06 ‐ Ingestão de Dados no Elasticsearch
A ingestão de dados é um aspecto crucial do uso do Elasticsearch, permitindo que você colete, enriqueça, transforme e indexe seus dados de várias fontes. Várias ferramentas podem ser usadas para esse fim, cada uma com suas particularidades: Ingest Pipelines, Beats, Elastic Agent e Logstash.

O Ingest Pipeline é um recurso do Elasticsearch que permite definir uma série de processadores que transformam, enriquecem ou manipulam dados antes de serem indexados. Esses pipelines são executados no momento da indexação, diretamente no nó do Elasticsearch, proporcionando uma maneira conveniente e eficiente de pré-processar os dados.
- Funcionalidades: Pode incluir a remoção de campos desnecessários, conversão de formatos de data, extração de partes de strings, entre outras transformações.
- Aplicabilidade: Ideal para transformações leves e quando não se necessita de um processamento externo complexo.
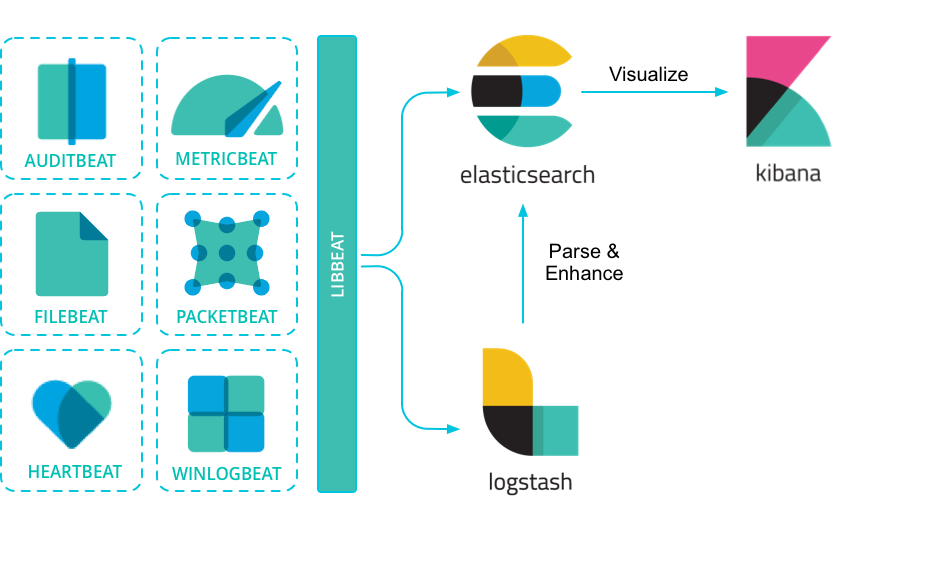
Beats são agentes leves de envio de dados que são instalados nas máquinas para coletar dados e enviá-los diretamente para o Elasticsearch ou para o Logstash para processamento adicional. Existem vários Beats para diferentes propósitos, como Filebeat para logs, Metricbeat para métricas, Packetbeat para tráfego de rede, etc.
- Funcionalidades: Cada Beat é projetado para uma fonte de dados específica, coletando dados e metadados relevantes.
- Aplicabilidade: Útil quando você deseja coletar dados diretamente das fontes sem transformações complexas.
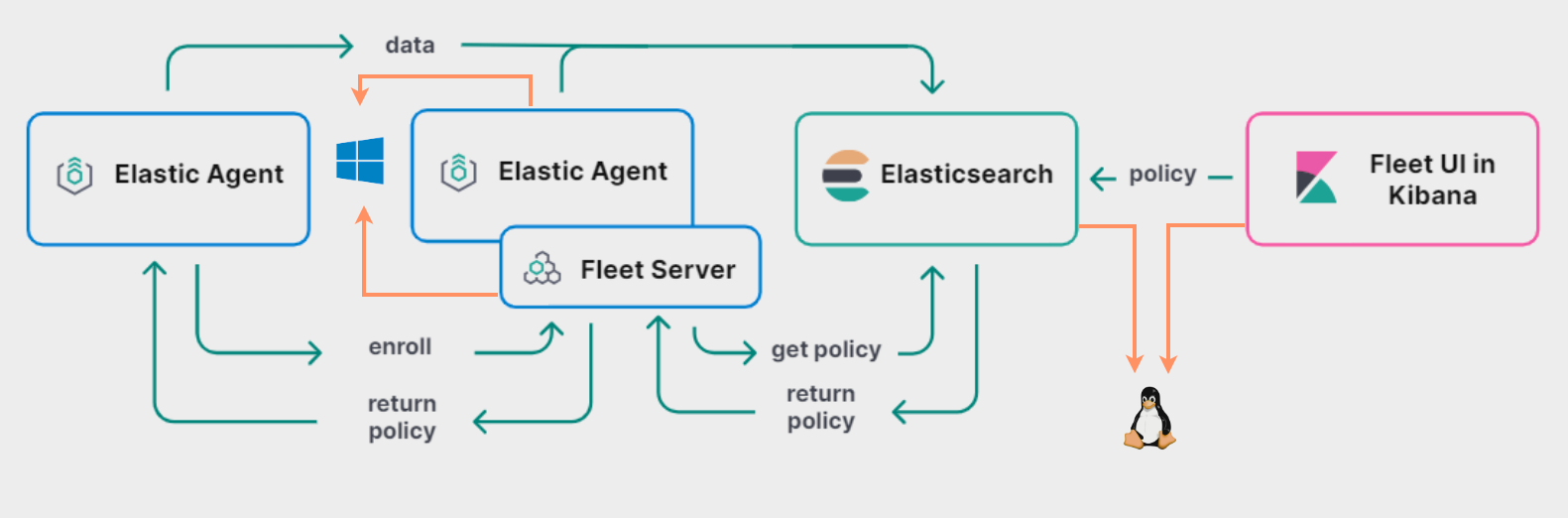
O Elastic Agent é uma ferramenta mais recente e unificada para observabilidade e segurança, podendo gerenciar vários Beats e integrar-se com o Fleet para gerenciamento centralizado. O Elastic Agent simplifica a coleta, transformação e envio de dados para o cluster do Elasticsearch.
- Funcionalidades: Oferece uma maneira unificada de implantar e gerenciar a coleta de dados em sua infraestrutura, podendo substituir o uso de múltiplos Beats.
- Aplicabilidade: Ideal para cenários onde é necessário uma solução de ingestão e gestão mais holística e integrada.
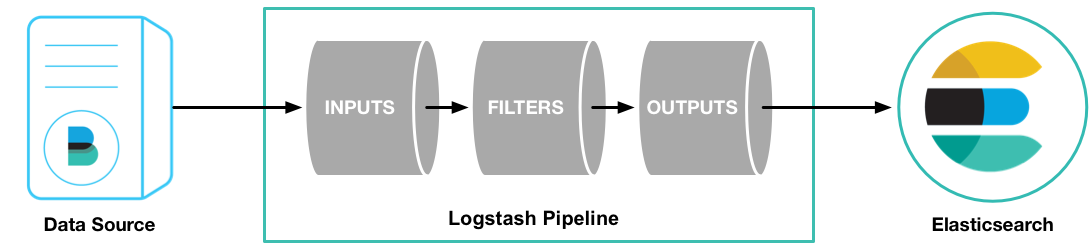
Logstash é uma ferramenta robusta de ingestão de dados que pode coletar, transformar e enviar dados para o Elasticsearch. Diferentemente dos Beats, o Logstash oferece uma ampla variedade de plugins de entrada, filtros e saídas, permitindo processamentos mais complexos e transformações de dados.
- Funcionalidades: Pode filtrar, analisar e transformar dados de diversas formas, com uma vasta gama de plugins disponíveis.
- Aplicabilidade: Recomendado para situações em que é necessário um processamento de dados mais complexo ou quando se trabalha com uma variedade mais ampla de fontes de dados.
- Beats e Elastic Agent: Direcionados para a coleta rápida e eficiente de dados de várias fontes, com o Elastic Agent oferecendo uma abordagem mais unificada e gerenciável.
- Logstash e Ingest Pipelines: Enquanto o Logstash é adequado para processamentos mais pesados e complexos, os Ingest Pipelines oferecem uma solução mais leve e direta dentro do próprio Elasticsearch.
- Integração: Todos esses componentes podem ser combinados de várias maneiras, dependendo dos requisitos específicos de ingestão, processamento e análise de dados.
Possíveis arquiteturas:

Neste laboratório, você aprenderá a instalar, configurar e utilizar o Filebeat e o Metricbeat no Linux Ubuntu, incluindo a configuração para a coleta de logs do sistema e logs do Tomcat, além de métricas do sistema. Também cobriremos o uso do Keystore para proteger informações sensíveis como senhas.
Nosso objetivo no laboratório a partir desse ponto será entender as funcionalidades das outras ferramentas. Estaremos trabalhando apenas com uma instância do elasticsearch e do kibana.
- Instale o Filebeat:
-
Faça o Download no diretório /tmp
-
Utilizando curl
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.15.1-amd64.deb sudo dpkg -i filebeat-8.15.1-amd64.deb
-
Utilizando
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.15.1-amd64.deb
sudo dpkg -i filebeat-8.15.1-amd64.deb
```
2. **Instale o Metricbeat:**
```bash
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.15.1-amd64.deb
sudo dpkg -i metricbeat-8.15.1-amd64.deb
```
```bash
wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.15.1-amd64.deb
sudo dpkg -i metricbeat-8.15.1-amd64.deb
```
## 6.2.2 Configuração dos Beats
1. **Crie e configure o Keystore para o Filebeat:**
```bash
sudo filebeat keystore create
sudo filebeat keystore add ES_PASSWORD
```
2. **Crie e configure o Keystore para o Metricbeat:**
```bash
sudo metricbeat keystore create
sudo metricbeat keystore add ES_PASSWORD
```
3. **Configure o Filebeat para coletar logs do sistema e logs do Tomcat:**
- Habilite o módulo system:
```bash
sudo filebeat modules enable system
```
- Habilite a coleta do módulo conforme exemplo aaixo:
```yaml
vi /etc/filebeat/modules.d/system.yml
- module: system
# Syslog
syslog:
enabled: true
auth:
enabled: true
```
- Baixe um arquivo de log do Tomcat para teste:
```bash
wget https://raw.githubusercontent.com/tornis/esstackenterprise/master/cap04-ingestao/tomcat.log
```
- Configure o Filebeat para ler o log do Tomcat com suporte a multiline:
Edite `/etc/filebeat/filebeat.yml`:
```yaml
filebeat.inputs:
- type: filestream
paths:
- /tmp/tomcat.log
multiline.pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:'
multiline.negate: false
multiline.match: after
setup.kibana:
host: "https://localhost:5601"
ssl.verification_mode: "none"
output.elasticsearch:
hosts: ["localhost:9200","localhost:9201","localhost:9202"]
preset: balanced
protocol: "https"
username: "elastic"
password: "${ES_PASSWORD}"
ssl.verification_mode: "none"
```
4. **Configure o Metricbeat para coletar métricas do sistema:**
- Habilite o módulo system:
```bash
sudo metricbeat modules enable system
```
- Atualize a configuração em `/etc/metricbeat/metricbeat.yml`:
```yaml
setup.kibana:
host: "https://localhost:5601"
ssl.verification_mode: "none"
output.elasticsearch:
hosts: ["localhost:9200","localhost:9201","localhost:9202"]
preset: balanced
protocol: "https"
username: "elastic"
password: "${ES_PASSWORD}"
ssl.verification_mode: "none"
```
## 6.2.3 Testando e Executando
1. **Teste as configurações e a conectividade:**
- Filebeat:
```bash
sudo filebeat test config
sudo filebeat test output
```
- Metricbeat:
```bash
sudo metricbeat test config
sudo metricbeat test modules
sudo metricbeat test output
```
2. **Execute o setup inicial para carregar dashboards Kibana, index templates e ingest pipelines:**
- Filebeat:
```bash
sudo filebeat setup
```
- Metricbeat:
```bash
sudo metricbeat setup
```
3. **Inicie os serviços:**
```bash
sudo systemctl start filebeat
sudo systemctl start metricbeat
```
Após completar esses passos, você terá o Filebeat configurado para coletar logs do sistema e do Tomcat, utilizando o recurso de multiline para logs do Tomcat, e o Metricbeat configurado para coletar métricas do sistema. Ambos os serviços estão seguramente configurados para comunicar com o Elasticsearch, usando senhas armazenadas no Keystore.
## 6.3 - Laboratório 2 - Instalando e Configurando o Elastic Agent e o Fleet Server
Neste laboratório, você aprenderá a instalar e configurar o Elastic Agent e o Fleet Server no Linux Ubuntu. O Elastic Agent é uma ferramenta unificada para coleta de dados que pode ser gerenciada centralmente pelo Kibana usando o Fleet. Vamos configurar o Elastic Agent para coletar logs e métricas do sistema. Para isso siga os passos abaixo:
1. **Configurando o Fleet Server**
Inicialmente acesse o menu e vá para o Menu>Stack Management>Fleet.
<img src="https://github.com/tornis/elasticstacktotal/blob/images/1.png" alt="drawing" width="200"/>
Agora clique em no botão **Add Fleet Server**
<img src="https://github.com/tornis/elasticstacktotal/blob/images/2.png" alt="drawing" width="600"/>
Preencha os campos conforme modelo abaixo. Não esqueça que o endereço ip deve estar acessível pelos agentes e com o https no endereço ok?
<img src="https://github.com/tornis/elasticstacktotal/blob/images/3.png" alt="drawing" width="600"/>
Após definido o endereço ip, o Fleet irá instalar a Policy conforme figura abaixo:
<img src="https://github.com/tornis/elasticstacktotal/blob/images/4.png" alt="drawing" width="600"/>
Agora ele fornece um passo a passo de como instar o Elastic Agent para que o o Fleet Server fique disponível. Siga os passo abaixo:
<img src="https://github.com/tornis/elasticstacktotal/blob/images/5.png" alt="drawing" width="600"/>
Durante a instalação o Elastic Agent irá perguntar se ele será um serviço do Linux e nesse caso digite "Y" para conforme que Sim:
Após instalação o Elastic Agent irá estabelecer a conexão com o Elasticsearch e validar as configurações. A tela abaixo deverá ser apresentada confirmado que o Elatic Agent e o Fleet Server está configurado e funcional:
<img src="https://github.com/tornis/elasticstacktotal/blob/images/6.png" alt="drawing" width="600"/>
Após feito a confirmação podemos voltar a tela do Fleet no qual podemos constatar que o Elastic Agent está ativo e configurado com a policy Fleet Server.
<img src="https://github.com/tornis/elasticstacktotal/blob/images/7.png" alt="drawing" width="800"/>
## 6.4 - Logstash - Indexando Banco de Dados
Neste tópico, vamos explorar como indexar dados de um banco de dados SQLite no Elasticsearch usando o Logstash. Vamos seguir um passo a passo para preparar o ambiente, configurar o Logstash e finalmente indexar os dados.
## 6.4.1 Preparação do Ambiente
1. **Instalação do Logstash e SQLite:**
Como root, instale o SQLite no Ubuntu:
```bash
sudo apt-get update
sudo apt-get install sqlite3
```
Como usuário elastic no Ubuntu:
```bash
su - elastic
bash
cd /opt/elastic
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.15.1-linux-x86_64.tar.gz
tar zxfv logstash-8.15.1-linux-x86_64.tar.gz
cd logstash-8.15.1
```
2. **Criação da Pasta Datasets:**
Mude para o usuário `elastic` e crie a pasta `datasets` em `/opt/elastic`:
```bash
sudo -u elastic mkdir -p /opt/elastic/datasets
```
3. **Download do Banco de Dados de Exemplo:**
Baixe o banco de dados SQLite de exemplo para a pasta `/opt/elastic/datasets`:
```bash
sudo -u elastic wget -P /opt/elastic/datasets https://raw.githubusercontent.com/tornis/esstackenterprise/master/datasets/chinook.db
```
4. **Download do Driver JDBC do SQLite:**
Baixe o driver JDBC do SQLite para a pasta `/opt/elastic/datasets`:
```bash
sudo -u elastic wget -P /opt/elastic/datasets https://github.com/tornis/esstackenterprise/raw/master/datasets/sqlite-jdbc-3.7.2.jar
```
5. **Download e Descompactação do Logstash:**
Baixe e descompacte o Logstash:
```bash
sudo -u elastic wget -P /opt/elastic https://artifacts.elastic.co/downloads/logstash/logstash-8.12.1-linux-x86_64.tar.gz
cd /opt/elastic
sudo -u elastic tar -xzf logstash-8.12.1-linux-x86_64.tar.gz
cd logstash-8.12.1
```
## 6.4.2 Configuração do Logstash
Após preparar o ambiente, vamos configurar o pipeline do Logstash para indexar os dados no Elasticsearch.
1. **Criação do Arquivo de Configuração:**
Crie o arquivo `config/database.conf` no diretório do Logstash com o seguinte conteúdo:
```bash
sudo -u elastic vi config/database.conf
```
```conf
input {
jdbc {
jdbc_driver_library => "/opt/elastic/datasets/sqlite-jdbc-3.7.2.jar"
jdbc_driver_class => "org.sqlite.JDBC"
jdbc_connection_string => "jdbc:sqlite:/opt/elastic/datasets/chinook.db"
jdbc_user => ""
schedule => "* * * * *"
tracking_column => "invoicedate"
tracking_column_type => "timestamp"
use_column_value => true
statement => "SELECT * from Customer c JOIN Invoice i on i.CustomerId = c.CustomerId WHERE i.InvoiceDate > :sql_last_value ORDER BY i.InvoiceDate ASC limit 5"
}
}
filter {
date {
match => [ "invoicedate", "yyyy-MM-dd HH:mm:ss" ]
}
}
output {
elasticsearch {
hosts => ["https://localhost:9200","localhost:9201","https://localhost:9202"]
ssl_enabled => true
ssl_verification_mode => "none"
index => "chinook-%{+YYYY.MM.dd}"
user => "elastic"
password => "123456"
}
}
```
**Explicação:**
- **input/jdbc**: Define a configuração para coletar dados do banco SQLite usando JDBC.
- `jdbc_driver_library`: Caminho para o driver JDBC do SQLite.
- `jdbc_driver_class`: Classe do driver JDBC.
- `jdbc_connection_string`: String de conexão com o banco de dados.
- `jdbc_user`: Nome do usuário para conexão (vazio para SQLite).
- `schedule`: Cronograma para executar a consulta.
- `tracking_column`: Coluna usada para rastrear as últimas alterações.
- `statement`: Consulta SQL para coletar dados.
- **filter/date**: Configura o filtro para analisar o campo de data.
- **output/elasticsearch**: Define como os dados serão enviados para o Elasticsearch.
- `hosts`: Endereços dos nós do Elasticsearch.
- `ssl_enabled` e `ssl_verification_mode`: Configurações para o uso de SSL.
- `index`: Padrão de nomeação do índice no Elasticsearch.
- `user` e `password`: Credenciais para o Elasticsearch.
Para ajustar o Logstash para carregar a configuração específica do arquivo `database.conf`, precisamos editar o arquivo `pipelines.yml`, que gerencia múltiplos pipelines dentro do Logstash. Veja como proceder:
## 6.4.3 Ajuste do Arquivo `pipelines.yml`
1. **Editar o Arquivo `pipelines.yml`:**
No diretório de instalação do Logstash, edite ou crie o arquivo `pipelines.yml`. Especifique o caminho do arquivo de configuração `database.conf`:
```bash
cd /opt/elastic/logstash-8.12.1
sudo -u elastic vi config/pipelines.yml
```
```yaml
- pipeline.id: chinook_pipeline
path.config: "/opt/elastic/logstash-8.12.1/config/database.conf"
```
Aqui, `pipeline.id` é um identificador único para o pipeline, e `path.config` aponta para o arquivo de configuração que acabamos de criar.
## 6.4.4 Iniciando o Logstash
Após configurar o arquivo `pipelines.yml`, podemos iniciar o Logstash para processar os dados conforme definido.
1. **Iniciar o Logstash:**
Navegue até o diretório do Logstash e execute o seguinte comando para iniciar o processo de ingestão:
```bash
sudo -u elastic /opt/elastic/logstash-8.12.1/bin/logstash
```
Esse comando inicia o Logstash e carrega a configuração especificada, iniciando a coleta de dados do banco de dados SQLite e indexando-os no Elasticsearch.
Ao executar esses passos, o Logstash irá periodicamente consultar o banco de dados SQLite conforme definido na consulta SQL em `database.conf`, e indexar os resultados no Elasticsearch. Você pode verificar o sucesso da operação observando os logs do Logstash e também verificando se os dados aparecem no índice especificado no Elasticsearch.
## 6.5 - Utilizando o Ingest Pipelines
Nesta seção, exploraremos uma outra abordagem de ingestão e tratamento de dados: os Ingest Pipelines. Uma distinção importante dos Ingest Pipelines em relação ao Logstash e aos Beats é que eles não buscam ativamente os dados para tratamento; em vez disso, os Ingest Pipelines recebem e processam as informações diretamente.
Esta técnica oferece uma maneira eficiente de realizar transformações e preparações nos dados antes de serem indexados no Elasticsearch. Ao compreender e utilizar os Ingest Pipelines, podemos otimizar o fluxo de dados e garantir que estejam prontos para serem consultados e analisados de forma eficaz.
## 6.5.1 Criando e gerindo pipelines
No Kibana, abra o menu principal e clique em Stack Management > Ingest Pipelines. Para criar um pipeline, clique em Create Pipeline > New Pipeline. Também é possível usar as APIs de ingestão no Dev Tools para criar e gerenciar pipelines. Sempre importante lembrar que os processors definidos são executados sequencialmente na ordem especificada.

Antes de usar um pipeline em produção, é recomendado que você teste ele utilizando documentos de amostra. Ao criar ou editar um pipeline no Kibana, clique em "Add documents". Na aba Documents, forneça documentos de amostra e clique em "Run the pipeline".
Da mesma forma, o Dev Tools também permite testar pipelines usando a API de simulação de pipeline. Você pode especificar um pipeline configurado no caminho da solicitação.
## 6.6 - Laboratório 3 - Criando um Ingest Pipeline
```json
PUT _ingest/pipeline/meu_pipeline
{
"processors": [
{
"set": {
"field": "idade",
"value": "40"
}
},
{
"dissect": {
"field": "classificacao",
"pattern": "%{fornecedor_status} %{fornecedor_negativado} %{fornecedor_ativo_receita}"
}
},
{
"html_strip": {
"field": "descricao_fornecedor"
}
}
]
}
```
## 6.6.1 Utilizando o pipeline para ingestão
- **Para cada documento**:
```json
POST fornecedor/_doc/3?pipeline=meu_pipeline
{
"codigo": 124,
"nome_fornecedor": "GOL Linhas Aereas",
"cnpj": "12222334000102",
"endereco": "Rua tal e etc",
"bairro": "Fulano",
"cidade": "Caxias",
"uf": "RJ",
"classificacao": "sim não ativo",
"descricao_fornecedor": "<br>teste de remoçao html</br>"
}
```
- **Para o índice**:
```json
PUT fornecedor_teste
{
"settings": {
"default_pipeline": "meu_pipeline"
}
}
```
```json
POST fornecedor_teste/_doc/1
{
"codigo": 124,
"nome_fornecedor": "GOL Linhas Aereas",
"cnpj": "12222334000102",
"endereco": "Rua tal e etc",
"bairro": "Fulano",
"cidade": "Caxias",
"uf": "RJ",
"classificacao": "sim não ativo",
"descricao_fornecedor": "<br>teste de remoçao html</br>"
}
```