diff --git a/site/docs/getting-started/quickstart/quickstart.md b/site/docs/getting-started/quickstart/quickstart.md
index 092af43b35..4cceb78bda 100644
--- a/site/docs/getting-started/quickstart/quickstart.md
+++ b/site/docs/getting-started/quickstart/quickstart.md
@@ -85,8 +85,7 @@ table.
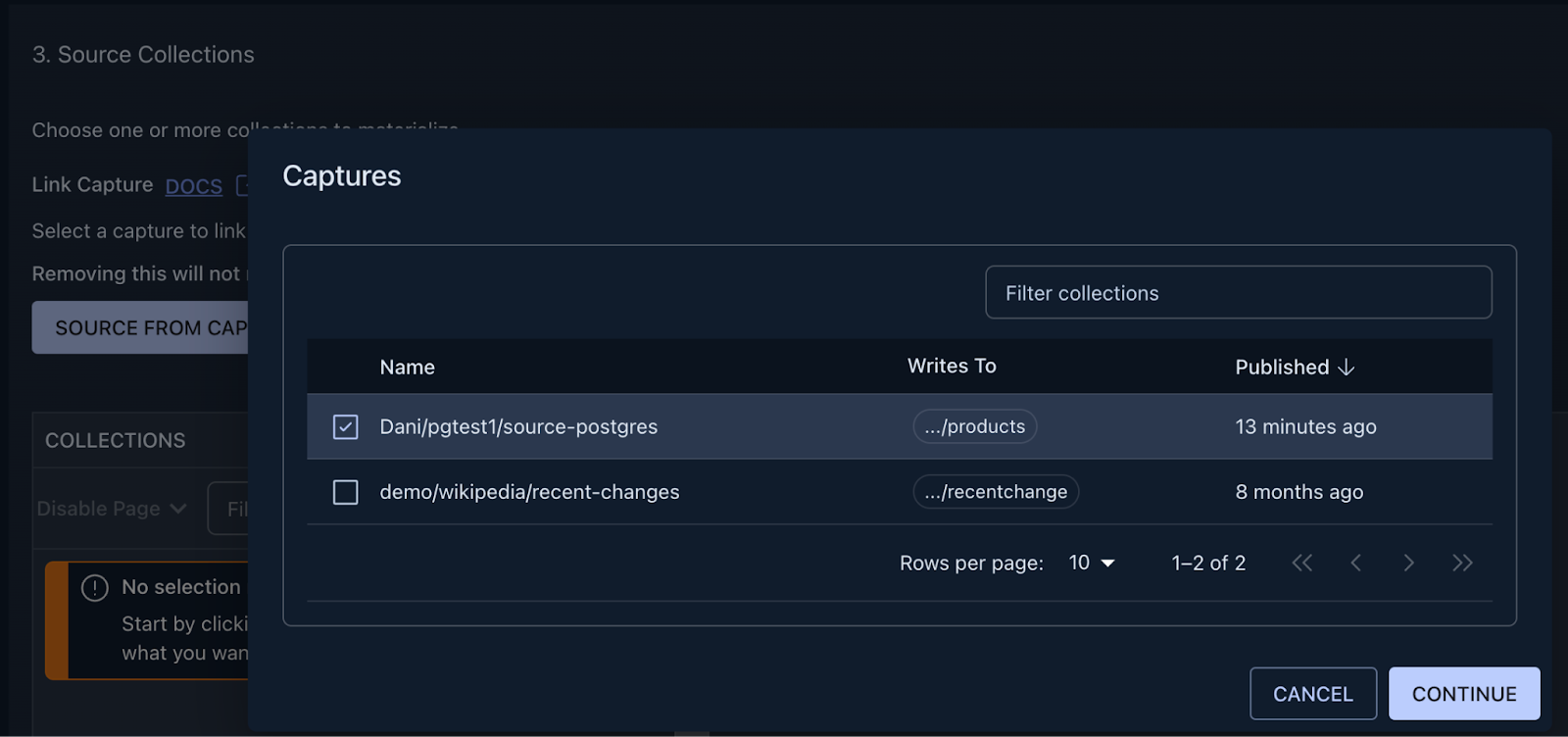
-After pressing continue, you are met with a few configuration options, but for now, feel free to press **Next,** then *
-*Save and Publish** in the top right corner, the defaults will work perfectly fine for this tutorial.
+After pressing continue, you are met with a few configuration options, but for now, feel free to press **Next,** then **Save and Publish** in the top right corner, the defaults will work perfectly fine for this tutorial.
A successful deployment will look something like this:
@@ -100,7 +99,7 @@ the data looks.
Looks like the data is arriving as expected, and the schema of the table is properly configured by the connector based
on the types of the original table in Postgres.
-To get a feel for how the data flow works; head over to the collection details page on the Flow web UI to see your
+To get a feel for how the data flow works, head over to the collection details page on the Flow web UI to see your
changes immediately. On the Snowflake end, they will be materialized after the next update.
## Next Steps
diff --git a/site/docs/getting-started/tutorials/continuous-materialized-view.md b/site/docs/getting-started/tutorials/continuous-materialized-view.md
index 9f4a575099..7361e5c9b0 100644
--- a/site/docs/getting-started/tutorials/continuous-materialized-view.md
+++ b/site/docs/getting-started/tutorials/continuous-materialized-view.md
@@ -27,7 +27,7 @@ Amazon RDS, Amazon Aurora, Google Cloud SQL, Azure Database for PostgreSQL, and
## Introduction
-Materialized views in Postgres give you a powerful way narrow down a huge dataset into a compact one that you can easily monitor.
+Materialized views in Postgres give you a powerful way to narrow down a huge dataset into a compact one that you can easily monitor.
But if your data is updating in real-time, traditional materialized views introduce latency. They're batch workflows — the query is run at a set interval.
To get around this, you'll need to perform a real-time transformation elsewhere.
diff --git a/site/docs/getting-started/tutorials/dataflow-s3-snowflake.md b/site/docs/getting-started/tutorials/dataflow-s3-snowflake.md
index 5f6bd810f0..f7d11139db 100644
--- a/site/docs/getting-started/tutorials/dataflow-s3-snowflake.md
+++ b/site/docs/getting-started/tutorials/dataflow-s3-snowflake.md
@@ -73,10 +73,10 @@ You'll start by creating your capture.
4. Click inside the **Name** box.
- Names of entities in Flow must be unique. They're organized by prefixes, similar to paths in a file system.
+ Names of entities in Flow must be unique. They're organized by prefixes, similar to paths in a file system.
- You'll see one or more prefixes pertaining to your organization.
- These prefixes represent the **namespaces** of Flow to which you have access.
+ You'll see one or more prefixes pertaining to your organization.
+ These prefixes represent the **namespaces** of Flow to which you have access.
5. Click your prefix from the dropdown and append a unique name after it. For example, `myOrg/yourname/citibiketutorial`.
@@ -115,13 +115,13 @@ Before you can materialize from Flow to Snowflake, you need to complete some set
1. Leave the Flow web app open. In a new window or tab, go to your Snowflake console.
- If you're a new trial user, you should have received instructions by email. For additional help in this section, see the [Snowflake documentation](https://docs.snowflake.com/en/user-guide-getting-started.html).
+ If you're a new trial user, you should have received instructions by email. For additional help in this section, see the [Snowflake documentation](https://docs.snowflake.com/en/user-guide-getting-started.html).
2. Create a new SQL worksheet if you don't have one open.
This provides an interface where you can run queries.
-3. Paste the follow script into the console, changing the value for `estuary_password` from `secret` to a strong password):
+3. Paste the following script into the console, changing the value for `estuary_password` from `secret` to a strong password:
```sql
set database_name = 'ESTUARY_DB';
diff --git a/site/docs/getting-started/tutorials/derivations_acmebank.md b/site/docs/getting-started/tutorials/derivations_acmebank.md
index 8903f50b1a..09697675e0 100644
--- a/site/docs/getting-started/tutorials/derivations_acmebank.md
+++ b/site/docs/getting-started/tutorials/derivations_acmebank.md
@@ -308,4 +308,4 @@ Reduction annotations also have some benefits over task state (like SQLite table
* Certain aggregations, such as recursive merging of tree-like structures,
are much simpler to express through reduction annotations vs implementing yourself.
-[See "Where to Accumulate?" for more discussion]../../concepts/derivations.md(#where-to-accumulate).
\ No newline at end of file
+[See "Where to Accumulate?" for more discussion](../../concepts/derivations.md#where-to-accumulate).
\ No newline at end of file
diff --git a/site/docs/getting-started/tutorials/postgresql_cdc_to_snowflake.md b/site/docs/getting-started/tutorials/postgresql_cdc_to_snowflake.md
index 569656b5f4..b27a3e7c7f 100644
--- a/site/docs/getting-started/tutorials/postgresql_cdc_to_snowflake.md
+++ b/site/docs/getting-started/tutorials/postgresql_cdc_to_snowflake.md
@@ -59,7 +59,8 @@ As this tutorial is focused on CDC replication from PostgreSQL, we’ll need a d
Save the below `yaml` snippet as a file called `docker-compose.yml`. This `docker-compose.yml` file contains the service definitions for the PostgreSQL database and the mock data generator service.
-:::tip Since V2, compose is integrated into your base Docker package, there’s no need to download any separate tooling!
+:::tip
+Since V2, compose is integrated into your base Docker package, there’s no need to download any separate tooling!
:::
```yaml title="docker-compose.yml"
@@ -112,7 +113,8 @@ Don’t be alarmed by all these Docker configurations, they are made to be repro
Next up, create a folder called `schemas` and paste the below SQL DDL into a file called `products.sql`. This file contains the schema of the demo data.
-:::note This file defines the schema via a create table statement, but the actual table creation happens in the `init.sql` file, this is just a quirk of the [Datagen](https://github.com/MaterializeInc/datagen) data generator tool.
+:::note
+This file defines the schema via a create table statement, but the actual table creation happens in the `init.sql` file, this is just a quirk of the [Datagen](https://github.com/MaterializeInc/datagen) data generator tool.
:::
```sql title="products.sql"
@@ -170,7 +172,8 @@ GRANT pg_read_all_data TO flow_capture;
Granting the `pg_read_all_data` privilege to the `flow_capture` user ensures that it can access and read data from all tables in the database, essential for capturing changes.
-:::note `pg_read_all_data` is used for convenience, but is not a hard requirement, since it is possible to grant a more granular set of permissions. For more details check out the [connector docs](https://docs.estuary.dev/reference/Connectors/capture-connectors/PostgreSQL/#self-hosted-postgresql).
+:::note
+`pg_read_all_data` is used for convenience, but is not a hard requirement, since it is possible to grant a more granular set of permissions. For more details check out the [connector docs](https://docs.estuary.dev/reference/Connectors/capture-connectors/PostgreSQL/#self-hosted-postgresql).
:::
```sql
@@ -201,7 +204,8 @@ A publication defines a set of tables whose changes will be replicated. In this
These commands configure the `flow_publication` publication to publish changes via partition root and add the specified tables to the publication. By setting `publish_via_partition_root` to true, the publication ensures that updates to partitioned tables are correctly captured and replicated.
-:::note The table in this tutorial is not partitioned, but we recommend always setting `publish_via_partition_root` when creating a publication.
+:::note
+The table in this tutorial is not partitioned, but we recommend always setting `publish_via_partition_root` when creating a publication.
:::
These objects form the backbone of a robust CDC replication setup, ensuring data consistency and integrity across systems. After the initial setup, you will not have to touch these objects in the future, unless you wish to start ingesting change events from a new table.
@@ -233,7 +237,8 @@ ngrok tcp 5432
You should immediately be greeted with a screen that contains the public URL for the tunnel we just started! In the example above, the public URL `5.tcp.eu.ngrok.io:14407` is mapped to `localhost:5432`, which is the address of the Postgres database.
-:::note Don’t close this window while working on the tutorial as this is required to keep the connections between Flow and the database alive.
+:::note
+Don’t close this window while working on the tutorial as this is required to keep the connections between Flow and the database alive.
:::
Before we jump into setting up the replication, you can quickly verify the data being properly generated by connecting to the database and peeking into the products table, as shown below:
@@ -412,9 +417,10 @@ And that’s pretty much it, you’ve successfully published a real-time CDC pip
Looks like the data is arriving as expected, and the schema of the table is properly configured by the connector based on the types of the original table in Postgres.
-To get a feel for how the data flow works; head over to the collection details page on the Flow web UI to see your changes immediately. On the Snowflake end, they will be materialized after the next update.
+To get a feel for how the data flow works, head over to the collection details page on the Flow web UI to see your changes immediately. On the Snowflake end, they will be materialized after the next update.
-:::note Based on your configuration of the "Update Delay" parameter when setting up the Snowflake Materialization, you might have to wait until the configured amount of time passes for your changes to make it to the destination.
+:::note
+Based on your configuration of the "Update Delay" parameter when setting up the Snowflake Materialization, you might have to wait until the configured amount of time passes for your changes to make it to the destination.
