@@ -111,19 +111,19 @@ Transformers是由一个团队领导的(非常大的)模型项目,该团
因此,微调模型具有较低的时间、数据、财务和环境成本。迭代不同的微调方案也更快、更容易,因为与完整的预训练相比,训练的约束更少。
-这个过程也会比从头开始的训练(除非你有很多数据)取得更好的效果,这就是为什么你应该总是尝试利用一个预训练的模型--一个尽可能接近你手头的任务的模型--并对其进行微调。
+这个过程也会比从头开始的训练(除非你有很多数据)取得更好的效果,这就是为什么你应该总是尝试利用一个预训练的模型——一个尽可能接近你手头的任务的模型——并对其进行微调。
-## 一般的体系结构 [[一般的体系结构]]
-在这一部分,我们将介绍Transformer模型的一般架构。如果你不理解其中的一些概念,不要担心;下文将详细介绍每个组件。
+## Transformer 模型的通用架构 [[Transformer 模型的通用架构]]
+在本节中,我们将概述 Transformer 模型的通用架构。如果你不理解其中的一些概念,不用担心;后面的章节将详细介绍每个组件。
-## 介绍 [[介绍]]
+## 简介 [[简介]]
该模型主要由两个块组成:
-* **Encoder (左侧)**: 编码器接收输入并构建其表示(其特征)。这意味着对模型进行了优化,以从输入中获得理解。
-* **Decoder (右侧)**: 解码器使用编码器的表示(特征)以及其他输入来生成目标序列。这意味着该模型已针对生成输出进行了优化。
+* **Encoder (左侧)**:编码器接收输入并构建其表示(特征)。这意味着模型的使命是从输入中获取理解。
+* **Decoder (右侧)**:解码器使用编码器的表示(特征)以及其他输入来生成目标序列。这意味着模型的使命是生成输出。

@@ -132,47 +132,45 @@ Transformers是由一个团队领导的(非常大的)模型项目,该团
这些部件中的每一个都可以独立使用,具体取决于任务:
-* **Encoder-only models**: 适用于需要理解输入的任务,如句子分类和命名实体识别。
-* **Decoder-only models**: 适用于生成任务,如文本生成。
-* **Encoder-decoder models** 或者 **sequence-to-sequence models**: 适用于需要根据输入进行生成的任务,如翻译或摘要。
+* **Encoder-only 模型**:适用于需要理解输入的任务,如句子分类和命名实体识别。
+* **Decoder-only 模型**:适用于生成任务,如文本生成。
+* **Encoder-decoder 模型** 或者 **sequence-to-sequence 模型**:适用于需要根据输入进行生成的任务,如翻译或摘要。
在后面的部分中,我们将单独地深入研究这些体系结构。
## 注意力层 [[注意力层]]
-Transformer模型的一个关键特性是*注意力层*。事实上,介绍Transformer架构的文章的标题是[“注意力就是你所需要的”](https://arxiv.org/abs/1706.03762)! 我们将在课程的后面更加深入地探索注意力层;现在,您需要知道的是,这一层将告诉模型在处理每个单词的表示时,要特别重视您传递给它的句子中的某些单词(并且或多或少地忽略其他单词)。
+Transformer 模型的一个关键特性是*注意力层*。事实上,提出 Transformer 架构的文章的标题是 [“Attention Is All You Need”](https://arxiv.org/abs/1706.03762) !我们将在课程的后面更加深入地探讨注意力层的细节;现在,你需要知道的是,这一层将告诉模型在处理每个单词的表示时,对不同单词的重视(忽略)程度。
-把它放在语境中,考虑将文本从英语翻译成法语的任务。在输入“You like this course”的情况下,翻译模型还需要注意相邻的单词“You”,以获得单词“like”的正确翻译,因为在法语中,动词“like”的变化取决于主题。然而,句子的其余部分对于该词的翻译没有用处。同样,在翻译“this”时,模型也需要注意“course”一词,因为“this”的翻译不同,取决于相关名词是单数还是复数。同样,句子中的其他单词对于“this”的翻译也不重要。对于更复杂的句子(以及更复杂的语法规则),模型需要特别注意可能出现在句子中更远位置的单词,以便正确地翻译每个单词。
+可以考虑一个例子,假如我们要将英语翻译成法语。给定输入“You like this course”时,翻译模型需要注意相邻的词“You”,才能获得“like”的正确翻译,因为在法语中,动词“like”的变形依赖于主语。然而,对于那个词的翻译,句子的其余部分并没有用。同样,当翻译“this”时,模型也需要注意词“course”,因为“this”的翻译依赖于关联名词是单数还是复数。再次,句子中的其他词对于“course”的翻译并不重要。对于更复杂的句子(和更复杂的语法规则),模型可能需要特别注意可能在句子中更远处出现的词,以正确翻译每个词。
同样的概念也适用于与自然语言相关的任何任务:一个词本身有一个含义,但这个含义受语境的影响很大,语境可以是研究该词之前或之后的任何其他词(或多个词)。
-现在您已经了解了注意力层的含义,让我们更仔细地了解Transformer架构。
+现在你对注意力层是什么有了一些了解,让我们更详细地看一下 Transformer 架构。
-## 原始的结构 [[原始的结构]]
+## Transformer 的原始结构 [[原始的结构]]
-Transformer架构最初是为翻译而设计的。在训练期间,编码器接收特定语言的输入(句子),而解码器需要输出对应语言的翻译。在编码器中,注意力层可以使用一个句子中的所有单词(正如我们刚才看到的,给定单词的翻译可以取决于它在句子中的其他单词)。然而,解码器是按顺序工作的,并且只能注意它已经翻译过的句子中的单词。例如,当我们预测了翻译目标的前三个单词时,我们将它们提供给解码器,然后解码器使用编码器的所有输入来尝试预测第四个单词。
+Transformer 架构最初是为翻译而设计的。在训练期间,编码器接收特定语言的输入(句子),而解码器需要输出对应语言的翻译。在编码器中,注意力层可以使用一个句子中的所有单词(正如我们刚才看到的,给定单词的翻译可以取决于它在句子中的其他单词)。然而,解码器是按顺序工作的,并且只能注意它已经翻译过的句子中的单词。例如,当我们预测了翻译目标的前三个单词时,我们将它们提供给解码器,然后解码器使用编码器的所有输出来尝试预测第四个单词。
-为了在训练过程中加快速度(当模型可以访问目标句子时),解码器会被输入整个目标,但不允许获取到要翻译的单词(如果它在尝试预测位置2的单词时可以访问位置2的单词,解码器就会偷懒,直接输出那个单词,从而无法学习到正确的语言关系!)。例如,当试图预测第4个单词时,注意力层只能获取位置1到3的单词。
+为了在训练过程中加快速度(当模型可以访问目标句子时),会将整个目标输入解码器,但不允许获取到要翻译的单词(如果它在尝试预测位置 2 的单词时可以访问位置 2 的单词,解码器就会偷懒,直接输出那个单词,从而无法学习到正确的语言关系!)。例如,当试图预测第 4 个单词时,注意力层只能获取位置 1 到 3 的单词。
-最初的Transformer架构如下所示,编码器位于左侧,解码器位于右侧:
+最初的 Transformer 架构如下所示,编码器位于左侧,解码器位于右侧:


-注意,解码器块中的第一个注意力层关联到解码器的所有(过去的)输入,但是第二注意力层使用编码器的输出。因此,它可以访问整个输入句子,以最好地预测当前单词。这是非常有用的,因为不同的语言可以有语法规则将单词按不同的顺序排列,或者句子后面提供的一些上下文可能有助于确定给定单词的最佳翻译。
+注意,解码器块中的第一个注意力层关联到解码器的所有(过去的)输入,但是第二个注意力层只使用编码器的输出。因此,它在预测当前单词时,可以使用整个句子的信息。这是非常有用的,因因为不同的语言可以有把词放在不同顺序的语法规则,或者句子后面提供的一些上下文可能有助于确定给定单词的最佳翻译。
-也可以在编码器/解码器中使用*注意力遮罩层*,以防止模型注意某些特殊单词。例如,在批处理句子时,填充特殊词使所有句子的长度一致。
+也可以在编码器/解码器中使用*attention mask(注意力掩码层)*,以防止模型关注到某些特殊单词。例如,用于在批量处理句子时使所有输入长度一致的特殊填充词。
-## 架构与参数 [[架构与参数]]
+## architecture(架构)与 checkpoints(权重参数又称检查点) [[architecture(架构)与 checkpoints(权重参数又称检查点)]]
-在本课程中,当我们深入探讨Transformers模型时,您将看到
-架构、参数和模型
-。 这些术语的含义略有不同:
+在本课程中,当我们深入探讨 Transformers 模型时,你将看到架构、参数和模型。这些术语的含义略有不同:
-* **架构**: 这是模型的骨架 -- 每个层的定义以及模型中发生的每个操作。
-* **Checkpoints**: 这些是将在给架构中结构中加载的权重。
-* **模型**: 这是一个笼统的术语,没有“架构”或“参数”那么精确:它可以指两者。为了避免歧义,本课程使用将使用架构和参数。
+* **architecture(架构)**:这是模型的骨架 —— 每个层的定义以及模型中发生的每个操作。
+* **Checkpoints(权重参数又称检查点)**:这些是将在给架构中结构中加载的权重参数,是一些具体的数值。
+* **Model(模型)**:这是一个笼统的术语,没有“架构”或“参数”那么精确:它可以指两者。为了避免歧义,本课程使用将使用架构和参数。
-例如,BERT是一个架构,而 `bert-base-cased`, 这是谷歌团队为BERT的第一个版本训练的一组权重参数,是一个参数。我们可以说“BERT模型”和"`bert-base-cased`模型."
+例如,BERT 是一个架构,而 `bert-base-cased` ,这是谷歌团队为 BERT 的第一个版本训练的一组权重参数,是一个参数。我们可以说“BERT 模型”和“ `bert-base-cased` 模型。”
diff --git a/chapters/zh-CN/chapter1/5.mdx b/chapters/zh-CN/chapter1/5.mdx
index 64b30d2d7..ee388deba 100644
--- a/chapters/zh-CN/chapter1/5.mdx
+++ b/chapters/zh-CN/chapter1/5.mdx
@@ -7,16 +7,16 @@
-“编码器”模型指仅使用编码器的Transformer模型。在每个阶段,注意力层都可以获取初始句子中的所有单词。这些模型通常具有“双向”注意力,被称为自编码模型。
+编码器模型仅使用 Transformer 模型的编码器部分。在每次计算过程中,注意力层都能访问整个句子的所有单词,这些模型通常具有“双向”(向前/向后)注意力,被称为自编码模型。
-这些模型的预训练通常围绕着以某种方式破坏给定的句子(例如:通过随机遮盖其中的单词),并让模型寻找或重建给定的句子。
+这些模型的预训练通常会使用某种方式破坏给定的句子(例如:通过随机遮盖其中的单词),并让模型寻找或重建给定的句子。
-“编码器”模型最适合于需要理解完整句子的任务,例如:句子分类、命名实体识别(以及更普遍的单词分类)和阅读理解后回答问题。
+“编码器”模型适用于需要理解完整句子的任务,例如:句子分类、命名实体识别(以及更普遍的单词分类)和阅读理解后回答问题。
该系列模型的典型代表有:
-- [ALBERT](https://huggingface.co/transformers/model_doc/albert.html)
-- [BERT](https://huggingface.co/transformers/model_doc/bert.html)
-- [DistilBERT](https://huggingface.co/transformers/model_doc/distilbert.html)
-- [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html)
-- [RoBERTa](https://huggingface.co/transformers/model_doc/roberta.html)
+- [ALBERT](https://huggingface.co/transformers/model_doc/albert)
+- [BERT](https://huggingface.co/transformers/model_doc/bert)
+- [DistilBERT](https://huggingface.co/transformers/model_doc/distilbert)
+- [ELECTRA](https://huggingface.co/transformers/model_doc/electra)
+- [RoBERTa](https://huggingface.co/transformers/model_doc/roberta)
diff --git a/chapters/zh-CN/chapter1/6.mdx b/chapters/zh-CN/chapter1/6.mdx
index 450d827f1..2d5006304 100644
--- a/chapters/zh-CN/chapter1/6.mdx
+++ b/chapters/zh-CN/chapter1/6.mdx
@@ -7,16 +7,15 @@
-“解码器”模型通常指仅使用解码器的Transformer模型。在每个阶段,对于给定的单词,注意力层只能获取到句子中位于将要预测单词前面的单词。这些模型通常被称为自回归模型。
+“解码器”模型仅使用 Transformer 模型的解码器部分。在每个阶段,对于给定的单词,注意力层只能获取到句子中位于将要预测单词前面的单词。这些模型通常被称为自回归模型。
“解码器”模型的预训练通常围绕预测句子中的下一个单词进行。
-这些模型最适合于涉及文本生成的任务。
+这些模型最适合处理文本生成的任务。
该系列模型的典型代表有:
-
-- [CTRL](https://huggingface.co/transformers/model_doc/ctrl.html)
-- [GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)
-- [GPT-2](https://huggingface.co/transformers/model_doc/gpt2.html)
-- [Transformer XL](https://huggingface.co/transformers/model_doc/transfor-xl.html)
+- [CTRL](https://huggingface.co/transformers/model_doc/ctrl)
+- [GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)
+- [GPT-2](https://huggingface.co/transformers/model_doc/gpt2)
+- [Transformer XL](https://huggingface.co/transformers/model_doc/transfor-xl)
diff --git a/chapters/zh-CN/chapter1/7.mdx b/chapters/zh-CN/chapter1/7.mdx
index 5e8b7c084..010e3af72 100644
--- a/chapters/zh-CN/chapter1/7.mdx
+++ b/chapters/zh-CN/chapter1/7.mdx
@@ -1,4 +1,4 @@
-# 序列到序列模型 [[序列到序列模型]]
+# 编码器-解码器模型 [[编码器-解码器模型]]
-编码器-解码器模型(也称为序列到序列模型)同时使用Transformer架构的编码器和解码器两个部分。在每个阶段,编码器的注意力层可以访问初始句子中的所有单词,而解码器的注意力层只能访问位于输入中将要预测单词前面的单词。
+编码器-解码器模型(也称为序列到序列模型)同时使用 Transformer 架构的编码器和解码器两个部分。在每个阶段,编码器的注意力层可以访问输入句子中的所有单词,而解码器的注意力层只能访问位于输入中将要预测单词前面的单词。
-这些模型的预训练可以使用训练编码器或解码器模型的方式来完成,但通常涉及更复杂的内容。例如,[T5](https://huggingface.co/t5-base)通过将文本的随机跨度(可以包含多个单词)替换为单个特殊单词来进行预训练,然后目标是预测该掩码单词替换的文本。
+这些模型的预训练可以使用训练编码器或解码器模型的方式来完成,但通常会更加复杂。例如, [T5](https://huggingface.co/t5-base) 通过用单个掩码特殊词替换随机文本范围(可能包含多个词)进行预训练,然后目标是预测被遮盖单词原始的文本。
序列到序列模型最适合于围绕根据给定输入生成新句子的任务,如摘要、翻译或生成性问答。
该系列模型的典型代表有:
-- [BART](https://huggingface.co/transformers/model_doc/bart.html)
-- [mBART](https://huggingface.co/transformers/model_doc/mbart.html)
-- [Marian](https://huggingface.co/transformers/model_doc/marian.html)
-- [T5](https://huggingface.co/transformers/model_doc/t5.html)
+- [BART](https://huggingface.co/transformers/model_doc/bart)
+- [mBART](https://huggingface.co/transformers/model_doc/mbart)
+- [Marian](https://huggingface.co/transformers/model_doc/marian)
+- [T5](https://huggingface.co/transformers/model_doc/t5)
diff --git a/chapters/zh-CN/chapter1/8.mdx b/chapters/zh-CN/chapter1/8.mdx
index 641590288..0929d80f8 100644
--- a/chapters/zh-CN/chapter1/8.mdx
+++ b/chapters/zh-CN/chapter1/8.mdx
@@ -7,9 +7,9 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/zh-CN/chapter1/section8.ipynb"},
]} />
-如果您打算在正式的项目中使用经过预训练或经过微调的模型。请注意:虽然这些模型是很强大,但它们也有局限性。其中最大的一个问题是,为了对大量数据进行预训练,研究人员通常会搜集所有他们能找到的内容,中间可能夹带一些意识形态或者价值观的刻板印象。
+如果你打算在正式的项目中使用经过预训练或经过微调的模型。请注意:虽然这些模型是很强大,但它们也有局限性。其中最大的一个问题是,为了对大量数据进行预训练,研究人员通常会搜集所有他们能找到的所有文字内容,中间可能夹带一些意识形态或者价值观的刻板印象。
-为了快速解释清楚这个问题,让我们回到一个使用BERT模型的pipeline的例子:
+为了快速解释清楚这个问题,让我们回到一个使用 BERT 模型的 pipeline 的例子:
```python
from transformers import pipeline
@@ -26,6 +26,6 @@ print([r["token_str"] for r in result])
['lawyer', 'carpenter', 'doctor', 'waiter', 'mechanic']
['nurse', 'waitress', 'teacher', 'maid', 'prostitute']
```
-当要求模型填写这两句话中缺少的单词时,模型给出的答案中,只有一个与性别无关(服务员/女服务员)。其他职业通常与某一特定性别相关,妓女最终进入了模型中与“女人”和“工作”相关的前五位。尽管BERT是使用经过筛选和清洗后,明显中立的数据集上建立的的Transformer模型,而不是通过从互联网上搜集数据(它是在[Wikipedia 英文](https://huggingface.co/datasets/wikipedia)和[BookCorpus](https://huggingface.co/datasets/bookcorpus)数据集)。
+当要求模型填写这两句话中缺少的单词时,模型给出的答案中,只有一个与性别无关(服务员/女服务员)。其他职业通常与某一特定性别相关,妓女最终进入了模型中与“女人”和“工作”相关的前五位。尽管 BERT 是少数使用经过筛选和清洗后,并且看似中立的数据集上建立的的 Transformer 模型,而不是通过从互联网上搜集数据(它使用的是 [Wikipedia 英文](https://huggingface.co/datasets/wikipedia) 和 [BookCorpus](https://huggingface.co/datasets/bookcorpus) 数据集),但是这种情况还是发生了。
-因此,当您使用这些工具时,您需要记住,使用的原始模型的时候,很容易生成性别歧视、种族主义或恐同内容。这种固有偏见不会随着微调模型而使消失。
\ No newline at end of file
+因此,当你使用这些工具时,你需要记住,使用的原始模型的时候,很容易生成性别歧视、种族主义或恐同内容。这种固有偏见不会随着微调模型而使消失。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter1/9.mdx b/chapters/zh-CN/chapter1/9.mdx
index 286a98fed..27061d5a6 100644
--- a/chapters/zh-CN/chapter1/9.mdx
+++ b/chapters/zh-CN/chapter1/9.mdx
@@ -5,12 +5,12 @@
classNames="absolute z-10 right-0 top-0"
/>
-在本章中,您了解了如何使用来自🤗Transformers的函数pipeline()处理不同的NLP任务。您还了解了如何在模型中心(hub)中搜索和使用模型,以及如何使用推理API直接在浏览器中测试模型。
+在本章中,你了解了如何使用来自🤗Transformers 的高级函数 `pipeline()` 处理不同的 NLP 任务。你还了解了如何在模型中心(hub)中搜索和使用模型,以及如何使用推理 API 直接在浏览器中测试模型。
-我们讨论了Transformer模型如何在应用层上工作,并讨论了迁移学习和微调的重要性。您可以使用完整的体系结构,也可以仅使用编码器或解码器,具体取决于您要解决的任务类型。下表总结了这一点:
+我们从最终的效果的角度讨论了 Transformer 模型的工作方式,并讨论了迁移学习和微调的重要性。一个关键的收获是:你可以使用完整的体系结构,也可以仅使用编码器或解码器,具体取决于你要解决的任务类型。下表总结了这一点:
| 模型 | 示例 | 任务|
| ---- | ---- |----|
-| 编码器 | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa |句子分类、命名实体识别、从文本中提取答案|
-| 解码器 | CTRL, GPT, GPT-2, Transformer XL |文本生成|
-| 编码器-解码器 | BART, T5, Marian, mBART |文本摘要、翻译、生成问题的回答|
\ No newline at end of file
+| 编码器 | ALBERT,BERT,DistilBERT,ELECTRA,RoBERTa |句子分类、命名实体识别、抽取式问答(从文本中提取答案)|
+| 解码器 | CTRL,GPT,GPT-2,Transformer XL |文本生成|
+| 编码器-解码器 | BART,T5,Marian,mBART |文本摘要、翻译、生成式问答(生成问题的回答类似 chatgpt)|
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter2/1.mdx b/chapters/zh-CN/chapter2/1.mdx
index 4f7f407bc..01f4c1523 100644
--- a/chapters/zh-CN/chapter2/1.mdx
+++ b/chapters/zh-CN/chapter2/1.mdx
@@ -5,18 +5,19 @@
classNames="absolute z-10 right-0 top-0"
/>
-正如你在 [Chapter 1](/course/chapter1),中看到的那样,Transformers模型通常非常大。对于数以百万计到数千万计数十亿的参数,训练和部署这些模型是一项复杂的任务。此外,由于几乎每天都在发布新模型,而且每种模型都有自己的实现,因此尝试它们绝非易事。
+正如你在 [第一章](/course/chapter1) ,中看到的那样,Transformers 模型通常规模庞大。包含数以百万计到数千万计数十亿的参数,训练和部署这些模型是一项复杂的任务。再者,新模型的推出几乎日新月异,而每种模型都有其独特的实现方式,尝试全部模型绝非易事。
-创建🤗 Transformers库就是为了解决这个问题。它的目标是提供一个API,通过它可以加载、训练和保存任何Transformer模型。这个库的主要特点是:
-- **易于使用**:下载、加载和使用最先进的NLP模型进行推理只需两行代码即可完成。
-- **灵活**:所有模型的核心都是简单的PyTorch **nn.Module** 或者 TensorFlow **tf.kears.Model**类,可以像在其各自的机器学习 (ML) 框架中的任何其他模型一样方便地进行处理。
-- **简单**:库中几乎没有任何抽象。 “All in one file”(所有代码在一个文件中)是一个核心概念:模型的前向传播完全定义在一个文件中,因此代码本身易于理解和修改
+🤗 Transformers 库应运而生,就是为了解决这个问题。它的目标是提供一个统一的 API 接口,通过它可以加载、训练和保存任何 Transformer 模型。该库的主要特点有:
+- **易于使用**:仅需两行代码,就能下载、加载并使用先进的 NLP 模型进行推理。
+- **灵活**:在本质上,所有的模型都是简单的 PyTorch nn.Module 或 TensorFlow tf.keras.Model 类,并可像在各自的机器学习(ML)框架中处理其他模型一样处理它们。
+- **简单**:该库几乎没有进行任何抽象化。🤗 Transformers 库一个核心概念是“全在一个文件中”:模型的前向传播完全在一个文件中定义,这使得代码本身易于理解和修改。
-最后一个特性使🤗 Transformers与其他ML库截然不同。这些模型不是基于通过文件共享的模块构建的;相反,每一个模型都有自己的网络结构(layers)。除了使模型更加容易接受和更容易理解,这还允许你轻松地在一个模型上实验,而且不影响其他模型。
+最后一个特性使🤗 Transformers 与其他 ML 库截然不同。模型并非建立在跨越多个代码文件共享的模块上;相反,每一个模型都有自己的层次结构。除了使模型更加容易接受和更容易理解,这还允许你轻松地在一个模型上实验,而且不影响其他模型。
-本章将从一个端到端的示例开始,在该示例中,我们一起使用模型和*tokenizer*分词器来复制[Chapter 1](/course/chapter1)中引入的函数`pipeline()`. 接下来,我们将讨论模型API:我们将深入研究模型和配置类,并向您展示如何加载模型以及如何将数值输入处理为输出预测。
+本章将从一个端到端(从输入端到输出端)的示例开始,在该示例中,我们一起使用模型和 tokenizer 来复刻 [第一章](/course/chapter1) 中看到的 `pipeline()` 函数。接下来,我们将讨论 `Model` API:我们将深入研究 `Model` 类和 `Config` 类,并向你展示如何加载模型,以及它如何将输入处理为输出。
+
+然后我们来看看 `tokenizer` API,它是 `pipeline()` 函数的另一个重要组成部分。在 `pipeline()` 中 `Tokenizer` 负责第一步和最后一步的处理,将文本转换到神经网络的输入,以及在需要时将其转换回文本。最后,我们将向你展示如何处理将多个句子整理为一个 batch 发送给模型,然后我们将更深入地研究 `tokenizer()` 函数。
-接下来,我们将介绍 *tokenizer* API,它是 `pipeline()` 函数的另一个主要组件。*tokenizer* 负责第一个和最后一个处理步骤,处理从文本到神经网络数值输入的转换,以及在需要时将数值转换回文本。最后,我们将向您展示如何处理将多个句子作为一个准备好的批次发送到模型中,然后通过更深入地了解高级 `tokenizer()` 函数来总结所有内容。
-⚠️ 为了从Model Hub和🤗Transformers的所有可用功能中获益,我们建议创建帐户.
+⚠️ 为了充分利用 Model Hub 和🤗 Transformers 提供的所有功能,我们建议你创建一个账户。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter2/2.mdx b/chapters/zh-CN/chapter2/2.mdx
index c0242bb79..da9a4b5fe 100644
--- a/chapters/zh-CN/chapter2/2.mdx
+++ b/chapters/zh-CN/chapter2/2.mdx
@@ -1,6 +1,6 @@
-# 管道的内部 [[管道的内部]]
+# Pipeline 的内部 [[Pipeline 的内部]]
{#if fw === 'pt'}
@@ -23,7 +23,7 @@
{/if}
-这是第一部分,根据您使用PyTorch或者TensorFlow,内容略有不同。点击标题上方的平台,选择您喜欢的平台!
+这是第一部分,根据你使用 PyTorch 或者 TensorFlow,内容略有不同。点击标题上方的平台,选择你喜欢的平台!
{#if fw === 'pt'}
@@ -32,7 +32,7 @@
{/if}
-让我们从一个完整的示例开始,看看在[Chapter 1](/course/chapter1)中执行以下代码时在幕后发生了什么
+让我们从一个完整的示例开始,看看在 [第一章](/course/chapter1) 中执行以下代码时在幕后发生了什么
```python
from transformers import pipeline
@@ -46,37 +46,36 @@ classifier(
)
```
-获得:
+获得如下输出:
```python out
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
```
-正如我们在[Chapter 1](/course/chapter1)中看到的,这个 pipeline 集成了三个步骤:预处理、模型推理和后处理:
+正如我们在 [第一章](/course/chapter1) 中看到的,这个 pipeline 集成了三个步骤:预处理、模型计算和后处理:


-让我们快速浏览一下这些内容。
+让我们先简单了解一下这三个步骤。
-## 使用分词器进行预处理 [[使用分词器进行预处理]]
+## 使用 tokenizer( tokenizer )进行预处理 [[使用 tokenizer( tokenizer )进行预处理]]
-与其他神经网络一样,Transformer模型无法直接处理原始文本, 因此pipeline的第一步是将文本输入转换为模型能够理解的数字。 为此,我们使用*tokenizer*(分词器),负责:
+与其他神经网络一样,Transformer 模型无法直接处理原始文本,因此我们管道的第一步是将文本输入转换为模型能够理解的数字。为此,我们使用 tokenizer( tokenizer ),它将负责:
-- 将输入拆分为单词、子单词或符号(如标点符号),称为标记(*token*)
-- 将每个标记(token)映射到一个整数
-- 添加其他可能对模型有用的输入:例如,位置编码等信息。
-- - 位置编码:指示每个词元在句子中的位置。
+- 将输入拆分为单词、子单词或符号(如标点符号),称为 **token**(标记)
+- 将每个标记(token)映射到一个数字,称为 **input ID**(inputs ID)
+- 添加模型需要的其他输入,例如特殊标记(如 `[CLS]` 和 `[SEP]` )
+- - 位置编码:指示每个标记在句子中的位置。
- - 段落标记:区分不同段落的文本。
- - 特殊标记:例如 [CLS] 和 [SEP] 标记,用于标识句子的开头和结尾。
+在使用模型时所有这些预处理都需要与模型预训练时的方式完全相同,因此我们首先需要从 [Model Hub](https://huggingface.co/models) 中下载这些信息。为此,我们使用 `AutoTokenizer` 类和它的 `from_pretrained()` 方法,并输入我们模型 checkpoint 的名称,它将自动获取与模型的 tokenizer 相关联的数据,并对其进行缓存(因此只有在你第一次运行下面的代码时才会下载)。
-所有预处理都需要以与模型预训练时完全相同的方式完成(保持分词方式的一致性非常重要,可以确保模型的性能和准确性),因此我们首先需要从[Model Hub](https://huggingface.co/models)中下载这些信息。为此,我们使用`AutoTokenizer`类及其`from_pretrained()`方法。使用我们模型的检查点名称,它将自动获取与模型的标记器相关联的数据,并对其进行缓存(因此只有在您第一次运行下面的代码时才会下载)。
-
-因为`sentiment-analysis`(情绪分析)Pipeline的默认检查点是`distilbert-base-uncased-finetuned-sst-2-english`(你可以看到它的模型介绍页[here](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)),我们运行以下程序:
+`sentiment-analysis` (情绪分析)管道默认的 checkpoint 是 `distilbert-base-uncased-finetuned-sst-2-english` (你可以在 [这里](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) )看到它的模型卡片,我们运行以下代码:
```python
from transformers import AutoTokenizer
@@ -85,11 +84,11 @@ checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
```
-一旦我们有了tokenizer,就可以直接将句子传递给它,然后我们会得到一个字典,它包含了可以输入到模型的数据。接下来,我们只需要将输入 ID 列表转换为张量即可。
+当我们有了 tokenizer,我们就可以直接将我们的句子传递给它,我们就会得到一个 `input ID(inputs ID)` 的列表!剩下要做的唯一一件事就是将 input ID 列表转换为 tensor(张量)。
-使用 🤗 Transformers 时,您无需担心它背后的机器学习框架,它可以是 PyTorch、TensorFlow或 Flax。不过,Transformer 模型只接受*张量*作为输入。如果您不熟悉张量,可以把它看作 NumPy 数组。NumPy 数组可以是标量 (0D)、向量 (1D)、矩阵 (2D) 或更高维度的数组,本质上就是一个张量。其他机器学习框架中的张量也类似,通常与 NumPy 数组一样容易创建。
+你在使用🤗 Transformers 时,您无需担心它背后的机器学习框架;它可能是 PyTorch 或 TensorFlow,或 Flax。但是,Transformers 模型只接受 `tensor(张量)` 作为输入。如果这是你第一次听说 tensor,你可以把它们想象成 NumPy 数组。NumPy 数组可以是标量(0D)、向量(1D)、矩阵(2D)或具有更多维度。这些都可以称为 tensor;其他 ML 框架的 tensor 使用方法也类似,通常与 NumPy 数组一样容易创建。
-要指定要返回的张量类型(PyTorch、TensorFlow或plain NumPy),我们使用`return_tensors`参数:
+我们可以使用 `return_tensors` 参数指定我们想要得到的 tensor 的类型(PyTorch、TensorFlow 或纯 NumPy),
{#if fw === 'pt'}
```python
@@ -111,11 +110,11 @@ print(inputs)
```
{/if}
-暂时不用担心填充和截断,我们稍后会解释它们。这里主要需要记住的是,您可以传入单个句子或句子列表,并指定想要返回的张量类型(如果不指定类型,则会返回嵌套列表)。
+现在不要担心 padding(填充)和 truncation(截断);我们稍后会解释这些。这里要记住的是,你可以传递一个句子或一组句子,还可以指定要返回的 tensor 类型(如果没有传递类型,默认返回的是 python 中的 list 格式)。
{#if fw === 'pt'}
-以下是PyTorch张量的结果:
+以下是 PyTorch 张量的结果:
```python out
{
@@ -131,7 +130,7 @@ print(inputs)
```
{:else}
-以下是TensorFlow张量的结果:
+以下是 TensorFlow 张量的结果:
```python out
{
@@ -149,11 +148,13 @@ print(inputs)
```
{/if}
-输出本身是一个包含两个键的字典,`input_ids` 和 `attention_mask`。 `input_ids` 包含两行整数(每个句子一行),它们是每个句子中各个 token 的唯一标识符。我们将在本章后面解释 `attention_mask` 的作用。
-## 模型推理 [[模型推理]]
+输出是一个包含两个键, `input_ids` 和 `attention_mask` 。 `input_ids` 包含两行整数(每个句子一行),它们是每个句子中 token 的 ID。我们将在本章后面解释什么是 `attention_mask` 。
+
+## 探索模型 [[探索模型]]
{#if fw === 'pt'}
-我们可以像使用*tokenizer*一样下载预训练模型。🤗 Transformers提供了一个`AutoModel`类,该类也有`from_pretrained()`方法:
+
+我们可以像使用 tokenizer 一样下载预训练模型。Transformers 提供了一个 `AutoModel` 类,它也有一个 `from_pretrained()` 方法:
```python
from transformers import AutoModel
@@ -162,33 +163,36 @@ checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
```
{:else}
-我们可以像使用*tokenizer*一样下载预训练模型。🤗 Transformers提供了一个`AutoModel`类,该类也有`from_pretrained()`方法:
+
+我们可以像使用 tokenizer 一样下载预训练模型。Transformers 提供了一个 `TFAutoModel` 类,它也有一个 `from_pretrained()` 方法:
```python
-from transformers import AutoModel
+from transformers import TFAutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = AutoModel.from_pretrained(checkpoint)
+model = TFAutoModel.from_pretrained(checkpoint)
```
{/if}
-在这段代码中,我们加载了之前在 pipeline 中使用的相同检查点(实际上它应该已经被缓存)并用它实例化了一个模型。
+在这段代码中,我们将之前在 pipeline 中使用的 checkpoint(实际上应该已经被缓存了)下载下来,并用它实例化了一个模型。
+
+这个模型只包含基本的 Transformer 模块:输入一些句子,它输出我们将称为 `hidden states(隐状态)` ,也被称为特征。每个输入,我们都可以获取一个高维向量,代表 Transformer 模型对该输入的上下文理解。
+
+如果这有些难以理解,不要担心。我们以后再解释。
-这个架构只包含基本的 Transformer 模块:给定一些输入,它会输出我们称之为*隐藏状态 (hidden states)* 的内容,也称为*特征 (features)*。对于每个模型输入,我们将检索一个高维向量,该向量表示 **Transformer 模型对该输入的上下文理解**。
-如果你现在对隐藏状态和上下文理解的概念还不理解,也不用担心,我们会在后续的内容中详细解释这些概念,并举例说明它们是如何工作的。
+这些隐状态本身就很有用,它们被称为模型头(head),通常是模型另一部分的输入。在 [第一章](/course/chapter1) 中,可以使用相同的体系结构的模型执行不同的任务,这是因为每个任务都有一个对应的模型头。
-虽然这些隐藏状态本身可能很有用,但它们通常作为下游任务的输入,例如模型*头部(head)*的输入。在[Chapter 1](/course/chapter1)中,我们介绍了可以使用相同的架构执行不同的任务,但每个任务都会有不同的头部与之关联。
-### 高维向量? [[高维向量?]]
+### 高维向量?[[高维向量?]]
-Transformers模块的向量输出通常较大。它通常有三个维度:
+Transformers 模块的矢量输出通常较大。它通常有三个维度:
-- **批次大小(Batch size)**: 一次处理的序列数(在我们的示例中为2)。
-- **序列长度 (Sequence length)**: 序列的数值表示的长度(在我们的示例中为16)。
-- **隐藏层维度(Hidden size)**: 每个模型输入的向量维度。
+- **Batch size**(批次大小):一次处理的序列数(在我们的示例中为 2)。
+- **Sequence length**(序列长度):表示序列(句子)的长度(在我们的示例中为 16)。
+- **Hidden size**(隐藏层大小):每个模型输入的向量维度。
-之所以说它是“高维度”的,是因为最后一个维度值。隐藏层维度可以非常大(对于较小的模型768 是常见的,而在较大的模型中,它可以达到 3072 或更多)。
+之所以说它是“高维度”的,是因为最后一个维度值。隐藏层维度可以非常大(对于较小的模型,常见的是 768,对于较大的模型,这个数字可以达到 3072 或更多)。
-我们可以通过将预处理后的输入数据传递给模型来验证这一点:
+如果我们将预处理的之后的值输入到模型中,我们会得到以下输入:
{#if fw === 'pt'}
```python
@@ -210,37 +214,38 @@ print(outputs.last_hidden_state.shape)
```
{/if}
-🤗 Transformers 模型的输出类似于 `namedtuple` 或字典。您可以通过属性 (就像我们之前所做的那样) 或键 (例如` outputs["last_hidden_state"]`) 来访问元素,甚至可以通过索引访问元素 (例如 `outputs[0]`),前提是您知道要查找的内容的位置。
-### 模型头:数值的意义 [[模型头:从数值中提取意义]]
+注意,🤗 Transformers 模型的输出有些像 `namedtuple` 或词典。你可以通过使用“.”+属性(就像我们在上面示例中所做的那样)或键( `outputs["last_hidden_state"]` )访问元素,如果你确切知道要查找的内容的位置( `outputs[0]` ),也可以通过索引访问元素。
-模型头接收隐藏状态的高维向量作为输入,并将其映射到另一个维度。它们通常由一个或几个线性层构成:
+### 模型头:理解数字的意义 [[模型头:理解数字的意义]]
+
+Transformers 模型的输出会直接发送到模型头进行处理。
+
+模型头通常由一个或几个线性层组成,它的输入是隐状态的高维向量,它会并将其投影到不同的维度。


-Transformers模型的输出直接发送到模型头进行处理。
+在此图中,模型由其嵌入层和后续层表示。嵌入层将 tokenize 后输入中的每个 inputs ID 转换为表示关联 token 的向量。后续层使用注意机制操纵这些向量,生成句子的最终表示。
-在此图中,模型由其嵌入层和后续层表示。嵌入层将标记化输入中的每个输入ID转换为表示关联标记(token)的向量。后续层使用注意机制操纵这些向量,以生成句子的最终表示。
+Transformers 中有许多不同的体系结构,每种体系结构都是围绕处理特定任务而设计的。以下是一个非详尽的列表:
-🤗 Transformers中有许多不同的体系结构,每种体系结构都是围绕处理特定任务而设计的。以下是一个非详尽的列表:
-
-- `*Model` (retrieve the hidden states)
-- `*ForCausalLM`
-- `*ForMaskedLM`
-- `*ForMultipleChoice`
-- `*ForQuestionAnswering`
-- `*ForSequenceClassification`
-- `*ForTokenClassification`
+- `*Model` (隐状态检索)
+- `*ForCausalLM`
+- `*ForMaskedLM`
+- `*ForMultipleChoice`
+- `*ForQuestionAnswering`
+- `*ForSequenceClassification`
+- `*ForTokenClassification`
- 以及其他 🤗
{#if fw === 'pt'}
-对于我们的示例,我们需要一个带有序列分类头部的模型(能够将句子分类为肯定或否定)。 因此,我们实际上不会使用 `AutoModel` 类,而是使用 `AutoModelForSequenceClassification`(`AutoModel` 类只包含基本的 Transformer 模块,它可以提取文本的特征,但不能进行分类。
-`AutoModelForSequenceClassification` 类在 `AutoModel` 的基础上添加了一个序列分类头部,可以将文本分类为不同的类别。
-):
+以情感分类为例,我们需要一个带有序列分类头的模型(能够将句子分类为积极或消极)。因此,我们不选用 `AutoModel` 类,而是使用 `AutoModelForSequenceClassification` 。也就是说前面写的 `model = AutoModel.from_pretrained(checkpoint)` 并不能得到情感分类任务的结果,因为没有加载 Model head。
+`AutoModelForSequenceClassification` 类在 `AutoModel` 的基础上添加了一个序列分类头部,可以
+将文本分类为不同的类别。
```python
from transformers import AutoModelForSequenceClassification
@@ -249,7 +254,8 @@ model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
```
{:else}
-For our example, we will need a model with a sequence classification head (to be able to classify the sentences as positive or negative). So, we won't actually use the `TFAutoModel` class, but `TFAutoModelForSequenceClassification`:
+
+以情感分类为例,我们需要一个带有序列分类头的模型(能够将句子分类为积极或消极)。因此,我们不选用 `TFAutoModel` 类,而是使用 `TFAutoModelForSequenceClassification` 。也就是说前面写的 model = TFAutoModel.from_pretrained(checkpoint)并不能得到情感分类任务的结果,因为没有加载 Model head。
```python
from transformers import TFAutoModelForSequenceClassification
@@ -260,8 +266,9 @@ outputs = model(inputs)
```
{/if}
-现在,如果我们观察输出的shape,维度将低得多:模型头将我们之前看到的高维向量作为输入,并输出包含两个值的向量(每个标签一个):
-正如您所见,输出向量的尺寸与输入向量相比要小得多。这是因为模型头将输入向量中的信息压缩成两个值,每个标签一个
+如果我们看一下现在输出的形状,其维度会降低很多:模型头接收我们之前看到的高维向量作为输入,并输出包含两个值(每种标签一个)的向量。正如您所见,输出向量的尺寸与输入向量相比要小得多。这是因为模型头将输入向量中的信息压缩成两个值,每个标签一个
+264 ```python 265 ```python:
+
```python
print(outputs.logits.shape)
```
@@ -280,11 +287,11 @@ torch.Size([2, 2])
{/if}
-因为我们只有两个句子和两个标签,所以我们从模型中得到的结果是2 x 2的维度。
+由于我们只有两个句子和两钟标签,所以我们从模型中得到的结果的形状是 2 x 2。
-## 对输出进行后处理 [[对输出进行后处理]]
+## 对输出进行后序处理 [[对输出进行后处理]]
-我们从模型中得到的输出值本身并不一定有意义。我们来看看,
+我们从模型中得到的输出值本身并不一定有意义。我们来看看,
```python
print(outputs.logits)
@@ -303,7 +310,8 @@ tensor([[-1.5607, 1.6123],
```
{/if}
-我们的模型预测第一句为 `[-1.5607, 1.6123]`,第二句为 `[4.1692, -3.3464]`。这些不是概率,而是 *logits*,即模型最后一层输出的原始、未经归一化的分数。为了将其转换为概率,它们需要经过[SoftMax](https://en.wikipedia.org/wiki/Softmax_function)层(所有 🤗 Transformers 模型都输出 logits,因为用于训练的损失函数通常会将最后的激活函数(例如 SoftMax)与实际的损失函数(例如交叉熵)融合在一起。
+我们的模型预测第一句为 `[-1.5607, 1.6123]` ,第二句为 `[ 4.1692, -3.3464]` 。这些不是概率,而是 `logits(对数几率)` ,是模型最后一层输出的原始的、未标准化的分数。要转换为概率,它们需要经过 [SoftMax](https://en.wikipedia.org/wiki/Softmax_function) 层(所有🤗Transformers 模型的输出都是 logits,因为训练时的损失函数通常会将最后的激活函数(如 SoftMax)与实际的损失函数(如交叉熵)融合):
+
{#if fw === 'pt'}
```py
import torch
@@ -333,12 +341,9 @@ tf.Tensor(
```
{/if}
-现在我们可以看到,模型预测第一句为`[0.0402, 0.9598]`,第二句为`[0.9995, 0.0005]`。这些数字代表了模型预测每个类别(否定或肯定)的概率分值。
-
-为了获得每个位置对应的标签,我们可以检查模型配置的`id2label`属性(下一节将对此进行详细介绍):
-为了将这些概率分值转换为可识别的标签(“否定”或“肯定”),我们需要参考模型配置中的 id2label 属性。该属性将每个模型输出的 ID 映射到相应的标签。
-
+现在我们可以看到,模型预测第一句的输出是 `[0.0402, 0.9598]` ,第二句 `[0.9995, 0.0005]` 。这些是可直接使用的概率分数。
+为了获得每个分数对应的标签,我们可以查看模型配置的 `id2label` 属性(下一节将对此进行详细介绍),该属性将每个模型输出的 ID 映射到相应的标签:
```python
model.config.id2label
@@ -348,15 +353,15 @@ model.config.id2label
{0: 'NEGATIVE', 1: 'POSITIVE'}
```
-根据 id2label 属性,我们可以得出以下结论:
+现在我们可以得出结论,模型预测如下:
+- 第一句:消极的概率:0.0402,积极的概率:0.9598
+- 第二句:消极的概率:0.9995,积极的概率:0.0005
-- 第一句:否定:0.0402,肯定:0.9598
-- 第二句:否定:0.9995,肯定:0.0005
+我们已经成功地复刻了管道的三个步骤:使用 tokenizer 进行预处理、通过模型传递输入以及后处理!接下来,让我们花一些时间深入了解这些步骤中的每一步。
-至此,我们已经成功完成了文本分类任务的三个步骤:使用*tokenizer*对文本进行预处理;将预处理后的文本输入到模型中;对模型的输出结果进行后处理,并将预测结果转换为可识别的标签。接下来,我们将对这三个步骤进行更详细的解释。
-✏️ **试试看!** 选择两个(或更多)你自己的文本并在管道中运行它们。然后自己复制在这里看到的步骤,并检查是否获得相同的结果!
+✏️ **试试看!** 选择两个(或更多)句子并分别在 `sentiment-analysis` 管道和自己实现的管道中运行它们。看一看是否获得的结果是不是相同的!
diff --git a/chapters/zh-CN/chapter2/3.mdx b/chapters/zh-CN/chapter2/3.mdx
index 47a19592e..e47c88240 100644
--- a/chapters/zh-CN/chapter2/3.mdx
+++ b/chapters/zh-CN/chapter2/3.mdx
@@ -29,48 +29,50 @@
{/if}
{#if fw === 'pt'}
-在本节中,我们将更详细地了解如何创建和使用模型。我们将使用
-AutoModel类,它极大程度的方便您从*checkpoint*实例化任何模型。
-AutoModel 类与其相关类本质上是对库中各种模型的简化包装。其智能之处在于能够自动识别检查点所对应的模型架构,并据此实例化相应的模型。
+在本节中,我们将更详细地了解如何创建和使用模型。我们将使用 `AutoModel` 类,当你希望从 checkpoint 实例化任何模型时,使用它非常方便。
+
+`AutoModel` 类及其所有的相关类其实就是对库中可用的各种模型的简单包装。它是一个智能的包装,因为它可以自动猜测你的 checkpoint 适合的模型架构,然后实例化一个具有相同架构的模型。
{:else}
-在本节中,我们将更详细地了解如何创建和使用模型。我们将使用
-AutoModel类,它极大程度的方便您从*checkpoint*实例化任何模型。
-AutoModel 类与其相关类本质上是对库中各种模型的简化包装。其智能之处在于能够自动识别检查点所对应的模型架构,并据此实例化相应的模型。
+在本节中,我们将更详细地了解如何创建和使用模型。我们将使用 `TFAutoModel` 类,当你希望从 checkpoint 实例化任何模型时,这非常方便。
+
+`TFAutoModel` 类及其所有的相关类其实就是对库中可用的各种模型的简单包装。它是一个智能的包装,因为它可以自动猜测你的 checkpoint 适合的模型架构,然后实例化一个具有相同架构的模型。
{/if}
-如果您知道要使用的模型类型,则可以使用直接定义其体系结构的类。让我们看看这是如何与BERT模型一起工作的。
+然而,如果你知道要使用模型的类型,你可以直接使用其架构相对应的模型类。让我们看看如何使用 BERT 模型。
-## 创建转换器 [[创建转换器]]
+## 创建 Transformer 模型 [[创建 Transformer 模型]]
-初始化BERT模型需要做的第一件事是加载配置对象:
+初始化 BERT 模型需要做的第一件事是加载 `Config` 对象:
{#if fw === 'pt'}
```py
from transformers import BertConfig, BertModel
-# Building the config
+# 初始化 Config 类
config = BertConfig()
-# Building the model from the config
+# 从 Config 类初始化模型
model = BertModel(config)
```
+
{:else}
+
```py
from transformers import BertConfig, TFBertModel
-# Building the config
+# 初始化 Config 类
config = BertConfig()
-# Building the model from the config
+# 从 Config 类初始化模型
model = TFBertModel(config)
```
{/if}
-配置包含许多用于构建模型的属性:
+`config` 中包含许多用于构建模型的属性:
```py
print(config)
@@ -88,12 +90,11 @@ BertConfig {
}
```
-虽然您还没有看到所有这些属性都做了什么,但您应该认识到其中的一些属性:`hidden_size`属性定义了`hidden_states`向量的大小,`num_hidden_layers`定义了Transformer模型的层数。
-
-### 不同的加载方式 [[不同的加载方式]]
+虽然可能你还不知道这些属性的含义,但其中一部分应该比较眼熟: `hidden_size` 属性定义了 `hidden_states(隐状态)` 向量的大小,而 `num_hidden_layers` 定义了 Transformer 模型的层数。
-从默认配置创建模型会使用随机值对其进行初始化:
+### 使用不同的加载方式 [[使用不同的加载方式]]
+使用默认配置创建模型会使用随机值对其进行初始化:
{#if fw === 'pt'}
```py
@@ -102,7 +103,7 @@ from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
-# Model is randomly initialized!
+# 模型已随机初始化!
```
{:else}
```py
@@ -111,18 +112,13 @@ from transformers import BertConfig, TFBertModel
config = BertConfig()
model = TFBertModel(config)
-# Model is randomly initialized!
+# 模型已随机初始化!
```
{/if}
+这个模型是可以运行并得到结果的,但它会输出胡言乱语;它需要先进行训练才能正常使用。我们可以根据手头的任务从头开始训练模型,但正如你在 [第一章](/course/chapter1) 中看到的,这将需要很长的时间和大量的数据,并且产生的碳足迹会对环境产生不可忽视的影响。为了避免不必要的重复工作,能够共享和复用已经训练过的模型是非常重要的。
-该模型可以在这种状态下使用,但会输出胡言乱语;首先需要对其进行训练,我们可以根据手头的任务从头开始训练模型,但正如您在
-[Chapter 1](/course/chapter1)
-所见,这将需要很长的时间和大量的数据,并将产生不可忽视的环境影响。为了避免不必要的重复工作,必须能够共享和重用已经训练过的模型。
-
-
-加载已经训练过的Transformers模型很简单-我们可以使用`from_pretrained()`
-方法:
+加载已经训练过的 Transformers 模型很简单——我们可以使用 `from_pretrained()` 方法:
{#if fw === 'pt'}
```py
@@ -131,7 +127,7 @@ from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
```
-正如您之前看到的,我们可以用等效的`AutoModel`类替换`BertModel`类。从现在开始,我们将这样做,因为这会产生检查点不可知的代码;如果您的代码适用于一个*checkpoint*,那么它应该与另一个*checkpoint*无缝地工作。即使体系结构不同,这也适用,只要检查点是针对类似任务(例如,情绪分析任务)训练的。
+正如你在上一小节看到的,从现在开始,我们会将 `BertModel` 替换为等效的 `AutoModel` 类,这样可以摆脱对 checkpoint 的依赖;如果你的代码适用于一个 checkpoint 那么它就可以在另一个 checkpoint 无缝地工作。即使体系结构不同,这也适用,只要 checkpoint 是针对同类的任务(例如,情绪分析任务)训练的。
{:else}
```py
@@ -140,37 +136,21 @@ from transformers import TFBertModel
model = TFBertModel.from_pretrained("bert-base-cased")
```
-正如您之前看到的,我们可以用等效的`AutoModel`替换`BertModel`类。从现在开始,我们将这样做,因为这会产生检查点不可知的代码;如果您的代码适用于一个*checkpoint*,那么它应该与另一个*checkpoint*无缝地工作。即使体系结构不同,这也适用,只要检查点是针对类似任务(例如,情绪分析任务)训练的。
+正如你在上一小节看到的,从现在开始,我们将用等效的 `TFAutoModel` 类替换 `TFBert` 模型。这样可以摆脱对 checkpoint 的依赖;如果你的代码适用于一个 checkpoint 那么它应该与另一个 checkpoint 无缝地工作。即使体系结构不同,这也适用,只要 checkpoint 是针对类似任务(例如,情绪分析任务)训练的。
{/if}
-在上面的代码示例中,我们没有使用BertConfig,而是通过`bert-base-cased`标识符加载了一个预训练模型。这是一个模型检查点,由`BERT`的作者自己训练;您可以在
-[model card](https://huggingface.co/bert-base-cased)中找到更多细节.
-
-
-
-该模型现在使用*checkpoint*的所有权重进行初始化。它可以直接用于对训练过的任务进行推理,也可以对新任务进行微调。通过预先训练重量而不是从头开始的训练,我们可以很快取得好的效果。
-
-
+在上述代码示例中,我们没有使用 `BertConfig` ,而是通过 `bert-base-cased` 标签加载了一个预训练模型。这是一个由 BERT 的作者训练的模型 checkpoint 权重;你可以在其 [模型卡片](https://huggingface.co/bert-base-cased) 中查看更多详细信息。
-权重已下载并缓存在缓存文件夹中(因此将来对from_pretrained()方法的调用将不会重新下载它们)默认为
-~/.cache/huggingface/transformers
-. 您可以通过设置
-HF_HOME
-环境变量来自定义缓存文件夹。
+现在,此模型已经用 checkpoint 的所有权重进行了初始化。它可以直接用于推理它训练过的任务,也可以在新任务上进行微调。通过使用预训练的权重进行训练,相比于从头开始训练,我们可以迅速获得比较好的结果。
+权重已下载并缓存在缓存文件夹中(因此,未来调用 `from_pretrained()` 方法的调用将不会重新下载它们)默认为 `~/.cache/huggingface/transformers` 。你可以通过设置 `HF_HOME` 环境变量来自定义缓存文件夹。
+加载模型的标识符可以是 Model Hub 上任何模型的标签,只要它与 BERT 架构兼容。可用的 BERT checkpoint 的完整列表可以在 [这里](https://huggingface.co/models?filter=bert) 找到。
-用于加载模型的标识符可以是模型中心Hub上任何模型的标识符,只要它与`BERT`体系结构兼容。可以找到可用的`BERT`*checkpoint*的完整列表
-[here](https://huggingface.co/models?filter=bert)
-.
### 保存模型 [[保存模型]]
-保存模型和加载模型一样简单--我们使用
-save_pretrained()
-方法,类似于
-from_pretrained()
-方法:
+保存模型和加载模型一样简单--我们使用 `save_pretrained()` 方法,该方法类似于 `from_pretrained()` 方法:
```py
model.save_pretrained("directory_on_my_computer")
@@ -192,33 +172,31 @@ config.json tf_model.h5
```
{/if}
-如果你看一下
-config.json
-文件,您将识别构建模型体系结构所需的属性。该文件还包含一些元数据,例如*checkpoint*的来源以及上次保存检查点时使用的🤗 Transformers版本。
+如果你看一下 `config.json` 文件,你会认出构建模型架构所需的属性。这个文件还包含一些元数据,例如 checkpoint 的来源,以及你上次保存 checkpoint 时所使用的 🤗 Transformers 版本。
{#if fw === 'pt'}
-这个 *pytorch_model.bin* 文件就是众所周知的*state dictionary*; 它包含模型的所有权重。这两个文件密切相关;这个配置是了解您的模型架构所必需的,而模型权重则是您模型的参数。
+
+`pytorch_model.bin` 文件被称为 `state dictionary(状态字典)` ;它包含了你的模型的所有权重。这两个文件是相辅相成的;配置文件是构建你的模型架构所必需的,而模型权重就是你的模型参数。
{:else}
-这个 *tf_model.h5* 文件就是众所周知的*state dictionary*; 它包含模型的所有权重。这两个文件密切相关;这个配置是了解您的模型架构所必需的,而模型权重则是您模型的参数。
+
+`tf_model.h5` 文件被称为 `state dictionary(状态字典)` ;它包含了你的模型的所有权重。这两个文件是相辅相成的;配置文件是构建你的模型架构所必需的,而模型权重就是你的模型参数。
{/if}
-### 使用Transformers模型进行推理 [[使用Transformers模型进行推理]]
+### 使用 Transformers 模型进行推理 [[使用 Transformers 模型进行推理]]
-既然您知道了如何加载和保存模型,那么让我们尝试使用它进行一些预测。Transformer模型只能处理数字——分词器生成的数字。但在我们讨论*Tokenizer*之前,让我们先探讨模型接受哪些输入。
+既然你知道了如何加载和保存模型,那么让我们尝试使用它进行一些预测。Transformer 模型只能处理数字——由 tokenizer 转化后的数字。但在我们讨论 tokenizer 之前,让我们探讨一下模型可以接受的输入是什么。
-*Tokenizer*可以将输入转换为适当的框架张量,但为了帮助您了解发生了什么,我们将快速了解在将输入发送到模型之前必须做什么。
+可以将输入转换为适当的框架张量,但为了帮助你了解发生了什么,我们将快速了解在将输入发送到模型之前必须做什么。
-假设我们有几个序列:
+假设我们有几个句子:
```py
sequences = ["Hello!", "Cool.", "Nice!"]
```
-*Tokenizer*将这些转换为词汇表索引,通常称为
-*input IDs*
-. 每个序列现在都是一个数字列表!结果是:
+tokenizer 将这些转换为词汇表索引,通常称为 `input IDs` 。每个句子现在都是一个数字列表!结果输出是:
```py no-format
encoded_sequences = [
@@ -228,15 +206,18 @@ encoded_sequences = [
]
```
-这是一个编码序列的列表:一个嵌套列表(列表的列表)。张量只接受矩形形状(可以想象成矩阵)。这个“数组”已经是矩形形状,因此将其转换为张量很容易:
+这是一个编码序列列表:一个列表列表。张量只接受矩形(形状规则的的列表:每一列元素的数量都相同)。这个数组已经是矩形了,因此将其转换为张量很容易:
{#if fw === 'pt'}
+
```py
import torch
model_inputs = torch.tensor(encoded_sequences)
```
+
{:else}
+
```py
import tensorflow as tf
@@ -246,16 +227,10 @@ model_inputs = tf.constant(encoded_sequences)
### 使用张量作为模型的输入 [[使用张量作为模型的输入]]
-
-
-在模型中使用张量非常简单-我们只需将输入称为模型:
-
+将张量输入给模型非常简单 —— 我们只需调用模型并输入:
```python
output = model(model_inputs)
```
-
-
-
-虽然模型接受许多不同的参数,但只有输入 ID 是必需的。 我们将在后面解释其他参数的作用以及何时需要它们,但首先我们需要仔细研究构建 Transformer 模型可以理解的输入的*tokenizer*。
\ No newline at end of file
+虽然模型接受很多不同的参数,但只有 input IDs 是必需的。我们稍后会解释其他参数的作用以及何时需要它们,但首先我们需要仔细研究一下如何构建 Transformer 模型能理解的输入。
diff --git a/chapters/zh-CN/chapter2/4.mdx b/chapters/zh-CN/chapter2/4.mdx
index f211b3db4..a5569f2aa 100644
--- a/chapters/zh-CN/chapter2/4.mdx
+++ b/chapters/zh-CN/chapter2/4.mdx
@@ -1,6 +1,6 @@
-# 标记器(Tokenizer) [[标记器(Tokenizer)]]
+# Tokenizers [[Tokenizers]]
{#if fw === 'pt'}
@@ -24,30 +24,30 @@
-标记器(Tokenizer)是 NLP 管道的核心组件之一。它们有一个目的:将文本转换为模型可以处理的数据。模型只能处理数字,因此标记器(Tokenizer)需要将我们的文本输入转换为数字数据。在本节中,我们将确切地探讨标记化管道中发生的事情。
+tokenizer 是 NLP 管道的核心组件之一。它们有一个非常明确的目的:将文本转换为模型可以处理的数据。模型只能处理数字,因此 tokenizer 需要将我们的文本输入转换为数字。在本节中,我们将确切地探讨 tokenization 管道中发生的事情。
-在 NLP 任务中,通常处理的数据是原始文本。这是此类文本的示例
+在 NLP 任务中,通常处理的原始数据是文本。这里是一个例子:
```
Jim Henson was a puppeteer
```
-但是,模型只能处理数字,因此我们需要找到一种将原始文本转换为数字的方法。这就是标记器(tokenizer)所做的,并且有很多方法可以解决这个问题。目标是找到最有意义的表示——即对模型最有意义的表示——并且如果可能的话,找到最小的表示。
+但是,模型只能处理数字,因此我们需要找到一种将原始文本转换为数字的方法。这就是 tokenizer 所做的,并且有很多方法可以解决这个问题。目标是找到最有意义的表达方式 —— 即对模型来说最有意义的方式 —— 如果可能,还要找到最简洁的表达方式。
-让我们看一下标记化算法的一些示例,并尝试回答您可能对标记化提出的一些问题。
+让我们看一下 tokenization 算法的一些示例,并尝试回答一些你可能对 tokenization 有的疑问。
-## 基于词的(Word-based) [[基于词的(Word-based)]]
+## 基于单词(Word-based)的 tokenization [[基于单词(Word-based)的 tokenization ]]
-想到的第一种标记器是基于词的(_word-based_).它通常很容易设置和使用,只需几条规则,并且通常会产生不错的结果。例如,在下图中,目标是将原始文本拆分为单词并为每个单词找到一个数字表示:
+想到的第一种 tokenizer 是基于词(word-based)的 tokenization。它通常很容易配置和使用,只需几条规则,并且通常会产生不错的结果。例如,在下图中,目标是将原始文本拆分为单词并为每个单词找到一个数字表示:


-有多种方法可以拆分文本。例如,我们可以通过应用Python的`split()`函数,使用空格将文本标记为单词:
+有多种方法可以拆分文本。例如,我们可以通过使用 Python 的 `split()` 函数,使用空格将文本分割为单词:
```py
tokenized_text = "Jim Henson was a puppeteer".split()
@@ -58,72 +58,72 @@ print(tokenized_text)
['Jim', 'Henson', 'was', 'a', 'puppeteer']
```
-还有一些单词标记器的变体,它们具有额外的标点符号规则。使用这种标记器,我们最终可以得到一些非常大的“词汇表”,其中词汇表由我们在语料库中拥有的独立标记的总数定义。
+此外,还有一些基于单词的 tokenizer 的变体,对标点符号有额外的规则。使用这类 tokenizer,我们最终可以得到一些非常大的“词汇表(vocabulary)”,其中词汇表的大小由我们在语料库中拥有的独立 tokens 的总数确定。
-每个单词都分配了一个 ID,从 0 开始一直到词汇表的大小。该模型使用这些 ID 来识别每个单词。
+每个单词都分配了一个 ID,从 0 开始一直到词汇表的大小。模型使用这些 ID 来识别每个词。
-如果我们想用基于单词的标记器(tokenizer)完全覆盖一种语言,我们需要为语言中的每个单词都有一个标识符,这将生成大量的标记。例如,英语中有超过 500,000 个单词,因此要构建从每个单词到输入 ID 的映射,我们需要跟踪这么多 ID。此外,像“dog”这样的词与“dogs”这样的词的表示方式不同,模型最初无法知道“dog”和“dogs”是相似的:它会将这两个词识别为不相关。这同样适用于其他相似的词,例如“run”和“running”,模型最初不会认为它们是相似的。
+如果我们想用基于单词的 tokenizer 完全覆盖一种语言,我们需要为语言中的每个单词设置一个标识符,这将生成大量的 tokens。例如,英语中有超过 500,000 个单词,因此要构建从每个单词到 ID 的映射,我们需要跟踪这么多 ID。此外,像“dog”这样的词与“dogs”这样的词的表示方式不同,模型最初无法知道“dog”和“dogs”是相似的:它会将这两个词识别为不相关。这同样适用于其他相似的词,例如“run”和“running”,模型最初也不会看到它们的相似性。
-最后,我们需要一个自定义标记(token)来表示不在我们词汇表中的单词。这被称为“未知”标记(token),通常表示为“[UNK]”或"<unk>"。如果你看到标记器产生了很多这样的标记,这通常是一个不好的迹象,因为它无法检索到一个词的合理表示,并且你会在这个过程中丢失信息。制作词汇表时的目标是以这样一种方式进行,即标记器将尽可能少的单词标记为未知标记。
+最后,我们需要一个自定义 token 来表示不在我们词汇表中的单词。这被称为“unknown” token,通常表示为“[UNK]”或“<unk>”。如果你看到 tokenizer 产生了很多这样的 token 这通常是一个不好的迹象,因为它无法检索到一个词的合理表示,并且你会在转化过程中丢失信息。制作词汇表时的其中一个目标是 tokenizer 将尽可能少的单词标记为未知 tokens。
-减少未知标记数量的一种方法是使用更深一层的标记器(tokenizer),即基于字符的(_character-based_)标记器(tokenizer)。
+减少未知 tokens 数量的一种方法是使用更深一层的 tokenizer 即基于字符(character-based)的 tokenizer
-## 基于字符(Character-based) [[基于字符(Character-based)]]
+## 基于字符(Character-based)的 tokenization [[基于字符(Character-based)的 tokenization ]]
-基于字符的标记器(tokenizer)将文本拆分为字符,而不是单词。这有两个主要好处:
+基于字符的 tokenizer 将文本拆分为字符,而不是单词。这有两个主要好处:
- 词汇量要小得多。
-- 词汇外(未知)标记(token)要少得多,因为每个单词都可以从字符构建。
+- unknown tokens (out-of-vocabulary)要少得多,因为每个单词都可以由字符构建。
-但是这里也出现了一些关于空格和标点符号的问题:
+但在此过程中也有一些问题,关于空格和标点符号:
-这种方法也不是完美的。由于现在表示是基于字符而不是单词,因此人们可能会争辩说,从直觉上讲,它的意义不大:每个字符本身并没有多大意义,而单词就是这种情况。然而,这又因语言而异;例如,在中文中,每个字符比拉丁语言中的字符包含更多的信息。
+这种方法也不是完美的。由于现在表示是基于字符而不是单词,因此人们可能会争辩说,从直觉上讲,它的意义不大:每个字符本身并没有多大意义,但是单词则不然。然而,这又因语言而异;例如,在中文中,每个字符比拉丁语言中的字符包含更多的信息。
-另一件要考虑的事情是,我们的模型最终会处理大量的词符(token):虽然使用基于单词的标记器(tokenizer),单词只会是单个标记,但当转换为字符时,它很容易变成 10 个或更多的词符(token)。
+另一件要考虑的因素是,这样做会导致我们的模型需要处理大量的 tokens:虽然一个单词在基于单词的 tokenizer 中只是一个 token,但当它被转换为字符时,很可能就变成了 10 个或更多的 tokens
-为了两全其美,我们可以使用结合这两种方法的第三种技术:*子词标记化(subword tokenization)*。
+为了两全其美,我们可以使用结合这两种方法的第三种技术:基于子词(subword)的 tokenization。
-## 子词标记化 [[子词标记化]]
+## 基于子词(subword)的 tokenization [[基于子词(subword)的 tokenization ]]
-子词分词算法依赖于这样一个原则,即不应将常用词拆分为更小的子词,而应将稀有词分解为有意义的子词。
+基于子词(subword)的 tokenization 算法依赖于这样一个原则:常用词不应被分解为更小的子词,但罕见词应被分解为有意义的子词。
-例如,“annoyingly”可能被认为是一个罕见的词,可以分解为“annoying”和“ly”。这两者都可能作为独立的子词出现得更频繁,同时“annoyingly”的含义由“annoying”和“ly”的复合含义保持。
+例如,“annoyingly”可能被视为一个罕见的词,可以分解为“annoying”和“ly”。这两者都可能作为独立的子词并且出现得更频繁,同时“annoyingly”的含义通过“annoying”和“ly”的复合含义得以保留。
-这是一个示例,展示了子词标记化算法如何标记序列“Let's do tokenization!”:
+这里有一个例子,展示了基于子词的 tokenization 算法如何将序列“Let's do tokenization!”分词:


-这些子词最终提供了很多语义含义:例如,在上面的示例中,“tokenization”被拆分为“token”和“ization”,这两个具有语义意义同时节省空间的词符(token)(只需要两个标记(token)代表一个长词)。这使我们能够对较小的词汇表进行相对较好的覆盖,并且几乎没有未知的标记
+这些子词最终提供了大量的语义信息:例如,在上面的例子中,“tokenization”被分割成“token”和“ization”,这两个 tokens 在保持空间效率的同时具有语义意义(只需要两个 tokens 就能表示一个长词)。这让我们能够在词汇量小的情况下获得相对良好的覆盖率,并且几乎没有未知的 token。
-这种方法在土耳其语等粘着型语言(agglutinative languages)中特别有用,您可以通过将子词串在一起来形成(几乎)任意长的复杂词。
+这种方法在土耳其语等粘着型语言(agglutinative languages)中特别有用,你可以通过将子词串在一起来形成(几乎)任意长的复杂词。
-### 还有更多! [[还有更多!]]
+### 还有更多![[还有更多!]]
不出所料,还有更多的技术。仅举几例:
-- Byte-level BPE, 用于 GPT-2
-- WordPiece, 用于 BERT
-- SentencePiece or Unigram, 用于多个多语言模型
+- Byte-level BPE,用于 GPT-2
+- WordPiece,用于 BERT
+- SentencePiece or Unigram,用于多个多语言模型
-您现在应该对标记器(tokenizers)的工作原理有足够的了解,以便开始使用 API。
+你现在应该对 tokenizer 的工作原理有足够的了解,可以开始使用 API 了。
## 加载和保存 [[加载和保存]]
-加载和保存标记器(tokenizer)就像使用模型一样简单。实际上,它基于相同的两种方法: `from_pretrained()` 和 `save_pretrained()` 。这些方法将加载或保存标记器(tokenizer)使用的算法(有点像*建筑学(architecture)*的模型)以及它的词汇(有点像*权重(weights)*模型)。
+加载和保存 tokenizer 就像使用模型一样简单。实际上,它基于相同的两种方法: `from_pretrained()` 和 `save_pretrained()` 。这些方法会加载或保存分词器使用的算法(有点像模型的架构(architecture))以及其词汇表(有点像模型的权重(weights))。
-加载使用与 BERT 相同的检查点训练的 BERT 标记器(tokenizer)与加载模型的方式相同,除了我们使用 `BertTokenizer` 类:
+加载使用与 BERT 相同的 checkpoint 训练的 BERT tokenizer 与加载模型的方式相同,只是换成了 `Bert tokenizer` 类:
```py
from transformers import BertTokenizer
@@ -132,10 +132,12 @@ tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
```
{#if fw === 'pt'}
-如同 `AutoModel`,`AutoTokenizer` 类将根据检查点名称在库中获取正确的标记器(tokenizer)类,并且可以直接与任何检查点一起使用:
+
+如同 `AutoModel` , `AutoTokenizer` 类将根据 checkpoint 名称在库中获取正确的 tokenizer 类,并且可以直接与任何 checkpoint 一起使用:
{:else}
-如同 `TFAutoModel`, `AutoTokenizer` 类将根据检查点名称在库中获取正确的标记器(tokenizer)类,并且可以直接与任何检查点一起使用:
+
+如同 `TFAutoModel` , `AutoTokenizer` 类将根据 checkpoint 名称在库中获取正确的 tokenizer 类,并且可以直接与任何 checkpoint 一起使用:
{/if}
@@ -145,7 +147,7 @@ from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
-我们现在可以使用标记器(tokenizer),如上一节所示:
+现在我们可以像在上一节中显示的那样使用 tokenizer:
```python
tokenizer("Using a Transformer network is simple")
@@ -157,29 +159,29 @@ tokenizer("Using a Transformer network is simple")
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
-保存标记器(tokenizer)与保存模型相同:
+保存 tokenizer 与保存模型完全相同:
```py
tokenizer.save_pretrained("directory_on_my_computer")
```
-我们在[Chapter 3](/Couse/chapter3)中将更多地谈论`token_type_ids`,稍后我们将解释 `attention_mask` 键。首先,让我们看看 `input_ids` 如何生成。为此,我们需要查看标记器(tokenizer)的中间方法。
+我们将在 [第三章](/Couse/chapter3) 中将更多地谈论 `token_type_ids` ,稍后我们将解释 `attention_mask` 。首先,让我们看看如何生成 `input_ids` 。为此,我们需要查看 tokenizer 的内部是如何实现的。
## 编码 [[编码]]
-将文本翻译成数字被称为编码(_encoding_).编码分两步完成:标记化,然后转换为输入 ID。
+将文本翻译成数字被称为编码(encoding)。编码分两步完成:分词,然后转换为 inputs ID。
-正如我们所见,第一步是将文本拆分为单词(或单词的一部分、标点符号等),通常称为*标记(token)*。有多个规则可以管理该过程,这就是为什么我们需要使用模型名称来实例化标记器(tokenizer),以确保我们使用模型预训练时使用的相同规则。
+正如我们所见,第一步是将文本拆分为单词(或部分单词、标点符号等),通常称为 tokens 不同的不同的分词器使用的算法也不一样,这就是为什么我们需要使用模型名称来实例化 tokenizer,以确保我们使用模型预训练时使用的相同的算法。
-第二步是将这些标记转换为数字,这样我们就可以用它们构建一个张量并将它们提供给模型。为此,标记器(tokenizer)有一个*词汇(vocabulary)*,这是我们在实例化它时下载的部分 `from_pretrained()` 方法。同样,我们需要使用模型预训练时使用的相同词汇。
+第二步是将这些 tokens 转换为数字,这样我们就可以用它们构建一个张量并将它们提供给模型。为此,tokenizer 有一个词汇表(vocabulary),这是我们在使用 `from_pretrained()` 方法实例化它时下载的部分。同样,我们需要使用与预训练模型时相同的词汇表。
-为了更好地理解这两个步骤,我们将分别探讨它们。请注意,我们将使用一些单独执行部分标记化管道的方法来向您展示这些步骤的中间结果,但实际上,您应该直接在您的输入上调用标记器(tokenizer)(如第 2 部分所示)。
+为了更好地理解这两个步骤,我们将分别探讨它们。请注意,我们将单独执行部分 tokenization 管道的方法来向你展示这些步骤的中间结果,但在实践中,你应该直接在你的输入上调用 tokenizer(如第 2 小节所示)。
-### 标记化 [[标记化]]
+### tokenization [[ tokenization ]]
-标记化过程由标记器(tokenizer)的`tokenize()` 方法实现:
+tokenization 过程由 tokenizer 的 `tokenize()` 方法实现:
```py
from transformers import AutoTokenizer
@@ -192,16 +194,17 @@ tokens = tokenizer.tokenize(sequence)
print(tokens)
```
-此方法的输出是一个字符串列表或标记(token):
+这个方法的输出是一个字符串列表,或者说 tokens
```python out
['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']
```
-这个标记器(tokenizer)是一个子词标记器(tokenizer):它对词进行拆分,直到获得可以用其词汇表表示的标记(token)。`transformer` 就是这种情况,它分为两个标记:`transform` 和 `##er`。
+这个 tokenizer 是一个基于子词的 tokenizer:它对词进行拆分,直到获得可以用其词汇表表示的 tokens。以 `transformer` 为例,它分为两个 tokens `transform` 和 `##er` 。
+
+### 从 tokens 到 inputs ID [[从 tokens 到 inputs ID]]
-### 从词符(token)到输入 ID [[从词符(token)到输入 ID]]
-输入 ID 的转换由标记器(tokenizer)的`convert_tokens_to_ids()`方法实现:
+inputs ID 的转换由 tokenizer 的 `convert_tokens_to_ids()` 方法实现:
```py
ids = tokenizer.convert_tokens_to_ids(tokens)
@@ -213,17 +216,17 @@ print(ids)
[7993, 170, 11303, 1200, 2443, 1110, 3014]
```
-这些输出一旦转换为适当的框架张量,就可以用作模型的输入,如本章前面所见。
+这些输出,一旦转换为适当的框架张量,就可以用作模型的输入,如本章前面所示。
-✏️ **试试看!** 在我们在第 2 节中使用的输入句子(“I've been waiting for a HuggingFace course my whole life.”和“I hate this so much!”)复制最后两个步骤(标记化和转换为输入 ID)。检查您获得的输入 ID 是否与我们之前获得的相同!
+✏️ **试试看!** 请将我们在第 2 节中使用的输入句子(“I've been waiting for a HuggingFace course my whole life.”和“I hate this so much!”)执行最后两个步骤(分词和转换为 inputs ID)。检查你获得的 inputs ID 是否与我们在第二节中获得的一致!
## 解码 [[解码]]
-*解码(Decoding)* 正好相反:从词汇索引中,我们想要得到一个字符串。这可以通过 `decode()` 方法实现,如下:
+解码(Decoding) 正好相反:从 inputs ID 到一个字符串。这以通过 `decode()` 方法实现:
```py
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
@@ -234,6 +237,6 @@ print(decoded_string)
'Using a Transformer network is simple'
```
-请注意, `decode` 方法不仅将索引转换回标记(token),还将属于相同单词的标记(token)组合在一起以生成可读的句子。当我们使用预测新文本的模型(根据提示生成的文本,或序列到序列问题(如翻译或摘要))时,这种行为将非常有用。
+请注意, `decode` 方法不仅将索引转换回 tokens,还将属于相同单词的 tokens 组合在一起以生成可读的句子。当我们使用预测新文本的模型(根据提示生成的文本,或序列到序列问题(如翻译或摘要))时,这样的功能将非常有用。
-到现在为止,您应该了解标记器(tokenizer)可以处理的原子操作:标记化、转换为 ID 以及将 ID 转换回字符串。然而,我们只是刮到了冰山一角。在下一节中,我们将采用我们的方法来克服它的限制,并看看如何克服它们。
+到现在为止,你应该了解 tokenizer 可以处理的原子操作:分词、转换为 ID 以及将 ID 转换回字符串。然而,我们只是瞥到了冰山一角。在下一节中,我们将继续探讨它能力的极限,并看看如何克服它们。
diff --git a/chapters/zh-CN/chapter2/5.mdx b/chapters/zh-CN/chapter2/5.mdx
index 576835144..26e529030 100644
--- a/chapters/zh-CN/chapter2/5.mdx
+++ b/chapters/zh-CN/chapter2/5.mdx
@@ -28,24 +28,21 @@
{/if}
-在上一节中,我们探讨了最简单的用例:对一个小长度的序列进行推理。然而,一些问题已经出现:
+在上一节中,我们探讨了最简单的案例:对一个较短的句子进行推理。然而,一些问题已经出现:
-* 我们如何处理多个序列?
+* 我们如何处理多个句子?
+* 我们如何处理不同长度的多个句子?
-* 我们如何处理多个序列不同长度?
+* 词汇索引是唯一可以让模型运行的输入吗?
+* 是否存在句子太长的问题?
-* 词汇索引是让模型正常工作的唯一输入吗?
-
-
-* 是否存在序列太长的问题?
-
-让我们看看这些问题会带来什么样的问题,以及如何使用🤗 Transformers API解决它们
+让我们看看这些问题会带来什么样的问题,以及如何使用🤗 Transformers API 解决它们
## 模型需要一批输入 [[模型需要一批输入]]
-在上一个练习中,您看到了序列如何转换为数字列表。让我们将此数字列表转换为张量,并将其发送到模型:
+在上一个练习中,你看到了句子如何转换为数字列表。让我们将此数字列表转换为张量,并将其发送到模型:
{#if fw === 'pt'}
```py
@@ -61,7 +58,7 @@ sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor(ids)
-# This line will fail.
+# 这一行会运行失败
model(input_ids)
```
@@ -82,7 +79,7 @@ sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = tf.constant(ids)
-# This line will fail.
+# 这一行会运行失败
model(input_ids)
```
@@ -91,9 +88,9 @@ InvalidArgumentError: Input to reshape is a tensor with 14 values, but the reque
```
{/if}
-哦,不!为什么失败了?“我们遵循了第2节中管道的步骤。
+哦,不!为什么失败了?“我们的确是按照第 2 节中管道的步骤一步步来做的。
-问题是我们向模型发送了一个序列,而🤗 Transformers模型默认情况下需要多个句子。在这里,当我们将分词器应用于一个应用程序时,我们尝试在幕后完成分词器所做的一切,但如果仔细观察,您会发现tokenizer不仅将输入ID列表转换为张量,还在其顶部添加了一个维度:
+问题是我们向模型发送了一个单独的句子,而🤗 Transformers 模型默认情况下需要一个句子列表。在这里,当我们试图重现 tokenizer 在输入 `sequence` 后在其内部进行的所有操作。但如果你仔细观察,你会发现 tokenizer 不仅仅是将 inputs ID 的列表转换为张量,它还在其上添加了一个维度:
{#if fw === 'pt'}
```py
@@ -118,7 +115,7 @@ array([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662,
```
{/if}
-让我们重试并添加一个新维度:
+让我们再试一次并添加一个新的维度:
{#if fw === 'pt'}
```py
@@ -162,7 +159,7 @@ print("Logits:", output.logits)
```
{/if}
-我们打印输入ID以及生成的logits-以下是输出:
+让我们打印 inputs ID 以及生成的 logits 值,以下是输出:
{#if fw === 'pt'}
```python out
@@ -178,23 +175,24 @@ Logits: tf.Tensor([[-2.7276208 2.8789377]], shape=(1, 2), dtype=float32)
```
{/if}
-*Batching* 是一次通过模型发送多个句子的行为。如果你只有一句话,你可以用一个序列构建一个批次:
+批处理(Batching)是一次性通过模型发送多个句子的行为。如果你只有一句话,你可以构建一个只有一个句子的 batch:
```
batched_ids = [ids, ids]
```
-这是一批两个相同的序列!
+这就是一个包含两个相同句子的 batch
-✏️ **试试看!** 将此列表转换为张量并通过模型传递。检查您是否获得与之前相同的登录(但是只有两次)
+✏️ **试试看!** 将这个 `batched_ids` 列表转换为张量,并通过你的模型进行处理。检查你是否得到了与之前相同的 logits 值(但是重复了两次)!
+
-批处理允许模型在输入多个句子时工作。使用多个序列就像使用单个序列构建批一样简单。不过,还有第二个问题。当你试图将两个(或更多)句子组合在一起时,它们的长度可能不同。如果您以前使用过张量,那么您知道它们必须是矩形,因此无法将输入ID列表直接转换为张量。为了解决这个问题,我们通常填充输入。
+批处理支持模型在输入多个句子时工作。使用多个句子就像使用单个句子构建批一样简单。不过,还有第二个问题。当你试图将两个(或更多)句子组合在一起时,它们的长度可能不同。如果你以前使用过张量,那么你知道它们必须是矩形,因此无法将 inputs ID 列表直接转换为张量。为了解决这个问题,我们通常填充输入(Padding)。
-## 填充输入 [[填充输入]]
+## 填充输入(Padding) [[填充输入(Padding)]]
以下列表不能转换为张量:
@@ -205,7 +203,7 @@ batched_ids = [
]
```
-为了解决这个问题,我们将使用填充使张量具有矩形。Padding通过在值较少的句子中添加一个名为Padding token的特殊单词来确保我们所有的句子长度相同。例如,如果你有10个包含10个单词的句子和1个包含20个单词的句子,填充将确保所有句子都包含20个单词。在我们的示例中,生成的张量如下所示:
+为了解决这个问题,我们将使用填充使张量成为标准的矩形。Padding 通过在值较少的句子中添加一个名为 `padding_id` 的特殊单词来确保我们所有的句子长度相同。例如,如果你有 10 个包含 10 个单词的句子和 1 个包含 20 个单词的句子,填充能确保所有句子都包含 20 个单词。在我们的示例中,填充后的张量如下所示:
```py no-format
padding_id = 100
@@ -216,8 +214,7 @@ batched_ids = [
]
```
-可以在tokenizer.pad_token_id中找到填充令牌ID. 让我们使用它,将我们的两句话分别发送到模型中,并分批发送到一起:
-
+我们可以在 `tokenizer.pad_token_id` 中找到填充 token 的 ID。让我们使用它,分别用模型处理这两个句子,然后再尝试将这两个句子放在一起用模型批处理:
{#if fw === 'pt'}
```py no-format
@@ -266,16 +263,15 @@ tf.Tensor(
```
{/if}
-我们批处理预测中的logits有点问题:第二行应该与第二句的logits相同,但我们得到了完全不同的值!
-
+咦,我们批处理预测中的 logits 值有点问题:第二行应该与第二句的 logits 相同,但我们得到了完全不同的值!
-这是因为Transformer模型的关键特性是关注层,它将每个标记上下文化。这些将考虑填充标记,因为它们涉及序列中的所有标记。为了在通过模型传递不同长度的单个句子时,或者在传递一批应用了相同句子和填充的句子时获得相同的结果,我们需要告诉这些注意层忽略填充标记。这是通过使用 attention mask来实现的。
+这是因为 Transformer 模型的关键特性:注意力层,它考虑了每个 token 的上下文信息。这具体来说,每个 token 的含义并非单独存在的,它的含义还取决于它在句子中的位置以及周围的其他 tokens。当我们使用填充(padding)来处理长度不同的句子时,我们会添加特殊的“填充 token”来使所有句子达到相同的长度。但是,注意力层会将这些填充 token 也纳入考虑,因为它们会关注序列中的所有 tokens。这就导致了一个问题:尽管填充 token 本身并没有实际的含义,但它们的存在会影响模型对句子的理解。我们需要告诉这些注意层忽略填充 token。这是通过使用注意力掩码(attention mask)层来实现的。
-## 注意力面具 [[注意力面具]]
+## 注意力掩码(attention mask)层 [[注意力掩码(attention mask)层]]
-*Attention masks*是与输入ID张量形状完全相同的张量,用0和1填充:1s表示应注意相应的标记,0s表示不应注意相应的标记(即,模型的注意力层应忽略它们)。
+注意力掩码(attention mask)是与 inputs ID 张量形状完全相同的张量,用 0 和 1 填充:1 表示应关注相应的 tokens,0 表示应忽略相应的 tokens(即,它们应被模型的注意力层忽视)。
-让我们用attention mask完成上一个示例:
+让我们用 attention mask 修改上一个示例:
{#if fw === 'pt'}
```py no-format
@@ -320,35 +316,26 @@ tf.Tensor(
```
{/if}
-现在我们得到了该批中第二个句子的相同登录。
+现在我们得到了批处理中第二句话相同的 logits 值。
-请注意,第二个序列的最后一个值是一个填充ID,它在attention mask中是一个0值。
+注意第二序列的最后一个值是填充 ID,其在注意力掩码中的值为 0。
-✏️ 试试看!在第2节中使用的两个句子上手动应用标记化(“我一生都在等待Hugging Face课程。”和“我非常讨厌这个!”)。通过模型传递它们,并检查您是否获得与第2节中相同的登录。现在使用填充标记将它们批处理在一起,然后创建适当的注意掩码。检查通过模型时是否获得相同的结果!
+✏️ **试试看!**在第二节使用的两个句子(“I've been waiting for a HuggingFace course my whole life.” 和 “I hate this so much!”)上手动进行 tokenize。将它们输入模型并检查你是否得到了与第二节相同的 logits 值。然后使用填充 token 将它们一起进行批处理,然后创建合适的注意力掩码。检查模型计算后是否得到了相同的结果!
-## 长序列 [[长序列]]
-
-对于Transformers模型,我们可以通过模型的序列长度是有限的。大多数模型处理多达512或1024个令牌的序列,当要求处理更长的序列时,会崩溃。此问题有两种解决方案:
-
-
-
-* 使用支持的序列长度较长的模型。
-
+## 更长的句子 [[更长的句子]]
-* 截断序列。
+对于 Transformers 模型,我们可以通过模型的序列长度是有限的。大多数模型处理多达 512 或 1024 个 的 tokens 序列,当使用模型处理更长的序列时,会崩溃。此问题有两种解决方案:
+* 使用支持更长序列长度的模型。
+* 截断你的序列。
-模型有不同的支持序列长度,有些模型专门处理很长的序列。
-[Longformer](https://huggingface.co/transformers/model_doc/longformer.html)
-这是一个例子,另一个是
-[LED](https://huggingface.co/transformers/model_doc/led.html)
-. 如果您正在处理一项需要很长序列的任务,我们建议您查看这些模型。
+不同的模型支持的序列长度各不相同,有些模型专门用于处理非常长的序列。例如 [Longformer](https://huggingface.co/transformers/model_doc/longformer) 和 [LED](https://huggingface.co/transformers/model_doc/led) 。如果你正在处理需要非常长序列的任务,我们建议你考虑使用这些模型。
-否则,我们建议您通过指定max_sequence_length参数:
+另外,我们建议你通过设定 `max_sequence_length` 参数来截断序列:
```py
sequence = sequence[:max_sequence_length]
diff --git a/chapters/zh-CN/chapter2/6.mdx b/chapters/zh-CN/chapter2/6.mdx
index 17dd3c2c8..48b567d68 100644
--- a/chapters/zh-CN/chapter2/6.mdx
+++ b/chapters/zh-CN/chapter2/6.mdx
@@ -1,6 +1,6 @@
-# 把它们放在一起 [[把它们放在一起]]
+# 综合应用 [[综合应用]]
{#if fw === 'pt'}
@@ -22,9 +22,9 @@
{/if}
-在最后几节中,我们一直在尽最大努力手工完成大部分工作。我们探讨了标记化器的工作原理,并研究了标记化、到输入ID的转换、填充、截断和注意掩码。
+在过去的几个章节中,我们已经尝试尽可能手动完成大部分工作。我们探索了 tokenizer 的运行机制,并且了解了分词、转换为 inputs ID、填充、截断以及注意力掩码的处理方式。
-然而,正如我们在第2节中所看到的,🤗 Transformers API可以通过一个高级函数为我们处理所有这些,我们将在这里深入讨论。当你直接在句子上调用标记器时,你会得到准备通过模型传递的输入
+然而,正如我们在第二节中看到的那样,🤗 Transformers API 能够通过一个高级函数为我们处理所有这些工作,接下来我们就要深入研究这个函数。当你直接在句子上调用你的 `tokenizer` 时,就可以得到转换后的可以直接放入模型的数据了:
```py
from transformers import AutoTokenizer
@@ -37,10 +37,9 @@ sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
```
-这里,`model_inputs`
-变量包含模型良好运行所需的一切。对于DistilBERT,它包括输入 ID和注意力掩码(attention mask)。其他接受额外输入的模型也会有标记器对象的输出。
+这里, `model_inputs` 变量包含模型运行所需的所有数据。在 DistilBERT 中,它包括 inputs ID 和注意力掩码(attention mask)。其他接受额外输入的模型也会有对应的 tokenizer 可以将输入转化为模型所需要的输入。
-正如我们将在下面的一些示例中看到的,这种方法非常强大。首先,它可以标记单个序列:
+正如我们将在下面的一些例子中看到的,这个函数非常强大。首先,它可以对单个句子进行处理:
```py
sequence = "I've been waiting for a HuggingFace course my whole life."
@@ -48,7 +47,7 @@ sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
```
-它还一次处理多个序列,并且API没有任何变化:
+它还一次处理多个多个,并且 API 的用法完全一致:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
@@ -56,51 +55,51 @@ sequences = ["I've been waiting for a HuggingFace course my whole life.", "So ha
model_inputs = tokenizer(sequences)
```
-它可以根据几个目标进行填充:
+它可以使用多种不同的方法对目标进行填充:
```py
-# Will pad the sequences up to the maximum sequence length
+# 将句子序列填充到最长句子的长度
model_inputs = tokenizer(sequences, padding="longest")
-# Will pad the sequences up to the model max length
+# 将句子序列填充到模型的最大长度
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
-# Will pad the sequences up to the specified max length
+# 将句子序列填充到指定的最大长度
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)
```
-它还可以截断序列:
+它还可以对序列进行截断:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
-# Will truncate the sequences that are longer than the model max length
+# 将截断比模型最大长度长的句子序列
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
-# Will truncate the sequences that are longer than the specified max length
+# 将截断长于指定最大长度的句子序列
model_inputs = tokenizer(sequences, max_length=8, truncation=True)
```
-标记器对象可以处理到特定框架张量的转换,然后可以直接发送到模型。例如,在下面的代码示例中,我们提示标记器从不同的框架返回张量——`"pt"`返回Py Torch张量,`"tf"`返回TensorFlow张量,`"np"`返回NumPy数组:
+`tokenizer` 对象可以处理指定框架张量的转换,然后可以直接发送到模型。例如,在下面的代码示例中,我们告诉 tokenizer 返回不同框架的张量 —— `"pt"` 返回 PyTorch 张量, `"tf"` 返回 TensorFlow 张量,而 `"np"` 则返回 NumPy 数组:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
-# Returns PyTorch tensors
+# 返回 PyTorch tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
-# Returns TensorFlow tensors
+# 返回 TensorFlow tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
-# Returns NumPy arrays
+# 返回 NumPy arrays
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")
```
-## 特殊词符(token) [[特殊词符(token)]]
+## 特殊的 tokens [[特殊的 tokens ]]
-如果我们看一下标记器返回的输入 ID,我们会发现它们与之前的略有不同:
+如果我们看一下 tokenizer 返回的 inputs ID,我们会发现它们与之前的略有不同:
```py
sequence = "I've been waiting for a HuggingFace course my whole life."
@@ -118,7 +117,7 @@ print(ids)
[1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]
```
-一个在开始时添加了一个标记(token) ID,一个在结束时添加了一个标记(token) ID。让我们解码上面的两个ID序列,看看这是怎么回事:
+句子的开始和结束分别增加了一个 inputs ID。我们来解码上述的两个 ID 序列,看看是怎么回事:
```py
print(tokenizer.decode(model_inputs["input_ids"]))
@@ -130,11 +129,11 @@ print(tokenizer.decode(ids))
"i've been waiting for a huggingface course my whole life."
```
-标记器在开头添加了特殊单词`[CLS]`,在结尾添加了特殊单词`[SEP]`。这是因为模型是用这些数据预训练的,所以为了得到相同的推理结果,我们还需要添加它们。请注意,有些模型不添加特殊单词,或者添加不同的单词;模型也可能只在开头或结尾添加这些特殊单词。在任何情况下,标记器都知道需要哪些词符,并将为您处理这些词符。
+ tokenizer 在开头添加了特殊单词 `[CLS]` ,在结尾添加了特殊单词 `[SEP]` 。这是因为模型在预训练时使用了这些字词,所以为了得到相同的推断结果,我们也需要添加它们。请注意,有些模型不添加特殊单词,或者添加不同的特殊单词;模型也可能只在开头或结尾添加这些特殊单词。无论如何,tokenizer 知道哪些是必需的,并会为你处理这些问题。
-## 结束:从标记器到模型 [[结束:从标记器到模型]]
+## 小结:从 tokenizer 到模型 [[小结:从 tokenizer 到模型]]
-现在我们已经看到了标记器对象在应用于文本时使用的所有单独步骤,让我们最后一次看看它如何处理多个序列(填充!),非常长的序列(截断!),以及多种类型的张量及其主要API:
+现在我们已经看到 `tokenizer` 对象在处理文本时的所有步骤,让我们最后再看一次它如何通过 tokenizer API 处理多个序列(填充!),非常长的序列(截断!)以及多种类型的张量:
{#if fw === 'pt'}
```py
diff --git a/chapters/zh-CN/chapter2/7.mdx b/chapters/zh-CN/chapter2/7.mdx
index b3924309b..b1cf2de2d 100644
--- a/chapters/zh-CN/chapter2/7.mdx
+++ b/chapters/zh-CN/chapter2/7.mdx
@@ -1,32 +1,24 @@
-# 基本用法完成! [[基本用法完成!]]
+# 基本用法完成![[基本用法完成!]]
-很好地完成了到这里的课程!总而言之,在本章中,您可以:
+恭喜你跟随课程走到这里!回顾一下,在这一章中,你已经:
-- 学习了Transformers模型的基本构造块。
+- 学习了 Transformers 模型的基本构造块。
+- 了解了 Tokenizer 管道的组成。
-- 了解了标记化管道的组成。
+- 了解了如何在实践中使用 Transformers 模型。
+- 学习了如何利用 tokenizer 将文本转换为模型可以理解的张量。
-- 了解了如何在实践中使用Transformers模型。
+- 设定了 tokenizer 和模型,可以从输入的文本获取预测的结果。
+- 了解了 inputs IDs 的局限性,并学习了关于注意力掩码(attention mask)的知识。
-- 学习了如何利用分词器将文本转换为模型可以理解的张量。
+- 试用了灵活且可配置的 Tokenizer 方法。
-
-- 将分词器和模型一起设置,以从文本到预测。
-
-
-- 了解了inputs IDs的局限性,并了解了attention mask。
-
-
-- 使用多功能和可配置的分词器方法。
-
-
-
-从现在起,您应该能够自由浏览🤗 Transformers文档:词汇听起来很熟悉,并且您已经看到了大部分时间将使用的方法。
+从现在开始,你应该能够自由浏览🤗 Transformers 文档:你会遇到许多看起来很熟悉的词汇;而且到目前为止,你已经见到了你大部分时间会使用的方法。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter2/8.mdx b/chapters/zh-CN/chapter2/8.mdx
index ff8f98b8c..26440c09e 100644
--- a/chapters/zh-CN/chapter2/8.mdx
+++ b/chapters/zh-CN/chapter2/8.mdx
@@ -9,68 +9,68 @@
classNames="absolute z-10 right-0 top-0"
/>
-### 1. 语言建模 Pipeline 的顺序是什么?
+### 1. 自然语言处理流程的顺序是什么?
-### 2. Transformer模型的输出有多少个维度,每个维度分别是什么?
+### 2. Transformer 模型的输出有的张量多少个维度,每个维度分别是什么?
-### 3.下列哪一个是Subword标记(Tokenization)的例子(从分词的颗粒度来划分)?
+### 3.下列哪一个是子词分词的例子(从分词的颗粒度来划分)?
-### 4.什么是模型的Head层?
+### 4.什么是模型头(Haed 层)?
{#if fw === 'pt'}
-### 5.什么是AutoModel?
+### 5.什么是 AutoModel?
AutoTrain 产品相混淆了?"
+ text: "根据你的数据自动进行训练的模型",
+ explain: "错误。你可能把 AutoModel 与 Hugging Face 的AutoTrain 产品相混淆了?"
},
{
- text: "一个根据Checkpoint(检查点)返回模型体系结构的对象",
- explain: "确切地说: AutoModel只需要知道初始化的Checkpoint(检查点)就可以返回正确的体系结构。",
+ text: "一个根据 checkpoint(检查点)返回模型体系结构的对象",
+ explain: "确切地说:AutoModel只需要知道初始化的 checkpoint(检查点)名称就可以返回正确的体系结构。",
correct: true
},
{
text: "一种可以自动检测输入语言来加载正确权重的模型",
- explain: "不正确; 虽然有些Checkpoint(检查点)和模型能够处理多种语言,但是没有内置的工具可以根据语言自动选择Checkpoint(检查点)。您应该前往 Model Hub 寻找完成所需任务的最佳Checkpoint(检查点)!"
+ explain: "不正确;虽然有些 checkpoint(检查点)和模型能够处理多种语言,但是没有内置的工具可以根据语言自动选择 checkpoint(检查点)。你应该前往 Model Hub 寻找完成所需任务的最佳 checkpoint(检查点)!"
}
]}
/>
{:else}
-### 5.什么是 TFAutoModel?
+### 5.什么是 TFAutoModel?
AutoTrain 产品相混淆了?"
+ text: "根据你的数据自动进行训练的模型",
+ explain: "错误。你可能把 TFAutoModel 与 Hugging Face 的AutoTrain 产品相混淆了?"
},
{
- text: "一个根据Checkpoint(检查点)返回模型体系结构的对象",
- explain: "确切地说: TFAutoModel只需要知道初始化的Checkpoint(检查点)就可以返回正确的体系结构。",
+ text: "一个根据 checkpoint(检查点)返回模型体系结构的对象",
+ explain: "确切地说:TFAutoModel只需要知道初始化的 checkpoint(检查点)名称就可以返回正确的体系结构。",
correct: true
},
{
text: "一种可以自动检测输入语言来加载正确权重的模型",
- explain: "不正确; 虽然有些Checkpoint(检查点)和模型能够处理多种语言,但是没有内置的工具可以根据语言自动选择Checkpoint(检查点)。您应该前往 Model Hub 寻找完成所需任务的最佳Checkpoint(检查点)!"
+ explain: "不正确;虽然有些 checkpoint(检查点)和模型能够处理多种语言,但是没有内置的工具可以根据语言自动选择 checkpoint(检查点)。你应该前往 Model Hub 寻找完成所需任务的最佳 checkpoint(检查点)!"
}
]}
/>
{/if}
-### 6.当将不同长度的序列批处理在一起时,需要进行哪些处理?
+### 6.当将不同长度的句子序列在一起批处理时,需要进行哪些处理?
-### 7.将 SoftMax激活函数应用于序列分类(Sequence Classification)模型的 logits 输出有什么意义?
+### 7.使用 SoftMax 激活函数对序列分类(Sequence Classification)模型的 logits 输出进行处理有什么意义?
-### 8.大多数标记器(Tokenizer)的API以什么方法为核心?
+### 8.Tokenizer API 的核心方法是哪一个?
编码 ,因为它可以将文本编码为id,将预测的id解码为文本",
- explain: "错! 虽然 编码 方法确实存在于标记器中,但是它不存在于模型中。"
+ text: "encode 因为它可以将文本编码为 ID,将预测的 ID 解码为文本",
+ explain: "错!虽然 encode 方法确实是 Tokenizer 中的方法之一,但是它并不是核心的方法,此外将预测 ID 解码为文本的是 decode。"
},
{
- text: "直接调用标记器(Tokenizer)对象。",
- explain: "完全正确!标记化器(Tokenizer) 的 __call__方法是一个非常强大的方法,可以处理几乎任何事情。它也是从模型中获取预测的方法。",
+ text: "直接调用 Tokenizer 对象。",
+ explain: "完全正确! tokenizer (Tokenizer) 的 __call__方法是一个非常强大的方法,可以处理几乎任何事情。它同时也可以从模型中获取预测。",
correct: true
},
{
text: "pad(填充)",
- explain: "错! pad(填充)非常有用,但它只是标记器(Tokenizer) API的一部分。"
+ explain: "错!pad(填充)非常有用,但它只是 Tokenizer API 的一部分。"
},
{
- text: "tokenize(标记)",
- explain: "可以说,tokenize(标记)方法是最有用的方法之一,但它不是标记器(Tokenizer) API的核心方法。"
+ text: "tokenize",
+ explain: "可以说,tokenize方法是最有用的方法之一,但它不是 Tokenizer API 的核心方法。"
}
]}
/>
-### 9.这个代码示例中的`result`变量包含什么?
+### 9.这个代码示例中的 `result` 变量包含什么?
```py
from transformers import AutoTokenizer
@@ -220,23 +220,23 @@ result = tokenizer.tokenize("Hello!")
__call__ 或 convert_tokens_to_ids方法的作用!"
+ text: "一个 ID 的列表",
+ explain: "不正确;这是 __call__ 或 convert_tokens_to_ids方法的作用!"
},
{
- text: "包含所有标记(Token)的字符串",
- explain: "这将是次优的,因为Tokenizer会将字符串拆分为多个标记的列表。"
+ text: "包含所有分词后的的字符串",
+ explain: "这将是次优的答案,因为 tokenize 方法会将字符串拆分为多个 tokens 的列表。"
}
]}
/>
{#if fw === 'pt'}
-### 10.下面的代码有什么错误吗?
+### 10.下面的代码有什么错误吗?
```py
from transformers import AutoTokenizer, AutoModel
@@ -251,22 +251,22 @@ result = model(**encoded)
choices={[
{
text: "不,看起来是对的。",
- explain: "不幸的是,将一个模型与一个用不同Checkpoint(检查点)训练的Tokenizer(标记器)耦合在并不是一个好主意。模型没有在这个这个Tokenizer(标记器)上训练来理解Tokenizer(标记器)的输出,因此模型输出(如果它可以运行的话)不会有任何意义。"
+ explain: "将一个模型与一个在不同 checkpoint 训练的 tokenizer 耦合在一起并不是一个好主意。模型没有在这个这个 tokenizer 上训练来理解 tokenizer 的输出,因此模型的输出(如果它可以运行的话)会是错乱的。"
},
{
- text: "Tokenizer(标记器)和模型应该来自相同的Checkpoint(检查点)。",
+ text: "Tokenizer 和模型应该来自相同的 checkpoint。",
explain: "对!",
correct: true
},
{
- text: "由于每个输入都是一个Batch,因此可以使用标记器(Tokenizer)对其进行平移和截断来改善这段代码。",
- explain: "的确,每个模型都需要Batch类型的输入。然而,截断或填充这个序列并不一定有意义,这里只有一句话,而这些技术是用来批处理一个句子列表的。"
+ text: "由于模型输入需要是一个 Batch,因此可以使用 tokenizer 对其进行截断或填充来改进这段代码。",
+ explain: "的确,模型输入需要是一个 Batch。然而,截断或填充这个序列并不一定有意义,这里只有一句话,而截断或填充这些技术是用来批处理一个句子列表使其长度一致的。"
}
]}
/>
{:else}
-### 10.下面的代码有什么错误吗?
+### 10.下面的代码有什么错误吗?
```py
from transformers import AutoTokenizer, TFAutoModel
@@ -281,16 +281,16 @@ result = model(**encoded)
choices={[
{
text: "不,看起来是对的。",
- explain: "不幸的是,将一个模型与一个用不同Checkpoint(检查点)训练的Tokenizer(标记器)耦合在并不是一个好主意。模型没有在这个这个Tokenizer(标记器)上训练来理解Tokenizer(标记器)的输出,因此模型输出(如果它可以运行的话)不会有任何意义。"
+ explain: "不幸的是,将一个模型与一个不同 checkpoint 训练的 tokenizer 耦合在并不是一个好主意。模型没有在这个这个 tokenizer 上训练来理解 tokenizer 的输出,因此模型的输出(如果它可以运行的话)会是错乱的。"
},
{
- text: "Tokenizer(标记器)和模型应该来自相同的Checkpoint(检查点)。",
+ text: "Tokenizer 和模型应该来自相同的 checkpoint。",
explain: "对!",
correct: true
},
{
- text: "由于每个输入都是一个Batch,因此可以使用标记器(Tokenizer)对其进行平移和截断来改善这段代码。",
- explain: "的确,每个模型都需要Batch类型的输入。然而,截断或填充这个序列并不一定有意义,这里只有一句话,而这些技术是用来批处理一个句子列表的。"
+ text: "由于每个输入都是一个 Batch,因此可以使用 tokenizer 对其进行平移和截断来改善这段代码。",
+ explain: "的确,每个模型都需要 Batch 类型的输入。然而,截断或填充这个序列并不一定有意义,这里只有一句话,而这些技术是用来批处理一个句子列表的。"
}
]}
/>
diff --git a/chapters/zh-CN/chapter3/1.mdx b/chapters/zh-CN/chapter3/1.mdx
index 2e1c920e1..13e70ddd9 100644
--- a/chapters/zh-CN/chapter3/1.mdx
+++ b/chapters/zh-CN/chapter3/1.mdx
@@ -7,20 +7,22 @@
classNames="absolute z-10 right-0 top-0"
/>
-在 [第二章](/course/chapter2) 我们探索了如何使用标记器(Tokenizer)和预训练模型进行预测。但是,如果您想为自己的数据集微调预训练模型,该怎么做呢?这就是本章的主题!你将学到:
+在 [第二章](/course/chapter2) 我们探索了如何使用 Tokenizer 和预训练模型进行预测。那么如何使用自己的数据集微调预训练模型呢?本章将解决这个问题!你将学到:
{#if fw === 'pt'}
-* 如何从模型中心(hub)准备大型数据集
-* 如何使用高级`训练`API微调一个模型
+
+* 如何从模型中心(hub)加载大型数据集
+* 如何使用高级的 `Trainer` API 微调一个模型
* 如何使用自定义训练过程
-* 如何利用🤗 Accelerate库在任何分布式设备上轻松运行自定义训练过程
+* 如何利用🤗 Accelerate 库在所有分布式设备上轻松运行自定义训练过程
{:else}
-* 如何从模型中心(hub)准备大型数据集
+
+* 如何从模型中心(hub)加载大型数据集
* 如何使用 Keras 微调模型
* 如何使用 Keras 进行预测
* 如何使用自定义指标
{/if}
-为了将经过训练的参数上传到Hugging Face Hub,您需要一个huggingface.co帐户: [创建一个账户](https://huggingface.co/join)
\ No newline at end of file
+为了将经过训练的参数上传到 Hugging Face Hub,你需要一个 huggingface.co 帐户: [创建一个账户](https://huggingface.co/join)
diff --git a/chapters/zh-CN/chapter3/2.mdx b/chapters/zh-CN/chapter3/2.mdx
index 03f5e61c0..b9d79afa2 100644
--- a/chapters/zh-CN/chapter3/2.mdx
+++ b/chapters/zh-CN/chapter3/2.mdx
@@ -23,13 +23,14 @@
{/if}
{#if fw === 'pt'}
-这一小节学习[第一小节](/course/chapter2)中提到的“如何使用模型中心(hub)大型数据集”,下面是我们用模型中心的数据在PyTorch上训练句子分类器的一个例子:
+
+在这一小节你将学习 [第一小节](/course/chapter2) 中提到的“如何使用模型中心(hub)加载大型数据集”,下面是用模型中心的数据在 PyTorch 上训练句子分类器的一个例子:
```python
import torch
from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
-# Same as before
+# 和之前一样
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
@@ -39,7 +40,7 @@ sequences = [
]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
-# This is new
+# 新增部分
batch["labels"] = torch.tensor([1, 1])
optimizer = AdamW(model.parameters())
@@ -47,15 +48,17 @@ loss = model(**batch).loss
loss.backward()
optimizer.step()
```
+
{:else}
-这一小节学习[第一小节](/course/chapter2)中提到的“如何使用模型中心(hub)大型数据集”,下面是我们用模型中心的数据在TensorFlow上训练句子分类器的一个例子:
+
+在这一小节你将学习 [第一小节](/course/chapter2) 中提到的“如何使用模型中心(hub)加载大型数据集”,下面是用模型中心的数据在 TensorFlow 上训练句子分类器的一个例子:
```python
import tensorflow as tf
import numpy as np
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
-# Same as before
+# 和之前一样
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
@@ -65,18 +68,19 @@ sequences = [
]
batch = dict(tokenizer(sequences, padding=True, truncation=True, return_tensors="tf"))
-# This is new
+# 新增部分
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy")
labels = tf.convert_to_tensor([1, 1])
model.train_on_batch(batch, labels)
```
+
{/if}
-当然,仅仅用两句话训练模型不会产生很好的效果。为了获得更好的结果,您需要准备一个更大的数据集。
+然而仅用两句话训练模型不会产生很好的效果,你需要准备一个更大的数据集才能得到更好的训练结果。
-在本节中,我们将使用MRPC(微软研究释义语料库)数据集作为示例,该数据集由威廉·多兰和克里斯·布罗克特在[这篇文章](https://www.aclweb.org/anthology/I05-5002.pdf)发布。该数据集由5801对句子组成,每个句子对带有一个标签,指示它们是否为同义(即,如果两个句子的意思相同)。我们在本章中选择了它,因为它是一个小数据集,所以很容易对它进行训练。
+在本节中,我们以 MRPC(微软研究院释义语料库)数据集为例,该数据集由威廉·多兰和克里斯·布罗克特在 [这篇文章](https://www.aclweb.org/anthology/I05-5002.pdf) 发布,由 5801 对句子组成,每个句子对带有一个标签来指示它们是否为同义(即两个句子的意思相同)。在本章选择该数据集的原因是它的数据体量小,容易对其进行训练。
-### 从模型中心(Hub)加载数据集 [[从模型中心(Hub)加载数据集]]
+## 从模型中心(Hub)加载数据集 [[从模型中心(Hub)加载数据集]]
{#if fw === 'pt'}
@@ -84,9 +88,14 @@ model.train_on_batch(batch, labels)
{/if}
-模型中心(hub)不只是包含模型;它也有许多不同语言的多个数据集。点击[数据集](https://huggingface.co/datasets)的链接即可进行浏览。我们建议您在阅读本节后阅读一下[加载和处理新的数据集](https://huggingface.co/docs/datasets/loading)这篇文章,这会让您对huggingface的darasets更加清晰。但现在,让我们使用MRPC数据集中的[GLUE 基准测试数据集](https://gluebenchmark.com/),它是构成MRPC数据集的10个数据集之一,这是一个学术基准,用于衡量机器学习模型在10个不同文本分类任务中的性能。
+模型中心(hub)不仅仅包含模型,还有许多别的语言的数据集。访问 [Datasets](https://huggingface.co/datasets) 的链接即可进行浏览。我们建议你在完成本节的学习后阅读一下 [加载和处理新的数据集](https://huggingface.co/docs/datasets/loading) 这篇文章,这会让你对 huggingface 的数据集理解更加清晰。现在让我们使用 MRPC 数据集中的 [GLUE 基准测试数据集](https://gluebenchmark.com) 作为我们训练所使用的数据集,它是构成 MRPC 数据集的 10 个数据集之一,作为一个用于衡量机器学习模型在 10 个不同文本分类任务中性能的学术基准。
+
+🤗 Datasets 库提供了一条非常便捷的命令,可以在模型中心(hub)上下载和缓存数据集。你可以以下代码下载 MRPC 数据集:
+
+
+⚠️ **警告** 确保你已经运行 `pip install datasets` 安装了 `datasets`。然后,再继续下面的加载 MRPC 数据集和打印出来查看其内容。
-🤗 Datasets库提供了一个非常便捷的命令,可以在模型中心(hub)上下载和缓存数据集。我们可以通过以下的代码下载MRPC数据集:
+
```py
from datasets import load_dataset
@@ -112,46 +121,52 @@ DatasetDict({
})
```
-正如你所看到的,我们获得了一个**DatasetDict**对象,其中包含训练集、验证集和测试集。每一个集合都包含几个列(**sentence1**, **sentence2**, **label**, and **idx**)以及一个代表行数的变量,即每个集合中的行的个数(因此,训练集中有3668对句子,验证集中有408对,测试集中有1725对)。
+现在我们获得了一个 `DatasetDict` 对象,这个对象包含训练集、验证集和测试集。每一个集合都包含 4 个列( `sentence1` , `sentence2` , `label` 和 `idx` )以及一个代表行数的变量(每个集合中的行的个数)。运行结果显示该训练集中有 3668 对句子,验证集中有 408 对,测试集中有 1725 对。
-默认情况下,此命令在下载数据集并缓存到 **~/.cache/huggingface/datasets**. 回想一下第2章,您可以通过设置**HF_HOME**环境变量来自定义缓存的文件夹。
+默认情况下,该命令会下载数据集并缓存到 `~/.cache/huggingface/datasets` 。回想在第 2 章中我们学到过,可以通过设置 `HF_HOME` 环境变量来自定义缓存的文件夹。
-我们可以访问我们数据集中的每一个**raw_train_dataset**对象,如使用字典:
+我们可以访问该数据集中的每一个 `raw_train_dataset` 对象,例如使用字典:
```py
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
```
-```python out
-{'idx': 0,
- 'label': 1,
- 'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
- 'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
+```python
+{
+ "idx": 0,
+ "label": 1,
+ "sentence1": 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
+ "sentence2": 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
+}
```
-我们可以看到标签已经是整数了,所以我们不需要对标签做任何预处理。要知道哪个数字对应于哪个标签,我们可以查看**raw_train_dataset**的**features**. 这将告诉我们每列的类型:
+现在可以看到标签已经是整数了,因此不需要对标签做任何预处理。如果想要知道不同数字对应标签的实际含义,我们可以查看 `raw_train_dataset` 的 `features` 。这告诉我们每列的类型:
```py
raw_train_dataset.features
```
-```python out
-{'sentence1': Value(dtype='string', id=None),
- 'sentence2': Value(dtype='string', id=None),
- 'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
- 'idx': Value(dtype='int32', id=None)}
+```python
+{
+ "sentence1": Value(dtype="string", id=None),
+ "sentence2": Value(dtype="string", id=None),
+ "label": ClassLabel(
+ num_classes=2, names=["not_equivalent", "equivalent"], names_file=None, id=None
+ ),
+ "idx": Value(dtype="int32", id=None),
+}
```
-在上面的例子之中,**Label(标签)** 是一种**ClassLabel(分类标签)**,使用整数建立起到类别标签的映射关系。**0**对应于**not_equivalent**,**1**对应于**equivalent**。
+上面的例子中的 `Label(标签)` 是一种 `ClassLabel(分类标签)` ,也就是使用整数建立起类别标签的映射关系。 `0` 对应于 `not_equivalent(非同义)` , `1` 对应于 `equivalent(同义)` 。
-✏️ **试试看!** 查看训练集的第15行元素和验证集的87行元素。他们的标签是什么?
+✏️ **试试看!** 查看训练集的第 15 行元素和验证集的 87 行元素。他们的标签是什么?
-### 预处理数据集 [[预处理数据集]]
+## 预处理数据集 [[预处理数据集]]
{#if fw === 'pt'}
@@ -159,7 +174,7 @@ raw_train_dataset.features
{/if}
-为了预处理数据集,我们需要将文本转换为模型能够理解的数字。正如你在[第二章](/course/chapter2)上看到的那样
+为了预处理数据集,我们需要将文本转换为模型能够理解的数字。在 [第二章](/course/chapter2) 我们已经学习过。这是通过一个 Tokenizer 完成的,我们可以向 Tokenizer 输入一个句子或一个句子列表。以下代码表示对每对句子中的所有第一句和所有第二句进行 tokenize:
```py
from transformers import AutoTokenizer
@@ -170,59 +185,108 @@ tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
```
-然而,在两句话传递给模型,预测这两句话是否是同义之前。我们需要这两句话依次进行适当的预处理。幸运的是,标记器不仅仅可以输入单个句子还可以输入一组句子,并按照我们的BERT模型所期望的输入进行处理:
+不过在将两句话传递给模型,预测这两句话是否是同义之前,我们需要给这两句话依次进行适当的预处理。Tokenizer 不仅仅可以输入单个句子,还可以输入一组句子,并按照 BERT 模型所需要的输入进行处理:
```py
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs
```
-```python out
-{
- 'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
- 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
- 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+```python
+{
+ "input_ids": [
+ 101,
+ 2023,
+ 2003,
+ 1996,
+ 2034,
+ 6251,
+ 1012,
+ 102,
+ 2023,
+ 2003,
+ 1996,
+ 2117,
+ 2028,
+ 1012,
+ 102,
+ ],
+ "token_type_ids": [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
+ "attention_mask": [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
}
```
-我们在[第二章](/course/chapter2) 讨论了**输入词id(input_ids)** 和 **注意力遮罩(attention_mask)** ,但我们在那个时候没有讨论**类型标记ID(token_type_ids)**。在这个例子中,**类型标记ID(token_type_ids)**的作用就是告诉模型输入的哪一部分是第一句,哪一部分是第二句。
+我们在 [第二章](/course/chapter2) 讨论了 `输入词id(input_ids)` 和 `注意力遮罩(attention_mask)` ,但尚未讨论 `token类型ID(token_type_ids)` 。在本例中, `token类型ID(token_type_ids)` 的作用就是告诉模型输入的哪一部分是第一句,哪一部分是第二句。
-✏️ ** 试试看!** 选取训练集中的第15个元素,将两句话分别标记为一对。结果和上方的例子有什么不同?
+✏️ ** 试试看!** 选取训练集中的第 15 个元素,将两句话分别进行tokenization。结果和上方的例子有什么不同?
-如果我们将**input_ids**中的id转换回文字:
+如果将 `input_ids` 中的 id 转换回文字:
```py
tokenizer.convert_ids_to_tokens(inputs["input_ids"])
```
-我们将得到:
+将得到:
-```python out
-['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
+```python
+[
+ "[CLS]",
+ "this",
+ "is",
+ "the",
+ "first",
+ "sentence",
+ ".",
+ "[SEP]",
+ "this",
+ "is",
+ "the",
+ "second",
+ "one",
+ ".",
+ "[SEP]",
+]
```
-所以我们看到模型需要输入的形式是 **[CLS] sentence1 [SEP] sentence2 [SEP]**。因此,当有两句话的时候。**类型标记ID(token_type_ids)** 的值是:
+所以我们看到模型需要输入的形式是 `[CLS] sentence1 [SEP] sentence2 [SEP]` 。所以当有两句话的时候, `token类型ID(token_type_ids)` 的值是:
-```python out
-['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
-[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
+```python
+[
+ "[CLS]",
+ "this",
+ "is",
+ "the",
+ "first",
+ "sentence",
+ ".",
+ "[SEP]",
+ "this",
+ "is",
+ "the",
+ "second",
+ "one",
+ ".",
+ "[SEP]",
+]
+[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
```
-如您所见,输入中 **[CLS] sentence1 [SEP]** 它们的类型标记ID均为**0**,而其他部分,对应于**sentence2 [SEP]**,所有的类型标记ID均为**1**.
+现在输入中 `[CLS] sentence1 [SEP]` 它们的 `token_type_ids` 均为 `0` ,而其他部分例如 `sentence2 [SEP]` ,所有的 `token_type_ids` 均为 `1` 。
+
+请注意,如果选择其他的 checkpoint,不一定具有 `token_type_ids` ,比如,DistilBERT 模型就不会返回。只有当 tokenizer 在预训练期间使用过这一层,也就是模型在构建时需要它们时,才会返回 `token_type_ids` 。
-请注意,如果选择其他的检查点,则不一定具有**类型标记ID(token_type_ids)**(例如,如果使用DistilBERT模型,就不会返回它们)。只有当它在预训练期间使用过这一层,模型在构建时依赖它们,才会返回它们。
+在这里,BERT 使用了带有 `token_type_ids` 的预训练 tokenizer,除了我们在 [第一章](/course/chapter1) 中讨论的掩码语言建模,还有一个额外的应用类型称为“下一句预测”。这个任务的目标是对句子对之间的关系进行建模。
-用类型标记ID对BERT进行预训练,并且使用[第一章](/course/chapter1)的遮罩语言模型,还有一个额外的应用类型,叫做下一句预测. 这项任务的目标是建立成对句子之间关系的模型。
-在下一个句子预测任务中,会给模型输入成对的句子(带有随机遮罩的标记),并被要求预测第二个句子是否紧跟第一个句子。为了提高模型的泛化能力,数据集中一半的两个句子在原始文档中挨在一起,另一半的两个句子来自两个不同的文档。
+在下一句预测任务中,会给模型输入成对的句子(带有随机遮罩的 token),并要求预测第二个句子是否紧跟第一个句子。为了使任务具有挑战性,提高模型的泛化能力,数据集中一有一半句子对中的句子在原始文档中顺序排列,另一半句子对中的两个句子来自两个不同的文档。
-一般来说,你不需要担心是否有**类型标记ID(token_type_ids)**。在您的标输入中:只要您对标记器和模型使用相同的检查点,一切都会很好,因为标记器知道向其模型提供什么。
+一般来说无需要担心在你的输入中是否需要有 `token_type_ids` 。只要你使用相同的 checkpoint 的 Tokenizer 和模型,Tokenizer 就会知道向模型提供什么,一切都会顺利进行。
-现在我们已经了解了标记器如何处理一对句子,我们可以使用它对整个数据集进行处理:如[之前的章节](/course/chapter2),我们可以给标记器提供一组句子,第一个参数是它第一个句子的列表,第二个参数是第二个句子的列表。这也与我们在[第二章](/course/chapter2)中看到的填充和截断选项兼容. 因此,预处理训练数据集的一种方法是:
+现在我们已经了解了 Tokenizer 如何处理一对句子,我们可以用它来处理整个数据集:就像在 [第二章](/course/chapter2) 中一样,我们可以给 Tokenizer 提供一对句子,第一个参数是它第一个句子的列表,第二个参数是第二个句子的列表。这也与我们在 [第二章](/course/chapter2) 中看到的填充和截断选项兼容。因此预处理训练数据集的一种方法是:
```py
tokenized_dataset = tokenizer(
@@ -233,27 +297,29 @@ tokenized_dataset = tokenizer(
)
```
-这很有效,但它的缺点是返回字典(字典的键是**输入词id(input_ids)** , **注意力遮罩(attention_mask)** 和 **类型标记ID(token_type_ids)**,字典的值是键所对应值的列表)。而且只有当您在转换过程中有足够的内存来存储整个数据集时才不会出错(而🤗数据集库中的数据集是以[Apache Arrow](https://arrow.apache.org/)文件存储在磁盘上,因此您只需将接下来要用的数据加载在内存中,因此会对内存容量的需求要低一些)。
+这种方法虽然有效,但有一个缺点是它返回的是一个字典(字典的键是 `输入词id(input_ids)` , `注意力遮罩(attention_mask)` 和 `token类型ID(token_type_ids)` ,字典的值是键所对应值的列表)。这意味着在转换过程中要有足够的内存来存储整个数据集才不会出错。不过来自🤗 Datasets 库中的数据集是以 [Apache Arrow](https://arrow.apache.org) 格式存储在磁盘上的,因此你只需将接下来要用的数据加载在内存中,而不是加载整个数据集,这对内存容量的需求比较友好。
-为了将数据保存为数据集,我们将使用[Dataset.map()](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map)方法,如果我们需要做更多的预处理而不仅仅是标记化,那么这也给了我们一些额外的自定义的方法。这个方法的工作原理是在数据集的每个元素上应用一个函数,因此让我们定义一个标记输入的函数:
+我们将使用 [Dataset.map()](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) 方法将数据保存为 dataset 格式,如果我们需要做更多的预处理而不仅仅是 tokenization 它还支持了一些额外的自定义的方法。 `map()` 方法的工作原理是使用一个函数处理数据集的每个元素。让我们定义一个对输入进行 tokenize 的函数:
```py
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
```
-此函数的输入是一个字典(与数据集的项类似),并返回一个包含**输入词id(input_ids)** , **注意力遮罩(attention_mask)** 和 **类型标记ID(token_type_ids)** 键的新字典。请注意,如果像上面的**示例**一样,如果键所对应的值包含多个句子(每个键作为一个句子列表),那么它依然可以工作,就像前面的例子一样标记器可以处理成对的句子列表。这样的话我们可以在调用**map()**使用该选项 **batched=True** ,这将显著加快标记与标记的速度。这个**标记器**来自[🤗 Tokenizers](https://github.com/huggingface/tokenizers)库由Rust编写而成。当我们一次给它大量的输入时,这个标记器可以非常快。
+该函数接收一个字典(与 dataset 的项类似)并返回一个包含 `输入词id(input_ids)` , `注意力遮罩(attention_mask)` 和 `token_type_ids` 键的新字典。请注意,如果 `example` 字典所对应的值包含多个句子(每个键作为一个句子列表),那么它依然可以运行,就像前面的例子一样, `tokenizer` 可以处理成对的句子列表,这样的话我们可以在调用 `map()` 时使用该选项 `batched=True` ,这将显著加快处理的速度。 `tokenizer` 来自 [🤗 Tokenizers](https://github.com/huggingface/tokenizers) 库,由 Rust 编写而成。当一次给它很多输入时,这个 `tokenizer` 可以处理地非常快。
-请注意,我们现在在标记函数中省略了**padding**参数。这是因为在标记的时候将所有样本填充到最大长度的效率不高。一个更好的做法:在构建批处理时填充样本更好,因为这样我们只需要填充到该批处理中的最大长度,而不是整个数据集的最大长度。当输入长度变化很大时,这可以节省大量时间和处理能力!
+请注意,我们暂时在 `tokenize_function` 中省略了 padding 参数。这是因为将所有的样本填充到最大长度有些浪费。一个更好的做法是:在构建 batch 的时候。这样我们只需要填充到每个 batch 中的最大长度,而不是整个数据集的最大长度。当输入长度不稳定时,这可以节省大量时间和处理能力!
-下面是我们如何在所有数据集上同时应用标记函数。我们在调用**map**时使用了**batch =True**,这样函数就可以同时应用到数据集的多个元素上,而不是分别应用到每个元素上。这将使我们的预处理快许多
+下面是我们如何使用一次性 `tokenize_function` 处理整个数据集。我们在调用 `map` 时使用了 `batch =True` ,这样函数就可以同时处理数据集的多个元素,而不是分别处理每个元素,这样可以更快进行预处理。
+
+以下是如何使用 tokenization 函数处理我们的整个数据集的方法。我们在调用 map 时使用了 `batched=True` ,因此该函数会一次性处理数据集的多个元素,而不是单独处理每个元素。这样可以实现更快的预处理。
```py
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
```
-🤗Datasets库应用这种处理的方式是向数据集添加新的字段,每个字段对应预处理函数返回的字典中的每个键:
+🤗Datasets 库进行这种处理的方式是向数据集添加新的字段,每个字段对应预处理函数返回的字典中的每个键:
```python out
DatasetDict({
@@ -272,42 +338,47 @@ DatasetDict({
})
```
-在使用预处理函数**map()**时,甚至可以通过传递**num_proc**参数使用并行处理。我们在这里没有这样做,因为🤗标记器库已经使用多个线程来更快地标记我们的样本,但是如果您没有使用该库支持的快速标记器,使用**num_proc**可能会加快预处理。
+在使用预处理函数 `map()` 时,甚至可以通过传递 `num_proc` 参数并行处理。我们在这里没有这样做,因为在这个例子中🤗 Tokenizers 库已经使用多线程来更快地对样本 tokenize,但是如果没有使用该库支持的快速 tokenizer,使用 `num_proc` 可能会加快预处理。
-我们的**标记函数(tokenize_function)**返回包含**输入词id(input_ids)** , **注意力遮罩(attention_mask)** 和 **类型标记ID(token_type_ids)** 键的字典,所以这三个字段被添加到数据集的标记的结果中。注意,如果预处理函数**map()**为现有键返回一个新值,那将会修改原有键的值。
+我们的 `tokenize_function` 返回包含 `输入词id(input_ids)` , `注意力遮罩(attention_mask)` 和 `token_type_ids` 键的字典,这三个字段被添加到数据集的三个集合里(训练集、验证集和测试集)。请注意,如果预处理函数 `map()` 为现有键返回一个新值,我们可以通过使用 `map()` 函数返回的新值修改现有的字段。
-最后一件我们需要做的事情是,当我们一起批处理元素时,将所有示例填充到最长元素的长度——我们称之为动态填充。
+我们最后需要做的是将所有示例填充到该 batch 中最长元素的长度,这种技术被称为动态填充。
-### 动态填充 [[动态填充]]
+## 动态填充 [[动态填充]]
{#if fw === 'pt'}
-负责在批处理中将数据整理为一个batch的函数称为*collate函数*。它是你可以在构建**DataLoader**时传递的一个参数,默认是一个函数,它将把你的数据集转换为PyTorch张量,并将它们拼接起来(如果你的元素是列表、元组或字典,则会使用递归)。这在我们的这个例子中下是不可行的,因为我们的输入不是都是相同大小的。我们故意在之后每个batch上进行填充,避免有太多填充的过长的输入。这将大大加快训练速度,但请注意,如果你在TPU上训练,这可能会导致问题——TPU喜欢固定的形状,即使这需要额外的填充。
+
+负责在批处理中将数据整理为一个 batch 的函数称为 `collate 函数` 。这是一个可以在构建 `DataLoader` 时传递的一个参数,默认是一个将你的数据集转换为 PyTorch 张量并将它们拼接起来的函数(如果你的元素是列表、元组或字典,则会使用递归进行拼接)。这在本例子中下是不可行的,因为我们的输入的大小可能是不相同的。我们特意推迟了填充的时间,只在每个 batch 上进行必要的填充,以避免出现有大量填充的过长输入。这将大大加快训练速度,但请注意,如果你在 TPU 上训练,需要注意一个问题——TPU 喜欢固定的形状,即使这需要额外填充很多无用的 token。
{:else}
-负责在批处理中将数据整理为一个batch的函数称为*collate函数*。它只会将您的样本转换为 tf.Tensor并将它们拼接起来(如果你的元素是列表、元组或字典,则会使用递归)。这在我们的这个例子中下是不可行的,因为我们的输入不是都是相同大小的。我们故意在之后每个batch上进行填充,避免有太多填充的过长的输入。这将大大加快训练速度,但请注意,如果你在TPU上训练,这可能会导致问题——TPU喜欢固定的形状,即使这需要额外的填充。
+负责在批处理中将数据整理为一个 batch 的函数称为 `collate 函数` 。默认的拼合函数只会将你的样本转换为 `tf.Tensor` 并将它们拼接起来(如果你的元素是列表、元组或字典,则会使用递归进行拼接)。这在本例中是不可行的,因为我们的输入不是都是相同大小的。我们特意推迟了填充时间,只在每个 batch 上进行填充,以避免有太多填充的过长的输入。这将大大加快训练速度,但请注意,如果你在 TPU 上训练,需要注意一个问题——TPU 喜欢固定的形状,即使这需要额外填充很多无用的 token。
{/if}
-为了解决句子长度统一的问题,我们必须定义一个collate函数,该函数会将每个batch句子填充到正确的长度。幸运的是,🤗transformer库通过**DataCollatorWithPadding**为我们提供了这样一个函数。当你实例化它时,需要一个标记器(用来知道使用哪个词来填充,以及模型期望填充在左边还是右边),并将做你需要的一切:
+为了解决句子长度不统一的问题,我们必须定义一个 collate 函数,该函数会将每个 batch 句子填充到正确的长度。幸运的是,🤗transformer 库通过 `DataCollatorWithPadding` 为我们提供了这样一个函数。当你实例化它时,它需要一个 tokenizer (用来知道使用哪种填充 token 以及模型期望在输入的左边填充还是右边填充),然后它会自动完成所有需要的操作:
{#if fw === 'pt'}
+
```py
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
+
{:else}
+
```py
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
```
+
{/if}
-为了测试这个新玩具,让我们从我们的训练集中抽取几个样本。这里,我们删除列**idx**, **sentence1**和**sentence2**,因为不需要它们,并查看一个batch中每个条目的长度:
+为了测试这个新东西,让我们从我们的训练集中抽取几个样本,在这里,我们删除列 `idx` , `sentence1` 和 `sentence2` ,因为不需要它们,而且删除包含字符串的列(我们不能用字符串创建张量),然后查看一个 batch 中每个条目的长度:
```py
samples = tokenized_datasets["train"][:8]
@@ -315,11 +386,13 @@ samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "se
[len(x) for x in samples["input_ids"]]
```
-```python out
+```python
[50, 59, 47, 67, 59, 50, 62, 32]
```
-毫无疑问,我们得到了不同长度的样本,从32到67。动态填充意味着该批中的所有样本都应该填充到长度为67,这是该批中的最大长度。如果没有动态填充,所有的样本都必须填充到整个数据集中的最大长度,或者模型可以接受的最大长度。让我们再次检查**data_collator**是否正确地动态填充了这批样本:
+不出所料,我们得到了不同长度的样本,从 32 到 67。动态填充意味着这个 batch 都应该填充到长度为 67,这是这个 batch 中的最大长度。如果没有动态填充,所有的样本都必须填充到整个数据集中的最大长度,或者模型可以接受的最大长度。让我们再次检查 `data_collator` 是否正确地动态填充了这批样本:
+
+```py:
```py
batch = data_collator(samples)
@@ -328,35 +401,39 @@ batch = data_collator(samples)
{#if fw === 'tf'}
-```python out
-{'attention_mask': TensorShape([8, 67]),
- 'input_ids': TensorShape([8, 67]),
- 'token_type_ids': TensorShape([8, 67]),
- 'labels': TensorShape([8])}
+```python
+{
+ "attention_mask": TensorShape([8, 67]),
+ "input_ids": TensorShape([8, 67]),
+ "token_type_ids": TensorShape([8, 67]),
+ "labels": TensorShape([8]),
+}
```
{:else}
-```python out
-{'attention_mask': torch.Size([8, 67]),
- 'input_ids': torch.Size([8, 67]),
- 'token_type_ids': torch.Size([8, 67]),
- 'labels': torch.Size([8])}
+```python
+{
+ "attention_mask": torch.Size([8, 67]),
+ "input_ids": torch.Size([8, 67]),
+ "token_type_ids": torch.Size([8, 67]),
+ "labels": torch.Size([8]),
+}
```
-看起来不错!现在,我们已经将原始文本转化为了模型可以处理的数据,我们已准备好对其进行微调!
+看起来不错!现在,我们已经从原始文本转化为了模型可以处理的数据,我们准备好对其进行微调。
{/if}
-✏️ ** 试试看!** 在GLUE SST-2数据集上应用预处理。它有点不同,因为它是由单个句子而不是成对的句子组成的,但是我们所做的其他事情看起来应该是一样的。另一个更难的挑战,请尝试编写一个可用于任何GLUE任务的预处理函数。
+✏️ ** 试试看!** 在 GLUE SST-2 数据集上复刻上述预处理。它有点不同,因为它是由单句而不是成对的句子组成的,但是我们所做的其他事情看起来应该是一样的。另一个进阶的挑战是尝试编写一个可用于任何 GLUE 任务的预处理函数。
{#if fw === 'tf'}
-现在我们有了dataset和data collator,我们需要将dataset批量地应用data collator。 我们可以手动加载批次并整理它们,但这需要大量工作,而且可能性能也不是很好。 相反,有一个简单的方法可以为这个问题提供高效的解决方案:`to_tf_dataset()`。 这将在您的数据集上调用一个 `tf.data.Dataset`的方法,这个方法带有一个可选的data collator功能。 `tf.data.Dataset` 是 Keras 可用于 `model.fit()` 的原生 TensorFlow 格式,因此这种方法会立即将🤗 Dataset 转换为可用于训练的格式。 让我们看看它在我们的数据集上是如何使用的!
+现在我们有了 dataset 和 data collator,我们需要使用 data collator 批量地处理 dataset。我们可以手动加载批次并进行整合,但这需要大量工作,性能也有可能不好。相反,有一个简单的方法为这个问题提供高效的解决方案: `to_tf_dataset()` 。它将把你的数据集包装一个 `tf.data.Dataset` 类中,这个方法带有一个可选的 data collator 功能。 `tf.data.Dataset` 是 TensorFlow 的本地格式,Keras 可以直接用它来进行 `model.fit()` ,因此这种方法会立即将🤗 Dataset 转换为可用于训练的格式。让我们用我们的数据集演示一下这个方法!
```py
tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
@@ -376,6 +453,6 @@ tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
)
```
-就是这样! 我们可以将这些数据集带入下一节,在经过所有艰苦的数据预处理工作之后,训练将变得非常简单。
+就是这样!我们可以把这些数据集带入下一节,在经过所有艰苦的数据预处理工作之后,训练将变得非常简单和愉快。
{/if}
diff --git a/chapters/zh-CN/chapter3/3.mdx b/chapters/zh-CN/chapter3/3.mdx
index efcdb0916..b67557bc5 100644
--- a/chapters/zh-CN/chapter3/3.mdx
+++ b/chapters/zh-CN/chapter3/3.mdx
@@ -11,9 +11,9 @@
-🤗 Transformers提供了一个 **Trainer** 类来帮助您在自己的数据集上微调任何预训练模型。完成上一节中的所有数据预处理工作后,您只需要执行几个步骤来创建 **Trainer** .最难的部分可能是为 **Trainer.train()**配置运行环境,因为它在 CPU 上运行速度会非常慢。如果您没有设置 GPU,您可以访问免费的 GPU 或 TPU[Google Colab](https://colab.research.google.com/).
+🤗 Transformers 提供了一个 `Trainer` 类,可以帮助你在数据集上微调任何预训练模型。在上一节中完成所有数据预处理工作后,你只需完成几个步骤来定义 `Trainer` 。最困难的部分可能是准备运行 `Trainer.train()` 所需的环境,因为在 CPU 上运行速度非常慢。如果你没有设置 GPU,可以使用 [Google Colab](https://colab.research.google.com/) (国内网络无法使用) 上获得免费的 GPU 或 TPU。
-下面的示例假设您已经执行了上一节中的示例。下面这段代码,概括了您需要提前运行的代码:
+下面的示例假设你已经执行了上一节中的示例。下面是在开始学习这一节之前你需要运行的代码:
```py
from datasets import load_dataset
@@ -34,7 +34,7 @@ data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
### Training [[Training]]
-在我们定义我们的 **Trainer** 之前首先要定义一个 **TrainingArguments** 类,它将包含 **Trainer**用于训练和评估的所有超参数。您唯一必须提供的参数是保存训练模型的目录,以及训练过程中的检查点。对于其余的参数,您可以保留默认值,这对于基本微调应该非常有效。
+在我们定义 `Trainer` 之前第一步要定义一个 `TrainingArguments` 类,它包含 `Trainer` 在训练和评估中使用的所有超参数。你只需要提供的参数是一个用于保存训练后的模型以及训练过程中的 checkpoint 的目录。对于其余的参数你可以保留默认值,这对于简单的微调应该效果就很好了。
```py
from transformers import TrainingArguments
@@ -44,11 +44,11 @@ training_args = TrainingArguments("test-trainer")
-💡 如果您想在训练期间自动将模型上传到 Hub,请将push_to_hub=True添加到TrainingArguments之中. 我们将在[第四章](/course/chapter4/3)中详细介绍这部分。
+💡 如果你想在训练期间自动将模型上传到 Hub,请将 `push_to_hub=True` 添加到 TrainingArguments 之中。我们将在 [第四章](/course/chapter4/3) 中详细介绍这部分。
-第二步是定义我们的模型。正如在[之前的章节](/2_Using Transformers/Introduction)一样,我们将使用 **AutoModelForSequenceClassification** 类,它有两个参数:
+第二步是定义我们的模型。与 [前一章](/course/chapter2) 一样,我们将使用 `AutoModelForSequenceClassification` 类,它有两个参数:
```py
from transformers import AutoModelForSequenceClassification
@@ -56,9 +56,9 @@ from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
-你会注意到,和[第二章](/course/chapter2)不一样的是,在实例化此预训练模型后会收到警告。这是因为 BERT 没有在句子对分类方面进行过预训练,所以预训练模型的头部已经被丢弃,而是添加了一个适合句子序列分类的新头部。警告表明一些权重没有使用(对应于丢弃的预训练头的那些),而其他一些权重被随机初始化(新头的那些)。最后鼓励您训练模型,这正是我们现在要做的。
+你会注意到,和 [第二章](/course/chapter2) 不同的是,在实例化此预训练模型后会收到警告。这是因为 BERT 没有在句子对分类方面进行过预训练,所以预训练模型的 head 已经被丢弃,而是添加了一个适合句子序列分类的新头部。这些警告表明一些权重没有使用(对应于被放弃的预训练头的权重),而有些权重被随机初始化(对应于新 head 的权重)。
-一旦我们有了我们的模型,我们就可以定义一个 **Trainer** 通过将之前构造的所有对象传递给它——我们的**model** 、**training_args** ,训练和验证数据集,**data_collator** ,和 **tokenizer** :
+一旦有了我们的模型,我们就可以定义一个 `Trainer` 把到目前为止构建的所有对象 —— `model` ,`training_args`,训练和验证数据集, `data_collator` 和 `tokenizer` 传递给 `Trainer` :
```py
from transformers import Trainer
@@ -73,23 +73,23 @@ trainer = Trainer(
)
```
-请注意,当您在这里完成**tokenizer**后,默认 **Trainer**使用 的**data_collator**会使用之前预定义的 **DataCollatorWithPadding** ,因此您可以在这个例子中跳过 **data_collator=data_collator**。在第 2 节中向您展示这部分处理仍然很重要!
+请注意,当你在这里传递 `tokenizer` 时, `Trainer` 默认使用的 `data_collator` 是之前预定义的 `DataCollatorWithPadding`。所以你可以在本例中可以跳过 `data_collator=data_collator` 一行。在第 2 节中向你展示这部分处理过程仍然很重要!
-为了让预训练模型在在我们的数据集上微调,我们只需要调用**Trainer**的**train()** 方法 :
+要在我们的数据集上微调模型,我们只需调用 `Trainer` 的 `train()` 方法:
```py
trainer.train()
```
-这将开始微调(在GPU上应该需要几分钟),并每500步报告一次训练损失。但是,它不会告诉您模型的性能如何(或质量如何)。这是因为:
+开始微调(在 GPU 上应该需要几分钟),每 500 步报告一次训练损失。然而它不会告诉你模型的性能(或质量)如何。这是因为:
-1. 我们没有通过将**evaluation_strategy**设置为“**steps**”(在每次更新参数的时候评估)或“**epoch**”(在每个epoch结束时评估)来告诉**Trainer**在训练期间进行评估。
-2. 我们没有为**Trainer**提供一个**compute_metrics()**函数来直接计算模型的好坏(否则评估将只输出loss,这不是一个非常直观的数字)。
+1. 我们没有告诉 Trainer 在训练过程中进行评估,比如将 `evaluation_strategy` 设置为“ `step` ”(在每个 `eval_steps` 步骤评估一次)或“ `epoch` ”(在每个 epoch 结束时评估)。
+2. 我们没有为 `Trainer` 提供一个 `compute_metrics()` 函数来计算上述评估过程的指标(否则评估将只会输出 loss,但这不是一个非常直观的数字)。
### 评估 [[评估]]
-让我们看看如何构建一个有用的 **compute_metrics()** 函数并在我们下次训练时使用它。该函数必须采用 **EvalPrediction** 对象(带有 **predictions** 和 **label_ids** 字段的参数元组)并将返回一个字符串到浮点数的字典(字符串是返回的指标的名称,而浮点数是它们的值)。我们可以使用 **Trainer.predict()** 命令来使用我们的模型进行预测:
+让我们看看如何构建一个有用的 `compute_metrics()` 函数,并在下次训练时使用它。该函数必须接收一个 `EvalPrediction` 对象(它是一个带有 `predictions` 和 `label_ids` 字段的参数元组),并将返回一个字符串映射到浮点数的字典(字符串是返回的指标名称,而浮点数是其值)。为了从我们的模型中获得预测结果,可以使用 `Trainer.predict()` 命令:
```py
predictions = trainer.predict(tokenized_datasets["validation"])
@@ -100,9 +100,7 @@ print(predictions.predictions.shape, predictions.label_ids.shape)
(408, 2) (408,)
```
- **predict()** 的输出结果是具有三个字段的命名元组: **predictions** , **label_ids** , 和 **metrics** .这 **metrics** 字段将只包含传递的数据集的loss,以及一些运行时间(预测所需的总时间和平均时间)。如果我们定义了自己的 **compute_metrics()** 函数并将其传递给 **Trainer** ,该字段还将包含**compute_metrics()**的结果。
-
-**predict()** 方法是具有三个字段的命名元组: **predictions** , **label_ids** , 和 **metrics** .这 **metrics** 字段将只包含传递的数据集的loss,以及一些运行时间(预测所需的总时间和平均时间)。如果我们定义了自己的 **compute_metrics()** 函数并将其传递给 **Trainer** ,该字段还将包含**compute_metrics()** 的结果。如你看到的, **predictions** 是一个形状为 408 x 2 的二维数组(408 是我们使用的数据集中元素的数量)。这些是我们传递给**predict()**的数据集的每个元素的结果(logits)(正如你在[之前的章节](/course/chapter2)看到的情况)。要将我们的预测的可以与真正的标签进行比较,我们需要在第二个轴上取最大值的索引:
+`predict()` 方法的输出另一个带有三个字段的命名元组: `predictions` `label_ids` 和 `metrics` `metrics` 字段将只包含所传递的数据集的损失,以及一些时间指标(总共花费的时间和平均预测时间)。当我们定义了自己的 `compute_metrics()` 函数并将其传递给 `Trainer` 该字段还将包含 `compute_metrics()` 返回的结果。`predict()` 是一个二维数组,形状为 408 × 2(408 是我们使用的数据集中的元素数量),这是我们传递给 `pprdict()` 的数据集中每个元素的 logits(正如在 [前一章](/course/chapter2) 中看到的,所有 Transformer 模型都返回 logits)。为了将它们转化为可以与我们的标签进行比较的预测值,我们需要找出第二个维度上取值最大的索引:
```py
import numpy as np
@@ -110,7 +108,7 @@ import numpy as np
preds = np.argmax(predictions.predictions, axis=-1)
```
-现在建立我们的 **compute_metric()** 函数来较为直观地评估模型的好坏,我们将使用 🤗 [Evaluate](https://github.com/huggingface/evaluate/) 库中的指标。我们可以像加载数据集一样轻松加载与 MRPC 数据集关联的指标,这次使用 **evaluate.load()** 函数。返回的对象有一个 **compute()**方法我们可以用来进行度量计算的方法:
+我们现在可以将这些 `preds` 与标签进行比较。为了构建我们的 `compute_metric()` 函数,我们将使用 🤗 [Evaluate](https://github.com/huggingface/evaluate/) 库中的指标。我们可以像加载数据集一样轻松地加载与 MRPC 数据集关联的指标,这次是使用 `evaluate.load()` 函数。返回的对象有一个 `compute()` 方法,我们可以用它来进行指标的计算:
```py
import evaluate
@@ -123,9 +121,9 @@ metric.compute(predictions=preds, references=predictions.label_ids)
{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
```
-您获得的确切结果可能会有所不同,因为模型头的随机初始化可能会影响最终建立的模型。在这里,我们可以看到我们的模型在验证集上的准确率为 85.78%,F1 分数为 89.97。这是用于评估 GLUE 基准的 MRPC 数据集结果的两个指标。而在[BERT 论文](https://arxiv.org/pdf/1810.04805.pdf)中展示的基础模型的 F1 分数为 88.9。那是 **uncased** 模型,而我们目前正在使用 **cased** 模型,通过改进得到了更好的结果。
+你得到的确切结果可能会有所不同,因为模型头部的随机初始化可能会改变其指标。在这里,我们可以看到我们的模型在验证集上的准确率为 85.78%,F1 分数为 89.97。这是用于评估 MRPC 数据集在 GLUE 基准测试中的结果的两个指标。在 BERT 论文中的表格中,基础模型的 F1 分数为 88.9。那是 uncased 模型,而我们现在正在使用 cased 模型,这解释了为什么我们得到了更好的结果。
-最后将所有东西打包在一起,我们得到了我们的 **compute_metrics()** 函数:
+最后把所有东西打包在一起,我们就得到了 `compute_metrics()` 函数:
```py
def compute_metrics(eval_preds):
@@ -135,7 +133,7 @@ def compute_metrics(eval_preds):
return metric.compute(predictions=predictions, references=labels)
```
-为了查看模型在每个训练周期结束的好坏,下面是我们如何使用**compute_metrics()**函数定义一个新的 **Trainer** :
+为了查看模型在每个训练周期结束时的好坏,下面是我们如何使用 `compute_metrics()` 函数定义一个新的 `Trainer`
```py
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
@@ -152,21 +150,19 @@ trainer = Trainer(
)
```
-请注意,我们设置了了一个新的 **TrainingArguments** 它的**evaluation_strategy** 设置为 **epoch** 并创建了一个新模型。如果不创建新的模型就直接训练,就只会继续训练之前我们已经训练过的模型。要启动新的训练运行,我们执行:
+请注意,我们设置了一个新的 `TrainingArguments` ,其 `evaluation_strategy` 设置为 `epoch` 并且创建了一个新模型。如果不创建新的模型就直接训练,就只会继续训练我们已经训练过的模型。为了启动新的训练,我们执行:
```py
trainer.train()
```
-这一次,它将在训练loss之外,还会输出每个 epoch 结束时的验证loss和指标。同样,由于模型的随机头部初始化,您达到的准确率/F1 分数可能与我们发现的略有不同,但它应该在同一范围内。
-
-这 **Trainer** 将在多个 GPU 或 TPU 上开箱即用,并提供许多选项,例如混合精度训练(在训练的参数中使用 **fp16 = True** )。我们将在第 10 章讨论它支持的所有内容。
+这一次,它将在每个 epoch 结束时在训练损失的基础上报告验证损失和指标。同样,由于模型的随机头部初始化,达到的准确率/F1 分数可能与我们发现的略有不同,这是由于模型头部的随机初始化造成的,但应该相差不多。 `Trainer` 可以在多个 GPU 或 TPU 上运行,并提供许多选项,例如混合精度训练(在训练的参数中使用 `fp16 = True` )。我们将在第十章讨论它支持的所有内容。
-使用**Trainer** API微调的介绍到此结束。对最常见的 NLP 任务执行此操作的示例将在[第 7 章](/course/chapter7)中给出,但现在让我们看看如何在纯 PyTorch 中执行相同的操作。
+使用 `Trainer` API 微调的介绍到此结束。在 [第七章](/course/chapter7) 中会给出一个对大多数常见的 NLP 任务进行训练的例子,但现在让我们看看如何在 PyTorch 中做相同的操作。
-✏️ **试试看!** 使用您在第 2 节中进行的数据处理,在 GLUE SST-2 数据集上微调模型。
+✏️ **试试看!** 使用你在第 2 节中学到的数据处理过程,在 GLUE SST-2 数据集上对模型进行微调。
diff --git a/chapters/zh-CN/chapter3/3_tf.mdx b/chapters/zh-CN/chapter3/3_tf.mdx
index 936c81e76..773224214 100644
--- a/chapters/zh-CN/chapter3/3_tf.mdx
+++ b/chapters/zh-CN/chapter3/3_tf.mdx
@@ -9,9 +9,9 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/zh-CN/chapter3/section3_tf.ipynb"},
]} />
-完成上一节中的所有数据预处理工作后,您只剩下最后的几个步骤来训练模型。 但是请注意,`model.fit()` 命令在 CPU 上运行会非常缓慢。 如果您没有GPU,则可以在 [Google Colab](https://colab.research.google.com/) 上使用免费的 GPU 或 TPU(需要梯子)。
+一旦完成上一节中的所有数据预处理工作后,你只剩下最后的几个步骤来训练模型。 但是请注意,`model.fit()` 命令在 CPU 上运行会非常缓慢。 如果你没有GPU,你可以在 [Google Colab](https://colab.research.google.com)(国内网络无法使用) 上使用免费的 GPU 或 TPU。
-这一节的代码示例假设您已经执行了上一节中的代码示例。 下面一个简短的摘要,包含了在开始学习这一节之前您需要的执行的代码:
+下面的代码示例假设你已经运行了上一节中的代码示例。 下面是在开始学习这一节之前你需要运行的代码:
```py
from datasets import load_dataset
@@ -48,17 +48,17 @@ tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
)
```
-### 训练模型 [[训练模型]]
+## 训练模型 [[训练模型]]
从🤗 Transformers 导入的 TensorFlow 模型已经是 Keras 模型。 下面的视频是对 Keras 的简短介绍。
-这意味着,一旦我们有了数据,就需要很少的工作就可以开始对其进行训练。
+这意味着一旦我们有了数据,只需要很少的工作就可以开始对其进行训练。
-和[第二章](/course/chapter2)使用的方法一样, 我们将使用二分类的 `TFAutoModelForSequenceClassification`类:
+和[第二章](/course/chapter2)使用的方法一样, 我们将使用二分类的 `TFAutoModelForSequenceClassification`类,我们将有两个标签:
```py
from transformers import TFAutoModelForSequenceClassification
@@ -66,13 +66,13 @@ from transformers import TFAutoModelForSequenceClassification
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
-您会注意到,与 [第二章](/course/chapter2) 不同的是,您在实例化此预训练模型后会收到警告。 这是因为 BERT 没有对句子对进行分类进行预训练,所以预训练模型的 head 已经被丢弃,而是插入了一个适合序列分类的新 head。 警告表明一些权重没有使用(对应于丢弃的预训练头),而其他一些权重是随机初始化的(新头的权重)。 最后鼓励您训练模型,这正是我们现在要做的。
+你会注意到,与 [第二章](/course/chapter2) 不同的是,在实例化这个预训练的模型后会收到警告。 这是因为 BERT 没有对句子对的分类进行预训练,所以预训练模型的 head 已经被丢弃,并且插入了一个适合序列分类的新 head。 警告表明,这些权重没有使用(对应于丢弃的预训练 head 权重),而其他一些权重是随机初始化的(对应于新 head 的权重)。 最后它建议你训练模型,这正是我们现在要做的。
-要在我们的数据集上微调模型,我们只需要在我们的模型上调用 `compile()` 方法,然后将我们的数据传递给 `fit()` 方法。 这将启动微调过程(在 GPU 上应该需要几分钟)并输出训练loss,以及每个 epoch 结束时的验证loss。
+为了在我们的数据集上微调模型,我们只需要在我们的模型上调用 `compile()` 方法,然后将我们的数据传递给 `fit()` 方法。 这将启动微调过程(在 GPU 上应该需要几分钟)并输出训练损失,以及每个 epoch 结束时的验证损失。
-请注意🤗 Transformers 模型具有大多数 Keras 模型所没有的特殊能力——它们可以自动使用内部计算的loss。 如果您没有在 `compile()` 中设置损失函数,他们将默认使用内部计算的损失。 请注意,要使用内部损失,您需要将标签作为输入的一部分传递,而不是作为单独的标签(这是在 Keras 模型中使用标签的正常方式)。 您将在课程的第 2 部分中看到这方面的示例,其中定义正确的损失函数可能很棘手。 然而,对于序列分类,标准的 Keras 损失函数可以正常工作,所以我们将在这里使用它。
+请注意🤗 Transformers 模型具有大多数 Keras 模型所没有的特殊能力——它们可以自动使用内部计算的损失。 如果你没有在 `compile()` 中设置损失参数,它们可以自动使用适当的损失函数,并在内部计算。 请注意,要使用内部损失,你需要将标签作为输入的一部分传入模型,而不是作为单独的标签(这是在 Keras 模型中使用标签的常规方式)。 你将在课程的第 2 部分中看到这方面的示例,正确定义损失函数可能会有些棘手。 然而对于序列分类来说,标准的 Keras 损失函数效果很好,因此我们将在这里使用它。
@@ -92,27 +92,28 @@ model.fit(
-请注意这里有一个非常常见的陷阱——你只是*可以*将损失的名称作为字符串传递给 Keras,但默认情况下,Keras 会假设你已经对输出应用了 softmax。 然而,许多模型在应用 softmax 之前就输出,也称为 *logits*。 我们需要告诉损失函数我们的模型是否经过了softmax,唯一的方法是直接调用它,而不是用字符串的名称。
+请注意这里有一个非常常见的陷阱——你可以把损失的名称作为一个字符串传递给 Keras,但默认情况下,Keras 会假设你已经对输出进行了 softmax。 然而,许多模型在经过 softmax 函数之前输出的是被称为 `logits` 的值。 我们需要告诉损失函数,我们的模型是否已经使用 softmax 函数进行了处理,唯一的方法是传递一个损失函数并且在参数的部分告诉模型,而不是只传递一个字符串。
-### 提升训练的效果 [[提升训练的效果]]
+## 改善训练的效果 [[改善训练的效果]]
-如果您尝试上面的代码,它肯定会运行,但您会发现loss只是缓慢或零星地下降。 主要原因是*学习率*。 与loss一样,当我们将优化器的名称作为字符串传递给 Keras 时,Keras 会初始化该优化器具有所有参数的默认值,包括学习率。 但是,根据长期经验,我们知道Transformer 模型更适合使用比 Adam 的默认值(1e-3)也写成为 10 的 -3 次方,或 0.001,低得多的学习率。 5e-5 (0.00005) 比默认值大约低 20 倍,是一个更好的起点。
+如果你尝试上述代码,它的确可以运行,但你会发现损失下降得很慢或者不规律。 主要原因是`学习率`。 与损失一样,当我们把优化器的名称作为字符串传递给 Keras 时,Keras 会初始化该优化器具有所有参数的默认值,包括学习率。 不过根据长期经验,我们知道Transformer 模型的通常的最佳学习率比 Adam 的默认值(即1e-3,也写成为 10 的 -3 次方,或 0.001)低得多。 5e-5(0.00005),是一个更好的起始点。
-除了降低学习率,我们还有第二个技巧:我们可以慢慢降低学习率。在训练过程中。 在文献中,您有时会看到这被称为 *decaying* 或 *annealing*学习率。 在 Keras 中,最好的方法是使用 *learning rate scheduler*。 一个好用的是`PolynomialDecay`——尽管有这个名字,但在默认设置下,它只是简单地从初始值线性衰减学习率值在训练过程中的最终值,这正是我们想要的。但是, 为了正确使用调度程序,我们需要告诉它训练的次数。 我们将在下面为其计算“num_train_steps”。
+除了降低学习率之外,我们还有第二个技巧:我们可以在训练过程中慢慢降低学习率。在文献中,你有时会看到这被称为 学习率的`衰减(decaying)` 或 `退火(annealing)`。 在 Keras 中,最好的方法是使用 `学习率调度器(learning rate scheduler)`。 一个好用的调度器是`PolynomialDecay`——尽管它的名字叫`PolynomialDecay(多项式衰减)`,但在默认设置下,它只是简单将学习率从初始值线性衰减到最终值,这正是我们想要的。不过为了正确使用调度程序,我们需要告诉它训练的次数。我们可以通过下面的`num_train_steps`计算得到。
```py
from tensorflow.keras.optimizers.schedules import PolynomialDecay
batch_size = 8
num_epochs = 3
-# 训练步数是数据集中的样本数除以batch size再乘以 epoch。
-# 注意这里的tf_train_dataset是一个转化为batch后的 tf.data.Dataset,
-# 不是原来的 Hugging Face Dataset,所以它的 len() 已经是 num_samples // batch_size。
+
+# 训练步数是数据集中的样本数量,除以 batch 大小,然后乘以总的 epoch 数。
+# 注意这里的 tf_train_dataset 是 batch 形式的 tf.data.Dataset,
+# 而不是原始的 Hugging Face Dataset ,所以使用 len() 计算它的长度已经是 num_samples // batch_size。
num_train_steps = len(tf_train_dataset) * num_epochs
lr_scheduler = PolynomialDecay(
initial_learning_rate=5e-5, end_learning_rate=0.0, decay_steps=num_train_steps
@@ -124,11 +125,11 @@ opt = Adam(learning_rate=lr_scheduler)
-🤗 Transformers 库还有一个 `create_optimizer()` 函数,它将创建一个具有学习率衰减的 `AdamW` 优化器。 这是一个便捷的方式,您将在本课程的后续部分中详细了解。
+🤗 Transformers 库还有一个 `create_optimizer()` 函数,它将创建一个具有学习率衰减的 `AdamW` 优化器。 这是一个快捷的方式,你将在本课程的后续部分中详细了解。
-现在我们有了全新的优化器,我们可以尝试使用它进行训练。 首先,让我们重新加载模型,以重置我们刚刚进行的训练运行对权重的更改,然后我们可以使用新的优化器对其进行编译:
+现在我们有了全新的优化器,我们可以尝试使用它进行训练。 首先,让我们重新加载模型,重新设置刚刚训练时的权重,然后我们可以使用新的优化器对其进行编译:
```py
import tensorflow as tf
@@ -146,22 +147,22 @@ model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
-💡 如果您想在训练期间自动将模型上传到 Hub,您可以在 `model.fit()` 方法中传递 `PushToHubCallback`。 我们将在 [第四章](/course/chapter4/3) 中进行介绍
+💡 如果你想在训练期间自动将模型上传到 Hub,你可以在 `model.fit()` 方法中传递一个 `PushToHubCallback`。 我们将在 [第四章](/course/chapter4/3) 中进一步了解这个问题。
-### 模型预测 [[模型预测]]
+## 模型预测 [[模型预测]]
-训练和观察的loss下降都非常好,但是如果我们想从训练后的模型中获得输出,或者计算一些指标,或者在生产中使用模型呢? 为此,我们可以使用`predict()` 方法。 这将返回模型的输出头的*logits*数值,每个类一个。
+训练和观察损失的下降都是非常好,但如果我们想从训练后的模型中得到输出,或者计算一些指标,或者在生产中使用模型,该怎么办呢?为此,我们可以使用`predict()` 方法。 这将返回模型的输出头的`logits`数值,每个类一个。
```py
preds = model.predict(tf_validation_dataset)["logits"]
```
-我们可以将这些 logit 转换为模型的类别预测,方法是使用 argmax 找到最高的 logit,它对应于最有可能的类别:
+我们可以通过使用 argmax 将这些 logits 转换为模型的类别预测,最高的 logits,对应于最有可能的类别
```py
class_preds = np.argmax(preds, axis=1)
@@ -172,7 +173,7 @@ print(preds.shape, class_preds.shape)
(408, 2) (408,)
```
-现在,让我们使用这些 `preds` 来计算一些指标! 我们可以像加载数据集一样轻松地加载与 MRPC 数据集相关的指标,这次使用的是 `evaluate.load()` 函数。 返回的对象有一个 `compute()` 方法,我们可以使用它来进行度量计算:
+现在,让我们使用这些 `preds` 来计算一些指标! 我们可以像加载数据集一样轻松地加载与 MRPC 数据集相关的指标,这次使用的是 `evaluate.load()` 函数。 返回的对象有一个 `compute()` 方法,我们可以使用它来进行指标的计算:
```py
import evaluate
@@ -185,6 +186,6 @@ metric.compute(predictions=class_preds, references=raw_datasets["validation"]["l
{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
```
-您获得的确切结果可能会有所不同,因为模型头的随机初始化可能会改变它获得的指标。 在这里,我们可以看到我们的模型在验证集上的准确率为 85.78%,F1 得分为 89.97。 这些是用于评估 GLUE 基准的 MRPC 数据集结果的两个指标。 [BERT 论文](https://arxiv.org/pdf/1810.04805.pdf) 中的表格报告了基本模型的 F1 分数为 88.9。 那是 `uncased` 模型,而我们目前使用的是 `cased` 模型,这解释了为什么我们会获得更好的结果。
+由于模型头的随机初始化可能会改变模型达到的指标,因此你得到的最终结果可能会有所不同。在这里,我们可以看到我们的模型在验证集上的准确率为85.78%,F1分数为89.97。 这就是用于评估 GLUE 基准的 MRPC 数据集上的结果两个指标。 [BERT 论文](https://arxiv.org/pdf/1810.04805.pdf) 中的表格报告了基本模型的 F1 分数为 88.9。 那是 `uncased` 模型,而我们目前使用的是 `cased` 模型,这也可以解释为什么我们会得到了更好的结果。
-使用 Keras API 进行微调的介绍到此结束。 [第 7 章](/course/chapter7)将给出对大多数常见 NLP 任务执行此操作的示例。如果您想在 Keras API 上磨练自己的技能,请尝试使第二节所使用的的数据处理在 GLUE SST-2 数据集上微调模型。
\ No newline at end of file
+关于使用 Keras API 进行微调的介绍到此结束。 在[第七章](/course/chapter7)将给出对大多数常见 NLP 任务微调或训练的示例。如果你想在 Keras API 上磨练自己的技能,请尝试使第2节所学的的数据处理技巧在 GLUE SST-2 数据集上微调模型。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter3/4.mdx b/chapters/zh-CN/chapter3/4.mdx
index bc8921f13..743f763f1 100644
--- a/chapters/zh-CN/chapter3/4.mdx
+++ b/chapters/zh-CN/chapter3/4.mdx
@@ -9,7 +9,7 @@
-现在,我们将了解如何在不使用`Trainer`类的情况下获得与上一节相同的结果。同样,我们假设您已经学习了第 2 节中的数据处理。下面是一个简短的总结,涵盖了您需要的所有内容:
+现在,我们将了解如何在不使用 `Trainer` 类的情况下实现与上一节相同的结果。同样,我们假设你已经完成了第 2 节中的数据处理。下面对第 2 节内容的一个简短总结,涵盖了你需要在本节之前运行的所有内容:
```py
from datasets import load_dataset
@@ -28,15 +28,15 @@ tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
-### 训练前的准备 [[训练前的准备]]
+## 训练前的准备 [[训练前的准备]]
-在实际编写我们的训练循环之前,我们需要定义一些对象。第一个是我们将用于迭代批次的数据加载器。我们需要对我们的`tokenized_datasets`做一些处理,来处理`Trainer`自动为我们做的一些事情。具体来说,我们需要:
+在正式开始编写我们的训练循环之前,我们需要定义一些对象。首先是我们将用于迭代 batch 的数据加载器。但在定义这些数据加载器之前,我们需要对我们的 `tokenized_datasets` 进行一些后处理,以自己实现一些 Trainer 自动为我们处理的内容。具体来说,我们需要:
-- 删除与模型不期望的值相对应的列(如`sentence1`和`sentence2`列)。
-- 将列名`label`重命名为`labels`(因为模型期望参数是`labels`)。
+- 删除与模型不需要的列(如 `sentence1` 和 `sentence2` 列)。
+- 将列名 `label` 重命名为 `labels` (因为模型默认的输入是 `labels` )。
- 设置数据集的格式,使其返回 PyTorch 张量而不是列表。
-针对上面的每个步骤,我们的 `tokenized_datasets` 都有一个方法:
+针对上面的每个步骤,我们的 `tokenized_datasets` 都有一个方法:
```py
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
@@ -45,13 +45,13 @@ tokenized_datasets.set_format("torch")
tokenized_datasets["train"].column_names
```
-然后,我们可以检查结果中是否只有模型能够接受的列:
+然后,我们可以检查结果中是否只有模型能够接受的列:
```python
["attention_mask", "input_ids", "labels", "token_type_ids"]
```
-至此,我们可以轻松定义数据加载器:
+至此,我们可以轻松定义数据加载器:
```py
from torch.utils.data import DataLoader
@@ -64,7 +64,7 @@ eval_dataloader = DataLoader(
)
```
-为了快速检验数据处理中没有错误,我们可以这样检验其中的一个批次:
+为了快速检验数据处理中没有错误,我们可以这样检验其中的一个 batch:
```py
for batch in train_dataloader:
@@ -79,16 +79,17 @@ for batch in train_dataloader:
'token_type_ids': torch.Size([8, 65])}
```
-请注意,实际的形状可能与您略有不同,因为我们为训练数据加载器设置了`shuffle=True`,并且模型会将句子填充到`batch`中的最大长度。
+请注意,这里的形状可能与你略有不同,因为我们为训练数据加载器设置了 `shuffle=True` ,并且模型会将句子填充到 `batch` 中的最大长度。
-现在我们已经完全完成了数据预处理(对于任何 ML 从业者来说都是一个令人满意但难以实现的目标),让我们将注意力转向模型。我们完全像在上一节中所做的那样实例化它:
+现在我们已经完全完成了数据预处理(对于任何 ML 从业者来说都是一个令人满意但难以实现的目标),让我们将注意力转向模型。我们会像在上一节中所做的那样实例化它:
```py
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
-为了确保训练过程中一切顺利,我们将`batch`传递给这个模型:
+
+为了确保训练过程中一切顺利,我们将 `batch` 传递给这个模型:
```py
outputs = model(**batch)
@@ -99,9 +100,9 @@ print(outputs.loss, outputs.logits.shape)
tensor(0.5441, grad_fn=) torch.Size([8, 2])
```
-当我们提供 `labels` 时, 🤗 Transformers 模型都将返回这个`batch`的`loss`,我们还得到了 `logits`(`batch`中的每个输入有两个,所以张量大小为 8 x 2)。
+当我们输入 `labels` 时,🤗 Transformers 模型都将返回这个 `batch` 的 `loss` ,我们还得到了 `logits` ( `batch` 中的每个输入有两个输出,所以张量大小为 8 x 2)。
-我们几乎准备好编写我们的训练循环了!我们只是缺少两件事:优化器和学习率调度器。由于我们试图自行实现 `Trainer`的功能,我们将使用相同的优化器和学习率调度器。`Trainer` 使用的优化器是 `AdamW` , 与 `Adam` 相同,但在权重衰减正则化方面有所不同(参见[“Decoupled Weight Decay Regularization”](https://arxiv.org/abs/1711.05101)作者:Ilya Loshchilov 和 Frank Hutter):
+我们几乎准备好编写我们的训练循环了!我们只是缺少两件事:优化器和学习率调度器。由于我们试图手动实现 `Trainer` 的功能,我们将使用相同的优化器和学习率调度器。 `Trainer` 使用的优化器是 `AdamW` ,它与 `Adam` 相同,但加入了权重衰减正则化的一点变化(参见 Ilya Loshchilov 和 Frank Hutter 的 [“Decoupled Weight Decay Regularization”](https://arxiv.org/abs/1711.05101) ):
```py
from transformers import AdamW
@@ -109,7 +110,7 @@ from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
```
-最后,默认使用的学习率调度器只是从最大值 (5e-5) 到 0 的线性衰减。 为了定义它,我们需要知道我们训练的次数,即所有数据训练的次数(epochs)乘以的数据量(这是我们所有训练数据的数量)。`Trainer`默认情况下使用三个`epochs`,因此我们定义训练过程如下:
+最后,默认使用的学习率调度器只是从最大值 (5e-5) 到 0 的线性衰减。为了定义它,我们需要知道我们训练的次数,即所有数据训练的次数(epochs)乘以的 batch 的数量(即我们训练数据加载器的长度)。 `Trainer` 默认情况下使用三个 `epochs` ,因此我们定义训练过程如下:
```py
from transformers import get_scheduler
@@ -129,9 +130,9 @@ print(num_training_steps)
1377
```
-### 训练循环 [[训练循环]]
+## 训练循环 [[训练循环]]
-最后一件事:如果我们可以访问 GPU,我们将希望使用 GPU(在 CPU 上,训练可能需要几个小时而不是几分钟)。为此,我们定义了一个 `device`,它在GPU可用的情况下指向GPU 我们将把我们的模型和`batche`放在`device`上:
+最后一件事:如果我们可以访问 GPU,我们将希望使用 GPU(在 CPU 上,训练可能需要几个小时而不是几分钟)。为此,我们定义了一个 `device` ,它在 GPU 可用的情况下指向 GPU,最后我们将把我们的模型和 `batch` 放在 `device` 上:
```py
import torch
@@ -145,7 +146,7 @@ device
device(type='cuda')
```
-我们现在准备好训练了!为了了解训练何时结束,我们使用 `tqdm` 库,在训练步骤数上添加了一个进度条:
+我们现在准备好训练了!为了知道训练何时结束,我们使用 `tqdm` 库,在训练步骤数上添加了一个进度条:
```py
from tqdm.auto import tqdm
@@ -166,12 +167,12 @@ for epoch in range(num_epochs):
progress_bar.update(1)
```
-您可以看到训练循环的核心与介绍中的非常相似。我们没有要求任何检验,所以这个训练循环不会告诉我们任何关于模型目前的状态。我们需要为此添加一个评估循环。
+你可以看到训练循环的核心与介绍中的非常相似。我们没有要求在训练的过程中进行检验,所以这个训练循环不会告诉我们任何关于模型目前的状态。我们需要为此添加一个评估循环。
-### 评估循环 [[评估循环]]
+## 评估循环 [[评估循环]]
-正如我们之前所做的那样,我们将使用 🤗 Evaluate 库提供的指标。我们已经了解了 `metric.compute()` 方法,当我们使用 `add_batch()`方法进行预测循环时,实际上该指标可以为我们累积所有 `batch` 的结果。一旦我们累积了所有 `batch` ,我们就可以使用 `metric.compute()` 得到最终结果 .以下是在评估循环中实现所有这些的方法:
+正如我们之前所做的那样,我们将使用 🤗 Evaluate 库提供的指标。我们已经了解了 `metric.compute()` 方法,当我们使用 `add_batch()` 方法进行预测循环时,实际上该指标可以为我们累积所有 `batch` 的结果。一旦我们累积了所有 `batch` ,我们就可以使用 `metric.compute()` 评估得到的结果。以下是如何在评估循环中实现所有这些的方法:
```py
import evaluate
@@ -194,19 +195,19 @@ metric.compute()
{'accuracy': 0.8431372549019608, 'f1': 0.8907849829351535}
```
-同样,由于模型头部初始化和数据改组的随机性,您的结果会略有不同,但它们应该在同一个范围内。
+同样,由于模型头部初始化和数据打乱的随机性,你的结果会略有不同,但应该相差不多。
-✏️ **试试看!** 修改之前的训练循环以在 SST-2 数据集上微调您的模型。
+✏️ **试试看!** 修改之前的训练循环以在 SST-2 数据集上微调你的模型。
-### S使用🤗 Accelerate加速您的训练循环 [[S使用🤗 Accelerate加速您的训练循环]]
+## 使用🤗 Accelerate 加速你的训练循环 [[使用🤗 Accelerate加速你的训练循环]]
-我们之前定义的训练循环在单个 CPU 或 GPU 上运行良好。但是使用[🤗 Accelerate](https://github.com/huggingface/accelerate)库,只需进行一些调整,我们就可以在多个 GPU 或 TPU 上启用分布式训练。从创建训练和验证数据加载器开始,我们的手动训练循环如下所示:
+我们之前定义的训练循环在单个 CPU 或 GPU 上运行良好。通过使用 [🤗 Accelerate](https://github.com/huggingface/accelerate) 库,只需进行一些调整,我们就可以在多个 GPU 或 TPU 上启用分布式训练。从创建训练和验证数据加载器开始,我们的手动训练循环如下所示:
```py
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
@@ -242,7 +243,7 @@ for epoch in range(num_epochs):
progress_bar.update(1)
```
-以下是变化:
+以下是更改的部分:
```diff
+ from accelerate import Accelerator
@@ -286,15 +287,17 @@ for epoch in range(num_epochs):
progress_bar.update(1)
```
-要添加的第一行是导入`Accelerator`。第二行实例化一个 `Accelerator`对象 ,它将查看环境并初始化适当的分布式设置。 🤗 Accelerate 为您处理数据在设备间的传递,因此您可以删除将模型放在设备上的那行代码(或者,如果您愿意,可使用 `accelerator.device` 代替 `device` )。
+要添加的第一行是导入 `Accelerator` 。第二行实例化一个 `Accelerator` 对象 它将查看环境并初始化适当的分布式设置。🤗 Accelerate 为你处理数据在设备间的数据传递,因此你可以删除将模型放在设备上的那行代码(或者,如果你愿意,可使用 `accelerator.device` 代替 `device` )。
-然后大部分工作会在将数据加载器、模型和优化器发送到的`accelerator.prepare()`中完成。这将会把这些对象包装在适当的容器中,以确保您的分布式训练按预期工作。要进行的其余更改是删除将`batch`放在 `device` 的那行代码(同样,如果您想保留它,您可以将其更改为使用 `accelerator.device` ) 并将 `loss.backward()` 替换为`accelerator.backward(loss)`。
+然后大部分工作会在将数据加载器、模型和优化器发送到的 `accelerator.prepare()` 中完成。这将会把这些对象包装在适当的容器中,以确保你的分布式训练按预期工作。要进行的其余更改是删除将 `batch` 放在 `device` 的那行代码(同样,如果你想保留它,你可以将其更改为使用 `accelerator.device` ) 并将 `loss.backward()` 替换为 `accelerator.backward(loss)` 。
-⚠️ 为了使云端 TPU 提供的加速发挥最大的效益,我们建议使用标记器(tokenizer)的 `padding=max_length` 和 `max_length` 参数将您的样本填充到固定长度。
+
+⚠️ 为了使云端 TPU 提供的加速中发挥最大的效益,我们建议使用 tokenizer 的 `padding=max_length` 和 `max_length` 参数将你的样本填充到固定长度。
+
-如果您想复制并粘贴来直接运行,以下是 🤗 Accelerate 的完整训练循环:
+如果你想复制并粘贴来直接运行,以下是 🤗 Accelerate 的完整训练循环:
```py
from accelerate import Accelerator
@@ -333,13 +336,13 @@ for epoch in range(num_epochs):
progress_bar.update(1)
```
-把这个放在 `train.py` 文件中,可以让它在任何类型的分布式设置上运行。要在分布式设置中试用它,请运行以下命令:
+把这个放在 `train.py` 文件中,可以让它在任何类型的分布式设置上运行。要在分布式设置中试用它,请运行以下命令:
```bash
accelerate config
```
-这将询问您几个配置的问题并将您的回答转储到此命令使用的配置文件中:
+这将询问你几个配置的问题并将你的回答保存到此命令使用的配置文件中:
```
accelerate launch train.py
@@ -347,7 +350,7 @@ accelerate launch train.py
这将启动分布式训练
-这将启动分布式训练。如果您想在 Notebook 中尝试此操作(例如,在 Colab 上使用 TPU 进行测试),只需将代码粘贴到 `training_function()` 并使用以下命令运行最后一个单元格:
+这将启动分布式训练。如果你想在 Notebook 中尝试此操作(例如,在 Colab 上使用 TPU 进行测试),只需将代码粘贴到一个 `training_function()` 函数中,并在最后一个单元格中运行:
```python
from accelerate import notebook_launcher
@@ -355,4 +358,4 @@ from accelerate import notebook_launcher
notebook_launcher(training_function)
```
-您可以在[🤗 Accelerate repo](https://github.com/huggingface/accelerate/tree/main/examples)找到更多的示例。
+你可以在 [🤗 Accelerate repo](https://github.com/huggingface/accelerate/tree/main/examples) 找到更多的示例。
diff --git a/chapters/zh-CN/chapter3/5.mdx b/chapters/zh-CN/chapter3/5.mdx
index ee69b3a3a..dce6ede80 100644
--- a/chapters/zh-CN/chapter3/5.mdx
+++ b/chapters/zh-CN/chapter3/5.mdx
@@ -1,23 +1,25 @@
-# 微调,检查! [[微调,检查!]]
+# 微调,检查![[微调,检查!]]
-这是非常令人高兴的! 在前两章中,您了解了模型和标记器(tokenizer),现在您知道如何针对您自己的数据对它们进行微调。回顾一下,在本章中,您:
+这是非常令人高兴的!在前两章中,你了解了模型和 Tokenizer,现在你知道如何针对你自己的数据对它们进行微调。回顾一下,在本章中,你:
{#if fw === 'pt'}
-* 了解了[Hub](https://huggingface.co/datasets)中的数据集
-* 学习了如何加载和预处理数据集,包括使用动态填充和整理器
-* 实现您自己的模型微调和评估
-* 实施了一个较为底层的训练循环
-* 使用 🤗 Accelerate 轻松调整您的训练循环,使其适用于多个 GPU 或 TPU
+
+* 了解了 [Hub](https://huggingface.co/datasets) 中的数据集
+* 学习了如何加载和预处理数据集,包括使用动态填充和数据整理器
+* 实现你自己的模型微调和评估
+* 实现了一个较为底层的训练循环
+* 使用 🤗 Accelerate 轻松调整你的训练循环,使其适用于多个 GPU 或 TPU
{:else}
-* 了解了[Hub](https://huggingface.co/datasets)中的数据集
+
+* 了解了 [Hub](https://huggingface.co/datasets) 中的数据集
* 学习了如何加载和预处理数据集
* 学习了如何使用 Keras 微调和评估模型
* 实现了自定义指标
diff --git a/chapters/zh-CN/chapter3/6.mdx b/chapters/zh-CN/chapter3/6.mdx
index bf93482ba..66ec54b1c 100644
--- a/chapters/zh-CN/chapter3/6.mdx
+++ b/chapters/zh-CN/chapter3/6.mdx
@@ -9,47 +9,46 @@
classNames="absolute z-10 right-0 top-0"
/>
-Test what you learned in this chapter!
+现在来测试一下本章所学内容吧!
-
-### 1.`emotion`数据集包含标记有情绪的 Twitter 消息。在[Hub](https://huggingface.co/datasets)中搜索它,然后读取数据集卡。哪一个不是它的基本情感?
+### 1. “emotion”数据集包含带有情绪标记的 Twitter 消息。请在 [ Hub ]( https://huggingface.co/datasets) 中进行搜索并读取数据集的数据卡片。判断哪一个基本情感不在这个数据集中?
-### 2.在[Hub](https://huggingface.co/datasets)中搜索`ar_sarcasm`数据集,它支持哪个任务?
+### 2. 在 [ Hub ]( https://huggingface.co/datasets) 中搜索`ar_sarcasm`数据集,该数据集支持哪个任务?
数据集卡 !"
+ explain: "不对,请再看看[数据卡片](https://huggingface.co/datasets/ar_sarcasm)!"
},
{
text: "命名实体识别",
- explain: "不是这样的ーー再看看 数据集卡 !"
+ explain: "不对,请再看看[数据卡片](https://huggingface.co/datasets/ar_sarcasm) !"
},
{
text: "回答问题",
@@ -58,215 +57,211 @@ Test what you learned in this chapter!
]}
/>
-### 3.BERT模型期望如何处理一对句子?
+### 3. 当输入一对句子时 BERT 模型会需要进行怎么样的预处理?
[SEP]标记来分割两个句子,但这并不是唯一的需求!"
+ text: "句子1的token序列 [ SEP ] 句子2的token序列",
+ explain: "需要使用一个特殊的 `[SEP]` token 来分隔两个句子,但是只有这一个还不够。"
},
{
- text: "[CLS]句子1 句子2",
- explain: "确实在最开始需要一个[CLS]标记的,但是这不是唯一的事情!"
+ text: "[CLS] 句子1的token序列 句子2的token序列",
+ explain: "需要一个特殊的 `[CLS]` token 来指示句子的开头,但是只有这一个还不够。"
},
{
- text: "[CLS]句子1 [SEP] 句子2 [SEP]",
- explain: "没错!",
+ text: "[CLS] 句子1的token序列 [SEP] 句子2的token序列 [SEP]",
+ explain: "正确!",
correct: true
},
{
- text: "[CLS]句子1 [SEP] 句子2",
- explain: "开头需要一个[CLS]特殊标记,还需要一个[SEP]特殊标记来分隔两个句子,但这还不是全部!"
+ text: "[CLS] 句子1的token序列 [SEP] 句子2的token序列",
+ explain: "需要一个特殊的 `[CLS]` token 来指示句子的开头,还需要一个特殊的 `[SEP]` token 来分隔两个句子,但这还不是需要全部的预处理。"
}
]}
/>
{#if fw === 'pt'}
-### 4.`Dataset.map()`方法的好处是什么?
+### 4. `Dataset.map ()`方法的好处是什么?
-### 5.什么是动态填充?
+### 5. 什么是动态填充?
-### 6.校对函数的用途是什么?
+### 6. collate 函数的用途是什么?
DataCollatorWithPadding。"
+ explain: "collate 函数用于处理单个 batch 处理,而不是整个数据集。此外,我们讨论的是所有 collate 函数通常的用途,而不是特定的 DataCollatorWithPadding "
},
{
- text: "它把所有的样品放在一起成一批",
- explain: "正确的!可以将校对函数作为DataLoader的参数传递。我们使用了DataCollatorWithPadding函数,该函数填充批处理中的所有项,使它们具有相同的长度。",
+ text: "它把所有的样本地放在一个 batch 里。",
+ explain: "正确!你可将 collate 函数作为 DataLoader函数的一个参数。 我们使用了 DataCollatorWithPadding 函数, 该函数对批次中的所有项目进行填充,使它们具有相同的长度。",
correct: true
},
{
- text: "它对整个数据集进行预处理。",
- explain: "这将是一个预处理函数,而不是校对函数。"
+ text: "它预处理整个数据集。",
+ explain: "预处理函数(preprocessing)用于预处理整个数据集,而不是 collate 函数。"
},
{
text: "它截断数据集中的序列。",
- explain: "校对函数用于处理单个批次,而不是整个数据集。如果您对截断感兴趣,可以使用标记器的truncate参数。"
+ explain: "collate 函数用于处理单个 batch 的处理,而不是整个数据集。如果你对截断感兴趣,可以使用 tokenizer 的 truncate 参数。"
}
]}
/>
-### 7.当你用一个预先训练过的语言模型(例如`bert-base-uncased`)实例化一个`AutoModelForXxx`类,这个类对应于一个不同于它所被训练的任务时会发生什么?
+### 7. 当你用一个预先训练过的语言模型(例如 `bert-base-uncased`)实例化一个`AutoModelForXxx`类,这个类与它所被训练的任务不匹配时会发生什么?
AutoModelForSequenceClassification配合bert-base-uncase 时,我们在实例化模型时会得到警告。预训练的头部不用于序列分类任务,因此它被丢弃,并用随机权重实例化一个新的头部。",
+ text: "丢弃预训练模型的头部,取而代之的是一个适合该任务的新头部。",
+ explain: "正确的。 例如,当我们将 AutoModelForSequenceClassification 与 bert-base-uncased 结合使用时,我们在实例化模型时将收到警告。 预训练的头不用于序列分类任务,因此它被丢弃,并使用随机初始化权重的用于序列分类任务的头。",
correct: true
},
{
text: "丢弃预先训练好的模型头部。",
- explain: "还有其他事情需要发生。 再试一次!"
+ explain: "还需要做其他事情,再试一次!"
},
{
- text: "无事发生,因为模型仍然可以针对不同的任务进行微调。",
- explain: "预训练模型的头部没有被训练来解决这个任务,所以我们应该丢弃头部!!"
+ text: "没有,因为模型仍然可以针对不同的任务进行微调。",
+ explain: "这个经过训练的模特的头没有经过训练来解决这个问题,所以我们应该丢弃该头部!"
}
]}
/>
-### 8.`TrainingArguments`的目的是什么?
+### 8.`TrainingArguments`的用途是什么?
训练器进行训练和评估的所有超参数。",
+ text: "它包含了所有用于训练和评估的超参数。",
explain: "正确!",
correct: true
},
{
text: "它指定模型的大小。",
- explain: "模型大小是由模型配置定义的,而不是类TrainingArguments。"
+ explain: "模型大小是由模型配置定义的,而不是由 `TrainingArguments` 类 。"
},
{
text: "它只包含用于评估的超参数。",
- explain: "在举例中,我们指定了模型及其检查点的保存位置。再试一次!"
- },
- {
- text: "它只包含用于训练的超参数。",
- explain: "在举例中,我们还使用了求值策略,因此这会影响求值。再试一次!"
+ explain: "在示例中,我们还指定了模型的超参数及其检查点的保存位置。 再试一次!"
}
]}
/>
-### 9.为什么要使用 🤗Accelerate 库?
+### 9.为什么要使用🤗 Accelerate 库?
Trainer所做的,而不是🤗Accelerate库。再试一次!”"
+ text: "它提供了一个高级 API,因此我不必实现自己的训练循环。",
+ explain: "这是我们使用 Trainer 所做的事情,而不是 🤗 Accelerate 库。 再试一次"
},
{
- text: "它使我们的训练循环工作在分布式策略上",
- explain: "正确! 随着🤗Accelerate库,你的训练循环将为多个GPU和TPU工作。",
+ text: "它使我们的训练循环运行在分布式架构上",
+ explain: "正确! 使用🤗 Accelerate 库,你的训练循环可以在多个 GPU 和 TPUs 上运行。",
correct: true
},
{
text: "它提供了更多的优化功能。",
- explain: "不,🤗Accelerate 库不提供任何优化功能。"
+ explain: "不,🤗 Accelerate 库不提供任何优化功能。"
}
]}
/>
{:else}
-### 4.当你用一个预先训练过的语言模型(例如`bert-base-uncased`)实例化一个`TFAutoModelForXxx`类时,会发生什么?
+### 4.当模型与预训练的任务不匹配时,例如使用预训练的语言模型(例如“`bert-base-uncased`”)实例化“`TFAutoModelForXxx`”类时会发生什么?
TFAutoModelForSequenceClassification配合bert-base-uncase时,我们在实例化模型时会得到警告。预训练的头部不用于序列分类任务,因此它被丢弃,并用随机权重实例化一个新的头部。",
+ text: "丢弃预训练模型的头部,并插入一个新的头部以适应新的任务。",
+ explain: "正确的。 例如,当我们将 `TFAutoModelForSequenceClassification `与 `bert-base-uncased` 结合使用时,我们在实例化模型时收到警告。 预训练的头不用于序列分类任务,因此它被丢弃,使用新的头并且随机初始化权重。",
correct: true
},
{
text: "丢弃预先训练好的模型头部。",
- explain: "还有其他事情需要发生。 再试一次!"
+ explain: "除此之外还有一些事情会发生, 再试一次!"
},
{
- text: "无事发生,因为模型仍然可以针对不同的任务进行微调。",
- explain: "预训练模型的头部没有被训练来解决这个任务,所以我们应该丢弃头部!!"
+ text: "没有,因为模型仍然可以针对不同的任务进行微调。",
+ explain: "这个经过训练的模特的头没有经过训练来解决这个问题,所以我们应该丢掉这个头!"
}
]}
/>
-### 5.来自`transfomers`的 TensorFlow 模型已经是 Keras 模型,这有什么好处?
+### 5.来自 `transformers` 的 TensorFlow 模型已经是 Keras 模型,这有什么好处?
TPUStrategy范围内运行所有内容,包括模型的初始化。"
+ text: "这些模型可在开箱即用的 TPU 上运行。",
+ explain: "差不多!但是还需要进行一些小的额外修改。例如,你需要在 TPUStrategy 范围内运行所有内容,包括模型的初始化。"
},
{
- text: "您可以利用现有的方法,如compile() 、fit()和predict() 。",
- explain: "正确! 一旦你有了这些数据,在这些数据上进行培训只需要很少的工作。",
+ text: "你可以利用现有方法,例如 compile()、fit() 和 predict()。",
+ explain: "正确! 一旦你有了数据,只需要很少的工作就可以在这些数据上进行训练。",
correct: true
},
{
- text: "你可以学习 Keras 和 transformers库。",
+ text: "你可以学习 Keras 以及 Transformer。",
explain: "没错,但我们要找的是别的东西:)",
correct: true
},
{
- text: "您可以轻松地计算与数据集相关的指标。",
+ text: "你可以轻松计算与数据集相关的指标。",
explain: "Keras 帮助我们训练和评估模型,而不是计算与数据集相关的指标。"
}
]}
/>
-### 6.如何定义自己的定制指标?
+### 6.如何定义自己的自定义指标?
tf.keras.metrics.Metric。",
+ text: "使用子类化 tf.keras.metrics.Metric。",
explain: "太好了!",
correct: true
},
@@ -275,13 +270,13 @@ Test what you learned in this chapter!
explain: "再试一次!"
},
{
- text: "通过使用带签名的可调用metric_fn(y_true, y_pred) 。",
+ text: "使用使用带有签名的 metric_fn(y_true, y_pred) 函数。",
explain: "正确!",
correct: true
},
{
- text: "通过谷歌搜索。",
- explain: "这不是我们要找的答案,但它应该能帮助你找到答案。",
+ text: "使用谷歌搜索。",
+ explain: "这不是我们要找的答案,不过它应该能帮助你找到答案。",
correct: true
}
]}
diff --git a/chapters/zh-CN/chapter4/1.mdx b/chapters/zh-CN/chapter4/1.mdx
index 32c8ef87e..2bf33daab 100644
--- a/chapters/zh-CN/chapter4/1.mdx
+++ b/chapters/zh-CN/chapter4/1.mdx
@@ -5,16 +5,18 @@
classNames="absolute z-10 right-0 top-0"
/>
-[Hugging Face Hub](https://huggingface.co/)---我们的主网站,是一个中央平台,在这个网站上任何人都可以查找、使用和贡献新的最先进的模型和数据集。它拥有各种各样的模型,公开可用的模型超过 10,000个。我们在本章去探索Hub中的模型,并在第 5 章中探索Hub中的数据集。
+我们的主网站——— [Hugging Face中心](https://huggingface.co/) 是一个集发现、使用及贡献最新先进模型与数据集为一体的中心平台。这里汇聚了超过 10,000 个公开可用的各种领域的模型。我们将在本章节专注探讨这些模型,并在第五章节深入讨论数据集。
-Hub 中的模型不仅限于🤗 Transformers 甚至 NLP。有用于自然语言处理的[Flair](https://github.com/flairNLP/flair),[AllenNLP](https://github.com/allenai/allennlp),[Asteroid](https://github.com/asteroid-team/asteroid)和用于音频检测的[pyannote](https://github.com/pyannote/pyannote-audio),以及对于视觉的[timm](https://github.com/rwightman/pytorch-image-models),这些例子只是Hub中冰山一角,更多的模型。可以由你去探索。
+Hub 中的模型不仅限于🤗 Transformers 或者是自然语言处理。这里有许多模型,比如用于自然语言处理的 [Flair](https://github.com/flairNLP/flair) 和 [AllenNLP](https://github.com/allenai/allennlp) 模型,用于音频检测的 [Asteroid](https://github.com/asteroid-team/asteroid) 和 [pyannote](https://github.com/pyannote/pyannote-audio) 模型,以及用于视觉的 [timm](https://github.com/rwightman/pytorch-image-models) 模型等,这些例子只是 Hub 中模型的冰山一角,更多的模型可以由你去探索。
-这些模型中的每一个都作为 Git 存储库托管,这允许进行版本控制和重现。在 Hub 上共享模型意味着将其向社区开放,让任何希望使用它的人都可以轻松访问它,从而使其他人不用为训练模型而苦恼就可以直接使用模型。
+这些模型中的每一个都以 Git 仓库的形式托管,方便进行版本控制和复现。在 Hub 上共享模型意味着向社区开放,让任何希望使用模型的人都可以轻松访问,从而使他们免于训练模型之苦,并且简化了模型分享和使用。
-此外,在 Hub 上共享模型会自动为该模型部署托管的推理 API。社区中的任何人都可以直接在模型页面上自由地测试它,使用自定义输入和适当的小部件。
+此外,在 Hub 上分享一个模型会自动为该模型部署一个推理 API。社区中的任何人都可以直接在模型页面上使用各自的输入和相应的小工具来进行测试。
-最棒的是是在 Hub 上共享和使用任何公共模型是完全免费的!如果您不想公开模型,也存在[付费计划](https://huggingface.co/pricing)。下面的视频显示了如何使用 Hub。
+最妙的是,在 Hub 上分享和使用任何公共模型都是完全免费的!如果你希望只把模型分享给特定的人,我们也有 [付费计划](https://huggingface.co/pricing) 。
+
+下面的视频展示了如何使用 Hub。
-这部分需要有一个 Huggingface.co 帐户,因为我们将在 Hugging Face Hub 上创建和管理存储库:[创建一个账户](https://huggingface.co/join)
\ No newline at end of file
+如果你想跟进实现这一部分内容,你需要有一个 Huggingface.co 帐户,因为这一节我们将在 Hugging Face Hub 上创建和管理存储库: [创建一个账户](https://huggingface.co/join)
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter4/2.mdx b/chapters/zh-CN/chapter4/2.mdx
index e40ba9d79..956ecd244 100644
--- a/chapters/zh-CN/chapter4/2.mdx
+++ b/chapters/zh-CN/chapter4/2.mdx
@@ -22,15 +22,15 @@
{/if}
-模型中心使选择合适的模型变得简单,因此只需几行代码即可在任何下游库中使用它。让我们来看看如何使用这些模型,以及如何将模型贡献到社区。
+模型中心使选择合适的模型变得简单,只需几行代码即可在任何下游库中使用它。让我们来看看如何使用这些模型,以及如何将模型贡献到社区。
-假设我们正在寻找一种可以执行 mask 填充的 French-based 模型。
+假设我们正在寻找一种可以执行掩码填充(mask filling 又称完形填空)的 French-based(法语)模型。

-我们选择 `camembert-base` 检查点来尝试一下。我们需要做的仅仅是输入 `camembert-base` 标识符!正如你在前几章中看到的,我们可以使用 `pipeline()` 功能:
+我们选择 `camembert-base` checkpoint 来尝试一下。我们需要做的仅仅是输入 `camembert-base` 标签!正如你在前几章中学习的,我们可以使用 `pipeline()` 功能:
```py
from transformers import pipeline
@@ -49,13 +49,13 @@ results = camembert_fill_mask("Le camembert est :)")
]
```
-如你所见,在管道中加载模型非常简单。你唯一需要注意的是所选检查点是否适合它将用于的任务。例如,这里我们正在将 `camembert-base` 检查点加载在 `fill-mask` 管道,这完全没问题。但是如果我们在 `text-classification` 管道加载检查点,结果没有任何意义,因为 `camembert-base` 不适合这个任务!我们建议使用 Hugging Face Hub 界面中的任务选择器来选择合适的检查点:
+如你所见,在管道中加载模型非常简单。你唯一需要注意的是所选 checkpoint 是否适合它将用于的任务。例如,这里我们正在将 `camembert-base` checkpoint 加载在 `fill-mask` 管道,这完全没问题。但是如果我们在 `text-classification` 管道中加载该 checkpoint 结果没有任何意义,因为 `camembert-base` 不适合这个任务!我们建议使用 Hugging Face Hub 中的任务选择器来选择合适的 checkpoint 。
-你还可以直接使用模型架构实例化检查点:
+你还可以直接使用模型架构实例化 checkpoint:
{#if fw === 'pt'}
```py
@@ -65,7 +65,7 @@ tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = CamembertForMaskedLM.from_pretrained("camembert-base")
```
-然而,我们建议使用 [`Auto*` 类](https://huggingface.co/transformers/model_doc/auto.html?highlight=auto#auto-classes),因为 `Auto*` 类设计与架构无关。前面的代码示例将只能在 CamemBERT 架构中加载可用的检查点,但使用 `Auto*` 类使切换不同的检查点变得简单:
+然而,我们建议使用 [`Auto*` 类](https://huggingface.co/transformers/model_doc/auto?highlight=auto#auto-classes) ,因为 `Auto*` 类在设计时不依赖模型架构。前面的代码示例将只能在 CamemBERT 架构中加载可用的 checkpoint,但使用 `Auto*` 类使切换不同的 checkpoint 变得简单:
```py
from transformers import AutoTokenizer, AutoModelForMaskedLM
@@ -81,7 +81,7 @@ tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = TFCamembertForMaskedLM.from_pretrained("camembert-base")
```
-然而,我们建议使用 [`TFAuto*` 类](https://huggingface.co/transformers/model_doc/auto.html?highlight=auto#auto-classes),因为 `TFAuto*` 类设计与架构无关。前面的代码示例将只能在 CamemBERT 架构中加载可用的检查点,但使用 `TFAuto*` 类使切换不同的检查点变得简单:
+然而,我们建议使用 [`TFAuto*` 类](https://huggingface.co/transformers/model_doc/auto?highlight=auto#auto-classes) ,因为 `TFAuto*` 类在设计时不依赖模型架构。前面的代码示例将只能在 CamemBERT 架构中加载可用的 checkpoint,但使用 `TFAuto*` 类使切换不同的 checkpoint 变得简单:
```py
from transformers import AutoTokenizer, TFAutoModelForMaskedLM
@@ -92,5 +92,5 @@ model = TFAutoModelForMaskedLM.from_pretrained("camembert-base")
{/if}
-使用预训练模型时,一定要检查它是如何训练的、在哪些数据集上训练的、它的局限性和偏差。所有这些信息都应在其模型卡片上注明。
+使用预训练模型时,一定要检查它是如何训练的、在哪些数据集上训练的、它的局限性和偏见。所有这些信息都应在其模型卡片上有所展示。
diff --git a/chapters/zh-CN/chapter4/3.mdx b/chapters/zh-CN/chapter4/3.mdx
index ba5e26550..a10f1e13d 100644
--- a/chapters/zh-CN/chapter4/3.mdx
+++ b/chapters/zh-CN/chapter4/3.mdx
@@ -22,22 +22,21 @@
{/if}
-在下面的步骤中,我们将看看将预训练模型分享到 🤗 Hub 的最简单方法。有可用的工具和实用程序可以让直接在 Hub 上共享和更新模型变得简单,我们将在下面进行探讨。
+接下来,我们将探索把预训练模型分享到 🤗 Hub 最便捷的方法。我们将一同研究一些工具和功能,它们可以简化直接在中心上分享和更新模型的流程。
-我们鼓励所有训练模型的用户通过与社区共享来做出贡献——共享模型,即使是在非常特定的数据集上进行训练,也将帮助他人,节省他们的时间和计算资源,并提供对有用的训练工件的访问。反过来,您可以从其他人所做的工作中受益!
+我们鼓励所有训练模型的用户通过与社区共享来做出贡献——即使是在特定数据集上训练的模型的分享,也能帮助他人,节省他们的时间和计算资源,并提供一些有用的训练成果。反过来,你可以从其他人所做的工作中受益!
-创建新模型存储库的方法有以下三种:
+创建模型存储仓库的方法有以下三种:
-- 使用 push_to_hub API 接口
-- 使用 huggingface_hub Python 库
-- 使用 web 界面
+- 使用 `push_to_hub` API 接口
+- 使用 `huggingface_hub` Python 库
+- 使用网页界面
-创建存储库后,您可以通过 git 和 git-lfs 将文件上传到其中。我们将在以下部分引导您创建模型存储库并将文件上传到它们
+创建仓库后,你可以通过 git 和 git-lfs 将文件上传到其中。我们将在以下部分带领你创建模型仓库并向其中上传文件。
-
-## 使用 push_to_hub API [[使用 push_to_hub API]]
+## 使用 `push_to_hub` API [[使用 push_to_hub API]]
{#if fw === 'pt'}
@@ -49,9 +48,11 @@
{/if}
-将文件上传到模型中心的最简单方法是利用 **push_to_hub** API 接口。
+将文件上传到 hub 的最简单方法是利用 `push_to_hub` API 接口。
+
+在进行下一步操作之前,你需要生成一个身份验证令牌,这样 `huggingface_hub` API 才会知道你是谁以及你对哪些空间具有写入权限。
-在继续之前,您需要生成一个身份验证令牌,以便 **huggingface_hub** API 知道您是谁以及您对哪些名称空间具有写入权限。确保你在一个环境中 **transformers** 已安装(见[安装](/course/chapter0))。如果您在笔记本中,可以使用以下功能登录:
+在一个安装了 `transformers` 环境中(参见 [第零章](/course/chapter0) )。如果你在 notebook 中,可以运行以下代码登录:
```python
from huggingface_hub import notebook_login
@@ -59,19 +60,19 @@ from huggingface_hub import notebook_login
notebook_login()
```
-在终端中,您可以运行:
+在终端中,你可以运行:
```bash
huggingface-cli login
```
-在这两种情况下,系统都会提示您输入用户名和密码,这与您用于登录 Hub 的用户名和密码相同。如果您还没有 Hub 配置文件,则应该创建一个[创建一个账户](https://huggingface.co/join)。
+在这两种情况下,系统都会提示你输入用户名和密码,这与你用于登录 Hub 的用户名和密码相同。如果你还没有 Huggingface 账户,则应该 [在这里](https://huggingface.co/join) 创建一个账户。
-好的!您现在已将身份验证令牌存储在缓存文件夹中。让我们创建一些存储库!
+好极了!现在已将你的身份验证令牌存储在了缓存文件夹中。让我们创建一些仓库!
{#if fw === 'pt'}
-如果你玩过 **Trainer** 用于训练模型的 API,将其上传到 Hub 的最简单方法是设置 **push_to_hub=True** 当你定义你的 **TrainingArguments** :
+如果你已经尝试使用过 `Trainer` API 训练模型,将其上传到 Hub 的最简单方法是在定义 `TrainingArguments` 时设置 `push_to_hub=True` :
```py
from transformers import TrainingArguments
@@ -81,11 +82,11 @@ training_args = TrainingArguments(
)
```
-你声明 **trainer.train()** 的时候, 这 **Trainer** 然后每次将您的模型保存到您的命名空间中的存储库中时(这里是每个时代),它将上传到模型中心。该存储库将命名为您选择的输出目录(此处 **bert-finetuned-mrpc** ) 但您可以选择不同的名称 **hub_model_id = a_different_name** 。
+这样,调用 `trainer.train()` 的时候, `Trainer` 会在每次保存模型时(这里是每个训练周期)将其上传到 Hub 中你的账户下的一个仓库。该仓库的名称与你选择的输出目录名称相同(这里是 `bert-finetuned-mrpc` ),但你可以通过 `hub_model_id = "a_different_name"` 指定一个不同的名称。
-要将您的模型上传到您所属的组织,只需将其传递给 **hub_model_id = my_organization/my_repo_name** 。
+若要将你的模型上传到你所属的组织,只需设置 `hub_model_id = my_organization/my_repo_name` 。
-训练结束后,你应该做最后的 **trainer.push_to_hub()** 上传模型的最新版本。它还将生成包含所有相关元数据的模型卡,报告使用的超参数和评估结果!以下是您可能会在此类模型卡中找到的内容示例:
+最后,需要在训练循环结束后运行 `trainer.push_to_hub()` 上传模型的最新版本。它还会生成一份包含所有相关元数据的模型卡片,包含使用的超参数和评估结果!以下是一个模型卡片的示例:

@@ -95,7 +96,7 @@ training_args = TrainingArguments(
{:else}
-如果您使用Keras来训练您的模型,则将其上传到Hub的最简单方法是在调用 **model.fit()** 时传递**PushToHubCallback**:
+如果你使用 Keras 来训练你的模型,则将其上传到 Hub 的最简单方法是在调用 `model.fit()` 添加 `PushToHubCallback` :
```py
from transformers import PushToHubCallback
@@ -105,15 +106,15 @@ callback = PushToHubCallback(
)
```
-然后,您应该在对**model.fit()**的调用中添加**callbacks=[callback]**。然后,每次将模型保存在命名空间的存储库中(此处为每个 epoch)时,回调都会将模型上传到 Hub。该存储库的名称将类似于您选择的输出目录(此处为**bert-finetuned-mrpc**),但您可以选择另一个名称,名称为**hub_model_id = a_different_name**。
+然后,你应该在调用 `model.fit()` 时添加 `callbacks=[callback]` 。回调函数将在每次保存模型时(这里是每个训练周期)将你的模型上传到 Hub 的你的账户下的一个仓库。该仓库的名称你选择的输出目录名称相同(此处为 `bert-finetuned-mrpc` ),但你可以通过 `hub_model_id = "a_different_name"` 指定一个不同的名称。
-要将您的模型上传到您所属的组织,只需将其传递给 **hub_model_id = my_organization/my_repo_name** 。
+要将你的模型上传到你所属的组织,只需设置如下 `hub_model_id = my_organization/my_repo_name` 。
{/if}
-在较低级别,可以通过模型、标记器和配置对象直接访问模型中心 **push_to_hub()** 方法。此方法负责创建存储库并将模型和标记器文件直接推送到存储库。与我们将在下面看到的 API 不同,不需要手动处理。
+在更底层,你可以通过直接在模型、tokenizer 和配置对象上调用 `push_to_hub()` 方法来访问模型中心。该方法能够同时创建仓库并直接将模型和 tokenizer 文件推送至仓库,无需手动操作,这与我们在下面要看到的 API 有些许不同。
-为了了解它是如何工作的,让我们首先初始化一个模型和一个标记器:
+为了了解它是如何工作的,让我们首先创建一个模型和一个 tokenizer
{#if fw === 'pt'}
@@ -139,34 +140,35 @@ tokenizer = AutoTokenizer.from_pretrained(checkpoint)
{/if}
-你可以自由地用这些做任何你想做的事情——向标记器添加标记,训练模型,微调它。一旦您对生成的模型、权重和标记器感到满意,您就可以利用 **push_to_hub()** 方法直接在 **model** 中:
+你可以随意进行一些操作——给 tokenizer 添加 tokens 训练模型,微调模型。直到你对最终的模型、权重和 tokenizer 满意。当你对的模最终的模型、权重和 tokenizer 感到满意,你就可以直接在 `model` 对象上调用 `push_to_hub()` 方法:
```py
model.push_to_hub("dummy-model")
```
-这将创建新的存储库 **dummy-model** 在您的个人资料中,并用您的模型文件填充它。
-对标记器执行相同的操作,以便所有文件现在都可以在此存储库中使用:
+这将在你的账户中创建新的 `dummy-model` 仓库,并将这个模型文件上传上去。
+
+对 tokenizer 也需要进行相同的操作:
```py
tokenizer.push_to_hub("dummy-model")
```
-如果您属于一个组织,只需指定 **organization** 上传到该组织的命名空间的参数:
+如果你属于一个组织,只需指定 `organization` 参数即可将模型上传到该组织的账户下:
```py
tokenizer.push_to_hub("dummy-model", organization="huggingface")
```
-如果您希望使用特定的 Hugging Face 令牌,您可以自由地将其指定给 **push_to_hub()** 方法也是:
+如果你希望使用特定的 Hugging Face 令牌,你也可以很方便地将其传递给 `push_to_hub()` 方法:
```py
tokenizer.push_to_hub("dummy-model", organization="huggingface", use_auth_token="
")
```
-现在前往模型中心找到您新上传的模型:*https://huggingface.co/user-or-organization/dummy-model*。
+现在你就可以前往 [模型中心](https://huggingface.co/user-or-organization/dummy-model) 查看你新上传的模型。
-单击“文件和版本”选项卡,您应该会在以下屏幕截图中看到可见的文件:
+单击“文件和版本(Files and versions)”选项卡,你应该能看到以下的文件:
{#if fw === 'pt'}
@@ -180,43 +182,38 @@ tokenizer.push_to_hub("dummy-model", organization="huggingface", use_auth_token=
-✏️ **试试看**!获取与检查点关联的模型和标记器,并使用该方法将它们上传到您的命名空间中的存储库。在删除之前,请仔细检查该存储库是否正确显示在您的页面上。
+✏️ **试试看** 获取与 `bert-base-cased` checkpoint 相关的模型和 tokenizer 并使用 `push_to_hub()` 方法将它们上传到你账户中的一个仓库。并请仔细检查该仓库在你的页面上显示是否正常。
-如您所见, **push_to_hub()** 方法接受多个参数,从而可以上传到特定的存储库或组织命名空间,或使用不同的 API 令牌。我们建议您查看直接在[🤗 Transformers documentation](https://huggingface.co/transformers/model_sharing.html)了解什么是可能的
+如你所见, `push_to_hub()` 方法接受多个参数,从而可以上传到特定的仓库或账户,除此之外还可以使用不同的 API 令牌验证身份。我们建议你直接查看 [🤗 Transformers 文档](https://huggingface.co/transformers/model_sharing) 了解更多的用法。
-这 **push_to_hub()** 方法由[huggingface_hub](https://github.com/huggingface/huggingface_hub)Python 包,为 Hugging Face Hub 提供直接 API。它集成在 🤗 Transformers 和其他几个机器学习库中,例如[allenlp](https://github.com/allenai/allennlp).虽然我们在本章中专注于 🤗 Transformers 集成,但将其集成到您自己的代码或库中很简单。
+位于 [huggingface_hub](https://github.com/huggingface/huggingface_hub) 库里的 `push_to_hub()` 方提供了直接面向 Hugging Face Hub 的 API。它集成在 🤗 Transformers 和其他几个机器学习库中,例如 [allenlp](https://github.com/allenai/allennlp) 。虽然我们在本章中专注于 🤗 Transformers 但将其集成到你自己的代码或库中很简单。
-跳到最后一部分,了解如何将文件上传到新创建的存储库!
+到了最后一部分,让我们看看如何将文件上传到你新创建的仓库!
-## 使用 huggingface_hub python库 [[使用 huggingface_hub python库]]
+## 使用 `huggingface_hub` python 库 [[使用 `huggingface_hub` python 库]]
+`huggingface_hub` Python 库是一个包,为模型和数据集中心提供了一系列工具。它提供了简单的方法和类,可以便捷地获取 hub 中仓库的信息以及管理仓库等常见任务。它在 git 的基础上提供了简单的 API,可以在你你的项目中管理这些仓库的内容,以及 hub 的一些功能。
-这 **huggingface_hub** Python 库是一个包,它为模型和数据集中心提供了一组工具。它为常见任务提供了简单的方法和类,例如
-获取有关模型中心上存储库的信息并对其进行管理。它提供了在 git 之上工作的简单 API 来管理这些存储库的内容并集成 Hub
-在您的项目和库中。
-
-类似于使用 **push_to_hub** API,这将要求您将 API 令牌保存在缓存中。为此,您需要使用 **login** 来自 CLI 的命令,如上一节所述(同样,确保在这些命令前面加上 **!** 字符(如果在 Google Colab 中运行):
+与使用 `push_to_hub` API 类似,这需要你将 API 令牌保存在缓存中。为此,你需要在操作系统的命令行使用 CLI 中的 `login` 命令,(如果在 Notebook 中运行,请在这些命令前添加 `!` 字符):
```bash
huggingface-cli login
-```
-
-这 **huggingface_hub** 包提供了几种对我们有用的方法和类。首先,有几种方法可以管理存储库的创建、删除等:
+``` `huggingface_hub` 包提供了几个非常便捷方法和类可以帮助我们完成 hub 的管理。首先,有一些方法可以管理仓库的创建、删除等:
```python no-format
from huggingface_hub import (
- # User management
+ # 用户管理
login,
logout,
whoami,
- # Repository creation and management
+ # 仓库创建和管理
create_repo,
delete_repo,
update_repo_visibility,
- # And some methods to retrieve/change information about the content
+ # 以及一些检索/更改文件的方法
list_models,
list_datasets,
list_metrics,
@@ -227,10 +224,9 @@ from huggingface_hub import (
```
-此外,它还提供了非常强大的 **Repository** 用于管理本地存储库的类。我们将在接下来的几节中探讨这些方法和该类,以了解如何利用它们。
-
-这 **create_repo** 方法可用于在模型中心上创建新存储库:
+此外,它还提供了非常强大的 `Repository` 类来管理本地仓库。我们将在接下来的几节中探讨这些方法和类,以理解如何利用它们。
+可以使用 `create_repo` 方法在 Hub 上创建新的仓库:
```py
from huggingface_hub import create_repo
@@ -238,7 +234,7 @@ from huggingface_hub import create_repo
create_repo("dummy-model")
```
-这将创建存储库 **dummy-model** 在您的命名空间中。如果愿意,您可以使用 **organization** 争论:
+这将在你的账户中创建 `dummy-model` 仓库。除此之外你还可以使用 `organization` 参数指定仓库应属于哪个组织:
```py
from huggingface_hub import create_repo
@@ -246,45 +242,47 @@ from huggingface_hub import create_repo
create_repo("dummy-model", organization="huggingface")
```
-这将创建 **dummy-model** 存储库中的 **huggingface** 命名空间,假设您属于该组织。
-其他可能有用的参数是:
+这将在 `huggingface` 组织的账户中创建 `dummy-model` 仓库,如果你属于该组织并且有创建仓库的权限。
-- private 以指定存储库是否应对其他人可见。
-- token 如果您想用给定的令牌覆盖存储在缓存中的令牌。
-- repo_type 如果你想创建一个或一个替代一个的而不是模型。接受的值和 datasetspace "dataset""space"。
+其他可能有用的一些参数有:
-创建存储库后,我们应该向其中添加文件!跳到下一部分以查看可以处理此问题的三种方法。
+- `private` ,用于指定仓库是否应对其他人可见。
+- `token` ,如果你希望使用特定的身份令牌,而不是缓存中的身份令牌。
+- `repo_type` ,如果你希望创建一个 `dataset` 或 `space` 而不是模型。需要将 `repo_type` 设置为 `"dataset"` 和 `"space"` 。
+创建仓库后,我们应该向其中添加文件!让我们到下一节,看看三种添加文件的方式。
## 使用网络界面 [[使用网络界面]]
-Web 界面提供了直接在 Hub 中管理存储库的工具。使用该界面,您可以轻松创建存储库、添加文件(甚至是大文件!)、探索模型、可视化差异等等。
+Web 界面提供了直接在 Hub 中管理仓库的工具。使用该界面,你可以轻松创建仓库、添加文件(甚至是大文件!)、探索模型、可视化差异等等。
-要创建新的存储库,请访问[huggingface.co/new](https://huggingface.co/new):
+要创建新的仓库,请访问 [huggingface.co/new](https://huggingface.co/new) :

-首先,指定存储库的所有者:这可以是您或您所属的任何组织。如果您选择一个组织,该模型将出现在该组织的页面上,并且该组织的每个成员都可以为存储库做出贡献。
+首先,指定仓库的所有者:这可以是你或你所属的组织。如果你选择一个组织,模型将在会显示在组织的页面上,组织的每个成员可以操作仓库。
-接下来,输入您的模型名称。这也将是存储库的名称。最后,您可以指定您的模型是公开的还是私有的。私人模特要求您拥有付费 Hugging Face 帐户,并允许您将模特隐藏在公众视野之外。
+接下来,输入你的模型名称。同时也是仓库的名称。最后,你可以指定你的模型是公开的还是私有的。私有的模型将被隐藏,对其他的用户不可见。
-创建模型存储库后,您应该看到如下页面:
+创建模型仓库后,你应该会看到如下页面:
-这是您的模型将被托管的地方。要开始填充它,您可以直接从 Web 界面添加 README 文件。
+这就是你的模型仓库会显示的页面。你可以直接从网页界面添加 README 文件来填写它。
-README 文件在 Markdown 中 - 随意使用它!本章的第三部分致力于构建模型卡。这些对于为您的模型带来价值至关重要,因为它们是您告诉其他人它可以做什么的地方。
+README 文件采用 Markdown 格式 - 你可以根据你的需要自由编写!
+
+这一章的下一部分将帮助你建立模型卡片。这些模型卡片对于提升模型的价值非常重要,因为它们可以告诉其他人你的模型能做什么。
-如果您查看“文件和版本”选项卡,您会发现那里还没有很多文件——只有自述文件你刚刚创建和.git 属性跟踪大文件的文件。
+如果你希望添加更多文件,点击页面顶部的 “Files and versions(文件和版本)” 标签页。在这里,你可以看到仓库的所有文件以及它们的版本。

@@ -294,15 +292,13 @@ README 文件在 Markdown 中 - 随意使用它!本章的第三部分致力于
## 上传模型文件 [[上传模型文件]]
-Hugging Face Hub 上的文件管理系统基于用于常规文件的 git 和 git-lfs(代表[Git Large File Storage](https://git-lfs.github.com/)) 对于较大的文件。
-
-在下一节中,我们将介绍将文件上传到 Hub 的三种不同方式:通过 **huggingface_hub** 并通过 git 命令。
+Hugging Face Hub 的文件管理系统基于 git 用于处理常规文件,对于较大的文件则需要使用 git-lfs(详情请参阅 [Git 大文件存储](https://git-lfs.github.com/) )
-### The `upload_file` approach [[The `upload_file` approach]]
+在下一节中,我们会讲述怎么以三种不同的方式将文件上传到 Hub: `upload_file` 方法、 `Repository` 类 以及通过 git 命令。
-使用 **upload_file** 不需要在您的系统上安装 git 和 git-lfs。它使用 HTTP POST 请求将文件直接推送到 🤗 Hub。这种方法的一个限制是它不能处理大于 5GB 的文件。
-如果您的文件大于 5GB,请按照下面详述的另外两种方法进行操作。API 可以按如下方式使用:
+### `upload_file` 方法 [[ `upload_file` 方法]]
+使用 `upload_file` 不需要在你的系统上安装 git 和 git-lfs。它使用 HTTP POST 请求将文件直接发送到 Hub。这种方法的一个限制是它不能上传大于 5GB 的文件。如果你的文件大于 5GB,请按照另外两种方法进行操作。 `upload_file` 的使用方法如下:
```py
from huggingface_hub import upload_file
@@ -313,20 +309,16 @@ upload_file(
)
```
-这将上传文件 **config.json** 可在 **path_to_file** 到存储库的根目录 **config.json** , 到 **dummy-model** 存储库。
-其他可能有用的参数是:
+以上的代码会把 `
` 位置的 `config.json` 文件上传到 `dummy-model` 仓库的根目录作为模型的 `config.json` 。其他可能有用的参数包括:
-- token,如果要通过给定的令牌覆盖缓存中存储的令牌。
-- repo_type, 如果你想要上传一个 `dataset` 或一个 `space` 而不是模型。 接受的值为 `"dataset"` 和 `"space"`.
+- `token` ,如果你希望在这里使用特定的身份令牌,而不是缓存中的身份令牌。
+- `repo_type` ,如果你希望创建一个 `dataset` 或 `space` 而不是模型。需要将 `repo_type` 设置为 `"dataset"` 和 `"space"` 。
+### `Repository` 类 [[ `Repository` 类]] `Repository` 类可以使用类似 git 的方式管理一个本地仓库。它解决了使用 git 可能遇到的大部分痛点,提供我们所需的所有功能。
-### The `Repository` class [[The `Repository` class]]
+使用这个类需要安装 git 和 git-lfs,所以请确保你已经安装了 git-lfs(如果没有安装,可以查看 [git-lfs 官网](https://git-lfs.github.com/) 的安装指南)并已经在操作系统里配置好了相关功能。
-以类似 git 的方式管理本地存储库。它抽象了 git 可能遇到的大部分痛点,以提供我们需要的所有功能。
-
-使用这个类需要安装 git 和 git-lfs,所以确保你已经安装了 git-lfs(参见[here](https://git-lfs.github.com/)安装说明)并在开始之前进行设置。
-
-为了开始使用我们刚刚创建的存储库,我们可以通过克隆远程存储库将其初始化到本地文件夹开始:
+为了开始使用我们刚刚创建的仓库,我们可以把远程仓库克隆到一个本地文件夹:
```py
from huggingface_hub import Repository
@@ -334,9 +326,9 @@ from huggingface_hub import Repository
repo = Repository("", clone_from="/dummy-model")
```
-这创建了文件夹 **path_to_dummy_folder** 在我们的工作目录中。该文件夹仅包含 **.gitattributes** 文件,因为这是通过实例化存储库时创建的唯一文件 **create_repo**。
+以上代码会在我们当前的工作目录中创建 `` 文件夹。此文件夹里只有 `.gitattributes` 文件,这是使用 `create_repo` 创建仓库时生成的文件。
-从现在开始,我们可以利用几种传统的 git 方法:
+从现在开始,我们可以利用许多传统的 git 方法:
```py
repo.git_pull()
@@ -346,24 +338,24 @@ repo.git_push()
repo.git_tag()
```
-另外!我们建议您查看 **Repository** 可用文件[here](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub#advanced-programmatic-repository-management)有关所有可用方法的概述。
+此外!我们建议你查看 [huggingface](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub#advanced-programmatic-repository-management) 的 `Repository` 文档,了解一下所有可用方法。
-目前,我们有一个模型和一个标记器,我们希望将其推送到模型中心。我们已经成功克隆了存储库,因此我们可以将文件保存在该存储库中。
+现在,我们有了一个模型和一个 tokenizer 我们希望将其推送到 hub。我们已经成功克隆了仓库,因此我们可以将文件保存到在该仓库的文件夹中。
-我们首先通过拉取最新更改来确保我们的本地克隆是最新的:
+首先,我们通过拉取最新的更改,确保我们的本地克隆是最新的:
```py
repo.git_pull()
```
-完成后,我们保存模型和标记器文件:
+完成后,我们保存模型和 tokenizer 文件:
```py
model.save_pretrained("")
tokenizer.save_pretrained("")
-```
+```
-这 **path_to_dummy_folder** 现在包含所有模型和标记器文件。我们遵循通常的 git 工作流程,将文件添加到暂存区,提交它们并将它们推送到模型中心:
+`` 现在已经存储了模型和 tokenizer 文件。我们遵循常规的 git 工作流程,将文件添加到暂存区,提交它们并推送它们到 hub:
```py
repo.git_add()
@@ -371,15 +363,15 @@ repo.git_commit("Add model and tokenizer files")
repo.git_push()
```
-恭喜!您刚刚将第一个文件推送到hub上。
+恭喜你!你刚刚在 hub 上推送了你的第一个文件。
-### The git-based approach [[The git-based approach]]
+### 基于 git 的方法 [[基于 git 的方法]]
-这是上传文件的非常简单的方法:我们将直接使用 git 和 git-lfs 来完成。大多数困难都被以前的方法抽象掉了,但是下面的方法有一些警告,所以我们将遵循一个更复杂的用例。
+这是上传文件的最基础方法:我们将直接使用 git 和 git-lfs 进行操作,相比于之前的方法难度更大同时也更加灵活。在前面的方法大部分的难点都已经被封装好的库解决,但是接下来的方法需要手动来解决它们,所以我们会尝试一个更复杂的使用案例。
-使用这个类需要安装 git 和 git-lfs,所以请确保你有[git-lfs](https://git-lfs.github.com/)安装(请参阅此处了解安装说明)并在开始之前进行设置。
+使用这个方法需要安装 git 和 git-lfs,所以请确保你已经安装了 git-lfs(如果没有安装,可以参见 [git-lfs 官网](https://git-lfs.github.com/) 的安装指南)并已经在操作系统里配置好了相关功能。
-首先从初始化 git-lfs 开始:
+首先,初始化 git-lfs:
```bash
git lfs install
@@ -390,19 +382,19 @@ Updated git hooks.
Git LFS initialized.
```
-完成后,第一步是克隆您的模型存储库:
+完成后,接下来需要克隆你的模型仓库:
```bash
git clone https://huggingface.co//
```
-我的用户名是 **lysandre** 我使用了模型名称 **dummy** ,所以对我来说,命令最终如下所示:
+我的用户名是 `lysandre` 我使用的模型的名称是 `dummy` ,所以对我来说,命令最终如下所示:
```
git clone https://huggingface.co/lysandre/dummy
```
-我现在有一个名为的文件夹假在我的工作目录中。我能 **cd** 进入文件夹并查看内容:
+我现在在工作目录中多了一个名为 dummy 的文件夹。我可以 cd 到这个文件夹,看看其中的内容:
```bash
cd dummy && ls
@@ -412,11 +404,11 @@ cd dummy && ls
README.md
```
-如果您刚刚使用 Hugging Face Hub 创建了您的存储库 **create_repo** 方法,这个文件夹应该只包含一个隐藏的 **.gitattributes** 文件。如果您按照上一节中的说明使用 Web 界面创建存储库,则该文件夹应包含一个自述文件文件旁边的隐藏 **.gitattributes** 文件,如图所示。
+如果你刚刚用的是 Hugging Face Hub 的 `create_repo` 方法创建的仓库,这个文件夹应该只包含一个隐藏的 .gitattributes 文件。如果你使用的是网页界面创建了一个仓库,那么文件夹应该只包含一个 README.md 文件和一个隐藏的 .gitattributes 文件。
-添加一个常规大小的文件,例如配置文件、词汇文件,或者基本上任何几兆字节以下的文件,就像在任何基于 git 的系统中所做的一样。但是,更大的文件必须通过 git-lfs 注册才能将它们推送到Hugging Face。
+较小的文件,如配置文件、词汇表文件,或者基本上任何几 MB 以下的文件,操作的方法就像我们平时使用 git 一样。然而,更大的文件必须通过 git-lfs 注册才能推送到 huggingface.co。
-让我们回到 Python 来生成我们想要提交到我们的虚拟存储库的模型和标记器:
+让我们回到 Python,生成一些我们希望提交到 dummy 仓库的模型和 tokenizer
{#if fw === 'pt'}
```py
@@ -427,7 +419,7 @@ checkpoint = "camembert-base"
model = AutoModelForMaskedLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-# Do whatever with the model, train it, fine-tune it...
+# 对模型进行一些操作,训练、微调...
model.save_pretrained("")
tokenizer.save_pretrained("")
@@ -441,14 +433,14 @@ checkpoint = "camembert-base"
model = TFAutoModelForMaskedLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-# Do whatever with the model, train it, fine-tune it...
+# 对模型进行一些操作,训练、微调...
model.save_pretrained("")
tokenizer.save_pretrained("")
```
{/if}
-现在我们已经保存了一些模型和标记器工件,让我们再看看假文件夹:
+现在我们已经保存了模型和 tokenizer 让我们再看一下 dummy 文件夹:
```bash
ls
@@ -459,22 +451,22 @@ ls
config.json pytorch_model.bin README.md sentencepiece.bpe.model special_tokens_map.json tokenizer_config.json tokenizer.json
```
-If you look at the file sizes (for example, with `ls -lh`), you should see that the model state dict file (*pytorch_model.bin*) is the only outlier, at more than 400 MB.
+如果你尝试查看文件大小(例如,使用 `ls -lh` ),你应该看到模型状态字典文件(pytorch_model.bin)是唯一的异常的文件,超过了 400 MB。
{:else}
```bash
config.json README.md sentencepiece.bpe.model special_tokens_map.json tf_model.h5 tokenizer_config.json tokenizer.json
```
-如果您查看文件大小(例如, **ls -lh** ),您应该会看到模型状态 dict 文件 (pytorch_model.bin) 是唯一的异常值,超过 400 MB。
+如果你尝试查看文件大小(例如, `ls -lh` ),你应该会看到模型状态字典文件 (t5_model.h5) 唯一的异常的文件,超过了 400 MB。
{/if}
-✏️ 从 web 界面创建存储库时,*.gitattributes* 文件会自动设置为将具有某些扩展名的文件,例如 *.bin* 和 *.h5* 视为大文件,git-lfs 会对其进行跟踪您无需进行必要的设置。
+✏️ 当通过网页界面创建仓库时, `.gitattributes` 文件会自动将某些扩展名(如 `.bin` 和 `.h5` )的文件视为大文件,你无需对 git-lfs 进行任何设置即可跟踪它们。
-我们现在可以继续进行,就像我们通常使用传统 Git 存储库一样。我们可以使用以下命令将所有文件添加到 Git 的暂存环境中 **git add** 命令:
+我们现在可以继续上传,就像我们使用传统 Git 仓库一样。我们可以使用以下命令将所有文件添加到 Git 的暂存环境中 `git add` 命令:
```bash
git add .
@@ -518,7 +510,7 @@ Changes to be committed:
```
{/if}
-同样,我们可以确保 git-lfs 使用其跟踪正确的文件 **status** 命令:
+同样,我们可以使用 `status` 命令查看 git-lfs 正在跟踪的文件:
```bash
git lfs status
@@ -544,7 +536,7 @@ Objects not staged for commit:
```
-我们可以看到所有文件都有 **Git** 作为处理程序,除了其中有 **LFS**的*pytorch_model.bin* 和 *sentencepiece.bpe.model*。
+我们可以看到所有文件都使用 `Git` 作为处理程序,除了 `pytorch_model.bin` 和 `sentencepiece.bpe.model` 它们的处理程序是 `LFS` 。
{:else}
```bash
@@ -566,11 +558,11 @@ Objects not staged for commit:
```
-我们可以看到所有文件都有 **Git** 作为处理程序,除了其中有 **LFS**的*t5_model.h5*。
+我们可以看到所有文件都使用 `Git` 作为处理程序,除了 `t5_model.h5` ,它的处理程序是 `LFS` 。
{/if}
-让我们继续最后的步骤,提交并推送到Hugging Face远程仓库:
+让我们继续进行最后的步骤,提交并推送到 huggingface.co 远程仓库:
```bash
git commit -m "First model version"
@@ -601,7 +593,7 @@ git commit -m "First model version"
```
{/if}
-推送可能需要一些时间,具体取决于您的互联网连接速度和文件大小:
+推送可能需要一些时间,具体取决于你的网络速度以及你的文件大小:
```bash
git push
@@ -620,13 +612,13 @@ To https://huggingface.co/lysandre/dummy
```
{#if fw === 'pt'}
-If we take a look at the model repository when this is finished, we can see all the recently added files:
+当这些都完成时,如果我们查看模型仓库,我们可以看到所有最近添加的文件:

-UI 允许您浏览模型文件和提交,并查看每个提交引入的差异:
+在Huggingface 的网页上你可以查看模型文件和提交,并查看每次提交引入的差异:

@@ -634,13 +626,13 @@ UI 允许您浏览模型文件和提交,并查看每个提交引入的差异
{:else}
-如果我们在完成后查看模型存储库,我们可以看到所有最近添加的文件:
+当这些都完成时,如果我们查看模型仓库,我们可以看到所有最近添加的文件:
-UI 允许您浏览模型文件和提交,并查看每个提交引入的差异:
+在Huggingface 的网页上你可以查看模型文件和提交,并查看每次提交引入的差异:

diff --git a/chapters/zh-CN/chapter4/4.mdx b/chapters/zh-CN/chapter4/4.mdx
index e844ac18a..3f78af83e 100644
--- a/chapters/zh-CN/chapter4/4.mdx
+++ b/chapters/zh-CN/chapter4/4.mdx
@@ -7,11 +7,11 @@
模型卡片是一个配置文件,可以说与模型存储库中的模型和 tokenizer 文件一样重要。它包含了模型的核心定义,确保了社区成员可以复现模型的结果,并提供一个其他成员可以在这个模型基础上构建他们的组件的平台。
-记录训练和评估过程并提供有关使用的数据以及已完成的预处理和后续处理的足够信息,有助于其他人了解对模型的能力——确保模型存在和目前的限制、偏差可以识别和理解。
+记录训练和评估过程并提供有关使用的数据以及已完成的预处理和后续处理的足够信息,有助于其他人了解对模型的能力——模型存的局限性、偏见以及模型有效或无效的使用场景。
-因此,创建清晰定义模型的模型卡片是非常重要的一步。在这里,我们提供了一些可以帮助您解决此问题的方法。创建模型卡片是通过您之前看到的 Markdown 文件:README.md 。
+因此,创建一个清晰定义你的模型的模型卡片是非常重要的一步。在这里,我们提供了一些可以帮助你创建模型卡片的建议。创建模型卡片的内容保存在你之前看到的 README.md 文件中,这是一个 Markdown 文件。
-“模型卡片”的概念源于谷歌的一个研究方向, Margaret Mitchell 等人在论文[“Model Cards for Model Reporting”](https://arxiv.org/abs/1810.03993)中首次提出,此处包含的许多信息均基于该论文,我们建议您查看这篇论文以了解为什么模型卡片在重视可重复性、可重用性和公平性的时候中如此重要。
+“模型卡片”的概念源于谷歌的一个研究方向,Margaret Mitchell 等人在论文 [“模型卡片用于模型报告”](https://arxiv.org/abs/1810.03993) 中首次提出,这里许多内容均基于该论文,我们建议你查看这篇论文以了解为什么模型卡片在实现可复现性、可重用性和公平性的中如此重要。
模型卡通常以非常简短的概述开始,说明模型的用途,然后是模型卡片需要的其他信息:
@@ -25,53 +25,53 @@
让我们来看看每个部分应该包含什么。
-### 模型描述: [[模型描述:]]
+### 模型描述:[[模型描述:]]
提供了有关模型的基本详细信息。这包括架构、版本、如果它是在论文中介绍的,是否有原始的实现可用?作者以及有关模型的一般信息、任何版权都应归于此处。这一部分还可以提及有关训练程序、参数和重要免责声明的一般信息。
-### 预期用途和限制: [[预期用途和限制:]]
+### 预期用途和限制:[[预期用途和限制:]]
在此描述模型可以适用的例子,包括可以应用它的语言、领域。模型卡的这一部分还可以记录已知超出模型范围的区域,或者可能表现不佳的区域。
-### 使用方法: [[使用方法:]]
+### 使用方法:[[使用方法:]]
-此部分应包括一些有关如何使用模型的示例。这可以展示使用 **pipeline()** 函数、模型和标记器类的使用以及其他任何您认为可能有帮助的代码。
+此部分应包括一些有关如何使用模型的示例。这可以展示使用 `pipeline()` 函数、模型和 tokenizer 的使用以及其他任何你认为可能有帮助的代码。
-### 训练数据: [[训练数据:]]
+### 训练数据:[[训练数据:]]
这部分应该指出模型是在哪个数据集上训练的。也欢迎对数据集进行简要描述。
-### 训练过程: [[训练过程:]]
+### 训练过程:[[训练过程:]]
-此部分中,您应该描述从再现性角度来看有用的训练的所有相关方面。这包括对数据进行的任何预处理和后处理,以及模型训练的批量数、批量大小、学习率等细节。
+此部分中,你应该描述从再现性角度来看有用的训练的所有相关方面。这包括对数据进行的任何预处理和后处理,以及模型训练的批量数、批量大小、学习率等细节。
-### 变量和指标: [[变量和指标:]]
+### 变量和指标:[[变量和指标:]]
-在这里,您应该描述您用于评估的指标,以及您测量的不同因素。提及使用了哪些指标、在哪个数据集上以及哪个数据集部分,可以轻松地将您的模型的性能与其他模型的性能进行比较。
+在这里,你应该描述你用于评估的指标,以及你测量的不同因素。提及使用了哪些指标、在哪个数据集上以及哪个数据集部分,可以轻松地将你的模型的性能与其他模型的性能进行比较。
-### 评价结果: [[评价结果:]]
+### 评估结果:[[评估结果:]]
这些应该提前在前面的部分告知,例如预期的使用效果和示例。最后,提供模型在评估数据集上的表现的指示。如果模型使用决策阈值,要么提供评估中使用的决策阈值,要么提供在不同阈值下针对预期用途进行评估的详细信息。
-## 例子 [[例子]]
+## 示例 [[示例]]
-查看以下几个精心制作的模型卡的例子:
+请查看以下几个精心制作的模型卡的示例:
-* [bert-base-cased](https://huggingface.co/bert-base-cased)
-* [gpt2](https://huggingface.co/gpt2)
-* [distilbert](https://huggingface.co/distilbert-base-uncased)
+* [bert-base-cased](https://huggingface.co/bert-base-cased)
+* [gpt2](https://huggingface.co/gpt2)
+* [distilbert](https://huggingface.co/distilbert-base-uncased)
-更多来自于不同组织和公司的示例可以在[这里](https://github.com/huggingface/model_card/blob/master/examples.md)查阅.
+更多来自于不同组织和公司的示例可以在 [模型卡片示例](https://github.com/huggingface/model_card/blob/master/examples.md) 中查阅.
-## 提示 [[提示]]
+## 注意事项 [[注意事项]]
-发布模型时不需要模型卡,制作一个模型时不需要包含上述所有部分。但是,模型的文档会使未来的用户受益,因此我们建议您尽自己的知识和能力填写尽可能多的部分。
+发布模型时,并非必须有模型卡片,制作一个模型时不需要包含上述所有部分。但是,模型的文档会使未来的用户受益,因此我们建议你尽你所知和能力所及地尽可能填写尽可能多的部分。
## 模型卡片元数据 [[模型卡片元数据]]
-如果您对 Hugging Face Hub 进行了一些探索,您应该已经看到某些模型属于某些类别:您可以按任务、语言、库等对其进行过滤。模型所属的类别来自于您在模型卡片标题中添加的元数据。
+如果你对 Hugging Face Hub 进行了一些探索,你应该已经看到某些模型属于某些类别:你可以按任务、语言、库等对其进行筛选。模型所属的类别来自于你在模型卡片头部中添加的元数据。
-例如,如果你看一下[`camembert-base` 模型卡片](https://huggingface.co/camembert-base/blob/main/README.md),您应该在模型卡标题中看到以下几行:
+例如,如果你看一下 [`camembert-base` 模型卡片](https://huggingface.co/camembert-base/blob/main/README.md) ,你应该在模型卡头部中看到以下几行:
```
---
@@ -82,6 +82,6 @@ datasets:
---
```
-该元数据由 Hugging Face Hub 解析,然后将这个模型识别为法语模型,拥有 MIT 许可证,在 Oscar 数据集上训练。
+该元数据由 Hugging Face Hub 解析,然后将这个模型为法语模型,拥有 MIT 许可证,在 Oscar 数据集上训练。
-允许的指定语言、许可证、标签、数据集、指标以及模型在训练时获得的评估结果在[全部模型卡片的规格](https://raw.githubusercontent.com/huggingface/huggingface_hub/main/modelcard.md)可以查阅。
\ No newline at end of file
+可以在 [全部模型卡片的规格](https://raw.githubusercontent.com/huggingface/huggingface_hub/main/modelcard.md) 查阅支持的语言、许可证、标签、数据集、指标以及模型在训练时获得的评估结果。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter4/5.mdx b/chapters/zh-CN/chapter4/5.mdx
index 5c3b9708d..9218fc5d9 100644
--- a/chapters/zh-CN/chapter4/5.mdx
+++ b/chapters/zh-CN/chapter4/5.mdx
@@ -1,12 +1,12 @@
-# Part 1 完结! [[Part 1 完结!]]
+# Part 1 完结![[Part 1 完结!]]
-这是课程第一部分的结尾!第 2 部分将在 11 月 15 日与大型社区活动一起发布,[点击这里](https://huggingface.co/blog/course-launch-event)查看更多信息.
+这是课程第一部分的结尾!第 2 部分将在 11 月 15 日与大型社区活动一起发布,更多信息请 [点击这里](https://huggingface.co/blog/course-launch-event) 。
-您现在应该能够针对文本分类问题(单个或成对句子)对预训练模型进行微调,并将结果上传到模型中心。为确保您掌握了第一部分的内容,您应该针对您感兴趣的想法进行尝试(不一定是英语)!一旦你完成,您可以在[Hugging Face 社区](https://discuss.huggingface.co/)的[这个话题](https://discuss.huggingface.co/t/share-your-projects/6803)分享您的项目。
+你现在应该能够针对文本分类问题(单个或成对句子)对预训练模型进行微调,并将结果上传到模型中心。为确保你掌握了第一部分的内容,你应该针对你感兴趣的想法进行尝试(不一定是英语)!一旦你完成,你可以在 [Hugging Face 社区](https://discuss.huggingface.co/) 的 [这个话题](https://discuss.huggingface.co/t/share-your-projects/6803) 分享你的项目。
-我们迫不及待地想看看您将用它构建什么!
\ No newline at end of file
+我们迫不及待地想看到你会用这些内容做出什么!
diff --git a/chapters/zh-CN/chapter4/6.mdx b/chapters/zh-CN/chapter4/6.mdx
index 8308af695..218ba78b9 100644
--- a/chapters/zh-CN/chapter4/6.mdx
+++ b/chapters/zh-CN/chapter4/6.mdx
@@ -10,31 +10,32 @@
/>
让我们测试一下你在本章所学的知识!
-
-### 1.Hub上的模型有什么限制?
+
+### 1.往Hub 上传模型有什么限制?
+
-### 2.如何管理Hub上的模型?
+### 2.如何管理 Hub 上的模型?
-### 3.你能使用Hugging Face Hub网页接口做什么?
+### 3.你能使用 Hugging Face Hub 网页接口做什么?
-### 4.模型卡是什么?
+### 4.什么是模型卡片?
-### 5.哪些🤗 Transformers 库的对象可以直接在 Hub 上通过`push_to_Hub()`共享?
+### 5.哪些🤗 Transformers 库的对象可以直接通过 `push_to_hub()` 分享到 Hub?
{#if fw === 'pt'}
push_to_hub方法,使用该方法将把所有标记器文件(词汇表、标记器的架构等)推送到给定的存储库。不过,这不是唯一正确的答案!",
+ text: " tokenizer ",
+ explain: "正确!所有 tokenizer 都有 `push_to_hub` 方法,使用该方法将把 tokenizer 的全部文件(词汇表、 tokenizer 的架构等)推送到给定的存储库。不过,这不是唯一正确的答案!",
correct: true
},
{
- text: "模型配置",
- explain: "对!所有模型配置都有push_to_hub方法,使用这个方法可以将它们推送到给定的存储库。你还有其他能共享的吗?",
+ text: "模型的 Config 对象",
+ explain: "对!所有模型的 Config 对象都有 `push_to_hub` 方法,使用这个方法可以将它们推送到给定的存储库。你还有其他的答案吗?",
correct: true
},
{
- text: "一个模型",
- explain: "正确! 所有模型都有push_to_hub方法,使用它会将它们及其配置文件推送到给定的存储库。不过,这并不是您可以共享的全部内容。",
+ text: "Model 类",
+ explain: "正确!所有的 Model 类都有 `push_to_hub` 方法,使用它会将它们及其配置文件推送到给定的存储库。不过,还有其他的正确答案",
correct: true
},
{
- text: "Trainer",
- explain: "没错————Trainer也实现了push_to_hub方法,并且使用它将模型、配置、标记器和模型卡草稿上传到给定的存储器。试试其他答案!",
+ text: "Trainer 类",
+ explain: "没错 —— `Trainer` 也实现了 `push_to_hub` 方法,并且使用它可以将模型、配置、 tokenizer 和模型卡片上传到指定的仓库。试试其他答案!",
correct: true
}
]}
@@ -132,89 +133,90 @@
push_to_hub方法,使用该方法将把所有标记器文件(词汇表、标记器的架构等)推送到给定的存储库。不过,这不是唯一正确的答案!",
+ text: " tokenizer ",
+ explain: "正确!所有 tokenizer 都有 `push_to_hub` 方法,使用该方法将把所有 tokenizer 文件(词汇表、 tokenizer 的架构等)推送到给定的存储库。不过,这不是唯一正确的答案!",
correct: true
},
{
- text: "模型配置",
- explain: "对!所有模型配置都有push_to_hub方法,使用这个方法可以将它们推送到给定的存储库。你还有其他能共享的吗?",
+ text: "模型的 Config 对象",
+ explain: "对!所有模型的 Config 对象都有 `push_to_hub` 方法,使用这个方法可以将它们推送到给定的存储库。你还有其他能共享的吗?",
correct: true
},
{
- text: "一个模型",
- explain: "正确! 所有模型都有push_to_hub方法,使用它会将它们及其配置文件推送到给定的存储库。不过,这并不是您可以共享的全部内容。",
+ text: "Model 类",
+ explain: "正确!所有Model 类都有 `push_to_hub` 方法,使用它会将它们及其配置文件推送到给定的存储库。不过,还有其他可以分享到hub。",
correct: true
},
{
- text: "以上都有专用的回调函数",
- explain: "正确————在训练期间,PushToHubCallback会定期将所有这些对象发送到存储器。",
+ text: "所有以上的对象都可以通过专用的回调方法共享到 hub",
+ explain: "正确 —— 在训练期间, `PushToHubCallback` 会定期将所有这些对象发送到 hub。",
correct: true
}
]}
/>
{/if}
-### 6.当使用`push_to_hub()`方法或 CLI 工具时,第一步是什么?
+### 6.当使用 `push_to_hub()` 方法或 CLI 工具时,第一步是什么?
-### 7.您正在使用一个模型和一个标记器————如何将它们上传到 Hub?
+### 7.你正在使用一个模型和一个 tokenizer ——如何将它们上传到 Hub?
+
huggingface_hub实用程序中。",
- explain: "模型和标记器已经受益于huggingface_hub 实用程序: 不需要额外的包装!"
+ text: "在 Python 运行时中,使用 `huggingface_hub` 中的方法进行封装。",
+ explain: "模型和 tokenizer 已经使用 `huggingface_hub` 封装过了:不需要额外的封装!"
},
{
- text: "将它们保存到磁盘并调用 transformers-cli upload-model",
- explain: "命令 upload-model 不存在。"
+ text: "将它们保存到磁盘并调用 `transformers-cli upload-model` ",
+ explain: "命令 `upload-model` 不存在。"
}
]}
/>
-### 8.您可以使用`Repository`类执行哪些 git 操作?
+### 8.你可以使用 `Repository` 类执行哪些 git 操作?
git_commit() 方法就是为此而存在的。",
+ text: "提交(commit)",
+ explain: "正确, `git_commit()` 方法就是为此而存在的。",
correct: true
},
{
- text: "拉取",
- explain: "这就是 git_pull() 方法的目的。",
+ text: "拉取(pull)",
+ explain: "这就是 `git_pull()` 方法的功能。",
correct: true
},
{
- text: "推送",
- explain: "方法 git_push() 可以做到这一点。",
+ text: "推送(push)",
+ explain: "方法 `git_push()` 可以做到这一点。",
correct: true
},
{
- text: "合并",
- explain: "不,这个操作在这个 API 中是不可能的。"
+ text: "合并(merge)",
+ explain: "不,这个操作在这个 API 中是无法实现的。"
}
]}
/>
diff --git a/chapters/zh-CN/chapter5/1.mdx b/chapters/zh-CN/chapter5/1.mdx
index c13d18b91..d626e75a2 100644
--- a/chapters/zh-CN/chapter5/1.mdx
+++ b/chapters/zh-CN/chapter5/1.mdx
@@ -5,18 +5,17 @@
classNames="absolute z-10 right-0 top-0"
/>
-在[第三章](/course/chapter3)第一次体验了🤗Datasets 库,并发现在微调模型时有三个主要步骤:
+我们在 [第三章](/course/chapter3) 第一次体验了🤗 Datasets 库,了解到微调模型主要有三个步骤:
-1. 从hugs Face Hub加载一个数据集。
-2. 使用Dataset.map()对数据进行预处理。
-3. 加载和计算指标(特征)。
+1. 从 Hugging Face Hub 加载数据集。
+2. 使用 `Dataset.map()` 预处理数据。
+3. 加载和计算指标(特征)。
-但这只是🤗 Datasets的表面功能而已!在本章中,我们将深入了解这个库。在此过程中,我们将找到以下问题的答案:
-
-* 当数据集不在hub上时,您该怎么做?
-* 如何对数据集进行切片?(如果你真正的特别需要使用pandas的时候该怎么办?)
-* 当你的数据集很大,会撑爆你笔记本电脑的RAM时,你会怎么做?
-* “内存映射”和Apache Arrow到底是什么?
+但这仅仅触及了🤗 Datasets 库能做的事情的冰山一角!在本章,我们将深入探索这个库。一路上,我们会找到以下问题的答案:
+* 当你的数据集不在 Hub 上时,你应该怎么做?
+* 你如何切分和操作数据集?(如果你非常需要使用 Pandas,该如何处理?)
+* 当你的数据集非常大,会撑爆你笔记本电脑的 RAM 时,你应该怎么办?
+* 什么是“内存映射”和 “Apache Arrow”?
* 如何创建自己的数据集并将其推送到中心?
-您在这里学到的技术将为您在[第6章](/course/chapter6)和[第7章](/course/chapter7)中的高级标记化和微调任务做好准备——所以,喝杯咖啡,让我们开始吧!
\ No newline at end of file
+你在这里学到的技术将为你在 [第六章](/course/chapter6) 和 [第七章](/course/chapter7) 中的高级 tokenization 和微调任务做好准备——所以,来杯咖啡,让我们开始吧!
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter5/2.mdx b/chapters/zh-CN/chapter5/2.mdx
index 555e35f70..478e457b5 100644
--- a/chapters/zh-CN/chapter5/2.mdx
+++ b/chapters/zh-CN/chapter5/2.mdx
@@ -1,4 +1,4 @@
-# 如果我的数据集不在 Hub 上怎么办? [[如果我的数据集不在 Hub 上怎么办?]]
+# 如果我的数据集不在 Hub 上怎么办?[[如果我的数据集不在 Hub 上怎么办?]]
-你知道如何使用[Hugging Face Hub](https://huggingface.co/datasets)下载数据集, 但你经常会发现自己正在处理存储在笔记本电脑或远程服务器上的数据。在本节中,我们将向您展示如何使用 🤗 Datasets来加载 Hugging Face Hub 上不可用的数据集。
+你已经知道如何使用 [Hugging Face Hub](https://huggingface.co/datasets) 中的数据集,但你往往会发现自己需要处理在自己的笔记本电脑或者网络上的数据集。在本节中,我们将展示如何使用🤗 Datasets 加载不在 Hugging Face Hub 中的数据集。
## 使用本地和远程数据集 [[使用本地和远程数据集]]
-🤗 Datasets 提供了加载脚本来加载本地和远程数据集。它支持几种常见的数据格式,例如:
+🤗 Datasets 提供了加载本地和远程数据集的方法。它支持几种常见的数据格式,例如:
-| Data format | Loading script | Example |
+| 数据格式 | 类型参数 | 加载的指令 |
| :----------------: | :------------: | :-----------------------------------------------------: |
-| CSV & TSV | `csv` | `load_dataset("csv", data_files="my_file.csv")` |
-| Text files | `text` | `load_dataset("text", data_files="my_file.txt")` |
-| JSON & JSON Lines | `json` | `load_dataset("json", data_files="my_file.jsonl")` |
-| Pickled DataFrames | `pandas` | `load_dataset("pandas", data_files="my_dataframe.pkl")` |
+| CSV & TSV | `csv` | `load_dataset("csv", data_files="my_file.csv")` |
+| Text files | `text` | `load_dataset("text", data_files="my_file.txt")` |
+| JSON & JSON Lines | `json` | `load_dataset("json", data_files="my_file.jsonl")` |
+| Pickled DataFrames | `pandas` | `load_dataset("pandas", data_files="my_dataframe.pkl")` |
-如表所示, 对于每种数据格式, 我们只需要使用 `load_dataset()` 函数, 使用 `data_files` 指定一个或多个文件的路径的参数。 让我们从本地文件加载数据集开始;稍后我们将看到如何对远程文件执行相同的操作。
+如表所示,对于每种数据格式,我们只需要在 `load_dataset()` 函数中指定数据的类型,并使用 `data_files` 指定一个或多个文件的路径的参数。首先,我们从加载本地文件的数据集开始;稍后,我们将看到如何使用远程文件做同样的事情。
## 加载本地数据集 [[加载本地数据集]]
-对于这个例子,我们将使用 [SQuAD-it dataset](https://github.com/crux82/squad-it/), 这是一个大规模的意大利语问答数据集。
+在这个例子中,我们将使用 [SQuAD-it 数据集](https://github.com/crux82/squad-it/) ,这是一个用于意大利语问答的大规模数据集。
-训练和测试都托管在 GitHub 上, 因此我们可以通过`wget`命令非常简单地下载它们:
+训练集和测试集都托管在 GitHub 上,因此我们可以通过 `wget` 命令非常轻易地下载它们:
```python
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz
```
-这将下载两个名为*SQuAD_it-train.json.gz* 和 *SQuAD_it-test.json.gz*的压缩文件, 我们可以用Linux的解压命令 `gzip`:
+这将下载两个名为 `SQuAD_it-train.json.gz` 和 `SQuAD_it-test.json.gz` 的压缩文件,我们可以用 Linux 的 `gzip` 命令解压他们:
```python
!gzip -dkv SQuAD_it-*.json.gz
@@ -46,15 +46,15 @@ SQuAD_it-test.json.gz: 87.4% -- replaced with SQuAD_it-test.json
SQuAD_it-train.json.gz: 82.2% -- replaced with SQuAD_it-train.json
```
-我们可以看到压缩文件已经被替换为SQuAD_it-train.json和SQuAD_it-test.json,并且数据以 JSON 格式存储。
+我们可以看到压缩文件已经被替换为 `SQuAD_it-train.json` 和 `SQuAD_it-test.json` ,并且数据以 JSON 格式存储。
-✎ 如果你想知道为什么上面的shell命令中哟与一个字符`!`,那是因为我们是在 Jupyter notebook 中运行它们。如果您想在终端中下载和解压缩数据集,只需删除前缀!即可。
+✏️ 如果你想知道为什么上面的 shell 命令中有一个 `!` ,那是因为我们现在是在 Jupyter notebook 中运行它们。如果你想在命令行中下载和解压缩数据集,只需删除前缀 `!` 即可。
-使用`load_dataset()`函数来加载JSON文件, 我们只需要知道我们是在处理普通的 JSON(类似于嵌套字典)还是 JSON 行(行分隔的 JSON)。像许多问答数据集一样, SQuAD-it 使用嵌套格式,所有文本都存储在 `data`文件中。这意味着我们可以通过指定参数`field`来加载数据集,如下所示:
+当我们使用 `load_dataset()` 函数来加载 JSON 文件时,我们需要知道我们是在处理普通的 JSON(类似于嵌套字典)还是 JSON Lines(每一行都是一个 JSON)。像许多问答数据集一样,SQuAD-it 使用的是嵌套字典,所有文本都存储在 `data` 字段中。这意味着我们可以通过使用参数 `field` 来加载数据集,如下所示:
```py
from datasets import load_dataset
@@ -62,7 +62,7 @@ from datasets import load_dataset
squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
```
-默认情况下, 加载本地文件会创建一个带有`train`的`DatasetDict` 对象。 我们可以通过 `squad_it_dataset`查看:
+默认情况下,加载本地文件会创建一个带有 `train` 标签的 `DatasetDict` 对象。我们可以在这里查看一下 `squad_it_dataset` 对象:
```py
squad_it_dataset
@@ -77,7 +77,7 @@ DatasetDict({
})
```
-这向我们显示了与训练集相关联的行数和列名。我们可以通过索引到 `train` 查看示例,如下所示:
+输出了与训练集的行数和列名。我们可以使用 `train` 标签来查看数据集中的一个示例,如下所示:
```py
squad_it_dataset["train"][0]
@@ -103,7 +103,7 @@ squad_it_dataset["train"][0]
}
```
-很好, 我们已经加载了我们的第一个本地数据集! 但是, 虽然这对训练集有效, 但是我们真正想要的是包括 `train` 和 `test` 的 `DatasetDict` 对象。这样的话就可以使用 `Dataset.map()` 函数同时处理训练集和测试集。 为此, 我们提供参数`data_files`的字典,将每个分割名称映射到与该分割相关联的文件:
+很好,我们已经加载了我们的第一个本地数据集!但是,也仅仅加载了训练集,我们真正想要的是包含 `train` 和 `test` 的 `DatasetDict` 对象。这样的话就可以使用 `Dataset.map()` 函数同时处理训练集和测试集。为此,我们向 `data_files` 参数输入一个字典,将数据集的标签名映射到相关联的文件:
```py
data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
@@ -124,28 +124,28 @@ DatasetDict({
})
```
-这正是我们想要的。现在, 现在,我们可以应用各种预处理技术来清理数据、标记评论等。
+这正是我们想要的。现在,我们可以使用各种预处理技术来清洗数据、tokenize 评论等等。
-
+
-`load_dataset()`函数的`data_files`参数非常灵活并且可以是单个文件路径、文件路径列表或将分割后的名称映射到文件路径的字典。您还可以根据Unix shell使用的规则对与指定模式匹配的文件进行全局定位(例如,您可以通过设置'data_files=“*.JSON”'将目录中的所有JSON文件作为单个拆分进行全局定位)。有关更多详细信息,请参阅🤗Datasets 文档。
+`load_dataset()` 函数的 `data_files` 参数非常灵活:可以是单个文件路径、文件路径列表或者是标签映射到文件路径的字典。你还可以根据 Unix shell 的规则,对符合指定模式的文件进行批量匹配(例如,你可以通过设置 `data_files="*.JSON"` 匹配目录中所有的 JSON 文件)。有关`load_dataset()`更多详细信息,请参阅 [🤗Datasets 文档](https://huggingface.co/docs/datasets/v2.12.0/en/loading#local-and-remote-files) 。
-🤗 Datasets实际上支持输入文件的自动解压,所以我们可以跳过使用`gzip`,直接设置 `data_files`参数传递压缩文件:
+🤗 Datasets 实际上支持自动解压输入文件,所以我们可以跳过使用 `gzip` ,直接将 `data_files` 参数设置为压缩文件:
```py
data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
```
-如果您不想手动解压缩许多 GZIP 文件,这会很有用。自动解压也适用于其他常见格式,如 ZIP 和 TAR,因此您只需将 `data_files` 设置为压缩文件所在的路径,你就可以开始了!
+如果你不想手动解压缩许多 GZIP 文件,这会很有用。自动解压也支持于其他常见格式,如 ZIP 和 TAR,因此你只需将 `data_files` 设置为压缩文件所在的路径,接下来就交给🤗 Datasets 吧!
-现在你知道如何在笔记本电脑或台式机上加载本地文件,让我们来看看加载远程文件。
+现在你知道如何在笔记本电脑或台式机上加载本地文件,让我们来看看如何加载远程文件。
## 加载远程数据集 [[加载远程数据集]]
-如果你在公司担任数据研究员或编码员,那么你要分析的数据集很有可能存储在某个远程服务器上。幸运的是,加载远程文件就像加载本地文件一样简单!我们没有提供本地文件的路径, 而是将`load_dataset()`的`data_files`参数指向存储远程文件的一个或多个URL。例如, 对于托管在 GitHub 上的 SQuAD-it 数据集, 我们可以将 `data_files` 指向 _SQuAD_it-*.json.gz_ 的网址,如下所示:
+如果你在公司担任数据研究员或编程员,那么你要分析的数据集很有可能存储在某个远程服务器上。幸运的是,加载远程文件就像加载本地文件一样简单!我们只需要将 `load_dataset()` 的 `data_files` 参数指向存储远程文件的一个或多个 URL。例如,对于托管在 GitHub 上的 SQuAD-it 数据集,我们可以将 `data_files` 设置为指向 `SQuAD_it-*.json.gz` 的网址,如下所示:
```py
url = "https://github.com/crux82/squad-it/raw/master/"
@@ -156,12 +156,11 @@ data_files = {
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
```
-这将返回和上面的本地例子相同的 `DatasetDict` 对象, 但省去了我们手动下载和解压 _SQuAD_it-*.json.gz_ 文件的步骤。这是我们对加载未托管在Hugging Face Hub的数据集的各种方法的总结。既然我们已经有了一个可以使用的数据集,让我们开始大展身手吧!
+这将返回和上面的本地例子相同的 `DatasetDict` 对象,但省去了我们手动下载和解压 `SQuAD_it-*.json.gz` 文件的步骤。这是我们对加载未托管在 Hugging Face Hub 的数据集的各种方法的总结。既然我们已经有了一个可以使用的数据集,让我们开始大展身手吧!
-✏️ **试试看!** 选择托管在GitHub或[UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php)上的另一个数据集并尝试使用上述技术在本地和远程加载它。另外,可以尝试加载CSV或者文本格式存储的数据集(有关这些格式的更多信息,请参阅[文档](https://huggingface.co/docs/datasets/loading#local-and-remote-files))。
+✏️ **试试看!** 选择托管在 GitHub 或 [UCI 机器学习仓库](https://archive.ics.uci.edu/ml/index.php) 上的另一个数据集并尝试使用上述技术在本地和远程加载它。另外,可以尝试加载 CSV 或者文本格式存储的数据集(有关这些格式的更多信息,请参阅 [文档](https://huggingface.co/docs/datasets/loading#local-and-remote-files) )。
-
diff --git a/chapters/zh-CN/chapter5/3.mdx b/chapters/zh-CN/chapter5/3.mdx
index 239780da7..163623d9f 100644
--- a/chapters/zh-CN/chapter5/3.mdx
+++ b/chapters/zh-CN/chapter5/3.mdx
@@ -1,4 +1,4 @@
-# 是时候来学一下切片了 [[是时候来学一下切片了]]
+# 分割和整理数据 [[分割和整理数据]]
-大多数情况下,您使用的数据都需根据模型所要求的输入进行清洗。在本节中,我们将探索 🤗 Datasets 提供的用于数据集清洗的各种功能。
+大多数情况下,你处理的数据并不能直接用于训练模型。在本节中,我们将探索🤗 Datasets 提供的各种功能,用于清洗你的数据集。
-## 切片与切分我们的数据 [[切片与切分我们的数据]]
+## 分割和整理我们的数据 [[分割和整理我们的数据]]
-与 Pandas 类似,🤗 Datasets 提供了几个函数来操作 **Dataset** 和 **DatasetDict** 对象。我们在[第三章](/course/chapter3)已经遇到了 **Dataset.map()** 方法,在本节中,我们将探索我们可以使用的其他功能。
+与 Pandas 类似,🤗 Datasets 提供了多个函数来操作 `Dataset` 和 `DatasetDict` 对象。我们在 [第三章](/course/chapter3) 已经遇到了 `Dataset.map()` 方法,在本节中,我们将探索一些其他可用的函数。
-对于这个例子,我们将使用托管在[加州大学欧文分校机器学习存储库](https://archive.ics.uci.edu/ml/index.php)的[药物审查数据集](https://archive.ics.uci.edu/ml/datasets/Drug+Review+Dataset+%28Drugs.com%29),其中包含患者对各种药物的评论,以及正在治疗的病情和患者满意度的 10 星评级。
+在本例中,我们将使用托管在 [加州大学欧文分校机器学习仓库](https://archive.ics.uci.edu/ml/index.php) 的 [药物审查数据集](https://archive.ics.uci.edu/ml/datasets/Drug+Review+Dataset+%28Drugs.com%29) ,其中包含患者对各种药物的评论,以及正在治疗的病情和患者满意度的 10 星评价。
-首先我们需要下载并提取数据,这可以通过 **wget** 和 **unzip** 命令:
+首先我们需要下载并解压数据,可以通过 `wget` 和 `unzip` 命令:
```py
!wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00462/drugsCom_raw.zip"
!unzip drugsCom_raw.zip
```
-由于 TSV 只是使用制表符而不是逗号作为分隔符的 CSV 变体,我们可以使用加载**csv**文件的**load_dataset()**函数并指定分隔符 示例如下:
+由于 TSV 仅仅是 CSV 的一个变体,它使用制表符而不是逗号作为分隔符,我们可以使用加载 `csv` 文件的 `load_dataset()` 函数并指定分隔符,来加载这些文件:
```py
from datasets import load_dataset
data_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"}
-# \t is the tab character in Python
+# \t 在python中是制表符的意思
drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
```
-在进行任何类型的数据分析时,一个好的做法是抽取一个小的随机样本,以快速了解您正在处理的数据类型。在🤗数据集中,我们可以通过链接 **Dataset.shuffle()** 和 **Dataset.select()** 共同来完成抽取:
+在进行数据分析时,获取一个小的随机样本以快速了解你正在处理数据的特点是一种好的实践。在🤗数据集中,我们可以通过链接 `Dataset.shuffle()` 和 `Dataset.select()` 函数创建一个随机的样本:
```py
drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000))
-# Peek at the first few examples
+# 细看前几个例子
drug_sample[:3]
```
@@ -54,20 +54,21 @@ drug_sample[:3]
'usefulCount': [36, 13, 128]}
```
-请注意,出于可以复现的目的,我们已将在**Dataset.shuffle()**选取了固定的随机数种子。 **Dataset.select()** 需要一个可迭代的索引,所以我们已经通过了 **range(1000)** 从随机打乱的数据集中选取前 1,000 个示例。从抽取的数据中,我们已经可以看到我们数据集的一些特点:
+请注意,出于可以复现的目的,我们已将在 `Dataset.shuffle()` 设定了固定的随机数种子。 `Dataset.select()` 需要一个可迭代的索引,所以我们传递了 `range(1000)` 从随机打乱的数据集中抽取前 1,000 个示例。从抽取的数据中,我们已经可以看到我们数据集中有一些特殊的地方:
-* **Unnamed: 0**这列看起来很像每个患者的匿名 ID。
-* **condition** 这列包含有描述健康状况的标签。
-* 评论长短不一,混合有 Python 行分隔符 (**\r\n**) 以及 HTML 字符代码,如** &\#039;**。
+* `Unnamed: 0` 这列看起来很像每个患者的匿名 ID。
+* `condition` 列包含了大小写混合的标签。
+* 评论长短不一,混合有 Python 行分隔符 ( `\r\n` ) 以及 HTML 字符代码,如 `&\#039;` 。
-让我们看看我们如何使用 🤗 Datasets 来处理这些问题。为了验证**Unnamed: 0** 列存储的是患者 ID的猜想,我们可以使用 **Dataset.unique()** 函数来验证匿名ID 的数量是否与拆分后每部分中的行数匹配:
+
+让我们看看我们如何使用 🤗 Datasets 来处理这些问题。为了验证 `Unnamed: 0` 列存储的是患者 ID 的猜想,我们可以使用 `Dataset.unique()` 函数来验证匿名 ID 的数量是否与分割后每个分组中的行数匹配:
```py
for split in drug_dataset.keys():
assert len(drug_dataset[split]) == len(drug_dataset[split].unique("Unnamed: 0"))
```
-这似乎证实了我们的假设,所以让我们把 **Unnamed: 0** 列重命名为患者的id。我们可以使用 **DatasetDict.rename_column()**函数一次性重命名DatasetDict中共有的列:
+这似乎证实了我们的假设,所以让我们把 `Unnamed: 0` 列重命名为患者的 id。我们可以使用 `DatasetDict.rename_column()` 函数来一次性重命名两个分组:
```py
drug_dataset = drug_dataset.rename_column(
@@ -91,11 +92,11 @@ DatasetDict({
-✏️ **试试看!** 使用 `Dataset.unique()` 函数查找训练和测试集中满足某个条件的药物经过去重之后的数量。
+✏️ **试试看!** 使用 `Dataset.unique()` 函数查找训练和测试集中的特定药物和病症的数量。
-接下来,让我们使用 **Dataset.map()**标准化所有 **condition** 标签 .正如我们在[第三章](/course/chapter3)中所做的那样,我们可以定义一个简单的函数,可以将该函数应用于**drug_dataset** 拆分后每部分的所有行:
+接下来,让我们使用 `Dataset.map()` 来规范所有的 `condition` 标签。正如我们在 [第三章](/course/chapter3) 中处理 tokenizer 一样,我们可以定义一个简单的函数,可以使用该函数 `drug_dataset` 处理每个分组的所有行:
```py
def lowercase_condition(example):
@@ -109,26 +110,26 @@ drug_dataset.map(lowercase_condition)
AttributeError: 'NoneType' object has no attribute 'lower'
```
-哦不,我们的map功能遇到了问题!从错误中我们可以推断出 **condition** 列存在 **None** , 不能转换为小写,因为它们不是字符串。让我们使用 **Dataset.filter()** 删除这些行 ,其工作方式类似于 **Dataset.map()** 。例如:
+哦不,我们的 map 函数遇到了问题!从错误中我们可以推断出 `condition` 列存在 `None` ,不能转换为小写,因为它们不是字符串。让我们使用 `Dataset.filter()` 删除这些行 其工作方式类似于 `Dataset.map()` 。例如:
```py
def filter_nones(x):
return x["condition"] is not None
```
-然后运行 **drug_dataset.filter(filter_nones)** ,我们可以在一行中使用lambda 函数.在 Python 中,lambda 函数是您无需明确命名即可使用的微函数(匿名函数)。它们一般采用如下形式:
+然后运行 `drug_dataset.filter(filter_nones)` ,我们可以用 lambda 函数在一行代码完成这个任务。在 Pyhton 中,lambda 函数是你无需明确命名即可使用的微函数(匿名函数)。它们一般采用如下形式:
```
lambda :
```
-其中**lambda** 是 Python 的特殊[关键字](https://docs.python.org/3/reference/lexical_analysis.html#keywords), **arguments** 是以逗号进行分隔的函数输入的列表/集合, **expression** 代表您希望执行的操作。例如,我们可以定义一个简单的 lambda 函数来对一个数字进行平方,如下所示:
+其中 `lambda` 是 Python 的特殊 [关键字](https://docs.python.org/3/reference/lexical_analysis.html#keywords) 之一, `arguments` 是以逗号进行分隔的函数参数的列表/集合, `expression` 代表你希望执行的操作。例如,我们可以定义一个简单的 lambda 函数来对一个数字进行平方,如下所示:
```
lambda x : x * x
```
-我们需要将要输入给这个函数值括在括号中:
+我们需要将要输入放在括号中:
```py
(lambda x: x * x)(3)
@@ -138,7 +139,7 @@ lambda x : x * x
9
```
-类似地,我们可以通过用逗号分隔多个参数来定义 lambda 函数。例如,我们可以按如下方式计算三角形的面积:
+同样,我们可以通过使用逗号分隔来定义带有多个参数的 lambda 函数。例如,我们可以按如下方式计算三角形的面积:
```py
(lambda base, height: 0.5 * base * height)(4, 8)
@@ -148,17 +149,17 @@ lambda x : x * x
16.0
```
-当您想定义小型、一次性使用的函数时,Lambda 函数非常方便(有关它们的更多信息,我们建议阅读安德烈·布尔高写的[真正的Python教程](https://realpython.com/python-lambda/))。在🤗 Datasets 中,我们可以使用 lambda 函数来定义简单的映射和过滤操作,所以让我们使用这个技巧来消除我们数据集中的 **None** 条目:
+当你想定义小型、一次性使用的函数时,lambda 函数非常方便(有关它们的更多信息,我们建议阅读 Andre Burgaud 写的 [真正的Python教程](https://realpython.com/python-lambda/) )。在🤗 Datasets 中,我们可以使用 lambda 函数来定义简单的映射和过滤操作,所以让我们使用这个技巧来删除我们数据集中的所有`condition` 为 `None`的记录:
```py
drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None)
-```
+```
-当 **None** 条目已删除,我们可以标准化我们的 **condition** 列:
+含有`None`的积累删除之后,我们可以规范我们的 `condition` 列:
```py
drug_dataset = drug_dataset.map(lowercase_condition)
-# Check that lowercasing worked
+# 检查一下转换后的结果
drug_dataset["train"]["condition"][:3]
```
@@ -168,22 +169,22 @@ drug_dataset["train"]["condition"][:3]
有用!现在我们已经清理了标签,让我们来看看清洗后的评论文本。
-## 创建新的数据列 [[创建新的数据列]]
+## 创建新的列 [[创建新的列]]
-每当您处理客户评论时,一个好的做法是检查每个评论中的字数。评论可能只是一个词,比如“太棒了!”或包含数千字的完整文章,根据实际的情况,您需要以不同的方式处理这些极端情况。为了计算每条评论中的单词数,我们将使用基于空格分割每个文本的粗略方法。
+每当我们处理客户评论时,一个好的习惯是检查评论的字数的分布。评论可能只是一个词,比如“太棒了!”或包含数千字的完整文章。在不同的使用场景,你需要以不同的方式处理这些极端情况。为了计算每条评论中的单词数,我们将使用空格分割每个文本进行粗略统计。
-让我们定义一个简单的函数来计算每条评论中的单词数:
+让我们定义一个简单的函数,计算每条评论的字数:
```py
def compute_review_length(example):
return {"review_length": len(example["review"].split())}
```
-与我们的 `lowercase_condition()` 函数不同,`compute_review_length()` 返回一个字典,其键与数据集中的列名之一不对应。 在这种情况下,当 `compute_review_length()` 传递给 `Dataset.map()` 时,它将应用于数据集中的所有行以创建新的 `review_length` 列:
+不同于我们的 `lowercase_condition()` 函数, `compute_review_length()` 返回一个字典,其键并不对应数据集中的某一列名称。在这种情况下,当 `compute_review_length()` 传递给 `Dataset.map()` 时,它将处理数据集中的所有行,最后返回值会创建一个新的 `review_length` 列:
```py
drug_dataset = drug_dataset.map(compute_review_length)
-# Inspect the first training example
+# 检查第一个训练样例
drug_dataset["train"][0]
```
@@ -198,7 +199,7 @@ drug_dataset["train"][0]
'review_length': 17}
```
-正如预期的那样,我们可以看到一个 **review_length** 列已添加到我们的训练集中。我们可以使用 **Dataset.sort()**对这个新列进行排序,然后查看极端长度的评论的样子:
+正如预期的那样,我们可以看到一个 `review_length` 列已添加到我们的训练集中。我们可以使用 `Dataset.sort()` 对这个新列进行排序,然后查看一下极端长度的评论是什么样的:
```py
drug_dataset["train"].sort("review_length")[:3]
@@ -215,15 +216,15 @@ drug_dataset["train"].sort("review_length")[:3]
'review_length': [1, 1, 1]}
```
-正如我们所猜想的那样,一些评论只包含一个词,虽然这对于情感分析来说可能没问题,但如果我们想要预测病情,这些评论可能并不适合。
+正如我们所猜想的那样,有些评论只包含一个词,虽然这对于情感分析任务来说还可以接受,但如果我们想要预测病情,那么它所提供的信息就不够丰富了。
-🙋向数据集添加新列的另一种方法是使用函数Dataset.add_column() 。这允许您输入Python 列表或 NumPy,在不适合使用Dataset.map()情况下可以很方便。
+🙋向数据集添加新列的另一种方法是使用函数 `Dataset.add_column()` ,在使用它时你可以通过 Python 列表或 NumPy 数组的方式提供数据,在不适合使用 `Dataset.map()` 情况下可以很方便。
-让我们使用 **Dataset.filter()** 功能来删除包含少于 30 个单词的评论。与我们对 **condition** 列的处理相似,我们可以通过选取评论的长度高于此阈值来过滤掉非常短的评论:
+让我们使用 `Dataset.filter()` 功能来删除包含少于 30 个单词的评论。这与我们过滤 `condition` 列的处理方式相似,我们可以通过设定评论长度的最小阈值,筛选出过短的评论:
```py
drug_dataset = drug_dataset.filter(lambda x: x["review_length"] > 30)
@@ -234,15 +235,15 @@ print(drug_dataset.num_rows)
{'train': 138514, 'test': 46108}
```
-如您所见,这已经从我们的原始训练和测试集中删除了大约 15% 的评论。
+如你所见,这个操作从我们的原始训练和测试集中删除了大约 15% 的评论。
-✏️ 试试看!使用 Dataset.sort() 函数查看单词数最多的评论。请参阅文档以了解您需要使用哪个参数按长度降序对评论进行排序。
+✏️ **试试看!**使用 `Dataset.sort()` 函数查看单词数最多的评论。你可以参阅 [文档](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) 了解如何按照评论的长度降序排序。
-我们需要处理的最后一件事是评论中是否存在 HTML 字符代码。我们可以使用 Python 的**html**模块取消这些字符的转义,如下所示:
+我们需要处理的最后一件事是处理评论中的 HTML 字符。我们可以使用 Python 的 `html` 模块来解码这些字符,如下所示:
```py
import html
@@ -255,19 +256,19 @@ html.unescape(text)
"I'm a transformer called BERT"
```
-我们将使用 **Dataset.map()** 对我们语料库中的所有 HTML 字符进行转义:
+我们将使用 `Dataset.map()` 对我们语料库中的所有 HTML 字符进行解码:
```python
drug_dataset = drug_dataset.map(lambda x: {"review": html.unescape(x["review"])})
```
-如您所见, **Dataset.map()** 方法对于处理数据非常有用——在示例中仅仅是浅尝辄止就有很大的收获!
+如你所见, `Dataset.map()` 方法对于处理数据非常有用,即使我们还没有完全了解它的所有功能!
-## map() 方法的超级加速 [[map() 方法的超级加速]]
+## `map()` 方法的超级加速 [[`map()` 方法的超级加速]]
-**Dataset.map()** 方法有一个 **batched** 参数,如果设置为 **True** , map 函数将会分批执行所需要进行的操作(批量大小是可配置的,但默认为 1,000)。例如,之前对所有 HTML 进行转义的 map 函数运行需要一些时间(您可以从进度条中读取所用时间)。我们可以通过使用列表推导同时处理多个元素来加快速度。
+`Dataset.map()` 方法有一个 `batched` 参数,如果设置为 `True` ,map 函数将会分批执行所需要进行的操作(批量大小是可配置的,但默认为 1,000)。例如,之前对所有 HTML 进行解码的 map 函数运行需要一些时间(你可以从进度条中看到所需的时间)。我们可以通过使用列表推导同时处理多个元素来加速。
-当您在使用 **Dataset.map()**函数时指定 **batched=True**。该函数会接收一个包含数据集字段的字典,每个值都是一个列表,而不仅仅是单个值。**Dataset.map()** 的返回值应该是相同的:一个包含我们想要更新或添加到数据集中的字段的字典,字典的键是要添加的字段,字典的值是结果的列表。例如,这是使用 **batched=True**对所有 HTML 字符进行转义的方法 :
+当你在使用 `Dataset.map()` 函数时设定 `batched=True` 。该函数需要接收一个包含数据集字段的字典,字典的值是一个列表。例如,这是使用 `batched=True` 对所有 HTML 字符进行解码的方法
```python
new_drug_dataset = drug_dataset.map(
@@ -275,9 +276,9 @@ new_drug_dataset = drug_dataset.map(
)
```
-如果您在笔记本中运行此代码,您会看到此命令的执行速度比前一个命令快得多。这不是因为我们的评论已经是处理过的——如果你重新执行上一节的指令(没有 **batched=True** ),它将花费与以前相同的时间。这是因为列表推导式通常比在同一代码中用 **for** 循环执行相同的代码更快,并且我们还通过同时访问多个元素而不是一个一个来处理来提高处理的速度。
+如果你在笔记本中运行此代码,你会看到此命令的执行速度比前一个命令快得多。这不是因为我们的评论已经是处理过的——如果你重新执行上一节的指令(没有 `batched=True` ),它将花费与之前相同的时间。这是因为列表推导式通常比在同一代码中用 `for` 循环执行相同的代码更快,并且我们还通过同时访问多个元素而不是一个一个来处理来提高处理的速度。
-在[第六章](/course/chapter6)我们将遇到的“快速”标记器,它可以快速标记大文本列表。使用 **Dataset.map()** 和 **batched=True** 是加速的关键。例如,要使用快速标记器标记所有药物评论,我们可以使用这样的函数:
+在 [第六章](/course/chapter6) 我们将遇到的“快速” tokenizer 它可以快速对长文本列表进行 tokenize。使用 `Dataset.map()` 搭配 `batched=True` 参数是加速的关键。例如,要使用快速 tokenizer 对所有药物评论 tokenize,我们可以使用如下的函数:
```python
from transformers import AutoTokenizer
@@ -289,32 +290,30 @@ def tokenize_function(examples):
return tokenizer(examples["review"], truncation=True)
```
-正如你在[第三章](/course/chapter3)所看到的,我们原本就可以将一个或多个示例传递给分词器,因此在**batched=True**是一个非必须的选项.让我们借此机会比较不同选项的性能。在笔记本中,您可以在您要测量的代码行之前添加 **%time**来测试改行运行所消耗的时间:
+正如我们在 [第三章](/course/chapter3) 所看到的,我们原本就可以将一个或多个示例传递给 tokenizer,因此在 `batched=True` 是一个非必须的选项。让我们借此机会比较不同选项的性能。在 notebook 中,你可以在你要测量的代码行之前添加 `%time` 来记录该行运行所消耗的时间:
```python no-format
%time tokenized_dataset = drug_dataset.map(tokenize_function, batched=True)
```
-您还可以通过将整个单元格计时 **%%time** 在单元格的开头。在我们执行此操作的硬件上,该指令显示 10.8 秒(这是写在“Wall time”之后的数字)。
+你也可以将 `%%time` 放置在单元格开头来统计整个单元格的执行时间。在我们的硬件上,该指令显示 10.8 秒(这就是真正(Wall time)的执行时间)。
-✏️ **试试看!** 使用和不使用 `batched=True` 执行相同的指令,然后使用慢速标记器尝试(在 `AutoTokenizer.from_pretrained()` 方法中添加 `use_fast=False`),这样你就可以看看在你的电脑上它需要多长的时间。
+✏️ **试试看!** 在有和无 `batched=True` 的情况下执行相同的指令,然后试试慢速 tokenizer (在 `AutoTokenizer.from_pretrained()` 方法中添加 `use_fast=False` ),这样你就可以测试一下在你的电脑上它需要多长的时间。
-以下是我们在使用和不使用批处理时使用快速和慢速分词器获得的结果:
+以下是我们在使用和不使用批处理时使用快速和慢速 tokenizer 获得的结果:
-Options | Fast tokenizer | Slow tokenizer
+选项 | 快速 tokenizer | 慢速 tokenizer
:--------------:|:--------------:|:-------------:
-`batched=True` | 10.8s | 4min41s
+`batched=True` | 10.8s | 4min41s
`batched=False` | 59.2s | 5min3s
-这意味着使用带有 **batched=True** 选项比没有批处理的慢选项快 30 倍——这真是太棒了!这就是为什么**AutoTokenizer** 的默认设置是**use_fast=True**的主要原因 (以及为什么它们被称为“快速”)。他们能够实现这样的加速,因为在底层的标记化代码是在 Rust 中执行的,Rust 是一种可以轻松并行化执行的语言。
-
-并行化也是快速标记器通过批处理实现近 6 倍加速的原因:单个标记化操作是不能并行的,但是当您想同时标记大量文本时,您可以将执行拆分为多个进程,每个进程都对自己的文本负责。
+这意味着使用快速 tokenizer 配合 `batched=True` 选项比没有批处理的慢速版本快 30 倍——这真的太 Amazing 了!这就是为什么在使用 `AutoTokenizer` 时,将会默认使用 `use_fast=True` 的主要原因 (以及为什么它们被称为“快速”的原因)。他们能够实现这样的加速,因为在底层的 tokenize 代码是在 Rust 中执行的,Rust 是一种可以易于并行化执行的语言。
-**Dataset.map()** 也有一些自己的并行化能力。由于它们不受 Rust 的支持,因此慢速分词器的速度赶不上快速分词器,但它们仍然会更快一些(尤其是当您使用没有快速版本的分词器时)。要启用多处理,请在**Dataset.map()**时使用 **num_proc** 参数并指定要在调用中使用的进程数 :
+并行化也是快速 tokenizer 通过批处理实现近 6 倍加速的原因:单个 tokenize 操作是不能并行的,但是当你想同时对大量文本进行 tokenize 时,你可以将执行过程拆分为多个进程,每个进程负责处理自己的文本。 `Dataset.map()` 也有一些自己的并行化能力。尽管它们没有 Rust 提供支持,但它们仍然可以帮助慢速 tokenizer 加速(尤其是当你使用的 tokenizer 没有快速版本时)。要启用多进程处理,请在调用 `Dataset.map()` 时使用 `num_proc` 参数并指定要在调用中使用的进程数
```py
slow_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
@@ -327,32 +326,32 @@ def slow_tokenize_function(examples):
tokenized_dataset = drug_dataset.map(slow_tokenize_function, batched=True, num_proc=8)
```
-您可以对处理的时间进行一些试验,以确定要使用的最佳进程数;在我们的例子中,8 似乎产生了最好的速度增益。以下是我们在使用和不使用多处理时所需要的时间:
+你可以对处理进行一些计时的试验,以确定最佳进程数;在我们的例子中,8 似乎产生了最好的速度增益。以下是我们在有无多进程处理的情况下,得到的结果:
-Options | Fast tokenizer | Slow tokenizer
-:--------------:|:--------------:|:-------------:
-`batched=True` | 10.8s | 4min41s
-`batched=False` | 59.2s | 5min3s
-`batched=True`, `num_proc=8` | 6.52s | 41.3s
-`batched=False`, `num_proc=8` | 9.49s | 45.2s
+选项 | 快速 tokenizer | 慢速 tokenizer
+:--------------:|:--------------:|:-------------:
+`batched=True` | 10.8s | 4min41s
+`batched=False` | 59.2s | 5min3s
+`batched=True` , `num_proc=8` | 6.52s | 41.3s
+`batched=False` , `num_proc=8` | 9.49s | 45.2s
-对于慢速分词器来说,这些结果要合理得多,但快速分词器的性能也得到了显着提高。但是请注意,情况并非总是如此——除了 **num_proc=8**,我们的测试表明,使用**batched=True**而不带有**num_proc**参数的选项处理起来更快。通常,我们不建议将 Python 多线程处理用于具有**batched=True**功能的快速标记器 .
+这个结果对于慢速分词器来说是更加友好了,但快速分词器的性能也得到了显著提升。但是请注意,情况并非总是如此—对于 `num_proc` 的其他值,在我们的测试中,使用 `batched=True` 而不带有 `num_proc` 参数的选项处理起来更快。总的来说,我们并不推荐在快速 tokenizer 和 `batched=True` 的情况下使用 Python 的多进程处理。
-使用num_proc以加快处理速度通常是一个好主意,只要您使用的函数还没有自己带有的进行某种多进程处理的方法。
+通常来说,使用 `num_proc` 以加快处理速度通常是一个好主意,只要你使用的函数本身没有进行某种类型的多进程处理。
-将所有这些功能浓缩到一个方法中已经非常了不起,但还有更多!使用 **Dataset.map()** 和 **batched=True** 您可以更改数据集中的元素数量。当你想从一个例子中创建几个训练特征时,这是非常有用的。我们将在[第七章](/course/chapter7).中进行的几个NLP任务的预处理中使用到这个功能,它非常便利。
+将所有这些功能浓缩到一个方法中已经非常了不起,但是还有更多!使用 `Dataset.map()` 和 `batched=True` 你可以更改数据集中的元素数量。当你想从一个样本中创建几个训练特征时,这是非常有用的。我们将在 [第七章](/course/chapter7) 中几个 NLP 任务的预处理中使用到这个功能,它非常便捷。
-💡在机器学习中,一个例子通常可以为我们的模型提供一组特征。在某些情况下,这些特征会储存在数据集的几个列,但在其他情况下(例如此处的例子和用于问答的数据),可以从单个示例的一列中提取多个特征
+💡在机器学习中,一个样本通常可以为我们的模型提供一组特征。在某些情况下,这组特征会储存在数据集的几个列,但在某些情况下(例如此处的例子和用于问答的数据),可以从单个样本的那一列中提取多个特征。
-让我们来看看它是如何工作的!在这里,我们将标记化我们的示例并将最大截断长度设置128,但我们将要求标记器返回全部文本块,而不仅仅是第一个。这可以用 **return_overflowing_tokens=True** :
+让我们来看看从一列中提取多个特征是如何实现的!在这里,我们将对我们的样本进行 tokenize 并将最大截断长度设置为 128,并且我们将要求 tokenizer 返回全部文本块,而不仅仅是第一个。这可以通过设置 `return_overflowing_tokens=True` 来实现:
```py
def tokenize_and_split(examples):
@@ -364,7 +363,7 @@ def tokenize_and_split(examples):
)
```
-在使用**Dataset.map()** 正式在整个数据集上开始处理之前让我们先在一个例子上测试一下:
+在使用 `Dataset.map()` 正式开始处理整个数据集之前,让我们先在一个样本上测试一下:
```py
result = tokenize_and_split(drug_dataset["train"][0])
@@ -375,7 +374,7 @@ result = tokenize_and_split(drug_dataset["train"][0])
[128, 49]
```
-瞧!我们在训练集中的第一个示例变成了两个特征,因为它被标记为超过我们指定的最大截断长度,因此结果被截成了两段:第一段长度为 128 ,第二段长度为 49 。现在让我们对所有元素执行此操作数据集!
+瞧!我们在训练集中的第一个样本变成了两个特征,因为它超过了我们指定的最大截断长度,因此被截成了两段:第一段长度为 128 第二段长度为 49 现在让我们对数据集的所有样本执行此操作!
```py
tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
@@ -385,9 +384,9 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-不好了!它没有起作用!为什么呢?查看错误消息会给我们一个线索:列的长度不匹配,一列长度为 1,463,另一列长度为 1,000。1,000行的"review"给出了 1,463 行的新特征,导致和原本的1000行数据不匹配。
+不好了!这并没有成功!为什么呢?查看错误消息会给我们一个线索:列的长度不匹配,一列长度为 1,463,另一列长度为 1,000。1,000 行的“重新”生成了 1,463 行的新特征,导致和原本的 1000 行的长度不匹配。
-问题出在我们试图混合两个不同大小的不同数据集: **drug_dataset** 列将有一定数量的元素(我们错误中的 1,000),但是我们正在构建**tokenized_dataset** 将有更多的元素(错误消息中的 1,463)。这不适用于 **Dataset** ,因此我们需要从旧数据集中删除列或使它们的大小与新数据集中的大小相同。我们可以用 **remove_columns** 参数:
+问题出在我们试图混合两个长度不同的数据集: `drug_dataset` 列将有 1000 个样本,但是我们正在构建 `tokenized_dataset` 列将有 1,463 个样本(因为我们使用 `return_overflowing_tokens=True` 将长评论分词成了多个样本)。这对 `Dataset` 来说不可行,所以我们需要要么删除旧数据集的列,要么使它们与新数据集中的尺寸相同。我们可以使用 `remove_columns` 参数来实现前者:
```py
tokenized_dataset = drug_dataset.map(
@@ -395,7 +394,7 @@ tokenized_dataset = drug_dataset.map(
)
```
-现在这个过程没有错误。我们可以通过比较长度来检查新数据集的元素是否比原始数据集多得多:
+现在这个过程没有错误。我们可以通过比较长度来检查我们的新数据集是否比原始数据集有更多的元素:
```py
len(tokenized_dataset["train"]), len(drug_dataset["train"])
@@ -405,7 +404,7 @@ len(tokenized_dataset["train"]), len(drug_dataset["train"])
(206772, 138514)
```
-我们提到我们还可以通过使旧列与新列的大小相同来处理长度不匹配的问题。为此,我们可以使用 **overflow_to_sample_mapping** 字段,当我们设置**return_overflowing_tokens=True** .它为我们提供了特征到它所产生的样本的映射。使用这个,我们可以将原始数据集中的每个键关联到一个合适大小的值列表中,通过遍历所有的数据来生成新特性:
+我们也可以通过使旧列与新列保持相同大小来处理不匹配长度的问题。为此,当我们设置 `return_overflowing_tokens=True` 时,可以使用 `overflow_to_sample_mapping` 字段。它给出了新特征索引到它源自的样本索引的映射。使用这个,我们可以将原始数据集中的每个键关联到一个合适大小的值列表中,通过遍历所有的数据来生成新特性:
```py
def tokenize_and_split(examples):
@@ -415,14 +414,14 @@ def tokenize_and_split(examples):
max_length=128,
return_overflowing_tokens=True,
)
- # Extract mapping between new and old indices
+ # 提取新旧索引之间的映射
sample_map = result.pop("overflow_to_sample_mapping")
for key, values in examples.items():
result[key] = [values[i] for i in sample_map]
return result
```
-我们可以使用**Dataset.map()**来进行批处理,这样无需我们删除旧列:
+可以看到它可以与 `Dataset.map()` 一起协作,无需我们删除旧列:
```py
tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
@@ -442,21 +441,21 @@ DatasetDict({
})
```
-我们获得了与以前相同数量的训练特征,但在这里我们保留了所有旧字段。如果您在使用模型计算之后需要它们进行一些后处理,您可能需要使用这种方法。
+我们获得了与之前数量相同的训练特征,并且在这里我们保留了所有旧字段。如果你在使用模型计算之后需要它们进行一些后续处理,你可能需要使用这种方法。
-您现在已经了解了 🤗 Datasets如何以各种方式用于预处理数据集。虽然🤗 Datasets 的处理功能会覆盖你大部分的模型训练需求,有时您可能需要切换到 Pandas 以使用更强大的功能,例如 **DataFrame.groupby()** 或用于可视化的高级 API。幸运的是,🤗 Datasets旨在与 Pandas、NumPy、PyTorch、TensorFlow 和 JAX 等库可以相互转换。让我们来看看这是如何工作的。
+你现在已经了解了如何使用 🤗 Datasets 以各种方式用于预处理数据集。虽然🤗 Datasets 的处理功能会覆盖你大部分的模型训练需求,有时你可能需要切换到 Pandas 以使用更强大的功能,例如 `DataFrame.groupby()` 或用于可视化的高级 API。幸运的是,🤗 Datasets 设计宗旨就是与 Pandas、NumPy、PyTorch、TensorFlow 和 JAX 等库可以相互转换。让我们来看看这是如何实现的。
-## `🤗 Datasets 和 DataFrames 的相互转换 [[`🤗 Datasets 和 DataFrames 的相互转换]]
+## 🤗 Datasets 和 DataFrames 的相互转换 [[ 🤗 Datasets 和 DataFrames 的相互转换]]
-为了实现各种第三方库之间的转换,🤗 Datasets 提供了一个 **Dataset.set_format()** 功能。此功能可以通过仅更改输出格式的,轻松切换到另一种格式,而不会影响底层数据格式,即 Apache Arrow。格式化会在数据本身上进行。为了演示,让我们将数据集转换为 Pandas:
+为了实现各种第三方库之间的转换,🤗 Datasets 提供了一个 `Dataset.set_format()` 函数。此函数可以通过仅更改输出格式的,轻松切换到另一种格式,而不会影响底层数据格式(以 Apache Arrow 方式进行存储)。为了演示,让我们把数据集转换为 Pandas:
```py
drug_dataset.set_format("pandas")
```
-现在,当我们访问数据集的元素时,我们会得到一个 **pandas.DataFrame** 而不是字典:
+现在,当我们访问数据集的元素时,我们会得到一个 `pandas.DataFrame` 而不是字典:
```py
drug_dataset["train"][:3]
@@ -482,7 +481,7 @@ drug_dataset["train"][:3]
95260 |
Guanfacine |
adhd |
- "My son is halfway through his fourth week of Intuniv..." |
+ "My son is halfway through his fourth week of Intuniv." |
8.0 |
April 27, 2010 |
192 |
@@ -493,7 +492,7 @@ drug_dataset["train"][:3]
92703 |
Lybrel |
birth control |
- "I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." |
+ "I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects." |
5.0 |
December 14, 2009 |
17 |
@@ -504,7 +503,7 @@ drug_dataset["train"][:3]
138000 |
Ortho Evra |
birth control |
- "This is my first time using any form of birth control..." |
+ "This is my first time using any form of birth control." |
8.0 |
November 3, 2015 |
10 |
@@ -513,7 +512,7 @@ drug_dataset["train"][:3]
-让我们创建一个 **pandas.DataFrame** 来选择 **drug_dataset[train]** 的所有元素:
+接下来我们从数据集中选择 `drug_dataset[train]` 的所有数据来得到训练集数据:
```py
train_df = drug_dataset["train"][:]
@@ -521,12 +520,12 @@ train_df = drug_dataset["train"][:]
-🚨 在底层,`Dataset.set_format()` 改变了数据集的 `__getitem__()` dunder 方法的返回格式。 这意味着当我们想从 `"pandas"` 格式的 `Dataset` 中创建像 `train_df` 这样的新对象时,我们需要对整个数据集进行切片以获得 `pandas.DataFrame`。 无论输出格式如何,您都可以自己验证 `drug_dataset["train"]` 的类型依然还是 `Dataset`。
+🚨 实际上, `Dataset.set_format()` 仅仅改变了数据集的 `__getitem__()` 方法的返回格式。这意味着当我们想从 `"pandas"` 格式的 `Dataset` 中创建像 `train_df` 这样的新对象时,我们需要对整个数据集进行切片([:])才可以获得 `pandas.DataFrame` 对象。无论输出格式如何,你都可以自己验证 `drug_dataset["train"]` 的类型依然还是 `Dataset` 。
-从这里我们可以使用我们想要的所有 Pandas 功能。例如,我们可以通过花式链接来计算 **condition**类之间的分布 :
+有了这个基础,我们可以使用我们想要的所有 Pandas 功能。例如,我们可以巧妙地链式操作,来计算 `condition` 列中不同类别的分布
```py
frequencies = (
@@ -577,7 +576,7 @@ frequencies.head()
-一旦我们完成了 Pandas 分析,我们总是通过使用对象 **Dataset.from_pandas()**方法可以创建一个新的 **Dataset** 如下:
+当我们完成了 Pandas 分析之后,我们可以使用对象 `Dataset.from_pandas()` 方法可以创建一个新的 `Dataset` 对象,如下所示:
```py
@@ -596,11 +595,11 @@ Dataset({
-✏️ **试试看!** 计算每种药物的平均评级并将结果存储在一个新的Dataset.
+✏️**试试看!**计算每种药物的平均评分并将结果存储在一个新的 Dataset 中。
-我们对 🤗 Datasets中可用的各种预处理技术的介绍到此结束。在最后一部分,让我们创建一个验证集来准备用于训练分类器的数据集。在此之前,我们将输出格式 **drug_dataset** 从 **pandas**重置到 **arrow** :
+到此为止,我们对🤗 Datasets 中可用的各种预处理技术的介绍就结束了。在本节的最后一部分,让我们为训练分类器创建一个验证集。在此之前,让我们将输出格式 `drug_dataset` 从 `pandas` 重置到 `arrow` :
```python
drug_dataset.reset_format()
@@ -608,15 +607,15 @@ drug_dataset.reset_format()
## 创建验证集 [[创建验证集]]
-尽管我们有一个可以用于评估的测试集,但在开发过程中保持测试集不变并创建一个单独的验证集是一个很好的做法。一旦您对模型在测试集上的表现感到满意,您就可以对验证集进行最终的检查。此过程有助于降低您过拟合测试集并部署在现实世界数据上失败的模型的风险。
+尽管我们有一个可以用于评估的测试集,但在开发过程中保持测试集不变并创建一个单独的验证集是一个很好的做法。一旦你对模型在测试集上的表现感到满意,你就可以使用验证集进行最终的检查。此过程有助于降低你过拟合测试集和部署在现实世界数据上失败的模型的风险。
-🤗 Datasets提供了一个基于**scikit-learn**的经典方法**Dataset.train_test_split()** .让我们用它把我们的训练集分成 **train** 和 **validation** (为了可以复现,我们将设置**seed**的值为一个常量):
+🤗 Datasets 提供了一个基于 `scikit-learn` 的经典方法: `Dataset.train_test_split()` 。让我们用它把我们的训练集分成 `train` 和 `validation` (为了可以复现,我们将设置 `seed` 的值为一个常量):
```py
drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42)
-# Rename the default "test" split to "validation"
+# 将默认的 "test" 部分重命名为 "validation"
drug_dataset_clean["validation"] = drug_dataset_clean.pop("test")
-# Add the "test" set to our `DatasetDict`
+# 将 "test" 部分添加到我们的 `DatasetDict` 中
drug_dataset_clean["test"] = drug_dataset["test"]
drug_dataset_clean
```
@@ -638,19 +637,19 @@ DatasetDict({
})
```
-太好了,我们现在已经准备好了一个数据集,可以用来训练一些模型了!在[第五节]](/course/chapter5/5)我们将向您展示如何将数据集上传到 Hugging Face Hub,但现在让我们查看在本地计算机上保存数据集的几种方法。
+太好了,我们现在已经准备好了一个适合训练模型的数据集了!在 [第五节](/course/chapter5/5) 我们将向你展示如何将数据集上传到 Hugging Face Hub,现在让我们先结束我们的分析,看一看在本地计算机上保存数据集的几种方法。
## 保存数据集 [[保存数据集]]
-虽然 🤗 Datasets 会缓存每个下载的数据集和对它执行的操作,但有时你会想要将数据集保存到磁盘(例如,以防缓存被删除)。如下表所示,🤗 Datasets 提供了三个主要功能来以不同的格式保存您的数据集:
+虽然 🤗 Datasets 会缓存每个下载的数据集和对它执行的操作,但有时你会想要将数据集保存到磁盘(比如,以防缓存被删除)。如下表所示,🤗 Datasets 提供了三个主要函数来以不同的格式保存你的数据集:
| 数据格式 | 对应的方法 |
| :---------: | :--------------------: |
| Arrow | `Dataset.save_to_disk()` |
-| CSV | `Dataset.to_csv()` |
-| JSON | `Dataset.to_json()` |
+| CSV | `Dataset.to_csv()` |
+| JSON | `Dataset.to_json()` |
例如,让我们以 Arrow 格式保存我们清洗过的数据集:
@@ -679,9 +678,9 @@ drug-reviews/
└── state.json
```
-在那里我们可以看到每个部分.arrow表,以及一些元数据数据集信息.json和状态文件保存在一起.您可以将 Arrow 格式视为一个精美的列和行的表格,它针对构建处理和传输大型数据集的高性能应用程序进行了优化。
+其中,我们可以看到,每个部分都有 `dataset.arrow` 表,以及保存元数据的 `dataset_info.json` 和 `state.json` 。你可以将 Arrow 格式视为一个优化过的列和行的精美表格,它针对构建处理和传输大型数据集的高性能应用程序进行了优化。
-保存数据集后,我们可以使用 **load_from_disk()** 功能从磁盘读取数据如下:
+保存数据集后,我们可以使用 `load_from_disk()` 功能从磁盘读取数据:
```py
from datasets import load_from_disk
@@ -707,14 +706,14 @@ DatasetDict({
})
```
-对于 CSV 和 JSON 格式,我们必须将每个部分存储为单独的文件。一种方法是迭代**DatasetDict**中的键和值 :
+对于 CSV 和 JSON 格式,我们必须将每个部分存储为单独的文件。一种方法是遍历 `DatasetDict` 中的键和值
```py
for split, dataset in drug_dataset_clean.items():
dataset.to_json(f"drug-reviews-{split}.jsonl")
```
-这将保存每个拆分都是[JSON的标准格式](https://jsonlines.org),其中数据集中的每一行都存储为一行 JSON。这是第一个示例:
+这将把每个部分保存为 [JSON Lines格式](https://jsonlines.org) ,其中数据集中的每一行都存储为一行 JSON。下面是第一个例子的样子:
```py
!head -n 1 drug-reviews-train.jsonl
@@ -724,7 +723,7 @@ for split, dataset in drug_dataset_clean.items():
{"patient_id":141780,"drugName":"Escitalopram","condition":"depression","review":"\"I seemed to experience the regular side effects of LEXAPRO, insomnia, low sex drive, sleepiness during the day. I am taking it at night because my doctor said if it made me tired to take it at night. I assumed it would and started out taking it at night. Strange dreams, some pleasant. I was diagnosed with fibromyalgia. Seems to be helping with the pain. Have had anxiety and depression in my family, and have tried quite a few other medications that haven't worked. Only have been on it for two weeks but feel more positive in my mind, want to accomplish more in my life. Hopefully the side effects will dwindle away, worth it to stick with it from hearing others responses. Great medication.\"","rating":9.0,"date":"May 29, 2011","usefulCount":10,"review_length":125}
```
-然后我们可以使用[第二节](/course/chapter5/2)学过的技术加载 JSON 文件如下:
+然后我们可以使用 [第二节](/course/chapter5/2) 中的技巧,按如下所示加载 JSON 文件
```py
data_files = {
@@ -735,9 +734,9 @@ data_files = {
drug_dataset_reloaded = load_dataset("json", data_files=data_files)
```
-这就是我们探索 🤗 Datasets 的旅程!现在我们有了一个清洗过的数据集,以下是您可以尝试的一些想法:
+至此,我们对使用🤗 Datasets 进行数据整理的探索就此结束!现在我们有了一个清洗过的数据集,以下是你可以尝试的一些想法:
-1. 使用[第3章](/course/chapter3)的技术来训练一个分类器,它可以根据药物评论预测病人的情况。
-2. 使用 [Chapter 1](/course/chapter1) 中的“summarization”管道生成评论摘要。
+1. 使用 [第三章](/course/chapter3) 的技术来训练一个分类器,它能够基于药品评价预测患者的病情。
+2. 使用 [第一章](/course/chapter1) 中的 `summarization` 管道生成评论的摘要。
-接下来,我们将看看 🤗 Datasets如何使您能够在不撑爆笔记本电脑内存的情况下处理庞大的数据集!
\ No newline at end of file
+接下来,我们将看看 🤗 Datasets 如何使你能够在不撑爆笔记本电脑内存的情况下处理庞大的数据集!
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter5/4.mdx b/chapters/zh-CN/chapter5/4.mdx
index bf34117ff..8625c67ae 100644
--- a/chapters/zh-CN/chapter5/4.mdx
+++ b/chapters/zh-CN/chapter5/4.mdx
@@ -1,4 +1,4 @@
-# 大数据? 🤗 Datasets 来救援! [[大数据? 🤗 Datasets 来救援!]]
+# 大数据?🤗 Datasets 应对有方![[大数据?🤗 Datasets 应对有方!]]
-如今,不难发现我们经常使用数GB的数据集, 特别是如果你打算从头开始预训练像 BERT 或者 GPT-2 这样的转换器。 在这种情况下, _加载_ 数据集就是一个挑战。例如, 用于预训练 GPT-2 的 WebText 语料库包含超过 800 万个文档和 40 GB 的文本 -- 将其加载到笔记本电脑的 RAM 中可能会让它抓狂!
+如今,处理 GB 级别的数据集已不再罕见,特别是如果你打算从头开始预训练像 BERT 或者 GPT-2 这样的 Transormer 模型。在这种情况下,甚至 `加载(load)` 数据集都可能成为挑战。例如,用于预训练 GPT-2 的 WebText 语料库包含超过 800 万个文档和 40 GB 的文本 —— 将其加载到笔记本电脑的 RAM 中都可能会让人抓狂!
-幸运的是, 🤗 Datasets 旨在克服这些限制。它通过将数据集作为内存映射文件来处理,并通过在语料库中流化条目来摆脱硬盘限制, 从而使你避免内存管理问题。
+幸运的是,🤗 Datasets 的设计旨在克服这些限制。它通过将数据集作为 `内存映射(memory-mapped)` 文件来处理,解放内存管理问题;并通过 `流式处理(streaming)` 来摆脱硬盘限制。
-在本节中, 我们将探索🤗 Datasets 的特性。它有一个称为 [the Pile](https://pile.eleuther.ai)的825 GB的语料库。 让我们开始吧!
+在本节中,我们将使用一个庞大的 825 GB 语料库——被称为 [the Pile](https://pile.eleuther.ai) 的数据集,来探索🤗 Datasets 的这些功能。让我们开始吧!
-## 什么是Pile? [[什么是Pile?]]
+## 什么是 the Pile?[[什么是 the Pile?]]
-The Pile 是由[EleutherAI](https://www.eleuther.ai)创建的一个英语文本语料库, 用于训练大规模语言模型。它包含各种各样的数据集, 涵盖科学文章, GitHub 代码库以及过滤的Web文本。训练语料库在[14 GB chunks](https://the-eye.eu/public/AI/pile/), 并且你也可以下载几个[单独的组件](https://the-eye.eu/public/AI/pile_preliminary_components/)。 让我们先来看看 PubMed Abstracts 数据集, 它是[PubMed](https://pubmed.ncbi.nlm.nih.gov/)上的1500万篇生物医学出版物的摘要的语料库。 数据集采用[JSON行格式](https://jsonlines.org) 并使用`zstandard`库进行压缩, 所以我们首先需要先安装`zstandard`库:
+The Pile 是由 [EleutherAI](https://www.eleuther.ai) 创建的一个用于训练大规模语言模型的英语文本语料库。它包含各种各样的数据集,涵盖科学文章,GitHub 代码库以及过滤后的 Web 文本。训练语料库以 [14 GB 的文件块](https://the-eye.eu/public/AI/pile/) 提供,并且你也可以下载几个 [单独的组件](https://the-eye.eu/public/AI/pile_preliminary_components/) 。让我们先来看看 PubMed Abstracts 部分,它是 [PubMed](https://pubmed.ncbi.nlm.nih.gov/) 上的 1500 万篇生物医学出版物的摘要的语料库。数据集采用 [JSON Lines格式](https://jsonlines.org) 并使用 `zstandard` 库进行压缩,所以我们首先需要先安装 `zstandard` 库:
```py
!pip install zstandard
```
-接下来, 我们可以使用[第二节](/course/chapter5/2)中所学的加载远程数据集的方法加载数据集:
+接下来,我们可以使用 [第二节](/course/chapter5/2) 中所学的加载远程数据集的方法加载数据集:
```py
from datasets import load_dataset
-# This takes a few minutes to run, so go grab a tea or coffee while you wait :)
+# 这需要几分钟才能运行,所以在你等待的时候去喝杯茶或咖啡 :)
data_files = "https://the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst"
pubmed_dataset = load_dataset("json", data_files=data_files, split="train")
pubmed_dataset
@@ -42,15 +42,15 @@ Dataset({
})
```
-我们可以看到我们的数据集中有 15,518,009 行和 2 列 -- 这是非常多的!
+我们可以看到我们的数据集中有 15,518,009 行和 2 列 —— 如此庞大!
-✎ 默认情况下, 🤗 Datasets 会自动解压加载数据集所需的文件。 如果你想保留硬盘空间, 你可以传递 `DownloadConfig(delete_extracted=True)` 到 `download_config` 的 `load_dataset()`参数. 有关更多详细信息, 请参阅文档](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig)。
+✏️ 默认情况下,🤗 Datasets 会自动解压加载数据集所需的文件。如果你想保留硬盘空间,你可以把 `DownloadConfig(delete_extracted=True)` 传递给 `load_dataset()` 的 `download_config` 参数。更多详细信息,请参阅 [文档](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig) 。
-让我们看看数据集的第一个元素的内容:
+让我们看看数据集的第一个元素的内容:
```py
pubmed_dataset[0]
@@ -61,53 +61,53 @@ pubmed_dataset[0]
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
```
-可以看到, 这看起来像是医学文章的摘要。 现在让我们看看我们使用了RAM的多少存储空间来加载数据集!
+可以看到,这看起来像是医学文章的摘要。现在,让我们看看加载数据集所使用的 RAM!
## 内存映射的魔力 [[内存映射的魔力]]
-在 Python 中测量内存使用情况的一个简单的方法是使用[`psutil`](https://psutil.readthedocs.io/en/latest/)库,它可以使用 `pip`安装, 如下所示:
+测量 Python 内存使用的简单方式是使用 [`psutil`](https://psutil.readthedocs.io/en/latest/) 库,可以通过如下方式安装:
```python
!pip install psutil
```
-它提供了一个 `Process` 类,这个类允许我们检查当前进程的内存使用情况, 如下所示:
+它提供了一个 `Process` 类,让我们可以检查当前进程的内存使用情况,如下所示:
```py
import psutil
-# Process.memory_info is expressed in bytes, so convert to megabytes
-print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
+# Process.memory_info 是以字节为单位的,所以转换为兆字节
+print(f"使用的RAM:{psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
```
```python out
RAM used: 5678.33 MB
```
-这里的`rss`属性是指 _常驻集_ 的大小, 它是进程在RAM中占用的内存比例。 这个测量结果也包括了 Python 编译器和我们加载的库所使用的内存, 所以实际上用于加载数据集的内存会更小一些。为了比较, 让我们使用 `dataset_size` 属性看看数据集在磁盘上有多大。 由于结果像之前一样用字节表示, 我们需要手动将其转换为GB:
+这里的 `rss` 属性是指 `常驻集(resident set size)` 的大小,它是进程在 RAM 中占用的内存的部分。这个测量结果也包括了 Python 解释器和我们加载的库所使用的内存,所以实际上用于加载数据集的内存会更小一些。作为比较,让我们使用 `dataset_size` 属性看看数据集在磁盘上上的大小。由于结果像之前一样以字节为单位,我们需要手动将其转换为 GB:
```py
-print(f"Number of files in dataset : {pubmed_dataset.dataset_size}")
+print(f"数据集中文件的数量 : {pubmed_dataset.dataset_size}")
size_gb = pubmed_dataset.dataset_size / (1024**3)
-print(f"Dataset size (cache file) : {size_gb:.2f} GB")
+print(f"数据集大小 (缓存文件) : {size_gb:.2f} GB")
```
```python out
-Number of files in dataset : 20979437051
-Dataset size (cache file) : 19.54 GB
+数据集中文件的数量 : 20979437051
+数据集大小 (缓存文件) : 19.54 GB
```
-非常棒 -- 尽管它将近20GB, 但我们能够占用很少的RAM空间加载和访问数据集!
+令人欣喜的是——尽管它将近 20GB 之大,我们却能用远小于此的 RAM 加载和访问数据集!
-✏️ **试试看!** 从[subsets](https://the-eye.eu/public/AI/pile_preliminary_components/)中选择一个大于你的笔记本或者台式机的RAM大小的子集, 用 🤗 Datasets加载这个数据集, 并且测量RAM的使用量。 请注意, 要获得准确的测量结果, 你需要在另一个进程中执行这个操作。你可以在 [the Pile paper](https://arxiv.org/abs/2101.00027)的表一中找到每个子集解压后的大小。
+✏️ **试试看!** 从 Pile 选择一个比你的笔记本电脑或台式机的 RAM 更大的 [子集](https://the-eye.eu/public/AI/pile_preliminary_components/) ,用 🤗 Datasets 加载这个数据集,并且测量 RAM 的使用量。请注意,为了获得准确的测量结果,你需要新开一个进程执行这个操作。你可以在 [the Pile paper](https://arxiv.org/abs/2101.00027) 的表 1 中找到每个子集解压后的大小。
-如果你熟悉 Pandas, 这个结果可能会让人感到很意外。因为 Wes Kinney 的著名的[经验法则](https://wesmckinney.com/blog/apache-arrow-pandas-internals/) 是你需要的RAM应该是数据集的大小的5倍到10倍。 那么 🤗 Datasets 是如何解决这个内存管理问题的呢? 🤗 Datasets 将每一个数据集看作一个[内存映射文件](https://en.wikipedia.org/wiki/Memory-mapped_file), 它提供了RAM和文件系统存储之间的映射, 该映射允许库访问和操作数据集的元素, 而且无需将其完全加载到内存中。
+如果你熟悉 Pandas,这个结果可能会让人感到很惊奇。因为根据 Wes Kinney 的著名的 [经验法则](https://wesmckinney.com/blog/apache-arrow-pandas-internals/) ,你通常需要 5 到 10 倍于你数据集大小的 RAM。那么 🤗 Datasets 是如何解决这个内存管理问题的呢?🤗 Datasets 将每一个数据集看作一个 [内存映射文件](https://en.wikipedia.org/wiki/Memory-mapped_file) ,它提供了 RAM 和文件系统存储之间的映射,该映射允许 Datasets 库无需将其完全加载到内存中即可访问和操作数据集的元素。
-内存映射文件也一个在多个进程之间共享, 这使得像 `Dataset.map()`之类的方法可以并行化, 并且无需移动或者赋值数据集。在底层, 这些功能都是由[Apache Arrow](https://arrow.apache.org)内存格式和[`pyarrow`](https://arrow.apache.org/docs/python/index.html)库提供的支持, 使得数据加载和处理速度快如闪电。 (更多有关Apache Arrow的详细信息以及与Pandas的比较, 请查看[Dejan Simic's blog post](https://towardsdatascience.com/apache-arrow-read-dataframe-with-zero-memory-69634092b1a).) 为了更清晰地看到这个过程, 让我们通过迭代PubMed Abstracts数据集中的所有元素来运行一个速度测试小程序:
+内存映射文件也一个在多个进程之间共享,这使得像 `Dataset.map()` 之类的方法可以在无需移动或者复制数据集的情况下实现并行化。在底层,这些功能都是由 [Apache Arrow](https://arrow.apache.org) 内存格式和 [`pyarrow`](https://arrow.apache.org/docs/python/index.html) 库实现的,这使得数据加载和处理速度快如闪电。(更多有关 Apache Arrow 的详细信息以及与 Pandas 的比较,请查看 [Dejan Simic的博客文章](https://towardsdatascience.com/apache-arrow-read-dataframe-with-zero-memory-69634092b1a) 。) 为了更清晰地看到这个过程,让我们通过遍历 PubMed 摘要数据集中的所有元素,运行一个小速度测试:
```py
import timeit
@@ -120,26 +120,25 @@ for idx in range(0, len(pubmed_dataset), batch_size):
time = timeit.timeit(stmt=code_snippet, number=1, globals=globals())
print(
- f"Iterated over {len(pubmed_dataset)} examples (about {size_gb:.1f} GB) in "
- f"{time:.1f}s, i.e. {size_gb/time:.3f} GB/s"
+ f"在 {time:.1f}s 内遍历了 {len(pubmed_dataset)}个示例(约 {size_gb:.1f} GB),即 {size_gb/time:.3f} GB/s"
)
```
```python out
-'Iterated over 15518009 examples (about 19.5 GB) in 64.2s, i.e. 0.304 GB/s'
+'在64.2s内遍历了15518009个示例(约19.5 GB),即0.304 GB/s'
```
-这里我们使用了 Python的 `timeit` 模块来测量执行 `code_snippet`所耗的时间。 你通常能以十分之几GB/s到几GB/s的速度迭代数据集。通过上述的方法就已经能够解决大多数大数据集加载的限制, 但是有时候你不得不使用一个很大的数据集, 它甚至都不能存储在笔记本电脑的硬盘上。例如, 如果我们尝试下载整个 Pile, 我们需要825GB的可用磁盘空间! 为了处理这种情况, 🤗 Datasets 提供了一个流式功能, 这个功能允许我们动态下载和访问元素, 并且不需要下载整个数据集。让我们来看看这个功能是如何工作的。
+这里我们使用了 Python 的 `timeit` 模块来测量执行 `code_snippet` 所耗的时间。你通常能以十分之几 GB/s 到几 GB/s 的速度遍历一个数据集。通过上述的方法就已经能够解决大多数大数据集加载的限制,但是有时候你不得不使用一个很大的数据集,它甚至都不能存储在笔记本电脑的硬盘上。例如,如果我们尝试下载整个 Pile,我们需要 825GB 的可用磁盘空间!为了处理这种情况,🤗 Datasets 提供了一个流式功能,这个功能允许我们动态下载和访问元素,并且不需要下载整个数据集。让我们来看看这个功能是如何工作的。
-💡在 Jupyter 笔记中你还可以使用[`%%timeit` magic function](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-timeit)为单元格计时。
+💡在 Jupyter 笔记中你还可以使用 [`%%timeit` 魔术函数](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-timeit) 为整个单元格计时。
## 流式数据集 [[流式数据集]]
-要使用数据集流, 你只需要将 `streaming=True` 参数传递给 `load_dataset()` 函数。接下来, 让我们再次加载 PubMed Abstracts 数据集, 但是采用流模式:
+要使用数据集流,你只需要将 `streaming=True` 参数传递给 `load_dataset()` 函数。接下来,让我们以流模式加载 PubMed 摘要数据集:
```py
pubmed_dataset_streamed = load_dataset(
@@ -147,7 +146,7 @@ pubmed_dataset_streamed = load_dataset(
)
```
-与我们在本章其他地方遇到的熟悉的 `Dataset` 不同, `streaming=True` 返回的对象是一个 `IterableDataset`。 顾名思义, 要访问 `IterableDataset` , 我们需要迭代它。我们可以按照如下方式访问流式数据集的第一个元素:
+不同于我们在这一章其它地方遇到的熟悉的 `Dataset` , `streaming=True` 返回的对象是一个 `IterableDataset` 。顾名思义,要访问 `IterableDataset` ,我们需要迭代它。我们可以按照如下方式访问流式数据集的第一个元素:
```py
@@ -159,7 +158,7 @@ next(iter(pubmed_dataset_streamed))
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
```
-如果您需要在训练期间标记流式数据集中的元素可以使用 `IterableDataset.map()`进行动态处理。该过程与我们在[第三章](/course/chapter3)中标记数据集的过程完全相同, 唯一的区别是输出是逐个返回的:
+如果你需要在训练期间对流式数据集中的元素 tokenize,可以使用 `IterableDataset.map()` 进行在线处理,而不需要等待数据集全部加载完毕。该过程与我们在 [第三章](/course/chapter3) 中对数据集 tokenize 的过程完全相同,唯一的区别是输出是逐个返回的:
```py
from transformers import AutoTokenizer
@@ -175,11 +174,11 @@ next(iter(tokenized_dataset))
-💡 你可以传递 `batched=True` 来通过流式加速标记化, 如同我们在上一节看到的那样。它将逐批处理示例; 默认的批量大小为 1,000, 可以使用 `batch_size` 参数指定批量大小。
+💡 为了加速流式的 tokenize,你可以传递 `batched=True` ,就像我们在上一节看到的那样。它会批量处理示例;默认的批大小是 1000,可以通过 `batch_size` 参数指定批量大小。
-你还可以使用 `IterableDataset.shuffle()` 打乱流式数据集, 但与 `Dataset.shuffle()` 不同的是这只会打乱预定义 `buffer_size` 中的元素:
+你还可以使用 `IterableDataset.shuffle()` 打乱流式数据集,但与 `Dataset.shuffle()` 不同的是这只会打乱预定义 `buffer_size` 中的元素:
```py
shuffled_dataset = pubmed_dataset_streamed.shuffle(buffer_size=10_000, seed=42)
@@ -191,7 +190,7 @@ next(iter(shuffled_dataset))
'text': 'Randomized study of dose or schedule modification of granulocyte colony-stimulating factor in platinum-based chemotherapy for elderly patients with lung cancer ...'}
```
-在这个示例中, 我们从缓冲区的前 10,000 个示例中随机选择了一个示例。一旦访问了一个示例, 它在缓冲区中的位置就会被语料库中的下一个示例填充 (即, 上述案例中的第 10,001个示例)。你还可以使用 `IterableDataset.take()` 和 `IterableDataset.skip()` 函数从流式数据集中选择元素, 它的作用类似于 `Dataset.select()`。例如, 要选择 PubMed Abstracts 数据集的前5个示例, 我们可以执行以下操作:
+在这个例子中,我们从缓冲区的前 10,000 个示例中随机选择了一个示例。一旦访问了一个示例,它在缓冲区中的位置就会被语料库中的下一个示例填充 (即,上述案例中的第 10,001 个示例)。你还可以使用 `IterableDataset.take()` 和 `IterableDataset.skip()` 函数从流式数据集中选择元素,它的作用类似于 `Dataset.select()` 。例如,要选择 PubMed Abstracts 数据集的前 5 个示例,我们可以执行以下代码:
```py
dataset_head = pubmed_dataset_streamed.take(5)
@@ -211,16 +210,16 @@ list(dataset_head)
'text': 'Oxygen supply in rural africa: a personal experience ...'}]
```
-同样, 你可以使用 `IterableDataset.skip()` 函数将打乱的数据集拆分为训练集和验证集, 如下所示:
+同样,你可以使用 `IterableDataset.skip()` 函数从打乱的数据集中创建训练集和验证集,如下所示:
```py
-# Skip the first 1,000 examples and include the rest in the training set
+# 跳过前 1,000 个示例 ,将其余部分创建为训练集
train_dataset = shuffled_dataset.skip(1000)
-# Take the first 1,000 examples for the validation set
+# 将前 1,000 个示例用于验证集
validation_dataset = shuffled_dataset.take(1000)
```
-让我们用一个常见的任务来进行我们对数据集流的最后探索: 将多个数据集组合在一起创建一个心得语料库。 🤗 Datasets 提供了一个 `interleave_datasets()` 函数, 它将一个 `IterableDataset` 对象列表组合为单个的 `IterableDataset`, 其中新数据集的元素是通过在列表中的对象交替获得的。当你试图组合大型数据集时, 这个函数特别有用, 让我们通过下面这个例子来试着组合 Pile的自由法律数据集,它是来自美国法院的51 GB的法律意见数据集:
+让我们用一个常见的任务来进行我们对数据集流的最后探索:将多个数据集组合在一起创建一个新的语料库。🤗 Datasets 提供了一个 `interleave_datasets()` 函数,它将一个 `IterableDataset` 对象列表组合为单个的 `IterableDataset` ,其中新数据集的元素是交替抽取列表中的数据集获得的。当你试图组合大型数据集时,这个函数特别有用,让我们通过下面这个例子来试着组合 Pile 的 FreeLaw 数据集,这是一个包含美国法院法律意见的 51 GB 数据集:
```py
law_dataset_streamed = load_dataset(
@@ -239,7 +238,7 @@ next(iter(law_dataset_streamed))
'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}
```
-这个数据集足够大, 可以对大多数笔记本电脑的RAM有足够的压力, 但是我们已经能够毫不费力地加载和访问它! 现在我们使用 `interleave_datasets()` 函数加载来自 FreeLaw 和 PubMed Abstracts 的数据集:
+这个数据集足够大,可以对大多数笔记本电脑的 RAM 有足够的压力,但是我们已经能够毫不费力地加载和访问它!现在我们使用 `interleave_datasets()` 函数将 FreeLaw 和 PubMed Abstracts 数据集的样本整合在一起:
```py
from itertools import islice
@@ -258,9 +257,9 @@ list(islice(combined_dataset, 2))
'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}]
```
-这里我们使用了来自Python的 `itertools` 模块的 `islice()` 函数从合并的数据集中选择前两个示例, 并且我们可以看到它们实际上就是两个源数据集中的前两个示例拼在一起形成的:
+这里我们使用了来自 Python 的 `itertools` 模块的 `islice()` 函数从合并的数据集中选择前两个示例,并且我们可以看到它们实际上就是两个源数据集中的前两个示例拼在一起形成的:
-最后, 如果你想流式传输整个825GB的 Pile, 你可以按照如下方式获取所有准备好的文件:
+最后,如果你想流式传输整个 825GB 的 Pile,你可以按照如下方式获取所有的预处理文件:
```py
base_url = "https://the-eye.eu/public/AI/pile/"
@@ -280,8 +279,8 @@ next(iter(pile_dataset["train"]))
-✏️ **试试看!** 使用像[`mc4`](https://huggingface.co/datasets/mc4) 或者 [`oscar`](https://huggingface.co/datasets/oscar)这样的大型 Common Crawl 语料库来创建一个流式多语言数据集, 该数据集代表你选择的国家/地区语言的口语比例。例如, 瑞士的四种民族语言分别是德语、法语、意大利语和罗曼什语, 因此你可以尝试根据根据口语比例对Oscar子集进行采用来创建瑞士语料库。
+✏️ **试试看!** 使用像 [`mc4`](https://huggingface.co/datasets/mc4) 或者 [`oscar`](https://huggingface.co/datasets/oscar) 这样的大型 Common Crawl 语料库来创建一个流式多语言数据集,该数据集代表你选择的国家/地区语言的口语比例。例如,瑞士的四种民族语言分别是德语、法语、意大利语和罗曼什语,因此你可以尝试根据根据口语比例对 Oscar 子集进行抽样来创建一个瑞士语料库。
-你现在拥有加载和处理各种类型和大小的数据集的所需的所有工具 -- 但是除非你非常幸运, 否则在你的NLP之旅中会有一个难题, 你将不得不创建一个数据集来解决手头的问题。这就是下一节的主题!
+你现在拥有加载和处理各种类型和大小的数据集的所需的所有工具 —— 但是除非你非常幸运,否则在你的 NLP 之旅中会有一个难题,你将不得不亲自创建一个数据集来解决手头的问题。这就是我们接下来要讨论的主题!
diff --git a/chapters/zh-CN/chapter5/5.mdx b/chapters/zh-CN/chapter5/5.mdx
index f6454f914..c3f203a11 100644
--- a/chapters/zh-CN/chapter5/5.mdx
+++ b/chapters/zh-CN/chapter5/5.mdx
@@ -7,36 +7,36 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/zh-CN/chapter5/section5.ipynb"},
]} />
-有时,不存在合适的数据集适用于您构建 NLP 应用,因此您需要自己创建。在本节中,我们将向您展示如何创建一个[GitHub issues](https://github.com/features/issues/)的语料库,GitHub issues通常用于跟踪 GitHub 存储库中的错误或功能。该语料库可用于各种目的,包括:
-* 探索关闭未解决的issue或拉取请求需要多长时间
-* 训练一个*多标签分类器*可以根据issue的描述(例如,“错误”、“增强”或“issue”)用元数据标记issue
-* 创建语义搜索引擎以查找与用户查询匹配的issue
+有时,不存在现有的合适的数据集适用于你构建 NLP 应用,因此你需要自己创建。在本节中,我们将向你展示如何创建一个由 [GitHub issues](https://github.com/features/issues/) 组成的的语料库,这些 issues 通常用于跟踪 GitHub 仓库中的错误或功能。该语料库可用于各种应用场景,包括:
+* 探索解决 issue 或合并 pull 请求需要多长时间
+* 训练一个 `多标签分类器(multilabel classifier)` 可以根据 issue 的描述为 issue 标上元数据标签(例如,“bug”、“enhancement(增强功能)”或“question”)
+* 创建语义搜索引擎以查找与用户查询匹配的 issue
-在这里,我们将专注于创建语料库,在下一节中,我们将探索语义搜索。我们将使用与流行的开源项目相关的 GitHub issue:🤗 Datasets!接下来让我们看看如何获取数据并探索这些issue中包含的信息。
+在这里,我们将关注如何创建语料库,在下一节中,我们将探索语义搜索。原汤化原食,我们将使用一个流行的开源项目的 GitHub issue:🤗 Datasets!接下来让我们看看如何获取数据并探索这些 issue 中包含的信息。
## 获取数据 [[获取数据]]
-您可以浏览 🤗 Datasets 中的所有issue[Issues tab](https://github.com/huggingface/datasets/issues).如以下屏幕截图所示,在撰写本文时,有 331 个未解决的issue和 668 个已关闭的issue。
+你可以点击 [Issues 选项卡](https://github.com/huggingface/datasets/issues) 浏览 🤗 Datasets 中的所有 issus。如以下屏幕截图所示,在撰写本文时,有 331 个未解决的 issue 和 668 个已关闭的 issue。
-如果您单击其中一个issue,您会发现它包含一个标题、一个描述和一组表征该issue的标签。下面的屏幕截图显示了一个示例.
+如果你单击其中一个 issue,你会发现它包含一个标题、一个描述和一组标签,这些标签是对 issue 的描述。下面的屏幕截图显示了一个示例:
-要下载所有存储库的issue,我们将使用[GitHub REST API](https://docs.github.com/en/rest)投票[Issues endpoint](https://docs.github.com/en/rest/reference/issues#list-repository-issues).此节点返回一个 JSON 对象列表,每个对象包含大量字段,其中包括标题和描述以及有关issue状态的元数据等。
+我们可以使用 [GitHub REST API](https://docs.github.com/en/rest) 遍历 [Issues 节点(endpoint)](https://docs.github.com/en/rest/reference/issues#list-repository-issues) 下载所有仓库的 issue。节点(endpoint)将返回一个 JSON 对象列表,每个对象包含大量字段,其中包括标题和描述以及有关 issue 状态的元数据等。
-下载issue的一种便捷方式是通过 **requests** 库,这是用 Python 中发出 HTTP 请求的标准方式。您可以通过运行以下的代码来安装库:
+我们将使用 `requests` 库来下载,这是用 Python 中发出 HTTP 请求的标准方式。你可以通过运行以下的代码来安装 `requests` 库:
```python
!pip install requests
```
-安装库后,您通过调用 **requests.get()** 功能来获取**Issues**节点。例如,您可以运行以下命令来获取第一页上的第一个Issues:
+安装库后,你通过调用 `requests.get()` 功能来获取 `Issues` 节点(endpoint)。例如,你可以运行以下命令来获取第一页上的第一个 Issues:
```py
import requests
@@ -45,7 +45,7 @@ url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=
response = requests.get(url)
```
-这 **response** 对象包含很多关于请求的有用信息,包括 HTTP 状态码:
+`response` 对象包含很多关于请求的有用信息,包括 HTTP 状态码:
```py
response.status_code
@@ -55,7 +55,7 @@ response.status_code
200
```
-其中一个状态码 **200** 表示请求成功(您可以[在这里](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes)找到可能的 HTTP 状态代码列表)。然而,我们真正感兴趣的是有效的信息,由于我们知道我们的issues是 JSON 格式,让我们按如下方式查看所有的信息:
+其中, `200` 状态表示请求成功(你可以在 [这里](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes) 找到所有可能的 HTTP 状态代码列表)。不过,我们真正感兴趣的是消息体中的有效信息,由于我们知道我们的 issues 是 JSON 格式,让我们按如下方式查看消息体的信息:
```py
response.json()
@@ -110,27 +110,28 @@ response.json()
'performed_via_github_app': None}]
```
-哇,这是很多信息!我们可以看到有用的字段,例如 **标题** , **内容** , **参与的成员**, **issue的描述信息**,以及打开issue的GitHub 用户的信息。
+哇,好大量的信息!我们可以看到有用的字段,我们可以看到诸如 `title` 、 `body` 和 `number` 等描述 issue 的有用字段,以及关于创建 issue 的 GitHub 用户的信息。
-✏️ 试试看!单击上面 JSON 中的几个 URL,以了解每个 GitHub issue中我url链接到的实际的地址。
+✏️ **试试看!**打开上面 JSON 中的一些 URL,以了解每个 GitHub issue 中 url 所链接的信息类型。
+
-如 GitHub[文档](https://docs.github.com/en/rest/overview/resources-in-the-rest-api#rate-limiting) 中所述,未经身份验证的请求限制为每小时 60 个请求。虽然你可以增加 **per_page** 查询参数以减少您发出的请求数量,您仍然会遭到任何超过几千个issue的存储库的速率限制。因此,您应该关注 GitHub 的[创建个人身份令牌](https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token),创建一个个人访问令牌这样您就可以将速率限制提高到每小时 5,000 个请求。获得令牌后,您可以将其包含在请求标头中:
+如 GitHub [文档](https://docs.github.com/en/rest/overview/resources-in-the-rest-api#rate-limiting) 中所述,未经身份验证的请求限制为每小时 60 个请求。虽然你可以增加 `per_page` 查询参数以减少你发出的请求次数,但你仍会在任何有几千个以上 issue 的仓库上触发速率限制。因此,你应该按照 GitHub 的 [说明](https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token) ,创建一个 `个人访问令牌(personal access token)` 这样你就可以将速率限制提高到每小时 5,000 个请求。获得令牌后,你可以将其放在请求标头中:
```py
-GITHUB_TOKEN = xxx # Copy your GitHub token here
+GITHUB_TOKEN = xxx # 将你的GitHub令牌复制到此处
headers = {"Authorization": f"token {GITHUB_TOKEN}"}
```
-⚠️ 不要与陌生人共享存在GITHUB令牌的笔记本。我们建议您在使用完后将GITHUB令牌删除,以避免意外泄漏此信息。一个更好的做法是,将令牌存储在.env文件中,并使用 [`python-dotenv` library](https://github.com/theskumar/python-dotenv) 为您自动将其作为环境变量加载。
+⚠️ 不要与陌生人共享存在 `GITHUB令牌` 的笔记本。我们建议你在使用完后将 `GITHUB令牌` 删除,以避免意外泄漏。一个更好的做法是,将令牌存储在.env 文件中,并使用 [`python-dotenv`库](https://github.com/theskumar/python-dotenv) 自动加载环境变量。
-现在我们有了访问令牌,让我们创建一个可以从 GitHub 存储库下载所有issue的函数:
+现在我们有了访问令牌,让我们创建一个可以从 GitHub 仓库下载所有 issue 的函数:
```py
import time
@@ -152,19 +153,19 @@ def fetch_issues(
batch = []
all_issues = []
- per_page = 100 # Number of issues to return per page
+ per_page = 100 ## 每页返回的 issue 的数量
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
- # Query with state=all to get both open and closed issues
+ # 使用 state=all 进行查询来获取 open 和 closed 的issue
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
- batch = [] # Flush batch for next time period
+ batch = [] # 重置batch
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
@@ -176,14 +177,14 @@ def fetch_issues(
)
```
-现在我们可以调用 **fetch_issues()** 批量下载所有issue,避免超过GitHub每小时的请求数限制;结果将存储在repository_name-issues.jsonl文件,其中每一行都是一个 JSON 对象,代表一个issue。让我们使用这个函数从 🤗 Datasets中抓取所有issue:
+现在我们可以调用 `fetch_issues()` 它将按批次下载所有 issue,以避免超过 GitHub 每小时请求次数的限制;结果将存储在 `repository_name-issues.jsonl` 文件,其中每一行都是一个 JSON 对象,代表一个 issue。让我们使用这个函数从 🤗 Datasets 中抓取所有 issue:
```py
-# Depending on your internet connection, this can take several minutes to run...
+# 取决于你的网络连接,这可能需要几分钟的时间来运行...
fetch_issues()
```
-下载issue后,我们可以使用我们 [section 2](/course/chapter5/2)新学会的方法在本地加载它们:
+下载 issue 后,我们可以使用我们在 [第二节](/course/chapter5/2) 新学会的方法在本地加载它们:
```py
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
@@ -197,20 +198,20 @@ Dataset({
})
```
-太好了,我们已经从头开始创建了我们的第一个数据集!但是为什么会有几千个issue,而🤗 Datasets存储库中的[Issues 选项卡](https://github.com/huggingface/datasets/issues)总共却只显示了大约 1,000 个issue🤔?如 GitHub [文档](https://docs.github.com/en/rest/reference/issues#list-issues-assigned-to-the-authenticated-user)中所述,那是因为我们也下载了所有的拉取请求:
+太好了,我们已经从头开始创建了我们的第一个数据集!但是为什么会有几千个 issue,而🤗 Datasets 仓库中的 [Issues 选项卡](https://github.com/huggingface/datasets/issues) 总共却只显示了大约 1,000 个 issue🤔?如 GitHub [文档](https://docs.github.com/en/rest/reference/issues#list-issues-assigned-to-the-authenticated-user) 中所述,那是因为我们不加下载了 issue 还下载了所有的 pull 请求:
->Git Hub的REST API v3认为每个pull请求都是一个issue,但并不是每个issue都是一个pull请求。因此,“Issues”节点可能在响应中同时返回issue和拉取请求。你可以通过pull_request 的 key来辨别pull请求。请注意,从“Issues”节点返回的pull请求的id将是一个issue id。
+> Git Hub 的 REST API v3 认为每个 pull 请求都是一个 issue,但事实上并不是每个 issue 都是一个 pull 请求。因此,“Issues”节点可能同时返回了 issue 和 pull 请求。你可以通过 `pull_request` 的 key 来辨别 pull 请求。请注意,从“Issues”节点返回的 pull 请求的 id 将是一个 issue id。
-由于issue和pull request的内容有很大的不同,我们先做一些小的预处理,让我们能够区分它们。
+由于 issue 和 pull request 的内容有很大的不同,我们先做一些小的预处理,让我们能够区分它们。
-## 清理数据 [[清理数据]]
+## 清洗数据 [[清洗数据]]
-上面来自 GitHub 文档的片段告诉我们, **pull_request** 列可用于区分issue和拉取请求。让我们随机挑选一些样本,看看有什么不同。我们将使用在[第三节](/course/chapter5/3), 学习的方法,使用 **Dataset.shuffle()** 和 **Dataset.select()** 抽取一个随机样本,然后将 **html_url** 和 **pull_request** 列使用zip函数打包,以便我们可以比较各种 URL:
+上面的 GitHub 文档告诉我们, `pull_request` 列可用于区分 issue 和 pull 请求。让我们随机挑选一些样本,看看有什么不同。我们将使用在 [第三节](/course/chapter5/3) ,学习的方法,使用 `Dataset.shuffle()` 和 `Dataset.select()` 抽取一个随机样本,然后将 `html_url` 和 `pull_request` 列使用 zip 函数组合起来,以便我们可以比较各种 URL:
```py
sample = issues_dataset.shuffle(seed=666).select(range(3))
-# Print out the URL and pull request entries
+# 打印出 URL 和 pull 请求
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")
@@ -227,7 +228,7 @@ for url, pr in zip(sample["html_url"], sample["pull_request"]):
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}
```
-这里我们可以看到,每个pull请求都与各种url相关联,而普通issue只有一个None条目。我们可以使用这一点不同来创建一个新的is_pull_request列通过检查pull_request字段是否为None来区分它们:
+这里我们可以看到,每个 pull 请求都与各种 url 相关联,而普通 issue 只有一个 `None` 条目。我们可以使用这一点不同来创建一个新的 `is_pull_request` 列,通过检查 `pull_request` 字段是否为 `None` 来区分它们:
```py
issues_dataset = issues_dataset.map(
@@ -237,21 +238,21 @@ issues_dataset = issues_dataset.map(
-✏️ 试试看!计算在 🤗 Datasets中解决issue所需的平均时间。您可能会发现 Dataset.filter()函数对于过滤拉取请求和未解决的issue很有用,并且您可以使用Dataset.set_format()函数将数据集转换为DataFrame,以便您可以轻松地按照需求修改创建和关闭的时间的格式(以时间戳格式)。
+✏️ **试试看!**计算在 🤗 Datasets 中解决 issue 所需的平均时间。你可能会发现 `Dataset.filter()` 函数对于过滤 pull 请求和未解决的 issue 很有用,并且你可以使用 `Dataset.set_format()` 函数将数据集转换为 `DataFrame` ,以便你可以轻松地按照需求修改 `创建(created_at)` 和 `关闭(closed_at)` 的时间的格式(以时间戳格式)。
-尽管我们可以通过删除或重命名某些列来进一步清理数据集,但在此阶段尽可能保持数据集“原始”状态通常是一个很好的做法,以便它可以在多个应用程序中轻松使用。在我们将数据集推送到 Hugging Face Hub 之前,让我们再添加一些缺少的数据:与每个issue和拉取请求相关的评论。我们接下来将添加它们——你猜对了——我们将依然使用GitHub REST API!
+尽管我们可以通过删除或重命名某些列来进一步清理数据集,但在此阶段尽可能保持数据集“原始”状态通常是一个很好的做法,以便它可以在多个不同的项目中轻松使用。在我们将数据集推送到 Hugging Face Hub 之前,让我们再添加一些缺少的数据:每个 issue 和 pull 中的评论。我们接下来将添加它们——你猜对了——我们将依然使用 GitHub REST API!
## 扩充数据集 [[扩充数据集]]
-如以下屏幕截图所示,与issue或拉取请求相关的评论提供了丰富的信息,特别是如果我们有兴趣构建搜索引擎来回答用户对这个项目的疑问。
+如以下截图所示,issue 或 pull 请求相关的评论提供了丰富的信息,特别是如果我们有兴趣构建搜索引擎来回答用户对这个仓库的疑问时,这些信息将非常有用。
-GitHub REST API 提供了一个 [评论节点](https://docs.github.com/en/rest/reference/issues#list-issue-comments) 返回与issue编号相关的所有评论。让我们测试节点以查看它返回的内容:
+GitHub REST API 提供了一个 [`Comments(评论)`节点](https://docs.github.com/en/rest/reference/issues#list-issue-comments) 返回与 issue 编号相关的所有评论。让我们测试一下该节点返回的内容:
```py
issue_number = 2792
@@ -287,11 +288,11 @@ response.json()
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
- 'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
+ 'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]
```
-我们可以看到注释存储在body字段中,所以让我们编写一个简单的函数,通过在response.json()中为每个元素挑选body内容来返回与某个issue相关的所有评论:
+我们可以看到评论存储在 `body` 字段中,因此让我们编写一个简单的函数,通过挑选出 `response.json()` 中每个元素的 `body` 内容,返回与某个 issue 相关的所有评论:
```py
def get_comments(issue_number):
@@ -300,18 +301,18 @@ def get_comments(issue_number):
return [r["body"] for r in response.json()]
-# Test our function works as expected
+# 测试我们的函数是否按预期工作
get_comments(2792)
```
```python out
-["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
+["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
```
-这看起来不错,所以让我们使用 **Dataset.map()** 方法在我们数据集中每个issue的添加一个**comments**列:
+这看起来不错,所以让我们使用 `Dataset.map()` 方法,为我们数据集中每个 issue 的添加一个 `comments` 列:
```py
-# Depending on your internet connection, this can take a few minutes...
+# 取决于你的网络连接,这可能需要几分钟时间...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)
@@ -323,14 +324,14 @@ issues_with_comments_dataset = issues_dataset.map(
-现在我们有了增强的数据集,是时候将它推送到 Hub 以便我们可以与社区共享它了! 上传数据集非常简单:就像 🤗 Transformers 中的模型和分词器一样,我们可以使用 `push_to_hub()` 方法来推送数据集。 为此,我们需要一个身份验证令牌,它可以通过首先使用 `notebook_login()` 函数登录到 Hugging Face Hub 来获得:
+现在我们有了扩充后的数据集,是时候将它推送到 Hub 并与社区共享了!上传数据集非常简单:就像 🤗 Transformers 中的模型和 tokenizer 一样,我们可以使用 `push_to_hub()` 方法来推送数据集。为此,我们需要一个身份验证令牌,它可以通过首先使用 `notebook_login()` 函数登录到 Hugging Face Hub 来获得:
```py
from huggingface_hub import notebook_login
notebook_login()
```
-这将创建一个小部件,您可以在其中输入您的用户名和密码, API 令牌将保存在~/.huggingface/令牌.如果您在终端中运行代码,则可以改为通过 CLI 登录:
+这将创建一个小部件,你可以在其中输入你的用户名和密码,API 令牌将保存在 `~/.huggingface/token` 中。如果你在终端中运行代码,则可以改为使用命令行登录:
```bash
huggingface-cli login
@@ -342,7 +343,7 @@ huggingface-cli login
issues_with_comments_dataset.push_to_hub("github-issues")
```
-之后,任何人都可以通过便捷地提供带有存储库 ID 作为 path 参数的 load_dataset() 来下载数据集:
+之后,任何人都可以通过便捷地使用附带仓库 ID 作为 `path` 参数的 `load_dataset()` 函数 来下载数据集:
```py
remote_dataset = load_dataset("lewtun/github-issues", split="train")
@@ -356,27 +357,29 @@ Dataset({
})
```
-很酷,我们已经将我们的数据集推送到 Hub,其他人可以使用它!只剩下一件重要的事情要做:添加一个数据卡这解释了语料库是如何创建的,并为使用数据集的其他提供一些其他有用的信息。
+很酷,我们已经将我们的数据集推送到 Hub,其他人可以使用它!只剩下一件重要的事情要做:添加一个数据卡片,解释语料库是如何创建的,并为使用数据集的其他提供一些其他有用的信息。
-💡 您还可以使用一些 Git 魔法直接从终端将数据集上传到 Hugging Face Hub。有关如何执行此操作的详细信息,请参阅 [🤗 Datasets guide](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) 指南。
+💡 你还可以使用一些 Git 技巧和 `huggingface-cli` 直接从终端将数据集上传到 Hugging Face Hub。有关如何执行此操作的详细信息,请参阅 [🤗 Datasets 指南](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) 指南。
## 创建数据集卡片 [[创建数据集卡片]]
-有据可查的数据集更有可能对其他人(包括你未来的自己!)有用,因为它们提供了上下文,使用户能够决定数据集是否与他们的任务相关,并评估任何潜在的偏见或与使用相关的风险。在 Hugging Face Hub 上,此信息存储在每个数据集存储库的自述文件文件。在创建此文件之前,您应该执行两个主要步骤:
+有据可查的数据集更有可能对其他人(包括你未来的自己!)有用,因为它们提供了数据集相关的信息,使用户能够决定数据集是否与他们的任务相关,并评估任何潜在的偏见或与使用相关的风险。
+
+在 Hugging Face Hub 上,此信息存储在每个数据集仓库的自述文件(`README.md`)。在创建此文件之前,你应该采取两个主要步骤:
-1. 使用[数据集标签应用程序](https://huggingface.co/datasets/tagging/) 创建YAML格式的元数据标签。这些标签用于各种各样的搜索功能,并确保您的数据集可以很容易地被社区成员找到。因为我们已经在这里创建了一个自定义数据集,所以您需要克隆数据集标签存储库并在本地运行应用程序。它的界面是这样的:
+1. 使用 [`datasets-tagging`应用程序](https://huggingface.co/datasets/tagging/) 创建 YAML 格式的元数据标签。这些标签用于 Hugging Face Hub 上的各种搜索功能,并确保你的数据集可以很容易地被社区成员找到。由于我们已经在这里创建了一个自定义数据集,所以你需要克隆数据集标签仓库( `datasets-tagging` )并在本地运行应用程序。它的界面是这样的:
-

+

@@ -384,15 +387,14 @@ Dataset({
-✏️试试看!使用应用程序和 [🤗 Datasets guide](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) 指南来完成 GitHub issue数据集的 README.md 文件。
+✏️**试试看!**使用 `dataset-tagging` 应用程序和 [🤗 Datasets 指南](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) 指南来完成 GitHub issue 数据集的 README.md 文件。
-很好! 我们在本节中看到,创建一个好的数据集可能非常复杂,但幸运的是,将其上传并与社区共享会很容易实现。在下一节中,我们将使用我们的新数据集创建一个带有 🤗 Datasets的语义搜索引擎,该数据集可以将issue与最相关的issue和评论进行匹配。
+很好!我们在本节中可以看到,创建一个好的数据集可能涉及相当多的工作,但幸运的是,将其上传并与社区共享会很容易实现。在下一节中,我们将使用我们的新数据集创建一个 🤗 Datasets 的语义搜索引擎,该引擎可以将输入匹配到最相关的 issue 和评论。
-✏️ 试试看!按照我们在本节中采取的步骤为您最喜欢的开源库创建一个 GitHub issue数据集(当然,选择 🤗 Datasets以外的其他东西!)。对于奖励积分,微调多标签分类器以预测该领域中存在的标签。
+✏️ **试试看!**按照我们在本节中采取的步骤为你最喜欢的开源库创建一个 GitHub issue 数据集(当然是除了 🤗 Datasets)。进阶的挑战:微调多标签分类器以预测在 `labels` 字段中出现的标签。
-
diff --git a/chapters/zh-CN/chapter5/6.mdx b/chapters/zh-CN/chapter5/6.mdx
index 6ded366a9..71a46b74a 100644
--- a/chapters/zh-CN/chapter5/6.mdx
+++ b/chapters/zh-CN/chapter5/6.mdx
@@ -22,13 +22,15 @@
{/if}
-在[第五小节](/course/chapter5/5), 我们从 🤗 Datasets 存储库创建了一个包含 GitHub 问题和评论的数据集。在本节中,我们将使用这些信息来构建一个搜索引擎,它可以帮助我们找到这个库最紧迫问题的答案!
+在 [第5小节](/course/chapter5/5) ,我们创建了一个 🤗 Datasets 仓库的 GitHub issues 和评论组成的数据集。在本节,我们将使用这些信息构建一个搜索引擎,帮助我们找到关于该库的最相关的 issue 的答案!
-## 使用嵌入进行语义搜索 [[使用嵌入进行语义搜索]]
+## 使用文本嵌入进行语义搜索 [[使用文本嵌入进行语义搜索]]
-正如我们在[第一章](/course/chapter1),学习的, 基于 Transformer 的语言模型会将文本中的每个标记转换为嵌入向量.事实证明,可以“汇集”各个嵌入向量来创建整个句子、段落或文档(在某些情况下)的向量表示。然后,通过计算每个嵌入之间的点积相似度(或其他一些相似度度量)并返回相似度最大的文档,这些嵌入可用于在语料库中找到相似的文档。在本节中,我们将使用嵌入来开发语义搜索引擎。与基于将查询中的关键字的传统方法相比,这些搜索引擎具有多种优势。
+正如我们在 [第一章](/course/chapter1) ,学习的,基于 Transformer 的语言模型会将文本中的每个 token 转换为嵌入向量。事实证明,我们可以 “池化(pool)” 嵌入向量以创建整个句子、段落或(在某些情况下)文档的向量表示。然后,通过计算每个嵌入之间的点积相似度(或其他一些相似度度量)并返回相似度最大的文档,这些嵌入可用于在语料库中找到相似的文档。
+
+在本节中,我们将使用文本嵌入向量来开发语义搜索引擎。与基于将查询中的关键字的传统方法相比,这些搜索引擎具有多种优势。

@@ -37,7 +39,7 @@
## 加载和准备数据集 [[加载和准备数据集]]
-我们需要做的第一件事是下载我们的 GitHub issues 数据集,所以让我们像往常那样使用 `load_dataset()`函数:
+首先,我们需要下载我们的 GitHub issues 数据集,所以让我们像往常那样使用 `load_dataset()` 函数:
```py
from datasets import load_dataset
@@ -54,7 +56,7 @@ Dataset({
})
```
-这里我们在load_dataset()中使用了默认的训练集分割,所以它返回一个数据集而不是数据集字典。第一项任务是过滤掉pull请求,因为这些请求很少用于回答用户提出的问题,而且会给我们的搜索引擎带来噪声。现在应该很熟悉了,我们可以使用dataset.filter()函数来排除数据集中的这些行。同时,让我们也过滤掉没有注释的行,因为这些行不会是用户提问的答案:
+在此,我们在 `load_dataset()` 中指定了默认的 `train(训练集)` 部分,因此它返回一个 `Dataset` 而不是 `DatasetDict` 。首要任务是排除掉拉取请求(pull),因为这些请求往往很少用于回答提出的 issue,会为我们的搜索引擎引入干扰。正如我们现在熟悉的那样,我们可以使用 `Dataset.filter()` 函数来排除数据集中的这些行。与此同时,让我们也筛选掉没有评论的行,因为这些行没有为用户提问提供回答:
```py
issues_dataset = issues_dataset.filter(
@@ -70,7 +72,7 @@ Dataset({
})
```
-我们可以看到我们的数据集中有很多列,其中大部分我们不需要构建我们的搜索引擎。从搜索的角度来看,信息量最大的列是 **title** , **body** , 和 **comments** ,而 **html_url** 为我们提供了一个回到源问题的链接。让我们使用 **Dataset.remove_columns()** 删除其余部分的功能:
+我们可以看到,我们的数据集中有很多列,其中大部分在构建我们的搜索引擎都不会使用。从搜索的角度来看,信息量最大的列是 `title` , `body` ,和 `comments` ,而 `html_url` 为我们提供了一个回到原 issue 的链接。让我们使用 `Dataset.remove_columns()` 删除其余的列:
```py
columns = issues_dataset.column_names
@@ -87,27 +89,27 @@ Dataset({
})
```
-为了创建我们的嵌入,我们将用问题的标题和正文来扩充每条评论,因为这些字段通常包含有用的上下文信息。因为我们的 **comments** 列当前是每个问题的评论列表,我们需要“重新组合”列,以便每一条评论都包含一个 **(html_url, title, body, comment)** 元组。在 Pandas 中,我们可以使用 [DataFrame.explode() 函数](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html), 它为类似列表的列中的每个元素创建一个新行,同时复制所有其他列值。为了看到它的实际效果,让我们首先切换到 Pandas的**DataFrame** 格式:
+为了创建我们的文本嵌入数据集,我们将用 issue 的标题和正文来扩充每条评论,因为这些字段通常包含有用的上下文信息。因为我们的 `comments` 列当前是每个 issue 的评论列表,我们需要“重新组合”列,使得每一行都是由一个 `(html_url, title, body, comment)` 元组组成。在 Pandas 中,我们可以使用 [DataFrame.explode() 函数](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html) 完成这个操作 它为类似列表的列中的每个元素创建一个新行,同时复制所有其他列值。让我们首先切换到 Pandas 的 `DataFrame` 格式:
```py
issues_dataset.set_format("pandas")
df = issues_dataset[:]
```
-如果我们检查这里的第一行 **DataFrame** 我们可以看到有四个评论与这个问题相关:
+如果我们检查这个 `DataFrame` 的第一行,我们可以看到这个 issue 有四个相关评论:
```py
df["comments"][0].tolist()
```
```python out
-['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
+['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
- 'cannot connect,even by Web browser,please check that there is some problems。',
+ 'cannot connect,even by Web browser,please check that there is some problems。',
'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
```
-我们希望这些评论中的每一条都得到一行。让我们检查是否是这种情况:
+我们希望使用 `explode()` 将这些评论中的每一条都展开成为一行。让我们看看是否可以做到:
```py
comments_df = df.explode("comments", ignore_index=True)
@@ -156,7 +158,7 @@ comments_df.head(4)
-太好了,我们可以看到评论成功被扩充, **comments** 是包含个人评论的列!现在我们已经完成了 Pandas要完成的部分功能,我们可以快速切换回 **Dataset** 通过加载 **DataFrame** 在内存中:
+非常好,我们可以看到其他三列已经被复制了,并且 `comments` 列里存放着单独的评论!现在我们已经完成了 Pandas 要完成的部分功能,我们可以通过加载内存中的 `DataFrame` 快速切换回 `Dataset` :
```py
from datasets import Dataset
@@ -177,11 +179,11 @@ Dataset({
-✏️ **试试看!** 看看能不能不用pandas就可以完成列的扩充; 这有点棘手; 你可能会发现 🤗 Datasets 文档的 ["Batch mapping"](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) 对这个任务很有用。
+✏️ **试试看!** 看看你是否可以使用 `Dataset.map()` 展开 `issues_dataset` 的 `comments` 列,这有点棘手;你可能会发现 🤗 Datasets 文档的 ["批处理映射(Batch mapping)"](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) 对这个任务很有用。
-现在我们每行有一个评论,让我们创建一个新的 **comments_length** 列来存放每条评论的字数:
+既然我们每行有一个评论,让我们创建一个新的 `comments_length` 列来存放每条评论的字数:
```py
comments_dataset = comments_dataset.map(
@@ -189,7 +191,7 @@ comments_dataset = comments_dataset.map(
)
```
-我们可以使用这个新列来过滤掉简短的评论,其中通常包括“cc @lewtun”或“谢谢!”之类与我们的搜索引擎无关的内容。虽然无法为过滤器选择的精确数字,但大约大于15 个单词似乎是一个不错的选择:
+我们可以使用这个新列来过滤掉简短的评论,其中通常包括“cc @lewtun”或“谢谢!”之类与我们的搜索引擎无关的内容。筛选的精确数字没有硬性规定,但大约大于 15 个单词似乎是一个不错的选择:
```py
comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
@@ -203,7 +205,7 @@ Dataset({
})
```
-稍微清理了我们的数据集后,让我们将问题标题、描述和评论连接到一个新的 **text** 列。像往常一样,我们可以编写一个简单的函数,并将其传递给 **Dataset.map()**来做到这些 :
+稍微清理了我们的数据集后,让我们使用 issue 标题、描述和评论构建一个新的 `text` 列。像往常一样,我们可以编写一个简单的函数,并将其传递给 `Dataset.map()` 来完成这些操作
```py
def concatenate_text(examples):
@@ -219,11 +221,11 @@ def concatenate_text(examples):
comments_dataset = comments_dataset.map(concatenate_text)
```
-我们终于准备好创建一些嵌入了!让我们来看看。
+我们终于准备好创建一些文本嵌入了!让我们继续。
## 创建文本嵌入 [[创建文本嵌入]]
-我们在[第二章](/course/chapter2) 学过,我们可以通过使用 **AutoModel** 类来完成词嵌入。我们需要做的就是选择一个合适的检查点来加载模型。幸运的是,有一个名为 **sentence-transformers** 专门用于创建词嵌入。如库中[文档](https://www.sbert.net/examples/applications/semantic-search/README.html#symmetric-vs-asymmetric-semantic-search), 所述的,我们这次要实现的是非对称语义搜索,因为我们有一个简短的查询,我们希望在比如问题评论等更长的文档中找到其答案。通过查看[模型概述表](https://www.sbert.net/docs/pretrained_models.html#model-overview) 我们可以发现 **multi-qa-mpnet-base-dot-v1** 检查点在语义搜索方面具有最佳性能,因此我们将在我们的应用程序中使用它。我们还将使用相同的检查点加载标记器:
+正如我们在 [第二章](/course/chapter2) 学过,我们可以通过使用 `AutoModel` 类来完成文本嵌入。首先需要做的就是选择一个合适的 checkpoint。幸运的是,有一个名为 `sentence-transformers` 的库专门用于创建文本嵌入。如库中的 [文档](https://www.sbert.net/examples/applications/semantic-search/README.html#symmetric-vs-asymmetric-semantic-search) 所述的,我们这次要实现的是非对称语义搜索(asymmetric semantic search),因为我们有一个简短的查询,我们希望在比如 issue 评论等更长的文档中找到其匹配的文本。通过查看 [模型概述表](https://www.sbert.net/docs/pretrained_models.html#model-overview) 我们可以发现 `multi-qa-mpnet-base-dot-v1` checkpoint 在语义搜索方面具有最佳性能,因此我们将使用它。我们还将使用这个 checkpoint 加载了对应的 tokenizer :
{#if fw === 'pt'}
@@ -235,7 +237,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
```
-为了加快嵌入过程,将模型和输入放在 GPU 设备上,所以现在让我们这样做:
+将模型和输入的文本放到 GPU 上会加速嵌入过程,所以让我们现在就这么做:
```py
import torch
@@ -254,19 +256,18 @@ tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = TFAutoModel.from_pretrained(model_ckpt, from_pt=True)
```
-请注意,我们已将 from_pt=True 设置为 from_pretrained() 方法的参数。这是因为 multi-qa-mpnet-base-dot-v1 检查点只有PyTorch权重,因此设置 from_pt=True 会自动将它们转换为TensorFlow格式。如您所见,在Transformers中的🤗框架之间切换非常简单!
+请注意,我们在调用 `from_pretrained()` 方法的时候添加了 `from_pt=True` 参数。这是因为 `multi-qa-mpnet-base-dot-v1` checkpoint 只有 PyTorch 权重,因此设置 `from_pt=True` 会自动将它们转换为 TensorFlow 格式。如你所见,在🤗 Transformers 中切换框架非常简单!
{/if}
-正如我们之前提到的,我们希望将 GitHub 问题语料库中的每个条目表示为单个向量,因此我们需要以某种方式“池化”或平均化我们的标记嵌入。一种流行的方法是在我们模型的输出上执行CLS 池化,我们只获取**[CLS]** 令牌的最后一个隐藏状态。以下函数为我们提供了这样的方法:
+根据我们之前的想法,我们希望将我们的 GitHub issue 中的每一条记录转化为一个单一的向量,所以我们需要以某种方式“池化(pool)”或平均每个词的嵌入向量。一种流行的方法是在我们模型的输出上进行 `CLS 池化` ,我们只需要收集 `[CLS]` token 的的最后一个隐藏状态。以下函数实现了这个功能:
```py
def cls_pooling(model_output):
return model_output.last_hidden_state[:, 0]
```
-接下来,我们将创建一个辅助函数,该函数将标记文档列表,将tensor放在 GPU 上,然后提供给模型,最后对输出使用CLS 池化:
-
+接下来,我们将创建一个辅助函数,它将对一组文档进行 tokenize,然后将张量放在 GPU 上,接着将它们喂给模型,最后对输出进行 CLS 池化:
{#if fw === 'pt'}
```py
@@ -279,7 +280,7 @@ def get_embeddings(text_list):
return cls_pooling(model_output)
```
-我们可以通过在我们的语料库中输入第一个文本条目并检查输出维度来测试该函数是否有效:
+我们可以将第一条数据喂给它并检查输出的形状来测试这个函数是否正常工作:
```py
embedding = get_embeddings(comments_dataset["text"][0])
@@ -290,7 +291,7 @@ embedding.shape
torch.Size([1, 768])
```
-太好了,我们已经将语料库中的第一个条目转换为 768 维向量!我们可以用 **Dataset.map()** 应用我们的 **get_embeddings()** 函数到我们语料库中的每一行,所以让我们创建一个新的 **embeddings** 列如下:
+太好了,我们已经将语料库中的第一个条目转换为了一个 768 维向量!我们可以用 `Dataset.map()` 将我们的 `get_embeddings()` 函数应用到我们语料库中的每一行,然后创建一个新的 `embeddings` 列:
```py
embeddings_dataset = comments_dataset.map(
@@ -310,7 +311,7 @@ def get_embeddings(text_list):
return cls_pooling(model_output)
```
-我们可以通过在我们的语料库中输入第一个文本条目并检查输出维度来测试该函数是否有效:
+我们可以将第一个文本条目喂给它并检查输出的形状来测试这个函数是否正常工作:
```py
embedding = get_embeddings(comments_dataset["text"][0])
@@ -321,7 +322,7 @@ embedding.shape
TensorShape([1, 768])
```
-太好了,我们已经将语料库中的第一个条目转换为 768 维向量!我们可以用 **Dataset.map()** 应用我们的 **get_embeddings()** 函数到我们语料库中的每一行,所以让我们创建一个新的 **embeddings** 列如下:
+太好了,我们已经将语料库中的第一个条目转换为了一个 768 维向量!我们可以用 `Dataset.map()` 将我们的 `get_embeddings()` 函数应用到我们语料库中的每一行,然后创建一个新的 `embeddings` 列:
```py
embeddings_dataset = comments_dataset.map(
@@ -331,18 +332,20 @@ embeddings_dataset = comments_dataset.map(
{/if}
-请注意,我们已经将嵌入转换为 NumPy 数组——这是因为当我们尝试使用 FAISS 索引它们时,🤗 Datasets需要这种格式,我们接下来会这样做。
+请注意,在上面的代码中我们已经将文本嵌入转换为 NumPy 数组——这是因为当我们尝试使用 FAISS 搜索它们时,🤗 Datasets 需要这种格式,让我们继续吧。
## 使用 FAISS 进行高效的相似性搜索 [[使用 FAISS 进行高效的相似性搜索]]
-现在我们有了一个词嵌入数据集,我们需要一些方法来搜索它们。为此,我们将在 🤗 Datasets中使用一种特殊的数据结构,称为 FAISS指数.[FAISS](https://faiss.ai/) (short for Facebook AI Similarity Search) (Facebook AI Similarity Search 的缩写)是一个提供高效算法来快速搜索和聚类嵌入向量的库。FAISS 背后的基本思想是创建一个特殊的数据结构,称为指数。这允许人们找到哪些嵌入词与输入的词嵌入相似。在 🤗 Datasets中创建一个 FAISS 索引很简单——我们使用 **Dataset.add_faiss_index()** 函数并指定我们要索引的数据集的哪一列:
+现在我们有了一个文本嵌入数据集,我们需要一些方法来搜索它们。为此,我们将使用🤗 Datasets 中一种特殊的数据结构,称为 FAISS 指数。 [FAISS](https://faiss.ai/) (Facebook AI Similarity Search 的缩写)是一个库,提供了用于快速搜索和聚类嵌入向量的高效算法。
+
+FAISS 背后的基本思想是创建一个特殊的数据结构,称为 `index(索引)` 它可以找到哪些嵌入与输入嵌入相似。在 🤗 Datasets 中创建一个 FAISS index(索引)很简单——我们使用 `Dataset.add_faiss_index()` 函数并指定我们要索引的数据集的哪一列:
```py
embeddings_dataset.add_faiss_index(column="embeddings")
```
-现在,我们可以使用**Dataset.get_nearest_examples()**函数进行最近邻居查找。让我们通过首先嵌入一个问题来测试这一点,如下所示:
+现在,我们可以使用 `Dataset.get_nearest_examples()` 函数进行最近邻居查找。让我们通过首先嵌入一个 issue 来测试这一点,如下所示:
{#if fw === 'pt'}
@@ -370,7 +373,7 @@ question_embedding.shape
{/if}
-就像文档一样,我们现在有一个 768 维向量表示查询,我们可以将其与整个语料库进行比较以找到最相似的嵌入:
+就像对文档进行嵌入一样,我们现在有一个表示查询的 768 维向量,我们可以将其与整个语料库进行比较以找到最相似的嵌入:
```py
scores, samples = embeddings_dataset.get_nearest_examples(
@@ -378,7 +381,7 @@ scores, samples = embeddings_dataset.get_nearest_examples(
)
```
- **Dataset.get_nearest_examples()** 函数返回一个分数元组,对查询和文档之间的相似度进行排序,以及一组最佳匹配的结果(这里是 5 个)。让我们把这些收集到一个 **pandas.DataFrame** 以便我们可以轻松地对它们进行排序:
+`Dataset.get_nearest_examples()` 函数返回一个元组,包括评分(评价查询和文档之间的相似程度)和对应的样本(这里是 5 个最佳匹配)。让我们把这些收集到一个 `pandas.DataFrame` ,这样我们就可以轻松地对它们进行排序:
```py
import pandas as pd
@@ -388,7 +391,7 @@ samples_df["scores"] = scores
samples_df.sort_values("scores", ascending=False, inplace=True)
```
-现在我们可以遍历前几行来查看我们的查询与评论的匹配程度:
+现在我们可以遍历前几行来查看我们的查询与评论的匹配程度如何:
```py
for _, row in samples_df.iterrows():
@@ -456,7 +459,7 @@ COMMENT: > here is my way to load a dataset offline, but it **requires** an onli
>
> import datasets
>
-> data = datasets.load_dataset(...)
+> data = datasets.load_dataset(.)
>
> data.save_to_disk(/YOUR/DATASET/DIR)
>
@@ -506,10 +509,10 @@ URL: https://github.com/huggingface/datasets/issues/824
"""
```
-我们的第二个搜索结果似乎与查询相符。
+不错!我们的输出的第 2 个结果似乎与查询匹配。
-✏️ 试试看!创建您自己的查询并查看您是否可以在检索到的文档中找到答案。您可能需要增加参数k以扩大搜索范围。
+✏️ 试试看!创建你自己的查询并查看你是否可以在检索到的文档中找到答案。你可能需要在 `Dataset.get_nearest_examples()` 增加参数 `k` 以扩大搜索范围。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter5/7.mdx b/chapters/zh-CN/chapter5/7.mdx
index 9f42af397..d42422160 100644
--- a/chapters/zh-CN/chapter5/7.mdx
+++ b/chapters/zh-CN/chapter5/7.mdx
@@ -1,16 +1,16 @@
-# 🤗 Datasets,回顾! [[🤗 Datasets,回顾!]]
+# 🤗 Datasets,完结![[🤗 Datasets,完结!]]
-这是对 🤗 Datasets 库的一次完整游览——祝贺你走到这一步!凭借从本章中获得的知识,您应该能够:
+这是对 🤗 Datasets 库的一次完整的探索——祝贺你走到这一步!凭借从本章中获得的知识,你应该能够:
-- 从任何地方加载数据集,无论是 Hugging Face Hub、您的笔记本电脑还是您公司的远程服务器。
-- 混合使用Dataset.map()和Dataset.filter()函数来整理数据。
-- 使用`Dataset.set_format()`在 Pandas 和 NumPy 等数据格式之间快速切换.
-- 创建您自己的数据集并将其推送到 Hugging Face Hub。.
-- 使用 Transformer 模型为您的文档创建词嵌入,并使用 FAISS 构建语义搜索引擎。.
+- 从任何地方加载数据集,无论是 Hugging Face Hub、你的笔记本电脑还是你公司的远程服务器。
+- 混合使用 `Dataset.map()` 和 `Dataset.filter()` 函数来整理数据。
+- 使用 `Dataset.set_format()` 在 Pandas 和 NumPy 等数据格式之间快速切换。
+- 创建你自己的数据集并将其推送到 Hugging Face Hub。
+- 使用 Transformer 模型为你的文档创建文本嵌入,并使用 FAISS 构建语义搜索引擎。
-在[第七章](/course/chapter7),当我们深入研究 Transformer 模型非常适合的核心 NLP 任务时,我们将充分利用所有这些。
\ No newline at end of file
+在 [第七章](/course/chapter7) ,我们将把所有这些用于深入研究 Transformer 模型擅长的核心 NLP 任务。不过,在跳到下一步之前,先用一次快速的小测验来检验你对 🤗 Datasets 的了解!
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter5/8.mdx b/chapters/zh-CN/chapter5/8.mdx
index 503108c9c..c3cf162ad 100644
--- a/chapters/zh-CN/chapter5/8.mdx
+++ b/chapters/zh-CN/chapter5/8.mdx
@@ -7,118 +7,118 @@
classNames="absolute z-10 right-0 top-0"
/>
-本章涵盖了很多方面! 如果你没有掌握所有细节, 不用担心; 在下一章将帮助你了解内部的事情是如何工作的。
+本章涵盖了很多方面!如果你没有掌握所有细节,不用担心;接下来的章节将继续帮助你了解🤗 Datasets 内在运作机制。
-不过, 在继续下一章之前, 让我们测试一下你在本章学到的内容。
+不过,在继续下一章之前,让我们测试一下你在本章学到的内容。
-### 1.🤗 Datasets中的 `load_dataset ()` 函数允许你从下列哪个位置加载数据集?
+### 1.🤗 Datasets 中的 `load_dataset ()` 函数允许你从下列哪个位置加载数据集?
load_dataset() 函数的 data_files 参数来加载本地数据集。",
+ explain: "正确!你可以将本地文件的路径传递给 `load_dataset()` 函数的 `data_files` 参数来加载本地数据集。",
correct: true
},
{
text: "Hugging Face Hub",
- explain: "正确! 你可以通过提供数据集 ID 在 Hub 上加载数据集, 例如 < code > load _ dataset ('em otion') 。",
+ explain: "正确!你可以通过提供数据集 ID 来加载 Hub 上的数据集,例如 `load_dataset('emotion')` 。",
correct: true
},
{
text: "远程服务器",
- explain: "正确! 你可以将URL传递给 load_dataset() 函数的 data_files 参数来加载远程文件。",
+ explain: "正确!你可以将 URL 传递给 `load_dataset()` 函数的 `data_files` 参数来加载远程文件。",
correct: true
},
]}
/>
-### 2.假设您加载了 GLUE 任务,如下所示:
+### 2.假设你按照以下方式加载了一个 GLUE 任务:
```py
from datasets import load_dataset
dataset = load_dataset("glue", "mrpc", split="train")
```
-以下哪个命令将从 `dataset` 中生成50个元素的随机样本?
+以下哪个命令可以从 `dataset` 中生成 50 个元素的随机样本?
dataset.sample(50)",
- explain: "这是不正确的——没有 Dataset.sample() 方法。"
+ text: " `dataset.sample (50)` ",
+ explain: "不正确 —— 没有 `Dataset.sample()` 方法。"
},
{
- text: "dataset.shuffle().select(range(50))",
- explain: "正确! 正如你在本章中看待的, 你首先打乱了数据集, 然后从中选择样本。",
+ text: " `dataset.shuffle().select(range(50))` ",
+ explain: "正确!正如你在这一章中所学到的,上面的代码首先打乱了数据集,然后从中选择样本。",
correct: true
},
{
- text: "dataset.select(range(50)).shuffle()",
- explain: "这是不正确的——尽管代码会运行, 但它只会随机处理数据集中的前50个元素。"
+ text: " `dataset.select(range(50)).shuffle()` ",
+ explain: "这是不正确的——尽管代码会运行,但它只会选取数据集的前 50 个元素然后打乱它们。"
}
]}
/>
-### 3.假设你有一个叫做宠物数据集的家庭宠物数据集,它有一个名字列表示每个宠物的名字。下列哪种方法可以让你过滤所有名字以字母"L"开头的宠物的数据?
+### 3.假设你有一个关于家庭宠物的数据集 `pets_dataset` ,它有一个 `name` 列表示每个宠物的名字。以下哪种方法可以筛选出所有名字以 "L" 开头的宠物数据?
pets_dataset.filter(lambda x: x['name'].startswith('L'))",
- explain: "正确! 为这些快速过滤使用 Python lambda 函数是一个好主意。你还能想到其他解决方案吗?",
+ text: " `pets_dataset.filter(lambda x: x ['name'].startswith ('L'))` ",
+ explain: "正确!使用 Python 的 lambda 函数来快速过滤是一个好主意。你能想出另一种解决方案吗?",
correct: true
},
{
- text: "pets_dataset.filter(lambda x['name'].startswith('L')",
- explain: "这是不正确的—— lambda 函数采用通用格式 lambda * arguments * : * expression * , 因此在这种情况下需要提供参数。"
+ text: " `pets_dataset.filter(lambda x ['name'].startswith ('L'))` ",
+ explain: "这是不正确的——lambda 函数通常的格式为: `lambda *arguments*:*expression*` , 因此在这种情况下需要提供 arguments。"
},
{
- text: "创建一个类似于 def filter_names(x) : return x['name'].startswith('L') 的函数并运行 pets_dataset.filter(filter_names) 。",
- explain: "正确!就像使用 Dataset.map() 一样,你可以将显式函数传递给 Dataset.filter() 。当你有一些不适合于简短 lambda 函数的复杂逻辑时,这是非常有用的。其他解决方案中还有哪一个可行?",
+ text: "创建一个类似于 `def filter_names (x) : return x['name'].startswith ('L')` 的函数,然后运行 `pets_dataset.filter(filter_names)` 。",
+ explain: "正确!就像使用 `Dataset.map ()` 一样,你可以将函数传递给 `Dataset.filter ()` 。当你有一些不适合 lambda 函数的复杂逻辑时,这很有用。其他解决方案中还有哪一个可行?",
correct: true
}
]}
/>
-### 4.什么是内存映射?
+### 4.什么是内存映射?
-### 5.下列哪一项是内存映射的主要好处?
+### 5.下列哪一项是内存映射的主要好处?
-### 6.为什么下面的代码是错误的?
+### 6.为什么下面的代码是错误的?
```py
from datasets import load_dataset
@@ -130,92 +130,92 @@ dataset[0]
choices={[
{
text: "它试图对一个太大而无法放入 RAM 的数据集进行流式处理。",
- explain: "这是不正确的---- 流数据集是动态解压的, 你可以用非常小的RAM处理TB大小的数据集!",
+ explain: "这是不正确的—— 流式处理数据集时是动态解压的,你可以用非常小的 RAM 处理 TB 量级的数据集!",
},
{
- text: "它尝试访问 IterableDataset 。",
- explain: "正确! IterableDataset 是一个生成器, 而不是一个容器, 因此你应该使用 next(iter(dataset)) 来访问它的元素。",
+ text: "它尝试访问 `IterableDataset` 。",
+ explain: "正确! `IterableDataset` 是一个生成器,而不是一个容器,因此你应该使用 `next(iter(dataset))` 来访问它的元素。",
correct: true
},
{
- text: "数据集 allocine 没有分割train。",
- explain: "这是不正确的---- 查看 Hub 上的[allocine数据集卡](https://huggingface.co/datasets/allocine), 看看它包含哪些拆分。"
+ text: "数据集 `allocine` 没有 `train` 部分。",
+ explain: "这是不正确的—— 查看 Hub 上的 [`allocine`数据卡片](https://huggingface.co/datasets/allocine) , 可以看到它有那几部分"
}
]}
/>
-### 7.创建数据集卡的主要好处是什么?
+### 7.创建数据集卡片的主要好处是什么?
-### 8.什么是语义搜索?
+### 8.什么是语义搜索?
-### 9.对于非对称语义搜索,通常有:
+### 9.对于非对称语义搜索,通常有:
-### 10.我可以使用数据集加载数据用于其他领域,如语音处理?
+### 10.我可以使用🤗 Datasets 来加载用于其他领域(如语音处理)的数据吗?
diff --git a/chapters/zh-CN/chapter6/1.mdx b/chapters/zh-CN/chapter6/1.mdx
index 077ee3277..960160671 100644
--- a/chapters/zh-CN/chapter6/1.mdx
+++ b/chapters/zh-CN/chapter6/1.mdx
@@ -5,15 +5,15 @@
classNames="absolute z-10 right-0 top-0"
/>
-在 [第三章] (/course/chapter3) 中,我们研究了如何在给定任务上微调模型。 当我们这样做时,我们需要使用与模型预训练相同的标记器——但是当我们想从头开始训练模型时该怎么办? 不过,使用在来自其他领域或语言的语料库上预训练的标记器通常不是最理想的。 例如,在英语语料库上训练的标记器在日语文本语料库上表现不佳,因为两种语言中空格和标点符号的使用非常不同。
+在 [第三章](/course/chapter3) 中,我们研究了如何在特定任务上微调模型。当我们需要微调模型时,我们需要使用与模型预训练相同的 tokenizer —— 但是当我们想从头开始训练模型时应该选用哪个 tokenizer ?使用在来自其他领域或语言的语料库上预训练的 tokenizer 通常不是最理想的。例如,在英语语料库上训练的 tokenizer 在日语文本语料库上效果会大打折扣,因为两种语言在空格和标点的使用上有着显著的差异。
-在本章中,您将学习如何在文本语料库上训练一个全新的标记器,然后将其用于预训练语言模型。 这一切都将在 [🤗 Tokenizers](https://github.com/huggingface/tokenizers) 库的帮助下完成,该库在 [🤗 Transformers](https://github.com /huggingface/transformers) 库之内。 我们将仔细研究这个库提供的功能,并探讨快速标记器与“慢”版本的区别。
+在本章中,你将学习如何在一份文本语料库上训练一个全新的 tokenizer,然后将使用它来预训练语言模型。这一切都将在 [🤗 Tokenizers](https://github.com/huggingface/tokenizers) 库的帮助下完成,该库提供了 [🤗 Transformers](https://github.com/huggingface/transformers) 库中的“快速” tokenizer 。 我们将深入探讨这个库所提供的功能,并研究“快速” tokenizer 与“慢速”版本的区别。
-我们将涵盖的主题包括:
+本章将涵盖以下主题:
-* 如何训练一个新的标记器,类似于给定检查点在新的文本语料库上使用的标记器
-* 快速标记器的特殊功能
-* 目前 NLP 中使用的三种主要子词标记化算法之间的差异
-* 如何使用🤗 Tokenizers 库从头开始构建标记器并在一些数据上对其进行训练
+* 如何在新的文本语料库上训练一个类似于给定 checkpoint 所使用的新 tokenizer
+* 快速 tokenizer 的特殊功能
+* 目前 NLP 中使用的三种主要子词 tokenization 算法之间的差异
+* 如何使用🤗 Tokenizers 库从头开始构建 tokenizer 并在一些数据上进行训练
-本章介绍的技术将使您为 [第 7 章](/course/chapter7/6) 中的部分做好准备,在那部分中,我们着眼于为 Python 源代码创建语言模型。 让我们首先看一下什么是“训练”标记器?
\ No newline at end of file
+本章介绍的技术将使你为 [第七章](/course/chapter7/6) 中的部分做好准备,在那部分中,我们将尝试为 Python 源代码创建语言模型。让我们首先看一下什么是“训练” tokenizer
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/10.mdx b/chapters/zh-CN/chapter6/10.mdx
index b1b485952..4cd7b16ef 100644
--- a/chapters/zh-CN/chapter6/10.mdx
+++ b/chapters/zh-CN/chapter6/10.mdx
@@ -1,4 +1,4 @@
-
+
# 章末小测验 [[章末小测验]]
@@ -7,229 +7,230 @@
classNames="absolute z-10 right-0 top-0"
/>
-让我们测试一下您在本章中学到了什么!
+让我们测试一下你在本章中学到了什么!
-### 1.你应该什么时候训练一个新的标记器?
+### 1.在什么时候你应该考虑训练一个新的 tokenizer ?
-### 2.当使用“ train_new_from_iterator()”时,使用文本列表生成器与文本列表相比有什么优点?
+### 2.当使用 `train_new_from_iterator()` 时,使用文本列表生成器与文本列表相比有什么优点?
train_new_from_iterator() 接受的唯一类型。",
+ text: "文本列表生成器是`train_new_from_iterator()`方法唯一接受的输入类型。",
explain: "文本列表是一种特殊的文本列表生成器,因此该方法也会接受这种方法。再试一次!"
},
{
- text: "您将避免立即将整个数据集载入内存中。",
- explain: "没错!每一批文本都会在你迭代的时候从内存中释放出来,如果你使用数据集存储文本的话,增益将尤其明显。",
+ text: "你可以避免一次性将整个数据集加载到内存中。",
+ explain: "正确!每个 batch 的文本在迭代时都将从内存中释放,如果你使用🤗 Datasets 存储你的文本,你会看到特别明显的收益。",
correct: true
},
{
- text: "这将允许 Tokenizers 库使用并行处理。",
- explain: "不,无论如何它都将使用并行处理。"
+ text: "这将允许🤗 Tokenizers 库使用多进程。",
+ explain: "不,即使随时文本列表它也会使用多进程。"
},
{
- text: "你训练的标记器将产生更好的文本。",
- explain: "Tokenizer 不生成文本——您是否将其与语言模型混淆了?"
+ text: "你训练的 Tokenizer 将生成效果更好的输出。",
+ explain: "Tokenizer 不生成文本——你是否将其与语言模型混淆了?"
}
]}
/>
-### 3.使用“快速”标记器的优点是什么?
+### 3.使用“快速” tokenizer 有什么优势?
+
-### 4.“token-classification”管道如何处理跨多个标记的实体?
+### 4. `token-classification` 管道如何处理跨越多个 tokens 的实体?
-### 5.“question-answering”流水线如何处理长上下文?
+### 5. `question-answering` 管道如何处理长上下文?
-### 6.什么是标准化?
+### 6.什么是标准化?
-### 7.什么是子词标记化的前标记化?
+### 7.什么是 tokenizer 的预分词?
-### 8.选择描述标记化 BPE 模式最准确的句子。
+### 8.选择描述 BPE 算法最准确的句子。
-### 9.选择适用于 WordPiece 标记模型的句子。
+### 9.选择描述 WordPiece 算法最准确的句子。
-### 10.选择适用于 Unigram 标记模式的句子。
+### 10.选择描述 Unigram 算法最准确的句子。
diff --git a/chapters/zh-CN/chapter6/2.mdx b/chapters/zh-CN/chapter6/2.mdx
index 87589bd04..1c24c35f4 100644
--- a/chapters/zh-CN/chapter6/2.mdx
+++ b/chapters/zh-CN/chapter6/2.mdx
@@ -1,4 +1,4 @@
-# 根据已有的tokenizer训练新的tokenizer [[根据已有的tokenizer训练新的tokenizer]]
+# 基于已有的 tokenizer 训练新的 tokenizer [[基于已有的 tokenizer 训练新的 tokenizer]]
-如果您感兴趣的语言中没有可用的语言模型,或者如果您的语料库与您的语言模型所训练的语料库有很大不同,您很可能希望从适合您的数据的标记器从头开始重新训练模型 . 这将需要在您的数据集上训练一个新的标记器。 但这究竟是什么意思? 当我们在 [第二章](/course/chapter2) 中第一次查看标记器时,我们看到大多数 Transformer 模型使用_子词分词算法_。 为了识别哪些子词是感兴趣的并且在手头的语料库中最常出现,标记器需要仔细查看语料库中的所有文本——我们称之为*training*的过程。 这种训练的确切规则取决于所使用的标记器的类型,我们将在本章后面讨论三种主要算法。
+如果你感兴趣的语言中没有可用的语言模型,或者你的语料库与语言模型训练时所使用的语料库差异很大,你可能需要从零开始重新训练一个适应你的数据的 tokenizer 模型。训练一个新的 tokenizer 是什么意思呢?从我们在 [第二章](/course/chapter2) 中第一次看到 tokenizer 开始,我们看到大多数 Transformer 模型使用 `子词分词算法` 。为了找到语料库中的常见子词,tokenizer 需要深入统计语料库中的所有文本——这个过程我们称之为 `训练 (training)` 。具体的训练规则取决于使用的 tokenizer 类型,我们将在本章后面的部分详细介绍三种主要算法。
-⚠️ 训练标记器与训练模型不同!模型训练使用随机梯度下降使每个batch的loss小一点。它本质上是随机的(这意味着在进行两次相同的训练时,您必须设置一些随机数种子才能获得相同的结果)。训练标记器是一个统计过程,它试图确定哪些子词最适合为给定的语料库选择,用于选择它们的确切规则取决于分词算法。它是确定性的,这意味着在相同的语料库上使用相同的算法进行训练时,您总是会得到相同的结果。
+⚠️ 训练 tokenizer 与训练模型不同!模型训练使用随机梯度下降使每个 batch 的 loss 小一点。它本质上是随机的(这意味着在即使两次训练的参数和算法完全相同,你也必须设置一些随机数种子才能获得相同的结果)。训练 tokenizer 是一个统计过程,它试图确定哪些子词最适合为给定的语料库选择,确定的过程取决于分词算法。它是确定性的,这意味着在相同的语料库上使用相同的算法进行训练时,得到的结果总是相同的。
## 准备语料库 [[准备语料库]]
-🤗 Transformers 中有一个非常简单的 API,你可以用它来训练一个新的标记器,使它与现有标记器相同的特征: **AutoTokenizer.train_new_from_iterator()** .为了复现这一点,假设我们想从头开始训练 GPT-2,但使用英语以外的语言。我们的首要任务是在训练语料库中收集该语言的大量数据。为了提供每个人都能理解的示例,我们在这里不会使用俄语或中文之类的语言,而是使用在特定领域的英语语言:Python 代码。
-
-[🤗 Datasets](https://github.com/huggingface/datasets)库可以帮助我们组装一个 Python 源代码语料库。我们将使用**load_dataset()**功能下载和缓存[CodeSearchNet](https://huggingface.co/datasets/code_search_net)数据集。该数据集是为[CodeSearchNet 挑战](https://wandb.ai/github/CodeSearchNet/benchmark)而创建的并包含来自 GitHub 上开源库的数百万种编程语言的函数。在这里,我们将加载此数据集的 Python 部分:
+在🤗 Transformers 中,有一个非常简单的 API 可以让你从旧的 tokenizer 训练一个新的 tokenizer 且新的 tokenizer 具有和旧 tokenizer 相同的特性,它就是: `AutoTokenizer.train_new_from_iterator()` 。为了演示这个功能,我们将尝试从零开始训练 GPT-2 模型,但是在非英语的语言上。我们首先需要做的就是在训练语料库中收集大量的目标语言数据。为了让每个人都能理解,我们不会使用俄语或汉语这样的语言,而是使用一种特殊的英语语言:Python 代码。
+ [🤗 Datasets](https://github.com/huggingface/datasets) 库可以帮助我们下载一个 Python 源代码语料库。我们将使用 `load_dataset()` 功能下载和缓存 [CodeSearchNet](https://huggingface.co/datasets/code_search_net) 数据集。该数据集是为 [CodeSearchNet 挑战](https://wandb.ai/github/CodeSearchNet/benchmark) 而创建的,其中包含了 GitHub 上开源库中的数百万个函数,涵盖了多种编程语言。在这里,我们将加载这个数据集的 Python 部分:
```py
from datasets import load_dataset
-# This can take a few minutes to load, so grab a coffee or tea while you wait!
+# 加载这个可能需要几分钟的时间,你可以趁此喝杯咖啡或茶!
raw_datasets = load_dataset("code_search_net", "python")
```
-我们可以查看训练集的部分,以查看我们数据集中有哪些列:
+我们可以查看训练集部分来看我们可以使用哪些列:
```py
raw_datasets["train"]
@@ -46,13 +45,14 @@ Dataset({
})
```
-我们可以看到数据集将文档字符串与代码分开,并且有他们各自的标记化后的结果。 这里。 我们将只使用 `whole_func_string` 列来训练我们的标记器。 我们可以通过指定到 `train` 中的一部分来查看这些函数的一个示例:
+我们可以看到数据集把函数的文档说明(func_documentation_string)与代码(func_code_string)分开保存,并提供了一个可以参考的分词后的结果(func_code_tokens)。在这里,我们仅使用 `whole_func_string` 列来训练我们的 tokenizer 我们可以通过索引来查看其中一个函数的示例:
+
```py
print(raw_datasets["train"][123456]["whole_func_string"])
```
-应该打印以下内容:
+应该输出以下内容:
```out
def handle_simple_responses(
@@ -69,16 +69,19 @@ def handle_simple_responses(
return self._accept_responses('OKAY', info_cb, timeout_ms=timeout_ms)
```
-我们需要做的第一件事是将数据集转换为迭代器文本列表 - 例如,文本列表。使用文本列表将使我们的标记器运行得更快(训练成批文本而不是一个接一个地处理单个文本),如果我们想避免一次将所有内容都放在内存中,它应该是一个迭代器。如果你的语料库很大,你会想要利用这样一个特性:🤗 Datasets 不会将所有内容都加载到 RAM 中,而是将数据集的元素存储在磁盘上。
+我们首先需要做的是将数据集转换为一个文本列表的 `迭代器` 例如,文本列表的列表。使用文本列表会使我们的 tokenizer 运行得更快(这样可以以文本批次为单位进行训练,而不是一次处理一个文本),并且使用迭代器可以不把所有内容都加载到内存中。如果你的语料库很大,你可能会想利用🤗 Datasets 将数据集的元素存储在磁盘上分批加载,而不是将所有内容加载到 RAM 的特性。
-执行以下操作将创建一个包含 1,000 个文本的列表的列表,但会将所有内容加载到内存中:
+下面的操作会创建一个由每个列包含 1000 个文本组成的文本列表,但会将所有内容加载到内存中:
```py
-# Don't uncomment the following line unless your dataset is small!
-# training_corpus = [raw_datasets["train"][i: i + 1000]["whole_func_string"] for i in range(0, len(raw_datasets["train"]), 1000)]
+# 除非你的数据集很小,否则不要直接运行下面的代码!
+# training_corpus = [
+# raw_datasets["train"][i: i + 1000]["whole_func_string"]
+# for i in range(0, len(raw_datasets["train"]), 1000)
+# ]
```
-使用 Python 生成器,我们可以避免 Python 将任何内容加载到内存中,直到真正需要为止。要创建这样的生成器,您只需要将括号替换为圆括号:
+通过使用 Python 生成器,我们可以使 Python 只将正在使用的数据加载到内存中。要创建这样一个生成器,你只需要将方括号替换为圆括号:
```py
training_corpus = (
@@ -87,9 +90,9 @@ training_corpus = (
)
```
-这行代码不会获取数据集的任何元素;它只是创建了一个可以在 Python 中使用的对象 **for** 环形。文本只会在您需要时加载(即,当您处于 **for** 需要它们的循环),并且一次只会加载 1,000 个文本。这样,即使您正在处理庞大的数据集,也不会耗尽所有内存。
+这行代码不会加载数据集的任何元素;它只创建了一个你可以在 Python for 循环中使用的对象。只有当你使用它们(即,当你在 `for` 循环尝试访问他们)时,文本才会被加载,而且一次只会加载 1000 个文本。这样,即使你在处理大型数据集,也不会耗尽所有内存。
-生成器对象的问题在于它只能使用一次,每次访问它将给出下一个值。 下面是一个例子:
+生成器对象的问题是它只能被使用一次。让我们尝试获取 2 次 10 个数字组成的列表:
```py
gen = (i for i in range(10))
@@ -97,14 +100,14 @@ print(list(gen))
print(list(gen))
```
-我们第一次得到了这个列表,然后是一个空列表:
+我们第一次得到了这个列表,第二次我们得到了一个空列表:
```python out
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[]
```
-这就是我们定义一个返回生成器的函数的原因:
+这就是为什么我们需要定义一个返回生成器的函数。通过每次调用函数生成一个新的生成器对象,我们可以多次使用生成器而不会遇到只能使用一次的限制。
```py
def get_training_corpus():
@@ -117,7 +120,7 @@ def get_training_corpus():
training_corpus = get_training_corpus()
```
-您还可以在一个 **for** 循环内部使用 **yield** 关键字定义您的生成器:
+你还可以在一个 `for` 循环内部使用 `yield` 关键字定义你的生成器:
```py
def get_training_corpus():
@@ -127,11 +130,11 @@ def get_training_corpus():
yield samples["whole_func_string"]
```
-这将产生与以前完全相同的生成器,但允许您使用比列表生成式中更复杂的逻辑。
+这将得到和上面列表生成器完全相同的生成器,但允许你在迭代器的过程中添加更复杂的逻辑。
-## 训练一个新的标记器 [[训练一个新的标记器]]
+## 训练一个新的 tokenizer [[训练一个新的 tokenizer ]]
-现在我们的语料库是文本批量迭代器的形式,我们准备训练一个新的标记器。为此,我们首先需要加载要与模型配对的标记器(此处为 GPT-2):
+现在我们已经将文本转化为迭代器形式准备好了我们的语料库,我们就可以开始训练新的 tokenizer 了。首先,我们需要加载我们想要与我们的模型匹配的 tokenizer (这我们这个例子中是 GPT-2):
```py
from transformers import AutoTokenizer
@@ -139,9 +142,9 @@ from transformers import AutoTokenizer
old_tokenizer = AutoTokenizer.from_pretrained("gpt2")
```
-即使我们要训练一个新的标记器,最好还是这样做以避免完全从头开始。这样,我们就不必指定任何关于标记化算法或我们想要使用的特殊标记;我们的新标记器将与 GPT-2 完全相同,唯一会改变的是输入的数据,这将取决于我们训练的语料。
+尽管我们要训练一个新的 tokenizer,但从旧的 tokenizer 开始初始化依然是个不错的主意,这样,我们就不必指定具体的 tokenization 算法或设置我们想要使用的特殊 tokens;我们新的 tokenizer 将与 GPT-2 完全相同,唯一的区别是词汇表,这将由我们的语料库通过训练来重新确定。
-首先让我们看看这个标记器将如何处理示例的数据:
+首先让我们看看旧的 tokenizer 将如何处理示例的数据:
```py
example = '''def add_numbers(a, b):
@@ -157,20 +160,21 @@ tokens
'Ġnumbers', 'Ġ`', 'a', '`', 'Ġand', 'Ġ`', 'b', '`', '."', '""', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
```
-这个标记器有一些特殊的符号,比如 **Ċ** 和 **Ġ** ,分别表示空格和换行符。正如我们所看到的,这不是太有效:标记器为每个空格返回单独的标记,当它可以将缩进级别组合在一起时(因为在代码中具有四个或八个空格的集合将非常普遍)。它也有点奇怪地拆分了函数名称,而习惯使用**_**的函数命名的方法。
+这个 tokenizer 输出了一些特殊的符号,比如 `Ċ` 和 `Ġ` ,分别表示空格和换行符。正如我们所看到的,这并不是非常高效:tokenizer 将每个空格视作为单独的 token,其实它可以将缩进级别组合在一起时(因为在代码中经常出现相邻在一起的四个或八个空格)。它也有点奇怪地拆分了函数名称,对使用 `_` 命名方法的函数并不友好。
-让我们训练一个新的标记器,看看它是否能解决这些问题。为此,我们将使用 **train_new_from_iterator()** 方法:
+让我们训练一个新的 tokenizer 看看它是否能解决这些问题。为此,我们将使用 `train_new_from_iterator()` 方法:
```py
tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, 52000)
```
-如果您的语料库非常大,此命令可能需要一些时间,但对于这个 1.6 GB 文本数据集,它的速度非常快(在具有 12 个内核的 AMD Ryzen 9 3900X CPU 上为 1 分 16 秒)。
-注意 **AutoTokenizer.train_new_from_iterator()** 仅当您使用的标记器是“快速(fast)”标记器时才有效。正如您将在下一节中看到的,🤗 Transformers 库包含两种类型的标记器:一些完全用 Python 编写,而另一些(快速的)由 🤗 Tokenizers 库支持,该库用[Rust](https://www.rust-lang.org)编程语言编写。 Python 是最常用于数据科学和深度学习应用程序的语言,但是当需要并行化以提高速度时,必须用另一种语言编写。例如,模型计算核心的矩阵乘法是用 CUDA 编写的,CUDA 是一个针对 GPU 的优化 C 库。
+如果你的语料库非常大,此命令可能需要一些时间,但对于这个 1.6 GB 文本数据集,它的速度非常快(在具有 12 个内核的 AMD Ryzen 9 3900X CPU 上仅需 1 分 16 秒)。
+
+注意 `AutoTokenizer.train_new_from_iterator()` 只有你使用的 tokenizer 是“快速(fast)” tokenizer 时才有效。下一节中,你将在看到,🤗 Transformers 库包含两种类型的 tokenizer 一些(慢速的)完全用 Python 编写,而另一些(快速的)由 🤗 Tokenizers 库支持,该库用 [Rust](https://www.rust-lang.org) 编程语言编写。Python 是最常用于数据科学和深度学习应用程序的语言,但是当需要并行化以提高速度时,就需要用另一种语言来编写。例如,模型计算核心的矩阵乘法是用 CUDA 编写的,这是一个针对 GPU 优化的 C 语言库。
-用纯 Python 训练一个全新的标记器会非常缓慢,这就是我们开发 🤗 Tokenizers库的原因。请注意,正如您无需学习 CUDA 语言即可在 GPU 上执行您的模型一样,您也无需学习 Rust 即可使用快速标记器。 🤗 Tokenizers 库为许多内部调用 Rust 代码的方法提供 Python 绑定;例如,并行化新标记器的训练,或者,正如我们在[第三章](/course/chapter3)中看到的,对一批输入进行标记化。
+用纯 Python 训练一个全新的 tokenizer 会非常缓慢,这就是我们开发 🤗 Tokenizers 库的原因。正如你无需学习 CUDA 语言即可在 GPU 上训练你的模型一样,你也无需学习 Rust 即可使用快速 tokenizer。🤗 Tokenizers 库为许多内部调用 Rust 代码的方法提供 Python 语言绑定;例如,并行化训练新的 tokenizer 或者像我们在 [第三章](/course/chapter3) 中看到的那样,对一批输入进行 tokenize。
-大多数 Transformer 模型都有可用的快速标记器(您可以[在这里](https://huggingface.co/transformers/#supported-frameworks)检查一些例外情况),如果 **AutoTokenizer** 可用,API 总是为您选择快速标记器。在下一节中,我们将看看快速标记器具有的其他一些特殊功能,这些功能对于标记分类和问答等任务非常有用。然而,在深入研究之前,让我们在上一个示例中尝试我们全新的标记器:
+大多数 Transformer 模型都有可用的快速 tokenizer (你可以 [在这里](https://huggingface.co/transformers/#supported-frameworks) 检查一些例外情况),如果 `AutoTokenizer` 可用,API 默认为你选择快速 tokenizer 在下一节中,我们将看看快速 tokenizer 具有的其他一些特殊功能,这些功能对于 token 分类和问答等任务非常有用。然而,在深入研究之前,让我们尝试在之前的例子上使用我们的全新 tokenizer
```py
tokens = tokenizer.tokenize(example)
@@ -182,7 +186,7 @@ tokens
'a', '`', 'Ġand', 'Ġ`', 'b', '`."""', 'ĊĠĠĠ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
```
-在这里我们再次看到特殊符号 **Ċ** 和 **Ġ** 表示空格和换行符,但我们也可以看到我们的标记器学习了一些高度特定于 Python 函数语料库的标记:例如,有一个 **ĊĠĠĠ** 表示缩进的标记,以及 **Ġ** 表示开始文档字符串的三个引号的标记。标记器还正确使用**_**命名的规范将函数名称拆分为 .这是一个非常紧凑的表示;相比之下,在同一个例子中使用简单的英语标记器会给我们一个更长的句子:
+在这里我们再次看到了表示空格和换行符的特殊符号 `Ċ` 和 `Ġ` ,但我们也可以看到我们的 tokenizer 学习了一些专属于 Python 函数语料库的 token:例如,有一个 `ĊĠĠĠ`token 表示缩进,以及 `Ġ` token 表示开始文档字符串的三个引号。tokenizer 也正确地在 `_` 上拆分了函数名称。这是一个非常紧凑的表示;相比之下,使用简单的英语 tokenizer 会得到一个更长的句子:
```py
print(len(tokens))
@@ -216,17 +220,17 @@ tokenizer.tokenize(example)
'Ġreturn', 'Ġx', 'Ġ@', 'Ġself', '.', 'weights', 'Ġ+', 'Ġself', '.', 'bias', 'ĊĠĠĠĠ']
```
-除了一个缩进对应的token,这里我们还可以看到一个双缩进的token: **ĊĠĠĠĠĠĠĠ** .特殊的 Python 词如 **class** , **init** , **call** , **self** , 和 **return** 每个都被标记为一个标记,我们可以看到,以及分裂 **_** 和 **.** 标记器甚至可以正确拆分驼峰式名称: **LinearLayer** 被标记为 **[ĠLinear, Layer]** .
+除了与缩进对应的 token 外,这里我们还可以看到一个与双缩进对应的 token : `ĊĠĠĠĠĠĠĠ` 。特殊的 Python 关键词如 `class` , `init` , `call` , `self` ,和 `return` 每个都被分配了一个 token ,我们还可以看到,除了可以在 `_` 和 `.` 上正确拆分,tokenizer 甚至可以正确拆分驼峰法命名的名称: `LinearLayer` 被分词为 `[ĠLinear, Layer]` 。
-## 保存标记器 [[保存标记器]]
+## 保存 tokenizer [[保存 tokenizer ]]
-为了确保我们以后可以使用它,我们需要保存我们的新标记器。就像模型一样,是通过 **save_pretrained()** 方法:
+为了确保我们以后可以使用它,我们需要保存我们的新 tokenizer 。像模型一样,是通过 `save_pretrained()` 方法进行保存:
```py
tokenizer.save_pretrained("code-search-net-tokenizer")
```
-这将创建一个名为的*code-search-net-tokenizer*的新文件夹,它将包含重新加载标记器所需要的所有文件。如果您想与您的同事和朋友分享这个标记器,您可以通过登录您的帐户将其上传到 Hub。如果您在notebook上工作,有一个方便的功能可以帮助您:
+这将创建一个名为的 `code-search-net-tokenizer` 的新文件夹,它将包含重新加载 tokenizer 所需要的所有文件。如果你想与你的同事和朋友分享这个 tokenizer 你可以通过登录你的帐户将其上传到 Hub。如果你在 notebook 上工作,有一个便捷的功能可以帮助你:
```python
from huggingface_hub import notebook_login
@@ -234,23 +238,23 @@ from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件,您可以在其中输入您的 Hugging Face 登录凭据。如果您不是在notebook上工作,只需在终端中输入以下行:
+这将显示一个小部件,你可以在其中输入你的 Hugging Face 账号密码。如果你不是在 notebook 上工作,只需在终端中输入以下行:
```bash
huggingface-cli login
```
-登录后,您可以通过执行以下命令来推送您的标记器:
+登录后,你可以通过执行以下命令来推送你的 tokenizer
```py
tokenizer.push_to_hub("code-search-net-tokenizer")
```
-这将在您的命名空间中创建一个名为**code-search-net-tokenizer**的新存储库 ,包含标记器文件。然后,您可以使用以下命令从任何地方加载标记器的 **from_pretrained()** 方法:
+这将在你的账户中创建一个名为 `code-search-net-tokenizer` 的新仓库,其中将包含 tokenizer 文件。然后,你可以使用 tokenizer 的 `from_pretrained()` 方法从任何地方加载 tokenizer 。
```py
-# Replace "huggingface-course" below with your actual namespace to use your own tokenizer
+# 将下面的 "huggingface-course" 替换为你的用户名来加载你的 tokenizer
tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
```
-您现在已准备好从头开始训练语言模型并根据您手头的任务对其进行微调!我们将在[第七章](/course/chapter7)进行这部分。但首先,在本章的其余部分,我们将仔细研究快速标记器,并详细探讨调用 **train_new_from_iterator()** 方法时实际发生的情况 .
+你现在已准备好从头开始训练语言模型并根据你手头的任务对其进行微调!我们将在 [第七章](/course/chapter7) 进行这部分。在本章的剩余部分,我们将仔细研究快速 tokenizer 并详细探讨调用 `train_new_from_iterator()` 方法时到底在幕后发生了什么。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/3.mdx b/chapters/zh-CN/chapter6/3.mdx
index 2cdcc95e3..1a9fea14a 100644
--- a/chapters/zh-CN/chapter6/3.mdx
+++ b/chapters/zh-CN/chapter6/3.mdx
@@ -1,6 +1,6 @@
-# 快速标记器的特殊能力 [[快速标记器的特殊能力]]
+# 快速 tokenizer 的特殊能力 [[快速 tokenizer 的特殊能力]]
{#if fw === 'pt'}
@@ -22,20 +22,18 @@
{/if}
-在本节中,我们将仔细研究 🤗 Transformers 中标记器的功能。到目前为止,我们只使用它们来标记输入或将 ID 解码回文本,但是标记器——尤其是那些由 🤗 Tokenizers 库支持的——可以做更多的事情。为了说明这些附加功能,我们将探索如何重现结果 **token-classification** (我们称之为 **ner** ) 和 **question-answering** 我们第一次在[Chapter 1](/course/chapter1)中遇到的管道.
+在本节中,我们将仔细研究 🤗 Transformers 中 tokenizer 的功能。到目前为止,我们只使用它们来对文本进行 tokenize 或将token ID 解码回文本,但是 tokenizer —— 特别是由🤗 Tokenizers 库支持的 tokenizer —— 能够做的事情还有很多。为了说明这些附加功能,我们将探讨如何复现在 [第一章](/course/chapter1) 中首次遇到的 `token-classification` (我们称之为 `ner` ) 和 `question-answering` 管道的结果。
-在接下来的讨论中,我们会经常区分“慢”和“快”分词器。慢速分词器是在 🤗 Transformers 库中用 Python 编写的,而快速版本是由 🤗 分词器提供的,它们是用 Rust 编写的。如果你还记得在[Chapter 5](/course/chapter5/3)中报告了快速和慢速分词器对药物审查数据集进行分词所需的时间的这张表,您应该知道为什么我们称它们为“快”和“慢”:
+在接下来的讨论中,我们会经常区分“慢速”和“快速” tokenizer 。慢速 tokenizer 是在 🤗 Transformers 库中用 Python 编写的,而快速版本是由 🤗 Tokenizers 提供的,它们是用 Rust 编写的。如果你还记得在 [第五章](/course/chapter5/3) 中对比了快速和慢速 tokenizer 对药物审查数据集进行 tokenize 所需的时间的这张表,你应该理解为什么我们称它们为“快速”和“慢速”:
-| | Fast tokenizer | Slow tokenizer
-:--------------:|:--------------:|:-------------:
-`batched=True` | 10.8s | 4min41s
-`batched=False` | 59.2s | 5min3s
+| | 快速 tokenizer | 慢速 tokenizer
+:--------------:|:--------------:|:-------------: `batched=True` | 10.8s | 4min41s `batched=False` | 59.2s | 5min3s
-⚠️ 对单个句子进行分词时,您不会总是看到相同分词器的慢速和快速版本之间的速度差异。事实上,快速版本实际上可能更慢!只有同时对大量文本进行标记时,您才能清楚地看到差异。
+⚠️ 对单个句子进行 tokenize 时,你不总是能看到同一个 tokenizer 的慢速和快速版本之间的速度差异。事实上,快速版本可能更慢!只有同时对大量文本进行 tokenize 时,你才能清楚地看到差异。
@@ -43,9 +41,11 @@
-分词器的输出不是简单的 Python 字典;我们得到的实际上是一个特殊的 **BatchEncoding** 目的。它是字典的子类(这就是为什么我们之前能够毫无问题地索引到该结果中的原因),但具有主要由快速标记器使用的附加方法。
+tokenizer 的输出不是简单的 Python 字典;我们得到的实际上是一个特殊的 `BatchEncoding` 对象。它是字典的子类(这就是为什么我们之前能够直接使用索引获取结果的原因),但是它还提供了一些主要由快速 tokenizer 提供的附加方法。
-除了它们的并行化能力之外,快速标记器的关键功能是它们始终跟踪最终标记来自的原始文本范围——我们称之为偏移映射.这反过来又解锁了诸如将每个单词映射到它生成的标记或将原始文本的每个字符映射到它内部的标记等功能,反之亦然。让我们看一个例子:
+除了它们的并行化能力之外,快速 tokenizer 的关键功能是它们始终跟踪最终 token 相对于的原始文本的映射——我们称之为 `偏移映射(offset mapping)` 。这反过来又解锁了如将每个词映射到它生成的 token,或者将原始文本的每个字符映射到它所在的 token 等功能。
+
+让我们看一个例子:
```py
from transformers import AutoTokenizer
@@ -56,13 +56,13 @@ encoding = tokenizer(example)
print(type(encoding))
```
-如前所述,我们得到一个 **BatchEncoding** 标记器输出中的对象:
+如前所述,我们从 tokenizer 得到了一个 `BatchEncoding` 对象:
```python out
```
-由于 **AutoTokenizer** 类默认选择快速标记器,我们可以使用附加方法 this **BatchEncoding** 对象提供。我们有两种方法来检查我们的分词器是快的还是慢的。我们可以检查 **is_fast** 的属性 **tokenizer** :
+由于 `AutoTokenizer` 类默认选择快速 tokenizer 因此我们可以使用 `BatchEncoding` 对象提供的附加方法。我们有两种方法来检查我们的 tokenizer 是快速的还是慢速的。我们可以检查 `tokenizer` 的 `is_fast` 属性:
```python
tokenizer.is_fast
@@ -72,7 +72,7 @@ tokenizer.is_fast
True
```
-或检查我们的相同属性 **encoding** :
+或检查我们 `encoding` 的 `is_fast` 属性:
```python
encoding.is_fast
@@ -82,7 +82,7 @@ encoding.is_fast
True
```
-让我们看看快速标记器使我们能够做什么。首先,我们可以访问令牌而无需将 ID 转换回令牌:
+让我们看看快速 tokenizer 能让为我们提供什么功能。首先,我们可以直接得到Ttokenization 之前的单词而无需将 ID 转换回单词:
```py
encoding.tokens()
@@ -93,7 +93,7 @@ encoding.tokens()
'Brooklyn', '.', '[SEP]']
```
-在这种情况下,索引 5 处的令牌是 **##yl** ,它是原始句子中“Sylvain”一词的一部分。我们也可以使用 **word_ids()** 获取每个标记来自的单词索引的方法:
+在这种情况下,索引 5 处的 token 是 `##yl` ,它是原始句子中“Sylvain”一词的一部分。我们也可以使用 `word_ids()` 方法来获取每个 token 原始单词的索引:
```py
encoding.word_ids()
@@ -103,19 +103,19 @@ encoding.word_ids()
[None, 0, 1, 2, 3, 3, 3, 3, 4, 5, 6, 7, 8, 8, 9, 10, 11, 12, None]
```
-我们可以看到分词器的特殊标记 **[CLS]** 和 **[SEP]** 被映射到 **None** ,然后每个标记都映射到它起源的单词。这对于确定一个标记是否在单词的开头或两个标记是否在同一个单词中特别有用。我们可以依靠 **##** 前缀,但它仅适用于类似 BERT 的分词器;这种方法适用于任何类型的标记器,只要它是快速的。在下一章中,我们将看到如何使用此功能将每个单词的标签正确应用于命名实体识别 (NER) 和词性 (POS) 标记等任务中的标记。我们还可以使用它来屏蔽来自屏蔽语言建模中来自同一单词的所有标记(一种称为全词掩码)。
+我们可以看到 tokenizer 的特殊 token `[CLS]` 和 `[SEP]` 被映射到 `None` ,然后每个 token 都映射到它来源的单词。这对于确定一个 token 是否在单词的开头或两个 token 是否在同一个单词中特别有用。对于 BERT 类型(BERT-like)的的 tokenizer 我们也可以依靠 `##` 前缀来实现这个功能;不过只要是快速 tokenizer 它所提供的 `word_ids()` 方法适用于任何类型的 tokenizer 。在下一章,我们将看到如何利用这种能力,将我们为每个词正确地对应到词汇任务中的标签,如命名实体识别(NER)和词性标注(POS)。我们也可以使用它在掩码语言建模(masked language modeling)中来遮盖来自同一词的所有 token(一种称为 `全词掩码(whole word masking)` 的技术)。
-一个词是什么的概念很复杂。例如,“I'll”(“I will”的缩写)算一两个词吗?它实际上取决于分词器和它应用的预分词操作。一些标记器只是在空格上拆分,因此他们会将其视为一个词。其他人在空格顶部使用标点符号,因此将其视为两个词。
+词的概念是复杂的。例如,“I'll”(“I will”的缩写)算作一个词还是两个词?这实际上取决于 tokenizer 和它采用的预分词操作。有些 tokenizer 只在空格处分割,所以它们会把这个看作是一个词。有些其他 tokenizer 在空格的基础之上还使用标点,所以会认为它是两个词。
-✏️ 试试看!从bert base cased和roberta base检查点创建一个标记器,并用它们标记“81s”。你观察到了什么?ID这个词是什么?
+✏️ **试试看!**从 `bert base cased` 和 `roberta base` checkpoint 创建一个 tokenizer 并用它们对“81s”进行分词。你观察到了什么?这些词的 ID 是什么?
-同样,有一个 **sentence_ids()** 我们可以用来将标记映射到它来自的句子的方法(尽管在这种情况下, **token_type_ids** 分词器返回的信息可以为我们提供相同的信息)。
+同样,我们还有一个 `sentence_ids()` 方法,可以用它把一个 token 映射到它原始的句子(尽管在这种情况下,tokenizer 返回的 `token_type_ids`也可以为我们提供相同的信息)。
-最后,我们可以将任何单词或标记映射到原始文本中的字符,反之亦然,通过 **word_to_chars()** 或者 **token_to_chars()** 和 **char_to_word()** 或者 **char_to_token()** 方法。例如, **word_ids()** 方法告诉我们 **##yl** 是索引 3 处单词的一部分,但它是句子中的哪个单词?我们可以这样发现:
+最后,我们可以通过 `word_to_chars()` 或 `token_to_chars()` 和 `char_to_word()` 或 `char_to_token()` 方法,将任何词或 token 映射到原始文本中的字符,反之亦然。例如, `word_ids()` 方法告诉我们 `##yl` 是索引 3 处单词的一部分,但它是句子中的哪个单词?我们可以这样找出来:
```py
start, end = encoding.word_to_chars(3)
@@ -126,17 +126,18 @@ example[start:end]
Sylvain
```
-正如我们之前提到的,这一切都是由快速标记器跟踪每个标记来自列表中的文本跨度这一事实提供支持的抵消.为了说明它们的用途,接下来我们将向您展示如何复制结果 **token-classification** 手动管道。
+如前所述,这一切都是由于快速分词器跟踪每个 token 来自的文本范围的一组*偏移*。为了阐明它们的作用,接下来我们将展示如何手动复现 `token-classification` 管道的结果。
+
-✏️ 试试看!创建您自己的示例文本,看看您是否能理解哪些标记与单词 ID 相关联,以及如何提取单个单词的字符跨度。对于奖励积分,请尝试使用两个句子作为输入,看看句子 ID 是否对您有意义。
+✏️ **试试看!** 使用自己的文本,看看你是否能理解哪些 token 与单词 ID 相关联,以及如何提取单个单词的字符跨度。附加题:请尝试使用两个句子作为输入,看看句子 ID 是否对你有意义。
-## 在令牌分类管道内 [[在令牌分类管道内]]
+## `token-classification` 管道内部流程 [[`token-classification`管道内部流程]]
-在[Chapter 1](/course/chapter1)我们第一次尝试使用 NER——任务是识别文本的哪些部分对应于个人、地点或组织等实体——使用 🤗 Transformers **pipeline()** 功能。然后,在[Chapter 2](/course/chapter2),我们看到了管道如何将从原始文本中获取预测所需的三个阶段组合在一起:标记化、通过模型传递输入和后处理。前两步 **token-classification** 管道与任何其他管道相同,但后处理稍微复杂一些 - 让我们看看如何!
+在 [第一章](/course/chapter1) 我们初次尝试实现命名实体识别(NER)——该任务是确定文本的哪些部分对应于人名、地名或组织名等实体——当时是使用🤗 Transformers 的 `pipeline()` 函数实现的。然后,在 [第二章](/course/chapter2) ,我们看到一个管道如何将获取原始文本到预测结果的三个阶段整合在一起:tokenize、通过模型处理输入和后处理。 `token-classification` 管道中的前两步与其他任何管道中的步骤相同,但后处理稍有复杂——让我们看看具体情况!
{#if fw === 'pt'}
@@ -148,9 +149,9 @@ Sylvain
{/if}
-### 通过管道获得基本结果 [[通过管道获得基本结果]]
+### 使用管道获得基本结果 [[使用管道获得基本结果]]
-首先,让我们获取一个标记分类管道,以便我们可以手动比较一些结果。默认使用的模型是[dbmdz/bert-large-cased-finetuned-conll03-english](https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english);它对句子执行 NER:
+首先,让我们获取一个 token 分类管道,以便我们可以手动比较一些结果。这次我们选用的模型是 [`dbmdz/bert-large-cased-finetuned-conll03-english`](https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english) ;我们使用它对句子进行 NER:
```py
from transformers import pipeline
@@ -170,7 +171,7 @@ token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
{'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
```
-该模型正确地将“Sylvain”生成的每个标记识别为一个人,将“Hugging Face”生成的每个标记识别为一个组织,将“Brooklyn”生成的标记识别为一个位置。我们还可以要求管道将对应于同一实体的令牌组合在一起:
+模型正确地识别出:“Sylvain”是一个人,“Hugging Face”是一个组织,以及“Brooklyn”是一个地点。我们也可以让管道将同一实体的 token 组合在一起:
```py
from transformers import pipeline
@@ -185,21 +186,19 @@ token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
{'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
```
-**aggregation_strategy** 选择将更改为每个分组实体计算的分数。和 **simple** 分数只是给定实体中每个标记的分数的平均值:例如,“Sylvain”的分数是我们在前面的示例中看到的标记分数的平均值 **S** , **##yl** , **##va** , 和 **##in** .其他可用的策略是:
-
-- `"first"`, 其中每个实体的分数是该实体的第一个标记的分数(因此对于“Sylvain”,它将是 0.993828,标记的分数)
+选择不同的 `aggregation_strategy` 可以更改每个分组实体计算的策略。对于 `simple` 策略,最终的分数就是给定实体中每个 token 的分数的平均值:例如,“Sylvain”的分数是我们在前一个例子中看到的 token `S` , `##yl` , `##va` ,和 `##in` 的分数的平均值。其他可用的策略包括:
-- `"max"`,其中每个实体的分数是该实体中标记的最大分数(因此对于“Hugging Face”,它将是 0.98879766,即“Face”的分数)
+- “first”,其中每个实体的分数是该实体的第一个 token 的分数(因此对于“Sylvain”,分数将是 0.993828,这是“S”的分数)
+- “max”,其中每个实体的分数是该实体中 token 的最大分数(因此对于“Hugging Face”,分数将是 0.98879766,即“Face”的分数)
+- “average”,其中每个实体的分数是组成该实体的单词分数的平均值(因此对于“Sylvain”,与“simple”策略相同,但“Hugging Face”的得分将是 0.9819,这是“Hugging”的分数 0.975 和“Face”的分数 0.98879 的平均值)
-- `"average"`, 其中每个实体的分数是组成该实体的单词分数的平均值(因此对于“Sylvain”,与“simple”策略,但“Hugging Face”的得分为 0.9819,“Hugging”得分的平均值为 0.975,“Face”得分为 0.98879)
-
-现在让我们看看如何在不使用pipeline()函数的情况下获得这些结果!
+现在让我们看看如何在不使用 `pipeline()` 函数的情况下获得这些结果!
### 从输入到预测 [[从输入到预测]]
{#if fw === 'pt'}
-首先,我们需要标记我们的输入并将其传递给模型。这是完全按照[Chapter 2](/course/chapter2);我们使用 **AutoXxx** 类,然后在我们的示例中使用它们:
+首先,我们需要将我们的输入进行 tokenization 并将其传递给模型。这个过程与 [第二章](/course/chapter2) 中的方法完全相同;我们使用 `AutoXxx` 类实例化 tokenizer 和模型,然后将我们的示例传递给它们:
```py
from transformers import AutoTokenizer, AutoModelForTokenClassification
@@ -213,7 +212,7 @@ inputs = tokenizer(example, return_tensors="pt")
outputs = model(**inputs)
```
-由于我们正在使用 **AutoModelForTokenClassification** 在这里,我们为输入序列中的每个标记获得一组 logits:
+由于我们在此使用了 `AutoModelForTokenClassification` ,所以我们得到了输入序列中每个 token 的一组 logits:
```py
print(inputs["input_ids"].shape)
@@ -227,7 +226,7 @@ torch.Size([1, 19, 9])
{:else}
-首先,我们需要标记我们的输入并将其传递给模型。这是完全按照[Chapter 2](/course/chapter2);我们使用 **AutoXxx** 类,然后在我们的示例中使用它们:
+首先,我们需要我们的输入 tokenization 并将其传递给模型。这个过程与 [第二章](/course/chapter2) 中的方法完全相同;我们使用 `TFAutoXxx` 类实例化 tokenizer 和模型,然后将我们的示例传递给它们:
```py
from transformers import AutoTokenizer, TFAutoModelForTokenClassification
@@ -241,7 +240,7 @@ inputs = tokenizer(example, return_tensors="tf")
outputs = model(**inputs)
```
-于我们正在使用 **AutoModelForTokenClassification** 在这里,我们为输入序列中的每个标记获得一组 logits:
+由于我们在此使用了 `TFAutoModelForTokenClassification` ,所以我们得到了输入序列中每个 token 的一组 logits:
```py
print(inputs["input_ids"].shape)
@@ -255,7 +254,7 @@ print(outputs.logits.shape)
{/if}
-我们有一个包含 19 个标记的 1 个序列的批次,模型有 9 个不同的标签,因此模型的输出具有 1 x 19 x 9 的形状。与文本分类管道一样,我们使用 softmax 函数来转换这些 logits到概率,我们采用 argmax 来获得预测(请注意,我们可以在 logits 上采用 argmax,因为 softmax 不会改变顺序):
+我们有一个包含 19 个 token 序列的 batch 和有 9 个不同的标签类型,所以模型的输出形状为 1 x 19 x 9。像文本分类管道一样,我们使用 softmax 函数将这些 logits 转化为概率,并取 argmax 来得到预测(请注意,我们可以在 logits 上直接算取 argmax,因为 softmax 不会改变顺序):
{#if fw === 'pt'}
@@ -285,7 +284,7 @@ print(predictions)
[0, 0, 0, 0, 4, 4, 4, 4, 0, 0, 0, 0, 6, 6, 6, 0, 8, 0, 0]
```
- **model.config.id2label** 属性包含索引到标签的映射,我们可以用它来理解预测:
+`model.config.id2label` 属性包含索引到标签的映射,我们可以用它来将预测转化为标签:
```py
model.config.id2label
@@ -303,16 +302,16 @@ model.config.id2label
8: 'I-LOC'}
```
-正如我们之前看到的,有 9 个标签: **O** 是不在任何命名实体中的标记的标签(它代表“外部”),然后我们为每种类型的实体(杂项、人员、组织和位置)提供两个标签。标签 **B-XXX** 表示令牌在实体的开头 **XXX** 和标签 **I-XXX** 表示令牌在实体内 **XXX** .例如,在当前示例中,我们希望我们的模型对令牌进行分类 **S** 作为 **B-PER** (一个人实体的开始)和令牌 **##yl** , **##va** 和 **##in** 作为 **I-PER** (在个人实体内)
+如前所述,这里有 9 个标签: `O` 是不在任何实体中的 token 的标签(它代表“outside”),然后我们为每种类型的实体(杂项、人员、组织和位置)提供两个标签:标签 `B-XXX` 表示 token 在实体 `XXX` 的开头,标签 `I-XXX` 表示 token 在实体 `XXX` 内部。例如,在当前的例子,我们期望我们的模型将 token `S` 分类为 `B-PER` (人物实体的开始),并且将 token `##yl` , `##va` 和 `##in` 分类为 `I-PER` (人物实体的内部)
-在这种情况下,您可能认为模型是错误的,因为它给出了标签 **I-PER** 对所有这四个令牌,但这并不完全正确。实际上有两种格式 **B-** 和 **I-** 标签:IOB1和IOB2. IOB2 格式(下面粉红色)是我们介绍的格式,而在 IOB1 格式(蓝色)中,标签以 **B-** 仅用于分隔相同类型的两个相邻实体。我们使用的模型在使用该格式的数据集上进行了微调,这就是它分配标签的原因 **I-PER** 到 **S** 令牌。
+你可能会觉得上面模型的输出是错误的,因为它给所有这四个 token 都标上了 `I-PER` 标签,但这样理解并不完全正确。对于 `B-` 和 `I-` 标签,实际上有两种格式:IOB1 和 IOB2。我们介绍的是 IOB2 格式(如下图所示的粉色),而在 IOB1 格式(蓝色)中,以 `B-` 开头的标签只用于分隔同一类型的两个相邻实体。我们正在使用的模型在使用该格式的数据集上进行了微调,这就是为什么它将 `S` token 标上了 `I-PER` 标签的原因。
-了这张地图,我们已经准备好(几乎完全)重现第一个管道的结果——我们可以获取每个未被归类为的标记的分数和标签 **O** :
+有了这个映射字典,我们就可以几乎完全复现管道的结果 —— 我们只需要获取每个没有被分类为 O 的 token 的得分和标签:
```py
results = []
@@ -339,7 +338,7 @@ print(results)
{'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn'}]
```
-这与我们之前的情况非常相似,只有一个例外:管道还为我们提供了有关 **start** 和 **end** 原始句子中的每个实体。这是我们的偏移映射将发挥作用的地方。要获得偏移量,我们只需要设置 **return_offsets_mapping=True** 当我们将分词器应用于我们的输入时:
+这与我们之前的结果非常相似,但有一点不同:pipeline 还给我们提供了每个实体在原始句子中的 `start` 和 `end` 的信息。如果要复现这个特性,这就是我们的偏移映射要发挥作用的地方。要获得偏移量,我们只需要在使用 tokenizer 器时设置 `return_offsets_mapping=True` :
```py
inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
@@ -351,20 +350,20 @@ inputs_with_offsets["offset_mapping"]
(33, 35), (35, 40), (41, 45), (46, 48), (49, 57), (57, 58), (0, 0)]
```
-每个元组是对应于每个标记的文本跨度,其中 **(0, 0)** 保留用于特殊令牌。我们之前看到索引 5 处的令牌是 **##yl** , 其中有 **(12, 14)** 作为这里的抵消。如果我们在示例中抓取相应的切片:
+每个元组都是每个 token 对应的文本范围,其中 `(0, 0)` 是为特殊 token 保留的。我们之前看到索引 5 的 token 是 `##yl` ,它所对应的偏移量是 `(12, 14)` 。如果我们截取我们例子中的对应片段:
```py
example[12:14]
```
-我们得到了正确的文本跨度,而没有 **##** :
+我们会得到没有 `##` 的文本:
```python out
yl
```
-使用这个,我们现在可以完成之前的结果:
+使用这个,我们现在可以完成之前的想法:
```py
results = []
@@ -400,13 +399,14 @@ print(results)
{'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
```
-这和我们从第一个管道中得到的一样!
+我们得到了与第一条 pipeline 相同的结果!
+
+### 实体分组 [[实体分组]]
-### 分组实体 [[分组实体]]
+使用偏移来确定每个实体的开始和结束的索引很方便,但这并不是它唯一的用法。当我们希望将实体分组在一起时,偏移映射将为我们省去很多复杂的代码。例如,如果我们想将 `Hu` 、 `##gging` 和 `Face` token 分组在一起,我们可以制定特殊规则,比如说前两个应该在去除 `##` 的同时连在一起, `Face` 应该在不以 `##` 开头的情况下增加空格 —— 但这些规则只适用于这种特定类型的分词器。当我们使用 SentencePiece 或 Byte-Pair-Encoding 分词器(在本章后面讨论)时就要重新写另外一套规则。
-使用偏移量来确定每个实体的开始和结束键很方便,但该信息并不是绝对必要的。然而,当我们想要将实体组合在一起时,偏移量将为我们节省大量混乱的代码。例如,如果我们想将令牌组合在一起 **Hu** , **##gging** , 和 **Face** ,我们可以制定特殊的规则,说前两个应该附加,同时删除 **##** ,以及 **Face** 应该添加一个空格,因为它不以 **##** — 但这仅适用于这种特定类型的标记器。我们必须为 SentencePiece 或 Byte-Pair-Encoding 分词器(本章稍后讨论)。
+有了偏移量,就可以免去为特定分词器定制特殊的分组规则:我们只需要取原始文本中以第一个 token 开始和最后一个 token 结束的范围。因此,假如说我们有 `Hu` 、 `##gging` 和 `Face` token,我们只需要从字符 33( `Hu` 的开始)截取到字符 45( `Face` 的结束):
-编写另一组规则。使用偏移量,所有自定义代码都消失了:我们可以在原始文本中获取从第一个标记开始到最后一个标记结束的跨度。所以,在令牌的情况下 **Hu** , **##gging** , 和 **Face** ,我们应该从字符 33(开始 **Hu** ) 并在字符 45 之前结束(结束 **Face** ):
```py
example[33:45]
@@ -416,7 +416,7 @@ example[33:45]
Hugging Face
```
-为了编写在对实体进行分组的同时对预测进行后处理的代码,我们将连续并标记为的实体分组在一起 **I-XXX** ,除了第一个,可以标记为 **B-XXX** 或者 **I-XXX** (因此,当我们得到一个实体时,我们停止对实体进行分组 **O** ,一种新型实体,或 **B-XXX** 这告诉我们一个相同类型的实体正在启动):
+为了编写处理预测结果并分组实体的代码,我们将对连续标记为 `I-XXX` 的实体进行分组,因为只有实体的第一个 token 可以被标记为 `B-XXX` 或 `I-XXX` ,因此,当我们遇到实体 `O` 、新类型的实体或 `B-XXX` 时,我们就可以停止聚合同一类型实体。
```py
import numpy as np
@@ -431,11 +431,11 @@ while idx < len(predictions):
pred = predictions[idx]
label = model.config.id2label[pred]
if label != "O":
- # Remove the B- or I-
+ # 删除 B- 或者 I-
label = label[2:]
start, _ = offsets[idx]
- # Grab all the tokens labeled with I-label
+ # 获取所有标有 I 标签的token
all_scores = []
while (
idx < len(predictions)
@@ -445,7 +445,7 @@ while idx < len(predictions):
_, end = offsets[idx]
idx += 1
- # The score is the mean of all the scores of the tokens in that grouped entity
+ # 分数是该分组实体中所有token分数的平均值
score = np.mean(all_scores).item()
word = example[start:end]
results.append(
@@ -462,7 +462,7 @@ while idx < len(predictions):
print(results)
```
-我们得到了与第二条管道相同的结果!
+我们得到了与第二条 pipeline 相同的结果!
```python out
[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
@@ -470,4 +470,4 @@ print(results)
{'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
```
-这些偏移量非常有用的另一个任务示例是问答。深入研究这个管道,我们将在下一节中进行,也将使我们能够了解 🤗 Transformers 库中标记器的最后一个功能:当我们将输入截断为给定长度时处理溢出的标记。
+另一个非常需要偏移量的任务领域是问答。我们将在下一部分深入探索这个 pipeline。同时我们也会看到🤗 Transformers 库中 tokenizer 的最后一个特性:在我们将输入超过给定长度时,处理溢出的 tokens。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/3b.mdx b/chapters/zh-CN/chapter6/3b.mdx
index 1c23ad523..c6c366722 100644
--- a/chapters/zh-CN/chapter6/3b.mdx
+++ b/chapters/zh-CN/chapter6/3b.mdx
@@ -1,6 +1,6 @@
-# QA 管道中的快速标记器 [[QA 管道中的快速标记器]]
+# 在 QA 管道中使用快速 tokenizer [[在 QA 管道中使用快速 tokenizer ]]
{#if fw === 'pt'}
@@ -22,7 +22,7 @@
{/if}
-我们现在将深入研究 **question-answering** 管道,看看如何利用偏移量从上下文中获取手头问题的答案,有点像我们在上一节中对分组实体所做的。然后我们将看到我们如何处理最终被截断的非常长的上下文。如果您对问答任务不感兴趣,可以跳过此部分。
+我们现在将深入研究 `question-answering` 管道,看看如何利用偏移量从上下文(context)中获取当前问题的答案,这与我们在上一节中处理分组实体的方式有些相似。我们会看到如何处理那些因为过长而最终被截断的上下文(context)。如果你对问答任务不感兴趣,可以跳过这一节。
{#if fw === 'pt'}
@@ -36,7 +36,7 @@
## 使用 `question-answering` 管道 [[使用 `question-answering` 管道]]
-正如我们在[Chapter 1](/course/chapter1),我们可以使用 **question-answering** 像这样的管道以获得问题的答案:
+正如我们在 [第一章](/course/chapter1) ,我们可以使用 `question-answering` 像这样的管道以获得问题的答案:
```py
from transformers import pipeline
@@ -57,7 +57,8 @@ question_answerer(question=question, context=context)
'answer': 'Jax, PyTorch and TensorFlow'}
```
-与其他管道不同,它不能截断和拆分长于模型接受的最大长度的文本(因此可能会丢失文档末尾的信息),此管道可以处理非常长的上下文,并将返回回答这个问题,即使它在最后:
+与其他不能处理超过模型接受的最大长度的文本的管道不同,这个管道可以处理非常长的上下文(context),并且即使答案在末尾也能返回问题的答案:
+
```py
long_context = """
@@ -107,11 +108,11 @@ question_answerer(question=question, context=long_context)
'answer': 'Jax, PyTorch and TensorFlow'}
```
-让我们看看它是如何做到这一切的!
+让我们看看它是如何做到这一点的!
## 使用模型进行问答 [[使用模型进行问答]]
-与任何其他管道一样,我们首先对输入进行标记化,然后通过模型将其发送。默认情况下用于的检查点 **question-answering** 管道是[distilbert-base-cased-distilled-squad](https://huggingface.co/distilbert-base-cased-distilled-squad)(名称中的“squad”来自模型微调的数据集;我们将在[Chapter 7](/course/chapter7/7)):
+与任何其他管道一样,我们首先对输入进行 tokenize,然后将其传入模型。 `question-answering` 管道默认情况下用于的 checkpoint 是 [distilbert-base-cased-distilled-squad](https://huggingface.co/distilbert-base-cased-distilled-squad) (名字中的"squad"源自模型微调所用的数据集;我们将在 [第七章](/course/chapter7/7) 详细讨论 SQuAD 数据集):
{#if fw === 'pt'}
@@ -141,14 +142,14 @@ outputs = model(**inputs)
{/if}
-请注意,我们将问题和上下文标记为一对,首先是问题
+请注意在这里,我们将问题放在前面和上下文放后面,一起作为一对进行tokenization。
-问答模型的工作方式与我们迄今为止看到的模型略有不同。以上图为例,该模型已经过训练,可以预测答案开始的标记的索引(此处为 21)和答案结束处的标记的索引(此处为 24)。这就是为什么这些模型不返回一个 logits 的张量,而是返回两个:一个用于对应于答案的开始标记的 logits,另一个用于对应于答案的结束标记的 logits。由于在这种情况下我们只有一个包含 66 个标记的输入,我们得到:
+问答模型的工作方式与我们迄今为止看到的模型略有不同。以上图为例,模型训练的目标是来预测答案开始的 token 的索引(这里是 21)和答案结束的 token 的索引(这里是 24)。这就是为什么这些模型不返回一个 logits 的张量,而是返回两个:一个对应于答案的开始 token 的 logits,另一个对应于答案的结束 token 的 logits。在这个例子中,我们的输入包含了 66 个 token ,因此我们得到:
```py
start_logits = outputs.start_logits
@@ -170,9 +171,9 @@ torch.Size([1, 66]) torch.Size([1, 66])
{/if}
-为了将这些 logits 转换为概率,我们将应用一个 softmax 函数——但在此之前,我们需要确保我们屏蔽了不属于上下文的索引。我们的输入是 **[CLS] question [SEP] context [SEP]** ,所以我们需要屏蔽问题的标记以及 **[SEP]** 令牌。我们将保留 **[CLS]** 然而,因为某些模型使用它来表示答案不在上下文中。
+为了将这些 logits 转换为概率,我们将使用一个 softmax 函数——但在此之前,我们需要确保我们屏蔽了不属于上下文的索引。我们的输入格式是 `[CLS] question [SEP] context [SEP]` ,所以我们需要屏蔽 question 的 tokens 以及 `[SEP]` token 。不过,我们将保留 `[CLS]` ,因为某些模型使用它来表示答案不在上下文中。
-由于我们将在之后应用 softmax,我们只需要用一个大的负数替换我们想要屏蔽的 logits。在这里,我们使用 **-10000** :
+由于我们将在之后使用 softmax,我们只需要将我们想要屏蔽的 logits 替换为一个大的负数就可以在计算 softmax 的时候屏蔽他们。在这里,我们使用 `-10000` :
{#if fw === 'pt'}
@@ -180,9 +181,9 @@ torch.Size([1, 66]) torch.Size([1, 66])
import torch
sequence_ids = inputs.sequence_ids()
-# Mask everything apart from the tokens of the context
+# 屏蔽除 context 之外的所有内容
mask = [i != 1 for i in sequence_ids]
-# Unmask the [CLS] token
+# 不屏蔽 [CLS] token
mask[0] = False
mask = torch.tensor(mask)[None]
@@ -196,9 +197,9 @@ end_logits[mask] = -10000
import tensorflow as tf
sequence_ids = inputs.sequence_ids()
-# Mask everything apart from the tokens of the context
+# 屏蔽除 context 之外的所有内容
mask = [i != 1 for i in sequence_ids]
-# Unmask the [CLS] token
+# 不屏蔽 [CLS] token
mask[0] = False
mask = tf.constant(mask)[None]
@@ -208,7 +209,7 @@ end_logits = tf.where(mask, -10000, end_logits)
{/if}
-现在我们已经正确屏蔽了与我们不想预测的位置相对应的 logits,我们可以应用 softmax:
+现在我们已经屏蔽了与我们不想预测的位置相对应的 logits,接下来我们可以使用 softmax:
{#if fw === 'pt'}
@@ -226,22 +227,24 @@ end_probabilities = tf.math.softmax(end_logits, axis=-1)[0].numpy()
{/if}
-在这个阶段,我们可以采用开始和结束概率的 argmax——但我们最终可能会得到一个大于结束索引的开始索引,所以我们需要采取更多的预防措施。我们将计算每个可能的概率 **start_index** 和 **end_index** 在哪里 **start_index <= end_index** ,然后取元组 **(start_index, end_index)** 以最高的概率。
+在这个阶段,我们可以取开始和结束概率的 argmax —— 但是我们可能会得到一个比结束索引大的开始索引,因此我们需要采取一些更多的措施来处理这些特殊情况。我们将在满足 `start_index <= end_index` 的前提下计算每个可能的 `start_index` 和 `end_index` 的概率,然后取概率最高的 `(start_index, end_index)` 元组。
+
+假设事件"答案开始于 `start_index` "和"答案结束于 `end_index` "是独立的,答案在 `start_index` 开始并在 `end_index` 结束的概率是:
-假设事件“答案开始于 **start_index** ”和“答案结束于 **end_index** ” 要独立,答案开始于的概率 **start_index** 并结束于 **end_index** 是:
+$$\mathrm{start\_probabilities}[\mathrm{start\_index}] \times\mathrm{end\_probabilities}[\mathrm{end\_index}]$$
-$$\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]$$
+所以,要计算所有的分数,我们只需要计算所有的 `start_index <= end_index` 的 \($$\mathrm{start\_probabilities}[\mathrm{start\_index}] \times\mathrm{end\_probabilities}[\mathrm{end\_index}]$$\) 的乘积。
-所以,要计算所有的分数,我们只需要计算所有的产品 \\(\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]\\) where `start_index <= end_index`.
-首先让我们计算所有可能的产品:
+首先让我们计算所有可能的乘积:
+
```py
scores = start_probabilities[:, None] * end_probabilities[None, :]
```
{#if fw === 'pt'}
-然后我们将屏蔽这些值 **start_index > end_index** 通过将它们设置为 **0** (其他概率都是正数)。这 **torch.triu()** 函数返回作为参数传递的 2D 张量的上三角部分,因此它会为我们做屏蔽:
+然后我们将 `start_index > end_index` 的值设置为 `0` 来屏蔽他们(其他概率都是正数)。 `torch.triu()` 函数返回传入的 2D 张量的上三角部分,所以我们可以使用它来完成屏蔽:
```py
import numpy as np
@@ -250,15 +253,15 @@ scores = torch.triu(scores)
```
{:else}
-然后我们将屏蔽这些值 **start_index > end_index** 通过将它们设置为 **0** (其他概率都是正数)。这 **torch.triu()** 函数返回作为参数传递的 2D 张量的上三角部分,因此它会为我们做屏蔽:
+然后我们将 `start_index > end_index` 的值设置为 `0` 来屏蔽他们(其他概率都是正数)。 `np.triu()` 函数返回传入的 2D 张量的上三角部分,所以我们做可以使用它来完成屏蔽:
```py
scores = np.triu(scores)
```
{/if}
-现在我们只需要得到最大值的索引。由于 PyTorch 将返回展平张量中的索引,因此我们需要使用地板除法 **//** 和模数 **%** 操作以获得 **start_index** 和 **end_index** :
+现在我们只需要得到最大值的索引。由于 PyTorch 将返回展平(flattened)后张量中的索引,因此我们需要使用向下取整的除法 `//` 和取模 `%` 操作来获得 `start_index` 和 `end_index` :
```py
max_index = scores.argmax().item()
@@ -267,7 +270,7 @@ end_index = max_index % scores.shape[1]
print(scores[start_index, end_index])
```
-我们还没有完全完成,但至少我们已经有了正确的答案分数(您可以通过将其与上一节中的第一个结果进行比较来检查这一点):
+我们还没有完全完成,但至少我们已经有了正确的答案分数(你可以通过将其与上一节中的第一个结果进行比较来检查这一点):
```python out
0.97773
@@ -275,11 +278,11 @@ print(scores[start_index, end_index])
-✏️ **试试看!** 计算五个最可能的答案的开始和结束索引。
+✏️ **试试看!** 计算五个最可能的答案的开始和结束索引。
-我们有 **start_index** 和 **end_index** 就标记而言的答案,所以现在我们只需要转换为上下文中的字符索引。这是偏移量非常有用的地方。我们可以像在令牌分类任务中一样抓住它们并使用它们:
+我们有了答案的 `start_index` 和 `end_index` ,所以现在我们只需要将他们转换为上下文中的字符索引。这就是偏移量将会非常有用的地方。我们可以像我们在 token 分类任务中那样获取偏移量并使用它们:
```py
inputs_with_offsets = tokenizer(question, context, return_offsets_mapping=True)
@@ -290,7 +293,8 @@ _, end_char = offsets[end_index]
answer = context[start_char:end_char]
```
-现在我们只需要格式化所有内容以获得我们的结果:
+现在我们只需要格式化所有内容,获取我们的结果:
+
```py
result = {
@@ -309,17 +313,17 @@ print(result)
'score': 0.97773}
```
-太棒了!这和我们的第一个例子一样!
+太棒了!这和我们上面获取的结果一样!
-✏️ **试试看!** 使用您之前计算的最佳分数来显示五个最可能的答案。要检查您的结果,请返回到第一个管道并在调用它时传入。
+✏️ **试试看!** 使用你之前计算的最佳分数来显示五个最可能的答案。你可以回到之前的 QA pipeline,并在调用时传入 `top_k=5` 来对比检查你的结果。
-## 处理长上下文 [[处理长上下文]]
+## 处理长文本 [[处理长文本]]
-如果我们尝试对我们之前作为示例使用的问题和长上下文进行标记化,我们将获得比在 **question-answering** 管道(即 384):
+如果我们尝试将我们之前使用的长问题和长上下文进行 tokenize,我们将得到一个比 `question-answering` pipeline 中使用的最大长度(384)更大的 tokens 数量:
```py
inputs = tokenizer(question, long_context)
@@ -330,7 +334,7 @@ print(len(inputs["input_ids"]))
461
```
-因此,我们需要在最大长度处截断我们的输入。有几种方法可以做到这一点,但我们不想截断问题,只想截断上下文。由于上下文是第二个句子,我们将使用 **"only_second"** 截断策略。那么出现的问题是问题的答案可能不在截断上下文中。例如,在这里,我们选择了一个答案在上下文末尾的问题,当我们截断它时,答案不存在
+所以,我们需要将我们的输入截断到模型允许输入的最大长度。我们可以用几种方式做到这一点,但我们不想截断问题部分,只想截断上下文部分,并且由于上下文部分是第二项,因此我们将使用 `"only_second"` 截断策略。然后又出现了新的问题:问题的答案可能在截断后被丢弃了,并没有在截断后保留下来的上下文文本中。例如,我们选了一个问题,其中的答案在上下文的末尾,当我们截断它时,答案就不在里面了:
```py
inputs = tokenizer(question, long_context, max_length=384, truncation="only_second")
@@ -373,9 +377,9 @@ Why should I use transformers?
"""
```
-这意味着模型将很难选择正确的答案。为了解决这个问题, **question-answering** 管道允许我们将上下文分成更小的块,指定最大长度。为确保我们不会在完全错误的位置拆分上下文以找到答案,它还包括块之间的一些重叠。
+这意味着模型将很难找到正确的答案。为了解决这个问题, `question-answering` 管道允许我们将上下文分成更小的块,指定最大长度。为了确保我们不在刚好可能找到答案的地方将上下文分割,它还在各块之间包含了一些重叠。
-我们可以让分词器(快或慢)通过添加来为我们做这件事 **return_overflowing_tokens=True** ,我们可以指定我们想要的重叠 **stride** 争论。这是一个使用较小句子的示例:
+我们可以通过添加 `return_overflowing_tokens=True` 参数,并可以用 `stride` 参数指定我们想要的重叠长度来让 tokenizer (快速或慢速)为我们做这个工作。下面是一个使用较短的句子的例子:
```py
sentence = "This sentence is not too long but we are going to split it anyway."
@@ -397,9 +401,9 @@ for ids in inputs["input_ids"]:
'[CLS] it anyway. [SEP]'
```
-正如我们所看到的,句子已被分成多个块,使得每个条目 **inputs["input_ids"]** 最多有 6 个标记(我们需要添加填充以使最后一个条目与其他条目的大小相同)并且每个条目之间有 2 个标记的重叠。
+正如我们所看到的,句子已被分成多个块,使得每个条目 `inputs["input_ids"]` 最多有 6 个 token (我们需要添加填充以使分割后的最后一个条目与其他条目的大小相同)并且每个条目之间有 2 个 token 的重叠。
-让我们仔细看看标记化的结果:
+让我们仔细看看tokenization的结果:
```py
print(inputs.keys())
@@ -409,7 +413,8 @@ print(inputs.keys())
dict_keys(['input_ids', 'attention_mask', 'overflow_to_sample_mapping'])
```
-正如预期的那样,我们得到了输入 ID 和一个注意力掩码。最后一个键, **overflow_to_sample_mapping** , 是一个映射,它告诉我们每个结果对应哪个句子——这里我们有 7 个结果,它们都来自我们通过标记器的(唯一)句子:
+
+正如我们所预期的,我们得到了inputs ID 和注意力掩码。最后一个键,overflow_to_sample_mapping,是一个映射,告诉我们每个结果对应哪个句子——在这里,我们有 7 个结果,它们都来自我们传递给 tokenizer 的(唯一的)句子:
```py
print(inputs["overflow_to_sample_mapping"])
@@ -419,7 +424,7 @@ print(inputs["overflow_to_sample_mapping"])
[0, 0, 0, 0, 0, 0, 0]
```
-当我们将几个句子标记在一起时,这更有用。例如,这个:
+当我们一起对多个句子 tokenize 时,这会更有用。例如,这个:
```py
sentences = [
@@ -433,16 +438,16 @@ inputs = tokenizer(
print(inputs["overflow_to_sample_mapping"])
```
-让我们:
+输出的结果是:
```python out
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
```
-这意味着第一个句子像以前一样分成 7 个块,接下来的 4 个块来自第二个句子。
+这意味着第一句话被分割成 7 个块,就像上面的例子一样,后面的 4 个块来自第二句话。
+现在让我们回到我们的长上下文。默认情况下, `question-answering pipeline` 使用我们之前提到的 384 作为最大长度,步长为 128,这与模型的微调方式相对应(你可以通过在调用 pipeline 时传递 `max_seq_len` 和 `stride` 参数来调整这些参数)。因此,我们在 tokenization 时将使用微调时使用的这些参数。我们还会添加填充(使样本具有相同的长度,这样我们就可以构建拼接成一个矩形的张量),并获取偏移量:
-现在让我们回到我们的长期背景。默认情况下 **question-answering** 管道使用的最大长度为 384,正如我们之前提到的,步长为 128,这对应于模型微调的方式(您可以通过传递 **max_seq_len** 和 **stride** 调用管道时的参数)。因此,我们将在标记化时使用这些参数。我们还将添加填充(具有相同长度的样本,因此我们可以构建张量)以及请求偏移量:
```py
inputs = tokenizer(
@@ -457,7 +462,8 @@ inputs = tokenizer(
)
```
-那些 **inputs** 将包含模型期望的输入 ID 和注意力掩码,以及偏移量和 **overflow_to_sample_mapping** 我们刚刚谈到。由于这两个不是模型使用的参数,我们将把它们从 **inputs** (我们不会存储地图,因为它在这里没有用)在将其转换为张量之前:
+这些 `inputs` 将包含模型期望的inputs ID 和注意力掩码,以及我们刚刚谈到的偏移量和 `overflow_to_sample_mapping` 。由于模型不需要这两个参数,我们将它们从 `inputs` 中删除(我们不会存储映射的字典,因为这在这里没有用)然后将 `inputs` 转换为张量:
+
{#if fw === 'pt'}
@@ -489,7 +495,7 @@ print(inputs["input_ids"].shape)
{/if}
-我们的长上下文被分成两部分,这意味着在它通过我们的模型后,我们将有两组开始和结束 logits:
+我们的长上下文被分成两部分,这意味着在经过我们的模型后,我们将得到两组开始和结束的 logits:
```py
outputs = model(**inputs)
@@ -513,17 +519,17 @@ torch.Size([2, 384]) torch.Size([2, 384])
{/if}
-和以前一样,我们在采用 softmax 之前首先屏蔽不属于上下文的标记。我们还屏蔽了所有填充标记(由注意掩码标记):
+和以前一样,我们在计算 softmax 之前屏蔽不属于上下文的 token 。我们还屏蔽了所有填充 token (如注意力掩码):
{#if fw === 'pt'}
```py
sequence_ids = inputs.sequence_ids()
-# Mask everything apart from the tokens of the context
+# 屏蔽除 context tokens 之外的所有内容
mask = [i != 1 for i in sequence_ids]
-# Unmask the [CLS] token
+# 取消对 [CLS] token 的屏蔽
mask[0] = False
-# Mask all the [PAD] tokens
+# 屏蔽所有的 [PAD] tokens
mask = torch.logical_or(torch.tensor(mask)[None], (inputs["attention_mask"] == 0))
start_logits[mask] = -10000
@@ -534,11 +540,11 @@ end_logits[mask] = -10000
```py
sequence_ids = inputs.sequence_ids()
-# Mask everything apart from the tokens of the context
+# 屏蔽除 context tokens 之外的所有内容
mask = [i != 1 for i in sequence_ids]
-# Unmask the [CLS] token
+# 取消对 [CLS] token的屏蔽
mask[0] = False
-# Mask all the [PAD] tokens
+# 屏蔽所有的 [PAD] tokens
mask = tf.math.logical_or(tf.constant(mask)[None], inputs["attention_mask"] == 0)
start_logits = tf.where(mask, -10000, start_logits)
@@ -565,7 +571,7 @@ end_probabilities = tf.math.softmax(end_logits, axis=-1).numpy()
{/if}
-下一步与我们对小上下文所做的类似,但我们对两个块中的每一个都重复它。我们将分数归因于所有可能的答案跨度,然后取得分最高的跨度:
+下一步与我们对短的上下文所做的类似,但在这里我们将对两个块分别进行处理。我们为所有可能的回答范围赋予一个得分,然后选择得分最高的范围:
{#if fw === 'pt'}
@@ -605,15 +611,16 @@ print(candidates)
[(0, 18, 0.33867), (173, 184, 0.97149)]
```
-这两个候选对应于模型能够在每个块中找到的最佳答案。该模型对正确答案在第二部分更有信心(这是一个好兆头!)。现在我们只需要将这两个标记跨度映射到上下文中的字符跨度(我们只需要映射第二个标记以获得我们的答案,但看看模型在第一个块中选择了什么很有趣)。
+这两个候选范围对应的是模型在每个块中能够找到的最好的答案。模型对于正确的答案在第二部分更有信心(这是个好兆头!)。现在我们只需要将这两个 token 范围映射到上下文中的字符范围(我们只需要映射第二个就能得到我们的答案,但是看看模型在第一块中选取了什么作为答案还是很有意思的)。
+
-✏️ **试试看!** 修改上面的代码以返回五个最可能的答案的分数和跨度(总计,而不是每个块)。
+✏️ **试试看!** 调整上面的代码,以返回五个最可能的答案的得分和范围(对于整个上下文,而不是单个块)。
-这 **offsets** 我们之前抓取的实际上是一个偏移量列表,每个文本块有一个列表:
+我们之前抓取 `offsets` 的实际上是一个偏移量列表,每个文本块都有一个列表:
```py
for candidate, offset in zip(candidates, offsets):
@@ -630,12 +637,12 @@ for candidate, offset in zip(candidates, offsets):
{'answer': 'Jax, PyTorch and TensorFlow', 'start': 1892, 'end': 1919, 'score': 0.97149}
```
-如果我们忽略第一个结果,我们会得到与这个长上下文的管道相同的结果——是的!
+如果我们选择分数最高的第二个结果,我们会得到与 QA 管道相同结果——耶!
-✏️ **试试看!** 使用您之前计算的最佳分数来显示五个最可能的答案(对于整个上下文,而不是每个块)。要检查您的结果,请返回到第一个管道并在调用它时传入。
+✏️ **试试看!** 使用你之前计算的最佳分数来显示五个最可能的答案(对于整个上下文,而不是单个块)。如果想要与 pipeline 对比检查你的结果的话,返回之前的 QA 管道,并在调用时传入 `top_k=5` 的参数。
-我们对分词器功能的深入研究到此结束。我们将在下一章再次将所有这些付诸实践,届时我们将向您展示如何在一系列常见的 NLP 任务上微调模型。
+我们已经结束了我们对 tokenizer 能力的深入探究。在下一章,我们将展示如何在一系列常见的 NLP 任务上微调模型,我们将对这些内容再次付诸实践。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/4.mdx b/chapters/zh-CN/chapter6/4.mdx
index 137aba74c..6064c0179 100644
--- a/chapters/zh-CN/chapter6/4.mdx
+++ b/chapters/zh-CN/chapter6/4.mdx
@@ -1,4 +1,4 @@
-# 标准化和预标记化 [[标准化和预标记化]]
+# 标准化和预分词 [[标准化和预分词]]
-在我们更深入地研究与 Transformer 模型(字节对编码 [BPE]、WordPiece 和 Unigram)一起使用的三种最常见的子词标记化算法之前,我们将首先看一下每个标记器应用于文本的预处理。以下是标记化管道中步骤的高级概述:
+在深入探讨 Transformer 模型常用的三种分词算法(字节对编码[BPE]、WordPiece 和 Unigram)之前,我们首先来看看 tokenizer 对文本进行了哪些预处理。以下是 tokenization 过程的高度概括:


-在将文本拆分为子标记之前(根据其模型),分词器执行两个步骤: _normalization_ 和 _pre-tokenization_.
+在分词(根据其模型)之前,tokenizer 需要进行两个步骤: `标准化(normalization)` 和 `预分词(pre-tokenization)` 。
-## 正常化 [[正常化]]
+## `标准化(normalization)` [[`标准化(normalization)`]]
-标准化步骤涉及一些常规清理,例如删除不必要的空格、小写和/或删除重音符号。如果你熟悉[Unicode normalization](http://www.unicode.org/reports/tr15/)(例如 NFC 或 NFKC),这也是 tokenizer 可能应用的东西。
+标准化步骤涉及一些常规清理,例如删除不必要的空格、小写和“/”或删除重音符号。如果你熟悉 [Unicode 标准化](http://www.unicode.org/reports/tr15/) (例如 NFC 或 NFKC),那么这也是 tokenizer 可能会使用的东西。
-🤗Transformers **tokenizer** 有一个属性叫做 **backend_tokenizer** 它提供了对 🤗 Tokenizers 库中底层标记器的访问:
+🤗 Transformers 的 `tokenizer` 具有一个名为 `backend_tokenizer` 的属性,该属性可以访问来自🤗 Tokenizers 库的底层 tokenizer 。
```py
from transformers import AutoTokenizer
@@ -35,7 +35,7 @@ print(type(tokenizer.backend_tokenizer))
```
-**normalizer** 的属性 **tokenizer** 对象有一个 **normalize_str()** 我们可以用来查看标准化是如何执行的方法:
+`tokenizer` 对象的 `normalizer` 属性具有一个 `normalize_str()` 方法,我们可以使用该方法查看如何进行标准化:
```py
print(tokenizer.backend_tokenizer.normalizer.normalize_str("Héllò hôw are ü?"))
@@ -45,22 +45,21 @@ print(tokenizer.backend_tokenizer.normalizer.normalize_str("Héllò hôw are ü?
'hello how are u?'
```
-在这个例子中,因为我们选择了 **bert-base-uncased** 检查点,标准化应用小写并删除重音。
+在这个例子中,由于我们选择了 `bert-base-uncased` checkpoint,所以会在标准化的过程中转换为小写并删除重音。
-✏️ **试试看!** 从检查点加载标记器并将相同的示例传递给它。您可以看到分词器的带壳和无壳版本之间的主要区别是什么?
-
+✏️ **试试看!** 从 `bert-base-cased` checkpoint 加载 tokenizer 并处理相同的示例。看一看 tokenizer 的 `cased` 和 `uncased` 版本之间的主要区别是什么?
-## 预标记化 [[预标记化]]
+## 预分词 [[预分词]]
-正如我们将在下一节中看到的,分词器不能单独在原始文本上进行训练。相反,我们首先需要将文本拆分为小实体,例如单词。这就是预标记化步骤的用武之地。 正如我们在[Chapter 2](/course/chapter2), 基于单词的标记器可以简单地将原始文本拆分为空白和标点符号的单词。这些词将是分词器在训练期间可以学习的子标记的边界。
+正如我们将在下一节中看到的,tokenizer 一般不会在原始文本上进行训练。因此,我们首先需要将文本拆分为更小的实体,例如单词。这就是预分词步骤的作用。正如我们在 [第二章](/course/chapter2) 中看到的,基于单词的 tokenizer 可以简单地根据空格和标点符号将原始文本拆分为单词。这些词将是 tokenizer 在训练期间可以学习的子词的边界。
-要查看快速分词器如何执行预分词,我们可以使用 **pre_tokenize_str()** 的方法 **pre_tokenizer** 的属性 **tokenizer** 目的:
+要查看快速 tokenizer 如何执行预分词,我们可以使用 `tokenizer` 对象的 `pre_tokenizer` 属性的 `pre_tokenize_str()` 方法:
```py
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
@@ -70,25 +69,26 @@ tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?
[('Hello', (0, 5)), (',', (5, 6)), ('how', (7, 10)), ('are', (11, 14)), ('you', (16, 19)), ('?', (19, 20))]
```
-请注意分词器如何已经跟踪偏移量,这就是它如何为我们提供上一节中使用的偏移量映射。这里分词器忽略了这两个空格,只用一个替换它们,但偏移量在 **are** 和 **you** 考虑到这一点。
+请注意 tokenizer 记录了偏移量,这是就是我们在前一节中使用的偏移映射。在这里 tokenizer 将两个空格并将它们替换为一个,从 `are` 和 `you` 之间的偏移量跳跃可以看出来这一点。
-由于我们使用的是 BERT 分词器,预分词涉及对空格和标点符号进行拆分。对于这一步,其他标记器可以有不同的规则。例如,如果我们使用 GPT-2 标记器:
+由于我们使用的是 BERT tokenizer 所以预分词会涉及到在空白和标点上进行分割。其他的 tokenizer 可能会对这一步有不同的规则。例如,如果我们使用 GPT-2 的 tokenizer
```py
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
```
-它也会在空格和标点符号上拆分,但它会保留空格并将它们替换为 **Ġ** 符号,如果我们解码令牌,则使其能够恢复原始空格:
+它也会在空格和标点符号上拆分,但它会保留空格并将它们替换为 `Ġ` 符号,如果我们对 tokens 进行解码,则使其能够恢复原始空格:
+
```python out
[('Hello', (0, 5)), (',', (5, 6)), ('Ġhow', (6, 10)), ('Ġare', (10, 14)), ('Ġ', (14, 15)), ('Ġyou', (15, 19)),
('?', (19, 20))]
```
-另请注意,与 BERT 分词器不同,此分词器不会忽略双空格
+也请注意,与 BERT tokenizer 不同的是,这个 tokenizer 不会忽略双空格。
-最后一个例子,让我们看一下基于 SentencePiece 算法的 T5 分词器:
+最后一个例子,让我们看一下基于 SentencePiece 算法的 T5 tokenizer
```py
tokenizer = AutoTokenizer.from_pretrained("t5-small")
@@ -99,26 +99,25 @@ tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?
[('▁Hello,', (0, 6)), ('▁how', (7, 10)), ('▁are', (11, 14)), ('▁you?', (16, 20))]
```
-与 GPT-2 标记器一样,这个标记器保留空格并用特定标记替换它们( **_** ),但 T5 分词器只在空格上拆分,而不是标点符号。还要注意,它默认在句子的开头添加了一个空格(之前 **Hello** ) 并忽略了之间的双空格 **are** 和 **you** .
+与 GPT-2 的 tokenizer 类似,这个 tokenizer 保留空格并用特定 token 替换它们( `_` ),但 T5 tokenizer 只在空格上拆分,不考虑标点符号。另外,它会在句子开头(在 `Hello` 之前)默认添加一个空格,并忽略 `are` 和 `you` 之间的双空格。
-现在我们已经了解了一些不同的标记器如何处理文本,我们可以开始探索底层算法本身。我们首先快速浏览一下广泛适用的 SentencePiece;然后,在接下来的三个部分中,我们将研究用于子词标记化的三种主要算法是如何工作的。
+现在我们对一些不同的 tokenizer 如何处理文本有了一些了解,接下来我们就可以开始探索底层算法本身。我们将先简要了解一下广泛适用的 SentencePiece;然后,在接下来的三节中,我们将研究用于子词分词的三种主要算法的工作原理。
-## 句子 [[句子]]
+## SentencePiece [[SentencePiece]]
-[SentencePiece](https://github.com/google/sentencepiece) 是一种用于文本预处理的标记化算法,您可以将其与我们将在接下来的三个部分中看到的任何模型一起使用。它将文本视为 Unicode 字符序列,并用特殊字符替换空格, **▁** .与 Unigram 算法结合使用(参见[section 7](/course/chapter7/7)), 它甚至不需要预标记化步骤,这对于不使用空格字符的语言(如中文或日语)非常有用。
+ [SentencePiece](https://github.com/google/sentencepiece) 是一种用于文本预处理的 tokenization 算法,你可以将其与我们将在接下来的三个部分中看到的任何模型一起使用。它将文本视为 Unicode 字符序列,并用特殊字符 `▁` 替换空格。与 Unigram 算法结合使用(参见 [第七节](/course/chapter7/7) )时,它甚至不需要预分词步骤,这对于不使用空格字符的语言(如中文或日语)非常有用。
-SentencePiece 的另一个主要特点是可逆标记化:由于没有对空格进行特殊处理,因此只需通过将它们连接起来并替换 **_** s 带空格——这会导致标准化的文本。正如我们之前看到的,BERT 分词器删除了重复的空格,因此它的分词是不可逆的。
+SentencePiece 的另一个主要特点是可逆 tokenization:由于没有对空格进行特殊处理,解码 tokens 的时候只需将它们连接起来,然后将 `_` 替换为空格,就可以还原原始的文本。如我们之前所见,BERT tokenizer 会删除重复的空格,所以它的分词不是可逆的。
## 算法概述 [[算法概述]]
-在下面的部分中,我们将深入研究三种主要的子词标记化算法:BPE(由 GPT-2 和其他人使用)、WordPiece(例如由 BERT 使用)和 Unigram(由 T5 和其他人使用)。在我们开始之前,这里是它们各自工作原理的快速概述。如果您还没有理解,请在阅读下一节后立即回到此表。
-
+在下面的部分中,我们将深入研究三种主要的子词 tokenization 算法:BPE(由 GPT-2 等使用)、WordPiece(由 BERT 使用)和 Unigram(由 T5 等使用)。在我们开始之前,先来快速了解它们各自的工作方式。如果你还不能理解,不妨在阅读接下来的每一节之后返回此表格进行查看。
-Model | BPE | WordPiece | Unigram
+模型 | BPE | WordPiece | Unigram
:----:|:---:|:---------:|:------:
-Training | Starts from a small vocabulary and learns rules to merge tokens | Starts from a small vocabulary and learns rules to merge tokens | Starts from a large vocabulary and learns rules to remove tokens
-Training step | Merges the tokens corresponding to the most common pair | Merges the tokens corresponding to the pair with the best score based on the frequency of the pair, privileging pairs where each individual token is less frequent | Removes all the tokens in the vocabulary that will minimize the loss computed on the whole corpus
-Learns | Merge rules and a vocabulary | Just a vocabulary | A vocabulary with a score for each token
-Encoding | Splits a word into characters and applies the merges learned during training | Finds the longest subword starting from the beginning that is in the vocabulary, then does the same for the rest of the word | Finds the most likely split into tokens, using the scores learned during training
+训练 | 从小型词汇表开始,学习合并 token 的规则 | 从小型词汇表开始,学习合并 token 的规则 | 从大型词汇表开始,学习删除 token 的规则
+训练步骤 | 合并对应最常见的 token 对 | 合并对应得分最高的 token 对,优先考虑每个独立 token 出现频率较低的对 | 删除会在整个语料库上最小化损失的词汇表中的所有 token
+学习 | 合并规则和词汇表 | 仅词汇表 | 含有每个 token 分数的词汇表
+编码 | 将一个单词分割成字符并使用在训练过程中学到的合并 | 从开始处找到词汇表中的最长子词,然后对其余部分做同样的事 | 使用在训练中学到找到最可能的 token 分割方式
现在让我们深入了解 BPE!
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/5.mdx b/chapters/zh-CN/chapter6/5.mdx
index e923db49b..4a8e1d4f7 100644
--- a/chapters/zh-CN/chapter6/5.mdx
+++ b/chapters/zh-CN/chapter6/5.mdx
@@ -1,4 +1,4 @@
-# 字节对编码标记化 [[字节对编码标记化]]
+# BPE tokenization 算法 [[BPE tokenization算法]]
-字节对编码(BPE)最初被开发为一种压缩文本的算法,然后在预训练 GPT 模型时被 OpenAI 用于标记化。许多 Transformer 模型都使用它,包括 GPT、GPT-2、RoBERTa、BART 和 DeBERTa。
+字节对编码(BPE)最初被开发为一种压缩文本的算法,然后在预训练 GPT 模型时被 OpenAI 用于 tokenization。许多 Transformer 模型都使用它,包括 GPT、GPT-2、RoBERTa、BART 和 DeBERTa。
-💡 本节深入介绍了BPE,甚至展示了一个完整的实现。如果你只想大致了解标记化算法,可以跳到最后。
+💡 本节深入介绍了 BPE,甚至展示了一个完整的实现。如果你只想大致了解 tokenization 算法,可以跳到最后。
-## 训练算法 [[训练算法]]
+## BPE 训练 [[BPE 训练]]
-BPE 训练首先计算语料库中使用的唯一单词集(在完成标准化和预标记化步骤之后),然后通过获取用于编写这些单词的所有符号来构建词汇表。一个非常简单的例子,假设我们的语料库使用了这五个词:
+BPE 训练首先计算语料库中使用的唯一单词集合(在完成标准化和预分词步骤之后),然后取出用来编写这些词的所有符号来构建词汇表。举一个非常简单的例子,假设我们的语料库使用了这五个词:
```
"hug", "pug", "pun", "bun", "hugs"
```
-基础词汇将是 `["b", "g", "h", "n", "p", "s", "u"]`。对于实际情况,基本词汇表将包含所有 ASCII 字符,至少,可能还包含一些 Unicode 字符。如果您正在标记的示例使用不在训练语料库中的字符,则该字符将转换为未知标记。这就是为什么许多 NLP 模型在分析带有表情符号的内容方面非常糟糕的原因之一。
+基础单词集合将是 `["b", "g", "h", "n", "p", "s", "u"]` 。在实际应用中,基本词汇表将至少包含所有 ASCII 字符,可能还包含一些 Unicode 字符。如果你正在 tokenization 不在训练语料库中的字符,则该字符将转换为未知 tokens,这就是为什么许多 NLP 模型在分析带有表情符号的内容的结果非常糟糕的原因之一。
-TGPT-2 和 RoBERTa 标记器(非常相似)有一个聪明的方法来处理这个问题: 他们不把单词看成是用 Unicode 字符写的,而是用字节写的。这样,基本词汇表的大小很小(256),但你能想到的每个字符仍将被包含在内,而不会最终转换为未知标记。这个技巧被称为 *字节级 BPE*。
+GPT-2 和 RoBERTa (这两者非常相似)的 tokenizer 有一个巧妙的方法来处理这个问题:他们不把单词看成是用 Unicode 字符编写的,而是用字节编写的。这样,基本词汇表的大小很小(256),但是能包含几乎所有你能想象的字符,而不会最终转换为未知 tokens 这个技巧被称为 `字节级(byte-level) BPE` 。
-获得这个基本词汇后,我们添加新的标记,直到通过学习*合并*达到所需的词汇量,这是将现有词汇表的两个元素合并为一个新元素的规则。因此,在开始时,这些合并将创建具有两个字符的标记,然后,随着训练的进行,会创建更长的子词。
+获得这个基础单词集合后,我们通过学习 `合并(merges)` 来添加新的 tokens 直到达到期望的词汇表大小。合并是将现有词汇表中的两个元素合并为一个新元素的规则。所以,一开始会创建出含有两个字符的 tokens 然后,随着训练的进展,会产生更长的子词。
-在分词器训练期间的任何一步,BPE 算法都会搜索最常见的现有标记对 ("对",这里我们指的是单词中的两个连续标记)。最频繁的一对将被合并,我们冲洗并重复下一步。
+在分词器训练期间的任何一步,BPE 算法都会搜索最常见的现有 tokens 对 (在这里,“对”是指一个词中的两个连续 tokens )。最常见的这一对会被合并,然后我们重复这个过程。
-回到我们之前的例子,让我们假设单词具有以下频率:
+回到我们之前的例子,让我们假设单词具有以下频率:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
-意味着 `"hug"` 在语料库中出现了10次, `"pug"` 5次, `"pun"` 12次, `"bun"` 4次, 以及 `"hugs"` 5次。我们通过将每个单词拆分为字符(形成我们初始词汇表的字符)来开始训练,这样我们就可以将每个单词视为一个标记列表:
+意思是 `"hug"` 在语料库中出现了 10 次, `"pug"` 出现了 5 次, `"pun"` 出现了 12 次, `"bun"` 出现了 4 次, `"hugs"` 出现了 5 次。我们通过将每个单词拆分为字符(形成我们初始词汇表的字符)来开始训练,这样我们就可以将每个单词视为一个 tokens 列表:
```
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
```
-然后我们看成对。这对 `("h", "u")` 出现在单词 `"hug"` 和 `"hugs"`中,所以语料库中总共有15次。不过,这并不是最频繁的一对:这个荣誉属于 `("u", "g")`,它出现在 `"hug"`, `"pug"`, 以及 `"hugs"`中,在词汇表中总共 20 次。
+然后我们看看相邻的字符对。 `("h", "u")` 在词 `"hug"` 和 `"hugs"` 中出现,所以在语料库中总共出现了 15 次。然而,最常见的对属于 `("u", "g")` ,它在 `"hug"` 、 `"pug"` 和 `"hugs"` 中出现,总共在词汇表中出现了 20 次。
-因此,标记器学习的第一个合并规则是 `("u", "g") -> "ug"`,意思就是 `"ug"` 将被添加到词汇表中,并且这对应该合并到语料库的所有单词中。在这个阶段结束时,词汇表和语料库看起来像这样:
+因此,tokenizer 学习的第一个合并规则是 `("u", "g") -> "ug"` ,意思就是 `"ug"` 将被添加到词汇表中,且应在语料库的所有词中合并这一对。在这个阶段结束时,词汇表和语料库看起来像这样:
```
-Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug"]
-Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
+词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug"]
+语料库: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
```
-现在我们有一些导致标记长于两个字符的对: 例如 `("h", "ug")`, 在语料库中出现15次。然而,这个阶段最频繁的对是 `("u", "n")`,在语料库中出现16次,所以学到的第二个合并规则是 `("u", "n") -> "un"`。将其添加到词汇表并合并所有现有的这个对,将出现:
+现在我们有一些对,继续合并的话会产生一个比两个字符长的 tokens 例如 `("h", "ug")` ,在语料库中出现 15 次。然而,这个阶段出现频率最高的对是 `("u", "n")` ,在语料库中出现 16 次,所以学到的第二个合并规则是 `("u", "n") -> "un"` 。将其添加到词汇表并合并所有现有的这个对,将出现:
```
-Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
-Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)
+词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
+语料库: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)
```
-现在最频繁的一对是 `("h", "ug")`,所以我们学习了合并规则 `("h", "ug") -> "hug"`,这给了我们第一个三个字母的标记。合并后,语料库如下所示:
+现在最频繁的一对是 `("h", "ug")` ,所以我们学习了合并规则 `("h", "ug") -> "hug"` ,这形成了我们第一个三个字母的 tokens 合并后,语料库如下所示:
```
-Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
-Corpus: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
+词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
+语料库: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
```
-我们继续这样合并,直到达到我们所需的词汇量。
+我们继续这样合并,直到达到我们所需的词汇量。
-✏️ **现在轮到你了!**你认为下一个合并规则是什么?
+✏️ **现在轮到你了!** 你认为下一个合并规则是什么?
-## 标记化算法 [[标记化算法]]
+## tokenization [[tokenization]]
-标记化紧跟训练过程,从某种意义上说,通过应用以下步骤对新输入进行标记:
+完成训练之后就可以对新的输入 tokenization 了,从某种意义上说,新的输入会依照以下步骤对新输入进行 tokenization:
-1. 规范化
-2. 预标记化
+1. 标准化
+2. 预分词
3. 将单词拆分为单个字符
-4. 将学习的合并规则按顺序应用于这些拆分
+4. 根据学习的合并规则,按顺序合并拆分的字符
-让我们以我们在训练期间使用的示例为例,学习三个合并规则:
+让我们以我们在训练期间使用的示例为例,Tokenizer 学习到了三个合并规则:
```
("u", "g") -> "ug"
@@ -97,19 +97,19 @@ Corpus: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5
("h", "ug") -> "hug"
```
-这个单词 `"bug"` 将被标记为 `["b", "ug"]`。然而 `"mug"`,将被标记为 `["[UNK]", "ug"]`,因为字母 `"m"` 不再基本词汇表中。同样,单词`"thug"` 会被标记为 `["[UNK]", "hug"]`: 字母 `"t"` 不在基本词汇表中,应用合并规则首先导致 `"u"` 和 `"g"` 被合并,然后是 `"hu"` 和 `"g"` 被合并。
+在这种情况下,单词 `"bug"` 将被转化为 `["b", "ug"]` 。然而 `"mug"` ,将被转换为 `["[UNK]", "ug"]` ,因为字母 `"m"` 不再基本词汇表中。同样,单词 `"thug"` 会被转换为 `["[UNK]", "hug"]` :字母 `"t"` 不在基本词汇表中,使用合并规则首先会将 `"u"` 和 `"g"` 合并,然后将 `"h"` 和 `"ug"` 合并。
-✏️ **现在轮到你了!** 你认为这个词 `"unhug"` 将如何被标记?
+✏️ **现在轮到你了!** 你认为这个词 `"unhug"` 将如何被 tokenization?
-## 实现 BPE [[实现 BPE]]
+## 实现 BPE 算法[[实现 BPE 算法]]
-现在让我们看一下 BPE 算法的实现。这不会是你可以在大型语料库上实际使用的优化版本;我们只是想向你展示代码,以便你可以更好地理解算法
+现在,让我们看一下 BPE 算法的实现。这并不是在大型语料库上实际使用的经过优化的版本;我们只是想向你展示代码,以便你可以更好地理解算法
-首先我们需要一个语料库,所以让我们用几句话创建一个简单的语料库:
+首先,我们需要一个语料库,让我们创建一个含有几句话的简单语料库:
```python
corpus = [
@@ -120,7 +120,7 @@ corpus = [
]
```
-接下来,我们需要将该语料库预先标记为单词。由于我们正在复制 BPE 标记器(如 GPT-2),我们将使用 `gpt2` 标记器作为预标记化的标记器:
+接下来,我们需要将该语料库预分词为单词。由于我们正在复现一个 BPE tokenizer (例如 GPT-2),我们将使用 `gpt2` 分词器进行预分词:
```python
from transformers import AutoTokenizer
@@ -128,7 +128,7 @@ from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
```
-然后我们在进行预标记化时计算语料库中每个单词的频率:
+然后,我们在进行预分词的同时计算语料库中每个单词的频率:
```python
from collections import defaultdict
@@ -151,7 +151,7 @@ defaultdict(int, {'This': 3, 'Ġis': 2, 'Ġthe': 1, 'ĠHugging': 1, 'ĠFace': 1,
'Ġthey': 1, 'Ġare': 1, 'Ġtrained': 1, 'Ġand': 1, 'Ġgenerate': 1, 'Ġtokens': 1})
```
-下一步是计算基本词汇,由语料库中使用的所有字符组成:
+下一步是计算基础词汇表,这由语料库中使用的所有字符组成:
```python
alphabet = []
@@ -170,19 +170,19 @@ print(alphabet)
't', 'u', 'v', 'w', 'y', 'z', 'Ġ']
```
-我们还在该词汇表的开头添加了模型使用的特殊标记。对于GPT-2,唯一的特殊标记是 `"<|endoftext|>"`:
+我们还在该词汇表的开头添加了模型使用的特殊 tokens 对于 GPT-2,唯一的特殊 tokens 是 `"<|endoftext|>"` :
```python
vocab = ["<|endoftext|>"] + alphabet.copy()
```
-我们现在需要将每个单词拆分为单独的字符,以便能够开始训练:
+我们现在需要将每个单词拆分为单独的字符,以便能够开始训练:
```python
splits = {word: [c for c in word] for word in word_freqs.keys()}
```
-现在我们已准备好进行训练,让我们编写一个函数来计算每对的频率。我们需要在训练的每个步骤中使用它:
+现在我们已准备好进行训练,让我们编写一个函数来计算每对字符的频率。我们需要在训练的每个步骤中使用它:
```python
def compute_pair_freqs(splits):
@@ -197,7 +197,7 @@ def compute_pair_freqs(splits):
return pair_freqs
```
-让我们来看看这个字典在初始拆分后的一部分:
+让我们来看看这个字典在初始合并后的一些结果:
```python
pair_freqs = compute_pair_freqs(splits)
@@ -217,7 +217,8 @@ for i, key in enumerate(pair_freqs.keys()):
('t', 'h'): 3
```
-现在, 找到最频繁的对只需要一个快速的循环:
+现在,只需要一个简单的循环就可以找到出现频率最高的对:
+
```python
best_pair = ""
@@ -235,14 +236,14 @@ print(best_pair, max_freq)
('Ġ', 't') 7
```
-所以第一个要学习的合并是 `('Ġ', 't') -> 'Ġt'`, 我们添加 `'Ġt'` 到词汇表:
+所以第一个要学习的合并规则是 `('Ġ', 't') -> 'Ġt'` ,我们将 `'Ġt'` 添加到词汇表:
```python
merges = {("Ġ", "t"): "Ġt"}
vocab.append("Ġt")
```
-要继续接下来的步骤,我们需要在我们的`分词`字典中应用该合并。让我们为此编写另一个函数:
+接下来,我们需要在我们的 `splits` 字典中进行这个合并。让我们为此编写另一个函数:
```python
def merge_pair(a, b, splits):
@@ -261,7 +262,7 @@ def merge_pair(a, b, splits):
return splits
```
-我们可以看看第一次合并的结果:
+我们可以观察一下第一次合并的结果:
```py
splits = merge_pair("Ġ", "t", splits)
@@ -272,7 +273,7 @@ print(splits["Ġtrained"])
['Ġt', 'r', 'a', 'i', 'n', 'e', 'd']
```
-现在我们有了循环所需的一切,直到我们学会了我们想要的所有合并。我们的目标是词汇量达到50:
+现在我们有了我们需要的所有代码,可以循环直到我们学习到我们想要的所有合并。让我们把目标词汇表的大小设定为 50:
```python
vocab_size = 50
@@ -290,7 +291,7 @@ while len(vocab) < vocab_size:
vocab.append(best_pair[0] + best_pair[1])
```
-结果,我们学习了 19 条合并规则(初始词汇表的大小 31 -- 30 字母字符,加上特殊标记):
+最终,我们学习了 19 条合并规则(初始词汇量为 31 —— 字母表中的 30 个字符,加上特殊 token ):
```py
print(merges)
@@ -303,7 +304,7 @@ print(merges)
('i', 'n'): 'in', ('Ġa', 'b'): 'Ġab', ('Ġtoken', 'i'): 'Ġtokeni'}
```
-词汇表由特殊标记、初始字母和所有合并结果组成:
+词汇表由特殊 token 初始字母和所有合并结果组成:
```py
print(vocab)
@@ -317,11 +318,11 @@ print(vocab)
-💡 在同一语料库上使用 `train_new_from_iterator()` 不会产生完全相同的词汇表。这是因为当有最频繁对的选择时,我们选择遇到的第一个, 而 🤗 Tokenizers 库根据内部ID选择第一个。
+💡 在同一语料库上使用 `train_new_from_iterator()` 可能不会产生完全相同的词汇表。这是因为当有多个出现频率最高的对时,我们选择遇到的第一个,而 🤗 Tokenizers 库根据内部 ID 选择第一个。
-为了对新文本进行分词,我们对其进行预分词、拆分,然后应用学到的所有合并规则:
+为了对新文本进行分词,我们对其进行预分词、拆分,然后使用学到的所有合并规则:
```python
def tokenize(text):
@@ -341,7 +342,8 @@ def tokenize(text):
return sum(splits, [])
```
-我们可以在任何由字母表中的字符组成的文本上尝试这个:
+我们可以尝试在任何由字母表中的字符组成的文本上进行此操作:
+
```py
tokenize("This is not a token.")
@@ -353,8 +355,8 @@ tokenize("This is not a token.")
-⚠️ 如果存在未知字符,我们的实现将抛出错误,因为我们没有做任何处理它们。GPT-2 实际上没有未知标记(使用字节级 BPE 时不可能得到未知字符),但这可能发生在这里,因为我们没有在初始词汇表中包含所有可能的字节。 BPE 的这方面超出了本节的范围,因此我们忽略了细节。
+⚠️ 如果存在未知字符,我们的实现将抛出错误,因为我们没有做任何处理它们。GPT-2 实际上没有未知 tokens (使用字节级 BPE 时不可能得到未知字符),但这里的代码可能会出现这个错误,因为我们并未在初始词汇中包含所有可能的字节。BPE 的这一部分已超出了本节的范围,因此我们省略了一些细节。
-这就是 BPE 算法!接下来,我们将看看 WordPiece。
\ No newline at end of file
+至此,BPE 算法的介绍就到此结束!接下来,我们将研究 WordPiece 算法。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/6.mdx b/chapters/zh-CN/chapter6/6.mdx
index 8f3b746ba..799c8737c 100644
--- a/chapters/zh-CN/chapter6/6.mdx
+++ b/chapters/zh-CN/chapter6/6.mdx
@@ -1,4 +1,4 @@
-# WordPiece 标记化 [[WordPiece 标记化]]
+# WordPiece tokenization 算法 [[WordPiece tokenization算法]]
-WordPiece 是 Google 为预训练 BERT 而开发的标记化算法。此后,它在不少基于 BERT 的 Transformer 模型中得到重用,例如 DistilBERT、MobileBERT、Funnel Transformers 和 MPNET。它在训练方面与 BPE 非常相似,但实际标记化的方式不同。
+WordPiece 是 Google 开发的用于 BERT 预训练的分词算法。自此之后,很多基于 BERT 的 Transformer 模型都复用了这种方法,比如 DistilBERT,MobileBERT,Funnel Transformers 和 MPNET。它在训练方面与 BPE 非常类似,但实际的分词方法有所不同。
-💡 本节深入介绍 WordPiece,甚至展示完整的实现。如果您只想大致了解标记化算法,可以跳到最后。
+💡 本节详细讲述了 WordPiece,甚至展示了一个完整的实现。如果你只想对这个分词算法有个大概的理解,可以直接跳到最后。
-## 训练算法 [[训练算法]]
+## WordPiece 训练 [[WordPiece 训练]]
-⚠️ Google 从未开源 WordPiece 训练算法的实现,因此以下是我们基于已发表文献的最佳猜测。它可能不是 100% 准确的。
+⚠️ Google 从未开源 WordPiece 训练算法的实现,因此以下是我们基于已发表文献的最佳猜测。它可能并非 100% 准确的。
-与 BPE 一样,WordPiece 从一个小词汇表开始,包括模型使用的特殊标记和初始字母表。因为它通过添加前缀来识别子词 (如同 `##` 对于 BERT),每个单词最初是通过将该前缀添加到单词内的所有字符来拆分的。所以,例如 `"word"` ,像这样拆分:
+与BPE 一样,WordPiece 也是从包含模型使用的特殊 tokens 和初始字母表的小词汇表开始的。由于它是通过添加前缀(如 BERT 中的 `##` )来识别子词的,每个词最初都会通过在词内部所有字符前添加该前缀进行分割。因此,例如 `"word"` 将被这样分割:
```
w ##o ##r ##d
```
-因此,初始字母表包含出现在单词开头的所有字符以及出现在单词内部的以 WordPiece 前缀开头的字符。
+因此,初始字母表包含所有出现在单词第一个位置的字符,以及出现在单词内部并带有 WordPiece 前缀的字符。
-然后,再次像 BPE 一样,WordPiece 学习合并规则。主要区别在于选择要合并的对的方式。WordPiece 不是选择最频繁的对,而是使用以下公式计算每对的分数:
+然后,同样像 BPE 一样,WordPiece 会学习合并规则。主要的不同之处在于合并对的选择方式。WordPiece 不是选择频率最高的对,而是对每对计算一个得分,使用以下公式:
-$$\mathrm{score} = (\mathrm{freq\_of\_pair}) / (\mathrm{freq\_of\_first\_element} \times \mathrm{freq\_of\_second\_element})$$
-通过将配对的频率除以其每个部分的频率的乘积, 该算法优先合并单个部分在词汇表中频率较低的对。例如,它不一定会合并 `("un", "##able")` 即使这对在词汇表中出现的频率很高,因为 `"un"` 和 `"##able"` 很可能每个词都出现在很多其他词中并且出现频率很高。相比之下,像 `("hu", "##gging")` 可能会更快地合并 (假设 "hugging" 经常出现在词汇表中),因为 `"hu"` 和 `"##gging"` 这两个词单独出现地频率可能较低。
+$$\mathrm{score} = (\mathrm{freq\_of\_pair}) / (\mathrm{freq\_of\_first\_element} \times\mathrm{freq\_of\_second\_element})$$
-让我们看看我们在 BPE 训练示例中使用的相同词汇:
+通过将两部分合在一起的频率除以其中各部分的频率的乘积,该算法优先合并那些在词汇表中单独出现出现的对。例如,即使 `("un", "##able")` 这对在词汇表中出现的频率很高,它也不一定会被合并,因为 `"un"` 和 `"##able"` 这两对可能会在很多其他词中出现,频率很高。相比之下,像 `("hu", "##gging")` 这样的对可能会更快地被合并(假设单词“hugging”在词汇表中出现的频率很高),因为 `"hu"` 和 `"##gging"` 可能分别出现的频率较低。
+
+我们使用与 BPE 示例相同的词汇表:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
-这里的拆分将是:
+经过分割之后将会是:
```
("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##g" "##s", 5)
```
-所以最初的词汇将是 `["b", "h", "p", "##g", "##n", "##s", "##u"]` (如果我们暂时忘记特殊标记)。最频繁的一对是 `("##u", "##g")` (目前20次),但 `"##u"` 单独出现的频率非常高,所以它的分数不是最高的(它是 1 / 36)。所有带有 `"##u"` 的对实际上都有相同的分数(1 / 36),所以分数最高的对是 `("##g", "##s")` -- 唯一没有 `"##u"` 的对-- 1 / 20,所以学习的第一个合并是 `("##g", "##s") -> ("##gs")`。
+所以最初的词汇表将会是 `["b", "h", "p", "##g", "##n", "##s", "##u"]` (如果我们暂时忽略特殊 tokens )。出现频率最高的一对是 `("##u", "##g")` (目前 20 次),但 `"##u"` 和其他单词一起出现的频率非常高,所以它的分数不是最高的(分数是 1 / 36)。所有带有 `"##u"` 的对实际上都有相同的分数(1 / 36),所以分数最高的对是 `("##g", "##s")` —— 唯一没有 `"##u"` 的对——分数是 1 / 20,所以学习的第一个合并是 `("##g", "##s") -> ("##gs")` 。
-请注意,当我们合并时,我们删除了两个标记之间的 `##`,所以我们添加 `"##gs"` 到词汇表中,并在语料库的单词中应用该合并:
+请注意,当我们合并时,我们会删除两个 tokens 之间的 `##` ,所以我们将 `"##gs"` 添加到词汇表中,并将语料库的单词按照改规则进行合并:
```
-Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs"]
-Corpus: ("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##gs", 5)
+词汇表: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs"]
+语料库: ("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##gs", 5)
```
-在这一点中, `"##u"` 是在所有可能的对中,因此它们最终都具有相同的分数。假设在这种情况下,第一对被合并, `("h", "##u") -> "hu"`。这使得我们:
+此时, `"##u"` 出现在所有可能的对中,因此它们最终都具有相同的分数。在这种情况下,第一个对会被合并,于是我们得到了 `("h", "##u") -> "hu"` 规则:
```
-Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu"]
-Corpus: ("hu" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hu" "##gs", 5)
+词汇表: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu"]
+语料库: ("hu" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hu" "##gs", 5)
```
-然后下一个最高的分数由 `("hu", "##g")` 和 `("hu", "##gs")` 共享(1/15,与其他所有对的 1/21 相比),因此合并得分最高的第一对:
+然后,下一个最佳得分的对是 `("hu", "##g")` 和 `("hu", "##gs")` (得分为 1/15,而所有其他配对的得分为 1/21),因此得分最高的第一对合并:
```
-Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu", "hug"]
-Corpus: ("hug", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hu" "##gs", 5)
+词汇表: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu", "hug"]
+语料库: ("hug", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hu" "##gs", 5)
```
-我们继续这样处理,直到达到我们所需的词汇量。
+然后我们就按此方式继续,直到我们达到所需的词汇表大小。
-✏️ **现在轮到你了!** 下一个合并规则是什么?
+✏️ **现在轮到你了!** 下一个合并规则是什么?
+
-## 标记化算法 [[标记化算法]]
+## tokenization 算法 [[tokenization 算法]]
-WordPiece 和 BPE 中的标记化的不同在于 WordPiece 只保存最终词汇,而不是学习的合并规则。从要标记的单词开始,WordPiece 找到词汇表中最长的子词,然后对其进行拆分。例如,如果我们使用上面例子中学到的词汇,对于单词 `"hugs"`,词汇表中从头开始的最长子词是 `"hug"`,所以我们在那里拆分并得到 `["hug", "##s"]`。 然后我们继续使用词汇表中的 `"##s"`,因此 `"hugs"` 的标记化是 `["hug", "##s"]`.
+WordPiece 和 BPE 的分词方式有所不同,WordPiece 只保存最终词汇表,而不保存学习到的合并规则。WordPiece 从待分词的词开始,找到词汇表中最长的子词,然后在其处分割。例如,如果我们使用上述示例中学习到的词汇表,对于词 `"hugs"` ,从开始处的最长子词在词汇表中是 `"hug"` ,所以我们在那里分割,得到 `["hug", "##s"]` 。然后我们继续处理 `"##s"` ,它在词汇表中,所以 `"hugs"` 的分词结果是 `["hug", "##s"]` 。
-使用 BPE, 我们将按顺序应用学习到的合并并将其标记为 `["hu", "##gs"]`,所以编码不同。
+如果使用 BPE,我们会按照学习到的合并规则进行合并,并将其分词为 `["hu", "##gs"]` ,不同的字词分词算法所以最终得到的编码是不同的。
-再举一个例子,让我们看看 `"bugs"` 将如何被标记化。 `"b"` 是从词汇表中单词开头开始的最长子词,所以我们在那里拆分并得到 `["b", "##ugs"]`。然后 `"##u"` 是词汇表中从 `"##ugs"` 开始的最长的子词,所以我们在那里拆分并得到 `["b", "##u, "##gs"]`。最后, `"##gs"` 在词汇表中,所以最后一个列表是 `"bugs"` 的标记化。
+再举一个例子,让我们看看 `"bugs"` 将如何分词的。 `"b"` 是从词汇表中单词开头开始的最长子词,所以我们在那里分割并得到 `["b", "##ugs"]` 。然后 `"##u"` 是词汇表中从 `"##ugs"` 开始的最长的子词,所以我们在那里拆分并得到 `["b", "##u, "##gs"]` 。最后, `"##gs"` 在词汇表中,因此 `"bugs"` 的分词结果是: `["b", "##u, "##gs"]` 。
-当分词达到无法在词汇表中找到子词的阶段时, 整个词被标记为未知 -- 例如, `"mug"` 将被标记为 `["[UNK]"]`,就像 `"bum"` (即使我们可以以 `"b"` 和 `"##u"` 开始, `"##m"` 不在词汇表中,由此产生的标记将只是 `["[UNK]"]`, 不是 `["b", "##u", "[UNK]"]`)。这是与 BPE 的另一个区别,BPE 只会将不在词汇表中的单个字符分类为未知。
+当分词过程中无法在词汇库中找到该子词时,整个词会被标记为 unknown(未知)—— 例如, `"mug"` 将被标记为 `["[UNK]"]` , `"bum"` 也是如此(即使我们的词汇表中包含 `"b"` 和 `"##u"` 开始,但是 `"##m"` 不在词汇表中,因此最终的分词结果只会是 `["[UNK]"]` ,而不是 `["b", "##u", "[UNK]"]` )。这是与 BPE 的另一个区别,BPE 只会将不在词汇库中的单个字符标记为 unknown。
-✏️ **现在轮到你了!** `"pugs"` 将被如何标记?
+✏️ **现在轮到你了!** `"pugs"` 将被如何分词?
## 实现 WordPiece [[实现 WordPiece]]
-现在让我们看一下 WordPiece 算法的实现。与 BPE 一样,这只是教学,你将无法在大型语料库中使用它。
+现在让我们看一下 WordPiece 算法的实现。与 BPE 一样,这只是教学示例,你不能在大型语料库上使用。
-我们将使用与 BPE 示例中相同的语料库:
+我们将使用与 BPE 示例中相同的语料库:
```python
corpus = [
@@ -112,7 +114,7 @@ corpus = [
]
```
-首先,我们需要将语料库预先标记为单词。由于我们正在复制 WordPiece 标记器 (如 BERT),因此我们将使用 `bert-base-cased` 标记器用于预标记化:
+首先,我们需要将语料库预分词为单词。由于我们正在复刻 WordPiece tokenizer (如 BERT),因此我们将使用 `bert-base-cased` tokenizer 进行预分词:
```python
from transformers import AutoTokenizer
@@ -120,7 +122,7 @@ from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
-然后我们在进行预标记化时计算语料库中每个单词的频率:
+然后我们在进行预分词的同时,计算语料库中每个单词的频率:
```python
from collections import defaultdict
@@ -143,7 +145,7 @@ defaultdict(
'trained': 1, 'and': 1, 'generate': 1, 'tokens': 1})
```
-正如我们之前看到的,字母表是由单词的所有第一个字母组成的唯一集合,以及出现在前缀为 `##` 的其他字母:
+如我们之前看到的,字母表是一个独特的集合,由所有单词的第一个字母以及所有以 `##` 为前缀和在单词中的其他字母组成:
```python
alphabet = []
@@ -166,13 +168,13 @@ print(alphabet)
'w', 'y']
```
-我们还在该词汇表的开头添加了模型使用的特殊标记。在使用 BERT 的情况下,它是列表 `["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]`:
+我们还在该词汇表的开头添加了模型使用的特殊 tokens,在使用 BERT 的情况下,特殊 tokens 是 `["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]` :
```python
vocab = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"] + alphabet.copy()
```
-接下来我们需要拆分每个单词, 所有不是第一个字母的字母都以 `##` 为前缀:
+接下来我们需要将每个单词进行分割,除了第一个字母外,其他字母都需要以 `##` 为前缀:
```python
splits = {
@@ -181,7 +183,7 @@ splits = {
}
```
-现在我们已经准备好训练了,让我们编写一个函数来计算每对的分数。我们需要在训练的每个步骤中使用它:
+现在我们已经准备好训练了,让我们编写一个函数来计算每对的分数。我们需要在训练的每个步骤中使用它:
```python
def compute_pair_scores(splits):
@@ -205,7 +207,7 @@ def compute_pair_scores(splits):
return scores
```
-让我们来看看这个字典在初始拆分后的一部分:
+让我们来看看在初始分割后的部分字典:
```python
pair_scores = compute_pair_scores(splits)
@@ -224,7 +226,7 @@ for i, key in enumerate(pair_scores.keys()):
('##h', '##e'): 0.011904761904761904
```
-现在,找到得分最高的对只需要一个快速循环:
+现在,只需要一个快速循环就可以找到得分最高的对:
```python
best_pair = ""
@@ -241,13 +243,13 @@ print(best_pair, max_score)
('a', '##b') 0.2
```
-所以第一个要学习的合并是 `('a', '##b') -> 'ab'`, 并且我们添加 `'ab'` 到词汇表中:
+所以第一个要学习的合并是 `('a', '##b') -> 'ab'` ,并且我们添加 `'ab'` 到词汇表中:
```python
vocab.append("ab")
```
-要继续接下来的步骤,我们需要在我们的 `拆分` 字典中应用该合并。让我们为此编写另一个函数:
+接下来,我们需要对 `splits` 字典进行这种合并。让我们为此写另一个函数:
```python
def merge_pair(a, b, splits):
@@ -266,7 +268,7 @@ def merge_pair(a, b, splits):
return splits
```
-我们可以看看第一次合并的结果:
+我们可以看看第一次合并的结果:
```py
splits = merge_pair("a", "##b", splits)
@@ -277,7 +279,7 @@ splits["about"]
['ab', '##o', '##u', '##t']
```
-现在我们有了循环所需的一切,直到我们学会了我们想要的所有合并。我们的目标词汇量为70:
+现在我们有了合并循环的所有代码。让我们设定词汇表的大小为 70:
```python
vocab_size = 70
@@ -297,7 +299,7 @@ while len(vocab) < vocab_size:
vocab.append(new_token)
```
-然后我们可以查看生成的词汇表:
+然后我们可以查看生成的词汇表:
```py
print(vocab)
@@ -311,15 +313,15 @@ print(vocab)
'##ut']
```
-正如我们所看到的,与 BPE 相比,这个标记器将单词的一部分作为标记学习得更快一些。
+如我们所见,相较于 BPE(字节对编码),此分词器在学习单词部分作为 tokens 时稍快一些。
-💡 在同一语料库上使用 `train_new_from_iterator()` 不会产生完全相同的词汇表。这是因为 🤗 Tokenizers 库没有为训练实现 WordPiece(因为我们不完全确定它的内部结构),而是使用 BPE。
+💡 在同一语料库上使用 `train_new_from_iterator()` 不会产生完全相同的词汇表。这是因为 🤗 Tokenizers 库没有为训练实现 WordPiece(因为我们不完全确定它的真实实现方式),而是使用了 BPE。
-为了对新文本进行分词,我们对其进行预分词、拆分,然后对每个单词应用分词算法。也就是说,我们从第一个词的开头寻找最大的子词并将其拆分,然后我们在第二部分重复这个过程,对于该词的其余部分和文本中的以下词,依此类推:
+要对新文本进行分词,我们先预分词,再进行分割,然后在每个词上使用分词算法。也就是说,我们寻找从第一个词开始的最大子词并将其分割,然后我们对第二部分重复此过程,以此类推,对该词以及文本中的后续词进行分割:
```python
def encode_word(word):
@@ -337,7 +339,7 @@ def encode_word(word):
return tokens
```
-让我们用词汇表中的一个单词和另一个不在词汇表中的单词进行测试:
+让我们使用词汇表中的一个词和一个不在词汇表中的词上测试一下:
```python
print(encode_word("Hugging"))
@@ -349,7 +351,7 @@ print(encode_word("HOgging"))
['[UNK]']
```
-现在,让我们编写一个标记文本的函数:
+现在,让我们编写一个对文本分词的函数:
```python
def tokenize(text):
@@ -359,7 +361,7 @@ def tokenize(text):
return sum(encoded_words, [])
```
-我们可以在任何文本上尝试:
+我们可以在任何文本上尝试:
```python
tokenize("This is the Hugging Face course!")
@@ -370,4 +372,4 @@ tokenize("This is the Hugging Face course!")
'##e', '[UNK]']
```
-这就是 WordPiece 算法的全部内容!现在让我们来看看 Unigram。
+这就是 WordPiece 算法的全部内容!现在让我们来看看 Unigram。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/7.mdx b/chapters/zh-CN/chapter6/7.mdx
index 95202c1e3..98e16f6fb 100644
--- a/chapters/zh-CN/chapter6/7.mdx
+++ b/chapters/zh-CN/chapter6/7.mdx
@@ -1,4 +1,4 @@
-# Unigram标记化 [[Unigram标记化]]
+# Unigram tokenization 算法 [[Unigram tokenization算法]]
-在 SentencePiece 中经常使用 Unigram 算法,该算法是 AlBERT、T5、mBART、Big Bird 和 XLNet 等模型使用的标记化算法。
+Unigram 算法常用于 SentencePiece 中,该切分算法被 AlBERT,T5,mBART,Big Bird 和 XLNet 等模型广泛采用。
-💡 本节深入介绍了 Unigram,甚至展示了一个完整的实现。如果你只想大致了解标记化算法,可以跳到最后。
+💡 本节将深入探讨 Unigram,甚至展示完整的实现过程。如果你只想大致了解 tokenization 算法,可以直接跳到章节末尾。
-## 训练算法 [[训练算法]]
+## Unigram 训练 [[Unigram 训练]]
-与 BPE 和 WordPiece 相比,Unigram 在另一个方向上工作:它从一个较大的词汇表开始,然后从中删除标记,直到达到所需的词汇表大小。有多种选项可用于构建基本词汇表:例如,我们可以采用预标记化单词中最常见的子串,或者在具有大词汇量的初始语料库上应用 BPE。
+与BPE 和 WordPiece 相比,Unigram 的工作方式正好相反:它从一个大词汇库开始,然后逐步删除词汇,直到达到目标词汇库大小。构建基础词汇库有多种方法:例如,我们可以选取预切分词汇中最常见的子串,或者在具有大词汇量的初始语料库上进行 BPE 得到一个初始词库。
-在训练的每一步,Unigram 算法都会在给定当前词汇的情况下计算语料库的损失。然后,对于词汇表中的每个符号,算法计算如果删除该符号,整体损失会增加多少,并寻找增加最少的符号。这些符号对语料库的整体损失影响较小,因此从某种意义上说,它们“不太需要”并且是移除的最佳候选者。
+在训练的每一步,Unigram 算法都会在给定当前词汇的情况下计算语料库的损失。然后,对于词汇表中的每个符号,算法计算如果删除该符号,整体损失会增加多少,并寻找删除后损失增加最少的符号。这些符号对语料库的整体损失影响较小,因此从某种意义上说,它们“相对不必要”并且是移除的最佳候选者。
-这是一个非常昂贵的操作,所以我们不只是删除与最低损失增加相关的单个符号,而且\\(p\\) (\\(p\\)是一个可以控制的超参数,通常是 10 或 20)与最低损失增加相关的符号的百分比。然后重复这个过程,直到词汇量达到所需的大小。
+这个过程非常消耗计算资源,因此我们不只是删除与最低损失增长相关的单个符号,而是删除与最低损失增长相关的百分之/p (p 是一个可以控制的超参数,通常是 10 或 20)的符号。然后重复此过程,直到词汇库达到所需大小。
-请注意,我们从不删除基本字符,以确保可以标记任何单词。
+注意,我们永远不会删除基础的单个字符,以确保任何词都能被切分。
-现在,这仍然有点模糊:算法的主要部分是计算语料库的损失,并查看当我们从词汇表中删除一些标记时它会如何变化,但我们还没有解释如何做到这一点。这一步依赖于 Unigram 模型的标记化算法,因此我们接下来将深入研究。
+然而,这仍然有些模糊:算法的主要部分是在词汇库中计算语料库的损失并观察当我们从词汇库中移除一些符号时损失如何变化,但我们尚未解释如何做到这一点。这一步依赖于 Unigram 模型的切分算法,接下来我们将深入研究。
-我们将重用前面示例中的语料库:
+我们将复用前面例子中的语料库:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
-对于此示例,我们将采用初始词汇表的所有严格子字符串:
+而在这个例子中,我们将取这个语料库中所有的子串作为初始词汇库:
```
["h", "u", "g", "hu", "ug", "p", "pu", "n", "un", "b", "bu", "s", "hug", "gs", "ugs"]
```
-## 标记化算法 [[标记化算法]]
+## tokenization 算法 [[tokenization算法]]
-Unigram 模型是一种语言模型,它认为每个标记都独立于它之前的标记。它是最简单的语言模型,从某种意义上说, 给定先前上下文的标记 X 的概率就是标记 X 的概率。因此,如果我们使用 Unigram 语言模型生成文本,我们将始终预测最常见的标记。
+Unigram 模型是一种语言模型,它认为每个符号都与其之前的符号独立。这是最简单的语言模型,因此给定之前的上下文情况下,符号 X 的概率就是符号 X 的概率。所以,如果我们使用 Unigram 语言模型来生成文本,我们的预测总会输出最常见的符号。
-给定标记的概率是它在原始语料库中的频率(我们找到它的次数),除以词汇表中所有标记的所有频率的总和(以确保概率总和为 1)。例如, `"ug"` 在 `"hug"` 、 `"pug"` 以及 `"hugs"` 中,所以它在我们的语料库中的频率为 20。
+给定符号的概率是其在原始语料库中的频率(我们计算它出现的次数),除以词汇库中所有符号的频率总和(以确保概率总和为 1)。例如, `"ug"` 出现在 `"hug"` , `"pug"` 和 `"hugs"` 中,所以它在我们的语料库中的频率是 20。
-以下是词汇表中所有可能的子词的出现频率:
+以下是词汇库中所有可能出现子词的频率:
```
("h", 15) ("u", 36) ("g", 20) ("hu", 15) ("ug", 20) ("p", 17) ("pu", 17) ("n", 16)
("un", 16) ("b", 4) ("bu", 4) ("s", 5) ("hug", 15) ("gs", 5) ("ugs", 5)
```
-所以,所有频率之和为210, 并且子词 `"ug"` 出现的概率是 20/210。
+所以,所有频率之和为 210,子词 `"ug"` 出现的概率是 20/210。
-✏️ **现在轮到你了!** 编写代码来计算上面的频率,并仔细检查显示的结果以及总和是否正确。
+✏️ **现在轮到你了!** 编写代码计算上述频率,然后验证结果的准确性,以及概率的总和是否正确。
-现在,为了对给定的单词进行标记,我们将所有可能的分割视为标记,并根据 Unigram 模型计算每个分割的概率。由于所有标记都被认为是独立的,所以这个概率只是每个标记概率的乘积。例如, `"pug"` 的标记化 `["p", "u", "g"]` 的概率为:
+现在,为了对一个给定的单词进行分词,我们会查看所有可能的分词组合,并根据 Unigram 模型计算出每种可能的概率。由于所有的分词都被视为独立的,因此这个单词分词的概率就是每个子词概率的乘积。例如,将 `"pug"` 分词为 `["p", "u", "g"]` 的概率为:
+
$$P([``p", ``u", ``g"]) = P(``p") \times P(``u") \times P(``g") = \frac{5}{210} \times \frac{36}{210} \times \frac{20}{210} = 0.000389$$
-相比之下,标记化 `["pu", "g"]` 的概率为:
+相比之下,将 “pug” 分词为 `["pu", "g"]` 的概率为:
$$P([``pu", ``g"]) = P(``pu") \times P(``g") = \frac{5}{210} \times \frac{20}{210} = 0.0022676$$
-所以一个更有可能。一般来说,具有尽可能少的标记的标记化将具有最高的概率(因为每个标记重复除以 210),这对应于我们直观想要的:将一个单词分成尽可能少的标记。
+因此,后者的可能性更大。一般来说,分词数最少的分词方式将具有最高的概率(因为每个分词都要除以 210),这正符合我们的直觉:将一个词分割为尽可能少的子词。
-使用 Unigram 模型对单词进行分词是概率最高的分词。在示例 `"pug"` 中,这里是我们为每个可能的分割获得的概率:
+利用 Unigram 模型对一个词进行分词,就是找出概率最高的分词方式。以 `"pug"` 为例,我们得到的各种可能分词方式的概率如下:
```
["p", "u", "g"] : 0.000389
@@ -80,13 +81,13 @@ $$P([``pu", ``g"]) = P(``pu") \times P(``g") = \frac{5}{210} \times \frac{20}{21
["pu", "g"] : 0.0022676
```
-所以, `"pug"` 将被标记为 `["p", "ug"]` 或者 `["pu", "g"]`, 取决于首先遇到这些分割中的哪一个(请注意,在更大的语料库中,这样的相等的情况很少见)。
+因此, `"pug"` 将被分词为 `["p", "ug"]` 或 `["pu", "g"]` ,取决于哪种分词方式排在前面(注意,在更大的语料库中,像这样的相等情况将很少见)。
-在这种情况下,很容易找到所有可能的分割并计算它们的概率,但一般来说会有点困难。有一种用于此的经典算法,称为 *维特比(Viterbi)算法*。本质上,我们可以构建一个图来检测给定单词的可能分割,如果从_a_到_b_的子词在词汇表中,则从字符_a_到字符_b_之间存在一个分支,并将子词的概率归因于该分支。
+在这个例子中,找出所有可能的分词方式并计算其概率是容易的,但在语料库比较大的情况下有些困难。有一个经典的算法可以用来计算这个概率,叫做 `Viterbi 算法` 。事实上,我们可以通过创建一个图来表示一个给定单词的所有可能分词,如果从字符 `a` 到字符 `b` 的子词在词汇表中,那么就存在一个从 `a` 到 `b` 的分支,分支的边就是进行这个切分的概率。
-为了在该图中找到将具有最佳分数的路径,维特比算法为单词中的每个位置确定在该位置结束的具有最佳分数的分段。由于我们从开始到结束,可以通过循环遍历以当前位置结尾的所有子词,然后使用该子词开始位置的最佳标记化分数来找到最佳分数。然后,我们只需要展开到达终点所采取的路径。
+为了在图中找到得分最高的路径,Viterbi 算法会确定出每个位置上结束的最佳得分分割。我们从头到尾进行处理,可以通过遍历所有在当前位置结束的子词,然后使用这个子词开始位置的最佳得分,找到最高得分。然后,我们只需要回溯走过的路径,就能找到最终的最优路径。
-让我们看一个使用我们的词汇表和单词 `"unhug"` 的例子。对于每个位置,以最好的分数结尾的子词如下:
+让我们看一个使用我们的词汇表和单词 `"unhug"` 的例子。对于每个位置,最佳切分子词的分数如下:
```
Character 0 (u): "u" (score 0.171429)
@@ -96,27 +97,28 @@ Character 3 (u): "un" "hu" (score 0.005442)
Character 4 (g): "un" "hug" (score 0.005442)
```
-因此 `"unhug"` 将被标记为 `["un", "hug"]`。
+因此 “unhug” 将被分词为 `["un", "hug"]` 。
+
-✏️ **现在轮到你了!** 确定单词 `"huggun"` 的标记化及其分数。
+✏️ **现在轮到你了!** 确定单词 “huggun” 的分词方式以及其得分。
## 回到训练 [[回到训练]]
-现在我们已经了解了标记化的工作原理,我们可以更深入地研究训练期间使用的损失。在任何给定的阶段,这个损失是通过对语料库中的每个单词进行标记来计算的,使用当前词汇表和由语料库中每个标记的频率确定的 Unigram 模型(如前所述)。
+我们已经了解了如何进行分词处理,接下来我们可以更详细地了解一下在训练过程中如何计算损失值。在训练的每个阶段,我们都会将语料库中的每个词进行分词,分词所使用的词表和 Unigram 模型是基于目前的情况(即根据每个词在语料库中出现的频率)来确定的。然后,基于这种分词结果,我们就可以计算出损失值(loss)。
-语料库中的每个词都有一个分数,损失是这些分数的负对数似然 -- 即所有词的语料库中所有词的总和 `-log(P(word))`。
+语料库中的每个词都有一个分数,损失(loss)值是这些分数的负对数似然 —— 即所有词的语料库中所有词的 `-log(P(word))` 总和
-让我们用以下语料库回到我们的例子:
+让我们回到我们的例子,以下是我们的语料库:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
-每个单词的标记化及其各自的分数是:
+每个单词的分词及其相应的得分如下:
```
"hug": ["hug"] (score 0.071428)
@@ -126,34 +128,34 @@ Character 4 (g): "un" "hug" (score 0.005442)
"hugs": ["hug", "s"] (score 0.001701)
```
-所以损失是:
+因此,损失值(loss)是:
```
10 * (-log(0.071428)) + 5 * (-log(0.007710)) + 12 * (-log(0.006168)) + 4 * (-log(0.001451)) + 5 * (-log(0.001701)) = 169.8
```
-现在我们需要计算删除每个标记如何影响损失。这相当乏味,所以我们在这里只对两个标记进行操作,并保存整个过程以备有代码来帮助我们。在这个(非常)特殊的情况下,我们对所有单词有两个等效的标记:正如我们之前看到的,例如, `"pug"` 可以以相同的分数被标记为 `["p", "ug"]`。因此,去除词汇表中的 `"pu"` 标记将给出完全相同的损失。
+现在,我们需要计算移除每个 token 对损失值的影响。这个过程颇为繁琐,所以我们这里仅对两个单词进行演示,在我们编写代码来协助处理这个过程时,再对全部的词进行 tokenization 的处理。在这个(非常)特殊的例子中,我们对单词的两种等效的分词方式:例如,“pug”可以被分词为 `["pu", "g"]` ,也可以被分词为 `["p", "ug"]` ,获得的分数是相同的。因此,去除词汇表中的 `"pu"` 损失值还会是一样的。
-另一方面,去除 `"hug"` 损失变得更糟, 因为 `"hug"` 和 `"hugs"` 的标记化会变成:
+但是,去除 `"hug"` 之后,损失会变得更糟,因为 `"hug"` 和 `"hugs"` 的 tokenization 会变成:
```
"hug": ["hu", "g"] (score 0.006802)
"hugs": ["hu", "gs"] (score 0.001701)
```
-这些变化将导致损失增加:
+这些变化将导致损失增加:
```
- 10 * (-log(0.071428)) + 10 * (-log(0.006802)) = 23.5
```
-因此, 标记 `"pu"`可能会从词汇表中删除,但不会删除 `"hug"`.
+因此, `"pu"` tokens 可能会从词汇表中移除,但 `"hug"` 则不会。
## 实现 Unigram [[实现 Unigram]]
-现在让我们在代码中实现我们迄今为止看到的所有内容。与 BPE 和 WordPiece 一样,这不是 Unigram 算法的有效实现(恰恰相反),但它应该可以帮助你更好地理解它。
+现在让我们在代码中实现上面看到的所内容。与 BPE 和 WordPiece 一样,这不是 Unigram 算法的高效实现(恰恰相反,这套代码的效率非常低),但它应该可以帮助你更好地理解它。
-我们将使用与之前相同的语料库作为示例:
+我们将使用与之前相同的语料库作为示例:
```python
corpus = [
@@ -164,7 +166,7 @@ corpus = [
]
```
-这一次,我们将使用 `xlnet-base-cased` 作为我们的模型:
+这次,我们将使用 `xlnet-base-cased` 作为我们的模型:
```python
from transformers import AutoTokenizer
@@ -172,7 +174,7 @@ from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
```
-与 BPE 和 WordPiece 一样,我们首先计算语料库中每个单词的出现次数:
+与 BPE 和 WordPiece 一样,我们首先计算语料库中每个单词的出现次数:
```python
from collections import defaultdict
@@ -187,7 +189,7 @@ for text in corpus:
word_freqs
```
-然后,我们需要将我们的词汇表初始化为大于我们最终想要的词汇量。我们必须包含所有基本字符(否则我们将无法标记每个单词),但对于较大的子字符串,我们将只保留最常见的字符,因此我们按频率对它们进行排序:
+然后,我们需要将我们的词汇表初始化为大于我们最终想要的词汇量。我们必须包含所有基本的单个字符(否则我们将无法对每个单词赋予一个 token ),但对于较大的子字符串,我们将只保留最常见的字符,因此我们按出现频率对它们进行排序:
```python
char_freqs = defaultdict(int)
@@ -195,11 +197,11 @@ subwords_freqs = defaultdict(int)
for word, freq in word_freqs.items():
for i in range(len(word)):
char_freqs[word[i]] += freq
- # Loop through the subwords of length at least 2
+ # 循环遍历长度至少为2的子字
for j in range(i + 2, len(word) + 1):
subwords_freqs[word[i:j]] += freq
-# Sort subwords by frequency
+# 按频率对子词排序
sorted_subwords = sorted(subwords_freqs.items(), key=lambda x: x[1], reverse=True)
sorted_subwords[:10]
```
@@ -208,7 +210,7 @@ sorted_subwords[:10]
[('▁t', 7), ('is', 5), ('er', 5), ('▁a', 5), ('▁to', 4), ('to', 4), ('en', 4), ('▁T', 3), ('▁Th', 3), ('▁Thi', 3)]
```
-我们用最优的子词对字符进行分组,以获得大小为 300 的初始词汇表:
+我们用最优的子词对字符进行分组,以获得大小为 300 的初始词汇表:
```python
token_freqs = list(char_freqs.items()) + sorted_subwords[: 300 - len(char_freqs)]
@@ -217,11 +219,11 @@ token_freqs = {token: freq for token, freq in token_freqs}
-💡 SentencePiece 使用一种称为增强后缀数组(ESA)的更高效算法来创建初始词汇表。
+💡 SentencePiece 使用一种名为增强后缀数组(ESA)的更高效的算法来创建初始词汇表。
-接下来,我们计算所有频率的总和,将频率转换为概率。对于我们的模型,我们将存储概率的对数,因为添加对数比乘以小数在数值上更稳定,这将简化模型损失的计算:
+接下来,我们需要计算所有频率的总和,将频率转化为概率。在我们的模型中,我们将存储概率的对数,因为相较于小数相乘,对数相加在数值上更稳定,而且这将简化模型损失的计算:
```python
from math import log
@@ -230,11 +232,11 @@ total_sum = sum([freq for token, freq in token_freqs.items()])
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}
```
-N现在主要功能是使用 Viterbi 算法标记单词的功能。正如我们之前看到的,该算法计算单词的每个子串的最佳分段,我们将其存储在名为 `best_segmentations` 的变量中。我们将在单词的每个位置(从 0 到其总长度)存储一个字典,有两个键:最佳分割中最后一个标记的开始索引,以及最佳分割的分数。使用最后一个标记的开始索引,一旦列表完全填充,我们将能够检索完整的分段。
+现在,主函数是使用 Viterbi 算法对单词进行分词。像我们之前看到的那样,这个算法会计算出每个词的最好的分割方式,我们把这个结果保存在一个叫做 `best_segmentations` 的变量里。我们会为词的每一个位置(从 0 开始,一直到词的总长度)都保存一个字典,字典里有两个键:最好的分割中最后一个词的起始位置,以及最好的分割的得分。有了最后一个词的起始位置,当我们把整个列表都填满后,我们就能找到完整的分割方式。
-填充列表只需两个循环:主循环遍历每个起始位置,第二个循环尝试从该起始位置开始的所有子字符串。如果子串在词汇表中,我们有一个新的词分段,直到该结束位置,我们将其与 `best_segmentations` 相比较。
+我们只需要两个循环就可以填充这个列表:一个主循环用来遍历每个可能的开始位置,第二个循环则试着找出所有以这个开始位置开始的子串。如果这个子串在我们的词表里,那么我们就找到了一个新的分词方式,这个分词方式会在当前位置结束。然后,我们会把这个新的分词方式和 `best_segmentations` 里的内容进行比较。
-一旦主循环完成,我们就从结尾开始,从一个开始位置跳到下一个,记录我们前进的标记,直到我们到达单词的开头:
+当主循环结束后,我们就从词的最后一个位置开始,然后一步步往前跳,跳过的每一步,我们都会记录下来,直到我们回到词的开头。
```python
def encode_word(word, model):
@@ -242,13 +244,13 @@ def encode_word(word, model):
{"start": None, "score": None} for _ in range(len(word))
]
for start_idx in range(len(word)):
- # This should be properly filled by the previous steps of the loop
+ # best_score_at_start应该由循环的前面的步骤计算和填充
best_score_at_start = best_segmentations[start_idx]["score"]
for end_idx in range(start_idx + 1, len(word) + 1):
token = word[start_idx:end_idx]
if token in model and best_score_at_start is not None:
score = model[token] + best_score_at_start
- # If we have found a better segmentation ending at end_idx, we update
+ # 如果我们发现以 end_idx 结尾的更好分段,我们会更新
if (
best_segmentations[end_idx]["score"] is None
or best_segmentations[end_idx]["score"] > score
@@ -257,7 +259,7 @@ def encode_word(word, model):
segmentation = best_segmentations[-1]
if segmentation["score"] is None:
- # We did not find a tokenization of the word -> unknown
+ # 我们没有找到单词的 tokens -> unknown
return [""], None
score = segmentation["score"]
@@ -273,7 +275,7 @@ def encode_word(word, model):
return tokens, score
```
-我们已经可以在一些词上尝试我们的初始模型:
+我们已经可以在一些词上尝试我们的初始模型:
```python
print(encode_word("Hopefully", model))
@@ -285,7 +287,7 @@ print(encode_word("This", model))
(['This'], 6.288267030694535)
```
-现在很容易计算模型在语料库上的损失!
+现在,计算语料库上的分词损失就很简单了!
```python
def compute_loss(model):
@@ -296,7 +298,7 @@ def compute_loss(model):
return loss
```
-我们可以检查它是否适用于我们拥有的模型:
+我们可以检查一下我们的模型是否有效:
```python
compute_loss(model)
@@ -306,7 +308,7 @@ compute_loss(model)
413.10377642940875
```
-计算每个标记的分数也不是很难;我们只需要计算通过删除每个标记获得的模型的损失:
+计算每个词的分数也并非难事;我们只需要计算通过删除每个词得到的模型的损失:
```python
import copy
@@ -316,7 +318,7 @@ def compute_scores(model):
scores = {}
model_loss = compute_loss(model)
for token, score in model.items():
- # We always keep tokens of length 1
+ # 我们将保留长度为 1 的 tokens
if len(token) == 1:
continue
model_without_token = copy.deepcopy(model)
@@ -325,7 +327,7 @@ def compute_scores(model):
return scores
```
-我们可以在给定的标记上尝试:
+我们可以试试看对于给定的词是否有效:
```python
scores = compute_scores(model)
@@ -333,7 +335,7 @@ print(scores["ll"])
print(scores["his"])
```
-自从 `"ll"` 用于标记化 `"Hopefully"`, 删除它可能会让我们使用标记 `"l"` 两次相反,我们预计它将产生正损失。 `"his"` 仅在单词`"This"` 内使用,它被标记为自身,所以我们期望它的损失为零。结果如下:
+因为 `"ll"` 这个子词在 `"Hopefully"` 这个词的分词中被使用了,如果我们把它删掉,我们可能会需要用两个 `"l"` 来代替,所以我们预计它会导致损失值增加。而 `"his"` 这个词只在 `"This"` 这个词里面被使用,而且 `"This"` 是作为一个完整的词被分割的,所以我们预计删除它的损失值变化会是零。下面就是实验结果:
```python out
6.376412403623874
@@ -342,18 +344,18 @@ print(scores["his"])
-💡 这种方法非常低效,因此 SentencePiece 使用了没有标记 X 的模型损失的近似值:它不是从头开始,而是通过其在剩余词汇表中的分段替换标记 X。这样,所有分数可以与模型损失同时计算。
+💡 这种方式效率非常低,所以 SentencePiece 使用了一种估算方法来计算如果没有 X token,模型的损失会是多少:它不是重新开始,而是只是用剩下的词表里 X token 的分词方式来替代它。这样,所有的得分都能在和模型损失一起的同时计算出来。
-完成所有这些后,我们需要做的最后一件事是将模型使用的特殊标记添加到词汇表中,然后循环直到我们从词汇表中修剪了足够的标记以达到我们想要的大小:
+至此,我们需要做的最后一件事就是将模型使用的特殊 tokens 添加到词汇表中,然后循环直到我们从词汇表中剪除足够多的 tokens 以达到我们期望的规模:
```python
percent_to_remove = 0.1
while len(model) > 100:
scores = compute_scores(model)
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
- # Remove percent_to_remove tokens with the lowest scores.
+ # 删除分数最低的percent_to_remov tokens 。
for i in range(int(len(model) * percent_to_remove)):
_ = token_freqs.pop(sorted_scores[i][0])
@@ -361,7 +363,7 @@ while len(model) > 100:
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}
```
-然后,为了标记一些文本,我们只需要应用预标记化,然后使用我们的 `encode_word()` 函数:
+然后,要对某些文本进行 tokenization,我们只需进行预分词然后使用我们的 `encode_word()` 函数:
```python
def tokenize(text, model):
@@ -378,4 +380,4 @@ tokenize("This is the Hugging Face course.", model)
['▁This', '▁is', '▁the', '▁Hugging', '▁Face', '▁', 'c', 'ou', 'r', 's', 'e', '.']
```
-Unigram 就是这样!希望现在你感觉自己是标记器所有方面的专家。在下一节中,我们将深入研究 🤗 Tokenizers 库的构建块,并向您展示如何使用它们来构建您自己的标记器。
+至此 Unigram 的介绍完毕!期望此刻你已感觉自身如同领域的专家一般。在下一节中,我们将深入探讨🤗Tokenizers 库的基本构造模块,并展示如何使用它们构建自己的 tokenizer
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/8.mdx b/chapters/zh-CN/chapter6/8.mdx
index 73e07c7fa..2ff99a64b 100644
--- a/chapters/zh-CN/chapter6/8.mdx
+++ b/chapters/zh-CN/chapter6/8.mdx
@@ -1,4 +1,4 @@
-# 逐块地构建标记器 [[逐块地构建标记器]]
+# 模块化构建 tokenizer [[模块化构建 tokenizer ]]
-正如我们在前几节中看到的,标记化包括几个步骤:
+正如我们在前几节中看到的,tokenization 包括几个步骤:
-- 规范化(任何认为必要的文本清理,例如删除空格或重音符号、Unicode 规范化等)
-- 预标记化(将输入拆分为单词)
-- 通过模型处理输入(使用预先拆分的词来生成一系列标记)
-- 后处理(添加标记器的特殊标记,生成注意力掩码和标记类型 ID)
+- 标准化(任何认为必要的文本清理,例如删除空格或重音符号、Unicode 规范化等)
+- 预分词(将输入拆分为单词)
+- 通过模型处理输入(使用预先拆分的词来生成一系列 tokens )
+- 后处理(添加 tokenizer 的特殊 tokens 生成注意力掩码和 token 类型 ID)
-提醒一下,这里再看一下整个过程
+作为复习,这里再看一遍整个过程:
-🤗 Tokenizers 库旨在为每个步骤提供多个选项,您可以将它们混合和匹配在一起。在本节中,我们将看到如何从头开始构建标记器,而不是像我们[第二节 2](/course/chapter6/2)那样从旧的标记器训练新的标记器.然后,您将能够构建您能想到的任何类型的标记器!
+🤗 Tokenizers 库旨在为每个步骤提供多个选项,你可以任意搭配这些选项。在这一节中,我们将看到如何从零开始构建 tokenizer,而不是像我们在 [第二节](/course/chapter6/2) 中那样从旧的 tokenizer 训练新的 tokenizer 然后,你将能够构建任何你能想到的类型的 tokenizer
-更准确地说,该库是围绕一个中央“Tokenizer”类构建的,构建这个类的每一部分可以在子模块的列表中重新组合:
+更精确地说,这个库围绕一个中心的 `Tokenizer` 类,实现了组成 `Tokenizer` 的各种子模块:
-- `normalizers` 包含你可以使用的所有可能的Normalizer类型(完整列表[在这里](https://huggingface.co/docs/tokenizers/api/normalizers))。
-- `pre_tokenizesr` 包含您可以使用的所有可能的PreTokenizer类型(完整列表[在这里](https://huggingface.co/docs/tokenizers/api/pre-tokenizers))。
-- `models` 包含您可以使用的各种类型的Model,如BPE、WordPiece和Unigram(完整列表[在这里](https://huggingface.co/docs/tokenizers/api/models))。
-- `trainers` 包含所有不同类型的 trainer,你可以使用一个语料库训练你的模型(每种模型一个;完整列表[在这里](https://huggingface.co/docs/tokenizers/api/trainers))。
-- `post_processors` 包含你可以使用的各种类型的PostProcessor(完整列表[在这里](https://huggingface.co/docs/tokenizers/api/post-processors))。
-- `decoders` 包含各种类型的Decoder,可以用来解码标记化的输出(完整列表[在这里](https://huggingface.co/docs/tokenizers/components#decoders))。
+- `normalizers` 包含所有可能使用的 `Normalizer(标准化)` 模块(完整列表 [在这里](https://huggingface.co/docs/tokenizers/api/normalizers) )。
+- `pre_tokenizesr` 包含所有可能使用的 `PreTokenizer(预处理)` 模块(完整列表 [在这里](https://huggi ngface.co/docs/tokenizers/api/pre-tokenizers) )。
+- `models` 包含了你可以使用的各种 `Model(子词分词算法模型)` 模块,如 `BPE` 、 `WordPiece` 和 `Unigram` (完整列表 [在这里](https://huggingface.co/docs/tokenizers/api/models) )。
+- `trainers` 包含所有不同类型的 `trainer` ,你可以使用它们在语料库上训练你的模型(每种模型一个;完整列表 [在这里](https://huggingface.co/docs/tokenizers/api/trainers) )。
+- `post_processors` 包含你可以使用的各种类型的 `PostProcessor(后处理)` 模块,(完整列表 [在这里](https://huggingface.co/docs/tokenizers/api/post-processors) )。
+- `decoders` 包含各种类型的 `Decoder` ,可以用来解码 tokenization 后的输出(完整列表 [在这里](https://huggingface.co/docs/tokenizers/components#decoders) )。
-您可以[在这里](https://huggingface.co/docs/tokenizers/components)找到完整的模块列表。
+你可以 [在这里](https://huggingface.co/docs/tokenizers/components) 找到完整的模块列表。
## 获取语料库 [[获取语料库]]
-为了训练我们的新标记器,我们将使用一个小的文本语料库(因此示例运行得很快)。获取语料库的步骤与我们在[在这章的开始]((/course/chapter6/2)那一小节,但这次我们将使用[WikiText-2](https://huggingface.co/datasets/wikitext)数据集:
+为了训练新的 tokenizer 我们将使用一小部分文本作为语料库(这样运行得更快)。获取语料库的步骤与我们在 [在这章的开头](/course/chapter6/2) 采取的步骤类似,但这次我们将使用 [WikiText-2](https://huggingface.co/datasets/wikitext) 数据集:
```python
from datasets import load_dataset
@@ -50,10 +50,9 @@ def get_training_corpus():
for i in range(0, len(dataset), 1000):
yield dataset[i : i + 1000]["text"]
```
+`get_training_corpus()` 函数是一个生成器,每次调用的时候将产生 1,000 个文本,我们将用它来训练 tokenizer 。
-**get_training_corpus()** 函数是一个生成器,每次调用的时候将产生 1,000 个文本,我们将用它来训练标记器。
-
-🤗 Tokenizers 也可以直接在文本文件上进行训练。以下是我们如何生成一个文本文件,其中包含我们可以在本地使用的来自 WikiText-2 的所有文本/输入:
+🤗 Tokenizers 也可以直接在文本文件上进行训练。以下是我们生成一个包含 WikiText-2 所有文本的代码,这样我们就可以在本地离线使用:
```python
with open("wikitext-2.txt", "w", encoding="utf-8") as f:
@@ -61,13 +60,13 @@ with open("wikitext-2.txt", "w", encoding="utf-8") as f:
f.write(dataset[i]["text"] + "\n")
```
-接下来,我们将向您展示如何逐块构建您自己的 BERT、GPT-2 和 XLNet 标记器。这将为我们提供三个主要标记化算法的示例:WordPiece、BPE 和 Unigram。让我们从 BERT 开始吧!
+接下来,我们将展示如何模块化地构建你自己的 BERT、GPT-2 和 XLNet tokenizer 这将包含主要的分词算法:WordPiece、BPE 和 Unigram 的例子。让我们从 BERT 开始吧!
-## 从头开始构建 WordPiece 标记器 [[从头开始构建 WordPiece 标记器]]
+## 从头开始构建 WordPiece tokenizer [[从头开始构建 WordPiece tokenizer ]]
-要使用 🤗 Tokenizers 库构建标记器,我们首先使用**model**实例化一个 **Tokenizer** 对象与 ,然后将 **normalizer** , **pre_tokenizer** , **post_processor** , 和 **decoder** 属性设置成我们想要的值。
+要用🤗 Tokenizers 库构建一个 tokenizer 我们首先实例化一个带有 `model` 的 `Tokenizer` 对象,然后将其 `normalizer` , `pre_tokenizer` , `post_processor` 和 `decoder` 属性设置为我们想要的值。
-对于这个例子,我们将创建一个 **Tokenizer** 使用 WordPiece 模型:
+以这个例子来说,我们将创建一个使用 WordPiece 模型的 `Tokenizer` :
```python
from tokenizers import (
@@ -83,15 +82,15 @@ from tokenizers import (
tokenizer = Tokenizer(models.WordPiece(unk_token="[UNK]"))
```
-我们必须指定 **unk_token** 这样模型才知道当它遇到以前没有见过的字符时要返回什么。我们可以在此处设置的其他参数包括我们模型的**vocab(字典)**(我们将训练模型,所以我们不需要设置它)和 **max_input_chars_per_word** 即每个单词的最大长度(比传递的值长的单词将被拆分)
+我们必须指定 `unk_token` ,这样当模型遇到它从未见过的字符时,它就会返回 `unk_token`。我们在这里可以设置的其他参数包括已有的 `vocab(词汇表)` (我们要重新训练模型,所以我们不需要设置这个)和 `max_input_chars_per_word` ,它指定了每个词的最大长度(比 `max_input_chars_per_word` 长的词将被拆分)。
-标记化的第一步是规范化,所以让我们从它开始。 由于 BERT 被广泛使用,所以有一个可以使用的 `BertNormalizer`,我们可以为 BERT 设置经典的选项:`lowercase(小写)` 和 `strip_accents(去除音调)`,不言自明; `clean_text` 删除所有控制字符并将重复的空格替换为一个; 和 `handle_chinese_chars`,在汉字周围放置空格。 要实现 `bert-base-uncased` ,我们可以这样设置这个规范器:
+tokenization 的第一步是标准化,所以我们从这里开始。由于 BERT 被广泛使用,所以我们可以使用 `BertNormalizer` ,我们可以为 BERT 设置经典参数: `lowercase(小写)` 和 `strip_accents(去除重音的字符)` , `clean_text` 用于删除所有控制字符并将重复的空格替换为一个空格;以及 `handle_chinese_chars` ,它将在中文字符周围添加空格。要复现 `bert-base-uncased` tokenizer 我们可以这样设置 `normalizer` :
```python
tokenizer.normalizer = normalizers.BertNormalizer(lowercase=True)
```
-然而,一般来说,在构建新的标记器时,您可以使用已经在 🤗 Tokenizers库中实现的非常方便的normalizer——所以让我们看看如何手动创建 BERT normalizer。 该库提供了一个“Lowercase(小写)”的normalizer和一个“StripAccents”的normalizer,您可以使用“序列”组合多个normalizer:
+然而,通常来说,当你构建一个新的 tokenizer 时,也需要同步构建一个新的 `normalizer` —— 所以我们来看看如何手动创建 `BERT normalizer` 。🤗 Tokenizers 库提供了一个 `Lowercase normalizer` 和一个 `StripAccents normalizer` ,并且你可以使用 Sequence 来组合多个 normalizer。
```python
tokenizer.normalizer = normalizers.Sequence(
@@ -99,9 +98,9 @@ tokenizer.normalizer = normalizers.Sequence(
)
```
-我们也在使用 **NFD** Unicode normalizer,否则 **StripAccents** normalizer 无法正确识别带重音的字符,因此没办法删除它们。
+我们还使用了一个 `NFD Unicode normalizer` ,否则,否则 `StripAccents normalizer` 将因为无法正确识别带有重音的字符,从而没办法去除重音。
-正如我们之前看到的,我们可以使用 **normalize** 的 **normalize_str()** 方法查看它对给定文本的影响:
+正如我们之前看到的,我们可以使用 `normalizer` 的 `normalize_str()` 方法来对它进行测试:
```python
print(tokenizer.normalizer.normalize_str("Héllò hôw are ü?"))
@@ -113,12 +112,13 @@ hello how are u?
-**更进一步**如果您在包含 unicode 字符的字符串上测试先前normalizers的两个版本,您肯定会注意到这两个normalizers并不完全等效。
-为了不过度使用 `normalizers.Sequence` 使版本过于复杂,我们没有包含当 `clean_text` 参数设置为 `True` 时 `BertNormalizer` 需要的正则表达式替换 - 这是默认行为。 但不要担心:通过在normalizer序列中添加两个 `normalizers.Replace` 可以在不使用方便的 `BertNormalizer` 的情况下获得完全相同的规范化。
+**更进一步**如果你在包含 unicode 字符的字符串上测试先前 normalizers 的两个版本,你肯定会注意到这两个 normalizers 并不完全等效。
+
+为了避免 `normalizers.Sequence` 过于复杂,我们的实现没有包含当 `clean_text` 参数设置为 `True` 时 `BertNormalizer` 需要的正则表达式替换 —— 而这是 `BertNormalizer` 默认会实现的。但不要担心:通过在 normalizer 序列中添加两个 `normalizers.Replace` 可以在不使用方便的 `BertNormalizer` 的情况下获得完全相同的标准化。
-接下来是预标记步骤。 同样,我们可以使用一个预构建的“BertPreTokenizer”:
+下一步是预分词。同样,我们可以使用预构建的 `BertPreTokenizer` :
```python
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
@@ -130,7 +130,7 @@ tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
tokenizer.pre_tokenizer = pre_tokenizers.Whitespace()
```
-请注意,`Whitespace` 预标记器会在空格和所有非字母、数字或下划线字符的字符上进行拆分,因此在本次的例子中上会根据空格和标点符号进行拆分:
+注意, `Whitespace` 会使用空格和所有不是字母、数字或下划线的字符进行分割,因此在本次的例子中上会根据空格和标点符号进行分割:
```python
tokenizer.pre_tokenizer.pre_tokenize_str("Let's test my pre-tokenizer.")
@@ -141,7 +141,7 @@ tokenizer.pre_tokenizer.pre_tokenize_str("Let's test my pre-tokenizer.")
('-', (17, 18)), ('tokenizer', (18, 27)), ('.', (27, 28))]
```
-如果您只想在空白处进行拆分,则应使用 **WhitespaceSplit** 代替预标记器:
+如果你只想使用空格进行分割,则应该使用 `WhitespaceSplit` :
```python
pre_tokenizer = pre_tokenizers.WhitespaceSplit()
@@ -152,7 +152,7 @@ pre_tokenizer.pre_tokenize_str("Let's test my pre-tokenizer.")
[("Let's", (0, 5)), ('test', (6, 10)), ('my', (11, 13)), ('pre-tokenizer.', (14, 28))]
```
-像normalizers一样,您可以使用 **Sequence** 组成几个预标记器:
+就像 normalizer 一样,你可以使用 `Sequence` 来组合几个预分词的步骤:
```python
pre_tokenizer = pre_tokenizers.Sequence(
@@ -166,29 +166,29 @@ pre_tokenizer.pre_tokenize_str("Let's test my pre-tokenizer.")
('-', (17, 18)), ('tokenizer', (18, 27)), ('.', (27, 28))]
```
-标记化管道的下一步是输入给模型。我们已经在初始化中指定了我们的模型,但我们仍然需要训练它,这将需要一个 **WordPieceTrainer** .在 🤗 Tokenizers 中实例化训练器时要记住的主要事情是,您需要将您打算使用的所有特殊标记传递给它 - 否则它不会将它们添加到词汇表中,因为它们不在训练语料库中:
+tokenization 流程的下一步是将输入数据传递给模型。我们已经在初始化时指定了我们的模型,但是我们还需要对其进行训练,这就需要一个 `WordPieceTrainer` 。在实例化一个🤗 Tokenizers 中的 `Trainer` 时,一件很重要的事情是,你需要将你打算使用的所有特殊 tokens 都传递给它——否则,由于它们不在训练语料库中,`Trainer` 就不会将它们添加到词汇表中:
```python
special_tokens = ["[UNK]", "[PAD]", "[CLS]", "[SEP]", "[MASK]"]
trainer = trainers.WordPieceTrainer(vocab_size=25000, special_tokens=special_tokens)
```
-以及指定 **vocab_size(词典大小)** 和 **special_tokens(特殊的标记)** ,我们可以设置 **min_frequency** (记号必须出现在词汇表中的次数)或更改 **continuing_subword_prefix** (如果我们想使用与 **##**指代存在与字词相同的前缀 )。
+除了指定 `vocab_size` 和 `special_tokens` ,我们还可以设置 `min_frequency` (一个 tokens 必须达到的最小的出现的次数才能被包含在词汇表中)或更改 `continuing_subword_prefix` (如果我们想使用其他的字符来替代 `##` )。
-要使用我们之前定义的迭代器训练我们的模型,我们只需要执行以下命令:
+我们只需要执行以下命令就可以使用我们之前定义的迭代器训练我们的模型:
```python
tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
```
-我们还可以使用文本文件来训练我们的标记器,它看起来像这样(我们需要先初始化一个空的 **WordPiece** ):
+我们还可以使用本地的文本文件来训练我们的 tokenizer 它看起来像这样(我们需要先使用 `WordPiece` 初始化一个空的模型):
```python
tokenizer.model = models.WordPiece(unk_token="[UNK]")
tokenizer.train(["wikitext-2.txt"], trainer=trainer)
```
-在这两种情况下,我们都可以通过调用文本来测试标记器 **encode()** 方法:
+在这两种情况下,我们都可以通过调用 `encode()` 方法来测试 tokenizer
```python
encoding = tokenizer.encode("Let's test this tokenizer.")
@@ -199,9 +199,9 @@ print(encoding.tokens)
['let', "'", 's', 'test', 'this', 'tok', '##eni', '##zer', '.']
```
-这个 **encoding** 获得的是一个 **Encoding**对象 ,它的属性中包含标记器的所有必要输出: **ids** , **type_ids** , **tokens** , **offsets** , **attention_mask** , **special_tokens_mask** , 和 **overflowing** .
+所得到的 `encoding` 是一个 `Encoding` 对象,它包含 tokenizer 的所有必要属性: `ids` 、 `type_ids` 、 `tokens` 、 `offsets` 、 `attention_mask` 、 `special_tokens_mask` 和 `overflowing` 。
-标记化管道的最后一步是后处理。我们需要添加 **[CLS]** 开头的标记和 **[SEP]** 标记在末尾(或在每个句子之后,如果我们有一对句子)。我们将使用一个 **TemplateProcessor** 为此,但首先我们需要知道 **[CLS]** 和 **[SEP]** 在词汇表中的ID:
+tokenizer 管道的最后一步是后处理。我们需要在开头添加 `[CLS]` token,然后在结束时(或在每句话后,如果我们有一对句子)添加 `[SEP]` token。我们将使用 `TemplateProcessor` 来完成这个任务,但首先我们需要知道词汇表中 `[CLS]` 和 `[SEP]` tokens 的 ID:
```python
cls_token_id = tokenizer.token_to_id("[CLS]")
@@ -213,9 +213,9 @@ print(cls_token_id, sep_token_id)
(2, 3)
```
-为了给 **TemplateProcessor** 编写模板,我们必须指定如何处理单个句子和一对句子。对于两者,我们都编写了我们想要使用的特殊标记;第一个(或单个)句子表示为 **$A** ,而第二个句子(如果对一对进行编码)表示为 **$B** .对于这些特殊标记和句子,我们还需要使用在冒号后指定相应的标记类型 ID。
+编写 `TemplateProcessor` 的模板时,我们必须指定如何处理单个句子和一对句子。对于这两者,我们写下我们想使用的特殊 tokens 第一句(或单句)用 `$A` 表示,而第二句(如果需要编码一对句子)用 `$B` 表示。对于这些(特殊 tokens 和句子),我们还需要在冒号后指定相应的 token 类型 ID。
-因此经典的 BERT 模板定义如下:
+因此,经典的 BERT 模板定义如下:
```python
tokenizer.post_processor = processors.TemplateProcessing(
@@ -225,9 +225,9 @@ tokenizer.post_processor = processors.TemplateProcessing(
)
```
-请注意,我们需要传递特殊标记的 ID,以便标记器可以正确地将特殊标记转换为它们的 ID。
+请注意,我们需要传递特殊 tokens 的 ID,这样 tokenizer 才能正确地将它们转换为它们的 ID。
-添加后,我们之前的示例将输出出:
+添加之后,我们再次对之前的例子进行 tokenization:
```python
encoding = tokenizer.encode("Let's test this tokenizer.")
@@ -238,7 +238,8 @@ print(encoding.tokens)
['[CLS]', 'let', "'", 's', 'test', 'this', 'tok', '##eni', '##zer', '.', '[SEP]']
```
-在一对句子中,我们得到了正确的结果:
+在一对句子中,我们也得到了正确的结果:
+
```python
encoding = tokenizer.encode("Let's test this tokenizer...", "on a pair of sentences.")
print(encoding.tokens)
@@ -250,13 +251,13 @@ print(encoding.type_ids)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
```
-我们几乎从头开始构建了这个标记器——但是还有最后一步是指定一个解码器:
+我们几乎从头开始构建了这个 tokenizer ——但是还有最后一步:指定一个解码器:
```python
tokenizer.decoder = decoders.WordPiece(prefix="##")
```
-让我们测试一下我们之前的 **encoding** :
+让我们在之前的 `encoding` 上测试一下它:
```python
tokenizer.decode(encoding.ids)
@@ -266,28 +267,29 @@ tokenizer.decode(encoding.ids)
"let's test this tokenizer... on a pair of sentences."
```
-很好!我们可以将标记器保存在一个 JSON 文件中,如下所示:
+很好!我们可以将 tokenizer 保存在一个 JSON 文件中,如下所示:
```python
tokenizer.save("tokenizer.json")
```
-然后我们可以使用**from_file()** 方法从该文件里重新加载 **Tokenizer** 对象:
+然后,我们可以在一个 `Tokenizer` 对象中使用 `from_file()` 方法重新加载该文件:
```python
new_tokenizer = Tokenizer.from_file("tokenizer.json")
```
-要在 🤗 Transformers 中使用这个标记器,我们必须将它包裹在一个 **PreTrainedTokenizerFast** 类中。我们可以使用泛型类,或者,如果我们的标记器对应于现有模型,则使用该类(例如这里的 **BertTokenizerFast** )。如果您应用本课来构建全新的标记器,则必须使用第一个选项。
+要在🤗 Transformers 中使用这个 tokenizer 我们需要将它封装在一个 `PreTrainedTokenizerFast` 类中。我们可以使用通用类(PreTrainedTokenizerFast),或者,如果我们的 tokenizer 对应于一个现有的模型,则可以使用该类(例如这里的 `BertTokenizerFast` )。如果你使用这个课程来构建一个全新的 tokenizer 并且没有一个现有的模型可以使用,就必须需要使用通用类。
+
+要将构建的 tokenizer 封装在 `PreTrainedTokenizerFast` 类中,我们可以将我们构建的 tokenizer 作为 `tokenizer_object` 传入,或者将我们保存的 tokenizer 文件作为 `tokenizer_file` 传入。要记住的关键一点是,我们需要手动设置所有的特殊 tokens,因为这个类不能从 `tokenizer` 对象推断出哪个符号是掩码符号, `[CLS]` 符号等:
-要将标记器包装在 `PreTrainedTokenizerFast` 类中,我们可以将我们构建的标记器作为`tokenizer_object` 传递,或者将我们保存为`tokenizer_file` 的标记器文件传递。 要记住的关键是我们必须手动设置所有特殊标记,因为该类无法从 `tokenizer` 对象推断出哪个标记是掩码标记、`[CLS]` 标记等:
```python
from transformers import PreTrainedTokenizerFast
wrapped_tokenizer = PreTrainedTokenizerFast(
tokenizer_object=tokenizer,
- # tokenizer_file="tokenizer.json", # You can load from the tokenizer file, alternatively
+ # tokenizer_file="tokenizer.json", # 也可以从tokenizer文件中加载
unk_token="[UNK]",
pad_token="[PAD]",
cls_token="[CLS]",
@@ -296,7 +298,7 @@ wrapped_tokenizer = PreTrainedTokenizerFast(
)
```
-如果您使用特定的标记器类(例如 **BertTokenizerFast** ),您只需要指定与默认标记不同的特殊标记(此处没有):
+如果你使用的是其他的 tokenizer 类(如 `BertTokenizerFast` ),你只需要指定那些与默认值不同的特殊符号(这里没有):
```python
from transformers import BertTokenizerFast
@@ -304,27 +306,26 @@ from transformers import BertTokenizerFast
wrapped_tokenizer = BertTokenizerFast(tokenizer_object=tokenizer)
```
-然后,您可以像使用任何其他 🤗 Transformers 标记器一样使用此标记器。你可以用 **save_pretrained()** 方法,或使用 **push_to_hub()** 方法。
+然后,你就可以像使用其他的🤗 Transformers tokenizer 一样使用这个 tokenizer 了。你可以使用 `save_pretrained()` 方法来保存它,或者使用 `push_to_hub()` 方法将它上传到 Hub。
-现在我们已经了解了如何构建 WordPiece 标记器,让我们对 BPE 标记器进行同样的操作。因为您已经知道了所有步骤,所以我们会进行地更快一点,并且只突出展示两者不一样的地方。
+既然我们已经看到了如何构建一个 WordPiece tokenizer。那么让我们也尝试构建 BPE tokenizer。这次我们会快一些,因为你已经知道所有的步骤,我们主要强调其中的区别。
-## 从头开始构建 BPE 标记器 [[从头开始构建 BPE 标记器]]
+## 从头开始构建 BPE tokenizer [[从头开始构建 BPE tokenizer ]]
-现在让我们构建一个 GPT-2 标记器。与 BERT 标记器一样,我们首先使用 **Tokenizer** 初始化一个BPE 模型:
+现在让我们构建一个 GPT-2 tokenizer,与 BERT tokenizer 一样,我们首先通过 BPE model 初始化一个 `Tokenizer` :
```python
tokenizer = Tokenizer(models.BPE())
```
-和 BERT 一样,如果我们有一个词汇表,我们可以用一个词汇表来初始化这个模型(在这种情况下,我们需要传递 `vocab` 和 `merges`),但是由于我们将从头开始训练,所以我们不需要这样去做。 我们也不需要指定“unk_token”,因为 GPT-2 使用的字节级 BPE,不需要“unk_token”。
+同样,类似于 BERT,如果我们已经有一个词汇表,我们也可以使用这个词汇表来初始化 GPT 模型(在这种情况下,我们需要传入 `vocab` 和 `merges` 参数),但是因为我们将从头开始训练,所以我们不需要做这个。我们也不需要指定 `unk_token` ,因为 GPT-2 使用字节级 BPE,这不需要它。
-GPT-2 不使用归一化器,因此我们跳过该步骤并直接进入预标记化:
+GPT-2 不使用 `normalizer` ,因此我们跳过该步骤并直接进入预分词:
```python
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
```
-
-我们在此处添加到 `ByteLevel` 的选项是不在句子开头添加空格(默认为ture)。 我们可以看一下使用这个标记器对之前示例文本的预标记:
+我们在这里给 `ByteLevel` 添加的选项的含义是不在句子的开始添加空格(默认为 ture)。我们可以看一下之前的示例文本经过预分词后的结果:
```python
tokenizer.pre_tokenizer.pre_tokenize_str("Let's test pre-tokenization!")
@@ -335,23 +336,23 @@ tokenizer.pre_tokenizer.pre_tokenize_str("Let's test pre-tokenization!")
('tokenization', (15, 27)), ('!', (27, 28))]
```
-接下来是需要训练的模型。对于 GPT-2,唯一的特殊标记是文本结束标记:
+接下来是需要训练的模型。对于 GPT-2,唯一的特殊符号是文本结束符:
```python
trainer = trainers.BpeTrainer(vocab_size=25000, special_tokens=["<|endoftext|>"])
tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
```
-与 `WordPieceTrainer` 以及 `vocab_size` 和 `special_tokens` 一样,我们可以指定 `min_frequency` 如果我们愿意,或者如果我们有一个词尾后缀(如 `` ),我们可以使用 `end_of_word_suffix` 设置它。
+就像 `WordPieceTrainer` 一样,除了 `vocab_size` 和 `special_tokens` ,我们也可以设置 `min_frequency` ,或者如果我们需要添加一个词尾后缀(如 `` ),我们可以用 `end_of_word_suffix` 设置它。
-这个标记器也可以在文本文件上训练:
+这个 tokenizer 也可以在本地的文本文件上训练:
```python
tokenizer.model = models.BPE()
tokenizer.train(["wikitext-2.txt"], trainer=trainer)
```
-让我们看一下示例文本的标记化后的结果:
+让我们看一下示例文本经过 tokenization 后的结果:
```python
encoding = tokenizer.encode("Let's test this tokenizer.")
@@ -362,13 +363,13 @@ print(encoding.tokens)
['L', 'et', "'", 's', 'Ġtest', 'Ġthis', 'Ġto', 'ken', 'izer', '.']
```
-我们对 GPT-2 标记器添加字节级后处理,如下所示:
+我们对 GPT-2 tokenizer 添加字节级后处理,如下所示:
```python
tokenizer.post_processor = processors.ByteLevel(trim_offsets=False)
```
-`trim_offsets = False` 选项指示我们应该保留以 'Ġ' 开头的标记的偏移量:这样偏移量的开头将指向单词之前的空格,而不是第一个单词的字符(因为空格在技术上是标记的一部分)。 让我们看看我们刚刚编码的文本的结果,其中 `'Ġtest'` 是索引第 4 处的标记:
+`trim_offsets = False` 这个选项告诉 post-processor,我们应该让那些以‘Ġ’开始的 tokens 的偏移量保持不变:这样,偏移量起始的索引将指向单词前的空格,而不是单词的第一个字符(因为空格在技术上是 token 的一部分)。让我们看一下我们编码示例文本的结果,其中 `'Ġtest'` 是索引 4 的 token
```python
sentence = "Let's test this tokenizer."
@@ -387,7 +388,7 @@ sentence[start:end]
tokenizer.decoder = decoders.ByteLevel()
```
-我们可以仔细检查它是否正常工作:
+我们可以再次检查它是否工作正常:
```python
tokenizer.decode(encoding.ids)
@@ -397,7 +398,7 @@ tokenizer.decode(encoding.ids)
"Let's test this tokenizer."
```
-很好!现在我们完成了,我们可以像以前一样保存标记器,并将它包装在一个 **PreTrainedTokenizerFast** 或者 **GPT2TokenizerFast** 如果我们想在 🤗 Transformers中使用它:
+太好了!现在我们完成了,我们可以像之前一样保存 tokenizer,并且如果我们想在🤗 Transformers 中使用它,可以将它封装在 `PreTrainedTokenizerFast` 类或者 `GPT2TokenizerFast` 类中:
```python
from transformers import PreTrainedTokenizerFast
@@ -417,11 +418,11 @@ from transformers import GPT2TokenizerFast
wrapped_tokenizer = GPT2TokenizerFast(tokenizer_object=tokenizer)
```
-作为最后一个示例,我们将向您展示如何从头开始构建 Unigram 标记器。
+作为最后一个示例,我们将向你展示如何从零开始构建 Unigram tokenizer
-## 从头开始构建 Unigram 标记器 [[从头开始构建 Unigram 标记器]]
+## 从零开始构建 Unigram tokenizer [[从零开始构建 Unigram tokenizer ]]
-现在让我们构建一个 XLNet 标记器。与之前的标记器一样,我们首先使用 Unigram 模型初始化一个 **Tokenizer** :
+现在让我们构建一个 XLNet tokenizer 与之前的 tokenizer 一样,我们首先使用 Unigram model 初始化一个 `Tokenizer` :
```python
tokenizer = Tokenizer(models.Unigram())
@@ -429,7 +430,7 @@ tokenizer = Tokenizer(models.Unigram())
同样,如果我们有词汇表,我们可以用词汇表初始化这个模型。
-对于标准化,XLNet 使用了一些替换的方法(来自 SentencePiece):
+在标准化步骤,XLNet 进行了一些替换(来自 SentencePiece 算法):
```python
from tokenizers import Regex
@@ -445,15 +446,15 @@ tokenizer.normalizer = normalizers.Sequence(
)
```
-这会取代 **“** 和 **”** 和 **”** 以及任何两个或多个空格与单个空格的序列,以及删除文本中的重音以进行标记。
+这会将``和''替换为",将任何连续两个或更多的空格替换为一个空格,同时还将去掉待分词文本中的重音符号。
-用于任何 SentencePiece 标记器的预标记器是 `Metaspace`:
+任何 SentencePiece tokenizer 使用的预 tokenizer 是 `Metaspace` :
```python
tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
```
-我们可以像以前一样查看示例文本的预标记化:
+我们可以像以前一样查看示例文本的预分词:
```python
tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
@@ -463,7 +464,7 @@ tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
[("▁Let's", (0, 5)), ('▁test', (5, 10)), ('▁the', (10, 14)), ('▁pre-tokenizer!', (14, 29))]
```
-接下来是需要训练的模型。 XLNet 有不少特殊的标记:
+接下来是需要训练的模型。XLNet 有不少特殊的 tokens
```python
special_tokens = ["", "", "", "", "", "", ""]
@@ -473,16 +474,16 @@ trainer = trainers.UnigramTrainer(
tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
```
-不要忘记`UnigramTrainer` 的一个非常重要的参数是`unk_token`。 我们还可以传递特定于 Unigram 算法的其他参数,例如删除标记的每个步骤的“shrinking_factor(收缩因子)”(默认为 0.75)或指定给定标记的最大长度的“max_piece_length”(默认为 16) .
+对于 `UnigramTrainer` 来说,一个非常重要的参数是 `unk_token` 。我们也可以传递一些 Unigram 算法独有的其他参数,例如我们可以设置每个删除 token 时的 `shrinking_factor` (默认为 0.75),或者指定 token 最大长度的 `max_piece_length` (默认为 16)。
-这个标记器也可以在文本文件上训练:
+这个 tokenizer 也可以在本地的文本文件上训练:
```python
tokenizer.model = models.Unigram()
tokenizer.train(["wikitext-2.txt"], trainer=trainer)
```
-让我们看一下示例文本的标记化后的结果:
+让我们看一下示例文本的 tokenization 后的结果:
```python
encoding = tokenizer.encode("Let's test this tokenizer.")
@@ -493,8 +494,7 @@ print(encoding.tokens)
['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.']
```
-A peculiarity of XLNet is that it puts the `` token at the end of the sentence, with a type ID of 2 (to distinguish it from the other tokens). It's padding on the left, as a result. We can deal with all the special tokens and token type IDs with a template, like for BERT, but first we have to get the IDs of the `` and `` tokens:
-XLNet 的一个特点是它将`` 标记放在句子的末尾,类型ID 为2(以将其与其他标记区分开来)。它会将结果填充在左侧。 我们可以使用模板处理所有特殊标记和标记类型 ID,例如 BERT,但首先我们必须获取 `` 和 `` 标记的 ID:
+XLNet 的一个特点是它将 `` token 放在句子的末尾,token 类型 ID 为 2(以区别于其他 tokens)。因此,它在左边进行填充。我们可以像对待 BERT 一样,用模板处理所有特殊 tokens 和 tokens 类型 ID,但首先我们需要获取 `` 和 `` tokens 的 ID:
```python
cls_token_id = tokenizer.token_to_id("")
@@ -516,7 +516,7 @@ tokenizer.post_processor = processors.TemplateProcessing(
)
```
-我们可以通过编码一对句子来测试它的工作原理:
+我们可以通过编码一对句子来测试它是否有效:
```python
encoding = tokenizer.encode("Let's test this tokenizer...", "on a pair of sentences!")
@@ -530,13 +530,13 @@ print(encoding.type_ids)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2]
```
-最后,我们添加一个 **Metaspace** 解码器:
+最后,我们添加一个 `Metaspace` 解码器:
```python
tokenizer.decoder = decoders.Metaspace()
```
-我们完成了这个标记器! 我们可以像以前一样保存标记器,如果我们想在 🤗 Transformers 中使用它,可以将它包装在 `PreTrainedTokenizerFast` 或 `XLNetTokenizerFast` 中。 使用 `PreTrainedTokenizerFast` 时要注意的一件事是,我们需要告诉🤗 Transformers 库应该在左侧填充特殊标记:
+我们完成了这个 tokenizer。我们可以像保存其他 tokenizer 一样保存它。如果我们想在 🤗 Transformers 中使用它,可以将它封装在 `PreTrainedTokenizerFast` 类或 `XLNetTokenizerFast` 类中。使用 `PreTrainedTokenizerFast` 类时需要注意的一点是,除了特殊 tokens 之外,我们还需要告诉🤗 Transformers 库在左边进行填充:
```python
from transformers import PreTrainedTokenizerFast
@@ -561,4 +561,4 @@ from transformers import XLNetTokenizerFast
wrapped_tokenizer = XLNetTokenizerFast(tokenizer_object=tokenizer)
```
-现在您已经了解了如何使用各种构建块来构建现有的标记器,您应该能够使用 🤗 tokenizer库编写您想要的任何标记器,并能够在 🤗 Transformers中使用它。
\ No newline at end of file
+现在你已经了解了如何使用各种模块来构建现有的 tokenizer,你应该能够使用 🤗 tokenizer 库编写你想要的任何 tokenizer 并能够在 🤗 Transformers 中使用它。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter6/9.mdx b/chapters/zh-CN/chapter6/9.mdx
index cb0c68169..61d507cdc 100644
--- a/chapters/zh-CN/chapter6/9.mdx
+++ b/chapters/zh-CN/chapter6/9.mdx
@@ -1,16 +1,16 @@
-# 标记器,回顾! [[标记器,回顾!]]
+# tokenizer 回顾![[ tokenizer ,回顾!]]
-完成这一章,辛苦了!
+恭喜你完成了这一章!
-在深入研究标记器之后,您应该:
+在深入研究 tokenizer 之后,你应该:
-- 能够使用旧的标记器作为模板来训练新的标记器
-- 了解如何使用偏移量将标记的位置映射到其原始文本范围
+- 能够使用旧的 tokenizer 作为模板来训练新的 tokenizer
+- 了解如何使用偏移量将 tokens 的位置映射到其原始文本范围
- 了解 BPE、WordPiece 和 Unigram 之间的区别
-- 能够混合和匹配 🤗 Tokenizers 库提供的块来构建您自己的标记器
-- 能够在 🤗 Transformers 库中使用该标记器
\ No newline at end of file
+- 能够混合使用 🤗 Tokenizers 库提供的块来构建你自己的 tokenizer
+- 能够在 🤗 Transformers 库中使用该 tokenizer
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter7/1.mdx b/chapters/zh-CN/chapter7/1.mdx
index 53e35918e..8617c8397 100644
--- a/chapters/zh-CN/chapter7/1.mdx
+++ b/chapters/zh-CN/chapter7/1.mdx
@@ -2,9 +2,9 @@
# 章节简介 [[章节简介]]
-在[第三章](/course/chapter3),您了解了如何微调文本分类的模型。在本章中,我们将处理以下常见的 NLP 任务:
+在 [第三章](/course/chapter3) ,你了解了如何微调文本分类模型。在本章中,我们将处理以下常见的 NLP 任务:
-- 词元(token)分类
+- Token 分类
- 掩码语言建模(如 BERT)
- 文本摘要
- 翻译
@@ -13,21 +13,21 @@
{#if fw === 'pt'}
-为此,您需要利用[第三章](/course/chapter3)中学到的 `Trainer` API 和 🤗 Accelerate 库、[第五章](/course/chapter5)中的 🤗 Datasets 库以及[第六章](/course/chapter6)中的 🤗 Tokenizers 库的所有知识。我们同样会将结果上传到模型中心,就像我们在[第四章](/course/chapter4)中所做的那样,所以这确实是融会贯通的一章!
+为此,你需要充分利用在 [第三章](/course/chapter3) 中学到的有关 `Trainer` API 和 🤗 Accelerate 库的知识,以及在 [第五章](/course/chapter5) 中学到的 🤗 Datasets 库和 [第六章](/course/chapter6) 中学到的 🤗 Tokenizers 库的知识。我们还会像在 [第四章](/course/chapter4) 中那样将结果上传到 Model Hub,所以这真的是所有所学内容融会贯通的一章!
-每个部分都可以独立阅读,并将向您展示如何使用 `Trainer` API 或按照您自己的训练循环训练模型,并采用 🤗 Accelerate 加速。你可以随意跳过任何一部分,专注于您最感兴趣的部分:`Trainer` API 非常适用于微调(fine-tuning)或训练您的模型,且无需担心幕后发生的事情;而采用 `Accelerate` 的训练循环可以让您更轻松地自定义所需的任何结构。
+本章的每个部分都可以独立阅读,它们将向你展示如何使用 `Trainer` API 或自己的训练循环来训练模型,同时使用 🤗 Accelerate 加速。你可以随意跳过其中任意部分,重点关注你最感兴趣的部分: `Trainer` API 非常适合微调(fine-tuning)或训练模型,而无需关注内部的实现细节,而使用 `Accelerate` 的训练循环将使你更容易自定义所需的任何结构。
{:else}
-为此,您需要利用[第三章](/course/chapter3)中学到的有关 Keras API、[第五章](/course/chapter5)中的 🤗 Datasets 库以及[第六章](/course/chapter6)中的 🤗 Tokenizers 库的所有知识。我们同样会将结果上传到模型中心,就像我们在[第四章](/course/chapter4)中所做的那样,所以这确实是融会贯通的一章!
+为此,你需要充分利用在 [第三章](/course/chapter3) 中学到的有关 `Keras` API、 [第五章](/course/chapter5) 中的 🤗 Datasets 库以及 [第六章](/course/chapter6) 中的 🤗 Tokenizers 库的所有知识。我们还会像在 [第四章](/course/chapter4) 中那样将结果上传到 Model Hub,所以这真的是所有所学内容融会贯通的一章!
-每个部分都可以独立阅读。
+本章每个部分都可以独立阅读。
{/if}
-如果您按顺序阅读这些部分,您会注意到它们有很多共同的代码和陈述。 重复是有意为之的,让您可以深入(或稍后返回)任何您感兴趣的任务并找到一个完整的工作示例。
+如果你按顺序阅读这些部分,你会注意到各小节在代码和描述上有许多相似之处。这种重复是有意为之的,让你可以随时钻研或对比学习任何感兴趣的任务,并且在每个任务中都可以找到一个完整的可运行示例。
diff --git a/chapters/zh-CN/chapter7/2.mdx b/chapters/zh-CN/chapter7/2.mdx
index e9f663157..330606138 100644
--- a/chapters/zh-CN/chapter7/2.mdx
+++ b/chapters/zh-CN/chapter7/2.mdx
@@ -22,15 +22,14 @@
{/if}
-我们将探索的第一个应用是Token分类。这个通用任务包括任何可以表述为“为句子中的词或字分配标签”的问题,例如:
-
-- **实体命名识别 (NER)**: 找出句子中的实体(如人物、地点或组织)。这可以通过为每个实体或“无实体”指定一个类别的标签。
-- **词性标注 (POS)**: 将句子中的每个单词标记为对应于特定的词性(如名词、动词、形容词等)。
-- **分块(chunking)**: 找到属于同一实体的Token。这个任务(可结合POS或NER)可以任何将一块Token作为制定一个标签(通常是B -),另一个标签(通常I -)表示Token是否是同一块,和第三个标签(通常是O)表示Token不属于任何块。也就是标出句子中的短语块,例如名词短语(NP),动词短语(VP)等。
+我们将首先探讨的应用是 Token 分类。这个通用任务涵盖了所有可以表述为“给句子中的词或字贴上标签”的问题,例如:
+- **实体命名识别 (NER)**:找出句子中的实体(如人物、地点或组织)。这可以通过为每个实体指定一个类别的标签,如果没有实体则会输出无实体的标签。
+- **词性标注 (POS)**:将句子中的每个单词标记为对应于特定的词性(如名词、动词、形容词等)。
+- **分块(chunking)**:找出属于同一实体的 tokens 这个任务(可以与词性标注或命名实体识别结合)可以被描述为将位于块开头的 token 赋予一个标签(通常是 “ `B-` ” (Begin),代表该token位于实体的开头),将位于块内的 tokens 赋予另一个标签(通常是 “ `I-` ”(inner)代表该token位于实体的内部),将不属于任何块的 tokens 赋予第三个标签(通常是 “ `O` ” (outer)代表该token不属于任何实体)。
-当然,还有很多其他类型的token分类问题;这些只是几个有代表性的例子。在本节中,我们将在 NER 任务上微调模型 (BERT),然后该模型将能够计算如下预测:
+当然,还有很多其他类型的 token 分类问题;这些只是几个有代表性的例子。在本节中,我们将在 NER 任务上微调模型 (BERT),然后该模型将能够生成如下预测:
@@ -39,21 +38,21 @@
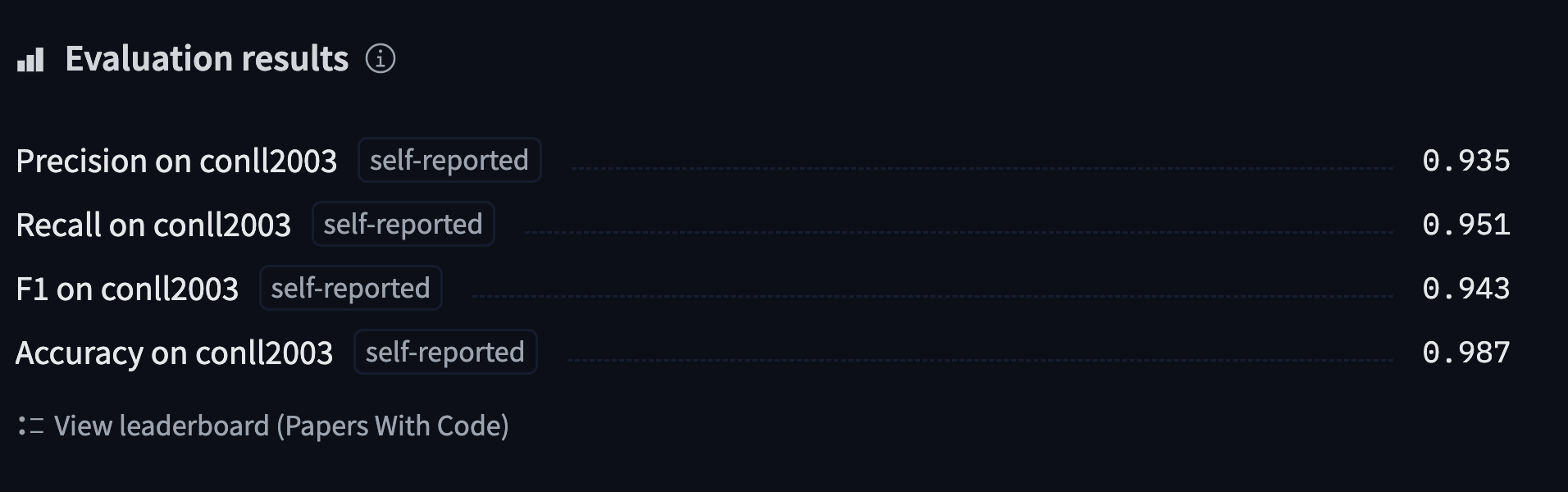 -您可以[在这里](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).找到我们将训练并上传到 Hub的模型,可以尝试输入一些句子看看模型的预测结果。
+你可以 [在这里](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn) 。找到我们将训练并上传到 Hub 的模型,可以尝试输入一些句子测试一下模型的预测结果。
## 准备数据 [[准备数据]]
-首先,我们需要一个适合标记分类的数据集。在本节中,我们将使用[CoNLL-2003 数据集](https://huggingface.co/datasets/conll2003), 其中包含来自路透社的新闻报道。
+首先,我们需要一个适合 token 分类的数据集。在本节中,我们将使用 [CoNLL-2003 数据集](https://huggingface.co/datasets/conll2003) ,该数据集来源于路透社的新闻报道。
-💡 只要您的数据集由带有相应标签的分割成单词并的文本组成,您就能够将这里描述的数据处理过程应用到您自己的数据集。如果需要复习如何在.Dataset中加载自定义数据,请参阅[Chapter 5](/course/chapter5)。
+💡 只要你的数据集由分词文本和对应的标签组成,就能够将这里描述的数据处理过程应用到自己的数据集中。如果需要复习如何在 `Dataset` 中加载自定义数据集,请复习 [第五章](/course/chapter5) 。
### CoNLL-2003 数据集 [[CoNLL-2003 数据集]]
-要加载 CoNLL-2003 数据集,我们使用 来自 🤗 Datasets 库的**load_dataset()** 方法:
+要加载 CoNLL-2003 数据集,我们可以使用🤗 Datasets 库的 `load_dataset()` 方法:
```py
from datasets import load_dataset
@@ -61,7 +60,7 @@ from datasets import load_dataset
raw_datasets = load_dataset("conll2003")
```
-这将下载并缓存数据集,就像和我们在[第三章](/course/chapter3) 加载GLUE MRPC 数据集一样。检查这个对象可以让我们看到存在哪些列,以及训练集、验证集和测试集之间是如何分割的:
+这将下载并缓存数据集,就像和我们在 [第三章](/course/chapter3) 加载 GLUE MRPC 数据集一样。查看 `raw_datasets` 对象可以让我们看到数据集中存在哪些列,以及训练集、验证集和测试集之间是如何划分的:
```py
raw_datasets
@@ -84,7 +83,7 @@ DatasetDict({
})
```
-特别是,我们可以看到数据集包含我们之前提到的三个任务的标签:NER、POS 和chunking。与其他数据集的一个很大区别是输入文本不是作为句子或文档呈现的,而是单词列表(最后一列称为 **tokens** ,但它包含的是这些词是预先标记化的输入,仍然需要通过标记器进行子词标记)。
+可以看到数据集包含了我们之前提到的三项任务的标签:命名实体识别(NER)、词性标注(POS)以及分块(chunking)。这个数据集与其他数据集的一个显著区别在于,输入文本的那一列并非以句子或整片的文本的形式存储,而是以单词列表的形式(最后一列被称为 `tokens` ,不过 `tokens` 列保存的还是单词,也就是说,这些预先分词的输入仍需要经过 tokenizer 进行子词分词处理)。
我们来看看训练集的第一个元素:
@@ -96,7 +95,7 @@ raw_datasets["train"][0]["tokens"]
['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
```
-由于我们要执行命名实体识别,我们将查看 NER 标签:
+由于我们要进行命名实体识别,让我们查看一下 NER 标签:
```py
raw_datasets["train"][0]["ner_tags"]
@@ -106,7 +105,7 @@ raw_datasets["train"][0]["ner_tags"]
[3, 0, 7, 0, 0, 0, 7, 0, 0]
```
-这一列是类标签的序列。元素的类型在ner_feature的feature属性中,我们可以通过查看该特性的names属性来访问名称列表:
+这些是可以直接训练的整数类别标签,当我们想要检查数据时,直接看整数的标签不是很直观。就像在文本分类中,我们可以通过查看数据集的 `features` 属性来找到这些整数和标签名称之间的对应关系:
```py
ner_feature = raw_datasets["train"].features["ner_tags"]
@@ -117,7 +116,7 @@ ner_feature
Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
```
-因此,这一列包含的元素是ClassLabels的序列。序列元素的类型在`ner_feature`的`feature`中,我们可以通过查看该`feature`的`names`属性来访问名称列表:
+因此,我们得到了 `ClassLabels` 类型的序列。序列中元素的类型存储在 `ner_feature` 的 `feature` 中,我们可以通过查看该 `feature` 的 `names` 属性来访问标签名称的列表:
```py
label_names = ner_feature.feature.names
@@ -128,15 +127,15 @@ label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
```
-我们在[第六章](/course/chapter6/3), 深入研究**token-classification** 管道时已经看到了这些标签 ,但为了快速复习:
+我们在 [第六章](/course/chapter6/3) 深入研究 `token-classification` 管道时已经看到过这些标签 我们在这里进行一个快速的回顾:
- `O` 表示这个词不对应任何实体。
-- `B-PER`/`I-PER`意味着这个词对应于人名实体的开头/内部。
-- `B-ORG`/`I-ORG` 的意思是这个词对应于组织名称实体的开头/内部。
-- `B-LOC`/`I-LOC` 指的是是这个词对应于地名实体的开头/内部。
-- `B-MISC`/`I-MISC` 表示该词对应于一个杂项实体的开头/内部。
+- `B-PER` / `I-PER` 意味着这个词对应于人名实体的开头/内部。
+- `B-ORG` / `I-ORG` 的意思是这个词对应于组织名称实体的开头/内部。
+- `B-LOC` / `I-LOC` 指的是是这个词对应于地名实体的开头/内部。
+- `B-MISC` / `I-MISC` 表示这个词对应一个其他实体(不属于特定类别或类别之外)的开头 / 内部。
-现在解码我们之前看到的标签:
+接下来使用对这些标签名对数据集的 `ner_tags` 进行解码,将得到以下输出结果:
```python
words = raw_datasets["train"][0]["tokens"]
@@ -158,18 +157,18 @@ print(line2)
'B-ORG O B-MISC O O O B-MISC O O'
```
-例如混合 **B-** 和 **I-** 标签,这是相同的代码在索引 4 的训练集元素上的预测结果:
+我们还可以查看训练集中索引为 4 的数据,它是一个同时包含 `B-` 和 `I-` 标签的例子:
```python out
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
```
-正如我们所看到的,跨越两个单词的实体,如“European Union”和“Werner Zwingmann”,模型为第一个单词标注了一个B-标签,为第二个单词标注了一个I-标签。
+正如我们在上面的输出中所看到的,跨越两个单词的实体,如“European Union”和“Werner Zwingmann”,数据集把第一个单词标注为了 `B-` 标签,将第二个单词标记为了 `I-` 标签。
-✏️ **轮到你了!** 使用 POS 或chunking标签识别同一个句子。
+✏️ **轮到你了!** 检查同一个句子的词性标注 (POS)或分块(chunking)列,查看输出的结果。
@@ -177,9 +176,9 @@ print(line2)
-像往常一样,我们的文本需要转换为Token ID,然后模型才能理解它们。正如我们在[第六章](/course/chapter6/)所学的那样。不过在标记任务中,一个很大的区别是我们有pre-tokenized的输入。幸运的是,tokenizer API可以很容易地处理这个问题;我们只需要用一个特殊的tokenizer。
+像往常一样,我们的文本需要转换为 Token ID,然后模型才能理解它们。正如我们在 [第六章](/course/chapter6/) 所学的那样。不过与 tokens 分类任务不同的是数据集已经完成了预分词,我们在处理的过程中不需要再次分词。幸运的是,tokenizer API 可以很容易地处理这种差异;我们只需要通过一个特殊的标志告诉 tokenizer即可。
-首先,让我们创建`tokenizer`对象。如前所述,我们将使用 BERT 预训练模型,因此我们将从下载并缓存关联的分词器开始:
+首先,让我们创建 `tokenizer` 对象。如前所述,我们将使用 BERT 预训练模型,因此我们将从下载并缓存关联的 `tokenizer` 开始:
```python
from transformers import AutoTokenizer
@@ -188,7 +187,7 @@ model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
```
-你可以更换把 `model_checkpoint` 更换为 [Hub](https://huggingface.co/models),上您喜欢的任何其他型号,或使用您本地保存的预训练模型和分词器。唯一的限制是分词器需要由 🤗 Tokenizers 库支持,有一个“快速”版本可用。你可以在[这张大表](https://huggingface.co/transformers/#supported-frameworks), 上看到所有带有快速版本的架构,或者检查 您可以通过查看它`is_fast` 属性来检测正在使用的`tokenizer`对象是否由 🤗 Tokenizers 支持:
+你可以更换把 `model_checkpoint` 更换为 [Hub](https://huggingface.co/models) 上你喜欢的任何其他模型,或使用本地保存的预训练模型和 `tokenizer`。唯一的限制是 tokenizer 需要由 🤗 Tokenizers 库支持,并且有一个“快速”版本可用。你可以在 [Huggingface 模型后端支持表](https://huggingface.co/transformers/#supported-frameworks) 上看到所有带有快速版本的 `tokenizer` 架构,或者你也可以通过查看它 `is_fast` 属性来检测正在使用的 `tokenizer` 对象是否由 🤗 Tokenizers 支持:
```py
tokenizer.is_fast
@@ -198,7 +197,7 @@ tokenizer.is_fast
True
```
-要对预先标记的输入进行标记,我们可以像往常一样使用我们的`tokenizer` 只需添加 `is_split_into_words=True`:
+我们可以像往常一样使用我们的 `tokenizer` 对预先分词的输入进行 `tokenize` ,只需额外添加 `is_split_into_words=True` 参数:
```py
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
@@ -209,8 +208,10 @@ inputs.tokens()
['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
```
-正如我们所见,分词器添加了模型使用的特殊Token(`[CLS]` 在开始和`[SEP]` 最后) 而大多数单词未被修改。然而,单词 `lamb`,被分为两个子单词 `la` and `##mb`。这导致了输入和标签之间的不匹配:标签列表只有9个元素,而我们的输入现在有12个token 。计算特殊Token很容易(我们知道它们在开头和结尾),但我们还需要确保所有标签与适当的单词对齐。
-幸运的是,由于我们使用的是快速分词器,因此我们可以访问🤗 Tokenizers超能力,这意味着我们可以轻松地将每个令牌映射到其相应的单词(如[Chapter 6](/course/chapter6/3)):
+如我们所见,`tokenizer` 在结果中添加了模型需要使用的特殊 tokens(在开头的 `[CLS]` ,在结尾的 `[SEP]` ),并且大部分单词保持不变。不过,单词 `lamb` 被分词为两个子词, `la` 和 `##mb` 。这导致了输入和标签之间的不匹配:标签列表只有 9 个元素,而我们的输入现在有 12 个 tokens。解决特殊 tokens 的问题很容易(我们已经知道了每个 `token` 开始和结束的位置),我们需要确保的是我们将所有的标签与正确的词对齐。
+
+
+幸运的是,由于我们使用的是快速 tokens 因此我们可以使用🤗 Tokenizers 超能力,这意味着我们可以轻松地将每个 token 映射到其相应的单词(如 [第六章](/course/chapter6/3) 中所学):
```py
inputs.word_ids()
@@ -220,7 +221,7 @@ inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
```
-通过一点点工作,我们可以扩展我们的标签列表以匹配token 。我们将应用的第一条规则是,特殊token 的标签为 `-100` 。这是因为默认情况下 `-100` 是一个在我们将使用的损失函数(交叉熵)中被忽略的索引。然后,每个token 都会获得与其所在单词的token 相同的标签,因为它们是同一实体的一部分。对于单词内部但不在开头的Token,我们将`B-` 替换为 `I-` (因为token 不以实体开头):
+只需要一点点工作,我们就可以扩展我们的标签列表。我们将添加的使其与 `token` 列表相匹配。 添加的第一条规则是,特殊 tokens 的标签设置为 `-100` 。这是因为默认情况下, `-100` 会被我们的损失函数(交叉熵)忽略。然后将每个 `token` 的标签设置为这个 `token` 所在单词开头的 `token` 的标签,因为同一个单词一定是同一个实体的一部分。最后将单词的内部 `tokens` 标签中的 `B-` 替换为 `I-`,因为该 `token` 不在实体的开头,`B-` 在每个实体中只应该出现一次:
```python
def align_labels_with_tokens(labels, word_ids):
@@ -228,17 +229,17 @@ def align_labels_with_tokens(labels, word_ids):
current_word = None
for word_id in word_ids:
if word_id != current_word:
- # Start of a new word!
+ # 新单词的开始!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
- # Special token
+ # 特殊的token
new_labels.append(-100)
else:
- # Same word as previous token
+ # 与前一个 tokens 类型相同的单词
label = labels[word_id]
- # If the label is B-XXX we change it to I-XXX
+ # 如果标签是 B-XXX 我们将其更改为 I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
@@ -246,7 +247,7 @@ def align_labels_with_tokens(labels, word_ids):
return new_labels
```
-让我们在我们的第一句话上试一试:
+让我们在数据集的第一个元素上试一试:
```py
labels = raw_datasets["train"][0]["ner_tags"]
@@ -260,15 +261,15 @@ print(align_labels_with_tokens(labels, word_ids))
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
```
-正如我们所看到的,我们的函数为开头和结尾的两个特殊标记添加了 `-100` ,并为分成两个标记的单词添加了一个新的`0` 。
+正如我们所看到的,我们的函数为开头和结尾添加了两个特殊 tokens :`-100` ,并为切分成两个 tokens 的单词添加了一个新的 `0` 标签。
-✏️ **轮到你了!** 一些研究人员更喜欢每个词只归属一个标签, 并分配 `-100` 给定词中的其他子标记。这是为了避免分解成大量子标记的长词对损失造成严重影响。按照此规则更改前一个函数使标签与输入id对齐。
+✏️ **轮到你了!** 有些研究人员更喜欢只为每个单只分配一个标签,对该单词其他部分的 token 分配 `-100` 标签。这是为了避免那些分解成许多子词的长单词对损失作出过多的贡献。请按照这个思路,改变之前的函数,使标签与 inputs ID 对齐。
-为了预处理我们的整个数据集,我们需要标记所有输入并在所有标签上应用 `align_labels_with_tokens()` 。为了利用我们的快速分词器的速度优势,最好同时对大量文本进行分词,因此我们将编写一个处理示例列表的函数并使用带 `batched=True` 有选项的 `Dataset.map()`方法 .与我们之前的示例唯一不同的是当分词器的输入是文本列表(或者像例子中的单词列表)时 `word_ids()` 函数需要获取我们想要单词的索引的ID,所以我们也添加它:
+为了预处理我们的整个数据集,我们需要对所有输入进行 `tokenize`,并使用 `align_labels_with_tokens()` 函数处理所有标签。为了充分利用快速 tokenizer 的优势,最好是同时对大量文本一起进行 `tokenize`,所以我们需要编写一个处理一组示例的函数,并使用带有 `batched=True` 参数的 `Dataset.map()` 方法。与我们之前的示例唯一不同的是,当 `tokenizer` 的输入是文本列表(或示例中单词的列表的列表)时, `word_ids()` 函数需要根据列表的索引获取 `token` 的 ID,所以我们也在下面的函数中添加了这个功能:
```py
def tokenize_and_align_labels(examples):
@@ -285,9 +286,9 @@ def tokenize_and_align_labels(examples):
return tokenized_inputs
```
-请注意,我们还没有填充我们的输入;我们稍后会在使用数据整理器创建batch时这样做。
+注意,我们还没有填充我们的输入,我们将在稍后使用数据整理器创建 `batch` 时进行。
-我们现在可以一次性将所有预处理应用于数据集的其他部分:
+我们现在可以一次性使用预处理函数处理整个数据集:
```py
tokenized_datasets = raw_datasets.map(
@@ -297,28 +298,27 @@ tokenized_datasets = raw_datasets.map(
)
```
-我们已经完成了最难的部分!现在数据已经被预处理了,实际的训练看起来很像我们[第三章](/course/chapter3)做的.
+我们已经完成了最困难的部分!现在数据已经经过了预处理,实际的训练过程将会与我们在 [第三章](/course/chapter3) 所做的很相似。
{#if fw === 'pt'}
## 使用 Trainer API 微调模型 [[使用 Trainer API 微调模型]]
-使用 `Trainer` 的实际代码会和以前一样;唯一的变化是数据整理成时批处理的方式和度量计算函数。
+使用 `Trainer` 的代码会和以前一样,唯一的变化是数据如何整理成 `batch` 以及计算评估的分数。
{:else}
## 使用 Keras 微调模型 [[使用 Keras 微调模型]]
-使用Keras的实际代码将与之前非常相似;唯一的变化是将数据整理成批处理的方式和指标计算函数。
+使用 `Keras` 的代码将与之前非常相似;唯一的变化是数据如何整理成 `batch` 以及计算评估的分数。
{/if}
+### 整理数据 [[整理数据]]
-### 数据排序 [[数据排序]]
-
-我们不能像[第三章](/course/chapter3)那样只使用一个 `DataCollatorWithPadding `因为这只会填充输入(输入 ID、注意掩码和标记类型 ID)。在这里我们的标签应该以与输入完全相同的方式填充,以便它们保持长度相同,使用 `-100 ` ,这样在损失计算中就可以忽略相应的预测。
+我们不能像 [第三章](/course/chapter3) 那样直接使用 `DataCollatorWithPadding` ,因为那样只会填充输入(inputs ID、注意掩码和 tokens 类型 ID)。除了输入部分,在这里我们还需要对标签也使用与输入完全相同的方式填充,以保证它与输入的大小相同。我们将使用 `-100` 进行填充,以便在损失计算中忽略填充的内容。
-这一切都是由一个 [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification)完成.它是一个带有填充的数据整理器它需要 `tokenizer ` 用于预处理输入:
+以上的这些过程可以由 [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification) 实现。它是一个带有填充功能的数据整理器,使用时只需要传入用于预处理输入的 `tokenizer` :
{#if fw === 'pt'}
@@ -340,7 +340,7 @@ data_collator = DataCollatorForTokenClassification(
{/if}
-为了在几个样本上测试这一点,我们可以在训练集中的示例列表上调用它:
+为了在几个样本上测试这个数据整理器,我们可以先在训练集中的几个示例上调用它:
```py
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
@@ -352,7 +352,7 @@ tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
```
-让我们将其与数据集中第一个和第二个元素的标签进行比较:
+将数据整理器的结果与数据集中未经处理的第一个和第二个元素的标签进行比较。
```py
for i in range(2):
@@ -366,11 +366,11 @@ for i in range(2):
{#if fw === 'pt'}
-正如我们所看到的,第二组标签的长度已经使用 `-100` 填充到与第一组标签相同。
+正如我们所看到的,已经使用 `-100` 将第二组标签填充到了与第一组标签相同的长度。
{:else}
-我们的数据整理器已准备就绪! 现在让我们使用它通过 `to_tf_dataset()` 方法制作一个 `tf.data.Dataset`。 您还可以使用 model.prepare_tf_dataset() 来使用更少的样板代码来执行此操作——您将在本章的其他部分中看到这一点。
+我们的数据整理器已准备就绪!现在让我们使用 `to_tf_dataset()` 方法创建一个 `tf.data.Dataset` 。除此之外,你还可以使用 `model.prepare_tf_dataset()` 来使用更少的模板代码来创建 `Dataset`——你将在本章的其他小节中看到这样的操作。
```py
tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
@@ -387,25 +387,24 @@ tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
)
```
-
- Next stop: the model itself.
+下一站:模型本身。
{/if}
{#if fw === 'tf'}
-### 定义模型
+### 初始化模型
-由于我们正在研究Token分类问题,因此我们将使用 `AutoModelForTokenClassification` 类。定义这个模型时要记住的主要事情是传递一些关于我们的标签数量的信息。执行此操作的最简单方法是将该数字传递给 `num_labels` 参数,但是如果我们想要一个很好的推理小部件,就像我们在本节开头看到的那样,最好设置正确的标签对应关系。
+由于我们正在研究 Token 分类问题,因此我们将使用 `TFAutoModelForTokenClassification` 类。实例化此模型时要记得传递我们标签的数量,最简单方法是将该数字传递给 `num_labels` 参数,但是如果我们想要创建一个就像我们在本节开头看到的那样的推理小部件,那么就需要用最标准的方法正确设置标签的对应关系。
-它们应该由两个字典设置, `id2label` 和 `label2id` ,其中包含从 ID 到标签的映射,反之亦然:
+最标准的方法是用两个字典 `id2label` 和 `label2id` 来设置它们,这两个字典包含从 ID 到标签的映射以及反向的映射:
```py
id2label = {str(i): label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}
```
-现在我们可以将它们传递给 `AutoModelForTokenClassification.from_pretrained()` 方法,它们将在模型的配置中设置,然后保存并上传到Hub:
+现在我们只需将这两个字典传递给 `TFAutoModelForTokenClassification.from_pretrained()` 方法,它们就会被保存在模型的配置中,然后被正确地保存和上传到 Hub:
```py
from transformers import TFAutoModelForTokenClassification
@@ -417,7 +416,7 @@ model = TFAutoModelForTokenClassification.from_pretrained(
)
```
-就像我们在[第三章](/course/chapter3),定义我们的 `AutoModelForSequenceClassification` ,创建模型会发出警告,提示一些权重未被使用(来自预训练头的权重)和一些其他权重被随机初始化(来自新Token分类头的权重),我们将要训练这个模型。我们将在一分钟内完成,但首先让我们仔细检查我们的模型是否具有正确数量的标签:
+就像我们在 [第三章](/course/chapter3) 中实例化 `TFAutoModelForTokenClassification` 类一样 创建模型会发出一个警告,提示一些权重未被使用(来自预训练模型头部的权重)和一些其他权重被随机初始化(来自新 Token 分类头部的权重),别担心,我们马上就要训练这些权重。首先让我们确认一下我们的模型是否具有正确的标签数量:
```python
model.config.num_labels
@@ -429,13 +428,13 @@ model.config.num_labels
-⚠️ 如果您的模型标签数量错误,则在稍后调用 `model.fit()` 时将收到一个模糊的错误。调试起来可能很烦人,因此请确保执行此检查以确认您具有预期的标签数。
+⚠️ 如果你的模型的标签数量错误,那么在后面调用 `model.fit()` 时,你会得到一个晦涩的错误。这可能会令人烦恼,所以确保你做了这个检查,确认你的标签数量是正确的。
### 微调模型
-现在,我们已准备好训练模型了!不过,我们首先要做两件事:应该登录到Hugging Face并定义我们的训练超参数。如果你在notebook上工作,有一个便利功能可以帮助你做到这一点:
+现在,我们已准备好训练模型了!不过,我们在这之前还要做两件事:登录到 Hugging Face 并设置我们的训练超参数。如果你在 notebook 上工作,有一个便捷函数可以帮助你做到这一点:
```python
from huggingface_hub import notebook_login
@@ -443,26 +442,26 @@ from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件,您可以在其中输入您的 Hugging Face 账号和密码。
+这将显示一个小部件,你可以在其中输入你的 Hugging Face 账号和密码。
-如果您不是在notebook上工作,只需在终端中输入以下行:
+如果你不是在 notebook 上工作,只需在终端中输入以下代码:
```bash
huggingface-cli login
```
-登录后,我们可以准备编译模型所需的一切。🤗 Transformers提供了一个方便的`create_optimizer()` 函数,该函数将为您提供一个`AdamW`优化器,其中包含适当的权重衰减和学习速率衰减设置,与内置的`Adam`优化器相似,这两者都将提高模型的性能:
+登录后,我们可以编译我们模型所需要的所有配置。🤗 Transformers 提供了一个便捷的 `create_optimizer()` 函数,与 `TensorFlow` 内置的 `Adam` 优化器相比,它可以提供一个带有恰当的权重衰减和学习率衰减机制的 `AdamW` 优化器,不过这两个机制都将提高模型的性能:
```python
from transformers import create_optimizer
import tensorflow as tf
-# Train in mixed-precision float16
+# 在混合精度 float16 中进行训练
tf.keras.mixed_precision.set_global_policy("mixed_float16")
-# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
-# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
-# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+# 训练步数是数据集中的样本数量,除以 batch 大小,然后乘以总的 epoch 数。
+# 注意这里的 tf_train_dataset 是 batch 形式的 tf.data.Dataset,
+# 而不是原始的 Hugging Face Dataset ,所以使用 len() 计算它的长度已经是 num_samples // batch_size。
num_epochs = 3
num_train_steps = len(tf_train_dataset) * num_epochs
@@ -475,9 +474,9 @@ optimizer, schedule = create_optimizer(
model.compile(optimizer=optimizer)
```
-还要注意,我们不为`compile()`提供`loss`参数。这是因为模型实际上可以在内部计算损失 - 如果您编译时没有损失并在输入字典中提供标签(就像我们在数据集中所做的那样),那么模型将使用该内部损失进行训练,这将适用于您选择的任务和模型类型。
+请注意,我们没有给 `compile()` 提供 `loss` 参数。这是因为模型实际上可以使用默认的方式自动计算损失 —— 如果你在编译时没有提供损失的计算方法或在输入中提供真实的标签值(就像我们在数据集中所做的那样),那么模型将使用内部默认的 `loss` 计算方法进行训练,具体的计算方式取决于你选择的任务和模型类型。
-接下来,我们定义一个`PushToHubCallback`,以便在训练期间将模型上传到 Hub,并使用该回调来拟合模型:
+接下来,我们定义一个 `PushToHubCallback` 回调函数,以便在训练期间将模型上传到 Hub,并在拟合模型时添加该回调函数:
```python
from transformers.keras_callbacks import PushToHubCallback
@@ -492,44 +491,43 @@ model.fit(
)
```
-您之前已经看过其中的大部分内容:我们设置了一些超参数(例如学习率、要训练的 epoch 数和权重衰减),然后我们指定 `push_to_hub=True` 表明我们想要保存模型并在每个时期结束时对其进行评估,并且我们想要将我们的结果上传到模型中心。请注意,可以使用hub_model_id参数指定要推送到的存储库的名称(特别是,必须使用这个参数来推送到一个组织)。例如,当我们将模型推送到[`huggingface-course` organization](https://huggingface.co/huggingface-course), 我们添加了 `hub_model_id=huggingface-course/bert-finetuned-ner` 到 `TrainingArguments` .默认情况下,使用的存储库将在您的命名空间中并以您设置的输出目录命名,因此在我们的例子中它将是 `sgugger/bert-finetuned-ner` .
+你可以使用 `hub_model_id` 参数指定你想要推送的仓库的全名(特别需要注意的是,如果你需要推送给某个组织,就必须使用这个参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们添加了 `hub_model_id="huggingface-course/bert-finetuned-ner"` 。默认情况下,这个仓库将保存在你的账户之内,并以你设置的输出目录命名,例如 `"cool_huggingface_user/bert-finetuned-ner"` 。
-💡 如果您正在使用的输出目录已经存在,那么输出目录必须是从同一个存储库clone下来的。如果不是,您将在声明 `model.fit()` 时遇到错误,并且需要设置一个新名称。
+💡 如果设置了模型保存的路径,并且在那里已经存在了一个非空的同名文件夹,那么该目录应该是 Hub 仓库克隆在本地的版本,如果不是,则会在调用 model.fit() 方法时收到一个错误,并需要设置一个新的路径。
-请注意,当训练发生时,每次保存模型时(这里是每个epooch),它都会在后台上传到 Hub。这样,如有必要,您将能够在另一台机器上继续您的训练。
+请注意,在训练过程中每次保存模型时(这里是每个 epooch),它都会在后台上传到 Hub。这样,如有需要,你将能够在另一台机器上继续你的训练。
-在此阶段,您可以使用模型中心上的推理小组件来测试模型并与朋友共享。您已经成功微调了令牌分类任务的模型 - 恭喜!但是,我们的模型到底有多好呢?我们应该评估一些指标来找出答案。
+到此阶段,你可以在模型 Hub 上使用推理小部件来测试你的模型并与你的朋友分享。你已经成功地在一个 tokens 分类任务上微调了一个模型——恭喜你!但我们的模型真的好用吗?我们应该找出一些指标来对模型进评估。
{/if}
-
### 评估指标 [[评估指标]]
{#if fw === 'pt'}
-为了让 `Trainer` 在每个epoch计算一个度量,我们需要定义一个 `compute_metrics()` 函数,该函数接受预测和标签数组,并返回一个包含度量名称和值的字典
+要让 `Trainer` 在每个周期计算一个指标,我们需要定义一个 `compute_metrics()` 函数,该函数的输入是预测值和标签的数组,并返回带有指标名称和评估结果的字典。
-用于评估Token分类预测的传统框架是 [*seqeval*](https://github.com/chakki-works/seqeval). 要使用此指标,我们首先需要安装seqeval库:
+用于评估 Token 分类预测的经典框架是 [*seqeval*](https://github.com/chakki-works/seqeval) 。要使用此指标,我们首先需要安装 seqeval 库:
```py
!pip install seqeval
```
-然后我们可以通过加载它 `evaluate.load()` 函数就像我们在[第三章](/course/chapter3)做的那样:
+然后我们可以通过 `evaluate.load()` 函数加载它,就像我们在 [第三章](/course/chapter3) 中所做的那样:
{:else}
-用于评估Token分类预测的传统框架是 [*seqeval*](https://github.com/chakki-works/seqeval). 要使用此指标,我们首先需要安装seqeval库:
+用于评估 Token 分类预测的经典框架是 [*seqeval*](https://github.com/chakki-works/seqeval) 。要使用此指标,我们首先需要安装 seqeval 库:
```py
!pip install seqeval
```
-然后我们可以通过`evaluate.load()` 函数加载它就像我们在[第三章](/course/chapter3)做的那样:
+然后我们可以通过 `evaluate.load()` 函数加载它,就像我们在 [第三章](/course/chapter3) 中所做的那样:
{/if}
@@ -539,8 +537,9 @@ import evaluate
metric = evaluate.load("seqeval")
```
-这个评估方式与标准精度不同:它实际上将标签列表作为字符串,而不是整数,因此在将预测和标签传递给它之前,我们需要完全解码它们。让我们看看它是如何工作的。首先,我们将获得第一个训练示例的标签:
+该指标和常规的评测指标有些区别:它需要字符串形式的标签列表而不是整数,所以我们需要在将它们传递给指标之前将预测值和标签由数字解码为字符串。让我们先用一些测试数据看看它是如何工作的:
+首先,获取第一个训练样本的标签。
```py
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
@@ -551,7 +550,7 @@ labels
['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
```
-然后我们可以通过更改索引 2 处的值来为那些创建假的预测:
+然后我们可以通过更改索引 2 处的值来为这些标签创建假的预测值来测试该指标:
```py
predictions = labels.copy()
@@ -559,7 +558,7 @@ predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])
```
-请注意,该指标的输入是预测列表(不仅仅是一个)和标签列表。这是输出:
+请注意,该指标的输入是预测列表(不是一个)和标签列表,输出结果如下:
```python out
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
@@ -572,9 +571,7 @@ metric.compute(predictions=[predictions], references=[labels])
{#if fw === 'pt'}
-它返回很多信息!我们获得每个单独实体以及整体的准确率、召回率和 F1 分数。对于我们的度量计算,我们将只保留总分,但可以随意调整 `compute_metrics()` 函数返回您想要查看的所有指标。
-
-这`compute_metrics()` 函数首先采用 logits 的 argmax 将它们转换为预测(像往常一样,logits 和概率的顺序相同,因此我们不需要应用 softmax)。然后我们必须将标签和预测从整数转换为字符串。我们删除标签为 `-100` 所有值 ,然后将结果传递给 `metric.compute()` 方法:
+结果返回很多信息!包括每个单独实体及整体的准确率、召回率和 F1 分数。在这里我们将只保留总分,但是你可以自由地调整 `compute_metrics()` 函数返回的所需要指标。这个函数中我们首先会先取预测 `logits` 的 `argmax`,并将其转换为预测值。 `compute_metrics()` 函数首先取 `logits` 的 `argmax`,将它们转换为预测值(通常情况下,logits 和概率的顺序是相同,所以我们不需要使用 softmax)。然后我们需要将标签和预测值都从整数转换为字符串。我们删除所有标签为 `-100` 的值,最后将结果传递给 `metric.compute()` 方法:
```py
import numpy as np
@@ -584,7 +581,7 @@ def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
- # Remove ignored index (special tokens) and convert to labels
+ # 删除忽略的索引(特殊 tokens )并转换为标签
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
@@ -599,13 +596,13 @@ def compute_metrics(eval_preds):
}
```
-现在已经完成了,我们几乎准备好定义我们的 `Trainer` .我们只需要一个 `model` 微调!
+现在已经完成了,我们下面就可以开始定义我们的 `Trainer` 了。接下来我们只需要一个 `model` 并对其微调!
{:else}
-它返回很多信息!我们获得每个单独实体以及整体的准确率、召回率和 F1 分数。对于我们的度量计算,我们将只保留总分,但可以随意调整 `compute_metrics()` 函数返回您想要查看的所有指标。
+它返回了大量的信息!我们获得每个单独实体以及整体的准确率、召回率和 F1 分数。现在,让我们看看如果我们尝试使用真实的模型预测来计算分数。
-这`compute_metrics()` 函数首先采用 logits 的 argmax 将它们转换为预测(像往常一样,logits 和概率的顺序相同,因此我们不需要应用 softmax)。然后我们必须将标签和预测从整数转换为字符串。我们删除标签为 `-100` 所有值 ,然后将结果传递给 `metric.compute()` 方法:
+在使用基于TensorFlow 的框架时,我们通常不会把预测拼接在一起,因为这样会导致序列长度不统一。这意味着我们不能直接使用 `model.predict()` 方法 —— 但这并不能阻止我们。我们可以逐批获取一些预测并在在此的过程中将它们拼接成一个大的列表,删除表示 `masking/padding` 的 `-100` tokens 然后在合并后的大列表上计算度量值:
```py
import numpy as np
@@ -637,7 +634,7 @@ metric.compute(predictions=[all_predictions], references=[all_labels])
'overall_accuracy': 0.97}
```
-与我们的模型相比,您的模型做得如何?如果您获得类似的数字,那么您的训练就是成功的!
+与我们的模型相比,你的模型的表现如何?如果你看到类似的数字,那么你的训练就成功了!
{/if}
@@ -645,16 +642,16 @@ metric.compute(predictions=[all_predictions], references=[all_labels])
### 定义模型
-由于我们正在研究Token分类问题,因此我们将使用 `AutoModelForTokenClassification` 类。定义这个模型时要记住的主要事情是传递一些关于我们的标签数量的信息。执行此操作的最简单方法是将该数字传递给 `num_labels` 参数,但是如果我们想要一个很好的推理小部件,就像我们在本节开头看到的那样,最好设置正确的标签对应关系。
+由于我们正在研究 Token 分类问题,因此我们将使用 `AutoModelForTokenClassification` 类。定义此模型时要记得传递我们标签的数量,最简单方法是将该数字传递给 `num_labels` 参数,但是如果我们想要一个就像我们在本节开头看到的那样的推理小部件,就需要用最标准的方法正确设置标签的对应关系。
-它们应该由两个字典设置, `id2label` 和 `label2id` ,其中包含从 ID 到标签的映射,反之亦然:
+最标准的方式是用两个字典 `id2label` 和 `label2id` 来设置标签,这两个字典包含从 ID 到标签的映射以及反向的映射:
```py
id2label = {str(i): label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}
```
-现在我们可以将它们传递给 `AutoModelForTokenClassification.from_pretrained()` 方法,它们将在模型的配置中设置,然后保存并上传到Hub:
+现在我们只需将它们传递给 `AutoModelForTokenClassification.from_pretrained()` 方法,它们就会被保存在模型的配置中,然后被正确地保存和上传到 Hub:
```py
from transformers import AutoModelForTokenClassification
@@ -666,7 +663,7 @@ model = AutoModelForTokenClassification.from_pretrained(
)
```
-就像我们在[第三章](/course/chapter3),定义我们的 `AutoModelForSequenceClassification` ,创建模型会发出警告,提示一些权重未被使用(来自预训练头的权重)和一些其他权重被随机初始化(来自新Token分类头的权重),我们将要训练这个模型。我们将在一分钟内完成,但首先让我们仔细检查我们的模型是否具有正确数量的标签:
+就像我们在 [第三章](/course/chapter3) 中定义 `AutoModelForSequenceClassification` 类一样 创建模型会发出一个警告,提示一些权重未被使用(来自预训练头部的权重)和一些其他权重被随机初始化(来自新 Token 分类头部的权重),不过不用担心,我们马上就要训练这些权重。在这之前,让我们先确认一下我们的模型是否具有正确的标签数量:
```python
model.config.num_labels
@@ -678,26 +675,21 @@ model.config.num_labels
-⚠️ 如果模型的标签数量错误,稍后调用Trainer.train()方法时会出现一个模糊的错误(类似于“CUDA error: device-side assert triggered”)。这是用户报告此类错误的第一个原因,因此请确保进行这样的检查以确认您拥有预期数量的标签。
+⚠️ 如果你的模型的标签数量有错误,那么在后面调用 `Trainer.train()` 时,你会得到一个晦涩的错误(类似于“CUDA error:device-side assert triggered”)。这可能会令人烦恼,所以确保你做了这个检查,确认你的标签数量是正确。
### 微调模型
-我们现在准备好训练我们的模型了!在定义我们的 `Trainer`之前,我们只需要做最后两件事:登录 Hugging Face 并定义我们的训练参数。如果您在notebook上工作,有一个方便的功能可以帮助您:
+我们现在准备好训练我们的模型了!在定义 `Trainer` 之前,我们只需要做最后两件事:登录 Hugging Face 并设置我们的训练参数。如果你在 notebook 上工作,有一个方便的小工具可以帮助你:
```python
from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件,您可以在其中输入您的 Hugging Face 账号和密码。如果您不是在notebook上工作,只需在终端中输入以下行:
-```bash
-huggingface-cli login
-```
-
-Once this is done, we can define our `TrainingArguments`:
+登录后,我们就可以设置我们的 `TrainingArguments` :
```python
from transformers import TrainingArguments
@@ -713,15 +705,15 @@ args = TrainingArguments(
)
```
-您之前已经看过其中的大部分内容:我们设置了一些超参数(例如学习率、要训练的 epoch 数和权重衰减),然后我们指定 `push_to_hub=True` 表明我们想要保存模型并在每个时期结束时对其进行评估,并且我们想要将我们的结果上传到模型中心。请注意,可以使用hub_model_id参数指定要推送到的存储库的名称(特别是,必须使用这个参数来推送到一个组织)。例如,当我们将模型推送到[`huggingface-course` organization](https://huggingface.co/huggingface-course), 我们添加了 `hub_model_id=huggingface-course/bert-finetuned-ner` 到 `TrainingArguments` 。默认情况下,使用的存储库将在您的命名空间中并以您设置的输出目录命名,因此在我们的例子中它将是 `sgugger/bert-finetuned-ner`。
+你已经对大多数内容有所了解了:我们设置了一些超参数(如学习率、训练的轮数和权重衰减),并设定 `push_to_hub=True` ,表示我们希望在每个训练轮次结束时保存并评估模型,然后将结果上传到模型中心。注意,你可以通过 `hub_model_id` 参数指定你想推送的仓库的名称(特别需要注意的是,如果你需要推送给某个组织,就必须使用这个参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们在 `TrainingArguments` 中添加了 `hub_model_id="huggingface-course/bert-finetuned-ner"` 。默认情况下,使用的仓库将保存在你的账户之内,并以你设置的输出目录命名,所以在我们的例子中,仓库的地址是 `"sgugger/bert-finetuned-ner"` 。
-💡 如果您正在使用的输出目录已经存在,那么输出目录必须是从同一个存储库clone下来的。如果不是,您将在声明 `Trainer` 时遇到错误,并且需要设置一个新名称。
+💡 如果你使用的输出路径已经存在一个同名的文件夹,那么它需要是你想推送到 hub 的仓库的克隆在本地的版本。如果不是,你将在声明 `Trainer` 时遇到一个错误,并需要设置一个新的路径。
-最后,我们只是将所有内容传递给 `Trainer` 并启动训练:
+最后,我们将所有内容传递给 `Trainer` 并启动训练:
```python
from transformers import Trainer
@@ -738,30 +730,31 @@ trainer = Trainer(
trainer.train()
```
-请注意,当训练发生时,每次保存模型时(这里是每个epooch),它都会在后台上传到 Hub。这样,如有必要,您将能够在另一台机器上继续您的训练。
+请注意,在训练过程中每次保存模型时(这里是每个 epooch),它都会在后台上传到 Hub。这样,如有必要,你将能够在另一台机器上继续你的训练。
-训练完成后,我们使用 `push_to_hub()` 确保我们上传模型的最新版本
+训练完成后,我们使用 `push_to_hub()` 上传模型的最新版本
```py
trainer.push_to_hub(commit_message="Training complete")
```
-This command returns the URL of the commit it just did, if you want to inspect it:
+如果你想检查一下是否上传成功,这个命令会返回刚刚执行的提交的 URL:
```python out
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
```
-这 `Trainer` 还创建了一张包含所有评估结果的模型卡并上传。在此阶段,您可以使用模型中心上的推理小部件来测试您的模型并与您的朋友分享。您已成功在Token分类任务上微调模型 - 恭喜!
+同时 `Trainer` 还创建并上传了一张包含所有评估结果的模型卡。到此阶段,你可以在模型 Hub 上使用推理小部件来测试你的模型并与你的朋友分享。你已经成功地在一个 tokens 分类任务上微调了一个模型——恭喜你!
-如果您想更深入地了解训练循环,我们现在将向您展示如何使用 🤗 Accelerate 做同样的事情。
+如果你想更深入地了解训练循环,我们现在将向你展示如何使用 🤗 Accelerate 做同样的事情。
## 自定义训练循环 [[自定义训练循环]]
-现在让我们看一下完整的训练循环,这样您可以轻松定义所需的部分。它看起来很像我们在[第三章](/course/chapter3/4), 所做的,对评估进行了一些更改。
+现在我们来看看完整的训练循环,这样你就可以轻松地定制你需要的部分。它与我们在 [第三章](/course/chapter3/4) 中所做的内容很相似,但对评估部分有一些改动。
### 做好训练前的准备 [[做好训练前的准备]]
-首先我们需要为我们的数据集构建 `DataLoader` 。我们将重用我们的 `data_collator` 作为一个 `collate_fn` 并打乱训练集,但不打乱验证集:
+
+首先我们需要为我们的数据集构建 `DataLoader` 。我们将 `data_collator` 传递给 `collate_fn` 参数并随机打乱训练集,但不打乱验证集:
```py
from torch.utils.data import DataLoader
@@ -777,7 +770,7 @@ eval_dataloader = DataLoader(
)
```
-接下来,我们重新实例化我们的模型,以确保我们不会从之前的训练继续训练,而是再次从 BERT 预训练模型开始:
+接下来我们重新实例化我们的模型,以确保我们不是继续之前的微调,而是重新开始从 BERT 微调预训练模型:
```py
model = AutoModelForTokenClassification.from_pretrained(
@@ -787,14 +780,15 @@ model = AutoModelForTokenClassification.from_pretrained(
)
```
-然后我们将需要一个优化器。我们将使用经典 `AdamW` ,这就像 `Adam` ,但在应用权重衰减的方式上进行了改进:
+然后我们需要一个优化器。我们将使用经典 `AdamW` ,它类似于 `Adam` ,但在权重衰减的方式上进行了改进:
+
```py
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
```
-Once we have all those objects, we can send them to the `accelerator.prepare()` method:
+当我们拥有了所有这些对象之后,我们就可以将它们发传递给 `accelerator.prepare()` 方法:
```py
from accelerate import Accelerator
@@ -807,11 +801,11 @@ model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
-🚨 如果您在 TPU 上进行训练,则需要将以上单元格中的所有代码移动到专用的训练函数中。有关详细信息,请参阅 [第3章](/course/chapter3)。
+🚨 如果你正在 TPU 上训练,你需要将上面单元格开始的所有代码移动到一个专门的训练函数中。更多详情请回顾 [第三章](/course/chapter3) 。
-现在我们已经发送了我们的 `train_dataloader` 到 `accelerator.prepare()` ,我们可以使用它的长度来计算训练步骤的数量。请记住,我们应该始终在准备好dataloader后执行此操作,因为该方法会改变其长度。我们使用经典线性学习率调度:
+现在我们已经将我们的 `train_dataloader` 传递给了 `accelerator.prepare()` 方法,我们还可以使用 `len()` 来计算训练步骤的数量。请记住,我们应该在准备好 `dataloader` 后再使用 `len()` ,因为改动 `dataloader` 会改变训练长度的数量。这里我们将使用一个从学习率衰减到 0 的经典线性学习率调度:
```py
from transformers import get_scheduler
@@ -828,7 +822,7 @@ lr_scheduler = get_scheduler(
)
```
-最后,要将我们的模型推送到 Hub,我们需要创建一个 `Repository` 工作文件夹中的对象。如果您尚未登录,请先登录 Hugging Face。我们将从我们想要为模型提供的模型 ID 中确定存储库名称(您可以自由地用自己的选择替换 `repo_name` ;它只需要包含您的用户名,可以使用`get_full_repo_name()`函数的查看目前的repo_name):
+最后,为了将我们的模型推送到 Hub,我们需要在一个工作文件夹中创建一个 `Repository` 对象。如果你还没有登录的话,首先需要登录到 Hugging Face,然后根据模型 ID 来确定仓库名称(你可以将 `repo_name` 替换为你喜欢的名字;只需要包含你的用户名即可,你可以使用 `get_full_repo_name()` 函数的查看目前的 `repo_name` ):
```py
from huggingface_hub import Repository, get_full_repo_name
@@ -842,24 +836,25 @@ repo_name
'sgugger/bert-finetuned-ner-accelerate'
```
-然后我们可以将该存储库克隆到本地文件夹中。 如果它已经存在,这个本地文件夹应该是我们正在使用的存储库的现有克隆:
+然后我们可以将该仓库克隆到本地文件夹中。如果本地已经存在同名的文件夹,这个本地文件夹必须是我们正在使用的仓库克隆在本地的版本:
```py
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
```
-我们现在可以通过调用 `repo.push_to_hub()` 方法上传保存在 `output_dir` 中的任何内容。 这将帮助我们在每个训练周期结束时上传中间模型。
+我们现在可以通过调用 `repo.push_to_hub()` 方法上传保存在 `output_dir` 中的所有内容。它帮助我们在每个训练周期结束时上传中间模型。
### 训练循环 [[训练循环]]
-我们现在准备编写完整的训练循环。为了简化它的评估部分,我们定义了这个 `postprocess()` 接受预测和标签并将它们转换为字符串列表的函数,也就是 `metric`对象需要的输入格式:
+
+我们现在准备编写完整的训练循环。为了简化其评估部分,我们定义了一个 `postprocess()` 函数,该函数会接收模型的预测和真实的标签,并将它们转换为字符串列表,也就是我们的 `metric` (评估函数)对象需要的输入格式。
```py
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
- # Remove ignored index (special tokens) and convert to labels
+ # 删除忽略的索引(特殊 tokens )并转换为标签
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
@@ -868,13 +863,13 @@ def postprocess(predictions, labels):
return true_labels, true_predictions
```
-然后我们可以编写训练循环。在定义一个进度条来跟踪训练的进行后,循环分为三个部分:
+然后我们可以编写训练循环。在定义一个进度条来跟踪训练的进度后,循环分为三个部分:
-- 训练本身,这是对`train_dataloader`的经典迭代,向前传递模型,然后反向传递和优化参数
-- 评估,在获得我们模型的输出后:因为两个进程可能将输入和标签填充成不同的形状,在调用`gather()`方法前我们需要使用`accelerator.pad_across_processes()`来让预测和标签形状相同。如果我们不这样做,评估要么出错,要么永远不会得到结果。然后,我们将结果发送给`metric.add_batch()`,并在计算循环结束后调用`metric.compute()`。
-- 保存和上传,首先保存模型和标记器,然后调用`repo.push_to_hub()`。注意,我们使用参数`blocking=False`告诉🤗 hub 库用在异步进程中推送。这样,训练将正常继续,并且该(长)指令将在后台执行。
+- 训练本身,这是经典的迭代过程,即在 `train_dataloader` 上进行迭代,在模型上前向传播训练数据,然后反向传递 `loss` 和优化参数
+- 评估,在获取模型在一个 `batch` 上的输出之后,这里有一个需要注意的地方:由于两个进程可能已将输入和标签填充到不同的形状,我们需要使用 `accelerator.pad_across_processes()` 使预测和真实的标签在调用 `gather()` 方法之前具有相同的形状。如果我们不这样做,评估循环将会出错或无限期卡住。最后我们将结果发送到 `metric.add_batch()` 方法中,并在评估循环结束时调用 `metric.compute()` 方法。
+- 保存和上传,首先保存模型和 `tokenizer` 然后调用 `repo.push_to_hub()` 方法。注意,我们使用参数 `blocking=False` 来告诉 🤗 `Hub` 库在一个异步进程中推送。这样,在训练时,这个指令在后台将模型和 `tokenizer` 推送到 `hub`。
-这是训练循环的完整代码:
+以下是完整的训练循环代码:
```py
from tqdm.auto import tqdm
@@ -883,7 +878,7 @@ import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
- # Training
+ # 训练
model.train()
for batch in train_dataloader:
outputs = model(**batch)
@@ -895,7 +890,7 @@ for epoch in range(num_train_epochs):
optimizer.zero_grad()
progress_bar.update(1)
- # Evaluation
+ # 评估
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
@@ -904,7 +899,7 @@ for epoch in range(num_train_epochs):
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
- # Necessary to pad predictions and labels for being gathered
+ # 填充模型的预测和标签后才能调用 gathere()
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
@@ -923,7 +918,7 @@ for epoch in range(num_train_epochs):
},
)
- # Save and upload
+ # 保存并上传
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
@@ -934,7 +929,7 @@ for epoch in range(num_train_epochs):
)
```
-果这是您第一次看到用 🤗 Accelerate 保存的模型,让我们花点时间检查一下它附带的三行代码:
+如果这是你第一次看到使用 🤗 Accelerate 保存模型,让我们花点时间来了解一下这个过程中的三行代码:
```py
accelerator.wait_for_everyone()
@@ -942,21 +937,22 @@ unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
```
-第一行是不言自明的:它告诉所有进程等到都处于那个阶段再继续(阻塞)。这是为了确保在保存之前,我们在每个过程中都有相同的模型。然后获取`unwrapped_model`,它是我们定义的基本模型。
-`accelerator.prepare()`方法将模型更改为在分布式训练中工作,所以它不再有`save_pretraining()`方法;`accelerator.unwrap_model()`方法将撤销该步骤。最后,我们调用`save_pretraining()`,但告诉该方法使用`accelerator.save()`而不是`torch.save()`。
+第一行是不言自明的:它告诉所有的进程先等待,直到所有的进程都处于这个阶段再继续(阻塞)。这是为了确保在保存之前,我们在每个进程中都有相同的模型。
+第二行代码用于获取 `unwrapped_model` ,它就是我们定义的基本模型。 `accelerator.prepare()` 方法会为了在分布式训练中工作而对模型进行了一些修改,所以它不再有 `save_pretraining()` 方法;使用 `accelerator.unwrap_model()` 方法可以撤销对模型的更改。
+在第三行代码中,我们调用 `save_pretraining()` ,并指定 `accelerator.save()` 作为 `save_function` 而不是默认的 `torch.save()` 。
-当完成之后,你应该有一个模型,它产生的结果与`Trainer`的结果非常相似。你可以在[hugs face-course/bert-fine - tuning -ner-accelerate](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate)中查看我们使用这个代码训练的模型。如果你想测试训练循环的任何调整,你可以直接通过编辑上面显示的代码来实现它们!
+完成这些操作后,你应该拥有一个与 `Trainer` 训练出的模型结果相当类似的模型。你可以在 [huggingface-course/bert-finetuned-ner-accelerate](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate) 查看我们使用这些代码训练的模型。如果你想在训练循环中测试任何调整,你可以直接通过编辑上面显示的代码来实现它们!
{/if}
## 使用微调模型 [[使用微调模型]]
-我们已经向您展示了如何使用我们在模型中心微调的模型和推理小部件。在本地使用它 `pipeline` ,您只需要指定正确的模型标识符:
+我们已经向你展示了如何使用在模型中心微调的模型和推理小部件。在本地使用 `pipeline` 来使用它非常容易,你只需要指定正确的模型标签:
```py
from transformers import pipeline
-# Replace this with your own checkpoint
+# 将此替换为你自己的 checkpoint
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
diff --git a/chapters/zh-CN/chapter7/3.mdx b/chapters/zh-CN/chapter7/3.mdx
index 4b4c8232e..32cc5d563 100644
--- a/chapters/zh-CN/chapter7/3.mdx
+++ b/chapters/zh-CN/chapter7/3.mdx
@@ -1,6 +1,6 @@
-# 微调掩码语言模型 [[微调掩码语言模型]]
+# 微调掩码语言模型(masked language model) [[微调掩码语言模型(masked language model)]]
{#if fw === 'pt'}
@@ -22,45 +22,43 @@
{/if}
-对于许多涉及 Transformer 模型的 NLP 程序, 你可以简单地从 Hugging Face Hub 中获取一个预训练的模型, 然后直接在你的数据上对其进行微调, 以完成手头的任务。只要用于预训练的语料库与用于微调的语料库没有太大区别, 迁移学习通常会产生很好的结果。
+对于许多涉及 Transformer 模型的 NLP 任务,你可以简单地从 Hugging Face Hub 中获取一个预训练的模型,然后直接在你的数据上对其进行微调,以完成手头的任务。只要用于预训练的语料库与用于微调的语料库没有太大区别,迁移学习通常会产生很好的结果。
-但是, 在某些情况下, 你需要先微调数据上的语言模型, 然后再训练特定于任务的head。例如, 如果您的数据集包含法律合同或科学文章, 像 BERT 这样的普通 Transformer 模型通常会将您语料库中的特定领域词视为稀有标记, 结果性能可能不尽如人意。通过在域内数据上微调语言模型, 你可以提高许多下游任务的性能, 这意味着您通常只需执行一次此步骤!
+但是,在某些情况下,你可能需要先在你的数据上微调语言模型,然后再训练特定于任务的 head。例如,如果你的数据集包含法律合同或科学文章,像 BERT 这样的普通 Transformer 模型通常会将你语料库中的特定领域词视为稀有 tokens ,导致性能可能不尽如人意。通过在特定领域内数据上微调语言模型,你可以提高许多下游任务的性能,这意味着你通常只需执行一次此步骤!
-这种在域内数据上微调预训练语言模型的过程通常称为 _领域适应_。 它于 2018 年由 [ULMFiT](https://arxiv.org/abs/1801.06146)推广, 这是使迁移学习真正适用于 NLP 的首批神经架构之一 (基于 LSTM)。 下图显示了使用 ULMFiT 进行域自适应的示例; 在本节中, 我们将做类似的事情, 但使用的是 Transformer 而不是 LSTM!
+这种在特定领域内数据上微调预训练语言模型的过程通常称为 `领域适应(domain adaptation)` 。它于 2018 年由 [ULMFiT](https://arxiv.org/abs/1801.06146) 推广, NLP 的首批神经架构之一 (基于 LSTM)。下图显示了使用 ULMFiT这是使迁移学习真正适用于 进行领域自适应的示例;在本节中,我们将做类似的事情,但我们将使用 Transformer 而不是 LSTM!
-在本节结束时, 你将在Hub上拥有一个[掩码语言模型(masked language model)](https://huggingface.co/huggingface-course/distilbert-base-uncased-finetuned-imdb?text=This+is+a+great+%5BMASK%5D.), 该模型可以自动完成句子, 如下所示:
+在本节结束时,你将在 Hub 上拥有一个 [掩码语言模型(masked language model)](https://huggingface.co/huggingface-course/distilbert-base-uncased-finetuned-imdb?text=This+is+a+great+%5BMASK%5D.) ,该模型可以自动补全句子,如下所示:
-
+
-让我们开始吧!
+让我们开始吧!
-🙋 如果您对“掩码语言建模”和“预训练模型”这两个术语感到陌生, 请查看[第一章](/course/chapter1), 我们在其中解释了所有这些核心概念, 并附有视频!
+🙋 如果你对“掩码语言建模”和“预训练模型”这两个术语感到陌生,请回顾 [第一章](/course/chapter1) ,我们在其中解释了所有这些核心概念,并附有视频!
## 选择用于掩码语言建模的预训练模型 [[选择用于掩码语言建模的预训练模型]]
-首先, 让我们为掩码语言建模选择一个合适的预训练模型。如以下屏幕截图所示, 你可以通过在[Hugging Face Hub](https://huggingface.co/models?pipeline_tag=fill-mask&sort=downloads)上应用"Fill-Mask"过滤器找到:
+首先,让我们为掩码语言建模选择一个合适的预训练模型。如以下屏幕截图所示,你可以通过在 [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=fill-mask&sort=downloads) 上选择“Fill-Mask”过滤器:
-
-尽管 BERT 和 RoBERTa 系列模型的下载量最大, 但我们将使用名为 [DistilBERT](https://huggingface.co/distilbert-base-uncased)的模型。
-可以更快地训练, 而下游性能几乎没有损失。这个模型使用一种称为[_知识蒸馏_](https://en.wikipedia.org/wiki/Knowledge_distillation)的特殊技术进行训练, 其中使用像 BERT 这样的大型“教师模型”来指导参数少得多的“学生模型”的训练。在本节中对知识蒸馏细节的解释会使我们离题太远, 但如果你有兴趣, 可以阅读所有相关内容 [_Natural Language Processing with Transformers_](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) (俗称Transformers教科书)。
+尽管 BERT 和 RoBERTa 系列模型的下载量最大,但我们将使用名为 [DistilBERT](https://huggingface.co/distilbert-base-uncased) 的模型。它可以更快地训练,而且对下游性能几乎没有损失。它使用了一种称为 [`知识蒸馏(knowledge distillation)`](https://en.wikipedia.org/wiki/Knowledge_distillation) 的特殊技术进行训练,其中使用像 BERT 这样的大型“教师模型”来指导参数少得多的“学生模型”的训练。在本节中对知识蒸馏进行详细解释会使我们偏离本节主题太远,但如果你有兴趣,可以阅读 [`使用 Transformers 进行自然语言处理(Natural Language Processing with Transformers)`](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) (俗称 Transformers 教科书)中知识蒸馏的相关内容。
{#if fw === 'pt'}
-让我们继续, 使用 `AutoModelForMaskedLM` 类下载 DistilBERT:
+让我们继续,我们可以使用 `AutoModelForMaskedLM` 类下载 DistilBERT:
```python
from transformers import AutoModelForMaskedLM
@@ -69,7 +67,7 @@ model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
```
-我们可以通过调用 `num_parameters()` 方法查看模型有多少参数:
+然后,我们可以通过调用 `num_parameters()` 方法查看模型有多少参数:
```python
distilbert_num_parameters = model.num_parameters() / 1_000_000
@@ -84,7 +82,7 @@ print(f"'>>> BERT number of parameters: 110M'")
{:else}
-让我们继续, 使用 `AutoModelForMaskedLM` 类下载 DistilBERT:
+让我们继续,我们可以使用 `TFAutoModelForMaskedLM` 类下载 DistilBERT:
```python
from transformers import TFAutoModelForMaskedLM
@@ -93,25 +91,29 @@ model_checkpoint = "distilbert-base-uncased"
model = TFAutoModelForMaskedLM.from_pretrained(model_checkpoint)
```
-我们可以通过调用 `summary()` 方法查看模型有多少参数:
+然后,我们可以通过调用 `summary()` 方法查看模型有多少参数:
```python
-model(model.dummy_inputs) # Build the model
+model(model.dummy_inputs) # 构建模型
model.summary()
```
```python out
Model: "tf_distil_bert_for_masked_lm"
_________________________________________________________________
-Layer (type) Output Shape Param #
+ Layer (type) Output Shape Param #
=================================================================
-distilbert (TFDistilBertMain multiple 66362880
-_________________________________________________________________
-vocab_transform (Dense) multiple 590592
-_________________________________________________________________
-vocab_layer_norm (LayerNorma multiple 1536
-_________________________________________________________________
-vocab_projector (TFDistilBer multiple 23866170
+ distilbert (TFDistilBertMai multiple 66362880
+ nLayer)
+
+ vocab_transform (Dense) multiple 590592
+
+ vocab_layer_norm (LayerNorm multiple 1536
+ alization)
+
+ vocab_projector (TFDistilBe multiple 23866170
+ rtLMHead)
+
=================================================================
Total params: 66,985,530
Trainable params: 66,985,530
@@ -121,13 +123,13 @@ _________________________________________________________________
{/if}
-DistilBERT 大约有 6700 万个参数, 大约比 BERT 基本模型小两倍, 这大致意味着训练的速度提高了两倍 -- 非常棒! 现在让我们看看这个模型预测什么样的标记最有可能完成一小部分文本:
+DistilBERT 大约有 6700 万个参数,大约只有 BERT base 模型的二分之一,这大致意味着训练的速度可以提高两倍 —— 非常棒!现在让我们看看对于下面的一小部分文本,这个模型最有可能预测什么:
```python
text = "This is a great [MASK]."
```
-作为人类, 我们可以想象 `[MASK]` 标记有很多可能性, 例如 "day"、 "ride" 或者 "painting"。对于预训练模型, 预测取决于模型所训练的语料库, 因为它会学习获取数据中存在的统计模式。与 BERT 一样, DistilBERT 在[English Wikipedia](https://huggingface.co/datasets/wikipedia) 和 [BookCorpus](https://huggingface.co/datasets/bookcorpus) 数据集上进行预训练, 所以我们期望对 `[MASK]` 的预测能够反映这些领域。为了预测掩码, 我们需要 DistilBERT 的标记器来生成模型的输入, 所以让我们也从 Hub 下载它:
+作为人类,我们可以想象 `[MASK]` token 有很多可能性,例如 “day”、“ride” 或者 “painting”。对于预训练模型,预测取决于模型所训练的语料库,因为它会学习获取数据中存在的语料统计分布。与 BERT 一样,DistilBERT 在 [English Wikipedia](https://huggingface.co/datasets/wikipedia) 和 [BookCorpus](https://huggingface.co/datasets/bookcorpus) 数据集上进行预训练,所以我们猜想模型对 `[MASK]` 的预测能够反映这些领域。为了预测 `[MASK]` ,我们需要 DistilBERT 的 tokenizer 来处理输入,所以让我们也从 Hub 下载它:
```python
from transformers import AutoTokenizer
@@ -135,7 +137,7 @@ from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
```
-使用标记器和模型, 我们现在可以将我们的文本示例传递给模型, 提取 logits, 并打印出前 5 个候选:
+有了 tokenizer 和模型,我们现在可以将我们的示例文本传递给模型,提取 logits,并打印出前 5 个候选词:
{#if fw === 'pt'}
@@ -144,10 +146,10 @@ import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
-# Find the location of [MASK] and extract its logits
+# 找到 [MASK] 的位置并提取其 logits
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
-# Pick the [MASK] candidates with the highest logits
+# 选择具有最高 logits 的 [MASK] 候选词
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
@@ -162,11 +164,11 @@ import tensorflow as tf
inputs = tokenizer(text, return_tensors="np")
token_logits = model(**inputs).logits
-# Find the location of [MASK] and extract its logits
+# 找到 [MASK] 的位置并提取其 logits
mask_token_index = np.argwhere(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
mask_token_logits = token_logits[0, mask_token_index, :]
-# Pick the [MASK] candidates with the highest logits
-# We negate the array before argsort to get the largest, not the smallest, logits
+# 选择具有最高 logits 的 [MASK] 候选词
+# 通过在 argsort 前对数组取负,来得到最大的 logits
top_5_tokens = np.argsort(-mask_token_logits)[:5].tolist()
for token in top_5_tokens:
@@ -183,12 +185,13 @@ for token in top_5_tokens:
'>>> This is a great feat.'
```
-我们可以从输出中看到模型的预测是指日常用语, 鉴于英语维基百科的基础, 这也许并不奇怪。让我们看看我们如何将这个领域改变为更小众的东西 -- 高度两极分化的电影评论!
-
+我们可以从输出中看到,模型的预测的是日常术语,虑到模型训练的语料数据主要来源于维基百科,这并不奇怪。现在让我们看看如何将这个领域改变成稍微更加独特——高度两极分化的电影评论!
## 数据集 [[数据集]]
-为了展示域适配, 我们将使用著名的[大型电影评论数据集(Large Movie Review Dataset)](https://huggingface.co/datasets/imdb) (或者简称为IMDb), 这是一个电影评论语料库, 通常用于对情感分析模型进行基准测试。通过在这个语料库上对 DistilBERT 进行微调, 我们预计语言模型将根据维基百科的事实数据调整其词汇表, 这些数据已经预先训练到电影评论中更主观的元素。我们可以使用🤗 Datasets中的`load_dataset()`函数从Hugging Face 中获取数据:
+为了展示领域适应性,我们将使用来自IMDB的 [大型电影评论数据集(Large Movie Review Dataset)](https://huggingface.co/datasets/imdb),这是一个电影评论语料库,通常用于对情感分析模型进行基准测试。通过在这个语料库上对 DistilBERT 进行微调,我们期望语言模型会从其预训练的维基百科的事实性数据,适应到更主观的电影评论的领域。
+
+首先,我们可以使用🤗 Datasets 中的 `load_dataset()` 函数从 Hugging Face 中获取数据:
```python
from datasets import load_dataset
@@ -214,7 +217,7 @@ DatasetDict({
})
```
-我们可以看到 `train` 和 `test` 每个拆分包含 25,000 条评论, 而有一个未标记的拆分称为 `unsupervised` 包含 50,000 条评论。让我们看一些示例, 以了解我们正在处理的文本类型。正如我们在本课程的前几章中所做的那样, 我们将链接 `Dataset.shuffle()` 和 `Dataset.select()` 函数创建随机样本:
+我们可以看到 `train` 和 `test` 分别包含了 25,000 条评论,还有一个没有的标签的 `unsupervised(无监督)` 部分包含 50,000 条评论。接下来让我们从里面取一些样本,来了解一下我们正在处理的文本的特点。正如我们在本课程的前几章中所做的那样,我们将把 `Dataset.shuffle()` 函数链接到 `Dataset.select()` 函数创建随机样本:
```python
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
@@ -236,23 +239,23 @@ for row in sample:
'>>> Label: 1'
```
-是的, 这些肯定是电影评论, 如果你年龄足够,你甚至可能会理解上次评论中关于拥有 VHS 版本的评论😜! 虽然我们不需要语言建模的标签, 但我们已经可以看到 `0` 表示负面评论, 而 `1` 对应正面。
+是的,这些肯定是电影评论,如果你年龄足够大,你甚至可能会理解上述评论中关于拥有 VHS (一种古老的盒式摄像机格式)版本的评论😜!虽然语言模型不需要预先标注好的标签,但我们已经可以看到数据集其实包含了标签, `0` 代表负面评论, `1` 代表正面评论。
-✏️ **试试看!** 创建 `无监督` 拆分的随机样本, 并验证标签既不是 `0` 也不是 `1`。在此过程中, 你还可以检查 `train` 和 `test` 拆分中的标签是否确实为 `0` 或 `1` -- 这是每个 NLP 从业者在新项目开始时都应该执行的有用的健全性检查!
+✏️ **试一试!** 创建一个 `unsupervised` 部分的随机样本,并验证其标签既不是 `0` 也不是 `1` 。或者,你也可以检查 `train` 和 `test` 部分的标签确实是 `0` 或 `1` —— 每个 NLP 实践者在开始新项目时都应该对数据标注进行的有用的、合理的检查!
-现在我们已经快速浏览了数据, 让我们深入研究为掩码语言建模做准备。正如我们将看到的, 与我们在[第三章](/course/chapter3)中看到的序列分类任务相比, 还需要采取一些额外的步骤。让我们继续!
+现在我们已经快速浏览了一下数据,接下来我们要深入准备这些数据以供进行掩码语言建模。如我们所见,与我们在 [第三章](https://chat.openai.com/course/chapter3) 看到的序列分类任务相比,这里需要采取一些额外的步骤。让我们开始吧!
## 预处理数据 [[预处理数据]]
-对于自回归和掩码语言建模, 一个常见的预处理步骤是连接所有示例, 然后将整个语料库拆分为相同大小的块。 这与我们通常的方法完全不同, 我们只是简单地标记单个示例。为什么要将所有内容连接在一起? 原因是单个示例如果太长可能会被截断, 这将导致丢失可能对语言建模任务有用的信息!
+对于自回归和掩码语言建模,常见的预处理步骤是将所有的文本拼接起来,然后再将整个语料库切割为相同大小的块。这与我们之前的做法有很大的不同,我们之前只是对单个的示例进行 tokenize。为什么要将所有的示例连接在一起呢?原因是如果单个示例太长,可能会被截断,这会导致我们失去可能对语言建模任务有用的信息!
-因此, 我们将像往常一样首先标记我们的语料库, 但是 _没有_ 在我们的标记器中设置 `truncation=True` 选项。 我们还将获取可用的单词 ID ((如果我们使用快速标记器, 它们是可用的, 如 [第六章](/course/chapter6/3)中所述), 因为我们稍后将需要它们来进行全字屏蔽。我们将把它包装在一个简单的函数中, 当我们在做的时候, 我们将删除 `text` 和 `label` 列, 因为我们不再需要它们:
+因此,我们首先会像往常一样对语料库进行 tokenize 处理,但是不在 tokenizer 中设置 `truncation=True` 选项。如果我们有可以使用快速 tokenizer(如 [第六章](/course/chapter6/3) 中所述),除此之外,我们还需要获取单词的 `ID`,因为后面我们需要用到它们来进行全词掩码。最后我们将把这个过程封装在一个简单的函数中,并删除 `text` 和 `label` 列,因为我们不再需要它们。
```python
def tokenize_function(examples):
@@ -262,7 +265,7 @@ def tokenize_function(examples):
return result
-# Use batched=True to activate fast multithreading!
+# 使用 batched=True 来激活快速多线程!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
@@ -286,9 +289,9 @@ DatasetDict({
})
```
-由于 DistilBERT 是一个类似 BERT 的模型, 我们可以看到编码文本由我们在其他章节中看到的 `input_ids` 和 `attention_mask` 组成, 以及我们添加的 `word_ids`。
+由于 DistilBERT 是一个类似 BERT 的模型,我们可以看到编码后的文本包含了我们在之前章节中看到的 `input_ids` 和 `attention_mask` ,以及我们添加的 `word_ids` 。
-现在我们已经标记了我们的电影评论, 下一步是将它们组合在一起并将结果分成块。 但是这些块应该有多大? 这最终将取决于你可用的 GPU 内存量, 但一个好的起点是查看模型的最大上下文大小是多少。这可以通过检查标记器的 `model_max_length` 属性来判断:
+现在我们已经对电影评论进行了 `tokenize`,下一步是将它们全部组合在一起并将结果分割成块。但是,这些块应该有多大呢?这最终将取决于你可以使用的显存大小,但一个好的起点是查看模型的最大上下文大小。这可以在 tokenizer 的 `model_max_length` 属性中找到:
```python
tokenizer.model_max_length
@@ -298,15 +301,15 @@ tokenizer.model_max_length
512
```
-该值来自于与检查点相关联的 *tokenizer_config.json* 文件; 在这种情况下, 我们可以看到上下文大小是 512 个标记, 就像 BERT 一样。
+该值来自于与 checkpoint 相关联的 `tokenizer_config.json` 文件;在我们的例子中,我们可以看到上下文大小是 512 个 `tokens` 与 BERT 模型一样。
-✏️ **试试看!** 一些 Transformer 模型, 例如 [BigBird](https://huggingface.co/google/bigbird-roberta-base) 和 [Longformer](hf.co/allenai/longformer-base-4096), 它们具有比BERT和其他早期Transformer模型更长的上下文长度。为这些检查点之一实例化标记器, 并验证 `model_max_length` 是否与模型卡上引用的内容一致。
+✏️ **试试看!** 一些 Transformer 模型,例如 [BigBird](https://huggingface.co/google/bigbird-roberta-base) 和 [Longformer](hf.co/allenai/longformer-base-4096) 具有比 BERT 和其他早期 Transformer 模型更长的上下文长度。选择一个 `checkpoint` 来实例化 `tokenizer` 并验证 `model_max_length` 是否与模型卡上标注的大小一致。
-因此, 以便在像Google Colab 那样的 GPU 上运行我们的实验, 我们将选择可以放入内存的更小一些的东西:
+因此,为了可以在像 Google Colab 那样的 GPU 上运行我们的实验,我们会选择一个稍小一点、可以放入内存中的分块大小:
```python
chunk_size = 128
@@ -314,14 +317,14 @@ chunk_size = 128
-请注意, 在实际场景中使用较小的块大小可能是有害的, 因此你应该使用与将应用模型的用例相对应的大小。
+注意,在实际应用场景中,使用小的块可能会有丢失长句子之间的语义信息从而对最终模型的性能产生不利的影响,所以如果显存条件允许的话,你应该选择一个与你将要使用模型的相匹配的大小。
-有趣的来了。为了展示串联是如何工作的, 让我们从我们的标记化训练集中取一些评论并打印出每个评论的标记数量:
+现在来到了最有趣的部分。为了展示如何把这些示例连接在一,我们从分词后的训练集中取出几个评论,并打印出每个评论的 token 数量:
```python
-# Slicing produces a list of lists for each feature
+# 切片会为每个特征生成一个列表的列表
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
@@ -334,7 +337,7 @@ for idx, sample in enumerate(tokenized_samples["input_ids"]):
'>>> Review 2 length: 192'
```
-然后我们可以用一个简单的字典理解来连接所有例子, 如下所示:
+然后,我们可以用一个简单的字典推导式将所有这些示例连接在一起,如下所示:
```python
concatenated_examples = {
@@ -348,7 +351,7 @@ print(f"'>>> Concatenated reviews length: {total_length}'")
'>>> Concatenated reviews length: 951'
```
-很棒, 总长度检查出来了 -- 现在, 让我们将连接的评论拆分为大小为 `block_size` 的块。为此, 我们迭代了 `concatenated_examples` 中的特征, 并使用列表理解来创建每个特征的切片。结果是每个特征的块字典:
+很棒,总长度计算出来了 —— 现在,让我们将连接的评论拆分为大小为 `chunk_size` 的块。为此,我们迭代了 `concatenated_examples` 中的特征,并使用列表推导式为每个特征分块。结果是一个字典,键是特征的名称,值是对应值经过分块的列表:
```python
chunks = {
@@ -371,34 +374,34 @@ for chunk in chunks["input_ids"]:
'>>> Chunk length: 55'
```
-正如你在这个例子中看到的, 最后一个块通常会小于最大块大小。有两种主要的策略来处理这个问题:
+正如你在这个例子中看到的,最后一个块通常会小于所设置的分块的大小。有两种常见的策略来处理这个问题:
-* 如果最后一个块小于 `chunk_size`, 请删除它。
-* 填充最后一个块, 直到其长度等于 `chunk_size`。
+* 如果最后一个块小于 `chunk_size` ,就丢弃。
+* 填充最后一个块,直到其长度等于 `chunk_size` 。
-我们将在这里采用第一种方法, 因此让我们将上述所有逻辑包装在一个函数中, 我们可以将其应用于我们的标记化数据集:
+我们将在这里采用第一种方法,最后让我们将上述所有逻辑包装在一个函数中,以便我们可以将其应用于我们的已分词数据集上:
```python
def group_texts(examples):
- # Concatenate all texts
+ # 拼接所有的文本
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
- # Compute length of concatenated texts
+ # 计算拼接文本的长度
total_length = len(concatenated_examples[list(examples.keys())[0]])
- # We drop the last chunk if it's smaller than chunk_size
+ # 如果最后一个块小于 chunk_size,我们将其丢弃
total_length = (total_length // chunk_size) * chunk_size
- # Split by chunks of max_len
+ # 按最大长度分块
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
- # Create a new labels column
+ # 创建一个新的 labels 列
result["labels"] = result["input_ids"].copy()
return result
```
-注意, 在 `group_texts()` 的最后一步中, 我们创建了一个新的 `labels` 列, 它是 `input_ids` 列的副本。我们很快就会看到, 这是因为在掩码语言建模中, 目标是预测输入批次中随机掩码的标记, 并通过创建一个 `labels` 列, 们为我们的语言模型提供了基础事实以供学习。
+注意,在 `group_texts()` 的最后一步,我们创建了一个新的 `labels` 列,它是通过复制 `input_ids` 列形成的。这是因为在掩码语言模型的目标是预测输入中随机遮住(Masked)的 token,我们保存了让我们的语言模型从中学习 `[Mask]` 的答案。
-现在, 让我们使用我们可信赖的 `Dataset.map()` 函数将 `group_texts()` 应用到我们的标记化数据集:
+现在,让我们使用我们强大的 `Dataset.map()` 函数将 `group_texts()` 应用到我们的已分词数据集上:
```python
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
@@ -422,7 +425,7 @@ DatasetDict({
})
```
-你可以看到, 对文本进行分组, 然后对文本进行分块, 产生的示例比我们最初的 25,000 用于 `train`和 `test` 拆分的示例多得多。那是因为我们现在有了涉及 _连续标记_ 的示例, 这些示例跨越了原始语料库中的多个示例。你可以通过在其中一个块中查找特殊的 `[SEP]` 和 `[CLS]` 标记来明确的看到这一点:
+通过对文本进行分块,我们得到了比原来的训练集和测试集的 25000 个例子多得多的评论数据。这是因为我们现在有了涉及跨越原始语料库中多个例子的连续标记的例子。你可以通过在其中一个块中查找特殊的 `[SEP]` 和 `[CLS]` tokens 来清晰地看到这一点:
```python
tokenizer.decode(lm_datasets["train"][1]["input_ids"])
@@ -432,7 +435,7 @@ tokenizer.decode(lm_datasets["train"][1]["input_ids"])
".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
```
-在此示例中, 你可以看到两篇重叠的电影评论, 一篇关于高中电影, 另一篇关于无家可归。 让我们也看看掩码语言建模的标签是什么样的:
+在这个例子中,你可以看到两个重叠的电影评论,一个关于高中电影,另一个关于无家可归的问题。让我们也检查一下掩码语言模型待预测的标签是什么样的:
```python out
tokenizer.decode(lm_datasets["train"][1]["labels"])
@@ -442,11 +445,11 @@ tokenizer.decode(lm_datasets["train"][1]["labels"])
".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
```
-正如前面的 `group_texts()` 函数所期望的那样, 这看起来与解码后的 `input_ids` 相同 -- 但是我们的模型怎么可能学到任何东西呢? 我们错过了一个关键步骤: 在输入中的随机位置插入 `[MASK]` 标记! 让我们看看如何使用特殊的数据整理器在微调期间即时执行此操作。
+正如我们上面的 `group_texts()` 函数所预期的那样,这看起来与解码的 `input_ids` 完全相同 —— 但是要怎么样才能让我们的的模型可以学习到一些东西呢?我们缺少一个关键的步骤:在输入中随机插入 `[MASK]` token!让我们看看如何在微调期间使用特殊的数据整理器来实时地完成这个步骤。
-## 使用 `Trainer` API 微调DistilBERT [[使用 `Trainer` API 微调DistilBERT]]
+## 使用 `Trainer` API 微调 DistilBERT [[使用 `Trainer` API 微调 DistilBERT]]
-微调屏蔽语言模型几乎与微调序列分类模型相同, 就像我们在 [第三章](/course/chapter3)所作的那样。 唯一的区别是我们需要一个特殊的数据整理器, 它可以随机屏蔽每批文本中的一些标记。幸运的是, 🤗 Transformers 为这项任务准备了专用的 `DataCollatorForLanguageModeling` 。我们只需要将它转递给标记器和一个 `mlm_probability` 参数, 该参数指定要屏蔽的标记的分数。我们将选择 15%, 这是 BERT 使用的数量也是文献中的常见选择:
+微调掩码语言模型几乎与微调序列分类模型相同,就像我们在 [第三章](/course/chapter3) 所做的那样。唯一的区别是我们需要一个特殊的数据整理器,它可以随机屏蔽每批文本中的一些 tokens。幸运的是,🤗 Transformers 为这项任务准备了专用的 `DataCollatorForLanguageModeling` 。我们只需要将 tokenizer 和一个 `mlm_probability` 参数(掩盖 tokens 的比例)传递给它。在这里我们将 `mlm_probability` 参数设置为 15%,这是 `BERT` 默认的数量,也是文献中最常见的选择。
```python
from transformers import DataCollatorForLanguageModeling
@@ -454,7 +457,7 @@ from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
```
-要了解随机掩码的工作原理, 让我们向数据整理器提供一些示例。由于它需要一个 `dict` 的列表, 其中每个 `dict` 表示单个连续文本块, 我们首先迭代数据集, 然后再将批次提供给整理器。我们删除了这个数据整理器的 `"word_ids"` 键, 因为它不需要它:
+为了了解随机掩码数据整理器的工作原理,让我们把一些例子输入到数据整理器。由于数据整理器期望接收一个字典列表,其中每个字典中存储一段连续文本的块,所以我们首先遍历数据集取出来一些样本数据,然后将样本数据输入到整理器。在输入到数据整理器之间,我们删除了 `word_ids` 这个键,因为它不需要这个键。
```python
samples = [lm_datasets["train"][i] for i in range(2)]
@@ -471,21 +474,20 @@ for chunk in data_collator(samples)["input_ids"]:
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'
```
-很棒, 成功了! 我们可以看到, `[MASK]` 标记已随机插入我们文本中的不同位置。 这些将是我们的模型在训练期间必须预测的标记 -- 数据整理器的美妙之处在于, 它将随机化每个批次的 `[MASK]` 插入!
+很棒,成功了!我们可以看到, `[MASK]` tokens 已随机插入我们文本中的不同位置。这些将是我们的模型在训练期间必须预测的 tokens —— 数据整理器的美妙之处在于,它会在每个 batch 中随机插入 `[MASK]` !
-✏️ **试试看!** 多次运行上面的代码片段, 看看随机屏蔽发生在你眼前! 还要将 `tokenizer.decode()` 方法替换为 `tokenizer.convert_ids_to_tokens()` 以查看有时会屏蔽给定单词中的单个标记, 而不是其他标记。
+✏️ **试一试!** 多运行上面的代码片段几次,亲眼看看随机遮蔽的效果!也可以用 `tokenizer.convert_ids_to_tokens()` 替换 `tokenizer.decode()` 方法,看看只把一个给定单词的单个 token 遮蔽,而保持这个单词其他 tokens 不变的效果。
{#if fw === 'pt'}
-随机掩码的一个副作用是, 当使用 `Trainer` 时, 我们的评估指标将不是确定性的, 因为我们对训练集和测试集使用相同的数据整理器。稍后我们会看到, 当我们使用 🤗 Accelerate 进行微调时, 我们将如何利用自定义评估循环的灵活性来冻结随机性。
-
+随机掩码的一个缺点是,当使用 `Trainer` 时,每次计算出来的评估结果会有些许不同,即使我们会对训练集和测试集使用相同的数据整理器。稍后,我们在学习使用 🤗 Accelerate 进行微调时, 就会看到如何利用灵活的自定义评估循环的来冻结随机性。
{/if}
-在为掩码语言建模训练模型时, 可以使用的一种技术是将整个单词一起屏蔽, 而不仅仅是单个标记。这种方法称为 _全词屏蔽_。 如果我们想使用全词屏蔽, 我们需要自己构建一个数据整理器。数据整理器只是一个函数, 它接受一个样本列表并将它们转换为一个批次, 所以现在让我们这样做吧! 我们将使用之前计算的单词 ID 在单词索引和相应标记之间进行映射, 然后随机决定要屏蔽哪些单词并将该屏蔽应用于输入。请注意, 除了与掩码对应的标签外, 所有的标签均为 `-100`。
+在为掩码语言建模训练模型时,不仅仅可以遮蔽单个 `token`,还可以一次遮蔽整个单词的所有 `token`,这种方法被称为全词屏蔽(whole word masking)。如果我们想使用全词屏蔽(whole word masking),我们就需要自己构建一个数据整理器。数据整理器的核心是一个函数,它接受一个样本列表并将它们转换为一个 `batch`,所以现在让我们这样做吧!我们将使用先前计算的`word ID`,构建一个单词索引和相应 `token` 之间的映射,然后随机决定遮蔽哪些单词,并使用这种方法对输入进行遮蔽。请注意,除了与掩码对应的标签外,所有其他的标签均应该设置为 `-100` 。
{#if fw === 'pt'}
@@ -502,7 +504,7 @@ def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
- # Create a map between words and corresponding token indices
+ # 创建一个单词与对应 token 索引之间的映射
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
@@ -513,7 +515,7 @@ def whole_word_masking_data_collator(features):
current_word_index += 1
mapping[current_word_index].append(idx)
- # Randomly mask words
+ # 随机遮蔽单词
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
@@ -543,7 +545,7 @@ def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
- # Create a map between words and corresponding token indices
+ # 创建一个单词与对应 token 索引之间的映射
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
@@ -554,7 +556,7 @@ def whole_word_masking_data_collator(features):
current_word_index += 1
mapping[current_word_index].append(idx)
- # Randomly mask words
+ # 随机遮蔽单词
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
@@ -571,7 +573,7 @@ def whole_word_masking_data_collator(features):
{/if}
-Next, we can try it on the same samples as before:
+接下来,我们可以在之前的样本上试试它:
```py
samples = [lm_datasets["train"][i] for i in range(2)]
@@ -589,11 +591,11 @@ for chunk in batch["input_ids"]:
-✏️ **试试看!** 多次运行上面的代码片段, 看看随机屏蔽发生在你眼前! 还要将 `tokenizer.decode()` 方法替换为 `tokenizer.convert_ids_to_tokens()` 以查看来自给定单词的标记始终被屏蔽在一起。
+✏️ **试试看!** 多次运行上面的代码片段,亲眼看看随机遮蔽的效果!也可以将 `tokenizer.decode()` 方法替换为 `tokenizer.convert_ids_to_tokens()` ,可以观察到给定单词的所有 tokens 总是被一起遮蔽。
-现在我们有两个数据整理器, 其余的微调步骤是标准的。如果您没有足够幸运地获得神话般的 P100 GPU 😭, 在 Google Colab 上进行训练可能需要一段时间, 因此我们将首先将训练集的大小缩减为几千个示例。别担心, 我们仍然会得到一个相当不错的语言模型! 在 🤗 Datasets 中快速下采样数据集的方法是通过我们在 [第五章](/course/chapter5) 中看到的 `Dataset.train_test_split()` 函数:
+现在我们有了两个数据整理器,剩下的微调步骤与其他任务类似都是标准的。如果你在 Google Colab 上运行并且没有幸运地分配到神秘的 P100 GPU😭,那么训练可能会需要一些时间,所以我们首先将训练集的大小减小到几千个例子。不用担心,我们仍然可以得到一个相当不错的语言模型!在 🤗 Datasets 中快速筛选数据集的方法是使用我们在 [第五章](/course/chapter5) 中看到的 `Dataset.train_test_split()` 函数:
```python
train_size = 10_000
@@ -618,7 +620,7 @@ DatasetDict({
})
```
-这会自动创建新的 `train` 和 `test` 拆分, 训练集大小设置为 10,000 个示例, 验证设置为其中的 10% -- 如果你有一个强大的 GPU, 可以随意增加它! 我们需要做的下一件事是登录 Hugging Face Hub。如果你在笔记本中运行此代码, 则可以使用以下实用程序函数执行此操作:
+运行上述代码会自动创建新的 `train` 和 `test` 数据集,训练集大小为 10,000 个示例,验证的大小是训练集的 10% —— 如果你有一个强大的 GPU,可以自行增加这个比例!我们接下来要做的事情是登录 Hugging Face Hub。如果你在 Notebook 中运行这段代码,你可以通过以下的工具函数进行登录:
```python
from huggingface_hub import notebook_login
@@ -626,17 +628,17 @@ from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件, 你可以在其中输入你的凭据。或者, 你可以运行:
+它将显示一个小部件,在其中你可以输入你的账号和密码进行登陆。或者,你也可以在你最喜欢的终端中输入指令:
```
huggingface-cli login
```
-在你最喜欢的终端中登录。
+然后在那里登录。
{#if fw === 'tf'}
-登录后,我们可以创建我们的“tf.data”数据集。 为此,我们将使用 `prepare_tf_dataset()` 方法,该方法使用我们的模型自动推断哪些列应进入数据集。 如果您想准确控制要使用的列,可以改用“Dataset.to_tf_dataset()”方法。 为了简单起见,我们在这里只使用标准数据整理器,但您也可以尝试整个单词屏蔽整理器并将结果作为练习进行比较:
+登录后,我们可以创建我们的 `tf.data` 数据集。我们将使用 `prepare_tf_dataset()` 方法,该方法会根据所使用的模型自动推断哪些列应该存入数据集。如果你想准确控制要使用的列,可以改用 `Dataset.to_tf_dataset()` 方法。为了简单起见,我们在这里只使用标准数据整理器,但你也可以尝试全词屏蔽(whole word masking)数据整理器,并作为一个练习对比一下效果:
```python
tf_train_dataset = model.prepare_tf_dataset(
@@ -653,10 +655,9 @@ tf_eval_dataset = model.prepare_tf_dataset(
batch_size=32,
)
```
+接下来我们使用🤗 Transformers 库的 `create_optimizer()` 函数来设置超参数并编译模型,该函数提供了一个带有线性学习率衰减的 `AdamW` 优化器。在 `compile()` 的参数中我们没有指定损失函数,这代表使用模型内置的默认损失函数,然后我们将训练精度设置为`mixed_float16` 。注意,如果你使用的是 Colab GPU 或者其他不支持 float16 加速的 GPU,你可能应该注释掉这一行。
-接下来, 我们设置训练超参数并编译模型。我们使用 🤗 Transformers 库中的 `create_optimizer()` 函数, 它提供了一个具有线性学习率衰减的 `AdamW` 优化器。我们还使用了模型内置的损失, 当没有损失被指定为 `compile()` 参数是, 这是默认值, 并且我们将训练精度设置为 `"mixed_float16"`。请注意,如果你使用的是Colab GPU或其他不支持float16加速的GPU, 你可能应该注释掉这一行。
-
-此外, 我们还设置了一个 `PushToHubCallback`, 它将在每个epoch后将模型保存到Hub。你可以使用 `hub_model_id` 参数指定你想要推送到的存储库的名称 (特别是你将必须使用该参数来推送到组织)。例如, 为了将模型推送到 [`huggingface-course` organization](https://huggingface.co/huggingface-course), 我们添加了 `hub_model_id="huggingface-course/distilbert-finetuned-imdb"`。默认情况下, 使用的存储库将位于你的命名空间中, 并以你设置的输出目录命名, 因此在我们的示例中, 它将是 `"lewtun/distilbert-finetuned-imdb"`。
+另外,我们还设置了一个 `PushToHubCallback` ,它将在每个 epoch 后将模型保存到 Hub。你可以使用 `hub_model_id` 参数指定你想推送到的仓库的名称(如果你想把它推送到一个组织,你必须使用这个参数)。例如,要将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) ,就需要添加 `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` 。在默认的情况下,模型的仓库将保存在你的账户中,并以你设置的输出目录命名,所以在我们的示例中,该仓库的名称是 `lewtun/distilbert-finetuned-imdb` 。
```python
from transformers import create_optimizer
@@ -672,7 +673,7 @@ optimizer, schedule = create_optimizer(
)
model.compile(optimizer=optimizer)
-# Train in mixed-precision float16
+# 使用 float16 精度进行混合精度训练
tf.keras.mixed_precision.set_global_policy("mixed_float16")
model_name = model_checkpoint.split("/")[-1]
@@ -681,17 +682,17 @@ callback = PushToHubCallback(
)
```
-我们现在已经准备好运行 `model.fit()` 了 -- 但在此之前, 让我们先简单地看看 _perplexity_, 它是评估语言模型性能的常用指标。
+我们现在已经准备好运行 `model.fit()` 了 —— 但在此之前,让我们先简单了解一下 `困惑度(perplexity)` ,它是一种常用的评估语言模型性能的指标。
{:else}
-登陆后, 我们可以指定 `Trainer` 参数:
+登陆后,我们可以指定 `Trainer` 的参数:
```python
from transformers import TrainingArguments
batch_size = 64
-# Show the training loss with every epoch
+# 在每个 epoch 输出训练的 loss
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
@@ -709,11 +710,11 @@ training_args = TrainingArguments(
)
```
-在这里, 我们调整了一些默认选项, 包括 `logging_steps` , 以确保我们跟踪每个epoch的训练损失。我们还使用了 `fp16=True` 来实现混合精度训练, 这给我们带来了另一个速度提升。默认情况下, `Trainer` 将删除不属于模型的 `forward()` 方法的列。这意味着, 如果你使用整个单词屏蔽排序器, 你还需要设置 `remove_unused_columns=False`, 以确保我们不会在训练期间丢失 `word_ids` 列。
+在这里,我们调整了一些默认选项,包括 `logging_steps` ,以确保我们可以跟踪每个 epoch 的训练损失。我们还使用了 `fp16=True` 来实现混合精度训练,从而进一步提高训练速度。默认情况下, `Trainer` 将删除模型的 `forward()` 方法中未使用的列。这意味着,如果你使用全词屏蔽(whole word masking)数据整理器,你还需要设置 `remove_unused_columns=False` ,以确保我们不会在训练期间丢失 `word_ids` 列。
-请注意, 你可以使用 `hub_model_id` 参数指定要推送到的存储库的名称((特别是你将必须使用该参数向组织推送)。例如, 当我们将模型推送到 [`huggingface-course` organization](https://huggingface.co/huggingface-course) 时, 我们添加了 `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` 到 `TrainingArguments` 中。默认情况下, 使用的存储库将在你的命名空间中并以你设置的输出目录命名, 因此在我们的示例中, 它将是 `"lewtun/distilbert-finetuned-imdb"`。
+请注意,你可以使用 `hub_model_id` 参数指定你想推送到的仓库的名称(如果你想把它推送到一个组织,就必须使用这个参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,就在 `TrainingArguments` 中添加了 `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` 。默认情况下,使用的仓库将保存在你的账户中并以你设置的输出目录命名,因此在我们的示例中,它将是 `"lewtun/distilbert-finetuned-imdb"` 。
-我们现在拥有实例化 `Trainer` 的所有成分。这里我们只使用标准的 `data_collator`, 但你可以尝试使用整个单词掩码整理器并比较结果作为练习:
+现在,我们拥有了初始化 `Trainer` 所需的所有要素。这里我们只使用了标准的 `data_collator` ,但你可以尝试使用全词屏蔽作为数据整理器的一个练习,并对比一下不同屏蔽方式的结果有什么不同:
```python
from transformers import Trainer
@@ -728,19 +729,19 @@ trainer = Trainer(
)
```
-我们现在准备运行 `trainer.train()` -- 但在此之前让我们简要地看一下 _perplexity_, 这是评估语言模型性能的常用指标。
+我们现在准备运行 `trainer.train()` —— 但在此之前让我们简要地看一下 `困惑度(perplexity)` ,这是评估语言模型性能常用的指标。
{/if}
-### 语言模型的perplexity [[语言模型的perplexity]]
+### 语言模型的困惑度(perplexity) [[语言模型的困惑度(perplexity)]]
-与文本分类或问答等其他任务不同, 在这些任务中, 我们会得到一个带标签的语料库进行训练, 而语言建模则没有任何明确的标签。那么我们如何确定什么是好的语言模型呢? 就像手机中的自动更正功能一样, 一个好的语言模型是为语法正确的句子分配高概率, 为无意义的句子分配低概率。为了让你更好地了解这是什么样子, 您可以在网上找到一整套 "autocorrect fails", 其中一个人手机中的模型产生了一些相当有趣 (而且通常不合适) 的结果!
+语言建模与文本分类或问答等其他任务有所不同,在其他任务中,我们会得到一个带标签的语料库进行训练,而语言建模则没有任何明确的标签。那么我们如何确定什么是好的语言模型呢?就像手机中的自动更正功能一样,一个好的语言模型会较高概率输出一个语法正确的句子,较低概率输出无意义的句子。为了给你一个更直观感受,你可以在网上找到一整套“自动更正失败”的例子。其中,人们手机中的模型产生了一些相当有趣(并且常常不妥当)的自动生成的结果!
{#if fw === 'pt'}
-假设我们的测试集主要由语法正确的句子组成, 那么衡量我们的语言模型质量的一种方法是计算它分配给测试集中所有句子中的下一个单词的概率。高概率表明模型对看不见的例子并不感到 "惊讶" 或 "疑惑", 并表明它已经学习了语言中的基本语法模式。 perplexity度有多种数学定义, 但我们将使用的定义是交叉熵损失的指数。因此, 我们可以通过 `Trainer.evaluate()` 函数计算测试集上的交叉熵损失, 然后取结果的指数来计算预训练模型的perplexity度:
+如果测试集主要由语法正确的句子组成,那么衡量语言模型质量的一种方式就是计算它给测试集中所有句子的下一个词的概率。高概率表示模型对未见过的例子不感到“惊讶”或“困惑”,这表明它已经学习了语言的基本语法模式。困惑度有很多种数学定义,我们将使用的定义是交叉熵损失的指数。具体方法是使用 `Trainer.evaluate()`方法计算测试集上的交叉熵损失,取结果的指数来计算预训练模型的困惑度。
```python
import math
@@ -751,7 +752,7 @@ print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
{:else}
-假设我们的测试集主要由语法正确的句子组成, 那么衡量我们的语言模型质量的一种方法是计算测试集所有句子中它分配给下一个单词的概率。高概率表明, 该模型表明该模型对未见过的示例不感到 "惊讶" 或 "困惑", 并表明它已经学会了该语言的基本语法模式。关于perplexity度有各种不同的数学定义, 但我们要用的定义是交叉熵损失的指数。因此, 我们可以通过 `model.evaluate()` 方法计算测试集上的交叉熵损失, 然后取结果的指数来计算我们预训练模型的perplexity度:
+如果测试集主要由语法正确的句子组成,那么衡量语言模型质量的一种方式就是计算它给测试集中所有句子的下一个词的概率。高概率表示模型对未见过的例子不感到“惊讶”或“困惑”,这表明它已经学习了语言的基本语法模式。困惑度有很多种数学定义,我们将使用的定义是交叉熵损失的指数。具体方法是使用 `model.evaluate()` 方法计算测试集上的交叉熵损失,取结果的指数来计算预训练模型的困惑度。
```python
import math
@@ -766,7 +767,7 @@ print(f"Perplexity: {math.exp(eval_loss):.2f}")
>>> Perplexity: 21.75
```
-较低的perplexity分数意味着更好的语言模型, 我们可以在这里看到我们的起始模型有一个较大的值。看看我们能不能通过微调来降低它! 为此, 我们首先运行训练循环:
+较低的困惑度分数意味着更好的语言模型,我们可以看到,我们的初始模型的困惑度相当地高。让我们看看我们是否可以通过微调来降低它!为此,我们首先运行训练循环:
{#if fw === 'pt'}
@@ -782,7 +783,7 @@ model.fit(tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback
{/if}
-然后像以前一样计算测试集上的perplexity度:
+然后像之前那样计算测试集上的结果困惑度:
{#if fw === 'pt'}
@@ -804,11 +805,11 @@ print(f"Perplexity: {math.exp(eval_loss):.2f}")
>>> Perplexity: 11.32
```
-很好 -- 这大大减少了困惑, 这告诉我们模型已经了解了一些关于电影评论领域的知识!
+太棒了——困惑度显著降低,这告诉我们模型已经学习到了电影评论领域的一些知识!
{#if fw === 'pt'}
-训练完成后, 我们可以将带有训练信息的模型卡推送到 Hub (检查点在训练过程中自行保存):
+一旦训练完成,我们可以将带有训练信息的模型卡片推送到 Hub(checkpoint 在训练过程中就已经保存了):
```python
trainer.push_to_hub()
@@ -818,29 +819,28 @@ trainer.push_to_hub()
-✏️ **轮到你了!** 将数据整理器改为全字屏蔽整理器后运行上面的训练。你有得到更好的结果吗?
+✏️ **轮到你了!** 将数据整理器改为全词屏蔽的数据整理器后运行上面的训练。你能得到更好的结果吗?
{#if fw === 'pt'}
-在我们的用例中, 我们不需要对训练循环做任何特别的事情, 但在某些情况下, 你可能需要实现一些自定义逻辑。对于这些应用, 你可以使用 🤗 Accelerate -- 让我们来看看吧!
+在我们的使用案例中,我们不需要对训练循环做任何特殊的处理,但在某些情况下,你可能需要实现一些自定义逻辑。对于这些应用,你可以使用 🤗 Accelerate —— 让我们看一看!
## 使用 🤗 Accelerate 微调 DistilBERT [[使用 🤗 Accelerate 微调 DistilBERT]]
-正如我们在 `Trainer` 中看到的, 对掩码语言模型的微调与 [第三章](/course/chapter3) 中的文本分类示例非常相似。事实上, 唯一的微妙之处是使用特殊的数据整理器, 我们已经在本节的前面介绍过了!
-
-然而, 我们看到 `DataCollatorForLanguageModeling` 还对每次评估应用随机掩码, 因此每次训练运行时, 我们都会看到perplexity度分数的一些波动。消除这种随机性来源的一种方法是应用掩码 _一次_ 在整个测试集上, 然后使用🤗 Transformers 中的默认数据整理器在评估期间收集批次。为了看看它是如何工作的, 让我们实现一个简单的函数, 将掩码应用于批处理, 类似于我们第一次遇到的 `DataCollatorForLanguageModeling`:
+从上面的 `Trainer` 训练流程中我们就能发现,微调一个掩码的语言模型与 [第三章](https://chat.openai.com/course/chapter3) 中的文本分类非常相似。事实上,唯一的不同之处是使用了一个特殊的数据整理器,我们已经在本节的前面讨论过这个问题了!
+然而,我们注意到 `DataCollatorForLanguageModeling` 在每次评估时也会进行随机遮罩,因此我们在每次训练运行中都会看到困惑度得分有些波动。消除这种随机性的一种方法是在整个测试集上 `仅进行一次` 遮罩,然后在评估过程中使用🤗 Transformers 中的默认数据整理器来收集 batch。为实现这个过程,让我们实现一个简单的函数,类似于我们第一次使用 `DataCollatorForLanguageModeling` 时进行遮罩的方式:
```python
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
- # Create a new "masked" column for each column in the dataset
+ # 为数据集中的每一列创建一个新的"masked"列
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}
```
-接下来, 我们将此函数应用于我们的测试集并删除未掩码的列, 以便我们可以用掩码的列替换它们。你可以通过用适当的替换上面的 `data_collator` 来使整个单词掩码, 在这种情况下, 你应该删除此处的第一行:
+接下来,我们将上述函数应用到测试集,并删除未进行遮罩的列,这样就实现了使用遮罩过的数据替换原始输入的数据。你可以通过将上述 `data_collator` 替换为支持全词遮罩的数据整理器并且删除下面的第一行(全词遮罩的数据整理器需要 `word_ids` 列来定位同一个单词中的不同 `token`)来实现全词遮罩
```py
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
@@ -858,7 +858,7 @@ eval_dataset = eval_dataset.rename_columns(
)
```
-然后我们可以像往常一样设置数据加载器, 但我们将使用🤗 Transformers 中的 `default_data_collator` 作为评估集:
+然后我们可以像往常一样设置 DataLoader,但我们将使用🤗 Transformers 中的 `default_data_collator` 来设置 DataLoader:
```python
from torch.utils.data import DataLoader
@@ -876,13 +876,13 @@ eval_dataloader = DataLoader(
)
```
-从这里开始, 我们遵循🤗 Accelerate 的标准步骤。第一个任务是加载预训练模型的新版本:
+从这里开始,我们将遵循🤗 Accelerate 的标准步骤。第一个任务是重新加载预训练模型:
```
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
```
-然后我们需要指定优化器; 我们将使用标准的 `AdamW`:
+然后我们需要指定优化器;我们将使用标准的 `AdamW` :
```python
from torch.optim import AdamW
@@ -890,7 +890,7 @@ from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
```
-有了这些对象, 我们现在可以准备使用 `Accelerator` 加速器进行训练的一切:
+有了这些对象,我们现在可以用 `Accelerator` 对象包装所有的组件,以进行训练:
```python
from accelerate import Accelerator
@@ -901,7 +901,7 @@ model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
)
```
-现在我们的模型、优化器和数据加载器都配置好了, 我们可以指定学习率调度器如下:
+现在我们的模型、优化器和 DataLoader 都配置好了,我们可以按照以下方式设置学习率调度器:
```python
from transformers import get_scheduler
@@ -918,7 +918,7 @@ lr_scheduler = get_scheduler(
)
```
-在训练之前要做的最后一件事是: 在 Hugging Face Hub 上创建一个模型库! 我们可以使用 🤗 Hub 库来首先生成我们的 repo 的全名:
+在开始训练之前,我们还需要做的最后一件事就是在 Hugging Face Hub 上创建一个模型仓库!我们可以使用🤗 Hub 库的 `get_full_repo_name`,生成我们仓库的全名:
```python
from huggingface_hub import get_full_repo_name
@@ -932,7 +932,7 @@ repo_name
'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'
```
-然后使用来自🤗 Hub 的 `Repository` 类:
+然后,我们可以使用🤗 Hub 的 `Repository` 类创建并克隆仓库:
```python
from huggingface_hub import Repository
@@ -941,7 +941,7 @@ output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)
```
-完成后, 只需写出完整的训练和评估循环即可:
+完成后,只需写出完整的训练和评估循环即可:
```python
from tqdm.auto import tqdm
@@ -951,7 +951,7 @@ import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
- # Training
+ # 训练
model.train()
for batch in train_dataloader:
outputs = model(**batch)
@@ -963,7 +963,7 @@ for epoch in range(num_train_epochs):
optimizer.zero_grad()
progress_bar.update(1)
- # Evaluation
+ # 评估
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
@@ -982,7 +982,7 @@ for epoch in range(num_train_epochs):
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
- # Save and upload
+ # 保存并上传
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
@@ -999,13 +999,13 @@ for epoch in range(num_train_epochs):
>>> Epoch 2: Perplexity: 10.729503505340409
```
-很棒, 我们已经能够评估每个 epoch 的perplexity度, 并确保多次训练运行是可重复的!
+很棒,我们已经能够评估每个 epoch 的困惑度,并确保运行的结果可以复现!
{/if}
## 使用我们微调的模型 [[使用我们微调的模型]]
-你可以通过在Hub上使用其他小部件或在本地使用🤗 Transformers 的`管道`于微调模型进行交互。让我们使用后者来下载我们的模型, 使用 `fill-mask` 管道:
+你可以使用 Hub 上的模型部件或者在本地使用🤗 Transformers 的 `pipeline` 加载微调模型预测文本。让我们使用后者通过 `fill-mask` pipeline 下载我们的模型:
```python
from transformers import pipeline
@@ -1015,7 +1015,7 @@ mask_filler = pipeline(
)
```
-然后, 我们可以向管道提供 "This is a great [MASK]" 示例文本, 并查看前 5 个预测是什么:
+然后我们可以将文本“This is a great [MASK]”提供给 pipeline,看看前 5 个预测是什么:
```python
preds = mask_filler(text)
@@ -1032,14 +1032,13 @@ for pred in preds:
'>>> this is a great character.'
```
-好的 -- 我们的模型显然已经调整了它的权重来预测与电影更密切相关的词!
+Nice!—— 我们的模型显然已经调整了它的权重来预测与电影更密切相关的词!
-这结束了我们训练语言模型的第一个实验。在 [第六节](/course/chapter7/section6)中你将学习如何从头开始训练像 GPT-2 这样的自回归模型; 如果你想了解如何预训练您自己的 Transformer 模型, 请前往那里!
+这标志着我们第一次训练语言模型的实验到现在就结束了。在 [第 6 节](https://chat.openai.com/course/en/chapter7/6) 中,你将学习如何从头开始训练一个自动回归模型,比如 GPT-2;如果你想看看如何预训练你自己的 Transformer 模型,就赶快去那里看看吧!
-✏️ **试试看!** 为了量化域适应的好处, 微调 IMDb 标签上的分类器和预先训练和微调的Distil BERT检查点。如果你需要复习文本分类, 请查看 [第三章](/course/chapter3)。
-
+✏️ **试试看!** 为了量化领域适应的好处,分别使用预训练和微调的 DistilBERT checkpoint 以及数据集自带的 IMDb 标签来微调一个分类器,并对比一下这个两个 checkpoint 的差异。如果你需要复习文本分类的知识,请查看 [第三章](/course/chapter3) 。
diff --git a/chapters/zh-CN/chapter7/4.mdx b/chapters/zh-CN/chapter7/4.mdx
index bb15ba4c7..715a3fdb9 100644
--- a/chapters/zh-CN/chapter7/4.mdx
+++ b/chapters/zh-CN/chapter7/4.mdx
@@ -22,16 +22,16 @@
{/if}
-现在让我们深入研究翻译。这是另一个[sequence-to-sequence 任务](/course/chapter1/7),这意味着这是一个可以表述为从一个序列到另一个序列的问题。从这个意义上说,这个问题非常类似[文本摘要](/course/chapter7/6),并且您可以将我们将在此处学习到的一些内容迁移到其他的序列到序列问题,例如:
+现在让我们深入研究翻译。这是另一个 [sequence-to-sequence 任务](/course/chapter1/7) ,着这是一个可以表述为输入是一个序列输出另一个序列的问题。从这个意义上说,这个问题非常类似 [文本摘要](/course/chapter7/6) ,并且你可以将我们将在此处学习到的一些技巧迁移到其他的序列到序列问题,例如:
-- **风格迁移** : 创建一个模型将某种风格迁移到一段文本(例如,正式的风格迁移到休闲的风格或莎士比亚英语到现代英语)
-- **生成问题的回答** :创建一个模型,在给定上下文的情况下生成问题的答案
+- **风格迁移** 创建一个模型将某种风格迁移到一段文本(例如,正式的风格迁移到休闲的风格,或从莎士比亚英语迁移到现代英语)。
+- **生成问题的回答** 创建一个模型,在给定上下文的情况下生成问题的答案。
-如果您有足够大的两种(或更多)语言的文本语料库,您可以从头开始训练一个新的翻译模型,就像我们在[因果语言建模](/course/chapter7/6)部分中所做的那样。然而,微调现有的翻译模型会更快,无论是从像 mT5 或 mBART 这样的多语言模型微调到特定的语言对,或者是专门用于从一种语言翻译成另一种语言的模型。
+如果你有足够大的两种(或更多)语言的文本语料库,你可以从头开始训练一个新的翻译模型,就像我们在 [因果语言建模](/course/chapter7/6) 部分中所做的那样。然而,微调现有的翻译模型会更快,无论是从像 mT5 或 mBART 这样的多语言模型微调到特定的语言对,还是从特定语料库的一种语言到另一种语言的专用翻译模型。
-在本节中,我们将对[KDE4 数据集](https://huggingface.co/datasets/kde4)上的Marian模型进行微调,该模型经过了从英语到法语的翻译预训练(因为很多“ Hugging Face”的员工会说这两种语言),它是[KDE应用程序](https://apps.kde.org/)本地化文件的数据集。我们将使用的模型已经在从[Opus 数据集](https://opus.nlpl.eu/)(实际上包含KDE4数据集)中提取的法语和英语文本的大型语料库上进行了预先训练。但是,即使我们使用的预训练模型在其预训练期间使用了这部分数据集,我们也会看到,经过微调后,我们可以得到一个更好的版本。
+在这一节中,我们将在 [KDE4 数据集](https://huggingface.co/datasets/kde4) 上微调一个预训练的 Marian 模型,用来把英语翻译成法语的(因为很多 Hugging Face 的员工都会说这两种语言)。KDE4 数据集是一个 [KDE 应用](https://apps.kde.org/) 本地化的数据集。我们将使用的模型已经在从 [Opus 数据集](https://opus.nlpl.eu/) (实际上包含 KDE4 数据集)中提取的法语和英语文本的大型语料库上进行了预先训练。不过,即使我们使用的预训练模型在其预训练期间使用了这部分数据集,我们也会看到,经过微调后,我们可以得到一个更好的版本。
完成后,我们将拥有一个模型,可以进行这样的翻译:
@@ -42,15 +42,15 @@
-您可以[在这里](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).找到我们将训练并上传到 Hub的模型,可以尝试输入一些句子看看模型的预测结果。
+你可以 [在这里](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn) 。找到我们将训练并上传到 Hub 的模型,可以尝试输入一些句子测试一下模型的预测结果。
## 准备数据 [[准备数据]]
-首先,我们需要一个适合标记分类的数据集。在本节中,我们将使用[CoNLL-2003 数据集](https://huggingface.co/datasets/conll2003), 其中包含来自路透社的新闻报道。
+首先,我们需要一个适合 token 分类的数据集。在本节中,我们将使用 [CoNLL-2003 数据集](https://huggingface.co/datasets/conll2003) ,该数据集来源于路透社的新闻报道。
-💡 只要您的数据集由带有相应标签的分割成单词并的文本组成,您就能够将这里描述的数据处理过程应用到您自己的数据集。如果需要复习如何在.Dataset中加载自定义数据,请参阅[Chapter 5](/course/chapter5)。
+💡 只要你的数据集由分词文本和对应的标签组成,就能够将这里描述的数据处理过程应用到自己的数据集中。如果需要复习如何在 `Dataset` 中加载自定义数据集,请复习 [第五章](/course/chapter5) 。
### CoNLL-2003 数据集 [[CoNLL-2003 数据集]]
-要加载 CoNLL-2003 数据集,我们使用 来自 🤗 Datasets 库的**load_dataset()** 方法:
+要加载 CoNLL-2003 数据集,我们可以使用🤗 Datasets 库的 `load_dataset()` 方法:
```py
from datasets import load_dataset
@@ -61,7 +60,7 @@ from datasets import load_dataset
raw_datasets = load_dataset("conll2003")
```
-这将下载并缓存数据集,就像和我们在[第三章](/course/chapter3) 加载GLUE MRPC 数据集一样。检查这个对象可以让我们看到存在哪些列,以及训练集、验证集和测试集之间是如何分割的:
+这将下载并缓存数据集,就像和我们在 [第三章](/course/chapter3) 加载 GLUE MRPC 数据集一样。查看 `raw_datasets` 对象可以让我们看到数据集中存在哪些列,以及训练集、验证集和测试集之间是如何划分的:
```py
raw_datasets
@@ -84,7 +83,7 @@ DatasetDict({
})
```
-特别是,我们可以看到数据集包含我们之前提到的三个任务的标签:NER、POS 和chunking。与其他数据集的一个很大区别是输入文本不是作为句子或文档呈现的,而是单词列表(最后一列称为 **tokens** ,但它包含的是这些词是预先标记化的输入,仍然需要通过标记器进行子词标记)。
+可以看到数据集包含了我们之前提到的三项任务的标签:命名实体识别(NER)、词性标注(POS)以及分块(chunking)。这个数据集与其他数据集的一个显著区别在于,输入文本的那一列并非以句子或整片的文本的形式存储,而是以单词列表的形式(最后一列被称为 `tokens` ,不过 `tokens` 列保存的还是单词,也就是说,这些预先分词的输入仍需要经过 tokenizer 进行子词分词处理)。
我们来看看训练集的第一个元素:
@@ -96,7 +95,7 @@ raw_datasets["train"][0]["tokens"]
['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
```
-由于我们要执行命名实体识别,我们将查看 NER 标签:
+由于我们要进行命名实体识别,让我们查看一下 NER 标签:
```py
raw_datasets["train"][0]["ner_tags"]
@@ -106,7 +105,7 @@ raw_datasets["train"][0]["ner_tags"]
[3, 0, 7, 0, 0, 0, 7, 0, 0]
```
-这一列是类标签的序列。元素的类型在ner_feature的feature属性中,我们可以通过查看该特性的names属性来访问名称列表:
+这些是可以直接训练的整数类别标签,当我们想要检查数据时,直接看整数的标签不是很直观。就像在文本分类中,我们可以通过查看数据集的 `features` 属性来找到这些整数和标签名称之间的对应关系:
```py
ner_feature = raw_datasets["train"].features["ner_tags"]
@@ -117,7 +116,7 @@ ner_feature
Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
```
-因此,这一列包含的元素是ClassLabels的序列。序列元素的类型在`ner_feature`的`feature`中,我们可以通过查看该`feature`的`names`属性来访问名称列表:
+因此,我们得到了 `ClassLabels` 类型的序列。序列中元素的类型存储在 `ner_feature` 的 `feature` 中,我们可以通过查看该 `feature` 的 `names` 属性来访问标签名称的列表:
```py
label_names = ner_feature.feature.names
@@ -128,15 +127,15 @@ label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
```
-我们在[第六章](/course/chapter6/3), 深入研究**token-classification** 管道时已经看到了这些标签 ,但为了快速复习:
+我们在 [第六章](/course/chapter6/3) 深入研究 `token-classification` 管道时已经看到过这些标签 我们在这里进行一个快速的回顾:
- `O` 表示这个词不对应任何实体。
-- `B-PER`/`I-PER`意味着这个词对应于人名实体的开头/内部。
-- `B-ORG`/`I-ORG` 的意思是这个词对应于组织名称实体的开头/内部。
-- `B-LOC`/`I-LOC` 指的是是这个词对应于地名实体的开头/内部。
-- `B-MISC`/`I-MISC` 表示该词对应于一个杂项实体的开头/内部。
+- `B-PER` / `I-PER` 意味着这个词对应于人名实体的开头/内部。
+- `B-ORG` / `I-ORG` 的意思是这个词对应于组织名称实体的开头/内部。
+- `B-LOC` / `I-LOC` 指的是是这个词对应于地名实体的开头/内部。
+- `B-MISC` / `I-MISC` 表示这个词对应一个其他实体(不属于特定类别或类别之外)的开头 / 内部。
-现在解码我们之前看到的标签:
+接下来使用对这些标签名对数据集的 `ner_tags` 进行解码,将得到以下输出结果:
```python
words = raw_datasets["train"][0]["tokens"]
@@ -158,18 +157,18 @@ print(line2)
'B-ORG O B-MISC O O O B-MISC O O'
```
-例如混合 **B-** 和 **I-** 标签,这是相同的代码在索引 4 的训练集元素上的预测结果:
+我们还可以查看训练集中索引为 4 的数据,它是一个同时包含 `B-` 和 `I-` 标签的例子:
```python out
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
```
-正如我们所看到的,跨越两个单词的实体,如“European Union”和“Werner Zwingmann”,模型为第一个单词标注了一个B-标签,为第二个单词标注了一个I-标签。
+正如我们在上面的输出中所看到的,跨越两个单词的实体,如“European Union”和“Werner Zwingmann”,数据集把第一个单词标注为了 `B-` 标签,将第二个单词标记为了 `I-` 标签。
-✏️ **轮到你了!** 使用 POS 或chunking标签识别同一个句子。
+✏️ **轮到你了!** 检查同一个句子的词性标注 (POS)或分块(chunking)列,查看输出的结果。
@@ -177,9 +176,9 @@ print(line2)
-像往常一样,我们的文本需要转换为Token ID,然后模型才能理解它们。正如我们在[第六章](/course/chapter6/)所学的那样。不过在标记任务中,一个很大的区别是我们有pre-tokenized的输入。幸运的是,tokenizer API可以很容易地处理这个问题;我们只需要用一个特殊的tokenizer。
+像往常一样,我们的文本需要转换为 Token ID,然后模型才能理解它们。正如我们在 [第六章](/course/chapter6/) 所学的那样。不过与 tokens 分类任务不同的是数据集已经完成了预分词,我们在处理的过程中不需要再次分词。幸运的是,tokenizer API 可以很容易地处理这种差异;我们只需要通过一个特殊的标志告诉 tokenizer即可。
-首先,让我们创建`tokenizer`对象。如前所述,我们将使用 BERT 预训练模型,因此我们将从下载并缓存关联的分词器开始:
+首先,让我们创建 `tokenizer` 对象。如前所述,我们将使用 BERT 预训练模型,因此我们将从下载并缓存关联的 `tokenizer` 开始:
```python
from transformers import AutoTokenizer
@@ -188,7 +187,7 @@ model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
```
-你可以更换把 `model_checkpoint` 更换为 [Hub](https://huggingface.co/models),上您喜欢的任何其他型号,或使用您本地保存的预训练模型和分词器。唯一的限制是分词器需要由 🤗 Tokenizers 库支持,有一个“快速”版本可用。你可以在[这张大表](https://huggingface.co/transformers/#supported-frameworks), 上看到所有带有快速版本的架构,或者检查 您可以通过查看它`is_fast` 属性来检测正在使用的`tokenizer`对象是否由 🤗 Tokenizers 支持:
+你可以更换把 `model_checkpoint` 更换为 [Hub](https://huggingface.co/models) 上你喜欢的任何其他模型,或使用本地保存的预训练模型和 `tokenizer`。唯一的限制是 tokenizer 需要由 🤗 Tokenizers 库支持,并且有一个“快速”版本可用。你可以在 [Huggingface 模型后端支持表](https://huggingface.co/transformers/#supported-frameworks) 上看到所有带有快速版本的 `tokenizer` 架构,或者你也可以通过查看它 `is_fast` 属性来检测正在使用的 `tokenizer` 对象是否由 🤗 Tokenizers 支持:
```py
tokenizer.is_fast
@@ -198,7 +197,7 @@ tokenizer.is_fast
True
```
-要对预先标记的输入进行标记,我们可以像往常一样使用我们的`tokenizer` 只需添加 `is_split_into_words=True`:
+我们可以像往常一样使用我们的 `tokenizer` 对预先分词的输入进行 `tokenize` ,只需额外添加 `is_split_into_words=True` 参数:
```py
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
@@ -209,8 +208,10 @@ inputs.tokens()
['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
```
-正如我们所见,分词器添加了模型使用的特殊Token(`[CLS]` 在开始和`[SEP]` 最后) 而大多数单词未被修改。然而,单词 `lamb`,被分为两个子单词 `la` and `##mb`。这导致了输入和标签之间的不匹配:标签列表只有9个元素,而我们的输入现在有12个token 。计算特殊Token很容易(我们知道它们在开头和结尾),但我们还需要确保所有标签与适当的单词对齐。
-幸运的是,由于我们使用的是快速分词器,因此我们可以访问🤗 Tokenizers超能力,这意味着我们可以轻松地将每个令牌映射到其相应的单词(如[Chapter 6](/course/chapter6/3)):
+如我们所见,`tokenizer` 在结果中添加了模型需要使用的特殊 tokens(在开头的 `[CLS]` ,在结尾的 `[SEP]` ),并且大部分单词保持不变。不过,单词 `lamb` 被分词为两个子词, `la` 和 `##mb` 。这导致了输入和标签之间的不匹配:标签列表只有 9 个元素,而我们的输入现在有 12 个 tokens。解决特殊 tokens 的问题很容易(我们已经知道了每个 `token` 开始和结束的位置),我们需要确保的是我们将所有的标签与正确的词对齐。
+
+
+幸运的是,由于我们使用的是快速 tokens 因此我们可以使用🤗 Tokenizers 超能力,这意味着我们可以轻松地将每个 token 映射到其相应的单词(如 [第六章](/course/chapter6/3) 中所学):
```py
inputs.word_ids()
@@ -220,7 +221,7 @@ inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
```
-通过一点点工作,我们可以扩展我们的标签列表以匹配token 。我们将应用的第一条规则是,特殊token 的标签为 `-100` 。这是因为默认情况下 `-100` 是一个在我们将使用的损失函数(交叉熵)中被忽略的索引。然后,每个token 都会获得与其所在单词的token 相同的标签,因为它们是同一实体的一部分。对于单词内部但不在开头的Token,我们将`B-` 替换为 `I-` (因为token 不以实体开头):
+只需要一点点工作,我们就可以扩展我们的标签列表。我们将添加的使其与 `token` 列表相匹配。 添加的第一条规则是,特殊 tokens 的标签设置为 `-100` 。这是因为默认情况下, `-100` 会被我们的损失函数(交叉熵)忽略。然后将每个 `token` 的标签设置为这个 `token` 所在单词开头的 `token` 的标签,因为同一个单词一定是同一个实体的一部分。最后将单词的内部 `tokens` 标签中的 `B-` 替换为 `I-`,因为该 `token` 不在实体的开头,`B-` 在每个实体中只应该出现一次:
```python
def align_labels_with_tokens(labels, word_ids):
@@ -228,17 +229,17 @@ def align_labels_with_tokens(labels, word_ids):
current_word = None
for word_id in word_ids:
if word_id != current_word:
- # Start of a new word!
+ # 新单词的开始!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
- # Special token
+ # 特殊的token
new_labels.append(-100)
else:
- # Same word as previous token
+ # 与前一个 tokens 类型相同的单词
label = labels[word_id]
- # If the label is B-XXX we change it to I-XXX
+ # 如果标签是 B-XXX 我们将其更改为 I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
@@ -246,7 +247,7 @@ def align_labels_with_tokens(labels, word_ids):
return new_labels
```
-让我们在我们的第一句话上试一试:
+让我们在数据集的第一个元素上试一试:
```py
labels = raw_datasets["train"][0]["ner_tags"]
@@ -260,15 +261,15 @@ print(align_labels_with_tokens(labels, word_ids))
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
```
-正如我们所看到的,我们的函数为开头和结尾的两个特殊标记添加了 `-100` ,并为分成两个标记的单词添加了一个新的`0` 。
+正如我们所看到的,我们的函数为开头和结尾添加了两个特殊 tokens :`-100` ,并为切分成两个 tokens 的单词添加了一个新的 `0` 标签。
-✏️ **轮到你了!** 一些研究人员更喜欢每个词只归属一个标签, 并分配 `-100` 给定词中的其他子标记。这是为了避免分解成大量子标记的长词对损失造成严重影响。按照此规则更改前一个函数使标签与输入id对齐。
+✏️ **轮到你了!** 有些研究人员更喜欢只为每个单只分配一个标签,对该单词其他部分的 token 分配 `-100` 标签。这是为了避免那些分解成许多子词的长单词对损失作出过多的贡献。请按照这个思路,改变之前的函数,使标签与 inputs ID 对齐。
-为了预处理我们的整个数据集,我们需要标记所有输入并在所有标签上应用 `align_labels_with_tokens()` 。为了利用我们的快速分词器的速度优势,最好同时对大量文本进行分词,因此我们将编写一个处理示例列表的函数并使用带 `batched=True` 有选项的 `Dataset.map()`方法 .与我们之前的示例唯一不同的是当分词器的输入是文本列表(或者像例子中的单词列表)时 `word_ids()` 函数需要获取我们想要单词的索引的ID,所以我们也添加它:
+为了预处理我们的整个数据集,我们需要对所有输入进行 `tokenize`,并使用 `align_labels_with_tokens()` 函数处理所有标签。为了充分利用快速 tokenizer 的优势,最好是同时对大量文本一起进行 `tokenize`,所以我们需要编写一个处理一组示例的函数,并使用带有 `batched=True` 参数的 `Dataset.map()` 方法。与我们之前的示例唯一不同的是,当 `tokenizer` 的输入是文本列表(或示例中单词的列表的列表)时, `word_ids()` 函数需要根据列表的索引获取 `token` 的 ID,所以我们也在下面的函数中添加了这个功能:
```py
def tokenize_and_align_labels(examples):
@@ -285,9 +286,9 @@ def tokenize_and_align_labels(examples):
return tokenized_inputs
```
-请注意,我们还没有填充我们的输入;我们稍后会在使用数据整理器创建batch时这样做。
+注意,我们还没有填充我们的输入,我们将在稍后使用数据整理器创建 `batch` 时进行。
-我们现在可以一次性将所有预处理应用于数据集的其他部分:
+我们现在可以一次性使用预处理函数处理整个数据集:
```py
tokenized_datasets = raw_datasets.map(
@@ -297,28 +298,27 @@ tokenized_datasets = raw_datasets.map(
)
```
-我们已经完成了最难的部分!现在数据已经被预处理了,实际的训练看起来很像我们[第三章](/course/chapter3)做的.
+我们已经完成了最困难的部分!现在数据已经经过了预处理,实际的训练过程将会与我们在 [第三章](/course/chapter3) 所做的很相似。
{#if fw === 'pt'}
## 使用 Trainer API 微调模型 [[使用 Trainer API 微调模型]]
-使用 `Trainer` 的实际代码会和以前一样;唯一的变化是数据整理成时批处理的方式和度量计算函数。
+使用 `Trainer` 的代码会和以前一样,唯一的变化是数据如何整理成 `batch` 以及计算评估的分数。
{:else}
## 使用 Keras 微调模型 [[使用 Keras 微调模型]]
-使用Keras的实际代码将与之前非常相似;唯一的变化是将数据整理成批处理的方式和指标计算函数。
+使用 `Keras` 的代码将与之前非常相似;唯一的变化是数据如何整理成 `batch` 以及计算评估的分数。
{/if}
+### 整理数据 [[整理数据]]
-### 数据排序 [[数据排序]]
-
-我们不能像[第三章](/course/chapter3)那样只使用一个 `DataCollatorWithPadding `因为这只会填充输入(输入 ID、注意掩码和标记类型 ID)。在这里我们的标签应该以与输入完全相同的方式填充,以便它们保持长度相同,使用 `-100 ` ,这样在损失计算中就可以忽略相应的预测。
+我们不能像 [第三章](/course/chapter3) 那样直接使用 `DataCollatorWithPadding` ,因为那样只会填充输入(inputs ID、注意掩码和 tokens 类型 ID)。除了输入部分,在这里我们还需要对标签也使用与输入完全相同的方式填充,以保证它与输入的大小相同。我们将使用 `-100` 进行填充,以便在损失计算中忽略填充的内容。
-这一切都是由一个 [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification)完成.它是一个带有填充的数据整理器它需要 `tokenizer ` 用于预处理输入:
+以上的这些过程可以由 [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification) 实现。它是一个带有填充功能的数据整理器,使用时只需要传入用于预处理输入的 `tokenizer` :
{#if fw === 'pt'}
@@ -340,7 +340,7 @@ data_collator = DataCollatorForTokenClassification(
{/if}
-为了在几个样本上测试这一点,我们可以在训练集中的示例列表上调用它:
+为了在几个样本上测试这个数据整理器,我们可以先在训练集中的几个示例上调用它:
```py
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
@@ -352,7 +352,7 @@ tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
```
-让我们将其与数据集中第一个和第二个元素的标签进行比较:
+将数据整理器的结果与数据集中未经处理的第一个和第二个元素的标签进行比较。
```py
for i in range(2):
@@ -366,11 +366,11 @@ for i in range(2):
{#if fw === 'pt'}
-正如我们所看到的,第二组标签的长度已经使用 `-100` 填充到与第一组标签相同。
+正如我们所看到的,已经使用 `-100` 将第二组标签填充到了与第一组标签相同的长度。
{:else}
-我们的数据整理器已准备就绪! 现在让我们使用它通过 `to_tf_dataset()` 方法制作一个 `tf.data.Dataset`。 您还可以使用 model.prepare_tf_dataset() 来使用更少的样板代码来执行此操作——您将在本章的其他部分中看到这一点。
+我们的数据整理器已准备就绪!现在让我们使用 `to_tf_dataset()` 方法创建一个 `tf.data.Dataset` 。除此之外,你还可以使用 `model.prepare_tf_dataset()` 来使用更少的模板代码来创建 `Dataset`——你将在本章的其他小节中看到这样的操作。
```py
tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
@@ -387,25 +387,24 @@ tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
)
```
-
- Next stop: the model itself.
+下一站:模型本身。
{/if}
{#if fw === 'tf'}
-### 定义模型
+### 初始化模型
-由于我们正在研究Token分类问题,因此我们将使用 `AutoModelForTokenClassification` 类。定义这个模型时要记住的主要事情是传递一些关于我们的标签数量的信息。执行此操作的最简单方法是将该数字传递给 `num_labels` 参数,但是如果我们想要一个很好的推理小部件,就像我们在本节开头看到的那样,最好设置正确的标签对应关系。
+由于我们正在研究 Token 分类问题,因此我们将使用 `TFAutoModelForTokenClassification` 类。实例化此模型时要记得传递我们标签的数量,最简单方法是将该数字传递给 `num_labels` 参数,但是如果我们想要创建一个就像我们在本节开头看到的那样的推理小部件,那么就需要用最标准的方法正确设置标签的对应关系。
-它们应该由两个字典设置, `id2label` 和 `label2id` ,其中包含从 ID 到标签的映射,反之亦然:
+最标准的方法是用两个字典 `id2label` 和 `label2id` 来设置它们,这两个字典包含从 ID 到标签的映射以及反向的映射:
```py
id2label = {str(i): label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}
```
-现在我们可以将它们传递给 `AutoModelForTokenClassification.from_pretrained()` 方法,它们将在模型的配置中设置,然后保存并上传到Hub:
+现在我们只需将这两个字典传递给 `TFAutoModelForTokenClassification.from_pretrained()` 方法,它们就会被保存在模型的配置中,然后被正确地保存和上传到 Hub:
```py
from transformers import TFAutoModelForTokenClassification
@@ -417,7 +416,7 @@ model = TFAutoModelForTokenClassification.from_pretrained(
)
```
-就像我们在[第三章](/course/chapter3),定义我们的 `AutoModelForSequenceClassification` ,创建模型会发出警告,提示一些权重未被使用(来自预训练头的权重)和一些其他权重被随机初始化(来自新Token分类头的权重),我们将要训练这个模型。我们将在一分钟内完成,但首先让我们仔细检查我们的模型是否具有正确数量的标签:
+就像我们在 [第三章](/course/chapter3) 中实例化 `TFAutoModelForTokenClassification` 类一样 创建模型会发出一个警告,提示一些权重未被使用(来自预训练模型头部的权重)和一些其他权重被随机初始化(来自新 Token 分类头部的权重),别担心,我们马上就要训练这些权重。首先让我们确认一下我们的模型是否具有正确的标签数量:
```python
model.config.num_labels
@@ -429,13 +428,13 @@ model.config.num_labels
-⚠️ 如果您的模型标签数量错误,则在稍后调用 `model.fit()` 时将收到一个模糊的错误。调试起来可能很烦人,因此请确保执行此检查以确认您具有预期的标签数。
+⚠️ 如果你的模型的标签数量错误,那么在后面调用 `model.fit()` 时,你会得到一个晦涩的错误。这可能会令人烦恼,所以确保你做了这个检查,确认你的标签数量是正确的。
### 微调模型
-现在,我们已准备好训练模型了!不过,我们首先要做两件事:应该登录到Hugging Face并定义我们的训练超参数。如果你在notebook上工作,有一个便利功能可以帮助你做到这一点:
+现在,我们已准备好训练模型了!不过,我们在这之前还要做两件事:登录到 Hugging Face 并设置我们的训练超参数。如果你在 notebook 上工作,有一个便捷函数可以帮助你做到这一点:
```python
from huggingface_hub import notebook_login
@@ -443,26 +442,26 @@ from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件,您可以在其中输入您的 Hugging Face 账号和密码。
+这将显示一个小部件,你可以在其中输入你的 Hugging Face 账号和密码。
-如果您不是在notebook上工作,只需在终端中输入以下行:
+如果你不是在 notebook 上工作,只需在终端中输入以下代码:
```bash
huggingface-cli login
```
-登录后,我们可以准备编译模型所需的一切。🤗 Transformers提供了一个方便的`create_optimizer()` 函数,该函数将为您提供一个`AdamW`优化器,其中包含适当的权重衰减和学习速率衰减设置,与内置的`Adam`优化器相似,这两者都将提高模型的性能:
+登录后,我们可以编译我们模型所需要的所有配置。🤗 Transformers 提供了一个便捷的 `create_optimizer()` 函数,与 `TensorFlow` 内置的 `Adam` 优化器相比,它可以提供一个带有恰当的权重衰减和学习率衰减机制的 `AdamW` 优化器,不过这两个机制都将提高模型的性能:
```python
from transformers import create_optimizer
import tensorflow as tf
-# Train in mixed-precision float16
+# 在混合精度 float16 中进行训练
tf.keras.mixed_precision.set_global_policy("mixed_float16")
-# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
-# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
-# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+# 训练步数是数据集中的样本数量,除以 batch 大小,然后乘以总的 epoch 数。
+# 注意这里的 tf_train_dataset 是 batch 形式的 tf.data.Dataset,
+# 而不是原始的 Hugging Face Dataset ,所以使用 len() 计算它的长度已经是 num_samples // batch_size。
num_epochs = 3
num_train_steps = len(tf_train_dataset) * num_epochs
@@ -475,9 +474,9 @@ optimizer, schedule = create_optimizer(
model.compile(optimizer=optimizer)
```
-还要注意,我们不为`compile()`提供`loss`参数。这是因为模型实际上可以在内部计算损失 - 如果您编译时没有损失并在输入字典中提供标签(就像我们在数据集中所做的那样),那么模型将使用该内部损失进行训练,这将适用于您选择的任务和模型类型。
+请注意,我们没有给 `compile()` 提供 `loss` 参数。这是因为模型实际上可以使用默认的方式自动计算损失 —— 如果你在编译时没有提供损失的计算方法或在输入中提供真实的标签值(就像我们在数据集中所做的那样),那么模型将使用内部默认的 `loss` 计算方法进行训练,具体的计算方式取决于你选择的任务和模型类型。
-接下来,我们定义一个`PushToHubCallback`,以便在训练期间将模型上传到 Hub,并使用该回调来拟合模型:
+接下来,我们定义一个 `PushToHubCallback` 回调函数,以便在训练期间将模型上传到 Hub,并在拟合模型时添加该回调函数:
```python
from transformers.keras_callbacks import PushToHubCallback
@@ -492,44 +491,43 @@ model.fit(
)
```
-您之前已经看过其中的大部分内容:我们设置了一些超参数(例如学习率、要训练的 epoch 数和权重衰减),然后我们指定 `push_to_hub=True` 表明我们想要保存模型并在每个时期结束时对其进行评估,并且我们想要将我们的结果上传到模型中心。请注意,可以使用hub_model_id参数指定要推送到的存储库的名称(特别是,必须使用这个参数来推送到一个组织)。例如,当我们将模型推送到[`huggingface-course` organization](https://huggingface.co/huggingface-course), 我们添加了 `hub_model_id=huggingface-course/bert-finetuned-ner` 到 `TrainingArguments` .默认情况下,使用的存储库将在您的命名空间中并以您设置的输出目录命名,因此在我们的例子中它将是 `sgugger/bert-finetuned-ner` .
+你可以使用 `hub_model_id` 参数指定你想要推送的仓库的全名(特别需要注意的是,如果你需要推送给某个组织,就必须使用这个参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们添加了 `hub_model_id="huggingface-course/bert-finetuned-ner"` 。默认情况下,这个仓库将保存在你的账户之内,并以你设置的输出目录命名,例如 `"cool_huggingface_user/bert-finetuned-ner"` 。
-💡 如果您正在使用的输出目录已经存在,那么输出目录必须是从同一个存储库clone下来的。如果不是,您将在声明 `model.fit()` 时遇到错误,并且需要设置一个新名称。
+💡 如果设置了模型保存的路径,并且在那里已经存在了一个非空的同名文件夹,那么该目录应该是 Hub 仓库克隆在本地的版本,如果不是,则会在调用 model.fit() 方法时收到一个错误,并需要设置一个新的路径。
-请注意,当训练发生时,每次保存模型时(这里是每个epooch),它都会在后台上传到 Hub。这样,如有必要,您将能够在另一台机器上继续您的训练。
+请注意,在训练过程中每次保存模型时(这里是每个 epooch),它都会在后台上传到 Hub。这样,如有需要,你将能够在另一台机器上继续你的训练。
-在此阶段,您可以使用模型中心上的推理小组件来测试模型并与朋友共享。您已经成功微调了令牌分类任务的模型 - 恭喜!但是,我们的模型到底有多好呢?我们应该评估一些指标来找出答案。
+到此阶段,你可以在模型 Hub 上使用推理小部件来测试你的模型并与你的朋友分享。你已经成功地在一个 tokens 分类任务上微调了一个模型——恭喜你!但我们的模型真的好用吗?我们应该找出一些指标来对模型进评估。
{/if}
-
### 评估指标 [[评估指标]]
{#if fw === 'pt'}
-为了让 `Trainer` 在每个epoch计算一个度量,我们需要定义一个 `compute_metrics()` 函数,该函数接受预测和标签数组,并返回一个包含度量名称和值的字典
+要让 `Trainer` 在每个周期计算一个指标,我们需要定义一个 `compute_metrics()` 函数,该函数的输入是预测值和标签的数组,并返回带有指标名称和评估结果的字典。
-用于评估Token分类预测的传统框架是 [*seqeval*](https://github.com/chakki-works/seqeval). 要使用此指标,我们首先需要安装seqeval库:
+用于评估 Token 分类预测的经典框架是 [*seqeval*](https://github.com/chakki-works/seqeval) 。要使用此指标,我们首先需要安装 seqeval 库:
```py
!pip install seqeval
```
-然后我们可以通过加载它 `evaluate.load()` 函数就像我们在[第三章](/course/chapter3)做的那样:
+然后我们可以通过 `evaluate.load()` 函数加载它,就像我们在 [第三章](/course/chapter3) 中所做的那样:
{:else}
-用于评估Token分类预测的传统框架是 [*seqeval*](https://github.com/chakki-works/seqeval). 要使用此指标,我们首先需要安装seqeval库:
+用于评估 Token 分类预测的经典框架是 [*seqeval*](https://github.com/chakki-works/seqeval) 。要使用此指标,我们首先需要安装 seqeval 库:
```py
!pip install seqeval
```
-然后我们可以通过`evaluate.load()` 函数加载它就像我们在[第三章](/course/chapter3)做的那样:
+然后我们可以通过 `evaluate.load()` 函数加载它,就像我们在 [第三章](/course/chapter3) 中所做的那样:
{/if}
@@ -539,8 +537,9 @@ import evaluate
metric = evaluate.load("seqeval")
```
-这个评估方式与标准精度不同:它实际上将标签列表作为字符串,而不是整数,因此在将预测和标签传递给它之前,我们需要完全解码它们。让我们看看它是如何工作的。首先,我们将获得第一个训练示例的标签:
+该指标和常规的评测指标有些区别:它需要字符串形式的标签列表而不是整数,所以我们需要在将它们传递给指标之前将预测值和标签由数字解码为字符串。让我们先用一些测试数据看看它是如何工作的:
+首先,获取第一个训练样本的标签。
```py
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
@@ -551,7 +550,7 @@ labels
['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
```
-然后我们可以通过更改索引 2 处的值来为那些创建假的预测:
+然后我们可以通过更改索引 2 处的值来为这些标签创建假的预测值来测试该指标:
```py
predictions = labels.copy()
@@ -559,7 +558,7 @@ predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])
```
-请注意,该指标的输入是预测列表(不仅仅是一个)和标签列表。这是输出:
+请注意,该指标的输入是预测列表(不是一个)和标签列表,输出结果如下:
```python out
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
@@ -572,9 +571,7 @@ metric.compute(predictions=[predictions], references=[labels])
{#if fw === 'pt'}
-它返回很多信息!我们获得每个单独实体以及整体的准确率、召回率和 F1 分数。对于我们的度量计算,我们将只保留总分,但可以随意调整 `compute_metrics()` 函数返回您想要查看的所有指标。
-
-这`compute_metrics()` 函数首先采用 logits 的 argmax 将它们转换为预测(像往常一样,logits 和概率的顺序相同,因此我们不需要应用 softmax)。然后我们必须将标签和预测从整数转换为字符串。我们删除标签为 `-100` 所有值 ,然后将结果传递给 `metric.compute()` 方法:
+结果返回很多信息!包括每个单独实体及整体的准确率、召回率和 F1 分数。在这里我们将只保留总分,但是你可以自由地调整 `compute_metrics()` 函数返回的所需要指标。这个函数中我们首先会先取预测 `logits` 的 `argmax`,并将其转换为预测值。 `compute_metrics()` 函数首先取 `logits` 的 `argmax`,将它们转换为预测值(通常情况下,logits 和概率的顺序是相同,所以我们不需要使用 softmax)。然后我们需要将标签和预测值都从整数转换为字符串。我们删除所有标签为 `-100` 的值,最后将结果传递给 `metric.compute()` 方法:
```py
import numpy as np
@@ -584,7 +581,7 @@ def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
- # Remove ignored index (special tokens) and convert to labels
+ # 删除忽略的索引(特殊 tokens )并转换为标签
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
@@ -599,13 +596,13 @@ def compute_metrics(eval_preds):
}
```
-现在已经完成了,我们几乎准备好定义我们的 `Trainer` .我们只需要一个 `model` 微调!
+现在已经完成了,我们下面就可以开始定义我们的 `Trainer` 了。接下来我们只需要一个 `model` 并对其微调!
{:else}
-它返回很多信息!我们获得每个单独实体以及整体的准确率、召回率和 F1 分数。对于我们的度量计算,我们将只保留总分,但可以随意调整 `compute_metrics()` 函数返回您想要查看的所有指标。
+它返回了大量的信息!我们获得每个单独实体以及整体的准确率、召回率和 F1 分数。现在,让我们看看如果我们尝试使用真实的模型预测来计算分数。
-这`compute_metrics()` 函数首先采用 logits 的 argmax 将它们转换为预测(像往常一样,logits 和概率的顺序相同,因此我们不需要应用 softmax)。然后我们必须将标签和预测从整数转换为字符串。我们删除标签为 `-100` 所有值 ,然后将结果传递给 `metric.compute()` 方法:
+在使用基于TensorFlow 的框架时,我们通常不会把预测拼接在一起,因为这样会导致序列长度不统一。这意味着我们不能直接使用 `model.predict()` 方法 —— 但这并不能阻止我们。我们可以逐批获取一些预测并在在此的过程中将它们拼接成一个大的列表,删除表示 `masking/padding` 的 `-100` tokens 然后在合并后的大列表上计算度量值:
```py
import numpy as np
@@ -637,7 +634,7 @@ metric.compute(predictions=[all_predictions], references=[all_labels])
'overall_accuracy': 0.97}
```
-与我们的模型相比,您的模型做得如何?如果您获得类似的数字,那么您的训练就是成功的!
+与我们的模型相比,你的模型的表现如何?如果你看到类似的数字,那么你的训练就成功了!
{/if}
@@ -645,16 +642,16 @@ metric.compute(predictions=[all_predictions], references=[all_labels])
### 定义模型
-由于我们正在研究Token分类问题,因此我们将使用 `AutoModelForTokenClassification` 类。定义这个模型时要记住的主要事情是传递一些关于我们的标签数量的信息。执行此操作的最简单方法是将该数字传递给 `num_labels` 参数,但是如果我们想要一个很好的推理小部件,就像我们在本节开头看到的那样,最好设置正确的标签对应关系。
+由于我们正在研究 Token 分类问题,因此我们将使用 `AutoModelForTokenClassification` 类。定义此模型时要记得传递我们标签的数量,最简单方法是将该数字传递给 `num_labels` 参数,但是如果我们想要一个就像我们在本节开头看到的那样的推理小部件,就需要用最标准的方法正确设置标签的对应关系。
-它们应该由两个字典设置, `id2label` 和 `label2id` ,其中包含从 ID 到标签的映射,反之亦然:
+最标准的方式是用两个字典 `id2label` 和 `label2id` 来设置标签,这两个字典包含从 ID 到标签的映射以及反向的映射:
```py
id2label = {str(i): label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}
```
-现在我们可以将它们传递给 `AutoModelForTokenClassification.from_pretrained()` 方法,它们将在模型的配置中设置,然后保存并上传到Hub:
+现在我们只需将它们传递给 `AutoModelForTokenClassification.from_pretrained()` 方法,它们就会被保存在模型的配置中,然后被正确地保存和上传到 Hub:
```py
from transformers import AutoModelForTokenClassification
@@ -666,7 +663,7 @@ model = AutoModelForTokenClassification.from_pretrained(
)
```
-就像我们在[第三章](/course/chapter3),定义我们的 `AutoModelForSequenceClassification` ,创建模型会发出警告,提示一些权重未被使用(来自预训练头的权重)和一些其他权重被随机初始化(来自新Token分类头的权重),我们将要训练这个模型。我们将在一分钟内完成,但首先让我们仔细检查我们的模型是否具有正确数量的标签:
+就像我们在 [第三章](/course/chapter3) 中定义 `AutoModelForSequenceClassification` 类一样 创建模型会发出一个警告,提示一些权重未被使用(来自预训练头部的权重)和一些其他权重被随机初始化(来自新 Token 分类头部的权重),不过不用担心,我们马上就要训练这些权重。在这之前,让我们先确认一下我们的模型是否具有正确的标签数量:
```python
model.config.num_labels
@@ -678,26 +675,21 @@ model.config.num_labels
-⚠️ 如果模型的标签数量错误,稍后调用Trainer.train()方法时会出现一个模糊的错误(类似于“CUDA error: device-side assert triggered”)。这是用户报告此类错误的第一个原因,因此请确保进行这样的检查以确认您拥有预期数量的标签。
+⚠️ 如果你的模型的标签数量有错误,那么在后面调用 `Trainer.train()` 时,你会得到一个晦涩的错误(类似于“CUDA error:device-side assert triggered”)。这可能会令人烦恼,所以确保你做了这个检查,确认你的标签数量是正确。
### 微调模型
-我们现在准备好训练我们的模型了!在定义我们的 `Trainer`之前,我们只需要做最后两件事:登录 Hugging Face 并定义我们的训练参数。如果您在notebook上工作,有一个方便的功能可以帮助您:
+我们现在准备好训练我们的模型了!在定义 `Trainer` 之前,我们只需要做最后两件事:登录 Hugging Face 并设置我们的训练参数。如果你在 notebook 上工作,有一个方便的小工具可以帮助你:
```python
from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件,您可以在其中输入您的 Hugging Face 账号和密码。如果您不是在notebook上工作,只需在终端中输入以下行:
-```bash
-huggingface-cli login
-```
-
-Once this is done, we can define our `TrainingArguments`:
+登录后,我们就可以设置我们的 `TrainingArguments` :
```python
from transformers import TrainingArguments
@@ -713,15 +705,15 @@ args = TrainingArguments(
)
```
-您之前已经看过其中的大部分内容:我们设置了一些超参数(例如学习率、要训练的 epoch 数和权重衰减),然后我们指定 `push_to_hub=True` 表明我们想要保存模型并在每个时期结束时对其进行评估,并且我们想要将我们的结果上传到模型中心。请注意,可以使用hub_model_id参数指定要推送到的存储库的名称(特别是,必须使用这个参数来推送到一个组织)。例如,当我们将模型推送到[`huggingface-course` organization](https://huggingface.co/huggingface-course), 我们添加了 `hub_model_id=huggingface-course/bert-finetuned-ner` 到 `TrainingArguments` 。默认情况下,使用的存储库将在您的命名空间中并以您设置的输出目录命名,因此在我们的例子中它将是 `sgugger/bert-finetuned-ner`。
+你已经对大多数内容有所了解了:我们设置了一些超参数(如学习率、训练的轮数和权重衰减),并设定 `push_to_hub=True` ,表示我们希望在每个训练轮次结束时保存并评估模型,然后将结果上传到模型中心。注意,你可以通过 `hub_model_id` 参数指定你想推送的仓库的名称(特别需要注意的是,如果你需要推送给某个组织,就必须使用这个参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们在 `TrainingArguments` 中添加了 `hub_model_id="huggingface-course/bert-finetuned-ner"` 。默认情况下,使用的仓库将保存在你的账户之内,并以你设置的输出目录命名,所以在我们的例子中,仓库的地址是 `"sgugger/bert-finetuned-ner"` 。
-💡 如果您正在使用的输出目录已经存在,那么输出目录必须是从同一个存储库clone下来的。如果不是,您将在声明 `Trainer` 时遇到错误,并且需要设置一个新名称。
+💡 如果你使用的输出路径已经存在一个同名的文件夹,那么它需要是你想推送到 hub 的仓库的克隆在本地的版本。如果不是,你将在声明 `Trainer` 时遇到一个错误,并需要设置一个新的路径。
-最后,我们只是将所有内容传递给 `Trainer` 并启动训练:
+最后,我们将所有内容传递给 `Trainer` 并启动训练:
```python
from transformers import Trainer
@@ -738,30 +730,31 @@ trainer = Trainer(
trainer.train()
```
-请注意,当训练发生时,每次保存模型时(这里是每个epooch),它都会在后台上传到 Hub。这样,如有必要,您将能够在另一台机器上继续您的训练。
+请注意,在训练过程中每次保存模型时(这里是每个 epooch),它都会在后台上传到 Hub。这样,如有必要,你将能够在另一台机器上继续你的训练。
-训练完成后,我们使用 `push_to_hub()` 确保我们上传模型的最新版本
+训练完成后,我们使用 `push_to_hub()` 上传模型的最新版本
```py
trainer.push_to_hub(commit_message="Training complete")
```
-This command returns the URL of the commit it just did, if you want to inspect it:
+如果你想检查一下是否上传成功,这个命令会返回刚刚执行的提交的 URL:
```python out
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
```
-这 `Trainer` 还创建了一张包含所有评估结果的模型卡并上传。在此阶段,您可以使用模型中心上的推理小部件来测试您的模型并与您的朋友分享。您已成功在Token分类任务上微调模型 - 恭喜!
+同时 `Trainer` 还创建并上传了一张包含所有评估结果的模型卡。到此阶段,你可以在模型 Hub 上使用推理小部件来测试你的模型并与你的朋友分享。你已经成功地在一个 tokens 分类任务上微调了一个模型——恭喜你!
-如果您想更深入地了解训练循环,我们现在将向您展示如何使用 🤗 Accelerate 做同样的事情。
+如果你想更深入地了解训练循环,我们现在将向你展示如何使用 🤗 Accelerate 做同样的事情。
## 自定义训练循环 [[自定义训练循环]]
-现在让我们看一下完整的训练循环,这样您可以轻松定义所需的部分。它看起来很像我们在[第三章](/course/chapter3/4), 所做的,对评估进行了一些更改。
+现在我们来看看完整的训练循环,这样你就可以轻松地定制你需要的部分。它与我们在 [第三章](/course/chapter3/4) 中所做的内容很相似,但对评估部分有一些改动。
### 做好训练前的准备 [[做好训练前的准备]]
-首先我们需要为我们的数据集构建 `DataLoader` 。我们将重用我们的 `data_collator` 作为一个 `collate_fn` 并打乱训练集,但不打乱验证集:
+
+首先我们需要为我们的数据集构建 `DataLoader` 。我们将 `data_collator` 传递给 `collate_fn` 参数并随机打乱训练集,但不打乱验证集:
```py
from torch.utils.data import DataLoader
@@ -777,7 +770,7 @@ eval_dataloader = DataLoader(
)
```
-接下来,我们重新实例化我们的模型,以确保我们不会从之前的训练继续训练,而是再次从 BERT 预训练模型开始:
+接下来我们重新实例化我们的模型,以确保我们不是继续之前的微调,而是重新开始从 BERT 微调预训练模型:
```py
model = AutoModelForTokenClassification.from_pretrained(
@@ -787,14 +780,15 @@ model = AutoModelForTokenClassification.from_pretrained(
)
```
-然后我们将需要一个优化器。我们将使用经典 `AdamW` ,这就像 `Adam` ,但在应用权重衰减的方式上进行了改进:
+然后我们需要一个优化器。我们将使用经典 `AdamW` ,它类似于 `Adam` ,但在权重衰减的方式上进行了改进:
+
```py
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
```
-Once we have all those objects, we can send them to the `accelerator.prepare()` method:
+当我们拥有了所有这些对象之后,我们就可以将它们发传递给 `accelerator.prepare()` 方法:
```py
from accelerate import Accelerator
@@ -807,11 +801,11 @@ model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
-🚨 如果您在 TPU 上进行训练,则需要将以上单元格中的所有代码移动到专用的训练函数中。有关详细信息,请参阅 [第3章](/course/chapter3)。
+🚨 如果你正在 TPU 上训练,你需要将上面单元格开始的所有代码移动到一个专门的训练函数中。更多详情请回顾 [第三章](/course/chapter3) 。
-现在我们已经发送了我们的 `train_dataloader` 到 `accelerator.prepare()` ,我们可以使用它的长度来计算训练步骤的数量。请记住,我们应该始终在准备好dataloader后执行此操作,因为该方法会改变其长度。我们使用经典线性学习率调度:
+现在我们已经将我们的 `train_dataloader` 传递给了 `accelerator.prepare()` 方法,我们还可以使用 `len()` 来计算训练步骤的数量。请记住,我们应该在准备好 `dataloader` 后再使用 `len()` ,因为改动 `dataloader` 会改变训练长度的数量。这里我们将使用一个从学习率衰减到 0 的经典线性学习率调度:
```py
from transformers import get_scheduler
@@ -828,7 +822,7 @@ lr_scheduler = get_scheduler(
)
```
-最后,要将我们的模型推送到 Hub,我们需要创建一个 `Repository` 工作文件夹中的对象。如果您尚未登录,请先登录 Hugging Face。我们将从我们想要为模型提供的模型 ID 中确定存储库名称(您可以自由地用自己的选择替换 `repo_name` ;它只需要包含您的用户名,可以使用`get_full_repo_name()`函数的查看目前的repo_name):
+最后,为了将我们的模型推送到 Hub,我们需要在一个工作文件夹中创建一个 `Repository` 对象。如果你还没有登录的话,首先需要登录到 Hugging Face,然后根据模型 ID 来确定仓库名称(你可以将 `repo_name` 替换为你喜欢的名字;只需要包含你的用户名即可,你可以使用 `get_full_repo_name()` 函数的查看目前的 `repo_name` ):
```py
from huggingface_hub import Repository, get_full_repo_name
@@ -842,24 +836,25 @@ repo_name
'sgugger/bert-finetuned-ner-accelerate'
```
-然后我们可以将该存储库克隆到本地文件夹中。 如果它已经存在,这个本地文件夹应该是我们正在使用的存储库的现有克隆:
+然后我们可以将该仓库克隆到本地文件夹中。如果本地已经存在同名的文件夹,这个本地文件夹必须是我们正在使用的仓库克隆在本地的版本:
```py
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
```
-我们现在可以通过调用 `repo.push_to_hub()` 方法上传保存在 `output_dir` 中的任何内容。 这将帮助我们在每个训练周期结束时上传中间模型。
+我们现在可以通过调用 `repo.push_to_hub()` 方法上传保存在 `output_dir` 中的所有内容。它帮助我们在每个训练周期结束时上传中间模型。
### 训练循环 [[训练循环]]
-我们现在准备编写完整的训练循环。为了简化它的评估部分,我们定义了这个 `postprocess()` 接受预测和标签并将它们转换为字符串列表的函数,也就是 `metric`对象需要的输入格式:
+
+我们现在准备编写完整的训练循环。为了简化其评估部分,我们定义了一个 `postprocess()` 函数,该函数会接收模型的预测和真实的标签,并将它们转换为字符串列表,也就是我们的 `metric` (评估函数)对象需要的输入格式。
```py
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
- # Remove ignored index (special tokens) and convert to labels
+ # 删除忽略的索引(特殊 tokens )并转换为标签
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
@@ -868,13 +863,13 @@ def postprocess(predictions, labels):
return true_labels, true_predictions
```
-然后我们可以编写训练循环。在定义一个进度条来跟踪训练的进行后,循环分为三个部分:
+然后我们可以编写训练循环。在定义一个进度条来跟踪训练的进度后,循环分为三个部分:
-- 训练本身,这是对`train_dataloader`的经典迭代,向前传递模型,然后反向传递和优化参数
-- 评估,在获得我们模型的输出后:因为两个进程可能将输入和标签填充成不同的形状,在调用`gather()`方法前我们需要使用`accelerator.pad_across_processes()`来让预测和标签形状相同。如果我们不这样做,评估要么出错,要么永远不会得到结果。然后,我们将结果发送给`metric.add_batch()`,并在计算循环结束后调用`metric.compute()`。
-- 保存和上传,首先保存模型和标记器,然后调用`repo.push_to_hub()`。注意,我们使用参数`blocking=False`告诉🤗 hub 库用在异步进程中推送。这样,训练将正常继续,并且该(长)指令将在后台执行。
+- 训练本身,这是经典的迭代过程,即在 `train_dataloader` 上进行迭代,在模型上前向传播训练数据,然后反向传递 `loss` 和优化参数
+- 评估,在获取模型在一个 `batch` 上的输出之后,这里有一个需要注意的地方:由于两个进程可能已将输入和标签填充到不同的形状,我们需要使用 `accelerator.pad_across_processes()` 使预测和真实的标签在调用 `gather()` 方法之前具有相同的形状。如果我们不这样做,评估循环将会出错或无限期卡住。最后我们将结果发送到 `metric.add_batch()` 方法中,并在评估循环结束时调用 `metric.compute()` 方法。
+- 保存和上传,首先保存模型和 `tokenizer` 然后调用 `repo.push_to_hub()` 方法。注意,我们使用参数 `blocking=False` 来告诉 🤗 `Hub` 库在一个异步进程中推送。这样,在训练时,这个指令在后台将模型和 `tokenizer` 推送到 `hub`。
-这是训练循环的完整代码:
+以下是完整的训练循环代码:
```py
from tqdm.auto import tqdm
@@ -883,7 +878,7 @@ import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
- # Training
+ # 训练
model.train()
for batch in train_dataloader:
outputs = model(**batch)
@@ -895,7 +890,7 @@ for epoch in range(num_train_epochs):
optimizer.zero_grad()
progress_bar.update(1)
- # Evaluation
+ # 评估
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
@@ -904,7 +899,7 @@ for epoch in range(num_train_epochs):
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
- # Necessary to pad predictions and labels for being gathered
+ # 填充模型的预测和标签后才能调用 gathere()
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
@@ -923,7 +918,7 @@ for epoch in range(num_train_epochs):
},
)
- # Save and upload
+ # 保存并上传
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
@@ -934,7 +929,7 @@ for epoch in range(num_train_epochs):
)
```
-果这是您第一次看到用 🤗 Accelerate 保存的模型,让我们花点时间检查一下它附带的三行代码:
+如果这是你第一次看到使用 🤗 Accelerate 保存模型,让我们花点时间来了解一下这个过程中的三行代码:
```py
accelerator.wait_for_everyone()
@@ -942,21 +937,22 @@ unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
```
-第一行是不言自明的:它告诉所有进程等到都处于那个阶段再继续(阻塞)。这是为了确保在保存之前,我们在每个过程中都有相同的模型。然后获取`unwrapped_model`,它是我们定义的基本模型。
-`accelerator.prepare()`方法将模型更改为在分布式训练中工作,所以它不再有`save_pretraining()`方法;`accelerator.unwrap_model()`方法将撤销该步骤。最后,我们调用`save_pretraining()`,但告诉该方法使用`accelerator.save()`而不是`torch.save()`。
+第一行是不言自明的:它告诉所有的进程先等待,直到所有的进程都处于这个阶段再继续(阻塞)。这是为了确保在保存之前,我们在每个进程中都有相同的模型。
+第二行代码用于获取 `unwrapped_model` ,它就是我们定义的基本模型。 `accelerator.prepare()` 方法会为了在分布式训练中工作而对模型进行了一些修改,所以它不再有 `save_pretraining()` 方法;使用 `accelerator.unwrap_model()` 方法可以撤销对模型的更改。
+在第三行代码中,我们调用 `save_pretraining()` ,并指定 `accelerator.save()` 作为 `save_function` 而不是默认的 `torch.save()` 。
-当完成之后,你应该有一个模型,它产生的结果与`Trainer`的结果非常相似。你可以在[hugs face-course/bert-fine - tuning -ner-accelerate](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate)中查看我们使用这个代码训练的模型。如果你想测试训练循环的任何调整,你可以直接通过编辑上面显示的代码来实现它们!
+完成这些操作后,你应该拥有一个与 `Trainer` 训练出的模型结果相当类似的模型。你可以在 [huggingface-course/bert-finetuned-ner-accelerate](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate) 查看我们使用这些代码训练的模型。如果你想在训练循环中测试任何调整,你可以直接通过编辑上面显示的代码来实现它们!
{/if}
## 使用微调模型 [[使用微调模型]]
-我们已经向您展示了如何使用我们在模型中心微调的模型和推理小部件。在本地使用它 `pipeline` ,您只需要指定正确的模型标识符:
+我们已经向你展示了如何使用在模型中心微调的模型和推理小部件。在本地使用 `pipeline` 来使用它非常容易,你只需要指定正确的模型标签:
```py
from transformers import pipeline
-# Replace this with your own checkpoint
+# 将此替换为你自己的 checkpoint
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
diff --git a/chapters/zh-CN/chapter7/3.mdx b/chapters/zh-CN/chapter7/3.mdx
index 4b4c8232e..32cc5d563 100644
--- a/chapters/zh-CN/chapter7/3.mdx
+++ b/chapters/zh-CN/chapter7/3.mdx
@@ -1,6 +1,6 @@
-# 微调掩码语言模型 [[微调掩码语言模型]]
+# 微调掩码语言模型(masked language model) [[微调掩码语言模型(masked language model)]]
{#if fw === 'pt'}
@@ -22,45 +22,43 @@
{/if}
-对于许多涉及 Transformer 模型的 NLP 程序, 你可以简单地从 Hugging Face Hub 中获取一个预训练的模型, 然后直接在你的数据上对其进行微调, 以完成手头的任务。只要用于预训练的语料库与用于微调的语料库没有太大区别, 迁移学习通常会产生很好的结果。
+对于许多涉及 Transformer 模型的 NLP 任务,你可以简单地从 Hugging Face Hub 中获取一个预训练的模型,然后直接在你的数据上对其进行微调,以完成手头的任务。只要用于预训练的语料库与用于微调的语料库没有太大区别,迁移学习通常会产生很好的结果。
-但是, 在某些情况下, 你需要先微调数据上的语言模型, 然后再训练特定于任务的head。例如, 如果您的数据集包含法律合同或科学文章, 像 BERT 这样的普通 Transformer 模型通常会将您语料库中的特定领域词视为稀有标记, 结果性能可能不尽如人意。通过在域内数据上微调语言模型, 你可以提高许多下游任务的性能, 这意味着您通常只需执行一次此步骤!
+但是,在某些情况下,你可能需要先在你的数据上微调语言模型,然后再训练特定于任务的 head。例如,如果你的数据集包含法律合同或科学文章,像 BERT 这样的普通 Transformer 模型通常会将你语料库中的特定领域词视为稀有 tokens ,导致性能可能不尽如人意。通过在特定领域内数据上微调语言模型,你可以提高许多下游任务的性能,这意味着你通常只需执行一次此步骤!
-这种在域内数据上微调预训练语言模型的过程通常称为 _领域适应_。 它于 2018 年由 [ULMFiT](https://arxiv.org/abs/1801.06146)推广, 这是使迁移学习真正适用于 NLP 的首批神经架构之一 (基于 LSTM)。 下图显示了使用 ULMFiT 进行域自适应的示例; 在本节中, 我们将做类似的事情, 但使用的是 Transformer 而不是 LSTM!
+这种在特定领域内数据上微调预训练语言模型的过程通常称为 `领域适应(domain adaptation)` 。它于 2018 年由 [ULMFiT](https://arxiv.org/abs/1801.06146) 推广, NLP 的首批神经架构之一 (基于 LSTM)。下图显示了使用 ULMFiT这是使迁移学习真正适用于 进行领域自适应的示例;在本节中,我们将做类似的事情,但我们将使用 Transformer 而不是 LSTM!
-在本节结束时, 你将在Hub上拥有一个[掩码语言模型(masked language model)](https://huggingface.co/huggingface-course/distilbert-base-uncased-finetuned-imdb?text=This+is+a+great+%5BMASK%5D.), 该模型可以自动完成句子, 如下所示:
+在本节结束时,你将在 Hub 上拥有一个 [掩码语言模型(masked language model)](https://huggingface.co/huggingface-course/distilbert-base-uncased-finetuned-imdb?text=This+is+a+great+%5BMASK%5D.) ,该模型可以自动补全句子,如下所示:
-
+
-让我们开始吧!
+让我们开始吧!
-🙋 如果您对“掩码语言建模”和“预训练模型”这两个术语感到陌生, 请查看[第一章](/course/chapter1), 我们在其中解释了所有这些核心概念, 并附有视频!
+🙋 如果你对“掩码语言建模”和“预训练模型”这两个术语感到陌生,请回顾 [第一章](/course/chapter1) ,我们在其中解释了所有这些核心概念,并附有视频!
## 选择用于掩码语言建模的预训练模型 [[选择用于掩码语言建模的预训练模型]]
-首先, 让我们为掩码语言建模选择一个合适的预训练模型。如以下屏幕截图所示, 你可以通过在[Hugging Face Hub](https://huggingface.co/models?pipeline_tag=fill-mask&sort=downloads)上应用"Fill-Mask"过滤器找到:
+首先,让我们为掩码语言建模选择一个合适的预训练模型。如以下屏幕截图所示,你可以通过在 [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=fill-mask&sort=downloads) 上选择“Fill-Mask”过滤器:
-
-尽管 BERT 和 RoBERTa 系列模型的下载量最大, 但我们将使用名为 [DistilBERT](https://huggingface.co/distilbert-base-uncased)的模型。
-可以更快地训练, 而下游性能几乎没有损失。这个模型使用一种称为[_知识蒸馏_](https://en.wikipedia.org/wiki/Knowledge_distillation)的特殊技术进行训练, 其中使用像 BERT 这样的大型“教师模型”来指导参数少得多的“学生模型”的训练。在本节中对知识蒸馏细节的解释会使我们离题太远, 但如果你有兴趣, 可以阅读所有相关内容 [_Natural Language Processing with Transformers_](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) (俗称Transformers教科书)。
+尽管 BERT 和 RoBERTa 系列模型的下载量最大,但我们将使用名为 [DistilBERT](https://huggingface.co/distilbert-base-uncased) 的模型。它可以更快地训练,而且对下游性能几乎没有损失。它使用了一种称为 [`知识蒸馏(knowledge distillation)`](https://en.wikipedia.org/wiki/Knowledge_distillation) 的特殊技术进行训练,其中使用像 BERT 这样的大型“教师模型”来指导参数少得多的“学生模型”的训练。在本节中对知识蒸馏进行详细解释会使我们偏离本节主题太远,但如果你有兴趣,可以阅读 [`使用 Transformers 进行自然语言处理(Natural Language Processing with Transformers)`](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) (俗称 Transformers 教科书)中知识蒸馏的相关内容。
{#if fw === 'pt'}
-让我们继续, 使用 `AutoModelForMaskedLM` 类下载 DistilBERT:
+让我们继续,我们可以使用 `AutoModelForMaskedLM` 类下载 DistilBERT:
```python
from transformers import AutoModelForMaskedLM
@@ -69,7 +67,7 @@ model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
```
-我们可以通过调用 `num_parameters()` 方法查看模型有多少参数:
+然后,我们可以通过调用 `num_parameters()` 方法查看模型有多少参数:
```python
distilbert_num_parameters = model.num_parameters() / 1_000_000
@@ -84,7 +82,7 @@ print(f"'>>> BERT number of parameters: 110M'")
{:else}
-让我们继续, 使用 `AutoModelForMaskedLM` 类下载 DistilBERT:
+让我们继续,我们可以使用 `TFAutoModelForMaskedLM` 类下载 DistilBERT:
```python
from transformers import TFAutoModelForMaskedLM
@@ -93,25 +91,29 @@ model_checkpoint = "distilbert-base-uncased"
model = TFAutoModelForMaskedLM.from_pretrained(model_checkpoint)
```
-我们可以通过调用 `summary()` 方法查看模型有多少参数:
+然后,我们可以通过调用 `summary()` 方法查看模型有多少参数:
```python
-model(model.dummy_inputs) # Build the model
+model(model.dummy_inputs) # 构建模型
model.summary()
```
```python out
Model: "tf_distil_bert_for_masked_lm"
_________________________________________________________________
-Layer (type) Output Shape Param #
+ Layer (type) Output Shape Param #
=================================================================
-distilbert (TFDistilBertMain multiple 66362880
-_________________________________________________________________
-vocab_transform (Dense) multiple 590592
-_________________________________________________________________
-vocab_layer_norm (LayerNorma multiple 1536
-_________________________________________________________________
-vocab_projector (TFDistilBer multiple 23866170
+ distilbert (TFDistilBertMai multiple 66362880
+ nLayer)
+
+ vocab_transform (Dense) multiple 590592
+
+ vocab_layer_norm (LayerNorm multiple 1536
+ alization)
+
+ vocab_projector (TFDistilBe multiple 23866170
+ rtLMHead)
+
=================================================================
Total params: 66,985,530
Trainable params: 66,985,530
@@ -121,13 +123,13 @@ _________________________________________________________________
{/if}
-DistilBERT 大约有 6700 万个参数, 大约比 BERT 基本模型小两倍, 这大致意味着训练的速度提高了两倍 -- 非常棒! 现在让我们看看这个模型预测什么样的标记最有可能完成一小部分文本:
+DistilBERT 大约有 6700 万个参数,大约只有 BERT base 模型的二分之一,这大致意味着训练的速度可以提高两倍 —— 非常棒!现在让我们看看对于下面的一小部分文本,这个模型最有可能预测什么:
```python
text = "This is a great [MASK]."
```
-作为人类, 我们可以想象 `[MASK]` 标记有很多可能性, 例如 "day"、 "ride" 或者 "painting"。对于预训练模型, 预测取决于模型所训练的语料库, 因为它会学习获取数据中存在的统计模式。与 BERT 一样, DistilBERT 在[English Wikipedia](https://huggingface.co/datasets/wikipedia) 和 [BookCorpus](https://huggingface.co/datasets/bookcorpus) 数据集上进行预训练, 所以我们期望对 `[MASK]` 的预测能够反映这些领域。为了预测掩码, 我们需要 DistilBERT 的标记器来生成模型的输入, 所以让我们也从 Hub 下载它:
+作为人类,我们可以想象 `[MASK]` token 有很多可能性,例如 “day”、“ride” 或者 “painting”。对于预训练模型,预测取决于模型所训练的语料库,因为它会学习获取数据中存在的语料统计分布。与 BERT 一样,DistilBERT 在 [English Wikipedia](https://huggingface.co/datasets/wikipedia) 和 [BookCorpus](https://huggingface.co/datasets/bookcorpus) 数据集上进行预训练,所以我们猜想模型对 `[MASK]` 的预测能够反映这些领域。为了预测 `[MASK]` ,我们需要 DistilBERT 的 tokenizer 来处理输入,所以让我们也从 Hub 下载它:
```python
from transformers import AutoTokenizer
@@ -135,7 +137,7 @@ from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
```
-使用标记器和模型, 我们现在可以将我们的文本示例传递给模型, 提取 logits, 并打印出前 5 个候选:
+有了 tokenizer 和模型,我们现在可以将我们的示例文本传递给模型,提取 logits,并打印出前 5 个候选词:
{#if fw === 'pt'}
@@ -144,10 +146,10 @@ import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
-# Find the location of [MASK] and extract its logits
+# 找到 [MASK] 的位置并提取其 logits
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
-# Pick the [MASK] candidates with the highest logits
+# 选择具有最高 logits 的 [MASK] 候选词
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
@@ -162,11 +164,11 @@ import tensorflow as tf
inputs = tokenizer(text, return_tensors="np")
token_logits = model(**inputs).logits
-# Find the location of [MASK] and extract its logits
+# 找到 [MASK] 的位置并提取其 logits
mask_token_index = np.argwhere(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
mask_token_logits = token_logits[0, mask_token_index, :]
-# Pick the [MASK] candidates with the highest logits
-# We negate the array before argsort to get the largest, not the smallest, logits
+# 选择具有最高 logits 的 [MASK] 候选词
+# 通过在 argsort 前对数组取负,来得到最大的 logits
top_5_tokens = np.argsort(-mask_token_logits)[:5].tolist()
for token in top_5_tokens:
@@ -183,12 +185,13 @@ for token in top_5_tokens:
'>>> This is a great feat.'
```
-我们可以从输出中看到模型的预测是指日常用语, 鉴于英语维基百科的基础, 这也许并不奇怪。让我们看看我们如何将这个领域改变为更小众的东西 -- 高度两极分化的电影评论!
-
+我们可以从输出中看到,模型的预测的是日常术语,虑到模型训练的语料数据主要来源于维基百科,这并不奇怪。现在让我们看看如何将这个领域改变成稍微更加独特——高度两极分化的电影评论!
## 数据集 [[数据集]]
-为了展示域适配, 我们将使用著名的[大型电影评论数据集(Large Movie Review Dataset)](https://huggingface.co/datasets/imdb) (或者简称为IMDb), 这是一个电影评论语料库, 通常用于对情感分析模型进行基准测试。通过在这个语料库上对 DistilBERT 进行微调, 我们预计语言模型将根据维基百科的事实数据调整其词汇表, 这些数据已经预先训练到电影评论中更主观的元素。我们可以使用🤗 Datasets中的`load_dataset()`函数从Hugging Face 中获取数据:
+为了展示领域适应性,我们将使用来自IMDB的 [大型电影评论数据集(Large Movie Review Dataset)](https://huggingface.co/datasets/imdb),这是一个电影评论语料库,通常用于对情感分析模型进行基准测试。通过在这个语料库上对 DistilBERT 进行微调,我们期望语言模型会从其预训练的维基百科的事实性数据,适应到更主观的电影评论的领域。
+
+首先,我们可以使用🤗 Datasets 中的 `load_dataset()` 函数从 Hugging Face 中获取数据:
```python
from datasets import load_dataset
@@ -214,7 +217,7 @@ DatasetDict({
})
```
-我们可以看到 `train` 和 `test` 每个拆分包含 25,000 条评论, 而有一个未标记的拆分称为 `unsupervised` 包含 50,000 条评论。让我们看一些示例, 以了解我们正在处理的文本类型。正如我们在本课程的前几章中所做的那样, 我们将链接 `Dataset.shuffle()` 和 `Dataset.select()` 函数创建随机样本:
+我们可以看到 `train` 和 `test` 分别包含了 25,000 条评论,还有一个没有的标签的 `unsupervised(无监督)` 部分包含 50,000 条评论。接下来让我们从里面取一些样本,来了解一下我们正在处理的文本的特点。正如我们在本课程的前几章中所做的那样,我们将把 `Dataset.shuffle()` 函数链接到 `Dataset.select()` 函数创建随机样本:
```python
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
@@ -236,23 +239,23 @@ for row in sample:
'>>> Label: 1'
```
-是的, 这些肯定是电影评论, 如果你年龄足够,你甚至可能会理解上次评论中关于拥有 VHS 版本的评论😜! 虽然我们不需要语言建模的标签, 但我们已经可以看到 `0` 表示负面评论, 而 `1` 对应正面。
+是的,这些肯定是电影评论,如果你年龄足够大,你甚至可能会理解上述评论中关于拥有 VHS (一种古老的盒式摄像机格式)版本的评论😜!虽然语言模型不需要预先标注好的标签,但我们已经可以看到数据集其实包含了标签, `0` 代表负面评论, `1` 代表正面评论。
-✏️ **试试看!** 创建 `无监督` 拆分的随机样本, 并验证标签既不是 `0` 也不是 `1`。在此过程中, 你还可以检查 `train` 和 `test` 拆分中的标签是否确实为 `0` 或 `1` -- 这是每个 NLP 从业者在新项目开始时都应该执行的有用的健全性检查!
+✏️ **试一试!** 创建一个 `unsupervised` 部分的随机样本,并验证其标签既不是 `0` 也不是 `1` 。或者,你也可以检查 `train` 和 `test` 部分的标签确实是 `0` 或 `1` —— 每个 NLP 实践者在开始新项目时都应该对数据标注进行的有用的、合理的检查!
-现在我们已经快速浏览了数据, 让我们深入研究为掩码语言建模做准备。正如我们将看到的, 与我们在[第三章](/course/chapter3)中看到的序列分类任务相比, 还需要采取一些额外的步骤。让我们继续!
+现在我们已经快速浏览了一下数据,接下来我们要深入准备这些数据以供进行掩码语言建模。如我们所见,与我们在 [第三章](https://chat.openai.com/course/chapter3) 看到的序列分类任务相比,这里需要采取一些额外的步骤。让我们开始吧!
## 预处理数据 [[预处理数据]]
-对于自回归和掩码语言建模, 一个常见的预处理步骤是连接所有示例, 然后将整个语料库拆分为相同大小的块。 这与我们通常的方法完全不同, 我们只是简单地标记单个示例。为什么要将所有内容连接在一起? 原因是单个示例如果太长可能会被截断, 这将导致丢失可能对语言建模任务有用的信息!
+对于自回归和掩码语言建模,常见的预处理步骤是将所有的文本拼接起来,然后再将整个语料库切割为相同大小的块。这与我们之前的做法有很大的不同,我们之前只是对单个的示例进行 tokenize。为什么要将所有的示例连接在一起呢?原因是如果单个示例太长,可能会被截断,这会导致我们失去可能对语言建模任务有用的信息!
-因此, 我们将像往常一样首先标记我们的语料库, 但是 _没有_ 在我们的标记器中设置 `truncation=True` 选项。 我们还将获取可用的单词 ID ((如果我们使用快速标记器, 它们是可用的, 如 [第六章](/course/chapter6/3)中所述), 因为我们稍后将需要它们来进行全字屏蔽。我们将把它包装在一个简单的函数中, 当我们在做的时候, 我们将删除 `text` 和 `label` 列, 因为我们不再需要它们:
+因此,我们首先会像往常一样对语料库进行 tokenize 处理,但是不在 tokenizer 中设置 `truncation=True` 选项。如果我们有可以使用快速 tokenizer(如 [第六章](/course/chapter6/3) 中所述),除此之外,我们还需要获取单词的 `ID`,因为后面我们需要用到它们来进行全词掩码。最后我们将把这个过程封装在一个简单的函数中,并删除 `text` 和 `label` 列,因为我们不再需要它们。
```python
def tokenize_function(examples):
@@ -262,7 +265,7 @@ def tokenize_function(examples):
return result
-# Use batched=True to activate fast multithreading!
+# 使用 batched=True 来激活快速多线程!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
@@ -286,9 +289,9 @@ DatasetDict({
})
```
-由于 DistilBERT 是一个类似 BERT 的模型, 我们可以看到编码文本由我们在其他章节中看到的 `input_ids` 和 `attention_mask` 组成, 以及我们添加的 `word_ids`。
+由于 DistilBERT 是一个类似 BERT 的模型,我们可以看到编码后的文本包含了我们在之前章节中看到的 `input_ids` 和 `attention_mask` ,以及我们添加的 `word_ids` 。
-现在我们已经标记了我们的电影评论, 下一步是将它们组合在一起并将结果分成块。 但是这些块应该有多大? 这最终将取决于你可用的 GPU 内存量, 但一个好的起点是查看模型的最大上下文大小是多少。这可以通过检查标记器的 `model_max_length` 属性来判断:
+现在我们已经对电影评论进行了 `tokenize`,下一步是将它们全部组合在一起并将结果分割成块。但是,这些块应该有多大呢?这最终将取决于你可以使用的显存大小,但一个好的起点是查看模型的最大上下文大小。这可以在 tokenizer 的 `model_max_length` 属性中找到:
```python
tokenizer.model_max_length
@@ -298,15 +301,15 @@ tokenizer.model_max_length
512
```
-该值来自于与检查点相关联的 *tokenizer_config.json* 文件; 在这种情况下, 我们可以看到上下文大小是 512 个标记, 就像 BERT 一样。
+该值来自于与 checkpoint 相关联的 `tokenizer_config.json` 文件;在我们的例子中,我们可以看到上下文大小是 512 个 `tokens` 与 BERT 模型一样。
-✏️ **试试看!** 一些 Transformer 模型, 例如 [BigBird](https://huggingface.co/google/bigbird-roberta-base) 和 [Longformer](hf.co/allenai/longformer-base-4096), 它们具有比BERT和其他早期Transformer模型更长的上下文长度。为这些检查点之一实例化标记器, 并验证 `model_max_length` 是否与模型卡上引用的内容一致。
+✏️ **试试看!** 一些 Transformer 模型,例如 [BigBird](https://huggingface.co/google/bigbird-roberta-base) 和 [Longformer](hf.co/allenai/longformer-base-4096) 具有比 BERT 和其他早期 Transformer 模型更长的上下文长度。选择一个 `checkpoint` 来实例化 `tokenizer` 并验证 `model_max_length` 是否与模型卡上标注的大小一致。
-因此, 以便在像Google Colab 那样的 GPU 上运行我们的实验, 我们将选择可以放入内存的更小一些的东西:
+因此,为了可以在像 Google Colab 那样的 GPU 上运行我们的实验,我们会选择一个稍小一点、可以放入内存中的分块大小:
```python
chunk_size = 128
@@ -314,14 +317,14 @@ chunk_size = 128
-请注意, 在实际场景中使用较小的块大小可能是有害的, 因此你应该使用与将应用模型的用例相对应的大小。
+注意,在实际应用场景中,使用小的块可能会有丢失长句子之间的语义信息从而对最终模型的性能产生不利的影响,所以如果显存条件允许的话,你应该选择一个与你将要使用模型的相匹配的大小。
-有趣的来了。为了展示串联是如何工作的, 让我们从我们的标记化训练集中取一些评论并打印出每个评论的标记数量:
+现在来到了最有趣的部分。为了展示如何把这些示例连接在一,我们从分词后的训练集中取出几个评论,并打印出每个评论的 token 数量:
```python
-# Slicing produces a list of lists for each feature
+# 切片会为每个特征生成一个列表的列表
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
@@ -334,7 +337,7 @@ for idx, sample in enumerate(tokenized_samples["input_ids"]):
'>>> Review 2 length: 192'
```
-然后我们可以用一个简单的字典理解来连接所有例子, 如下所示:
+然后,我们可以用一个简单的字典推导式将所有这些示例连接在一起,如下所示:
```python
concatenated_examples = {
@@ -348,7 +351,7 @@ print(f"'>>> Concatenated reviews length: {total_length}'")
'>>> Concatenated reviews length: 951'
```
-很棒, 总长度检查出来了 -- 现在, 让我们将连接的评论拆分为大小为 `block_size` 的块。为此, 我们迭代了 `concatenated_examples` 中的特征, 并使用列表理解来创建每个特征的切片。结果是每个特征的块字典:
+很棒,总长度计算出来了 —— 现在,让我们将连接的评论拆分为大小为 `chunk_size` 的块。为此,我们迭代了 `concatenated_examples` 中的特征,并使用列表推导式为每个特征分块。结果是一个字典,键是特征的名称,值是对应值经过分块的列表:
```python
chunks = {
@@ -371,34 +374,34 @@ for chunk in chunks["input_ids"]:
'>>> Chunk length: 55'
```
-正如你在这个例子中看到的, 最后一个块通常会小于最大块大小。有两种主要的策略来处理这个问题:
+正如你在这个例子中看到的,最后一个块通常会小于所设置的分块的大小。有两种常见的策略来处理这个问题:
-* 如果最后一个块小于 `chunk_size`, 请删除它。
-* 填充最后一个块, 直到其长度等于 `chunk_size`。
+* 如果最后一个块小于 `chunk_size` ,就丢弃。
+* 填充最后一个块,直到其长度等于 `chunk_size` 。
-我们将在这里采用第一种方法, 因此让我们将上述所有逻辑包装在一个函数中, 我们可以将其应用于我们的标记化数据集:
+我们将在这里采用第一种方法,最后让我们将上述所有逻辑包装在一个函数中,以便我们可以将其应用于我们的已分词数据集上:
```python
def group_texts(examples):
- # Concatenate all texts
+ # 拼接所有的文本
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
- # Compute length of concatenated texts
+ # 计算拼接文本的长度
total_length = len(concatenated_examples[list(examples.keys())[0]])
- # We drop the last chunk if it's smaller than chunk_size
+ # 如果最后一个块小于 chunk_size,我们将其丢弃
total_length = (total_length // chunk_size) * chunk_size
- # Split by chunks of max_len
+ # 按最大长度分块
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
- # Create a new labels column
+ # 创建一个新的 labels 列
result["labels"] = result["input_ids"].copy()
return result
```
-注意, 在 `group_texts()` 的最后一步中, 我们创建了一个新的 `labels` 列, 它是 `input_ids` 列的副本。我们很快就会看到, 这是因为在掩码语言建模中, 目标是预测输入批次中随机掩码的标记, 并通过创建一个 `labels` 列, 们为我们的语言模型提供了基础事实以供学习。
+注意,在 `group_texts()` 的最后一步,我们创建了一个新的 `labels` 列,它是通过复制 `input_ids` 列形成的。这是因为在掩码语言模型的目标是预测输入中随机遮住(Masked)的 token,我们保存了让我们的语言模型从中学习 `[Mask]` 的答案。
-现在, 让我们使用我们可信赖的 `Dataset.map()` 函数将 `group_texts()` 应用到我们的标记化数据集:
+现在,让我们使用我们强大的 `Dataset.map()` 函数将 `group_texts()` 应用到我们的已分词数据集上:
```python
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
@@ -422,7 +425,7 @@ DatasetDict({
})
```
-你可以看到, 对文本进行分组, 然后对文本进行分块, 产生的示例比我们最初的 25,000 用于 `train`和 `test` 拆分的示例多得多。那是因为我们现在有了涉及 _连续标记_ 的示例, 这些示例跨越了原始语料库中的多个示例。你可以通过在其中一个块中查找特殊的 `[SEP]` 和 `[CLS]` 标记来明确的看到这一点:
+通过对文本进行分块,我们得到了比原来的训练集和测试集的 25000 个例子多得多的评论数据。这是因为我们现在有了涉及跨越原始语料库中多个例子的连续标记的例子。你可以通过在其中一个块中查找特殊的 `[SEP]` 和 `[CLS]` tokens 来清晰地看到这一点:
```python
tokenizer.decode(lm_datasets["train"][1]["input_ids"])
@@ -432,7 +435,7 @@ tokenizer.decode(lm_datasets["train"][1]["input_ids"])
".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
```
-在此示例中, 你可以看到两篇重叠的电影评论, 一篇关于高中电影, 另一篇关于无家可归。 让我们也看看掩码语言建模的标签是什么样的:
+在这个例子中,你可以看到两个重叠的电影评论,一个关于高中电影,另一个关于无家可归的问题。让我们也检查一下掩码语言模型待预测的标签是什么样的:
```python out
tokenizer.decode(lm_datasets["train"][1]["labels"])
@@ -442,11 +445,11 @@ tokenizer.decode(lm_datasets["train"][1]["labels"])
".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
```
-正如前面的 `group_texts()` 函数所期望的那样, 这看起来与解码后的 `input_ids` 相同 -- 但是我们的模型怎么可能学到任何东西呢? 我们错过了一个关键步骤: 在输入中的随机位置插入 `[MASK]` 标记! 让我们看看如何使用特殊的数据整理器在微调期间即时执行此操作。
+正如我们上面的 `group_texts()` 函数所预期的那样,这看起来与解码的 `input_ids` 完全相同 —— 但是要怎么样才能让我们的的模型可以学习到一些东西呢?我们缺少一个关键的步骤:在输入中随机插入 `[MASK]` token!让我们看看如何在微调期间使用特殊的数据整理器来实时地完成这个步骤。
-## 使用 `Trainer` API 微调DistilBERT [[使用 `Trainer` API 微调DistilBERT]]
+## 使用 `Trainer` API 微调 DistilBERT [[使用 `Trainer` API 微调 DistilBERT]]
-微调屏蔽语言模型几乎与微调序列分类模型相同, 就像我们在 [第三章](/course/chapter3)所作的那样。 唯一的区别是我们需要一个特殊的数据整理器, 它可以随机屏蔽每批文本中的一些标记。幸运的是, 🤗 Transformers 为这项任务准备了专用的 `DataCollatorForLanguageModeling` 。我们只需要将它转递给标记器和一个 `mlm_probability` 参数, 该参数指定要屏蔽的标记的分数。我们将选择 15%, 这是 BERT 使用的数量也是文献中的常见选择:
+微调掩码语言模型几乎与微调序列分类模型相同,就像我们在 [第三章](/course/chapter3) 所做的那样。唯一的区别是我们需要一个特殊的数据整理器,它可以随机屏蔽每批文本中的一些 tokens。幸运的是,🤗 Transformers 为这项任务准备了专用的 `DataCollatorForLanguageModeling` 。我们只需要将 tokenizer 和一个 `mlm_probability` 参数(掩盖 tokens 的比例)传递给它。在这里我们将 `mlm_probability` 参数设置为 15%,这是 `BERT` 默认的数量,也是文献中最常见的选择。
```python
from transformers import DataCollatorForLanguageModeling
@@ -454,7 +457,7 @@ from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
```
-要了解随机掩码的工作原理, 让我们向数据整理器提供一些示例。由于它需要一个 `dict` 的列表, 其中每个 `dict` 表示单个连续文本块, 我们首先迭代数据集, 然后再将批次提供给整理器。我们删除了这个数据整理器的 `"word_ids"` 键, 因为它不需要它:
+为了了解随机掩码数据整理器的工作原理,让我们把一些例子输入到数据整理器。由于数据整理器期望接收一个字典列表,其中每个字典中存储一段连续文本的块,所以我们首先遍历数据集取出来一些样本数据,然后将样本数据输入到整理器。在输入到数据整理器之间,我们删除了 `word_ids` 这个键,因为它不需要这个键。
```python
samples = [lm_datasets["train"][i] for i in range(2)]
@@ -471,21 +474,20 @@ for chunk in data_collator(samples)["input_ids"]:
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'
```
-很棒, 成功了! 我们可以看到, `[MASK]` 标记已随机插入我们文本中的不同位置。 这些将是我们的模型在训练期间必须预测的标记 -- 数据整理器的美妙之处在于, 它将随机化每个批次的 `[MASK]` 插入!
+很棒,成功了!我们可以看到, `[MASK]` tokens 已随机插入我们文本中的不同位置。这些将是我们的模型在训练期间必须预测的 tokens —— 数据整理器的美妙之处在于,它会在每个 batch 中随机插入 `[MASK]` !
-✏️ **试试看!** 多次运行上面的代码片段, 看看随机屏蔽发生在你眼前! 还要将 `tokenizer.decode()` 方法替换为 `tokenizer.convert_ids_to_tokens()` 以查看有时会屏蔽给定单词中的单个标记, 而不是其他标记。
+✏️ **试一试!** 多运行上面的代码片段几次,亲眼看看随机遮蔽的效果!也可以用 `tokenizer.convert_ids_to_tokens()` 替换 `tokenizer.decode()` 方法,看看只把一个给定单词的单个 token 遮蔽,而保持这个单词其他 tokens 不变的效果。
{#if fw === 'pt'}
-随机掩码的一个副作用是, 当使用 `Trainer` 时, 我们的评估指标将不是确定性的, 因为我们对训练集和测试集使用相同的数据整理器。稍后我们会看到, 当我们使用 🤗 Accelerate 进行微调时, 我们将如何利用自定义评估循环的灵活性来冻结随机性。
-
+随机掩码的一个缺点是,当使用 `Trainer` 时,每次计算出来的评估结果会有些许不同,即使我们会对训练集和测试集使用相同的数据整理器。稍后,我们在学习使用 🤗 Accelerate 进行微调时, 就会看到如何利用灵活的自定义评估循环的来冻结随机性。
{/if}
-在为掩码语言建模训练模型时, 可以使用的一种技术是将整个单词一起屏蔽, 而不仅仅是单个标记。这种方法称为 _全词屏蔽_。 如果我们想使用全词屏蔽, 我们需要自己构建一个数据整理器。数据整理器只是一个函数, 它接受一个样本列表并将它们转换为一个批次, 所以现在让我们这样做吧! 我们将使用之前计算的单词 ID 在单词索引和相应标记之间进行映射, 然后随机决定要屏蔽哪些单词并将该屏蔽应用于输入。请注意, 除了与掩码对应的标签外, 所有的标签均为 `-100`。
+在为掩码语言建模训练模型时,不仅仅可以遮蔽单个 `token`,还可以一次遮蔽整个单词的所有 `token`,这种方法被称为全词屏蔽(whole word masking)。如果我们想使用全词屏蔽(whole word masking),我们就需要自己构建一个数据整理器。数据整理器的核心是一个函数,它接受一个样本列表并将它们转换为一个 `batch`,所以现在让我们这样做吧!我们将使用先前计算的`word ID`,构建一个单词索引和相应 `token` 之间的映射,然后随机决定遮蔽哪些单词,并使用这种方法对输入进行遮蔽。请注意,除了与掩码对应的标签外,所有其他的标签均应该设置为 `-100` 。
{#if fw === 'pt'}
@@ -502,7 +504,7 @@ def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
- # Create a map between words and corresponding token indices
+ # 创建一个单词与对应 token 索引之间的映射
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
@@ -513,7 +515,7 @@ def whole_word_masking_data_collator(features):
current_word_index += 1
mapping[current_word_index].append(idx)
- # Randomly mask words
+ # 随机遮蔽单词
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
@@ -543,7 +545,7 @@ def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
- # Create a map between words and corresponding token indices
+ # 创建一个单词与对应 token 索引之间的映射
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
@@ -554,7 +556,7 @@ def whole_word_masking_data_collator(features):
current_word_index += 1
mapping[current_word_index].append(idx)
- # Randomly mask words
+ # 随机遮蔽单词
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
@@ -571,7 +573,7 @@ def whole_word_masking_data_collator(features):
{/if}
-Next, we can try it on the same samples as before:
+接下来,我们可以在之前的样本上试试它:
```py
samples = [lm_datasets["train"][i] for i in range(2)]
@@ -589,11 +591,11 @@ for chunk in batch["input_ids"]:
-✏️ **试试看!** 多次运行上面的代码片段, 看看随机屏蔽发生在你眼前! 还要将 `tokenizer.decode()` 方法替换为 `tokenizer.convert_ids_to_tokens()` 以查看来自给定单词的标记始终被屏蔽在一起。
+✏️ **试试看!** 多次运行上面的代码片段,亲眼看看随机遮蔽的效果!也可以将 `tokenizer.decode()` 方法替换为 `tokenizer.convert_ids_to_tokens()` ,可以观察到给定单词的所有 tokens 总是被一起遮蔽。
-现在我们有两个数据整理器, 其余的微调步骤是标准的。如果您没有足够幸运地获得神话般的 P100 GPU 😭, 在 Google Colab 上进行训练可能需要一段时间, 因此我们将首先将训练集的大小缩减为几千个示例。别担心, 我们仍然会得到一个相当不错的语言模型! 在 🤗 Datasets 中快速下采样数据集的方法是通过我们在 [第五章](/course/chapter5) 中看到的 `Dataset.train_test_split()` 函数:
+现在我们有了两个数据整理器,剩下的微调步骤与其他任务类似都是标准的。如果你在 Google Colab 上运行并且没有幸运地分配到神秘的 P100 GPU😭,那么训练可能会需要一些时间,所以我们首先将训练集的大小减小到几千个例子。不用担心,我们仍然可以得到一个相当不错的语言模型!在 🤗 Datasets 中快速筛选数据集的方法是使用我们在 [第五章](/course/chapter5) 中看到的 `Dataset.train_test_split()` 函数:
```python
train_size = 10_000
@@ -618,7 +620,7 @@ DatasetDict({
})
```
-这会自动创建新的 `train` 和 `test` 拆分, 训练集大小设置为 10,000 个示例, 验证设置为其中的 10% -- 如果你有一个强大的 GPU, 可以随意增加它! 我们需要做的下一件事是登录 Hugging Face Hub。如果你在笔记本中运行此代码, 则可以使用以下实用程序函数执行此操作:
+运行上述代码会自动创建新的 `train` 和 `test` 数据集,训练集大小为 10,000 个示例,验证的大小是训练集的 10% —— 如果你有一个强大的 GPU,可以自行增加这个比例!我们接下来要做的事情是登录 Hugging Face Hub。如果你在 Notebook 中运行这段代码,你可以通过以下的工具函数进行登录:
```python
from huggingface_hub import notebook_login
@@ -626,17 +628,17 @@ from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件, 你可以在其中输入你的凭据。或者, 你可以运行:
+它将显示一个小部件,在其中你可以输入你的账号和密码进行登陆。或者,你也可以在你最喜欢的终端中输入指令:
```
huggingface-cli login
```
-在你最喜欢的终端中登录。
+然后在那里登录。
{#if fw === 'tf'}
-登录后,我们可以创建我们的“tf.data”数据集。 为此,我们将使用 `prepare_tf_dataset()` 方法,该方法使用我们的模型自动推断哪些列应进入数据集。 如果您想准确控制要使用的列,可以改用“Dataset.to_tf_dataset()”方法。 为了简单起见,我们在这里只使用标准数据整理器,但您也可以尝试整个单词屏蔽整理器并将结果作为练习进行比较:
+登录后,我们可以创建我们的 `tf.data` 数据集。我们将使用 `prepare_tf_dataset()` 方法,该方法会根据所使用的模型自动推断哪些列应该存入数据集。如果你想准确控制要使用的列,可以改用 `Dataset.to_tf_dataset()` 方法。为了简单起见,我们在这里只使用标准数据整理器,但你也可以尝试全词屏蔽(whole word masking)数据整理器,并作为一个练习对比一下效果:
```python
tf_train_dataset = model.prepare_tf_dataset(
@@ -653,10 +655,9 @@ tf_eval_dataset = model.prepare_tf_dataset(
batch_size=32,
)
```
+接下来我们使用🤗 Transformers 库的 `create_optimizer()` 函数来设置超参数并编译模型,该函数提供了一个带有线性学习率衰减的 `AdamW` 优化器。在 `compile()` 的参数中我们没有指定损失函数,这代表使用模型内置的默认损失函数,然后我们将训练精度设置为`mixed_float16` 。注意,如果你使用的是 Colab GPU 或者其他不支持 float16 加速的 GPU,你可能应该注释掉这一行。
-接下来, 我们设置训练超参数并编译模型。我们使用 🤗 Transformers 库中的 `create_optimizer()` 函数, 它提供了一个具有线性学习率衰减的 `AdamW` 优化器。我们还使用了模型内置的损失, 当没有损失被指定为 `compile()` 参数是, 这是默认值, 并且我们将训练精度设置为 `"mixed_float16"`。请注意,如果你使用的是Colab GPU或其他不支持float16加速的GPU, 你可能应该注释掉这一行。
-
-此外, 我们还设置了一个 `PushToHubCallback`, 它将在每个epoch后将模型保存到Hub。你可以使用 `hub_model_id` 参数指定你想要推送到的存储库的名称 (特别是你将必须使用该参数来推送到组织)。例如, 为了将模型推送到 [`huggingface-course` organization](https://huggingface.co/huggingface-course), 我们添加了 `hub_model_id="huggingface-course/distilbert-finetuned-imdb"`。默认情况下, 使用的存储库将位于你的命名空间中, 并以你设置的输出目录命名, 因此在我们的示例中, 它将是 `"lewtun/distilbert-finetuned-imdb"`。
+另外,我们还设置了一个 `PushToHubCallback` ,它将在每个 epoch 后将模型保存到 Hub。你可以使用 `hub_model_id` 参数指定你想推送到的仓库的名称(如果你想把它推送到一个组织,你必须使用这个参数)。例如,要将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) ,就需要添加 `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` 。在默认的情况下,模型的仓库将保存在你的账户中,并以你设置的输出目录命名,所以在我们的示例中,该仓库的名称是 `lewtun/distilbert-finetuned-imdb` 。
```python
from transformers import create_optimizer
@@ -672,7 +673,7 @@ optimizer, schedule = create_optimizer(
)
model.compile(optimizer=optimizer)
-# Train in mixed-precision float16
+# 使用 float16 精度进行混合精度训练
tf.keras.mixed_precision.set_global_policy("mixed_float16")
model_name = model_checkpoint.split("/")[-1]
@@ -681,17 +682,17 @@ callback = PushToHubCallback(
)
```
-我们现在已经准备好运行 `model.fit()` 了 -- 但在此之前, 让我们先简单地看看 _perplexity_, 它是评估语言模型性能的常用指标。
+我们现在已经准备好运行 `model.fit()` 了 —— 但在此之前,让我们先简单了解一下 `困惑度(perplexity)` ,它是一种常用的评估语言模型性能的指标。
{:else}
-登陆后, 我们可以指定 `Trainer` 参数:
+登陆后,我们可以指定 `Trainer` 的参数:
```python
from transformers import TrainingArguments
batch_size = 64
-# Show the training loss with every epoch
+# 在每个 epoch 输出训练的 loss
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
@@ -709,11 +710,11 @@ training_args = TrainingArguments(
)
```
-在这里, 我们调整了一些默认选项, 包括 `logging_steps` , 以确保我们跟踪每个epoch的训练损失。我们还使用了 `fp16=True` 来实现混合精度训练, 这给我们带来了另一个速度提升。默认情况下, `Trainer` 将删除不属于模型的 `forward()` 方法的列。这意味着, 如果你使用整个单词屏蔽排序器, 你还需要设置 `remove_unused_columns=False`, 以确保我们不会在训练期间丢失 `word_ids` 列。
+在这里,我们调整了一些默认选项,包括 `logging_steps` ,以确保我们可以跟踪每个 epoch 的训练损失。我们还使用了 `fp16=True` 来实现混合精度训练,从而进一步提高训练速度。默认情况下, `Trainer` 将删除模型的 `forward()` 方法中未使用的列。这意味着,如果你使用全词屏蔽(whole word masking)数据整理器,你还需要设置 `remove_unused_columns=False` ,以确保我们不会在训练期间丢失 `word_ids` 列。
-请注意, 你可以使用 `hub_model_id` 参数指定要推送到的存储库的名称((特别是你将必须使用该参数向组织推送)。例如, 当我们将模型推送到 [`huggingface-course` organization](https://huggingface.co/huggingface-course) 时, 我们添加了 `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` 到 `TrainingArguments` 中。默认情况下, 使用的存储库将在你的命名空间中并以你设置的输出目录命名, 因此在我们的示例中, 它将是 `"lewtun/distilbert-finetuned-imdb"`。
+请注意,你可以使用 `hub_model_id` 参数指定你想推送到的仓库的名称(如果你想把它推送到一个组织,就必须使用这个参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,就在 `TrainingArguments` 中添加了 `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` 。默认情况下,使用的仓库将保存在你的账户中并以你设置的输出目录命名,因此在我们的示例中,它将是 `"lewtun/distilbert-finetuned-imdb"` 。
-我们现在拥有实例化 `Trainer` 的所有成分。这里我们只使用标准的 `data_collator`, 但你可以尝试使用整个单词掩码整理器并比较结果作为练习:
+现在,我们拥有了初始化 `Trainer` 所需的所有要素。这里我们只使用了标准的 `data_collator` ,但你可以尝试使用全词屏蔽作为数据整理器的一个练习,并对比一下不同屏蔽方式的结果有什么不同:
```python
from transformers import Trainer
@@ -728,19 +729,19 @@ trainer = Trainer(
)
```
-我们现在准备运行 `trainer.train()` -- 但在此之前让我们简要地看一下 _perplexity_, 这是评估语言模型性能的常用指标。
+我们现在准备运行 `trainer.train()` —— 但在此之前让我们简要地看一下 `困惑度(perplexity)` ,这是评估语言模型性能常用的指标。
{/if}
-### 语言模型的perplexity [[语言模型的perplexity]]
+### 语言模型的困惑度(perplexity) [[语言模型的困惑度(perplexity)]]
-与文本分类或问答等其他任务不同, 在这些任务中, 我们会得到一个带标签的语料库进行训练, 而语言建模则没有任何明确的标签。那么我们如何确定什么是好的语言模型呢? 就像手机中的自动更正功能一样, 一个好的语言模型是为语法正确的句子分配高概率, 为无意义的句子分配低概率。为了让你更好地了解这是什么样子, 您可以在网上找到一整套 "autocorrect fails", 其中一个人手机中的模型产生了一些相当有趣 (而且通常不合适) 的结果!
+语言建模与文本分类或问答等其他任务有所不同,在其他任务中,我们会得到一个带标签的语料库进行训练,而语言建模则没有任何明确的标签。那么我们如何确定什么是好的语言模型呢?就像手机中的自动更正功能一样,一个好的语言模型会较高概率输出一个语法正确的句子,较低概率输出无意义的句子。为了给你一个更直观感受,你可以在网上找到一整套“自动更正失败”的例子。其中,人们手机中的模型产生了一些相当有趣(并且常常不妥当)的自动生成的结果!
{#if fw === 'pt'}
-假设我们的测试集主要由语法正确的句子组成, 那么衡量我们的语言模型质量的一种方法是计算它分配给测试集中所有句子中的下一个单词的概率。高概率表明模型对看不见的例子并不感到 "惊讶" 或 "疑惑", 并表明它已经学习了语言中的基本语法模式。 perplexity度有多种数学定义, 但我们将使用的定义是交叉熵损失的指数。因此, 我们可以通过 `Trainer.evaluate()` 函数计算测试集上的交叉熵损失, 然后取结果的指数来计算预训练模型的perplexity度:
+如果测试集主要由语法正确的句子组成,那么衡量语言模型质量的一种方式就是计算它给测试集中所有句子的下一个词的概率。高概率表示模型对未见过的例子不感到“惊讶”或“困惑”,这表明它已经学习了语言的基本语法模式。困惑度有很多种数学定义,我们将使用的定义是交叉熵损失的指数。具体方法是使用 `Trainer.evaluate()`方法计算测试集上的交叉熵损失,取结果的指数来计算预训练模型的困惑度。
```python
import math
@@ -751,7 +752,7 @@ print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
{:else}
-假设我们的测试集主要由语法正确的句子组成, 那么衡量我们的语言模型质量的一种方法是计算测试集所有句子中它分配给下一个单词的概率。高概率表明, 该模型表明该模型对未见过的示例不感到 "惊讶" 或 "困惑", 并表明它已经学会了该语言的基本语法模式。关于perplexity度有各种不同的数学定义, 但我们要用的定义是交叉熵损失的指数。因此, 我们可以通过 `model.evaluate()` 方法计算测试集上的交叉熵损失, 然后取结果的指数来计算我们预训练模型的perplexity度:
+如果测试集主要由语法正确的句子组成,那么衡量语言模型质量的一种方式就是计算它给测试集中所有句子的下一个词的概率。高概率表示模型对未见过的例子不感到“惊讶”或“困惑”,这表明它已经学习了语言的基本语法模式。困惑度有很多种数学定义,我们将使用的定义是交叉熵损失的指数。具体方法是使用 `model.evaluate()` 方法计算测试集上的交叉熵损失,取结果的指数来计算预训练模型的困惑度。
```python
import math
@@ -766,7 +767,7 @@ print(f"Perplexity: {math.exp(eval_loss):.2f}")
>>> Perplexity: 21.75
```
-较低的perplexity分数意味着更好的语言模型, 我们可以在这里看到我们的起始模型有一个较大的值。看看我们能不能通过微调来降低它! 为此, 我们首先运行训练循环:
+较低的困惑度分数意味着更好的语言模型,我们可以看到,我们的初始模型的困惑度相当地高。让我们看看我们是否可以通过微调来降低它!为此,我们首先运行训练循环:
{#if fw === 'pt'}
@@ -782,7 +783,7 @@ model.fit(tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback
{/if}
-然后像以前一样计算测试集上的perplexity度:
+然后像之前那样计算测试集上的结果困惑度:
{#if fw === 'pt'}
@@ -804,11 +805,11 @@ print(f"Perplexity: {math.exp(eval_loss):.2f}")
>>> Perplexity: 11.32
```
-很好 -- 这大大减少了困惑, 这告诉我们模型已经了解了一些关于电影评论领域的知识!
+太棒了——困惑度显著降低,这告诉我们模型已经学习到了电影评论领域的一些知识!
{#if fw === 'pt'}
-训练完成后, 我们可以将带有训练信息的模型卡推送到 Hub (检查点在训练过程中自行保存):
+一旦训练完成,我们可以将带有训练信息的模型卡片推送到 Hub(checkpoint 在训练过程中就已经保存了):
```python
trainer.push_to_hub()
@@ -818,29 +819,28 @@ trainer.push_to_hub()
-✏️ **轮到你了!** 将数据整理器改为全字屏蔽整理器后运行上面的训练。你有得到更好的结果吗?
+✏️ **轮到你了!** 将数据整理器改为全词屏蔽的数据整理器后运行上面的训练。你能得到更好的结果吗?
{#if fw === 'pt'}
-在我们的用例中, 我们不需要对训练循环做任何特别的事情, 但在某些情况下, 你可能需要实现一些自定义逻辑。对于这些应用, 你可以使用 🤗 Accelerate -- 让我们来看看吧!
+在我们的使用案例中,我们不需要对训练循环做任何特殊的处理,但在某些情况下,你可能需要实现一些自定义逻辑。对于这些应用,你可以使用 🤗 Accelerate —— 让我们看一看!
## 使用 🤗 Accelerate 微调 DistilBERT [[使用 🤗 Accelerate 微调 DistilBERT]]
-正如我们在 `Trainer` 中看到的, 对掩码语言模型的微调与 [第三章](/course/chapter3) 中的文本分类示例非常相似。事实上, 唯一的微妙之处是使用特殊的数据整理器, 我们已经在本节的前面介绍过了!
-
-然而, 我们看到 `DataCollatorForLanguageModeling` 还对每次评估应用随机掩码, 因此每次训练运行时, 我们都会看到perplexity度分数的一些波动。消除这种随机性来源的一种方法是应用掩码 _一次_ 在整个测试集上, 然后使用🤗 Transformers 中的默认数据整理器在评估期间收集批次。为了看看它是如何工作的, 让我们实现一个简单的函数, 将掩码应用于批处理, 类似于我们第一次遇到的 `DataCollatorForLanguageModeling`:
+从上面的 `Trainer` 训练流程中我们就能发现,微调一个掩码的语言模型与 [第三章](https://chat.openai.com/course/chapter3) 中的文本分类非常相似。事实上,唯一的不同之处是使用了一个特殊的数据整理器,我们已经在本节的前面讨论过这个问题了!
+然而,我们注意到 `DataCollatorForLanguageModeling` 在每次评估时也会进行随机遮罩,因此我们在每次训练运行中都会看到困惑度得分有些波动。消除这种随机性的一种方法是在整个测试集上 `仅进行一次` 遮罩,然后在评估过程中使用🤗 Transformers 中的默认数据整理器来收集 batch。为实现这个过程,让我们实现一个简单的函数,类似于我们第一次使用 `DataCollatorForLanguageModeling` 时进行遮罩的方式:
```python
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
- # Create a new "masked" column for each column in the dataset
+ # 为数据集中的每一列创建一个新的"masked"列
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}
```
-接下来, 我们将此函数应用于我们的测试集并删除未掩码的列, 以便我们可以用掩码的列替换它们。你可以通过用适当的替换上面的 `data_collator` 来使整个单词掩码, 在这种情况下, 你应该删除此处的第一行:
+接下来,我们将上述函数应用到测试集,并删除未进行遮罩的列,这样就实现了使用遮罩过的数据替换原始输入的数据。你可以通过将上述 `data_collator` 替换为支持全词遮罩的数据整理器并且删除下面的第一行(全词遮罩的数据整理器需要 `word_ids` 列来定位同一个单词中的不同 `token`)来实现全词遮罩
```py
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
@@ -858,7 +858,7 @@ eval_dataset = eval_dataset.rename_columns(
)
```
-然后我们可以像往常一样设置数据加载器, 但我们将使用🤗 Transformers 中的 `default_data_collator` 作为评估集:
+然后我们可以像往常一样设置 DataLoader,但我们将使用🤗 Transformers 中的 `default_data_collator` 来设置 DataLoader:
```python
from torch.utils.data import DataLoader
@@ -876,13 +876,13 @@ eval_dataloader = DataLoader(
)
```
-从这里开始, 我们遵循🤗 Accelerate 的标准步骤。第一个任务是加载预训练模型的新版本:
+从这里开始,我们将遵循🤗 Accelerate 的标准步骤。第一个任务是重新加载预训练模型:
```
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
```
-然后我们需要指定优化器; 我们将使用标准的 `AdamW`:
+然后我们需要指定优化器;我们将使用标准的 `AdamW` :
```python
from torch.optim import AdamW
@@ -890,7 +890,7 @@ from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
```
-有了这些对象, 我们现在可以准备使用 `Accelerator` 加速器进行训练的一切:
+有了这些对象,我们现在可以用 `Accelerator` 对象包装所有的组件,以进行训练:
```python
from accelerate import Accelerator
@@ -901,7 +901,7 @@ model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
)
```
-现在我们的模型、优化器和数据加载器都配置好了, 我们可以指定学习率调度器如下:
+现在我们的模型、优化器和 DataLoader 都配置好了,我们可以按照以下方式设置学习率调度器:
```python
from transformers import get_scheduler
@@ -918,7 +918,7 @@ lr_scheduler = get_scheduler(
)
```
-在训练之前要做的最后一件事是: 在 Hugging Face Hub 上创建一个模型库! 我们可以使用 🤗 Hub 库来首先生成我们的 repo 的全名:
+在开始训练之前,我们还需要做的最后一件事就是在 Hugging Face Hub 上创建一个模型仓库!我们可以使用🤗 Hub 库的 `get_full_repo_name`,生成我们仓库的全名:
```python
from huggingface_hub import get_full_repo_name
@@ -932,7 +932,7 @@ repo_name
'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'
```
-然后使用来自🤗 Hub 的 `Repository` 类:
+然后,我们可以使用🤗 Hub 的 `Repository` 类创建并克隆仓库:
```python
from huggingface_hub import Repository
@@ -941,7 +941,7 @@ output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)
```
-完成后, 只需写出完整的训练和评估循环即可:
+完成后,只需写出完整的训练和评估循环即可:
```python
from tqdm.auto import tqdm
@@ -951,7 +951,7 @@ import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
- # Training
+ # 训练
model.train()
for batch in train_dataloader:
outputs = model(**batch)
@@ -963,7 +963,7 @@ for epoch in range(num_train_epochs):
optimizer.zero_grad()
progress_bar.update(1)
- # Evaluation
+ # 评估
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
@@ -982,7 +982,7 @@ for epoch in range(num_train_epochs):
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
- # Save and upload
+ # 保存并上传
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
@@ -999,13 +999,13 @@ for epoch in range(num_train_epochs):
>>> Epoch 2: Perplexity: 10.729503505340409
```
-很棒, 我们已经能够评估每个 epoch 的perplexity度, 并确保多次训练运行是可重复的!
+很棒,我们已经能够评估每个 epoch 的困惑度,并确保运行的结果可以复现!
{/if}
## 使用我们微调的模型 [[使用我们微调的模型]]
-你可以通过在Hub上使用其他小部件或在本地使用🤗 Transformers 的`管道`于微调模型进行交互。让我们使用后者来下载我们的模型, 使用 `fill-mask` 管道:
+你可以使用 Hub 上的模型部件或者在本地使用🤗 Transformers 的 `pipeline` 加载微调模型预测文本。让我们使用后者通过 `fill-mask` pipeline 下载我们的模型:
```python
from transformers import pipeline
@@ -1015,7 +1015,7 @@ mask_filler = pipeline(
)
```
-然后, 我们可以向管道提供 "This is a great [MASK]" 示例文本, 并查看前 5 个预测是什么:
+然后我们可以将文本“This is a great [MASK]”提供给 pipeline,看看前 5 个预测是什么:
```python
preds = mask_filler(text)
@@ -1032,14 +1032,13 @@ for pred in preds:
'>>> this is a great character.'
```
-好的 -- 我们的模型显然已经调整了它的权重来预测与电影更密切相关的词!
+Nice!—— 我们的模型显然已经调整了它的权重来预测与电影更密切相关的词!
-这结束了我们训练语言模型的第一个实验。在 [第六节](/course/chapter7/section6)中你将学习如何从头开始训练像 GPT-2 这样的自回归模型; 如果你想了解如何预训练您自己的 Transformer 模型, 请前往那里!
+这标志着我们第一次训练语言模型的实验到现在就结束了。在 [第 6 节](https://chat.openai.com/course/en/chapter7/6) 中,你将学习如何从头开始训练一个自动回归模型,比如 GPT-2;如果你想看看如何预训练你自己的 Transformer 模型,就赶快去那里看看吧!
-✏️ **试试看!** 为了量化域适应的好处, 微调 IMDb 标签上的分类器和预先训练和微调的Distil BERT检查点。如果你需要复习文本分类, 请查看 [第三章](/course/chapter3)。
-
+✏️ **试试看!** 为了量化领域适应的好处,分别使用预训练和微调的 DistilBERT checkpoint 以及数据集自带的 IMDb 标签来微调一个分类器,并对比一下这个两个 checkpoint 的差异。如果你需要复习文本分类的知识,请查看 [第三章](/course/chapter3) 。
diff --git a/chapters/zh-CN/chapter7/4.mdx b/chapters/zh-CN/chapter7/4.mdx
index bb15ba4c7..715a3fdb9 100644
--- a/chapters/zh-CN/chapter7/4.mdx
+++ b/chapters/zh-CN/chapter7/4.mdx
@@ -22,16 +22,16 @@
{/if}
-现在让我们深入研究翻译。这是另一个[sequence-to-sequence 任务](/course/chapter1/7),这意味着这是一个可以表述为从一个序列到另一个序列的问题。从这个意义上说,这个问题非常类似[文本摘要](/course/chapter7/6),并且您可以将我们将在此处学习到的一些内容迁移到其他的序列到序列问题,例如:
+现在让我们深入研究翻译。这是另一个 [sequence-to-sequence 任务](/course/chapter1/7) ,着这是一个可以表述为输入是一个序列输出另一个序列的问题。从这个意义上说,这个问题非常类似 [文本摘要](/course/chapter7/6) ,并且你可以将我们将在此处学习到的一些技巧迁移到其他的序列到序列问题,例如:
-- **风格迁移** : 创建一个模型将某种风格迁移到一段文本(例如,正式的风格迁移到休闲的风格或莎士比亚英语到现代英语)
-- **生成问题的回答** :创建一个模型,在给定上下文的情况下生成问题的答案
+- **风格迁移** 创建一个模型将某种风格迁移到一段文本(例如,正式的风格迁移到休闲的风格,或从莎士比亚英语迁移到现代英语)。
+- **生成问题的回答** 创建一个模型,在给定上下文的情况下生成问题的答案。
-如果您有足够大的两种(或更多)语言的文本语料库,您可以从头开始训练一个新的翻译模型,就像我们在[因果语言建模](/course/chapter7/6)部分中所做的那样。然而,微调现有的翻译模型会更快,无论是从像 mT5 或 mBART 这样的多语言模型微调到特定的语言对,或者是专门用于从一种语言翻译成另一种语言的模型。
+如果你有足够大的两种(或更多)语言的文本语料库,你可以从头开始训练一个新的翻译模型,就像我们在 [因果语言建模](/course/chapter7/6) 部分中所做的那样。然而,微调现有的翻译模型会更快,无论是从像 mT5 或 mBART 这样的多语言模型微调到特定的语言对,还是从特定语料库的一种语言到另一种语言的专用翻译模型。
-在本节中,我们将对[KDE4 数据集](https://huggingface.co/datasets/kde4)上的Marian模型进行微调,该模型经过了从英语到法语的翻译预训练(因为很多“ Hugging Face”的员工会说这两种语言),它是[KDE应用程序](https://apps.kde.org/)本地化文件的数据集。我们将使用的模型已经在从[Opus 数据集](https://opus.nlpl.eu/)(实际上包含KDE4数据集)中提取的法语和英语文本的大型语料库上进行了预先训练。但是,即使我们使用的预训练模型在其预训练期间使用了这部分数据集,我们也会看到,经过微调后,我们可以得到一个更好的版本。
+在这一节中,我们将在 [KDE4 数据集](https://huggingface.co/datasets/kde4) 上微调一个预训练的 Marian 模型,用来把英语翻译成法语的(因为很多 Hugging Face 的员工都会说这两种语言)。KDE4 数据集是一个 [KDE 应用](https://apps.kde.org/) 本地化的数据集。我们将使用的模型已经在从 [Opus 数据集](https://opus.nlpl.eu/) (实际上包含 KDE4 数据集)中提取的法语和英语文本的大型语料库上进行了预先训练。不过,即使我们使用的预训练模型在其预训练期间使用了这部分数据集,我们也会看到,经过微调后,我们可以得到一个更好的版本。
完成后,我们将拥有一个模型,可以进行这样的翻译:
@@ -42,15 +42,15 @@
 -与前面的部分一样,您可以使用以下代码找到我们将训练并上传到 Hub 的实际模型,并[在这里](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.)查看模型输出的结果
+与前面几节一样,你可以使用以下代码找到我们将训练并上传到 Hub 的实际模型,并 [在这里](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.) 查看模型输出的结果。
## 准备数据 [[准备数据]]
-为了从头开始微调或训练翻译模型,我们需要一个适合该任务的数据集。如前所述,我们将使用[KDE4 数据集](https://huggingface.co/datasets/kde4)在本节中,但您可以很容易地调整代码以使用您自己的数据,只要您有要互译的两种语言的句子对。如果您需要复习如何将自定义数据加载到 **Dataset** 可以复习一下[第五章](/course/chapter5).
+为了从头开始微调或训练翻译模型,我们需要一个适合该任务的数据集。如前所述,我们将使用 [KDE4 数据集](https://huggingface.co/datasets/kde4) 。只要数据集中有互译的两种语言的句子对,就可以很容易地调整本节的代码以使用自己的数据集进行微调。如果你需要复习如何将自定义数据加载到 `Dataset` ,可以复习一下 [第五章](/course/chapter5) 。
### KDE4 数据集 [[KDE4 数据集]]
-像往常一样,我们使用 **load_dataset()** 函数:
+像往常一样,我们使用 `load_dataset()` 函数下载数据集:
```py
from datasets import load_dataset
@@ -58,7 +58,7 @@ from datasets import load_dataset
raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
```
-如果您想使用不同的语言对,您可以使用它们的代码来指定它们。该数据集共有 92 种语言可用;您可以通过[数据集卡片](https://huggingface.co/datasets/kde4)展开其上的语言标签来查看它们.
+如果你想使用其他的语言对,你可以使用语言代码来设置你想使用的语言对。该数据集共有 92 种语言可用;你可以通过展开 [数据集卡片](https://huggingface.co/datasets/kde4) 上的语言标签来查看数据集支持的语言标签。
-与前面的部分一样,您可以使用以下代码找到我们将训练并上传到 Hub 的实际模型,并[在这里](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.)查看模型输出的结果
+与前面几节一样,你可以使用以下代码找到我们将训练并上传到 Hub 的实际模型,并 [在这里](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.) 查看模型输出的结果。
## 准备数据 [[准备数据]]
-为了从头开始微调或训练翻译模型,我们需要一个适合该任务的数据集。如前所述,我们将使用[KDE4 数据集](https://huggingface.co/datasets/kde4)在本节中,但您可以很容易地调整代码以使用您自己的数据,只要您有要互译的两种语言的句子对。如果您需要复习如何将自定义数据加载到 **Dataset** 可以复习一下[第五章](/course/chapter5).
+为了从头开始微调或训练翻译模型,我们需要一个适合该任务的数据集。如前所述,我们将使用 [KDE4 数据集](https://huggingface.co/datasets/kde4) 。只要数据集中有互译的两种语言的句子对,就可以很容易地调整本节的代码以使用自己的数据集进行微调。如果你需要复习如何将自定义数据加载到 `Dataset` ,可以复习一下 [第五章](/course/chapter5) 。
### KDE4 数据集 [[KDE4 数据集]]
-像往常一样,我们使用 **load_dataset()** 函数:
+像往常一样,我们使用 `load_dataset()` 函数下载数据集:
```py
from datasets import load_dataset
@@ -58,7 +58,7 @@ from datasets import load_dataset
raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
```
-如果您想使用不同的语言对,您可以使用它们的代码来指定它们。该数据集共有 92 种语言可用;您可以通过[数据集卡片](https://huggingface.co/datasets/kde4)展开其上的语言标签来查看它们.
+如果你想使用其他的语言对,你可以使用语言代码来设置你想使用的语言对。该数据集共有 92 种语言可用;你可以通过展开 [数据集卡片](https://huggingface.co/datasets/kde4) 上的语言标签来查看数据集支持的语言标签。
 @@ -77,7 +77,7 @@ DatasetDict({
})
```
-我们有 210,173 对句子,但在一次训练过程中,我们需要创建自己的验证集。正如我们在[第五章](/course/chapter5)学的的那样, **Dataset** 有一个 **train_test_split()** 方法,可以帮我们拆分数据集。我们将设定固定的随机数种子:
+我们下载的数据集有 210,173 对句子,在一次训练过程中,除了训练集,我们也需要创建自己的验证集。正如我们在 [第五章](/course/chapter5) 学的的那样, `Dataset` 有一个 `train_test_split()` 方法可以帮助我们。我们将设置一个固定的随机数种子以保证结果可以复现:
```py
split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
@@ -97,7 +97,7 @@ DatasetDict({
})
```
-我们可以将 **test** 的键重命名为 **validation** 像这样:
+我们可以像下面这样将 `test` 键重命名为 `validation`:
```py
split_datasets["validation"] = split_datasets.pop("test")
@@ -114,7 +114,7 @@ split_datasets["train"][1]["translation"]
'fr': 'Par défaut, développer les fils de discussion'}
```
-我们得到一个字典,其中包含我们请求的两种语言的两个句子。这个充满技术计算机科学术语的数据集的一个特殊之处在于它们都完全用法语翻译。然而,法国工程师通常很懒惰,在交谈时,大多数计算机科学专用词汇都用英语表述。例如,“threads”这个词很可能出现在法语句子中,尤其是在技术对话中;但在这个数据集中,它被翻译成更正确的“fils de Discussion”。我们使用的预训练模型已经在一个更大的法语和英语句子语料库上进行了预训练,采用了更简单的选择,即保留单词的原样:
+我们得到一个包含我们选择的两种语言的两个句子的字典。这个充满技术计算机科学术语的数据集的一个特殊之处在于它们都完全用法语翻译。然而现实中,法国工程师在交谈时,大多数计算机科学专用词汇都用英语表述。例如,“threads”这个词很可能出现在法语句子中,尤其是在技术对话中;但在这个数据集中,它被翻译成更准确的“fils de Discussion”。我们使用的预训练模型已经在一个更大的法语和英语句子语料库上进行了预训练,所以输出的是原始的英语表达:
```py
from transformers import pipeline
@@ -128,8 +128,8 @@ translator("Default to expanded threads")
[{'translation_text': 'Par défaut pour les threads élargis'}]
```
-这种情况的另一个例子是“plugin”这个词,它不是正式的法语词,但大多数母语人士都能理解,也不会费心去翻译。
-在 KDE4 数据集中,这个词在法语中被翻译成更正式的“module d’extension”:
+这种情况的另一个例子可以在“plugin”这个词上看到,它并非正式的法语词汇,但大多数母语是法语的人都能够看懂并且不会去翻译它。不过,在 KDE4 数据集中,这个词被翻译成了更正式的法语词汇“module d'extension”:
+
```py
split_datasets["train"][172]["translation"]
```
@@ -151,13 +151,13 @@ translator(
[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
```
-看看我们的微调模型是否能识别数据集的这些特殊性。(剧透警告:它会)。
+看看我们的微调模型是否能学习到数据集的这些特殊特性。(剧透警告:它能)。
-✏️ **轮到你了!** 另一个在法语中经常使用的英语单词是“email”。在训练数据集中找到使用这个词的第一个样本。它是如何翻译的?预训练模型如何翻译同一个英文句子?
+✏️ **轮到你了!** 另一个在法语中经常使用的英语单词是“email”。在训练数据集中找到使用这个词的第一个样本。在数据集中它是如何翻译的?预训练模型如何翻译同一个英文句子?
@@ -165,7 +165,7 @@ translator(
-您现在应该知道我们的下一步该做些什么了:所有文本都需要转换为token ID,以便模型能够理解它们。对于这个任务,我们需要同时标记输入和目标。我们的首要任务是创建我们的 **tokenizer** 对象。如前所述,我们将使用 Marian 英语到法语的预训练模型。如果您使用另一对语言尝试此代码,请确保调整模型Checkpoint。[Helsinki-NLP](https://huggingface.co/Helsinki-NLP)组织提供了多种语言的一千多种模型。
+你现在应该可以预测我们的下一步该做些什么了:将所有文本转换为 token IDs 的集合,这样模型才可以理解它们。对于这个任务,我们需要同时对原始文本和翻译后的文本同时进行 tokenize。首先,我们需要创建 `tokenizer` 对象。如前所述,我们将使用 Marian 英语到法语的预训练模型。如果你使用下面的代码微调另一对语言,请记得更改下面代码中的 checkpoint。 [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) 组织提供了超过一千个多语言模型。
```python
from transformers import AutoTokenizer
@@ -174,17 +174,17 @@ model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="pt")
```
-您可以将 **model_checkpoint** 更换为[Hub](https://huggingface.co/models)上你喜欢的任何其他型号,或本地保存的预训练模型和标记器。
+你也可以将 `model_checkpoint` 替换为你从 [Hub](https://huggingface.co/models) 中选择的其他模型,或者一个保存了预训练模型和 tokenizer 的本地文件夹。
-💡 如果正在使用mart、mBART-50或M2 M100等多语言标记器,则需要在tokenizer中设置tokenizer.src_lang和tokenizer.tgt_lang为正确的输入和目标的语言代码。
+💡 如果你在使用一个多语言的 tokenizer,比如 mBART,mBART-50,或者 M2M100,你需要通过设置 `tokenizer.src_lang` 和 `tokenizer.tgt_lang` 来在 tokenizer 中指定输入和目标的语言代码。
-我们的数据准备非常简单。 只有一件事要记住; 您需要确保分词器以输出语言(此处为法语)处理目标。 您可以通过将目标传递给分词器的 __call__ 方法的 text_targets 参数来完成此操作。
+我们的数据准备相当简单。只有一点要记住;你需要确保 tokenizer 处理的目标是输出语言(在这里是法语)。你可以通过将目标语言传递给 tokenizer 的 `__call__` 方法的 `text_targets` 参数来完成此操作。
-为了了解这是如何工作的,让我们处理训练集中每种语言的一个样本:
+为了演示设置的方法,让我们处理训练集中的一个样本:
```python
en_sentence = split_datasets["train"][1]["translation"]["en"]
@@ -198,7 +198,7 @@ inputs
{'input_ids': [47591, 12, 9842, 19634, 9, 0], 'attention_mask': [1, 1, 1, 1, 1, 1], 'labels': [577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]}
```
-正如我们所见,输出包含与英语句子关联的输入 ID,而与法语句子关联的 ID 存储在“labels”字段中。 如果您忘记表明您正在对标签进行分词,它们将由输入分词器进行分词,这在 Marian 模型的情况下根本不会顺利进行:
+我们可以看到,输出包含了与英语句子的 `inputs IDs`,而与法语句子的 IDs 存储在 `labels` 字段中。如果你忘记设置 labels 的 `tokenizer`,默认情况下 `labels` 将由输入的 `tokenizer`(语言类型不一样) 进行 `tokenize`,对于 Marian 模型来说,效果不会很好。
```python
wrong_targets = tokenizer(fr_sentence)
@@ -211,9 +211,9 @@ print(tokenizer.convert_ids_to_tokens(inputs["labels"]))
['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
```
-正如我们所看到的,使用英语标记器来预处理法语句子会产生更多的标记,因为标记器不知道任何法语单词(除了那些也出现在英语语言中的单词,比如“discussion”)。
+如你所见,如果用英语的 tokenizer 来预处理法语句子,会产生更多的 tokens,因为这个 tokenizer 不认识任何法语单词(除了那些在英语里也出现的,比如“discussion”)。
-由于“inputs”是一个包含我们常用键(输入 ID、注意掩码等)的字典,最后一步是定义我们将应用于数据集的预处理函数:
+最后一步是定义我们数据集的预处理函数:
```python
max_length = 128
@@ -228,21 +228,21 @@ def preprocess_function(examples):
return model_inputs
```
-请注意,我们为输入和输出设置了相同的最大长度。由于我们处理的文本看起来很短,我们使用 128。
+请注意,上述代码也为输入和输出设置了相同的最大长度。由于要处理的文本看起来很短,因此在这里将最大长度设置为 128。
-💡如果你使用的是T5模型(更具体地说,是T5 -xxx检查点之一),模型将需要文本输入有一个前缀来表示正在进行的任务,例如从英语到法语的翻译
+💡 如果你正在使用 T5 模型(更具体地说,一个 `t5-xxx` checkpoint ),模型会期望文本输入有一个前缀指示目前的任务,比如 `translate: English to French:` 。
-⚠️ 我们不关注目标的注意力掩码,因为模型不会需要它。相反,对应于填充标记的标签应设置为-100,以便在loss计算中忽略它们。这将在稍后由我们的数据整理器完成,因为我们正在应用动态填充,但是如果您在此处使用填充,您应该调整预处理函数以将与填充标记对应的所有标签设置为 -100。
+⚠️ 我们不需要对待遇测的目标设置注意力掩码,因为模型序列到序列的不会需要它。不过,我们应该将填充(padding) token 对应的标签设置为 `-100` ,以便在 loss 计算中忽略它们。由于我们正在使用动态填充,这将在稍后由我们的数据整理器完成,但是如果你在此处就打算进行填充,你应该调整预处理函数,将所有填充(padding) token 对应的标签设置为 `-100` 。
-我们现在可以对数据集的所有数据一次性应用该预处理:
+我们现在可以一次性使用上述预处理处理数据集的所有数据。
```py
tokenized_datasets = split_datasets.map(
@@ -252,15 +252,15 @@ tokenized_datasets = split_datasets.map(
)
```
-现在数据已经过预处理,我们准备好微调我们的预训练模型!
+现在数据已经过预处理,我们准备好微调我们的预训练模型了!
{#if fw === 'pt'}
-## 使用 Trainer API 微调模型 [[使用 Trainer API 微调模型]]
+## 使用 `Trainer` API 微调模型 [[使用 `Trainer` API 微调模型]]
-使用 `Trainer` 的实际代码将与以前相同,只是稍作改动:我们在这里使用 [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer), 它是 `Trainer` 的子类,它可以正确处理这种序列到序列的评估,并使用 `generate()` 方法来预测输入的输出。 当我们讨论评估指标时,我们将更详细地探讨这一点。
+使用 `Trainer` 的代码将与以前相同,只是稍作改动:我们在这里将使用 [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) ,它是 `Trainer` 的子类,它使用 `generate()` 方法来预测输入的输出结果,并且可以正确处理这种序列到序列的评估。当我们讨论评估指标时,我们将更详细地探讨这一点。
-首先,我们需要一个实际的模型来进行微调。 我们将使用通常的 `AutoModel` API:
+首先,我们需要一个模型来进行微调。我们将使用常用的 `AutoModel` API:
```py
from transformers import AutoModelForSeq2SeqLM
@@ -272,7 +272,7 @@ model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
## 使用 Keras 微调模型 [[使用 Keras 微调模型]]
-首先,我们需要一个实际的模型来进行微调。 我们将使用通常的 `AutoModel` API:
+首先,我们需要一个模型来进行微调。我们将使用常用的 `AutoModel` API:
```py
from transformers import TFAutoModelForSeq2SeqLM
@@ -282,19 +282,19 @@ model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
-💡 `Helsinki-NLP/opus-mt-en-fr` checkpoint只有 PyTorch 的权重,所以在使用`from_pretrained()`方法加载模型时不会使用 `from_pt=True` 参数。 当您指定`from_pt=True`,库会自动下载并转换PyTorch 为您提供权重。 如您所见,使用🤗transormer 在两者之间切换非常简单
+💡 `Helsinki-NLP/opus-mt-en-fr` checkpoint 只有 PyTorch 的权重,所以如果你尝试使用 `from_pretrained()` 方法加载模型并且忘记设置`from_pt=True` 参数的时候,你会得到一个错误。当你设定 `from_pt=True` 时,🤗transormer 会自动下载并为你转换 PyTorch 权重。如你所见,使用🤗transormer 在两种框架之间切换非常简单。
{/if}
-请注意,这次我们使用的是在翻译任务上训练过的模型,并且实际上已经可以使用,因此没有关于丢失权重或新初始化权重的警告。
+注意,这次我们使用的是一个已经在翻译任务上进行过训练的模型,实际上已经可以直接使用了,所以没有收到关于缺少权重或重新初始化的权重的警告。
### 数据整理 [[数据整理]]
-我们需要一个数据整理器来处理动态批处理的填充。在本例中,我们不能像[第3章](/course/chapter3)那样使用带填充的**DataCollatorWithPadding**,因为它只填充输入(输入ID、注意掩码和令牌类型ID)。我们的标签也应该填充到标签中遇到的最大长度。而且,如前所述,用于填充标签的填充值应为-100,而不是标记器的填充标记,以确保在损失计算中忽略这些填充值。
+在这个任务中,我们需要一个数据整理器来动态批处理填充。因此,我们不能像 [第三章](/course/chapter3) 那样直接使用 `DataCollatorWithPadding` ,因为它只填充输入的部分(inputs ID、注意掩码和 token 类型 ID)。我们的标签也应该被填充到所有标签中最大的长度。而且,如前所述,用于填充标签的填充值应为 `-100` ,而不是 tokenizer 默认的的填充 token,这样才可以在确保在损失计算中忽略这些填充值。
-这一切都可以由 [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq) 完成。 与 `DataCollatorWithPadding` 一样,它采用用于预处理输入的`tokenizer`,但它也采用`model`。 这是因为数据整理器还将负责准备解码器输入 ID,它们是标签偏移之后形成的,开头带有特殊标记。 由于不同架构的这种转变略有不同,因此“DataCollatorForSeq2Seq”需要知道“模型”对象:
+上述的这些需求都可以由 [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq) 完成。它与 `DataCollatorWithPadding` 一样,它接收用于预处理输入的 `tokenizer` ,同时它也接收一个 `model` 参数。这是因为数据整理器还将负责准备解码器 `inputs ID`,它们是标签偏移之后形成的,开头带有特殊 `token` 。由于对于不同的模型架构有稍微不同的偏移方式,所以 `DataCollatorForSeq2Seq` 还需要接收 `model` 对象:
{#if fw === 'pt'}
@@ -314,7 +314,7 @@ data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="t
{/if}
-为了在几个样本上进行测试,我们只需在我们标记化训练集中的部分数据上调用它:
+为了在几个样本上进行测试,我们在已经完成 tokenize 的训练集中的部分数据上调用它,测试一下其功能:
```py
batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
@@ -325,7 +325,7 @@ batch.keys()
dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
```
-我们可以检查我们的标签是否已使用 **-100** 填充到批次的最大长度:
+我们可以检查我们的标签是否已经用 `-100` 填充到 batch 的最大长度:
```py
batch["labels"]
@@ -338,7 +338,7 @@ tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
550, 7032, 5821, 7907, 12649, 0]])
```
-我们还可以查看解码器输入 ID,看看它们是标签的偏移形成的版本:
+我们还可以查看解码器的 inputs ID,可以看到它们是标签经过偏移后的结果:
```py
batch["decoder_input_ids"]
@@ -365,11 +365,10 @@ for i in range(1, 3):
{#if fw === 'pt'}
-我们将把这个 `data_collator` 传递给 `Seq2SeqTrainer`。 接下来,让我们看一下评估指标。
-
+把 `data_collator` 传递给 `Seq2SeqTrainer` 后就完成了数据整理。接下来,让我们看一下评估指标。
{:else}
-我们现在可以使用 `data_collator` 将我们的每个数据集转换为 `tf.data.Dataset`,准备好进行训练:
+我们现在可以使用 `data_collator` 将我们的每个数据集转换为 `tf.data.Dataset` ,这样就完成了数据整理:
```python
tf_train_dataset = model.prepare_tf_dataset(
@@ -395,22 +394,22 @@ tf_eval_dataset = model.prepare_tf_dataset(
{#if fw === 'pt'}
-`Seq2SeqTrainer` 添加到其超类 `Trainer` 的功能是在评估或预测期间使用 `generate()` 方法的能力。 在训练期间,模型将使用带有注意掩码的“decoder_input_ids”,以确保它不使用预测的标记之后的标记,以加快训练速度。 在推理过程中,我们将无法使用预测的标记之后的标记,因为我们没有标签,因此使用相同的设置使用带有注意掩码的“decoder_input_ids”,评估我们的模型是个好主意。
+`Seq2SeqTrainer` 是 `Trainer` 类的一个子类,它的主要增强特性是在评估或预测时使用 `generate()` 方法。在训练过程中,模型会利用 `decoder_input_ids` 和一个特殊的注意力掩码来加速训练。这种方法允许模型在预测下一个token时看到部分目标序列,但确保它不会使用预测token之后的信息。这种优化策略显著提高了训练效率。然而,在实际的推理过程中,我们没有真实的标签值,因此无法生成 `decoder_input_ids` 和相应的注意力掩码。这意味着我们无法在推理时使用这种训练时的优化方法。
-正如我们在[第一章](/course/chapter1/6)看到的,解码器通过一个一个地预测标记来执行推理——这是🤗 Transformers 在幕后通过 **generate()** 方法实现的。如果我们设置 predict_with_generate=True,Seq2 Seq Trainer 将允许我们使用该方法进行评估。
+为了确保评估结果能够准确反映模型在实际使用中的表现,我们应该在评估阶段模拟真实推理的条件。这意味着我们需要使用在 [第一章](/course/chapter1/6) 中介绍的 🤗 Transformers 库中的 `generate()` 方法。该方法能够逐个生成token,真实地模拟推理过程,而不是依赖于训练时的优化技巧。要启用这个功能,我们需要在训练时添加 `predict_with_generate=True` 参数。这样做可以确保我们的评估结果更加接近模型在实际应用中的表现。
{/if}
-用于翻译的传统指标是[BLEU 分数](https://en.wikipedia.org/wiki/BLEU), 由Kishore Papineni等人在[2002年的一篇文章](https://aclanthology.org/P02-1040.pdf)中引入。BLEU 分数评估翻译与其标签的接近程度。它不衡量模型生成输出的可懂度或语法正确性,而是使用统计规则来确保生成输出中的所有单词也出现在目标中。此外,如果相同单词在目标中没有重复,则有规则惩罚相同单词的重复(以避免模型输出类似 **the the the the the**的句子 ) 并输出比目标中短的句子(以避免模型输出像 **the** 这样的句子)。
+用于翻译的传统指标是 [BLEU 分数](https://en.wikipedia.org/wiki/BLEU) ,它最初由 Kishore Papineni 等人在 2002 年的 [一篇文章](https://aclanthology.org/P02-1040.pdf) 中引入。BLEU 分数评估翻译与参考翻译的接近程度。它不衡量模型生成输出的可理解性或语法正确性,而是使用统计规则来确保生成输出中的所有单词也出现在参考的输出中。此外,还有一些规则对重复的词进行惩罚,如果这些词在输出中重复出现(模型输出像“the the the the the”这样的句子);或者输出的句子长度比目标中的短(模型输出像“the”这样的句子)都会被惩罚。
-BLEU 的一个缺点是它需要文本已经被分词,这使得比较使用不同标记器的模型之间的分数变得困难。因此,当今用于基准翻译模型的最常用指标是[SacreBLEU](https://github.com/mjpost/sacrebleu),它通过标准化标记化步骤解决了这个缺点(和其他的一些缺点)。要使用此指标,我们首先需要安装 SacreBLEU 库:
+BLEU 的一个缺点是的输入是已分词的文本,这使得比较使用不同分词器的模型之间的分数变得困难。因此,当今用于评估翻译模型的最常用指标是 [SacreBLEU](https://github.com/mjpost/sacrebleu) ,它通过标准化的分词步骤解决了这个缺点(和其他的一些缺点)。要使用此指标,我们首先需要安装 SacreBLEU 库:
```py
!pip install sacrebleu
```
-然后我们可以就像我们在[第三章](/course/chapter3)那样通过 **evaluate.load()** 加载它 :
+然后我们可以就像在 [第三章](/course/chapter3) 那样通过 `evaluate.load()` 加载它
```py
import evaluate
@@ -418,7 +417,7 @@ import evaluate
metric = evaluate.load("sacrebleu")
```
-该指标将文本作为输入和目标结果。它旨在接受多个可接受的目标,因为同一个句子通常有多个可接受的翻译——我们使用的数据集只提供一个,但在 NLP 中找到将多个句子作为标签的数据集不是一个难题。因此,预测结果应该是一个句子列表,而参考应该是一个句子列表的列表。
+SacreBLEU 指标中待评估的预测和参考的目标译文输入的格式都是文本。它的设计是为了支持多个参考翻译,因为同一句话通常有多种可接受的翻译——虽然我们使用的数据集只提供一个,但在 NLP 中找到将多个句子作为标签的数据集是很常见的。因此,预测结果应该是一个句子列表,而参考应该是一个句子列表的列表。
让我们尝试一个例子:
@@ -444,7 +443,7 @@ metric.compute(predictions=predictions, references=references)
'ref_len': 13}
```
-这得到了 46.75 的 BLEU 分数,这是相当不错的——作为参考,原始 Transformer 模型在[“Attention Is All You Need” 论文](https://arxiv.org/pdf/1706.03762.pdf)类似的英语和法语翻译任务中获得了 41.8 的 BLEU 分数! (有关各个指标的更多信息,例如 **counts** 和 **bp** ,见[SacreBLEU 仓库](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74).) 另一方面,如果我们尝试使用翻译模型中经常出现的两种糟糕的预测类型(大量重复或太短),我们将得到相当糟糕的 BLEU 分数:
+达到了 46.75 的 BLEU 分数,这是相当不错的——作为参考,原始 Transformer 模型在 [“Attention Is All You Need” 论文](https://arxiv.org/pdf/1706.03762.pdf) 类似的英语和法语翻译任务中获得了 41.8 的 BLEU 分数!(关于其他指标的含义,例如 `counts` 和 `bp` ,可以参见 [SacreBLEU仓库](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74) )另一方面,如果我们尝试将翻译模型中经常出现的两种糟糕的预测类型(大量重复或太短)输入给指标计算的函数,我们将得到相当糟糕的 BLEU 分数:
```py
predictions = ["This This This This"]
@@ -490,7 +489,9 @@ metric.compute(predictions=predictions, references=references)
{#if fw === 'tf'}
-为了将模型输出的向量转换为可以使用的文本,我们将使用 `tokenizer.batch_decode()` 方法。 我们只需要清除标签中的所有“-100”; tokenizer 将自动对填充令牌执行相同的操作。 让我们定义一个函数,它接受我们的模型和数据集并计算其指标。 我们还将使用一个可以显着提高性能的技巧 - 使用 TensorFlow 的加速线性代数编译器 [XLA](https://www.tensorflow.org/xla) 编译我们的生成代码。 XLA 对模型的计算图应用了各种优化,并显着提高了速度和内存使用率。 正如 Hugging Face [博客](https://huggingface.co/blog/tf-xla-generate) 中所述,当我们的输入形状变化不大时,XLA 效果最佳。 为了处理这个问题,我们将输入填充为 128 的倍数,并使用填充整理器创建一个新数据集,然后我们将 @tf.function(jit_compile=True) 装饰器应用于我们的生成函数,将整个函数标记为使用 XLA 进行编译。
+为了将模型的输出转化为评估指标可以使用的文本,我们将利用 `tokenizer.batch_decode()` 方法。因为 tokenizer 会自动处理填充 `tokens`,所以我们只需要清理所有标签中的 填充的`-100` 。让我们定义一个函数,这个函数会接收一个模型和一个数据集,并在其上计算 BLEU 指标。
+
+我们还将使用一个显著提升性能的技巧 - 使用 [XLA](https://www.tensorflow.org/xla) ,TensorFlow 的线性代数加速编译器,编译我们的生成代码。XLA 对模型的计算图进行了各种优化,从而显著提升了速度和内存使用率。如 Hugging Face 的 [博客](https://huggingface.co/blog/tf-xla-generate) 所述,当我们的输入形状比较整齐时,XLA 能够很好地提高计算效率。因此,我们需要用填充整理器制作一个新的数据集,把输入补齐到 128 的倍数,然后我们使用 `@tf.function(jit_compile=True)` 装饰器装饰我们的生成函数,这将把整个函数标记为使用 XLA 编译。
```py
import numpy as np
@@ -545,7 +546,7 @@ def compute_metrics():
{:else}
-为了从模型输出到度量可以使用的文本,我们将使用 `tokenizer.batch_decode()` 方法。 我们只需要清理标签中的所有 `-100`(标记器将自动对填充标记执行相同操作):
+为了将模型的输出转化为评估指标可以使用的文本,我们将使用 `tokenizer.batch_decode()` 方法。因为 tokenizer 会自动处理填充的 tokens,所以我们只需要清理标签中的所有 `-100` token:
```py
import numpy as np
@@ -553,17 +554,17 @@ import numpy as np
def compute_metrics(eval_preds):
preds, labels = eval_preds
- # In case the model returns more than the prediction logits
+ # 如果模型返回的内容超过了预测的logits
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
- # Replace -100s in the labels as we can't decode them
+ # 由于我们无法解码 -100,因此将标签中的 -100 替换掉
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
- # Some simple post-processing
+ # 一些简单的后处理
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
@@ -577,7 +578,7 @@ def compute_metrics(eval_preds):
### 微调模型 [[微调模型]]
-第一步是登录 Hugging Face,这样您就可以将结果上传到模型中心。有一个方便的功能可以帮助您在notebook中完成此操作:
+第一步是登录 Hugging Face,这样你就可以在训练过程中将结果上传到 Hub中。有一个方便的功能可以帮助你在 notebook 中完成登陆:
```python
from huggingface_hub import notebook_login
@@ -585,9 +586,9 @@ from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件,您可以在其中输入您的 Hugging Face 登录凭据。
+这将显示一个小部件,你可以在其中输入你的 Hugging Face 登录凭据。
-如果您不是在notebook上运行代码,只需在终端中输入以下行:
+如果你不是在 notebook 上运行代码,可以在终端中输入以下命令:
```bash
huggingface-cli login
@@ -595,8 +596,7 @@ huggingface-cli login
{#if fw === 'tf'}
-在我们开始之前,让我们看看我们在没有任何训练的情况下从我们的模型中得到了什么样的结果:
-
+在我们开始之前,让我们看看我们在没有任何训练的情况下我们的模型效果怎么样。
```py
print(compute_metrics())
```
@@ -605,16 +605,17 @@ print(compute_metrics())
{'bleu': 33.26983701454733}
```
-一旦完成,我们就可以准备编译和训练模型所需的一切。 注意当使用 `tf.keras.mixed_precision.set_global_policy("mixed_float16")`时——这将告诉 Keras 使用 float16 进行训练,这可以显着提高支持它的 GPU(Nvidia 20xx/V100 或更高版本)的速度。
+现在可以准备编译和训练模型了。运行 `tf.keras.mixed_precision.set_global_policy("mixed_float16")` 后, Keras 将使用 float16 精度进行训练,这样可以显著提高支持半精度 GPU(Nvidia 20xx/V100 或更高版本)的训练速度
```python
from transformers import create_optimizer
from transformers.keras_callbacks import PushToHubCallback
import tensorflow as tf
-# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
-# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
-# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+# 训练步数是数据集中的样本数量,除以 batch 大小,然后乘以总的 epoch 数。
+# 注意这里的 tf_train_dataset 是 batch 形式的 tf.data.Dataset,
+# 而不是原始的 Hugging Face Dataset ,所以使用 len() 计算它的长度已经是 num_samples // batch_size。
+
num_epochs = 3
num_train_steps = len(tf_train_dataset) * num_epochs
@@ -626,11 +627,11 @@ optimizer, schedule = create_optimizer(
)
model.compile(optimizer=optimizer)
-# Train in mixed-precision float16
+# 使用 float16 混合精度进行训练
tf.keras.mixed_precision.set_global_policy("mixed_float16")
```
-接下来,我们定义一个 `PushToHubCallback` 以便在训练期间将我们的模型上传到 Hub,正如我们在 [第 2 节]((/course/chapter7/2)) 中看到的,然后我们只需拟合模型时添加该回调函数:
+接下来就像我们在 [第 2 节](/course/chapter7/2) 中学到的,我们将定义一个 `PushToHubCallback` 回调函数,并拟合模型的时候添加该回调函数,这样就可以训练期间将我们的模型上传到 Hub。
```python
from transformers.keras_callbacks import PushToHubCallback
@@ -647,15 +648,15 @@ model.fit(
)
```
-请注意,您可以使用 `hub_model_id` 参数指定要推送到的存储库的名称(当您想把模型推送到指定的组织的时候,您也必须使用此参数)。 例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们添加了 `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` 到 `Seq2SeqTrainingArguments`。 默认情况下,使用的存储库将在您的命名空间中,并以您设置的输出目录命名,因此这里将是 `"sgugger/marian-finetuned-kde4-en-to-fr"`。
+请注意,你可以使用 `hub_model_id` 参数指定要推送到的模型仓库的名称(当你想把模型推送到指定的组织的时候,就必须使用此参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们在 `Seq2SeqTrainingArguments`添加了 `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` 。默认情况下,该仓库将保存在你的账户里,并以你设置的输出目录命名,因此在我们的例子中它是 `"sgugger/marian-finetuned-kde4-en-to-fr"` 。
-💡如果您使用的输出目录已经存在,则它需要是您要推送到的存储库的本地克隆。如果不是,您将在定义您的名称时会遇到错误,并且需要设置一个新名称。
+💡如果正在使用的输出目录已经存在一个同名的文件夹,则它应该是目标推送仓库的在本地克隆在本地的版本。如果不是,当调用 `model.fit()` 时会收到错误,并需要设置一个新的路径。
-最后,让我们看看训练结束后我们的指标是什么样的:
+最后,让我们看看训练结束后我们的模型的 BLEU 的分数:
```py
print(compute_metrics())
@@ -665,11 +666,11 @@ print(compute_metrics())
{'bleu': 57.334066271545865}
```
-在这个阶段,您可以使用模型中心上的推理小部件来测试您的模型并与您的朋友分享。 您已经成功地微调了翻译任务中的模型——恭喜!
+在这个阶段,你可以使用模型中心上的推理小部件来测试你的模型并与你的朋友分享。恭喜你,你已经成功地在翻译任务上微调了一个模型!
{:else}
-一旦完成,我们就可以定义我们的 `Seq2SeqTrainingArguments`。 与 `Trainer` 一样,我们使用 `TrainingArguments` 的子类,其中包含更多可以设置的字段:
+完成这些步骤之后,我们就可以定义我们的 `Seq2SeqTrainingArguments` 了。与 `Trainer` 一样,它是 `TrainingArguments` 的子类,其中包含更多可以设置的字段:
```python
from transformers import Seq2SeqTrainingArguments
@@ -690,23 +691,22 @@ args = Seq2SeqTrainingArguments(
)
```
-除了通常的超参数(如学习率、训练轮数、批次大小和一些权重衰减)之外,与我们在前几节中看到的相比,这里有一些变化:
+除了通常的超参数(如学习率、训练轮数、批次大小和一些权重衰减)之外,这里的部分参数与我们在前面章节看到的有一些不同:
-- 我们没有设置任何定期评估,因为评估需要耗费一定的时间;我们只会在训练开始之前和结束之后评估我们的模型一次。
-- 我们设置fp16=True,这可以加快支持fp16的 GPU 上的训练速度。
-- 和上面我们讨论的那样,我们设置predict_with_generate=True
-- 我们用push_to_hub=True在每个 epoch 结束时将模型上传到 Hub。
+- 我们没有设置定期进行评估,因为评估需要耗费一定的时间;我们将只在训练开始之前和结束之后评估我们的模型一次。
+- 我们设置 `fp16=True` ,这可以加快在支持 fp16 的 GPU 上的训练速度。
+- 和之前我们讨论的一样,我们设置 `predict_with_generate=True` 。
+- 我们设置了 `push_to_hub=True` ,在每个 epoch 结束时将模型上传到 Hub。
-请注意,您可以使用 `hub_model_id` 参数指定要推送到的存储库的名称(当您想把模型推送到指定的组织的时候,您也必须使用此参数)。 例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们添加了 `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` 到 `Seq2SeqTrainingArguments`。 默认情况下,使用的存储库将在您的命名空间中,并以您设置的输出目录命名,因此这里将是 `"sgugger/marian-finetuned-kde4-en-to-fr"`。
+请注意,你可以使用 `hub_model_id` 参数指定要推送到的存储库的名称(当你想把模型推送到指定的组织的时候,就必须使用此参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们在 `Seq2SeqTrainingArguments` 添加了 `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` 。默认情况下,该仓库将保存在你的账户中,并以你设置的输出目录命名,因此在我们的例子中它是 `"sgugger/marian-finetuned-kde4-en-to-fr"` 。
-💡如果您使用的输出目录已经存在,则它需要是您要推送到的存储库的本地克隆。如果不是,您将在定义您的名称时会遇到错误,并且需要设置一个新名称。
+💡如果你使用的输出目录已经存在一个同名的文件夹,则它应该是推送的仓库克隆在本地的版本。如果不是,你将在定义你的 `Seq2SeqTrainer` 名称时会遇到错误,并且需要设置一个新名称。
-
-最后,我们需要将所有内容传递给 **Seq2SeqTrainer** :
+最后,我们将所有内容传递给 `Seq2SeqTrainer` :
```python
from transformers import Seq2SeqTrainer
@@ -722,7 +722,7 @@ trainer = Seq2SeqTrainer(
)
```
-在训练之前,我们将首先查看我们的模型获得的分数,以仔细检查我们的微调没有让事情变得更糟。此命令需要一些时间,因此您可以在执行时喝杯咖啡:
+在开始训练之前,我们先查看一下我们的模型目前的 BLEU 分数,以确保我们的微调并未使情况变得更糟。这个命令需要一些时间,所以你可以在执行期间去喝杯咖啡:
```python
trainer.evaluate(max_length=max_length)
@@ -736,7 +736,7 @@ trainer.evaluate(max_length=max_length)
'eval_steps_per_second': 0.341}
```
-BLEU的分数还不错,这反映了我们的模型已经擅长将英语句子翻译成法语句子。
+BLEU 得分为 39 并不算太差,这反映了我们的模型已经擅长将英语句子翻译成法语句子。
接下来是训练,这也需要一些时间:
@@ -744,9 +744,9 @@ BLEU的分数还不错,这反映了我们的模型已经擅长将英语句子
trainer.train()
```
-请注意,当训练发生时,每次保存模型时(这里是每个时期),它都会在后台上传到 Hub。这样,如有必要,您将能够在另一台机器上继续您的训练。
+请注意,在训练过程中,每当保存模型时(这里是每个 epoch),它都会在后台将模型上传到 Hub。这样,如有必要,你将能够在另一台机器上继续你的训练。
-训练完成后,我们再次评估我们的模型——希望我们会看到 BLEU 分数有所改善!
+训练完成后,我们再次评估我们的模型——希望我们会看到 BLEU 分数有所提高!
```py
trainer.evaluate(max_length=max_length)
@@ -761,23 +761,23 @@ trainer.evaluate(max_length=max_length)
'epoch': 3.0}
```
-这是近 14 点的改进,这很棒。
+可以看到近 14 点的改进,这很棒!
-最后,我们使用 **push_to_hub()** 方法来确保我们上传模型的最新版本。这 **Trainer** 还创建了一张包含所有评估结果的模型卡并上传。此模型卡包含可帮助模型中心为推理演示选择小部件的元数据。通常不需要做额外的更改,因为它可以从模型类中推断出正确的小部件,但在这种情况下,相同的模型类可以用于所有类型的序列到序列问题,所以我们指定它是一个翻译模型:
+最后,我们使用 `push_to_hub()` 方法来确保我们上传了模型最新的版本。 `Trainer` 还创建了一张包含所有评估结果的模型卡片并上传到 Hub 。这个模型卡片包含了可以帮助 Hub 为推理演示选择小部件的元数据,通常情况下我们不需要做额外的更改,因为它可以从模型类中推断出正确的小部件,但在这个示例中,它只能通过模型类推断这是一个序列到序列的问题,所以我们补充一下具体的模型类别。
```py
trainer.push_to_hub(tags="translation", commit_message="Training complete")
```
-如果您想检查命令执行的结果,此命令将返回它刚刚执行的提交的 URL,可以打开url进行检查:
+如果你想检查命令执行的结果,此命令将返回它刚刚执行的提交的 URL,你可以打开 url 进行检查:
```python out
'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
```
-在此阶段,您可以使用模型中心上的推理小部件来测试您的模型并与您的朋友分享。您已成功微调翻译任务的模型 - 恭喜!
+在此阶段,你可以在 Model Hub 上使用推理小部件来测试你的模型,并与你的朋友分享。你已经成功地在翻译任务上进行了模型的微调,恭喜你!
-如果您想更深入地了解训练循环,我们现在将向您展示如何使用 🤗 Accelerate 做同样的事情。
+如果你想更深入地了解训练循环,我们现在将向你展示如何使用 🤗 Accelerate 做同样的事情。
{/if}
@@ -785,11 +785,11 @@ trainer.push_to_hub(tags="translation", commit_message="Training complete")
## 自定义训练循环 [[自定义训练循环]]
-现在让我们看一下完整的训练循环,以便您可以轻松自定义所需的部分。它看起来很像我们在[本章第二节](/course/chapter7/2)和[第三章第四小节](/course/chapter3/4)所做的。
+我们现在来看一下完整的训练循环,这样你就可以轻松定制你需要的部分。它将与我们在 [第 2 节](https://chat.openai.com/course/chapter7/2) 和 [第 3 节](https://chat.openai.com/course/chapter3/4) 中做的非常相似。
### 准备训练所需的一切 [[准备训练所需的一切]]
-您已经多次看到所有这些,因此这一块会简略进行。首先我们将构建我们的数据集的**DataLoader** ,在将数据集设置为 **torch** 格式,我们就得到了 PyTorch 张量:
+由于这里的步骤在之前的章节已经出现过很多次,因此这里只做简略说明。首先,我们将数据集设置为 `torch` 格式,这样可以将数据集的格式转换为 `PyTorch` 张量,然后我们用数据集构建 `DataLoader` :
```py
from torch.utils.data import DataLoader
@@ -820,7 +820,7 @@ from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
```
-一旦我们拥有所有这些对象,我们就可以将它们发送到 `accelerator.prepare()` 方法。 请记住,如果您想在 Colab 笔记本训练中使用TPU,则需要将所有这些代码移动到训练函数中,并且不应执行任何实例化“加速器”的对象。
+准备好这些对象,我们就可以将它们发送到 `accelerator.prepare()` 方法中。请记住,如果你想在 Colab Notebook 上使用 TPU 进行训练,你需要将所有这些代码移动到一个训练函数中,并且这个训练函数不应该包含实例化 `Accelerator` `的代码。换句话说,Accelerator` 的实例化应该在这个函数之外进行。这么做的原因是,TPU 在 Colab 中的工作方式有些特殊。TPU 运行时会重新执行整个单元格的代码,因此如果 `Accelerator` 的实例化在训练函数内部,它可能会被多次实例化,导致错误。
```py
from accelerate import Accelerator
@@ -831,7 +831,7 @@ model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
)
```
-现在我们已经发送了我们的 **train_dataloader** 到 **accelerator.prepare()** ,我们可以使用它的长度来计算训练步骤的数量。请记住,我们应该始终在准备好数据加载器后执行此操作,因为该方法会更改 **DataLoader** .我们使用从学习率衰减到 0 的经典线性学习率调度:
+现在我们已经将我们的 `train_dataloader` 发送到 `accelerator.prepare()` 方法中了,现在我们可以使用它的长度来计算训练步骤的数量。请记住,我们应该始终在准备好数据加载器后再执行此操作,因为更改数据加载器会改变 `DataLoader` 的长度。然后,我们使用学习率衰减到 0 的经典线性学习率调度:
```py
from transformers import get_scheduler
@@ -848,7 +848,7 @@ lr_scheduler = get_scheduler(
)
```
-最后,要将我们的模型推送到 Hub,我们需要创建一个 **Repository** 工作文件夹中的对象。如果您尚未登录,请先登录 Hugging Face。我们将从我们想要为模型提供的模型 ID 中确定存储库名称(您可以自由地用自己的选择替换 **repo_name** ;它需要包含您的用户名,可以使用**get_full_repo_name()**函数的查看目前的repo_name):
+最后,为了将我们的模型推送到 Hugging Face Hub,我们需要在一个工作文件夹中创建一个 `Repository` 对象。如果你尚未登录 Hugging Face,请先进行登录。我们将根据模型 ID 来确定仓库名称。你可以使用自己选择的名称替换 `repo_name`,但请确保包含你的用户名。如果你不确定当前的用户名,可以使用` get_full_repo_name()` 函数来查看:
```py
from huggingface_hub import Repository, get_full_repo_name
@@ -862,18 +862,18 @@ repo_name
'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
```
-然后我们可以在本地文件夹中克隆该存储库。如果它已经存在,这个本地文件夹应该是我们正在使用的存储库的克隆:
+然后我们可以在本地文件夹中克隆该存储库。如果已经存在一个同名的文件夹,这个本地文件夹应该是我们正在使用的存储库克隆到本地的版本:
```py
output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
```
-我们现在可以通过调用 **repo.push_to_hub()** 方法上传我们保存的任何内容 **output_dir** 。这将帮助我们在每个 epoch 结束时上传过程中的模型。
+现在,我们可以通过调用 `repo.push_to_hub()` 方法上传我们在 `output_dir` 中保存的所有文件。这将帮助我们在每个 epoch 结束时上传中间模型。
### 训练循环 [[训练循环]]
-我们现在准备编写完整的训练循环。为了简化它的评估部分,我们定义了这个 **postprocess()** 函数接收预测结果和正确标签并将它们转换为我们 **metric** 对象所需要的字符串列表:
+我们现在准备编写完整的训练循环。为了简化其评估部分,我们定义了这个 `postprocess()` 函数用于接收预测值和参考翻译对于的标签值,并将其转换为 `metric` 对象所需要的字符串列表。:
```py
def postprocess(predictions, labels):
@@ -882,21 +882,23 @@ def postprocess(predictions, labels):
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
- # Replace -100 in the labels as we can't decode them.
+ # 替换标签中的 -100,因为我们无法解码它们。
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
- # Some simple post-processing
+ # 一些简单的后处理
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
return decoded_preds, decoded_labels
```
-训练循环看起来和[本章第二节](/course/chapter7/2)与[第三章](/course/chapter3)很像,在评估部分有一些不同 - 所以让我们专注于这一点!
+训练循环看起来和本章 [第 2 节](/course/chapter7/2) 与 [第三章](/course/chapter3) 中代码很相似,只是在评估部分有一些不同 —— 所以让我们重点关注一下这一点!
+
+首先要注意的是,我们使用 `generate()` 方法来计算预测,但这是我们基础模型上的一个方法,而不是🤗 Accelerate 在 `prepare()` 方法中创建的封装模型。这就是为什么我们首先 `unwrap_model` ,然后调用此方法。
-首先要注意的是我们使用 `generate()` 方法来计算预测,但这是我们基础模型上的一个方法,而不是包装模型🤗 Accelerate 在 `prepare()` 方法中创建。 这就是为什么我们先解包模型,然后调用这个方法。
+首先要注意的是,我们用来计算预测的 `generate()` 函数是基础模型上的一个方法,而不是🤗 Accelerate 在 `prepare()` 函数中创建的封装模型。这就是在调用此函数之前先调用`unwrap_model`,的原因。
-第二件事是,就像[token 分类](/course/chapter7/2),两个进程可能将输入和标签填充为不同的形状,因此我们在调用 **gather()** 方法之前使用 **accelerator.pad_across_processes()** 使预测和标签具有相同的形状。如果我们不这样做,评估要么出错,要么永远在阻塞。
+第二个要注意的是,就像 [token 分类](https://chat.openai.com/course/chapter7/2) 一样,在训练和评估这两个过程可能以不同的形状对输入和标签进行了填充,所以我们在调用 `gather()` 函数之前使用 `accelerator.pad_across_processes()` 方法,使预测和标签具有相同的形状。如果我们不这么做,那么评估的过程将会出错或被永远挂起。
```py
from tqdm.auto import tqdm
@@ -905,7 +907,7 @@ import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
- # Training
+ # 训练
model.train()
for batch in train_dataloader:
outputs = model(**batch)
@@ -917,7 +919,7 @@ for epoch in range(num_train_epochs):
optimizer.zero_grad()
progress_bar.update(1)
- # Evaluation
+ # 评估
model.eval()
for batch in tqdm(eval_dataloader):
with torch.no_grad():
@@ -928,7 +930,7 @@ for epoch in range(num_train_epochs):
)
labels = batch["labels"]
- # Necessary to pad predictions and labels for being gathered
+ # 需要填充预测和标签才能调用gather()
generated_tokens = accelerator.pad_across_processes(
generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
)
@@ -943,7 +945,7 @@ for epoch in range(num_train_epochs):
results = metric.compute()
print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
- # Save and upload
+ # 保存和上传
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
@@ -960,18 +962,18 @@ epoch 1, BLEU score: 54.24
epoch 2, BLEU score: 54.44
```
-完成此操作后,您应该有一个模型,其结果与使用 `Seq2SeqTrainer` 训练的模型非常相似。 您可以在 [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate)查看训练完的结果。 如果您想测试对训练循环的任何调整,您可以通过编辑上面显示的代码直接实现它们!
+训练完成之后,你就有了一个模型,最终的 BLEU 分数应该与 `Seq2SeqTrainer` 训练的模型非常相似。你可以在 [huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate) 上查看我们使用此代码训练的模型。如果你想测试对训练循环的任何调整,你可以直接通过编辑上面的代码来实现!
{/if}
## 使用微调后的模型 [[使用微调后的模型]]
-我们已经向您展示了如何将我们在模型中心微调的模型与推理小部件一起使用。 要在“管道”中本地使用它,我们只需要指定正确的模型标识符:
+我们已经向你展示了如何在模型 Hub 上使用我们微调的模型。要在本地的 `pipeline` 中使用它,我们只需要指定正确的模型标识符:
```py
from transformers import pipeline
-# Replace this with your own checkpoint
+# 将其替换成你自己的 checkpoint
model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
translator = pipeline("translation", model=model_checkpoint)
translator("Default to expanded threads")
@@ -981,7 +983,7 @@ translator("Default to expanded threads")
[{'translation_text': 'Par défaut, développer les fils de discussion'}]
```
-正如预期的那样,我们的预训练模型将其知识适应了我们对其进行微调的语料库,而不是单独留下英文单词“threads”,而是将其翻译成法语官方版本。 “”的翻译也是一样的:
+和预想的一样,我们的预训练模型适应了我们微调它的语料库,没有保留英语单词“threads”,而是将它翻译成官方的法语版本。对于“plugin”也是如此:
```py
translator(
@@ -993,10 +995,10 @@ translator(
[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
```
-风格适应的另一个很好的例子!
+这是另一个领域适应的好例子!
-✏️ **轮到你了!** “电子邮件”这个词在模型返回了什么?
+✏️ **轮到你了!** 把之前找到的包含单词“email”样本输入模型,会返回什么结果?
diff --git a/chapters/zh-CN/chapter7/5.mdx b/chapters/zh-CN/chapter7/5.mdx
index 95d18d246..f50469f85 100644
--- a/chapters/zh-CN/chapter7/5.mdx
+++ b/chapters/zh-CN/chapter7/5.mdx
@@ -23,19 +23,19 @@
{/if}
-在本节中,我们将看看如何使用 Transformer 模型将长文档压缩为摘要,这项任务称为文本摘要.这是最具挑战性的 NLP 任务之一,因为它需要一系列能力,例如理解长篇文章和生成能够捕捉文档中主要主题的连贯文本。但是,如果做得好,文本摘要是一种强大的工具,可以减轻领域专家详细阅读长文档的负担,从而加快各种业务流程。
+在本节中,我们将看看如何使用 Transformer 模型将长篇文档压缩为摘要,这项任务称为文本摘要。这是最具挑战性的自然语言处理(NLP)任务之一,因为它需要一系列能力,例如理解长篇文章并且生成能够捕捉文档中主要主题的连贯文本。但是,如果做得好,文本摘要是一种强大的工具,可以减轻各个领域的人详细阅读长文档的负担,从而加快业务流程。
-尽管在[Hugging Face Hub](https://huggingface.co/models?pipeline_tag=summarization=downloads)上已经存在各种微调模型用于文本摘要,几乎所有这些都只适用于英文文档。因此,为了在本节中添加一些变化,我们将为英语和西班牙语训练一个双语模型。在本节结束时,您将有一个可以总结客户评论的[模型](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es)。
+尽管在 [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=summarization=downloads) 上已经存在各种提取文本摘要的微调模型,但是几乎所有的这些模型都只适用于英文文档。因此,为了在本节中添加一些不一样的特点,我们将为英语和西班牙语训练一个双语模型。在本节结束时,你将有一个可以总结客户评论的 [模型](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es) 。
-如下所示:正如我们将看到的,这些摘要很简洁,因为它们是从客户在产品评论中提供的标题中学到的。让我们首先为这项任务准备一个合适的双语语料库。
+如果你试一试的话,就发现模型能够生成非常简洁的摘要,因为它们是从客户在产品评论中提供的标题中学到的。让我们首先为这项任务准备一个合适的双语语料库。
## 准备多语言语料库 [[准备多语言语料库]]
-我们将使用[多语言亚马逊评论语料库](https://huggingface.co/datasets/amazon_reviews_multi)创建我们的双语摘要器。该语料库由六种语言的亚马逊产品评论组成,通常用于对多语言分类器进行基准测试。然而,由于每条评论都附有一个简短的标题,我们可以使用标题作为我们模型学习的目标摘要!首先,让我们从 Hugging Face Hub 下载英语和西班牙语子集:
+我们将使用 [多语言亚马逊评论语料库](https://huggingface.co/datasets/amazon_reviews_multi) 创建我们的双语摘要器。该语料库由六种语言的亚马逊产品评论组成,通常用于多语言分类器的基准测试。然而,由于每条评论都附有一个简短的标题,我们可以使用标题作为我们模型学习的参考摘要!首先,让我们从 Hugging Face Hub 下载英语和西班牙语子集:
```python
from datasets import load_dataset
@@ -62,7 +62,7 @@ DatasetDict({
})
```
-如您所见,对于每种语言,都有 200,000 条评论 **train** 拆分,每个评论有 5,000 条评论 **validation** 和 **test** 分裂。我们感兴趣的评论信息包含在 **review_body** 和 **review_title** 列。让我们通过创建一个简单的函数来查看一些示例,该函数使用我们在[第五章](/course/chapter5)学到过:
+如你所见,在英语数据集的 `train` 部分有 200,000 条评论, `validation` 和 `test` 部分有 5,000 条评论。我们感兴趣的评论正文和标题保存在 `review_body` 和 `review_title` 列中。让我们通过创建一个简单的函数来从训练集中随机抽取一些样本,该函数使用我们在 [第五章](/course/chapter5) 学到过:
```python
def show_samples(dataset, num_samples=3, seed=42):
@@ -88,16 +88,16 @@ show_samples(english_dataset)
-✏️ **试试看!** 更改 `Dataset.shuffle()` 命令中的随机种子以探索语料库中的其他评论。 如果您是说西班牙语的人,请查看 `spanish_dataset` 中的一些评论,看看标题是否也像合理的摘要。
+✏️ **试试看!** 更改 `Dataset.shuffle()` 命令中的随机种子以探索语料库中的其他评论。如果你是说西班牙语的人,请查看 `spanish_dataset` 中的一些评论,看看标题是否像是合理的摘要。
-此示例显示了人们通常在网上找到的评论的多样性,从正面到负面(以及介于两者之间的所有内容!)。尽管标题为“meh”的示例信息量不大,但其他标题看起来像是对评论本身的体面总结。在单个 GPU 上训练所有 400,000 条评论的摘要模型将花费太长时间,因此我们将专注于为单个产品领域生成摘要。为了了解我们可以选择哪些域,让我们将 **english_dataset** 转换到 **pandas.DataFrame** 并计算每个产品类别的评论数量:
+这个示例显示了人们通常在网上评论的多样性,从积极的到消极的(以及介于两者之间的评论!)。尽管带有“meh”标题的示例的信息量不大,但其他标题看起来像是对评论本身的不错的总结。在单个 GPU 上训练所有 400,000 条评论的摘要模型将花费太长时间,因此我们将专注于为单个产品领域生成摘要。为了了解我们可以选择哪些领域,让我们将 `english_dataset` 转换为 `pandas.DataFrame` ,并计算每个产品类别的评论数量:
```python
english_dataset.set_format("pandas")
english_df = english_dataset["train"][:]
-# Show counts for top 20 products
+# 显示前 20 个产品的数量
english_df["product_category"].value_counts()[:20]
```
@@ -125,7 +125,7 @@ book 3756
Name: product_category, dtype: int64
```
-英语数据集中最受欢迎的产品是家居用品、服装和无线电子产品。不过,为了坚持亚马逊的主题,让我们专注于总结书籍的评论——毕竟,这是亚马逊这家公司成立的基础!我们可以看到两个符合要求的产品类别( **book** 和 **digital_ebook_purchase** ),所以让我们为这些产品过滤两种语言的数据集。正如我们在[第五章](/course/chapter5)学到的, 这 **Dataset.filter()** 函数允许我们非常有效地对数据集进行切片,因此我们可以定义一个简单的函数来执行此操作:
+在英语数据集中,最受欢迎的产品是家居用品、服装和无线电子产品。不过,为了带有亚马逊的特色,让我们专注于总结书籍的评论——毕竟,这是亚马逊这家公司成立的基础!我们可以看到两个符合要求的产品类别( `book` 和 `digital_ebook_purchase` ),所以让我们用这两个产品类别过滤两种语言的数据集。正如我们在 [第五章](/course/chapter5) 学到的, `Dataset.filter()` 函数可以让我们非常有效地对数据集进行切片,所以我们可以定义一个简单的函数来进行此操作:
```python
def filter_books(example):
@@ -135,13 +135,13 @@ def filter_books(example):
)
```
-现在,当我们将此函数应用于 **english_dataset** 和 **spanish_dataset** ,结果将只包含涉及书籍类别的那些行。在应用过滤器之前,让我们将**english_dataset**的格式从 **pandas** 切换回到 **arrow** :
+当我们使用这个函数对 `english_dataset` 和 `spanish_dataset` 过滤后,结果将只包含涉及书籍类别的那些行。在使用过滤器之前,让我们将 `english_dataset` 的格式从 `"pandas"` 切换回 `"arrow"` :
```python
english_dataset.reset_format()
```
-然后我们可以应用过滤器功能,作为健全性检查,让我们检查评论样本,看看它们是否确实与书籍有关:
+然后我们可以使用过滤器功能,作为一个基本的检查,让我们检查一些评论的样本,看看它们是否确实与书籍有关:
```python
spanish_books = spanish_dataset.filter(filter_books)
@@ -160,7 +160,7 @@ show_samples(english_books)
'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
```
-好的,我们可以看到评论并不是严格意义上的书籍,可能是指日历和 OneNote 等电子应用程序等内容。尽管如此,该领域似乎适合训练摘要模型。在我们查看适合此任务的各种模型之前,我们还有最后一点数据准备要做:将英语和西班牙语评论合并为一个 **DatasetDict** 目的。 🤗 Datasets 提供了一个方便的 **concatenate_datasets()** 函数(顾名思义)合并 **Dataset** 对象。因此,为了创建我们的双语数据集,我们将遍历每个拆分,连接该拆分的数据集,并打乱结果以确保我们的模型不会过度拟合单一语言:
+好吧,我们可以看到评论并不是严格意义上的书籍,也可能是指日历和 OneNote 等电子应用程序等内容。尽管如此,该领域似乎也适合训练摘要模型。在我们查筛选适合此任务的各种模型之前,我们还有最后一点数据准备要做:将英文和西班牙文评论作为单个 `DatasetDict` 对象组合起来。🤗 Datasets 提供了一个方便的 `concatenate_datasets()` 函数,它(名如其实)将把两个 `Dataset` 对象堆叠在一起。因此,为了创建我们的双语数据集,我们将遍历数据集的每个部分,并打乱结果以确保我们的模型不会过度拟合单一语言:
```python
from datasets import concatenate_datasets, DatasetDict
@@ -173,7 +173,7 @@ for split in english_books.keys():
)
books_dataset[split] = books_dataset[split].shuffle(seed=42)
-# Peek at a few examples
+# 挑选一些样例
show_samples(books_dataset)
```
@@ -188,37 +188,37 @@ show_samples(books_dataset)
'>> Review: igual que el anterior'
```
-这当然看起来像是英语和西班牙语评论的混合!现在我们有了一个训练语料库,最后要检查的一件事是评论中单词的分布及其标题。这对于摘要任务尤其重要,其中数据中的简短参考摘要会使模型偏向于仅在生成的摘要中输出一两个单词。下面的图显示了单词分布,我们可以看到有些标题严重偏向于 1-2 个单词:
+这的确看起来像是混合了英语和西班牙语的评论!现在我们有了一个训练语料库,最后要检查的一件事是评论及其标题中单词的分布。这对于摘要任务尤其重要,其中数据中如果出现大量参考摘要过于简短会使模型偏向于生成的摘要中仅有一两个单词。下面的图中显示了单词分布,我们可以看到有些标题严重偏向于 1-2 个单词:
-为了解决这个问题,我们将过滤掉标题非常短的示例,以便我们的模型可以生成更有趣的摘要。由于我们正在处理英文和西班牙文文本,因此我们可以使用粗略的启发式方法在空白处拆分标题,然后使用我们可信赖的 **Dataset.filter()** 方法如下:
+为了解决这个问题,我们将过滤掉标题非常短的示例,以便我们的模型可以生成更有效的摘要。由于我们正在处理英文和西班牙文文本,因此我们可以使用粗略的启发式方法在空白处拆分标题的单词,然后用我们强大的 `Dataset.filter()` 方法如下:
```python
books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)
```
-现在我们已经准备好了我们的语料库,让我们来看看一些可以对其进行微调的可能的 Transformer 模型!
+现在我们已经准备好了我们的语料库,让我们来看看一些可以对其进行微调的可选的 Transformer 模型!
## 文本摘要模型 [[文本摘要模型]]
-如果你仔细想想,文本摘要是一种类似于机器翻译的任务:我们有一个像评论这样的文本正文,我们希望将其“翻译”成一个较短的版本,以捕捉输入的显着特征。因此,大多数用于文本摘要的 Transformer 模型采用了我们在[第一章](/course/chapter1)遇到的编码器-解码器架构。尽管有一些例外,例如 GPT 系列模型,它们在few-shot(少量微调)之后也可以提取摘要。下表列出了一些流行的预训练模型,可以对其进行微调以进行汇总。
+如果你仔细想想,文本摘要是一种类似于机器翻译的任务:我们有一个像评论这样的文本正文,我们希望将其“翻译”成一个较短的版本,同时捕捉到输入文本的主要特征。因此,大多数用于文本摘要的 Transformer 模型采用了我们在 [第一章](/course/chapter1) 遇到的编码器-解码器架构。尽管有一些例外,例如 GPT 系列模型,它们在 few-shot(少量微调)之后也可以提取摘要。下表列出了一些可以进行摘要微调的流行预训练模型。
-| Transformer 模型 | 描述 | 多种语言? |
+| Transformer 模型 | 描述 | 多种言?|
| :---------: | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-----------: |
-| [GPT-2](https://huggingface.co/gpt2-xl) | 虽然训练为自回归语言模型,但您可以通过在输入文本末尾附加“TL;DR”来使 GPT-2 生成摘要。 | ❌ |
-| [PEGASUS](https://huggingface.co/google/pegasus-large) | 在预训练是的目标是来预测多句子文本中的屏蔽句子。 这个预训练目标比普通语言建模更接近文本摘要,并且在流行的基准测试中得分很高。 | ❌ |
-| [T5](https://huggingface.co/t5-base) | 通用的 Transformer 架构,在文本到文本的框架中制定所有任务; 例如,模型文本摘要的输入格式是`summarize: ARTICLE`。 | ❌ |
-| [mT5](https://huggingface.co/google/mt5-base) | T5 的多语言版本,在多语言 Common Crawl 语料库 (mC4) 上进行预训练,涵盖 101 种语言。 | ✅ |
-| [BART](https://huggingface.co/facebook/bart-base) | 一种新颖的 Transformer 架构,其中包含经过训练的编码器和解码器堆栈,以重建被破坏的输入,结合了 BERT 和 GPT-2 的预训练方案。 | ❌ |
-| [mBART-50](https://huggingface.co/facebook/mbart-large-50) | BART 的多语言版本,预训练了 50 种语言。 | ✅ |
+| [GPT-2](https://huggingface.co/gpt2-xl) | 虽然训练为自回归语言模型,但你可以通过在输入文本末尾附加“TL;DR”来使 GPT-2 生成摘要。| ❌ |
+| [PEGASUS](https://huggingface.co/google/pegasus-large) | 在预训练时的目标是来预测多句子文本中的屏蔽句子。这个预训练目标比普通语言建模更接近文本摘要,并且在流行的基准测试中得分很高。| ❌ |
+| [T5](https://huggingface.co/t5-base) | 通用的 Transformer 架构,所有任务都以文本到文本的框架进行描述;例如,模型文本摘要的输入格式是 `summarize: ARTICLE` 。| ❌ |
+| [mT5](https://huggingface.co/google/mt5-base) | T5 的多语言版本,在多语言 Common Crawl 语料库 (mC4) 上进行预训练,涵盖了 101 种语言。| ✅ |
+| [BART](https://huggingface.co/facebook/bart-base) | 一种新颖的 Transformer 架构,其中包含经过训练的编码器和解码器堆栈,以重建被破坏的输入,结合了 BERT 和 GPT-2 的预训练方案。| ❌ |
+| [mBART-50](https://huggingface.co/facebook/mbart-large-50) | BART 的多语言版本,预训练了 50 种语言。| ✅ |
-从此表中可以看出,大多数用于摘要的 Transformer 模型(以及大多数 NLP 任务)都是单语的。如果您的任务是使用“有大量语料库”的语言(如英语或德语),这很好,但对于世界各地正在使用的数千种其他语言,则不然。幸运的是,有一类多语言 Transformer 模型,如 mT5 和 mBART,可以解决问题。这些模型是使用语言建模进行预训练的,但有一点不同:它们不是在一种语言的语料库上训练,而是同时在 50 多种语言的文本上进行联合训练!
+从此表中可以看出,大多数用于摘要的 Transformer 模型(以及大多数 NLP 任务)都是单一语言的。如果你的任务所使用的语言是“有大量语料库”(如英语或德语)的语言,这很好。但对于世界各地正在使用的数千种其他语言,则不然。幸运的是,有一类多语言 Transformer 模型,如 mT5 和 mBART,可以解决问题。这些模型也是使用因果语言建模进行预训练的,但有一点不同:它们不是在一种语言的语料库上训练,而是同时在 50 多种语言的文本上进行联合训练!
-我们将使用 mT5,这是一种基于 T5 的有趣架构,在文本到文本框架中进行了预训练。在 T5 中,每个 NLP 任务都是根据提示前缀来制定的,例如 **summarize:** 这使模型使生成的文本适应提示。如下图所示,这让 T5 变得非常通用,因为你可以用一个模型解决很多任务!
+我们将使用 mT5,这是一种基于 T5 的有趣架构,在文本到文本任务中进行了预训练。在 T5 中,每个 NLP 任务都是以任务前缀(如 `summarize:` )的形式定义的,模型根据不同的任务生成不同的文本。如下图所示,这让 T5 变得非常通用,因为你可以用一个模型解决很多任务!
@@ -77,7 +77,7 @@ DatasetDict({
})
```
-我们有 210,173 对句子,但在一次训练过程中,我们需要创建自己的验证集。正如我们在[第五章](/course/chapter5)学的的那样, **Dataset** 有一个 **train_test_split()** 方法,可以帮我们拆分数据集。我们将设定固定的随机数种子:
+我们下载的数据集有 210,173 对句子,在一次训练过程中,除了训练集,我们也需要创建自己的验证集。正如我们在 [第五章](/course/chapter5) 学的的那样, `Dataset` 有一个 `train_test_split()` 方法可以帮助我们。我们将设置一个固定的随机数种子以保证结果可以复现:
```py
split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
@@ -97,7 +97,7 @@ DatasetDict({
})
```
-我们可以将 **test** 的键重命名为 **validation** 像这样:
+我们可以像下面这样将 `test` 键重命名为 `validation`:
```py
split_datasets["validation"] = split_datasets.pop("test")
@@ -114,7 +114,7 @@ split_datasets["train"][1]["translation"]
'fr': 'Par défaut, développer les fils de discussion'}
```
-我们得到一个字典,其中包含我们请求的两种语言的两个句子。这个充满技术计算机科学术语的数据集的一个特殊之处在于它们都完全用法语翻译。然而,法国工程师通常很懒惰,在交谈时,大多数计算机科学专用词汇都用英语表述。例如,“threads”这个词很可能出现在法语句子中,尤其是在技术对话中;但在这个数据集中,它被翻译成更正确的“fils de Discussion”。我们使用的预训练模型已经在一个更大的法语和英语句子语料库上进行了预训练,采用了更简单的选择,即保留单词的原样:
+我们得到一个包含我们选择的两种语言的两个句子的字典。这个充满技术计算机科学术语的数据集的一个特殊之处在于它们都完全用法语翻译。然而现实中,法国工程师在交谈时,大多数计算机科学专用词汇都用英语表述。例如,“threads”这个词很可能出现在法语句子中,尤其是在技术对话中;但在这个数据集中,它被翻译成更准确的“fils de Discussion”。我们使用的预训练模型已经在一个更大的法语和英语句子语料库上进行了预训练,所以输出的是原始的英语表达:
```py
from transformers import pipeline
@@ -128,8 +128,8 @@ translator("Default to expanded threads")
[{'translation_text': 'Par défaut pour les threads élargis'}]
```
-这种情况的另一个例子是“plugin”这个词,它不是正式的法语词,但大多数母语人士都能理解,也不会费心去翻译。
-在 KDE4 数据集中,这个词在法语中被翻译成更正式的“module d’extension”:
+这种情况的另一个例子可以在“plugin”这个词上看到,它并非正式的法语词汇,但大多数母语是法语的人都能够看懂并且不会去翻译它。不过,在 KDE4 数据集中,这个词被翻译成了更正式的法语词汇“module d'extension”:
+
```py
split_datasets["train"][172]["translation"]
```
@@ -151,13 +151,13 @@ translator(
[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
```
-看看我们的微调模型是否能识别数据集的这些特殊性。(剧透警告:它会)。
+看看我们的微调模型是否能学习到数据集的这些特殊特性。(剧透警告:它能)。
-✏️ **轮到你了!** 另一个在法语中经常使用的英语单词是“email”。在训练数据集中找到使用这个词的第一个样本。它是如何翻译的?预训练模型如何翻译同一个英文句子?
+✏️ **轮到你了!** 另一个在法语中经常使用的英语单词是“email”。在训练数据集中找到使用这个词的第一个样本。在数据集中它是如何翻译的?预训练模型如何翻译同一个英文句子?
@@ -165,7 +165,7 @@ translator(
-您现在应该知道我们的下一步该做些什么了:所有文本都需要转换为token ID,以便模型能够理解它们。对于这个任务,我们需要同时标记输入和目标。我们的首要任务是创建我们的 **tokenizer** 对象。如前所述,我们将使用 Marian 英语到法语的预训练模型。如果您使用另一对语言尝试此代码,请确保调整模型Checkpoint。[Helsinki-NLP](https://huggingface.co/Helsinki-NLP)组织提供了多种语言的一千多种模型。
+你现在应该可以预测我们的下一步该做些什么了:将所有文本转换为 token IDs 的集合,这样模型才可以理解它们。对于这个任务,我们需要同时对原始文本和翻译后的文本同时进行 tokenize。首先,我们需要创建 `tokenizer` 对象。如前所述,我们将使用 Marian 英语到法语的预训练模型。如果你使用下面的代码微调另一对语言,请记得更改下面代码中的 checkpoint。 [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) 组织提供了超过一千个多语言模型。
```python
from transformers import AutoTokenizer
@@ -174,17 +174,17 @@ model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="pt")
```
-您可以将 **model_checkpoint** 更换为[Hub](https://huggingface.co/models)上你喜欢的任何其他型号,或本地保存的预训练模型和标记器。
+你也可以将 `model_checkpoint` 替换为你从 [Hub](https://huggingface.co/models) 中选择的其他模型,或者一个保存了预训练模型和 tokenizer 的本地文件夹。
-💡 如果正在使用mart、mBART-50或M2 M100等多语言标记器,则需要在tokenizer中设置tokenizer.src_lang和tokenizer.tgt_lang为正确的输入和目标的语言代码。
+💡 如果你在使用一个多语言的 tokenizer,比如 mBART,mBART-50,或者 M2M100,你需要通过设置 `tokenizer.src_lang` 和 `tokenizer.tgt_lang` 来在 tokenizer 中指定输入和目标的语言代码。
-我们的数据准备非常简单。 只有一件事要记住; 您需要确保分词器以输出语言(此处为法语)处理目标。 您可以通过将目标传递给分词器的 __call__ 方法的 text_targets 参数来完成此操作。
+我们的数据准备相当简单。只有一点要记住;你需要确保 tokenizer 处理的目标是输出语言(在这里是法语)。你可以通过将目标语言传递给 tokenizer 的 `__call__` 方法的 `text_targets` 参数来完成此操作。
-为了了解这是如何工作的,让我们处理训练集中每种语言的一个样本:
+为了演示设置的方法,让我们处理训练集中的一个样本:
```python
en_sentence = split_datasets["train"][1]["translation"]["en"]
@@ -198,7 +198,7 @@ inputs
{'input_ids': [47591, 12, 9842, 19634, 9, 0], 'attention_mask': [1, 1, 1, 1, 1, 1], 'labels': [577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]}
```
-正如我们所见,输出包含与英语句子关联的输入 ID,而与法语句子关联的 ID 存储在“labels”字段中。 如果您忘记表明您正在对标签进行分词,它们将由输入分词器进行分词,这在 Marian 模型的情况下根本不会顺利进行:
+我们可以看到,输出包含了与英语句子的 `inputs IDs`,而与法语句子的 IDs 存储在 `labels` 字段中。如果你忘记设置 labels 的 `tokenizer`,默认情况下 `labels` 将由输入的 `tokenizer`(语言类型不一样) 进行 `tokenize`,对于 Marian 模型来说,效果不会很好。
```python
wrong_targets = tokenizer(fr_sentence)
@@ -211,9 +211,9 @@ print(tokenizer.convert_ids_to_tokens(inputs["labels"]))
['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
```
-正如我们所看到的,使用英语标记器来预处理法语句子会产生更多的标记,因为标记器不知道任何法语单词(除了那些也出现在英语语言中的单词,比如“discussion”)。
+如你所见,如果用英语的 tokenizer 来预处理法语句子,会产生更多的 tokens,因为这个 tokenizer 不认识任何法语单词(除了那些在英语里也出现的,比如“discussion”)。
-由于“inputs”是一个包含我们常用键(输入 ID、注意掩码等)的字典,最后一步是定义我们将应用于数据集的预处理函数:
+最后一步是定义我们数据集的预处理函数:
```python
max_length = 128
@@ -228,21 +228,21 @@ def preprocess_function(examples):
return model_inputs
```
-请注意,我们为输入和输出设置了相同的最大长度。由于我们处理的文本看起来很短,我们使用 128。
+请注意,上述代码也为输入和输出设置了相同的最大长度。由于要处理的文本看起来很短,因此在这里将最大长度设置为 128。
-💡如果你使用的是T5模型(更具体地说,是T5 -xxx检查点之一),模型将需要文本输入有一个前缀来表示正在进行的任务,例如从英语到法语的翻译
+💡 如果你正在使用 T5 模型(更具体地说,一个 `t5-xxx` checkpoint ),模型会期望文本输入有一个前缀指示目前的任务,比如 `translate: English to French:` 。
-⚠️ 我们不关注目标的注意力掩码,因为模型不会需要它。相反,对应于填充标记的标签应设置为-100,以便在loss计算中忽略它们。这将在稍后由我们的数据整理器完成,因为我们正在应用动态填充,但是如果您在此处使用填充,您应该调整预处理函数以将与填充标记对应的所有标签设置为 -100。
+⚠️ 我们不需要对待遇测的目标设置注意力掩码,因为模型序列到序列的不会需要它。不过,我们应该将填充(padding) token 对应的标签设置为 `-100` ,以便在 loss 计算中忽略它们。由于我们正在使用动态填充,这将在稍后由我们的数据整理器完成,但是如果你在此处就打算进行填充,你应该调整预处理函数,将所有填充(padding) token 对应的标签设置为 `-100` 。
-我们现在可以对数据集的所有数据一次性应用该预处理:
+我们现在可以一次性使用上述预处理处理数据集的所有数据。
```py
tokenized_datasets = split_datasets.map(
@@ -252,15 +252,15 @@ tokenized_datasets = split_datasets.map(
)
```
-现在数据已经过预处理,我们准备好微调我们的预训练模型!
+现在数据已经过预处理,我们准备好微调我们的预训练模型了!
{#if fw === 'pt'}
-## 使用 Trainer API 微调模型 [[使用 Trainer API 微调模型]]
+## 使用 `Trainer` API 微调模型 [[使用 `Trainer` API 微调模型]]
-使用 `Trainer` 的实际代码将与以前相同,只是稍作改动:我们在这里使用 [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer), 它是 `Trainer` 的子类,它可以正确处理这种序列到序列的评估,并使用 `generate()` 方法来预测输入的输出。 当我们讨论评估指标时,我们将更详细地探讨这一点。
+使用 `Trainer` 的代码将与以前相同,只是稍作改动:我们在这里将使用 [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) ,它是 `Trainer` 的子类,它使用 `generate()` 方法来预测输入的输出结果,并且可以正确处理这种序列到序列的评估。当我们讨论评估指标时,我们将更详细地探讨这一点。
-首先,我们需要一个实际的模型来进行微调。 我们将使用通常的 `AutoModel` API:
+首先,我们需要一个模型来进行微调。我们将使用常用的 `AutoModel` API:
```py
from transformers import AutoModelForSeq2SeqLM
@@ -272,7 +272,7 @@ model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
## 使用 Keras 微调模型 [[使用 Keras 微调模型]]
-首先,我们需要一个实际的模型来进行微调。 我们将使用通常的 `AutoModel` API:
+首先,我们需要一个模型来进行微调。我们将使用常用的 `AutoModel` API:
```py
from transformers import TFAutoModelForSeq2SeqLM
@@ -282,19 +282,19 @@ model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
-💡 `Helsinki-NLP/opus-mt-en-fr` checkpoint只有 PyTorch 的权重,所以在使用`from_pretrained()`方法加载模型时不会使用 `from_pt=True` 参数。 当您指定`from_pt=True`,库会自动下载并转换PyTorch 为您提供权重。 如您所见,使用🤗transormer 在两者之间切换非常简单
+💡 `Helsinki-NLP/opus-mt-en-fr` checkpoint 只有 PyTorch 的权重,所以如果你尝试使用 `from_pretrained()` 方法加载模型并且忘记设置`from_pt=True` 参数的时候,你会得到一个错误。当你设定 `from_pt=True` 时,🤗transormer 会自动下载并为你转换 PyTorch 权重。如你所见,使用🤗transormer 在两种框架之间切换非常简单。
{/if}
-请注意,这次我们使用的是在翻译任务上训练过的模型,并且实际上已经可以使用,因此没有关于丢失权重或新初始化权重的警告。
+注意,这次我们使用的是一个已经在翻译任务上进行过训练的模型,实际上已经可以直接使用了,所以没有收到关于缺少权重或重新初始化的权重的警告。
### 数据整理 [[数据整理]]
-我们需要一个数据整理器来处理动态批处理的填充。在本例中,我们不能像[第3章](/course/chapter3)那样使用带填充的**DataCollatorWithPadding**,因为它只填充输入(输入ID、注意掩码和令牌类型ID)。我们的标签也应该填充到标签中遇到的最大长度。而且,如前所述,用于填充标签的填充值应为-100,而不是标记器的填充标记,以确保在损失计算中忽略这些填充值。
+在这个任务中,我们需要一个数据整理器来动态批处理填充。因此,我们不能像 [第三章](/course/chapter3) 那样直接使用 `DataCollatorWithPadding` ,因为它只填充输入的部分(inputs ID、注意掩码和 token 类型 ID)。我们的标签也应该被填充到所有标签中最大的长度。而且,如前所述,用于填充标签的填充值应为 `-100` ,而不是 tokenizer 默认的的填充 token,这样才可以在确保在损失计算中忽略这些填充值。
-这一切都可以由 [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq) 完成。 与 `DataCollatorWithPadding` 一样,它采用用于预处理输入的`tokenizer`,但它也采用`model`。 这是因为数据整理器还将负责准备解码器输入 ID,它们是标签偏移之后形成的,开头带有特殊标记。 由于不同架构的这种转变略有不同,因此“DataCollatorForSeq2Seq”需要知道“模型”对象:
+上述的这些需求都可以由 [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq) 完成。它与 `DataCollatorWithPadding` 一样,它接收用于预处理输入的 `tokenizer` ,同时它也接收一个 `model` 参数。这是因为数据整理器还将负责准备解码器 `inputs ID`,它们是标签偏移之后形成的,开头带有特殊 `token` 。由于对于不同的模型架构有稍微不同的偏移方式,所以 `DataCollatorForSeq2Seq` 还需要接收 `model` 对象:
{#if fw === 'pt'}
@@ -314,7 +314,7 @@ data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="t
{/if}
-为了在几个样本上进行测试,我们只需在我们标记化训练集中的部分数据上调用它:
+为了在几个样本上进行测试,我们在已经完成 tokenize 的训练集中的部分数据上调用它,测试一下其功能:
```py
batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
@@ -325,7 +325,7 @@ batch.keys()
dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
```
-我们可以检查我们的标签是否已使用 **-100** 填充到批次的最大长度:
+我们可以检查我们的标签是否已经用 `-100` 填充到 batch 的最大长度:
```py
batch["labels"]
@@ -338,7 +338,7 @@ tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
550, 7032, 5821, 7907, 12649, 0]])
```
-我们还可以查看解码器输入 ID,看看它们是标签的偏移形成的版本:
+我们还可以查看解码器的 inputs ID,可以看到它们是标签经过偏移后的结果:
```py
batch["decoder_input_ids"]
@@ -365,11 +365,10 @@ for i in range(1, 3):
{#if fw === 'pt'}
-我们将把这个 `data_collator` 传递给 `Seq2SeqTrainer`。 接下来,让我们看一下评估指标。
-
+把 `data_collator` 传递给 `Seq2SeqTrainer` 后就完成了数据整理。接下来,让我们看一下评估指标。
{:else}
-我们现在可以使用 `data_collator` 将我们的每个数据集转换为 `tf.data.Dataset`,准备好进行训练:
+我们现在可以使用 `data_collator` 将我们的每个数据集转换为 `tf.data.Dataset` ,这样就完成了数据整理:
```python
tf_train_dataset = model.prepare_tf_dataset(
@@ -395,22 +394,22 @@ tf_eval_dataset = model.prepare_tf_dataset(
{#if fw === 'pt'}
-`Seq2SeqTrainer` 添加到其超类 `Trainer` 的功能是在评估或预测期间使用 `generate()` 方法的能力。 在训练期间,模型将使用带有注意掩码的“decoder_input_ids”,以确保它不使用预测的标记之后的标记,以加快训练速度。 在推理过程中,我们将无法使用预测的标记之后的标记,因为我们没有标签,因此使用相同的设置使用带有注意掩码的“decoder_input_ids”,评估我们的模型是个好主意。
+`Seq2SeqTrainer` 是 `Trainer` 类的一个子类,它的主要增强特性是在评估或预测时使用 `generate()` 方法。在训练过程中,模型会利用 `decoder_input_ids` 和一个特殊的注意力掩码来加速训练。这种方法允许模型在预测下一个token时看到部分目标序列,但确保它不会使用预测token之后的信息。这种优化策略显著提高了训练效率。然而,在实际的推理过程中,我们没有真实的标签值,因此无法生成 `decoder_input_ids` 和相应的注意力掩码。这意味着我们无法在推理时使用这种训练时的优化方法。
-正如我们在[第一章](/course/chapter1/6)看到的,解码器通过一个一个地预测标记来执行推理——这是🤗 Transformers 在幕后通过 **generate()** 方法实现的。如果我们设置 predict_with_generate=True,Seq2 Seq Trainer 将允许我们使用该方法进行评估。
+为了确保评估结果能够准确反映模型在实际使用中的表现,我们应该在评估阶段模拟真实推理的条件。这意味着我们需要使用在 [第一章](/course/chapter1/6) 中介绍的 🤗 Transformers 库中的 `generate()` 方法。该方法能够逐个生成token,真实地模拟推理过程,而不是依赖于训练时的优化技巧。要启用这个功能,我们需要在训练时添加 `predict_with_generate=True` 参数。这样做可以确保我们的评估结果更加接近模型在实际应用中的表现。
{/if}
-用于翻译的传统指标是[BLEU 分数](https://en.wikipedia.org/wiki/BLEU), 由Kishore Papineni等人在[2002年的一篇文章](https://aclanthology.org/P02-1040.pdf)中引入。BLEU 分数评估翻译与其标签的接近程度。它不衡量模型生成输出的可懂度或语法正确性,而是使用统计规则来确保生成输出中的所有单词也出现在目标中。此外,如果相同单词在目标中没有重复,则有规则惩罚相同单词的重复(以避免模型输出类似 **the the the the the**的句子 ) 并输出比目标中短的句子(以避免模型输出像 **the** 这样的句子)。
+用于翻译的传统指标是 [BLEU 分数](https://en.wikipedia.org/wiki/BLEU) ,它最初由 Kishore Papineni 等人在 2002 年的 [一篇文章](https://aclanthology.org/P02-1040.pdf) 中引入。BLEU 分数评估翻译与参考翻译的接近程度。它不衡量模型生成输出的可理解性或语法正确性,而是使用统计规则来确保生成输出中的所有单词也出现在参考的输出中。此外,还有一些规则对重复的词进行惩罚,如果这些词在输出中重复出现(模型输出像“the the the the the”这样的句子);或者输出的句子长度比目标中的短(模型输出像“the”这样的句子)都会被惩罚。
-BLEU 的一个缺点是它需要文本已经被分词,这使得比较使用不同标记器的模型之间的分数变得困难。因此,当今用于基准翻译模型的最常用指标是[SacreBLEU](https://github.com/mjpost/sacrebleu),它通过标准化标记化步骤解决了这个缺点(和其他的一些缺点)。要使用此指标,我们首先需要安装 SacreBLEU 库:
+BLEU 的一个缺点是的输入是已分词的文本,这使得比较使用不同分词器的模型之间的分数变得困难。因此,当今用于评估翻译模型的最常用指标是 [SacreBLEU](https://github.com/mjpost/sacrebleu) ,它通过标准化的分词步骤解决了这个缺点(和其他的一些缺点)。要使用此指标,我们首先需要安装 SacreBLEU 库:
```py
!pip install sacrebleu
```
-然后我们可以就像我们在[第三章](/course/chapter3)那样通过 **evaluate.load()** 加载它 :
+然后我们可以就像在 [第三章](/course/chapter3) 那样通过 `evaluate.load()` 加载它
```py
import evaluate
@@ -418,7 +417,7 @@ import evaluate
metric = evaluate.load("sacrebleu")
```
-该指标将文本作为输入和目标结果。它旨在接受多个可接受的目标,因为同一个句子通常有多个可接受的翻译——我们使用的数据集只提供一个,但在 NLP 中找到将多个句子作为标签的数据集不是一个难题。因此,预测结果应该是一个句子列表,而参考应该是一个句子列表的列表。
+SacreBLEU 指标中待评估的预测和参考的目标译文输入的格式都是文本。它的设计是为了支持多个参考翻译,因为同一句话通常有多种可接受的翻译——虽然我们使用的数据集只提供一个,但在 NLP 中找到将多个句子作为标签的数据集是很常见的。因此,预测结果应该是一个句子列表,而参考应该是一个句子列表的列表。
让我们尝试一个例子:
@@ -444,7 +443,7 @@ metric.compute(predictions=predictions, references=references)
'ref_len': 13}
```
-这得到了 46.75 的 BLEU 分数,这是相当不错的——作为参考,原始 Transformer 模型在[“Attention Is All You Need” 论文](https://arxiv.org/pdf/1706.03762.pdf)类似的英语和法语翻译任务中获得了 41.8 的 BLEU 分数! (有关各个指标的更多信息,例如 **counts** 和 **bp** ,见[SacreBLEU 仓库](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74).) 另一方面,如果我们尝试使用翻译模型中经常出现的两种糟糕的预测类型(大量重复或太短),我们将得到相当糟糕的 BLEU 分数:
+达到了 46.75 的 BLEU 分数,这是相当不错的——作为参考,原始 Transformer 模型在 [“Attention Is All You Need” 论文](https://arxiv.org/pdf/1706.03762.pdf) 类似的英语和法语翻译任务中获得了 41.8 的 BLEU 分数!(关于其他指标的含义,例如 `counts` 和 `bp` ,可以参见 [SacreBLEU仓库](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74) )另一方面,如果我们尝试将翻译模型中经常出现的两种糟糕的预测类型(大量重复或太短)输入给指标计算的函数,我们将得到相当糟糕的 BLEU 分数:
```py
predictions = ["This This This This"]
@@ -490,7 +489,9 @@ metric.compute(predictions=predictions, references=references)
{#if fw === 'tf'}
-为了将模型输出的向量转换为可以使用的文本,我们将使用 `tokenizer.batch_decode()` 方法。 我们只需要清除标签中的所有“-100”; tokenizer 将自动对填充令牌执行相同的操作。 让我们定义一个函数,它接受我们的模型和数据集并计算其指标。 我们还将使用一个可以显着提高性能的技巧 - 使用 TensorFlow 的加速线性代数编译器 [XLA](https://www.tensorflow.org/xla) 编译我们的生成代码。 XLA 对模型的计算图应用了各种优化,并显着提高了速度和内存使用率。 正如 Hugging Face [博客](https://huggingface.co/blog/tf-xla-generate) 中所述,当我们的输入形状变化不大时,XLA 效果最佳。 为了处理这个问题,我们将输入填充为 128 的倍数,并使用填充整理器创建一个新数据集,然后我们将 @tf.function(jit_compile=True) 装饰器应用于我们的生成函数,将整个函数标记为使用 XLA 进行编译。
+为了将模型的输出转化为评估指标可以使用的文本,我们将利用 `tokenizer.batch_decode()` 方法。因为 tokenizer 会自动处理填充 `tokens`,所以我们只需要清理所有标签中的 填充的`-100` 。让我们定义一个函数,这个函数会接收一个模型和一个数据集,并在其上计算 BLEU 指标。
+
+我们还将使用一个显著提升性能的技巧 - 使用 [XLA](https://www.tensorflow.org/xla) ,TensorFlow 的线性代数加速编译器,编译我们的生成代码。XLA 对模型的计算图进行了各种优化,从而显著提升了速度和内存使用率。如 Hugging Face 的 [博客](https://huggingface.co/blog/tf-xla-generate) 所述,当我们的输入形状比较整齐时,XLA 能够很好地提高计算效率。因此,我们需要用填充整理器制作一个新的数据集,把输入补齐到 128 的倍数,然后我们使用 `@tf.function(jit_compile=True)` 装饰器装饰我们的生成函数,这将把整个函数标记为使用 XLA 编译。
```py
import numpy as np
@@ -545,7 +546,7 @@ def compute_metrics():
{:else}
-为了从模型输出到度量可以使用的文本,我们将使用 `tokenizer.batch_decode()` 方法。 我们只需要清理标签中的所有 `-100`(标记器将自动对填充标记执行相同操作):
+为了将模型的输出转化为评估指标可以使用的文本,我们将使用 `tokenizer.batch_decode()` 方法。因为 tokenizer 会自动处理填充的 tokens,所以我们只需要清理标签中的所有 `-100` token:
```py
import numpy as np
@@ -553,17 +554,17 @@ import numpy as np
def compute_metrics(eval_preds):
preds, labels = eval_preds
- # In case the model returns more than the prediction logits
+ # 如果模型返回的内容超过了预测的logits
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
- # Replace -100s in the labels as we can't decode them
+ # 由于我们无法解码 -100,因此将标签中的 -100 替换掉
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
- # Some simple post-processing
+ # 一些简单的后处理
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
@@ -577,7 +578,7 @@ def compute_metrics(eval_preds):
### 微调模型 [[微调模型]]
-第一步是登录 Hugging Face,这样您就可以将结果上传到模型中心。有一个方便的功能可以帮助您在notebook中完成此操作:
+第一步是登录 Hugging Face,这样你就可以在训练过程中将结果上传到 Hub中。有一个方便的功能可以帮助你在 notebook 中完成登陆:
```python
from huggingface_hub import notebook_login
@@ -585,9 +586,9 @@ from huggingface_hub import notebook_login
notebook_login()
```
-这将显示一个小部件,您可以在其中输入您的 Hugging Face 登录凭据。
+这将显示一个小部件,你可以在其中输入你的 Hugging Face 登录凭据。
-如果您不是在notebook上运行代码,只需在终端中输入以下行:
+如果你不是在 notebook 上运行代码,可以在终端中输入以下命令:
```bash
huggingface-cli login
@@ -595,8 +596,7 @@ huggingface-cli login
{#if fw === 'tf'}
-在我们开始之前,让我们看看我们在没有任何训练的情况下从我们的模型中得到了什么样的结果:
-
+在我们开始之前,让我们看看我们在没有任何训练的情况下我们的模型效果怎么样。
```py
print(compute_metrics())
```
@@ -605,16 +605,17 @@ print(compute_metrics())
{'bleu': 33.26983701454733}
```
-一旦完成,我们就可以准备编译和训练模型所需的一切。 注意当使用 `tf.keras.mixed_precision.set_global_policy("mixed_float16")`时——这将告诉 Keras 使用 float16 进行训练,这可以显着提高支持它的 GPU(Nvidia 20xx/V100 或更高版本)的速度。
+现在可以准备编译和训练模型了。运行 `tf.keras.mixed_precision.set_global_policy("mixed_float16")` 后, Keras 将使用 float16 精度进行训练,这样可以显著提高支持半精度 GPU(Nvidia 20xx/V100 或更高版本)的训练速度
```python
from transformers import create_optimizer
from transformers.keras_callbacks import PushToHubCallback
import tensorflow as tf
-# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
-# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
-# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+# 训练步数是数据集中的样本数量,除以 batch 大小,然后乘以总的 epoch 数。
+# 注意这里的 tf_train_dataset 是 batch 形式的 tf.data.Dataset,
+# 而不是原始的 Hugging Face Dataset ,所以使用 len() 计算它的长度已经是 num_samples // batch_size。
+
num_epochs = 3
num_train_steps = len(tf_train_dataset) * num_epochs
@@ -626,11 +627,11 @@ optimizer, schedule = create_optimizer(
)
model.compile(optimizer=optimizer)
-# Train in mixed-precision float16
+# 使用 float16 混合精度进行训练
tf.keras.mixed_precision.set_global_policy("mixed_float16")
```
-接下来,我们定义一个 `PushToHubCallback` 以便在训练期间将我们的模型上传到 Hub,正如我们在 [第 2 节]((/course/chapter7/2)) 中看到的,然后我们只需拟合模型时添加该回调函数:
+接下来就像我们在 [第 2 节](/course/chapter7/2) 中学到的,我们将定义一个 `PushToHubCallback` 回调函数,并拟合模型的时候添加该回调函数,这样就可以训练期间将我们的模型上传到 Hub。
```python
from transformers.keras_callbacks import PushToHubCallback
@@ -647,15 +648,15 @@ model.fit(
)
```
-请注意,您可以使用 `hub_model_id` 参数指定要推送到的存储库的名称(当您想把模型推送到指定的组织的时候,您也必须使用此参数)。 例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们添加了 `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` 到 `Seq2SeqTrainingArguments`。 默认情况下,使用的存储库将在您的命名空间中,并以您设置的输出目录命名,因此这里将是 `"sgugger/marian-finetuned-kde4-en-to-fr"`。
+请注意,你可以使用 `hub_model_id` 参数指定要推送到的模型仓库的名称(当你想把模型推送到指定的组织的时候,就必须使用此参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们在 `Seq2SeqTrainingArguments`添加了 `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` 。默认情况下,该仓库将保存在你的账户里,并以你设置的输出目录命名,因此在我们的例子中它是 `"sgugger/marian-finetuned-kde4-en-to-fr"` 。
-💡如果您使用的输出目录已经存在,则它需要是您要推送到的存储库的本地克隆。如果不是,您将在定义您的名称时会遇到错误,并且需要设置一个新名称。
+💡如果正在使用的输出目录已经存在一个同名的文件夹,则它应该是目标推送仓库的在本地克隆在本地的版本。如果不是,当调用 `model.fit()` 时会收到错误,并需要设置一个新的路径。
-最后,让我们看看训练结束后我们的指标是什么样的:
+最后,让我们看看训练结束后我们的模型的 BLEU 的分数:
```py
print(compute_metrics())
@@ -665,11 +666,11 @@ print(compute_metrics())
{'bleu': 57.334066271545865}
```
-在这个阶段,您可以使用模型中心上的推理小部件来测试您的模型并与您的朋友分享。 您已经成功地微调了翻译任务中的模型——恭喜!
+在这个阶段,你可以使用模型中心上的推理小部件来测试你的模型并与你的朋友分享。恭喜你,你已经成功地在翻译任务上微调了一个模型!
{:else}
-一旦完成,我们就可以定义我们的 `Seq2SeqTrainingArguments`。 与 `Trainer` 一样,我们使用 `TrainingArguments` 的子类,其中包含更多可以设置的字段:
+完成这些步骤之后,我们就可以定义我们的 `Seq2SeqTrainingArguments` 了。与 `Trainer` 一样,它是 `TrainingArguments` 的子类,其中包含更多可以设置的字段:
```python
from transformers import Seq2SeqTrainingArguments
@@ -690,23 +691,22 @@ args = Seq2SeqTrainingArguments(
)
```
-除了通常的超参数(如学习率、训练轮数、批次大小和一些权重衰减)之外,与我们在前几节中看到的相比,这里有一些变化:
+除了通常的超参数(如学习率、训练轮数、批次大小和一些权重衰减)之外,这里的部分参数与我们在前面章节看到的有一些不同:
-- 我们没有设置任何定期评估,因为评估需要耗费一定的时间;我们只会在训练开始之前和结束之后评估我们的模型一次。
-- 我们设置fp16=True,这可以加快支持fp16的 GPU 上的训练速度。
-- 和上面我们讨论的那样,我们设置predict_with_generate=True
-- 我们用push_to_hub=True在每个 epoch 结束时将模型上传到 Hub。
+- 我们没有设置定期进行评估,因为评估需要耗费一定的时间;我们将只在训练开始之前和结束之后评估我们的模型一次。
+- 我们设置 `fp16=True` ,这可以加快在支持 fp16 的 GPU 上的训练速度。
+- 和之前我们讨论的一样,我们设置 `predict_with_generate=True` 。
+- 我们设置了 `push_to_hub=True` ,在每个 epoch 结束时将模型上传到 Hub。
-请注意,您可以使用 `hub_model_id` 参数指定要推送到的存储库的名称(当您想把模型推送到指定的组织的时候,您也必须使用此参数)。 例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们添加了 `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` 到 `Seq2SeqTrainingArguments`。 默认情况下,使用的存储库将在您的命名空间中,并以您设置的输出目录命名,因此这里将是 `"sgugger/marian-finetuned-kde4-en-to-fr"`。
+请注意,你可以使用 `hub_model_id` 参数指定要推送到的存储库的名称(当你想把模型推送到指定的组织的时候,就必须使用此参数)。例如,当我们将模型推送到 [`huggingface-course` 组织](https://huggingface.co/huggingface-course) 时,我们在 `Seq2SeqTrainingArguments` 添加了 `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` 。默认情况下,该仓库将保存在你的账户中,并以你设置的输出目录命名,因此在我们的例子中它是 `"sgugger/marian-finetuned-kde4-en-to-fr"` 。
-💡如果您使用的输出目录已经存在,则它需要是您要推送到的存储库的本地克隆。如果不是,您将在定义您的名称时会遇到错误,并且需要设置一个新名称。
+💡如果你使用的输出目录已经存在一个同名的文件夹,则它应该是推送的仓库克隆在本地的版本。如果不是,你将在定义你的 `Seq2SeqTrainer` 名称时会遇到错误,并且需要设置一个新名称。
-
-最后,我们需要将所有内容传递给 **Seq2SeqTrainer** :
+最后,我们将所有内容传递给 `Seq2SeqTrainer` :
```python
from transformers import Seq2SeqTrainer
@@ -722,7 +722,7 @@ trainer = Seq2SeqTrainer(
)
```
-在训练之前,我们将首先查看我们的模型获得的分数,以仔细检查我们的微调没有让事情变得更糟。此命令需要一些时间,因此您可以在执行时喝杯咖啡:
+在开始训练之前,我们先查看一下我们的模型目前的 BLEU 分数,以确保我们的微调并未使情况变得更糟。这个命令需要一些时间,所以你可以在执行期间去喝杯咖啡:
```python
trainer.evaluate(max_length=max_length)
@@ -736,7 +736,7 @@ trainer.evaluate(max_length=max_length)
'eval_steps_per_second': 0.341}
```
-BLEU的分数还不错,这反映了我们的模型已经擅长将英语句子翻译成法语句子。
+BLEU 得分为 39 并不算太差,这反映了我们的模型已经擅长将英语句子翻译成法语句子。
接下来是训练,这也需要一些时间:
@@ -744,9 +744,9 @@ BLEU的分数还不错,这反映了我们的模型已经擅长将英语句子
trainer.train()
```
-请注意,当训练发生时,每次保存模型时(这里是每个时期),它都会在后台上传到 Hub。这样,如有必要,您将能够在另一台机器上继续您的训练。
+请注意,在训练过程中,每当保存模型时(这里是每个 epoch),它都会在后台将模型上传到 Hub。这样,如有必要,你将能够在另一台机器上继续你的训练。
-训练完成后,我们再次评估我们的模型——希望我们会看到 BLEU 分数有所改善!
+训练完成后,我们再次评估我们的模型——希望我们会看到 BLEU 分数有所提高!
```py
trainer.evaluate(max_length=max_length)
@@ -761,23 +761,23 @@ trainer.evaluate(max_length=max_length)
'epoch': 3.0}
```
-这是近 14 点的改进,这很棒。
+可以看到近 14 点的改进,这很棒!
-最后,我们使用 **push_to_hub()** 方法来确保我们上传模型的最新版本。这 **Trainer** 还创建了一张包含所有评估结果的模型卡并上传。此模型卡包含可帮助模型中心为推理演示选择小部件的元数据。通常不需要做额外的更改,因为它可以从模型类中推断出正确的小部件,但在这种情况下,相同的模型类可以用于所有类型的序列到序列问题,所以我们指定它是一个翻译模型:
+最后,我们使用 `push_to_hub()` 方法来确保我们上传了模型最新的版本。 `Trainer` 还创建了一张包含所有评估结果的模型卡片并上传到 Hub 。这个模型卡片包含了可以帮助 Hub 为推理演示选择小部件的元数据,通常情况下我们不需要做额外的更改,因为它可以从模型类中推断出正确的小部件,但在这个示例中,它只能通过模型类推断这是一个序列到序列的问题,所以我们补充一下具体的模型类别。
```py
trainer.push_to_hub(tags="translation", commit_message="Training complete")
```
-如果您想检查命令执行的结果,此命令将返回它刚刚执行的提交的 URL,可以打开url进行检查:
+如果你想检查命令执行的结果,此命令将返回它刚刚执行的提交的 URL,你可以打开 url 进行检查:
```python out
'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
```
-在此阶段,您可以使用模型中心上的推理小部件来测试您的模型并与您的朋友分享。您已成功微调翻译任务的模型 - 恭喜!
+在此阶段,你可以在 Model Hub 上使用推理小部件来测试你的模型,并与你的朋友分享。你已经成功地在翻译任务上进行了模型的微调,恭喜你!
-如果您想更深入地了解训练循环,我们现在将向您展示如何使用 🤗 Accelerate 做同样的事情。
+如果你想更深入地了解训练循环,我们现在将向你展示如何使用 🤗 Accelerate 做同样的事情。
{/if}
@@ -785,11 +785,11 @@ trainer.push_to_hub(tags="translation", commit_message="Training complete")
## 自定义训练循环 [[自定义训练循环]]
-现在让我们看一下完整的训练循环,以便您可以轻松自定义所需的部分。它看起来很像我们在[本章第二节](/course/chapter7/2)和[第三章第四小节](/course/chapter3/4)所做的。
+我们现在来看一下完整的训练循环,这样你就可以轻松定制你需要的部分。它将与我们在 [第 2 节](https://chat.openai.com/course/chapter7/2) 和 [第 3 节](https://chat.openai.com/course/chapter3/4) 中做的非常相似。
### 准备训练所需的一切 [[准备训练所需的一切]]
-您已经多次看到所有这些,因此这一块会简略进行。首先我们将构建我们的数据集的**DataLoader** ,在将数据集设置为 **torch** 格式,我们就得到了 PyTorch 张量:
+由于这里的步骤在之前的章节已经出现过很多次,因此这里只做简略说明。首先,我们将数据集设置为 `torch` 格式,这样可以将数据集的格式转换为 `PyTorch` 张量,然后我们用数据集构建 `DataLoader` :
```py
from torch.utils.data import DataLoader
@@ -820,7 +820,7 @@ from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
```
-一旦我们拥有所有这些对象,我们就可以将它们发送到 `accelerator.prepare()` 方法。 请记住,如果您想在 Colab 笔记本训练中使用TPU,则需要将所有这些代码移动到训练函数中,并且不应执行任何实例化“加速器”的对象。
+准备好这些对象,我们就可以将它们发送到 `accelerator.prepare()` 方法中。请记住,如果你想在 Colab Notebook 上使用 TPU 进行训练,你需要将所有这些代码移动到一个训练函数中,并且这个训练函数不应该包含实例化 `Accelerator` `的代码。换句话说,Accelerator` 的实例化应该在这个函数之外进行。这么做的原因是,TPU 在 Colab 中的工作方式有些特殊。TPU 运行时会重新执行整个单元格的代码,因此如果 `Accelerator` 的实例化在训练函数内部,它可能会被多次实例化,导致错误。
```py
from accelerate import Accelerator
@@ -831,7 +831,7 @@ model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
)
```
-现在我们已经发送了我们的 **train_dataloader** 到 **accelerator.prepare()** ,我们可以使用它的长度来计算训练步骤的数量。请记住,我们应该始终在准备好数据加载器后执行此操作,因为该方法会更改 **DataLoader** .我们使用从学习率衰减到 0 的经典线性学习率调度:
+现在我们已经将我们的 `train_dataloader` 发送到 `accelerator.prepare()` 方法中了,现在我们可以使用它的长度来计算训练步骤的数量。请记住,我们应该始终在准备好数据加载器后再执行此操作,因为更改数据加载器会改变 `DataLoader` 的长度。然后,我们使用学习率衰减到 0 的经典线性学习率调度:
```py
from transformers import get_scheduler
@@ -848,7 +848,7 @@ lr_scheduler = get_scheduler(
)
```
-最后,要将我们的模型推送到 Hub,我们需要创建一个 **Repository** 工作文件夹中的对象。如果您尚未登录,请先登录 Hugging Face。我们将从我们想要为模型提供的模型 ID 中确定存储库名称(您可以自由地用自己的选择替换 **repo_name** ;它需要包含您的用户名,可以使用**get_full_repo_name()**函数的查看目前的repo_name):
+最后,为了将我们的模型推送到 Hugging Face Hub,我们需要在一个工作文件夹中创建一个 `Repository` 对象。如果你尚未登录 Hugging Face,请先进行登录。我们将根据模型 ID 来确定仓库名称。你可以使用自己选择的名称替换 `repo_name`,但请确保包含你的用户名。如果你不确定当前的用户名,可以使用` get_full_repo_name()` 函数来查看:
```py
from huggingface_hub import Repository, get_full_repo_name
@@ -862,18 +862,18 @@ repo_name
'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
```
-然后我们可以在本地文件夹中克隆该存储库。如果它已经存在,这个本地文件夹应该是我们正在使用的存储库的克隆:
+然后我们可以在本地文件夹中克隆该存储库。如果已经存在一个同名的文件夹,这个本地文件夹应该是我们正在使用的存储库克隆到本地的版本:
```py
output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
```
-我们现在可以通过调用 **repo.push_to_hub()** 方法上传我们保存的任何内容 **output_dir** 。这将帮助我们在每个 epoch 结束时上传过程中的模型。
+现在,我们可以通过调用 `repo.push_to_hub()` 方法上传我们在 `output_dir` 中保存的所有文件。这将帮助我们在每个 epoch 结束时上传中间模型。
### 训练循环 [[训练循环]]
-我们现在准备编写完整的训练循环。为了简化它的评估部分,我们定义了这个 **postprocess()** 函数接收预测结果和正确标签并将它们转换为我们 **metric** 对象所需要的字符串列表:
+我们现在准备编写完整的训练循环。为了简化其评估部分,我们定义了这个 `postprocess()` 函数用于接收预测值和参考翻译对于的标签值,并将其转换为 `metric` 对象所需要的字符串列表。:
```py
def postprocess(predictions, labels):
@@ -882,21 +882,23 @@ def postprocess(predictions, labels):
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
- # Replace -100 in the labels as we can't decode them.
+ # 替换标签中的 -100,因为我们无法解码它们。
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
- # Some simple post-processing
+ # 一些简单的后处理
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
return decoded_preds, decoded_labels
```
-训练循环看起来和[本章第二节](/course/chapter7/2)与[第三章](/course/chapter3)很像,在评估部分有一些不同 - 所以让我们专注于这一点!
+训练循环看起来和本章 [第 2 节](/course/chapter7/2) 与 [第三章](/course/chapter3) 中代码很相似,只是在评估部分有一些不同 —— 所以让我们重点关注一下这一点!
+
+首先要注意的是,我们使用 `generate()` 方法来计算预测,但这是我们基础模型上的一个方法,而不是🤗 Accelerate 在 `prepare()` 方法中创建的封装模型。这就是为什么我们首先 `unwrap_model` ,然后调用此方法。
-首先要注意的是我们使用 `generate()` 方法来计算预测,但这是我们基础模型上的一个方法,而不是包装模型🤗 Accelerate 在 `prepare()` 方法中创建。 这就是为什么我们先解包模型,然后调用这个方法。
+首先要注意的是,我们用来计算预测的 `generate()` 函数是基础模型上的一个方法,而不是🤗 Accelerate 在 `prepare()` 函数中创建的封装模型。这就是在调用此函数之前先调用`unwrap_model`,的原因。
-第二件事是,就像[token 分类](/course/chapter7/2),两个进程可能将输入和标签填充为不同的形状,因此我们在调用 **gather()** 方法之前使用 **accelerator.pad_across_processes()** 使预测和标签具有相同的形状。如果我们不这样做,评估要么出错,要么永远在阻塞。
+第二个要注意的是,就像 [token 分类](https://chat.openai.com/course/chapter7/2) 一样,在训练和评估这两个过程可能以不同的形状对输入和标签进行了填充,所以我们在调用 `gather()` 函数之前使用 `accelerator.pad_across_processes()` 方法,使预测和标签具有相同的形状。如果我们不这么做,那么评估的过程将会出错或被永远挂起。
```py
from tqdm.auto import tqdm
@@ -905,7 +907,7 @@ import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
- # Training
+ # 训练
model.train()
for batch in train_dataloader:
outputs = model(**batch)
@@ -917,7 +919,7 @@ for epoch in range(num_train_epochs):
optimizer.zero_grad()
progress_bar.update(1)
- # Evaluation
+ # 评估
model.eval()
for batch in tqdm(eval_dataloader):
with torch.no_grad():
@@ -928,7 +930,7 @@ for epoch in range(num_train_epochs):
)
labels = batch["labels"]
- # Necessary to pad predictions and labels for being gathered
+ # 需要填充预测和标签才能调用gather()
generated_tokens = accelerator.pad_across_processes(
generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
)
@@ -943,7 +945,7 @@ for epoch in range(num_train_epochs):
results = metric.compute()
print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
- # Save and upload
+ # 保存和上传
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
@@ -960,18 +962,18 @@ epoch 1, BLEU score: 54.24
epoch 2, BLEU score: 54.44
```
-完成此操作后,您应该有一个模型,其结果与使用 `Seq2SeqTrainer` 训练的模型非常相似。 您可以在 [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate)查看训练完的结果。 如果您想测试对训练循环的任何调整,您可以通过编辑上面显示的代码直接实现它们!
+训练完成之后,你就有了一个模型,最终的 BLEU 分数应该与 `Seq2SeqTrainer` 训练的模型非常相似。你可以在 [huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate) 上查看我们使用此代码训练的模型。如果你想测试对训练循环的任何调整,你可以直接通过编辑上面的代码来实现!
{/if}
## 使用微调后的模型 [[使用微调后的模型]]
-我们已经向您展示了如何将我们在模型中心微调的模型与推理小部件一起使用。 要在“管道”中本地使用它,我们只需要指定正确的模型标识符:
+我们已经向你展示了如何在模型 Hub 上使用我们微调的模型。要在本地的 `pipeline` 中使用它,我们只需要指定正确的模型标识符:
```py
from transformers import pipeline
-# Replace this with your own checkpoint
+# 将其替换成你自己的 checkpoint
model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
translator = pipeline("translation", model=model_checkpoint)
translator("Default to expanded threads")
@@ -981,7 +983,7 @@ translator("Default to expanded threads")
[{'translation_text': 'Par défaut, développer les fils de discussion'}]
```
-正如预期的那样,我们的预训练模型将其知识适应了我们对其进行微调的语料库,而不是单独留下英文单词“threads”,而是将其翻译成法语官方版本。 “”的翻译也是一样的:
+和预想的一样,我们的预训练模型适应了我们微调它的语料库,没有保留英语单词“threads”,而是将它翻译成官方的法语版本。对于“plugin”也是如此:
```py
translator(
@@ -993,10 +995,10 @@ translator(
[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
```
-风格适应的另一个很好的例子!
+这是另一个领域适应的好例子!
-✏️ **轮到你了!** “电子邮件”这个词在模型返回了什么?
+✏️ **轮到你了!** 把之前找到的包含单词“email”样本输入模型,会返回什么结果?
diff --git a/chapters/zh-CN/chapter7/5.mdx b/chapters/zh-CN/chapter7/5.mdx
index 95d18d246..f50469f85 100644
--- a/chapters/zh-CN/chapter7/5.mdx
+++ b/chapters/zh-CN/chapter7/5.mdx
@@ -23,19 +23,19 @@
{/if}
-在本节中,我们将看看如何使用 Transformer 模型将长文档压缩为摘要,这项任务称为文本摘要.这是最具挑战性的 NLP 任务之一,因为它需要一系列能力,例如理解长篇文章和生成能够捕捉文档中主要主题的连贯文本。但是,如果做得好,文本摘要是一种强大的工具,可以减轻领域专家详细阅读长文档的负担,从而加快各种业务流程。
+在本节中,我们将看看如何使用 Transformer 模型将长篇文档压缩为摘要,这项任务称为文本摘要。这是最具挑战性的自然语言处理(NLP)任务之一,因为它需要一系列能力,例如理解长篇文章并且生成能够捕捉文档中主要主题的连贯文本。但是,如果做得好,文本摘要是一种强大的工具,可以减轻各个领域的人详细阅读长文档的负担,从而加快业务流程。
-尽管在[Hugging Face Hub](https://huggingface.co/models?pipeline_tag=summarization=downloads)上已经存在各种微调模型用于文本摘要,几乎所有这些都只适用于英文文档。因此,为了在本节中添加一些变化,我们将为英语和西班牙语训练一个双语模型。在本节结束时,您将有一个可以总结客户评论的[模型](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es)。
+尽管在 [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=summarization=downloads) 上已经存在各种提取文本摘要的微调模型,但是几乎所有的这些模型都只适用于英文文档。因此,为了在本节中添加一些不一样的特点,我们将为英语和西班牙语训练一个双语模型。在本节结束时,你将有一个可以总结客户评论的 [模型](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es) 。
-如下所示:正如我们将看到的,这些摘要很简洁,因为它们是从客户在产品评论中提供的标题中学到的。让我们首先为这项任务准备一个合适的双语语料库。
+如果你试一试的话,就发现模型能够生成非常简洁的摘要,因为它们是从客户在产品评论中提供的标题中学到的。让我们首先为这项任务准备一个合适的双语语料库。
## 准备多语言语料库 [[准备多语言语料库]]
-我们将使用[多语言亚马逊评论语料库](https://huggingface.co/datasets/amazon_reviews_multi)创建我们的双语摘要器。该语料库由六种语言的亚马逊产品评论组成,通常用于对多语言分类器进行基准测试。然而,由于每条评论都附有一个简短的标题,我们可以使用标题作为我们模型学习的目标摘要!首先,让我们从 Hugging Face Hub 下载英语和西班牙语子集:
+我们将使用 [多语言亚马逊评论语料库](https://huggingface.co/datasets/amazon_reviews_multi) 创建我们的双语摘要器。该语料库由六种语言的亚马逊产品评论组成,通常用于多语言分类器的基准测试。然而,由于每条评论都附有一个简短的标题,我们可以使用标题作为我们模型学习的参考摘要!首先,让我们从 Hugging Face Hub 下载英语和西班牙语子集:
```python
from datasets import load_dataset
@@ -62,7 +62,7 @@ DatasetDict({
})
```
-如您所见,对于每种语言,都有 200,000 条评论 **train** 拆分,每个评论有 5,000 条评论 **validation** 和 **test** 分裂。我们感兴趣的评论信息包含在 **review_body** 和 **review_title** 列。让我们通过创建一个简单的函数来查看一些示例,该函数使用我们在[第五章](/course/chapter5)学到过:
+如你所见,在英语数据集的 `train` 部分有 200,000 条评论, `validation` 和 `test` 部分有 5,000 条评论。我们感兴趣的评论正文和标题保存在 `review_body` 和 `review_title` 列中。让我们通过创建一个简单的函数来从训练集中随机抽取一些样本,该函数使用我们在 [第五章](/course/chapter5) 学到过:
```python
def show_samples(dataset, num_samples=3, seed=42):
@@ -88,16 +88,16 @@ show_samples(english_dataset)
-✏️ **试试看!** 更改 `Dataset.shuffle()` 命令中的随机种子以探索语料库中的其他评论。 如果您是说西班牙语的人,请查看 `spanish_dataset` 中的一些评论,看看标题是否也像合理的摘要。
+✏️ **试试看!** 更改 `Dataset.shuffle()` 命令中的随机种子以探索语料库中的其他评论。如果你是说西班牙语的人,请查看 `spanish_dataset` 中的一些评论,看看标题是否像是合理的摘要。
-此示例显示了人们通常在网上找到的评论的多样性,从正面到负面(以及介于两者之间的所有内容!)。尽管标题为“meh”的示例信息量不大,但其他标题看起来像是对评论本身的体面总结。在单个 GPU 上训练所有 400,000 条评论的摘要模型将花费太长时间,因此我们将专注于为单个产品领域生成摘要。为了了解我们可以选择哪些域,让我们将 **english_dataset** 转换到 **pandas.DataFrame** 并计算每个产品类别的评论数量:
+这个示例显示了人们通常在网上评论的多样性,从积极的到消极的(以及介于两者之间的评论!)。尽管带有“meh”标题的示例的信息量不大,但其他标题看起来像是对评论本身的不错的总结。在单个 GPU 上训练所有 400,000 条评论的摘要模型将花费太长时间,因此我们将专注于为单个产品领域生成摘要。为了了解我们可以选择哪些领域,让我们将 `english_dataset` 转换为 `pandas.DataFrame` ,并计算每个产品类别的评论数量:
```python
english_dataset.set_format("pandas")
english_df = english_dataset["train"][:]
-# Show counts for top 20 products
+# 显示前 20 个产品的数量
english_df["product_category"].value_counts()[:20]
```
@@ -125,7 +125,7 @@ book 3756
Name: product_category, dtype: int64
```
-英语数据集中最受欢迎的产品是家居用品、服装和无线电子产品。不过,为了坚持亚马逊的主题,让我们专注于总结书籍的评论——毕竟,这是亚马逊这家公司成立的基础!我们可以看到两个符合要求的产品类别( **book** 和 **digital_ebook_purchase** ),所以让我们为这些产品过滤两种语言的数据集。正如我们在[第五章](/course/chapter5)学到的, 这 **Dataset.filter()** 函数允许我们非常有效地对数据集进行切片,因此我们可以定义一个简单的函数来执行此操作:
+在英语数据集中,最受欢迎的产品是家居用品、服装和无线电子产品。不过,为了带有亚马逊的特色,让我们专注于总结书籍的评论——毕竟,这是亚马逊这家公司成立的基础!我们可以看到两个符合要求的产品类别( `book` 和 `digital_ebook_purchase` ),所以让我们用这两个产品类别过滤两种语言的数据集。正如我们在 [第五章](/course/chapter5) 学到的, `Dataset.filter()` 函数可以让我们非常有效地对数据集进行切片,所以我们可以定义一个简单的函数来进行此操作:
```python
def filter_books(example):
@@ -135,13 +135,13 @@ def filter_books(example):
)
```
-现在,当我们将此函数应用于 **english_dataset** 和 **spanish_dataset** ,结果将只包含涉及书籍类别的那些行。在应用过滤器之前,让我们将**english_dataset**的格式从 **pandas** 切换回到 **arrow** :
+当我们使用这个函数对 `english_dataset` 和 `spanish_dataset` 过滤后,结果将只包含涉及书籍类别的那些行。在使用过滤器之前,让我们将 `english_dataset` 的格式从 `"pandas"` 切换回 `"arrow"` :
```python
english_dataset.reset_format()
```
-然后我们可以应用过滤器功能,作为健全性检查,让我们检查评论样本,看看它们是否确实与书籍有关:
+然后我们可以使用过滤器功能,作为一个基本的检查,让我们检查一些评论的样本,看看它们是否确实与书籍有关:
```python
spanish_books = spanish_dataset.filter(filter_books)
@@ -160,7 +160,7 @@ show_samples(english_books)
'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
```
-好的,我们可以看到评论并不是严格意义上的书籍,可能是指日历和 OneNote 等电子应用程序等内容。尽管如此,该领域似乎适合训练摘要模型。在我们查看适合此任务的各种模型之前,我们还有最后一点数据准备要做:将英语和西班牙语评论合并为一个 **DatasetDict** 目的。 🤗 Datasets 提供了一个方便的 **concatenate_datasets()** 函数(顾名思义)合并 **Dataset** 对象。因此,为了创建我们的双语数据集,我们将遍历每个拆分,连接该拆分的数据集,并打乱结果以确保我们的模型不会过度拟合单一语言:
+好吧,我们可以看到评论并不是严格意义上的书籍,也可能是指日历和 OneNote 等电子应用程序等内容。尽管如此,该领域似乎也适合训练摘要模型。在我们查筛选适合此任务的各种模型之前,我们还有最后一点数据准备要做:将英文和西班牙文评论作为单个 `DatasetDict` 对象组合起来。🤗 Datasets 提供了一个方便的 `concatenate_datasets()` 函数,它(名如其实)将把两个 `Dataset` 对象堆叠在一起。因此,为了创建我们的双语数据集,我们将遍历数据集的每个部分,并打乱结果以确保我们的模型不会过度拟合单一语言:
```python
from datasets import concatenate_datasets, DatasetDict
@@ -173,7 +173,7 @@ for split in english_books.keys():
)
books_dataset[split] = books_dataset[split].shuffle(seed=42)
-# Peek at a few examples
+# 挑选一些样例
show_samples(books_dataset)
```
@@ -188,37 +188,37 @@ show_samples(books_dataset)
'>> Review: igual que el anterior'
```
-这当然看起来像是英语和西班牙语评论的混合!现在我们有了一个训练语料库,最后要检查的一件事是评论中单词的分布及其标题。这对于摘要任务尤其重要,其中数据中的简短参考摘要会使模型偏向于仅在生成的摘要中输出一两个单词。下面的图显示了单词分布,我们可以看到有些标题严重偏向于 1-2 个单词:
+这的确看起来像是混合了英语和西班牙语的评论!现在我们有了一个训练语料库,最后要检查的一件事是评论及其标题中单词的分布。这对于摘要任务尤其重要,其中数据中如果出现大量参考摘要过于简短会使模型偏向于生成的摘要中仅有一两个单词。下面的图中显示了单词分布,我们可以看到有些标题严重偏向于 1-2 个单词:
-为了解决这个问题,我们将过滤掉标题非常短的示例,以便我们的模型可以生成更有趣的摘要。由于我们正在处理英文和西班牙文文本,因此我们可以使用粗略的启发式方法在空白处拆分标题,然后使用我们可信赖的 **Dataset.filter()** 方法如下:
+为了解决这个问题,我们将过滤掉标题非常短的示例,以便我们的模型可以生成更有效的摘要。由于我们正在处理英文和西班牙文文本,因此我们可以使用粗略的启发式方法在空白处拆分标题的单词,然后用我们强大的 `Dataset.filter()` 方法如下:
```python
books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)
```
-现在我们已经准备好了我们的语料库,让我们来看看一些可以对其进行微调的可能的 Transformer 模型!
+现在我们已经准备好了我们的语料库,让我们来看看一些可以对其进行微调的可选的 Transformer 模型!
## 文本摘要模型 [[文本摘要模型]]
-如果你仔细想想,文本摘要是一种类似于机器翻译的任务:我们有一个像评论这样的文本正文,我们希望将其“翻译”成一个较短的版本,以捕捉输入的显着特征。因此,大多数用于文本摘要的 Transformer 模型采用了我们在[第一章](/course/chapter1)遇到的编码器-解码器架构。尽管有一些例外,例如 GPT 系列模型,它们在few-shot(少量微调)之后也可以提取摘要。下表列出了一些流行的预训练模型,可以对其进行微调以进行汇总。
+如果你仔细想想,文本摘要是一种类似于机器翻译的任务:我们有一个像评论这样的文本正文,我们希望将其“翻译”成一个较短的版本,同时捕捉到输入文本的主要特征。因此,大多数用于文本摘要的 Transformer 模型采用了我们在 [第一章](/course/chapter1) 遇到的编码器-解码器架构。尽管有一些例外,例如 GPT 系列模型,它们在 few-shot(少量微调)之后也可以提取摘要。下表列出了一些可以进行摘要微调的流行预训练模型。
-| Transformer 模型 | 描述 | 多种语言? |
+| Transformer 模型 | 描述 | 多种言?|
| :---------: | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-----------: |
-| [GPT-2](https://huggingface.co/gpt2-xl) | 虽然训练为自回归语言模型,但您可以通过在输入文本末尾附加“TL;DR”来使 GPT-2 生成摘要。 | ❌ |
-| [PEGASUS](https://huggingface.co/google/pegasus-large) | 在预训练是的目标是来预测多句子文本中的屏蔽句子。 这个预训练目标比普通语言建模更接近文本摘要,并且在流行的基准测试中得分很高。 | ❌ |
-| [T5](https://huggingface.co/t5-base) | 通用的 Transformer 架构,在文本到文本的框架中制定所有任务; 例如,模型文本摘要的输入格式是`summarize: ARTICLE`。 | ❌ |
-| [mT5](https://huggingface.co/google/mt5-base) | T5 的多语言版本,在多语言 Common Crawl 语料库 (mC4) 上进行预训练,涵盖 101 种语言。 | ✅ |
-| [BART](https://huggingface.co/facebook/bart-base) | 一种新颖的 Transformer 架构,其中包含经过训练的编码器和解码器堆栈,以重建被破坏的输入,结合了 BERT 和 GPT-2 的预训练方案。 | ❌ |
-| [mBART-50](https://huggingface.co/facebook/mbart-large-50) | BART 的多语言版本,预训练了 50 种语言。 | ✅ |
+| [GPT-2](https://huggingface.co/gpt2-xl) | 虽然训练为自回归语言模型,但你可以通过在输入文本末尾附加“TL;DR”来使 GPT-2 生成摘要。| ❌ |
+| [PEGASUS](https://huggingface.co/google/pegasus-large) | 在预训练时的目标是来预测多句子文本中的屏蔽句子。这个预训练目标比普通语言建模更接近文本摘要,并且在流行的基准测试中得分很高。| ❌ |
+| [T5](https://huggingface.co/t5-base) | 通用的 Transformer 架构,所有任务都以文本到文本的框架进行描述;例如,模型文本摘要的输入格式是 `summarize: ARTICLE` 。| ❌ |
+| [mT5](https://huggingface.co/google/mt5-base) | T5 的多语言版本,在多语言 Common Crawl 语料库 (mC4) 上进行预训练,涵盖了 101 种语言。| ✅ |
+| [BART](https://huggingface.co/facebook/bart-base) | 一种新颖的 Transformer 架构,其中包含经过训练的编码器和解码器堆栈,以重建被破坏的输入,结合了 BERT 和 GPT-2 的预训练方案。| ❌ |
+| [mBART-50](https://huggingface.co/facebook/mbart-large-50) | BART 的多语言版本,预训练了 50 种语言。| ✅ |
-从此表中可以看出,大多数用于摘要的 Transformer 模型(以及大多数 NLP 任务)都是单语的。如果您的任务是使用“有大量语料库”的语言(如英语或德语),这很好,但对于世界各地正在使用的数千种其他语言,则不然。幸运的是,有一类多语言 Transformer 模型,如 mT5 和 mBART,可以解决问题。这些模型是使用语言建模进行预训练的,但有一点不同:它们不是在一种语言的语料库上训练,而是同时在 50 多种语言的文本上进行联合训练!
+从此表中可以看出,大多数用于摘要的 Transformer 模型(以及大多数 NLP 任务)都是单一语言的。如果你的任务所使用的语言是“有大量语料库”(如英语或德语)的语言,这很好。但对于世界各地正在使用的数千种其他语言,则不然。幸运的是,有一类多语言 Transformer 模型,如 mT5 和 mBART,可以解决问题。这些模型也是使用因果语言建模进行预训练的,但有一点不同:它们不是在一种语言的语料库上训练,而是同时在 50 多种语言的文本上进行联合训练!
-我们将使用 mT5,这是一种基于 T5 的有趣架构,在文本到文本框架中进行了预训练。在 T5 中,每个 NLP 任务都是根据提示前缀来制定的,例如 **summarize:** 这使模型使生成的文本适应提示。如下图所示,这让 T5 变得非常通用,因为你可以用一个模型解决很多任务!
+我们将使用 mT5,这是一种基于 T5 的有趣架构,在文本到文本任务中进行了预训练。在 T5 中,每个 NLP 任务都是以任务前缀(如 `summarize:` )的形式定义的,模型根据不同的任务生成不同的文本。如下图所示,这让 T5 变得非常通用,因为你可以用一个模型解决很多任务!
@@ -226,11 +226,11 @@ books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) >

-100 来标记特殊 token 。",
+ explain: "这不是 token 分类特有的 —— 我们总是用 -100 作为我们想在损失中忽略的 token 的标签。"
},
{
- text: "因为互联网上有大量的文本",
- explain: "的确如此! 但这并不是唯一的区别。",
+ text: "在进行截断/填充时,我们需要确保将待预测的标签截断或填充到与输入相同的大小",
+ explain: "的确如此!但这并不是唯一的区别。",
correct: true
}
]}
/>
-### 3.当我们对标记分类问题中的单词进行标记并希望标记时,会出现什么问题?
+### 3.在 token 分类问题中,当我们分词并想要子词分词时,会出现什么问题?
+
-100 标记为 < code > ,以便在丢失时忽略它们。"
+ text: "Tokenizer 添加了特殊的 token ,我们没有这些 token 的标签。",
+ explain: "我们把这些 token ID设置为 -100,所以在计算损失时它们会被忽略。"
},
{
- text: "每个单词可以产生几个标记,所以我们最终得到的标记比标签多。",
- explain: "这是主要的问题,我们需要将原始标签与标记对齐。",
+ text: "每个词可能产生多个 token ,因此我们最终会得到比我们拥有的标签更多的 token 。",
+ explain: "这是主要的问题,我们需要将原始的标签与 token 对齐。",
correct: true
},
{
- text: "因为目标是按顺序排列的文本问题",
- explain: "这是不正确的; 我们需要尽可能多的标签,否则我们的模型就会出错。"
+ text: "添加的 token 没有标签,所以没有问题。",
+ explain: "这是不正确的;我们需要和 token 相同数量的标签,否则我们的模型会报错。"
}
]}
/>
@@ -77,92 +80,92 @@ Let's test what you learned in this chapter!
-### 5.掩码语言建模问题中的标签是什么?
+### 5.掩码语言建模问题中的标签是什么?
-### 6.这些任务中的哪一个可以看作是一个顺序到顺序的问题?
+### 6.哪些任务可以被看作是序列到序列的问题?
-100 来标记特殊标记。",
+ text: "将一段中文文本翻译成英文。",
explain: "这绝对是一个从序列到序列的问题。你能发现另一个吗?",
correct: true
},
{
- text: "修正我侄子/朋友发来的信息,使它们用正确的英语",
- explain: "这是一种翻译问题,所以肯定是一个顺序到顺序的任务。但这不是唯一正确的答案!",
+ text: "修正我侄子/朋友发来的信息,纠正他们的语法错误",
+ explain: "这是一种翻译问题,所以绝对是一个序列到序列的任务。这不是唯一的正确答案。",
correct: true
}
]}
/>
-### 7.对于序列到序列的问题,预处理数据的正确方法是什么?
+### 7.对于序列到序列的问题,预处理数据的正确方法是什么?
input = ... 和 < code > target = ... 。",
- explain: "这可能是我们将来添加的一个 API,但现在不可能。"
+ text: "输入和目标必须一起发送到 tokenizer ,使用 `input = ...` 和 `target = ...` 。",
+ explain: "这可能是我们未来要添加的一个 API,但现在还不行。"
},
{
- text: "输入和目标都必须在对标记器的两个独立调用中进行预处理。",
- explain: "不,这是在训练一个模型; 这里没有适应性。"
+ text: "输入和目标都必须在 tokenizer 的两次独立调用中进行预处理。",
+ explain: "这是正确的,但是不完整。你还需要做一些事情来确保 tokenizer 正确处理两者。"
},
{
- text: "因为我们在训练之后计算度量",
- explain: "不是在序列分类问题; 目标也是文本,我们需要转换成数字!"
+ text: "像往常一样,我们只需要对输入进行 tokenize",
+ explain: "在一个序列到序列问题中,并不仅仅是输入文本需要进行 tokenize,目标文本也需要进行同样的转换!"
},
{
- text: "输入必须发送到标记器,目标也是如此,但需要使用特殊的上下文管理器。",
- explain: "没错,标记器需要由上下文管理器放入目标模式。",
+ text: "输入序列和目标序列都需要通过特殊的上下文管理器分别发送给 tokenizer 进行预处理。",
+ explain: "这是正确的, tokenizer 需要通过该上下文管理器找到目标序列的范围并进行处理。",
correct: true
}
]}
@@ -170,71 +173,73 @@ Let's test what you learned in this chapter!
{#if fw === 'pt'}
-### 8.为什么序列到序列问题有一个特定的“培训者”子类?
+### 8.为什么需要有一个特定的 `Trainer `子类来解决序列到序列问题?
+
-100 的标签",
- explain: "这根本不是习惯性的损失,而是损失总是通过计算得到的。"
+ text: "因为序列到序列问题使用自定义的损失计算方法,忽略 -100 的标签",
+ explain: "这根本不是自定义的损失计算方法,而是自然语言处理中一种常规的忽略特定 token 计算方式。"
},
{
- text: "当您拥有大量可用数据时,即使有一个经过预先训练的模型可以处理这些数据",
- explain: "没错。 Sequence-to-sequence models' predictions are often run using the generate() method.",
+ text: "因为序列到序列问题需要特殊的评估循环",
+ explain: "没错。序列到序列模型的预测通常需要使用 generate() 方法",
correct: true
},
{
- text: "文本是作为单词给出的,所以我们只需要应用子词的标记。",
- explain: "< code > Trainer 并不关心这些,因为它们以前已经被预处理过。"
+ text: "因为该问题中的预测目标是序列到序列中问题部分的文本",
+ explain: "这不是Trainer需要考虑的部分,因为这些文本在进入`Tranier`之前已经被预处理过。"
},
{
text: "因为我们在序列到序列问题中使用了两个模型",
- explain: "我们确实在某种程度上使用了两种模型,编码器和解码器,但是它们被组合在一个模型中。"
+ explain: "我们确实以某种方式使用两种模型,编码器和解码器,但它们被组合在一个模型中"
}
]}
/>
{:else}
-### 9.为什么在 Transformer 模型上调用“ compile ()”时通常不需要指定损失?
+### 9.为什么在 Transformer 模型上调用 `compile()` 时通常不需要指定损失的计算方法?
+
input = ... 和 < code > target = ... 。",
+ text: "因为默认使用模型的内部损失计算方法",
explain: "没错!",
correct: true
},
{
- text: "因为我们在训练之后计算指标",
- explain: "这可以被定义为一个从序列到序列的问题,尽管这不是唯一正确的答案。"
+ text: "因为我们在训练后计算评估指标",
+ explain: "我们确实经常这样做,但这并不能解释我们在训练中优化的损失值是从哪里得到的。"
},
{
- text: "因为损失是在“ model.fit ()”中指定的",
- explain: "不,损失函数在运行‘ model.com pile ()’时是固定的,不能在‘ model.fit ()’中更改。"
+ text: "因为损失是在`model.fit()`中指定的",
+ explain: "不,一旦运行`model.compile()`,损失函数就总是固定的,并且不能在`model.fit()`中更改。"
}
]}
/>
{/if}
-### 10.你应该在什么时候预先训练一个新的模型?
+### 10.你应该在什么时候预先训练一个新的模型?
-### 11.为什么在大量的文本上预先训练一个语言模型是很容易的呢?
+### 11.为什么在大量的文本上预先训练一个语言模型是很容易的呢?
+
-### 12.问答任务的预处理数据时,主要的挑战是什么?
+### 12.问答任务预处理数据时,主要的挑战是什么?
+
-### 13.问题回答中的后处理通常是怎样进行的?
+### 13.问答任务中的后处理通常是怎样进行的?
diff --git a/chapters/zh-CN/chapter8/1.mdx b/chapters/zh-CN/chapter8/1.mdx
index 7f2e8f531..fbb89a62b 100644
--- a/chapters/zh-CN/chapter8/1.mdx
+++ b/chapters/zh-CN/chapter8/1.mdx
@@ -1,12 +1,12 @@
# 介绍 [[介绍]]
-既然您知道如何使用🤗 Transformers处理最常见的NLP任务,您应该能够开始自己的项目了!在本章中,我们将探讨遇到问题时该怎么做。您将学习如何成功调试代码或训练,以及如果自己无法解决问题,如何向社区寻求帮助。如果您认为您在其中一个拥抱人脸库中发现了错误,我们将向您展示报告它的最佳方式,以便尽快解决问题。
+现在,你已经知道如何使用🤗 Transformers 处理最常见的 NLP 任务,可以开始调试自己的项目了!在本章中我们将探讨可能遇到的问题以及解决方法。你将学习如何成功调试代码和训练,以及在无法自行解决问题时如何向社区寻求帮助。如果你发现了 Hugging Face 库中的一个 bug,我们会告诉你报告 bug 的最佳方法,以便尽快解决问题。
-更准确地说,在本章中,您将学习:
+更准确地说,在本章中,你将学习:
- 出现错误时要做的第一件事
-- 如何在网上寻求帮助[forums](https://discuss.huggingface.co/)
-- 如何调试您的训练管道
+- 如何在 [论坛](https://discuss.huggingface.co) 寻求帮助
+- 如何调试你的训练管道
- 如何写一个好问题
-当然,所有这些都与 🤗 Transformers 或Hugging Face 生态无关;本章的经验教训适用于大多数开源项目!
+当然,所有这些都与 🤗 Transformers 或 Hugging Face 生态无关;本章的经验教训适用于大多数开源项目!
diff --git a/chapters/zh-CN/chapter8/2.mdx b/chapters/zh-CN/chapter8/2.mdx
index bcab43e75..151113931 100644
--- a/chapters/zh-CN/chapter8/2.mdx
+++ b/chapters/zh-CN/chapter8/2.mdx
@@ -7,11 +7,11 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/chapter8/section2.ipynb"},
]} />
-在本节中, 我们将研究当你尝试从新调整的 Transformer 模型生成预测时可能发生的一些常见错误。这将为 [第四节](/course/chapter8/section4) 做准备, 我们将探索如何调试训练阶段本身。
+在本节中,我们将研究当你尝试从新调整的 Transformer 模型生成预测时可能发生的一些常见错误。本节为将 [第四节](/course/chapter8/section4) 做准备,在那一节中探索如何调试训练阶段本身。
-我们为这一节准备了一个 [模板模型库](https://huggingface.co/lewtun/distilbert-base-uncased-finetuned-squad-d5716d28), 如果你想运行本章中的代码, 你首先需要将模型复制到你的 [Hugging Face Hub](https://huggingface.co) 账号。为此, 首先通过在 Jupyter 笔记本中运行以下任一命令来登录:
+我们为这一节准备了一个 [模板仓库](https://huggingface.co/lewtun/distilbert-base-uncased-finetuned-squad-d5716d28) ,如果你想运行本章中的代码,首先需要将模型复制到自己的 [Hugging Face Hub](https://huggingface.co) 账号。这需要你在 Jupyter Notebook 中运行以下命令来登录:
```python
from huggingface_hub import notebook_login
@@ -19,13 +19,13 @@ from huggingface_hub import notebook_login
notebook_login()
```
-或在你最喜欢的终端中执行以下操作:
+或在你最喜欢的终端中执行以下操作:
```bash
huggingface-cli login
```
-这将提示你输入用户名和密码, 并将在下面保存一个令牌 *~/.cache/huggingface/*。登录后, 你可以使用以下功能复制模板存储库:
+这里将会提示你输入用户名和密码,登陆后会自动在 `~/.cache/huggingface/` 保存一个令牌 完成登录后,可以使用以下功能克隆模板仓库:
```python
from distutils.dir_util import copy_tree
@@ -33,32 +33,32 @@ from huggingface_hub import Repository, snapshot_download, create_repo, get_full
def copy_repository_template():
- # Clone the repo and extract the local path
+ # 克隆仓库并提取本地路径
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
- # Create an empty repo on the Hub
+ # 在 Hub 上创建一个新仓库
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
- # Clone the empty repo
+ # 克隆空仓库
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
- # Copy files
+ # 复制文件
copy_tree(template_repo_dir, new_repo_dir)
- # Push to Hub
+ # 上传到 Hub 上
repo.push_to_hub()
```
-现在, 当你调用 `copy_repository_template()` 时, 它将在你的帐户下创建模板存储库的副本。
+现在当你调用 `copy_repository_template()` 时,它将在你的帐户下创建模板仓库的副本。
-## 从 🤗 Transformers 调试管道 [[从 🤗 Transformers 调试管道]]
+## 调试 🤗 Transformers 的 `pipeline` [[调试 🤗 Transformers 的 `pipeline`]]
-要开始我们调试 Transformer 模型的奇妙世界之旅, 请考虑以下场景: 你正在与一位同事合作进行问答项目, 以帮助电子商务网站的客户找到有关消费品的答案。你的同事给你发了一条消息, 比如:
+接下来要开始我们调试 Transformer 模型的奇妙世界之旅,请考虑以下情景:你正在与一位同事合作开发一个问答的项目,这个项目可以帮助电子商务网站的客户找到有关消费品一些问题的回答。假如你的同事给你发了这样一条消息:
-> 嗨! 我刚刚使用了抱抱脸课程的 [第七章](/course/chapter7/7) 中的技术进行了一个实验, 并在 SQuAD 上获得了一些很棒的结果! 我认为我们可以用这个模型作为我们项目的起点。Hub上的模型ID是 "lewtun/distillbert-base-uncased-finetuned-squad-d5716d28"。请随意测试一下 :)
+> 嗨!我刚刚使用了 Hugging Face 课程的 [第七章](/course/chapter7/7) 中的技术进行了一个实验,并在 SQuAD 上获得了一些很棒的结果!我觉得我们可以用这个模型作为项目的起点。Hub 上的模型 ID 是 `lewtun/distillbert-base-uncased-finetuned-squad-d5716d28`。你来测试一下 )
-你首先想到的是使用 🤗 Transformers 中的 `管道`:
+你首先想到的是使用 🤗 Transformers 中的 `pipeline` :
```python
from transformers import pipeline
@@ -77,21 +77,21 @@ OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-
"""
```
-哦不对, 好像出了什么问题! 如果你是编程新手, 这些类型的错误一开始看起来有点神秘 (甚至是一个 `OSError`?!)。这里显示的错误只是一个更大的错误报告的最后一部分, 称为 _Python traceback_ (又名堆栈跟踪)。例如, 如果你在 Google Colab 上运行此代码, 你应该会看到类似于以下屏幕截图的内容:
+啊哦,好像出了什么问题!如果你是编程新手,这类错误一开始看起来有点神秘 ( `OSError` 到底是什么?)。其实这里显示的错误只是全部错误报告中最后一部分,称为 `Python traceback` (又名堆栈跟踪)。例如,如果你在 Google Colab 上运行此代码,你应该会看到类似于以下屏幕截图的内容:
-这些报告中包含很多信息, 所以让我们一起来看看关键部分。首先要注意的是, 应该从 _从底部到顶部_ 读取回溯。如果你习惯于从上到下阅读英文文本, 这可能听起来很奇怪,但它反映了这样一个事实,即回溯显示了在下载模型和标记器时 `管道` 进行的函数调用序列。(查看 [第二章](/course/chapter2) 了解有关 `pipeline` 如何在后台工作的更多详细信息。)
+这些报告中包含很多信息,让我们一起来看看关键部分。阅读这样的报告时的阅读顺序比较特殊,应该按照从底部到顶部的顺序阅读,如果你习惯于从上到下阅读文本,这可能听起来很奇怪,但它反映了一个事实:traceback 显示了在下载模型和 tokenizer 时 `pipeline` 函数调用的顺序。(查看 [第二章](/course/chapter2) 了解有关 `pipeline` 内部原理的更多详细信息。)
-🚨 看到Google Colab 回溯中 "6 帧" 周围的蓝色框了吗? 这是 Colab 的一个特殊功能, 它将回溯压缩为"帧"。如果你似乎无法找到错误的来源, 请确保通过单击这两个小箭头来展开完整的回溯。
+🚨 看到 Google Colab 中 traceback 中间 “6 frames” 的椭圆形蓝色框了吗?这是 Colab 的一个特殊功能,它会自动将 traceback 的中间部分压缩为“frames”。如果你无法找到错误的来源,可以通过单击这两个小箭头来展开完整的 traceback。
-这意味着回溯的最后一行指示最后一条错误消息并给出引发的异常的名称。在这种情况下, 异常类型是`OSError`, 表示与系统相关的错误。如果我们阅读随附的错误消息, 我们可以看到模型的 *config.json* 文件似乎有问题, 我们给出了两个修复它的建议:
+这意味着 traceback 的最后一行显示的是最后一条错误消息和引发的异常名称。在这里,异常类型是 `OSError` ,表示这个错误与系统相关。如果我们阅读随之附着的错误消息,我们就可以看到模型的 `config.json` 文件似乎有问题,这里给出了两个修复的建议:
```python out
"""
@@ -105,23 +105,23 @@ Make sure that:
-💡 如果你遇到难以理解的错误消息, 只需将该消息复制并粘贴到 Google 或 [Stack Overflow](https://stackoverflow.com/) 搜索栏中 (是的, 真的!)。你很可能不是第一个遇到错误的人, 这是找到社区中其他人发布的解决方案的好方法。例如, 在 Stack Overflow 上搜索 `OSError: Can't load config for` 给出了几个[hits](https://stackoverflow.com/search?q=OSError%3A+Can%27t+load+config+for+), 可能是用作解决问题的起点。
+💡 如果你遇到难以理解的错误消息,只需将该消息复制并粘贴到 Google 或 [Stack Overflow](https://stackoverflow.com) 搜索栏中。你很有可能不是第一个遇到错误的人,因此很有可能在社区中找到其他人发布的解决方案。例如,在 Stack Overflow 上搜索 `OSError: Can't load config for` 给出了几个 [结果](https://stackoverflow.com/search?q=OSError%3A+Can%27t+load+config+for+) ,可以作为你解决问题的起点。
-第一个建议是要求我们检查模型ID是否真的正确, 所以首先要做的就是复制标识符并将其粘贴到Hub的搜索栏中:
+第一个建议是检查模型 ID 是否真的正确,所以首先要做的就是复制标签并将其粘贴到 Hub 的搜索栏中:
-嗯, 看起来我们同事的模型确实不在 Hub 上... 啊哈, 但是模型名称中有一个错字! DistilBERT 的名称中只有一个 "l", 所以让我们解决这个问题并寻找 "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28":
+嗯,看起来你同事的模型确实不在 Hub 上。但是仔细看模型名称就会发现,里面有一个错别字!正确的 DistilBERT 的名称中只有一个 “l”,所以让我们修正后寻找 `lewtun/distilbert-base-uncased-finetuned-squad-d5716d28`:
-好的, 这很受欢迎。现在让我们尝试使用正确的模型 ID 再次下载模型:
+好的,这次有结果了。现在让我们使用正确的模型 ID 再次尝试下载模型:
```python
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
@@ -138,7 +138,7 @@ OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d
"""
```
-啊, 再次挫败 -- 欢迎来到机器学习工程师的日常生活! 因为我们已经修复了模型 ID, 所以问题一定出在存储库本身。访问 🤗 Hub 上存储库内容的一种快速方法是通过 `huggingface_hub` 库的 `list_repo_files()` 方法:
+啊,再次失败。不要气馁,欢迎来到机器学习工程师的日常生活!前面我们已经修正了模型 ID,所以问题一定出在仓库本身。这里提供一种快速访问 🤗 Hub 上仓库内容的方法——通过 `huggingface_hub` 库的 `list_repo_files()` 函数:
```python
from huggingface_hub import list_repo_files
@@ -150,7 +150,7 @@ list_repo_files(repo_id=model_checkpoint)
['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']
```
-有趣 -- 似乎没有配置文件存储库中的 *config.json* 文件! 难怪我们的 `pipeline` 无法加载模型; 我们的同事一定是在微调后忘记将这个文件推送到 Hub。在这种情况下, 问题似乎很容易解决: 我们可以要求他们添加文件, 或者, 因为我们可以从模型 ID 中看到使用的预训练模型是 [`distilbert-base-uncased`](https://huggingface.co/distilbert-base-uncased), 我们可以下载此模型的配置并将其推送到我们的存储库以查看是否可以解决问题。让我们试试看。使用我们在 [第二章](/course/chapter2) 中学习的技术, 我们使用 `AutoConfig` 类下载模型的配置:
+ 奇怪的是——仓库中似乎没有配置 `config.json` 文件!难怪我们的 `pipeline` 无法加载模型;你的同事一定是在微调后忘记将这个文件上传到 Hub。在这种情况下问题似乎很容易解决:要求他添加文件,或者我们从模型 ID 中可以看出使用的预训练模型是 [`distilbert-base-uncased`](https://huggingface.co/distilbert-base-uncased) ,因此我们可以直接下载此模型的配置文件并将其上传到你们的仓库后查看这样是否可以解决问题。在这里涉及到 [第二章](/course/chapter2) 中学习的技巧,使用 `AutoConfig` 类下载模型的配置文件:
```python
from transformers import AutoConfig
@@ -161,17 +161,17 @@ config = AutoConfig.from_pretrained(pretrained_checkpoint)
-🚨 我们在这里采用的方法并不是万无一失的, 因为我们的同事可能在微调模型之前已经调整了 `distilbert-base-uncased` 配置。在现实生活中, 我们想首先检查它们, 但出于本节的目的, 我们假设它们使用默认配置。
+🚨 在这里采用的方法并不是百分之百可靠的,因为你的同事可能在微调模型之前已经调整了 `distilbert-base-uncased` 配置。在现实情况中,我们应该先与他们核实,但在本节中,我们先假设他们使用的是默认配置。
-然后我们可以使用配置的 `push_to_hub()` 方法将其推送到我们的模型存储库:
+上一步成功后,可以使用 `config` 的 `push_to_hub()` 方法将其上传到模型仓库:
```python
config.push_to_hub(model_checkpoint, commit_message="Add config.json")
```
-现在我们可以通过从最新提交的 `main` 分支中加载模型来测试这是否有效:
+现在可以通过从最新提交的 `main` 分支中加载模型来测试是否有效:
```python
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
@@ -198,33 +198,31 @@ reader(question=question, context=context)
'answer': 'the task of extracting an answer from a text given a question'}
```
-哇哦, 成功了!让我们回顾一下你刚刚学到的东西:
+成功了!让我们回顾一下你刚刚学到的东西:
-- Python 中的错误消息称为 _tracebacks_ , 并从下到上阅读。错误消息的最后一行通常包含定位问题根源所需的信息。
-- 如果最后一行没有包含足够的信息, 请按照您的方式进行回溯, 看看您是否可以确定源代码中发生错误的位置。
-- 如果没有任何错误消息可以帮助您调试问题, 请尝试在线搜索类似问题的解决方案。
-- `huggingface_hub`
-// 🤗 Hub?
-库提供了一套工具, 你可以使用这些工具与 Hub 上的存储库进行交互和调试。
+- Python 中的错误消息称为 `tracebacks` ,注意需要从下到上阅读。错误消息的最后一行通常包含定位问题根源所需的信息。
+- 如果最后一行没有包含足够的信息,需要进行 `tracebacks` (向上逐级查看),看看是否可以确定源代码中发生错误的位置。
+- 如果没有任何错误消息可以帮助你调试问题,请尝试在线搜索类似问题的解决方案。
+- `huggingface_hub` 库提供了一套工具,你可以使用这些工具与 Hub 上的仓库进行交互和调试。
-现在你知道如何调试管道, 让我们看一下模型本身前向传递中的一个更棘手的示例。
+现在你知道如何调试 `pipeline` ,让我们来看一个更棘手的例子,即调试模型本身的前向传播的过程。
-## 调试模型的前向传递 [[调试模型的前向传递]]
+## 调试模型的前向传播 [[调试模型的前向传播]]
-尽管 `pipeline` 对于大多数需要快速生成预测的应用程序来说非常有用, 有时您需要访问模型的 logits (例如, 如果您有一些想要应用的自定义后处理)。为了看看在这种情况下会出现什么问题, 让我们首先从 `pipeline` 中获取模型和标记器:
+尽管 `pipeline` 对于大多数需要快速生成预测结果的来说非常应用场景有用,但是有时你需要访问模型的 logits (比如你想要实现一些的自定义后续处理)。为了看看在这种情况下可能会出现什么问题,让我们首先从 `pipeline` 中获取模型和 `tokenizers`
```python
tokenizer = reader.tokenizer
model = reader.model
```
-接下来我们需要一个问题, 那么让我们看看是否支持我们最喜欢的框架:
+接下来我们需要提出一个问题,看看在这个上下文中的模型是否受支持我们最喜欢的框架:
```python
question = "Which frameworks can I use?"
```
-正如我们在 [第七章](/course/chapter7) 中学习的, 我们需要采取的通常步骤是对输入进行标记化, 提取开始和结束标记的对数, 然后解码答案范围:
+正如我们在 [第七章](/course/chapter7) 中学习的,我们接下来需要对输入进行 tokenize,提取起始和结束 token 的 logits,然后解码答案所在的文本范围:
```python
import torch
@@ -234,9 +232,9 @@ input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
-# Get the most likely beginning of answer with the argmax of the score
+# 计算分数的 argmax 获取最有可能的答案开头
answer_start = torch.argmax(answer_start_scores)
-# Get the most likely end of answer with the argmax of the score
+# 计算分数的 argmax 获取最有可能的答案结尾
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
@@ -288,15 +286,15 @@ AttributeError: 'list' object has no attribute 'size'
"""
```
-噢, 看起来我们的代码中有一个错误!但我们不怕一点调试。您可以在笔记本中使用 Python 调试器:
+看起来我们的代码中有一个错误!不用紧张,你可以在 Notebook 中使用 Python 调试器:
-或在终端中:
+或者跟随我们一起从终端中逐步试验找到错误:
-在这里, 阅读错误消息告诉我们 `'list' object has no attribute 'size'`, 我们可以看到一个 `-->` 箭头指向 `model(**inputs)` 中出现问题的行。你可以使用 Python 调试器以交互方式调试它, 但现在我们只需打印出一部分 `inputs`, 看看我们有什么:
+在这里,错误消息告诉我们 `'list' object has no attribute 'size'` ,我们可以看到一个 `-->` 箭头指向 `model(**inputs)` 中引发问题的行。你可以使用 Python 调试器用交互方式来调试它,但在这里我们只需打印出一部分 `inputs` ,检查一下它的值:
```python
inputs["input_ids"][:5]
@@ -306,7 +304,7 @@ inputs["input_ids"][:5]
[101, 2029, 7705, 2015, 2064]
```
-这当然看起来像一个普通的 Python `list`, 但让我们仔细检查一下类型:
+这当然看起来像一个普通的 Python `list` ,但让我们仔细检查一下类型:
```python
type(inputs["input_ids"])
@@ -316,7 +314,7 @@ type(inputs["input_ids"])
list
```
-是的, 这肯定是一个 Python `list`。那么出了什么问题呢? 回忆 [第二章](/course/chapter2) 🤗 Transformers 中的 `AutoModelForXxx` 类在 _tensors_ 上运行(PyTorch或者or TensorFlow), 一个常见的操作是使用 `Tensor.size()` 方法提取张量的维度, 例如, 在 PyTorch 中。让我们再看看回溯, 看看哪一行触发了异常:
+是的,的确是一个 Python `list` 。那么出了什么问题呢?回想一下我们在 [第二章](/course/chapter2) 🤗 Transformers 中的 `AutoModelForXxx` 类中的 `tensors` (PyTorch 或者 TensorFlow)进行的操作,例如在 PyTorch 中,一个常见的操作是使用 `Tensor.size()` 方法提取张量的维度。让我们再回到 traceback 中,看看哪一行触发了异常:
```
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
@@ -329,13 +327,13 @@ list
AttributeError: 'list' object has no attribute 'size'
```
-看起来我们的代码试图调用 `input_ids.size()`, 但这显然不适用于 Python `list`, 这只是一个容器。我们如何解决这个问题? 在 Stack Overflow 上搜索错误消息给出了很多相关的 [hits](https://stackoverflow.com/search?q=AttributeError%3A+%27list%27+object+has+no+attribute+%27size%27&s=c15ec54c-63cb-481d-a749-408920073e8f)。单击第一个会显示与我们类似的问题, 答案如下面的屏幕截图所示:
+看起来我们的代码试图调用 `input_ids.size()` ,但 `.size()` 方法显然不适用于 Python 的 `list` , `list` 只是一个容器,不是一个对象。我们如何解决这个问题呢?在 Stack Overflow 上搜索错误消息,可以找到很多相关的 [结果](https://stackoverflow.com/search?q=AttributeError%3A+%27list%27+object+has+no+attribute+%27size%27&s=c15ec54c-63cb-481d-a749-408920073e8f) 。单击第一个搜索结果,就会找到与我们类似的问题的答案,答案如下面的屏幕截图所示:
-答案建议我们添加 `return_tensors='pt'` 到标记器, 所以让我们看看这是否适合我们:
+这里建议我们添加 `return_tensors='pt'` 到 Tokenizer,让我们测试一下是否可以帮助我们解决问题:
```python out
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
@@ -343,9 +341,9 @@ input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
-# Get the most likely beginning of answer with the argmax of the score
+# 计算分数的 argmax 获取最有可能的答案开头
answer_start = torch.argmax(answer_start_scores)
-# Get the most likely end of answer with the argmax of the score
+# 计算分数的 argmax 获取最有可能的答案结尾
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
@@ -361,4 +359,4 @@ Answer: pytorch, tensorflow, and jax
"""
```
-不错, 成功了! 这是 Stack Overflow 非常有用的一个很好的例子: 通过识别类似的问题, 我们能够从社区中其他人的经验中受益。然而, 像这样的搜索并不总是会产生相关的答案, 那么在这种情况下你能做什么呢? 幸运的是, 有一个受欢迎的开发者社区 [Hugging Face forums](https://discuss.huggingface.co/) 可以帮助你! 在下一节中, 我们将看看如何设计可能得到回答的优秀论坛问题。
\ No newline at end of file
+成功了!这是一个很好的例子,展示了 Stack Overflow 社区的实用性,搜索类似的问题,我们能够从社区中其他人的经验中受益。然而,像我们这样的搜索不是总能找到相关的答案,那么在这种情况下你该怎么办呢?幸运的是,在 [Hugging Face 论坛](https://discuss.huggingface.co/) 上有一个友好的开发者社区可以帮助你!在下一节中,我们将看看在该平台中有效地得到问题的回答。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter8/3.mdx b/chapters/zh-CN/chapter8/3.mdx
index 988b342cf..b84f47347 100644
--- a/chapters/zh-CN/chapter8/3.mdx
+++ b/chapters/zh-CN/chapter8/3.mdx
@@ -15,17 +15,17 @@
-在左侧,您可以看到各种主题分组的所有类别,而右侧显示了最新的主题。主题是包含标题、类别和描述的帖子;它与我们在创建自己的数据集时看到的 GitHub 问题格式非常相似[Chapter 5](/course/chapter5).顾名思义,[Beginners](https://discuss.huggingface.co/c/beginners/5)类别主要面向刚开始使用 Hugging Face 库和生态系统的人。欢迎对任何库提出任何问题,无论是调试一些代码还是寻求有关如何做某事的帮助。 (也就是说,如果您的问题特别涉及某个图书馆,您可能应该前往论坛上的相应图书馆类别。)
+在左侧,你可以看到各种主题分组的所有类别,而右侧显示了最新的主题。一个主题包含标题、类别和描述;它与我们在 [第五章](/course/chapter5) 中创建自己的数据集时看到的 GitHub issue 格式非常相似 顾名思义, [Beginners(初学者)](https://discuss.huggingface.co/c/beginners/5) 类别主要面向刚开始使用 Hugging Face 库和生态系统的人。在这里,欢迎你对任何库提出任何问题,无论是调试一些代码还是寻求有关如何做某事的帮助。(话虽如此,如果你的问题特属于某个库,你更应该前往论坛上对应库所在的类别。)
-同样,the [Intermediate](https://discuss.huggingface.co/c/intermediate/6)和[Research](https://discuss.huggingface.co/c/research/7)类别用于更高级的问题,例如关于图书馆或您想讨论的一些很酷的新 NLP 研究。
+同样, [Intermediate(中级)](https://discuss.huggingface.co/c/intermediate/6) 和 [Research(研究)](https://discuss.huggingface.co/c/research/7) 类别用于更高级的问题,例如关于库或一些有趣的自然语言处理前沿研究的讨论。
-当然,我们也应该提到[Course](https://discuss.huggingface.co/c/course/20)类别,您可以在其中提出与 Hugging Face 课程相关的任何问题!
+当然,我们也应该提到 [Course](https://discuss.huggingface.co/c/course/20) 类别,你可以在里面提出与 Hugging Face Course 相关的任何问题!
-选择类别后,您就可以编写第一个主题了。 你可以找一些[guidelines](https://discuss.huggingface.co/t/how-to-request-support/3128) 在有关如何执行此操作的论坛中,在本节中,我们将看看构成一个好的主题的一些功能。
+选择类别后,就可以编写第一个主题了。你可以阅读一下 [指南](https://discuss.huggingface.co/t/how-to-request-support/3128) ,里面会教你如何撰写主题。在本节中,我们将一起学习如何撰写一个好的主题。
-## 写一篇好的论坛帖子 [[写一篇好的论坛帖子]]
+## 写一篇高质量的论坛帖子 [[写一篇高质量的论坛帖子]]
-作为一个运行示例,假设我们试图从 Wikipedia 文章生成嵌入表示以创建自定义搜索引擎。像往常一样,我们按如下方式加载分词器和模型:
+举个例子,假如我们要将 Wikipedia 文章转化为向量嵌入用来创建自定义搜索引擎。通常情况下,我们会用如下的方法加载 Tokenizer 和模型:
```python
from transformers import AutoTokenizer, AutoModel
@@ -35,7 +35,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModel.from_pretrained(model_checkpoint)
```
-现在我们尝试将[变形金刚的维基百科](https://en.wikipedia.org/wiki/Transformers)的一整段进行嵌入表示(热知识:变形金刚的英文就是 Transformers ,而现在 Transformers 作为一个 🤗 Python 库也被越来越多人熟知):
+现在假设我们尝试将维基百科文章中关于 [变形金刚](https://en.wikipedia.org/wiki/Transformers) (指的是变形金刚系列作品,而不是 Transformers 库!热知识:Transformers 作为一个 🤗 Python 库被越来越多人熟知,它和变形金刚的英文名字一模一样)的整个部分转化为嵌入的向量表示:
```python
text = """
@@ -88,79 +88,79 @@ logits = model(**inputs).logits
IndexError: index out of range in self
```
-呃,我们遇到了一个问题——错误信息比我们看到的要神秘得多[section 2](/course/chapter8/section2)!我们无法确定完整回溯的正面或反面,因此我们决定转向 Hugging Face 论坛寻求帮助。我们如何设计主题?
+糟糕,我们遇到了一个问题——而且错误消息比我们在 [第2节](/course/chapter8/section2) 中看到的要难懂得多!我们无法理解完整的 traceback 信息,因此我们决定向 Hugging Face 论坛寻求帮助。我们该如何撰写主题呢?
-首先,我们需要点击右上角的“新建主题”按钮(注意,要创建主题,我们需要登录):
+首先,我们需要点击右上角的“New Topic”按钮(请注意,要创建主题,需要先登录账号):

-这会出现一个写作界面,我们可以在其中输入我们的主题标题,选择一个类别,并起草内容:
+这里会出现一个写作界面,我们可以在其中输入 Topic 的标题,选择一个类别,并起草内容:
-由于错误似乎仅与 🤗 Transformers有关,因此我们将为该类别选择此错误。我们第一次尝试解释这个问题可能看起来像这样:
+由于错误似乎仅与 🤗 Transformers 有关,因此我们将错误类别选择为该类别。第一次尝试解释这个问题可能看起来像这样:
-尽管本主题包含我们需要帮助的错误消息,但其编写方式存在一些问题:
+尽这个主题包含这个错误消息,但撰写方式存在一些问题:
-1. 标题描述性不是很强,因此浏览论坛的任何人都无法在不阅读正文的情况下分辨出主题的内容。
+1. 标题描述性不是很强,这会导致浏览论坛的人在没有阅读正文的情况下无法知道主题是关于什么的。
-2. 正文没有提供足够的信息,说明错误来自何处以及如何重现错误。
+2. 正文没有提供足够的信息说明错误的来源以及如何重现错误。
-3. 这个话题直接用一种有点苛刻的语气标记了几个人。
+3. 正文中以某种要求的语气直接 @ 了几个人。
-像这样的主题不太可能很快得到答案(如果他们得到了答案),那么让我们看看如何改进它。我们将从选择一个好标题的第一个问题开始。
+像这样的主题不太可能很快得到答案(如果有答复的话),需要对其进行改进。我们将从解决第一个问题,选择一个好的标题开始。
### 选择描述性标题 [[选择描述性标题]]
-如果您想就代码中的错误寻求帮助,一个好的经验法则是在标题中包含足够的信息,以便其他人可以快速确定他们是否认为他们可以回答您的问题。在我们的运行示例中,我们知道正在引发的异常的名称,并有一些提示它是在模型的前向传递中触发的,我们调用 **model(**inputs)** .为了传达这一点,一个可能的标题可能是:
+如果你想就代码中的错误寻求帮助,一个好的经验法则是在标题中包含足够的信息,以便其他人可以快速确定他们是否可以回答你的问题。在我们的运行示例中,我们知道正在引发的异常名称,并有一些错误提示表示它是在模型的前向传递中触发的,即我们调用 `model(**inputs)` 的位置。为了传达这一信息,一个可能的标题可能是:
-> 自动建模正向传递中的索引错误的来源?
+> AutoModel 前向传递中的 IndexError 来源?
-这个标题告诉读者在哪里你认为错误来自,如果他们遇到了 **IndexError** 在此之前,他们很有可能知道如何调试它。当然,标题可以是您想要的任何内容,也可以是其他变体,例如:
+这个标题告诉读者你认为的错误可能的来源,如果他们遇到了 `IndexError` 他们很可能知道如何回答你。当然,标题可以是其他的任何形式,其他可选的变体如下:
-> 为什么我的模型会产生索引错误?
+> 为什么我的模型会产生 IndexError?
-也可以。现在我们有了一个描述性的标题,让我们来看看改善主体。
+这种标题也是可以的。现在我们有了一个描述性的标题,让我们来看看如何改善正文。
### 设置代码段的格式 [[设置代码段的格式]]
-如:也可以。现在我们有了一个描述性的标题,让我们来看看改善身体。在 IDE 中阅读源代码已经够难的了,但是当将代码复制粘贴为纯文本时就更难了!幸运的是,Hugging Face 论坛支持使用 Markdown,因此您应该始终用三个反引号 (```) 将代码块括起来,以便更容易阅读。让我们这样做来美化错误消息——在我们这样做的时候,让我们让正文比我们的原始版本更有礼貌:
+现在我们有了一个描述性的标题,让我们来看看如何改善代码段的格式。在 IDE 中阅读源代码已经够难的了,但是当将代码复制粘贴为纯文本时就更难了!不过 Hugging Face 论坛支持使用 Markdown 将原始代码高亮,标准格式是用三个反引号 (```) 将代码块包裹起来。这样可以让正文比上面的原始版本看起来更加美观:
-正如您在屏幕截图中看到的,将代码块括在反引号中会将原始文本转换为格式化代码,并带有颜色样式!另请注意,单个反引号可用于格式化内联变量,就像我们所做的那样 **distilbert-base-uncased** .这个主题看起来好多了,如果幸运的话,我们可能会在社区中找到可以猜测错误是什么的人。然而,与其依靠运气,不如让我们在其完整的血腥细节中包含回溯,让生活更轻松!
+正如你在屏幕截图中看到的,将代码块包裹在反引号中会将原始文本转换为带有颜色样式的格式化代码!另外,单个反引号可用于格式化内联变量,比如 `distilbert-base-uncased` 这样。这个主题看起来好多了,再加上一点运气,我们可能会在社区中遇到一些可以猜出错误的原因的人。然而,与其依靠运气,不如撰写完整而详细的回溯信息使定位问题更容易!
-### 包括完整的回溯 [[包括完整的回溯]]
+### 包括完整的回溯信息 [[包括完整的回溯信息]]
-由于回溯的最后一行通常足以调试您自己的代码,因此很容易在您的主题中提供它以“节省空间”。虽然本意是好的,但这实际上使它更难供其他人调试问题,因为回溯中较高的信息也非常有用。因此,一个好的做法是复制并粘贴所有的回溯,同时确保它的格式很好。由于这些回溯可能会很长,有些人更喜欢在解释了源代码之后再展示它们。我们开工吧。现在,我们的论坛主题如下所示:
+通常情况下 `traceback ` 的最后一行足以调试自己的代码,但是只提供这一行虽然“节省空间”单可能会使他人定位问题变得更加困难,因为 `traceback` 中更上面的信息也可能非常有用。因此,一个好的做法是复制并粘贴整个的 `traceback` ,同时确保它的格式不被破坏。但是这些 `traceback` 可能会很长,所以可以在对源代码进行解释之后再展示它们。按照这个思路现在来对我们的问题帖子进行修改,修改之后的帖子如下所示:
-
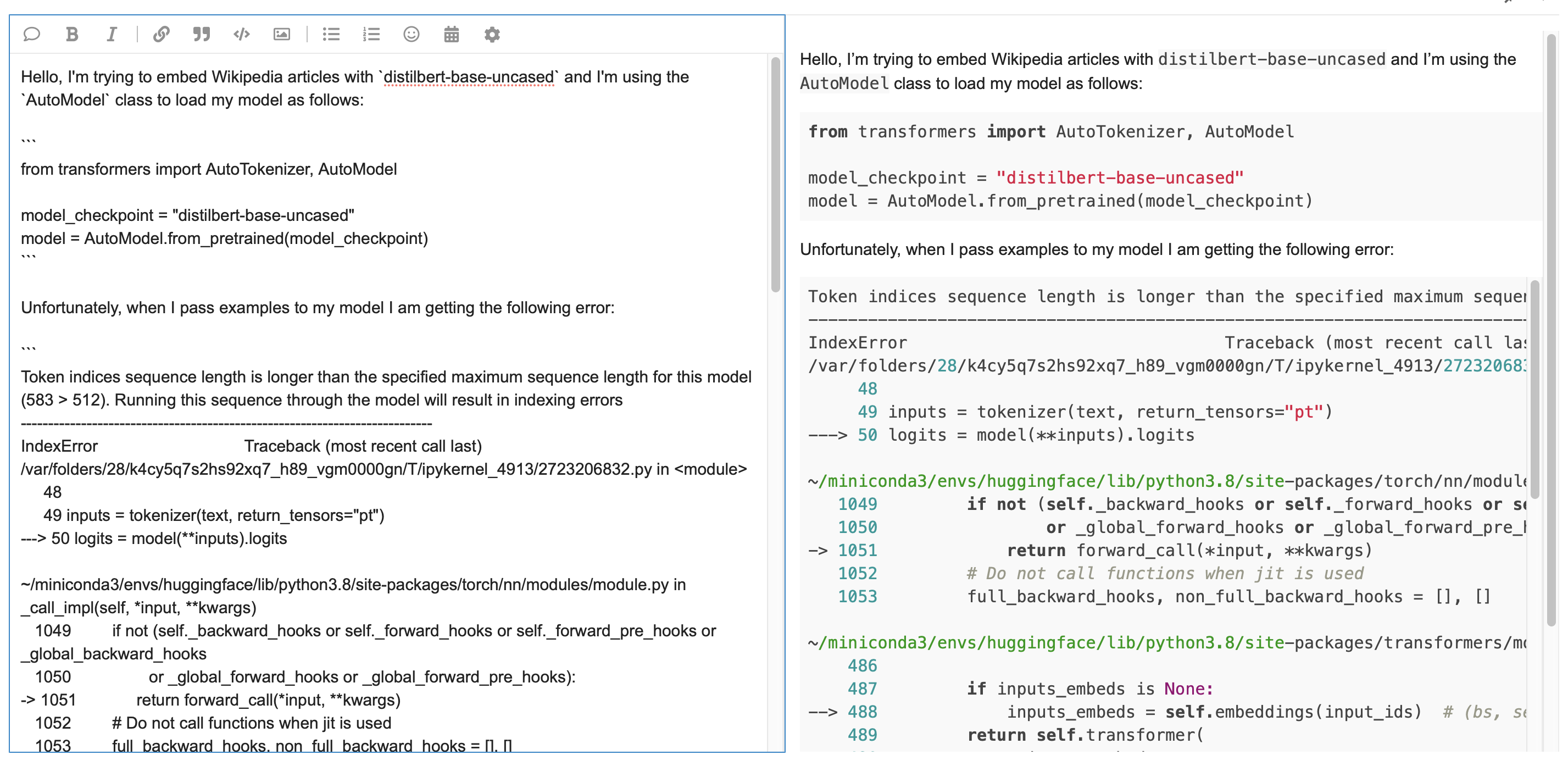
+

-这提供了更多信息,细心的读者可能会指出问题似乎是由于回溯中的这一行而传递了一个长输入:
+这提供了更多信息,细心的读者可能会发现:问题似乎是由于 `traceback` 中的这行代码导致输入过长:
-> 令牌索引序列长度长于为此模型指定的最大序列长度 (583 > 512)。
+> Token 索引序列的长度大于此模型指定的最大序列长度 (583 > 512)。
-但是,通过提供触发错误的实际代码,我们可以让他们更轻松。我们现在就这样做。
+然而,我们可以通过提供触发错误的原始代码进一步改善问题描述。现在,我们就来做这件事。
-### 提供可重复的示例 [[提供可重复的示例]]
+### 提供可复现的示例 [[提供可复现的示例]]
-如果您曾经尝试过调试其他人的代码,那么您可能首先尝试重现他们报告的问题,以便您可以开始通过回溯来查明错误。在论坛上获得(或提供)帮助时没有什么不同,所以如果你能提供一个重现错误的小例子真的很有帮助。有一半的时间,简单地完成这个练习将帮助你找出问题所在。在任何情况下,我们的示例缺少的部分是显示输入我们提供给模型的。这样做会为我们提供类似于以下完整示例的内容:
+如果你曾经尝试过调试其他人的代码,那么你可能首先尝试的复现他们报告的问题,这样你就可以逐步查找错误。在论坛上获取(或提供)帮助也不例外,如果你能提供一个复现错误的小例子真的很有帮助。这里有个示例帖子:
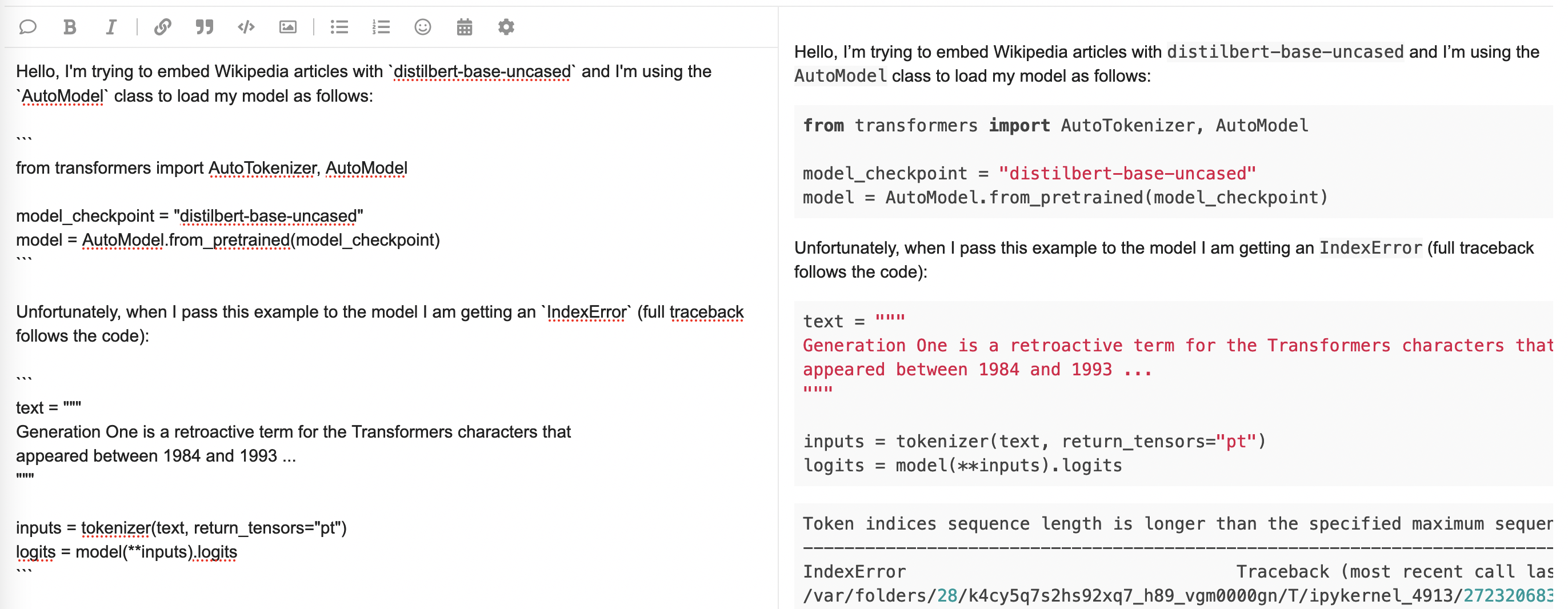
-该主题现在包含相当多的信息,并且它的编写方式更可能吸引社区的注意力并获得有用的答案。有了这些基本指南,您现在可以创建很棒的主题来找到您的 🤗 Transformers问题的答案!
+该帖子目前包含相当多的信息,并且它的撰写格式更可能吸引社区其他用户的注意,从而跟可能获得有用的答案。有了这些基本指南,你现在可以创建很棒的帖子来找到所遇到的 🤗 Transformers 问题的答案!
diff --git a/chapters/zh-CN/chapter8/4.mdx b/chapters/zh-CN/chapter8/4.mdx
index 46358c847..d7ce5d279 100644
--- a/chapters/zh-CN/chapter8/4.mdx
+++ b/chapters/zh-CN/chapter8/4.mdx
@@ -9,17 +9,17 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/chapter8/section4.ipynb"},
]} />
-你已经编写了一个漂亮的脚本来训练或微调给定任务的模型,尽职尽责地遵循 [Chapter 7](/course/chapter7) 中的建议。 但是当你启动命令 `trainer.train()` 时,可怕的事情发生了:你得到一个错误😱! 或者更糟糕的是,一切似乎都很好,训练运行没有错误,但生成的模型很糟糕。 在本节中,我们将向您展示如何调试此类问题。
+假如你已经尽可能地遵循 [第七章](/course/chapter7) 中的建议,编写了一段漂亮的代码来训练或微调给定任务的模型。但是当你启动命令 `trainer.train()` 时,可怕的事情发生了:你得到一个错误😱!或者更糟糕的是,虽然看起来一切似乎都正常,训练运行没有错误,但生成的模型很糟糕。在本节中,我们将向你展示如何调试此类问题。
## 调试训练管道 [[调试训练管道]]
-当您在 `trainer.train()` 中遇到错误时,它可能来自多个来源,因为 `Trainer` 通常会将很多东西放在一起组合运行。 它将datasets转换为dataloaders,因此问题可能出在datasets中,或者在尝试将datasets的元素一起批处理时出现问题。 然后它需要准备一批数据并将其提供给模型,因此问题可能出在模型代码中。 之后,它会计算梯度并执行优化器,因此问题也可能出在您的优化器中。 即使训练一切顺利,如果您的评估指标有问题,评估期间仍然可能出现问题。
+当你在 `trainer.train()` 中遇到错误时,它有可能来自多个不同的来源,因为 `Trainer` 会将很多模块放在一起组合运行。首先它会将 datasets 转换为 dataloaders 因此问题可能出在 datasets 中,或者在尝试将 datasets 的元素一起批处理时出现问题。接着它会准备一批数据并将其提供给模型,因此问题可能出在模型代码中。之后,它会计算梯度并执行优化器,因此问题也可能出在你的优化器中。即使训练一切顺利,如果你的评估指标有问题,评估期间仍然可能出现问题。
-调试 `trainer.train()` 中出现的错误的最佳方法是手动检查整个管道,看看哪里出了问题。 错误通常很容易解决。
+调试 `trainer.train()` 中出现的错误的最佳方法是手动检查整个管道,看看哪里出了问题。通常情况下,错误很容易解决。
-为了证明这一点,我们将使用以下脚本(尝试)在 [MNLI 数据集](https://huggingface.co/datasets/glue)上微调 DistilBERT 模型:
+为了讲解这个过程,我们将尝试使用以下脚本在 [MNLI 数据集](https://huggingface.co/datasets/glue) 上微调 DistilBERT 模型:
```py
from datasets import load_dataset
@@ -70,7 +70,7 @@ trainer = Trainer(
trainer.train()
```
-如果你尝试执行它,你会遇到一个相当神秘的错误:
+如果你尝试运行它,你会遇到一个相当晦涩的错误:
```python out
'ValueError: You have to specify either input_ids or inputs_embeds'
@@ -78,9 +78,9 @@ trainer.train()
### 检查数据 [[检查数据]]
-这是不言而喻的,如果你的数据被破坏,“Trainer”将无法形成批次,更不用说训练你的模型了。 所以首先,你需要看看你的训练集中有什么。
+显而易见,如果你的数据损坏了, `Trainer` 将无法将数据整理成 batch,更不用说训练你的模型了。因此,首先需要检查一下你的训练集里面的内容。
-为了避免花费无数小时试图检查和修复不是错误来源的东西,我们建议您使用 `trainer.train_dataset` 进行检查。 所以让我们在这里这样做:
+为了避免花费无数小时试图修复不是错误来源的问题,避免多次封装的干扰,我们建议你只使用 `trainer.train_dataset` 进行检查。所以让我们在这里这样尝试一下:
```py
trainer.train_dataset[0]
@@ -93,9 +93,9 @@ trainer.train_dataset[0]
'premise': 'Conceptually cream skimming has two basic dimensions - product and geography.'}
```
-你注意到有什么不对吗? 与缺少有关 `input_ids` 的错误消息相结合,应该让您意识到数据集里是文本,而不是模型可以理解的数字。 在这个例子,输出的原始错误信息非常具有误导性,因为 `Trainer` 会自动删除与模型签名不匹配的列(即模型预期的参数)。 这意味着在这里,除了标签之外的所有东西都被丢弃了。 因此,创建批次然后将它们发送到模型没有问题,而模型又抱怨它没有收到正确的输入。
+你注意到有什么不对吗?与缺少 `input_ids` 的错误消息相结合,你应该可以意识到数据集里是文本,而不是模型可以理解的数字。在这个例子中,输出的原始错误信息非常具有误导性,因为 `Trainer` 会自动删除与模型配置中不需要的列 (即模型预期的输入参数)。这意味着在这里,除了标签之外的所有东西都被丢弃了。因此,创建 batch 然后将它们发送到模型时没有问题,但是模型会提示没有收到正确的输入。
-为什么没有处理数据生成标记呢? 我们确实在数据集上使用了“Dataset.map()”方法来对每个样本应用标记器。 但是如果你仔细看代码,你会发现我们在将训练和评估集传递给`Trainer`时犯了一个错误。 我们在这里没有使用 `tokenized_datasets`,而是使用了 `raw_datasets` 🤦。 所以让我们解决这个问题!
+为什么模型没有得到 input_ids 这一列呢?我们确实在数据集上调用了 `Dataset.map()` 方法,并使用 `tokenizer` 处理了每个样本。但是如果你仔细看代码,你会发现我们在将训练和评估集传递给 `Trainer` 时犯了一个错误。我们在这里没有使用 `tokenized_datasets` ,而是使用了 `raw_datasets` 🤦。所以让我们来解决这个问题!
```py
from datasets import load_dataset
@@ -146,13 +146,13 @@ trainer = Trainer(
trainer.train()
```
-这个新代码现在会给出一个不同的错误:
+运行这个新代码会输出一个新的错误😥:
```python out
'ValueError: expected sequence of length 43 at dim 1 (got 37)'
```
-查看traceback,我们可以看到错误发生在数据整理步骤中:
+查看 traceback,我们可以看到错误发生在数据整理步骤中:
```python out
~/git/transformers/src/transformers/data/data_collator.py in torch_default_data_collator(features)
@@ -163,9 +163,9 @@ trainer.train()
109 return batch
```
-所以,我们应该去研究一下那个。 然而,在我们这样做之前,让我们完成检查我们的数据, 先确定它100%是正确的。
+所以,我们应该去研究一下那个。然而,在检查数据整理步骤之前,请先完成所有的数据检查,确定数据是100% 正确的。
-在调试课程的内容时,您应该始终做的一件事是查看模型的解码输入。 我们无法理解直接提供给它的数字,所以我们应该看看这些数字代表什么。 例如,在计算机视觉中,这意味着查看您传递的图片像素的解码,在语音中意味着解码后的音频样本,对于我们的 NLP 示例,这意味着使用我们的标记器解码的输入:
+在调试训练数据时,你应该始终要记得检查解码后的原始文本输入,而不是一大串编码后的数字。因为我们无法理解直接提供给它的数字,所以我们应该看看这些数字代表什么。例如,在计算机视觉中,这意味着查看你传递解码后的像素图片,在语音中意味着解码后的音频样本,对于我们的 NLP 示例,这意味着应该检查 `tokenizer` 解码后的原始输入文本:
```py
tokenizer.decode(trainer.train_dataset[0]["input_ids"])
@@ -175,7 +175,7 @@ tokenizer.decode(trainer.train_dataset[0]["input_ids"])
'[CLS] conceptually cream skimming has two basic dimensions - product and geography. [SEP] product and geography are what make cream skimming work. [SEP]'
```
-所以这似乎是正确的。 您应该对输入中的所有键执行此操作:
+它看起来没什么问题,让我们使用相同的操作检查其他的键。
```py
trainer.train_dataset[0].keys()
@@ -185,7 +185,7 @@ trainer.train_dataset[0].keys()
dict_keys(['attention_mask', 'hypothesis', 'idx', 'input_ids', 'label', 'premise'])
```
-请注意,与模型接受的输入不对应的键将被自动丢弃,因此这里我们将仅保留 `input_ids`、`attention_mask` 和 `label`(将重命名为 `labels`)。 要仔细检查模型输入的列,您可以打印模型的类,然后查看其文档:
+请注意,模型不能接收的输入对应的键将被自动丢弃,因此这里我们将仅需要检查 `input_ids` 、 `attention_mask` 和 `label` (它将被重命名为 `labels` )。为了防止记错,可以先打印模型的类,然后在其文档中看看它需要输入哪些列。
```py
type(trainer.model)
@@ -195,9 +195,9 @@ type(trainer.model)
transformers.models.distilbert.modeling_distilbert.DistilBertForSequenceClassification
```
-所以在我们的例子中,我们在[在这个页面](https://huggingface.co/transformers/model_doc/distilbert.html#distilbertforsequenceclassification)可以检查上接受的参数。 `Trainer` 也会记录它丢弃的列。
+所以在我们的这个例子中,我们可以在 [模型文档](https://huggingface.co/transformers/model_doc/distilbert.html#distilbertforsequenceclassification) 中查看这个模型接受的参数。同样的 `Trainer` 也会记录它丢弃的列。
-我们通过解码检查了输入 ID 是否正确。 接下来是检查 `attention_mask`:
+我们通过解码检查了 `inputs ID` 是否正确。接下来应该检查 `attention_mask` :
```py
trainer.train_dataset[0]["attention_mask"]
@@ -207,7 +207,7 @@ trainer.train_dataset[0]["attention_mask"]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
-由于我们没有在预处理中应用填充,这看起来非常自然。 为确保该注意掩码没有问题,让我们检查它与输入 ID 的长度是否相同:
+由于我们没有在预处理中使用填充,这看起来没什么问题。为确保该注意掩码没有问题,让我们检查它与 `inputs ID` 的长度是否相同:
```py
len(trainer.train_dataset[0]["attention_mask"]) == len(
@@ -219,7 +219,7 @@ len(trainer.train_dataset[0]["attention_mask"]) == len(
True
```
-那挺好的! 最后,让我们检查一下我们的标签:
+那挺好的!最后,让我们检查一下我们的标签:
```py
trainer.train_dataset[0]["label"]
@@ -229,7 +229,7 @@ trainer.train_dataset[0]["label"]
1
```
-与输入 ID 一样,这是一个本身并没有真正意义的数字。 正如我们之前看到的,整数和标签名称之间的映射存储在数据集相应 *feature* 的 `names` 属性中:
+与inputs ID 一样,这是一个本身并没有真正意义的数字,我们需要检查的是它所对应的真实的标签名称是否是正确的。正如我们之前学到的,标签 ID 和标签名之间的映射存储在数据集 `features` 里的 `names` 属性中:
```py
trainer.train_dataset.features["label"].names
@@ -239,30 +239,30 @@ trainer.train_dataset.features["label"].names
['entailment', 'neutral', 'contradiction']
```
-所以`1`表示`neutral`,表示我们上面看到的两句话并不矛盾,也没有包含关系。 这似乎是正确的!
+所以 `1` 表示 `neutral` ,表示我们上面看到的两句话并不矛盾,也没有包含关系。这也看起来是正确的!
-我们这里没有令牌类型 ID,因为 DistilBERT 不需要它们; 如果您的模型中有一些,您还应该确保它们正确匹配输入中第一句和第二句的位置。
+我们这里没有 token 类型 ID,因为 DistilBERT 不需要它们;如果你的模型中有,你还应该确保 token 类型 ID 可以正确匹配输入中第一句和第二句的位置。
-✏️ **轮到你了!** 检查训练数据集的第二个元素是否正确。
+✏️ **轮到你了!** 检查训练数据集的第二个条数据是否正确。
-我们在这里只对训练集进行检查,但您当然应该以同样的方式仔细检查验证集和测试集。
+我们在这里只对训练集进行检查,但你当然应该以同样的方式仔细检查验证集和测试集。
-现在我们知道我们的数据集看起来不错,是时候检查训练管道的下一步了。
+现在我们知道我们的数据集看起来不错,下一步是时候检查训练管道了。
### 从 datasets 到 dataloaders [[从 datasets 到 dataloaders]]
-训练管道中可能出错的下一件事是当“Trainer”尝试从训练或验证集形成批次时。 一旦你确定 `Trainer` 的数据集是正确的,你可以尝试通过执行以下操作手动形成一个批次(可以将 `train` 替换为 `eval` 用于验证数据加载器):
+训练管道中可能出错的下一个操作发生在 `Trainer` 尝试从训练或验证集中生成 batch 时。当你确定 `Trainer` 的数据集是正确的后,你可以尝试通过执行以下代码手动形成一个 batch(当要测试验证集的 dataloaders 时,可以将 `train` 替换为 `eval` ):
```py
for batch in trainer.get_train_dataloader():
break
```
-此代码创建训练数据加载器,然后对其进行迭代,在第一次迭代时停止。 如果代码执行没有错误,那么您就有了可以检查的第一个训练批次,如果代码出错,您可以确定问题出在数据加载器中,如下所示:
+上述代码会创建训练集的数据加载器,然后对其进行迭代一次。如果代码执行没有错误,那么你就有了可以检查的第一个 batch,如果代码出错,你可以确定问题出在数据加载器中,如下所示:
```python out
~/git/transformers/src/transformers/data/data_collator.py in torch_default_data_collator(features)
@@ -275,8 +275,7 @@ for batch in trainer.get_train_dataloader():
ValueError: expected sequence of length 45 at dim 1 (got 76)
```
-检查trackback的最后一个堆栈的输出应该足以给你一个线索,但让我们做更多的挖掘。 批处理创建过程中的大多数问题是由于将示例整理到单个批处理中而出现的,因此在有疑问时首先要检查的是您的 DataLoader 正在使用什么 collate_fn:
-
+Trackback 的最后一个堆栈的输出应该足够给你一些线索,但让我们再深入挖掘一下创建 batch 的过程。创建 batch 过程中的大多数问题是在将数据整理到单个 batch 中时出现的, 因此在出现问题时首先要检查的是 DataLoader 正在使用的 `collate_fn`:
```py
data_collator = trainer.get_train_dataloader().collate_fn
data_collator
@@ -286,9 +285,9 @@ data_collator
Dict[str, Any]>
```
-所以,目前使用的是 `default_data_collator`,但这不是我们在这种情况下想要的。 我们希望将示例填充到批处理中最长的句子,这是由 `DataCollatorWithPadding` 整理器完成的。 而这个数据收集器应该是默认被 `Trainer` 使用的,为什么这里没有使用呢?
+所以,目前使用的是 `default_data_collator` ,但这不是我们在这个示例中想要使用的 `collate_fn` 。我们希望将 `batch` 中的每个句子填充到 `batch` 中最长的句子,这项功能是由 `DataCollatorWithPadding` 整理器实现的。而 `Trainer` 默认使用的数据整理器就是它,为什么这里没有使用呢?
-答案是因为我们没有将 `tokenizer` 传递给 `Trainer`,所以它无法创建我们想要的 `DataCollatorWithPadding`。 在实践中,您应该明确地传递您想要使用的数据整理器,以确保避免这些类型的错误。 让我们调整我们的代码来做到这一点:
+答案是因为我们在上面的代码中并没有把 `tokenizer` 传递给 `Trainer` ,所以它无法创建我们想要的 `DataCollatorWithPadding` 。在实践中,你应该明确地传递你想要使用的数据整理器,以确保避免这些类型的错误。让我们修改代码以实现这一点:
```py
from datasets import load_dataset
@@ -345,22 +344,22 @@ trainer = Trainer(
trainer.train()
```
-好消息? 我们没有得到与以前相同的错误,这绝对是进步。 坏消息? 我们得到了一个臭名昭著的 CUDA 错误:
+好消息是,我们没有得到与以前相同的错误,这绝对是进步。坏消息是,我们得到了一个臭名昭著的 CUDA 错误:
```python out
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
```
-这很糟糕,因为 CUDA 错误通常很难调试。 我们稍后会看到如何解决这个问题,但首先让我们完成对批处理创建的分析。
+这很糟糕,因为 CUDA 错误通常很难调试。我们将在稍后再解决这个问题,现在让我们先完成对创建的 `batch` 的分析。
-如果您确定您的数据整理器是正确的,则应尝试将其应用于数据集的几个样本:
+如果你确定你的数据整理器是正确的,那么应该尝试用它来处理数据集的几个样本,检查一下在创建样本的时候是否会出现错误:
```py
data_collator = trainer.get_train_dataloader().collate_fn
batch = data_collator([trainer.train_dataset[i] for i in range(4)])
```
-此代码将失败,因为 `train_dataset` 包含字符串列,`Trainer` 通常会删除这些列。 您可以手动删除它们,或者如果您想准确地修改 `Trainer` 在幕后所做的事情,您可以调用私有的 `Trainer._remove_unused_columns()` 方法来执行此操作:
+上述代码运行失败,因为 `train_dataset` 包含字符串列, `Trainer` 通常会删除这些列,在这样的单步调试中,我们可以调用私有的 `trainer._remove_unused_ columns()` 方法手动删除这些列。:
```py
data_collator = trainer.get_train_dataloader().collate_fn
@@ -368,26 +367,26 @@ actual_train_set = trainer._remove_unused_columns(trainer.train_dataset)
batch = data_collator([actual_train_set[i] for i in range(4)])
```
-如果错误仍然存在,您应该能够手动调试数据整理器内部以确定具体的问题。
+如果又出现了新的错误,则应该手动调试数据整理器以确定具体的问题。
-现在我们已经调试了批处理创建过程,是时候将数据传递给模型了!
+现在我们已经调试了创建 `batch` 过程,是时候将数据传递给模型了!
### 检查模型 [[检查模型]]
-您应该能够通过执行以下命令来获得一个批次的数据:
+你可以通过执行以下命令来获得一个 `batch` 的数据:
```py
for batch in trainer.get_train_dataloader():
break
```
-如果您在notebook中运行此代码,您可能会收到与我们之前看到的类似的 CUDA 错误,在这种情况下,您需要重新启动notebook并重新执行最后一个片段,而不运行 `trainer.train()` 行.这是关于 CUDA 错误的第二个最烦人的事情:它们会破坏您的Cuda内核,而且无法恢复。它们最烦人的事情是它们很难调试。
+如果你在 notebook 中运行此代码,你可能会收到与我们之前看到的类似的 CUDA 错误,在这种情况下,你需要重新启动 notebook 并重新执行最后一段代码,但是暂时不要运行 `trainer.train()` 这一行命令。这是关于 CUDA 错误的第二个最烦人的事情:它们会破坏你的 Cuda 内核,而且无法恢复。它们最烦人的事情是它们很难调试。
-这是为什么?它与 GPU 的工作方式有关。它们在并行执行大量操作方面非常有效,但缺点是当其中一条指令导致错误时,您不会立即知道。只有当程序在 GPU 上调用多个进程的同步处理时,它才会意识到出现问题,因此错误实际上是在与创建它的原因无关的地方引发的。例如,如果我们查看之前的trackback,错误是在向后传递期间引发的,但我们会在一分钟内看到它实际上源于向前传递中的某些东西。
+这是为什么?它与 GPU 的工作方式有关。它们在并行执行大量操作方面非常有效,但缺点是当其中一条指令导致错误时,你不会立即知道。只有当程序在 GPU 上调用多个进程的同步处理时,才会输出一些错误信息,但事实上真实触发错误的地方往往与输出错误信息的地方并不一致。例如,如果我们查看之前的 Trackback,错误是在反向传播期间引发的,但我们会在一分钟后看到错误实际上源于前向传播的某些东西。
-那么我们如何调试这些错误呢?答案很简单:我们没有。除非您的 CUDA 错误是内存不足错误(这意味着您的 GPU 中没有足够的内存),否则您应该始终返回 CPU 进行调试。
+那么我们如何调试这些错误呢?答案很简单:不调试。除非你的 CUDA 错误是内存不足错误(这意味着你的 GPU 中没有足够的内存),除此之外你应该始终返回到 CPU 进行调试。
-为此,我们只需将模型放回 CPU 上并在我们的一批数据中调用它——“DataLoader”返回的那批数据尚未移动到 GPU:
+为此,我们只需将模型放回 CPU 然后将一个 `batch` 的数据送入模型。现在 `DataLoader` 返回的那批数据还尚未移动到 GPU,因此可以直接送入这个 `batch`:
```python
outputs = trainer.model.cpu()(**batch)
@@ -404,7 +403,8 @@ outputs = trainer.model.cpu()(**batch)
IndexError: Target 2 is out of bounds.
```
-所以,思路越来越清晰了。 我们现在在损失计算中没有出现 CUDA 错误,而是有一个“IndexError”(因此与我们之前所说的反向传播无关)。 更准确地说,我们可以看到是Target 2 造成了错误,所以这是检查模型标签数量的好时机:
+现在,情况越来越明朗了。损失计算中没有出现CUDA 错误,而出现了一个 `IndexError`
+(因此与反向传播无关)。我们可以看到是 Target 2 造成了错误,这个时候通常应该检查一下模型标签的数量。
```python
trainer.model.config.num_labels
@@ -414,7 +414,7 @@ trainer.model.config.num_labels
2
```
-有两个标签,只允许 0 和 1 作为目标,但是根据错误信息我们得到一个 2。得到一个 2 实际上是正常的:如果我们记得我们之前提取的标签名称,有三个,所以我们有索引 0 , 1 和 2 在我们的数据集中。 问题是我们没有告诉我们的模型,它应该创建三个标签。 所以让我们解决这个问题!
+可以看到,模型有两个标签,只有 0 和 1 作为目标,但是根据错误信息我们得到一个 2。得到一个 2 实际上是正常的:如果你还有印象,我们之前提取了三个标签名称,所以在我们的数据集中我们有 0、1 和 2 三个标签索引,而问题是我们并没有告诉模型,它应该创建三个标签。让我们解决这个问题!
```py
from datasets import load_dataset
@@ -470,7 +470,7 @@ trainer = Trainer(
)
```
-我们还没有包含 `trainer.train()` 行,以便花时间检查一切是否正常。 如果我们请求一个批次的数据并将其传递给我们的模型,它现在可以正常工作了!
+为了方便检查一切是否正常,现在先不要运行 `trainer.train()` 命令。先请求一个 batch 的数据并将其传递给我们的模型,如果它现在可以正常工作了!
```py
for batch in trainer.get_train_dataloader():
@@ -479,7 +479,7 @@ for batch in trainer.get_train_dataloader():
outputs = trainer.model.cpu()(**batch)
```
-下一步是回到 GPU 并检查一切是否仍然有效:
+那么下一步就可以回到 GPU 并检查我们的修改是否仍然有效:
```py
import torch
@@ -490,20 +490,20 @@ batch = {k: v.to(device) for k, v in batch.items()}
outputs = trainer.model.to(device)(**batch)
```
-如果仍然出现错误,请确保重新启动notebook并仅执行脚本的最后一个版本。
+如果仍然出现错误,请确保重新启动 notebook 并仅执行最后一版的代码(如果之前出现了CUDA 错误,那么CUDA 内核就会被破坏,之后哪怕执行正确的代码也会出现错误)。
### 执行一个优化器步骤 [[执行一个优化器步骤]]
-现在我们知道我们可以构建实际通过模型检查的成批次的数据,我们已经为训练管道的下一步做好准备:计算梯度并执行优化步骤。
+现在我们已经可以构建通过模型检查的成批次的数据,我们已经为训练管道的下一步做好准备:接下来是计算梯度并执行优化器迭代。
-第一部分只是在 loss 上调用 `backward()` 方法:
+第一部分是在 loss 上调用 `backward()` 方法:
```py
loss = outputs.loss
loss.backward()
```
-在这个阶段很少出现错误,但如果确实出现错误,请返回 CPU 以获取有用的错误消息。
+在这个阶段很少出现错误,但如果确实出现错误,那么需要返回 CPU 来获取更有用的错误消息。
要执行优化步骤,我们只需要创建 `optimizer` 并调用它的 `step()` 方法:
@@ -512,26 +512,26 @@ trainer.create_optimizer()
trainer.optimizer.step()
```
-同样,如果您在 `Trainer` 中使用默认优化器,则在此阶段您不应该收到错误,但如果您有自定义优化器,则可能会出现一些问题需要在这里调试。 如果您在此阶段遇到奇怪的 CUDA 错误,请不要忘记返回 CPU。 说到 CUDA 错误,前面我们提到了一个特殊情况。 现在让我们来看看。
+同样,如果你在 `Trainer` 中使用默认优化器,那么在此阶段你不应该收到错误,但如果你有自定义优化器,则可能会出现一些问题,需要在这里调试。如果你在此阶段遇到奇怪的 CUDA 错误,请不要忘记返回 CPU。说到 CUDA 错误,前面我们提到了一个特殊情况。现在让我们来看看这种情况。
-### 处理 CUDA out-of-memory错误 [[处理 CUDA out-of-memory错误]]
+### 处理 CUDA out-of-memory 错误 [[处理 CUDA out-of-memory错误]]
-每当您收到以`RuntimeError: CUDA out of memory`开头的错误消息时,这表明您的 GPU 内存不足。 这与您的代码没有直接关联,并且它可能发生在运行良好的代码中。 此错误意味着您试图在 GPU 的内部存储器中放入太多东西,这导致了错误。 与其他 CUDA 错误一样,您需要重新启动内核才能再次运行训练。
+每当你收到以 `RuntimeError: CUDA out of memory` 开头的错误消息时,这表明你的显存不足。这与你的代码没有直接关系,并且它也可能发生在运行良好的代码中。此错误意味着你试图在 GPU 的显存中放入太多东西,这导致了错误。与其他 CUDA 错误一样,你需要重新启动内核才能再次运行训练。
-要解决这个问题,您只需要使用更少的 GPU 空间——这往往说起来容易做起来难。 首先,确保您没有同时在 GPU 上运行两个模型(当然,除非您的问题需要这样做)。 然后,您可能应该减少batch的大小,因为它直接影响模型的所有中间输出的大小及其梯度。 如果问题仍然存在,请考虑使用较小版本的模型。
+要解决这个问题,你只需要使用更少的显存—这往往说起来容易做起来难。首先,确保你没有同时在 GPU 上运行两个模型(当然,除非在解决问题时必须要这样做)。然后,你可能应该减少 batch 的大小,因为它直接影响模型的所有中间输出的大小及其梯度。如果问题仍然存在,请考虑使用较小版本的模型,或者更换有更大显存的设备。
-在课程的下一部分中,我们将介绍更先进的技术,这些技术可以帮助您减少内存占用并让您微调最大的模型。
+在课程的下一部分中,我们将介绍更先进的技术,这些技术可以帮助你减少内存占用并让你微调超大的模型。
### 评估模型 [[评估模型]]
-现在我们已经解决了代码的所有问题,一切都很完美,训练应该可以顺利进行,对吧? 没那么快! 如果你运行 `trainer.train()` 命令,一开始一切看起来都不错,但过一会儿你会得到以下信息:
+现在我们已经解决了所有的代码问题,一切都很完美,训练应该可以顺利进行,对吧?没那么快!如果你运行 `trainer.train()` 命令,一开始一切看起来都不错,但过一会儿你会得到以下信息:
```py
-# This will take a long time and error out, so you shouldn't run this cell
+# 这将花费很长时间并且会出错,所以不要直接运行这个单元
trainer.train()
```
@@ -539,9 +539,9 @@ trainer.train()
TypeError: only size-1 arrays can be converted to Python scalars
```
-您将意识到此错误出现在评估阶段,因此这是我们需要调试的最后一件事。
+你将意识到此错误出现在评估阶段,因此这是我们需要调试的最后一件事。
-您可以像这样在训练中独立运行`Trainer`的评估循环:
+你可以独立于训练,单独运行 Trainer 的评估循环,如下所示:
```py
trainer.evaluate()
@@ -553,11 +553,11 @@ TypeError: only size-1 arrays can be converted to Python scalars
-💡 您应该始终确保在启动 `trainer.train()` 之前 `trainer.evaluate()`是可以运行的,以避免在遇到错误之前浪费大量计算资源。
+💡 你应该始终确保在启动 `trainer.train()` 之前 `trainer.evaluate()` 是可以运行的,以避免在遇到错误之前浪费大量计算资源。
-在尝试调试评估循环中的问题之前,您应该首先确保您已经查看了数据,能够正确地形成批处理,并且可以在其上运行您的模型。 我们已经完成了所有这些步骤,因此可以执行以下代码而不会出错:
+在尝试调试评估循环中的问题之前,你应该首先确保你已经检查了数据,能够正确地形成了 batch 并且可以在其上运行你的模型。我们已经完成了所有这些步骤,因此可以执行以下代码而不会出错:
```py
for batch in trainer.get_eval_dataloader():
@@ -569,18 +569,18 @@ with torch.no_grad():
outputs = trainer.model(**batch)
```
-稍等一会儿,错误出现,在评估阶段结束时,如果我们查看trackback,我们会看到:
+稍等一会儿,错误就会出现,在评估阶段结束时输出了一个错误,如果我们查看 Trackback,我们会看到:
```python trace
~/git/datasets/src/datasets/metric.py in add_batch(self, predictions, references)
- 431 """
+ 431
432 batch = {"predictions": predictions, "references": references}
--> 433 batch = self.info.features.encode_batch(batch)
434 if self.writer is None:
435 self._init_writer()
```
-这告诉我们错误源自 `datasets/metric.py` 模块——所以这是我们的 `compute_metrics()` 函数的问题。 它需要一个带有 logits 和标签的元组作为 NumPy 数组,所以让我们尝试输入它:
+这告诉我们错误源自 `datasets/metric.py` 模块所以很有可能是计算 `compute_metrics()` 函数时出现的问题。它需要输入 NumPy 数组格式的 logits 值和标签的元组,所以让我们尝试将其提供给它:
```py
predictions = outputs.logits.cpu().numpy()
@@ -593,7 +593,7 @@ compute_metrics((predictions, labels))
TypeError: only size-1 arrays can be converted to Python scalars
```
-我们得到同样的错误,所以问题肯定出在那个函数上。 如果我们回顾它的代码,我们会发现它只是将“预测”和“真实的标签”转发到“metric.compute()”。 那么这种方法有问题吗? 并不真地。 让我们快速浏览一下形状:
+我们得到了同样的错误,所以问题肯定出在那个函数上。如果我们回顾它的代码,我们会发现它只是将 `predictions` 和 `labels` 转发到 `metric.compute()` 。那么这种方法有问题吗?不一定。让我们快速浏览一下输入的形状:
```py
predictions.shape, labels.shape
@@ -603,7 +603,7 @@ predictions.shape, labels.shape
((8, 3), (8,))
```
-我们的预测仍然是 logits,而不是实际的预测,这就是metrics返回这个(有点模糊)错误的原因。 修复很简单; 我们只需要在 `compute_metrics()` 函数中添加一个 argmax:
+我们的模型预测的输出是三个标签的 logits 值,而不是概率最高的标签id,这就是 metrics 返回这个(有点模糊)错误的原因。修复很简单;我们只需要在 `compute_metrics()` 函数中添加一个 argmax:
```py
import numpy as np
@@ -622,9 +622,9 @@ compute_metrics((predictions, labels))
{'accuracy': 0.625}
```
-现在我们的错误已修复! 这是最后一个,所以我们的脚本现在将正确训练模型。
+现在我们的错误已修复!这是最后一个错误,所以我们的脚本现在将可以正确地训练一个模型。
-作为参考,这里是完全修正好的脚本:
+作为参考,这里是完全修复的代码:
```py
import numpy as np
@@ -683,44 +683,43 @@ trainer = Trainer(
trainer.train()
```
-在这种情况下,如果没有更多错误,我们的脚本将微调一个应该给出合理结果的模型。 但是,如果训练没有任何错误,而训练出来的模型根本表现不佳,我们该怎么办? 这是机器学习中最难的部分,我们将向您展示一些可以提供帮助的技术。
-
+在这种情况下,如果没有更多错误,我们的脚本将微调一个应该给出合理结果的模型。但是,如果训练没有任何错误,而训练出来的模型根本表现不佳,我们该怎么办?这是机器学习中最难的部分,我们将向你展示一些可以帮助解决这类问题的技巧。
-💡 如果您使用手动训练循环,则相同的步骤也适用于调试训练管道,而且更容易将它们分开。 但是,请确保您没有忘记正确位置的 `model.eval()` 或 `model.train()`,或者每个步骤中的 `zero_grad()`!
+💡 如果你使用的是手动训练循环,调试训练流程时也需要遵循相同的步骤,而且更容易将训练中的各个步骤分开调试。但是,请确保你没有忘记在合适的位置调用 `model.eval()` 或 `model.train()` ,也不要忘记在每个步骤中使用 `zero_grad()` !
## 在训练期间调试静默(没有任何错误提示)错误 [[在训练期间调试静默(没有任何错误提示)错误]]
-我们可以做些什么来调试一个没有错误地完成但没有得到好的结果的训练? 我们会在这里给你一些提示,但请注意,这种调试是机器学习中最难的部分,并且没有神奇的答案。
+如何调试一个没有错误但也没有得到好的结果的训练?接下来会给出一些可以参考的做法,但请注意,这种调试是机器学习中最难的部分,并且没有万能的灵丹妙药。
-### 检查您的数据(再次!) [[检查您的数据(再次!)]]
+### 再次检查你的数据 [[再次检查你的数据]]
-只有在理论上可以从您的数据中学到任何东西时,您的模型才会学到一些东西。 如果存在损坏数据的错误或标签是随机属性的,那么您很可能不会在数据集上获得任何知识。 因此,始终首先仔细检查您的解码输入和标签,然后问自己以下问题:
+理论上,只有数据中存在可以学习的知识,模型才会学到一些知识。如果数据已经被损坏了或标签是随机的,那么模型很可能无法从数据集中获得任何知识。因此,始终首先仔细检查你的解码后的输入和真实的标签,然后问自己以下问题:
-- 解码后的数据是否可以理解?
-- 你认同这些标签吗?
+- 解码后的文本数据你是否可以正常阅读和理解?
+- 你认同这些标签对于文本的描述吗?
- 有没有一个标签比其他标签更常见?
-- 如果模型预测随机的答案/总是相同的答案,那么loss/评估指标应该是多少?
+- 如果模型预测的答案是随机的或总是相同的,那么 loss/ 评估指标应该是多少,是否模型根本没能学到任何知识?
-⚠️ 如果您正在进行分布式训练,请在每个过程中打印数据集的样本,并三次检查您是否得到相同的结果。 一个常见的错误是在数据创建中有一些随机性来源,这使得每个进程都有不同版本的数据集。
+⚠️ 如果你正在进行分布式训练,请在每个进程中打印数据集的样本并仔细核对,确保你得到的是相同的内容。一个常见的错误是在数据创建过程中有一些随机性,导致每个进程具有不同版本的数据集。
-查看您的数据后,查看模型的一些预测并对其进行解码。 如果模型总是预测同样的事情,那可能是因为你的数据集偏向一个类别(针对分类问题); 过采样稀有类等技术可能会有所帮助。
+在检查数据后,可以检查模型的一些预测并对其进行解码。 如果模型总是预测同样的类别,那么可能是因为这个类别在数据集中的比例比较高(针对分类问题); 过采样稀有类等技术可能会对解决这种问题有帮助。或者,这也可能是由训练的设置(如错误的超参数设置)引起的。
-如果您在初始模型上获得的loss/评估指标与您期望的随机预测的loss/评估指标非常不同,请仔细检查您的loss或评估指标的计算方式,因为那里可能存在错误。 如果您使用最后添加的多个loss,请确保它们具有相同的规模。
+如果在初始模型上获得的 loss/ 评估指标与预估的随机时预测的 loss/ 评估指标非常不同,则应该仔细检查 loss/ 评估指标的计算方式,因为其中可能存在错误。如果使用多个 loss,并将其相加计算最后的loss,则应该确保它们具有相同的比例大小。
-当您确定您的数据是完美的时,您可以通过一个简单的测试来查看模型是否能够对其进行训练。
+当你确定你的数据是完美的之后,则可以通过一个简单的过拟合测试来查看模型是否能够用其进行训练。
-### 在一批上过度拟合你的模型 [[在一批上过度拟合你的模型]]
+### 在一个 batch 上过拟合模型 [[在一个 batch 上过拟合模型]]
-过度拟合通常是我们在训练时尽量避免的事情,因为这意味着模型没有学习识别我们想要的一般特征,而只是记住了训练样本。 在这种情况下,一遍又一遍地尝试在一个批次上训练您的模型是一个很好的测试,可以检查您的问题是否可以通过您尝试训练的模型来解决。 它还将帮助您查看您的初始学习率是否太高。
+过拟合通常是在训练时尽量避免的事情,因为这意味着模型没有识别并学习我们想要的一般特征,而只是记住了训练样本。 但一遍又一遍地尝试在一个 batch 上训练模型可以检查数据集所描述的问题是否可以通过训练的模型来解决, 它还将帮助查看你的初始学习率是否太高了。
-一旦你定义了你的 `Trainer` 之后,这样做真的很容易; 只需获取一批训练数据,然后仅使用该批次运行一个小型手动训练循环,大约 20 步:
+在定义好 `Trainer` 之后,这样做真的很容易;只需获取一批训练数据,然后仅使用这个 `batch` 运行一个小型手动训练循环,大约 20 步:
```py
for batch in trainer.get_train_dataloader():
@@ -739,11 +738,11 @@ for _ in range(20):
-💡 如果您的训练数据不平衡,请确保构建一批包含所有标签的训练数据。
+💡 如果你的训练数据不平衡,请确保构建一批包含所有标签的训练数据。
-生成的模型在一个“批次”上应该有接近完美的结果。 让我们计算结果预测的指标:
+生成的模型在一个 `batch` 上应该有接近完美的结果。让我们计算结果预测的评估指标:
```py
with torch.no_grad():
@@ -758,33 +757,33 @@ compute_metrics((preds.cpu().numpy(), labels.cpu().numpy()))
{'accuracy': 1.0}
```
-100% 准确率,现在这是一个很好的过拟合示例(这意味着如果你在任何其他句子上尝试你的模型,它很可能会给你一个错误的答案)!
+100% 准确率,现在这是一个很好的过拟合示例(这意味着如果你在任何其他句子上尝试你的模型,它很可能会给你一个错误的答案)!
-如果你没有设法让你的模型获得这样的完美结果,这意味着你构建问题或数据的方式有问题,所以你应该修复它。 只有当你可以通过过拟合测试时,你才能确定你的模型实际上可以学到一些东西。
+如果你没有设法让你的模型获得这样的完美结果,这意味着构建问题的方式或数据有问题。只有当你通过了过拟合测试,才能确定你的模型理论上确实可以学到一些东西。
-⚠️ 在此测试之后,您将不得不重新创建您的模型和“Trainer”,因为获得的模型可能无法在您的完整数据集上恢复和学习有用的东西。
+⚠️ 在此测试之后,你需要创建模型和 `Trainer` ,因为获得的模型可能无法在你的完整数据集上恢复和学习有用的东西。
-### 在你有第一个基线之前不要调整任何东西 [[在你有第一个基线之前不要调整任何东西]]
+### 在你有第一个 baseline 模型之前不要调整任何东西 [[在你有第一个baseline 模型之前不要调整任何东西]]
-超参数调优总是被强调为机器学习中最难的部分,但这只是帮助您在指标上有所收获的最后一步。 大多数情况下,`Trainer` 的默认超参数可以很好地为您提供良好的结果,因此在您获得超出数据集基线的东西之前,不要开始进行耗时且昂贵的超参数搜索 .
+超参数调优总是被强调为机器学习中最难的部分,但这只是帮助你在指标上有所收获的最后一步。大多数情况下, `Trainer` 的默认超参数可以很好地为你提供良好的结果,因此在你拥有数据集上的 baseline 模型之前,不要急于进行耗时和昂贵的超参数搜索。
-一旦你有一个足够好的模型,你就可以开始稍微调整一下。 不要尝试使用不同的超参数启动一千次运行,而是比较一个超参数的不同值的几次运行,以了解哪个影响最大。
+在有一个足够好的模型后,就可以开始微调了。尽量避免使用不同的超参数进行一千次运行,而要比较一个超参数取不同数值的几次运行,从而了解哪个超参数的影响最大,从而理解超参数值的改变与于模型训练之间的关系。
-如果您正在调整模型本身,不要尝试任何您无法合理证明的事情。 始终确保您返回过拟合测试以验证您的更改没有产生任何意外后果。
+如果正在调整模型本身,请保持简单,不要直接对模型进行非常复杂的无法理解或者证明的修改,要一步步修改,同时尝试理解和证明这次修改对模型产生的影响,并且 确保通过过拟合测试来验证修改没有引发其他的问题。
### 请求帮忙 [[请求帮忙]]
-希望您会在本节中找到一些可以帮助您解决问题的建议,但如果不是这样,请记住您可以随时在 [论坛](https://discuss.huggingface.co/) 上向社区提问。
+希望你会在本课程中找到一些可以帮助你解决问题的建议,除此之外可以随时在 [论坛](https://discuss.huggingface.co/) 上向社区提问。
以下是一些可能有用的额外资源:
-- [“作为工程最佳实践工具的再现性”](https://docs.google.com/presentation/d/1yHLPvPhUs2KGI5ZWo0sU-PKU3GimAk3iTsI38Z-B5Gw/edit#slide=id.p),作者:Joel Grus
-- [“神经网络调试清单”](https://towardsdatascience.com/checklist-for-debugging-neural-networks-d8b2a9434f21) 作者:Cecelia Shao
-- [“如何对机器学习代码进行单元测试”](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765) by Chase Roberts
-- [“训练神经网络的秘诀”](http://karpathy.github.io/2019/04/25/recipe/)作者:Andrej Karpathy
+-Joel Grus 的 [“作为工程最佳实践工具的再现性”](https://docs.google.com/presentation/d/1yHLPvPhUs2KGI5ZWo0sU-PKU3GimAk3iTsI38Z-B5Gw/edit#slide=id.p)
+- Cecelia Shao 的 [“神经网络调试清单”](https://towardsdatascience.com/checklist-for-debugging-neural-networks-d8b2a9434f21)
+- Chase Roberts 的 [“如何对机器学习代码进行单元测试”](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765)
+- Andrej Karpathy 的 [“训练神经网络的秘诀”](http://karpathy.github.io/2019/04/25/recipe)
-当然,并不是你在训练神经网络时遇到的每一个问题都是你自己的错! 如果您在 🤗 Transformers 或 🤗 Datasets 库中遇到看起来不正确的内容,您可能遇到了错误。 你应该告诉我们这一切,在下一节中,我们将准确解释如何做到这一点。
+当然,并不是你在训练神经网络时遇到的每个问题都是你自己的错!如果你在🤗 Transformers 或🤗 Datasets 库中遇到了似乎不正确的东西,你可能遇到了一个错误。你应该告诉我们所有这些问题,在下一节中,我们将详细解释如何做到这一点。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter8/4_tf.mdx b/chapters/zh-CN/chapter8/4_tf.mdx
index b23b67fa9..f70e60508 100644
--- a/chapters/zh-CN/chapter8/4_tf.mdx
+++ b/chapters/zh-CN/chapter8/4_tf.mdx
@@ -1,6 +1,6 @@
-# Debugging the training pipeline [[Debugging the training pipeline]]
+# 调试训练管道 [[调试训练管道]]
-你已经编写了一个漂亮的脚本来训练或微调给定任务的模型,尽职尽责地遵循 [第七章](/course/chapter7) 中的建议。 但是当你启动命令 `model.fit()` 时,可怕的事情发生了:你得到一个错误😱! 或者更糟糕的是,一切似乎都很好,训练运行没有错误,但生成的模型很糟糕。 在本节中,我们将向您展示如何调试此类问题。
+假如你已经尽可能地遵循 [第七章](/course/chapter7) 中的建议,编写了一个漂亮的脚本来训练或微调给定任务的模型。 但是当你启动命令 `model.fit()` 时,你得到一个错误😱! 或者更糟的是虽然看起来一切似乎都正常,训练运行没有错误,但生成的模型却很糟糕。 在本节中,我们将向你展示如何调试此类问题。
-## Debugging the training pipeline
+## 调试训练管道 [[调试训练管道]]
-The problem when you encounter an error in `model.fit()` is that it could come from multiple sources, as training usually brings together a lot of things that you've been working on up until that point. The problem could be something wrong in your dataset, or some issue when trying to batch elements of the datasets together. Or it could be something wrong in the model code, or your loss function or optimizer. And even if everything goes well for training, something could still go wrong during the evaluation if there is a problem with your metric.
+当你在运行 `model.fit()` 中遇到错误时,它有可能来自多个不同的来源,因为 `Trainer` 通常将之前的许多工作汇集到一起。比如有可能是你的数据集有问题,或者可能是在尝试将数据集的元素汇集在一起做批处理时出现问题,又或者模型代码、损失函数或优化器中存在问题,另外即使训练过程一切顺利,如果选取的评估指标有问题,评估过程中仍然可能出现错误。
-The best way to debug an error that arises in `model.fit()` is to manually go through this whole pipeline to see where things went awry. The error is then often very easy to solve.
+所以调试 `model.fit()` 中出现的错误的最佳方法是手动检查整个管道,看看哪里出了问题。
-To demonstrate this, we will use the following script that (tries to) fine-tune a DistilBERT model on the [MNLI dataset](https://huggingface.co/datasets/glue):
-
-当您在 `model.fit()` 中遇到错误时,问题在于它可能来自多个来源,因为训练通常会汇集很多您在此之前一直在做的事情。 问题可能是您的数据集中有问题,或者是在尝试将数据集的元素批处理在一起时出现问题。 或者模型代码、损失函数或优化器中可能有问题。 即使训练一切顺利,如果您的指标有问题,评估期间仍然可能出现问题。
-
-调试 `model.fit()` 中出现的错误的最佳方法是手动检查整个管道,看看哪里出了问题。 错误通常很容易解决。
-
-为了证明这一点,我们将使用以下脚本(尝试)在 [MNLI 数据集](https://huggingface.co/datasets/glue)上微调 DistilBERT 模型:
+这里我们将使用以下脚本在 [MNLI 数据集](https://huggingface.co/datasets/glue)上微调 DistilBERT 模型:
```py
from datasets import load_dataset
@@ -61,28 +55,28 @@ model.compile(loss="sparse_categorical_crossentropy", optimizer="adam")
model.fit(train_dataset)
```
-如果您尝试执行它,在进行数据集转换时可能会收到一些“VisibleDeprecationWarning”——这是我们已知的 UX 问题,因此请忽略它。 如果你在 2021 年 11 月之后阅读这门课程并且它仍在继续,那么请在推特上 @carrigmat 上发送愤怒的推文,直到他修复它。
+如果执行这段代码,在进行数据集转换时可能会收到一些`VisibleDeprecationWarning`——这是已知的 UX 问题,可以忽略。 如果你在 2021 年 11 月之后学习本课程时还有这个问题,可以在推特上 @carrigmat 上发表推文敦促作者进行修复。
-然而,更严重的问题是我们得到了一个彻底的错误。 它真的非常长:
+然而更严重的问题是你得到了一个段很长的报错:
```python out
ValueError: No gradients provided for any variable: ['tf_distil_bert_for_sequence_classification/distilbert/embeddings/word_embeddings/weight:0', '...']
```
-这意味着什么? 我们试图训练我们的数据,但我们没有梯度? 这很令人困惑。 我们甚至不知道该如何开始调试类似的东西? 当你得到的错误并不能立即表明问题出在哪里时,最好的解决方案通常是按顺序检查所有内容,确保在每个阶段一切看起来都是正确的。 当然,开始的地方总是...
+这是什么意思?我们在数据上训练模型,但却没有梯度? 你甚至可能不知道该如何进行调试。当你不能从得到的报错消息直接找到问题出在哪里时,最好的解决方法通常是按顺序检查所有内容,确保在每个阶段一切看起来都正常。
-### 检查您的数据 [[检查您的数据]]
+### 检查你的数据 [[检查你的数据]]
-这是不言而喻的,但如果您的数据已损坏,Keras 将无法为您修复它。 所以首先,你需要看看你的训练集中有什么。
+显而易见,如果你的数据已损坏,Keras 不具备自动修复数据的功能。因此需要手动排查数据错误,首先要做的事情是查看训练集中的内容。
-尽管查看 `raw_datasets` 和 `tokenized_datasets` 很诱人,但我们强烈建议您在数据将要进入模型的地方直接查看数据。 这意味着应该从您使用 `to_tf_dataset()` 函数创建的 `tf.data.Dataset` 读取输出! 那么我们该怎么做呢? `tf.data.Dataset` 对象一次给我们整个批次并且不支持索引,所以我们不能只请求 `train_dataset[0]`。 但是,我们可以礼貌地向它要一批:
+尽管查看 `raw_datasets` 和 `tokenized_datasets` 比较容易,他们都是没有经过处理的数据,比较接近人的阅读习惯。但强烈建议你在数据将要输入模型的地方直接查看数据。 这意味着你应该试着读取使用 `to_tf_dataset()` 函数创建的 `tf.data.Dataset` 的输出! 那应该怎么做呢? `tf.data.Dataset` 对象一次给我们整个 `batch` 的数据,并且不支持索引,所以不能使用 `train_dataset[0]` 来获取 `batch` 中的第一个数据。 但是我们可以先向它请求一个 `batch`:
```py
for batch in train_dataset:
break
```
-`break` 在一次迭代后结束循环,因此这会抓取来自`train_dataset` 的第一批并将其保存为`batch`。 现在,让我们看看里面有什么:
+`break` 在第一次迭代后自动结束循环,我们可以使用它来抓取 `train_dataset` 的第一批数据并将其保存为 `batch`。 现在,让我们看看里面有什么:
```python out
{'attention_mask': }
```
-这看起来不错,不是吗?我们将 `labels` 、`attention_mask` 和 `input_ids` 传递给模型,这应该是计算输出和计算损失所需的一切。那么为什么我们没有梯度呢?仔细看:我们将单个字典作为输入传递,但训练批次通常是输入张量或字典,加上标签张量。我们的标签只是我们输入字典中的一个键。
+看起来一切正常,对吧?我们将 `labels` 、`attention_mask` 和 `input_ids` 传递给模型,这的确是模型计算输出和计算损失所需的数据。那么为什么没有梯度呢?仔细看:仔细看,我们将输入模型的输入数据和真实的标签值放入一个字典中传递给了模型,但训练批次通常是模型的输入数据加上真实的标签值。而现在真实的标签值只是输入字典中的一个键,并没有独立出来。
-这是一个问题吗?实际上,并非总是如此!但这是您在使用 TensorFlow 训练 Transformer 模型时会遇到的最常见问题之一。我们的模型都可以在内部计算损失,但要做到这一点,需要在输入字典中传递标签。这是当我们没有为 `compile()` 指定损失值时使用的损失。另一方面,Keras 通常希望标签与输入字典分开传递,如果你不这样做,损失计算通常会失败。
+这是一个错误吗?实际上并不总是!不过这是在使用 TensorFlow 训练 Transformer 模型时会遇到的最常见问题之一。如果运行 `compile()` 时没有指定所使用的损失函数,那么模型可以使用内部默认的损失函数自动计算损失,这个时候就需要将输入模型的数据和真实的标签值放入一个字典中传递给模型。如果想要使用自定义的损失函数,在使用 Keras 时通常需要将真实的标签值与输入字典分开传递给模型,否则损失计算通常会失败。
-问题现在变得更清楚了:我们传递了一个“损失”参数,这意味着我们要求 Keras 为我们计算损失,但我们将标签作为模型的输入传递,而不是放在 Keras 期望的地方的!我们需要二选一:要么使用模型的内部损失并将标签保留在原处,要么继续使用 Keras 损失,但将标签移动到 Keras 期望的位置。为简单起见,让我们采用第一种方法。将对 `compile()` 的调用更改为:
+问题现在变得清晰了,我们传递了一个 loss 参数,这意味着要求 Keras 使用自定义的损失函数计算损失。但是,我们将真实的标签值放入了输入的字典中传递给了模型,并没有放在 Keras 期望的位置!因此,我们需要从两种方法中二选一,要么删除自定义的损失函数使用模型的内部损失并将真实的标签值保留在原处,要么继续使用自定义的Keras 损失但将真实的标签值移动到Keras 期望的位置。为了简单起见,在这里可以采用第一种方法。将对 `compile()` 的调用更改如下。
```py
model.compile(optimizer="adam")
```
-现在我们将使用模型的内部损失,这个问题应该解决了!
+现在我们可以使用模型的内部自动计算损失,这个问题解决了!
-✏️ **轮到你了!** 作为我们解决其他问题后的可选挑战,你可以尝试回到这一步,让模型使用原始 Keras 计算的损失而不是内部损失。 您需要将 `"labels"` 添加到 `to_tf_dataset()` 的 `label_cols` 参数,以确保正确输出标签,这将为您提供梯度——但我们指定的损失还有一个问题 . 训练仍然会遇到这个问题,学习会非常缓慢,并且会在多次训练损失时达到稳定状态。 你能弄清楚它是什么吗?
+✏️ **轮到你了!** 作为解决其他问题后的可选挑战,你可以尝试回到这一步,让模型使用原始 Keras 计算的损失而不是内部损失。 你需要将 `"labels"` 添加到 `to_tf_dataset()` 的 `label_cols` 参数,并且确保 `to_tf_dataset()` 输出真实的标签来提供梯度,但是我们指定的损失还有一个问题。即使在这个问题上可以进行训练,学习速度仍然会非常慢,并且 loss 会达到一个较高的值。你能找出问题在哪里吗?
+
+如果你卡住了,这是一个 ROT13 编码的提示(如果你不熟悉 ROT13,可以在[这里](https://rot13.com/)解码。):Vs lbh ybbx ng gur bhgchgf bs FrdhraprPynffvsvpngvba zbqryf va Genafsbezref, gurve svefg bhgchg vf `ybtvgf`. Jung ner ybtvgf?(查看 Transformers 中 `SequenceClassification` 模型的输出,第一个输出是“logits”。思考什么是 logits ?它所代表的实际含义是什么?)
-一个 ROT13 编码的提示,如果你卡住了:Vs lbh ybbx ng gur bhgchgf bs FrdhraprPynffvsvpngvba zbqryf va Genafsbezref, gurve svefg bhgchg vf `ybtvgf`。 荣格纳 ybtvgf?
+还有一个提示:
-第二个提示:Jura lbh fcrpvsl bcgvzvmref, npgvingvbaf 是 ybffrf jvgu fgevatf, Xrenf frgf nyy gur nethzrag inyhrf gb gurve qrsnhygf。 Jung nethzragf qbrf FcnefrPngrtbevpnyPebffragebcl unir, naq jung ner gurve qrsnhygf?
+Jura lbh fcrpvsl bcgvzvmref, npgvingvbaf be ybffrf jvgu fgevatf, Xrenf frgf nyy gur nethzrag inyhrf gb gurve qrsnhygf. Jung nethzragf qbrf FcnefrPngrtbevpnyPebffragebcl unir, naq jung ner gurve qrsnhygf?(当训练模型时直接使用字符串告诉模型指定优化器、激活函数或损失函数时,Keras 会使用优化器、激活函数或损失函数参数值的默认值。
+`SparseCategoricalCrossentropy` 损失函数有哪些参数,它们的默认值是什么?
+)
-现在,让我们尝试训练。 我们现在应该得到梯度,所以希望(这里播放不祥的音乐)我们可以调用 `model.fit()` 一切都会正常工作!
+现在让我们尝试继续进行训练。 如今已经得到梯度,所以希望(此处播放令人不安的音乐)只需调用`model.fit()`,一切都会正常工作!
```python out
246/24543 [..............................] - ETA: 15:52 - loss: nan
-```
-
-Oh no.
+```
+哦不。
-`nan` 不是一个非常令人开心的损失值。 尽管如此,我们已经检查了我们的数据,它看起来还不错。 如果这不是问题,我们下一步该去哪里? 显而易见的下一步是...
+`nan` 不是一个正常的损失值。我们已经检查了我们的数据,看起来一切正常。如果问题不在数据,那么我们接下来检查哪里呢?很明显的下一步是...
-### 检查你的模型 [[检查你的模型]]
+### 检查模型 [[检查模型]]
-`model.fit()` 是 Keras 中一个非常方便的函数,但它为您做了很多事情,这使得准确找到问题发生的位置变得更加棘手。 如果您正在调试您的模型,一个真正有用的策略是只将一个批次传递给模型,并详细查看该批次的输出。 如果模型抛出错误,另一个非常有用的提示是使用 `run_eagerly=True` `compile()` 模型。 这会使它变慢很多,但它会使错误消息更容易理解,因为它们会准确地指出问题发生在模型代码的哪个位置。
+`model.fit()` 是 Keras 中一个很方便的函数,但这个函数一次性做了很多事情,这使准确定位问题发生的位置变得更加棘手。 如果你正在调试模型,那么一个明智的策略是考虑只将一个批次传递给模型,并查看该批次的详细输出。 如果模型抛出错误,另一个非常有用的提示是可以将`run_eagerly=True`参数传递给 `compile()`。 这会使它训练过程变慢很多,但可以使输出的错误消息变得更容易理解,因为它会准确地指出问题发生在模型代码的哪个位置。
-不过,目前我们还不需要 `run_eagerly`。 让我们通过模型运行我们之前得到的“批处理”,看看输出是什么样子的:
+不过目前我们还不需要 `run_eagerly`。让我们将之前得到的 `batch` 输入模型,并查看输出的结果:
```py
model(batch)
@@ -168,16 +165,16 @@ array([[nan, nan],
[nan, nan]], dtype=float32)>, hidden_states=None, attentions=None)
```
-嗯,这很棘手。一切都是`nan`!但这很奇怪,不是吗?我们所有的 logits 怎么会变成“nan”? `nan` 的意思是“不是数字”。 `nan` 值经常出现在您执行禁止操作时,例如除以零。但是,在机器学习中了解 `nan` 非常重要的一件事是,该值倾向于*传播*。如果将一个数字乘以 `nan`,则输出也是 `nan`。如果你在输出、损失或梯度的任何地方得到一个“nan”,那么它会迅速传播到你的整个模型中——因为当那个“nan”值通过你的网络传播回来时,你会得到nan 梯度,当使用这些梯度计算权重更新时,您将获得 nan 权重,这些权重将计算更多的 nan 输出!很快,整个网络将只是“nan”的一大块。一旦发生这种情况,就很难看出问题是从哪里开始的。我们如何隔离“nan”第一次出现的地方?
+嗯,这看起来很棘手。所有的值都是`nan`!但是这很奇怪,对吧?为什么所有的 logits 都变成了`nan`?`nan`表示“不是一个数字”。经常出现在执行非法操作时,例如除以零。但在机器学习中有关于 `nan` 有一个重要的经验——这个值往往会传播。如果将一个数字乘 `nan`,则输出也是 `nan`。如果在输出、损失或梯度的任何地方得到一个 `nan`,那么它会迅速传播到整个模型中。因为当那个 `nan` 值通过你的网络传播回来时,会得到 `nan` 梯度,当使用这些梯度计算权重更新时,将获得 `nan` 权重,这些权重将计算更多的 `nan` 输出!很快整个网络就会变成一个大块 `nan`。一旦发生这种情况,就很难看出问题是从哪里开始的。我们如何确定`nan`最先出现的位置呢?
-答案是尝试*重新初始化*我们的模型。一旦我们开始训练,我们就会在某个地方得到一个“nan”,它很快就会传播到整个模型中。所以,让我们从检查点加载模型而不做任何权重更新,看看我们从哪里得到一个 `nan` 值:
+答案是“重新初始化”我们的模型。一旦我们开始训练,我们就会在某个地方得到一个 `nan`,并很快就会传播到整个模型中。所以可以从检查点加载模型而不做任何权重更新,进而排查出最开始的时候是从哪里得到一个 `nan` 值:
```py
model = TFAutoModelForSequenceClassification.from_pretrained(model_checkpoint)
model(batch)
```
-当我们运行它时,我们得到:
+当我们运行它时,可以得到:
```py out
TFSequenceClassifierOutput(loss=, hidden_states=None, attentions=None)
```
-*现在*我们到了某个地方! 我们的 logits 中没有 `nan` 值,这令人放心。 但是我们确实在损失中看到了一些“nan”值! 这些样本有什么特别导致这个问题的吗? 让我们看看它们是哪些(请注意,如果您自己运行此代码,您可能会得到不同的索引,因为数据集已被随机打乱):
+现在我们到了 logits 中没有 `nan` 值的地方,这是一个好的开始。但是我们确实在损失中看到了一些 `nan` 值,这些出现 `nan` 的样本有什么特别之处可以导致这个问题吗?(请注意,你运行此代码时可能会得到不同的索引,因为数据集已被随机打乱):
```python
import numpy as np
@@ -317,7 +314,7 @@ array([[ 101, 2007, 2032, 2001, 1037, 16480, 3917, 2594, 4135,
0, 0, 0, 0]])
```
-嗯,这里有很多东西,但没有什么不寻常的。 让我们看看标签:
+目前没有什么不寻常之处。 让我们检查一下标签:
```python out
labels = batch['labels'].numpy()
@@ -328,7 +325,7 @@ labels[indices]
array([2, 2, 2, 2, 2, 2, 2, 2, 2])
```
-啊! `nan` 样本都具有相同的标签,即标签 2。这是一个非常明显的提示。 当我们的标签为 2 时,我们会得到loss为 `nan`,这表明这是检查模型中标签数量的好时机:
+啊!所有的 `nan` 样本都具有相同的标签,即标签 `2` 。这是一个非常明显的提示, 当我们的标签为 `2` 时,我们会得到loss为 `nan`,现在是时候检查一下模型的标签了:
```python
model.config.num_labels
@@ -338,7 +335,7 @@ model.config.num_labels
2
```
-现在我们看到了问题:模型认为只有两个类,但标签上升到 2,这意味着实际上有三个类(因为 0 也是一个类)。 这就是我们得到“nan”的方式——通过尝试计算不存在的类的损失! 让我们尝试改变它并再次拟合模型:
+这表明模型认为只有两个类,但是标签的取值范围是从 0 到 2,这意味着实际上有三个类别(因为 0 也是一个类)。这就是我们得到`nan`的原因——尝试计算不存在的类别的损失。让我们改变标签的取值范围并再次拟合模型。
```
model = TFAutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=3)
@@ -349,16 +346,15 @@ model.fit(train_dataset)
```python out
869/24543 [>.............................] - ETA: 15:29 - loss: 1.1032
```
+训练在正常进行!没有了`nan`,损失也在下降……有点。如果你观察一段时间,你可能会觉得有点不耐烦,虽然我们的损失正在一点点减少,但总体还是一直居高不下。先停止训练并尝试考虑可能导致此问题的原因。到目前为止,我们很确定数据和模型都没有问题,但是我们的模型的学习效果并不是特别好。还剩下什么?是时候...
-我们在训练! 没有更多的'nan's,我们的损失正在减少......有点。 如果你观察一段时间,你可能会开始有点不耐烦,因为损失值一直居高不下。 让我们在这里停止训练并尝试考虑可能导致此问题的原因。 在这一点上,我们很确定数据和模型都没有问题,但是我们的模型并没有很好地学习。 还剩下什么? 是时候...
-
-### 检查你的超参数 [[检查你的超参数]]
+### 检查超参数 [[检查超参数]]
-如果你回头看上面的代码,你可能根本看不到任何超参数,除了 `batch_size`,这似乎不是罪魁祸首。不过,不要被迷惑;总是有超参数,如果你看不到它们,那只是意味着你不知道它们的设置是什么。特别要记住关于 Keras 的一个关键点:如果您使用字符串设置损失函数、优化器或激活函数,_它的所有参数都将设置为它们的默认值_。这意味着即使为此使用字符串非常方便,但在这样做时您应该非常小心,因为它很容易对您隐藏关键的事情。 (任何尝试上述方式的人都应该仔细注意这一事实。)
+如果你回头看上面的代码,根本看不到别的超参数,除了 `batch_size`,而 `batch_size` 似乎不太可能是问题的原因。不过,不要被表象迷惑;超参数始终存在,如果你看不到它们,那只意味着你不知道它们默认被设置成了什么。这里强调一个关于 Keras 的关键点:如果使用字符串设置损失函数、优化器或激活函数,“它的所有参数都将设置为默认值”。这意味着即使使用字符串非常方便,但在这样做时应该非常小心,因为它很容易隐藏一些关键的问题。(尝试上面的可选挑战的人应该注意到了这一点。)
-在这种情况下,我们在哪里设置了带有字符串的参数?我们最初使用字符串设置损失,但我们不再这样做了。但是,我们正在使用字符串设置优化器。难道这对我们隐瞒了什么?让我们看看[关于它的一些讨论](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam)。
+在这个例子中,我们在哪里使用了字符串参数呢 ?最初我们使用字符串设置了损失函数,但现在我们已经去掉了。除此之外,我们还使用字符串设置了优化器。其中是否隐藏了什么信息呢?让我们查看一下优化器的[参数](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam):
-这里有什么需要注意的吗?没错——学习率!当我们只使用字符串“adam”时,我们将获得默认的学习率,即 0.001,即 1e-3。这对于transormer模型来说太高了!一般来说,我们建议您的模型尝试 1e-5 和 1e-4 之间的学习率;这比我们在这里实际使用的值小 10X 到 100X 之间。听起来这可能是一个主要问题,所以让我们尝试减少它。为此,我们需要导入实际的“优化器”对象。当我们这样做的时候,让我们从检查点重新初始化模型,以防高学习率的训练损坏了它的权重:
+这里需要注意学习率。当我们只使用字符串“adam”时,将使用默认的学习率 0.001(即 1e-3)。这对于transormer模型来说太高了,一般来说,我们建议尝试学习率在 1e-5 到 1e-4 之间的值;这比默认的值小 10倍 到 100倍。这听起来可能是一个导致loss下降很缓慢的原因,所以让我们尝试减小学习率。为此我们需要导入`optimizer` 对象,在`optimizer` 对象中设置学习率。让我们从`checkpoint` 重新初始化模型,以防刚刚过高的学习率的训练破坏了权重:
```python
from tensorflow.keras.optimizers import Adam
@@ -369,11 +365,11 @@ model.compile(optimizer=Adam(5e-5))
-💡您还可以从🤗 Transformers 中导入 `create_optimizer()` 函数,这将为您提供具有正确权重衰减以及学习率预热和学习率衰减的 AdamW 优化器。 此优化器通常会产生比使用默认 Adam 优化器获得的结果稍好一些的结果。
+💡除了从 Keras 中导入 `Adam` 优化器你还可以从🤗 Transformers 中导入 `create_optimizer()` 函数,这将提供具有正确的权重衰减和学习率预热和衰减的 AdamW 优化器。 此优化器通常会比使用默认 `Adam` 优化器的效果稍好一些。
-现在,我们可以尝试使用新的、改进后的学习率来拟合模型:
+现在,我们可以使用改进后的学习率来拟合模型:
```python
model.fit(train_dataset)
@@ -383,107 +379,106 @@ model.fit(train_dataset)
319/24543 [..............................] - ETA: 16:07 - loss: 0.9718
```
-现在我们的损失真的在某个地方! 训练终于看起来奏效了。 这里有一个教训:当你的模型正在运行但损失没有下降,并且你确定你的数据没问题时,检查学习率和权重衰减等超参数是个好主意。 将其中任何一个设置得太高很可能导致训练在高损失值下“停滞”。
+现在训练终于看起来奏效了。当你的模型在正常训练但损失没有下降,同时确定数据没问题时,可以检查学习率和权重衰减等超参数,其中任何一个设置得太高很可能导致训练的损失值居高不下。
## 其他潜在问题 [[其他潜在问题]]
-我们已经涵盖了上面脚本中的问题,但您可能会遇到其他几个常见错误。 让我们看一个(非常不完整的)列表。
+我们已经涵盖了上面脚本中存在的所有问题,但是还有其他一些常见错误可能会遇到。让我们来看一个(不太完整的)列表。
### 处理内存不足错误 [[处理内存不足错误]]
-内存不足的迹象是“分配张量时出现 OOM”之类的错误——OOM 是“内存不足”的缩写。 在处理大型语言模型时,这是一个非常常见的危险。 如果遇到这种情况,一个好的策略是将批量大小减半并重试。 但请记住,有些型号*非常*大。 例如,全尺寸 GPT-2 的参数为 1.5B,这意味着您将需要 6 GB 的内存来存储模型,另外需要 6 GB 的内存用于梯度下降! 无论您使用什么批量大小,训练完整的 GPT-2 模型通常需要超过 20 GB 的 VRAM,而只有少数 GPU 拥有。 像“distilbert-base-cased”这样更轻量级的模型更容易运行,训练也更快。
+内存不足指的是`OOM when allocating tensor`之类的错误——OOM 是`out of memory`的缩写。 在处理大型语言模型时,这是一个非常常见的错误。 如遇此种情况,可以将 batch size 减半并重试。 但有些尺寸非常大,比如全尺寸 GPT-2 的参数为 1.5B,这意味着你将需要 6 GB 的内存来存储模型,另外需要 6 GB 的内存用于梯度下降! 无论你使用什么 batch size ,训练完整的 GPT-2 模型通常都需要超过 20 GB 的 VRAM,然而这只有少数 GPU 才可以做到。 像`distilbert-base-cased`这样更轻量级的模型更容易训练,并且训练速度也更快。
-在课程的下一部分中,我们将介绍更先进的技术,这些技术可以帮助您减少内存占用并让您微调最大的模型。
+在课程的下一部分中,我们将介绍更先进的技术,这些技术可以帮助你减少内存占用并微调超大的模型。
### TensorFlow 🦛饿饿 [[TensorFlow 🦛饿饿]]
-您应该注意的 TensorFlow 的一个特殊怪癖是,它会在您加载模型或进行任何训练后立即为自己分配 *所有 * GPU 内存,然后根据需要分配该内存。这与其他框架的行为不同,例如 PyTorch,后者根据 CUDA 的需要分配内存,而不是在内部进行。 TensorFlow 方法的一个优点是,当您耗尽内存时,它通常会给出有用的错误,并且它可以从该状态恢复而不会导致整个 CUDA 内核崩溃。但也有一个重要的缺点:如果你同时运行两个 TensorFlow 进程,那么**你将度过一段糟糕的时光**。
+TensorFlow 的一个与众不同的特点是它会在加载模型或进行任何训练后会立即向系统请求所需的所有显存,然后在内部再将请求到的显存划分给不同的模块。这与其他框架的行为不同,例如 PyTorch根据 CUDA 的需要动态分配内存,而不是在内部进行。 TensorFlow 方法的一个优点是当内存耗尽时,它通常会给出可以帮助我们定位问题的错误信息,并且可以从错误状态恢复而不会导致整个 CUDA 内核崩溃。但是,如果同时运行两个 TensorFlow 进程,那么势必会因为预先分配内存导致内存爆炸。
-如果您在 Colab 上运行,则无需担心这一点,但如果您在本地运行,这绝对是您应该小心的事情。特别要注意,关闭笔记本选项卡并不一定会关闭该笔记本!您可能需要选择正在运行的笔记本(带有绿色图标的笔记本)并在目录列表中手动关闭它们。任何使用 TensorFlow 的正在运行的笔记本仍可能占用大量 GPU 内存,这意味着您启动的任何新笔记本都可能会遇到一些非常奇怪的问题。
+如果你在 Google Colab 上运行则无需担心这一点,但如果在本地运行,则应该小心是否成功释放了显存。特别要注意,关闭Notebook选项卡并不一定会彻底关闭该 Notebook !需要选择正在运行的 Notebook (带有绿色图标的 Notebook )并在目录列表中手动关闭它们。任何使用 TensorFlow 的正在运行的 Notebook 都可能占用大量显存,这意味着启动的任何新的使用TensorFlow 的 Notebook 可能会遇到一些非常奇怪的问题。
-如果您开始运行之前正确的代码却收到有关 CUDA、BLAS 或 cuBLAS 的错误,这通常是罪魁祸首。您可以使用类似 `nvidia-smi` 的命令来检查 - 当您关闭或重新启动当前笔记本时,您的大部分内存是否空闲,或者是否仍在使用中?如果它仍在使用中,则有其他东西在占用它!
+如果在运行正确的代码后收到有关 CUDA、BLAS 或 CUBLAS 的错误,那么问题来源通常是类似的,可以使用类似 `nvidia-smi` 的命令来检查。当关闭或重新启动当前 Notebook 时,要查看大部分显存是否空闲或者仍在使用,如果仍在使用中,则代表仍然有其他东西在占用内存。
-### 检查您的数据(再次!) [[检查您的数据(再次!)]]
+### 再次检查你的数据 [[再次检查你的数据]]
-只有在理论上可以从您的数据中学到任何东西时,您的模型才会学到一些东西。 如果存在损坏数据的错误或标签是随机属性的,那么您很可能不会在数据集上获得任何知识。这里一个有用的工具是`tokenizer.decode()`。 这会将 `input_ids` 转换回字符串,因此您可以查看数据并查看您的训练数据是否正在教授您希望它教授的内容。 例如,像我们上面所做的那样从 `tf.data.Dataset` 中获取 `batch` 后,您可以像这样解码第一个元素:
+理论上,只有数据中存在可以学习的知识,模型才会学到一些知识。如果数据已经被损坏了或标签是随机的,那么模型很可能无法从数据集中获得任何知识。这里一个有用的工具是解决该问题的一个有用的方法是使用 `tokenizer.decode()`将 `input_ids` 转换回字符串, 可以通过这个方法来查看数据和对应的标签是否正常。例如,像我们下面所做的那样, 从 `tf.data.Dataset` 中获取 `batch`,并解码第一个元素。
```py
input_ids = batch["input_ids"].numpy()
tokenizer.decode(input_ids[0])
```
-Then you can compare it with the first label, like so:
+接着检查所对应的第一个数据的真实标签。
```py
labels = batch["labels"].numpy()
label = labels[0]
```
-一旦您可以像这样查看您的数据,您可以问自己以下问题:
+在查看数据时,可以对以下问题进行检查。
-- 解码后的数据是否可以理解?
-- 你认同这些标签吗?
+- 解码后的文本数据你是否可以正常阅读和理解?
+- 你认同这些标签对于文本的描述吗?
- 有没有一个标签比其他标签更常见?
-- 如果模型预测随机的答案/总是相同的答案,那么loss/评估指标应该是多少?
+- 如果模型预测的答案是随机的或总是相同的,那么 loss/ 评估指标应该是多少,是否模型根本没能学到任何知识?
-查看您的数据后,查看模型的一些预测并对其进行解码。 如果模型总是预测同样的事情,那可能是因为你的数据集偏向一个类别(针对分类问题); 过采样稀有类等技术可能会有所帮助。
+在检查数据后,可以检查模型的一些预测并对其进行解码。 如果模型总是预测同样的类别,那么可能是因为这个类别在数据集中的比例比较高(针对分类问题); 过采样稀有类等技术可能会对解决这种问题有帮助。或者,这也可能是由训练的设置(如错误的超参数设置)引起的。
-如果您在初始模型上获得的loss/评估指标与您期望的随机预测的loss/评估指标非常不同,请仔细检查您的loss或评估指标的计算方式,因为那里可能存在错误。 如果您使用最后添加的多个loss,请确保它们具有相同的规模。
+如果在初始模型上获得的 loss/ 评估指标与预估的随机时预测的 loss/ 评估指标非常不同,则应该仔细检查 loss/ 评估指标的计算方式,因为其中可能存在错误。如果使用多个 loss,并将其相加计算最后的loss,则应该确保它们具有相同的比例大小。
-当您确定您的数据是完美的时,您可以通过一个简单的测试来查看模型是否能够对其进行训练。
+当你确定你的数据是完美的之后,则可以通过一个简单的过拟合测试来查看模型是否能够用其进行训练。
-### 在一批上过度拟合你的模型 [[在一批上过度拟合你的模型]]
+### 在一个 batch 上过拟合模型 [[在一个 batch 上过拟合模型]]
-过度拟合通常是我们在训练时尽量避免的事情,因为这意味着模型没有学习识别我们想要的一般特征,而只是记住了训练样本。 但是,一遍又一遍地尝试在一个批次上训练您的模型是一个很好的测试,可以检查您构建的问题是否可以通过您尝试训练的模型来解决。 它还将帮助您查看您的初始学习率是否太高。
+过拟合通常是在训练时尽量避免的事情,因为这意味着模型没有识别并学习我们想要的一般特征,而只是记住了训练样本。 但一遍又一遍地尝试在一个 batch 上训练模型可以检查数据集所描述的问题是否可以通过训练的模型来解决, 它还将帮助查看你的初始学习率是否太高了。
-一旦你定义了你的“模型”,这样做真的很容易; 只需获取一批训练数据,然后将该“批次”视为您的整个数据集,并在其上fit大量epoch:
+在定义 Trainer 后,只需获取一个 batch 训练数据,然后将这个 batch 视为整个数据集,并在上面拟合大量 epoch 即可:
```py
for batch in train_dataset:
break
-# Make sure you have run model.compile() and set your optimizer, [[Make sure you have run model.compile() and set your optimizer,]]
-# and your loss/metrics if you're using them [[and your loss/metrics if you're using them]]
+# 确保已经运行了 model.compile() 并设置了优化器和损失/指标
model.fit(batch, epochs=20)
```
-💡 如果您的训练数据不平衡,请确保构建一批包含所有标签的训练数据。
+💡 如果训练数据不平衡,请确保构建的这个 batch 包含训练数据中所有的标签。
-生成的模型在“批次”上应该有接近完美的结果,损失迅速下降到 0(或您正在使用的损失的最小值)。
+生成的模型在一个 batch 上应该有接近完美的结果,损失迅速下降到 0(或你正在使用的损失的最小值)。
-如果你没有设法让你的模型获得这样的完美结果,这意味着你构建问题或数据的方式有问题,所以你应该修复它。 只有当你设法通过过拟合测试时,你才能确定你的模型实际上可以学到一些东西。
+如果你没有设法让你的模型获得这样的完美结果,这意味着构建问题的方式或数据有问题。只有当你通过了过拟合测试,才能确定你的模型理论上确实可以学到一些东西。
-⚠️ 在此测试之后,您将不得不重新创建您的模型和“Trainer”,因为获得的模型可能无法在您的完整数据集上恢复和学习有用的东西。
+⚠️ 在此测试之后,你需要创建模型和 `Trainer` ,因为经过过拟合测试的模型可能无法恢复正常的参数范围,从而无法在完整数据集上学到有用的知识。
-### 在你有第一个基线之前不要调整任何东西 [[在你有第一个基线之前不要调整任何东西]]
+### 在你有第一个 baseline 模型之前不要调整任何东西 [[在你有第一个 baseline 模型之前不要调整任何东西]]
-超参数调整总是被强调为机器学习中最难的部分,但这只是帮助您在指标上获得一点点提升的最后一步。 例如将默认的 Adam 学习率 1e-3 与 Transformer 模型一起使用,当然会使学习进行得非常缓慢或完全停止,但大多数时候“合理”的超参数,例如从 1e-5 到 5e-5 的学习率,会很好地给你带来好的结果。因此,在您获得超出数据集基线的东西之前,不要开始进行耗时且昂贵的超参数搜索。
+超参数调整总是被是为机器学习中最难的部分,但这只是帮助你在指标上获得一点点提升的最后一步。 例如,使用学习率为 1e-3 的Adam 优化器训练 Transformer 模型时,当然会使学习进行得非常缓慢或完全停止,在大多数时候,合理的超参数会带来更好的结果, 如 1e-5 到 5e-5 的学习率。不过,在你有了 baseline 模型之前,请不要试图进行耗时且昂贵的超参数搜索。
-一旦你有一个足够好的模型,你就可以开始稍微调整一下。 不要尝试使用不同的超参数启动一千次运行,而是比较一个超参数的不同值的几次运行,以了解哪个影响最大。
+在有一个足够好的模型后,就可以开始微调了。尽量避免使用不同的超参数进行一千次运行,而要比较一个超参数取不同数值的几次运行,从而了解哪个超参数的影响最大,从而理解超参数值的改变与于模型训练之间的关系。
-如果您正在调整模型本身,不要尝试任何您无法合理证明的事情。 始终确保您返回过拟合测试以验证您的更改没有产生任何意外后果。
+如果正在调整模型本身,请保持简单,不要直接对模型进行非常复杂的无法理解或者证明的修改,要一步步修改,同时尝试理解和证明这次修改对模型产生的影响,并且 确保通过过拟合测试来验证修改没有引发其他的问题。
### 请求帮忙 [[请求帮忙]]
-希望您会在本节中找到一些可以帮助您解决问题的建议,但如果不是这样,请记住您可以随时在 [论坛](https://discuss.huggingface.co/) 上向社区提问。
+希望你会在本课程中找到一些可以帮助你解决问题的建议,除此之外可以随时在 [论坛](https://discuss.huggingface.co/) 上向社区提问。
以下是一些可能有用的额外资源:
-- [“作为工程最佳实践工具的再现性”](https://docs.google.com/presentation/d/1yHLPvPhUs2KGI5ZWo0sU-PKU3GimAk3iTsI38Z-B5Gw/edit#slide=id.p),作者:Joel Grus
-- [“神经网络调试清单”](https://towardsdatascience.com/checklist-for-debugging-neural-networks-d8b2a9434f21) 作者:Cecelia Shao
-- [“如何对机器学习代码进行单元测试”](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765) by Chase Roberts
-- [“训练神经网络的秘诀”](http://karpathy.github.io/2019/04/25/recipe/)作者:Andrej Karpathy
+-Joel Grus 的 [“作为工程最佳实践工具的再现性”](https://docs.google.com/presentation/d/1yHLPvPhUs2KGI5ZWo0sU-PKU3GimAk3iTsI38Z-B5Gw/edit#slide=id.p)
+- Cecelia Shao 的 [“神经网络调试清单”](https://towardsdatascience.com/checklist-for-debugging-neural-networks-d8b2a9434f21)
+- Chase Roberts 的 [“如何对机器学习代码进行单元测试”](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765)
+- Andrej Karpathy 的 [“训练神经网络的秘诀”](http://karpathy.github.io/2019/04/25/recipe)
-当然,并不是你在训练神经网络时遇到的每一个问题都是你自己的错! 如果您在 🤗 Transformers 或 🤗 Datasets 库中遇到看起来不正确的内容,您可能遇到了错误。 你应该告诉我们这一切,在下一节中,我们将准确解释如何做到这一点。
+当然,并非你在训练神经网络时遇到的每个问题都是你自己的错!如果你在 🤗 Transformers 或 🤗 Datasets 库中遇到看起来不正确的内容而导致无法解决的问题,请及时告知我们。在下一节中,我们将准确解释如何进行这一步。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter8/5.mdx b/chapters/zh-CN/chapter8/5.mdx
index e7164be66..d5cb0793e 100644
--- a/chapters/zh-CN/chapter8/5.mdx
+++ b/chapters/zh-CN/chapter8/5.mdx
@@ -7,40 +7,41 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/chapter8/section5.ipynb"},
]} />
-当您遇到 Hugging Face 库中的一个看起来不正确的东西时,您一定要告诉我们,以便我们可以修复它(就此而言,任何开源库也是如此)。如果您不能完全确定错误是在您自己的代码中还是在我们的某个库中,那么首先要检查的是[forums](https://discuss.huggingface.co/).社区会帮助你解决这个问题,Hugging Face 团队也会密切关注那里的讨论。
+当你在使用 Hugging Face 库时遇到了不正常的情况,你应该及时告诉我们,这样我们才能修复它(对于任何开源库都是一样)。如果你不确定 bug 是在你自己的代码中还是在我们的库中,首先可以在 [论坛](https://discuss.huggingface.co) 进行搜索。论坛中的帖子有可能会帮助你找出问题所在,同时Hugging Face 团队也会密切关注那里的讨论。
-当您确定手头有错误时,第一步是构建一个最小的可重现示例。
+当你确定手头上有一个 bug 时,第一步是构建一个最小可复现的示例。
+
## 创建一个最小的可重现示例 [[创建一个最小的可重现示例]]
-隔离产生错误的代码段非常重要,因为 Hugging Face 团队中没有人是魔术师(目前),他们无法修复他们看不到的东西。顾名思义,最小的可重现示例应该是可重现的。这意味着它不应依赖于您可能拥有的任何外部文件或数据。尝试用一些看起来像真实值的虚拟值替换您正在使用的数据,但仍然会产生相同的错误。
+创建一个最小可复现的示例非常重要,因为 Hugging Face 团队中没有人是魔术师(至少目前还没有),他们不能修复他们看不到的问题。一个最小可复现的示例应该是可复现的,这意味着它不应依赖于你可能有的任何外部文件或数据。尝试用一些看起来像真实数据的虚拟值替换你正在使用的数据,并且仍然产生相同的错误。
-🚨🤗 Transformers 存储库中的许多问题都没有解决,因为用于复制它们的数据不可访问。
+🚨🤗 Transformers 仓库中有很多未解决的问题,因为无法访问复现这些问题的数据。
-一旦你有一些自包含的东西,你可以尝试将它减少到更少的代码行,构建我们所谓的最小的可重复示例.虽然这需要你做更多的工作,但如果你提供一个漂亮的、简短的错误重现器,你几乎可以保证得到帮助和修复。
+在创建了一个包含所遇见的问题示例后,你可以尝试将其进一步简化,构建我们所说的“最小可复现示例”。虽然这需要你多做一些工作,但如果你提供了一个简洁明了的 bug 复现,那么几乎可以肯定会得到帮助和修复。
-如果您觉得足够舒服,请检查发生错误的源代码。您可能会找到问题的解决方案(在这种情况下,您甚至可以提出拉取请求来修复它),但更一般地说,这可以帮助维护人员在阅读您的报告时更好地理解来源。
+如果你感觉足够自信,可以检查一下你的 bug 发生的源代码。你可能会找到解决问题的方法(在这种情况下,你甚至可以发起一个修复它的 pull request 请求),但更一般地说,这可以帮助维护人员在阅读你的报告时更好地理解源代码。
## 填写问题模板 [[填写问题模板]]
-当您提交问题时,您会注意到有一个模板需要填写。我们将按照[🤗 Transformers issues](https://github.com/huggingface/transformers/issues/new/choose)在这里,但是如果您在另一个存储库中报告问题,则需要相同类型的信息。不要将模板留空:花时间填写它可以最大限度地提高您获得答案和解决问题的机会。
+当你提交问题时,需要填写一个模板。我们将在这里遵循 [🤗 Transformers issues](https://github.com/huggingface/transformers/issues/new/choose) 的模板,但如果你在其他仓库中报告问题,也需要提供相同类型的信息。请不要将模板留空,花时间填写模板将最大程度地增加你得到答案和解决问题的机会。
-通常,在提交问题时,请始终保持礼貌。这是一个开源项目,因此您使用的是免费软件,没有人有任何义务帮助您。您可能会在您的问题中包含您认为合理的批评,但是维护人员很可能会认为它很糟糕并且不会急于帮助您。确保你阅读了[code of conduct](https://github.com/huggingface/transformers/blob/master/CODE_OF_CONDUCT.md)项目的。
+一般来说,当提交问题时,要保持礼貌。这是一个开源项目,所以你使用的是免费软件,没有人有义务帮助你。你可以在你的问题中包含你认为合理的批评,但维护者可能会对此感到不满,从而拒绝立即提供帮助。确保你阅读了该项目的 [行为准则](https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md) 。
-### 包括您的环境信息 [[包括您的环境信息]]
+### 提供环境信息 [[提供环境信息]]
-🤗 Transformers 提供了一个实用程序来获取我们需要的关于您的环境的所有信息。只需在终端中输入以下内容:
+🤗 Transformers 提供了一个实用程序来获取有关于你环境的所有信息。只需在终端中输入以下内容:
```
transformers-cli env
```
-你应该得到这样的东西:
+将得到以下输出:
```out
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
@@ -57,29 +58,34 @@ Copy-and-paste the text below in your GitHub issue and FILL OUT the two last poi
- Using distributed or parallel set-up in script?:
```
-您还可以添加一个 **!** 在开始的时候 **transformers-cli env** 命令从笔记本单元执行它,然后在问题的开头复制并粘贴结果。
+如果你在 notebook 单元执行它,你还需要在 `transformers-cli env` 命令开始前添加一个 `!` ,然后把结果复制到你问题帖子的开头。
-### 标记人员 [[标记人员]]
+### 标记相关人员 [[标记相关人员]]
-通过输入标记人员 **@** 其次是他们的 GitHub 句柄将向他们发送通知,以便他们会看到您的问题并可能会更快地回复。适度使用它,因为如果您标记的人没有直接链接,他们可能不喜欢收到通知。如果您查看了与您的错误相关的源文件,您应该在您认为对您的问题负责的行中标记最后一个进行更改的人(您可以通过查看 GitHub 上的所述行找到此信息,选择它,然后单击“查看 git blame”)。
+使用 `@` 后跟上 GitHub 用户名来标记他人,可以向他们发送通知,这样他们就会看到你的问题来尽可能更快地回复你。如果你标记的人与你的问题没有直接联系请谨慎使用,因为他们可能不喜欢收到通知。如果你查看了与你的错误相关的源文件,就应该标记上一次对你认为造成问题的行进行修改的人(可以在 GitHub 上查看该行,选择它然后点击 “View git blame”来找到这些信息)。
-否则,模板会提供要标记的人的建议。一般来说,不要标记超过三个人!
+如果没有进行标记,那么我们的模板会自动提供要标记的人的建议。一般不要标记超过三个人。
-### 包含一格可重复的示例 [[包含一格可重复的示例]]
+### 包含一个可重复的示例 [[包含一个可重复的示例]]
-如果您已经设法创建了一个产生错误的独立示例,那么现在是包含它的时候了!键入一行包含三个反引号,后跟 **python** , 像这样:
+如果你已经创建了一个产生错误的独立示例,请键入一行包含三个反引号,后跟 `python` ,像这样:
```
-```python
+```python
```
-然后粘贴您的最小可重现示例并键入一个带有三个反引号的新行。这将确保您的代码格式正确。如果您没有设法创建可重现的示例,请以清晰的步骤解释您是如何解决问题的。如果可以,请包含指向错误所在的 Google Colab 笔记本的链接。你分享的信息越多,维护者就越有能力回复你。在所有情况下,您都应该复制并粘贴您收到的整个错误消息。如果您在 Colab 中工作,请记住,堆栈跟踪中的某些帧可能会自动折叠,因此请确保在复制之前展开它们。与代码示例一样,将该错误消息放在两行之间,并带有三个反引号,因此格式正确。
+然后粘贴你的最小可复现示例,并在新的一行上输入三个反引号。这将就会将代码格式化并且高亮以提高代码的可读性。
+
+如果你没有成功创建一个可复现的示例,清楚地描述你遇到问题的步骤。如果可以的话,包括一个你遇到错误的 Google Colab 笔记本的链接。你分享的信息越多,维护者就更有可能回复你。
+
+解决问题的线索可能在错误信息的不同位置,因此在任何情况下都应该复制并粘贴收到的整个错误消息。如果在 Google Colab 中工作,则要记住堆栈跟踪可能会自动折叠,因此请确保在复制之前将其展开。与代码示例一样,将该错误消息放在带有三个反引号的两行之间。
### 描述预期行为 [[描述预期行为]]
-用几行解释你期望得到什么,以便维护人员完全掌握问题。这部分通常很明显,所以应该用一句话来形容,但在某些情况下,您可能有很多话要说。
+用几句话描述代码正确运行时预期的效果,有助于维护者完全理解问题。预期的效果在解决错误问题的帖子中通常会很明显,可以用一句话来概括,但在某些情况下可能需要描述很多内容。
-## 然后什么? [[然后什么?]]
+## 提交?[[提交?]]
-提交您的问题后,请确保快速检查一切是否正常。如果您犯了错误,您可以编辑问题,或者如果您发现问题与您最初的想法不同,甚至可以更改其标题。如果你没有得到答案,就没有必要对人进行 ping 操作。如果几天内没有人帮助您,很可能没有人能理解您的问题。不要犹豫,回到可重现的例子。你能不能让它更短更切题?如果您在一周内没有得到答复,您可以留言温和地寻求帮助,特别是如果您已编辑问题以包含有关该问题的更多信息。
+在提交问题后,请快速检查一遍提交的帖子是否是正确的。如果出现错误,你可以重新编辑问题,如果发现问题与最初的想法不同,甚至可以更改标题。
+即使没有很快得到答案,也不要很急切地去提醒别人。如果几天内没有人提供帮助,那么很可能没有人能理解我们的问题,不要犹豫,回到可复现的示例。修改一下,让它更加简洁明了。如果在一周内没有得到答复,那么可以温和地留言寻求帮助,特别是你已经修改过,添加了更多有效信息的问题。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter8/6.mdx b/chapters/zh-CN/chapter8/6.mdx
index f33712406..4e85d8cb6 100644
--- a/chapters/zh-CN/chapter8/6.mdx
+++ b/chapters/zh-CN/chapter8/6.mdx
@@ -1,7 +1,5 @@
-# 第2部分完成! [[第2部分完成!]]
+# 第 2 部分完成![[第2部分完成!]]
-恭喜,您已经完成了课程的第二部分!我们正在积极研究第三个,所以订阅我们的[newsletter](https://huggingface.curated.co/)以确保您不会错过它的发布。
+恭喜,你已经完成了课程的第二部分!你现在应该能够处理一系列 NLP 任务,并对它们进行微调或预训练模型。不要忘记在 [Model Hub](https://huggingface.co/models) 和社区分享你的结果。
-。您现在应该能够处理一系列 NLP 任务,并对它们进行微调或预训练模型。不要忘记与社区分享您的结果[Model Hub](https://huggingface.co/models).
-
-我们迫不及待地想看看您将利用所获得的知识构建什么!
+我们迫不及待地想看到你利用所学知识创造出什么样的作品!
diff --git a/chapters/zh-CN/chapter8/7.mdx b/chapters/zh-CN/chapter8/7.mdx
index 9bfb36bc0..ffa679375 100644
--- a/chapters/zh-CN/chapter8/7.mdx
+++ b/chapters/zh-CN/chapter8/7.mdx
@@ -2,47 +2,47 @@
# 章末小测验 [[章末小测验]]
-让我们测试一下你在本章学到的东西!
+让我们测试一下你在本章学到的东西!
-### 1.应该按照什么顺序读取 Python 回溯?
+### 1. 应该按照什么顺序读取 Python 回溯?
-### 2.什么是最小可再生示例?
+### 2. 什么是最小可复现示例?
-### 3.假设你尝试运行以下代码,它抛出一个错误:
+### 3. 假设你尝试运行以下代码,它抛出一个错误:
```py
from transformers import GPT3ForSequenceClassification
@@ -55,60 +55,60 @@ from transformers import GPT3ForSequenceClassification
# ImportError: cannot import name 'GPT3ForSequenceClassification' from 'transformers' (/Users/lewtun/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/__init__.py)
```
-以下哪项可能是论坛主题标题寻求帮助的好选择?
+以下哪项可能是有助于寻求帮助的论坛帖子的标题呢?
GPT3ForSequenceClassification ?",
- explain: "不错的选择!这个标题是简洁的,并给读者一个线索,什么可能是错误的(即,gpt-3不支持在🤗 Transformers)。",
+ text: "为什么我不能导入 GPT3ForSequenceClassification ?",
+ explain: "不错的选择!这个标题是简洁的,并给读者一个线索,什么可能是错误的(即🤗 Transformers 不支持 GPT-3)。",
correct: true
},
{
- text: "Gpt-3在🤗 Transformers中支持吗?",
+ text: "🤗 Transformers 支持 GPT-3吗?",
explain: "好主意! 用问题作为主题标题是向社区传达问题的好方法。",
correct: true
}
]}
/>
-### 4.假设您试图运行 'trainer.train ()',但是遇到了一个神秘的错误,这个错误不能准确地告诉您错误来自哪里。下列哪一项是您应该首先在您的培训管道中寻找错误的地方?
+### 4. 假设你试图运行 `trainer.train ()`,但是遇到了一个错误,这个错误不能准确地告诉你错误来自哪里。下列哪一项是你应该首先在你的训练管道中寻找错误的地方?
-### 5.调试 CUDA 错误的最好方法是什么?
+### 5. 调试 CUDA 错误的最好方法是什么?
-### 6.修复 GitHub 上的问题最好的方法是什么?
+### 6. 修复 GitHub 上的问题最好的方法是什么?
-### 7.为什么对一个批处理进行过度调试通常是一种好的调试技术?
+### 7. 为什么对一个 batch 进行过拟合通常是一种好的调试技术?
-### 8.为什么在 🤗 Transformers 存储库中创建新问题时,使用 transformers-cli env 包含有关计算环境的详细信息是个好主意?
+### 8. 为什么在 🤗 Transformers 存储库中创建新问题时,使用 transformers-cli env 包含有关计算环境的详细信息是个好主意?
-* 一个抽取式**问题回答**模型,它接受上下文段落和一个任务并输出一个结果和一个概率分数(我们在[第7章](/course/chapter7/7)中讨论了这种模型):
+* 一个**抽取式问答**模型,它可以输入一段材料和一个问题,输出从这段话中找到的问题的答案和一个概率分数(我们在 [第七章](/course/chapter7/7) 中讨论过这种模型):
-* 一个**背景去除**模型,它接收图像并输出去除背景的图像:
+* 一个**背景去除**模型,它可以输入一张图像,并返回去除背景的图像:
-本章分为两个部分,包括_概念_和_应用程序_。在您了解每个部分的概念后,您将应用它来构建特定类型的演示,范围从图像分类到语音识别。当你读完本章时,你将能够用几行 Python 代码构建这些演示(以及更多!)。
+本章分为两个部分,包括 `基础概念` 和 `应用示例` 。在了解每个部分的概念后,你可以使用它来构建不同类型的演示,从图像分类到语言模型再到到语音识别。当你读完本章时,你就能够仅用几行 Python 代码构建这些演示并且可以根据需要定制和修改Web演示。
-👀 点击 Hugging Face Spaces 以查看机器学习社区构建的许多机器学习演示的最新示例!
+👀 点击 [Hugging Face Spaces](https://huggingface.co/spaces) 就可以查看机器学习社区构建最新的许多机器学习演示示例!
diff --git a/chapters/zh-CN/chapter9/2.mdx b/chapters/zh-CN/chapter9/2.mdx
index 9910c483c..4b9a44bb1 100644
--- a/chapters/zh-CN/chapter9/2.mdx
+++ b/chapters/zh-CN/chapter9/2.mdx
@@ -7,14 +7,18 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/chapter9/section2.ipynb"},
]} />
-让我们从安装 Gradio 开始吧! 由于它是一个 Python 包,只需运行:
+让我们从安装 Gradio 开始吧!与安装其他 Python 包一样,只需运行:
-`$ pip install gradio `
+```bash
+pip install gradio
+
+```
+
+Gradio 支持所有常见的平台,无论是从你最喜欢的 Python IDE、Jupyter notebook 还是 Google Colab 🤯!
-您可以在任何地方运行 Gradio,无论是从您最喜欢的 Python IDE、Jupyter notebook 还是 Google Colab 🤯!
所以无论你在哪里运行 Python,都可以安装 Gradio!
-让我们从一个简单的“Hello World”示例开始,熟悉 Gradio 语法:
+让我们从一个简单的“Hello World”示例开始熟悉 Gradio 语法:
```py
import gradio as gr
@@ -29,19 +33,19 @@ demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch()
```
-让我们看一下上面的代码:
+让我们逐步解释上面的代码:
--首先,我们定义一个名为 `greet()` 的函数。 在这种情况下,它是一个在您的名字前添加“Hello”的简单函数,但它通常可以是 *any* Python 函数。 例如,在机器学习应用程序中,此函数将*调用模型以对输入进行预测*并返回输出。
-- 然后,我们创建一个带有三个参数的 Gradio `Interface`,`fn`、`inputs` 和 `outputs`。 这些参数定义了预测函数,以及我们想要的输入和输出组件的_type_。 在我们的例子中,两个组件都是简单的文本框。
-- 然后我们在我们创建的 `Interface` 上调用 `launch()` 方法。
+- 首先,我们定义一个名为 `greet()` 的函数。在这个例子中,它是一个在你的名字前添加“Hello”的简单函数,不过它可以被替换为任意的 Python 函数。例如,在机器学习的演示中,该函数可以调用机器学习模型对输入进行预测并返回输出。
+- 然后,我们创建一个带有三个参数 `fn` 、 `inputs` 和 `outputs` 的 Gradio `Interface` 。这些参数定义了预测函数,以及我们想要的输入和输出组件的类型。在我们的这个例子中,输入和输出组件都是简单的文本框。
+- 最后我们调用创建的 `Interface` 上的 `launch()` 方法。
-如果你运行这段代码,下面的界面会自动出现在 Jupyter/Colab notebook 中,或者在浏览器中弹出 **[http://localhost:7860](http://localhost:7860/)** 如果运行 从一个脚本。
+如果你运行这段代码,下面的界面会自动出现在 Jupyter/Colab notebook 中,或者如果在一个脚本中运行,会自动在浏览器中弹出 ** [http://localhost:7860](http://localhost:7860) ** 。
-立即尝试使用您自己的姓名或其他输入来使用此 GUI!
+现在,试着使用你自己的名字或其他的输入来试一试这个 GUI!
-您会注意到,在这个 GUI 中,Gradio 自动推断输入参数的名称 (`name`)并将其应用为文本框顶部的标签。 如果你想改变它怎么办?或者,如果您想以其他方式自定义文本框? 在这种情况下,您可以实例化一个表示输入组件的类对象。
+你会注意到,在这个 GUI 中,在这个例子中,Gradio 会根据输入参数的名称(`name`)自动推断文本框顶部的标签。如果你想改变这个标签怎么办?或者,如果你想自定义这个文本框的其他属性?在这种情况下,你可以实例化一个表示输入组件的类。
看看下面的例子:
@@ -53,7 +57,7 @@ def greet(name):
return "Hello " + name
-# We instantiate the Textbox class
+# 我们将文本框类实例化
textbox = gr.Textbox(label="Type your name here:", placeholder="John Doe", lines=2)
gr.Interface(fn=greet, inputs=textbox, outputs="text").launch()
@@ -61,19 +65,18 @@ gr.Interface(fn=greet, inputs=textbox, outputs="text").launch()
-在这里,我们创建了一个带有标签、占位符和一组行数的输入文本框。您可以对输出文本框执行相同的操作,但我们现在将其保留。
-
-我们已经看到,只需几行代码,Gradio 就可以让您围绕任何具有任何类型输入或输出的函数创建一个简单的界面。 在本节中,我们从一个简单的文本框开始,但在接下来的部分中,我们将介绍其他类型的输入和输出。 现在让我们看看在 Gradio 应用程序中包含一些 NLP。
+在上面的代码中,我们创建了一个带有自定义标签、预设的占位符和固定行数的输入文本框。同时,你也可以自定义输出文本框,但我们现在先不管它。
+我们已经看到,只需几行代码,Gradio 就能让你围绕任何函数创建一个简单的界面,同时兼容各种类型的输入或输出。在本节中,我们先从一个简单的文本框开始,但在接下来的节中,我们将介绍其他类型的输入和输出。现在让我们看一下如何在 Gradio 应用中包含一些自然语言处理(NLP)模型。
-## 🤖 包括模型预测 [[🤖 包括模型预测]]
+## 🤖 使用模型预测 [[🤖 使用模型预测]]
-现在让我们构建一个简单的界面,让您可以演示像 GPT-2 这样的**文本生成**模型。
+现在让我们构建一个简单的界面,让你可以在这个界面中演示像 GPT-2 这样的**文本生成**模型。
我们将使用 🤗 Transformers 中的 `pipeline()` 函数加载我们的模型。
-如果您需要快速复习,您可以返回到 [第 1 章中的那个部分](/course/chapter1/3#text-generation)。
+如果你需要快速复习,你可以返回到 [第一章](/course/chapter1/3#text-generation) 进行回顾。
-首先,我们定义一个接受文本提示并返回文本完成的预测函数:
+首先,我们定义一个预测函数,它接收一个文本输入并返回文本生成的结果:
```py
from transformers import pipeline
@@ -86,7 +89,7 @@ def predict(prompt):
return completion
```
-此函数完成您提供的提示,您可以使用自己的输入提示运行它以查看它是如何工作的。 这是一个示例(您可能会得到不同的完成):
+此函数会不断接龙补全输入,你可以自己尝试各种输入来查看它是如何运行的。下面是一个示例(你可能会得到不同的输出结果):
```
predict("My favorite programming language is")
@@ -96,7 +99,7 @@ predict("My favorite programming language is")
>> My favorite programming language is Haskell. I really enjoyed the Haskell language, but it doesn't have all the features that can be applied to any other language. For example, all it does is compile to a byte array.
```
-现在我们有了一个生成预测的函数,我们可以像之前一样创建和启动一个“接口”:
+现在我们有了一个生成预测的函数,接下来可以像之前一样创建和启动一个 `Interface` :
```py
import gradio as gr
@@ -105,8 +108,8 @@ gr.Interface(fn=predict, inputs="text", outputs="text").launch()
```
-就是这样! 您现在可以使用此接口使用 GPT-2 模型生成文本,如下所示 🤯.
+就是这样!你现在可以在 Interface 创建的 Web 网页上使用 GPT-2 模型生成文本,如下所示 🤯:
-继续阅读以了解如何使用 Gradio 构建其他类型的演示!
\ No newline at end of file
+接下来,让我们一起了解一下如何使用 Gradio 构建其他输入输出类型的演示!
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter9/3.mdx b/chapters/zh-CN/chapter9/3.mdx
index 90ccb717b..9b4bda890 100644
--- a/chapters/zh-CN/chapter9/3.mdx
+++ b/chapters/zh-CN/chapter9/3.mdx
@@ -1,4 +1,4 @@
-# 了解接口类 [[了解接口类]]
+# 了解 Interface 类 [[了解 Interface 类]]
-在本节中,我们将仔细研究 `Interface` 类,并了解用于创建其的主要参数。
+在这一节中,我们将更详细地了解 `Interface` 类,并理解创建 Interface 时使用的主要参数的含义和设置方法。
-## 如何创建接口 [[如何创建接口]]
+## 如何创建 Interface [[如何创建 Interface]]
-您会注意到 `Interface` 类有 3 个必需参数:
+你会注意到 `Interface` 类有 3 个必需参数: `Interface(fn, inputs, outputs, ...)`
-`Interface(fn, inputs, outputs, ...)`
+这些参数的含义是:
-这些参数是:
+- `fn` :由 Gradio 接口包装的预测函数。该函数可以接受一个或多个参数并返回一个或多个值
+- `inputs` :输入组件类型。Gradio 提供了许多预构建的组件,例如 `image` 或 `mic` 。
+- `outputs` :输出组件类型。同样,Gradio 提供了许多预构建的组件,例如 `image` 或 `label` 。
- - `fn`: 由 Gradio 接口包装的预测函数。 该函数可以接受一个或多个参数并返回一个或多个值
- - `inputs`: 输入组件类型。 Gradio 提供了许多预构建的组件,例如`"image"` 或`"mic"`。
- - `outputs`: 输出组件类型。 同样,Gradio 提供了许多预构建的组件,例如 `“图像”`或“标签”`。
+可以使用组件的完整列表请参阅 [Gradio 文档](https://gradio.app/docs) 。每个预构建的组件都可以通过实例化该组件对应的类来定制。
-有关组件的完整列表,[请参阅 Gradio 文档](https://gradio.app/docs)。 每个预构建的组件都可以通过实例化该组件对应的类来定制。
+例如,正如我们在 [前一小节](/course/chapter9/2) 中看到的,你可以将一个 `Textbox(lines=7, label="Prompt")` 组件传递给 `inputs` 参数,而不是将 `"textbox"` 以字符串形式传递进去,这样就可以创建一个 7 行并包含一个标签的文本框。
-例如,正如我们在 [上一节](/course/chapter9/2) 中看到的,您可以传入一个 `Textbox(lines=7, label="Prompt")` 组件来创建一个包含 7 行和一个标签的文本框,而不是将 `"textbox"` 传递给 `inputs` 参数。
-让我们看另一个例子,这次是一个 `Audio` 组件。
+让我们看另一个例子,这个例子使用了 `Audio` 组件。
-## 一个带音频的简单示例 [[一个带音频的简单示例]]
+## 一个音频组件的简单示例
-如前所述,Gradio 提供了许多不同的输入和输出。
-因此,让我们构建一个适用于音频的“接口”。
+如前所述,Gradio 提供了许多不同的输入和输出组件。因此,让我们构建一个适用于音频的 `Interface` 。
-在这个例子中,我们将构建一个音频到音频的函数,它需要一个音频文件并简单地反转它。
+在这个例子中,我们将构建一个输入和输出都是音频的函数,它可以接收一个音频文件后将其反转并返回。
-我们将使用 `Audio` 组件作为输入。 使用 `Audio` 组件时,您可以指定希望音频的 `source` 是用户上传的文件还是用户录制声音的麦克风。 在这种情况下,让我们将其设置为“麦克风”。 只是为了好玩,我们会在我们的“音频”中添加一个标签,上面写着“在这里说话……”。
+我们将使用 `Audio` 组件作为输入。使用 `Audio` 组件时,你可以通过 `source` 指定输入音频的方式是上传的音频文件还是通过麦克风实时录制的声音。在这个例子中,让我们将其设置为“麦克风”。为了让交互更加友好,我们会在我们的 `Audio` 上添加一个标签,上面写着“Speak here.”。
-此外,我们希望将音频作为 numpy 数组接收,以便我们可以轻松地“反转”它。 所以我们将 `"type"` 设置为 `"numpy"`,它会传递输入data 作为 (`sample_rate`, `data`) 的元组进入我们的函数。
-
-我们还将使用 `Audio` 输出组件,它可以自动将具有采样率和 numpy 数据数组的元组渲染为可播放的音频文件。 在这种情况下,我们不需要进行任何自定义,因此我们将使用字符串快捷方式“audio”。
+此外,我们希望函数接收的音频是 `numpy` 数组格式,这样我们可以轻松地“反转”它。因此我们将 `"type"` 设置为 `"numpy"` ,它会将传递输入 data 转换为 `(sample_rate,data)` 的元组输入到我们的函数。
+我们还将使用 `Audio` 作为输出组件,它可以自动将根据采样率和音频数据将 numpy 数组渲染为可播放的音频文件。因此,在这个例子中不需要对输出组件进行修改,只需要传递一个 `"audio"` 字符串。
```py
import numpy as np
@@ -55,24 +52,24 @@ mic = gr.Audio(source="microphone", type="numpy", label="Speak here...")
gr.Interface(reverse_audio, mic, "audio").launch()
```
-上面的代码会产生一个类似下面的界面(如果你的浏览器没有
-询问您的麦克风权限, open the demo in a separate tab.)
+上面的代码将生成一个如下所示的界面(如果你的浏览器没有要求你授权麦克风权限,请在 新标签页中打开演示。)
-您现在应该能够录制自己的声音并听到自己在反向说话 - 怪异 👻!
+现在你可以录制你的声音并听到倒放的音频了 - 太神奇了 👻!
+
+## 处理多个输入和输出
-## 处理多个输入和输出 [[处理多个输入和输出]]
+假设我们有一个更复杂的预测函数,有多个输入和输出。在下面的示例中,我我们有一个函数,它接收一个下拉框索引、一个滑块值和一个数字,并返回一个特定音调的音频样本。
-假设我们有一个更复杂的函数,有多个输入和输出。在下面的示例中,我们有一个接受下拉索引、滑块值和数字的函数,并返回一个音调的音频样本。
+让我们看看该如何传递输入和输出组件列表,看看你能不能理解他们。
-看看我们如何传递输入和输出组件列表,看看你能不能跟上正在发生的事情。
+关键要传递:
-这里的关键是当你通过时:
* 输入组件列表,每个组件依次对应一个参数。
* 输出组件列表,每个组件对应一个返回值。
-下面的代码片段显示了三个输入组件如何与 `generate_tone()` 函数的三个参数对齐:
+下面的代码片段显示了三个输入组件如何与 `generate_tone()` 函数的三个参数一一对齐:
```py
import numpy as np
@@ -104,28 +101,25 @@ gr.Interface(
+### `launch()` 方法
-### `launch()` 方法 [[`launch()` 方法]]
+到目前为止,我们已经使用了 `launch()` 方法来启动界面,但是我们还没有真正讨论过它的作用。
-到目前为止,我们已经使用了`launch()`方法来启动界面,但是我们
-还没有真正讨论过它的作用。
+默认情况下, `launch()` 方法将在本地运行一个 Web 服务器来启动演示。如果你在 Jupyter 或 Colab Notebook 中运行代码,那么 Gradio 会将演示 GUI 嵌入到 Notebook 中,以便你可以轻松使用它。
-默认情况下,`launch()` 方法将在 Web 服务器中启动演示正在本地运行。 如果您在 Jupyter 或 Colab 笔记本中运行代码,那么Gradio 会将演示 GUI 嵌入到笔记本中,以便您轻松使用它。
+你可以通过不同的参数自定义 `launch()` 的行为:
-您可以通过不同的参数自定义 `launch()` 的行为:
-
- - `inline` - whether to display the interface inline on Python notebooks.
- - `inbrowser` - whether to automatically launch the interface in a new tab on the default browser.
- - `share` - whether to create a publicly shareable link from your computer for the interface. Kind of like a Google Drive link!
+ - `inline` —— 是否在 Python Notebook 中内联显示接口。
+ - `inbrowser` —— 是否在默认浏览器的新标签页中自动打开演示页面。
+ - `share` —— 是否在你的计算机上创建一个公开可共享的链接。有点像 Google Drive 的链接!
我们将在下一节中更详细地介绍 `share` 参数!
-## ✏️ 让我们应用它! [[✏️ 让我们应用它!]]
+## ✏️ 让我们实践一下!
-让我们构建一个界面,让您演示 **speech-recognition** 模型。
-为了让它变得有趣,我们将接受 *or* 麦克风输入或上传的文件。
+让我们构建一个演示语音识别模型的演示。为了让它变得有趣,我们将同时支持从麦克风实时录制或上传的文件。
-像往常一样,我们将使用 🤗 Transformers 中的 `pipeline()` 函数加载我们的语音识别模型。如果您需要快速复习,您可以返回 [第 1 章中的那个部分](/course/chapter1/3)。 接下来,我们将实现一个 `transcribe_audio()` 函数来处理音频并返回转录。 最后,我们将把这个函数包装在一个 `Interface` 中,其中 `Audio` 组件用于输入,只有文本用于输出。 总而言之,此应用程序的代码如下:
+像往常一样,我们将使用 🤗 Transformers 中的 `pipeline()` 函数加载我们的语音识别模型。如果你需要快速复习回顾,你可以返回第一章。接下来,我们将实现一个 `transcribe_audio()` 函数来处理音频并返回转录后的文本。最后,我们将把这个函数包装在一个 `Interface` 中,将输入的类型设置为 `Audio` 组件,将输出的类型设置为文本。汇总起来,这个演示的代码如下:
```py
from transformers import pipeline
@@ -155,13 +149,10 @@ gr.Interface(
).launch()
```
-如果您的浏览器没有要求您提供麦克风权限,open the demo in a separate tab.
+如果你的浏览器没有要求你授权麦克风权限,请在新标签页中打开演示。
+就是这样!现在你可以使用这个界面来转录音频了。请注意,在这个例子中我们将 `optional` 参数设置为了 `True` ,这样用户可以提供麦克风的实时录音或音频文件中任意一种作为输入(或两者都不提供,但这将返回错误消息)。
-就是这样! 您现在可以使用此界面来转录音频。 注意这里
-通过将 `optional` 参数作为 `True` 传递,我们允许用户
-提供麦克风或音频文件(或两者都不提供,但这会返回错误消息)。
-
-继续看看如何与他人分享您的界面!
\ No newline at end of file
+接下来,我们将学习如何与他人分享你的演示!
diff --git a/chapters/zh-CN/chapter9/4.mdx b/chapters/zh-CN/chapter9/4.mdx
index 676084ce1..e7e5a8315 100644
--- a/chapters/zh-CN/chapter9/4.mdx
+++ b/chapters/zh-CN/chapter9/4.mdx
@@ -1,5 +1,6 @@
# 与他人分享演示 [[与他人分享演示]]
+
-现在您已经构建了一个演示,您可能希望与其他人分享它。 梯度演示
-可以通过两种方式共享:使用 ***temporary share link*** 或 ***permanent hosting on Spaces***。
+现在你已经构建了一个演示,你可能希望将其分享给你的同事或者朋友一起体验一下。Gradio 演示可以通过两种方式进行分享:使用 **临时的共享链接** 或者 **在 Spaces 上永久托管**。
-我们将很快介绍这两种方法。 但在分享演示之前,您可能需要完善它 💅.
+我们将稍后快速介绍这两种方法。但在分享演示之前,你可能需要完善它 💅。
-### 打磨你的 Gradio 演示: [[打磨你的 Gradio 演示:]]
+### 打磨你的 Gradio 演示:[[打磨你的 Gradio 演示:]]
-为了给你的演示添加额外的内容,`Interface` 类支持一些可选参数:
- - `title`:你可以给你的演示一个标题,它出现在输入和输出组件的上方。
- - `description`:您可以为界面提供描述(文本、Markdown 或 HTML),显示在输入和输出组件的上方和标题下方。
- - `article`:您还可以编写扩展文章(文本、Markdown 或 HTML)来解释界面。如果提供,它会出现在输入和输出组件的_下方。
- - `theme`:不喜欢默认颜色?将主题设置为使用 `default`、`huggingface`、`grass`、`peach` 之一。您还可以添加 `dark-` 前缀,例如`dark-peach` 用于深色主题(或者只是 `dark` 用于默认的深色主题)。
- - `examples`:为了让您的演示*更易于使用*,您可以为函数提供一些示例输入。它们出现在 UI 组件下方,可用于填充界面。这些应该作为嵌套列表提供,其中外部列表由样本组成,每个内部列表对应于每个输入组件的输入组成。
- - `live`:如果你想让你的演示“活”,这意味着你的模型每次输入更改时都会重新运行,你可以设置 `live=True`。这对使用快速模型很有意义(我们将在本节末尾看到一个示例)
-使用上面的选项,我们最终得到了一个更完整的界面。 运行下面的代码,以便与 Rick and Morty 聊天:
+为了使演示使用起来更清晰, `Interface` 类支持一些可选参数:
+ - `title` :你可以给你的演示创建一个标题,它将显示在输入和输出组件的上方。
+ - `description` :你可以为界面提供描述(以文本、Markdown 或 HTML 形式),显示在输入和输出组件的上方和标题下方。
+ - `article` :你还可以编写扩展的文章(以文本、Markdown 或 HTML 形式)来解释界面。如果提供,它会出现在输入和输出组件的下方。
+ - `theme` :如果不喜欢默认颜色?你可以将主题可以设置为 `default` 、 `huggingface` 、 `grass` 、 `peach` 之一。同时你还可以添加 `dark-` 前缀,例如 `dark-peach` 用于深色主题(或者仅使用 `dark` 表示默认的深色主题)。
+ - `examples` :为了让你的演示更易于使用,你可以为函数提供一些示例输入。它们出现在 UI 组件下方,点击后可以自动填充到输入和输出。示例的格式应该是多层的列表,外层列表包含每个示例,每个内层的列表包含与每个输入组件对应的输入。
+ - `live` :如果你想使你的演示“实时”反馈,即每次输入更改时自动重新运行模型,你可以设置 `live=True` 。这对运行比较快的模型很有意义(我们将在本节末尾看到一个示例)
+
+完善上述选项后,我们就得到了一个更完整的界面。运行以下代码,你可以与 Rick 和 Morty 进行对话:
```py
title = "Ask Rick a Question"
@@ -48,37 +49,36 @@ gr.Interface(
).launch()
```
-使用上面的选项,我们最终得到了一个更完整的界面。 试试下面的界面:
+使用上面的选项,我们最终得到了一个更完整的界面。试试下面的界面:
-### 使用临时链接分享您的演示 [[使用临时链接分享您的演示]]
-现在我们已经有了机器学习模型的工作演示,让我们学习如何轻松共享指向我们界面的链接。
-通过在 `launch()` 方法中设置 `share=True` 可以轻松地公开共享接口:
+### 使用临时链接分享你的演示 [[使用临时链接分享你的演示]]
+
+现在我们已经有了机器学习模型的工作演示,接下来将学习如何轻松地通过链接将演示共享给其他人。
+通过在 `launch()` 方法中设置 `share=True` 可以就轻松地公开共享接口:
```python
gr.Interface(classify_image, "image", "label").launch(share=True)
```
-这会生成一个公开的、可共享的链接,您可以将其发送给任何人! 当您发送此链接时,另一方的用户可以在浏览器中试用该模型长达 72 小时。 因为处理发生在您的设备上(只要您的设备保持开启!),您不必担心打包任何依赖项。 如果您使用 Google Colab 笔记本工作,则始终会自动创建共享链接。 它通常看起来像这样:**XXXXX.gradio.app**。 虽然链接是通过 Gradio 链接提供的,但我们只是您本地服务器的代理,不会存储通过接口发送的任何数据。
+运行上面的代码会生成一个公开的、可共享的链接,你可以将其发送给任何人!得到此链接的用户可以在浏览器中试用该模型,时间长达 72 小时,时间长达 72 小时。因为处理发生在运行代码的设备上(设备需保持开启),所以无须打包任何依赖项。如果你使用 Google Colab 笔记本工作,则默认会自动创建共享链接。它通常看起来像这样:**XXXXX.gradio.app**。虽然链接是通过 Gradio 链接提供的,但 Gradio 只是提供了一个本地服务器的代理,不会存储通过接口发送的任何数据。
-但是请记住,这些链接是可公开访问的,这意味着任何人都可以使用您的模型进行预测! 因此,请确保不要通过您编写的函数公开任何敏感信息,或允许在您的设备上发生任何关键更改。 如果设置 `share=False`(默认值),则仅创建本地链接。
+但是请记住,这些链接是可公开访问的,这意味着任何人都可以使用你的模型进行预测!因此,请确保不要使用你编写的函数公开任何敏感信息,也不要允许其中的代码对你的设备进行任何重要更改。如果设置 `share=False` (默认值就是False),则仅创建本地链接。
-### 在 Hugging Face Spaces 上托管您的演示 [[在 Hugging Face Spaces 上托管您的演示]]
+### 在 Hugging Face Spaces 上托管你的演示 [[在 Hugging Face Spaces 上托管你的演示]]
-可以传递给同事的共享链接很酷,但是如何永久托管您的演示并让它存在于互联网上自己的“空间”中?
+可以传递给同事的共享链接很酷,但是如何在互联网上永久托管你的演示并使其具有自己的“space”呢?
-Hugging Face Spaces 提供了在互联网上永久托管 Gradio 模型的基础设施,**免费**! Spaces 允许您创建并推送到(公共或私人)存储库,
-你的 Gradio 在哪里
-接口代码将存在于 `app.py` 文件中。 [阅读分步教程](https://huggingface.co/blog/gradio-spaces) 开始使用,或观看下面的示例视频。
+Hugging Face Spaces 提供了在互联网上永久托管你的 Gradio 模型的基础设施, 并且 **完全免费** !你可以将你创建 Space 推送到(公共或私有)仓库,在其中,你的 Gradio 界面代码需要存储在一个 `app.py` 文件中。 请 [阅读分步教程](https://huggingface.co/blog/gradio-spaces) 开始使用 Hugging Face Spaces ,或观看下面的示例视频。
-## ✏️ 让我们应用它! [[✏️ 让我们应用它!]]
+## ✏️ 让我们实现它![[✏️ 让我们实现它!]]
-使用到目前为止我们在各节中学到的知识,让我们创建我们在[本章第一节](/course/chapter9/1)中看到的草图识别演示。 让我们为我们的界面添加一些自定义并设置 `share=True` 以创建一个我们可以传递的公共链接。
+现在,让我们使用到目前为止我们在各节中学到的知识,尝试创建我们在 [本章第一节](/course/chapter9/1) 中看到的草图识别演示。我们会在界面中添加一些自定义配置并设置 `share=True` 以创建一个可以与其他人共享的链接。
-我们可以从 [class_names.txt](https://huggingface.co/spaces/dawood/Sketch-Recognition/blob/main/class_names.txt) 加载标签,并从 [pytorch_model.bin](https://huggingface.co/spaces/dawood/Sketch-Recognition/blob/main/pytorch_model.bin)加载预训练的 pytorch 模型 。 通过点击链接并单击文件预览左上角的下载来下载这些文件。 让我们看看下面的代码,看看我们如何使用这些文件来加载我们的模型并创建一个`predict()`函数:
+首先,我们可以从 [class_names.txt](https://huggingface.co/spaces/dawood/Sketch-Recognition/blob/main/class_names.txt) 加载标签,并从 [pytorch_model.bin](https://huggingface.co/spaces/dawood/Sketch-Recognition/blob/main/pytorch_model.bin) 加载预训练的 pytorch 模型。通过点击链接并点击文件预览左上角的下载来下载这些文件。然后使用下面的代码加载模型并创建一个 `predict()` 函数:
```py
from pathlib import Path
import torch
@@ -116,7 +116,7 @@ def predict(im):
return {LABELS[i]: v.item() for i, v in zip(indices, values)}
```
-现在我们有了一个`predict()`函数。 下一步是定义并启动我们的渐变界面:
+现在我们有了一个 `predict()` 函数。下一步是设置并启动我们的 gradio 界面:
```py
interface = gr.Interface(
@@ -135,10 +135,8 @@ interface.launch(share=True)
-注意 `Interface` 中的 `live=True` 参数,这意味着草图演示使
-每次有人在画板上画画时的预测(没有提交按钮!)。
+注意 `Interface` 中设置了 `live=True` 参数,这意味着每当有人在画板上绘制时,草图演示都会实时进行预测(无需点击提交按钮!)。
-此外,我们还在 `launch()` 方法中设置了 `share=True` 参数。
-这将创建一个公共链接,您可以发送给任何人! 当您发送此链接时,对方的用户可以尝试草图识别模型。 重申一下,您还可以在 Hugging Face Spaces 上托管模型,这就是我们能够嵌入上面的演示的方式。
+此外,我们还在 `launch()` 方法中设置了 `share=True` 参数。这将创建一个公共链接,你可以发送给任何人!当你发送此链接时,对方可以尝试草图识别模型。重申一下,你还可以在 Hugging Face Spaces 上托管模型,这也是本教程中我们在网页上展示演示的方式。
-接下来,我们将介绍 Gradio 可用于 Hugging Face 生态系统的其他方式!
\ No newline at end of file
+接下来,我们将学习将 Gradio 与 Hugging Face 生态系统结合的其他用法!
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter9/5.mdx b/chapters/zh-CN/chapter9/5.mdx
index 77200b830..60f3ef4ce 100644
--- a/chapters/zh-CN/chapter9/5.mdx
+++ b/chapters/zh-CN/chapter9/5.mdx
@@ -1,5 +1,6 @@
# 与 Hugging Face Hub 整合 [[与 Hugging Face Hub 整合]]
+
-为了让你的生活更轻松, Gradio 直接与 Hugging Face Hub 和 Hugging Face Spaces 集成。你可以仅使用 *一行代码* 从中心和空间加载演示。
+如果觉得本地加载模型有些麻烦,为了让使用模型更轻松,Gradio 可以直接与 Hugging Face Hub 和 Hugging Face Spaces 集成。你可以仅使用一行代码从 Hub 和 Spaces 加载在线的数千个模型。
### 从 Hugging Face Hub 加载模型 [[从 Hugging Face Hub 加载模型]]
-首先, 从 Hugging Face 通过 Hub 提供的数千个模型中选择一个, 如 [第四章](/course/chapter4/2) 中所述。
-使用特殊的 `Interface.load()` 方法, 你可以传递 `"model/"` (或者, 等效的, `"huggingface/"`) 后面是模型名称。例如, 这里是为大型语言模型 [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B)构建演示的代码, 添加几个示例输入:
+首先,在 [第四章](/course/chapter4/2) 中所述的数千个模型中选择一个。
+
+使用特殊的 `Interface.load()` 方法,你可以传递 `"model/模型名称"` (或等效的 `"huggingface/模型名称"` )。例如,下面的代码是使用 [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) 构建的一个演示,它是一个大型语言模型,示例代码如下:
```py
import gradio as gr
@@ -20,32 +22,26 @@ import gradio as gr
title = "GPT-J-6B"
description = "Gradio Demo for GPT-J 6B, a transformer model trained using Ben Wang's Mesh Transformer JAX. 'GPT-J' refers to the class of model, while '6B' represents the number of trainable parameters. To use it, simply add your text, or click one of the examples to load them. Read more at the links below."
article = "GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model
"
-examples = [
- ["The tower is 324 metres (1,063 ft) tall,"],
- ["The Moon's orbit around Earth has"],
- ["The smooth Borealis basin in the Northern Hemisphere covers 40%"],
-]
gr.Interface.load(
"huggingface/EleutherAI/gpt-j-6B",
inputs=gr.Textbox(lines=5, label="Input Text"),
title=title,
description=description,
article=article,
- examples=examples,
- enable_queue=True,
).launch()
```
-上述代码将生成以下界面:
+运行上述代码将生成以下界面:
-以这种方式加载模型使用 Hugging Face 的 [Inference API](https://huggingface.co/inference-api),而不是将模型加载到内存中。这对于像 GPT-J 或 T0pp这样需要大量 RAM 的大型模型是理想的。
+以这种方式加载模型使用的是 Hugging Face 的 [Inference API](https://huggingface.co/inference-api) ,而不是将模型加载到内存中。这对于像 GPT-J 或 T0pp 这样需要大量 RAM 的大型模型是最理想的方式。
+
+### 从 Hugging Face Spaces 中加载 [[从 Hugging Face Spaces 中加载]]
-### 从 Hugging Face Spaces 空间加载 [[从 Hugging Face Spaces 空间加载]]
-要从hugs Face Hub加载任何空间并在本地重新创建它, 你可以将 `spaces/` 传递给 `Interface`, 再加上空间的名称。
+除了模型,还可以将 `spaces/space名称` 传递给 Interface,这样就可以在本地修改和运行 Hugging Face Spaces 中的任何 Space。
-还记得第 1 节中删除图像背景的演示吗? 让我们从 Hugging Face Spaces 加载它:
+还记得第 1 节中删除图像背景的演示吗?让我们从 Hugging Face Spaces 加载它:
```py
gr.Interface.load("spaces/abidlabs/remove-bg").launch()
@@ -53,7 +49,7 @@ gr.Interface.load("spaces/abidlabs/remove-bg").launch()
-从Hub或Spaces加载演示的一个很酷的地方是, 你可以通过覆盖任何参数来自定义它们。在这里, 我们添加一个标题并让它与网络摄像头一起使用:
+从Hub 或 Spaces 加载演示的一个很酷的地方是,你可以通过覆盖任何参数来进行一些自定义的调整。在这里,我们添加一个标题并将输入改为了网络摄像头:
```py
gr.Interface.load(
@@ -63,4 +59,4 @@ gr.Interface.load(
-现在我们已经探索了几种将Gradio与hugs Face Hub集成的方法, 让我们来看看 `Interface` 类的一些高级功能。这就是下一节的主题!
\ No newline at end of file
+现在我们已经探索了一些将 Gradio 与 hugs Face Hub 集成的方法,在下一节让我们来看看 `Interface` 类的一些高级功能。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter9/6.mdx b/chapters/zh-CN/chapter9/6.mdx
index 2f0a939a8..e6a030aa5 100644
--- a/chapters/zh-CN/chapter9/6.mdx
+++ b/chapters/zh-CN/chapter9/6.mdx
@@ -1,4 +1,5 @@
-# 高级接口功能 [[高级接口功能]]
+# Interface 的高级功能 [[Interface 的高级功能]]
+
-现在我们可以构建和共享一个基本接口, 让我们来探索一些更高级的特性, 如状态和解释。
+现在我们已经能够构建和共享基本界面了,让我们来探索一些 Interface 更高级的功能,比如会话状态和解释。
-### 使用状态保存数据 [[使用状态保存数据]]
+### 使用会话状态保存数据 [[使用会话状态保存数据]]
-Gradio 支持 *会话状态*, 其中数据在页面加载中的多个提交中持续存在。会话状态对于构建演示很有用, 例如, 你希望在用户与模型交互时保留数据的聊天机器人。请注意, 会话状态不会在模型的不同用户之间共享数据。
+Gradio 支持存储会话状态,以及保留多次提交的数据。会话状态对于构建聊天机器人等需要在用户与模型交互时保持数据的演示非常有用。请注意,会话状态不会在不同用户之间共享数据。
-要将数据存储在会话状态中, 你需要做三件事:
+要将数据存储在会话状态中,你需要做三件事:
-1. 向函数中传递一个 *额外的参数* , 该参数表示接口的状态。
-1. 在函数结束时, 将状态的更新值作为 *额外的返回值* 返回。
-1. 在创建`接口`时添加 'state' 输入和 'state' 输出组件。
+1. 向预测函数中传递一个额外的参数,该参数表示 Interface 此时的状态。
+2. 在预测函数结束时,将状态的更新值添加到函数的返回值中。
+3. 在创建 `Interface` 时添加 `state` 输入和 `state` 输出组件。
-请参阅下面的聊天机器人示例:
+请参考下面的聊天机器人示例:
```py
import random
@@ -53,11 +54,12 @@ iface.launch()
-请注意输出组件的状态如何在提交之间保持不变。注意: 可以给 state 参数传入一个默认值, 作为 state 的初始值。
+请注意,输出组件的每次提交都被记录了下来。
+注:我们还可以向状态参数传递一个默认值,该值会作为会话状态的初始值。
### 通过解释来理解预测 [[通过解释来理解预测]]
-大多数机器学习模型都是黑盒子, 函数的内部逻辑对终端用户是隐藏的。为了提高透明度, 我们通过简单地将 Interface 类中的解释关键字设置为默认值, 使向模型添加解释变得非常容易。这允许你的用户理解输入的哪些部分负责输出。看看下面这个简单的接口, 它显示了一个还包括解释的图像分类器:
+大多数机器学习模型都是黑盒子,函数的内部逻辑对使用的用户是隐藏的。为了提高透明度,我们设计了一个功能,使得为模型添加解释非常简单,只需将 Interface 类中的 interpretation 参数设置为 `default` 即可。这样,你的用户就可以理解输入的哪些部分对输出有影响。请看下面的简单界面示例,显示了一个带有解释功能的图像分类器:
```py
import requests
@@ -65,9 +67,9 @@ import tensorflow as tf
import gradio as gr
-inception_net = tf.keras.applications.MobileNetV2() # load the model
+inception_net = tf.keras.applications.MobileNetV2() # 加载模型
-# Download human-readable labels for ImageNet.
+# 下载 ImageNet 的可读标签
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
@@ -88,10 +90,11 @@ gr.Interface(
).launch()
```
-通过提交一个输入, 然后单击输出组件下的Interpret来测试解释功能。
+提交一个输入,单击输出组件中的“Interpret”按钮,将显示图像中的哪一部分区域对
+分类的结果产生了影响。
-除了Gradio提供的默认解释方法之外, 你还可以为 `interpretation` 参数指定 `shap`, 并设置 `num_shap` 参数。这使用基于 Shapley 的解释, 你可以在 [here](https://christophm.github.io/interpretable-ml-book/shap.html) 阅读更多信息。最后, 还可以将自己的解释函数传入 `interpretation` 参数。在Gradio的入门页面 [here](https://gradio.app/getting_started/) 中可以看到一个例子。
+除了 Gradio 提供的默认解释方法之外,你还可以在 `interpretation` 参数中指定 `shap` ,并设置 `num_shap` 参数。这将使用基于 Shapley 的解释方法,你可以在 [这里](https://christophm.github.io/interpretable-ml-book/shap.html) 阅读关于 `shap` 更多的信息。最后,还可以将自己的解释函数传入 `interpretation` 参数。在 Gradio 的 [开始页面](https://gradio.app/getting_started/) 中可以看到一个例子。
-这结束了我们对Gradio的`Interface`类的深入研究。正如我们所看到的, 这个类使用几行Python代码创建机器学习演示变得简单。然而, 有时你会想通过改变布局或链接多个预测函数来定制你的demo。如果我们能以某种方式将 `接口` 分成可定制的 "块", 那不是很好吗? 幸运的是, 有! 这是最后一部分的主题。
\ No newline at end of file
+这就是我们对 Gradio 的 `Interface` 类的深入研究。正如我们所看到的,这个类使得用几行 Python 代码创建机器学习演示变得简单。然而,有时你会想通过改变布局或将多个预测函数链接在一起来定制你的演示。如果我们能以某种方式将 `Interface` 拆分可定制的 “块”,那不是很好吗?幸运的是,我们可以做到!这是最后一节的主题。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter9/7.mdx b/chapters/zh-CN/chapter9/7.mdx
index 208a2f163..df418c83d 100644
--- a/chapters/zh-CN/chapter9/7.mdx
+++ b/chapters/zh-CN/chapter9/7.mdx
@@ -1,4 +1,4 @@
-# Gradio 块简介 [[Gradio 块简介]]
+# Gradio Blocks 简介 [[Gradio Blocks 简介]]
-在前面的部分中, 我们已经使用 `Interface` 类探索并创建了演示。在本节中, 我们将介绍我们 **新开发**的称为`gradio.Blocks`低级API。
+在之前的章节中,我们已经探索并使用 `Interface` 类创建了一些演示。在本章中,我们将介绍我们新开发的低级 API,名为 `gradio.Blocks` 。
-现在, `接口`和`块`之间有什么区别?
+那么,`Interface` 和 `Blocks` 之间有什么区别呢?
-- ⚡ `接口`: 一个高级 API, 让你只需提供输入和输出列表即可创建完整的机器学习演示。
+- ⚡ `Interface` :一个高级 API,你只需提供输入和输出列表即可创建完整的机器学习演示。
-- 🧱 `块`: :一个低级的 API, 它允许你完全控制你的应用程序的数据流和布局。您可以使用`块`(如 "构建块")构建非常复杂的多步骤应用程序。
+- 🧱 `Blocks` :一个低级的 API,你可以使用它来完全控制你的应用程序的数据流和布局。你可以使用 `Blocks` (类似于“构建的砖块”)构建非常复杂的多步骤应用程序。
-### 为什么要块 🧱? [[为什么要块 🧱?]]
+### 为什么要使用 Blocks 🧱?[[ 为什么要使用 Blocks 🧱]]
-正如我们在前几节中看到的, `Interface` 类允许你使用几行代码轻松创建成熟的机器学习demo。`Interface` API 非常易于使用, 但缺乏 `Blocks` API 提供的灵活性。例如, 你可能想要:
+正如我们在前几节中看到的,通过 `Interface` 类可以仅仅使用几行代码轻松创建成熟的机器学习 demo。 `Interface` API 非常易于使用,但灵活性不如 `Blocks` API。例如,你可能想要:
-- 将相关演示组合为一个web应用程序中的多个选项卡
-- 更改demo的布局, 例如指定输入和输出的位置
-- 具有多步骤接口, 其中一个模型的输出成为下一个模型的输入, 或者通常具有更灵活的数据流
-- 根据用户输入更改组件的属性 (例如, 下拉列表中的选项) 或其可见性
+- 将相关演示组合为一个 web 应用程序中的多个选项卡
+- 更改 demo 的布局,例如指定输入和输出的位置
+- 创建多步骤界面,其中一个模型的输出成为下一个模型的输入,或者通常具有更灵活的数据流
+- 根据用户输入更改组件的属性 (例如,下拉列表中的选项) 或隐藏/显示部分组件
-我们将在下面探讨所有这些概念。
+我们将在下面探讨所有这些需求。
-### 使用块创建简单demo [[使用块创建简单demo]]
+### 使用块创建简单 demo [[使用块创建简单demo]]
-安装 Gradio 后, 将以下代码作为 Python 脚本、Jupyter 笔记本或 Colab 笔记本运行。
+安装 Gradio 后,然后在 Python 脚本、Jupyter 笔记本或 Colab 笔记本运行下面的代码,就可以使用 Block 翻转字符串。
```py
import gradio as gr
@@ -58,33 +58,33 @@ demo.launch()
-上述简单示例介绍了块的4个基本概念:
+上面简单示例介绍了 Blocks 的 4 个基本概念:
-1. 块允许你允许你构建结合markdown、HTML、按钮和交互组件的web应用程序, 只需在一个带有gradio的Python中实例化对象。
+1. 通过在 `with gradio.Blocks` 上下文中实例化 Python 对象,Blocks 支持构建组合了 markdown、HTML、按钮和交互式组件的 Web 网页。
-🙋如果你不熟悉 Python 中的 `with` 语句, 我们建议你查看来自 Real Python 的极好的[教程](https://realpython.com/python-with-statement/)。看完后回到这里 🤗
+🙋如果你不熟悉 Python 中的 `with` 语句,我们建议你先查看优秀的 [realpython 教程](https://realpython.com/python-with-statement) 后再回来查看🤗。
-实例化组件的顺序很重要, 因为每个元素都按照创建的顺序呈现到 Web 应用程序中。(更复杂的布局在下面讨论)
+实例化组件的顺序很重要,因为每个元素都按照创建的顺序渲染到 Web 网页中。(更复杂的布局将在下面讨论)
-2. 你可以在代码中的任何位置定义常规 Python 函数, 并使用`块`在用户输入的情况下运行它们。在我们的示例中, 们有一个"翻转"输入文本的简单函数, 但你可以编写任何 Python 函数, 从简单的计算到处理机器学习模型的预测。
+2. 你可以在代码中的任何位置定义常规 Python 函数,并指定 `Blocks` 在用户输入的情况下运行它们。在我们的示例中,我们使用了一个可以“翻转”输入的文本简单的函数,这个函数可以是任意的Python 函数,从简单的计算到处理来自机器学习模型的预测等。
-3. 你可以将事件指定给任何`块`组件。这将在组件被单击、更改等情况下运行函数。当你分配一个事件时, 你传入三个参数: `fn`: 应该被调用的函数, `inputs`: 输入组件的(列表), 以及 `outputs`: 应该被调用的输出组件的(列表)。
+3. 你可以将事件指定给任何 `Blocks` 组件。这些事件可以支持在组件被单击、更改等情况下运行函数。当你分配一个事件时,你需要传入三个参数: `fn` :应该被调用的函数, `inputs` :输入组件(列表),以及 `outputs` :应该被调用的输出组件(列表)。
- 在上面的示例中, 当名为 `input` 的 `Textbox` 中的值发生变化时, 我们运行 `flip_text()` 函数。该事件读取`输入`中的值, 将其作为名称参数传递给 `flip_text()`, 然后它返回一个值, 该值被分配给我们的第二个名为 `output` 的 `Textbox`。
+ 在上面的示例中,当名为 `input` 的 `Textbox` 中的值发生变化时,会自动触发事件运行 `flip_text()` 函数。该事件读取第一个名为 `input` 的 `Textbox` 中的值,将其作为参数传递给 `flip_text()` ,然后 `flip_text()` 会返回一个值,该值会被分配给我们的第二个名为 `output` 的 `Textbox` 。
- 要查看每个组件支持的事件列表, 请参阅 Gradio [文档](https://www.gradio.app/docs/)。
+ 要查看每个组件所支持的事件列表,请参阅 Gradio [文档](https://www.gradio.app/docs) 。
-4. 块会根据你定义的事件触发器自动确定组件是否应该是交互式的 (接受用户输入)。在我们的示例中, 第一个文本框是交互式的, 因为它的值由 `flip_text()` 函数使用。第二个文本框不是交互式的, 因为它的值从不用作输入。在某些情况下, 你可能想要覆盖它, 你可以通过传递一个布尔值给组件的`交互`参数(例如 `gr.Textbox(placeholder="Flip this text", interactive=True)`)。
+4. Blocks 会根据你定义的事件触发器自动确定组件是否是交互式的 (可以接受用户输入)。在我们的示例中,第一个文本框是交互式的,因为它的值能够被 `flip_text()` 函数使用。第二个文本框不是交互式的,因为它的值从未用作输入。在某些情况下,你可能想要覆盖自动的判断,你可以给组件的 `interactive` 参数传递一个布尔值来覆盖自动的判断。(例如 `gr.Textbox(placeholder="Flip this text", interactive=True)` )。
### 自定义演示的布局 [[自定义演示的布局]]
-我们如何使用`块`来定制我们的演示的布局? 默认情况下, `块`在一列中垂直呈现创建的组件。你可以通过使用 `with gradio.Column():` 创建其他列或使用 `with gradio.Row():` 创建其他行并在这些上下文中创建组件来改变这一点。
+我们如何使用 `Blocks` 来定制我们的演示的布局?默认情况下, `Blocks` 在一列中垂直排列创建的组件。你可以通过使用 `with gradio.Column():` 创建一列或使用 `with gradio.Row():` 创建一行,并且还可以在这些列或者行的上下文中创建其他的组件来更改布局。
-你应该记住: 在 `列` 下创建的任何组件(这也是默认设置) 都将垂直布局。在 `Row` 下创建的任何组件都将水平布局, 类似于 [Web 开发中的 flexbox 模型](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Flexible_Box_Layout/Basic_Concepts_of_Flexbox)。
+你应该记住:在 `Column` 下创建的任何组件(这也是默认设置) 都将垂直排列。在 `Row` 下创建的任何组件都将水平排列,类似于 [Web 开发中的 flexbox 模型](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Flexible_Box_Layout/Basic_Concepts_of_Flexbox) 。
-最后, 你还可以使用 `with gradio.Tabs()` 上下文管理器为您的demo创建选项卡。在此上下文中, 您可以通过使用 `gradio.TabItem(name_of_tab):` 指定来创建多个选项卡。在 `gradio.TabItem(name_of_tab):` 中创建的任何组件都会出现在该选项卡中。
+最后,你还可以使用 `with gradio.Tabs()` 上下文管理器为你的 demo 创建选项卡。在做个饭上下文中,你可以通过使用 `gradio.TabItem(name_of_tab):` 指定来创建多个选项卡。在 `gradio.TabItem(name_of_tab):` 中创建的任何组件都会排列在该选项卡中。
-现在让我们在demo中添加一个 `flip_image()`函数并添加一个翻转图像的新选项卡。下面是一个带有 2 个选项卡的示例, 也使用了一个行:
+现在让我们在 demo 中添加一个 `flip_image()` 函数并添加一个翻转图像的新选项卡。下面是具有 2 个选项卡并使用了一个 Row 的示例:
```py
import numpy as np
@@ -123,22 +123,21 @@ demo.launch()
-
-你会注意到, 在这个示例中, 我们还在每个选项卡中创建了一个 `Button` 组件, 并且我们为每个按钮分配了一个点击事件,这是实际运行该函数的事件。
+你会注意到,在本示例中,我们在每个选项卡中都创建了一个 `Button` 组件,并且为每个按钮分配了一个点击事件,点击后运行事件对应的函数。
### 探索事件和状态 [[探索事件和状态]]
-正如你可以控制布局一样, `块` 可以让你对触发函数调用的事件进行细粒度控制。每个组件和许多布局都有它们支持的特定事件。
+使用 `Blocks` 不仅可以控制布局,还可以让你对触发函数调用的事件进行细粒度控制。每个组件和许多布局都有它们支持的特定事件。
-例如, `Textbox` 组件有两个事件: `change()` (当文本框内的值发生变化时), 和 `submit()` (当用户在关注文本框时按下enter键)。更复杂的组件可以有更多的事件: 例如,`Audio`组件也有单独的事件, 用于播放、清除、暂停音频文件等。请参阅文档了解每个组件支持的事件。
+例如, `Textbox` 组件有两个事件: `change()` (当文本框内的值发生变化时),和 `submit()` (当用户在文本框上输入并按下回车键时)。更复杂的组件可以有更多的事件:例如, `Audio` 组件还具有播放音频文件、清除音频文件、暂停等各种独立事件。更多的独立事件请参阅每个组件支持的事件的文档。
-你可以将事件触发器附加到这些事件中的一个、一个或多个。你可以通过在组件实例中调用事件名称作为函数来创建一个事件触发器 -- 例如 `textbox.change(...)` 或 `btn.click(...)`。如前所述, 该函数接受三个参数:
+你可以使用事件触发器将要运行的函数附加到一个、多个或全部事件中。例如,你可以通过在组件实例中调用事件名称作为函数来创建一个事件触发器 —— 例如 `textbox.change(...)` 或 `btn.click(...)` 。如前所述,该函数接受三个参数:
-- `fn`: 要运行的函数
-- `inputs`: 组件的(列表), 其值应作为函数的输入参数提供。每个组件的值按顺序映射到相应的函数参数。如果函数不带任何参数, 则此参数可以为 None。
-- `outputs`: 应根据函数返回的值更新其值的组件(列表)。每个返回值按顺序设置相应组件的值。如果函数不返回任何内容, 则此参数可以为None。
+- `fn` :要运行的函数
+- `inputs` :应作为函数的输入参数提供的组件(列表)。每个组件的值按顺序映射到相应的函数参数。如果函数不带任何参数,则此参数可以为 None。
+- `outputs` :应根据函数返回的值更新的组件(列表)。函数的每个返回值都按照顺序赋值给相应组件。如果函数不返回任何内容,则此参数可以为 None。
-你甚至可以使输入和输出组件成为同一个组件, 就像我们在这个使用 GPT 模型进行文本补全的示例中所做的那样:
+你甚至可以使输入和输出组件设置为同一个组件,就像我们在这个使用 GPT 模型进行文本补全的示例中所做的那样:
```py
import gradio as gr
@@ -147,7 +146,7 @@ api = gr.Interface.load("huggingface/EleutherAI/gpt-j-6B")
def complete_with_gpt(text):
- # Use the last 50 characters of the text as context
+ # 使用文本的最后 50 个字符作为上下文
return text[:-50] + api(text[-50:])
@@ -162,9 +161,9 @@ demo.launch()
-### 创建多步demo [[创建多步demo]]
+### 创建多步骤 demo [[创建多步骤 demo]]
-在某些情况下, 您可能需要一个 _多步骤的demo_, 其中重用一个函数的输出作为下一个函数的输入。使用 `块` 很容易做到这一点, 因为你可以使用组件作为一个事件触发器的输入, 但作为另一个事件触发器的输出。看看下面示例中的文本组件, 它的值是语音到文本模型的结果, 但也被传递到情感分析模型:
+在某些情况下,你可能需要一个多步骤演示,将其中一个函数的输出作为下一个函数的输入。使用 `Blocks` 很容易做到这一点,因为你可以使用一个组件作为一个事件触发器的输入,同时又作为另一个事件触发器的输出。看一下下面的示例,文本组件的输入是语音转文本模型的结果,同时,这个文本也被传递到情感分析模型中:
```py
from transformers import pipeline
@@ -204,9 +203,9 @@ demo.launch()
### 更新组件属性 [[更新组件属性]]
-到目前为止, 我们已经了解了如何创建事件来更新另一个组件的值。但是, 如果您想更改组件的其他属性, 例如文本框的可见性或单选按钮组中的选项, 会发生什么? 您可以通过返回组件类的 `update()` 方法而不是函数的常规返回值来做到这一点。
+到目前为止,我们已经了解了如何创建事件来更新另一个组件的值。但是,如果你想更改组件的其他属性,例如文本框的显示/隐藏或单选按钮中的选项,又该怎么办呢?你可以通过返回组件类的 `update()` 方法来代替函数的常规返回值来做到这一点。
-这很容易用一个例子来说明:
+这很容易用一个例子来说明:
```py
import gradio as gr
@@ -231,6 +230,6 @@ with gr.Blocks() as block:
block.launch()
```
-
+
-我们刚刚探索了`块`的所有核心概念! 就像 `参数一样`, 你可以创建很酷的demo, 可以通过在`launch()`方法中使用`share=True`来共享, 或者部署在[Hugging Face Spaces](https://huggingface.co/spaces)上。
\ No newline at end of file
+我们刚刚探索了 `Blocks` 的所有核心概念!就像 `Interfaces` 一样 你可以创建很酷的 demo,可以通过在 `launch()` 方法中使用 `share=True` 选项创建共享的链接,或者部署在 [Hugging Face Spaces](https://huggingface.co/spaces) 上。
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter9/8.mdx b/chapters/zh-CN/chapter9/8.mdx
index 0382eb43b..33703ed4e 100644
--- a/chapters/zh-CN/chapter9/8.mdx
+++ b/chapters/zh-CN/chapter9/8.mdx
@@ -1,19 +1,19 @@
-# Gradio,回顾! [[Gradio,回顾!]]
+# Gradio,回顾![[Gradio,回顾!]]
-关于使用 Gradio 构建酷炫的 ML 演示的章节到此结束 - 我们希望您喜欢它!回顾一下,在本章中,我们学习了:
+关于使用 Gradio 构建酷炫的 ML 演示的章节到此结束 —— 希望你会喜欢!回顾一下,在本章中,我们学习了:
- 如何使用高级 `Interface` API 创建 Gradio 演示,以及如何配置不同的输入和输出模式。
-- 通过临时链接和托管在 [Hugging Face Spaces](https://huggingface.co/spaces) 上共享 Gradio 演示的不同方式。
-- 如何将 Gradio 演示与 Hugging Face Hub 上的Model和Space集成在一起。
-- 高级功能,例如在演示中存储状态或提供身份验证。
+- 使用临时链接或者托管在 [Hugging Face Spaces](https://huggingface.co/spaces) 上共享 Gradio 演示。
+- 如何将 Gradio 演示与 Hugging Face Hub 上的 Model 和 Space 集成在一起。
+- 高级功能,例如在演示中存储状态或模型解释等高级功能。
- 如何使用 Gradio Blocks 完全控制演示的数据流和布局。
-如果您想测试您对本章所涵盖概念的理解,请查看下一节中的测验!
+如果你想测试你对本章所涵盖概念的理解,请查看下一节中的测验!
-## 下一步去哪里? [[下一步去哪里?]]
+## 下一步去哪里?[[下一步去哪里?]]
-如果您想了解有关 Gradio 的更多信息,您可以
+如果你想了解有关 Gradio 的更多信息,你可以
-- 看看 repo 中的 [Demos](https://github.com/gradio-app/gradio/tree/main/demo),那里有很多例子。
-- 请参阅 [指南](https://gradio.app/guides/) 页面,您可以在其中找到有关酷炫和高级功能的指南。
-- 查看 [文档](https://gradio.app/docs/) 页面了解详情。
+- 看看仓库中的 [Demos](https://github.com/gradio-app/gradio/tree/main/demo) ,那里有很多例子。
+- 请参阅 [指南](https://gradio.app/guides) 页面,你可以在其中找到有关酷炫和高级功能的指南。
+- 查看 [文档](https://gradio.app/docs) 页面了解详细信息。
diff --git a/chapters/zh-CN/chapter9/9.mdx b/chapters/zh-CN/chapter9/9.mdx
index 9027af836..7e46efe6f 100644
--- a/chapters/zh-CN/chapter9/9.mdx
+++ b/chapters/zh-CN/chapter9/9.mdx
@@ -9,115 +9,115 @@
classNames="absolute z-10 right-0 top-0"
/>
-让我们测试一下您在本章中学到了什么!
+让我们测试一下你在本章中学到了什么!
-### 1.你能利用Grado做什么?
+### 1. 你能使用Gradio做什么?
share = True 参数,可以生成一个共享链接发送给任何人。",
+ explain: "在启动方法中添加 share = True 参数,可以生成一个共享链接发送给任何人。",
correct: true
},
{
- text: "调试模型",
- explain: "Grado演示的一个优点是能够用真实数据测试模型,您可以实时更改并观察模型的预测变化,从而帮助您调试模型。",
+ text: "测试模型的效果",
+ explain: "Gradio的一个优点是能够用真实数据测试模型,可以实时更改输入并观察模型的预测变化,从而帮助你测试模型。",
correct: true
},
{
text: "训练你的模型",
- explain: "在你的模型被训练之后,Grado 被设计用来进行模型推理。",
+ explain: "在你的模型被训练之后,Gradio 用来进行模型推理。",
}
]}
/>
-### 2.Grado只在 PyTorch 模型上工作
+### 2. Gradio只能在 PyTorch 模型上工作
-### 3.你可以在哪里发布一个 GRadio 演示?
+### 3. 可以在哪里运行一个 Gradio 演示?
-### 4.Gdio 主要是为 NLP 模型设计的
+### 4. Gradio 主要是为 NLP 模型设计的
-### 5.下列哪些特性是由 Grado 支持的?
+### 5. 下列哪些特性是由 Gradio 支持的?
gr. Interface.load () 方法加载任何 Hugging Face 模型",
+ text: "从 HuggingFace 的模型中心或 HuggingFace Space 加载模型",
+ explain: "正确 —— 使用 gr.Interface.load () 方法可以加载任何 Hugging Face 模型",
correct: true
}
]}
/>
-### 6.下列哪一种是从 Hub 或 Spaces 加载 Huggging Face 模型的有效方法?
+### 6. 下列哪一种是从 Hub 或 Spaces 加载 Huggging Face 模型的有效方法?
-### 7.创建您的 Gradio 接口时,您必须添加以下步骤:
+### 7. 创建你的 Gradio Interface时,必须添加以下步骤:
-### 8.Gradio 库包括以下哪些组件?
+### 8. Gradio 库包括以下哪些组件?
-### 9.Gradio允许你做什么?
+### 9. 你可以使用 Gradio 做些什么?
-### 10.你可以共享一个`Blocks`演示的公共链接,并创建一个`Blocks`的演示在HuggingFace空间。
+### 10. 你可以共享一个`Blocks`演示的公共链接,并在HuggingFace space创建一个`Blocks`的演示。
 -这将安装一个非常轻量级的 🤗 Transformers。并没有安装机器学习框架(如 PyTorch 或 TensorFlow)。由于之后我们将使用该库的许多不同功能,我们建议安装开发版本,它带有几乎所有所需的依赖项:
+这将安装一个没有安装机器学习框架(如 PyTorch 或 TensorFlow)非常轻量级的 🤗 Transformers。由于之后我们将使用该库的许多不同功能,我们建议安装开发版本,它带有几乎所有所需的依赖项:
```
!pip install transformers[sentencepiece]
```
-这将需要一些时间,但当完成之后您就做好学习剩下的课程的环境准备了!
+这将需要一些时间,但当完成之后你就做好学习剩下的课程环境的全部准备了!
## 使用 Python 虚拟环境 [[使用 Python 虚拟环境]]
-如果您更喜欢使用 Python 虚拟环境,那么第一步是在您的系统上安装 Python。我们建议您按照[这个教程](https://realpython.com/installing-python/)进行配置。
+如果你更喜欢使用 Python 虚拟环境,那么第一步是在你的系统上安装 Python。我们建议你按照 [该指南](https://realpython.com/installing-python/) 进行配置。
-安装 Python 后,您应该能够在终端中运行 Python 命令。您可以先运行以下命令来检验爱装是否正确,然后再继续下一步:`python --version`。这应该会打印出您系统上现在可用的 Python 版本。
+安装 Python 后,你应该能够在终端中运行 Python 命令。你可以先运行此命令: `python --version` 来检验安装是否正确,然后再继续下一步。这应该会打印出你系统上现在可用的 Python 版本。
-在终端中运行 Python 命令(例如 `python --version`)时,您应该将运行命令的这个Python视为系统上的“默认”Python。我们建议保持这个默认的Python安装程序没有任何包,当运行某个程序的时候就为那个程序创建一个单独的运行环境 - 这样,每个应用程序都可以有自己的依赖项和包,您无需担心与其他应用程序潜在的兼容性问题。
+在终端中运行 Python 命令(例如 `python --version` )时,运行命令的这个 Python 可以视为系统上的“默认”Python。我们建议保持这个默认的 Python 安装程序没有任何包,当运行某个程序的时候就为那个程序创建一个单独的运行环境 —— 这样,每个应用程序都可以有自己的依赖项和包,你无需担心与其他应用程序潜在的兼容性问题。
-在 Python 中,这是通过 [*虚拟环境*](https://docs.python.org/3/tutorial/venv.html)实现的,虚拟环境会创建许多目录树,每个目录树都包含具有特定 Python 版本的 Python 安装以及应用程序所需的所有包。可以使用许多不同的工具来创建这样的虚拟环境,但在此我们将使用官方 Python 包:[`venv`](https://docs.python.org/3/library/venv.html#module-venv).
+在 Python 中,这是通过 [*虚拟环境*](https://docs.python.org/3/tutorial/venv.html) 实现的,虚拟环境会创建许多目录树,每个目录树都包含具有特定 Python 版本的 Python 安装以及应用程序所需的所有包。可以使用许多不同的工具来创建这样的虚拟环境,但在此我们将使用官方 Python 包: [`venv`](https://docs.python.org/3/library/venv.html#module-venv) 。
-首先,创建您希望Transformers所在的目录 - 例如,您可能希望在主目录的根目录下创建一个名为 *Transformers-course* 的新目录:
+首先,创建你希望 Transformers 所在的目录 - 例如,你可能希望在主目录的根目录下创建一个名为 `Transformers-course` 的新目录:
```
mkdir ~/transformers-course
@@ -69,7 +69,7 @@ cd ~/transformers-course
python -m venv .env
```
-您现在应该在原本为空的文件夹中看到一个名为 *.env* 的目录:
+你现在应该在原本为空的文件夹中看到一个名为 `.env` 的目录:
```
ls -a
@@ -79,17 +79,17 @@ ls -a
. .. .env
```
-您可以使用`activate`和`deactivate`命令来控制进入和退出您的虚拟环境:
+你可以使用 `activate` 和 `deactivate` 命令来控制进入和退出你的虚拟环境:
```
-# Activate the virtual environment
+# 激活虚拟环境
source .env/bin/activate
-# Deactivate the virtual environment
+# 退出虚拟环境
deactivate
```
-您可以通过运行 `which python` 命令来检测虚拟环境是否被激活:如果它指向虚拟环境,那么您已经成功激活了它!
+你可以通过运行 `which python` 命令来检测虚拟环境是否被激活:如果它指向虚拟环境,那么你已经成功激活了它!
```
which python
@@ -101,10 +101,10 @@ which python
### 安装依赖 [[安装依赖]]
-与使用 Google Colab 实例的上一节一样,您现在需要安装继续所需的包。 同样,您可以使用 `pip` 包管理器安装 🤗 Transformers 的开发版本:
+与前面使用 Google Colab 的部分一样,你现在需要安装继续学习所需的软件包。同样,你可以使用 `pip` 包管理器安装 🤗 Transformers 的开发版本:
```
pip install "transformers[sentencepiece]"
```
-您现在已准备就绪,可以开始了!
\ No newline at end of file
+你现在已准备就绪,可以开始了!
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter1/1.mdx b/chapters/zh-CN/chapter1/1.mdx
index 1300aa63b..e509d628f 100644
--- a/chapters/zh-CN/chapter1/1.mdx
+++ b/chapters/zh-CN/chapter1/1.mdx
@@ -5,12 +5,11 @@
classNames="absolute z-10 right-0 top-0"
/>
-## 欢迎来到🤗课程 [[欢迎来到🤗课程]]
+## 欢迎来到🤗 Hugging Face 课程 [[欢迎来到🤗 Hugging Face 课程]]
-这将安装一个非常轻量级的 🤗 Transformers。并没有安装机器学习框架(如 PyTorch 或 TensorFlow)。由于之后我们将使用该库的许多不同功能,我们建议安装开发版本,它带有几乎所有所需的依赖项:
+这将安装一个没有安装机器学习框架(如 PyTorch 或 TensorFlow)非常轻量级的 🤗 Transformers。由于之后我们将使用该库的许多不同功能,我们建议安装开发版本,它带有几乎所有所需的依赖项:
```
!pip install transformers[sentencepiece]
```
-这将需要一些时间,但当完成之后您就做好学习剩下的课程的环境准备了!
+这将需要一些时间,但当完成之后你就做好学习剩下的课程环境的全部准备了!
## 使用 Python 虚拟环境 [[使用 Python 虚拟环境]]
-如果您更喜欢使用 Python 虚拟环境,那么第一步是在您的系统上安装 Python。我们建议您按照[这个教程](https://realpython.com/installing-python/)进行配置。
+如果你更喜欢使用 Python 虚拟环境,那么第一步是在你的系统上安装 Python。我们建议你按照 [该指南](https://realpython.com/installing-python/) 进行配置。
-安装 Python 后,您应该能够在终端中运行 Python 命令。您可以先运行以下命令来检验爱装是否正确,然后再继续下一步:`python --version`。这应该会打印出您系统上现在可用的 Python 版本。
+安装 Python 后,你应该能够在终端中运行 Python 命令。你可以先运行此命令: `python --version` 来检验安装是否正确,然后再继续下一步。这应该会打印出你系统上现在可用的 Python 版本。
-在终端中运行 Python 命令(例如 `python --version`)时,您应该将运行命令的这个Python视为系统上的“默认”Python。我们建议保持这个默认的Python安装程序没有任何包,当运行某个程序的时候就为那个程序创建一个单独的运行环境 - 这样,每个应用程序都可以有自己的依赖项和包,您无需担心与其他应用程序潜在的兼容性问题。
+在终端中运行 Python 命令(例如 `python --version` )时,运行命令的这个 Python 可以视为系统上的“默认”Python。我们建议保持这个默认的 Python 安装程序没有任何包,当运行某个程序的时候就为那个程序创建一个单独的运行环境 —— 这样,每个应用程序都可以有自己的依赖项和包,你无需担心与其他应用程序潜在的兼容性问题。
-在 Python 中,这是通过 [*虚拟环境*](https://docs.python.org/3/tutorial/venv.html)实现的,虚拟环境会创建许多目录树,每个目录树都包含具有特定 Python 版本的 Python 安装以及应用程序所需的所有包。可以使用许多不同的工具来创建这样的虚拟环境,但在此我们将使用官方 Python 包:[`venv`](https://docs.python.org/3/library/venv.html#module-venv).
+在 Python 中,这是通过 [*虚拟环境*](https://docs.python.org/3/tutorial/venv.html) 实现的,虚拟环境会创建许多目录树,每个目录树都包含具有特定 Python 版本的 Python 安装以及应用程序所需的所有包。可以使用许多不同的工具来创建这样的虚拟环境,但在此我们将使用官方 Python 包: [`venv`](https://docs.python.org/3/library/venv.html#module-venv) 。
-首先,创建您希望Transformers所在的目录 - 例如,您可能希望在主目录的根目录下创建一个名为 *Transformers-course* 的新目录:
+首先,创建你希望 Transformers 所在的目录 - 例如,你可能希望在主目录的根目录下创建一个名为 `Transformers-course` 的新目录:
```
mkdir ~/transformers-course
@@ -69,7 +69,7 @@ cd ~/transformers-course
python -m venv .env
```
-您现在应该在原本为空的文件夹中看到一个名为 *.env* 的目录:
+你现在应该在原本为空的文件夹中看到一个名为 `.env` 的目录:
```
ls -a
@@ -79,17 +79,17 @@ ls -a
. .. .env
```
-您可以使用`activate`和`deactivate`命令来控制进入和退出您的虚拟环境:
+你可以使用 `activate` 和 `deactivate` 命令来控制进入和退出你的虚拟环境:
```
-# Activate the virtual environment
+# 激活虚拟环境
source .env/bin/activate
-# Deactivate the virtual environment
+# 退出虚拟环境
deactivate
```
-您可以通过运行 `which python` 命令来检测虚拟环境是否被激活:如果它指向虚拟环境,那么您已经成功激活了它!
+你可以通过运行 `which python` 命令来检测虚拟环境是否被激活:如果它指向虚拟环境,那么你已经成功激活了它!
```
which python
@@ -101,10 +101,10 @@ which python
### 安装依赖 [[安装依赖]]
-与使用 Google Colab 实例的上一节一样,您现在需要安装继续所需的包。 同样,您可以使用 `pip` 包管理器安装 🤗 Transformers 的开发版本:
+与前面使用 Google Colab 的部分一样,你现在需要安装继续学习所需的软件包。同样,你可以使用 `pip` 包管理器安装 🤗 Transformers 的开发版本:
```
pip install "transformers[sentencepiece]"
```
-您现在已准备就绪,可以开始了!
\ No newline at end of file
+你现在已准备就绪,可以开始了!
\ No newline at end of file
diff --git a/chapters/zh-CN/chapter1/1.mdx b/chapters/zh-CN/chapter1/1.mdx
index 1300aa63b..e509d628f 100644
--- a/chapters/zh-CN/chapter1/1.mdx
+++ b/chapters/zh-CN/chapter1/1.mdx
@@ -5,12 +5,11 @@
classNames="absolute z-10 right-0 top-0"
/>
-## 欢迎来到🤗课程 [[欢迎来到🤗课程]]
+## 欢迎来到🤗 Hugging Face 课程 [[欢迎来到🤗 Hugging Face 课程]]
 -- 第 1 章到第 4 章介绍了 🤗 Transformers 库的主要概念。在本课程的这一部分结束时,您将熟悉 Transformer 模型的工作原理,并将了解如何使用 [Hugging Face Hub](https://huggingface.co/models) 中的模型,在数据集上对其进行微调,并在 Hub 上分享您的结果。
-- 第 5 章到第 8 章在深入研究经典 NLP 任务之前,教授 🤗 Datasets和 🤗 Tokenizers的基础知识。在本部分结束时,您将能够自己解决最常见的 NLP 问题。
-- 第 9 章到第 12 章更加深入,探讨了如何使用 Transformer 模型处理语音处理和计算机视觉中的任务。在此过程中,您将学习如何构建和分享模型,并针对生产环境对其进行优化。在这部分结束时,您将准备好将🤗 Transformers 应用于(几乎)任何机器学习问题!
+- 第 1 章到第 4 章介绍了 🤗 Transformers 库的主要概念。在本课程的这一部分结束时,你将了解 Transformer 模型的工作原理,并将了解如何使用 [Hugging Face Hub](https://huggingface.co/models) 中的模型,在数据集上对其进行微调,并在 Hub 上分享你的结果。
+- 第 5 章到第 8 章在深入研究经典 NLP 任务之前,教授 🤗 Datasets 和 🤗 Tokenizers 的基础知识。在本部分结束时,你将能够自己解决最常见的 NLP 问题。
+- 第 9 章到第 12 章将超越 NLP,探讨如何使用 Transformer 模型解决语音处理和计算机视觉任务。在此过程中,你将学习如何构建和分享模型的演示,并将它们优化为生产环境。完成这部分课程后,你将准备好将 🤗 Transformers 应用于(几乎)任何机器学习问题!
这个课程:
* 需要良好的 Python 知识
-* 最好先学习深度学习入门课程,例如[DeepLearning.AI](https://www.deeplearning.ai/) 提供的 [fast.ai实用深度学习教程](https://course.fast.ai/)
-* 不需要事先具备 [PyTorch](https://pytorch.org/) 或 [TensorFlow](https://www.tensorflow.org/) 知识,虽然熟悉其中任何一个都会对huggingface的学习有所帮助
+* 在完成入门深度学习课程后效果更佳,例如 [DeepLearning.AI](https://www.deeplearning.ai/) 提供的 [fast.ai实用深度学习教程](https://course.fast.ai/)
+* 不需要事先具备 [PyTorch](https://pytorch.org/) 或 [TensorFlow](https://www.tensorflow.org/) 知识,虽然熟悉其中任何一个都会对学习有所帮助
-完成本课程后,我们建议您查看 [DeepLearning.AI的自然语言处理系列课程](https://www.coursera.org/specializations/natural-language-processing?utm_source=deeplearning-ai&utm_medium=institutions&utm_campaign=20211011-nlp-2-hugging_face-page-nlp-refresh),其中涵盖了广泛的传统 NLP 模型,如朴素贝叶斯和 LSTM,这些模型非常值得了解!
+完成本课程后,我们建议你查看 [DeepLearning.AI的自然语言处理系列课程](https://www.coursera.org/specializations/natural-language-processing?utm_source=deeplearning-ai&utm_medium=institutions&utm_campaign=20211011-nlp-2-hugging_face-page-nlp-refresh) ,该课程涵盖了诸如朴素贝叶斯和 LSTM 等传统 NLP 模型的广泛内容,非常值得了解!
## 我们是谁?[[我们是谁?]]
关于作者:
-[**Abubakar Abid**](https://huggingface.co/abidlabs) 在斯坦福大学获得应用机器学习博士学位。 在攻读博士学位期间,他创立了 [Gradio](https://github.com/gradio-app/gradio),这是一个开源 Python 库,已用于构建超过 600,000 个机器学习演示。 Gradio 被 Hugging Face 收购,Abubakar 现在是该公司的机器学习团队负责人。
+ [**Abubakar Abid**](https://huggingface.co/abidlabs) 在斯坦福大学获得应用机器学习博士学位。在攻读博士学位期间,他创立了 [Gradio](https://github.com/gradio-app/gradio) ,这是一个开源 Python 库,已用于构建超过 600,000 个机器学习演示。Gradio 被 Hugging Face 收购,Abubakar 现在在 Hugging Face 担任机器学习团队负责人。
-[**Matthew Carrigan**](https://huggingface.co/Rocketknight1) 是 Hugging Face 的机器学习工程师。他住在爱尔兰都柏林,之前在 Parse.ly 担任机器学习工程师,在此之前,他在Trinity College Dublin担任博士后研究员。他不相信我们会通过扩展现有架构来实现 AGI,但无论如何都对机器人充满希望。
+ [**Matthew Carrigan**](https://huggingface.co/Rocketknight1) 是 Hugging Face 的机器学习工程师。他住在爱尔兰都柏林,之前在 Parse.ly 担任机器学习工程师,在此之前,他在 Trinity College Dublin 担任博士后研究员。他不相信我们会通过扩展现有架构来实现 AGI,但仍然对机器人永生抱有很高的期望。
-[**Lysandre Debut**](https://huggingface.co/lysandre) 是 Hugging Face 的机器学习工程师,从早期的开发阶段就一直致力于 🤗 Transformers 库。他的目标是通过使用非常简单的 API 开发工具,让每个人都可以使用 NLP。
+ [**Lysandre Debut**](https://huggingface.co/lysandre) 是 Hugging Face 的机器学习工程师,从早期的开发阶段就一直致力于 🤗 Transformers 库。他的目标是通过使用非常简单的 API 开发工具,让 NLP 对每个人都变得易用。
-[**Sylvain Gugger**](https://huggingface.co/sgugger) 是 Hugging Face 的一名研究工程师,也是 🤗Transformers库的核心维护者之一。此前,他是 fast.ai 的一名研究科学家,他与Jeremy Howard 共同编写了[Deep Learning for Coders with fastai and Py Torch](https://learning.oreilly.com/library/view/deep-learning-for/9781492045519/)。他的主要研究重点是通过设计和改进允许模型在有限资源上快速训练的技术,使深度学习更容易普及。
+ [**Sylvain Gugger**](https://huggingface.co/sgugger) 是 Hugging Face 的一名研究工程师,也是 🤗Transformers 库的核心维护者之一。此前,他是 fast.ai 的一名研究科学家,他与 Jeremy Howard 共同编写了 [Deep Learning for Coders with fastai and Py Torch](https://learning.oreilly.com/library/view/deep-learning-for/9781492045519/) 。他的研究重点是通过设计和改进技术,使模型在有限资源上进行快速训练,使深度学习更容易普及。
-[**Dawood Khan**](https://huggingface.co/dawoodkhan82) 是 Hugging Face 的机器学习工程师。 他来自纽约,毕业于纽约大学计算机科学专业。 在担任 iOS 工程师几年后,Dawood 辞职并与其他联合创始人一起创办了 Gradio。 Gradio 最终被 Hugging Face 收购。
+ [**Dawood Khan**](https://huggingface.co/dawoodkhan82) 是 Hugging Face 的机器学习工程师。他来自纽约,毕业于纽约大学计算机科学专业。在担任 iOS 工程师几年后,Dawood 辞职并与其他联合创始人一起创办了 Gradio。Gradio 最终被 Hugging Face 收购。
-[**Merve Noyan**](https://huggingface.co/sgugger) 是 Hugging Face 的开发者倡导者,致力于开发工具并围绕它们构建内容,以使每个人的机器学习平民化。
+ [**Merve Noyan**](https://huggingface.co/sgugger) 是 Hugging Face 的开发者倡导者,致力于开发工具并围绕它们构建内容,以使每个人都可以使用机器学习。
-[**Lucile Saulnier**](https://huggingface.co/SaulLu) 是 Hugging Face 的机器学习工程师,负责开发和支持开源工具的使用。她还积极参与了自然语言处理领域的许多研究项目,例如协作训练和 BigScience。
+ [**Lucile Saulnier**](https://huggingface.co/SaulLu) 是 Hugging Face 的机器学习工程师,负责开发和支持开源工具的使用。她还积极参与了自然语言处理领域的许多研究项目,例如协作训练和 BigScience。
-[**Lewis Tunstall**](https://huggingface.co/lewtun) 是 Hugging Face 的机器学习工程师,专注于开发开源工具并使更广泛的社区可以使用它们。他也是即将出版的一本书[O’Reilly book on Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/)的作者之一。
+ [**Lewis Tunstall**](https://huggingface.co/lewtun) 是 Hugging Face 的机器学习工程师,专注于开发开源工具并使更广泛的社区可以使用它们。他也是即将出版的一本书 [O’Reilly book on Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) 的作者之一。
-[**Leandro von Werra**](https://huggingface.co/lvwerra) 是 Hugging Face 开源团队的机器学习工程师,也是即将出版的一本书[O’Reilly book on Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/)的作者之一。他拥有多年的行业经验,通过在整个机器学习堆栈中工作,将 NLP 项目投入生产。
+ [**Leandro von Werra**](https://huggingface.co/lvwerra) 是 Hugging Face 开源团队的机器学习工程师,也是即将出版的一本书 [O’Reilly book on Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) 的作者之一。他拥有多年的行业经验,并在整个机器学习技术栈上进行了工作。
## FAQ[[faq]]
-这里有一些经常被提到的问题:
+这里有一些经常被提到的问题:
- **参加本课程是否会获得认证?**
-目前,我们没有获得此课程的任何认证。 但是,我们正在为 Hugging Face 生态系统制定认证计划——敬请期待!
+目前我们还没有为这门课程提供认证。然而,我们正在为 Hugging Face 生态系统制定认证计划——敬请期待!
- **我应该在这门课程上花多少时间?**
-本课程的每一章都设计为在 1 周内完成,每周大约需要 6-8 小时的学习时间。 但是,您可以花尽可能多的时间来完成课程。
+本课程的每一章都设计为在 1 周内完成,每周大约需要 6-8 小时的学习时间。但是,但你可以根据自己的需要随意安排学习时间。
- **如果我有问题,我可以在哪里提问?**
-如果您对课程的任何部分有疑问,只需单击页面顶部的“*提问*”横幅,系统就会自动重定向到 [Hugging Face 论坛](https:// discuss.huggingface.co/):
+如果你对课程的任何部分有疑问,只需单击页面顶部的“*提问*”横幅,系统就会自动跳转到 [Hugging Face 论坛](https:// discuss.huggingface.co/) :
-- 第 1 章到第 4 章介绍了 🤗 Transformers 库的主要概念。在本课程的这一部分结束时,您将熟悉 Transformer 模型的工作原理,并将了解如何使用 [Hugging Face Hub](https://huggingface.co/models) 中的模型,在数据集上对其进行微调,并在 Hub 上分享您的结果。
-- 第 5 章到第 8 章在深入研究经典 NLP 任务之前,教授 🤗 Datasets和 🤗 Tokenizers的基础知识。在本部分结束时,您将能够自己解决最常见的 NLP 问题。
-- 第 9 章到第 12 章更加深入,探讨了如何使用 Transformer 模型处理语音处理和计算机视觉中的任务。在此过程中,您将学习如何构建和分享模型,并针对生产环境对其进行优化。在这部分结束时,您将准备好将🤗 Transformers 应用于(几乎)任何机器学习问题!
+- 第 1 章到第 4 章介绍了 🤗 Transformers 库的主要概念。在本课程的这一部分结束时,你将了解 Transformer 模型的工作原理,并将了解如何使用 [Hugging Face Hub](https://huggingface.co/models) 中的模型,在数据集上对其进行微调,并在 Hub 上分享你的结果。
+- 第 5 章到第 8 章在深入研究经典 NLP 任务之前,教授 🤗 Datasets 和 🤗 Tokenizers 的基础知识。在本部分结束时,你将能够自己解决最常见的 NLP 问题。
+- 第 9 章到第 12 章将超越 NLP,探讨如何使用 Transformer 模型解决语音处理和计算机视觉任务。在此过程中,你将学习如何构建和分享模型的演示,并将它们优化为生产环境。完成这部分课程后,你将准备好将 🤗 Transformers 应用于(几乎)任何机器学习问题!
这个课程:
* 需要良好的 Python 知识
-* 最好先学习深度学习入门课程,例如[DeepLearning.AI](https://www.deeplearning.ai/) 提供的 [fast.ai实用深度学习教程](https://course.fast.ai/)
-* 不需要事先具备 [PyTorch](https://pytorch.org/) 或 [TensorFlow](https://www.tensorflow.org/) 知识,虽然熟悉其中任何一个都会对huggingface的学习有所帮助
+* 在完成入门深度学习课程后效果更佳,例如 [DeepLearning.AI](https://www.deeplearning.ai/) 提供的 [fast.ai实用深度学习教程](https://course.fast.ai/)
+* 不需要事先具备 [PyTorch](https://pytorch.org/) 或 [TensorFlow](https://www.tensorflow.org/) 知识,虽然熟悉其中任何一个都会对学习有所帮助
-完成本课程后,我们建议您查看 [DeepLearning.AI的自然语言处理系列课程](https://www.coursera.org/specializations/natural-language-processing?utm_source=deeplearning-ai&utm_medium=institutions&utm_campaign=20211011-nlp-2-hugging_face-page-nlp-refresh),其中涵盖了广泛的传统 NLP 模型,如朴素贝叶斯和 LSTM,这些模型非常值得了解!
+完成本课程后,我们建议你查看 [DeepLearning.AI的自然语言处理系列课程](https://www.coursera.org/specializations/natural-language-processing?utm_source=deeplearning-ai&utm_medium=institutions&utm_campaign=20211011-nlp-2-hugging_face-page-nlp-refresh) ,该课程涵盖了诸如朴素贝叶斯和 LSTM 等传统 NLP 模型的广泛内容,非常值得了解!
## 我们是谁?[[我们是谁?]]
关于作者:
-[**Abubakar Abid**](https://huggingface.co/abidlabs) 在斯坦福大学获得应用机器学习博士学位。 在攻读博士学位期间,他创立了 [Gradio](https://github.com/gradio-app/gradio),这是一个开源 Python 库,已用于构建超过 600,000 个机器学习演示。 Gradio 被 Hugging Face 收购,Abubakar 现在是该公司的机器学习团队负责人。
+ [**Abubakar Abid**](https://huggingface.co/abidlabs) 在斯坦福大学获得应用机器学习博士学位。在攻读博士学位期间,他创立了 [Gradio](https://github.com/gradio-app/gradio) ,这是一个开源 Python 库,已用于构建超过 600,000 个机器学习演示。Gradio 被 Hugging Face 收购,Abubakar 现在在 Hugging Face 担任机器学习团队负责人。
-[**Matthew Carrigan**](https://huggingface.co/Rocketknight1) 是 Hugging Face 的机器学习工程师。他住在爱尔兰都柏林,之前在 Parse.ly 担任机器学习工程师,在此之前,他在Trinity College Dublin担任博士后研究员。他不相信我们会通过扩展现有架构来实现 AGI,但无论如何都对机器人充满希望。
+ [**Matthew Carrigan**](https://huggingface.co/Rocketknight1) 是 Hugging Face 的机器学习工程师。他住在爱尔兰都柏林,之前在 Parse.ly 担任机器学习工程师,在此之前,他在 Trinity College Dublin 担任博士后研究员。他不相信我们会通过扩展现有架构来实现 AGI,但仍然对机器人永生抱有很高的期望。
-[**Lysandre Debut**](https://huggingface.co/lysandre) 是 Hugging Face 的机器学习工程师,从早期的开发阶段就一直致力于 🤗 Transformers 库。他的目标是通过使用非常简单的 API 开发工具,让每个人都可以使用 NLP。
+ [**Lysandre Debut**](https://huggingface.co/lysandre) 是 Hugging Face 的机器学习工程师,从早期的开发阶段就一直致力于 🤗 Transformers 库。他的目标是通过使用非常简单的 API 开发工具,让 NLP 对每个人都变得易用。
-[**Sylvain Gugger**](https://huggingface.co/sgugger) 是 Hugging Face 的一名研究工程师,也是 🤗Transformers库的核心维护者之一。此前,他是 fast.ai 的一名研究科学家,他与Jeremy Howard 共同编写了[Deep Learning for Coders with fastai and Py Torch](https://learning.oreilly.com/library/view/deep-learning-for/9781492045519/)。他的主要研究重点是通过设计和改进允许模型在有限资源上快速训练的技术,使深度学习更容易普及。
+ [**Sylvain Gugger**](https://huggingface.co/sgugger) 是 Hugging Face 的一名研究工程师,也是 🤗Transformers 库的核心维护者之一。此前,他是 fast.ai 的一名研究科学家,他与 Jeremy Howard 共同编写了 [Deep Learning for Coders with fastai and Py Torch](https://learning.oreilly.com/library/view/deep-learning-for/9781492045519/) 。他的研究重点是通过设计和改进技术,使模型在有限资源上进行快速训练,使深度学习更容易普及。
-[**Dawood Khan**](https://huggingface.co/dawoodkhan82) 是 Hugging Face 的机器学习工程师。 他来自纽约,毕业于纽约大学计算机科学专业。 在担任 iOS 工程师几年后,Dawood 辞职并与其他联合创始人一起创办了 Gradio。 Gradio 最终被 Hugging Face 收购。
+ [**Dawood Khan**](https://huggingface.co/dawoodkhan82) 是 Hugging Face 的机器学习工程师。他来自纽约,毕业于纽约大学计算机科学专业。在担任 iOS 工程师几年后,Dawood 辞职并与其他联合创始人一起创办了 Gradio。Gradio 最终被 Hugging Face 收购。
-[**Merve Noyan**](https://huggingface.co/sgugger) 是 Hugging Face 的开发者倡导者,致力于开发工具并围绕它们构建内容,以使每个人的机器学习平民化。
+ [**Merve Noyan**](https://huggingface.co/sgugger) 是 Hugging Face 的开发者倡导者,致力于开发工具并围绕它们构建内容,以使每个人都可以使用机器学习。
-[**Lucile Saulnier**](https://huggingface.co/SaulLu) 是 Hugging Face 的机器学习工程师,负责开发和支持开源工具的使用。她还积极参与了自然语言处理领域的许多研究项目,例如协作训练和 BigScience。
+ [**Lucile Saulnier**](https://huggingface.co/SaulLu) 是 Hugging Face 的机器学习工程师,负责开发和支持开源工具的使用。她还积极参与了自然语言处理领域的许多研究项目,例如协作训练和 BigScience。
-[**Lewis Tunstall**](https://huggingface.co/lewtun) 是 Hugging Face 的机器学习工程师,专注于开发开源工具并使更广泛的社区可以使用它们。他也是即将出版的一本书[O’Reilly book on Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/)的作者之一。
+ [**Lewis Tunstall**](https://huggingface.co/lewtun) 是 Hugging Face 的机器学习工程师,专注于开发开源工具并使更广泛的社区可以使用它们。他也是即将出版的一本书 [O’Reilly book on Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) 的作者之一。
-[**Leandro von Werra**](https://huggingface.co/lvwerra) 是 Hugging Face 开源团队的机器学习工程师,也是即将出版的一本书[O’Reilly book on Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/)的作者之一。他拥有多年的行业经验,通过在整个机器学习堆栈中工作,将 NLP 项目投入生产。
+ [**Leandro von Werra**](https://huggingface.co/lvwerra) 是 Hugging Face 开源团队的机器学习工程师,也是即将出版的一本书 [O’Reilly book on Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) 的作者之一。他拥有多年的行业经验,并在整个机器学习技术栈上进行了工作。
## FAQ[[faq]]
-这里有一些经常被提到的问题:
+这里有一些经常被提到的问题:
- **参加本课程是否会获得认证?**
-目前,我们没有获得此课程的任何认证。 但是,我们正在为 Hugging Face 生态系统制定认证计划——敬请期待!
+目前我们还没有为这门课程提供认证。然而,我们正在为 Hugging Face 生态系统制定认证计划——敬请期待!
- **我应该在这门课程上花多少时间?**
-本课程的每一章都设计为在 1 周内完成,每周大约需要 6-8 小时的学习时间。 但是,您可以花尽可能多的时间来完成课程。
+本课程的每一章都设计为在 1 周内完成,每周大约需要 6-8 小时的学习时间。但是,但你可以根据自己的需要随意安排学习时间。
- **如果我有问题,我可以在哪里提问?**
-如果您对课程的任何部分有疑问,只需单击页面顶部的“*提问*”横幅,系统就会自动重定向到 [Hugging Face 论坛](https:// discuss.huggingface.co/):
+如果你对课程的任何部分有疑问,只需单击页面顶部的“*提问*”横幅,系统就会自动跳转到 [Hugging Face 论坛](https:// discuss.huggingface.co/) :
 -请注意,如果您想在完成课程后进行更多练习,论坛上还提供了[项目灵感](https://discuss.huggingface.co/c/course/course-event/25) 列表。
+请注意,如果你想在完成课程后进行更多练习,论坛上还提供了 [项目灵感](https://discuss.huggingface.co/c/course/course-event/25) 列表,如果你希望在完成课程后进行更多实践,可以参考这些想法。
- **我在哪里可以获得课程的代码?**
对于每个部分,单击页面顶部的横幅可以在 Google Colab 或 Amazon SageMaker Studio Lab 中运行代码:
-
-请注意,如果您想在完成课程后进行更多练习,论坛上还提供了[项目灵感](https://discuss.huggingface.co/c/course/course-event/25) 列表。
+请注意,如果你想在完成课程后进行更多练习,论坛上还提供了 [项目灵感](https://discuss.huggingface.co/c/course/course-event/25) 列表,如果你希望在完成课程后进行更多实践,可以参考这些想法。
- **我在哪里可以获得课程的代码?**
对于每个部分,单击页面顶部的横幅可以在 Google Colab 或 Amazon SageMaker Studio Lab 中运行代码:
- +
+ -[🤗 Transformers 库](https://github.com/huggingface/transformers)提供了创建和使用这些共享模型的功能。[模型中心(hub)](https://huggingface.co/models)包含数千个任何人都可以下载和使用的预训练模型。您还可以将自己的模型上传到 Hub!
+[🤗 Transformers 库](https://github.com/huggingface/transformers) 提供了创建和使用这些共享模型的功能。 [Hugging Face 模型中心(以下简称“Hub”)](https://huggingface.co/models) 包含数千个任何人都可以下载和使用的预训练模型。你还可以将自己的模型上传到 Hub!
-[🤗 Transformers 库](https://github.com/huggingface/transformers)提供了创建和使用这些共享模型的功能。[模型中心(hub)](https://huggingface.co/models)包含数千个任何人都可以下载和使用的预训练模型。您还可以将自己的模型上传到 Hub!
+[🤗 Transformers 库](https://github.com/huggingface/transformers) 提供了创建和使用这些共享模型的功能。 [Hugging Face 模型中心(以下简称“Hub”)](https://huggingface.co/models) 包含数千个任何人都可以下载和使用的预训练模型。你还可以将自己的模型上传到 Hub!






 @@ -96,13 +96,13 @@ Transformers是由一个团队领导的(非常大的)模型项目,该团
这种预训练通常是在非常大量的数据上进行的。因此,它需要大量的数据,而且训练可能需要几周的时间。
-另一方面,*微调*是在模型经过预训练后完成的训练。要执行微调,首先需要获取一个经过预训练的语言模型,然后使用特定于任务的数据集执行额外的训练。等等,为什么不直接为最后的任务而训练呢?有几个原因:
+另一方面,微调(Fine-tuning)是在模型经过预训练后完成的训练。要执行微调,首先需要获取一个经过预训练的语言模型,然后使用特定于任务的数据集进行额外的训练。等等,为什么不直接为实际的最终任务而训练模型呢?有几个原因:
-* 预训练模型已经在与微调数据集有一些相似之处的数据集上进行了训练。因此,微调过程能够利用模型在预训练期间获得的知识(例如,对于NLP问题,预训练模型将对您在任务中使用的语言有某种统计规律上的理解)。
+* 预训练模型已经在与微调数据集有一些相似之处的数据集上进行了训练。因此,微调过程能够利用模型在预训练期间获得的知识(例如,对于 NLP 问题,预训练模型将对你在任务中使用的语言有某种统计规律上的理解)。
* 由于预训练模型已经在大量数据上进行了训练,因此微调需要更少的数据来获得不错的结果。
* 出于同样的原因,获得好结果所需的时间和资源要少得多
-例如,可以利用英语的预训练过的模型,然后在arXiv语料库上对其进行微调,从而形成一个基于科学/研究的模型。微调只需要有限的数据量:预训练模型获得的知识可以“迁移”到目标任务上,因此被称为*迁移学习*。
+例如,可以利用英语的预训练过的模型,然后在 arXiv 语料库上对其进行微调,从而形成一个基于科学研究的模型。微调只需要有限的数据量:预训练模型获得的知识可以“迁移”到目标任务上,因此被称为迁移学习(transfer learning)。
@@ -96,13 +96,13 @@ Transformers是由一个团队领导的(非常大的)模型项目,该团
这种预训练通常是在非常大量的数据上进行的。因此,它需要大量的数据,而且训练可能需要几周的时间。
-另一方面,*微调*是在模型经过预训练后完成的训练。要执行微调,首先需要获取一个经过预训练的语言模型,然后使用特定于任务的数据集执行额外的训练。等等,为什么不直接为最后的任务而训练呢?有几个原因:
+另一方面,微调(Fine-tuning)是在模型经过预训练后完成的训练。要执行微调,首先需要获取一个经过预训练的语言模型,然后使用特定于任务的数据集进行额外的训练。等等,为什么不直接为实际的最终任务而训练模型呢?有几个原因:
-* 预训练模型已经在与微调数据集有一些相似之处的数据集上进行了训练。因此,微调过程能够利用模型在预训练期间获得的知识(例如,对于NLP问题,预训练模型将对您在任务中使用的语言有某种统计规律上的理解)。
+* 预训练模型已经在与微调数据集有一些相似之处的数据集上进行了训练。因此,微调过程能够利用模型在预训练期间获得的知识(例如,对于 NLP 问题,预训练模型将对你在任务中使用的语言有某种统计规律上的理解)。
* 由于预训练模型已经在大量数据上进行了训练,因此微调需要更少的数据来获得不错的结果。
* 出于同样的原因,获得好结果所需的时间和资源要少得多
-例如,可以利用英语的预训练过的模型,然后在arXiv语料库上对其进行微调,从而形成一个基于科学/研究的模型。微调只需要有限的数据量:预训练模型获得的知识可以“迁移”到目标任务上,因此被称为*迁移学习*。
+例如,可以利用英语的预训练过的模型,然后在 arXiv 语料库上对其进行微调,从而形成一个基于科学研究的模型。微调只需要有限的数据量:预训练模型获得的知识可以“迁移”到目标任务上,因此被称为迁移学习(transfer learning)。
 @@ -111,19 +111,19 @@ Transformers是由一个团队领导的(非常大的)模型项目,该团
因此,微调模型具有较低的时间、数据、财务和环境成本。迭代不同的微调方案也更快、更容易,因为与完整的预训练相比,训练的约束更少。
-这个过程也会比从头开始的训练(除非你有很多数据)取得更好的效果,这就是为什么你应该总是尝试利用一个预训练的模型--一个尽可能接近你手头的任务的模型--并对其进行微调。
+这个过程也会比从头开始的训练(除非你有很多数据)取得更好的效果,这就是为什么你应该总是尝试利用一个预训练的模型——一个尽可能接近你手头的任务的模型——并对其进行微调。
-## 一般的体系结构 [[一般的体系结构]]
-在这一部分,我们将介绍Transformer模型的一般架构。如果你不理解其中的一些概念,不要担心;下文将详细介绍每个组件。
+## Transformer 模型的通用架构 [[Transformer 模型的通用架构]]
+在本节中,我们将概述 Transformer 模型的通用架构。如果你不理解其中的一些概念,不用担心;后面的章节将详细介绍每个组件。
@@ -111,19 +111,19 @@ Transformers是由一个团队领导的(非常大的)模型项目,该团
因此,微调模型具有较低的时间、数据、财务和环境成本。迭代不同的微调方案也更快、更容易,因为与完整的预训练相比,训练的约束更少。
-这个过程也会比从头开始的训练(除非你有很多数据)取得更好的效果,这就是为什么你应该总是尝试利用一个预训练的模型--一个尽可能接近你手头的任务的模型--并对其进行微调。
+这个过程也会比从头开始的训练(除非你有很多数据)取得更好的效果,这就是为什么你应该总是尝试利用一个预训练的模型——一个尽可能接近你手头的任务的模型——并对其进行微调。
-## 一般的体系结构 [[一般的体系结构]]
-在这一部分,我们将介绍Transformer模型的一般架构。如果你不理解其中的一些概念,不要担心;下文将详细介绍每个组件。
+## Transformer 模型的通用架构 [[Transformer 模型的通用架构]]
+在本节中,我们将概述 Transformer 模型的通用架构。如果你不理解其中的一些概念,不用担心;后面的章节将详细介绍每个组件。























 -
- +
+