Data Visualization
The purpose of this page is to review various approaches to data visualization, to support questioners in interpreting results.
These topics will be addressed in the sections that follow:
- Common relationships in quantitative data
- Visual options for encoding quantitative data
- Best practices for encoding select quantitative data relationships
- Other considerations
- Special Topics
- References of note
- Web visualization drafting and display tools
Following the discussion of visualization strategies and tactics, an overview of open source visualization technologies will be provided, complete with a sampling of representative visualizations. The reference for most of the information presented here is Stephen Few's Show Me the Numbers: Designing Tables and Graphs to Enlighten which is regarded to be one of the most comprehensive guides to the design of strong data visualizations.
## Common relationships in quantitative data Quantitative data consists of numbers. When visualized, quantitative data is usually depicted _relative_ to some other category of interest. These **categorical** descriptions, or scales, come in three flavors: * **Nominal** - Categories of data that aren't really related, but instead just described by name (e.g. Doctor A, Doctor B, Doctor C) * **Ordinal** - Categories of data that are related in that they follow an implied order, although they aren't really quantified (e.g. underweight, normal weight, overweight) * **Interval** - Categories of data are related, ordered and represent quantitative values themselves (e.g. BMI < 15, BMI >= 15 and <25, BMI >=25)When selecting a graphical design, it is best to start by identifying the relationship you'd like to communicate with your quantitative data set. Depending on the selection of the categorical descriptors, you will likely want to communicate one of the seven following data relationships:
Here, you just want to place categorical data measures side by side to facilitate comparison, with no desire to encourage ranking or identification of larger data patterns.
- Number of patients per doctor
- Number of tests per patient
Here, you want to facilitate more than just a comparison of nominal categories. You want to draw attention to the relationship that exists between a category and its quantitative value in some order (e.g., from smallest to largest).
- KEYWORDS: larger than, smaller than, equal to, greater than
- Number of patients per doctor, ordered by doctor with most to least patients
- Number of telephone consultations by clinic, ordered by clinic with most to least consultations
Here, you want to depict the relationship of quantitative measures as they were captured in time.
- KEYWORDS: change, rise, fluctuate, decline, grow, trend
- Billing revenues per month
- Average number of minutes between check-in and examination per hour of operation
- Lab values at given times of day
Here, a set of nominal, ordinal or interval categories are depicted so that it becomes possible to see what proportion of the total quantity is represented by a given category.
- KEYWORDS: rate of total, percentage of total, share of total, accounts for X of total
- Percentage of clinic revenue earned by clinic physicians
- Percentage of clinic patients according to age bracket
Here, you are interested in illustrating how a set of quantitative values belonging to certain categories differ from a set of reference values.
- KEYWORDS: variance, difference, plus or minus, relative to
- Average difference between target weight and actual weight in patients from three different intervention groups
- Degree to which systolic blood pressure measurement changed compared to previous month's value
Here, you want to depict select facets of a quantitative data set (e.g. lowest values, highest values, medians, averages, etc) as they were observed across, and/or within, a range of ordinal or interval categories.
- KEYWORDS: frequency, distribution, range, concentration, normal curve
- Number of visits to clinics A thru Z by all patients, in ascending age categories
- Number of active medications in all patients, in ascending intervals of BMI
Here, you want to illustrate how two sets of quantitative data relate to one another, perhaps to look for a possible causal relationship.
- KEYWORDS: increases with, varies with, follows, affected by, caused by
- Correlation between serum hemoglobin and ferritin lab results in 1000 patients
And here is a list of visual attributes that are commonly used to encode categorical items:
- 2-D position- each category's value(s) occupy a distinct space in the graph
- Hue - each category's value(s) have a distinct color
- Point shape - each category's value(s) have a distinct shape
- Fill pattern - each category's value(s) have a distinct fill (can be problematic if fill selection is poor)
- Line style - each category's value(s) have a distinct line style
And, finally, here are the common "pre-attentive" visual attributes that can be manipulated to communicate quantities of things. Keep in mind that our powers of perception are such that they can be overwhelmed by manipulating more than two visual attributes within a single graphical visualization - especially when variants are too subtle to be easily perceived:
- 2-D position - higher things (or rightmost things) are perceived to represent greater quantities
- Length - longer things are perceived to represent greater quantities
- Width - wider things are perceived to represent greater quantities. However, length does this better.
- Size- larger things are perceived to represent greater quantities. However, our ability to translate size differences, especially differences between 2-D areas, to quantity differences is limited
- Color Intensity - more saturated things are perceived to represent greater quantities. However, our ability to translate intensity differences to quantity differences is limited.
Now, on to some best practices for using certain graph types to represent common quantitative data relationships.
## Best practices for encoding select quantitative data relationships When designing a graph, always ask yourself: * "What is the relationship in my data set that I am trying to communicate?"Once you've selected that relationship, use the guides below to select the graph type and encoding tactics to produce a superior graph.
- Goal: Emphasize distinctness between quantitative values of each category
- Best bet: Horizontal or vertical bar chart
- Exceptions: If the quantities across categories are so similar that they mask differences, consider narrowing the quantitative scale (i.e., not starting at zero) and replacing bars with points to create a dot plot, rather than a bar chart.
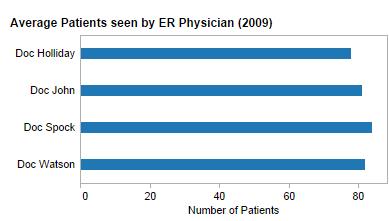

- Goal: Emphasize both distinctness of categorical values and relative sizes
- Best bet: Bar chart, sorted by bar length. If you want to highlight the lowest values, order according to ascending lengths from either left to right or top to bottom depending on graph orientation.
- Exceptions: Again, if categorical quantities are excessively similar, narrow the scale and replace bars with dots.


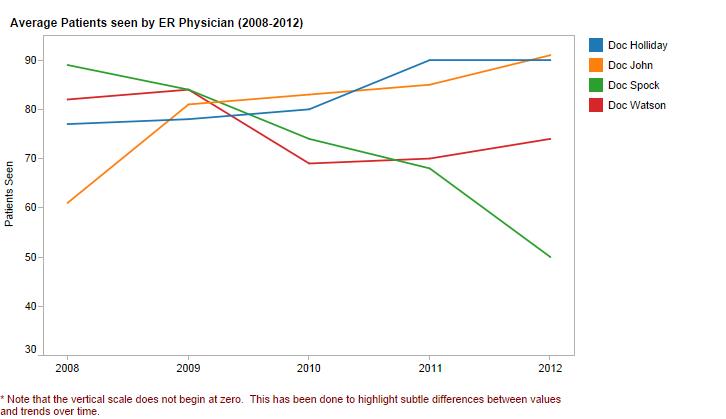
- Goal: Display quantitative values as they were observed sequentially in time.
- Best bet: Line graph - with or without points
- Exception: If you want to emphasize each distinct category (e.g. sales per month), more than you want to illustrate the pattern over time, consider using vertical bars in a bar chart. And, if you want to demonstrate how the distribution of values differed in distinct time periods, consider using vertical boxes in a box plot.
- Exception: If the values were not collected at regular intervals, use only points as a line may suggest data was known at an interval where it was never actually measured.
- Avoid: Using horizontal orientations for bar charts and box plots because people will tend to project the flow of time onto the x-axis, when in fact, that dimension will reflect quantity and not intervals of time.


- Goal: Display the proportion of each category's quantity to the whole.
- Best bet: Bar charts - ranked or unranked, horizontal or vertical. Use a good title so that people understand they are looking at a parts-to-whole display.
- Exception: If your quantitative axis uses units of measure rather than percentages and you want viewers to simultaneously see the wholes of each category, as well as be able to better estimate the values of each corresponding sub-category, then consider using stacked bars in either a horizontal or vertical stacked bar chart.
- Avoid: Pie charts. Our ability to accurately compare 2-D areas of pie wedges pales in comparison to our ability to compare lengths and 2-D positions. Thus, bars always communicate quantity better than wedges.
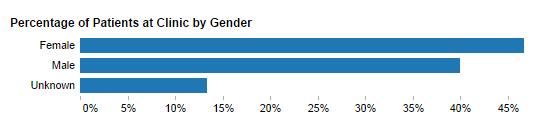

- Goal: Display differences between one or more quantitative data sets and a reference data set.
- Best bet: Bar charts - ranked or unranked, horizontal or vertical - with a quantitative axis where zero represents no deviation at all. Use one bar per category to directly illustrate the deviance between each pair of actual and reference values.
- Exception: If you wish to display deviation through time, then use a time-series like line graph and again plot the deviation directly using just a single line.
- Avoid: Using a separate bar or line for only the actual and reference values, which then requires viewers to a) deduce the quantity expressed by each bar or point along the line and then b) calculate the difference between those quantities. Always provide a direct visualization of the deviance.


Here, we need to consider whether we are talking about a single or a multiple distribution:
- Goal: Show how values from a single data set were observed across, and/or within, a range of ordinal or interval categories
- Best bet: Vertical bars with no spaces between interval categories - otherwise known as a histogram.
- Exception: If you want viewers to see the shape of the overall dataset distribution more than you want them to focus on the values of individual intervals, then use a line rather than bars. This will give you what is called a frequency polygon.
- Exception: If you have a small data set, and want the viewer to be able to visualize every data point in the distribution, then consider using points in a strip plot. If your data set is a little larger then you can consider using points that are slightly transparent and jittered so that variations in color intensity can be used to represent quantitative differences.



- Goal: Show how values from multiple data sets are distributed across, and/or within, a range of ordinal or interval categories
- Best bet: If you've got just a few datasets, a desire to provide a lot of information about the distribution of each dataset within each interval, and a smart audience and/or you are good teacher, box plots (horizontal or vertical) are hard to beat. They communicate a lot of information about a category's distribution, but they take time to interpret. To create an easier to interpret box plot, considering using boxes (sans whiskers) to represent just three of the seven facts that a full box-and-whisker shape is capable to communicating: the high, low and median values of a distribution.
- Exceptions: If you've only got a few distributions to visualize, consider using a series of lines to give you a set of overlaid frequency polygons. Again, the frequency polygons will highlight the overall shape of each distribution across the categories of interest, rather than draw attention to values at just select points.
- Exceptions: If each dataset has only a few values, and you want to draw attention to those individual values as well as depict the overall distribution in each category, then consider using points in a horizontal or vertical strip plot.

Note that just a single dataset's distribution is illustrated here. It is difficult to find a tool to create box plots using multiple data sets. Imagine that a second box was added for each row in the above chart and that is what a multi-data set distribution might look like.

- Goal: Investigate possible relationships between two sets of quantitative values
- Best bet: Points and trend lines in the form of a scatter plot are best suited to this task.
- Exception: If you think the viewers may be unfamiliar with scatter plots, or will have a hard time noticing the correlation between data sets, then consider creating two bar charts that you will display side-by-side (or one on top of the other, if you opt to use vertical bars). Moreover, rank the first bar chart in ascending or descending order. If there is a pattern between quantitative values of each data set, the use of side-by-side bars will display it quite strongly.


Color Brewer provides some easy colour schemes for representing data. It is also useful to see how colour can help and / or hinder comprehension of the data.
At times you will want to graph data sets using more than one quantitative scale and more than one or two categorical variables. To avoid situations using multiple axes and an overwhelming number of bars, lines or points, consider using multiple small graphs arranged in a horizontal or vertical panel or matrix. The small multiples or trellis graphs allow the viewer to see individual categorical patterns as well as pick out patterns in the large collection of categories.

The silly seven are:
- Pastry charts (pies and donuts)
- Radar charts
- Area charts for combining part-to-whole and time-series relationships
- Circle charts
- Unit charts
- Funnel charts
- Waterfall charts for simple part-to-whole relationships
And avoid 3-D trickery for all graph types. 3-D trickery, while it gives a slick look, it impedes accurate interpretation of the data. 3D pastry charts should be avoided at all costs.
Graphs are great tools to use when the shape of the data is capable of conveying the desired message and when you want a display to reveal relationships among sets of values. Other times though, tables are better way of communicating messages about data. Use tables when:
- Readers want to lookup individual values
- Values will need to be easily compared against one another
- Precise values are required
- Quantitative values include more than one unit of measure (which on a graph would require multiple quantitative scales)
- Both detail and summary values are included
I've found very little on this topic in the literature. While these two papers on short on actual visualization examples, they do talk about the underlying processes involved in crafting visualizations of data quality challenges in data sets:
- Pernici, B., & Scannapieco, M. (2003). Data quality in web information systems. In Journal on Data Semantics I (pp. 48–68). Springer. Retrieved from http://link.springer.com/chapter/10.1007/978-3-540-39733-5_3
- Kandel, S., Parikh, R., Paepcke, A., Hellerstein, J. M., & Heer, J. (2012). Profiler: Integrated statistical analysis and visualization for data quality assessment. In Proceedings of the International Working Conference on Advanced Visual Interfaces (pp. 547–554). Retrieved from http://dl.acm.org/citation.cfm?id=2254659
However, taking into consideration the set of data relationships described in the preceding sections, I feel that the relationship most pertinent to the visualization of data quality is that of deviation. Once ideal values for various data quality dimensions are established, and once actual values are collected, displays of deviation between actual and reference values would effectively be displayed using a horizontal or vertical bar chart. As a companion chart, one could also add a second bar chart that features the data quality metric as a percentage with a hash mark to represent the respective reference goal. Small multiples, using ranked bar charts, could then be used to compare a number of practices and a number of measures.

I found this set of papers, posted on this very informative site belonging to an assistant professor of Data Visualization, to be very helpful:
- Cleveland, W. S., & McGill, R. (1984). Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods. Journal of the American Statistical Association, 79(387), 531–554. doi:10.2307/2288400
- Card, S. K., & Mackinlay, J. (1997). The structure of the information visualization design space. In Information Visualization, 1997. Proceedings., IEEE Symposium on (pp. 92–99). Retrieved from http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=636792
- Ahlberg, C., & Shneiderman, B. (1994). Visual information seeking: tight coupling of dynamic query filters with starfield displays. In Proceedings of the SIGCHI conference on Human factors in computing systems (pp. 313–317). Retrieved from http://dl.acm.org/citation.cfm?id=191775
- Healey, C. G., Booth, K. S., & Enns, J. T. (1996). High-speed visual estimation using preattentive processing. ACM Transactions on Computer-Human Interaction (TOCHI), 3(2), 107–135.
- Mackinlay, J. (1986). Automating the design of graphical presentations of relational information. ACM Transactions on Graphics (TOG), 5(2), 110–141.
- Rogowitz, B. E., Treinish, L. A., & Bryson, S. (1996). How not to lie with visualization. Computers in Physics, 10(3), 268–273.
- Shneiderman, B. (1996). The eyes have it: A task by data type taxonomy for information visualizations. In Visual Languages, 1996. Proceedings., IEEE Symposium on (pp. 336–343). Retrieved from http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=545307
- Savva, M., Kong, N., Chhajta, A., Fei-Fei, L., Agrawala, M., & Heer, J. (2011). Revision: Automated classification, analysis and redesign of chart images. In Proceedings of the 24th annual ACM symposium on User interface software and technology (pp. 393–402). Retrieved from http://dl.acm.org/citation.cfm?id=2047247
- Segel, E., & Heer, J. (2010). Narrative visualization: Telling stories with data. Visualization and Computer Graphics, IEEE Transactions on, 16(6), 1139–1148.
- Heer, J., & Bostock, M. (2010). Crowdsourcing graphical perception: using mechanical turk to assess visualization design. In Proceedings of the 28th international conference on Human factors in computing systems (pp. 203–212). Retrieved from http://dl.acm.org/citation.cfm?id=1753357
- Lin, S., Fortuna, J., Kulkarni, C., Stone, M., & Heer, J. (n.d.). Selecting Semantically-Resonant Colors for Data Visualization. Retrieved from http://vis.stanford.edu/files/2013-SemanticColor-EuroVis.pdf
- http://hci.stanford.edu/jheer/projects/
- http://fellinlovewithdata.com/
- http://www.perceptualedge.com/library.php
I did not come across any visualization papers that describe peculiar requirements or perceptual idiosyncrasies that would need to be taken into consideration for primary care, or even health care, viewers of data visualizations. However, here is an excellent presentation from the Lead Information Designer at CIHI on the topic of visualizing healthcare data for health systems planners and regular Canadians, as seen here.
## Web visualization drafting and display tools Here is a brief round-up of data visualization options for building and/or deploying graphs for the web. Firstly, while there are many tools that provide scripts for creating some graph types, there are few that provide an ability to create the full set of graphs we've talked about so far. Secondly, virtually all of the graphing libraries I've come across make use of javascript and other popular javascript libraries, such as jQuery to transform the data into web graphs. Finally, only a subset of libraries are free or free for non-profit use. Taking these things into consideration, in the list below, I've tried to give just an overview of two solutions I think will likely be top contenders for use in the hQuery reporting instrument:A cadillac of data visualization, D3 is an open source javascript library that allows for the creation of interactive, animated or static graphs using existing web standards including CSS, HTML and SVG. It is less of a visualization library and more of a tool to help attach data to graphics generated within the browser.
Pros:
- All graph types are possible to construct using D3
- D3 is free
- D3 is very flexible in terms of graphical design by offering very granular control over all chart elements
- D3 can handle a variety of data inputs including JSON and other data documents (TSV, CSV, etc)
Cons:
- D3, out of the box is not compatible with all browsers, namely IE8 and below. However, there are rather simple workarounds.
- D3 is not as simple to implement as some other graphing libraries in that graphing scripts need to be written (or at least modified from existing examples) rather than just passing data to pre-existing functions that construct entire graphs. Still, there are other libraries which offer more out-of-the box reusable D3 graphing functions, most notably http://nvd3.org/. Others include Rickshaw and xCharts. Furthermore, it would be feasible to take the time and craft a set of scripts for core charts using D3 that you could then re-use for most of your future visualization needs
The next contender is HighCharts. This proprietary (but free for non-profit use) javascript library features greater browser compatibility, out-of-the box support for printing, and functions more like a true library of graphical options in that graphs are produced more than they are composed. This is likely the best place to start if you don't need all graph types and don't want to spend a significant amount of time crafting visualizations.
Pros:
- Free for non-profit use
- Easier to implement
- Works on all browsers including mobile devices
- Support for printing built in
- Accepts a variety of inputs
- Although proprietary, you can download and modify the source for advanced customization
Cons:
- Do not have absolute control over all visual elements
- Seems to feature support for all graphs, minus the dot plots and perhaps the bar chart with negative values
To my surprise, there were not that many options for web graphing that can provide good coverage of the graph types covered above which are also free. If however, you wanted to piece together your visualization offerings with a variety of graphing libraries, then you could consider taking bits and pieces from these HighChart-like products, listed here in order of most likely to please:
SCOOP is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
