Pandas是Python中用于数据处理和分析的库,尤其对于大数据行业的数据清洗很有帮助。
通过带有标签的列和索引,Pandas 使我们可以以一种所有人都能理解的方式来处理数据。它可以让我们毫不费力地从诸如 csv 类型的文件中导入数据。我们可以用它快速地对数据进行复杂的转换和过滤等操作。
对于使用 Python 库,第一步必然是import:
import pandas as pdPandas 基于两种数据类型,series 和 dataframe。
series是一种一维的数据类型,其中的每个元素都有各自的标签。可以当作一个由带标签的元素组成的 numpy 数组。标签可以是数字或者字符。dataframe是一个二维的、表格型的数据结构。Pandas的dataframe可以储存许多不同类型的数据,并且每个轴都有标签。你可以把它当作一个series的字典。
read_csv():读取csv文件为dataframe# Reading a csv into Pandas. df = pd.read_csv('uk_rain_2014.csv', header=0)
read_excel():用法类似read_csv(),用来读取Excel文件df.head():查看前5行数据df.tail():查看前最后5行数据
to_csv():dataframe存入csv文件# Reading a csv into Pandas. df.to_csv('new.csv')
- 获取一列,返回的是
series:df['rain_octsep']df.rain_octsep:也像访问属性一样访问列
- 获取多列:
df[['water_year', 'rain_octsep']] - Change Column labels 改变列标签
df.columns = ['water_year','rain_octsep', 'outflow_octsep',
'rain_decfeb', 'outflow_decfeb',
'rain_junaug', 'outflow_junaug']len(df):返回数据集的总行数
df.ix[i, j]:返回i行j列的单元格数据,i、j可以是index或者labeldf.ix[i0:i1, j0:j1]:支持slicing,返回一个sub-dataframedf.['label'].unique():获得唯一的值列表
- 根据column范围筛选数据(
布尔过滤 boolean masking):- 注意:条件里不能用 and 关键字,因为会引发操作顺序的问题。必须用 & 和圆括号。
- 当使用字符串过滤时,需要用
.str.[string method],而不能直接在字符串上调用字符方法。
df1 = df[df['Released'] >= 1980] # 年份大于1980的所有数据
df[(df.rain_octsep < 1000) & (df.outflow_octsep < 4000)]
df[df.water_year.str.startswith('199')] # 使用字符串过滤可以根据索引来获取某一行,而且获取行数据的方法是根据标签的类型变化而变化的。
- 如果标签是数字型的,可以通过 iloc 来引用:
df.iloc[30] # 获得index是30的行数据
- 也许数据集中有年份或者年龄的列,可能想通过年份或年龄来引用行,这时候就可以设置一个(或者多个)新的索引:
df = df.set_index(['water_year']) df.head(5)
- 上面的代码仅将
water_year列设置为索引。如果想设置多个索引,只需要在list中加入多个列的名字即可。df.loc['2000/01']
- 还有一个引用列的常用常用方法
ix。loc是基于标签的,而iloc是基于数字的,而ix是基于标签的查询方法,但它同时也支持数字型索引作为备选。注意:ix具有轻微的不可预测性,它所支持的数字型索引只是备选,可能会导致ix产生一些奇怪的结果,比如将一个数字解释为一个位置。而使用iloc和loc会很安全、可预测。但ix比iloc和loc要快一些。
将索引排序通常会很有用,在 Pandas 中,我们可以对 dataframe 调用 sort_index 方法进行排序。
df.sort_index(ascending=False)当将一列设置为索引的时候,它就不再是数据的一部分了。如果你想将索引恢复为数据,调用set_index 相反的方法 reset_index 即可:
有时你想对数据集中的数据进行改变或者某种操作。比方说,你有一列年份的数据,你需要新的一列来表示这些年份对应的年代。Pandas 中有两个非常有用的函数, apply 和 applymap 。
def base_year(year):
base_year = year[:4]
base_year= pd.to_datetime(base_year).year
return base_year
df['year'] = df.water_year.apply(base_year)
df.head(5)- groupby()
- max() 、 min() 、mean()
- unstack()
- pivot():旋转
将有两个相关联的数据集放在一起:
rain_jpn = pd.read_csv('jpn_rain.csv')
rain_jpn.columns = ['year', 'jpn_rainfall']
uk_jpn_rain = df.merge(rain_jpn, on='year')
uk_jpn_rain.head(5)需要通过 on 关键字来指定需要合并的列。通常你可以省略这个参数,Pandas 将会自动选择要合并的列。
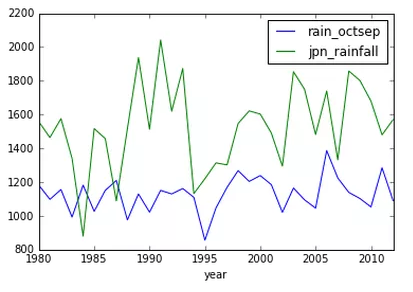
Matplotlib 很棒,但是想要绘制出还算不错的图表却要写不少代码,而有时你只是想粗略的做个图来探索下数据,搞清楚数据的含义。Pandas 通过 plot 来解决这个问题:
uk_jpn_rain.plot(x='year', y=['rain_octsep', 'jpn_rainfall'])