We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
(读论文)推荐系统之ctr预估-NFM模型解析 https://ift.tt/XU6lZMm Jesse_jia
本人才疏学浅,不足之处欢迎大家指出和交流。
今天要分享的是另一个Deep模型NFM(串行结构)。NFM也是用FM+DNN来对ctr问题建模的,相比于之前提到的Wide&Deep(Google)、DeepFM(华为+哈工大)、PNN(上交)和之后会分享的的DCN(Google)、DIN(阿里)等,NFM有什么优点呢,下面就走进模型我们一起来看看吧。
原文:Neural Factorization Machines for Sparse Predictive Analytics
老生常谈,再聊数据特点:对于广告中的大量的类别特征,特征组合也是非常多的。传统的做法是通过人工特征工程或者利用决策树来进行特征选择,选择出比较重要的特征。但是这样的做法都有一个缺点,就是:无法学习训练集中没有出现的特征组合。
最近几年,Embedding-based方法开始成为主流,通过把高维稀疏的输入_embed_到低维度的稠密的隐向量空间中,模型可以学习到训练集中没有出现过的特征组合。
Embedding-based大致可以分为两类:
1.factorization machine-based linear models
2.neural network-based non-linear models(具体就不再展开了)
FM:以线性的方式学习二阶特征交互,对于捕获现实数据非线性和复杂的内在结构表达力不够;
深度网络:例如Wide&Deep 和DeepCross,简单地拼接特征embedding向量不会考虑任何的特征之间的交互, 但是能够学习特征交互的非线性层的深层网络结构又很难训练优化;
而NFM摒弃了直接把嵌入向量拼接输入到神经网络的做法,在嵌入层之后增加了_Bi-Interaction_操作来对二阶组合特征进行建模。这使得low level的输入表达的信息更加的丰富,极大的提高了后面隐藏层学习高阶非线性组合特征的能力。
与FM(因式分解机)相似,NFM使用实值特征向量。给定一个稀疏向量x∈Rn作为输入,其中特征值为xi=0表示第i个特征不存在,NFM预估的目标为:
其中第一项和第二项是线性回归部分,与FM相似,FM模拟数据的全局偏差和特征权重。第三项f(x)是NFM的核心组成部分,用于建模特征交互。它是一个多层前馈神经网络。如下图所示,接下来,我们一层一层地阐述f(x)的设计。模型整体结构图如下所示:
和其他的DNN模型处理稀疏输入一样,Embedding将输入转换到低维度的稠密的嵌入空间中进行处理。这里做稍微不同的处理是,使用原始的特征值乘以Embedding vector,使得模型也可以处理real valued feature。
Bi是Bi-linear的缩写,这一层其实是一个pooling层操作,它把很多个向量转换成一个向量,形式化如下:
fbi的输入是整个的嵌入向量,xi ,xj是特征取值,vi, vj是特征对应的嵌入向量。中间的操作表示对应位置相乘。所以原始的嵌入向量任意两个都进行组合,对应位置相乘结果得到一个新向量;然后把这些新向量相加,就得到了Bi-Interaction的输出。这个输出只有一个向量,维度仍然是K,可以理解为就是FM的二阶输出。
注:Bi-Interaction并没有引入额外的参数,而且它的计算复杂度也是线性的,参考FM的优化方法,化简如下:
这个跟其他的模型基本一样,堆积隐藏层以期来学习高阶组合特征。一般选用constant的效果要好一些。
最后一层隐藏层Zl到输出层最后预测结果形式化如下:其中h是中间的网络参数。考虑到前面的各层隐藏层权重矩阵,f(x)形式化如下:
这里相比于FM其实多出的参数其实就是隐藏层的参数,所以说FM也可以看做是一个神经网络架构,就是去掉隐藏层的NFM。
实质:
NFM最重要的区别就在于Bi-Interaction Layer。Wide&Deep和DeepCross都是用拼接操作(concatenation)替换了Bi-Interaction。
Concatenation操作的最大缺点就是它并没有考虑任何的特征组合信息,所以就全部依赖后面的MLP去学习特征组合,但是很不幸,MLP的学习优化非常困难。
使用Bi-Interaction考虑到了二阶特征组合,使得输入的表示包含更多的信息,减轻了后面MLP部分的学习压力,所以可以用更简单的模型(实验中只用了一层隐层),取得更好的效果。
NFM主要的特点如下:
1. NFM核心就是在NN中引入了Bilinear Interaction(Bi-Interaction) pooling操作。基于此,NN可以在low level就学习到包含更多信息的组合特征。
2. 通过deepen FM来学习高阶的非线性的组合特征。
3. NFM相比于上面提到的DNN模型,模型结构更浅、更简单(shallower structure),但是性能更好,训练和调整参数更加容易。
所以,依旧是FM+DNN的组合套路,不同之处在于如何处理Embedding向量,这也是各个模型重点关注的地方。现在来看业界就如何用DNN来处理高维稀疏的数据并没有一个统一普适的方法,依旧在摸索中。
实现DeepFM的一个Demo,感兴趣的童鞋可以看下我的github。
The text was updated successfully, but these errors were encountered:
No branches or pull requests
(读论文)推荐系统之ctr预估-NFM模型解析
https://ift.tt/XU6lZMm
Jesse_jia
本人才疏学浅,不足之处欢迎大家指出和交流。
今天要分享的是另一个Deep模型NFM(串行结构)。NFM也是用FM+DNN来对ctr问题建模的,相比于之前提到的Wide&Deep(Google)、DeepFM(华为+哈工大)、PNN(上交)和之后会分享的的DCN(Google)、DIN(阿里)等,NFM有什么优点呢,下面就走进模型我们一起来看看吧。
原文:Neural Factorization Machines for Sparse Predictive Analytics
1、问题由来
老生常谈,再聊数据特点:对于广告中的大量的类别特征,特征组合也是非常多的。传统的做法是通过人工特征工程或者利用决策树来进行特征选择,选择出比较重要的特征。但是这样的做法都有一个缺点,就是:无法学习训练集中没有出现的特征组合。
最近几年,Embedding-based方法开始成为主流,通过把高维稀疏的输入_embed_到低维度的稠密的隐向量空间中,模型可以学习到训练集中没有出现过的特征组合。
Embedding-based大致可以分为两类:
1.factorization machine-based linear models
2.neural network-based non-linear models
(具体就不再展开了)
FM:以线性的方式学习二阶特征交互,对于捕获现实数据非线性和复杂的内在结构表达力不够;
深度网络:例如Wide&Deep 和DeepCross,简单地拼接特征embedding向量不会考虑任何的特征之间的交互, 但是能够学习特征交互的非线性层的深层网络结构又很难训练优化;
而NFM摒弃了直接把嵌入向量拼接输入到神经网络的做法,在嵌入层之后增加了_Bi-Interaction_操作来对二阶组合特征进行建模。这使得low level的输入表达的信息更加的丰富,极大的提高了后面隐藏层学习高阶非线性组合特征的能力。
2、NFM
2.1 NFM Model
与FM(因式分解机)相似,NFM使用实值特征向量。给定一个稀疏向量x∈Rn作为输入,其中特征值为xi=0表示第i个特征不存在,NFM预估的目标为:
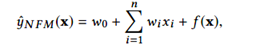
其中第一项和第二项是线性回归部分,与FM相似,FM模拟数据的全局偏差和特征权重。第三项f(x)是NFM的核心组成部分,用于建模特征交互。它是一个多层前馈神经网络。如下图所示,接下来,我们一层一层地阐述f(x)的设计。
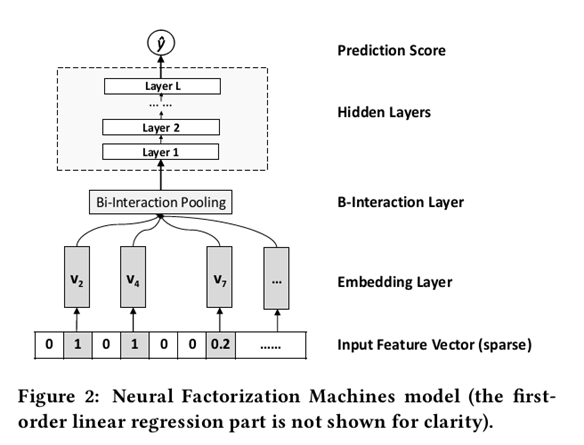
模型整体结构图如下所示:
2.1.1 Embedding Layer
和其他的DNN模型处理稀疏输入一样,Embedding将输入转换到低维度的稠密的嵌入空间中进行处理。这里做稍微不同的处理是,使用原始的特征值乘以Embedding vector,使得模型也可以处理real valued feature。
2.1.2 Bi-Interaction Layer
Bi是Bi-linear的缩写,这一层其实是一个pooling层操作,它把很多个向量转换成一个向量,形式化如下:
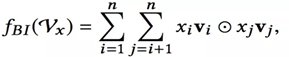
fbi的输入是整个的嵌入向量,xi ,xj是特征取值,vi, vj是特征对应的嵌入向量。中间的操作表示对应位置相乘。所以原始的嵌入向量任意两个都进行组合,对应位置相乘结果得到一个新向量;然后把这些新向量相加,就得到了Bi-Interaction的输出。这个输出只有一个向量,维度仍然是K,可以理解为就是FM的二阶输出。
注:Bi-Interaction并没有引入额外的参数,而且它的计算复杂度也是线性的,参考FM的优化方法,化简如下:
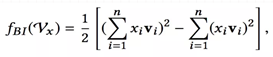
2.1.3 Hidden Layer
这个跟其他的模型基本一样,堆积隐藏层以期来学习高阶组合特征。一般选用constant的效果要好一些。
2.1.4 Prediction Layer
最后一层隐藏层Zl到输出层最后预测结果形式化如下:
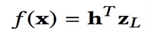
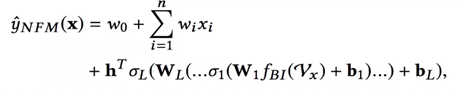
其中h是中间的网络参数。考虑到前面的各层隐藏层权重矩阵,f(x)形式化如下:
这里相比于FM其实多出的参数其实就是隐藏层的参数,所以说FM也可以看做是一个神经网络架构,就是去掉隐藏层的NFM。
2.2 NFM vs Wide&Deep、DeepCross
实质:
NFM最重要的区别就在于Bi-Interaction Layer。Wide&Deep和DeepCross都是用拼接操作(concatenation)替换了Bi-Interaction。
Concatenation操作的最大缺点就是它并没有考虑任何的特征组合信息,所以就全部依赖后面的MLP去学习特征组合,但是很不幸,MLP的学习优化非常困难。
使用Bi-Interaction考虑到了二阶特征组合,使得输入的表示包含更多的信息,减轻了后面MLP部分的学习压力,所以可以用更简单的模型(实验中只用了一层隐层),取得更好的效果。
3、总结(具体的对比实验和实现细节等请参阅原论文)
NFM主要的特点如下:
1. NFM核心就是在NN中引入了Bilinear Interaction(Bi-Interaction) pooling操作。基于此,NN可以在low level就学习到包含更多信息的组合特征。
2. 通过deepen FM来学习高阶的非线性的组合特征。
3. NFM相比于上面提到的DNN模型,模型结构更浅、更简单(shallower structure),但是性能更好,训练和调整参数更加容易。
所以,依旧是FM+DNN的组合套路,不同之处在于如何处理Embedding向量,这也是各个模型重点关注的地方。现在来看业界就如何用DNN来处理高维稀疏的数据并没有一个统一普适的方法,依旧在摸索中。
实现DeepFM的一个Demo,感兴趣的童鞋可以看下我的github。
via Jesse's Blog
December 5, 2024 at 06:17PM
The text was updated successfully, but these errors were encountered: