diff --git a/all_agents_tutorials/ReelAgent.ipynb b/all_agents_tutorials/ReelAgent.ipynb
new file mode 100644
index 0000000..f0f9993
--- /dev/null
+++ b/all_agents_tutorials/ReelAgent.ipynb
@@ -0,0 +1,971 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "BmhCqKG2cfAZ"
+ },
+ "source": [
+ "# Reel-Agent for Addictive Learning with langchain\n",
+ "\n",
+ "# Overview 🔎\n",
+ "\n",
+ "The tutorial demonstrates how to generate addictive video generation like reels in instagram by using Langchain for script generation, Eleven labs for text to speech, Assembly AI to generate subtitles and moviepy to add speech and subtitles to video\n",
+ "\n",
+ "## Motivation\n",
+ "\n",
+ "Modern apps like YouTube and Instagram have shortened attention spans, making it harder for people to engage with text-heavy content like PDFs. This project uses AI to extract interesting facts from PDFs and presents them in short, engaging videos, such as Minecraft parkour, making information more accessible and captivating.\n",
+ "\n",
+ "## Key Components\n",
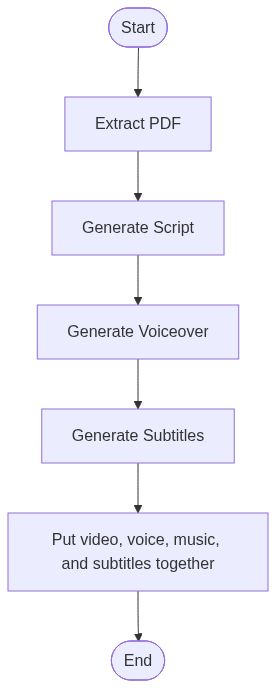
+ " 1. **[PDF Text Extraction](#pdftextextract)**: The project begins by extracting text from the provided PDF using the pypdf library. This ensures all textual content is consolidated into a single string for further processing.\n",
+ "\n",
+ "2. **[AI-Powered Fact Generation](#aipoweredfactgeneration)**: OpenAI's GPT model is used to extract interesting and specific facts from the PDF content. A structured prompt ensures the generated output aligns with the project's goals.\n",
+ "\n",
+ "3. **[Script Generation](#scriptgeneration)**: Using the extracted facts, the system creates engaging scripts for short videos. These scripts are designed to capture attention quickly, such as by using hooks or interesting questions.\n",
+ "\n",
+ "4. **[Audio Generation](#audiogeneration)**: Generate engaing voiceovers from our script using text-to-speech API to keep the user engaed.\n",
+ "\n",
+ "5. **[Subtitles genearation](#subtitlesgenearation)**: Generate the .srt file for subtitles from audio file to add it in the video.\n",
+ "\n",
+ "6. **[Video Creation](#videocreation)**: The moviepy library is used to combine the audio, music and subtitles with video templates eg. Minecraft parkour visuals, ensuring the videos are both engaging and educational.\n",
+ "\n",
+ "\n",
+ "## Implementation\n",
+ "- OpenAi's GPT: To Extract facts from pdf and generate the script for video\n",
+ "- Eleven Labs: To Generate audio from the script using Text to speech\n",
+ "- Assembly AI: To create subtitles from audio\n",
+ "- MoviePy: To integrate audio and subtitles with a base background video\n",
+ "\n",
+ "\n",
+ "## Conclusion\n",
+ "\n",
+ "This project demonstrates the use of AI to transform dense and complex PDF content into engaging, bite-sized video formats. By leveraging modern tools like OpenAI's language models and creative visuals, it bridges the gap between traditional text-based information and the fast-paced, visually-driven preferences of today's audiences. The result is a powerful tool that not only makes information more accessible but also promotes learning in a way that's fun and aligned with modern attention spans.\n",
+ "\n",
+ "### Future improvements\n",
+ "Include adding customization options for video themes or expanding support for more content types, ensuring the tool continues to evolve with user needs.
\n",
+ "Adding images to the video using api's or web scrapping.\n",
+ "\n",
+ "\n",
+ "[](https://mermaid.live/edit#pako:eNpdkc1uwyAMx18Fceqk9AVy2GXpdq3UaoeRHlxwEqQAETHZpqrvPppA1pYDYPvvjx9cuHQKecmb3n3LDjyxY1VbFteBorUR83F6WXy7H_IgSaST7av3U1JLrwcSH2jRA2GyU_DTaYluQv8fX105P5xJU4_jXYnsSpI3Z87aotgHYpNW6Ao23aoUzIRRy4KBVWzMSYxci9StDXZWbUTcMsrMxbbb1wz1QDgHFoZ7vtm9jv4Et-Tk_k9YczARPOAsI1jFC27QG9Aq_sblJql5HN9gzct4VdhA6Knmtb1GKQRyh18reUk-YMG9C23Hywb6MVphUPEBKw2tB5MlA9gv50wSXf8AHlyp0A)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IVsBFv-rZKpp"
+ },
+ "source": [
+ "## Install and import required libraries"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "U5HfhBFRZaV1",
+ "outputId": "d6ca8ef7-32be-49fa-8a4c-81a50c4b9887"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install langchain langchain-openai langchain_core pypdf moviepy assemblyai"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "MRQbp06OZbXb"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import requests\n",
+ "import urllib\n",
+ "import time\n",
+ "from pypdf import PdfReader\n",
+ "from langchain_core.prompts import ChatPromptTemplate, PromptTemplate\n",
+ "from langchain_openai import ChatOpenAI\n",
+ "from pydantic import BaseModel, Field\n",
+ "from langchain_core.output_parsers import JsonOutputParser\n",
+ "import assemblyai as aai\n",
+ "from moviepy.editor import *\n",
+ "from moviepy.editor import VideoFileClip\n",
+ "from moviepy.video.fx import crop\n",
+ "from moviepy.video.tools.subtitles import SubtitlesClip\n",
+ "from moviepy.config import change_settings\n",
+ "from google.colab import userdata"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "57X77lLeZcJ7"
+ },
+ "source": [
+ "Set up your Gemini API Key\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "aFbK9LPKZ-u-"
+ },
+ "outputs": [],
+ "source": [
+ "os.environ[\"OPENAI_API_KEY\"] = userdata.get('OPENAI_API_KEY')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qASmKB9OeEVR"
+ },
+ "source": [
+ "## PDF Text Extraction\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lGljG1r8WylX"
+ },
+ "source": [
+ "Download the pdf that you want to use"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "Ffa5LMVIZZCW",
+ "outputId": "6fc23b4a-7a19-48f2-d73a-8dd79bb69f66"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "--2024-11-26 06:13:25-- https://arxiv.org/pdf/1706.03762\n",
+ "Resolving arxiv.org (arxiv.org)... 151.101.67.42, 151.101.131.42, 151.101.195.42, ...\n",
+ "Connecting to arxiv.org (arxiv.org)|151.101.67.42|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 2215244 (2.1M) [application/pdf]\n",
+ "Saving to: ‘1706.03762’\n",
+ "\n",
+ "\r1706.03762 0%[ ] 0 --.-KB/s \r1706.03762 100%[===================>] 2.11M --.-KB/s in 0.06s \n",
+ "\n",
+ "2024-11-26 06:13:25 (38.1 MB/s) - ‘1706.03762’ saved [2215244/2215244]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "!wget https://arxiv.org/pdf/1706.03762\n",
+ "!mv 1706.03762 attention_is_all_you_need.pdf"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "T2obAYIGaoHf"
+ },
+ "outputs": [],
+ "source": [
+ "#Extracts contents from the pdf\n",
+ "def read_pdf():\n",
+ " reader = PdfReader(\"attention_is_all_you_need.pdf\")\n",
+ " text = \"\"\n",
+ " for page in reader.pages:\n",
+ " text += page.extract_text()\n",
+ " return text"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "aV7M4OHxWy4J"
+ },
+ "source": [
+ "## AI-Powered Fact Generation\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "i4eKwhNYa8Pg"
+ },
+ "outputs": [],
+ "source": [
+ "#from extracted content it gets facts and insights\n",
+ "def get_facts(text):\n",
+ " facts_prompt = ChatPromptTemplate.from_template(\"\"\"\n",
