You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
I am trying to train an ML model on time series data. The input is 10 timeseries which are essentially a sensor data. The output is another set of three time series. I feed the model with the window of 100. So, the input shape becomes (100, 10). I want to predict output time series values for single time step. So, the output shape becomes (1, 3). (If I create mini batches of size say x, the input and output shapes become (x, 100, 10) and (x, 1, 3)).
My approach is to first overfit the model on smaller number of records. See if model is indeed learning / able to overfit the data. Then add some regularization (mostly dropout) and then try to train the model on full dataset.
First, I tried to overfit LSTM model on small dataset and visualised the outcome. It did well. So, I tried to train it on the whole dataset. It did okayish, but still struggled at some places. The LSTM model which I tried is as follows:
I tried adding dropouts too, but it did not yield any significant improvement. So, I tried to train PatchTST transformer model. First, I tried to overfit smaller model and did well. In fact, when I visualized the output, I realised that it was able to get tighter overfit than the LSTM model. So, I tried to train it on the whole dataset. But the performance was not at all closer to LSTM.
The initial version of PatchTST I tried is as follows:
And some more combinations. These hyperparameter combinations are selected so that I can fit the model in GPU with 24GB memory. However, no configuration yield validation loss comparable to LSTM. These are the LSTM vs PatchTST curves:
The corresponding learning rate curves are as follows:
I used to step down the learning rate if the performance does not improve for 7 epochs.
What I am missing here? Do I miss any time series transformer related insight?
PS1: Yes, the base LR starts from 0.00005, followed by step down to 0.000005, 0.0000005, 0.00000005. I know these are excessively tiny. But, in the beginning I tried to train LSTM with bigger base like 0.001, LR 0.005, 0.0005 etc, but it did not work at all. It all started working only after starting with 0.00005. May be because my sensor values themselves are very tiny.
PS2: It might seem that the LSTM val loss has already reached near 0. But, thats only because I have higher validation loss PatchTST runs in the plot. If I remove them and add LSTM overfitting run, then it looks something like this:
The text was updated successfully, but these errors were encountered:
Mahesha999
changed the title
How to do hyper param optimization to improve beat the performance of LSTM?
How to do hyper param tuning to improve beat the performance of LSTM?
Oct 7, 2024
Mahesha999
changed the title
How to do hyper param tuning to improve beat the performance of LSTM?
How to do hyper param tuning to improve the performance of LSTM?
Oct 7, 2024
Mahesha999
changed the title
How to do hyper param tuning to improve the performance of LSTM?
How to finetune hyper parameters to beat the LSTM performance?
Oct 7, 2024
I am trying to train an ML model on time series data. The input is 10 timeseries which are essentially a sensor data. The output is another set of three time series. I feed the model with the window of 100. So, the input shape becomes
(100, 10). I want to predict output time series values for single time step. So, the output shape becomes(1, 3). (If I create mini batches of size sayx, the input and output shapes become(x, 100, 10)and(x, 1, 3)).My approach is to first overfit the model on smaller number of records. See if model is indeed learning / able to overfit the data. Then add some regularization (mostly dropout) and then try to train the model on full dataset.
First, I tried to overfit LSTM model on small dataset and visualised the outcome. It did well. So, I tried to train it on the whole dataset. It did okayish, but still struggled at some places. The LSTM model which I tried is as follows:
I tried adding dropouts too, but it did not yield any significant improvement. So, I tried to train PatchTST transformer model. First, I tried to overfit smaller model and did well. In fact, when I visualized the output, I realised that it was able to get tighter overfit than the LSTM model. So, I tried to train it on the whole dataset. But the performance was not at all closer to LSTM.
The initial version of PatchTST I tried is as follows:
With this as base config, I tried different changes to it for hyper parameter optimization:
And some more combinations. These hyperparameter combinations are selected so that I can fit the model in GPU with 24GB memory. However, no configuration yield validation loss comparable to LSTM. These are the LSTM vs PatchTST curves:
The corresponding learning rate curves are as follows:
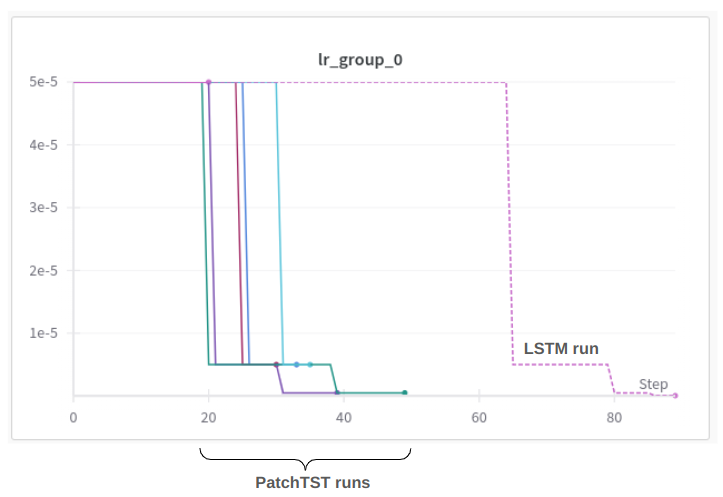
I used to step down the learning rate if the performance does not improve for 7 epochs.
What I am missing here? Do I miss any time series transformer related insight?
PS1: Yes, the base LR starts from 0.00005, followed by step down to 0.000005, 0.0000005, 0.00000005. I know these are excessively tiny. But, in the beginning I tried to train LSTM with bigger base like 0.001, LR 0.005, 0.0005 etc, but it did not work at all. It all started working only after starting with 0.00005. May be because my sensor values themselves are very tiny.
PS2: It might seem that the LSTM val loss has already reached near 0. But, thats only because I have higher validation loss PatchTST runs in the plot. If I remove them and add LSTM overfitting run, then it looks something like this:
The text was updated successfully, but these errors were encountered: