update = accuracyHelper(labels, predictions);
- totalInstances.compute(key, (k, v) -> v + update.getKey());
- correctInstances.compute(key, (k, v) -> v + update.getValue().sum().getLong());
+ NDArray value = update.getValue();
+ NDArray sum = value.sum();
+ long correct = sum.getLong();
+ for (String key : keys) {
+ totalInstances.compute(key, (k, v) -> v + update.getKey());
+ correctInstances.compute(key, (k, v) -> v + correct);
+ }
+ value.close();
+ sum.close();
}
/** {@inheritDoc} */
diff --git a/api/src/main/java/ai/djl/training/evaluator/BoundingBoxError.java b/api/src/main/java/ai/djl/training/evaluator/BoundingBoxError.java
index 4af9e5de3d1..ab2d554142d 100644
--- a/api/src/main/java/ai/djl/training/evaluator/BoundingBoxError.java
+++ b/api/src/main/java/ai/djl/training/evaluator/BoundingBoxError.java
@@ -63,10 +63,18 @@ public void addAccumulator(String key) {
/** {@inheritDoc} */
@Override
public void updateAccumulator(String key, NDList labels, NDList predictions) {
+ updateAccumulators(new String[] {key}, labels, predictions);
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void updateAccumulators(String[] keys, NDList labels, NDList predictions) {
NDArray boundingBoxError = evaluate(labels, predictions);
float update = boundingBoxError.sum().getFloat();
- totalInstances.compute(key, (k, v) -> v + boundingBoxError.size());
- ssdBoxPredictionError.compute(key, (k, v) -> v + update);
+ for (String key : keys) {
+ totalInstances.compute(key, (k, v) -> v + boundingBoxError.size());
+ ssdBoxPredictionError.compute(key, (k, v) -> v + update);
+ }
}
/** {@inheritDoc} */
diff --git a/api/src/main/java/ai/djl/training/evaluator/Evaluator.java b/api/src/main/java/ai/djl/training/evaluator/Evaluator.java
index 6d2c5995601..c373471f6cf 100644
--- a/api/src/main/java/ai/djl/training/evaluator/Evaluator.java
+++ b/api/src/main/java/ai/djl/training/evaluator/Evaluator.java
@@ -74,6 +74,25 @@ public String getName() {
*/
public abstract void addAccumulator(String key);
+ /**
+ * Updates the evaluator with the given keys based on a {@link NDList} of labels and
+ * predictions.
+ *
+ * This is a synchronized operation. You should only call it at the end of a batch or epoch.
+ *
+ *
This is an alternative to @{link {@link #updateAccumulator(String, NDList, NDList)}} that
+ * may be more efficient when updating multiple accumulators at once.
+ *
+ * @param keys the keys of all the accumulators to update
+ * @param labels a {@code NDList} of labels
+ * @param predictions a {@code NDList} of predictions
+ */
+ public void updateAccumulators(String[] keys, NDList labels, NDList predictions) {
+ for (String key : keys) {
+ updateAccumulator(key, labels, predictions);
+ }
+ }
+
/**
* Updates the evaluator with the given key based on a {@link NDList} of labels and predictions.
*
diff --git a/api/src/main/java/ai/djl/training/evaluator/IndexEvaluator.java b/api/src/main/java/ai/djl/training/evaluator/IndexEvaluator.java
index a7fe08b610e..aa12cae628c 100644
--- a/api/src/main/java/ai/djl/training/evaluator/IndexEvaluator.java
+++ b/api/src/main/java/ai/djl/training/evaluator/IndexEvaluator.java
@@ -67,6 +67,12 @@ public void updateAccumulator(String key, NDList labels, NDList predictions) {
evaluator.updateAccumulator(key, getLabels(labels), getPredictions(predictions));
}
+ /** {@inheritDoc} */
+ @Override
+ public void updateAccumulators(String[] keys, NDList labels, NDList predictions) {
+ evaluator.updateAccumulators(keys, getLabels(labels), getPredictions(predictions));
+ }
+
/** {@inheritDoc} */
@Override
public void resetAccumulator(String key) {
diff --git a/api/src/main/java/ai/djl/training/listener/EarlyStoppingListener.java b/api/src/main/java/ai/djl/training/listener/EarlyStoppingListener.java
new file mode 100644
index 00000000000..6c013c37715
--- /dev/null
+++ b/api/src/main/java/ai/djl/training/listener/EarlyStoppingListener.java
@@ -0,0 +1,281 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.training.listener;
+
+import ai.djl.training.Trainer;
+import ai.djl.training.TrainingResult;
+
+import java.time.Duration;
+
+/**
+ * Listener that allows the training to be stopped early if the validation loss is not improving, or
+ * if time has expired.
+ *
+ *
Usage: Add this listener to the training config, and add it as the last one.
+ *
+ *
+ * new DefaultTrainingConfig(...)
+ * .addTrainingListeners(EarlyStoppingListener.builder()
+ * .setEpochPatience(1)
+ * .setEarlyStopPctImprovement(1)
+ * .setMaxDuration(Duration.ofMinutes(42))
+ * .setMinEpochs(1)
+ * .build()
+ * );
+ *
+ *
+ * Then surround the fit with a try catch that catches the {@link
+ * EarlyStoppingListener.EarlyStoppedException}.
+ * Example:
+ *
+ *
+ * try {
+ * EasyTrain.fit(trainer, 5, trainDataset, testDataset);
+ * } catch (EarlyStoppingListener.EarlyStoppedException e) {
+ * // handle early stopping
+ * log.info("Stopped early at epoch {} because: {}", e.getEpoch(), e.getMessage());
+ * }
+ *
+ *
+ *
+ * Note: Ensure that Metrics are set on the trainer.
+ */
+public final class EarlyStoppingListener implements TrainingListener {
+ private final double objectiveSuccess;
+
+ private final int minEpochs;
+ private final long maxMillis;
+ private final double earlyStopPctImprovement;
+ private final int epochPatience;
+
+ private long startTimeMills;
+ private double prevLoss;
+ private int numberOfEpochsWithoutImprovements;
+
+ private EarlyStoppingListener(
+ double objectiveSuccess,
+ int minEpochs,
+ long maxMillis,
+ double earlyStopPctImprovement,
+ int earlyStopPatience) {
+ this.objectiveSuccess = objectiveSuccess;
+ this.minEpochs = minEpochs;
+ this.maxMillis = maxMillis;
+ this.earlyStopPctImprovement = earlyStopPctImprovement;
+ this.epochPatience = earlyStopPatience;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void onEpoch(Trainer trainer) {
+ int currentEpoch = trainer.getTrainingResult().getEpoch();
+ // stopping criteria
+ final double loss = getLoss(trainer.getTrainingResult());
+ if (currentEpoch >= minEpochs) {
+ if (loss < objectiveSuccess) {
+ throw new EarlyStoppedException(
+ currentEpoch,
+ String.format(
+ "validation loss %s < objectiveSuccess %s",
+ loss, objectiveSuccess));
+ }
+ long elapsedMillis = System.currentTimeMillis() - startTimeMills;
+ if (elapsedMillis >= maxMillis) {
+ throw new EarlyStoppedException(
+ currentEpoch,
+ String.format("%s ms elapsed >= %s maxMillis", elapsedMillis, maxMillis));
+ }
+ // consider early stopping?
+ if (Double.isFinite(prevLoss)) {
+ double goalImprovement = prevLoss * (100 - earlyStopPctImprovement) / 100.0;
+ boolean improved = loss <= goalImprovement; // false if any NANs
+ if (improved) {
+ numberOfEpochsWithoutImprovements = 0;
+ } else {
+ numberOfEpochsWithoutImprovements++;
+ if (numberOfEpochsWithoutImprovements >= epochPatience) {
+ throw new EarlyStoppedException(
+ currentEpoch,
+ String.format(
+ "failed to achieve %s%% improvement %s times in a row",
+ earlyStopPctImprovement, epochPatience));
+ }
+ }
+ }
+ }
+ if (Double.isFinite(loss)) {
+ prevLoss = loss;
+ }
+ }
+
+ private static double getLoss(TrainingResult trainingResult) {
+ Float vLoss = trainingResult.getValidateLoss();
+ if (vLoss != null) {
+ return vLoss;
+ }
+ Float tLoss = trainingResult.getTrainLoss();
+ if (tLoss == null) {
+ return Double.NaN;
+ }
+ return tLoss;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void onTrainingBatch(Trainer trainer, BatchData batchData) {
+ // do nothing
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void onValidationBatch(Trainer trainer, BatchData batchData) {
+ // do nothing
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void onTrainingBegin(Trainer trainer) {
+ this.startTimeMills = System.currentTimeMillis();
+ this.prevLoss = Double.NaN;
+ this.numberOfEpochsWithoutImprovements = 0;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void onTrainingEnd(Trainer trainer) {
+ // do nothing
+ }
+
+ /**
+ * Creates a builder to build a {@link EarlyStoppingListener}.
+ *
+ * @return a new builder
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ /** A builder for a {@link EarlyStoppingListener}. */
+ public static final class Builder {
+ private final double objectiveSuccess;
+ private int minEpochs;
+ private long maxMillis;
+ private double earlyStopPctImprovement;
+ private int epochPatience;
+
+ /** Constructs a {@link Builder} with default values. */
+ public Builder() {
+ this.objectiveSuccess = 0;
+ this.minEpochs = 0;
+ this.maxMillis = Long.MAX_VALUE;
+ this.earlyStopPctImprovement = 0;
+ this.epochPatience = 0;
+ }
+
+ /**
+ * Set the minimum # epochs, defaults to 0.
+ *
+ * @param minEpochs the minimum # epochs
+ * @return this builder
+ */
+ public Builder optMinEpochs(int minEpochs) {
+ this.minEpochs = minEpochs;
+ return this;
+ }
+
+ /**
+ * Set the maximum duration a training run should take, defaults to Long.MAX_VALUE in ms.
+ *
+ * @param duration the maximum duration a training run should take
+ * @return this builder
+ */
+ public Builder optMaxDuration(Duration duration) {
+ this.maxMillis = duration.toMillis();
+ return this;
+ }
+
+ /**
+ * Set the maximum # milliseconds a training run should take, defaults to Long.MAX_VALUE.
+ *
+ * @param maxMillis the maximum # milliseconds a training run should take
+ * @return this builder
+ */
+ public Builder optMaxMillis(int maxMillis) {
+ this.maxMillis = maxMillis;
+ return this;
+ }
+
+ /**
+ * Consider early stopping if not x% improvement, defaults to 0.
+ *
+ * @param earlyStopPctImprovement the percentage improvement to consider early stopping,
+ * must be between 0 and 100.
+ * @return this builder
+ */
+ public Builder optEarlyStopPctImprovement(double earlyStopPctImprovement) {
+ this.earlyStopPctImprovement = earlyStopPctImprovement;
+ return this;
+ }
+
+ /**
+ * Stop if insufficient improvement for x epochs in a row, defaults to 0.
+ *
+ * @param epochPatience the number of epochs without improvement to consider stopping, must
+ * be greater than 0.
+ * @return this builder
+ */
+ public Builder optEpochPatience(int epochPatience) {
+ this.epochPatience = epochPatience;
+ return this;
+ }
+
+ /**
+ * Builds a {@link EarlyStoppingListener} with the specified values.
+ *
+ * @return a new {@link EarlyStoppingListener}
+ */
+ public EarlyStoppingListener build() {
+ return new EarlyStoppingListener(
+ objectiveSuccess, minEpochs, maxMillis, earlyStopPctImprovement, epochPatience);
+ }
+ }
+
+ /**
+ * Thrown when training is stopped early, the message will contain the reason why it is stopped
+ * early.
+ */
+ public static class EarlyStoppedException extends RuntimeException {
+ private static final long serialVersionUID = 1L;
+ private final int stopEpoch;
+
+ /**
+ * Constructs an {@link EarlyStoppedException} with the specified message and epoch.
+ *
+ * @param stopEpoch the epoch at which training was stopped early
+ * @param message the message/reason why training was stopped early
+ */
+ public EarlyStoppedException(int stopEpoch, String message) {
+ super(message);
+ this.stopEpoch = stopEpoch;
+ }
+
+ /**
+ * Gets the epoch at which training was stopped early.
+ *
+ * @return the epoch at which training was stopped early.
+ */
+ public int getStopEpoch() {
+ return stopEpoch;
+ }
+ }
+}
diff --git a/api/src/main/java/ai/djl/training/listener/EvaluatorTrainingListener.java b/api/src/main/java/ai/djl/training/listener/EvaluatorTrainingListener.java
index 1dbfe4117cd..2556a026259 100644
--- a/api/src/main/java/ai/djl/training/listener/EvaluatorTrainingListener.java
+++ b/api/src/main/java/ai/djl/training/listener/EvaluatorTrainingListener.java
@@ -144,9 +144,7 @@ private void updateEvaluators(Trainer trainer, BatchData batchData, String[] acc
for (Device device : batchData.getLabels().keySet()) {
NDList labels = batchData.getLabels().get(device);
NDList predictions = batchData.getPredictions().get(device);
- for (String accumulator : accumulators) {
- evaluator.updateAccumulator(accumulator, labels, predictions);
- }
+ evaluator.updateAccumulators(accumulators, labels, predictions);
}
}
}
diff --git a/api/src/main/java/ai/djl/training/loss/AbstractCompositeLoss.java b/api/src/main/java/ai/djl/training/loss/AbstractCompositeLoss.java
index 2a46416190a..2e2cdcb8c86 100644
--- a/api/src/main/java/ai/djl/training/loss/AbstractCompositeLoss.java
+++ b/api/src/main/java/ai/djl/training/loss/AbstractCompositeLoss.java
@@ -80,10 +80,10 @@ public void addAccumulator(String key) {
/** {@inheritDoc} */
@Override
- public void updateAccumulator(String key, NDList labels, NDList predictions) {
+ public void updateAccumulators(String[] keys, NDList labels, NDList predictions) {
for (int i = 0; i < components.size(); i++) {
Pair inputs = inputForComponent(i, labels, predictions);
- components.get(i).updateAccumulator(key, inputs.getKey(), inputs.getValue());
+ components.get(i).updateAccumulators(keys, inputs.getKey(), inputs.getValue());
}
}
diff --git a/api/src/main/java/ai/djl/training/loss/Loss.java b/api/src/main/java/ai/djl/training/loss/Loss.java
index a661a3e9a0e..bcf39d23b39 100644
--- a/api/src/main/java/ai/djl/training/loss/Loss.java
+++ b/api/src/main/java/ai/djl/training/loss/Loss.java
@@ -385,10 +385,18 @@ public void addAccumulator(String key) {
/** {@inheritDoc} */
@Override
public void updateAccumulator(String key, NDList labels, NDList predictions) {
+ updateAccumulators(new String[] {key}, labels, predictions);
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void updateAccumulators(String[] keys, NDList labels, NDList predictions) {
// this is a synchronized operation, only call it at end of batch or epoch
float update = evaluate(labels, predictions).sum().getFloat();
- totalInstances.compute(key, (k, v) -> v + 1);
- totalLoss.compute(key, (k, v) -> v + update);
+ for (String key : keys) {
+ totalInstances.compute(key, (k, v) -> v + 1);
+ totalLoss.compute(key, (k, v) -> v + update);
+ }
}
/** {@inheritDoc} */
diff --git a/api/src/main/java/ai/djl/training/tracker/LinearTracker.java b/api/src/main/java/ai/djl/training/tracker/LinearTracker.java
index 986117d2b65..08bee48da87 100644
--- a/api/src/main/java/ai/djl/training/tracker/LinearTracker.java
+++ b/api/src/main/java/ai/djl/training/tracker/LinearTracker.java
@@ -12,7 +12,6 @@
*/
package ai.djl.training.tracker;
-import ai.djl.training.tracker.WarmUpTracker.Builder;
import ai.djl.util.Preconditions;
/**
diff --git a/api/src/main/java/ai/djl/training/util/ProgressBar.java b/api/src/main/java/ai/djl/training/util/ProgressBar.java
index 6300116dc5b..ae36640f01d 100644
--- a/api/src/main/java/ai/djl/training/util/ProgressBar.java
+++ b/api/src/main/java/ai/djl/training/util/ProgressBar.java
@@ -29,10 +29,14 @@ public final class ProgressBar implements Progress {
private long progress;
private int currentPercent;
private char progressChar = getProgressChar();
+ private boolean disableProgressBar;
/** Creates an instance of {@code ProgressBar} with a maximum value of 1. */
public ProgressBar() {
max = 1;
+ disableProgressBar =
+ Boolean.parseBoolean(Utils.getEnvOrSystemProperty("DJL_DISABLE_PROGRESS_BAR"))
+ || Boolean.getBoolean("disableProgressBar");
}
/**
@@ -43,6 +47,7 @@ public ProgressBar() {
* @param max the maximum value
*/
public ProgressBar(String message, long max) {
+ this();
reset(message, max);
}
@@ -55,6 +60,7 @@ public ProgressBar(String message, long max) {
* @param trailingMessage the trailing message to be shown
*/
public ProgressBar(String message, long max, String trailingMessage) {
+ this();
reset(message, max);
this.trailingMessage = trailingMessage;
}
@@ -91,7 +97,7 @@ public void increment(long increment) {
@Override
@SuppressWarnings("PMD.SystemPrintln")
public void update(long progress, String additionalMessage) {
- if (Boolean.getBoolean("disableProgressBar") || max <= 1) {
+ if (disableProgressBar || max <= 1) {
return;
}
diff --git a/api/src/main/java/ai/djl/translate/PaddingStackBatchifier.java b/api/src/main/java/ai/djl/translate/PaddingStackBatchifier.java
index 3f3bb1b2d6e..f026bd431c9 100644
--- a/api/src/main/java/ai/djl/translate/PaddingStackBatchifier.java
+++ b/api/src/main/java/ai/djl/translate/PaddingStackBatchifier.java
@@ -29,10 +29,17 @@ public final class PaddingStackBatchifier implements Batchifier {
private static final long serialVersionUID = 1L;
+ @SuppressWarnings("serial")
private List arraysToPad;
+
+ @SuppressWarnings("serial")
private List dimsToPad;
+
private transient List paddingSuppliers;
+
+ @SuppressWarnings("serial")
private List paddingSizes;
+
private boolean includeValidLengths;
private PaddingStackBatchifier(Builder builder) {
diff --git a/api/src/main/java/ai/djl/util/Ec2Utils.java b/api/src/main/java/ai/djl/util/Ec2Utils.java
index 178c3d7efe7..5408182964f 100644
--- a/api/src/main/java/ai/djl/util/Ec2Utils.java
+++ b/api/src/main/java/ai/djl/util/Ec2Utils.java
@@ -97,7 +97,7 @@ public static String readMetadata(String key) {
* @param engine the default engine name
*/
public static void callHome(String engine) {
- if (Boolean.getBoolean("offline")
+ if (Utils.isOfflineMode()
|| Boolean.parseBoolean(Utils.getEnvOrSystemProperty("OPT_OUT_TRACKING"))
|| System.currentTimeMillis() - lastCheckIn < ONE_DAY) {
return;
diff --git a/api/src/main/java/ai/djl/util/StringPair.java b/api/src/main/java/ai/djl/util/StringPair.java
new file mode 100644
index 00000000000..a42e739614b
--- /dev/null
+++ b/api/src/main/java/ai/djl/util/StringPair.java
@@ -0,0 +1,27 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.util;
+
+/** A class containing the string key-value pair. */
+public class StringPair extends Pair {
+
+ /**
+ * Constructs a {@code Pair} instance with key and value.
+ *
+ * @param key the key
+ * @param value the value
+ */
+ public StringPair(String key, String value) {
+ super(key, value);
+ }
+}
diff --git a/api/src/main/java/ai/djl/util/TarUtils.java b/api/src/main/java/ai/djl/util/TarUtils.java
new file mode 100644
index 00000000000..d4a6e42b230
--- /dev/null
+++ b/api/src/main/java/ai/djl/util/TarUtils.java
@@ -0,0 +1,69 @@
+/*
+ * Copyright 2024 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.util;
+
+import org.apache.commons.compress.archivers.tar.TarArchiveEntry;
+import org.apache.commons.compress.archivers.tar.TarArchiveInputStream;
+import org.apache.commons.compress.compressors.gzip.GzipCompressorInputStream;
+import org.apache.commons.io.input.CloseShieldInputStream;
+
+import java.io.BufferedInputStream;
+import java.io.IOException;
+import java.io.InputStream;
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.nio.file.StandardCopyOption;
+
+/** Utilities for working with zip files. */
+public final class TarUtils {
+
+ private TarUtils() {}
+
+ /**
+ * Un-compress a tar ball from InputStream.
+ *
+ * @param is the InputStream
+ * @param dir the target directory
+ * @param gzip if the bar ball is gzip
+ * @throws IOException for failures to untar the input directory
+ */
+ public static void untar(InputStream is, Path dir, boolean gzip) throws IOException {
+ InputStream bis;
+ if (gzip) {
+ bis = new GzipCompressorInputStream(new BufferedInputStream(is));
+ } else {
+ bis = new BufferedInputStream(is);
+ }
+ bis = CloseShieldInputStream.wrap(bis);
+ try (TarArchiveInputStream tis = new TarArchiveInputStream(bis)) {
+ TarArchiveEntry entry;
+ while ((entry = tis.getNextEntry()) != null) {
+ String entryName = ZipUtils.removeLeadingFileSeparator(entry.getName());
+ if (entryName.contains("..")) {
+ throw new IOException("Malicious zip entry: " + entryName);
+ }
+ Path file = dir.resolve(entryName).toAbsolutePath();
+ if (entry.isDirectory()) {
+ Files.createDirectories(file);
+ } else {
+ Path parentFile = file.getParent();
+ if (parentFile == null) {
+ throw new AssertionError("Parent path should never be null: " + file);
+ }
+ Files.createDirectories(parentFile);
+ Files.copy(tis, file, StandardCopyOption.REPLACE_EXISTING);
+ }
+ }
+ }
+ }
+}
diff --git a/api/src/main/java/ai/djl/util/Utils.java b/api/src/main/java/ai/djl/util/Utils.java
index c8e1bd514ac..270958d5b40 100644
--- a/api/src/main/java/ai/djl/util/Utils.java
+++ b/api/src/main/java/ai/djl/util/Utils.java
@@ -357,6 +357,20 @@ public static Path getCacheDir() {
return Paths.get(cacheDir);
}
+ /**
+ * Returns if offline mode is enabled.
+ *
+ * @return true if offline mode is enabled
+ */
+ public static boolean isOfflineMode() {
+ String mode = getenv("DJL_OFFLINE", System.getProperty("ai.djl.offline"));
+ if (mode != null) {
+ return Boolean.parseBoolean(mode);
+ }
+ // backward compatible
+ return Boolean.getBoolean("offline");
+ }
+
/**
* Returns nested model directory if the directory contains only one subdirectory.
*
@@ -481,7 +495,7 @@ public static InputStream openUrl(String url) throws IOException {
*/
public static InputStream openUrl(URL url) throws IOException {
String protocol = url.getProtocol();
- if (Boolean.getBoolean("offline")
+ if (isOfflineMode()
&& ("http".equalsIgnoreCase(protocol) || "https".equalsIgnoreCase(protocol))) {
throw new IOException("Offline model is enabled.");
}
diff --git a/api/src/main/java/ai/djl/util/ZipUtils.java b/api/src/main/java/ai/djl/util/ZipUtils.java
index f1a4889af0b..7c8c298a6cb 100644
--- a/api/src/main/java/ai/djl/util/ZipUtils.java
+++ b/api/src/main/java/ai/djl/util/ZipUtils.java
@@ -52,7 +52,7 @@ public static void unzip(InputStream is, Path dest) throws IOException {
ZipEntry entry;
Set set = new HashSet<>();
while ((entry = zis.getNextEntry()) != null) {
- String name = entry.getName();
+ String name = removeLeadingFileSeparator(entry.getName());
if (name.contains("..")) {
throw new IOException("Malicious zip entry: " + name);
}
@@ -121,6 +121,16 @@ private static void addToZip(Path root, Path file, ZipOutputStream zos) throws I
}
}
+ static String removeLeadingFileSeparator(String name) {
+ int index = 0;
+ for (; index < name.length(); index++) {
+ if (name.charAt(index) != File.separatorChar) {
+ break;
+ }
+ }
+ return name.substring(index);
+ }
+
private static final class ValidationInputStream extends FilterInputStream {
private static final int ZIP64_LOCSIG = 0x07064b50; // "PK\006\007"
@@ -223,7 +233,7 @@ private End findEND(ByteBuffer bb) throws IOException {
// Let's do some extra verification, we don't care about the
// performance in this situation.
int cenpos = end.endpos - end.cenlen;
- int locpos = cenpos - end.cenoff;
+ int locpos = Math.toIntExact(cenpos - end.cenoff);
if (cenpos < 0
|| locpos < 0
|| bb.getInt(cenpos) != CENSIG
@@ -243,7 +253,7 @@ private End findEND(ByteBuffer bb) throws IOException {
// end64 candidate found,
int cenlen64 = Math.toIntExact(bb.getLong(relativePos + 40));
- int cenoff64 = Math.toIntExact(bb.getLong(relativePos + 48));
+ long cenoff64 = bb.getLong(relativePos + 48);
// double-check
if (cenlen64 != end.cenlen && end.cenlen > 0
|| cenoff64 != end.cenoff && end.cenoff > 0) {
@@ -303,7 +313,7 @@ private List initCEN(byte[] header) throws IOException {
private static final class End {
int cenlen; // 4 bytes
- int cenoff; // 4 bytes
+ long cenoff; // 4 bytes
int endpos; // 4 bytes
}
}
diff --git a/api/src/main/java/ai/djl/util/cuda/CudaUtils.java b/api/src/main/java/ai/djl/util/cuda/CudaUtils.java
index b0b8e3e4247..1de074ea6c8 100644
--- a/api/src/main/java/ai/djl/util/cuda/CudaUtils.java
+++ b/api/src/main/java/ai/djl/util/cuda/CudaUtils.java
@@ -22,7 +22,11 @@
import org.slf4j.LoggerFactory;
import java.io.File;
+import java.io.IOException;
+import java.io.InputStream;
import java.lang.management.MemoryUsage;
+import java.util.ArrayList;
+import java.util.List;
import java.util.Locale;
import java.util.regex.Pattern;
@@ -33,6 +37,8 @@ public final class CudaUtils {
private static final CudaLibrary LIB = loadLibrary();
+ private static String[] gpuInfo;
+
private CudaUtils() {}
/**
@@ -49,7 +55,15 @@ public static boolean hasCuda() {
*
* @return the number of GPUs available in the system
*/
+ @SuppressWarnings("PMD.NonThreadSafeSingleton")
public static int getGpuCount() {
+ if (Boolean.getBoolean("ai.djl.util.cuda.fork")) {
+ if (gpuInfo == null) {
+ gpuInfo = execute(-1); // NOPMD
+ }
+ return Integer.parseInt(gpuInfo[0]);
+ }
+
if (LIB == null) {
return 0;
}
@@ -79,7 +93,19 @@ public static int getGpuCount() {
*
* @return the version of CUDA runtime
*/
+ @SuppressWarnings("PMD.NonThreadSafeSingleton")
public static int getCudaVersion() {
+ if (Boolean.getBoolean("ai.djl.util.cuda.fork")) {
+ if (gpuInfo == null) {
+ gpuInfo = execute(-1);
+ }
+ int version = Integer.parseInt(gpuInfo[1]);
+ if (version == -1) {
+ throw new IllegalArgumentException("No cuda device found.");
+ }
+ return version;
+ }
+
if (LIB == null) {
throw new IllegalStateException("No cuda library is loaded.");
}
@@ -95,9 +121,6 @@ public static int getCudaVersion() {
* @return the version string of CUDA runtime
*/
public static String getCudaVersionString() {
- if (LIB == null) {
- throw new IllegalStateException("No cuda library is loaded.");
- }
int version = getCudaVersion();
int major = version / 1000;
int minor = (version / 10) % 10;
@@ -111,6 +134,14 @@ public static String getCudaVersionString() {
* @return the CUDA compute capability
*/
public static String getComputeCapability(int device) {
+ if (Boolean.getBoolean("ai.djl.util.cuda.fork")) {
+ String[] ret = execute(device);
+ if (ret.length != 3) {
+ throw new IllegalArgumentException(ret[0]);
+ }
+ return ret[0];
+ }
+
if (LIB == null) {
throw new IllegalStateException("No cuda library is loaded.");
}
@@ -137,6 +168,16 @@ public static MemoryUsage getGpuMemory(Device device) {
throw new IllegalArgumentException("Only GPU device is allowed.");
}
+ if (Boolean.getBoolean("ai.djl.util.cuda.fork")) {
+ String[] ret = execute(device.getDeviceId());
+ if (ret.length != 3) {
+ throw new IllegalArgumentException(ret[0]);
+ }
+ long total = Long.parseLong(ret[1]);
+ long used = Long.parseLong(ret[2]);
+ return new MemoryUsage(-1, used, used, total);
+ }
+
if (LIB == null) {
throw new IllegalStateException("No GPU device detected.");
}
@@ -155,8 +196,42 @@ public static MemoryUsage getGpuMemory(Device device) {
return new MemoryUsage(-1, committed, committed, total[0]);
}
+ /**
+ * The main entrypoint to get CUDA information with command line.
+ *
+ * @param args the command line arguments.
+ */
+ @SuppressWarnings("PMD.SystemPrintln")
+ public static void main(String[] args) {
+ int gpuCount = getGpuCount();
+ if (args.length == 0) {
+ if (gpuCount <= 0) {
+ System.out.println("0,-1");
+ return;
+ }
+ int cudaVersion = getCudaVersion();
+ System.out.println(gpuCount + "," + cudaVersion);
+ return;
+ }
+ try {
+ int deviceId = Integer.parseInt(args[0]);
+ if (deviceId < 0 || deviceId >= gpuCount) {
+ System.out.println("Invalid device: " + deviceId);
+ return;
+ }
+ MemoryUsage mem = getGpuMemory(Device.gpu(deviceId));
+ String cc = getComputeCapability(deviceId);
+ System.out.println(cc + ',' + mem.getMax() + ',' + mem.getUsed());
+ } catch (NumberFormatException e) {
+ System.out.println("Invalid device: " + args[0]);
+ }
+ }
+
private static CudaLibrary loadLibrary() {
try {
+ if (Boolean.getBoolean("ai.djl.util.cuda.fork")) {
+ return null;
+ }
if (System.getProperty("os.name").startsWith("Win")) {
String path = Utils.getenv("PATH");
if (path == null) {
@@ -187,15 +262,40 @@ private static CudaLibrary loadLibrary() {
} catch (UnsatisfiedLinkError e) {
logger.debug("cudart library not found.");
logger.trace("", e);
- return null;
- } catch (IncompatibleClassChangeError e) {
+ } catch (LinkageError e) {
logger.warn("You have a conflict version of JNA in the classpath.");
logger.debug("", e);
- return null;
} catch (SecurityException e) {
logger.warn("Access denied during loading cudart library.");
logger.trace("", e);
- return null;
+ }
+ return null;
+ }
+
+ private static String[] execute(int deviceId) {
+ try {
+ String javaHome = System.getProperty("java.home");
+ String classPath = System.getProperty("java.class.path");
+ String os = System.getProperty("os.name");
+ List cmd = new ArrayList<>(4);
+ if (os.startsWith("Win")) {
+ cmd.add(javaHome + "\\bin\\java.exe");
+ } else {
+ cmd.add(javaHome + "/bin/java");
+ }
+ cmd.add("-cp");
+ cmd.add(classPath);
+ cmd.add("ai.djl.util.cuda.CudaUtils");
+ if (deviceId >= 0) {
+ cmd.add(String.valueOf(deviceId));
+ }
+ Process ps = new ProcessBuilder(cmd).redirectErrorStream(true).start();
+ try (InputStream is = ps.getInputStream()) {
+ String line = Utils.toString(is).trim();
+ return line.split(",");
+ }
+ } catch (IOException e) {
+ throw new IllegalArgumentException("Failed get GPU information", e);
}
}
diff --git a/api/src/test/java/ai/djl/DeviceTest.java b/api/src/test/java/ai/djl/DeviceTest.java
index 92a0474c6e7..a69a502739b 100644
--- a/api/src/test/java/ai/djl/DeviceTest.java
+++ b/api/src/test/java/ai/djl/DeviceTest.java
@@ -13,6 +13,7 @@
package ai.djl;
+import ai.djl.Device.MultiDevice;
import ai.djl.engine.Engine;
import org.testng.Assert;
@@ -37,6 +38,9 @@ public void testDevice() {
System.setProperty("test_key", "test");
Engine.debugEnvironment();
+
+ Assert.assertEquals(1, Device.cpu().getDevices().size());
+ Assert.assertEquals(2, new MultiDevice(Device.gpu(1), Device.gpu(2)).getDevices().size());
}
@Test
@@ -54,5 +58,9 @@ public void testDeviceName() {
Device defaultDevice = Engine.getInstance().defaultDevice();
Assert.assertEquals(Device.fromName(""), defaultDevice);
Assert.assertEquals(Device.fromName(null), defaultDevice);
+
+ Assert.assertEquals(
+ Device.fromName("gpu1+gpu2"), new MultiDevice(Device.gpu(2), Device.gpu(1)));
+ Assert.assertEquals(Device.fromName("gpu1+gpu2"), new MultiDevice("gpu", 1, 3));
}
}
diff --git a/api/src/test/java/ai/djl/inference/streaming/PublisherBytesSupplierTest.java b/api/src/test/java/ai/djl/inference/streaming/PublisherBytesSupplierTest.java
index 8c140688124..a8b2bdfab62 100644
--- a/api/src/test/java/ai/djl/inference/streaming/PublisherBytesSupplierTest.java
+++ b/api/src/test/java/ai/djl/inference/streaming/PublisherBytesSupplierTest.java
@@ -15,32 +15,38 @@
import org.testng.Assert;
import org.testng.annotations.Test;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.ExecutionException;
import java.util.concurrent.atomic.AtomicInteger;
public class PublisherBytesSupplierTest {
@Test
- public void test() {
+ public void test() throws ExecutionException, InterruptedException {
AtomicInteger contentCount = new AtomicInteger();
PublisherBytesSupplier supplier = new PublisherBytesSupplier();
- // Add to supplier without subscriber
- supplier.appendContent(new byte[] {1}, false);
- Assert.assertEquals(contentCount.get(), 0);
+ new Thread(
+ () -> {
+ // Add to supplier without subscriber
+ supplier.appendContent(new byte[] {1}, false);
+ // Add to supplier with subscriber
+ supplier.appendContent(new byte[] {1}, true);
+ })
+ .start();
// Subscribing with data should trigger subscriptions
- supplier.subscribe(
- d -> {
- if (d == null) {
- // Do nothing on completion
- return;
- }
- contentCount.getAndIncrement();
- });
- Assert.assertEquals(contentCount.get(), 1);
+ CompletableFuture future =
+ supplier.subscribe(
+ d -> {
+ if (d == null) {
+ // Do nothing on completion
+ return;
+ }
+ contentCount.getAndIncrement();
+ });
- // Add to supplier with subscriber
- supplier.appendContent(new byte[] {1}, true);
+ future.get();
Assert.assertEquals(contentCount.get(), 2);
}
}
diff --git a/api/src/test/java/ai/djl/modality/cv/translator/YoloV8TranslatorFactoryTest.java b/api/src/test/java/ai/djl/modality/cv/translator/YoloV8TranslatorFactoryTest.java
new file mode 100644
index 00000000000..8fbbae7301b
--- /dev/null
+++ b/api/src/test/java/ai/djl/modality/cv/translator/YoloV8TranslatorFactoryTest.java
@@ -0,0 +1,76 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.modality.cv.translator;
+
+import ai.djl.Model;
+import ai.djl.modality.Input;
+import ai.djl.modality.Output;
+import ai.djl.modality.cv.Image;
+import ai.djl.modality.cv.output.DetectedObjects;
+import ai.djl.translate.BasicTranslator;
+import ai.djl.translate.Translator;
+
+import org.testng.Assert;
+import org.testng.annotations.BeforeClass;
+import org.testng.annotations.Test;
+
+import java.io.InputStream;
+import java.net.URL;
+import java.nio.file.Path;
+import java.util.HashMap;
+import java.util.Map;
+
+public class YoloV8TranslatorFactoryTest {
+
+ private YoloV8TranslatorFactory factory;
+
+ @BeforeClass
+ public void setUp() {
+ factory = new YoloV8TranslatorFactory();
+ }
+
+ @Test
+ public void testGetSupportedTypes() {
+ Assert.assertEquals(factory.getSupportedTypes().size(), 5);
+ }
+
+ @Test
+ public void testNewInstance() {
+ Map arguments = new HashMap<>();
+ try (Model model = Model.newInstance("test")) {
+ Translator translator1 =
+ factory.newInstance(Image.class, DetectedObjects.class, model, arguments);
+ Assert.assertTrue(translator1 instanceof YoloV8Translator);
+
+ Translator translator2 =
+ factory.newInstance(Path.class, DetectedObjects.class, model, arguments);
+ Assert.assertTrue(translator2 instanceof BasicTranslator);
+
+ Translator translator3 =
+ factory.newInstance(URL.class, DetectedObjects.class, model, arguments);
+ Assert.assertTrue(translator3 instanceof BasicTranslator);
+
+ Translator translator4 =
+ factory.newInstance(InputStream.class, DetectedObjects.class, model, arguments);
+ Assert.assertTrue(translator4 instanceof BasicTranslator);
+
+ Translator translator5 =
+ factory.newInstance(Input.class, Output.class, model, arguments);
+ Assert.assertTrue(translator5 instanceof ImageServingTranslator);
+
+ Assert.assertThrows(
+ IllegalArgumentException.class,
+ () -> factory.newInstance(Image.class, Output.class, model, arguments));
+ }
+ }
+}
diff --git a/api/src/test/java/ai/djl/ndarray/NDSerializerTest.java b/api/src/test/java/ai/djl/ndarray/NDSerializerTest.java
index 0e38c2d8be6..98ba896883b 100644
--- a/api/src/test/java/ai/djl/ndarray/NDSerializerTest.java
+++ b/api/src/test/java/ai/djl/ndarray/NDSerializerTest.java
@@ -97,6 +97,23 @@ public void testNDSerializer() throws IOException {
}
}
+ @Test
+ public void testStringTensor() {
+ try (NDManager manager = NDManager.newBaseManager("PyTorch")) {
+ NDArray array = manager.create("hello");
+ byte[] buf = array.encode();
+ NDArray decoded = NDArray.decode(manager, buf);
+ Assert.assertTrue(decoded.getShape().isScalar());
+
+ array = manager.create(new String[] {"hello", "world"});
+ buf = array.encode();
+ decoded = NDArray.decode(manager, buf);
+ Assert.assertEquals(decoded.getShape(), array.getShape());
+ Assert.assertEquals(decoded.toStringArray()[1], "world");
+ Assert.assertEquals(decoded, array);
+ }
+ }
+
private static byte[] encode(NDArray array) throws IOException {
try (ByteArrayOutputStream bos = new ByteArrayOutputStream()) {
NDSerializer.encodeAsNumpy(array, bos);
@@ -107,7 +124,7 @@ private static byte[] encode(NDArray array) throws IOException {
private static NDArray decode(NDManager manager, byte[] data) throws IOException {
try (ByteArrayInputStream bis = new ByteArrayInputStream(data)) {
- return NDSerializer.decodeNumpy(manager, bis);
+ return NDList.decode(manager, bis).get(0);
}
}
diff --git a/api/src/test/java/ai/djl/repository/JarRepositoryTest.java b/api/src/test/java/ai/djl/repository/JarRepositoryTest.java
index 4599214fab5..c1370d1da69 100644
--- a/api/src/test/java/ai/djl/repository/JarRepositoryTest.java
+++ b/api/src/test/java/ai/djl/repository/JarRepositoryTest.java
@@ -45,7 +45,7 @@ public void testResource() throws IOException {
URL[] url = {jarFile.toUri().toURL()};
try {
Thread.currentThread().setContextClassLoader(new URLClassLoader(url));
- Repository repo = Repository.newInstance("test", "jar:///test.zip?hash=1");
+ Repository repo = Repository.newInstance("test", "jar:///test.zip");
Assert.assertEquals("test", repo.getName());
Assert.assertTrue(repo.isRemote());
@@ -55,6 +55,12 @@ public void testResource() throws IOException {
Artifact artifact = repo.resolve(list.get(0), null);
repo.prepare(artifact);
Assert.assertEquals(1, artifact.getFiles().size());
+
+ repo = Repository.newInstance("test", "jar:///test.zip?ignore_real_uri=true");
+ list = repo.getResources();
+ artifact = repo.resolve(list.get(0), null);
+ Path p = repo.getResourceDirectory(artifact);
+ Assert.assertFalse(Files.exists(p));
} finally {
Thread.currentThread().setContextClassLoader(null);
}
diff --git a/api/src/test/java/ai/djl/repository/ZooTest.java b/api/src/test/java/ai/djl/repository/ZooTest.java
index 2b44f967144..29fc10391aa 100644
--- a/api/src/test/java/ai/djl/repository/ZooTest.java
+++ b/api/src/test/java/ai/djl/repository/ZooTest.java
@@ -17,6 +17,7 @@
import ai.djl.modality.Output;
import ai.djl.repository.zoo.Criteria;
import ai.djl.repository.zoo.ModelNotFoundException;
+import ai.djl.repository.zoo.ModelZoo;
import org.testng.Assert;
import org.testng.annotations.Test;
@@ -48,4 +49,11 @@ public void testInvalidCriteria()
Criteria criteria = Criteria.builder().build();
criteria.loadModel();
}
+
+ @Test
+ public void testModelZooResolver() {
+ ModelZoo.setModelZooResolver(groupId -> null);
+ ModelZoo zoo = ModelZoo.getModelZoo("unknown");
+ Assert.assertNull(zoo);
+ }
}
diff --git a/api/src/test/java/ai/djl/translate/TranslatorTest.java b/api/src/test/java/ai/djl/translate/TranslatorTest.java
index 5ce63faa29d..1a636af7787 100644
--- a/api/src/test/java/ai/djl/translate/TranslatorTest.java
+++ b/api/src/test/java/ai/djl/translate/TranslatorTest.java
@@ -83,6 +83,10 @@ public void testBatchTranslator() throws IOException, ModelException, TranslateE
Predictor predictor = model.newPredictor()) {
Classifications[] res = predictor.predict(inputs);
Assert.assertEquals(res.length, 2);
+ int intValue = model.intProperty("something", -1);
+ Assert.assertEquals(intValue, -1);
+ long longValue = model.longProperty("something", -1L);
+ Assert.assertEquals(longValue, -1L);
}
}
}
diff --git a/api/src/test/java/ai/djl/util/SecurityManagerTest.java b/api/src/test/java/ai/djl/util/SecurityManagerTest.java
index fd9b5db72bc..1e9eb17f63c 100644
--- a/api/src/test/java/ai/djl/util/SecurityManagerTest.java
+++ b/api/src/test/java/ai/djl/util/SecurityManagerTest.java
@@ -74,8 +74,11 @@ public void checkPermission(Permission perm) {
}
};
System.setSecurityManager(sm);
-
- Assert.assertFalse(CudaUtils.hasCuda());
- Assert.assertEquals(CudaUtils.getGpuCount(), 0);
+ try {
+ Assert.assertFalse(CudaUtils.hasCuda());
+ Assert.assertEquals(CudaUtils.getGpuCount(), 0);
+ } finally {
+ System.setSecurityManager(null);
+ }
}
}
diff --git a/api/src/test/java/ai/djl/util/ZipUtilsTest.java b/api/src/test/java/ai/djl/util/ZipUtilsTest.java
index 4340019de55..387715bbd44 100644
--- a/api/src/test/java/ai/djl/util/ZipUtilsTest.java
+++ b/api/src/test/java/ai/djl/util/ZipUtilsTest.java
@@ -45,6 +45,19 @@ public void testEmptyZipFile() throws IOException {
}
}
+ @Test
+ public void testOffendingTar() throws IOException {
+ Path path = Paths.get("src/test/resources/offending.tar");
+ Path output = Paths.get("build/output");
+ Path file = output.resolve("tmp/empty.txt");
+ Utils.deleteQuietly(file);
+ Files.createDirectories(output);
+ try (InputStream is = Files.newInputStream(path)) {
+ TarUtils.untar(is, output, false);
+ }
+ Assert.assertTrue(Files.exists(file));
+ }
+
@Test
public void testInvalidZipFile() throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
diff --git a/api/src/test/java/ai/djl/util/cuda/CudaUtilsTest.java b/api/src/test/java/ai/djl/util/cuda/CudaUtilsTest.java
index de1c5cb4a20..a6ad7e52122 100644
--- a/api/src/test/java/ai/djl/util/cuda/CudaUtilsTest.java
+++ b/api/src/test/java/ai/djl/util/cuda/CudaUtilsTest.java
@@ -20,8 +20,6 @@
import org.testng.annotations.Test;
import java.lang.management.MemoryUsage;
-import java.util.Arrays;
-import java.util.List;
public class CudaUtilsTest {
@@ -30,6 +28,9 @@ public class CudaUtilsTest {
@Test
public void testCudaUtils() {
if (!CudaUtils.hasCuda()) {
+ Assert.assertThrows(CudaUtils::getCudaVersionString);
+ Assert.assertThrows(() -> CudaUtils.getComputeCapability(0));
+ Assert.assertThrows(() -> CudaUtils.getGpuMemory(Device.gpu()));
return;
}
// Possible to have CUDA and not have a GPU.
@@ -37,16 +38,24 @@ public void testCudaUtils() {
return;
}
- int cudaVersion = CudaUtils.getCudaVersion();
+ String cudaVersion = CudaUtils.getCudaVersionString();
String smVersion = CudaUtils.getComputeCapability(0);
MemoryUsage memoryUsage = CudaUtils.getGpuMemory(Device.gpu());
logger.info("CUDA runtime version: {}, sm: {}", cudaVersion, smVersion);
logger.info("Memory usage: {}", memoryUsage);
- Assert.assertTrue(cudaVersion >= 9020, "cuda 9.2+ required.");
+ Assert.assertNotNull(cudaVersion);
+ Assert.assertNotNull(smVersion);
+ }
- List supportedSm = Arrays.asList("37", "52", "60", "61", "70", "75");
- Assert.assertTrue(supportedSm.contains(smVersion), "Unsupported cuda sm: " + smVersion);
+ @Test
+ public void testCudaUtilsWithFork() {
+ System.setProperty("ai.djl.util.cuda.fork", "true");
+ try {
+ testCudaUtils();
+ } finally {
+ System.clearProperty("ai.djl.util.cuda.fork");
+ }
}
}
diff --git a/api/src/test/resources/offending.tar b/api/src/test/resources/offending.tar
new file mode 100644
index 00000000000..3a767ae55ac
Binary files /dev/null and b/api/src/test/resources/offending.tar differ
diff --git a/apt.txt b/apt.txt
index 7083f85c374..c89953ff1f9 100644
--- a/apt.txt
+++ b/apt.txt
@@ -1 +1 @@
-openjdk-11-jdk
+openjdk-17-jdk
diff --git a/basicdataset/README.md b/basicdataset/README.md
index 37bab679551..1c9ac977198 100644
--- a/basicdataset/README.md
+++ b/basicdataset/README.md
@@ -29,7 +29,7 @@ You can pull the module from the central Maven repository by including the follo
ai.djl
basicdataset
- 0.23.0
+ 0.27.0
```
diff --git a/basicdataset/src/main/java/ai/djl/basicdataset/cv/classification/FashionMnist.java b/basicdataset/src/main/java/ai/djl/basicdataset/cv/classification/FashionMnist.java
index a92a9b6a3d4..deef04907be 100644
--- a/basicdataset/src/main/java/ai/djl/basicdataset/cv/classification/FashionMnist.java
+++ b/basicdataset/src/main/java/ai/djl/basicdataset/cv/classification/FashionMnist.java
@@ -30,6 +30,7 @@
import java.io.IOException;
import java.io.InputStream;
+import java.nio.ByteBuffer;
import java.util.Map;
/**
@@ -118,8 +119,9 @@ private NDArray readData(Artifact.Item item, long length) throws IOException {
byte[] buf = Utils.toByteArray(is);
try (NDArray array =
manager.create(
- new Shape(length, IMAGE_WIDTH, IMAGE_HEIGHT, 1), DataType.UINT8)) {
- array.set(buf);
+ ByteBuffer.wrap(buf),
+ new Shape(length, IMAGE_WIDTH, IMAGE_HEIGHT, 1),
+ DataType.UINT8)) {
return array.toType(DataType.FLOAT32, false);
}
}
@@ -132,8 +134,8 @@ private NDArray readLabel(Artifact.Item item) throws IOException {
}
byte[] buf = Utils.toByteArray(is);
- try (NDArray array = manager.create(new Shape(buf.length), DataType.UINT8)) {
- array.set(buf);
+ try (NDArray array =
+ manager.create(ByteBuffer.wrap(buf), new Shape(buf.length), DataType.UINT8)) {
return array.toType(DataType.FLOAT32, false);
}
}
diff --git a/basicdataset/src/main/java/ai/djl/basicdataset/cv/classification/Mnist.java b/basicdataset/src/main/java/ai/djl/basicdataset/cv/classification/Mnist.java
index 164ba9876cb..5503e721caa 100644
--- a/basicdataset/src/main/java/ai/djl/basicdataset/cv/classification/Mnist.java
+++ b/basicdataset/src/main/java/ai/djl/basicdataset/cv/classification/Mnist.java
@@ -30,6 +30,7 @@
import java.io.IOException;
import java.io.InputStream;
+import java.nio.ByteBuffer;
import java.util.Map;
/**
@@ -111,8 +112,9 @@ private NDArray readData(Artifact.Item item, long length) throws IOException {
}
byte[] buf = Utils.toByteArray(is);
- try (NDArray array = manager.create(new Shape(length, 28, 28, 1), DataType.UINT8)) {
- array.set(buf);
+ try (NDArray array =
+ manager.create(
+ ByteBuffer.wrap(buf), new Shape(length, 28, 28, 1), DataType.UINT8)) {
return array.toType(DataType.FLOAT32, false);
}
}
@@ -123,10 +125,9 @@ private NDArray readLabel(Artifact.Item item) throws IOException {
if (is.skip(8) != 8) {
throw new AssertionError("Failed skip data.");
}
-
byte[] buf = Utils.toByteArray(is);
- try (NDArray array = manager.create(new Shape(buf.length), DataType.UINT8)) {
- array.set(buf);
+ try (NDArray array =
+ manager.create(ByteBuffer.wrap(buf), new Shape(buf.length), DataType.UINT8)) {
return array.toType(DataType.FLOAT32, false);
}
}
diff --git a/basicdataset/src/main/java/ai/djl/basicdataset/tabular/ListFeatures.java b/basicdataset/src/main/java/ai/djl/basicdataset/tabular/ListFeatures.java
index 42fc1744451..b04ae800a10 100644
--- a/basicdataset/src/main/java/ai/djl/basicdataset/tabular/ListFeatures.java
+++ b/basicdataset/src/main/java/ai/djl/basicdataset/tabular/ListFeatures.java
@@ -44,6 +44,7 @@ public ListFeatures(int initialCapacity) {
*
* @param source the source list
*/
+ @SuppressWarnings("this-escape")
public ListFeatures(List source) {
super(source.size());
addAll(source);
diff --git a/basicdataset/src/main/resources/imagenet/extract_imagenet.py b/basicdataset/src/main/resources/imagenet/extract_imagenet.py
index c618fe05e44..2f161b5757a 100644
--- a/basicdataset/src/main/resources/imagenet/extract_imagenet.py
+++ b/basicdataset/src/main/resources/imagenet/extract_imagenet.py
@@ -14,6 +14,7 @@
_VAL_TAR = 'ILSVRC2012_img_val.tar'
_VAL_TAR_SHA1 = '5f3f73da3395154b60528b2b2a2caf2374f5f178'
+
def download(url, path=None, overwrite=False, sha1_hash=None):
"""Download an given URL
Parameters
@@ -42,26 +43,29 @@ def download(url, path=None, overwrite=False, sha1_hash=None):
else:
fname = path
- if overwrite or not os.path.exists(fname) or (sha1_hash and not check_sha1(fname, sha1_hash)):
+ if overwrite or not os.path.exists(fname) or (
+ sha1_hash and not check_sha1(fname, sha1_hash)):
dirname = os.path.dirname(os.path.abspath(os.path.expanduser(fname)))
if not os.path.exists(dirname):
os.makedirs(dirname)
- print('Downloading %s from %s...'%(fname, url))
+ print('Downloading %s from %s...' % (fname, url))
r = requests.get(url, stream=True)
if r.status_code != 200:
- raise RuntimeError("Failed downloading url %s"%url)
+ raise RuntimeError("Failed downloading url %s" % url)
total_length = r.headers.get('content-length')
with open(fname, 'wb') as f:
- if total_length is None: # no content length header
+ if total_length is None: # no content length header
for chunk in r.iter_content(chunk_size=1024):
- if chunk: # filter out keep-alive new chunks
+ if chunk: # filter out keep-alive new chunks
f.write(chunk)
else:
total_length = int(total_length)
for chunk in tqdm(r.iter_content(chunk_size=1024),
total=int(total_length / 1024. + 0.5),
- unit='KB', unit_scale=False, dynamic_ncols=True):
+ unit='KB',
+ unit_scale=False,
+ dynamic_ncols=True):
f.write(chunk)
if sha1_hash and not check_sha1(fname, sha1_hash):
@@ -72,25 +76,34 @@ def download(url, path=None, overwrite=False, sha1_hash=None):
return fname
+
def parse_args():
parser = argparse.ArgumentParser(
description='Setup the ImageNet dataset.',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
- parser.add_argument('--download-dir', required=True,
- help="The directory that contains downloaded tar files")
+ parser.add_argument(
+ '--download-dir',
+ required=True,
+ help="The directory that contains downloaded tar files")
parser.add_argument('--target-dir',
help="The directory to store extracted images")
- parser.add_argument('--checksum', action='store_true',
+ parser.add_argument('--checksum',
+ action='store_true',
help="If check integrity before extracting.")
- parser.add_argument('--with-rec', action='store_true',
+ parser.add_argument('--with-rec',
+ action='store_true',
help="If build image record files.")
- parser.add_argument('--num-thread', type=int, default=1,
- help="Number of threads to use when building image record file.")
+ parser.add_argument(
+ '--num-thread',
+ type=int,
+ default=1,
+ help="Number of threads to use when building image record file.")
args = parser.parse_args()
if args.target_dir is None:
args.target_dir = args.download_dir
return args
+
def check_sha1(filename, sha1_hash):
"""Check whether the sha1 hash of the file content matches the expected hash.
@@ -116,11 +129,13 @@ def check_sha1(filename, sha1_hash):
return sha1.hexdigest() == sha1_hash
+
def check_file(filename, checksum, sha1):
if not os.path.exists(filename):
- raise ValueError('File not found: '+filename)
+ raise ValueError('File not found: ' + filename)
if checksum and not check_sha1(filename, sha1):
- raise ValueError('Corrupted file: '+filename)
+ raise ValueError('Corrupted file: ' + filename)
+
def build_rec_process(img_dir, train=False, num_thread=1):
rec_dir = os.path.abspath(os.path.join(img_dir, '../rec'))
@@ -141,14 +156,8 @@ def build_rec_process(img_dir, train=False, num_thread=1):
# execution
import sys
cmd = [
- sys.executable,
- script_path,
- rec_dir,
- img_dir,
- '--recursive',
- '--pass-through',
- '--pack-label',
- '--num-thread',
+ sys.executable, script_path, rec_dir, img_dir, '--recursive',
+ '--pass-through', '--pack-label', '--num-thread',
str(num_thread)
]
subprocess.call(cmd)
@@ -156,87 +165,75 @@ def build_rec_process(img_dir, train=False, num_thread=1):
os.remove(lst_path)
print('ImageRecord file for ' + prefix + ' has been built!')
+
+def is_within_directory(directory, target):
+ abs_directory = os.path.abspath(directory)
+ abs_target = os.path.abspath(target)
+ prefix = os.path.commonprefix([abs_directory, abs_target])
+ return prefix == abs_directory
+
+
+def safe_extract(tar, path=".", members=None, *, numeric_owner=False):
+ for member in tar.getmembers():
+ member_path = os.path.join(path, member.name)
+ if not is_within_directory(path, member_path):
+ raise Exception("Attempted Path Traversal in Tar File")
+ tar.extractall(path, members, numeric_owner=numeric_owner)
+
+
def extract_train(tar_fname, target_dir, with_rec=False, num_thread=1):
os.makedirs(target_dir)
with tarfile.open(tar_fname) as tar:
- print("Extracting "+tar_fname+"...")
+ print("Extracting " + tar_fname + "...")
# extract each class one-by-one
pbar = tqdm(total=len(tar.getnames()))
for class_tar in tar:
- pbar.set_description('Extract '+class_tar.name)
- tar.extract(class_tar, target_dir)
+ pbar.set_description('Extract ' + class_tar.name)
class_fname = os.path.join(target_dir, class_tar.name)
+ if not is_within_directory(target_dir, class_fname):
+ raise Exception("Attempted Path Traversal in Tar File")
+
+ tar.extract(class_tar, target_dir)
class_dir = os.path.splitext(class_fname)[0]
os.mkdir(class_dir)
with tarfile.open(class_fname) as f:
- def is_within_directory(directory, target):
-
- abs_directory = os.path.abspath(directory)
- abs_target = os.path.abspath(target)
-
- prefix = os.path.commonprefix([abs_directory, abs_target])
-
- return prefix == abs_directory
-
- def safe_extract(tar, path=".", members=None, *, numeric_owner=False):
-
- for member in tar.getmembers():
- member_path = os.path.join(path, member.name)
- if not is_within_directory(path, member_path):
- raise Exception("Attempted Path Traversal in Tar File")
-
- tar.extractall(path, members, numeric_owner=numeric_owner)
-
-
safe_extract(f, class_dir)
+
os.remove(class_fname)
pbar.update(1)
pbar.close()
if with_rec:
build_rec_process(target_dir, True, num_thread)
+
def extract_val(tar_fname, target_dir, with_rec=False, num_thread=1):
os.makedirs(target_dir)
print('Extracting ' + tar_fname)
with tarfile.open(tar_fname) as tar:
- def is_within_directory(directory, target):
-
- abs_directory = os.path.abspath(directory)
- abs_target = os.path.abspath(target)
-
- prefix = os.path.commonprefix([abs_directory, abs_target])
-
- return prefix == abs_directory
-
- def safe_extract(tar, path=".", members=None, *, numeric_owner=False):
-
- for member in tar.getmembers():
- member_path = os.path.join(path, member.name)
- if not is_within_directory(path, member_path):
- raise Exception("Attempted Path Traversal in Tar File")
-
- tar.extractall(path, members, numeric_owner=numeric_owner)
-
-
safe_extract(tar, target_dir)
+
# build rec file before images are moved into subfolders
if with_rec:
build_rec_process(target_dir, False, num_thread)
# move images to proper subfolders
- val_maps_file = os.path.join(os.path.dirname(__file__), 'imagenet_val_maps.pklz')
+ val_maps_file = os.path.join(os.path.dirname(__file__),
+ 'imagenet_val_maps.pklz')
with gzip.open(val_maps_file, 'rb') as f:
dirs, mappings = pickle.load(f)
for d in dirs:
os.makedirs(os.path.join(target_dir, d))
for m in mappings:
- os.rename(os.path.join(target_dir, m[0]), os.path.join(target_dir, m[1], m[0]))
+ os.rename(os.path.join(target_dir, m[0]),
+ os.path.join(target_dir, m[1], m[0]))
+
def main():
args = parse_args()
target_dir = os.path.expanduser(args.target_dir)
if os.path.exists(target_dir):
- raise ValueError('Target dir ['+target_dir+'] exists. Remove it first')
+ raise ValueError('Target dir [' + target_dir +
+ '] exists. Remove it first')
download_dir = os.path.expanduser(args.download_dir)
train_tar_fname = os.path.join(download_dir, _TRAIN_TAR)
@@ -247,8 +244,11 @@ def main():
build_rec = args.with_rec
if build_rec:
os.makedirs(os.path.join(target_dir, 'rec'))
- extract_train(train_tar_fname, os.path.join(target_dir, 'train'), build_rec, args.num_thread)
- extract_val(val_tar_fname, os.path.join(target_dir, 'val'), build_rec, args.num_thread)
+ extract_train(train_tar_fname, os.path.join(target_dir, 'train'),
+ build_rec, args.num_thread)
+ extract_val(val_tar_fname, os.path.join(target_dir, 'val'), build_rec,
+ args.num_thread)
+
if __name__ == '__main__':
main()
diff --git a/basicdataset/src/test/resources/mlrepo/dataset/cv/ai/djl/basicdataset/mnist/metadata.json b/basicdataset/src/test/resources/mlrepo/dataset/cv/ai/djl/basicdataset/mnist/metadata.json
index 5e5c1b81a95..0b5f61d1d32 100644
--- a/basicdataset/src/test/resources/mlrepo/dataset/cv/ai/djl/basicdataset/mnist/metadata.json
+++ b/basicdataset/src/test/resources/mlrepo/dataset/cv/ai/djl/basicdataset/mnist/metadata.json
@@ -19,23 +19,23 @@
"snapshot": false,
"files": {
"train_data": {
- "uri": "https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/dataset/mnist/train-images-idx3-ubyte.gz",
- "sha1Hash": "6c95f4b05d2bf285e1bfb0e7960c31bd3b3f8a7d",
- "size": 9912422
+ "uri": "https://mlrepo.djl.ai/dataset/cv/ai/djl/basicdataset/mnist/1.0/train-images-idx3-ubyte.gz",
+ "sha1Hash": "0e0d45c28981154deda73aabc437dc09aa5a4fd1",
+ "size": 9822052
},
"train_labels": {
- "uri": "https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/dataset/mnist/train-labels-idx1-ubyte.gz",
- "sha1Hash": "2a80914081dc54586dbdf242f9805a6b8d2a15fc",
- "size": 28881
+ "uri": "https://mlrepo.djl.ai/dataset/cv/ai/djl/basicdataset/mnist/1.0/train-labels-idx1-ubyte.gz",
+ "sha1Hash": "af3fbf34a4396c1ee1a6128dfde57812d8abe06e",
+ "size": 28902
},
"test_data": {
- "uri": "https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/dataset/mnist/t10k-images-idx3-ubyte.gz",
- "sha1Hash": "c3a25af1f52dad7f726cce8cacb138654b760d48",
- "size": 1648877
+ "uri": "https://mlrepo.djl.ai/dataset/cv/ai/djl/basicdataset/mnist/1.0/t10k-images-idx3-ubyte.gz",
+ "sha1Hash": "5a939b565aa3e5063d816efc7f3dfb721135648d",
+ "size": 1634335
},
"test_labels": {
- "uri": "https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/dataset/mnist/t10k-labels-idx1-ubyte.gz",
- "sha1Hash": "763e7fa3757d93b0cdec073cef058b2004252c17",
+ "uri": "https://mlrepo.djl.ai/dataset/cv/ai/djl/basicdataset/mnist/1.0/t10k-labels-idx1-ubyte.gz",
+ "sha1Hash": "0e4e66587e3a14f5775793e2ae10d1c48be8ae46",
"size": 4542
}
}
diff --git a/basicdataset/src/test/resources/mlrepo/dataset/nlp/ai/djl/basicdataset/wikitext-2/metadata.json b/basicdataset/src/test/resources/mlrepo/dataset/nlp/ai/djl/basicdataset/wikitext-2/metadata.json
index f9c64dc8028..1f31ac3afcd 100644
--- a/basicdataset/src/test/resources/mlrepo/dataset/nlp/ai/djl/basicdataset/wikitext-2/metadata.json
+++ b/basicdataset/src/test/resources/mlrepo/dataset/nlp/ai/djl/basicdataset/wikitext-2/metadata.json
@@ -20,10 +20,10 @@
"name": "wikitext-2",
"files": {
"wikitext-2": {
- "uri": "https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip",
- "sha1Hash": "3c914d17d80b1459be871a5039ac23e752a53cbe",
+ "uri": "https://mlrepo.djl.ai/dataset/nlp/ai/djl/basicdataset/wikitext-2/1.0/wikitext-2-v1.zip",
+ "sha1Hash": "46965bdeca1d8165e688598752ca467bb5bee018",
"name": "",
- "size": 4475746
+ "size": 4475596
}
}
}
diff --git a/bom/README.md b/bom/README.md
index 44519846712..ecb4f092234 100644
--- a/bom/README.md
+++ b/bom/README.md
@@ -22,7 +22,7 @@ will need to mention the type as pom and the scope as import) as the following:
ai.djl
bom
- 0.23.0
+ 0.27.0
pom
import
@@ -38,7 +38,7 @@ will need to mention the type as pom and the scope as import) as the following:
ai.djl
bom
- 0.23.0
+ 0.27.0
pom
import
@@ -65,7 +65,7 @@ will need to mention the type as pom and the scope as import) as the following:
- First you need add BOM into your build.gradle file as the following:
```
- implementation platform("ai.djl:bom:0.23.0")
+ implementation platform("ai.djl:bom:0.27.0")
```
- Then you import the desired DJL modules into to you pom.xml file (no version is needed):
diff --git a/bom/build.gradle b/bom/build.gradle
index 4708978b5b5..0c509740f92 100644
--- a/bom/build.gradle
+++ b/bom/build.gradle
@@ -19,7 +19,6 @@ dependencies {
api "ai.djl:basicdataset:${version}"
api "ai.djl:model-zoo:${version}"
api "ai.djl:djl-zero:${version}"
- api "ai.djl:serving:${version}"
api "ai.djl.android:core:${version}"
api "ai.djl.android:onnxruntime:${version}"
api "ai.djl.android:pytorch-native:${version}"
@@ -28,6 +27,7 @@ dependencies {
api "ai.djl.fasttext:fasttext-engine:${version}"
api "ai.djl.hadoop:hadoop:${version}"
api "ai.djl.huggingface:tokenizers:${version}"
+ api "ai.djl.llama:llama:${version}"
api "ai.djl.ml.lightgbm:lightgbm:${version}"
api "ai.djl.ml.xgboost:xgboost-gpu:${version}"
api "ai.djl.ml.xgboost:xgboost:${version}"
@@ -43,6 +43,9 @@ dependencies {
api "ai.djl.pytorch:pytorch-model-zoo:${version}"
api "ai.djl.sentencepiece:sentencepiece:${version}"
api "ai.djl.spark:spark_2.12:${version}"
+ api "ai.djl.serving:prometheus:${version}"
+ api "ai.djl.serving:serving:${version}"
+ api "ai.djl.serving:wlm:${version}"
api "ai.djl.tablesaw:tablesaw:${version}"
api "ai.djl.tensorflow:tensorflow-api:${version}"
api "ai.djl.tensorflow:tensorflow-engine:${version}"
@@ -115,15 +118,12 @@ publishing {
addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cpu", "win-x86_64", "${pytorch_version}")
addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cpu-precxx11", "linux-x86_64", "${pytorch_version}")
addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cpu-precxx11", "linux-aarch64", "${pytorch_version}")
- addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu116", "linux-x86_64", "1.12.1")
- addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu116", "win-x86_64", "1.12.1")
- addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu116-precxx11", "linux-x86_64", "1.12.1")
+ addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu121", "linux-x86_64", "${pytorch_version}")
+ addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu121", "win-x86_64", "${pytorch_version}")
+ addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu121-precxx11", "linux-x86_64", "${pytorch_version}")
addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu117", "linux-x86_64", "1.13.1")
addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu117", "win-x86_64", "1.13.1")
addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu117-precxx11", "linux-x86_64", "1.13.1")
- addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu118", "linux-x86_64", "${pytorch_version}")
- addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu118", "win-x86_64", "${pytorch_version}")
- addDependency(dependencies, "ai.djl.pytorch", "pytorch-native-cu118-precxx11", "linux-x86_64", "${pytorch_version}")
addDependency(dependencies, "ai.djl.tensorflow", "tensorflow-native-cpu", "osx-x86_64", "${tensorflow_version}")
addDependency(dependencies, "ai.djl.tensorflow", "tensorflow-native-cpu", "linux-x86_64", "${tensorflow_version}")
addDependency(dependencies, "ai.djl.tensorflow", "tensorflow-native-cpu", "win-x86_64", "${tensorflow_version}")
diff --git a/build.gradle b/build.gradle
index f98b86c4e51..ca6f7e68133 100644
--- a/build.gradle
+++ b/build.gradle
@@ -44,6 +44,7 @@ configure(javaProjects()) {
targetCompatibility = JavaVersion.VERSION_11
options.compilerArgs << "-proc:none" << "-Xlint:all,-options,-static,-removal" << "-Werror"
}
+ javadoc.options.addStringOption("Xdoclint:none", "-quiet")
apply plugin: 'eclipse'
@@ -88,7 +89,7 @@ configure(javaProjects()) {
systemProperty "disableProgressBar", "true"
systemProperty "nightly", System.getProperty("nightly", "false")
if (gradle.startParameter.offline) {
- systemProperty "offline", "true"
+ systemProperty "ai.djl.offline", "true"
}
// This is used to avoid overriding on default engine for modules:
// mxnet-engine, mxnet-model-zoo, api (MockEngine), basicdataset, fasttext, etc
diff --git a/djl-zero/README.md b/djl-zero/README.md
index 2d2c473cc88..91c84554c58 100644
--- a/djl-zero/README.md
+++ b/djl-zero/README.md
@@ -49,6 +49,6 @@ You can pull the module from the central Maven repository by including the follo
ai.djl
djl-zero
- 0.23.0
+ 0.27.0
```
diff --git a/docker/README.md b/docker/README.md
index 5b5bd01be2b..0df33be9f83 100644
--- a/docker/README.md
+++ b/docker/README.md
@@ -1,10 +1,12 @@
# Docker Resources
+
DJL provides docker files that you can use to setup containers with the appropriate environment for certain platforms.
We recommend setting up a docker container with the provided Dockerfile when developing for the following
platforms and/or engines.
## Windows
+
You can use the [docker file](https://github.com/deepjavalibrary/djl/blob/master/docker/windows/Dockerfile) provided by us.
Please note that this docker will only work with Windows server 2019 by default. If you want it to work with other
versions of Windows, you need to pass the version as an argument as follows:
@@ -14,19 +16,20 @@ docker build --build-arg version=
```
## TensorRT
+
You can use the [docker file](https://github.com/deepjavalibrary/djl/blob/master/docker/tensorrt/Dockerfile) provided by us.
This docker file is a modification of the one provided by NVIDIA in
-[TensorRT](https://github.com/NVIDIA/TensorRT/blob/8.4.1/docker/ubuntu-18.04.Dockerfile) to include JDK11.
-By default this sets up a container using Ubuntu 18.04 and CUDA 11.6.2. You can build the container with other versions as follows,
+[TensorRT](https://github.com/NVIDIA/TensorRT/blob/8.4.1/docker/ubuntu-18.04.Dockerfile) to include JDK17.
+By default this sets up a container using Ubuntu 18.04 and CUDA 11.6.2. You can build the container with other versions as follows,
but keep in mind the TensorRT software requirements outlined [here](https://github.com/NVIDIA/TensorRT#prerequisites):
```bash
docker build --build-arg OS_VERSION= --build-arg CUDA_VERSION=
```
-To run the container, we recommend using `nvidia-docker run ...` to ensure cuda driver and runtime are compatible.
+To run the container, we recommend using `nvidia-docker run ...` to ensure cuda driver and runtime are compatible.
-We recommend that you follow the setup steps in the [TensorRT guide](https://github.com/NVIDIA/TensorRT) if you
-need access to the full suite of tools TensorRT provides, such as `trtexec` which can convert onnx models to
-uff tensorrt models. When following that guide, make sure to use the DJL provided
-[docker file](https://github.com/deepjavalibrary/djl/blob/master/docker/tensorrt/Dockerfile) to enable JDK11 in the docker container.
+We recommend that you follow the setup steps in the [TensorRT guide](https://github.com/NVIDIA/TensorRT) if you
+need access to the full suite of tools TensorRT provides, such as `trtexec` which can convert onnx models to
+uff tensorrt models. When following that guide, make sure to use the DJL provided
+[docker file](https://github.com/deepjavalibrary/djl/blob/master/docker/tensorrt/Dockerfile) to enable JDK17 in the docker container.
diff --git a/docker/spark/Dockerfile b/docker/spark/Dockerfile
index b715899e2f1..b777d5a69ed 100644
--- a/docker/spark/Dockerfile
+++ b/docker/spark/Dockerfile
@@ -13,7 +13,7 @@ FROM 314815235551.dkr.ecr.us-east-2.amazonaws.com/sagemaker-spark-processing:3.3
LABEL maintainer="djl-dev@amazon.com"
# Install dependencies
-ARG DJL_VERSION=0.23.0
+ARG DJL_VERSION=0.24.0
ARG JNA_VERSION=5.13.0
ARG JAVACV_VERSION=1.5.9
ARG JAVACPP_VERSION=1.5.9
diff --git a/docker/tensorrt/Dockerfile b/docker/tensorrt/Dockerfile
index 3a99bb9cb5d..a92dad12f4d 100644
--- a/docker/tensorrt/Dockerfile
+++ b/docker/tensorrt/Dockerfile
@@ -14,15 +14,43 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-ARG CUDA_VERSION=11.6.2
-ARG OS_VERSION=18.04
-FROM nvidia/cuda:${CUDA_VERSION}-cudnn8-devel-ubuntu${OS_VERSION}
+ARG CUDA_VERSION=12.2.2
-ENV TRT_VERSION 8.4.1.5
+FROM nvidia/cuda:${CUDA_VERSION}-devel-ubuntu20.04
+
+ENV NV_CUDNN_VERSION 8.9.6.50
+ENV NV_CUDNN_PACKAGE_NAME "libcudnn8"
+
+ARG CUDA_VERSION_MAJOR_MINOR=12.2
+
+ENV NV_CUDNN_PACKAGE "libcudnn8=$NV_CUDNN_VERSION-1+cuda${CUDA_VERSION_MAJOR_MINOR}"
+ENV NV_CUDNN_PACKAGE_DEV "libcudnn8-dev=$NV_CUDNN_VERSION-1+cuda${CUDA_VERSION_MAJOR_MINOR}"
+
+ENV TRT_VERSION 9.2.0.5
SHELL ["/bin/bash", "-c"]
RUN mkdir -p /workspace
-# Install Required Libraries
+RUN apt-get update && apt-get install -y --no-install-recommends \
+ ${NV_CUDNN_PACKAGE} \
+ ${NV_CUDNN_PACKAGE_DEV} \
+ && apt-mark hold ${NV_CUDNN_PACKAGE_NAME} \
+ && rm -rf /var/lib/apt/lists/*
+
+# Setup user account
+ARG uid=1000
+ARG gid=1000
+RUN groupadd -r -f -g ${gid} djl && useradd -o -r -l -u ${uid} -g ${gid} -ms /bin/bash djl
+RUN usermod -aG sudo djl
+RUN echo 'djl:djl' | chpasswd
+RUN mkdir -p /workspace && chown djl /workspace
+
+# Required to build Ubuntu 20.04 without user prompts with DLFW container
+ENV DEBIAN_FRONTEND=noninteractive
+
+# Update CUDA signing key
+RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/3bf863cc.pub
+
+# Install requried libraries
RUN apt-get update && apt-get install -y software-properties-common
RUN add-apt-repository ppa:ubuntu-toolchain-r/test
RUN apt-get update && apt-get install -y --no-install-recommends \
@@ -42,7 +70,7 @@ RUN apt-get update && apt-get install -y --no-install-recommends \
fakeroot \
dh-make \
build-essential \
- openjdk-11-jdk && \
+ openjdk-17-jdk &&\
apt-get clean -y && rm -rf /var/lib/apt/lists/*
# Install python3
@@ -53,17 +81,24 @@ RUN apt-get update && apt-get install -y --no-install-recommends \
python3-wheel &&\
cd /usr/local/bin &&\
ln -s /usr/bin/python3 python &&\
- ln -s /usr/bin/pip3 pip && \
+ ln -s /usr/bin/pip3 pip &&\
apt-get clean -y && rm -rf /var/lib/apt/lists/*
# Install TensorRT
-RUN v="${TRT_VERSION%.*}-1+cuda${CUDA_VERSION%.*}" &&\
- apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub &&\
- apt-get update &&\
- sudo apt-get install libnvinfer8=${v} libnvonnxparsers8=${v} libnvparsers8=${v} libnvinfer-plugin8=${v} \
- libnvinfer-dev=${v} libnvonnxparsers-dev=${v} libnvparsers-dev=${v} libnvinfer-plugin-dev=${v} \
- python3-libnvinfer=${v}; \
- apt-get clean -y && rm -rf /var/lib/apt/lists/*
+RUN if [ "${CUDA_VERSION:0:2}" = "11" ]; then \
+ wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/9.2.0/tensorrt-9.2.0.5.linux.x86_64-gnu.cuda-11.8.tar.gz \
+ && tar -xf tensorrt-9.2.0.5.linux.x86_64-gnu.cuda-11.8.tar.gz \
+ && cp -a TensorRT-9.2.0.5/lib/*.so* /usr/lib/x86_64-linux-gnu \
+ && pip install TensorRT-9.2.0.5/python/tensorrt-9.2.0.post11.dev5-cp38-none-linux_x86_64.whl ;\
+elif [ "${CUDA_VERSION:0:2}" = "12" ]; then \
+ wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/9.2.0/tensorrt-9.2.0.5.linux.x86_64-gnu.cuda-12.2.tar.gz \
+ && tar -xf tensorrt-9.2.0.5.linux.x86_64-gnu.cuda-12.2.tar.gz \
+ && cp -a TensorRT-9.2.0.5/lib/*.so* /usr/lib/x86_64-linux-gnu \
+ && pip install TensorRT-9.2.0.5/python/tensorrt-9.2.0.post12.dev5-cp38-none-linux_x86_64.whl ;\
+else \
+ echo "Invalid CUDA_VERSION"; \
+ exit 1; \
+fi
# Install Cmake
RUN cd /tmp && \
@@ -72,19 +107,16 @@ RUN cd /tmp && \
./cmake-3.14.4-Linux-x86_64.sh --prefix=/usr/local --exclude-subdir --skip-license && \
rm ./cmake-3.14.4-Linux-x86_64.sh
-RUN cd /usr/local/bin && \
- wget https://ngc.nvidia.com/downloads/ngccli_cat_linux.zip && \
- unzip ngccli_cat_linux.zip && \
- chmod u+x ngc-cli/ngc && \
- rm ngccli_cat_linux.zip ngc-cli.md5 && \
- echo "no-apikey\nascii\n" | ngc-cli/ngc config set
-
+# Download NGC client
+RUN cd /usr/local/bin && wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/ngc-apps/ngc_cli/versions/3.38.0/files/ngccli_linux.zip -O ngccli_linux.zip && unzip ngccli_linux.zip && chmod u+x ngc-cli/ngc && rm ngccli_linux.zip ngc-cli.md5 && echo "no-apikey\nascii\n" | ngc-cli/ngc config set
# Set environment and working directory
ENV TRT_LIBPATH /usr/lib/x86_64-linux-gnu
ENV TRT_OSSPATH /workspace/TensorRT
ENV PATH="${PATH}:/usr/local/bin/ngc-cli"
ENV LD_LIBRARY_PATH="${LD_LIBRARY_PATH}:${TRT_OSSPATH}/build/out:${TRT_LIBPATH}"
+ENV JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64
WORKDIR /workspace
+USER djl
RUN ["/bin/bash"]
diff --git a/docker/windows/Dockerfile b/docker/windows/Dockerfile
index 31567b3168b..10989e8a4c8 100644
--- a/docker/windows/Dockerfile
+++ b/docker/windows/Dockerfile
@@ -11,4 +11,4 @@ RUN powershell -Command \
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1')); \
choco feature disable --name showDownloadProgress
-RUN choco install -y openjdk11
+RUN choco install -y openjdk17
diff --git a/docs/README.md b/docs/README.md
index cdd02661c78..7749d39eb5f 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -2,7 +2,7 @@
This folder contains examples and documentation for the Deep Java Library (DJL) project.
-## [JavaDoc API Reference](https://javadoc.djl.ai/)
+## [JavaDoc API Reference](https://djl.ai/website/javadoc.html)
Note: when searching in JavaDoc, if your access is denied, please try removing the string `undefined` in the url.
@@ -20,14 +20,14 @@ Note: when searching in JavaDoc, if your access is denied, please try removing t
- [Troubleshooting](development/troubleshooting.md)
- [Inference Optimization](development/inference_performance_optimization.md)
-## [Jupyter notebook tutorials](../jupyter/README.md)
+## [Jupyter notebook tutorials](http://docs.djl.ai/docs/demos/jupyter/index.html)
-- **[Beginner Jupyter Tutorial](../jupyter/tutorial/README.md)**
-- [Run object detection with model zoo](../jupyter/object_detection_with_model_zoo.ipynb)
-- [Load pre-trained PyTorch model](../jupyter/load_pytorch_model.ipynb)
-- [Load pre-trained Apache MXNet model](../jupyter/load_mxnet_model.ipynb)
-- [Transfer learning example](../jupyter/transfer_learning_on_cifar10.ipynb)
-- [Question answering example](../jupyter/BERTQA.ipynb)
+- **[Beginner Jupyter Tutorial](http://docs.djl.ai/docs/demos/jupyter/tutorial/index.html)**
+- [Run object detection with model zoo](http://docs.djl.ai/docs/demos/jupyter/object_detection_with_model_zoo.html)
+- [Load pre-trained PyTorch model](http://docs.djl.ai/docs/demos/jupyter/load_pytorch_model.html)
+- [Load pre-trained Apache MXNet model](http://docs.djl.ai/docs/demos/jupyter/load_mxnet_model.html)
+- [Transfer learning example](http://docs.djl.ai/docs/demos/jupyter/transfer_learning_on_cifar10.html)
+- [Question answering example](http://docs.djl.ai/docs/demos/jupyter/BERTQA.html)
## [API Examples](../examples/README.md)
diff --git a/docs/development/cache_management.md b/docs/development/cache_management.md
index b0b56460e54..2bdacb9a699 100644
--- a/docs/development/cache_management.md
+++ b/docs/development/cache_management.md
@@ -30,10 +30,10 @@ ONNXRuntime will extract native libraries into system default temporary-file dir
### Huggingface tokenizer
-If the `TOKENIZERS_CACHE` environment variable is set, Huggingface tokenizer will store cache files in it.
+If the `HF_HOME` or `HF_HUB_CACHE` environment variable is set, Huggingface tokenizer will store cache files in it.
It is the responsibility of the user to make sure this path is correct. Otherwise, we try to use
the default cache directory as defined for each OS:
-- macOS: `/Users/{user}/Library/Caches/huggingface/tokenizers`
-- linux: `/home/{user}/.cache/huggingface/tokenizers`
-- windows: `C:\Users\{user}\AppData\Local\huggingface\tokenizers`
+- macOS: `/Users/{user}/.cache/huggingface/hub`
+- linux: `/home/{user}/.cache/huggingface/hub`
+- windows: `C:\Users\{user}\.cache\huggingface\hub`
diff --git a/docs/development/example_dataset.md b/docs/development/example_dataset.md
index 35e071f728b..2f9fb456e02 100644
--- a/docs/development/example_dataset.md
+++ b/docs/development/example_dataset.md
@@ -1,4 +1,4 @@
-## Example CSV Dataset
+# Custom CSV Dataset Example
If the provided Datasets don't meet your requirements, you can also easily extend our dataset to create your own customized dataset.
@@ -24,8 +24,8 @@ api group: 'org.apache.commons', name: 'commons-csv', version: '1.7'
In order to extend the dataset, the following dependencies are required:
```
-api "ai.djl:api:0.23.0"
-api "ai.djl:basicdataset:0.23.0"
+api "ai.djl:api:0.27.0"
+api "ai.djl:basicdataset:0.27.0"
```
There are four parts we need to implement for CSVDataset.
diff --git a/docs/development/external_libraries.md b/docs/development/external_libraries.md
index 7f57fec3165..701fb9d0a03 100644
--- a/docs/development/external_libraries.md
+++ b/docs/development/external_libraries.md
@@ -1,5 +1,4 @@
-
-## DJL external dependencies
+# DJL external dependencies
This document contains external libraries that DJL depends on and their versions.
diff --git a/docs/development/inference_performance_optimization.md b/docs/development/inference_performance_optimization.md
index 27bccfd3f3e..0fdc67d999c 100644
--- a/docs/development/inference_performance_optimization.md
+++ b/docs/development/inference_performance_optimization.md
@@ -85,6 +85,23 @@ You can enable it by setting the environment variable:
You might see an exception if a data type or operator is not supported with the oneDNN device.
+#### oneDNN(MKLDNN) tuning on AWS Graviton3
+AWS Graviton3(E) (e.g. c7g/m7g/r7g, c7gn and Hpc7g instances) supports BF16 format for ML acceleration. This can be enabled in oneDNN by setting the below environment variable
+```
+grep -q bf16 /proc/cpuinfo && export DNNL_DEFAULT_FPMATH_MODE=BF16
+```
+To avoid redundant primitive creation latency overhead, enable primitive caching by setting the LRU cache capacity. Please note this caching feature increases the memory footprint. It is recommended to tune the capacity to an optimal value for a given use case.
+
+```
+export LRU_CACHE_CAPACITY=1024
+```
+
+In addition to avoiding the redundant allocations, tensor memory allocation latencies can be optimized with Linux transparent huge pages (THP). To enable THP allocations, set the following torch environment variable.
+```
+export THP_MEM_ALLOC_ENABLE=1
+```
+Please refer to [PyTorch Graviton tutorial](https://pytorch.org/tutorials/recipes/inference_tuning_on_aws_graviton.html) for more details on how to achieve the best PyTorch inference performance on AWS Graviton3 instances.
+
#### CuDNN acceleration
PyTorch has a special flag that is used for a CNN or related network speed up. If your input size won't change frequently,
you may benefit from enabling this configuration in your model:
diff --git a/docs/development/profiler.md b/docs/development/profiler.md
index 6db5739483c..4a2a9f626e4 100644
--- a/docs/development/profiler.md
+++ b/docs/development/profiler.md
@@ -1,4 +1,4 @@
-## Profiler (Experimental)
+# Engine Profiler Support
Currently, DJL supports experimental profilers for developers that
investigate the performance of operator execution as well as memory consumption.
diff --git a/docs/development/setup.md b/docs/development/setup.md
index e4eb73b2501..fb290eb0e3a 100644
--- a/docs/development/setup.md
+++ b/docs/development/setup.md
@@ -10,13 +10,13 @@ you can use the $JAVA_HOME environment variable to control which version of Java
For ubuntu:
```bash
-sudo apt-get install openjdk-11-jdk
+sudo apt-get install openjdk-17-jdk
```
For centos
```bash
-sudo yum install java-11-openjdk
+sudo yum install java-17-openjdk
```
For Mac:
@@ -24,7 +24,7 @@ For Mac:
```bash
brew tap homebrew/cask-versions
brew update
-brew install --cask temurin11
+brew install --cask zulu17
```
You can also download and install [Oracle JDK](https://www.oracle.com/technetwork/java/javase/overview/index.html)
diff --git a/docs/get.md b/docs/get.md
index 8c4c34502ad..2c6e8b99968 100644
--- a/docs/get.md
+++ b/docs/get.md
@@ -99,7 +99,7 @@ dependencies {
implementation platform("ai.djl:bom:-SNAPSHOT")
}
```
-Currently, the ` = 0.21.0`.
+Currently, the ` = 0.28.0`.
This snapshot version is the same as the custom DJL repository.
You also need to change directory to `djl/bom`. Then build and publish it to maven local same as what was done in `djl`.
diff --git a/docs/hybrid_engine.md b/docs/hybrid_engine.md
index 58bdbe69cb4..cc6ec9400d2 100644
--- a/docs/hybrid_engine.md
+++ b/docs/hybrid_engine.md
@@ -21,17 +21,17 @@ to run in a hybrid mode:
To use it along with Apache MXNet for additional API support, add the following two dependencies:
```
-runtimeOnly "ai.djl.mxnet:mxnet-engine:0.23.0"
+runtimeOnly "ai.djl.mxnet:mxnet-engine:0.27.0"
```
You can also use PyTorch or TensorFlow Engine as the supplemental engine by adding their corresponding dependencies.
```
-runtimeOnly "ai.djl.pytorch:pytorch-engine:0.23.0"
+runtimeOnly "ai.djl.pytorch:pytorch-engine:0.27.0"
```
```
-runtimeOnly "ai.djl.tensorflow:tensorflow-engine:0.23.0"
+runtimeOnly "ai.djl.tensorflow:tensorflow-engine:0.27.0"
```
## How Hybrid works
diff --git a/docs/interactive_tool.md b/docs/interactive_tool.md
index ed102fedc8d..d7d267db710 100644
--- a/docs/interactive_tool.md
+++ b/docs/interactive_tool.md
@@ -63,7 +63,7 @@ After that, click `run` and you should see the following result:
Finally, you can get the running project setup by clicking `Get Template`. This will bring you a gradle project that can be used in your local machine.
-## [Java Jupyter Notebook](../jupyter/README.md)
+## [Java Jupyter Notebook](http://docs.djl.ai/docs/demos/jupyter/index.html)
Wait a second, are we talking about hosting Jupyter Notebook in python?
No, it’s Java 11, only.
@@ -71,9 +71,9 @@ No, it’s Java 11, only.
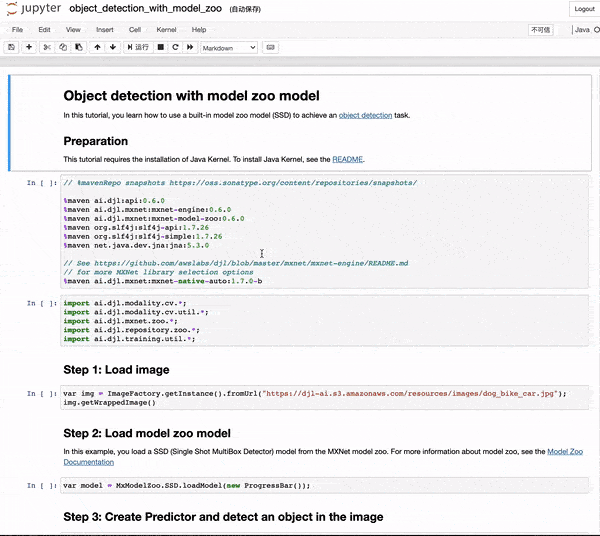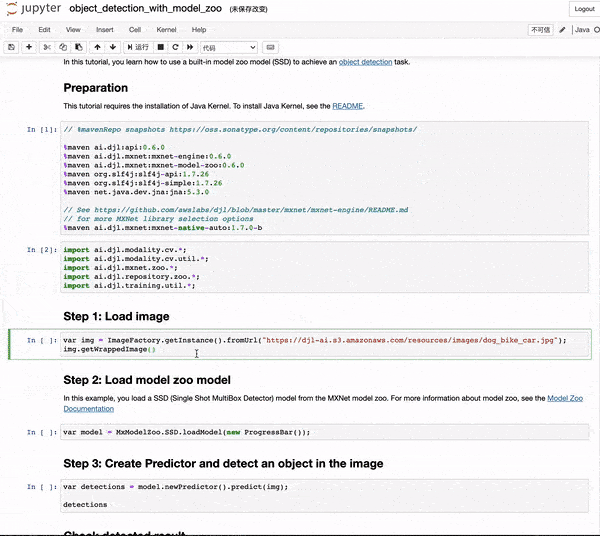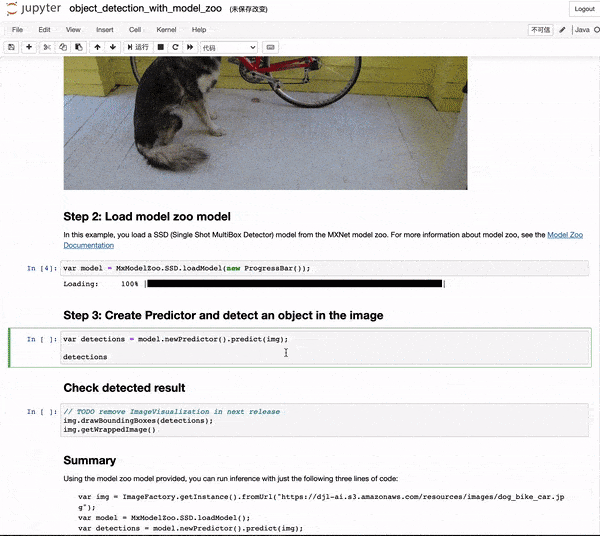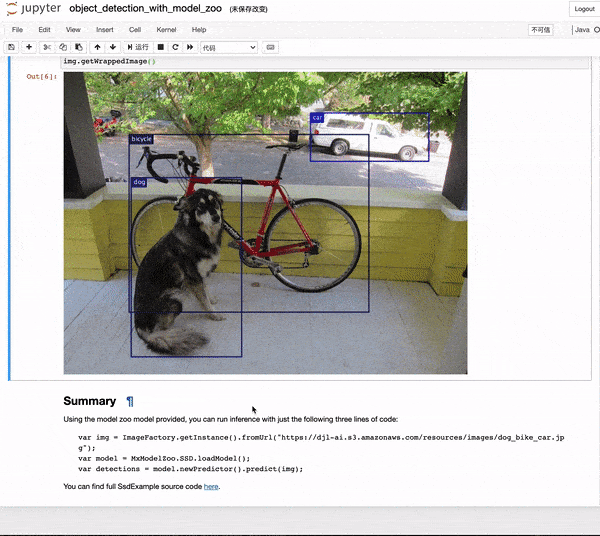
Inspired by Spencer Park’s [IJava project](https://github.com/SpencerPark/IJava), we integrated DJL with Jupyter Notebooks.
-For more information on the simple setup, follow the instructions in [DJL Jupyter notebooks](../jupyter/README.md#setup).
+For more information on the simple setup, follow the instructions in [DJL Jupyter notebooks](http://docs.djl.ai/docs/demos/jupyter/index.html#setup).
After that, use the Jupyter Notebook freely in your hosted server. You can do all kinds of work, like block building and plotting a graph.
-There are [tutorials and instructions](../jupyter/README.md#djl---jupyter-notebooks) to guide you how you can run training and/or inference with Java.
+There are [tutorials and instructions](http://docs.djl.ai/docs/demos/jupyter/index.html#djl---jupyter-notebooks) to guide you how you can run training and/or inference with Java.
## About Future Lab
diff --git a/docs/load_model.md b/docs/load_model.md
index 621d7514605..3c0afec26e9 100644
--- a/docs/load_model.md
+++ b/docs/load_model.md
@@ -181,7 +181,7 @@ Here is a few tips you can use to help you debug model loading issue:
See [here](development/configure_logging.md#configure-logging-level) for how to enable debug log
#### List models programmatically in your code
-You can use [ModelZoo.listModels()](https://javadoc.io/static/ai.djl/api/0.23.0/ai/djl/repository/zoo/ModelZoo.html#listModels--) API to query available models.
+You can use [ModelZoo.listModels()](https://javadoc.io/static/ai.djl/api/0.27.0/ai/djl/repository/zoo/ModelZoo.html#listModels--) API to query available models.
#### List available models using DJL command line
diff --git a/docs/mkdocs.yml b/docs/mkdocs.yml
index c911bf43b2d..ef7c46d331a 100644
--- a/docs/mkdocs.yml
+++ b/docs/mkdocs.yml
@@ -61,15 +61,15 @@ nav:
- 'docs/faq.md'
- Tutorials:
- Beginner Tutorial:
- - 'jupyter/tutorial/01_create_your_first_network.ipynb'
- - 'jupyter/tutorial/02_train_your_first_model.ipynb'
- - 'jupyter/tutorial/03_image_classification_with_your_model.ipynb'
+ - 'docs/demos/jupyter/tutorial/01_create_your_first_network.ipynb'
+ - 'docs/demos/jupyter/tutorial/02_train_your_first_model.ipynb'
+ - 'docs/demos/jupyter/tutorial/03_image_classification_with_your_model.ipynb'
- 'docs/d2l.md'
- - 'jupyter/rank_classification_using_BERT_on_Amazon_Review.ipynb'
- - 'jupyter/transfer_learning_on_cifar10.ipynb'
+ - 'docs/demos/jupyter/rank_classification_using_BERT_on_Amazon_Review.ipynb'
+ - 'docs/demos/jupyter/transfer_learning_on_cifar10.ipynb'
- Load your own BERT:
- - BERT with MXNet: 'jupyter/mxnet/load_your_own_mxnet_bert.ipynb'
- - BERT with PyTorch: 'jupyter/pytorch/load_your_own_pytorch_bert.ipynb'
+ - BERT with MXNet: 'docs/demos/jupyter/mxnet/load_your_own_mxnet_bert.ipynb'
+ - BERT with PyTorch: 'docs/demos/jupyter/pytorch/load_your_own_pytorch_bert.ipynb'
- Guides:
- Models:
- 'docs/load_model.md'
@@ -97,25 +97,25 @@ nav:
- PyTorch NDArray Operators: 'docs/pytorch/pytorch-djl-ndarray-cheatsheet.md'
- PyTorch Model Zoo: 'engines/pytorch/pytorch-model-zoo/README.md'
- Import PyTorch Model: 'docs/pytorch/how_to_convert_your_model_to_torchscript.md'
- - Load a PyTorch Model: 'jupyter/load_pytorch_model.ipynb'
+ - Load a PyTorch Model: 'docs/demos/jupyter/load_pytorch_model.ipynb'
- TensorFlow:
- Overview: 'engines/tensorflow/README.md'
- TensorFlow Engine: 'engines/tensorflow/tensorflow-engine/README.md'
- TensorFlow Model Zoo: 'engines/tensorflow/tensorflow-model-zoo/README.md'
- Import TensorFlow Model: 'docs/tensorflow/how_to_import_tensorflow_models_in_DJL.md'
- - Load a TensorFlow Model: 'jupyter/tensorflow/pneumonia_detection.ipynb'
+ - Load a TensorFlow Model: 'docs/demos/jupyter/tensorflow/pneumonia_detection.ipynb'
- Apache MXNet:
- Overview: 'engines/mxnet/README.md'
- MXNet Engine: 'engines/mxnet/mxnet-engine/README.md'
- MXNet Model Zoo: 'engines/mxnet/mxnet-model-zoo/README.md'
- Import Gluon Model: 'docs/mxnet/how_to_convert_your_model_to_symbol.md'
- - Load a MXNet Model: 'jupyter/load_mxnet_model.ipynb'
+ - Load a MXNet Model: 'docs/demos/jupyter/load_mxnet_model.ipynb'
- Backend Optimizer for MXNet: 'docs/mxnet/mxnet_backend_optimizer.md'
- Hybrid engines:
- Hybrid engine overview: 'docs/hybrid_engine.md'
- ONNX Runtime:
- Overview: 'engines/onnxruntime/onnxruntime-engine/README.md'
- - Load a ONNX Model: 'jupyter/onnxruntime/machine_learning_with_ONNXRuntime.ipynb'
+ - Load a ONNX Model: 'docs/demos/jupyter/onnxruntime/machine_learning_with_ONNXRuntime.ipynb'
- PaddlePaddle:
- Overview: 'engines/paddlepaddle/README.md'
- PaddlePaddle Engine: 'engines/paddlepaddle/paddlepaddle-engine/README.md'
@@ -124,11 +124,11 @@ nav:
- English: 'docs/paddlepaddle/how_to_create_paddlepaddle_model.md'
- 中文: 'docs/paddlepaddle/how_to_create_paddlepaddle_model_zh.md'
- Facemask detection using PaddlePaddle:
- - English: 'jupyter/paddlepaddle/face_mask_detection_paddlepaddle.ipynb'
- - 中文: 'jupyter/paddlepaddle/face_mask_detection_paddlepaddle_zh.ipynb'
+ - English: 'docs/demos/jupyter/paddlepaddle/face_mask_detection_paddlepaddle.ipynb'
+ - 中文: 'docs/demos/jupyter/paddlepaddle/face_mask_detection_paddlepaddle_zh.ipynb'
- PaddleOCR example:
- - English: 'jupyter/paddlepaddle/paddle_ocr_java.ipynb'
- - 中文: 'jupyter/paddlepaddle/paddle_ocr_java_zh.ipynb'
+ - English: 'docs/demos/jupyter/paddlepaddle/paddle_ocr_java.ipynb'
+ - 中文: 'docs/demos/jupyter/paddlepaddle/paddle_ocr_java_zh.ipynb'
- XGBoost: 'engines/ml/xgboost/README.md'
- LightGBM: 'engines/ml/lightgbm/README.md'
- TensorRT: 'engines/tensorrt/README.md'
@@ -153,15 +153,49 @@ nav:
- 'docs/serving/serving/docs/inference.md'
- 'docs/serving/serving/docs/modes.md'
- 'docs/serving/serving/docs/console.md'
- - 'docs/serving/serving/docs/configuration.md'
- - 'docs/serving/serving/docs/configurations.md'
- - 'docs/serving/serving/docs/workflows.md'
+ - Configuration:
+ - 'docs/serving/serving/docs/configuration.md'
+ - 'docs/serving/serving/docs/configurations_global.md'
+ - 'docs/serving/serving/docs/configurations.md'
+ - 'docs/serving/serving/docs/workflows.md'
+ - 'docs/serving/serving/docs/configurations_model.md'
- 'docs/serving/serving/docs/architecture.md'
- HTTP API:
- 'docs/serving/serving/docs/inference_api.md'
- 'docs/serving/serving/docs/management_api.md'
- 'docs/serving/serving/docs/plugin_management.md'
- 'docs/serving/wlm/README.md'
+ - Large Model Inference:
+ - 'docs/serving/serving/docs/lmi/README.md'
+ - User Guides:
+ - 'docs/serving/serving/docs/lmi/user_guides/README.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/starting-guide.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/deepspeed_user_guide.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/lmi-dist_user_guide.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/vllm_user_guide.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/tnx_user_guide.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/trt_llm_user_guide.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/hf_accelerate.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/lmi_input_output_schema.md'
+ - 'docs/serving/serving/docs/lmi/user_guides/chat_input_output_schema.md'
+ - Deployment Guides:
+ - 'docs/serving/serving/docs/lmi/deployment_guide/README.md'
+ - 'docs/serving/serving/docs/lmi/deployment_guide/model-artifacts.md'
+ - 'docs/serving/serving/docs/lmi/deployment_guide/instance-type-selection.md'
+ - 'docs/serving/serving/docs/lmi/deployment_guide/backend-selection.md'
+ - 'docs/serving/serving/docs/lmi/deployment_guide/configurations.md'
+ - 'docs/serving/serving/docs/lmi/deployment_guide/deploying-your-endpoint.md'
+ - 'docs/serving/serving/docs/lmi/deployment_guide/benchmarking-your-endpoint.md'
+ - 'docs/serving/serving/docs/lmi/deployment_guide/testing-custom-script.md'
+ - Tutorials:
+ - 'docs/serving/serving/docs/lmi/tutorials/seq_scheduler_tutorial.md'
+ - 'docs/serving/serving/docs/lmi/tutorials/trtllm_aot_tutorial.md'
+ - 'docs/serving/serving/docs/lmi/tutorials/trtllm_manual_convert_tutorial.md'
+ - 'docs/serving/serving/docs/lmi/tutorials/tnx_aot_tutorial.md'
+ - Conceptual Guides:
+ - 'docs/serving/serving/docs/lmi/conceptual_guide/lmi_engine.md'
+ - SageMaker LMI containers resources:
+ - 'docs/demos/aws/sagemaker/large-model-inference/README.md'
- Demos:
- Demos: 'docs/demos/README.md'
- AWS:
diff --git a/docs/mxnet/how_to_convert_your_model_to_symbol.md b/docs/mxnet/how_to_convert_your_model_to_symbol.md
index be178afe437..57a5b8a9b05 100644
--- a/docs/mxnet/how_to_convert_your_model_to_symbol.md
+++ b/docs/mxnet/how_to_convert_your_model_to_symbol.md
@@ -1,4 +1,4 @@
-## How to convert your Gluon model to an MXNet Symbol
+# How to convert your Gluon model to an MXNet Symbol
DJL currently supports symbolic model loading from MXNet.
A gluon [HybridBlock](https://mxnet.apache.org/api/python/docs/api/gluon/hybrid_block.html) can be converted into a symbol for loading by doing as follows:
diff --git a/docs/paddlepaddle/how_to_create_paddlepaddle_model.md b/docs/paddlepaddle/how_to_create_paddlepaddle_model.md
index 042acbd2d61..b78d4406946 100644
--- a/docs/paddlepaddle/how_to_create_paddlepaddle_model.md
+++ b/docs/paddlepaddle/how_to_create_paddlepaddle_model.md
@@ -157,5 +157,5 @@ predictor.predict(list);
As mentioned, you need to find out what is the input for the model, like images usually interpret as NCHW (batch_size, channel, height, width).
-However, usage like this is really basic, you can write a `Translator` in DJL for it. You can find some code examples [here](../../jupyter/paddlepaddle/face_mask_detection_paddlepaddle.ipynb).
+However, usage like this is really basic, you can write a `Translator` in DJL for it. You can find some code examples [here](http://docs.djl.ai/docs/demos/jupyter/paddlepaddle/face_mask_detection_paddlepaddle.html).
diff --git a/docs/paddlepaddle/how_to_create_paddlepaddle_model_zh.md b/docs/paddlepaddle/how_to_create_paddlepaddle_model_zh.md
index 74e5dec634f..5f79d713783 100644
--- a/docs/paddlepaddle/how_to_create_paddlepaddle_model_zh.md
+++ b/docs/paddlepaddle/how_to_create_paddlepaddle_model_zh.md
@@ -156,4 +156,4 @@ predictor.predict(list);
在这里,你需要知道模型的输入输出格式, 比如图片经常表达成 NCHW (批大小, RGB通道, 高度, 宽度)的多维矩阵。
-虽然这样可以让模型跑起来, 但是最好还是结合 DJL 的 `Translator` class 使用。你可以在 [这里](../../jupyter/paddlepaddle/face_mask_detection_paddlepaddle.ipynb) 找到一些示例代码。
+虽然这样可以让模型跑起来, 但是最好还是结合 DJL 的 `Translator` class 使用。你可以在 [这里](http://docs.djl.ai/docs/demos/jupyter/paddlepaddle/face_mask_detection_paddlepaddle.html) 找到一些示例代码。
diff --git a/docs/pytorch/how_to_convert_your_model_to_torchscript.md b/docs/pytorch/how_to_convert_your_model_to_torchscript.md
index 4dd4b3102d7..f90ee468764 100644
--- a/docs/pytorch/how_to_convert_your_model_to_torchscript.md
+++ b/docs/pytorch/how_to_convert_your_model_to_torchscript.md
@@ -1,4 +1,4 @@
-## How to convert your PyTorch model to TorchScript
+# How to convert your PyTorch model to TorchScript
There are two ways to convert your model to TorchScript: tracing and scripting.
We will only demonstrate the first one, tracing, but you can find information about scripting from the PyTorch documentation.
diff --git a/docs/pytorch/pytorch-djl-ndarray-cheatsheet.md b/docs/pytorch/pytorch-djl-ndarray-cheatsheet.md
index 7416ec50bab..37d24276d82 100644
--- a/docs/pytorch/pytorch-djl-ndarray-cheatsheet.md
+++ b/docs/pytorch/pytorch-djl-ndarray-cheatsheet.md
@@ -1,4 +1,4 @@
-## PyTorch NDArray operators
+# PyTorch NDArray operators
In the following examples, we assume
diff --git a/docs/quick_start.md b/docs/quick_start.md
index f352a39156a..b7072a50a59 100644
--- a/docs/quick_start.md
+++ b/docs/quick_start.md
@@ -1,7 +1,7 @@
# Quick start
Deep Java Library (DJL) is designed to be easy to get started with and simple to use.
-The easiest way to learn DJL is to read the [beginner tutorial](../jupyter/tutorial/README.md) or
+The easiest way to learn DJL is to read the [beginner tutorial](http://docs.djl.ai/docs/demos/jupyter/tutorial/README.md) or
our [examples](../examples/README.md).
You can also view our 1.5 hour long (in 8 x ~10 minute segments) DJL 101 tutorial video series:
@@ -22,7 +22,7 @@ See [DJL Future Labs](interactive_tool.md)
## Beginner tutorial
-To get started, we recommend that you follow our short [beginner tutorial](../jupyter/tutorial/README.md). It takes you through some of the basics of deep learning to create a model, train your model, and run inference using your trained model.
+To get started, we recommend that you follow our short [beginner tutorial](http://docs.djl.ai/docs/demos/jupyter/tutorial/index.html). It takes you through some of the basics of deep learning to create a model, train your model, and run inference using your trained model.
## Run examples
@@ -33,10 +33,10 @@ All of our examples are executed by a simple command. For detailed command line
- [Train your first model](../examples/docs/train_mnist_mlp.md)
- [Single-shot Object Detection inference example](../examples/docs/object_detection.md)
- [More examples](https://github.com/deepjavalibrary/djl/tree/master/examples)
-- [Jupyter examples](../jupyter/README.md)
+- [Jupyter examples](http://docs.djl.ai/docs/demos/jupyter/index.html)
## Other resources
-- [JavaDoc API Reference](https://javadoc.djl.ai/)
+- [JavaDoc API Reference](https://djl.ai/website/javadoc.html)
- [Contributor Documentation](development/README.md)
- [FAQ](faq.md)
diff --git a/docs/telemetry.md b/docs/telemetry.md
index d6ff9b20bc1..256adf00a49 100644
--- a/docs/telemetry.md
+++ b/docs/telemetry.md
@@ -20,5 +20,5 @@ System.setProperty("OPT_OUT_TRACKING", "true")
Usage tracking is also disable in `offline` mode:
```java
-System.setProperty("offline", "true")
+System.setProperty("ai.djl.offline", "true")
```
diff --git a/engines/llama/.gitignore b/engines/llama/.gitignore
new file mode 100644
index 00000000000..3428b3b2f53
--- /dev/null
+++ b/engines/llama/.gitignore
@@ -0,0 +1,3 @@
+jnilib/
+llama.cpp/
+models/
diff --git a/engines/llama/CMakeLists.txt b/engines/llama/CMakeLists.txt
new file mode 100644
index 00000000000..d1fc8131db8
--- /dev/null
+++ b/engines/llama/CMakeLists.txt
@@ -0,0 +1,23 @@
+cmake_minimum_required(VERSION 3.12 FATAL_ERROR)
+
+project(djl_llama CXX)
+
+set(CMAKE_POSITION_INDEPENDENT_CODE ON)
+set(BUILD_SHARED_LIBS ON)
+
+set(JAVA_AWT_LIBRARY NotNeeded)
+set(JAVA_AWT_INCLUDE_PATH NotNeeded)
+find_package(JNI REQUIRED)
+
+add_subdirectory(llama.cpp)
+include(build-args.cmake)
+add_library(djl_llama SHARED src/main/native/ai_djl_llama.cpp)
+
+target_include_directories(djl_llama PRIVATE
+ ${JNI_INCLUDE_DIRS}
+ src/main/native
+ llama.cpp
+ llama.cpp/common
+ build/include)
+target_link_libraries(djl_llama PRIVATE common llama ${LLAMA_EXTRA_LIBS})
+target_compile_features(djl_llama PRIVATE cxx_std_11)
diff --git a/engines/llama/build-args.cmake b/engines/llama/build-args.cmake
new file mode 100644
index 00000000000..dee0db659cd
--- /dev/null
+++ b/engines/llama/build-args.cmake
@@ -0,0 +1,639 @@
+if (APPLE)
+ set(LLAMA_METAL_DEFAULT ON)
+else()
+ set(LLAMA_METAL_DEFAULT OFF)
+endif()
+
+# general
+option(LLAMA_NATIVE "llama: enable -march=native flag" ON)
+
+# instruction set specific
+if (LLAMA_NATIVE)
+ set(INS_ENB OFF)
+else()
+ set(INS_ENB ON)
+endif()
+
+option(LLAMA_AVX "llama: enable AVX" ${INS_ENB})
+option(LLAMA_AVX2 "llama: enable AVX2" ${INS_ENB})
+option(LLAMA_AVX512 "llama: enable AVX512" OFF)
+option(LLAMA_AVX512_VBMI "llama: enable AVX512-VBMI" OFF)
+option(LLAMA_AVX512_VNNI "llama: enable AVX512-VNNI" OFF)
+option(LLAMA_FMA "llama: enable FMA" ${INS_ENB})
+# in MSVC F16C is implied with AVX2/AVX512
+if (NOT MSVC)
+ option(LLAMA_F16C "llama: enable F16C" ${INS_ENB})
+endif()
+
+# 3rd party libs
+option(LLAMA_ACCELERATE "llama: enable Accelerate framework" ON)
+option(LLAMA_BLAS "llama: use BLAS" OFF)
+set(LLAMA_BLAS_VENDOR "Generic" CACHE STRING "llama: BLAS library vendor")
+option(LLAMA_CUBLAS "llama: use CUDA" OFF)
+#option(LLAMA_CUDA_CUBLAS "llama: use cuBLAS for prompt processing" OFF)
+option(LLAMA_CUDA_FORCE_DMMV "llama: use dmmv instead of mmvq CUDA kernels" OFF)
+option(LLAMA_CUDA_FORCE_MMQ "llama: use mmq kernels instead of cuBLAS" OFF)
+set(LLAMA_CUDA_DMMV_X "32" CACHE STRING "llama: x stride for dmmv CUDA kernels")
+set(LLAMA_CUDA_MMV_Y "1" CACHE STRING "llama: y block size for mmv CUDA kernels")
+option(LLAMA_CUDA_F16 "llama: use 16 bit floats for some calculations" OFF)
+set(LLAMA_CUDA_KQUANTS_ITER "2" CACHE STRING "llama: iters./thread per block for Q2_K/Q6_K")
+set(LLAMA_CUDA_PEER_MAX_BATCH_SIZE "128" CACHE STRING
+ "llama: max. batch size for using peer access")
+option(LLAMA_HIPBLAS "llama: use hipBLAS" OFF)
+option(LLAMA_CLBLAST "llama: use CLBlast" OFF)
+option(LLAMA_METAL "llama: use Metal" ${LLAMA_METAL_DEFAULT})
+option(LLAMA_METAL_NDEBUG "llama: disable Metal debugging" OFF)
+option(LLAMA_MPI "llama: use MPI" OFF)
+option(LLAMA_QKK_64 "llama: use super-block size of 64 for k-quants" OFF)
+
+
+#
+# Compile flags
+#
+
+set(CMAKE_CXX_STANDARD 11)
+set(CMAKE_CXX_STANDARD_REQUIRED true)
+set(CMAKE_C_STANDARD 11)
+set(CMAKE_C_STANDARD_REQUIRED true)
+set(THREADS_PREFER_PTHREAD_FLAG ON)
+find_package(Threads REQUIRED)
+include(CheckCXXCompilerFlag)
+
+# enable libstdc++ assertions for debug builds
+if (CMAKE_SYSTEM_NAME MATCHES "Linux")
+ add_compile_definitions($<$:_GLIBCXX_ASSERTIONS>)
+endif()
+
+if (NOT MSVC)
+ if (LLAMA_SANITIZE_THREAD)
+ add_compile_options(-fsanitize=thread)
+ link_libraries(-fsanitize=thread)
+ endif()
+
+ if (LLAMA_SANITIZE_ADDRESS)
+ add_compile_options(-fsanitize=address -fno-omit-frame-pointer)
+ link_libraries(-fsanitize=address)
+ endif()
+
+ if (LLAMA_SANITIZE_UNDEFINED)
+ add_compile_options(-fsanitize=undefined)
+ link_libraries(-fsanitize=undefined)
+ endif()
+endif()
+
+if (APPLE AND LLAMA_ACCELERATE)
+ find_library(ACCELERATE_FRAMEWORK Accelerate)
+ if (ACCELERATE_FRAMEWORK)
+ message(STATUS "Accelerate framework found")
+
+ add_compile_definitions(GGML_USE_ACCELERATE)
+ add_compile_definitions(ACCELERATE_NEW_LAPACK)
+ add_compile_definitions(ACCELERATE_LAPACK_ILP64)
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ${ACCELERATE_FRAMEWORK})
+ else()
+ message(WARNING "Accelerate framework not found")
+ endif()
+endif()
+
+if (LLAMA_METAL)
+ find_library(FOUNDATION_LIBRARY Foundation REQUIRED)
+ find_library(METAL_FRAMEWORK Metal REQUIRED)
+ find_library(METALKIT_FRAMEWORK MetalKit REQUIRED)
+
+ message(STATUS "Metal framework found")
+ set(GGML_HEADERS_METAL ggml-metal.h)
+ set(GGML_SOURCES_METAL ggml-metal.m)
+
+ add_compile_definitions(GGML_USE_METAL)
+ if (LLAMA_METAL_NDEBUG)
+ add_compile_definitions(GGML_METAL_NDEBUG)
+ endif()
+
+ # get full path to the file
+ #add_compile_definitions(GGML_METAL_DIR_KERNELS="${CMAKE_CURRENT_SOURCE_DIR}/")
+
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS}
+ ${FOUNDATION_LIBRARY}
+ ${METAL_FRAMEWORK}
+ ${METALKIT_FRAMEWORK}
+ )
+endif()
+if (LLAMA_BLAS)
+ if (LLAMA_STATIC)
+ set(BLA_STATIC ON)
+ endif()
+ if ($(CMAKE_VERSION) VERSION_GREATER_EQUAL 3.22)
+ set(BLA_SIZEOF_INTEGER 8)
+ endif()
+
+ set(BLA_VENDOR ${LLAMA_BLAS_VENDOR})
+ find_package(BLAS)
+
+ if (BLAS_FOUND)
+ message(STATUS "BLAS found, Libraries: ${BLAS_LIBRARIES}")
+
+ if ("${BLAS_INCLUDE_DIRS}" STREQUAL "")
+ # BLAS_INCLUDE_DIRS is missing in FindBLAS.cmake.
+ # see https://gitlab.kitware.com/cmake/cmake/-/issues/20268
+ find_package(PkgConfig REQUIRED)
+ if (${LLAMA_BLAS_VENDOR} MATCHES "Generic")
+ pkg_check_modules(DepBLAS REQUIRED blas)
+ elseif (${LLAMA_BLAS_VENDOR} MATCHES "OpenBLAS")
+ pkg_check_modules(DepBLAS REQUIRED openblas)
+ elseif (${LLAMA_BLAS_VENDOR} MATCHES "FLAME")
+ pkg_check_modules(DepBLAS REQUIRED blis)
+ elseif (${LLAMA_BLAS_VENDOR} MATCHES "ATLAS")
+ pkg_check_modules(DepBLAS REQUIRED blas-atlas)
+ elseif (${LLAMA_BLAS_VENDOR} MATCHES "FlexiBLAS")
+ pkg_check_modules(DepBLAS REQUIRED flexiblas_api)
+ elseif (${LLAMA_BLAS_VENDOR} MATCHES "Intel")
+ # all Intel* libraries share the same include path
+ pkg_check_modules(DepBLAS REQUIRED mkl-sdl)
+ elseif (${LLAMA_BLAS_VENDOR} MATCHES "NVHPC")
+ # this doesn't provide pkg-config
+ # suggest to assign BLAS_INCLUDE_DIRS on your own
+ if ("${NVHPC_VERSION}" STREQUAL "")
+ message(WARNING "Better to set NVHPC_VERSION")
+ else()
+ set(DepBLAS_FOUND ON)
+ set(DepBLAS_INCLUDE_DIRS "/opt/nvidia/hpc_sdk/${CMAKE_SYSTEM_NAME}_${CMAKE_SYSTEM_PROCESSOR}/${NVHPC_VERSION}/math_libs/include")
+ endif()
+ endif()
+ if (DepBLAS_FOUND)
+ set(BLAS_INCLUDE_DIRS ${DepBLAS_INCLUDE_DIRS})
+ else()
+ message(WARNING "BLAS_INCLUDE_DIRS neither been provided nor been automatically"
+ " detected by pkgconfig, trying to find cblas.h from possible paths...")
+ find_path(BLAS_INCLUDE_DIRS
+ NAMES cblas.h
+ HINTS
+ /usr/include
+ /usr/local/include
+ /usr/include/openblas
+ /opt/homebrew/opt/openblas/include
+ /usr/local/opt/openblas/include
+ /usr/include/x86_64-linux-gnu/openblas/include
+ )
+ endif()
+ endif()
+
+ message(STATUS "BLAS found, Includes: ${BLAS_INCLUDE_DIRS}")
+ add_compile_options(${BLAS_LINKER_FLAGS})
+ add_compile_definitions(GGML_USE_OPENBLAS)
+ if (${BLAS_INCLUDE_DIRS} MATCHES "mkl" AND (${LLAMA_BLAS_VENDOR} MATCHES "Generic" OR ${LLAMA_BLAS_VENDOR} MATCHES "Intel"))
+ add_compile_definitions(GGML_BLAS_USE_MKL)
+ endif()
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ${BLAS_LIBRARIES})
+ set(LLAMA_EXTRA_INCLUDES ${LLAMA_EXTRA_INCLUDES} ${BLAS_INCLUDE_DIRS})
+
+ else()
+ message(WARNING "BLAS not found, please refer to "
+ "https://cmake.org/cmake/help/latest/module/FindBLAS.html#blas-lapack-vendors"
+ " to set correct LLAMA_BLAS_VENDOR")
+ endif()
+endif()
+
+if (LLAMA_QKK_64)
+ add_compile_definitions(GGML_QKK_64)
+endif()
+
+if (LLAMA_CUBLAS)
+ cmake_minimum_required(VERSION 3.17)
+
+ find_package(CUDAToolkit)
+ if (CUDAToolkit_FOUND)
+ message(STATUS "cuBLAS found")
+
+ enable_language(CUDA)
+
+ set(GGML_HEADERS_CUDA ggml-cuda.h)
+ set(GGML_SOURCES_CUDA ggml-cuda.cu)
+
+ add_compile_definitions(GGML_USE_CUBLAS)
+# if (LLAMA_CUDA_CUBLAS)
+# add_compile_definitions(GGML_CUDA_CUBLAS)
+# endif()
+ if (LLAMA_CUDA_FORCE_DMMV)
+ add_compile_definitions(GGML_CUDA_FORCE_DMMV)
+ endif()
+ if (LLAMA_CUDA_FORCE_MMQ)
+ add_compile_definitions(GGML_CUDA_FORCE_MMQ)
+ endif()
+ add_compile_definitions(GGML_CUDA_DMMV_X=${LLAMA_CUDA_DMMV_X})
+ add_compile_definitions(GGML_CUDA_MMV_Y=${LLAMA_CUDA_MMV_Y})
+ if (DEFINED LLAMA_CUDA_DMMV_Y)
+ add_compile_definitions(GGML_CUDA_MMV_Y=${LLAMA_CUDA_DMMV_Y}) # for backwards compatibility
+ endif()
+ if (LLAMA_CUDA_F16 OR LLAMA_CUDA_DMMV_F16)
+ add_compile_definitions(GGML_CUDA_F16)
+ endif()
+ add_compile_definitions(K_QUANTS_PER_ITERATION=${LLAMA_CUDA_KQUANTS_ITER})
+ add_compile_definitions(GGML_CUDA_PEER_MAX_BATCH_SIZE=${LLAMA_CUDA_PEER_MAX_BATCH_SIZE})
+
+ if (LLAMA_STATIC)
+ if (WIN32)
+ # As of 12.3.1 CUDA Tookit for Windows does not offer a static cublas library
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} CUDA::cudart_static CUDA::cublas CUDA::cublasLt)
+ else ()
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} CUDA::cudart_static CUDA::cublas_static CUDA::cublasLt_static)
+ endif()
+ else()
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} CUDA::cudart CUDA::cublas CUDA::cublasLt)
+ endif()
+
+ if (NOT DEFINED CMAKE_CUDA_ARCHITECTURES)
+ # 52 == lowest CUDA 12 standard
+ # 60 == f16 CUDA intrinsics
+ # 61 == integer CUDA intrinsics
+ # 70 == compute capability at which unrolling a loop in mul_mat_q kernels is faster
+ if (LLAMA_CUDA_F16 OR LLAMA_CUDA_DMMV_F16)
+ set(CMAKE_CUDA_ARCHITECTURES "60;61;70") # needed for f16 CUDA intrinsics
+ else()
+ set(CMAKE_CUDA_ARCHITECTURES "52;61;70") # lowest CUDA 12 standard + lowest for integer intrinsics
+ #set(CMAKE_CUDA_ARCHITECTURES "") # use this to compile much faster, but only F16 models work
+ endif()
+ endif()
+ message(STATUS "Using CUDA architectures: ${CMAKE_CUDA_ARCHITECTURES}")
+
+ else()
+ message(WARNING "cuBLAS not found")
+ endif()
+endif()
+
+if (LLAMA_MPI)
+ cmake_minimum_required(VERSION 3.10)
+ find_package(MPI)
+ if (MPI_C_FOUND)
+ message(STATUS "MPI found")
+ set(GGML_HEADERS_MPI ggml-mpi.h)
+ set(GGML_SOURCES_MPI ggml-mpi.c ggml-mpi.h)
+ add_compile_definitions(GGML_USE_MPI)
+ add_compile_definitions(${MPI_C_COMPILE_DEFINITIONS})
+ if (NOT MSVC)
+ add_compile_options(-Wno-cast-qual)
+ endif()
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ${MPI_C_LIBRARIES})
+ set(LLAMA_EXTRA_INCLUDES ${LLAMA_EXTRA_INCLUDES} ${MPI_C_INCLUDE_DIRS})
+ # Even if you're only using the C header, C++ programs may bring in MPI
+ # C++ functions, so more linkage is needed
+ if (MPI_CXX_FOUND)
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ${MPI_CXX_LIBRARIES})
+ endif()
+ else()
+ message(WARNING "MPI not found")
+ endif()
+endif()
+
+if (LLAMA_CLBLAST)
+ find_package(CLBlast)
+ if (CLBlast_FOUND)
+ message(STATUS "CLBlast found")
+
+ set(GGML_HEADERS_OPENCL ggml-opencl.h)
+ set(GGML_SOURCES_OPENCL ggml-opencl.cpp)
+
+ add_compile_definitions(GGML_USE_CLBLAST)
+
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} clblast)
+ else()
+ message(WARNING "CLBlast not found")
+ endif()
+endif()
+
+if (LLAMA_HIPBLAS)
+ list(APPEND CMAKE_PREFIX_PATH /opt/rocm)
+
+ if (NOT ${CMAKE_C_COMPILER_ID} MATCHES "Clang")
+ message(WARNING "Only LLVM is supported for HIP, hint: CC=/opt/rocm/llvm/bin/clang")
+ endif()
+ if (NOT ${CMAKE_CXX_COMPILER_ID} MATCHES "Clang")
+ message(WARNING "Only LLVM is supported for HIP, hint: CXX=/opt/rocm/llvm/bin/clang++")
+ endif()
+
+ find_package(hip)
+ find_package(hipblas)
+ find_package(rocblas)
+
+ if (${hipblas_FOUND} AND ${hip_FOUND})
+ message(STATUS "HIP and hipBLAS found")
+ add_compile_definitions(GGML_USE_HIPBLAS GGML_USE_CUBLAS)
+ add_library(ggml-rocm OBJECT ggml-cuda.cu ggml-cuda.h)
+ if (BUILD_SHARED_LIBS)
+ set_target_properties(ggml-rocm PROPERTIES POSITION_INDEPENDENT_CODE ON)
+ endif()
+ if (LLAMA_CUDA_FORCE_DMMV)
+ target_compile_definitions(ggml-rocm PRIVATE GGML_CUDA_FORCE_DMMV)
+ endif()
+ if (LLAMA_CUDA_FORCE_MMQ)
+ target_compile_definitions(ggml-rocm PRIVATE GGML_CUDA_FORCE_MMQ)
+ endif()
+ target_compile_definitions(ggml-rocm PRIVATE GGML_CUDA_DMMV_X=${LLAMA_CUDA_DMMV_X})
+ target_compile_definitions(ggml-rocm PRIVATE GGML_CUDA_MMV_Y=${LLAMA_CUDA_MMV_Y})
+ target_compile_definitions(ggml-rocm PRIVATE K_QUANTS_PER_ITERATION=${LLAMA_CUDA_KQUANTS_ITER})
+ set_source_files_properties(ggml-cuda.cu PROPERTIES LANGUAGE CXX)
+ target_link_libraries(ggml-rocm PRIVATE hip::device PUBLIC hip::host roc::rocblas roc::hipblas)
+
+ if (LLAMA_STATIC)
+ message(FATAL_ERROR "Static linking not supported for HIP/ROCm")
+ endif()
+ set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ggml-rocm)
+ else()
+ message(WARNING "hipBLAS or HIP not found. Try setting CMAKE_PREFIX_PATH=/opt/rocm")
+ endif()
+endif()
+
+function(get_flags CCID CCVER)
+ set(C_FLAGS "")
+ set(CXX_FLAGS "")
+
+ if (CCID MATCHES "Clang")
+ set(C_FLAGS -Wunreachable-code-break -Wunreachable-code-return)
+ set(CXX_FLAGS -Wunreachable-code-break -Wunreachable-code-return -Wmissing-prototypes -Wextra-semi)
+
+ if (
+ (CCID STREQUAL "Clang" AND CCVER VERSION_GREATER_EQUAL 3.8.0) OR
+ (CCID STREQUAL "AppleClang" AND CCVER VERSION_GREATER_EQUAL 7.3.0)
+ )
+ set(C_FLAGS ${C_FLAGS} -Wdouble-promotion)
+ endif()
+ elseif (CCID STREQUAL "GNU")
+ set(C_FLAGS -Wdouble-promotion)
+ set(CXX_FLAGS -Wno-array-bounds)
+
+ if (CCVER VERSION_GREATER_EQUAL 7.1.0)
+ set(CXX_FLAGS ${CXX_FLAGS} -Wno-format-truncation)
+ endif()
+ if (CCVER VERSION_GREATER_EQUAL 8.1.0)
+ set(CXX_FLAGS ${CXX_FLAGS} -Wextra-semi)
+ endif()
+ endif()
+
+ set(GF_C_FLAGS ${C_FLAGS} PARENT_SCOPE)
+ set(GF_CXX_FLAGS ${CXX_FLAGS} PARENT_SCOPE)
+endfunction()
+
+if (LLAMA_ALL_WARNINGS)
+ if (NOT MSVC)
+ set(WARNING_FLAGS -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function)
+ set(C_FLAGS -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes
+ -Werror=implicit-int -Werror=implicit-function-declaration)
+ set(CXX_FLAGS -Wmissing-declarations -Wmissing-noreturn)
+
+ set(C_FLAGS ${WARNING_FLAGS} ${C_FLAGS})
+ set(CXX_FLAGS ${WARNING_FLAGS} ${CXX_FLAGS})
+
+ get_flags(${CMAKE_CXX_COMPILER_ID} ${CMAKE_CXX_COMPILER_VERSION})
+
+ add_compile_options("$<$:${C_FLAGS};${GF_C_FLAGS}>"
+ "$<$:${CXX_FLAGS};${GF_CXX_FLAGS}>")
+ else()
+ # todo : msvc
+ set(C_FLAGS "")
+ set(CXX_FLAGS "")
+ endif()
+endif()
+
+if (LLAMA_CUBLAS)
+ set(CUDA_FLAGS ${CXX_FLAGS} -use_fast_math)
+ if (NOT MSVC)
+ set(CUDA_FLAGS ${CUDA_FLAGS} -Wno-pedantic)
+ endif()
+
+ if (LLAMA_ALL_WARNINGS AND NOT MSVC)
+ set(NVCC_CMD ${CMAKE_CUDA_COMPILER} .c)
+ if (NOT CMAKE_CUDA_HOST_COMPILER STREQUAL "")
+ set(NVCC_CMD ${NVCC_CMD} -ccbin ${CMAKE_CUDA_HOST_COMPILER})
+ endif()
+
+ execute_process(
+ COMMAND ${NVCC_CMD} -Xcompiler --version
+ OUTPUT_VARIABLE CUDA_CCFULLVER
+ ERROR_QUIET
+ )
+
+ if (NOT CUDA_CCFULLVER MATCHES clang)
+ set(CUDA_CCID "GNU")
+ execute_process(
+ COMMAND ${NVCC_CMD} -Xcompiler "-dumpfullversion -dumpversion"
+ OUTPUT_VARIABLE CUDA_CCVER
+ ERROR_QUIET
+ )
+ else()
+ if (CUDA_CCFULLVER MATCHES Apple)
+ set(CUDA_CCID "AppleClang")
+ else()
+ set(CUDA_CCID "Clang")
+ endif()
+ string(REGEX REPLACE "^.* version ([0-9.]*).*$" "\\1" CUDA_CCVER ${CUDA_CCFULLVER})
+ endif()
+
+ message("-- CUDA host compiler is ${CUDA_CCID} ${CUDA_CCVER}")
+
+ get_flags(${CUDA_CCID} ${CUDA_CCVER})
+ list(JOIN GF_CXX_FLAGS " " CUDA_CXX_FLAGS) # pass host compiler flags as a single argument
+ if (NOT CUDA_CXX_FLAGS STREQUAL "")
+ set(CUDA_FLAGS ${CUDA_FLAGS} -Xcompiler ${CUDA_CXX_FLAGS})
+ endif()
+ endif()
+
+ add_compile_options("$<$:${CUDA_FLAGS}>")
+endif()
+
+if (WIN32)
+ add_compile_definitions(_CRT_SECURE_NO_WARNINGS)
+
+ if (BUILD_SHARED_LIBS)
+ set(CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS ON)
+ endif()
+endif()
+
+if (LLAMA_LTO)
+ include(CheckIPOSupported)
+ check_ipo_supported(RESULT result OUTPUT output)
+ if (result)
+ set(CMAKE_INTERPROCEDURAL_OPTIMIZATION TRUE)
+ else()
+ message(WARNING "IPO is not supported: ${output}")
+ endif()
+endif()
+
+# this version of Apple ld64 is buggy
+execute_process(
+ COMMAND ${CMAKE_C_COMPILER} ${CMAKE_EXE_LINKER_FLAGS} -Wl,-v
+ ERROR_VARIABLE output
+ OUTPUT_QUIET
+)
+if (output MATCHES "dyld-1015\.7")
+ add_compile_definitions(HAVE_BUGGY_APPLE_LINKER)
+endif()
+
+# Architecture specific
+# TODO: probably these flags need to be tweaked on some architectures
+# feel free to update the Makefile for your architecture and send a pull request or issue
+message(STATUS "CMAKE_SYSTEM_PROCESSOR: ${CMAKE_SYSTEM_PROCESSOR}")
+if (MSVC)
+ string(TOLOWER "${CMAKE_GENERATOR_PLATFORM}" CMAKE_GENERATOR_PLATFORM_LWR)
+ message(STATUS "CMAKE_GENERATOR_PLATFORM: ${CMAKE_GENERATOR_PLATFORM}")
+else ()
+ set(CMAKE_GENERATOR_PLATFORM_LWR "")
+endif ()
+
+if (NOT MSVC)
+ if (LLAMA_STATIC)
+ add_link_options(-static)
+ if (MINGW)
+ add_link_options(-static-libgcc -static-libstdc++)
+ endif()
+ endif()
+ if (LLAMA_GPROF)
+ add_compile_options(-pg)
+ endif()
+endif()
+
+if ((${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm") OR (${CMAKE_SYSTEM_PROCESSOR} MATCHES "aarch64") OR ("${CMAKE_GENERATOR_PLATFORM_LWR}" MATCHES "arm64"))
+ message(STATUS "ARM detected")
+ if (MSVC)
+ add_compile_definitions(__ARM_NEON)
+ add_compile_definitions(__ARM_FEATURE_FMA)
+ add_compile_definitions(__ARM_FEATURE_DOTPROD)
+ # add_compile_definitions(__ARM_FEATURE_FP16_VECTOR_ARITHMETIC) # MSVC doesn't support vdupq_n_f16, vld1q_f16, vst1q_f16
+ add_compile_definitions(__aarch64__) # MSVC defines _M_ARM64 instead
+ else()
+ check_cxx_compiler_flag(-mfp16-format=ieee COMPILER_SUPPORTS_FP16_FORMAT_I3E)
+ if (NOT "${COMPILER_SUPPORTS_FP16_FORMAT_I3E}" STREQUAL "")
+ add_compile_options(-mfp16-format=ieee)
+ endif()
+ if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "armv6")
+ # Raspberry Pi 1, Zero
+ add_compile_options(-mfpu=neon-fp-armv8 -mno-unaligned-access)
+ endif()
+ if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "armv7")
+ # Raspberry Pi 2
+ add_compile_options(-mfpu=neon-fp-armv8 -mno-unaligned-access -funsafe-math-optimizations)
+ endif()
+ if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "armv8")
+ # Raspberry Pi 3, 4, Zero 2 (32-bit)
+ add_compile_options(-mno-unaligned-access)
+ endif()
+ endif()
+elseif (${CMAKE_SYSTEM_PROCESSOR} MATCHES "^(x86_64|i686|AMD64)$" OR "${CMAKE_GENERATOR_PLATFORM_LWR}" MATCHES "^(x86_64|i686|amd64|x64)$" )
+ message(STATUS "x86 detected")
+ if (MSVC)
+ # instruction set detection for MSVC only
+ if (LLAMA_NATIVE)
+ include(${llama.cpp_SOURCE_DIR}/cmake/FindSIMD.cmake)
+ endif ()
+ if (LLAMA_AVX512)
+ add_compile_options($<$:/arch:AVX512>)
+ add_compile_options($<$:/arch:AVX512>)
+ # MSVC has no compile-time flags enabling specific
+ # AVX512 extensions, neither it defines the
+ # macros corresponding to the extensions.
+ # Do it manually.
+ if (LLAMA_AVX512_VBMI)
+ add_compile_definitions($<$:__AVX512VBMI__>)
+ add_compile_definitions($<$:__AVX512VBMI__>)
+ endif()
+ if (LLAMA_AVX512_VNNI)
+ add_compile_definitions($<$:__AVX512VNNI__>)
+ add_compile_definitions($<$:__AVX512VNNI__>)
+ endif()
+ elseif (LLAMA_AVX2)
+ add_compile_options($<$:/arch:AVX2>)
+ add_compile_options($<$:/arch:AVX2>)
+ elseif (LLAMA_AVX)
+ add_compile_options($<$:/arch:AVX>)
+ add_compile_options($<$:/arch:AVX>)
+ endif()
+ else()
+ if (LLAMA_NATIVE)
+ add_compile_options(-march=native)
+ endif()
+ if (LLAMA_F16C)
+ add_compile_options(-mf16c)
+ endif()
+ if (LLAMA_FMA)
+ add_compile_options(-mfma)
+ endif()
+ if (LLAMA_AVX)
+ add_compile_options(-mavx)
+ endif()
+ if (LLAMA_AVX2)
+ add_compile_options(-mavx2)
+ endif()
+ if (LLAMA_AVX512)
+ add_compile_options(-mavx512f)
+ add_compile_options(-mavx512bw)
+ endif()
+ if (LLAMA_AVX512_VBMI)
+ add_compile_options(-mavx512vbmi)
+ endif()
+ if (LLAMA_AVX512_VNNI)
+ add_compile_options(-mavx512vnni)
+ endif()
+ endif()
+elseif (${CMAKE_SYSTEM_PROCESSOR} MATCHES "ppc64")
+ message(STATUS "PowerPC detected")
+ if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "ppc64le")
+ add_compile_options(-mcpu=powerpc64le)
+ else()
+ add_compile_options(-mcpu=native -mtune=native)
+ #TODO: Add targets for Power8/Power9 (Altivec/VSX) and Power10(MMA) and query for big endian systems (ppc64/le/be)
+ endif()
+else()
+ message(STATUS "Unknown architecture")
+endif()
+
+if (MINGW)
+ # Target Windows 8 for PrefetchVirtualMemory
+ add_compile_definitions(_WIN32_WINNT=0x602)
+endif()
+
+#
+# POSIX conformance
+#
+
+# clock_gettime came in POSIX.1b (1993)
+# CLOCK_MONOTONIC came in POSIX.1-2001 / SUSv3 as optional
+# posix_memalign came in POSIX.1-2001 / SUSv3
+# M_PI is an XSI extension since POSIX.1-2001 / SUSv3, came in XPG1 (1985)
+add_compile_definitions(_XOPEN_SOURCE=600)
+
+# Somehow in OpenBSD whenever POSIX conformance is specified
+# some string functions rely on locale_t availability,
+# which was introduced in POSIX.1-2008, forcing us to go higher
+if (CMAKE_SYSTEM_NAME MATCHES "OpenBSD")
+ remove_definitions(-D_XOPEN_SOURCE=600)
+ add_compile_definitions(_XOPEN_SOURCE=700)
+endif()
+
+# Data types, macros and functions related to controlling CPU affinity and
+# some memory allocation are available on Linux through GNU extensions in libc
+if (CMAKE_SYSTEM_NAME MATCHES "Linux")
+ add_compile_definitions(_GNU_SOURCE)
+endif()
+
+# RLIMIT_MEMLOCK came in BSD, is not specified in POSIX.1,
+# and on macOS its availability depends on enabling Darwin extensions
+# similarly on DragonFly, enabling BSD extensions is necessary
+if (
+ CMAKE_SYSTEM_NAME MATCHES "Darwin" OR
+ CMAKE_SYSTEM_NAME MATCHES "iOS" OR
+ CMAKE_SYSTEM_NAME MATCHES "tvOS" OR
+ CMAKE_SYSTEM_NAME MATCHES "DragonFly"
+)
+ add_compile_definitions(_DARWIN_C_SOURCE)
+endif()
+
+# alloca is a non-standard interface that is not visible on BSDs when
+# POSIX conformance is specified, but not all of them provide a clean way
+# to enable it in such cases
+if (CMAKE_SYSTEM_NAME MATCHES "FreeBSD")
+ add_compile_definitions(__BSD_VISIBLE)
+endif()
+if (CMAKE_SYSTEM_NAME MATCHES "NetBSD")
+ add_compile_definitions(_NETBSD_SOURCE)
+endif()
+if (CMAKE_SYSTEM_NAME MATCHES "OpenBSD")
+ add_compile_definitions(_BSD_SOURCE)
+endif()
diff --git a/engines/llama/build.cmd b/engines/llama/build.cmd
new file mode 100644
index 00000000000..83ccf65198c
--- /dev/null
+++ b/engines/llama/build.cmd
@@ -0,0 +1,23 @@
+@rem https://chocolatey.org/docs/installation#install-with-cmdexe
+@rem to install rust java etc..
+@rem choco install jdk17 -y
+
+set VERSION="%1"
+
+if exist "llama.cpp" (
+ echo Found "llama.cpp"
+) else (
+ git clone https://github.com/ggerganov/llama.cpp.git -b %VERSION%
+)
+
+if exist build rd /q /s build
+md build\classes
+cd build
+javac -classpath "%2" -sourcepath ..\src\main\java\ ..\src\main\java\ai\djl\llama\jni\LlamaLibrary.java -h include -d classes
+cmake ..
+cmake --build . --config Release
+
+@rem for nightly ci
+md jnilib\win-x86_64
+copy Release\djl_llama.dll jnilib\win-x86_64\
+copy bin\Release\llama.dll jnilib\win-x86_64\
diff --git a/engines/llama/build.gradle b/engines/llama/build.gradle
new file mode 100644
index 00000000000..73feb62fc5e
--- /dev/null
+++ b/engines/llama/build.gradle
@@ -0,0 +1,108 @@
+import java.util.zip.GZIPInputStream
+
+group "ai.djl.llama"
+
+dependencies {
+ api project(":api")
+
+ testImplementation project(":testing")
+ testImplementation "org.slf4j:slf4j-simple:${slf4j_version}"
+}
+
+compileJava.dependsOn(processResources)
+
+processResources {
+ outputs.dir file("${project.projectDir}/build/classes/java/main/native/lib")
+ doLast {
+ def url = "https://publish.djl.ai/llama/${llamacpp_version}/jnilib/${djl_version}"
+ def files = new String[]{
+ "linux-x86_64/libdjl_llama.so",
+ "linux-x86_64/libllama.so",
+ "linux-aarch64/libdjl_llama.so",
+ "linux-aarch64/libllama.so",
+ "osx-x86_64/libdjl_llama.dylib",
+ "osx-x86_64/libllama.dylib",
+ "osx-x86_64/ggml-metal.metal",
+ "osx-aarch64/libdjl_llama.dylib",
+ "osx-aarch64/libllama.dylib",
+ "osx-aarch64/ggml-metal.metal",
+ "win-x86_64/djl_llama.dll",
+ "win-x86_64/llama.dll",
+ }
+ def jnilibDir = "${project.projectDir}/jnilib/${djl_version}"
+ files.each { entry ->
+ def file = new File("${jnilibDir}/${entry}")
+ if (file.exists()) {
+ project.logger.lifecycle("prebuilt or cached file found for ${entry}")
+ } else if (!project.hasProperty("jni")) {
+ project.logger.lifecycle("Downloading ${url}/${entry}")
+ file.getParentFile().mkdirs()
+ def downloadPath = new URL("${url}/${entry}")
+ downloadPath.withInputStream { i -> file.withOutputStream { it << i } }
+ }
+ }
+ copy {
+ from jnilibDir
+ into "${project.projectDir}/build/classes/java/main/native/lib"
+ }
+
+ // write properties
+ def propFile = file("${project.projectDir}/build/classes/java/main/native/lib/llama.properties")
+ propFile.text = "version=${llamacpp_version}-${version}\n"
+
+ url = "https://mlrepo.djl.ai/model/nlp/text_generation/ai/djl/huggingface/gguf/models.json.gz"
+ def prefix = "${project.projectDir}/build/classes/java/main/nlp/text_generation"
+ def file = new File("${prefix}/ai.djl.huggingface.gguf.json")
+ if (file.exists()) {
+ project.logger.lifecycle("gguf index file already exists")
+ } else {
+ project.logger.lifecycle("Downloading gguf index file")
+ file.getParentFile().mkdirs()
+ def downloadPath = new URL(url)
+ downloadPath.withInputStream { i -> file.withOutputStream { it << new GZIPInputStream(i) } }
+ }
+ }
+}
+
+publishing {
+ publications {
+ maven(MavenPublication) {
+ pom {
+ name = "DJL NLP utilities for Llama.cpp"
+ description = "Deep Java Library (DJL) NLP utilities for llama.cpp"
+ url = "http://www.djl.ai/engines/${project.name}"
+ }
+ }
+ }
+}
+
+apply from: file("${rootProject.projectDir}/tools/gradle/cpp-formatter.gradle")
+
+tasks.register('compileJNI') {
+ doFirst {
+ def cp = configurations.runtimeClasspath.resolve().stream().map {f->f.toString()}.toList()
+ if (System.properties['os.name'].toLowerCase(Locale.ROOT).contains("mac")
+ || System.properties['os.name'].toLowerCase(Locale.ROOT).contains("linux")) {
+ def arch = System.properties["os.arch"] == "amd64" ? "x86_64" : System.properties["os.arch"]
+ exec {
+ commandLine "bash", "build.sh", llamacpp_version, arch, String.join(":", cp)
+ }
+ } else {
+ exec {
+ commandLine "${project.projectDir}/build.cmd", llamacpp_version, String.join(";", cp)
+ }
+ }
+
+ // for ci to upload to S3
+ def ciDir = "${project.projectDir}/jnilib/${djl_version}/"
+ copy {
+ from "${project.projectDir}/build/jnilib"
+ into ciDir
+ }
+ delete System.getProperty("user.home") + "/.djl.ai/llama"
+ }
+}
+
+clean.doFirst {
+ delete System.getProperty("user.home") + "/.djl.ai/llama"
+}
diff --git a/engines/llama/build.sh b/engines/llama/build.sh
new file mode 100755
index 00000000000..1b6e7d4e1fa
--- /dev/null
+++ b/engines/llama/build.sh
@@ -0,0 +1,45 @@
+#!/usr/bin/env bash
+
+set -e
+WORK_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+NUM_PROC=1
+if [[ -n $(command -v nproc) ]]; then
+ NUM_PROC=$(nproc)
+elif [[ -n $(command -v sysctl) ]]; then
+ NUM_PROC=$(sysctl -n hw.ncpu)
+fi
+PLATFORM=$(uname | tr '[:upper:]' '[:lower:]')
+
+VERSION=$1
+ARCH=$2
+CLASSPATH=$3
+
+pushd $WORK_DIR
+if [ ! -d "llama.cpp" ]; then
+ git clone https://github.com/ggerganov/llama.cpp.git -b $VERSION
+fi
+
+if [ ! -d "build" ]; then
+ mkdir build
+fi
+cd build
+
+rm -rf classes
+mkdir classes
+javac -classpath $CLASSPATH -sourcepath ../src/main/java/:../../../api/src/main/java ../src/main/java/ai/djl/llama/jni/LlamaLibrary.java -h include -d classes
+cmake ..
+cmake --build . --config Release -- -j "${NUM_PROC}"
+
+popd
+
+# for nightly ci
+if [[ $PLATFORM == 'darwin' ]]; then
+ mkdir -p build/jnilib/osx-$ARCH
+ cp -f build/libdjl_llama.dylib build/jnilib/osx-$ARCH/
+ cp -f build/llama.cpp/libllama.dylib build/jnilib/osx-$ARCH/
+ cp -f llama.cpp/ggml-metal.metal build/jnilib/osx-$ARCH/
+elif [[ $PLATFORM == 'linux' ]]; then
+ mkdir -p build/jnilib/linux-$ARCH
+ cp -f build/libdjl_llama.so build/jnilib/linux-$ARCH/
+ cp -f build/llama.cpp/libllama.so build/jnilib/linux-$ARCH/
+fi
diff --git a/engines/llama/gradlew b/engines/llama/gradlew
new file mode 120000
index 00000000000..343e0d2caa4
--- /dev/null
+++ b/engines/llama/gradlew
@@ -0,0 +1 @@
+../../gradlew
\ No newline at end of file
diff --git a/engines/llama/src/main/java/ai/djl/llama/engine/LlamaEngine.java b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaEngine.java
new file mode 100644
index 00000000000..75fdf5a5d8c
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaEngine.java
@@ -0,0 +1,110 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+
+package ai.djl.llama.engine;
+
+import ai.djl.Device;
+import ai.djl.Model;
+import ai.djl.engine.Engine;
+import ai.djl.engine.EngineException;
+import ai.djl.llama.jni.LibUtils;
+import ai.djl.ndarray.NDManager;
+import ai.djl.util.Platform;
+import ai.djl.util.passthrough.PassthroughNDManager;
+
+/** The {@code LlamaEngine} is an implementation of the {@link Engine} based on the llama.cpp. */
+public final class LlamaEngine extends Engine {
+
+ public static final String ENGINE_NAME = "Llama";
+ static final int RANK = 10;
+
+ private Engine alternativeEngine;
+ private boolean initialized;
+
+ private LlamaEngine() {
+ try {
+ LibUtils.loadLibrary();
+ } catch (EngineException e) { // NOPMD
+ throw e;
+ } catch (Throwable t) {
+ throw new EngineException("Failed to load llama.cpp native library", t);
+ }
+ }
+
+ static Engine newInstance() {
+ return new LlamaEngine();
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public Engine getAlternativeEngine() {
+ if (!initialized && !Boolean.getBoolean("ai.djl.llama.disable_alternative")) {
+ Engine engine = Engine.getInstance();
+ if (engine.getRank() < getRank()) {
+ // alternativeEngine should not have the same rank as Llama
+ alternativeEngine = engine;
+ }
+ initialized = true;
+ }
+ return alternativeEngine;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public String getEngineName() {
+ return ENGINE_NAME;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public int getRank() {
+ return RANK;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public String getVersion() {
+ Platform platform = Platform.detectPlatform("llama");
+ return platform.getVersion();
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public boolean hasCapability(String capability) {
+ return false;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public Model newModel(String name, Device device) {
+ return new LlamaModel(name, newBaseManager(device));
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public NDManager newBaseManager() {
+ return newBaseManager(null);
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public NDManager newBaseManager(Device device) {
+ return PassthroughNDManager.INSTANCE;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public String toString() {
+ return getEngineName() + ':' + getVersion() + ", " + getEngineName() + ':' + getVersion();
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/engine/LlamaEngineProvider.java b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaEngineProvider.java
new file mode 100644
index 00000000000..ca5cc646498
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaEngineProvider.java
@@ -0,0 +1,42 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.engine;
+
+import ai.djl.engine.Engine;
+import ai.djl.engine.EngineProvider;
+
+/** {@code LlamaEngineProvider} is the Llama implementation of {@link EngineProvider}. */
+public class LlamaEngineProvider implements EngineProvider {
+
+ /** {@inheritDoc} */
+ @Override
+ public String getEngineName() {
+ return LlamaEngine.ENGINE_NAME;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public int getEngineRank() {
+ return LlamaEngine.RANK;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public Engine getEngine() {
+ return InstanceHolder.INSTANCE;
+ }
+
+ private static class InstanceHolder {
+ static final Engine INSTANCE = LlamaEngine.newInstance();
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/engine/LlamaInput.java b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaInput.java
new file mode 100644
index 00000000000..4b4d332fc9f
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaInput.java
@@ -0,0 +1,430 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.engine;
+
+import ai.djl.llama.jni.InputParameters;
+
+import com.google.gson.annotations.SerializedName;
+
+import java.util.Map;
+
+/** A class hold input data for Llama model. */
+public class LlamaInput {
+
+ private String inputs;
+ private String prefix;
+ private String suffix;
+ private Parameters parameters;
+
+ /**
+ * Returns the input prompt.
+ *
+ * @return the input prompt
+ */
+ public String getInputs() {
+ return inputs;
+ }
+
+ /**
+ * Sets the input prompt.
+ *
+ * @param inputs the input prompt
+ */
+ public void setInputs(String inputs) {
+ this.inputs = inputs;
+ }
+
+ /**
+ * Returns the prompt prefix.
+ *
+ * @return the prompt prefix
+ */
+ public String getPrefix() {
+ return prefix;
+ }
+
+ /**
+ * Sets the prompt prefix.
+ *
+ * @param prefix the prompt prefix
+ */
+ public void setPrefix(String prefix) {
+ this.prefix = prefix;
+ }
+
+ /**
+ * Returns the prompt suffix.
+ *
+ * @return the prompt suffix
+ */
+ public String getSuffix() {
+ return suffix;
+ }
+
+ /**
+ * Sets the prompt suffix.
+ *
+ * @param suffix the prompt suffix
+ */
+ public void setSuffix(String suffix) {
+ this.suffix = suffix;
+ }
+
+ /**
+ * Returns the input parameters.
+ *
+ * @return the input parameters
+ */
+ public Parameters getParameters() {
+ if (parameters == null) {
+ parameters = new Parameters();
+ }
+ return parameters;
+ }
+
+ /**
+ * Sets the input parameters.
+ *
+ * @param parameters the input parameters
+ */
+ public void setParameters(Parameters parameters) {
+ this.parameters = parameters;
+ }
+
+ /** The input parameters class. */
+ public static final class Parameters {
+
+ @SerializedName("max_new_tokens")
+ private int nPredict;
+
+ @SerializedName("number_keep")
+ private int nKeep;
+
+ @SerializedName("number_probabilities")
+ private int nProbs;
+
+ @SerializedName("top_k")
+ private int topK;
+
+ @SerializedName("top_p")
+ private float topP;
+
+ @SerializedName("tfs_z")
+ private float tfsZ;
+
+ @SerializedName("typical_p")
+ private float typicalP;
+
+ @SerializedName("temperature")
+ private float temperature;
+
+ @SerializedName("repeat_penalty")
+ private float repeatPenalty;
+
+ @SerializedName("repeat_last_n")
+ private int repeatLastN;
+
+ @SerializedName("frequency_penalty")
+ private float frequencyPenalty;
+
+ @SerializedName("presence_penalty")
+ private float presencePenalty;
+
+ @SerializedName("penalize_nl")
+ private boolean penalizeNl;
+
+ @SerializedName("ignore_eos")
+ private boolean ignoreEos;
+
+ @SerializedName("mirostat")
+ private int mirostat;
+
+ @SerializedName("mirostat_tau")
+ private float mirostatTau;
+
+ @SerializedName("mirostat_eta")
+ private float mirostatEta;
+
+ @SerializedName("number_beams")
+ private int nBeams;
+
+ @SerializedName("seed")
+ private int seed;
+
+ @SerializedName("logit_bias")
+ private Map logitBias;
+
+ @SerializedName("grammar")
+ private String grammar;
+
+ @SerializedName("anti_prompt")
+ private String[] antiPrompt;
+
+ /**
+ * Sets the max new tokens.
+ *
+ * @param maxNewTokens the max new tokens
+ */
+ public void setMaxNewTokens(int maxNewTokens) {
+ this.nPredict = maxNewTokens;
+ }
+
+ /**
+ * Sets the number of keep.
+ *
+ * @param nKeep the number of keep
+ */
+ public void setNumberKeep(int nKeep) {
+ this.nKeep = nKeep;
+ }
+
+ /**
+ * Sets the number of probabilities.
+ *
+ * @param nProbs the number of probabilities
+ */
+ public void setNumberProbabilities(int nProbs) {
+ this.nProbs = nProbs;
+ }
+
+ /**
+ * Sets the top K.
+ *
+ * @param topK the top K
+ */
+ public void setTopK(int topK) {
+ this.topK = topK;
+ }
+
+ /**
+ * Sets the top P.
+ *
+ * @param topP the top P
+ */
+ public void setTopP(float topP) {
+ this.topP = topP;
+ }
+
+ /**
+ * Sets the tfs Z.
+ *
+ * @param tfsZ the tfs Z
+ */
+ public void setTfsZ(float tfsZ) {
+ this.tfsZ = tfsZ;
+ }
+
+ /**
+ * Sets the typical P.
+ *
+ * @param typicalP the typical P
+ */
+ public void setTypicalP(float typicalP) {
+ this.typicalP = typicalP;
+ }
+
+ /**
+ * Sets the temperature.
+ *
+ * @param temperature the temperature
+ */
+ public void setTemperature(float temperature) {
+ this.temperature = temperature;
+ }
+
+ /**
+ * Sets the repeat penalty.
+ *
+ * @param repeatPenalty the repeat penalty
+ */
+ public void setRepeatPenalty(float repeatPenalty) {
+ this.repeatPenalty = repeatPenalty;
+ }
+
+ /**
+ * Sets the repeat last N.
+ *
+ * @param repeatLastN the repeat last N
+ */
+ public void setRepeatLastN(int repeatLastN) {
+ this.repeatLastN = repeatLastN;
+ }
+
+ /**
+ * Sets the frequency penalty.
+ *
+ * @param frequencyPenalty the frequency penalty
+ */
+ public void setFrequencyPenalty(float frequencyPenalty) {
+ this.frequencyPenalty = frequencyPenalty;
+ }
+
+ /**
+ * Sets the presence penalty.
+ *
+ * @param presencePenalty the presence penalty
+ */
+ public void setPresencePenalty(float presencePenalty) {
+ this.presencePenalty = presencePenalty;
+ }
+
+ /**
+ * Sets the penalize nl.
+ *
+ * @param penalizeNl the penalize nl
+ */
+ public void setPenalizeNl(boolean penalizeNl) {
+ this.penalizeNl = penalizeNl;
+ }
+
+ /**
+ * Sets if ignore EOS.
+ *
+ * @param ignoreEos if ignore EOS
+ */
+ public void setIgnoreEos(boolean ignoreEos) {
+ this.ignoreEos = ignoreEos;
+ }
+
+ /**
+ * Sets the mirostat.
+ *
+ * @param mirostat the mirostat
+ */
+ public void setMirostat(int mirostat) {
+ this.mirostat = mirostat;
+ }
+
+ /**
+ * Sets the mirostat TAU.
+ *
+ * @param mirostatTau the mirostat TAU
+ */
+ public void setMirostatTau(float mirostatTau) {
+ this.mirostatTau = mirostatTau;
+ }
+
+ /**
+ * Sets the mirostat ETA.
+ *
+ * @param mirostatEta the mirostat ETA
+ */
+ public void setMirostatEta(float mirostatEta) {
+ this.mirostatEta = mirostatEta;
+ }
+
+ /**
+ * Sets the number of beams.
+ *
+ * @param nBeams the number of beams
+ */
+ public void setNumberBeams(int nBeams) {
+ this.nBeams = nBeams;
+ }
+
+ /**
+ * Sets the seed.
+ *
+ * @param seed the seed
+ */
+ public void setSeed(int seed) {
+ this.seed = seed;
+ }
+
+ /**
+ * Sets the logit bias.
+ *
+ * @param logitBias the logit bias
+ */
+ public void setLogitBias(Map logitBias) {
+ this.logitBias = logitBias;
+ }
+
+ /**
+ * Sets the grammar template.
+ *
+ * @param grammar the grammar template
+ */
+ public void setGrammar(String grammar) {
+ this.grammar = grammar;
+ }
+
+ /**
+ * Sets the anti prompt.
+ *
+ * @param antiPrompt the anti prompt
+ */
+ public void setAntiPrompt(String[] antiPrompt) {
+ this.antiPrompt = antiPrompt;
+ }
+
+ /**
+ * Returns the {@link InputParameters} object.
+ *
+ * @return the {@link InputParameters} object
+ */
+ public InputParameters toInputParameters() {
+ setDefaultValue();
+ return new InputParameters(
+ nPredict,
+ nKeep,
+ nProbs,
+ topK,
+ topP,
+ tfsZ,
+ typicalP,
+ temperature,
+ repeatPenalty,
+ repeatLastN,
+ frequencyPenalty,
+ presencePenalty,
+ penalizeNl,
+ ignoreEos,
+ mirostat,
+ mirostatTau,
+ mirostatEta,
+ nBeams,
+ seed,
+ logitBias,
+ grammar,
+ antiPrompt);
+ }
+
+ private void setDefaultValue() {
+ if (nPredict == 0) {
+ nPredict = -1;
+ }
+ if (topK == 0) {
+ topK = 40;
+ }
+ if (topP == 0) {
+ topP = 0.95f;
+ }
+ if (tfsZ == 0) {
+ tfsZ = 1f;
+ }
+ if (typicalP == 0) {
+ typicalP = 1f;
+ }
+ if (temperature == 0) {
+ temperature = 0.8f;
+ }
+ if (repeatPenalty == 0) {
+ repeatPenalty = 1.10f;
+ }
+ if (repeatLastN == 0) {
+ repeatLastN = 64;
+ }
+ }
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/engine/LlamaModel.java b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaModel.java
new file mode 100644
index 00000000000..0ff3c6d70c0
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaModel.java
@@ -0,0 +1,112 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.engine;
+
+import ai.djl.BaseModel;
+import ai.djl.Model;
+import ai.djl.llama.jni.LlamaLibrary;
+import ai.djl.llama.jni.ModelParameters;
+import ai.djl.ndarray.NDManager;
+import ai.djl.ndarray.types.DataType;
+import ai.djl.nn.Blocks;
+
+import java.io.FileNotFoundException;
+import java.io.IOException;
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.util.Map;
+
+/** {@code LlamaModel} is the llama.cpp implementation of {@link Model}. */
+public class LlamaModel extends BaseModel {
+
+ private long handle = -1;
+
+ /**
+ * Constructs a new Model on a given device.
+ *
+ * @param name the model name
+ * @param manager the {@link NDManager} to holds the NDArray
+ */
+ LlamaModel(String name, NDManager manager) {
+ super(name);
+ this.manager = manager;
+ this.manager.setName("llamaModel");
+ dataType = DataType.FLOAT32;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void load(Path modelPath, String prefix, Map options) throws IOException {
+ setModelDir(modelPath);
+ wasLoaded = true;
+ if (block != null) {
+ throw new UnsupportedOperationException("Llama does not support dynamic blocks");
+ }
+
+ if (prefix == null) {
+ prefix = modelName;
+ }
+
+ // search for .onnx file with prefix, folder name or "model.onnx"
+ Path modelFile = findModelFile(prefix, modelDir.toFile().getName(), "model.gguf");
+ if (modelFile == null) {
+ throw new FileNotFoundException(".gguf file not found in: " + modelPath);
+ }
+
+ ModelParameters param = new ModelParameters(options);
+ handle = LlamaLibrary.loadModel(modelFile.toString(), param);
+ block = Blocks.identityBlock();
+ }
+
+ long getHandle() {
+ return handle;
+ }
+
+ private Path findModelFile(String... prefixes) {
+ if (Files.isRegularFile(modelDir)) {
+ Path file = modelDir;
+ modelDir = modelDir.getParent();
+ String fileName = file.toFile().getName();
+ if (fileName.endsWith(".gguf")) {
+ modelName = fileName.substring(0, fileName.length() - 5);
+ } else {
+ modelName = fileName;
+ }
+ return file;
+ }
+ for (String prefix : prefixes) {
+ Path modelFile = modelDir.resolve(prefix);
+ if (Files.isRegularFile(modelFile)) {
+ return modelFile;
+ }
+ if (!prefix.endsWith(".gguf")) {
+ modelFile = modelDir.resolve(prefix + ".gguf");
+ if (Files.isRegularFile(modelFile)) {
+ return modelFile;
+ }
+ }
+ }
+ return null;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void close() {
+ if (handle == -1) {
+ return;
+ }
+ LlamaLibrary.delete(handle);
+ handle = -1;
+ super.close();
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/engine/LlamaTranslator.java b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaTranslator.java
new file mode 100644
index 00000000000..c8d3692b160
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaTranslator.java
@@ -0,0 +1,107 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.engine;
+
+import ai.djl.inference.streaming.IteratorBytesSupplier;
+import ai.djl.llama.jni.InputParameters;
+import ai.djl.llama.jni.LlamaLibrary;
+import ai.djl.llama.jni.Token;
+import ai.djl.llama.jni.TokenIterator;
+import ai.djl.modality.Input;
+import ai.djl.modality.Output;
+import ai.djl.ndarray.BytesSupplier;
+import ai.djl.ndarray.NDList;
+import ai.djl.translate.NoBatchifyTranslator;
+import ai.djl.translate.TranslatorContext;
+import ai.djl.util.JsonUtils;
+
+import java.util.Iterator;
+
+/** Built-in {@code Translator} that provides preprocessing and postprocessing for llama.cpp. */
+public class LlamaTranslator implements NoBatchifyTranslator {
+
+ private long handle;
+
+ /** {@inheritDoc} */
+ @Override
+ public void prepare(TranslatorContext ctx) {
+ LlamaModel model = (LlamaModel) ctx.getModel();
+ handle = model.getHandle();
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public NDList processInput(TranslatorContext ctx, I input) {
+ if (input instanceof String) {
+ ctx.setAttachment("out", generate((String) input));
+ } else if (input instanceof LlamaInput) {
+ ctx.setAttachment("out", generate((LlamaInput) input));
+ } else if (input instanceof Input) {
+ String prompt = ((Input) input).getData().getAsString();
+ TokenIterator it = generate(prompt);
+ Output output = new Output();
+ output.add(new IteratorBytesSupplier(new OutputIterator(it)));
+ ctx.setAttachment("out", output);
+ }
+ return new NDList();
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ @SuppressWarnings("unchecked")
+ public O processOutput(TranslatorContext ctx, NDList list) {
+ return (O) ctx.getAttachment("out");
+ }
+
+ private TokenIterator generate(String input) {
+ LlamaInput in = JsonUtils.GSON.fromJson(input, LlamaInput.class);
+ return generate(in);
+ }
+
+ private TokenIterator generate(LlamaInput in) {
+ InputParameters param = in.getParameters().toInputParameters();
+ String prefix = in.getPrefix();
+ String suffix = in.getSuffix();
+ String inputs = in.getInputs();
+ if (prefix != null && suffix != null) {
+ LlamaLibrary.infill(handle, prefix, prefix, param);
+ } else if (inputs != null && !inputs.isEmpty()) {
+ LlamaLibrary.generate(handle, inputs, param);
+ } else {
+ throw new IllegalArgumentException("Unsupported input format");
+ }
+ return new TokenIterator(handle);
+ }
+
+ private static final class OutputIterator implements Iterator {
+
+ private TokenIterator it;
+
+ public OutputIterator(TokenIterator it) {
+ this.it = it;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public boolean hasNext() {
+ return it.hasNext();
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public BytesSupplier next() {
+ Token token = it.next();
+ return BytesSupplier.wrap(JsonUtils.GSON.toJson(token) + "\n");
+ }
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/engine/LlamaTranslatorFactory.java b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaTranslatorFactory.java
new file mode 100644
index 00000000000..089b5055b51
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/engine/LlamaTranslatorFactory.java
@@ -0,0 +1,60 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.engine;
+
+import ai.djl.Model;
+import ai.djl.llama.jni.TokenIterator;
+import ai.djl.modality.Input;
+import ai.djl.modality.Output;
+import ai.djl.translate.Translator;
+import ai.djl.translate.TranslatorFactory;
+import ai.djl.util.Pair;
+
+import java.io.Serializable;
+import java.lang.reflect.Type;
+import java.util.HashSet;
+import java.util.Map;
+import java.util.Set;
+
+/** A {@link TranslatorFactory} that creates a {@link LlamaTranslator} instance. */
+public class LlamaTranslatorFactory implements TranslatorFactory, Serializable {
+
+ private static final long serialVersionUID = 1L;
+
+ private static final Set> SUPPORTED_TYPES = new HashSet<>();
+
+ static {
+ SUPPORTED_TYPES.add(new Pair<>(String.class, TokenIterator.class));
+ SUPPORTED_TYPES.add(new Pair<>(LlamaInput.class, TokenIterator.class));
+ SUPPORTED_TYPES.add(new Pair<>(Input.class, Output.class));
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public Set> getSupportedTypes() {
+ return SUPPORTED_TYPES;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public boolean isSupported(Class input, Class output) {
+ return true;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public Translator newInstance(
+ Class input, Class output, Model model, Map arguments) {
+ return new LlamaTranslator<>();
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/engine/package-info.java b/engines/llama/src/main/java/ai/djl/llama/engine/package-info.java
new file mode 100644
index 00000000000..226e7a6ddb8
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/engine/package-info.java
@@ -0,0 +1,15 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+
+/** Contains classes to interface with the underlying Llama Engine. */
+package ai.djl.llama.engine;
diff --git a/engines/llama/src/main/java/ai/djl/llama/jni/InputParameters.java b/engines/llama/src/main/java/ai/djl/llama/jni/InputParameters.java
new file mode 100644
index 00000000000..d13abc5ef90
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/jni/InputParameters.java
@@ -0,0 +1,314 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.jni;
+
+import java.util.Map;
+
+/** A class holds input parameters. */
+@SuppressWarnings({"PMD.UnusedPrivateField", "PMD.UnusedAssignment"})
+public class InputParameters {
+
+ private int nPredict;
+ private int nKeep;
+ private int nProbs;
+ private int topK;
+ private float topP;
+ private float tfsZ;
+ private float typicalP;
+ private float temperature;
+ private float repeatPenalty;
+ private int repeatLastN;
+ private float frequencyPenalty;
+ private float presencePenalty;
+ private boolean penalizeNl;
+ private boolean ignoreEos;
+ private int mirostat;
+ private float mirostatTau;
+ private float mirostatEta;
+ private int nBeams;
+ private int seed;
+ private Map logitBias;
+ private String grammar;
+ private String[] antiPrompt;
+
+ /**
+ * Constructs new {@code InputParameters} instance.
+ *
+ * @param nPredict the max new tokens
+ * @param nKeep the number of keep
+ * @param nProbs the number of probabilities
+ * @param topK the top K
+ * @param topP the top P
+ * @param tfsZ the tfs Z
+ * @param typicalP the typical P
+ * @param temperature the temperature
+ * @param repeatPenalty the repeat penalty
+ * @param repeatLastN the repeat last N
+ * @param frequencyPenalty the frequency penalty
+ * @param presencePenalty the presence penalty
+ * @param penalizeNl the penalize nl
+ * @param ignoreEos the ignore EOS
+ * @param mirostat the mirostat
+ * @param mirostatTau the mirostat TAU
+ * @param mirostatEta the mirostat ETA
+ * @param nBeams the number of beams
+ * @param seed the seed
+ * @param logitBias the logit bias
+ * @param grammar the grammar
+ * @param antiPrompt the anti prompt
+ */
+ public InputParameters(
+ int nPredict,
+ int nKeep,
+ int nProbs,
+ int topK,
+ float topP,
+ float tfsZ,
+ float typicalP,
+ float temperature,
+ float repeatPenalty,
+ int repeatLastN,
+ float frequencyPenalty,
+ float presencePenalty,
+ boolean penalizeNl,
+ boolean ignoreEos,
+ int mirostat,
+ float mirostatTau,
+ float mirostatEta,
+ int nBeams,
+ int seed,
+ Map logitBias,
+ String grammar,
+ String[] antiPrompt) {
+ this.nPredict = nPredict;
+ this.nKeep = nKeep;
+ this.nProbs = nProbs;
+ this.topK = topK;
+ this.topP = topP;
+ this.tfsZ = tfsZ;
+ this.typicalP = typicalP;
+ this.temperature = temperature;
+ this.repeatPenalty = repeatPenalty;
+ this.repeatLastN = repeatLastN;
+ this.frequencyPenalty = frequencyPenalty;
+ this.presencePenalty = presencePenalty;
+ this.penalizeNl = penalizeNl;
+ this.ignoreEos = ignoreEos;
+ this.mirostat = mirostat;
+ this.mirostatTau = mirostatTau;
+ this.mirostatEta = mirostatEta;
+ this.nBeams = nBeams;
+ this.seed = seed;
+ this.logitBias = logitBias;
+ this.grammar = grammar;
+ this.antiPrompt = antiPrompt;
+ }
+
+ /**
+ * Returns the max new tokens.
+ *
+ * @return the max new tokens
+ */
+ public int getMaxNewTokens() {
+ return nPredict;
+ }
+
+ /**
+ * Returns the number of keep.
+ *
+ * @return the number of keep
+ */
+ public int getNumberKeep() {
+ return nKeep;
+ }
+
+ /**
+ * Returns the number of probabilities.
+ *
+ * @return the number of probabilities
+ */
+ public int getNumberProbabilities() {
+ return nProbs;
+ }
+
+ /**
+ * Returns the top K.
+ *
+ * @return the top K
+ */
+ public int getTopK() {
+ return topK;
+ }
+
+ /**
+ * Return the top P.
+ *
+ * @return the top P
+ */
+ public float getTopP() {
+ return topP;
+ }
+
+ /**
+ * Return the TfsZ.
+ *
+ * @return the TfsZ
+ */
+ public float getTfsZ() {
+ return tfsZ;
+ }
+
+ /**
+ * Return the typical P.
+ *
+ * @return the typical P
+ */
+ public float getTypicalP() {
+ return typicalP;
+ }
+
+ /**
+ * Return the temperature.
+ *
+ * @return the temperature
+ */
+ public float getTemperature() {
+ return temperature;
+ }
+
+ /**
+ * Return the repeat penalty.
+ *
+ * @return the repeat penalty
+ */
+ public float getRepeatPenalty() {
+ return repeatPenalty;
+ }
+
+ /**
+ * Return the repeat last N.
+ *
+ * @return the repeat last N
+ */
+ public int getRepeatLastN() {
+ return repeatLastN;
+ }
+
+ /**
+ * Return the frequency penalty.
+ *
+ * @return the frequency penalty
+ */
+ public float getFrequencyPenalty() {
+ return frequencyPenalty;
+ }
+
+ /**
+ * Return the presence penalty.
+ *
+ * @return the presence penalty
+ */
+ public float getPresencePenalty() {
+ return presencePenalty;
+ }
+
+ /**
+ * Return the penalize NL.
+ *
+ * @return the penalize NL
+ */
+ public boolean isPenalizeNl() {
+ return penalizeNl;
+ }
+
+ /**
+ * Returns {@code true} if ignore EOS.
+ *
+ * @return {@code true} if ignore EOS
+ */
+ public boolean isIgnoreEos() {
+ return ignoreEos;
+ }
+
+ /**
+ * Returns the mirostat.
+ *
+ * @return the mirostat
+ */
+ public int getMirostat() {
+ return mirostat;
+ }
+
+ /**
+ * Returns the mirostat TAU.
+ *
+ * @return the mirostat TAU
+ */
+ public float getMirostatTau() {
+ return mirostatTau;
+ }
+
+ /**
+ * Returns the mirostat ETA.
+ *
+ * @return the mirostat ETA
+ */
+ public float getMirostatEta() {
+ return mirostatEta;
+ }
+
+ /**
+ * Returns the number of beams.
+ *
+ * @return the number of beams
+ */
+ public int getNumberBeams() {
+ return nBeams;
+ }
+
+ /**
+ * Returns the seed.
+ *
+ * @return the seed
+ */
+ public int getSeed() {
+ return seed;
+ }
+
+ /**
+ * Returns the logit bias.
+ *
+ * @return the logit bias
+ */
+ public Map getLogitBias() {
+ return logitBias;
+ }
+
+ /**
+ * Returns the grammar template.
+ *
+ * @return the grammar template
+ */
+ public String getGrammar() {
+ return grammar;
+ }
+
+ /**
+ * Returns the anti-prompt.
+ *
+ * @return the anti-prompt
+ */
+ public String[] getAntiPrompt() {
+ return antiPrompt;
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/jni/LibUtils.java b/engines/llama/src/main/java/ai/djl/llama/jni/LibUtils.java
new file mode 100644
index 00000000000..d51a4fe2e5e
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/jni/LibUtils.java
@@ -0,0 +1,99 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.jni;
+
+import ai.djl.util.ClassLoaderUtils;
+import ai.djl.util.Platform;
+import ai.djl.util.Utils;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.io.InputStream;
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.nio.file.StandardCopyOption;
+import java.util.ArrayList;
+import java.util.List;
+
+/** Utilities for finding the llama.cpp native binary on the System. */
+public final class LibUtils {
+
+ private static final Logger logger = LoggerFactory.getLogger(LibUtils.class);
+
+ private static final String LIB_NAME = System.mapLibraryName("djl_llama");
+ private static final String LLAMA_NAME = System.mapLibraryName("llama");
+
+ private LibUtils() {}
+
+ /** Loads llama.cpp native library. */
+ public static void loadLibrary() {
+ List libs = new ArrayList<>(3);
+ libs.add(LLAMA_NAME);
+ libs.add(LIB_NAME);
+ if (System.getProperty("os.name").startsWith("Mac")) {
+ libs.add("ggml-metal.metal");
+ }
+ Path dir = copyJniLibraryFromClasspath(libs.toArray(new String[0]));
+ logger.debug("Loading llama.cpp library from: {}", dir);
+
+ for (int i = 0; i < 2; ++i) {
+ String lib = libs.get(i);
+ String path = dir.resolve(lib).toString();
+ logger.debug("Loading native library: {}", path);
+ String nativeHelper = System.getProperty("ai.djl.llama.native_helper");
+ if (nativeHelper != null && !nativeHelper.isEmpty()) {
+ ClassLoaderUtils.nativeLoad(nativeHelper, path);
+ } else {
+ System.load(path); // NOPMD
+ }
+ }
+ }
+
+ private static Path copyJniLibraryFromClasspath(String... libs) {
+ Path cacheDir = Utils.getEngineCacheDir("llama");
+ Platform platform = Platform.detectPlatform("llama");
+ String classifier = platform.getClassifier();
+ String version = platform.getVersion();
+ Path dir = cacheDir.resolve(version + '-' + classifier);
+ Path path = dir.resolve(LIB_NAME);
+ logger.debug("Using cache dir: {}", dir);
+ if (Files.exists(path)) {
+ return dir.toAbsolutePath();
+ }
+
+ Path tmp = null;
+ try {
+ Files.createDirectories(cacheDir);
+ tmp = Files.createTempDirectory(cacheDir, "tmp");
+
+ for (String libName : libs) {
+ String libPath = "native/lib/" + classifier + "/" + libName;
+ logger.info("Extracting {} to cache ...", libPath);
+ try (InputStream is = ClassLoaderUtils.getResourceAsStream(libPath)) {
+ Path target = tmp.resolve(libName);
+ Files.copy(is, target, StandardCopyOption.REPLACE_EXISTING);
+ }
+ }
+ Utils.moveQuietly(tmp, dir);
+ return dir.toAbsolutePath();
+ } catch (IOException e) {
+ throw new IllegalStateException("Cannot copy jni files", e);
+ } finally {
+ if (tmp != null) {
+ Utils.deleteQuietly(tmp);
+ }
+ }
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/jni/LlamaLibrary.java b/engines/llama/src/main/java/ai/djl/llama/jni/LlamaLibrary.java
new file mode 100644
index 00000000000..5d40fa29830
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/jni/LlamaLibrary.java
@@ -0,0 +1,37 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.jni;
+
+/** Native library for llama.cpp. */
+@SuppressWarnings("MissingJavadocMethod")
+public final class LlamaLibrary {
+
+ private LlamaLibrary() {}
+
+ public static native long loadModel(String filePath, ModelParameters param);
+
+ public static native void generate(long handle, String prompt, InputParameters param);
+
+ public static native void infill(
+ long handle, String prefix, String suffix, InputParameters param);
+
+ public static native Token getNext(long handle, long count, long pos);
+
+ public static native float[] embed(long handle, String prompt);
+
+ public static native int[] encode(long handle, String prompt);
+
+ public static native byte[] decodeBytes(long handle, int[] tokens);
+
+ public static native void delete(long handle);
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/jni/ModelParameters.java b/engines/llama/src/main/java/ai/djl/llama/jni/ModelParameters.java
new file mode 100644
index 00000000000..e3e440474a8
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/jni/ModelParameters.java
@@ -0,0 +1,114 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.jni;
+
+import java.util.Map;
+
+/** A class holds llama.cpp model loading parameters. */
+@SuppressWarnings("PMD.SingularField")
+public final class ModelParameters {
+
+ private int nThreads;
+ private int nCtx;
+ private int nBatch;
+ private int nGpuLayers;
+ private int mainGpu;
+ private float ropeFreqBase;
+ private float ropeFreqScale;
+ private boolean mulMatQ;
+ private boolean f16Kv;
+ private boolean logitsAll;
+ private boolean vocabOnly;
+ private boolean useMmap;
+ private boolean useMlock;
+ private boolean embedding;
+ private boolean memoryF16;
+ private boolean memTest;
+ private boolean numa;
+ private boolean verbosePrompt;
+ private float[] tensorSplit;
+ private String loraAdapter;
+ private String loraBase;
+
+ /**
+ * Constructs a new {@code ModelParameters} instance.
+ *
+ * @param options the model loading options
+ */
+ public ModelParameters(Map options) {
+ nThreads = intValue(options, "number_threads", Runtime.getRuntime().availableProcessors());
+ nCtx = intValue(options, "max_context_length", 512);
+ nBatch = intValue(options, "max_rolling_batch", 512);
+ nGpuLayers = intValue(options, "number_gpu_layers", -1);
+ mainGpu = intValue(options, "tensor_parallel_degree", 0);
+ ropeFreqBase = floatValue(options, "rope_freq_base");
+ ropeFreqScale = floatValue(options, "ropeFreqScale");
+ f16Kv = booleanValue(options, "f16_kv");
+ mulMatQ = booleanValue(options, "mulmat_q", true);
+ logitsAll = booleanValue(options, "logits_all");
+ vocabOnly = booleanValue(options, "vocab_only");
+ useMmap = booleanValue(options, "use_mmap", true);
+ useMlock = booleanValue(options, "use_mlock");
+ embedding = booleanValue(options, "embedding");
+ memoryF16 = booleanValue(options, "memory_f16", true);
+ memTest = booleanValue(options, "mem_test");
+ numa = booleanValue(options, "numa");
+ verbosePrompt = booleanValue(options, "verbose_prompt");
+ String val = stringValue(options, "tensor_split");
+ if (val != null && !val.isEmpty()) {
+ String[] tokens = val.split(",");
+ tensorSplit = new float[tokens.length];
+ for (int i = 0; i < tokens.length; ++i) {
+ tensorSplit[i] = Float.parseFloat(tokens[i].trim());
+ }
+ }
+ loraAdapter = stringValue(options, "lora_adapter");
+ loraBase = stringValue(options, "loraBase");
+ }
+
+ private static int intValue(Map arguments, String key, int def) {
+ Object value = arguments.get(key);
+ if (value == null) {
+ return def;
+ }
+ return (int) Double.parseDouble(value.toString());
+ }
+
+ private static float floatValue(Map arguments, String key) {
+ Object value = arguments.get(key);
+ if (value == null) {
+ return 0f;
+ }
+ return (float) Double.parseDouble(value.toString());
+ }
+
+ private static boolean booleanValue(Map arguments, String key) {
+ return booleanValue(arguments, key, false);
+ }
+
+ private static boolean booleanValue(Map arguments, String key, boolean def) {
+ Object value = arguments.get(key);
+ if (value == null) {
+ return def;
+ }
+ return Boolean.parseBoolean(value.toString());
+ }
+
+ private static String stringValue(Map arguments, String key) {
+ Object value = arguments.get(key);
+ if (value == null) {
+ return null;
+ }
+ return value.toString();
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/jni/Token.java b/engines/llama/src/main/java/ai/djl/llama/jni/Token.java
new file mode 100644
index 00000000000..b8d74306b56
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/jni/Token.java
@@ -0,0 +1,87 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.jni;
+
+import ai.djl.util.JsonUtils;
+
+import java.nio.charset.StandardCharsets;
+import java.util.Map;
+
+/** The output token class. */
+public final class Token {
+
+ private int token;
+ private String text;
+ private Map probabilities;
+ transient long count;
+ transient long pos;
+ transient boolean hasNext;
+
+ /**
+ * Constructs a new {@code Token} instance.
+ *
+ * @param token the token id
+ * @param generated the token text
+ * @param probabilities the token probabilities
+ * @param count the generated token count
+ * @param pos the token index
+ * @param hasNext has more tokens
+ */
+ public Token(
+ int token,
+ byte[] generated,
+ Map probabilities,
+ long count,
+ long pos,
+ boolean hasNext) {
+ this.token = token;
+ this.text = new String(generated, StandardCharsets.UTF_8);
+ this.probabilities = probabilities;
+ this.count = count;
+ this.pos = pos;
+ this.hasNext = hasNext;
+ }
+
+ /**
+ * Returns the token id.
+ *
+ * @return the token id
+ */
+ public int getToken() {
+ return token;
+ }
+
+ /**
+ * Returns the token text.
+ *
+ * @return the token text
+ */
+ public String getText() {
+ return text;
+ }
+
+ /**
+ * Returns the token probabilities.
+ *
+ * @return the token probabilities
+ */
+ public Map getProbabilities() {
+ return probabilities;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public String toString() {
+ return JsonUtils.GSON.toJson(this) + '\n';
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/jni/TokenIterator.java b/engines/llama/src/main/java/ai/djl/llama/jni/TokenIterator.java
new file mode 100644
index 00000000000..cab6575d8f7
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/jni/TokenIterator.java
@@ -0,0 +1,69 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.jni;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.concurrent.atomic.AtomicBoolean;
+
+/** A iterator class holds generated tokens. */
+public class TokenIterator implements Iterator {
+
+ private static final Logger logger = LoggerFactory.getLogger(TokenIterator.class);
+
+ private static AtomicBoolean active = new AtomicBoolean();
+
+ private long handle;
+ private long count;
+ private long pos;
+ private boolean hasNext;
+
+ /**
+ * Constructs a new {@code TokenIterator} instance.
+ *
+ * @param handle the llama.cpp handle
+ */
+ public TokenIterator(long handle) {
+ this.handle = handle;
+ hasNext = true;
+ if (!active.compareAndSet(false, true)) {
+ active.set(true);
+ logger.warn("Previous inference has been reset");
+ }
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public boolean hasNext() {
+ return hasNext;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public Token next() {
+ if (!hasNext) {
+ throw new NoSuchElementException();
+ }
+ Token token = LlamaLibrary.getNext(handle, count, pos);
+ count = token.count;
+ pos = token.pos;
+ hasNext = token.hasNext;
+ if (!hasNext) {
+ active.set(false);
+ }
+ return token;
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/jni/package-info.java b/engines/llama/src/main/java/ai/djl/llama/jni/package-info.java
new file mode 100644
index 00000000000..6f429aceda2
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/jni/package-info.java
@@ -0,0 +1,14 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+/** Contains classes to interface with the native llama.cpp code. */
+package ai.djl.llama.jni;
diff --git a/engines/llama/src/main/java/ai/djl/llama/zoo/LlamaModelZoo.java b/engines/llama/src/main/java/ai/djl/llama/zoo/LlamaModelZoo.java
new file mode 100644
index 00000000000..91b6e55050a
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/zoo/LlamaModelZoo.java
@@ -0,0 +1,176 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.zoo;
+
+import ai.djl.Application;
+import ai.djl.repository.Repository;
+import ai.djl.repository.zoo.ModelLoader;
+import ai.djl.repository.zoo.ModelZoo;
+import ai.djl.util.ClassLoaderUtils;
+import ai.djl.util.JsonUtils;
+import ai.djl.util.Utils;
+
+import com.google.gson.reflect.TypeToken;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.io.InputStream;
+import java.io.Reader;
+import java.io.Writer;
+import java.lang.reflect.Type;
+import java.net.URI;
+import java.net.URL;
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.time.Duration;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.Map;
+import java.util.Set;
+import java.util.zip.GZIPInputStream;
+
+/** LlamaModelZoo is a repository that contains llama.cpp models. */
+public class LlamaModelZoo extends ModelZoo {
+
+ private static final Logger logger = LoggerFactory.getLogger(LlamaModelZoo.class);
+
+ private static final String REPO = "https://mlrepo.djl.ai/";
+ private static final Repository REPOSITORY = Repository.newInstance("gguf", REPO);
+ private static final String GROUP_ID = "ai.djl.huggingface.gguf";
+
+ private static final long ONE_DAY = Duration.ofDays(1).toMillis();
+
+ private volatile boolean initialized; // NOPMD
+
+ LlamaModelZoo() {}
+
+ /** {@inheritDoc} */
+ @Override
+ public String getGroupId() {
+ return GROUP_ID;
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public Set getSupportedEngines() {
+ return Collections.singleton("Llama");
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public Collection getModelLoaders() {
+ init();
+ return super.getModelLoaders();
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public ModelLoader getModelLoader(String name) {
+ init();
+ return super.getModelLoader(name);
+ }
+
+ private void init() {
+ if (!initialized) {
+ synchronized (LlamaModelZoo.class) {
+ if (!initialized) {
+ Application app = Application.NLP.TEXT_GENERATION;
+ Map map = listModels(app);
+ for (Map.Entry entry : map.entrySet()) {
+ String artifactId = entry.getKey();
+ Map gguf = entry.getValue().getGguf();
+ if (gguf != null) {
+ for (String key : gguf.keySet()) {
+ addModel(REPOSITORY.model(app, GROUP_ID, artifactId, "0.0.1", key));
+ }
+ }
+ }
+ initialized = true;
+ }
+ }
+ }
+ }
+
+ private Map listModels(Application app) {
+ try {
+ String path = "model/" + app.getPath() + "/ai/djl/huggingface/gguf/";
+ Path dir = Utils.getCacheDir().resolve("cache/repo/" + path);
+ if (Files.notExists(dir)) {
+ Files.createDirectories(dir);
+ } else if (!Files.isDirectory(dir)) {
+ logger.warn("Failed initialize cache directory: {}", dir);
+ return Collections.emptyMap();
+ }
+ Type type = new TypeToken>() {}.getType();
+
+ Path file = dir.resolve("models.json");
+ if (Files.exists(file)) {
+ long lastModified = Files.getLastModifiedTime(file).toMillis();
+ if (Utils.isOfflineMode() || System.currentTimeMillis() - lastModified < ONE_DAY) {
+ try (Reader reader = Files.newBufferedReader(file)) {
+ return JsonUtils.GSON.fromJson(reader, type);
+ }
+ }
+ }
+
+ URL url = URI.create(REPO).resolve(path + "models.json.gz").toURL();
+ Path tmp = Files.createTempFile(dir, "models", ".tmp");
+ try (GZIPInputStream gis = new GZIPInputStream(Utils.openUrl(url))) {
+ String json = Utils.toString(gis);
+ try (Writer writer = Files.newBufferedWriter(tmp)) {
+ writer.write(json);
+ }
+ Utils.moveQuietly(tmp, file);
+ return JsonUtils.GSON.fromJson(json, type);
+ } catch (IOException e) {
+ logger.warn("Failed to download Huggingface gguf index: {}", app);
+ if (Files.exists(file)) {
+ try (Reader reader = Files.newBufferedReader(file)) {
+ return JsonUtils.GSON.fromJson(reader, type);
+ }
+ }
+
+ String resource = app.getPath() + "/" + GROUP_ID + ".json";
+ try (InputStream is = ClassLoaderUtils.getResourceAsStream(resource)) {
+ String json = Utils.toString(is);
+ try (Writer writer = Files.newBufferedWriter(tmp)) {
+ writer.write(json);
+ }
+ Utils.moveQuietly(tmp, file);
+ return JsonUtils.GSON.fromJson(json, type);
+ }
+ } finally {
+ Utils.deleteQuietly(tmp);
+ }
+ } catch (IOException e) {
+ logger.warn("Failed load gguf index file", e);
+ }
+
+ return Collections.emptyMap();
+ }
+
+ private static final class ModelDetail {
+
+ private Map gguf;
+
+ public Map getGguf() {
+ return gguf;
+ }
+
+ public void setGguf(Map gguf) {
+ this.gguf = gguf;
+ }
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/zoo/LlamaZooProvider.java b/engines/llama/src/main/java/ai/djl/llama/zoo/LlamaZooProvider.java
new file mode 100644
index 00000000000..ba2b04722c1
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/zoo/LlamaZooProvider.java
@@ -0,0 +1,29 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.zoo;
+
+import ai.djl.repository.zoo.ModelZoo;
+import ai.djl.repository.zoo.ZooProvider;
+
+/**
+ * An Huggingface llama.cpp model zoo provider implements the {@link
+ * ai.djl.repository.zoo.ZooProvider} interface.
+ */
+public class LlamaZooProvider implements ZooProvider {
+
+ /** {@inheritDoc} */
+ @Override
+ public ModelZoo getModelZoo() {
+ return new LlamaModelZoo();
+ }
+}
diff --git a/engines/llama/src/main/java/ai/djl/llama/zoo/package-info.java b/engines/llama/src/main/java/ai/djl/llama/zoo/package-info.java
new file mode 100644
index 00000000000..a9c1df64cd0
--- /dev/null
+++ b/engines/llama/src/main/java/ai/djl/llama/zoo/package-info.java
@@ -0,0 +1,14 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+/** Contains the built-in {@link ai.djl.llama.zoo.LlamaModelZoo}. */
+package ai.djl.llama.zoo;
diff --git a/engines/llama/src/main/javadoc/overview.html b/engines/llama/src/main/javadoc/overview.html
new file mode 100644
index 00000000000..05dec7d0bd4
--- /dev/null
+++ b/engines/llama/src/main/javadoc/overview.html
@@ -0,0 +1,14 @@
+
+
+
+
+
+This document is the API specification for the Deep Java Library (DJL) Llama Engine.
+
+
+ The Llama Engine module contains the Llama.cpp implementation of the DJL EngineProvider.
+ See here for more details.
+
+
+
+
diff --git a/engines/llama/src/main/native/ai_djl_llama.cpp b/engines/llama/src/main/native/ai_djl_llama.cpp
new file mode 100644
index 00000000000..1d6072751f2
--- /dev/null
+++ b/engines/llama/src/main/native/ai_djl_llama.cpp
@@ -0,0 +1,1025 @@
+#include
+#include
+#include
+#include
+
+#include "ai_djl_llama_jni_LlamaLibrary.h"
+#include "common.h"
+#include "grammar-parser.h"
+#include "llama.h"
+#include "sampling.h"
+
+// classes
+static jclass c_lib_utils = 0;
+static jclass c_model_params = 0;
+static jclass c_input_params = 0;
+static jclass c_token = 0;
+static jclass c_standard_charsets = 0;
+static jclass c_string = 0;
+static jclass c_hash_map = 0;
+static jclass c_map = 0;
+static jclass c_set = 0;
+static jclass c_entry = 0;
+static jclass c_integer = 0;
+static jclass c_float = 0;
+static jclass c_logger = 0;
+static jclass c_engine_exception = 0;
+
+// constructors
+static jmethodID cc_token = 0;
+static jmethodID cc_hash_map = 0;
+static jmethodID cc_integer = 0;
+static jmethodID cc_float = 0;
+
+// methods
+static jmethodID m_get_bytes = 0;
+static jmethodID m_entry_set = 0;
+static jmethodID m_set_iterator = 0;
+static jmethodID m_iterator_has_next = 0;
+static jmethodID m_iterator_next = 0;
+static jmethodID m_entry_key = 0;
+static jmethodID m_entry_value = 0;
+static jmethodID m_map_put = 0;
+static jmethodID m_int_value = 0;
+static jmethodID m_float_value = 0;
+static jmethodID m_log_debug = 0;
+static jmethodID m_log_info = 0;
+static jmethodID m_log_warn = 0;
+static jmethodID m_log_error = 0;
+
+// fields
+static jfieldID f_logger = 0;
+// inference parameters
+static jfieldID f_n_predict = 0;
+static jfieldID f_n_keep = 0;
+static jfieldID f_n_probs = 0;
+static jfieldID f_logit_bias = 0;
+static jfieldID f_top_k = 0;
+static jfieldID f_top_p = 0;
+static jfieldID f_tfs_z = 0;
+static jfieldID f_typical_p = 0;
+static jfieldID f_temperature = 0;
+static jfieldID f_repeat_penalty = 0;
+static jfieldID f_repeat_last_n = 0;
+static jfieldID f_frequency_penalty = 0;
+static jfieldID f_presence_penalty = 0;
+static jfieldID f_penalize_nl = 0;
+static jfieldID f_ignore_eos = 0;
+static jfieldID f_mirostat = 0;
+static jfieldID f_mirostat_tau = 0;
+static jfieldID f_mirostat_eta = 0;
+static jfieldID f_n_beams = 0;
+static jfieldID f_grammar = 0;
+static jfieldID f_antiprompt = 0;
+static jfieldID f_infer_seed = 0;
+// model parameters
+static jfieldID f_n_threads = 0;
+static jfieldID f_n_ctx = 0;
+static jfieldID f_n_batch = 0;
+static jfieldID f_n_gpu_layers = 0;
+static jfieldID f_main_gpu = 0;
+static jfieldID f_tensor_split = 0;
+static jfieldID f_rope_freq_base = 0;
+static jfieldID f_rope_freq_scale = 0;
+static jfieldID f_mul_mat_q = 0;
+static jfieldID f_f16_kv = 0;
+static jfieldID f_logits_all = 0;
+static jfieldID f_vocab_only = 0;
+static jfieldID f_use_mmap = 0;
+static jfieldID f_use_mlock = 0;
+static jfieldID f_embedding = 0;
+static jfieldID f_lora_adapter = 0;
+static jfieldID f_lora_base = 0;
+static jfieldID f_memory_f16 = 0;
+static jfieldID f_mem_test = 0;
+static jfieldID f_numa = 0;
+static jfieldID f_verbose_prompt = 0;
+// log level
+static jfieldID f_utf_8 = 0;
+// objects
+static jobject o_utf_8 = 0;
+static jobject o_logger = 0;
+
+static JavaVM *g_vm = nullptr;
+
+static void null_log_callback(enum ggml_log_level level, const char *text, void *user_data) {}
+
+JNIEXPORT jint JNICALL JNI_OnLoad(JavaVM *vm, void *reserved) {
+ JNIEnv *env = 0;
+
+ if (JNI_OK != vm->GetEnv((void **) &env, JNI_VERSION_1_1)) {
+ return JNI_ERR;
+ }
+
+ log_disable();
+ llama_log_set(null_log_callback, nullptr);
+
+ // find classes
+ c_input_params = env->FindClass("ai/djl/llama/jni/InputParameters");
+ c_model_params = env->FindClass("ai/djl/llama/jni/ModelParameters");
+ c_lib_utils = env->FindClass("ai/djl/llama/jni/LibUtils");
+ c_token = env->FindClass("ai/djl/llama/jni/Token");
+ c_engine_exception = env->FindClass("ai/djl/engine/EngineException");
+ c_logger = env->FindClass("org/slf4j/Logger");
+ c_standard_charsets = env->FindClass("java/nio/charset/StandardCharsets");
+ c_string = env->FindClass("java/lang/String");
+ c_hash_map = env->FindClass("java/util/HashMap");
+ c_map = env->FindClass("java/util/Map");
+ c_set = env->FindClass("java/util/Set");
+ c_entry = env->FindClass("java/util/Map$Entry");
+ c_integer = env->FindClass("java/lang/Integer");
+ c_float = env->FindClass("java/lang/Float");
+
+ // create references
+ c_input_params = (jclass) env->NewGlobalRef(c_input_params);
+ c_model_params = (jclass) env->NewGlobalRef(c_model_params);
+ c_lib_utils = (jclass) env->NewGlobalRef(c_lib_utils);
+ c_token = (jclass) env->NewGlobalRef(c_token);
+ c_engine_exception = (jclass) env->NewGlobalRef(c_engine_exception);
+ c_logger = (jclass) env->NewGlobalRef(c_logger);
+ c_string = (jclass) env->NewGlobalRef(c_string);
+ c_hash_map = (jclass) env->NewGlobalRef(c_hash_map);
+ c_map = (jclass) env->NewGlobalRef(c_map);
+ c_set = (jclass) env->NewGlobalRef(c_set);
+ c_entry = (jclass) env->NewGlobalRef(c_entry);
+ c_integer = (jclass) env->NewGlobalRef(c_integer);
+ c_float = (jclass) env->NewGlobalRef(c_float);
+
+ // find constructors
+ cc_token = env->GetMethodID(c_token, "", "(I[BLjava/util/Map;JJZ)V");
+ cc_hash_map = env->GetMethodID(c_hash_map, "", "()V");
+ cc_integer = env->GetMethodID(c_integer, "", "(I)V");
+ cc_float = env->GetMethodID(c_float, "", "(F)V");
+
+ // find methods
+ m_get_bytes = env->GetMethodID(c_string, "getBytes", "(Ljava/lang/String;)[B");
+ m_entry_set = env->GetMethodID(c_map, "entrySet", "()Ljava/util/Set;");
+ m_entry_key = env->GetMethodID(c_entry, "getKey", "()Ljava/lang/Object;");
+ m_entry_value = env->GetMethodID(c_entry, "getValue", "()Ljava/lang/Object;");
+ m_map_put = env->GetMethodID(c_map, "put", "(Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object;");
+ m_int_value = env->GetMethodID(c_integer, "intValue", "()I");
+ m_float_value = env->GetMethodID(c_float, "floatValue", "()F");
+ m_log_debug = env->GetMethodID(c_logger, "debug", "(Ljava/lang/String;)V");
+ m_log_info = env->GetMethodID(c_logger, "info", "(Ljava/lang/String;)V");
+ m_log_warn = env->GetMethodID(c_logger, "warn", "(Ljava/lang/String;)V");
+ m_log_error = env->GetMethodID(c_logger, "error", "(Ljava/lang/String;)V");
+
+ // find fields
+ f_logger = env->GetStaticFieldID(c_lib_utils, "logger", "Lorg/slf4j/Logger;");
+
+ f_n_predict = env->GetFieldID(c_input_params, "nPredict", "I");
+ f_n_keep = env->GetFieldID(c_input_params, "nKeep", "I");
+ f_n_probs = env->GetFieldID(c_input_params, "nProbs", "I");
+ f_logit_bias = env->GetFieldID(c_input_params, "logitBias", "Ljava/util/Map;");
+ f_top_k = env->GetFieldID(c_input_params, "topK", "I");
+ f_top_p = env->GetFieldID(c_input_params, "topP", "F");
+ f_tfs_z = env->GetFieldID(c_input_params, "tfsZ", "F");
+ f_typical_p = env->GetFieldID(c_input_params, "typicalP", "F");
+ f_temperature = env->GetFieldID(c_input_params, "temperature", "F");
+ f_repeat_penalty = env->GetFieldID(c_input_params, "repeatPenalty", "F");
+ f_repeat_last_n = env->GetFieldID(c_input_params, "repeatLastN", "I");
+ f_frequency_penalty = env->GetFieldID(c_input_params, "frequencyPenalty", "F");
+ f_presence_penalty = env->GetFieldID(c_input_params, "presencePenalty", "F");
+ f_penalize_nl = env->GetFieldID(c_input_params, "penalizeNl", "Z");
+ f_ignore_eos = env->GetFieldID(c_input_params, "ignoreEos", "Z");
+ f_mirostat = env->GetFieldID(c_input_params, "mirostat", "I");
+ f_mirostat_tau = env->GetFieldID(c_input_params, "mirostatTau", "F");
+ f_mirostat_eta = env->GetFieldID(c_input_params, "mirostatEta", "F");
+ f_n_beams = env->GetFieldID(c_input_params, "nBeams", "I");
+ f_grammar = env->GetFieldID(c_input_params, "grammar", "Ljava/lang/String;");
+ f_antiprompt = env->GetFieldID(c_input_params, "antiPrompt", "[Ljava/lang/String;");
+ f_infer_seed = env->GetFieldID(c_input_params, "seed", "I");
+
+ f_n_threads = env->GetFieldID(c_model_params, "nThreads", "I");
+ f_n_ctx = env->GetFieldID(c_model_params, "nCtx", "I");
+ f_n_batch = env->GetFieldID(c_model_params, "nBatch", "I");
+ f_n_gpu_layers = env->GetFieldID(c_model_params, "nGpuLayers", "I");
+ f_main_gpu = env->GetFieldID(c_model_params, "mainGpu", "I");
+ f_tensor_split = env->GetFieldID(c_model_params, "tensorSplit", "[F");
+ f_rope_freq_base = env->GetFieldID(c_model_params, "ropeFreqBase", "F");
+ f_rope_freq_scale = env->GetFieldID(c_model_params, "ropeFreqScale", "F");
+ f_mul_mat_q = env->GetFieldID(c_model_params, "mulMatQ", "Z");
+ f_f16_kv = env->GetFieldID(c_model_params, "f16Kv", "Z");
+ f_logits_all = env->GetFieldID(c_model_params, "logitsAll", "Z");
+ f_vocab_only = env->GetFieldID(c_model_params, "vocabOnly", "Z");
+ f_use_mmap = env->GetFieldID(c_model_params, "useMmap", "Z");
+ f_use_mlock = env->GetFieldID(c_model_params, "useMlock", "Z");
+ f_embedding = env->GetFieldID(c_model_params, "embedding", "Z");
+ f_lora_adapter = env->GetFieldID(c_model_params, "loraAdapter", "Ljava/lang/String;");
+ f_lora_base = env->GetFieldID(c_model_params, "loraBase", "Ljava/lang/String;");
+ f_memory_f16 = env->GetFieldID(c_model_params, "memoryF16", "Z");
+ f_mem_test = env->GetFieldID(c_model_params, "memTest", "Z");
+ f_numa = env->GetFieldID(c_model_params, "numa", "Z");
+ f_verbose_prompt = env->GetFieldID(c_model_params, "verbosePrompt", "Z");
+
+ f_utf_8 = env->GetStaticFieldID(c_standard_charsets, "UTF_8", "Ljava/nio/charset/Charset;");
+ o_utf_8 = env->NewStringUTF("UTF-8");
+ o_utf_8 = (jobject) env->NewGlobalRef(o_utf_8);
+ o_logger = env->GetStaticObjectField(c_lib_utils, f_logger);
+ o_logger = (jobject) env->NewGlobalRef(o_logger);
+
+ if (env->ExceptionCheck()) {
+ env->ExceptionDescribe();
+ return JNI_ERR;
+ }
+
+ return JNI_VERSION_1_1;
+}
+
+JNIEXPORT void JNICALL JNI_OnUnload(JavaVM *vm, void *reserved) {
+ JNIEnv *env = 0;
+
+ if (JNI_OK != vm->GetEnv((void **) &env, JNI_VERSION_1_1)) {
+ return;
+ }
+
+ env->DeleteGlobalRef(c_input_params);
+ env->DeleteGlobalRef(c_model_params);
+ env->DeleteGlobalRef(c_token);
+ env->DeleteGlobalRef(c_string);
+ env->DeleteGlobalRef(c_hash_map);
+ env->DeleteGlobalRef(c_map);
+ env->DeleteGlobalRef(c_set);
+ env->DeleteGlobalRef(c_entry);
+ env->DeleteGlobalRef(c_integer);
+ env->DeleteGlobalRef(c_float);
+ env->DeleteGlobalRef(c_logger);
+ env->DeleteGlobalRef(c_engine_exception);
+
+ env->DeleteGlobalRef(o_utf_8);
+}
+
+static void log(JNIEnv *env, enum ggml_log_level level, const char *text) {
+ jstring java_text = env->NewStringUTF(text);
+
+ switch (level) {
+ case GGML_LOG_LEVEL_ERROR:
+ env->CallVoidMethod(o_logger, m_log_error, java_text);
+ break;
+ case GGML_LOG_LEVEL_WARN:
+ env->CallVoidMethod(o_logger, m_log_warn, java_text);
+ break;
+ case GGML_LOG_LEVEL_INFO:
+ env->CallVoidMethod(o_logger, m_log_info, java_text);
+ break;
+ default:
+ env->CallVoidMethod(o_logger, m_log_debug, java_text);
+ break;
+ }
+ env->DeleteLocalRef(java_text);
+}
+
+static void log(JNIEnv *env, enum ggml_log_level level, std::string text) { log(env, level, text.c_str()); }
+
+static std::string parse_jstring(JNIEnv *env, jstring java_string) {
+ const jbyteArray string_bytes = (jbyteArray) env->CallObjectMethod(java_string, m_get_bytes, o_utf_8);
+
+ size_t length = (size_t) env->GetArrayLength(string_bytes);
+ jbyte *byte_elements = env->GetByteArrayElements(string_bytes, nullptr);
+
+ std::string string = std::string((char *) byte_elements, length);
+
+ env->ReleaseByteArrayElements(string_bytes, byte_elements, JNI_ABORT);
+ env->DeleteLocalRef(string_bytes);
+
+ return string;
+}
+
+static int parse_jinteger(JNIEnv *env, jobject java_integer) {
+ if (!java_integer) return 0;
+ return env->CallIntMethod(java_integer, m_int_value);
+}
+
+static float parse_jfloat(JNIEnv *env, jobject java_float) {
+ if (!java_float) return 0;
+ return env->CallFloatMethod(java_float, m_float_value);
+}
+
+static jbyteArray parse_jbytes(JNIEnv *env, std::string string) {
+ jsize len = string.size();
+ jbyteArray bytes = env->NewByteArray(len);
+ env->SetByteArrayRegion(bytes, 0, len, reinterpret_cast(string.c_str()));
+ return bytes;
+}
+
+// completion token output with probabilities
+struct completion_token_output {
+ struct token_prob {
+ llama_token tok;
+ float prob;
+ };
+
+ std::vector probs;
+ llama_token tok;
+};
+
+static size_t common_part(const std::vector &a, const std::vector &b) {
+ size_t i;
+ for (i = 0; i < a.size() && i < b.size() && a[i] == b[i]; i++) {
+ }
+ return i;
+}
+
+enum stop_type {
+ STOP_FULL,
+ STOP_PARTIAL,
+};
+
+static bool ends_with(const std::string &str, const std::string &suffix) {
+ return str.size() >= suffix.size() && 0 == str.compare(str.size() - suffix.size(), suffix.size(), suffix);
+}
+
+static size_t find_partial_stop_string(const std::string &stop, const std::string &text) {
+ if (!text.empty() && !stop.empty()) {
+ const char text_last_char = text.back();
+ for (int64_t char_index = stop.size() - 1; char_index >= 0; char_index--) {
+ if (stop[char_index] == text_last_char) {
+ const std::string current_partial = stop.substr(0, char_index + 1);
+ if (ends_with(text, current_partial)) {
+ return text.size() - char_index - 1;
+ }
+ }
+ }
+ }
+ return std::string::npos;
+}
+
+template
+static std::string tokens_to_str(llama_context *ctx, Iter begin, Iter end) {
+ std::string ret;
+ for (; begin != end; ++begin) {
+ ret += llama_token_to_piece(ctx, *begin);
+ }
+ return ret;
+}
+
+// format incomplete utf-8 multibyte character for output
+static std::string tokens_to_output_formatted_string(const llama_context *ctx, const llama_token token) {
+ std::string out = token == -1 ? "" : llama_token_to_piece(ctx, token);
+ // if the size is 1 and first bit is 1, meaning it's a partial character
+ // (size > 1 meaning it's already a known token)
+ if (out.size() == 1 && (out[0] & 0x80) == 0x80) {
+ std::stringstream ss;
+ ss << std::hex << (out[0] & 0xff);
+ std::string res(ss.str());
+ out = "byte: \\x" + res;
+ }
+ return out;
+}
+
+struct jllama_context {
+ bool has_next_token = false;
+ std::string generated_text;
+ std::vector generated_token_probs;
+
+ size_t num_prompt_tokens = 0;
+ size_t num_tokens_predicted = 0;
+ size_t n_past = 0;
+ size_t n_remain = 0;
+
+ std::string prompt;
+ std::vector embd;
+ std::vector last_n_tokens;
+
+ llama_model *model = nullptr;
+ llama_context *ctx = nullptr;
+ gpt_params params;
+ llama_sampling_context ctx_sampling;
+ int n_ctx;
+
+ grammar_parser::parse_state parsed_grammar;
+ llama_grammar *grammar = nullptr;
+
+ bool truncated = false;
+ bool stopped_eos = false;
+ bool stopped_word = false;
+ bool stopped_limit = false;
+ std::string stopping_word;
+ int32_t multibyte_pending = 0;
+
+ std::mutex mutex;
+
+ std::unique_lock lock() { return std::unique_lock(mutex); }
+
+ ~jllama_context() {
+ if (ctx) {
+ llama_free(ctx);
+ ctx = nullptr;
+ }
+ if (model) {
+ llama_free_model(model);
+ model = nullptr;
+ }
+ if (grammar) {
+ llama_grammar_free(grammar);
+ grammar = nullptr;
+ }
+ }
+
+ void rewind() {
+ params.antiprompt.clear();
+ params.sparams.grammar.clear();
+ num_prompt_tokens = 0;
+ num_tokens_predicted = 0;
+ generated_text = "";
+ generated_text.reserve(n_ctx);
+ generated_token_probs.clear();
+ truncated = false;
+ stopped_eos = false;
+ stopped_word = false;
+ stopped_limit = false;
+ stopping_word = "";
+ multibyte_pending = 0;
+ n_remain = 0;
+ n_past = 0;
+
+ if (grammar != nullptr) {
+ llama_grammar_free(grammar);
+ grammar = nullptr;
+ ctx_sampling = *llama_sampling_init(params.sparams);
+ }
+ }
+
+ bool loadModel(const gpt_params ¶ms_) {
+ params = params_;
+ std::tie(model, ctx) = llama_init_from_gpt_params(params);
+ if (model == nullptr) {
+ return false;
+ }
+ n_ctx = llama_n_ctx(ctx);
+ last_n_tokens.resize(n_ctx);
+ std::fill(last_n_tokens.begin(), last_n_tokens.end(), 0);
+ return true;
+ }
+
+ std::vector tokenize(std::string prompt, bool add_bos) const {
+ return ::llama_tokenize(ctx, prompt, add_bos);
+ }
+
+ bool loadGrammar(JNIEnv *env) {
+ if (!params.sparams.grammar.empty()) {
+ parsed_grammar = grammar_parser::parse(params.sparams.grammar.c_str());
+ // will be empty (default) if there are parse errors
+ if (parsed_grammar.rules.empty()) {
+ log(env, GGML_LOG_LEVEL_ERROR, "grammar parse error");
+ return false;
+ }
+ grammar_parser::print_grammar(stderr, parsed_grammar);
+
+ {
+ auto it = params.sparams.logit_bias.find(llama_token_eos(model));
+ if (it != params.sparams.logit_bias.end() && it->second == -INFINITY) {
+ log(env, GGML_LOG_LEVEL_WARN, "EOS token is disabled, which will cause most grammars to fail");
+ }
+ }
+
+ std::vector grammar_rules(parsed_grammar.c_rules());
+ grammar = llama_grammar_init(grammar_rules.data(), grammar_rules.size(), parsed_grammar.symbol_ids.at("root"));
+ }
+ ctx_sampling = *llama_sampling_init(params.sparams);
+ return true;
+ }
+
+ void loadInfill(JNIEnv *env) {
+ bool suff_rm_leading_spc = true;
+ if (params.input_suffix.find_first_of(" ") == 0 && params.input_suffix.size() > 1) {
+ params.input_suffix.erase(0, 1);
+ suff_rm_leading_spc = false;
+ }
+
+ auto prefix_tokens = tokenize(params.input_prefix, false);
+ auto suffix_tokens = tokenize(params.input_suffix, false);
+ const int space_token = 29871;
+ if (suff_rm_leading_spc && suffix_tokens[0] == space_token) {
+ suffix_tokens.erase(suffix_tokens.begin());
+ }
+ prefix_tokens.insert(prefix_tokens.begin(), llama_token_prefix(model));
+ prefix_tokens.insert(prefix_tokens.begin(), llama_token_bos(model)); // always add BOS
+ prefix_tokens.insert(prefix_tokens.end(), llama_token_suffix(model));
+ prefix_tokens.insert(prefix_tokens.end(), suffix_tokens.begin(), suffix_tokens.end());
+ prefix_tokens.push_back(llama_token_middle(model));
+ auto prompt_tokens = prefix_tokens;
+
+ num_prompt_tokens = prompt_tokens.size();
+
+ if (params.n_keep < 0) {
+ params.n_keep = (int) num_prompt_tokens;
+ }
+ params.n_keep = std::min(params.n_ctx - 4, params.n_keep);
+
+ // if input prompt is too big, truncate like normal
+ if (num_prompt_tokens >= (size_t) params.n_ctx) {
+ // todo we probably want to cut from both sides
+ const int n_left = (params.n_ctx - params.n_keep) / 2;
+ std::vector new_tokens(prompt_tokens.begin(), prompt_tokens.begin() + params.n_keep);
+ const int erased_blocks = (num_prompt_tokens - params.n_keep - n_left - 1) / n_left;
+ new_tokens.insert(
+ new_tokens.end(), prompt_tokens.begin() + params.n_keep + erased_blocks * n_left, prompt_tokens.end());
+ std::copy(prompt_tokens.end() - params.n_ctx, prompt_tokens.end(), last_n_tokens.begin());
+
+ log(env, GGML_LOG_LEVEL_INFO, "input truncated n_left=" + std::to_string(n_left));
+
+ truncated = true;
+ prompt_tokens = new_tokens;
+ } else {
+ const size_t ps = num_prompt_tokens;
+ std::fill(last_n_tokens.begin(), last_n_tokens.end() - ps, 0);
+ std::copy(prompt_tokens.begin(), prompt_tokens.end(), last_n_tokens.end() - ps);
+ }
+
+ // compare the evaluated prompt with the new prompt
+ n_past = common_part(embd, prompt_tokens);
+ embd = prompt_tokens;
+
+ if (n_past == num_prompt_tokens) {
+ // we have to evaluate at least 1 token to generate logits.
+ n_past--;
+ }
+
+ // since #3228 we now have to manually manage the KV cache
+ llama_kv_cache_seq_rm(ctx, 0, n_past, -1);
+
+ has_next_token = true;
+ }
+
+ void loadPrompt(JNIEnv *env) {
+ auto prompt_tokens = tokenize(prompt, true); // always add BOS
+
+ num_prompt_tokens = prompt_tokens.size();
+
+ if (params.n_keep < 0) {
+ params.n_keep = (int) num_prompt_tokens;
+ }
+ params.n_keep = std::min(n_ctx - 4, params.n_keep);
+
+ // if input prompt is too big, truncate like normal
+ if (num_prompt_tokens >= (size_t) n_ctx) {
+ const int n_left = (n_ctx - params.n_keep) / 2;
+ std::vector new_tokens(prompt_tokens.begin(), prompt_tokens.begin() + params.n_keep);
+ const int erased_blocks = (num_prompt_tokens - params.n_keep - n_left - 1) / n_left;
+ new_tokens.insert(
+ new_tokens.end(), prompt_tokens.begin() + params.n_keep + erased_blocks * n_left, prompt_tokens.end());
+ std::copy(prompt_tokens.end() - n_ctx, prompt_tokens.end(), last_n_tokens.begin());
+
+ log(env, GGML_LOG_LEVEL_INFO, "input truncated n_left=" + std::to_string(n_left));
+
+ truncated = true;
+ prompt_tokens = new_tokens;
+ } else {
+ const size_t ps = num_prompt_tokens;
+ std::fill(last_n_tokens.begin(), last_n_tokens.end() - ps, 0);
+ std::copy(prompt_tokens.begin(), prompt_tokens.end(), last_n_tokens.end() - ps);
+ }
+
+ // compare the evaluated prompt with the new prompt
+ n_past = common_part(embd, prompt_tokens);
+
+ embd = prompt_tokens;
+ if (n_past == num_prompt_tokens) {
+ // we have to evaluate at least 1 token to generate logits.
+ n_past--;
+ }
+
+ // since #3228 we now have to manually manage the KV cache
+ llama_kv_cache_seq_rm(ctx, 0, n_past, -1);
+
+ has_next_token = true;
+ }
+
+ void beginCompletion() {
+ // number of tokens to keep when resetting context
+ n_remain = params.n_predict;
+ llama_set_rng_seed(ctx, params.seed);
+ }
+
+ completion_token_output nextToken(JNIEnv *env) {
+ completion_token_output result;
+ result.tok = -1;
+
+ if (embd.size() >= (size_t) n_ctx) {
+ // Shift context
+
+ const int n_left = n_past - params.n_keep - 1;
+ const int n_discard = n_left / 2;
+
+ llama_kv_cache_seq_rm(ctx, 0, params.n_keep + 1, params.n_keep + n_discard + 1);
+ llama_kv_cache_seq_shift(ctx, 0, params.n_keep + 1 + n_discard, n_past, -n_discard);
+
+ for (size_t i = params.n_keep + 1 + n_discard; i < embd.size(); i++) {
+ embd[i - n_discard] = embd[i];
+ }
+ embd.resize(embd.size() - n_discard);
+
+ n_past -= n_discard;
+
+ truncated = true;
+ log(env, GGML_LOG_LEVEL_INFO, "input truncated n_left=" + std::to_string(n_left));
+ }
+
+ bool tg = true;
+ while (n_past < embd.size()) {
+ int n_eval = (int) embd.size() - n_past;
+ tg = n_eval == 1;
+ if (n_eval > params.n_batch) {
+ n_eval = params.n_batch;
+ }
+
+ if (llama_decode(ctx, llama_batch_get_one(&embd[n_past], n_eval, n_past, 0))) {
+ log(env, GGML_LOG_LEVEL_ERROR, "failed to eval n_eval=" + std::to_string(n_eval));
+ has_next_token = false;
+ return result;
+ }
+ n_past += n_eval;
+ }
+
+ if (params.n_predict == 0) {
+ has_next_token = false;
+ result.tok = llama_token_eos(model);
+ return result;
+ }
+
+ {
+ // out of user input, sample next token
+ result.tok = llama_sampling_sample(&ctx_sampling, ctx, NULL);
+
+ llama_token_data_array candidates_p = {ctx_sampling.cur.data(), ctx_sampling.cur.size(), false};
+
+ const int32_t n_probs = params.sparams.n_probs;
+ if (params.sparams.temp <= 0 && n_probs > 0) {
+ // For llama_sample_token_greedy we need to sort candidates
+ llama_sample_softmax(ctx, &candidates_p);
+ }
+
+ for (size_t i = 0; i < std::min(candidates_p.size, (size_t) n_probs); ++i) {
+ result.probs.push_back({candidates_p.data[i].id, candidates_p.data[i].p});
+ }
+
+ llama_sampling_accept(&ctx_sampling, ctx, result.tok, true);
+ if (tg) {
+ num_tokens_predicted++;
+ }
+ }
+
+ // add it to the context
+ embd.push_back(result.tok);
+ // decrement remaining sampling budget
+ --n_remain;
+
+ if (!embd.empty() && embd.back() == llama_token_eos(model)) {
+ // stopping_word = llama_token_to_piece(ctx, embd.back());
+ has_next_token = false;
+ stopped_eos = true;
+ return result;
+ }
+
+ has_next_token = params.n_predict == -1 || n_remain != 0;
+ return result;
+ }
+
+ size_t findStoppingStrings(const std::string &text, const size_t last_token_size, const stop_type type) {
+ size_t stop_pos = std::string::npos;
+ for (const std::string &word : params.antiprompt) {
+ size_t pos;
+ if (type == STOP_FULL) {
+ const size_t tmp = word.size() + last_token_size;
+ const size_t from_pos = text.size() > tmp ? text.size() - tmp : 0;
+ pos = text.find(word, from_pos);
+ } else {
+ pos = find_partial_stop_string(word, text);
+ }
+ if (pos != std::string::npos && (stop_pos == std::string::npos || pos < stop_pos)) {
+ if (type == STOP_FULL) {
+ stopping_word = word;
+ stopped_word = true;
+ has_next_token = false;
+ }
+ stop_pos = pos;
+ }
+ }
+ return stop_pos;
+ }
+
+ completion_token_output doCompletion(JNIEnv *env) {
+ auto token_with_probs = nextToken(env);
+
+ const std::string token_text = token_with_probs.tok == -1 ? "" : llama_token_to_piece(ctx, token_with_probs.tok);
+ generated_text += token_text;
+
+ if (params.sparams.n_probs > 0) {
+ generated_token_probs.push_back(token_with_probs);
+ }
+
+ if (multibyte_pending > 0) {
+ multibyte_pending -= token_text.size();
+ } else if (token_text.size() == 1) {
+ const char c = token_text[0];
+ // 2-byte characters: 110xxxxx 10xxxxxx
+ if ((c & 0xE0) == 0xC0) {
+ multibyte_pending = 1;
+ // 3-byte characters: 1110xxxx 10xxxxxx 10xxxxxx
+ } else if ((c & 0xF0) == 0xE0) {
+ multibyte_pending = 2;
+ // 4-byte characters: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
+ } else if ((c & 0xF8) == 0xF0) {
+ multibyte_pending = 3;
+ } else {
+ multibyte_pending = 0;
+ }
+ }
+
+ if (multibyte_pending > 0 && !has_next_token) {
+ has_next_token = true;
+ n_remain++;
+ }
+
+ if (!has_next_token && n_remain == 0) {
+ stopped_limit = true;
+ }
+
+ return token_with_probs;
+ }
+
+ std::vector getEmbedding(JNIEnv *env) {
+ static const int n_embd = llama_n_embd(model);
+ if (!params.embedding) {
+ log(env, GGML_LOG_LEVEL_ERROR, "embedding disabled");
+ return std::vector(n_embd, 0.0f);
+ }
+ const float *data = llama_get_embeddings(ctx);
+ std::vector embedding(data, data + n_embd);
+ return embedding;
+ }
+};
+
+static gpt_params parse_model_params(JNIEnv *env, jobject jparams, jstring java_file_path) {
+ gpt_params params;
+
+ params.model = parse_jstring(env, java_file_path);
+ params.n_threads = env->GetIntField(jparams, f_n_threads);
+ params.n_ctx = env->GetIntField(jparams, f_n_ctx);
+ params.n_batch = env->GetIntField(jparams, f_n_batch);
+ params.n_gpu_layers = env->GetIntField(jparams, f_n_gpu_layers);
+ params.main_gpu = env->GetIntField(jparams, f_main_gpu);
+ params.rope_freq_base = env->GetFloatField(jparams, f_rope_freq_base);
+ params.rope_freq_scale = env->GetFloatField(jparams, f_rope_freq_scale);
+ params.mul_mat_q = env->GetBooleanField(jparams, f_mul_mat_q);
+ params.embedding = env->GetBooleanField(jparams, f_embedding);
+ params.escape = env->GetIntField(jparams, f_n_predict);
+ params.use_mmap = env->GetBooleanField(jparams, f_use_mmap);
+ params.use_mlock = env->GetBooleanField(jparams, f_use_mlock);
+ params.numa = env->GetBooleanField(jparams, f_numa);
+ params.verbose_prompt = env->GetBooleanField(jparams, f_verbose_prompt);
+
+ if (params.model_alias == "unknown") {
+ params.model_alias = params.model;
+ }
+
+ return params;
+}
+
+static void setup_infer_params(JNIEnv *env, jllama_context *llama, jobject jparams) {
+ auto ¶ms = llama->params;
+
+ params.seed = env->GetIntField(jparams, f_infer_seed);
+ params.n_predict = env->GetIntField(jparams, f_n_predict);
+ params.n_keep = env->GetIntField(jparams, f_n_keep);
+
+ auto &sparams = params.sparams;
+
+ sparams.top_k = env->GetIntField(jparams, f_top_k);
+ sparams.top_p = env->GetFloatField(jparams, f_top_p);
+ sparams.tfs_z = env->GetFloatField(jparams, f_tfs_z);
+ sparams.typical_p = env->GetFloatField(jparams, f_typical_p);
+ sparams.temp = env->GetFloatField(jparams, f_temperature);
+ sparams.penalty_repeat = env->GetFloatField(jparams, f_repeat_penalty);
+ sparams.n_prev = env->GetIntField(jparams, f_repeat_last_n);
+ sparams.penalty_freq = env->GetFloatField(jparams, f_frequency_penalty);
+ sparams.penalty_present = env->GetFloatField(jparams, f_presence_penalty);
+ sparams.penalize_nl = env->GetBooleanField(jparams, f_penalize_nl);
+ sparams.mirostat = env->GetIntField(jparams, f_mirostat);
+ sparams.mirostat_tau = env->GetFloatField(jparams, f_mirostat_tau);
+ sparams.mirostat_eta = env->GetFloatField(jparams, f_mirostat_eta);
+ sparams.n_probs = env->GetIntField(jparams, f_n_probs);
+
+ jstring j_grammar = (jstring) env->GetObjectField(jparams, f_grammar);
+ if (j_grammar != nullptr) {
+ sparams.grammar = parse_jstring(env, j_grammar);
+ env->DeleteLocalRef(j_grammar);
+ if (!llama->loadGrammar(env)) {
+ env->ThrowNew(c_engine_exception, "could not load grammar");
+ }
+ }
+
+ sparams.logit_bias.clear();
+ jboolean ignore_eos = env->GetBooleanField(jparams, f_ignore_eos);
+ if (ignore_eos) {
+ sparams.logit_bias[llama_token_eos(llama->model)] = -INFINITY;
+ }
+
+ jobject logit_bias = env->GetObjectField(jparams, f_logit_bias);
+ if (logit_bias != nullptr) {
+ jobject entry_set = env->CallObjectMethod(logit_bias, m_entry_set);
+ jobject iterator = env->CallObjectMethod(entry_set, m_set_iterator);
+ while (env->CallBooleanMethod(iterator, m_iterator_has_next)) {
+ jobject entry = env->CallObjectMethod(iterator, m_iterator_next);
+ jobject key = env->CallObjectMethod(entry, m_entry_key);
+ jobject value = env->CallObjectMethod(entry, m_entry_value);
+
+ int tok = parse_jinteger(env, key);
+ float bias = parse_jfloat(env, value);
+ sparams.logit_bias[tok] = bias;
+
+ env->DeleteLocalRef(entry);
+ env->DeleteLocalRef(key);
+ env->DeleteLocalRef(value);
+ }
+ }
+
+ params.antiprompt.clear();
+ jobjectArray antiprompt = (jobjectArray) env->GetObjectField(jparams, f_antiprompt);
+ if (antiprompt != nullptr) {
+ jsize array_length = env->GetArrayLength(antiprompt);
+ for (jsize i = 0; i < array_length; i++) {
+ jstring java_string = (jstring) env->GetObjectArrayElement(antiprompt, i);
+ if (java_string != nullptr) {
+ std::string string = parse_jstring(env, java_string);
+ params.antiprompt.push_back(string);
+ env->DeleteLocalRef(java_string);
+ }
+ }
+ }
+
+ llama->ctx_sampling = *llama_sampling_init(params.sparams);
+}
+
+static void setup_answering(JNIEnv *env, jllama_context *llama, jstring prompt, jobject params) {
+ llama->prompt = parse_jstring(env, prompt);
+ llama->params.input_prefix = "";
+ llama->params.input_suffix = "";
+ setup_infer_params(env, llama, params);
+}
+
+static void setup_infilling(JNIEnv *env, jllama_context *llama, jstring prefix, jstring suffix, jobject params) {
+ llama->prompt = "";
+ llama->params.input_prefix = parse_jstring(env, prefix);
+ llama->params.input_suffix = parse_jstring(env, suffix);
+ setup_infer_params(env, llama, params);
+}
+
+JNIEXPORT jlong JNICALL Java_ai_djl_llama_jni_LlamaLibrary_loadModel(
+ JNIEnv *env, jclass clazz, jstring file_path, jobject jparams) {
+ gpt_params params = parse_model_params(env, jparams, file_path);
+
+ jllama_context *llama = new jllama_context;
+ llama_backend_init(false);
+
+ if (!llama->loadModel(params)) {
+ env->ThrowNew(c_engine_exception, "could not load model from given file path");
+ return 0;
+ }
+
+ return reinterpret_cast(llama);
+}
+
+JNIEXPORT void JNICALL Java_ai_djl_llama_jni_LlamaLibrary_generate(
+ JNIEnv *env, jclass clazz, jlong handle, jstring prompt, jobject params) {
+ auto *llama = reinterpret_cast(handle);
+
+ llama->rewind();
+ llama_reset_timings(llama->ctx);
+ setup_answering(env, llama, prompt, params);
+
+ llama->loadPrompt(env);
+ llama->beginCompletion();
+}
+
+JNIEXPORT void JNICALL Java_ai_djl_llama_jni_LlamaLibrary_infill(
+ JNIEnv *env, jclass clazz, jlong handle, jstring prefix, jstring suffix, jobject params) {
+ auto *llama = reinterpret_cast(handle);
+
+ llama->rewind();
+
+ llama_reset_timings(llama->ctx);
+
+ setup_infilling(env, llama, prefix, suffix, params);
+
+ llama->loadInfill(env);
+ llama->beginCompletion();
+}
+
+JNIEXPORT jobject JNICALL Java_ai_djl_llama_jni_LlamaLibrary_getNext(
+ JNIEnv *env, jclass clazz, jlong handle, jlong sent_count, jlong sent_token_probs_index) {
+ auto *llama = reinterpret_cast(handle);
+
+ completion_token_output token_with_probs;
+ while (llama->has_next_token) {
+ token_with_probs = llama->doCompletion(env);
+ if (token_with_probs.tok >= 0 && llama->multibyte_pending <= 0) {
+ break;
+ }
+ }
+ const std::string token_text = llama_token_to_piece(llama->ctx, token_with_probs.tok);
+
+ size_t pos = std::min((size_t) sent_count, llama->generated_text.size());
+
+ const std::string str_test = llama->generated_text.substr(pos);
+ bool is_stop_full = false;
+ size_t stop_pos = llama->findStoppingStrings(str_test, token_text.size(), STOP_FULL);
+ if (stop_pos != std::string::npos) {
+ is_stop_full = true;
+ llama->generated_text.erase(llama->generated_text.begin() + pos + stop_pos, llama->generated_text.end());
+ pos = std::min((size_t) sent_count, llama->generated_text.size());
+ } else {
+ is_stop_full = false;
+ stop_pos = llama->findStoppingStrings(str_test, token_text.size(), STOP_PARTIAL);
+ }
+
+ std::string to_send;
+ if (stop_pos == std::string::npos ||
+ // Send rest of the text if we are at the end of the generation
+ (!llama->has_next_token && !is_stop_full && stop_pos > 0)) {
+ to_send = llama->generated_text.substr(pos, std::string::npos);
+
+ sent_count += to_send.size();
+ std::vector probs_output = {};
+
+ if (llama->params.sparams.n_probs > 0) {
+ const std::vector to_send_toks = llama_tokenize(llama->ctx, to_send, false);
+ size_t probs_pos = std::min((size_t) sent_token_probs_index, llama->generated_token_probs.size());
+ size_t probs_stop_pos =
+ std::min(sent_token_probs_index + to_send_toks.size(), llama->generated_token_probs.size());
+ if (probs_pos < probs_stop_pos) {
+ probs_output = std::vector(
+ llama->generated_token_probs.begin() + probs_pos, llama->generated_token_probs.begin() + probs_stop_pos);
+ }
+ sent_token_probs_index = probs_stop_pos;
+ }
+ } else {
+ to_send = "";
+ }
+
+ jobject o_probabilities = env->NewObject(c_hash_map, cc_hash_map);
+ for (const auto &tp : token_with_probs.probs) {
+ jobject jtoken = env->NewObject(c_integer, cc_integer, tp.tok);
+ jobject jprob = env->NewObject(c_float, cc_float, tp.prob);
+ env->CallObjectMethod(o_probabilities, m_map_put, jtoken, jprob);
+ }
+
+ jbyteArray jbytes = parse_jbytes(env, to_send);
+ return env->NewObject(c_token, cc_token, token_with_probs.tok, jbytes, o_probabilities, sent_count,
+ sent_token_probs_index, llama->has_next_token);
+}
+
+JNIEXPORT jfloatArray JNICALL Java_ai_djl_llama_jni_LlamaLibrary_embed(
+ JNIEnv *env, jclass clazz, jlong handle, jstring java_prompt) {
+ auto *llama = reinterpret_cast(handle);
+
+ llama->rewind();
+ llama_reset_timings(llama->ctx);
+ llama->prompt = parse_jstring(env, java_prompt);
+ llama->params.n_predict = 0;
+ llama->loadPrompt(env);
+ llama->beginCompletion();
+ llama->doCompletion(env);
+
+ static const int n_embd = llama_n_embd(llama->model);
+ const float *data = llama_get_embeddings(llama->ctx);
+ std::vector embedding(data, data + n_embd);
+
+ jfloatArray java_embedding = env->NewFloatArray(embedding.size());
+ env->SetFloatArrayRegion(java_embedding, 0, embedding.size(), reinterpret_cast(embedding.data()));
+
+ return java_embedding;
+}
+
+JNIEXPORT jintArray JNICALL Java_ai_djl_llama_jni_LlamaLibrary_encode(
+ JNIEnv *env, jclass clazz, jlong handle, jstring jprompt) {
+ auto *llama = reinterpret_cast(handle);
+
+ std::string prompt = parse_jstring(env, jprompt);
+ std::vector tokens = llama->tokenize(prompt, false);
+
+ jintArray java_tokens = env->NewIntArray(tokens.size());
+ env->SetIntArrayRegion(java_tokens, 0, tokens.size(), reinterpret_cast(tokens.data()));
+
+ return java_tokens;
+}
+
+JNIEXPORT jbyteArray JNICALL Java_ai_djl_llama_jni_LlamaLibrary_decodeBytes(
+ JNIEnv *env, jclass clazz, jlong handle, jintArray java_tokens) {
+ auto *llama = reinterpret_cast(handle);
+
+ jsize length = env->GetArrayLength(java_tokens);
+ jint *elements = env->GetIntArrayElements(java_tokens, nullptr);
+ std::vector tokens(elements, elements + length);
+ std::string text = tokens_to_str(llama->ctx, tokens.cbegin(), tokens.cend());
+
+ env->ReleaseIntArrayElements(java_tokens, elements, 0);
+
+ return parse_jbytes(env, text);
+}
+
+JNIEXPORT void JNICALL Java_ai_djl_llama_jni_LlamaLibrary_delete(JNIEnv *env, jclass clazz, jlong handle) {
+ auto *llama = reinterpret_cast(handle);
+ delete llama;
+}
diff --git a/engines/llama/src/main/resources/META-INF/services/ai.djl.engine.EngineProvider b/engines/llama/src/main/resources/META-INF/services/ai.djl.engine.EngineProvider
new file mode 100644
index 00000000000..d2f8ca8e42c
--- /dev/null
+++ b/engines/llama/src/main/resources/META-INF/services/ai.djl.engine.EngineProvider
@@ -0,0 +1 @@
+ai.djl.llama.engine.LlamaEngineProvider
diff --git a/engines/llama/src/main/resources/META-INF/services/ai.djl.repository.zoo.ZooProvider b/engines/llama/src/main/resources/META-INF/services/ai.djl.repository.zoo.ZooProvider
new file mode 100644
index 00000000000..92f6245340f
--- /dev/null
+++ b/engines/llama/src/main/resources/META-INF/services/ai.djl.repository.zoo.ZooProvider
@@ -0,0 +1 @@
+ai.djl.llama.zoo.LlamaZooProvider
diff --git a/engines/llama/src/test/java/ai/djl/llama/engine/LlamaInputTest.java b/engines/llama/src/test/java/ai/djl/llama/engine/LlamaInputTest.java
new file mode 100644
index 00000000000..429cd569392
--- /dev/null
+++ b/engines/llama/src/test/java/ai/djl/llama/engine/LlamaInputTest.java
@@ -0,0 +1,101 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.engine;
+
+import ai.djl.llama.engine.LlamaInput.Parameters;
+import ai.djl.llama.jni.InputParameters;
+import ai.djl.util.JsonUtils;
+
+import org.testng.Assert;
+import org.testng.annotations.Test;
+
+import java.io.IOException;
+import java.io.Reader;
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.nio.file.Paths;
+import java.util.Map;
+
+public class LlamaInputTest {
+
+ @Test
+ public void testInputParameters() throws IOException {
+ Path file = Paths.get("src/test/resources/inputs.json");
+ try (Reader reader = Files.newBufferedReader(file)) {
+ LlamaInput in = JsonUtils.GSON.fromJson(reader, LlamaInput.class);
+ checkParameters(in);
+ }
+
+ Parameters param = new Parameters();
+ LlamaInput in = new LlamaInput();
+ in.setInputs("prompt");
+ in.setPrefix("prefix");
+ in.setSuffix("suffix");
+ in.setParameters(param);
+ param.setMaxNewTokens(2);
+ param.setNumberKeep(2);
+ param.setNumberProbabilities(2);
+ param.setTopK(2);
+ param.setTopP(2f);
+ param.setTfsZ(2f);
+ param.setTypicalP(2f);
+ param.setTemperature(2f);
+ param.setRepeatPenalty(2f);
+ param.setRepeatLastN(2);
+ param.setFrequencyPenalty(2f);
+ param.setFrequencyPenalty(2f);
+ param.setPresencePenalty(2f);
+ param.setPenalizeNl(true);
+ param.setIgnoreEos(true);
+ param.setMirostat(2);
+ param.setMirostatTau(2f);
+ param.setMirostatEta(2f);
+ param.setNumberBeams(5);
+ param.setSeed(2);
+ Map logitBias = Map.of(2, 0.4f, 3, 0.5f);
+ param.setLogitBias(logitBias);
+ param.setGrammar("grammar");
+ param.setAntiPrompt(new String[] {"User: "});
+ checkParameters(in);
+ }
+
+ private void checkParameters(LlamaInput in) {
+ InputParameters param = in.getParameters().toInputParameters();
+ Assert.assertEquals(param.getMaxNewTokens(), 2);
+ Assert.assertEquals(param.getNumberKeep(), 2);
+ Assert.assertEquals(param.getNumberProbabilities(), 2);
+ Assert.assertEquals(param.getTopK(), 2);
+ Assert.assertEquals(param.getTopP(), 2f);
+ Assert.assertEquals(param.getTfsZ(), 2f);
+ Assert.assertEquals(param.getTypicalP(), 2f);
+ Assert.assertEquals(param.getTemperature(), 2f);
+ Assert.assertEquals(param.getRepeatPenalty(), 2f);
+ Assert.assertEquals(param.getRepeatLastN(), 2);
+ Assert.assertEquals(param.getFrequencyPenalty(), 2f);
+ Assert.assertEquals(param.getFrequencyPenalty(), 2f);
+ Assert.assertEquals(param.getPresencePenalty(), 2f);
+ Assert.assertTrue(param.isPenalizeNl());
+ Assert.assertTrue(param.isIgnoreEos());
+ Assert.assertEquals(param.getMirostat(), 2);
+ Assert.assertEquals(param.getMirostatTau(), 2f);
+ Assert.assertEquals(param.getMirostatEta(), 2f);
+ Assert.assertEquals(param.getNumberBeams(), 5);
+ Assert.assertEquals(param.getSeed(), 2);
+ Map logitBias = param.getLogitBias();
+ Assert.assertNotNull(logitBias);
+ Assert.assertEquals(logitBias.size(), 2);
+ Assert.assertEquals(logitBias.get(2), 0.4f);
+ Assert.assertNotNull(param.getGrammar());
+ Assert.assertNotNull(param.getAntiPrompt()[0], "User: ");
+ }
+}
diff --git a/engines/llama/src/test/java/ai/djl/llama/engine/LlamaTest.java b/engines/llama/src/test/java/ai/djl/llama/engine/LlamaTest.java
new file mode 100644
index 00000000000..7b372ee4258
--- /dev/null
+++ b/engines/llama/src/test/java/ai/djl/llama/engine/LlamaTest.java
@@ -0,0 +1,143 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.engine;
+
+import ai.djl.ModelException;
+import ai.djl.engine.Engine;
+import ai.djl.engine.StandardCapabilities;
+import ai.djl.inference.Predictor;
+import ai.djl.llama.jni.Token;
+import ai.djl.llama.jni.TokenIterator;
+import ai.djl.modality.Input;
+import ai.djl.modality.Output;
+import ai.djl.ndarray.NDManager;
+import ai.djl.repository.zoo.Criteria;
+import ai.djl.repository.zoo.ZooModel;
+import ai.djl.testing.TestRequirements;
+import ai.djl.training.util.DownloadUtils;
+import ai.djl.translate.TranslateException;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+import org.testng.Assert;
+import org.testng.annotations.AfterClass;
+import org.testng.annotations.BeforeClass;
+import org.testng.annotations.Test;
+
+import java.io.IOException;
+import java.net.URI;
+import java.nio.file.Path;
+import java.nio.file.Paths;
+
+public class LlamaTest {
+
+ private static final Logger logger = LoggerFactory.getLogger(LlamaTest.class);
+
+ @BeforeClass
+ public void setUp() {
+ System.setProperty("DJL_CACHE_DIR", "build/cache");
+ }
+
+ @AfterClass
+ public void tierDown() {
+ System.clearProperty("DJL_CACHE_DIR");
+ }
+
+ @Test
+ public void testLlamaVersion() {
+ Engine engine = Engine.getEngine("Llama");
+ Assert.assertEquals(engine.getVersion(), "b1696-" + Engine.getDjlVersion());
+ Assert.assertNotNull(engine.toString());
+ Assert.assertEquals(engine.getRank(), 10);
+ Assert.assertFalse(engine.hasCapability(StandardCapabilities.CUDA));
+ Assert.assertNull(engine.getAlternativeEngine());
+ try (NDManager manager = engine.newBaseManager()) {
+ Assert.assertNotNull(manager);
+ }
+ }
+
+ @Test
+ public void testLlama() throws TranslateException, ModelException, IOException {
+ TestRequirements.nightly();
+ downloadModel();
+ Path path = Paths.get("models");
+ Criteria criteria =
+ Criteria.builder()
+ .setTypes(String.class, TokenIterator.class)
+ .optModelPath(path)
+ .optModelName("tinyllama-1.1b-1t-openorca.Q4_K_M")
+ .optEngine("Llama")
+ .optOption("number_gpu_layers", "43")
+ .optTranslatorFactory(new LlamaTranslatorFactory())
+ .build();
+
+ String prompt =
+ "{\"inputs\": \"<|im_start|>system\n"
+ + "{system_message}<|im_end|>\n"
+ + "<|im_start|>user\n"
+ + "{prompt}<|im_end|>\n"
+ + "<|im_start|>assistant\", \"parameters\": {\"max_new_tokens\": 10}}";
+ try (ZooModel model = criteria.loadModel();
+ Predictor predictor = model.newPredictor()) {
+ TokenIterator it = predictor.predict(prompt);
+ StringBuilder sb = new StringBuilder();
+ while (it.hasNext()) {
+ Token token = it.next();
+ Assert.assertNotNull(token.getText());
+ Assert.assertTrue(token.getToken() >= 0);
+ Assert.assertNotNull(token.getProbabilities());
+ sb.append(token.getText());
+ logger.info("{}", token);
+ }
+ Assert.assertTrue(sb.length() > 1);
+ }
+ }
+
+ @Test
+ public void testLlamaInfill() throws TranslateException, ModelException, IOException {
+ TestRequirements.nightly();
+ downloadModel();
+ Path path = Paths.get("models/tinyllama-1.1b-1t-openorca.Q4_K_M.gguf");
+ Criteria criteria =
+ Criteria.builder()
+ .setTypes(Input.class, Output.class)
+ .optModelPath(path)
+ .optOption("number_gpu_layers", "43")
+ .optEngine("Llama")
+ .optTranslatorFactory(new LlamaTranslatorFactory())
+ .build();
+
+ String prompt =
+ "{\n"
+ + " \"prefix\":\"def remove_non_ascii(s: str) -> str:\n\",\n"
+ + " \"suffix\":\"\n return result\n\",\n"
+ + " \"parameters\":{\n"
+ + " \"max_new_tokens\": 10"
+ + " }\n"
+ + "}";
+ try (ZooModel model = criteria.loadModel();
+ Predictor predictor = model.newPredictor()) {
+ Input in = new Input();
+ in.add("data", prompt);
+ Output out = predictor.predict(in);
+ Assert.assertNotNull(out.getData().getAsString());
+ }
+ }
+
+ private void downloadModel() throws IOException {
+ String url =
+ "https://huggingface.co/TheBloke/TinyLlama-1.1B-1T-OpenOrca-GGUF/resolve/main/tinyllama-1.1b-1t-openorca.Q4_K_M.gguf?download=true";
+ Path dir = Paths.get("models/tinyllama-1.1b-1t-openorca.Q4_K_M.gguf");
+ DownloadUtils.download(URI.create(url).toURL(), dir, null);
+ }
+}
diff --git a/engines/llama/src/test/java/ai/djl/llama/engine/package-info.java b/engines/llama/src/test/java/ai/djl/llama/engine/package-info.java
new file mode 100644
index 00000000000..b2ee786419f
--- /dev/null
+++ b/engines/llama/src/test/java/ai/djl/llama/engine/package-info.java
@@ -0,0 +1,14 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+/** Contains test classes for llama engine. */
+package ai.djl.llama.engine;
diff --git a/engines/llama/src/test/java/ai/djl/llama/zoo/LlamaModelZooTest.java b/engines/llama/src/test/java/ai/djl/llama/zoo/LlamaModelZooTest.java
new file mode 100644
index 00000000000..fab7bacb9e3
--- /dev/null
+++ b/engines/llama/src/test/java/ai/djl/llama/zoo/LlamaModelZooTest.java
@@ -0,0 +1,62 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.llama.zoo;
+
+import ai.djl.repository.zoo.ModelLoader;
+import ai.djl.repository.zoo.ModelZoo;
+import ai.djl.util.Utils;
+
+import org.testng.Assert;
+import org.testng.annotations.Test;
+
+import java.nio.file.Paths;
+import java.util.Collection;
+
+public class LlamaModelZooTest {
+
+ @Test
+ public void testLlamaModelZoo() {
+ System.setProperty("DJL_CACHE_DIR", "build/cache");
+ Utils.deleteQuietly(Paths.get("build/cache/cache"));
+ try {
+ ModelZoo zoo = ModelZoo.getModelZoo("ai.djl.huggingface.gguf");
+ Collection models = zoo.getModelLoaders();
+ Assert.assertFalse(models.isEmpty());
+ Assert.assertEquals(zoo.getSupportedEngines().size(), 1);
+ ModelLoader loader = zoo.getModelLoader("TinyLlama/TinyLlama-1.1B-Chat-v0.6");
+ Assert.assertNotNull(loader);
+
+ ModelZoo llamaModelZoo = new LlamaModelZoo();
+ Assert.assertFalse(llamaModelZoo.getModelLoaders().isEmpty());
+ } finally {
+ System.clearProperty("DJL_CACHE_DIR");
+ }
+ }
+
+ @Test
+ public void testOffLine() {
+ System.setProperty("DJL_CACHE_DIR", "build/cache");
+ System.setProperty("ai.djl.offline", "true");
+ Utils.deleteQuietly(Paths.get("build/cache/cache"));
+ try {
+ // static variables cannot not be initialized properly if directly use LlamaModelZoo()
+ ModelZoo.getModelZoo("ai.djl.huggingface.gguf");
+
+ ModelZoo zoo = new LlamaModelZoo();
+ Assert.assertFalse(zoo.getModelLoaders().isEmpty());
+ } finally {
+ System.clearProperty("DJL_CACHE_DIR");
+ System.clearProperty("ai.djl.offline");
+ }
+ }
+}
diff --git a/engines/llama/src/test/java/ai/djl/llama/zoo/package-info.java b/engines/llama/src/test/java/ai/djl/llama/zoo/package-info.java
new file mode 100644
index 00000000000..145b2ddcca9
--- /dev/null
+++ b/engines/llama/src/test/java/ai/djl/llama/zoo/package-info.java
@@ -0,0 +1,14 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+/** Contains test classes for llama model zoo. */
+package ai.djl.llama.zoo;
diff --git a/engines/llama/src/test/resources/inputs.json b/engines/llama/src/test/resources/inputs.json
new file mode 100644
index 00000000000..ab77386e1b6
--- /dev/null
+++ b/engines/llama/src/test/resources/inputs.json
@@ -0,0 +1,33 @@
+{
+ "prefix": "def remove_non_ascii(s: str) -> str:",
+ "suffix": " return result",
+ "parameters": {
+ "max_new_tokens": 2,
+ "number_keep": 2,
+ "number_probabilities": 2,
+ "top_k": 2,
+ "top_p": 2,
+ "tfs_z": 2,
+ "typical_p": 2,
+ "temperature": 2,
+ "repeat_penalty": 2,
+ "repeat_last_n": 2,
+ "frequency_penalty": 2,
+ "presence_penalty": 2,
+ "penalize_nl": true,
+ "ignore_eos": true,
+ "mirostat": 2,
+ "mirostat_tau": 2,
+ "mirostat_eta": 2,
+ "number_beams": 5,
+ "seed": 2,
+ "logit_bias": {
+ "2": 0.4,
+ "5": 0.6
+ },
+ "grammar": "root ::= (expr \"=\" term \"\\n\")+\nexpr ::= term ([-+*/] term)*\nterm ::= [0-9]",
+ "anti_prompt": [
+ "User: "
+ ]
+ }
+}
diff --git a/engines/ml/lightgbm/README.md b/engines/ml/lightgbm/README.md
index 3ea950c8935..b74fae73082 100644
--- a/engines/ml/lightgbm/README.md
+++ b/engines/ml/lightgbm/README.md
@@ -36,13 +36,13 @@ LightGBM can only run on top of the Linux/Mac/Windows machine using x86_64.
## Installation
You can pull the LightGBM engine from the central Maven repository by including the following dependency:
-- ai.djl.ml.lightgbm:lightgbm:0.23.0
+- ai.djl.ml.lightgbm:lightgbm:0.27.0
```xml
ai.djl.ml.lightgbm
lightgbm
- 0.23.0
+ 0.27.0
runtime
```
diff --git a/engines/ml/lightgbm/src/main/java/ai/djl/ml/lightgbm/LgbmEngineProvider.java b/engines/ml/lightgbm/src/main/java/ai/djl/ml/lightgbm/LgbmEngineProvider.java
index a253ce3d246..f8c84c753ef 100644
--- a/engines/ml/lightgbm/src/main/java/ai/djl/ml/lightgbm/LgbmEngineProvider.java
+++ b/engines/ml/lightgbm/src/main/java/ai/djl/ml/lightgbm/LgbmEngineProvider.java
@@ -18,8 +18,6 @@
/** {@code LgbmEngineProvider} is the LightGBM implementation of {@link EngineProvider}. */
public class LgbmEngineProvider implements EngineProvider {
- private static volatile Engine engine; // NOPMD
-
/** {@inheritDoc} */
@Override
public String getEngineName() {
@@ -35,11 +33,10 @@ public int getEngineRank() {
/** {@inheritDoc} */
@Override
public Engine getEngine() {
- if (engine == null) {
- synchronized (LgbmEngineProvider.class) {
- engine = LgbmEngine.newInstance();
- }
- }
- return engine;
+ return InstanceHolder.INSTANCE;
+ }
+
+ private static class InstanceHolder {
+ static final Engine INSTANCE = LgbmEngine.newInstance();
}
}
diff --git a/engines/ml/lightgbm/src/main/java/ai/djl/ml/lightgbm/LgbmSymbolBlock.java b/engines/ml/lightgbm/src/main/java/ai/djl/ml/lightgbm/LgbmSymbolBlock.java
index 0bb92645a89..826b1a0f900 100644
--- a/engines/ml/lightgbm/src/main/java/ai/djl/ml/lightgbm/LgbmSymbolBlock.java
+++ b/engines/ml/lightgbm/src/main/java/ai/djl/ml/lightgbm/LgbmSymbolBlock.java
@@ -46,6 +46,7 @@ public class LgbmSymbolBlock extends AbstractSymbolBlock implements AutoCloseabl
* @param iterations the number of iterations the model was trained for
* @param handle the Booster handle
*/
+ @SuppressWarnings("this-escape")
public LgbmSymbolBlock(LgbmNDManager manager, int iterations, SWIGTYPE_p_p_void handle) {
this.handle = new AtomicReference<>(handle);
this.iterations = iterations;
diff --git a/engines/ml/xgboost/README.md b/engines/ml/xgboost/README.md
index d69f1830193..d10f770c956 100644
--- a/engines/ml/xgboost/README.md
+++ b/engines/ml/xgboost/README.md
@@ -37,13 +37,13 @@ XGBoost can only run on top of the Linux/Mac machine. User can build from source
## Installation
You can pull the XGBoost engine from the central Maven repository by including the following dependency:
-- ai.djl.ml.xgboost:xgboost:0.23.0
+- ai.djl.ml.xgboost:xgboost:0.27.0
```xml
ai.djl.ml.xgboost
xgboost
- 0.23.0
+ 0.27.0
runtime
```
diff --git a/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbEngineProvider.java b/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbEngineProvider.java
index 19cba32cc71..5859f3f344d 100644
--- a/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbEngineProvider.java
+++ b/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbEngineProvider.java
@@ -18,8 +18,6 @@
/** {@code XgbEngineProvider} is the XGBoost implementation of {@link EngineProvider}. */
public class XgbEngineProvider implements EngineProvider {
- private static volatile Engine engine; // NOPMD
-
/** {@inheritDoc} */
@Override
public String getEngineName() {
@@ -35,11 +33,10 @@ public int getEngineRank() {
/** {@inheritDoc} */
@Override
public Engine getEngine() {
- if (engine == null) {
- synchronized (XgbEngineProvider.class) {
- engine = XgbEngine.newInstance();
- }
- }
- return engine;
+ return InstanceHolder.INSTANCE;
+ }
+
+ private static class InstanceHolder {
+ static final Engine INSTANCE = XgbEngine.newInstance();
}
}
diff --git a/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbModel.java b/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbModel.java
index bf41acb9b6c..1b3c5ae277f 100644
--- a/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbModel.java
+++ b/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbModel.java
@@ -80,6 +80,8 @@ private Path findModelFile(String prefix) {
String fileName = file.toFile().getName();
if (fileName.endsWith(".json")) {
modelName = fileName.substring(0, fileName.length() - 5);
+ } else if (fileName.endsWith(".xgb")) {
+ modelName = fileName.substring(0, fileName.length() - 4);
} else {
modelName = fileName;
}
@@ -90,13 +92,22 @@ private Path findModelFile(String prefix) {
}
Path modelFile = modelDir.resolve(prefix);
if (Files.notExists(modelFile) || !Files.isRegularFile(modelFile)) {
- if (prefix.endsWith(".json")) {
+ if (prefix.endsWith(".json") || prefix.endsWith(".xgb")) {
return null;
}
modelFile = modelDir.resolve(prefix + ".json");
- if (Files.notExists(modelFile) || !Files.isRegularFile(modelFile)) {
- return null;
+ if (Files.isRegularFile(modelFile)) {
+ return modelFile;
+ }
+ modelFile = modelDir.resolve(prefix + ".xgb");
+ if (Files.isRegularFile(modelFile)) {
+ return modelFile;
+ }
+ modelFile = modelDir.resolve("model.xgb");
+ if (Files.isRegularFile(modelFile)) {
+ return modelFile;
}
+ return null;
}
return modelFile;
}
diff --git a/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbNDManager.java b/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbNDManager.java
index 3b56cbca241..81f9708e72b 100644
--- a/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbNDManager.java
+++ b/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbNDManager.java
@@ -39,6 +39,7 @@ public class XgbNDManager extends BaseNDManager {
private static final XgbNDManager SYSTEM_MANAGER = new SystemManager();
private float missingValue = Float.NaN;
+ private int nthread = 1;
private XgbNDManager(NDManager parent, Device device) {
super(parent, device);
@@ -57,6 +58,15 @@ public void setMissingValue(float missingValue) {
this.missingValue = missingValue;
}
+ /**
+ * Sets the default number of threads.
+ *
+ * @param nthread the default number of threads
+ */
+ public void setNthread(int nthread) {
+ this.nthread = nthread;
+ }
+
/** {@inheritDoc} */
@Override
public ByteBuffer allocateDirect(int capacity) {
@@ -166,7 +176,7 @@ public NDArray createCSR(Buffer buffer, long[] indptr, long[] indices, Shape sha
int[] intIndices = Arrays.stream(indices).mapToInt(Math::toIntExact).toArray();
float[] data = new float[buffer.remaining()];
((FloatBuffer) buffer).get(data);
- long handle = JniUtils.createDMatrixCSR(indptr, intIndices, data);
+ long handle = JniUtils.createDMatrixCSR(indptr, intIndices, data, missingValue, nthread);
return new XgbNDArray(this, alternativeManager, handle, shape, SparseFormat.CSR);
}
diff --git a/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbSymbolBlock.java b/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbSymbolBlock.java
index 1e2bcddd999..43a9e129dea 100644
--- a/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbSymbolBlock.java
+++ b/engines/ml/xgboost/src/main/java/ai/djl/ml/xgboost/XgbSymbolBlock.java
@@ -45,6 +45,7 @@ public class XgbSymbolBlock extends AbstractSymbolBlock implements AutoCloseable
* @param manager the manager to use for the block
* @param handle the Booster handle
*/
+ @SuppressWarnings("this-escape")
public XgbSymbolBlock(XgbNDManager manager, long handle) {
this.handle = new AtomicReference<>(handle);
this.manager = manager;
diff --git a/engines/ml/xgboost/src/main/java/ml/dmlc/xgboost4j/java/JniUtils.java b/engines/ml/xgboost/src/main/java/ml/dmlc/xgboost4j/java/JniUtils.java
index fefbe7f0716..eb071552fd0 100644
--- a/engines/ml/xgboost/src/main/java/ml/dmlc/xgboost4j/java/JniUtils.java
+++ b/engines/ml/xgboost/src/main/java/ml/dmlc/xgboost4j/java/JniUtils.java
@@ -67,9 +67,12 @@ public static long createDMatrix(ColumnBatch columnBatch, float missing, int nth
return handles[0];
}
- public static long createDMatrixCSR(long[] indptr, int[] indices, float[] array) {
+ public static long createDMatrixCSR(
+ long[] indptr, int[] indices, float[] array, float missing, int nthread) {
long[] handles = new long[1];
- checkCall(XGBoostJNI.XGDMatrixCreateFromCSREx(indptr, indices, array, 0, handles));
+ checkCall(
+ XGBoostJNI.XGDMatrixCreateFromCSR(
+ indptr, indices, array, 0, missing, nthread, handles));
return handles[0];
}
diff --git a/engines/ml/xgboost/src/test/java/ai/djl/ml/xgboost/XgbModelTest.java b/engines/ml/xgboost/src/test/java/ai/djl/ml/xgboost/XgbModelTest.java
index 0b09ed6807c..acbfa998867 100644
--- a/engines/ml/xgboost/src/test/java/ai/djl/ml/xgboost/XgbModelTest.java
+++ b/engines/ml/xgboost/src/test/java/ai/djl/ml/xgboost/XgbModelTest.java
@@ -53,7 +53,7 @@ public void downloadXGBoostModel() throws IOException {
@Test
public void testVersion() {
Engine engine = Engine.getEngine("XGBoost");
- Assert.assertEquals("1.7.5", engine.getVersion());
+ Assert.assertEquals("2.0.3", engine.getVersion());
}
/*
@@ -93,6 +93,7 @@ public void testNDArray() {
try (XgbNDManager manager =
(XgbNDManager) XgbNDManager.getSystemManager().newSubManager()) {
manager.setMissingValue(Float.NaN);
+ manager.setNthread(1);
NDArray zeros = manager.zeros(new Shape(1, 2));
Assert.expectThrows(UnsupportedOperationException.class, zeros::toFloatArray);
diff --git a/engines/mxnet/jnarator/build.gradle b/engines/mxnet/jnarator/build.gradle
index b9cc0d4cd5f..b9fd8ceab14 100644
--- a/engines/mxnet/jnarator/build.gradle
+++ b/engines/mxnet/jnarator/build.gradle
@@ -17,6 +17,11 @@ dependencies {
checkstyleMain.source = 'src/main/java'
pmdMain.source = 'src/main/java'
+compileJava {
+ options.compilerArgs.clear()
+ options.compilerArgs << "--release" << "11" << "-proc:none" << "-Xlint:all,-options,-static"
+}
+
jar {
manifest {
attributes (
diff --git a/engines/mxnet/jnarator/src/main/java/ai/djl/mxnet/jnarator/JnaGenerator.java b/engines/mxnet/jnarator/src/main/java/ai/djl/mxnet/jnarator/JnaGenerator.java
index 3105ec9cd48..ba3e18fea3b 100644
--- a/engines/mxnet/jnarator/src/main/java/ai/djl/mxnet/jnarator/JnaGenerator.java
+++ b/engines/mxnet/jnarator/src/main/java/ai/djl/mxnet/jnarator/JnaGenerator.java
@@ -276,6 +276,7 @@ public void writeNativeSize() throws IOException {
writer.append(" public NativeSizeByReference() {\n");
writer.append(" this(new NativeSize(0));\n");
writer.append(" }\n\n");
+ writer.append(" @SuppressWarnings(\"this-escape\")\n");
writer.append(" public NativeSizeByReference(NativeSize value) {\n");
writer.append(" super(NativeSize.SIZE);\n");
writer.append(" setValue(value);\n");
diff --git a/engines/mxnet/mxnet-engine/README.md b/engines/mxnet/mxnet-engine/README.md
index cef559f1e31..92f94848550 100644
--- a/engines/mxnet/mxnet-engine/README.md
+++ b/engines/mxnet/mxnet-engine/README.md
@@ -7,7 +7,7 @@ This module contains the Deep Java Library (DJL) EngineProvider for Apache MXNet
We don't recommend that developers use classes in this module directly. Use of these classes
will couple your code with Apache MXNet and make switching between engines difficult. Even so,
developers are not restricted from using engine-specific features. For more information,
-see [NDManager#invoke()](https://javadoc.io/static/ai.djl/api/0.23.0/ai/djl/ndarray/NDManager.html#invoke-java.lang.String-ai.djl.ndarray.NDArray:A-ai.djl.ndarray.NDArray:A-ai.djl.util.PairList-).
+see [NDManager#invoke()](https://javadoc.io/static/ai.djl/api/0.27.0/ai/djl/ndarray/NDManager.html#invoke-java.lang.String-ai.djl.ndarray.NDArray:A-ai.djl.ndarray.NDArray:A-ai.djl.util.PairList-).
## Documentation
@@ -33,7 +33,7 @@ You can pull the MXNet engine from the central Maven repository by including the
ai.djl.mxnet
mxnet-engine
- 0.23.0
+ 0.27.0
runtime
```
diff --git a/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/CachedOp.java b/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/CachedOp.java
index 62398b1868e..b1ca8e49aa4 100644
--- a/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/CachedOp.java
+++ b/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/CachedOp.java
@@ -63,6 +63,7 @@ public class CachedOp extends NativeResource {
* @param dataIndices the input data names required by the model and their corresponding
* location
*/
+ @SuppressWarnings("this-escape")
public CachedOp(
Pointer handle,
MxNDManager manager,
diff --git a/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxEngineProvider.java b/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxEngineProvider.java
index f30a6a89252..5f45116f615 100644
--- a/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxEngineProvider.java
+++ b/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxEngineProvider.java
@@ -18,8 +18,6 @@
/** {@code MxEngineProvider} is the MXNet implementation of {@link EngineProvider}. */
public class MxEngineProvider implements EngineProvider {
- private static volatile Engine engine; // NOPMD
-
/** {@inheritDoc} */
@Override
public String getEngineName() {
@@ -35,11 +33,10 @@ public int getEngineRank() {
/** {@inheritDoc} */
@Override
public Engine getEngine() {
- if (engine == null) {
- synchronized (MxEngineProvider.class) {
- engine = MxEngine.newInstance();
- }
- }
- return engine;
+ return InstanceHolder.INSTANCE;
+ }
+
+ private static class InstanceHolder {
+ static final Engine INSTANCE = MxEngine.newInstance();
}
}
diff --git a/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxNDArray.java b/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxNDArray.java
index 87ccba78e96..8b884b3993a 100644
--- a/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxNDArray.java
+++ b/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxNDArray.java
@@ -888,6 +888,13 @@ public NDArray atan() {
return manager.invoke("_npi_arctan", this, null);
}
+ /** {@inheritDoc} */
+ @Override
+ public NDArray atan2(NDArray other) {
+ other = manager.from(other);
+ return manager.invoke("_npi_arctan2", new NDArray[] {this, other}, null);
+ }
+
/** {@inheritDoc} */
@Override
public NDArray sinh() {
@@ -1153,6 +1160,18 @@ public NDArray stft(
throw new UnsupportedOperationException("Not implemented yet.");
}
+ /** {@inheritDoc} */
+ @Override
+ public NDArray fft2(long[] sizes, long[] axes) {
+ throw new UnsupportedOperationException("Not implemented yet.");
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public NDArray ifft2(long[] sizes, long[] axes) {
+ throw new UnsupportedOperationException("Not implemented yet.");
+ }
+
/** {@inheritDoc} */
@Override
public NDArray reshape(Shape shape) {
@@ -1601,6 +1620,12 @@ public NDArray erfinv() {
return manager.invoke("erfinv", this, null);
}
+ /** {@inheritDoc} */
+ @Override
+ public NDArray erf() {
+ return manager.invoke("erf", this, null);
+ }
+
/** {@inheritDoc} */
@Override
public NDArray norm(boolean keepDims) {
diff --git a/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxParameterServer.java b/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxParameterServer.java
index 36bead164e4..952ca2f0995 100644
--- a/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxParameterServer.java
+++ b/engines/mxnet/mxnet-engine/src/main/java/ai/djl/mxnet/engine/MxParameterServer.java
@@ -40,6 +40,7 @@ public class MxParameterServer extends NativeResource implements Parame
*
* @param optimizer the optimizer to use for the parameter server updates
*/
+ @SuppressWarnings("this-escape")
public MxParameterServer(Optimizer optimizer) {
super(createdKVStore());
callback = new OptimizerCallback(optimizer);
diff --git a/engines/mxnet/mxnet-model-zoo/README.md b/engines/mxnet/mxnet-model-zoo/README.md
index c4f44fe358c..8c03913c776 100644
--- a/engines/mxnet/mxnet-model-zoo/README.md
+++ b/engines/mxnet/mxnet-model-zoo/README.md
@@ -27,7 +27,7 @@ You can pull the MXNet engine from the central Maven repository by including the
ai.djl.mxnet
mxnet-model-zoo
- 0.23.0
+ 0.27.0
```
diff --git a/engines/mxnet/mxnet-model-zoo/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/mxnet/yolo/metadata.json b/engines/mxnet/mxnet-model-zoo/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/mxnet/yolo/metadata.json
index a5c3a140933..81a0fdc944a 100644
--- a/engines/mxnet/mxnet-model-zoo/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/mxnet/yolo/metadata.json
+++ b/engines/mxnet/mxnet-model-zoo/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/mxnet/yolo/metadata.json
@@ -55,7 +55,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_darknet_voc_416",
"properties": {
"dataset": "voc",
"version": "3",
@@ -80,11 +80,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_darknet53_voc-416x416/yolo-symbol.json",
+ "name": "yolo3_darknet_voc_416-symbol.json",
"sha1Hash": "488dfc61afdb9022901673c048e3773041a20669",
"size": 216997
},
"parameters": {
"uri": "0.0.1/yolo3_darknet53_voc-416x416/yolo-0000.params.gz",
+ "name": "yolo3_darknet_voc_416-0000.params",
"sha1Hash": "e71611a6eda9d475b941a3c57d6e447e54e22b6d",
"size": 228664813
}
@@ -93,7 +95,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_mobilenet_voc_320",
"properties": {
"dataset": "voc",
"version": "3",
@@ -118,11 +120,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_mobilenet1.0_voc-320x320/yolo-symbol.json",
+ "name": "yolo3_mobilenet_voc_320-symbol.json",
"sha1Hash": "367e425d3ffa1fc06355dc88b96f5c0c408e224c",
"size": 147800
},
"parameters": {
"uri": "0.0.1/yolo3_mobilenet1.0_voc-320x320/yolo-0000.params.gz",
+ "name": "yolo3_mobilenet_voc_320-0000.params",
"sha1Hash": "69f6935e53f69560ced1718bfa73935f9db7412d",
"size": 89818905
}
@@ -131,7 +135,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_mobilenet_voc_41",
"properties": {
"dataset": "voc",
"version": "3",
@@ -156,11 +160,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_mobilenet1.0_voc-416x416/yolo-symbol.json",
+ "name": "yolo3_mobilenet_voc_416-symbol.json",
"sha1Hash": "1f537495fd8ad952d4c7a3bc3160583a55269469",
"size": 147800
},
"parameters": {
"uri": "0.0.1/yolo3_mobilenet1.0_voc-416x416/yolo-0000.params.gz",
+ "name": "yolo3_mobilenet_voc_416-0000.params",
"sha1Hash": "3a5bedb5122c970375d4ee10a78e990832fda1cb",
"size": 89818919
}
@@ -169,7 +175,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_darknet_coco_320",
"properties": {
"dataset": "coco",
"version": "3",
@@ -194,11 +200,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_darknet53_coco-320x320/yolo-symbol.json",
+ "name": "yolo3_darknet_coco_320-symbol.json",
"sha1Hash": "17e60b0b141d81fb5534dec02252fdf9364a1087",
"size": 217009
},
"parameters": {
"uri": "0.0.1/yolo3_darknet53_coco-320x320/yolo-0000.params.gz",
+ "name": "yolo3_darknet_coco_320-0000.params",
"sha1Hash": "06c5ddb4c6daf1839fed15d5566e49968edf60b5",
"size": 229889985
}
@@ -207,7 +215,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_darknet_coco_416",
"properties": {
"dataset": "coco",
"version": "3",
@@ -232,11 +240,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_darknet53_coco-416x416/yolo-symbol.json",
+ "name": "yolo3_darknet_coco_416-symbol.json",
"sha1Hash": "ccb6cc9e479e12992059f3196ce55cda9bfb6d3e",
"size": 217009
},
"parameters": {
"uri": "0.0.1/yolo3_darknet53_coco-416x416/yolo-0000.params.gz",
+ "name": "yolo3_darknet_coco_416-0000.params",
"sha1Hash": "b290675ce6b79eb35fc315c475d82423fa7621c1",
"size": 229889985
}
@@ -245,7 +255,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_darknet_coco_608",
"properties": {
"dataset": "coco",
"version": "3",
@@ -270,11 +280,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_darknet53_coco-608x608/yolo-symbol.json",
+ "name": "yolo3_darknet_coco_608-symbol.json",
"sha1Hash": "a7cb07555e06571007516298dc1f238bc90baf72",
"size": 217009
},
"parameters": {
"uri": "0.0.1/yolo3_darknet53_coco-608x608/yolo-0000.params.gz",
+ "name": "yolo3_darknet_coco_608-0000.params",
"sha1Hash": "2efd6cd89723913d96b66642a225ea56e03e7fa2",
"size": 229889985
}
@@ -283,7 +295,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_mobilenet_coco_320",
"properties": {
"dataset": "coco",
"version": "3",
@@ -308,11 +320,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_mobilenet1.0_coco-320x320/yolo-symbol.json",
+ "name": "yolo3_mobilenet_coco_320-symbol.json",
"sha1Hash": "8ac07f8169228b5e720804f36a4dadb37817f4c3",
"size": 147812
},
"parameters": {
"uri": "0.0.1/yolo3_mobilenet1.0_coco-320x320/yolo-0000.params.gz",
+ "name": "yolo3_mobilenet_coco_320-0000.params",
"sha1Hash": "d9fa1ad5413abb8f8df81ba729fa7a115836f833",
"size": 91257892
}
@@ -321,7 +335,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_mobilenet_coco_416",
"properties": {
"dataset": "coco",
"version": "3",
@@ -346,11 +360,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_mobilenet1.0_coco-416x416/yolo-symbol.json",
+ "name": "yolo3_mobilenet_coco_416-symbol.json",
"sha1Hash": "c6a85feca8d849fed6a82a6e70cdc351ec36027f",
"size": 147812
},
"parameters": {
"uri": "0.0.1/yolo3_mobilenet1.0_coco-416x416/yolo-0000.params.gz",
+ "name": "yolo3_mobilenet_coco_416-0000.params",
"sha1Hash": "061e21037dcd5ac011190585437f4fbab4952a3b",
"size": 91257867
}
@@ -359,7 +375,7 @@
{
"version": "0.0.1",
"snapshot": false,
- "name": "yolo",
+ "name": "yolo3_mobilenet_coco_608",
"properties": {
"dataset": "coco",
"version": "3",
@@ -384,11 +400,13 @@
},
"symbol": {
"uri": "0.0.1/yolo3_mobilenet1.0_coco-608x608/yolo-symbol.json",
+ "name": "yolo3_mobilenet_coco_608-symbol.json",
"sha1Hash": "10e47405a1744788ccb533bca20b2608770eeec3",
"size": 147812
},
"parameters": {
"uri": "0.0.1/yolo3_mobilenet1.0_coco-608x608/yolo-0000.params.gz",
+ "name": "yolo3_mobilenet_coco_608-0000.params",
"sha1Hash": "f8fd4e8955ee90d4060d2544ed285b232c8085da",
"size": 91257867
}
diff --git a/engines/mxnet/native/build.gradle b/engines/mxnet/native/build.gradle
index 3f8ee285054..dc9d6e5e12d 100644
--- a/engines/mxnet/native/build.gradle
+++ b/engines/mxnet/native/build.gradle
@@ -89,6 +89,7 @@ flavorNames.each { flavor ->
}
from file("${BINARY_ROOT}/${flavor}/${osName}")
archiveClassifier = "${osName}-x86_64"
+ archiveBaseName = "mxnet-native-${flavor}"
manifest {
attributes("Automatic-Module-Name": "ai.djl.mxnet_native_${flavor}_${osName}")
diff --git a/engines/onnxruntime/onnxruntime-android/README.md b/engines/onnxruntime/onnxruntime-android/README.md
index e304e78d5c3..6e00ea2af60 100644
--- a/engines/onnxruntime/onnxruntime-android/README.md
+++ b/engines/onnxruntime/onnxruntime-android/README.md
@@ -6,13 +6,13 @@ This module contains the DJL ONNX Runtime engine for Android.
## Installation
You can pull the ONNX Runtime for Android from the central Maven repository by including the following dependency:
-- ai.djl.android:onnxruntime:0.23.0
+- ai.djl.android:onnxruntime:0.27.0
```xml
ai.djl.android
onnxruntime
- 0.23.0
+ 0.27.0
runtime
```
diff --git a/engines/onnxruntime/onnxruntime-engine/README.md b/engines/onnxruntime/onnxruntime-engine/README.md
index c287819d23f..36a2f1a3cd1 100644
--- a/engines/onnxruntime/onnxruntime-engine/README.md
+++ b/engines/onnxruntime/onnxruntime-engine/README.md
@@ -37,13 +37,13 @@ for the official ONNX Runtime project.
## Installation
You can pull the ONNX Runtime engine from the central Maven repository by including the following dependency:
-- ai.djl.onnxruntime:onnxruntime-engine:0.23.0
+- ai.djl.onnxruntime:onnxruntime-engine:0.27.0
```xml
ai.djl.onnxruntime
onnxruntime-engine
- 0.23.0
+ 0.27.0
runtime
```
@@ -61,7 +61,7 @@ Maven:
ai.djl.onnxruntime
onnxruntime-engine
- 0.23.0
+ 0.27.0
runtime
@@ -73,7 +73,7 @@ Maven:
com.microsoft.onnxruntime
onnxruntime_gpu
- 1.14.0
+ 1.17.1
runtime
```
@@ -81,10 +81,10 @@ Maven:
Gradle:
```groovy
-implementation("ai.djl.onnxruntime:onnxruntime-engine:0.23.0") {
+implementation("ai.djl.onnxruntime:onnxruntime-engine:0.27.0") {
exclude group: "com.microsoft.onnxruntime", module: "onnxruntime"
}
-implementation "com.microsoft.onnxruntime:onnxruntime_gpu:1.14.0"
+implementation "com.microsoft.onnxruntime:onnxruntime_gpu:1.17.1"
```
#### Enable TensorRT execution
diff --git a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtEngine.java b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtEngine.java
index 89599722435..43312fb18e8 100644
--- a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtEngine.java
+++ b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtEngine.java
@@ -97,7 +97,7 @@ public int getRank() {
/** {@inheritDoc} */
@Override
public String getVersion() {
- return "1.15.1";
+ return "1.17.1";
}
/** {@inheritDoc} */
diff --git a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtEngineProvider.java b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtEngineProvider.java
index c673b3dcbf1..005c0fa25f1 100644
--- a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtEngineProvider.java
+++ b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtEngineProvider.java
@@ -18,8 +18,6 @@
/** {@code OrtEngineProvider} is the ONNX Runtime implementation of {@link EngineProvider}. */
public class OrtEngineProvider implements EngineProvider {
- private static volatile Engine engine; // NOPMD
-
/** {@inheritDoc} */
@Override
public String getEngineName() {
@@ -35,11 +33,10 @@ public int getEngineRank() {
/** {@inheritDoc} */
@Override
public Engine getEngine() {
- if (engine == null) {
- synchronized (OrtEngineProvider.class) {
- engine = OrtEngine.newInstance();
- }
- }
- return engine;
+ return InstanceHolder.INSTANCE;
+ }
+
+ private static class InstanceHolder {
+ static final Engine INSTANCE = OrtEngine.newInstance();
}
}
diff --git a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtModel.java b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtModel.java
index 86877e47a21..e8b6008cf7e 100644
--- a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtModel.java
+++ b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtModel.java
@@ -70,12 +70,14 @@ public void load(Path modelPath, String prefix, Map options)
throw new UnsupportedOperationException("ONNX Runtime does not support dynamic blocks");
}
- if (prefix == null) {
- prefix = modelName;
+ Path modelFile;
+ if (prefix != null) {
+ modelFile = findModelFile(prefix);
+ } else {
+ // search for .onnx file with folder name or "model.onnx"
+ modelFile = findModelFile(modelName, modelDir.toFile().getName(), "model.onnx");
}
- // search for .onnx file with prefix, folder name or "model.onnx"
- Path modelFile = findModelFile(prefix, modelDir.toFile().getName(), "model.onnx");
if (modelFile == null) {
throw new FileNotFoundException(".onnx file not found in: " + modelPath);
}
diff --git a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtSymbolBlock.java b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtSymbolBlock.java
index aa54b43f376..4e8df210d40 100644
--- a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtSymbolBlock.java
+++ b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/engine/OrtSymbolBlock.java
@@ -59,6 +59,7 @@ public class OrtSymbolBlock extends AbstractSymbolBlock implements AutoCloseable
* @param session the {@link OrtSession} contains the model information
* @param manager the {@link NDManager} to holds the NDArray
*/
+ @SuppressWarnings("this-escape")
public OrtSymbolBlock(OrtSession session, OrtNDManager manager) {
this.session = session;
this.manager = manager;
diff --git a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/zoo/OrtModelZoo.java b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/zoo/OrtModelZoo.java
index 9d8037cfa8b..d61cb81f1ee 100644
--- a/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/zoo/OrtModelZoo.java
+++ b/engines/onnxruntime/onnxruntime-engine/src/main/java/ai/djl/onnxruntime/zoo/OrtModelZoo.java
@@ -31,6 +31,7 @@ public class OrtModelZoo extends ModelZoo {
OrtModelZoo() {
addModel(REPOSITORY.model(CV.IMAGE_CLASSIFICATION, GROUP_ID, "resnet", "0.0.1"));
addModel(REPOSITORY.model(CV.OBJECT_DETECTION, GROUP_ID, "yolo5s", "0.0.1"));
+ addModel(REPOSITORY.model(CV.OBJECT_DETECTION, GROUP_ID, "yolov8n", "0.0.1"));
addModel(REPOSITORY.model(Tabular.SOFTMAX_REGRESSION, GROUP_ID, "iris_flowers", "0.0.1"));
}
diff --git a/engines/onnxruntime/onnxruntime-engine/src/test/java/ai/djl/onnxruntime/engine/OrtTest.java b/engines/onnxruntime/onnxruntime-engine/src/test/java/ai/djl/onnxruntime/engine/OrtTest.java
index b3d8225a898..c16070161e7 100644
--- a/engines/onnxruntime/onnxruntime-engine/src/test/java/ai/djl/onnxruntime/engine/OrtTest.java
+++ b/engines/onnxruntime/onnxruntime-engine/src/test/java/ai/djl/onnxruntime/engine/OrtTest.java
@@ -84,14 +84,16 @@ public void testOrt() throws TranslateException, ModelException, IOException {
Model m = Model.newInstance("model", "OnnxRuntime");
Path path = model.getModelPath();
- Assert.assertThrows(() -> m.load(path, null));
Assert.assertThrows(() -> m.load(path, "invalid.onnx"));
- Path modelFile = path.resolve(model.getName() + ".onnx");
- m.load(modelFile);
-
+ m.load(path, null);
m.close();
+ Model m2 = Model.newInstance("model", "OnnxRuntime");
+ Path modelFile = path.resolve(model.getName() + ".onnx");
+ m2.load(modelFile);
+ m2.close();
+
// Test load model from stream
Model stream = Model.newInstance("model", "OnnxRuntime");
try (InputStream is = Files.newInputStream(modelFile)) {
diff --git a/engines/onnxruntime/onnxruntime-engine/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/onnxruntime/yolov8n/metadata.json b/engines/onnxruntime/onnxruntime-engine/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/onnxruntime/yolov8n/metadata.json
new file mode 100644
index 00000000000..1e0169a2561
--- /dev/null
+++ b/engines/onnxruntime/onnxruntime-engine/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/onnxruntime/yolov8n/metadata.json
@@ -0,0 +1,40 @@
+{
+ "metadataVersion": "0.2",
+ "resourceType": "model",
+ "application": "cv/object_detection",
+ "groupId": "ai.djl.onnxruntime",
+ "artifactId": "yolov8n",
+ "name": "yolov8n",
+ "description": "YoloV8 Model",
+ "website": "http://www.djl.ai/engines/onnxruntime/model-zoo",
+ "licenses": {
+ "license": {
+ "name": "The Apache License, Version 2.0",
+ "url": "https://www.apache.org/licenses/LICENSE-2.0"
+ }
+ },
+ "artifacts": [
+ {
+ "version": "0.0.1",
+ "snapshot": false,
+ "name": "yolov8n",
+ "arguments": {
+ "width": 640,
+ "height": 640,
+ "resize": true,
+ "rescale": true,
+ "optApplyRatio": true,
+ "threshold": 0.6,
+ "translatorFactory": "ai.djl.modality.cv.translator.YoloV8TranslatorFactory"
+ },
+ "files": {
+ "model": {
+ "uri": "0.0.1/yolov8n.zip",
+ "name": "",
+ "sha1Hash": "9fbad7f706713843cbb8c8d6a56c81a640ec6fa2",
+ "size": 11053839
+ }
+ }
+ }
+ ]
+}
diff --git a/engines/paddlepaddle/paddlepaddle-engine/README.md b/engines/paddlepaddle/paddlepaddle-engine/README.md
index 9e65fb76601..0e9643bda1a 100644
--- a/engines/paddlepaddle/paddlepaddle-engine/README.md
+++ b/engines/paddlepaddle/paddlepaddle-engine/README.md
@@ -30,7 +30,7 @@ You can pull the PaddlePaddle engine from the central Maven repository by includ
ai.djl.paddlepaddle
paddlepaddle-engine
- 0.23.0
+ 0.27.0
runtime
```
diff --git a/engines/paddlepaddle/paddlepaddle-engine/src/main/java/ai/djl/paddlepaddle/engine/PpEngineProvider.java b/engines/paddlepaddle/paddlepaddle-engine/src/main/java/ai/djl/paddlepaddle/engine/PpEngineProvider.java
index e2b5bdd35a0..59e5cd90724 100644
--- a/engines/paddlepaddle/paddlepaddle-engine/src/main/java/ai/djl/paddlepaddle/engine/PpEngineProvider.java
+++ b/engines/paddlepaddle/paddlepaddle-engine/src/main/java/ai/djl/paddlepaddle/engine/PpEngineProvider.java
@@ -18,8 +18,6 @@
/** {@code PpEngineProvider} is the PaddlePaddle implementation of {@link EngineProvider}. */
public class PpEngineProvider implements EngineProvider {
- private static volatile Engine engine; // NOPMD
-
/** {@inheritDoc} */
@Override
public String getEngineName() {
@@ -35,11 +33,10 @@ public int getEngineRank() {
/** {@inheritDoc} */
@Override
public Engine getEngine() {
- if (engine == null) {
- synchronized (PpEngineProvider.class) {
- engine = PpEngine.newInstance();
- }
- }
- return engine;
+ return InstanceHolder.INSTANCE;
+ }
+
+ private static class InstanceHolder {
+ static final Engine INSTANCE = PpEngine.newInstance();
}
}
diff --git a/engines/paddlepaddle/paddlepaddle-model-zoo/README.md b/engines/paddlepaddle/paddlepaddle-model-zoo/README.md
index e2c9cf6036c..09aef220bf9 100644
--- a/engines/paddlepaddle/paddlepaddle-model-zoo/README.md
+++ b/engines/paddlepaddle/paddlepaddle-model-zoo/README.md
@@ -26,7 +26,7 @@ from the central Maven repository by including the following dependency:
ai.djl.paddlepaddle
paddlepaddle-model-zoo
- 0.23.0
+ 0.27.0
```
diff --git a/engines/paddlepaddle/paddlepaddle-native/build.gradle b/engines/paddlepaddle/paddlepaddle-native/build.gradle
index 74a573debad..de1ea58da2b 100644
--- a/engines/paddlepaddle/paddlepaddle-native/build.gradle
+++ b/engines/paddlepaddle/paddlepaddle-native/build.gradle
@@ -213,6 +213,7 @@ flavorNames.each { flavor ->
}
from file("${BINARY_ROOT}/${flavor}/${osName}")
archiveClassifier = "${osName}-x86_64"
+ archiveBaseName = "paddlepaddle-native-${flavor}"
manifest {
attributes("Automatic-Module-Name": "ai.djl.paddlepaddle_native_${flavor}_${osName}")
diff --git a/engines/pytorch/pytorch-engine/README.md b/engines/pytorch/pytorch-engine/README.md
index ef74cf98808..a0d246626c6 100644
--- a/engines/pytorch/pytorch-engine/README.md
+++ b/engines/pytorch/pytorch-engine/README.md
@@ -24,13 +24,13 @@ The javadocs output is built in the `build/doc/javadoc` folder.
## Installation
You can pull the PyTorch engine from the central Maven repository by including the following dependency:
-- ai.djl.pytorch:pytorch-engine:0.23.0
+- ai.djl.pytorch:pytorch-engine:0.27.0
```xml
ai.djl.pytorch
pytorch-engine
- 0.23.0
+ 0.27.0
runtime
```
@@ -46,6 +46,11 @@ The following table illustrates which pytorch version that DJL supports:
| PyTorch engine version | PyTorch native library version |
|------------------------|-------------------------------------------|
+| pytorch-engine:0.28.0 | 1.13.1, **2.1.2** |
+| pytorch-engine:0.27.0 | 1.13.1, **2.1.1** |
+| pytorch-engine:0.26.0 | 1.13.1, 2.0.1, **2.1.1** |
+| pytorch-engine:0.25.0 | 1.11.0, 1.12.1, **1.13.1**, 2.0.1 |
+| pytorch-engine:0.24.0 | 1.11.0, 1.12.1, **1.13.1**, 2.0.1 |
| pytorch-engine:0.23.0 | 1.11.0, 1.12.1, **1.13.1**, 2.0.1 |
| pytorch-engine:0.22.1 | 1.11.0, 1.12.1, **1.13.1**, 2.0.0 |
| pytorch-engine:0.21.0 | 1.11.0, 1.12.1, **1.13.1** |
@@ -110,21 +115,21 @@ export PYTORCH_FLAVOR=cpu
### macOS
For macOS, you can use the following library:
-- ai.djl.pytorch:pytorch-jni:2.0.1-0.23.0
-- ai.djl.pytorch:pytorch-native-cpu:2.0.1:osx-x86_64
+- ai.djl.pytorch:pytorch-jni:2.1.1-0.27.0
+- ai.djl.pytorch:pytorch-native-cpu:2.1.1:osx-x86_64
```xml
ai.djl.pytorch
pytorch-native-cpu
osx-x86_64
- 2.0.1
+ 2.1.1
runtime
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
@@ -134,21 +139,21 @@ For macOS, you can use the following library:
### macOS M1
For macOS M1, you can use the following library:
-- ai.djl.pytorch:pytorch-jni:2.0.1-0.23.0
-- ai.djl.pytorch:pytorch-native-cpu:2.0.1:osx-aarch64
+- ai.djl.pytorch:pytorch-jni:2.1.1-0.27.0
+- ai.djl.pytorch:pytorch-native-cpu:2.1.1:osx-aarch64
```xml
ai.djl.pytorch
pytorch-native-cpu
osx-aarch64
- 2.0.1
+ 2.1.1
runtime
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
@@ -159,29 +164,29 @@ installed on your GPU machine, you can use one of the following library:
#### Linux GPU
-- ai.djl.pytorch:pytorch-jni:2.0.1-0.23.0
-- ai.djl.pytorch:pytorch-native-cu118:2.0.1:linux-x86_64 - CUDA 11.8
+- ai.djl.pytorch:pytorch-jni:2.1.1-0.27.0
+- ai.djl.pytorch:pytorch-native-cu121:2.1.1:linux-x86_64 - CUDA 12.1
```xml
ai.djl.pytorch
- pytorch-native-cu118
+ pytorch-native-cu121
linux-x86_64
- 2.0.1
+ 2.1.1
runtime
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
### Linux CPU
-- ai.djl.pytorch:pytorch-jni:2.0.1-0.23.0
-- ai.djl.pytorch:pytorch-native-cpu:2.0.1:linux-x86_64
+- ai.djl.pytorch:pytorch-jni:2.1.1-0.27.0
+- ai.djl.pytorch:pytorch-native-cpu:2.1.1:linux-x86_64
```xml
@@ -189,20 +194,20 @@ installed on your GPU machine, you can use one of the following library:
pytorch-native-cpu
linux-x86_64
runtime
- 2.0.1
+ 2.1.1
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
### For aarch64 build
-- ai.djl.pytorch:pytorch-jni:2.0.1-0.23.0
-- ai.djl.pytorch:pytorch-native-cpu-precxx11:2.0.1:linux-aarch64
+- ai.djl.pytorch:pytorch-jni:2.1.1-0.27.0
+- ai.djl.pytorch:pytorch-native-cpu-precxx11:2.1.1:linux-aarch64
```xml
@@ -210,12 +215,12 @@ installed on your GPU machine, you can use one of the following library:
pytorch-native-cpu-precxx11
linux-aarch64
runtime
- 2.0.1
+ 2.1.1
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
@@ -225,22 +230,22 @@ installed on your GPU machine, you can use one of the following library:
We also provide packages for the system like CentOS 7/Ubuntu 14.04 with GLIBC >= 2.17.
All the package were built with GCC 7, we provided a newer `libstdc++.so.6.24` in the package that contains `CXXABI_1.3.9` to use the package successfully.
-- ai.djl.pytorch:pytorch-jni:2.0.1-0.23.0
-- ai.djl.pytorch:pytorch-native-cu118-precxx11:2.0.1:linux-x86_64 - CUDA 11.8
-- ai.djl.pytorch:pytorch-native-cpu-precxx11:2.0.1:linux-x86_64 - CPU
+- ai.djl.pytorch:pytorch-jni:2.1.1-0.27.0
+- ai.djl.pytorch:pytorch-native-cu121-precxx11:2.1.1:linux-x86_64 - CUDA 12.1
+- ai.djl.pytorch:pytorch-native-cpu-precxx11:2.1.1:linux-x86_64 - CPU
```xml
ai.djl.pytorch
- pytorch-native-cu118-precxx11
+ pytorch-native-cu121-precxx11
linux-x86_64
- 2.0.1
+ 2.1.1
runtime
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
@@ -250,13 +255,13 @@ All the package were built with GCC 7, we provided a newer `libstdc++.so.6.24` i
ai.djl.pytorch
pytorch-native-cpu-precxx11
linux-x86_64
- 2.0.1
+ 2.1.1
runtime
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
@@ -271,29 +276,29 @@ For the Windows platform, you can choose between CPU and GPU.
#### Windows GPU
-- ai.djl.pytorch:pytorch-jni:2.0.1-0.23.0
-- ai.djl.pytorch:pytorch-native-cu118:2.0.1:win-x86_64 - CUDA 11.8
+- ai.djl.pytorch:pytorch-jni:2.1.1-0.27.0
+- ai.djl.pytorch:pytorch-native-cu121:2.1.1:win-x86_64 - CUDA 12.1
```xml
ai.djl.pytorch
- pytorch-native-cu118
+ pytorch-native-cu121
win-x86_64
- 2.0.1
+ 2.1.1
runtime
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
### Windows CPU
-- ai.djl.pytorch:pytorch-jni:2.0.1-0.23.0
-- ai.djl.pytorch:pytorch-native-cpu:2.0.1:win-x86_64
+- ai.djl.pytorch:pytorch-jni:2.1.1-0.27.0
+- ai.djl.pytorch:pytorch-native-cpu:2.1.1:win-x86_64
```xml
@@ -301,12 +306,12 @@ For the Windows platform, you can choose between CPU and GPU.
pytorch-native-cpu
win-x86_64
runtime
- 2.0.1
+ 2.1.1
ai.djl.pytorch
pytorch-jni
- 2.0.1-0.23.0
+ 2.1.1-0.27.0
runtime
```
diff --git a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtEngineProvider.java b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtEngineProvider.java
index 57ae6c09d34..42ca3c5b8a5 100644
--- a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtEngineProvider.java
+++ b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtEngineProvider.java
@@ -37,7 +37,9 @@ public int getEngineRank() {
public Engine getEngine() {
if (engine == null) {
synchronized (PtEngineProvider.class) {
- engine = PtEngine.newInstance();
+ if (engine == null) {
+ engine = PtEngine.newInstance();
+ }
}
}
return engine;
diff --git a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtModel.java b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtModel.java
index e72e98c9495..e409918a091 100644
--- a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtModel.java
+++ b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtModel.java
@@ -18,6 +18,7 @@
import ai.djl.Model;
import ai.djl.ndarray.types.DataType;
import ai.djl.nn.Parameter;
+import ai.djl.nn.Parameter.Type;
import ai.djl.pytorch.jni.JniUtils;
import ai.djl.training.Trainer;
import ai.djl.training.TrainingConfig;
@@ -32,6 +33,7 @@
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.ArrayList;
+import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.function.Predicate;
@@ -64,13 +66,17 @@ public void load(Path modelPath, String prefix, Map options)
throws IOException, MalformedModelException {
setModelDir(modelPath);
wasLoaded = true;
- if (prefix == null) {
+
+ Path modelFile;
+ if (prefix != null) {
+ modelFile = findModelFile(prefix);
+ } else {
+ // search for .pt file with modelName, folder name or "model.pt"
+ modelFile = findModelFile(modelName, modelDir.toFile().getName(), "model.pt");
prefix = modelName;
}
if (block == null) {
- // search for .pt file with prefix, folder name or "model.pt"
- Path modelFile = findModelFile(prefix, modelDir.toFile().getName(), "model.pt");
if (modelFile == null) {
String fileName = prefix.endsWith(".pt") ? prefix : prefix + ".pt";
throw new FileNotFoundException(fileName + " file not found in: " + modelDir);
@@ -131,7 +137,8 @@ public void load(Path modelPath, String prefix, Map options)
/** {@inheritDoc} */
@Override
- public void load(InputStream modelStream, Map options) throws IOException {
+ public void load(InputStream modelStream, Map options)
+ throws IOException, MalformedModelException {
boolean mapLocation = false;
if (options != null) {
mapLocation = Boolean.parseBoolean((String) options.get("mapLocation"));
@@ -145,11 +152,26 @@ public void load(InputStream modelStream, Map options) throws IOExcep
* @param modelStream the stream of the model file
* @param mapLocation force load to specified device if true
* @throws IOException model loading error
+ * @throws MalformedModelException if model file is corrupted
*/
- public void load(InputStream modelStream, boolean mapLocation) throws IOException {
- modelDir = Files.createTempDirectory("pt-model");
- modelDir.toFile().deleteOnExit();
- block = JniUtils.loadModule((PtNDManager) manager, modelStream, mapLocation, false);
+ public void load(InputStream modelStream, boolean mapLocation)
+ throws IOException, MalformedModelException {
+ wasLoaded = true;
+ if (block == null) {
+ modelDir = Files.createTempDirectory("pt-model");
+ modelDir.toFile().deleteOnExit();
+ block = JniUtils.loadModule((PtNDManager) manager, modelStream, mapLocation, false);
+
+ /*
+ * By default, the parameters are frozen, since the previous version before adding this
+ * trainParam, they were frozen due to the setting JITCallGuard guard, which disables
+ * autograd. Also, the pretrained parameters usually should not be updated too much. It
+ * is safe to freeze it. Users may unfreeze it and set their learning rate small.
+ */
+ block.freezeParameters(true);
+ } else {
+ readParameters(modelStream, Collections.emptyMap());
+ }
}
private Path findModelFile(String... prefixes) {
@@ -189,7 +211,9 @@ public Trainer newTrainer(TrainingConfig trainingConfig) {
}
if (wasLoaded) {
// Unfreeze parameters if training directly
- block.freezeParameters(false);
+ block.freezeParameters(
+ false,
+ p -> p.getType() != Type.RUNNING_MEAN && p.getType() != Type.RUNNING_VAR);
}
for (Pair> pair : initializer) {
if (pair.getKey() != null && pair.getValue() != null) {
diff --git a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtNDArray.java b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtNDArray.java
index 9e36ec35884..551a16d0359 100644
--- a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtNDArray.java
+++ b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtNDArray.java
@@ -60,6 +60,7 @@ public class PtNDArray extends NativeResource implements NDArray {
* @param manager the manager to attach the new array to
* @param handle the pointer to the native PyTorch memory
*/
+ @SuppressWarnings("this-escape")
public PtNDArray(PtNDManager manager, long handle) {
super(handle);
this.manager = manager;
@@ -76,6 +77,7 @@ public PtNDArray(PtNDManager manager, long handle) {
* @param handle the pointer to the native PyTorch memory
* @param data the direct buffer of the data
*/
+ @SuppressWarnings("this-escape")
public PtNDArray(PtNDManager manager, long handle, ByteBuffer data) {
super(handle);
this.manager = manager;
@@ -93,10 +95,12 @@ public PtNDArray(PtNDManager manager, long handle, ByteBuffer data) {
* @param strs the string array
* @param shape the {@link Shape} of the {@link NDArray}
*/
+ @SuppressWarnings("this-escape")
public PtNDArray(PtNDManager manager, String[] strs, Shape shape) {
super(-1L);
this.manager = manager;
this.strs = strs;
+ this.sparseFormat = SparseFormat.DENSE;
this.shape = shape;
this.dataType = DataType.STRING;
NDScope.register(this);
@@ -222,6 +226,10 @@ public NDArray stopGradient() {
/** {@inheritDoc} */
@Override
public ByteBuffer toByteBuffer() {
+ if (getDataType() == DataType.STRING) {
+ throw new UnsupportedOperationException(
+ "toByteBuffer is not supported for String tensor.");
+ }
return JniUtils.getByteBuffer(this);
}
@@ -426,6 +434,9 @@ public boolean contentEquals(NDArray other) {
if (getDataType() != other.getDataType()) {
return false;
}
+ if (getDataType() == DataType.STRING) {
+ return Arrays.equals(toStringArray(), other.toStringArray());
+ }
return JniUtils.contentEqual(this, manager.from(other));
}
@@ -888,6 +899,12 @@ public PtNDArray atan() {
return JniUtils.atan(this);
}
+ /** {@inheritDoc} */
+ @Override
+ public PtNDArray atan2(NDArray other) {
+ return JniUtils.atan2(this, manager.from(other));
+ }
+
/** {@inheritDoc} */
@Override
public PtNDArray sinh() {
@@ -1097,6 +1114,18 @@ public NDArray stft(
this, nFft, hopLength, (PtNDArray) window, center, normalize, returnComplex);
}
+ /** {@inheritDoc} */
+ @Override
+ public NDArray fft2(long[] sizes, long[] axes) {
+ return JniUtils.fft2(this, sizes, axes);
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public NDArray ifft2(long[] sizes, long[] axes) {
+ return JniUtils.ifft2(this, sizes, axes);
+ }
+
/** {@inheritDoc} */
@Override
public PtNDArray reshape(Shape shape) {
@@ -1539,6 +1568,12 @@ public PtNDArray erfinv() {
return JniUtils.erfinv(this);
}
+ /** {@inheritDoc} */
+ @Override
+ public PtNDArray erf() {
+ return JniUtils.erf(this);
+ }
+
/** {@inheritDoc} */
@Override
public PtNDArray inverse() {
diff --git a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtNDArrayEx.java b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtNDArrayEx.java
index fa4ee81f26c..b7f92cbd1c3 100644
--- a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtNDArrayEx.java
+++ b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtNDArrayEx.java
@@ -13,6 +13,7 @@
package ai.djl.pytorch.engine;
import ai.djl.ndarray.NDArray;
+import ai.djl.ndarray.NDArrays;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.NDUtils;
@@ -24,6 +25,8 @@
import ai.djl.nn.recurrent.RNN;
import ai.djl.pytorch.jni.JniUtils;
+import java.util.Arrays;
+import java.util.Comparator;
import java.util.List;
/** {@code PtNDArrayEx} is the PyTorch implementation of the {@link NDArrayEx}. */
@@ -760,7 +763,152 @@ public NDList multiBoxDetection(
float nmsThreshold,
boolean forceSuppress,
int nmsTopK) {
- throw new UnsupportedOperationException("Not implemented");
+ assert (inputs.size() == 3);
+
+ NDArray clsProb = inputs.get(0);
+ NDArray locPred = inputs.get(1);
+ NDArray anchors = inputs.get(2).reshape(new Shape(-1, 4));
+
+ NDManager ndManager = array.getManager();
+
+ NDArray variances = ndManager.create(new float[] {0.1f, 0.1f, 0.2f, 0.2f});
+
+ assert (variances.size() == 4); // << "Variance size must be 4";
+ final int numClasses = (int) clsProb.size(1);
+ final int numAnchors = (int) clsProb.size(2);
+ final int numBatches = (int) clsProb.size(0);
+
+ final float[] pAnchor = anchors.toFloatArray();
+
+ // [id, prob, xmin, ymin, xmax, ymax]
+ // TODO Move to NDArray-based implementation
+ NDList batchOutputs = new NDList();
+ for (int nbatch = 0; nbatch < numBatches; ++nbatch) {
+ float[][] outputs = new float[numAnchors][6];
+ final float[] pClsProb = clsProb.get(nbatch).toFloatArray();
+ final float[] pLocPred = locPred.get(nbatch).toFloatArray();
+
+ for (int i = 0; i < numAnchors; ++i) {
+ // find the predicted class id and probability
+ float score = -1;
+ int id = 0;
+ for (int j = 1; j < numClasses; ++j) {
+ float temp = pClsProb[j * numAnchors + i];
+ if (temp > score) {
+ score = temp;
+ id = j;
+ }
+ }
+
+ if (id > 0 && score < threshold) {
+ id = 0;
+ }
+
+ // [id, prob, xmin, ymin, xmax, ymax]
+ outputs[i][0] = id - 1;
+ outputs[i][1] = score;
+ int offset = i * 4;
+ float[] pAnchorRow4 = new float[4];
+ pAnchorRow4[0] = pAnchor[offset];
+ pAnchorRow4[1] = pAnchor[offset + 1];
+ pAnchorRow4[2] = pAnchor[offset + 2];
+ pAnchorRow4[3] = pAnchor[offset + 3];
+ float[] pLocPredRow4 = new float[4];
+ pLocPredRow4[0] = pLocPred[offset];
+ pLocPredRow4[1] = pLocPred[offset + 1];
+ pLocPredRow4[2] = pLocPred[offset + 2];
+ pLocPredRow4[3] = pLocPred[offset + 3];
+ float[] outRowLast4 =
+ transformLocations(
+ pAnchorRow4,
+ pLocPredRow4,
+ clip,
+ variances.toFloatArray()[0],
+ variances.toFloatArray()[1],
+ variances.toFloatArray()[2],
+ variances.toFloatArray()[3]);
+ outputs[i][2] = outRowLast4[0];
+ outputs[i][3] = outRowLast4[1];
+ outputs[i][4] = outRowLast4[2];
+ outputs[i][5] = outRowLast4[3];
+ }
+
+ outputs =
+ Arrays.stream(outputs)
+ .filter(o -> o[0] >= 0)
+ .sorted(Comparator.comparing(o -> -o[1]))
+ .toArray(float[][]::new);
+
+ // apply nms
+ for (int i = 0; i < outputs.length; ++i) {
+ for (int j = i + 1; j < outputs.length; ++j) {
+ if (outputs[i][0] == outputs[j][0]) {
+ float[] outputsIRow4 = new float[4];
+ float[] outputsJRow4 = new float[4];
+ outputsIRow4[0] = outputs[i][2];
+ outputsIRow4[1] = outputs[i][3];
+ outputsIRow4[2] = outputs[i][4];
+ outputsIRow4[3] = outputs[i][5];
+ outputsJRow4[0] = outputs[j][2];
+ outputsJRow4[1] = outputs[j][3];
+ outputsJRow4[2] = outputs[j][4];
+ outputsJRow4[3] = outputs[j][5];
+ float iou = calculateOverlap(outputsIRow4, outputsJRow4);
+ if (iou >= nmsThreshold) {
+ outputs[j][0] = -1;
+ }
+ }
+ }
+ }
+ batchOutputs.add(ndManager.create(outputs));
+ } // end iter batch
+
+ NDArray pOutNDArray = NDArrays.stack(batchOutputs);
+ NDList resultNDList = new NDList();
+ resultNDList.add(pOutNDArray);
+ assert (resultNDList.size() == 1);
+ return resultNDList;
+ }
+
+ private float[] transformLocations(
+ final float[] anchors,
+ final float[] locPred,
+ final boolean clip,
+ final float vx,
+ final float vy,
+ final float vw,
+ final float vh) {
+ float[] outRowLast4 = new float[4];
+ // transform predictions to detection results
+ float al = anchors[0];
+ float at = anchors[1];
+ float ar = anchors[2];
+ float ab = anchors[3];
+ float aw = ar - al;
+ float ah = ab - at;
+ float ax = (al + ar) / 2.f;
+ float ay = (at + ab) / 2.f;
+ float px = locPred[0];
+ float py = locPred[1];
+ float pw = locPred[2];
+ float ph = locPred[3];
+ float ox = px * vx * aw + ax;
+ float oy = py * vy * ah + ay;
+ float ow = (float) (Math.exp(pw * vw) * aw / 2);
+ float oh = (float) (Math.exp(ph * vh) * ah / 2);
+ outRowLast4[0] = clip ? Math.max(0f, Math.min(1f, ox - ow)) : (ox - ow);
+ outRowLast4[1] = clip ? Math.max(0f, Math.min(1f, oy - oh)) : (oy - oh);
+ outRowLast4[2] = clip ? Math.max(0f, Math.min(1f, ox + ow)) : (ox + ow);
+ outRowLast4[3] = clip ? Math.max(0f, Math.min(1f, oy + oh)) : (oy + oh);
+ return outRowLast4;
+ }
+
+ private float calculateOverlap(final float[] a, final float[] b) {
+ float w = Math.max(0f, Math.min(a[2], b[2]) - Math.max(a[0], b[0]));
+ float h = Math.max(0f, Math.min(a[3], b[3]) - Math.max(a[1], b[1]));
+ float i = w * h;
+ float u = (a[2] - a[0]) * (a[3] - a[1]) + (b[2] - b[0]) * (b[3] - b[1]) - i;
+ return u <= 0.f ? 0f : (i / u);
}
/** {@inheritDoc} */
diff --git a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtSymbolBlock.java b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtSymbolBlock.java
index 8bc28a2c21b..7075cb05efa 100644
--- a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtSymbolBlock.java
+++ b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/engine/PtSymbolBlock.java
@@ -67,6 +67,7 @@ public class PtSymbolBlock extends AbstractSymbolBlock implements AutoCloseable
* @param manager the manager to use for the block
* @param handle the module handle
*/
+ @SuppressWarnings("this-escape")
public PtSymbolBlock(PtNDManager manager, long handle) {
this(manager);
this.handle = new AtomicReference<>(handle);
diff --git a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/JniUtils.java b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/JniUtils.java
index aad38ae8f0c..40a6a0065bc 100644
--- a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/JniUtils.java
+++ b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/JniUtils.java
@@ -1040,6 +1040,18 @@ public static PtNDArray stft(
return new PtNDArray(ndArray.getManager(), handle);
}
+ public static PtNDArray fft2(PtNDArray ndArray, long[] sizes, long[] axes) {
+ return new PtNDArray(
+ ndArray.getManager(),
+ PyTorchLibrary.LIB.torchFft2(ndArray.getHandle(), sizes, axes));
+ }
+
+ public static PtNDArray ifft2(PtNDArray ndArray, long[] sizes, long[] axes) {
+ return new PtNDArray(
+ ndArray.getManager(),
+ PyTorchLibrary.LIB.torchIfft2(ndArray.getHandle(), sizes, axes));
+ }
+
public static PtNDArray real(PtNDArray ndArray) {
long handle = PyTorchLibrary.LIB.torchViewAsReal(ndArray.getHandle());
if (handle == -1) {
@@ -1145,6 +1157,12 @@ public static PtNDArray atan(PtNDArray ndArray) {
ndArray.getManager(), PyTorchLibrary.LIB.torchAtan(ndArray.getHandle()));
}
+ public static PtNDArray atan2(PtNDArray self, PtNDArray other) {
+ return new PtNDArray(
+ self.getManager(),
+ PyTorchLibrary.LIB.torchAtan2(self.getHandle(), other.getHandle()));
+ }
+
public static PtNDArray sqrt(PtNDArray ndArray) {
return new PtNDArray(
ndArray.getManager(), PyTorchLibrary.LIB.torchSqrt(ndArray.getHandle()));
@@ -1334,6 +1352,11 @@ public static PtNDArray erfinv(PtNDArray ndArray) {
ndArray.getManager(), PyTorchLibrary.LIB.torchErfinv(ndArray.getHandle()));
}
+ public static PtNDArray erf(PtNDArray ndArray) {
+ return new PtNDArray(
+ ndArray.getManager(), PyTorchLibrary.LIB.torchErf(ndArray.getHandle()));
+ }
+
public static PtNDArray inverse(PtNDArray ndArray) {
return new PtNDArray(
ndArray.getManager(), PyTorchLibrary.LIB.torchInverse(ndArray.getHandle()));
diff --git a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/LibUtils.java b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/LibUtils.java
index 9d422463910..83e0f5b5b95 100644
--- a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/LibUtils.java
+++ b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/LibUtils.java
@@ -65,6 +65,7 @@ public final class LibUtils {
private static final Pattern VERSION_PATTERN =
Pattern.compile("(\\d+\\.\\d+\\.\\d+(-[a-z]+)?)(-SNAPSHOT)?(-\\d+)?");
+ private static final Pattern LIB_PATTERN = Pattern.compile("(.*\\.(so(\\.\\d+)*|dll|dylib))");
private static LibTorch libTorch;
@@ -106,10 +107,19 @@ public static String getLibtorchPath() {
private static void loadLibTorch(LibTorch libTorch) {
Path libDir = libTorch.dir.toAbsolutePath();
- if ("1.8.1".equals(getVersion()) && System.getProperty("os.name").startsWith("Mac")) {
- // PyTorch 1.8.1 libtorch_cpu.dylib cannot be loaded individually
- return;
+ if (Files.exists(libDir.resolve("libstdc++.so.6"))) {
+ String libstd = Utils.getEnvOrSystemProperty("LIBSTDCXX_LIBRARY_PATH");
+ if (libstd != null) {
+ try {
+ logger.info("Loading libstdc++.so.6 from: {}", libstd);
+ System.load(libstd);
+ } catch (UnsatisfiedLinkError e) {
+ logger.warn("Failed Loading libstdc++.so.6 from: {}", libstd);
+ }
+ }
}
+ String libExclusion = Utils.getEnvOrSystemProperty("PYTORCH_LIBRARY_EXCLUSION", "");
+ Set exclusion = new HashSet<>(Arrays.asList(libExclusion.split(",")));
boolean isCuda = libTorch.flavor.contains("cu");
List deferred =
Arrays.asList(
@@ -120,6 +130,7 @@ private static void loadLibTorch(LibTorch libTorch) {
System.mapLibraryName("torch_cuda_cpp"),
System.mapLibraryName("torch_cuda_cu"),
System.mapLibraryName("torch_cuda"),
+ System.mapLibraryName("nvfuser_codegen"),
System.mapLibraryName("torch"));
Set loadLater = new HashSet<>(deferred);
@@ -128,12 +139,16 @@ private static void loadLibTorch(LibTorch libTorch) {
paths.filter(
path -> {
String name = path.getFileName().toString();
- if (!isCuda
+ if (!LIB_PATTERN.matcher(name).matches()
+ || exclusion.contains(name)) {
+ return false;
+ } else if (!isCuda
&& name.contains("nvrtc")
&& name.contains("cudart")
&& name.contains("nvTools")) {
return false;
- } else if (name.startsWith("libarm_compute-")) {
+ } else if (name.startsWith("libarm_compute-")
+ || name.startsWith("libopenblasp")) {
rank.put(path, 2);
return true;
} else if (name.startsWith("libarm_compute_")) {
@@ -219,10 +234,21 @@ private static Path findJniLibrary(LibTorch libTorch) {
String djlVersion = libTorch.apiVersion;
String flavor = libTorch.flavor;
+ // Looking for JNI in libTorch.dir first
+ Path libDir = libTorch.dir.toAbsolutePath();
+ Path path = libDir.resolve(djlVersion + '-' + JNI_LIB_NAME);
+ if (Files.exists(path)) {
+ return path;
+ }
+ path = libDir.resolve(JNI_LIB_NAME);
+ if (Files.exists(path)) {
+ return path;
+ }
+
// always use cache dir, cache dir might be different from libTorch.dir
Path cacheDir = Utils.getEngineCacheDir("pytorch");
Path dir = cacheDir.resolve(version + '-' + flavor + '-' + classifier);
- Path path = dir.resolve(djlVersion + '-' + JNI_LIB_NAME);
+ path = dir.resolve(djlVersion + '-' + JNI_LIB_NAME);
if (Files.exists(path)) {
return path;
}
@@ -349,8 +375,9 @@ private static void loadNativeLibrary(String path) {
String nativeHelper = System.getProperty("ai.djl.pytorch.native_helper");
if (nativeHelper != null && !nativeHelper.isEmpty()) {
ClassLoaderUtils.nativeLoad(nativeHelper, path);
+ } else {
+ System.load(path); // NOPMD
}
- System.load(path); // NOPMD
}
private static LibTorch downloadPyTorch(Platform platform) {
@@ -541,8 +568,10 @@ private static final class LibTorch {
if (flavor == null || flavor.isEmpty()) {
if (CudaUtils.getGpuCount() > 0) {
flavor = "cu" + CudaUtils.getCudaVersionString() + "-precxx11";
- } else {
+ } else if ("linux".equals(platform.getOsPrefix())) {
flavor = "cpu-precxx11";
+ } else {
+ flavor = "cpu";
}
}
}
diff --git a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/PyTorchLibrary.java b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/PyTorchLibrary.java
index c0f7b553ab2..54fc5419145 100644
--- a/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/PyTorchLibrary.java
+++ b/engines/pytorch/pytorch-engine/src/main/java/ai/djl/pytorch/jni/PyTorchLibrary.java
@@ -273,6 +273,10 @@ native long torchStft(
boolean normalize,
boolean returnComplex);
+ native long torchFft2(long handle, long[] sizes, long[] axes);
+
+ native long torchIfft2(long handle, long[] sizes, long[] axes);
+
native long torchViewAsReal(long handle);
native long torchViewAsComplex(long handle);
@@ -332,6 +336,8 @@ native long[] torchUnique(
native long torchAtan(long handle);
+ native long torchAtan2(long self, long other);
+
native long torchSqrt(long handle);
native long torchSinh(long handle);
@@ -405,6 +411,8 @@ native long tensorUniform(
native long torchErfinv(long handle);
+ native long torchErf(long handle);
+
native long torchInverse(long self);
native long torchNNInterpolate(long handle, long[] size, int mode, boolean alignCorners);
diff --git a/engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/LibUtilsTest.java b/engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/ALibUtilsTest.java
similarity index 73%
rename from engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/LibUtilsTest.java
rename to engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/ALibUtilsTest.java
index 617d2cfb809..f6cfda91106 100644
--- a/engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/LibUtilsTest.java
+++ b/engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/ALibUtilsTest.java
@@ -18,17 +18,21 @@
import org.testng.annotations.BeforeClass;
import org.testng.annotations.Test;
-public class LibUtilsTest {
+// Ensure this test run first
+public class ALibUtilsTest {
@BeforeClass
public void setup() {
- System.setProperty(
- "ai.djl.pytorch.native_helper", "ai.djl.pytorch.integration.LibUtilsTest");
+ System.setProperty("ai.djl.pytorch.native_helper", ALibUtilsTest.class.getName());
+ System.setProperty("STDCXX_LIBRARY_PATH", "/usr/lib/non-exists");
+ System.setProperty("PYTORCH_PRECXX11", "true");
}
@AfterClass
public void teardown() {
System.clearProperty("ai.djl.pytorch.native_helper");
+ System.clearProperty("LIBSTDCXX_LIBRARY_PATH");
+ System.clearProperty("PYTORCH_PRECXX11");
}
@Test
diff --git a/engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/MpsTest.java b/engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/MpsTest.java
index 8b4e2326f26..e8f6e5d405f 100644
--- a/engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/MpsTest.java
+++ b/engines/pytorch/pytorch-engine/src/test/java/ai/djl/pytorch/integration/MpsTest.java
@@ -13,6 +13,7 @@
package ai.djl.pytorch.integration;
import ai.djl.Device;
+import ai.djl.modality.Classifications;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
@@ -21,6 +22,9 @@
import org.testng.SkipException;
import org.testng.annotations.Test;
+import java.util.Arrays;
+import java.util.List;
+
public class MpsTest {
@Test
@@ -36,4 +40,39 @@ public void testMps() {
Assert.assertEquals(array.getDevice().getDeviceType(), "mps");
}
}
+
+ private static boolean checkMpsCompatible() {
+ return "aarch64".equals(System.getProperty("os.arch"))
+ && System.getProperty("os.name").startsWith("Mac");
+ }
+
+ @Test
+ public void testToTensorMPS() {
+ if (!checkMpsCompatible()) {
+ throw new SkipException("MPS toTensor test requires Apple Silicon macOS.");
+ }
+
+ // Test that toTensor does not fail on MPS (e.g. due to use of float64 for division)
+ try (NDManager manager = NDManager.newBaseManager(Device.fromName("mps"))) {
+ NDArray array = manager.create(127f).reshape(1, 1, 1, 1);
+ NDArray tensor = array.getNDArrayInternal().toTensor();
+ Assert.assertEquals(tensor.toFloatArray(), new float[] {127f / 255f});
+ }
+ }
+
+ @Test
+ public void testClassificationsMPS() {
+ if (!checkMpsCompatible()) {
+ throw new SkipException("MPS classification test requires Apple Silicon macOS.");
+ }
+
+ // Test that classifications do not fail on MPS (e.g. due to conversion of probabilities to
+ // float64)
+ try (NDManager manager = NDManager.newBaseManager(Device.fromName("mps"))) {
+ List names = Arrays.asList("First", "Second", "Third", "Fourth", "Fifth");
+ NDArray tensor = manager.create(new float[] {0f, 0.125f, 1f, 0.5f, 0.25f});
+ Classifications classifications = new Classifications(names, tensor);
+ Assert.assertEquals(classifications.best().getClassName(), "Third");
+ }
+ }
}
diff --git a/engines/pytorch/pytorch-jni/build.gradle b/engines/pytorch/pytorch-jni/build.gradle
index 450c832e803..c2b0ee9dc7b 100644
--- a/engines/pytorch/pytorch-jni/build.gradle
+++ b/engines/pytorch/pytorch-jni/build.gradle
@@ -24,7 +24,13 @@ processResources {
"osx-x86_64/cpu/libdjl_torch.dylib",
"win-x86_64/cpu/djl_torch.dll"
]
- if (ptVersion.startsWith("2.0.")) {
+ if (ptVersion.startsWith("2.1.")) {
+ files.add("linux-aarch64/cpu-precxx11/libdjl_torch.so")
+ files.add("linux-x86_64/cu121/libdjl_torch.so")
+ files.add("linux-x86_64/cu121-precxx11/libdjl_torch.so")
+ files.add("win-x86_64/cu121/djl_torch.dll")
+ files.add("osx-aarch64/cpu/libdjl_torch.dylib")
+ } else if (ptVersion.startsWith("2.0.")) {
files.add("linux-aarch64/cpu-precxx11/libdjl_torch.so")
files.add("linux-x86_64/cu118/libdjl_torch.so")
files.add("linux-x86_64/cu118-precxx11/libdjl_torch.so")
diff --git a/engines/pytorch/pytorch-model-zoo/README.md b/engines/pytorch/pytorch-model-zoo/README.md
index 8d3113842e1..41f677fdd6c 100644
--- a/engines/pytorch/pytorch-model-zoo/README.md
+++ b/engines/pytorch/pytorch-model-zoo/README.md
@@ -25,7 +25,7 @@ You can pull the PyTorch engine from the central Maven repository by including t
ai.djl.pytorch
pytorch-model-zoo
- 0.23.0
+ 0.27.0
```
diff --git a/engines/pytorch/pytorch-model-zoo/src/main/java/ai/djl/pytorch/zoo/PtModelZoo.java b/engines/pytorch/pytorch-model-zoo/src/main/java/ai/djl/pytorch/zoo/PtModelZoo.java
index ea70871eff0..abb820cced9 100644
--- a/engines/pytorch/pytorch-model-zoo/src/main/java/ai/djl/pytorch/zoo/PtModelZoo.java
+++ b/engines/pytorch/pytorch-model-zoo/src/main/java/ai/djl/pytorch/zoo/PtModelZoo.java
@@ -38,6 +38,7 @@ public class PtModelZoo extends ModelZoo {
REPOSITORY.model(CV.IMAGE_CLASSIFICATION, GROUP_ID, "resnet18_embedding", "0.0.1"));
addModel(REPOSITORY.model(CV.OBJECT_DETECTION, GROUP_ID, "ssd", "0.0.1"));
addModel(REPOSITORY.model(CV.OBJECT_DETECTION, GROUP_ID, "yolov5s", "0.0.1"));
+ addModel(REPOSITORY.model(CV.OBJECT_DETECTION, GROUP_ID, "yolov8n", "0.0.1"));
addModel(REPOSITORY.model(NLP.QUESTION_ANSWER, GROUP_ID, "bertqa", "0.0.1"));
addModel(REPOSITORY.model(NLP.SENTIMENT_ANALYSIS, GROUP_ID, "distilbert", "0.0.1"));
addModel(REPOSITORY.model(CV.IMAGE_GENERATION, GROUP_ID, "biggan-deep", "0.0.1"));
diff --git a/engines/pytorch/pytorch-model-zoo/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/pytorch/yolov8n/metadata.json b/engines/pytorch/pytorch-model-zoo/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/pytorch/yolov8n/metadata.json
new file mode 100644
index 00000000000..399b79b4889
--- /dev/null
+++ b/engines/pytorch/pytorch-model-zoo/src/test/resources/mlrepo/model/cv/object_detection/ai/djl/pytorch/yolov8n/metadata.json
@@ -0,0 +1,40 @@
+{
+ "metadataVersion": "0.2",
+ "resourceType": "model",
+ "application": "cv/object_detection",
+ "groupId": "ai.djl.pytorch",
+ "artifactId": "yolov8n",
+ "name": "yolov8n",
+ "description": "YoloV8 Model",
+ "website": "http://www.djl.ai/engines/onnxruntime/model-zoo",
+ "licenses": {
+ "license": {
+ "name": "The Apache License, Version 2.0",
+ "url": "https://www.apache.org/licenses/LICENSE-2.0"
+ }
+ },
+ "artifacts": [
+ {
+ "version": "0.0.1",
+ "snapshot": false,
+ "name": "yolov8n",
+ "arguments": {
+ "width": 640,
+ "height": 640,
+ "resize": true,
+ "rescale": true,
+ "optApplyRatio": true,
+ "threshold": 0.6,
+ "translatorFactory": "ai.djl.modality.cv.translator.YoloV8TranslatorFactory"
+ },
+ "files": {
+ "model": {
+ "uri": "0.0.1/yolov8n.zip",
+ "name": "",
+ "sha1Hash": "a868778452ef8d6d2f9cb7109a9e14a64e851d48",
+ "size": 11183356
+ }
+ }
+ }
+ ]
+}
diff --git a/engines/pytorch/pytorch-native/CMakeLists.txt b/engines/pytorch/pytorch-native/CMakeLists.txt
index 4453186be6f..c53d71dc93e 100644
--- a/engines/pytorch/pytorch-native/CMakeLists.txt
+++ b/engines/pytorch/pytorch-native/CMakeLists.txt
@@ -60,11 +60,12 @@ if(USE_CUDA)
endif()
add_library(djl_torch SHARED ${SOURCE_FILES})
+set_property(TARGET djl_torch PROPERTY CXX_STANDARD 17)
+
# build host
if(NOT BUILD_ANDROID)
target_link_libraries(djl_torch "${TORCH_LIBRARIES}")
target_include_directories(djl_torch PUBLIC build/include ${JNI_INCLUDE_DIRS} ${UTILS_INCLUDE_DIR})
- set_property(TARGET djl_torch PROPERTY CXX_STANDARD 14)
# We have to kill the default rpath and use current dir
set(CMAKE_SKIP_RPATH TRUE)
if(${CMAKE_SYSTEM_NAME} MATCHES "Linux")
diff --git a/engines/pytorch/pytorch-native/build.gradle b/engines/pytorch/pytorch-native/build.gradle
index b4a195e109f..99a658bf3ed 100644
--- a/engines/pytorch/pytorch-native/build.gradle
+++ b/engines/pytorch/pytorch-native/build.gradle
@@ -24,6 +24,8 @@ if (project.hasProperty("cu11")) {
FLAVOR = "cu117"
} else if (VERSION.startsWith("2.0.")) {
FLAVOR = "cu118"
+ } else if (VERSION.startsWith("2.1.")) {
+ FLAVOR = "cu121"
} else {
throw new GradleException("Unsupported PyTorch version: ${VERSION}")
}
@@ -88,15 +90,17 @@ def prepareNativeLib(String binaryRoot, String ver) {
def officialPytorchUrl = "https://download.pytorch.org/libtorch"
def aarch64PytorchUrl = "https://djl-ai.s3.amazonaws.com/publish/pytorch"
- String cu11
+ String cuda
if (ver.startsWith("1.11.")) {
- cu11 = "cu113"
+ cuda = "cu113"
} else if (ver.startsWith("1.12.")) {
- cu11 = "cu116"
+ cuda = "cu116"
} else if (ver.startsWith("1.13.")) {
- cu11 = "cu117"
+ cuda = "cu117"
} else if (ver.startsWith("2.0.")) {
- cu11 = "cu118"
+ cuda = "cu118"
+ } else if (ver.startsWith("2.1.")) {
+ cuda = "cu121"
} else {
throw new GradleException("Unsupported PyTorch version: ${ver}")
}
@@ -105,10 +109,10 @@ def prepareNativeLib(String binaryRoot, String ver) {
"cpu/libtorch-cxx11-abi-shared-with-deps-${ver}%2Bcpu.zip" : "cpu/linux-x86_64",
"cpu/libtorch-macos-${ver}.zip" : "cpu/osx-x86_64",
"cpu/libtorch-win-shared-with-deps-${ver}%2Bcpu.zip" : "cpu/win-x86_64",
- "${cu11}/libtorch-cxx11-abi-shared-with-deps-${ver}%2B${cu11}.zip": "${cu11}/linux-x86_64",
- "${cu11}/libtorch-win-shared-with-deps-${ver}%2B${cu11}.zip" : "${cu11}/win-x86_64",
+ "${cuda}/libtorch-cxx11-abi-shared-with-deps-${ver}%2B${cuda}.zip": "${cuda}/linux-x86_64",
+ "${cuda}/libtorch-win-shared-with-deps-${ver}%2B${cuda}.zip" : "${cuda}/win-x86_64",
"cpu/libtorch-shared-with-deps-${ver}%2Bcpu.zip" : "cpu-precxx11/linux-x86_64",
- "${cu11}/libtorch-shared-with-deps-${ver}%2B${cu11}.zip" : "${cu11}-precxx11/linux-x86_64"
+ "${cuda}/libtorch-shared-with-deps-${ver}%2B${cuda}.zip" : "${cuda}-precxx11/linux-x86_64"
]
def aarch64Files = [
@@ -138,17 +142,12 @@ def copyNativeLibToOutputDir(Map fileStoreMap, String binaryRoot
from zipTree(file)
into outputDir
}
- // CPU dependencies
- copy {
- from("${outputDir}/libtorch/lib/") {
- include "libc10.*", "c10.dll", "libiomp5*.*", "libarm_compute*.*", "libgomp*.*", "libnvfuser_codegen.so", "libtorch.*", "libtorch_cpu.*", "torch.dll", "torch_cpu.dll", "fbgemm.dll", "asmjit.dll", "uv.dll", "nvfuser_codegen.dll"
- }
- into("${outputDir}/native/lib")
- }
- // GPU dependencies
+ delete "${outputDir}/libtorch/lib/*.lib"
+ delete "${outputDir}/libtorch/lib/*.a"
+
copy {
from("${outputDir}/libtorch/lib/") {
- include "libtorch_cuda*.so", "torch_cuda*.dll", "libc10_cuda.so", "c10_cuda.dll", "libcaffe2_nvrtc.so", "libnvrtc*.so.*", "libcudart*.*", "*nvToolsExt*.*", "cudnn*.dll", "caffe2_nvrtc.dll", "nvrtc64*.dll", "uv.dll", "libcublas*", "zlibwapi.dll"
+ include "libarm_compute*", "libc10_cuda.so", "libc10.*", "libcaffe2_nvrtc.so", "libcu*", "libgfortran-*", "libgomp*", "libiomp*", "libnv*", "libopenblasp-*", "libtorch_cpu.*", "libtorch_cuda*.so", "libtorch.*", "asmjit.dll", "c10_cuda.dll", "c10.dll", "caffe2_nvrtc.dll", "cu*.dll", "fbgemm.dll", "nv*.dll", "torch_cpu.dll", "torch_cuda*.dll", "torch.dll", "uv.dll", "zlibwapi.dll"
}
into("${outputDir}/native/lib")
}
@@ -287,9 +286,9 @@ tasks.register('uploadS3') {
"${BINARY_ROOT}/cpu/win-x86_64/native/lib/",
"${BINARY_ROOT}/cpu-precxx11/linux-aarch64/native/lib/",
"${BINARY_ROOT}/cpu-precxx11/linux-x86_64/native/lib/",
- "${BINARY_ROOT}/cu118/linux-x86_64/native/lib/",
- "${BINARY_ROOT}/cu118/win-x86_64/native/lib/",
- "${BINARY_ROOT}/cu118-precxx11/linux-x86_64/native/lib/"
+ "${BINARY_ROOT}/cu121/linux-x86_64/native/lib/",
+ "${BINARY_ROOT}/cu121/win-x86_64/native/lib/",
+ "${BINARY_ROOT}/cu121-precxx11/linux-x86_64/native/lib/"
]
uploadDirs.each { item ->
fileTree(item).files.name.each {
diff --git a/engines/pytorch/pytorch-native/build.sh b/engines/pytorch/pytorch-native/build.sh
index 78c59d6bf2a..ae0456bec62 100755
--- a/engines/pytorch/pytorch-native/build.sh
+++ b/engines/pytorch/pytorch-native/build.sh
@@ -23,22 +23,22 @@ ARCH=$4
if [[ ! -d "libtorch" ]]; then
if [[ $PLATFORM == 'linux' ]]; then
- if [[ ! "$FLAVOR" =~ ^(cpu|cu102|cu113|cu116|cu117|cu118)$ ]]; then
+ if [[ ! "$FLAVOR" =~ ^(cpu|cu102|cu113|cu116|cu117|cu118|cu121)$ ]]; then
echo "$FLAVOR is not supported."
exit 1
fi
if [[ $ARCH == 'aarch64' ]]; then
- curl -s https://djl-ai.s3.amazonaws.com/publish/pytorch/${VERSION}/libtorch${AARCH64_CXX11ABI}-shared-with-deps-${VERSION}-aarch64.zip | jar xv
+ curl -s https://djl-ai.s3.amazonaws.com/publish/pytorch/${VERSION}/libtorch${AARCH64_CXX11ABI}-shared-with-deps-${VERSION}-aarch64.zip | jar xv > /dev/null
else
- curl -s https://download.pytorch.org/libtorch/${FLAVOR}/libtorch${CXX11ABI}-shared-with-deps-${VERSION}%2B${FLAVOR}.zip | jar xv
+ curl -s https://download.pytorch.org/libtorch/${FLAVOR}/libtorch${CXX11ABI}-shared-with-deps-${VERSION}%2B${FLAVOR}.zip | jar xv > /dev/null
fi
elif [[ $PLATFORM == 'darwin' ]]; then
if [[ $ARCH == 'aarch64' ]]; then
- curl -s https://djl-ai.s3.amazonaws.com/publish/pytorch/${VERSION}/libtorch-macos-${VERSION}-aarch64.zip | jar xv
+ curl -s https://djl-ai.s3.amazonaws.com/publish/pytorch/${VERSION}/libtorch-macos-${VERSION}-aarch64.zip | jar xv > /dev/null
else
- curl -s https://download.pytorch.org/libtorch/cpu/libtorch-macos-${VERSION}.zip | jar xv
+ curl -s https://download.pytorch.org/libtorch/cpu/libtorch-macos-${VERSION}.zip | jar xv > /dev/null
fi
else
echo "$PLATFORM is not supported."
@@ -62,6 +62,12 @@ mkdir classes
javac -sourcepath ../../pytorch-engine/src/main/java/ ../../pytorch-engine/src/main/java/ai/djl/pytorch/jni/PyTorchLibrary.java -h include -d classes
cmake -DCMAKE_PREFIX_PATH=libtorch -DPT_VERSION=${PT_VERSION} -DUSE_CUDA=$USE_CUDA ..
cmake --build . --config Release -- -j "${NUM_PROC}"
+if [[ "$FLAVOR" = cu* ]]; then
+ # avoid link with libcudart.so.11.0
+ sed -i -r "s/\/usr\/local\/cuda(.{5})?\/lib64\/lib(cudart|nvrtc).so//g" CMakeFiles/djl_torch.dir/link.txt
+ rm libdjl_torch.so
+ . CMakeFiles/djl_torch.dir/link.txt
+fi
if [[ $PLATFORM == 'darwin' ]]; then
install_name_tool -add_rpath @loader_path libdjl_torch.dylib
diff --git a/engines/pytorch/pytorch-native/build_android.sh b/engines/pytorch/pytorch-native/build_android.sh
index b37dd96a86d..72050b20a85 100755
--- a/engines/pytorch/pytorch-native/build_android.sh
+++ b/engines/pytorch/pytorch-native/build_android.sh
@@ -20,7 +20,7 @@ if [[ ! -d libtorch_android/"$FLAVOR" ]]; then
mkdir -p libtorch_android/"$FLAVOR"
cd libtorch_android/"$FLAVOR"
echo "Downloading https://publish.djl.ai/pytorch/$VERSION/android_native/${FLAVOR}_native.zip"
- curl -s "https://publish.djl.ai/pytorch/$VERSION/android_native/${FLAVOR}_native.zip" | jar xv
+ curl -s "https://publish.djl.ai/pytorch/$VERSION/android_native/${FLAVOR}_native.zip" | jar xv > /dev/null
mv install/include include
cd -
fi
diff --git a/engines/pytorch/pytorch-native/src/main/native/ai_djl_pytorch_jni_PyTorchLibrary_torch_other.cc b/engines/pytorch/pytorch-native/src/main/native/ai_djl_pytorch_jni_PyTorchLibrary_torch_other.cc
index 5a65e1eca69..08932098da9 100644
--- a/engines/pytorch/pytorch-native/src/main/native/ai_djl_pytorch_jni_PyTorchLibrary_torch_other.cc
+++ b/engines/pytorch/pytorch-native/src/main/native/ai_djl_pytorch_jni_PyTorchLibrary_torch_other.cc
@@ -34,6 +34,28 @@ JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchFft(
API_END_RETURN()
}
+JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchFft2(
+ JNIEnv* env, jobject jthis, jlong jhandle, jlongArray js, jlongArray jaxes) {
+ API_BEGIN()
+ const auto* tensor_ptr = reinterpret_cast(jhandle);
+ const std::vector sizes = djl::utils::jni::GetVecFromJLongArray(env, js);
+ const std::vector axes = djl::utils::jni::GetVecFromJLongArray(env, jaxes);
+ const auto* result_ptr = new torch::Tensor(torch::fft_fft2(*tensor_ptr, sizes, axes));
+ return reinterpret_cast(result_ptr);
+ API_END_RETURN()
+}
+
+JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchIfft2(
+ JNIEnv* env, jobject jthis, jlong jhandle, jlongArray js, jlongArray jaxes) {
+ API_BEGIN()
+ const auto* tensor_ptr = reinterpret_cast(jhandle);
+ const std::vector sizes = djl::utils::jni::GetVecFromJLongArray(env, js);
+ const std::vector axes = djl::utils::jni::GetVecFromJLongArray(env, jaxes);
+ const auto* result_ptr = new torch::Tensor(torch::fft_ifft2(*tensor_ptr, sizes, axes));
+ return reinterpret_cast(result_ptr);
+ API_END_RETURN()
+}
+
JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchStft(JNIEnv* env, jobject jthis, jlong jhandle,
jlong jn_fft, jlong jhop_length, jlong jwindow, jboolean jcenter, jboolean jnormalize, jboolean jreturn_complex) {
#ifdef V1_11_X
diff --git a/engines/pytorch/pytorch-native/src/main/native/ai_djl_pytorch_jni_PyTorchLibrary_torch_pointwise.cc b/engines/pytorch/pytorch-native/src/main/native/ai_djl_pytorch_jni_PyTorchLibrary_torch_pointwise.cc
index 28e40e916be..ccf2616dc65 100644
--- a/engines/pytorch/pytorch-native/src/main/native/ai_djl_pytorch_jni_PyTorchLibrary_torch_pointwise.cc
+++ b/engines/pytorch/pytorch-native/src/main/native/ai_djl_pytorch_jni_PyTorchLibrary_torch_pointwise.cc
@@ -355,6 +355,16 @@ JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchAtan(JNIEnv*
API_END_RETURN()
}
+JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchAtan2(
+JNIEnv* env, jobject jthis, jlong jself, jlong jother) {
+ API_BEGIN()
+ const auto* self_ptr = reinterpret_cast(jself);
+ const auto* other_ptr = reinterpret_cast(jother);
+ const auto* result_ptr = new torch::Tensor(self_ptr->atan2(*other_ptr));
+ return reinterpret_cast(result_ptr);
+ API_END_RETURN()
+}
+
JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchSqrt(JNIEnv* env, jobject jthis, jlong jhandle) {
API_BEGIN()
const auto* tensor_ptr = reinterpret_cast(jhandle);
@@ -496,6 +506,14 @@ JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchErfinv(JNIEn
API_END_RETURN()
}
+JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchErf(JNIEnv* env, jobject jthis, jlong jhandle) {
+ API_BEGIN()
+ const auto* tensor_ptr = reinterpret_cast(jhandle);
+ const auto* result_ptr = new torch::Tensor(tensor_ptr->erf());
+ return reinterpret_cast(result_ptr);
+ API_END_RETURN()
+}
+
JNIEXPORT jlong JNICALL Java_ai_djl_pytorch_jni_PyTorchLibrary_torchInverse(JNIEnv* env, jobject jthis, jlong jself) {
API_BEGIN()
const auto* self_ptr = reinterpret_cast(jself);
diff --git a/engines/tensorflow/tensorflow-api/README.md b/engines/tensorflow/tensorflow-api/README.md
index fd2741dc9e4..12766d87669 100644
--- a/engines/tensorflow/tensorflow-api/README.md
+++ b/engines/tensorflow/tensorflow-api/README.md
@@ -16,6 +16,6 @@ You can pull the TensorFlow core java API from the central Maven repository by i
ai.djl.tensorflow
tensorflow-api
- 0.23.0
+ 0.27.0
```
diff --git a/engines/tensorflow/tensorflow-engine/README.md b/engines/tensorflow/tensorflow-engine/README.md
index 57bcdda98d7..17573ed7127 100644
--- a/engines/tensorflow/tensorflow-engine/README.md
+++ b/engines/tensorflow/tensorflow-engine/README.md
@@ -28,13 +28,13 @@ The javadocs output is built in the `build/doc/javadoc` folder.
You can pull the TensorFlow engine from the central Maven repository by including the following dependency:
-- ai.djl.tensorflow:tensorflow-engine:0.23.0
+- ai.djl.tensorflow:tensorflow-engine:0.27.0
```xml
ai.djl.tensorflow
tensorflow-engine
- 0.23.0
+ 0.27.0
runtime
```
diff --git a/engines/tensorflow/tensorflow-engine/src/main/java/ai/djl/tensorflow/engine/TfEngineProvider.java b/engines/tensorflow/tensorflow-engine/src/main/java/ai/djl/tensorflow/engine/TfEngineProvider.java
index d964ea5c295..ad440a47951 100644
--- a/engines/tensorflow/tensorflow-engine/src/main/java/ai/djl/tensorflow/engine/TfEngineProvider.java
+++ b/engines/tensorflow/tensorflow-engine/src/main/java/ai/djl/tensorflow/engine/TfEngineProvider.java
@@ -37,7 +37,9 @@ public int getEngineRank() {
public Engine getEngine() {
if (engine == null) {
synchronized (TfEngineProvider.class) {
- engine = TfEngine.newInstance();
+ if (engine == null) {
+ engine = TfEngine.newInstance();
+ }
}
}
return engine;
diff --git a/engines/tensorflow/tensorflow-engine/src/main/java/ai/djl/tensorflow/engine/TfNDArray.java b/engines/tensorflow/tensorflow-engine/src/main/java/ai/djl/tensorflow/engine/TfNDArray.java
index 07c31bacd99..419be4c09f6 100644
--- a/engines/tensorflow/tensorflow-engine/src/main/java/ai/djl/tensorflow/engine/TfNDArray.java
+++ b/engines/tensorflow/tensorflow-engine/src/main/java/ai/djl/tensorflow/engine/TfNDArray.java
@@ -457,6 +457,12 @@ public NDArray erfinv() {
return manager.opExecutor("Erfinv").addInput(this).buildSingletonOrThrow();
}
+ /** {@inheritDoc} */
+ @Override
+ public NDArray erf() {
+ return manager.opExecutor("Erf").addInput(this).buildSingletonOrThrow();
+ }
+
/** {@inheritDoc} */
@Override
public NDArray norm(boolean keepDims) {
@@ -911,6 +917,12 @@ public NDArray atan() {
return manager.opExecutor("Atan").addInput(this).buildSingletonOrThrow();
}
+ /** {@inheritDoc} */
+ @Override
+ public NDArray atan2(NDArray other) {
+ return manager.opExecutor("Atan2").addInput(this).addInput(other).buildSingletonOrThrow();
+ }
+
/** {@inheritDoc} */
@Override
public NDArray sinh() {
@@ -1172,6 +1184,18 @@ public NDArray stft(
throw new UnsupportedOperationException("Not implemented yet.");
}
+ /** {@inheritDoc} */
+ @Override
+ public NDArray fft2(long[] sizes, long[] axes) {
+ throw new UnsupportedOperationException("Not implemented yet.");
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public NDArray ifft2(long[] sizes, long[] axes) {
+ throw new UnsupportedOperationException("Not implemented yet.");
+ }
+
/** {@inheritDoc} */
@Override
public NDArray reshape(Shape shape) {
diff --git a/engines/tensorflow/tensorflow-model-zoo/README.md b/engines/tensorflow/tensorflow-model-zoo/README.md
index b34154fa126..663f3ff840a 100644
--- a/engines/tensorflow/tensorflow-model-zoo/README.md
+++ b/engines/tensorflow/tensorflow-model-zoo/README.md
@@ -26,7 +26,7 @@ from the central Maven repository by including the following dependency:
ai.djl.tensorflow
tensorflow-model-zoo
- 0.23.0
+ 0.27.0
```
diff --git a/engines/tensorflow/tensorflow-native/build.gradle b/engines/tensorflow/tensorflow-native/build.gradle
index 8138d93334d..56cd6eed9e2 100644
--- a/engines/tensorflow/tensorflow-native/build.gradle
+++ b/engines/tensorflow/tensorflow-native/build.gradle
@@ -153,6 +153,7 @@ flavorNames.each { flavor ->
}
from file("${BINARY_ROOT}/${flavor}/${osName}")
archiveClassifier = "${osName}-x86_64"
+ archiveBaseName = "tensorflow-native-${flavor}"
manifest {
attributes("Automatic-Module-Name": "ai.djl.tensorflow_native_${flavor}_${osName}")
diff --git a/engines/tensorrt/CMakeLists.txt b/engines/tensorrt/CMakeLists.txt
index 21c1e64d96e..6c56505d6ef 100644
--- a/engines/tensorrt/CMakeLists.txt
+++ b/engines/tensorrt/CMakeLists.txt
@@ -7,10 +7,10 @@ set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(JAVA_AWT_LIBRARY NotNeeded)
set(JAVA_AWT_INCLUDE_PATH NotNeeded)
find_package(JNI REQUIRED)
-#find_library(TRT_ONNX_PARSER
-# NAMES nvonnxparser
-# PATH_SUFFIXES lib
-# REQUIRED)
+find_library(TRT_ONNX_PARSER
+ NAMES nvonnxparser
+ PATH_SUFFIXES lib
+ REQUIRED)
find_path(UTILS_INCLUDE_DIR
NAMES djl/utils.h
@@ -37,4 +37,4 @@ target_include_directories(djl_trt PUBLIC
main/native
trt/include
build/include)
-target_link_libraries(djl_trt nvonnxparser nvparsers)
+target_link_libraries(djl_trt nvonnxparser)
diff --git a/engines/tensorrt/README.md b/engines/tensorrt/README.md
index 6373386479e..f3844b18aa0 100644
--- a/engines/tensorrt/README.md
+++ b/engines/tensorrt/README.md
@@ -28,13 +28,13 @@ The javadocs output is generated in the `build/doc/javadoc` folder.
## Installation
You can pull the TensorRT engine from the central Maven repository by including the following dependency:
-- ai.djl.tensorrt:tensorrt:0.23.0
+- ai.djl.tensorrt:tensorrt:0.27.0
```xml
ai.djl.tensorrt
tensorrt
- 0.23.0
+ 0.27.0
runtime
```
diff --git a/engines/tensorrt/build.sh b/engines/tensorrt/build.sh
index c2ad26c00a2..2f31d1146bf 100755
--- a/engines/tensorrt/build.sh
+++ b/engines/tensorrt/build.sh
@@ -8,7 +8,8 @@ VERSION="$(cat ../../gradle.properties | awk -F '=' '/trt_version/ {print $2}')"
if [ ! -d "trt" ];
then
- git clone https://github.com/NVIDIA/TensorRT.git -b $VERSION trt
+ git clone --recurse-submodules https://github.com/NVIDIA/TensorRT.git -b v$VERSION trt
+ cp -f trt/parsers/onnx/NvOnnxParser.h trt/include
fi
if [ ! -d "build" ];
diff --git a/engines/tensorrt/src/main/java/ai/djl/tensorrt/engine/TrtEngineProvider.java b/engines/tensorrt/src/main/java/ai/djl/tensorrt/engine/TrtEngineProvider.java
index 05a7eceeb41..d92ed9e449d 100644
--- a/engines/tensorrt/src/main/java/ai/djl/tensorrt/engine/TrtEngineProvider.java
+++ b/engines/tensorrt/src/main/java/ai/djl/tensorrt/engine/TrtEngineProvider.java
@@ -18,8 +18,6 @@
/** {@code TrtEngineProvider} is the TensorRT implementation of {@link EngineProvider}. */
public class TrtEngineProvider implements EngineProvider {
- private static volatile Engine engine; // NOPMD
-
/** {@inheritDoc} */
@Override
public String getEngineName() {
@@ -35,11 +33,10 @@ public int getEngineRank() {
/** {@inheritDoc} */
@Override
public Engine getEngine() {
- if (engine == null) {
- synchronized (TrtEngineProvider.class) {
- engine = TrtEngine.newInstance();
- }
- }
- return engine;
+ return InstanceHolder.INSTANCE;
+ }
+
+ private static class InstanceHolder {
+ static final Engine INSTANCE = TrtEngine.newInstance();
}
}
diff --git a/engines/tensorrt/src/main/java/ai/djl/tensorrt/engine/TrtModel.java b/engines/tensorrt/src/main/java/ai/djl/tensorrt/engine/TrtModel.java
index 44047e0e614..6a8ddb3a54c 100644
--- a/engines/tensorrt/src/main/java/ai/djl/tensorrt/engine/TrtModel.java
+++ b/engines/tensorrt/src/main/java/ai/djl/tensorrt/engine/TrtModel.java
@@ -62,7 +62,10 @@ public void load(Path modelPath, String prefix, Map options) throws I
if (modelFile == null) {
modelFile = findModelFile(modelDir.toFile().getName());
if (modelFile == null) {
- throw new FileNotFoundException(prefix + ".* file not found in: " + modelDir);
+ modelFile = findModelFile("model.onnx");
+ if (modelFile == null) {
+ throw new FileNotFoundException(prefix + ".* file not found in: " + modelDir);
+ }
}
}
String filePath = modelFile.toString();
diff --git a/engines/tensorrt/src/test/java/ai/djl/tensorrt/engine/TrtEngineTest.java b/engines/tensorrt/src/test/java/ai/djl/tensorrt/engine/TrtEngineTest.java
index 96066b380e1..d800ca13369 100644
--- a/engines/tensorrt/src/test/java/ai/djl/tensorrt/engine/TrtEngineTest.java
+++ b/engines/tensorrt/src/test/java/ai/djl/tensorrt/engine/TrtEngineTest.java
@@ -26,9 +26,9 @@ public void getVersion() {
try {
Engine engine = Engine.getEngine("TensorRT");
version = engine.getVersion();
- } catch (Exception ignore) {
+ } catch (Throwable ignore) {
throw new SkipException("Your os configuration doesn't support TensorRT.");
}
- Assert.assertEquals(version, "8.4.1");
+ Assert.assertEquals(version, "9.2.0");
}
}
diff --git a/engines/tensorrt/src/test/java/ai/djl/tensorrt/engine/TrtNDManagerTest.java b/engines/tensorrt/src/test/java/ai/djl/tensorrt/engine/TrtNDManagerTest.java
index 24d734af54c..09001f0e2da 100644
--- a/engines/tensorrt/src/test/java/ai/djl/tensorrt/engine/TrtNDManagerTest.java
+++ b/engines/tensorrt/src/test/java/ai/djl/tensorrt/engine/TrtNDManagerTest.java
@@ -28,7 +28,7 @@ public void testNDArray() {
Engine engine;
try {
engine = Engine.getEngine("TensorRT");
- } catch (Exception ignore) {
+ } catch (Throwable ignore) {
throw new SkipException("Your os configuration doesn't support TensorRT.");
}
if (!engine.defaultDevice().isGpu()) {
diff --git a/engines/tensorrt/src/test/java/ai/djl/tensorrt/integration/TrtTest.java b/engines/tensorrt/src/test/java/ai/djl/tensorrt/integration/TrtTest.java
index 105e057ba0a..2e3215cf464 100644
--- a/engines/tensorrt/src/test/java/ai/djl/tensorrt/integration/TrtTest.java
+++ b/engines/tensorrt/src/test/java/ai/djl/tensorrt/integration/TrtTest.java
@@ -49,7 +49,7 @@ public void testTrtOnnx() throws ModelException, IOException, TranslateException
Engine engine;
try {
engine = Engine.getEngine("TensorRT");
- } catch (Exception ignore) {
+ } catch (Throwable ignore) {
throw new SkipException("Your os configuration doesn't support TensorRT.");
}
if (!engine.defaultDevice().isGpu()) {
@@ -70,12 +70,12 @@ public void testTrtOnnx() throws ModelException, IOException, TranslateException
}
}
- @Test
+ @Test(enabled = false)
public void testTrtUff() throws ModelException, IOException, TranslateException {
Engine engine;
try {
engine = Engine.getEngine("TensorRT");
- } catch (Exception ignore) {
+ } catch (Throwable ignore) {
throw new SkipException("Your os configuration doesn't support TensorRT.");
}
if (!engine.defaultDevice().isGpu()) {
@@ -107,12 +107,12 @@ public void testTrtUff() throws ModelException, IOException, TranslateException
}
}
- @Test
+ @Test(enabled = false)
public void testSerializedEngine() throws ModelException, IOException, TranslateException {
Engine engine;
try {
engine = Engine.getEngine("TensorRT");
- } catch (Exception ignore) {
+ } catch (Throwable ignore) {
throw new SkipException("Your os configuration doesn't support TensorRT.");
}
Device device = engine.defaultDevice();
diff --git a/engines/tflite/tflite-engine/README.md b/engines/tflite/tflite-engine/README.md
index b1dd8fc9778..6a285b50f4e 100644
--- a/engines/tflite/tflite-engine/README.md
+++ b/engines/tflite/tflite-engine/README.md
@@ -24,13 +24,13 @@ The javadocs output is built in the `build/doc/javadoc` folder.
## Installation
You can pull the TensorFlow Lite engine from the central Maven repository by including the following dependency:
-- ai.djl.tflite:tflite-engine:0.23.0
+- ai.djl.tflite:tflite-engine:0.27.0
```xml
ai.djl.tflite
tflite-engine
- 0.23.0
+ 0.27.0
runtime
```
diff --git a/engines/tflite/tflite-engine/src/main/java/ai/djl/tflite/engine/TfLiteEngineProvider.java b/engines/tflite/tflite-engine/src/main/java/ai/djl/tflite/engine/TfLiteEngineProvider.java
index aa0fdb73d21..fb61551a3bf 100644
--- a/engines/tflite/tflite-engine/src/main/java/ai/djl/tflite/engine/TfLiteEngineProvider.java
+++ b/engines/tflite/tflite-engine/src/main/java/ai/djl/tflite/engine/TfLiteEngineProvider.java
@@ -18,8 +18,6 @@
/** {@code TfLiteEngineProvider} is the TFLite implementation of {@link EngineProvider}. */
public class TfLiteEngineProvider implements EngineProvider {
- private static volatile Engine engine; // NOPMD
-
/** {@inheritDoc} */
@Override
public String getEngineName() {
@@ -35,11 +33,10 @@ public int getEngineRank() {
/** {@inheritDoc} */
@Override
public Engine getEngine() {
- if (engine == null) {
- synchronized (TfLiteEngineProvider.class) {
- engine = TfLiteEngine.newInstance();
- }
- }
- return engine;
+ return InstanceHolder.INSTANCE;
+ }
+
+ private static class InstanceHolder {
+ static final Engine INSTANCE = TfLiteEngine.newInstance();
}
}
diff --git a/engines/tflite/tflite-native/build.gradle b/engines/tflite/tflite-native/build.gradle
index eb045331c12..3e2a6008f38 100644
--- a/engines/tflite/tflite-native/build.gradle
+++ b/engines/tflite/tflite-native/build.gradle
@@ -155,6 +155,7 @@ flavorNames.each { flavor ->
from file("src/main/resources")
from file("${project.buildDir}/classes/java/main")
archiveClassifier = "${osName}"
+ archiveBaseName = "tflite-native-${flavor}"
manifest {
attributes("Automatic-Module-Name": "ai.djl.tflite_native_${flavor}_${osName}")
diff --git a/examples/docs/image_classification.md b/examples/docs/image_classification.md
index 1f515f9680f..c8f331320a8 100644
--- a/examples/docs/image_classification.md
+++ b/examples/docs/image_classification.md
@@ -6,7 +6,7 @@ In this example, you learn how to implement inference code with Deep Java Librar
The image classification example code can be found at [ImageClassification.java](https://github.com/deepjavalibrary/djl/blob/master/examples/src/main/java/ai/djl/examples/inference/ImageClassification.java).
-You can also use the [Jupyter notebook tutorial](../../jupyter/tutorial/03_image_classification_with_your_model.ipynb).
+You can also use the [Jupyter notebook tutorial](http://docs.djl.ai/docs/demos/jupyter/tutorial/03_image_classification_with_your_model.html).
The Jupyter notebook explains the key concepts in detail.
## Setup Guide
diff --git a/examples/docs/object_detection.md b/examples/docs/object_detection.md
index 7d0898128b9..84286fb6e00 100644
--- a/examples/docs/object_detection.md
+++ b/examples/docs/object_detection.md
@@ -7,7 +7,7 @@ In this example, you learn how to implement inference code with a [ModelZoo mode
The source code can be found at [ObjectDetection.java](https://github.com/deepjavalibrary/djl/blob/master/examples/src/main/java/ai/djl/examples/inference/ObjectDetection.java).
-You can also use the [Jupyter notebook tutorial](../../jupyter/object_detection_with_model_zoo.ipynb).
+You can also use the [Jupyter notebook tutorial](http://docs.djl.ai/docs/demos/jupyter/object_detection_with_model_zoo.html).
The Jupyter notebook explains the key concepts in detail.
## Setup guide
diff --git a/examples/docs/stable_diffusion.md b/examples/docs/stable_diffusion.md
index 7eb544646ee..be3cbb48d6e 100644
--- a/examples/docs/stable_diffusion.md
+++ b/examples/docs/stable_diffusion.md
@@ -1,4 +1,4 @@
-## Stable Diffusion in DJL
+# Stable Diffusion in DJL
[Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) is an open-source model
developed by Stability.ai. It aimed to produce images (artwork, pictures, etc.) based on
diff --git a/examples/docs/train_cifar10_resnet.md b/examples/docs/train_cifar10_resnet.md
index cfaf03f8a61..1cdfcb495c2 100644
--- a/examples/docs/train_cifar10_resnet.md
+++ b/examples/docs/train_cifar10_resnet.md
@@ -5,7 +5,7 @@ In this example, you learn how to train the [CIFAR-10](https://www.cs.toronto.ed
You can find the example source code in: [TrainResnetWithCifar10.java](https://github.com/deepjavalibrary/djl/blob/master/examples/src/main/java/ai/djl/examples/training/transferlearning/TrainResnetWithCifar10.java).
-You can also find the Jupyter notebook tutorial [here](../../jupyter/transfer_learning_on_cifar10.ipynb).
+You can also find the Jupyter notebook tutorial [here](http://docs.djl.ai/docs/demos/jupyter/transfer_learning_on_cifar10.html).
The Jupyter notebook explains the key concepts in detail.
## Setup guide
diff --git a/examples/docs/train_mnist_mlp.md b/examples/docs/train_mnist_mlp.md
index 72b591d062a..40a32ca365f 100644
--- a/examples/docs/train_mnist_mlp.md
+++ b/examples/docs/train_mnist_mlp.md
@@ -6,7 +6,7 @@ In this example, you learn how to train the MNIST dataset with Deep Java Library
The source code for this example can be found at [TrainMnist.java](https://github.com/deepjavalibrary/djl/blob/master/examples/src/main/java/ai/djl/examples/training/TrainMnist.java).
-You can also use the [Jupyter notebook tutorial](../../jupyter/tutorial/02_train_your_first_model.ipynb).
+You can also use the [Jupyter notebook tutorial](http://docs.djl.ai/docs/demos/jupyter/tutorial/02_train_your_first_model.html).
The Jupyter notebook explains the key concepts in detail.
## Setup guide
diff --git a/examples/pom.xml b/examples/pom.xml
index 9eb2ee32fa0..e6a09987174 100644
--- a/examples/pom.xml
+++ b/examples/pom.xml
@@ -5,12 +5,12 @@
ai.djl
examples
- 0.24.0-SNAPSHOT
+ 0.28.0-SNAPSHOT
11
11
- 0.24.0-SNAPSHOT
+ 0.28.0-SNAPSHOT
ai.djl.examples.inference.ObjectDetection
@@ -41,7 +41,7 @@
org.apache.logging.log4j
log4j-slf4j-impl
- 2.18.0
+ 2.21.0
ai.djl
diff --git a/examples/src/main/java/ai/djl/examples/inference/BertQaInference.java b/examples/src/main/java/ai/djl/examples/inference/BertQaInference.java
index b667cd29f90..093e159bebb 100644
--- a/examples/src/main/java/ai/djl/examples/inference/BertQaInference.java
+++ b/examples/src/main/java/ai/djl/examples/inference/BertQaInference.java
@@ -34,9 +34,8 @@
* See:
*
*
- * - the jupyter
- * demo with more information about BERT.
+ *
- the jupyter demo with more
+ * information about BERT.
*
- the docs
* for information about running this example.
diff --git a/examples/src/main/java/ai/djl/examples/inference/Yolov8Detection.java b/examples/src/main/java/ai/djl/examples/inference/Yolov8Detection.java
new file mode 100644
index 00000000000..3d2cfb26409
--- /dev/null
+++ b/examples/src/main/java/ai/djl/examples/inference/Yolov8Detection.java
@@ -0,0 +1,86 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.examples.inference;
+
+import ai.djl.ModelException;
+import ai.djl.inference.Predictor;
+import ai.djl.modality.cv.Image;
+import ai.djl.modality.cv.ImageFactory;
+import ai.djl.modality.cv.output.DetectedObjects;
+import ai.djl.modality.cv.translator.YoloV8TranslatorFactory;
+import ai.djl.repository.zoo.Criteria;
+import ai.djl.repository.zoo.ZooModel;
+import ai.djl.training.util.ProgressBar;
+import ai.djl.translate.TranslateException;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.io.OutputStream;
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.nio.file.Paths;
+
+/** An example of inference using an yolov8 model. */
+public final class Yolov8Detection {
+
+ private static final Logger logger = LoggerFactory.getLogger(Yolov8Detection.class);
+
+ private Yolov8Detection() {}
+
+ public static void main(String[] args) throws IOException, ModelException, TranslateException {
+ DetectedObjects detection = Yolov8Detection.predict();
+ logger.info("{}", detection);
+ }
+
+ public static DetectedObjects predict() throws IOException, ModelException, TranslateException {
+ Path imgPath = Paths.get("src/test/resources/yolov8_test.jpg");
+ Image img = ImageFactory.getInstance().fromFile(imgPath);
+
+ Criteria criteria =
+ Criteria.builder()
+ .setTypes(Image.class, DetectedObjects.class)
+ .optModelUrls("djl://ai.djl.onnxruntime/yolov8n")
+ .optEngine("OnnxRuntime")
+ .optArgument("width", 640)
+ .optArgument("height", 640)
+ .optArgument("resize", true)
+ .optArgument("toTensor", true)
+ .optArgument("applyRatio", true)
+ .optArgument("threshold", 0.6f)
+ // for performance optimization maxBox parameter can reduce number of
+ // considered boxes from 8400
+ .optArgument("maxBox", 1000)
+ .optTranslatorFactory(new YoloV8TranslatorFactory())
+ .optProgress(new ProgressBar())
+ .build();
+
+ try (ZooModel model = criteria.loadModel();
+ Predictor predictor = model.newPredictor()) {
+ Path outputPath = Paths.get("build/output");
+ Files.createDirectories(outputPath);
+
+ DetectedObjects detection = predictor.predict(img);
+ if (detection.getNumberOfObjects() > 0) {
+ img.drawBoundingBoxes(detection);
+ Path output = outputPath.resolve("yolov8_detected.png");
+ try (OutputStream os = Files.newOutputStream(output)) {
+ img.save(os, "png");
+ }
+ logger.info("Detected object saved in: {}", output);
+ }
+ return detection;
+ }
+ }
+}
diff --git a/examples/src/main/java/ai/djl/examples/inference/face/FaceDetectionTranslator.java b/examples/src/main/java/ai/djl/examples/inference/face/FaceDetectionTranslator.java
index c5a04065d5f..088558d6b0b 100644
--- a/examples/src/main/java/ai/djl/examples/inference/face/FaceDetectionTranslator.java
+++ b/examples/src/main/java/ai/djl/examples/inference/face/FaceDetectionTranslator.java
@@ -40,8 +40,6 @@ public class FaceDetectionTranslator implements Translator CHW RGB -> BGR
// The network by default takes float32
@@ -78,6 +78,10 @@ public NDList processInput(TranslatorContext ctx, Image input) {
/** {@inheritDoc} */
@Override
public DetectedObjects processOutput(TranslatorContext ctx, NDList list) {
+
+ int width = (int) ctx.getAttachment("width");
+ int height = (int) ctx.getAttachment("height");
+
NDManager manager = ctx.getNDManager();
double scaleXY = variance[0];
double scaleWH = variance[1];
diff --git a/examples/src/main/java/ai/djl/examples/inference/nlp/TextGeneration.java b/examples/src/main/java/ai/djl/examples/inference/nlp/TextGeneration.java
index acbaa152f8c..59cba679ba2 100644
--- a/examples/src/main/java/ai/djl/examples/inference/nlp/TextGeneration.java
+++ b/examples/src/main/java/ai/djl/examples/inference/nlp/TextGeneration.java
@@ -59,6 +59,7 @@ public static String generateTextWithPyTorchGreedy()
SearchConfig config = new SearchConfig();
config.setMaxSeqLength(60);
+ // You can use src/main/python/trace_gpt2.py to trace gpt2 model
String url = "https://djl-misc.s3.amazonaws.com/test/models/gpt2/gpt2_pt.zip";
Criteria criteria =
@@ -160,6 +161,20 @@ public static String[] generateTextWithOnnxRuntimeBeam()
long padTokenId = 220;
config.setPadTokenId(padTokenId);
+ // The model is converted optimum:
+ // https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#exporting-a-model-using-past-keysvalues-in-the-decoder
+ /*
+ * optimum-cli export onnx --model gpt2 gpt2_onnx/
+ *
+ * from transformers import AutoTokenizer
+ * from optimum.onnxruntime import ORTModelForCausalLM
+ *
+ * tokenizer = AutoTokenizer.from_pretrained("./gpt2_onnx/")
+ * model = ORTModelForCausalLM.from_pretrained("./gpt2_onnx/")
+ * inputs = tokenizer("My name is Arthur and I live in", return_tensors="pt")
+ * gen_tokens = model.generate(**inputs)
+ * print(tokenizer.batch_decode(gen_tokens))
+ */
String url = "https://djl-misc.s3.amazonaws.com/test/models/gpt2/gpt2_onnx.zip";
Criteria criteria =
diff --git a/examples/src/main/python/trace_gpt2.py b/examples/src/main/python/trace_gpt2.py
new file mode 100644
index 00000000000..33c3badb08d
--- /dev/null
+++ b/examples/src/main/python/trace_gpt2.py
@@ -0,0 +1,73 @@
+import torch
+from transformers import GPT2LMHeadModel, GPT2Tokenizer
+
+model_name = 'gpt2-large'
+tokenizer = GPT2Tokenizer.from_pretrained(model_name)
+
+# add the EOS token as PAD token to avoid warnings
+model = GPT2LMHeadModel.from_pretrained(model_name, pad_token_id=tokenizer.eos_token_id, torchscript=True)
+
+# %% model_inputs
+output_attentions = False
+output_hidden_states = False
+model_inputs = {}
+
+model_inputs['past_key_values'] = torch.load(
+ "../data/nested_tuple_" + model_name + ".pt")
+past_seq = model_inputs['past_key_values'][0][0].shape[-2]
+model_inputs['input_ids'] = torch.tensor([[404]])
+model_inputs['position_ids'] = torch.tensor([[past_seq]])
+# |attention_mask| = `len(past_key_values) + len(input_ids)`
+model_inputs['attention_mask'] = torch.ones(past_seq + 1, dtype=torch.int64)
+
+model_inputs['use_cache'] = True
+model_inputs['token_type_ids'] = None
+
+model_inputs['return_dict'] = False
+model_inputs['output_attentions'] = False
+model_inputs['output_hidden_states'] = False
+
+# This is a testing of text generation
+outputs = model(**model_inputs)
+
+# %% Wrapper class of GPT2LMHeadModel
+from typing import Tuple
+
+class Tracable(torch.nn.Module):
+ def __init__(self, config: dict):
+ super().__init__()
+ self.model = GPT2LMHeadModel.from_pretrained(model_name, pad_token_id=tokenizer.eos_token_id, torchscript=True)
+ self.config = {'use_cache': config.get('use_cache', True),
+ 'token_type_ids': config.get('token_type_ids', None),
+ 'return_dict': config.get('return_dict', False),
+ 'output_attentions': config.get('output_attentions', False),
+ 'output_hidden_states': config.get('output_hidden_states', True)}
+
+ def forward(self, my_input_ids, position_ids, attention_mask, past_key_values):
+ return self.model(input_ids=my_input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ **self.config) # return_tensor = True
+
+# %% create class
+config = {}
+tracable = Tracable(config)
+input = (model_inputs['input_ids'],
+ model_inputs['position_ids'],
+ model_inputs['attention_mask'],
+ model_inputs['past_key_values'])
+
+output = tracable(*input)
+
+# %% trace
+tracable.eval()
+
+traced_model = torch.jit.trace(tracable, input)
+torch.jit.save(traced_model, "../traced_GPT2_hidden.pt")
+
+out1 = traced_model(*input)
+
+# %% load back
+loaded_model = torch.jit.load("../traced_GPT2_hidden.pt")
+out2 = loaded_model(*input)
diff --git a/examples/src/test/java/ai/djl/examples/inference/Yolov8DetectionTest.java b/examples/src/test/java/ai/djl/examples/inference/Yolov8DetectionTest.java
new file mode 100644
index 00000000000..35e3fc434aa
--- /dev/null
+++ b/examples/src/test/java/ai/djl/examples/inference/Yolov8DetectionTest.java
@@ -0,0 +1,40 @@
+/*
+ * Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance
+ * with the License. A copy of the License is located at
+ *
+ * http://aws.amazon.com/apache2.0/
+ *
+ * or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES
+ * OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions
+ * and limitations under the License.
+ */
+package ai.djl.examples.inference;
+
+import ai.djl.ModelException;
+import ai.djl.modality.Classifications;
+import ai.djl.modality.cv.output.DetectedObjects;
+import ai.djl.testing.TestRequirements;
+import ai.djl.translate.TranslateException;
+
+import org.testng.Assert;
+import org.testng.annotations.Test;
+
+import java.io.IOException;
+
+public class Yolov8DetectionTest {
+
+ @Test
+ public void testYolov8Detection() throws ModelException, TranslateException, IOException {
+ TestRequirements.engine("MXNet", "PyTorch");
+
+ DetectedObjects result = Yolov8Detection.predict();
+
+ Assert.assertTrue(result.getNumberOfObjects() >= 1);
+ Classifications.Classification obj = result.best();
+ String className = obj.getClassName();
+ Assert.assertEquals(className, "dog");
+ Assert.assertTrue(obj.getProbability() > 0.6);
+ }
+}
diff --git a/examples/src/test/java/ai/djl/examples/training/TrainPikachuTest.java b/examples/src/test/java/ai/djl/examples/training/TrainPikachuTest.java
index 2a61e25862e..1a5699836c8 100644
--- a/examples/src/test/java/ai/djl/examples/training/TrainPikachuTest.java
+++ b/examples/src/test/java/ai/djl/examples/training/TrainPikachuTest.java
@@ -27,7 +27,6 @@ public class TrainPikachuTest {
@Test
public void testDetection() throws IOException, MalformedModelException, TranslateException {
- TestRequirements.engine("MXNet");
TestRequirements.nightly();
String[] args;
diff --git a/examples/src/test/java/ai/djl/testing/TestRequirements.java b/examples/src/test/java/ai/djl/testing/TestRequirements.java
index e8c9bd4bdda..01eef756201 100644
--- a/examples/src/test/java/ai/djl/testing/TestRequirements.java
+++ b/examples/src/test/java/ai/djl/testing/TestRequirements.java
@@ -14,6 +14,7 @@
import ai.djl.engine.Engine;
import ai.djl.engine.EngineException;
+import ai.djl.util.Utils;
import org.testng.SkipException;
@@ -45,7 +46,7 @@ public static void weekly() {
/** Requires a test not be run in offline mode. */
public static void notOffline() {
- if (Boolean.getBoolean("offline")) {
+ if (Utils.isOfflineMode()) {
throw new SkipException("This test can not run while offline");
}
}
diff --git a/examples/src/test/resources/yolov8_synset.txt b/examples/src/test/resources/yolov8_synset.txt
new file mode 100644
index 00000000000..ffba2064933
--- /dev/null
+++ b/examples/src/test/resources/yolov8_synset.txt
@@ -0,0 +1,84 @@
+# Classes for coco dataset on which yelov8 is trained
+# source config https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml.
+# COCO dataset website: https://cocodataset.org/#home
+# Ultralytics Coco doc page: https://docs.ultralytics.com/datasets/detect/coco/
+person
+bicycle
+car
+motorbike
+aeroplane
+bus
+train
+truck
+boat
+traffic light
+fire hydrant
+stop sign
+parking meter
+bench
+bird
+cat
+dog
+horse
+sheep
+cow
+elephant
+bear
+zebra
+giraffe
+backpack
+umbrella
+handbag
+tie
+suitcase
+frisbee
+skis
+snowboard
+sports ball
+kite
+baseball bat
+baseball glove
+skateboard
+surfboard
+tennis racket
+bottle
+wine glass
+cup
+fork
+knife
+spoon
+bowl
+banana
+apple
+sandwich
+orange
+broccoli
+carrot
+hot dog
+pizza
+donut
+cake
+chair
+sofa
+pottedplant
+bed
+diningtable
+toilet
+tvmonitor
+laptop
+mouse
+remote
+keyboard
+cell phone
+microwave
+oven
+toaster
+sink
+refrigerator
+book
+clock
+vase
+scissors
+teddy bear
+hair drier
+toothbrush
\ No newline at end of file
diff --git a/examples/src/test/resources/yolov8_test.jpg b/examples/src/test/resources/yolov8_test.jpg
new file mode 100644
index 00000000000..01e43374348
Binary files /dev/null and b/examples/src/test/resources/yolov8_test.jpg differ
diff --git a/examples/src/test/resources/yolov8n.onnx b/examples/src/test/resources/yolov8n.onnx
new file mode 100644
index 00000000000..430f7f2beb0
Binary files /dev/null and b/examples/src/test/resources/yolov8n.onnx differ
diff --git a/extensions/audio/README.md b/extensions/audio/README.md
index 7e2c89692bc..6ec5ade8feb 100644
--- a/extensions/audio/README.md
+++ b/extensions/audio/README.md
@@ -23,6 +23,6 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.audio
audio
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/aws-ai/README.md b/extensions/aws-ai/README.md
index 829df0bb0ca..95f7bf2568a 100644
--- a/extensions/aws-ai/README.md
+++ b/extensions/aws-ai/README.md
@@ -58,6 +58,6 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.aws
aws-ai
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/fasttext/README.md b/extensions/fasttext/README.md
index 6f5a25064ea..16003dd3927 100644
--- a/extensions/fasttext/README.md
+++ b/extensions/fasttext/README.md
@@ -34,7 +34,7 @@ You can pull the fastText engine from the central Maven repository by including
ai.djl.fasttext
fasttext-engine
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/fasttext/src/test/java/ai/djl/fasttext/CookingStackExchangeTest.java b/extensions/fasttext/src/test/java/ai/djl/fasttext/CookingStackExchangeTest.java
index 5b421ff431f..4395ddf1a6c 100644
--- a/extensions/fasttext/src/test/java/ai/djl/fasttext/CookingStackExchangeTest.java
+++ b/extensions/fasttext/src/test/java/ai/djl/fasttext/CookingStackExchangeTest.java
@@ -41,6 +41,7 @@
import java.io.IOException;
import java.io.InputStream;
+import java.net.URI;
import java.net.URL;
import java.nio.file.Files;
import java.nio.file.Path;
@@ -129,7 +130,9 @@ public void testWord2Vec() throws IOException, MalformedModelException, ModelNot
public void testBlazingText() throws IOException, ModelException {
TestRequirements.nightly();
- URL url = new URL("https://resources.djl.ai/test-models/blazingtext_classification.bin");
+ URL url =
+ URI.create("https://resources.djl.ai/test-models/blazingtext_classification.bin")
+ .toURL();
Path path = Paths.get("build/tmp/model");
Path modelFile = path.resolve("text_classification.bin");
if (!Files.exists(modelFile)) {
diff --git a/extensions/hadoop/README.md b/extensions/hadoop/README.md
index b3c4ebcc762..38ed91747c8 100644
--- a/extensions/hadoop/README.md
+++ b/extensions/hadoop/README.md
@@ -52,6 +52,6 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.hadoop
hadoop
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/opencv/README.md b/extensions/opencv/README.md
index d6c58f518dc..c8f88a80475 100644
--- a/extensions/opencv/README.md
+++ b/extensions/opencv/README.md
@@ -23,6 +23,6 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.opencv
opencv
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/sentencepiece/README.md b/extensions/sentencepiece/README.md
index 4308308111f..2dba43c86a9 100644
--- a/extensions/sentencepiece/README.md
+++ b/extensions/sentencepiece/README.md
@@ -23,6 +23,6 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.sentencepiece
sentencepiece
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/spark/README.md b/extensions/spark/README.md
index 02ebcc07a1d..957a3f8a3ff 100644
--- a/extensions/spark/README.md
+++ b/extensions/spark/README.md
@@ -34,7 +34,7 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.spark
spark_2.12
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/spark/setup/djl_spark/util/files_util.py b/extensions/spark/setup/djl_spark/util/files_util.py
index 5e31fc9e177..dd9224000cf 100644
--- a/extensions/spark/setup/djl_spark/util/files_util.py
+++ b/extensions/spark/setup/djl_spark/util/files_util.py
@@ -70,6 +70,21 @@ def download_and_extract(url, path):
:param url: The url of the tar file.
:param path: The path to the file to download to.
"""
+
+ def is_within_directory(directory, target):
+ abs_directory = os.path.abspath(directory)
+ abs_target = os.path.abspath(target)
+ prefix = os.path.commonprefix([abs_directory, abs_target])
+ return prefix == abs_directory
+
+ def safe_extract(tar, path=".", members=None, *, numeric_owner=False):
+ for member in tar.getmembers():
+ member_path = os.path.join(path, member.name)
+ if not is_within_directory(path, member_path):
+ raise Exception("Attempted Path Traversal in Tar File")
+
+ tar.extractall(path, members, numeric_owner=numeric_owner)
+
if not os.path.exists(path):
os.makedirs(path)
if not os.listdir(path):
@@ -78,9 +93,9 @@ def download_and_extract(url, path):
if url.startswith("s3://"):
s3_download(url, tmp_file)
with tarfile.open(name=tmp_file, mode="r:gz") as t:
- t.extractall(path=path)
+ safe_extract(t, path=path)
elif url.startswith("http://") or url.startswith("https://"):
with urlopen(url) as response, open(tmp_file, 'wb') as f:
shutil.copyfileobj(response, f)
with tarfile.open(name=tmp_file, mode="r:gz") as t:
- t.extractall(path=path)
+ safe_extract(t, path=path)
diff --git a/extensions/tablesaw/README.md b/extensions/tablesaw/README.md
index 010c6395eb9..8e092a3df61 100644
--- a/extensions/tablesaw/README.md
+++ b/extensions/tablesaw/README.md
@@ -25,6 +25,6 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.tablesaw
tablesaw
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/timeseries/README.md b/extensions/timeseries/README.md
index 9706c9334a4..f5629124a76 100644
--- a/extensions/timeseries/README.md
+++ b/extensions/timeseries/README.md
@@ -245,6 +245,6 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.timeseries
timeseries
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/timeseries/docs/forecast_with_M5_data.md b/extensions/timeseries/docs/forecast_with_M5_data.md
index a4f1a24a1d9..4eb1587a66c 100644
--- a/extensions/timeseries/docs/forecast_with_M5_data.md
+++ b/extensions/timeseries/docs/forecast_with_M5_data.md
@@ -1,5 +1,7 @@
# Forecast the future in a timeseries data with Deep Java Library (DJL)
+
## -- Demonstration on M5forecasting and airpassenger datasests
+
Junyuan Zhang, Kexin Feng
Time series data are commonly seen in the world. They can contain valued information that helps forecast for the future, monitor the status of a procedure and feedforward a control. Generic applications includes the following: sales forecasting, stock market analysis, yield projections, process and quality control, and many many more. See [link1](https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc41.htm) and [link2](https://www.influxdata.com/time-series-forecasting-methods/#:~:text=Time%20series%20forecasting%20means%20to,on%20what%20has%20already%20happened) for further examples of timeseries data.
@@ -54,7 +56,7 @@ repositories {
}
dependencies {
implementation "org.apache.logging.log4j:log4j-slf4j-impl:2.17.1"
- implementation platform("ai.djl:bom:0.23.0")
+ implementation platform("ai.djl:bom:0.27.0")
implementation "ai.djl:api"
implementation "ai.djl.timeseries"
runtimeOnly "ai.djl.mxnet:mxnet-engine"
diff --git a/extensions/timeseries/src/main/java/ai/djl/timeseries/evaluator/Rmsse.java b/extensions/timeseries/src/main/java/ai/djl/timeseries/evaluator/Rmsse.java
index 5b642285c3e..9edb45ff5f0 100644
--- a/extensions/timeseries/src/main/java/ai/djl/timeseries/evaluator/Rmsse.java
+++ b/extensions/timeseries/src/main/java/ai/djl/timeseries/evaluator/Rmsse.java
@@ -94,15 +94,23 @@ public void addAccumulator(String key) {
/** {@inheritDoc} */
@Override
public void updateAccumulator(String key, NDList labels, NDList predictions) {
+ updateAccumulators(new String[] {key}, labels, predictions);
+ }
+
+ /** {@inheritDoc} */
+ @Override
+ public void updateAccumulators(String[] keys, NDList labels, NDList predictions) {
Pair update = evaluateHelper(labels, predictions);
- totalInstances.compute(key, (k, v) -> v + update.getKey());
- totalLoss.compute(
- key,
- (k, v) -> {
- try (NDArray array = update.getValue().sum()) {
- return v + array.getFloat();
- }
- });
+ for (String key : keys) {
+ totalInstances.compute(key, (k, v) -> v + update.getKey());
+ totalLoss.compute(
+ key,
+ (k, v) -> {
+ try (NDArray array = update.getValue().sum()) {
+ return v + array.getFloat();
+ }
+ });
+ }
}
/** {@inheritDoc} */
diff --git a/extensions/tokenizers/README.md b/extensions/tokenizers/README.md
index 1b85625572c..fc700007baf 100644
--- a/extensions/tokenizers/README.md
+++ b/extensions/tokenizers/README.md
@@ -23,7 +23,7 @@ You can pull the module from the central Maven repository by including the follo
ai.djl.huggingface
tokenizers
- 0.23.0
+ 0.27.0
```
diff --git a/extensions/tokenizers/build.cmd b/extensions/tokenizers/build.cmd
index 3a481d33bab..d83f2c1ed74 100644
--- a/extensions/tokenizers/build.cmd
+++ b/extensions/tokenizers/build.cmd
@@ -3,7 +3,7 @@
@rem choco install rust -y
@rem choco install jdk8 -y
-set VERSION=python-v"%1"
+set VERSION=v"%1"
if exist "tokenizers" (
echo Found "tokenizers"
diff --git a/extensions/tokenizers/build.sh b/extensions/tokenizers/build.sh
index 4ba45a09965..229e8124914 100755
--- a/extensions/tokenizers/build.sh
+++ b/extensions/tokenizers/build.sh
@@ -10,7 +10,7 @@ elif [[ -n $(command -v sysctl) ]]; then
fi
PLATFORM=$(uname | tr '[:upper:]' '[:lower:]')
-VERSION=python-v$1
+VERSION=v$1
ARCH=$2
pushd $WORK_DIR
diff --git a/extensions/tokenizers/rust/Cargo.toml b/extensions/tokenizers/rust/Cargo.toml
index f6b846f636c..17bdd47b132 100644
--- a/extensions/tokenizers/rust/Cargo.toml
+++ b/extensions/tokenizers/rust/Cargo.toml
@@ -5,8 +5,8 @@ authors = ["Frank Liu "]
edition = "2018"
[dependencies]
-jni = "0.19.0"
-tokenizers = { path = "../tokenizers/tokenizers", version = "*" }
+jni = "0.21.1"
+tokenizers = { path = "../tokenizers/tokenizers", version = "*", features = ["http"] }
[target.'cfg(target_os = "linux")'.dependencies]
openssl = { version = "0.10", features = ["vendored"] }
diff --git a/extensions/tokenizers/rust/src/lib.rs b/extensions/tokenizers/rust/src/lib.rs
index d1c0c455c19..3352f98aa8a 100644
--- a/extensions/tokenizers/rust/src/lib.rs
+++ b/extensions/tokenizers/rust/src/lib.rs
@@ -15,25 +15,29 @@
extern crate tokenizers as tk;
use std::str::FromStr;
+
+use jni::objects::{
+ JClass, JLongArray, JMethodID, JObject, JObjectArray, JString, JValue, ReleaseMode,
+};
+use jni::sys::{jboolean, jint, jlong, jsize, jvalue, JNI_TRUE};
+use jni::JNIEnv;
+use tk::models::bpe::BPE;
use tk::tokenizer::{EncodeInput, Encoding};
use tk::utils::padding::{PaddingParams, PaddingStrategy};
use tk::utils::truncation::{TruncationParams, TruncationStrategy};
use tk::Tokenizer;
use tk::{FromPretrainedParameters, Offsets};
-use tk::models::bpe::BPE;
-
-use jni::objects::{JClass, JMethodID, JObject, JString, JValue, ReleaseMode};
-use jni::sys::{jboolean, jint, jlong, jlongArray, jobjectArray, jsize, jstring, JNI_TRUE};
-use jni::JNIEnv;
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_createTokenizer(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_createTokenizer<
+ 'local,
+>(
+ mut env: JNIEnv<'local>,
_: JObject,
input: JString,
) -> jlong {
let identifier: String = env
- .get_string(input)
+ .get_string(&input)
.expect("Couldn't get java string!")
.into();
@@ -50,13 +54,15 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
}
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_createTokenizerFromString(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_createTokenizerFromString<
+ 'local,
+>(
+ mut env: JNIEnv<'local>,
_: JObject,
json: JString,
) -> jlong {
let data: String = env
- .get_string(json)
+ .get_string(&json)
.expect("Couldn't get java string!")
.into();
@@ -72,19 +78,21 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
// Tokenizer using BPE model
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_createBpeTokenizer(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_createBpeTokenizer<
+ 'local,
+>(
+ mut env: JNIEnv<'local>,
_: JObject,
vocabulary: JString,
merges: JString,
) -> jlong {
let vocabulary: String = env
- .get_string(vocabulary)
+ .get_string(&vocabulary)
.expect("Couldn't get java string!")
.into();
let merges: String = env
- .get_string(merges)
+ .get_string(&merges)
.expect("Couldn't get java string!")
.into();
@@ -99,7 +107,7 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
#[no_mangle]
pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_deleteTokenizer(
- _env: JNIEnv,
+ _: JNIEnv,
_: JObject,
handle: jlong,
) {
@@ -107,8 +115,8 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
}
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_encode(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_encode<'local>(
+ mut env: JNIEnv<'local>,
_: JObject,
handle: jlong,
input: JString,
@@ -116,7 +124,7 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
) -> jlong {
let tokenizer = cast_handle::(handle);
let sequence: String = env
- .get_string(input)
+ .get_string(&input)
.expect("Couldn't get java string!")
.into();
@@ -134,8 +142,10 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
}
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_encodeDual(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_encodeDual<
+ 'local,
+>(
+ mut env: JNIEnv<'local>,
_: JObject,
handle: jlong,
text: JString,
@@ -144,11 +154,11 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
) -> jlong {
let tokenizer = cast_handle::(handle);
let sequence1: String = env
- .get_string(text)
+ .get_string(&text)
.expect("Couldn't get text string!")
.into();
let sequence2: String = env
- .get_string(text_pair)
+ .get_string(&text_pair)
.expect("Couldn't get text_pair string!")
.into();
@@ -167,20 +177,22 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
}
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_encodeList(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_encodeList<
+ 'local,
+>(
+ mut env: JNIEnv<'local>,
_: JObject,
handle: jlong,
- inputs: jobjectArray,
+ inputs: JObjectArray<'local>,
add_special_tokens: jboolean,
) -> jlong {
let tokenizer = cast_handle::(handle);
- let len = env.get_array_length(inputs).unwrap();
+ let len = env.get_array_length(&inputs).unwrap();
let mut array: Vec = Vec::new();
for i in 0..len {
- let item = env.get_object_array_element(inputs, i).unwrap().into();
+ let item = env.get_object_array_element(&inputs, i).unwrap().into();
let value: String = env
- .get_string(item)
+ .get_string(&item)
.expect("Couldn't get java string!")
.into();
array.push(value);
@@ -200,20 +212,22 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
}
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_batchEncode(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_batchEncode<
+ 'local,
+>(
+ mut env: JNIEnv<'local>,
_: JObject,
handle: jlong,
- inputs: jobjectArray,
+ inputs: JObjectArray<'local>,
add_special_tokens: jboolean,
-) -> jlongArray {
+) -> JLongArray<'local> {
let tokenizer = cast_handle::(handle);
- let len = env.get_array_length(inputs).unwrap();
+ let len = env.get_array_length(&inputs).unwrap();
let mut array: Vec = Vec::new();
for i in 0..len {
- let item = env.get_object_array_element(inputs, i).unwrap().into();
+ let item = env.get_object_array_element(&inputs, i).unwrap().into();
let value: String = env
- .get_string(item)
+ .get_string(&item)
.expect("Couldn't get java string!")
.into();
array.push(value);
@@ -229,31 +243,33 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
let size = handles.len() as jsize;
let ret = env.new_long_array(size).unwrap();
- env.set_long_array_region(ret, 0, &handles).unwrap();
+ env.set_long_array_region(&ret, 0, &handles).unwrap();
ret
}
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_batchEncodePair(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_batchEncodePair<
+ 'local,
+>(
+ mut env: JNIEnv<'local>,
_: JObject,
handle: jlong,
- text: jobjectArray,
- text_pair: jobjectArray,
+ text: JObjectArray<'local>,
+ text_pair: JObjectArray<'local>,
add_special_tokens: jboolean,
-) -> jlongArray {
+) -> JLongArray<'local> {
let tokenizer = cast_handle::(handle);
- let len = env.get_array_length(text).unwrap();
+ let len = env.get_array_length(&text).unwrap();
let mut array: Vec = Vec::new();
for i in 0..len {
- let item1 = env.get_object_array_element(text, i).unwrap().into();
- let item2 = env.get_object_array_element(text_pair, i).unwrap().into();
+ let item1 = env.get_object_array_element(&text, i).unwrap().into();
+ let item2 = env.get_object_array_element(&text_pair, i).unwrap().into();
let sequence1: String = env
- .get_string(item1)
+ .get_string(&item1)
.expect("Couldn't get text string!")
.into();
let sequence2: String = env
- .get_string(item2)
+ .get_string(&item2)
.expect("Couldn't get text_pair string!")
.into();
@@ -273,13 +289,13 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
let size = handles.len() as jsize;
let ret = env.new_long_array(size).unwrap();
- env.set_long_array_region(ret, 0, &handles).unwrap();
+ env.set_long_array_region(&ret, 0, &handles).unwrap();
ret
}
#[no_mangle]
pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_deleteEncoding(
- _env: JNIEnv,
+ _: JNIEnv,
_: JObject,
handle: jlong,
) {
@@ -287,11 +303,13 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
}
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_getTokenIds(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_getTokenIds<
+ 'local,
+>(
+ env: JNIEnv<'local>,
_: JObject,
handle: jlong,
-) -> jlongArray {
+) -> JLongArray<'local> {
let encoding = cast_handle::(handle);
let ids = encoding.get_ids();
let len = ids.len() as jsize;
@@ -301,17 +319,19 @@ pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_
long_ids.push(*i as jlong)
}
- let array: jlongArray = env.new_long_array(len).unwrap();
- env.set_long_array_region(array, 0, &long_ids).unwrap();
+ let array = env.new_long_array(len).unwrap();
+ env.set_long_array_region(&array, 0, &long_ids).unwrap();
array
}
#[no_mangle]
-pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_getTypeIds(
- env: JNIEnv,
+pub extern "system" fn Java_ai_djl_huggingface_tokenizers_jni_TokenizersLibrary_getTypeIds<
+ 'local,
+>(
+ env: JNIEnv<'local>,
_: JObject,
handle: jlong,
-) -> jlongArray {
+) -> JLongArray<'local> {
let encoding = cast_handle::