+ " You are a research agent. You are given this information {information}. Your goal is to boil down to interesting and specific insights from this information.\n",
+ "\n",
+ " 1. Interesting: Insights that people will find surprising or non-obvious.\n",
+ "\n",
+ " 2. Specific: Insights that avoid generalities and include specific examples from the expert. Here is your topic of focus and set of goals.\n",
+ "\n",
+ " 3. Provide your answer in points\n",
+ "\n",
+ " 4. Do not make up your answer on your own and use the information that is provided to you.\n",
+ " \"\"\")\n",
+ "\n",
+ " llm = ChatOpenAI(\n",
+ " model=\"gpt-4o-mini\",\n",
+ " )\n",
+ "\n",
+ " chain = facts_prompt | llm\n",
+ " return chain.invoke({\"information\": text}).content\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "J4meC0zdW1At"
+ },
+ "source": [
+ "## Script Generation\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "WuV9sNLxW1WT"
+ },
+ "source": [
+ "Create a script class for better structure and generating script using OpenAI"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "w4TNouzSbYo0"
+ },
+ "outputs": [],
+ "source": [
+ "class Script(BaseModel):\n",
+ " script: str = Field(description=\"script for the video\")\n",
+ " title: str = Field(description=\"title of the video\")\n",
+ " description: str = Field(description=\"description of the video\")\n",
+ " keywords: list[str] = Field(description=\"keywords for the video\")\n",
+ "\n",
+ "class Scripts(BaseModel):\n",
+ " scripts: list[Script]\n",
+ "\n",
+ "parser = JsonOutputParser(pydantic_object=Scripts)\n",
+ "\n",
+ "# create scripts for the reel using the facts\n",
+ "def create_scripts(facts):\n",
+ " script_prompt = PromptTemplate(template = \"\"\"\n",
+ " .\\n{format_instructions}\\\n",
+ " You are an expert script writer. You are tasked with writing scripts for 20-second video that plays on YouTube. Given these facts {facts} you need to write five engaging scripts keeping these facts in the context of the script.\n",
+ " keep in mind\n",
+ "\n",
+ " 1. Your scripts should not sound monotonous.\n",
+ "\n",
+ " 2. Each script should start with an engaging pitch that hooks viewers to watch the entire video. for example, you can use a fact or a question at the start of the video.\n",
+ " \"\"\",\n",
+ " input_variables=[\"facts\"],\n",
+ " partial_variables={\"format_instructions\": parser.get_format_instructions()}\n",
+ " )\n",
+ "\n",
+ " llm = ChatOpenAI(\n",
+ " model=\"gpt-4o-mini\",\n",
+ " )\n",
+ " chain = script_prompt | llm | parser\n",
+ "\n",
+ " return chain.invoke({\"facts\": facts})"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "W82EJa-KvwWn"
+ },
+ "outputs": [],
+ "source": [
+ "# read text from pdf\n",
+ "text = read_pdf()\n",
+ "\n",
+ "# find facts from the pdf\n",
+ "facts = get_facts(text)\n",
+ "\n",
+ "# Generate scripts for the reel using the facts\n",
+ "scripts = create_scripts(facts)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nInQu1llW1uh"
+ },
+ "source": [
+ "## Audio Generation\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RrD4AaqqW2El"
+ },
+ "source": [
+ "### Create the audio from the script using text-to-speech API
\n",
+ "We will be using eleven labs. You can get your eleven labs API Key from [Eleven labs](https://elevenlabs.io/)\n",
+ "\n",
+ "Use appropiate voice and voice settings to make it more engaging
\n",
+ "\n",
+ "Refer [Eleven Lab's Voice Selection](https://elevenlabs.io/docs/product/speech-synthesis/voice-selection) for voice selection
\n",
+ "\n",
+ "\n",
+ "Refer [Eleven Lab's Voice Settings](https://elevenlabs.io/docs/product/speech-synthesis/voice-settings) for voice settings
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "skdgKF2KfqoD"
+ },
+ "outputs": [],
+ "source": [
+ "voices_data = {\n",
+ " \"name\": \"Rachel\",\n",
+ " \"description\": \"A smooth and natural voice ideal for conversational and professional use cases.\",\n",
+ " \"voice_id\": \"21m00Tcm4TlvDq8ikWAM\",\n",
+ " \"voice_settings\": {\n",
+ " \"pitch\": 1.0,\n",
+ " \"speed\": 1.3,\n",
+ " \"intonation\": \"balanced\",\n",
+ " \"clarity\": \"high\",\n",
+ " \"volume\": \"normal\"\n",
+ " }\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Z3qCwcjbg2w1"
+ },
+ "source": [
+ "Set up your Eleven Labs API Key"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9qOr5WDGg3Bl"
+ },
+ "outputs": [],
+ "source": [
+ "XI_API_KEY = userdata.get('XI_API_KEY')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3XmToChefwhI"
+ },
+ "source": [
+ "Text to Speech [ElevenLab's API Reference](https://elevenlabs.io/docs/api-reference/text-to-speech)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "r33MLphffuRl",
+ "outputId": "1778ee17-2244-408a-f137-0d295f63d0e9"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Audio stream saved successfully to output.mp3.\n"
+ ]
+ }
+ ],
+ "source": [
+ "\n",
+ "CHUNK_SIZE = 1024\n",
+ "\n",
+ "VOICE_ID = voices_data[\"voice_id\"]\n",
+ "TEXT_TO_SPEAK = scripts[\"scripts\"][0][\"script\"]\n",
+ "voice_settings = voices_data[\"voice_settings\"]\n",
+ "\n",
+ "tts_url = f\"https://api.elevenlabs.io/v1/text-to-speech/{VOICE_ID}/stream\"\n",
+ "headers = {\n",
+ " \"Accept\": \"application/json\",\n",
+ " \"xi-api-key\": XI_API_KEY\n",
+ "}\n",
+ "\n",
+ "data = {\n",
+ " \"text\": TEXT_TO_SPEAK,\n",
+ " \"model_id\": \"eleven_multilingual_v2\",\n",
+ " \"voice_settings\": {\n",
+ " \"stability\": 0.5,\n",
+ " \"similarity_boost\": 0.8,\n",
+ " \"style\": 0.0,\n",
+ " \"use_speaker_boost\": True,\n",
+ " **voice_settings\n",
+ " }\n",
+ "}\n",
+ "\n",
+ "response = requests.post(tts_url, headers=headers, json=data, stream=True)\n",
+ "\n",
+ "# Handle response\n",
+ "\n",
+ "if response.ok:\n",
+ " output_path = f\"output.mp3\"\n",
+ " with open(output_path, \"wb\") as audio_file:\n",
+ " for chunk in response.iter_content(chunk_size=CHUNK_SIZE):\n",
+ " audio_file.write(chunk)\n",
+ " print(f\"Audio stream saved successfully to {output_path}.\")\n",
+ "else:\n",
+ " print(f\"Error {response.status_code}: {response.text}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qPgpfwQ_W2W1"
+ },
+ "source": [
+ "## Subtitles genearation\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ModvBXaEhRvD"
+ },
+ "source": [
+ "### Generate subtitles\n",
+ "\n",
+ "We will be using [Assembly AI](https://www.assemblyai.com) to generate our subtitles."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "xPnrV_0ngjMw"
+ },
+ "source": [
+ "Set your Assembly AI key"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QfJU6TW5gfG2"
+ },
+ "outputs": [],
+ "source": [
+ "aai.settings.api_key = userdata.get(\"ASSEMBLYAI_API_KEY\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "PlK__ubtfpoH",
+ "outputId": "34202a9e-cea9-43f0-c624-64ba217ba2bb"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "1\n",
+ "00:00:00,320 --> 00:00:00,808\n",
+ "Did you know that\n",
+ "\n",
+ "2\n",
+ "00:00:01,308 --> 00:00:01,496\n",
+ "the transformer\n",
+ "\n",
+ "3\n",
+ "00:00:01,537 --> 00:00:02,593\n",
+ "architecture can cut\n",
+ "\n",
+ "4\n",
+ "00:00:02,649 --> 00:00:03,393\n",
+ "training time by\n",
+ "\n",
+ "5\n",
+ "00:00:03,409 --> 00:00:04,033\n",
+ "more than half\n",
+ "\n",
+ "6\n",
+ "00:00:04,089 --> 00:00:04,801\n",
+ "compared to older\n",
+ "\n",
+ "7\n",
+ "00:00:04,833 --> 00:00:07,089\n",
+ "models? In just 3.5\n",
+ "\n",
+ "8\n",
+ "00:00:07,137 --> 00:00:08,625\n",
+ "days on eight GPUs,\n",
+ "\n",
+ "9\n",
+ "00:00:08,745 --> 00:00:09,729\n",
+ "it achieved a bleu\n",
+ "\n",
+ "10\n",
+ "00:00:09,777 --> 00:00:11,481\n",
+ "score of 28.4 for\n",
+ "\n",
+ "11\n",
+ "00:00:11,513 --> 00:00:12,297\n",
+ "English to German\n",
+ "\n",
+ "12\n",
+ "00:00:12,361 --> 00:00:14,137\n",
+ "translation that's\n",
+ "\n",
+ "13\n",
+ "00:00:14,161 --> 00:00:15,073\n",
+ "revolutionary in the\n",
+ "\n",
+ "14\n",
+ "00:00:15,089 --> 00:00:15,705\n",
+ "world of machine\n",
+ "\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "!touch video.srt\n",
+ "FILE_URL = \"./output.mp3\"\n",
+ "transcriber = aai.Transcriber()\n",
+ "transcript = transcriber.transcribe(FILE_URL)\n",
+ "subtitles = transcript.export_subtitles_srt(20)\n",
+ "f = open(\"video.srt\",\"w\")\n",
+ "f.write(subtitles)\n",
+ "if transcript.status == aai.TranscriptStatus.error:\n",
+ " print(transcript.error)\n",
+ "else:\n",
+ " print(subtitles)\n",
+ "f.close()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "G-DkAwDmYn8S"
+ },
+ "source": [
+ "# Video Creation\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "BXmfctUWiF3b"
+ },
+ "source": [
+ "### Integrate audio with video using moviepy\n",
+ "\n",
+ "Add audio to any attention grabbing background video using moviepy. We are using this [Video](https://drive.google.com/file/d/14kiCtrgoCwJzcdYFmZP3FKhoiUBFgVrv/view?usp=sharing)
\n",
+ "Also add background [music](https://drive.google.com/file/d/1mWBAD2b-vj3HZayAVeVk2PGsAYZDJLpf/view?usp=sharing) to make it more engaging\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "OV1xqUpHqan4",
+ "outputId": "87a39f92-058a-41e4-8a2b-8a0c446b44f1"
+ },
+ "outputs": [],
+ "source": [
+ "!wget https://github.com/Dark-Knight499/AgentCraftHAckathon-ReelAgent/raw/refs/heads/main/videoplayback.mp4\n",
+ "!wget https://github.com/Dark-Knight499/AgentCraftHAckathon-ReelAgent/raw/refs/heads/main/music.mp3"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "Z80SKzTdiiMf",
+ "outputId": "4befe53a-eadd-4801-cddc-1fc5b93f4baa"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Moviepy - Building video reel.mp4.\n",
+ "MoviePy - Writing audio in reelTEMP_MPY_wvf_snd.mp4\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": []
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "MoviePy - Done.\n",
+ "Moviepy - Writing video reel.mp4\n",
+ "\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": []
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Moviepy - Done !\n",
+ "Moviepy - video ready reel.mp4\n"
+ ]
+ }
+ ],
+ "source": [
+ "from moviepy.editor import VideoFileClip, AudioFileClip, concatenate_videoclips,CompositeAudioClip\n",
+ "from moviepy.audio.fx.all import audio_loop\n",
+ "\n",
+ "video = VideoFileClip(\"./videoplayback.mp4\")\n",
+ "audio = AudioFileClip(\"./output.mp3\")\n",
+ "music = AudioFileClip(\"./music.mp3\")\n",
+ "video_loops = int(audio.duration // video.duration) + 1\n",
+ "video = concatenate_videoclips([video] * video_loops).subclip(0, audio.duration)\n",
+ "music = audio_loop(music, duration=video.duration)\n",
+ "music = music.volumex(0.1)\n",
+ "audio_music = CompositeAudioClip([music,audio])\n",
+ "final_video = video.set_audio(audio_music)\n",
+ "final_video.write_videofile(\"reel.mp4\", codec=\"libx264\", audio_codec=\"aac\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wiQwgIa0i8Lk"
+ },
+ "source": [
+ "### Add subtitles to our video\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "80FP0KsQjGgl"
+ },
+ "source": [
+ "Install Imagemagick and ffmpeg to add subtitles in the video"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "M-wYhx1ljA4Q"
+ },
+ "outputs": [],
+ "source": [
+ "!apt update &> /dev/null\n",
+ "!apt install imagemagick &> /dev/null\n",
+ "!apt install ffmpeg &> /dev/null\n",
+ "!pip3 install moviepy[optional] &> /dev/null\n",
+ "!sed -i '/] 7.76K --.-KB/s in 0s \n",
+ "\n",
+ "2024-11-26 06:16:03 (84.5 MB/s) - ‘policy.xml’ saved [7947/7947]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "!wget https://gist.githubusercontent.com/Kaif987/38fca3821fbbcbd7b60cb54df348c2e8/raw/7745747309ffb1982467b138d07f6f2405a5da34/policy.xml\n",
+ "!mv policy.xml /etc/ImageMagick-6/policy.xml"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HT5-4EPhjpwL"
+ },
+ "source": [
+ "Install the font that would like to be used in subtitles or use can use the default fonts
\n",
+ "We will be using Impact Font"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "i-vRKh0mj_z2",
+ "outputId": "03b074bd-9965-4264-fd7a-0ac6d126ff58"
+ },
+ "outputs": [],
+ "source": [
+ "!wget -O Impact.ttf \"https://github.com/sophilabs/macgifer/blob/master/static/font/impact.ttf\"\n",
+ "!mkdir -p ~/.fonts\n",
+ "!mv Impact.ttf ~/.fonts\n",
+ "!fc-cache -f -v"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tYfMuuOnkH7m"
+ },
+ "source": [
+ "Finally we add the subtitles to our video using moviepy"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "TKLt8xl7kMdx",
+ "outputId": "f31c3033-45b4-4076-b407-6cf3296659e3"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "/bin/bash: line 1: os.environ[IMAGEMAGICK_BINARY]: command not found\n",
+ "Moviepy - Building video final_reel.mp4.\n",
+ "MoviePy - Writing audio in final_reelTEMP_MPY_wvf_snd.mp4\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": []
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "MoviePy - Done.\n",
+ "Moviepy - Writing video final_reel.mp4\n",
+ "\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "t: 100%|██████████| 987/987 [01:28<00:00, 12.23it/s, now=None]WARNING:py.warnings:/usr/local/lib/python3.10/dist-packages/moviepy/video/io/ffmpeg_reader.py:123: UserWarning: Warning: in file reel.mp4, 2764800 bytes wanted but 0 bytes read,at frame 986/988, at time 16.43/16.45 sec. Using the last valid frame instead.\n",
+ " warnings.warn(\"Warning: in file %s, \"%(self.filename)+\n",
+ "\n"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Moviepy - Done !\n",
+ "Moviepy - video ready final_reel.mp4\n"
+ ]
+ }
+ ],
+ "source": [
+ "!os.environ[\"IMAGEMAGICK_BINARY\"] = \"/usr/bin/convert\"\n",
+ "change_settings({\"IMAGEMAGICK_BINARY\": r\"/usr/bin/convert\"})\n",
+ "generator = lambda txt: TextClip(txt, font='Impact', fontsize=50, color='white',stroke_color=\"black\",stroke_width=1)\n",
+ "subtitles = SubtitlesClip(\"video.srt\", generator)\n",
+ "video = VideoFileClip(\"reel.mp4\")\n",
+ "result = CompositeVideoClip([video, subtitles.set_pos(('center'))])\n",
+ "result.write_videofile(\"final_reel.mp4\", fps=video.fps, remove_temp=True, codec=\"libx264\", audio_codec=\"aac\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Video Explanation : [Youtube](https://youtu.be/KyztEFW2nvg)
\n",
+ "*The documentation has been updated"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Demo Videos"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Video1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ ""
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 3,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "from IPython.display import Video\n",
+ "\n",
+ "# Display the video\n",
+ "Video(\"../images/Reel Agent - Video1.mp4\", embed=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Video-2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "