Introduced in "Communication-Efficient Learning of Deep Networks from Decentralized Data" by Brendan McMahan et al., Federated Learning flips the paradigm of machine learning.
When training a machine learning model based on client data, instead of having the data be sent from the clients to the server, the model is sent from the server to the clients.
This project provides a multi-threaded simulation of the Federated Averaging Algorithm presented in the paper, using PyTorch and Python.
The framework is tested against the MNIST dataset (in federated.py) and compared with a regular baseline (in base.py).
The following is a simplified overview of the Federated Averaging algorithm presenetd in McMahan et al.:
- The server initiates a plain machine learning model with given weights

- The server sends the model to each client
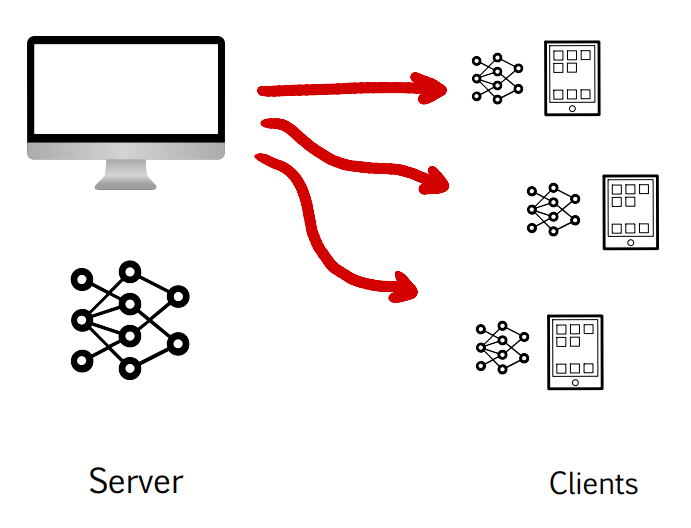
- The clients update their copy of the model with their local dataset
- The clients send back the model to the server

- The server averages all the weights of all the models that it has received back, weighted by the size of local dataset of each client. This average represents the weights of the trained model

- Steps 2-5 are then continually repeated when the clients obtain new data
The framework is tested against the MNIST dataset and compared with a regular baseline.
The Federated Learning simulator achieved 92% accuracy training on the MNIST dataset, which I compared to a standard baseline that achieved 95% accuracy. While performance was compromised, it is very minimal compared to the privacy-preserving advantages that this framework offers.