This program classifies a given MP3-file of human speech into 2 types: American English or British English.
You need to put an MP3-file of someone's speech into the data/inference/mp3/ directory. The speech is better to be 17-25 seconds long.
ONE MAJOR RESTRICTION IS REQUIRED: SPEECH MUST BE EITHER AMERICAN OR BRITISH. This means that if you try to predict German/Spanish/French/Russian/dog-barking/noise the neural network will not be able to distinguish them and you will get American or British prediction anyway.
The algorithm can be described as following:
- Convert an mp3 file into a wav file via FFmpeg.
- Trim the first n and m seconds (default: n = 1, m = 1).
- Remove all the silent gaps and noises between sentences and words so it becomes a continuous speech.
- Cut this sound into pieces of a fixed size (default: 4 seconds) and save them.
- Create spectrograms on different scales and combine them into one image. Short-time Fourier Transform and its variation are used to get spectrograms. Here's how it looks:
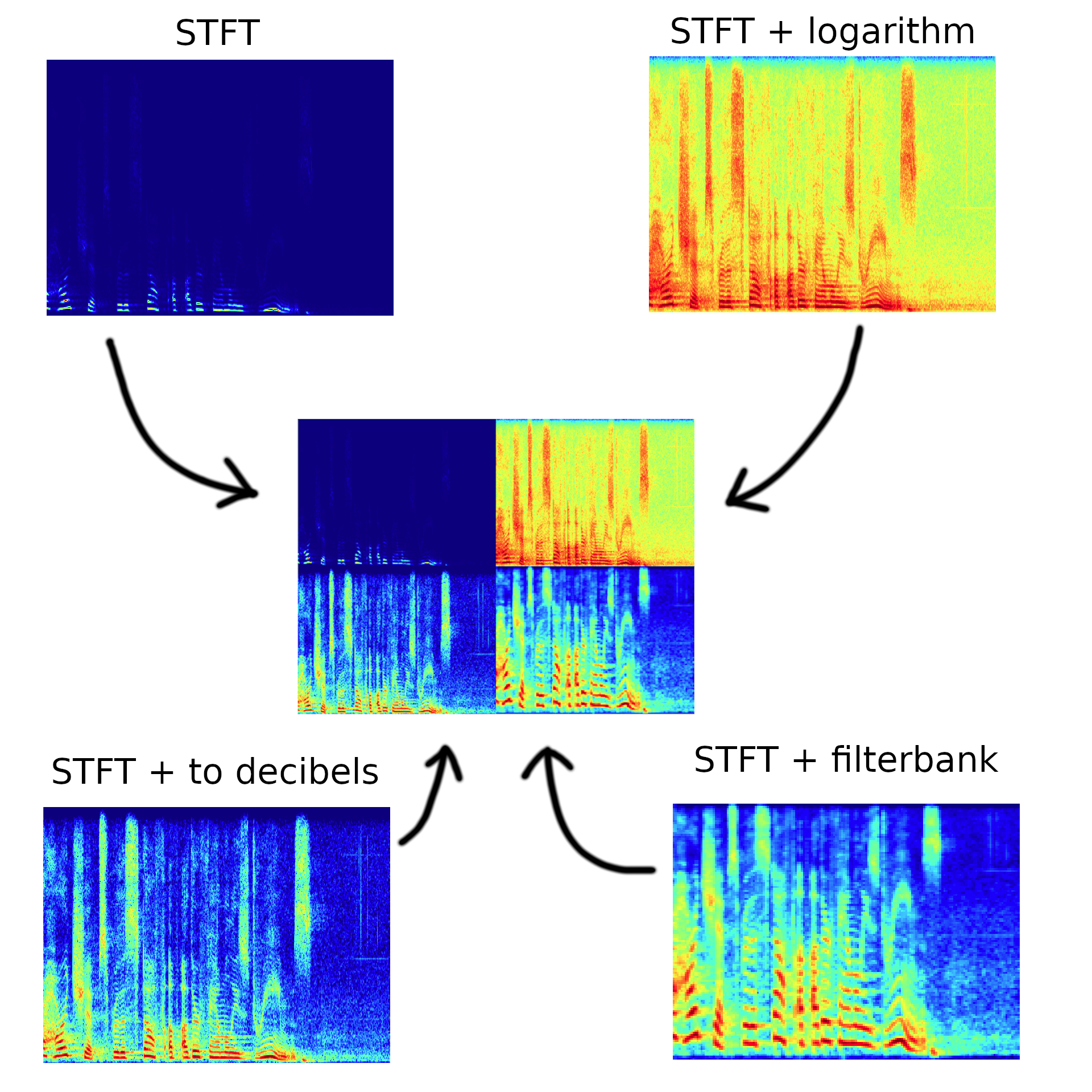
- Load a network that is already trained out by me. Basically, I took the ResNet50 network pre-trained on the ImageNet dataset and added a custom output layer (transfer learning). So, it's a convolutional model:
![]()
- Calculate an average prediction based on all pieces of the cut mp3.
- Additionally, a saliency map can be generated.