We provide ImageNet-1K training commands here. Please check INSTALL.md for installation instructions first. Please refer to OpenMixup implementation for RSB A3 and ImageNet-21K training.
Taking MogaNet-T as an example, you can use the following command to run this experiment on a single machine (8GPUs):
python -m torch.distributed.launch --nproc_per_node=8 train.py \
--model moganet_tiny --img_size 224 --drop_path 0.1 \
--epochs 300 --batch_size 128 --lr 1e-3 --weight_decay 0.04 \
--aa rand-m7-mstd0.5-inc1 --crop_pct 0.9 --mixup 0.1 \
--amp --native_amp \
--data_dir /path/to/imagenet-1k \
--experiment /path/to/save_results
- Batch size scaling. The effective batch size is equal to
--nproc_per_node*--batch_size. In the example above, the effective batch size is8*128 = 1024. Running on one machine, we can reduce--batch_sizeand use--ampto avoid OOM issues while keeping the total batch size unchanged. As for fp16 training with Pytorch>=1.6.0, we recommend using--amp --native_ampinstead of apex-amp. - Learning rate scaling. The default learning rate setting is
lr=1e-3 / bs1024. We find thatlr=2e-3 / bs1024andlr=1e-3 / bs512produce better performances and more stable training for MogaNet-XT/T and MogaNet-S/B/L/XL. - EMA evaluation. We adopt the EMA trick for MogaNet-S/B/L using
--model_emaand--model_ema_decay 0.9999for better performances. - The difference between this repo and OpenMixup's implementation. In OpenMixup, we adopt
attn_force_fp32to run the gating functions with fp32 to avoid inf or nan during fp16 training. We found that if we useattn_force_fp32=Trueduring training, it should also keepattn_force_fp32=Trueduring evaluation because the difference between the output results of usingattn_force_fp32or not. It will not affect performances of fully fine-tuning but the results of transfer learning (e.g., COCO Mask-RCNN freezes the parameters of the first stage). We setattn_force_fp32to true in OpenMixup while turning it off in this repo (to facilitate code migration).
To train other MogaNet variants, --model and --drop_path need to be changed. Examples with single-machine commands are given below:
MogaNet-XT
Single-machine (8GPUs) with the input size of 224:python -m torch.distributed.launch --nproc_per_node=8 train.py \
--model moganet_xtiny --img_size 224 --drop_path 0.05 \
--epochs 300 --batch_size 128 --lr 1e-3 --weight_decay 0.03 \
--aa rand-m7-mstd0.5-inc1 --crop_pct 0.9 --mixup 0.1 \
--amp --native_amp \
--data_dir /path/to/imagenet-1k \
--experiment /path/to/save_results
MogaNet-Tiny
Single-machine (8GPUs) with the input size of 224:python -m torch.distributed.launch --nproc_per_node=8 train.py \
--model moganet_tiny --img_size 224 --drop_path 0.1 \
--epochs 300 --batch_size 128 --lr 1e-3 --weight_decay 0.04 \
--aa rand-m7-mstd0.5-inc1 --crop_pct 0.9 --mixup 0.1 \
--amp --native_amp \
--data_dir /path/to/imagenet-1k \
--experiment /path/to/save_results
Single-machine (8GPUs) with the input size of 256:
python -m torch.distributed.launch --nproc_per_node=8 train.py \
--model moganet_tiny --img_size 256 --drop_path 0.1 \
--epochs 300 --batch_size 128 --lr 1e-3 --weight_decay 0.04 \
--aa rand-m7-mstd0.5-inc1 --crop_pct 0.9 --mixup 0.1 \
--amp --native_amp \
--data_dir /path/to/imagenet-1k \
--experiment /path/to/save_results
MogaNet-Small
Single-machine (8GPUs) with the input size of 224 with EMA (you can evaluate it without EMA):python -m torch.distributed.launch --nproc_per_node=8 train.py \
--model moganet_small --img_size 224 --drop_path 0.1 \
--epochs 300 --batch_size 128 --lr 1e-3 --weight_decay 0.05 \
--crop_pct 0.9 --min_lr 1e-5 \
--model_ema --model_ema_decay 0.9999 \
--data_dir /path/to/imagenet-1k \
--experiment /path/to/save_results
MogaNet-Base
Single-machine (8GPUs) with the input size of 224 with EMA:python -m torch.distributed.launch --nproc_per_node=8 train.py \
--model moganet_base --img_size 224 --drop_path 0.2 \
--epochs 300 --batch_size 128 --lr 1e-3 --weight_decay 0.05 \
--crop_pct 0.9 --min_lr 1e-5 \
--model_ema --model_ema_decay 0.9999 \
--data_dir /path/to/imagenet-1k \
--experiment /path/to/save_results
MogaNet-Large
Single-machine (8GPUs) with the input size of 224 with EMA:python -m torch.distributed.launch --nproc_per_node=8 train.py \
--model moganet_large --img_size 224 --drop_path 0.3 \
--epochs 300 --batch_size 128 --lr 1e-3 --weight_decay 0.05 \
--crop_pct 0.9 --min_lr 1e-5 \
--model_ema --model_ema_decay 0.9999 \
--data_dir /path/to/imagenet-1k \
--experiment /path/to/save_results
MogaNet-XLarge
Single-machine (8GPUs) with the input size of 224 and the batch size of 512 with EMA:python -m torch.distributed.launch --nproc_per_node=8 train.py \
--model moganet_xlarge --img_size 224 --drop_path 0.4 \
--epochs 300 --batch_size 64 --lr 1e-3 --weight_decay 0.05 \
--crop_pct 0.9 --min_lr 1e-5 \
--model_ema --model_ema_decay 0.9999 \
--data_dir /path/to/imagenet-1k \
--experiment /path/to/save_results
Taking MogaNet-T as an example, you can use the following command to run the validation on ImageNet val set:
python validate.py \
--model moganet_tiny --img_size 224 --crop_pct 0.9 \
--data_dir /path/to/imagenet-1k \
--checkpoint /path/to/checkpoint.tar.gz
- In the example above, we test the model in 224x224x3 resolutions (modified by
--img_size 224or--img_size 224 224 3) without using the EMA model. Please add--use_emato enable EMA evaluation for MogaNet-Small, MogaNet-Base, and MogaNet-Large. Running on one machine, we can use--num_gpuand use--ampto avoid OOM issues.
To evaluate other MogaNet variants, --model and --use_ema need to be changed. Examples with single-machine commands are given below:
MogaNet-XT
Single-machine (8GPUs) validation with the input size of 224x224x3:python validate.py \
--model moganet_xtiny --img_size 224 --crop_pct 0.9 --num_gpu 8 \
--data_dir /path/to/imagenet-1k \
--checkpoint /path/to/checkpoint.tar.gz
MogaNet-Tiny
Single-machine (8GPUs) validation with the input size of 224x224x3:python validate.py \
--model moganet_tiny --img_size 224 --crop_pct 0.9 --num_gpu 8 \
--data_dir /path/to/imagenet-1k \
--checkpoint /path/to/checkpoint.tar.gz
MogaNet-Small
Single-machine (8GPUs) validation with the input size of 224x224x3:python validate.py \
--model moganet_small --img_size 224 --crop_pct 0.9 --num_gpu 8 --use_ema \
--data_dir /path/to/imagenet-1k \
--checkpoint /path/to/checkpoint.tar.gz
MogaNet-Base
Single-machine (8GPUs) validation with the input size of 224x224x3:python validate.py \
--model moganet_base --img_size 224 --crop_pct 0.9 --num_gpu 8 --use_ema \
--data_dir /path/to/imagenet-1k \
--checkpoint /path/to/checkpoint.tar.gz
MogaNet-Large
Single-machine (8GPUs) validation with the input size of 224x224x3:python validate.py \
--model moganet_large --img_size 224 --crop_pct 0.9 --num_gpu 8 --use_ema \
--data_dir /path/to/imagenet-1k \
--checkpoint /path/to/checkpoint.tar.gz
MogaNet-XLarge
Single-machine (8GPUs) validation with the input size of 224x224x3:python validate.py \
--model moganet_xlarge --img_size 224 --crop_pct 0.9 --num_gpu 8 --use_ema \
--data_dir /path/to/imagenet-1k \
--checkpoint /path/to/checkpoint.tar.gz
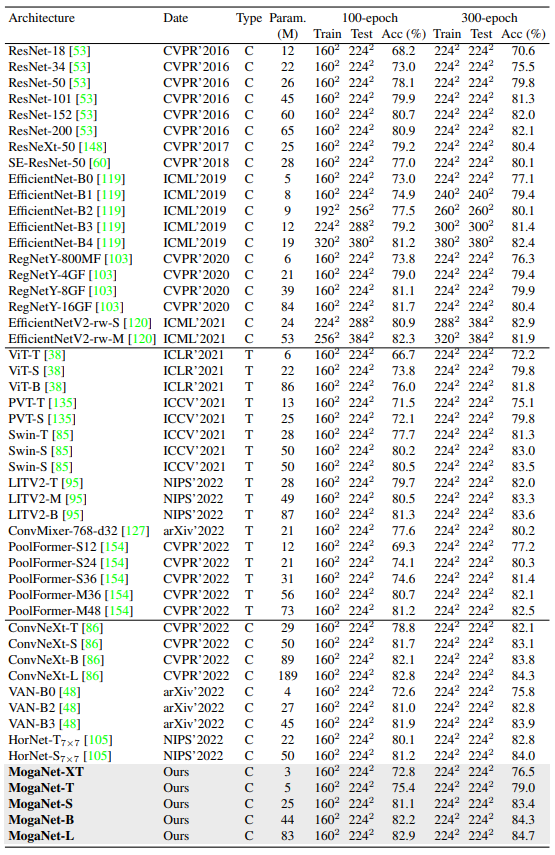
We provide comperhansive ImageNet-1K performances of all parameter scales with the modern training setting (i.e., DeiT) in our latest arXiv version.
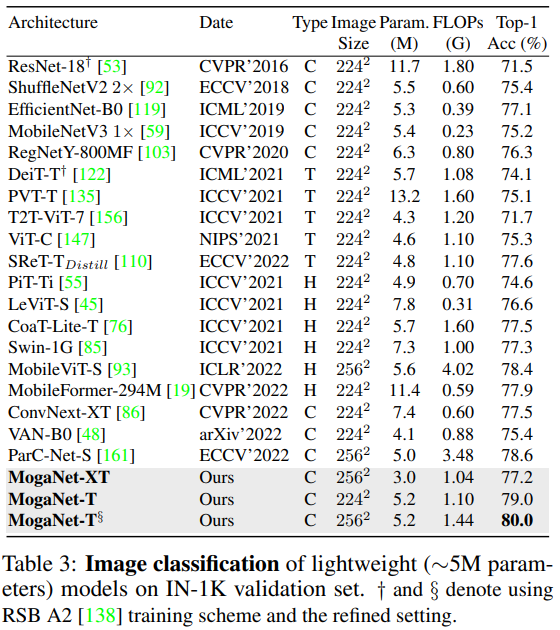
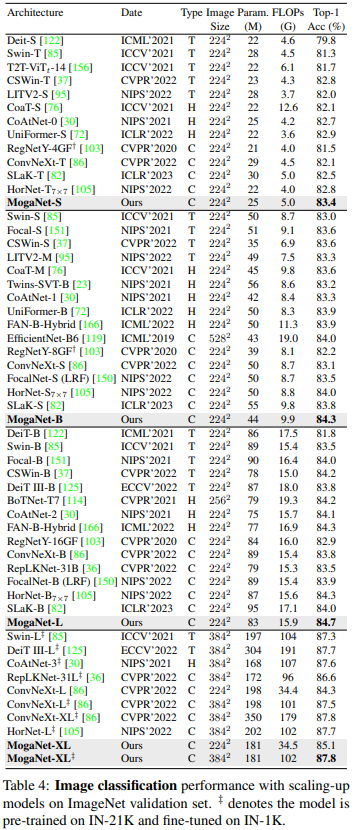
We also provide comperhansive results of popular network architectures using RSB-A3 training settings.