Jonas Mueller, Aditya Thyagarajan, AAAI-2016
This paper proposes a siamese adaptation of the Long Short-Term Memory [LSTM] network for labeled data comprised of pairs of variable-length sequences. The proposed model is applied to assess semantic similarity between sentences, improving over the state of the art, outperforming carefully handcrafted features and recently proposed neural network systems of greater complexity.
Main contributions:
-
A simple adaptation of the LSTM has been trained on paired examples to learn a highly structured space of sentence-representations that captures rich semantics.
-
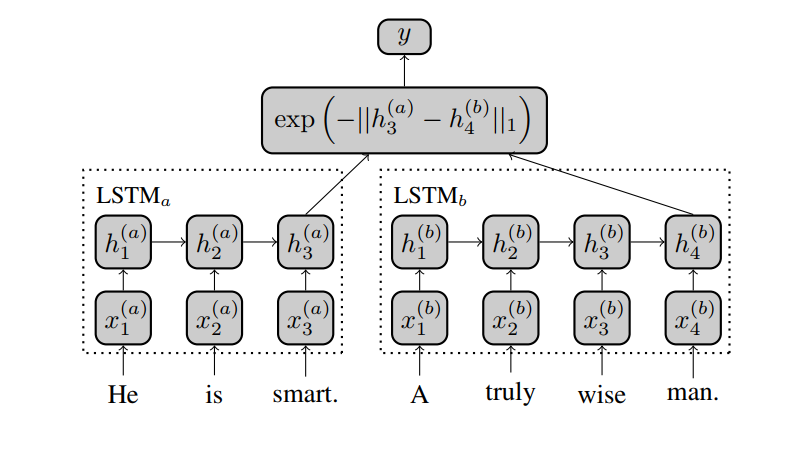
The model uses LSTMs to read in word-vectors representing each input sentence and employs its final hidden state as a vector representation for each sentence. This vector representation is used to calculate the similarity between the input sentences.
-
Unlike previous works on sentence similarity, which employ manual feature generation, substantial architectural engineering in their models or complex learning algorithms on the representations, the model proposed here consists of just two simple LSTM networks with tied weights. Also, a simple similarity function is used which forces the LSTM to entirely capture the semantic differences during training.
-
L1 vs L2 norm: Using a L2 rather than L1 norm in the similarity function can lead to undesirable plateaus in the overall objective function
-
Data augmentation: To ensure invariance to precise wording, and generate more training examples, 10,022 additional training examples are generated by replacing random words with one of their synonyms found in Wordnet [Miller 1995].
-
Pre-training: The MaLSTM is pre-trained on separate sentence-pair data provided for the earlier SemEval 2013 Semantic Textual Similarity task [Agirre and Cer 2013]. The weights resulting from this pre-training thus form our starting point for the SICK data
-
The model is trained on the explicit task of semantic similarity, hence semantic structure in the resulting representation is immediately evident, unlike previous works which rely on complex operations over their learned representation.
-
Even though the representations have been learned for sentence similarity, they perform almost as good as previously proposed methods for "Entailment classification" task. This shows that the representations are able to store the general semantics of the sentences.
- Due to limited training data, performance gains by switching to multi-layer or bidirectional LSTMs have not been evaluated.
https://github.com/dhwajraj/deep-siamese-text-similarity/
https://github.com/aditya1503/Siamese-LSTM