[Question] Memory keep increase in MetaAdam due to gradient link #218
Comments
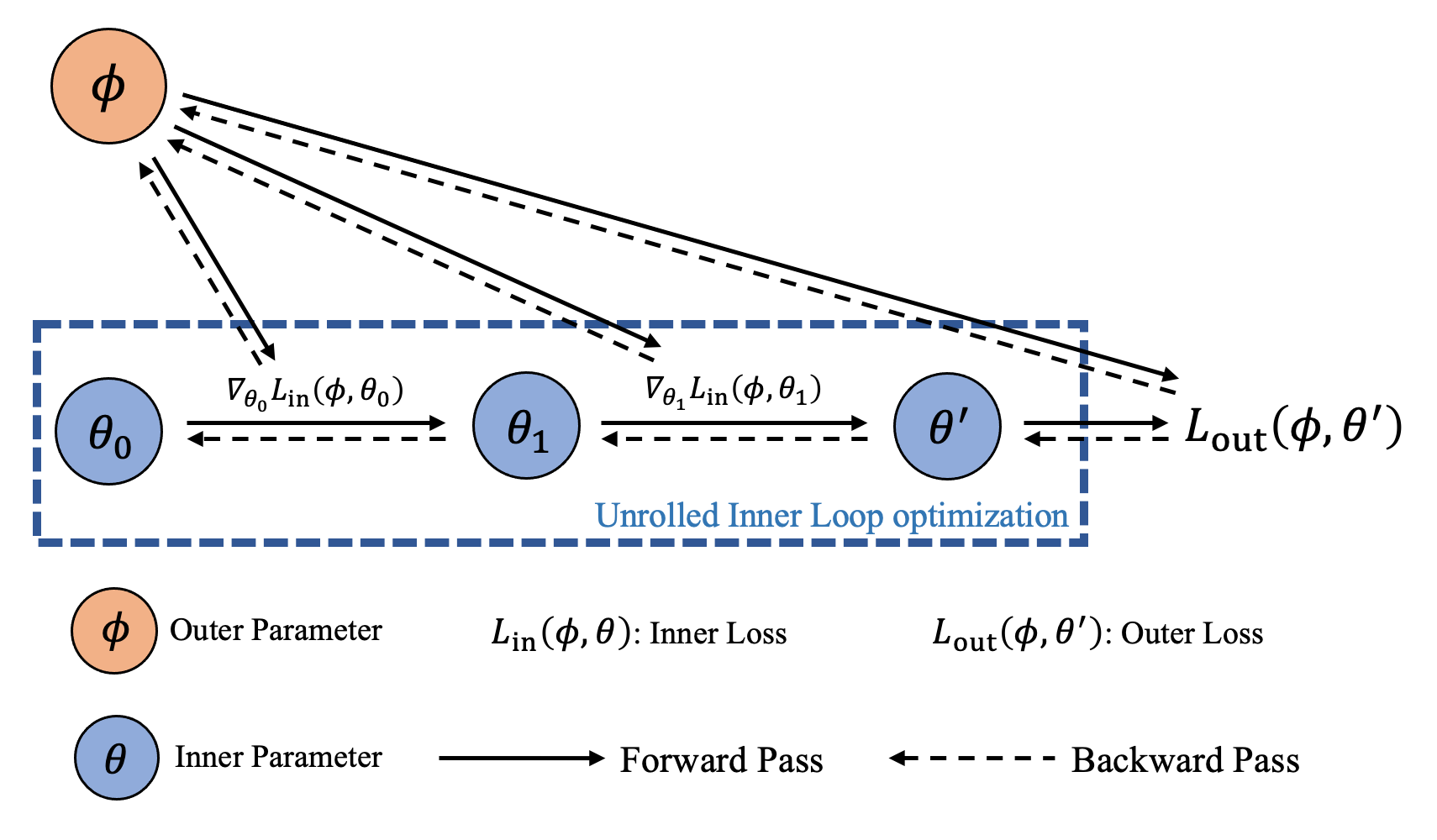
Hi @ycsos, this is intentional and it is the mechanism behind the explicit hyper-gradient.
You should not detach the computation graph in the inner loop. And you need to detach the graph in the outer loop using |
|
I understand explicit hyper-gradient. mean. but what I want to do in only inference (no need save any activation) the model. I think only detach the outer loop is not enough, the tensor in inner loop is also linked, so when come to next step, the tensor cannot be release. in this |
|
@XuehaiPan thank you for your reply, In my view torchopt.stop_gradient only detach the link for input tensor, but grad link between inner loop is also connected, like optimizer update parameters? that is totally right in training, but in inference, we don't need keep grad connect, and cause torch cannot release these tensor. |
Hi, meta optimizers designed specifically for bilevel optimization algorithms. To meet your need, maybe you can directly use functional api. |

thank you very much !now I understand the design of torchopt |

{kind=link}
@ycsos I opened a PR to resolve this. |
meta_optim = torchopt.MetaAdam(model, lr=0.1)
loss = compute_loss(model, batch)
with torch.no_grad():
meta_optim.step(loss)do you test the code? I have a question, you put step function under torch.no_grad(), and in torchopt/optim/meta/base.py Line 84 , you get the flat_new_params will be not requires_grad? torch.autograd.grad is no need under torch.enable_grad() ? so with step function maybe only need to add explict .requires_grad_() in update to model parameters |
Required prerequisites
What version of TorchOpt are you using?
0.7.3
System information
Problem description
when use torchopt.MetaAdam and step some times, the memory use in gpu are continuously increase. It should not be, will you excute next step, the tensor create in the former step is no need should be release. I find the reason: metaOptimizer not detach the gradient link in optimizer. and former tensor was not release by torch due to dependency.
you can run the test code, the first one memory increase by step increase. and second one (I change the code to detach the grad link) the memory is stable when step increase:


before:
after:
Reproducible example code
The Python snippets:
Command lines:
Traceback
current: 62526464 90054144 106309632 122827264 138558464 155600384 171331584 187587072 204104704 219835904Expected behavior
Additional context
No response
The text was updated successfully, but these errors were encountered: