+
+
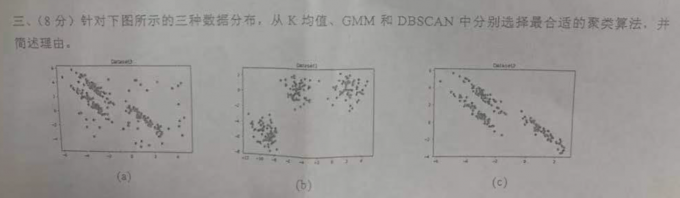
Go基础学习(微软教程)
+
+
什么是 Go?
+
Go 语言表现力强,且简单明了。 它在设计时考虑了惯用语言,这使程序员能够高效地编写高效且可靠的代码。 以 Go 语言编写的程序可以在 Unix 系统上运行,例如 Linux 和 macOS,还有 Windows。 Go 语言之所以值得注意,部分原因在于它独特的并发机制,使得编写可同时利用多个内核的程序非常容易。 它主要是一种强化静态类型的语言,这意味着变量类型在编译时是已知的。 不过,它确实具有一些动态类型化功能。
+
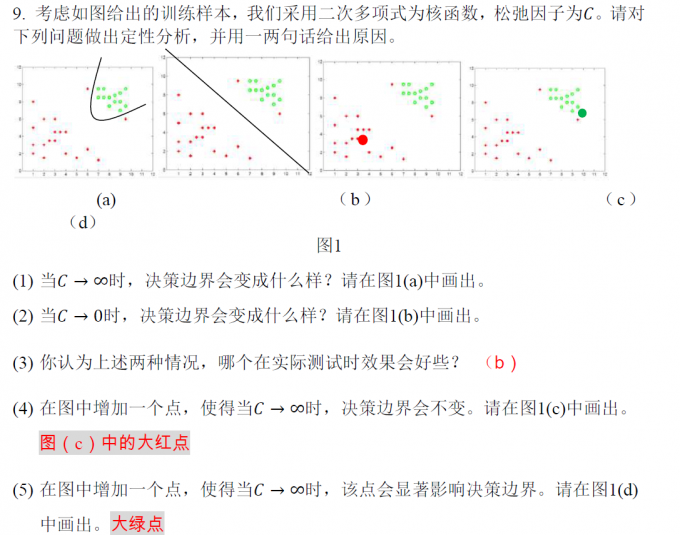
下面是 Go 编程语言的基本原理优势:
+
+- Go 许可证是完全开放源代码的。
+- Go 程序编译为单独的二进制文件,这样更易于共享和分发。
+- 交叉编译到各种平台和操作系统
+- Go 语言致力于使语言变得简单,并用更少的代码行执行更多操作。
+- 并发是头等概念,使任何函数可以作为轻量级线程运行,而程序员只需少量工作。
+- Go 语言提供自动内存管理,包括垃圾回收。
+- 编译和执行速度很快。
+- Go 语言需要使用所有代码,否则会引发错误。
+- 有一种官方格式设置可帮助保持项目之间的一致性。
+- Go 语言具有大量全面标准库,并且可以在不使用第三方依赖项的情况下生成多个应用程序。
+- Go 保证语言与以前版本的后向兼容性。
+
+
安装Go
+
如果不想在本地安装 Go,可以使用 Go Playground。 Go Playground 是一款 Web 服务,可在浏览器中运行 Go 应用程序。
+
本地安装包下载地址
+
wget https://go.dev/dl/go1.19.1.linux-amd64.tar.gz // 版本号可能改变
+
提取本地安装包
+
sudo tar -C /usr/local -xzf go1.19.1.linux-amd64.tar.gz
+
编辑配置文件,添加到环境变量:
+
vim ~/.bashrc
+export PATH=$PATH:/usr/local/go/bin
+source ~/.bashrc
+
确认是否已经安装好:
+
+
go version go1.19.1 linux/amd64
+
配置Go工作区
+
Go 在组织项目文件方面与其他编程语言不同。 首先,Go 是在工作区的概念下工作的。 工作区就是应用程序源代码所在的位置。 所有 Go 项目共享同一个工作区。 不过,从版本 1.11 开始,Go 已开始更改此方法。 你尚且不必担心,因为我们将在下一个模块中介绍工作区。 现在,Go 工作区位于 $HOME/go,但如果需要,可以为所有项目设置其他位置。
+
若要将工作区设置为其他位置,可以使用 $GOPATH 环境变量。 在处理更复杂的项目时,此环境变量有助于避免将来出现问题。
+
export GOPATH=/mnt/d/Programming_Design/Go
+
Go 工作区文件夹
+
每个 Go 工作区都包含三个基本文件夹:
+
+- bin :包含应用程序中的可执行文件。
+- src :包括位于工作站中的所有应用程序源代码。
+- pkg :包含可用库的已编译版本。 编译器可以链接这些库,而无需重新编译它们。
+
+
例如,工作站文件夹结构树可能与下面的示例类似:
+
bin/
+ hello
+ coolapp
+pkg/
+ github.com/gorilla/
+ mux.a
+src/
+ github.com/golang/example/
+ .git/
+ hello/
+ hello.go
+
VSCode Go 插件
+
在安装插件之前要先更改go的源
+
The "gopls" command is not available. Run "go install -v golang.org/x/tools/gopls@latest" to install.
+
然后点击上边的窗口的install All,即可完成插件的安装
+
第一个Go应用
+
文件夹组织形式:
+
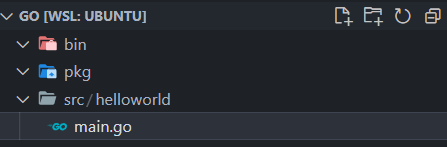
+
package main
+
+import "fmt"
+
+func main() {
+ fmt.Println("Hello World!")
+}
+
+
运行:
+
+
+
只生成二进制文件但是不运行:
+
+
代码解释
+
我们在 package main 语句中告诉 Go,我们将要创建的应用是一个可执行程序(可以运行的文件)。 我们的“Hello World!”应用是 main 包的一部分。
+
包是一组常用的源代码文件。 每个可执行应用都具有此第一行,即使项目或文件具有不同的名称。
+
import 语句使你的程序可以访问其他包中的其他代码。 在本例中,fmt 为标准库包。
+
你需要此 import 语句,因为你将在此程序的稍后部分使用此包中的函数将消息打印到屏幕上。 可以在程序中包含你想要或需要的任意数量的 import 语句。 但是,Go 在这方面是惯用的。 如果导入包,但不使用包中的相应函数,应用将不会进行编译。 Visual Studio Code 的一大功能是,当你保存文件时,它会自动删除程序中未使用的导入。
+
VSCode 是自动帮助我们删除的,但是和Python什么的不一样,如果多了冗余的包程序是无法运行的。
+
# command-line-arguments
+./main.go:4:8: imported and not used: "math"
+
func 语句是用于声明函数的保留字。 第一个函数名为“main”,因为它是程序的起始点。 整个 package main 中只能有一个 main() 函数(在第一行中定义的那个)。 在 main() 函数中,你调用了 fmt 包中的 Println 函数。 你发送了你希望在屏幕上看到的文本消息。
+
声明和使用变量
+
声明变量
+
var firstName string
+var secondName, lastName string
+var age int
+
+
+var (
+ thirdName, fourthName string
+ secondage int
+)
+
(VSCode会自动进行格式化,完全不用担心格式的问题)
+
初始化变量
+
可以在声明的时候直接对变量进行初始化,会自动对变量的类型进行推断,不用显式指定类型
+
var (
+ firstName string = "John"
+ lastName string = "Doe"
+ age int = 32
+)
+
等价于下面的写法:
+
var (
+ firstName, lastName, age = "John", "Doe", 32
+)
+
在main函数内部声明+初始化(更加常用)
+
package main
+
+import "fmt"
+
+func main() {
+ firstName, lastName := "John", "Doe"
+ age := 32
+ fmt.Println(firstName, lastName, age)
+}
+
+
请注意,在定义变量名称后,需要在此处加入一个冒号等于号 (:=) 和相应的值。 使用冒号等于号时, 要声明的变量必须是新变量 。 如果使用冒号等于号并已经声明该变量,将不会对程序进行编译。
+
声明常量
+
用于声明常量的关键字是 const
+
const HTTPStatusOK = 200
+
+const (
+ StatusOK = 0
+ StatusConnectionReset = 1
+ StatusOtherError = 2
+)
+
常量和变量之间既有相似之处,也有一些重要差异。 例如,你可以在不使用常量的情况下声明常量。 你不会收到错误消息。 不能使用冒号等于号来声明常量。 如果采用这种方式,Go 会发出警告。
+
在 Go 中,当你(在函数内部)声明一个变量但不使用它时,Go 会抛出错误,而不是像某些其他编程语言一样抛出警告。
+
基本数据类型
+
整数数字
+
一般来说,定义整数类型的关键字是 int。 但 Go 还提供了 int8、int16、int32 和 int64 类型,其大小分别为 8、16、32 或 64 位的整数。 使用 32 位操作系统时,如果只是使用 int,则大小通常为 32 位。 在 64 位系统上,int 大小通常为 64 位。 但是,此行为可能因计算机而不同。 可以使用 uint。 但是,只有在出于某种原因需要将值表示为无符号数字的情况下,才使用此类型。 此外,Go 还提供 uint8、uint16、uint32 和 uint64 类型。
+
var integer8 int8 = 127
+var integer16 int16 = 32767
+var integer32 int32 = 2147483647
+var integer64 int64 = 9223372036854775807
+
不能进行隐式转换,如果两个变量的类型不同,需要进行强制转换,否则编译不能通过。
+
浮点数字
+
Go 提供两种浮点数大小的数据类型:float32 和 float64。 如果需要存储较大的数字,则可以使用这些类型,这些类型无法适应前面提到的任何一个整数类型。 这两种类型的区别是它们可以容纳的最大位数。
+
var float32 float32 = 2147483647
+var float64 float64 = 9223372036854775807
+fmt.Println(float32, float64)
+
可以使用 math 包中提供的 math.MaxFloat32 和 math.MaxFloat64 常量来查找这两种类型的限制。
+
package main
+
+import (
+ "fmt"
+ "math"
+)
+
+func main() {
+ fmt.Println(math.MaxFloat32, math.MaxFloat64)
+}
+
3.4028234663852886e+38 1.7976931348623157e+308
+
布尔型
+
布尔类型仅可能有两个值:true 和 false。 你可以使用关键字 bool 声明布尔类型。 Go 不同于其他编程语言,在 Go 中,你不能将布尔类型隐式转换为 0 或 1。
+
var featureFlag bool = true
+
字符串
+
最后,让我们看一下编程语言中最常见的数据类型:string。 在 Go 中,关键字 string 用于表示字符串数据类型。 若要初始化字符串变量,你需要在双引号(")中定义值。 单引号(')用于单个字符(以及 runes,正如我们在上一节所述)。
+
var firstName string = "John"
+lastName := "Doe"
+fmt.Println(firstName, lastName)
+
+
默认值
+
到目前为止,几乎每次声明变量时,都使用值对其进行了初始化。 但与在其他编程语言中不同的是,在 Go 中,如果你不对变量初始化,所有数据类型都有默认值。 此功能非常方便,因为在使用之前,你无需检查变量是否已初始化。
+
下面列出了我们目前浏览过类型的几个默认值:
+
+int 类型的 0(及其所有子类型,如 int64)float32 和 float64 类型的 +0.000000e+000bool 类型的 falsestring 类型的空值
+
类型转换
+
Go 中隐式强制转换不起作用。 接下来,需要显式强制转换。 Go 提供了将一种数据类型转换为另一种数据类型的一些本机方法。
+
一种方法是对每个类型使用内置函数,如下所示:
+
var integer16 int16 = 127
+var integer32 int32 = 32767
+fmt.Println(int32(integer16) + integer32)
+
Go 的另一种转换方法是使用 strconv 包。 将 string 与 int
+
package main
+
+import (
+ "fmt"
+ "strconv"
+)
+
+func main() {
+ i, _ := strconv.Atoi("-42")
+ s := strconv.Itoa(-42)
+ fmt.Println(i, s)
+}
+
+
有一个下划线 (_) 用作变量的名称。 在 Go 中(或Python中),这意味着我们不会使用该变量的值,而是要将其忽略。
+
创建函数
+
在 Go 中,函数允许你将一组可以从应用程序的其他部分调用的语句组合在一起。 你可以使用函数来组织代码并使其更易于阅读,而不是创建包含许多语句的程序。 更具可读性的代码也更易于维护。
+
与之交互的函数是 main() 函数。 Go 中的所有可执行程序都具有此函数,因为它是程序的起点。 你的程序中只能有一个 main() 函数。
+
命令行参数
+
package main
+
+import (
+ "fmt"
+ "os"
+ "strconv"
+)
+
+func main() {
+ number1, _ := strconv.Atoi(os.Args[1])
+ number2, _ := strconv.Atoi(os.Args[2])
+ fmt.Println("Sum:", number1+number2)
+}
+
os.Args 变量包含传递给程序的每个命令行参数。 由于这些值的类型为 string,因此需要将它们转换为 int 以进行求和。
+
> go run main.go 3 5
+Sum: 8
+
自定义函数
+
使用 func 关键字来定义函数,然后为其指定名称。 在命名后,指定函数的参数列表。 你可以指定零个或多个参数。 你还可以定义函数的返回类型,该函数也可以是零个或多个。 (我们将在下一节中讨论如何返回多个值)。在定义所有这些值之后,你可以编写函数的正文内容。
+
package main
+
+import (
+ "fmt"
+ "os"
+ "strconv"
+)
+
+func main() {
+ sum := sum(os.Args[1], os.Args[2])
+ fmt.Println("Sum:", sum)
+}
+
+func sum(number1 string, number2 string) int {
+ int1, _ := strconv.Atoi(number1)
+ int2, _ := strconv.Atoi(number2)
+ return int1 + int2
+}
+
此代码创建一个名为 sum 的函数,该函数采用两个 string 参数,并将它们强制转换为 int,然后返回求和所得的结果。 定义返回类型时,函数需要返回该类型的值。
+
在 Go 中,你还可以为函数的返回值设置名称,将其当作一个变量。
+
func sum(number1 string, number2 string) (result int) {
+ int1, _ := strconv.Atoi(number1)
+ int2, _ := strconv.Atoi(number2)
+ result = int1 + int2
+ return
+}
+
返回多个值
+
package main
+
+import (
+ "fmt"
+ "os"
+ "strconv"
+)
+
+func main() {
+ sum, mul := calc(os.Args[1], os.Args[2])
+ fmt.Println("Sum:", sum)
+ fmt.Println("Mul:", mul)
+}
+
+func calc(number1 string, number2 string) (sum int, mul int) {
+ int1, _ := strconv.Atoi(number1)
+ int2, _ := strconv.Atoi(number2)
+ sum = int1 + int2
+ mul = int1 * int2
+ return
+}
+
> go run main.go 3 5
+Sum: 8
+Mul: 15
+
更改函数参数值(指针)
+
将值传递给函数时,该函数中的每个更改都不会影响调用方。 Go 是“按值传递”编程语言。 每次向函数传递值时,Go 都会使用该值并创建本地副本(内存中的新变量)。 在函数中对该变量所做的更改都不会影响你向函数发送的更改。
+
指针是包含另一个变量的内存地址的变量。 当你发送指向某个函数的指针时,不会传递值,而是传递地址内存。 因此,对该变量所做的每个更改都会影响调用方。
+
在 Go 中,有两个运算符可用于处理指针:
+
+& 运算符使用其后对象的地址。* 运算符取消引用指针。 也就是说,你可以前往指针中包含的地址访问其中的对象。
+
package main
+
+import "fmt"
+
+func main() {
+ firstName := "John"
+ updateName(&firstName)
+ fmt.Println(firstName)
+}
+
+func updateName(name *string) {
+ *name = "David"
+}
+
+
首先要做的就是修改函数的签名,以指明你要接收指针。 为此,请将参数类型从 string 更改为 *string。 (后者仍是字符串,但现在它是指向字符串 的 指针。)然后,将新值分配给该变量时,需要在该变量的左侧添加星号 (*) 以暂停该变量的值。 调用 updateName 函数时,系统不会发送值,而是发送变量的内存地址。 这就是前面的代码在变量左侧带有 & 符号的原因。
+
了解包
+
Go 包与其他编程语言中的库或模块类似。 你可以打包代码,并在其他位置重复使用它。 包的源代码可以分布在多个 .go 文件中。 到目前为止,我们已编写 main 包,并对其他本地包进行了一些引用。
+
main 包
+
你可能注意到,在 Go 中,甚至最直接的程序都是包的一部分。 通常情况下,默认包是 main 包,即目前为止一直使用的包。 如果程序是 main 包的一部分,Go 会生成二进制文件。 运行该文件时,它将调用 main() 函数。
+
换句话说,当你使用 main 包时,程序将生成独立的可执行文件。 但当程序非是 main 包的一部分时,Go 不会生成二进制文件。 它生成包存档文件(扩展名为“.a”的文件)。
+
在 Go 中,包名称需遵循约定。 包使用其导入路径的最后一部分作为名称。 例如,Go 标准库包含名为 math/cmplx 的包,该包提供用于处理复数的有用代码。 此包的导入路径为 math/cmplx,导入包的方式如下所示:
+
+
创建包
+
在名为 calculator 的目录中 创建名为 sum.go 的文件。 树目录应如下列目录所示:
+
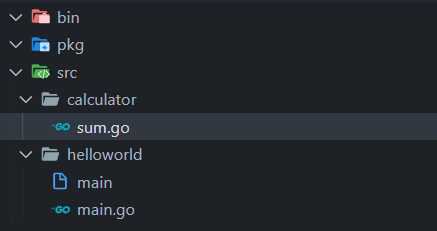
+
用包的名称初始化 sum.go 文件:
+
+
你现在可以开始编写包的函数和变量。 不同于其他编程语言,Go 不会提供 public 或 private 关键字,以指示是否可以从包的内外部调用变量或函数。 但 Go 须遵循以下两个简单规则:
+
+- 如需将某些内容设为专用内容,请以小写字母开始。
+- 如需将某些内容设为公共内容,请以大写字母开始。
+
+
接下来,让我们将以下代码添加到我们要创建的计算器包:
+
package calculator
+
+var logMessage = "[LOG]"
+
+
+var Version = "1.0"
+
+func internalSum(number int) int {
+ return number - 1
+}
+
+
+func Sum(number1, number2 int) int {
+ return number1 + number2
+}
+
让我们看一下该代码中的一些事项:
+
+- 只能从包内调用
logMessage 变量。
+- 可以从任何位置访问
Version 变量。 建议你添加注释来描述此变量的用途。 (此描述适用于包的任何用户。)
+- 只能从包内调用
internalSum 函数。
+- 可以从任何位置访问
Sum 函数。 建议你添加注释来描述此函数的用途。
+
+
若要确认一切正常,可在 calculator 目录中运行 go build 命令。 如果执行此操作,请注意系统不会生成可执行的二进制文件。
+
创建模块
+
你已将计算器功能放入包中。 现在可以将包放到模块中。 Go 模块通常包含可提供相关功能的包。 包的模块还指定了 Go 运行你组合在一起的代码所需的上下文。 此上下文信息包括编写代码时所用的 Go 版本。
+
此外,模块还有助于其他开发人员引用代码的特定版本,并更轻松地处理依赖项。 另一个优点是,我们的程序源代码无需严格存在于 $GOPATH/src 目录中。 如果释放该限制,则可以更方便地在其他项目中同时使用不同包版本。
+
(下面与教程不同,自己探索出了一个可用不报错的方法)
+
VSCode GOPATH设置:"go.gopath": "/mnt/d/Programming_Design/Go"
+
首先设置 go env -w GO111MODULE=on
+
如果 helloworld要引用 calculator,则文件夹的组织形式如下:
+

+
在 $GOPATH/src/calculator创建 go.mod文件,其中文件第一行与文件夹同名
+
module calculator
+
+go 1.19
+
在 $GOPATH/src/helloworld创建 go.mod文件,其中文件第一行与文件夹同名,下面要写好版本号和包的路径
+
module helloworld
+
+go 1.19
+
+require "calculator" v1.0.0
+replace "calculator" => "../calculator"
+
然后可以导入这个包并运行主文件
+
package main
+
+import (
+ "calculator"
+ "fmt"
+)
+
+func main() {
+ total := calculator.Sum(3, 5)
+ fmt.Println(total)
+ fmt.Println("Version: ", calculator.Version)
+}
+
+
+
引用外部(第三方)包
+
有时,程序需要引用其他开发人员编写的包。
+
测试后不是很明白,基本上是在主文件和 .mod文件中写入包的名称和版本即可。然后根据控制台的输出将包安装好即可使用
+
main.go:
+
package main
+
+import (
+ "calculator"
+ "fmt"
+
+ "rsc.io/quote"
+)
+
+func main() {
+ total := calculator.Sum(3, 5)
+ fmt.Println(total)
+ fmt.Println("Version: ", calculator.Version)
+ fmt.Println(quote.Hello())
+}
+
go.mod:
+
module helloworld
+
+go 1.19
+
+require (
+ calculator v1.0.0
+ rsc.io/quote v1.5.2
+)
+
+require (
+ golang.org/x/text v0.0.0-20170915032832-14c0d48ead0c
+ rsc.io/sampler v1.3.0
+)
+
+replace calculator => ../calculator
+
输出:
+
8
+Version: 1.0
+Ahoy, world!
+
使用控制流
+
if 语句的语法
+
与其他编程语言不同的是,在 Go 中,你不需要在条件中使用括号。 else 子句可选。 但是,大括号仍然是必需的。 此外,为了减少行,Go 不支持三元 if 语句,因此每次都需要编写完整的 if 语句。
+
package main
+
+import "fmt"
+
+func givemeanumber() int {
+ return -1
+}
+
+func main() {
+ if num := givemeanumber(); num < 0 {
+ fmt.Println(num, "is negative")
+ } else if num < 10 {
+ fmt.Println(num, "has only one digit")
+ } else {
+ fmt.Println(num, "has multiple digits")
+ }
+}
+
其中,有一个在 Go 中常见的约定进行高效编程的方式 if num := givemeanumber(); num < 0,同时接收函数的返回值,但是不重复进行接收,然后使用到if语句中进行判断。当然这个 num变量在 if的外部是无法使用的。
+
使用 switch 语句控制流
+
像其他编程语言一样,Go 支持 switch 语句。 可以使用 switch 语句来避免链接多个 if 语句。 使用 switch 语句,就不需维护和读取包含多个 if 语句的代码。 这些语句还可以让复杂的条件更易于构造。 请参阅以下部分的 switch 语句。
+
普通的switch语句:
+
package main
+
+import (
+ "fmt"
+ "math/rand"
+ "time"
+)
+
+func main() {
+ sec := time.Now().Unix()
+ rand.Seed(sec)
+ i := rand.Int31n(10)
+
+ switch i {
+ case 0:
+ fmt.Print("zero...")
+ case 1:
+ fmt.Print("one...")
+ case 2:
+ fmt.Print("two...")
+ default:
+ fmt.Print("no match...")
+ }
+
+ fmt.Println("ok")
+}
+
有时,多个表达式仅与一个 case 语句匹配。 在 Go 中,如果希望 case 语句包含多个表达式,请使用逗号 (,) 来分隔表达式。 此方法可避免代码重复。
+
package main
+
+import "fmt"
+
+func location(city string) (string, string) {
+ var region string
+ var continent string
+ switch city {
+ case "Delhi", "Hyderabad", "Mumbai", "Chennai", "Kochi":
+ region, continent = "India", "Asia"
+ case "Lafayette", "Louisville", "Boulder":
+ region, continent = "Colorado", "USA"
+ case "Irvine", "Los Angeles", "San Diego":
+ region, continent = "California", "USA"
+ default:
+ region, continent = "Unknown", "Unknown"
+ }
+ return region, continent
+}
+func main() {
+ region, continent := location("Irvine")
+ fmt.Printf("John works in %s, %s\n", region, continent)
+}
+
+
John works in California, USA
+
在 case 语句的表达式中包含的值对应于 switch 语句验证的变量的数据类型。
+
调用函数
+
switch 还可以调用函数。 在该函数中,可以针对可能的返回值编写 case 语句。
+
第一种是在switch上调用函数,对返回值进行判断
+
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ switch time.Now().Weekday().String() {
+ case "Monday", "Tuesday", "Wednesday", "Thursday", "Friday":
+ fmt.Println("It's time to learn some Go.")
+ default:
+ fmt.Println("It's weekend, time to rest!")
+ }
+
+ fmt.Println(time.Now().Weekday().String())
+}
+
+
It's time to learn some Go.
+Wednesday
+
第二种是在case上调用函数
+
package main
+
+import (
+ "fmt"
+ "regexp"
+)
+
+func main() {
+ var email = regexp.MustCompile(`^[^@]+@[^@.]+\.[^@.]+`)
+ var phone = regexp.MustCompile(`^[(]?[0-9][0-9][0-9][). \-]*[0-9][0-9][0-9][.\-]?[0-9][0-9][0-9][0-9]`)
+
+ contact := "foo@bar.com"
+
+ switch {
+ case email.MatchString(contact):
+ fmt.Println(contact, "is an email")
+ case phone.MatchString(contact):
+ fmt.Println(contact, "is a phone number")
+ default:
+ fmt.Println(contact, "is not recognized")
+ }
+}
+
+
+
上面的 switch 语句中省略了条件,就像在 if 语句中那样。 此模式类似于比较 true 值,就像强制 switch 语句一直运行一样。
+
一个条件 switch 块比一长串的 if 和 else if 语句更易于维护。
+
使逻辑进入到下一个 case
+
在某些编程语言中,你会在每个 case 语句末尾写一个 break 关键字。 但在 Go 中,当逻辑进入某个 case 时,它会退出 switch 块,除非你显式停止它。 若要使逻辑进入到下一个紧邻的 case,请使用 fallthrough 关键字。
+
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ switch num := 15; {
+ case num < 50:
+ fmt.Printf("%d is less than 50\n", num)
+ fallthrough
+ case num > 100:
+ fmt.Printf("%d is greater than 100\n", num)
+ fallthrough
+ case num < 200:
+ fmt.Printf("%d is less than 200\n", num)
+ }
+}
+
+
15 is less than 50
+15 is greater than 100
+15 is less than 200
+
请注意,由于 num 为 15(小于 50),因此它与第一个 case 匹配。 但是,num 不大于 100。 由于第一个 case 语句包含 fallthrough 关键字,因此逻辑会立即转到下一个 case 语句,而不会对该 case 进行验证。 因此,在使用 fallthrough 关键字时必须谨慎。 该代码产生的行为可能不是你想要的。
+
for 表达式
+
另一个常用控制流是循环。 Go 只使用一个循环构造,即 for 循环。 但是,你可以通过多种方式表示循环。
+
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ sum := 0
+ for i := 1; i <= 100; i++ {
+ sum += i
+ }
+ fmt.Println("sum of 1..100 is", sum)
+}
+
+
+
空预处理语句和后处理语句
+
package main
+
+import (
+ "fmt"
+ "math/rand"
+ "time"
+)
+
+func main() {
+ var num int64
+ rand.Seed(time.Now().Unix())
+ for num != 5 {
+ num = rand.Int63n(15)
+ fmt.Println(num)
+ }
+}
+
只要 num 变量保存的值与 5 不同,程序就会输出一个随机数。
+
无限循环和 break 语句
+
可以在 Go 中编写的另一种循环模式是无限循环。 在这种情况下,你不编写条件表达式,也不编写预处理语句或后处理语句, 而是采取退出循环的方式进行编写。 否则,逻辑永远都不会退出。 若要使逻辑退出循环,请使用 break 关键字。
+
package main
+
+import (
+ "fmt"
+ "math/rand"
+ "time"
+)
+
+func main() {
+ var num int32
+ sec := time.Now().Unix()
+ rand.Seed(sec)
+
+ for {
+ fmt.Print("Writing inside the loop...")
+ if num = rand.Int31n(10); num == 5 {
+ fmt.Println("finish!")
+ break
+ }
+ fmt.Println(num)
+ }
+}
+
+
在 Go 中,可以使用 continue 关键字跳过循环的当前迭代。 例如,可以使用此关键字在循环继续之前运行验证。 也可以在编写无限循环并需要等待资源变得可用时使用它。
+
package main
+
+import "fmt"
+
+func main() {
+ sum := 0
+ for num := 1; num <= 100; num++ {
+ if num%5 == 0 {
+ continue
+ }
+ sum += num
+ }
+ fmt.Println("The sum of 1 to 100, but excluding numbers divisible by 5, is", sum)
+}
+
+
The sum of 1 to 100, but excluding numbers divisible by 5, is 4000
+
使用 defer、panic 和 recover 函数进行控制
+
defer 函数
+
在 Go 中,defer 语句会推迟函数(包括任何参数)的运行,直到包含 defer 语句的函数完成。 通常情况下,当你想要避免忘记任务(例如关闭文件或运行清理进程)时,可以推迟某个函数的运行。
+
可以根据需要推迟任意多个函数。 defer 语句按逆序运行,先运行最后一个,最后运行第一个。
+
package main
+
+import "fmt"
+
+func main() {
+ for i := 1; i <= 4; i++ {
+ defer fmt.Println("deferred", -i)
+ fmt.Println("regular", i)
+ }
+}
+
+
regular 1
+regular 2
+regular 3
+regular 4
+deferred -4
+deferred -3
+deferred -2
+deferred -1
+
在此示例中,请注意,每次推迟 fmt.Println("deferred", -i) 时,都会存储 i 的值,并会将其运行任务添加到队列中。 在 main() 函数输出完 regular 值后,所有推迟的调用都会运行。 这就是你看到输出采用逆序(后进先出)的原因。
+
defer 函数的一个典型用例是在使用完文件后将其关闭。
+
package main
+
+import (
+ "fmt"
+ "io"
+ "os"
+)
+
+func main() {
+ newfile, error := os.Create("learnGo.txt")
+ if error != nil {
+ fmt.Println("Error: Could not create file.")
+ return
+ }
+ defer newfile.Close()
+
+ if _, error = io.WriteString(newfile, "Learning Go!"); error != nil {
+ fmt.Println("Error: Could not write to file.")
+ return
+ }
+
+ newfile.Sync()
+}
+
+
创建或打开某个文件后,可以推迟 .Close() 函数的执行,以免在你完成后忘记关闭该文件。
+
panic 函数
+
运行时错误会使 Go 程序崩溃,例如尝试通过使用超出范围的索引或取消引用 nil 指针来访问数组。 你也可以强制程序崩溃。
+
内置 panic() 函数可以停止 Go 程序中的正常控制流。 当你使用 panic 调用时,任何延迟的函数调用都将正常运行。 进程会在堆栈中继续,直到所有函数都返回。 然后,程序会崩溃并记录日志消息。 此消息包含错误信息和堆栈跟踪,有助于诊断问题的根本原因。
+
调用 panic() 函数时,可以添加任何值作为参数。 通常,你会发送一条错误消息,说明为什么会进入紧急状态。
+
例如,下面的代码将 panic 和 defer 函数组合在一起。 尝试运行此代码以了解控制流的中断。 请注意,清理过程仍会运行。
+
package main
+
+import "fmt"
+
+func highlow(high int, low int) {
+ if high < low {
+ fmt.Println("Panic!")
+ panic("highlow() low greater than high")
+ }
+ defer fmt.Println("Deferred: highlow(", high, ",", low, ")")
+ fmt.Println("Call: highlow(", high, ",", low, ")")
+
+ highlow(high, low+1)
+}
+
+func main() {
+ highlow(2, 0)
+ fmt.Println("Program finished successfully!")
+}
+
+
Call: highlow( 2 , 0 )
+Call: highlow( 2 , 1 )
+Call: highlow( 2 , 2 )
+Panic!
+Deferred: highlow( 2 , 2 )
+Deferred: highlow( 2 , 1 )
+Deferred: highlow( 2 , 0 )
+panic: highlow() low greater than high
+
+goroutine 1 [running]:
+main.highlow(0x4b8018?, 0xc000012018?)
+ /mnt/d/Programming_Design/Go/src/helloworld/main.go:8 +0x285
+main.highlow(0x2, 0x2)
+ /mnt/d/Programming_Design/Go/src/helloworld/main.go:13 +0x211
+main.highlow(0x2, 0x1)
+ /mnt/d/Programming_Design/Go/src/helloworld/main.go:13 +0x211
+main.highlow(0x2, 0x0)
+ /mnt/d/Programming_Design/Go/src/helloworld/main.go:13 +0x211
+main.main()
+ /mnt/d/Programming_Design/Go/src/helloworld/main.go:17 +0x25
+exit status 2
+
下面是运行代码时会发生的情况:
+
+- 一切正常运行。 程序将输出传递到
highlow() 函数中的高值和低值。
+- 如果
low 的值大于 high 的值,则程序会崩溃。 会显示“Panic!”消息。 此时,控制流中断,所有推迟的函数都开始输出“Deferred...”消息。
+- 程序崩溃,并显示完整的堆栈跟踪。 不会显示“
Program finished successfully!”消息。
+
+
recover 函数
+
有时,你可能想要避免程序崩溃,改为在内部报告错误。 或者,你可能想要先清理混乱情况,然后再让程序崩溃。 例如,你可能想要关闭与某个资源的连接,以免出现更多问题。
+
Go 提供内置 recover() 函数,让你可以在程序崩溃之后重新获得控制权。 你只会在你同时调用 defer 的函数中调用 recover。 如果调用 recover() 函数,则在正常运行的情况下,它会返回 nil,没有任何其他作用。
+
尝试修改前面的代码中的 main 函数,以添加对 recover() 的调用,如下所示:
+
package main
+
+import "fmt"
+
+func highlow(high int, low int) {
+ if high < low {
+ fmt.Println("Panic!")
+ panic("highlow() low greater than high")
+ }
+ defer fmt.Println("Deferred: highlow(", high, ",", low, ")")
+ fmt.Println("Call: highlow(", high, ",", low, ")")
+
+ highlow(high, low+1)
+}
+
+func main() {
+ defer func() {
+ handler := recover()
+ if handler != nil {
+ fmt.Println("main(): recover", handler)
+ }
+ }()
+
+ highlow(2, 0)
+ fmt.Println("Program finished successfully!")
+}
+
+
Call: highlow( 2 , 0 )
+Call: highlow( 2 , 1 )
+Call: highlow( 2 , 2 )
+Panic!
