Auto-WEKA is a tool for automating the selection of methods and hyperparameters of WEKA. This repository contains an extended version of Auto-WEKA now supporting the optimisation of MultiComponent Predictive Systems (MCPS).

Many different machine learning algorithms can easily be used off the shelf. Many of these methods are implemented in the open source WEKA package. However, each of these algorithms has its hyperparameters that can drastically change their performance, and there are a staggeringly large number of possible alternatives overall. Auto-WEKA considers the problem of simultaneously composing an MCPS and setting its hyperparameters, going beyond previous methods that address these issues in isolation. Auto-WEKA does this using a fully automated approach, leveraging recent innovations in Bayesian optimization. We hope that Auto-WEKA will help non-expert users to more effectively identify machine learning algorithms and hyperparameter settings appropriate to their applications, hence achieving improved performance.
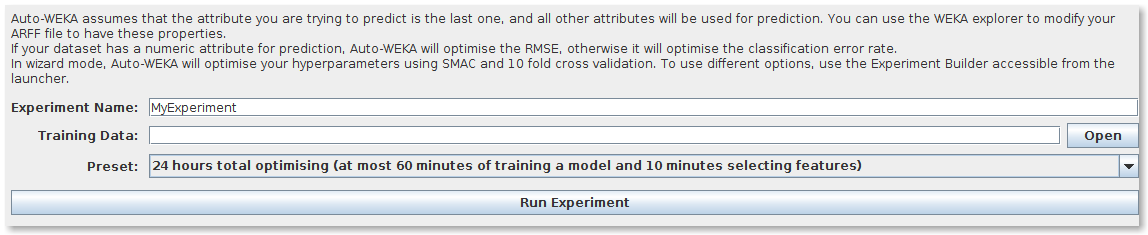
Auto-WEKA includes a wizard to find the best MCPS of a given dataset without any user interaction, apart from providing a dataset and a time budget.
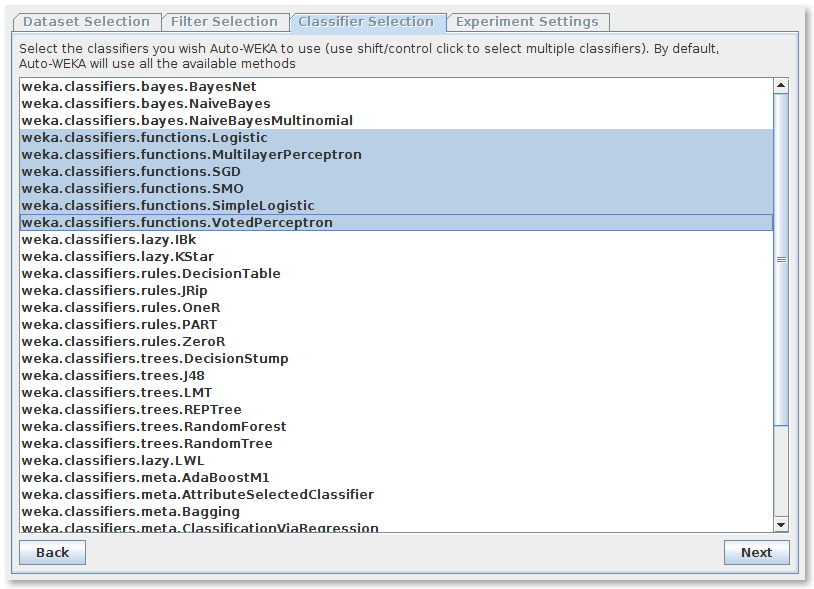
Auto-WEKA allows selecting between a list of all WEKA methods and different optimisation strategies and parameters.
This repository provides supplementary documents for a research journal article on search space reduction titled: "On Taking Advantage of Opportunistic Meta-knowledge to Reduce Configuration Spaces for Automated Machine Learning." (https://github.com/UTS-CASLab/autoweka/tree/master/autoweka4mcps/doc/spacereduction/)
The abstract of the article is as follows:
Optimisation efficiency and the model accuracy attainable for a fixed time budget suffer if this pipeline configuration space is excessively large.
A key research question is whether it is both possible and practical to preemptively avoid costly evaluations of poorly performing ML pipelines by leveraging their historical performance for various ML tasks, i.e. meta-knowledge.
This research formulates the problem of configuration space reduction in the context of AutoML.
Given a pool of available ML components, it then investigates whether previous experience can recommend the most promising subset to use as a configuration space when initiating a pipeline composition/optimisation process for a new ML problem, i.e.~running AutoML on a new dataset.
Specifically, we conduct experiments to explore (1) what size the reduced search space should be and (2) which strategy to use when recommending the most promising subset.
The previous experience comes in the form of classifier/regressor accuracy rankings derived from either (1) a substantial but non-exhaustive number of pipeline evaluations made during historical AutoML runs, i.e. opportunistic meta-knowledge, or (2) comprehensive cross-validated evaluations of classifiers/regressors with default hyperparameters, i.e. systematic meta-knowledge.
Overall, numerous experiments with the AutoWeka4MCPS package, including ones leveraging similarities between datasets via the relative landmarking method, suggest that (1) opportunistic/systematic meta-knowledge can improve ML outcomes, typically in line with how relevant that meta-knowledge is, and (2) configuration-space culling is optimal when it is neither too conservative nor too radical.
However, the utility and impact of meta-knowledge depend critically on numerous facets of its generation and exploitation, warranting extensive analysis; these are often overlooked/underappreciated within AutoML and meta-learning literature.
In particular, we observe strong sensitivity to the challenge of a dataset, i.e. whether specificity in choosing a predictor leads to significantly better performance.
Ultimately, identifying difficult datasets, thus defined, is crucial to both generating informative meta-knowledge bases and understanding optimal search-space reduction strategies.
For those wishing to explore search-space reduction in AutoWeka4MCPS for themselves, please select filters and predictors when creating experiments, as mentioned in the previous section. To more closely mimic the experiments in the article, use the following script, which is created to run experiments on virtual machines (VMs). The experiment settings can be created and stored in cloud storage such as Dropbox or Google Drive. This script moves experiment settings to VMs to run experiments, makes a zip file of experiment results, and moves them to the cloud storage.
// move the experiment folder from dropbox to the experiment folder of AutoWeka4MCPS
xcopy C:\..\add7_shuttle_seed0 C:\..\autoweka4mcps\experiments\add7_shuttle_seed0\ /E/H
// move the configuration file to the experiment folder of AutoWeka4MCPS
xcopy C:\Users\Administrator\Dropbox\add_configs\add7\add7_shuttle_seed0\listofexperiments.properties C:\experiments\tools\autoweka4mcps-a\autoweka4mcps\ /Y
// run experiments
cd C:\experiments\tools\autoweka4mcps-a\autoweka4mcps
java -Xmx2048m -cp autoweka4mcps.jar autoweka.command.App C:\..\autoweka4mcps\listofexperiments.properties
// zip experiments and move to dropbox
"C:\Program Files\7-Zip\7z.exe" a -r "C:\..\autoweka4mcps\experiments\add7_shuttle_seedx.zip" "C:\..\autoweka4mcps\experiments\*.*"
move "C:\..\autoweka4mcps\experiments\add7_shuttle_seedx.zip" "C:\..\Dropbox\add_configs_results\"
The mean error rate and structure of the best pipelines can be extracted using the following script: https://github.com/UTS-CASLab/autoweka/blob/master/autoweka4mcps/src/uts/landmarking/GenerateAnalysisReport.java
- Please watch the video tutorial for a quick start guide with the user interface (autoweka4mcps/autoweka4mcps_quick_start_guide_ui.mp4)
- It is necessary to allocate more memory for AutoWeka4MCPS to deal with large datasets, e.g., allocating 2GB memory:
cd autoweka4mcps
java -Xmx2048m -jar autoweka4mcps.jar
-
SMAC Configuration: Please configure the file path to SMAC in the following file autoweka.smac.SMACExperimentConstructor.properties
-
The experiments folders have to be put in the parent folder of AutoWeka4MCPS (default)
- Tien-Dung Nguyen, David Jacob Kedziora, Katarzyna Musial, and Bogdan Gabrys. "Exploring Opportunistic Meta-knowledge to Reduce Search Spaces for Automated Machine Learning.". In The International Joint Conference on Neural Network IJCNN. IEEE, 2021.
- David Jacob Kedziora, Katarzyna Musial, and Bogdan Gabrys. "AutonoML: Towards an Integrated Framework for Autonomous Machine Learning." arXiv preprint arXiv:2012.12600 (2020). (Under Review)
- Tien-Dung Nguyen, Bogdan Gabrys, and Katarzyna Musial. "AutoWeka4MCPS-AVATAR: Accelerating Automated Machine Learning Pipeline Composition and Optimisation.". Expert Systems with Applications 185, 2021.
- Tien-Dung Nguyen, Tomasz Maszczyk, Katarzyna Musial, Marc-Andre Zöller, and Bogdan Gabrys. "AVATAR-Machine Learning Pipeline Evaluation Using Surrogate Model". In International Symposium on Intelligent Data Analysis, pp. 352-365. Springer, Cham, 2020.
- Manuel Martin Salvador, Marcin Budka, and Bogdan Gabrys. "Automatic composition and optimisation of multicomponent predictive systems with an extended Auto-WEKA" Submitted to IEEE Transactions on Automation Science and Engineering, 2018. [slides] [results]
- Manuel Martin Salvador, Marcin Budka, and Bogdan Gabrys. "Modelling Multi-Component Predictive Systems as Petri Nets". Submitted to 15th Annual Industrial Simulation Conference, 2017 (under review). [branch]
- Manuel Martin Salvador, Marcin Budka, and Bogdan Gabrys. "Effects of change propagation resulting from adaptive preprocessing in multicomponent predictive systems". In Proc. of the 20th International Conference KES-2016.
- Manuel Martin Salvador, Marcin Budka, and Bogdan Gabrys. "Adapting Multicomponent Predictive Systems using Hybrid Adaptation Strategies with Auto-WEKA in Process Industry". In Proc. of the 2016 Workshop on Automatic Machine Learning at ICML 2016. [branch] [results]
- Manuel Martin Salvador, Marcin Budka, and Bogdan Gabrys. "Towards automatic composition of multicomponent predictive systems" In Proc. of HAIS 2016, 2016. [slides] [results]
- Chris Thornton, Frank Hutter, Holger Hoos, and Kevin Leyton-Brown. "Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classifiaction Algorithms" In Proc. of KDD 2013, 2013.
- This version of Auto-WEKA is extended by integrating the AVATAR (https://github.com/UTS-AAi/AVATAR) . The AVATAR evaluates the validity of ML pipelines using a surrogate model that enables to accelerate automatic ML pipeline composition and optimisation.
- [Tien-Dung Nguyen] (https://www.linkedin.com/in/tien-dung-nguyen-29bb42170/), University of Technology Sydney, Australia
- [Professor Bogdan Gabrys] (http://bogdan-gabrys.com/), University of Technology Sydney, Australia
- [Associate Professor Katarzyna Musial Gabrys] (http://www.katarzyna-musial.com/), University of Technology Sydney, Australia
- [Tomasz.Maszczyk], University of Technology Sydney, Australia
- [Marc-André Zöller] (https://www.researchgate.net/profile/Marc_Andre_Zoeller), USU Software AG, Germany
- [Simon Kocbek] (https://www.uts.edu.au/staff/simon.kocbek), University of Technology Sydney, Australia
- Manuel Martin Salvador, PhD Candidate (Bournemouth University)
- Marcin Budka, Senior Lecturer (Bournemouth University)
- Bogdan Gabrys, Professor (Bournemouth University)
- Chris Thornton, M.Sc. Student (UBC)
- Frank Hutter, Assistant Professor (Freiburg University)
- Holger Hoos, Professor (UBC)
- Kevin Leyton-Brown, Associate Professor (UBC)
This version was developed using as base Auto-WEKA 0.5 from http://www.cs.ubc.ca/labs/beta/Projects/autoweka/
This software is intended for research purposes and not recommended for production environments. Support is not guaranteed, but please contact us if you have any question or would like to collaborate.
GNU General Public License v3 (see LICENSE)