This repo contains the source code for our paper:
Unsupervised Multilingual Word Embeddings
Xilun Chen,
Claire Cardie
EMNLP 2018
paper,
bibtex
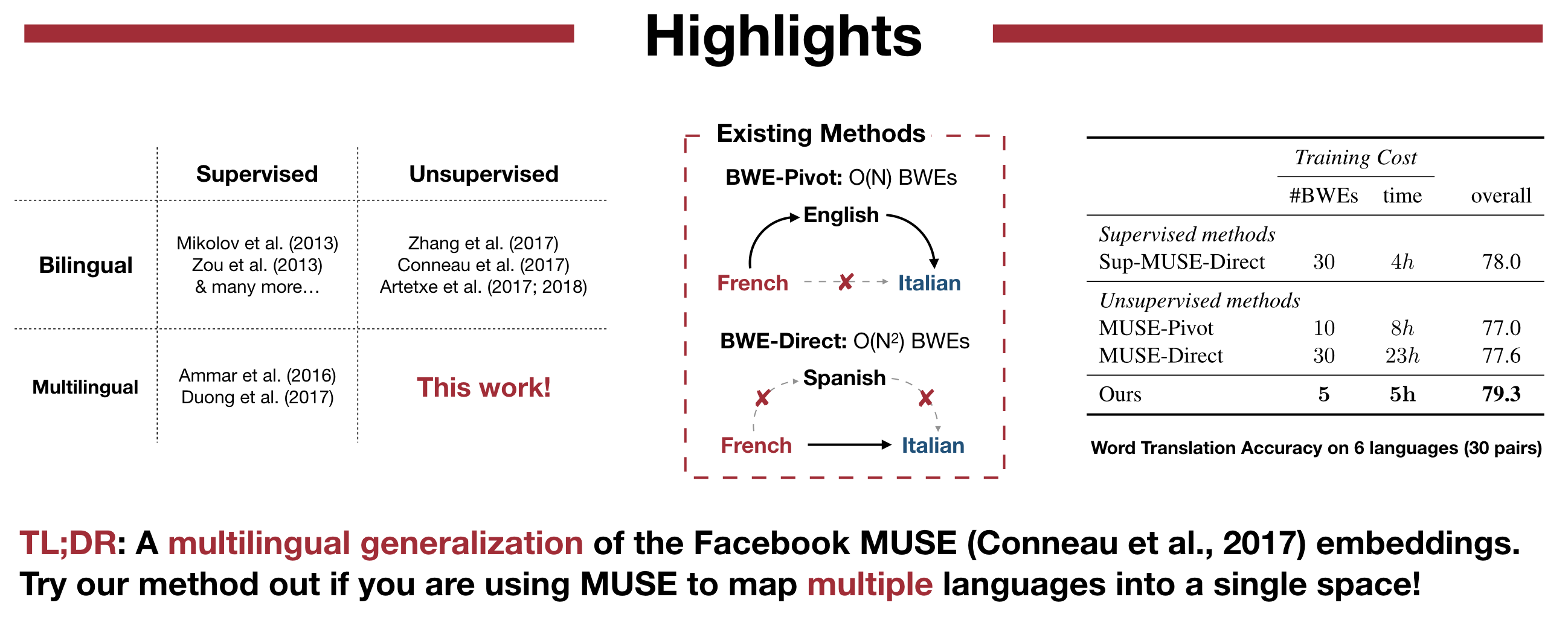
- Python 3.6 with NumPy/SciPy
- PyTorch 0.4
- Faiss (recommended) for fast nearest neighbor search (CPU or GPU).
Faiss is optional for GPU users - though Faiss-GPU will greatly speed up nearest neighbor search - and highly recommended for CPU users. Faiss can be installed using "conda install faiss-cpu -c pytorch" or "conda install faiss-gpu -c pytorch".
The evaluation datasets from MUSE can be downloaded by simply running (in data/):
./get_evaluation.shNote: Requires bash 4. The download of Europarl is disabled by default (slow), you can enable it here.
For pre-trained monolingual word embeddings, we adopt the same fastText Wikipedia embeddings recommended by the MUSE authors.
For example, you can download the English (en) embeddings this way:
# English fastText Wikipedia embeddings
curl -Lo data/fasttext-vectors/wiki.en.vec https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.en.vecpython unsupervised.py --src_langs de fr es it pt --tgt_lang enThis was not explored in the paper, but our MPSR method can in principle be applied to the supervised setting as well. No adversarial training will take place, and the Procrustes method in MUSE is replaced by our MPSR algorithm to learn multilingual embeddings. For example, the following command can be used to train (weakly) supervised UMWEs with identical characters served as supervsion.
python supervised.py --src_langs de fr es it pt --tgt_lang en --dico_train identical_charTo save time, not all language pairs are evaluated during training. You may run the evaluation script perform full evaluation. The test results are saved in 'evaluate.log' in the model folder.
python evaluate.py --src_langs de fr es it pt --tgt_lang en --eval_pairs all --exp_id [your exp_id]By default, the aligned embeddings are exported to a text format at the end of experiments: --export txt. Exporting embeddings to a text file can take a while if you have a lot of embeddings. For a very fast export, you can set --export pth to export the embeddings in a PyTorch binary file, or simply disable the export (--export "").
When loading embeddings, the model can load:
- PyTorch binary files previously generated by UMWE (.pth files)
- fastText binary files previously generated by fastText (.bin files)
- text files (text file with one word embedding per line)
The two first options are very fast and can load 1 million embeddings in a few seconds, while loading text files can take a while.
This work is developed based on MUSE by Alexis Conneau, Guillaume Lample, et al. from Facebook Inc., used under CC BY-NC 4.0.
This work is licensed under CC BY-NC 4.0 by Xilun Chen.