循环)中捕获到的。
我们一旦在某个块中找到一个空闲的bit并成功分配,就不再考虑后续的块。第 28 行体现了提前返回的思路。
警告
Rust 语法卡片:闭包
闭包是持有外部环境变量的函数。所谓外部环境, 就是指创建闭包时所在的词法作用域。Rust中定义的闭包,按照对外部环境变量的使用方式(借用、复制、转移所有权),分为三个类型: Fn、FnMut、FnOnce。Fn类型的闭包会在闭包内部以共享借用的方式使用环境变量;FnMut类型的闭包会在闭包内部以独占借用的方式使用环境变量;而FnOnce类型的闭包会在闭包内部以所有者的身份使用环境变量。由此可见,根据闭包内使用环境变量的方式,即可判断创建出来的闭包的类型。
接下来看 Bitmap 如何回收一个bit:
// easy-fs/src/bitmap.rs
/// Return (block_pos, bits64_pos, inner_pos)
fn decomposition(mut bit: usize) -> (usize, usize, usize) {
let block_pos = bit / BLOCK_BITS;
bit = bit % BLOCK_BITS;
(block_pos, bit / 64, bit % 64)
}
impl Bitmap {
pub fn dealloc(&self, block_device: &Arc<dyn BlockDevice>, bit: usize) {
let (block_pos, bits64_pos, inner_pos) = decomposition(bit);
get_block_cache(
block_pos + self.start_block_id,
Arc::clone(block_device)
).lock().modify(0, |bitmap_block: &mut BitmapBlock| {
assert!(bitmap_block[bits64_pos] & (1u64 << inner_pos) > 0);
bitmap_block[bits64_pos] -= 1u64 << inner_pos;
});
}
}
dealloc 方法首先调用 decomposition 函数将bit编号 bit 分解为区域中的块编号 block_pos 、块内的组编号 bits64_pos 以及组内编号 inner_pos 的三元组,这样就能精确定位待回收的bit,随后将其清零即可。
在磁盘上的索引节点区域,每个块上都保存着若干个索引节点 DiskInode :
// easy-fs/src/layout.rs
const INODE_DIRECT_COUNT: usize = 28;
#[repr(C)]
pub struct DiskInode {
pub size: u32,
pub direct: [u32; INODE_DIRECT_COUNT],
pub indirect1: u32,
pub indirect2: u32,
type_: DiskInodeType,
}
#[derive(PartialEq)]
pub enum DiskInodeType {
File,
Directory,
}
每个文件/目录在磁盘上均以一个 DiskInode 的形式存储。其中包含文件/目录的元数据: size 表示文件/目录内容的字节数, type_ 表示索引节点的类型 DiskInodeType ,目前仅支持文件 File 和目录 Directory 两种类型。其余的 direct/indirect1/indirect2 都是存储文件内容/目录内容的数据块的索引,这也是索引节点名字的由来。
为了尽可能节约空间,在进行索引的时候,块的编号用一个 u32 存储。索引方式分成直接索引和间接索引两种:
- 当文件很小的时候,只需用到直接索引,
direct数组中最多可以指向INODE_DIRECT_COUNT个数据块,当取值为 28 的时候,通过直接索引可以找到 14KiB 的内容。 - 当文件比较大的时候,不仅直接索引的
direct数组装满,还需要用到一级间接索引indirect1。它指向一个一级索引块,这个块也位于磁盘布局的数据块区域中。这个一级索引块中的每个u32都用来指向数据块区域中一个保存该文件内容的数据块,因此,最多能够索引 5124=128 个数据块,对应 64KiB 的内容。 - 当文件大小超过直接索引和一级索引支持的容量上限 78KiB 的时候,就需要用到二级间接索引
indirect2。它指向一个位于数据块区域中的二级索引块。二级索引块中的每个u32指向一个不同的一级索引块,这些一级索引块也位于数据块区域中。因此,通过二级间接索引最多能够索引 128×64KiB=8MiB 的内容。
为了充分利用空间,我们将 DiskInode 的大小设置为 128 字节,每个块正好能够容纳 4 个 DiskInode 。在后续需要支持更多类型的元数据的时候,可以适当缩减直接索引 direct 的块数,并将节约出来的空间用来存放其他元数据,仍可保证 DiskInode 的总大小为 128 字节。
通过 initialize 方法可以初始化一个 DiskInode 为一个文件或目录:
// easy-fs/src/layout.rs
impl DiskInode {
/// indirect1 and indirect2 block are allocated only when they are needed.
pub fn initialize(&mut self, type_: DiskInodeType) {
self.size = 0;
self.direct.iter_mut().for_each(|v| *v = 0);
self.indirect1 = 0;
self.indirect2 = 0;
self.type_ = type_;
}
}
需要注意的是, indirect1/2 均被初始化为 0 。因为最开始文件内容的大小为 0 字节,并不会用到一级/二级索引。为了节约空间,我们会完全按需分配一级/二级索引块。此外,直接索引 direct 也被清零。
is_file 和 is_dir 两个方法可以用来确认 DiskInode 的类型为文件还是目录:
// easy-fs/src/layout.rs
impl DiskInode {
pub fn is_dir(&self) -> bool {
self.type_ == DiskInodeType::Directory
}
pub fn is_file(&self) -> bool {
self.type_ == DiskInodeType::File
}
}
get_block_id 方法体现了 DiskInode 最重要的数据块索引功能,它可以从索引中查到它自身用于保存文件内容的第 block_id 个数据块的块编号,这样后续才能对这个数据块进行访问:
1// easy-fs/src/layout.rs
2
3const INODE_INDIRECT1_COUNT: usize = BLOCK_SZ / 4;
4const INDIRECT1_BOUND: usize = DIRECT_BOUND + INODE_INDIRECT1_COUNT;
5type IndirectBlock = [u32; BLOCK_SZ / 4];
6
7impl DiskInode {
8 pub fn get_block_id(&self, inner_id: u32, block_device: &Arc<dyn BlockDevice>) -> u32 {
9 let inner_id = inner_id as usize;
10 if inner_id < INODE_DIRECT_COUNT {
11 self.direct[inner_id]
12 } else if inner_id < INDIRECT1_BOUND {
13 get_block_cache(self.indirect1 as usize, Arc::clone(block_device))
14 .lock()
15 .read(0, |indirect_block: &IndirectBlock| {
16 indirect_block[inner_id - INODE_DIRECT_COUNT]
17 })
18 } else {
19 let last = inner_id - INDIRECT1_BOUND;
20 let indirect1 = get_block_cache(
21 self.indirect2 as usize,
22 Arc::clone(block_device)
23 )
24 .lock()
25 .read(0, |indirect2: &IndirectBlock| {
26 indirect2[last / INODE_INDIRECT1_COUNT]
27 });
28 get_block_cache(
29 indirect1 as usize,
30 Arc::clone(block_device)
31 )
32 .lock()
33 .read(0, |indirect1: &IndirectBlock| {
34 indirect1[last % INODE_INDIRECT1_COUNT]
35 })
36 }
37 }
38}
这里需要说明的是:
- 第 10/12/18 行分别利用直接索引/一级索引和二级索引,具体选用哪种索引方式取决于
block_id所在的区间。 - 在对一个索引块进行操作的时候,我们将其解析为磁盘数据结构
IndirectBlock,实质上就是一个u32数组,每个都指向一个下一级索引块或者数据块。 - 对于二级索引的情况,需要先查二级索引块找到挂在它下面的一级索引块,再通过一级索引块找到数据块。
在初始化之后文件/目录的 size 均为 0 ,此时并不会索引到任何数据块。它需要通过 increase_size 方法逐步扩充容量。在扩充的时候,自然需要一些新的数据块来作为索引块或是保存内容的数据块。我们需要先编写一些辅助方法来确定在容量扩充的时候额外需要多少块:
// easy-fs/src/layout.rs
impl DiskInode {
/// Return block number correspond to size.
pub fn data_blocks(&self) -> u32 {
Self::_data_blocks(self.size)
}
fn _data_blocks(size: u32) -> u32 {
(size + BLOCK_SZ as u32 - 1) / BLOCK_SZ as u32
}
/// Return number of blocks needed include indirect1/2.
pub fn total_blocks(size: u32) -> u32 {
let data_blocks = Self::_data_blocks(size) as usize;
let mut total = data_blocks as usize;
// indirect1
if data_blocks > INODE_DIRECT_COUNT {
total += 1;
}
// indirect2
if data_blocks > INDIRECT1_BOUND {
total += 1;
// sub indirect1
total += (data_blocks - INDIRECT1_BOUND + INODE_INDIRECT1_COUNT - 1) / INODE_INDIRECT1_COUNT;
}
total as u32
}
pub fn blocks_num_needed(&self, new_size: u32) -> u32 {
assert!(new_size >= self.size);
Self::total_blocks(new_size) - Self::total_blocks(self.size)
}
}
data_blocks 方法可以计算为了容纳自身 size 字节的内容需要多少个数据块。计算的过程只需用 size 除以每个块的大小 BLOCK_SZ 并向上取整。而 total_blocks 不仅包含数据块,还需要统计索引块。计算的方法也很简单,先调用 data_blocks 得到需要多少数据块,再根据数据块数目所处的区间统计索引块即可。 blocks_num_needed 可以计算将一个 DiskInode 的 size 扩容到 new_size 需要额外多少个数据和索引块。这只需要调用两次 total_blocks 作差即可。
下面给出 increase_size 方法的接口:
// easy-fs/src/layout.rs
impl DiskInode {
pub fn increase_size(
&mut self,
new_size: u32,
new_blocks: Vec<u32>,
block_device: &Arc<dyn BlockDevice>,
);
}
其中 new_size 表示容量扩充之后的文件大小; new_blocks 是一个保存了本次容量扩充所需块编号的向量,这些块都是由上层的磁盘块管理器负责分配的。 increase_size 的实现有些复杂,在这里不详细介绍。大致的思路是按照直接索引、一级索引再到二级索引的顺序进行扩充。
有些时候我们还需要清空文件的内容并回收所有数据和索引块。这是通过 clear_size 方法来实现的:
// easy-fs/src/layout.rs
impl DiskInode {
/// Clear size to zero and return blocks that should be deallocated.
///
/// We will clear the block contents to zero later.
pub fn clear_size(&mut self, block_device: &Arc<dyn BlockDevice>) -> Vec<u32>;
}
它会将回收的所有块的编号保存在一个向量中返回给磁盘块管理器。它的实现原理和 increase_size 一样也分为多个阶段,在这里不展开。
接下来需要考虑通过 DiskInode 来读写它索引的那些数据块中的数据。这些数据可以被视为一个字节序列,而每次我们都是选取其中的一段连续区间进行操作,以 read_at 为例:
1// easy-fs/src/layout.rs
2
3type DataBlock = [u8; BLOCK_SZ];
4
5impl DiskInode {
6 pub fn read_at(
7 &self,
8 offset: usize,
9 buf: &mut [u8],
10 block_device: &Arc<dyn BlockDevice>,
11 ) -> usize {
12 let mut start = offset;
13 let end = (offset + buf.len()).min(self.size as usize);
14 if start >= end {
15 return 0;
16 }
17 let mut start_block = start / BLOCK_SZ;
18 let mut read_size = 0usize;
19 loop {
20 // calculate end of current block
21 let mut end_current_block = (start / BLOCK_SZ + 1) * BLOCK_SZ;
22 end_current_block = end_current_block.min(end);
23 // read and update read size
24 let block_read_size = end_current_block - start;
25 let dst = &mut buf[read_size..read_size + block_read_size];
26 get_block_cache(
27 self.get_block_id(start_block as u32, block_device) as usize,
28 Arc::clone(block_device),
29 )
30 .lock()
31 .read(0, |data_block: &DataBlock| {
32 let src = &data_block[start % BLOCK_SZ..start % BLOCK_SZ + block_read_size];
33 dst.copy_from_slice(src);
34 });
35 read_size += block_read_size;
36 // move to next block
37 if end_current_block == end { break; }
38 start_block += 1;
39 start = end_current_block;
40 }
41 read_size
42 }
43}
它的含义是:将文件内容从 offset 字节开始的部分读到内存中的缓冲区 buf 中,并返回实际读到的字节数。如果文件剩下的内容还足够多,那么缓冲区会被填满;不然的话文件剩下的全部内容都会被读到缓冲区中。具体实现上有很多细节,但大致的思路是遍历位于字节区间 start,end 中间的那些块,将它们视为一个 DataBlock (也就是一个字节数组),并将其中的部分内容复制到缓冲区 buf 中适当的区域。 start_block 维护着目前是文件内部第多少个数据块,需要首先调用 get_block_id 从索引中查到这个数据块在块设备中的块编号,随后才能传入 get_block_cache 中将正确的数据块缓存到内存中进行访问。
在第 14 行进行了简单的边界条件判断,如果要读取的内容超出了文件的范围那么直接返回 0 表示读取不到任何内容。
write_at 的实现思路基本上和 read_at 完全相同。但不同的是 write_at 不会出现失败的情况,传入的整个缓冲区的数据都必定会被写入到文件中。当从 offset 开始的区间超出了文件范围的时候,就需要调用者在调用 write_at 之前提前调用 increase_size 将文件大小扩充到区间的右端保证写入的完整性。
作为一个文件而言,它的内容在文件系统或内核看来没有任何既定的格式,都只是一个字节序列。因此每个保存内容的数据块都只是一个字节数组:
// easy-fs/src/layout.rs
type DataBlock = [u8; BLOCK_SZ];
然而,目录的内容却需要遵从一种特殊的格式。在我们的实现中,它可以看成一个目录项的序列,每个目录项都是一个二元组,二元组的首个元素是目录下面的一个文件(或子目录)的文件名(或目录名),另一个元素则是文件(或子目录)所在的索引节点编号。目录项相当于目录树结构上的孩子指针,我们需要通过它来一级一级的找到实际要访问的文件或目录。目录项 DirEntry 的定义如下:
// easy-fs/src/layout.rs
const NAME_LENGTH_LIMIT: usize = 27;
#[repr(C)]
pub struct DirEntry {
name: [u8; NAME_LENGTH_LIMIT + 1],
inode_number: u32,
}
pub const DIRENT_SZ: usize = 32;
目录项 Dirent 最大允许保存长度为 27 的文件/目录名(数组 name 中最末的一个字节留给 \0 ),且它自身占据空间 32 字节,每个数据块可以存储 16 个目录项。我们可以通过 empty 和 new 分别生成一个空的目录项或是一个合法的目录项:
// easy-fs/src/layout.rs
impl DirEntry {
pub fn empty() -> Self {
Self {
name: [0u8; NAME_LENGTH_LIMIT + 1],
inode_number: 0,
}
}
pub fn new(name: &str, inode_number: u32) -> Self {
let mut bytes = [0u8; NAME_LENGTH_LIMIT + 1];
&mut bytes[..name.len()].copy_from_slice(name.as_bytes());
Self {
name: bytes,
inode_number,
}
}
}
在从目录的内容中读取目录项或者是将目录项写入目录的时候,我们需要将目录项转化为缓冲区(即字节切片)的形式来符合 read_at OR write_at 接口的要求:
// easy-fs/src/layout.rs
impl DirEntry {
pub fn as_bytes(&self) -> &[u8] {
unsafe {
core::slice::from_raw_parts(
self as *const _ as usize as *const u8,
DIRENT_SZ,
)
}
}
pub fn as_bytes_mut(&mut self) -> &mut [u8] {
unsafe {
core::slice::from_raw_parts_mut(
self as *mut _ as usize as *mut u8,
DIRENT_SZ,
)
}
}
}
此外,通过 name 和 inode_number 方法可以取出目录项中的内容:
// easy-fs/src/layout.rs
impl DirEntry {
pub fn name(&self) -> &str {
let len = (0usize..).find(|i| self.name[*i] == 0).unwrap();
core::str::from_utf8(&self.name[..len]).unwrap()
}
pub fn inode_number(&self) -> u32 {
self.inode_number
}
}
本层的代码在 efs.rs 中。
上面介绍了 easy-fs 的磁盘布局设计以及数据的组织方式——即各类磁盘数据结构。但是它们都是以比较零散的形式分开介绍的,也并没有体现出磁盘布局上各个区域是如何划分的。实现 easy-fs 的整体磁盘布局,将各段区域及上面的磁盘数据结构结构整合起来就是简易文件系统 EasyFileSystem 的职责。它知道每个布局区域所在的位置,磁盘块的分配和回收也需要经过它才能完成,因此某种意义上讲它还可以看成一个磁盘块管理器。
注意从这一层开始,所有的数据结构就都放在内存上了。
// easy-fs/src/efs.rs
pub struct EasyFileSystem {
pub block_device: Arc<dyn BlockDevice>,
pub inode_bitmap: Bitmap,
pub data_bitmap: Bitmap,
inode_area_start_block: u32,
data_area_start_block: u32,
}
EasyFileSystem 包含索引节点和数据块的两个位图 inode_bitmap 和 data_bitmap ,还记录下索引节点区域和数据块区域起始块编号方便确定每个索引节点和数据块在磁盘上的具体位置。我们还要在其中保留块设备的一个指针 block_device ,在进行后续操作的时候,该指针会被拷贝并传递给下层的数据结构,让它们也能够直接访问块设备。
通过 create 方法可以在块设备上创建并初始化一个 easy-fs 文件系统:
1// easy-fs/src/efs.rs
2
3impl EasyFileSystem {
4 pub fn create(
5 block_device: Arc<dyn BlockDevice>,
6 total_blocks: u32,
7 inode_bitmap_blocks: u32,
8 ) -> Arc<Mutex<Self>> {
9 // calculate block size of areas & create bitmaps
10 let inode_bitmap = Bitmap::new(1, inode_bitmap_blocks as usize);
11 let inode_num = inode_bitmap.maximum();
12 let inode_area_blocks =
13 ((inode_num * core::mem::size_of::<DiskInode>() + BLOCK_SZ - 1) / BLOCK_SZ) as u32;
14 let inode_total_blocks = inode_bitmap_blocks + inode_area_blocks;
15 let data_total_blocks = total_blocks - 1 - inode_total_blocks;
16 let data_bitmap_blocks = (data_total_blocks + 4096) / 4097;
17 let data_area_blocks = data_total_blocks - data_bitmap_blocks;
18 let data_bitmap = Bitmap::new(
19 (1 + inode_bitmap_blocks + inode_area_blocks) as usize,
20 data_bitmap_blocks as usize,
21 );
22 let mut efs = Self {
23 block_device: Arc::clone(&block_device),
24 inode_bitmap,
25 data_bitmap,
26 inode_area_start_block: 1 + inode_bitmap_blocks,
27 data_area_start_block: 1 + inode_total_blocks + data_bitmap_blocks,
28 };
29 // clear all blocks
30 for i in 0..total_blocks {
31 get_block_cache(
32 i as usize,
33 Arc::clone(&block_device)
34 )
35 .lock()
36 .modify(0, |data_block: &mut DataBlock| {
37 for byte in data_block.iter_mut() { *byte = 0; }
38 });
39 }
40 // initialize SuperBlock
41 get_block_cache(0, Arc::clone(&block_device))
42 .lock()
43 .modify(0, |super_block: &mut SuperBlock| {
44 super_block.initialize(
45 total_blocks,
46 inode_bitmap_blocks,
47 inode_area_blocks,
48 data_bitmap_blocks,
49 data_area_blocks,
50 );
51 });
52 // write back immediately
53 // create a inode for root node "/"
54 assert_eq!(efs.alloc_inode(), 0);
55 let (root_inode_block_id, root_inode_offset) = efs.get_disk_inode_pos(0);
56 get_block_cache(
57 root_inode_block_id as usize,
58 Arc::clone(&block_device)
59 )
60 .lock()
61 .modify(root_inode_offset, |disk_inode: &mut DiskInode| {
62 disk_inode.initialize(DiskInodeType::Directory);
63 });
64 Arc::new(Mutex::new(efs))
65 }
66}
- 第 10~21 行根据传入的参数计算每个区域各应该包含多少块。根据 inode 位图的大小计算 inode 区域至少需要多少个块才能够使得 inode 位图中的每个bit都能够有一个实际的 inode 可以对应,这样就确定了 inode 位图区域和 inode 区域的大小。剩下的块都分配给数据块位图区域和数据块区域。我们希望数据块位图中的每个bit仍然能够对应到一个数据块,但是数据块位图又不能过小,不然会造成某些数据块永远不会被使用。因此数据块位图区域最合理的大小是剩余的块数除以 4097 再上取整,因为位图中的每个块能够对应 4096 个数据块。其余的块就都作为数据块使用。
- 第 22 行创建我们的
EasyFileSystem实例efs。 - 第 30 行首先将块设备的前
total_blocks个块清零,因为我们的 easy-fs 要用到它们,这也是为初始化做准备。 - 第 41 行将位于块设备编号为 0 块上的超级块进行初始化,只需传入之前计算得到的每个区域的块数就行了。
- 第 54~63 行我们要做的事情是创建根目录
/。首先需要调用alloc_inode在 inode 位图中分配一个 inode ,由于这是第一次分配,它的编号固定是 0 。接下来需要将分配到的 inode 初始化为 easy-fs 中的唯一一个目录,我们需要调用get_disk_inode_pos来根据 inode 编号获取该 inode 所在的块的编号以及块内偏移,之后就可以将它们传给get_block_cache和modify了。
通过 open 方法可以从一个已写入了 easy-fs 镜像的块设备上打开我们的 easy-fs :
// easy-fs/src/efs.rs
impl EasyFileSystem {
pub fn open(block_device: Arc<dyn BlockDevice>) -> Arc<Mutex<Self>> {
// read SuperBlock
get_block_cache(0, Arc::clone(&block_device))
.lock()
.read(0, |super_block: &SuperBlock| {
assert!(super_block.is_valid(), "Error loading EFS!");
let inode_total_blocks =
super_block.inode_bitmap_blocks + super_block.inode_area_blocks;
let efs = Self {
block_device,
inode_bitmap: Bitmap::new(
1,
super_block.inode_bitmap_blocks as usize
),
data_bitmap: Bitmap::new(
(1 + inode_total_blocks) as usize,
super_block.data_bitmap_blocks as usize,
),
inode_area_start_block: 1 + super_block.inode_bitmap_blocks,
data_area_start_block: 1 + inode_total_blocks + super_block.data_bitmap_blocks,
};
Arc::new(Mutex::new(efs))
})
}
}
它只需将块设备编号为 0 的块作为超级块读取进来,就可以从中知道 easy-fs 的磁盘布局,由此可以构造 efs 实例。
EasyFileSystem 知道整个磁盘布局,即可以从 inode位图 或数据块位图上分配的 bit 编号,来算出各个存储inode和数据块的磁盘块在磁盘上的实际位置。
// easy-fs/src/efs.rs
impl EasyFileSystem {
pub fn get_disk_inode_pos(&self, inode_id: u32) -> (u32, usize) {
let inode_size = core::mem::size_of::<DiskInode>();
let inodes_per_block = (BLOCK_SZ / inode_size) as u32;
let block_id = self.inode_area_start_block + inode_id / inodes_per_block;
(block_id, (inode_id % inodes_per_block) as usize * inode_size)
}
pub fn get_data_block_id(&self, data_block_id: u32) -> u32 {
self.data_area_start_block + data_block_id
}
}
inode 和数据块的分配/回收也由它负责:
// easy-fs/src/efs.rs
impl EasyFileSystem {
pub fn alloc_inode(&mut self) -> u32 {
self.inode_bitmap.alloc(&self.block_device).unwrap() as u32
}
/// Return a block ID not ID in the data area.
pub fn alloc_data(&mut self) -> u32 {
self.data_bitmap.alloc(&self.block_device).unwrap() as u32 + self.data_area_start_block
}
pub fn dealloc_data(&mut self, block_id: u32) {
get_block_cache(
block_id as usize,
Arc::clone(&self.block_device)
)
.lock()
.modify(0, |data_block: &mut DataBlock| {
data_block.iter_mut().for_each(|p| { *p = 0; })
});
self.data_bitmap.dealloc(
&self.block_device,
(block_id - self.data_area_start_block) as usize
)
}
}
注意:
alloc_data和dealloc_data分配/回收数据块传入/返回的参数都表示数据块在块设备上的编号,而不是在数据块位图中分配的bit编号;dealloc_inode未实现,因为现在还不支持文件删除。
服务于文件相关系统调用的索引节点层的代码在 vfs.rs 中。
EasyFileSystem 实现了我们设计的磁盘布局并能够将所有块有效的管理起来。但是对于文件系统的使用者而言,他们往往不关心磁盘布局是如何实现的,而是更希望能够直接看到目录树结构中逻辑上的文件和目录。为此我们设计索引节点 Inode 暴露给文件系统的使用者,让他们能够直接对文件和目录进行操作。 Inode 和 DiskInode 的区别从它们的名字中就可以看出: DiskInode 放在磁盘块中比较固定的位置,而 Inode 是放在内存中的记录文件索引节点信息的数据结构。
// easy-fs/src/vfs.rs
pub struct Inode {
block_id: usize,
block_offset: usize,
fs: Arc<Mutex<EasyFileSystem>>,
block_device: Arc<dyn BlockDevice>,
}
block_id 和 block_offset 记录该 Inode 对应的 DiskInode 保存在磁盘上的具体位置方便我们后续对它进行访问。 fs 是指向 EasyFileSystem 的一个指针,因为对 Inode 的种种操作实际上都是要通过底层的文件系统来完成。
仿照 BlockCache::read/modify ,我们可以设计两个方法来简化对于 Inode 对应的磁盘上的 DiskInode 的访问流程,而不是每次都需要 get_block_cache.lock.read/modify :
// easy-fs/src/vfs.rs
impl Inode {
fn read_disk_inode<V>(&self, f: impl FnOnce(&DiskInode) -> V) -> V {
get_block_cache(
self.block_id,
Arc::clone(&self.block_device)
).lock().read(self.block_offset, f)
}
fn modify_disk_inode<V>(&self, f: impl FnOnce(&mut DiskInode) -> V) -> V {
get_block_cache(
self.block_id,
Arc::clone(&self.block_device)
).lock().modify(self.block_offset, f)
}
}
下面我们分别介绍文件系统的使用者对于文件系统的一些常用操作:
文件系统的使用者在通过 EasyFileSystem::open 从装载了 easy-fs 镜像的块设备上打开 easy-fs 之后,要做的第一件事情就是获取根目录的 Inode 。因为我们目前仅支持绝对路径,对于任何文件/目录的索引都必须从根目录开始向下逐级进行。等到索引完成之后,我们才能对文件/目录进行操作。事实上 EasyFileSystem 提供了另一个名为 root_inode 的方法来获取根目录的 Inode :
// easy-fs/src/efs.rs
impl EasyFileSystem {
pub fn root_inode(efs: &Arc<Mutex<Self>>) -> Inode {
let block_device = Arc::clone(&efs.lock().block_device);
// acquire efs lock temporarily
let (block_id, block_offset) = efs.lock().get_disk_inode_pos(0);
// release efs lock
Inode::new(
block_id,
block_offset,
Arc::clone(efs),
block_device,
)
}
}
// easy-fs/src/vfs.rs
impl Inode {
/// We should not acquire efs lock here.
pub fn new(
block_id: u32,
block_offset: usize,
fs: Arc<Mutex<EasyFileSystem>>,
block_device: Arc<dyn BlockDevice>,
) -> Self {
Self {
block_id: block_id as usize,
block_offset,
fs,
block_device,
}
}
}
在 root_inode 中,主要是在 Inode::new 的时候将传入的 inode_id 设置为 0 ,因为根目录对应于文件系统中第一个分配的 inode ,因此它的 inode_id 总会是 0 。同时在设计上,我们不会在 Inode::new 中尝试获取整个 EasyFileSystem 的锁来查询 inode 在块设备中的位置,而是在调用它之前预先查询并作为参数传过去。
前面 提到过,为了尽可能简化我们的实现,我们所实现的是一个扁平化的文件系统,即在目录树上仅有一个目录——那就是作为根节点的根目录。所有的文件都在根目录下面。于是,我们不必实现目录索引。文件索引的查找比较简单,仅需在根目录的目录项中根据文件名找到文件的 inode 编号即可。由于没有子目录的存在,这个过程只会进行一次。
// easy-fs/src/vfs.rs
impl Inode {
pub fn find(&self, name: &str) -> Option<Arc<Inode>> {
let fs = self.fs.lock();
self.read_disk_inode(|disk_inode| {
self.find_inode_id(name, disk_inode)
.map(|inode_id| {
let (block_id, block_offset) = fs.get_disk_inode_pos(inode_id);
Arc::new(Self::new(
block_id,
block_offset,
self.fs.clone(),
self.block_device.clone(),
))
})
})
}
fn find_inode_id(
&self,
name: &str,
disk_inode: &DiskInode,
) -> Option<u32> {
// assert it is a directory
assert!(disk_inode.is_dir());
let file_count = (disk_inode.size as usize) / DIRENT_SZ;
let mut dirent = DirEntry::empty();
for i in 0..file_count {
assert_eq!(
disk_inode.read_at(
DIRENT_SZ * i,
dirent.as_bytes_mut(),
&self.block_device,
),
DIRENT_SZ,
);
if dirent.name() == name {
return Some(dirent.inode_number() as u32);
}
}
None
}
}
find 方法只会被根目录 Inode 调用,文件系统中其他文件的 Inode 不会调用这个方法。它首先调用 find_inode_id 方法尝试从根目录的 DiskInode 上找到要索引的文件名对应的 inode 编号。这就需要将根目录内容中的所有目录项都读到内存进行逐个比对。如果能够找到的话, find 方法会根据查到 inode 编号对应生成一个 Inode 用于后续对文件的访问。
这里需要注意的是,包括 find 在内所有暴露给文件系统的使用者的文件系统操作(还包括接下来将要介绍的几种),全程均需持有 EasyFileSystem 的互斥锁(相对的,文件系统内部的操作如之前的 Inode::new 或是上面的 find_inode_id 都是假定在已持有 efs 锁的情况下才被调用的,因此它们不应尝试获取锁)。这能够保证在多核情况下,同时最多只能有一个核在进行文件系统相关操作。这样也许会带来一些不必要的性能损失,但我们目前暂时先这样做。如果我们在这里加锁的话,其实就能够保证块缓存的互斥访问了。
ls 方法可以收集根目录下的所有文件的文件名并以向量的形式返回,这个方法只有根目录的 Inode 才会调用:
// easy-fs/src/vfs.rs
impl Inode {
pub fn ls(&self) -> Vec<String> {
let _fs = self.fs.lock();
self.read_disk_inode(|disk_inode| {
let file_count = (disk_inode.size as usize) / DIRENT_SZ;
let mut v: Vec<String> = Vec::new();
for i in 0..file_count {
let mut dirent = DirEntry::empty();
assert_eq!(
disk_inode.read_at(
i * DIRENT_SZ,
dirent.as_bytes_mut(),
&self.block_device,
),
DIRENT_SZ,
);
v.push(String::from(dirent.name()));
}
v
})
}
}
注解
Rust 语法卡片: _ 在匹配中的使用方法
可以看到在 ls 操作中,我们虽然获取了 efs 锁,但是这里并不会直接访问 EasyFileSystem 实例,其目的仅仅是锁住该实例避免其他核在同时间的访问造成并发冲突。因此,我们将其绑定到以 _ 开头的变量 _fs 中,这样即使我们在其作用域中并没有使用它,编译器也不会报警告。然而,我们不能将其绑定到变量 _ 上。因为从匹配规则可以知道这意味着该操作会被编译器丢弃,从而无法达到获取锁的效果。
create 方法可以在根目录下创建一个文件,该方法只有根目录的 Inode 会调用:
1// easy-fs/src/vfs.rs
2
3impl Inode {
4 pub fn create(&self, name: &str) -> Option<Arc<Inode>> {
5 let mut fs = self.fs.lock();
6 if self.modify_disk_inode(|root_inode| {
7 // assert it is a directory
8 assert!(root_inode.is_dir());
9 // has the file been created?
10 self.find_inode_id(name, root_inode)
11 }).is_some() {
12 return None;
13 }
14 // create a new file
15 // alloc a inode with an indirect block
16 let new_inode_id = fs.alloc_inode();
17 // initialize inode
18 let (new_inode_block_id, new_inode_block_offset)
19 = fs.get_disk_inode_pos(new_inode_id);
20 get_block_cache(
21 new_inode_block_id as usize,
22 Arc::clone(&self.block_device)
23 ).lock().modify(new_inode_block_offset, |new_inode: &mut DiskInode| {
24 new_inode.initialize(DiskInodeType::File);
25 });
26 self.modify_disk_inode(|root_inode| {
27 // append file in the dirent
28 let file_count = (root_inode.size as usize) / DIRENT_SZ;
29 let new_size = (file_count + 1) * DIRENT_SZ;
30 // increase size
31 self.increase_size(new_size as u32, root_inode, &mut fs);
32 // write dirent
33 let dirent = DirEntry::new(name, new_inode_id);
34 root_inode.write_at(
35 file_count * DIRENT_SZ,
36 dirent.as_bytes(),
37 &self.block_device,
38 );
39 });
40
41 let (block_id, block_offset) = fs.get_disk_inode_pos(new_inode_id);
42 // return inode
43 Some(Arc::new(Self::new(
44 block_id,
45 block_offset,
46 self.fs.clone(),
47 self.block_device.clone(),
48 )))
49 // release efs lock automatically by compiler
50 }
51}
- 第 6~13 行,检查文件是否已经在根目录下,如果找到的话返回
None; - 第 14~25 行,为待创建文件分配一个新的 inode 并进行初始化;
- 第 26~39 行,将待创建文件的目录项插入到根目录的内容中使得之后可以索引过来。
在以某些标志位打开文件(例如带有 CREATE 标志打开一个已经存在的文件)的时候,需要首先将文件清空。在索引到文件的 Inode 之后可以调用 clear 方法:
// easy-fs/src/vfs.rs
impl Inode {
pub fn clear(&self) {
let mut fs = self.fs.lock();
self.modify_disk_inode(|disk_inode| {
let size = disk_inode.size;
let data_blocks_dealloc = disk_inode.clear_size(&self.block_device);
assert!(data_blocks_dealloc.len() == DiskInode::total_blocks(size) as usize);
for data_block in data_blocks_dealloc.into_iter() {
fs.dealloc_data(data_block);
}
});
}
}
这会将之前该文件占据的索引块和数据块在 EasyFileSystem 中回收。
从根目录索引到一个文件之后可以对它进行读写,注意,和 DiskInode 一样,这里的读写作用在字节序列的一段区间上:
// easy-fs/src/vfs.rs
impl Inode {
pub fn read_at(&self, offset: usize, buf: &mut [u8]) -> usize {
let _fs = self.fs.lock();
self.read_disk_inode(|disk_inode| {
disk_inode.read_at(offset, buf, &self.block_device)
})
}
pub fn write_at(&self, offset: usize, buf: &[u8]) -> usize {
let mut fs = self.fs.lock();
self.modify_disk_inode(|disk_inode| {
self.increase_size((offset + buf.len()) as u32, disk_inode, &mut fs);
disk_inode.write_at(offset, buf, &self.block_device)
})
}
}
具体实现比较简单,需要注意在 DiskInode::write_at 之前先调用 increase_size 对自身进行扩容:
// easy-fs/src/vfs.rs
impl Inode {
fn increase_size(
&self,
new_size: u32,
disk_inode: &mut DiskInode,
fs: &mut MutexGuard<EasyFileSystem>,
) {
if new_size < disk_inode.size {
return;
}
let blocks_needed = disk_inode.blocks_num_needed(new_size);
let mut v: Vec<u32> = Vec::new();
for _ in 0..blocks_needed {
v.push(fs.alloc_data());
}
disk_inode.increase_size(new_size, v, &self.block_device);
}
}
这里会从 EasyFileSystem 中分配一些用于扩容的数据块并传给 DiskInode::increase_size 。
easy-fs 架构设计的一个优点在于它可以在Rust应用开发环境(Windows/macOS/Ubuntu)中,按照应用程序库的开发方式来进行测试,不必过早的放到内核中测试运行。众所周知,内核运行在裸机环境上,在上面是很难调试的。而在我们的开发环境上对于调试的支持更为完善,从基于命令行的 GDB 到 IDE 提供的图形化调试界面都能给我们带来很大帮助。另外一点是,由于需要放到在裸机上运行的内核中, easy-fs 只能使用 no_std 模式,因此无法使用 println! 等宏来打印调试信息。但是在我们的开发环境上作为一个应用运行的时候,我们可以暂时让使用它的应用程序调用标准库 std ,这也会带来一些方便。
easy-fs 的测试放在另一个名为 easy-fs-fuse 的应用程序中,不同于 easy-fs ,它是一个支持 std 的应用程序 ,能够在Rust应用开发环境上运行并很容易调试。
从文件系统的使用者角度来看,它仅需要提供一个实现了 BlockDevice Trait 的块设备用来装载文件系统,之后就可以使用 Inode 来方便的进行文件系统操作了。但是在开发环境上,我们如何来提供这样一个块设备呢?答案是用 Host OS 上的一个文件进行模拟。
// easy-fs-fuse/src/main.rs
use std::fs::File;
use easy-fs::BlockDevice;
const BLOCK_SZ: usize = 512;
struct BlockFile(Mutex<File>);
impl BlockDevice for BlockFile {
fn read_block(&self, block_id: usize, buf: &mut [u8]) {
let mut file = self.0.lock().unwrap();
file.seek(SeekFrom::Start((block_id * BLOCK_SZ) as u64))
.expect("Error when seeking!");
assert_eq!(file.read(buf).unwrap(), BLOCK_SZ, "Not a complete block!");
}
fn write_block(&self, block_id: usize, buf: &[u8]) {
let mut file = self.0.lock().unwrap();
file.seek(SeekFrom::Start((block_id * BLOCK_SZ) as u64))
.expect("Error when seeking!");
assert_eq!(file.write(buf).unwrap(), BLOCK_SZ, "Not a complete block!");
}
}
std::file::File 由 Rust 标准库 std 提供,可以访问 Host OS 上的一个文件。我们将它包装成 BlockFile 类型来模拟一块磁盘,为它实现 BlockDevice 接口。注意 File 本身仅通过 read/write 接口是不能实现随机读写的,在访问一个特定的块的时候,我们必须先 seek 到这个块的开头位置。
测试主函数为 easy-fs-fuse/src/main.rs 中的 efs_test 函数中,我们只需在 easy-fs-fuse 目录下 cargo test 即可执行该测试:
running 1 test
test efs_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 1.27s
看到上面的内容就说明测试通过了。
efs_test 展示了 easy-fs 库的使用方法,大致分成以下几个步骤:
let block_file = Arc::new(BlockFile(Mutex::new({
let f = OpenOptions::new()
.read(true)
.write(true)
.create(true)
.open("target/fs.img")?;
f.set_len(8192 * 512).unwrap();
f
})));
EasyFileSystem::create(
block_file.clone(),
4096,
1,
);
第一步我们需要打开块设备。这里我们在 HostOS 创建文件 easy-fs-fuse/target/fs.img 来新建一个块设备,并将它的容量设置为 8192 个块即 4MiB 。在创建的时候需要将它的访问权限设置为可读可写。
由于我们在进行测试,需要初始化测试环境,因此我们在块设备 block_file 上初始化 easy-fs 文件系统,这会将 block_file 用于放置 easy-fs 镜像的前 4096 个块上的数据覆盖,然后变成仅有一个根目录的初始文件系统。如果块设备上已经放置了一个合法的 easy-fs 镜像,则我们不必这样做。
let efs = EasyFileSystem::open(block_file.clone());
这是通常进行的第二个步骤。
let root_inode = EasyFileSystem::root_inode(&efs);
这是通常进行的第三个步骤。
拿到根目录 root_inode 之后,可以通过它进行各种文件操作,目前支持以下几种:
- 通过
create创建文件。 - 通过
ls列举根目录下的文件。 - 通过
find根据文件名索引文件。
当通过索引获取根目录下的一个文件的 inode 之后则可以进行如下操作:
- 通过
clear将文件内容清空。 - 通过
read/write_at读写文件,注意我们需要将读写在文件中开始的位置offset作为一个参数传递进去。
测试方法在这里不详细介绍,大概是每次清空文件 filea 的内容,向其中写入一个不同长度的随机数字字符串,然后再全部读取出来,验证和写入的内容一致。其中有一个细节是:用来生成随机字符串的 rand crate 并不支持 no_std ,因此只有在用户态我们才能更容易进行测试。
在第六章中我们需要将所有的应用都链接到内核中,随后在应用管理器中通过应用名进行索引来找到应用的 ELF 数据。这样做有一个缺点,就是会造成内核体积过度膨胀。在 k210 平台上可以很明显的感觉到从第五章开始随着应用数量的增加,向开发板上烧写内核镜像的耗时显著增长。同时这也会浪费内存资源,因为未被执行的应用也占据了内存空间。在实现了我们自己的文件系统之后,终于可以将这些应用打包到 easy-fs 镜像中放到磁盘中,当我们要执行应用的时候只需从文件系统中取出ELF 执行文件格式的应用 并加载到内存中执行即可,这样就避免了上面的那些问题。
easy-fs-fuse 的主体 easy-fs-pack 函数就实现了这个功能:
1// easy-fs-fuse/src/main.rs
2
3use clap::{Arg, App};
4
5fn easy_fs_pack() -> std::io::Result<()> {
6 let matches = App::new("EasyFileSystem packer")
7 .arg(Arg::with_name("source")
8 .short("s")
9 .long("source")
10 .takes_value(true)
11 .help("Executable source dir(with backslash)")
12 )
13 .arg(Arg::with_name("target")
14 .short("t")
15 .long("target")
16 .takes_value(true)
17 .help("Executable target dir(with backslash)")
18 )
19 .get_matches();
20 let src_path = matches.value_of("source").unwrap();
21 let target_path = matches.value_of("target").unwrap();
22 println!("src_path = {}\ntarget_path = {}", src_path, target_path);
23 let block_file = Arc::new(BlockFile(Mutex::new({
24 let f = OpenOptions::new()
25 .read(true)
26 .write(true)
27 .create(true)
28 .open(format!("{}{}", target_path, "fs.img"))?;
29 f.set_len(8192 * 512).unwrap();
30 f
31 })));
32 // 4MiB, at most 4095 files
33 let efs = EasyFileSystem::create(
34 block_file.clone(),
35 8192,
36 1,
37 );
38 let root_inode = Arc::new(EasyFileSystem::root_inode(&efs));
39 let apps: Vec<_> = read_dir(src_path)
40 .unwrap()
41 .into_iter()
42 .map(|dir_entry| {
43 let mut name_with_ext = dir_entry.unwrap().file_name().into_string().unwrap();
44 name_with_ext.drain(name_with_ext.find('.').unwrap()..name_with_ext.len());
45 name_with_ext
46 })
47 .collect();
48 for app in apps {
49 // load app data from host file system
50 let mut host_file = File::open(format!("{}{}", target_path, app)).unwrap();
51 let mut all_data: Vec<u8> = Vec::new();
52 host_file.read_to_end(&mut all_data).unwrap();
53 // create a file in easy-fs
54 let inode = root_inode.create(app.as_str()).unwrap();
55 // write data to easy-fs
56 inode.write_at(0, all_data.as_slice());
57 }
58 // list apps
59 for app in root_inode.ls() {
60 println!("{}", app);
61 }
62 Ok(())
63}
- 为了实现
easy-fs-fuse和os/user的解耦,第 6~21 行使用clapcrate 进行命令行参数解析,需要通过-s和-t分别指定应用的源代码目录和保存应用 ELF 的目录而不是在easy-fs-fuse中硬编码。如果解析成功的话它们会分别被保存在变量src_path和target_path中。 - 第 23~38 行依次完成:创建 4MiB 的 easy-fs 镜像文件、进行 easy-fs 初始化、获取根目录 inode 。
- 第 39 行获取源码目录中的每个应用的源代码文件并去掉后缀名,收集到向量
apps中。 - 第 48 行开始,枚举
apps中的每个应用,从放置应用执行程序的目录中找到对应应用的 ELF 文件(这是一个 HostOS 上的文件)并将数据读入内存。接着需要在我们的 easy-fs 中创建一个同名文件并将 ELF 数据写入到这个文件中。这个过程相当于将 HostOS 上的文件系统中的一个文件复制到我们的 easy-fs 中。
尽管没有进行任何同步写回磁盘的操作,我们也不用担心块缓存中的修改没有写回磁盘。因为在 easy-fs-fuse 这个应用正常退出的过程中,块缓存因生命周期结束会被回收,届时如果 modified 标志为 true 就会将修改写回磁盘。
在 drivers 子模块中的 block/mod.rs 中,我们可以找到内核访问的块设备实例 BLOCK_DEVICE :
// os/drivers/block/mod.rs
#[cfg(feature = "board_qemu")]
type BlockDeviceImpl = virtio_blk::VirtIOBlock;
#[cfg(feature = "board_k210")]
type BlockDeviceImpl = sdcard::SDCardWrapper;
lazy_static! {
pub static ref BLOCK_DEVICE: Arc<dyn BlockDevice> = Arc::new(BlockDeviceImpl::new());
}
qemu 和 k210 平台上的块设备是不同的。在 qemu 上,我们使用 VirtIOBlock 访问 VirtIO 块设备;而在 k210 上,我们使用 SDCardWrapper 来访问插入 k210 开发板上真实的 microSD 卡,它们都实现了 easy-fs 要求的 BlockDevice Trait 。通过 #[cfg(feature)] 可以在编译的时候根据编译参数调整 BlockDeviceImpl 具体为哪个块设备,之后将它全局实例化为 BLOCK_DEVICE 使得内核的其他模块可以访问。
在启动 Qemu 模拟器的时候,我们可以配置参数来添加一块 VirtIO 块设备:
1# os/Makefile
2
3FS_IMG := ../user/target/$(TARGET)/$(MODE)/fs.img
4
5run-inner: build
6ifeq ($(BOARD),qemu)
7 @qemu-system-riscv64 \
8 -machine virt \
9 -nographic \
10 -bios $(BOOTLOADER) \
11 -device loader,file=$(KERNEL_BIN),addr=$(KERNEL_ENTRY_PA) \
12 -drive file=$(FS_IMG),if=none,format=raw,id=x0 \
13 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
- 第 12 行,我们为虚拟机添加一块虚拟硬盘,内容为我们之前通过
easy-fs-fuse工具打包的包含应用 ELF 的 easy-fs 镜像,并命名为x0。 - 第 13 行,我们将硬盘
x0作为一个 VirtIO 总线中的一个块设备接入到虚拟机系统中。virtio-mmio-bus.0表示 VirtIO 总线通过 MMIO 进行控制,且该块设备在总线中的编号为 0 。
内存映射 I/O (MMIO, Memory-Mapped I/O) 指的是外设的设备寄存器可以通过特定的物理内存地址来访问,每个外设的设备寄存器都分布在没有交集的一个或数个物理地址区间中,不同外设的设备寄存器所占的物理地址空间也不会产生交集,且这些外设物理地址区间也不会和RAM的物理内存所在的区间存在交集。从 RV64 平台 Qemu 的 源码 中可以找到 VirtIO 总线的 MMIO 物理地址区间为从 0x10001000 开头的 4KiB 。为了能够在内核中访问 VirtIO 总线,我们就必须在内核地址空间中对特定内存区域提前进行映射:
// os/src/config.rs
#[cfg(feature = "board_qemu")]
pub const MMIO: &[(usize, usize)] = &[
(0x10001000, 0x1000),
];使用透明的恒等映射,从而让内核可以兼容于直接访问物理地址的设备驱动库。
这部分内容还有些不饶熟悉,三轮的时候在详细计笔记
其实早在第一章的时候,就非常简单介绍了QEMU模拟的RISC-V 64计算机中存在的外设:UART、时钟、virtio-net/block/console/gpu等。并且在第一章,我们就已经通过RustSBI间接地接触过串口设备了。但我们写的OS是通过RustSBI提供的一个SBI调用 SBI_CONSOLE_PUTCHAR 来完成字符输出功能的。
在第三章,为了能实现抢占式调度,引入了时钟这个外设,也是通过SBI调用 SBI_SET_TIMER 来帮助操作系统在固定时间间隔内获得控制权。而到了第五章,我们通过另外一个SBI调用 SBI_CONSOLE_GETCHAR 来获得输入的字符能力。这时的操作系统就拥有了与使用者进行简单字符交互的能力了。
后来在第七章又引入了另外一个外设virtio-block设备,即一个虚拟的磁盘设备。还通过这个存储设备完成了对数据的持久存储,并在其上实现了访问持久性数据的文件系统。对virtio-block设备的I/O访问没有通过RustSBI来完成,而是直接调用了 virtio_drivers crate中的 virtio-blk 设备驱动程序来实现的。但我们并没有深入分析这个设备驱动程序的具体实现。
计算机的发展历史可体现为计算机硬件中各个部件的复杂度和集成度的变化发展过程。而在I/O设备变化过程,除了外设硬件的多样性越来越广和集成度越来越高,与CPU进行交互的能力也越来越强。在计算机发展过程中,I/O设备先后出现了很多,也消亡了不少。
现在I/O设备的种类繁多,我们可以从数据传输的特点来给I/O设备进行分类。早期的UNIX把I/O设备分为两类:块设备(block device)和字符设备(character device)。块设备(比如磁盘)把信息存储在固定大小的块中,每个块有独立的地址。块的大小一般在0.5KB至32KB不等。块设备的I/O传输以一个或多个完整的(连续的)块为单位。另一类I/O设备是字符设备,字符设备(如串口,键盘等)以单个字符为单位发送或接收一个字符流。字符设备不需要寻址,只需访问I/O设备提供的相关接口即可获得/发出字符信息流。
后来随着网络的普及,又出现了一类设备:网络设备。网络面向报文而不是面向字符流,也不是面向数据块,还具有数据丢失等可靠性问题,因此将网络设备映射为常见的文件比较困难。为此UNIX的早期继承者BSD(Berkeley Software Distribution)提出了socket接口和对应操作,形成了事实上的TCP/IP网络API标准。..
多设备
CPU连接的设备越来越多,需要在CPU与I/O设备之间增加了一层–I/O控制器(如串口控制器等)。CPU可通过对I/O控制器进行编程来控制各种设备。其特点是CPU给I/O控制器发出I/O命令或读写数据,由I/O控制器来直接控制I/O设备和传达I/O设备的信息给CPU。CPU还需通过访问I/O控制器相关寄存器获取I/O设备的当前状态。其特点是CPU需要轮询检查设备情况,对于低速设备(如串口等)而言,高速CPU和低速设备之间是一种串行执行的过程,导致CPU利用率低。 随着设备的增多,I/O控制器也逐渐通用化(如各种总线接口等),把不同设备连接在一起,并能把设备间共性的部分进行集中管理。
同时,为了简化CPU与各种设备的连接,出现了 总线(bus) 。总线代表连接在一起的设备需要共同遵守的I/O时序,不同总线(如I2c总线、USB总线、PCI总线等)的I/O时序是不同的。
支持中断的设备
CPU与外设的性能差距在加大,为了不让CPU把时间浪费在等待外设上,即为了解决CPU利用率低的问题,I/O控制器扩展了中断机制(如Intel推出的8259可编程中断控制器)。CPU发出I/O命令后,无需轮询忙等,可以干其他事情。但外设完成I/O操作后,会通过I/O控制器产生外部中断,让CPU来响应这个外部中断。由于CPU无需一直等待外设执行I/O操作,这样就能让CPU和外设并行执行,提高整个系统的执行效率。
高吞吐量设备-----DMA
某些高性能外设(SSD,网卡等)的性能在逐步提高,如果每次中断产生的I/O数据传输量少,那么I/O设备(如硬盘/SSD等)要在短期内传输大量数据就会频繁中断CPU,导致中断处理的总体开销很大,系统效率会降低。通过DMA(Direct Memory Access,直接内存访问)控制器(如Intel推出8237DMA控制器等),可以让外设在CPU没有访问内存的时间段中,以数据块的方式进行外设和内存之间的数据传输,且不需要CPU的干预。这样I/O设备的传输效率就大大提高了。CPU只需在开始传送前发出DMA指令,并在外设结束DMA操作后响应其发出的中断信息即可。
在上述的I/O设备发展过程可以看到, CPU主要有三种方式可以与外设进行数据传输:Programmed I/O (简称PIO)、Interrupt、Direct Memory Access (简称DMA)。
PIO指CPU通过发出I/O指令的方式来进行数据传输。PIO方式可以进一步细分为基于Memory-mapped的PIO(简称MMIO)和Port-mapped的PIO(简称PMIO),MMIO是将I/O设备物理地址映射到内存地址空间,这样CPU就可以通过普通访存指令将数据送到I/O设备在主存上的位置,从而完成数据传输。
对于PMIO,I/O设备有自己独立的地址空间,CPU若要访问I/O设备,则需要使用特殊的I/O指令,如x86处理器中的 IN 、OUT 指令。CPU直接使用I/O指令就可以访问到对应的设备。
programmed I/o 的不足:如果采用PIO方式让CPU来获取外设的执行结果,那么这样的I/O软件中有一个CPU读外设相关寄存器的循环,直到CPU收到可继续执行I/O操作的外设信息后,CPU才能进一步做其它事情。当外设(如串口)的处理速度远低于CPU的时候,将使CPU处于不必要的忙等的低效状态中。
中断机制的出现,极大地缓解了CPU的负担。 分为一下步骤:
- CPU可通过PIO方式来通知外设
- 只要I/O设备有了CPU需要的数据,便会发出中断请求信号
- CPU发完通知后,就可以继续执行与I/O设备无关的其它事情
- 中断控制器会检查I/O设备是否准备好进行传输数据,并发出中断请求信号给CPU
- 当CPU检测到中断信号,CPU会打断当前执行,并处理I/O传输
如果外设每传一个字节都要产生一次中断,那系统执行效率还是很低。DMA技术是指I/O设备可以在没有CPU参与的情况下完成大块数据的传输,使得CPU从I/O任务中解脱出来,从而提高了系统的整体性能。在后面的小节中,我们会进一步介绍基于I/O控制器的轮询,中断等方式的设备驱动的设计与实现。
注解
DMA技术工作流程
当CPU想与外设交换一块数据时,它会向DMA控制器发出一条命令。命令内容包括:读或写操作标记,相关的I/O设备的地址,内存的起始地址和长度。然后CPU继续其它工作。DMA控制器收到命令后,会直接从内存中或向内存传送整块数据,这个传输过程不再需要通过CPU进行操作。传送结束后,DMA控制器会通过I/O控制器给CPU发送一个表示DMA操作结束的中断。CPU在收到中断后,知道这次I/O操作完成,可进行后续相关事务的处理。
在后续讲解的virtio-blk, virtio-gpu等模拟设备中,就是通过DMA来传输数据的。
对于一个外设而言,它包含了两部分重要组成部分。第一部分是对外向系统其他部分展现的设备I/O接口(hardware I/O interface),这样操作系统才能通过接口来管理控制外设。所有设备都有自己的特定接口以及典型交互的协议。第二部分是对内的内部结构,包含了设备相关物理实现。由于外在接口的多样性,使得操作系统难以统一管理外设。
如果我们不考虑具体的设备,而是站在一个高度抽象的角度来让软件管理设备,那么我们就不用太关注设备的内部结构,而重点考虑设备的接口如何进行简化。其实一个简化的抽象设备接口需要包括三部分:状态、命令、数据。软件可以读取并查看设备的当前状态,从而根据设备当前状态决定下一步的I/O访问请求;而软件是通过一系列的命令来要求设备完成某个具体的I/O访问请求;在完成一个I/O访问请求中,会涉及到将数据传给设备或从设备接收数据。CPU与设备间的I/O接口的交互协议如下所示:
while STATUS == BUSY {}; // 等待设备执行完毕
DATA = data; // 把数据传给设备
COMMAND = command; // 发命令给设备
while STATUS == BUSY {}; // 等待设备执行完毕
引入中断机制后,这个简化的抽象设备接口需要包括四部分:状态、命令、数据、中断。CPU与设备间的I/O接口的交互协议如下所示:
DATA = data; // 把数据传给设备
COMMAND = command; // 发命令给设备
do_otherwork(); // 做其它事情
... // I/O设备完成I/O操作,并产生中断
... // CPU执行被打断以响应中断
trap_handler(); // 执行中断处理例程中的相关I/O中断处理
restore_do_otherwork();// 恢复CPU之前被打断的执行
... // 可继续进行I/O操作
中断机制允许CPU的高速计算与外设的慢速I/O操作可以重叠(overlap),CPU不用花费时间等待外设执行的完成,这样就形成CPU与外设的并行执行,这是提高CPU利用率和系统效率的关键。
站在软件的角度来看,为提高一大块数据传输效率引入的DMA机制并没有改变抽象设备接口的四个部分。仅仅是上面协议伪码中的 data 变成了 data block 。这样传输单个数据产生的中断频度会大大降低,从而进一步提高CPU利用率和系统效率。
这里描述了站在软件角度上的抽象设备接口的交互协议。如果站在操作系统的角度,还需把这种设备抽象稍微再具体一点,从而能够在操作系统中实现对设备的管理
在具体实现上,当设备打开时,流中的两个末端管理的内核模块自动连接;中间模块是根据用户程序的请求动态附加的。为了能够方便动态地插入不同的流处理模块,这些中间模块的读写接口被设定为相同。
每个流处理模块由一对队列(queue)组成,每个方向一个队列。队列不仅包括数据队列本身,还包括两个例程和一些状态信息。一个是put例程,它由邻居模块调用以将消息放入数据队列中。另一个是服务(service)例程,被安排在有工作要做的时候执行。状态信息包括指向下游下一个队列的指针、各种标志以及指向队列实例化所需的附加状态信息的指针
对于操作系统如何有效管理I/O设备的相关探索还在继续,但环境已经有所变化。随着互联网和云计算的兴起,在数据中心的物理服务器上通过虚拟机技术(Virtual Machine Monitor, Hypervisor等),运行多个虚拟机(Virtual Machine),并在虚拟机中运行guest操作系统的模式成为一种主流。但当时存在多种虚拟机技术,如Xen、VMware、KVM等,要支持虚拟化x86、Power等不同的处理器和各种具体的外设,并都要求让以Linux为代表的guest OS能在其上高效的运行。这对于虚拟机和操作系统来说,实在是太繁琐和困难了。
IBM资深工程师 Rusty Russell 在开发Lguest(Linux 内核中的的一个hypervisor(一种高效的虚拟计算机的系统软件))时,深感写模拟计算机中的高效虚拟I/O设备的困难,且编写I/O设备的驱动程序繁杂且很难形成一种统一的表示。于是他经过仔细琢磨,提出了一组通用I/O设备的抽象 – virtio规范。虚拟机(VMM或Hypervisor)提供virtio设备的实现,virtio设备有着统一的virtio接口,guest操作系统只要能够实现这些通用的接口,就可以管理和控制各种virtio设备。而虚拟机与guest操作系统的virtio设备驱动程序间的通道是基于共享内存的异步访问方式来实现的,效率很高。虚拟机会进一步把相关的virtio设备的I/O操作转换成物理机上的物理外设的I/O操作。这就完成了整个I/O处理过程。
从用户进程的角度看,用户进程是通过I/O相关的系统调用(简称I/O系统调用)来进行I/O操作的。在UNIX环境中,I/O系统调用有多种不同类型的执行模型。根据Richard Stevens的经典书籍“UNIX Network Programming Volume 1: The Sockets Networking ”的6.2节“I/O Models ”的介绍,大致可以分为五种I/O执行模型(I/O Execution Model,简称IO Model, IO模型):
- blocking IO
- nonblocking IO
- IO multiplexing
- signal driven IO
- asynchronous IO
当一个用户进程发出一个 read I/O系统调用时,主要经历两个阶段:
- 等待数据准备好 (Waiting for the data to be ready)
- 把数据从内核拷贝到用户进程中(Copying the data from the kernel to the process)
上述五种IO模型在这两个阶段有不同的处理方式。需要注意,阻塞与非阻塞关注的是进程的执行状态:
- 阻塞:进程执行系统调用后会被阻塞
- 非阻塞:进程执行系统调用后不会被阻塞
同步和异步关注的是消息通信机制:
- 同步:用户进程与操作系统(设备驱动)之间的操作是经过双方协调的,步调一致的
- 异步:用户进程与操作系统(设备驱动)之间并不需要协调,都可以随意进行各自的操作
基于阻塞IO模型的文件读系统调用 – read 的执行过程是:
- 用户进程发出
read系统调用; - 内核发现所需数据没在I/O缓冲区中,需要向磁盘驱动程序发出I/O操作,并让用户进程处于阻塞状态;
- 磁盘驱动程序把数据从磁盘传到I/O缓冲区后,通知内核(一般通过中断机制),内核会把数据从I/O缓冲区拷贝到用户进程的buffer中,并唤醒用户进程(即用户进程处于就绪态);
- 内核从内核态返回到用户态的用户态进程,此时
read系统调用完成。
所以阻塞IO(blocking IO)的特点就是用户进程在I/O执行的两个阶段(等待数据和拷贝数据两个阶段)都是阻塞的。
当然,如果正好用户进程所需数据位于内存中,那么内核会把数据从I/O缓冲区拷贝到用户进程的buffer中,并从内核态返回到用户态的用户态进程, read 系统调用完成。这个由于I/O缓冲带了的优化结果不会让用户进程处于阻塞状态。
基于非阻塞IO模型的文件读系统调用 – read 的执行过程是:
- 用户进程发出
read系统调用; - 内核发现所需数据没在I/O缓冲区中,需要向磁盘驱动程序发出I/O操作,并不会让用户进程处于阻塞状态,而是立刻返回一个error;
- 用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作(这一步操作可以重复多次);
- 磁盘驱动程序把数据从磁盘传到I/O缓冲区后,通知内核(一般通过中断机制),内核在收到通知且再次收到了用户进程的system call后,会马上把数据从I/O缓冲区拷贝到用户进程的buffer中;
- 内核从内核态返回到用户态的用户态进程,此时
read系统调用完成。
所以,在非阻塞式IO的特点是用户进程不会被内核阻塞,而是需要不断的主动询问内核所需数据准备好了没有。非阻塞系统调用相比于阻塞系统调用的的差异在于在被调用之后会立即返回。
使用系统调用 fcntl( fd, F_SETFL, O_NONBLOCK ) 可以将对某文件句柄 fd 进行的读写访问设为非阻塞IO模型的读写访问.
IO multiplexing对应的I/O系统调用是 select 和 epoll 等,也称这种IO方式为事件驱动IO(event driven IO)。 select 和 epoll 的优势在于,采用单进程方式就可以同时处理多个文件或网络连接的I/O操作。其基本工作机制就是通过 select 或 epoll 系统调用来不断的轮询用户进程关注的所有文件句柄或socket,当某个文件句柄或socket有数据到达了,select 或 epoll 系统调用就会返回到用户进程,用户进程再调用 read 系统调用,让内核将数据从内核的I/O缓冲区拷贝到用户进程的buffer中。
在多路复用IO模型中,对于用户进程关注的每一个文件句柄或socket,一般都设置成为non-blocking,只是用户进程是被select 或 epoll 系统调用阻塞住了。select/epoll 的优势并不是对于单个文件或socket的I/O访问性能更好,而是在于有很多个文件或socket的I/O访问下,其总体效率会高。
当进程发出一个 read 系统调用时,会向内核注册一个信号处理函数,然后系统调用返回,进程不会被阻塞,而是继续执行。当内核中的IO数据就绪时,会发送一个信号给进程,进程便在信号处理函数中调用IO读取数据。此模型的特点是,采用了回调机制,这样开发和调试应用的难度加大。
用户进程发起 read 异步系统调用之后,立刻就可以开始去做其它的事**。而另一方面,从内核的角度看,当它收到一个 read 异步系统调用之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞情况**。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会通知用户进程,告诉它read操作完成了。
- 设备初始化,即完成对设备的初始配置,分配I/O操作所需的内存,设置好中断处理例程
- 如果设备会产生中断,需要有处理这个设备中断的中断处理例程(Interrupt Handler)
- 根据操作系统上层模块(如文件系统)的要求(如读磁盘数据),给I/O设备发出命令
- 与操作系统上层模块进行交互,完成上层模块的要求(如上传读出的磁盘数据)
执行模式:
从驱动程序I/O操作的执行模式上看,主要有两种模式的I/O操作:异步和同步。
同步模式:类似函数调用,从应用程序发出I/O请求,通过同步的系统调用传递到操作系统内核中,操作系统内核的各个层级进行相应处理,并最终把相关的I/O操作命令转给了驱动程序。一般情况下,驱动程序完成相应的I/O操作会比较慢(相对于CPU而言),所以操作系统会让代表应用程序的进程进入等待状态,进行进程切换。但相应的I/O操作执行完毕后(操作系统通过轮询或中断方式感知),操作系统会在合适的时机唤醒等待的进程,从而进程能够继续执行。
异步I/O操作是一个效率更高的执行模式,即应用程序发出I/O请求后,并不会等待此I/O操作完成,而是继续处理应用程序的其它任务(这个任务切换会通过运行时库或操作系统来完成)。调用异步I/O操作的应用程序需要通过某种方式(比如某种异步通知机制)来确定I/O操作何时完成。这部分可以通过协程技术来实现,但目前我们不会就此展开讨论。
编写驱动程序代码需要注意规避三方面的潜在风险的技术准备措施:
- 了解硬件规范:从而能够正确地与硬件交互,并能处理访问硬件出错的情况;
- 了解操作系统,由于驱动程序与它所管理的设备会同时执行,也可能与操作系统其他模块并行访问相关共享资源,所以需要考虑同步互斥的问题(后续会深入讲解操作系统同步互斥机制),并考虑到申请资源失败后的处理;
- 理解驱动程序执行中所在的可能的上下文环境:如果是在进行中断处理(如在执行
trap_handler函数),那是在中断上下文中执行;如果是在代表进程的内核线程中执行后续的I/O操作(如收发TCP包),那是在内核线程上下文执行。这样才能写出正确的驱动程序。
首先,我们需要了解OS管理的计算机硬件系统– QEMU riscv-64 virt machine 。这表示了一台虚拟的RISC-V 64计算机,CPU的个数是可以通过参数 -cpu num 配置的,内存也是可通过参数 -m numM/G 来配置。这是标配信息。这台虚拟计算机还有很多外设信息,每个设备在物理上连接到了父设备上最后再通过总线等连接起来构成一整个设备树。QEMU 可以把它模拟的机器细节信息全都导出到dtb格式的二进制文件中,并可通过 dtc Device Tree Compiler工具转成可理解的文本文件。如想详细了解这个文件的格式说明可以参考 Devicetree Specification 。
$ qemu-system-riscv64 -machine virt -machine dumpdtb=riscv64-virt.dtb -bios default
qemu-system-riscv64: info: dtb dumped to riscv64-virt.dtb. Exiting.
$ dtc -I dtb -O dts -o riscv64-virt.dts riscv64-virt.dtb
$ less riscv64-virt.dts
#就可以看到QEMU RV64 virt计算机的详细硬件(包括各种外设)细节,包括CPU,内存,串口,时钟和各种virtio设备的信息。
一个典型的设备树如下图所示:
操作系统在启动后需要了解计算机系统中所有接入的设备,这就要有一个读取全部已接入设备信息的能力,而设备信息放在哪里,又是谁帮我们来做的呢?在 RISC-V 中,这个一般是由 bootloader,即 OpenSBI or RustSBI 固件完成的。它来完成对于包括物理内存在内的各外设的探测,将探测结果以 设备树二进制对象(DTB,Device Tree Blob) 的格式保存在物理内存中的某个地方
如果要让操作系统处理外设中断,就需要对中断控制器进行初始化设置。在RISC-V中,与外设连接的I/O控制器的一个重要组成是平台级中断控制器(Platform-Level Interrupt Controller,PLIC),它汇聚了各种外设的中断信号,并连接到CPU的外部中断引脚上。
通过RISC-V的 mie 寄存器中的 meie 位,可以控制这个引脚是否接收外部中断信号。当然,通过RISC-V中M Mode的中断委托机制,也可以在RISC-V的S Mode下,通过 sie 寄存器中的 seie 位,对中断信号是否接收进行控制
CPU可以通过MMIO方式来对PLIC进行管理,下面是一下与PLIC相关的寄存器:
寄存器 地址 功能描述
Priority 0x0c00_0000 设置特定中断源的优先级
Pending 0x0c00_1000 包含已触发(正在处理)的中断列表
Enable 0x0c00_2000 启用/禁用某些中断源
Threshold 0x0c20_0000 设置中断能够触发的阈值
Claim 0x0c20_0004 按优先级顺序返回下一个中断
Complete 0x0c20_0004 写操作表示完成对特定中断的处理
在QEMU qemu/include/hw/riscv/virt.h 的源码中,可以看到
enum {
UART0_IRQ = 10,
RTC_IRQ = 11,
VIRTIO_IRQ = 1, /* 1 to 8 */
VIRTIO_COUNT = 8,
PCIE_IRQ = 0x20, /* 32 to 35 */
VIRTIO_NDEV = 0x35 /* Arbitrary maximum number of interrupts */
};
可以看到串口UART0的中断号是10,virtio设备的中断号是1~8。通过 dtc Device Tree Compiler工具生成的文本文件,我们也可以发现上述中断信号信息,以及基于MMIO的外设寄存器信息。在后续的驱动程序中,这些信息我们可以用到。
操作系统如要响应外设的中断,需要做两方面的初始化工作。
-
首先是完成第三章讲解的中断初始化过程,并需要把
sie寄存器中的seie位设置为1,让CPU能够接收通过PLIC传来的外部设备中断信号。 -
然后还需要通过MMIO方式对PLIC的寄存器进行初始设置,才能让外设产生的中断传到CPU处。
其主要操作包括
- 设置外设中断的优先级
- 设置外设中断的阈值,优先级小于等于阈值的中断会被屏蔽
- 激活外设中断,即把
Enable寄存器的外设中断编号为索引的位设置为1
但外设产生中断后,CPU并不知道具体是哪个设备传来的中断,这可以通过读PLIC的 Claim 寄存器来了解。 Claim 寄存器会返回PLIC接收到的优先级最高的中断;如果没有外设中断产生,读 Claim 寄存器会返回 0。
完成上述前期准备工作后,我们就可以开始设计实现驱动程序程序了。 首先我们要管理是物理上存在的串口设备。 串口(Universal Asynchronous Receiver-Transmitter,简称UART)是一种在嵌入式系统中常用的用于传输、接收系列数据的外部设备。串行数据传输是逐位(bit)顺序发送数据的过程。
我们在第一章其实就接触了串口,但当时是通过RustSBI来帮OS完成对串口的访问,即OS只需发出两种SBI调用请求就可以输出和获取字符了。但这种便捷性是有代价的。比如OS在调用获取字符的SBI调用请求后,RustSBI如果没收到串口字符,会返回 -1 ,这样OS只能采用类似轮询的方式来继续查询。到第七章为止的串口驱动不支持中断是导致在多进程情况下,系统效率低下的主要原因之一。大家也不要遗憾,我们的第一阶段的目标是 Just do it ,先把OS做出来,在第二阶段再逐步优化改进。
接下来,我们就需要开始尝试脱离RustSBI的帮助,在操作系统中完成支持中断机制的串口驱动。
通过查找 dtc 工具生成的 riscv64-virt.dts 文件,我们可以看到串口设备相关的MMIO模式的寄存器信息和中断相关信息。
...
chosen {
bootargs = [00];
stdout-path = "/uart@10000000";
};
uart@10000000 {
interrupts = <0x0a>;
interrupt-parent = <0x02>;
clock-frequency = <0x384000>;
reg = <0x00 0x10000000 0x00 0x100>;
compatible = "ns16550a";
};
chosen 节点的内容表明字符输出会通过串口设备打印出来。uart@10000000 节点表明串口设备中寄存器的MMIO起始地址为 0x10000000 ,范围在 0x00~0x100 区间内,中断号为 0x0a 。 clock-frequency 表示时钟频率,其值为0x38400 ,即3.6864 MHz。 [](https://rcore-os.github.io/rCore-Tutorial-Book-v3/chapter8/2device-driver-1.html#id10)compatible =“ ns16550a” 表示串口的硬件规范兼容NS16550A。
在如下情况下,串口会产生中断:
- 有新的输入数据进入串口的接收缓存
- 串口完成了缓存中数据的发送
- 串口发送出现错误
这里我们仅关注有输入数据时串口产生的中断。
了解QEMU模拟的兼容NS16550A硬件规范是写驱动程序的准备工作。在 UART 中,可访问的 I/O寄存器一共有8个。访问I/O寄存器的方法把串口寄存器的MMIO起始地址加上偏移量,就是各个寄存器的MMIO地址了。
先看串口输出,由于不设置和处理输出后产生中断的情况,使得整个输出操作比较简单。
即向偏移量为 0 的串口控制寄存器的MMIO地址写8位字符即可。
let ptr = UART_ADDR as *mut u8;
ptr.add(0).write_volatile(c);
但对于串口输入的处理,由于要考虑中断,相对就要复杂一些。对于操作系统的一般处理过程是,
- 首先是能接收中断,即在
trap_handler中通过访问scause寄存器,能够识别出有外部中断产生。 - 然后再进一步通过读PLIC的
Claim寄存器来了解是否是收到了串口发来的输入中断。 - 如果确定是,就通过对串口寄存器的偏移量为
0的串口控制寄存器的MMIO地址进行读一个字节的操作, - 从而获得通过串口输入的字符。
在我们的具体实现中,与上述的一般中断处理过程不太一样。
- 首先操作系统通过自定义的
SBI_DEVICE_HANDLERSBI调用,告知RustSBI在收到外部中断后, - 要跳转到到的操作系统中处理外部中断的函数
device_trap_handler。 - 这样,在外部中断产生后,先由RustSBI在M Mode下接收的,并转到S Mode,交由
device_trap_handler内核函数进一步处理。 - 接下来就是 PLIC识别出是串口中断号
10后, - 最终交由
uart::InBuffer结构的peinding函数处理。
let c = Uart::new().get().unwrap();
self.buffer[self.write_idx] = c;
self.write_idx = (self.write_idx + 1) % 128;
这个 uart::InBuffer 结构实际上是一个环形队列,新的输入数据会覆盖队列中旧的输入数据。
在目前的操作系统实现中,当一个进程通过 sys_read 系统调用来获取串口字符时,并没有用上中断机制。但一个进程读不到字符的时候,将会被操作系统调度到就绪队列的尾部,等待下一次执行的时刻。这其实就是一种变相的轮询方式来获取串口的输入字符。这里其实是可以对进程管理做的一个改进,来避免进程通过轮询的方式检查串口字符输入。
os进程串口输入改进
如果一个进程通过系统调用想获取串口输入,但此时串口还没有输入的字符,那么就设置一个进程等待串口输入的等待队列,然后把当前进程设置等待状态,并挂在这个等待队列上,把CPU让给其它就绪进程执行。当产生串口输入中断后,操作系统将查找等待串口输入的等待队列上的进程,把它唤醒并加入到就绪队列中。这样但这个进程再次执行时,就可以获取到串口数据了。
驱动程序(终章)
本节主要介绍了QMU模拟的RISC-V计算机中的virtio设备的架构和重要组成部分
以及面向virtio设备的驱动程序的主要功能
并对virtio-blk设备及其驱动程序,virtio-gpu设备及其驱动程序进行了比较深入的分析。
一个完整的virtio-blk的I/O写请求由三部分组成,包括表示I/O写请求信息的结构 BlkReq ,要传输的数据块 buf,一个表示设备响应信息的结构 BlkResp 。这三部分需要三个描述符来表示;
(驱动程序处理)接着调用 VirtQueue.add 函数,从描述符表中申请三个空闲描述符,每项指向一个内存块,填写上述三部分的信息,并将三个描述符连接成一个描述符链表;
(驱动程序处理)接着调用 VirtQueue.notify 函数,写MMIO模式的 queue_notify 寄存器,即向 virtio-blk设备发出通知;
(设备处理)virtio-blk设备收到通知后,通过比较 last_avail (初始为0)和 AvailRing 中的 idx 判断是否有新的请求待处理(如果 last_vail 小于 AvailRing 中的 idx ,则表示有新请求)。如果有,则 last_avail 加1,并以 last_avail 为索引从描述符表中找到这个I/O请求对应的描述符链来获知完整的请求信息,并完成存储块的I/O写操作;
(设备处理)设备完成I/O写操作后(包括更新包含 BlkResp 的Descriptor),将已完成I/O的描述符放入UsedRing对应的ring项中,并更新idx,代表放入一个响应;如果设置了中断机制,还会产生中断来通知操作系统响应中断;
(驱动程序处理)驱动程序可用轮询机制查看设备是否有响应(持续调用 VirtQueue.can_pop 函数),通过比较内部的 VirtQueue.last_used_idx 和 VirtQueue.used.idx 判断是否有新的响应。如果有,则取出响应(并更新 last_used_idx ),将完成响应对应的三项Descriptor回收,最后将结果返回给用户进程。当然,也可通过中断机制来响应