Alexander Selivanov, Kristina Ivanova, Lucy Airapetyan, Vitaly Protasov.
- python 3.6+
- pytorch 1.4+
- transformers
- We reimplemented the original article: code2vec by U. Alon et al.
- We improved F1-score on the test dataset of java14m-data here you can find dataset.
- Weights of two models you can find here
| Best F1-scores: | Our implementation | U. Alon work | With BERT |
|---|---|---|---|
| Batch size 128 Test | 0.17671 | 0.1752 | 0.1689 |
| Batch size 128 Validation | 0.20213 | - | 0.17341 |
| Batch size 1024 Test | 0.16372 | - | - |
| Batch size 1024 Validation | 0.1887 | - | - |
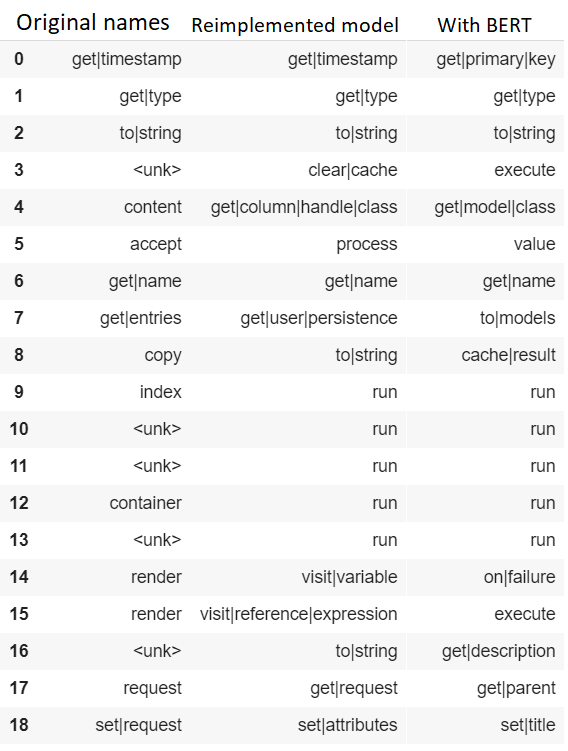
- Also, we applied Bert architecture instead of attention layer in the original article. Results you can see below:
- First of all, you can open ipython notebook in colab via the button above. Just run all cells, it's easy to do.
- Without notebook in the console:
git clone https://github.com/Vitaly-Protasov/DL_project_skoltech
cd DL_project_skoltech
./download data.sh
python3 to_train_article_model.py
- Install transformers library, we used it:
pip3 install transformers
- Run python file for training:
python3 to_train_bert.py
As the parameters which you need to vary are batch_size of validation and train datasets, learning rate and weight decay for optimization algorithm.
Here you can see how our models predict names