-
Notifications
You must be signed in to change notification settings - Fork 2
/
index_es.Rmd
141 lines (89 loc) · 7.41 KB
/
index_es.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
---
title: "IPO-es"
output:
html_document:
theme: readable
css: style.css
toc: TRUE
#toc_float: TRUE
includes:
before_body: header_es.html
in_header: head_github-activity.html
---
<div class="mycontent">
# IPO (Input-Procesamiento-Output) Protocolo para flujo de investigación reproducible
Para bajar un ejemplo de la estructura de carpetas click [aquí](https://juancarloscastillo.github.io/ipo/IPO_template/IPO-Project_template.tar.gz).
Comentarios y sugerencias a: [[email protected]]([email protected])
---
Esta es una plantilla/protocolo de carpetas de proyecto basada en el protocolo **TIER** (Integridad de Enseñanza en Investigación Empírica). TIER "promueve la integración de principios y prácticas relacionadas con la transparencia y la replicabilidad en el entrenamiento en investigación de los científicos sociales". (más información en [https://www.projecttier.org/](https://www.projecttier.org/)).
La implementación de la reproducibilidad en este tipo de protocolos se basa en generar un **conjunto de archivos auto-contenidos** organizado en una estructura de proyecto que cualquier persona pueda compartir y ejecutar. En otras palabras, debe tener todo lo que necesita para ejecutar y volver a ejecutar el análisis.

El protocolo **IPO** sigue la lógica de TIER, pero con algunas innovaciones:
- intenta un modelo fácil de memorizar y relacionado con el flujo de trabajo de análisis (Input-Procesamiento-Output = IPO), donde el procesamiento se refiere a la preparación y análisis de datos.
- agrega una carpeta "Input", que tiene un alcance más amplio que la carpeta "Datos" original en TIER, pero también otras posibles entradas, como imágenes externas y archivos de bibliografía.
- la carpeta de datos también se simplifica, incluyendo ahora solo una estructura "original" y "procesada".
- modifica los archivos a .md/.Rmd (archivos Markdown) en lugar de .txt. Markdown es un lenguaje de texto con marcas mínimas de formato que luego se pueden convertir a otros formatos como pdf y / o html (por ejemplo, cuando se usa R / Rmarkdown). Pero, en el fondo, son simples archivos txt con solo otra extensión.
### Archivos y estructura de carpetas
Para descargar un ejemplo de la estructura de carpetas del protocolo, haga click [aquí](https://juancarloscastillo.github.io/ipo/IPO_template/IPO-Project_template.tar.gz).
La estructura se detalla en el siguiente esquema:
```
├── input: información externa como datos, imágenes, .bib:
| ├── data:
│ ├── original : archivos de datos originales y metadatos disponibles
│ ├── proc : archivos de datos procesados
│ ├── imagenes
│ ├── bib: archivos de bibliografía
│ ├── prereg: archivos de pre-registro si están disponibles
|
├── procesamiento:
│ - preparacion.Rmd
│ - analisis.Rmd
│
├── output: tablas, gráficos y otras salidas del procesamiento.
│ ├── graphs
│ ├── tables
|
- readme.md : archivo general de introducción
- paper.md o paper.Rmd / paper.html / paper.pdf: el artículo/paper
```
### Principios básicos
- **orden**: trabajar pensando en alguien que no esté familiarizado con el proyecto pueda entenderlo y reproducirlo sin mayores instrucciones que la referencia a este protocolo y otra información que esté en el archivo readme.md. O piense en usted dentro de 5 años: ¿podrá comprender y reproducir esto?
- **comentar los códigos**: registrar brevemente los motivos de cualquier decisión
- el código de preparación debería comenzar a cargando los datos originales y terminar guardando los datos procesados en la carpeta correspondiente (proc).
El flujo de trabajo asociado a estos principios se presenta en el siguiente esquema:
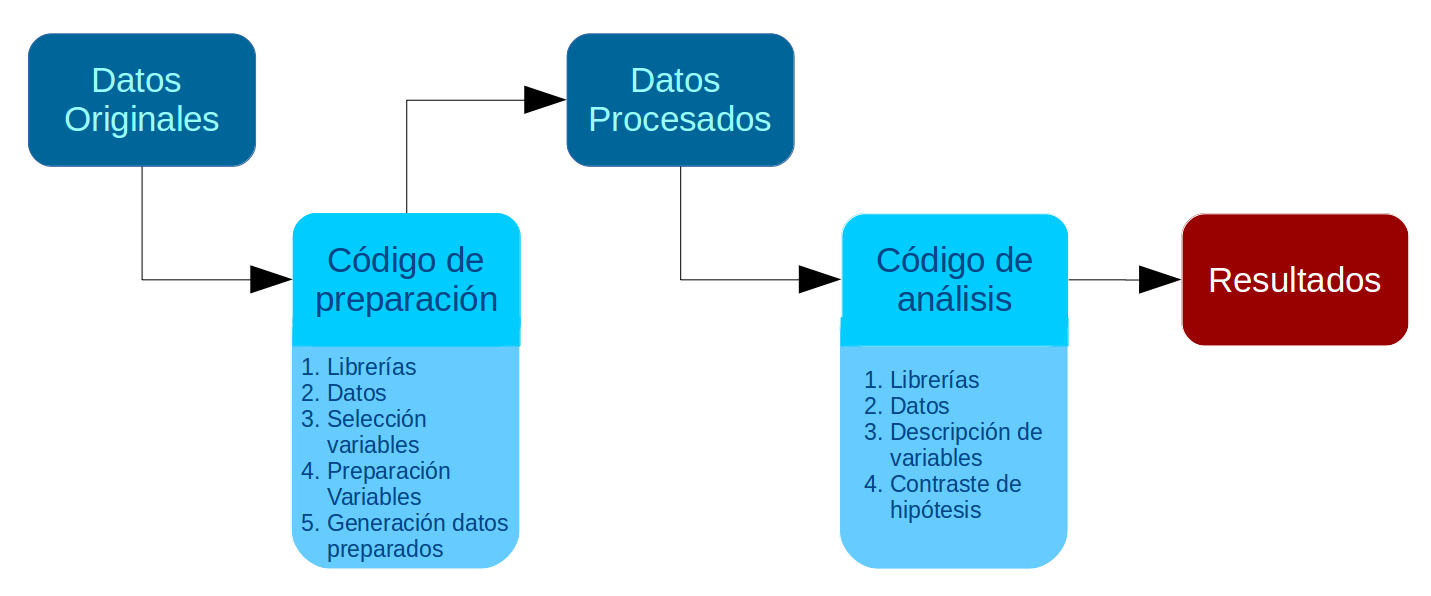
### Ejemplo
Un ejemplo mínimo para probar la implementación del protocolo se puede bajar [aquí](https://juancarloscastillo.github.io/ipo/IPO_miniex/IPO_miniex.tar.gz)
### Notas
- como el entorno R / Rmarkdown permite combinar texto, análisis y resultados, las carpetas de procesamiento y output pueden resultar redundantes. Este es probablemente el caso de análisis e informes breves. Sin embargo, cuando se trabaja en un proyecto tipo artículo o tesis, es aconsejable separar input, procesamiento y output en aras del orden y la reproducibilidad a pesar de trabajar con Rmarkdown.
- para facilitar el trabajo en Rstudio, es posible que desee hacer de la carpeta del proyecto una carpeta **Rproject**. Esto hará que el directorio de trabajo se remita automáticamente a la raíz, además de activar otras funciones dentro de Rstudio. Para esto, en Rstudio simplemente vaya a Archivo-> Nuevo proyecto-> Directorio existente y apunte a la carpeta del proyecto. Esto creará un archivo con la extensión .Rproj que, al hacer clic, abrirá Rstudio con la carpeta del proyecto como raíz. De esta manera, evita generar directorios de trabajo individuales locales (el comando R `setwd`), que no facilitan la reproducibilidad. Si se logra entender por qué no se debe referir en el código a un directorio local (como con `setwd`), entonces está más cerca de entender el sentido de la reproducibilidad.
- además de tener una carpeta de proyecto donde está contenida toda la información, la clave técnica para trabajar dentro de esta estructura es guardar y cargar archivos ubicados en diferentes lugares a través de **rutas relativas** (relative paths), lo que permite conectar diferentes archivos dentro del mismo proyecto/carpeta. Por ejemplo, para cargar un archivo de datos desde la carpeta `original` desde el código `preparacion.Rmd`:
```
load("../input/data/original/data.csv")
```
Los caracteres `../` significan "un nivel más arriba" en la estructura de carpetas. En este caso, tomando como referencia una secuencia de comandos dentro de la carpeta `procesamiento`, debemos subir a la carpeta `proyecto` o raíz, y desde allí bajar a `input/data/original/data.csv`
- para guardar tablas y cualquier salida producida en R, utilice la función `sink`. Por ejemplo, para una tabla descriptiva `stargazer` de` data`:
```
sink("output/tables/table1.txt")
stargazer(data, )
sink()
```
El sentido de esto es señalar primero en qué archivo guardar o "hundir" (sink) lo que viene a continuación, y dejar de guardar con `sink ()`
Luego, para llamar el archivo desde paper.Rmd:
`<div><object data="output/tables/table1.txt"></object></div>`
- para guardar gráficos, después de producir y ver el gráfico:
```
dev.copy(png,"output/graphs/graph1.png",width=600,
height=600); dev.off()
```
Luego, para llamar al gráfico desde el archivo paper.Rmd:
```

```
### Trabajo futuro:
- IPO-RGit: manteniendo la misma estructura básica, esta versión es una actualización para aprovechar todas las herramientas de reproducibilidad, colaboración y publicación ofrecidas por los entornos de trabajo Rmarkdown / Github. Se puede ver un ejemplo de esta implementación de trabajo en progreso [aquí.](https://juancarloscastillo.github.io/merit-scale/)
## Github activity feed
<div id="feed"></div>
# {-}
<br><br><br>
</div>