The requested file was not found.
Please click here to go to the home page, or have a look at the website modules below.
The requested file was not found.
Please click here to go to the home page, or have a look at the website modules below.
Homework 1 is in the form of a jupyter notebook. You must complete it and submit it on moodle (for students enrolled on this course).
This homework will run fine on regular CPU (no need for GPU). If you want to run it locally (on your laptop), you can follow the procedure described in Module 0. Note that if you cloned the GitHub repository, the homework will be in the folder /notebooks/HW1
Homework 1 is in the form of a jupyter notebook. You must complete it and submit it on moodle (for students enrolled on this course).
This homework will run fine on regular CPU (no need for GPU). If you want to run it locally (on your laptop), you can follow the procedure described in Module 0. Note that if you cloned the GitHub repository, the homework will be in the folder /notebooks/HW1

Homework 2 is in the form of a jupyter notebook. You must complete it and submit it on moodle (for students enrolled on this course).
This homework will run fine on regular CPU (no need for GPU). If you want to run it locally (on your laptop), you can follow the procedure described in Module 0. Note that if you cloned the GitHub repository, the homework will be in the folder /notebooks/HW2
Homework 2 is in the form of a jupyter notebook. You must complete it and submit it on moodle (for students enrolled on this course).
This homework will run fine on regular CPU (no need for GPU). If you want to run it locally (on your laptop), you can follow the procedure described in Module 0. Note that if you cloned the GitHub repository, the homework will be in the folder /notebooks/HW2

Homework 3 is in the form of a jupyter notebook. You must complete it and submit it on moodle (for students enrolled on this course).
Homework 3 is in the form of a jupyter notebook. You must complete it and submit it on moodle (for students enrolled on this course).
This site collects resources to learn Deep Learning in the form of Modules available through the sidebar on the left. As a student, you can walk through the modules at your own pace and interact with others thanks to the associated Discord server. You don’t need any special hardware or software.
The main goal of the course is to allow students to understand papers, blog posts and codes available online and to adapt them to their projects as soon as possible. In particular, we avoid the use of any high-level neural networks API and focus on the PyTorch library in Python.
The course is divided into sessions (containing possibly several modules), each session requiring a significant amount of coding. At the end of this course, students were able to read very recent papers and reproduce (or even ameliorate) their experiments.
All the code used in this course is available on the GitHub repository dataflowr/notebooks. You will find the solutions to the practicals on this repo! You can fork the repo if you want to run the code locally: GitHub Docs about fork then follow the steps in Module 0. Most of the code will not require a GPU.
⚠ When a GPU is required , you can launch the code on colab by following the corresponding link given in the module (see for example Module 1).
Pre-requisites:
Mathematics: basics of linear algebra, probability, differential calculus and optimization
Programming: Python. Test your proficiency: quiz
Start right away and train a deep neural network on a GPU with Module 1 - Introduction & General Overview
Be sure to build your own classifier with more dogs and cats in the practicals. Things to remember
you do not need to understand everything to run a deep learning model! But the main goal of this course will be to come back to each step done today and understand them...
to use the dataloader from Pytorch, you need to follow the API (i.e. for classification store your dataset in folders)
using a pretrained model and modifying it to adapt it to a similar task is easy.
if you do not understand why we take this loss, that's fine, we'll cover that in Module 3.
even with a GPU, avoid unnecessary computations!
Module 2b - Automatic differentiation + Practicals
MLP from scratch start of HW1
Pytorch tensors = Numpy on GPU + gradients!
in deep learning, broadcasting is used everywhere. The rules are the same as for Numpy.
Automatic differentiation is not only the chain rule! Backpropagation algorithm (or dual numbers) is a clever algorithm to implement automatic differentiation...
Module 5 - Stacking layers and overfitting a MLP on CIFAR10
how to regularize with dropout and uncertainty estimation with MC Dropout: Module 15 - Dropout
Loss vs Accuracy. Know your loss for a classification task!
know your optimizer (Module 4)
know how to build a neural net with torch.nn.module (Module 5)
know how to use convolution and pooling layers (kernel, stride, padding)
know how to use dropout
Module 8b - Collaborative filtering and build your own recommender system: 08_collaborative_filtering_empty.ipynb (on a larger dataset 08_collaborative_filtering_1M.ipynb)
Module 8c - Word2vec and build your own word embedding 08_Word2vec_pytorch_empty.ipynb
Module 16 - Batchnorm and check your understanding with 16_simple_batchnorm_eval.ipynb and more 16_batchnorm_simple.ipynb
start of Homework 2: Class Activation Map and adversarial examples
know how to use dataloader
to deal with categorical variables in deep learning, use embeddings
in the case of word embedding, starting in an unsupervised setting, we built a supervised task (i.e. predicting central / context words in a window) and learned the representation thanks to negative sampling
know your batchnorm
architectures with skip connections allows deeper models
Module 9a: Autoencoders and code your noisy autoencoder 09_AE_NoisyAE.ipynb
Module 10: Generative Adversarial Networks and code your GAN, Conditional GAN and InfoGAN 10_GAN_double_moon.ipynb
start of Homework 3: VAE for MNIST clustering and generation
Module 11b - Recurrent Neural Networks practice and predict engine failure with 11_predicitions_RNN_empty.ipynb
Correcting the PyTorch tutorial on attention in seq2seq: 12_seq2seq_attention.ipynb
Build your own microGPT: GPT_hist.ipynb
Build your own Real NVP: Normalizing_flows_empty.ipynb
Train your own DDPM on MNIST: ddpm_nano_empty.ipynb
Finetuning on CIFAR10: ddpm_micro_sol.ipynb
For more updates: 
and check the
Marc Lelarge, Andrei Bursuc with Jill-Jênn Vie
Super fast track to learn the basics of deep learning from scratch:
Have a look at the slides of Module 1: Introduction & General Overview
Run the notebook (or in colab) of Module 2a: Pytorch Tensors
Run the notebook (or in colab) of Module 2b: Automatic Differentiation
Check the Minimal working examples of Module 3: Loss functions for classification. If you do not understand, have a look at the slides.
Have a look at the slides of Module 4: Optimization for Deep Learning
Try playback speed 1.5 for the video from Module 5: Stacking layers.
Run the notebook (or in colab) of Module 6: Convolutional Neural Network
Try playback speed 2 for the video from Module 7: Dataloading
Have a look at the slides of Module 8a: Embedding layers
Well done! Now you have time to enjoy deep learning!
Join the GitHub repo dataflowr and make a pull request. What are pull requests?
Thanks to Daniel Huynh, Eric Daoud, Simon Coste
Materials from this site is used for courses at ENS and X.
This site collects resources to learn Deep Learning in the form of Modules available through the sidebar on the left. As a student, you can walk through the modules at your own pace and interact with others thanks to the associated Discord server. You don’t need any special hardware or software.
The main goal of the course is to allow students to understand papers, blog posts and codes available online and to adapt them to their projects as soon as possible. In particular, we avoid the use of any high-level neural networks API and focus on the PyTorch library in Python.
The course is divided into sessions (containing possibly several modules), each session requiring a significant amount of coding. At the end of this course, students were able to read very recent papers and reproduce (or even ameliorate) their experiments.
All the code used in this course is available on the GitHub repository dataflowr/notebooks. You will find the solutions to the practicals on this repo! You can fork the repo if you want to run the code locally: GitHub Docs about fork then follow the steps in Module 0. Most of the code will not require a GPU.
⚠ When a GPU is required , you can launch the code on colab by following the corresponding link given in the module (see for example Module 1).
Pre-requisites:
Mathematics: basics of linear algebra, probability, differential calculus and optimization
Programming: Python. Test your proficiency: quiz
Start right away and train a deep neural network on a GPU with Module 1 - Introduction & General Overview
Be sure to build your own classifier with more dogs and cats in the practicals. Things to remember
you do not need to understand everything to run a deep learning model! But the main goal of this course will be to come back to each step done today and understand them...
to use the dataloader from Pytorch, you need to follow the API (i.e. for classification store your dataset in folders)
using a pretrained model and modifying it to adapt it to a similar task is easy.
if you do not understand why we take this loss, that's fine, we'll cover that in Module 3.
even with a GPU, avoid unnecessary computations!
Module 2b - Automatic differentiation + Practicals
MLP from scratch start of HW1
Pytorch tensors = Numpy on GPU + gradients!
in deep learning, broadcasting is used everywhere. The rules are the same as for Numpy.
Automatic differentiation is not only the chain rule! Backpropagation algorithm (or dual numbers) is a clever algorithm to implement automatic differentiation...
Module 5 - Stacking layers and overfitting a MLP on CIFAR10
how to regularize with dropout and uncertainty estimation with MC Dropout: Module 15 - Dropout
Loss vs Accuracy. Know your loss for a classification task!
know your optimizer (Module 4)
know how to build a neural net with torch.nn.module (Module 5)
know how to use convolution and pooling layers (kernel, stride, padding)
know how to use dropout
Module 8b - Collaborative filtering and build your own recommender system: 08_collaborative_filtering_empty.ipynb (on a larger dataset 08_collaborative_filtering_1M.ipynb)
Module 8c - Word2vec and build your own word embedding 08_Word2vec_pytorch_empty.ipynb
Module 16 - Batchnorm and check your understanding with 16_simple_batchnorm_eval.ipynb and more 16_batchnorm_simple.ipynb
start of Homework 2: Class Activation Map and adversarial examples
know how to use dataloader
to deal with categorical variables in deep learning, use embeddings
in the case of word embedding, starting in an unsupervised setting, we built a supervised task (i.e. predicting central / context words in a window) and learned the representation thanks to negative sampling
know your batchnorm
architectures with skip connections allows deeper models
Module 9a: Autoencoders and code your noisy autoencoder 09_AE_NoisyAE.ipynb
Module 10: Generative Adversarial Networks and code your GAN, Conditional GAN and InfoGAN 10_GAN_double_moon.ipynb
start of Homework 3: VAE for MNIST clustering and generation
Module 11b - Recurrent Neural Networks practice and predict engine failure with 11_predicitions_RNN_empty.ipynb
Correcting the PyTorch tutorial on attention in seq2seq: 12_seq2seq_attention.ipynb
Build your own microGPT: GPT_hist.ipynb
Build your own Real NVP: Normalizing_flows_empty.ipynb
Train your own DDPM on MNIST: ddpm_nano_empty.ipynb
Finetuning on CIFAR10: ddpm_micro_sol.ipynb
For more updates:
and check the
Marc Lelarge, Andrei Bursuc with Jill-Jênn Vie
Super fast track to learn the basics of deep learning from scratch:
Have a look at the slides of Module 1: Introduction & General Overview
Run the notebook (or in colab) of Module 2a: Pytorch Tensors
Run the notebook (or in colab) of Module 2b: Automatic Differentiation
Check the Minimal working examples of Module 3: Loss functions for classification. If you do not understand, have a look at the slides.
Have a look at the slides of Module 4: Optimization for Deep Learning
Try playback speed 1.5 for the video from Module 5: Stacking layers.
Run the notebook (or in colab) of Module 6: Convolutional Neural Network
Try playback speed 2 for the video from Module 7: Dataloading
Have a look at the slides of Module 8a: Embedding layers
Well done! Now you have time to enjoy deep learning!
Join the GitHub repo dataflowr and make a pull request. What are pull requests?
Thanks to Daniel Huynh, Eric Daoud, Simon Coste
Materials from this site is used for courses at ENS and X.
Even for a personal project, we recommend to make a simple Julia package (like in python you use virtual environment). This is a simple tutorial to help you coding an app in Julia.
You need to have Julia installed and a GitHub account.
We'll be using PkgSkeleton.jl which allows to simplify the creation of packages. First check your git configuration (as it will be used to create the package) with:
git config --listEven for a personal project, we recommend to make a simple Julia package (like in python you use virtual environment). This is a simple tutorial to help you coding an app in Julia.
You need to have Julia installed and a GitHub account.
We'll be using PkgSkeleton.jl which allows to simplify the creation of packages. First check your git configuration (as it will be used to create the package) with:
git config --listYou should see your user.name, your user.email and github.user, if not then use for example:
git config --global user.name "firstname lastname"
git config --global user.email "bla.bla@domain.ext"
@@ -35,7 +35,7 @@ Star
Edit this page on  - Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
+ Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
- Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
+ Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
To run the notebooks locally, we recommend the following procedure:
First clone the GitHub repository containing the notebooks. The following command will create a directory notebooks with all the files from the repository inside:
$ git clone https://github.com/dataflowr/notebooks.gitTo run the notebooks locally, we recommend the following procedure:
First clone the GitHub repository containing the notebooks. The following command will create a directory notebooks with all the files from the repository inside:
$ git clone https://github.com/dataflowr/notebooks.gitThen, create a virtual environment: the following command will create a directory dldiy and also create directories inside it (so you might want to create this directory inside /notebooks)
Table of Contents
0:00 Intro
0:31 Goal of this lecture
2:08 What is deep learning?
7:06 Why deep learning now?
9:33 Deep learning pipeline
12:17 General overview
16:02 Organization of the course
18:24 A first example in Colab (setting)
19:35 Dogs vs cats (data wrangling)
25:50 Data processing (dataset and dataloader)
40:51 VGG model
45:55 Modifying the last layer
49:50 Choosing your loss and optimizer for training
57:40 Precomputing features
1:03:39 Qualitative analysis
⚠ Dogs and Cats with VGG: static notebook, code (GitHub) or running in colab GPU is required for this notebook ⚠
⚠ More dogs and cats with VGG and resnet in colab GPU is required for this notebook ⚠
Table of Contents
0:00 Intro
0:31 Goal of this lecture
2:08 What is deep learning?
7:06 Why deep learning now?
9:33 Deep learning pipeline
12:17 General overview
16:02 Organization of the course
18:24 A first example in Colab (setting)
19:35 Dogs vs cats (data wrangling)
25:50 Data processing (dataset and dataloader)
40:51 VGG model
45:55 Modifying the last layer
49:50 Choosing your loss and optimizer for training
57:40 Precomputing features
1:03:39 Qualitative analysis
⚠ Dogs and Cats with VGG: static notebook, code (GitHub) or running in colab GPU is required for this notebook ⚠
⚠ More dogs and cats with VGG and resnet in colab GPU is required for this notebook ⚠
Table of Contents
Table of Contents
Table of Contents
Understanding LSTM Networks by Christopher Olah
Table of Contents
Understanding LSTM Networks by Christopher Olah
Table of Contents
RNNs can generate bounded hierarchical languages with optimal memory (2020) John Hewitt, Michael Hahn, Surya Ganguli, Percy Liang, Christopher D. Manning arXiv:2010.07515
Self-Attention Networks Can Process Bounded Hierarchical Languages (2021) Shunyu Yao, Binghui Peng, Christos Papadimitriou, Karthik Narasimhan arXiv:2105.11115
Table of Contents
RNNs can generate bounded hierarchical languages with optimal memory (2020) John Hewitt, Michael Hahn, Surya Ganguli, Percy Liang, Christopher D. Manning arXiv:2010.07515
Self-Attention Networks Can Process Bounded Hierarchical Languages (2021) Shunyu Yao, Binghui Peng, Christos Papadimitriou, Karthik Narasimhan arXiv:2105.11115
Table of Contents
Table of Contents
Table of Contents
The first attention mechanism was proposed in Neural Machine Translation by Jointly Learning to Align and Translate by Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio (presented at ICLR 2015).
The task considered is English-to-French translation and the attention mechanism is proposed to extend a seq2seq architecture by adding a context vector in the RNN decoder so that, the hidden states for the decoder are computed recursively as where is the previously predicted token and predictions are made in a probabilist manner as where and are the current hidden state and context of the decoder.
Now the main novelty is the introduction of the context which is a weighted average of all the hidden states of the encoder: where is the length of the input sequence, are the corresponding hidden states of the decoder and . Hence the context allows passing direct information from the 'relevant' part of the input to the decoder. The coefficients are computed from the current hidden state of the decoder and all the hidden states from the encoder as explained below (taken from the original paper):

In Attention for seq2seq, you can play with a simple model and code the attention mechanism proposed in the paper. For the alignment network (used to define the coefficient ), we take a MLP with activations.
You will learn about seq2seq, teacher-forcing for RNNs and build the attention mechanism. To simplify things, we do not deal with batches (see Batches with sequences in Pytorch for more on that). The solution for this practical is provided in Attention for seq2seq- solution
Note that each is a real number so that we can display the matrix of 's where ranges over the input tokens and over the output tokens, see below (taken from the paper):
We now describe the attention mechanism proposed in Attention Is All You Need by Vaswani et al. First, we recall basic notions from retrieval systems: query/key/value illustrated by an example: search for videos on Youtube. In this example, the query is the text in the search bar, the key is the metadata associated with the videos which are the values. Hence a score can be computed from the query and all the keys. Finally, the matched video with the highest score is returned.
We see that we can formalize this process as follows: if is the current query and and are all the keys and values in the database, we return
where .
Note that this formalism allows us to recover the way contexts were computed above (where the score function was called the alignment network). Now, we will change the score function and consider dot-product attention: . Note that for this definition to make sense, both the query and the key need to live in the same space and is the dimension of this space.
Given inputs in denoted by a matrix and a database containing samples in denoted by a matrix , we define:
Now self-attention is simply obtained with (so that ) and . In summary, self-attention layer can take as input any tensor of the form (for any ) has parameters:
and produce (with same and as for the input). is the dimension of the input and is a hyper-parameter of the self-attention layer:
with the convention that (resp. ) is the -th column of (resp. the -th column of ). Note that the notation might be a bit confusing. Recall that is always taking as input a vector and returning a (normalized) vector. In practice, most of the time, we are dealing with batches so that the function is taking as input a matrix (or tensor) and we need to normalize according to the right axis! Named tensor notation see below deals with this notational issue. I also find the interpretation given below helpful:
Mental model for self-attention: self-attention interpreted as taking expectation
where the mappings and represent query, key and value.
Multi-head attention combines several such operations in parallel, and is the concatenation of the results along the feature dimension to which is applied one more linear transformation.
To finish the description of a transformer block, we need to define two last layers: Layer Norm and Feed Forward Network.
The Layer Norm used in the transformer block is particularly simple as it acts on vectors and standardizes it as follows: for , we define
and then the Layer Norm has two parameters and
where we used the natural broadcasting rule for subtracting the mean and dividing by std and is component-wise multiplication.
A Feed Forward Network is an MLP acting on vectors: for , we define
where , , , .
Each of these layers is applied on each of the inputs given to the transformer block as depicted below:
![]()
Note that this block is equivariant: if we permute the inputs, then the outputs will be permuted with the same permutation. As a result, the order of the input is irrelevant to the transformer block. In particular, this order cannot be used. The important notion of positional encoding allows us to take order into account. It is a deterministic unique encoding for each time step that is added to the input tokens.
In Transformers using Named Tensor Notation, we derive the formal equations for the Transformer block using named tensor notation.
Now is the time to have fun building a simple transformer block and to think like transformers (open in colab).


Table of Contents
The first attention mechanism was proposed in Neural Machine Translation by Jointly Learning to Align and Translate by Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio (presented at ICLR 2015).
The task considered is English-to-French translation and the attention mechanism is proposed to extend a seq2seq architecture by adding a context vector in the RNN decoder so that, the hidden states for the decoder are computed recursively as where is the previously predicted token and predictions are made in a probabilist manner as where and are the current hidden state and context of the decoder.
Now the main novelty is the introduction of the context which is a weighted average of all the hidden states of the encoder: where is the length of the input sequence, are the corresponding hidden states of the decoder and . Hence the context allows passing direct information from the 'relevant' part of the input to the decoder. The coefficients are computed from the current hidden state of the decoder and all the hidden states from the encoder as explained below (taken from the original paper):
In Attention for seq2seq, you can play with a simple model and code the attention mechanism proposed in the paper. For the alignment network (used to define the coefficient ), we take a MLP with activations.
You will learn about seq2seq, teacher-forcing for RNNs and build the attention mechanism. To simplify things, we do not deal with batches (see Batches with sequences in Pytorch for more on that). The solution for this practical is provided in Attention for seq2seq- solution
Note that each is a real number so that we can display the matrix of 's where ranges over the input tokens and over the output tokens, see below (taken from the paper):
We now describe the attention mechanism proposed in Attention Is All You Need by Vaswani et al. First, we recall basic notions from retrieval systems: query/key/value illustrated by an example: search for videos on Youtube. In this example, the query is the text in the search bar, the key is the metadata associated with the videos which are the values. Hence a score can be computed from the query and all the keys. Finally, the matched video with the highest score is returned.
We see that we can formalize this process as follows: if is the current query and and are all the keys and values in the database, we return
where .
Note that this formalism allows us to recover the way contexts were computed above (where the score function was called the alignment network). Now, we will change the score function and consider dot-product attention: . Note that for this definition to make sense, both the query and the key need to live in the same space and is the dimension of this space.
Given inputs in denoted by a matrix and a database containing samples in denoted by a matrix , we define:
Now self-attention is simply obtained with (so that ) and . In summary, self-attention layer can take as input any tensor of the form (for any ) has parameters:
and produce (with same and as for the input). is the dimension of the input and is a hyper-parameter of the self-attention layer:
with the convention that (resp. ) is the -th column of (resp. the -th column of ). Note that the notation might be a bit confusing. Recall that is always taking as input a vector and returning a (normalized) vector. In practice, most of the time, we are dealing with batches so that the function is taking as input a matrix (or tensor) and we need to normalize according to the right axis! Named tensor notation see below deals with this notational issue. I also find the interpretation given below helpful:
Mental model for self-attention: self-attention interpreted as taking expectation
where the mappings and represent query, key and value.
Multi-head attention combines several such operations in parallel, and is the concatenation of the results along the feature dimension to which is applied one more linear transformation.
To finish the description of a transformer block, we need to define two last layers: Layer Norm and Feed Forward Network.
The Layer Norm used in the transformer block is particularly simple as it acts on vectors and standardizes it as follows: for , we define
and then the Layer Norm has two parameters and
where we used the natural broadcasting rule for subtracting the mean and dividing by std and is component-wise multiplication.
A Feed Forward Network is an MLP acting on vectors: for , we define
where , , , .
Each of these layers is applied on each of the inputs given to the transformer block as depicted below:
![]()
Note that this block is equivariant: if we permute the inputs, then the outputs will be permuted with the same permutation. As a result, the order of the input is irrelevant to the transformer block. In particular, this order cannot be used. The important notion of positional encoding allows us to take order into account. It is a deterministic unique encoding for each time step that is added to the input tokens.
In Transformers using Named Tensor Notation, we derive the formal equations for the Transformer block using named tensor notation.
Now is the time to have fun building a simple transformer block and to think like transformers (open in colab).
Table of Contents
notebook (you need to install Julia) or use:
![]()
Table of Contents
notebook (you need to install Julia) or use:
![]()
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
This module presents the work: Denoising Diffusion Probabilistic Models by Jonathan Ho, Ajay Jain, Pieter Abbeel (2020). It starts with a description of the algorithm, then provides some notebooks to implement it on MNIST and CIFAR10 and finishes with some technical details.
Table of Contents

Given a schedule ,
We define and , then we have
Hence, we have
class DDPM(nn.Module):
+ ddpm Module 18a - Denoising Diffusion Probabilistic Models
This module presents the work: Denoising Diffusion Probabilistic Models by Jonathan Ho, Ajay Jain, Pieter Abbeel (2020). It starts with a description of the algorithm, then provides some notebooks to implement it on MNIST and CIFAR10 and finishes with some technical details.
Table of Contents
Algorithm
Forward diffusion process
Given a schedule ,
We define and , then we have
Hence, we have
class DDPM(nn.Module):
def __init__(self, network, num_timesteps,
beta_start=0.0001, beta_end=0.02, device=device):
super(DDPM, self).__init__()
@@ -57,4 +57,4 @@
pred_prev_sample = pred_prev_sample + variance
- return pred_prev_sample
Summary: Denoising Diffusion Probabilistic Models
(J. Ho, A. Jain, P. Abbeel 2020)
Given a schedule , the forward diffusion process is defined by: and .
With and , we see that, with :
The law is explicit: with, Training: to approximate the reversed diffusion by a neural network given by and , we maximize the usual Variational bound: With the change of variable: ignoring the prefactor and sampling instead of summing over all , the loss is finally: Sampling: to simulate the reversed diffusion with the learned starting from , iterate for : Implementation

MNIST
The training of this notebook on colab takes approximately 20 minutes.
ddpm_nano_empty.ipynb is the notebook where you code the DDPM algorithm (a simple UNet is provided for the network ), its training and the sampling. You should get results like this:

Here is the corresponding solution: ddpm_nano_sol.ipynb
CIFAR10
The training of this notebook on colab takes approximately 20 minutes (so do not expect high-quality pictures!). Still, after finetuning on specific classes, we see that the model learns features of the class.

With a bit more training (100 epochs), you can get results like this:



Technical details
Note that the Denoising Diffusion Probabilistic Model is the same for MNIST and CIFAR10, we only change the UNet learning to reverse the noise. For CIFAR10, we adapt the UNet provided in Module 9b. Indeed, you can still use the code provided here for DDPM with other architectures like more complex ones with self-attention like this Unet coded by lucidrains which is the one used in the original paper.
In the paper, the authors used Exponential Moving Average (EMA) on model parameters with a decay factor of . This is not implemented here to keep the code as simple as possible.
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+ return pred_prev_sample(J. Ho, A. Jain, P. Abbeel 2020)
Given a schedule , the forward diffusion process is defined by: and .
With and , we see that, with :
The training of this notebook on colab takes approximately 20 minutes.
ddpm_nano_empty.ipynb is the notebook where you code the DDPM algorithm (a simple UNet is provided for the network ), its training and the sampling. You should get results like this:
Here is the corresponding solution: ddpm_nano_sol.ipynb
The training of this notebook on colab takes approximately 20 minutes (so do not expect high-quality pictures!). Still, after finetuning on specific classes, we see that the model learns features of the class.
With a bit more training (100 epochs), you can get results like this:
Note that the Denoising Diffusion Probabilistic Model is the same for MNIST and CIFAR10, we only change the UNet learning to reverse the noise. For CIFAR10, we adapt the UNet provided in Module 9b. Indeed, you can still use the code provided here for DDPM with other architectures like more complex ones with self-attention like this Unet coded by lucidrains which is the one used in the original paper.
In the paper, the authors used Exponential Moving Average (EMA) on model parameters with a decay factor of . This is not implemented here to keep the code as simple as possible.

in Zeroshot_with_CLIP.ipynb we build a zero-shop classifier using the pretrained CLIP network and improve its performance with descriptors generated with GPT.
CLIP Learning Transferable Visual Models From Natural Language Supervision (ICML 2021) Alec Radford et al.
Visual Classification via Description from Large Language Models (ICLR 2023) Menon, Sachit and Vondrick, Carl
Table of Contents
0:00 Recap
1:43 Introduction to tensors
4:32 Sizes
5:25 Bridge to numpy
11:10 Broadcasting
14:35 Inplace modification
16:30 Shared memory
18:40 Cuda
22:34 CIFAR dataset
To check your understanding of the material, you can do the quizzes
Table of Contents
0:00 Recap
1:43 Introduction to tensors
4:32 Sizes
5:25 Bridge to numpy
11:10 Broadcasting
14:35 Inplace modification
16:30 Shared memory
18:40 Cuda
22:34 CIFAR dataset
To check your understanding of the material, you can do the quizzes
Table of Contents
0:00 Recap
0:40 A simple example (more in the practicals)
3:44 Pytorch tensor: requires_grad field
6:44 Pytorch backward function
9:05 The chain rule on our example
16:00 Linear regression
18:00 Gradient descent with numpy...
27:30 ... with pytorch tensors
31:30 Using autograd
34:35 Using a neural network (linear layer)
39:50 Using a pytorch optimizer
44:00 algorithm: how automatic differentiation works
Automatic differentiation: a simple example static notebook, code (GitHub) in colab
notebook used in the video for the linear regression. If you want to open it in colab
backprop slide (used for the practical below)
To check your understanding of automatic differentiation, you can do the quizzes
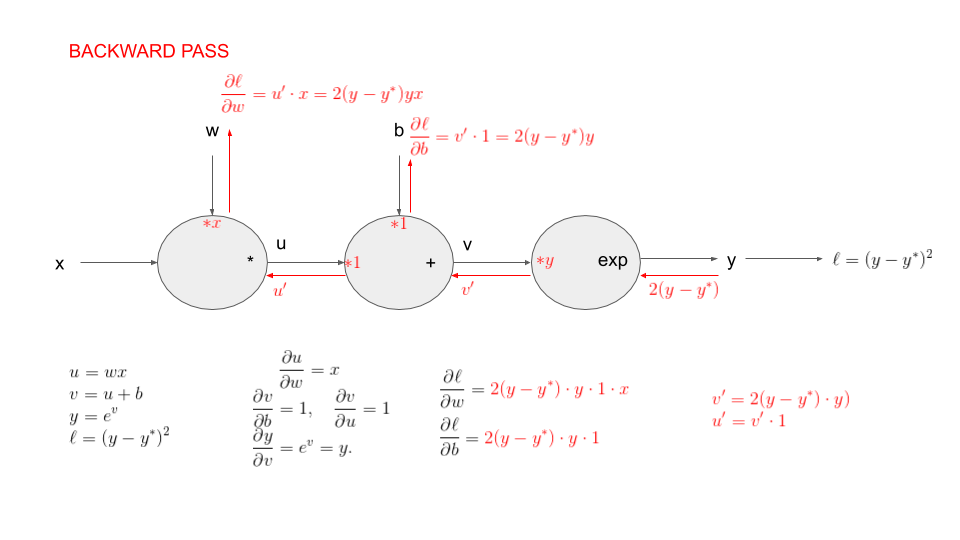
practicals in colab Coding backprop.
Adapt your code to solve the following challenge:
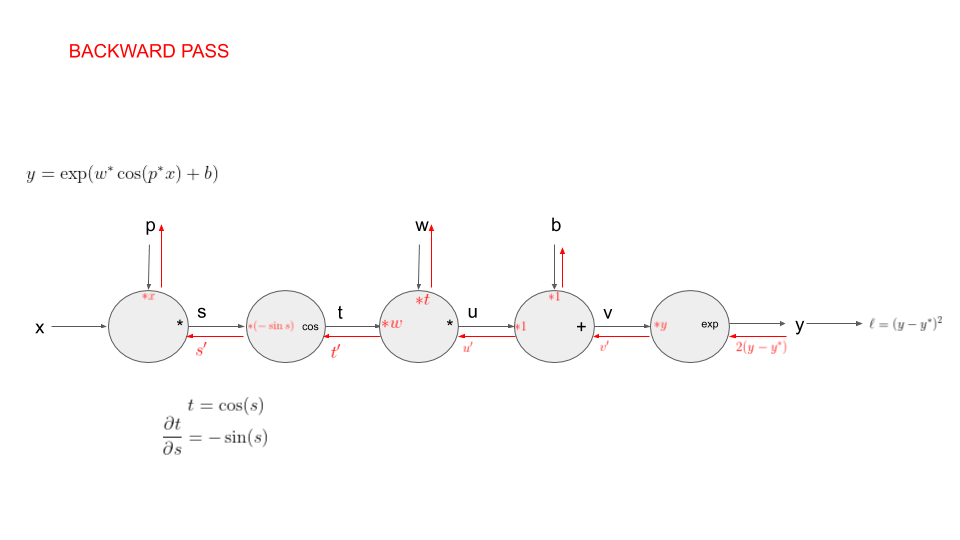
Some small modifications:
First modification: we now generate points where , i.e is obtained by applying a deterministic function to with parameters and . Our goal is still to recover the parameters and from the observations .
Second modification: we now generate points where , i.e is obtained by applying a deterministic function to with parameters , and . Our goal is still to recover the parameters from the observations .
Table of Contents
0:00 Recap
0:40 A simple example (more in the practicals)
3:44 Pytorch tensor: requires_grad field
6:44 Pytorch backward function
9:05 The chain rule on our example
16:00 Linear regression
18:00 Gradient descent with numpy...
27:30 ... with pytorch tensors
31:30 Using autograd
34:35 Using a neural network (linear layer)
39:50 Using a pytorch optimizer
44:00 algorithm: how automatic differentiation works
Automatic differentiation: a simple example static notebook, code (GitHub) in colab
notebook used in the video for the linear regression. If you want to open it in colab
backprop slide (used for the practical below)
To check your understanding of automatic differentiation, you can do the quizzes
practicals in colab Coding backprop.
Adapt your code to solve the following challenge:
Some small modifications:
First modification: we now generate points where , i.e is obtained by applying a deterministic function to with parameters and . Our goal is still to recover the parameters and from the observations .
Second modification: we now generate points where , i.e is obtained by applying a deterministic function to with parameters , and . Our goal is still to recover the parameters from the observations .
Table of Contents
Let , we define its Jacobian as:
Hence the Jacobian is a linear map from to such that for and :
The term is a Jacobian Vector Product (JVP), corresponding to the interpretation where the Jacobian is the linear map: , where .
In machine learning, we are computing gradient of the loss function with respect to the parameters. In particular, if the parameters are high-dimensional, the loss is a real number. Hence, consider a real-valued function , so that . We have
To do this computation, if we start from the right so that we start with a matrix times a vector to obtain a vector (of size ) and we need to make another matrix times a vector, resulting in operations. If we start from the left with the matrix-matrix multiplication, we get operations. Hence we see that as soon as , starting for the right is much more efficient. Note however that doing the computation from the right to the left requires keeping in memory the values of , and .
Backpropagation is an efficient algorithm computing the gradient "from the right to the left", i.e. backward. In particular, we will need to compute quantities of the form: with which can be rewritten which is a Vector Jacobian Product (VJP), correponding to the interpretation where the Jacobian is the linear map: , composed with the linear map so that .
example: let where and . We clearly have
Note that here, we are slightly abusing notations and considering the partial function . To see this, we can write so that
Then recall from definitions that
Now we clearly have
Note that multiplying on the left is actually convenient when using broadcasting, i.e. we can take a batch of input vectors of shape without modifying the math above.
In PyTorch, torch.autograd provides classes and functions implementing automatic differentiation of arbitrary scalar-valued functions. To create a custom autograd.Function, subclass this class and implement the forward() and backward() static methods. Here is an example:
class Exp(Function):
+ Dataflowr - Deep Learning DIY Module 2c - Automatic differentiation: VJP and intro to JAX
Table of Contents
Autodiff and Backpropagation
Jacobian
Let , we define its Jacobian as:
Hence the Jacobian is a linear map from to such that for and :
The term is a Jacobian Vector Product (JVP), corresponding to the interpretation where the Jacobian is the linear map: , where .
Chain composition
In machine learning, we are computing gradient of the loss function with respect to the parameters. In particular, if the parameters are high-dimensional, the loss is a real number. Hence, consider a real-valued function , so that . We have
To do this computation, if we start from the right so that we start with a matrix times a vector to obtain a vector (of size ) and we need to make another matrix times a vector, resulting in operations. If we start from the left with the matrix-matrix multiplication, we get operations. Hence we see that as soon as , starting for the right is much more efficient. Note however that doing the computation from the right to the left requires keeping in memory the values of , and .
Backpropagation is an efficient algorithm computing the gradient "from the right to the left", i.e. backward. In particular, we will need to compute quantities of the form: with which can be rewritten which is a Vector Jacobian Product (VJP), correponding to the interpretation where the Jacobian is the linear map: , composed with the linear map so that .
example: let where and . We clearly have
Note that here, we are slightly abusing notations and considering the partial function . To see this, we can write so that
Then recall from definitions that
Now we clearly have
Note that multiplying on the left is actually convenient when using broadcasting, i.e. we can take a batch of input vectors of shape without modifying the math above.
Implementation
In PyTorch, torch.autograd provides classes and functions implementing automatic differentiation of arbitrary scalar-valued functions. To create a custom autograd.Function, subclass this class and implement the forward() and backward() static methods. Here is an example:
class Exp(Function):
@staticmethod
def forward(ctx, i):
result = i.exp()
@@ -9,4 +9,4 @@
result, = ctx.saved_tensors
return grad_output * result
# Use it by calling the apply method:
-output = Exp.apply(input)
You can have a look at Module 2b to learn more about this approach as well as MLP from scratch.
Backprop the functional way
Here we will implement in numpy a different approach mimicking the functional approach of JAX see The Autodiff Cookbook.
Each function will take 2 arguments: one being the input x and the other being the parameters w. For each function, we build 2 vjp functions taking as argument a gradient , and corresponding to and so that these functions return and respectively. To summarize, for , , and, ,
Then backpropagation is simply done by first computing the gradient of the loss and then composing the vjp functions in the right order.
Practice
intro to JAX: autodiff the functional way autodiff_functional_empty.ipynb and its solution autodiff_functional_sol.ipynb
Linear regression in JAX linear_regression_jax.ipynb
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+output = Exp.apply(input)You can have a look at Module 2b to learn more about this approach as well as MLP from scratch.
Here we will implement in numpy a different approach mimicking the functional approach of JAX see The Autodiff Cookbook.
Each function will take 2 arguments: one being the input x and the other being the parameters w. For each function, we build 2 vjp functions taking as argument a gradient , and corresponding to and so that these functions return and respectively. To summarize, for , , and, ,
Then backpropagation is simply done by first computing the gradient of the loss and then composing the vjp functions in the right order.
intro to JAX: autodiff the functional way autodiff_functional_empty.ipynb and its solution autodiff_functional_sol.ipynb
Linear regression in JAX linear_regression_jax.ipynb
Table of Contents
0:00 Recap
2:25 How to choose your loss?
3:18 A probabilistic model for linear regression
7:50 Gradient descent, learning rate, SGD
11:30 Pytorch code for gradient descent
15:15 A probabilistic model for logistic regression
17:27 Notations (information theory)
20:58 Likelihood for logistic regression
22:43 BCELoss
23:41 BCEWithLogitsLoss
25:37 Beware of the reduction parameter
27:27 Softmax regression
30:52 NLLLoss
34:48 Classification in pytorch
36:36 Why maximizing accuracy directly is hard?
38:24 Classification in deep learning
40:50 Regression without knowing the underlying model
42:58 Overfitting in polynomial regression
45:20 Validation set
48:55 Notion of risk and hypothesis space
54:40 estimation error and approximation error
BCELossimport torch.nn as nn
+ Dataflowr - Deep Learning DIY Module 3 - Loss functions for classification
Table of Contents
Loss functions for classification
0:00 Recap
2:25 How to choose your loss?
3:18 A probabilistic model for linear regression
7:50 Gradient descent, learning rate, SGD
11:30 Pytorch code for gradient descent
15:15 A probabilistic model for logistic regression
17:27 Notations (information theory)
20:58 Likelihood for logistic regression
22:43 BCELoss
23:41 BCEWithLogitsLoss
25:37 Beware of the reduction parameter
27:27 Softmax regression
30:52 NLLLoss
34:48 Classification in pytorch
36:36 Why maximizing accuracy directly is hard?
38:24 Classification in deep learning
40:50 Regression without knowing the underlying model
42:58 Overfitting in polynomial regression
45:20 Validation set
48:55 Notion of risk and hypothesis space
54:40 estimation error and approximation error
Slides and Notebook
Minimal working examples
BCELoss
import torch.nn as nn
m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3,4,5)
@@ -10,4 +10,4 @@
C = 8
input = torch.randn(3,C,4,5)
target = torch.empty(3,4,5 dtype=torch.long).random_(0,C)
-assert loss1(m(input),target) == loss2(input,target)
Quiz
To check you know your loss, you can do the quizzes
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+assert loss1(m(input),target) == loss2(input,target)To check you know your loss, you can do the quizzes
Table of Contents
0:00 Recap
0:31 Plan
1:14 Optimization in deep learning
3:44 Gradient descent variants
7:58 Setting for the jupyter notebook
9:49 Vanilla gradient descent
12:14 Momentum
15:38 Nesterov accelerated gradient descent
18:00 Adagrad
20:06 RMSProp
22:11 Adam
24:39 AMSGrad
27:09 Pytorch optimizers
An overview of gradient descent optimization algorithms by Sebastian Ruder
Gradient-based optimization A short introduction to optimization in Deep Learning, by Christian S. Perone
Table of Contents
0:00 Recap
0:31 Plan
1:14 Optimization in deep learning
3:44 Gradient descent variants
7:58 Setting for the jupyter notebook
9:49 Vanilla gradient descent
12:14 Momentum
15:38 Nesterov accelerated gradient descent
18:00 Adagrad
20:06 RMSProp
22:11 Adam
24:39 AMSGrad
27:09 Pytorch optimizers
An overview of gradient descent optimization algorithms by Sebastian Ruder
Gradient-based optimization A short introduction to optimization in Deep Learning, by Christian S. Perone
Table of Contents
0:00 Recap
1:35 Plan of the lesson: define a NN model
2:24 MLP with pytorch Sequential
6:41 Using Torch.nn.module
10:08 Writing a pytorch module
Table of Contents
0:00 Recap
1:35 Plan of the lesson: define a NN model
2:24 MLP with pytorch Sequential
6:41 Using Torch.nn.module
10:08 Writing a pytorch module
Table of Contents
0:00 Recap
0:52 MNIST dataset
2:56 A simple binary classifier
6:21 Precision and recall
8:44 Filters and convolutions
19:40 Max pooling
Table of Contents
0:00 Recap
0:52 MNIST dataset
2:56 A simple binary classifier
6:21 Precision and recall
8:44 Filters and convolutions
19:40 Max pooling
Table of Contents
0:00 Recap
1:09 Plan of the lesson
2:08 Dataloading
4:40 Example 1: torchvision.datasets.Imagefolder
9:45 Example 2: dataset from numpy arrays
14:47 Example 3: custom dataloader
Table of Contents
0:00 Recap
1:09 Plan of the lesson
2:08 Dataloading
4:40 Example 1: torchvision.datasets.Imagefolder
9:45 Example 2: dataset from numpy arrays
14:47 Example 3: custom dataloader
Table of Contents
Table of Contents
Table of Contents
Table of Contents
Table of Contents
-word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method by Yoav Goldberg and Omer Levy
Table of Contents
-word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method by Yoav Goldberg and Omer Levy
Table of Contents
Table of Contents


Table of Contents
The image below is taken from this very good blog post on normalizing flows: blogpost

Here we only describe flow-based generative models, you can have look at VAE and GAN.
A flow-based generative model is constructed by a sequence of invertible transformations. The main advantage of flows is that the model explicitly learns the data distribution \(p(\mathbf{x})\) and therefore the loss function is simply the negative log-likelihood.
Given a sample \(\mathbf{x}\) and a prior \(p(\mathbf{z})\), we compute \(f(\mathbf{x}) = \mathbf{z}\) with an invertible function \(f\) that will be learned. Given \(f\) and the prior \(p(\mathbf{z})\), we can compute the evidence \(p(\mathbf{x})\) thanks to the change of variable formula:
where \(\dfrac{\partial f(\mathbf{x})}{\partial \mathbf{x}}\) is the Jacobian matrix of \(f\). Recall that given a function mapping a \(n\)-dimensional input vector \(\mathbf{x}\) to a \(m\)-dimensional output vector, \(f: \mathbb{R}^n \mapsto \mathbb{R}^m\), the matrix of all first-order partial derivatives of this function is called the Jacobian matrix, \(J_f\) where one entry on the i-th row and j-th column is \((J_f(\mathbf{x}))_{ij} = \frac{\partial f_i(\mathbf{x})}{\partial x_j}\):
Below, we will parametrize \(f\) with a neural network and learn \(f\) by maximizing \(\ln p(\mathbf{x})\). More precisely, given a dataset \((\mathbf{x}_1,\dots,\mathbf{x}_n)\) and a model provided by a prior \(p(\mathbf{z})\) and a neural network \(f\), we optimize the weights of \(f\) by minimizing:
We need to ensure that \(f\) is always invertible and that the determinant is simple to compute.
Real NVP (introduced by Laurent Dinh, Jascha Sohl-Dickstein, Samy Bengio in 2016) uses function \(f\) obtained by stacking affine coupling layers which for an input \(\mathbf{x}\in \mathbb{R}^D\) produce the output \(\mathbf{y}\in\mathbb{R}^D\) defined by (with \( d < D \) ):
\[\begin{aligned} \mathbf{y}_{1:d} &= \mathbf{x}_{1:d}\\ \mathbf{y}_{d+1:D} &= \mathbf{x}_{d+1:D} \odot \exp\left(s(\mathbf{x}_{1:d})\right) +t(\mathbf{x}_{1:d}) , \end{aligned}\]where \(s\) (scale) and \(t\) (translation) are neural networks mapping \(\mathbb{R}^d\) to \(\mathbb{R}^{D-d}\) and \(\odot\) is the element-wise product.
For any functions \(s\) and \(t\), the affine coupling layer is invertible:
The Jacobian of an affine coupling layer is a lower triangular matrix:
Hence the determinant is simply the product of terms on the diagonal:
Note that, we do not need to compute the Jacobian of \(s\) or \(t\) and to compute \(f^{-1}\), we do not need to compute the inverse of \(s\) or \(t\) (which might not exist!). In other words, we can take arbitrary complex functions for \(s\) and \(t\).
In one affine coupling layer, some dimensions (channels) remain unchanged. To make sure all the inputs have a chance to be altered, the model reverses the ordering in each layer so that different components are left unchanged. Following such an alternating pattern, the set of units which remain identical in one transformation layer are always modified in the next.
This can be implemented with binary masks. First, we can extend the scale and neural networks to mappings form \(\mathbb{R}^D\) to \(\mathbb{R}^D\). Then taking a mask \(\mathbf{b} = (1,\dots,1,0,\dots,0)\) with \(d\) ones, so that we have for the affine layer:
Note that we have
and to invert the affine layer:
Now we alternates the binary mask \(\mathbf{b}\) from one coupling layer to the other.
Note, that the formula given in the paper is slightly different:
\[\mathbf{y} = \mathbf{b} \odot \mathbf{x} + (1 - \mathbf{b}) \odot \Big(\mathbf{x} \odot \exp\big(s(\mathbf{b} \odot \mathbf{x})\big) + t(\mathbf{b} \odot \mathbf{x})\Big),\]but the 2 formulas give the same result!
Table of Contents
The image below is taken from this very good blog post on normalizing flows: blogpost
Here we only describe flow-based generative models, you can have look at VAE and GAN.
A flow-based generative model is constructed by a sequence of invertible transformations. The main advantage of flows is that the model explicitly learns the data distribution \(p(\mathbf{x})\) and therefore the loss function is simply the negative log-likelihood.
Given a sample \(\mathbf{x}\) and a prior \(p(\mathbf{z})\), we compute \(f(\mathbf{x}) = \mathbf{z}\) with an invertible function \(f\) that will be learned. Given \(f\) and the prior \(p(\mathbf{z})\), we can compute the evidence \(p(\mathbf{x})\) thanks to the change of variable formula:
where \(\dfrac{\partial f(\mathbf{x})}{\partial \mathbf{x}}\) is the Jacobian matrix of \(f\). Recall that given a function mapping a \(n\)-dimensional input vector \(\mathbf{x}\) to a \(m\)-dimensional output vector, \(f: \mathbb{R}^n \mapsto \mathbb{R}^m\), the matrix of all first-order partial derivatives of this function is called the Jacobian matrix, \(J_f\) where one entry on the i-th row and j-th column is \((J_f(\mathbf{x}))_{ij} = \frac{\partial f_i(\mathbf{x})}{\partial x_j}\):
Below, we will parametrize \(f\) with a neural network and learn \(f\) by maximizing \(\ln p(\mathbf{x})\). More precisely, given a dataset \((\mathbf{x}_1,\dots,\mathbf{x}_n)\) and a model provided by a prior \(p(\mathbf{z})\) and a neural network \(f\), we optimize the weights of \(f\) by minimizing:
We need to ensure that \(f\) is always invertible and that the determinant is simple to compute.
Real NVP (introduced by Laurent Dinh, Jascha Sohl-Dickstein, Samy Bengio in 2016) uses function \(f\) obtained by stacking affine coupling layers which for an input \(\mathbf{x}\in \mathbb{R}^D\) produce the output \(\mathbf{y}\in\mathbb{R}^D\) defined by (with \( d < D \) ):
\[\begin{aligned} \mathbf{y}_{1:d} &= \mathbf{x}_{1:d}\\ \mathbf{y}_{d+1:D} &= \mathbf{x}_{d+1:D} \odot \exp\left(s(\mathbf{x}_{1:d})\right) +t(\mathbf{x}_{1:d}) , \end{aligned}\]where \(s\) (scale) and \(t\) (translation) are neural networks mapping \(\mathbb{R}^d\) to \(\mathbb{R}^{D-d}\) and \(\odot\) is the element-wise product.
For any functions \(s\) and \(t\), the affine coupling layer is invertible:
The Jacobian of an affine coupling layer is a lower triangular matrix:
Hence the determinant is simply the product of terms on the diagonal:
Note that, we do not need to compute the Jacobian of \(s\) or \(t\) and to compute \(f^{-1}\), we do not need to compute the inverse of \(s\) or \(t\) (which might not exist!). In other words, we can take arbitrary complex functions for \(s\) and \(t\).
In one affine coupling layer, some dimensions (channels) remain unchanged. To make sure all the inputs have a chance to be altered, the model reverses the ordering in each layer so that different components are left unchanged. Following such an alternating pattern, the set of units which remain identical in one transformation layer are always modified in the next.
This can be implemented with binary masks. First, we can extend the scale and neural networks to mappings form \(\mathbb{R}^D\) to \(\mathbb{R}^D\). Then taking a mask \(\mathbf{b} = (1,\dots,1,0,\dots,0)\) with \(d\) ones, so that we have for the affine layer:
Note that we have
and to invert the affine layer:
Now we alternates the binary mask \(\mathbf{b}\) from one coupling layer to the other.
Note, that the formula given in the paper is slightly different:
\[\mathbf{y} = \mathbf{b} \odot \mathbf{x} + (1 - \mathbf{b}) \odot \Big(\mathbf{x} \odot \exp\big(s(\mathbf{b} \odot \mathbf{x})\big) + t(\mathbf{b} \odot \mathbf{x})\Big),\]but the 2 formulas give the same result!
author: Marc Lelarge, course: dataflowr, module: Convolutional neural network
date: June 8, 2021
In the module on CNN, we presented the convolutional layers as learnable filters. In particular, we have seen that these layers have a particular form of weight sharing (only the parameters of the kernel need to be learned). The motivation for restricting our attention to this particular weight sharing comes from a long history in signal processing. Here, we would like to recover the intuition for convolutions from first principles.
So let's pretend, we do not know anything about signal processing and we would like to build from scratch a new neural network taking as input an image and producing as output another image. For example in semantic segmentation, each pixel in the input image is linked to a class as shown below (source: DeepLab): 
Clearly in this case, when a object moves in the image, we want the associated labels to move with it. Hence, before constructing such a neural network, we first need to figure out a way to build a layer having this property: when an object is translated in an image, the output of the layer should be translated with the same translation. This is what we will do here.
Here we formalize our problem and simplify it a little bit while keeping its main features. First, instead of images, we will deal with 1D signal of length : . Now translation in 1D is also called a shift: corresponds to the shift to the right. Note that we also need to define in order to keep a signal of length . We will always deal with indices as integers modulo so that and we define . Note that we can write as a matrix:
The mathematical problem is now to find a linear layer which is equivariant with respect to the shift: when the input is shifted, the output is also shifted. Hence, we are looking for a matrix with the shift invariance property:
There is a simple way to approximate a shift invariant layer from an arbitrary matrix : start from and then make it more and more shift invariant by decreasing . When this quantity is zero, we get a shift invariant matrix.
Here is a gradient descent algorithm to solve the problem:
coded in Julia:
using LinearAlgebra, Zygote, Plots
+ Convolutions from first principles Convolutions (and Discrete Fourier Transform) from first principles
author: Marc Lelarge, course: dataflowr, module: Convolutional neural network
date: June 8, 2021
Motivation
In the module on CNN, we presented the convolutional layers as learnable filters. In particular, we have seen that these layers have a particular form of weight sharing (only the parameters of the kernel need to be learned). The motivation for restricting our attention to this particular weight sharing comes from a long history in signal processing. Here, we would like to recover the intuition for convolutions from first principles.
So let's pretend, we do not know anything about signal processing and we would like to build from scratch a new neural network taking as input an image and producing as output another image. For example in semantic segmentation, each pixel in the input image is linked to a class as shown below (source: DeepLab):
Clearly in this case, when a object moves in the image, we want the associated labels to move with it. Hence, before constructing such a neural network, we first need to figure out a way to build a layer having this property: when an object is translated in an image, the output of the layer should be translated with the same translation. This is what we will do here.
Mathematical model
Here we formalize our problem and simplify it a little bit while keeping its main features. First, instead of images, we will deal with 1D signal of length : . Now translation in 1D is also called a shift: corresponds to the shift to the right. Note that we also need to define in order to keep a signal of length . We will always deal with indices as integers modulo so that and we define . Note that we can write as a matrix:
The mathematical problem is now to find a linear layer which is equivariant with respect to the shift: when the input is shifted, the output is also shifted. Hence, we are looking for a matrix with the shift invariance property:
Learning a solution
There is a simple way to approximate a shift invariant layer from an arbitrary matrix : start from and then make it more and more shift invariant by decreasing . When this quantity is zero, we get a shift invariant matrix.
Here is a gradient descent algorithm to solve the problem:
coded in Julia:
using LinearAlgebra, Zygote, Plots
const n = 100
S = circshift(Matrix{Float64}(I, n, n),(1,0))
@@ -91,4 +91,4 @@
end
plot(target, (-1.,1.)...,label="target")
ylims!((-10,10))
-plot!(pred, (-1.,1.)...,label="pred")

We see that we get a pretty good approximation of our target polynomial. Below is the a gif showing the convergence of our network towards the target:

By stacking convolutions with kernel of size 3, we obtained a network with a receptive field of size 9.
Thanks for reading!
Follow on twitter!
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+plot!(pred, (-1.,1.)...,label="pred")
We see that we get a pretty good approximation of our target polynomial. Below is the a gif showing the convergence of our network towards the target:
By stacking convolutions with kernel of size 3, we obtained a network with a receptive field of size 9.
Follow on twitter!
author: Marc Lelarge, course: dataflowr
run the code or open it in Colab
date: April 15, 2021
Here, we focus on Graph Convolution Networks (GCN) introduced by Kipf and Welling in their paper Semi-Supervised Classification with Graph Convolutional Networks. The GCN layer is one of the simplest Graph Neural Network layer defined by:
where means that nodes and are neighbors in the graph , and are the respective degrees of nodes and (i.e. their number of neighbors in the graph) and is the embedding representation of node at layer and is a trainable weight matrix of shape [size_input_feature, size_output_feature].
The inductive bias of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not encountered. For GCN, we argue that the inductive bias can be formulated as a simple spectral property of the algorithm: GCN acts as low-pass filters. This arguments follows from recent works Simplifying Graph Convolutional Networks by Wu, Souza, Zhang, Fifty, Yu, Weinberger and Revisiting Graph Neural Networks: All We Have is Low-Pass Filters by NT and Maehara.
Here we will study a very simple case and relate the inductive bias of GCN to the property of the Fiedler vector of the graph. We'll consider the more general setting in a subsequent post.
We consider undirected graphs with vertices denoted by . means that nodes and are neighbors in , i.e. . We denote by its adjacency matrix and by the diagonal matrix of degrees. The vector of degrees is denoted by so that . The components of a vector are denoted but sometimes it is convenient to see the vector as a function from to and use the notation instead of .
We'll start with an unsupervised problem: given one graph, find a partition of its node in communities. In this case, we make the hypothesis that individuals tend to associate and bond with similar others, which is known as homophily.
To study this problem, we will focus on the Zachary's karate club and try to recover the split of the club from the graph of connections. The pytorch-geometric library will be very convenient.
Note that GCN are not appropriate in an unsupervised setting as no learning is possible without any label on the vertices. However, this is not a problem here as we will not train the GCN! In more practical settings, GCN are used in a semi-supervised setting where a few labels are revealed for a few nodes (more on this in the section with the Cora dataset).
from torch_geometric.datasets import KarateClub
+ Dataflowr - Deep Learning DIY Inductive bias in GCN: a spectral perspective
author: Marc Lelarge, course: dataflowr
run the code or open it in Colab
date: April 15, 2021
Here, we focus on Graph Convolution Networks (GCN) introduced by Kipf and Welling in their paper Semi-Supervised Classification with Graph Convolutional Networks. The GCN layer is one of the simplest Graph Neural Network layer defined by:
where means that nodes and are neighbors in the graph , and are the respective degrees of nodes and (i.e. their number of neighbors in the graph) and is the embedding representation of node at layer and is a trainable weight matrix of shape [size_input_feature, size_output_feature].
The inductive bias of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not encountered. For GCN, we argue that the inductive bias can be formulated as a simple spectral property of the algorithm: GCN acts as low-pass filters. This arguments follows from recent works Simplifying Graph Convolutional Networks by Wu, Souza, Zhang, Fifty, Yu, Weinberger and Revisiting Graph Neural Networks: All We Have is Low-Pass Filters by NT and Maehara.
Here we will study a very simple case and relate the inductive bias of GCN to the property of the Fiedler vector of the graph. We'll consider the more general setting in a subsequent post.
Notations
We consider undirected graphs with vertices denoted by . means that nodes and are neighbors in , i.e. . We denote by its adjacency matrix and by the diagonal matrix of degrees. The vector of degrees is denoted by so that . The components of a vector are denoted but sometimes it is convenient to see the vector as a function from to and use the notation instead of .
Community detection in the Karate Club
We'll start with an unsupervised problem: given one graph, find a partition of its node in communities. In this case, we make the hypothesis that individuals tend to associate and bond with similar others, which is known as homophily.
To study this problem, we will focus on the Zachary's karate club and try to recover the split of the club from the graph of connections. The pytorch-geometric library will be very convenient.
Note that GCN are not appropriate in an unsupervised setting as no learning is possible without any label on the vertices. However, this is not a problem here as we will not train the GCN! In more practical settings, GCN are used in a semi-supervised setting where a few labels are revealed for a few nodes (more on this in the section with the Cora dataset).
from torch_geometric.datasets import KarateClub
dataset = KarateClub()
print(f'Dataset: {dataset}:')
@@ -194,7 +194,7 @@ Th
Edit this page on
- Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
+ Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
diff --git a/modules/extras/clip/diagram.png b/modules/extras/clip/diagram.png
new file mode 100644
index 0000000..a1b5ec9
Binary files /dev/null and b/modules/extras/clip/diagram.png differ
diff --git a/modules/extras/graph_invariant/index.html b/modules/extras/graph_invariant/index.html
index 6db989b..d43fa1c 100644
--- a/modules/extras/graph_invariant/index.html
+++ b/modules/extras/graph_invariant/index.html
@@ -1 +1 @@
- Exploiting Graph Invariants in Deep Learning Exploiting Graph Invariants in Deep Learning
0:48 Skip the french part! Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+ Exploiting Graph Invariants in Deep Learning Exploiting Graph Invariants in Deep Learning
0:48 Skip the french part! Edit this page on Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
diff --git a/modules/extras/invariant_equivariant/index.html b/modules/extras/invariant_equivariant/index.html
index 9a0d0f5..104de26 100644
--- a/modules/extras/invariant_equivariant/index.html
+++ b/modules/extras/invariant_equivariant/index.html
@@ -1 +1 @@
- Invariant and Equivariant layers Invariant and equivariant layers with applications to GNN, PointNet and Transformers
author: Marc Lelarge, course: dataflowr
date: April 23, 2021
Invariant and equivariant functions
As shown in the module on GNN, invariant and equivariant functions are crucial for GNN. For example, the message passing GNN (MGNN) layer is defined by:
where means that nodes and are neighbors and the function should not depend on the order of the elements in the multiset . This layer is applied in parallel to all nodes (with the same function ) producing a mapping from to with where is the number of nodes in the graph (and only real hidden states are considered for simplicity). It is easy to see that is an equivariant function, i.e. permuting its input will permute its output.
Another example of invariant and equivariant functions is given by the attention layer defined for a tensor of row queries, the keys and the values, by
The queries are obtained from a tensor by and the keys and values are obtained from a tensor by and . We see that when the queries are fixed, the attention layer is invariant in the pair (keys, values):
hence is invariant in . Similarly, when the pair (keys, values) is fixed, the attention layer is equivariant in the queries:
hence is equivariant in . If , we get the self-attention layer so that is equivariant in .
In this post, we will characterize invariant and equivariant functions following the ideas given in the paper Deep Sets.
Representation of invariant and equivariant functions
We start with some definitions.
For a vector and a permutation , we define
Definitions:
A function is invariant if for all and all , we have .
A function is equivariant if for all and all , we have .
We can now state our main result:
Theorem
invariant case: let be a continuous function. is invariant if and only if there are continuous functions and such that
equivariant case: let be a continuous function. is equivariant if and only if there are continuous functions and such that
We give some remarks before providing the proof below. For the sake of simplicity, we consider here a fixed number of points on the unit interval . For results with a varying number of points, see On the Limitations of Representing Functions on Sets and for points in higher dimension with , see On Universal Equivariant Set Networks and Expressive Power of Invariant and Equivariant Graph Neural Networks.
Our proof will make the mapping explicit and it will not depend on the function . The mapping can be seen as an embedding of the points in in a space of high-dimension. Indeed this embedding space has to be of dimension at least the number of points in order to ensure universality. This is an important remark as in learning scenario, the size of the embedding is typically fixed and hence will limit the expressiveness of the algorithm.
Coming back to the GNN layer (1), our result on the invariant case tells us that we can always rewrite it as:
and the dimension of the embedding needs to be of the same order as the maximum degree in the graph. Note that (8) is not of the form of (7) as the sum inside the function is taken only on neighbors. Indeed, we know that message passing GNN are not universal (see Expressive Power of Invariant and Equivariant Graph Neural Networks).
As a last remark, note that the original PointNet architecture is of the form which is not universal equivariant. Indeed, it is impossible to approximate the equivariant function as shown below (we denote ):
and these quantities cannot be small together. Hence PointNet is not universal equivariant but as shown in On Universal Equivariant Set Networks, modifying PointNet by adding the term inside the function as in (7) makes it universal equivariant. We refer to Are Transformers universal approximators of sequence-to-sequence functions? for similar results about transformers based on self-attention.
Proof of the Theorem
We first show that the equivariant case is not more difficult than the invariant case. Assume that we proved the invariant case. Consider a permutation such that so that gives for the first component:
For any , the mapping is invariant. Hence by (6), we have
Now consider a permutation such that and for , then we have
hence and (7) follows.
Hence, we only need to prove (6) and follow the proof given in Deep Sets. We start with a crucial result stating that a set of real points is characterized by the first moments of its empirical measure. Let see what it means for : we can recover the values of and from the quantities and . To see that this is correct, note that
so that . As a result, we have
and clearly and can be recovered as the roots of this polynomial whose coefficients are functions of and . The result below extends this argument for a general :
Proposition
Let , where , be defined by
is injective and has a continuous inverse mapping.
The proof follows from Newton's identities. For , we denote by the power sums and by the elementary symmetric polynomials (note that all polynomials are function of the ):
From Newton's identities, we have for ,
so that, we can express the elementary symmetric polynomials from the power sums:
Note that and since
if then so that and , showing that is injective.
Hence we proved that where is the image of , is a bijection. We need now to prove that is continuous and we'll prove it directly. Let , we need to show that . Now if , since is compact, this means that there exists a convergent subsequence of with . But by continuity of , we have , so that we get a contradiction and hence proved the continuity of , finishing the proof of the proposition.
We are now ready to prove (6). Let be defined by and . Note that and , where is the vector with components sorted in non-decreasing order. Hence as soon as f is invariant, we have so that (6) is valid. We only need to extend the function from the domain to in a continuous way. This can be done by considering the projection on the compact and define .
Follow on twitter!
Thanks for reading!
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+ Invariant and Equivariant layers Invariant and equivariant layers with applications to GNN, PointNet and Transformers
author: Marc Lelarge, course: dataflowr
date: April 23, 2021
Invariant and equivariant functions
As shown in the module on GNN, invariant and equivariant functions are crucial for GNN. For example, the message passing GNN (MGNN) layer is defined by:
where means that nodes and are neighbors and the function should not depend on the order of the elements in the multiset . This layer is applied in parallel to all nodes (with the same function ) producing a mapping from to with where is the number of nodes in the graph (and only real hidden states are considered for simplicity). It is easy to see that is an equivariant function, i.e. permuting its input will permute its output.
Another example of invariant and equivariant functions is given by the attention layer defined for a tensor of row queries, the keys and the values, by
The queries are obtained from a tensor by and the keys and values are obtained from a tensor by and . We see that when the queries are fixed, the attention layer is invariant in the pair (keys, values):
hence is invariant in . Similarly, when the pair (keys, values) is fixed, the attention layer is equivariant in the queries:
hence is equivariant in . If , we get the self-attention layer so that is equivariant in .
In this post, we will characterize invariant and equivariant functions following the ideas given in the paper Deep Sets.
Representation of invariant and equivariant functions
We start with some definitions.
For a vector and a permutation , we define
Definitions:
A function is invariant if for all and all , we have .
A function is equivariant if for all and all , we have .
We can now state our main result:
Theorem
invariant case: let be a continuous function. is invariant if and only if there are continuous functions and such that
equivariant case: let be a continuous function. is equivariant if and only if there are continuous functions and such that
We give some remarks before providing the proof below. For the sake of simplicity, we consider here a fixed number of points on the unit interval . For results with a varying number of points, see On the Limitations of Representing Functions on Sets and for points in higher dimension with , see On Universal Equivariant Set Networks and Expressive Power of Invariant and Equivariant Graph Neural Networks.
Our proof will make the mapping explicit and it will not depend on the function . The mapping can be seen as an embedding of the points in in a space of high-dimension. Indeed this embedding space has to be of dimension at least the number of points in order to ensure universality. This is an important remark as in learning scenario, the size of the embedding is typically fixed and hence will limit the expressiveness of the algorithm.
Coming back to the GNN layer (1), our result on the invariant case tells us that we can always rewrite it as:
and the dimension of the embedding needs to be of the same order as the maximum degree in the graph. Note that (8) is not of the form of (7) as the sum inside the function is taken only on neighbors. Indeed, we know that message passing GNN are not universal (see Expressive Power of Invariant and Equivariant Graph Neural Networks).
As a last remark, note that the original PointNet architecture is of the form which is not universal equivariant. Indeed, it is impossible to approximate the equivariant function as shown below (we denote ):
and these quantities cannot be small together. Hence PointNet is not universal equivariant but as shown in On Universal Equivariant Set Networks, modifying PointNet by adding the term inside the function as in (7) makes it universal equivariant. We refer to Are Transformers universal approximators of sequence-to-sequence functions? for similar results about transformers based on self-attention.
Proof of the Theorem
We first show that the equivariant case is not more difficult than the invariant case. Assume that we proved the invariant case. Consider a permutation such that so that gives for the first component:
For any , the mapping is invariant. Hence by (6), we have
Now consider a permutation such that and for , then we have
hence and (7) follows.
Hence, we only need to prove (6) and follow the proof given in Deep Sets. We start with a crucial result stating that a set of real points is characterized by the first moments of its empirical measure. Let see what it means for : we can recover the values of and from the quantities and . To see that this is correct, note that
so that . As a result, we have
and clearly and can be recovered as the roots of this polynomial whose coefficients are functions of and . The result below extends this argument for a general :
Proposition
Let , where , be defined by
is injective and has a continuous inverse mapping.
The proof follows from Newton's identities. For , we denote by the power sums and by the elementary symmetric polynomials (note that all polynomials are function of the ):
From Newton's identities, we have for ,
so that, we can express the elementary symmetric polynomials from the power sums:
Note that and since
if then so that and , showing that is injective.
Hence we proved that where is the image of , is a bijection. We need now to prove that is continuous and we'll prove it directly. Let , we need to show that . Now if , since is compact, this means that there exists a convergent subsequence of with . But by continuity of , we have , so that we get a contradiction and hence proved the continuity of , finishing the proof of the proposition.
We are now ready to prove (6). Let be defined by and . Note that and , where is the vector with components sorted in non-decreasing order. Hence as soon as f is invariant, we have so that (6) is valid. We only need to extend the function from the domain to in a continuous way. This can be done by considering the projection on the compact and define .
Follow on twitter!
Thanks for reading!
Edit this page on Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
diff --git a/modules/extras/jupyterlab/index.html b/modules/extras/jupyterlab/index.html
index 37ebca4..01b9fc0 100644
--- a/modules/extras/jupyterlab/index.html
+++ b/modules/extras/jupyterlab/index.html
@@ -1,4 +1,4 @@
- Dataflowr - Deep Learning DIY JupyterLab
This post explains how to install and configure JupyterLab.
Installation
If you are using virtual environments it's preferable to install JupyterLab outside a virtual environment and add them later as kernels.
JupyterLab can be installed from pip:
pip3 instal jupyterlab
+ Dataflowr - Deep Learning DIY JupyterLab
This post explains how to install and configure JupyterLab.
Installation
If you are using virtual environments it's preferable to install JupyterLab outside a virtual environment and add them later as kernels.
JupyterLab can be installed from pip:
pip3 instal jupyterlab
Then launch it with the following command:
jupyter-lab
If you are used to using tmux, you can run JupyterLab in the background with the following command:
@@ -67,7 +67,7 @@ Edit this page on
- Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
+ Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
diff --git a/modules/graph0/index.html b/modules/graph0/index.html
index 019ea54..a23d527 100644
--- a/modules/graph0/index.html
+++ b/modules/graph0/index.html
@@ -1 +1 @@
- Dataflowr - Deep Learning DIY Module - Deep Learning on graphs
Table of Contents
Introduction
Slides for a short overview
Node embedding
Course: Node embedding
Signal processing on graphs
Course: Signal processing on graphs
Related post: Inductive bias in GCN: a spectral perspective
Graph embedding
Course:Graph embedding
Related post: Invariant and equivariant layers with applications to GNN, PointNet and Transformers
More advanced material
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+ Dataflowr - Deep Learning DIY Module - Deep Learning on graphs
Table of Contents
Introduction
Slides for a short overview
Node embedding
Course: Node embedding
Signal processing on graphs
Course: Signal processing on graphs
Related post: Inductive bias in GCN: a spectral perspective
Graph embedding
Course:Graph embedding
Related post: Invariant and equivariant layers with applications to GNN, PointNet and Transformers
More advanced material
Edit this page on Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
diff --git a/modules/graph1/index.html b/modules/graph1/index.html
index 3b21f63..45113c9 100644
--- a/modules/graph1/index.html
+++ b/modules/graph1/index.html
@@ -1 +1 @@
- Dataflowr - Deep Learning DIY Module - Deep Learning on graphs (1)
Table of Contents
Node embedding
0:00 Introduction
2:12 Language model
5:04 Skip-gram model
8:44 Hierarchical softmax
11:19 DeepWalk
14:26 Negative sampling
19:10 node2vec
22:28 results on les Misérables
25:10 results for multi-label classification Slides
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+ Dataflowr - Deep Learning DIY Module - Deep Learning on graphs (1)
Table of Contents
Node embedding
0:00 Introduction
2:12 Language model
5:04 Skip-gram model
8:44 Hierarchical softmax
11:19 DeepWalk
14:26 Negative sampling
19:10 node2vec
22:28 results on les Misérables
25:10 results for multi-label classification Slides
Edit this page on Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
diff --git a/modules/graph2/index.html b/modules/graph2/index.html
index 1a2eb87..0277c17 100644
--- a/modules/graph2/index.html
+++ b/modules/graph2/index.html
@@ -1 +1 @@
- Dataflowr - Deep Learning DIY Module - Deep Learning on graphs (2)
Table of Contents
Signal processing on graphs
0:00 Introduction
1:40 Signal processing on graphs
3:04 Recap on Fourier analysis
5:04 Spectral graph theory
13:44 Graph Fourier analysis
16:38 Filtering
18:33 Filtering on graphs
22:01 Learning a localized kernel
25:03 Chebyshev polynomials
30:28 Convolutional neural networks on graphs Slides
Notebook
Posts
Inductive bias in GCN: a spectral perspective (run the code or open it in Colab)
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+ Dataflowr - Deep Learning DIY Module - Deep Learning on graphs (2)
Table of Contents
Signal processing on graphs
0:00 Introduction
1:40 Signal processing on graphs
3:04 Recap on Fourier analysis
5:04 Spectral graph theory
13:44 Graph Fourier analysis
16:38 Filtering
18:33 Filtering on graphs
22:01 Learning a localized kernel
25:03 Chebyshev polynomials
30:28 Convolutional neural networks on graphs Slides
Notebook
Posts
Inductive bias in GCN: a spectral perspective (run the code or open it in Colab)
Edit this page on Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
diff --git a/modules/graph3/index.html b/modules/graph3/index.html
index b0b7852..e94cc1a 100644
--- a/modules/graph3/index.html
+++ b/modules/graph3/index.html
@@ -1 +1 @@
- Dataflowr - Deep Learning DIY Module - Deep Learning on graphs (3)
Table of Contents
Graph embedding
0:00 Introduction
1:30 Graph embedding
2:43 How to represent graphs?
3:58 Why graph symmetries matter?
8:25 Invariant and equivariant functions
12:30 Message passing GNN
16:02 The many flavors of MGNN
20:00 Separating power
22:51 2-Weisfeiler-Lehman test
26:59 How powerful are MGNN
28:27 Empirical results
29:10 Graphs as higher order tensors
31:45 Invariant and equivariant linear operator
35:47 Invariant linear GNN
38:18 Folklore GNN Slides
Post
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+ Dataflowr - Deep Learning DIY Module - Deep Learning on graphs (3)
Table of Contents
Graph embedding
0:00 Introduction
1:30 Graph embedding
2:43 How to represent graphs?
3:58 Why graph symmetries matter?
8:25 Invariant and equivariant functions
12:30 Message passing GNN
16:02 The many flavors of MGNN
20:00 Separating power
22:51 2-Weisfeiler-Lehman test
26:59 How powerful are MGNN
28:27 Empirical results
29:10 Graphs as higher order tensors
31:45 Invariant and equivariant linear operator
35:47 Invariant linear GNN
38:18 Folklore GNN Slides
Post
Edit this page on Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
diff --git a/modules/privacy-preserving-ML/index.html b/modules/privacy-preserving-ML/index.html
index 5e56a43..a2b3480 100644
--- a/modules/privacy-preserving-ML/index.html
+++ b/modules/privacy-preserving-ML/index.html
@@ -1 +1 @@
- Dataflowr - Deep Learning DIY Module - Privacy Preserving Machine Learning
by Daniel Huynh
Table of Contents
Privacy Preserving Machine Learning
0:00 Presentation
2:50 Context and cloud data threads
5:15 Confidential Computing (CC)
7:12 Intel SGX
8:40 Enclave
12:19 Azure Attestation Service
13:25 Use cases
14:50 Abdstraction layers for enclaves
15:57 Open enclave SDK
16:27 Lightweight OS + Demo (Graphene SGX)
23:44 Multi-party machine learning
26:50 Q&A
33:26 Homomorphic Encryption (HE)
37:20 CKKS encoder
41:29 Homomorphic Encryption high-level view
42:24 Homomorphic Encryption in practice
45:17 Demo with TenSEAL
50:25 Demo Homomorphic Random Forests
1:01:38 to go beyond
1:02:28 Secure Multi-Party Computing (MPC)
1:07:58 Conclusion Slides and code
to go beyond
Edit this page on Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
+ Dataflowr - Deep Learning DIY Module - Privacy Preserving Machine Learning
by Daniel Huynh
Table of Contents
Privacy Preserving Machine Learning
0:00 Presentation
2:50 Context and cloud data threads
5:15 Confidential Computing (CC)
7:12 Intel SGX
8:40 Enclave
12:19 Azure Attestation Service
13:25 Use cases
14:50 Abdstraction layers for enclaves
15:57 Open enclave SDK
16:27 Lightweight OS + Demo (Graphene SGX)
23:44 Multi-party machine learning
26:50 Q&A
33:26 Homomorphic Encryption (HE)
37:20 CKKS encoder
41:29 Homomorphic Encryption high-level view
42:24 Homomorphic Encryption in practice
45:17 Demo with TenSEAL
50:25 Demo Homomorphic Random Forests
1:01:38 to go beyond
1:02:28 Secure Multi-Party Computing (MPC)
1:07:58 Conclusion Slides and code
to go beyond
Edit this page on Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
\ No newline at end of file
diff --git a/notebooks_md/01_intro/index.html b/notebooks_md/01_intro/index.html
index b1e1b3b..33bf371 100644
--- a/notebooks_md/01_intro/index.html
+++ b/notebooks_md/01_intro/index.html
@@ -1,4 +1,4 @@
- Dataflowr - Deep Learning DIY 
You are viewing the static version of the notebook, you can get the code (GitHub) or run it in colab
Module 1: Using CNN for dogs vs cats
To illustrate the Deep Learning pipeline seen in Module 1, we are going to use a pretrained model to enter the Dogs vs Cats competition at Kaggle.
There are 25,000 labelled dog and cat photos available for training, and 12,500 in the test set that we have to try to label for this competition. According to the Kaggle web-site, when this competition was launched (end of 2013): "State of the art: The current literature suggests machine classifiers can score above 80% accuracy on this task". So if you can beat 80%, then you will be at the cutting edge as of 2013!
Imports
import numpy as np
+ Dataflowr - Deep Learning DIY
You are viewing the static version of the notebook, you can get the code (GitHub) or run it in colab
Module 1: Using CNN for dogs vs cats
To illustrate the Deep Learning pipeline seen in Module 1, we are going to use a pretrained model to enter the Dogs vs Cats competition at Kaggle.
There are 25,000 labelled dog and cat photos available for training, and 12,500 in the test set that we have to try to label for this competition. According to the Kaggle web-site, when this competition was launched (end of 2013): "State of the art: The current literature suggests machine classifiers can score above 80% accuracy on this task". So if you can beat 80%, then you will be at the cutting edge as of 2013!
Imports
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
@@ -344,7 +344,7 @@ Conclusion
Edit this page on
- Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
+ Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
diff --git a/notebooks_md/02a_basics/index.html b/notebooks_md/02a_basics/index.html
index f318d5f..12ef7d4 100644
--- a/notebooks_md/02a_basics/index.html
+++ b/notebooks_md/02a_basics/index.html
@@ -1,4 +1,4 @@
- Dataflowr - Deep Learning DIY
You are viewing the static version of the notebook, you can get the code (GitHub) or run it in colab
You can also do the quizzes
Module 2: PyTorch tensors and automatic differentiation
import matplotlib.pyplot as plt
+ Dataflowr - Deep Learning DIY
You are viewing the static version of the notebook, you can get the code (GitHub) or run it in colab
You can also do the quizzes
Module 2: PyTorch tensors and automatic differentiation
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import numpy as np
torch.__version__
@@ -243,7 +243,7 @@ Edit this page on
- Last modified: September 15, 2023. Website built with Franklin.jl and the Julia programming language.
+ Last modified: November 12, 2023. Website built with Franklin.jl and the Julia programming language.
diff --git a/package-lock.json b/package-lock.json
index 21bb504..801b617 100644
--- a/package-lock.json
+++ b/package-lock.json
@@ -5,13 +5,13 @@
"packages": {
"": {
"dependencies": {
- "highlight.js": "^11.8.0"
+ "highlight.js": "^11.9.0"
}
},
"node_modules/highlight.js": {
- "version": "11.8.0",
- "resolved": "https://registry.npmjs.org/highlight.js/-/highlight.js-11.8.0.tgz",
- "integrity": "sha512-MedQhoqVdr0U6SSnWPzfiadUcDHfN/Wzq25AkXiQv9oiOO/sG0S7XkvpFIqWBl9Yq1UYyYOOVORs5UW2XlPyzg==",
+ "version": "11.9.0",
+ "resolved": "https://registry.npmjs.org/highlight.js/-/highlight.js-11.9.0.tgz",
+ "integrity": "sha512-fJ7cW7fQGCYAkgv4CPfwFHrfd/cLS4Hau96JuJ+ZTOWhjnhoeN1ub1tFmALm/+lW5z4WCAuAV9bm05AP0mS6Gw==",
"engines": {
"node": ">=12.0.0"
}
diff --git a/package.json b/package.json
index e37b17c..c849f52 100644
--- a/package.json
+++ b/package.json
@@ -1,5 +1,5 @@
{
"dependencies": {
- "highlight.js": "^11.8.0"
+ "highlight.js": "^11.9.0"
}
}
diff --git a/sitemap.xml b/sitemap.xml
index 5fe39e1..eb3cb74 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -3,277 +3,283 @@
https://dataflowr.github.io/website/modules/18a-diffusion/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/5-stacking-layers/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/14a-depth/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/graph0/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/graph1/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/notebooks_md/02a_basics/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/extras/jupyterlab/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/15-dropout/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/homework/1-mlp-from-scratch/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/homework/3-VAE/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/2b-automatic-differentiation/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/extras/graph_invariant/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/13-siamese/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/graph2/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/extras/invariant_equivariant/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/3-loss-functions-for-classification/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/extras/Convolutions_first/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/homework/2-CAM-adversarial/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/graph3/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/extras/GCN_inductivebias_spectral/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/12-intro-julia/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/notebooks_md/01_intro/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/8c-word2vec/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/9c-flows/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/1-intro-general-overview/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/privacy-preserving-ML/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/0-sotfware-installation/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/0-julia-setup/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/8b-collaborative-filtering/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/6-convolutional-neural-network/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/11a-recurrent-neural-networks-theory/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/4-optimization-for-deep-learning/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/10-generative-adversarial-networks/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/17-resnets/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/14b-depth/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/9b-unet/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/9a-autoencoders/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/2c-jax/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/11c-batches-with-sequences/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/16-batchnorm/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/8a-embedding-layers/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/7-dataloading/index.html
- 2023-09-15
+ 2023-11-12
+ monthly
+ 0.5
+
+
+ https://dataflowr.github.io/website/modules/19-clip/index.html
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/12-attention/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/2a-pytorch-tensors/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5
https://dataflowr.github.io/website/modules/11b-recurrent-neural-networks-practice/index.html
- 2023-09-15
+ 2023-11-12
monthly
0.5

