该项目已经不再维护,并且已经被合并 Scrapy Tutorial Series: Web Scraping Using Python
该项目包含
- 一份任务列表,这份任务列表包含了爬虫开发过程中的一些基本知识点,每一个任务都是一个小的测验,当你循序渐进的完成了这个任务列表中的任务时,你将有能力面对爬虫实际开发过程中一些更复杂的情况。这个任务列表的创意来自 code kata
- 一份爬虫开发过程中的注意事项和笔记,这些笔记能有效提高你的开发效率,还会介绍一些非常有用的工具
对于想用scrapy学习爬虫开发的人来说,官方文档是一个学习的好地方,但是官方文档只是关注了scrapy这个项目本身,很多爬虫开发过程中需要了解和注意的知识点都没有在文档中进行提及,所以我创建了这个项目
我不会再这个项目里面过多的谈及scrapy的组件和特性因为很多特性对于大多数爬虫开发不是必须的。 所以强烈建议你在开始这个项目之前通过 official doc 对scrapy有一个基本的了解, 对于scrapy使用的问题可以参考官方文档。
http://scrapy-guru.readthedocs.io/en/latest/index.html
OSX, Linux, python 2.7+, python 3.4+
首先,通过下面的流程图对运行流程有基本了解,然后阅读 basic concepts 对这个项目中的一些基本概念有一个基本了解.
安装配置完成之后,开始试着完成doc中的任务列表,考虑到学习曲线,在这里建议读者按照文档中的任务顺序来完成任务。在项目中新建爬虫,写入代码,并运行查看运行结果,项目中已经有一个样本爬虫, basic_extract 可以以它为模板来开发。每个任务我都写了答案爬虫,稍后会在另一个项目中单独放出源代码。
点开可看大图
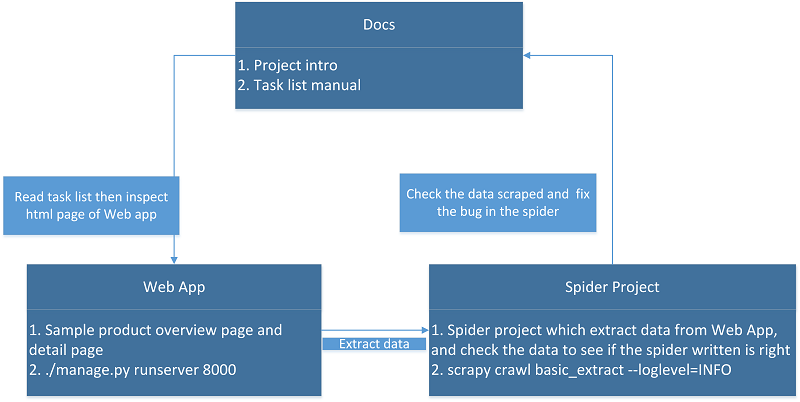
考虑到有朋友英语不好,在这里用文字简单解释一下
- 网上爬虫教程都是抓取的互联网上的某个网站或网页,由于年代久远可能导致爬虫代码无法再新的网页上正常工作,所以在这个项目里我用django 写了一个专门供爬虫抓取的webapp,这个webapp里的不同页面会模拟不同网站的工作机制.每一个任务都是单独针对某一种情况编写爬虫来获得目标信息,通过这些任务的训练,这样在处理掺杂多种知识点的实际复杂情况时,就会变得得心应手,游刃有余。
- 如果爬虫代码写得有错误,在运行时会抛出异常,如果抓取的数据有错误,爬虫框架的pipeline会自动对比抓取的数据并在终端给出错误提示,帮助排错.
Here is the directory structure:
.
├── docs
│ ├── Makefile
│ ├── build
│ └── source
├── requirements.txt
├── spider_project
│ ├── release
│ ├── scrapy.cfg
│ └── spider_project
└── webapp
├── content
├── db.sqlite3
├── manage.py
├── staticfiles
├── templates
└── webapp
docs包含了这个项目的文档webapp是一个由``Django``开发的web应用, 这个应用给我们展示商品详细信息和商品列表, 编写的爬虫就是要从这里抓取信息。spider_project是一个``Scrapy``项目, 爬虫代码就是在这个项目里面工作
下图展示的是一个样例商品页面,由 webapp 展示
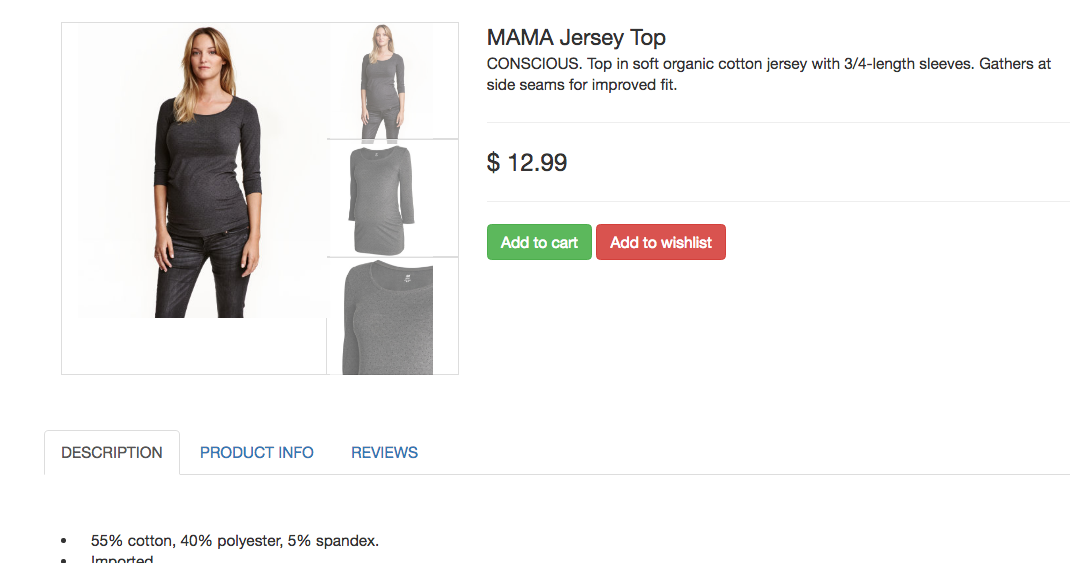
根据这个任务 task 我们要抓取这个商品的名称和商品说明
这是我们完成的爬虫的部分代码:
class Basic_extractSpider(scrapy.Spider):
taskid = "basic_extract"
name = taskid
entry = "content/detail_basic"
def parse_entry_page(self, response):
item = SpiderProjectItem()
item["taskid"] = self.taskid
data = {}
title = response.xpath("//div[@class='product-title']/text()").extract()
desc = response.xpath("//section[@class='container product-info']//li/text()").extract()
data["title"] = title
data["desc"] = desc
item["data"] = data
yield item
在命令行中运行爬虫,爬虫就会从 self.entry 这个入口开始抓取并处理数据,如果抓取的数据有错误,那么爬虫框架会将错误打印到终端上来帮助你排错。