Questions and thoughts(fix of making user dict, unidic terms and mecab_node_t attributes) #75
Comments
|
It sounds like you have three separate issues, so to address them... A. Applying taku910/mecab#70 I'll consider it, but it may take me a while to get to it. If you build fugashi from source you can use a local version of MeCab as the base, which would allow you to resolve your issue immediately. Based on my understanding of the issue, the resulting dictionary should work fine with unpatched MeCab. B. Comments on UniDic 3.2 data Thank you for pointing out the difference in the fields. I had a little trouble understanding what you were saying, so for my reference:
I am surprised that form and lform differ for クリエイティヴ, I'm not entirely sure what the logic is there. If you have any further insight it would be appreciated, I'll look at this. It would probably be best to mail the UniDic maintainers for clarification though, unless this is already in the manual. C. Adding access to further node fields I would consider it but wouldn't treat it with priority - like most advanced features in MeCab, I've never known anyone to use it. I would be happy to take a look at a PR. Thank you for taking the time to create a Github account and post this. However, I will note that asking multiple questions in one issue makes it a little hard to follow. For now, I consider A. resolved, B. to require further investigation, and C. to be open. I made a new issue for C at #76 and we can use this thread to continue to discuss B. |
|
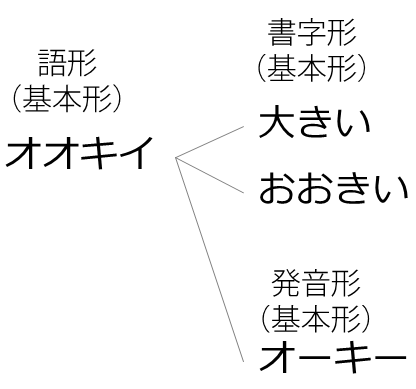
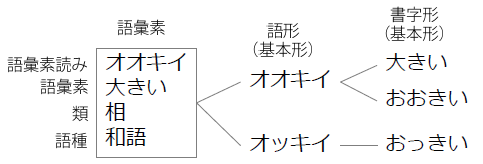
Regarding form 語形出現形 of point B. 階層的な見出し構造 of UniDic: 語形 is written in katakana. 「大きい」and「おおきい」 書字形基本形「大きい」
書字形基本形「おおきい」 (written in hiragana 平仮名)
Its casual expression「おっきい」has different pronunciation, so it is regarded as another 語形. These variations are grouped under 語彙素, the highest level of the hierarchy, 「回」,「下位」and「貝」 By having this hierarchy from 書字形 to 語彙素, it makes it possible to distinguish the queries Above is my understanding from the glossary page. For creative:
Its lform (lemma form) 語彙素読み is クリエーティブ
I hope it helps clarify the logic a bit. Thank you for your reply. |
|
Thank you for the clarification, that is helpful to understanding. I do have one question - are you just clarifying this, or do you propose a change to fugashi (or maybe my UniDic docs) somewhere? |
|
I suggest the following changes in README.md of unidic-py: Modify:
Add description for type: (Please copy the code for folding) Add description for form and formBase: Add an example for lid: 語彙表ID. |
Includes suggestions from polm/fugashi#75.
|
Thank you for the clarification, I have added your suggestions to the README, so I will mark this as resolved. |
Hi polm,
I have couple of questions regarding fugashi and unidic-py.
A. Could you apply the fix (Update dictionary.cpp) into the build of mecab inside fugashi?
taku910/mecab#70
When I tried to build user dic as suggested in https://taku910.github.io/mecab/dic.html, I got left-id.def or right-id.def may be broken error when
i. trying to leave left-id and right-id empty and let it auto assign the ids
麩菓子,,,100,名詞,普通名詞,一般,,, ...
fugashi-build-dict -d "D:/Dict/unidic-cwj-202302" -u foo.dic foo.csv
ii. trying to leave the cost empty and let it auto estismate the cost
菓子,16570,17953,,名詞,普通名詞,一般,,, ...
fugashi-build-dict -m "D:/Dict/unidic-cwj-202302/model.bin" -d "D:/Dict/unidic-cwj-202302" -u foo2.csv -f utf8 -t utf8 -a foo.csv
I can build foo.dic successfully if I manually fill in the left and right ids and the cost
The pull request mentioned above is very attractive to make the auto estimation work.
related:
https://stackoverflow.com/questions/66299029/how-does-one-determine-what-the-left-and-right-context-ids-should-be-when-buildi
B. some thoughts on the terms in unidic in lex.csv
The column of lex.csv of the latest dic (written version, i.e. unidic-cwj-202302.zip) is same as UnidicFeatures29 (# schema used in 2.2.0, 2.3.0).
Here are some of my thoughts and findings on the fields:
i. type seems to be 語彙素類
type,pos1,pos2,pos3,pos4
人名,名詞,固有名詞,人名,一般
他,感動詞,フィラー,,
他,感動詞,一般,,
他,接続詞,,,*
体,代名詞,,,*
体,名詞,助動詞語幹,,
体,名詞,普通名詞,サ変可能,*
体,名詞,普通名詞,サ変形状詞可能,*
体,名詞,普通名詞,一般,*
体,名詞,普通名詞,副詞可能,*
体,名詞,普通名詞,助数詞可能,*
体,名詞,普通名詞,形状詞可能,*
係助,助詞,係助詞,,
副助,助詞,副助詞,,
助動,助動詞,,,*
助動,形状詞,助動詞語幹,,
助数,接尾辞,名詞的,助数詞,*
名,名詞,固有名詞,人名,名
固有名,名詞,固有名詞,一般,*
国,名詞,固有名詞,地名,国
地名,名詞,固有名詞,地名,一般
姓,名詞,固有名詞,人名,姓
接助,助詞,接続助詞,,
接尾体,接尾辞,名詞的,サ変可能,*
接尾体,接尾辞,名詞的,一般,*
接尾体,接尾辞,名詞的,副詞可能,*
接尾用,接尾辞,動詞的,,
接尾相,接尾辞,形容詞的,,
接尾相,接尾辞,形状詞的,,
接頭,接頭辞,,,*
数,名詞,数詞,,
格助,助詞,格助詞,,
準助,助詞,準体助詞,,
用,動詞,一般,,
用,動詞,非自立可能,,
相,副詞,,,*
相,形容詞,一般,,
相,形容詞,非自立可能,,
相,形状詞,タリ,,
相,形状詞,一般,,
相,連体詞,,,*
終助,助詞,終助詞,,
補助,空白,,,*
補助,補助記号,一般,,
補助,補助記号,句点,,
補助,補助記号,括弧閉,,
補助,補助記号,括弧開,,
補助,補助記号,読点,,
補助,補助記号,AA,一般,*
補助,補助記号,AA,顔文字,*
記号,記号,一般,,
記号,記号,文字,,
ii. about form 語形出現形
In the hierarchy of 語彙素 --> 語形 --> 書字形, 発音形
pron is more similar to form than kana except that long vowels are indicated with a ー, so 講師 is こーし.
kana is more like the written katakana of the word
Please see the following example:
surface,pron,form,kana,lform,lemma
打ち込まう,ウチコモー,ウチコモウ,ウチコマウ,ウチコム,打ち込む
打ち込もふ,ウチコモー,ウチコモウ,ウチコモフ,ウチコム,打ち込む
クリエイティヴ,クリエーティブ,クリエイティブ,クリエイティヴ,クリエーティブ,クリエーティブ-creative
C. Could you also provide wrapper functions for other fields in mecab_node_t as well?
https://taku910.github.io/mecab/doxygen/structmecab__node__t.html
some of the attributes like right attribute id, left attribute id, word cost, best accumulative cost from bos node to this node, isbest, etc
are useful to figure out how the cost varies in a sentence, and maybe useful for adjusting the cost in user dic
Thank you.
The text was updated successfully, but these errors were encountered: