Image-to-image translation (I2I) is a task that aims to translate an image from a source domain to a target domain, like from horses to zebra, from cat to tigers, etc. The popular Disney Cartoon filter in social media such as Snapchat and Tiktok is said to be using a GAN model that generates convincing cartoon versions of your photo/video in real time. This shows how widely used GAN is in our everyday life to deal with image translation tasks. Among the popular SOTA GAN models for image to cartoon translations, how well do they perform and what use cases are they best suited for?
This project evaluates the performance of the existing well-performing GAN models, such as CycleGAN, U-GAT-IT on the image to cartoon translation task based on a series of metrics:
- Variation of model’s loss in the training process
- Model’s evolution of performance based on sample outputs over epochs in the training process
- Eg. Comparison of sample outputs, whether there are strange artifacts in the image out of nowhere
- Model’s performance on bad cases:
- Eg. Whether the model can process glasses or hats
- Model’s ability to generalize to tasks in other domains (different styles of Cartoon)
- Data Preprocessing: Data loading, Train-test split, Data selection
- Train these models from scratch: CycleGAN (57 epochs, each 1000 iterations), U-GAT-IT (8 epochs, each 10000 iterations), photo2cartoon (9000 iterations)
- Finetune pre-trained models on the disney dataset: photo2cartoon (2000 iterations)
- Data augmentation and diversification using fine-tuned StyleGAN (13 epochs)

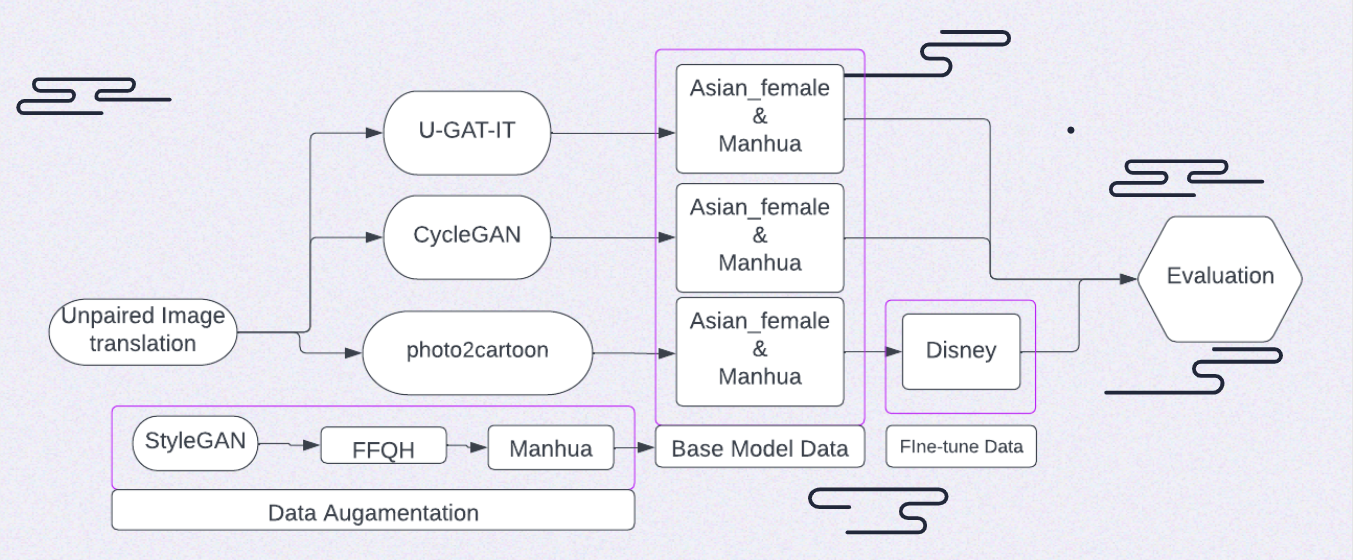
- This repository consists of multiple google Colab notebooks, each notebook contains the link to the model and dataset, preprocesses the data, and conducts an photo2cartoon translation experiment on a model:
- CycleGANtest.ipynb (experiment on CycleGAN)
- UGATITtest(1).ipynb (first trial on U-GAT-IT, model checkpoint not saved)
- UGATITtest(2).ipynb (second trial on U-GAT-IT, model checkpoint saved)
- photo2cartoon_base: pretrained base model for photo2cartoon model. (manhua, asian woman dataset)
- photo2cartoon_finetune: find-tune photo2cartoon model on the disney dataset
- styleGAN2: styleGAN2 model pretrained on FFQH, fine-tuned on Manhua
Please follow the instruction in the Colab notebooks (the order of the notebooks does not matter).
- CycleGAN has pretty robust performance in terms of different facial features: eg. big and small eyes, glasses.
- U-GAT-IT is slow to train, performs slightly worse than CycleGAN, yet it maintains the spatial structure of the original picture.
- photo2cartoon is the original model, performs very well. However, when trying to transfer the result into another domain, namely disney, it doesn't give any useful results.
- StyleGAN2 is very good at generating manhua photos, it is useful for data augmentation.
- loss:

- transitions:



- loss:









- Model performance is highly affected by the resolution of input image and whether the facial features are recognizable (no bangs, glasses, etc.)
- Fast convergence of loss doesn’t represent the superiority of a model!
- Sometimes the goodness of a model is random (we trained a model from scratch twice because once the checkpoint wasn’t saved, and we discovered that their results differs).
Datasets:
- Asian Photos: https://github.com/JingchunCheng/All-Age-Faces-Dataset
- Manhua style Cartoon: https://drive.google.com/file/d/1lsQS8hOCquMFKJFhK_z-n03ixWGkjT2P/view
- All-Race Photos dataset generated from StyleGAN2:
- Cartoon dataset generated from StyleGAN2: https://mega.nz/file/HslSXS4a#7UBanJTjJqUl_2Z-JmAsreQYiJUKC-8UlZDR0rUsarw
Models we evaluated:
- CycleGAN: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
- U-GAT-IT: https://github.com/taki0112/UGATIT
- photo2cartoon: https://github.com/minivision-ai/photo2cartoon/blob/master/README_EN.md
Model for Data Augmentation:
- StyleGAN: https://github.com/NVlabs/stylegan2
Link to the saved model checkpoints: