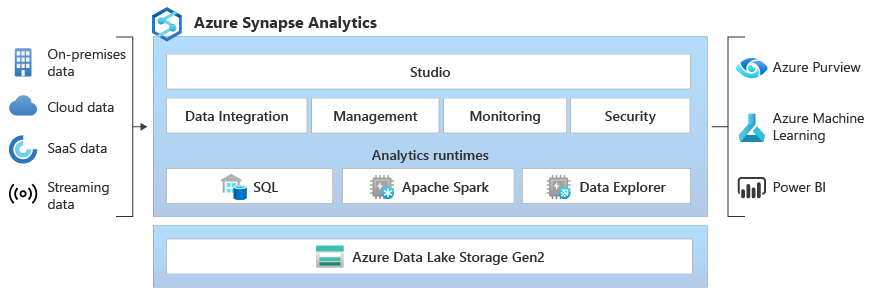
- SQL used in enterprise data warehousing and Spark Pool used for big data
- Data Explorer for log and time series analytics
- Pipelines for data integration and ETL/ELT
- Integration with other Azure services such as Power BI, CosmosDB, and AzureML
- A Synapse workspace belongs to a specific region and has an associated ADLS Gen2 account and file system (for storing temporary data)
- A workspace allows you to perform analytics with SQL and Apache spark. Resources available for SQL and Spark analytics are organized into SQL and Spark pools
- A workspace has Linked services: essentially connection strings that define the connection information needed for the workspace to connect to external resources
- Synapse SQL is the ability to do T-SQL based analytics in Synapse workspace.
- Synapse SQL has two consumption models: dedicated SQL pools and serverless SQL pools
- Spark with Synapse
- Spark Notebooks for doing data Data Science and Engineering use Scala, PySpark, C#, and SparkSQL
- Spark job definitions for running batch Spark jobs using jar files
- Synapse Pipelines
- Provides Data Integration - move data between services and orchestrate activities
- Azure Data Explorer
- Provides an interactive query experience to unlock insights from log and telemetry data
- Data Explorer pools are dedicated clusters that includes two or more compute nodes
- Local SSD storage as hot cache for optimized query performance
- Multiple blob storage as cold cache for persistence
- Data Explorer databases are hosted on Data Explorer pools and are logical entities made up of collections of tables and other database objects
- Tables are database objects that contain data that is organized using a traditional relational data model
- External Tables are tables that reference a storage or SQL data source outside the Data Explorer database