+Deferred: highlow( 2 , 2 )
+Deferred: highlow( 2 , 1 )
+Deferred: highlow( 2 , 0 )
+main(): recover highlow() low greater than high
+
在 main() 函数中,你会将一个可以调用 recover() 函数的匿名函数推迟。 当程序处于紧急状态时,对 recover() 的调用无法返回 nil。 你可以在此处执行一些操作来清理混乱,但在本例中,你只是简单地输出一些内容。
+
panic 和 recover 函数的组合是 Go 处理异常的惯用方式。 其他编程语言使用 try/catch 块。 Go 首选此处所述的方法。
+
练习 - 在 Go 中使用控制流
+
编写 FizzBuzz 程序
+
首先,编写一个用于输出数字(1 到 100)的程序,其中有以下变化:
+
+- 如果数字可被 3 整除,则输出
Fizz。
+- 如果数字可被 5 整除,则输出
Buzz。
+- 如果数字可同时被 3 和 5 整除,则输出
FizzBuzz。
+- 如果前面的情况都不符合,则输出该数字。
+
+
尝试使用 switch 语句。
+
package main
+
+import (
+ "fmt"
+ "strconv"
+)
+
+func fizzbuzz(num int) string {
+ switch {
+ case num%15 == 0:
+ return "FizzBuzz"
+ case num%3 == 0:
+ return "Fizz"
+ case num%5 == 0:
+ return "Buzz"
+ }
+ return strconv.Itoa(num)
+}
+
+func main() {
+ for num := 1; num <= 100; num++ {
+ fmt.Println(fizzbuzz(num))
+ }
+}
+
查找质数
+
编写一个程序来查找小于 20 的所有质数。 质数是大于 1 的任意数字,只能被它自己和 1 整除。 “整除”表示经过除法运算后没有余数。 与大多数编程语言一样,Go 还提供了一种方法来检查除法运算是否产生余数。 我们可以使用模数 %(百分号)运算符。
+
在本练习中,你将更新一个名为 findprimes 的函数,以检查数值是否为质数。 该函数有一个整数参数,并返回一个布尔值。 函数通过检查是否有余数来测试输入数字是否为质数。 如果数字为质数,则该函数返回 true。
+
package main
+
+import "fmt"
+
+func findprimes(number int) bool {
+ for i := 2; i < number; i++ {
+ if number%i == 0 {
+ return false
+ }
+ }
+
+ if number > 1 {
+ return true
+ } else {
+ return false
+ }
+}
+
+func main() {
+ fmt.Println("Prime numbers less than 20:")
+
+ for number := 1; number < 20; number++ {
+ if findprimes(number) {
+ fmt.Printf("%v ", number)
+ }
+ }
+ fmt.Println()
+}
+
Prime numbers less than 20:
+2 3 5 7 11 13 17 19
+
要求用户输入一个数字,如果该数字为负数,则进入紧急状态
+
编写一个要求用户输入一个数字的程序。 在开始时使用以下代码片段:
+
此程序要求用户输入一个数字,然后将其输出。 修改示例代码,使之符合以下要求:
+
+- 持续要求用户输入一个整数。 此循环的退出条件应该是用户输入了一个负数。
+- 当用户输入负数时,让程序崩溃。 然后输出堆栈跟踪错误。
+- 如果数字为 0,则输出“
0 is neither negative nor positive”。 继续要求用户输入数字。
+- 如果数字为正数,则输出“
You entered: X”(其中的 X 为输入的数字)。 继续要求用户输入数字。
+
+
package main
+
+import "fmt"
+
+func main() {
+ val := 0
+ for {
+ fmt.Print("Enter number: ")
+ fmt.Scanf("%d", &val)
+ if val < 0 {
+ panic("Negative!")
+ } else if val == 0 {
+ fmt.Println("0 is neither negative nor positive")
+ } else {
+ fmt.Printf("You entered: %d\n", val)
+ }
+ }
+}
+
使用数组
+
Go 中的数组是一种特定类型且长度固定的数据结构。 它们可具有零个或多个元素,你必须在声明或初始化它们时定义大小。 此外,它们一旦创建,就无法调整大小。 鉴于这些原因,数组在 Go 程序中并不常用,但它们是切片和映射的基础。
+
声明数组
+
要在 Go 中声明数组,必须定义其元素的数据类型以及该数组可容纳的元素数目。 然后,可采用下标表示法访问数组中的每个元素,其中第一个元素是 0,最后一个元素是数组长度减去 1(长度 - 1)。
+
package main
+
+import "fmt"
+
+func main() {
+ var a [3]int
+ a[1] = 10
+ fmt.Println(a[0])
+ fmt.Println(a[1])
+ fmt.Println(a[len(a)-1])
+}
+
+
已声明的数组访问其元素时不会遇到错误。 默认情况下,Go 会用默认数据类型初始化每个元素。 这样的话,int 的默认值为零。 不过,你可为特定位置分配值。 这就是为什么你会看到 a[1] = 10。 你可采用上述表示法来访问该元素。 另请注意,为了打印出第一个元素,我们使用了 a[0]。 为了打印出最后一个元素,我们使用了 a[len(a)-1]。 len 函数是 Go 中的内置函数,用于获取数组、切片或映射中的元素数。
+
初始化数组
+
声明数组时,还可使用非默认值来初始化数组。
+
package main
+
+import "fmt"
+
+func main() {
+ cities := [5]string{"New York", "Paris", "Berlin", "Madrid"}
+ fmt.Println("Cities:", cities)
+}
+
Cities: [New York Paris Berlin Madrid ]
+
数组中的省略号
+
如果你不知道你将需要多少个位置,但知道你将具有多少数据,那么还有一种声明和初始化数组的方法是使用省略号 (...)
+
package main
+
+import "fmt"
+
+func main() {
+ cities := [...]string{"New York", "Paris", "Berlin", "Madrid"}
+ fmt.Println("Cities:", cities)
+}
+
另一种有趣的数组初始化方法是使用省略号并仅为最新的位置指定值。
+
package main
+
+import "fmt"
+
+func main() {
+ numbers := [...]int{99: -1}
+ fmt.Println("First Position:", numbers[0])
+ fmt.Println("Last Position:", numbers[99])
+ fmt.Println("Length:", len(numbers))
+}
+
+
First Position: 0
+Last Position: -1
+Length: 100
+
注意数组的长度是 100,因为你为第 99 个位置指定了一个值。
+
多维数组
+
如果需要处理复杂数据结构,请记住 Go 支持多维数组。
+
package main
+
+import "fmt"
+
+func main() {
+ var twoD [3][5]int
+ for i := 0; i < 3; i++ {
+ for j := 0; j < 5; j++ {
+ twoD[i][j] = (i + 1) * (j + 1)
+ }
+ fmt.Println("Row", i, twoD[i])
+ }
+ fmt.Println("\nAll at once:", twoD)
+}
+
+
Row 0 [1 2 3 4 5]
+Row 1 [2 4 6 8 10]
+Row 2 [3 6 9 12 15]
+
+All at once: [[1 2 3 4 5] [2 4 6 8 10] [3 6 9 12 15]]
+
了解切片
+
与数组一样,切片也是 Go 中的一种数据类型,它表示一系列类型相同的元素。 不过,与数组更重要的区别是切片的大小是动态的,不是固定的。
+
切片是数组或另一个切片之上的数据结构。 我们将源数组或切片称为基础数组。 通过切片,可访问整个基础数组,也可仅访问部分元素。
+
切片只有 3 个组件:
+
+- 指向基础数组中第一个可访问元素的指针 。 此元素不一定是数组的第一个元素
array[0]。
+- 切片的长度 。 切片中的元素数目。
+- 切片的容量 。 切片开头与基础数组结束之间的元素数目。
+
+
声明和初始化切片
+
要声明切片,可采用与声明数组相同的方式操作。
+
package main
+
+import "fmt"
+
+func main() {
+ months := []string{"January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"}
+ fmt.Println(months)
+ fmt.Println("Length:", len(months))
+ fmt.Println("Capacity:", cap(months))
+}
+
[January February March April May June July August September October November December]
+Length: 12
+Capacity: 12
+
切片项
+
Go 支持切片运算符 s[i:p],其中:
+
+s 表示数组。i 表示指向要添加到新切片的基础数组(或另一个切片)的第一个元素的指针。 变量 i 对应于数组 array[i] 中索引位置 i 处的元素。 请记住,此元素不一定是基础数组的第一个元素 array[0]。p 表示创建新切片时要使用的基础数组中的元素数目。 变量 p 对应于可用于新切片的基础数组中的最后一个元素。 可在位置 array[i+1] 找到基础数组中位置 p 处的元素。 请注意,此元素不一定是基础数组的最后一个元素 array[len(array)-1]。
+
package main
+
+import "fmt"
+
+func main() {
+ months := []string{"January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"}
+ quarter1 := months[0:3]
+ quarter2 := months[3:6]
+ quarter3 := months[6:9]
+ quarter4 := months[9:12]
+ fmt.Println(quarter1, len(quarter1), cap(quarter1))
+ fmt.Println(quarter2, len(quarter2), cap(quarter2))
+ fmt.Println(quarter3, len(quarter3), cap(quarter3))
+ fmt.Println(quarter4, len(quarter4), cap(quarter4))
+}
+
[January February March] 3 12
+[April May June] 3 9
+[July August September] 3 6
+[October November December] 3 3
+
注意,切片的长度不变,但容量不同。 我们来了解 quarter2 切片。 声明此切片时,你指出希望切片从位置编号 3 开始,最后一个元素位于位置编号 6。 切片长度为 3 个元素,但容量为 9,原因是基础数组有更多元素或位置可供使用,但对切片而言不可见。
+
切片容量仅指出切片可扩展的程度。 因此可从 quarter2 创建扩展切片
+
package main
+
+import "fmt"
+
+func main() {
+ months := []string{"January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"}
+ quarter2 := months[3:6]
+ quarter2Extended := quarter2[:4]
+ fmt.Println(quarter2, len(quarter2), cap(quarter2))
+ fmt.Println(quarter2Extended, len(quarter2Extended), cap(quarter2Extended))
+}
+
[April May June] 3 9
+[April May June July] 4 9
+
追加项
+
切片与数组之间有何不同? 第一个区别是切片的大小不是固定的,而是动态的。 创建切片后,可向其添加更多元素,这样切片就会扩展。
+
Go 提供了内置函数 append(slice, element),便于你向切片添加元素。 将要修改的切片和要追加的元素作为值发送给该函数。 然后,append 函数会返回一个新的切片,将其存储在变量中。 对于要更改的切片,变量可能相同。
+
package main
+
+import "fmt"
+
+func main() {
+ var numbers []int
+ for i := 0; i < 10; i++ {
+ numbers = append(numbers, i)
+ fmt.Printf("%d\tcap=%d\t%v\n", i, cap(numbers), numbers)
+ }
+}
+
0 cap=1 [0]
+1 cap=2 [0 1]
+2 cap=4 [0 1 2]
+3 cap=4 [0 1 2 3]
+4 cap=8 [0 1 2 3 4]
+5 cap=8 [0 1 2 3 4 5]
+6 cap=8 [0 1 2 3 4 5 6]
+7 cap=8 [0 1 2 3 4 5 6 7]
+8 cap=16 [0 1 2 3 4 5 6 7 8]
+9 cap=16 [0 1 2 3 4 5 6 7 8 9]
+
当切片容量不足以容纳更多元素时,Go 的容量将翻倍。 它将新建一个具有新容量的基础数组。 无需执行任何操作即可使容量增加。 Go 会自动扩充容量。
+
删除项
+
Go 没有内置函数用于从切片中删除元素。 可使用上述切片运算符 s[i:p] 来新建一个仅包含所需元素的切片。
+
package main
+
+import "fmt"
+
+func main() {
+ letters := []string{"A", "B", "C", "D", "E"}
+ remove := 2
+
+ if remove < len(letters) {
+
+ fmt.Println("Before", letters, "Remove ", letters[remove])
+
+ letters = append(letters[:remove], letters[remove+1:]...)
+
+ fmt.Println("After", letters)
+ }
+
+}
+
Before [A B C D E] Remove C
+After [A B D E]
+
创建切片的副本
+
Go 具有内置函数 copy(dst, src []Type) 用于创建切片的副本。
+
更改切片中的元素时,基础数组将随之更改。
+
package main
+
+import "fmt"
+
+func main() {
+ letters := []string{"A", "B", "C", "D", "E"}
+ fmt.Println("Before", letters)
+
+ slice1 := letters[0:2]
+ slice2 := letters[1:4]
+
+ slice1[1] = "Z"
+
+ fmt.Println("After", letters)
+ fmt.Println("Slice2", slice2)
+}
+
+
Before [A B C D E]
+After [A Z C D E]
+Slice2 [Z C D]
+
创建副本则不会产生影响
+
package main
+
+import "fmt"
+
+func main() {
+ letters := []string{"A", "B", "C", "D", "E"}
+ fmt.Println("Before", letters)
+
+ slice1 := letters[0:2]
+
+ slice2 := make([]string, 3)
+ copy(slice2, letters[1:4])
+
+ slice1[1] = "Z"
+
+ fmt.Println("After", letters)
+ fmt.Println("Slice2", slice2)
+}
+
Before [A B C D E]
+After [A Z C D E]
+Slice2 [B C D]
+
使用映射
+
Go 中的映射是一个哈希表,是键值对的集合。 映射中所有的键都必须具有相同的类型,它们的值也是如此。 不过,可对键和值使用不同的类型。 例如,键可以是数字,值可以是字符串。 若要访问映射中的特定项,可引用该项的键。
+
声明和初始化映射
+
若要声明映射,需要使用 map 关键字。 然后,定义键和值类型,如下所示:map[T]T。
+
package main
+
+import "fmt"
+
+func main() {
+ studentsAge := map[string]int{
+ "john": 32,
+ "bob": 31,
+ }
+ fmt.Println(studentsAge)
+}
+
+
+
如果不想使用项来初始化映射,可使用内置函数 make() 在上一部分创建切片。
+
添加项
+
要添加项,无需像对切片一样使用内置函数。 映射更加简单。 你只需定义键和值即可。 如果没有键值对,则该项会添加到映射中。
+
package main
+
+import "fmt"
+
+func main() {
+ studentsAge := make(map[string]int)
+ studentsAge["john"] = 32
+ studentsAge["bob"] = 31
+ fmt.Println(studentsAge)
+}
+
访问项
+
若要访问映射中的项,可使用常用的下标表示法 m[key]
+
在映射中使用下标表示法时,即使映射中没有键,你也总会获得默认值的响应。
+
package main
+
+import "fmt"
+
+func main() {
+ studentsAge := make(map[string]int)
+ studentsAge["john"] = 32
+ studentsAge["bob"] = 31
+ fmt.Println("Bob's age is", studentsAge["bob"])
+ fmt.Println("Christy's age is", studentsAge["christy"])
+}
+
Bob's age is 31
+Christy's age is 0
+
在很多情况下,访问映射中没有的项时 Go 不会返回错误,这是正常的。 但有时需要知道某个项是否存在。 在 Go 中,映射的下标表示法可生成两个值。 第一个是项的值。 第二个是指示键是否存在的布尔型标志。
+
package main
+
+import "fmt"
+
+func main() {
+ studentsAge := make(map[string]int)
+ studentsAge["john"] = 32
+ studentsAge["bob"] = 31
+
+ age, exist := studentsAge["christy"]
+ if exist {
+ fmt.Println("Christy's age is", age)
+ } else {
+ fmt.Println("Christy's age couldn't be found")
+ }
+}
+
+
Christy's age couldn't be found
+
删除项
+
若要从映射中删除项,请使用内置函数 delete()。
+
package main
+
+import "fmt"
+
+func main() {
+ studentsAge := make(map[string]int)
+ studentsAge["john"] = 32
+ studentsAge["bob"] = 31
+ delete(studentsAge, "bob")
+ delete(studentsAge, "christy")
+ fmt.Println(studentsAge)
+}
+
+
+
如果你尝试删除不存在的项,Go 不会执行 panic
+
映射中的循环
+
最后,让我们看看如何在映射中进行循环来以编程方式访问其所有的项。 为此,可使用基于范围的循环
+
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ studentsAge := make(map[string]int)
+ studentsAge["john"] = 32
+ studentsAge["bob"] = 31
+ for name, age := range studentsAge {
+ fmt.Printf("%s\t%d\n", name, age)
+ }
+}
+
+
+
range 会首先生成项的键,然后再生成该项的值。 可使用 _ 变量忽略其中任何一个
+
使用结构
+
有时,你需要在一个结构中表示字段的集合。在 Go 中,可使用结构将可能构成记录的不同字段组合在一起。Go 中的结构也是一种数据结构,它可包含零个或多个任意类型的字段,并将它们表示为单个实体。
+
声明和初始化结构
+
若要声明结构,需要使用 struct 关键字,还要使用希望新的数据类型具有的字段及其类型的列表。
+
若要访问结构的各个字段,可使用点表示法 (.) 做到这一点
+
可使用 & 运算符生成指向结构的指针以修改结构中的项
+
package main
+
+import "fmt"
+
+type Employee struct {
+ ID int
+ FirstName string
+ LastName string
+ Address string
+}
+
+func main() {
+ employee := Employee{LastName: "Doe", FirstName: "John"}
+ fmt.Println(employee)
+ employeeCopy := &employee
+ employeeCopy.FirstName = "David"
+ fmt.Println(employee)
+}
+
{0 John Doe }
+{0 David Doe }
+
结构嵌入
+
通过 Go 中的结构,可将某结构嵌入到另一结构中。
+
package main
+
+import "fmt"
+
+type Person struct {
+ ID int
+ FirstName string
+ LastName string
+ Address string
+}
+
+type Employee struct {
+ Person
+ ManagerID int
+}
+
+type Contractor struct {
+ Person
+ CompanyID int
+}
+
+func main() {
+ employee := Employee{
+ Person: Person{
+ FirstName: "John",
+ },
+ }
+ employee.LastName = "Doe"
+ employee.ManagerID = 2
+ fmt.Println(employee)
+}
+
+
+
用 JSON 编码和解码结构
+
最后,可使用结构来对 JSON 中的数据进行编码和解码。 Go 对 JSON 格式提供很好的支持,该格式已包含在标准库包中。
+
你还可执行一些操作,例如重命名结构中字段的名称。 例如,假设你不希望 JSON 输出显示 FirstName 而只显示 name,或者忽略空字段, 可使用如下例所示的字段标记:
+
然后,若要将结构编码为 JSON,请使用 json.Marshal 函数。 若要将 JSON 字符串解码为数据结构,请使用 json.Unmarshal 函数。 下例将所有内容组合在一起,将员工数组编码为 JSON,并将输出解码为新的变量:
+
package main
+
+import (
+ "encoding/json"
+ "fmt"
+)
+
+type Person struct {
+ ID int
+ FirstName string `json:"name"`
+ LastName string
+ Address string `json:"address,omitempty"`
+}
+
+type Employee struct {
+ Person
+ ManagerID int
+}
+
+type Contractor struct {
+ Person
+ CompanyID int
+}
+
+func main() {
+ employees := []Employee{
+ {
+ Person: Person{
+ LastName: "Doe", FirstName: "John",
+ },
+ },
+ {
+ Person: Person{
+ LastName: "Campbell", FirstName: "David",
+ },
+ },
+ }
+
+ data, _ := json.Marshal(employees)
+ fmt.Printf("%s\n", data)
+
+ var decoded []Employee
+ json.Unmarshal(data, &decoded)
+ fmt.Printf("%v\n", decoded)
+}
+
[{"ID":0,"name":"John","LastName":"Doe","ManagerID":0},{"ID":0,"name":"David","LastName":"Campbell","ManagerID":0}]
+[{{0 John Doe } 0} {{0 David Campbell } 0}]
+
练习 - 数据类型
+
编写一个程序来计算斐波纳契数列
+
在这第一个挑战中,你将编写一个程序来计算某个数字的斐波纳契数列。 这是在学习新语言时要编码的一个典型的编程练习。 你将编写一个函数,它返回一个包含按斐波纳契数列排列的所有数字的切片,而这些数字是通过根据用户输入的大于 2 的数字计算得到的。 让我们假设小于 2 的数字会导致错误,并返回一个 nil 切片。
+
请记住,斐波那契数列是一个数字列表,其中每个数字是前两个斐波那契数字之和。 例如,数字 6 的序列是 1,1,2,3,5,8,数字 7 的序列是 1,1,2,3,5,8,13,数字 8 的序列是 1,1,2,3,5,8,13,21,以此类推。
+
package main
+
+import "fmt"
+
+func fibonacci(n int) []int {
+ if n < 2 {
+ return make([]int, 0)
+ }
+
+ nums := make([]int, n)
+ nums[0], nums[1] = 1, 1
+
+ for i := 2; i < n; i++ {
+ nums[i] = nums[i-1] + nums[i-2]
+ }
+
+ return nums
+}
+
+func main() {
+ var num int
+
+ fmt.Print("What's the Fibonacci sequence you want? ")
+ fmt.Scanln(&num)
+ fmt.Println("The Fibonacci sequence is:", fibonacci(num))
+}
+
+
创建罗马数字转换器
+
编写一个程序来转换罗马数字(例如将 MCLX 转换成 1,160)。 使用映射加载要用于将字符串字符转换为数字的基本罗马数字。 例如,M 将是映射中的键,其值将为 1000。 使用以下字符串字符映射表列表:
+
+M => 1000D => 500C => 100L => 50X => 10V => 5I => 1
+
如果用户输入的字母与上述列表中的不同,则打印一个错误。
+
请记住在有些情况下,较小的数字会排在较大的数字前面,因此不能仅仅将数字相加。 例如,数字 MCM 应打印为 1,900。
+
package main
+
+import (
+ "fmt"
+)
+
+func romanToArabic(numeral string) int {
+ romanMap := map[rune]int{
+ 'M': 1000,
+ 'D': 500,
+ 'C': 100,
+ 'L': 50,
+ 'X': 10,
+ 'V': 5,
+ 'I': 1,
+ }
+
+ arabicVals := make([]int, len(numeral)+1)
+
+ for index, digit := range numeral {
+ if val, present := romanMap[digit]; present {
+ arabicVals[index] = val
+ } else {
+ fmt.Printf("Error: The roman numeral %s has a bad digit: %c\n", numeral, digit)
+ return 0
+ }
+ }
+
+ total := 0
+
+ for index := 0; index < len(numeral); index++ {
+ if arabicVals[index] < arabicVals[index+1] {
+ arabicVals[index] = -arabicVals[index]
+ }
+ total += arabicVals[index]
+ }
+
+ return total
+}
+func main() {
+ fmt.Println("MCLX is", romanToArabic("MCLX"))
+ fmt.Println("MCMXCIX is ", romanToArabic("MCMXCIX"))
+ fmt.Println("MCMZ is", romanToArabic("MCMZ"))
+}
+
+
如何在 Go 中处理错误
+
编写程序时,需要考虑程序失败的各种方式,并且需要管理失败。 无需让用户看到冗长而混乱的堆栈跟踪错误。 让他们看到有关错误的有意义的信息更好。 正如你所看到的,Go 具有 panic 和 recover 之类的内置函数来管理程序中的异常或意外行为。 但错误是已知的失败,你的程序应该可以处理它们。
+
Go 的错误处理方法只是一种只需要 if 和 return 语句的控制流机制。 例如,在调用函数以从 employee 对象获取信息时,可能需要了解该员工是否存在。 Go 处理此类预期错误的一贯方法如下所示:
+
employee, err := getInformation(1000)
+if err != nil {
+
+}
+
注意 getInformation 函数返回了 employee 结构,还返回了错误作为第二个值。 该错误可能为 nil。 如果错误为 nil,则表示成功。 如果错误不是 nil,则表示失败。 非 nil 错误附带一条错误消息,你可以打印该错误消息,也可以记录该消息(更可取)。
+
错误处理策略
+
当函数返回错误时,该错误通常是最后一个返回值。 正如上一部分所介绍的那样,调用方负责检查是否存在错误并处理错误。
+
你可能还需要在传播错误之前添加更多信息。 为此,可以使用 fmt.Errorf() 函数,该函数与我们之前看到的函数类似,但它返回一个错误。 例如,你可以向错误添加更多上下文,但仍返回原始错误,如下所示:
+
func getInformation(id int) (*Employee, error) {
+ employee, err := apiCallEmployee(1000)
+ if err != nil {
+ return nil, fmt.Errorf("got an error when getting the employee information: %v", err)
+ }
+ return employee, nil
+}
+
另一种策略是在错误为暂时性错误时运行重试逻辑。 例如,可以使用重试策略调用函数三次并等待两秒钟
+
func getInformation(id int) (*Employee, error) {
+ for tries := 0; tries < 3; tries++ {
+ employee, err := apiCallEmployee(1000)
+ if err == nil {
+ return employee, nil
+ }
+
+ fmt.Println("Server is not responding, retrying ...")
+ time.Sleep(time.Second * 2)
+ }
+
+ return nil, fmt.Errorf("server has failed to respond to get the employee information")
+}
+
创建可重用的错误
+
有时错误消息数会增加,你需要维持秩序。 或者,你可能需要为要重用的常见错误消息创建一个库。 在 Go 中,你可以使用 errors.New() 函数创建错误并在若干部分中重复使用这些错误,如下所示:
+
var ErrNotFound = errors.New("Employee not found!")
+
+func getInformation(id int) (*Employee, error) {
+ if id != 1001 {
+ return nil, ErrNotFound
+ }
+
+ employee := Employee{LastName: "Doe", FirstName: "John"}
+ return &employee, nil
+}
+
最后,如果你具有错误变量,则在处理调用方函数中的错误时可以更具体。 errors.Is() 函数允许你比较获得的错误的类型
+
employee, err := getInformation(1000)
+if errors.Is(err, ErrNotFound) {
+ fmt.Printf("NOT FOUND: %v\n", err)
+} else {
+ fmt.Print(employee)
+}
+
用于错误处理的推荐做法
+
在 Go 中处理错误时,请记住下面一些推荐做法:
+
+- 始终检查是否存在错误,即使预期不存在。 然后正确处理它们,以免向最终用户公开不必要的信息。
+- 在错误消息中包含一个前缀,以便了解错误的来源。 例如,可以包含包和函数的名称。
+- 创建尽可能多的可重用错误变量。
+- 了解使用返回错误和 panic 之间的差异。 不能执行其他操作时再使用 panic。 例如,如果某个依赖项未准备就绪,则程序运行无意义(除非你想要运行默认行为)。
+- 在记录错误时记录尽可能多的详细信息(我们将在下一部分介绍记录方法),并打印出最终用户能够理解的错误。
+
+
如何在 Go 中记录
+
日志在程序中发挥着重要作用,因为它们是在出现问题时你可以检查的信息源。 通常,发生错误时,最终用户只会看到一条消息,指示程序出现问题。 从开发人员的角度来看,我们需要简单错误消息以外的更多信息。 这主要是因为我们想要再现该问题以编写适当的修补程序。
+
log 包
+
对于初学者,Go 提供了一个用于处理日志的简单标准包。 可以像使用 fmt 包一样使用此包。 该标准包不提供日志级别,且不允许为每个包配置单独的记录器。 如果需要编写更复杂的日志记录配置,可以使用记录框架执行此操作。
+
package main
+
+import (
+ "log"
+)
+
+func main() {
+ log.Print("Hey, I'm a log!")
+}
+
+
2022/10/05 15:37:16 Hey, I'm a log!
+
默认情况下,log.Print() 函数将日期和时间添加为日志消息的前缀。 你可以通过使用 fmt.Print() 获得相同的行为,但使用 log 包还能执行其他操作,例如将日志发送到文件。 稍后我们将详细介绍 log 包功能。
+
你可以使用 log.Fatal() 函数记录错误并结束程序,就像使用 os.Exit(1) 一样。
+
package main
+
+import (
+ "fmt"
+ "log"
+)
+
+func main() {
+ log.Fatal("Hey, I'm an error log!")
+ fmt.Print("Can you see me?")
+}
+
+
2022/10/05 15:38:56 Hey, I'm an error log!
+exit status 1
+
使用 log.Panic() 函数时会出现类似行为,但是还会获取错误堆栈跟踪。
+
另一重要函数是 log.SetPrefix()。 可使用它向程序的日志消息添加前缀。
+
package main
+
+import (
+ "log"
+)
+
+func main() {
+ log.SetPrefix("main(): ")
+ log.Print("Hey, I'm a log!")
+ log.Fatal("Hey, I'm an error log!")
+}
+
+
main(): 2022/10/05 15:40:36 Hey, I'm a log!
+main(): 2022/10/05 15:40:36 Hey, I'm an error log!
+exit status 1
+
记录到文件
+
除了将日志打印到控制台之外,你可能还希望将日志发送到文件,以便稍后或实时处理这些日志。
+
package main
+
+import (
+ "log"
+ "os"
+)
+
+func main() {
+ file, err := os.OpenFile("info.log", os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644)
+ if err != nil {
+ log.Fatal(err)
+ }
+
+ defer file.Close()
+
+ log.SetOutput(file)
+ log.Print("Hey, I'm a log!")
+}
+
最后,可能有 log 包中的函数不足以处理问题的情况。 你可能会发现,使用记录框架而不编写自己的库很有用。 Go 的几个记录框架有 Logrus、zerolog、zap 和 Apex。
+
在 Go 中使用方法
+
面向对象编程 (OOP) 是一种广受欢迎的编程模式,大部分编程语言都支持(至少部分支持)。 Go 是其中一种语言,但它并不完全支持所有 OOP 原则。
+
Go 中的方法是一种特殊类型的函数,但存在一个简单的区别:你必须在函数名称之前加入一个额外的参数。 此附加参数称为 接收方 。
+
如你希望分组函数并将其绑定到自定义类型,则方法非常有用。 Go 中的这一方法类似于在其他编程语言中创建类,因为它允许你实现面向对象编程 (OOP) 模型中的某些功能,例如嵌入、重载和封装。
+
声明方法
+
到目前为止,你仅将结构用作可在 Go 中创建的另一种自定义类型。 在此模块中你将了解到,通过添加方法你可以将行为添加到你所创建的结构中。
+
在声明方法之前,必须先创建结构。 假设你想要创建一个几何包,并决定创建一个名为 triangle 的三角形结构作为此程序包的一个组成部分。 然后,你需要使用一种方法来计算此三角形的周长。 你可以在 Go 中将其表示为:
+
type triangle struct {
+ size int
+}
+
+func (t triangle) perimeter() int {
+ return t.size * 3
+}
+
结构看起来像普通结构,但 perimeter() 函数在函数名称之前有一个类型 triangle 的额外参数。 也就是说,在使用结构时,你可以按如下方式调用函数:
+
func main() {
+ t := triangle{3}
+ fmt.Println("Perimeter:", t.perimeter())
+}
+
如果尝试按平常的方式调用 perimeter() 函数,则此函数将无法正常工作,因为此函数的签名表明它需要接收方。 正因如此,调用此方法的唯一方式是先声明一个结构,获取此方法的访问权限。 这也意味着,只要此方法属于不同的结构,你甚至可以为其指定相同的名称。 例如,你可以使用 perimeter() 函数声明一个 square 结构,具体如下所示:
+
package main
+
+import "fmt"
+
+type triangle struct {
+ size int
+}
+
+type square struct {
+ size int
+}
+
+func (t triangle) perimeter() int {
+ return t.size * 3
+}
+
+func (s square) perimeter() int {
+ return s.size * 4
+}
+
+func main() {
+ t := triangle{3}
+ s := square{4}
+ fmt.Println("Perimeter (triangle):", t.perimeter())
+ fmt.Println("Perimeter (square):", s.perimeter())
+}
+
+
Perimeter (triangle): 9
+Perimeter (square): 16
+
通过对 perimeter() 函数的两次调用,编译器将根据接收方类型来确定要调用的函数。 这有助于在各程序包之间保持函数的一致性和名称的简短,并避免将包名称作为前缀。
+
方法中的指针
+
有时,方法需要更新变量,或者,如果参数太大,则可能需要避免复制它。 在遇到此类情况时,你需要使用指针传递变量的地址。 在之前的模块中,当我们在讨论指针时提到,每次在 Go 中调用函数时,Go 都会复制每个参数值以便使用。
+
如果你需要更新方法中的接收方变量,也会执行相同的行为。 例如,假设你要创建一个新方法以使三角形的大小增加一倍。 你需要在接收方变量中使用指针,具体如下所示:
+
func (t *triangle) doubleSize() {
+ t.size *= 2
+}
+
如果方法仅可访问接收方的信息,则不需要在接收方变量中使用指针。 但是,依据 Go 的约定,如果结构的任何方法具有指针接收方,则此结构的所有方法都必须具有指针接收方,即使某个方法不需要也是如此。
+
声明其他类型的方法
+
方法的一个关键方面在于,需要为任何类型定义方法,而不只是针对自定义类型(如结构)进行定义。 但是,你不能通过属于其他包的类型来定义结构。 因此,不能在基本类型(如 string)上创建方法。
+
尽管如此,你仍然可以利用一点技巧,基于基本类型创建自定义类型,然后将其用作基本类型。 例如,假设你要创建一个方法,以将字符串从小写字母转换为大写字母。 你可以按如下所示写入方法:
+
package main
+
+import (
+ "fmt"
+ "strings"
+)
+
+type upperstring string
+
+func (s upperstring) Upper() string {
+ return strings.ToUpper(string(s))
+}
+
+func main() {
+ s := upperstring("Learning Go!")
+ fmt.Println(s)
+ fmt.Println(s.Upper())
+}
+
+
嵌入方法
+
在之前的模块中,您已了解到可以在一个结构中使用属性,并将同一属性嵌入另一个结构中。 也就是说,可以重用来自一个结构的属性,以避免出现重复并保持代码库的一致性。 类似的观点也适用于方法。 即使接收方不同,也可以调用已嵌入结构的方法。
+
例如,假设你想要创建一个带有逻辑的新三角形结构,以加入颜色。 此外,你还希望继续使用之前声明的三角形结构。 然后,你可以初始化 coloredTriangle 结构,并从 triangle 结构调用 perimeter() 方法(甚至访问其字段)
+
package main
+
+import "fmt"
+
+type triangle struct {
+ size int
+}
+
+type coloredTriangle struct {
+ triangle
+ color string
+}
+
+func (t triangle) perimeter() int {
+ return t.size * 3
+}
+
+func main() {
+ t := coloredTriangle{triangle{3}, "blue"}
+ fmt.Println("Size:", t.size)
+ fmt.Println("Perimeter", t.perimeter())
+}
+
+
+
重载方法
+
让我们回到之前讨论过的 triangle 示例。 如果要在 coloredTriangle 结构中更改 perimeter() 方法的实现,会发生什么情况? 不能存在两个同名的函数。 但是,因为方法需要额外参数(接收方),所以,你可以使用一个同名的方法,只要此方法专门用于要使用的接收方即可。 这就是重载方法的方式。
+
如果你仍需要从 triangle 结构调用 perimeter() 方法,则可通过对其进行显示访问来执行此操作
+
package main
+
+import "fmt"
+
+type triangle struct {
+ size int
+}
+
+type coloredTriangle struct {
+ triangle
+ color string
+}
+
+func (t coloredTriangle) perimeter() int {
+ return t.size * 3 * 2
+}
+
+func (t triangle) perimeter() int {
+ return t.size * 3
+}
+
+func main() {
+ t := coloredTriangle{triangle{3}, "blue"}
+ fmt.Println("Size:", t.size)
+ fmt.Println("Perimeter (colored)", t.perimeter())
+ fmt.Println("Perimeter (normal)", t.triangle.perimeter())
+}
+
+
方法中的封装
+
“封装”表示对象的发送方(客户端)无法访问某个方法。 通常,在其他编程语言中,你会将 private 或 public 关键字放在方法名称之前。 在 Go 中,只需使用大写标识符,即可公开方法,使用非大写的标识符将方法设为私有方法。
+
Go 中的封装仅在程序包之间有效。 换句话说,你只能隐藏来自其他程序包的实现详细信息,而不能隐藏程序包本身。
+
package geometry
+
+type Triangle struct {
+ size int
+}
+
+func (t *Triangle) doubleSize() {
+ t.size *= 2
+}
+
+func (t *Triangle) SetSize(size int) {
+ t.size = size
+}
+
+func (t *Triangle) Perimeter() int {
+ t.doubleSize()
+ return t.size * 3
+}
+
package main
+
+import (
+ "fmt"
+ "geometry"
+)
+
+func main() {
+ t := geometry.Triangle{}
+ t.SetSize(3)
+ fmt.Println("Perimeter", t.Perimeter())
+}
+
+
在 Go 中使用接口
+
Go 中的接口是一种用于表示其他类型的行为的数据类型。 接口类似于对象应满足的蓝图或协定。 在你使用接口时,你的基本代码将变得更加灵活、适应性更强,因为你编写的代码未绑定到特定的实现。 因此,你可以快速扩展程序的功能。
+
与其他编程语言中的接口不同,Go 中的接口是满足隐式实现的。 Go 并不提供用于实现接口的关键字,因此,如果你之前使用的是其他编程语言中的接口,但不熟悉 Go,那么此概念可能会造成混淆。
+
声明接口
+
Go 中的接口是一种抽象类型,只包括具体类型必须拥有或实现的方法。 正因如此,我们说接口类似于蓝图。
+
假设你希望在几何包中创建一个接口来指示形状必须实现的方法。 你可以按如下所示定义接口:
+
type Shape interface {
+ Perimeter() float64
+ Area() float64
+}
+
Shape 接口表示你想要考虑 Shape 的任何类型都需要同时具有 Perimeter() 和 Area() 方法。 例如,在创建 Square 结构时,它必须实现两种方法,而不是仅实现一种。 另外,请注意接口不包含这些方法的实现细节(例如,用于计算某个形状的周长和面积)。 接口仅表示一种协定。 三角形、圆圈和正方形等形状有不同的计算面积和周长方式。
+
实现接口
+
正如上文所讨论的内容,你没有用于实现接口的关键字。 当 Go 中的接口具有接口所需的所有方法时,则满足按类型的隐式实现。
+
让我们创建一个 Square 结构,此结构具有 Shape 接口中的两个方法
+
type Square struct {
+ size float64
+}
+
+func (s Square) Area() float64 {
+ return s.size * s.size
+}
+
+func (s Square) Perimeter() float64 {
+ return s.size * 4
+}
+
请注意 Square 结构的方法签名与 Shape 接口的签名的匹配方式。
+
func main() {
+ var s Shape = Square{3}
+ fmt.Printf("%T\n", s)
+ fmt.Println("Area: ", s.Area())
+ fmt.Println("Perimeter:", s.Perimeter())
+}
+
main.Square
+Area: 9
+Perimeter: 12
+
此时,无论你是否使用接口,都没有任何区别。 接下来,让我们创建另一种类型,如 Circle,然后进行相同的操作:
+
package main
+
+import (
+ "fmt"
+ "math"
+)
+
+type Shape interface {
+ Perimeter() float64
+ Area() float64
+}
+
+type Square struct {
+ size float64
+}
+
+func (s Square) Area() float64 {
+ return s.size * s.size
+}
+
+func (s Square) Perimeter() float64 {
+ return s.size * 4
+}
+
+type Circle struct {
+ radius float64
+}
+
+func (c Circle) Area() float64 {
+ return math.Pi * c.radius * c.radius
+}
+
+func (c Circle) Perimeter() float64 {
+ return 2 * math.Pi * c.radius
+}
+
+func printInformation(s Shape) {
+ fmt.Printf("%T\n", s)
+ fmt.Println("Area: ", s.Area())
+ fmt.Println("Perimeter:", s.Perimeter())
+ fmt.Println()
+}
+
+func main() {
+ var s Shape = Square{3}
+ printInformation(s)
+
+ c := Circle{6}
+ printInformation(c)
+}
+
+
main.Square
+Area: 9
+Perimeter: 12
+
+main.Circle
+Area: 113.09733552923255
+Perimeter: 37.69911184307752
+
使用接口的优点在于,对于 Shape的每个新类型或实现,printInformation 函数都不需要更改。 正如之前所述,当你使用接口时,代码会变得更灵活、更容易扩展。
+
扩展现有实现
+
假设你具有以下代码,并且希望通过编写负责处理某些数据的 Writer 方法的自定义实现来扩展其功能。
+
通过使用以下代码,你可以创建一个程序,此程序使用 GitHub API 从 Microsoft 获取三个存储库:
+
package main
+
+import (
+ "fmt"
+ "io"
+ "net/http"
+ "os"
+)
+
+func main() {
+ resp, err := http.Get("https://api.github.com/users/microsoft/repos?page=15&per_page=5")
+ if err != nil {
+ fmt.Println("Error:", err)
+ os.Exit(1)
+ }
+
+ io.Copy(os.Stdout, resp.Body)
+}
+
改写后:
+
package main
+
+import (
+ "encoding/json"
+ "fmt"
+ "io"
+ "net/http"
+ "os"
+)
+
+type GitHubResponse []struct {
+ FullName string `json:"full_name"`
+}
+
+type customWriter struct{}
+
+func (w customWriter) Write(p []byte) (n int, err error) {
+ var resp GitHubResponse
+ json.Unmarshal(p, &resp)
+ for _, r := range resp {
+ fmt.Println(r.FullName)
+ }
+ return len(p), nil
+}
+
+func main() {
+ resp, err := http.Get("https://api.github.com/users/microsoft/repos?page=15&per_page=5")
+ if err != nil {
+ fmt.Println("Error:", err)
+ os.Exit(1)
+ }
+
+ writer := customWriter{}
+ io.Copy(writer, resp.Body)
+}
+
+
编写自定义服务器 API
+
最后,我们一起来探讨接口的另一种用例,如果你要创建服务器 API,你可能会发现此用例非常实用。 编写 Web 服务器的常用方式是使用 net/http 程序包中的 http.Handler 接口
+
package main
+
+import (
+ "fmt"
+ "log"
+ "net/http"
+)
+
+
+type dollars float32
+
+func (d dollars) String() string {
+ return fmt.Sprintf("$%.2f", d)
+}
+
+
+
+type database map[string]dollars
+
+
+func (db database) ServeHTTP(w http.ResponseWriter, req *http.Request) {
+ for item, price := range db {
+ fmt.Fprintf(w, "%s: %s\n", item, price)
+ }
+}
+
+
+func main() {
+ db := database{"Go T-Shirt": 25, "Go Jacket": 55}
+ log.Fatal(http.ListenAndServe("localhost:8000", db))
+}
+
练习 - 方法和接口
+
创建用于管理在线商店的程序包
+
编写一个程序,此程序使用自定义程序包来管理在线商店的帐户。 你的挑战包括以下四个要素:
+
+- 创建一个名为
Account 的自定义类型,此类型包含帐户所有者的名字和姓氏。 此类型还必须加入 ChangeName 的功能。
+- 创建另一个名为
Employee 的自定义类型,此类型包含用于将贷方数额存储为类型 float64 并嵌入 Account 对象的变量。 类型还必须包含 AddCredits、RemoveCredits 和 CheckCredits 的功能。 你需要展示你可以通过 Employee 对象更改帐户名称。
+- 将字符串方法写入
Account 对象,以便按包含名字和姓氏的格式打印 Employee 名称。
+- 最后,编写使用已创建程序包的程序,并测试此挑战中列出的所有功能。 也就是说,主程序应更改名称、打印名称、添加贷方、删除贷方以及检查余额。
+
+
package main
+
+import (
+ "errors"
+ "fmt"
+)
+
+type Account struct {
+ firstname string
+ lastname string
+}
+
+func (a *Account) ChangeName(afterfirstname string) {
+ a.firstname = afterfirstname
+}
+
+type Employee struct {
+ Account
+ credit float64
+}
+
+func (e Employee) String() string {
+ return fmt.Sprintf("Firstname:%s,Lastname:%s,Credit:%.2f\n", e.firstname, e.lastname, e.credit)
+}
+
+func CreateEmployee(firstname, lastname string, credit float64) (*Employee, error) {
+ return &Employee{Account{firstname, lastname}, credit}, nil
+}
+
+func (e *Employee) AddCredits(amount float64) (float64, error) {
+ if amount > 0.0 {
+ e.credit += amount
+ return e.credit, nil
+ }
+ return 0.0, errors.New("invalid amount")
+}
+
+func (e *Employee) RemoveCredits(amount float64) (float64, error) {
+ if e.credit-amount < 0 {
+ return 0.0, errors.New("too much")
+ }
+ if amount < 0 {
+ return 0.0, errors.New("invalid amount")
+ }
+ e.credit -= amount
+ return e.credit, nil
+}
+
+func (e Employee) CheckCredits() float64 {
+ return e.credit
+}
+
+func main() {
+ bruce, _ := CreateEmployee("Bruce", "Lee", 500)
+ fmt.Println(bruce.CheckCredits())
+ credits, err := bruce.AddCredits(250)
+ if err != nil {
+ fmt.Println("Error:", err)
+ } else {
+ fmt.Println("New Credits Balance = ", credits)
+ }
+
+ _, err = bruce.RemoveCredits(2500)
+ if err != nil {
+ fmt.Println("Can't withdraw or overdrawn!", err)
+ }
+
+ bruce.ChangeName("Mark")
+
+ fmt.Println(bruce)
+}
+
+
goroutine(轻量线程)
+
并发是独立活动的组合,就像 Web 服务器虽然同时处理多个用户请求,但它是自主运行的。 并发在当今的许多程序中都存在。 Web 服务器就是一个例子,但你也能看到,在批量处理大量数据时也需要使用并发。
+
Go 有两种编写并发程序的样式。 一种是在其他语言中通过线程实现的传统样式。
+
Go 实现并发的方法
+
通常,编写并发程序时最大的问题是在进程之间共享数据。 Go 采用不同于其他编程语言的通信方式,因为 Go 是通过 channel 来回传递数据的。 这意味着只有一个活动 (goroutine) 有权访问数据,设计上不存在争用条件。 学完本模块中的 goroutine 和 channel 之后,你将更好地理解 Go 的并发方法。
+
可以使用下面的标语来概括 Go 的方法:“不是通过共享内存通信,而是通过通信共享内存。”
+
Goroutine
+
goroutine 是轻量线程中的并发活动,而不是在操作系统中进行的传统活动。 假设你有一个写入输出的程序和另一个计算两个数字相加的函数。 一个并发程序可以有数个 goroutine 同时调用这两个函数。
+
我们可以说,程序执行的第一个 goroutine 是 main() 函数。 如果要创建其他 goroutine,则必须在调用该函数之前使用 go 关键字
+
func main(){
+ login()
+ go launch()
+}
+
许多程序喜欢使用匿名函数来创建 goroutine
+
func main(){
+ login()
+ go func() {
+ launch()
+ }()
+}
+
编写并发程序
+
由于我们只想将重点放在并发部分,因此我们使用现有程序来检查 API 终结点是否响应。
+
串行程序:
+
package main
+
+import (
+ "fmt"
+ "net/http"
+ "time"
+)
+
+func main() {
+ start := time.Now()
+
+ apis := []string{
+ "https://management.azure.com",
+ "https://dev.azure.com",
+ "https://api.github.com",
+ "https://outlook.office.com/",
+ "https://api.somewhereintheinternet.com/",
+ "https://graph.microsoft.com",
+ }
+
+ for _, api := range apis {
+ _, err := http.Get(api)
+ if err != nil {
+ fmt.Printf("ERROR: %s is down!\n", api)
+ continue
+ }
+
+ fmt.Printf("SUCCESS: %s is up and running!\n", api)
+ }
+
+ elapsed := time.Since(start)
+ fmt.Printf("Done! It took %v seconds!\n", elapsed.Seconds())
+}
+
+
SUCCESS: https://management.azure.com is up and running!
+SUCCESS: https://dev.azure.com is up and running!
+SUCCESS: https://api.github.com is up and running!
+SUCCESS: https://outlook.office.com/ is up and running!
+ERROR: https://api.somewhereintheinternet.com/ is down!
+SUCCESS: https://graph.microsoft.com is up and running!
+Done! It took 5.163787068 seconds!
+
同时检查所有站点?我们需要并发运行的代码部分是向站点进行 HTTP 调用的部分。 换句话说,我们需要为程序要检查的每个 API 创建一个 goroutine。为了创建 goroutine,我们需要在调用函数前使用 go 关键字。
+
首先创建一个新函数:
+
func checkAPI(api string) {
+ _, err := http.Get(api)
+ if err != nil {
+ fmt.Printf("ERROR: %s is down!\n", api)
+ return
+ }
+
+ fmt.Printf("SUCCESS: %s is up and running!\n", api)
+}
+
修改 main() 函数中的代码,为每个 API 创建一个 goroutine
+
for _, api := range apis {
+ go checkAPI(api)
+}
+
Done! It took 3.42e-05 seconds!
+
即使看起来 checkAPI 函数没有运行,它实际上是在运行。 它只是没有时间完成。
+
添加 time.Sleep(3 * time.Second)
+
ERROR: https://api.somewhereintheinternet.com/ is down!
+SUCCESS: https://api.github.com is up and running!
+SUCCESS: https://management.azure.com is up and running!
+SUCCESS: https://dev.azure.com is up and running!
+SUCCESS: https://outlook.office.com/ is up and running!
+SUCCESS: https://graph.microsoft.com is up and running!
+Done! It took 3.001536063 seconds!
+
将 channel 用作通信机制
+
Go 中的 channel 是 goroutine 之间的通信机制。 这就是为什么我们之前说过 Go 实现并发的方式是:“不是通过共享内存通信,而是通过通信共享内存。”需要将值从一个 goroutine 发送到另一个时,可以使用通道。
+
Channel 语法
+
由于 channel 是发送和接收数据的通信机制,因此它也有类型之分。 这意味着你只能发送 channel 支持的数据类型。 除使用关键字 chan 作为 channel 的数据类型外,还需指定将通过 channel 传递的数据类型,如 int 类型。
+
每次声明一个 channel 或希望在函数中指定一个 channel 作为参数时,都需要使用 chan <type>,如 chan int。 要创建 channel,需使用内置的 make() 函数,如下所示:
+
+
一个 channel 可以执行两项操作:发送数据和接收数据。 若要指定 channel 具有的操作类型,需要使用 channel 运算符 <-。 此外,在 channel 中发送数据和接收数据属于阻止操作。
+
如果希望 channel 仅发送数据,则必须在 channel 之后使用 <- 运算符。 如果希望 channel 接收数据,则必须在 channel 之前使用 <- 运算符
+
+
可在 channel 中执行的另一项操作是关闭 channel
+
+
关闭 channel 时,你希望数据将不再在该 channel 中发送。 如果试图将数据发送到已关闭的 channel,则程序将发生严重错误。 如果试图通过已关闭的 channel 接收数据,则可以读取发送的所有数据。 随后的每次“读取”都将返回一个零值。
+
使用 channel 来删除睡眠功能并稍做清理:
+
package main
+
+import (
+ "fmt"
+ "net/http"
+ "time"
+)
+
+
+func checkAPI(api string, ch chan string) {
+ _, err := http.Get(api)
+ if err != nil {
+ ch <- fmt.Sprintf("ERROR: %s is down!\n", api)
+ return
+ }
+ ch <- fmt.Sprintf("SUCCESS: %s is up and running!\n", api)
+}
+
+func main() {
+
+ ch := make(chan string)
+
+ start := time.Now()
+
+ apis := []string{
+ "https://management.azure.com",
+ "https://dev.azure.com",
+ "https://api.github.com",
+ "https://outlook.office.com/",
+ "https://api.somewhereintheinternet.com/",
+ "https://graph.microsoft.com",
+ }
+
+ for _, api := range apis {
+ go checkAPI(api, ch)
+ }
+ fmt.Print(<-ch)
+
+ elapsed := time.Since(start)
+ fmt.Printf("Done! It took %v seconds!\n", elapsed.Seconds())
+}
+
+
ERROR: https://api.somewhereintheinternet.com/ is down!
+Done! It took 0.088759104 seconds!
+
但是事实上并没有实现功能
+
无缓冲 channel
+
使用 make() 函数创建 channel 时,会创建一个无缓冲 channel,这是默认行为。 无缓冲 channel 会阻止发送操作,直到有人准备好接收数据。 这就是为什么我们之前说发送和接收都属于阻止操作。 这也是上面的程序在收到第一条消息后立即停止的原因。
+
我们可以说 fmt.Print(<-ch) 会阻止程序,因为它从 channel 读取,并等待一些数据到达。 一旦有任何数据到达,它就会继续下一行,然后程序完成。
+
其他 goroutine 发生了什么? 它们仍在运行,但都没有在侦听。 而且,由于程序提前完成,一些 goroutine 无法发送数据。
+
读取数据和接收数据都属于阻止操作
+
要解决此问题,只需更改循环的代码,然后只接收确定要发送的数据
+
package main
+
+import (
+ "fmt"
+ "net/http"
+ "time"
+)
+
+
+func checkAPI(api string, ch chan string) {
+ _, err := http.Get(api)
+ if err != nil {
+ ch <- fmt.Sprintf("ERROR: %s is down!\n", api)
+ return
+ }
+ ch <- fmt.Sprintf("SUCCESS: %s is up and running!\n", api)
+}
+
+func main() {
+
+ ch := make(chan string)
+
+ start := time.Now()
+
+ apis := []string{
+ "https://management.azure.com",
+ "https://dev.azure.com",
+ "https://api.github.com",
+ "https://outlook.office.com/",
+ "https://api.somewhereintheinternet.com/",
+ "https://graph.microsoft.com",
+ }
+
+ for _, api := range apis {
+ go checkAPI(api, ch)
+ }
+ for i := 0; i < len(apis); i++ {
+ fmt.Print(<-ch)
+ }
+
+ elapsed := time.Since(start)
+ fmt.Printf("Done! It took %v seconds!\n", elapsed.Seconds())
+}
+
+
ERROR: https://api.somewhereintheinternet.com/ is down!
+SUCCESS: https://api.github.com is up and running!
+SUCCESS: https://management.azure.com is up and running!
+SUCCESS: https://graph.microsoft.com is up and running!
+SUCCESS: https://dev.azure.com is up and running!
+SUCCESS: https://outlook.office.com/ is up and running!
+Done! It took 1.029620196 seconds!
+
无缓冲 channel 在同步发送和接收操作。 即使使用并发,通信也是同步的。
+
有缓冲 channel
+
默认情况下 channel 是无缓冲行为。 这意味着只有存在接收操作时,它们才接受发送操作。 否则,程序将永久被阻止等待。
+
有时需要在 goroutine 之间进行此类同步。 但是,有时你可能只需要实现并发,而不需要限制 goroutine 之间的通信方式。
+
有缓冲 channel 在不阻止程序的情况下发送和接收数据,因为有缓冲 channel 的行为类似于队列。 创建 channel 时,可以限制此队列的大小
+
package main
+
+import (
+ "fmt"
+)
+
+func send(ch chan string, message string) {
+ ch <- message
+}
+
+func main() {
+ size := 4
+ ch := make(chan string, size)
+ send(ch, "one")
+ send(ch, "two")
+ send(ch, "three")
+ send(ch, "four")
+ fmt.Println("All data sent to the channel ...")
+
+ for i := 0; i < size; i++ {
+ fmt.Println(<-ch)
+ }
+
+ fmt.Println("Done!")
+}
+
+
All data sent to the channel ...
+one
+two
+three
+four
+Done!
+
channel 与 goroutine 有着紧密的联系。 如果没有另一个 goroutine 从 channel 接收数据,则整个程序可能会永久处于被阻止状态。
+
func main() {
+ size := 2
+ ch := make(chan string, size)
+ send(ch, "one")
+ send(ch, "two")
+ go send(ch, "three")
+ go send(ch, "four")
+ fmt.Println("All data sent to the channel ...")
+
+ for i := 0; i < 4; i++ {
+ fmt.Println(<-ch)
+ }
+
+ fmt.Println("Done!")
+}
+
无缓冲 channel 与有缓冲 channel
+
现在,你可能想知道何时使用这两种类型。 这完全取决于你希望 goroutine 之间的通信如何进行。 无缓冲 channel 同步通信。 它们保证每次发送数据时,程序都会被阻止,直到有人从 channel 中读取数据。
+
相反,有缓冲 channel 将发送和接收操作解耦。 它们不会阻止程序,但你必须小心使用,因为可能最终会导致死锁(如前文所述)。 使用无缓冲 channel 时,可以控制可并发运行的 goroutine 的数量。 例如,你可能要对 API 进行调用,并且想要控制每秒执行的调用次数。 否则,你可能会被阻止。
+
Channel 方向
+
Go 中 channel 的一个有趣特性是,在使用 channel 作为函数的参数时,可以指定 channel 是要发送数据还是接收数据。 随着程序的增长,可能会使用大量的函数,这时候,最好记录每个 channel 的意图,以便正确使用它们。 或者,你要编写一个库,并希望将 channel 公开为只读,以保持数据一致性。
+
要定义 channel 的方向,可以使用与读取或接收数据时类似的方式进行定义。 但是你在函数参数中声明 channel 时执行此操作。 将 channel 类型定义为函数中的参数的语法如下所示:
+
+
通过仅接收的 channel 发送数据时,在编译程序时会出现错误。
+
让我们使用以下程序作为两个函数的示例,一个函数用于读取数据,另一个函数用于发送数据:
+
package main
+
+import "fmt"
+
+func send(ch chan<- string, message string) {
+ fmt.Printf("Sending: %#v\n", message)
+ ch <- message
+}
+
+func read(ch <-chan string) {
+ fmt.Printf("Receiving: %#v\n", <-ch)
+}
+
+func main() {
+ ch := make(chan string, 1)
+ send(ch, "Hello World!")
+ read(ch)
+}
+
运行程序时,将看到以下输出:
+
Sending: "Hello World!"
+Receiving: "Hello World!"
+
程序阐明每个函数中每个 channel 的意图。 如果试图使用一个 channel 在一个仅用于接收数据的 channel 中发送数据,将会出现编译错误。 例如,尝试执行如下所示的操作:
+
func read(ch <-chan string) {
+ fmt.Printf("Receiving: %#v\n", <-ch)
+ ch <- "Bye!"
+}
+
运行程序时,将看到以下错误:
+
# command-line-arguments
+./main.go:12:5: invalid operation: ch <- "Bye!" (send to receive-only type <-chan string)
+
编译错误总比误用 channel 好。
+
多路复用
+
最后,让我们讨论一个关于如何在使用 select 关键字的同时与多个 channel 交互的简短主题。 有时,在使用多个 channel 时,需要等待事件发生。 例如,当程序正在处理的数据中出现异常时,可以包含一些逻辑来取消操作。
+
select 语句的工作方式类似于 switch 语句,但它适用于 channel。 它会阻止程序的执行,直到它收到要处理的事件。 如果它收到多个事件,则会随机选择一个。
+
select 语句的一个重要方面是,它在处理事件后完成执行。 如果要等待更多事件发生,则可能需要使用循环。
+
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func process(ch chan string) {
+ time.Sleep(3 * time.Second)
+ ch <- "Done processing!"
+}
+
+func replicate(ch chan string) {
+ time.Sleep(1 * time.Second)
+ ch <- "Done replicating!"
+}
+
+func main() {
+ ch1 := make(chan string)
+ ch2 := make(chan string)
+ go process(ch1)
+ go replicate(ch2)
+
+ for i := 0; i < 2; i++ {
+ select {
+ case process := <-ch1:
+ fmt.Println(process)
+ case replicate := <-ch2:
+ fmt.Println(replicate)
+ }
+ }
+}
+
+
Done replicating!
+Done processing!
+
请注意,replicate 函数先完成。 这就是你在终端中先看到其输出的原因。 main 函数存在一个循环,因为 select 语句在收到事件后立即结束,但我们仍在等待 process 函数完成。
+
练习 - 利用并发方法更快地计算斐波纳契数
+
实现并发的改进版本。 完成此操作需要几秒钟的时间(不超过 15 秒),应使用有缓冲 channel。
+
package main
+
+import (
+ "fmt"
+ "math/rand"
+ "time"
+)
+
+func fib(number float64, ch chan string) {
+ x, y := 1.0, 1.0
+ for i := 0; i < int(number); i++ {
+ x, y = y, x+y
+ }
+
+ r := rand.Intn(3)
+ time.Sleep(time.Duration(r) * time.Second)
+
+ ch <- fmt.Sprintf("Fib(%v): %v\n", number, x)
+}
+
+func main() {
+ ch := make(chan string, 15)
+
+ start := time.Now()
+
+ for i := 1; i < 15; i++ {
+ go fib(float64(i), ch)
+ }
+
+ for i := 1; i < 15; i++ {
+ fmt.Printf(<-ch)
+ }
+
+ elapsed := time.Since(start)
+ fmt.Printf("Done! It took %v seconds!\n", elapsed.Seconds())
+}
+
+
编写一个新版本以计算斐波纳契数,直到用户使用 fmt.Scanf() 函数在终端中输入 quit。 如果用户按 Enter,则应计算新的斐波纳契数。
+
使用两个无缓冲 channel:一个用于计算斐波纳契数,另一个用于等待用户的“退出”消息。 你需要使用 select 语句。
+
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+var quit = make(chan bool)
+
+func fib(c chan int) {
+ x, y := 1, 1
+
+ for {
+ select {
+ case c <- x:
+ x, y = y, x+y
+ case <-quit:
+ fmt.Println("Done calculating Fibonacci!")
+ return
+ }
+ }
+}
+
+func main() {
+ start := time.Now()
+
+ command := ""
+ data := make(chan int)
+
+ go fib(data)
+
+ for {
+ num := <-data
+ fmt.Println(num)
+ fmt.Scanf("%s", &command)
+ if command == "quit" {
+ quit <- true
+ break
+ }
+ }
+
+ time.Sleep(1 * time.Second)
+
+ elapsed := time.Since(start)
+ fmt.Printf("Done! It took %v seconds!\n", elapsed.Seconds())
+}
+
+
+
+

 +
+


 +
+
 +
+



 +
+

 +
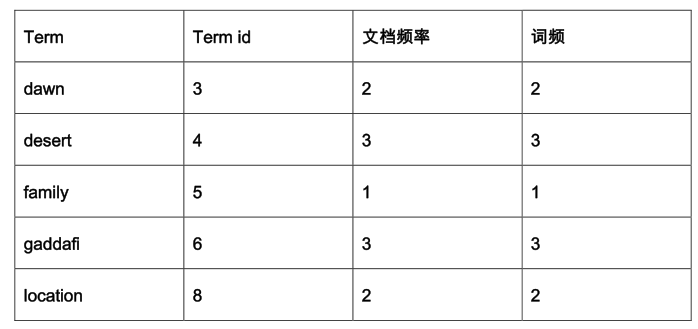
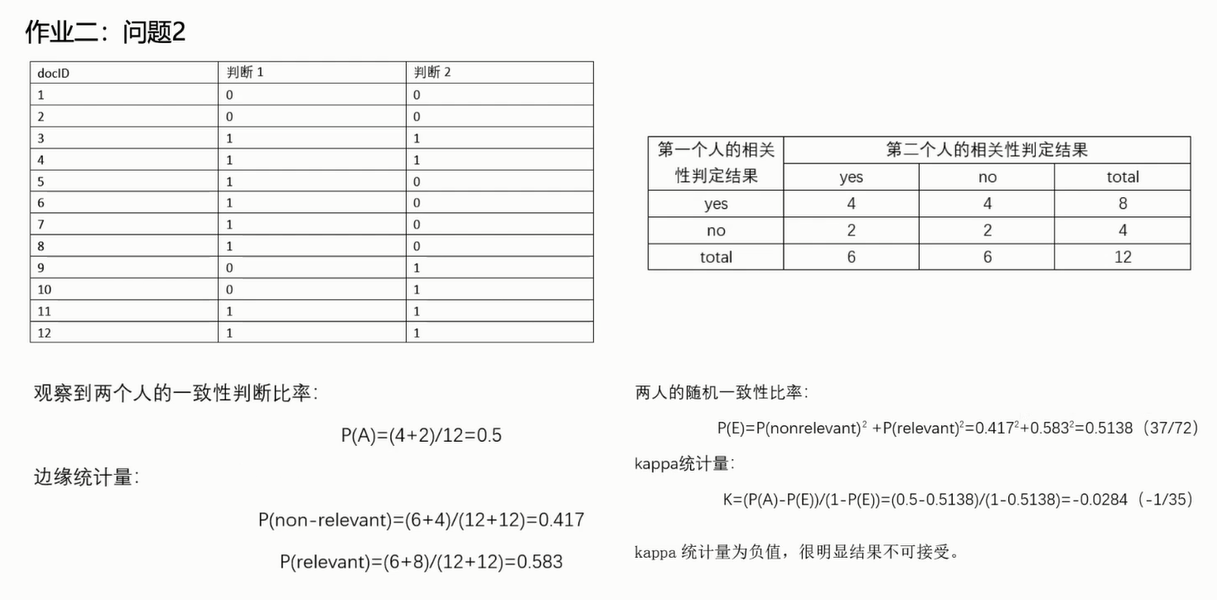
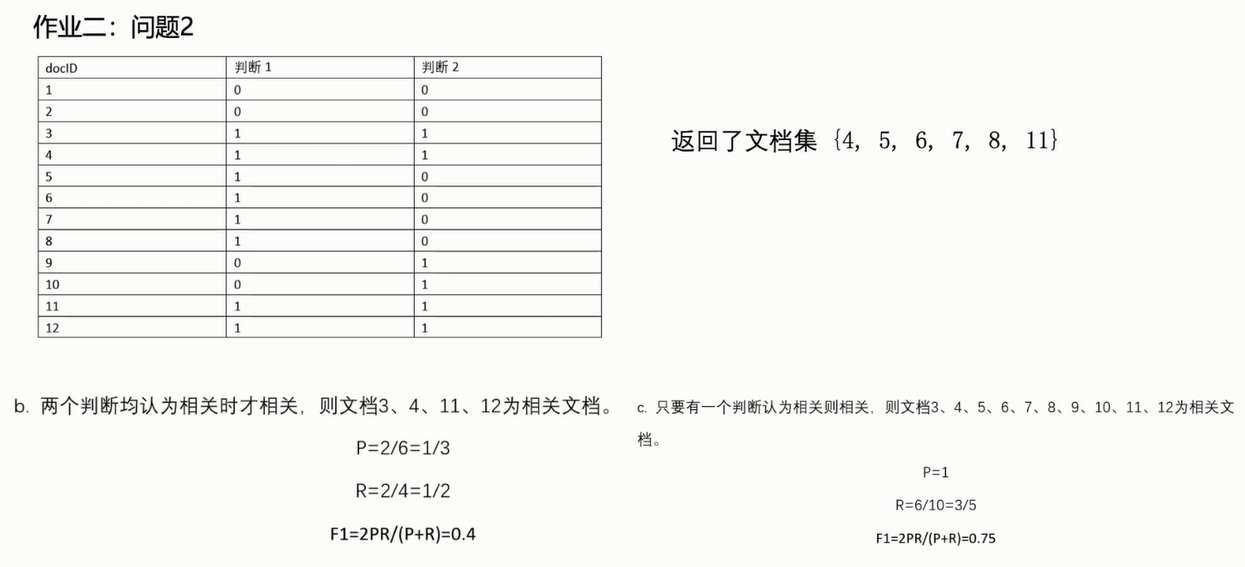
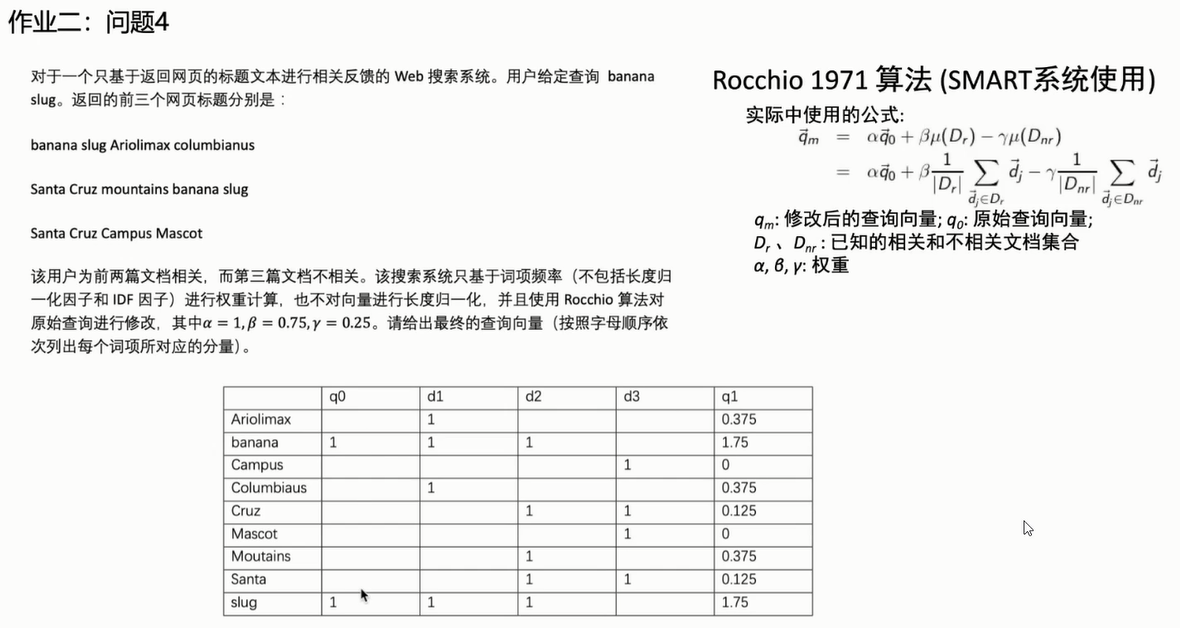
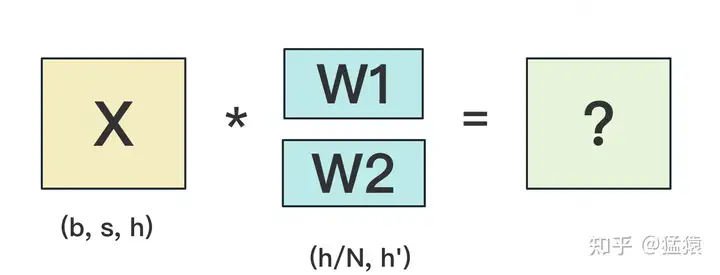
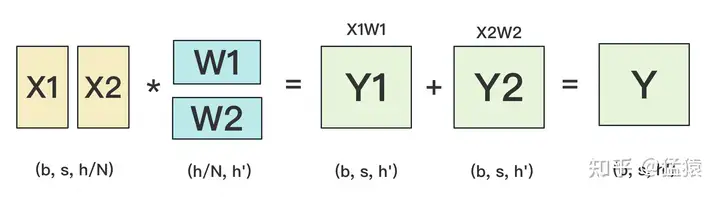
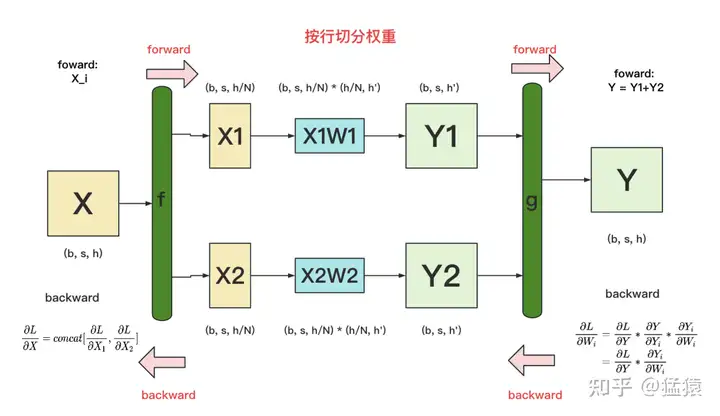
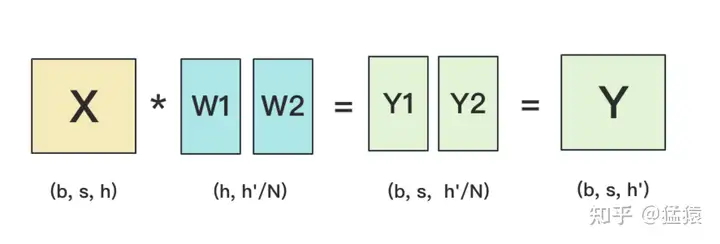
+ ,可以转换为
,可以转换为

 +
+ +
+ +
+




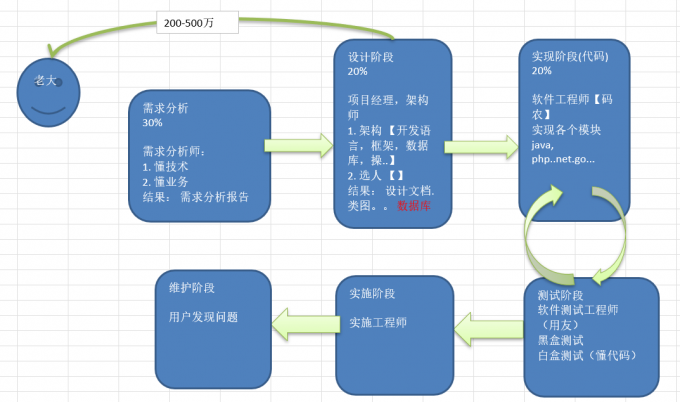
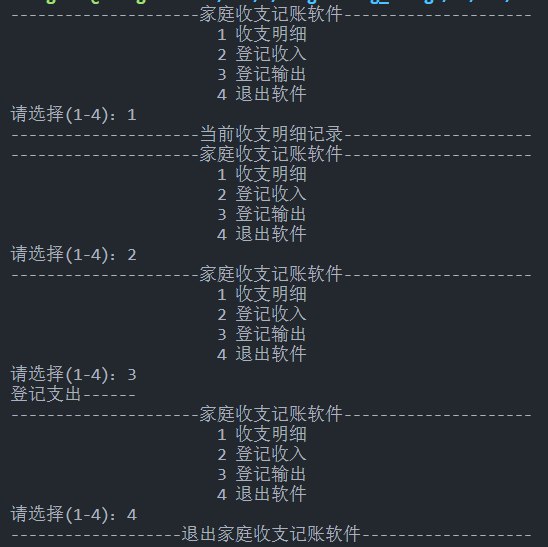
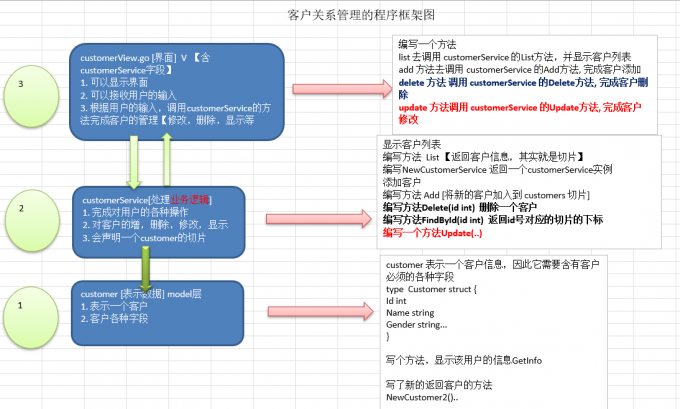
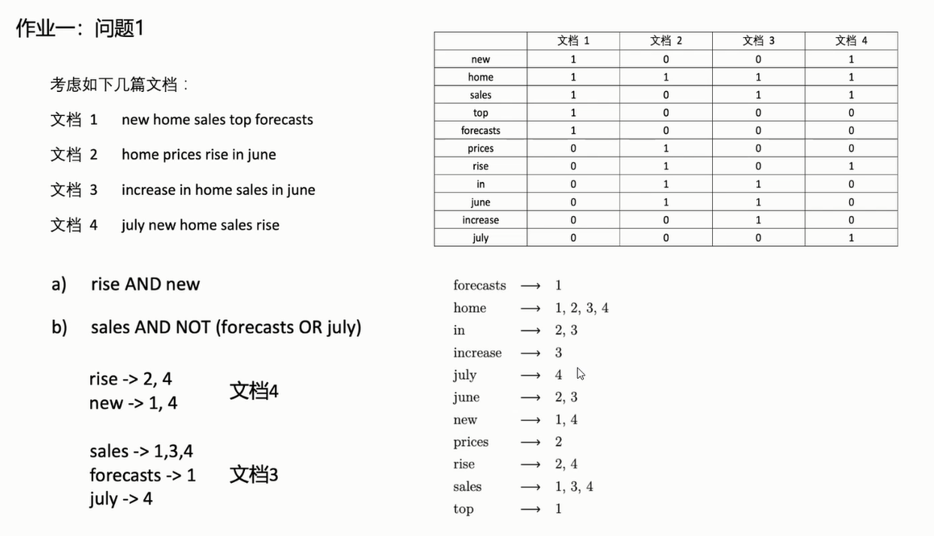






















































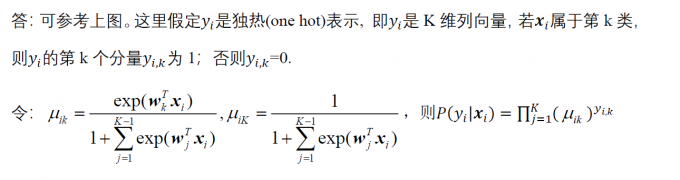
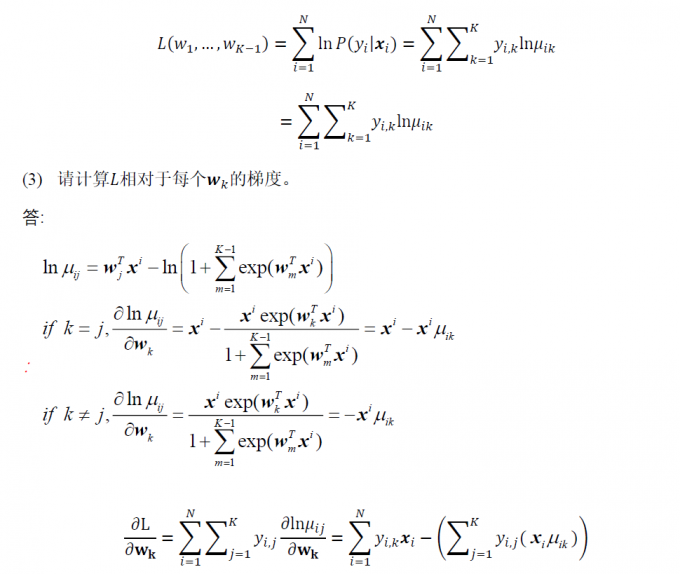
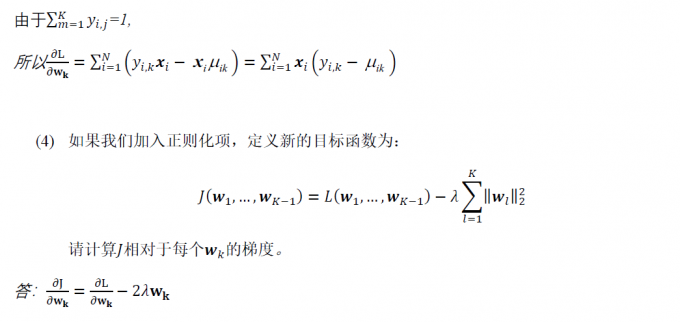

























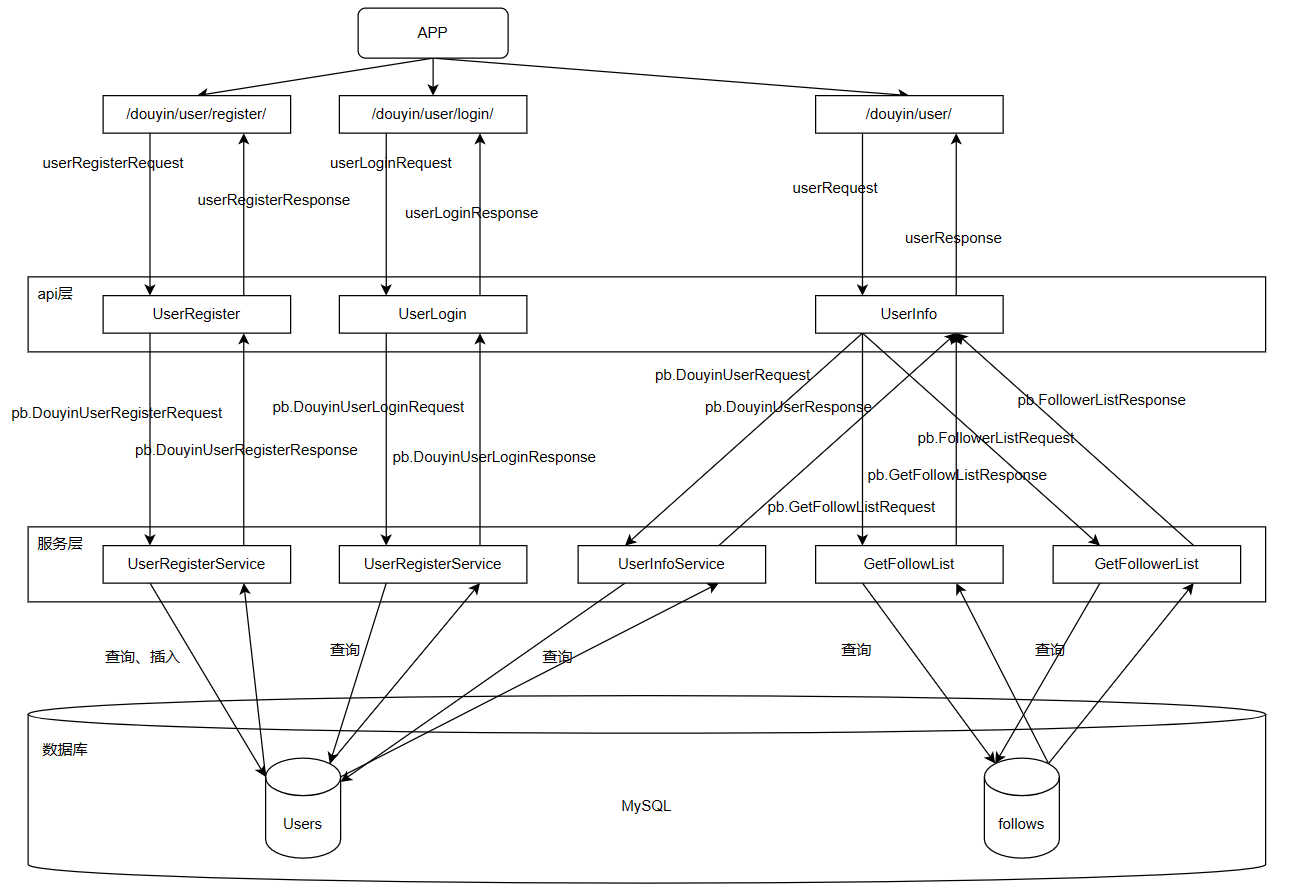
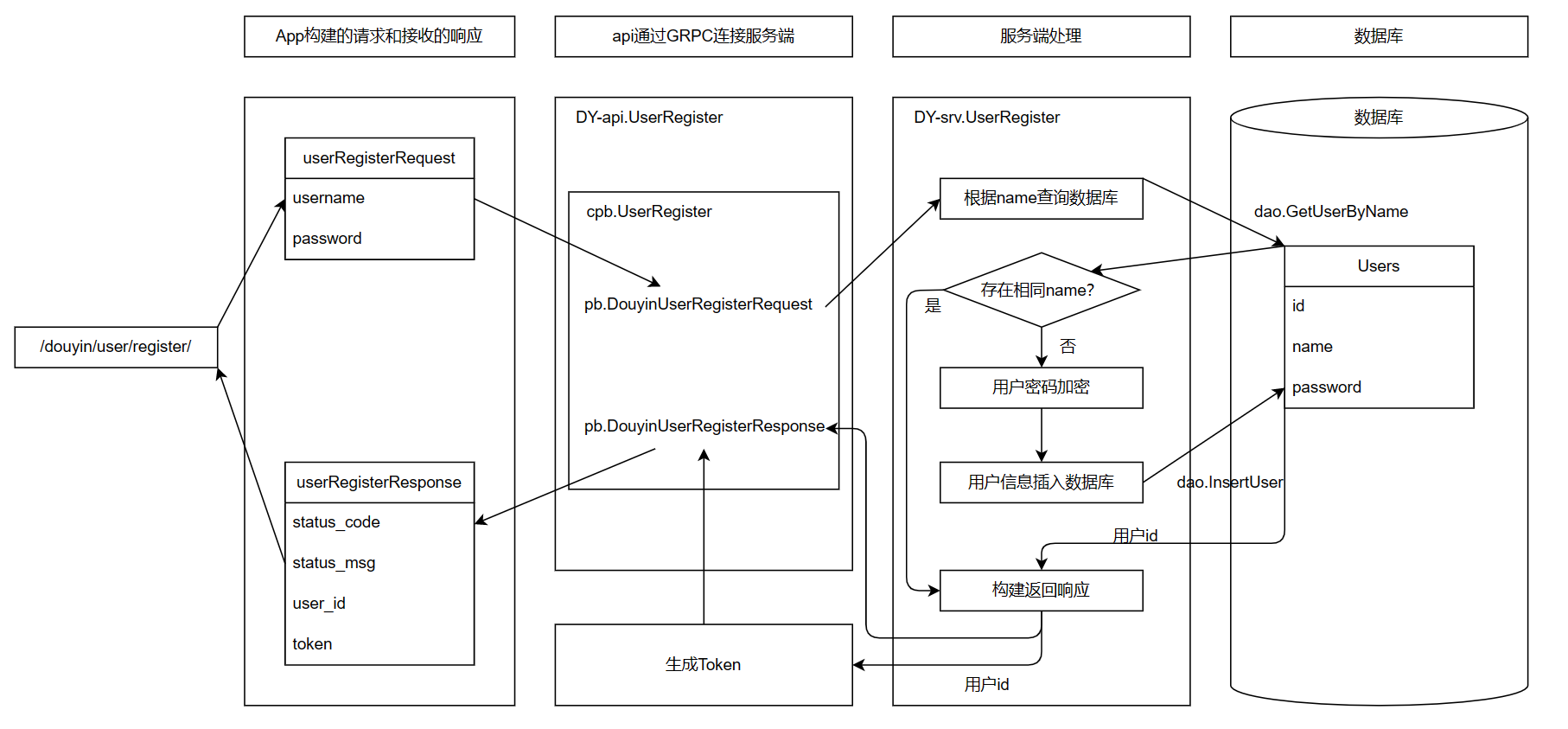
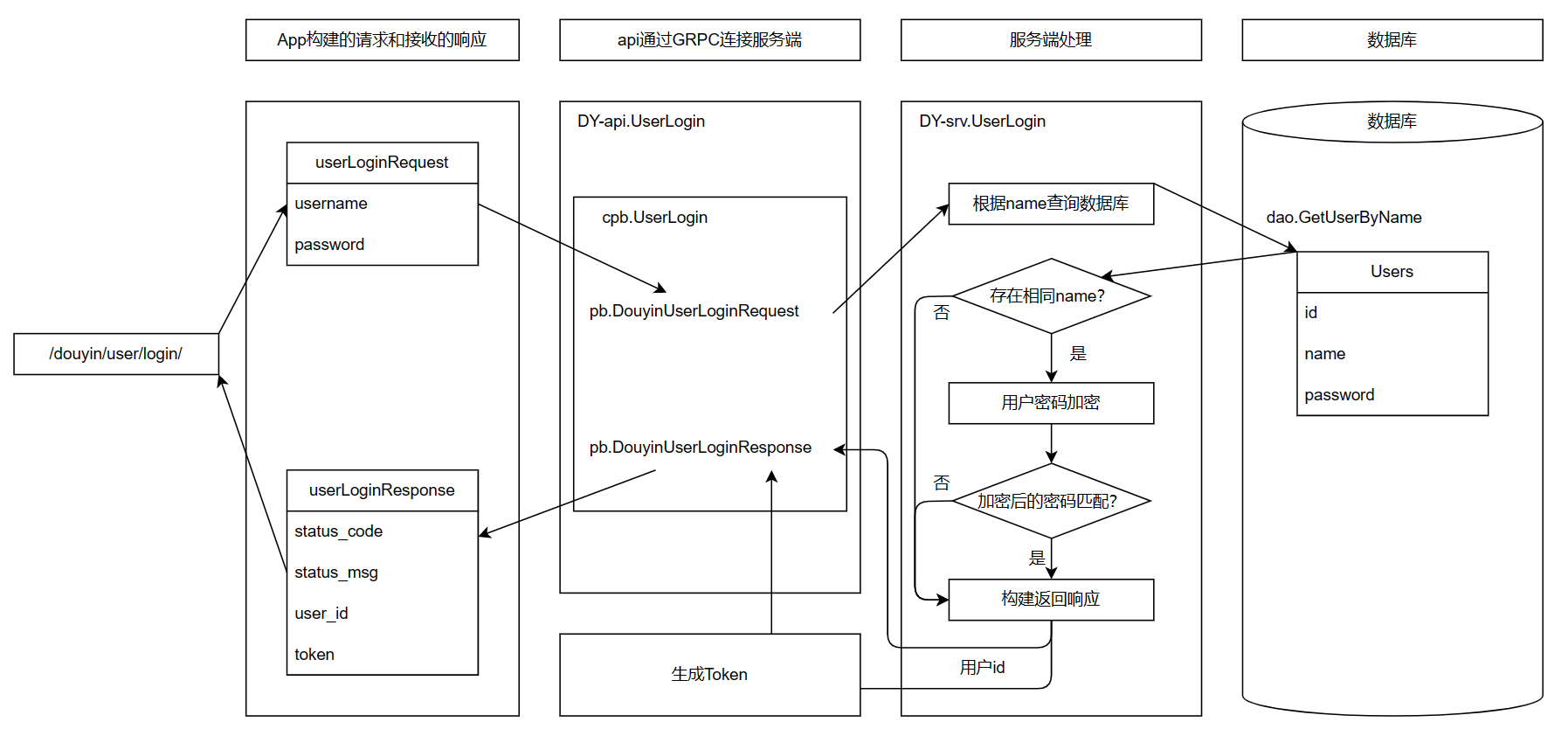
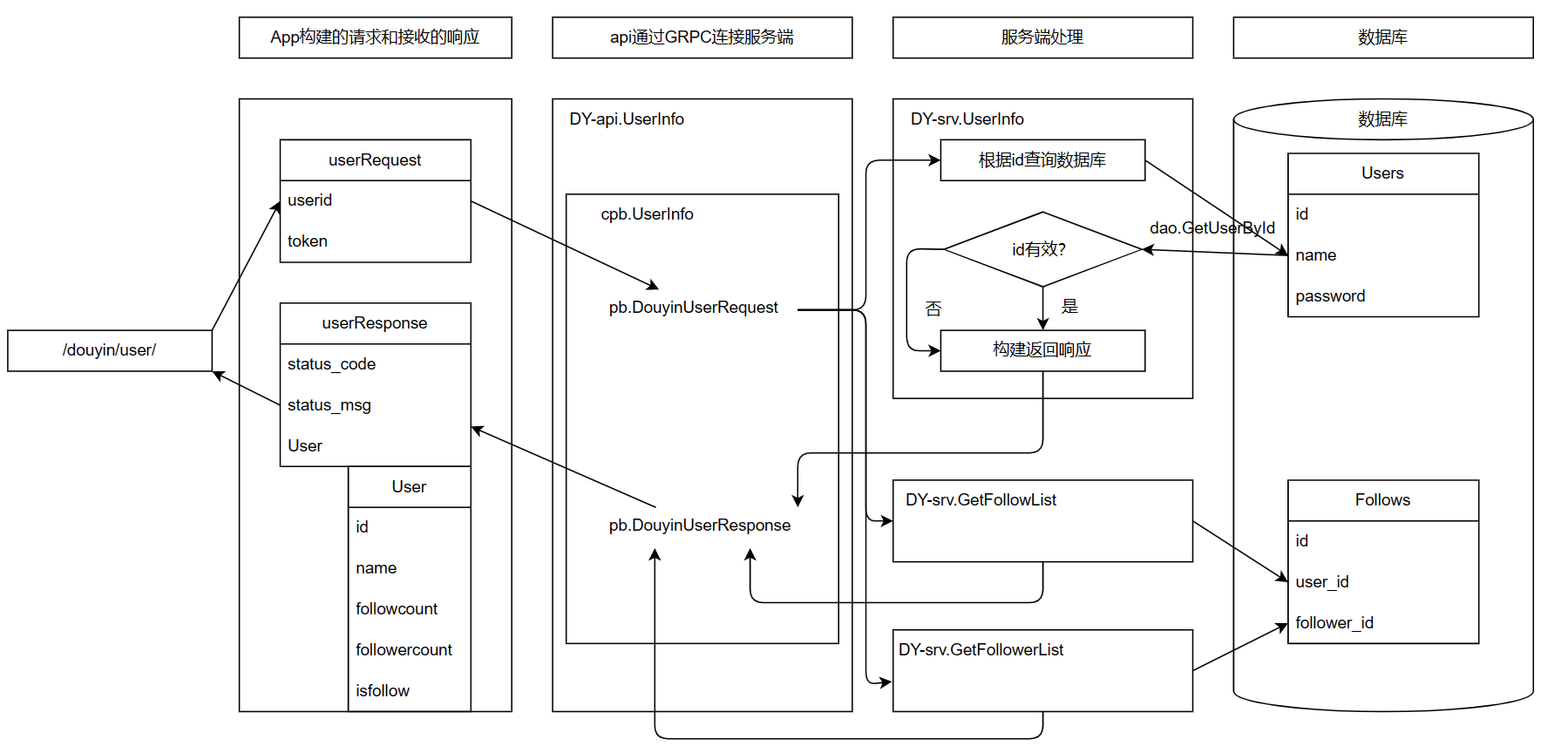
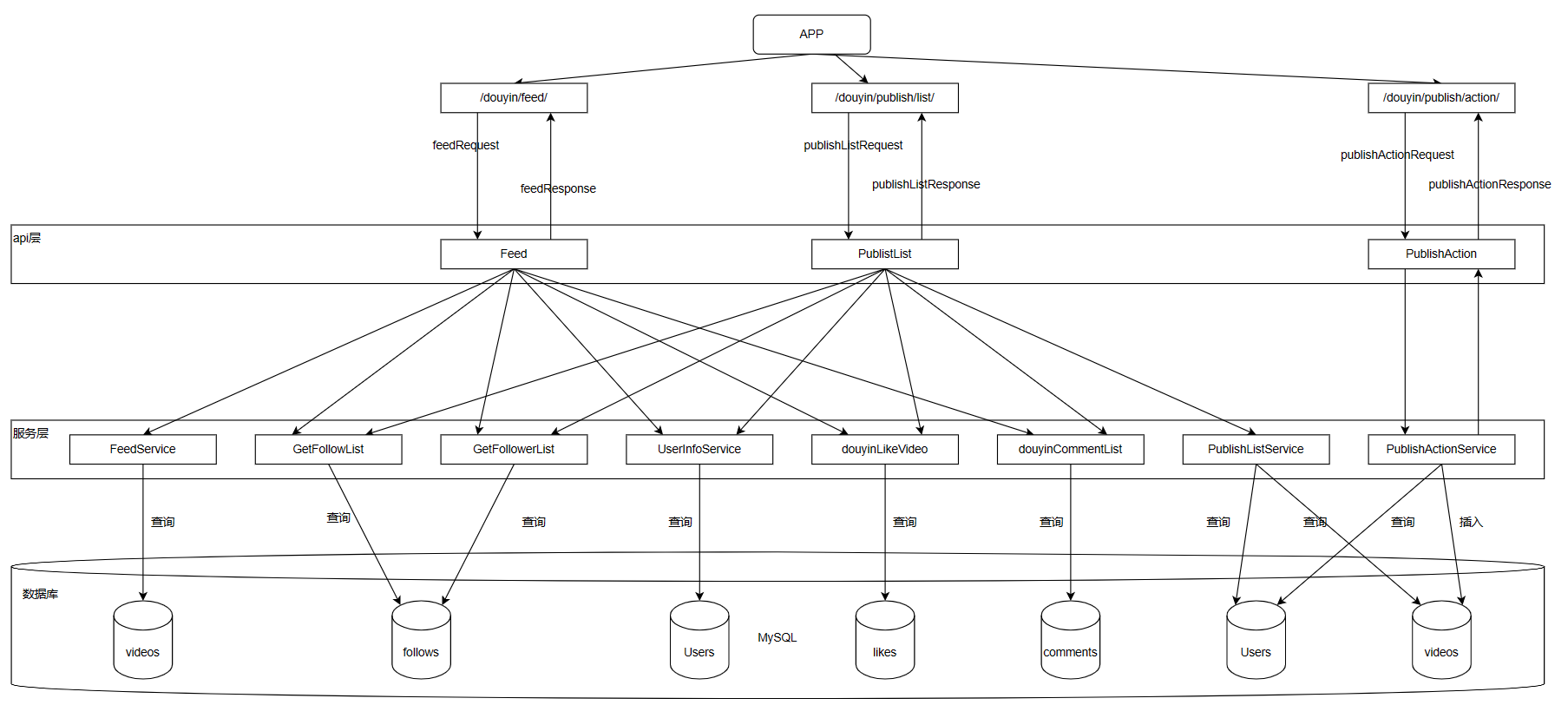
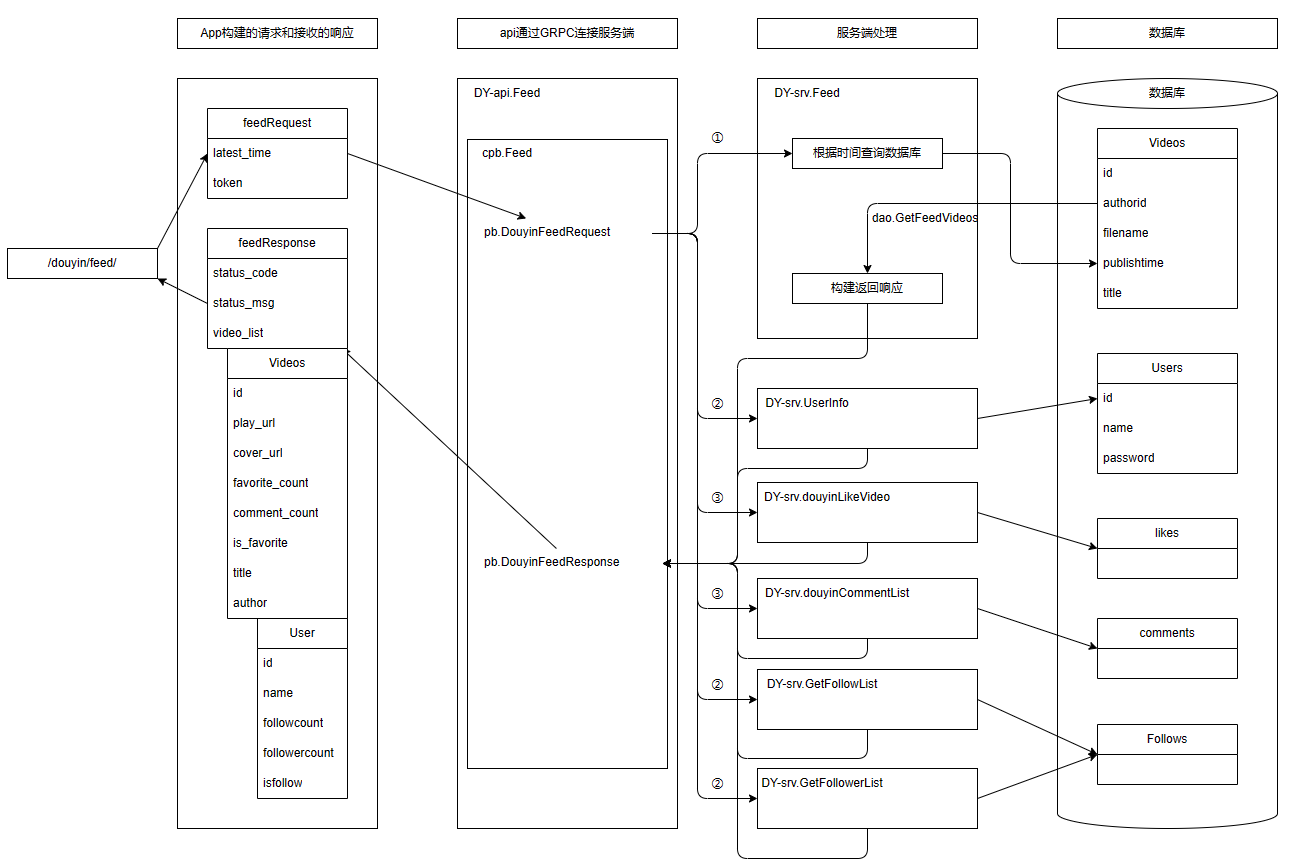
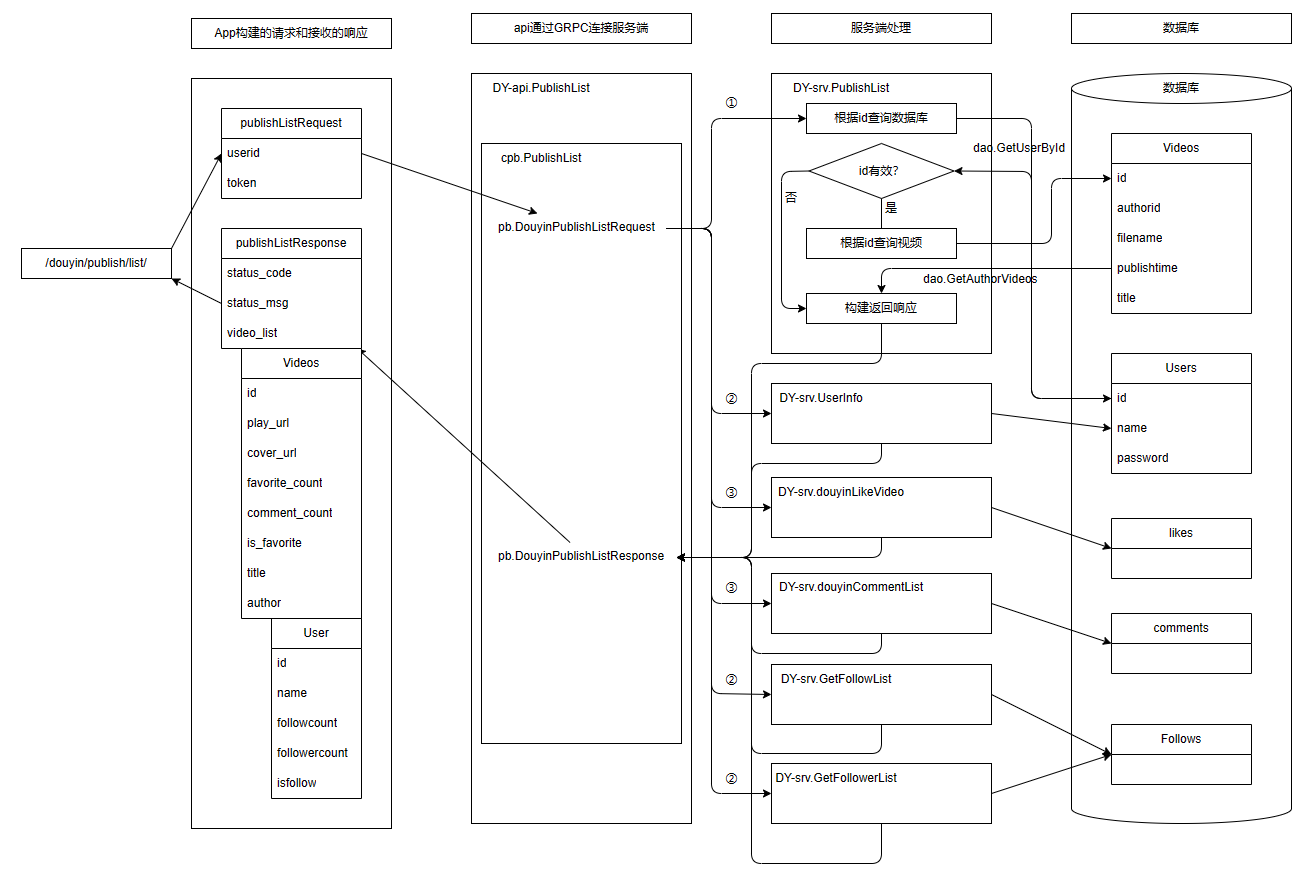
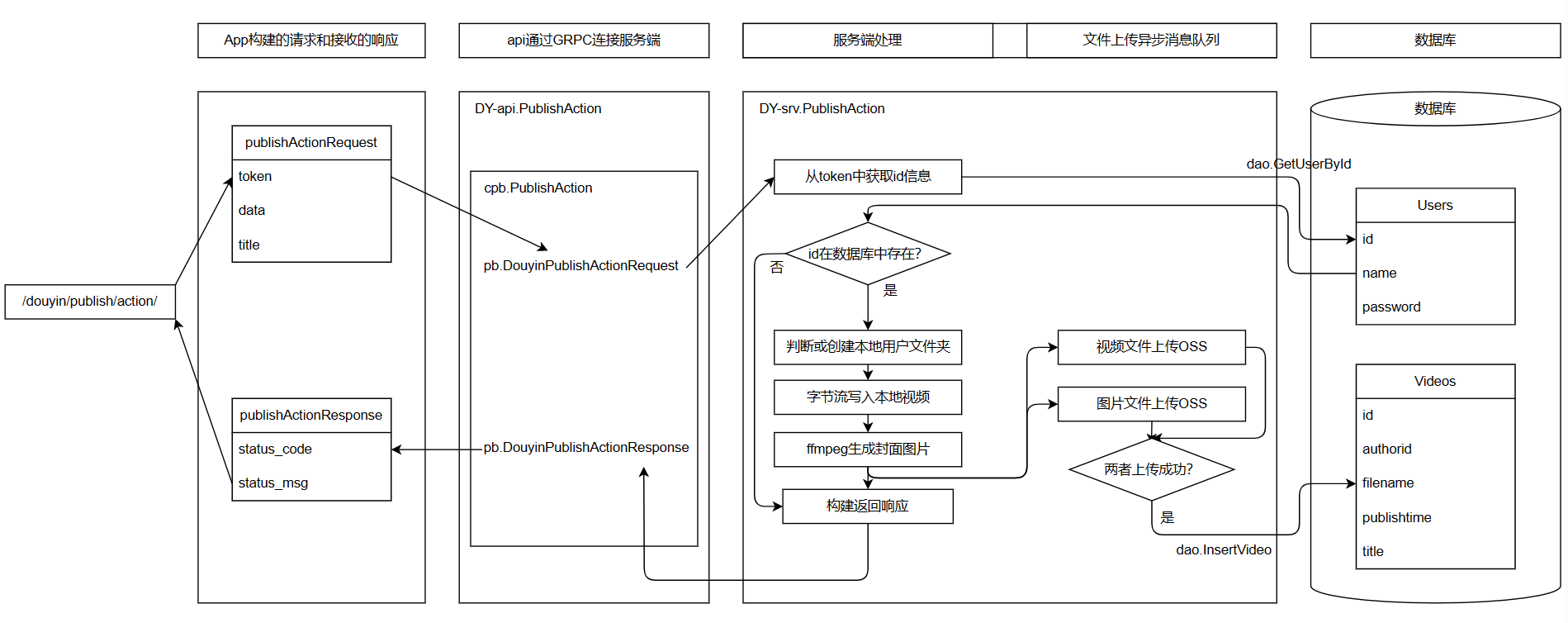




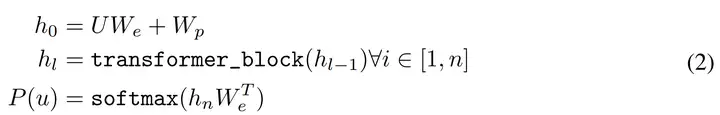
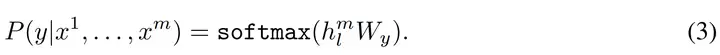
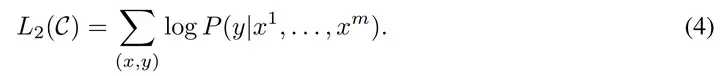
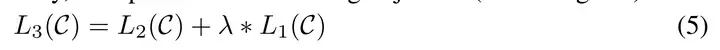




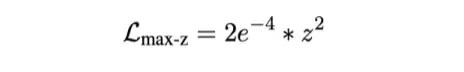













 +
+