We developed StreamingDataset to optimize training of large datasets stored on the cloud while prioritizing speed, affordability, and scalability.
Specifically crafted for multi-gpu & multi-node (with DDP, FSDP, etc...), distributed training with large models, it enhances accuracy, performance, and user-friendliness. Now, training efficiently is possible regardless of the data's location. Simply stream in the required data when needed.
The StreamingDataset is compatible with any data type, including images, text, video, audio, geo-spatial, and multimodal data and it is a drop-in replacement for your PyTorch IterableDataset class. For example, it is used by Lit-GPT to pretrain LLMs.
Imagenet-1.2M is a commonly used dataset to compare computer vision models. Its training dataset contains 1,281,167 images.
In this benchmark, we measured the streaming speed (images per second) loaded from AWS S3 for several frameworks.
Find the reproducible Studio Benchmark.
| Framework | Images / sec 1st Epoch (float32) | Images / sec 2nd Epoch (float32) | Images / sec 1st Epoch (torch16) | Images / sec 2nd Epoch (torch16) |
|---|---|---|---|---|
| PL Data | 5800.34 | 6589.98 | 6282.17 | 7221.88 |
| Web Dataset | 3134.42 | 3924.95 | 3343.40 | 4424.62 |
| Mosaic ML | 2898.61 | 5099.93 | 2809.69 | 5158.98 |
Higher is better.
| Framework | Train Conversion Time | Val Conversion Time | Dataset Size | # Files |
|---|---|---|---|---|
| PL Data | 10:05 min | 00:30 min | 143.1 GB | 2.339 |
| Web Dataset | 32:36 min | 01:22 min | 147.8 GB | 1.144 |
| Mosaic ML | 49:49 min | 01:04 min | 143.1 GB | 2.298 |
The dataset needs to be converted into an optimized format for cloud streaming. We measured how fast the 1.2 million images are converted.
Faster is better.
We have built end-to-end free Studios showing all the steps to prepare the following datasets:
| Dataset | Data type | Studio |
|---|---|---|
| LAION-400M | Image & description | Use or explore LAION-400MILLION dataset |
| Chesapeake Roads Spatial Context | Image & Mask | Convert GeoSpatial data to Lightning Streaming |
| Imagenet 1M | Image & Label | Benchmark cloud data-loading libraries |
| SlimPajama & StartCoder | Text | Prepare the TinyLlama 1T token dataset |
| English Wikepedia | Text | Embed English Wikipedia under 5 dollars |
| Generated | Parquet Files | Convert parquets to Lightning Streaming |
Lightning Studios are fully reproducible cloud IDE with data, code, dependencies, etc...
Lightning Data can be installed with pip:
pip install -U litdataConvert your raw dataset into Lightning Streaming format using the optimize operator. More formats are coming...
import numpy as np
from litdata import optimize
from PIL import Image
# Store random images into the chunks
def random_images(index):
data = {
"index": index,
"image": Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)),
"class": np.random.randint(10),
}
return data # The data is serialized into bytes and stored into chunks by the optimize operator.
if __name__ == "__main__":
optimize(
fn=random_images, # The function applied over each input.
inputs=list(range(1000)), # Provide any inputs. The fn is applied on each item.
output_dir="my_dataset", # The directory where the optimized data are stored.
num_workers=4, # The number of workers. The inputs are distributed among them.
chunk_bytes="64MB" # The maximum number of bytes to write into a chunk.
)The optimize operator supports any data structures and types. Serialize whatever you want.
Cloud providers such as AWS, Google Cloud, Azure, etc.. provide command line client to upload your data to their storage.
Here is an example with AWS S3.
⚡ aws s3 cp --recursive my_dataset s3://my-bucket/my_datasetfrom litdata import StreamingDataset
from torch.utils.data import DataLoader
# Remote path where full dataset is persistently stored
input_dir = 's3://pl-flash-data/my_dataset'
# Create streaming dataset
dataset = StreamingDataset(input_dir, shuffle=True)
# Check any elements
sample = dataset[50]
img = sample['image']
cls = sample['class']
# Create PyTorch DataLoader
dataloader = DataLoader(dataset)Here is an illustration showing how the StreamingDataset works under the hood.
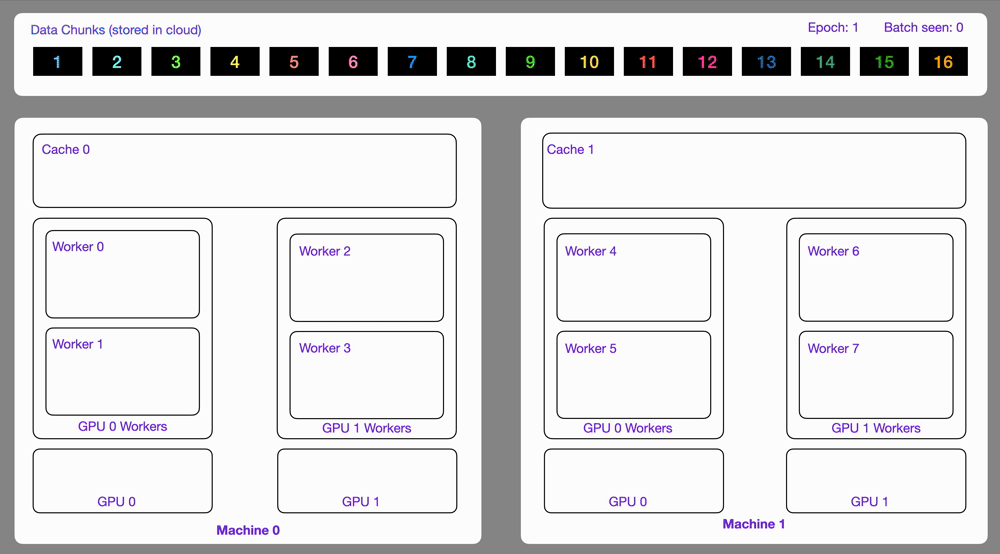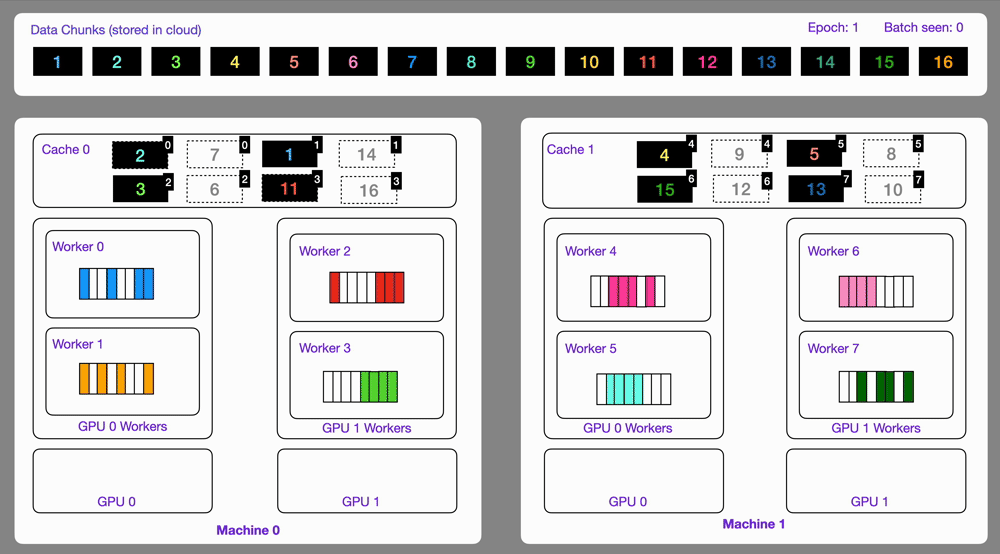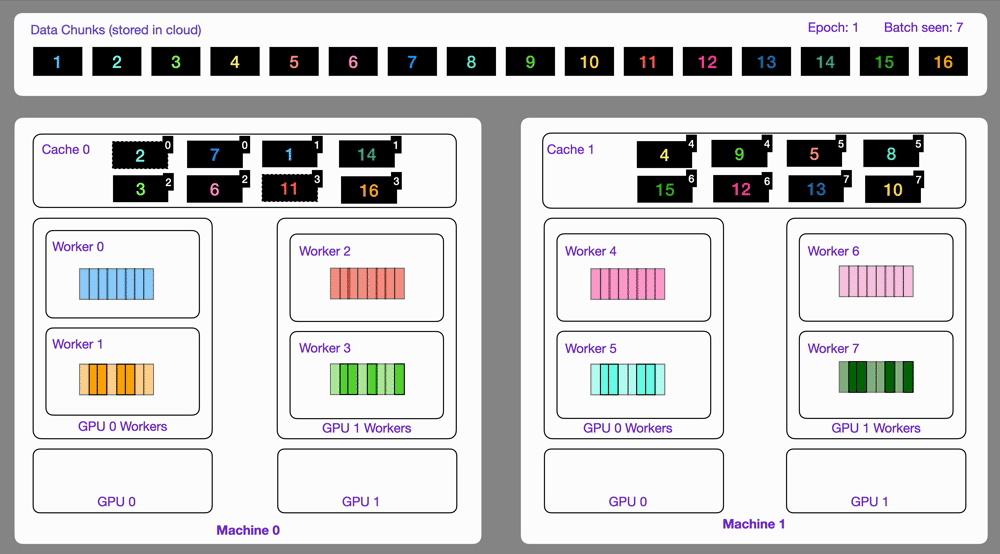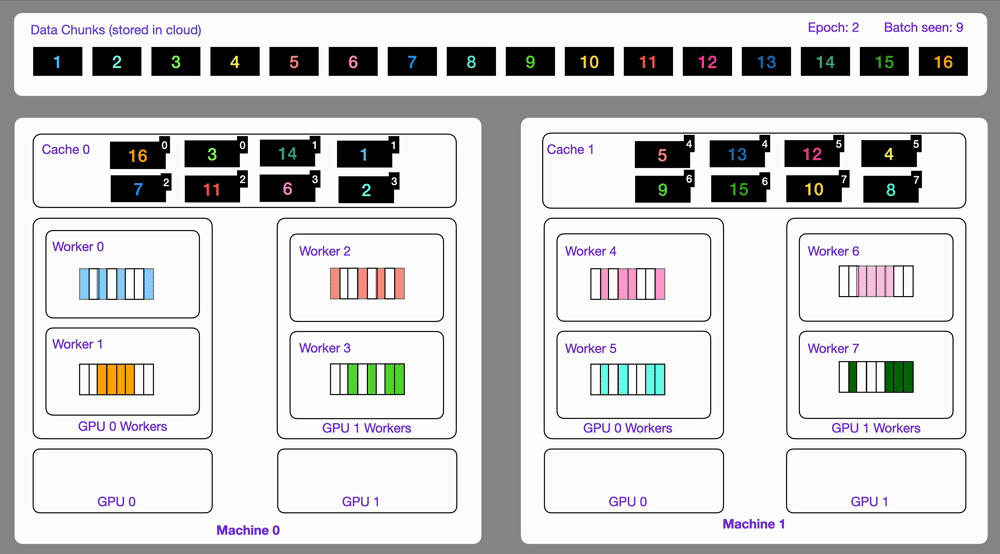
Similar to optimize, the map operator can be used to transform data by applying a function over a list of item and persist all the files written inside the output directory.
We generates 1000 images and upload them to AWS S3.
import os
from PIL import Image
import numpy as np
data_dir = "my_images"
os.makedirs(data_dir, exist_ok=True)
for i in range(1000):
width = np.random.randint(224, 320)
height = np.random.randint(224, 320)
image_path = os.path.join(data_dir, f"{i}.JPEG")
Image.fromarray(
np.random.randint(0, 256, (width, height, 3), np.uint8)
).save(image_path, format="JPEG", quality=90)⚡ aws s3 cp --recursive my_images s3://my-bucket/my_imagesimport os
from litdata import map
from PIL import Image
input_dir = "s3://my-bucket/my_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
if __name__ == "__main__":
map(
fn=resize_image,
inputs=inputs,
output_dir="s3://my-bucket/my_resized_images",
num_workers=4,
)To scale data processing, create a free account on lightning.ai platform. With the platform, the optimize and map can start multiple machines to make data processing drastically faster as follows:
from litdata import optimize, Machine
optimize(
...
num_nodes=32,
machine=Machine.DATA_PREP, # You can select between dozens of optimized machines
)OR
from litdata import map, Machine
map(
...
num_nodes=32,
machine=Machine.DATA_PREP, # You can select between dozens of optimized machines
)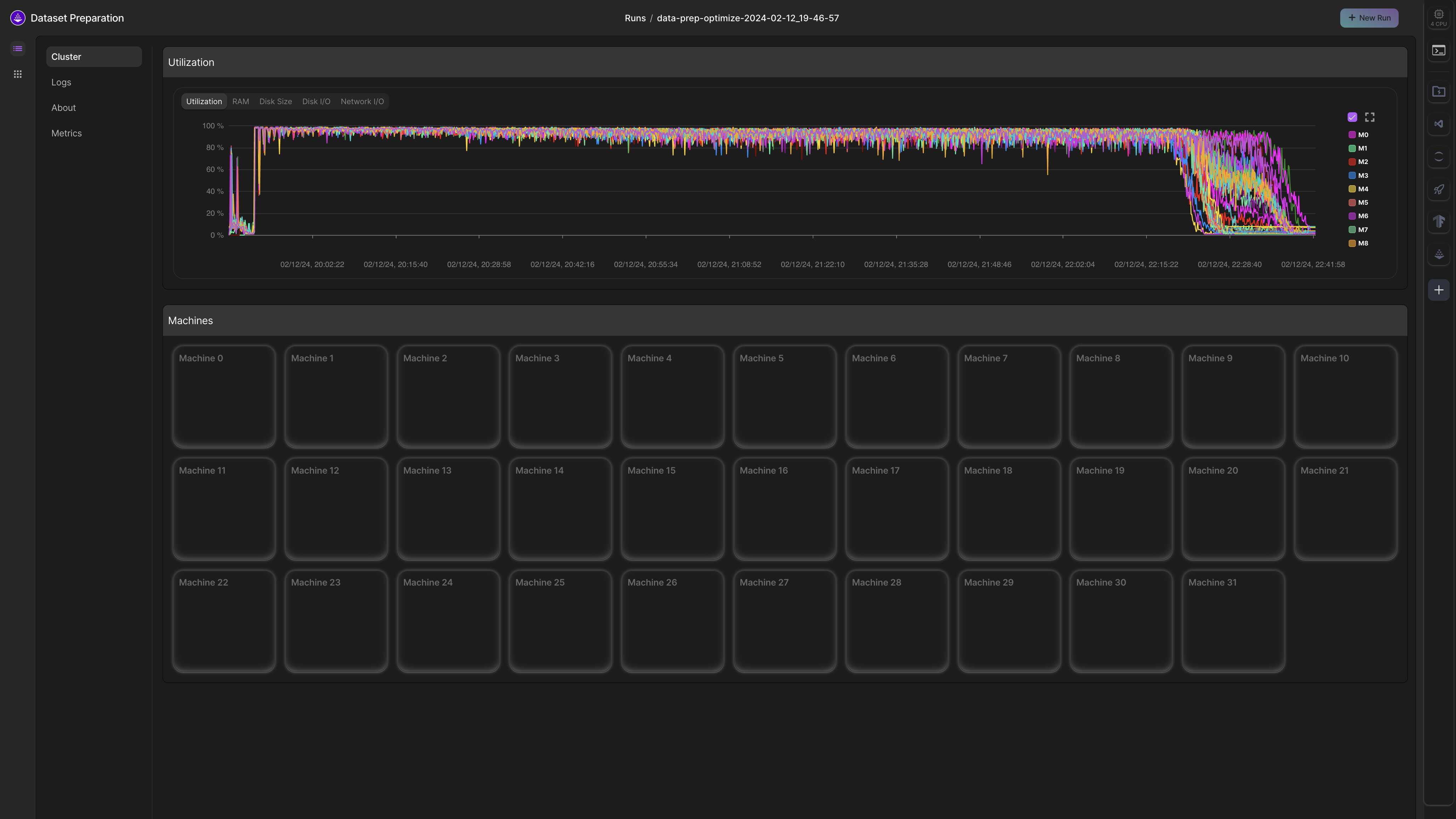
The Data Prep Job UI from the LAION 400M Studio where we used 32 machines with 32 CPU each to download 400 million images in only 2 hours.
The StreamingDataset and StreamingDataLoader takes care of everything for you. They automatically make sure each rank receives different batch of data. There is nothing for you to do if you use them.
You can easily experiment with dataset mixtures using the CombinedStreamingDataset.
from litdata import StreamingDataset, CombinedStreamingDataset
from litdata.streaming.item_loader import TokensLoader
from tqdm import tqdm
import os
from torch.utils.data import DataLoader
train_datasets = [
StreamingDataset(
input_dir="s3://tinyllama-template/slimpajama/train/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
StreamingDataset(
input_dir="s3://tinyllama-template/starcoder/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
]
# Mix SlimPajama data and Starcoder data with these proportions:
weights = (0.693584, 0.306416)
combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights)
train_dataloader = DataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# Iterate over the combined datasets
for batch in tqdm(train_dataloader):
passLightning Data provides a stateful StreamingDataLoader. This simplifies resuming training over large datasets.
Note: The StreamingDataLoader is used by Lit-GPT to pretrain LLMs. The statefulness still works when using a mixture of datasets with the CombinedStreamingDataset.
import os
import torch
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset("s3://my-bucket/my-data", shuffle=True)
dataloader = StreamingDataLoader(dataset, num_workers=os.cpu_count(), batch_size=64)
# Restore the dataLoader state if it exists
if os.path.isfile("dataloader_state.pt"):
state_dict = torch.load("dataloader_state.pt")
dataloader.load_state_dict(state_dict)
# Iterate over the data
for batch_idx, batch in enumerate(dataloader):
# Store the state every 1000 batches
if batch_idx % 1000 == 0:
torch.save(dataloader.state_dict(), "dataloader_state.pt")The StreamingDataLoader supports profiling your data loading. Simply use the profile_batches argument as follows:
from litdata import StreamingDataset, StreamingDataLoader
StreamingDataLoader(..., profile_batches=5)This generates a Chrome trace called result.json. You can visualize this trace by opening Chrome browser at the chrome://tracing URL and load the trace inside.
Access the data you need when you need it.
from litdata import StreamingDataset
dataset = StreamingDataset(...)
print(len(dataset)) # display the length of your data
print(dataset[42]) # show the 42th element of the datasetfrom litdata import StreamingDataset, StreamingDataLoader
import torchvision.transforms.v2.functional as F
class ImagenetStreamingDataset(StreamingDataset):
def __getitem__(self, index):
image = super().__getitem__(index)
return F.resize(image, (224, 224))
dataset = ImagenetStreamingDataset(...)
dataloader = StreamingDataLoader(dataset, batch_size=4)
for batch in dataloader:
print(batch.shape)
# Out: (4, 3, 224, 224)Limit the size of the cache holding the chunks.
from litdata import StreamingDataset
dataset = StreamingDataset(..., max_cache_size="10GB")When processing large files like compressed parquet files, you can use python yield to process and store one item at the time.
from pathlib import Path
import pyarrow.parquet as pq
from litdata import optimize
from tokenizer import Tokenizer
from functools import partial
# 1. Define a function to convert the text within the parquet files into tokens
def tokenize_fn(filepath, tokenizer=None):
parquet_file = pq.ParquetFile(filepath)
# Process per batch to reduce RAM usage
for batch in parquet_file.iter_batches(batch_size=8192, columns=["content"]):
for text in batch.to_pandas()["content"]:
yield tokenizer.encode(text, bos=False, eos=True)
# 2. Generate the inputs
input_dir = "/teamspace/s3_connections/tinyllama-template"
inputs = [str(file) for file in Path(f"{input_dir}/starcoderdata").rglob("*.parquet")]
# 3. Store the optimized data wherever you want under "/teamspace/datasets" or "/teamspace/s3_connections"
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # Note: You can use HF tokenizer or any others
inputs=inputs,
output_dir="/teamspace/datasets/starcoderdata",
chunk_size=(2049 * 8012),
)We welcome any contributions, pull requests, or issues. If you use the Streaming Dataset for your own project, please reach out to us on Slack or Discord.