| title | description | published | date | tags | editor | dateCreated |
|---|---|---|---|---|---|---|
后端面试八股速记 |
true |
2024-04-28 13:20:38 UTC |
markdown |
2024-03-24 02:44:57 UTC |
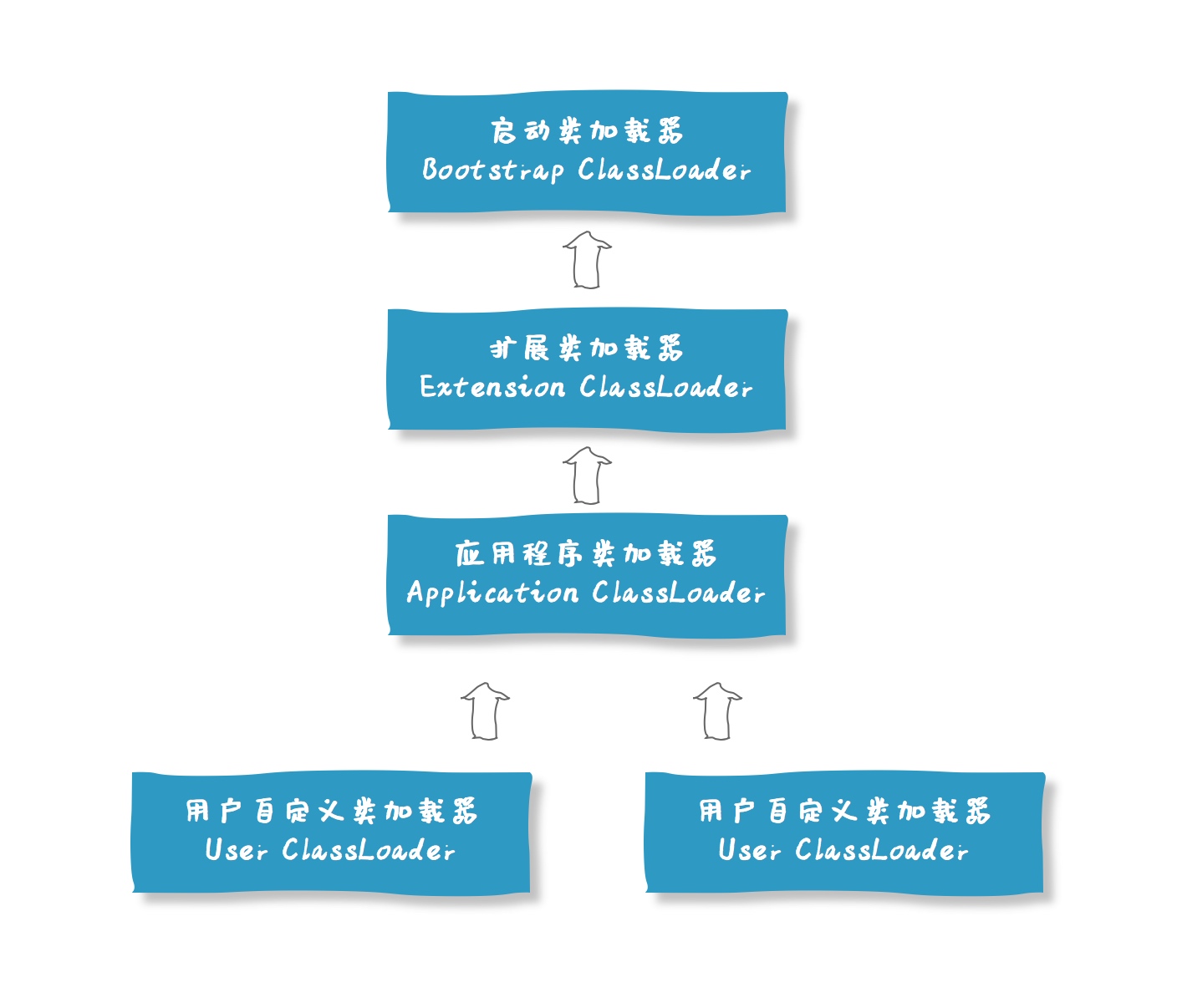
首先去由父加载器去加载,父加载器没有继续委托,最终找不到由应用程序加载器加载。
- 安全
- 避免重复加载
打破双亲委派机制:
重写ClassLoader的findClass方法,不会打破这个机制,只是当父类加载器加载不了的时,会使用自己制定的加载方法
重写ClassLoader的loadClass方法,会打破双亲委派机制
可以自己根据路径获取字节码,然后使用defineClass加载对象。
- 智慧团建自动转移团支部。分析接口,伪装一下直接调接口
- 高中机房XP机器,有保护系统。每次开机需要重新配置环境变量,使用bat自动配置,将安装在其他地方的应用图标copy到桌面
- 抢课脚本
- 钉钉机器人,仓库部署情况
C数据一致性
A可用性
P分区容错性,如果两个分系统之间通信丢失了,整个系统不能崩溃
P必须满足,分为CP系统和AP系统
cache-aside:直接向数据源写入,删除缓存中的数据
cache-as-sor:
- read-through,与cache-aside类似,上面的方法需要读取不到时手动实现缓存,这个方法由缓存内部自己实现,对应用层透明
- write-through, 直写式,同时写回数据源和缓存,更新完成才返回。一致性强,效率低。
- write-back,回写式,直接写入缓存,然后异步写入数据源。一致性弱。
已有:
- redis二级缓存
- 分区间计算余票
- 转乘算法
解决高并发、高可用、高性能问题
- 分布式缓存。目前仅使用了单机缓存,并且数据量小。如果数据量大可以使用分布式缓存。然后借助一致性哈希之类算法实现数据访问
- 逻辑上,引入候补机制,有车次时(放票时),先在后端检查候补订单,仍有余票才放出。防止高并发
- 转乘的计算使用线程池
- 使用消息队列,将瞬时的抢票流量装入消息队列,后台从消息队列中取数据
- 异步处理,座位锁定成功之后就返回,然后装入消息队列让下游去处理订单生成等流程。(美团下单感觉是这么做的)
相同点
(1)都不能被实例化 (2)接口的实现类或抽象类的子类都只有实现了接口或抽象类中的方法后才能实例化。
(3)如果子类是抽象类,可以不全部实现父类的方法,否则必须实现父类(接口)的全部方法
不同点
(1)接口只有定义,不能有方法的实现,java 1.8中可以定义default方法体,而抽象类可以有定义与实现,方法可在抽象类中实现。
(2)实现接口的关键字为implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。所以,使用接口可以间接地实现多重继承。
(3)接口强调特定功能的实现,而抽象类强调所属关系。
(4)接口成员变量默认为public static final,必须赋初值,不能被修改;其所有的成员方法都是public、abstract的。抽象类中成员变量默认default,可在子类中被重新定义,也可被重新赋值;抽象方法被abstract修饰,不能被private、static、synchronized和native等修饰,必须以分号结尾,不带花括号。
红黑树是一种自平衡的二叉搜索树,它通过在每个节点上增加一个颜色属性(红色或黑色)来维护其平衡状态,红黑树的特性包括:
- 每个节点是红色或黑色。
- 根节点是黑色。
- 所有叶子节点(即空节点)都是黑色。
- 如果一个节点是红色的,那么它的两个子节点都是黑色的。
- 从任意节点到其任何叶子的简单路径上都包含相同数目的黑色节点。
这些特性确保了红黑树的平衡,并且任何路径的长度都不会比最短路径长出两倍以上,红黑树在插入和删除节点时可能会破坏这些特性,此时需要进行颜色调整和旋转操作以重新平衡树,红黑树的实现广泛应用于数据库索引、C++ STL中的map和set容器,以及路由算法等领域。
信号量
共享内存
管道
消息队列
socket
信号
- 继承Thread类,实现run方法。(单继承特性,有局限)
- 实现Runnable接口,实现一个执行目标类target对象,然后创建新的thread线程把target填进去。
- 实现Callable接口。实现call方法。有返回值。
- 线程池
实现Runnable VS 继承Thread
- a.覆写Runnable接口实现多线程可以避免单继承局限
- b.实现Runnable()可以更好的体现共享的概念
互斥条件
请求并保持
非剥夺
循环等待
private volatile static DoubleCheckSingleton instance;//volatile防止指令重排
//私有的构造方法
private DoubleCheckSingleton() {}
public static DoubleCheckSingleton getInstance(){
if(instance==null){ //第一层检查,提高效率
synchronized (DoubleCheckSingleton.class){
if(instance==null){ //第二层检查,放在同步代码块中,防止出现多次实例化
instance=new DoubleCheckSingleton();
}
}
}
return instance;
}volatile 防止指令重排,告知所有对于变量的访问都需要从内存中获取
synchronized临界区。通过synchronized(Object) 来进行同步,通过wait和notify和notifyAll来通信
reentrantLock方式,使用lock加锁,通过signal、signalAll和await来进行通信
信号量
管道
- 1.提高响应速度,如果线程池有空闲线程的话,可以直接复用这个线程执行任务,而不用去创建。
- 2.减少资源占用,每次都创建线程都需要申请资源,而使用线程池可以复用已创建的线程。
- 3.可以控制并发数,可以通过设置线程池的最大线程数量来控制最大并发数,如果每次都是创建新线程,来了大量的请求,可能会因为创建的线程过多,造成内存溢出。
- 4.更加方便来管理线程资源。
基于内存
单线程(没有上下文切换,不用考虑锁)
数据结构专门设计的(简单动态字符串)
多路复用IO模型
强制缓存:cache-control和expires字段
协商缓存:etag字段和if-modified-since+last-modified字段
长连接:防止重复三次握手
支持管道传输:解决了发送方的队头阻塞,没有解决响应的队头阻塞
队头阻塞:存在队头阻塞问题
使用双向流传输
消息头压缩
单TCP的多路复用
服务端推送
二进制格式传输
缺陷:TCP层的队头阻塞问题,多个流复用同一个TCP连接,如果一个流阻塞了,那么其他的流都会被阻塞。
使用基于UDP的QUIC协议
无队头阻塞:丢包时只会阻塞流
更快的建立连接:TLS握手的过程与QUIC握手同时进行
连接迁移:使用连接ID标识,而不是四元组(IP、端口),双方IP变化时可以复用之前的上下文。
在http的三次握手之后执行SSL/TLS的握手过程。
混合加密
数字签名(摘要)
数字证书
私有:
- 程序计数器
- 虚拟机栈
- 本地方法栈
共享:
- 堆
- 方法区
垃圾回收的时机:程序空闲时、内存不足时
回收算法:标记清除、标记整理、复制
CMS:老年代回收器,使用标记清除算法。老年代使用超过一定阈值的时候开始回收。分为四个阶段
- 初始标记:应用停止工作,GC标记所有与roots直接相连的对象,速度很快。STW
- 并发标记:应用线程与GC同时工作,GC标记所有可达对象,速度比较慢,但是并行。需要追踪期间应用程序添加的引用。
- 重新标记:应用停止工作,GC处理在并发标记期间增加的黑色到白色点的引用。STW。
- 并发清除:并发的清除所有未被标记的对象。
优点:并发收集、应用程序低停顿。
缺点:使用标记清除算法会导致有空间碎片。有浮动垃圾(在并发标记期间成为垃圾的对象)。
G1:
既是老年代回收器也是新生代回收器。
细节上是复制,整体看是标记整理。
将空间分为很多region,每个region属于老年代或者年轻代(并不固定,可能改变),如果年轻代的使用超过某个阈值,就会触发young GC,方法是eden与survivor0和survivor1来回倒腾,然后可能晋升。
如果老年代的使用超过了IHOP,就会触发混合收集,不止收集年轻代,也收集老年代。方法如下:
- 初始标记:STW,标记所有root能关联到的对象
- 并发标记:遍历整个图
- 最终标记:STW,处理并发标记期间消失的灰色到白色点的引用。
- 筛选回收:STW,对于每个region根据回收价值和成本进行排序,然后根据设置的停顿时间决定回收的region。

-
类加载
去方法区运行池里找引用,检查是否已经被加载和初始化,如果已经被加载了,就进行后续流程,否则加载类
-
内存分配
如果垃圾收集器带有空间压缩整理的功能,那么使用指针碰撞,直接移动指针
否则如果垃圾收集器是基于清楚算法的,那么就要维护一个列表记录哪些可用,哪些不可用
-
对象初始化(虚拟机层面)
将一些信息存储在Object header中
-
对象初始化(java层面)
先静后动、先父后子、先变量后代码块、构造器。
-
解决内存分配的多线程并发竞争问题
添加CAS锁,失败重试
预先给线程分配TLAB,如果TLAB使用完,那么再使用CAS的方法
- 互斥锁:如果获取锁失败则放弃CPU、切换线程。
- 自旋锁:如果获取锁失败则忙等待。
- 读写锁:当写锁没有被持有时,读锁可以多个线程持有。分为读优先锁和写优先锁
- 乐观锁:冲突概率很低的时候可以使用乐观锁,全程不加锁,修改资源后再检查是否有冲突。重试成本高。
redis的每条写命令都写到AOF日志中。顺序是:先写到数据库,再更新日志。原因是:避免检查开销,防止阻塞写到数据库的操作。缺点:如果写到数据库但是没更新日志会不一致、会阻塞下一条命令。
首先会把日志写到缓冲区,然后定时调用fsync把数据写到磁盘。
写回策略(本质是调用fsync的时机不同):每次更新日志都同步到磁盘、每秒更新、不主动更新(由OS决定时机)。一致性越来越差,效率越来越高。
AOF重写:防止AOF文件过大如果有个多次修改同一键值,只保留最后一个。在主进程上进行,会阻塞命令执行。先写到新的AOF文件,再覆盖。原地重写会导致污染。
AOF后台重写:bgwriteaof(),创建子进程,初始时与父进程(主进程)共享内存。使用写时复制(COW)策略,当主进程更改内存的时候会复制内存,并设置为可读写。减少复制内存的开销。后台重写在重写过程中的命令无法写入,所以需要一个AOF重写缓冲区,当AOF重写完成后追加到日志文件后面
将所有的内存数据保存到磁盘中。分为save(在主线程保存)和bgsave(后台保存)
采取的是全量快照的方式,开销大,不适合频繁触发,一般5分钟一次。
bgsave采取的是COW策略,减小开销。
AOF恢复时比RDB慢
RDB占用存储空间小
RDB对于主线程占用小,不需要进行磁盘IO
RDB fork子进程时可能比较耗时
RDB COW时,如果频繁修改会占用很多内存,最大可能多一倍内存
崩溃时,RDB会丢失部分时间的数据。
AOF丢失数据少
AOF易懂
AOF比RDB大
速度可能比RDB慢
在AOF重写的过程中,先使用RDB的策略将整个二进制文件写到新的AOF文件中,然后将AOF重写缓冲区的内容追加进去。
定时删除
定期删除
惰性删除
每过一段时间(可以设置,默认是1s10次)随机抽取20(写死的)个key检查是否过期,删除过期的,如果过期的超过5个那么继续抽查。最多抽查20ms
-
刚开始的时候RPC用于C/S架构,http用于B/S架构
-
服务发现
-
RPC有连接池
-
PB更小,更简略。性能更好。
从物理存储的角度来看,索引分为聚簇索引(主键索引)、二级索引(辅助索引)。
这两个区别在前面也提到了:
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
所以,在查询时使用了二级索引,如果查询的数据能在二级索引里查询的到,那么就不需要回表,这个过程就是覆盖索引。如果查询的数据不在二级索引里,就会先检索二级索引,找到对应的叶子节点,获取到主键值后,然后再检索主键索引,就能查询到数据了,这个过程就是回表。