Tôi đã từng học Machine Learning trong vòng 2 tháng và tôi tin bạn cũng có thể làm được.
Lộ trình sẽ giúp bạn nắm chắc công nghệ này từ cơ bản đến nâng cao, xây dựng Machine Learning model từ python thuần cho đến các thư viện cao cấp như TensorFlow hay Keras. Đi sâu phân tích bản chất vấn đề là giá trị cốt lõi của khóa học này.
P/S: Hãy để lại 1 star để team có động lực xuất bản các phần tiếp theo và cũng đừng quên chia sẻ tới bạn bè của bạn.
- 1. Kiến thức toán học cần thiết
- 2. Kỹ năng lập trình Python
- 3. Thư viện Numpy và TensorFlow
- 4. Bài toán hồi quy (Regression)
- 5. Bài toán phân loại (Classification)
- 6. Xây dựng mô hình Decision Trees và Random Forests
- 7. Xây dựng mạng Neural Network
- 8. Xây dựng mạng Convolutional Neural Network (CNN)
- 9. Xây dựng mạng Recurrent Neural Network (RNN)
- 10. Triển khai (Deploy) Machine Learning Model trên Production
- 11. Machine Learning trên trình duyệt và TensorFlowJS
-
a. Đại số tuyến tính
Nếu các bạn có nhiều thời gian và sự kiên trì thì có thể học toàn bộ khóa này MIT 18.06 Linear Algebra, Spring 2005 . Nhưng đối với bản thân tôi có những phần trong khóa này đến bây giờ tôi vẫn chưa dùng đến. Vì thế nếu bạn không có nhiều thời gian, muốn tăng nhanh tốc độ thì có thể học theo từng phần tôi nhấn mạnh ở phía dưới đây.
- Scalar/Vector
- Giới thiệu vector/scalar và các thành phần của chúng: Vector basics - Khan Academy
- Thực hành với Numpy
- Ma trận (Matrix)
- Giới thiệu về ma trận: Introduction to matrices - Khan Academy
- Thực hành với Numpy
- Chuyển vị ma trận
- Cách chuyển vị ma trận và những vấn đề liên quan: Transpose of a matrix - Khan Academy
- Thực hành với Numpy
- Norm Vector
- Norm L1/L2: Vector Norms
- Thực hành với Numpy
- Tensor
- Giới thiệu về Tensor: Tensors for Beginners 0: Tensor Definition
- Các phép toán với ma trận
- Phép cộng ma trận
- Phương pháp cộng/trừ ma trận: Matrix addition and subtraction | Matrices | Precalculus | Khan Academy
- Thực hành với Numpy
- Phép nhân ma trận
- Các phương pháp nhân ma trận: Lec 3 | MIT 18.06 Linear Algebra, Spring 2005
- Thực hành với Numpy
- Tích Hadamard/Element-Wise
- Phương pháp tính tích Element-Wise: Element-Wise Multiplication and Division of Matrices
- Phép cộng ma trận
- Ma trận đơn vị
- Miêu tả ma trận đơn vị: Identity matrix | Matrices | Precalculus | Khan Academy
- Ma trận nghịch đảo
- Phương pháp tính ma trận nghịch đảo: Lec 3 | MIT 18.06 Linear Algebra, Spring 2005
- Scalar/Vector
-
b. Đạo hàm
-
Đây là series kinh điển để nhắc lại kiến thức đạo hàm của bạn. Essence of calculus - 3Blue1Brown
-
Anh Tiệp có một bài rất đầy đủ về đạo hàm ở đây: Machine Learning cơ bản - Phần Toán. Hãy thực hành tính toán phần 3.5, tôi đảm bảo bạn sẽ nắm chắc được đạo hàm trên vector và ma trận.
-
Ngoài phần cơ bản quan trọng thì việc nắm thuần thục Chain Rule và Production Rule là rất quan trọng đặc biệt là dành cho thuật toán Backpropagation trong Deep Learing. Bạn hãy xem kỹ video này: Visualizing the chain rule and product rule | Essence of calculus, chapter 4
-
-
c. Lý thuyết xác suất
- Các khái niệm cơ bản
- Những khái niệm cơ bản: Basic theoretical probability
- Xác suất sử dụng không gian mẫu: Probability using sample spaces
- Tiên đề xác suất: Axioms of Probability
- Các loại xác suất
- Xác suất có điều kiện:
- Giới thiệu: Dependent probability introduction | Probability and Statistics | Khan Academy
- Các ví dụ liên quan: Dependent probability example | Probability and Statistics | Khan Academy
- Công thức Bayes: CRITICAL THINKING - Fundamentals: Bayes' Theorem
- Xác suất độc lập: Compound probability of independent events | Probability and Statistics | Khan Academy
- Xác suất có điều kiện:
- Biến ngẫu nhiên và phân phối xác suất: Biến ngẫu nhiên và phân phối xác suất
- Các khái niệm cơ bản
Python là ngôn ngữ được dùng nhiều nhất để làm Machine Learning vì tính đơn giản gọn nhẹ của nó. Nhưng để đưa vào Production thì tôi nghĩ Javascript cũng là một lựa chọn không tồi. Tôi sẽ chia sẻ về Machine Learning với Javascript trong các phần tiếp theo.
-
a. Cài đặt Python và các thư viện cần thiết:
-
b. Tính chất đặc điểm
Python là ngôn ngữ thông dịch có:
- Điểm mạnh:
- Dễ viết/ Dễ đọc
- Quy trình phát triển phần mềm nhanh vì dòng lệnh được thông dịch thành mã máy và thực thi ngay lập tức
- Có nhiều thư viện mạnh để tính toán cũng như làm Machine Learning như Numpy, Sympy, Scipy, Matplotlib, Pandas, TensorFlow, Keras, vv.
- Điểm yếu:
- Mang đầy đủ điểm yếu của các ngôn ngữ thông dịch như tốc độ chậm, tiềm tàng lỗi trong quá trình thông dịch, source code dễ dàng bị dịch ngược.
- Ngôn ngữ có tính linh hoạt cao nên thiếu tính chặt chẽ.
- Điểm mạnh:
-
c. Các hàm dựng sẵn và kiểu dữ liệu trên Python
-
Các kiểu dữ liệu trong Python
Phần này được thiết kế dựa trên khóa Data Structures & Algorithms in Python - Udacity nhưng tôi sẽ đi sâu hơn vào các ví dụ thực tế hơn là chỉ dừng lại ở lý thuyết. Bên cạnh đó tôi sẽ giúp các bạn nắm rõ một số Data Structure quan trọng trong Machine Learning như Graph và Tree.
- Integer, Float và Boolean
- String
- List-Based Collection
- Dictionary
- Set
- Graph
-
d. Vòng lặp
-
e. Hàm
-
a. Numpy
-
Giới thiệu về NumPy
- Trang chủ của NumPy
- NumPy là viết tắt của "Numerical Python", là một thư viện chuyên để xử lý, tính toán vector, ma trận.
- NumPy thường được sử dụng cùng SciPy và Matplotlib để thay thế cho MatLab vô cùng đắt đỏ.
- Được viết bằng Python và C nên tốc độ thực thi tốt.
-
Các APIs
-
-
b. TensorFlow
-
a. Mô hình Hồi quy tuyến tính (Linear Regression Model)
-
Định nghĩa
-
Mô phỏng thực tế
-
b. Hàm mất mát (Loss Function)
- Định nghĩa
- Mô phỏng thực tế
-
c. Thuật toán tối ưu Loss Function (Optimization Algorithms)
- Normal Equation
- Công thức toán học
- Điểm mạnh
- Điểm yếu
- Gradient Descent
- Công thức toán học
- Điểm mạnh
- Điểm yếu
- Normal Equation
-
d. Bài toán thực tế
- Bài toán đo lường Hiệu quả sản xuất
- Vấn đề
- Giải quyết bằng mô hình Hồi quy tuyến tính
- Bài toán đo lường Hiệu quả sản xuất

-
a. Mô hình Hồi quy Logistic (Logistic Regression Model)
- Định nghĩa
- Mô phỏng thực tế
-
b. Phân loại 2 lớp (Binary Classification)
- Định nghĩa
- Hàm phi tuyến sigmoid
- Hàm mất mát (Loss Function)
- Thuật toán Gradient Descent
-
c. Phân loại nhiều lớp (Multiclass Classification)
- Định nghĩa
- Hàm mất mát (Loss Function)
- Thuật toán Gradient Descent
-
d. Hiện tượng Overfitting và một số cách khắc phục
-
e. Đánh giá mô hình
-
a. Mô hình Cây quyết định (Decision Trees)
- Định nghĩa
- Mô phỏng thực tế
-
b. Các thuật toán
- ID3
- C4.5
- C5.0
- CART
-
c. Triển khai thuật toán CART
- Câu hỏi (Question)
-
d. Bài toán phân loại ô tô
- Vấn đề
- Giải quyết bằng mô hình Cây quyết định
-
e. Mô hình Random Forests
- Định nghĩa
-
a. Neural Network
- Định nghĩa
- Mô phỏng thực tế
-
b. Hàm kích hoạt phi tuyến
- Sigmoid
- Tanh
- ReLU
-
c. Thuật toán lan truyền ngược (backpropagation)
- Ôn lại đạo hàm hàm hợp (Chain Rule)
- Công thức
- Mô phỏng thực tế
-
d. Thuật toán tối ưu Loss Function (Optimization Algorithms)
- Thuật toán Gradient Descent
-
e. Một số vấn đề khi huấn luyện Neural Network
-
a. Convolutional Neural Network
-
Định nghĩa
Convolutional Neural Networks tương đồng với mạng Neural Networks thông thường, bao gồm nhiều neuron với mục đích học được các tham số (weights và biases). Mạng này có:
- Đầu vào: Những bức ảnh dưới dạng Pixel
- Đầu ra: Các lớp cần phân loại
Ví dụ tôi muốn làm bài toán phân loại chó mèo, thì đầu vào của tôi là rất nhiều ảnh chó mèo và lớp đầu ra có 2 neuron đại diện tương ứng cho chó và mèo.
-
Mô phỏng thực tế
-
Ứng dụng thực tế
Bài toán Ảnh minh họa Phân loại đối tượng trong ảnh (Image Classification) Phát hiện đối tượng (Object Detection) Phụ đề cho ảnh (Image Captioning) Phân đoạn ảnh (Image Segementation) Xử lý ảnh (Image Processing)
Ảnh từ cs231, analyticsvidhya, iospress, quora, slideshare
-
Quá trình mạng nhận diện một ảnh (Inference)
- Bước 1: Ảnh sẽ được chuyển về dưới dạng ma trận các pixel
- Bước 2: Ma trận của ảnh khi đi qua các lớp ẩn (hidden layer) sẽ được trích xuất đặc trưng cũng như biến đối phi tuyến thành ma trận kích thước nhỏ hơn nhưng chứa đựng nhiều đặc trưng của bức ảnh hơn.
- Bước 3: Sau khi ma trận của ảnh được biến đổi, nó được đưa qua lớp cuối cùng là một layer 2 neuron, mỗi neuron này sẽ đại diện cho xác suất ảnh đưa vào là chó hoặc mèo.
-
-
b. Tại sao lại cần dùng Convolutional Neural Network?
-
Nhược điểm của mạng kết nối đầy đủ (Fully Connected Network)
- Dễ bị Overfit do lượng tham số cần học quá lớn và data quá nhỏ
- Mạng không phân loại được cùng một đối tượng nhưng ở vị trí khác nhau trong ảnh
-
Ưu điểm của mạng CNN
- Lượng tham số ít hơn nhiều so với mạng kết nối đầy đủ. Các lớp tích chập (CONV), các lớp Pooling giúp trích xuất đặc trưng của ảnh khiến ma trận ảnh đi qua mỗi lớp nhỏ dần đi, vì thế lượng tham số cần học cũng giảm theo.
- Có tính kháng dịch chuyển. Vì loại đi những dữ liệu thừa có ảnh hưởng đến vị trí của đối tượng nên mạng nhận diện chính xác một đối tượng nằm ở các vị trí khác nhau trong một ảnh.
-
-
c. Các mạng CNN thông dụng
- VGG 16
- ResNet
- GoogleNet
-
d. Phép tích chập (Convolution)
-
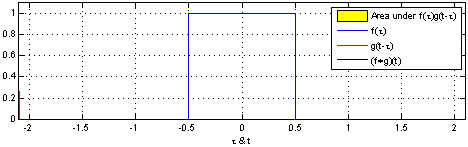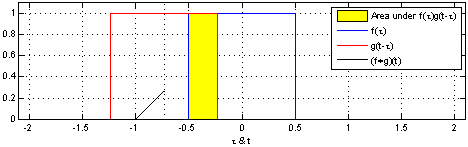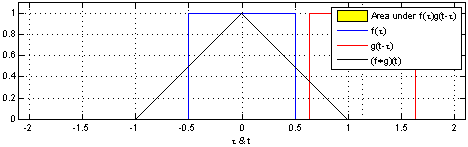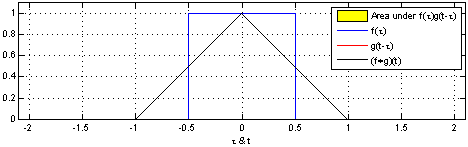
Công thức
Mô phỏng công thức:
Hàm f(x) đại diện là ô vuông màu xanh và Hàm g(t-x) đại diện cho ô vuông màu đỏ. Tích chập (f*g)[n] thể hiện mức độ giao hoán của hai hàm f(x) và g(t-x) tại ví trí n.
- Tại vị trí n mà 2 hàm giao hoán mạnh nhất, tức là 2 ô vuông trùng nhau thì giá trị tích chập là lớn nhất
- Tại vị trí n mà 2 hàm không giao hoán, tức là 2 ô vuông không trùng nhau thì giá trị tích chập là bằng 0
- Giá trị tích chập tăng dần tỉ lệ thuận với mức độ giao hoán của 2 hàm
Sử dụng tích chập, ta có thể trích xuất tính chất từ ma trận của ảnh dựa trên những ma trận nhỏ (filter) cho sẵn.
-
Tích chập 1D rời rạc
- Tích chập 2D rời rạc
Ảnh từ machinelearninguru
-
-
e. Pooling
- Max-Pooling
- Average-Pooling
-
f. Cấu trúc mạng
Ảnh từ cs231 - Stanford











Phần này được mô phỏng chủ yếu trên bài nói của tôi tại Google I/O Extended Hanoi 2018. Slide và code của bài nói này nằm tại đây.
- a. Lịch sử TensorFlowJS
- b. Các API chính của TensorFlowJS
- c. Xây dựng mô hình Hồi quy tuyến tính
- d. Xây dựng mạng Convolutional Neural Network(CNN)
- e. MobileNet
- f. Transfer Learning