diff --git a/NSF_1.gif b/NSF_1.gif
new file mode 100644
index 0000000..0395652
Binary files /dev/null and b/NSF_1.gif differ
diff --git a/NSF_2.gif b/NSF_2.gif
new file mode 100644
index 0000000..ebd73dd
Binary files /dev/null and b/NSF_2.gif differ
diff --git a/NSF_3.gif b/NSF_3.gif
new file mode 100644
index 0000000..948defa
Binary files /dev/null and b/NSF_3.gif differ
diff --git a/README.md b/README.md
index 9969c32..eef32aa 100644
--- a/README.md
+++ b/README.md
@@ -1,5 +1,61 @@
-# PointNetVlad-Pytorch
-Unofficial PyTorch implementation of PointNetVlad (https://github.com/mikacuy/pointnetvlad)
+# Self-Supervised Visual Place Recognition by Mining Temporal and Feature Neighborhoods
+[Chao Chen](https://scholar.google.com/citations?hl=en&user=WOBQbwQAAAAJ), [Xinhao Liu](https://gaaaavin.github.io), [Xuchu Xu](https://www.xuchuxu.com), [Li Ding](https://www.hajim.rochester.edu/ece/lding6/), [Yiming Li](https://scholar.google.com/citations?user=i_aajNoAAAAJ), [Ruoyu Wang](https://github.com/ruoyuwangeel4930), [Chen Feng](https://scholar.google.com/citations?user=YeG8ZM0AAAAJ)
+
+**"A Novel self-supervised VPR model capable of retrieving positives from various orientations."**
+
+
+[](https://svgshare.com/i/Zhy.svg)
+[](https://github.com/Joechencc/TF-VPR)
+[](https://github.com/Joechencc/TF-VPR/stargazers/)
+
+
+
+
+## Abstract
+
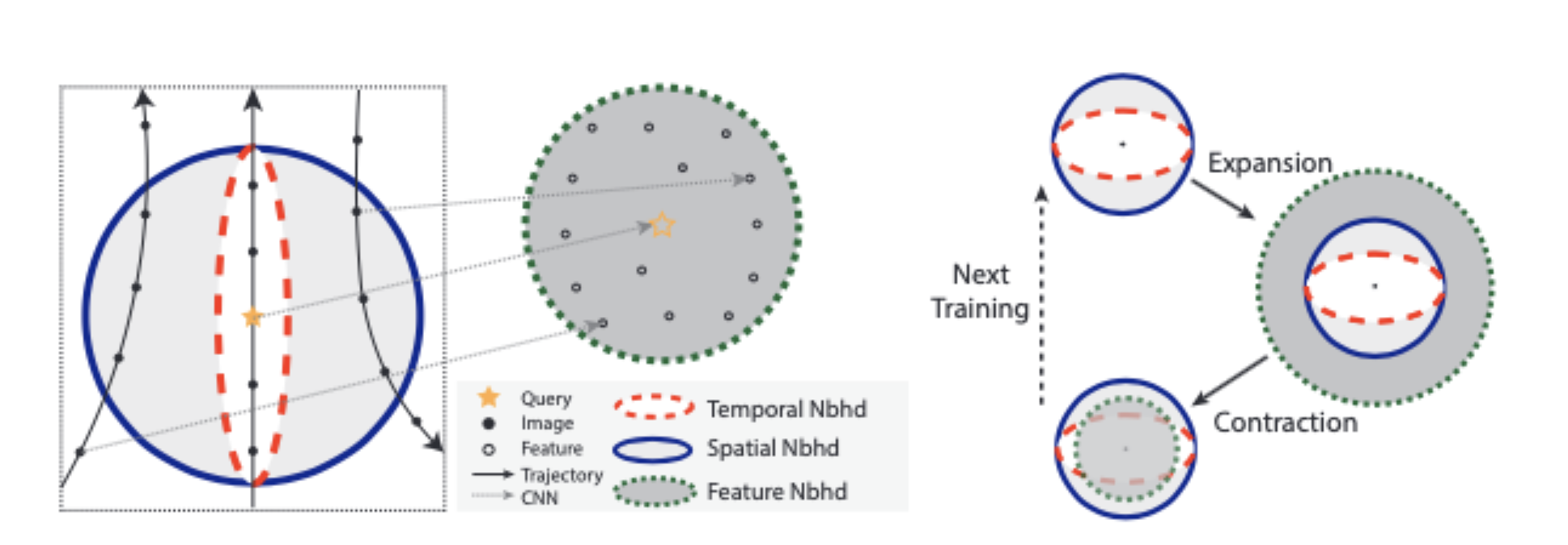
+Visual place recognition (VPR) using deep networks has achieved state-of-the-art performance. However, most of the related approaches require a training set with ground truth sensor poses to obtain the positive and negative samples of each observation's spatial neighborhoods. When such knowledge is unknown, the temporal neighborhoods from a sequentially collected data stream could be exploited for self-supervision, although with suboptimal performance. Inspired by noisy label learning, we propose a novel self-supervised VPR framework that uses both the temporal neighborhoods and the learnable feature neighborhoods to discover the unknown spatial neighborhoods. Our method follows an iterative training paradigm which alternates between: (1) representation learning with data augmentation, (2) positive set expansion to include the current feature space neighbors, and (3) positive set contraction via geometric verification. We conduct comprehensive experiments on both simulated and real datasets, with input of both images and point clouds. The results demonstrate that our method outperforms the baselines in both recall rate, robustness, and a novel metric we proposed for VPR, the orientation diversity.
+
+## Dataset
+
+Download links:
+- For Pointcloud: Please refer to DeepMapping paper, https://github.com/ai4ce/PointCloudSimulator
+- For Real-world Panoramic RGB: https://drive.google.com/drive/u/0/folders/1ErXzIx0je5aGSRFbo5jP7oR8gPrdersO
+
+You could find more detailed documents on our [website](https://github.com/Joechencc/TF-VPR/edit/RGB_SPTM/README.md)!
+
+TF-VPR follows the same file structure as the [PointNetVLAD](https://github.com/mikacuy/pointnetvlad):
+```
+TF-VPR
+├── loss # loss function
+├── models # network model
+| ├── PointNetVlad.py # PointNetVLAD network model
+| ├── ImageNetVlad.py # NetVLAD network model
+| ...
+├── generating_queries # Preprocess the data, initial the label, and generate Pickle file
+| ├── generate_test_RGB_sets.py # Generate the test pickle file
+| ├── generate_training_tuples_RGB_baseline_batch.py # Generate the train pickle file
+| ...
+├── results # Results are saved here
+├── config.py # Config file
+├── evaluate.py # evaluate file
+├── loading_pointcloud.py # file loading script
+├── train_pointnetvlad.py # Main file to train TF-VPR
+| ...
+```
+Point cloud TF-VPR result:
+
+
+
+RGB TF-VPR result:
+
+
+
+Real-world RGB TF-VPR result:
+
+
+
+# Note
I kept almost everything not related to tensorflow as the original implementation.
The main differences are:
@@ -7,34 +63,50 @@ The main differences are:
* Configuration file (config.py)
* Evaluation on the eval dataset after every epochs
-This implementation achieved an average top 1% recall on oxford baseline of 84.81%
-
### Pre-Requisites
-* PyTorch 0.4.0
-* tensorboardX
+- PyTorch 0.4.0
+- tensorboardX
+- open3d-python 0.4
+- scipy
+- matplotlib
+- numpy
### Generate pickle files
```
cd generating_queries/
# For training tuples in our baseline network
-python generate_training_tuples_baseline.py
-
-# For training tuples in our refined network
-python generate_training_tuples_refine.py
+python generate_training_tuples_RGB_baseline_batch.py
# For network evaluation
-python generate_test_sets.py
+python generate_test_RGB_sets.py
```
### Train
```
-python train_pointnetvlad.py --dataset_folder $DATASET_FOLDER
+python train_pointnetvlad.py
```
### Evaluate
```
-python evaluate.py --dataset_folder $DATASET_FOLDER
+python evaluate.py
```
Take a look at train_pointnetvlad.py and evaluate.py for more parameters
+
+## Benchmark
+
+We implement SPTM, TF-VPR, and supervise version, please check the other branches for reference
+
+
diff --git a/config.py b/config.py
index 55289a2..d7e4329 100644
--- a/config.py
+++ b/config.py
@@ -1,13 +1,18 @@
# GLOBAL
NUM_POINTS = 256
-FEATURE_OUTPUT_DIM = 3839
+GRID_X = 1080
+GRID_Y = 1920
+SIZED_GRID_X = 64*4
+SIZED_GRID_Y = 64
+FEATURE_OUTPUT_DIM = 512
RESULTS_FOLDER = "results/"
OUTPUT_FILE = "results/results.txt"
+file_name = "Goffs"
LOG_DIR = 'log/'
MODEL_FILENAME = "model.ckpt"
-DATASET_FOLDER = '../../benchmark_datasets/'
+DATASET_FOLDER = '/mnt/NAS/home/cc/data/habitat/Goffs'
# TRAIN
BATCH_NUM_QUERIES = 2
@@ -18,7 +23,7 @@
BASE_LEARNING_RATE = 0.000005
MOMENTUM = 0.9
OPTIMIZER = 'ADAM'
-MAX_EPOCH = 20
+MAX_EPOCH = 50
MARGIN_1 = 0.5
MARGIN_2 = 0.2
@@ -31,9 +36,10 @@
TRAIN_FILE = 'generating_queries/training_queries_baseline.pickle'
TEST_FILE = 'generating_queries/test_queries_baseline.pickle'
+scene_list = ['Goffs']#,'Nimmons','Reyno','Spotswood','Springhill','Stilwell']
# LOSS
-LOSS_FUNCTION = 'quadruplet'
+LOSS_FUNCTION = 'triplet'
LOSS_LAZY = True
TRIPLET_USE_BEST_POSITIVES = False
LOSS_IGNORE_ZERO_BATCH = False
@@ -45,7 +51,7 @@
EVAL_DATABASE_FILE = 'generating_queries/evaluation_database.pickle'
EVAL_QUERY_FILE = 'generating_queries/evaluation_query.pickle'
-
+INIT_TRUST = 3
def cfg_str():
out_string = ""
diff --git a/evaluate.py b/evaluate.py
index 4ece9da..5ebb7ac 100644
--- a/evaluate.py
+++ b/evaluate.py
@@ -4,7 +4,7 @@
import socket
import importlib
import os
-os.environ["CUDA_VISIBLE_DEVICES"] = "3"
+os.environ["CUDA_VISIBLE_DEVICES"] = "2"
import sys
import torch
import torch.nn as nn
@@ -45,38 +45,28 @@ def evaluate():
print("ave_one_percent_recall:"+str(ave_one_percent_recall))
-def evaluate_model(model,save=False):
+def evaluate_model(model,optimizer,epoch,scene_index,save=False,full_pickle=False):
if save:
torch.save({
'state_dict': model.state_dict(),
+ 'optimizer': optimizer.state_dict(),
+ 'epoch': epoch,
}, cfg.LOG_DIR + "checkpoint.pth.tar")
- #checkpoint = torch.load(cfg.LOG_DIR + "checkpoint.pth.tar")
- #saved_state_dict = checkpoint['state_dict']
- #model.load_state_dict(saved_state_dict)
- DATABASE_SETS = get_sets_dict(cfg.EVAL_DATABASE_FILE)
-
- QUERY_SETS = get_sets_dict(cfg.EVAL_QUERY_FILE)
- '''
- QUERY_SETS = []
- for i in range(4):
- QUERY = {}
- for j in range(len(QUERY_SETS_temp)//4):
- #QUERY[len(QUERY.keys())] = {"query":QUERY_SETS_temp[i][j]['query'],
- # "x":float(QUERY_SETS_temp[i][j]['x']),
- # "y":float(QUERY_SETS_temp[i][j]['y']),
- # }
- QUERY[len(QUERY.keys())] = QUERY_SETS_temp[i][j]
- QUERY_SETS.append(QUERY)
- '''
+ print("epoch:"+str(epoch))
+
+ if full_pickle:
+ DATABASE_SETS = get_sets_dict('generating_queries/evaluation_database_full.pickle')
+ QUERY_SETS = get_sets_dict('generating_queries/evaluation_query_full.pickle')
+ else:
+ DATABASE_SETS = get_sets_dict(cfg.EVAL_DATABASE_FILE)
+ QUERY_SETS = get_sets_dict(cfg.EVAL_QUERY_FILE)
+
+ cfg.RESULTS_FOLDER = os.path.join("results/", cfg.scene_list[scene_index])
+
if not os.path.exists(cfg.RESULTS_FOLDER):
os.mkdir(cfg.RESULTS_FOLDER)
- recall = np.zeros(25)
- count = 0
- similarity = []
- one_percent_recall = []
-
DATABASE_VECTORS = []
QUERY_VECTORS = []
@@ -86,49 +76,45 @@ def evaluate_model(model,save=False):
for j in range(len(QUERY_SETS)):
QUERY_VECTORS.append(get_latent_vectors(model, QUERY_SETS[j]))
+ recall_1 = 0#np.zeros(int(round(len_tr/1000)))
+ recall_5 = 0#np.zeros(int(round(len_tr/200)))
+ recall_10 = 0#np.zeros(int(round(len_tr/100)))
+ ### Save Evaluate vectors
+ if full_pickle:
+ return DATABASE_VECTORS
+
+ else:
+ file_name = os.path.join(cfg.RESULTS_FOLDER, "database"+str(epoch)+".npy")
+ np.save(file_name, np.array(DATABASE_VECTORS))
+ print("saving for DATABASE_VECTORS to "+str(file_name))
+
#############
- for m in range(len(QUERY_SETS)):
- for n in range(len(QUERY_SETS)):
- if (m == n):
- continue
- pair_recall, pair_similarity, pair_opr = get_recall(
- m, n, DATABASE_VECTORS, QUERY_VECTORS, QUERY_SETS)
- recall += np.array(pair_recall)
- count += 1
- one_percent_recall.append(pair_opr)
- for x in pair_similarity:
- similarity.append(x)
- #########
-
-
- ### Save Evaluate vectors
- file_name = os.path.join(cfg.RESULTS_FOLDER, "database.npy")
- np.save(file_name, np.array(DATABASE_VECTORS))
- print("saving for DATABASE_VECTORS to "+str(file_name))
-
- ave_recall = recall / count
- # print(ave_recall)
- # print(similarity)
- average_similarity = np.mean(similarity)
- # print(average_similarity)
+ pair_recall_1, pair_recall_5, pair_recall_10= get_recall(
+ 0, 0, DATABASE_VECTORS, QUERY_VECTORS, QUERY_SETS)
+ recall_1 = np.array(pair_recall_1)
+ recall_5 = np.array(pair_recall_5)
+ recall_10 = np.array(pair_recall_10)
+
+ print("recall_1:"+str(recall_1))
- ave_one_percent_recall = np.mean(one_percent_recall)
- # print(ave_one_percent_recall)
+ #########
- #print("os.path.join(/home/cc/PointNet-torch2,cfg.OUTPUT_FILE,log.txt):"+str(os.path.join("/home/cc/PointNet-torch2",cfg.OUTPUT_FILE,"log.txt")))
- #assert(0)
- with open(os.path.join("/home/cc/Supervised-PointNetVlad",cfg.OUTPUT_FILE), "w") as output:
- output.write("Average Recall @N:\n")
- output.write(str(ave_recall))
+ ave_recall_1 = recall_1 #/ count
+ ave_recall_5 = recall_5 #/ count
+ ave_recall_10 = recall_10 #/ count
+
+ with open(os.path.join(cfg.OUTPUT_FILE), "w") as output:
+ output.write("Average Recall @1:\n")
+ output.write(str(ave_recall_1)+"\n")
+ output.write("Average Recall @5:\n")
+ output.write(str(ave_recall_5)+"\n")
+ output.write("Average Recall @10:\n")
+ output.write(str(ave_recall_10)+"\n")
output.write("\n\n")
- output.write("Average Similarity:\n")
- output.write(str(average_similarity))
- output.write("\n\n")
- output.write("Average Top 1% Recall:\n")
- output.write(str(ave_one_percent_recall))
-
- return ave_one_percent_recall
+
+ return ave_recall_1, ave_recall_5, ave_recall_10
+
def get_latent_vectors(model, dict_to_process):
@@ -145,20 +131,21 @@ def get_latent_vectors(model, dict_to_process):
file_names = []
for index in file_indices:
file_names.append(dict_to_process[index]["query"])
- queries = load_pc_files(file_names,True)
-
+
+ queries = load_image_files(file_names,False)
+
with torch.no_grad():
feed_tensor = torch.from_numpy(queries).float()
feed_tensor = feed_tensor.unsqueeze(1)
feed_tensor = feed_tensor.to(device)
- out = model(feed_tensor)
-
+ out= model(feed_tensor)
+
out = out.detach().cpu().numpy()
out = np.squeeze(out)
#out = np.vstack((o1, o2, o3, o4))
q_output.append(out)
-
+
q_output = np.array(q_output)
if(len(q_output) != 0):
q_output = q_output.reshape(-1, q_output.shape[-1])
@@ -171,7 +158,7 @@ def get_latent_vectors(model, dict_to_process):
for index in file_indices:
file_names.append(dict_to_process[index]["query"])
- queries = load_pc_files(file_names,True)
+ queries = load_image_files(file_names,False)
with torch.no_grad():
feed_tensor = torch.from_numpy(queries).float()
@@ -187,46 +174,69 @@ def get_latent_vectors(model, dict_to_process):
q_output = output
model.train()
-
+
return q_output
def get_recall(m, n, DATABASE_VECTORS, QUERY_VECTORS, QUERY_SETS):
+ database_output = DATABASE_VECTORS[m] #2048*256
+ queries_output = QUERY_VECTORS[n] #10*256
+
- database_output = DATABASE_VECTORS[m]
- queries_output = QUERY_VECTORS[n]
- # print(len(queries_output))
database_nbrs = KDTree(database_output)
num_neighbors = 25
- recall = [0] * num_neighbors
-
- top1_similarity_score = []
- one_percent_retrieved = 0
- threshold = max(int(round(len(database_output)/100.0)), 1)
-
- num_evaluated = 0
- for i in range(len(queries_output)):
- true_neighbors = QUERY_SETS[n][i][m]
- if(len(true_neighbors) == 0):
- continue
- num_evaluated += 1
- distances, indices = database_nbrs.query(
- np.array([queries_output[i]]),k=num_neighbors)
- for j in range(len(indices[0])):
- if indices[0][j] in true_neighbors:
- if(j == 0):
- similarity = np.dot(
- queries_output[i], database_output[indices[0][j]])
- top1_similarity_score.append(similarity)
- recall[j] += 1
- break
-
- if len(list(set(indices[0][0:threshold]).intersection(set(true_neighbors)))) > 0:
- one_percent_retrieved += 1
-
- one_percent_recall = (one_percent_retrieved/float(num_evaluated))*100
- recall = (np.cumsum(recall)/float(num_evaluated))*100
- return recall, top1_similarity_score, one_percent_recall
+
+ recalls = []
+ similarity_scores = []
+ N_percent_recalls = []
+
+ n_values = [1,5,10,20]
+ for value in n_values:
+
+ num_evaluated = 0
+ recall_N_per = 0
+ for i in range(len(queries_output)):
+
+ true_neighbors = QUERY_SETS[n][i][m]
+
+ if(len(true_neighbors) == 0):
+ continue
+ num_evaluated += 1
+ distances, indices = database_nbrs.query(
+ np.array([queries_output[i]]),k=value+11)
+
+
+ compare_a = indices[0][0:50].tolist()
+ k_nearest = 10
+ pos_index_range = list(range(-k_nearest//2, (k_nearest//2)+1))
+ for pos_index in pos_index_range:
+ try:
+ compare_a.remove(pos_index+i)
+ except:
+ pass
+ compare_a = compare_a[:(value)]
+
+ compare_b = true_neighbors
+ try:
+ compare_b.remove(i)
+ except:
+ pass
+ compare_a = set(compare_a)
+
+ compare_b = set(compare_b)
+ if len(list(compare_a.intersection(compare_b))) > 0:
+ recall_N_per += 1
+
+ if float(num_evaluated)!=0:
+ recall_N = (recall_N_per/float(num_evaluated))*100
+
+ else:
+ recall_N = 0
+ recalls.append(recall_N)
+
+ recall_1, recall_5, recall_10 = recalls[0], recalls[1], recalls[2]
+
+ return recall_1, recall_5, recall_10#, top1_similarity_score, top5_similarity_score, top10_similarity_score, one_percent_recall, five_percent_recall, ten_percent_recall
if __name__ == "__main__":
@@ -249,8 +259,6 @@ def get_recall(m, n, DATABASE_VECTORS, QUERY_VECTORS, QUERY_SETS):
help='PointNetVlad Dataset Folder')
FLAGS = parser.parse_args()
- #BATCH_SIZE = FLAGS.batch_size
- #cfg.EVAL_BATCH_SIZE = FLAGS.eval_batch_size
cfg.NUM_POINTS = 4096
cfg.FEATURE_OUTPUT_DIM = 256
cfg.EVAL_POSITIVES_PER_QUERY = FLAGS.positives_per_query
@@ -267,6 +275,9 @@ def get_recall(m, n, DATABASE_VECTORS, QUERY_VECTORS, QUERY_SETS):
cfg.OUTPUT_FILE = cfg.RESULTS_FOLDER + 'results.txt'
cfg.MODEL_FILENAME = "model.ckpt"
- cfg.DATASET_FOLDER = FLAGS.dataset_folder
+ # cfg.DATASET_FOLDER = FLAGS.dataset_folder
+ cfg.RESULTS_FOLDER = os.path.join("results/", cfg.scene_names[scene_index])
+ if not os.path.isdir(cfg.RESULTS_FOLDER):
+ os.mkdir(cfg.RESULTS_FOLDER)
evaluate()
diff --git a/generating_queries/generate_test_RGB_sets.py b/generating_queries/generate_test_RGB_sets.py
new file mode 100644
index 0000000..95a8066
--- /dev/null
+++ b/generating_queries/generate_test_RGB_sets.py
@@ -0,0 +1,207 @@
+import os
+import sys
+import pickle
+import random
+import set_path
+
+import numpy as np
+import pandas as pd
+from sklearn.neighbors import KDTree
+
+import config as cfg
+
+import scipy.io as sio
+import torch
+import json
+
+##########################################
+
+def output_to_file(output, filename):
+ with open(filename, 'wb') as handle:
+ pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
+ print("Done ", filename)
+
+#########################################
+def construct_query_dict(df_centroids, df_database, folder_num, traj_len, filename_train, filename_test, nn_ind, r_mid, r_ind, test=False, evaluate_all=False):
+ database_trees = []
+ test_trees = []
+ if not evaluate_all:
+ tree = KDTree(df_centroids[['x','y']])
+ ind_nn = tree.query_radius(df_centroids[['x','y']],r=nn_ind)
+ ind_r = tree.query_radius(df_centroids[['x','y']], r=r_ind)
+ queries_sets = []
+ database_sets = []
+
+ #for folder in range(folder_num):
+ queries = {}
+ for i in range(len(df_centroids)):
+ #temp_indx = folder*len(df_centroids)//folder_num + i
+ temp_indx = i
+ query = df_centroids.iloc[temp_indx]["file"]
+ #print("folder:"+str(folder))
+ #print("query:"+str(query))
+ if not evaluate_all:
+ queries[len(queries.keys())] = {"query":query,
+ "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
+ else:
+ queries[len(queries.keys())] = {"query":query}
+
+ queries_sets.append(queries)
+ if not evaluate_all:
+ test_tree = KDTree(df_centroids[['x','y']])
+ test_trees.append(test_tree)
+
+ ###############################
+ #for folder in range(folder_num):
+ dataset = {}
+ for i in range(len(df_database)):
+ #temp_indx = folder*len(df_database)//folder_num + i
+ temp_indx = i
+ data = df_database.iloc[temp_indx]["file"]
+ if not evaluate_all:
+ dataset[len(dataset.keys())] = {"query":data,
+ "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y']) }
+ else:
+ dataset[len(dataset.keys())] = {"query":data}
+ database_sets.append(dataset)
+ if not evaluate_all:
+ database_tree = KDTree(df_database[['x','y']])
+ database_trees.append(database_tree)
+ ##################################
+ if test:
+ if not evaluate_all:
+ #for i in range(len(database_sets)):
+ tree = database_trees[0]
+ #for j in range(len(queries_sets)):
+ #if(i == j):
+ # continue
+ #print("len(queries_sets[j].keys():"+str(len(queries_sets[j].keys())))
+ #assert(0)
+ for key in range(len(queries_sets[0].keys())):
+ coor = np.array(
+ [[queries_sets[0][key]["x"],queries_sets[0][key]["y"]]])
+ index = tree.query_radius(coor, r=r_mid)
+ # indices of the positive matches in database i of each query (key) in test set j
+ queries_sets[0][key][0] = index[0].tolist()
+ else:
+ pass
+
+ output_to_file(queries_sets, filename_test)
+ output_to_file(database_sets, filename_train)
+
+def generate(scene_index, evaluate_all = False, inside=True):
+ base_path = "/mnt/NAS/home/cc/data/habitat_4/train"
+ runs_folder = cfg.scene_list[scene_index]
+ #runs_folder = "Goffs"
+ pre_dir = os.path.join(base_path, runs_folder)
+
+ nn_ind = 0.2
+ r_mid = 0.2
+ r_ind = 0.6
+
+ filename = "gt_pose.mat"
+
+ folders = list(sorted(os.listdir(pre_dir)))
+
+ if evaluate_all == False:
+ index_list = list(range(len(folders)))
+ else:
+ index_list = list(range(len(folders)))
+
+ fold_list = []
+ for index in index_list:
+ fold_list.append(folders[index])
+
+ all_files = []
+ for fold in fold_list:
+ files_ = []
+ files = list(sorted(os.listdir(os.path.join(pre_dir, fold))))
+ files.remove('gt_pose.mat')
+ # print("len(files):"+str(len(files)))
+ for ind in range(len(files)):
+ file_ = "panoimg_"+str(ind)+".png"
+ files_.append(os.path.join(pre_dir, fold, file_))
+ all_files.extend(files_)
+ # all_files.remove('trajectory.mp4')
+ # all_files = [i for i in all_files if not i.endswith(".npy")]
+
+ traj_len = len(all_files)
+ file_size = traj_len/len(fold_list)
+
+ # Initialize pandas DataFrame
+ if evaluate_all:
+ df_train = pd.DataFrame(columns=['file'])
+ df_test = pd.DataFrame(columns=['file'])
+ else:
+ df_train = pd.DataFrame(columns=['file','x','y'])
+ df_test = pd.DataFrame(columns=['file','x','y'])
+
+ if not evaluate_all:
+ df_files_test = []
+ df_files_train =[]
+
+ df_locations_tr_x = []
+ df_locations_tr_y = []
+
+ df_locations_ts_x = []
+ df_locations_ts_y = []
+
+ # print("os.path.join(pre_dir,filename):"+str(os.path.join(pre_dir,filename)))
+ df_locations = torch.zeros((traj_len, 3), dtype = torch.float)
+ for count, fold in enumerate(fold_list):
+ data = sio.loadmat(os.path.join(pre_dir,fold,filename))
+ df_location = data['pose']
+ df_locations[int(count*file_size):int((count+1)*file_size)] = torch.tensor(df_location, dtype = torch.float)
+
+ # df_locations = df_locations['pose']
+ # df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
+ else:
+ df_files_test = []
+ df_files_train =[]
+
+ #n-40 Training 40 testing
+ test_sample = len(fold_list)*10
+ test_index = random.choices(range(traj_len), k=test_sample)
+ train_index = list(range(traj_len))
+ #for i in test_index:
+ # train_index.pop(i)
+ if not evaluate_all:
+ df_locations_tr_x.extend(list(df_locations[train_index,0]))
+ df_locations_tr_y.extend(list(df_locations[train_index,2]))
+
+ df_locations_ts_x.extend(list(df_locations[test_index,0]))
+ df_locations_ts_y.extend(list(df_locations[test_index,2]))
+
+ for indx in range(traj_len):
+ # file_ = 'panoimg_'+str(indx)+'.png'
+ if indx in test_index:
+ df_files_test.append(all_files[indx])
+ df_files_train.append(all_files[indx])
+
+ if not evaluate_all:
+ df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
+ columns =['file','x', 'y'])
+ df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
+ columns =['file','x', 'y'])
+ else:
+ df_train = pd.DataFrame(list(zip(df_files_train)),
+ columns =['file'])
+ df_test = pd.DataFrame(list(zip(df_files_test)),
+ columns =['file'])
+ print("Number of training submaps: "+str(len(df_train['file'])))
+ print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
+
+
+ #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
+ if inside == False:
+ if not evaluate_all:
+ construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database.pickle", "generating_queries/evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
+ else:
+ construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database_full.pickle", "generating_queries/evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
+ else:
+ if not evaluate_all:
+ construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database.pickle", "evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
+ else:
+ construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database_full.pickle", "evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
+if __name__ == "__main__":
+ generate(1, evaluate_all=True)
diff --git a/generating_queries/generate_test_cc_sets.py b/generating_queries/generate_test_cc_sets.py
deleted file mode 100644
index 5cf9df6..0000000
--- a/generating_queries/generate_test_cc_sets.py
+++ /dev/null
@@ -1,159 +0,0 @@
-import os
-import pickle
-import random
-import set_path
-
-import numpy as np
-import pandas as pd
-from sklearn.neighbors import KDTree
-
-import config as cfg
-
-import scipy.io as sio
-import torch
-
-BASE_DIR = os.path.dirname(os.path.abspath(__file__))
-base_path = cfg.DATASET_FOLDER
-
-runs_folder = "dm_data"
-filename = "gt_pose.mat"
-pointcloud_fols = "/pointcloud_20m_10overlap/"
-
-print("cfg.DATASET_FOLDER:"+str(cfg.DATASET_FOLDER))
-
-cc_dir = "/home/cc/"
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-
-folders = []
-
-# All runs are used for training (both full and partial)
-index_list = [11,14,15,17]
-print("Number of runs: "+str(len(index_list)))
-for index in index_list:
- print("all_folders[index]:"+str(all_folders[index]))
- folders.append(all_folders[index])
-print(folders)
-
-
-#####For training and test data split#####
-
-def check_in_test_set(northing, easting, points, x_width, y_width):
- in_test_set = False
- for point in points:
- if(point[0]-x_width < northing and northing < point[0]+x_width and point[1]-y_width < easting and easting < point[1]+y_width):
- in_test_set = True
- break
- return in_test_set
-##########################################
-
-def output_to_file(output, filename):
- with open(filename, 'wb') as handle:
- pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
- print("Done ", filename)
-
-#########################################
-def construct_query_dict(df_centroids, df_database, folder_num, filename_train, filename_test, test=False):
- database_trees = []
- test_trees = []
- tree = KDTree(df_centroids[['x','y']])
- ind_nn = tree.query_radius(df_centroids[['x','y']],r=15)
- ind_r = tree.query_radius(df_centroids[['x','y']], r=50)
- queries_sets = []
- database_sets = []
- for folder in range(folder_num):
- queries = {}
- for i in range(len(df_centroids)//folder_num):
- temp_indx = folder*len(df_centroids)//folder_num + i
- query = df_centroids.iloc[temp_indx]["file"]
- #print("folder:"+str(folder))
- #print("query:"+str(query))
- queries[len(queries.keys())] = {"query":query,
- "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
- queries_sets.append(queries)
- test_tree = KDTree(df_centroids[['x','y']])
- test_trees.append(test_tree)
-
- for folder in range(folder_num):
- dataset = {}
- for i in range(len(df_database)//folder_num):
- temp_indx = folder*len(df_database)//folder_num + i
- data = df_database.iloc[temp_indx]["file"]
- dataset[len(dataset.keys())] = {"query":data,
- "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y'])}
- database_sets.append(dataset)
- database_tree = KDTree(df_database[['x','y']])
- database_trees.append(database_tree)
-
- if test:
- for i in range(len(database_sets)):
- tree = database_trees[i]
- for j in range(len(queries_sets)):
- if(i == j):
- continue
- for key in range(len(queries_sets[j].keys())):
- coor = np.array(
- [[queries_sets[j][key]["x"],queries_sets[j][key]["y"]]])
- index = tree.query_radius(coor, r=25)
- #print("index:"+str(index))
- # indices of the positive matches in database i of each query (key) in test set j
- queries_sets[j][key][i] = index[0].tolist()
-
- output_to_file(queries_sets, filename_test)
- output_to_file(database_sets, filename_train)
-
-# Initialize pandas DataFrame
-df_train = pd.DataFrame(columns=['file','x','y'])
-df_test = pd.DataFrame(columns=['file','x','y'])
-
-df_files_test = []
-df_files_train =[]
-
-df_locations_tr_x = []
-df_locations_tr_y = []
-df_locations_ts_x = []
-df_locations_ts_y = []
-
-for folder in folders:
- df_locations = sio.loadmat(os.path.join(
- cc_dir,runs_folder,folder,filename))
-
- df_locations = df_locations['pose']
- df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
-
- #2038 Training 10 testing
- test_index = random.choices(range(len(df_locations)), k=10)
- train_index = list(range(df_locations.shape[0]))
- #for i in test_index:
- # train_index.pop(i)
-
- df_locations_tr_x.extend(list(df_locations[train_index,0]))
- df_locations_tr_y.extend(list(df_locations[train_index,1]))
- df_locations_ts_x.extend(list(df_locations[test_index,0]))
- df_locations_ts_y.extend(list(df_locations[test_index,1]))
-
- all_files = list(sorted(os.listdir(os.path.join(cc_dir,runs_folder,folder))))
- all_files.remove('gt_pose.mat')
- all_files.remove('gt_pose.png')
-
- for (indx, file_) in enumerate(all_files):
- if indx in test_index:
- df_files_test.append(os.path.join(cc_dir,runs_folder,folder,file_))
- df_files_train.append(os.path.join(cc_dir,runs_folder,folder,file_))
-
-print("df_locations_tr_x:"+str(len(df_locations_tr_x)))
-print("df_files_test:"+str(len(df_files_test)))
-
-df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
- columns =['file','x', 'y'])
-df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
- columns =['file','x', 'y'])
-
-print("Number of training submaps: "+str(len(df_train['file'])))
-print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
-
-print("df_train:"+str(len(df_train)))
-
-
-
-#construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
-construct_query_dict(df_test, df_train, len(folders),"evaluation_database.pickle", "evaluation_query.pickle", True)
diff --git a/generating_queries/generate_test_sets.py b/generating_queries/generate_test_sets.py
deleted file mode 100644
index e8f9d0e..0000000
--- a/generating_queries/generate_test_sets.py
+++ /dev/null
@@ -1,169 +0,0 @@
-import os
-import pickle
-import random
-
-import set_path
-
-import numpy as np
-import pandas as pd
-from sklearn.neighbors import KDTree
-
-import config as cfg
-
-#####For training and test data split#####
-x_width = 150
-y_width = 150
-
-# For Oxford
-p1 = [5735712.768124,620084.402381]
-p2 = [5735611.299219,620540.270327]
-p3 = [5735237.358209,620543.094379]
-p4 = [5734749.303802,619932.693364]
-
-# For University Sector
-p5 = [363621.292362,142864.19756]
-p6 = [364788.795462,143125.746609]
-p7 = [363597.507711,144011.414174]
-
-# For Residential Area
-p8 = [360895.486453,144999.915143]
-p9 = [362357.024536,144894.825301]
-p10 = [361368.907155,145209.663042]
-
-p_dict = {"oxford":[p1,p2,p3,p4], "university":[
- p5,p6,p7], "residential": [p8,p9,p10], "business":[]}
-
-
-def check_in_test_set(northing, easting, points, x_width, y_width):
- in_test_set = False
- for point in points:
- if(point[0]-x_width < northing and northing < point[0]+x_width and point[1]-y_width < easting and easting < point[1]+y_width):
- in_test_set = True
- break
- return in_test_set
-##########################################
-
-
-def output_to_file(output, filename):
- with open(filename, 'wb') as handle:
- pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
- print("Done ", filename)
-
-
-def construct_query_and_database_sets(base_path, runs_folder, folders, pointcloud_fols, filename, p, output_name):
- database_trees = []
- test_trees = []
- for folder in folders:
- print(folder)
- df_database = pd.DataFrame(columns=['file','northing','easting'])
- df_test = pd.DataFrame(columns=['file','northing','easting'])
-
- df_locations = pd.read_csv(os.path.join(
- base_path,runs_folder,folder,filename),sep=',')
- # df_locations['timestamp']=runs_folder+folder+pointcloud_fols+df_locations['timestamp'].astype(str)+'.bin'
- # df_locations=df_locations.rename(columns={'timestamp':'file'})
- for index, row in df_locations.iterrows():
- # entire business district is in the test set
- if(output_name == "business"):
- df_test = df_test.append(row, ignore_index=True)
- elif(check_in_test_set(row['northing'], row['easting'], p, x_width, y_width)):
- df_test = df_test.append(row, ignore_index=True)
- df_database = df_database.append(row, ignore_index=True)
-
- database_tree = KDTree(df_database[['northing','easting']])
- test_tree = KDTree(df_test[['northing','easting']])
- database_trees.append(database_tree)
- test_trees.append(test_tree)
-
- test_sets = []
- database_sets = []
- for folder in folders:
- database = {}
- test = {}
- df_locations = pd.read_csv(os.path.join(
- base_path,runs_folder,folder,filename),sep=',')
- df_locations['timestamp'] = runs_folder+folder + \
- pointcloud_fols+df_locations['timestamp'].astype(str)+'.bin'
- df_locations = df_locations.rename(columns={'timestamp':'file'})
- for index,row in df_locations.iterrows():
- # entire business district is in the test set
- if(output_name == "business"):
- test[len(test.keys())] = {
- 'query':row['file'],'northing':row['northing'],'easting':row['easting']}
- elif(check_in_test_set(row['northing'], row['easting'], p, x_width, y_width)):
- test[len(test.keys())] = {
- 'query':row['file'],'northing':row['northing'],'easting':row['easting']}
- database[len(database.keys())] = {
- 'query':row['file'],'northing':row['northing'],'easting':row['easting']}
- database_sets.append(database)
- test_sets.append(test)
-
- for i in range(len(database_sets)):
- tree = database_trees[i]
- for j in range(len(test_sets)):
- if(i == j):
- continue
- for key in range(len(test_sets[j].keys())):
- coor = np.array(
- [[test_sets[j][key]["northing"],test_sets[j][key]["easting"]]])
- index = tree.query_radius(coor, r=25)
- # indices of the positive matches in database i of each query (key) in test set j
- test_sets[j][key][i] = index[0].tolist()
-
- output_to_file(database_sets, output_name+'_evaluation_database.pickle')
- output_to_file(test_sets, output_name+'_evaluation_query.pickle')
-
-
-# Building database and query files for evaluation
-BASE_DIR = os.path.dirname(os.path.abspath(__file__))
-base_path = cfg.DATASET_FOLDER
-cc_dir = "/mnt/ab0fe826-9b3c-455c-bb72-5999d52034e0/deepmapping/benchmark_datasets/"
-
-# For Oxford
-folders = []
-runs_folder = "oxford/"
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-index_list = [5,6,7,9,10,11,12,13,14,15,16,17,18,19,22,24,31,32,33,38,39,43,44]
-print(len(index_list))
-for index in index_list:
- folders.append(all_folders[index])
-
-print(folders)
-construct_query_and_database_sets(cc_dir, runs_folder, folders, "/pointcloud_20m/",
- "pointcloud_locations_20m.csv", p_dict["oxford"], "oxford")
-
-# For University Sector
-folders = []
-runs_folder = "inhouse_datasets/"
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-uni_index = range(10,15)
-for index in uni_index:
- folders.append(all_folders[index])
-
-print(folders)
-construct_query_and_database_sets(cc_dir, runs_folder, folders, "/pointcloud_25m_25/",
- "pointcloud_centroids_25.csv", p_dict["university"], "university")
-
-# For Residential Area
-folders = []
-runs_folder = "inhouse_datasets/"
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-res_index = range(5,10)
-for index in res_index:
- folders.append(all_folders[index])
-
-print(folders)
-construct_query_and_database_sets(cc_dir, runs_folder, folders, "/pointcloud_25m_25/",
- "pointcloud_centroids_25.csv", p_dict["residential"], "residential")
-
-# For Business District
-folders = []
-runs_folder = "inhouse_datasets/"
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-bus_index = range(5)
-for index in bus_index:
- folders.append(all_folders[index])
-
-print(folders)
-construct_query_and_database_sets(cc_dir, runs_folder, folders, "/pointcloud_25m_25/",
- "pointcloud_centroids_25.csv", p_dict["business"], "business")
diff --git a/generating_queries/generate_training_tuples_RGB_baseline.py b/generating_queries/generate_training_tuples_RGB_baseline.py
new file mode 100644
index 0000000..7f52437
--- /dev/null
+++ b/generating_queries/generate_training_tuples_RGB_baseline.py
@@ -0,0 +1,255 @@
+import os
+import sys
+import pickle
+import random
+import set_path
+
+import numpy as np
+import pandas as pd
+from sklearn.neighbors import KDTree
+
+import config as cfg
+
+import scipy.io as sio
+import torch
+
+#####For training and test data split#####
+
+def check_in_test_set(northing, easting, points, x_width, y_width):
+ in_test_set = False
+ for point in points:
+ if(point[0]-x_width < northing and northing < point[0]+x_width and point[1]-y_width < easting and easting < point[1]+y_width):
+ in_test_set = True
+ break
+ return in_test_set
+##########################################
+
+
+def construct_query_dict(df_files, df_indice, filename):
+ queries = {}
+
+ for i in range(len(ind_nn)):
+ query = df_centroids.iloc[i]["file"]
+ positives = np.setdiff1d(ind_nn[i],[i]).tolist()
+ negatives = np.setdiff1d(
+ df_centroids.index.values.tolist(),ind_r[i]).tolist()
+ random.shuffle(negatives)
+ queries[i] = {"query":df_centroids.iloc[i]['file'],
+ "positives":positives,"negatives":negatives}
+
+ with open(filename, 'wb') as handle:
+ pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
+
+ print("Done ", filename)
+
+def direction_filter(positives, df_centroids, index):
+ filted_pos = []
+ ref_roll = df_centroids.iloc[index]['roll']
+ ref_pitch = df_centroids.iloc[index]['pitch']
+ ref_yaw = df_centroids.iloc[index]['yaw']
+ for pos in positives:
+ pos_roll = df_centroids.iloc[pos]['roll']
+ pos_pitch = df_centroids.iloc[pos]['pitch']
+ pos_yaw = df_centroids.iloc[pos]['yaw']
+ if abs(ref_roll- pos_roll)< np.pi /2 and abs(ref_pitch- pos_pitch)< np.pi /2 and abs(ref_roll- pos_roll)< np.pi /2:
+ filted_pos.append(pos)
+ return positives
+
+def construct_dict(df_files, df_all, df_index, filename, folder_sizes, all_folder_sizes, folder_num, all_folders, pre_dir, definite_positives=None):
+ queries = {}
+ for num in range(folder_num):
+ #print("df_files:"+str(len(df_files)))
+ if num == 0:
+ overhead = 0
+ file_overhead = 0
+ else:
+ overhead = 0
+ file_overhead = 0
+ for i in range(num):
+ overhead = overhead + all_folder_sizes[i]
+ file_overhead = file_overhead + folder_sizes[i]
+
+ df_centroids = df_all[overhead:overhead + all_folder_sizes[num]]
+ df_folder_index = df_index[file_overhead: file_overhead + folder_sizes[num]]
+
+ tree = KDTree(df_centroids[['x','y','z']])
+ ind_r = tree.query_radius(df_centroids[['x','y','z']], r=1.8)
+
+ for ind in range(len(df_folder_index)):
+ i = df_folder_index[ind]
+ radius = 0.2
+ n_radius = 1.8
+ ind_nn = tree.query_radius(df_centroids[['x','y','z']],r=radius)
+ query = df_centroids.iloc[i]["file"]
+ pre_positives = np.setdiff1d(ind_nn[i],[i]).tolist()
+ positives = direction_filter(pre_positives, df_centroids, i)
+ negatives = np.setdiff1d(df_centroids.index.values.tolist(),ind_r[i]).tolist()
+
+ count = 0
+ while(len(positives)<4 or len(positives)>20):
+ if len(positives)<4:
+ radius = radius+0.2
+ ind_nn = tree.query_radius(df_centroids[['x','y','z']],r=radius)
+ query = df_centroids.iloc[i]["file"]
+ positives = np.setdiff1d(ind_nn[i],[i]).tolist()
+ positives = direction_filter(positives, df_centroids, i)
+ elif len(positives)>20:
+ radius = radius - 0.02
+ ind_nn = tree.query_radius(df_centroids[['x','y','z']],r=radius)
+ query = df_centroids.iloc[i]["file"]
+ positives = np.setdiff1d(ind_nn[i],[i]).tolist()
+ positives = direction_filter(positives, df_centroids, i)
+ if count>100:
+ assert(0)
+
+ while(len(negatives)<18):
+ n_radius = n_radius - 0.1
+ ind_r = tree.query_radius(df_centroids[['x','y','z']], r=n_radius)
+ negatives = np.setdiff1d(df_centroids.index.values.tolist(),ind_r[i]).tolist()
+ assert(n_radius>=0)
+ assert(len(positives)>=2)
+ assert(len(negatives)>=18)
+
+ positives = list(np.array(positives)+overhead)
+ queries[ind+file_overhead] = {"query":df_centroids.iloc[i]['file'],
+ "positives":positives,"negatives":negatives}
+
+ #print("queries:"+str(i))
+ #print("positives:"+str((positives)))
+ #print("negatives_max:"+str(max(negatives)))
+ #print("negatives_min:"+str(min(negatives)))
+ with open(filename, 'wb') as handle:
+ pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
+
+ print("Done ", filename)
+
+def generate(definite_positives=None, inside=True):
+ BASE_DIR = os.path.dirname(os.path.abspath(__file__))
+ base_path = "/data2/cc_data/AVD/"
+ runs_folder = "ActiveVisionDataset/"
+
+ pre_dir = os.path.join(base_path, runs_folder)
+
+ # Initialize pandas DataFrame
+
+ df_train = pd.DataFrame(columns=['file','x','y','z','roll','pitch','yaw'])
+ df_test = pd.DataFrame(columns=['file','x','y','z','roll','pitch','yaw'])
+ df_all = pd.DataFrame(columns=['file','x','y','z','roll','pitch','yaw'])
+
+ df_files_test = []
+ df_files_train =[]
+ df_files = []
+
+ df_locations_tr_x = []
+ df_locations_tr_y = []
+ df_locations_tr_z = []
+ df_locations_tr_roll = []
+ df_locations_tr_pitch = []
+ df_locations_tr_yaw = []
+
+ df_locations_ts_x = []
+ df_locations_ts_y = []
+ df_locations_ts_z = []
+ df_locations_ts_roll = []
