This repository contains the implementation of the paper "Deep Learning for Suicide and Depression Identification with Unsupervised Label Correction" by Ayaan Haque*, Viraaj Reddi*, and Tyler Giallanza from Saratoga High School and Princeton University. In ICANN, 2021.
We present SDCNL to address the unexplored issue of classifying between depression and more severe suicidal tendencies using web-scraped data. In particular, we leverage Reddit data, develop a novel label correction method to remove inherent noise in the data using unsupervised learning, and develop a deep-learning classifier based on pre-trained transformers.

Early detection of suicidal ideation in depressed individuals can allow for adequate medical attention and support, which in many cases is life-saving. Recent NLP research focuses on classifying, from a given piece of text, if an individual is suicidal or clinically healthy. However, there have been no major attempts to automate the process of determining when depression turns into suicidal ideation, which is an important clinical challenge. Due to the scarce availability of EHR data, suicide notes, or other similar verified sources, web query data has emerged as a promising alternative. Online sources, such as Reddit, allow for anonymity that prompts honest disclosure of symptoms, making it a plausible source even in a clinical setting. However, these online datasets also result in lower performance, which can be attributed to the inherent noise in web-scraped labels, which necessitates a noise-removal process. Thus, we propose SDCNL, a suicide versus depression classification method through a deep learning approach. We utilize online content from Reddit to train our algorithm, and to verify and correct noisy labels, we propose a novel unsupervised label correction method which, unlike previous work, does not require prior noise distribution information. Our extensive experimentation with multiple deep word embedding models and classifiers display the strong performance of the method in a new, challenging classification application.

The SDCNL method is outlined in the figure above. We begin by processing text data scraped from Reddit with word embedding models, which convert raw text into numerical representations called embeddings. These embeddings are then processed with an unsupervised dimensionality reduction algorithm. This is a necessary procedure due to the nature of clustering algorithms, which do not perform well in high-dimensional domains. The reduced embeddings are then inputted into a clustering-based algorithm which separates the embeddings into a pre-determined number of classes. This clustering algorithm is unsupervised, allowing it to be independent of noise in the labels. The class predictions of the algorithm are treated as an alternate set of labels, and these predicted labels are compared against the ground-truth labels using a confidence-based thresholding procedure in order to correct the ground-truth labels. The corrected set of labels are then used to train a deep neural classifier in a supervised fashion.
We provide our data with the proper train/test split in the data folder. We develop a primary dataset based on our task of suicide or depression classification. This dataset is web-scraped from Reddit. We collect our data from subreddits using the Python Reddit API. We specifically scrape from two subreddits, r/SuicideWatch and r/Depression. The dataset contains 1,895 total posts. We utilize two fields from the scraped data: the original text of the post as our inputs, and the subreddit it belongs to as labels. Posts from r/SuicideWatch are labeled as suicidal, and posts from r/Depression are labeled as depressed.
The data is provided in .csv format. To scrape more recent data, use the web-scraper.py script.
A brief summary of our results and figures are shown below.
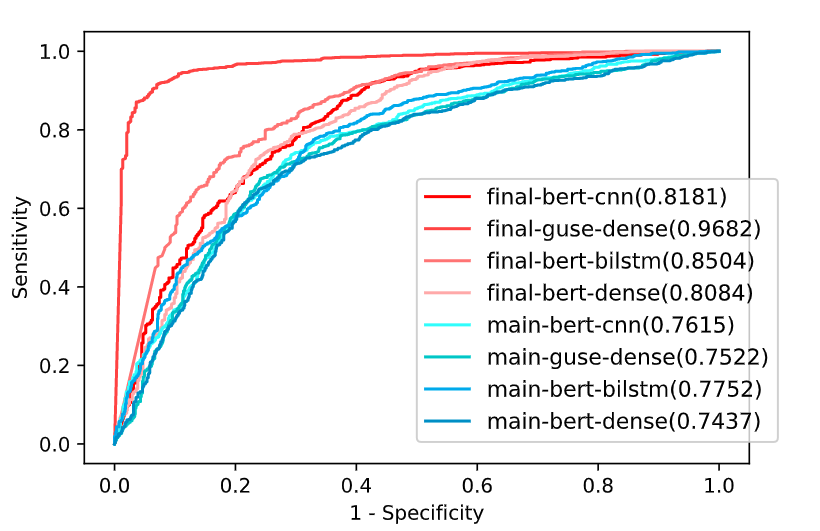

Our scripts and code are provided in the repo.
The below list details how to utilize the SDCNL method. All models and code are implemented with proper hyperparameters.
Embedding Models (Transformer)- convert raw text to word embeddngs- Label Correction
Dimensionality Reduction- Reduce the dimensions of the word embeddings for clusteringClustering Method- Cluster the word embeddings to assign labels based on class probabilitiesThreshold-based correction- use a threshold to determine whether to use the ground truth label or unsupervised clustering label
Classification- use the word embedding features and corrected set of labels to train a final classifier
If you found our code or paper useful, please consider citing.
@misc{haque2021deep,
title={Deep Learning for Suicide and Depression Identification with Unsupervised Label Correction},
author={Ayaan Haque and Viraaj Reddi and Tyler Giallanza},
year={2021},
eprint={2102.09427},
archivePrefix={arXiv},
primaryClass={cs.LG}
}