新浪微博是国内主要的社交舆论平台,对社交媒体中的数据进行采集是舆论分析的方法之一。本项目无需cookie,可以连续爬取一个或多个新浪微博用户信息、用户微博及其微博评论转发。
抓取用户信息


$ git clone https://github.com/XWang20/WeiboCrawler.git
本项目Python版本为Python3.8
$ cd WeiboCrawler
$ python -m pip install -r requirements.txt
默认使用MongoDB数据库,可在settings.py中修改URL和数据库名,默认为localhost、weibo。
在命令行中运行以下命令:
抓取用户信息
$ scrapy crawl user
抓取用户微博
$ scrapy crawl mblog
抓取微博转发
$ scrapy crawl repost
抓取微博评论
$ scrapy crawl comment
-
关键词检索,需要将
./WeiboCrawler/spiders/mblog.py中第28行代码替换为urls = init_url_by_search(),并在init_url_by_search()中增加关键词列表。 -
采集id和时间范围等信息可根据自己实际需要重写
./WeiboCrawler/spiders/*.py中的start_requests函数。 -
输出方式:支持输出到mongo数据库中,或输出json或csv文件。
如果输出json或csv文件,需要在命令后加入-o *.json或-o *.csv,例如:
$ scrapy crawl user -o user.csv
如果输出到mongo数据库中,需要将./WeiboCrawler/settings.py中 mongo 数据库的部分取消注释:
ITEM_PIPELINES = {
'WeiboCrawler.pipelines.MongoPipeline': 400,
}
MONGO_URI = 'localhost'
MONGO_DB = 'weibo'
-
添加账号cookie:可在settings.py中添加默认头,或在start_request函数中添加。
-
默认下载延迟为3,可在settings.py修改DOWNLOAD_DELAY。
-
默认会爬取二级评论,如果不需要可以在comment.py中注释以下代码:
if comment['total_number']:
secondary_url = 'https://m.weibo.cn/comments/hotFlowChild?cid=' + comment['idstr']
yield Request(secondary_url, callback=self.parse_secondary_comment, meta={"mblog_id": mblog_id})- 单用户微博最多采集200页,每页最多10条 限制可以通过添加账号cookie解决。
- 多线程:(单ip池或单账号不建议采用多线程) 在settings.py文件中将以下代码取消注释:
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 100
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 100
CONCURRENT_REQUESTS_PER_IP = 100- 代理ip池
- 填写middlewares.py中的
fetch_proxy函数。 - 在settings.py文件中将以下代码取消注释:
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'WeiboCrawler.middlewares.IPProxyMiddleware': 100,
}- 在settings.py文件中将DOWNLOAD_DELAY设置为0。
DOWNLOAD_DELAY = 0- _id: 用户ID
- nick_name: 昵称
- gender: 性别
- brief_introduction: 简介
- location: 所在地
- mblogs_num: 微博数
- follows_num: 关注数
- fans_num: 粉丝数
- vip_level: 会员等级
- authentication: 认证,对于已认证用户该字段会显示认证信息
- person_url: 首页链接
- _id: 微博id
- bid: 微博bid
- weibo_url: 微博URL
- created_at: 微博发表时间
- like_num: 点赞数
- repost_num: 转发数
- comment_num: 评论数
- content: 微博内容
- user_id: 发表该微博用户的id
- tool: 发布微博的工具
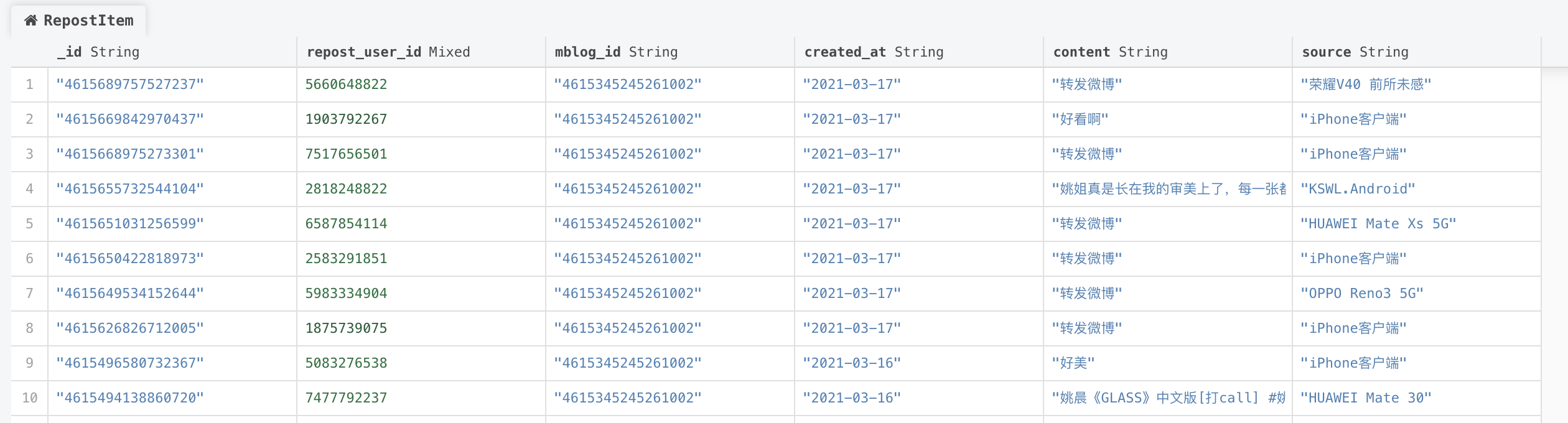
- _id: 转发id
- repost_user_id: 转发用户的id
- content: 转发的内容
- mblog_id: 转发的微博的id
- created_at: 转发时间
- source: 转发工具
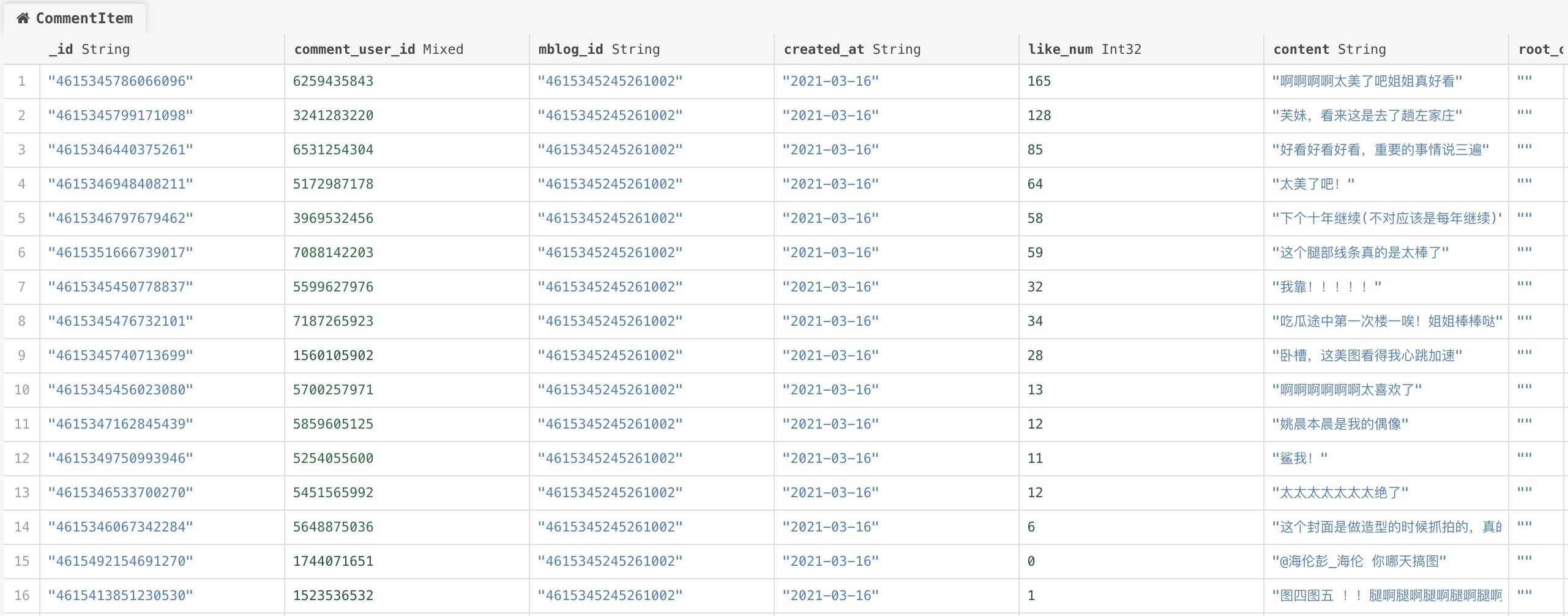
- _id: 评论id
- comment_user_id: 评论用户的id
- content: 评论的内容
- mblog_id: 评论的微博的id
- created_at: 评论发表时间
- like_num: 点赞数
- root_comment_id: 根评论id,只有二级评论有该项
- img_url: 图片地址
- reply_comment_id: 评论的id,只有二级评论有该项
本项目参考了dataabc/weibo-crawler和nghuyong/WeiboSpider,感谢他们的开源。
欢迎为本项目贡献力量。欢迎大家提交PR、通过issue提建议(如新功能、改进方案等)、通过issue告知项目存在哪些bug、缺点等。
如有问题和交流,也欢迎联系我:[email protected]