+ df_locations_ts_pitch = []
+ df_locations_ts_yaw = []
+
+ df_locations_x = []
+ df_locations_y = []
+ df_locations_z = []
+ df_locations_roll = []
+ df_locations_pitch = []
+ df_locations_yaw = []
+
+ all_folders = sorted(os.listdir(pre_dir))
+ folder_num = len(all_folders)
+
+ folder_sizes_train = []
+ folder_sizes_test = []
+ folder_sizes = []
+ filename = "gt_pose.mat"
+
+ all_file_index = []
+ test_index = []
+ train_index = []
+
+ for index,folder in enumerate(all_folders):
+ df_locations = sio.loadmat(os.path.join(
+ pre_dir,folder,filename))
+ df_locations = df_locations['pose']
+ df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
+
+ file_index = list(range(df_locations.shape[0]))
+ folder_sizes.append(df_locations.shape[0])
+
+ if index == 0:
+ overhead = 0
+ else:
+ overhead = 0
+ for i in range(index):
+ overhead = overhead + folder_sizes[i]
+
+ #n Training 10 testing
+ all_file_index.extend(list(file_index))
+
+ tst_index = random.sample(range(len(df_locations)), k=10)
+ test_index.extend(list(tst_index))
+
+ trn_index = list(range(df_locations.shape[0]))
+ for ts_ind in tst_index:
+ trn_index.remove(ts_ind)
+ train_index.extend(list(trn_index))
+
+ folder_sizes_train.append(len(trn_index))
+ folder_sizes_test.append(10)
+
+ df_locations_tr_x.extend(list(df_locations[trn_index,0]))
+ df_locations_tr_y.extend(list(df_locations[trn_index,1]))
+ df_locations_tr_z.extend(list(df_locations[trn_index,2]))
+ df_locations_tr_roll.extend(list(df_locations[trn_index,3]))
+ df_locations_tr_pitch.extend(list(df_locations[trn_index,4]))
+ df_locations_tr_yaw.extend(list(df_locations[trn_index,5]))
+
+ df_locations_ts_x.extend(list(df_locations[tst_index,0]))
+ df_locations_ts_y.extend(list(df_locations[tst_index,1]))
+ df_locations_ts_z.extend(list(df_locations[tst_index,2]))
+ df_locations_ts_roll.extend(list(df_locations[tst_index,3]))
+ df_locations_ts_pitch.extend(list(df_locations[tst_index,4]))
+ df_locations_ts_yaw.extend(list(df_locations[tst_index,5]))
+
+ df_locations_x.extend(list(df_locations[file_index,0]))
+ df_locations_y.extend(list(df_locations[file_index,1]))
+ df_locations_z.extend(list(df_locations[file_index,2]))
+ df_locations_roll.extend(list(df_locations[file_index,3]))
+ df_locations_pitch.extend(list(df_locations[file_index,4]))
+ df_locations_yaw.extend(list(df_locations[file_index,5]))
+
+ all_files = list(sorted(os.listdir(os.path.join(pre_dir,folder,"jpg_rgb"))))
+
+ for (indx, file_) in enumerate(all_files):
+ if indx in tst_index:
+ df_files_test.append(os.path.join(pre_dir,folder,"jpg_rgb",file_))
+ else:
+ df_files_train.append(os.path.join(pre_dir,folder,"jpg_rgb",file_))
+ df_files.append(os.path.join(pre_dir,folder,"jpg_rgb",file_))
+
+ #print("df_locations_tr_x:"+str(len(df_locations_tr_x)))
+ df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y, df_locations_tr_z,df_locations_tr_roll,df_locations_tr_pitch,df_locations_tr_yaw)),
+ columns =['file','x', 'y', 'z', 'roll', 'pitch', 'yaw'])
+ df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y, df_locations_ts_z, df_locations_ts_roll, df_locations_ts_pitch, df_locations_ts_yaw)),
+ columns =['file','x', 'y', 'z', 'roll', 'pitch', 'yaw'])
+ df_all = pd.DataFrame(list(zip(df_files, df_locations_x, df_locations_y, df_locations_z, df_locations_roll, df_locations_pitch, df_locations_yaw)),
+ columns =['file','x', 'y', 'z', 'roll', 'pitch', 'yaw'])
+
+
+ if inside == True:
+ construct_dict(df_train, df_all, train_index, "training_queries_baseline.pickle", folder_sizes_train, folder_sizes, folder_num, all_folders, pre_dir)
+ construct_dict(df_test, df_all, test_index, "test_queries_baseline.pickle", folder_sizes_test, folder_sizes, folder_num, all_folders, pre_dir)
+ construct_dict(df_all, df_all, all_file_index, "db_queries_baseline.pickle", folder_sizes, folder_sizes, folder_num, all_folders, pre_dir)
+ else:
+ construct_dict(df_train, df_all, train_index, "generating_queries/training_queries_baseline.pickle", folder_sizes_train, folder_sizes, folder_num, all_folders, pre_dir, definite_positives=definite_positives)
+ construct_dict(df_test, df_all, test_index, "generating_queries/test_queries_baseline.pickle", folder_sizes_test, folder_sizes, folder_num, all_folders, pre_dir, definite_positives=definite_positives)
+ construct_dict(df_all, df_all, all_file_index, "generating_queries/db_queries_baseline.pickle", folder_sizes, folder_sizes, folder_num, all_folders, pre_dir, definite_positives=definite_positives)
+
+if __name__ == "__main__":
+ generate()
diff --git a/generating_queries/generate_training_tuples_RGB_baseline_batch.py b/generating_queries/generate_training_tuples_RGB_baseline_batch.py
new file mode 100644
index 0000000..38408e7
--- /dev/null
+++ b/generating_queries/generate_training_tuples_RGB_baseline_batch.py
@@ -0,0 +1,138 @@
+import os
+import sys
+import pickle
+import random
+import set_path
+
+import numpy as np
+import pandas as pd
+from sklearn.neighbors import KDTree
+
+import config as cfg
+
+import scipy.io as sio
+import torch
+
+#####For training and test data split#####
+
+def construct_dict(folder_num, df_files, df_files_all, df_indices, filename, pre_dir, k_nearest, k_furthest, traj_len, definite_positives=None):
+ pos_index_range = list(range(-k_nearest//2, (k_nearest//2)+1))
+ mid_index_range = list(range(-k_nearest, (k_nearest)+1))
+ queries = {}
+ count = 0
+ traj_len = int(len(df_files_all)/folder_num)
+ for df_indice in df_indices:
+ cur_fold_num = int(df_indice//traj_len)
+ file_index = int(df_indice%traj_len)
+ positive_l = []
+ negative_l = list(range(cur_fold_num*traj_len, (cur_fold_num+1)*traj_len, 1))
+
+ cur_indice = df_indice % traj_len
+
+ for index_pos in pos_index_range:
+ if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
+ positive_l.append(index_pos + df_indice)
+ for index_pos in mid_index_range:
+ if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
+ negative_l.remove(index_pos + df_indice)
+ #positive_l.append(df_indice)
+ #positive_l.append(df_indice)
+ #negative_l.remove(df_indice)
+
+ if definite_positives is not None:
+ if len(definite_positives)==1:
+ if definite_positives[0][df_indice].ndim ==2:
+ positive_l.extend(definite_positives[0][df_indice][0])
+ negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice][0]]
+ else:
+ positive_l.extend(definite_positives[0][df_indice])
+ negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice]]
+ else:
+ positive_l.extend(definite_positives[df_indice])
+ positive_l = list(set(positive_l))
+ negative_l = [i for i in negative_l if i not in definite_positives[df_indice]]
+
+ queries[count] = {"query":df_files[count],
+ "positives":positive_l,"negatives":negative_l}
+ count = count + 1
+
+ with open(filename, 'wb') as handle:
+ pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
+
+ print("Done ", filename)
+
+def generate(scene_index, data_index, definite_positives=None, inside=True):
+ base_path = "/mnt/NAS/home/cc/data/habitat_4/train/"
+ run_folder = cfg.scene_list[scene_index]
+ base_path = os.path.join(base_path,run_folder)
+ pre_dir = base_path
+ '''
+ runs_folder = cfg.scene_names[scene_index]
+ print("runs_folder2:"+str(runs_folder))
+
+ pre_dir = os.path.join(base_path, runs_folder)
+ print("pre_dir:"+str(pre_dir))
+ '''
+ filename = "gt_pose.mat"
+
+ # Initialize pandas DataFrame
+ k_nearest = 10
+ k_furthest = 50
+
+ df_train = pd.DataFrame(columns=['file','positives','negatives'])
+ df_test = pd.DataFrame(columns=['file','positives','negatives'])
+
+ df_files_test = []
+ df_files_train =[]
+ df_files = []
+
+ df_indices_train = []
+ df_indices_test = []
+ df_indices = []
+
+ fold_list = list(sorted(os.listdir(base_path)))
+ all_files = []
+ for fold in fold_list:
+ files_ = []
+ files = list(sorted(os.listdir(os.path.join(base_path, fold))))
+ files.remove('gt_pose.mat')
+ # print("len(files):"+str(len(files)))
+ for ind in range(len(files)):
+ file_ = "panoimg_"+str(ind)+".png"
+ files_.append(os.path.join(base_path, fold, file_))
+ all_files.extend(files_)
+
+ traj_len = len(all_files)
+
+ #n Training 10 testing
+ test_sample = len(fold_list)*10
+ file_index = list(range(traj_len))
+ test_index = random.sample(range(traj_len), k=test_sample)
+ train_index = list(range(traj_len))
+ for ts_ind in test_index:
+ train_index.remove(ts_ind)
+
+ for indx in range(traj_len):
+ # file_ = 'panoimg_'+str(indx)+'.png'
+ if indx in test_index:
+ df_files_test.append(all_files[indx])
+ df_indices_test.append(indx)
+ else:
+ df_files_train.append(all_files[indx])
+ df_indices_train.append(indx)
+ df_files.append(all_files[indx])
+ df_indices.append(indx)
+
+ if inside == True:
+ construct_dict(len(fold_list),df_files_train, df_files,df_indices_train, "train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
+ construct_dict(len(fold_list), df_files_test, df_files,df_indices_test, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
+ construct_dict(len(fold_list), df_files,df_files, df_indices, "train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
+
+ else:
+ construct_dict(len(fold_list), df_files_train,df_files, df_indices_train, "generating_queries/train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
+ construct_dict(len(fold_list), df_files_test,df_files, df_indices_test, "generating_queries/train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
+ construct_dict(len(fold_list), df_files,df_files, df_indices, "generating_queries/train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
+
+if __name__ == "__main__":
+ for i in range(1):
+ generate(0,i)
diff --git a/generating_queries/generate_training_tuples_baseline.py b/generating_queries/generate_training_tuples_baseline.py
deleted file mode 100644
index 8658158..0000000
--- a/generating_queries/generate_training_tuples_baseline.py
+++ /dev/null
@@ -1,93 +0,0 @@
-import os
-import pickle
-import random
-
-import set_path
-import config as cfg
-
-import numpy as np
-import pandas as pd
-from sklearn.neighbors import KDTree
-
-BASE_DIR = os.path.dirname(os.path.abspath(__file__))
-base_path = cfg.DATASET_FOLDER
-
-runs_folder = "oxford/"
-filename = "pointcloud_locations_20m_10overlap.csv"
-pointcloud_fols = "/pointcloud_20m_10overlap/"
-
-cc_dir = "/mnt/ab0fe826-9b3c-455c-bb72-5999d52034e0/deepmapping/benchmark_datasets/"
-
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-
-folders = []
-
-# All runs are used for training (both full and partial)
-index_list = range(len(all_folders)-1)
-print("Number of runs: "+str(len(index_list)))
-for index in index_list:
- folders.append(all_folders[index])
-print(folders)
-
-#####For training and test data split#####
-x_width = 150
-y_width = 150
-p1 = [5735712.768124,620084.402381]
-p2 = [5735611.299219,620540.270327]
-p3 = [5735237.358209,620543.094379]
-p4 = [5734749.303802,619932.693364]
-p = [p1,p2,p3,p4]
-
-
-def check_in_test_set(northing, easting, points, x_width, y_width):
- in_test_set = False
- for point in points:
- if(point[0]-x_width < northing and northing < point[0]+x_width and point[1]-y_width < easting and easting < point[1]+y_width):
- in_test_set = True
- break
- return in_test_set
-##########################################
-
-
-def construct_query_dict(df_centroids, filename):
- tree = KDTree(df_centroids[['northing','easting']])
- ind_nn = tree.query_radius(df_centroids[['northing','easting']],r=10)
- ind_r = tree.query_radius(df_centroids[['northing','easting']], r=50)
- queries = {}
- for i in range(len(ind_nn)):
- query = df_centroids.iloc[i]["file"]
- positives = np.setdiff1d(ind_nn[i],[i]).tolist()
- negatives = np.setdiff1d(
- df_centroids.index.values.tolist(),ind_r[i]).tolist()
- random.shuffle(negatives)
- queries[i] = {"query":query,
- "positives":positives,"negatives":negatives}
-
- with open(filename, 'wb') as handle:
- pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
-
- print("Done ", filename)
-
-
-# Initialize pandas DataFrame
-df_train = pd.DataFrame(columns=['file','northing','easting'])
-df_test = pd.DataFrame(columns=['file','northing','easting'])
-
-for folder in folders:
- df_locations = pd.read_csv(os.path.join(
- cc_dir,runs_folder,folder,filename),sep=',')
- df_locations['timestamp'] = runs_folder+folder + \
- pointcloud_fols+df_locations['timestamp'].astype(str)+'.bin'
- df_locations = df_locations.rename(columns={'timestamp':'file'})
-
- for index, row in df_locations.iterrows():
- if(check_in_test_set(row['northing'], row['easting'], p, x_width, y_width)):
- df_test = df_test.append(row, ignore_index=True)
- else:
- df_train = df_train.append(row, ignore_index=True)
-
-print("Number of training submaps: "+str(len(df_train['file'])))
-print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
-print("df_train:"+str(df_train['file']))
-construct_query_dict(df_train,"training_queries_baseline.pickle")
-construct_query_dict(df_test,"test_queries_baseline.pickle")
diff --git a/generating_queries/generate_training_tuples_cc_baseline.py b/generating_queries/generate_training_tuples_cc_baseline.py
deleted file mode 100644
index 2ce0ba6..0000000
--- a/generating_queries/generate_training_tuples_cc_baseline.py
+++ /dev/null
@@ -1,128 +0,0 @@
-import os
-import pickle
-import random
-import set_path
-
-import numpy as np
-import pandas as pd
-from sklearn.neighbors import KDTree
-
-import config as cfg
-
-import scipy.io as sio
-import torch
-
-BASE_DIR = os.path.dirname(os.path.abspath(__file__))
-base_path = cfg.DATASET_FOLDER
-
-runs_folder = "dm_data/"
-filename = "gt_pose.mat"
-pointcloud_fols = "/pointcloud_20m_10overlap/"
-
-print("cfg.DATASET_FOLDER:"+str(cfg.DATASET_FOLDER))
-
-cc_dir = "/home/cc/"
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-
-folders = []
-
-# All runs are used for training (both full and partial)
-index_list = range(10)
-print("Number of runs: "+str(len(index_list)))
-for index in index_list:
- folders.append(all_folders[index])
-print(folders)
-
-
-#####For training and test data split#####
-
-def check_in_test_set(northing, easting, points, x_width, y_width):
- in_test_set = False
- for point in points:
- if(point[0]-x_width < northing and northing < point[0]+x_width and point[1]-y_width < easting and easting < point[1]+y_width):
- in_test_set = True
- break
- return in_test_set
-##########################################
-
-
-def construct_query_dict(df_centroids, filename):
- tree = KDTree(df_centroids[['x','y']])
- ind_nn = tree.query_radius(df_centroids[['x','y']],r=15)
- ind_r = tree.query_radius(df_centroids[['x','y']], r=50)
- queries = {}
-
- for i in range(len(ind_nn)):
- query = df_centroids.iloc[i]["file"]
- positives = np.setdiff1d(ind_nn[i],[i]).tolist()
- negatives = np.setdiff1d(
- df_centroids.index.values.tolist(),ind_r[i]).tolist()
- random.shuffle(negatives)
- queries[i] = {"query":df_centroids.iloc[i]['file'],
- "positives":positives,"negatives":negatives}
-
- with open(filename, 'wb') as handle:
- pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
-
- print("Done ", filename)
-
-
-# Initialize pandas DataFrame
-df_train = pd.DataFrame(columns=['file','x','y'])
-df_test = pd.DataFrame(columns=['file','x','y'])
-
-df_files_test = []
-df_files_train =[]
-
-df_locations_tr_x = []
-df_locations_tr_y = []
-df_locations_ts_x = []
-df_locations_ts_y = []
-
-for folder in folders:
- df_locations = sio.loadmat(os.path.join(
- cc_dir,runs_folder,folder,filename))
-
- df_locations = df_locations['pose']
- df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
-
- #2038 Training 10 testing
- test_index = random.sample(range(len(df_locations)), k=10)
- train_index = list(range(df_locations.shape[0]))
- for i in test_index:
- train_index.remove(i)
-
- df_locations_tr_x.extend(list(df_locations[train_index,0]))
- df_locations_tr_y.extend(list(df_locations[train_index,1]))
- df_locations_ts_x.extend(list(df_locations[test_index,0]))
- df_locations_ts_y.extend(list(df_locations[test_index,1]))
-
-
- all_files = list(sorted(os.listdir(os.path.join(cc_dir,runs_folder,folder))))
- all_files.remove('gt_pose.mat')
- all_files.remove('gt_pose.png')
-
- for (indx, file_) in enumerate(all_files):
- if indx in test_index:
- df_files_test.append(os.path.join(cc_dir,runs_folder,folder,file_))
- else:
- df_files_train.append(os.path.join(cc_dir,runs_folder,folder,file_))
-
-print("df_locations_tr_x:"+str(len(df_locations_tr_x)))
-print("df_files_test:"+str(len(df_files_test)))
-
-df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
- columns =['file','x', 'y'])
-df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
- columns =['file','x', 'y'])
-
-
-
-print("Number of training submaps: "+str(len(df_train['file'])))
-print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
-
-print("df_train:"+str(len(df_train)))
-print("df_test:"+str(len(df_test)))
-
-construct_query_dict(df_train,"training_queries_baseline.pickle")
-construct_query_dict(df_test,"test_queries_baseline.pickle")
diff --git a/generating_queries/generate_training_tuples_cc_refine.py b/generating_queries/generate_training_tuples_cc_refine.py
deleted file mode 100644
index 8d01a20..0000000
--- a/generating_queries/generate_training_tuples_cc_refine.py
+++ /dev/null
@@ -1,127 +0,0 @@
-import os
-import pickle
-import random
-import set_path
-
-import numpy as np
-import pandas as pd
-from sklearn.neighbors import KDTree
-
-import config as cfg
-
-#####For training and test data split#####
-x_width = 150
-y_width = 150
-
-# For Oxford
-p1 = [5735712.768124,620084.402381]
-p2 = [5735611.299219,620540.270327]
-p3 = [5735237.358209,620543.094379]
-p4 = [5734749.303802,619932.693364]
-
-# For University Sector
-p5 = [363621.292362,142864.19756]
-p6 = [364788.795462,143125.746609]
-p7 = [363597.507711,144011.414174]
-
-# For Residential Area
-p8 = [360895.486453,144999.915143]
-p9 = [362357.024536,144894.825301]
-p10 = [361368.907155,145209.663042]
-
-p = [p1,p2,p3,p4,p5,p6,p7,p8,p9,p10]
-
-
-def check_in_test_set(northing, easting, points, x_width, y_width):
- in_test_set = False
- # print(northing)
- for point in points:
- if(point[0]-x_width < northing and northing < point[0]+x_width and point[1]-y_width < easting and easting < point[1]+y_width):
- in_test_set = True
- break
- return in_test_set
-##########################################
-
-
-def construct_query_dict(df_centroids, filename):
- tree = KDTree(df_centroids[['northing','easting']])
- ind_nn = tree.query_radius(df_centroids[['northing','easting']],r=12.5)
- ind_r = tree.query_radius(df_centroids[['northing','easting']], r=50)
- queries = {}
- print(len(ind_nn))
- for i in range(len(ind_nn)):
- query = df_centroids.iloc[i]["file"]
- positives = np.setdiff1d(ind_nn[i],[i]).tolist()
- negatives = np.setdiff1d(
- df_centroids.index.values.tolist(),ind_r[i]).tolist()
- random.shuffle(negatives)
- queries[i] = {"query":query,
- "positives":positives,"negatives":negatives}
-
- with open(filename, 'wb') as handle:
- pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
-
- print("Done ", filename)
-
-cc_dir = "/mnt/ab0fe826-9b3c-455c-bb72-5999d52034e0/deepmapping/benchmark_datasets/"
-BASE_DIR = os.path.dirname(os.path.abspath(__file__))
-base_path = cfg.DATASET_FOLDER
-runs_folder = "inhouse_datasets/"
-filename = "pointcloud_centroids_10.csv"
-pointcloud_fols = "/pointcloud_25m_10/"
-
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-
-folders = []
-index_list = range(5,15)
-for index in index_list:
- folders.append(all_folders[index])
-
-print(folders)
-
-# Initialize pandas DataFrame
-df_train = pd.DataFrame(columns=['file','northing','easting'])
-
-for folder in folders:
- df_locations = pd.read_csv(os.path.join(
- cc_dir, runs_folder, folder,filename),sep=',')
- df_locations['timestamp'] = runs_folder+folder + \
- pointcloud_fols+df_locations['timestamp'].astype(str)+'.bin'
- df_locations = df_locations.rename(columns={'timestamp':'file'})
- for index, row in df_locations.iterrows():
- if(check_in_test_set(row['northing'], row['easting'], p, x_width, y_width)):
- continue
- else:
- df_train = df_train.append(row, ignore_index=True)
-
-print(len(df_train['file']))
-
-
-# Combine with Oxford data
-runs_folder = "oxford/"
-filename = "pointcloud_locations_20m_10overlap.csv"
-pointcloud_fols = "/pointcloud_20m_10overlap/"
-
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-
-folders = []
-index_list = range(len(all_folders)-1)
-for index in index_list:
- folders.append(all_folders[index])
-
-print(folders)
-
-for folder in folders:
- df_locations = pd.read_csv(os.path.join(
- cc_dir,runs_folder,folder,filename),sep=',')
- df_locations['timestamp'] = runs_folder+folder + \
- pointcloud_fols+df_locations['timestamp'].astype(str)+'.bin'
- df_locations = df_locations.rename(columns={'timestamp':'file'})
- for index, row in df_locations.iterrows():
- if(check_in_test_set(row['northing'], row['easting'], p, x_width, y_width)):
- continue
- else:
- df_train = df_train.append(row, ignore_index=True)
-
-print("Number of training submaps: "+str(len(df_train['file'])))
-construct_query_dict(df_train,"training_queries_refine.pickle")
diff --git a/generating_queries/generate_training_tuples_refine.py b/generating_queries/generate_training_tuples_refine.py
deleted file mode 100644
index 8d01a20..0000000
--- a/generating_queries/generate_training_tuples_refine.py
+++ /dev/null
@@ -1,127 +0,0 @@
-import os
-import pickle
-import random
-import set_path
-
-import numpy as np
-import pandas as pd
-from sklearn.neighbors import KDTree
-
-import config as cfg
-
-#####For training and test data split#####
-x_width = 150
-y_width = 150
-
-# For Oxford
-p1 = [5735712.768124,620084.402381]
-p2 = [5735611.299219,620540.270327]
-p3 = [5735237.358209,620543.094379]
-p4 = [5734749.303802,619932.693364]
-
-# For University Sector
-p5 = [363621.292362,142864.19756]
-p6 = [364788.795462,143125.746609]
-p7 = [363597.507711,144011.414174]
-
-# For Residential Area
-p8 = [360895.486453,144999.915143]
-p9 = [362357.024536,144894.825301]
-p10 = [361368.907155,145209.663042]
-
-p = [p1,p2,p3,p4,p5,p6,p7,p8,p9,p10]
-
-
-def check_in_test_set(northing, easting, points, x_width, y_width):
- in_test_set = False
- # print(northing)
- for point in points:
- if(point[0]-x_width < northing and northing < point[0]+x_width and point[1]-y_width < easting and easting < point[1]+y_width):
- in_test_set = True
- break
- return in_test_set
-##########################################
-
-
-def construct_query_dict(df_centroids, filename):
- tree = KDTree(df_centroids[['northing','easting']])
- ind_nn = tree.query_radius(df_centroids[['northing','easting']],r=12.5)
- ind_r = tree.query_radius(df_centroids[['northing','easting']], r=50)
- queries = {}
- print(len(ind_nn))
- for i in range(len(ind_nn)):
- query = df_centroids.iloc[i]["file"]
- positives = np.setdiff1d(ind_nn[i],[i]).tolist()
- negatives = np.setdiff1d(
- df_centroids.index.values.tolist(),ind_r[i]).tolist()
- random.shuffle(negatives)
- queries[i] = {"query":query,
- "positives":positives,"negatives":negatives}
-
- with open(filename, 'wb') as handle:
- pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
-
- print("Done ", filename)
-
-cc_dir = "/mnt/ab0fe826-9b3c-455c-bb72-5999d52034e0/deepmapping/benchmark_datasets/"
-BASE_DIR = os.path.dirname(os.path.abspath(__file__))
-base_path = cfg.DATASET_FOLDER
-runs_folder = "inhouse_datasets/"
-filename = "pointcloud_centroids_10.csv"
-pointcloud_fols = "/pointcloud_25m_10/"
-
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-
-folders = []
-index_list = range(5,15)
-for index in index_list:
- folders.append(all_folders[index])
-
-print(folders)
-
-# Initialize pandas DataFrame
-df_train = pd.DataFrame(columns=['file','northing','easting'])
-
-for folder in folders:
- df_locations = pd.read_csv(os.path.join(
- cc_dir, runs_folder, folder,filename),sep=',')
- df_locations['timestamp'] = runs_folder+folder + \
- pointcloud_fols+df_locations['timestamp'].astype(str)+'.bin'
- df_locations = df_locations.rename(columns={'timestamp':'file'})
- for index, row in df_locations.iterrows():
- if(check_in_test_set(row['northing'], row['easting'], p, x_width, y_width)):
- continue
- else:
- df_train = df_train.append(row, ignore_index=True)
-
-print(len(df_train['file']))
-
-
-# Combine with Oxford data
-runs_folder = "oxford/"
-filename = "pointcloud_locations_20m_10overlap.csv"
-pointcloud_fols = "/pointcloud_20m_10overlap/"
-
-all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
-
-folders = []
-index_list = range(len(all_folders)-1)
-for index in index_list:
- folders.append(all_folders[index])
-
-print(folders)
-
-for folder in folders:
- df_locations = pd.read_csv(os.path.join(
- cc_dir,runs_folder,folder,filename),sep=',')
- df_locations['timestamp'] = runs_folder+folder + \
- pointcloud_fols+df_locations['timestamp'].astype(str)+'.bin'
- df_locations = df_locations.rename(columns={'timestamp':'file'})
- for index, row in df_locations.iterrows():
- if(check_in_test_set(row['northing'], row['easting'], p, x_width, y_width)):
- continue
- else:
- df_train = df_train.append(row, ignore_index=True)
-
-print("Number of training submaps: "+str(len(df_train['file'])))
-construct_query_dict(df_train,"training_queries_refine.pickle")
diff --git a/loading_pointclouds.py b/loading_pointclouds.py
index 2bf20db..97d5bfd 100644
--- a/loading_pointclouds.py
+++ b/loading_pointclouds.py
@@ -4,9 +4,9 @@
import random
import config as cfg
from open3d import read_point_cloud
+import cv2
def get_queries_dict(filename):
- # key:{'query':file,'positives':[files],'negatives:[files], 'neighbors':[keys]}
with open(filename, 'rb') as handle:
print("filename:"+str(filename))
queries = pickle.load(handle)
@@ -15,7 +15,6 @@ def get_queries_dict(filename):
def get_sets_dict(filename):
- #[key_dataset:{key_pointcloud:{'query':file,'northing':value,'easting':value}},key_dataset:{key_pointcloud:{'query':file,'northing':value,'easting':value}}, ...}
with open(filename, 'rb') as handle:
trajectories = pickle.load(handle)
print("Trajectories Loaded.")
@@ -24,7 +23,6 @@ def get_sets_dict(filename):
def load_pc_file(filename,full_path=False):
# returns Nx3 matrix
- #print("filename:"+str(filename))
if full_path:
pc = read_point_cloud(os.path.join(filename))
else:
@@ -35,7 +33,6 @@ def load_pc_file(filename,full_path=False):
print("Error in pointcloud shape")
return np.array([])
- #pc = np.reshape(pc,(pc.shape[0]//3, 3))
return pc
@@ -50,6 +47,31 @@ def load_pc_files(filenames,full_path):
pcs = np.array(pcs)
return pcs
+def load_image_file(filename, full_path=False):
+ if full_path:
+ image = cv2.imread(filename)
+ dim = (128,128)
+ image = cv2.resize(image, dim,interpolation = cv2.INTER_AREA)
+ else:
+ image = cv2.imread(os.path.join("/home/chao1804/Desktop/AVD/ActiveVisionDataset/", filename))
+ dim = (128,128)
+ image = cv2.resize(image, dim,interpolation = cv2.INTER_AREA)
+ image = np.asarray(image, dtype=np.float32)
+
+ if(image.shape[2] != 3):
+ print("Error in pointcloud shape")
+ return np.array([])
+ #pc = np.reshape(pc,(pc.shape[0]//3, 3))
+ return image
+
+
+def load_image_files(filenames,full_path):
+ images = []
+ for filename in filenames:
+ image = load_image_file(filename, full_path=full_path)
+ images.append(image)
+ images = np.asarray(images, dtype=np.float32)
+ return images
def rotate_point_cloud(batch_data):
""" Randomly rotate the point clouds to augument the dataset
@@ -90,18 +112,16 @@ def jitter_point_cloud(batch_data, sigma=0.005, clip=0.05):
def get_query_tuple(dict_value, num_pos, num_neg, QUERY_DICT, hard_neg=[], other_neg=False):
- # get query tuple for dictionary entry
- # return list [query,positives,negatives]
- query = load_pc_file(dict_value["query"]) # Nx3
+ query = load_image_file(dict_value["query"]) # Nx3
random.shuffle(dict_value["positives"])
pos_files = []
-
+
for i in range(num_pos):
pos_files.append(QUERY_DICT[dict_value["positives"][i]]["query"])
- #positives= load_pc_files(dict_value["positives"][0:num_pos])
- positives = load_pc_files(pos_files,full_path=True)
+
+ positives = load_image_files(pos_files,full_path=True)
neg_files = []
neg_indices = []
@@ -118,14 +138,13 @@ def get_query_tuple(dict_value, num_pos, num_neg, QUERY_DICT, hard_neg=[], other
neg_indices.append(i)
j = 0
while(len(neg_files) < num_neg):
-
if not dict_value["negatives"][j] in hard_neg:
neg_files.append(
QUERY_DICT[dict_value["negatives"][j]]["query"])
neg_indices.append(dict_value["negatives"][j])
j += 1
-
- negatives = load_pc_files(neg_files,full_path=True)
+
+ negatives = load_image_files(neg_files,full_path=True)
if other_neg is False:
return [query, positives, negatives]
@@ -144,7 +163,7 @@ def get_query_tuple(dict_value, num_pos, num_neg, QUERY_DICT, hard_neg=[], other
if(len(possible_negs) == 0):
return [query, positives, negatives, np.array([])]
- neg2 = load_pc_file(QUERY_DICT[possible_negs[0]]["query"],full_path=True)
+ neg2 = load_image_file(QUERY_DICT[possible_negs[0]]["query"],full_path=True)
return [query, positives, negatives, neg2]
@@ -157,7 +176,6 @@ def get_rotated_tuple(dict_value, num_pos, num_neg, QUERY_DICT, hard_neg=[], oth
pos_files = []
for i in range(num_pos):
pos_files.append(QUERY_DICT[dict_value["positives"][i]]["query"])
- #positives= load_pc_files(dict_value["positives"][0:num_pos])
positives = load_pc_files(pos_files)
p_rot = rotate_point_cloud(positives)
@@ -210,7 +228,6 @@ def get_rotated_tuple(dict_value, num_pos, num_neg, QUERY_DICT, hard_neg=[], oth
def get_jittered_tuple(dict_value, num_pos, num_neg, QUERY_DICT, hard_neg=[], other_neg=False):
query = load_pc_file(dict_value["query"]) # Nx3
- #q_rot= rotate_point_cloud(np.expand_dims(query, axis=0))
q_jit = jitter_point_cloud(np.expand_dims(query, axis=0))
q_jit = np.squeeze(q_jit)
@@ -218,7 +235,6 @@ def get_jittered_tuple(dict_value, num_pos, num_neg, QUERY_DICT, hard_neg=[], ot
pos_files = []
for i in range(num_pos):
pos_files.append(QUERY_DICT[dict_value["positives"][i]]["query"])
- #positives= load_pc_files(dict_value["positives"][0:num_pos])
positives = load_pc_files(pos_files)
p_jit = jitter_point_cloud(positives)
diff --git a/loss/__pycache__/pointnetvlad_loss.cpython-36.pyc b/loss/__pycache__/pointnetvlad_loss.cpython-36.pyc
deleted file mode 100644
index 43f148a..0000000
Binary files a/loss/__pycache__/pointnetvlad_loss.cpython-36.pyc and /dev/null differ
diff --git a/models/ImageNetVlad.py b/models/ImageNetVlad.py
new file mode 100644
index 0000000..089ca82
--- /dev/null
+++ b/models/ImageNetVlad.py
@@ -0,0 +1,459 @@
+from __future__ import print_function
+import torch
+import torch.nn as nn
+import torch.nn.parallel
+import torch.utils.data
+from torch.autograd import Variable
+import numpy as np
+import torch.nn.functional as F
+import math
+import torchvision.models as models
+
+class NetVLAD_Image(nn.Module):
+ """NetVLAD layer implementation"""
+ def __init__(self, num_clusters=64, dim=128,
+ normalize_input=True, vladv2=False):
+
+ """
+ Args:
+ num_clusters : int
+ The number of clusters
+
+ dim : int
+ Dimension of descriptors
+
+ alpha : float
+ Parameter of initialization. Larger value is harder assignment.
+
+ normalize_input : bool
+ If true, descriptor-wise L2 normalization is applied to input.
+
+ vladv2 : bool
+ If true, use vladv2 otherwise use vladv1
+ """
+
+ super(NetVLAD_Image, self).__init__()
+ self.num_clusters = num_clusters
+ self.dim = dim
+ self.alpha = 0
+ self.vladv2 = vladv2
+ self.normalize_input = normalize_input
+ self.conv = nn.Conv2d(dim, num_clusters, kernel_size=(1, 1), bias=vladv2)
+ self.centroids = nn.Parameter(torch.rand(num_clusters, dim))
+
+ def init_params(self, clsts, traindescs):
+
+ #TODO replace numpy ops with pytorch ops
+ if self.vladv2 == False:
+ clstsAssign = clsts / np.linalg.norm(clsts, axis=1, keepdims=True)
+ dots = np.dot(clstsAssign, traindescs.T)
+ dots.sort(0)
+ dots = dots[::-1, :] # sort, descending
+
+ self.alpha = (-np.log(0.01) / np.mean(dots[0,:] - dots[1,:])).item()
+ self.centroids = nn.Parameter(torch.from_numpy(clsts))
+ self.conv.weight = nn.Parameter(torch.from_numpy(self.alpha*clstsAssign).unsqueeze(2).unsqueeze(3))
+ self.conv.bias = None
+ else:
+ knn = NearestNeighbors(n_jobs=-1) #TODO faiss?
+ knn.fit(traindescs)
+ del traindescs
+ dsSq = np.square(knn.kneighbors(clsts, 2)[1])
+ del knn
+ self.alpha = (-np.log(0.01) / np.mean(dsSq[:,1] - dsSq[:,0])).item()
+ self.centroids = nn.Parameter(torch.from_numpy(clsts))
+ del clsts, dsSq
+
+ self.conv.weight = nn.Parameter(
+ (2.0 * self.alpha * self.centroids).unsqueeze(-1).unsqueeze(-1)
+ )
+
+ self.conv.bias = nn.Parameter(
+ - self.alpha * self.centroids.norm(dim=1)
+ )
+
+ def forward(self, x):
+ N, C = x.shape[:2]
+
+ if self.normalize_input:
+ x = F.normalize(x, p=2, dim=1) # across descriptor dim
+
+ # soft-assignment
+ soft_assign = self.conv(x).view(N, self.num_clusters, -1)
+ soft_assign = F.softmax(soft_assign, dim=1)
+ x_flatten = x.view(N, C, -1)
+
+ # calculate residuals to each clusters
+ vlad = torch.zeros([N, self.num_clusters, C], dtype=x.dtype, layout=x.layout, device=x.device)
+ for C in range(self.num_clusters): # slower than non-looped, but lower memory usage
+ residual = x_flatten.unsqueeze(0).permute(1, 0, 2, 3) - \
+ self.centroids[C:C+1, :].expand(x_flatten.size(-1), -1, -1).permute(1, 2, 0).unsqueeze(0)
+ residual *= soft_assign[:,C:C+1,:].unsqueeze(2)
+ vlad[:,C:C+1,:] = residual.sum(dim=-1)
+
+ vlad = F.normalize(vlad, p=2, dim=2) # intra-normalization
+ vlad = vlad.view(x.size(0), -1) # flatten
+ vlad = F.normalize(vlad, p=2, dim=1) # L2 normalize
+
+ return vlad
+
+class NetVLAD_Image2(nn.Module):
+ """NetVLAD layer implementation"""
+ def __init__(self, num_clusters=64, dim=128, alpha=100.0,
+ normalize_input=True):
+ """
+ Args:
+ num_clusters : int
+ The number of clusters
+ dim : int
+ Dimension of descriptors
+ alpha : float
+ Parameter of initialization. Larger value is harder assignment.
+ normalize_input : bool
+ If true, descriptor-wise L2 normalization is applied to input.
+ """
+ super(NetVLAD_Image, self).__init__()
+ self.num_clusters = num_clusters
+ self.dim = dim
+ self.alpha = alpha
+ self.normalize_input = normalize_input
+ self.conv = nn.Conv2d(dim, num_clusters, kernel_size=(1, 1), bias=True)
+ self.centroids = nn.Parameter(torch.rand(num_clusters, dim))
+ self._init_params()
+
+ def _init_params(self):
+ self.conv.weight = nn.Parameter(
+ (2.0 * self.alpha * self.centroids).unsqueeze(-1).unsqueeze(-1)
+ )
+
+ self.conv.bias = nn.Parameter(
+ - self.alpha * self.centroids.norm(dim=1)
+ )
+
+ def forward(self, x):
+ N, C = x.shape[:2]
+ if self.normalize_input:
+ x = F.normalize(x, p=2, dim=1) # across descriptor dim
+
+ # soft-assignment
+ soft_assign = self.conv(x).view(N, self.num_clusters, -1)
+ soft_assign = F.softmax(soft_assign, dim=1)
+ x_flatten = x.view(N, C, -1)
+
+ # calculate residuals to each clusters
+ residual = x_flatten.expand(self.num_clusters, -1, -1, -1).permute(1, 0, 2, 3) - \
+ self.centroids.expand(x_flatten.size(-1), -1, -1).permute(1, 2, 0).unsqueeze(0)
+ residual *= soft_assign.unsqueeze(2)
+
+ vlad = residual.sum(dim=-1)
+ vlad = F.normalize(vlad, p=2, dim=2) # intra-normalization
+ vlad = vlad.view(x.size(0), -1) # flatten
+ vlad = F.normalize(vlad, p=2, dim=1) # L2 normalize
+ return vlad
+
+class NetVLADLoupe(nn.Module):
+ def __init__(self, feature_size, max_samples, cluster_size, output_dim,
+ gating=True, add_batch_norm=True, is_training=True):
+ super(NetVLADLoupe, self).__init__()
+ self.feature_size = feature_size
+ self.max_samples = max_samples
+ self.output_dim = output_dim
+ self.is_training = is_training
+ self.gating = gating
+ self.add_batch_norm = add_batch_norm
+ self.cluster_size = cluster_size
+ self.softmax = nn.Softmax(dim=-1)
+ self.cluster_weights = nn.Parameter(torch.randn(
+ feature_size, cluster_size) * 1 / math.sqrt(feature_size))
+ self.cluster_weights2 = nn.Parameter(torch.randn(
+ 1, feature_size, cluster_size) * 1 / math.sqrt(feature_size))
+ self.hidden1_weights = nn.Parameter(
+ torch.randn(cluster_size * feature_size, output_dim) * 1 / math.sqrt(feature_size))
+
+ if add_batch_norm:
+ self.cluster_biases = None
+ self.bn1 = nn.BatchNorm1d(cluster_size)
+ else:
+ self.cluster_biases = nn.Parameter(torch.randn(
+ cluster_size) * 1 / math.sqrt(feature_size))
+ self.bn1 = None
+
+ self.bn2 = nn.BatchNorm1d(output_dim)
+
+ if gating:
+ self.context_gating = GatingContext(
+ output_dim, add_batch_norm=add_batch_norm)
+
+ def forward(self, x):
+ x = x.transpose(1, 3).contiguous()
+ x = x.view((-1, self.max_samples, self.feature_size))
+ activation = torch.matmul(x, self.cluster_weights)
+ if self.add_batch_norm:
+ # activation = activation.transpose(1,2).contiguous()
+ activation = activation.view(-1, self.cluster_size)
+ activation = self.bn1(activation)
+ activation = activation.view(-1,
+ self.max_samples, self.cluster_size)
+ # activation = activation.transpose(1,2).contiguous()
+ else:
+ activation = activation + self.cluster_biases
+ activation = self.softmax(activation)
+ activation = activation.view((-1, self.max_samples, self.cluster_size))
+
+ a_sum = activation.sum(-2, keepdim=True)
+ a = a_sum * self.cluster_weights2
+
+ activation = torch.transpose(activation, 2, 1)
+ x = x.view((-1, self.max_samples, self.feature_size))
+ vlad = torch.matmul(activation, x)
+ vlad = torch.transpose(vlad, 2, 1)
+ vlad = vlad - a
+
+ vlad = F.normalize(vlad, dim=1, p=2)
+ vlad = vlad.view((-1, self.cluster_size * self.feature_size))
+ vlad = F.normalize(vlad, dim=1, p=2)
+
+ vlad = torch.matmul(vlad, self.hidden1_weights)
+
+ vlad = self.bn2(vlad)
+
+ if self.gating:
+ vlad = self.context_gating(vlad)
+
+ return vlad
+
+
+class GatingContext(nn.Module):
