Hipe是基于C++11编写的跨平台的、高性能的、简单易用且功能强大的线程池框架(threadpool framework),每秒能够空跑几百万以上的任务。其内置了三个职责分明的独立线程池:SteadyThreadPond稳定线程池、DynamicThreadPond动态线程池和BalancedThreadPond均衡线程池,并提供了诸如任务包装器、计时器、支持重定向的同步输出流、C++11自旋锁等实用的工具。使用者可以根据业务类型单独使用或者结合使用三种线程池来提供高并发服务。以下三种线程池分别称为Hipe-Steady、Hipe-Balance和Hipe-Dynamic。
bilibili源码剖析视频:https://space.bilibili.com/499976060 (根据源码迭代持续更新)
#include "./Hipe/hipe.h"
using namespace hipe;
// SteadyThreadPond是Hipe的核心线程池类
SteadyThreadPond pond(8);
// 提交任务,没有返回值。传入lambda表达式或者其它可调用类型
// util::print()是Hipe提供的标准输出接口,让调用者可以像写python一样简单
pond.submit([]{ util::print("HanYa said ", "hello world\n"); });
// 带返回值的提交
auto ret = pond.submitForReturn([]{ return 2023; });
util::print("task return ", ret.get());
// 主线程等待所有任务被执行
pond.waitForTasks();
// 主动关闭线程池,否则当线程池类被析构时由线程池自动调用
pond.close();
#include "./Hipe/hipe.h"
using namespace hipe;
int main()
{
// 动态线程池
DynamicThreadPond pond(8);
HipeFutures<int> futures;
for (int i = 0; i < 5; ++i) {
auto ret = pond.submitForReturn([i]{ return i+1; });
futures.push_back(std::move(ret));
}
// 等待所有任务被执行
futures.wait();
// 获取所有异步任务结果
auto rets = futures.get();
for (int i = 0; i < 5; ++i) {
util::print("return ", rets[i]);
}
}
#include "./Hipe/hipe.h"
#include <vector>
using namespace hipe;
int main()
{
// 均衡线程池,参数2为线程池缓冲任务容量
BalancedThreadPond pond(8, 800);
// 任务容器
std::vector<std::function<void()>> tasks;
int task_numb = 5;
for (int i = 0; i < task_numb; ++i) {
tasks.emplace_back([]{ /* empty task */ });
}
// 批量提交任务
pond.submitInBatch(tasks, task_numb);
pond.waitForTasks();
}
#include "./Hipe/hipe.h"
using namespace hipe;
int main() {
DynamicThreadPond pond(8);
// 添加线程
pond.addThreads(8);
// 等待线程进入工作循环中
pond.waitForThreads();
// 获取已在运行的线程数
util::print("Now the the number of running thread is: ", pond.getRunningThreadNumb());
// 调整线程数为零。与调用: pond.delThreads(16)的作用相同;
pond.adjustThreads(0);
// 当调用调整线程数的接口时,线程数的期望值会立刻改变
util::print("Expect the number of thread now is: ", pond.getExpectThreadNumb());
// 但此时线程可能还在删除过程中,因此此时运行中的线程的数量不会是零,会逐渐减少。
util::print("Get running thread count again: ", pond.getRunningThreadNumb());
// 等待线程全部关闭
pond.waitForThreads();
// 回收关闭的线程,否则当线程池析构时自动回收所有关闭的线程
pond.joinDeadThreads();
// 删除所有线程并回收所有死亡线程(线程池析构时也会自动调用close)
pond.close();
}
更多接口的调用请大家阅读hipe/interfaces/,里面有几乎全部的接口测试,并且每一个函数调用都有较为详细的注释。
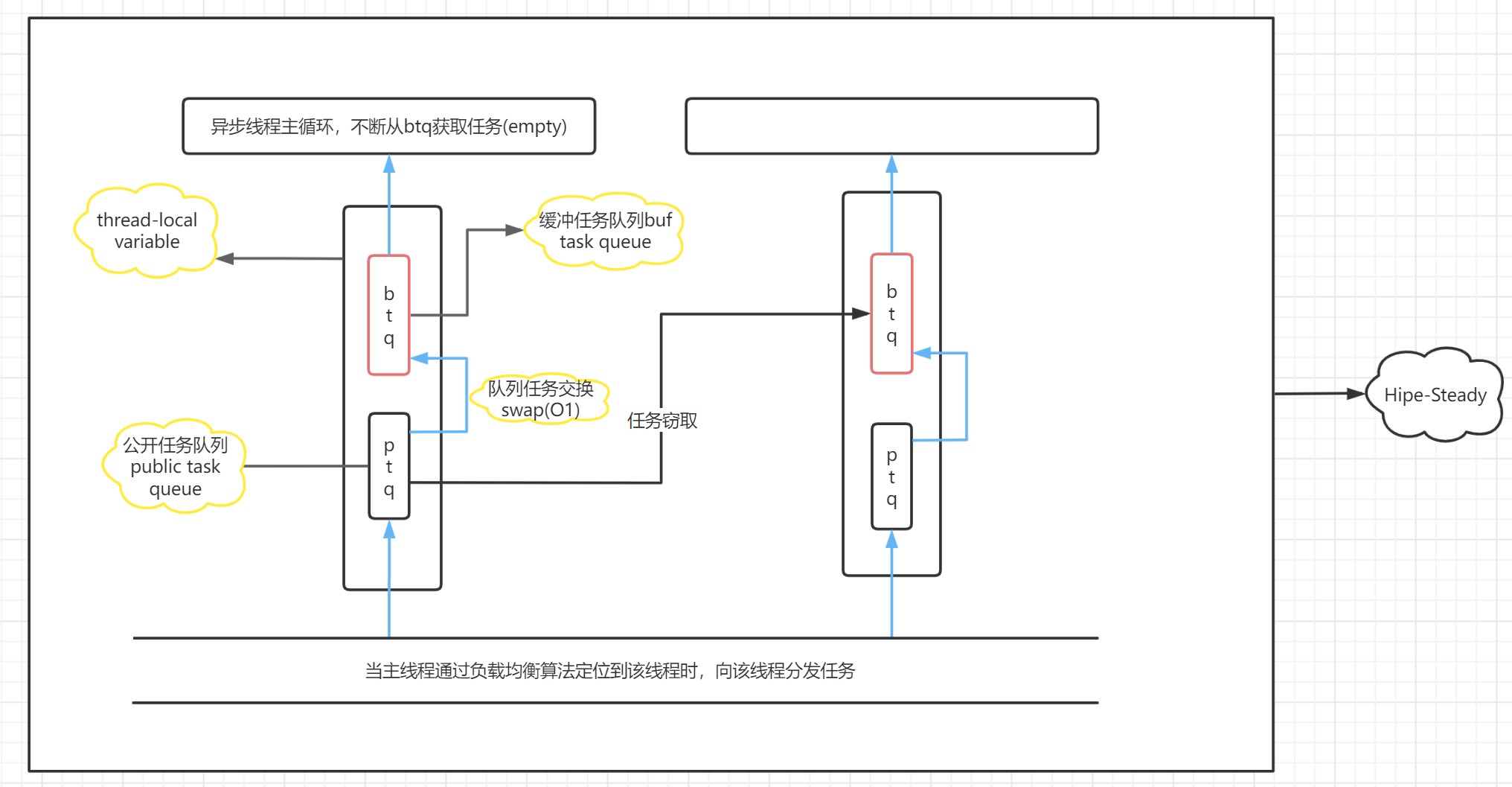
Hipe-Steady是Hipe提供的稳定的、具有固定线程数的线程池。支持批量提交任务和批量执行任务、支持有界任务队列和无界任务队列、支持池中线程的任务窃取机制。任务溢出时支持注册回调并执行或者抛出异常。
Hipe-Steady所调用的线程类DqThread为每个线程都分配了公开任务队列、缓冲任务队列和控制线程的同步变量(thread-local机制),尽量降低乒乓缓存和线程同步对线程池性能的影响。工作线程通过队列替换批量下载公开队列的任务到缓冲队列中执行。生产线程则通过公开任务队列为工作线程分配任务(采用了一种优于轮询的负载均衡机制)。公开队列和缓冲队列(或说私有队列)替换的机制进行读写分离,再通过加轻锁(C++11原子量实现的自旋锁)的方式极大地提高了线程池的性能。
由于其底层的实现机制,Hipe-Steady适用于稳定的(避免超时任务阻塞线程)、任务量大(任务传递的优势得以体现)的任务流。也可以说Hipe-Steady适合作为核心线程池(能够处理基准任务并长时间运行),而当可以定制容量的Hipe-Steady面临任务数量超过设定值时 —— 即任务溢出时,我们可以通过定制的回调函数拉取出溢出的任务,并把这些任务推到我们的动态线程池DynamicThreadPond中。在这个情景中,DynamicThreadPond或许可以被叫做CacheThreadPond缓冲线程池。关于二者之间如何协调运作,大家可以阅读Hipe/demo/demo1.cpp.在这个demo中我们展示了如何把DynamicThreadPond用作Hipe-Steady的缓冲池。
框架图
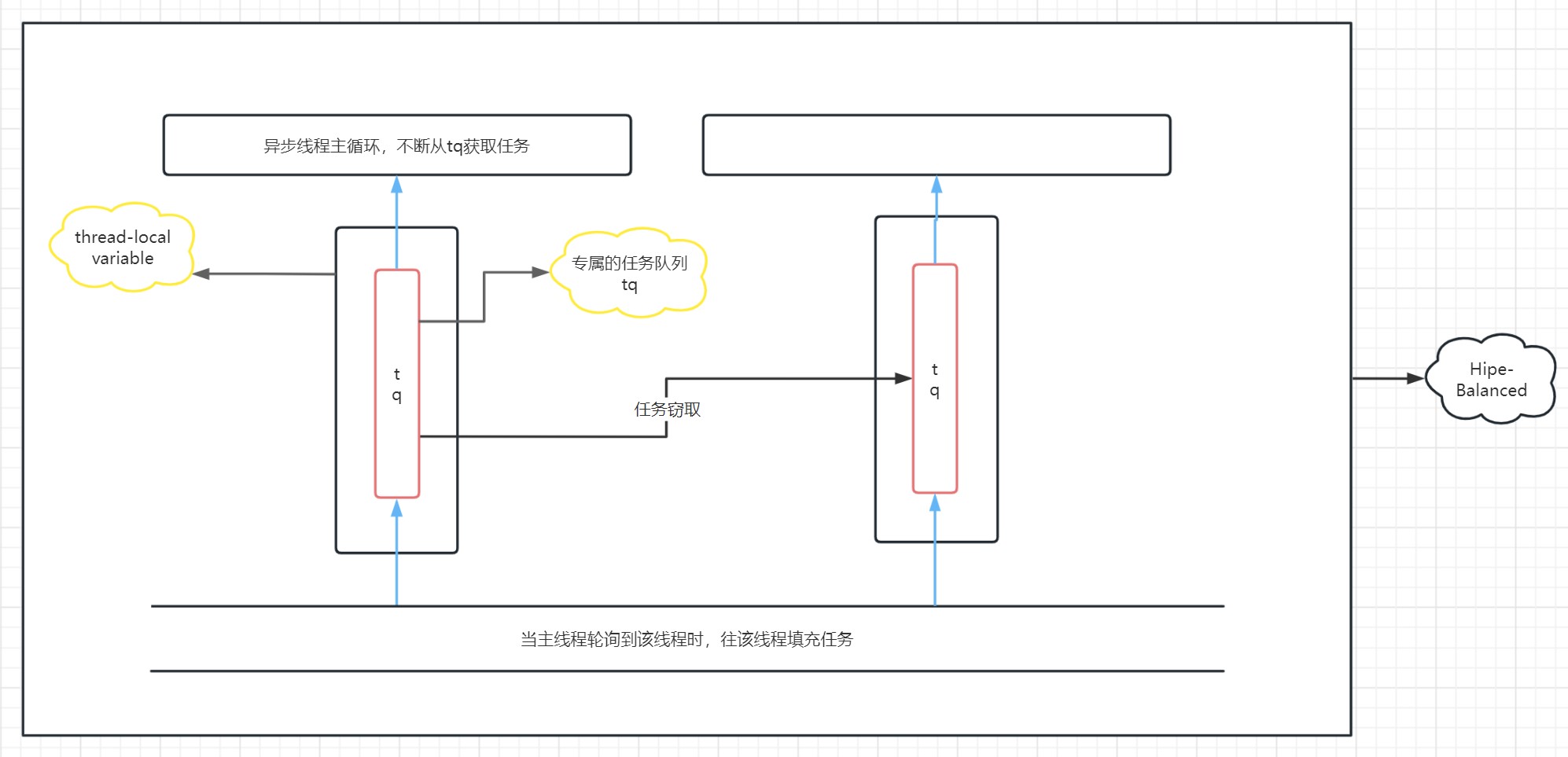
Hipe-Balance对比Hipe-Steady除了对其所使用的线程类做了简化之外,其余的机制包括线程间负载均衡和任务溢出机制等都是相同的。提供的接口也是相同的。同时,与Hipe-Steady面向批量任务的思想不同,Hipe-Balance采用的是与Hipe-Dynamic相同的面向单个任务的思想,即每次只获取一个任务并执行。这也使得二者工作线程的工作方式略有不同。
决定Hipe-Balanced和Hipe-Steay之间机制差异的根本原因在于其所采用的线程类的不同。前者采用的是Oqthread,译为单队列线程。内置了单条任务队列,主线程采用一种优于轮询的负载均衡机制向线程类内部的任务队列分发任务,工作线程直接查询该任务队列并获取任务。后者采用的是DqThread,译为双队列线程,采用的是队列交换的机制。
相比于Hipe-Steady,Hipe-Balanced在异步线程与主线程之间竞争次数较多的时候性能会有所下降,同时其批量提交接口的表现也会有所下降,甚至有可能低于其提交单个任务的接口(具体还要考虑任务类型等许多复杂的因素)。但是由于线程类中只有一条任务队列,因此所有任务都是可以被窃取的。这也导致Hipe-Balance在面对不稳定的任务流时(可能会有超时任务)具有更好的表现。
框架图
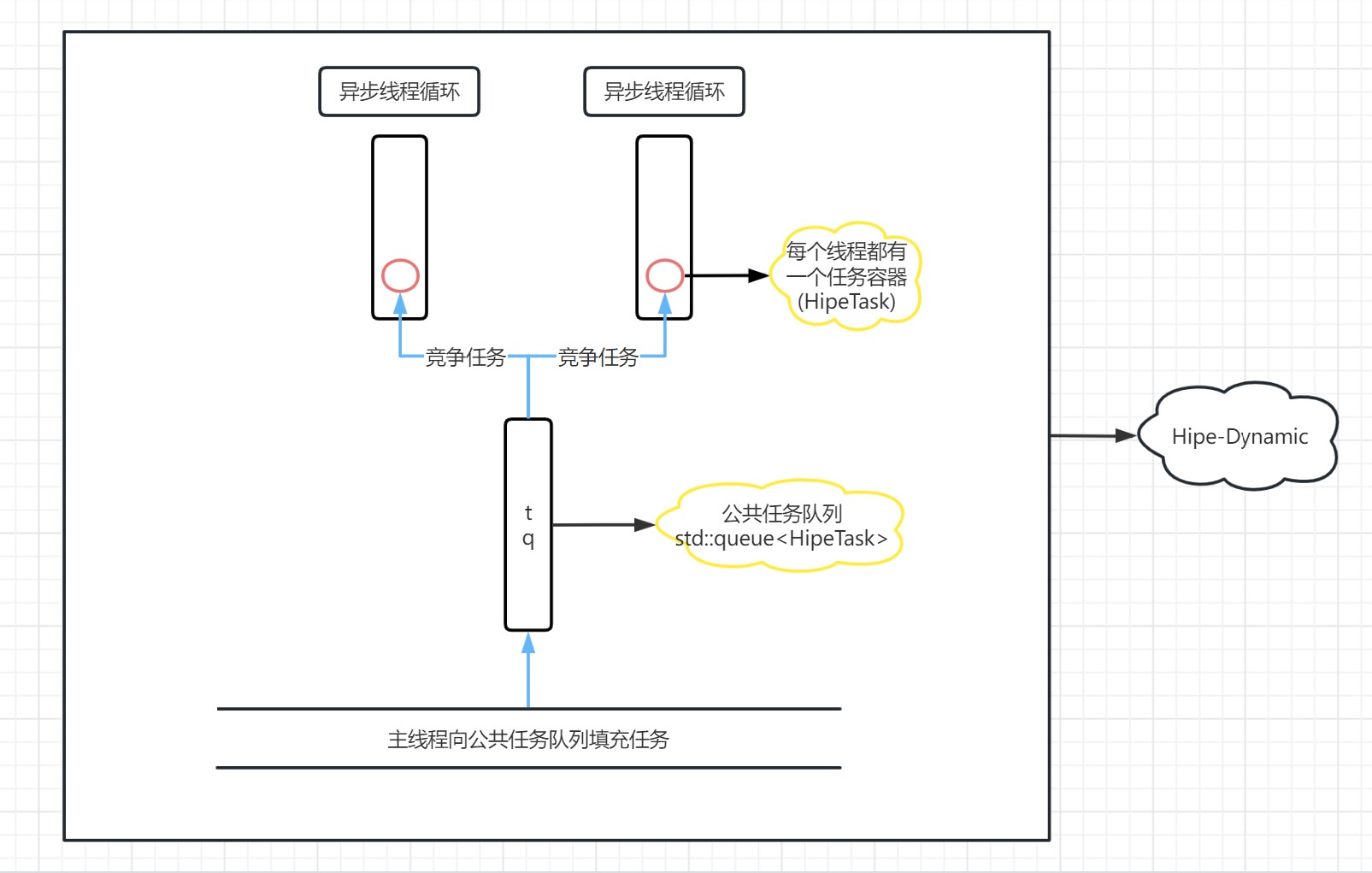
Hipe-Dynamic是Hipe提供的动态的、能够扩缩容的线程池。支持批量提交任务、支持线程池吞吐任务速率监测、支持无界队列。当没有任务时所有线程会被自动挂起(阻塞等待条件变量的通知),较为节约CPU资源。
Hipe-Dynamic采用的是多线程竞争单任务队列的模型。该任务队列是无界的,能够容蓄大量的任务,直至系统资源耗尽。由于Hipe-Dynamic管理的线程没有私有的任务队列且面向单个任务,因此能够被灵活地调度。同时,为了能动态调节线程数,Hipe-Dynamic还提供了能监测线程池执行速率的接口,其使用实例在Hipe/demo/demo2。
由于Hipe-Dynamic的接口较为简单,如果需要了解更多接口的调用,可以阅读接口测试文件Hipe/interfaces/或者Hipe/demo/demo2。
框架图
bshoshany/thread-pool (以下简称BS)是在GitHub上开源的已收获了1k+stars 的C++线程池,采用C++17编写,具有轻量,高效的特点。我们通过加速比测试和空任务测试,对比BS和Hipe的性能。实际上BS的底层机制与Hipe-Dynamic相似,都是多线程竞争一条任务队列,并且在没有任务时被条件变量阻塞。同时我们也通过其它任务测试和批量接口测试,对比Hipe-Steady和Hipe-Balance的性能差异。
测试机器:16核_ubuntu20.04 (以下测试都开启O2优化)
测试原理: 通过执行计算密集型的任务,与单线程进行对比,进而算出线程池的加速比。每次测试都会重复5遍并取平均值。
// ================================================
// computation intensive task(计算密集型任务)
// ================================================
int vec_size = 4096;
int vec_nums = 2048;
std::vector<std::vector<double>> results(vec_nums, std::vector<double>(vec_size));
void computation_intensive_task() {
for (int i = 0; i < vec_nums; ++i) {
for (int j = 0; j < vec_size; ++j) {
results[i][j] = std::log(std::sqrt(std::exp(std::sin(i) + std::cos(j))));
}
}
}以下是执行结果。为了结果更准确,我们每次测试都只测一个线程池(或单线程),然后等待机器散热。每次测试中间隔了30~40秒。
=======================================================
* Test Single-thread Performance *
=======================================================
threads: 1 | task-type: compute mode | task-numb: 4 | time-cost-per-task: 201.92240(ms)
=======================================================
* Test C++(17) Thread-Pool BS *
=======================================================
threads: 16 | task-type: compute mode | task-numb: 4 | time-cost-per-task: 54.28629(ms)
threads: 16 | task-type: compute mode | task-numb: 16 | time-cost-per-task: 20.71979(ms)
threads: 16 | task-type: compute mode | task-numb: 28 | time-cost-per-task: 22.93107(ms)
threads: 16 | task-type: compute mode | task-numb: 40 | time-cost-per-task: 25.67357(ms)
threads: 16 | task-type: compute mode | task-numb: 52 | time-cost-per-task: 25.85536(ms)
threads: 16 | task-type: compute mode | task-numb: 64 | time-cost-per-task: 22.94270(ms)
=================================================================
* Test C++(11) Thread-Pool Hipe-Dynamic *
=================================================================
threads: 16 | task-type: compute mode | task-numb: 4 | time-cost-per-task: 54.00041(ms)
threads: 16 | task-type: compute mode | task-numb: 16 | time-cost-per-task: 20.91941(ms)
threads: 16 | task-type: compute mode | task-numb: 28 | time-cost-per-task: 22.59373(ms)
threads: 16 | task-type: compute mode | task-numb: 40 | time-cost-per-task: 26.15185(ms)
threads: 16 | task-type: compute mode | task-numb: 52 | time-cost-per-task: 25.70997(ms)
threads: 16 | task-type: compute mode | task-numb: 64 | time-cost-per-task: 23.45609(ms)
================================================================
* Test C++(11) Thread-Pool Hipe-Steady *
================================================================
threads: 16 | task-type: compute mode | task-numb: 4 | time-cost-per-task: 79.93079(ms)
threads: 16 | task-type: compute mode | task-numb: 16 | time-cost-per-task: 20.50024(ms)
threads: 16 | task-type: compute mode | task-numb: 28 | time-cost-per-task: 24.34773(ms)
threads: 16 | task-type: compute mode | task-numb: 40 | time-cost-per-task: 27.41396(ms)
threads: 16 | task-type: compute mode | task-numb: 52 | time-cost-per-task: 28.06915(ms)
threads: 16 | task-type: compute mode | task-numb: 64 | time-cost-per-task: 22.93314(ms)
=================================================================
* Test C++(11) Thread-Pool Hipe-Balance *
=================================================================
threads: 16 | task-type: compute mode | task-numb: 4 | time-cost-per-task: 83.34004(ms)
threads: 16 | task-type: compute mode | task-numb: 16 | time-cost-per-task: 20.42817(ms)
threads: 16 | task-type: compute mode | task-numb: 28 | time-cost-per-task: 24.87741(ms)
threads: 16 | task-type: compute mode | task-numb: 40 | time-cost-per-task: 27.32333(ms)
threads: 16 | task-type: compute mode | task-numb: 52 | time-cost-per-task: 27.96282(ms)
threads: 16 | task-type: compute mode | task-numb: 64 | time-cost-per-task: 22.91393(ms)
计算最佳加速比
公式:
单线程的平均任务耗时/多线程的最小平均任务耗时(四舍五入)
结果:
BS: 9.75
Hipe-Dynamic: 9.65
Hipe-Steady: 9.85
Hipe-Balance: 9.88
结果分析:四个线程池在加速比方面的性能十分相近,这可能是因为任务数较少,执行任务的时间较长且在执行过程中不涉及缓存一致性等其它因素。因此线程池内部的编写细节对整体加速比的影响不大。
测试原理: 通过提交大量的空任务到线程池中,对比两种线程池处理空任务的能力,其主要影响因素为线程同步任务以及工作线程循环过程中的其它开销。
===================================
* Test C++(17) Thread Pool BS *
===================================
threads: 16 | task-type: empty task | task-numb: 100 | time-cost: 0.00112(s)
threads: 16 | task-type: empty task | task-numb: 1000 | time-cost: 0.01055(s)
threads: 16 | task-type: empty task | task-numb: 10000 | time-cost: 0.09404(s)
threads: 16 | task-type: empty task | task-numb: 100000 | time-cost: 0.94548(s)
threads: 16 | task-type: empty task | task-numb: 1000000 | time-cost: 9.49177(s)
=============================================
* Test C++(11) Thread Pool Hipe-Dynamic *
=============================================
threads: 16 | task-type: empty task | task-numb: 100 | time-cost: 0.00149(s)
threads: 16 | task-type: empty task | task-numb: 1000 | time-cost: 0.01063(s)
threads: 16 | task-type: empty task | task-numb: 10000 | time-cost: 0.09377(s)
threads: 16 | task-type: empty task | task-numb: 100000 | time-cost: 0.94485(s)
threads: 16 | task-type: empty task | task-numb: 1000000 | time-cost: 9.42167(s)
============================================
* Test C++(11) Thread Pool Hipe-Steady *
============================================
threads: 16 | task-type: empty task | task-numb: 100 | time-cost: 0.00129(s)
threads: 16 | task-type: empty task | task-numb: 1000 | time-cost: 0.00020(s)
threads: 16 | task-type: empty task | task-numb: 10000 | time-cost: 0.00211(s)
threads: 16 | task-type: empty task | task-numb: 100000 | time-cost: 0.03234(s)
threads: 16 | task-type: empty task | task-numb: 1000000 | time-cost: 0.21916(s)
=============================================
* Test C++(11) Thread Pool Hipe-Balance *
=============================================
threads: 16 | task-type: empty task | task-numb: 100 | time-cost: 0.00005(s)
threads: 16 | task-type: empty task | task-numb: 1000 | time-cost: 0.00022(s)
threads: 16 | task-type: empty task | task-numb: 10000 | time-cost: 0.00228(s)
threads: 16 | task-type: empty task | task-numb: 100000 | time-cost: 0.02098(s)
threads: 16 | task-type: empty task | task-numb: 1000000 | time-cost: 0.20107(s)
=============================================
* End of the test *
=============================================
结果分析: 可以看到在处理空任务这一方面Hipe-Steady和Hipe-Balance具有巨大的优势,在处理1000000个空任务时性能是BS和Hipe-Dynamic的45倍左右。而如果Hipe-steady采用批量提交的接口的话,能够达到约50倍左右的性能提升。
测试原理:我们采用的是一个内存密集型任务(只在任务中申请一个vector),同时将线程数限制在较少的4条来对比Hipe-Steay和Hipe-Balance的性能。用于证明在某种情况下,例如工作线程的工作速度与主线程分配任务给该线程的速度相等,主线程与工作线程形成较强的竞争的情况下,Hipe-Steady对比Hipe-Balance更加卓越。其中的关键就是Hipe-Steady通过队列交换实现了部分读写分离,减少了一部分潜在的竞争。(每次测试20次并取平均值)
=============================================
* Hipe-Steady Run Memory Intensive Task *
=============================================
thread-numb: 4 | task-numb: 1000000 | test-times: 20 | mean-time-cost: 0.17990(s)
==============================================
* Hipe-Balance Run Memory Intensive Task *
==============================================
thread-numb: 4 | task-numb: 1000000 | test-times: 20 | mean-time-cost: 0.21142(s)
因此,如果你能确保任务的执行时间是十分稳定的,不存在超时任务阻塞线程的情况。那么你有理由采用Hipe-Steady来提供更高效的服务的。但是如果你担心超时任务阻塞线程的话,那么我更推荐采用Hipe-Balance来作为核心线程池提供服务。具体还要应用到实际中进行调试。
注意:单次批量提交的任务数为10个。每次测试之间留有30秒以上的时间间隔。
<<测试1>>
测试原理:调用Hipe-Steady和Hipe-Balance的批量提交接口提交大量的空任务,同时不开启任务缓冲区限制机制,即采用无界队列。通过结果对比展示延长单次加锁时间对两个线程池性能的影响。需要注意,如果我们开启了任务缓冲区限制机制,即采用了有界队列,则批量提交时两个线程池采用的是与单次提交相同的加锁策略。即每提交一个任务到队列中时加一次锁。
=============================================================
* Test C++(11) Thread Pool Hipe-Steady-Batch-Submit(10) *
=============================================================
threads: 16 | task-type: empty task | task-numb: 100 | time-cost: 0.00602(s)
threads: 16 | task-type: empty task | task-numb: 1000 | time-cost: 0.00016(s)
threads: 16 | task-type: empty task | task-numb: 10000 | time-cost: 0.00163(s)
threads: 16 | task-type: empty task | task-numb: 100000 | time-cost: 0.01128(s)
threads: 16 | task-type: empty task | task-numb: 1000000 | time-cost: 0.17955(s)
threads: 16 | task-type: empty task | task-numb: 10000000 | time-cost: 1.34524(s)
threads: 16 | task-type: empty task | task-numb: 100000000 | time-cost: 11.54472(s)
==============================================================
* Test C++(11) Thread Pool Hipe-Balance-Batch-Submit(10) *
==============================================================
threads: 16 | task-type: empty task | task-numb: 100 | time-cost: 0.00573(s)
threads: 16 | task-type: empty task | task-numb: 1000 | time-cost: 0.00026(s)
threads: 16 | task-type: empty task | task-numb: 10000 | time-cost: 0.00135(s)
threads: 16 | task-type: empty task | task-numb: 100000 | time-cost: 0.01880(s)
threads: 16 | task-type: empty task | task-numb: 1000000 | time-cost: 0.18571(s)
threads: 16 | task-type: empty task | task-numb: 10000000 | time-cost: 1.71107(s)
threads: 16 | task-type: empty task | task-numb: 100000000 | time-cost: 15.39781(s)
<<测试2>>
测试原理:调用Hipe-Steady和Hipe-Balance的批量提交接口提交大量的空任务,同时开启任务缓冲区限制机制,即采用有界队列。通过结果对比展示增强主线程与工作线程间竞争对两个线程池性能的影响。此时加锁策略为每次提交一次任务就加一次锁。
=============================================================
* Test C++(11) Thread Pool Hipe-Steady-Batch-Submit(10) *
=============================================================
threads: 16 | task-type: empty task | task-numb: 100 | time-cost: 0.00038(s)
threads: 16 | task-type: empty task | task-numb: 1000 | time-cost: 0.00019(s)
threads: 16 | task-type: empty task | task-numb: 10000 | time-cost: 0.00143(s)
threads: 16 | task-type: empty task | task-numb: 100000 | time-cost: 0.01231(s)
threads: 16 | task-type: empty task | task-numb: 1000000 | time-cost: 0.23335(s)
threads: 16 | task-type: empty task | task-numb: 10000000 | time-cost: 1.45892(s)
threads: 16 | task-type: empty task | task-numb: 100000000 | time-cost: 13.32421(s)
==============================================================
* Test C++(11) Thread Pool Hipe-Balance-Batch-Submit(10) *
==============================================================
threads: 16 | task-type: empty task | task-numb: 100 | time-cost: 0.00006(s)
threads: 16 | task-type: empty task | task-numb: 1000 | time-cost: 0.00047(s)
threads: 16 | task-type: empty task | task-numb: 10000 | time-cost: 0.00664(s)
threads: 16 | task-type: empty task | task-numb: 100000 | time-cost: 0.01784(s)
threads: 16 | task-type: empty task | task-numb: 1000000 | time-cost: 0.18197(s)
threads: 16 | task-type: empty task | task-numb: 10000000 | time-cost: 1.43280(s)
threads: 16 | task-type: empty task | task-numb: 100000000 | time-cost: 16.73147(s)
编译:
导入头文件后无需再链接头文件(采用的编译工具能自动识别头文件),在编译末尾加上-lpthread即可。如采用g++进行编译:
g++ ./demo1.cpp -o demo -lpthread && ./demo
一些错误使用方法:
1 将waitForTasks()接口作为同一个线程池的任务来执行,会导致执行该任务的线程永远阻塞。例如:
SteadyThreadPond pond(8);
pond.submut([&]{pond.waitForTasks();});2 主线程和异步线程调用相同的线程池接口,导致数据竞争,引发程序中断。需要注意!Hipe的所有接口都在实现时均不考虑线程之间的竞争问题。
可以异步调用的接口,如动态线程池调整线程数的接口等已在Hipe/demo/demo2.cpp中演示
在稳定性测试过程中,我给Hipe-Steady和Hipe-Balance做了快速推入大量任务的测试。调用了submit()、submitForReturn()和submitInBatch三个接口,分别推入1000000个任务。而对Hipe-Dynamic的测试除了测试提交任务的接口,还测试了添加线程addThreads()、减少线程delThreads和调整线程数adjustThreads的接口。通过运行Hipe/stability/run.sh脚本对以上测试文件编译后的文件进行测试,最终对Hipe-Steady和Hipe-Balance测试了200次,对Hipe-Dynamic测试了10000次,通过率结尾100%。结果见Hipe/stability/run.sh
尽管如此,Hipe仍需要时间的检验,也需要诸位的帮助。希望大家能一起出力,将Hipe变得更好吧。
- 通过优化锁来提高三个线程池的性能
- 通过优化任务来提高线程池的性能(采用栈空间构造任务,当然是否有真正的提升还需要测试)
- 在基本不影响原来性能的前提下,为Hipe-Balance和Hipe-Steady添加扩缩容机制。(私以为可以采用util::block来预先设置最大容量,再在内部做线程数调整)
- 为Hipe提供执行的日志系统,用于监测Hipe执行的总体情况
- 如果采用C++14以上的C++版本能做到更高的性能的话,提供相应的版本。
最后,本人学识有限,目前也是在不断地学习中。如果您发现了Hipe的不足之处,请在issue中提出或者提PR,我非常欢迎并在此提前感谢各位。世事无常,也许有一天Hipe能在C++并发领域成长为真正的佼佼者,解决众多开发者的并发难题!对此我十分期待。
有几点小小的规范,请诸君谅解并遵守:
- 通过稳定性测试
- 通过
Hipe/.clang-format进行统一的格式化(可以直接运行脚本bash format.sh,记得先下载clang-format) - 尽量在每次改动(可能有几个改动)的附近附上改动理由(形式不限)
- 除非有合理的理由,否则不要随意修改变量名
稳定性测试: 运行
Hipe/stability/run.sh脚本进行测试,测试结果会被保存到了Hipe/stability/result.txt。这个步骤应该放到提交完所有的改动之后。 最后一次commit应该是用于合并稳定性测试的结果。注意! 尽量不要为了加快运行时间而调低脚本参数,当然调高参数以提高测试强度是可以被接受的。在我的机器上每一次测试持续大约1~2分钟。)
.
├── LICENSE.txt 协议
├── README.md
├── balanced_pond.h 均衡线程池
├── benchmark 性能测试文件夹
│ ├── BS_thread_pool.hpp BS源码
│ ├── compare_batch_submit.cpp 对比Hipe-Steady和Hipe-Balance的批量提交接口
│ ├── compare_other_task.cpp 对比Hipe-Steady和Hipe-Balance执行其它任务的性能(内存密集型任务)
│ ├── compare_submit.cpp 对比Hipe-Steady和Hipe-Balance执行空任务的性能
│ ├── makefile
│ ├── test_empty_task.cpp 测试几种线程池执行空任务的性能
│ └── test_speedup.cpp 加速比测试
├── compat.h 封装一点编译优化指令
├── format.sh 格式化源文件的简单脚本
├── demo
│ ├── demo1.cpp 将动态线程池用作缓冲池
│ └── demo2.cpp 动态调整动态线程池
├── dynamic_pond.h 动态线程池
├── header.h 定义类线程类基类和Hipe-Steady+Hipe-Balance的基类(定义了提交任务、任务溢出、负载均衡)
├── hipe.h 头文件(导入此文件即可使用)
├── interfaces 测试接口
│ ├── makefile
│ ├── test_dynamic_pond_interface.cpp
│ └── test_steady_pond_interface.cpp
├── stability 稳定性测试
│ ├── run.sh 协助测试的脚本
│ ├── test_dynamic.cpp 测试动态线程池的稳定性(推入大量任务、动态调整线程并做多次测试)
| ├── test_balance.cpp 测试均衡线程池的稳定性(推入大量任务并做多次测试)
│ └── test_steady.cpp 测试稳定线程池的稳定性(推入大量任务并做多次测试)
├── steady_pond.h 稳定线程池
└── util.h 工具包(任务包装器,计时器,同步输出流......)
Hipe参与贡献者
一直支持我的女朋友小江和我的父母、姐姐。
《C++并发编程实战》
《Java并发编程的艺术》
BS的贡献者
小林技术交流群中的各位大佬
阿里大佬 Chunel
QQ邮箱:[email protected]