

简体中文
为了完成“Python四川疫情爬虫可视化统计”(以下简称《四川疫情可视化爬虫》),将项目的开发设计形成文档,完成对项目的分解和需求定义,因项目和时间关系,将四川疫情可视化爬虫的设计实现设计整理成“四川疫情可视化爬虫”详细设计说明书,最终呈现项目的完整流程和实现方案。
本文段主要解决了实现该项目需求的程序模块的具体功能实现问题。包括如何把该系统划分成若干个模块、决定各个模块之间的接口、模块之间传递的信息,以及数据结构、模块结构的设计等。在以下的详细设计报告中将对系统的功能进行详细设计说明。
2020年随着冬季的到来,新冠疫情病毒可谓是越发猖狂。近段时间我国的上海、新疆、内蒙古、黑龙江、四川等地相继出现了疫情反弹的现象,所幸及时得到控制,并没有让病毒向外扩散。这些病毒都是本土新增,并不是境外输入。四川新增新型冠状病毒肺炎确诊病例又本地与输入病例组成,全省其它市州无新增无症状感染者。为了更好统计四川的疫情每日数据,对比省内各市州的疫情情况。通过大数据分析十五天内疫情期间最热门的词汇。
本文使用表1-3-1所显示的面向用户的术语,定义包括通用在本文档中的专用解释。
| 表1-3-1 术语/定义 | |
|---|---|
| 术语/略缩语 | 说明 |
| 开发方 | Python项目小组 |
| 用 户 | 社区、学校、公共区域 |
| 四川疫情可视化爬虫 | Python四川疫情爬虫可视化统计 |
四川疫情可视化爬虫项目,项目分为两个功能模块,一个是通过爬虫获取每日最新的疫情数据,并对爬取的数据进行统计、对比、汇总等可视化操作,更为直观方便对疫情数据进行分析等。第二各模块主要是通过爬取《国家社会组织管理局》每日公开文章资料[1],对前十五天内的疫情热门词汇进行爬取分析得到社会最关的方向是什么。
通过前面阶段的分析和了解,结合项目实际问题,综合得出以下功能点,见表2-2-1所示。
| 表2-2-1 系统功能 | ||
| 功能需求 | 功能点 | 优先级 |
| 爬虫获取项目数据 | 爬取疫情每日最新数据 | 高 |
| 爬虫获取项目数据 | 新闻信息抓取 | 高 |
| 疫情数据可视化 | 绘制地区区域内分类柱状图 | 高 |
| 疫情数据可视化 | 绘制地区区域内疫情患者柱状图 | 高 |
| 疫情数据可视化 | 绘制地区区域内疫情对比柱状图 | 高 |
| 疫情数据可视化 | 绘制四川省疫情统计地图 | 高 |
| 高频词汇可视化 | 绘制疫情新闻热门词云 | 高 |
| 保存疫情数据 | 通过爬虫保存全国疫情最新情况 | 中 |
| 保存疫情数据 | 保存区域(四川)每日疫情情况 | 中 |
| 保存疫情数据 | 保存地区区域内所有市州疫情数据 | 高 |
| 系统性能 | 支持3000/秒并发请求 | 中 |
[1] 中国社会组织公共服务平台由中华人民共和国民政部社会组织管理局主办,旨在通过互联网宣传社会组织领域有关法律法规政策,在线公开办事指南,提供网上办事服务,提高社会组织登记管理工作的透明度和工作效率,服务社会公众和广大社会组织(含慈善组织、志愿服务组织、专业社工机构),为各级登记管理机关、社会组织以及有关研究机构之间加强工作交流和理论探讨提供环境。
以图形和文字等形式形象得描述系统的整体物理架构模型,解释系统组成结构,重要节点,及其之间的物理联系方式,具体框架见图3-1-1所示
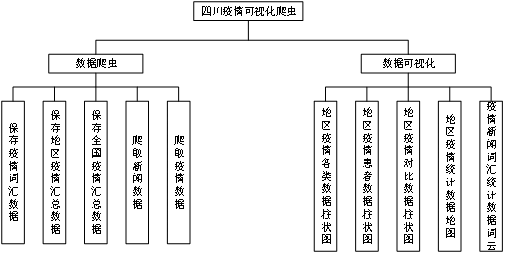
图3-1-1 四川疫情可视化,系统功能框架设计
分析爬虫项目及可视化等操作,制定了项目技术架构模型,解释项目技术组成结构,重要节点,具体框架见图3-2-1所示。
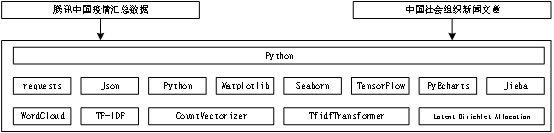
图3-2-1 四川疫情可视化,项目技术框架设计
因项目需要疫情实时数据,我们通过分析目前公开的数据分享平台“腾讯新闻”,里面提供完整、全面的疫情数据。所以我们的目标就是通过Python来爬取腾讯新闻网实时疫情数据,其原理主要是通过Requests获取Json请求,从而得到各省、各市的疫情数据。
访问腾讯疫情实时分析平台(https://news.qq.com/zt2020/page/feiyan.htm),在通过浏览器自带的 “审查元素”查看源代码及网址的HTTP请求接口“服务器”反馈的数据,如图4-1-1所示.
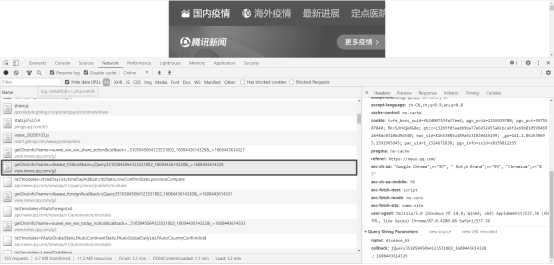
图4-1-1 爬虫目标网站数据分析
在设计疫情数据爬虫接口时考虑到了接口的通用性,只需要修改爬虫地址就可以进行爬取数据,将爬虫请求地址都封装成常量,需要修改直接改常量即可。
| 表 4-1-2 疫情爬虫接口定义 | |||
| 序号 | 接口定义 | 参数 | 返回 |
| 1 | def getCountryData(REQUEST_URL) | 爬虫目标地址 | 全国疫情数据 |
我们在通过通过分析URL地址、请求方法、参数及响应格式,可以获取JSON数据,注意URL需要增加一个时间戳。获取数据的键值及三十四各个省份。接着通过分析全国数据列表中在查找四川获取四川省的疫情数据集合(表4-1-3)。
| 表 4-1-3 疫情解析接口定义 | |||
| 序号 | 接口定义 | 参数 | 返回 |
| 1 | def findDataByChain(COVID_ChainData) | 全国疫情数据 | 全国汇总统计数据 |
| 2 | def findRegionDataList(data, region) | 疫情数据,地区 | 地区疫情数据 |
保存疫情爬虫数据主要就是为了方便后面通过爬虫得到数据进行数据可视化操作,所以保存爬虫数据是必须的。保存数据设置了统一CSV数据文件格式。第一个方便写入数据,CSV数据结构类似于数据库可以循环进行读写数据。第二方便绘图读取数据。
项目需要保存全国疫情数据为TXT文件,可以进行项目后期的数据分析;而地区数据这需要保存为TXT,通过读取TXT文件中的数据可以进行可视化数据操作(表4-2-1)。
接口说明,在保存接口中的Type形参变量表示两种含义:Type为一保存全国数据为TXT文件,反正Type为二保存地区疫情数据为TXT。
| 表 4-2-1 疫情TXT保存接口定义 | |||
| 序号 | 接口定义 | 参数1 | 参数2 |
| 1 | def saveTxtFileByData(data, Type) | 全国疫情数据 | 保存类型路径 |
| 2 | def saveTxtFileByData(data, Type) | 全国疫情数 | 保存类型路径 |
Python四川疫情爬虫可视化项目中的绘制地区区域内分类柱状图、绘制地区区域内疫情患者柱状图、绘制地区区域内疫情对比柱状图、绘制四川省疫情统计地图等功能都要读取CSV数据文件在进行绘制。可视化功能中主要需要两个地区(四川)疫情保存CSV接口(4-2-2)。
| 表 4-2-2 疫情CSV保存接口定义 | ||
| 序号 | 接口定义 | 参数1 |
| 1 | def saveCSVByRegion(regionDataList) | 地区各城市分类统计数据 |
| 2 | def saveCSVByRegionContrast(regionDataList) | 地区各城市对比统计数据 |
在爬虫接口包括爬取网站数据接口、解析数据接口、保存数据接口等。这写接口需要进行面向对象开发,将接口中公用数据接口进行封装为对应的常量接口,方便调用。还需要再编写接口注释,方便小组或其它文档阅读者更好的理解项目开发逻辑。
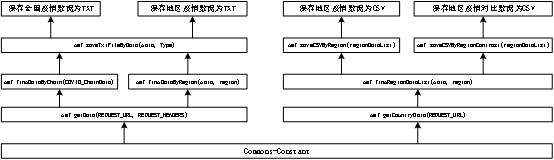
图4-3 爬虫疫情数据封装优化
程序接口设计中需要添加方法创建注释说明,其中包括文档注释,接口注释,参数注释。注释设计模板参考附录一:项目注释模板设计。
再可视化模块使用的为Matplotlib来进行绘制地区分类统计柱状图。是一种以长方形的长度为变量的统计图表。长条图用来比较两个或以上的价值(不同时间或者不同条件),只有一个变量,通常利用于较小的数据集分析。长条图亦可横向排列,或用多维方式表达。
在统计学中,直方图(英语:Histogram)是一种对数据分布情况的图形表示,是一种二维统计图表,它的两个坐标分别是统计样本和该样本对应的某个属性的度量。个变量,通常利用于较小的数据集分析。长条图亦可横向排列,或用多维方式表达。
绘制地区(四川)各市州的疫情统计数据,主要统计新增感染人数、死亡人数、痊愈人数和感染总人数的数据可视化。
绘制地区区域内分类柱状图需要先得到地区(四川)的分类统计数据(表5-1-1)。
| 表 5-1-1 地区区域内分类柱状图接口定义 | |||
| 序号 | 接口定义 | 参数1 | 参数2 |
| 1 | def countryDataByRegion(data, region) | 疫情数据 | 地区名称(四川) |
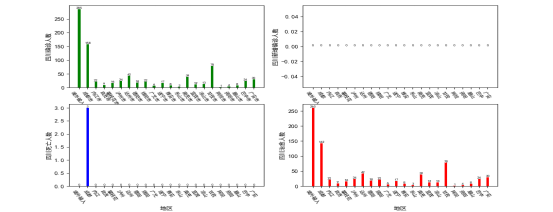
图5-1-1 地区区域内分类柱状图
我们使用Seaborn绘制全国各地区柱状图,Seaborn是在Matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。安装Seaborn库步骤参考。
绘制地区区域内疫情感染者柱状图需要先得到地区(四川)的各地区的疫情感染人数统计数据(表5-2-1)。
| 表 5-2-1 地区区域内疫情感染者柱状图接口定义 | |||
| 序号 | 接口定义 | 参数1 | 参数2 |
| 1 | def drawChartByRegion(data, region) | 地区统计数据 | 地区名称(四川) |
绘图接口会先查询有无当天的疫情最新统计数据CSV文件,如果没有数据文件,就会调用爬虫接口和保存数据CSV接口完成最新数据抓取然后再进行绘图。
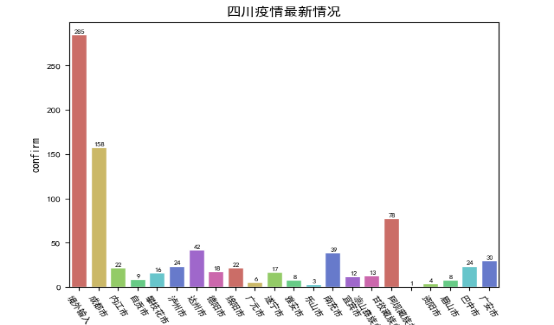
图5-2-1 地区区域内疫情感染者柱状图
我们使用Seaborn绘制全国各地区柱状图,Seaborn是在Matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。安装Seaborn库步骤参考项目部署。
绘制地区区域内疫情对比柱状图需要先得到地区(四川)的各地区疫情分类感染人数统计数据(表5-3-1)。
| 表 5-3-1 绘制地区区域内疫情对比柱状图接口定义 | |||
| 序号 | 接口定义 | 参数1 | 参数2 |
| 1 | def drawChartColumn(data, region) | 地区统计数据 | 地区名称(四川) |
接口会先查询有无当天的疫情区域对比最新统计数据CSV文件,如果没有数据文件,就会调用疫情爬虫接口和疫情对比保存数据CSV接口完成最新数据抓取,再进行绘图显示。
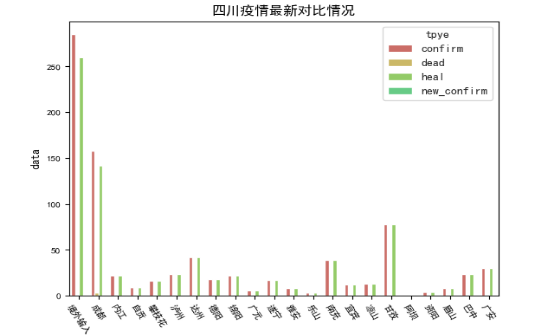
图5-3-1 地区区域内疫情感染者柱状图
我们Echarts技术进行地区疫情可视化地图生成。ECharts是一个纯Javascript的图表库,兼容当前绝大部分浏览器,底层依赖轻量级的Canvas类库ZRender,提供直观、生动、可交互、可高度个性化定制的数据可视化图表。安装依赖库教程参考项目部署。
绘制地区疫情感染人数地图,需要先得到地区(四川)的各地区疫情感染人数最新统计数据(表5-4-1)。
| 表 5-3-1 绘制地区区域内疫情对比柱状图接口定义 | |||
| 序号 | 接口定义 | 参数1 | 参数2 |
| 1 | def dramMapByRegion(data, region) | 地区统计数据 | 地区名称(四川) |
接口会先查询有无当天的疫情区域最新统计数据CSV文件,如果没有数据文件,就会调用疫情爬虫接口和疫情地区保存数据CSV接口完成最新数据抓取,再进行地图绘图显示。
绘制图形无数据,需要补充城市的完整称呼,比如“成都市”、“凉山彝族自治州”等。
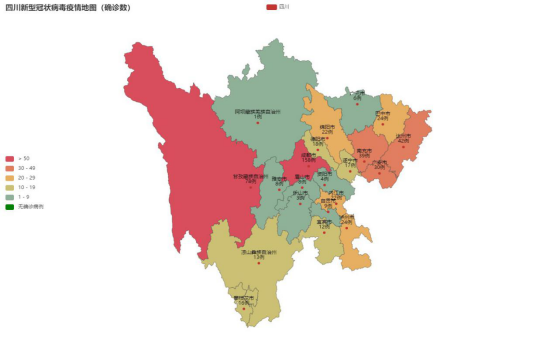
图5-4-1 地区(四川)疫情统计地图
功能模块为网络爬虫、可视化分析、GIS地图显示、情感分析、舆情分析、主题挖掘、威胁情报溯源、知识图谱、预测预警及AI和NLP应用等。我们主要通过网络爬虫爬取新闻文章中的词语,统计分析词语的频率得到疫情高频词汇数据,在对数据进行可视化生成词云,方便预测预警,舆情分析等。
再设计接口先确定数据来源,我们以《国家社会组织管理局》官网疫情相关文章为数据来源。分析网站文章内容结构,通过浏览器“审查元素”查看源代码并获取新闻内容、文章URL、时间等图6-1-1。其中文章内容的标签结构表6-1-1-1。

图6-6-1 国家社会组织管理局文章内容结构
| 表 6-1-1 绘章内容的标签结构 | ||
| 序号 | 标签名称 | 标签结构 |
| 1 | 标题 | text_html.xpath(’//[@id=“fontinfo”]/p[2]/b[1]//text()’) |
| 2 | 时间 | text_html.xpath(’/html/body/div[2]/div/ul[1]/li[3]/strong/text()’)[0][5:] |
| 3 | 文章URL | text_html.xpath(’/html/body/div[2]/div/ul[1]/li[2]/a[2]/@href’)[0] |
| 4 | 文章内容 | text_html.xpath(’//[@id=“fontinfo”]/p[last()]//text()’)[0] |
| 5 | 其它内容 | text_html.xpath(’//[@id=“fontinfo”]//text()’) |
爬虫接口先通过内容网站进行数据爬取,再将数据保存为TXT文件,为后面的文章内容分析,数据统计,词云生成提供数据来源。所有新闻内容爬虫接口包括两部分;a.数据爬取接口;b.数据解析保存接口表6-1-2。
| 表 6-1-2 新闻内容爬虫及数据保存接口定义 | |||
| 序号 | 接口定义 | 参数1 | 参数2 |
| 1 | def getHotWords(saveTxtDataURL, REQUEST_URL) | 数据保存地址 | 爬虫URL |
| 2 | def saveStatisticalHighFrequencyWord(saveURL ,requestURL) | 数据保存地址 | 爬虫URL |
得到文章内容数据TXT文件,接着我们将新闻正文文本数据进行中文分词,对数据进行的一些初步处理,包括缺失值填写、噪声处理、不一致数据修正、中文分词等,其目标是通过分析解析文章得到更标准、高质量的数据,纠正错误异常数据,从而提升分析的结果。
中文文本预处理的基本步骤,包括中文分词、词性标注、数据清洗、特征提取(向量空间模型存储)、权重计算(TF-IDF)等。Jieba工具是最常用的中文文本分词和处理的工具之一,它能实现中文分词、词性标注、关键词抽取、获取词语位置等功能。
新闻文章原文通过数据清洗回得到一个词语统计CSV文件,文件中记录词语的频率。
| 表 6-2-2 生成新闻内容高频词汇词云接口定义 | |||
| 序号 | 接口定义 | 参数1 | 参数2 |
| 1 | def DramMapHotWords(saveURL, REQUEST_URL) | SVC数据地址 | 爬虫URL |
词云分析主要包括两种方法,调用WordCloud扩展包画图,调用PyEcharts中的WordCloud子包画图,为考虑操作时效,我们选择第第二张生成高频词云方法。

图6-2-3 新闻内容高频词汇词云
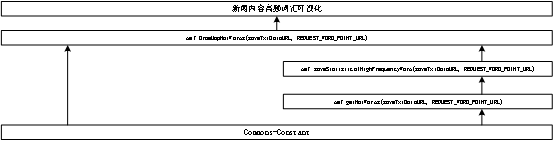
图6-3 新闻内容爬虫与词云可视化接口封装
程序接口设计中需要添加方法创建注释说明,其中包括文档注释,接口注释,参数注释。注释设计模板参考附录一:项目注释模板设计。
用一览表的方式说朗每种可能的出错或故障情况出现时,系统输出信息的形式、含意及解决办法。详细错误见表7-1所示。
| 表 7-1 项目出错故障说明 | ||
| 序号 | Message | Explain |
| 1 | socket.error: [Errno 10054] | 远程主机关闭请求 |
| 2 | A bytes-like object is required, not ‘str’ | 带上User-Agent |
(1) 项目中的生成区域疫情统计地图显示数据为绘制图形无数据,如下图所示显示NaN,需要补充城市的完整称呼,比如“成都市”、“凉山彝族自治州”等。
(2) 项目使用运行需要依赖第三方的Python库[1],出现无对应库报错时。可以通过命令安装项目依赖库(具体详见requirements.txt文件)[2]。安装依赖库只需要运行项目根目录中的InstallLibraries.py脚本文件即可。
(3) 使用绘制新闻高频词云接口爬取数据可能会等待较长时间,会出现超时,我们需要关闭运行再次调用接口即可。
[1] Python 标准库非常庞大,所提供的组件涉及范围十分广泛,正如以下内容目录所显示的。这个库包含了多个内置模块 (以 C 编写),Python 程序员必须依靠它们来实现系统级功能,例如文件 I/O,此外还有大量以 Python 编写的模块,提供了日常编程中许多问题的标准解决方案。其中有些模块经过专门设计,通过将特定平台功能抽象化为平台中立的 API 来鼓励和加强 Python 程序的可移植性。
[2] requirements.txt文件,里面记录了当前程序的所有依赖包及版本号,其作用是用来在另一个环境上重新构建项目所需要的运行环境依赖。requirements.txt通过pip命令自动生成和安装,生成requirements.txt文件pip freeze > requirements.txt
安装requirements.txt依赖 pip install -r requirements.txt。
(1) 再项目的根目录下有安装项目依赖的Python运行文件(InstallLibraries.py),通过CMD命令行工具运行python ./InstallLibraries.py 或运行 ./InstallLibraries.py
(1) 进入项目根目录中的src文件夹中,通过运行TestMain.py文件即可启动项目
参考博客:python项目打包exe运行
项目根目录(自定义)
|---- src 项目源码文件夹
|---- commons 项目公共工具类
|---- CommonsException.py 项目定义异常处理
|---- Constant.py 项目常量定义类
|---- GetCOVIDData.py 疫情数据爬虫接口
|---- GetJournalism.py 新闻内容爬虫接口
|---- SaveFile.py 保存爬虫数据到本地接口
|---- draw 项目所有绘图接口
|---- DistrictChart.py 绘制区域地区数据统计柱状图
|---- DramMapByRegion.py 绘制地区疫情统计地图
|---- DrawRegionalComparisonHistogram.py 绘制地区对比柱状图
|---- StatisticalHighFrequencyWord.py 绘制新闻高频词云
|---- file 项目爬虫或数据分析保存的数据文件
|---- csv 保存csv数据文件
|---- img 可视化视图截图
|---- map 地图文件
|---- txt txt数据文件
|---- TestMain.py 项目运行入口
|---- InstallLibraries.py 项目安装程序
|---- requirements.txt 项目依赖列表
- 文档注释

附图 1-1 文档版权模块注释
- 接口注释

附图 1-2 接口模块注释
- 属性注释

附图 1-3 属性模块注释