+ def __init__(self, dim, add_batch_norm=True):
+ super(GatingContext, self).__init__()
+ self.dim = dim
+ self.add_batch_norm = add_batch_norm
+ self.gating_weights = nn.Parameter(
+ torch.randn(dim, dim) * 1 / math.sqrt(dim))
+ self.sigmoid = nn.Sigmoid()
+
+ if add_batch_norm:
+ self.gating_biases = None
+ self.bn1 = nn.BatchNorm1d(dim)
+ else:
+ self.gating_biases = nn.Parameter(
+ torch.randn(dim) * 1 / math.sqrt(dim))
+ self.bn1 = None
+
+ def forward(self, x):
+ gates = torch.matmul(x, self.gating_weights)
+
+ if self.add_batch_norm:
+ gates = self.bn1(gates)
+ else:
+ gates = gates + self.gating_biases
+
+ gates = self.sigmoid(gates)
+
+ activation = x * gates
+
+ return activation
+
+
+class Flatten(nn.Module):
+ def __init__(self):
+ nn.Module.__init__(self)
+
+ def forward(self, input):
+ return input.view(input.size(0), -1)
+
+
+class STN2d(nn.Module):
+ def __init__(self, num_points=256, k=2, use_bn=True):
+ super(STN2d, self).__init__()
+ self.k = k
+ self.kernel_size = 2 if k == 2 else 1
+ self.channels = 1 if k == 2 else k
+ self.num_points = num_points
+ self.use_bn = use_bn
+ self.conv1 = torch.nn.Conv2d(self.channels, 64, (1, self.kernel_size))
+ self.conv2 = torch.nn.Conv2d(64, 128, (1,1))
+ self.conv3 = torch.nn.Conv2d(128, 1024, (1,1))
+ self.mp1 = torch.nn.MaxPool2d((num_points, 1), 1)
+ self.fc1 = nn.Linear(1024, 512)
+ self.fc2 = nn.Linear(512, 256)
+ self.fc3 = nn.Linear(256, k*k)
+ self.fc3.weight.data.zero_()
+ self.fc3.bias.data.zero_()
+ self.relu = nn.ReLU()
+
+ if use_bn:
+ self.bn1 = nn.BatchNorm2d(64)
+ self.bn2 = nn.BatchNorm2d(128)
+ self.bn3 = nn.BatchNorm2d(1024)
+ self.bn4 = nn.BatchNorm1d(512)
+ self.bn5 = nn.BatchNorm1d(256)
+
+ def forward(self, x):
+ batchsize = x.size()[0]
+ if self.use_bn:
+ x = F.relu(self.bn1(self.conv1(x)))
+ x = F.relu(self.bn2(self.conv2(x)))
+ x = F.relu(self.bn3(self.conv3(x)))
+ else:
+ x = F.relu(self.conv1(x))
+ x = F.relu(self.conv2(x))
+ x = F.relu(self.conv3(x))
+ x = self.mp1(x)
+ x = x.view(-1, 1024)
+
+ if self.use_bn:
+ x = F.relu(self.bn4(self.fc1(x)))
+ x = F.relu(self.bn5(self.fc2(x)))
+ else:
+ x = F.relu(self.fc1(x))
+ x = F.relu(self.fc2(x))
+ x = self.fc3(x)
+
+ iden = Variable(torch.from_numpy(np.eye(self.k).astype(np.float32))).view(
+ 1, self.k*self.k).repeat(batchsize, 1)
+ if x.is_cuda:
+ iden = iden.cuda()
+ x = x + iden
+ x = x.view(-1, self.k, self.k)
+ return x
+
+
+class STN3d(nn.Module):
+ def __init__(self, num_points=2500, k=3, use_bn=True):
+ super(STN3d, self).__init__()
+ self.k = k
+ self.kernel_size = 3 if k == 3 else 1
+ self.channels = 1 if k == 3 else k
+ self.num_points = num_points
+ self.use_bn = use_bn
+ self.conv1 = torch.nn.Conv2d(self.channels, 64, (1, self.kernel_size))
+ self.conv2 = torch.nn.Conv2d(64, 128, (1,1))
+ self.conv3 = torch.nn.Conv2d(128, 1024, (1,1))
+ self.mp1 = torch.nn.MaxPool2d((num_points, 1), 1)
+ self.fc1 = nn.Linear(1024, 512)
+ self.fc2 = nn.Linear(512, 256)
+ self.fc3 = nn.Linear(256, k*k)
+ self.fc3.weight.data.zero_()
+ self.fc3.bias.data.zero_()
+ self.relu = nn.ReLU()
+
+ if use_bn:
+ self.bn1 = nn.BatchNorm2d(64)
+ self.bn2 = nn.BatchNorm2d(128)
+ self.bn3 = nn.BatchNorm2d(1024)
+ self.bn4 = nn.BatchNorm1d(512)
+ self.bn5 = nn.BatchNorm1d(256)
+
+ def forward(self, x):
+ batchsize = x.size()[0]
+ if self.use_bn:
+ x = F.relu(self.bn1(self.conv1(x)))
+ x = F.relu(self.bn2(self.conv2(x)))
+ x = F.relu(self.bn3(self.conv3(x)))
+ else:
+ x = F.relu(self.conv1(x))
+ x = F.relu(self.conv2(x))
+ x = F.relu(self.conv3(x))
+ x = self.mp1(x)
+ x = x.view(-1, 1024)
+
+ if self.use_bn:
+ x = F.relu(self.bn4(self.fc1(x)))
+ x = F.relu(self.bn5(self.fc2(x)))
+ else:
+ x = F.relu(self.fc1(x))
+ x = F.relu(self.fc2(x))
+ x = self.fc3(x)
+
+ iden = Variable(torch.from_numpy(np.eye(self.k).astype(np.float32))).view(
+ 1, self.k*self.k).repeat(batchsize, 1)
+ if x.is_cuda:
+ iden = iden.cuda()
+ x = x + iden
+ x = x.view(-1, self.k, self.k)
+ return x
+
+
+class ObsFeatAVD(nn.Module):
+ """Feature extractor for 2D organized point clouds"""
+ def __init__(self, n_out=1024, num_points=2500, global_feat=True, feature_transform=False, max_pool=True):
+ super(ObsFeatAVD, self).__init__()
+ self.n_out = n_out
+ self.global_feature = global_feat
+ self.feature_transform = feature_transform
+ self.max_pool = max_pool
+ k = 3
+ p = int(np.floor(k / 2)) + 2
+ self.stn = STN3d(num_points=num_points, k=3, use_bn=False)
+ self.feature_trans = STN3d(num_points=num_points, k=64, use_bn=False)
+ self.conv1 = nn.Conv2d(3,64,kernel_size=k,padding=p,dilation=3)
+ self.conv2 = nn.Conv2d(64,128,kernel_size=k,padding=p,dilation=3)
+ self.conv3 = nn.Conv2d(128,256,kernel_size=k,padding=p,dilation=3)
+ self.conv7 = nn.Conv2d(256,self.n_out,kernel_size=k,padding=p,dilation=3)
+ self.amp = nn.AdaptiveMaxPool2d(1)
+
+ def forward(self, x):
+ batchsize = x.size()[0]
+ trans = self.stn(x)
+ x = torch.matmul(torch.squeeze(x), trans)
+ x = x.view(batchsize, 1, -1, 3)
+ x = x.permute(0,3,1,2)
+ assert(x.shape[1]==3),"the input size must be "
+ x = F.relu(self.conv1(x))
+ x = F.relu(self.conv2(x))
+ x = F.relu(self.conv3(x))
+ x = self.conv7(x)
+ if self.max_pool:
+ x = self.amp(x)
+ #x = x.view(-1,self.n_out) #
+ x = x.permute(0,2,3,1)
+ return x
+
+class ImageNetfeat(nn.Module):
+ def __init__(self, global_feat=True, feature_transform=False, max_pool=True):
+ super(ImageNetfeat, self).__init__()
+ encoder = models.vgg16(pretrained=True)
+ layers = list(encoder.features.children())[:-2]
+
+ self.base_model = nn.Sequential(*layers)
+
+ def forward(self, x):
+ B,_,g_x,g_y,_ = x.shape
+ result = self.base_model(x.reshape(B,3,g_x,g_y))
+ return result
+
+class ImageNetVlad(nn.Module):
+ def __init__(self, grid_x=256, grid_y=256, global_feat=True, feature_transform=False, max_pool=True, output_dim=1024):
+ super(ImageNetVlad, self).__init__()
+
+ self.obs_feat_extractor = ImageNetfeat(global_feat=global_feat,
+ feature_transform=feature_transform, max_pool=max_pool)
+
+ dim = list(self.obs_feat_extractor.parameters())[-1].shape[0]
+ self.net_vlad = NetVLAD_Image(num_clusters=32, dim=512, vladv2=True)
+ self.fc1 = nn.Linear(16384, 4096)
+ self.bn1 = nn.BatchNorm1d(4096)
+ self.fc2 = nn.Linear(4096, output_dim)
+ self.bn2 = nn.BatchNorm1d(output_dim)
+ self.relu = nn.ReLU()
+
+ def forward(self, x):
+ x = self.obs_feat_extractor(x)
+ x = self.net_vlad(x)
+ x = self.relu(self.bn1(self.fc1(x)))
+ x = self.relu(self.bn2(self.fc2(x)))
+
+ return x
+
+
+if __name__ == '__main__':
+ num_points = 256
+ sim_data = Variable(torch.rand(44, 1, num_points, 3))
+ sim_data = sim_data.cuda()
+
+ pnv = PointNetVlad.PointNetVlad(global_feat=True, feature_transform=True, max_pool=False,
+ output_dim=256, num_points=num_points).cuda()
+ pnv.train()
+ out3 = pnv(sim_data)
+ print('pnv', out3.size())
diff --git a/models/__pycache__/PointNetVlad.cpython-36.pyc b/models/__pycache__/PointNetVlad.cpython-36.pyc
deleted file mode 100644
index 79f37ec..0000000
Binary files a/models/__pycache__/PointNetVlad.cpython-36.pyc and /dev/null differ
diff --git a/train_pointnetvlad.py b/train_pointnetvlad.py
index 0de2d5d..bb2c845 100644
--- a/train_pointnetvlad.py
+++ b/train_pointnetvlad.py
@@ -1,3 +1,4 @@
+import datetime
#import torch
#device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
import argparse
@@ -9,20 +10,21 @@
import numpy as np
from sklearn.neighbors import KDTree, NearestNeighbors
+import generating_queries.generate_training_tuples_RGB_baseline_batch as generate_dataset_tt
+import generating_queries.generate_test_RGB_sets as generate_dataset_eval
import config as cfg
import evaluate
import loss.pointnetvlad_loss as PNV_loss
-import models.PointNetVlad as PNV
+import models.Verification as VFC
+import models.ImageNetVlad as INV
import torch
import torch.nn as nn
from loading_pointclouds import *
from tensorboardX import SummaryWriter
from torch.autograd import Variable
from torch.backends import cudnn
-
-os.environ["CUDA_VISIBLE_DEVICES"] = "0"
-
+import scipy.io as sio
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
@@ -39,8 +41,8 @@
help='Number of potential positives in each training tuple [default: 2]')
parser.add_argument('--negatives_per_query', type=int, default=18,
help='Number of definite negatives in each training tuple [default: 18]')
-parser.add_argument('--max_epoch', type=int, default=20,
- help='Epoch to run [default: 20]')
+parser.add_argument('--max_epoch', type=int, default=100,
+ help='Epoch to run [default: 100]')
parser.add_argument('--batch_num_queries', type=int, default=2,
help='Batch Size during training [default: 2]')
parser.add_argument('--learning_rate', type=float, default=0.000005,
@@ -57,7 +59,7 @@
help='Margin for hinge loss [default: 0.5]')
parser.add_argument('--margin_2', type=float, default=0.2,
help='Margin for hinge loss [default: 0.2]')
-parser.add_argument('--loss_function', default='quadruplet', choices=[
+parser.add_argument('--loss_function', default='triplet', choices=[
'triplet', 'quadruplet'], help='triplet or quadruplet [default: quadruplet]')
parser.add_argument('--loss_not_lazy', action='store_false',
help='If present, do not use lazy variant of loss')
@@ -67,16 +69,14 @@
help='If present, use best positives, otherwise use hardest positives')
parser.add_argument('--resume', action='store_true',
help='If present, restore checkpoint and resume training')
-parser.add_argument('--dataset_folder', default='../../dataset/',
+parser.add_argument('--dataset_folder', default='/mnt/NAS/home/cc/data/habitat_5',
help='PointNetVlad Dataset Folder')
FLAGS = parser.parse_args()
-cfg.BATCH_NUM_QUERIES = FLAGS.batch_num_queries
#cfg.EVAL_BATCH_SIZE = 12
-cfg.NUM_POINTS = 256
-cfg.TRAIN_POSITIVES_PER_QUERY = FLAGS.positives_per_query
-cfg.TRAIN_NEGATIVES_PER_QUERY = FLAGS.negatives_per_query
-cfg.MAX_EPOCH = FLAGS.max_epoch
+cfg.GRID_X = 1080
+cfg.GRID_Y = 1920
+cfg.MAX_EPOCH = cfg.MAX_EPOCH
cfg.BASE_LEARNING_RATE = FLAGS.learning_rate
cfg.MOMENTUM = FLAGS.momentum
cfg.OPTIMIZER = FLAGS.optimizer
@@ -84,15 +84,14 @@
cfg.DECAY_RATE = FLAGS.decay_rate
cfg.MARGIN1 = FLAGS.margin_1
cfg.MARGIN2 = FLAGS.margin_2
-cfg.FEATURE_OUTPUT_DIM = 256
-cfg.LOSS_FUNCTION = FLAGS.loss_function
cfg.TRIPLET_USE_BEST_POSITIVES = FLAGS.triplet_use_best_positives
cfg.LOSS_LAZY = FLAGS.loss_not_lazy
cfg.LOSS_IGNORE_ZERO_BATCH = FLAGS.loss_ignore_zero_batch
-cfg.TRAIN_FILE = 'generating_queries/training_queries_baseline.pickle'
-cfg.TEST_FILE = 'generating_queries/test_queries_baseline.pickle'
+cfg.TRAIN_FILE = 'generating_queries/train_pickle/training_queries_baseline_0.pickle'
+cfg.TEST_FILE = 'generating_queries/train_pickle/test_queries_baseline_0.pickle'
+cfg.DB_FILE = 'generating_queries/train_pickle/db_queries_baseline_0.pickle'
cfg.LOG_DIR = FLAGS.log_dir
if not os.path.exists(cfg.LOG_DIR):
@@ -103,11 +102,11 @@
cfg.RESULTS_FOLDER = FLAGS.results_dir
print("cfg.RESULTS_FOLDER:"+str(cfg.RESULTS_FOLDER))
-cfg.DATASET_FOLDER = FLAGS.dataset_folder
# Load dictionary of training queries
TRAINING_QUERIES = get_queries_dict(cfg.TRAIN_FILE)
TEST_QUERIES = get_queries_dict(cfg.TEST_FILE)
+DB_QUERIES = get_queries_dict(cfg.DB_FILE)
cfg.BN_INIT_DECAY = 0.5
cfg.BN_DECAY_DECAY_RATE = 0.5
@@ -120,6 +119,9 @@
TOTAL_ITERATIONS = 0
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+cfg.margin = 0.1
+
+#scene_list = ["Micanopy", "Nimmons", "Reyno", "Spotswood", "Springhill", "Stilwell"]
def get_bn_decay(batch):
bn_momentum = cfg.BN_INIT_DECAY * \
@@ -135,30 +137,41 @@ def log_string(out_str):
# learning rate halfed every 5 epoch
-
def get_learning_rate(epoch):
learning_rate = cfg.BASE_LEARNING_RATE * ((0.9) ** (epoch // 5))
learning_rate = max(learning_rate, 0.00001) # CLIP THE LEARNING RATE!
return learning_rate
-def train():
- global HARD_NEGATIVES, TOTAL_ITERATIONS
+def train(scene_index):
+ train_start = datetime.datetime.now()
+ global HARD_NEGATIVES, TOTAL_ITERATIONS, TRAINING_QUERIES
bn_decay = get_bn_decay(0)
#tf.summary.scalar('bn_decay', bn_decay)
-
+ generate_dataset_tt.generate(scene_index, 0, inside=False)
+ generate_dataset_eval.generate(scene_index, False, inside=False)
+ generate_dataset_eval.generate(scene_index, True, inside=False)
+ TRAINING_QUERIES = get_queries_dict(cfg.TRAIN_FILE)
+ TEST_QUERIES = get_queries_dict(cfg.TEST_FILE)
+ DB_QUERIES = get_queries_dict(cfg.DB_FILE)
+
+ cfg.RESULTS_FOLDER = os.path.join("results/", cfg.scene_list[scene_index])
+ if not os.path.isdir(cfg.RESULTS_FOLDER):
+ os.mkdir(cfg.RESULTS_FOLDER)
#loss = lazy_quadruplet_loss(q_vec, pos_vecs, neg_vecs, other_neg_vec, MARGIN1, MARGIN2)
if cfg.LOSS_FUNCTION == 'quadruplet':
loss_function = PNV_loss.quadruplet_loss
+ elif cfg.LOSS_FUNCTION == 'triplet_RI':
+ loss_function = PNV_loss.triplet_loss_RI
else:
- loss_function = PNV_loss.triplet_loss_wrapper
+ loss_function = PNV_loss.triplet_loss
learning_rate = get_learning_rate(0)
train_writer = SummaryWriter(os.path.join(cfg.LOG_DIR, 'train'))
#test_writer = SummaryWriter(os.path.join(cfg.LOG_DIR, 'test'))
- model = PNV.PointNetVlad(global_feat=True, feature_transform=True,
- max_pool=False, output_dim=cfg.FEATURE_OUTPUT_DIM, num_points=cfg.NUM_POINTS)
+ model = INV.ImageNetVlad(global_feat=True, feature_transform=True,
+ max_pool=False, output_dim=cfg.FEATURE_OUTPUT_DIM, grid_x = cfg.GRID_X, grid_y = cfg.GRID_Y)
model = model.to(device)
parameters = filter(lambda p: p.requires_grad, model.parameters())
@@ -178,10 +191,16 @@ def train():
checkpoint = torch.load(resume_filename)
saved_state_dict = checkpoint['state_dict']
starting_epoch = checkpoint['epoch']
+ print("starting_epoch:"+str(starting_epoch))
+ #starting_epoch = starting_epoch +1
TOTAL_ITERATIONS = starting_epoch * len(TRAINING_QUERIES)
-
+ starting_epoch = starting_epoch +1
model.load_state_dict(saved_state_dict)
optimizer.load_state_dict(checkpoint['optimizer'])
+ #trusted_positives = sio.loadmat("results/trusted_positives_folder/trusted_positives_"+str(starting_epoch)+".mat")['data']
+ #potential_positives = sio.loadmat("results/trusted_positives_folder/potential_positives_"+str(starting_epoch)+".mat")['data']
+ #potential_distributions = sio.loadmat("results/trusted_positives_folder/potential_distributions_"+str(starting_epoch)+".mat")['data']
+
else:
starting_epoch = 0
@@ -191,24 +210,36 @@ def train():
LOG_FOUT.write("\n")
LOG_FOUT.flush()
+ try:
+ potential_positives
+ except NameError:
+ potential_positives = None
+ potential_distributions = None
+ trusted_positives = None
+
+ #criterion = nn.TripletMarginLoss(margin=cfg.margin**0.5,
+ # p=2, reduction='sum').to(device)
+
for epoch in range(starting_epoch, cfg.MAX_EPOCH):
print(epoch)
print()
+
log_string('**** EPOCH %03d ****' % (epoch))
sys.stdout.flush()
-
- train_one_epoch(model, optimizer, train_writer, loss_function, epoch)
+
+ train_one_epoch(model, optimizer, train_writer, loss_function, epoch, scene_index, TRAINING_QUERIES, TEST_QUERIES, DB_QUERIES)
log_string('EVALUATING...')
- cfg.OUTPUT_FILE = cfg.RESULTS_FOLDER + 'results_' + str(epoch) + '.txt'
-
- eval_recall = evaluate.evaluate_model(model, True)
- log_string('EVAL RECALL: %s' % str(eval_recall))
+ cfg.OUTPUT_FILE = os.path.join(cfg.RESULTS_FOLDER , 'results_' + str(epoch) + '.txt')
+
+ eval_recall_1, eval_recall_5, eval_recall_10 = evaluate.evaluate_model(model,optimizer,epoch,scene_index,True)
- train_writer.add_scalar("Val Recall", eval_recall, epoch)
+ log_string('EVAL RECALL_1: %s' % str(eval_recall_1))
+ log_string('EVAL RECALL_5: %s' % str(eval_recall_5))
+ log_string('EVAL RECALL_10: %s' % str(eval_recall_10))
-def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
+def train_one_epoch(model, optimizer, train_writer, loss_function, epoch, scene_index, TRAINING_QUERIES, TEST_QUERIES, DB_QUERIES):
global HARD_NEGATIVES
global TRAINING_LATENT_VECTORS, TOTAL_ITERATIONS
@@ -221,17 +252,21 @@ def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
# Shuffle train files
train_file_idxs = np.arange(0, len(TRAINING_QUERIES.keys()))
np.random.shuffle(train_file_idxs)
+
for i in range(len(train_file_idxs)//cfg.BATCH_NUM_QUERIES):
- #for i in range(2):
- # for i in range (5):
+ #for i in range(3):
batch_keys = train_file_idxs[i *
cfg.BATCH_NUM_QUERIES:(i+1)*cfg.BATCH_NUM_QUERIES]
q_tuples = []
-
+
faulty_tuple = False
no_other_neg = False
for j in range(cfg.BATCH_NUM_QUERIES):
+
if (len(TRAINING_QUERIES[batch_keys[j]]["positives"]) < cfg.TRAIN_POSITIVES_PER_QUERY):
+ print("len(TRAINING_QUERIES[batch_keys[j]][positives]:"+str(len(TRAINING_QUERIES[batch_keys[j]]["positives"])))
+ print("cfg.TRAIN_POSITIVES_PER_QUERY:"+str(cfg.TRAIN_POSITIVES_PER_QUERY))
+ assert(0)
faulty_tuple = True
break
@@ -239,10 +274,7 @@ def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
if (len(TRAINING_LATENT_VECTORS) == 0):
q_tuples.append(
get_query_tuple(TRAINING_QUERIES[batch_keys[j]], cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY,
- TRAINING_QUERIES, hard_neg=[], other_neg=True))
- #print("q_tuples:"+str(q_tuples))
- # q_tuples.append(get_rotated_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_neg=[], other_neg=True))
- # q_tuples.append(get_jittered_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_neg=[], other_neg=True))
+ DB_QUERIES, hard_neg=[], other_neg=True))
elif (len(HARD_NEGATIVES.keys()) == 0):
query = get_feature_representation(
@@ -254,9 +286,7 @@ def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
query, negatives, num_to_take)
q_tuples.append(
get_query_tuple(TRAINING_QUERIES[batch_keys[j]], cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY,
- TRAINING_QUERIES, hard_negs, other_neg=True))
- # q_tuples.append(get_rotated_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True))
- # q_tuples.append(get_jittered_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True))
+ DB_QUERIES, hard_negs, other_neg=True))
else:
query = get_feature_representation(
TRAINING_QUERIES[batch_keys[j]]['query'], model)
@@ -269,11 +299,9 @@ def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
HARD_NEGATIVES[batch_keys[j]], hard_negs))
q_tuples.append(
get_query_tuple(TRAINING_QUERIES[batch_keys[j]], cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY,
- TRAINING_QUERIES, hard_negs, other_neg=True))
- # q_tuples.append(get_rotated_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True))
- # q_tuples.append(get_jittered_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True))
+ DB_QUERIES, hard_negs, other_neg=True))
- if (q_tuples[j][3].shape[0] != cfg.NUM_POINTS):
+ if (q_tuples[j][3].shape[2] != 3):
no_other_neg = True
break
@@ -286,7 +314,7 @@ def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
log_string('----' + str(i) + '-----')
log_string('----' + 'NO OTHER NEG' + '-----')
continue
-
+
queries = []
positives = []
negatives = []
@@ -303,9 +331,8 @@ def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
other_neg = np.expand_dims(other_neg, axis=1)
positives = np.array(positives, dtype=np.float32)
negatives = np.array(negatives, dtype=np.float32)
-
log_string('----' + str(i) + '-----')
- if (len(queries.shape) != 4):
+ if (len(queries.shape) != 5):
log_string('----' + 'FAULTY QUERY' + '-----')
continue
@@ -314,16 +341,9 @@ def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
output_queries, output_positives, output_negatives, output_other_neg = run_model(
model, queries, positives, negatives, other_neg)
- #print("output_queries:"+str(output_queries))
- #print("output_positives:"+str(output_positives))
- #print("output_negatives:"+str(output_negatives))
- #print("output_other_neg:"+str(output_other_neg))
-
- #print("negatives:"+str(negatives))
- #print("other_neg:"+str(other_neg))
- #print("queries:"+str(queries))
- loss = loss_function(output_queries, output_positives, output_negatives, output_other_neg, cfg.MARGIN_1, cfg.MARGIN_2, use_min=cfg.TRIPLET_USE_BEST_POSITIVES, lazy=cfg.LOSS_LAZY, ignore_zero_loss=cfg.LOSS_IGNORE_ZERO_BATCH)
+
+ loss = loss_function(output_queries, output_positives, output_negatives, 0.1, use_min=cfg.TRIPLET_USE_BEST_POSITIVES, lazy=cfg.LOSS_LAZY, ignore_zero_loss=cfg.LOSS_IGNORE_ZERO_BATCH)
loss.backward()
optimizer.step()
@@ -331,37 +351,12 @@ def train_one_epoch(model, optimizer, train_writer, loss_function, epoch):
train_writer.add_scalar("Loss", loss.cpu().item(), TOTAL_ITERATIONS)
TOTAL_ITERATIONS += cfg.BATCH_NUM_QUERIES
- # EVALLLL
- if (epoch > 5 and i % (1400 // cfg.BATCH_NUM_QUERIES) == 29):
- TRAINING_LATENT_VECTORS = get_latent_vectors(
- model, TRAINING_QUERIES)
- print("Updated cached feature vectors")
-
- if (i % (6000 // cfg.BATCH_NUM_QUERIES) == 101):
- if isinstance(model, nn.DataParallel):
- model_to_save = model.module
- else:
- model_to_save = model
- save_name = cfg.LOG_DIR + cfg.MODEL_FILENAME
- torch.save({
- 'epoch': epoch,
- 'iter': TOTAL_ITERATIONS,
- 'state_dict': model_to_save.state_dict(),
- 'optimizer': optimizer.state_dict(),
- },
- save_name)
- print("Model Saved As " + save_name)
-
def get_feature_representation(filename, model):
model.eval()
- queries = load_pc_files([filename])
+ queries = load_image_files([filename],False)
queries = np.expand_dims(queries, axis=1)
- # if(BATCH_NUM_QUERIES-1>0):
- # fake_queries=np.zeros((BATCH_NUM_QUERIES-1,1,NUM_POINTS,3))
- # q=np.vstack((queries,fake_queries))
- # else:
- # q=queries
+
with torch.no_grad():
q = torch.from_numpy(queries).float()
q = q.to(device)
@@ -402,7 +397,7 @@ def get_latent_vectors(model, dict_to_process):
file_names = []
for index in file_indices:
file_names.append(dict_to_process[index]["query"])
- queries = load_pc_files(file_names,True)
+ queries = load_image_files(file_names,False)
feed_tensor = torch.from_numpy(queries).float()
feed_tensor = feed_tensor.unsqueeze(1)
@@ -422,22 +417,12 @@ def get_latent_vectors(model, dict_to_process):
# handle edge case
for q_index in range((len(train_file_idxs) // batch_num * batch_num), len(dict_to_process.keys())):
index = train_file_idxs[q_index]
- queries = load_pc_files([dict_to_process[index]["query"]])
+ queries = load_image_files([dict_to_process[index]["query"]],False)
queries = np.expand_dims(queries, axis=1)
- # if (BATCH_NUM_QUERIES - 1 > 0):
- # fake_queries = np.zeros((BATCH_NUM_QUERIES - 1, 1, NUM_POINTS, 3))
- # q = np.vstack((queries, fake_queries))
- # else:
- # q = queries
-
- #fake_pos = np.zeros((BATCH_NUM_QUERIES, POSITIVES_PER_QUERY, NUM_POINTS, 3))
- #fake_neg = np.zeros((BATCH_NUM_QUERIES, NEGATIVES_PER_QUERY, NUM_POINTS, 3))
- #fake_other_neg = np.zeros((BATCH_NUM_QUERIES, 1, NUM_POINTS, 3))
- #o1, o2, o3, o4 = run_model(model, q, fake_pos, fake_neg, fake_other_neg)
with torch.no_grad():
queries_tensor = torch.from_numpy(queries).float()
- o1 = model(queries_tensor)
+ o1 = model(queries_tensor.to(device))
output = o1.detach().cpu().numpy()
output = np.squeeze(output)
@@ -447,7 +432,6 @@ def get_latent_vectors(model, dict_to_process):
q_output = output
model.train()
- print(q_output.shape)
return q_output
@@ -458,22 +442,27 @@ def run_model(model, queries, positives, negatives, other_neg, require_grad=True
other_neg_tensor = torch.from_numpy(other_neg).float()
feed_tensor = torch.cat(
(queries_tensor, positives_tensor, negatives_tensor, other_neg_tensor), 1)
- feed_tensor = feed_tensor.view((-1, 1, cfg.NUM_POINTS, 3))
+ feed_tensor = feed_tensor.view((-1, 1, cfg.SIZED_GRID_X, cfg.SIZED_GRID_Y, 3))
+
feed_tensor.requires_grad_(require_grad)
feed_tensor = feed_tensor.to(device)
- #print("feed_tensor:"+str(feed_tensor))
+ #print("feed_tensor:"+str(feed_tensor.shape))
if require_grad:
output = model(feed_tensor)
else:
with torch.no_grad():
output = model(feed_tensor)
- #print("output:"+str(output))
- output = output.view(cfg.BATCH_NUM_QUERIES, -1, cfg.FEATURE_OUTPUT_DIM)
+ # print("output:"+str(output.shape))
+
+ output = output.view(cfg.BATCH_NUM_QUERIES, -1, output.shape[-1])
+ #rot_output = rot_output.view(cfg.BATCH_NUM_QUERIES, -1, rot_output.shape[-1])
o1, o2, o3, o4 = torch.split(
output, [1, cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY, 1], dim=1)
-
- return o1, o2, o3, o4
+ #ro1, ro2, ro3, ro4 = torch.split(
+ # rot_output, [1, cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY, 1], dim=1)
+ return o1, o2, o3, o4#, ro1, ro2, ro3, ro4
if __name__ == "__main__":
- train()
+ for i in range(len(cfg.scene_list)):
+ train(i)