diff --git a/.all-contributorsrc b/.all-contributorsrc
index af015a72..c98fa241 100644
--- a/.all-contributorsrc
+++ b/.all-contributorsrc
@@ -62,13 +62,6 @@
"profile": "https://github.com/18jeffreyma",
"contributions": []
},
- {
- "login": "alxrod",
- "name": "Alex Rodriguez",
- "avatar_url": "https://avatars.githubusercontent.com/alxrod",
- "profile": "https://github.com/alxrod",
- "contributions": []
- },
{
"login": "andreamurillomtz",
"name": "Andrea Murillo",
@@ -77,10 +70,10 @@
"contributions": []
},
{
- "login": "NaN",
- "name": "Aghyad Deeb",
- "avatar_url": "https://www.gravatar.com/avatar/c7cf3d1bf98282a09365243108c4b69c?d=identicon&s=100",
- "profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
+ "login": "alxrod",
+ "name": "Alex Rodriguez",
+ "avatar_url": "https://avatars.githubusercontent.com/alxrod",
+ "profile": "https://github.com/alxrod",
"contributions": []
},
{
@@ -90,13 +83,6 @@
"profile": "https://github.com/arnaumarin",
"contributions": []
},
- {
- "login": "DivyaAmirtharaj",
- "name": "Divya",
- "avatar_url": "https://avatars.githubusercontent.com/DivyaAmirtharaj",
- "profile": "https://github.com/DivyaAmirtharaj",
- "contributions": []
- },
{
"login": "aptl26",
"name": "Aghyad Deeb",
@@ -104,6 +90,20 @@
"profile": "https://github.com/aptl26",
"contributions": []
},
+ {
+ "login": "NaN",
+ "name": "Aghyad Deeb",
+ "avatar_url": "https://www.gravatar.com/avatar/ed2ab3b597061ab95ce3d598a6af5305?d=identicon&s=100",
+ "profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
+ "contributions": []
+ },
+ {
+ "login": "DivyaAmirtharaj",
+ "name": "Divya",
+ "avatar_url": "https://avatars.githubusercontent.com/DivyaAmirtharaj",
+ "profile": "https://github.com/DivyaAmirtharaj",
+ "contributions": []
+ },
{
"login": "oishib",
"name": "oishib",
@@ -112,10 +112,10 @@
"contributions": []
},
{
- "login": "jared-ni",
- "name": "Jared Ni",
- "avatar_url": "https://avatars.githubusercontent.com/jared-ni",
- "profile": "https://github.com/jared-ni",
+ "login": "Ekhao",
+ "name": "Emil Njor",
+ "avatar_url": "https://avatars.githubusercontent.com/Ekhao",
+ "profile": "https://github.com/Ekhao",
"contributions": []
},
{
@@ -125,13 +125,6 @@
"profile": "https://github.com/michael-schnebly",
"contributions": []
},
- {
- "login": "Ekhao",
- "name": "Emil Njor",
- "avatar_url": "https://avatars.githubusercontent.com/Ekhao",
- "profile": "https://github.com/Ekhao",
- "contributions": []
- },
{
"login": "ELSuitorHarvard",
"name": "ELSuitorHarvard",
@@ -140,10 +133,10 @@
"contributions": []
},
{
- "login": "mmaz",
- "name": "Mark Mazumder",
- "avatar_url": "https://avatars.githubusercontent.com/mmaz",
- "profile": "https://github.com/mmaz",
+ "login": "jared-ni",
+ "name": "Jared Ni",
+ "avatar_url": "https://avatars.githubusercontent.com/jared-ni",
+ "profile": "https://github.com/jared-ni",
"contributions": []
},
{
@@ -154,10 +147,17 @@
"contributions": []
},
{
- "login": "colbybanbury",
- "name": "Colby Banbury",
- "avatar_url": "https://avatars.githubusercontent.com/colbybanbury",
- "profile": "https://github.com/colbybanbury",
+ "login": "mmaz",
+ "name": "Mark Mazumder",
+ "avatar_url": "https://avatars.githubusercontent.com/mmaz",
+ "profile": "https://github.com/mmaz",
+ "contributions": []
+ },
+ {
+ "login": "AditiR-42",
+ "name": "Aditi Raju",
+ "avatar_url": "https://avatars.githubusercontent.com/AditiR-42",
+ "profile": "https://github.com/AditiR-42",
"contributions": []
},
{
@@ -169,18 +169,11 @@
},
{
"login": "eliasab16",
- "name": "eliasab@college.harvard.edu",
+ "name": "eliasab16",
"avatar_url": "https://avatars.githubusercontent.com/eliasab16",
"profile": "https://github.com/eliasab16",
"contributions": []
},
- {
- "login": "pongtr",
- "name": "Pong Trairatvorakul",
- "avatar_url": "https://avatars.githubusercontent.com/pongtr",
- "profile": "https://github.com/pongtr",
- "contributions": []
- },
{
"login": "Naeemkh",
"name": "naeemkh",
@@ -189,10 +182,24 @@
"contributions": []
},
{
- "login": "AditiR-42",
- "name": "Aditi Raju",
- "avatar_url": "https://avatars.githubusercontent.com/AditiR-42",
- "profile": "https://github.com/AditiR-42",
+ "login": "colbybanbury",
+ "name": "Colby Banbury",
+ "avatar_url": "https://avatars.githubusercontent.com/colbybanbury",
+ "profile": "https://github.com/colbybanbury",
+ "contributions": []
+ },
+ {
+ "login": "pongtr",
+ "name": "Pong Trairatvorakul",
+ "avatar_url": "https://avatars.githubusercontent.com/pongtr",
+ "profile": "https://github.com/pongtr",
+ "contributions": []
+ },
+ {
+ "login": "arbass22",
+ "name": "Andrew Bass",
+ "avatar_url": "https://avatars.githubusercontent.com/arbass22",
+ "profile": "https://github.com/arbass22",
"contributions": []
},
{
@@ -210,10 +217,10 @@
"contributions": []
},
{
- "login": "arbass22",
- "name": "Andrew Bass",
- "avatar_url": "https://avatars.githubusercontent.com/arbass22",
- "profile": "https://github.com/arbass22",
+ "login": "zishenwan",
+ "name": "Zishen",
+ "avatar_url": "https://avatars.githubusercontent.com/zishenwan",
+ "profile": "https://github.com/zishenwan",
"contributions": []
},
{
@@ -223,20 +230,6 @@
"profile": "https://github.com/gnodipac886",
"contributions": []
},
- {
- "login": "sjohri20",
- "name": "Shreya Johri",
- "avatar_url": "https://avatars.githubusercontent.com/sjohri20",
- "profile": "https://github.com/sjohri20",
- "contributions": []
- },
- {
- "login": "eezike",
- "name": "Emeka Ezike",
- "avatar_url": "https://avatars.githubusercontent.com/eezike",
- "profile": "https://github.com/eezike",
- "contributions": []
- },
{
"login": "jessicaquaye",
"name": "Jessica Quaye",
@@ -261,7 +254,7 @@
{
"login": "NaN",
"name": "Annie Laurie Cook",
- "avatar_url": "https://www.gravatar.com/avatar/2fa0de133f70a90662eda1aaf7027910?d=identicon&s=100",
+ "avatar_url": "https://www.gravatar.com/avatar/e3db2854e2dbbb8a86ff9ea230242397?d=identicon&s=100",
"profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
@@ -272,17 +265,31 @@
"profile": "https://github.com/ciyer64",
"contributions": []
},
+ {
+ "login": "V0XNIHILI",
+ "name": "Douwe den Blanken",
+ "avatar_url": "https://avatars.githubusercontent.com/V0XNIHILI",
+ "profile": "https://github.com/V0XNIHILI",
+ "contributions": []
+ },
+ {
+ "login": "sjohri20",
+ "name": "Shreya Johri",
+ "avatar_url": "https://avatars.githubusercontent.com/sjohri20",
+ "profile": "https://github.com/sjohri20",
+ "contributions": []
+ },
{
"login": "NaN",
"name": "Jothi Ramaswamy",
- "avatar_url": "https://www.gravatar.com/avatar/2f2bc37ef696518ed7ca0eb5d080a261?d=identicon&s=100",
+ "avatar_url": "https://www.gravatar.com/avatar/bcb9dfbd4a3bbc68f1d3ef006d831df0?d=identicon&s=100",
"profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
{
"login": "NaN",
"name": "Costin-Andrei Oncescu",
- "avatar_url": "https://www.gravatar.com/avatar/71a91e508d72cf751695d32eaf74f866?d=identicon&s=100",
+ "avatar_url": "https://www.gravatar.com/avatar/b3fac9436f61a38d88caa8c9a12f4d32?d=identicon&s=100",
"profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
@@ -292,6 +299,13 @@
"avatar_url": "https://avatars.githubusercontent.com/vijay-edu",
"profile": "https://github.com/vijay-edu",
"contributions": []
+ },
+ {
+ "login": "eezike",
+ "name": "Emeka Ezike",
+ "avatar_url": "https://avatars.githubusercontent.com/eezike",
+ "profile": "https://github.com/eezike",
+ "contributions": []
}
],
"repoType": "github",
diff --git a/.github/workflows/contributors/update_contributors.py b/.github/workflows/contributors/update_contributors.py
index 175be68c..f654d322 100644
--- a/.github/workflows/contributors/update_contributors.py
+++ b/.github/workflows/contributors/update_contributors.py
@@ -189,6 +189,12 @@ def main(_):
commit_data_df.drop('has_username', axis=1, inplace=True)
commit_data_df.drop('name_length', axis=1, inplace=True)
+ # If the user_full_name is an email address, replace it with the username
+ commit_data_df['user_full_name'] = commit_data_df.apply(
+ lambda row: row['username'] if '@' in row['user_full_name'] else row[
+ 'user_full_name'],
+ axis=1)
+
def generate_gravatar_url(name):
name_list = list(name)
random.shuffle(name_list)
diff --git a/.vscode/ltex.dictionary.en-US.txt b/.vscode/ltex.dictionary.en-US.txt
new file mode 100644
index 00000000..dd0b3fd4
--- /dev/null
+++ b/.vscode/ltex.dictionary.en-US.txt
@@ -0,0 +1,4 @@
+TinyML
+edX
+neuromorphic
+EdgeImpulse
diff --git a/.vscode/settings.json b/.vscode/settings.json
new file mode 100644
index 00000000..acae39c6
--- /dev/null
+++ b/.vscode/settings.json
@@ -0,0 +1,11 @@
+{
+ "spellright.language": [
+ "en"
+ ],
+ "spellright.documentTypes": [
+ "markdown",
+ "latex",
+ "plaintext",
+ "quarto"
+ ]
+}
\ No newline at end of file
diff --git a/README.md b/README.md
index 5cfd72fa..20a22ae0 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,4 @@
-# CS249r: MACHINE LEARNING SYSTEMS for TinyML
+# MACHINE LEARNING SYSTEMS with tinyML
[](#contributors)
@@ -105,53 +105,55 @@ quarto render

Marcelo Rovai
|

Sophia Cho
|

Jeffrey Ma
|
- 
Alex Rodriguez
|

Andrea Murillo
|
+
Alex Rodriguez
|
- 
Aghyad Deeb
|

arnaumarin
|
- 
Divya
|

Aghyad Deeb
|
+ 
Aghyad Deeb
|
+
Divya
|

oishib
|
- 
Jared Ni
|
- 
Michael Schnebly
|

Emil Njor
|
+
Michael Schnebly
|

ELSuitorHarvard
|
- 
Mark Mazumder
|
+
Jared Ni
|
+ 
Henry Bae
|
-
Henry Bae
|
- 
Colby Banbury
|
+
Mark Mazumder
|
+ 
Aditi Raju
|

Shvetank Prakash
|
- 
eliasab@college.harvard.edu
|
- 
Pong Trairatvorakul
|
+
eliasab16
|
+ 
naeemkh
|
-
naeemkh
|
-
Aditi Raju
|
+
Colby Banbury
|
+
Pong Trairatvorakul
|
+ 
Andrew Bass
|

Jennifer Zhou
|

Marco Zennaro
|
-
Andrew Bass
|
+ 
Zishen
|

Eric D
|
- 
Shreya Johri
|
- 
Emeka Ezike
|

Jessica Quaye
|

Jason Yik
|
+ 
happyappledog
|
-
happyappledog
|
- 
Annie Laurie Cook
|
+ 
Annie Laurie Cook
|

Curren Iyer
|
- 
Jothi Ramaswamy
|
- 
Costin-Andrei Oncescu
|
+ 
Douwe den Blanken
|
+
Shreya Johri
|
+ 
Jothi Ramaswamy
|
+ 
Costin-Andrei Oncescu
|

Vijay Edupuganti
|
+
Emeka Ezike
|
diff --git a/acknowledgements.qmd b/acknowledgements.qmd
index fd1bf553..8f2aaa60 100644
--- a/acknowledgements.qmd
+++ b/acknowledgements.qmd
@@ -1,6 +1,6 @@
# Acknowledgements {.unnumbered}
-Assembling this book has been an incredible journey, spanning several years of hard work. The initial idea for this book sprang from the tinyML edX course, and its realization would not have been possible without the invaluable contributions of countless individuals. We are deeply indebted to the researchers whose groundbreaking work laid the foundation for this book.
+Assembling this book has been an incredible journey, spanning several years of hard work. The initial idea for this book sprang from the TinyML edX course, and its realization would not have been possible without the invaluable contributions of countless individuals. We are deeply indebted to the researchers whose groundbreaking work laid the foundation for this book.
We extend our heartfelt gratitude to the GitHub community. Whether you contributed an entire section, a single sentence, or merely corrected a typo, your efforts have significantly enhanced this book. We deeply appreciate everyone's time, expertise, and commitment. This book is as much yours as it is ours.
@@ -10,4 +10,4 @@ We also owe a great deal to the team at GitHub. You've revolutionized the way pe
To all who pick up this book—thank you! We wrote it with you in mind, hoping to provoke thought, inspire questions, and perhaps even ignite a spark of inspiration. After all, what is the point of writing if no one is reading?
-Last but certainly not least, our deepest thanks go to our friends, families, mentors, and all the kind souls who have supported us emotionally and intellectually as this book came to fruition.
\ No newline at end of file
+Last but certainly not least, our deepest thanks go to our friends, families, mentors, and all the kind souls who have supported us emotionally and intellectually as this book came to fruition.
diff --git a/ai_for_good.qmd b/ai_for_good.qmd
index dec411e1..257eb91d 100644
--- a/ai_for_good.qmd
+++ b/ai_for_good.qmd
@@ -2,8 +2,7 @@

-
-By aligning AI progress with human values, goals, and ethics, the ultimate goal of ML systems (at any scale) is to be a technology that reflects human principles and aspirations. Initiatives under "AI for Good" promote the development of AI to tackle the [UN Sustainable Development Goals](https://www.undp.org/sustainable-development-goals) (SDGs) using embedded AI technologies, expanding access to AI education, amongst other things. While it is now clear that AI will be an instrumental part of progress towards the SDGs, its adoption and impact are limited by the immense power consumption, strong connectivity requirements and high costs of cloud-based deployments. TinyML, applowing ML models to run on low-cost and low-power microcontrollers, can circumvent many of these issues.
+By aligning AI progress with human values, goals, and ethics, the ultimate goal of ML systems (at any scale) is to be a technology that reflects human principles and aspirations. Initiatives under "AI for Good" promote the development of AI to tackle the [UN Sustainable Development Goals](https://www.undp.org/sustainable-development-goals) (SDGs) using embedded AI technologies, expanding access to AI education, amongst other things. While it is now clear that AI will be an instrumental part of progress towards the SDGs, its adoption and impact are limited by the immense power consumption, strong connectivity requirements and high costs of cloud-based deployments. TinyML, allowing ML models to run on low-cost and low-power microcontrollers, can circumvent many of these issues.
> The "AI for Good" movement plays a critical role in cultivating a future where an AI-empowered society is more just, sustainable, and prosperous for all of humanity.
@@ -13,9 +12,9 @@ By aligning AI progress with human values, goals, and ethics, the ultimate goal
* Understand how TinyML can help advance the UN Sustainable Development Goals in areas like health, agriculture, education, and the environment.
-* Recognize the versatility of TinyML for enabling localized, low-cost solutions tailored to community needs.
+* Recognize the versatility of TinyML for enabling localized, low-cost solutions tailored to community needs.
-* Consider challenges of adopting TinyML globally such as limited training, data constraints, accessibility, and cultural barriers.
+* Consider challenges of adopting TinyML globally such as limited training, data constraints, accessibility, and cultural barriers.
* Appreciate the importance of collaborative, ethical approaches to develop and deploy TinyML to best serve local contexts.
@@ -25,48 +24,47 @@ By aligning AI progress with human values, goals, and ethics, the ultimate goal
## Introduction
-To give ourselves a framework around which to think about AI for social good, we will be following the UN Sustainable Development Goals (SDGs). The UN SDGs are a collection of 17 global goals adopted by the United Nations in 2015 as part of the 2030 Agenda for Sustainable Development. The SDGs address global challenges related to poverty, inequality, climate change, environmental degradation, prosperity, and peace and justice.
+To give ourselves a framework around which to think about AI for social good, we will be following the UN Sustainable Development Goals (SDGs). The UN SDGs are a collection of 17 global goals adopted by the United Nations in 2015 as part of the 2030 Agenda for Sustainable Development. The SDGs address global challenges related to poverty, inequality, climate change, environmental degradation, prosperity, and peace and justice.
What is special about SDGs is that they are a collection of interlinked objectives designed to serve as a "shared blueprint for peace and prosperity for people and the planet, now and into the future.". The SDGs emphasize the interconnected environmental, social and economic aspects of sustainable development by putting sustainability at their center.
-A recent study [@vinuesa2020role] highlights the influence of AI on all aspects of sustainable development, in particular on the 17 Sustainable Development Goals (SDGs) and 169 targets internationally defined in the 2030 Agenda for Sustainable Development. The study shows that AI can act as an enabler for 134 targets through technological improvements, but it also highlights the challenges of AI on some of the targets. When considering AI and societal outcomes, the study shows that AI can benefit 67 targets, but it also warns about the issues related to the implementation of AI in countries with different cultural values and wealth.
-
-[](https://www.google.com/url?sa=i&url=https%3A%2F%2Fwww.un.org%2Fsustainabledevelopment%2Fblog%2F2015%2F12%2Fsustainable-development-goals-kick-off-with-start-of-new-year%2F&psig=AOvVaw1vppNt_HtUx3YM8Tzd7s_-&ust=1695950945167000&source=images&cd=vfe&opi=89978449&ved=0CBAQjRxqFwoTCOCG1t-TzIEDFQAAAAAdAAAAABAD)
+A recent study [@vinuesa2020role] highlights the influence of AI on all aspects of sustainable development, in particular on the 17 Sustainable Development Goals (SDGs) and 169 targets internationally defined in the 2030 Agenda for Sustainable Development. The study shows that AI can act as an enabler for 134 targets through technological improvements, but it also highlights the challenges of AI on some targets. When considering AI and societal outcomes, the study shows that AI can benefit 67 targets, but it also warns about the issues related to the implementation of AI in countries with different cultural values and wealth.
+[](https://www.google.com/url?sa=i&url=https%3A%2F%2Fwww.un.org%2Fsustainabledevelopment%2Fblog%2F2015%2F12%2Fsustainable-development-goals-kick-off-with-start-of-new-year%2F&psig=AOvVaw1vppNt_HtUx3YM8Tzd7s_-&ust=1695950945167000&source=images&cd=vfe&opi=89978449&ved=0CBAQjRxqFwoTCOCG1t-TzIEDFQAAAAAdAAAAABAD)
In the context of our book, here is how TinyML could potentially help advance at least _some_ of these SDG goals.
-- **Goal 1 - No Poverty**: TinyML could help provide low-cost solutions for tasks like crop monitoring to improve agricultural yields in developing countries.
+* **Goal 1 - No Poverty**: TinyML could help provide low-cost solutions for tasks like crop monitoring to improve agricultural yields in developing countries.
-- **Goal 2 - Zero Hunger**: TinyML could enable localized and precise crop health monitoring and disease detection to reduce crop losses.
+* **Goal 2 - Zero Hunger**: TinyML could enable localized and precise crop health monitoring and disease detection to reduce crop losses.
-- **Goal 3 - Good Health and Wellbeing**: TinyML could help enable low-cost medical diagnosis tools for early detection and prevention of diseases in remote areas.
+* **Goal 3 - Good Health and Wellbeing**: TinyML could help enable low-cost medical diagnosis tools for early detection and prevention of diseases in remote areas.
-- **Goal 6 - Clean Water and Sanitation**: TinyML could monitor water quality and detect contaminants to ensure access to clean drinking water.
+* **Goal 6 - Clean Water and Sanitation**: TinyML could monitor water quality and detect contaminants to ensure access to clean drinking water.
-- **Goal 7 - Affordable and Clean Energy**: TinyML could optimize energy consumption and enable predictive maintenance for renewable energy infrastructure.
+* **Goal 7 - Affordable and Clean Energy**: TinyML could optimize energy consumption and enable predictive maintenance for renewable energy infrastructure.
-- **Goal 11 - Sustainable Cities and Communities**: TinyML could enable intelligent traffic management, air quality monitoring, and optimized resource management in smart cities.
+* **Goal 11 - Sustainable Cities and Communities**: TinyML could enable intelligent traffic management, air quality monitoring, and optimized resource management in smart cities.
-- **Goal 13 - Climate Action**: TinyML could monitor deforestation and track reforestation efforts. It could also help predict extreme weather events.
+* **Goal 13 - Climate Action**: TinyML could monitor deforestation and track reforestation efforts. It could also help predict extreme weather events.
The portability, lower power requirements, and real-time analytics enabled by TinyML make it well-suited for addressing several sustainability challenges faced by developing regions. Widespread deployment of power solutions has the potential to provide localized and cost-effective monitoring to help achieve some of the UN SDGs. In the rest of the sections, we will dive into the details of how TinyML is useful across many of the sectors that have the potential to address the UN SDGs.
## Agriculture
-Agriculture is essential to achieving many of the UN Sustainable Development Goals, including eradicating hunger and malnutrition, promoting economic growth, and using natural resources sustainably. TinyML can be a valuable tool to help advance sustainable agriculture, especially for smallholder farmers in developing regions.
+Agriculture is essential to achieving many of the UN Sustainable Development Goals, including eradicating hunger and malnutrition, promoting economic growth, and using natural resources sustainably. TinyML can be a valuable tool to help advance sustainable agriculture, especially for smallholder farmers in developing regions.
TinyML solutions can provide real-time monitoring and data analytics for crop health and growing conditions - all without reliance on connectivity infrastructure. For example, low-cost camera modules connected to microcontrollers can monitor for disease, pests, and nutritional deficiencies. TinyML algorithms can analyze the images to detect issues early before they spread and damage yields. This kind of precision monitoring can optimize inputs like water, fertilizer, and pesticides - improving efficiency and sustainability.
-Other sensors like GPS units and accelerometers can track microclimate conditions, soil humidity, and livestock wellbeing. Local real-time data helps farmers respond and adapt better to changes in the field. TinyML analytics at the edge avoids lag, network disruptions, and high data costs of cloud-based systems. And localized systems allow for customization to specific crops, diseases, and regional issues.
+Other sensors like GPS units and accelerometers can track microclimate conditions, soil humidity, and livestock wellbeing. Local real-time data helps farmers respond and adapt better to changes in the field. TinyML analytics at the edge avoids lag, network disruptions, and high data costs of cloud-based systems. And localized systems allow for customization to specific crops, diseases, and regional issues.
Widespread TinyML applications can help digitize smallholder farms to increase productivity, incomes, and resilience. The low cost of hardware and minimal connectivity requirements make solutions accessible. Projects across the developing world have shown the benefits:
-* Microsoft's [FarmBeats](https://www.microsoft.com/en-us/research/project/farmbeats-iot-agriculture/) project is an end-to-end approach to enable data-driven farming by using low-cost sensors, drones, and vision and machine learning algorithms ¹. The project aims to solve the problem of limited adoption of technology in farming due to the lack of power and internet connectivity in farms and the farmers' limited technology savviness. The project's goal is to increase farm productivity and reduce costs by coupling data with the farmer's knowledge and intuition about their farm. The project has been successful in enabling actionable insights from data by building artificial intelligence (AI) or machine learning (ML) models based on fused data sets.
+* Microsoft's [FarmBeats](https://www.microsoft.com/en-us/research/project/farmbeats-iot-agriculture/) project is an end-to-end approach to enable data-driven farming by using low-cost sensors, drones, and vision and machine learning algorithms ¹. The project aims to solve the problem of limited adoption of technology in farming due to the lack of power and internet connectivity in farms and the farmers' limited technology savviness. The project's goal is to increase farm productivity and reduce costs by coupling data with the farmer's knowledge and intuition about their farm. The project has been successful in enabling actionable insights from data by building artificial intelligence (AI) or machine learning (ML) models based on fused data sets.
* In Sub-Saharan Africa, off-the-shelf cameras and edge AI cut cassava losses to disease from 40% down to 5%, protecting a staple crop [@ramcharan2017deep].
-- In Indonesia, sensors monitor microclimates across rice paddies, optimizing water usage even with erratic rains [@tirtalistyani2022indonesia].
+* In Indonesia, sensors monitor microclimates across rice paddies, optimizing water usage even with erratic rains [@tirtalistyani2022indonesia].
With greater investment and integration into rural advisory services, TinyML could transform small-scale agriculture and improve livelihoods for farmers worldwide. The technology effectively brings the benefits of precision agriculture to disconnected regions most in need.
@@ -74,9 +72,9 @@ With greater investment and integration into rural advisory services, TinyML cou
### Expanding Access
-Universal health coverage and quality care remain out of reach for millions worldwide. A shortage of medical professionals severely limits access to even basic diagnosis and treatment in many regions. Additionally, healthcare infrastructure like clinics, hospitals, and utilities to power complex equipment are lacking. These gaps disproportionately impact marginalized communities, exacerbating health disparities.
+Universal health coverage and quality care remain out of reach for millions worldwide. A shortage of medical professionals severely limits access to even basic diagnosis and treatment in many regions. Additionally, healthcare infrastructure like clinics, hospitals, and utilities to power complex equipment are lacking. These gaps disproportionately impact marginalized communities, exacerbating health disparities.
-TinyML offers a promising technological solution to help expand access to quality healthcare globally. TinyML refers to the ability to deploy machine learning algorithms on microcontrollers, tiny chips with processing power, memory, and connectivity. TinyML enables real-time data analysis and intelligence in low-powered, compact devices.
+TinyML offers a promising technological solution to help expand access to quality healthcare globally. TinyML refers to the ability to deploy machine learning algorithms on microcontrollers, tiny chips with processing power, memory, and connectivity. TinyML enables real-time data analysis and intelligence in low-powered, compact devices.
This creates opportunities for transformative medical tools that are portable, affordable, and accessible. TinyML software and hardware can be optimized to run even in resource-constrained environments. For example, a TinyML system could analyze symptoms or make diagnostic predictions using minimal computing power, no continuous internet connectivity, and a battery or solar power source. These capabilities can bring medical-grade screening and monitoring directly to underserved patients.
@@ -84,7 +82,7 @@ This creates opportunities for transformative medical tools that are portable, a
Early detection of diseases is one major application. Small sensors paired with TinyML software can identify symptoms before conditions escalate or visible signs appear. For instance, [cough monitors](https://stradoslabs.com/cough-monitoring-and-respiratory-trial-data-collection-landing) with embedded machine learning can pick up on acoustic patterns indicative of respiratory illness, malaria, or tuberculosis. Detecting diseases at onset improves outcomes and reduces healthcare costs.
-A detailed example could be given for using TinyML to monitor pneumonia in children. Pneumonia is a leading cause of death for children under 5, and detecting it early is critical. A startup called [Respira Labs](https://www.samayhealth.com/) has developed a low-cost wearable audio sensor that uses TinyML algorithms to analyze coughs and identify symptoms of respiratory illnesses like pneumonia. The device contains a microphone sensor and microcontroller that runs a neural network model trained to classify respiratory sounds. It can identify features like wheezing, crackling, and stridor that may indicate pneumonia. The device is designed to be highly accessible - it has a simple strap, requires no battery or charging, and results are provided through LED lights and audio cues.
+A detailed example could be given for using TinyML to monitor pneumonia in children. Pneumonia is a leading cause of death for children under 5, and detecting it early is critical. A startup called [Respira Labs](https://www.samayhealth.com/) has developed a low-cost wearable audio sensor that uses TinyML algorithms to analyze coughs and identify symptoms of respiratory illnesses like pneumonia. The device contains a microphone sensor and microcontroller that runs a neural network model trained to classify respiratory sounds. It can identify features like wheezing, crackling, and stridor that may indicate pneumonia. The device is designed to be highly accessible - it has a simple strap, requires no battery or charging, and results are provided through LED lights and audio cues.
Another example involves researchers at UNIFEI in Brazil who have developed a low-cost device that leverages TinyML to monitor heart rhythms. Their innovative solution addresses a critical need - atrial fibrillation and other heart rhythm abnormalities often go undiagnosed due to the prohibitive cost and limited availability of screening tools. The device overcomes these barriers through its ingenious design. It uses an off-the-shelf microcontroller that costs only a few dollars, along with a basic pulse sensor. By minimizing complexity, the device becomes accessible to under-resourced populations. The TinyML algorithm running locally on the microcontroller analyzes pulse data in real time to detect irregular heart rhythms. This life-saving heart monitoring device demonstrates how TinyML enables powerful AI capabilities to be deployed in cost-effective, user-friendly designs.
@@ -92,19 +90,19 @@ TinyML's versatility also shows promise for tackling infectious diseases. Resear
### Infectious Disease Control
-Mosquitoes remain the most deadly disease vector worldwide, transmitting illnesses that infect over one billion people annually [@Vectorbo78:online]. Diseases like malaria, dengue, and Zika are especially prevalent in resource-limited regions lacking robust infrastructure for mosquito control. Monitoring local mosquito populations is essential to prevent outbreaks and properly target interventions.
+Mosquitoes remain the most deadly disease vector worldwide, transmitting illnesses that infect over one billion people annually [@Vectorbo78:online]. Diseases like malaria, dengue, and Zika are especially prevalent in resource-limited regions lacking robust infrastructure for mosquito control. Monitoring local mosquito populations is essential to prevent outbreaks and properly target interventions.
Traditional monitoring methods are expensive, labor-intensive, and difficult to deploy remotely. The proposed TinyML solution aims to overcome these barriers. Small microphones coupled with machine learning algorithms can classify mosquitoes by species based on minute differences in wing oscillations. The TinyML software runs efficiently on low-cost microcontrollers, eliminating the need for continuous connectivity.
-A collaborative research team from the University of Khartoum and the ICTP is exploring an innovative solution using TinyML. In a recent paper, they presented a low-cost device that can identify disease-spreading mosquito species through their wingbeat sounds [@altayeb2022classifying].
+A collaborative research team from the University of Khartoum and the ICTP is exploring an innovative solution using TinyML. In a recent paper, they presented a low-cost device that can identify disease-spreading mosquito species through their wing beat sounds [@altayeb2022classifying].
This portable, self-contained system shows great promise for entomology. The researchers suggest it could revolutionize insect monitoring and vector control strategies in remote areas. By providing cheaper, easier mosquito analytics, TinyML could significantly bolster malaria eradication efforts. Its versatility and minimal power needs make it ideal for field use in isolated, off-grid regions with scarce resources but high disease burden.
### TinyML Design Contest in Healthcare
-The first TinyML contest in healthcare, TDC’22 [@jia2023life], was held in 2022 to motivate participating teams to design AI/ML algorithms for detecting life-threatening ventricular arrhythmias (VAs) and deploy them on Implantable Cardioverter Defibrillators (ICDs). VAs are the main cause of sudden cardiac death (SCD). People at high risk of SCD rely on the ICD to deliver proper and timely defibrillation treatment (i.e., shocking the heart back into normal rhythm) when experiencing life-threatening VAs.
+The first TinyML contest in healthcare, TDC’22 [@jia2023life], was held in 2022 to motivate participating teams to design AI/ML algorithms for detecting life-threatening ventricular arrhythmias (VAs) and deploy them on Implantable Cardioverter Defibrillators (ICDs). VAs are the main cause of sudden cardiac death (SCD). People at high risk of SCD rely on the ICD to deliver proper and timely defibrillation treatment (i.e., shocking the heart back into normal rhythm) when experiencing life-threatening VAs.
-An on-device algorithm for early and timely life-threatening VA detection will increase the chances of survival. The proposed AI/ML algorithm needed to be deployed and executed on an extremely low-power and resource-constrained microcontroller (MCU) (a $10 development board with an ARM Cortex-M4 core at 80 MHz, 256 kB of flash memory and 64 kB of SRAM). The submitted designs were evaluated by metrics measured on the MCU for (1) detection performance; (2) inference latency; and (3) memory occupation by the program of AI/ML algorithms.
+An on-device algorithm for early and timely life-threatening VA detection will increase the chances of survival. The proposed AI/ML algorithm needed to be deployed and executed on an extremely low-power and resource-constrained microcontroller (MCU) (a $10 development board with an ARM Cortex-M4 core at 80 MHz, 256 kB of flash memory and 64 kB of SRAM). The submitted designs were evaluated by metrics measured on the MCU for (1) detection performance; (2) inference latency; and (3) memory occupation by the program of AI/ML algorithms.
The champion, GaTech EIC Lab, obtained 0.972 in $F_\beta$ (F1 score with a higher weight to recall), 1.747 ms in latency and 26.39 kB in memory footprint with a deep neural network. An ICD with an on-device VA detection algorithm was [implanted in a clinical trial](https://youtu.be/vx2gWzAr85A?t=2359).
@@ -124,7 +122,7 @@ As sensors and algorithms continue improving, TinyML networks may generate more
TinyML is emerging as a powerful tool for environmental conservation and sustainability efforts. Recent research has highlighted numerous applications of tiny machine learning across domains like wildlife monitoring, natural resource management, and tracking climate change.
-One example is using TinyML for real-time wildlife tracking and protection. Researchers have developed [Smart Wildlife Tracker](https://www.hackster.io/dhruvsheth_/eletect-tinyml-and-iot-based-smart-wildlife-tracker-c03e5a) devices that leverage TinyML algorithms to detect poaching activities. The collars contain sensors like cameras, microphones, and GPS to continuously monitor the surrounding environment. Embedded machine learning models analyze the audio and visual data to identify threats like nearby humans or gunshots. Early poaching detection gives wildlife rangers critical information to intervene and take action.
+One example is using TinyML for real-time wildlife tracking and protection. Researchers have developed [Smart Wildlife Tracker](https://www.hackster.io/dhruvsheth_/eletect-tinyml-and-iot-based-smart-wildlife-tracker-c03e5a) devices that leverage TinyML algorithms to detect poaching activities. The collars contain sensors like cameras, microphones, and GPS to continuously monitor the surrounding environment. Embedded machine learning models analyze the audio and visual data to identify threats like nearby humans or gunshots. Early poaching detection gives wildlife rangers critical information to intervene and take action.
Other projects apply TinyML to study animal behavior through sensors. The smart wildlife collar uses accelerometers and acoustic monitoring to track elephant movements, communication, and moods [@Verma_2022]. The low-power TinyML collar devices transmit rich data on elephant activities while avoiding burdensome Battery changes. This helps researchers unobtrusively observe elephant populations to inform conservation strategies.
@@ -138,11 +136,11 @@ In disaster response, speed and safety are paramount. But rubble and wreckage cr
When buildings collapse after earthquakes, small drones can prove invaluable. Equipped with TinyML navigation algorithms, micro-sized drones like the [CrazyFlie](https://www.bitcraze.io/) can traverse cramped voids and map pathways beyond human reach [@duisterhof2019learning]. Obstacle avoidance allows the drones to weave through unstable debris. This autonomous mobility lets them rapidly sweep areas humans cannot access.
-{{< video https://www.youtube.com/watch?v=wmVKbX7MOnU >}}
+{{< video >}}
Crucially, onboard sensors and TinyML processors analyze real-time data to identify signs of survivors. Thermal cameras detect body heat, microphones pick up calls for help, and gas sensors warn of leaks [@duisterhof2021sniffy]. Processing data locally using TinyML allows for quick interpretation to guide rescue efforts. As conditions evolve, the drones can adapt by adjusting their search patterns and priorities.
-{{< video https://www.youtube.com/watch?v=hj_SBSpK5qg >}}
+{{< video >}}
Additionally, coordinated swarms of drones unlock new capabilities. By collaborating and sharing insights, drone teams achieve a comprehensive view of the situation. Blanketing disaster sites allows TinyML algorithms to fuse and analyze data from multiple vantage points. This amplifies situational awareness beyond individual drones [@duisterhof2021sniffy].
@@ -170,7 +168,7 @@ With machine learning algorithms running locally on microcontrollers, compact ac
Similarly, mobility devices could use on-device vision processing to identify obstacles and terrain characteristics. This enables enhanced navigation and safety for the visually impaired. Companies like [Envision](https://www.letsenvision.com/) are developing smart glasses, converting visual information into speech, with embedded TinyML to guide the blind by detecting objects, text, and traffic signals.
-{{< video https://youtu.be/oGWinIKDOdc >}}
+{{< video >}}
TinyML could even power responsive prosthetic limbs. By analyzing nerve signals and sensory data like muscle tension, prosthetics and exoskeletons with embedded ML can move and adjust grip dynamically. This makes control more natural and intuitive. Companies are creating affordable, everyday bionic hands using TinyML. And for those with speech difficulties, voice-enabled devices with TinyML can generate personalized vocal outputs from non-verbal inputs. Pairs by Anthropic translates gestures into natural speech tailored for individual users.
@@ -180,9 +178,9 @@ With thoughtful and inclusive design, TinyML promises more autonomy and dignity
## Infrastructure and Urban Planning
-As urban populations swell, cities face immense challenges in efficiently managing resources and infrastructure. TinyML presents a powerful tool for developing intelligent systems to optimize city operations and sustainability. It could revolutionize energy efficiency in smart buildings.
+As urban populations swell, cities face immense challenges in efficiently managing resources and infrastructure. TinyML presents a powerful tool for developing intelligent systems to optimize city operations and sustainability. It could revolutionize energy efficiency in smart buildings.
-Machine learning models can learn to predict and regulate energy usage based on occupancy patterns. Miniaturized sensors placed throughout buildings can provide granular, real-time data on space utilization, temperature, and more [@seyedzadeh2018machine]. This visibility allows TinyML systems to minimize waste by optimizing heating, cooling, lighting, etc.
+Machine learning models can learn to predict and regulate energy usage based on occupancy patterns. Miniaturized sensors placed throughout buildings can provide granular, real-time data on space utilization, temperature, and more [@seyedzadeh2018machine]. This visibility allows TinyML systems to minimize waste by optimizing heating, cooling, lighting, etc.
These examples demonstrate TinyML’s huge potential for efficient, sustainable city infrastructure. But urban planners must consider privacy, security, and accessibility to ensure responsible adoption. With careful implementation, TinyML could profoundly modernize urban life.
@@ -194,7 +192,7 @@ A foremost challenge is limited access to training and hardware [@ooko2021tinyml
Data limitations also pose hurdles. TinyML models require quality localized datasets, but these are scarce in under-resourced environments. Creating frameworks to ethically crowdsource data could address this. But data collection should benefit local communities directly, not just extract value.
-Optimizing power usage and connectivity will be vital for sustainability. TinyML’s low power needs make it ideal for off-grid use cases. Integrating battery or solar can enable continuous operation. Adapting devices for low-bandwidth transmission where internet is limited also maximizes impact.
+Optimizing power usage and connectivity will be vital for sustainability. TinyML’s low power needs make it ideal for off-grid use cases. Integrating battery or solar can enable continuous operation. Adapting devices for low-bandwidth transmission where internet is limited also maximizes impact.
Cultural and language barriers further complicate adoption. User interfaces and devices should account for all literacy levels and avoid excluding subgroups. Voice-controllable solutions in local dialects can enhance accessibility.
@@ -206,4 +204,4 @@ TinyML presents a tremendous opportunity to harness the power of artificial inte
However, realizing TinyML's full potential requires holistic collaboration. Researchers, policymakers, companies and local stakeholders must work together to provide training, establish ethical frameworks, co-design solutions, and adapt them to community needs. Only through inclusive development and deployment can TinyML deliver on its promise to bridge inequities and uplift vulnerable populations without leaving any behind.
-If cultivated responsibly, TinyML could democratize opportunity and accelerate progress on global priorities from poverty alleviation to climate resilience. The technology represents a new wave of applied AI to empower societies, promote sustainability, and propel all of humanity collectively towards greater justice, prosperity and peace. TinyML provides a glimpse into an AI-enabled future that is accessible to all.
\ No newline at end of file
+If cultivated responsibly, TinyML could democratize opportunity and accelerate progress on global priorities from poverty alleviation to climate resilience. The technology represents a new wave of applied AI to empower societies, promote sustainability, and propel all of humanity collectively towards greater justice, prosperity and peace. TinyML provides a glimpse into an AI-enabled future that is accessible to all.
diff --git a/benchmarking.qmd b/benchmarking.qmd
index bded2b5c..bffccdc6 100644
--- a/benchmarking.qmd
+++ b/benchmarking.qmd
@@ -2,24 +2,25 @@

-Benchmarking is a critical part of developing and deploying machine learning systems, especially for tinyML applications. Benchmarks allow developers to measure and compare the performance of different model architectures, training procedures, and deployment strategies. This provides key insights into which approaches work best for the problem at hand and the constraints of the deployment environment.
+Benchmarking is a critical part of developing and deploying machine learning systems, especially for tinyML applications. Benchmarks allow developers to measure and compare the performance of different model architectures, training procedures, and deployment strategies. This provides key insights into which approaches work best for the problem at hand and the constraints of the deployment environment.
This chapter will provide an overview of popular ML benchmarks, best practices for benchmarking, and how to use benchmarks to improve model development and system performance. It aims to provide developers with the right tools and knowledge to effectively benchmark and optimize their systems, especially for tinyML systems.
-::: {.callout-tip}
+::: {.callout-tip}
+
## Learning Objectives
-* Understand the purpose and goals of benchmarking AI systems, including performance assessment, resource evaluation, validation, and more.
+* Understand the purpose and goals of benchmarking AI systems, including performance assessment, resource evaluation, validation, and more.
* Learn about the different types of benchmarks - micro, macro, and end-to-end - and their role in evaluating different aspects of an AI system.
-* Become familiar with the key components of an AI benchmark, including datasets, tasks, metrics, baselines, reproducibility rules, and more.
+* Become familiar with the key components of an AI benchmark, including datasets, tasks, metrics, baselines, reproducibility rules, and more.
* Understand the distinction between training and inference, and how each phase warrants specialized ML systems benchmarking.
* Learn about system benchmarking concepts like throughput, latency, power, and computational efficiency.
-* Appreciate the evolution of model benchmarking from accuracy to more holistic metrics like fairness, robustness and real-world applicability.
+* Appreciate the evolution of model benchmarking from accuracy to more holistic metrics like fairness, robustness and real-world applicability.
* Recognize the growing role of data benchmarking in evaluating issues like bias, noise, balance and diversity.
@@ -75,7 +76,7 @@ In AI, benchmarks play a crucial role in driving progress and innovation. While
### Community Consensus
-A key prepragoative for any benchmark to be impactful is that it must reflect the shared priorities and values of the broader research community. Benchmarks designed in isolation risk failing to gain acceptance if they overlook key metrics considered important by leading groups. Through collaborative development with open participation from academic labs, companies, and other stakeholders, benchmarks can incorporate collective input on critical capabilities worth measuring. This helps ensure the benchmarks evaluate aspects the community agrees are essential to advance the field. The process of reaching alignment on tasks and metrics itself supports converging on what matters most.
+A key prerogative for any benchmark to be impactful is that it must reflect the shared priorities and values of the broader research community. Benchmarks designed in isolation risk failing to gain acceptance if they overlook key metrics considered important by leading groups. Through collaborative development with open participation from academic labs, companies, and other stakeholders, benchmarks can incorporate collective input on critical capabilities worth measuring. This helps ensure the benchmarks evaluate aspects the community agrees are essential to advance the field. The process of reaching alignment on tasks and metrics itself supports converging on what matters most.
Furthermore, benchmarks published with broad co-authorship from respected institutions carry authority and validity that convinces the community to adopt them as trusted standards. Benchmarks perceived as biased by particular corporate or institutional interests breed skepticism. Ongoing community engagement through workshops and challenges is also key after initial release, and that is what, for instance, led to the success of ImageNet. As research rapidly progresses, collective participation enables continual refinement and expansion of benchmarks over time.
@@ -87,15 +88,15 @@ Community consensus brings benchmarks lasting relevance while fragmentation caus
As AI systems grow in complexity and ubiquity, the need for comprehensive benchmarking becomes paramount. Within this context, benchmarks are often classified into three primary categories: Hardware, Model, and Data. Let's delve into why each of these buckets is essential and the significance of evaluating AI from these three distinct dimensions:
-#### System Benchmarks
+### System Benchmarks
AI computations, especially those in deep learning, are resource-intensive. The hardware on which these computations run plays a pivotal role in determining the speed, efficiency, and scalability of AI solutions. Consequently, hardware benchmarks help evaluate the performance of CPUs, GPUs, TPUs, and other accelerators in the context of AI tasks. By understanding hardware performance, developers can make informed choices about which hardware platforms are best suited for specific AI applications. Furthermore, hardware manufacturers use these benchmarks to identify areas for improvement, driving innovation in AI-specific chip designs.
-#### Model Benchmarks
+### Model Benchmarks
The architecture, size, and complexity of AI models vary widely. Different models have different computational demands and offer varying levels of accuracy and efficiency. Model benchmarks help us assess the performance of various AI architectures on standardized tasks. They provide insights into the speed, accuracy, and resource demands of different models. By benchmarking models, researchers can identify best-performing architectures for specific tasks, guiding the AI community towards more efficient and effective solutions. Additionally, these benchmarks aid in tracking the progress of AI research, showcasing advancements in model design and optimization.
-#### Data Benchmarks
+### Data Benchmarks
AI, particularly machine learning, is inherently data-driven. The quality, size, and diversity of data influence the training efficacy and generalization capability of AI models. Data benchmarks focus on the datasets used in AI training and evaluation. They provide standardized datasets that the community can use to train and test models, ensuring a level playing field for comparisons. Moreover, these benchmarks highlight challenges in data quality, diversity, and representation, pushing the community to address biases and gaps in AI training data. By understanding data benchmarks, researchers can also gauge how models might perform in real-world scenarios, ensuring robustness and reliability.
@@ -127,11 +128,11 @@ Macro-benchmarks provide a holistic view, assessing the end-to-end performance o
Examples: These benchmarks evaluate the AI model:
-* [MLPerf Inference](https://github.com/mlcommons/inference)[@reddi2020mlperf]: An industry-standard set of benchmarks for measuring the performance of machine learning software and hardware. MLPerf has a suite of dedicated benchmarks for specific scales, such as [MLPerf Mobile](https://github.com/mlcommons/mobile_app_open) for mobile class devices and [MLPerf Tiny](https://github.com/mlcommons/tiny), which focuses on microcontrollers and other resource-constrained devices.
+* [MLPerf Inference][https://github.com/mlcommons/inference](@reddi2020mlperf): An industry-standard set of benchmarks for measuring the performance of machine learning software and hardware. MLPerf has a suite of dedicated benchmarks for specific scales, such as [MLPerf Mobile](https://github.com/mlcommons/mobile_app_open) for mobile class devices and [MLPerf Tiny](https://github.com/mlcommons/tiny), which focuses on microcontrollers and other resource-constrained devices.
* [EEMBC's MLMark](https://github.com/eembc/mlmark): A benchmarking suite for evaluating the performance and power efficiency of embedded devices running machine learning workloads. This benchmark provides insights into how different hardware platforms handle tasks like image recognition or audio processing.
-* [AI-Benchmark](https://ai-benchmark.com/)[@ignatov2018ai]: A benchmarking tool designed for Android devices, it valuates the performance of AI tasks on mobile devices, encompassing various real-world scenarios like image recognition, face parsing, and optical character recognition.
+* [AI-Benchmark][https://ai-benchmark.com/](@ignatov2018ai): A benchmarking tool designed for Android devices, it valuates the performance of AI tasks on mobile devices, encompassing various real-world scenarios like image recognition, face parsing, and optical character recognition.
#### End-to-end Benchmarks
@@ -213,7 +214,7 @@ The development life cycle of a machine learning model involves two critical pha
Benchmarking the training phase provides insights into how different model architectures, hyperparameter values, and optimization algorithms impact the time and resources needed to train the model. For instance, benchmarking shows how neural network depth affects training time on a given dataset. Benchmarking also reveals how hardware accelerators like GPUs and TPUs can speed up training.
-On the other hand, benchmarking inference evaluates model performance in real-world conditions after deployment. Key metrics include latency, throughput, memory footprint, and power consumption. Inference benchmarking determines if an model meets the requirements of its target application regarding response time and device constraints, which is typically the focus of tinyML but we will discsuss these broadly to make sure we have a general understanding.
+On the other hand, benchmarking inference evaluates model performance in real-world conditions after deployment. Key metrics include latency, throughput, memory footprint, and power consumption. Inference benchmarking determines if an model meets the requirements of its target application regarding response time and device constraints, which is typically the focus of tinyML but we will discuss these broadly to make sure we have a general understanding.
### Training Benchmarks
@@ -235,9 +236,9 @@ Training metrics, when viewed from a systems perspective, offer insights that tr
The following metrics are often considered important:
-1. **Training Time:** The time taken to train a model from scratch until it reaches a satisfactory performance level. It is a direct measure of the computational resources required to train a model. For example, [Google's BERT](https://arxiv.org/abs/1810.04805)[@devlin2018bert] model is a natural language processing model that requires several days to train on a massive corpus of text data using multiple GPUs. The long training time is a significant challenge in terms of resource consumption and cost.
+1. **Training Time:** The time taken to train a model from scratch until it reaches a satisfactory performance level. It is a direct measure of the computational resources required to train a model. For example, [Google's BERT][https://arxiv.org/abs/1810.04805](@devlin2018bert) model is a natural language processing model that requires several days to train on a massive corpus of text data using multiple GPUs. The long training time is a significant challenge in terms of resource consumption and cost.
-2. **Scalability:** How well the training process can handle increases in data size or model complexity. Scalability can be assessed by measuring training time, memory usage, and other resource consumption as data size or model complexity increases. [OpenAI's GPT-3](https://arxiv.org/abs/2005.14165)[@brown2020language] model has 175 billion parameters, making it one of the largest language models in existence. Training GPT-3 required extensive engineering efforts to scale up the training process to handle the massive model size. This involved the use of specialized hardware, distributed training, and other techniques to ensure that the model could be trained efficiently.
+2. **Scalability:** How well the training process can handle increases in data size or model complexity. Scalability can be assessed by measuring training time, memory usage, and other resource consumption as data size or model complexity increases. [OpenAI's GPT-3][https://arxiv.org/abs/2005.14165](@brown2020language) model has 175 billion parameters, making it one of the largest language models in existence. Training GPT-3 required extensive engineering efforts to scale up the training process to handle the massive model size. This involved the use of specialized hardware, distributed training, and other techniques to ensure that the model could be trained efficiently.
3. **Resource Utilization:** The extent to which the training process utilizes available computational resources such as CPU, GPU, memory, and disk I/O. High resource utilization can indicate an efficient training process, while low utilization can suggest bottlenecks or inefficiencies. For instance, training a convolutional neural network (CNN) for image classification requires significant GPU resources. Utilizing multi-GPU setups and optimizing the training code for GPU acceleration can greatly improve resource utilization and training efficiency.
@@ -255,7 +256,7 @@ The following metrics are often considered important:
10. **Reproducibility:** The ability to reproduce the results of the training process. Reproducibility is important for verifying the correctness and validity of a model. However, there are often variations due to stochastic network characteristics and this makes it hard to reproduce the precise behavior of applications being trained, and this can present a challenge for benchmarking.
-By benchmarking for these types of metrics, we can obtain a comprehensive view of the performance and efficiency of the training process from a systems perspective, which can help identify areas for improvement and ensure that resources are used effectively.
+By benchmarking for these types of metrics, we can obtain a comprehensive view of the performance and efficiency of the training process from a systems' perspective, which can help identify areas for improvement and ensure that resources are used effectively.
#### Tasks
@@ -268,7 +269,8 @@ Selecting a handful of representative tasks for benchmarking machine learning sy
5. **Scalability and Resource Requirements:** Different tasks may have different scalability and resource requirements. Some tasks may require extensive computational resources, while others can be performed with minimal resources. Selecting tasks that are representative of the general resource requirements in machine learning is difficult.
6. **Evaluation Metrics:** The metrics used to evaluate the performance of machine learning models vary between tasks. Some tasks may have well-established evaluation metrics, while others may lack clear or standardized metrics. This can make it challenging to compare performance across different tasks.
7. **Generalizability of Results:** The results obtained from benchmarking on a specific task may not be generalizable to other tasks. This means that the performance of a machine learning system on a selected task may not be indicative of its performance on other tasks.
-8.
+8.
+
It is important to carefully consider these factors when designing benchmarks to ensure that they are meaningful and relevant to the diverse range of tasks encountered in machine learning.
#### Benchmarks
@@ -309,9 +311,9 @@ Metrics:
Consider a scenario where we want to benchmark the training of an image classification model on a specific hardware platform.
-1. ** Task:** The task is to train a convolutional neural network (CNN) for image classification on the CIFAR-10 dataset.
-2. ** Benchmark:** We can use the MLPerf Training benchmark for this task. It includes an image classification workload that is relevant to our task.
-3. ** Metrics:** We will measure the following metrics:
+1. **Task:** The task is to train a convolutional neural network (CNN) for image classification on the CIFAR-10 dataset.
+2. **Benchmark:** We can use the MLPerf Training benchmark for this task. It includes an image classification workload that is relevant to our task.
+3. **Metrics:** We will measure the following metrics:
* Training time to reach a target accuracy of 90%.
* Throughput in terms of images processed per second.
@@ -435,7 +437,7 @@ Keyword spotting was selected as a task because it is a common usecase in TinyML
#### Dataset
-[Google Speech Commands](https://www.tensorflow.org/datasets/catalog/speech_commands)[@warden2018speech] was selected as the best dataset to represent the task. The dataset is well established in the research community and has permissive licensing which allows it to be easily used in a benchmark.
+[Google Speech Commands][https://www.tensorflow.org/datasets/catalog/speech_commands](@warden2018speech) was selected as the best dataset to represent the task. The dataset is well established in the research community and has permissive licensing which allows it to be easily used in a benchmark.
#### Model
@@ -451,7 +453,7 @@ MLPerf Tiny uses [EEMBCs EnergyRunner™ benchmark harness](https://github.com/e
#### Baseline Submission
-Baseline submissions are critical for contextualizing results and acting as a reference point to help participants get started. The baseline submission should prioritise simplicity and readability over state of the art performance. The keyword spotting baseline uses a standard [STM microcontroller](https://www.st.com/en/microcontrollers-microprocessors.html) as it's hardware and [TensorFlow Lite for Microcontrollers](https://www.tensorflow.org/lite/microcontrollers)[@david2021tensorflow] as it's inference framework.
+Baseline submissions are critical for contextualizing results and acting as a reference point to help participants get started. The baseline submission should prioritize simplicity and readability over state of the art performance. The keyword spotting baseline uses a standard [STM microcontroller](https://www.st.com/en/microcontrollers-microprocessors.html) as it's hardware and [TensorFlow Lite for Microcontrollers][https://www.tensorflow.org/lite/microcontrollers](@david2021tensorflow) as it's inference framework.
### Challenges and Limitations
@@ -462,7 +464,8 @@ While benchmarking provides a structured methodology for performance evaluation
* Limited reproducibility - Varying hardware, software versions, codebases and other factors can reduce reproducibility of benchmark results. MLPerf addresses this by providing reference implementations and environment specification.
* Misalignment with end goals - Benchmarks focusing only on speed or accuracy metrics may misalign with real-world objectives like cost and power efficiency. Benchmarks must reflect all critical performance axes.
* Rapid staleness - Due to the fast pace of advancements in AI and computing, benchmarks and their datasets can become outdated quickly. Maintaining up-to-date benchmarks is thus a persistent challenge.
-*
+*
+
But of all these, perhaps the most important challenge is dealing with benchmark engineering.
#### Hardware Lottery
@@ -513,13 +516,13 @@ Standardization of benchmarks is another important solution to mitigate benchmar
Third-party verification of results can also be a valuable tool in mitigating benchmark engineering. This involves having an independent third party verify the results of a benchmark test to ensure their credibility and reliability. Third-party verification can help to build confidence in the results and can provide a valuable means of validating the performance and capabilities of AI systems.
-Resource: [Benchmarking TinyML Systems: Challenges and Directions](https://arxiv.org/pdf/2003.04821.pdf)[@banbury2020benchmarking]
+Resource: [Benchmarking TinyML Systems: Challenges and Directions][https://arxiv.org/pdf/2003.04821.pdf](@banbury2020benchmarking)

Figure 1: The modular design of MLPerf Tiny enables both the direct comparison of solutions and the demonstration of an improvement over the reference. The reference implementations are fully implemented solutions that allow individual components to be swapped out. The components in green can be modified in either division, and the orange components can only be modified in the open division. The reference implementations also act as the baseline for the results.
-Source: MLPerf Tiny Benchmark (https://arxiv.org/pdf/2106.07597.pdf)
+Source: MLPerf Tiny Benchmark ()
## Model Benchmarking
@@ -537,7 +540,7 @@ The [MNIST dataset](https://www.tensorflow.org/datasets/catalog/mnist), created

-Source: https://en.wikipedia.org/wiki/File:MnistExamplesModified.png
+Source:
#### ImageNet (2009)
@@ -545,14 +548,14 @@ Fast forward to 2009, and we see the introduction of the [ImageNet dataset](http

-Source: https://cv.gluon.ai/_images/imagenet_banner.jpeg
+Source:
#### COCO (2014)
-The [Common Objects in Context (COCO) dataset](https://cocodataset.org/)[@lin2014microsoft], released in 2014, further expanded the landscape of machine learning datasets by introducing a richer set of annotations. COCO consists of images containing complex scenes with multiple objects, and each image is annotated with object bounding boxes, segmentation masks, and captions. This dataset has been instrumental in advancing research in object detection, segmentation, and image captioning.
+The [Common Objects in Context (COCO) dataset][https://cocodataset.org/](@lin2014microsoft), released in 2014, further expanded the landscape of machine learning datasets by introducing a richer set of annotations. COCO consists of images containing complex scenes with multiple objects, and each image is annotated with object bounding boxes, segmentation masks, and captions. This dataset has been instrumental in advancing research in object detection, segmentation, and image captioning.

-https://cocodataset.org/images/coco-examples.jpg
+
#### GPT-3 (2020)
@@ -560,7 +563,7 @@ While the above examples primarily focus on image datasets, there have been sign
#### Present and Future
-Today, we have a plethora of datasets spanning various domains, including healthcare, finance, social sciences, and more. The following characteristics are how we can taxonomiize the space and growth of machine learning datasets that fuel model development.
+Today, we have a plethora of datasets spanning various domains, including healthcare, finance, social sciences, and more. The following characteristics are how we can taxonomize the space and growth of machine learning datasets that fuel model development.
1. **Diversity of Data Sets:** The variety of data sets available to researchers and engineers has expanded dramatically over the years, covering a wide range of fields, including natural language processing, image recognition, and more. This diversity has fueled the development of specialized machine learning models tailored to specific tasks, such as translation, speech recognition, and facial recognition.
@@ -626,7 +629,7 @@ The size of a machine learning model is an essential aspect that directly impact
FLOPs measure the number of floating-point operations a model performs to generate a prediction. For example, a model with a high number of FLOPs requires substantial computational resources to process the vast number of operations, which may render it impractical for certain applications. Conversely, a model with a lower FLOP count is more lightweight and can be easily deployed in scenarios where computational resources are limited.
-Let's consider an example. BERT (Bidirectional Encoder Representations from Transformers)[@devlin2018bert], a popular natural language processing model, has over 340 million parameters, making it a large model with high accuracy and impressive performance across a range of tasks. However, the sheer size of BERT, coupled with its high FLOP count, makes it a computationally intensive model that may not be suitable for real-time applications or deployment on edge devices with limited computational capabilities.
+Let's consider an example. BERT [Bidirectional Encoder Representations from Transformers](@devlin2018bert), a popular natural language processing model, has over 340 million parameters, making it a large model with high accuracy and impressive performance across a range of tasks. However, the sheer size of BERT, coupled with its high FLOP count, makes it a computationally intensive model that may not be suitable for real-time applications or deployment on edge devices with limited computational capabilities.
In light of this, there has been a growing interest in developing smaller models that can achieve similar performance levels as their larger counterparts while being more efficient in terms of computational load. DistilBERT, for instance, is a smaller version of BERT that retains 97% of its performance while being 40% smaller in terms of parameter count. The reduction in size also translates to a lower FLOP count, making DistilBERT a more practical choice for resource-constrained scenarios.
@@ -763,14 +766,13 @@ While this integrated perspective represents an emerging trend, the field has mu
Emerging technologies can be particularly challenging to design benchmarks for given their significant differences from existing techniques. Standard benchmarks used for existing technologies may not highlight the key features of the new approach, while completely new benchmarks may be seen as contrived to favor the emerging technology over others, or yet may be so different from existing benchmarks that they cannot be understood and lose insightful value. Thus, benchmarks for emerging technologies must balance around fairness, applicability, and ease of comparison with existing benchmarks.
-An example emerging technology where benchmarking has proven to be especially difficult is in [Neuromorphic Computing](@sec-neuromorphic). Using the brain as a source of inspiration for scalable, robust, and energy-efficient general intelligence, neuromorphic computing [@schuman2022] directly incorporates biologically realistic mechanisms in both computing algorithms and hardware, such as spiking neural networks [@maass1997networks] and non-von Neumann architectures for executing them [@davies2018loihi, @modha2023neural]. From a full-stack perspective of models, training techniques, and hardware systems, neuromorphic computing differs from conventional hardware and AI, thus there is a key challenge towards developing benchmarks which are fair and useful for guiding the technology.
-
-An ongoing initiative towards developing standard neuromorphic benchmarks is NeuroBench [@yik2023neurobench]. In order to suitably benchmark neuromorphics, NeuroBench follows high-level principles of *inclusiveness* through task and metric applicability to both neuromorphic and non-neuromorphic solutions, *actionability* of implementation using common tooling, and *iterative* updates to continue to ensure relevance as the field rapidly grows. NeuroBench and other benchmarks for emerging technologies provide critical guidance for future techniques which may be necessary as the scaling limits of existing approaches draw nearer.
+An example emerging technology where benchmarking has proven to be especially difficult is in [Neuromorphic Computing](@sec-neuromorphic). Using the brain as a source of inspiration for scalable, robust, and energy-efficient general intelligence, neuromorphic computing [@schuman2022] directly incorporates biologically realistic mechanisms in both computing algorithms and hardware, such as spiking neural networks [@maass1997networks] and non-von Neumann architectures for executing them [@davies2018loihi, @modha2023neural]. From a full-stack perspective of models, training techniques, and hardware systems, neuromorphic computing differs from conventional hardware and AI, thus there is a key challenge towards developing benchmarks which are fair and useful for guiding the technology.
+An ongoing initiative towards developing standard neuromorphic benchmarks is NeuroBench [@yik2023neurobench]. In order to suitably benchmark neuromorphics, NeuroBench follows high-level principles of _inclusiveness_ through task and metric applicability to both neuromorphic and non-neuromorphic solutions, _actionability_ of implementation using common tooling, and _iterative_ updates to continue to ensure relevance as the field rapidly grows. NeuroBench and other benchmarks for emerging technologies provide critical guidance for future techniques which may be necessary as the scaling limits of existing approaches draw nearer.
## Conclusion
-What gets measured gets improved. This chapter has explored the multifaceted nature of benchmarking spanning systems, models, and data. Benchmarking is important to advancing AI by providing the essential measurements to track progress.
+What gets measured gets improved. This chapter has explored the multifaceted nature of benchmarking spanning systems, models, and data. Benchmarking is important to advancing AI by providing the essential measurements to track progress.
ML system benchmarks enable optimization across metrics like speed, efficiency, and scalability. Model benchmarks drive innovation through standardized tasks and metrics beyond just accuracy. And data benchmarks highlight issues of quality, balance and representation.
@@ -780,4 +782,4 @@ As AI grows more complex, comprehensive benchmarking becomes even more critical.
Benchmarking provides the compass to guide progress in AI. By persistently measuring and openly sharing results, we can navigate towards systems that are performant, robust and trustworthy. If AI is to properly serve societal and human needs, it must be benchmarked with humanity's best interests in mind. To this end, there are emerging areas such as benchmarking the safety of AI systems but that's for another day and perhaps something we can discuss further in Generative AI!
-Benchmarking is a continuously evolving topic. The article [The Olympics of AI: Benchmarking Machine Learning Systems](https://towardsdatascience.com/the-olympics-of-ai-benchmarking-machine-learning-systems-c4b2051fbd2b) covers several emerging subfields in AI benchmarking, including robotics, extended reality, and neuromorphic computing that we encourage the reader to pursue.
\ No newline at end of file
+Benchmarking is a continuously evolving topic. The article [The Olympics of AI: Benchmarking Machine Learning Systems](https://towardsdatascience.com/the-olympics-of-ai-benchmarking-machine-learning-systems-c4b2051fbd2b) covers several emerging subfields in AI benchmarking, including robotics, extended reality, and neuromorphic computing that we encourage the reader to pursue.
diff --git a/case_studies.qmd b/case_studies.qmd
index 9523d102..9a3ad48f 100644
--- a/case_studies.qmd
+++ b/case_studies.qmd
@@ -1,8 +1,9 @@
# Case Studies
::: {.callout-tip}
+
## Learning Objectives
-* coming soon.
+* Coming soon.
:::
diff --git a/community.qmd b/community.qmd
index a8228fb5..95d0bef6 100644
--- a/community.qmd
+++ b/community.qmd
@@ -1,6 +1,6 @@
# Communities
-Welcome to our dedicated hub for TinyML enthusiasts. Whether you are a seasoned developer, a researcher, or a curious hobbyist looking to dive into the world of TinyML, this page is a non exhaustive list of community resources and forums to help you get started and thrive in this domain. From vibrant online communities and educational platforms to blogs and social media groups, discover a world brimming with knowledge, collaboration, and innovation. Begin your TinyML journey here, where opportunities for learning and networking are just a click away!
+Welcome to our dedicated hub for TinyML enthusiasts. Whether you are a seasoned developer, a researcher, or a curious hobbyist looking to dive into the world of TinyML, this page is a non-exhaustive list of community resources and forums to help you get started and thrive in this domain. From vibrant online communities and educational platforms to blogs and social media groups, discover a world brimming with knowledge, collaboration, and innovation. Begin your TinyML journey here, where opportunities for learning and networking are just a click away!
## Online Forums
@@ -25,11 +25,12 @@ Welcome to our dedicated hub for TinyML enthusiasts. Whether you are a seasoned
3. **Tiny Machine Learning Open Education Initiative (TinyMLedu)**
Website: [TinyML Open Education Initiative](https://tinymledu.org/)
Description: The website offers links to educational materials on TinyML, training events and research papers.
+
## Social Media Groups
1. **LinkedIn Groups**
Description: Join TinyML groups on LinkedIn to connect with professionals and enthusiasts in the field.
-
+
2. **Twitter**
Description: Follow TinyML enthusiasts, organizations, and experts on Twitter for the latest news and updates.
Example handles to follow:
@@ -46,4 +47,4 @@ Welcome to our dedicated hub for TinyML enthusiasts. Whether you are a seasoned
Website: [Meetup](https://www.meetup.com/pro/tinyml)
Description: Search for TinyML groups on Meetup to find local or virtual gatherings.
-Remember to always check the credibility and activity level of the platforms and groups before diving in to ensure a productive experience.
\ No newline at end of file
+Remember to always check the credibility and activity level of the platforms and groups before diving in to ensure a productive experience.
diff --git a/contributors.qmd b/contributors.qmd
index aefc24a6..a69b919a 100644
--- a/contributors.qmd
+++ b/contributors.qmd
@@ -79,53 +79,55 @@ We extend our sincere thanks to the diverse group of individuals who have genero
Marcelo Rovai
|
Sophia Cho
|
Jeffrey Ma
|
-
Alex Rodriguez
|
Andrea Murillo
|
+
Alex Rodriguez
|
-
Aghyad Deeb
|
arnaumarin
|
-
Divya
|
Aghyad Deeb
|
+
Aghyad Deeb
|
+
Divya
|
oishib
|
-
Jared Ni
|
-
Michael Schnebly
|
Emil Njor
|
+
Michael Schnebly
|
ELSuitorHarvard
|
-
Mark Mazumder
|
+
Jared Ni
|
+
Henry Bae
|
-
Henry Bae
|
-
Colby Banbury
|
+
Mark Mazumder
|
+
Aditi Raju
|
Shvetank Prakash
|
-
eliasab@college.harvard.edu
|
-
Pong Trairatvorakul
|
+
eliasab16
|
+
naeemkh
|
-
naeemkh
|
-
Aditi Raju
|
+
Colby Banbury
|
+
Pong Trairatvorakul
|
+
Andrew Bass
|
Jennifer Zhou
|
Marco Zennaro
|
-
Andrew Bass
|
+
Zishen
|
Eric D
|
-
Shreya Johri
|
-
Emeka Ezike
|
Jessica Quaye
|
Jason Yik
|
+
happyappledog
|
-
happyappledog
|
-
Annie Laurie Cook
|
+
Annie Laurie Cook
|
Curren Iyer
|
-
Jothi Ramaswamy
|
-
Costin-Andrei Oncescu
|
+
Douwe den Blanken
|
+
Shreya Johri
|
+
Jothi Ramaswamy
|
+
Costin-Andrei Oncescu
|
Vijay Edupuganti
|
+
Emeka Ezike
|
diff --git a/copyright.qmd b/copyright.qmd
index 22434f67..52a34b0e 100644
--- a/copyright.qmd
+++ b/copyright.qmd
@@ -9,4 +9,3 @@ For details on authorship, contributions, and how to contribute, please see the
All trademarks and registered trademarks mentioned in this book are the property of their respective owners.
The information provided in this book is believed to be accurate and reliable. However, the authors, editors, and publishers cannot be held liable for any damages caused or alleged to be caused either directly or indirectly by the information contained in this book.
-
diff --git a/data_engineering.qmd b/data_engineering.qmd
index 57ee1d56..c6234027 100644
--- a/data_engineering.qmd
+++ b/data_engineering.qmd
@@ -5,13 +5,14 @@
Data is the lifeblood of AI systems. Without good data, even the most advanced machine learning algorithms will fail. In this section, we will dive into the intricacies of building high-quality datasets to fuel our AI models. Data engineering encompasses the processes of collecting, storing, processing, and managing data for training machine learning models.
::: {.callout-tip}
+
## Learning Objectives
* Understand the importance of clearly defining the problem statement and objectives when embarking on a ML project.
* Recognize various data sourcing techniques like web scraping, crowdsourcing, and synthetic data generation, along with their advantages and limitations.
-* Appreciate the need for thoughtful data labeling, using manual or AI-assisted approaches, to create high-quality training datasets.
+* Appreciate the need for thoughtful data labeling, using manual or AI-assisted approaches, to create high-quality training datasets.
* Briefly learn different methods for storing and managing data such as databases, data warehouses, and data lakes.
@@ -19,7 +20,7 @@ Data is the lifeblood of AI systems. Without good data, even the most advanced m
* Understand how licensing protocols govern legal data access and usage, necessitating careful compliance.
-* Recognize key challenges in data engineering, including privacy risks, representation gaps, legal restrictions around data access, and balancing competing priorities.
+* Recognize key challenges in data engineering, including privacy risks, representation gaps, legal restrictions around data access, and balancing competing priorities.
:::
@@ -76,36 +77,36 @@ In this context, using KWS as an example, we can break each of the steps out as
2. **Setting Clear Objectives:**
The objectives for a KWS system might include:
- - Achieving a specific accuracy rate (e.g., 98% accuracy in keyword detection).
- - Ensuring low latency (e.g., keyword detection and response within 200 milliseconds).
- - Minimizing power consumption to extend battery life on embedded devices.
- - Ensuring the model's size is optimized for the available memory on the device.
+ * Achieving a specific accuracy rate (e.g., 98% accuracy in keyword detection).
+ * Ensuring low latency (e.g., keyword detection and response within 200 milliseconds).
+ * Minimizing power consumption to extend battery life on embedded devices.
+ * Ensuring the model's size is optimized for the available memory on the device.
3. **Benchmarks for Success:**
Establish clear metrics to measure the success of the KWS system. This could include:
- - True Positive Rate: The percentage of correctly identified keywords.
- - False Positive Rate: The percentage of non-keywords incorrectly identified as keywords.
- - Response Time: The time taken from keyword utterance to system response.
- - Power Consumption: Average power used during keyword detection.
+ * True Positive Rate: The percentage of correctly identified keywords.
+ * False Positive Rate: The percentage of non-keywords incorrectly identified as keywords.
+ * Response Time: The time taken from keyword utterance to system response.
+ * Power Consumption: Average power used during keyword detection.
4. **Stakeholder Engagement and Understanding:**
Engage with stakeholders, which might include device manufacturers, hardware and software developers, and end-users. Understand their needs, capabilities, and constraints. For instance:
- - Device manufacturers might prioritize low power consumption.
- - Software developers might emphasize ease of integration.
- - End-users would prioritize accuracy and responsiveness.
+ * Device manufacturers might prioritize low power consumption.
+ * Software developers might emphasize ease of integration.
+ * End-users would prioritize accuracy and responsiveness.
5. **Understanding the Constraints and Limitations of Embedded Systems:**
Embedded devices come with their own set of challenges:
- - Memory Limitations: KWS models need to be lightweight to fit within the memory constraints of embedded devices. Typically, KWS models might need to be as small as 16KB to fit in the always-on island of the SoC. Moreover, this is just the model size. Additional application code for pre-processing may also need to fit within the memory constraints.
- - Processing Power: The computational capabilities of embedded devices are limited (few hundred MHz of clock speed), so the KWS model must be optimized for efficiency.
- - Power Consumption: Since many embedded devices are battery-powered, the KWS system must be power-efficient.
- - Environmental Challenges: Devices might be deployed in various environments, from quiet bedrooms to noisy industrial settings. The KWS system must be robust enough to function effectively across these scenarios.
+ * Memory Limitations: KWS models need to be lightweight to fit within the memory constraints of embedded devices. Typically, KWS models might need to be as small as 16KB to fit in the always-on island of the SoC. Moreover, this is just the model size. Additional application code for pre-processing may also need to fit within the memory constraints.
+ * Processing Power: The computational capabilities of embedded devices are limited (few hundred MHz of clock speed), so the KWS model must be optimized for efficiency.
+ * Power Consumption: Since many embedded devices are battery-powered, the KWS system must be power-efficient.
+ * Environmental Challenges: Devices might be deployed in various environments, from quiet bedrooms to noisy industrial settings. The KWS system must be robust enough to function effectively across these scenarios.
6. **Data Collection and Analysis:**
For a KWS system, the quality and diversity of data are paramount. Considerations might include:
- - Variety of Accents: Collect data from speakers with various accents to ensure wide-ranging recognition.
- - Background Noises: Include data samples with different ambient noises to train the model for real-world scenarios.
- - Keyword Variations: People might either pronounce keywords differently or have slight variations in the wake word itself. Ensure the dataset captures these nuances.
+ * Variety of Accents: Collect data from speakers with various accents to ensure wide-ranging recognition.
+ * Background Noises: Include data samples with different ambient noises to train the model for real-world scenarios.
+ * Keyword Variations: People might either pronounce keywords differently or have slight variations in the wake word itself. Ensure the dataset captures these nuances.
7. **Iterative Feedback and Refinement:**
Once a prototype KWS system is developed, it's crucial to test it in real-world scenarios, gather feedback, and iteratively refine the model. This ensures that the system remains aligned with the defined problem and objectives. This is important because the deployment scenarios change over time as things evolve.
@@ -120,7 +121,7 @@ Platforms like [Kaggle](https://www.kaggle.com/) and [UCI Machine Learning Repos
The quality assurance that comes with popular pre-existing datasets is important to consider because several datasets have errors in them. For instance, [the ImageNet dataset was found to have over 6.4% errors](https://arxiv.org/abs/2103.14749). Given their widespread use, any errors or biases in these datasets are often identified and rectified by the community. This assurance is especially beneficial for students and newcomers to the field, as they can focus on learning and experimentation without worrying about data integrity. Supporting documentation that often accompanies existing datasets is invaluable, though this generally applies only to widely used datasets. Good documentation provides insights into the data collection process, variable definitions, and sometimes even offers baseline model performances. This information not only aids understanding but also promotes reproducibility in research, a cornerstone of scientific integrity; currently there is a crisis around [improving reproducibility in machine learning systems](https://arxiv.org/abs/2003.12206). When other researchers have access to the same data, they can validate findings, test new hypotheses, or apply different methodologies, thus allowing us to build on each other's work more rapidly.
-While platforms like Kaggle and UCI Machine Learning Repository are invaluable resources, it's essential to understand the context in which the data was collected. Researchers should be wary of potential overfitting when using popular datasets, as multiple models might have been trained on them, leading to inflated performance metrics. Sometimes these [datasets do not reflect the real-world data](https://venturebeat.com/uncategorized/3-big-problems-with-datasets-in-ai-and-machine-learning/).
+While platforms like Kaggle and UCI Machine Learning Repository are invaluable resources, it's essential to understand the context in which the data was collected. Researchers should be wary of potential overfitting when using popular datasets, as multiple models might have been trained on them, leading to inflated performance metrics. Sometimes these [datasets do not reflect the real-world data](https://venturebeat.com/uncategorized/3-big-problems-with-datasets-in-ai-and-machine-learning/).
In addition, bias, validity, and reproducibility issues may exist in these datasets and in recent years there is a growing awareness of these issues. Furthermore, using the same dataset to train different models as shown in the figure below can sometimes create misalignment, where the models do not accurately reflect the real world (see @fig-misalignment).
@@ -136,7 +137,7 @@ Beyond computer vision, web scraping supports the gathering of textual data for
Web scraping can also collect structured data like stock prices, weather data, or product information for analytical applications. Once data is scraped, it is essential to store it in a structured manner, often using databases or data warehouses. Proper data management ensures the usability of the scraped data for future analysis and applications.
-However, while web scraping offers numerous advantages, there are significant limitations and ethical considerations to bear in mind. Not all websites permit scraping, and violating these restrictions can lead to legal repercussions. It is also unethical and potentially illegal to scrape copyrighted material or private communications. Ethical web scraping mandates adherence to a website's 'robots.txt' file, which outlines the sections of the site that can be accessed and scraped by automated bots.
+However, while web scraping offers numerous advantages, there are significant limitations and ethical considerations to bear in mind. Not all websites permit scraping, and violating these restrictions can lead to legal repercussions. It is also unethical and potentially illegal to scrape copyrighted material or private communications. Ethical web scraping mandates adherence to a website's 'robots.txt' file, which outlines the sections of the site that can be accessed and scraped by automated bots.
To deter automated scraping, many websites implement rate limits. If a bot sends too many requests in a short period, it might be temporarily blocked, restricting the speed of data access. Additionally, the dynamic nature of web content means that data scraped at different intervals might lack consistency, posing challenges for longitudinal studies. Though there are emerging trends like [Web Navigation](https://arxiv.org/abs/1812.09195) where machine learning algorithms can automatically navigate the website to access the dynamic content.
@@ -146,7 +147,7 @@ Privacy concerns arise when scraping personal data, emphasizing the need for ano
While web scraping can be a scalable method to amass large training datasets for AI systems, its applicability is confined to specific data types. For example, sourcing data for Inertial Measurement Units (IMU) for gesture recognition is not straightforward through web scraping. At most, one might be able to scrape an existing dataset.
-Web scraping can yield inconsistent or inaccurate data. For example, the photo in @fig-traffic-light shows up when you search 'traffic light' on Google images. It is an image from 1914 that shows outdated traffic lights, which are also barely discernable because of the image's poor quality.
+Web scraping can yield inconsistent or inaccurate data. For example, the photo in @fig-traffic-light shows up when you search 'traffic light' on Google images. It is an image from 1914 that shows outdated traffic lights, which are also barely discernible because of the image's poor quality.
](images/data_engineering/1914_traffic.jpeg){#fig-traffic-light}
@@ -192,7 +193,7 @@ Data sourcing and data storage go hand-in-hand and it is necessary to store data
**Database** **Data Warehouse** **Data Lake**
-------------- ------------------- --------------------- -------------------
**Purpose** Operational and Analytical Analytical
- transactional
+ transactional
**Data type** Structured Structured Structured,
semi-structured
@@ -201,7 +202,7 @@ Data sourcing and data storage go hand-in-hand and it is necessary to store data
**Scale** Small to large Large volumes of Large volumes of
volumes of data integrated data diverse data
- **Examples** MySQL Google BigQuery, Google Cloud
+**Examples** MySQL Google BigQuery, Google Cloud
Amazon Redshift, Storage, AWS S3,
Microsoft Azure Azure Data Lake
Synapse. Storage
@@ -215,33 +216,33 @@ The stored data is often accompanied by metadata, which is defined as 'data abou
Data governance (see @fig-governance) utilizes three integrative approaches: planning and control, organizational, and risk-based.
-- **The planning and control approach**, common in IT, aligns business and technology through annual cycles and continuous adjustments, focusing on policy-driven, auditable governance.
+* **The planning and control approach**, common in IT, aligns business and technology through annual cycles and continuous adjustments, focusing on policy-driven, auditable governance.
-- **The organizational approach** emphasizes structure, establishing authoritative roles like Chief Data Officers, ensuring responsibility and accountability in governance.
+* **The organizational approach** emphasizes structure, establishing authoritative roles like Chief Data Officers, ensuring responsibility and accountability in governance.
-- **The risk-based approach**, intensified by AI advancements, focuses on identifying and managing inherent risks in data and algorithms, especially addressing AI-specific issues through regular assessments and proactive risk management strategies, allowing for incidental and preventive actions to mitigate undesired algorithm impacts.
+* **The risk-based approach**, intensified by AI advancements, focuses on identifying and managing inherent risks in data and algorithms, especially addressing AI-specific issues through regular assessments and proactive risk management strategies, allowing for incidental and preventive actions to mitigate undesired algorithm impacts.
{#fig-governance}
Some examples of data governance across different sectors include:
-- **Medicine:** [[Health Information Exchanges(HIEs)]{.underline}](https://www.healthit.gov/topic/health-it-and-health-information-exchange-basics/what-hie) enable the sharing of health information across different healthcare providers to improve patient care. They implement strict data governance practices to maintain data accuracy, integrity, privacy, and security, complying with regulations such as the [[Health Insurance Portability and Accountability Act (HIPAA)]{.underline}](https://www.cdc.gov/phlp/publications/topic/hipaa.html). Governance policies ensure that patient data is only shared with authorized entities and that patients can control access to their information.
+* **Medicine:** [[Health Information Exchanges(HIEs)]{.underline}](https://www.healthit.gov/topic/health-it-and-health-information-exchange-basics/what-hie) enable the sharing of health information across different healthcare providers to improve patient care. They implement strict data governance practices to maintain data accuracy, integrity, privacy, and security, complying with regulations such as the [[Health Insurance Portability and Accountability Act (HIPAA)]{.underline}](https://www.cdc.gov/phlp/publications/topic/hipaa.html). Governance policies ensure that patient data is only shared with authorized entities and that patients can control access to their information.
-- **Finance:** [[Basel III Framework]{.underline}](https://www.bis.org/bcbs/basel3.htm) is an international regulatory framework for banks. It ensures that banks establish clear policies, practices, and responsibilities for data management, ensuring data accuracy, completeness, and timeliness. Not only does it enable banks to meet regulatory compliance, it also prevents financial crises by more effective management of risks.
+* **Finance:** [[Basel III Framework]{.underline}](https://www.bis.org/bcbs/basel3.htm) is an international regulatory framework for banks. It ensures that banks establish clear policies, practices, and responsibilities for data management, ensuring data accuracy, completeness, and timeliness. Not only does it enable banks to meet regulatory compliance, it also prevents financial crises by more effective management of risks.
-- **Government:** Governments agencies managing citizen data, public records, and administrative information implement data governance to manage data transparently and securely. Social Security System in the US, and Aadhar system in India are good examples of such governance systems.
+* **Government:** Governments agencies managing citizen data, public records, and administrative information implement data governance to manage data transparently and securely. Social Security System in the US, and Aadhar system in India are good examples of such governance systems.
**Special data storage considerations for tinyML**
***Efficient Audio Storage Formats:*** Keyword spotting systems need specialized audio storage formats to enable quick keyword searching in audio data. Traditional formats like WAV and MP3 store full audio waveforms, which require extensive processing to search through. Keyword spotting uses compressed storage optimized for snippet-based search. One approach is to store compact acoustic features instead of raw audio. Such a workflow would involve:
-- *Extracting acoustic features* - Mel-frequency cepstral coefficients (MFCCs) are commonly used to represent important audio characteristics.
+* **Extracting acoustic features:** Mel-frequency cepstral coefficients (MFCCs) are commonly used to represent important audio characteristics.
-- *Creating Embeddings*- Embeddings transform extracted acoustic features into continuous vector spaces, enabling more compact and representative data storage. This representation is essential in converting high-dimensional data, like audio, into a format that's more manageable and efficient for computation and storage.
+* **Creating Embeddings:** Embeddings transform extracted acoustic features into continuous vector spaces, enabling more compact and representative data storage. This representation is essential in converting high-dimensional data, like audio, into a format that's more manageable and efficient for computation and storage.
-- *Vector quantization* - This technique is used to represent high-dimensional data, like embeddings, with lower-dimensional vectors, reducing storage needs. Initially, a codebook is generated from the training data to define a set of code vectors representing the original data vectors. Subsequently, each data vector is matched to the nearest codeword according to the codebook, ensuring minimal loss of information.
+* **Vector quantization:** This technique is used to represent high-dimensional data, like embeddings, with lower-dimensional vectors, reducing storage needs. Initially, a codebook is generated from the training data to define a set of code vectors representing the original data vectors. Subsequently, each data vector is matched to the nearest codeword according to the codebook, ensuring minimal loss of information.
-- *Sequential storage* - The audio is fragmented into short frames, and the quantized features (or embeddings) for each frame are stored sequentially to maintain the temporal order, preserving the coherence and context of the audio data.
+* **Sequential storage:** The audio is fragmented into short frames, and the quantized features (or embeddings) for each frame are stored sequentially to maintain the temporal order, preserving the coherence and context of the audio data.
This format enables decoding the features frame-by-frame for keyword matching. Searching the features is faster than decompressing the full audio.
@@ -257,9 +258,9 @@ Proper data cleaning is a crucial step that directly impacts model performance.
Data often comes from diverse sources and can be unstructured or semi-structured. Thus, it’s essential to process and standardize it, ensuring it adheres to a uniform format. Such transformations may include:
-- Normalizing numerical variables
-- Encoding categorical variables
-- Using techniques like dimensionality reduction
+* Normalizing numerical variables
+* Encoding categorical variables
+* Using techniques like dimensionality reduction
Data validation serves a broader role than just ensuring adherence to certain standards like preventing temperature values from falling below absolute zero. These types of issues arise in TinyML because sensors may malfunction or temporarily produce incorrect readings, such transients are not uncommon. Therefore, it is imperative to catch data errors early before they propagate through the data pipeline. Rigorous validation processes, including verifying the initial annotation practices, detecting outliers, and handling missing values through techniques like mean imputation, contribute directly to the quality of datasets. This, in turn, impacts the performance, fairness, and safety of the models trained on them.
@@ -277,42 +278,45 @@ There is a boom of data processing pipelines, these are commonly found in ML ope
Data labeling is an important step in creating high-quality training datasets for machine learning models. Labels provide the ground truth information that allows models to learn relationships between inputs and desired outputs. This section covers key considerations around selecting label types, formats, and content to capture the necessary information for given tasks. It discusses common annotation approaches, from manual labeling to crowdsourcing to AI-assisted methods, and best practices for ensuring label quality through training, guidelines, and quality checks. Ethical treatment of human annotators is also something we emphasize. The integration of AI to accelerate and augment human annotation is also explored. Understanding labeling needs, challenges, and strategies is essential for constructing reliable, useful datasets that can train performant, trustworthy machine learning systems.
-**Label Types**
+### Label Types
Labels capture information about key tasks or concepts. Common label types (see @fig-labels) include binary classification, bounding boxes, segmentation masks, transcripts, captions, etc. The choice of label format depends on the use case and resource constraints, as more detailed labels require greater effort to collect (@Johnson-Roberson_Barto_Mehta_Sridhar_Rosaen_Vasudevan_2017).
{#fig-labels}
-Unless focused on self-supervised learning, a dataset will likely provide labels addressing one or more tasks of interest. Dataset creators must consider what information labels should capture and how they can practically obtain the necessary labels, given their unique resource constraints. Creators must first decide what type(s) of content labels should capture. For example, a creator interested in car detection would want to label cars in their dataset. Still, they might also consider whether to simultaneously collect labels for other tasks that the dataset could potentially be used for in the future, such as pedestrian detection.
+Unless focused on self-supervised learning, a dataset will likely provide labels addressing one or more tasks of interest. Dataset creators must consider what information labels should capture and how they can practically obtain the necessary labels, given their unique resource constraints. Creators must first decide what type(s) of content labels should capture. For example, a creator interested in car detection would want to label cars in their dataset. Still, they might also consider whether to simultaneously collect labels for other tasks that the dataset could potentially be used for in the future, such as pedestrian detection.
Additionally, annotators can potentially provide metadata that provides insight into how the dataset represents different characteristics of interest (see: Data Transparency). The Common Voice dataset, for example, includes various types of metadata that provide information about the speakers, recordings, and dataset quality for each language represented (@Ardila_Branson_Davis_Henretty_Kohler_Meyer_Morais_Saunders_Tyers_Weber_2020). They include demographic splits showing the number of recordings by speaker age range and gender. This allows us to see the breakdown of who contributed recordings for each language. They also include statistics like average recording duration and total hours of validated recordings. These give insights into the nature and size of the datasets for each language. Additionally, quality control metrics like the percentage of recordings that have been validated are useful to know how complete and clean the datasets are. The metadata also includes normalized demographic splits scaled to 100% for comparison across languages. This highlights representation differences between higher and lower resource languages.
Next, creators must determine the format of those labels. For example, a creator interested in car detection might choose between binary classification labels that say whether a car is present, bounding boxes that show the general locations of any cars, or pixel-wise segmentation labels that show the exact location of each car. Their choice of label format may depend both on their use case and their resource constraints, as finer-grained labels are typically more expensive and time-consuming to acquire.
-**Annotation Methods:**
+### Annotation Methods
+
Common annotation approaches include manual labeling, crowdsourcing, and semi-automated techniques. Manual labeling by experts yields high quality but lacks scalability. Crowdsourcing enables distributed annotation by non-experts, often through dedicated platforms (@Sheng_Zhang_2019). Weakly supervised and programmatic methods can reduce manual effort by heuristically or automatically generating labels (@Ratner_Hancock_Dunnmon_Goldman_Ré_2018).
After deciding on their labels' desired content and format, creators begin the annotation process. To collect large numbers of labels from human annotators, creators frequently rely on dedicated annotation platforms, which can connect them to teams of human annotators. When using these platforms, creators may have little insight to annotators’ backgrounds and levels of experience with topics of interest. However, some platforms offer access to annotators with specific expertise (e.g. doctors).
-**Ensuring Label Quality:**
+### Ensuring Label Quality
+
There is no guarantee that the data labels are actually correct. @fig-hard-labels shows some examples of hard labeling cases. It is possible that despite the best instructions being given to labelers, they still mislabel some images (@Northcutt_Athalye_Mueller_2021). Strategies like quality checks, training annotators, and collecting multiple labels per datapoint can help ensure label quality. For ambiguous tasks, multiple annotators can help identify controversial datapoints and quantify disagreement levels.
{#fig-hard-labels}
When working with human annotators, it is important to offer fair compensation and otherwise prioritize ethical treatment, as annotators can be exploited or otherwise harmed during the labeling process (Perrigo, 2023). For example, if a dataset is likely to contain disturbing content, annotators may benefit from having the option to view images in grayscale (@Google).
-**AI-Assisted Annotation:**
-ML has an insatiable demand for data. Therefore, no amount of data is sufficient data. This raises the question of how we can get more labeled data. Rather than always generating and curating data manually, we can rely on existing AI models to help label datasets more quickly and cheaply, though often with lower quality than human annotation. This can be done in various ways (see @fig-weak-supervision for examples), such as the following:
+### AI-Assisted Annotation
+
+ML has an insatiable demand for data. Therefore, no amount of data is sufficient data. This raises the question of how we can get more labeled data. Rather than always generating and curating data manually, we can rely on existing AI models to help label datasets more quickly and cheaply, though often with lower quality than human annotation. This can be done in various ways (see @fig-weak-supervision for examples), such as the following:
-- **Pre-annotation:** AI models can generate preliminary labels for a dataset using methods such as semi-supervised learning (@Chapelle_Scholkopf_Zien), which humans can then review and correct. This can save a significant amount of time, especially for large datasets.
-- **Active learning:** AI models can identify the most informative data points in a dataset, which can then be prioritized for human annotation. This can help improve the labeled dataset's quality while reducing the overall annotation time.
-- **Quality control:** AI models can be used to identify and flag potential errors in human annotations. This can help to ensure the accuracy and consistency of the labeled dataset.
+* **Pre-annotation:** AI models can generate preliminary labels for a dataset using methods such as semi-supervised learning (@Chapelle_Scholkopf_Zien), which humans can then review and correct. This can save a significant amount of time, especially for large datasets.
+* **Active learning:** AI models can identify the most informative data points in a dataset, which can then be prioritized for human annotation. This can help improve the labeled dataset's quality while reducing the overall annotation time.
+* **Quality control:** AI models can be used to identify and flag potential errors in human annotations. This can help to ensure the accuracy and consistency of the labeled dataset.
Here are some examples of how AI-assisted annotation has been proposed to be useful:
-- **Medical imaging:** AI-assisted annotation is being used to label medical images, such as MRI scans and X-rays (@Krishnan_Rajpurkar_Topol_2022). Carefully annotating medical datasets is extremely challenging, especially at scale, since domain experts are both scarce and it becomes a costly effort. This can help to train AI models to diagnose diseases and other medical conditions more accurately and efficiently.
-- **Self-driving cars:** AI-assisted annotation is being used to label images and videos from self-driving cars. This can help to train AI models to identify objects on the road, such as other vehicles, pedestrians, and traffic signs.
-- **Social media:** AI-assisted annotation is being used to label social media posts, such as images and videos. This can help to train AI models to identify and classify different types of content, such as news, advertising, and personal posts.
+* **Medical imaging:** AI-assisted annotation is being used to label medical images, such as MRI scans and X-rays (@Krishnan_Rajpurkar_Topol_2022). Carefully annotating medical datasets is extremely challenging, especially at scale, since domain experts are both scarce and it becomes a costly effort. This can help to train AI models to diagnose diseases and other medical conditions more accurately and efficiently.
+* **Self-driving cars:** AI-assisted annotation is being used to label images and videos from self-driving cars. This can help to train AI models to identify objects on the road, such as other vehicles, pedestrians, and traffic signs.
+* **Social media:** AI-assisted annotation is being used to label social media posts, such as images and videos. This can help to train AI models to identify and classify different types of content, such as news, advertising, and personal posts.
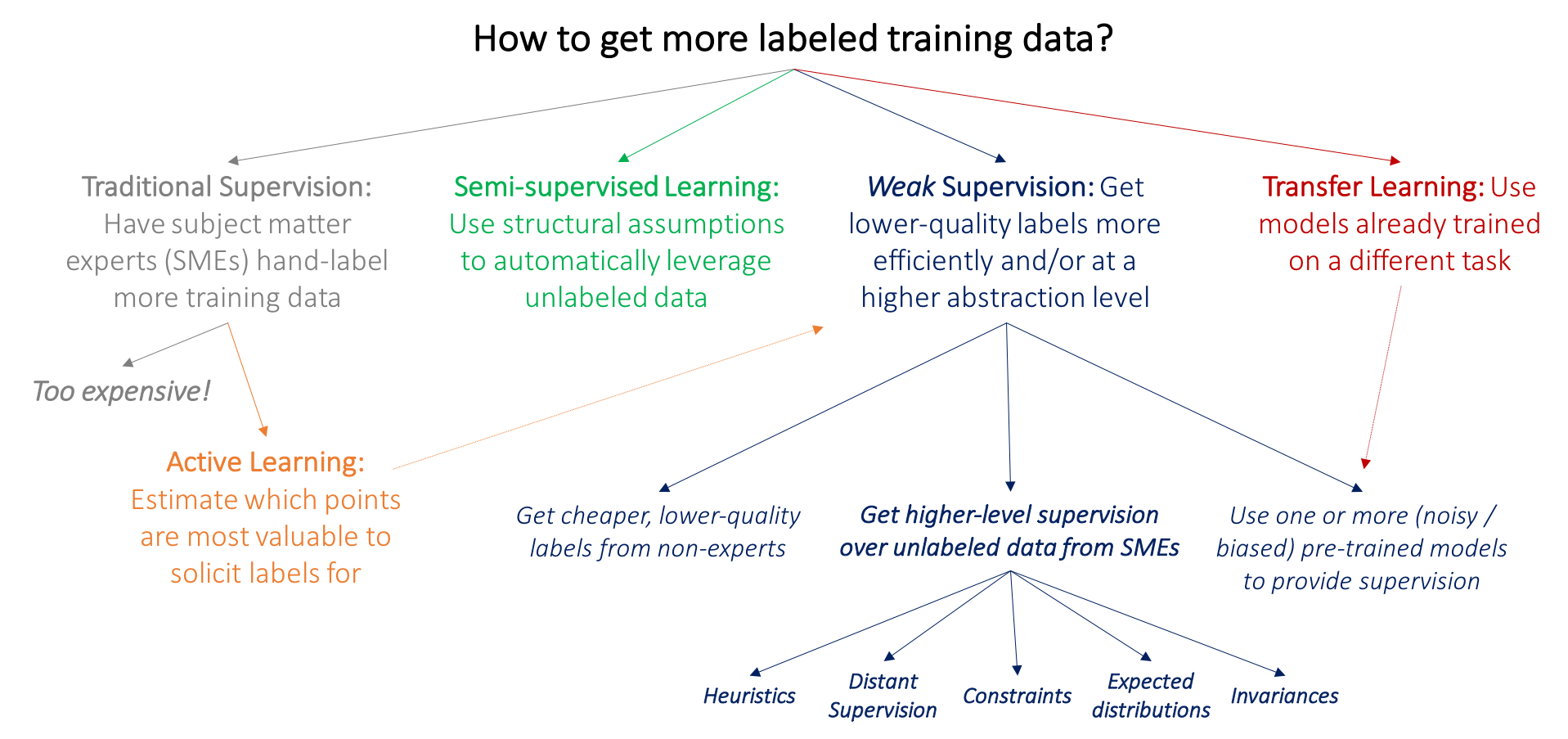{#fig-weak-supervision}
@@ -331,11 +335,11 @@ and therefore enabling reproducibility.
**Key Concepts**
-- *Commits:* It is an immutable snapshot of the data at a specific point in time, representing a unique version. Every commit is associated with a unique identifier to allow
+* **Commits:** It is an immutable snapshot of the data at a specific point in time, representing a unique version. Every commit is associated with a unique identifier to allow
-- *Branches*: Branching allows developers and data scientists to diverge from the main line of development and continue to work independently without affecting other branches. This is especially useful when experimenting with new features or models, enabling parallel development and experimentation without the risk of corrupting the stable, main branch.
+* **Branches:** Branching allows developers and data scientists to diverge from the main line of development and continue to work independently without affecting other branches. This is especially useful when experimenting with new features or models, enabling parallel development and experimentation without the risk of corrupting the stable, main branch.
-- *Merges:* Merges help to integrate changes from different branches while maintaining the integrity of the data.
+* **Merges:** Merges help to integrate changes from different branches while maintaining the integrity of the data.
With data version control in place, we are able to track the changes as shown in @fig-data-version-ctrl, reproduce previous results by reverting to older versions, and collaborate safely by branching off and isolating the changes.
@@ -355,18 +359,18 @@ Creators working on embedded systems may have unusual priorities when cleaning t
On the other hand, embedded AI systems are often expected to provide especially accurate performance in unpredictable real-world settings. This may lead creators to design datasets specifically to represent variations in potential inputs and promote model robustness. As a result, they may define a narrow scope for their project but then aim for deep coverage within those bounds. For example, creators of the doorbell model mentioned above might try to cover variations in data arising from:
-- Geographically, socially and architecturally diverse neighborhoods
-- Different types of artificial and natural lighting
-- Different seasons and weather conditions
-- Obstructions (e.g. raindrops or delivery boxes obscuring the camera’s view)
+* Geographically, socially and architecturally diverse neighborhoods
+* Different types of artificial and natural lighting
+* Different seasons and weather conditions
+* Obstructions (e.g. raindrops or delivery boxes obscuring the camera’s view)
-As described above, creators may consider crowdsourcing or synthetically generating data to include these different kinds of variations.
+As described above, creators may consider crowdsourcing or synthetically generating data to include these different kinds of variations.
## Data Transparency
-By providing clear, detailed documentation, creators can help developers understand how best to use their datasets. Several groups have suggested standardized documentation formats for datasets, such as Data Cards (@Pushkarna_Zaldivar_Kjartansson_2022), datasheets (@Gebru_Morgenstern_Vecchione_Vaughan_Wallach_III_Crawford_2021), data statements (@Bender_Friedman_2018), or Data Nutrition Labels (@Holland_Hosny_Newman_Joseph_Chmielinski_2020). When releasing a dataset, creators may describe what kinds of data they collected, how they collected and labeled it, and what kinds of use cases may be a good or poor fit for the dataset. Quantitatively, it may be appropriate to provide a breakdown of how well the dataset represents different groups (e.g. different gender groups, different cameras).
+By providing clear, detailed documentation, creators can help developers understand how best to use their datasets. Several groups have suggested standardized documentation formats for datasets, such as Data Cards (@Pushkarna_Zaldivar_Kjartansson_2022), datasheets (@Gebru_Morgenstern_Vecchione_Vaughan_Wallach_III_Crawford_2021), data statements (@Bender_Friedman_2018), or Data Nutrition Labels (@Holland_Hosny_Newman_Joseph_Chmielinski_2020). When releasing a dataset, creators may describe what kinds of data they collected, how they collected and labeled it, and what kinds of use cases may be a good or poor fit for the dataset. Quantitatively, it may be appropriate to provide a breakdown of how well the dataset represents different groups (e.g. different gender groups, different cameras).
-@fig-data-card shows an example of a data card for a computer vision (CV) dataset. It includes some basic information about the dataset and instructions on how to use or not to use the dataset, including known biases.
+@fig-data-card shows an example of a data card for a computer vision (CV) dataset. It includes some basic information about the dataset and instructions on how to use or not to use the dataset, including known biases.
{#fig-data-card}
@@ -376,8 +380,8 @@ When producing documentation, creators should also clearly specify how users can
Some laws and regulations promote also data transparency through new requirements for organizations:
-- General Data Protection Regulation (GDPR) in European Union: It establishes strict requirements for processing and protecting personal data of EU citizens. It mandates plain language privacy policies that clearly explain what data is collected, why it is used, how long it is stored, and with whom it is shared. GDPR also mandates that privacy notices must include details on legal basis for processing, data transfers, retention periods, rights to access and deletion, and contact info for data controllers.
-- California's Consumer Privacy Act (CCPA): CCPA requires clear privacy policies and opt-out rights for the sale of personal data. Significantly, it also establishes rights for consumers to request their specific data be disclosed. Businesses must provide copies of collected personal information along with details on what it is used for, what categories are collected, and what third parties receive it. Consumers can identify data points they believe are inaccurate. The law represents a major step forward in empowering personal data access.
+* General Data Protection Regulation (GDPR) in European Union: It establishes strict requirements for processing and protecting personal data of EU citizens. It mandates plain language privacy policies that clearly explain what data is collected, why it is used, how long it is stored, and with whom it is shared. GDPR also mandates that privacy notices must include details on legal basis for processing, data transfers, retention periods, rights to access and deletion, and contact info for data controllers.
+* California's Consumer Privacy Act (CCPA): CCPA requires clear privacy policies and opt-out rights for the sale of personal data. Significantly, it also establishes rights for consumers to request their specific data be disclosed. Businesses must provide copies of collected personal information along with details on what it is used for, what categories are collected, and what third parties receive it. Consumers can identify data points they believe are inaccurate. The law represents a major step forward in empowering personal data access.
There are several current challenges in ensuring data transparency, especially because it requires significant time and financial resources. Data systems are also quite complex, and full transparency can be difficult to achieve in these cases. Full transparency may also overwhelm the consumers with too much detail. And finally, it is also important to balance the tradeoff between transparency and privacy.
@@ -387,17 +391,17 @@ Many high-quality datasets either come from proprietary sources or contain copyr
For instance, ImageNet, one of the most extensively utilized datasets for computer vision research, is a case in point. A majority of its images were procured from public online sources without obtaining explicit permissions, sparking ethical concerns (Prabhu and Birhane, 2020). Accessing the ImageNet dataset for corporations requires registration and adherence to its terms of use, which restricts commercial usage ([[ImageNet]{.underline}](https://www.image-net.org/#), 2021). Major players like Google and Microsoft invest significantly in licensing datasets to enhance their ML vision systems. However, the cost factor restricts accessibility for researchers from smaller companies with constrained budgets.
-The legal domain of data licensing has seen major cases that help define parameters of fair use. A prominent example is *Authors Guild, Inc. v. Google, Inc.* This 2005 lawsuit alleged that Google\'s book scanning project infringed copyrights by displaying snippets without permission. However, the courts ultimately ruled in Google\'s favor, upholding fair use based on the transformative nature of creating a searchable index and showing limited text excerpts. This precedent provides some legal grounds for arguing fair use protections apply to indexing datasets and generating representative samples for machine learning. However, restrictions specified in licenses remain binding, so comprehensive analysis of licensing terms is critical. The case demonstrates why negotiations with data providers are important to enable legal usage within acceptable bounds.
+The legal domain of data licensing has seen major cases that help define parameters of fair use. A prominent example is _Authors Guild, Inc. v. Google, Inc._ This 2005 lawsuit alleged that Google\'s book scanning project infringed copyrights by displaying snippets without permission. However, the courts ultimately ruled in Google\'s favor, upholding fair use based on the transformative nature of creating a searchable index and showing limited text excerpts. This precedent provides some legal grounds for arguing fair use protections apply to indexing datasets and generating representative samples for machine learning. However, restrictions specified in licenses remain binding, so comprehensive analysis of licensing terms is critical. The case demonstrates why negotiations with data providers are important to enable legal usage within acceptable bounds.
**New Data Regulations and Their Implications**
New data regulations also impact licensing practices. The legislative landscape is evolving with regulations like the EU's [[Artificial Intelligence Act]{.underline}](https://digital-strategy.ec.europa.eu/en/policies/european-approach-artificial-intelligence), which is poised to regulate AI system development and use within the European Union (EU). This legislation:
-1. Classifies AI systems by risk.
+1. Classifies AI systems by risk.
-2. Mandates development and usage prerequisites.
+2. Mandates development and usage prerequisites.
-3. Emphasizes data quality, transparency, human oversight, and accountability.
+3. Emphasizes data quality, transparency, human oversight, and accountability.
Additionally, the EU Act addresses the ethical dimensions and operational challenges in sectors such as healthcare and finance. Key elements include the prohibition of AI systems posing \"unacceptable\" risks, stringent conditions for high-risk systems, and minimal obligations for \"limited risk\" AI systems. The proposed European AI Board will oversee and ensure efficient regulation implementation.
@@ -415,4 +419,4 @@ Dataset licensing is a multifaceted domain intersecting technology, ethics, and
## Conclusion
-Data is the fundamental building block of AI systems. Without quality data, even the most advanced machine learning algorithms will fail. Data engineering encompasses the end-to-end process of collecting, storing, processing and managing data to fuel the development of machine learning models. It begins with clearly defining the core problem and objectives, which guides effective data collection. Data can be sourced from diverse means including existing datasets, web scraping, crowdsourcing and synthetic data generation. Each approach involves tradeoffs between factors like cost, speed, privacy and specificity. Once data is collected, thoughtful labeling through manual or AI-assisted annotation enables the creation of high-quality training datasets. Proper storage in databases, warehouses or lakes facilitates easy access and analysis. Metadata provides contextual details about the data. Data processing transforms raw data into a clean, consistent format ready for machine learning model development. Throughout this pipeline, transparency through documentation and provenance tracking is crucial for ethics, auditability and reproducibility. Data licensing protocols also govern legal data access and use. Key challenges in data engineering include privacy risks, representation gaps, legal restrictions around proprietary data, and the need to balance competing constraints like speed versus quality. By thoughtfully engineering high-quality training data, machine learning practitioners can develop accurate, robust and responsible AI systems, including for embedded and tinyML applications.
\ No newline at end of file
+Data is the fundamental building block of AI systems. Without quality data, even the most advanced machine learning algorithms will fail. Data engineering encompasses the end-to-end process of collecting, storing, processing and managing data to fuel the development of machine learning models. It begins with clearly defining the core problem and objectives, which guides effective data collection. Data can be sourced from diverse means including existing datasets, web scraping, crowdsourcing and synthetic data generation. Each approach involves tradeoffs between factors like cost, speed, privacy and specificity. Once data is collected, thoughtful labeling through manual or AI-assisted annotation enables the creation of high-quality training datasets. Proper storage in databases, warehouses or lakes facilitates easy access and analysis. Metadata provides contextual details about the data. Data processing transforms raw data into a clean, consistent format ready for machine learning model development. Throughout this pipeline, transparency through documentation and provenance tracking is crucial for ethics, auditability and reproducibility. Data licensing protocols also govern legal data access and use. Key challenges in data engineering include privacy risks, representation gaps, legal restrictions around proprietary data, and the need to balance competing constraints like speed versus quality. By thoughtfully engineering high-quality training data, machine learning practitioners can develop accurate, robust and responsible AI systems, including for embedded and tinyML applications.
diff --git a/dl_primer.qmd b/dl_primer.qmd
index 400ff778..88ac6f11 100644
--- a/dl_primer.qmd
+++ b/dl_primer.qmd
@@ -5,6 +5,7 @@
This section offers a brief introduction to deep learning, starting with an overview of its history, applications, and relevance to embedded AI systems. It examines the core concepts like neural networks, highlighting key components like perceptrons, multilayer perceptrons, activation functions, and computational graphs. The primer also briefly explores major deep learning architecture, contrasting their applications and uses. Additionally, it compares deep learning to traditional machine learning to equip readers with the general conceptual building blocks to make informed choices between deep learning and traditional ML techniques based on problem constraints, setting the stage for more advanced techniques and applications that will follow in subsequent chapters.
::: {.callout-tip}
+
## Learning Objectives
* Understand the basic concepts and definitions of deep neural networks.
@@ -99,8 +100,7 @@ Backpropagation is a key algorithm in training deep neural networks. This phase
Grasping these foundational concepts paves the way to understanding more intricate deep learning architectures and techniques, fostering the development of more sophisticated and efficacious applications, especially within the realm of embedded AI systems.
-{{< video https://www.youtube.com/embed/aircAruvnKk?si=qfkBf8MJjC2WSyw3 >}}
-
+{{< video >}}
### Model Architectures
@@ -161,21 +161,21 @@ To succinctly highlight the differences, a comparative table illustrates the con
#### Data Availability and Volume
-- **Amount of Data**: Traditional machine learning algorithms, such as decision trees or Naive Bayes, are often more suitable when data availability is limited, offering robust predictions even with smaller datasets. This is particularly true in cases like medical diagnostics for disease prediction and customer segmentation in marketing.
+* **Amount of Data**: Traditional machine learning algorithms, such as decision trees or Naive Bayes, are often more suitable when data availability is limited, offering robust predictions even with smaller datasets. This is particularly true in cases like medical diagnostics for disease prediction and customer segmentation in marketing.
-- **Data Diversity and Quality**: Traditional machine learning algorithms are flexible in handling various data types and often require less preprocessing compared to deep learning models. They may also be more robust in situations with noisy data.
+* **Data Diversity and Quality**: Traditional machine learning algorithms are flexible in handling various data types and often require less preprocessing compared to deep learning models. They may also be more robust in situations with noisy data.
#### Complexity of the Problem
-- **Problem Granularity**: Problems that are simple to moderately complex, which may involve linear or polynomial relationships between variables, often find a better fit with traditional machine learning methods.
+* **Problem Granularity**: Problems that are simple to moderately complex, which may involve linear or polynomial relationships between variables, often find a better fit with traditional machine learning methods.
-- **Hierarchical Feature Representation**: Deep learning models are excellent in tasks that require hierarchical feature representation, such as image and speech recognition. However, not all problems require this level of complexity, and traditional machine learning algorithms may sometimes offer simpler and equally effective solutions.
+* **Hierarchical Feature Representation**: Deep learning models are excellent in tasks that require hierarchical feature representation, such as image and speech recognition. However, not all problems require this level of complexity, and traditional machine learning algorithms may sometimes offer simpler and equally effective solutions.
#### Hardware and Computational Resources
-- **Resource Constraints**: The availability of computational resources often influences the choice between traditional ML and deep learning. The former is generally less resource-intensive and thus preferable in environments with hardware limitations or budget constraints.
+* **Resource Constraints**: The availability of computational resources often influences the choice between traditional ML and deep learning. The former is generally less resource-intensive and thus preferable in environments with hardware limitations or budget constraints.
-- **Scalability and Speed**: Traditional machine learning algorithms, like support vector machines (SVM), often allow for faster training times and easier scalability, particularly beneficial in projects with tight timelines and growing data volumes.
+* **Scalability and Speed**: Traditional machine learning algorithms, like support vector machines (SVM), often allow for faster training times and easier scalability, particularly beneficial in projects with tight timelines and growing data volumes.
#### Regulatory Compliance
@@ -187,9 +187,9 @@ Understanding the decision-making process is easier with traditional machine lea
### Making an Informed Choice
-Given the constraints of embedded AI systems, understanding the differences between traditional ML techniques and deep learning becomes essential. Both avenues offer unique advantages, and their distinct characteristics often dictate the choice of one over the other in different scenarios.
+Given the constraints of embedded AI systems, understanding the differences between traditional ML techniques and deep learning becomes essential. Both avenues offer unique advantages, and their distinct characteristics often dictate the choice of one over the other in different scenarios.
-Despite this, deep learning has been steadily outperforming traditional machine learning methods in several key areas due to a combination of abundant data, computational advancements, and proven effectiveness in complex tasks.
+Despite this, deep learning has been steadily outperforming traditional machine learning methods in several key areas due to a combination of abundant data, computational advancements, and proven effectiveness in complex tasks.
Here are some specific reasons why we focus on deep learning in this text:
@@ -217,6 +217,6 @@ Next, we tackled the challenges one might face when embedding deep learning algo
Furthermore, we delved into an examination of the limitations of deep learning. Through a series of discussions, we unraveled the challenges faced in deep learning applications and outlined scenarios where traditional machine learning might outperform deep learning. These sections are crucial for fostering a balanced view of the capabilities and limitations of deep learning.
-In this primer, we have equipped you with the knowledge to make informed choices between deploying traditional machine learning or deep learning techniques, depending on the unique demands and constraints of a specific problem.
+In this primer, we have equipped you with the knowledge to make informed choices between deploying traditional machine learning or deep learning techniques, depending on the unique demands and constraints of a specific problem.
As we conclude this chapter, we hope you are now well-equipped with the basic "language" of deep learning, prepared to delve deeper into the subsequent chapters with a solid understanding and critical perspective. The journey ahead is filled with exciting opportunities and challenges in embedding AI within systems.
diff --git a/efficient_ai.qmd b/efficient_ai.qmd
index 3b535eff..bf365636 100644
--- a/efficient_ai.qmd
+++ b/efficient_ai.qmd
@@ -3,15 +3,16 @@
Efficiency in artificial intelligence (AI) is not simply a luxury; it is a necessity. In this chapter, we dive into the key concepts that underpin efficiency in AI systems. The computational demands placed on neural networks can be daunting, even for the most minimal of systems. For AI to be seamlessly integrated into everyday devices and essential systems, it must perform optimally within the constraints of limited resources, all while maintaining its efficacy. The pursuit of efficiency guarantees that AI models are streamlined, rapid, and sustainable, thereby widening their applicability across a diverse array of platforms and scenarios.
::: {.callout-tip}
+
## Learning Objectives
-- Recognize the need for efficient AI in TinyML/edge devices.
+- Recognize the need for efficient AI in TinyML/edge devices.
- Understand the need for efficient model architectures like MobileNets and SqueezeNet.
- Understand why techniques for model compression are important.
-- Get an inclination for why efficient AI hardware is important.
+- Get an inclination for why efficient AI hardware is important.
- Appreciate the significance of numerics and their representations.
@@ -25,11 +26,11 @@ The focus is on gaining a conceptual understanding of the motivations and signif
## Introduction
-Training models can consume a significant amount of energy, sometimes equivalent to the carbon footprint of sizable industrial processes. We will cover some of these sustainability details in the [AI Sustainability](./sustainable_ai.qmd) chapter. On the deployment side, if these models are not optimized for efficiency, they can quickly drain device batteries, demand excessive memory, or fall short of real-time processing needs. Through this introduction, our objective is to elucidate the nuances of efficiency, setting the groundwork for a comprehensive exploration in the subsequent chapters.
+Training models can consume a significant amount of energy, sometimes equivalent to the carbon footprint of sizable industrial processes. We will cover some of these sustainability details in the [AI Sustainability](./sustainable_ai.qmd) chapter. On the deployment side, if these models are not optimized for efficiency, they can quickly drain device batteries, demand excessive memory, or fall short of real-time processing needs. Through this introduction, our objective is to elucidate the nuances of efficiency, setting the groundwork for a comprehensive exploration in the subsequent chapters.
## The Need for Efficient AI
-Efficiency takes on different connotations based on where AI computations occur. Let's take a brief moment to revisit and differentiate between Cloud, Edge, and TinyML in terms of efficiency.
+Efficiency takes on different connotations based on where AI computations occur. Let's take a brief moment to revisit and differentiate between Cloud, Edge, and TinyML in terms of efficiency.

@@ -43,7 +44,7 @@ The spectrum from Cloud to TinyML represents a shift from vast, centralized comp
## Efficient Model Architectures
-Choosing the right model architecture is as crucial as optimizing it. In recent years, researchers have explored some novel architectures that can have inherently fewer parameters while maintaining strong performance.
+Choosing the right model architecture is as crucial as optimizing it. In recent years, researchers have explored some novel architectures that can have inherently fewer parameters while maintaining strong performance.
**MobileNets**: MobileNets are a class of efficient models for mobile and embedded vision applications [@howard2017mobilenets]. The key idea that led to the success of MobileNets is the use of depth-wise separable convolutions which significantly reduce the number of parameters and computations in the network. MobileNetV2 and V3 further enhance this design with the introduction of inverted residuals and linear bottlenecks.
@@ -53,7 +54,7 @@ Choosing the right model architecture is as crucial as optimizing it. In recent
## Efficient Model Compression
-Model compression methods are very important for bringing deep learning models to devices with limited resources. These techniques reduce the size, energy consumption, and computational demands of models without a significant loss in accuracy. At a high level, the methods can briefly be binned into the following fundamental methods:
+Model compression methods are very important for bringing deep learning models to devices with limited resources. These techniques reduce the size, energy consumption, and computational demands of models without a significant loss in accuracy. At a high level, the methods can briefly be binned into the following fundamental methods:
**Pruning**: This is akin to trimming the branches of a tree. This was first thought of in the [Optimal Brain Damage](https://proceedings.neurips.cc/paper/1989/file/6c9882bbac1c7093bd25041881277658-Paper.pdf) paper [@lecun1989optimal]. This was later popularized in the context of deep learning by @han2016deep. In pruning, certain weights or even entire neurons are removed from the network, based on specific criteria. This can significantly reduce the model size. There are various strategies, like weight pruning, neuron pruning, and structured pruning. We will explore these in more detail in @sec-pruning.
@@ -77,11 +78,11 @@ Efficient hardware for inference not only speeds up the process but also saves e
## Efficient Numerics
-Machine learning, and especially deep learning, involves enormous amounts of computation. Models can have millions to billions of parameters, and these are often trained on vast datasets. Every operation, every multiplication or addition, demands computational resources. Therefore, the precision of the numbers used in these operations can have a significant impact on the computational speed, energy consumption, and memory requirements. This is where the concept of efficient numerics comes into play.
+Machine learning, and especially deep learning, involves enormous amounts of computation. Models can have millions to billions of parameters, and these are often trained on vast datasets. Every operation, every multiplication or addition, demands computational resources. Therefore, the precision of the numbers used in these operations can have a significant impact on the computational speed, energy consumption, and memory requirements. This is where the concept of efficient numerics comes into play.
### Numerical Formats
-There are many different types of numerics. Numerics have a long history in computing systems.
+There are many different types of numerics. Numerics have a long history in computing systems.
**Floating point**: Known as single-precision floating-point, FP32 utilizes 32 bits to represent a number, incorporating its sign, exponent, and fraction. FP32 is widely adopted in many deep learning frameworks and offers a balance between accuracy and computational requirements. It's prevalent in the training phase for many neural networks due to its sufficient precision in capturing minute details during weight updates.
@@ -124,11 +125,11 @@ Numerical efficiency matters for machine learning workloads for a number of reas
## Evaluating Models
-It's worth noting that the actual benefits and trade-offs can vary based on the specific architecture of the neural network, the dataset, the task, and the hardware being used. Before deciding on a numeric precision, it's advisable to perform experiments to evaluate the impact on the desired application.
+It's worth noting that the actual benefits and trade-offs can vary based on the specific architecture of the neural network, the dataset, the task, and the hardware being used. Before deciding on a numeric precision, it's advisable to perform experiments to evaluate the impact on the desired application.
### Efficiency Metrics
-To guide this process systematically, it is important to have a deep understanding of model evaluation methods. When assessing AI models' effectiveness and suitability for various applications, efficiency metrics come to the forefront.
+To guide this process systematically, it is important to have a deep understanding of model evaluation methods. When assessing AI models' effectiveness and suitability for various applications, efficiency metrics come to the forefront.
**FLOPs (Floating Point Operations)** gauge the computational demands of a model. For instance, a modern neural network like BERT has billions of FLOPs, which might be manageable on a powerful cloud server but would be taxing on a smartphone. Higher FLOPs can lead to more prolonged inference times and more significant power drain, especially on devices without specialized hardware accelerators. Hence, for real-time applications such as video streaming or gaming, models with lower FLOPs might be more desirable.
@@ -158,10 +159,10 @@ In essence, a thorough comparative analysis transcends numerical metrics. It's a
## Conclusion
-Efficient AI is extremely important as we push towards broader and more diverse real-world deployment of machine learning. This chapter provided an overview, exploring the various methodologies and considerations behind achieving efficient AI, starting with the fundamental need, similarities and differences across cloud, edge, and TinyML systems.
+Efficient AI is extremely important as we push towards broader and more diverse real-world deployment of machine learning. This chapter provided an overview, exploring the various methodologies and considerations behind achieving efficient AI, starting with the fundamental need, similarities and differences across cloud, edge, and TinyML systems.
-We saw that efficient model architectures can be useful for optimizations. Model compression techniques such as pruning, quantization, and knowledge distillation exist to help reduce computational demands and memory footprint without significantly impacting accuracy. Specialized hardware like TPUs and NN accelerators offer optimized silicon for the operations and data flow of neural networks. And efficient numerics strike a balance between precision and efficiency, enabling models to attain robust performance using minimal resources. In the subsequent chapters, we will dive deeper into each of these different topics and explore them in great depth and detail.
+We saw that efficient model architectures can be useful for optimizations. Model compression techniques such as pruning, quantization, and knowledge distillation exist to help reduce computational demands and memory footprint without significantly impacting accuracy. Specialized hardware like TPUs and NN accelerators offer optimized silicon for the operations and data flow of neural networks. And efficient numerics strike a balance between precision and efficiency, enabling models to attain robust performance using minimal resources. In the subsequent chapters, we will dive deeper into each of these different topics and explore them in great depth and detail.
-Together, these form a holistic framework for efficient AI. But the journey doesn't end here. Achieving optimally efficient intelligence requires continued research and innovation. As models become more sophisticated, datasets grow larger, and applications diversify into specialized domains, efficiency must evolve in lockstep. Measuring real-world impact would need nuanced benchmarks and standardized metrics beyond simplistic accuracy figures.
+Together, these form a holistic framework for efficient AI. But the journey doesn't end here. Achieving optimally efficient intelligence requires continued research and innovation. As models become more sophisticated, datasets grow larger, and applications diversify into specialized domains, efficiency must evolve in lockstep. Measuring real-world impact would need nuanced benchmarks and standardized metrics beyond simplistic accuracy figures.
Moreover, efficient AI expands beyond technological optimization but also encompasses costs, environmental impact, and ethical considerations for the broader societal good. As AI permeates across industries and daily lives, a comprehensive outlook on efficiency underpins its sustainable and responsible progress. The subsequent chapters will build upon these foundational concepts, providing actionable insights and hands-on best practices for developing and deploying efficient AI solutions.
diff --git a/embedded_ml.qmd b/embedded_ml.qmd
index 79d30f79..23dc9321 100644
--- a/embedded_ml.qmd
+++ b/embedded_ml.qmd
@@ -5,23 +5,24 @@
Before delving into the intricacies of TinyML, it's crucial to grasp the distinctions among Cloud ML, Edge ML, and TinyML. In this chapter, we'll explore each of these facets individually before comparing and contrasting them.
::: {.callout-tip}
+
## Learning Objectives
* Compare Cloud ML, Edge ML, and TinyML in terms of processing location, latency, privacy, computational power, etc.
-* Identify benefits and challenges of each embedded ML approach.
+* Identify benefits and challenges of each embedded ML approach.
* Recognize use cases suited for Cloud ML, Edge ML, and TinyML.
* Trace the evolution of embedded systems and machine learning.
-* Contrast different embedded ML approaches to select the right implementation based on application requirements.
+* Contrast different embedded ML approaches to select the right implementation based on application requirements.
:::
## Introduction
-ML is rapidly evolving, with new paradigms emerging that are reshaping how these algorithms are developed, trained, and deployed. In particular, the area of embedded machine learning is experiencing significant innovation, driven by the proliferation of smart sensors, edge devices, and microcontrollers. This chapter explores the landscape of embedded machine learning, covering the key approaches of Cloud ML, Edge ML, and TinyML.
+ML is rapidly evolving, with new paradigms emerging that are reshaping how these algorithms are developed, trained, and deployed. In particular, the area of embedded machine learning is experiencing significant innovation, driven by the proliferation of smart sensors, edge devices, and microcontrollers. This chapter explores the landscape of embedded machine learning, covering the key approaches of Cloud ML, Edge ML, and TinyML.

@@ -41,6 +42,8 @@ At its foundation, Cloud ML utilizes a powerful blend of high-capacity servers,
The cloud environment excels in data processing and model training, designed to manage large data volumes and complex computations. Models crafted in Cloud ML can leverage vast amounts of data, processed and analyzed centrally, thereby enhancing the model's learning and predictive performance.
+)](images/imgs_embedded_ml/cloud_ml_tpu.jpg)
+
### Benefits
Cloud ML is synonymous with immense computational power, adept at handling complex algorithms and large datasets. This is particularly advantageous for machine learning models that demand significant computational resources, effectively circumventing the constraints of local setups.
@@ -256,10 +259,11 @@ The embedded ML landscape is in a state of rapid evolution, poised to enable int
Now would be a great time for you to try out a small computer vision model out of the box.
::: {.callout-tip}
+
## Nicla Vision
If you want to play with an embedded system, try out the Nicla Vision
[Computer Vision](./image_classification.qmd)
-:::
\ No newline at end of file
+:::
diff --git a/embedded_sys.qmd b/embedded_sys.qmd
index ae4a6c05..457dab73 100644
--- a/embedded_sys.qmd
+++ b/embedded_sys.qmd
@@ -7,27 +7,27 @@ In the domain of TinyML, embedded systems serve as the bedrock, providing a robu
As we journey further into this chapter, we will demystify the intricate yet captivating realm of embedded systems, gaining insights into their structural design, operational features, and the crucial part they play in enabling TinyML applications. From an introduction to the fundamentals of microcontroller units to a deep dive into the interfaces and peripherals that amplify their capabilities, this chapter aims to be a comprehensive guide for understanding the nuanced aspects of embedded systems within the TinyML landscape.
::: {.callout-tip}
+
## Learning Objectives
-* Understand the definition, characteristics, history, and importance of embedded systems, especially in relation to tinyML.
+* Understand the definition, characteristics, history, and importance of embedded systems, especially in relation to tinyML.
* Examine the embedded system architecture including microcontrollers vs microprocessors, memory types and management, and System on Chip (SoC).
* Explore embedded system programming including languages like C and Python, firmware development, and real-time operating systems (RTOS).
-* Discuss interfaces and peripherals like digital/analog I/O, communication protocols, etc.
+* Discuss interfaces and peripherals like digital/analog I/O, communication protocols, etc.
-* Analyze power management considerations, energy-efficient design, and battery management.
+* Analyze power management considerations, energy-efficient design, and battery management.
-* Understand real-time characteristics of embedded systems including clocks, timing, task scheduling, and error handling.
+* Understand real-time characteristics of embedded systems including clocks, timing, task scheduling, and error handling.
-* Evaluate security, reliability and safety-critical aspects of embedded systems.
+* Evaluate security, reliability and safety-critical aspects of embedded systems.
* Identify future trends and challenges like edge computing, scalability, and market opportunities.
:::
-
## Basics and Components
### Definition and Characteristics
@@ -74,27 +74,27 @@ The architectural layout of embedded systems serves as the schematic that outlin
Comprehending the distinctions between microcontrollers and microprocessors is essential for understanding the basics of embedded system architecture. In this section, we will explore the unique attributes of each:
-- **Microcontrollers**
+* **Microcontrollers**
Microcontrollers are compact, integrated circuits engineered to control specific functions within an embedded system. They incorporate a processor, memory, and input/output peripherals within a single unit, as depicted in @fig-microcontroller, simplifying the overall system design. Microcontrollers are generally employed in applications where computational demands are moderate and cost-effectiveness is a primary consideration.
**Characteristics**:
- - Single-chip solution
- - On-chip memory and peripherals
- - Minimal energy consumption
- - Well-suited for control-oriented tasks
+ * Single-chip solution
+ * On-chip memory and peripherals
+ * Minimal energy consumption
+ * Well-suited for control-oriented tasks
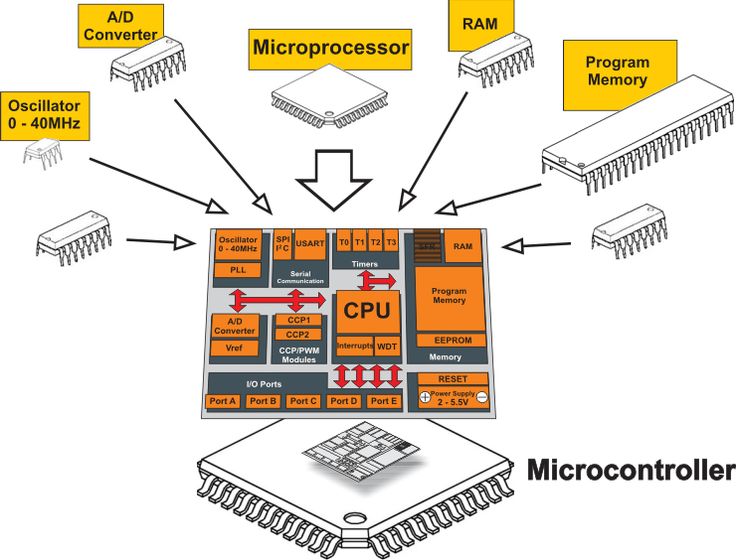{#fig-microcontroller width=70%}
-- **Microprocessors**
+* **Microprocessors**
In contrast, microprocessors are more intricate and serve as the central processing unit within a system. They lack the integrated memory and input/output peripherals commonly found in microcontrollers. These processors are typically present in systems requiring elevated computational power and adaptability. They are suitable for devices where high processing power is a necessity and the tasks are data-intensive.
**Characteristics**:
- - Necessitates external components like memory and input/output peripherals
- - Elevated processing power in comparison to microcontrollers
- - Greater flexibility for connectivity with diverse components
- - Well-suited for data-intensive tasks
+ * Necessitates external components like memory and input/output peripherals
+ * Elevated processing power in comparison to microcontrollers
+ * Greater flexibility for connectivity with diverse components
+ * Well-suited for data-intensive tasks

@@ -102,29 +102,29 @@ Comprehending the distinctions between microcontrollers and microprocessors is e
Embedded systems utilize a variety of memory types, each fulfilling specific roles. Efficient memory management is vital for optimizing both performance and resource utilization. The following section elaborates on different types of memory and their management within the context of embedded systems:
-- **ROM (Read-Only Memory)**: This non-volatile memory retains data written during the manufacturing process and remains unaltered throughout the lifespan of the device. It houses firmware and boot-up instructions.
+* **ROM (Read-Only Memory)**: This non-volatile memory retains data written during the manufacturing process and remains unaltered throughout the lifespan of the device. It houses firmware and boot-up instructions.
-- **RAM (Random Access Memory)**: This volatile memory stores transient data generated during system operation. It is faster and permits read-write operations, but data is lost when power is disconnected.
+* **RAM (Random Access Memory)**: This volatile memory stores transient data generated during system operation. It is faster and permits read-write operations, but data is lost when power is disconnected.
-- **Flash Memory**: This is a type of non-volatile memory that can be electrically erased and reprogrammed. It is commonly used for storing firmware or data that must be retained between system reboots.
+* **Flash Memory**: This is a type of non-volatile memory that can be electrically erased and reprogrammed. It is commonly used for storing firmware or data that must be retained between system reboots.
**Memory Management**:
-- **Static Memory Allocation**: In this approach, memory is allocated prior to runtime and remains fixed throughout system operation.
+* **Static Memory Allocation**: In this approach, memory is allocated prior to runtime and remains fixed throughout system operation.
-- **Dynamic Memory Allocation**: Here, memory is allocated during runtime, offering flexibility but introducing the risk of increased complexity and potential memory leaks.
+* **Dynamic Memory Allocation**: Here, memory is allocated during runtime, offering flexibility but introducing the risk of increased complexity and potential memory leaks.
### System on Chip (SoC)
The majority of embedded systems are Systems on Chip (SoCs). An SoC embodies an advanced level of integration technology, incorporating most components required to construct a complete system onto a single chip. It often includes a microprocessor or microcontroller, blocks of memory, peripheral interfaces, and other requisite components for a fully operational system. Below is a detailed examination of its characteristics and applications:
-- **Integration of Multiple Components**: SoCs consolidate multiple components like CPUs, memory, and peripherals onto a single chip, facilitating higher levels of integration and reducing the need for external components.
+* **Integration of Multiple Components**: SoCs consolidate multiple components like CPUs, memory, and peripherals onto a single chip, facilitating higher levels of integration and reducing the need for external components.
-- **Power Efficiency**: The high degree of integration often results in SoCs being more power-efficient compared to systems assembled from separate chips.
+* **Power Efficiency**: The high degree of integration often results in SoCs being more power-efficient compared to systems assembled from separate chips.
-- **Cost-Effectiveness**: The integrated nature leads to reduced manufacturing expenses, as fewer individual components are needed.
+* **Cost-Effectiveness**: The integrated nature leads to reduced manufacturing expenses, as fewer individual components are needed.
-- **Applications**: SoCs are employed in a diverse range of sectors including mobile computing, automotive electronics, and Internet of Things devices where compact form factors and energy efficiency are highly valued.
+* **Applications**: SoCs are employed in a diverse range of sectors including mobile computing, automotive electronics, and Internet of Things devices where compact form factors and energy efficiency are highly valued.
Here is a list of widely recognized SoCs that have found substantial applications across various domains:
@@ -156,15 +156,15 @@ Each of these Systems on Chip (SoCs) offers a unique array of features and capab
Programming for embedded systems differs significantly from traditional software development, being specifically designed to navigate the constraints of limited resources and real-time requirements commonly associated with embedded hardware. This section aims to shed light on the distinct programming languages employed, delve into the subtleties of firmware development, and explore the pivotal role of Real-time Operating Systems (RTOS) in this specialized domain.
-### Programming Languages: C, C++, Python, etc.
+### Programming Languages: C, C++, Python, etc
Choosing the right programming languages is essential in embedded systems, often emphasizing direct hardware interaction and memory usage optimization. Here, we will examine the unique attributes of these languages and how they differ from those commonly used in more conventional computing systems:
-- **C**: Often considered the bedrock of embedded systems programming, the C language enables direct engagement with hardware, providing capabilities for bit-wise operations and memory address manipulation. Its procedural nature and low-level functionalities make it the preferred choice for resource-constrained environments, particularly for firmware development.
+* **C**: Often considered the bedrock of embedded systems programming, the C language enables direct engagement with hardware, providing capabilities for bit-wise operations and memory address manipulation. Its procedural nature and low-level functionalities make it the preferred choice for resource-constrained environments, particularly for firmware development.
-- **C++**: Building upon the foundational principles of C, C++ incorporates object-oriented features, promoting organized and modular code development. Despite its inherent complexity, it is employed in scenarios where higher-level abstractions do not undermine the detailed control offered by C.
+* **C++**: Building upon the foundational principles of C, C++ incorporates object-oriented features, promoting organized and modular code development. Despite its inherent complexity, it is employed in scenarios where higher-level abstractions do not undermine the detailed control offered by C.
-- **Python**: Although not a traditional choice for embedded systems due to its higher memory consumption and runtime delays, Python is gradually gaining traction in the embedded sphere, particularly in systems with less stringent resource limitations. A specialized variant known as MicroPython has been developed, optimized for microcontrollers and retaining the simplicity and ease of Python. This flexible programming paradigm facilitates quick prototyping and development, as illustrated by the code snippet below that interfaces with pins on a [PyBoard](https://store.micropython.org/).
+* **Python**: Although not a traditional choice for embedded systems due to its higher memory consumption and runtime delays, Python is gradually gaining traction in the embedded sphere, particularly in systems with less stringent resource limitations. A specialized variant known as MicroPython has been developed, optimized for microcontrollers and retaining the simplicity and ease of Python. This flexible programming paradigm facilitates quick prototyping and development, as illustrated by the code snippet below that interfaces with pins on a [PyBoard](https://store.micropython.org/).
```python
import pyb # Package from PyBoard
@@ -229,11 +229,11 @@ If you examine @fig-nicla-io closely, you will notice indications of I/O pinouts
Communication protocols act as the channels that enable communication between various components within or connected to an embedded system. Let us examine some commonly used ones:
-- **SPI (Serial Peripheral Interface)**: This synchronous serial communication protocol is primarily used for short-distance communication in embedded systems. For instance, it is frequently employed in communications with SD cards and TFT displays.
+* **SPI (Serial Peripheral Interface)**: This synchronous serial communication protocol is primarily used for short-distance communication in embedded systems. For instance, it is frequently employed in communications with SD cards and TFT displays.
-- **I2C (Inter-Integrated Circuit)**: This multi-master, multi-slave, packet-switched, single-ended, serial communication bus is widely used in embedded systems to connect low-speed peripherals to motherboards, embedded systems, or cell phones. It is valued for its simplicity and low pin count.
+* **I2C (Inter-Integrated Circuit)**: This multi-master, multi-slave, packet-switched, single-ended, serial communication bus is widely used in embedded systems to connect low-speed peripherals to motherboards, embedded systems, or cell phones. It is valued for its simplicity and low pin count.
-- **UART (Universal Asynchronous Receiver-Transmitter)**: This protocol enables asynchronous serial communication between devices. It is commonly used in embedded systems to transmit data between devices over a serial port, such as sending data logs from a sensor node to a computer.
+* **UART (Universal Asynchronous Receiver-Transmitter)**: This protocol enables asynchronous serial communication between devices. It is commonly used in embedded systems to transmit data between devices over a serial port, such as sending data logs from a sensor node to a computer.
Compared to general-purpose systems, communication protocols in embedded systems are often more finely tuned for speed and reliability, especially in critical applications where data transmission integrity is crucial. Additionally, these protocols may be directly integrated into the microcontroller, facilitating more cohesive and seamless interactions between components, a feature less commonly observed in general-purpose systems.
@@ -265,10 +265,6 @@ Managing batteries is an integral component of power management strategies in em
By focusing on these elements, engineers can create systems that not only meet functional requirements but do so in a manner that reflects a deep understanding of the broader impacts of technology on society and the environment.
-
-
-
-
Engineers are tasked with implementing methods such as effective charge regulation, protection against voltage spikes, and thermal monitoring to ensure the longevity and health of the battery. Additionally, the incorporation of systems that can tap into renewable energy sources like solar or kinetic energy can augment battery reserves, leading to enduring and eco-friendly solutions.
The emphasis on power management is driven by the imperative to make the most of available resources, prolong battery longevity, and minimize operational expenditures. In scenarios where the embedded systems are situated in remote or hard-to-reach locations, adept power management can substantially cut down on the frequency of maintenance visits, thereby guaranteeing continuous and seamless functionality.
@@ -355,7 +351,6 @@ At the same time, burgeoning opportunities are emerging in sectors like consumer
The table provides a side-by-side comparison between these two distinct types of computing systems, covering a range of categories including processing power, memory capabilities, user interface, and real-time functionalities, among others. The aim of this comparative analysis is to offer readers a concise yet thorough understanding of the unique attributes and specificities of both conventional and embedded computing systems. This, in turn, enables a more nuanced and informed grasp of their respective roles in today's computing landscape.
-
| Category | Traditional Computing System | Embedded System Architecture |
|-----------------------------|-----------------------------------------|------------------------------------------|
| **Hardware Characteristics**| | |
@@ -379,14 +374,14 @@ The table provides a side-by-side comparison between these two distinct types of
| Cost | Variable (Can be high depending on specifications) | Generally Lower (Due to focused functionalities) |
| Use Cases | General (Various applications across sectors) | Specific (Dedicated to particular tasks or applications) |
-
As we gaze into the future, it's clear that the realm of embedded systems stands on the cusp of a transformative era, characterized by groundbreaking innovations, abundant opportunities, and formidable challenges. The horizon is replete with the promise of enhanced connectivity, heightened intelligence, and superior efficiency, carving out a trajectory where embedded systems will serve as the guiding force behind society's technological progress. The path forward is one of discovery and adaptability, where the confluence of technological prowess and creative ingenuity will sculpt a future that is not only rich in technological advancements but also attuned to the intricate and continually shifting needs of a dynamic global landscape. It's a field teeming with possibilities, inviting trailblazers to embark on a journey to define the parameters of a bright and flourishing future.
## Exercises
-Now would be a great time for you to get your hands on a real embedded device, and get it setup.
+Now would be a great time for you to get your hands on a real embedded device, and get it setup.
::: {.callout-tip}
+
## Nicla Vision
If you want to play with an embedded system, try out the Nicla Vision
diff --git a/frameworks.qmd b/frameworks.qmd
index a4e40927..972916b7 100644
--- a/frameworks.qmd
+++ b/frameworks.qmd
@@ -2,11 +2,12 @@

-In this chapter, we explore the landscape of AI frameworks that serve as the foundation for developing machine learning systems. AI frameworks provide the essential tools, libraries, and environments necessary to design, train, and deploy machine learning models. We delve into the evolutionary trajectory of these frameworks, dissect the workings of TensorFlow, and provide insights into the core components and advanced features that define these frameworks.
+In this chapter, we explore the landscape of AI frameworks that serve as the foundation for developing machine learning systems. AI frameworks provide the essential tools, libraries, and environments necessary to design, train, and deploy machine learning models. We delve into the evolutionary trajectory of these frameworks, dissect the workings of TensorFlow, and provide insights into the core components and advanced features that define these frameworks.
Furthermore, we investigate the specialization of frameworks tailored to specific needs, the emergence of frameworks specifically designed for embedded AI, and the criteria for selecting the most suitable framework for your project. This exploration will be rounded off by a glimpse into the future trends that are expected to shape the landscape of ML frameworks in the coming years.
::: {.callout-tip}
+
## Learning Objectives
* Understand the evolution and capabilities of major machine learning frameworks. This includes graph execution models, programming paradigms, hardware acceleration support, and how they have expanded over time.
@@ -15,7 +16,7 @@ Furthermore, we investigate the specialization of frameworks tailored to specifi
* Compare frameworks across different environments like cloud, edge, and tinyML. Learn how frameworks specialize based on computational constraints and hardware.
-* Dive deeper into embedded and tinyML focused frameworks like TensorFlow Lite Micro, CMSIS-NN, TinyEngine etc. and how they optimize for microcontrollers.
+* Dive deeper into embedded and tinyML focused frameworks like TensorFlow Lite Micro, CMSIS-NN, TinyEngine etc. and how they optimize for microcontrollers.
* Explore model conversion and deployment considerations when choosing a framework, including aspects like latency, memory usage, and hardware support.
@@ -27,358 +28,127 @@ Furthermore, we investigate the specialization of frameworks tailored to specifi
## Introduction
-Machine learning frameworks provide the tools and infrastructure to
-efficiently build, train, and deploy machine learning models. In this
-chapter, we will explore the evolution and key capabilities of major
-frameworks like [TensorFlow (TF)](https://www.tensorflow.org/), [PyTorch](https://pytorch.org/), and specialized frameworks for
-embedded devices. We will dive into the components like computational
-graphs, optimization algorithms, hardware acceleration, and more that
-enable developers to quickly construct performant models. Understanding
-these frameworks is essential to leverage the power of deep learning
-across the spectrum from cloud to edge devices.
-
-ML frameworks handle much of the complexity of model development through
-high-level APIs and domain-specific languages that allow practitioners
-to quickly construct models by combining pre-made components and
-abstractions. For example, frameworks like TensorFlow and PyTorch
-provide Python APIs to define neural network architectures using layers,
-optimizers, datasets, and more. This enables rapid iteration compared to
-coding every model detail from scratch.
-
-A key capability offered by frameworks is distributed training engines
-that can scale model training across clusters of GPUs and TPUs. This
-makes it feasible to train state-of-the-art models with billions or
-trillions of parameters on vast datasets. Frameworks also integrate with
-specialized hardware like NVIDIA GPUs to further accelerate training via
-optimizations like parallelization and efficient matrix operations.
-
-In addition, frameworks simplify deploying finished models into
-production through tools like [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving) for scalable model
-serving and [TensorFlow Lite](https://www.tensorflow.org/lite) for optimization on mobile and edge devices.
-Other valuable capabilities include visualization, model optimization
-techniques like quantization and pruning, and monitoring metrics during
-training.
-
-Leading open source frameworks like TensorFlow, PyTorch, and [MXNet](https://mxnet.apache.org/versions/1.9.1/) power
-much of AI research and development today. Commercial offerings like
-[Amazon SageMaker](https://aws.amazon.com/pm/sagemaker/?trk=b6c2fafb-22b1-4a97-a2f7-7e4ab2c7aa28&sc_channel=ps&ef_id=CjwKCAjws9ipBhB1EiwAccEi1JpbBz6j4t7sRUoAiKFDc0mi59faZYge5MuFecAU6zGDQYTFz9NnaBoCV-wQAvD_BwE:G:s&s_kwcid=AL!4422!3!651751060692!e!!g!!amazon%20sagemaker!19852662230!145019225977) and [Microsoft Azure Machine Learning](https://azure.microsoft.com/en-us/free/machine-learning/search/?ef_id=_k_CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE_k_&OCID=AIDcmm5edswduu_SEM__k_CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE_k_&gad=1&gclid=CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE) integrate these
-open source frameworks with proprietary capabilities and enterprise
-tools.
-
-Machine learning engineers and practitioners leverage these robust
-frameworks to focus on high-value tasks like model architecture, feature
-engineering, and hyperparameter tuning instead of infrastructure. The
-goal is to efficiently build and deploy performant models that solve
-real-world problems.
-
-In this chapter, we will explore today\'s leading cloud frameworks and
-how they have adapted models and tools specifically for embedded and
-edge deployment. We will compare programming models, supported hardware,
-optimization capabilities, and more to fully understand how frameworks
-enable scalable machine learning from the cloud to the edge.
+Machine learning frameworks provide the tools and infrastructure to efficiently build, train, and deploy machine learning models. In this chapter, we will explore the evolution and key capabilities of major frameworks like [TensorFlow (TF)](https://www.tensorflow.org/), [PyTorch](https://pytorch.org/), and specialized frameworks for embedded devices. We will dive into the components like computational graphs, optimization algorithms, hardware acceleration, and more that enable developers to quickly construct performant models. Understanding these frameworks is essential to leverage the power of deep learning across the spectrum from cloud to edge devices.
+
+ML frameworks handle much of the complexity of model development through high-level APIs and domain-specific languages that allow practitioners to quickly construct models by combining pre-made components and abstractions. For example, frameworks like TensorFlow and PyTorch provide Python APIs to define neural network architectures using layers, optimizers, datasets, and more. This enables rapid iteration compared to coding every model detail from scratch.
+
+A key capability offered by frameworks is distributed training engines that can scale model training across clusters of GPUs and TPUs. This makes it feasible to train state-of-the-art models with billions or trillions of parameters on vast datasets. Frameworks also integrate with specialized hardware like NVIDIA GPUs to further accelerate training via optimizations like parallelization and efficient matrix operations.
+
+In addition, frameworks simplify deploying finished models into production through tools like [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving) for scalable model serving and [TensorFlow Lite](https://www.tensorflow.org/lite) for optimization on mobile and edge devices. Other valuable capabilities include visualization, model optimization techniques like quantization and pruning, and monitoring metrics during training.
+
+Leading open source frameworks like TensorFlow, PyTorch, and [MXNet](https://mxnet.apache.org/versions/1.9.1/) power much of AI research and development today. Commercial offerings like [Amazon SageMaker](https://aws.amazon.com/pm/sagemaker/?trk¶c2fafb-22b1-4a97-a2f7-7e4ab2c7aa28&sc_channel=ps&ef_id=CjwKCAjws9ipBhB1EiwAccEi1JpbBz6j4t7sRUoAiKFDc0mi59faZYge5MuFecAU6zGDQYTFz9NnaBoCV-wQAvD_BwE:G:s&s_kwcid=AL!4422!3!651751060692!e!!g!!amazon sagemaker!19852662230!145019225977) and [Microsoft Azure Machine Learning](https://azure.microsoft.com/en-us/free/machine-learning/search/?ef_id=_k_CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE_k_&OCID=AIDcmm5edswduu_SEM__k_CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE_k_&gad=1&gclid=CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE) integrate these open source frameworks with proprietary capabilities and enterprise tools.
+
+Machine learning engineers and practitioners leverage these robust frameworks to focus on high-value tasks like model architecture, feature engineering, and hyperparameter tuning instead of infrastructure. The goal is to efficiently build and deploy performant models that solve real-world problems.
+
+In this chapter, we will explore today\'s leading cloud frameworks and how they have adapted models and tools specifically for embedded and edge deployment. We will compare programming models, supported hardware, optimization capabilities, and more to fully understand how frameworks enable scalable machine learning from the cloud to the edge.
## Framework Evolution
-Machine learning frameworks have evolved significantly over time to meet
-the diverse needs of machine learning practitioners and advancements in
-AI techniques. A few decades ago, building and training machine learning
-models required extensive low-level coding and infrastructure. Machine
-learning frameworks have evolved considerably over the past decade to
-meet the expanding needs of practitioners and rapid advances in deep
-learning techniques. Early neural network research was constrained by
-insufficient data and compute power. Building and training machine
-learning models required extensive low-level coding and infrastructure.
-But the release of large datasets like [ImageNet](https://www.image-net.org/) [@deng2009imagenet] and advancements
-in parallel GPU computing unlocked the potential for far deeper neural
-networks.
-
-The first ML frameworks, [Theano](https://pypi.org/project/Theano/#:~:text=Theano%20is%20a%20Python%20library,a%20similar%20interface%20to%20NumPy's.) by @al2016theano and [Caffe](https://caffe.berkeleyvision.org/) by @jia2014caffe, were developed
-by academic institutions (Montreal Institute for Learning Algorithms,
-Berkeley Vision and Learning Center). Amid a growing interest in deep
-learning due to state-of-the-art performance of AlexNet @krizhevsky2012imagenet on the
-ImageNet dataset, private companies and individuals began developing ML
-frameworks, resulting in frameworks such as [Keras](https://keras.io/) by @chollet2018keras, [Chainer](https://chainer.org/) by @tokui2015chainer,
-TensorFlow from Google [@abadi2016tensorflow], [CNTK](https://learn.microsoft.com/en-us/cognitive-toolkit/) by Microsoft [@seide2016cntk], and PyTorch by
-Facebook [@paszke2019pytorch].
-
-Many of these ML frameworks can be divided into categories, namely
-high-level vs. low-level frameworks and static vs. dynamic computational
-graph frameworks. High-level frameworks provide a higher level of
-abstraction than low-level frameworks. That is, high-level frameworks
-have pre-built functions and modules for common ML tasks, such as
-creating, training, and evaluating common ML models as well as
-preprocessing data, engineering features, and visualizing data, which
-low-level frameworks do not have. Thus, high-level frameworks may be
-easier to use, but are not as customizable as low-level frameworks (i.e.
-users of low-level frameworks can define custom layers, loss functions,
-optimization algorithms, etc.). Examples of high-level frameworks
-include TensorFlow/Keras and PyTorch. Examples of low-level ML
-frameworks include TensorFlow with low-level APIs, Theano, Caffe,
-Chainer, and CNTK.
-
-Frameworks like Theano and Caffe used static computational graphs which
-required rigidly defining the full model architecture upfront. Static
-graphs require upfront declaration and limit flexibility. Dynamic graphs
-construct on-the-fly for more iterative development. But around 2016,
-frameworks began adopting dynamic graphs like PyTorch and TensorFlow 2.0
-which can construct graphs on-the-fly. This provides greater flexibility
-for model development. We will discuss these concepts and details later
-on in the AI Training section.
-
-The development of these frameworks facilitated an explosion in model
-size and complexity over time---from early multilayer perceptrons and
-convolutional networks to modern transformers with billions or trillions
-of parameters. In 2016, ResNet models by @he2016deep achieved record ImageNet accuracy
-with over 150 layers and 25 million parameters. Then in 2020, the GPT-3
-language model from OpenAI [@brown2020language] pushed parameters to an astonishing 175 billion using
-model parallelism in frameworks to train across thousands of GPUs and
-TPUs.
-
-Each generation of frameworks unlocked new capabilities that powered
-advancement:
-
-- Theano and TensorFlow (2015) introduced computational graphs and automatic differentiation to simplify model building.
-
-- CNTK (2016) pioneered efficient distributed training by combining model and data parallelism.
-
-- PyTorch (2016) provided imperative programming and dynamic graphs for flexible experimentation.
-
-- TensorFlow 2.0 (2019) made eager execution default for intuitiveness and debugging.
-
-- TensorFlow Graphics (2020) added 3D data structures to handle point clouds and meshes.
-
-In recent years, there has been a convergence on the frameworks.
-TensorFlow and PyTorch have become the overwhelmingly dominant ML
-frameworks, representing more than 95% of ML frameworks used in research
-and production. Keras was integrated into TensorFlow in 2019; Preferred
-Networks transitioned Chainer to PyTorch in 2019; and Microsoft stopped
-actively developing CNTK in 2022 in favor of supporting PyTorch on
-Windows.
-
-{width="3.821385608048994in"
-height="2.5558081802274715in"}
-
-However, a one-size-fits-all approach does not work well across the
-spectrum from cloud to tiny edge devices. Different frameworks represent
-various philosophies around graph execution, declarative versus
-imperative APIs, and more. Declarative defines what the program should
-do while imperative focuses on how it should do it step-by-step. For
-instance, TensorFlow uses graph execution and declarative-style modeling
-while PyTorch adopts eager execution and imperative modeling for more
-Pythonic flexibility. Each approach carries tradeoffs that we will
-discuss later in the Basic Components section.
-
-Today\'s advanced frameworks enable practitioners to develop and deploy
-increasingly complex models - a key driver of innovation in the AI
-field. But they continue to evolve and expand their capabilities for the
-next generation of machine learning. To understand how these systems
-continue to evolve, we will dive deeper into TensorFlow as an example of
-how the framework grew in complexity over time.
+Machine learning frameworks have evolved significantly over time to meet the diverse needs of machine learning practitioners and advancements in AI techniques. A few decades ago, building and training machine learning models required extensive low-level coding and infrastructure. Machine learning frameworks have evolved considerably over the past decade to meet the expanding needs of practitioners and rapid advances in deep learning techniques. Early neural network research was constrained by insufficient data and compute power. Building and training machine learning models required extensive low-level coding and infrastructure. But the release of large datasets like [ImageNet](https://www.image-net.org/) [@deng2009imagenet] and advancements in parallel GPU computing unlocked the potential for far deeper neural networks.
+
+The first ML frameworks, [Theano](https://pypi.org/project/Theano/#:~:text=Theano is a Python library,a similar interface to NumPy's.) by @al2016theano and [Caffe](https://caffe.berkeleyvision.org/) by @jia2014caffe, were developed by academic institutions (Montreal Institute for Learning Algorithms, Berkeley Vision and Learning Center). Amid a growing interest in deep learning due to state-of-the-art performance of AlexNet @krizhevsky2012imagenet on the ImageNet dataset, private companies and individuals began developing ML frameworks, resulting in frameworks such as [Keras](https://keras.io/) by @chollet2018keras, [Chainer](https://chainer.org/) by @tokui2015chainer, TensorFlow from Google [@abadi2016tensorflow], [CNTK](https://learn.microsoft.com/en-us/cognitive-toolkit/) by Microsoft [@seide2016cntk], and PyTorch by Facebook [@paszke2019pytorch].
+
+Many of these ML frameworks can be divided into categories, namely high-level vs. low-level frameworks and static vs. dynamic computational graph frameworks. High-level frameworks provide a higher level of abstraction than low-level frameworks. That is, high-level frameworks have pre-built functions and modules for common ML tasks, such as creating, training, and evaluating common ML models as well as preprocessing data, engineering features, and visualizing data, which low-level frameworks do not have. Thus, high-level frameworks may be easier to use, but are not as customizable as low-level frameworks (i.e. users of low-level frameworks can define custom layers, loss functions, optimization algorithms, etc.). Examples of high-level frameworks include TensorFlow/Keras and PyTorch. Examples of low-level ML frameworks include TensorFlow with low-level APIs, Theano, Caffe, Chainer, and CNTK.
+
+Frameworks like Theano and Caffe used static computational graphs which required rigidly defining the full model architecture upfront. Static graphs require upfront declaration and limit flexibility. Dynamic graphs construct on-the-fly for more iterative development. But around 2016, frameworks began adopting dynamic graphs like PyTorch and TensorFlow 2.0 which can construct graphs on-the-fly. This provides greater flexibility for model development. We will discuss these concepts and details later on in the AI Training section.
+
+The development of these frameworks facilitated an explosion in model size and complexity over time---from early multilayer perceptrons and convolutional networks to modern transformers with billions or trillions of parameters. In 2016, ResNet models by @he2016deep achieved record ImageNet accuracy with over 150 layers and 25 million parameters. Then in 2020, the GPT-3 language model from OpenAI [@brown2020language] pushed parameters to an astonishing 175 billion using model parallelism in frameworks to train across thousands of GPUs and TPUs.
+
+Each generation of frameworks unlocked new capabilities that powered advancement:
+
+* Theano and TensorFlow (2015) introduced computational graphs and automatic differentiation to simplify model building.
+
+* CNTK (2016) pioneered efficient distributed training by combining model and data parallelism.
+
+* PyTorch (2016) provided imperative programming and dynamic graphs for flexible experimentation.
+
+* TensorFlow 2.0 (2019) made eager execution default for intuitiveness and debugging.
+
+* TensorFlow Graphics (2020) added 3D data structures to handle point clouds and meshes.
+
+In recent years, there has been a convergence on the frameworks. TensorFlow and PyTorch have become the overwhelmingly dominant ML frameworks, representing more than 95% of ML frameworks used in research and production. Keras was integrated into TensorFlow in 2019; Preferred Networks transitioned Chainer to PyTorch in 2019; and Microsoft stopped actively developing CNTK in 2022 in favor of supporting PyTorch on Windows.
+
+{width="3.821385608048994in" height="2.5558081802274715in"}
+
+However, a one-size-fits-all approach does not work well across the spectrum from cloud to tiny edge devices. Different frameworks represent various philosophies around graph execution, declarative versus imperative APIs, and more. Declarative defines what the program should do while imperative focuses on how it should do it step-by-step. For instance, TensorFlow uses graph execution and declarative-style modeling while PyTorch adopts eager execution and imperative modeling for more Pythonic flexibility. Each approach carries tradeoffs that we will discuss later in the Basic Components section.
+
+Today\'s advanced frameworks enable practitioners to develop and deploy increasingly complex models - a key driver of innovation in the AI field. But they continue to evolve and expand their capabilities for the next generation of machine learning. To understand how these systems continue to evolve, we will dive deeper into TensorFlow as an example of how the framework grew in complexity over time.
## DeepDive into TensorFlow
-TensorFlow was developed by the Google Brain team and was released as an
-open-source software library on November 9, 2015. It was designed for
-numerical computation using data flow graphs and has since become
-popular for a wide range of machine learning and deep learning
-applications.
+TensorFlow was developed by the Google Brain team and was released as an open-source software library on November 9, 2015. It was designed for numerical computation using data flow graphs and has since become popular for a wide range of machine learning and deep learning applications.
-TensorFlow is both a training and inference framework and provides
-built-in functionality to handle everything from model creation and
-training, to deployment. Since its initial development, the TensorFlow
-ecosystem has grown to include many different "varieties" of TensorFlow
-that are each intended to allow users to support ML on different
-platforms. In this section, we will mainly discuss only the core
-package.
+TensorFlow is both a training and inference framework and provides built-in functionality to handle everything from model creation and training, to deployment. Since its initial development, the TensorFlow ecosystem has grown to include many different "varieties" of TensorFlow that are each intended to allow users to support ML on different platforms. In this section, we will mainly discuss only the core package.
### TF Ecosystem
-1. [TensorFlow Core](https://www.tensorflow.org/tutorials): primary package that most developers engage with. It provides a comprehensive, flexible platform for defining, training, and deploying machine learning models. It includes tf.keras as its high-level API.
+1. [TensorFlow Core](https://www.tensorflow.org/tutorials): primary package that most developers engage with. It provides a comprehensive, flexible platform for defining, training, and deploying machine learning models. It includes tf.keras as its high-level API.
-2. [TensorFlow Lite](https://www.tensorflow.org/lite): designed for deploying lightweight models on mobile, embedded, and edge devices. It offers tools to convert TensorFlow models to a more compact format suitable for limited-resource devices and provides optimized pre-trained models for mobile.
+2. [TensorFlow Lite](https://www.tensorflow.org/lite): designed for deploying lightweight models on mobile, embedded, and edge devices. It offers tools to convert TensorFlow models to a more compact format suitable for limited-resource devices and provides optimized pre-trained models for mobile.
-3. [TensorFlow.js](https://www.tensorflow.org/js): JavaScript library that allows training and deployment of machine learning models directly in the browser or on Node.js. It also provides tools for porting pre-trained TensorFlow models to the browser-friendly format.
+3. [TensorFlow.js](https://www.tensorflow.org/js): JavaScript library that allows training and deployment of machine learning models directly in the browser or on Node.js. It also provides tools for porting pre-trained TensorFlow models to the browser-friendly format.
-4. [TensorFlow on Edge Devices (Coral)](https://developers.googleblog.com/2019/03/introducing-coral-our-platform-for.html): platform of hardware components and software tools from Google that allows the execution of TensorFlow models on edge devices, leveraging Edge TPUs for acceleration.
+4. [TensorFlow on Edge Devices (Coral)](https://developers.googleblog.com/2019/03/introducing-coral-our-platform-for.html): platform of hardware components and software tools from Google that allows the execution of TensorFlow models on edge devices, leveraging Edge TPUs for acceleration.
-5. [TensorFlow Federated (TFF)](https://www.tensorflow.org/federated): framework for machine learning and other computations on decentralized data. TFF facilitates federated learning, allowing model training across many devices without centralizing the data.
+5. [TensorFlow Federated (TFF)](https://www.tensorflow.org/federated): framework for machine learning and other computations on decentralized data. TFF facilitates federated learning, allowing model training across many devices without centralizing the data.
-6. [TensorFlow Graphics](https://www.tensorflow.org/graphics): library for using TensorFlow to carry out graphics-related tasks, including 3D shapes and point clouds processing, using deep learning.
+6. [TensorFlow Graphics](https://www.tensorflow.org/graphics): library for using TensorFlow to carry out graphics-related tasks, including 3D shapes and point clouds processing, using deep learning.
-7. [TensorFlow Hub](https://www.tensorflow.org/hub): repository of reusable machine learning model components to allow developers to reuse pre-trained model components, facilitating transfer learning and model composition
+7. [TensorFlow Hub](https://www.tensorflow.org/hub): repository of reusable machine learning model components to allow developers to reuse pre-trained model components, facilitating transfer learning and model composition
-8. [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving): framework designed for serving and deploying machine learning models for inference in production environments. It provides tools for versioning and dynamically updating deployed models without service interruption.
+8. [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving): framework designed for serving and deploying machine learning models for inference in production environments. It provides tools for versioning and dynamically updating deployed models without service interruption.
-9. [TensorFlow Extended (TFX)](https://www.tensorflow.org/tfx): end-to-end platform designed to deploy and manage machine learning pipelines in production settings. TFX encompasses components for data validation, preprocessing, model training, validation, and serving.
+9. [TensorFlow Extended (TFX)](https://www.tensorflow.org/tfx): end-to-end platform designed to deploy and manage machine learning pipelines in production settings. TFX encompasses components for data validation, preprocessing, model training, validation, and serving.
-TensorFlow was developed to address the limitations of DistBelief [@abadi2016tensorflow]---the
-framework in use at Google from 2011 to 2015---by providing flexibility
-along three axes: 1) defining new layers, 2) refining training
-algorithms, and 3) defining new training algorithms. To understand what
-limitations in DistBelief led to the development of TensorFlow, we will
-first give a brief overview of the Parameter Server Architecture that
-DistBelief employed [@dean2012large].
+TensorFlow was developed to address the limitations of DistBelief [@abadi2016tensorflow]---the framework in use at Google from 2011 to 2015---by providing flexibility along three axes: 1) defining new layers, 2) refining training algorithms, and 3) defining new training algorithms. To understand what limitations in DistBelief led to the development of TensorFlow, we will first give a brief overview of the Parameter Server Architecture that DistBelief employed [@dean2012large].
-The Parameter Server (PS) architecture is a popular design for
-distributing the training of machine learning models, especially deep
-neural networks, across multiple machines. The fundamental idea is to
-separate the storage and management of model parameters from the
-computation used to update these parameters:
+The Parameter Server (PS) architecture is a popular design for distributing the training of machine learning models, especially deep neural networks, across multiple machines. The fundamental idea is to separate the storage and management of model parameters from the computation used to update these parameters:
-**Storage**: The storage and management of model parameters were handled
-by the stateful parameter server processes. Given the large scale of
-models and the distributed nature of the system, these parameters were
-sharded across multiple parameter servers. Each server maintained a
-portion of the model parameters, making it \"stateful\" as it had to
-maintain and manage this state across the training process.
+**Storage**: The storage and management of model parameters were handled by the stateful parameter server processes. Given the large scale of models and the distributed nature of the system, these parameters were sharded across multiple parameter servers. Each server maintained a portion of the model parameters, making it \"stateful\" as it had to maintain and manage this state across the training process.
-**Computation**: The worker processes, which could be run in parallel,
-were stateless and purely computational, processing data and computing
-gradients without maintaining any state or long-term memory [@li2014communication].
+**Computation**: The worker processes, which could be run in parallel, were stateless and purely computational, processing data and computing gradients without maintaining any state or long-term memory [@li2014communication].
-DistBelief and its architecture defined above were crucial in enabling
-distributed deep learning at Google but also introduced limitations that
-motivated the development of TensorFlow:
+DistBelief and its architecture defined above were crucial in enabling distributed deep learning at Google but also introduced limitations that motivated the development of TensorFlow:
### Static Computation Graph
-In the parameter server architecture, model parameters are distributed
-across various parameter servers. Since DistBelief was primarily
-designed for the neural network paradigm, parameters corresponded to a
-fixed structure of the neural network. If the computation graph were
-dynamic, the distribution and coordination of parameters would become
-significantly more complicated. For example, a change in the graph might
-require the initialization of new parameters or the removal of existing
-ones, complicating the management and synchronization tasks of the
-parameter servers. This made it harder to implement models outside the
-neural framework or models that required dynamic computation graphs.
-
-TensorFlow was designed to be a more general computation framework where
-the computation is expressed as a data flow graph. This allows for a
-wider variety of machine learning models and algorithms outside of just
-neural networks, and provides flexibility in refining models.
+In the parameter server architecture, model parameters are distributed across various parameter servers. Since DistBelief was primarily designed for the neural network paradigm, parameters corresponded to a fixed structure of the neural network. If the computation graph were dynamic, the distribution and coordination of parameters would become significantly more complicated. For example, a change in the graph might require the initialization of new parameters or the removal of existing ones, complicating the management and synchronization tasks of the parameter servers. This made it harder to implement models outside the neural framework or models that required dynamic computation graphs.
+
+TensorFlow was designed to be a more general computation framework where the computation is expressed as a data flow graph. This allows for a wider variety of machine learning models and algorithms outside of just neural networks, and provides flexibility in refining models.
### Usability & Deployment
-The parameter server model involves a clear delineation of roles (worker
-nodes and parameter servers), and is optimized for data center
-deployments which might not be optimal for all use cases. For instance,
-on edge devices or in other non-data center environments, this division
-introduces overheads or complexities.
+The parameter server model involves a clear delineation of roles (worker nodes and parameter servers), and is optimized for data center deployments which might not be optimal for all use cases. For instance, on edge devices or in other non-data center environments, this division introduces overheads or complexities.
-TensorFlow was built to run on multiple platforms, from mobile devices
-and edge devices, to cloud infrastructure. It also aimed to provide ease
-of use between local and distributed training, and to be more
-lightweight, and developer friendly.
+TensorFlow was built to run on multiple platforms, from mobile devices and edge devices, to cloud infrastructure. It also aimed to provide ease of use between local and distributed training, and to be more lightweight, and developer friendly.
### Architecture Design
-Rather than using the parameter server architecture, TensorFlow instead
-deploys tasks across a cluster. These tasks are named processes that can
-communicate over a network, and each can execute TensorFlow\'s core
-construct: the dataflow graph, and interface with various computing
-devices (like CPUs or GPUs). This graph is a directed representation
-where nodes symbolize computational operations, and edges depict the
-tensors (data) flowing between these operations.
-
-Despite the absence of traditional parameter servers, some tasks, called
-"PS tasks", still perform the role of storing and managing parameters,
-reminiscent of parameter servers in other systems. The remaining tasks,
-which usually handle computation, data processing, and gradient
-calculations, are referred to as \"worker tasks.\" TensorFlow\'s PS
-tasks can execute any computation representable by the dataflow graph,
-meaning they aren\'t just limited to parameter storage, and the
-computation can be distributed. This capability makes them significantly
-more versatile and gives users the power to program the PS tasks using
-the standard TensorFlow interface, the same one they\'d use to define
-their models. As mentioned above, dataflow graphs' structure also makes
-it inherently good for parallelism allowing for processing of large
-datasets.
+Rather than using the parameter server architecture, TensorFlow instead deploys tasks across a cluster. These tasks are named processes that can communicate over a network, and each can execute TensorFlow\'s core construct: the dataflow graph, and interface with various computing devices (like CPUs or GPUs). This graph is a directed representation where nodes symbolize computational operations, and edges depict the tensors (data) flowing between these operations.
+
+Despite the absence of traditional parameter servers, some tasks, called "PS tasks", still perform the role of storing and managing parameters, reminiscent of parameter servers in other systems. The remaining tasks, which usually handle computation, data processing, and gradient calculations, are referred to as \"worker tasks.\" TensorFlow\'s PS tasks can execute any computation representable by the dataflow graph, meaning they aren\'t just limited to parameter storage, and the computation can be distributed. This capability makes them significantly more versatile and gives users the power to program the PS tasks using the standard TensorFlow interface, the same one they\'d use to define their models. As mentioned above, dataflow graphs' structure also makes it inherently good for parallelism allowing for processing of large datasets.
### Built-in Functionality & Keras
-TensorFlow includes libraries to help users develop and deploy more
-use-case specific models, and since this framework is open-source, this
-list continues to grow. These libraries address the entire ML
-development life-cycle: data preparation, model building, deployment, as
-well as responsible AI.
-
-Additionally, one of TensorFlow's biggest advantages is its integration
-with Keras, though as we will cover in the next section, Pytorch recently also added a Keras integration. Keras is another ML framework that was built to be extremely
-user-friendly and as a result has a high level of abstraction. We will
-cover Keras in more depth later in this chapter, but when discussing its
-integration with TensorFlow, the most important thing to note is that it
-was originally built to be backend agnostic. This means users could
-abstract away these complexities, offering a cleaner, more intuitive way
-to define and train models without worrying about compatibility issues
-with different backends. TensorFlow users had some complaints about the
-usability and readability of TensorFlow's API, so as TF gained
-prominence it integrated Keras as its high-level API. This integration
-offered major benefits to TensorFlow users since it introduced more
-intuitive readability, and portability of models while still taking
-advantage of powerful backend features, Google support, and
-infrastructure to deploy models on various platforms.
+TensorFlow includes libraries to help users develop and deploy more use-case specific models, and since this framework is open-source, this list continues to grow. These libraries address the entire ML development life-cycle: data preparation, model building, deployment, as well as responsible AI.
+
+Additionally, one of TensorFlow's biggest advantages is its integration with Keras, though as we will cover in the next section, Pytorch recently also added a Keras integration. Keras is another ML framework that was built to be extremely user-friendly and as a result has a high level of abstraction. We will cover Keras in more depth later in this chapter, but when discussing its integration with TensorFlow, the most important thing to note is that it was originally built to be backend agnostic. This means users could abstract away these complexities, offering a cleaner, more intuitive way to define and train models without worrying about compatibility issues with different backends. TensorFlow users had some complaints about the usability and readability of TensorFlow's API, so as TF gained prominence it integrated Keras as its high-level API. This integration offered major benefits to TensorFlow users since it introduced more intuitive readability, and portability of models while still taking advantage of powerful backend features, Google support, and infrastructure to deploy models on various platforms.
### Limitations and Challenges
-TensorFlow is one of the most popular deep learning frameworks but does
-have criticisms and weaknesses-- mostly focusing on usability, and
-resource usage. The rapid pace of updates through its support from
-Google, while advantageous, has sometimes led to issues of backward
-compatibility, deprecated functions, and shifting documentation.
-Additionally, even with the Keras implementation, the syntax and
-learning curve of TensorFlow can be difficult for new users. One major
-critique of TensorFlow is its high overhead and memory consumption due
-to the range of built in libraries and support. Some of these concerns
-can be addressed by using pared down versions, but can still be limiting
-in resource-constrained environments.
+TensorFlow is one of the most popular deep learning frameworks but does have criticisms and weaknesses-- mostly focusing on usability, and resource usage. The rapid pace of updates through its support from Google, while advantageous, has sometimes led to issues of backward compatibility, deprecated functions, and shifting documentation. Additionally, even with the Keras implementation, the syntax and learning curve of TensorFlow can be difficult for new users. One major critique of TensorFlow is its high overhead and memory consumption due to the range of built in libraries and support. Some of these concerns can be addressed by using pared down versions, but can still be limiting in resource-constrained environments.
### PyTorch vs. TensorFlow
-PyTorch and TensorFlow have established themselves as frontrunners in
-the industry. Both frameworks offer robust functionalities, but they
-differ in terms of their design philosophies, ease of use, ecosystem,
-and deployment capabilities.
-
-**Design Philosophy and Programming Paradigm:** PyTorch uses a dynamic
-computational graph, termed as eager execution. This makes it intuitive
-and facilitates debugging since operations are executed immediately and
-can be inspected on-the-fly. In comparison, earlier versions of
-TensorFlow were centered around a static computational graph, which
-required the graph\'s complete definition before execution. However,
-TensorFlow 2.0 introduced eager execution by default, making it more
-aligned with PyTorch in this regard. PyTorch\'s dynamic nature and
-Python based approach has enabled its simplicity and flexibility,
-particularly for rapid prototyping. TensorFlow\'s static graph approach
-in its earlier versions had a steeper learning curve; the introduction
-of TensorFlow 2.0, with its Keras integration as the high-level API, has
-significantly simplified the development process.
-
-**Deployment:** PyTorch is heavily favored in research environments,
-deploying PyTorch models in production settings was traditionally
-challenging. However, with the introduction of TorchScript and the
-TorchServe tool, deployment has become more feasible. One of
-TensorFlow\'s strengths lies in its scalability and deployment
-capabilities, especially on embedded and mobile platforms with
-TensorFlow Lite. TensorFlow Serving and TensorFlow.js further facilitate
-deployment in various environments, thus giving it a broader reach in
-the ecosystem.
-
-**Performance:** Both frameworks offer efficient hardware acceleration
-for their operations. However, TensorFlow has a slightly more robust
-optimization workflow, such as the XLA (Accelerated Linear Algebra)
-compiler, which can further boost performance. Its static computational
-graph, in the early versions, was also advantageous for certain
-optimizations.
-
-**Ecosystem:** PyTorch has a growing ecosystem with tools like
-TorchServe for serving models and libraries like TorchVision, TorchText,
-and TorchAudio for specific domains. As we mentioned earlier, TensorFlow
-has a broad and mature ecosystem. TensorFlow Extended (TFX) provides an
-end-to-end platform for deploying production machine learning pipelines.
-Other tools and libraries include TensorFlow Lite, TensorFlow.js,
-TensorFlow Hub, and TensorFlow Serving.
+PyTorch and TensorFlow have established themselves as frontrunners in the industry. Both frameworks offer robust functionalities, but they differ in terms of their design philosophies, ease of use, ecosystem, and deployment capabilities.
+
+**Design Philosophy and Programming Paradigm:** PyTorch uses a dynamic computational graph, termed as eager execution. This makes it intuitive and facilitates debugging since operations are executed immediately and can be inspected on-the-fly. In comparison, earlier versions of TensorFlow were centered around a static computational graph, which required the graph\'s complete definition before execution. However, TensorFlow 2.0 introduced eager execution by default, making it more aligned with PyTorch in this regard. PyTorch\'s dynamic nature and Python based approach has enabled its simplicity and flexibility, particularly for rapid prototyping. TensorFlow\'s static graph approach in its earlier versions had a steeper learning curve; the introduction of TensorFlow 2.0, with its Keras integration as the high-level API, has significantly simplified the development process.
+
+**Deployment:** PyTorch is heavily favored in research environments, deploying PyTorch models in production settings was traditionally challenging. However, with the introduction of TorchScript and the TorchServe tool, deployment has become more feasible. One of TensorFlow\'s strengths lies in its scalability and deployment capabilities, especially on embedded and mobile platforms with TensorFlow Lite. TensorFlow Serving and TensorFlow.js further facilitate deployment in various environments, thus giving it a broader reach in the ecosystem.
+
+**Performance:** Both frameworks offer efficient hardware acceleration for their operations. However, TensorFlow has a slightly more robust optimization workflow, such as the XLA (Accelerated Linear Algebra) compiler, which can further boost performance. Its static computational graph, in the early versions, was also advantageous for certain optimizations.
+
+**Ecosystem:** PyTorch has a growing ecosystem with tools like TorchServe for serving models and libraries like TorchVision, TorchText, and TorchAudio for specific domains. As we mentioned earlier, TensorFlow has a broad and mature ecosystem. TensorFlow Extended (TFX) provides an end-to-end platform for deploying production machine learning pipelines. Other tools and libraries include TensorFlow Lite, TensorFlow.js, TensorFlow Hub, and TensorFlow Serving.
Here's a summarizing comparative analysis:
@@ -390,237 +160,87 @@ Here's a summarizing comparative analysis:
| Ecosystem | TorchServe, TorchVision, TorchText, TorchAudio | TensorFlow Extended (TFX), TensorFlow Lite, TensorFlow.js, TensorFlow Hub, TensorFlow Serving |
| Ease of Use | Preferred for its Pythonic approach and rapid prototyping | Initially steep learning curve; Simplified with Keras in TensorFlow 2.0 |
-
## Basic Framework Components
### Tensor data structures
-To understand tensors, let us start from the familiar concepts in linear
-algebra. Vectors can be represented as a stack of numbers in a
-1-dimensional array. Matrices follow the same idea, and one can think of
-them as many vectors being stacked on each other, making it 2
-dimensional. Higher dimensional tensors work the same way. A
-3-dimensional tensor is simply a set of matrices stacked on top of each
-other in another direction. The figure below demonstrates this step.
-Therefore, vectors and matrices can be considered special cases of
-tensors, with 1D and 2D dimensions respectively.
+To understand tensors, let us start from the familiar concepts in linear algebra. Vectors can be represented as a stack of numbers in a 1-dimensional array. Matrices follow the same idea, and one can think of them as many vectors being stacked on each other, making it 2 dimensional. Higher dimensional tensors work the same way. A 3-dimensional tensor is simply a set of matrices stacked on top of each other in another direction. The figure below demonstrates this step. Therefore, vectors and matrices can be considered special cases of tensors, with 1D and 2D dimensions respectively.
{width="3.9791666666666665in" height="1.9672287839020122in" caption="Visualization of Tensor Data Structure" align="center"}
-Defining formally, in machine learning, tensors are a multi-dimensional
-array of numbers. The number of dimensions defines the rank of the
-tensor. As a generalization of linear algebra, the study of tensors is
-called multilinear algebra. There are noticeable similarities between
-matrices and higher ranked tensors. First, it is possible to extend the
-definitions given in linear algebra to tensors, such as with
-eigenvalues, eigenvectors, and rank (in the linear algebra sense) .
-Furthermore, with the way that we have defined tensors, it is possible
-to turn higher dimensional tensors into matrices. This turns out to be
-very critical in practice, as multiplication of abstract representations
-of higher dimensional tensors are often completed by first converting
-them into matrices for multiplication.
-
-Tensors offer a flexible data structure with its ability to represent
-data in higher dimensions. For example, to represent color image data,
-for each of the pixel values (in 2 dimensions), one needs the color
-values for red, green and blue. With tensors, it is easy to contain
-image data in a single 3-dimensional tensor with each of the numbers
-within it representing a certain color value in the certain location of
-the image. Extending even further, if we wanted to store a series of
-images, we can simply extend the dimensions such that the new dimension
-(to create a 4-dimensional tensor) represents the different images that
-we have. This is exactly what the famous [MNIST](https://www.tensorflow.org/datasets/catalog/mnist) dataset does,
-loading a single 4-dimensional tensor when one calls to load the
-dataset, allowing a compact representation of all the data in one place.
+Defining formally, in machine learning, tensors are a multi-dimensional array of numbers. The number of dimensions defines the rank of the tensor. As a generalization of linear algebra, the study of tensors is called multilinear algebra. There are noticeable similarities between matrices and higher ranked tensors. First, it is possible to extend the definitions given in linear algebra to tensors, such as with eigenvalues, eigenvectors, and rank (in the linear algebra sense) . Furthermore, with the way that we have defined tensors, it is possible to turn higher dimensional tensors into matrices. This turns out to be very critical in practice, as multiplication of abstract representations of higher dimensional tensors are often completed by first converting them into matrices for multiplication.
+
+Tensors offer a flexible data structure with its ability to represent data in higher dimensions. For example, to represent color image data, for each of the pixel values (in 2 dimensions), one needs the color values for red, green and blue. With tensors, it is easy to contain image data in a single 3-dimensional tensor with each of the numbers within it representing a certain color value in the certain location of the image. Extending even further, if we wanted to store a series of images, we can simply extend the dimensions such that the new dimension (to create a 4-dimensional tensor) represents the different images that we have. This is exactly what the famous [MNIST](https://www.tensorflow.org/datasets/catalog/mnist) dataset does, loading a single 4-dimensional tensor when one calls to load the dataset, allowing a compact representation of all the data in one place.
### Computational graphs
#### Graph Definition
-Computational graphs are a key component of deep learning frameworks
-like TensorFlow and PyTorch. They allow us to express complex neural
-network architectures in a way that can be efficiently executed and
-differentiated. A computational graph consists of a directed acyclic
-graph (DAG) where each node represents an operation or variable, and
-edges represent data dependencies between them.
+Computational graphs are a key component of deep learning frameworks like TensorFlow and PyTorch. They allow us to express complex neural network architectures in a way that can be efficiently executed and differentiated. A computational graph consists of a directed acyclic graph (DAG) where each node represents an operation or variable, and edges represent data dependencies between them.
-For example, a node might represent a matrix multiplication operation,
-taking two input matrices (or tensors) and producing an output matrix
-(or tensor). To visualize this, consider the simple example below. The
-directed acyclic graph above computes $z = x \times y$, where each of
-the variables are just numbers.
+For example, a node might represent a matrix multiplication operation, taking two input matrices (or tensors) and producing an output matrix (or tensor). To visualize this, consider the simple example below. The directed acyclic graph above computes $z = x \times y$, where each of the variables are just numbers.
{width="50%" height="auto" align="center" caption="Basic Example of Computational Graph"}
-Underneath the hood, the computational graphs represent abstractions for
-common layers like convolutional, pooling, recurrent, and dense layers,
-with data including activations, weights, biases, are represented in
-tensors. Convolutional layers form the backbone of CNN models for
-computer vision. They detect spatial patterns in input data through
-learned filters. Recurrent layers like LSTMs and GRUs enable processing
-sequential data for tasks like language translation. Attention layers
-are used in transformers to draw global context from the entire input.
-
-Broadly speaking, layers are higher level abstractions that define
-computations on top of those tensors. For example, a Dense layer
-performs a matrix multiplication and addition between input/weight/bias
-tensors. Note that a layer operates on tensors as inputs and outputs and
-the layer itself is not a tensor. Some key differences:
-
-- Layers contain states like weights and biases. Tensors are
- stateless, just holding data.
-
-- Layers can modify internal state during training. Tensors are
- immutable/read-only.
-
-- Layers are higher level abstractions. Tensors are lower level,
- directly representing data and math operations.
-
-- Layers define fixed computation patterns. Tensors flow between
- layers during execution.
-
-- Layers are used indirectly when building models. Tensors flow
- > between layers during execution.
-
-So while tensors are a core data structure that layers consume and
-produce, layers have additional functionality for defining parameterized
-operations and training. While a layer configures tensor operations
-under the hood, the layer itself remains distinct from the tensor
-objects. The layer abstraction makes building and training neural
-networks much more intuitive. This sort of abstraction enables
-developers to build models by stacking these layers together, without
-having to implement the layer logic themselves. For example, calling
-`tf.keras.layers.Conv2D` in TensorFlow creates a convolutional layer. The
-framework handles computing the convolutions, managing parameters, etc.
-This simplifies model development, allowing developers to focus on
-architecture rather than low-level implementations. Layer abstractions
-utilize highly optimized implementations for performance. They also
-enable portability, as the same architecture can run on different
-hardware backends like GPUs and TPUs.
-
-In addition, computational graphs include activation functions like
-ReLU, sigmoid, and tanh that are essential to neural networks and many
-frameworks provide these as standard abstractions. These functions
-introduce non-linearities that enable models to approximate complex
-functions. Frameworks provide these as simple, pre-defined operations
-that can be used when constructing models. For example, tf.nn.relu in
-TensorFlow. This abstraction enables flexibility, as developers can
-easily swap activation functions for tuning performance. Pre-defined
-activations are also optimized by the framework for faster execution.
-
-In recent years, models like ResNets and MobileNets have emerged as
-popular architectures, with current frameworks pre-packaging these as
-computational graphs. Rather than worrying about the fine details,
-developers can utilize them as a starting point, customizing as needed
-by substituting layers. This simplifies and speeds up model development,
-avoiding reinventing architectures from scratch. Pre-defined models
-include well-tested, optimized implementations that ensure good
-performance. Their modular design also enables transferring learned
-features to new tasks via transfer learning. In essence, these
-pre-defined architectures provide high-performance building blocks to
-quickly create robust models.
-
-These layer abstractions, activation functions, and predefined
-architectures provided by the frameworks are what constitute a
-computational graph. When a user defines a layer in a framework (e.g.
-tf.keras.layers.Dense()), the framework is configuring computational
-graph nodes and edges to represent that layer. The layer parameters like
-weights and biases become variables in the graph. The layer computations
-become operation nodes (such as the x and y in the figure above). When
-you call an activation function like tf.nn.relu(), the framework adds a
-ReLU operation node to the graph. Predefined architectures are just
-pre-configured subgraphs that can be inserted into your model\'s graph.
-Thus, model definition via high-level abstractions creates a
-computational graph. The layers, activations, and architectures we use
-become graph nodes and edges.
-
-When we define a neural network architecture in a framework, we are
-implicitly constructing a computational graph. The framework uses this
-graph to determine operations to run during training and inference.
-Computational graphs bring several advantages over raw code and that's
-one of the core functionalities that is offered by a good ML framework:
-
-- Explicit representation of data flow and operations
-
-- Ability to optimize graph before execution
-
-- Automatic differentiation for training
-
-- Language agnosticism - graph can be translated to run on GPUs, TPUs, etc.
-
-- Portability - graph can be serialized, saved, and restored later
-
-Computational graphs are the fundamental building blocks of ML
-frameworks. Model definition via high-level abstractions creates a
-computational graph. The layers, activations, and architectures we use
-become graph nodes and edges. The framework compilers and optimizers
-operate on this graph to generate executable code. Essentially, the
-abstractions provide a developer-friendly API for building computational
-graphs. Under the hood, it\'s still graphs all the way down! So while
-you may not directly manipulate graphs as a framework user, they enable
-your high-level model specifications to be efficiently executed. The
-abstractions simplify model-building while computational graphs make it
-possible.
+Underneath the hood, the computational graphs represent abstractions for common layers like convolutional, pooling, recurrent, and dense layers, with data including activations, weights, biases, are represented in tensors. Convolutional layers form the backbone of CNN models for computer vision. They detect spatial patterns in input data through learned filters. Recurrent layers like LSTMs and GRUs enable processing sequential data for tasks like language translation. Attention layers are used in transformers to draw global context from the entire input.
+
+Broadly speaking, layers are higher level abstractions that define computations on top of those tensors. For example, a Dense layer performs a matrix multiplication and addition between input/weight/bias tensors. Note that a layer operates on tensors as inputs and outputs and the layer itself is not a tensor. Some key differences:
+
+* Layers contain states like weights and biases. Tensors are stateless, just holding data.
+
+* Layers can modify internal state during training. Tensors are immutable/read-only.
+
+* Layers are higher level abstractions. Tensors are lower level, directly representing data and math operations.
+
+* Layers define fixed computation patterns. Tensors flow between layers during execution.
+
+* Layers are used indirectly when building models. Tensors flow between layers during execution.
+
+So while tensors are a core data structure that layers consume and produce, layers have additional functionality for defining parameterized operations and training. While a layer configures tensor operations under the hood, the layer itself remains distinct from the tensor objects. The layer abstraction makes building and training neural networks much more intuitive. This sort of abstraction enables developers to build models by stacking these layers together, without having to implement the layer logic themselves. For example, calling `tf.keras.layers.Conv2D` in TensorFlow creates a convolutional layer. The framework handles computing the convolutions, managing parameters, etc. This simplifies model development, allowing developers to focus on architecture rather than low-level implementations. Layer abstractions utilize highly optimized implementations for performance. They also enable portability, as the same architecture can run on different hardware backends like GPUs and TPUs.
+
+In addition, computational graphs include activation functions like ReLU, sigmoid, and tanh that are essential to neural networks and many frameworks provide these as standard abstractions. These functions introduce non-linearities that enable models to approximate complex functions. Frameworks provide these as simple, pre-defined operations that can be used when constructing models. For example, tf.nn.relu in TensorFlow. This abstraction enables flexibility, as developers can easily swap activation functions for tuning performance. Pre-defined activations are also optimized by the framework for faster execution.
+
+In recent years, models like ResNets and MobileNets have emerged as popular architectures, with current frameworks pre-packaging these as computational graphs. Rather than worrying about the fine details, developers can utilize them as a starting point, customizing as needed by substituting layers. This simplifies and speeds up model development, avoiding reinventing architectures from scratch. Pre-defined models include well-tested, optimized implementations that ensure good performance. Their modular design also enables transferring learned features to new tasks via transfer learning. In essence, these pre-defined architectures provide high-performance building blocks to quickly create robust models.
+
+These layer abstractions, activation functions, and predefined architectures provided by the frameworks are what constitute a computational graph. When a user defines a layer in a framework (e.g. tf.keras.layers.Dense()), the framework is configuring computational graph nodes and edges to represent that layer. The layer parameters like weights and biases become variables in the graph. The layer computations become operation nodes (such as the x and y in the figure above). When you call an activation function like tf.nn.relu(), the framework adds a ReLU operation node to the graph. Predefined architectures are just pre-configured subgraphs that can be inserted into your model\'s graph. Thus, model definition via high-level abstractions creates a computational graph. The layers, activations, and architectures we use become graph nodes and edges.
+
+When we define a neural network architecture in a framework, we are implicitly constructing a computational graph. The framework uses this graph to determine operations to run during training and inference. Computational graphs bring several advantages over raw code and that's one of the core functionalities that is offered by a good ML framework:
+
+* Explicit representation of data flow and operations
+
+* Ability to optimize graph before execution
+
+* Automatic differentiation for training
+
+* Language agnosticism - graph can be translated to run on GPUs, TPUs, etc.
+
+* Portability - graph can be serialized, saved, and restored later
+
+Computational graphs are the fundamental building blocks of ML frameworks. Model definition via high-level abstractions creates a computational graph. The layers, activations, and architectures we use become graph nodes and edges. The framework compilers and optimizers operate on this graph to generate executable code. Essentially, the abstractions provide a developer-friendly API for building computational graphs. Under the hood, it\'s still graphs all the way down! So while you may not directly manipulate graphs as a framework user, they enable your high-level model specifications to be efficiently executed. The abstractions simplify model-building while computational graphs make it possible.
#### Static vs. Dynamic Graphs
-Deep learning frameworks have traditionally followed one of two
-approaches for expressing computational graphs.
+Deep learning frameworks have traditionally followed one of two approaches for expressing computational graphs.
-**Static graphs (declare-then-execute):** With this model, the entire
-computational graph must be defined upfront before it can be run. All
-operations and data dependencies must be specified during the
-declaration phase. TensorFlow originally followed this static approach -
-models were defined in a separate context, then a session was created to
-run them. The benefit of static graphs is they allow more aggressive
-optimization, since the framework can see the full graph. But it also
-tends to be less flexible for research and interactivity. Changes to the
-graph require re-declaring the full model.
+**Static graphs (declare-then-execute):** With this model, the entire computational graph must be defined upfront before it can be run. All operations and data dependencies must be specified during the declaration phase. TensorFlow originally followed this static approach - models were defined in a separate context, then a session was created to run them. The benefit of static graphs is they allow more aggressive optimization, since the framework can see the full graph. But it also tends to be less flexible for research and interactivity. Changes to the graph require re-declaring the full model.
For example:
-```{{python}}
-x = tf.placeholder(tf.float32)
-y = tf.matmul(x, weights) + biases
-```
-
-The model is defined separately from execution, like building a
-blueprint. For TensorFlow 1.x, this is done using tf.Graph(). All ops
-and variables must be declared upfront. Subsequently, the graph is
-compiled and optimized before running. Execution is done later by
-feeding in tensor values.
-
-**Dynamic graphs (define-by-run):** In contrast to declare (all) first
-and then execute, the graph is built dynamically as execution happens.
-There is no separate declaration phase - operations execute immediately
-as they are defined. This style is more imperative and flexible,
-facilitating experimentation.
-
-PyTorch uses dynamic graphs, building the graph on-the-fly as execution
-happens. For example, consider the following code snippet, where the
-graph is built as the execution is taking place:
-
-```{{python}}
-x = torch.randn(4,784)
-y = torch.matmul(x, weights) + biases
-```
-
-In the above example, there are no separate compile/build/run phases.
-Ops define and execute immediately. With dynamic graphs, definition is
-intertwined with execution. This provides a more intuitive, interactive
-workflow. But the downside is less potential for optimizations, since
-the framework only sees the graph as it is built.
-
-Recently, however, the distinction has blurred as frameworks adopt both
-modes. TensorFlow 2.0 defaults to dynamic graph mode, while still
-letting users work with static graphs when needed. Dynamic declaration
-makes frameworks easier to use, while static models provide optimization
-benefits. The ideal framework offers both options.
-
-Static graph declaration provides optimization opportunities but less
-interactivity. While dynamic execution offers flexibility and ease of
-use, it may have performance overhead. Here is a table comparing the
-pros and cons of static vs dynamic execution graphs:
+```{{python}} x = tf.placeholder(tf.float32) y = tf.matmul(x, weights) + biases ```
+
+The model is defined separately from execution, like building a blueprint. For TensorFlow 1.x, this is done using tf.Graph(). All ops and variables must be declared upfront. Subsequently, the graph is compiled and optimized before running. Execution is done later by feeding in tensor values.
+
+**Dynamic graphs (define-by-run):** In contrast to declare (all) first and then execute, the graph is built dynamically as execution happens. There is no separate declaration phase - operations execute immediately as they are defined. This style is more imperative and flexible, facilitating experimentation.
+
+PyTorch uses dynamic graphs, building the graph on-the-fly as execution happens. For example, consider the following code snippet, where the graph is built as the execution is taking place:
+
+```{{python}} x = torch.randn(4,784) y = torch.matmul(x, weights) + biases ```
+
+In the above example, there are no separate compile/build/run phases. Ops define and execute immediately. With dynamic graphs, definition is intertwined with execution. This provides a more intuitive, interactive workflow. But the downside is less potential for optimizations, since the framework only sees the graph as it is built.
+
+Recently, however, the distinction has blurred as frameworks adopt both modes. TensorFlow 2.0 defaults to dynamic graph mode, while still letting users work with static graphs when needed. Dynamic declaration makes frameworks easier to use, while static models provide optimization benefits. The ideal framework offers both options.
+
+Static graph declaration provides optimization opportunities but less interactivity. While dynamic execution offers flexibility and ease of use, it may have performance overhead. Here is a table comparing the pros and cons of static vs dynamic execution graphs:
| Execution Graph | Pros | Cons |
| --- | --- | --- |
@@ -629,88 +249,31 @@ pros and cons of static vs dynamic execution graphs:
### Data Pipeline Tools
-Computational graphs can only be as good as the data they learn from and
-work on. Therefore, feeding training data efficiently is crucial for
-optimizing deep neural networks performance, though it is often
-overlooked as one of the core functionalities. Many modern AI frameworks
-provide specialized pipelines to ingest, process, and augment datasets
-for model training.
+Computational graphs can only be as good as the data they learn from and work on. Therefore, feeding training data efficiently is crucial for optimizing deep neural networks performance, though it is often overlooked as one of the core functionalities. Many modern AI frameworks provide specialized pipelines to ingest, process, and augment datasets for model training.
#### Data Loaders
-At the core of these pipelines are data loaders, which handle reading
-examples from storage formats like CSV files or image folders. Reading
-training examples from sources like files, databases, object storage,
-etc. is the job of the data loaders. Deep learning models require
-diverse data formats depending on the application. Among the popular
-formats are CSV: A versatile, simple format often used for tabular data.
-TFRecord: TensorFlow\'s proprietary format, optimized for performance.
-Parquet: Columnar storage, offering efficient data compression and
-retrieval. JPEG/PNG: Commonly used for image data. WAV/MP3: Prevalent
-formats for audio data. For instance, `tf.data` is TensorFlows's
-dataloading pipeline: .
-
-Data loaders batch examples to leverage vectorization support in
-hardware. Batching refers to grouping multiple data points for
-simultaneous processing, leveraging the vectorized computation
-capabilities of hardware like GPUs. While typical batch sizes range from
-32-512 examples, the optimal size often depends on the memory footprint
-of the data and the specific hardware constraints. Advanced loaders can
-stream virtually unlimited datasets from disk and cloud storage.
-Streaming large datasets from disk or networks instead of loading fully
-into memory. This enables virtually unlimited dataset sizes.
-
-Data loaders can also shuffle data across epochs for randomization, and
-preprocess features in parallel with model training to expedite the
-training process. Randomly shuffling the order of examples between
-training epochs reduces bias and improves generalization.
-
-Data loaders also support caching and prefetching strategies to optimize
-data delivery for fast, smooth model training. Caching preprocessed
-batches in memory so they can be reused efficiently during multiple
-training steps. Caching these batches in memory eliminates redundant
-processing. Prefetching, on the other hand, involves preloading
-subsequent batches, ensuring that the model never idles waiting for
-data.
+At the core of these pipelines are data loaders, which handle reading examples from storage formats like CSV files or image folders. Reading training examples from sources like files, databases, object storage, etc. is the job of the data loaders. Deep learning models require diverse data formats depending on the application. Among the popular formats are CSV: A versatile, simple format often used for tabular data. TFRecord: TensorFlow\'s proprietary format, optimized for performance. Parquet: Columnar storage, offering efficient data compression and retrieval. JPEG/PNG: Commonly used for image data. WAV/MP3: Prevalent formats for audio data. For instance, `tf.data` is TensorFlows's dataloading pipeline: .
+
+Data loaders batch examples to leverage vectorization support in hardware. Batching refers to grouping multiple data points for simultaneous processing, leveraging the vectorized computation capabilities of hardware like GPUs. While typical batch sizes range from 32-512 examples, the optimal size often depends on the memory footprint of the data and the specific hardware constraints. Advanced loaders can stream virtually unlimited datasets from disk and cloud storage. Streaming large datasets from disk or networks instead of loading fully into memory. This enables virtually unlimited dataset sizes.
+
+Data loaders can also shuffle data across epochs for randomization, and preprocess features in parallel with model training to expedite the training process. Randomly shuffling the order of examples between training epochs reduces bias and improves generalization.
+
+Data loaders also support caching and prefetching strategies to optimize data delivery for fast, smooth model training. Caching preprocessed batches in memory so they can be reused efficiently during multiple training steps. Caching these batches in memory eliminates redundant processing. Prefetching, on the other hand, involves preloading subsequent batches, ensuring that the model never idles waiting for data.
### Data Augmentation
-Besides loading, data augmentation expands datasets synthetically.
-Augmentations apply random transformations like flipping, cropping,
-rotating, altering color, adding noise etc. for images. For audio,
-common augmentations involve mixing clips with background noise, or
-modulating speed/pitch/volume.
-
-Augmentations increase variation in the training data. Frameworks like
-TensorFlow and PyTorch simplify applying random augmentations each epoch
-by integrating into the data pipeline.By programmatically increasing
-variation in the training data distribution, augmentations reduce
-overfitting and improve model generalization.
-
-Many frameworks make it easy to integrate augmentations into the data
-pipeline so they are applied on-the-fly each epoch. Together, performant
-data loaders and extensive augmentations enable practitioners to feed
-massive, varied datasets to neural networks efficiently. Hands-off data
-pipelines represent a significant improvement in usability and
-productivity. They allow developers to focus more on model architecture
-and less on data wrangling when training deep learning models.
+Besides loading, data augmentation expands datasets synthetically. Augmentations apply random transformations like flipping, cropping, rotating, altering color, adding noise etc. for images. For audio, common augmentations involve mixing clips with background noise, or modulating speed/pitch/volume.
+
+Augmentations increase variation in the training data. Frameworks like TensorFlow and PyTorch simplify applying random augmentations each epoch by integrating into the data pipeline.By programmatically increasing variation in the training data distribution, augmentations reduce overfitting and improve model generalization.
+
+Many frameworks make it easy to integrate augmentations into the data pipeline so they are applied on-the-fly each epoch. Together, performant data loaders and extensive augmentations enable practitioners to feed massive, varied datasets to neural networks efficiently. Hands-off data pipelines represent a significant improvement in usability and productivity. They allow developers to focus more on model architecture and less on data wrangling when training deep learning models.
### Optimization Algorithms
-Training a neural network is fundamentally an iterative process that
-seeks to minimize a loss function. At its core, the goal is to fine-tune
-the model weights and parameters to produce predictions as close as
-possible to the true target labels. Machine learning frameworks have
-greatly streamlined this process by offering extensive support in three
-critical areas: loss functions, optimization algorithms, and
-regularization techniques.
-
-Loss Functions are useful to quantify the difference between the
-model\'s predictions and the true values. Different datasets require a
-different loss function to perform properly, as the loss function tells
-the computer the "objective" for it to aim to. Commonly used loss
-functions are Mean Squared Error (MSE) for regression tasks and
-Cross-Entropy Loss for classification tasks.
+Training a neural network is fundamentally an iterative process that seeks to minimize a loss function. At its core, the goal is to fine-tune the model weights and parameters to produce predictions as close as possible to the true target labels. Machine learning frameworks have greatly streamlined this process by offering extensive support in three critical areas: loss functions, optimization algorithms, and regularization techniques.
+
+Loss Functions are useful to quantify the difference between the model\'s predictions and the true values. Different datasets require a different loss function to perform properly, as the loss function tells the computer the "objective" for it to aim to. Commonly used loss functions are Mean Squared Error (MSE) for regression tasks and Cross-Entropy Loss for classification tasks.
To demonstrate some of the loss functions, imagine that you have a set of inputs and the corresponding outputs, $Y_n$ that denotes the output of $n$'th value. The inputs are fed into the model, and the model outputs a prediction, which we can call $\hat{Y_n}$. With the predicted value and the real value, we can for example use the MSE to calculate the loss function:
@@ -720,363 +283,129 @@ If the problem is a classification problem, we do not want to use the MSE, since
$$Cross-Entropy = -\sum_{n=1}^{N}Y_n\log(\hat{Y_n})$$
+Once the loss like above is computed, we need methods to adjust the model\'s parameters to reduce this loss or error during the training process. To do so, current frameworks use a gradient based approach, where it computes how much changes tuning the weights in a certain way changes the value of the loss function. Knowing this gradient, the model moves in the direction that reduces the gradient. There are many challenges associated with this, however, primarily stemming from the fact that the optimization problem is not convex, making it very easy to solve, and more details about this will come in the AI Training section. Modern frameworks come equipped with efficient implementations of several optimization algorithms, many of which are variants of gradient descent algorithms with stochastic methods and adaptive learning rates. More information with clear examples can be found in the AI Training section.
-
-Once the loss like above is computed, we need methods to adjust the model\'s
-parameters to reduce this loss or error during the training process. To
-do so, current frameworks use a gradient based approach, where it
-computes how much changes tuning the weights in a certain way changes
-the value of the loss function. Knowing this gradient, the model moves
-in the direction that reduces the gradient. There are many challenges
-associated with this, however, primarily stemming from the fact that the
-optimization problem is not convex, making it very easy to solve, and
-more details about this will come in the AI Training section. Modern
-frameworks come equipped with efficient implementations of several
-optimization algorithms, many of which are variants of gradient descent
-algorithms with stochastic methods and adaptive learning rates. More
-information with clear examples can be found in the AI Training section.
-
-Last but not least, overly complex models tend to overfit, meaning they
-perform well on the training data but fail to generalize to new, unseen
-data (see Overfitting). To counteract this, regularization methods are
-employed to penalize model complexity and encourage it to learn simpler
-patterns. Dropout for instance randomly sets a fraction of input units
-to 0 at each update during training, which helps prevent overfitting.
+Last but not least, overly complex models tend to overfit, meaning they perform well on the training data but fail to generalize to new, unseen data (see Overfitting). To counteract this, regularization methods are employed to penalize model complexity and encourage it to learn simpler patterns. Dropout for instance randomly sets a fraction of input units to 0 at each update during training, which helps prevent overfitting.
However, there are cases where the problem is more complex than what the model can represent, and this may result in underfitting. Therefore, choosing the right model architecture is also a critical step in the training process. Further heuristics and techniques are discussed in the AI Training section.
-Frameworks also provide efficient implementations of gradient descent,
-Adagrad, Adadelta, and Adam. Adding regularization like dropout and
-L1/L2 penalties prevents overfitting during training. Batch
-normalization accelerates training by normalizing inputs to layers.
+Frameworks also provide efficient implementations of gradient descent, Adagrad, Adadelta, and Adam. Adding regularization like dropout and L1/L2 penalties prevents overfitting during training. Batch normalization accelerates training by normalizing inputs to layers.
### Model Training Support
-Before training a defined neural network model, a compilation step is
-required. During this step, the high-level architecture of the neural
-network is transformed into an optimized, executable format. This
-process comprises several steps. The construction of the computational
-graph is the first step. It represents all the mathematical operations
-and data flow within the model. We discussed this earlier.
-
-During training, the focus is on executing the computational graph.
-Every parameter within the graph, such as weights and biases, is
-assigned an initial value. This value might be random or based on a
-predefined logic, depending on the chosen initialization method.
-
-The next critical step is memory allocation. Essential memory is
-reserved for the model\'s operations on both CPUs and GPUs, ensuring
-efficient data processing. The model\'s operations are then mapped to
-the available hardware resources, particularly GPUs or TPUs, to expedite
-computation. Once compilation is finalized, the model is prepared for
-training.
-
-The training process employs various tools to enhance efficiency. Batch
-processing is commonly used to maximize computational throughput.
-Techniques like vectorization enable operations on entire data arrays,
-rather than proceeding element-wise, which bolsters speed. Optimizations
-such as kernel fusion (refer to the Optimizations chapter) amalgamate
-multiple operations into a single action, minimizing computational
-overhead. Operations can also be segmented into phases, facilitating the
-concurrent processing of different mini-batches at various stages.
-
-Frameworks consistently checkpoint the state, preserving intermediate
-model versions during training. This ensures that if an interruption
-occurs, the progress isn\'t wholly lost, and training can recommence
-from the last checkpoint. Additionally, the system vigilantly monitors
-the model\'s performance against a validation data set. Should the model
-begin to overfit (that is, if its performance on the validation set
-declines), training is automatically halted, conserving computational
-resources and time.
-
-ML frameworks incorporate a blend of model compilation, enhanced batch
-processing methods, and utilities such as checkpointing and early
-stopping. These resources manage the complex aspects of performance,
-enabling practitioners to zero in on model development and training. As
-a result, developers experience both speed and ease when utilizing the
-capabilities of neural networks.
+Before training a defined neural network model, a compilation step is required. During this step, the high-level architecture of the neural network is transformed into an optimized, executable format. This process comprises several steps. The construction of the computational graph is the first step. It represents all the mathematical operations and data flow within the model. We discussed this earlier.
+
+During training, the focus is on executing the computational graph. Every parameter within the graph, such as weights and biases, is assigned an initial value. This value might be random or based on a predefined logic, depending on the chosen initialization method.
+
+The next critical step is memory allocation. Essential memory is reserved for the model\'s operations on both CPUs and GPUs, ensuring efficient data processing. The model\'s operations are then mapped to the available hardware resources, particularly GPUs or TPUs, to expedite computation. Once compilation is finalized, the model is prepared for training.
+
+The training process employs various tools to enhance efficiency. Batch processing is commonly used to maximize computational throughput. Techniques like vectorization enable operations on entire data arrays, rather than proceeding element-wise, which bolsters speed. Optimizations such as kernel fusion (refer to the Optimizations chapter) amalgamate multiple operations into a single action, minimizing computational overhead. Operations can also be segmented into phases, facilitating the concurrent processing of different mini-batches at various stages.
+
+Frameworks consistently checkpoint the state, preserving intermediate model versions during training. This ensures that if an interruption occurs, the progress isn\'t wholly lost, and training can recommence from the last checkpoint. Additionally, the system vigilantly monitors the model\'s performance against a validation data set. Should the model begin to overfit (that is, if its performance on the validation set declines), training is automatically halted, conserving computational resources and time.
+
+ML frameworks incorporate a blend of model compilation, enhanced batch processing methods, and utilities such as checkpointing and early stopping. These resources manage the complex aspects of performance, enabling practitioners to zero in on model development and training. As a result, developers experience both speed and ease when utilizing the capabilities of neural networks.
### Validation and Analysis
-After training deep learning models, frameworks provide utilities to
-evaluate performance and gain insights into the models\' workings. These
-tools enable disciplined experimentation and debugging.
+After training deep learning models, frameworks provide utilities to evaluate performance and gain insights into the models\' workings. These tools enable disciplined experimentation and debugging.
#### Evaluation Metrics
-Frameworks include implementations of common evaluation metrics for
-validation:
+Frameworks include implementations of common evaluation metrics for validation:
-- Accuracy - Fraction of correct predictions overall. Widely used for classification.
+* Accuracy - Fraction of correct predictions overall. Widely used for classification.
-- Precision - Of positive predictions, how many were actually positive. Useful for imbalanced datasets.
+* Precision - Of positive predictions, how many were actually positive. Useful for imbalanced datasets.
-- Recall - Of actual positives, how many did we predict correctly. Measures completeness.
+* Recall - Of actual positives, how many did we predict correctly. Measures completeness.
-- F1-score - Harmonic mean of precision and recall. Combines both metrics.
+* F1-score - Harmonic mean of precision and recall. Combines both metrics.
-- AUC-ROC - Area under ROC curve. Used for classification threshold analysis.
+* AUC-ROC - Area under ROC curve. Used for classification threshold analysis.
-- MAP - Mean Average Precision. Evaluates ranked predictions in retrieval/detection.
+* MAP - Mean Average Precision. Evaluates ranked predictions in retrieval/detection.
-- Confusion Matrix - Matrix that shows the true positives, true negatives, false positives, and false negatives. Provides a more detailed view of classification performance.
+* Confusion Matrix - Matrix that shows the true positives, true negatives, false positives, and false negatives. Provides a more detailed view of classification performance.
-These metrics quantify model performance on validation data for
-comparison.
+These metrics quantify model performance on validation data for comparison.
#### Visualization
Visualization tools provide insight into models:
-- Loss curves - Plot training and validation loss over time to spot overfitting.
-
+* Loss curves - Plot training and validation loss over time to spot overfitting.
+* Activation grids - Illustrate features learned by convolutional filters.
-- Activation grids - Illustrate features learned by convolutional filters.
+* Projection - Reduce dimensionality for intuitive visualization.
-- Projection - Reduce dimensionality for intuitive visualization.
+* Precision-recall curves - Assess classification tradeoffs.
-- Precision-recall curves - Assess classification tradeoffs.
-
-Tools like [TensorBoard](https://www.tensorflow.org/tensorboard/scalars_and_keras)
-for TensorFlow and [TensorWatch](https://github.com/microsoft/tensorwatch) for PyTorch enable
-real-time metrics and visualization during training.
+Tools like [TensorBoard](https://www.tensorflow.org/tensorboard/scalars_and_keras) for TensorFlow and [TensorWatch](https://github.com/microsoft/tensorwatch) for PyTorch enable real-time metrics and visualization during training.
### Differentiable programming
-With the machine learning training methods such as backpropagation
-relying on the change in the loss function with respect to the change in
-weights (which essentially is the definition of derivatives), the
-ability to quickly and efficiently train large machine learning models
-rely on the computer's ability to take derivatives. This makes
-differentiable programming one of the most important elements of a
-machine learning framework.
-
-There are primarily four methods that we can use to make computers take
-derivatives. First, we can manually figure out the derivatives by hand
-and input them to the computer. One can see that this would quickly
-become a nightmare with many layers of neural networks, if we had to
-compute all the derivatives in the backpropagation steps by hand.
-Another method is symbolic differentiation using computer algebra
-systems such as Mathematica, but this can introduce a layer of
-inefficiency, as there needs to be a level of abstraction to take
-derivatives. Numerical derivatives, the practice of approximating
-gradients using finite difference methods, suffer from many problems
-including high computational costs, and larger grid size can lead to a
-significant amount of errors. This leads to automatic differentiation,
-which exploits the primitive functions that computers use to represent
-operations to obtain an exact derivative. With automatic
-differentiation, computational complexity of computing the gradient is
-proportional to computing the function itself. Intricacies of automatic
-differentiation are not dealt with by end users now, but resources to
-learn more can be found widely, such as from
-[here](https://www.cs.toronto.edu/~rgrosse/courses/csc321_2018/slides/lec10.pdf).
-Automatic differentiation and differentiable programming today is
-ubiquitous and is done efficiently and automatically by modern machine
-learning frameworks.
+With the machine learning training methods such as backpropagation relying on the change in the loss function with respect to the change in weights (which essentially is the definition of derivatives), the ability to quickly and efficiently train large machine learning models rely on the computer's ability to take derivatives. This makes differentiable programming one of the most important elements of a machine learning framework.
+
+There are primarily four methods that we can use to make computers take derivatives. First, we can manually figure out the derivatives by hand and input them to the computer. One can see that this would quickly become a nightmare with many layers of neural networks, if we had to compute all the derivatives in the backpropagation steps by hand. Another method is symbolic differentiation using computer algebra systems such as Mathematica, but this can introduce a layer of inefficiency, as there needs to be a level of abstraction to take derivatives. Numerical derivatives, the practice of approximating gradients using finite difference methods, suffer from many problems including high computational costs, and larger grid size can lead to a significant amount of errors. This leads to automatic differentiation, which exploits the primitive functions that computers use to represent operations to obtain an exact derivative. With automatic differentiation, computational complexity of computing the gradient is proportional to computing the function itself. Intricacies of automatic differentiation are not dealt with by end users now, but resources to learn more can be found widely, such as from [here](https://www.cs.toronto.edu/~rgrosse/courses/csc321_2018/slides/lec10.pdf). Automatic differentiation and differentiable programming today is ubiquitous and is done efficiently and automatically by modern machine learning frameworks.
### Hardware Acceleration
-The trend to continuously train and deploy larger machine learning
-models has essentially made hardware acceleration support a necessity
-for machine learning platforms. Deep layers of neural networks require
-many matrix multiplications, which attracts hardware that can compute
-matrix operations fast and in parallel. In this landscape, two types of
-hardware architectures, the [GPU and
-TPU](https://cloud.google.com/tpu/docs/intro-to-tpu), have
-emerged as leading choices for training machine learning models.
-
-The use of hardware accelerators began with
-[AlexNet](https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf),
-which paved the way for future works to utilize GPUs as hardware
-accelerators for training computer vision models. GPUs, or Graphics
-Processing Units, excel in handling a large number of computations at once, making them
-ideal for the matrix operations that are central to neural network
-training. Their architecture, designed for rendering graphics, turns out
-to be perfect for the kind of mathematical operations required in
-machine learning. While they are very useful for machine learning tasks
-and have been implemented in many hardware platforms, GPU's are still
-general purpose in that they can be used for other applications.
-
-On the other hand, [Tensor Processing
-Units](https://cloud.google.com/tpu/docs/intro-to-tpu)
-(TPU) are hardware units designed specifically for neural networks. They
-focus on the multiply and accumulate (MAC) operation, and their hardware
-essentially consists of a large hardware matrix that contains elements
-efficiently computing the MAC operation. This concept called the [systolic
-array
-architecture](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1653825),
-was pioneered by @kung1979systolic, but has
-proven to be a useful structure to efficiently compute matrix products
-and other operations within neural networks (such as convolutions).
-
-While TPU's can drastically reduce training times, it also has
-disadvantages. For example, many operations within the machine learning
-frameworks (primarily TensorFlow here since the TPU directly integrates
-with it) are not supported with the TPU's. It also cannot support custom
-custom operations from the machine learning frameworks, and the network
-design must closely align to the hardware capabilities.
-
-Today, NVIDIA GPUs dominate training, aided by software libraries like
-[CUDA](https://developer.nvidia.com/cuda-toolkit),
-[cuDNN](https://developer.nvidia.com/cudnn), and
-[TensorRT.](https://developer.nvidia.com/tensorrt#:~:text=NVIDIA%20TensorRT%2DLLM%20is%20an,knowledge%20of%20C%2B%2B%20or%20CUDA.)
-Frameworks also tend to include optimizations to maximize performance on
-these hardware types, like pruning unimportant connections and fusing
-layers. Combining these techniques with hardware acceleration provides
-greater efficiency. For inference, hardware is increasingly moving
-towards optimized ASICs and SoCs. Google\'s TPUs accelerate models in
-data centers. Apple, Qualcomm, and others now produce AI-focused mobile
-chips. The NVIDIA Jetson family targets autonomous robots.
+The trend to continuously train and deploy larger machine learning models has essentially made hardware acceleration support a necessity for machine learning platforms. Deep layers of neural networks require many matrix multiplications, which attracts hardware that can compute matrix operations fast and in parallel. In this landscape, two types of hardware architectures, the [GPU and TPU](https://cloud.google.com/tpu/docs/intro-to-tpu), have emerged as leading choices for training machine learning models.
+
+The use of hardware accelerators began with [AlexNet](https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf), which paved the way for future works to utilize GPUs as hardware accelerators for training computer vision models. GPUs, or Graphics Processing Units, excel in handling a large number of computations at once, making them ideal for the matrix operations that are central to neural network training. Their architecture, designed for rendering graphics, turns out to be perfect for the kind of mathematical operations required in machine learning. While they are very useful for machine learning tasks and have been implemented in many hardware platforms, GPU's are still general purpose in that they can be used for other applications.
+
+On the other hand, [Tensor Processing Units](https://cloud.google.com/tpu/docs/intro-to-tpu) (TPU) are hardware units designed specifically for neural networks. They focus on the multiply and accumulate (MAC) operation, and their hardware essentially consists of a large hardware matrix that contains elements efficiently computing the MAC operation. This concept called the [systolic array architecture](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber�53825), was pioneered by @kung1979systolic, but has proven to be a useful structure to efficiently compute matrix products and other operations within neural networks (such as convolutions).
+
+While TPU's can drastically reduce training times, it also has disadvantages. For example, many operations within the machine learning frameworks (primarily TensorFlow here since the TPU directly integrates with it) are not supported with the TPU's. It also cannot support custom custom operations from the machine learning frameworks, and the network design must closely align to the hardware capabilities.
+
+Today, NVIDIA GPUs dominate training, aided by software libraries like [CUDA](https://developer.nvidia.com/cuda-toolkit), [cuDNN](https://developer.nvidia.com/cudnn), and [TensorRT.](https://developer.nvidia.com/tensorrt#:~:text=NVIDIA TensorRT-LLM is an,knowledge of C++ or CUDA.) Frameworks also tend to include optimizations to maximize performance on these hardware types, like pruning unimportant connections and fusing layers. Combining these techniques with hardware acceleration provides greater efficiency. For inference, hardware is increasingly moving towards optimized ASICs and SoCs. Google\'s TPUs accelerate models in data centers. Apple, Qualcomm, and others now produce AI-focused mobile chips. The NVIDIA Jetson family targets autonomous robots.
## Advanced Features {#sec-ai_frameworks-advanced}
### Distributed training
-As machine learning models have become larger over the years, it has
-become essential for large models to utilize multiple computing nodes in
-the training process. This process, called distributed learning, has
-allowed for higher training capabilities, but has also imposed
-challenges in implementation.
-
-We can consider three different ways to spread the work of training
-machine learning models to multiple computing nodes. Input data
-partitioning, referring to multiple processors running the same model on
-different input partitions. This is the easiest to implement that is
-available for many machine learning frameworks. The more challenging
-distribution of work comes with model parallelism, which refers to
-multiple computing nodes working on different parts of the model, and
-pipelined model parallelism, which refers to multiple computing nodes
-working on different layers of the model on the same input. The latter
-two mentioned here are active research areas.
-
-ML frameworks that support distributed learning include TensorFlow
-(through its
-[tf.distribute](https://www.tensorflow.org/api_docs/python/tf/distribute)
-module), PyTorch (through its
-[torch.nn.DataParallel](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html)
-and
-[torch.nn.DistributedDataParallel](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html)
-modules), and MXNet (through its
-[gluon](https://mxnet.apache.org/versions/1.9.1/api/python/docs/api/gluon/index.html)
-API).
+As machine learning models have become larger over the years, it has become essential for large models to utilize multiple computing nodes in the training process. This process, called distributed learning, has allowed for higher training capabilities, but has also imposed challenges in implementation.
+
+We can consider three different ways to spread the work of training machine learning models to multiple computing nodes. Input data partitioning, referring to multiple processors running the same model on different input partitions. This is the easiest to implement that is available for many machine learning frameworks. The more challenging distribution of work comes with model parallelism, which refers to multiple computing nodes working on different parts of the model, and pipelined model parallelism, which refers to multiple computing nodes working on different layers of the model on the same input. The latter two mentioned here are active research areas.
+
+ML frameworks that support distributed learning include TensorFlow (through its [tf.distribute](https://www.tensorflow.org/api_docs/python/tf/distribute) module), PyTorch (through its [torch.nn.DataParallel](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) and [torch.nn.DistributedDataParallel](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) modules), and MXNet (through its [gluon](https://mxnet.apache.org/versions/1.9.1/api/python/docs/api/gluon/index.html) API).
### Model Conversion
-Machine learning models have various methods to be represented in order
-to be used within different frameworks and for different device types.
-For example, a model can be converted to be compatible with inference
-frameworks within the mobile device. The default format for TensorFlow
-models is checkpoint files containing weights and architectures, which
-are needed in case we have to retrain the models. But for mobile
-deployment, models are typically converted to TensorFlow Lite format.
-TensorFlow Lite uses a compact flatbuffer representation and
-optimizations for fast inference on mobile hardware, discarding all the
-unnecessary baggage associated with training metadata such as checkpoint
-file structures.
-
-The default format for TensorFlow models is checkpoint files containing
-weights and architectures. For mobile deployment, models are typically
-converted to TensorFlow Lite format. TensorFlow Lite uses a compact
-flatbuffer representation and optimizations for fast inference on mobile
-hardware.
-
-Model optimizations like quantization (see [Optimizations](./optimizations.qmd) chapter) can further optimize models for target architectures like mobile. This
-reduces precision of weights and activations to `uint8` or `int8` for a
-smaller footprint and faster execution with supported hardware
-accelerators. For post-training quantization, TensorFlow\'s converter
-handles analysis and conversion automatically.
-
-Frameworks like TensorFlow simplify deploying trained models to mobile
-and embedded IoT devices through easy conversion APIs for TFLite format
-and quantization. Ready-to-use conversion enables high performance
-inference on mobile without manual optimization burden. Besides TFLite,
-other common targets include TensorFlow.js for web deployment,
-TensorFlow Serving for cloud services, and TensorFlow Hub for transfer
-learning. TensorFlow\'s conversion utilities handle these scenarios to
-streamline end-to-end workflows.
-
-More information about model conversion in TensorFlow is linked
-[here](https://www.tensorflow.org/lite/models/convert).
+Machine learning models have various methods to be represented in order to be used within different frameworks and for different device types. For example, a model can be converted to be compatible with inference frameworks within the mobile device. The default format for TensorFlow models is checkpoint files containing weights and architectures, which are needed in case we have to retrain the models. But for mobile deployment, models are typically converted to TensorFlow Lite format. TensorFlow Lite uses a compact flatbuffer representation and optimizations for fast inference on mobile hardware, discarding all the unnecessary baggage associated with training metadata such as checkpoint file structures.
+
+The default format for TensorFlow models is checkpoint files containing weights and architectures. For mobile deployment, models are typically converted to TensorFlow Lite format. TensorFlow Lite uses a compact flatbuffer representation and optimizations for fast inference on mobile hardware.
+
+Model optimizations like quantization (see [Optimizations](./optimizations.qmd) chapter) can further optimize models for target architectures like mobile. This reduces precision of weights and activations to `uint8` or `int8` for a smaller footprint and faster execution with supported hardware accelerators. For post-training quantization, TensorFlow\'s converter handles analysis and conversion automatically.
+
+Frameworks like TensorFlow simplify deploying trained models to mobile and embedded IoT devices through easy conversion APIs for TFLite format and quantization. Ready-to-use conversion enables high performance inference on mobile without manual optimization burden. Besides TFLite, other common targets include TensorFlow.js for web deployment, TensorFlow Serving for cloud services, and TensorFlow Hub for transfer learning. TensorFlow\'s conversion utilities handle these scenarios to streamline end-to-end workflows.
+
+More information about model conversion in TensorFlow is linked [here](https://www.tensorflow.org/lite/models/convert).
### AutoML, No-Code/Low-Code ML
-In many cases, machine learning can have a relatively high barrier of
-entry compared to other fields. To successfully train and deploy models,
-one needs to have a critical understanding of a variety of disciplines,
-from data science (data processing, data cleaning), model structures
-(hyperparameter tuning, neural network architecture), hardware
-(acceleration, parallel processing), and more depending on the problem
-at hand. The complexity of these problems have led to the introduction
-to frameworks such as AutoML, which aims to make "Machine learning
-available for non-Machine Learning exports" and to "automate research in
-machine learning". They have constructed AutoWEKA, which aids in the
-complex process of hyperparameter selection, as well as Auto-sklearn and
-Auto-pytorch, an extension of AutoWEKA into the popular sklearn and
-PyTorch Libraries.
-
-While these works of automating parts of machine learning tasks are
-underway, others have focused on constructing machine learning models
-easier by deploying no-code/low code machine learning, utilizing a drag
-and drop interface with an easy to navigate user interface. Companies
-such as Apple, Google, and Amazon have already created these easy to use
-platforms to allow users to construct machine learning models that can
-integrate to their ecosystem.
-
-These steps to remove barrier to entry continue to democratize machine
-learning and make it easier to access for beginners and simplify
-workflow for experts.
+In many cases, machine learning can have a relatively high barrier of entry compared to other fields. To successfully train and deploy models, one needs to have a critical understanding of a variety of disciplines, from data science (data processing, data cleaning), model structures (hyperparameter tuning, neural network architecture), hardware (acceleration, parallel processing), and more depending on the problem at hand. The complexity of these problems have led to the introduction to frameworks such as AutoML, which aims to make "Machine learning available for non-Machine Learning exports" and to "automate research in machine learning". They have constructed AutoWEKA, which aids in the complex process of hyperparameter selection, as well as Auto-sklearn and Auto-pytorch, an extension of AutoWEKA into the popular sklearn and PyTorch Libraries.
+
+While these works of automating parts of machine learning tasks are underway, others have focused on constructing machine learning models easier by deploying no-code/low code machine learning, utilizing a drag and drop interface with an easy to navigate user interface. Companies such as Apple, Google, and Amazon have already created these easy to use platforms to allow users to construct machine learning models that can integrate to their ecosystem.
+
+These steps to remove barrier to entry continue to democratize machine learning and make it easier to access for beginners and simplify workflow for experts.
### Advanced Learning Methods
#### Transfer Learning
-Transfer learning is the practice of using knowledge gained from a
-pretrained model to train and improve performance of a model that is for
-a different task. For example, datasets that have been trained on
-ImageNet datasets such as MobileNet and ResNet can help classify other
-image datasets. To do so, one may freeze the pretrained model, utilizing
-it as a feature extractor to train a much smaller model that is built on
-top of the feature extraction. One can also fine tune the entire model
-to fit the new task.
-
-Transfer learning has a series of challenges, in
-that the modified model may not be able to conduct its original tasks
-after transfer learning. Papers such as ["Learning without
-Forgetting"](https://browse.arxiv.org/pdf/1606.09282.pdf) by @li2017learning
-aims to address these challenges and have been implemented in
-modern machine learning platforms.
+Transfer learning is the practice of using knowledge gained from a pretrained model to train and improve performance of a model that is for a different task. For example, datasets that have been trained on ImageNet datasets such as MobileNet and ResNet can help classify other image datasets. To do so, one may freeze the pretrained model, utilizing it as a feature extractor to train a much smaller model that is built on top of the feature extraction. One can also fine tune the entire model to fit the new task.
+
+Transfer learning has a series of challenges, in that the modified model may not be able to conduct its original tasks after transfer learning. Papers such as ["Learning without Forgetting"](https://browse.arxiv.org/pdf/1606.09282.pdf) by @li2017learning aims to address these challenges and have been implemented in modern machine learning platforms.
#### Federated Learning
-Consider the problem of labeling items that are present in a photo from
-personal devices. One may consider moving the image data from the
-devices to a central server, where a single model will train Using these
-image data provided by the devices. However, this presents many
-potential challenges. First, with many devices one needs a massive
-network infrastructure to move and store data from these devices to a
-central location. With the number of devices that are present today this
-is often not feasible, and very costly. Furthermore, there are privacy
-challenges associated with moving personal data, such as Photos central
-servers.
-
-Federated learning by @mcmahan2023communicationefficient is
-a form of distributed computing that resolves these issues by
-distributing the models into personal devices for them to be trained on
-device. At the beginning, a base global model is trained on a central
-server to be distributed to all devices. Using this base model, the
-devices individually compute the gradients and send them back to the
-central hub. Intuitively this is the transfer of model parameters
-instead of the data itself. This innovative approach allows the model to
-be trained with many different datasets (which, in our example, would be
-the set of images that are on personal devices), without the need to
-transfer a large amount of potentially sensitive data. However,
-federated learning also comes with a series of challenges.
-
-In many real-world situations, data collected from devices may not come with suitable labels. This issue is compounded by the fact that users, who are often the primary source of data, can be unreliable. This unreliability means that even when data is labeled, there's no guarantee of its accuracy or relevance. Furthermore, each user's data is unique, resulting in a significant variance in the data generated by different users. This non-IID nature of data, coupled with the unbalanced data production where some users generate more data than others, can adversely impact the performance of the global model. Researchers have worked to compensate for this, such as by
-adding a proximal term to achieve a balance between the local and global
-model, and adding a frozen [global hypersphere
-classifier](https://arxiv.org/abs/2207.09413).
+Consider the problem of labeling items that are present in a photo from personal devices. One may consider moving the image data from the devices to a central server, where a single model will train Using these image data provided by the devices. However, this presents many potential challenges. First, with many devices one needs a massive network infrastructure to move and store data from these devices to a central location. With the number of devices that are present today this is often not feasible, and very costly. Furthermore, there are privacy challenges associated with moving personal data, such as Photos central servers.
+
+Federated learning by @mcmahan2023communicationefficient is a form of distributed computing that resolves these issues by distributing the models into personal devices for them to be trained on device. At the beginning, a base global model is trained on a central server to be distributed to all devices. Using this base model, the devices individually compute the gradients and send them back to the central hub. Intuitively this is the transfer of model parameters instead of the data itself. This innovative approach allows the model to be trained with many different datasets (which, in our example, would be the set of images that are on personal devices), without the need to transfer a large amount of potentially sensitive data. However, federated learning also comes with a series of challenges.
+
+In many real-world situations, data collected from devices may not come with suitable labels. This issue is compounded by the fact that users, who are often the primary source of data, can be unreliable. This unreliability means that even when data is labeled, there's no guarantee of its accuracy or relevance. Furthermore, each user's data is unique, resulting in a significant variance in the data generated by different users. This non-IID nature of data, coupled with the unbalanced data production where some users generate more data than others, can adversely impact the performance of the global model. Researchers have worked to compensate for this, such as by adding a proximal term to achieve a balance between the local and global model, and adding a frozen [global hypersphere classifier](https://arxiv.org/abs/2207.09413).
There are additional challenges associated with federated learning. The number of mobile device owners can far exceed the average number of training samples on each device, leading to substantial communication overhead. This issue is particularly pronounced in the context of mobile networks, which are often used for such communication and can be unstable. This instability can result in delayed or failed transmission of model updates, thereby affecting the overall training process.
@@ -1084,63 +413,19 @@ The heterogeneity of device resources is another hurdle. Devices participating i
## Framework Specialization
-Thus far, we have talked about ML frameworks generally. However,
-typically frameworks are optimized based on the target environment\'s
-computational capabilities and application requirements, ranging from
-the cloud to the edge to tiny devices. Choosing the right framework is
-crucial based on the target environment for deployment. This section
-provides an overview of the major types of AI frameworks tailored for
-cloud, edge, and tinyML environments to help understand the similarities
-and differences between these different ecosystems.
+Thus far, we have talked about ML frameworks generally. However, typically frameworks are optimized based on the target environment\'s computational capabilities and application requirements, ranging from the cloud to the edge to tiny devices. Choosing the right framework is crucial based on the target environment for deployment. This section provides an overview of the major types of AI frameworks tailored for cloud, edge, and tinyML environments to help understand the similarities and differences between these different ecosystems.
### Cloud
-Cloud-based AI frameworks assume access to ample computational power,
-memory, and storage resources in the cloud. They generally support both
-training and inference. Cloud-based AI frameworks are suited for
-applications where data can be sent to the cloud for processing, such as
-cloud-based AI services, large-scale data analytics, and web
-applications. Popular cloud AI frameworks include the ones we mentioned
-earlier such as TensorFlow, PyTorch, MXNet, Keras, and others. These
-frameworks utilize technologies like GPUs, TPUs, distributed training,
-and AutoML to deliver scalable AI. Concepts like model serving, MLOps,
-and AIOps relate to the operationalization of AI in the cloud. Cloud AI
-powers services like Google Cloud AI and enables transfer learning using
-pre-trained models.
+Cloud-based AI frameworks assume access to ample computational power, memory, and storage resources in the cloud. They generally support both training and inference. Cloud-based AI frameworks are suited for applications where data can be sent to the cloud for processing, such as cloud-based AI services, large-scale data analytics, and web applications. Popular cloud AI frameworks include the ones we mentioned earlier such as TensorFlow, PyTorch, MXNet, Keras, and others. These frameworks utilize technologies like GPUs, TPUs, distributed training, and AutoML to deliver scalable AI. Concepts like model serving, MLOps, and AIOps relate to the operationalization of AI in the cloud. Cloud AI powers services like Google Cloud AI and enables transfer learning using pre-trained models.
### Edge
-Edge AI frameworks are tailored for deploying AI models on edge devices,
-such as IoT devices, smartphones, and edge servers. Edge AI frameworks
-are optimized for devices with moderate computational resources,
-offering a balance between power and performance. Edge AI frameworks are
-ideal for applications requiring real-time or near-real-time processing,
-including robotics, autonomous vehicles, and smart devices. Key edge AI
-frameworks include TensorFlow Lite, PyTorch Mobile, CoreML, and others.
-They employ optimizations like model compression, quantization, and
-efficient neural network architectures. Hardware support includes CPUs,
-GPUs, NPUs and accelerators like the Edge TPU. Edge AI enables use cases
-like mobile vision, speech recognition, and real-time anomaly detection.
+Edge AI frameworks are tailored for deploying AI models on edge devices, such as IoT devices, smartphones, and edge servers. Edge AI frameworks are optimized for devices with moderate computational resources, offering a balance between power and performance. Edge AI frameworks are ideal for applications requiring real-time or near-real-time processing, including robotics, autonomous vehicles, and smart devices. Key edge AI frameworks include TensorFlow Lite, PyTorch Mobile, CoreML, and others. They employ optimizations like model compression, quantization, and efficient neural network architectures. Hardware support includes CPUs, GPUs, NPUs and accelerators like the Edge TPU. Edge AI enables use cases like mobile vision, speech recognition, and real-time anomaly detection.
### Embedded
-TinyML frameworks are specialized for deploying AI models on extremely
-resource-constrained devices, specifically microcontrollers and sensors
-within the IoT ecosystem. TinyML frameworks are designed for devices
-with severely limited resources, emphasizing minimal memory and power
-consumption. TinyML frameworks are specialized for use cases on
-resource-constrained IoT devices for applications such as predictive
-maintenance, gesture recognition, and environmental monitoring. Major
-tinyML frameworks include TensorFlow Lite Micro, uTensor, and ARM NN.
-They optimize complex models to fit within kilobytes of memory through
-techniques like quantization-aware training and reduced precision.
-TinyML allows intelligent sensing across battery-powered devices,
-enabling collaborative learning via federated learning. The choice of
-framework involves balancing model performance and computational
-constraints of the target platform, whether cloud, edge or tinyML. Here
-is a summary table comparing the major AI frameworks across cloud, edge,
-and tinyML environments:
-
+TinyML frameworks are specialized for deploying AI models on extremely resource-constrained devices, specifically microcontrollers and sensors within the IoT ecosystem. TinyML frameworks are designed for devices with severely limited resources, emphasizing minimal memory and power consumption. TinyML frameworks are specialized for use cases on resource-constrained IoT devices for applications such as predictive maintenance, gesture recognition, and environmental monitoring. Major tinyML frameworks include TensorFlow Lite Micro, uTensor, and ARM NN. They optimize complex models to fit within kilobytes of memory through techniques like quantization-aware training and reduced precision. TinyML allows intelligent sensing across battery-powered devices, enabling collaborative learning via federated learning. The choice of framework involves balancing model performance and computational constraints of the target platform, whether cloud, edge or tinyML. Here is a summary table comparing the major AI frameworks across cloud, edge, and tinyML environments:
| Framework Type | Examples | Key Technologies | Use Cases |
|----------------|-----------------------------------|-------------------------------------------------------------------------|------------------------------------------------------|
@@ -1148,210 +433,85 @@ and tinyML environments:
| Edge AI | TensorFlow Lite, PyTorch Mobile, Core ML | Model optimization, compression, quantization, efficient NN architectures | Mobile apps, robots, autonomous systems, real-time processing |
| TinyML | TensorFlow Lite Micro, uTensor, ARM NN | Quantization-aware training, reduced precision, neural architecture search | IoT sensors, wearables, predictive maintenance, gesture recognition |
-
**Key differences:**
-- Cloud AI leverages massive computational power for complex models
- > using GPUs/TPUs and distributed training
+* Cloud AI leverages massive computational power for complex models using GPUs/TPUs and distributed training
-- Edge AI optimizes models to run locally on resource-constrained edge
- > devices.
+* Edge AI optimizes models to run locally on resource-constrained edge devices.
-- TinyML fits models into extremely low memory and compute
- > environments like microcontrollers
+* TinyML fits models into extremely low memory and compute environments like microcontrollers
## Embedded AI Frameworks {#sec-ai_frameworks_embedded}
### Resource Constraints
-Embedded systems face severe resource constraints that pose unique
-challenges for deploying machine learning models compared to traditional
-computing platforms. For example, microcontroller units (MCUs) commonly
-used in IoT devices often have:
-
-- **RAM** in the range of tens of kilobytes to a few megabytes. The
- popular [ESP8266 MCU](https://www.espressif.com/en/products/socs/esp8266) has around 80KB RAM available to developers.
- This contrasts with 8GB or more on typical laptops and desktops
- today.
-
-- **Flash storage** ranging from hundreds of kilobytes to a few
- megabytes. The Arduino Uno microcontroller provides just 32KB of
- storage for code. Standard computers today have disk storage in
- the order of terabytes.
-
-- **Processing power** from just a few MHz to approximately 200MHz.
- The ESP8266 operates at 80MHz. This is several orders of magnitude
- slower than multi-GHz multi-core CPUs in servers and high-end
- laptops.
-
-These tight constraints make training machine learning models directly
-on microcontrollers infeasible in most cases. The limited RAM precludes
-handling large datasets for training. Energy usage for training would
-also quickly deplete battery-powered devices. Instead, models are
-trained on resource-rich systems and deployed on microcontrollers for
-optimized inference. But even inference poses challenges:
-
-1. **Model Size:** AI models are too large to fit on embedded and IoT
- devices. This necessitates the need for model compression
- techniques, such as quantization, pruning, and knowledge
- distillation. Additionally, as we will see, many of the frameworks used by developers for
- AI development have large amounts of overhead, and built in
- libraries that embedded systems can't support.
-
-2. **Complexity of Tasks:** With only tens of KBs to a few MBs of RAM,
- IoT devices and embedded systems are constrained in the complexity
- of tasks they can handle. Tasks that require large datasets or
- sophisticated algorithms-- for example LLMs-- which would run
- smoothly on traditional computing platforms, might be infeasible
- on embedded systems without compression or other optimization
- techniques due to memory limitations.
-
-3. **Data Storage and Processing:** Embedded systems often process data
- in real-time and might not store large amounts of data locally.
- Conversely, traditional computing systems can hold and process
- large datasets in memory, enabling faster data operations and
- analysis as well as real-time updates.
-
-4. **Security and Privacy:** Limited memory also restricts the
- complexity of security algorithms and protocols, data encryption,
- reverse engineering protections, and more that can be implemented
- on the device. This can potentially make some IoT devices more
- vulnerable to attacks.
-
-Consequently, specialized software optimizations and ML frameworks
-tailored for microcontrollers are necessary to work within these tight
-resource bounds. Clever optimization techniques like quantization,
-pruning and knowledge distillation compress models to fit within limited
-memory (see Optimizations section). Learnings from neural architecture
-search help guide model designs.
-
-Hardware improvements like dedicated ML accelerators on microcontrollers
-also help alleviate constraints. For instance, [Qualcomm's Hexagon DSP](https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor)
-provides acceleration for TensorFlow Lite models on Snapdragon mobile
-chips. [Google's Edge TPU](https://cloud.google.com/edge-tpu) packs ML performance into a tiny ASIC for edge
-devices. [ARM Ethos-U55](https://www.arm.com/products/silicon-ip-cpu/ethos/ethos-u55) offers efficient inference on Cortex-M class
-microcontrollers. These customized ML chips unlock advanced capabilities
-for resource-constrained applications.
-
-Generally, due to the limited processing power, it's almost always
-infeasible to train AI models on IoT or embedded systems. Instead,
-models are trained on powerful traditional computers (often with GPUs)
-and then deployed on the embedded device for inference. TinyML
-specifically deals with this, ensuring models are lightweight enough for
-real-time inference on these constrained devices.
+Embedded systems face severe resource constraints that pose unique challenges for deploying machine learning models compared to traditional computing platforms. For example, microcontroller units (MCUs) commonly used in IoT devices often have:
+
+* **RAM** in the range of tens of kilobytes to a few megabytes. The popular [ESP8266 MCU](https://www.espressif.com/en/products/socs/esp8266) has around 80KB RAM available to developers. This contrasts with 8GB or more on typical laptops and desktops today.
+
+* **Flash storage** ranging from hundreds of kilobytes to a few megabytes. The Arduino Uno microcontroller provides just 32KB of storage for code. Standard computers today have disk storage in the order of terabytes.
+
+* **Processing power** from just a few MHz to approximately 200MHz. The ESP8266 operates at 80MHz. This is several orders of magnitude slower than multi-GHz multi-core CPUs in servers and high-end laptops.
+
+These tight constraints make training machine learning models directly on microcontrollers infeasible in most cases. The limited RAM precludes handling large datasets for training. Energy usage for training would also quickly deplete battery-powered devices. Instead, models are trained on resource-rich systems and deployed on microcontrollers for optimized inference. But even inference poses challenges:
+
+1. **Model Size:** AI models are too large to fit on embedded and IoT devices. This necessitates the need for model compression techniques, such as quantization, pruning, and knowledge distillation. Additionally, as we will see, many of the frameworks used by developers for AI development have large amounts of overhead, and built in libraries that embedded systems can't support.
+
+2. **Complexity of Tasks:** With only tens of KBs to a few MBs of RAM, IoT devices and embedded systems are constrained in the complexity of tasks they can handle. Tasks that require large datasets or sophisticated algorithms-- for example LLMs-- which would run smoothly on traditional computing platforms, might be infeasible on embedded systems without compression or other optimization techniques due to memory limitations.
+
+3. **Data Storage and Processing:** Embedded systems often process data in real-time and might not store large amounts of data locally. Conversely, traditional computing systems can hold and process large datasets in memory, enabling faster data operations and analysis as well as real-time updates.
+
+4. **Security and Privacy:** Limited memory also restricts the complexity of security algorithms and protocols, data encryption, reverse engineering protections, and more that can be implemented on the device. This can potentially make some IoT devices more vulnerable to attacks.
+
+Consequently, specialized software optimizations and ML frameworks tailored for microcontrollers are necessary to work within these tight resource bounds. Clever optimization techniques like quantization, pruning and knowledge distillation compress models to fit within limited memory (see Optimizations section). Learnings from neural architecture search help guide model designs.
+
+Hardware improvements like dedicated ML accelerators on microcontrollers also help alleviate constraints. For instance, [Qualcomm's Hexagon DSP](https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor) provides acceleration for TensorFlow Lite models on Snapdragon mobile chips. [Google's Edge TPU](https://cloud.google.com/edge-tpu) packs ML performance into a tiny ASIC for edge devices. [ARM Ethos-U55](https://www.arm.com/products/silicon-ip-cpu/ethos/ethos-u55) offers efficient inference on Cortex-M class microcontrollers. These customized ML chips unlock advanced capabilities for resource-constrained applications.
+
+Generally, due to the limited processing power, it's almost always infeasible to train AI models on IoT or embedded systems. Instead, models are trained on powerful traditional computers (often with GPUs) and then deployed on the embedded device for inference. TinyML specifically deals with this, ensuring models are lightweight enough for real-time inference on these constrained devices.
### Frameworks & Libraries
-Embedded AI frameworks are software tools and libraries designed to
-enable AI and ML capabilities on embedded systems. These frameworks are essential for
-bringing AI to IoT devices, robotics, and other
-edge computing platforms and they are designed to work where
-computational resources, memory, and power consumption are limited.
+Embedded AI frameworks are software tools and libraries designed to enable AI and ML capabilities on embedded systems. These frameworks are essential for bringing AI to IoT devices, robotics, and other edge computing platforms and they are designed to work where computational resources, memory, and power consumption are limited.
### Challenges
-While embedded systems present an enormous opportunity for deploying
-machine learning to enable intelligent capabilities at the edge, these
-resource-constrained environments also pose significant challenges.
-Unlike typical cloud or desktop environments rich with computational
-resources, embedded devices introduce severe constraints around memory,
-processing power, energy efficiency, and specialized hardware. As a
-result, existing machine learning techniques and frameworks designed for
-server clusters with abundant resources do not directly translate to
-embedded systems. This section uncovers some of the challenges and
-opportunities for embedded systems and ML frameworks.
+While embedded systems present an enormous opportunity for deploying machine learning to enable intelligent capabilities at the edge, these resource-constrained environments also pose significant challenges. Unlike typical cloud or desktop environments rich with computational resources, embedded devices introduce severe constraints around memory, processing power, energy efficiency, and specialized hardware. As a result, existing machine learning techniques and frameworks designed for server clusters with abundant resources do not directly translate to embedded systems. This section uncovers some of the challenges and opportunities for embedded systems and ML frameworks.
**Fragmented Ecosystem**
-The lack of a unified ML framework led to a highly fragmented ecosystem.
-Engineers at companies like [STMicroelectronics](https://www.st.com/), [NXP Semiconductors](https://www.nxp.com/), and
-[Renesas](https://www.renesas.com/) had to develop custom solutions tailored to their specific
-microcontroller and DSP architectures. These ad-hoc frameworks required
-extensive manual optimization for each low-level hardware platform. This
-made porting models extremely difficult, requiring redevelopment for new
-Arm, RISC-V or proprietary architectures.
-
-**Disparate Hardware Needs **
-
-Without a shared framework, there was no standard way to assess
-hardware's capabilities. Vendors like Intel, Qualcomm and NVIDIA
-created integrated solutions blending model, software and hardware
-improvements. This made it hard to discern the sources of performance
-gains - whether new chip designs like Intel's low-power x86 cores or
-software optimizations were responsible. A standard framework was needed
-so vendors could evaluate their hardware's capabilities in a fair,
-reproducible way.
+The lack of a unified ML framework led to a highly fragmented ecosystem. Engineers at companies like [STMicroelectronics](https://www.st.com/), [NXP Semiconductors](https://www.nxp.com/), and [Renesas](https://www.renesas.com/) had to develop custom solutions tailored to their specific microcontroller and DSP architectures. These ad-hoc frameworks required extensive manual optimization for each low-level hardware platform. This made porting models extremely difficult, requiring redevelopment for new Arm, RISC-V or proprietary architectures.
+
+**Disparate Hardware Needs**
+
+Without a shared framework, there was no standard way to assess hardware's capabilities. Vendors like Intel, Qualcomm and NVIDIA created integrated solutions blending model, software and hardware improvements. This made it hard to discern the sources of performance gains - whether new chip designs like Intel's low-power x86 cores or software optimizations were responsible. A standard framework was needed so vendors could evaluate their hardware's capabilities in a fair, reproducible way.
**Lack of Portability**
-Adapting models trained in common frameworks like TensorFlow or PyTorch
-to run efficiently on microcontrollers was very challenging without
-standardized tools. It required time-consuming manual translation of
-models to run on specialized DSPs from companies like CEVA or low-power
-Arm M-series cores. There were no turnkey tools enabling portable
-deployment across different architectures.
+Adapting models trained in common frameworks like TensorFlow or PyTorch to run efficiently on microcontrollers was very challenging without standardized tools. It required time-consuming manual translation of models to run on specialized DSPs from companies like CEVA or low-power Arm M-series cores. There were no turnkey tools enabling portable deployment across different architectures.
-**Incomplete Infrastructure **
+**Incomplete Infrastructure**
-The infrastructure to support key model development workflows was
-lacking. There was minimal support for compression techniques to fit
-large models within constrained memory budgets. Tools for quantization
-to lower precision for faster inference were missing. Standardized APIs
-for integration into applications were incomplete. Essential
-functionality like on-device debugging, metrics, and performance
-profiling was absent. These gaps increased the cost and difficulty of
-embedded ML development.
+The infrastructure to support key model development workflows was lacking. There was minimal support for compression techniques to fit large models within constrained memory budgets. Tools for quantization to lower precision for faster inference were missing. Standardized APIs for integration into applications were incomplete. Essential functionality like on-device debugging, metrics, and performance profiling was absent. These gaps increased the cost and difficulty of embedded ML development.
**No Standard Benchmark**
-Without unified benchmarks, there was no standard way to assess and
-compare the capabilities of different hardware platforms from vendors
-like NVIDIA, Arm and Ambiq Micro. Existing evaluations relied on
-proprietary benchmarks tailored to showcased strengths of particular
-chips. This made it impossible to objectively measure hardware
-improvements in a fair, neutral manner. This topic is discussed in more detail in the [Benchmarking AI](./benchmarking.qmd) chapter.
+Without unified benchmarks, there was no standard way to assess and compare the capabilities of different hardware platforms from vendors like NVIDIA, Arm and Ambiq Micro. Existing evaluations relied on proprietary benchmarks tailored to showcased strengths of particular chips. This made it impossible to objectively measure hardware improvements in a fair, neutral manner. This topic is discussed in more detail in the [Benchmarking AI](./benchmarking.qmd) chapter.
**Minimal Real-World Testing**
-Much of the benchmarks relied on synthetic data. Rigorously testing
-models on real-world embedded applications was difficult without
-standardized datasets and benchmarks. This raised questions on how
-performance claims would translate to real-world usage. More extensive
-testing was needed to validate chips in actual use cases.
+Much of the benchmarks relied on synthetic data. Rigorously testing models on real-world embedded applications was difficult without standardized datasets and benchmarks. This raised questions on how performance claims would translate to real-world usage. More extensive testing was needed to validate chips in actual use cases.
-The lack of shared frameworks and infrastructure slowed TinyML adoption,
-hampering the integration of ML into embedded products. Recent
-standardized frameworks have begun addressing these issues through
-improved portability, performance profiling, and benchmarking support.
-But ongoing innovation is still needed to enable seamless,
-cost-effective deployment of AI to edge devices.
+The lack of shared frameworks and infrastructure slowed TinyML adoption, hampering the integration of ML into embedded products. Recent standardized frameworks have begun addressing these issues through improved portability, performance profiling, and benchmarking support. But ongoing innovation is still needed to enable seamless, cost-effective deployment of AI to edge devices.
**Summary**
-The absence of standardized frameworks, benchmarks, and infrastructure
-for embedded ML has traditionally hampered adoption. However, recent
-progress has been made in developing shared frameworks like TensorFlow
-Lite Micro and benchmark suites like MLPerf Tiny that aim to accelerate
-the proliferation of TinyML solutions. But overcoming the fragmentation
-and difficulty of embedded deployment remains an ongoing process.
+The absence of standardized frameworks, benchmarks, and infrastructure for embedded ML has traditionally hampered adoption. However, recent progress has been made in developing shared frameworks like TensorFlow Lite Micro and benchmark suites like MLPerf Tiny that aim to accelerate the proliferation of TinyML solutions. But overcoming the fragmentation and difficulty of embedded deployment remains an ongoing process.
## Examples
-Machine learning deployment on microcontrollers and other embedded
-devices often requires specially optimized software libraries and
-frameworks to work within the tight constraints of memory, compute, and
-power. Several options exist for performing inference on such
-resource-limited hardware, each with their own approach to optimizing
-model execution. This section will explore the key characteristics and
-design principles behind TFLite Micro, TinyEngine, and CMSIS-NN,
-providing insight into how each framework tackles the complex problem of
-high-accuracy yet efficient neural network execution on
-microcontrollers. They showcase different approaches for implementing
-efficient TinyML frameworks.
-
-The table summarizes the key differences and similarities between these
-three specialized machine learning inference frameworks for embedded
-systems and microcontrollers.
+Machine learning deployment on microcontrollers and other embedded devices often requires specially optimized software libraries and frameworks to work within the tight constraints of memory, compute, and power. Several options exist for performing inference on such resource-limited hardware, each with their own approach to optimizing model execution. This section will explore the key characteristics and design principles behind TFLite Micro, TinyEngine, and CMSIS-NN, providing insight into how each framework tackles the complex problem of high-accuracy yet efficient neural network execution on microcontrollers. They showcase different approaches for implementing efficient TinyML frameworks.
+
+The table summarizes the key differences and similarities between these three specialized machine learning inference frameworks for embedded systems and microcontrollers.
| Framework | TensorFlow Lite Micro | TinyEngine | CMSIS-NN |
|------------------------|:----------------------------:|:--------------------------------------:|:--------------------------------------:|
@@ -1365,367 +525,148 @@ systems and microcontrollers.
| **Optimization Approach** | Some code generation features | Specialized kernels, operator fusion | Architecture-specific assembly optimizations |
| **Key Benefits** | Flexibility, portability, ease of updating models | Maximizes performance, optimized memory usage | Hardware acceleration, standardized API, portability |
-
-In the following sections, we will dive into understanding each of these
-in greater detail.
+In the following sections, we will dive into understanding each of these in greater detail.
### Interpreter
-[TensorFlow Lite Micro (TFLM)](https://www.tensorflow.org/lite/microcontrollers) is a machine learning inference framework
-designed for embedded devices with limited resources. It uses an
-interpreter to load and execute machine learning models, which provides
-flexibility and ease of updating models in the field [@david2021tensorflow].
+[TensorFlow Lite Micro (TFLM)](https://www.tensorflow.org/lite/microcontrollers) is a machine learning inference framework designed for embedded devices with limited resources. It uses an interpreter to load and execute machine learning models, which provides flexibility and ease of updating models in the field [@david2021tensorflow].
-Traditional interpreters often have significant branching overhead,
-which can reduce performance. However, machine learning model
-interpretation benefits from the efficiency of long-running kernels,
-where each kernel runtime is relatively large and helps mitigate
-interpreter overhead.
+Traditional interpreters often have significant branching overhead, which can reduce performance. However, machine learning model interpretation benefits from the efficiency of long-running kernels, where each kernel runtime is relatively large and helps mitigate interpreter overhead.
-An alternative to an interpreter-based inference engine is to generate
-native code from a model during export. This can improve performance,
-but it sacrifices portability and flexibility, as the generated code
-needs recompilation for each target platform and must be replaced
-entirely to modify a model.
+An alternative to an interpreter-based inference engine is to generate native code from a model during export. This can improve performance, but it sacrifices portability and flexibility, as the generated code needs recompilation for each target platform and must be replaced entirely to modify a model.
-TFLM strikes a balance between the simplicity of code compilation and
-the flexibility of an interpreter-based approach by incorporating
-certain code-generation features. For example, the library can be
-constructed solely from source files, offering much of the compilation
-simplicity associated with code generation while retaining the benefits
-of an interpreter-based model execution framework.
+TFLM strikes a balance between the simplicity of code compilation and the flexibility of an interpreter-based approach by incorporating certain code-generation features. For example, the library can be constructed solely from source files, offering much of the compilation simplicity associated with code generation while retaining the benefits of an interpreter-based model execution framework.
-An interpreter-based approach offers several benefits over code
-generation for machine learning inference on embedded devices:
+An interpreter-based approach offers several benefits over code generation for machine learning inference on embedded devices:
-- **Flexibility:** Models can be updated in the field without recompiling
- the entire application.
+* **Flexibility:** Models can be updated in the field without recompiling the entire application.
-- **Portability:** The interpreter can be used to execute models on
- different target platforms without porting the code.
+* **Portability:** The interpreter can be used to execute models on different target platforms without porting the code.
-- **Memory efficiency:** The interpreter can share code across multiple
- models, reducing memory usage.
+* **Memory efficiency:** The interpreter can share code across multiple models, reducing memory usage.
-- **Ease of development:** Interpreters are easier to develop and maintain
- than code generators.
+* **Ease of development:** Interpreters are easier to develop and maintain than code generators.
-TensorFlow Lite Micro is a powerful and flexible framework for machine
-learning inference on embedded devices. Its interpreter-based approach
-offers several benefits over code generation, including flexibility,
-portability, memory efficiency, and ease of development.
+TensorFlow Lite Micro is a powerful and flexible framework for machine learning inference on embedded devices. Its interpreter-based approach offers several benefits over code generation, including flexibility, portability, memory efficiency, and ease of development.
### Compiler-based
-[TinyEngine](https://github.com/mit-han-lab/tinyengine) by is an ML inference framework designed specifically for
-resource-constrained microcontrollers. It employs several optimizations
-to enable high-accuracy neural network execution within the tight
-constraints of memory, compute, and storage on microcontrollers [@lin2020mcunet].
-
-While inference frameworks like TFLite Micro use interpreters to execute
-the neural network graph dynamically at runtime, this adds significant
-overhead in terms of memory usage to store metadata, interpretation
-latency, and lack of optimizations, although TFLite argues that the
-overhead is small. TinyEngine eliminates this overhead by employing a
-code generation approach. During compilation, it analyzes the network
-graph and generates specialized code to execute just that model. This
-code is natively compiled into the application binary, avoiding runtime
-interpretation costs.
-
-Conventional ML frameworks schedule memory per layer, trying to minimize
-usage for each layer separately. TinyEngine does model-level scheduling
-instead, analyzing memory usage across layers. It allocates a common
-buffer size based on the max memory needs of all layers. This buffer is
-then shared efficiently across layers to increase data reuse.
-
-TinyEngine also specializes the kernels for each layer through
-techniques like tiling, unrolling, and fusing operators. For example, it
-will generate unrolled compute kernels with the exact number of loops
-needed for a 3x3 or 5x5 convolution. These specialized kernels extract
-maximum performance from the microcontroller hardware. It uses depthwise
-convolutions that are optimized to minimize memory allocations by
-computing each channel\'s output in-place over the input channel data.
-This technique exploits the channel-separable nature of depthwise
-convolutions to reduce peak memory size.
-
-Similar to TFLite Micro, the compiled TinyEngine binary only includes
-ops needed for a specific model rather than all possible operations.
-This results in a very small binary footprint, keeping code size low for
-memory-constrained devices.
-
-One difference between TFLite Micro and TinyEngine is that the latter is
-co-designed with "TinyNAS," an architecture search method for
-microcontroller models, similar to differential NAS for
-microcontrollers. The efficiency of TinyEngine allows exploring larger
-and more accurate models through NAS. It also provides feedback to
-TinyNAS on which models can fit within the hardware constraints.
-
-Through all these various custom techniques like static compilation,
-model-based scheduling, specialized kernels, and co-design with NAS,
-TinyEngine enables high-accuracy deep learning inference within the
-tight resource constraints of microcontrollers.
+[TinyEngine](https://github.com/mit-han-lab/tinyengine) by is an ML inference framework designed specifically for resource-constrained microcontrollers. It employs several optimizations to enable high-accuracy neural network execution within the tight constraints of memory, compute, and storage on microcontrollers [@lin2020mcunet].
+
+While inference frameworks like TFLite Micro use interpreters to execute the neural network graph dynamically at runtime, this adds significant overhead in terms of memory usage to store metadata, interpretation latency, and lack of optimizations, although TFLite argues that the overhead is small. TinyEngine eliminates this overhead by employing a code generation approach. During compilation, it analyzes the network graph and generates specialized code to execute just that model. This code is natively compiled into the application binary, avoiding runtime interpretation costs.
+
+Conventional ML frameworks schedule memory per layer, trying to minimize usage for each layer separately. TinyEngine does model-level scheduling instead, analyzing memory usage across layers. It allocates a common buffer size based on the max memory needs of all layers. This buffer is then shared efficiently across layers to increase data reuse.
+
+TinyEngine also specializes the kernels for each layer through techniques like tiling, unrolling, and fusing operators. For example, it will generate unrolled compute kernels with the exact number of loops needed for a 3x3 or 5x5 convolution. These specialized kernels extract maximum performance from the microcontroller hardware. It uses depthwise convolutions that are optimized to minimize memory allocations by computing each channel\'s output in-place over the input channel data. This technique exploits the channel-separable nature of depthwise convolutions to reduce peak memory size.
+
+Similar to TFLite Micro, the compiled TinyEngine binary only includes ops needed for a specific model rather than all possible operations. This results in a very small binary footprint, keeping code size low for memory-constrained devices.
+
+One difference between TFLite Micro and TinyEngine is that the latter is co-designed with "TinyNAS," an architecture search method for microcontroller models, similar to differential NAS for microcontrollers. The efficiency of TinyEngine allows exploring larger and more accurate models through NAS. It also provides feedback to TinyNAS on which models can fit within the hardware constraints.
+
+Through all these various custom techniques like static compilation, model-based scheduling, specialized kernels, and co-design with NAS, TinyEngine enables high-accuracy deep learning inference within the tight resource constraints of microcontrollers.
### Library
-[CMSIS-NN](https://www.keil.com/pack/doc/CMSIS/NN/html/index.html), standing for Cortex Microcontroller Software Interface
-Standard for Neural Networks, is a software library devised by ARM. It
-offers a standardized interface for deploying neural network inference
-on microcontrollers and embedded systems, with a particular focus on
-optimization for ARM Cortex-M processors [@lai2018cmsis].
-
-**Neural Network Kernels:** CMSIS-NN is equipped with highly efficient
-kernels that handle fundamental neural network operations such as
-convolution, pooling, fully connected layers, and activation functions.
-It caters to a broad range of neural network models by supporting both
-floating-point and fixed-point arithmetic. The latter is especially
-beneficial for resource-constrained devices as it curtails memory and
-computational requirements (Quantization).
-
-**Hardware Acceleration:** CMSIS-NN harnesses the power of Single
-Instruction, Multiple Data (SIMD) instructions available on many
-Cortex-M processors. This allows for parallel processing of multiple
-data elements within a single instruction, thereby boosting
-computational efficiency. Certain Cortex-M processors feature Digital
-Signal Processing (DSP) extensions that CMSIS-NN can exploit for
-accelerated neural network execution. The library also incorporates
-assembly-level optimizations tailored to specific microcontroller
-architectures to further enhance performance.
-
-**Standardized API:** CMSIS-NN offers a consistent and abstracted API
-that protects developers from the complexities of low-level hardware
-details. This makes the integration of neural network models into
-applications simpler. It may also encompass tools or utilities for
-converting popular neural network model formats into a format that is
-compatible with CMSIS-NN.
-
-**Memory Management:** CMSIS-NN provides functions for efficient memory
-allocation and management, which is vital in embedded systems where
-memory resources are scarce. It ensures optimal memory usage during
-inference and in some instances, allows for in-place operations to
-further decrease memory overhead.
-
-**Portability**: CMSIS-NN is designed with portability in mind across
-various Cortex-M processors. This enables developers to write code that
-can operate on different microcontrollers without significant
-modifications.
-
-**Low Latency:** CMSIS-NN minimizes inference latency, making it an
-ideal choice for real-time applications where swift decision-making is
-paramount.
-
-**Energy Efficiency:** The library is designed with a focus on energy
-efficiency, making it suitable for battery-powered and
-energy-constrained devices.
+[CMSIS-NN](https://www.keil.com/pack/doc/CMSIS/NN/html/index.html), standing for Cortex Microcontroller Software Interface Standard for Neural Networks, is a software library devised by ARM. It offers a standardized interface for deploying neural network inference on microcontrollers and embedded systems, with a particular focus on optimization for ARM Cortex-M processors [@lai2018cmsis].
+
+**Neural Network Kernels:** CMSIS-NN is equipped with highly efficient kernels that handle fundamental neural network operations such as convolution, pooling, fully connected layers, and activation functions. It caters to a broad range of neural network models by supporting both floating-point and fixed-point arithmetic. The latter is especially beneficial for resource-constrained devices as it curtails memory and computational requirements (Quantization).
+
+**Hardware Acceleration:** CMSIS-NN harnesses the power of Single Instruction, Multiple Data (SIMD) instructions available on many Cortex-M processors. This allows for parallel processing of multiple data elements within a single instruction, thereby boosting computational efficiency. Certain Cortex-M processors feature Digital Signal Processing (DSP) extensions that CMSIS-NN can exploit for accelerated neural network execution. The library also incorporates assembly-level optimizations tailored to specific microcontroller architectures to further enhance performance.
+
+**Standardized API:** CMSIS-NN offers a consistent and abstracted API that protects developers from the complexities of low-level hardware details. This makes the integration of neural network models into applications simpler. It may also encompass tools or utilities for converting popular neural network model formats into a format that is compatible with CMSIS-NN.
+
+**Memory Management:** CMSIS-NN provides functions for efficient memory allocation and management, which is vital in embedded systems where memory resources are scarce. It ensures optimal memory usage during inference and in some instances, allows for in-place operations to further decrease memory overhead.
+
+**Portability**: CMSIS-NN is designed with portability in mind across various Cortex-M processors. This enables developers to write code that can operate on different microcontrollers without significant modifications.
+
+**Low Latency:** CMSIS-NN minimizes inference latency, making it an ideal choice for real-time applications where swift decision-making is paramount.
+
+**Energy Efficiency:** The library is designed with a focus on energy efficiency, making it suitable for battery-powered and energy-constrained devices.
## Choosing the Right Framework
-Choosing the right machine learning framework for a given application
-requires carefully evaluating models, hardware, and software
-considerations. By analyzing these three aspects - models, hardware, and
-software - ML engineers can select the optimal framework and customize
-as needed for efficient and performant on-device ML applications. The
-goal is to balance model complexity, hardware limitations, and software
-integration to design a tailored ML pipeline for embedded and edge
-devices.
+Choosing the right machine learning framework for a given application requires carefully evaluating models, hardware, and software considerations. By analyzing these three aspects - models, hardware, and software - ML engineers can select the optimal framework and customize as needed for efficient and performant on-device ML applications. The goal is to balance model complexity, hardware limitations, and software integration to design a tailored ML pipeline for embedded and edge devices.
{width="100%" height="auto" align="center" caption="TensorFlow Framework Comparison - General"}
### Model
-TensorFlow supports significantly more ops than TensorFlow Lite and
-TensorFlow Lite Micro as it is typically used for research or cloud
-deployment, which require a large number of and more flexibility with
-operators (ops),. TensorFlow Lite supports select ops for on-device
-training, whereas TensorFlow Micro does not. TensorFlow Lite also
-supports dynamic shapes and quantization aware training, but TensorFlow
-Micro does not. In contrast, TensorFlow Lite and TensorFlow Micro offer
-native quantization tooling and support, where quantization refers to
-the process of transforming an ML program into an approximated
-representation with available lower precision operations.
+TensorFlow supports significantly more ops than TensorFlow Lite and TensorFlow Lite Micro as it is typically used for research or cloud deployment, which require a large number of and more flexibility with operators (ops),. TensorFlow Lite supports select ops for on-device training, whereas TensorFlow Micro does not. TensorFlow Lite also supports dynamic shapes and quantization aware training, but TensorFlow Micro does not. In contrast, TensorFlow Lite and TensorFlow Micro offer native quantization tooling and support, where quantization refers to the process of transforming an ML program into an approximated representation with available lower precision operations.
### Software
-{width="100%" height="auto" align="center" caption="TensorFlow Framework Comparison - Model"}
-
+{width="100%" height="auto" align="center" caption="TensorFlow Framework Comparison - Model"}
-TensorFlow Lite Micro does not have OS support, while TensorFlow and
-TensorFlow Lite do, in order to reduce memory overhead, make startup
-times faster, and consume less energy. TensorFlow Lite Micro can be used
-in conjunction with real-time operating systems (RTOS) like FreeRTOS,
-Zephyr, and Mbed OS. TensorFlow Lite and TensorFlow Lite Micro support
-model memory mapping, allowing models to be directly accessed from flash
-storage rather than loaded into RAM, whereas TensorFlow does not.
-TensorFlow and TensorFlow Lite support accelerator delegation to
-schedule code to different accelerators, whereas TensorFlow Lite Micro
-does not, as embedded systems tend not to have a rich array of
-specialized accelerators.
+TensorFlow Lite Micro does not have OS support, while TensorFlow and TensorFlow Lite do, in order to reduce memory overhead, make startup times faster, and consume less energy. TensorFlow Lite Micro can be used in conjunction with real-time operating systems (RTOS) like FreeRTOS, Zephyr, and Mbed OS. TensorFlow Lite and TensorFlow Lite Micro support model memory mapping, allowing models to be directly accessed from flash storage rather than loaded into RAM, whereas TensorFlow does not. TensorFlow and TensorFlow Lite support accelerator delegation to schedule code to different accelerators, whereas TensorFlow Lite Micro does not, as embedded systems tend not to have a rich array of specialized accelerators.
### Hardware
{width="100%" height="auto" align="center" caption="TensorFlow Framework Comparison - Hardware"}
-TensorFlow Lite and TensorFlow Lite Micro have significantly smaller
-base binary sizes and base memory footprints compared to TensorFlow. For
-example, a typical TensorFlow Lite Micro binary is less than 200KB,
-whereas TensorFlow is much larger. This is due to the
-resource-constrained environments of embedded systems. TensorFlow
-provides support for x86, TPUs, and GPUs like NVIDIA, AMD, and Intel.
-TensorFlow Lite provides support for Arm Cortex A and x86 processors
-commonly used in mobile and tablets. The latter is stripped out of all
-the training logic that is not necessary for ondevice deployment.
-TensorFlow Lite Micro provides support for microcontroller-focused Arm
-Cortex M cores like M0, M3, M4, and M7, as well as DSPs like Hexagon and
-SHARC and MCUs like STM32, NXP Kinetis, Microchip AVR.
-
-Selecting the appropriate AI framework is essential to ensure that
-embedded systems can efficiently execute AI models. There are key
-factors to consider when choosing a machine learning framework, with a
-focus on ease of use, community support, performance, scalability,
-integration with data engineering tools, and integration with model
-optimization tools. By understanding these factors, you can make
-informed decisions and maximize the potential of your machine learning
-initiatives.
+TensorFlow Lite and TensorFlow Lite Micro have significantly smaller base binary sizes and base memory footprints compared to TensorFlow. For example, a typical TensorFlow Lite Micro binary is less than 200KB, whereas TensorFlow is much larger. This is due to the resource-constrained environments of embedded systems. TensorFlow provides support for x86, TPUs, and GPUs like NVIDIA, AMD, and Intel. TensorFlow Lite provides support for Arm Cortex A and x86 processors commonly used in mobile and tablets. The latter is stripped out of all the training logic that is not necessary for ondevice deployment. TensorFlow Lite Micro provides support for microcontroller-focused Arm Cortex M cores like M0, M3, M4, and M7, as well as DSPs like Hexagon and SHARC and MCUs like STM32, NXP Kinetis, Microchip AVR.
+
+Selecting the appropriate AI framework is essential to ensure that embedded systems can efficiently execute AI models. There are key factors to consider when choosing a machine learning framework, with a focus on ease of use, community support, performance, scalability, integration with data engineering tools, and integration with model optimization tools. By understanding these factors, you can make informed decisions and maximize the potential of your machine learning initiatives.
### Other Factors
-When evaluating AI frameworks for embedded systems, several other key
-factors beyond models, hardware, and software should be considered.
+When evaluating AI frameworks for embedded systems, several other key factors beyond models, hardware, and software should be considered.
#### Performance
-Performance is critical in embedded systems where computational
-resources are limited. Evaluate the framework\'s ability to optimize
-model inference for embedded hardware. Factors such as model
-quantization and hardware acceleration support play a crucial role in
-achieving efficient inference.
+Performance is critical in embedded systems where computational resources are limited. Evaluate the framework\'s ability to optimize model inference for embedded hardware. Factors such as model quantization and hardware acceleration support play a crucial role in achieving efficient inference.
#### Scalability
-Scalability is essential when considering the potential growth of an
-embedded AI project. The framework should support the deployment of
-models on a variety of embedded devices, from microcontrollers to more
-powerful processors. It should also handle both small-scale and
-large-scale deployments seamlessly.
+Scalability is essential when considering the potential growth of an embedded AI project. The framework should support the deployment of models on a variety of embedded devices, from microcontrollers to more powerful processors. It should also handle both small-scale and large-scale deployments seamlessly.
#### Integration with Data Engineering Tools
-Data engineering tools are essential for data preprocessing and pipeline
-management. An ideal AI framework for embedded systems should seamlessly
-integrate with these tools, allowing for efficient data ingestion,
-transformation, and model training.
+Data engineering tools are essential for data preprocessing and pipeline management. An ideal AI framework for embedded systems should seamlessly integrate with these tools, allowing for efficient data ingestion, transformation, and model training.
#### Integration with Model Optimization Tools
-Model optimization is crucial to ensure that AI models are well-suited
-for embedded deployment. Evaluate whether the framework integrates with
-model optimization tools, such as TensorFlow Lite Converter or ONNX
-Runtime, to facilitate model quantization and size reduction.
+Model optimization is crucial to ensure that AI models are well-suited for embedded deployment. Evaluate whether the framework integrates with model optimization tools, such as TensorFlow Lite Converter or ONNX Runtime, to facilitate model quantization and size reduction.
#### Ease of Use
-The ease of use of an AI framework significantly impacts development
-efficiency. A framework with a user-friendly interface and clear
-documentation reduces the learning curve for developers. Consideration
-should be given to whether the framework supports high-level APIs,
-allowing developers to focus on model design rather than low-level
-implementation details. This factor is incredibly important for embedded
-systems, which have less features that typical developers might be
-accustomed to.
+The ease of use of an AI framework significantly impacts development efficiency. A framework with a user-friendly interface and clear documentation reduces the learning curve for developers. Consideration should be given to whether the framework supports high-level APIs, allowing developers to focus on model design rather than low-level implementation details. This factor is incredibly important for embedded systems, which have less features that typical developers might be accustomed to.
#### Community Support
-Community support plays another essential factor. Frameworks with active
-and engaged communities often have well-maintained codebases, receive
-regular updates, and provide valuable forums for problem-solving. As a
-result, community support plays into Ease of Use as well because it
-ensures that developers have access to a wealth of resources, including
-tutorials and example projects. Community support provides some
-assurance that the framework will continue to be supported for future
-updates. There are only a handful of frameworks that cater to TinyML
-needs. Of that, TensorFlow Lite Micro is the most popular and has the
-most community support.
+Community support plays another essential factor. Frameworks with active and engaged communities often have well-maintained codebases, receive regular updates, and provide valuable forums for problem-solving. As a result, community support plays into Ease of Use as well because it ensures that developers have access to a wealth of resources, including tutorials and example projects. Community support provides some assurance that the framework will continue to be supported for future updates. There are only a handful of frameworks that cater to TinyML needs. Of that, TensorFlow Lite Micro is the most popular and has the most community support.
## Future Trends in ML Frameworks
### Decomposition
-Currently, the ML system stack consists of four abstractions, namely (1)
-computational graphs, (2) tensor programs, (3) libraries and runtimes,
-and (4) hardware
-primitives.
+Currently, the ML system stack consists of four abstractions, namely (1) computational graphs, (2) tensor programs, (3) libraries and runtimes, and (4) hardware primitives.
-{fig-align="center" width=70%}
+{fig-align="center" widthp%}
-This has led to vertical (i.e. between abstraction levels) and
-horizontal (i.e. library-driven vs. compilation-driven approaches to
-tensor computation) boundaries, which hinder innovation for ML. Future
-work in ML frameworks can look toward breaking these boundaries. In
-December 2021, [Apache TVM](https://tvm.apache.org/2021/12/15/tvm-unity) Unity was proposed, which aimed to facilitate
-interactions between the different abstraction levels (as well as the
-people behind them, such as ML scientists, ML engineers, and hardware
-engineers) and co-optimize decisions in all four abstraction levels.
+This has led to vertical (i.e. between abstraction levels) and horizontal (i.e. library-driven vs. compilation-driven approaches to tensor computation) boundaries, which hinder innovation for ML. Future work in ML frameworks can look toward breaking these boundaries. In December 2021, [Apache TVM](https://tvm.apache.org/2021/12/15/tvm-unity) Unity was proposed, which aimed to facilitate interactions between the different abstraction levels (as well as the people behind them, such as ML scientists, ML engineers, and hardware engineers) and co-optimize decisions in all four abstraction levels.
### High-Performance Compilers & Libraries
-As ML frameworks further develop, high-performance compilers and
-libraries will continue to emerge. Some current examples include
-[TensorFlow
-XLA](https://www.tensorflow.org/xla/architecture) and
-Nvidia's
-[CUTLASS](https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/),
-which accelerate linear algebra operations in computational graphs, and
-Nvidia's
-[TensorRT](https://developer.nvidia.com/tensorrt), which
-accelerates and optimizes inference.
+As ML frameworks further develop, high-performance compilers and libraries will continue to emerge. Some current examples include [TensorFlow XLA](https://www.tensorflow.org/xla/architecture) and Nvidia's [CUTLASS](https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/), which accelerate linear algebra operations in computational graphs, and Nvidia's [TensorRT](https://developer.nvidia.com/tensorrt), which accelerates and optimizes inference.
### ML for ML Frameworks
-We can also use ML to improve ML frameworks in the future. Some current
-uses of ML for ML frameworks include:
+We can also use ML to improve ML frameworks in the future. Some current uses of ML for ML frameworks include:
-- hyperparameter optimization using techniques such as Bayesian
- optimization, random search, and grid search
+* hyperparameter optimization using techniques such as Bayesian optimization, random search, and grid search
-- neural architecture search (NAS) to automatically search for optimal
- network architectures
+* neural architecture search (NAS) to automatically search for optimal network architectures
-- AutoML, which as described in @sec-ai_frameworks-advanced,
- automates the ML pipeline.
+* AutoML, which as described in @sec-ai_frameworks-advanced, automates the ML pipeline.
## Conclusion
-In summary, selecting the optimal framework requires thoroughly
-evaluating options against criteria like usability, community support,
-performance, hardware compatibility, and model conversion abilities.
-There is no universal best solution, as the right framework depends on
-the specific constraints and use case.
-
-For extremely resource constrained microcontroller-based platforms,
-TensorFlow Lite Micro currently provides a strong starting point. Its
-comprehensive optimization tooling like quantization mapping and kernel
-optimizations enables high performance on devices like Arm Cortex-M and
-RISC-V processors. The active developer community ensures accessible
-technical support. Seamless integration with TensorFlow for training and
-converting models makes the workflow cohesive.
-
-For platforms with more capable CPUs like Cortex-A, TensorFlow Lite for
-Microcontrollers expand possibilities. They provide greater flexibility
-for custom and advanced models beyond the core operators in TFLite
-Micro. However, this comes at the cost of a larger memory footprint.
-These frameworks are ideal for automotive systems, drones, and more
-powerful edge devices that can benefit from greater model
-sophistication.
-
-Frameworks specifically built for specialized hardware like CMSIS-NN on
-Cortex-M processors can further maximize performance, but sacrifice
-portability. Integrated frameworks from processor vendors tailor the
-stack to their architectures. This can unlock the full potential of
-their chips but lock you into their ecosystem.
-
-Ultimately, choosing the right framework involves finding the best match
-between its capabilities and the requirements of the target platform.
-This requires balancing tradeoffs between performance needs, hardware
-constraints, model complexity, and other factors. Thoroughly assessing
-intended models, use cases, and evaluating options against key metrics
-will guide developers towards picking the ideal framework for their
-embedded ML application.
\ No newline at end of file
+In summary, selecting the optimal framework requires thoroughly evaluating options against criteria like usability, community support, performance, hardware compatibility, and model conversion abilities. There is no universal best solution, as the right framework depends on the specific constraints and use case.
+
+For extremely resource constrained microcontroller-based platforms, TensorFlow Lite Micro currently provides a strong starting point. Its comprehensive optimization tooling like quantization mapping and kernel optimizations enables high performance on devices like Arm Cortex-M and RISC-V processors. The active developer community ensures accessible technical support. Seamless integration with TensorFlow for training and converting models makes the workflow cohesive.
+
+For platforms with more capable CPUs like Cortex-A, TensorFlow Lite for Microcontrollers expand possibilities. They provide greater flexibility for custom and advanced models beyond the core operators in TFLite Micro. However, this comes at the cost of a larger memory footprint. These frameworks are ideal for automotive systems, drones, and more powerful edge devices that can benefit from greater model sophistication.
+
+Frameworks specifically built for specialized hardware like CMSIS-NN on Cortex-M processors can further maximize performance, but sacrifice portability. Integrated frameworks from processor vendors tailor the stack to their architectures. This can unlock the full potential of their chips but lock you into their ecosystem.
+
+Ultimately, choosing the right framework involves finding the best match between its capabilities and the requirements of the target platform. This requires balancing tradeoffs between performance needs, hardware constraints, model complexity, and other factors. Thoroughly assessing intended models, use cases, and evaluating options against key metrics will guide developers towards picking the ideal framework for their embedded ML application.
diff --git a/generative_ai.qmd b/generative_ai.qmd
index b48d0b1c..12ced622 100644
--- a/generative_ai.qmd
+++ b/generative_ai.qmd
@@ -1,6 +1,7 @@
# Generative AI
::: {.callout-tip}
+
## Learning Objectives
* coming soon.
@@ -15,17 +16,17 @@ I'll be candid - this chapter might be a bit of a leap. As of now, the concept o
Explanation: This section will introduce readers to the basics of generative AI, emphasizing its importance and role in the modern technology landscape, particularly within the domain of embedded systems. This sets the stage for a deeper exploration of the specific aspects and applications of generative AI in the following sections.
-- Definition and Overview
-- Importance in Embedded AI
-- Overview of Generative AI Models
+* Definition and Overview
+* Importance in Embedded AI
+* Overview of Generative AI Models
## Generative Models
Explanation: In this section, readers will build a basic foundation by learning about different generative models. Understanding the general working principles and characteristics of these models may help set the stage to think about the applications and issues down the road.
-- Variational Autoencoders (VAEs)
-- Generative Adversarial Networks (GANs)
-- Restricted Boltzmann Machines (RBMs)
+* Variational Autoencoders (VAEs)
+* Generative Adversarial Networks (GANs)
+* Restricted Boltzmann Machines (RBMs)
## Applications of Generative Models for Embedded Systems
@@ -33,38 +34,38 @@ Explanation: This section delves into the practical applications of generative m
### Creative Applications
-- Generating realistic images and videos
-- Producing text and music compositions
-- Other innovative content creations
+* Generating realistic images and videos
+* Producing text and music compositions
+* Other innovative content creations
### Data Augmentation
-- Augmenting existing datasets for sensors
-- Enhancing machine learning model training on embedded devices
-- Tackling data limitations on embedded systems
+* Augmenting existing datasets for sensors
+* Enhancing machine learning model training on embedded devices
+* Tackling data limitations on embedded systems
### Personalization
-- Generating custom recommendations
-- Facilitating multi-language text translations
-- Enhancing user experiences through tailored content
+* Generating custom recommendations
+* Facilitating multi-language text translations
+* Enhancing user experiences through tailored content
## Challenges and Opportunities
Explanation: This critical section directly ties generative AI to embedded systems, offering a balanced view of the challenges and opportunities this integration brings about. Through this discussion, readers will gain insights into the synergies between generative AI and embedded systems, paving the way for future developments and practical applications.
-- Challenges of implementing generative AI models on embedded systems
- - Resource constraints
- - Power limitations
-- Strategies for optimizing generative AI models for embedded systems
- - Model quantization
- - Pruning
- - Hardware acceleration
-- Can likely refer back to the previous chapters for these details.
+* Challenges of implementing generative AI models on embedded systems
+ * Resource constraints
+ * Power limitations
+* Strategies for optimizing generative AI models for embedded systems
+ * Model quantization
+ * Pruning
+ * Hardware acceleration
+* Can likely refer back to the previous chapters for these details.
## Conclusion
Explanation: This section serves as a summation of the chapter, revisiting the important points discussed and emphasizing the potential impacts of generative AI in the industry. It aims to reinforce the knowledge acquired and inspire readers to further explore or initiate projects in the field of generative AI and embedded systems.
-- Recap of key takeaways
-- Encouragement for deeper exploration and practical engagement in the field
\ No newline at end of file
+* Recap of key takeaways
+* Encouragement for deeper exploration and practical engagement in the field
diff --git a/hw_acceleration.qmd b/hw_acceleration.qmd
index 1a022931..e751bddc 100644
--- a/hw_acceleration.qmd
+++ b/hw_acceleration.qmd
@@ -1,12 +1,13 @@
-# AI Acceleration
+# AI Acceleration

-Machine learning has emerged as a transformative technology across many industries. However, deploying ML capabilities in real-world edge devices faces challenges due to limited computing resources. Specialized hardware acceleration has become essential to enable high-performance machine learning under these constraints. Hardware accelerators optimize compute-intensive operations like inference using custom silicon optimized for matrix multiplications. This provides dramatic speedups over general-purpose CPUs, unlocking real-time execution of advanced models on size, weight and power-constrained devices.
+Machine learning has emerged as a transformative technology across many industries. However, deploying ML capabilities in real-world edge devices faces challenges due to limited computing resources. Specialized hardware acceleration has become essential to enable high-performance machine learning under these constraints. Hardware accelerators optimize compute-intensive operations like inference using custom silicon optimized for matrix multiplications. This provides dramatic speedups over general-purpose CPUs, unlocking real-time execution of advanced models on size, weight and power-constrained devices.
This chapter provides essential background on hardware acceleration techniques for embedded machine learning and their tradeoffs. The goal is to equip readers to make informed hardware selections and software optimizations to develop performant on-device ML capabilities.
::: {.callout-tip}
+
## Learning Objectives
* Understand why hardware acceleration is needed for AI workloads
@@ -26,7 +27,8 @@ This chapter provides essential background on hardware acceleration techniques f
:::
## Introduction
-Machine learning has emerged as a transformative technology across many industries, enabling systems to learn and improve from data. To deploy machine learning capabilities in real-world environments, there is a growing demand for embedded ML solutions - where models are built into edge devices like smartphones, home appliances and autonomous vehicles. However, these edge devices have limited computing resources compared to data center servers.
+
+Machine learning has emerged as a transformative technology across many industries, enabling systems to learn and improve from data. To deploy machine learning capabilities in real-world environments, there is a growing demand for embedded ML solutions - where models are built into edge devices like smartphones, home appliances and autonomous vehicles. However, these edge devices have limited computing resources compared to data center servers.
To enable high-performance machine learning on resource-constrained edge devices, specialized hardware acceleration has become essential. Hardware acceleration refers to using custom silicon chips and architectures to offload compute-intensive ML operations from the main processor. In neural networks, the most intensive computations are the matrix multiplications during inference. Hardware accelerators can optimize these matrix operations, providing 10-100x speedups over general-purpose CPUs. This acceleration unlocks the ability to run advanced neural network models in real-time on devices with size, weight and power constraints.
@@ -34,11 +36,11 @@ This chapter overviews hardware acceleration techniques for embedded machine lea
## Background and Basics
-### Historical Background
+### Historical Background
The origins of hardware acceleration date back to the 1960s, with the advent of floating point math co-processors to offload calculations from the main CPU. One early example was the [Intel 8087](https://en.wikipedia.org/wiki/Intel_8087) chip released in 1980 to accelerate floating point operations for the 8086 processor. This established the practice of using specialized processors to handle math-intensive workloads efficiently.
-In the 1990s, the first [graphics processing units (GPUs)](https://en.wikipedia.org/wiki/History_of_the_graphics_processor) emerged to process graphics pipelines for rendering and gaming rapidly. Nvidia's [GeForce 256](https://en.wikipedia.org/wiki/GeForce_256) in 1999 was one of the earliest programmable GPUs capable of running custom software algorithms. GPUs exemplify domain-specific fixed-function accelerators as well as evolving into parallel programmable accelerators.
+In the 1990s, the first [graphics processing units (GPUs)](https://en.wikipedia.org/wiki/History_of_the_graphics_processor) emerged to process graphics pipelines for rendering and gaming rapidly. Nvidia's [GeForce 256](https://en.wikipedia.org/wiki/GeForce_256) in 1999 was one of the earliest programmable GPUs capable of running custom software algorithms. GPUs exemplify domain-specific fixed-function accelerators as well as evolving into parallel programmable accelerators.
In the 2000s, GPUs were applied to general-purpose computing under [GPGPU](https://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units). Their high memory bandwidth and computational throughput made them well-suited for math-intensive workloads. This included breakthroughs in using GPUs to accelerate training of deep learning models such as [AlexNet](https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html) in 2012.
@@ -50,9 +52,9 @@ This evolution demonstrates how hardware acceleration has focused on solving com
The evolution of hardware acceleration is closely tied to the broader history of computing. In the early decades, chip design was governed by Moore's Law and Dennard Scaling, which predicted the exponential growth in transistor density and proportional improvements in power and performance. This was held through the single-core era.
-However, as @patterson2016computer describe, technological constraints eventually forced a transition to the multicore era, with chips containing multiple processing cores to deliver gains in performance. As power limitations prevented further scaling, this led to "dark silicon" ([Dark Silicon](https://en.wikipedia.org/wiki/Dark_silicon)) where not all chip areas could be simultaneously active [@xiu2019time].
+However, as @patterson2016computer describe, technological constraints eventually forced a transition to the multicore era, with chips containing multiple processing cores to deliver gains in performance. As power limitations prevented further scaling, this led to "dark silicon" ([Dark Silicon](https://en.wikipedia.org/wiki/Dark_silicon)) where not all chip areas could be simultaneously active [@xiu2019time].
-The concept of dark silicon emerged as a consequence of these constraints. "Dark silicon" refers to portions of the chip that cannot be powered on at the same time due to thermal and power limitations. Essentially, as the density of transistors increased, the proportion of the chip that could be actively used without overheating or exceeding power budgets shrank.
+The concept of dark silicon emerged as a consequence of these constraints. "Dark silicon" refers to portions of the chip that cannot be powered on at the same time due to thermal and power limitations. Essentially, as the density of transistors increased, the proportion of the chip that could be actively used without overheating or exceeding power budgets shrank.
This phenomenon meant that while chips had more transistors, not all could be operational simultaneously, limiting potential performance gains. This power crisis necessitated a shift to the accelerator era, with specialized hardware units tailored for specific tasks to maximize efficiency. The explosion in AI workloads further drove demand for customized accelerators. Enabling factors included new programming languages, software tools, and manufacturing advances.
@@ -70,9 +72,9 @@ Performance refers to the throughput of computational work per unit time, common
Hardware accelerators aim to maximize performance within set power budgets. This requires careful balancing of parallelism, clock frequency of the chip, operating voltage of the chip, workload optimization and other techniques to maximize operations per watt.
-- **Performance** = Throughput * Efficiency
-- **Throughput** ~= Parallelism * Clock Frequency
-- **Efficiency** = Operations / Watt
+* **Performance** = Throughput * Efficiency
+* **Throughput** ~= Parallelism * Clock Frequency
+* **Efficiency** = Operations / Watt
For example, GPUs achieve high throughput via massively parallel architectures. However, their efficiency is lower than customized ASICs like Google's TPU that optimize for a specific workload.
@@ -90,11 +92,11 @@ Accelerator design involves squeezing maximim performance within area constraint
The target workload dictates optimal accelerator architectures. Some of the key considerations include:
-- **Memory vs Compute boundedness:** Memory-bound workloads require more memory bandwidth, while compute-bound apps need arithmetic throughput.
-- **Data locality:** Data movement should be minimized for efficiency. Near-compute memory helps.
-- **Bit-level operations:** Low precision datatypes like INT8/INT4 optimize compute density.
-- **Data parallelism:** Multiple replicated compute units allow parallel execution.
-- **Pipelining:** Overlapped execution of operations increases throughput.
+* **Memory vs Compute boundedness:** Memory-bound workloads require more memory bandwidth, while compute-bound apps need arithmetic throughput.
+* **Data locality:** Data movement should be minimized for efficiency. Near-compute memory helps.
+* **Bit-level operations:** Low precision datatypes like INT8/INT4 optimize compute density.
+* **Data parallelism:** Multiple replicated compute units allow parallel execution.
+* **Pipelining:** Overlapped execution of operations increases throughput.
Understanding workload characteristics enables customized acceleration. For example, convolutional neural networks use sliding window operations that are optimally mapped to spatial arrays of processing elements.
@@ -131,13 +133,13 @@ The progression begins with the most specialized option, ASICs purpose-built for
An Application-Specific Integrated Circuit (ASIC) is a type of [integrated circuit](https://en.wikipedia.org/wiki/Integrated_circuit) (IC) that is custom-designed for a specific application or workload, rather than for general-purpose use. Unlike CPUs and GPUs, ASICs do not support multiple applications or workloads. Rather, they are optimized to perform a single task extremely efficiently. Apple’s M1/2/3, AMD’s Neoverse, Intel’s i5/7/9, Google’s TPUs, and NVIDIA’s GPUs are all examples of ASICs.
-ASICs achieve this efficiency by tailoring every aspect of the chip design - the underlying logic gates, electronic components, architecture, memory, I/O, and manufacturing process - specifically for the target application. This level of customization allows removing any unnecessary logic or functionality required for general computation. The result is an IC that maximizes performance and power efficiency on the desired workload. The efficiency gains from application-specific hardware are so substantial that these software-centric firms are dedicating enormous engineering resources to designing customized ASICs.
+ASICs achieve this efficiency by tailoring every aspect of the chip design - the underlying logic gates, electronic components, architecture, memory, I/O, and manufacturing process - specifically for the target application. This level of customization allows removing any unnecessary logic or functionality required for general computation. The result is an IC that maximizes performance and power efficiency on the desired workload. The efficiency gains from application-specific hardware are so substantial that these software-centric firms are dedicating enormous engineering resources to designing customized ASICs.
The rise of more complex machine learning algorithms has made the performance advantages enabled by tailored hardware acceleration a key competitive differentiator, even for companies traditionally concentrated on software engineering. ASICs have become a high-priority investment for major cloud providers aiming to offer faster AI computation.
#### Advantages
-ASICs provide significant benefits over general purpose processors like CPUs and GPUs due to their customized nature. The key advantages include the following.
+ASICs provide significant benefits over general purpose processors like CPUs and GPUs due to their customized nature. The key advantages include the following.
##### Maximized Performance and Efficiency
@@ -147,25 +149,25 @@ For example, [Google's Tensor Processing Units (TPUs)](https://cloud.google.com/
As a result, TPU ASICs achieve over an order of magnitude higher efficiency in operations per watt than general purpose GPUs on ML workloads by maximizing performance and minimizing power consumption through a full-stack custom hardware design.
-##### Specialized On-Chip Memory
+##### Specialized On-Chip Memory
-ASICs incorporate on-chip SRAM and caches specifically optimized to feed data to the computational units. For example, Apple's M1 system-on-a-chip contains special low-latency SRAM to accelerate the performance of its Neural Engine machine learning hardware. Large local memory with high bandwidth enables keeping data as close as possible to the processing elements. This provides tremendous speed advantages compared to off-chip DRAM access, which is up to 100x slower.
+ASICs incorporate on-chip SRAM and caches specifically optimized to feed data to the computational units. For example, Apple's M1 system-on-a-chip contains special low-latency SRAM to accelerate the performance of its Neural Engine machine learning hardware. Large local memory with high bandwidth enables keeping data as close as possible to the processing elements. This provides tremendous speed advantages compared to off-chip DRAM access, which is up to 100x slower.
Data locality and optimizing memory hierarchy is crucial for both high throughput and low power.Below is a table "Numbers Everyone Should Know" from [Jeff Dean](https://research.google/people/jeff/).
| Operation | Latency | Notes |
-|-|-|-|
+|-|-|-|
| L1 cache reference | 0.5 ns | |
-| Branch mispredict | 5 ns | |
+| Branch mispredict | 5 ns | |
| L2 cache reference | 7 ns | |
| Mutex lock/unlock | 25 ns | |
-| Main memory reference | 100 ns | |
+| Main memory reference | 100 ns | |
| Compress 1K bytes with Zippy | 3,000 ns | 3 μs |
-| Send 1 KB bytes over 1 Gbps network | 10,000 ns | 10 μs |
-| Read 4 KB randomly from SSD | 150,000 ns | 150 μs |
+| Send 1 KB bytes over 1 Gbps network | 10,000 ns | 10 μs |
+| Read 4 KB randomly from SSD | 150,000 ns | 150 μs |
| Read 1 MB sequentially from memory | 250,000 ns | 250 μs |
| Round trip within same datacenter | 500,000 ns | 0.5 ms |
-| Read 1 MB sequentially from SSD | 1,000,000 ns | 1 ms |
+| Read 1 MB sequentially from SSD | 1,000,000 ns | 1 ms |
| Disk seek | 10,000,000 ns | 10 ms |
| Read 1 MB sequentially from disk | 20,000,000 ns | 20 ms |
| Send packet CA->Netherlands->CA | 150,000,000 ns | 150 ms |
@@ -179,44 +181,47 @@ Unlike general purpose processors, ASICs can be designed to natively support cus
ASIC architectures can leverage much higher parallelism tuned for the target workload versus general purpose CPUs or GPUs. More computational units tailored for the application means more operations execute simultaneously. Highly parallel ASICs achieve tremendous throughput for data parallel workloads like neural network inference.
##### Advanced Process Nodes
+
Cutting edge manufacturing processes allow packing more transistors into smaller die areas, increasing density. ASICs designed specifically for high volume applications can better amortize the costs of bleeding edge process nodes.
#### Disadvantages
##### Long Design Timelines
-The engineering process of designing and validating an ASIC can take 2-3 years. Synthesizing the architecture using hardware description languages, taping out the chip layout, and fabricating the silicon on advanced process nodes involves long development cycles. For example, to tape out a 7nm chip, teams need to carefully define specifications, write the architecture in HDL, synthesize the logic gates, place components, route all interconnections, and finalize the layout to send for fabrication. This very large scale integration (VLSI) flow means ASIC design and manufacturing can traditionally take 2-5 years.
+The engineering process of designing and validating an ASIC can take 2-3 years. Synthesizing the architecture using hardware description languages, taping out the chip layout, and fabricating the silicon on advanced process nodes involves long development cycles. For example, to tape out a 7nm chip, teams need to carefully define specifications, write the architecture in HDL, synthesize the logic gates, place components, route all interconnections, and finalize the layout to send for fabrication. This very large scale integration (VLSI) flow means ASIC design and manufacturing can traditionally take 2-5 years.
There are a few key reasons why the long design timelines of ASICs, often 2-3 years, can be challenging for machine learning workloads:
-- **ML algorithms evolve rapidly:** New model architectures, training techniques, and network optimizations are constantly emerging. For example, Transformers became hugely popular in NLP in just the last few years. By the time an ASIC finishes tapeout, the optimal architecture for a workload may have changed.
-- **Datasets grow quickly:** ASICs designed for certain model sizes or datatypes can become undersized relative to demand. For instance, natural language models are scaling exponentially with more data and parameters. A chip designed for BERT might not accommodate GPT-3.
-- **ML applications change frequently:** The industry focus shifts between computer vision, speech, NLP, recommender systems etc. An ASIC optimized for image classification may have less relevance in a few years.
-- **Faster design cycles with GPUs/FPGAs:** Programmable accelerators like GPUs can adapt much quicker by upgrading software libraries and frameworks. New algorithms can be deployed without hardware changes.
-- **Time-to-market needs:** Getting a competitive edge in ML requires rapidly experimenting with new ideas and deploying them. Waiting several years for an ASIC is not aligned with fast iteration.
+* **ML algorithms evolve rapidly:** New model architectures, training techniques, and network optimizations are constantly emerging. For example, Transformers became hugely popular in NLP in just the last few years. By the time an ASIC finishes tapeout, the optimal architecture for a workload may have changed.
+* **Datasets grow quickly:** ASICs designed for certain model sizes or datatypes can become undersized relative to demand. For instance, natural language models are scaling exponentially with more data and parameters. A chip designed for BERT might not accommodate GPT-3.
+* **ML applications change frequently:** The industry focus shifts between computer vision, speech, NLP, recommender systems etc. An ASIC optimized for image classification may have less relevance in a few years.
+* **Faster design cycles with GPUs/FPGAs:** Programmable accelerators like GPUs can adapt much quicker by upgrading software libraries and frameworks. New algorithms can be deployed without hardware changes.
+* **Time-to-market needs:** Getting a competitive edge in ML requires rapidly experimenting with new ideas and deploying them. Waiting several years for an ASIC is not aligned with fast iteration.
The pace of innovation in ML is not well matched to the multi-year timescale for ASIC development. Significant engineering efforts are required to extend ASIC lifespan through modular architectures, process scaling, model compression, and other techniques. But the rapid evolution of ML makes fixed function hardware challenging.
-##### High Non-Recurring Engineering Costs
+##### High Non-Recurring Engineering Costs
+
The fixed costs of taking an ASIC from design to high volume manufacturing can be very capital intensive, often tens of millions of dollars. Photomask fabrication for taping out chips in advanced process nodes, packaging, and one-time engineering efforts are expensive. For instance, a 7nm chip tapeout alone could cost tens of millions of dollars. The high non-recurring engineering (NRE) investment narrows ASIC viability to high-volume production use cases where the upfront cost can be amortized.

*Table from [Enabling Cheaper Design](https://semiengineering.com/enabling-cheaper-design/)*
##### Complex Integration and Programming
+
ASICs require extensive software integration work including drivers, compilers, OS support, and debugging tools. They also need expertise in electrical and thermal packaging. Additionally, programming ASIC architectures efficiently can involve challenges like workload partitioning and scheduling across many parallel units. The customized nature necessitates significant integration efforts to turn raw hardware into fully operational accelerators.
While ASICs provide massive efficiency gains on target applications by tailoring every aspect of the hardware design to one specific task, their fixed nature results in tradeoffs in flexibility and development costs compared to programmable accelerators, which must be weighed based on the application.
### Field-Programmable Gate Arrays (FPGAs)
-FPGAs are programmable integrated circuits that can be reconfigured for different applications. Their customizable nature provides advantages for accelerating AI algorithms compared to fixed ASICs or inflexible GPUs. While Google, Meta, and NVIDIA which are looking at putting ASICs in data centers, Microsoft deployed FPGAs in their data centers [@putnam_reconfigurable_2014] in 2011 to efficiently serve diverse data center workloads.
+FPGAs are programmable integrated circuits that can be reconfigured for different applications. Their customizable nature provides advantages for accelerating AI algorithms compared to fixed ASICs or inflexible GPUs. While Google, Meta, and NVIDIA which are looking at putting ASICs in data centers, Microsoft deployed FPGAs in their data centers [@putnam_reconfigurable_2014] in 2011 to efficiently serve diverse data center workloads.
#### Advantages
FPGAs provide several benefits over GPUs and ASICs for accelerating machine learning workloads.
-##### Flexibility Through Reconfigurable Fabric
+##### Flexibility Through Reconfigurable Fabric
The key advantage of FPGAs is the ability to reconfigure the underlying fabric to implement custom architectures optimized for different models, unlike fixed-function ASICs. For example, quant trading firms use FPGAs to accelerate their algorithms because they change frequently, and the low NRE cost of FPGAs is more viable than taping out new ASICs.
@@ -231,7 +236,7 @@ While FPGAs may not achieve the utmost performance and efficiency of workload-sp
FPGA architectures can leverage spatial parallelism and pipelining by tailoring the hardware design to mirror the parallelism in ML models. For example, Intel's HARPv2 FPGA platform splits the layers of an MNIST convolutional network across separate processing elements to maximize throughput. Unique parallel patterns like tree ensemble evaluations are also possible on FPGAs. Deep pipelines with optimized buffering and dataflow can be customized to each model's structure and datatypes. This level of tailored parallelism and pipelining is not feasible on GPUs.
-##### Low Latency On-Chip Memory
+##### Low Latency On-Chip Memory
Large amounts of high bandwidth on-chip memory enables localized storage for weights and activations. For instance, Xilinx Versal FPGAs contain 32MB of low latency RAM blocks along with dual-channel DDR4 interfaces for external memory. Bringing memory physically closer to the compute units reduces access latency. This provides significant speed advantages over GPUs that must traverse PCIe or other system buses to reach off-chip GDDR6 memory.
@@ -249,7 +254,7 @@ FPGAs cannot match the raw throughput numbers of ASICs customized for a specific
This is because FPGAs are composed of basic building blocks - configurable logic blocks, RAM blocks, and interconnects. Vendors provide a set amount of these resources. To program FPGAs, engineers write HDL code and compile into bitstreams that rearrange the fabric, which has inherent overheads versus an ASIC purpose-built for one computation.
-##### Programming Complexity
+##### Programming Complexity
To optimize FPGA performance, engineers must program the architectures in low-level hardware description languages like Verilog or VHDL. This requires hardware design expertise and longer development cycles versus higher level software frameworks like TensorFlow. Maximizing utilization can be challenging despite advances in high-level synthesis from C/C++.
@@ -257,7 +262,7 @@ To optimize FPGA performance, engineers must program the architectures in low-le
To change FPGA configurations requires reloading a new bitstream, which has considerable latency and storage size costs. For example, partial reconfiguration on Xilinx FPGAs can take 100s of milliseconds. This makes dynamically swapping architectures in real-time infeasible. The bitstream storage also consumes on-chip memory.
-##### Diminishing Gains on Advanced Nodes
+##### Diminishing Gains on Advanced Nodes
While smaller process nodes benefit ASICs greatly, they provide less advantages for FPGAs. At 7nm and below, effects like process variation, thermal constraints, and aging disproportionately impact FPGA performance. The overheads of configurable fabric also diminish gains vs fixed function ASICs.
@@ -270,17 +275,17 @@ FPGAs have found widespread application in various fields, including medical ima
The first digital signal processor core was built in 1948 by Texas Instruments ([“The Evolution of Audio DSPs
"](https://audioxpress.com/article/the-evolution-of-audio-dsps)). Traditionally, DSPs would have logic to allow them to directly access digital/audio data in memory, perform an arithmetic operation (multiply-add-accumulate–MAC–was one of the most common operations) and then write the result back to memory. The DSP would also include specialized analog components to retrieve said digital/audio data.
-Once we entered the smartphone era, DSPs started encompassing more sophisticated tasks. They required Bluetooth, Wi-Fi, and cellular connectivity. Media also became much more complex. Today, it’s not common to have entire chips dedicated to just DSP, but a System on Chip would include DSPs in addition to general-purpose CPUs. For example, Qualcomm’s [Hexagon Digital Signal Processor](https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor) claims to be a “world-class processor with both CPU and DSP functionality to support deeply embedded processing needs of the mobile platform for both multimedia and modem functions.” [Google Tensors](https://blog.google/products/pixel/google-tensor-g3-pixel-8/), the chip in the Google Pixel phones, also includes both CPUs and specialized DSP engines.
+Once we entered the smartphone era, DSPs started encompassing more sophisticated tasks. They required Bluetooth, Wi-Fi, and cellular connectivity. Media also became much more complex. Today, it’s not common to have entire chips dedicated to just DSP, but a System on Chip would include DSPs in addition to general-purpose CPUs. For example, Qualcomm’s [Hexagon Digital Signal Processor](https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor) claims to be a “world-class processor with both CPU and DSP functionality to support deeply embedded processing needs of the mobile platform for both multimedia and modem functions.” [Google Tensors](https://blog.google/products/pixel/google-tensor-g3-pixel-8/), the chip in the Google Pixel phones, also includes both CPUs and specialized DSP engines.
#### Advatages
-DSPs architecturally provide advantages in vector math throughput, low latency memory access, power efficiency, and support for diverse datatypes - making them well-suited for embedded ML acceleration.
+DSPs architecturally provide advantages in vector math throughput, low latency memory access, power efficiency, and support for diverse datatypes - making them well-suited for embedded ML acceleration.
##### Optimized Architecture for Vector Math
DSPs contain specialized data paths, register files, and instructions optimized specifically for vector math operations commonly used in machine learning models. This includes dot product engines, MAC units, and SIMD capabilities tailored for vector/matrix calculations. For example, the CEVA-XM6 DSP (["Ceva SensPro Fuses AI and Vector DSP"](https://www.ceva-dsp.com/wp-content/uploads/2020/04/Ceva-SensPro-Fuses-AI-and-Vector-DSP.pdf)) has 512-bit vector units to accelerate convolutions. This efficiency on vector math workloads is far beyond general CPUs.
-##### Low Latency On-Chip Memory
+##### Low Latency On-Chip Memory
DSPs integrate large amounts of fast on-chip SRAM memory to hold data locally for processing. Bringing memory physically closer to the computation units reduces access latency. For example, Analog's SHARC+ DSP contains 10MB of on-chip SRAM. This high-bandwidth local memory provides speed advantages for real-time applications.
@@ -300,7 +305,7 @@ DSPs make architectural tradeoffs that limit peak throughput, precision, and mod
DSPs cannot match the raw computational throughput of GPUs or customized ASICs designed specifically for machine learning. For example, Qualcomm's Cloud AI 100 ASIC delivers 480 TOPS on INT8, while their Hexagon DSP provides 10 TOPS. DSPs lack the massive parallelism of GPU SM units.
-##### Slower Double Precision Performance
+##### Slower Double Precision Performance
Most DSPs are not optimized for higher precision floating point needed in some ML models. Their dot product engines focus on INT8/16 and FP32 which provides better power efficiency. But 64-bit floating point throughput is much lower. This can limit usage in models requiring high precision.
@@ -314,7 +319,7 @@ Efficiently programming DSP architectures requires expertise in parallel program
### Graphics Processing Units (GPUs)
-The term graphics processing unit existed since at least the 1980s. There had always been a demand for graphics hardware in both video game consoles (high demand, needed to be relatively lower cost) and scientific simulations (lower demand, but needed higher resolution, could be at a high price point).
+The term graphics processing unit existed since at least the 1980s. There had always been a demand for graphics hardware in both video game consoles (high demand, needed to be relatively lower cost) and scientific simulations (lower demand, but needed higher resolution, could be at a high price point).
The term was popularized, however, in 1999 when NVIDIA launched the GeForce 256 mainly targeting the PC games market sector [@lindholm_nvidia_2008]. As PC games became more sophisticated, NVIDIA GPUs became more programmable over time as well. Soon, users realized they could take advantage of this programmability and run a variety of non-graphics related workloads on GPUs and benefit from the underlying architecture. And so, starting in the late 2000s, GPUs became general-purpose graphics processing units or GP-GPUs.
@@ -342,7 +347,7 @@ The economies of scale of graphics processing make GPUs broadly accessible in da
##### Programmable Architecture
-While not fully flexible as FPGAs, GPUs do provide programmability via CUDA and shader languages to customize computations. Developers can optimize data access patterns, create new ops, and tune precisions for evolving models and algorithms.
+While not fully flexible as FPGAs, GPUs do provide programmability via CUDA and shader languages to customize computations. Developers can optimize data access patterns, create new ops, and tune precisions for evolving models and algorithms.
#### Disadvatages
@@ -350,11 +355,11 @@ While GPUs have become the standard accelerator for deep learning, their archite
##### Less Efficient than Custom ASICs
-The statement "GPUs are less efficient than ASICs" could spark intense debate within the ML/AI field and cause this book to explode 🤯.
+The statement "GPUs are less efficient than ASICs" could spark intense debate within the ML/AI field and cause this book to explode 🤯.
Typically, GPUs are perceived as less efficient than ASICs because the latter are custom-built for specific tasks and thus can operate more efficiently by design. GPUs, with their general-purpose architecture, are inherently more versatile and programmable, catering to a broad spectrum of computational tasks beyond ML/AI.
-However, modern GPUs, however, have evolved to include specialized hardware support for essential AI operations, such as generalized matrix multiplication (GEMM) and other matrix operations, which are critical for running ML models effectively. These enhancements have significantly improved the efficiency of GPUs for AI tasks, to the point where they can rival the performance of ASICs for certain applications.
+However, modern GPUs, however, have evolved to include specialized hardware support for essential AI operations, such as generalized matrix multiplication (GEMM) and other matrix operations, which are critical for running ML models effectively. These enhancements have significantly improved the efficiency of GPUs for AI tasks, to the point where they can rival the performance of ASICs for certain applications.
Consequently, some might argue that contemporary GPUs represent a convergence of sorts, incorporating specialized, ASIC-like capabilities within a flexible, general-purpose processing framework. This adaptability has blurred the lines between the two types of hardware, with GPUs offering a strong balance of specialization and programmability that is well-suited to the dynamic needs of ML/AI research and development.
@@ -382,15 +387,15 @@ The recent groundbreaking research conducted by OpenAI [@brown2020language] with
The term CPUs has a long history that dates back to 1955 [@weik_survey_1955] while the first microprocessor CPU–the Intel 4004–was invented in 1971 ([Who Invented the Microprocessor?](https://computerhistory.org/blog/who-invented-the-microprocessor/)). Compilers compile high-level programming languages like Python, Java, or C to assembly instructions (x86, ARM, RISC-V, etc.) for CPUs to process. The set of instructions a CPU understands is called the “instruction set” and must be agreed upon by both the hardware and software running atop it (See section 5 for a more in-depth description on instruction set architectures–ISAs).
-An overview of significant developments in CPUs:
+An overview of significant developments in CPUs:
* **Single-core Era (1950s- 2000):** This era is known for seeing aggressive microarchitectural improvements. Techniques like speculative execution (executing an instruction before the previous one was done), out-of-order execution (re-ordering instructions to be more effective), and wider issue widths (executing multiple instructions at once) were implemented to increase instruction throughput. The term “System on Chip” also originated in this era as different analog components (components designed with transistors) and digital components (components designed with hardware description languages that are mapped to transistors) were put on the same platform to achieve some task.
-* **Multi-core Era (2000s):** Driven by the decrease of Moore’s Law, this era is marked by scaling the number of cores within a CPU. Now tasks can be split across many different cores each with its own datapath and control unit. Many of the issues arising in this era pertained to how to share certain resources, which resources to share, and how to maintain coherency and consistency across all the cores.
-* **Sea of accelerators (2010s):** Again, driven by the decrease of Moore’s law, this era is marked by offloading more complicated tasks to accelerators (widgets) attached the the main datapath in CPUs. It’s common to see accelerators dedicated to various AI workloads, as well as image/digital processing, and cryptography. In these designs, CPUs are often described more as arbiters, deciding which tasks should be processed rather than doing the processing itself. Any task could still be run on the CPU rather than the accelerators, but the CPU would generally be slower. However, the cost of designing and especially programming the accelerator became be a non-trivial hurdle that led to a spike of interest in design-specific libraries (DSLs).
+* **Multi-core Era (2000s):** Driven by the decrease of Moore’s Law, this era is marked by scaling the number of cores within a CPU. Now tasks can be split across many different cores each with its own datapath and control unit. Many of the issues arising in this era pertained to how to share certain resources, which resources to share, and how to maintain coherency and consistency across all the cores.
+* **Sea of accelerators (2010s):** Again, driven by the decrease of Moore’s law, this era is marked by offloading more complicated tasks to accelerators (widgets) attached the the main datapath in CPUs. It’s common to see accelerators dedicated to various AI workloads, as well as image/digital processing, and cryptography. In these designs, CPUs are often described more as arbiters, deciding which tasks should be processed rather than doing the processing itself. Any task could still be run on the CPU rather than the accelerators, but the CPU would generally be slower. However, the cost of designing and especially programming the accelerator became be a non-trivial hurdle that led to a spike of interest in design-specific libraries (DSLs).
* **Presence in data centers:** Although we often hear that GPUs dominate the data center marker, CPUs are still well suited for tasks that don’t inherently possess a large amount of parallelism. CPUs often handle serial and small tasks and coordinate the data center as a whole.
* **On the edge:** Given the tighter resource constraints on the edge, edge CPUs often only implement a subset of the techniques developed in the sing-core era because these optimizations tend to be heavy on power and area consumption. Edge CPUs still maintain a relatively simple datapath with limited memory capacities.
-Traditionally, CPUs have been synonymous with general-purpose computing–a term that has also changed as the “average” workload a consumer would run changes over time. For example, floating point components were once considered reserved for “scientific computing” so it was usually implemented as a co-processor (a modular component that worked in tandem with the datapath) and seldom deployed to average consumers. Compare this attitude to today, where FPUs are built into every datapath.
+Traditionally, CPUs have been synonymous with general-purpose computing–a term that has also changed as the “average” workload a consumer would run changes over time. For example, floating point components were once considered reserved for “scientific computing” so it was usually implemented as a co-processor (a modular component that worked in tandem with the datapath) and seldom deployed to average consumers. Compare this attitude to today, where FPUs are built into every datapath.
#### Advatages
@@ -426,7 +431,7 @@ While providing some advantages, general-purpose CPUs also come with limitations
CPUs lack the specialized architectures for massively parallel processing that GPUs and other accelerators provide. Their general-purpose design results in lower computational throughput for the highly parallelizable math operations common in ML models [@jouppi2017datacenter].
-##### Not Optimized for Data Parallelism
+##### Not Optimized for Data Parallelism
The architectures of CPUs are not specifically optimized for data parallel workloads inherent to AI [@Sze2017-ak]. They allocate substantial silicon area to instruction decoding, speculative execution, caching, and flow control that provide little benefit for the array operations used in neural networks ([AI Inference Acceleration on CPUs](https://www.intel.com/content/www/us/en/developer/articles/technical/ai-inference-acceleration-on-intel-cpus.html#gs.0w9qn2)).
@@ -443,9 +448,9 @@ While suitable for intermittent inference, sustaining near-peak throughput for t
### Comparison
| Accelerator | Description | Key Advantages | Key Disadvantages |
-|-|-|-|-|
+|-|-|-|-|
| ASICs | Custom ICs designed for target workload like AI inference | Maximizes perf/watt.
Optimized for tensor ops
Low latency on-chip memory | Fixed architecture lacks flexibility
High NRE cost
Long design cycles |
-| FPGAs | Reconfigurable fabric with programmable logic and routing | Flexible architecture
Low latency memory access | Lower perf/watt than ASICs
Complex programming |
+| FPGAs | Reconfigurable fabric with programmable logic and routing | Flexible architecture
Low latency memory access | Lower perf/watt than ASICs
Complex programming |
| GPUs | Originally for graphics, now used for neural network acceleration | High throughput
Parallel scalability
Software ecosystem with CUDA | Not as power efficient as ASICs.
Require high memory bandwidth |
| CPUs | General purpose processors | Programmability
Ubiquitous availability | Lower performance for AI workloads |
@@ -501,19 +506,19 @@ The key goal is tailoring the hardware capabilities to match the algorithms and
The software stack can be optimized to better leverage the underlying hardware capabilities:
-- **Model Parallelism:** Parallelize matrix computations like convolution or attention layers to maximize throughput on vector engines.
-- **Memory Optimization:** Tune data layouts to improve cache locality based on hardware profiling. This maximizes reuse and minimizes expensive DRAM access.
-- **Custom Operations:** Incorporate specialized ops like low precision INT4 or bfloat16 into models to capitalize on dedicated hardware support.
-- **Dataflow Mapping:** Explicitly map model stages to computational units to optimize data movement on hardware.
+* **Model Parallelism:** Parallelize matrix computations like convolution or attention layers to maximize throughput on vector engines.
+* **Memory Optimization:** Tune data layouts to improve cache locality based on hardware profiling. This maximizes reuse and minimizes expensive DRAM access.
+* **Custom Operations:** Incorporate specialized ops like low precision INT4 or bfloat16 into models to capitalize on dedicated hardware support.
+* **Dataflow Mapping:** Explicitly map model stages to computational units to optimize data movement on hardware.
#### Algorithm-Driven Hardware Specialization
Hardware can be tailored to better suit the characteristics of ML algorithms:
-- **Custom Datatypes:** Support low precision INT8/4 or bfloat16 in hardware for higher arithmetic density.
-- **On-Chip Memory:** Increase SRAM bandwidth and lower access latency to match model memory access patterns.
-- **Domain-Specific Ops:** Add hardware units for key ML functions like FFTs or matrix multiplication to reduce latency and energy.
-- **Model Profiling:** Use model simulation and profiling to identify computational hotspots and guide hardware optimization.
+* **Custom Datatypes:** Support low precision INT8/4 or bfloat16 in hardware for higher arithmetic density.
+* **On-Chip Memory:** Increase SRAM bandwidth and lower access latency to match model memory access patterns.
+* **Domain-Specific Ops:** Add hardware units for key ML functions like FFTs or matrix multiplication to reduce latency and energy.
+* **Model Profiling:** Use model simulation and profiling to identify computational hotspots and guide hardware optimization.
The key is collaborative feedback - insights from hardware profiling
guide software optimizations, while algorithmic advances inform hardware
@@ -560,15 +565,15 @@ Tight co-design bears the risk of overfitting optimizations to current algorithm
Engineers comfortable with established discrete hardware or software design practices may resist adopting unfamiliar collaborative workflows. Projects could face friction in transitioning to co-design, despite long-term benefits.
-## Software for AI Hardware
+## Software for AI Hardware
At this time it should be obvious that specialized hardware accelerators like GPUs, TPUs, and FPGAs are essential to delivering high-performance artificial intelligence applications. But to leverage these hardware platforms effectively, an extensive software stack is required spanning the entire development and deployment lifecycle. Frameworks and libraries form the backbone of AI hardware, offering sets of robust, pre-built code, algorithms, and functions specifically optimized to perform a wide array of AI tasks on the different hardware. They are designed to simplify the complexities involved in utilizing the hardware from scratch, which can be time-consuming and prone to error. Software plays an important role in the following:
-- Providing programming abstractions and models like CUDA and OpenCL to map computations onto accelerators.
-- Integrating accelerators into popular deep learning frameworks like TensorFlow and PyTorch.
-- Compilers and tools to optimize across the hardware-software stack.
-- Simulation platforms to model hardware and software together.
-- Infrastructure to manage deployment on accelerators.
+* Providing programming abstractions and models like CUDA and OpenCL to map computations onto accelerators.
+* Integrating accelerators into popular deep learning frameworks like TensorFlow and PyTorch.
+* Compilers and tools to optimize across the hardware-software stack.
+* Simulation platforms to model hardware and software together.
+* Infrastructure to manage deployment on accelerators.
```{mermaid}
%%| label: fig-ai-stack
@@ -586,11 +591,11 @@ This expansive software ecosystem is as important as the hardware itself in deli
Programming models provide abstractions to map computations and data onto heterogeneous hardware accelerators:
-- **[CUDA](https://developer.nvidia.com/cuda-toolkit):** Nvidia's parallel programming model to leverage GPUs using extensions to languages like C/C++. Allows launching kernels across GPU cores [@luebke2008cuda].
-- **[OpenCL](https://www.khronos.org/opencl/):** Open standard for writing programs spanning CPUs, GPUs, FPGAs and other accelerators. Specifies a heterogeneous computing framework [@munshi2009opencl].
-- **[OpenGL/WebGL](https://www.opengl.org):** 3D graphics programming interfaces that can map general-purpose code to GPU cores [@segal1999opengl].
-- **[Verilog](https://www.verilog.com)/VHDL**: Hardware description languages (HDLs) used to configure FPGAs as AI accelerators by specifying digital circuits [@gannot1994verilog].
-- **[TVM](https://tvm.apache.org):** Compiler framework providing Python frontend to optimize and map deep learning models onto diverse hardware back-ends [@chen2018tvm].
+* **[CUDA](https://developer.nvidia.com/cuda-toolkit):** Nvidia's parallel programming model to leverage GPUs using extensions to languages like C/C++. Allows launching kernels across GPU cores [@luebke2008cuda].
+* **[OpenCL](https://www.khronos.org/opencl/):** Open standard for writing programs spanning CPUs, GPUs, FPGAs and other accelerators. Specifies a heterogeneous computing framework [@munshi2009opencl].
+* **[OpenGL/WebGL](https://www.opengl.org):** 3D graphics programming interfaces that can map general-purpose code to GPU cores [@segal1999opengl].
+* **[Verilog](https://www.verilog.com)/VHDL**: Hardware description languages (HDLs) used to configure FPGAs as AI accelerators by specifying digital circuits [@gannot1994verilog].
+* **[TVM](https://tvm.apache.org):** Compiler framework providing Python frontend to optimize and map deep learning models onto diverse hardware back-ends [@chen2018tvm].
Key challenges include expressing parallelism, managing memory across devices, and matching algorithms to hardware capabilities. Abstractions must balance portability with allowing hardware customization. Programming models enable developers to harness accelerators without hardware expertise. More of these details are discussed in the [AI frameworks](frameworks.qmd) section.
@@ -598,10 +603,10 @@ Key challenges include expressing parallelism, managing memory across devices, a
Specialized libraries and runtimes provide software abstractions to access and maximize utilization of AI accelerators:
-- **Math Libraries:** Highly optimized implementations of linear algebra primitives like GEMM, FFTs, convolutions etc. tailored to target hardware. [Nvidia cuBLAS](https://developer.nvidia.com/cublas), [Intel MKL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html), and [Arm compute libraries](https://www.arm.com/technologies/compute-library) are examples.
-- **Framework Integrations:** Libraries to accelerate deep learning frameworks like TensorFlow, PyTorch, and MXNet on supported hardware. For example, [cuDNN](https://developer.nvidia.com/cudnn) for accelerating CNNs on Nvidia GPUs.
-- **Runtimes:** Software to handle execution on accelerators, including scheduling, synchronization, memory management and other tasks. [Nvidia TensorRT](https://developer.nvidia.com/tensorrt) is an inference optimizer and runtime.
-- **Drivers and Firmware:** Low-level software to interface with hardware, initialize devices, and handle execution. Vendors like Xilinx provide drivers for their accelerator boards.
+* **Math Libraries:** Highly optimized implementations of linear algebra primitives like GEMM, FFTs, convolutions etc. tailored to target hardware. [Nvidia cuBLAS](https://developer.nvidia.com/cublas), [Intel MKL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html), and [Arm compute libraries](https://www.arm.com/technologies/compute-library) are examples.
+* **Framework Integrations:** Libraries to accelerate deep learning frameworks like TensorFlow, PyTorch, and MXNet on supported hardware. For example, [cuDNN](https://developer.nvidia.com/cudnn) for accelerating CNNs on Nvidia GPUs.
+* **Runtimes:** Software to handle execution on accelerators, including scheduling, synchronization, memory management and other tasks. [Nvidia TensorRT](https://developer.nvidia.com/tensorrt) is an inference optimizer and runtime.
+* **Drivers and Firmware:** Low-level software to interface with hardware, initialize devices, and handle execution. Vendors like Xilinx provide drivers for their accelerator boards.
For instance, PyTorch integrators use cuDNN and cuBLAS libraries to accelerate training on Nvidia GPUs. The TensorFlow XLA runtime optimizes and compiles models for accelerators like TPUs. Drivers initialize devices and offload operations.
@@ -613,9 +618,9 @@ Libraries, runtimes and drivers provide optimized building blocks that deep lear
Optimizing compilers play a key role in extracting maximum performance and efficiency from hardware accelerators for AI workloads. They apply optimizations spanning algorithmic changes, graph-level transformations, and low-level code generation.
-- **Algorithm Optimization:** Techniques like quantization, pruning, and neural architecture search to enhance model efficiency and match hardware capabilities.
-- **Graph Optimizations:** Graph-level optimizations like operator fusion, rewriting, and layout transformations to optimize performance on target hardware.
-- **Code Generation:** Generating optimized low-level code for accelerators from high-level models and frameworks.
+* **Algorithm Optimization:** Techniques like quantization, pruning, and neural architecture search to enhance model efficiency and match hardware capabilities.
+* **Graph Optimizations:** Graph-level optimizations like operator fusion, rewriting, and layout transformations to optimize performance on target hardware.
+* **Code Generation:** Generating optimized low-level code for accelerators from high-level models and frameworks.
For example, the TVM open compiler stack applies quantization for a BERT model targeting Arm GPUs. It fuses pointwise convolution operations and transforms weight layout to optimize memory access. Finally it emits optimized OpenGL code to run the workload on the GPU.
@@ -627,9 +632,9 @@ However, efficiently mapping complex models introduces challenges like efficient
Simulation software is important in hardware-software co-design. It enables joint modeling of proposed hardware architectures and software stacks:
-- **Hardware Simulation:** Platforms like [Gem5](https://www.gem5.org) allow detailed simulation of hardware components like pipelines, caches, interconnects, and memory hierarchies. Engineers can model hardware changes without physical prototyping [@binkert2011gem5].
-- **Software Simulation:** Compiler stacks like [TVM](https://tvm.apache.org) support simulation of machine learning workloads to estimate performance on target hardware architectures. This assists with software optimizations.
-- **Co-simulation:** Unified platforms like the SCALE-Sim [@samajdar2018scale] integrate hardware and software simulation into a single tool. This enables what-if analysis to quantify the system-level impacts of cross-layer optimizations early in the design cycle.
+* **Hardware Simulation:** Platforms like [Gem5](https://www.gem5.org) allow detailed simulation of hardware components like pipelines, caches, interconnects, and memory hierarchies. Engineers can model hardware changes without physical prototyping [@binkert2011gem5].
+* **Software Simulation:** Compiler stacks like [TVM](https://tvm.apache.org) support simulation of machine learning workloads to estimate performance on target hardware architectures. This assists with software optimizations.
+* **Co-simulation:** Unified platforms like the SCALE-Sim [@samajdar2018scale] integrate hardware and software simulation into a single tool. This enables what-if analysis to quantify the system-level impacts of cross-layer optimizations early in the design cycle.
For example, an FPGA-based AI accelerator design could be simulated using Verilog hardware description language and synthesized into a Gem5 model. Verilog is well-suited for describing the digital logic and interconnects that make up the accelerator architecture. Using Verilog allows the designer to specify the datapaths, control logic, on-chip memories, and other components that will be implemented in the FPGA fabric. Once the Verilog design is complete, it can be synthesized into a model that simulates the behavior of the hardware, such as using the Gem5 simulator. Gem5 is useful for this task because it allows modeling of full systems including processors, caches, buses, and custom accelerators. Gem5 supports interfacing Verilog models of hardware to the simulation, enabling unified system modeling.
@@ -647,18 +652,18 @@ The [benchmarking chapter](benchmarking.qmd) explores this topic in great detail
Benchmarking suites such as MLPerf, Fathom, and AI Benchmark offer a set of standardized tests that can be used across different hardware platforms. These suites measure AI accelerator performance across various neural networks and machine learning tasks, from basic image classification to complex language processing. By providing a common ground for comparison, they help ensure that performance claims are consistent and verifiable. These "tools" are applied not only to guide the development of hardware but also to ensure that the software stack leverages the full potential of the underlying architecture.
-- **MLPerf**: Includes a broad set of benchmarks covering both training [@mattson2020mlperf] and inference [@reddi2020mlperf] for a range of machine learning tasks.
-- **Fathom**: Focuses on core operations found in deep learning models, emphasizing their execution on different architectures [@adolf2016fathom].
-- **AI Benchmark**: Targets mobile and consumer devices, assessing AI performance in end-user applications [@ignatov2018ai].
+* **MLPerf**: Includes a broad set of benchmarks covering both training [@mattson2020mlperf] and inference [@reddi2020mlperf] for a range of machine learning tasks.
+* **Fathom**: Focuses on core operations found in deep learning models, emphasizing their execution on different architectures [@adolf2016fathom].
+* **AI Benchmark**: Targets mobile and consumer devices, assessing AI performance in end-user applications [@ignatov2018ai].
Benchmarks also have performance metrics that are the quantifiable measures used to evaluate the effectiveness of AI accelerators. These metrics provide a comprehensive view of an accelerator's capabilities and are used to guide the design and selection process for AI systems. Common metrics include:
-- **Throughput**: Usually measured in operations per second, this metric indicates the volume of computations an accelerator can handle.
-- **Latency**: The time delay from input to output in a system, vital for real-time processing tasks.
-- **Energy Efficiency**: Calculated as computations per watt, representing the trade-off between performance and power consumption.
-- **Cost Efficiency**: This evaluates the cost of operation relative to performance, an essential metric for budget-conscious deployments.
-- **Accuracy**: Particularly in inference tasks, the precision of computations is critical and sometimes balanced against speed.
-- **Scalability**: The ability of the system to maintain performance gains as the computational load scales up.
+* **Throughput**: Usually measured in operations per second, this metric indicates the volume of computations an accelerator can handle.
+* **Latency**: The time delay from input to output in a system, vital for real-time processing tasks.
+* **Energy Efficiency**: Calculated as computations per watt, representing the trade-off between performance and power consumption.
+* **Cost Efficiency**: This evaluates the cost of operation relative to performance, an essential metric for budget-conscious deployments.
+* **Accuracy**: Particularly in inference tasks, the precision of computations is critical and sometimes balanced against speed.
+* **Scalability**: The ability of the system to maintain performance gains as the computational load scales up.
Benchmark results give insights beyond just numbers - they can reveal bottlenecks in the software and hardware stack. For example, benchmarks may show how increased batch size improves GPU utilization by providing more parallelism. Or how compiler optimizations boost TPU performance. These learnings enable continuous optimization [@jia2019beyond].
@@ -714,17 +719,17 @@ This optimization effort is not just about making incremental improvements to ex
### Overcoming Resource Constraints
-Resource constraints also pose a significant challenge for Edge AI accelerators, as these specialized hardware and software solutions must deliver robust performance within the limitations of edge devices. Due to power and size limitations, edge AI accelerators often have restricted computation, memory, and storage capacity [@lin2022ondevice]. This scarcity of resources necessitates a careful allocation of processing capabilities to execute machine learning models efficiently.
+Resource constraints also pose a significant challenge for Edge AI accelerators, as these specialized hardware and software solutions must deliver robust performance within the limitations of edge devices. Due to power and size limitations, edge AI accelerators often have restricted computation, memory, and storage capacity [@lin2022ondevice]. This scarcity of resources necessitates a careful allocation of processing capabilities to execute machine learning models efficiently.
Moreover, managing constrained resources demands innovative approaches, including model quantization [@lin2023awq] [@Li2020Additive], pruning [@wang2020apq], and optimizing inference pipelines. Edge AI accelerators must strike a delicate balance between providing meaningful AI functionality and not exhausting the available resources, all while maintaining low power consumption. Overcoming these resource constraints is crucial to ensure the successful deployment of AI at the edge, where many applications, from IoT to mobile devices, rely on the efficient use of limited hardware resources to deliver real-time and intelligent decision-making.
## Emerging Technologies
-Thus far we have discussed AI hardware technology in the context of conventional von Neumann architecture design and CMOS-based implementation. These specialized AI chips offer benefits like higher throughput and power efficiency but rely on traditional computing principles. The relentless growth in demand for AI compute power is driving innovations in integration methods for AI hardware.
+Thus far we have discussed AI hardware technology in the context of conventional von Neumann architecture design and CMOS-based implementation. These specialized AI chips offer benefits like higher throughput and power efficiency but rely on traditional computing principles. The relentless growth in demand for AI compute power is driving innovations in integration methods for AI hardware.
-Two leading approaches have emerged for maximizing compute density - wafer-scale integration and chiplet-based architectures, which we will discuss in this section. Looking much further ahead, we will look into emerging technologies that diverge from conventional architectures and adopt fundamentally different approaches for AI-specialized computing.
+Two leading approaches have emerged for maximizing compute density - wafer-scale integration and chiplet-based architectures, which we will discuss in this section. Looking much further ahead, we will look into emerging technologies that diverge from conventional architectures and adopt fundamentally different approaches for AI-specialized computing.
-Some of these unconventional paradigms include neuromorphic computing which mimics biological neural networks, quantum computing that leverages quantum mechanical effects, and optical computing utilizing photons instead of electrons. Beyond novel computing substrates, new device technologies are enabling additional gains through better memory and interconnect.
+Some of these unconventional paradigms include neuromorphic computing which mimics biological neural networks, quantum computing that leverages quantum mechanical effects, and optical computing utilizing photons instead of electrons. Beyond novel computing substrates, new device technologies are enabling additional gains through better memory and interconnect.
Examples include memristors for in-memory computing and nanophotonics for integrated photonic communication. Together, these technologies offer the potential for orders of magnitude improvements in speed, efficiency, and scalability compared to current AI hardware. We will examine these in this section.
@@ -736,11 +741,11 @@ In the past, AI compute was primarily performed on CPUs and GPUs built using con
As AI workloads have grown, there is increasing demand for tighter integration between compute, memory, and communication elements. Some key drivers of integration include:
-- **Minimizing data movement:** Tight integration reduces latency and power for moving data between components. This improves efficiency.
-- **Customization:** Tailoring all components of a system to AI workloads allows optimizations throughout the hardware stack.
-- **Parallelism:** Integrating a large number of processing elements enables massively parallel computation.
-- **Density:** Tighter integration allows packing more transistors and memory into a given area.
-- **Cost:** Economies of scale from large integrated systems can reduce costs.
+* **Minimizing data movement:** Tight integration reduces latency and power for moving data between components. This improves efficiency.
+* **Customization:** Tailoring all components of a system to AI workloads allows optimizations throughout the hardware stack.
+* **Parallelism:** Integrating a large number of processing elements enables massively parallel computation.
+* **Density:** Tighter integration allows packing more transistors and memory into a given area.
+* **Cost:** Economies of scale from large integrated systems can reduce costs.
In response, new manufacturing techniques like wafer-scale fabrication and advanced packaging now allow much higher levels of integration. The goal is to create unified, specialized AI compute complexes tailored for deep learning and other AI algorithms. Tighter integration is key to delivering the performance and efficiency needed for the next generation of AI.
@@ -756,8 +761,7 @@ By designing the wafer as one integrated logic unit, data transfer between eleme
However, the ultra-large scale also poses difficulties for manufacturability and yield with wafer-scale designs. Defects in any region of the wafer can make (certian parts of) the chip unusable. And specialized lithography techniques are required to produce such large dies. So wafer-scale integration pursues the maximum performance gains from integration but requires overcoming substantial fabrication challenges. The following video will provide additional context.
-{{< video https://www.youtube.com/watch?v=Fcob512SJz0 >}}
-
+{{< video >}}
#### Chiplets for AI
@@ -769,16 +773,16 @@ Chiplets are interconnected using advanced packaging techniques like high-densit
Some key advantages of using chiplets for AI include:
-- **Flexibility:** Flexibility: Chiplets allow combining different chip types, process nodes, and memories tailored for each function. This is more modular versus a fixed wafer-scale design.
-- **Yield:** Smaller chiplets have higher yield than a gigantic wafer-scale chip. Defects are contained to individual chiplets.
-- **Cost:** Leverages existing manufacturing capabilities versus requiring specialized new processes. Reduces costs by reusing mature fabrication.
-- **Compatibility:** Can integrate with more conventional system architectures like PCIe and standard DDR memory interfaces.
+* **Flexibility:** Flexibility: Chiplets allow combining different chip types, process nodes, and memories tailored for each function. This is more modular versus a fixed wafer-scale design.
+* **Yield:** Smaller chiplets have higher yield than a gigantic wafer-scale chip. Defects are contained to individual chiplets.
+* **Cost:** Leverages existing manufacturing capabilities versus requiring specialized new processes. Reduces costs by reusing mature fabrication.
+* **Compatibility:** Can integrate with more conventional system architectures like PCIe and standard DDR memory interfaces.
However, chiplets also face integration and performance challenges:
-- Lower density compared to wafer-scale, as chiplets are limited in size.
-- Added latency when communicating between chiplets versus monolithic integration. Requires optimization for low-latency interconnect.
-- Advanced packaging adds complexity versus wafer-scale integration, though this is arguable.
+* Lower density compared to wafer-scale, as chiplets are limited in size.
+* Added latency when communicating between chiplets versus monolithic integration. Requires optimization for low-latency interconnect.
+* Advanced packaging adds complexity versus wafer-scale integration, though this is arguable.
The key objective of chiplets is finding the right balance between modular flexibility and integration density for optimal AI performance. Chiplets aim for efficient AI acceleration while working within the constraints of conventional manufacturing techniques. Overall, chiplets take a middle path between the extremes of wafer-scale integration and fully discrete components. This provides practical benefits but may sacrifice some computational density and efficiency versus a theoretical wafer-size system.
@@ -794,7 +798,7 @@ Spiking neural networks (SNNs) [@maass1997networks] are computational models sui
![Neurons communicate via spikes. (a) Diagram of a neuron. (b) Measuring an action potential propagated along the axon of a neuron. Only the action potential is detectable along the axon. (c) The neuron's spike is approximated with a binary representation. (d) Event-Driven Processing (e) Active Pixel Sensor and Dynamic Vision Sensor. Figure taken from [@10242251]](images/hw_acceleration/aimage4.png)
-{{< video https://www.youtube.com/watch?v=yihk_8XnCzg >}}
+{{< video >}}
Specialized nanoelectronic devices called memristors [@chua1971memristor] serve as the synaptic components in neuromorphic systems. Memristors act as non-volatile memory with adjustable conductance, emulating the plasticity of real synapses. By combining memory and processing functions, memristors enable in-situ learning without separate data transfers. However, memristor technology has not yet reached maturity and scalability for commercial hardware.
@@ -846,9 +850,9 @@ Ethically, the incorporation of smart, machine-learning-driven sensors within th
Memory technologies are critical to AI hardware, but conventional DDR DRAM and SRAM create bottlenecks. AI workloads require high bandwidth (>1 TB/s) and extreme scientific applications of AI require extremely low latency (<50 ns) to feed data to compute units [@duarte2022fastml], high density (>128Gb) to store large model parameters and data sets, and excellent energy efficiency (<100 fJ/b) for embedded use [@verma2019memory]. New memories are needed to meet these demands. Emerging options include several new technologies:
-- Resistive RAM (ReRAM) can improve density with simple, passive arrays. However, challenges around variability remain [@chi2016prime].
-- Phase change memory (PCM) exploits the unique properties of chalcogenide glass. Crystalline and amorphous phases have different resistances. Intel's Optane DCPMM provides fast (100ns), high endurance PCM. But challenges include limited write cycles and high reset current [@burr2016recent].
-- 3D stacking can also boost memory density and bandwidth by vertically integrating memory layers with TSV interconnects [@loh20083d]. For example, HBM provides 1024-bit wide interfaces.
+* Resistive RAM (ReRAM) can improve density with simple, passive arrays. However, challenges around variability remain [@chi2016prime].
+* Phase change memory (PCM) exploits the unique properties of chalcogenide glass. Crystalline and amorphous phases have different resistances. Intel's Optane DCPMM provides fast (100ns), high endurance PCM. But challenges include limited write cycles and high reset current [@burr2016recent].
+* 3D stacking can also boost memory density and bandwidth by vertically integrating memory layers with TSV interconnects [@loh20083d]. For example, HBM provides 1024-bit wide interfaces.
New memory technologies are critical to unlock the next level of AI hardware performance and efficiency through their innovative cell architectures and materials. Realizing their benefits in commercial systems remains an ongoing challenge.
@@ -870,18 +874,18 @@ Optical computing utilizes photons and photonic devices rather than traditional
Some specific advantages of optical computing include:
-- **High throughput:** Photons can transmit with bandwidths >100 Tb/s using wavelength division multiplexing.
-- **Low latency:** Photons interact on femtosecond timescales, millions of times faster than silicon transistors.
-- **Parallelism:** Multiple data signals can propagate through the same optical medium simultaneously.
-- **Low power:** Photonic circuits utilizing waveguides and resonators can achieve complex logic and memory with only microwatts of power.
+* **High throughput:** Photons can transmit with bandwidths >100 Tb/s using wavelength division multiplexing.
+* **Low latency:** Photons interact on femtosecond timescales, millions of times faster than silicon transistors.
+* **Parallelism:** Multiple data signals can propagate through the same optical medium simultaneously.
+* **Low power:** Photonic circuits utilizing waveguides and resonators can achieve complex logic and memory with only microwatts of power.
However, optical computing currently faces significant challenges:
-- Lack of optical memory equivalent to electronic RAM
-- Requires conversion between optical and electrical domains.
-- Limited set of available optical components compared to rich electronics ecosystem.
-- Immature integration methods to combine photonics with traditional CMOS chips.
-- Complex programming models required to handle parallelism.
+* Lack of optical memory equivalent to electronic RAM
+* Requires conversion between optical and electrical domains.
+* Limited set of available optical components compared to rich electronics ecosystem.
+* Immature integration methods to combine photonics with traditional CMOS chips.
+* Complex programming models required to handle parallelism.
As a result, optical computing is still in the very early research stage despite its promising potential. But technical breakthroughs could enable it to complement electronics and unlock performance gains for AI workloads. Companies like Lightmatter are pioneering early optical AI accelerators. Long term, it could represent a revolutionary computing substrate if key challenges are overcome.
@@ -893,16 +897,16 @@ Multiple qubits can also be entangled, leading to exponential information densit
Quantum algorithms carefully manipulate these inherently quantum mechanical effects to solve problems like optimization or search more efficiently than their classical counterparts in theory.
-- Faster training of deep neural networks by exploiting quantum parallelism for linear algebra operations.
-- Efficient quantum ML algorithms making use of the unique capabilities of qubits.
-- Quantum neural networks with inherent quantum effects baked into the model architecture.
-- Quantum optimizers leveraging quantum annealing or adiabatic algorithms for combinatorial optimization problems.
+* Faster training of deep neural networks by exploiting quantum parallelism for linear algebra operations.
+* Efficient quantum ML algorithms making use of the unique capabilities of qubits.
+* Quantum neural networks with inherent quantum effects baked into the model architecture.
+* Quantum optimizers leveraging quantum annealing or adiabatic algorithms for combinatorial optimization problems.
However, quantum states are fragile and prone to errors that require error-correcting protocols. The non-intuitive nature of quantum programming also introduces challenges not present in classical computing.
-- Noisy and fragile quantum bits difficult to scale up. The largest quantum computer today has less than 100 qubits.
-- Restricted set of available quantum gates and circuits relative to classical programming.
-- Lack of datasets and benchmarks to evaluate quantum ML in practical domains.
+* Noisy and fragile quantum bits difficult to scale up. The largest quantum computer today has less than 100 qubits.
+* Restricted set of available quantum gates and circuits relative to classical programming.
+* Lack of datasets and benchmarks to evaluate quantum ML in practical domains.
While meaningful quantum advantage for ML remains far off, active research at companies like [D-Wave](https://www.dwavesys.com/company/about-d-wave/), [Rigetti](https://www.rigetti.com/), and [IonQ](https://ionq.com/) is advancing quantum computer engineering and quantum algorithms. Major technology companies like Google, [IBM](https://www.ibm.com/quantum?utm_content=SRCWW&p1=Search&p4C700050385964705&p5=e&gclid=Cj0KCQjw-pyqBhDmARIsAKd9XIPD9U1Sjez_S0z5jeDDE4nRyd6X_gtVDUKJ-HIolx2vOc599KgW8gAaAv8gEALw_wcB&gclsrc=aw.ds), and Microsoft are actively exploring quantum computing. Google recently announced a 72-qubit quantum processor called [Bristlecone](https://blog.research.google/2018/03/a-preview-of-bristlecone-googles-new.html) and plans to build a 49-qubit commercial quantum system. Microsoft also has an active research program in topological quantum computing and collaborates with quantum startup [IonQ](https://ionq.com/)
@@ -910,7 +914,7 @@ Quantum techniques may first make inroads for optimization before more generaliz
## Future Trends
-Thus far in this chapter, we have primarily explored how to design specialized hardware that is optimized for machine learning workloads and algorithms. For example, we discussed how GPUs and TPUs have architectures tailored for neural network training and inference. However, we have not yet discussed an emerging and exciting area - using machine learning to aid in the hardware design process itself.
+Thus far in this chapter, we have primarily explored how to design specialized hardware that is optimized for machine learning workloads and algorithms. For example, we discussed how GPUs and TPUs have architectures tailored for neural network training and inference. However, we have not yet discussed an emerging and exciting area - using machine learning to aid in the hardware design process itself.
The hardware design process involves many complex stages, including specification, high-level modeling, simulation, synthesis, verification, prototyping, and fabrication. Traditionally, much of this process requires extensive human expertise, effort, and time. However, recent advances in machine learning are enabling parts of the hardware design workflow to be automated and enhanced using ML techniques.
@@ -927,10 +931,10 @@ Applying ML to hardware design automation holds enormous promise to make the pro
A major opportunity for machine learning in hardware design is automating parts of the complex and tedious design workflow. Hardware design automation (HDA) broadly refers to using ML techniques like reinforcement learning, genetic algorithms, and neural networks to automate tasks like synthesis, verification, floorplanning, and more. A few examples of where ML for HDA shows real promise:
-- **Automated circuit synthesis:** Circuit synthesis involves converting a high-level description of desired logic into an optimized gate-level netlist implementation. This complex process has many design considerations and tradeoffs. ML agents can be trained through reinforcement learning to explore the design space and output optimized syntheses automatically. Startups like [Symbiotic EDA](https://www.symbioticeda.com/) are bringing this technology to market.
-- **Automated chip floorplanning:** Floorplanning refers to strategically placing different components on a chip die area. ML techniques like genetic algorithms can be used to automate floorplan optimization to minimize wire length, power consumption, and other objectives. This is extremely valuable as chip complexity increases.
-- **ML hardware simulators:** Training deep neural network models to predict how hardware designs will perform as simulators can accelerate the simulation process by over 100x compared to traditional RTL simulations.
-- **Automated code translation:** Converting hardware description languages like Verilog to optimized RTL implementations is critical but time-consuming. ML models can be trained to act as translator agents and automate parts of this process.
+* **Automated circuit synthesis:** Circuit synthesis involves converting a high-level description of desired logic into an optimized gate-level netlist implementation. This complex process has many design considerations and tradeoffs. ML agents can be trained through reinforcement learning to explore the design space and output optimized syntheses automatically. Startups like [Symbiotic EDA](https://www.symbioticeda.com/) are bringing this technology to market.
+* **Automated chip floorplanning:** Floorplanning refers to strategically placing different components on a chip die area. ML techniques like genetic algorithms can be used to automate floorplan optimization to minimize wire length, power consumption, and other objectives. This is extremely valuable as chip complexity increases.
+* **ML hardware simulators:** Training deep neural network models to predict how hardware designs will perform as simulators can accelerate the simulation process by over 100x compared to traditional RTL simulations.
+* **Automated code translation:** Converting hardware description languages like Verilog to optimized RTL implementations is critical but time-consuming. ML models can be trained to act as translator agents and automate parts of this process.
The benefits of HDA using ML are reduced design time, superior optimizations, and exploration of design spaces too complex for manual approaches. This can accelerate hardware development and lead to better designs.
@@ -940,10 +944,10 @@ Challenges include limits of ML generalization, the black-box nature of some tec
Simulating and verifying hardware designs is critical before manufacturing to ensure the design behaves as intended. Traditional approaches like register-transfer level (RTL) simulation are complex and time-consuming. ML introduces new opportunities to enhance hardware simulation and verification. Some examples include:
-- **Surrogate modeling for simulation:** Highly accurate surrogate models of a design can be built using neural networks. These models predict outputs from inputs much faster than RTL simulation, enabling fast design space exploration. Companies like Ansys use this technique.
-- **ML simulators:** Large neural network models can be trained on RTL simulations to learn to mimic the functionality of a hardware design. Once trained, the NN model can act as a highly efficient simulator to use for regression testing and other tasks. Graphcore has demonstrated over 100x speedup with this approach.
-- **Formal verification using ML:** Formal verification mathematically proves properties about a design. ML techniques can help generate verification properties and can learn to solve the complex formal proofs needed. This automates parts of this challenging process. Startups like Cortical.io are bringing ML formal verification solutions to market.
-- **Bug detection:** ML models can be trained to process hardware designs and identify potential issues. This assists human designers in inspecting complex designs and finding bugs. Facebook has shown bug detection models for their server hardware.
+* **Surrogate modeling for simulation:** Highly accurate surrogate models of a design can be built using neural networks. These models predict outputs from inputs much faster than RTL simulation, enabling fast design space exploration. Companies like Ansys use this technique.
+* **ML simulators:** Large neural network models can be trained on RTL simulations to learn to mimic the functionality of a hardware design. Once trained, the NN model can act as a highly efficient simulator to use for regression testing and other tasks. Graphcore has demonstrated over 100x speedup with this approach.
+* **Formal verification using ML:** Formal verification mathematically proves properties about a design. ML techniques can help generate verification properties and can learn to solve the complex formal proofs needed. This automates parts of this challenging process. Startups like Cortical.io are bringing ML formal verification solutions to market.
+* **Bug detection:** ML models can be trained to process hardware designs and identify potential issues. This assists human designers in inspecting complex designs and finding bugs. Facebook has shown bug detection models for their server hardware.
The key benefits of applying ML to simulation and verification are faster design validation turnaround times, more rigorous testing, and reduced human effort. Challenges include verifying ML model correctness and handling corner cases. ML promises to significantly accelerate testing workflows.
@@ -951,10 +955,10 @@ The key benefits of applying ML to simulation and verification are faster design
Designing hardware architectures optimized for performance, power, and efficiency is a key goal. ML introduces new techniques to automate and enhance architecture design space exploration for both general-purpose and specialized hardware like ML accelerators. Some promising examples include:
-- **Neural architecture search for hardware:** Search techniques like evolutionary algorithms can automatically generate novel hardware architectures by mutating and mixing design attributes like cache size, number of parallel units, memory bandwidth, and so on. This expands the design space beyond human limitations.
-- **ML-based architecture optimizers:** ML agents can be trained with reinforcement learning to tweak architectures to optimize for desired objectives like throughput or power. The agent explores the space of possible configurations to find high-performing, efficient designs.
-- **Predictive modeling for optimization:** - ML models can be trained to predict hardware performance, power, and efficiency metrics for a given architecture. These become "surrogate models" for fast optimization and space exploration by substituting lengthy simulations.
-- **Specialized accelerator optimization:** - For specialized chips like tensor processing units for AI, automated architecture search techniques based on ML/evolutionary algorithms show promise for finding fast, efficient designs.
+* **Neural architecture search for hardware:** Search techniques like evolutionary algorithms can automatically generate novel hardware architectures by mutating and mixing design attributes like cache size, number of parallel units, memory bandwidth, and so on. This expands the design space beyond human limitations.
+* **ML-based architecture optimizers:** ML agents can be trained with reinforcement learning to tweak architectures to optimize for desired objectives like throughput or power. The agent explores the space of possible configurations to find high-performing, efficient designs.
+* **Predictive modeling for optimization:** - ML models can be trained to predict hardware performance, power, and efficiency metrics for a given architecture. These become "surrogate models" for fast optimization and space exploration by substituting lengthy simulations.
+* **Specialized accelerator optimization:** - For specialized chips like tensor processing units for AI, automated architecture search techniques based on ML/evolutionary algorithms show promise for finding fast, efficient designs.
The benefits of using ML include superior design space exploration, automated optimization, and reduced manual effort. Challenges include long training times for some techniques and local optima limitations. But ML for hardware architecture holds great potential for unlocking performance and efficiency gains.
@@ -962,42 +966,43 @@ The benefits of using ML include superior design space exploration, automated op
Once a hardware design is complete, it moves to manufacturing. But variability and defects during manufacturing can impact yields and quality. ML techniques are now being applied to improve fabrication processes and reduce defects. Some examples include:
-- **Predictive maintenance:** ML models can analyze equipment sensor data over time and identify signals that predict maintenance needs before failure. This enables proactive upkeep that can come in very handy in the costly fabrication process.
-- **Process optimization:** Supervised learning models can be trained on process data to identify factors that lead to low yields. The models can then optimize parameters to improve yields, throughput, or consistency.
-- **Yield prediction:** By analyzing test data from fabricated designs using techniques like regression trees, ML models can predict yields early in production. This allows process adjustments.
-- **Defect detection:** Computer vision ML techniques can be applied to images of designs to identify defects invisible to the human eye. This enables precision quality control and root cause analysis.
-- **Proactive failure analysis:** - By analyzing structured and unstructured process data, ML models can help predict, diagnose, and prevent issues that lead to downstream defects and failures.
+* **Predictive maintenance:** ML models can analyze equipment sensor data over time and identify signals that predict maintenance needs before failure. This enables proactive upkeep that can come in very handy in the costly fabrication process.
+* **Process optimization:** Supervised learning models can be trained on process data to identify factors that lead to low yields. The models can then optimize parameters to improve yields, throughput, or consistency.
+* **Yield prediction:** By analyzing test data from fabricated designs using techniques like regression trees, ML models can predict yields early in production. This allows process adjustments.
+* **Defect detection:** Computer vision ML techniques can be applied to images of designs to identify defects invisible to the human eye. This enables precision quality control and root cause analysis.
+* **Proactive failure analysis:** - By analyzing structured and unstructured process data, ML models can help predict, diagnose, and prevent issues that lead to downstream defects and failures.
Applying ML to manufacturing enables process optimization, real-time quality control, predictive maintenance, and ultimately higher yields. Challenges include managing complex manufacturing data and variations. But ML is poised to transform semiconductor manufacturing.
### Toward Foundation Models for Hardware Design
-As we have seen, machine learning is opening up new possibilities across the hardware design workflow, from specification to manufacturing. However, current ML techniques are still narrow in scope and require extensive domain-specific engineering. The long-term vision is the development of general artificial intelligence systems that can be applied with versatility across hardware design tasks.
-To fully realize this vision, investment and research are needed to develop foundation models for hardware design. These are unified, general-purpose ML models and architectures that can learn complex hardware design skills with the right training data and objectives.
+As we have seen, machine learning is opening up new possibilities across the hardware design workflow, from specification to manufacturing. However, current ML techniques are still narrow in scope and require extensive domain-specific engineering. The long-term vision is the development of general artificial intelligence systems that can be applied with versatility across hardware design tasks.
+
+To fully realize this vision, investment and research are needed to develop foundation models for hardware design. These are unified, general-purpose ML models and architectures that can learn complex hardware design skills with the right training data and objectives.
Realizing foundation models for end-to-end hardware design will require:
-- Accumulation of large, high-quality, labeled datasets across hardware design stages to train foundation models.
-- Advances in multi-modal, multi-task ML techniques to handle the diversity of hardware design data and tasks.
-- Interfaces and abstraction layers to connect foundation models to existing design flows and tools.
-- Development of simulation environments and benchmarks to train and test foundation models on hardware design capabilities.
-- Methods to explain and interpret the design decisions and optimizations made by ML models for trust and verification.
-- Compilation techniques to optimize foundation models for efficient deployment across hardware platforms.
+* Accumulation of large, high-quality, labeled datasets across hardware design stages to train foundation models.
+* Advances in multi-modal, multi-task ML techniques to handle the diversity of hardware design data and tasks.
+* Interfaces and abstraction layers to connect foundation models to existing design flows and tools.
+* Development of simulation environments and benchmarks to train and test foundation models on hardware design capabilities.
+* Methods to explain and interpret the design decisions and optimizations made by ML models for trust and verification.
+* Compilation techniques to optimize foundation models for efficient deployment across hardware platforms.
-While significant research remains, foundation models represent the most transformative long-term goal for imbuing AI into the hardware design process. Democratizing hardware design via versatile, automated ML systems promises to unlock a new era of optimized, efficient, and innovative chip design. The journey ahead is filled with open challenges and opportunities.
+While significant research remains, foundation models represent the most transformative long-term goal for imbuing AI into the hardware design process. Democratizing hardware design via versatile, automated ML systems promises to unlock a new era of optimized, efficient, and innovative chip design. The journey ahead is filled with open challenges and opportunities.
We encourage you to read [Architecture 2.0](https://www.sigarch.org/architecture-2-0-why-computer-architects-need-a-data-centric-ai-gymnasium/) if ML-aided computer architecture design [@krishnan2023archgym] interests you. Alternatively, you can watch the below video.
-{{< video https://www.youtube.com/watch?v=F5Eieaz7u1I&ab_channel=OpenComputeProject >}}
+{{< video >}}
## Conclusion
-Specialized hardware acceleration has become indispensable for enabling performant and efficient artificial intelligence applications as models and datasets explode in complexity. In this chapter, we examined the limitations of general-purpose processors like CPUs for AI workloads. Their lack of parallelism and computational throughput cannot train or run state-of-the-art deep neural networks quickly. These motivations have driven innovations in customized accelerators.
+Specialized hardware acceleration has become indispensable for enabling performant and efficient artificial intelligence applications as models and datasets explode in complexity. In this chapter, we examined the limitations of general-purpose processors like CPUs for AI workloads. Their lack of parallelism and computational throughput cannot train or run state-of-the-art deep neural networks quickly. These motivations have driven innovations in customized accelerators.
-We surveyed GPUs, TPUs, FPGAs and ASICs specifically designed for the math-intensive operations inherent to neural networks. By covering this spectrum of options, we aimed to provide a framework for reasoning through accelerator selection based on constraints around flexibility, performance, power, cost, and other factors.
+We surveyed GPUs, TPUs, FPGAs and ASICs specifically designed for the math-intensive operations inherent to neural networks. By covering this spectrum of options, we aimed to provide a framework for reasoning through accelerator selection based on constraints around flexibility, performance, power, cost, and other factors.
We also explored the role of software in actively enabling and optimizing AI acceleration. This spans programming abstractions, frameworks, compilers and simulators. We discussed hardware-software co-design as a proactive methodology for building more holistic AI systems by closely integrating algorithm innovation and hardware advances.
But there is so much more to come! Exciting frontiers like analog computing, optical neural networks, and quantum machine learning represent active research directions that could unlock orders of magnitude improvements in efficiency, speed, and scale compared to present paradigms.
-In the end, specialized hardware acceleration remains indispensable for unlocking the performance and efficiency necessary to fulfill the promise of artificial intelligence from cloud to edge. We hope this chapter actively provided useful background and insights into the rapid innovation occurring in this domain.
\ No newline at end of file
+In the end, specialized hardware acceleration remains indispensable for unlocking the performance and efficiency necessary to fulfill the promise of artificial intelligence from cloud to edge. We hope this chapter actively provided useful background and insights into the rapid innovation occurring in this domain.
diff --git a/images/imgs_embedded_ml/cloud_ml_tpu.jpg b/images/imgs_embedded_ml/cloud_ml_tpu.jpg
new file mode 100644
index 00000000..af7c74ad
Binary files /dev/null and b/images/imgs_embedded_ml/cloud_ml_tpu.jpg differ
diff --git a/introduction.qmd b/introduction.qmd
index 2c3450a6..56548a39 100644
--- a/introduction.qmd
+++ b/introduction.qmd
@@ -6,7 +6,7 @@ Welcome to this comprehensive exploration of Tiny Machine Learning (TinyML). Thi
## What's Inside
-The book starts with a foundational look at embedded systems and machine learning, focusing on deep learning methods due to their effectiveness across various tasks. We then guide you through the entire machine learning workflow, from data engineering to advanced model training.
+The book starts with a foundational look at embedded systems and machine learning, focusing on deep learning methods due to their effectiveness across various tasks. We then guide you through the entire machine learning workflow, from data engineering to advanced model training.
We also delve into TinyML model optimization and deployment, with a special emphasis on on-device learning. You'll find comprehensive discussions on current hardware acceleration techniques and model lifecycle management. Additionally, we explore the sustainability and ecological impact of AI, and how TinyML fits into this larger conversation.
diff --git a/ondevice_learning.qmd b/ondevice_learning.qmd
index 7aab5733..697cfa23 100644
--- a/ondevice_learning.qmd
+++ b/ondevice_learning.qmd
@@ -2,16 +2,17 @@

-On-device Learning represents a significant innovation for embedded and edge IoT devices, enabling models to train and update directly on small local devices. This contrasts with traditional methods where models are trained on expansive cloud computing resources before deployment. With On-Device Learning, devices like smart speakers, wearables, and industrial sensors can refine models in real-time based on local data, without needing to transmit data externally. For example, a voice-enabled smart speaker could learn and adapt to its owner's speech patterns and vocabulary right on the device. But there is no such thing as free lunch, therefore in this chapter, we will discuss both the benefits and the limitations of on-device learning.
+On-device Learning represents a significant innovation for embedded and edge IoT devices, enabling models to train and update directly on small local devices. This contrasts with traditional methods where models are trained on expansive cloud computing resources before deployment. With On-Device Learning, devices like smart speakers, wearables, and industrial sensors can refine models in real-time based on local data, without needing to transmit data externally. For example, a voice-enabled smart speaker could learn and adapt to its owner's speech patterns and vocabulary right on the device. But there is no such thing as free lunch, therefore in this chapter, we will discuss both the benefits and the limitations of on-device learning.
::: {.callout-tip}
+
## Learning Objectives
* Understand on-device learning and how it differs from cloud-based training
* Recognize the benefits and limitations of on-device learning
-* Examine strategies to adapt models through complexity reduction, optimization, and data compression
+* Examine strategies to adapt models through complexity reduction, optimization, and data compression
* Understand related concepts like federated learning and transfer learning
@@ -19,21 +20,19 @@ On-device Learning represents a significant innovation for embedded and edge IoT
:::
-
## Introduction
On-device Learning refers to the process of training ML models directly on the device where they are deployed, as opposed to traditional methods where models are trained on powerful servers and then deployed to devices. This method is particularly relevant to TinyML, where ML systems are integrated into tiny, resource-constrained devices.
-An example of On-Device Learning can be seen in a smart thermostat that adapts to user behavior over time. Initially, the thermostat may have a generic model that understands basic patterns of usage. However, as it is exposed to more data, such as the times the user is home or away, preferred temperatures, and external weather conditions, the thermostat can refine its model directly on the device to provide a personalized experience for the user. This is all done without the need to send data back to a central server for processing.
+An example of On-Device Learning can be seen in a smart thermostat that adapts to user behavior over time. Initially, the thermostat may have a generic model that understands basic patterns of usage. However, as it is exposed to more data, such as the times the user is home or away, preferred temperatures, and external weather conditions, the thermostat can refine its model directly on the device to provide a personalized experience for the user. This is all done without the need to send data back to a central server for processing.
-Another example is in predictive text on smartphones. As users type, the phone learns from the user’s language patterns and suggests words or phrases that are likely to be used next. This learning happens directly on the device, and the model updates in real-time as more data is collected. A widely used real-world example of on-device learning is Gboard. On an Android phone, Gboard learns from typing and dictation patterns to enhance the experience for all users.
+Another example is in predictive text on smartphones. As users type, the phone learns from the user’s language patterns and suggests words or phrases that are likely to be used next. This learning happens directly on the device, and the model updates in real-time as more data is collected. A widely used real-world example of on-device learning is Gboard. On an Android phone, Gboard learns from typing and dictation patterns to enhance the experience for all users.
)](images/ondevice_intro.png)
-
## Advantages and Limitations
-On-Device Learning provides a number of advantages over traditional cloud-based ML. By keeping data and models on the device, it eliminates the need for costly data transmission and addresses privacy concerns. This allows for more personalized, responsive experiences as the model can adapt in real-time to user behavior.
+On-Device Learning provides a number of advantages over traditional cloud-based ML. By keeping data and models on the device, it eliminates the need for costly data transmission and addresses privacy concerns. This allows for more personalized, responsive experiences as the model can adapt in real-time to user behavior.
However, On-Device Learning also comes with tradeoffs. The limited compute resources on consumer devices can make it challenging to run complex models locally. Datasets are also more restricted since they consist only of user-generated data from a single device. Additionally, updating models requires pushing out new versions rather than seamless cloud updates.
@@ -51,9 +50,9 @@ Regulations like the Health Insurance Portability and Accountability Act ([HIPAA
On-device learning is not just beneficial for individual users; it has significant implications for organizations and sectors dealing with highly sensitive data. For instance, within the military, on-device learning empowers frontline systems to adapt models and function independently of connections to central servers that could potentially be compromised. By localizing data processing and learning, critical and sensitive information is staunchly protected. However, this comes with the trade-off that individual devices take on more value and may incentivize theft or destruction, as they become sole carriers of specialized AI models. Care must be taken to secure devices themselves when transitioning to on-device learning.
-It is also important in preserving the privacy, security, and regulatory compliance of personal and sensitive data. Training and operating models locally, as opposed to in the cloud, substantially augments privacy measures, ensuring that user data is safeguarded from potential threats.
+It is also important in preserving the privacy, security, and regulatory compliance of personal and sensitive data. Training and operating models locally, as opposed to in the cloud, substantially augments privacy measures, ensuring that user data is safeguarded from potential threats.
-However, this is not entirely intuitive because on-device learning could instead open systems up to new privacy attacks.
+However, this is not entirely intuitive because on-device learning could instead open systems up to new privacy attacks.
With valuable data summaries and model updates permanently stored on individual devices, it may be much harder to physically and digitally protect them compared to a large computing cluster. While on-device learning reduces the amount of data compromised in any one breach, it could also introduce new dangers by dispersing sensitive information across many decentralized endpoints. Careful security practices are still essential for on-device systems.
#### Regulatory Compliance
@@ -80,49 +79,48 @@ Another key benefit of on-device learning is the potential for IoT devices to co
### Limitations
-While traditional cloud-based ML systems have access to nearly endless computing resources, on-device learning is often restricted by the limitations in computational and storage power of the edge device that the model is trained on. By definition, an [edge device](http://arxiv.org/abs/1911.00623) is a device with restrained computing, memory, and energy resources, that cannot be easily increased or decreased. Thus, the reliance on edge devices can restrict the complexity, efficiency, and size of on-device ML models.
+While traditional cloud-based ML systems have access to nearly endless computing resources, on-device learning is often restricted by the limitations in computational and storage power of the edge device that the model is trained on. By definition, an [edge device](http://arxiv.org/abs/1911.00623) is a device with restrained computing, memory, and energy resources, that cannot be easily increased or decreased. Thus, the reliance on edge devices can restrict the complexity, efficiency, and size of on-device ML models.
#### Compute resources
-Traditional cloud-based ML systems utilize large servers with multiple high-end GPUs or TPUs that provide nearly endless computational power and memory. For example, services like Amazon Web Services (AWS) [EC2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html) allow configuring clusters of GPU instances for massively parallel training.
+Traditional cloud-based ML systems utilize large servers with multiple high-end GPUs or TPUs that provide nearly endless computational power and memory. For example, services like Amazon Web Services (AWS) [EC2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html) allow configuring clusters of GPU instances for massively parallel training.
-In contrast, on-device learning is restricted by the hardware limitations of the edge device it runs on. Edge devices refer to endpoints like smartphones, embedded electronics, and IoT devices. By definition, these devices have highly restrained computing, memory, and energy resources compared to the cloud.
+In contrast, on-device learning is restricted by the hardware limitations of the edge device it runs on. Edge devices refer to endpoints like smartphones, embedded electronics, and IoT devices. By definition, these devices have highly restrained computing, memory, and energy resources compared to the cloud.
For example, a typical smartphone or Raspberry Pi may only have a few CPU cores, a few GB of RAM, and a small battery. Even more resource-constrained are TinyML microcontroller devices such as the [Arduino Nano BLE Sense](https://store-usa.arduino.cc/products/arduino-nano-33-ble-sense). The resources are fixed on these devices and can't easily be increased on demand like scaling cloud infrastructure. This reliance on edge devices directly restricts the complexity, efficiency, and size of models that can be deployed for on-device training:
-- **Complexity**: Limits on memory, computing, and power restrict model architecture design, constraining the number of layers and parameters.
-- **Efficiency**: Models must be heavily optimized through methods like quantization and pruning to run faster and consume less energy.
-- **Size**: Actual model files must be compressed as much as possible to fit within the storage limitations of edge devices.
+* **Complexity**: Limits on memory, computing, and power restrict model architecture design, constraining the number of layers and parameters.
+* **Efficiency**: Models must be heavily optimized through methods like quantization and pruning to run faster and consume less energy.
+* **Size**: Actual model files must be compressed as much as possible to fit within the storage limitations of edge devices.
Thus, while the cloud offers endless scalability, on-device learning must operate within the tight resource constraints of endpoint hardware. This requires careful co-design of streamlined models, training methods, and optimizations tailored specifically for edge devices.
#### Dataset Size, Accuracy, and Generalization
-In addition to limited computing resources, on-device learning is also constrained in terms of the dataset available for training models.
+In addition to limited computing resources, on-device learning is also constrained in terms of the dataset available for training models.
-In the cloud, models are trained on massive, diverse datasets like ImageNet or Common Crawl. For example, ImageNet contains over 14 million images carefully categorized across thousands of classes.
+In the cloud, models are trained on massive, diverse datasets like ImageNet or Common Crawl. For example, ImageNet contains over 14 million images carefully categorized across thousands of classes.
On-device learning instead relies on smaller, decentralized data silos unique to each device. A smartphone camera roll may contain only thousands of photos centered around a user's specific interests and environments.
-
This decentralized data leads to a lack of IID (independent and identically distributed) data. For instance, two friends may take many photos of the same places and objects, meaning their data distributions are highly correlated rather than independent.
Reasons data may be non-IID in on-device settings:
-- **User heterogeneity**: different users have different interests and environments.
-- **Device differences:** sensors, regions, and demographics affect data.
-- **Temporal effects:** time of day, seasonal impacts on data.
+* **User heterogeneity**: different users have different interests and environments.
+* **Device differences:** sensors, regions, and demographics affect data.
+* **Temporal effects:** time of day, seasonal impacts on data.
The effectiveness of ML relies heavily on large, diverse training data. With small, localized datasets, on-device models may fail to generalize across different user populations and environments.
For example, a disease detection model trained only on images from a single hospital would not generalize well to other patient demographics. Without extensive, diverse medical images, the model's real-world performance would suffer.
-Thus, while cloud-based learning leverages massive datasets, on-device learning relies on much smaller, decentralized data silos unique to each user.
+Thus, while cloud-based learning leverages massive datasets, on-device learning relies on much smaller, decentralized data silos unique to each user.
The limited data and optimizations required for on-device learning can negatively impact model accuracy and generalization:
-- Small datasets increase overfitting risk. For example, a fruit classifier trained on 100 images risks overfitting compared to one trained on 1 million diverse images.
-- Noisy user-generated data reduces quality. Sensor noise or improper data labeling by non-experts may degrade training.
-- Optimizations like pruning and quantization trade off accuracy for efficiency. An 8-bit quantized model runs faster but less accurately than a 32-bit model.
+* Small datasets increase overfitting risk. For example, a fruit classifier trained on 100 images risks overfitting compared to one trained on 1 million diverse images.
+* Noisy user-generated data reduces quality. Sensor noise or improper data labeling by non-experts may degrade training.
+* Optimizations like pruning and quantization trade off accuracy for efficiency. An 8-bit quantized model runs faster but less accurately than a 32-bit model.
So while cloud models achieve high accuracy with massive datasets and no constraints, on-device models can struggle to generalize. Some studies show that on-device training matches cloud accuracy on select tasks. However, performance on real-world workloads requires further study [@lin2022device].
@@ -130,64 +128,65 @@ For instance, a cloud model can accurately detect pneumonia in chest X-rays from
Unreliable accuracy limits the real-world applicability of on-device learning for mission-critical uses like disease diagnosis or self-driving vehicles.
-On-device training is also slower than the cloud due to limited resources. Even if each iteration is faster, the overall training process takes longer.
+On-device training is also slower than the cloud due to limited resources. Even if each iteration is faster, the overall training process takes longer.
For example, a real-time robotics application may require model updates within milliseconds. On-device training on small embedded hardware may take seconds or minutes per update - too slow for real-time use.
Accuracy, generalization, and speed challenges pose hurdles to adopting on-device learning for real-world production systems, especially when reliability and low latency are critical.
-## Ondevice Adaptation
+## On-device Adaptation
-In an ML task, resource consumption [mainly](http://arxiv.org/abs/1911.00623) comes from three sources:
+In an ML task, resource consumption [mainly](http://arxiv.org/abs/1911.00623) comes from three sources:
-* The ML model itself;
+* The ML model itself;
* The optimization process during model learning
-* Storing and processing the dataset used for learning.
+* Storing and processing the dataset used for learning.
-Correspondingly, there are three approaches to adapting existing ML algorithms onto resource-constrained devices:
+Correspondingly, there are three approaches to adapting existing ML algorithms onto resource-constrained devices:
* Reducing the complexity of the ML model
* Modifying optimizations to reduce training resource requirements
* Creating new storage-efficient data representations
-In the following section, we will review these on-device learning adaptation methods. More details on model optimizations can be found in the [Model Optimizations](./optimizations.qmd) chapter.
+In the following section, we will review these on-device learning adaptation methods. More details on model optimizations can be found in the [Model Optimizations](./optimizations.qmd) chapter.
### Reducing Model Complexity
-In this section, we will briefly discuss ways to reduce model complexity to adapt ML models on-device. For details of reducing model complexity, please refer to the Model Optimization Chapter.
+In this section, we will briefly discuss ways to reduce model complexity to adapt ML models on-device. For details of reducing model complexity, please refer to the Model Optimization Chapter.
#### Traditional ML Algorithms
-Due to the compute and memory limitations of edge devices, select traditional ML algorithms are great candidates for on-device learning applications due to their lightweight nature. Some example algorithms with low resource footprints include Naive Bayes Classifier, Support Vector Machines (SVMs), Linear Regression, Logistic Regression, and select Decision Tree algorithms.
+Due to the compute and memory limitations of edge devices, select traditional ML algorithms are great candidates for on-device learning applications due to their lightweight nature. Some example algorithms with low resource footprints include Naive Bayes Classifier, Support Vector Machines (SVMs), Linear Regression, Logistic Regression, and select Decision Tree algorithms.
-With some refinements, these classical ML algorithms can be adapted to specific hardware architectures and perform simple tasks, and their low performance requirements make it easy to integrate continuous learning even on edge devices.
+With some refinements, these classical ML algorithms can be adapted to specific hardware architectures and perform simple tasks, and their low performance requirements make it easy to integrate continuous learning even on edge devices.
#### Pruning
-Pruning is a technique used to reduce the size and complexity of an ML model to improve their efficiency and generalization performance. This is beneficial for training models on edge devices, where we want to minimize the resource usage while maintaining competitive accuracy.
-The primary goal of pruning is to remove parts of the model that do not contribute significantly to its predictive power while retaining the most informative aspects. In the context of decision trees, pruning involves removing some of the branches (subtrees) from the tree, leading to a smaller and simpler tree. In the context of DNN, pruning is used to reduce the number of neurons (units) or connections in the network.
+Pruning is a technique used to reduce the size and complexity of an ML model to improve their efficiency and generalization performance. This is beneficial for training models on edge devices, where we want to minimize the resource usage while maintaining competitive accuracy.
+
+The primary goal of pruning is to remove parts of the model that do not contribute significantly to its predictive power while retaining the most informative aspects. In the context of decision trees, pruning involves removing some of the branches (subtrees) from the tree, leading to a smaller and simpler tree. In the context of DNN, pruning is used to reduce the number of neurons (units) or connections in the network.
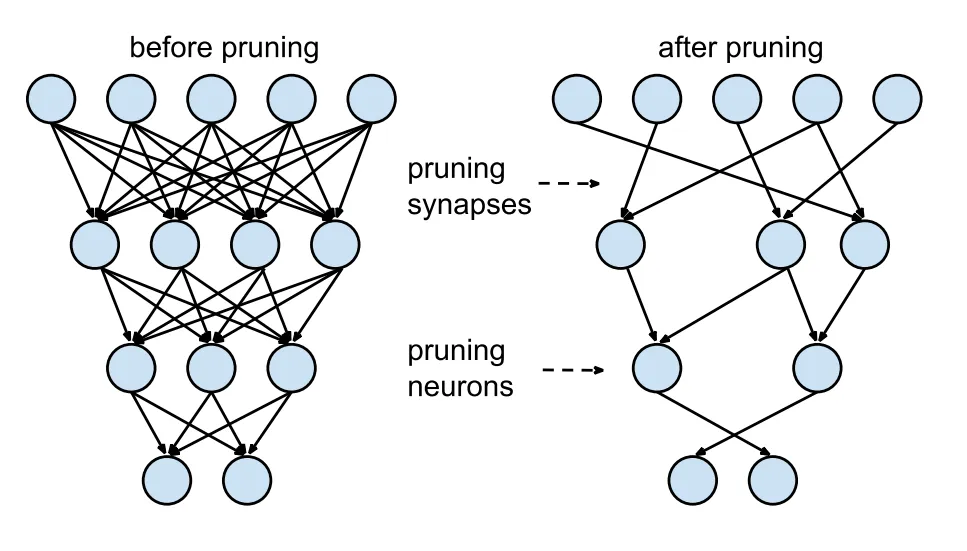)](images/ondevice_pruning.png)
#### Reducing Complexity of Deep Learning Models
-Traditional cloud-based DNN frameworks have too much memory overhead to be used on-device. [For example](http://arxiv.org/abs/2206.15472), deep learning systems like PyTorch and TensorFlow require hundreds of megabytes of memory overhead when training models such as [MobilenetV2](https://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html), and the overhead scales as the number of training parameters increases.
+Traditional cloud-based DNN frameworks have too much memory overhead to be used on-device. [For example](http://arxiv.org/abs/2206.15472), deep learning systems like PyTorch and TensorFlow require hundreds of megabytes of memory overhead when training models such as [MobilenetV2](https://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html), and the overhead scales as the number of training parameters increases.
-Traditional cloud-based DNN frameworks have too much memory overhead to be used on-device. For example, deep learning systems like PyTorch and TensorFlow require hundreds of megabytes of memory overhead when training models such as MobilenetV2-w0.35, and the overhead scales as the number of training parameters increases.
+Traditional cloud-based DNN frameworks have too much memory overhead to be used on-device. For example, deep learning systems like PyTorch and TensorFlow require hundreds of megabytes of memory overhead when training models such as MobilenetV2-w0.35, and the overhead scales as the number of training parameters increases.
Current research for lightweight DNNs mostly explore CNN architectures. Several bare-metal frameworks designed for running Neural Network on MCUs by keeping computational overhead and memory footprint low also exist. Some examples include MNN, TVM, and TensorFlow Lite. However, they can only perform inference during forward pass and lack support for back-propagation. While these models are designed for edge deployment, their reduction in model weights and architectural connections led to reduced resource requirements for continuous learning.
-The tradeoff between performance and model support is clear when adapting the most popular DNN systems. How do we adapt existing DNN models to resource-constrained settings while maintaining support for back-propagation and continuous learning? Latest research suggests algorithm and system codesign techniques that help reduce the resource consumption of ML training on edge devices. Utilizing techniques such as quantization-aware scaling (QAS), sparse updates, and other cutting edge techniques, on-device learning is possible on embedded systems with a few hundred kilobytes of RAM without additional memory while maintaining [high accuracy](http://arxiv.org/abs/2206.15472).
+The tradeoff between performance and model support is clear when adapting the most popular DNN systems. How do we adapt existing DNN models to resource-constrained settings while maintaining support for back-propagation and continuous learning? Latest research suggests algorithm and system codesign techniques that help reduce the resource consumption of ML training on edge devices. Utilizing techniques such as quantization-aware scaling (QAS), sparse updates, and other cutting edge techniques, on-device learning is possible on embedded systems with a few hundred kilobytes of RAM without additional memory while maintaining [high accuracy](http://arxiv.org/abs/2206.15472).
-### Modifying Optimization Processes
+### Modifying Optimization Processes
-Choosing the right optimization strategy is important for DNN training on-device, since this allows for the finding of a good local minimum. This optimization strategy must also consider limited memory and power since training occurs on-device.
+Choosing the right optimization strategy is important for DNN training on-device, since this allows for the finding of a good local minimum. This optimization strategy must also consider limited memory and power since training occurs on-device.
#### Quantization-Aware Scaling
Quantization is a common method for reducing the memory footprint of DNN training. Although this could introduce new errors, these errors can be mitigated by designing a model to characterize this statistical error. For example, models could use stochastic rounding or introduce the quantization error into the gradient updates.
-A specific algorithmic technique is Quantization-Aware Scaling (QAS), used to improve the performance of neural networks on low-precision hardware, such as edge devices and mobile devices or TinyML systems, by adjusting the scale factors during the quantization process.
+A specific algorithmic technique is Quantization-Aware Scaling (QAS), used to improve the performance of neural networks on low-precision hardware, such as edge devices and mobile devices or TinyML systems, by adjusting the scale factors during the quantization process.
As you recall from the Optimizations chapter, quantization is the process of mapping a continuous range of values to a discrete set of values. In the context of neural networks, quantization often involves reducing the precision of the weights and activations from 32-bit floating point to lower-precision formats such as 8-bit integers. This reduction in precision can significantly reduce the computational cost and memory footprint of the model, making it suitable for deployment on low-precision hardware.
@@ -205,11 +204,11 @@ The QAS process involves two main steps:
QAS is used to overcome the difficulties of optimizing models on tiny devices. Without needing hyperparamter tuning. QAS automatically scales tensor gradients with various bit-precisions. This in turn stabilizes the training process and matches the accuracy of floating-point precision.
-#### Sparse Updates
+#### Sparse Updates
-Although QAS enables optimizing a quantized model, it uses a large amount of memory that is unrealistic for on-device training. So spare update is used to reduce the memory footprint of full backward computation. Instead of pruning weights for inference, sparse update prunes the gradient during backwards propagation to update the model sparsely. In other words, sparse update skips computing gradients of less important layers and sub-tensors.
+Although QAS enables optimizing a quantized model, it uses a large amount of memory that is unrealistic for on-device training. So spare update is used to reduce the memory footprint of full backward computation. Instead of pruning weights for inference, sparse update prunes the gradient during backwards propagation to update the model sparsely. In other words, sparse update skips computing gradients of less important layers and sub-tensors.
-However, determining the optimal sparse update scheme given a constraining memory budget can be challenging due to the large search space. For example, the MCUNet model has 43 convolutional layers and a search space of approximately 1030. One technique to address this issue is contribution analysis. Contribution analysis measures the accuracy improvement from biases (updating the last few biases compared to only updating the classifier) and weights (updating the weight of one extra layer compared to only having a bias update). By trying to maximize these improvements, contribution analysis automatically derives an optimal sparse update scheme for enabling on-device training.
+However, determining the optimal sparse update scheme given a constraining memory budget can be challenging due to the large search space. For example, the MCUNet model has 43 convolutional layers and a search space of approximately 1030. One technique to address this issue is contribution analysis. Contribution analysis measures the accuracy improvement from biases (updating the last few biases compared to only updating the classifier) and weights (updating the weight of one extra layer compared to only having a bias update). By trying to maximize these improvements, contribution analysis automatically derives an optimal sparse update scheme for enabling on-device training.
#### Layer-Wise Training
@@ -221,7 +220,7 @@ The strategy of trading computation for memory involves releasing some of the me
### Developing New Data Representations
-The dimensionality and volume of the training data can significantly impact on-device adaptation. So another technique for adapting models onto resource-cosntrained devices is to represent datasets in a more efficient way.
+The dimensionality and volume of the training data can significantly impact on-device adaptation. So another technique for adapting models onto resource-cosntrained devices is to represent datasets in a more efficient way.
#### Data Compression
@@ -233,7 +232,7 @@ Other more common methods of data compression focus on reducing the dimensionali
Transfer learning is a ML technique where a model developed for a particular task is reused as the starting point for a model on a second task. In the context of on-device AI, transfer learning allows us to leverage pre-trained models that have already learned useful representations from large datasets, and fine-tune them for specific tasks using smaller datasets directly on the device. This can significantly reduce the computational resources and time required for training models from scratch.
-Let's take the example of a smart sensor application that uses on-device AI to recognize objects in images captured by the device. Traditionally, this would require sending the image data to a server, where a large neural network model processes the data and sends back the results. With on-device AI, the model is stored and runs directly on-device, eliminating the need to send data to a server.
+Let's take the example of a smart sensor application that uses on-device AI to recognize objects in images captured by the device. Traditionally, this would require sending the image data to a server, where a large neural network model processes the data and sends back the results. With on-device AI, the model is stored and runs directly on-device, eliminating the need to send data to a server.
If we want to customize the model for the on-device characteristics, training a neural network model from scratch on the device would however be impractical due to the limited computational resources and battery life. This is where transfer learning comes in. Instead of training a model from scratch, we can take a pre-trained model, such as a convolutional neural network (CNN) or a transformer network that has been trained on a large dataset of images, and fine-tune it for our specific object recognition task. This fine-tuning can be done directly on the device using a smaller dataset of images relevant to the task. By leveraging the pre-trained model, we can reduce the computational resources and time required for training, while still achieving high accuracy for the object recognition task.
@@ -262,7 +261,7 @@ This method significantly reduces the time and computational resources required
### Post-Deployment Adaptation
-Deployment to a device need not mark the culmination of a ML model's educational trajectory. With the advent of transfer learning, we open the doors to the deployment of adaptive ML models to real-world scenarios, catering to the personalized needs of users.
+Deployment to a device need not mark the culmination of a ML model's educational trajectory. With the advent of transfer learning, we open the doors to the deployment of adaptive ML models to real-world scenarios, catering to the personalized needs of users.
Consider a real-world application where a parent wishes to identify their child in a collection of images from a school event on their smartphone. In this scenario, the parent is faced with the challenge of locating their child amidst images of many other children. Here, transfer learning can be employed to fine-tune an embedded system's model to this unique and specialized task. Initially, the system might use a generic model trained to recognize faces in images. However, with transfer learning, the system can adapt this model to recognize the specific features of the user's child.
@@ -289,6 +288,7 @@ There are advantages to reusing the features:
2. **Boosting Performance:** Transfer learning has been proven to boost the performance of models on tasks with limited data. The knowledge gained from the source task can provide a valuable starting point and lead to faster convergence and improved accuracy on the target task.
### Core Concepts
+
Understanding the core concepts of transfer learning is essential for effectively utilizing this powerful approach in ML. Here we'll break down some of the main principles and components that underlie the process of transfer learning.
#### Source and Target Tasks
@@ -300,16 +300,18 @@ If we have a model trained to recognize various fruits in images (source task),
#### Representation Transfer
Representation transfer is about transferring the learned representations (features) from the source task to the target task. There are three main types of representation transfer:
-- Instance Transfer: This involves reusing the data instances from the source task in the target task.
-- Feature-Representation Transfer: This involves transferring the learned feature representations from the source task to the target task.
-- Parameter Transfer: This involves transferring the learned parameters (weights) of the model from the source task to the target task.
+* Instance Transfer: This involves reusing the data instances from the source task in the target task.
+* Feature-Representation Transfer: This involves transferring the learned feature representations from the source task to the target task.
+* Parameter Transfer: This involves transferring the learned parameters (weights) of the model from the source task to the target task.
In natural language processing, a model trained to understand the syntax and grammar of a language (source task) can have its learned representations transferred to a new model designed to perform sentiment analysis (target task).
-#### Fine-Tuning
+#### Fine-Tuning
+
Fine-tuning is the process of adjusting the parameters of a pre-trained model to adapt it to the target task. This typically involves updating the weights of the model's layers, especially the last few layers, to make the model more relevant for the new task. In image classification, a model pre-trained on a general dataset like ImageNet (source task) can be fine-tuned by adjusting the weights of its layers to perform well on a specific classification task, like recognizing specific animal species (target task).
-#### Feature Extractions
+#### Feature Extractions
+
Feature extraction involves using a pre-trained model as a fixed feature extractor, where the output of the model's intermediate layers is used as features for the target task. This approach is particularly useful when the target task has a small dataset, as the pre-trained model's learned features can significantly enhance performance. In medical image analysis, a model pre-trained on a large dataset of general medical images (source task) can be used as a feature extractor to provide valuable features for a new model designed to recognize specific types of tumors in X-ray images (target task).
### Types of Transfer Learning
@@ -331,9 +333,9 @@ Unsupervised transfer learning is used when the source and target tasks are rela
#### Comparison and Trade-offs
By leveraging these different types of transfer learning, practitioners can choose the approach that best fits the nature of their tasks and available data, ultimately leading to more effective and efficient ML models. So in summary:
-- Inductive: different source and target tasks, different domains
-- Transductive: different source and target tasks, same domain
-- Unsupervised: unlabeled source data, transfers feature representations
+* Inductive: different source and target tasks, different domains
+* Transductive: different source and target tasks, same domain
+* Unsupervised: unlabeled source data, transfers feature representations
Here's a matrix that outlines in a bit more detail the similarities and differences between the types of transfer learning:
@@ -345,7 +347,7 @@ Here's a matrix that outlines in a bit more detail the similarities and differen
| **Objective** | Improve target task performance with source data | Transfer knowledge from source to target domain | Leverage source task to improve target task performance without labeled data |
| **Example** | ImageNet to bird classification | Sentiment analysis in different languages | Topic modeling for different text data |
-### Constraints and Considerations
+### Constraints and Considerations
When engaging in transfer learning, there are several factors that must be considered to ensure successful knowledge transfer and model performance. Here's a breakdown of some key factors:
@@ -379,11 +381,11 @@ The modern internet is full of large networks of connected devices. Whether it
Federated learning offers a solution to these problems: train models partially on the edge devices and only communicate model updates to the cloud. In 2016, a team from Google designed architecture for federated learning that attempts to address these problems.
-In their initial paper Google outlines a principle federated learning algorithm called FederatedAveraging. Specifically, FederatedAveraging performs stochastic gradient descent (SGD) over several different edge devices. In this process, each device calculates a gradient $g_k = \nabla F_k(w_t)$ which is then applied to update the server side weights as (with $\eta$ as learning rate across $k$ clients):
+In their initial paper Google outlines a principle federated learning algorithm called FederatedAveraging. Specifically, FederatedAveraging performs stochastic gradient descent (SGD) over several different edge devices. In this process, each device calculates a gradient $g_k = \nabla F_k(w_t)$ which is then applied to update the server side weights as (with $\eta$ as learning rate across $k$ clients):
$$
w_{t+1} \rightarrow w_t - \eta \sum_{k=1}^{K} \frac{n_k}{n}g_k
$$
-This boils down the basic algorithm for federated learning on the right. For each round of training, the server takes a random set of the client devices and calls each client to train on its local batch using the most recent server side weights. Those weights then get returned to the server where they are collected individually then averaged to update the global model weights.
+This boils down the basic algorithm for federated learning on the right. For each round of training, the server takes a random set of the client devices and calls each client to train on its local batch using the most recent server side weights. Those weights then get returned to the server where they are collected individually then averaged to update the global model weights.
)](images/ondevice_fed_averaging.png)
@@ -391,18 +393,17 @@ With this proposed structure, there are a few key vectors for optimizing federat
### Communication Efficiency
-
One of the key bottlenecks in federated learning is communication. Every time a client trains the model, they must communicate back to the server their updates. Similarly, once the server has averaged all the updates, it must send them back to the client. On large networks of millions of devices, this incurs huge bandwidth and resource cost. As the field of federated learning advances, a few optimizations have been developed to minimize this communication. To address the footprint of the model, researchers have developed model compression techniques. In the client server protocol, federated learning can also minimize communication through selective sharing of updates on clients. Finally, efficient aggregation techniques can also streamline the communication process.
### Model Compression
-In standard federated learning, the server must communicate the entire model to each client and then the client must send back all of the updated weights. This means that the easiest way to reduce both the memory and communication footprint on the client is to minimize the size of the model needed to be communicated. To do this, we can employ all of the previously discussed model optimization strategies.
+In standard federated learning, the server must communicate the entire model to each client and then the client must send back all of the updated weights. This means that the easiest way to reduce both the memory and communication footprint on the client is to minimize the size of the model needed to be communicated. To do this, we can employ all of the previously discussed model optimization strategies.
-In 2022, another team at Google proposed wherein each client communicates via a compressed format and decompresses the model on the fly for training [@yang2023online], allocating and deallocating the full memory for the model only for a short period while training. The model is compressed through a range of various quantization strategies elaborated upon in their paper. Meanwhile the server can update the uncompressed model, decompressing and applying updates as they come in.
+In 2022, another team at Google proposed wherein each client communicates via a compressed format and decompresses the model on the fly for training [@yang2023online], allocating and deallocating the full memory for the model only for a short period while training. The model is compressed through a range of various quantization strategies elaborated upon in their paper. Meanwhile the server can update the uncompressed model, decompressing and applying updates as they come in.
### Selective Update Sharing
-There are a breadth of methods for selectively sharing updates. The general principle is that reducing the portion of the model that the clients are training on the edge reduces the memory necessary for training and the size of communication to the server. In basic federated learning, the client trains the entire model. This means that when a client sends an update to the server it has gradients for every weight in the network.
+There are a breadth of methods for selectively sharing updates. The general principle is that reducing the portion of the model that the clients are training on the edge reduces the memory necessary for training and the size of communication to the server. In basic federated learning, the client trains the entire model. This means that when a client sends an update to the server it has gradients for every weight in the network.
However, we cannot just reduce communication by sending pieces of those gradients to the server from each client because the gradients are part of an entire update required to improve the model. Instead, you need to architecturally design the model such that the clients each train only a small portion of the broader model, reducing the total communication while still gaining the benefit of training on client data. A paper from the University of Sheffield applies this concept to a CNN by splitting the global model into two parts: an upper and lower part as shown below [@shi2022data].
@@ -420,11 +421,11 @@ In addition to security enhancing aggregation methods, there are several modific
When using federated learning to train a model across many client devices, it is convenient to consider the data to be independent and identically distributed (IID) across all clients. When data is IID, the model will converge faster and perform better because each local update on any given client is more representative of the broader dataset. This makes aggregation straightforward as you can directly average all clients. However, this is not how data often appears in the real world. Consider a few of the following ways in which data may be non-IID:
-- If you are learning on a set of health-monitor devices, different device models could mean different sensor qualities and properties. This means that low quality sensors and devices may produce data, and therefore model updates distinctly different than high quality ones
+* If you are learning on a set of health-monitor devices, different device models could mean different sensor qualities and properties. This means that low quality sensors and devices may produce data, and therefore model updates distinctly different than high quality ones
-- A smart keyboard trained to perform autocorrect. If you have a disproportionate amount of devices from a certain region the slang, sentence structure, or even language they were using could skew more model updates towards a certain style of typing
+* A smart keyboard trained to perform autocorrect. If you have a disproportionate amount of devices from a certain region the slang, sentence structure, or even language they were using could skew more model updates towards a certain style of typing
-- If you have wildlife sensors in remote areas, connectivity may not be equally distributed causing some clients in certain regions to be able to send more model updates than others. If those regions have different wildlife activity from certain species, that could skew the updates toward those animals
+* If you have wildlife sensors in remote areas, connectivity may not be equally distributed causing some clients in certain regions to be able to send more model updates than others. If those regions have different wildlife activity from certain species, that could skew the updates toward those animals
There are a few approaches to addressing non-IID data in federated learning. One approach would be to change the aggregation algorithm. If you use a weighted aggregation algorithm, you can adjust based on different client properties like region, sensor properties, or connectivity [@zhao2018federated].
@@ -432,60 +433,61 @@ There are a few approaches to addressing non-IID data in federated learning. One
Considering all of the factors influencing the efficacy of federated learning like IID data and communication, client selection is key component to ensuring a system trains well. Selecting the wrong clients can skew the dataset, resulting in non-IID data. Similarly, choosing clients randomly with bad network connections can slow down communication. Therefore, when selecting the right subset of clients, several key characteristics must be considered.
-When selecting clients, there are three main components to consider: data heterogeneity, resource allocation, and communication cost. To address data heterogeneity, we can select for clients on the previously proposed metrics in the non-IID section. In federated learning, all devices may not have the same amount of compute, resulting in some being more inefficient at training than others. When selecting a subset of clients for training, one must consider a balance of data heterogeneity and available resources. In an ideal scenario, you can always select the subset of clients with the greatest resources. However, this may skew your dataset so a balance must be struck. Communication differences add another layer to this, you do not want to be bottlenecked by waiting for devices with poor connections to transmit their entire updates. Therefore, you must also consider choosing a subset of diverse yet well-connected devices.
+When selecting clients, there are three main components to consider: data heterogeneity, resource allocation, and communication cost. To address data heterogeneity, we can select for clients on the previously proposed metrics in the non-IID section. In federated learning, all devices may not have the same amount of compute, resulting in some being more inefficient at training than others. When selecting a subset of clients for training, one must consider a balance of data heterogeneity and available resources. In an ideal scenario, you can always select the subset of clients with the greatest resources. However, this may skew your dataset so a balance must be struck. Communication differences add another layer to this, you do not want to be bottlenecked by waiting for devices with poor connections to transmit their entire updates. Therefore, you must also consider choosing a subset of diverse yet well-connected devices.
### An Example of Deployed Federated Learning: G board
-A primary example of a deployed federated learning system is Google’s Keyboard, Gboard, for android devices. In their implementation of federated learning for the keyboard, Google focused on employing differential privacy techniques to protect the user’s data and identity. Gboard leverages language models for several key features such as Next Word Prediction (NWP), Smart Compose (SC), and On-The-Fly rescoring (OTF) [@xu2023federated].
+A primary example of a deployed federated learning system is Google’s Keyboard, Gboard, for android devices. In their implementation of federated learning for the keyboard, Google focused on employing differential privacy techniques to protect the user’s data and identity. Gboard leverages language models for several key features such as Next Word Prediction (NWP), Smart Compose (SC), and On-The-Fly rescoring (OTF) [@xu2023federated].
-NWP will anticipate the next word the user is trying to type based on the previous one. SC gives inline suggestions to speed up the typing based on each character. OTF will re-rank the proposed next words based on the active typing process. All three of these models need to run quickly on the edge and federated learning can accelerate training on the users' data. However, uploading every word a user typed to the cloud for training would be a massive privacy violation. Therefore, federated learning with an emphasis on differential privacy protects the user while still enabling a better user experience.
+NWP will anticipate the next word the user is trying to type based on the previous one. SC gives inline suggestions to speed up the typing based on each character. OTF will re-rank the proposed next words based on the active typing process. All three of these models need to run quickly on the edge and federated learning can accelerate training on the users' data. However, uploading every word a user typed to the cloud for training would be a massive privacy violation. Therefore, federated learning with an emphasis on differential privacy protects the user while still enabling a better user experience.
-![Examples of Google G Board Features (Credit: (Zheng et al., 2023)[https://arxiv.org/abs/2305.18465])](images/ondevice_gboard_example.png)
+)](images/ondevice_gboard_example.png)
To accomplish this goal, Google employed their algorithm DP-FTRL which provides a formal guarantee that trained models will not memorize specific user data or identities. DP-FTRL combined with secure aggregation, a strategy of encrypting model updates, provides an optimal balance of privacy and utility. Furthermore, adaptive clipping is applied in the aggregation process to limit the impact of individual users on the global model. Through a combination of all of these techniques, Google can continuously refine their keyboard while preserving user privacy in a formally provable way.
-![Google's System Design for Differential Privacy in G Board (Credit: (Zheng et al., 2023)[https://arxiv.org/abs/2305.18465])](images/ondevice_gboard_approach.png)
+)](images/ondevice_gboard_approach.png)
### Benchmarking for Federated Learning: MedPerf
-One of the richest examples of data on the edge is medical devices. These devices store some of the most personal data on users but offer huge advances in personalized treatment and better accuracy in medical AI. Given these two factors, medical devices are the perfect use case for federated learning. [MedPerf](https://doi.org/10.1038/s42256-023-00652-2) is an open source platform used to benchmark models using federated evaluation [@karargyris2023federated]. Instead of just training models via federated learning, MedPerf takes the model to edge devices to test it against personalized data while preserving privacy. In this way a benchmark committee can evaluate various models in the real world on edge devices while still preserving patient anonymity.
+One of the richest examples of data on the edge is medical devices. These devices store some of the most personal data on users but offer huge advances in personalized treatment and better accuracy in medical AI. Given these two factors, medical devices are the perfect use case for federated learning. [MedPerf](https://doi.org/10.1038/s42256-023-00652-2) is an open source platform used to benchmark models using federated evaluation [@karargyris2023federated]. Instead of just training models via federated learning, MedPerf takes the model to edge devices to test it against personalized data while preserving privacy. In this way a benchmark committee can evaluate various models in the real world on edge devices while still preserving patient anonymity.
## Security Concerns
Performing ML model training and adaptation on end-user devices also introduces security risks that must be addressed. Some key security concerns include:
-- **Exposure of private data**: Training data may be leaked or stolen from devices
-- **Data poisoning**: Adversaries can manipulate training data to degrade model performance
-- **Model extraction**: Attackers may attempt to steal trained model parameters
-- **Membership inference**: Models may reveal participation of specific users' data
-- **Evasion attacks**: Specially crafted inputs can cause misclassification
+* **Exposure of private data**: Training data may be leaked or stolen from devices
+* **Data poisoning**: Adversaries can manipulate training data to degrade model performance
+* **Model extraction**: Attackers may attempt to steal trained model parameters
+* **Membership inference**: Models may reveal participation of specific users' data
+* **Evasion attacks**: Specially crafted inputs can cause misclassification
-Any system that performs learning on-device introduces security concerns, as it may expose vulnerabilities in larger scale models. There are numerous security risks associated with any ML model, but these risks have specific consequences for on-device learning. Fortunately, there are methods to mitigate these risks to improve the real-world performance of on-device learning.
+Any system that performs learning on-device introduces security concerns, as it may expose vulnerabilities in larger scale models. There are numerous security risks associated with any ML model, but these risks have specific consequences for on-device learning. Fortunately, there are methods to mitigate these risks to improve the real-world performance of on-device learning.
### Data Poisoning
+
On-device ML introduces unique data security challenges compared to traditional cloud-based training. In particular, data poisoning attacks pose a serious threat during on-device learning. Adversaries can manipulate training data to degrade model performance when deployed.
Several data poisoning attack techniques exist:
-* **Label Flipping:** It involves applying incorrect labels to samples. For instance, in image classification, cat photos may be labeled as dogs to confuse the model. Flipping even [10% of labels](https://proceedings.mlr.press/v139/schwarzschild21a.html) can have significant consequences on the model.
-* **Data Insertion:** It introduces fake or distorted inputs into the training set. This could include pixelated images, noisy audio, or garbled text.
-* **Logic Corruption:** This alters the underlying [patterns](https://www.worldscientific.com/doi/10.1142/S0218001414600027) in data to mislead the model. In sentiment analysis, highly negative reviews may be marked positive through this technique. For this reason, recent surveys have shown that many companies are more [afraid of data poisoning](https://proceedings.mlr.press/v139/schwarzschild21a.html) than other adversarial ML concerns.
+* **Label Flipping:** It involves applying incorrect labels to samples. For instance, in image classification, cat photos may be labeled as dogs to confuse the model. Flipping even [10% of labels](https://proceedings.mlr.press/v139/schwarzschild21a.html) can have significant consequences on the model.
+* **Data Insertion:** It introduces fake or distorted inputs into the training set. This could include pixelated images, noisy audio, or garbled text.
+* **Logic Corruption:** This alters the underlying [patterns](https://www.worldscientific.com/doi/10.1142/S0218001414600027) in data to mislead the model. In sentiment analysis, highly negative reviews may be marked positive through this technique. For this reason, recent surveys have shown that many companies are more [afraid of data poisoning](https://proceedings.mlr.press/v139/schwarzschild21a.html) than other adversarial ML concerns.
What makes data poisoning alarming is how it exploits the discrepancy between curated datasets and live training data. Consider a cat photo dataset collected from the internet. In the weeks later when this data trains a model on-device, new cat photos on the web differ significantly.
-With data poisoning, attackers purchase domains and upload content that influences a portion of the training data. Even small data changes significantly impact the model's learned behavior. Consequently, poisoning can instill racist, sexist, or other harmful biases if unchecked.
+With data poisoning, attackers purchase domains and upload content that influences a portion of the training data. Even small data changes significantly impact the model's learned behavior. Consequently, poisoning can instill racist, sexist, or other harmful biases if unchecked.
[Microsoft Tay](https://en.wikipedia.org/wiki/Tay_(chatbot)) was a chatbot launched by Microsoft in 2016. It was designed to learn from its interactions with users on social media platforms like Twitter. Unfortunately, Microsoft Tay became a prime example of data poisoning in ML models. Within 24 hours of its launch, Microsoft had to take Tay offline because it had started producing offensive and inappropriate messages, including hate speech and racist comments. This occurred because some users on social media intentionally fed Tay with harmful and offensive input, which the chatbot then learned from and incorporated into its responses.
This incident is a clear example of data poisoning because malicious actors intentionally manipulated the data used to train and inform the chatbot's responses. The data poisoning resulted in the chatbot adopting harmful biases and producing output that was not intended by its developers. It demonstrates how even small amounts of maliciously crafted data can have a significant impact on the behavior of ML models, and highlights the importance of implementing robust data filtering and validation mechanisms to prevent such incidents from occurring.
-The real-world impacts of such biases could be dangerous. Rigorous data validation, anomaly detection, and tracking of data provenance are critical defensive measures. Adopting frameworks like Five Safes ensures models are trained on high-quality, representative data [@desai2016five].
+The real-world impacts of such biases could be dangerous. Rigorous data validation, anomaly detection, and tracking of data provenance are critical defensive measures. Adopting frameworks like Five Safes ensures models are trained on high-quality, representative data [@desai2016five].
Data poisoning is a pressing concern for secure on-device learning, since data at the endpoint cannot be easily monitored in real-time and if models are allowed to adapt on their own then we run the risk of the device acting malicously. But continued research in adversarial ML aims to develop robust solutions to detect and mitigate such data attacks.
### Adversarial Attacks
-During the training phase, attackers might inject malicious data into the training dataset, which can subtly alter the model's behavior. For example, an attacker could add images of cats that are labeled as dogs into a dataset used to train an image classification model. If done cleverly, the model's accuracy might not significantly drop, and the attack could go unnoticed. The model would then incorrectly classify some cats as dogs, which could have consequences depending on the application.
+During the training phase, attackers might inject malicious data into the training dataset, which can subtly alter the model's behavior. For example, an attacker could add images of cats that are labeled as dogs into a dataset used to train an image classification model. If done cleverly, the model's accuracy might not significantly drop, and the attack could go unnoticed. The model would then incorrectly classify some cats as dogs, which could have consequences depending on the application.
In an embedded security camera system, for instance, this could allow an intruder to avoid detection by wearing a specific pattern that the model has been tricked into classifying as non-threatening.
@@ -520,24 +522,23 @@ Photos are an especially high-risk data type because they often contain identifi
To defend against model inversion, one would need to take precautions like adding noise to the model outputs or using privacy-preserving machine learning techniques like [federated learning](@sec-fl) to train the on-device model. The goal is to prevent attackers from being able to reconstruct the original training data.
-
### On-Device Learning Security Concerns
While data poisoning and adversarial attacks are common concerns for ML models in general, on-device learning introduces unique security risks. When on-device variants of large-scale models are published, adversaries can exploit these smaller models to attack their larger counterparts. Research has demonstrated that as on-device models and full-scale models become more similar, the vulnerability of the original large-scale models increases significantly. For instance, evaluations across 19 Deep Neural Networks (DNNs) revealed that exploiting on-device models could increase the vulnerability of the original large-scale models by [up to 100 times](http://arxiv.org/abs/2212.13700).
There are three primary types of security risks specific to on-device learning:
-- **Transfer-Based Attacks**: These attacks exploit the transferability property between a surrogate model (an approximation of the target model, similar to an on-device model) and a remote target model (the original full-scale model). Attackers generate adversarial examples using the surrogate model, which can then be used to deceive the target model. For example, imagine an on-device model designed to identify spam emails. An attacker could use this model to generate a spam email that is not detected by the larger, full-scale email filtering system.
+* **Transfer-Based Attacks**: These attacks exploit the transferability property between a surrogate model (an approximation of the target model, similar to an on-device model) and a remote target model (the original full-scale model). Attackers generate adversarial examples using the surrogate model, which can then be used to deceive the target model. For example, imagine an on-device model designed to identify spam emails. An attacker could use this model to generate a spam email that is not detected by the larger, full-scale email filtering system.
-- **Optimization-Based Attacks**: These attacks generate adversarial examples for transfer-based attacks using some form of objective function, and iteratively modify inputs to achieve the desired outcome. Gradient estimation attacks, for example, approximate the model’s gradient using query outputs (such as softmax confidence scores), while gradient-free attacks use the model’s final decision (the predicted class) to approximate the gradient, albeit requiring many more queries.
+* **Optimization-Based Attacks**: These attacks generate adversarial examples for transfer-based attacks using some form of objective function, and iteratively modify inputs to achieve the desired outcome. Gradient estimation attacks, for example, approximate the model’s gradient using query outputs (such as softmax confidence scores), while gradient-free attacks use the model’s final decision (the predicted class) to approximate the gradient, albeit requiring many more queries.
-- **Query Attacks with Transfer Priors**: These attacks combine elements of transfer-based and optimization-based attacks. They reverse engineer on-device models to serve as surrogates for the target full-scale model. In other words, attackers use the smaller on-device model to understand how the larger model works, and then use this knowledge to attack the full-scale model.
+* **Query Attacks with Transfer Priors**: These attacks combine elements of transfer-based and optimization-based attacks. They reverse engineer on-device models to serve as surrogates for the target full-scale model. In other words, attackers use the smaller on-device model to understand how the larger model works, and then use this knowledge to attack the full-scale model.
By understanding these specific risks associated with on-device learning, we can develop more robust security protocols to protect both on-device and full-scale models from potential attacks.
### Mitigation of On-Device Learning Risks
-To mitigate the numerous security risks associated with on-device learning, a variety of methods can be employed. These methods may be specific to the type of attack or serve as a general tool to bolster security.
+To mitigate the numerous security risks associated with on-device learning, a variety of methods can be employed. These methods may be specific to the type of attack or serve as a general tool to bolster security.
One strategy to reduce security risks is to diminish the similarity between on-device models and full-scale models, thereby reducing transferability by up to 90%. This method, known as similarity-unpairing, addresses the problem that arises when adversaries exploit the input-gradient similarity between the two models. By fine-tuning the full-scale model to create a new version with similar accuracy but different input gradients, we can then construct the on-device model by quantizing this updated full-scale model. This unpairing reduces the vulnerability of on-device models by limiting the exposure of the original full-scale model. Importantly, the order of finetuning and quantization can be varied while still achieving risk mitigation [@hong2023publishing].
@@ -552,23 +553,24 @@ Furthermore, on-device models often utilize well-known or open-source datasets,
Lastly, the Adversarial Threat Landscape for Artificial-Intelligence Systems ([ATLAS](https://atlas.mitre.org/)) serves as a valuable matrix tool that helps assess the risk profile of on-device models, empowering developers to identify and [mitigate](https://www.eetimes.com/cybersecurity-threats-loom-over-endpoint-ai-systems/?_gl=1%2A17zgs0d%2A_ga%2AMTY0MzA1MTAyNS4xNjk4MDgyNzc1%2A_ga_ZLV02RYCZ8%2AMTY5ODA4Mjc3NS4xLjAuMTY5ODA4Mjc3NS42MC4wLjA) potential risks proactively.
### Securing Training Data
+
There are a variety of different ways to secure on-device training data. Each of these concepts in itself is really deep and could be worth a class by itself. So here we'll briefly allude to those concepts so you're aware about what to learn further.
-#### Encryption
+#### Encryption
-Encryption serves as the first line of defense for training data. This involves implementing end-to-end encryption for both local storage on devices and communication channels to prevent unauthorized access to raw training data. Trusted execution environments, such as [Intel SGX](https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html) and [ARM TrustZone](https://www.arm.com/technologies/trustzone-for-cortex-a#:~:text=Arm%20TrustZone%20technology%20offers%20an,trust%20based%20on%20PSA%20guidelines.), are essential for facilitating secure training on encrypted data.
+Encryption serves as the first line of defense for training data. This involves implementing end-to-end encryption for both local storage on devices and communication channels to prevent unauthorized access to raw training data. Trusted execution environments, such as [Intel SGX](https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html) and [ARM TrustZone](https://www.arm.com/technologies/trustzone-for-cortex-a#:~:text=Arm%20TrustZone%20technology%20offers%20an,trust%20based%20on%20PSA%20guidelines.), are essential for facilitating secure training on encrypted data.
Additionally, when aggregating updates from multiple devices, secure multi-party computation protocols can be employed to enhance security [@kairouz2015secure]. A practical application of this is in collaborative on-device learning, where cryptographic privacy-preserving aggregation of user model updates can be implemented. This technique effectively hides individual user data even during the aggregation phase.
#### Differential Privacy
-Differential privacy is another crucial strategy for protecting training data. By injecting calibrated statistical noise into the data, we can mask individual records while still extracting valuable population patterns [@dwork2014algorithmic]. Managing the privacy budget across multiple training iterations and reducing noise as the model converges is also vital [@abadi2016deep]. Methods such as formally provable differential privacy, which may include adding Laplace or Gaussian noise scaled to the dataset's sensitivity, can be employed.
+Differential privacy is another crucial strategy for protecting training data. By injecting calibrated statistical noise into the data, we can mask individual records while still extracting valuable population patterns [@dwork2014algorithmic]. Managing the privacy budget across multiple training iterations and reducing noise as the model converges is also vital [@abadi2016deep]. Methods such as formally provable differential privacy, which may include adding Laplace or Gaussian noise scaled to the dataset's sensitivity, can be employed.
#### Anomaly Detection
Anomaly detection plays a pivotal role in identifying and mitigating potential data poisoning attacks. This can be achieved through statistical analyses like Principal Component Analysis (PCA) and clustering, which help to detect deviations in aggregated training data. Time-series methods such as [Cumulative Sum (CUSUM)](https://en.wikipedia.org/wiki/CUSUM) charts are useful for identifying shifts indicative of potential poisoning. Comparing current data distributions with previously seen clean data distributions can also help to flag anomalies. Moreover, suspected poisoned batches should be removed from the training update aggregation process. For example, spot checks on subsets of training images on devices can be conducted using photoDNA hashes to identify poisoned inputs.
-#### Input Data Validation
+#### Input Data Validation
Lastly, input data validation is essential for ensuring the integrity and validity of input data before it is fed into the training model, thereby protecting against adversarial payloads. Similarity measures, such as cosine distance, can be employed to catch inputs that deviate significantly from the expected distribution. Suspicious inputs that may contain adversarial payloads should be quarantined and sanitized. Furthermore, parser access to training data should be restricted to validated code paths only. Leveraging hardware security features, such as ARM Pointer Authentication, can prevent memory corruption (ARM Limited, 2023). An example of this is implementing input integrity checks on audio training data used by smart speakers before processing by the speech recognition model [@chen2023learning].
@@ -576,7 +578,7 @@ Lastly, input data validation is essential for ensuring the integrity and validi
Embedded inference frameworks like TF-Lite Micro [@david2021tensorflow], TVM [@chen2018tvm], and MCUNet [@lin2020mcunet] provide a slim runtime for running neural network models on microcontrollers and other resource-constrained devices. However, they don't support on-device training. Training requires its own set of specialized tools due to the impact of quantization on gradient calculation and the memory footprint of backpropagation [@lin2022device].
-In recent years, there are a handful of tools and frameworks that have started to emerge that enable on-device training, and these include Tiny Training Engine [@lin2022device], TinyTL [@cai2020tinytl], and TinyTrain [@kwon2023tinytrain].
+In recent years, there are a handful of tools and frameworks that have started to emerge that enable on-device training, and these include Tiny Training Engine [@lin2022device], TinyTL [@cai2020tinytl], and TinyTrain [@kwon2023tinytrain].
### Tiny Training Engine
@@ -586,28 +588,28 @@ Tiny Training Engine (TTE) uses several techniques to optimize memory usage and
Specifically, TTE follows four main steps:
-- During compile time, TTE traces the forward propagation graph and derives the corresponding backward graph for backpropagation. This allows [differentiation](https://harvard-edge.github.io/cs249r_book/frameworks.html#differentiable-programming) to happen at compile time rather than runtime.
-- TTE prunes any nodes representing frozen weights from the backward graph. Frozen weights are weights that are not updated during training to reduce certain neurons' impact. Pruning their nodes saves memory.
-- TTE reorders the gradient descent operators to interleave them with the backward pass computations. This scheduling minimizes memory footprints.
-- TTE uses code generation to compile the optimized forward and backward graphs, which are then deployed for on-device training.
+* During compile time, TTE traces the forward propagation graph and derives the corresponding backward graph for backpropagation. This allows [differentiation](https://harvard-edge.github.io/cs249r_book/frameworks.html#differentiable-programming) to happen at compile time rather than runtime.
+* TTE prunes any nodes representing frozen weights from the backward graph. Frozen weights are weights that are not updated during training to reduce certain neurons' impact. Pruning their nodes saves memory.
+* TTE reorders the gradient descent operators to interleave them with the backward pass computations. This scheduling minimizes memory footprints.
+* TTE uses code generation to compile the optimized forward and backward graphs, which are then deployed for on-device training.
### Tiny Transfer Learning
-Tiny Transfer Learning (TinyTL) enables memory-efficient on-device training through a technique called weight freezing. During training, much of the memory bottleneck comes from storing intermediate activations and updating the weights in the neural network.
+Tiny Transfer Learning (TinyTL) enables memory-efficient on-device training through a technique called weight freezing. During training, much of the memory bottleneck comes from storing intermediate activations and updating the weights in the neural network.
To reduce this memory overhead, TinyTL freezes the majority of the weights so they do not need to be updated during training. This eliminates the need to store intermediate activations for frozen parts of the network. TinyTL only fine-tunes the bias terms, which are much smaller than the weights.

-Freezing weights is applicable not just to fully-connected layers but also to convolutional and normalization layers. However, only adapting the biases limits the model's ability to learn and adapt to new data.
+Freezing weights is applicable not just to fully-connected layers but also to convolutional and normalization layers. However, only adapting the biases limits the model's ability to learn and adapt to new data.
To increase adaptability without much additional memory, TinyTL uses a small residual learning model. This refines the intermediate feature maps to produce better outputs, even with fixed weights. The residual model introduces minimal overhead - less than 3.8% on top of the base model.
By freezing most weights TinyTL significantly cuts down memory usage during on-device training. The residual model then allows it to still adapt and learn effectively for the task. The combined approach provides memory-efficient on-device training with minimal impact on model accuracy.
-### Tiny Train
+### Tiny Train
-TinyTrain significantly reduces the time required for on-device training by selectively updating only certain parts of the model. It does this using a technique called task-adaptive sparse updating.
+TinyTrain significantly reduces the time required for on-device training by selectively updating only certain parts of the model. It does this using a technique called task-adaptive sparse updating.
Based on the user data, memory, and compute available on the device, TinyTrain dynamically chooses which layers of the neural network to update during training. This layer selection is optimized to reduce computation and memory usage while maintaining high accuracy.
@@ -615,12 +617,11 @@ Based on the user data, memory, and compute available on the device, TinyTrain d
More specifically, TinyTrain first does offline pretraining of the model. During pretraining, it not only trains the model on the task data but also meta-trains the model. Meta-training means training the model on metadata about the training process itself. This meta-learning improves the model's ability to adapt accurately even when limited data is available for the target task.
-Then, during the online adaptation stage when the model is being customized on the device, TinyTrain performs task-adaptive sparse updates. Using the criteria around the device's capabilities, it selects only certain layers to update through backpropagation. The layers are chosen to balance accuracy, memory usage, and computation time.
+Then, during the online adaptation stage when the model is being customized on the device, TinyTrain performs task-adaptive sparse updates. Using the criteria around the device's capabilities, it selects only certain layers to update through backpropagation. The layers are chosen to balance accuracy, memory usage, and computation time.
By sparsely updating layers tailored to the device and task, TinyTrain is able to significantly reduce on-device training time and resource usage. The offline meta-training also improves accuracy when adapting with limited data. Together, these methods enable fast, efficient, and accurate on-device training.
-### Comparison
-
+### Comparison
Here is a table summarizing the key similarities and differences between the Tiny Training Engine, TinyTL, and TinyTrain frameworks:
@@ -632,11 +633,11 @@ Here is a table summarizing the key similarities and differences between the Tin
## Conclusion
-The concept of on-device learning is increasingly important for increasing the usability and scalability of TinyML. This chapter explored the intricacies of on-device learning, exploring its advantages and limitations, adaptation strategies, key related algorithms and techniques, security implications, and existing and emerging on-device training frameworks.
+The concept of on-device learning is increasingly important for increasing the usability and scalability of TinyML. This chapter explored the intricacies of on-device learning, exploring its advantages and limitations, adaptation strategies, key related algorithms and techniques, security implications, and existing and emerging on-device training frameworks.
-On-device learning is, undoubtedly, a groundbreaking paradigm that brings forth numerous advantages for embedded and edge ML deployments. By performing training directly on the endpoint devices, on-device learning obviates the need for continuous cloud connectivity, making it particularly well-suited for IoT and edge computing applications. It comes with benefits such as improved privacy, ease of compliance, and resource efficiency. At the same time, on-device learning faces limitations related to hardware constraints, limited data size, and reduced model accuracy and generalization.
+On-device learning is, undoubtedly, a groundbreaking paradigm that brings forth numerous advantages for embedded and edge ML deployments. By performing training directly on the endpoint devices, on-device learning obviates the need for continuous cloud connectivity, making it particularly well-suited for IoT and edge computing applications. It comes with benefits such as improved privacy, ease of compliance, and resource efficiency. At the same time, on-device learning faces limitations related to hardware constraints, limited data size, and reduced model accuracy and generalization.
-Mechanisms such as reduced model complexity, optimization and data compression techniques, and related learning methods such as transfer learning and federated learning allow models to adapt to learn and evolve under resource constraints, thus serving as the bedrock for effective ML on edge devices.
+Mechanisms such as reduced model complexity, optimization and data compression techniques, and related learning methods such as transfer learning and federated learning allow models to adapt to learn and evolve under resource constraints, thus serving as the bedrock for effective ML on edge devices.
The critical security concerns in on-device learning highlighted in this chapter, ranging from data poisoning and adversarial attacks to specific risks introduced by on-device learning, must be addressed in real workloads for on-device learning to be a viable paradigm. Effective mitigation strategies, such as data validation, encryption, differential privacy, anomaly detection, and input data validation, are crucial to safeguard on-device learning systems from these threats.
diff --git a/ops.qmd b/ops.qmd
index 102b2912..be45997e 100644
--- a/ops.qmd
+++ b/ops.qmd
@@ -5,21 +5,22 @@
This chapter explores the practices and architectures needed to effectively develop, deploy, and manage ML models across their entire lifecycle. We examine the various phases of the ML process including data collection, model training, evaluation, deployment, and monitoring. The importance of automation, collaboration, and continuous improvement is also discussed. We contrast different environments for ML model deployment, from cloud servers to embedded edge devices, and analyze their distinct constraints. Through concrete examples, we demonstrate how to tailor ML system design and operations for reliable and optimized model performance in any target environment. The goal is to provide readers with a comprehensive understanding of ML model management so they can successfully build and run ML applications that sustainably deliver value.
::: {.callout-tip}
+
## Learning Objectives
* Understand what is MLOps and why it is needed
* Learn the architectural patterns for traditional MLOps
-* Contrast traditional vs. embedded MLOps across the ML lifecycle
+* Contrast traditional vs. embedded MLOps across the ML lifecycle
-* Identify key constraints of embedded environments
+* Identify key constraints of embedded environments
* Learn strategies to mitigate embedded ML challenges
* Examine real-world case studies demonstrating embedded MLOps principles
-* Appreciate the need for holistic technical and human approaches
+* Appreciate the need for holistic technical and human approaches
:::
@@ -27,7 +28,7 @@ This chapter explores the practices and architectures needed to effectively deve
Machine Learning Operations (MLOps), is a systematic approach that combines machine learning (ML), data science, and software engineering to automate the end-to-end ML lifecycle. This includes everything from data preparation and model training to deployment and maintenance. MLOps ensures that ML models are developed, deployed, and maintained efficiently and effectively.
-Let's start by taking a general example (i.e., non-edge ML) case. Consider a ridesharing company that wants to deploy a machine-learning model to predict rider demand in real time. The data science team spends months developing a model, but when it's time to deploy, they realize it needs to be compatible with the engineering team's production environment. Deploying the model requires rebuilding it from scratch - costing weeks of additional work. This is where MLOps comes in.
+Let's start by taking a general example (i.e., non-edge ML) case. Consider a ridesharing company that wants to deploy a machine-learning model to predict rider demand in real time. The data science team spends months developing a model, but when it's time to deploy, they realize it needs to be compatible with the engineering team's production environment. Deploying the model requires rebuilding it from scratch - costing weeks of additional work. This is where MLOps comes in.
With MLOps, there are protocols and tools in place to ensure that the model developed by the data science team can be seamlessly deployed and integrated into the production environment. In essence, MLOps removes friction during the development, deployment, and maintenance of ML systems. It improves collaboration between teams through defined workflows and interfaces. MLOps also accelerates iteration speed by enabling continuous delivery for ML models.
@@ -39,17 +40,17 @@ Major organizations adopt MLOps to boost productivity, increase collaboration, a
## Historical Context
-MLOps has its roots in DevOps, which is a set of practices that combines software development (Dev) and IT operations (Ops) to shorten the development lifecycle and provide continuous delivery of high-quality software. The parallels between MLOps and DevOps are evident in their focus on automation, collaboration, and continuous improvement. In both cases, the goal is to break down silos between different teams (developers, operations, and, in the case of MLOps, data scientists and ML engineers) and to create a more streamlined and efficient process. It is useful to understand the history of this evolution to better understand MLOps in the context of traditional systems.
+MLOps has its roots in DevOps, which is a set of practices that combines software development (Dev) and IT operations (Ops) to shorten the development lifecycle and provide continuous delivery of high-quality software. The parallels between MLOps and DevOps are evident in their focus on automation, collaboration, and continuous improvement. In both cases, the goal is to break down silos between different teams (developers, operations, and, in the case of MLOps, data scientists and ML engineers) and to create a more streamlined and efficient process. It is useful to understand the history of this evolution to better understand MLOps in the context of traditional systems.
### DevOps
-The term "DevOps" was first coined in 2009 by [Patrick Debois](https://www.jedi.be/), a consultant and Agile practitioner. Debois organized the first [DevOpsDays](https://www.devopsdays.org/) conference in Ghent, Belgium, in 2009, which brought together development and operations professionals to discuss ways to improve collaboration and automate processes.
+The term "DevOps" was first coined in 2009 by [Patrick Debois](https://www.jedi.be/), a consultant and Agile practitioner. Debois organized the first [DevOpsDays](https://www.devopsdays.org/) conference in Ghent, Belgium, in 2009, which brought together development and operations professionals to discuss ways to improve collaboration and automate processes.
-DevOps has its roots in the [Agile](https://agilemanifesto.org/) movement, which began in the early 2000s. Agile provided the foundation for a more collaborative approach to software development and emphasized small, iterative releases. However, Agile primarily focused on collaboration between development teams. As Agile methodologies became more popular, organizations realized the need to extend this collaboration to operations teams as well.
+DevOps has its roots in the [Agile](https://agilemanifesto.org/) movement, which began in the early 2000s. Agile provided the foundation for a more collaborative approach to software development and emphasized small, iterative releases. However, Agile primarily focused on collaboration between development teams. As Agile methodologies became more popular, organizations realized the need to extend this collaboration to operations teams as well.
-The siloed nature of development and operations teams often led to inefficiencies, conflicts, and delays in software delivery. This need for better collaboration and integration between these teams led to the [DevOps](https://www.atlassian.com/devops) movement. In a sense, DevOps can be seen as an extension of the Agile principles to include operations teams.
+The siloed nature of development and operations teams often led to inefficiencies, conflicts, and delays in software delivery. This need for better collaboration and integration between these teams led to the [DevOps](https://www.atlassian.com/devops) movement. In a sense, DevOps can be seen as an extension of the Agile principles to include operations teams.
-The key principles of DevOps include collaboration, automation, continuous integration and delivery, and feedback. DevOps focuses on automating the entire software delivery pipeline, from development to deployment. It aims to improve the collaboration between development and operations teams, utilizing tools like [Jenkins](https://www.jenkins.io/), [Docker](https://www.docker.com/), and [Kubernetes](https://kubernetes.io/) to streamline the development lifecycle.
+The key principles of DevOps include collaboration, automation, continuous integration and delivery, and feedback. DevOps focuses on automating the entire software delivery pipeline, from development to deployment. It aims to improve the collaboration between development and operations teams, utilizing tools like [Jenkins](https://www.jenkins.io/), [Docker](https://www.docker.com/), and [Kubernetes](https://kubernetes.io/) to streamline the development lifecycle.
While Agile and DevOps share common principles around collaboration and feedback, DevOps specifically targets the integration of development and IT operations - expanding Agile beyond just development teams. It introduces practices and tools to automate software delivery and enhance the speed and quality of software releases.
@@ -110,7 +111,7 @@ For example, when a data scientist checks improvements to an image classificatio
By connecting the disparate steps from development to deployment under continuous automation, CI/CD pipelines empower teams to iterate and deliver ML models rapidly. Integrating MLOps tools like MLflow enhances model packaging, versioning, and pipeline traceability. CI/CD is integral for progressing models beyond prototypes into sustainable business systems.
-### Model Training
+### Model Training
In the model training phase, data scientists actively experiment with different ML architectures and algorithms to create optimized models that effectively extract insights and patterns from data. MLOps introduces best practices and automation to make this iterative process more efficient and reproducible.
@@ -218,14 +219,14 @@ For example, a data scientist may use Weights & Biases to analyze an anomaly det
Enabling transparency, traceability and communication via MLOps empowers teams to remove bottlenecks and accelerate delivery of impactful ML systems.
-
## Hidden Technical Debt in ML Systems
Technical debt is an increasingly pressing issue for ML systems (see Figure 14.2). This metaphor, originally proposed in the 1990s, likens the long-term costs of quick software development to financial debt. Just as some financial debt powers beneficial growth, carefully managed technical debt enables rapid iteration. However, left unchecked, accumulating technical debt can outweigh any gains.
![Figure 14.2: The schematic represents various components that contribute to hidden technical debt in ML systems. It shows the interconnected nature of configuration, data collection, and feature extraction, which are foundational to the ML codebase. Data verification is highlighted as a critical step that precedes the utilization of machine resource management, analysis tools, and process management tools. These components, in turn, support the serving infrastructure required to deploy ML models. Finally, monitoring is depicted as an essential but often underemphasized component that operates alongside and provides feedback to the entire system, ensuring performance and reliability. [@sculley2015hidden]](images/ai_ops/hidden_debt.png)
-### Model Boundary Erosion
+### Model Boundary Erosion
+
Unlike traditional software, ML lacks clear boundaries between components as seen in the diagram above. This erosion of abstraction creates entanglements that exacerbate technical debt in several ways:
### Entanglement
@@ -236,42 +237,43 @@ Tight coupling between ML model components makes isolating changes difficult. Mo

-Building models sequentially creates risky dependencies where later models rely on earlier ones. For example, taking an existing model and fine-tuning it for a new use case seems efficient. However, this bakes in assumptions from the original model that may eventually need correction.
+Building models sequentially creates risky dependencies where later models rely on earlier ones. For example, taking an existing model and fine-tuning it for a new use case seems efficient. However, this bakes in assumptions from the original model that may eventually need correction.
There are several factors that inform the decision to build models sequentially or not:
* **Dataset size and rate of growth:** With small, static datasets, it often makes sense to fine-tune existing models. For large, growing datasets, training custom models from scratch allows more flexibility to account for new data.
* **Available computing resources:** Fine-tuning requires less resources than training large models from scratch. With limited resources, leveraging existing models may be the only feasible approach.
-
+
While fine-tuning can be efficient, modifying foundational components later becomes extremely costly due to the cascading effects on subsequent models. Careful thought should be given to identifying points where introducing fresh model architectures, even with large resource requirements, can avoid correction cascades down the line (see Figure 14.3). There are still scenarios where sequential model building makes sense, so it entails weighing these tradeoffs around efficiency, flexibility, and technical debt.
### Undeclared Consumers
-Once ML model predictions are made available, many downstream systems may silently consume them as inputs for further processing. However, the original model was not designed to accommodate this broad reuse. Due to the inherent opacity of ML systems, it becomes impossible to fully analyze the impact of the model's outputs as inputs elsewhere. Changes to the model can then have expensive and dangerous consequences by breaking undiscovered dependencies.
+Once ML model predictions are made available, many downstream systems may silently consume them as inputs for further processing. However, the original model was not designed to accommodate this broad reuse. Due to the inherent opacity of ML systems, it becomes impossible to fully analyze the impact of the model's outputs as inputs elsewhere. Changes to the model can then have expensive and dangerous consequences by breaking undiscovered dependencies.
Undeclared consumers can also enable hidden feedback loops if their outputs indirectly influence the original model's training data. Mitigations include restricting access to predictions, defining strict service contracts, and monitoring for signs of un-modelled influences. Architecting ML systems to encapsulate and isolate their effects limits the risks from unanticipated propagation.
-### Data Dependency Debt
+### Data Dependency Debt
-Data dependency debt refers to unstable and underutilized data dependencies which can have detrimental and hard to detect repercussions. While this is a key contributor to tech debt for traditional software, those systems can benefit from the use of widely available tools for static analysis by compilers and linkers to identify dependencies of these types. ML systems lack similar tooling.
+Data dependency debt refers to unstable and underutilized data dependencies which can have detrimental and hard to detect repercussions. While this is a key contributor to tech debt for traditional software, those systems can benefit from the use of widely available tools for static analysis by compilers and linkers to identify dependencies of these types. ML systems lack similar tooling.
One mitigation for unstable data dependencies is to use versioning which ensures the stability of inputs but comes with the cost of managing multiple sets of data and the potential for staleness of the data. A mitigation for underutilized data dependencies is to conduct exhaustive leave-one-feature-out evaluation.
-### Analysis Debt from Feedback Loops
+### Analysis Debt from Feedback Loops
Unlike traditional software, ML systems can change their own behavior over time, making it difficult to analyze pre-deployment. This debt manifests in feedback loops, both direct and hidden.
-Direct feedback loops occur when a model influences its own future inputs, such as by recommending products to users that in turn shape future training data. Hidden loops arise indirectly between models, such as two systems that interact via real-world environments. Gradual feedback loops are especially hard to detect. These loops lead to analysis debt – the inability to fully predict how a model will act after release. They undermine pre-deployment validation by enabling unmodeled self-influence.
+Direct feedback loops occur when a model influences its own future inputs, such as by recommending products to users that in turn shape future training data. Hidden loops arise indirectly between models, such as two systems that interact via real-world environments. Gradual feedback loops are especially hard to detect. These loops lead to analysis debt – the inability to fully predict how a model will act after release. They undermine pre-deployment validation by enabling unmodeled self-influence.
Careful monitoring and canary deployments help detect feedback. But fundamental challenges remain in understanding complex model interactions. Architectural choices that reduce entanglement and coupling mitigate analysis debt's compounding effect.
-### Pipeline Jungles
+### Pipeline Jungles
ML workflows often lack standardized interfaces between components. This leads teams to incrementally "glue" together pipelines with custom code. What emerges are "pipeline jungles" – tangled preprocessing steps that are brittle and resist change. Avoiding modifications to these messy pipelines causes teams to experiment through alternate prototypes. Soon, multiple ways of doing everything proliferate. The lack of abstractions and interfaces then impedes sharing, reuse, and efficiency.
Technical debt accumulates as one-off pipelines solidify into legacy constraints. Teams sink time into managing idiosyncratic code rather than maximizing model performance. Architectural principles like modularity and encapsulation are needed to establish clean interfaces. Shared abstractions enable interchangeable components, prevent lock-in, and promote best practice diffusion across teams. Breaking free of pipeline jungles ultimately requires enforcing standards that prevent accretion of abstraction debt. The benefits of interfaces and APIs that tame complexity outweigh the transitional costs.
-### Configuration Debt
+### Configuration Debt
+
ML systems involve extensive configuration of hyperparameters, architectures, and other tuning parameters. However, configuration is often an afterthought, lacking rigor and testing. Ad hoc configurations proliferate, amplified by the many knobs available for tuning complex ML models.
This accumulation of technical debt has several consequences. Fragile and outdated configurations lead to hidden dependencies and bugs that cause production failures. Knowledge about optimal configurations is isolated rather than shared, leading to redundant work. Reproducing and comparing results becomes difficult when configuration lacks documentation. Legacy constraints accrete as teams fear changing poorly understood configurations.
@@ -305,17 +307,17 @@ With thoughtful design, though, it is possible to build quickly at first while r
### Summary
-Although financial debt is a good metaphor to understand the tradeoffs, it differs from technical debt in its measurability. Technical debt lacks the ability to be fully tracked and quantified. This makes it hard for teams to navigate the tradeoffs between moving quickly and inherently introducing more debt versus taking the time to pay down that debt.
+Although financial debt is a good metaphor to understand the tradeoffs, it differs from technical debt in its measurability. Technical debt lacks the ability to be fully tracked and quantified. This makes it hard for teams to navigate the tradeoffs between moving quickly and inherently introducing more debt versus taking the time to pay down that debt.
-The [Hidden Technical Debt of Machine Learning Systems](https://papers.nips.cc/paper_files/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf) paper spreads awareness of the nuances of ML system specific tech debt and encourages additional development in the broad area of maintainable ML.
+The [Hidden Technical Debt of Machine Learning Systems](https://papers.nips.cc/paper_files/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf) paper spreads awareness of the nuances of ML system specific tech debt and encourages additional development in the broad area of maintainable ML.
## Roles and Responsibilities
-Given the vastness of MLOps, successfully implementing ML systems requires diverse skills and close collaboration between people with different areas of expertise. While data scientists build the core ML models, it takes cross-functional teamwork to successfully deploy these models into production environments and enable them to deliver business value in a sustainable way.
+Given the vastness of MLOps, successfully implementing ML systems requires diverse skills and close collaboration between people with different areas of expertise. While data scientists build the core ML models, it takes cross-functional teamwork to successfully deploy these models into production environments and enable them to deliver business value in a sustainable way.
MLOps provides the framework and practices for coordinating the efforts of various roles involved in developing, deploying and running MLg systems. Bridging traditional silos between data, engineering and operations teams is key to MLOps success. Enabling seamless collaboration through the machine learning lifecycle accelerates benefit realization while ensuring long-term reliability and performance of ML models.
-We will look at some of the key roles involved in MLOps and their primary responsibilities. Understanding the breadth of skills needed to operationalize ML models provides guidance on assembling MLOps teams. It also clarifies how the workflows between different roles fit together under the overarching MLOps methodology.
+We will look at some of the key roles involved in MLOps and their primary responsibilities. Understanding the breadth of skills needed to operationalize ML models provides guidance on assembling MLOps teams. It also clarifies how the workflows between different roles fit together under the overarching MLOps methodology.
### Data Engineers
@@ -364,10 +366,10 @@ The ML engineering team enables data science models to progress smoothly into su
DevOps engineers enable MLOps by building and managing the underlying infrastructure for developing, deploying, and monitoring ML models. They provide the cloud architecture and automation pipelines. Their main responsibilities include:
-* Provisioning and managing cloud infrastructure for ML workflows using IaC tools like Terraform, Docker, Kubernetes.
+* Provisioning and managing cloud infrastructure for ML workflows using IaC tools like Terraform, Docker, Kubernetes.
* Developing CI/CD pipelines for model retraining, validation, and deployment. Integrating ML tools into the pipeline like MLflow, Kubeflow.
* Monitoring model and infrastructure performance using tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), [ELK stack](https://aws.amazon.com/what-is/elk-stack/). Building alerts and dashboards.
-* Implementing governance practices around model development, testing, and promotion. Enabling reproducibility and traceability.
+* Implementing governance practices around model development, testing, and promotion. Enabling reproducibility and traceability.
* Embedding ML models within applications. Exposing models via APIs and microservices for integration.
* Optimizing infrastructure performance and costs. Leveraging autoscaling, spot instances, and availability across regions.
@@ -396,11 +398,11 @@ We will briefly review the challenges with embedded systems so taht it sets the
### Limited Compute Resources
-Embedded devices like microcontrollers and mobile phones have much more constrained compute power compared to data center machines or GPUs. A typical microcontroller may have only KB of RAM, MHz of CPU speed, and no GPU. For example, a microcontroller in a smartwatch may only have a 32-bit processor running at 50MHz with 256KB of RAM. This allows relatively simple ML models like small linear regressions or random forests, but more complex deep neural networks would be infeasible. Strategies to mitigate this include quantization, pruning, efficient model architectures, and offloading certain computations to the cloud when connectivity allows.
+Embedded devices like microcontrollers and mobile phones have much more constrained compute power compared to data center machines or GPUs. A typical microcontroller may have only KB of RAM, MHz of CPU speed, and no GPU. For example, a microcontroller in a smartwatch may only have a 32-bit processor running at 50MHz with 256KB of RAM. This allows relatively simple ML models like small linear regressions or random forests, but more complex deep neural networks would be infeasible. Strategies to mitigate this include quantization, pruning, efficient model architectures, and offloading certain computations to the cloud when connectivity allows.
### Constrained Memory
-With limited memory, storing large ML models and datasets directly on embedded devices is often infeasible. For example, a deep neural network model can easily take hundreds of MB, which exceeds the storage capacity of many embedded systems. Consider this example. A wildlife camera that captures images to detect animals may have only a 2GB memory card. This is insufficient to store a deep learning model for image classification that is often hundreds of MB in size. Consequently, this requires optimization of memory usage through methods like weights compression, lower-precision numerics, and streaming inference pipelines.
+With limited memory, storing large ML models and datasets directly on embedded devices is often infeasible. For example, a deep neural network model can easily take hundreds of MB, which exceeds the storage capacity of many embedded systems. Consider this example. A wildlife camera that captures images to detect animals may have only a 2GB memory card. This is insufficient to store a deep learning model for image classification that is often hundreds of MB in size. Consequently, this requires optimization of memory usage through methods like weights compression, lower-precision numerics, and streaming inference pipelines.
### Intermittent Connectivity
@@ -408,21 +410,23 @@ Many embedded devices operate in remote environments without reliable internet c
### Power Limitations
-Embedded devices like phones, wearables, and remote sensors are battery-powered. Continual inference and communication can quickly drain those batteries, limiting functionality. For example, a smart collar tagging endangered animals runs on a small battery. Continuously running a GPS tracking model would drain the battery within days. The collar has to carefully schedule when to activate the model. Thus, embedded ML has to carefully manage tasks to conserve power. Techniques include optimized hardware accelerators, prediction caching, and adaptive model execution.
+Embedded devices like phones, wearables, and remote sensors are battery-powered. Continual inference and communication can quickly drain those batteries, limiting functionality. For example, a smart collar tagging endangered animals runs on a small battery. Continuously running a GPS tracking model would drain the battery within days. The collar has to carefully schedule when to activate the model. Thus, embedded ML has to carefully manage tasks to conserve power. Techniques include optimized hardware accelerators, prediction caching, and adaptive model execution.
### Fleet Management
-For mass-produced embedded devices, there can be millions of units deployed in the field to orchestrate updates for. Hypothetically, updating a fraud detection model on 100 million (future smart) credit cards requires securely pushing updates to each distributed device rather than a centralized data center. Such distributed scale makes fleet-wide management much harder than a centralized server cluster. It requires intelligent protocols for over-the-air updates, handling connectivity issues, and monitoring resource constraints across devices.
+For mass-produced embedded devices, there can be millions of units deployed in the field to orchestrate updates for. Hypothetically, updating a fraud detection model on 100 million (future smart) credit cards requires securely pushing updates to each distributed device rather than a centralized data center. Such distributed scale makes fleet-wide management much harder than a centralized server cluster. It requires intelligent protocols for over-the-air updates, handling connectivity issues, and monitoring resource constraints across devices.
### On-Device Data Collection
-Collecting useful training data requires engineering both the sensors on device as well as the software pipelines. This is unlike servers where we can pull data from external sources. Challenges include handling sensor noise. Sensors on an industrial machine detect vibrations and temperature to predict maintenance needs. This requires tuning the sensors and sampling rates to capture useful data.
+
+Collecting useful training data requires engineering both the sensors on device as well as the software pipelines. This is unlike servers where we can pull data from external sources. Challenges include handling sensor noise. Sensors on an industrial machine detect vibrations and temperature to predict maintenance needs. This requires tuning the sensors and sampling rates to capture useful data.
### Device-Specific Personalization
-A smart speaker learns an individual user's voice patterns and speech cadence to improve recognition accuracy, all while protecting privacy. Adapting ML models to specific devices and users is important but this poses privacy challenges. On-device learning allows personalization without transmitting as much private data. But balancing model improvement, privacy preservation, and constraints requires novel techniques.
+
+A smart speaker learns an individual user's voice patterns and speech cadence to improve recognition accuracy, all while protecting privacy. Adapting ML models to specific devices and users is important but this poses privacy challenges. On-device learning allows personalization without transmitting as much private data. But balancing model improvement, privacy preservation, and constraints requires novel techniques.
### Safety Considerations
-For extremely large embedded ML in systems like self-driving vehicles, there are serious safety risks if not engineered carefully. Self-driving cars must undergo extensive track testing in simulated rain, snow, and obstacle scenarios to ensure safe operation before deployment. This requires extensive validation, fail-safes, simulators, and standards compliance before deployment.
+For extremely large embedded ML in systems like self-driving vehicles, there are serious safety risks if not engineered carefully. Self-driving cars must undergo extensive track testing in simulated rain, snow, and obstacle scenarios to ensure safe operation before deployment. This requires extensive validation, fail-safes, simulators, and standards compliance before deployment.
### Diverse Hardware Targets
@@ -430,7 +434,7 @@ There are a diverse range of embedded processors including ARM, x86, specialized
### Testing Coverage
-Rigorously testing edge cases is difficult with constrained embedded resources for simulation. But exhaustive testing is critical in systems like self-driving cars. Exhaustively testing an autopilot model requires millions of simulated kilometers exposing it to extremely rare events like sensor failures. Therefore, strategies like synthetic data generation, distributed simulation, and chaos engineering help improve coverage.
+Rigorously testing edge cases is difficult with constrained embedded resources for simulation. But exhaustive testing is critical in systems like self-driving cars. Exhaustively testing an autopilot model requires millions of simulated kilometers exposing it to extremely rare events like sensor failures. Therefore, strategies like synthetic data generation, distributed simulation, and chaos engineering help improve coverage.
### Concept Drift Detection
@@ -451,19 +455,19 @@ So, while traditional MLOps and embedded MLOps share the common goal of deployin
This time we will group the subtopics under broader categories to streamline the structure of our thought process on MLOps. This structure will help you understand how different aspects of MLOps are interconnected and why each is important for the efficient operation of ML systems as we discuss the challenges in the context of embedded systems.
* Model Lifecycle Management
- * Data Management: Handling data ingestion, validation, and version control.
- * Model Training: Techniques and practices for effective and scalable model training.
- * Model Evaluation: Strategies for testing and validating model performance.
- * Model Deployment: Approaches for deploying models into production environments.
+ * Data Management: Handling data ingestion, validation, and version control.
+ * Model Training: Techniques and practices for effective and scalable model training.
+ * Model Evaluation: Strategies for testing and validating model performance.
+ * Model Deployment: Approaches for deploying models into production environments.
-* Development and Operations Integration
- * CI/CD Pipelines: Integrating ML models into continuous integration and continuous deployment pipelines.
- * Infrastructure Management: Setting up and maintaining the infrastructure required for training and deploying models.
- * Communication & Collaboration: Ensuring smooth communication and collaboration practices between data scientists, ML engineers, and operations teams.
+* Development and Operations Integration
+ * CI/CD Pipelines: Integrating ML models into continuous integration and continuous deployment pipelines.
+ * Infrastructure Management: Setting up and maintaining the infrastructure required for training and deploying models.
+ * Communication & Collaboration: Ensuring smooth communication and collaboration practices between data scientists, ML engineers, and operations teams.
* Operational Excellence
- * Monitoring: Techniques for monitoring model performance, data drift, and operational health.
- * Governance: Implementing policies for model auditability, compliance, and ethical considerations.
+ * Monitoring: Techniques for monitoring model performance, data drift, and operational health.
+ * Governance: Implementing policies for model auditability, compliance, and ethical considerations.
### Model Lifecycle Management
@@ -511,7 +515,7 @@ In traditional MLOps, new model versions are directly deployed onto servers via
For deeply embedded devices lacking connectivity, model delivery relies on physical interfaces like USB or UART serial connections. The model packaging still follows similar principles to OTA updates, but the deployment mechanism is tailored for the capabilities of the edge hardware. Moreover, specialized OTA protocols optimized for IoT networks are often used rather than standard WiFi or Bluetooth protocols. Key factors include efficiency, reliability, security, and telemetry like progress tracking. Solutions like [Mender.io](https://mender.io/) provide embedded-focused OTA services handling differential updates across device fleets.
-### Development and Operations Integration
+### Development and Operations Integration
#### CI/CD Pipelines
@@ -561,7 +565,7 @@ In essence, embedded MLOps mandates continuous coordination between data scienti
In traditional MLOps, monitoring focuses on tracking model accuracy, performance metrics and data drift centrally. But embedded MLOps must account for decentralized monitoring across diverse edge devices and environments.
-Edge devices require optimized data collection to transmit key monitoring metrics without overloading networks. Metrics help assess model performance, data patterns, resource usage and other behaviors on remote devices.
+Edge devices require optimized data collection to transmit key monitoring metrics without overloading networks. Metrics help assess model performance, data patterns, resource usage and other behaviors on remote devices.
With limited connectivity, more analysis occurs at the edge before aggregating insights centrally. Gateways play a key role in monitoring fleet health and coordinating software updates. Confirmed indicators are eventually propagated to the cloud.
@@ -595,23 +599,23 @@ Here is a comparison table highlighting similarities and differences between Tra
|-|-|-|
| Data Management | Large datasets, data lakes, feature stores | On-device data capture, edge caching and processing |
| Model Development | Leverage deep learning, complex neural nets, GPU training | Constraints on model complexity, need for optimization |
-| Deployment | Server clusters, cloud deployment, low latency at scale | OTA deployment to devices, intermittent connectivity |
+| Deployment | Server clusters, cloud deployment, low latency at scale | OTA deployment to devices, intermittent connectivity |
| Monitoring | Dashboards, logs, alerts for cloud model performance | On-device monitoring of predictions, resource usage |
| Retraining | Retrain models on new data | Federated learning from devices, edge retraining |
| Infrastructure | Dynamic cloud infrastructure | Heterogeneous edge/cloud infrastructure |
-| Collaboration | Shared experiment tracking and model registry | Collaboration for device-specific optimization |
+| Collaboration | Shared experiment tracking and model registry | Collaboration for device-specific optimization |
So while Embedded MLOps shares foundational MLOps principles, it faces unique constraints to tailor workflows and infrastructure specifically for resource-constrained edge devices.
## Commercial Offerings
-While no replacement for understanding the principles, there are an increasing number of commercial offerings that help ease the burden of building ML pipelines and integrating tools together to build, test, deploy, and monitor ML models in production.
+While no replacement for understanding the principles, there are an increasing number of commercial offerings that help ease the burden of building ML pipelines and integrating tools together to build, test, deploy, and monitor ML models in production.
### Traditional MLOps
-Google, Microsoft, and Amazon all offer their own version of managed ML services. These include services that manage model training and experimentation, model hosting and scaling, and monitoring. These offerings are available via an API and client SDKs, as well as through web UIs. While it is possible to build your own end-to-end MLOps solutions using pieces from each, the greatest ease of use benefits come by staying within a single provider ecosystem to take advantage of interservice integrations.
+Google, Microsoft, and Amazon all offer their own version of managed ML services. These include services that manage model training and experimentation, model hosting and scaling, and monitoring. These offerings are available via an API and client SDKs, as well as through web UIs. While it is possible to build your own end-to-end MLOps solutions using pieces from each, the greatest ease of use benefits come by staying within a single provider ecosystem to take advantage of interservice integrations.
-I will provide a quick overview of the services offered that fit into each part of the MLOps life cycle described above, providing examples of offerings from different providers. The space is moving very quickly; new companies and products are entering the scene very rapidly, and these are not meant to serve as an endorsement of a particular company’s offering.
+I will provide a quick overview of the services offered that fit into each part of the MLOps life cycle described above, providing examples of offerings from different providers. The space is moving very quickly; new companies and products are entering the scene very rapidly, and these are not meant to serve as an endorsement of a particular company’s offering.
#### Data Management
@@ -619,7 +623,7 @@ Data storage and versioning are table stakes for any commercial offering and mos
#### Model Training
-Managed training services are where cloud providers really shine, as they provide on demand access to hardware that is out of reach for most smaller companies. They bill only for hardware during training time, and this puts GPU accelerated training within reach of even the smallest developer teams. The level of control that developers have over their training workflow can vary widely depending on their needs. Some providers have services that provide little more than access to the resources and rely on the developer to manage the training loop, logging, and model storage themselves. Other services are as simple as pointing to a base model and a labeled data set to kick off a fully managed fine tuning job (example: [Vertex AI Fine Tuning](https://cloud.google.com/vertex-ai/docs/generative-ai/models/tune-models)).
+Managed training services are where cloud providers really shine, as they provide on demand access to hardware that is out of reach for most smaller companies. They bill only for hardware during training time, and this puts GPU accelerated training within reach of even the smallest developer teams. The level of control that developers have over their training workflow can vary widely depending on their needs. Some providers have services that provide little more than access to the resources and rely on the developer to manage the training loop, logging, and model storage themselves. Other services are as simple as pointing to a base model and a labeled data set to kick off a fully managed fine tuning job (example: [Vertex AI Fine Tuning](https://cloud.google.com/vertex-ai/docs/generative-ai/models/tune-models)).
A word of warning: As of 2023, GPU hardware demand well exceeds the supply and as a result cloud providers are rationing access to their GPUs, and in some data center regions may be unavailable or require long term contracts.
@@ -643,12 +647,12 @@ Despite the proliferation of new ML Ops tools in response to the increase in dem
[Edge Impulse](https://edgeimpulse.com/) is an end-to-end development platform for creating and deploying machine learning models onto edge devices such as microcontrollers and small processors. It aims to make embedded machine learning more accessible to software developers through its easy-to-use web interface and integrated tools for data collection, model development, optimization and deployment. It's key capabilities include:
-- Intuitive drag and drop workflow for building ML models without coding required
-- Tools for acquiring, labeling, visualizing and preprocessing data from sensors
-- Choice of model architectures including neural networks and unsupervised learning
-- Model optimization techniques to balance performance metrics and hardware constraints
-- Seamless deployment onto edge devices through compilation, SDKs and benchmarks
-- Collaboration features for teams and integration with other platforms
+* Intuitive drag and drop workflow for building ML models without coding required
+* Tools for acquiring, labeling, visualizing and preprocessing data from sensors
+* Choice of model architectures including neural networks and unsupervised learning
+* Model optimization techniques to balance performance metrics and hardware constraints
+* Seamless deployment onto edge devices through compilation, SDKs and benchmarks
+* Collaboration features for teams and integration with other platforms
With Edge Impulse, developers with limited data science expertise can develop specialized ML models that run efficiently within small computing environments. It provides a comprehensive solution for creating embedded intelligence and taking machine learning to the edge.
@@ -658,7 +662,7 @@ Edge Impulse was designed with seven key principles in mind: accessibility, end-

-What makes Edge Impulse notable is its comprehensive yet intuitive end-to-end workflow. Developers start by uploading their data, either through file upload or command line interface (CLI) tools, after which they can examine raw samples and visualize the distribution of data in the training and test splits. Next, users can pick from a variety of preprocessing “blocks” to facilitate digital signal processing (DSP). While default parameter values are provided, users have the option to customize the parameters as needed, with considerations around memory and latency displayed. Users can easily choose their neural network architecture - without any code needed.
+What makes Edge Impulse notable is its comprehensive yet intuitive end-to-end workflow. Developers start by uploading their data, either through file upload or command line interface (CLI) tools, after which they can examine raw samples and visualize the distribution of data in the training and test splits. Next, users can pick from a variety of preprocessing “blocks” to facilitate digital signal processing (DSP). While default parameter values are provided, users have the option to customize the parameters as needed, with considerations around memory and latency displayed. Users can easily choose their neural network architecture - without any code needed.
Thanks to the platform’s visual editor, users can customize the components of the architecture and the specific parameters, all while ensuring that the model is still trainable. Users can also leverage unsupervised learning algorithms, such as K-means clustering and Gaussian mixture models (GMM).
@@ -698,13 +702,13 @@ While most ML research focuses on the model-dominant steps such as training and
### ClinAIOps
-Let’s take a look at MLOps in the context of medical health monitoring to better understand how MLOps “matures” in the context of a real world deployment. Specifically, let’s consider continuous therapeutic monitoring (CTM) enabled by wearable devices and sensors , providing the opportunity for more frequent and personalized adjustments to treatments by capturing detailed physiological data from patients.
+Let’s take a look at MLOps in the context of medical health monitoring to better understand how MLOps “matures” in the context of a real world deployment. Specifically, let’s consider continuous therapeutic monitoring (CTM) enabled by wearable devices and sensors , providing the opportunity for more frequent and personalized adjustments to treatments by capturing detailed physiological data from patients.
Wearable ML enabled sensors enable continuous physiological and activity monitoring outside of clinics, opening up possibilities for timely, data-driven adjustments of therapies. For example, wearable insulin biosensors [@wearableinsulin] and wrist-worn ECG sensors for glucose monitoring [@glucosemonitor] can automate insulin dosing for diabetes, wrist-worn ECG and PPG sensors can adjust blood thinners based on atrial fibrillation patterns [@plasma; @afib], and accelerometers tracking gait can trigger preventative care for declining mobility in the elderly [@gaitathome]. The variety of signals that can now be captured passively and continuously allows therapy titration and optimization tailored to each patient’s changing needs. By closing the loop between physiological sensing and therapeutic response with TinyML and ondevice learning, wearables are poised to transform many areas of personalized medicine.
ML holds great promise in analyzing CTM data to provide data-driven recommendations for therapy adjustments. But simply deploying AI models in silos, without integrating them properly into clinical workflows and decision making, can lead to poor adoption or suboptimal outcomes. In other words, thinking about MLOps alone is simply insufficient to make them useful in practice. What is needed are frameworks to seamlessly incorporate AI and CTM into real-world clinical practice as this study shows.
-This case study analyzes “ClinAIOps” as a model for embedded ML operations in complex clinical environments [@Chen2023]. We provide an overview of the framework and why it's needed, walk through an application example, and discuss key implementation challenges related to model monitoring, workflow integration, and stakeholder incentives. Analyzing real-world examples like ClinAIOps illuminates crucial principles and best practices needed for reliable and effective AI Ops across many domains.
+This case study analyzes “ClinAIOps” as a model for embedded ML operations in complex clinical environments [@Chen2023]. We provide an overview of the framework and why it's needed, walk through an application example, and discuss key implementation challenges related to model monitoring, workflow integration, and stakeholder incentives. Analyzing real-world examples like ClinAIOps illuminates crucial principles and best practices needed for reliable and effective AI Ops across many domains.
Traditional MLOps frameworks are insufficient for integrating continuous therapeutic monitoring (CTM) and AI in clinical settings for a few key reasons:
@@ -728,7 +732,7 @@ Thus, effectively integrating AI/ML and CTM in clinical practice requires more t
The ClinAIOps framework (see Figure 14.7) provides these mechanisms through three feedback loops. The loops are useful for coordinating the insights from continuous physiological monitoring, clinician expertise, and AI guidance via feedback loops, enabling data-driven precision medicine while maintaining human accountability. ClinAIOps provides a model for effective human-AI symbiosis in healthcare.
-These feedback loops which we will discuss below help maintain clinician responsibility and control over treatment plans, by reviewing AI suggestions before they impact patients. They help dynamically customize AI model behavior and outputs to each patient's changing health status. They help improve model accuracy and clinical utility over time by learning from clinician and patient responses. They facilitate shared decision-making and personalized care during patient-clinician interactions. They enable rapid optimization of therapies based on frequent patient data that clinicians cannot manually analyze.
+These feedback loops which we will discuss below help maintain clinician responsibility and control over treatment plans, by reviewing AI suggestions before they impact patients. They help dynamically customize AI model behavior and outputs to each patient's changing health status. They help improve model accuracy and clinical utility over time by learning from clinician and patient responses. They facilitate shared decision-making and personalized care during patient-clinician interactions. They enable rapid optimization of therapies based on frequent patient data that clinicians cannot manually analyze.

@@ -772,7 +776,7 @@ In the Patient-Clinician loop (see Figure 14.8), the in-person visits would focu
#### MLOps vs. ClinAIOps
-The hypertension example illustrates well why traditional MLOps is insufficient for many real-world AI applications, and why frameworks like ClinAIOps are needed instead.
+The hypertension example illustrates well why traditional MLOps is insufficient for many real-world AI applications, and why frameworks like ClinAIOps are needed instead.
With hypertension, simply developing and deploying an ML model for adjusting medications would fail without considering the broader clinical context. The patient, clinician, and health system each have concerns that shape adoption. And the AI model cannot optimize blood pressure outcomes alone - it requires integrating with workflows, behaviors, and incentives.
@@ -784,7 +788,7 @@ With hypertension, simply developing and deploying an ML model for adjusting med
* Liability for treatment outcomes is unclear with just an ML model. ClinAIOps maintains human accountability.
* Health systems would lack incentive to change workflows without demonstrating value. ClinAIOps aligns stakeholders.
-The hypertension case clearly shows the need to look beyond just training and deploying a performant ML model to considering the entire human-AI socio-technical system. This is the key gap ClinAIOps aims to address over traditional MLOps. Put another way, traditional MLOps is overly tech-focused on automating ML model development and deployment, while ClinAIOps incorporates clinical context and human-AI coordination through multi-stakeholder feedback loops.
+The hypertension case clearly shows the need to look beyond just training and deploying a performant ML model to considering the entire human-AI socio-technical system. This is the key gap ClinAIOps aims to address over traditional MLOps. Put another way, traditional MLOps is overly tech-focused on automating ML model development and deployment, while ClinAIOps incorporates clinical context and human-AI coordination through multi-stakeholder feedback loops.
Here is a table comparing them. The point of this table is to highlight how when MLOps is put into practice, we need to think about more than just ML models.
@@ -796,11 +800,12 @@ Here is a table comparing them. The point of this table is to highlight how when
| Objective | Operationalize ML deployments | Optimize patient health outcomes |
| Processes | Automated pipelines and infrastructure | Integrates clinical workflows and oversight |
| Data considerations | Building training datasets | Privacy, ethics, protected health information |
-| Model validation | Testing model performance metrics | Clinical evaluation of recommendations |
+| Model validation | Testing model performance metrics | Clinical evaluation of recommendations |
| Implementation | Focuses on technical integration | Aligns incentives of human stakeholders |
#### Summary
-In complex domains like healthcare, successfully deploying AI requires moving beyond a narrow focus on just training and deploying performant ML models. As illustrated through the hypertension example, real-world integration of AI necessitates coordinating diverse stakeholders, aligning incentives, validating recommendations, and maintaining accountability. Frameworks like ClinAIOps, which facilitate collaborative human-AI decision making through integrated feedback loops, are needed to address these multifaceted challenges. Rather than just automating tasks, AI must augment human capabilities and clinical workflows. This allows AI to deliver a positive impact on patient outcomes, population health, and healthcare efficiency.
+
+In complex domains like healthcare, successfully deploying AI requires moving beyond a narrow focus on just training and deploying performant ML models. As illustrated through the hypertension example, real-world integration of AI necessitates coordinating diverse stakeholders, aligning incentives, validating recommendations, and maintaining accountability. Frameworks like ClinAIOps, which facilitate collaborative human-AI decision making through integrated feedback loops, are needed to address these multifaceted challenges. Rather than just automating tasks, AI must augment human capabilities and clinical workflows. This allows AI to deliver a positive impact on patient outcomes, population health, and healthcare efficiency.
## Conclusion
@@ -810,4 +815,4 @@ This chapter provided an in-depth analysis of key differences between traditiona
Through concrete examples like Oura Ring and ClinAIOps, we demonstrated applied principles for embedded MLOps. The case studies highlighted critical considerations beyond just core ML engineering, like aligning stakeholder incentives, maintaining accountability, and coordinating human-AI decision making. This underscores the need for a holistic approach spanning both technical and human elements.
-While embedded MLOps faces impediments, emerging tools like Edge Impulse and lessons from pioneers help accelerate TinyML innovation. A solid understanding of foundational MLOps principles tailored to embedded environments will empower more organizations to overcome constraints and deliver distributed AI capabilities. As frameworks and best practices mature, seamlessly integrating ML into edge devices and processes will transform industries through localized intelligence.
\ No newline at end of file
+While embedded MLOps faces impediments, emerging tools like Edge Impulse and lessons from pioneers help accelerate TinyML innovation. A solid understanding of foundational MLOps principles tailored to embedded environments will empower more organizations to overcome constraints and deliver distributed AI capabilities. As frameworks and best practices mature, seamlessly integrating ML into edge devices and processes will transform industries through localized intelligence.
diff --git a/optimizations.qmd b/optimizations.qmd
index 91b6c79e..af6f2514 100644
--- a/optimizations.qmd
+++ b/optimizations.qmd
@@ -5,13 +5,14 @@
When machine learning models are deployed on systems, especially on resource-constrained embedded systems, the optimization of models is a necessity. While machine learning inherently often demands substantial computational resources, the systems are inherently limited in memory, processing power, and energy. This chapter will dive into the art and science of optimizing machine learning models to ensure they are lightweight, efficient, and effective when deployed in TinyML scenarios.
::: {.callout-tip}
+
## Learning Objectives
* Learn techniques like pruning, knowledge distillation and specialized model architectures to represent models more efficiently
* Understand quantization methods to reduce model size and enable faster inference through reduced precision numerics
-* Explore hardware-aware optimization approaches to match models to target device capabilities
+* Explore hardware-aware optimization approaches to match models to target device capabilities
* Discover software tools like frameworks and model conversion platforms that enable deployment of optimized models
@@ -83,10 +84,10 @@ A widely adopted and effective strategy for systematically pruning structures re
There are several techniques for assigning these importance scores:
-- Weight magnitude-based pruning assigns scores based on the absolute values of the weights. Components with very small weights contribute minimally to activations and can be removed.
-- Gradient-based pruning utilizes the gradients of the loss function with respect to each weight to determine sensitivity. Weights with low gradient magnitudes when altered have little effect on the loss and can be pruned.
-- Activation-based pruning tracks activation values for neurons/filters over a validation dataset. Consistently low activation values suggest less relevance, warranting removal.
-- Taylor expansion approximates the change in loss function from removing a given weight. Weights with negligible impact on loss are prime candidates for pruning.
+* Weight magnitude-based pruning assigns scores based on the absolute values of the weights. Components with very small weights contribute minimally to activations and can be removed.
+* Gradient-based pruning utilizes the gradients of the loss function with respect to each weight to determine sensitivity. Weights with low gradient magnitudes when altered have little effect on the loss and can be pruned.
+* Activation-based pruning tracks activation values for neurons/filters over a validation dataset. Consistently low activation values suggest less relevance, warranting removal.
+* Taylor expansion approximates the change in loss function from removing a given weight. Weights with negligible impact on loss are prime candidates for pruning.
The idea is to measure, either directly or indirectly, the contribution of each component to the model's output. Structures with minimal influence according to the defined criteria are pruned first. This enables selective, optimized pruning that maximally compresses models while preserving predictive capacity. In general, it is important to evaluate the impact of removing particular structures on the model's output.
@@ -148,7 +149,6 @@ More formally, the lottery ticket hypothesis is a concept in deep learning that

-
#### Challenges & Limitations
There is no free lunch with pruning optimizations, with some choices coming with wboth improvements and costs to considers. Below we discuss some tradeoffs for practitioners to consider.
@@ -257,11 +257,11 @@ One edge friendly architecture design is depthwise separable convolutions. Commo
In this vein, a number of recent architectures have been, from inception, specifically designed for maximizing accuracy on an edge deployment, notably SqueezeNet, MobileNet, and EfficientNet.
-* [SqueezeNet]([https://arxiv.org/abs/1602.07360](https://arxiv.org/abs/1602.07360)) by @iandola2016squeezenet for instance, utilizes a compact architecture with 1x1 convolutions and fire modules to minimize the number of parameters while maintaining strong accuracy.
+* [SqueezeNet]([https://arxiv.org/abs/1602.07360](https://arxiv.org/abs/1602.07360)) by @iandola2016squeezenet for instance, utilizes a compact architecture with 1x1 convolutions and fire modules to minimize the number of parameters while maintaining strong accuracy.
-* [MobileNet]([https://arxiv.org/abs/1704.04861](https://arxiv.org/abs/1704.04861)) by @howard2017mobilenets, on the other hand, employs the aforementioned depthwise separable convolutions to reduce both computation and model size.
+* [MobileNet]([https://arxiv.org/abs/1704.04861](https://arxiv.org/abs/1704.04861)) by @howard2017mobilenets, on the other hand, employs the aforementioned depthwise separable convolutions to reduce both computation and model size.
-* [EfficientNet]([https://arxiv.org/abs/1905.11946](https://arxiv.org/abs/1905.11946)) by @tan2020efficientnet takes a different approach by optimizing network scaling (i.e. varying the depth, width and resolution of a network) and compound scaling, a more nuanced variation network scaling, to achieve superior performance with fewer parameters.
+* [EfficientNet]([https://arxiv.org/abs/1905.11946](https://arxiv.org/abs/1905.11946)) by @tan2020efficientnet takes a different approach by optimizing network scaling (i.e. varying the depth, width and resolution of a network) and compound scaling, a more nuanced variation network scaling, to achieve superior performance with fewer parameters.
These models are essential in the context of edge computing where limited processing power and memory require lightweight yet effective models that can efficiently perform tasks such as image recognition, object detection, and more. Their design principles showcase the importance of intentionally tailored model architecture for edge computing, where performance and efficiency must fit within constraints.
@@ -275,7 +275,6 @@ Similarly, MorphNet is a neural network optimization framework designed to autom
TinyNAS and MorphNet represent a few of the many significant advancements in the field of systematic neural network optimization, allowing architectures to be systematically chosen and generated to fit perfectly within problem constraints.
-
## Efficient Numerics Representation {#sec-model_ops_numerics}
Numerics representation involves a myriad of considerations, including but not limited to, the precision of numbers, their encoding formats, and the arithmetic operations facilitated. It invariably involves a rich array of different trade-offs, where practitioners are tasked with navigating between numerical accuracy and computational efficiency. For instance, while lower-precision numerics may offer the allure of reduced memory usage and expedited computations, they concurrently present challenges pertaining to numerical stability and potential degradation of model accuracy.
@@ -325,17 +324,16 @@ Precision, delineating the exactness with which a number is represented, bifurca
| **Binary** | Minimal memory footprint (only 1 bit per parameter)
Extremely fast inference due to bitwise operations
Power efficient | Significant accuracy drop for many tasks
Complex training dynamics due to extreme quantization. |
| **Ternary** | Low memory usage but slightly more than binary
Offers a middle ground between representation and efficiency | Accuracy might still be lower than higher precision models
Training dynamics can be complex. |
-
#### Numeric Encoding and Storage
Numeric encoding, the art of transmuting numbers into a computer-amenable format, and their subsequent storage are critical for computational efficiency. For instance, floating-point numbers might be encoded using the IEEE 754 standard, which apportions bits among sign, exponent, and fraction components, thereby enabling the representation of a vast array of values with a single format. There are a few new IEEE floating point formats that have been defined specifically for AI workloads:
-- [bfloat16](https://cloud.google.com/tpu/docs/bfloat16)- A 16-bit floating point format introduced by Google. It has 8 bits for exponent, 7 bits for mantissa and 1 bit for sign. Offers a reduced precision compromise between 32-bit float and 8-bit integers. Supported on many hardware accelerators.
-- [posit](https://ieeexplore.ieee.org/document/9399648) - A configurable format that can represent different levels of precision based on exponent bits. Aims to be more efficient than IEEE 754 binary floats. Has adjustable dynamic range and precision.
-- [Flexpoint](https://arxiv.org/abs/1711.02213) - A format introduced by Intel that can dynamically adjust precision across layers or within a layer. Allows tuning precision to accuracy and hardware requirements.
-- [BF16ALT](https://developer.arm.com/documentation/ddi0596/2020-12/SIMD-FP-Instructions/BFMLALB--BFMLALT--vector---BFloat16-floating-point-widening-multiply-add-long--vector--) - A proposed 16-bit format by ARM as an alternative to bfloat16. Uses additional bit in exponent to prevent overflow/underflow.
-- [TF32](https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/) - Introduced by Nvidia for Ampere GPUs. Uses 10 bits for exponent instead of 8 bits like FP32. Improves model training performance while maintaining accuracy.
-- [FP8](https://arxiv.org/abs/2209.05433) - 8-bit floating point format that keeps 6 bits for mantissa and 2 bits for exponent. Enables better dynamic range than integers.
+* [bfloat16](https://cloud.google.com/tpu/docs/bfloat16)- A 16-bit floating point format introduced by Google. It has 8 bits for exponent, 7 bits for mantissa and 1 bit for sign. Offers a reduced precision compromise between 32-bit float and 8-bit integers. Supported on many hardware accelerators.
+* [posit](https://ieeexplore.ieee.org/document/9399648) - A configurable format that can represent different levels of precision based on exponent bits. Aims to be more efficient than IEEE 754 binary floats. Has adjustable dynamic range and precision.
+* [Flexpoint](https://arxiv.org/abs/1711.02213) - A format introduced by Intel that can dynamically adjust precision across layers or within a layer. Allows tuning precision to accuracy and hardware requirements.
+* [BF16ALT](https://developer.arm.com/documentation/ddi0596/2020-12/SIMD-FP-Instructions/BFMLALB--BFMLALT--vector---BFloat16-floating-point-widening-multiply-add-long--vector--) - A proposed 16-bit format by ARM as an alternative to bfloat16. Uses additional bit in exponent to prevent overflow/underflow.
+* [TF32](https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/) - Introduced by Nvidia for Ampere GPUs. Uses 10 bits for exponent instead of 8 bits like FP32. Improves model training performance while maintaining accuracy.
+* [FP8](https://arxiv.org/abs/2209.05433) - 8-bit floating point format that keeps 6 bits for mantissa and 2 bits for exponent. Enables better dynamic range than integers.
The key goals of these new formats are to provide lower precision alternatives to 32-bit floats for better computational efficiency and performance on AI accelerators while maintaining model accuracy. They offer different tradeoffs in terms of precision, range and implementation cost/complexity.
@@ -379,7 +377,6 @@ In addition to pure runtimes, there is also a concern over energy efficiency. No

-
#### Hardware Compatibility
Ensuring compatibility and optimized performance across diverse hardware platforms is another challenge in numerics representation. Different hardware, such as CPUs, GPUs, TPUs, and FPGAs, have varying capabilities and optimizations for handling different numeric precisions. For example, certain GPUs might be optimized for Float32 computations, while others might provide accelerations for Float16. Developing and optimizing ML models that can leverage the specific numerical capabilities of different hardware, while ensuring that the model maintains its accuracy and robustness, requires careful consideration and potentially additional development and testing efforts.
@@ -396,36 +393,36 @@ To understand and appreciate the nuances let's consider some use case examples.
In the domain of autonomous vehicles, ML models are employed to interpret sensor data and make real-time decisions. The models must process high-dimensional data from various sensors (e.g., LiDAR, cameras, radar) and execute numerous computations within a constrained time frame to ensure safe and responsive vehicle operation. So the trade-offs here would include:
-- Memory Usage: Storing and processing high-resolution sensor data, especially in floating-point formats, can consume substantial memory.
-- Computational Complexity: Real-time processing demands efficient computations, where higher-precision numerics might impede the timely execution of control actions.
+* Memory Usage: Storing and processing high-resolution sensor data, especially in floating-point formats, can consume substantial memory.
+* Computational Complexity: Real-time processing demands efficient computations, where higher-precision numerics might impede the timely execution of control actions.
##### Mobile Health Applications
Mobile health applications often utilize ML models for tasks like activity recognition, health monitoring, or predictive analytics, operating within the resource-constrained environment of mobile devices. The trade-offs here would include:
-- Precision and Accuracy Trade-offs: Employing lower-precision numerics to conserve resources might impact the accuracy of health predictions or anomaly detections, which could have significant implications for user health and safety.
-- Hardware Compatibility: Models need to be optimized for diverse mobile hardware, ensuring efficient operation across a wide range of devices with varying numerical computation capabilities.
+* Precision and Accuracy Trade-offs: Employing lower-precision numerics to conserve resources might impact the accuracy of health predictions or anomaly detections, which could have significant implications for user health and safety.
+* Hardware Compatibility: Models need to be optimized for diverse mobile hardware, ensuring efficient operation across a wide range of devices with varying numerical computation capabilities.
##### High-Frequency Trading (HFT) Systems
HFT systems leverage ML models to make rapid trading decisions based on real-time market data. These systems demand extremely low-latency responses to capitalize on short-lived trading opportunities.
-- Computational Complexity: The models must process and analyze vast streams of market data with minimal latency, where even slight delays, potentially introduced by higher-precision numerics, can result in missed opportunities.
-- Precision and Accuracy Trade-offs: Financial computations often demand high numerical precision to ensure accurate pricing and risk assessments, posing challenges in balancing computational efficiency and numerical accuracy.
+* Computational Complexity: The models must process and analyze vast streams of market data with minimal latency, where even slight delays, potentially introduced by higher-precision numerics, can result in missed opportunities.
+* Precision and Accuracy Trade-offs: Financial computations often demand high numerical precision to ensure accurate pricing and risk assessments, posing challenges in balancing computational efficiency and numerical accuracy.
##### Edge-Based Surveillance Systems
Surveillance systems deployed on edge devices, like security cameras, utilize ML models for tasks like object detection, activity recognition, and anomaly detection, often operating under stringent resource constraints.
-- Memory Usage: Storing pre-trained models and processing video feeds in real-time demands efficient memory usage, which can be challenging with high-precision numerics.
-- Hardware Compatibility: Ensuring that models can operate efficiently on edge devices with varying hardware capabilities and optimizations for different numeric precisions is crucial for widespread deployment.
+* Memory Usage: Storing pre-trained models and processing video feeds in real-time demands efficient memory usage, which can be challenging with high-precision numerics.
+* Hardware Compatibility: Ensuring that models can operate efficiently on edge devices with varying hardware capabilities and optimizations for different numeric precisions is crucial for widespread deployment.
##### Scientific Simulations
ML models are increasingly being utilized in scientific simulations, such as climate modeling or molecular dynamics simulations, to enhance predictive capabilities and reduce computational demands.
-- Precision and Accuracy Trade-offs: Scientific simulations often require high numerical precision to ensure accurate and reliable results, which can conflict with the desire to reduce computational demands via lower-precision numerics.
-- Computational Complexity: The models must manage and process complex, high-dimensional simulation data efficiently to ensure timely results and enable large-scale or long-duration simulations.
+* Precision and Accuracy Trade-offs: Scientific simulations often require high numerical precision to ensure accurate and reliable results, which can conflict with the desire to reduce computational demands via lower-precision numerics.
+* Computational Complexity: The models must manage and process complex, high-dimensional simulation data efficiently to ensure timely results and enable large-scale or long-duration simulations.
These examples illustrate diverse scenarios where the challenges of numerics representation in ML models are prominently manifested. Each system presents a unique set of requirements and constraints, necessitating tailored strategies and solutions to navigate the challenges of memory usage, computational complexity, precision-accuracy trade-offs, and hardware compatibility.
@@ -535,7 +532,7 @@ Asymmetric quantization maps real values to an asymmetrical clipping range that
#### Granularity
-Upon deciding the type of clipping range, it is essential to tighten the range to allow a model to retain as much of its accuracy as possible. We'll be taking a look at convolutional neural networks as our way of exploring methods that fine tune the granularity of clipping ranges for quantization. The input activation of a layer in our CNN undergoes convolution with multiple convolutional filters. Every convolutional filter can possess a unique range of values. Consequently, one distinguishing feature of quantization approaches is the precision with which the clipping range [α,β] is determined for the weights.
+Upon deciding the type of clipping range, it is essential to tighten the range to allow a model to retain as much of its accuracy as possible. We'll be taking a look at convolutional neural networks as our way of exploring methods that fine tune the granularity of clipping ranges for quantization. The input activation of a layer in our CNN undergoes convolution with multiple convolutional filters. Every convolutional filter can possess a unique range of values. Consequently, one distinguishing feature of quantization approaches is the precision with which the clipping range [α,β] is determined for the weights.

@@ -562,7 +559,7 @@ The two prevailing techniques for quantizing models are Post Training Quantizati
**Post Training Quantization** - Post-training quantization (PTQ) is a quantization technique where the model is quantized after it has been trained. The model is trained in floating point and then weights and activations are quantized as a post-processing step. This is the simplest approach and does not require access to the training data. Unlike Quantization-Aware Training (QAT), PTQ sets weight and activation quantization parameters directly, making it low-overhead and suitable for limited or unlabeled data situations. However, not readjusting the weights after quantizing, especially in low-precision quantization can lead to very different behavior and thus lower accuracy. To tackle this, techniques like bias correction, equalizing weight ranges, and adaptive rounding methods have been developed. PTQ can also be applied in zero-shot scenarios, where no training or testing data are available. This method has been made even more efficient to benefit compute- and memory- intensive large language models. Recently, SmoothQuant, a training-free, accuracy-preserving, and general-purpose PTQ solution which enables 8-bit weight, 8-bit activation quantization for LLMs, has been developed, demonstrating up to 1.56x speedup and 2x memory reduction for LLMs with negligible loss in accuracy [(@smoothquant)](https://arxiv.org/abs/2211.10438).
-
+

@@ -590,7 +587,6 @@ The two prevailing techniques for quantizing models are Post Training Quantizati
| Accuracy vs. Cost | ✗ | ✓ | ✗ |
| Adaptability vs. Overhead | ✗ | ✗ | ✓ |
-
### Weights vs. Activations
Weight Quantization: Involves converting the continuous or high-precision weights of a model to lower-precision, such as converting Float32 weights to quantized INT8 (integer) weights. This reduces the model size, thereby reducing the memory required to store the model and the computational resources needed to perform inference. For example, consider a weight matrix in a neural network layer with Float32 weights as [0.215, -1.432, 0.902, ...]. Through weight quantization, these might be mapped to INT8 values like [27, -183, 115, ...], significantly reducing the memory required to store them.
@@ -603,7 +599,7 @@ Activation Quantization: Involves quantizing the activation values (outputs of l
Quantization invariably introduces a trade-off between model size/performance and accuracy. While it significantly reduces the memory footprint and can accelerate inference, especially on hardware optimized for low-precision arithmetic, the reduced precision can degrade model accuracy.
-Model Size: A model with weights represented as Float32 being quantized to INT8 can theoretically reduce the model size by a factor of 4, enabling it to be deployed on devices with limited memory.
+Model Size: A model with weights represented as Float32 being quantized to INT8 can theoretically reduce the model size by a factor of 4, enabling it to be deployed on devices with limited memory.

@@ -645,7 +641,6 @@ Focusing only on the accuracy when performing Neural Architecture Search leads t
![Taxonomy of HW-NAS [@ijcai2021p592]](images/modeloptimization_HW-NAS.png)
-
#### Single Target, Fixed Platfrom Configuration
The goal here is to find the best architecture in terms of accuracy and hardware efficiency for one fixed target hardware. For a specific hardware, the Arduino Nicla Vision for example, this category of HW-NAS will look for the architecture that optimizes accuracy, latency, energy consumption, etc.
@@ -678,7 +673,6 @@ Then, TinyNAS performs a search operation on the chosen space to find the optima
![A diagram showing how search spaces with high probability of finding an architecture with large number of FLOPs provide models with higher accuracy [@lin2020mcunet]](images/modeloptimization_TinyNAS.png)
-
#### Topology-Aware NAS
Focuses on creating and optimizing a search space that aligns with the hardware topology of the device. [@zhang2019autoshrink]
@@ -727,7 +721,6 @@ Pruning is a fundamental approach to compress models to make them compatible wit
![A figure showing the sparse columns of the filter matrix of a CNN that are aggregated to create a dense matrix that, leading to smaller dimensions in the matrix and more efficient computations. [@kung2018packing]
-
#### Optimization Frameworks
Optimization Frameworks have been introduced to exploit the specific capabilities of the hardware to accelerate the software. One example of such a framework is hls4ml. This open-source software-hardware co-design workflow aids in interpreting and translating machine learning algorithms for implementation with both FPGA and ASIC technologies, enhancing their. Features such as network optimization, new Python APIs, quantization-aware pruning, and end-to-end FPGA workflows are embedded into the hls4ml framework, leveraging parallel processing units, memory hierarchies, and specialized instruction sets to optimize models for edge hardware. Moreover, hls4ml is capable of translating machine learning algorithms directly into FPGA firmware.
@@ -742,14 +735,12 @@ In a contrasting approach, hardware can be custom-designed around software requi
![A diagram showing how an FPGA was used to offload data preprocessing of the general purpose computation unit. [@app112211073]](images/modeloptimization_preprocessor.png)
-
#### SplitNets
SplitNets were introduced in the context of Head-Mounted systems. They distribute the Deep Neural Networks (DNNs) workload among camera sensors and an aggregator. This is particularly compelling the in context of TinyML. The SplitNet framework is a split-aware NAS to find the optimal neural network architecture to achieve good accuracy, split the model among the sensors and the aggregator, and minimize the communication between the sensors and the aggregator. Minimal communication is important in TinyML where memory is highly constrained, this way the sensors conduct some of the processing on their chips and then they send only the necessary information to the aggregator. When testing on ImageNet, SplitNets were able to reduce the latency by one order of magnitude on head-mounted devices. This can be helpful when the sensor has its own chip. [@dong2022splitnets]
![A chart showing a comparison between the performance of SplitNets vs all on sensor and all on aggregator approaches. [@dong2022splitnets]](images/modeloptimization_SplitNets.png)
-
#### Hardware Specific Data Augmentation
Each edge device may possess unique sensor characteristics, leading to specific noise patterns that can impact model performance. One example is audio data, where variations stemming from the choice of microphone are prevalent. Applications such as Keyword Spotting can experience substantial enhancements by incorporating data recorded from devices similar to those intended for deployment. Fine-tuning of existing models can be employed to adapt the data precisely to the sensor's distinctive characteristics.
@@ -764,9 +755,9 @@ Without the extensive software innovation across frameworks, optimization tools
Major machine learning frameworks like TensorFlow, PyTorch, and MXNet provide libraries and APIs to allow common model optimization techniques to be applied without requiring custom implementations. For example, TensorFlow offers the TensorFlow Model Optimization Toolkit which contains modules like:
-- [quantization](https://www.tensorflow.org/model_optimization/api_docs/python/tfmot/quantization/keras/quantize_model) - Applies quantization-aware training to convert floating point models to lower precision like int8 with minimal accuracy loss. Handles weight and activation quantization.
-- [sparsity](https://www.tensorflow.org/model_optimization/api_docs/python/tfmot/sparsity/keras) - Provides pruning APIs to induce sparsity and remove unnecessary connections in models like neural networks. Can prune weights, layers, etc.
-- [clustering](https://www.tensorflow.org/model_optimization/api_docs/python/tfmot/clustering) - Supports model compression by clustering weights into groups for higher compression rates.
+* [quantization](https://www.tensorflow.org/model_optimization/api_docs/python/tfmot/quantization/keras/quantize_model) - Applies quantization-aware training to convert floating point models to lower precision like int8 with minimal accuracy loss. Handles weight and activation quantization.
+* [sparsity](https://www.tensorflow.org/model_optimization/api_docs/python/tfmot/sparsity/keras) - Provides pruning APIs to induce sparsity and remove unnecessary connections in models like neural networks. Can prune weights, layers, etc.
+* [clustering](https://www.tensorflow.org/model_optimization/api_docs/python/tfmot/clustering) - Supports model compression by clustering weights into groups for higher compression rates.
These APIs allow users to enable optimization techniques like quantization and pruning without directly modifying model code. Parameters like target sparsity rates, quantization bit-widths etc. can be configured. Similarly, PyTorch provides torch.quantization for converting models to lower precision representations. TorchTensor and TorchModule form the base classes for quantization support. It also offers torch.nn.utils.prune for built-in pruning of models. MXNet offers gluon.contrib layers that add quantization capabilities like fixed point rounding and stochastic rounding of weights/activations during training. This allows quantization to be readily included in gluon models.
@@ -776,9 +767,9 @@ The core benefit of built-in optimizations is that users can apply them without
Automated optimization tools provided by frameworks can analyze models and automatically apply optimizations like quantization, pruning, and operator fusion to make the process easier and accessible without excessive manual tuning. In effect, this builds on top of the previous section. For example, TensorFlow provides the TensorFlow Model Optimization Toolkit which contains modules like:
-- [QuantizationAwareTraining](https://www.tensorflow.org/model_optimization/guide/quantization/training) - Automatically quantizes weights and activations in a model to lower precision like UINT8 or INT8 with minimal accuracy loss. It inserts fake quantization nodes during training so that the model can learn to be quantization-friendly.
-- [Pruning](https://www.tensorflow.org/model_optimization/guide/pruning/pruning_with_keras) - Automatically removes unnecessary connections in a model based on analysis of weight importance. Can prune entire filters in convolutional layers or attention heads in transformers. Handles iterative re-training to recover any accuracy loss.
-- [GraphOptimizer](https://www.tensorflow.org/guide/graph_optimization) - Applies graph optimizations like operator fusion to consolidate operations and reduce execution latency, especially for inference.
+* [QuantizationAwareTraining](https://www.tensorflow.org/model_optimization/guide/quantization/training) - Automatically quantizes weights and activations in a model to lower precision like UINT8 or INT8 with minimal accuracy loss. It inserts fake quantization nodes during training so that the model can learn to be quantization-friendly.
+* [Pruning](https://www.tensorflow.org/model_optimization/guide/pruning/pruning_with_keras) - Automatically removes unnecessary connections in a model based on analysis of weight importance. Can prune entire filters in convolutional layers or attention heads in transformers. Handles iterative re-training to recover any accuracy loss.
+* [GraphOptimizer](https://www.tensorflow.org/guide/graph_optimization) - Applies graph optimizations like operator fusion to consolidate operations and reduce execution latency, especially for inference.

diff --git a/privacy_security.qmd b/privacy_security.qmd
index 72786522..02d79bb4 100644
--- a/privacy_security.qmd
+++ b/privacy_security.qmd
@@ -2,7 +2,7 @@

-Ensuring security and privacy is a critical concern when developing real-world machine learning systems. As machine learning is increasingly applied to sensitive domains like healthcare, finance, and personal data, protecting confidentiality and preventing misuse of data and models becomes imperative. Anyone aiming to build robust and responsible ML systems must have a grasp of potential security and privacy risks such as data leaks, model theft, adversarial attacks, bias, and unintended access to private information. We also need to understand best practices for mitigating these risks. Most importantly, security and privacy cannot be an afterthought and must be proactively addressed throughout the ML system development lifecycle - from data collection and labeling to model training, evaluation, and deployment. Embedding security and privacy considerations into each stage of building, deploying and managing machine learning systems is essential for safely unlocking the benefits of AI.
+Ensuring security and privacy is a critical concern when developing real-world machine learning systems. As machine learning is increasingly applied to sensitive domains like healthcare, finance, and personal data, protecting confidentiality and preventing misuse of data and models becomes imperative. Anyone aiming to build robust and responsible ML systems must have a grasp of potential security and privacy risks such as data leaks, model theft, adversarial attacks, bias, and unintended access to private information. We also need to understand best practices for mitigating these risks. Most importantly, security and privacy cannot be an afterthought and must be proactively addressed throughout the ML system development lifecycle - from data collection and labeling to model training, evaluation, and deployment. Embedding security and privacy considerations into each stage of building, deploying and managing machine learning systems is essential for safely unlocking the benefits of AI.
::: {.callout-tip}
@@ -34,9 +34,9 @@ Machine learning has evolved substantially from its academic origins, where priv
These events highlighted the growing need to address privacy in ML systems. In this chapter, we explore privacy and security considerations together, as they are inherently linked in ML:
-- Privacy refers to controlling access to sensitive user data, such as financial information or biometric data collected by an ML application.
+* Privacy refers to controlling access to sensitive user data, such as financial information or biometric data collected by an ML application.
-- Security protects ML systems and data from hacking, theft, and misuse.
+* Security protects ML systems and data from hacking, theft, and misuse.
For example, an ML-powered home security camera must secure video feeds against unauthorized access. It also needs privacy protections to ensure only intended users can view the footage. A breach of either security or privacy could expose private user moments.
@@ -50,13 +50,13 @@ We hope you will gain the principles to develop secure, ethical, embedded ML app
In this chapter, we will be talking about security and privacy together, so there are key terms that we need to be clear about.
-- **Privacy:** For instance, consider an ML-powered home security camera that identifies and records potential threats. This camera records identifiable information, including faces, of individuals who approach, and potentially enter, this home. Privacy concerns may surround who can access this data.
+* **Privacy:** For instance, consider an ML-powered home security camera that identifies and records potential threats. This camera records identifiable information, including faces, of individuals who approach, and potentially enter, this home. Privacy concerns may surround who can access this data.
-- **Security:** Consider an ML-powered home security camera that identifies and records potential threats. The security aspect would involve ensuring that these video feeds and recognition models aren't accessible to hackers.
+* **Security:** Consider an ML-powered home security camera that identifies and records potential threats. The security aspect would involve ensuring that these video feeds and recognition models aren't accessible to hackers.
-- **Threat:** Using our home security camera example, a threat could be a hacker trying to gain access to live feeds or stored videos, or using false inputs to trick the system.
+* **Threat:** Using our home security camera example, a threat could be a hacker trying to gain access to live feeds or stored videos, or using false inputs to trick the system.
-- **Vulnerability:** A common vulnerability might be a poorly secured network through which the camera connects to the internet, which could be exploited to access the data.
+* **Vulnerability:** A common vulnerability might be a poorly secured network through which the camera connects to the internet, which could be exploited to access the data.
## Historical Precedents
@@ -76,7 +76,7 @@ This breach was significant due to its sophistication; Stuxnet specifically targ
The Jeep Cherokee hack was a groundbreaking event demonstrating the risks inherent in increasingly connected automobiles [@miller2019lessons]. In a controlled demonstration, security researchers remotely exploited a vulnerability in the Uconnect entertainment system, which had a cellular connection to the internet. They were able to control the vehicle's engine, transmission, and brakes, alarming the automotive industry into recognizing the severe safety implications of cyber vulnerabilities in vehicles.
-{{< video https://www.youtube.com/watch?v=MK0SrxBC1xs&ab_channel=WIRED title="Hackers Remotely Kill a Jeep on a Highway" }}
+{{< video title="Hackers Remotely Kill a Jeep on a Highway" }}
While this wasn't an attack on an ML system per se, the reliance of modern vehicles on embedded systems for safety-critical functions has significant parallels to the deployment of ML in embedded systems, underscoring the need for robust security at the hardware level.
@@ -84,7 +84,7 @@ While this wasn't an attack on an ML system per se, the reliance of modern vehic
The Mirai botnet involved the infection of networked devices such as digital cameras and DVR players [@antonakakis2017understanding]. In October 2016, the botnet was used to conduct one of the largest [DDoS](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-attack/) attacks ever, disrupting internet access across the United States. The attack was possible because many devices used default usernames and passwords, which were easily exploited by the Mirai malware to control the devices.
-{{< video https://www.youtube.com/watch?v=1pywzRTJDaY >}}
+{{< video >}}
Although the devices were not ML-based, the incident is a stark reminder of what can happen when numerous embedded devices with poor security controls are networked together, a situation that is becoming more common with the growth of ML-based IoT devices.
@@ -120,11 +120,11 @@ To understand model inversion attacks, consider a facial recognition system used
The methodology of model inversion typically involves the following steps:
-- **Accessing Model Outputs:** The attacker queries the ML model with input data and observes the outputs. This is often done through a legitimate interface, like a public API.
+* **Accessing Model Outputs:** The attacker queries the ML model with input data and observes the outputs. This is often done through a legitimate interface, like a public API.
-- **Analyzing Confidence Scores:** For each input, the model provides a confidence score that reflects how similar the input is to the training data.
+* **Analyzing Confidence Scores:** For each input, the model provides a confidence score that reflects how similar the input is to the training data.
-- **Reverse-Engineering:** By analyzing the confidence scores or output probabilities, attackers can use optimization techniques to reconstruct what they believe is close to the original input data.
+* **Reverse-Engineering:** By analyzing the confidence scores or output probabilities, attackers can use optimization techniques to reconstruct what they believe is close to the original input data.
One historical example of such a vulnerability being explored was the research on inversion attacks against the U.S. Netflix Prize dataset, where researchers demonstrated that it was possible to learn about an individual's movie preferences, which could lead to privacy breaches [@narayanan2006break].
@@ -136,19 +136,19 @@ Model theft attacks can be divided into two categories based on the desired asse
In these attacks, the objective is to extract information about concrete metrics, such as the learned parameters of a network, the fine-tuned hyperparameters, and the model's internal layer architecture [@oliynyk2023know].
-- **Learned Parameters:** adversaries aim to steal the learned knowledge (weights and biases) of a model in order to replicate it. Parameter theft is generally used in conjunction with other attacks, such as architecture theft, which lacks parameter knowledge.
+* **Learned Parameters:** adversaries aim to steal the learned knowledge (weights and biases) of a model in order to replicate it. Parameter theft is generally used in conjunction with other attacks, such as architecture theft, which lacks parameter knowledge.
-- **Fine-Tuned Hyperparameters:** training is costly, and finding the right configuration of hyperparameters (such as the learning rate and regularization) can be a very long and expensive process.Thus, stealing an optimized model's hyperparameters can allow an adversary to replicate the model without the high training costs.
+* **Fine-Tuned Hyperparameters:** training is costly, and finding the right configuration of hyperparameters (such as the learning rate and regularization) can be a very long and expensive process.Thus, stealing an optimized model's hyperparameters can allow an adversary to replicate the model without the high training costs.
-- **Model Architecture:** this attack is concerned with the specific design and structure of the model, such as layers, neurons, and connectivity patterns. Aside from the reduction in associated training costs it can provide an attacker, this type of theft is especially dangerous because it concerns core IP theft, which can affect a company's competitive edge. Architecture theft can be achieved by exploiting side-channel attacks (discussed later).
+* **Model Architecture:** this attack is concerned with the specific design and structure of the model, such as layers, neurons, and connectivity patterns. Aside from the reduction in associated training costs it can provide an attacker, this type of theft is especially dangerous because it concerns core IP theft, which can affect a company's competitive edge. Architecture theft can be achieved by exploiting side-channel attacks (discussed later).
##### Stealing Approximate Model Behavior
Instead of focusing on extracting exact numerical values of the model's parameters, these attacks aim at reproducing the model's behavior (predictions and effectiveness), decision-making, and high-level characteristics [@oliynyk2023know]. These techniques aim at achieving similar outcomes while allowing for internal deviations in parameters and architecture. Types of approximate behavior theft include achieving the same level of effectiveness and obtaining prediction consistency.
-- **Level of Effectiveness:** Rather than focus on the precise parameter values, attackers aim to replicate the model's decision-making capabilities. This is done through understanding the overall behavior of the model. Consider a scenario where an attacker wants to copy the behavior of an image classification model. Through analysis of the model's decision boundaries, the attack tunes their model to reach a level of effectiveness comparable to the original model. This could entail analyzing 1) the confusion matrix to understand the balance of prediction metrics (true positive, true negative, false positive, false negative), and 2)other performance metrics, such as F1 score and precision, to ensure that the two models are comparable.
+* **Level of Effectiveness:** Rather than focus on the precise parameter values, attackers aim to replicate the model's decision-making capabilities. This is done through understanding the overall behavior of the model. Consider a scenario where an attacker wants to copy the behavior of an image classification model. Through analysis of the model's decision boundaries, the attack tunes their model to reach a level of effectiveness comparable to the original model. This could entail analyzing 1) the confusion matrix to understand the balance of prediction metrics (true positive, true negative, false positive, false negative), and 2)other performance metrics, such as F1 score and precision, to ensure that the two models are comparable.
-- **Prediction Consistency:** The attacker tries to align their model's prediction patterns with those of the target model. This involves matching prediction outputs (both positive and negative) on the same set of inputs and ensuring distributional consistency across different classes. For instance, consider a natural language processing (NLP) model that generates sentiment analysis for move reviews (labels reviews as positive, neutral, or negative). The attacker will try to fine-tune their model to match the prediction of the original models on the same set of movie reviews. This includes ensuring that the model makes the same mistakes (mispredictions) that the targeted model makes.
+* **Prediction Consistency:** The attacker tries to align their model's prediction patterns with those of the target model. This involves matching prediction outputs (both positive and negative) on the same set of inputs and ensuring distributional consistency across different classes. For instance, consider a natural language processing (NLP) model that generates sentiment analysis for move reviews (labels reviews as positive, neutral, or negative). The attacker will try to fine-tune their model to match the prediction of the original models on the same set of movie reviews. This includes ensuring that the model makes the same mistakes (mispredictions) that the targeted model makes.
#### Case Study
@@ -166,11 +166,11 @@ Data poisoning is an attack where the training data is tampered with, leading to
The process usually involves the following steps:
-- **Injection:** The attacker adds incorrect or misleading examples into the training set. These examples are often designed to look normal to cursory inspection but have been carefully crafted to disrupt the learning process.
+* **Injection:** The attacker adds incorrect or misleading examples into the training set. These examples are often designed to look normal to cursory inspection but have been carefully crafted to disrupt the learning process.
-- **Training:** The ML model trains on this manipulated dataset and develops skewed understandings of the data patterns.
+* **Training:** The ML model trains on this manipulated dataset and develops skewed understandings of the data patterns.
-- **Deployment:** Once the model is deployed, the corrupted training leads to flawed decision-making or predictable vulnerabilities the attacker can exploit.
+* **Deployment:** Once the model is deployed, the corrupted training leads to flawed decision-making or predictable vulnerabilities the attacker can exploit.
The impacts of data poisoning extend beyond just classification errors or accuracy drops. For instance, if incorrect or malicious data is introduced into a traffic sign recognition system's training set, the model may learn to misclassify stop signs as yield signs, which can have dangerous real-world consequences, especially in embedded autonomous systems like autonomous vehicles.
@@ -186,9 +186,9 @@ There are six main categories of data poisoning [@oprea2022poisoning]:
* **Subpopulation Attacks:** here attackers selectively choose to compromise a subset of the testing samples, while maintaining accuracy on the rest of the samples. You can think of these attacks as a combination of availability and targeted attacks:performing availability attacks (performance degradation) within the scope of a targeted subset. Although subpopulation attacks may seem very similar to targeted attacks, the two have clear differences:
-- **Scope:** while targeted attacks target a selected set of samples,subpopulation attacks target a general subpopulation with similar feature representations. For example, in a targeted attack, an actor inserts manipulated images of a 'speed bump' warning sign(with carefully crafted perturbation or patterns), which causes an autonomous car to fail to recognize such sign and slow down. On the other hand, manipulating all samples of people with a British accent so that a speech recognition model would misclassify aBritish person's speech is an example of a subpopulation attack.
+* **Scope:** while targeted attacks target a selected set of samples,subpopulation attacks target a general subpopulation with similar feature representations. For example, in a targeted attack, an actor inserts manipulated images of a 'speed bump' warning sign(with carefully crafted perturbation or patterns), which causes an autonomous car to fail to recognize such sign and slow down. On the other hand, manipulating all samples of people with a British accent so that a speech recognition model would misclassify aBritish person's speech is an example of a subpopulation attack.
-- **Knowledge:** while targeted attacks require a high degree of familiarity with the data, subpopulation attacks require less intimate knowledge in order to be effective.
+* **Knowledge:** while targeted attacks require a high degree of familiarity with the data, subpopulation attacks require less intimate knowledge in order to be effective.
#### Case Study 1
@@ -224,11 +224,11 @@ Adversarial attacks exploit the way ML models learn and make decisions during in
Adversarial attacks fall under different scenarios:
-- **Whitebox Attacks:** the attacker possess full knowledge of the target model's internal workings, including the training data,parameters, and architecture. This comprehensive access creates favorable conditions for an attacker to exploit the model's vulnerabilities. The attacker can take advantage of specific and subtle weaknesses to craft effective adversarial examples.
+* **Whitebox Attacks:** the attacker possess full knowledge of the target model's internal workings, including the training data,parameters, and architecture. This comprehensive access creates favorable conditions for an attacker to exploit the model's vulnerabilities. The attacker can take advantage of specific and subtle weaknesses to craft effective adversarial examples.
-- **Blackbox Attacks:** in contrast to whitebox attacks, in blackbox attacks, the attacker has little to no knowledge of the target model. To carry out the attack, the adversarial actor needs to make careful observations of the model's output behavior.
+* **Blackbox Attacks:** in contrast to whitebox attacks, in blackbox attacks, the attacker has little to no knowledge of the target model. To carry out the attack, the adversarial actor needs to make careful observations of the model's output behavior.
-- **Greybox Attacks:** these fall in between blackbox and whitebox attacks. The attacker has only partial knowledge about the target model's internal design. For example, the attacker could have knowledge about training data but not the architecture or parameters. In the real-world, practical attacks fall under both blackbox and greybox scenarios.
+* **Greybox Attacks:** these fall in between blackbox and whitebox attacks. The attacker has only partial knowledge about the target model's internal design. For example, the attacker could have knowledge about training data but not the architecture or parameters. In the real-world, practical attacks fall under both blackbox and greybox scenarios.
The landscape of machine learning models is both complex and broad, especially given their relatively recent integration into commercial applications. This rapid adoption, while transformative, has brought to light numerous vulnerabilities within these models. Consequently, a diverse array of adversarial attack methods has emerged, each strategically exploiting different aspects of different models. Below, we highlight a subset of these methods, showcasing the multifaceted nature of adversarial attacks on machine learning models:
@@ -286,15 +286,15 @@ Another example is the physical tampering of biometric scanners used for access
There are several ways that physical tampering can occur in ML hardware:
-- **Manipulating sensors:** Consider an autonomous vehicle that relies on cameras and LiDAR for situational awareness. An attacker could carefully calibrate the physical alignment of these sensors to introduce blindspots or distort critical distances. This could impair object detection and endanger passengers.
+* **Manipulating sensors:** Consider an autonomous vehicle that relies on cameras and LiDAR for situational awareness. An attacker could carefully calibrate the physical alignment of these sensors to introduce blindspots or distort critical distances. This could impair object detection and endanger passengers.
-- **Hardware trojans:** Malicious circuit modifications can introduce trojans that activate under certain inputs. For example, an ML accelerator chip could function normally until a rare trigger case occurs, causing it to accelerate unsafely.
+* **Hardware trojans:** Malicious circuit modifications can introduce trojans that activate under certain inputs. For example, an ML accelerator chip could function normally until a rare trigger case occurs, causing it to accelerate unsafely.
-- **Tampering with memory:** Physically exposing and manipulating memory chips could allow extraction of encrypted ML model parameters.Fault injection techniques can also corrupt model data to degrade accuracy.
+* **Tampering with memory:** Physically exposing and manipulating memory chips could allow extraction of encrypted ML model parameters.Fault injection techniques can also corrupt model data to degrade accuracy.
-- **Introducing backdoors:** Gaining physical access to servers, an adversary could use hardware keyloggers to capture passwords and create backdoor accounts for persistent access. These could then be used to exfiltrate ML training data over time.
+* **Introducing backdoors:** Gaining physical access to servers, an adversary could use hardware keyloggers to capture passwords and create backdoor accounts for persistent access. These could then be used to exfiltrate ML training data over time.
-- **Supply chain attacks:** Manipulating third-party hardware components or compromising manufacturing and shipping channels creates systemic vulnerabilities that are difficult to detect and remediate.
+* **Supply chain attacks:** Manipulating third-party hardware components or compromising manufacturing and shipping channels creates systemic vulnerabilities that are difficult to detect and remediate.
### Fault-injection Attacks
@@ -348,7 +348,7 @@ The example above shows how we can infer information about the encryption proces
For additional details, please see the following video:
-{{< video https://www.youtube.com/watch?v=2iDLfuEBcs8&ab_channel=ColinO'Flynn title="ECED4406 - 0x501 Power Analysis Attacks" }}
+{{< video title="ECED4406 - 0x501 Power Analysis Attacks" }}
Another example is an ML system for speech recognition, which processes voice commands to perform actions. By measuring the time it takes for the system to respond to commands or the power used during processing, an attacker could infer what commands are being processed and thus learn about the system's operational patterns. Even more subtle, the sound emitted by a computer's fan or hard drive could change in response to the workload, which a sensitive microphone could pick up and analyze to determine what kind of operations are being performed.
@@ -366,13 +366,13 @@ Leaky interfaces in embedded systems are often overlooked backdoors that can bec
An interface becomes "leaky" when it exposes more information than it should, often due to a lack of stringent access controls or inadequate shielding of the transmitted data. Here are some real-world examples of leaky interface issues causing security problems in IoT and embedded devices:
-- **Baby Monitors:** Many WiFi-enabled baby monitors have been found to have unsecured interfaces for remote access. This allowed attackers to gain live audio and video feeds from people's homes, representing a major [privacy violation](https://www.fox19.com/story/25310628/hacked-baby-monitor/).
+* **Baby Monitors:** Many WiFi-enabled baby monitors have been found to have unsecured interfaces for remote access. This allowed attackers to gain live audio and video feeds from people's homes, representing a major [privacy violation](https://www.fox19.com/story/25310628/hacked-baby-monitor/).
-- **Pacemakers:** Interface vulnerabilities were discovered in some [pacemakers](https://www.fda.gov/medical-devices/medical-device-recalls/abbott-formally-known-st-jude-medical-recalls-assuritytm-and-enduritytm-pacemakers-potential) that could allow attackers to manipulate cardiac functions if exploited. This presents a potential life-threatening scenario.
+* **Pacemakers:** Interface vulnerabilities were discovered in some [pacemakers](https://www.fda.gov/medical-devices/medical-device-recalls/abbott-formally-known-st-jude-medical-recalls-assuritytm-and-enduritytm-pacemakers-potential) that could allow attackers to manipulate cardiac functions if exploited. This presents a potential life-threatening scenario.
-- **Smart Lightbulbs:** A researcher found he could access unencrypted data from smart lightbulbs via a debug interface, including WiFi credentials, allowing him to gain access to the connected network [@dhanjani2015abusing].
+* **Smart Lightbulbs:** A researcher found he could access unencrypted data from smart lightbulbs via a debug interface, including WiFi credentials, allowing him to gain access to the connected network [@dhanjani2015abusing].
-- **Smart Cars:** The OBD-II diagnostic port has been shown to provide an attack vector into automotive systems if left unsecured.Researchers were able to take control of brakes and other components through it [@miller2015remote].
+* **Smart Cars:** The OBD-II diagnostic port has been shown to provide an attack vector into automotive systems if left unsecured.Researchers were able to take control of brakes and other components through it [@miller2015remote].
While the above are not directly connected with ML, consider the example of a smart home system with an embedded ML component that controls home security based on behavior patterns it learns over time. The system includes a maintenance interface accessible via the local network for software updates and system checks. If this interface does not require strong authentication or if the data transmitted through it is not encrypted, an attacker on the same network could potentially gain access to it. They could then eavesdrop on the homeowner's daily routines or reprogram the security settings by manipulating the firmware.
@@ -436,43 +436,43 @@ For instance, a TEE can protect ML model parameters from being extracted by mali
In ML systems, TEEs can:
-- Securely perform model training and inference, ensuring that the computation results remain confidential.
+* Securely perform model training and inference, ensuring that the computation results remain confidential.
-- Protect the confidentiality of input data, like biometric information, used for personal identification or sensitive classification tasks.
+* Protect the confidentiality of input data, like biometric information, used for personal identification or sensitive classification tasks.
-- Secure ML models by preventing reverse engineering, which can protect proprietary information and maintain a competitive advantage.
+* Secure ML models by preventing reverse engineering, which can protect proprietary information and maintain a competitive advantage.
-- Enable secure updates to ML models, ensuring that updates come from a trusted source and have not been tampered with in transit.
+* Enable secure updates to ML models, ensuring that updates come from a trusted source and have not been tampered with in transit.
The importance of TEEs in ML hardware security stems from their ability to protect against external and internal threats, including the following:
-- **Malicious Software:** TEEs can prevent high-privilege malware from accessing sensitive areas of the ML system.
+* **Malicious Software:** TEEs can prevent high-privilege malware from accessing sensitive areas of the ML system.
-- **Physical Tampering:** By integrating with hardware security measures, TEEs can protect against physical tampering that attempts to bypass software security.
+* **Physical Tampering:** By integrating with hardware security measures, TEEs can protect against physical tampering that attempts to bypass software security.
-- **Side-channel Attacks:** Although not impenetrable, TEEs can mitigate certain side-channel attacks by controlling access to sensitive operations and data patterns.
+* **Side-channel Attacks:** Although not impenetrable, TEEs can mitigate certain side-channel attacks by controlling access to sensitive operations and data patterns.
#### Mechanics
The fundamentals of TEEs (see @fig-enclave) contain four main parts:
-- **Isolated Execution:** Code within a TEE runs in a separate environment from the device's main operating system. This isolation protects the code from unauthorized access by other applications.
+* **Isolated Execution:** Code within a TEE runs in a separate environment from the device's main operating system. This isolation protects the code from unauthorized access by other applications.
-- **Secure Storage:** TEEs can store cryptographic keys,authentication tokens, and sensitive data securely, preventing access by regular applications running outside the TEE.
+* **Secure Storage:** TEEs can store cryptographic keys,authentication tokens, and sensitive data securely, preventing access by regular applications running outside the TEE.
-- **Integrity Protection:** TEEs can verify the integrity of code and data, ensuring that they have not been altered before execution or during storage.
+* **Integrity Protection:** TEEs can verify the integrity of code and data, ensuring that they have not been altered before execution or during storage.
-- **Data Encryption:** Data handled within a TEE can be encrypted,making it unreadable to entities without the proper keys, which are also managed within the TEE.
+* **Data Encryption:** Data handled within a TEE can be encrypted,making it unreadable to entities without the proper keys, which are also managed within the TEE.
Here are some examples of TEEs that provide hardware-based security for sensitive applications:
-- **[ARMTrustZone](https://www.arm.com/technologies/trustzone-for-cortex-m):**Creates secure and normal world execution environments isolated using hardware controls. Implemented in many mobile chipsets.
+* **[ARMTrustZone](https://www.arm.com/technologies/trustzone-for-cortex-m):**Creates secure and normal world execution environments isolated using hardware controls. Implemented in many mobile chipsets.
-- **[IntelSGX](https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html):**Intel's Software Guard Extensions provide an enclave for code execution that protects against certain software attacks,specifically OS layer attacks. Used to safeguard workloads in the cloud.
+* **[IntelSGX](https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html):**Intel's Software Guard Extensions provide an enclave for code execution that protects against certain software attacks,specifically OS layer attacks. Used to safeguard workloads in the cloud.
-- **[Qualcomm Secure ExecutionEnvironment](https://www.qualcomm.com/products/features/mobile-security-solutions):**Hardware sandbox on Qualcomm chipsets for mobile payment and authentication apps.
+* **[Qualcomm Secure ExecutionEnvironment](https://www.qualcomm.com/products/features/mobile-security-solutions):**Hardware sandbox on Qualcomm chipsets for mobile payment and authentication apps.
-- **[Apple SecureEnclave](https://support.apple.com/guide/security/secure-enclave-sec59b0b31ff/web):**TEE for biometric data and key management on iPhones and iPads.Facilitates mobile payments.
+* **[Apple SecureEnclave](https://support.apple.com/guide/security/secure-enclave-sec59b0b31ff/web):**TEE for biometric data and key management on iPhones and iPads.Facilitates mobile payments.
.](images/security_privacy/image1.png){#fig-enclave}
@@ -510,11 +510,11 @@ The integrity of an ML system is critical from the moment it is powered on. A co
Secure Boot helps protect embedded ML hardware in several ways:
-- **Protecting ML Data:** Ensuring that the data used by ML models, which may include private or sensitive information, is not exposed to tampering or theft during the boot process.
+* **Protecting ML Data:** Ensuring that the data used by ML models, which may include private or sensitive information, is not exposed to tampering or theft during the boot process.
-- **Guarding Model Integrity:** Maintaining the integrity of the ML models themselves, as tampering with the model could lead to incorrect or malicious outcomes.
+* **Guarding Model Integrity:** Maintaining the integrity of the ML models themselves, as tampering with the model could lead to incorrect or malicious outcomes.
-- **Secure Model Updates:** Enabling secure updates to ML models and algorithms, ensuring that updates are authenticated and have not been altered.
+* **Secure Model Updates:** Enabling secure updates to ML models and algorithms, ensuring that updates are authenticated and have not been altered.
#### Mechanics
@@ -646,15 +646,13 @@ Techniques like de-identification, aggregation, anonymization, and federation ca
Many embedded ML applications handle sensitive user data under HIPAA, GDPR, and CCPA regulations. Understanding the protections mandated by these laws is crucial for building compliant systems.
-- [HIPAA](https://www.hhs.gov/hipaa/for-professionals/privacy/index.html#:~:text=The HIPAA Privacy Rule establishes,care providers that conduct certain)governs medical data privacy and security in the US, with severe penalties for violations. Any health-related embedded ML devices like diagnostic wearables or assistive robots would need to implement controls like audit trails, access controls, and encryption prescribed by HIPAA.
+* [HIPAA]( HIPAA Privacy Rule establishes,care providers that conduct certain)governs medical data privacy and security in the US, with severe penalties for violations. Any health-related embedded ML devices like diagnostic wearables or assistive robots would need to implement controls like audit trails, access controls, and encryption prescribed by HIPAA.
+* [GDPR](https://gdpr-info.eu/) imposes transparency,retention limits, and user rights around EU citizen data, even when processed by companies outside the EU. Smart home systems capturing family conversations or location patterns would needGDPR compliance. Key requirements include data minimization,encryption, and mechanisms for consent and erasure.
-- [GDPR](https://gdpr-info.eu/) imposes transparency,retention limits, and user rights around EU citizen data, even when processed by companies outside the EU. Smart home systems capturing family conversations or location patterns would needGDPR compliance. Key requirements include data minimization,encryption, and mechanisms for consent and erasure.
+* [CCPA]( CCPA applies to for,, households, or devices; or)in California focuses on protecting consumer data privacy through provisions like required disclosures and opt-out rights. IoT gadgets like smart speakers and fitness trackers used byCalifornians would likely fall under its scope.
-
-- [CCPA](https://oag.ca.gov/privacy/ccpa#:~:text=The CCPA applies to for,, households, or devices; or)in California focuses on protecting consumer data privacy through provisions like required disclosures and opt-out rights. IoT gadgets like smart speakers and fitness trackers used byCalifornians would likely fall under its scope.
-
-- CCPA was the first state specific set of regulations surrounding privacy concerns. Following the CCPA, similar regulations were also enacted in [10 other states](https://pro.bloomberglaw.com/brief/state-privacy-legislation-tracker/), with some states proposing bills for consumer data privacy protections.
+* CCPA was the first state specific set of regulations surrounding privacy concerns. Following the CCPA, similar regulations were also enacted in [10 other states](https://pro.bloomberglaw.com/brief/state-privacy-legislation-tracker/), with some states proposing bills for consumer data privacy protections.
Additionally, when relevant to the application, sector-specific rules govern telematics, financial services, utilities, etc. Best practices like privacy by design, impact assessments, and maintaining audit trails help embed compliance, if it is not already required by law. Given potentially costly penalties, consulting legal/compliance teams is advisable when developing regulated embedded ML systems.
@@ -666,7 +664,7 @@ If medical data is de-identified thoroughly, HIPAA guidelines do not directly ap
Safe Harbor methods are most commonly used for de-identifying protected healthcare information, due to the limited resources needed in comparison to Expert Determination methods. Safe Harbor de-identification requires datasets to be scrubbed of any data that falls into one of 18 categories. The following categories are listed as sensitive information based on the Safe Harbor standard:
-- Name, Geographic locator, Birthdate, Phone Number, Email Address, IPAddresses, Social Security Numbers, Medical Record Numbers, HealthPlan Beneficiary Numbers, Device Identifiers and Serial Numbers,Certificate/License Numbers (Birth Certificate, Drivers License,etc), Account Numbers, Vehicle Identifiers, Website URLs, FullFace Photos and Comparable Images, Biometric Identifiers, Any other unique identifiers
+* Name, Geographic locator, Birthdate, Phone Number, Email Address, IPAddresses, Social Security Numbers, Medical Record Numbers, HealthPlan Beneficiary Numbers, Device Identifiers and Serial Numbers,Certificate/License Numbers (Birth Certificate, Drivers License,etc), Account Numbers, Vehicle Identifiers, Website URLs, FullFace Photos and Comparable Images, Biometric Identifiers, Any other unique identifiers
For a majority of these categories, all data is required to be removed regardless of the circumstances. For other categories, including geographical information and birthdate, the data can be partially removed enough to make the information hard to re-identify. For example, if a zip code is large enough, the first 3 digits of the zipcode can still remain, since there are enough people in the geographic area to make re-identification difficult. Birthdates need to be scrubbed of all elements except for birth year, and all ages above 89 years old need to be aggregated into a 90+ category.
@@ -686,11 +684,11 @@ Where possible, ephemeral data that briefly resides in memory without persisting
Data minimization can be broken down into [3 categories](https://dl.acm.org/doi/pdf/10.1145/3397271.3401034?casa_token=NrOifKo6dPMAAAAA:Gl5NZNpZMiuSRpJblj43c1cNXkXyv7oEOuYlOfX2qvT8e-9mOLoLQQYz29itxVh6xakKm8haWRs):
-1. "Data must be *adequate* in relation to the purpose that is pursued." Data omission can limit the accuracy of models trained on the data, and any general usefulness of a dataset. Dataminimization requires a minimum amount of data to be collected from users, while still creating a dataset that adds value to others.
+1. "Data must be _adequate_ in relation to the purpose that is pursued." Data omission can limit the accuracy of models trained on the data, and any general usefulness of a dataset. Dataminimization requires a minimum amount of data to be collected from users, while still creating a dataset that adds value to others.
-2. The data collected from users must be *relevant* to the purpose of the data collection.
+2. The data collected from users must be _relevant_ to the purpose of the data collection.
-3. The data collected from users should be *limited* to only the data that is absolutely necessary from users in order to fulfill the purpose of the initial data collection. If similarly robust and accurate results can be obtained from a smaller dataset, any additional data beyond this smaller dataset is not necessary and should not be collected.
+3. The data collected from users should be _limited_ to only the data that is absolutely necessary from users in order to fulfill the purpose of the initial data collection. If similarly robust and accurate results can be obtained from a smaller dataset, any additional data beyond this smaller dataset is not necessary and should not be collected.
Emerging techniques like differential privacy, federated learning, and synthetic data generation allow for deriving useful insights from less raw user data. Performing data flow mapping and impact assessments help identify opportunities to minimize raw data usage.
@@ -698,7 +696,7 @@ Methodologies like Privacy by Design [@cavoukian2009privacy] consider such minim
#### Case Study - Performance Based Data Minimization
-Performance based data minimization [@Biega2020Oper] focuses on expanding upon the third category of data minimization mentioned above, namely *limitation*. It specifically defines the robustness of model results on a given dataset by certain performance metrics, such that data should not be additionally collected if it does not significantly improve performance. Performance metrics can be divided into two categories:
+Performance based data minimization [@Biega2020Oper] focuses on expanding upon the third category of data minimization mentioned above, namely _limitation_. It specifically defines the robustness of model results on a given dataset by certain performance metrics, such that data should not be additionally collected if it does not significantly improve performance. Performance metrics can be divided into two categories:
1. Global data minimization performance
@@ -776,16 +774,13 @@ To illustrate the trade-off of privacy and accuracy in ($\epsilon$, $\delta$)-di
The key points to remember about differential privacy is the following:
-- **Adding Noise:** The fundamental technique in differential privacy is adding controlled random noise to the data or query results.This noise masks the contribution of individual data points.
-
+* **Adding Noise:** The fundamental technique in differential privacy is adding controlled random noise to the data or query results.This noise masks the contribution of individual data points.
-- **Balancing Act:** There's a balance between privacy and accuracy.More noise (lower ϵ) in the data means higher privacy but less accuracy in the model's results.
+* **Balancing Act:** There's a balance between privacy and accuracy.More noise (lower ϵ) in the data means higher privacy but less accuracy in the model's results.
+* **Universality:** Differential privacy doesn't rely on assumptions about what an attacker knows. This makes it robust against re-identification attacks, where an attacker tries to uncover individual data.
-- **Universality:** Differential privacy doesn't rely on assumptions about what an attacker knows. This makes it robust against re-identification attacks, where an attacker tries to uncover individual data.
-
-
-- **Applicability:** It's applicable to various types of data and queries, making it a versatile tool for privacy-preserving data analysis.
+* **Applicability:** It's applicable to various types of data and queries, making it a versatile tool for privacy-preserving data analysis.
#### Trade-offs
@@ -833,13 +828,13 @@ By leaving the raw data distributed and exchanging only temporary model updates,
Imagine a group of hospitals that want to collaborate on a study to predict patient outcomes based on their symptoms. However, due to privacy concerns and regulations like HIPAA, they cannot share their patient data with each other. Here's how Federated Learning can help.
-- **Local Training:** Each hospital trains a machine learning model on its own patient data. This training happens locally, meaning thedata never leaves the hospital's servers.
+* **Local Training:** Each hospital trains a machine learning model on its own patient data. This training happens locally, meaning thedata never leaves the hospital's servers.
-- **Model Sharing:** After training, each hospital only sends the model (specifically, the parameters or weights of the model) to acentral server. They do not send any patient data.
+* **Model Sharing:** After training, each hospital only sends the model (specifically, the parameters or weights of the model) to acentral server. They do not send any patient data.
-- **Aggregating Models:** The central server aggregates these models from all hospitals into a single, more robust model. This process typically involves averaging the model parameters.
+* **Aggregating Models:** The central server aggregates these models from all hospitals into a single, more robust model. This process typically involves averaging the model parameters.
-- **Benefit:** The end result is a machine learning model that has learned from a wide range of patient data without any of that sensitive data having to be shared or leave its original location.
+* **Benefit:** The end result is a machine learning model that has learned from a wide range of patient data without any of that sensitive data having to be shared or leave its original location.
#### Trade-offs
@@ -973,25 +968,25 @@ The core idea behind MPC protocols is to divide the computation into steps that
The main approaches used in MPC include:
-- **Homomorphic encryption:** Special encryption allows computations to be carried out on encrypted data without decrypting it.
+* **Homomorphic encryption:** Special encryption allows computations to be carried out on encrypted data without decrypting it.
-- **Secret sharing:** The private data is divided into random shares that are distributed to each party. Computations are done locally on the shares and finally reconstructed.
+* **Secret sharing:** The private data is divided into random shares that are distributed to each party. Computations are done locally on the shares and finally reconstructed.
-- **Oblivious transfer:** A protocol where a receiver obtains a subset of data from a sender, but the sender does not know which specific data was transferred.
+* **Oblivious transfer:** A protocol where a receiver obtains a subset of data from a sender, but the sender does not know which specific data was transferred.
-- **Garbled circuits:** The function to be computed is represented as a Boolean circuit that is encrypted ("garbled") in a way that allows joint evaluation without revealing inputs.
+* **Garbled circuits:** The function to be computed is represented as a Boolean circuit that is encrypted ("garbled") in a way that allows joint evaluation without revealing inputs.
#### Trade-offs
While MPC protocols provide strong privacy guarantees, they come at a high computational cost compared to plain computations. Every secure operation like addition, multiplication, comparison, etc requires orders of magnitude more processing than the equivalent unencrypted operation. This overhead stems from the underlying cryptographic techniques:
-- In partially homomorphic encryption, each computation on ciphertexts requires costly public-key operations. Fully homomorphic encryption has even higher overheads.
+* In partially homomorphic encryption, each computation on ciphertexts requires costly public-key operations. Fully homomorphic encryption has even higher overheads.
-- Secret sharing divides data into multiple shares, so even basic operations require manipulating many shares.
+* Secret sharing divides data into multiple shares, so even basic operations require manipulating many shares.
-- Oblivious transfer and garbled circuits add masking and encryption to hide data access patterns and execution flows.
+* Oblivious transfer and garbled circuits add masking and encryption to hide data access patterns and execution flows.
-- MPC systems require extensive communication and interaction between parties to jointly compute on shares/ciphertexts.
+* MPC systems require extensive communication and interaction between parties to jointly compute on shares/ciphertexts.
As a result, MPC protocols can slow down computations by 3-4 orders of magnitude compared to plain implementations. This becomes prohibitively expensive for large datasets and models. Therefore, training machine learning models on encrypted data using MPC remains infeasible today for realistic dataset sizes due to the overhead. Clever optimizations and approximations are needed to make MPC practical.
@@ -1007,15 +1002,15 @@ The primary challenge of synthesizing data is to ensure adversaries are unable t
Researchers can freely share this synthetic data and collaborate on modeling without revealing any private medical information. Well-constructed synthetic data protects privacy while providing utility for developing accurate models. Key techniques to prevent reconstruction of the original data include adding differential privacy noise during training, enforcing plausibility constraints, and using multiple diverse generative models. Here are some common approaches for generating synthetic data:
-- **Generative Adversarial Networks (GANs):** GANs (see @fig-gans) are a type of AI algorithm used in unsupervised learning where two neural networks contest against each other in a game. The generator network is responsible for producing the synthetic data and the discriminator network evaluates the authenticity of the data by distinguishing between fake data created by the generator network and the real data. The discriminator acts as a metric on how similar the fake and real data are to one another. It is highly effective at generating realistic data and is, therefore, a popular approach for generating synthetic data.
+* **Generative Adversarial Networks (GANs):** GANs (see @fig-gans) are a type of AI algorithm used in unsupervised learning where two neural networks contest against each other in a game. The generator network is responsible for producing the synthetic data and the discriminator network evaluates the authenticity of the data by distinguishing between fake data created by the generator network and the real data. The discriminator acts as a metric on how similar the fake and real data are to one another. It is highly effective at generating realistic data and is, therefore, a popular approach for generating synthetic data.
{#fig-gans}
-- **Variational Autoencoders (VAEs):** VAEs are neural networks that are capable of learning complex probability distributions and balance between data generation quality and computational efficiency. They encode data into a latent space where they learn the distribution in order to decode the data back.
+* **Variational Autoencoders (VAEs):** VAEs are neural networks that are capable of learning complex probability distributions and balance between data generation quality and computational efficiency. They encode data into a latent space where they learn the distribution in order to decode the data back.
-- **Data Augmentation:** This involves applying transformations to existing data to create new, altered data. For example, flipping,rotating, and scaling (uniformly or non-uniformly) original images can help create a more diverse, robust image dataset before training an ML model.
+* **Data Augmentation:** This involves applying transformations to existing data to create new, altered data. For example, flipping,rotating, and scaling (uniformly or non-uniformly) original images can help create a more diverse, robust image dataset before training an ML model.
-- **Simulations:** Mathematical models can simulate real-world systems or processes to mimic real-world phenomena. This is highly useful in scientific research, urban planning, and economics.
+* **Simulations:** Mathematical models can simulate real-world systems or processes to mimic real-world phenomena. This is highly useful in scientific research, urban planning, and economics.
#### Benefits
@@ -1023,13 +1018,13 @@ While synthetic data may be necessary due to privacy or compliance risks, it is
There are several motivations for using synthetic data in machine learning:
-- **Privacy and compliance:** Synthetic data avoids exposing personal information, allowing more open sharing and collaboration. This is important when working with sensitive datasets like healthcare records or financial information.
+* **Privacy and compliance:** Synthetic data avoids exposing personal information, allowing more open sharing and collaboration. This is important when working with sensitive datasets like healthcare records or financial information.
-- **Data scarcity:** When insufficient real-world data is available,synthetic data can augment training datasets. This improves model accuracy when limited data is a bottleneck.
+* **Data scarcity:** When insufficient real-world data is available,synthetic data can augment training datasets. This improves model accuracy when limited data is a bottleneck.
-- **Model testing:** Synthetic data provides privacy-safe sandboxes for testing model performance, debugging issues, and monitoring for bias.
+* **Model testing:** Synthetic data provides privacy-safe sandboxes for testing model performance, debugging issues, and monitoring for bias.
-- **Data labeling:** High-quality labeled training data is often scarce and expensive. Synthetic data can help auto-generate labeled examples.
+* **Data labeling:** High-quality labeled training data is often scarce and expensive. Synthetic data can help auto-generate labeled examples.
#### Trade-offs
@@ -1055,7 +1050,6 @@ While all the techniques we have discussed thus far aim to enable privacy-preser
## Conclusion
-Machine learning hardware security is a critical concern as embedded ML systems are increasingly deployed in safety-critical domains like medical devices, industrial controls, and autonomous vehicles. We have explored various threats spanning hardware bugs, physical attacks, side channels, supply chain risks and more. Defenses like TEEs, secure boot, PUFs, and hardware security modules provide multilayer protection tailored for resource-constrained embedded devices.
+Machine learning hardware security is a critical concern as embedded ML systems are increasingly deployed in safety-critical domains like medical devices, industrial controls, and autonomous vehicles. We have explored various threats spanning hardware bugs, physical attacks, side channels, supply chain risks and more. Defenses like TEEs, secure boot, PUFs, and hardware security modules provide multilayer protection tailored for resource-constrained embedded devices.
However, continual vigilance is essential to track emerging attack vectors and address potential vulnerabilities through secure engineering practices across the hardware lifecycle. As ML and embedded ML spreads, maintaining rigorous security foundations that match the field's accelerating pace of innovation remains imperative.
-
diff --git a/test.qmd b/test.qmd
deleted file mode 100644
index 72a22085..00000000
--- a/test.qmd
+++ /dev/null
@@ -1,3 +0,0 @@
-# Testing page
-
-testing if this will render
diff --git a/tools.qmd b/tools.qmd
index 743354b0..7fe69a98 100644
--- a/tools.qmd
+++ b/tools.qmd
@@ -27,7 +27,6 @@ This is a non-exhaustive list of tools and frameworks that are available for emb
| 2 | Edge Impulse | A platform providing tools for creating machine learning models optimized for edge devices | Data collection, model training, deployment on tiny devices |
| 3 | ONNX Runtime | A performance-optimized engine for running ONNX models, fine-tuned for edge devices | Cross-platform deployment of machine learning models |
-
### **Libraries and APIs**
| No | Library/API | Description | Use Cases |
diff --git a/workflow.qmd b/workflow.qmd
index e1e650dc..87681f7a 100644
--- a/workflow.qmd
+++ b/workflow.qmd
@@ -7,10 +7,11 @@ In this chapter, we'll explore the machine learning (ML) workflow, setting the s
The ML workflow is a structured approach that guides professionals and researchers through the process of developing, deploying, and maintaining ML models. This workflow is generally divided into several crucial stages, each contributing to the effective development of intelligent systems.
::: {.callout-tip}
+
## Learning Objectives
* Understand the ML workflow and gain insights into the structured approach and stages involved in developing, deploying, and maintaining machine learning models.
-
+
* Learn about the unique challenges and distinctions between workflows for Traditional machine learning and embedded AI.
* Appreciate the various roles involved in ML projects and understand their respective responsibilities and significance.
@@ -30,10 +31,10 @@ The ML workflow is a structured approach that guides professionals and researche
Developing a successful machine learning model requires a systematic workflow. This end-to-end process enables you to build, deploy and maintain models effectively. It typically involves the following key steps:
1. **Problem Definition** - Start by clearly articulating the specific problem you want to solve. This focuses your efforts during data collection and model building.
-2. **Data Collection to Preparation** - Gather relevant, high-quality training data that captures all aspects of the problem. Clean and preprocess the data to get it ready for modeling.
-3. **Model Selection and Training** - Choose a machine learning algorithm suited to your problem type and data. Consider pros and cons of different approaches. Feed the prepared data into the model to train it. Training time varies based on data size and model complexity.
+2. **Data Collection to Preparation** - Gather relevant, high-quality training data that captures all aspects of the problem. Clean and preprocess the data to get it ready for modeling.
+3. **Model Selection and Training** - Choose a machine learning algorithm suited to your problem type and data. Consider pros and cons of different approaches. Feed the prepared data into the model to train it. Training time varies based on data size and model complexity.
4. **Model Evaluation** - Test the trained model on new unseen data to measure its predictive accuracy. Identify any limitations.
-6. **Model Deployment** - Integrate the validated model into applications or systems to start operationalization.
+6. **Model Deployment** - Integrate the validated model into applications or systems to start operationalization.
7. **Monitor and Maintain** - Track model performance in production. Retrain periodically on new data to keep it current.
Following this structured **ML workflow** helps guide you through the key phases of development. It ensures you build effective and robust models that are ready for real-world deployment. The end result is higher quality models that solve your business needs.
@@ -50,24 +51,28 @@ The ML workflow is iterative, requiring ongoing monitoring and potential adjustm
The ML workflow serves as a universal guide, applicable across various platforms including cloud-based solutions, edge computing, and tinyML. However, the workflow for Embedded AI introduces unique complexities and challenges, which not only make it a captivating domain but also pave the way for remarkable innovations.
### Resource Optimization
-- **Traditional ML Workflow**: Prioritizes model accuracy and performance, often leveraging abundant computational resources in cloud or data center environments.
-- **Embedded AI Workflow**: Requires careful planning to optimize model size and computational demands, given the resource constraints of embedded systems. Techniques like model quantization and pruning are crucial.
+
+* **Traditional ML Workflow**: Prioritizes model accuracy and performance, often leveraging abundant computational resources in cloud or data center environments.
+* **Embedded AI Workflow**: Requires careful planning to optimize model size and computational demands, given the resource constraints of embedded systems. Techniques like model quantization and pruning are crucial.
### Real-time Processing
-- **Traditional ML Workflow**: Less emphasis on real-time processing, often relying on batch data processing.
-- **Embedded AI Workflow**: Prioritizes real-time data processing, making low latency and quick execution essential, especially in applications like autonomous vehicles and industrial automation.
+
+* **Traditional ML Workflow**: Less emphasis on real-time processing, often relying on batch data processing.
+* **Embedded AI Workflow**: Prioritizes real-time data processing, making low latency and quick execution essential, especially in applications like autonomous vehicles and industrial automation.
### Data Management and Privacy
-- **Traditional ML Workflow**: Processes data in centralized locations, often necessitating extensive data transfer and focusing on data security during transit and storage.
-- **Embedded AI Workflow**: Leverages edge computing to process data closer to its source, reducing data transmission and enhancing privacy through data localization.
+
+* **Traditional ML Workflow**: Processes data in centralized locations, often necessitating extensive data transfer and focusing on data security during transit and storage.
+* **Embedded AI Workflow**: Leverages edge computing to process data closer to its source, reducing data transmission and enhancing privacy through data localization.
### Hardware-Software Integration
-- **Traditional ML Workflow**: Typically operates on general-purpose hardware, with software development occurring somewhat independently.
-- **Embedded AI Workflow**: Involves a more integrated approach to hardware and software development, often incorporating custom chips or hardware accelerators to achieve optimal performance.
+
+* **Traditional ML Workflow**: Typically operates on general-purpose hardware, with software development occurring somewhat independently.
+* **Embedded AI Workflow**: Involves a more integrated approach to hardware and software development, often incorporating custom chips or hardware accelerators to achieve optimal performance.
## Roles & Responsibilities
-Creating an ML solution, especially for embedded AI, is a multidisciplinary effort involving various specialists.
+Creating an ML solution, especially for embedded AI, is a multidisciplinary effort involving various specialists.
Here's a rundown of the typical roles involved:
diff --git a/zoo_datasets.qmd b/zoo_datasets.qmd
index 0f963766..fd4672d2 100644
--- a/zoo_datasets.qmd
+++ b/zoo_datasets.qmd
@@ -28,4 +28,4 @@
- Description: A dataset containing recordings of common spoken words in various languages, useful for speech recognition projects targeting multiple languages.
- [Link to the Dataset](https://mlcommons.org/en/multilingual-spoken-words/)
-Remember to verify the dataset's license or terms of use to ensure it can be used for your intended purpose.
\ No newline at end of file
+Remember to verify the dataset's license or terms of use to ensure it can be used for your intended purpose.
diff --git a/zoo_models.qmd b/zoo_models.qmd
index da8d430a..e57464e1 100644
--- a/zoo_models.qmd
+++ b/zoo_models.qmd
@@ -1,2 +1 @@
## Model Zoo
-