diff --git a/docs-website/sidebars.js b/docs-website/sidebars.js
index c18d8671318f64..bcb06affedcff0 100644
--- a/docs-website/sidebars.js
+++ b/docs-website/sidebars.js
@@ -780,6 +780,11 @@ module.exports = {
label: "Getting Started With GraphQL",
id: "docs/api/graphql/getting-started",
},
+ {
+ type: "doc",
+ label: "GraphQL Best Practices",
+ id: "docs/api/graphql/graphql-best-practices",
+ },
{
type: "doc",
label: "Access Token Management",
diff --git a/docs/api/graphql/graphql-best-practices.md b/docs/api/graphql/graphql-best-practices.md
new file mode 100644
index 00000000000000..669dd9620bf885
--- /dev/null
+++ b/docs/api/graphql/graphql-best-practices.md
@@ -0,0 +1,1022 @@
+import Tabs from '@theme/Tabs';
+import TabItem from '@theme/TabItem';
+
+# GraphQL Best Practices
+
+## Introduction:
+
+DataHub’s GraphQL API is designed to power the UI. The following guidelines are written with this use-case in mind.
+
+## General Best Practices
+
+### Query Optimizations
+
+> One of GraphQL's biggest advantages over a traditional REST API is its support for **declarative data fetching**. Each component can (and should) query exactly the fields it requires to render, with no superfluous data sent over the network. If instead your root component executes a single, enormous query to obtain data for all of its children, it might query on behalf of components that *aren't even rendered* given the current state. This can result in a delayed response, and it drastically reduces the likelihood that the query's result can be reused by a **server-side response cache**. [[ref](https://www.apolloGraphQL.com/docs/react/data/operation-best-practices#query-only-the-data-you-need-where-you-need-it)]
+>
+1. Minimize over-fetching by only requesting data needed to be displayed.
+2. Limit result counts and use pagination (additionally see section below on `Deep Pagination`).
+3. Avoid deeply nested queries and instead break out queries into separate requests for the nested objects.
+
+### Client-side Caching
+
+Clients, such as Apollo Client (javascript, python `apollo-client-python`), offer [client-side caching](https://www.apolloGraphQL.com/docs/react/caching/overview) to prevent requests to the service and are able to understand the content of the GraphQL query. This enables more advanced caching vs HTTP response caching.
+
+### Reuse Pieces of Query Logic with Fragments
+
+One powerful feature of GraphQL that we recommend you use is [fragments](https://hygraph.com/learn/GraphQL/fragments). Fragments allow you to define pieces of a query that you can reuse across any client-side query that you define. Basically, you can define a set of fields that you want to query, and reuse it in multiple places.
+
+This technique makes maintaining your GraphQL queries much more doable. For example, if you want to request a new field for an entity type across many queries, you’re able to update it in one place if you’re leveraging fragments.
+
+## Search Query Best Practices
+
+### Deep Pagination: search* vs scroll* APIs
+
+`search*` APIs such as [`searchAcrossEntities`](https://datahubproject.io/docs/GraphQL/queries/#searchacrossentities) are designed for minimal pagination (< ~50). They do not perform well for deep pagination requests. Use the equivalent `scroll*` APIs such as [`scrollAcrossEntities`](https://datahubproject.io/docs/GraphQL/queries/#scrollacrossentities) when expecting the need to paginate deeply into the result set.
+
+Note: that it is impossible to use `search*` for paginating beyond 10k results.
+
+#### Examples
+
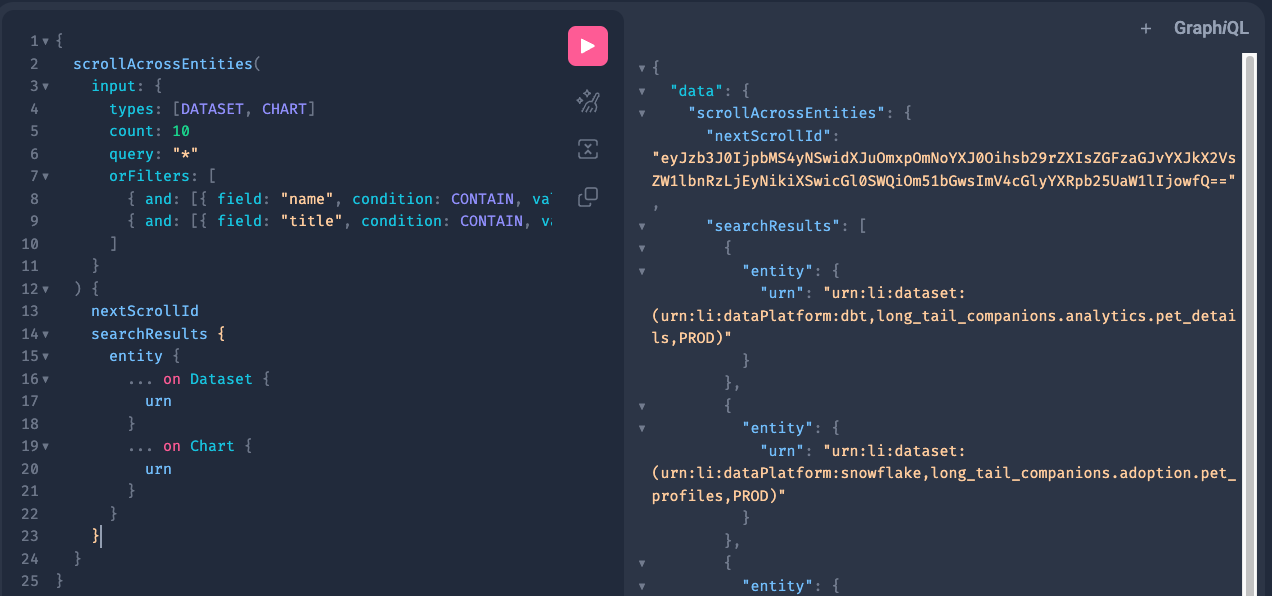
+In the following examples we demonstrate pagination for both `scroll*` and `search*` requests. This particular request is searching for two entities, Datasets and Charts, that
+contain `pet` in the entities' name or title. The results will only include the URN for the entities.
+
+
+
+Page 1 Request:
+
+```graphql
+{
+ scrollAcrossEntities(
+ input: {
+ types: [DATASET, CHART]
+ count: 2
+ query: "*"
+ orFilters: [
+ { and: [{ field: "name", condition: CONTAIN, values: ["pet"] }] },
+ { and: [{ field: "title", condition: CONTAIN, values: ["pet"] }] }
+ ]
+ }
+ ) {
+ nextScrollId
+ searchResults {
+ entity {
+ ... on Dataset {
+ urn
+ }
+ ... on Chart {
+ urn
+ }
+ }
+ }
+ }
+}
+```
+
+Page 1 Result:
+
+```json
+{
+ "data": {
+ "scrollAcrossEntities": {
+ "nextScrollId": "eyJzb3J0IjpbMi4wNzk2ODc2LCJ1cm46bGk6ZGF0YXNldDoodXJuOmxpOmRhdGFQbGF0Zm9ybTpzbm93Zmxha2UsbG9uZ190YWlsX2NvbXBhbmlvbnMuYWRvcHRpb24ucGV0X3Byb2ZpbGVzLFBST0QpIl0sInBpdElkIjpudWxsLCJleHBpcmF0aW9uVGltZSI6MH0=",
+ "searchResults": [
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:dbt,long_tail_companions.analytics.pet_details,PROD)"
+ }
+ },
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.pet_profiles,PROD)"
+ }
+ }
+ ]
+ }
+ },
+ "extensions": {}
+}
+```
+
+Page 2 Request:
+
+```graphql
+{
+ scrollAcrossEntities(
+ input: {
+ scrollId: "eyJzb3J0IjpbMi4wNzk2ODc2LCJ1cm46bGk6ZGF0YXNldDoodXJuOmxpOmRhdGFQbGF0Zm9ybTpzbm93Zmxha2UsbG9uZ190YWlsX2NvbXBhbmlvbnMuYWRvcHRpb24ucGV0X3Byb2ZpbGVzLFBST0QpIl0sInBpdElkIjpudWxsLCJleHBpcmF0aW9uVGltZSI6MH0="
+ types: [DATASET, CHART]
+ count: 2
+ query: "*"
+ orFilters: [
+ { and: [{ field: "name", condition: CONTAIN, values: ["pet"] }] },
+ { and: [{ field: "title", condition: CONTAIN, values: ["pet"] }] }
+ ]
+ }
+ ) {
+ nextScrollId
+ searchResults {
+ entity {
+ ... on Dataset {
+ urn
+ }
+ ... on Chart {
+ urn
+ }
+ }
+ }
+ }
+}
+```
+
+Page 2 Result:
+
+```json
+{
+ "data": {
+ "scrollAcrossEntities": {
+ "nextScrollId": "eyJzb3J0IjpbMS43MTg3NSwidXJuOmxpOmRhdGFzZXQ6KHVybjpsaTpkYXRhUGxhdGZvcm06c25vd2ZsYWtlLGxvbmdfdGFpbF9jb21wYW5pb25zLmFkb3B0aW9uLnBldHMsUFJPRCkiXSwicGl0SWQiOm51bGwsImV4cGlyYXRpb25UaW1lIjowfQ==",
+ "searchResults": [
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:dbt,long_tail_companions.analytics.pet_status_history,PROD)"
+ }
+ },
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.pets,PROD)"
+ }
+ }
+ ]
+ }
+ },
+ "extensions": {}
+}
+```
+
+
+
+Page 1 Request:
+
+```graphql
+{
+ searchAcrossEntities(
+ input: {
+ types: [DATASET, CHART]
+ count: 2,
+ start: 0
+ query: "*"
+ orFilters: [
+ { and: [{ field: "name", condition: CONTAIN, values: ["pet"] }] },
+ { and: [{ field: "title", condition: CONTAIN, values: ["pet"] }] }
+ ]
+ }
+ ) {
+ searchResults {
+ entity {
+ ... on Dataset {
+ urn
+ }
+ ... on Chart {
+ urn
+ }
+ }
+ }
+ }
+}
+```
+
+Page 1 Response:
+
+```json
+{
+ "data": {
+ "searchAcrossEntities": {
+ "searchResults": [
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:dbt,long_tail_companions.analytics.pet_details,PROD)"
+ }
+ },
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.pet_profiles,PROD)"
+ }
+ }
+ ]
+ }
+ },
+ "extensions": {}
+}
+```
+
+Page 2 Request:
+
+```graphql
+{
+ searchAcrossEntities(
+ input: {
+ types: [DATASET, CHART]
+ count: 2,
+ start: 2
+ query: "*"
+ orFilters: [
+ { and: [{ field: "name", condition: CONTAIN, values: ["pet"] }] },
+ { and: [{ field: "title", condition: CONTAIN, values: ["pet"] }] }
+ ]
+ }
+ ) {
+ searchResults {
+ entity {
+ ... on Dataset {
+ urn
+ }
+ ... on Chart {
+ urn
+ }
+ }
+ }
+ }
+}
+```
+
+Page 2 Response:
+
+```json
+{
+ "data": {
+ "searchAcrossEntities": {
+ "searchResults": [
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:dbt,long_tail_companions.analytics.pet_status_history,PROD)"
+ }
+ },
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.pets,PROD)"
+ }
+ }
+ ]
+ }
+ },
+ "extensions": {}
+}
+```
+
+
+
+### SearchFlags: Highlighting and Aggregation
+
+When performing queries which accept [`searchFlags`](https://datahubproject.io/docs/GraphQL/inputObjects#searchflags) and highlighting and aggregation is not needed, be sure to disable these flags.
+
+- skipHighlighting: true
+- skipAggregates: true
+
+As a fallback, if only certain fields require highlighting use `customHighlightingFields` to limit highlighting to the specific fields.
+
+
+
+
+Example for skipping highlighting and aggregates, typically used for scrolling search requests.
+
+```graphql
+{
+ scrollAcrossEntities(
+ input: {types: [DATASET], count: 2, query: "pet", searchFlags: {skipAggregates: true, skipHighlighting: true}}
+ ) {
+ searchResults {
+ entity {
+ ... on Dataset {
+ urn
+ }
+ }
+ matchedFields {
+ name
+ value
+ }
+ }
+ facets {
+ displayName
+ aggregations {
+ value
+ count
+ }
+ }
+ }
+}
+```
+
+Response:
+
+Note that a few `matchedFields` are still returned by default [`urn`, `customProperties`]
+
+```json
+{
+ "data": {
+ "scrollAcrossEntities": {
+ "searchResults": [
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:dbt,long_tail_companions.analytics.pet_details,PROD)"
+ },
+ "matchedFields": [
+ {
+ "name": "urn",
+ "value": ""
+ },
+ {
+ "name": "customProperties",
+ "value": ""
+ }
+ ]
+ },
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.analytics.pet_details,PROD)"
+ },
+ "matchedFields": [
+ {
+ "name": "urn",
+ "value": ""
+ },
+ {
+ "name": "customProperties",
+ "value": ""
+ }
+ ]
+ }
+ ],
+ "facets": []
+ }
+ },
+ "extensions": {}
+}
+```
+
+
+
+
+
+Custom highlighting can be used for searchAcrossEntities when only a limited number of fields are useful for highlighting. In this example we specifically request highlighting for `description`.
+
+```graphql
+{
+ searchAcrossEntities(
+ input: {types: [DATASET], count: 2, query: "pet", searchFlags: {customHighlightingFields: ["description"]}}
+ ) {
+ searchResults {
+ entity {
+ ... on Dataset {
+ urn
+ }
+ }
+ matchedFields {
+ name
+ value
+ }
+ }
+ }
+}
+```
+
+Response:
+
+```json
+{
+ "data": {
+ "searchAcrossEntities": {
+ "searchResults": [
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:dbt,long_tail_companions.analytics.pet_details,PROD)"
+ },
+ "matchedFields": [
+ {
+ "name": "urn",
+ "value": ""
+ },
+ {
+ "name": "customProperties",
+ "value": ""
+ },
+ {
+ "name": "description",
+ "value": "Table with all pet-related details"
+ }
+ ]
+ },
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.analytics.pet_details,PROD)"
+ },
+ "matchedFields": [
+ {
+ "name": "urn",
+ "value": ""
+ },
+ {
+ "name": "customProperties",
+ "value": ""
+ }
+ ]
+ }
+ ]
+ }
+ },
+ "extensions": {}
+}
+```
+
+
+
+
+
+### Aggregation
+
+When aggregation is required with `searchAcrossEntities`, it is possible to set the `count` to 0 to avoid fetching the top search hits, only returning the aggregations. Alternatively [aggregateAcrossEntities](https://datahubproject.io/docs/GraphQL/queries#aggregateacrossentities) provides counts and can provide faster results from server-side caching.
+
+Request:
+
+```graphql
+{
+ searchAcrossEntities(
+ input: {types: [DATASET], count: 0, query: "pet", searchFlags: {skipHighlighting: true}}
+ ) {
+ searchResults {
+ entity {
+ ... on Dataset {
+ urn
+ }
+ }
+ matchedFields {
+ name
+ value
+ }
+ }
+ facets {
+ displayName
+ aggregations {
+ value
+ count
+ }
+ }
+ }
+}
+```
+
+Response:
+
+```json
+{
+ "data": {
+ "searchAcrossEntities": {
+ "searchResults": [],
+ "facets": [
+ {
+ "displayName": "Container",
+ "aggregations": [
+ {
+ "value": "urn:li:container:b41c14bc5cb3ccfbb0433c8cbdef2992",
+ "count": 4
+ },
+ {
+ "value": "urn:li:container:701919de0ec93cb338fe9bac0b35403c",
+ "count": 3
+ }
+ ]
+ },
+ {
+ "displayName": "Sub Type",
+ "aggregations": [
+ {
+ "value": "table",
+ "count": 9
+ },
+ {
+ "value": "view",
+ "count": 6
+ },
+ {
+ "value": "explore",
+ "count": 5
+ },
+ {
+ "value": "source",
+ "count": 4
+ },
+ {
+ "value": "incremental",
+ "count": 1
+ }
+ ]
+ },
+ {
+ "displayName": "Type",
+ "aggregations": [
+ {
+ "value": "DATASET",
+ "count": 24
+ }
+ ]
+ },
+ {
+ "displayName": "Environment",
+ "aggregations": [
+ {
+ "value": "PROD",
+ "count": 24
+ }
+ ]
+ },
+ {
+ "displayName": "Glossary Term",
+ "aggregations": [
+ {
+ "value": "urn:li:glossaryTerm:Adoption.DaysInStatus",
+ "count": 1
+ },
+ {
+ "value": "urn:li:glossaryTerm:Ecommerce.HighRisk",
+ "count": 1
+ },
+ {
+ "value": "urn:li:glossaryTerm:Classification.Confidential",
+ "count": 1
+ }
+ ]
+ },
+ {
+ "displayName": "Domain",
+ "aggregations": [
+ {
+ "value": "urn:li:domain:094dc54b-0ebc-40a6-a4cf-e1b75e8b8089",
+ "count": 6
+ },
+ {
+ "value": "urn:li:domain:7d64d0fa-66c3-445c-83db-3a324723daf8",
+ "count": 2
+ }
+ ]
+ },
+ {
+ "displayName": "Owned By",
+ "aggregations": [
+ {
+ "value": "urn:li:corpGroup:Adoption",
+ "count": 5
+ },
+ {
+ "value": "urn:li:corpuser:shannon@longtail.com",
+ "count": 4
+ },
+ {
+ "value": "urn:li:corpuser:admin",
+ "count": 2
+ },
+ {
+ "value": "urn:li:corpGroup:Analytics Engineering",
+ "count": 2
+ },
+ {
+ "value": "urn:li:corpuser:avigdor@longtail.com",
+ "count": 1
+ },
+ {
+ "value": "urn:li:corpuser:prentiss@longtail.com",
+ "count": 1
+ },
+ {
+ "value": "urn:li:corpuser:tasha@longtail.com",
+ "count": 1
+ },
+ {
+ "value": "urn:li:corpuser:ricca@longtail.com",
+ "count": 1
+ },
+ {
+ "value": "urn:li:corpuser:emilee@longtail.com",
+ "count": 1
+ }
+ ]
+ },
+ {
+ "displayName": "Platform",
+ "aggregations": [
+ {
+ "value": "urn:li:dataPlatform:looker",
+ "count": 8
+ },
+ {
+ "value": "urn:li:dataPlatform:dbt",
+ "count": 7
+ },
+ {
+ "value": "urn:li:dataPlatform:snowflake",
+ "count": 7
+ },
+ {
+ "value": "urn:li:dataPlatform:s3",
+ "count": 1
+ },
+ {
+ "value": "urn:li:dataPlatform:mongodb",
+ "count": 1
+ }
+ ]
+ },
+ {
+ "displayName": "Tag",
+ "aggregations": [
+ {
+ "value": "urn:li:tag:prod_model",
+ "count": 3
+ },
+ {
+ "value": "urn:li:tag:pii",
+ "count": 2
+ },
+ {
+ "value": "urn:li:tag:business critical",
+ "count": 2
+ },
+ {
+ "value": "urn:li:tag:business_critical",
+ "count": 2
+ },
+ {
+ "value": "urn:li:tag:Tier1",
+ "count": 1
+ },
+ {
+ "value": "urn:li:tag:prod",
+ "count": 1
+ }
+ ]
+ },
+ {
+ "displayName": "Type",
+ "aggregations": [
+ {
+ "value": "DATASET",
+ "count": 24
+ }
+ ]
+ }
+ ]
+ }
+ },
+ "extensions": {}
+}
+```
+
+### Limit Search Entity Types
+
+When querying for specific entities, enumerate only the entity types required using `types` , for example [`DATASET` , `CHART`]
+
+### Limit Results
+
+Limit search results based on the amount of information being requested. For example, a minimal number of attributes can fetch 1,000 - 2,000 results in a single page, however as the number of attributes increases (especially nested objects) the `count` should be lowered, 20-25 for very complex requests.
+
+## Lineage Query Best Practices
+
+There are two primary ways to query lineage:
+
+### Search Across Lineage
+
+`searchAcrossLineage` / `scrollAcrossLineage` root query:
+
+- Recommended for all lineage queries
+- Only the shortest path is guaranteed to show up in `paths`
+- Supports querying indirect lineage (depth > 1)
+ - Depending on the fanout of the lineage, 3+ hops may not return data, use 1-hop queries for the fastest response times.
+ - Specify using a filter with name `"degree"` and values `"1"` , `"2"`, and / or `"3+"`
+
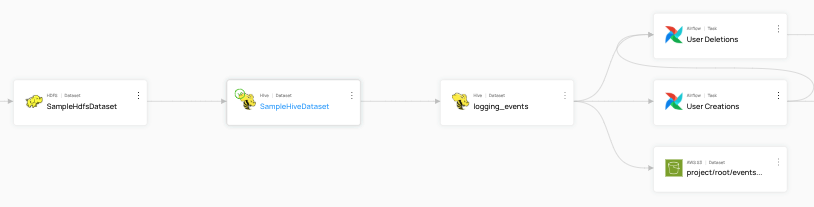
+The following examples are demonstrated using sample data for `urn:li:dataset:(urn:li:dataPlatform:hive,SampleHiveDataset,PROD)`.
+
+
+  +
+
+
+
+
+
+The following example queries show UPSTREAM lineage with progressively higher degrees, first with degree `["1"]` and then `["1","2"]`.
+
+1-Hop Upstreams:
+
+Request:
+
+```graphql
+{
+ searchAcrossLineage(
+ input: {urn: "urn:li:dataset:(urn:li:dataPlatform:hive,SampleHiveDataset,PROD)", query: "*", count: 10, start: 0, direction: UPSTREAM, orFilters: [{and: [{field: "degree", condition: EQUAL, values: ["1"]}]}], searchFlags: {skipAggregates: true, skipHighlighting: true}}
+ ) {
+ start
+ count
+ total
+ searchResults {
+ entity {
+ urn
+ type
+ ... on Dataset {
+ name
+ }
+ }
+ paths {
+ path {
+ ... on Dataset {
+ urn
+ }
+ }
+ }
+ degree
+ }
+ }
+}
+```
+
+Response:
+
+```json
+{
+ "data": {
+ "searchAcrossLineage": {
+ "start": 0,
+ "count": 10,
+ "total": 1,
+ "searchResults": [
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)",
+ "type": "DATASET",
+ "name": "SampleHdfsDataset"
+ },
+ "paths": [
+ {
+ "path": [
+ {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hive,SampleHiveDataset,PROD)"
+ },
+ {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)"
+ }
+ ]
+ }
+ ],
+ "degree": 1
+ }
+ ]
+ }
+ },
+ "extensions": {}
+}
+```
+
+
+
+1-Hop & 2-Hop Upstreams:
+
+Request:
+
+```graphql
+{
+ searchAcrossLineage(
+ input: {urn: "urn:li:dataset:(urn:li:dataPlatform:hive,SampleHiveDataset,PROD)", query: "*", count: 10, start: 0, direction: UPSTREAM, orFilters: [{and: [{field: "degree", condition: EQUAL, values: ["1","2"]}]}], searchFlags: {skipAggregates: true, skipHighlighting: true}}
+ ) {
+ start
+ count
+ total
+ searchResults {
+ entity {
+ urn
+ type
+ ... on Dataset {
+ name
+ }
+ }
+ paths {
+ path {
+ ... on Dataset {
+ urn
+ }
+ }
+ }
+ degree
+ }
+ }
+}
+```
+
+```json
+{
+ "data": {
+ "searchAcrossLineage": {
+ "start": 0,
+ "count": 10,
+ "total": 2,
+ "searchResults": [
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)",
+ "type": "DATASET",
+ "name": "SampleHdfsDataset"
+ },
+ "paths": [
+ {
+ "path": [
+ {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hive,SampleHiveDataset,PROD)"
+ },
+ {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)"
+ }
+ ]
+ }
+ ],
+ "degree": 1
+ },
+ {
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:kafka,SampleKafkaDataset,PROD)",
+ "type": "DATASET",
+ "name": "SampleKafkaDataset"
+ },
+ "paths": [
+ {
+ "path": [
+ {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hive,SampleHiveDataset,PROD)"
+ },
+ {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)"
+ },
+ {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:kafka,SampleKafkaDataset,PROD)"
+ }
+ ]
+ }
+ ],
+ "degree": 2
+ }
+ ]
+ }
+ },
+ "extensions": {}
+}
+```
+
+
+
+
+### Lineage Subquery
+
+The previous query requires a root or starting node in the lineage graph. The following request offers a way to request lineage for multiple nodes at once with a few limitations.
+
+`lineage` query on `EntityWithRelationship` entities:
+
+- A more direct reflection of the graph index
+- 1-hop lineage only
+- Multiple URNs
+- Should not be requested too many times in a single request. 20 is a tested limit
+
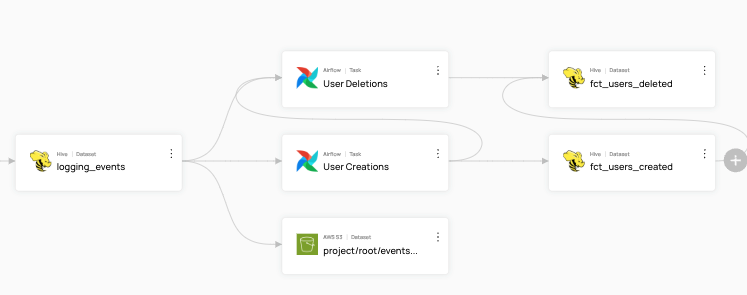
+The following examples are based on the sample lineage graph shown here:
+
+
+  +
+
+
+Example Request:
+
+```graphql
+query getBulkEntityLineageV2($urns: [String!]! = ["urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_123)", "urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_456)"]) {
+ entities(urns: $urns) {
+ urn
+ type
+ ... on DataJob {
+ jobId
+ dataFlow {
+ flowId
+ }
+ properties {
+ name
+ }
+ upstream: lineage(input: {direction: UPSTREAM, start: 0, count: 10}) {
+ total
+ relationships {
+ type
+ entity {
+ urn
+ type
+ }
+ }
+ }
+ downstream: lineage(input: {direction: DOWNSTREAM, start: 0, count: 10}) {
+ total
+ relationships {
+ type
+ entity {
+ urn
+ type
+ }
+ }
+ }
+ }
+ }
+}
+```
+
+Example Response:
+
+```json
+{
+ "data": {
+ "entities": [
+ {
+ "urn": "urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_123)",
+ "type": "DATA_JOB",
+ "jobId": "task_123",
+ "dataFlow": {
+ "flowId": "dag_abc"
+ },
+ "properties": {
+ "name": "User Creations"
+ },
+ "upstream": {
+ "total": 1,
+ "relationships": [
+ {
+ "type": "Consumes",
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)",
+ "type": "DATASET"
+ }
+ }
+ ]
+ },
+ "downstream": {
+ "total": 2,
+ "relationships": [
+ {
+ "type": "DownstreamOf",
+ "entity": {
+ "urn": "urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_456)",
+ "type": "DATA_JOB"
+ }
+ },
+ {
+ "type": "Produces",
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)",
+ "type": "DATASET"
+ }
+ }
+ ]
+ }
+ },
+ {
+ "urn": "urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_456)",
+ "type": "DATA_JOB",
+ "jobId": "task_456",
+ "dataFlow": {
+ "flowId": "dag_abc"
+ },
+ "properties": {
+ "name": "User Deletions"
+ },
+ "upstream": {
+ "total": 2,
+ "relationships": [
+ {
+ "type": "DownstreamOf",
+ "entity": {
+ "urn": "urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_123)",
+ "type": "DATA_JOB"
+ }
+ },
+ {
+ "type": "Consumes",
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)",
+ "type": "DATASET"
+ }
+ }
+ ]
+ },
+ "downstream": {
+ "total": 1,
+ "relationships": [
+ {
+ "type": "Produces",
+ "entity": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)",
+ "type": "DATASET"
+ }
+ }
+ ]
+ }
+ }
+ ]
+ },
+ "extensions": {}
+}
+```
\ No newline at end of file
diff --git a/docs/api/graphql/how-to-set-up-graphql.md b/docs/api/graphql/how-to-set-up-graphql.md
index 2be2f935b12b10..a36b52204b1d04 100644
--- a/docs/api/graphql/how-to-set-up-graphql.md
+++ b/docs/api/graphql/how-to-set-up-graphql.md
@@ -1,3 +1,6 @@
+import Tabs from '@theme/Tabs';
+import TabItem from '@theme/TabItem';
+
# How To Set Up GraphQL
## Preparing Local Datahub Deployment
@@ -29,6 +32,7 @@ DataHub provides a browser-based GraphQL Explorer Tool ([GraphiQL](https://githu
This interface allows you to easily craft queries and mutations against real metadata stored in your live DataHub deployment.
To experiment with GraphiQL before deploying it in your live DataHub deployment, you can access a demo site provided by DataHub at https://demo.datahubproject.io/api/graphiql.
+
For instance, you can create a tag by posting the following query:
```json
@@ -43,6 +47,29 @@ mutation createTag {
For a detailed usage guide, check out [How to use GraphiQL](https://www.gatsbyjs.com/docs/how-to/querying-data/running-queries-with-graphiql/).
+To navigate to `GraphiQL` on the demo site or your local instance, select `GraphiQL` from the user profile drop-down menu as
+shown below.
+
+
+
+
+  +
+
+
+
+
+
+  +
+
+
+
+
+This link will then display the following interface for exploring GraphQL queries.
+
+
+  +
+
+
### CURL
CURL is a command-line tool used for transferring data using various protocols including HTTP, HTTPS, and others.