变长记录主要分为以下几种类型:
-
大小变化的数据项
字段中含有 varchar 等不定长字段。
-
重复字段
一行记录中一个字段重复出现多次,但重复的次数没有规律。
-
可变格式记录
不知道记录中有哪些字段、字段是否有重复、字段的类型、字段的长度等,例如 XML 类型的数据。
-
大字段
通常说的 blob 字段,可能需要几个块链接在一起存储。
例如上节示例的 SQL 语句中的 address 字段,是一个 varchar 类型,在存储中一般的存储原则是先存定长,再存变长。例如在 header 之后,使用一些存储空间来保存变长字段的地址长度和具体地址,最后通过访问该地址的若干长度,即可访问变长字段的完整内容。
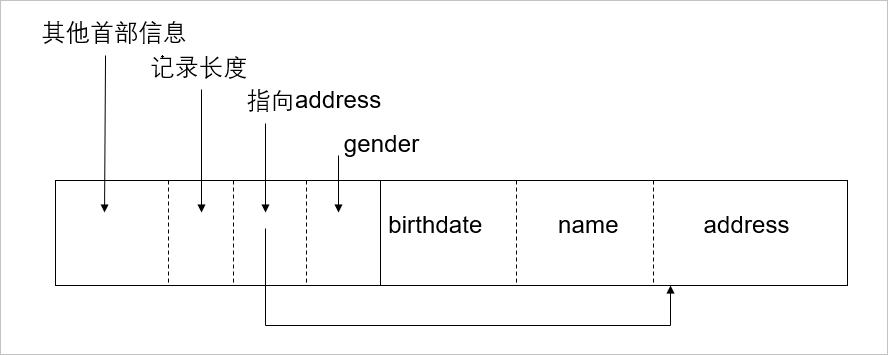
重复字段有两种存储方式。第一种与变长字段的存储类似,其思想是把重复字段的地址使用一段空间进行保存,并把重复的字段紧密的放到行的最后,再根据这个地址访问到第一个重复字段,因为字段长度已知,因此从第一个地址往后遍历直到获取所有重复字段,如下图所示。
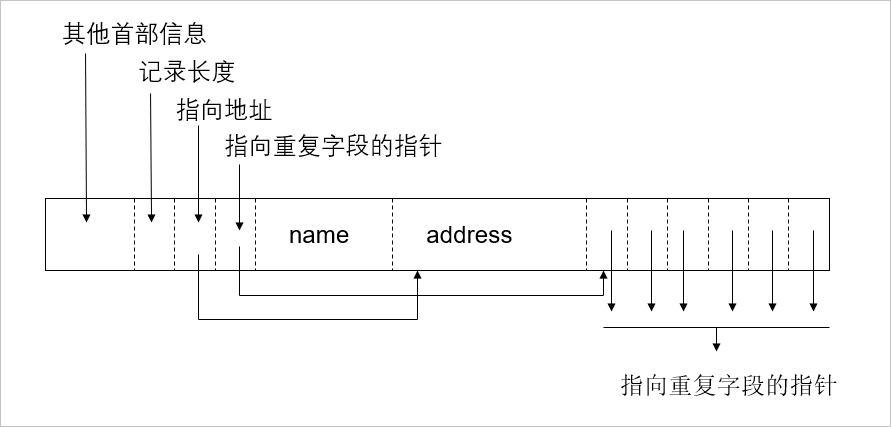
另外一种存储方式是通过类似索引的方式分块存储。如下图所示,在第一个块上,除了记录定长字段外,还需要把非定长字段的指针以及非定长字段的长度保存起来,而指针指向的是另外一个块具体的数据,这种方式有好也有坏,好处是保持了第一个块上所有字段的定长属性,方便查询,坏处是访问数据时增加了额外的磁盘 IO。
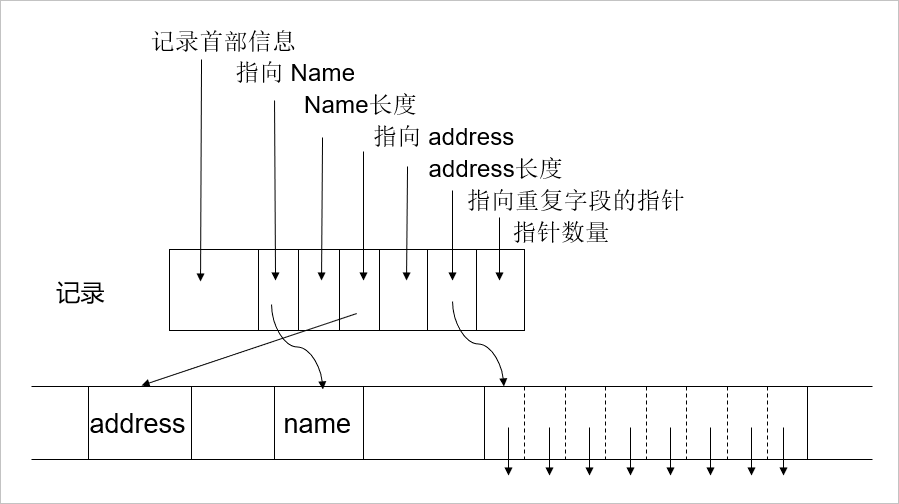
可变格式的记录,通俗来讲就是字段没有固定格式的记录,在数据库的维度来说是指没有具体表结构的数据,是非结构化的数据,例如 XML 文件。
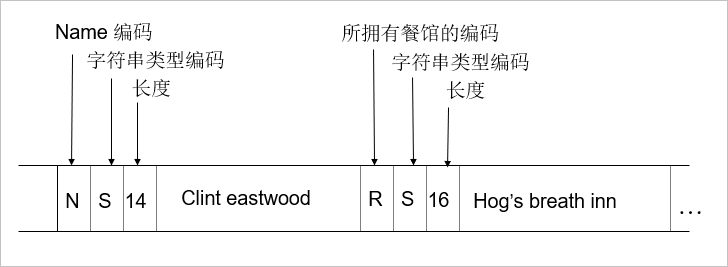
示例:假设要记录一个人的信息,包括姓名、投资的餐馆等,可能字段固定但是内容不固定。这个时候可以使用标记(如姓名)以及类型(如 string)加上长度来记录,例如下图中的 N 表示 name,S 表示 string 类型,14 表示 name 的长度。这样做的好处是即便不知道存储的格式,但是可以把一些特征标识保存起来,最后根据标识解析出数据。
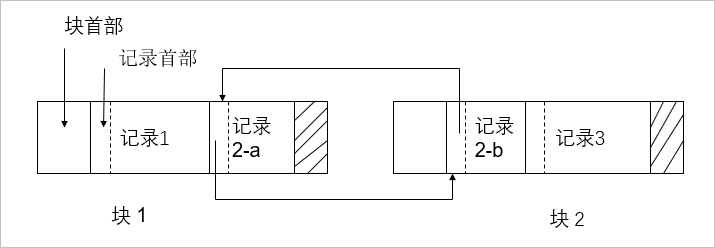
所谓大值,是指在一个块中无法存储的记录,大值涉及多个块之间的交互。
示例:如下图记录 2 存储时,分成了两部分进行存储,分别是记录 2-a 和记录 2-b,其中在存储记录 2-a 的时候,需要额外的存储空间来保存一些数据:一是标识,表明这是一个记录的片段;二是片段的序号,如这是第 1 个片段,或者第 N 个片段;最后还要保存指向下一个片段的指针,用于跨块之间的访问。
blob 是大值字段类型,常见的 blob 是音视频文件。通常 blob 需要多个连续块,或者块的链表进行保存,并通过分散保存在多盘中间,提高单位时间的访问效率。
例如我们在观看电影时,电影数据并不会全部加载到内存中,而是在播放到某个片段之前,把对应的数据从磁盘中加载到内存,或者我们快进到某个片段时,能够快速的把该片段对应的内容加载进来。这里其实就是建立 blob 的索引来快速定位到具体的 blob 块。
本节只简单介绍列存的概念,暂不对列存做深入讨论。
-
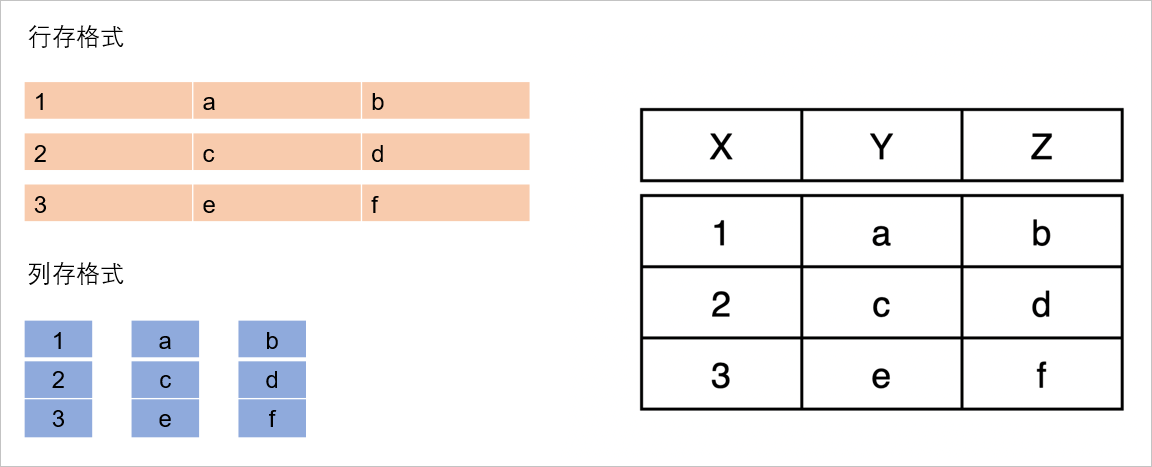
行存
简单来说就是按行存储,例如上图有一张表,表结构中有 X Y Z 三个字段,表中插入了三条记录。如图中黄色是行存的形式,可以看到数据是按照表结构的行来存储的,大部分传统的关系型数据库都是以行存为基础。
-
列存
列存顾名思义是按照表结构的列来存储,如上图中蓝色是列存的形式。
可能有人会有疑问,如果插入了很多行记录,按照列存会不会导致一列的数据非常大?当然是会的,但是数据库会把这一列使用多个存储单元进行存储,甚至可能跨越多个磁盘。
即便这样,列存也有天然的优势,例如因为列值的类型都一样,列存天然适合做数据压缩,这对于控制存储成本是非常有利的。再者,我们可能只针对某几列的数据进行数据分析,因此列存也非常合适 AP 系统。列存的具体优缺点如下:
优点:
-
按需读取列,减少非必要数据的访问。
-
列字段类型统一,非常利于做压缩。
-
利于做列的聚合操作。
-
适合做大数据分析,AP 性能好。
缺点:
-
写入/更新耗时相对行存较长,TP 性能差。
-
不适合做频繁的删除操作。