:::
diff --git a/site/docs/getting-started/tutorials/real-time-cdc-with-mongodb.md b/site/docs/getting-started/tutorials/real-time-cdc-with-mongodb.md
index 1a5942118d..eecc6b2f82 100644
--- a/site/docs/getting-started/tutorials/real-time-cdc-with-mongodb.md
+++ b/site/docs/getting-started/tutorials/real-time-cdc-with-mongodb.md
@@ -54,7 +54,8 @@ MongoDB supports various types of change events, each catering to different aspe
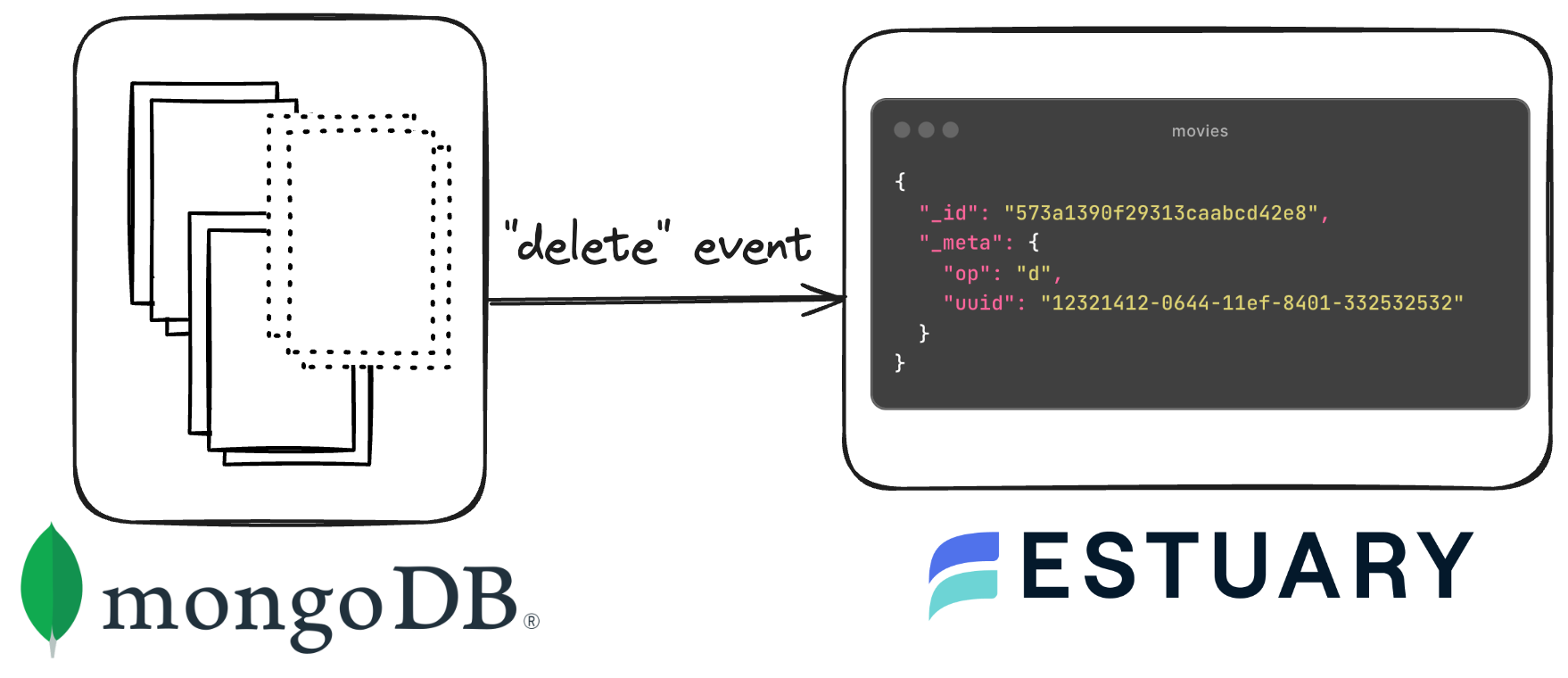
- Delete Events: Signaled when documents are removed from a collection.
-:::note In MongoDB, if you delete a key from a document, the corresponding change event that gets fired is an "update" event. This may seem counterintuitive at first, but in MongoDB, updates are atomic operations that can modify specific fields within a document, including removing keys. So, when a key is deleted from a document, MongoDB interprets it as an update operation where the specific field (i.e., the key) is being removed, resulting in an "update" event being generated in the oplog.
+:::note
+In MongoDB, if you delete a key from a document, the corresponding change event that gets fired is an "update" event. This may seem counterintuitive at first, but in MongoDB, updates are atomic operations that can modify specific fields within a document, including removing keys. So, when a key is deleted from a document, MongoDB interprets it as an update operation where the specific field (i.e., the key) is being removed, resulting in an "update" event being generated in the oplog.
:::
@@ -121,7 +122,8 @@ Navigate to the “Network Access” page using the left hand sidebar, and using
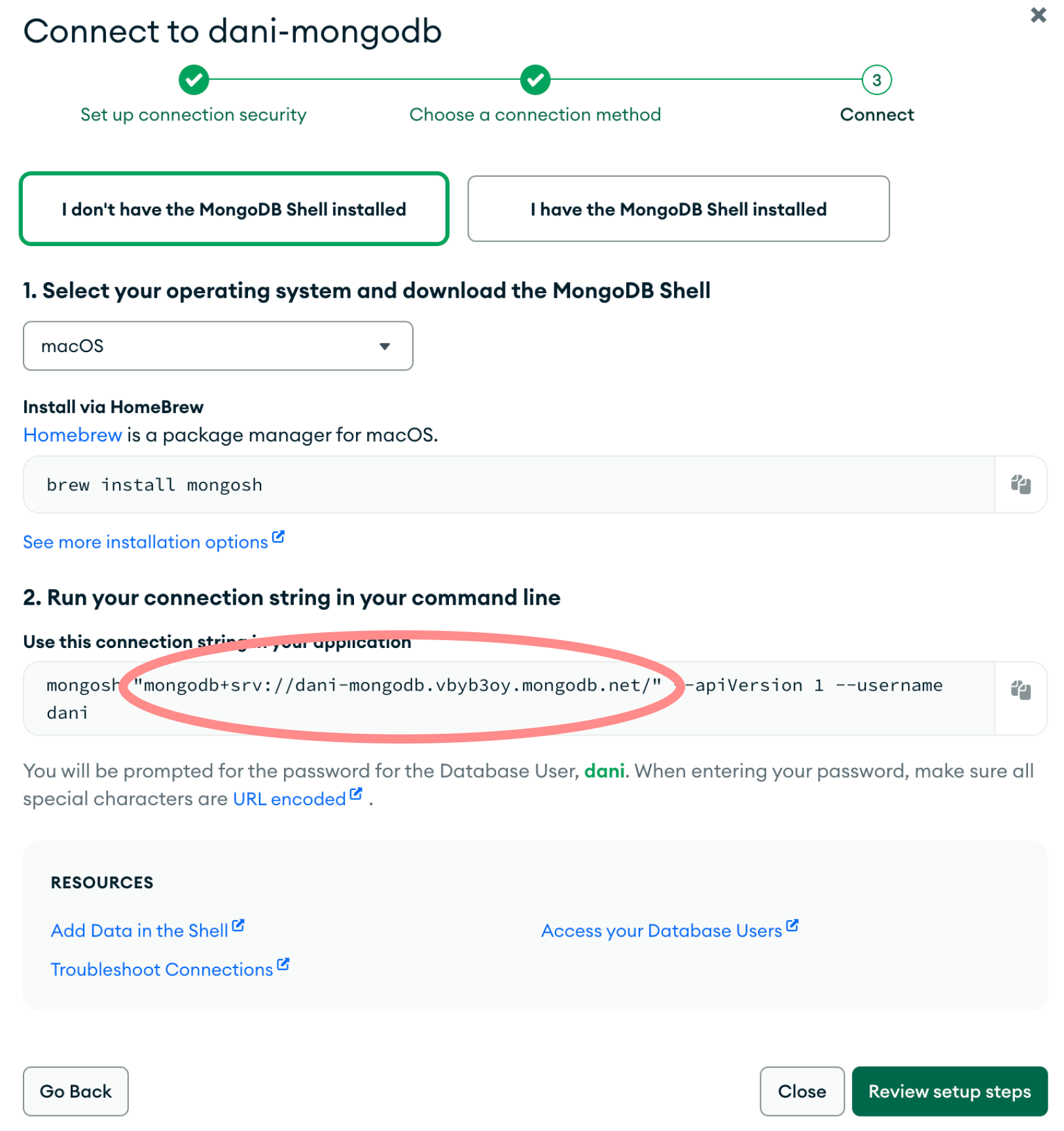
Next, find your connection string by navigating to the `mongosh` setup page by clicking the “Connect” button on the database overview section, then choosing the “Shell” option.
-:::note You’re not going to set up `mongosh` for this tutorial, but this is the easiest way to get ahold of the connection string we’ll be using.
+:::note
+You’re not going to set up `mongosh` for this tutorial, but this is the easiest way to get ahold of the connection string we’ll be using.
:::
@@ -160,7 +162,8 @@ Before we initialize the connector, let’s talk a little bit about how incoming
The **documents** of your flows are stored in **collections**: real-time data lakes of JSON documents in cloud storage.
-:::note Keep in mind, these are not the same documents and collections as the ones in MongoDB, only the names are similar, but we are talking about separate systems.
+:::note
+Keep in mind, these are not the same documents and collections as the ones in MongoDB, only the names are similar, but we are talking about separate systems.
:::
Collections being stored in an object storage mean that once you start capturing data, you won’t have to worry about it not being available to replay – object stores such as S3 can be configured to cheaply store data forever. See [docs page](https://docs.estuary.dev/concepts/collections/#documents) for more information about documents.
@@ -216,7 +219,8 @@ Incremental backfills in the MongoDB connector follow a straightforward approach
In the event of a pause in the connector's process, it resumes capturing change events from the point of interruption. However, the connector's ability to accomplish this depends on the size of the replica set oplog. In certain scenarios where the pause duration is significant enough for the oplog to purge old change events, the connector may necessitate redoing the backfill to maintain data consistency.
-:::tip To ensure reliable data capture, it is recommended to [adjust the oplog size](https://www.mongodb.com/docs/manual/tutorial/change-oplog-size/#c.-change-the-oplog-size-of-the-replica-set-member) or set a [minimum retention period](https://www.mongodb.com/docs/manual/reference/command/replSetResizeOplog/#minimum-oplog-retention-period). A recommended minimum retention period of at least 24 hours is sufficient for most cases.
+:::tip
+To ensure reliable data capture, it is recommended to [adjust the oplog size](https://www.mongodb.com/docs/manual/tutorial/change-oplog-size/#c.-change-the-oplog-size-of-the-replica-set-member) or set a [minimum retention period](https://www.mongodb.com/docs/manual/reference/command/replSetResizeOplog/#minimum-oplog-retention-period). A recommended minimum retention period of at least 24 hours is sufficient for most cases.
:::
## Real-time CDC
diff --git a/site/docs/guides/connect-network.md b/site/docs/guides/connect-network.md
index 454f7f19b0..a0355b0dd2 100644
--- a/site/docs/guides/connect-network.md
+++ b/site/docs/guides/connect-network.md
@@ -10,7 +10,7 @@ You configure this in the `networkTunnel` section of applicable capture or mater
before you can do so, you need a properly configured SSH server on your internal network or cloud hosting platform.
:::tip
-If permitted by your organization, a quicker way to connect to a secure database is to [allowlist the Estuary IP addresses](/reference/allow-ip-addresses)
+If permitted by your organization, a quicker way to connect to a secure database is to [allowlist the Estuary IP addresses](/reference/allow-ip-addresses).
For help completing this task on different cloud hosting platforms,
see the documentation for the [connector](../reference/Connectors/README.md) you're using.
@@ -37,6 +37,7 @@ to add your SSH server to your capture or materialization definition.
- `ssh://sshuser@ec2-198-21-98-1.compute-1.amazonaws.com`
- `ssh://sshuser@198.21.98.1`
- `ssh://sshuser@198.21.98.1:22`
+
:::info Hint
The [SSH default port is 22](https://www.ssh.com/academy/ssh/port).
Depending on where your server is hosted, you may not be required to specify a port,
@@ -55,12 +56,12 @@ to add your SSH server to your capture or materialization definition.
ssh-keygen -p -N "" -m pem -f /path/to/key
```
-Taken together, these configuration details would allow you to log into the SSH server from your local machine.
-They'll allow the connector to do the same.
+ Taken together, these configuration details would allow you to log into the SSH server from your local machine.
+ They'll allow the connector to do the same.
-5. Configure your internal network to allow the SSH server to access your capture or materialization endpoint.
+4. Configure your internal network to allow the SSH server to access your capture or materialization endpoint.
-6. To grant external access to the SSH server, it's essential to configure your network settings accordingly. The approach you take will be dictated by your organization's IT policies. One recommended step is to [allowlist the Estuary IP addresses](/reference/allow-ip-addresses). This ensures that connections from this specific IP are permitted through your network's firewall or security measures.
+5. To grant external access to the SSH server, it's essential to configure your network settings accordingly. The approach you take will be dictated by your organization's IT policies. One recommended step is to [allowlist the Estuary IP addresses](/reference/allow-ip-addresses). This ensures that connections from this specific IP are permitted through your network's firewall or security measures.
## Setup for AWS
diff --git a/site/docs/guides/create-dataflow.md b/site/docs/guides/create-dataflow.md
index 161dd84780..7248d4fa62 100644
--- a/site/docs/guides/create-dataflow.md
+++ b/site/docs/guides/create-dataflow.md
@@ -37,9 +37,9 @@ credentials provided by your Estuary account manager.
3. Choose the appropriate **Connector** for your desired data source.
- A form appears with the properties required for that connector.
- A documentation page with details about that connector appears in the side panel.
- You can also browse the [connectors reference](../reference/Connectors/capture-connectors/README.md) in your browser.
+ A form appears with the properties required for that connector.
+ A documentation page with details about that connector appears in the side panel.
+ You can also browse the [connectors reference](../reference/Connectors/capture-connectors/README.md) in your browser.
4. Type a name for your capture.
@@ -50,11 +50,11 @@ credentials provided by your Estuary account manager.
5. Fill out the required properties and click **Next**.
- Flow uses the provided information to initiate a connection to the source system.
- It identifies one or more data **resources** — these may be tables, data streams, or something else, depending on the connector. These are each mapped to a **collection**.
+ Flow uses the provided information to initiate a connection to the source system.
+ It identifies one or more data **resources** — these may be tables, data streams, or something else, depending on the connector. These are each mapped to a **collection**.
- The **Output Collections** browser appears, showing this list of available collections.
- You can decide which ones you want to capture.
+ The **Output Collections** browser appears, showing this list of available collections.
+ You can decide which ones you want to capture.
6. Look over the list of available collections. All are selected by default.
You can remove collections you don't want to capture, change collection names, and for some connectors, modify other properties.
@@ -64,12 +64,12 @@ Narrow down a large list of available collections by typing in the **Search Bind
:::
- If you're unsure which collections you want to keep or remove, you can look at their [schemas](../concepts/README.md#schemas).
+ If you're unsure which collections you want to keep or remove, you can look at their [schemas](../concepts/README.md#schemas).
7. In the **Output Collections** browser, select a collection and click the **Collection** tab to view its schema and collection key.
-.
- For many source systems, you'll notice that the collection schemas are quite permissive.
- You'll have the option to apply more restrictive schemas later, when you materialize the collections.
+
+ For many source systems, you'll notice that the collection schemas are quite permissive.
+ You'll have the option to apply more restrictive schemas later, when you materialize the collections.
8. If you made any changes to output collections, click **Next** again.
@@ -83,8 +83,8 @@ Now that you've captured data into one or more collections, you can materialize
1. Find the tile for your desired data destination and click **Materialization**.
- The page populates with the properties required for that connector.
- More details are on each connector are provided in the [connectors reference](../reference/Connectors/materialization-connectors/README.md).
+ The page populates with the properties required for that connector.
+ More details on each connector are provided in the [connectors reference](../reference/Connectors/materialization-connectors/README.md).
2. Choose a unique name for your materialization like you did when naming your capture; for example, `acmeCo/myFirstMaterialization`.
@@ -92,15 +92,15 @@ Now that you've captured data into one or more collections, you can materialize
4. Click **Next**.
- Flow initiates a connection with the destination system.
+ Flow initiates a connection with the destination system.
- The Endpoint Config has collapsed and the **Source Collections** browser is now prominent.
- It shows each collection you captured previously.
- All of them will be mapped to a **resource** in the destination.
- Again, these may be tables, data streams, or something else.
- When you publish the Data Flow, Flow will create these new resources in the destination.
+ The Endpoint Config has collapsed and the **Source Collections** browser is now prominent.
+ It shows each collection you captured previously.
+ All of them will be mapped to a **resource** in the destination.
+ Again, these may be tables, data streams, or something else.
+ When you publish the Data Flow, Flow will create these new resources in the destination.
- Now's your chance to make changes to the collections before you materialize them.
+ Now's your chance to make changes to the collections before you materialize them.
5. Optionally remove some collections or add additional collections.
diff --git a/site/docs/guides/derivation_tutorial_sql.md b/site/docs/guides/derivation_tutorial_sql.md
index 322787d972..cb31c918fa 100644
--- a/site/docs/guides/derivation_tutorial_sql.md
+++ b/site/docs/guides/derivation_tutorial_sql.md
@@ -16,7 +16,8 @@ Before continuing, sign in to the Estuary Flow dashboard, make sure you enable a
Execute the below command to display the documents in the `demo/wikipedia/recentchange-sampled` collection:
-::note This collection is a 3% sample of the enormous `demo/wikipedia/recentchange` collection which contains millions of documents. Since the purpose of this tutorial is to demonstrate a proof of concept, we avoid publishing a derivation that processes hundreds of gigabytes of data.
+:::note
+This collection is a 3% sample of the enormous `demo/wikipedia/recentchange` collection which contains millions of documents. Since the purpose of this tutorial is to demonstrate a proof of concept, we avoid publishing a derivation that processes hundreds of gigabytes of data.
:::
```shell
@@ -231,7 +232,8 @@ flowctl preview --source flow.yaml --name Dani/derivation-tutorial/edits-by-user
As you can see, the output format matches the defined schema. The last step would be to publish your derivation to Flow, which you can also do using `flowctl`.
-:::warning Publishing the derivation will initialize the transformation on the live, real-time Wikipedia stream, make sure to delete it after completing the tutorial.
+:::warning
+Publishing the derivation will initialize the transformation on the live, real-time Wikipedia stream, make sure to delete it after completing the tutorial.
:::
```shell
diff --git a/site/docs/guides/flowctl/create-derivation.md b/site/docs/guides/flowctl/create-derivation.md
index e477620c2f..49050de396 100644
--- a/site/docs/guides/flowctl/create-derivation.md
+++ b/site/docs/guides/flowctl/create-derivation.md
@@ -24,7 +24,7 @@ If you need help, see the [guide to create a Data Flow](../create-dataflow.md).
* [GitPod](https://www.gitpod.io/), the cloud development environment integrated with Flow.
GitPod comes ready for derivation writing, with stubbed out files and flowctl installed. You'll need a GitLab, GitHub, or BitBucket account to log in.
- * Your local development environment. * [Install flowctl locally](../get-started-with-flowctl.md)
+ * Your local development environment. [Install flowctl locally](../get-started-with-flowctl.md).
## Get started with GitPod
@@ -40,12 +40,12 @@ You'll write your derivation using GitPod, a cloud development environment integ
For example, if your organization is `acmeCo`, you might choose the `acmeCo/resources/anvils` collection.
-4. Set the transformation language to either **SQL** and **TypeScript**.
+4. Set the transformation language to either **SQL** or **TypeScript**.
SQL transformations can be a more approachable place to start if you're new to derivations.
TypeScript transformations can provide more resiliency against failures through static type checking.
-5. Give your derivation a name. From the dropdown, choose the name of your catalog prefix and append a unique name, for example `acmeCo/resources/anvil-status.`
+5. Give your derivation a name. From the dropdown, choose the name of your catalog prefix and append a unique name, for example `acmeCo/resources/anvil-status`.
6. Click **Proceed to GitPod** to create your development environment. Sign in with one of the available account types.
@@ -256,25 +256,25 @@ Creating a derivation locally is largely the same as using GitPod, but has some
1. Write the [schema](../../concepts/schemas.md) you'd like your derivation to conform to and specify the [collection key](../../concepts/collections.md#keys). Reference the source collection's schema, and keep in mind the transformation required to get from the source schema to the new schema.
- 2. Add the `derive` stanza. See examples for [SQL](#add-a-sql-derivation-in-gitpod) and [TypeScript](#add-a-sql-derivation-in-gitpod) above. Give your transform a a unique name.
+ 2. Add the `derive` stanza. See examples for [SQL](#add-a-sql-derivation-in-gitpod) and [TypeScript](#add-a-sql-derivation-in-gitpod) above. Give your transform a unique name.
-3. Stub out the SQL or TypeScript files for your transform.
+6. Stub out the SQL or TypeScript files for your transform.
```console
flowctl generate --source flow.yaml
```
-4. Locate the generated file, likely in the same subdirectory as the `flow.yaml` file you've been working in.
+7. Locate the generated file, likely in the same subdirectory as the `flow.yaml` file you've been working in.
-5. Write your transformation.
+8. Write your transformation.
-6. Preview the derivation locally.
+9. Preview the derivation locally.
```console
flowctl preview --source flow.yaml
```
-7. If the preview output appears how you'd expect, **publish** the derivation.
+10. If the preview output appears how you'd expect, **publish** the derivation.
```console
flowctl catalog publish --source flow.yaml
diff --git a/site/docs/guides/how_to_generate_refresh_token.md b/site/docs/guides/how_to_generate_refresh_token.md
index 20cabc29a8..51d89c9a4e 100644
--- a/site/docs/guides/how_to_generate_refresh_token.md
+++ b/site/docs/guides/how_to_generate_refresh_token.md
@@ -2,7 +2,7 @@
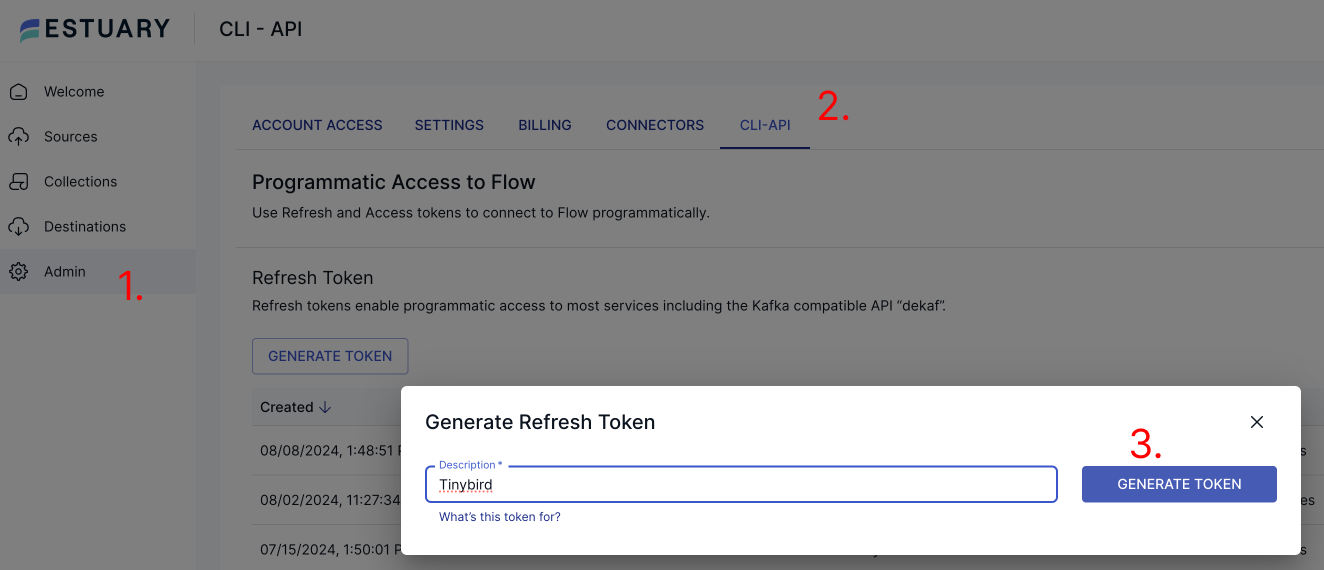
To generate a Refresh Token, navigate to the Admin page, then head over to the CLI-API section.
-Press the Generate token button to bing up the modal where you are able to give your token a name.
+Press the Generate token button to bring up the modal where you are able to give your token a name.
Choose a name that you will be able to use to identify which service your token is meant to give access to.
diff --git a/site/docs/guides/howto_join_two_collections_typescript.md b/site/docs/guides/howto_join_two_collections_typescript.md
index e8b21f0ef5..81f7c100cb 100644
--- a/site/docs/guides/howto_join_two_collections_typescript.md
+++ b/site/docs/guides/howto_join_two_collections_typescript.md
@@ -63,7 +63,7 @@ If you see something similar, you’re good to continue!
Set up your folder structure so you can organize the resources required for the derivation. Create a working directory to follow along, and inside, create a `flow.yaml` file.
-Inside your `flow.yaml `file, add the following contents:
+Inside your `flow.yaml` file, add the following contents:
```yaml
collections:
@@ -117,7 +117,7 @@ collections:
- /customer_id
```
-Let’s take a look at this in a bit more detail. Essentially, we define one collection which it’s a `derivation` that is the result of two transformations.
+Let’s take a look at this in a bit more detail. Essentially, we define one collection which is a `derivation` that is the result of two transformations.
In the schema definition, we specify what structure we want the documents of the result collection to take on.
@@ -155,9 +155,10 @@ In the schema definition, we specify what structure we want the documents of the
Because you are going to implement a 1-to-many join using the two source collections, it’s important to pay attention to what reduction strategy Flow uses.
-There are two `merge` strategies defined here, one for the `customers_with_orders `collection and for the nested `orders` array.
+There are two `merge` strategies defined here, one for the `customers_with_orders` collection and for the nested `orders` array.
-:::note Merge reduces the left-hand side and right-hand side by recursively reducing shared document locations. The LHS and RHS must either both be objects, or both be arrays.
+:::note
+Merge reduces the left-hand side and right-hand side by recursively reducing shared document locations. The LHS and RHS must either both be objects, or both be arrays.
:::
For the nested merge, you have to define a key, which is one or more JSON pointers that are relative to the reduced location. If both sides are arrays and a merge key is present, then a deep sorted merge of the respective items is done, as ordered by the key. In this case, setting it to `order_id` will cause the reduction to collect all orders for a given customer.
diff --git a/site/docs/guides/system-specific-dataflows/firestore-to-dwh.md b/site/docs/guides/system-specific-dataflows/firestore-to-dwh.md
index b82caf8f12..68e7604f20 100644
--- a/site/docs/guides/system-specific-dataflows/firestore-to-dwh.md
+++ b/site/docs/guides/system-specific-dataflows/firestore-to-dwh.md
@@ -31,12 +31,12 @@ If you don't have one, visit the web app to register for free.
## Introduction
In Estuary Flow, you create **Data Flows** to transfer data from **source** systems to **destination** systems in real time.
-In this use case, your source is an Google Cloud Firestore NoSQL database and your destination is a Snowflake data warehouse.
+In this use case, your source is a Google Cloud Firestore NoSQL database and your destination is a Snowflake data warehouse.
After following this guide, you'll have a Data Flow that comprises:
* A **capture**, which ingests data from Firestore
-* Several **collection**, cloud-backed copies of [Firestore collections](https://cloud.google.com/firestore/docs/data-model) in the Flow system
+* Several **collections**, cloud-backed copies of [Firestore collections](https://cloud.google.com/firestore/docs/data-model) in the Flow system
* A **materialization**, which pushes the collections to Snowflake
The capture and materialization rely on plug-in components called **connectors**.
@@ -53,7 +53,7 @@ credentials provided by your Estuary account manager.
3. Find the **Google Firestore** tile and click **Capture**.
- A form appears with the properties required for a Firestore capture.
+ A form appears with the properties required for a Firestore capture.
4. Type a name for your capture.
@@ -70,11 +70,11 @@ credentials provided by your Estuary account manager.
6. Click **Next**.
- Flow uses the provided configuration to initiate a connection with Firestore.
+ Flow uses the provided configuration to initiate a connection with Firestore.
- It maps each available Firestore collection to a possible Flow collection. It also generates minimal schemas for each collection.
+ It maps each available Firestore collection to a possible Flow collection. It also generates minimal schemas for each collection.
- You can use the **Source Collections** browser to remove or modify collections. You'll have the chance to tighten up each collection's JSON schema later, when you materialize to Snowflake.
+ You can use the **Source Collections** browser to remove or modify collections. You'll have the chance to tighten up each collection's JSON schema later, when you materialize to Snowflake.
:::tip
If you make any changes to collections, click **Next** again.
@@ -82,9 +82,9 @@ credentials provided by your Estuary account manager.
7. Once you're satisfied with the collections to be captured, click **Save and Publish**.
- You'll see a notification when the capture publishes successfully.
+ You'll see a notification when the capture publishes successfully.
- The data currently in your Firestore database has been captured, and future updates to it will be captured continuously.
+ The data currently in your Firestore database has been captured, and future updates to it will be captured continuously.
8. Click **Materialize Collections** to continue.
@@ -94,7 +94,7 @@ Next, you'll add a Snowflake materialization to connect the captured data to its
1. Locate the **Snowflake** tile and click **Materialization**.
- A form appears with the properties required for a Snowflake materialization.
+ A form appears with the properties required for a Snowflake materialization.
2. Choose a unique name for your materialization like you did when naming your capture; for example, `acmeCo/mySnowflakeMaterialization`.
@@ -111,13 +111,13 @@ Next, you'll add a Snowflake materialization to connect the captured data to its
4. Click **Next**.
- Flow uses the provided configuration to initiate a connection to Snowflake.
+ Flow uses the provided configuration to initiate a connection to Snowflake.
- You'll be notified if there's an error. In that case, fix the configuration form or Snowflake setup as needed and click **Next** to try again.
+ You'll be notified if there's an error. In that case, fix the configuration form or Snowflake setup as needed and click **Next** to try again.
- Once the connection is successful, the Endpoint Config collapses and the **Source Collections** browser becomes prominent.
- It shows the collections you captured previously.
- Each of them will be mapped to a Snowflake table.
+ Once the connection is successful, the Endpoint Config collapses and the **Source Collections** browser becomes prominent.
+ It shows the collections you captured previously.
+ Each of them will be mapped to a Snowflake table.
5. In the **Source Collections** browser, optionally change the name in the **Table** field for each collection.
@@ -127,9 +127,9 @@ Next, you'll add a Snowflake materialization to connect the captured data to its
7. For each collection, apply a stricter schema to be used for the materialization.
- Firestore has a flat data structure.
- To materialize data effectively from Firestore to Snowflake, you should apply a schema can translate to a table structure.
- Flow's **Schema Inference** tool can help.
+ Firestore has a flat data structure.
+ To materialize data effectively from Firestore to Snowflake, you should apply a schema that can translate to a table structure.
+ Flow's **Schema Inference** tool can help.
1. In the Source Collections browser, choose a collection and click its **Collection** tab.
diff --git a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
index 9b67b6a7d0..33c1ff6e1e 100644
--- a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
+++ b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
@@ -8,7 +8,7 @@ This connector uses change data capture (CDC) to continuously capture updates in
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-postgres:dev`](https://github.com/estuary/connectors/pkgs/container/source-postgres) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-For managed PostgreSQL insteances that do not support logical replication, we offer a [PostgreSQL Batch Connector](./postgres-batch/) as an alternative.
+For managed PostgreSQL instances that do not support logical replication, we offer a [PostgreSQL Batch Connector](./postgres-batch/) as an alternative.
## Supported versions and platforms
diff --git a/site/docs/reference/Connectors/capture-connectors/Salesforce/salesforce-historical-data.md b/site/docs/reference/Connectors/capture-connectors/Salesforce/salesforce-historical-data.md
index 8c19b25f2d..0867552413 100644
--- a/site/docs/reference/Connectors/capture-connectors/Salesforce/salesforce-historical-data.md
+++ b/site/docs/reference/Connectors/capture-connectors/Salesforce/salesforce-historical-data.md
@@ -9,8 +9,6 @@ For help using both connectors in parallel, [contact your Estuary account manage
This connector is available for use in the Flow web application.
For local development or open-source workflows, [`ghcr.io/estuary/source-salesforce:dev`](https://ghcr.io/estuary/source-salesforce:dev) provides the latest connector image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
This connector can capture the following Salesforce [standard objects](https://developer.salesforce.com/docs/atlas.en-us.object_reference.meta/object_reference/sforce_api_objects_list.htm), if present in your account:
diff --git a/site/docs/reference/Connectors/capture-connectors/airtable.md b/site/docs/reference/Connectors/capture-connectors/airtable.md
index 77d3d92c19..65e7754425 100644
--- a/site/docs/reference/Connectors/capture-connectors/airtable.md
+++ b/site/docs/reference/Connectors/capture-connectors/airtable.md
@@ -5,8 +5,6 @@ This connector captures data from Airtable into Flow collections.
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-airtable:dev`](https://ghcr.io/estuary/source-airtable:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Prerequisites
* An active Airtable account
diff --git a/site/docs/reference/Connectors/capture-connectors/azure-blob-storage.md b/site/docs/reference/Connectors/capture-connectors/azure-blob-storage.md
index 2acbb3a813..637da0ec4f 100644
--- a/site/docs/reference/Connectors/capture-connectors/azure-blob-storage.md
+++ b/site/docs/reference/Connectors/capture-connectors/azure-blob-storage.md
@@ -3,7 +3,7 @@
This connector captures data from an Azure Blob Storage Account.
-It is available for use in the Flow web application. For local development or open-source workflows, `[ghcr.io/estuary/source-azure-blob-storage:dev](https://ghcr.io/estuary/source-s3:dev)` provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
+It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-azure-blob-storage:dev`](https://ghcr.io/estuary/source-s3:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
## **Prerequisites**
diff --git a/site/docs/reference/Connectors/capture-connectors/facebook-marketing.md b/site/docs/reference/Connectors/capture-connectors/facebook-marketing.md
index d5f556a207..a0696a32c9 100644
--- a/site/docs/reference/Connectors/capture-connectors/facebook-marketing.md
+++ b/site/docs/reference/Connectors/capture-connectors/facebook-marketing.md
@@ -5,9 +5,6 @@ This connector captures data from the Facebook Marketing API into Flow collectio
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-facebook-marketing:dev`](https://ghcr.io/estuary/source-facebook-marketing:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
The following data resources are supported:
diff --git a/site/docs/reference/Connectors/capture-connectors/google-ads.md b/site/docs/reference/Connectors/capture-connectors/google-ads.md
index 709e6cd270..588c0ef902 100644
--- a/site/docs/reference/Connectors/capture-connectors/google-ads.md
+++ b/site/docs/reference/Connectors/capture-connectors/google-ads.md
@@ -5,8 +5,6 @@ This connector captures data from [resources](https://developers.google.com/goog
[`ghcr.io/estuary/source-google-ads:dev`](https://ghcr.io/estuary/source-google-ads:dev) provides the latest connector image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
The following data resources are supported.
diff --git a/site/docs/reference/Connectors/capture-connectors/google-sheets.md b/site/docs/reference/Connectors/capture-connectors/google-sheets.md
index 56601688c6..fe77b02127 100644
--- a/site/docs/reference/Connectors/capture-connectors/google-sheets.md
+++ b/site/docs/reference/Connectors/capture-connectors/google-sheets.md
@@ -5,11 +5,9 @@ This connector captures data from a Google Sheets spreadsheet.
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-google-sheets:dev`](https://ghcr.io/estuary/source-google-sheets:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Prerequisites
-There are two ways to authenticate with Google when capturing data from a Sheet: using OAuth2, and manually,by generating a service account key.
+There are two ways to authenticate with Google when capturing data from a Sheet: using OAuth2, and manually, by generating a service account key.
Their prerequisites differ.
OAuth is recommended for simplicity in the Flow web app;
diff --git a/site/docs/reference/Connectors/capture-connectors/hubspot.md b/site/docs/reference/Connectors/capture-connectors/hubspot.md
index 7101eaaa13..76b2d4a87c 100644
--- a/site/docs/reference/Connectors/capture-connectors/hubspot.md
+++ b/site/docs/reference/Connectors/capture-connectors/hubspot.md
@@ -7,8 +7,6 @@ Estuary offers a in-house real time version of this connector. For more informat
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-hubspot:dev`](https://ghcr.io/estuary/source-hubspot:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
By default, each resource associated with your Hubspot account is mapped to a Flow collection through a separate binding.
diff --git a/site/docs/reference/Connectors/capture-connectors/iterable.md b/site/docs/reference/Connectors/capture-connectors/iterable.md
index b07fd1eb0a..3c3820c2ea 100644
--- a/site/docs/reference/Connectors/capture-connectors/iterable.md
+++ b/site/docs/reference/Connectors/capture-connectors/iterable.md
@@ -5,8 +5,6 @@ This connector captures data from Iterable into Flow collections.
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-iterable:dev`](https://ghcr.io/estuary/source-iterable:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
The following data resources are supported through the Iterable APIs:
diff --git a/site/docs/reference/Connectors/capture-connectors/jira.md b/site/docs/reference/Connectors/capture-connectors/jira.md
index dce36f3de7..36a9d4f34c 100644
--- a/site/docs/reference/Connectors/capture-connectors/jira.md
+++ b/site/docs/reference/Connectors/capture-connectors/jira.md
@@ -5,8 +5,6 @@ This connector captures data from Jira into Flow collections.
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-jira:dev`](https://ghcr.io/estuary/source-jira:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
The following data resources are supported through the Jira APIs:
diff --git a/site/docs/reference/Connectors/capture-connectors/linkedin-ads.md b/site/docs/reference/Connectors/capture-connectors/linkedin-ads.md
index b49b605ac1..d216fb518a 100644
--- a/site/docs/reference/Connectors/capture-connectors/linkedin-ads.md
+++ b/site/docs/reference/Connectors/capture-connectors/linkedin-ads.md
@@ -5,8 +5,6 @@ This connector captures data from LinkedIn Ads into Flow collections through the
[`ghcr.io/estuary/source-linkedin-ads:dev`](https://ghcr.io/estuary/source-linkedin-ads:dev) provides the latest connector image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
The following data resources are supported:
diff --git a/site/docs/reference/Connectors/capture-connectors/linkedin-pages.md b/site/docs/reference/Connectors/capture-connectors/linkedin-pages.md
index d8bc872678..8c46d14ba2 100644
--- a/site/docs/reference/Connectors/capture-connectors/linkedin-pages.md
+++ b/site/docs/reference/Connectors/capture-connectors/linkedin-pages.md
@@ -4,8 +4,6 @@
This connector captures data from one LinkedIn Page into Flow collections via the [LinkedIn Marketing API](https://learn.microsoft.com/en-us/linkedin/marketing/integrations/marketing-integrations-overview?view=li-lms-2024-03).
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Prerequisites
* An existing LinkedIn Account
diff --git a/site/docs/reference/Connectors/capture-connectors/mailchimp.md b/site/docs/reference/Connectors/capture-connectors/mailchimp.md
index c15e1d20f6..e828aab0d7 100644
--- a/site/docs/reference/Connectors/capture-connectors/mailchimp.md
+++ b/site/docs/reference/Connectors/capture-connectors/mailchimp.md
@@ -7,8 +7,6 @@ Three data resources are supported, each of which is mapped to a Flow collection
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-mailchimp:dev`](https://ghcr.io/estuary/source-mailchimp:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Prerequisites
There are two ways to authenticate with MailChimp when capturing data: using OAuth2, and manually, with an API key.
diff --git a/site/docs/reference/Connectors/capture-connectors/mixpanel.md b/site/docs/reference/Connectors/capture-connectors/mixpanel.md
index ab2a28fed7..3ecf50fbe2 100644
--- a/site/docs/reference/Connectors/capture-connectors/mixpanel.md
+++ b/site/docs/reference/Connectors/capture-connectors/mixpanel.md
@@ -5,8 +5,6 @@ This connector captures data from MixPanel into Flow collections.
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-mixpanel:dev`](https://ghcr.io/estuary/source-mixpanel:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
The following data resources are supported through the MixPanel APIs:
diff --git a/site/docs/reference/Connectors/capture-connectors/twilio.md b/site/docs/reference/Connectors/capture-connectors/twilio.md
index a08454cc74..c8ae25a869 100644
--- a/site/docs/reference/Connectors/capture-connectors/twilio.md
+++ b/site/docs/reference/Connectors/capture-connectors/twilio.md
@@ -4,8 +4,6 @@ This connector captures data from Twilio into Flow collections.
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-twilio:dev`](https://ghcr.io/estuary/source-twilio:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
The following data resources are supported through the Twilio APIs:
diff --git a/site/docs/reference/Connectors/capture-connectors/zendesk-support.md b/site/docs/reference/Connectors/capture-connectors/zendesk-support.md
index 8cfec95863..b0483f6dc2 100644
--- a/site/docs/reference/Connectors/capture-connectors/zendesk-support.md
+++ b/site/docs/reference/Connectors/capture-connectors/zendesk-support.md
@@ -4,8 +4,6 @@ This connector captures data from Zendesk into Flow collections.
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-zendesk-support:dev`](https://ghcr.io/estuary/source-zendesk-support:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
-This connector is based on an open-source connector from a third party, with modifications for performance in the Flow system.
-
## Supported data resources
The following data resources are supported through the Zendesk API: