-
Notifications
You must be signed in to change notification settings - Fork 45
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* fix_multimodal_eval_pipeline * fix_multimodal_eval_pipeline * fix_multimodal_eval_pipeline
- Loading branch information
1 parent
37bbd04
commit e1c4318
Showing
6 changed files
with
229 additions
and
39 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,44 @@ | ||
| { | ||
| "examples": [ | ||
| { | ||
| "query": "2023年春夏期间,哪种泛户外运动在社交平台上的讨论声量最高?", | ||
| "query_by": null, | ||
| "reference_contexts": [ | ||
| ": 在赛事和政策的双重推动下,国民运动户外参与意愿高涨,超过六成的受访者表示近一年显著增加了运动户外的频率,各类运动项目正在快速走向“全民化”。新的一年,随着巴黎奥运会、美洲杯等赛事的举办,全民运动热情将进一步被激发。对于品牌而言,这是一个难得的市场机遇,通过精准地选中和锁定与运动相关的目标人群,品牌可以有效地实现用户收割。 \n\n \n\n悦己驱动,运动边界向轻量泛户外持续延伸 \n\n国民参与运动户外活动更多来自“悦己”观念的驱动,近7成的受访者表示他们主要是为了“强身健体/享受大自然”,因此轻量级、易开展的活动项目更受广大普通受众的青睐。近三年,社交平台关于“泛户外运动”的讨论热度持续走高,更是在23年春夏期间迎来一波小高峰:细分到具体的活动项目上,垂钓讨论声量较高;露营也保持较高声量,其经历过22年的大爆发、23年的行业调整,预计24年已经进入更深精细化运营;此外城市骑行热度也在不断上升,成为当下新兴的小众活动。" | ||
| ], | ||
| "reference_node_id": null, | ||
| "reference_image_url_list": [ | ||
| "https://pai-rag.oss-cn-hangzhou.aliyuncs.com/pairag/doc_images/2024春夏淘宝天猫运动户外行业趋势白皮书_淘宝/d4e624aceb4043839c924e33c075e388.jpeg", | ||
| "https://pai-rag.oss-cn-hangzhou.aliyuncs.com/pairag/doc_images/2024春夏淘宝天猫运动户外行业趋势白皮书_淘宝/52d1353d4577698891e7710ae12e18b1.jpeg", | ||
| "https://pai-rag.oss-cn-hangzhou.aliyuncs.com/pairag/doc_images/2024春夏淘宝天猫运动户外行业趋势白皮书_淘宝/4f77ded6421ddadd519ab9ef1601a784.jpeg" | ||
| ], | ||
| "reference_answer": "根据给定的材料,2023年春夏期间,垂钓在社交平台上的讨论声量最高。\n\n", | ||
| "reference_answer_by": null, | ||
| "predicted_contexts": null, | ||
| "predicted_node_id": null, | ||
| "predicted_node_score": null, | ||
| "predicted_image_url_list": null, | ||
| "predicted_answer": "", | ||
| "predicted_answer_by": null | ||
| }, | ||
| { | ||
| "query": "狄尔泰属于哪个教育学流派?", | ||
| "query_by": null, | ||
| "reference_contexts": [], | ||
| "reference_node_id": null, | ||
| "reference_image_url_list": [ | ||
| "https://pai-rag.oss-cn-hangzhou.aliyuncs.com/pairag/doc_images/教育文档/思维导图.jpeg" | ||
| ], | ||
| "reference_answer": "狄尔泰属于文化教育学流派。\n\n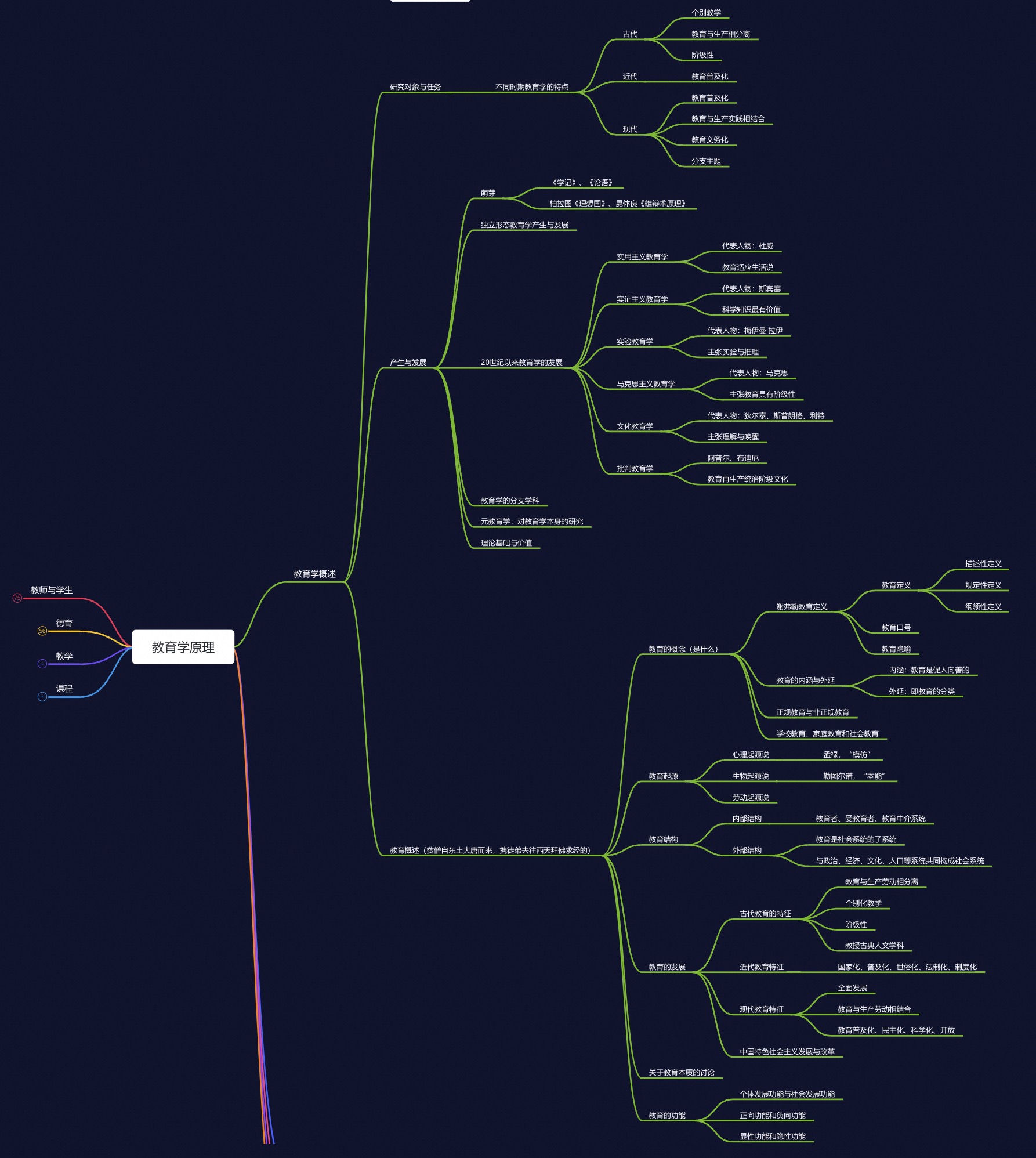", | ||
| "reference_answer_by": null, | ||
| "predicted_contexts": null, | ||
| "predicted_node_id": null, | ||
| "predicted_node_score": null, | ||
| "predicted_image_url_list": null, | ||
| "predicted_answer": "", | ||
| "predicted_answer_by": null | ||
| } | ||
| ], | ||
| "labelled": true, | ||
| "predicted": false | ||
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,154 @@ | ||
| # QCA GENERATION AND EVALUATION | ||
|
|
||
| RAG评估工具是一种用于测试和评估基于检索的文本生成系统的方法或框架,评估的内容包括检索的准确性、生成内容的质量和相关性等,评估指标包括精确度、召回率、一致性和合理性等。它可以帮助开发人员更好地了解和优化 RAG 应用,使其更适用于实际应用。相对于人工评估,RAG 评估工具更加客观、准确和高效,并且可以通过自动化的方式进行大规模的评估,从而让应用更快地进行迭代和优化。 | ||
|
|
||
| ## 评估方式 | ||
|
|
||
| 在yaml文件里配置评估实验,并运行以下命令进行评估 | ||
|
|
||
| ```bash | ||
| run_eval_exp [-i yaml_path] [--o output_path] | ||
| ``` | ||
|
|
||
| 配置案例可参考src/pai_rag/config/evaluation/config.yaml | ||
|
|
||
| ### 实验类型一:根据文档内容,创建评估数据集,进行RAG系统评估 | ||
|
|
||
| 1. 示例配置如下 | ||
|
|
||
| ```yaml | ||
| - name: "exp1" | ||
| eval_data_path: "example_data/eval_docs_text" | ||
| eval_modal_llm: | ||
| source: "dashscope" | ||
| model: "qwen-max" | ||
| max_tokens: 1024 | ||
| rag_setting_file: "src/pai_rag/config/evaluation/settings_eval_for_text.toml" | ||
| ``` | ||
| 2. 参数说明: | ||
| - name: 评估实验名称。 | ||
| - eval_data_path: 评估数据集路径,支持本地文件路径,或者oss路径。 | ||
| - eval_modal_llm: 用于评估大模型的配置,支持dashscope、openai、paieas等。 | ||
| - rag_setting_file: rag配置文件路径。 | ||
| 3. 评估维度: | ||
| Retrieval | ||
| | 指标 | 说明 | | ||
| | ------- | ----------------- | | ||
| | hitrate | 分数属于[0,1]区间 | | ||
| | mrr | 分数属于[0,1]区间 | | ||
| Response | ||
| | 指标 | 说明 | | ||
| | ------------ | ------------------------------------ | | ||
| | faithfulness | 分数为0或1,其中1是相关,0是不相关 | | ||
| | correctness | 分数在1到5之间,其中1为最低,5为最高 | | ||
| ### 实验类型二:根据文档内容,创建评估数据集,进行多模态大模型评估 | ||
| 1. 示例配置如下 | ||
| ```yaml | ||
| - name: "exp2" | ||
| eval_data_path: "example_data/eval_docs_text" | ||
| eval_modal_llm: | ||
| source: "dashscope" | ||
| model: "qwen-max" | ||
| max_tokens: 1024 | ||
| rag_setting_file: "src/pai_rag/config/evaluation/settings_eval_for_image.toml" | ||
| tested_multimodal_llm: | ||
| source: "dashscope" | ||
| model: "qwen-vl-max" | ||
| max_tokens: 1024 | ||
| ``` | ||
| 2. 参数说明: | ||
| - name: 评估实验名称。 | ||
| - eval_data_path: 评估数据集路径,支持本地文件路径,或者oss路径。 | ||
| - eval_modal_llm: 用于评估大模型的配置,支持dashscope、openai、paieas等。 | ||
| - rag_setting_file: rag配置文件路径。 | ||
| - tested_multimodal_llm: 待评估的评估大模型的配置 | ||
| 3. 评估维度: | ||
| Response | ||
| | 指标 | 说明 | | ||
| | ------------ | ------------------------------------ | | ||
| | faithfulness | 分数为0或1,其中1是相关,0是不相关 | | ||
| | correctness | 分数在1到5之间,其中1为最低,5为最高 | | ||
| ### 实验类型三:已有评估数据集json文件, 进行多模态大模型评估 | ||
| 1. 示例配置如下 | ||
| ```yaml | ||
| - name: "exp3" | ||
| qca_dataset_path: "data/eval_dataset/multimodal_eval_dataset_zh_example.json" | ||
| eval_modal_llm: | ||
| source: "dashscope" | ||
| model: "qwen-max" | ||
| max_tokens: 1024 | ||
| rag_setting_file: "src/pai_rag/config/evaluation/settings_eval_for_image.toml" | ||
| tested_multimodal_llm: | ||
| source: "dashscope" | ||
| model: "qwen-vl-max" | ||
| max_tokens: 1024 | ||
| ``` | ||
| 2. 参数说明: | ||
| - name: 评估实验名称。 | ||
| - qca_dataset_path: 评估数据集json文件路径,支持本地文件路径。 | ||
| - eval_modal_llm: 用于评估大模型的配置,支持dashscope、openai、paieas等。 | ||
| - rag_setting_file: rag配置文件路径。 | ||
| - tested_multimodal_llm: 待评估的评估大模型的配置 | ||
| 3. 评估数据集格式 | ||
| ```json | ||
| { | ||
| "examples": [ | ||
| { | ||
| "query": "2023年春夏期间,哪种泛户外运动在社交平台上的讨论声量最高?", | ||
| "query_by": null, | ||
| "reference_contexts": [ | ||
| ": 在赛事和政策的双重推动下,国民运动户外参与意愿高涨,超过六成的受访者表示近一年显著增加了运动户外的频率,各类运动项目正在快速走向“全民化”。新的一年,随着巴黎奥运会、美洲杯等赛事的举办,全民运动热情将进一步被激发。对于品牌而言,这是一个难得的市场机遇,通过精准地选中和锁定与运动相关的目标人群,品牌可以有效地实现用户收割。 \n\n \n\n悦己驱动,运动边界向轻量泛户外持续延伸 \n\n国民参与运动户外活动更多来自“悦己”观念的驱动,近7成的受访者表示他们主要是为了“强身健体/享受大自然”,因此轻量级、易开展的活动项目更受广大普通受众的青睐。近三年,社交平台关于“泛户外运动”的讨论热度持续走高,更是在23年春夏期间迎来一波小高峰:细分到具体的活动项目上,垂钓讨论声量较高;露营也保持较高声量,其经历过22年的大爆发、23年的行业调整,预计24年已经进入更深精细化运营;此外城市骑行热度也在不断上升,成为当下新兴的小众活动。" | ||
| ], | ||
| "reference_node_id": null, | ||
| "reference_image_url_list": [ | ||
| "https://pai-rag.oss-cn-hangzhou.aliyuncs.com/pairag/doc_images/2024春夏淘宝天猫运动户外行业趋势白皮书_淘宝/d4e624aceb4043839c924e33c075e388.jpeg", | ||
| "https://pai-rag.oss-cn-hangzhou.aliyuncs.com/pairag/doc_images/2024春夏淘宝天猫运动户外行业趋势白皮书_淘宝/52d1353d4577698891e7710ae12e18b1.jpeg", | ||
| "https://pai-rag.oss-cn-hangzhou.aliyuncs.com/pairag/doc_images/2024春夏淘宝天猫运动户外行业趋势白皮书_淘宝/4f77ded6421ddadd519ab9ef1601a784.jpeg" | ||
| ], | ||
| "reference_answer": "根据给定的材料,2023年春夏期间,垂钓在社交平台上的讨论声量最高。\n\n", | ||
| "reference_answer_by": null, | ||
| "predicted_contexts": null, | ||
| "predicted_node_id": null, | ||
| "predicted_node_score": null, | ||
| "predicted_image_url_list": null, | ||
| "predicted_answer": "", | ||
| "predicted_answer_by": null | ||
| } | ||
| ], | ||
| "labelled": true, | ||
| "predicted": false | ||
| } | ||
| ``` | ||
|
|
||
| 说明:必须要有query、reference_contexts或reference_image_url_list、reference_answer字段。 并且labelled: true、predicted: false | ||
|
|
||
| 4. 评估维度: | ||
|
|
||
| Response | ||
|
|
||
| | 指标 | 说明 | | ||
| | ------------ | ------------------------------------ | | ||
| | faithfulness | 分数为0或1,其中1是相关,0是不相关 | | ||
| | correctness | 分数在1到5之间,其中1为最低,5为最高 | |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters