This project aims to perform sentiment analysis on tweets related to ChatGPT, a popular language model developed by OpenAI. The dataset used for training and testing consists of 219,293 tweets collected over a month. Each tweet is classified as positive ("good"), negative ("bad"), or ("neutral").
The main objectives of this project are as follows:
- Practice text classification using machine learning classification models and word embeddings.
- Develop a sentiment analysis classifier for ChatGPT tweets.
- Evaluate the performance of the classifier on a testing set.
- Allow users to input new tweets and predict their sentiment using the trained model.
- Compare and analyze the performance of different classification models (CNN, LSTM) with varying hyperparameters.
The dataset used for training the sentiment analysis model consists of 219,293 tweets collected over a month. Each tweet is labeled with one of the following sentiments:
- Positive: Tweets expressing positive opinions, satisfaction, or enthusiasm about ChatGPT.
- Negative: Tweets expressing negative opinions, dissatisfaction, or criticism about ChatGPT.
- Neutral: Tweets that do not convey any strong sentiment or opinion about ChatGPT.
The dataset is provided in a CSV file format, with each entry containing the tweet text and its corresponding sentiment label.
Here are some examples of the dataset:
- " ChatGPT about @kunalb11 - English essay writing is going to go for a toss! https:// t.co/8t2GKX3Lcl " => Bad
- " Me: How are you doing?\n\nChatGPT: As a language model trained by OpenAI, I don't have the ability to feel emotions or have experiences. I'm a computer program designed to provide information and answer questions to the best of my ability. Is there something else you'd like to ask? https:// t.co/R28Hk0WgAY " => Good
- " OpenAI ChatGPT: Optimizing Language Models for Dialogue https:// t.co/KrH1kX3sZ6 (https:// t.co/TbeOPjiX9v) " => Neutral
The project consists of two phases:
In this phase, the following preprocessing steps are applied to clean and prepare the dataset:
- Tokenization
- Lemmatization
- Removing links, mentions, stopwords, and non-words
- Lowercasing the text
- Word embeddings also are applied as one of the preprocessing steps to enhance the representation of words in the dataset.
The dataset is then split into 80% for training and 20% for testing the classifier.
In this phase, a sentiment analysis classifier is built and trained on the preprocessed dataset. Two models, CNN and LSTM, are used for classification. Each model is trained multiple times with different hyperparameters to optimize performance.
The following outputs are generated:
- Accuracy of the trained model after testing on the testing set.
- Prediction of sentiment (positive, negative, or neutral) for new user input tweets using the trained model.
- A report that includes the models used, best hyperparameters for each model, and the accuracy for all trials. It also includes model architecture, hyperparameter details, and accuracy and loss graphs.
To gain insights into the sentiment distribution in the dataset, we analyzed the majority sentiment among the tweets. The majority sentiment classifies tweets as either positive, negative, or neutral based on the sentiment label that occurs most frequently. This analysis helps us understand the overall sentiment representation in the data.
To visualize the sentiment distribution, we created a bar plot showing the number of tweets in each sentiment category. Here is the sentiment distribution based on the majority sentiment:

As seen in the plot, the majority sentiment in the dataset is negative, followed by positive and neutral sentiments.
The project utilizes two models: CNN and LSTM, with each model trained multiple times (trials) to achieve high accuracy.
To provide a visual representation of the accuracy achieved in each trial of the CNN model, we created a bar plot. The plot displays the accuracy of each trial, making it easier to compare the performance of different trials. Here is the plot:
.png?raw=true)
The plot shows the accuracy achieved in each trial of the CNN model. The x-axis represents the trial number, while the y-axis represents the accuracy percentage. Each bar represents the accuracy achieved in a specific trial.
To visualize the accuracy achieved in each trial of the LSTM model, we created a bar plot. The plot allows for easy comparison of the performance of different trials. Here is the plot:
.png?raw=true)
The plot displays the accuracy achieved in each trial of the LSTM model. The x-axis represents the trial number, and the y-axis represents the accuracy percentage. Each bar corresponds to the accuracy achieved in a specific trial.
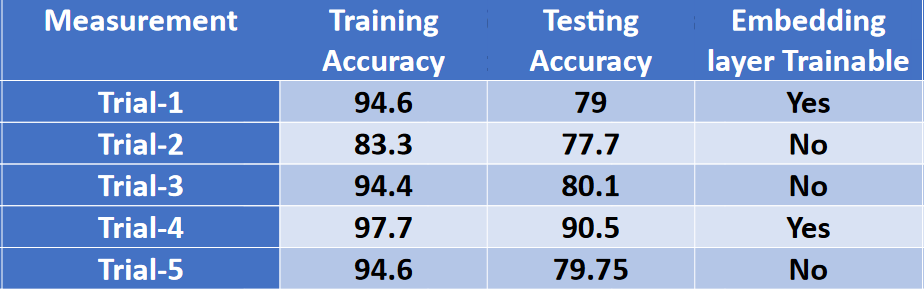
The best accuracy is achieved in Trial-4:
- Training Accuracy: 97.7%
- Testing Accuracy: 90.5%
.png?raw=true)
The best accuracy is achieved in Trial-5:
- Training Accuracy: 96.8%
- Testing Accuracy: 91.1%
.png?raw=true)
The report includes detailed comparisons of the training trials for both CNN and LSTM models. Here are some measurements for each trial:

To run the code in the FinalChatGPT_SentimentAnalysis.ipynb notebook, the following dependencies are required:
- pandas
- numpy
- seaborn
- re
- tensorflow
- matplotlib
- string
- keras
- nltk
Make sure to install these dependencies before running the code. You can use the pip install command followed by the package name to install them.
- The word embedding used in this project is "glove.6B.300d.txt," which showed the best accuracy compared to other embedding files.
- The dictionary used in the models contains 32,000 words. An experiment with 15,000 words was also conducted, resulting in similar accuracy.
- Clone the project repository to your local machine.
- Make sure you have the required dependencies installed.
- Open the
FinalChatGPT_SentimentAnalysis.ipynbnotebook using Jupyter Notebook or any compatible environment. - Run the code cells in the notebook sequentially to preprocess the data, train the models, and evaluate their performance.
- Refer to the report for a detailed analysis of the project, including model comparisons, hyperparameters, and accuracy results.
- Use the trained models to predict the sentiment of new tweets by providing them as input to the models.
- Enjoy exploring the sentiment analysis capabilities of the ChatGPT Sentiment Analysis project!
This project aims to perform sentiment analysis on tweets related to ChatGPT using machine learning models. By preprocessing the data, selecting appropriate models, training and optimizing them, and evaluating their performance, we can determine the best approach for sentiment analysis on ChatGPT tweets.
The results of this project will provide valuable insights into the sentiment distribution of ChatGPT tweets and offer a practical tool for analyzing the sentiment of new tweets. The sentiment analysis tool can be further enhanced and integrated into various applications to understand public opinion, customer feedback, and user sentiment regarding ChatGPT and related topics.
For a more detailed report with all the trials and results, please refer to the full project report, which includes comprehensive information on each phase, model performance, hyperparameter optimization, and evaluation metrics.
Contributions to this project are welcome. If you find any issues or have suggestions for improvement, please open an issue or submit a pull request. Your contributions can help enhance the Accuracies of models.
This Project was created by a team of two computer science students at Faculty of Computers and Artificial Intelligence Cairo University. The team members are:
This Project is based on Natural Language Processing (NLP) Course at Faculty of Computers and Artificial Intelligence Cairo University. We would like to thank Dr. Hanaa Bayomi Ali for his guidance and support throughout this course.
This project is licensed under the MIT License.