



This repository contains the PyTorch (1.0+) implementation of Open-Unmix, a deep neural network reference implementation for music source separation, applicable for researchers, audio engineers and artists. Open-Unmix provides ready-to-use models that allow users to separate pop music into four stems: vocals, drums, bass and the remaining other instruments. The models were pre-trained on the MUSDB18 dataset. See details at apply pre-trained model.
Related Projects: open-unmix-pytorch | open-unmix-nnabla | musdb | museval | norbert
Open-Unmix is based on a three-layer bidirectional deep LSTM. The model learns to predict the magnitude spectrogram of a target, like vocals, from the magnitude spectrogram of a mixture input. Internally, the prediction is obtained by applying a mask on the input. The model is optimized in the magnitude domain using mean squared error and the actual separation is done in a post-processing step involving a multichannel wiener filter implemented using norbert. To perform separation into multiple sources, multiple models are trained for each particular target. While this makes the training less comfortable, it allows great flexibility to customize the training data for each target source.
Open-Unmix operates in the time-frequency domain to perform its prediction. The input of the model is either:
- A time domain signal tensor of shape
(nb_samples, nb_channels, nb_timesteps), wherenb_samplesare the samples in a batch,nb_channelsis 1 or 2 for mono or stereo audio, respectively, andnb_timestepsis the number of audio samples in the recording.
In that case, the model computes spectrograms with torch.STFT on the fly.
- Alternatively open-unmix also takes magnitude spectrograms directly (e.g. when pre-computed and loaded from disk).
In that case, the input is of shape (nb_frames, nb_samples, nb_channels, nb_bins), where nb_frames and nb_bins are the time and frequency-dimensions of a Short-Time-Fourier-Transform.
The input spectrogram is standardized using the global mean and standard deviation for every frequency bin across all frames. Furthermore, we apply batch normalization in multiple stages of the model to make the training more robust against gain variation.
The LSTM is not operating on the original input spectrogram resolution. Instead, in the first step after the normalization, the network learns to compresses the frequency and channel axis of the model to reduce redundancy and make the model converge faster.
The core of open-unmix is a three layer bidirectional LSTM network. Due to its recurrent nature, the model can be trained and evaluated on arbitrary length of audio signals. Since the model takes information from past and future simultaneously, the model cannot be used in an online/real-time manner. An uni-directional model can easily be trained as described here.
After applying the LSTM, the signal is decoded back to its original input dimensionality. In the last steps the output is multiplied with the input magnitude spectrogram, so that the models is asked to learn a mask.
Since PyTorch currently lacks an invertible STFT, the synthesis is performed in numpy. For inference, we rely on an implementation of a multichannel Wiener filter that is a very popular way of filtering multichannel audio for several applications, notably speech enhancement and source separation. The norbert module assumes to have some way of estimating power-spectrograms for all the audio sources (non-negative) composing a mixture.
For installation we recommend to use the Anaconda python distribution. To create a conda environment for open-unmix, simply run:
conda env create -f environment-X.yml where X is either [cpu-linux, gpu-linux-cuda10, cpu-osx], depending on your system. For now, we haven't tested windows support.
We also provide a docker container as an alternative to anaconda. That way performing separation of a local track in ~/Music/track1.wav can be performed in a single line:
docker run -v ~/Music/:/data -it faroit/open-unmix-pytorch python test.py "/data/track1.wav" --outdir /data/track1
We provide two pre-trained models:
-
umxhq(default) trained on MUSDB18-HQ which comprises the same tracks as in MUSDB18 but un-compressed which yield in a full bandwidth of 22050 Hz. -
umxis trained on the regular MUSDB18 which is bandwidth limited to 16 kHz do to AAC compression. This model should be used for comparison with other (older) methods for evaluation in SiSEC18.
To separate audio files (wav, flac, ogg - but not mp3) files just run:
python test.py input_file.wav --model umxhqA more detailed list of the parameters used for the separation is given in the inference.md document. We provide a jupyter notebook on google colab to experiment with open-unmix and to separate files online without any installation setup.
The pre-trained models can be loaded from other pytorch based repositories using torch.hub.load:
torch.hub.load('sigsep/open-unmix-pytorch', 'umxhq', target='vocals')When a path instead of a model-name is provided to --model the pre-trained model will be loaded from disk.
python test.py --model /path/to/model/root/directory input_file.wavNote that model usually contains individual models for each target and performs separation using all models. E.g. if model_path contains vocals and drums models, two output files are generated.
To perform evaluation in comparison to other SISEC systems, you would need to install the museval package using
pip install museval
and then run the evaluation using
python eval.py --outdir /path/to/musdb/estimates --evaldir /path/to/museval/results
Open-Unmix yields state-of-the-art results compared to participants from SiSEC 2018. The performance of UMXHQ and UMX is almost identical since it was evaluated on compressed STEMS.
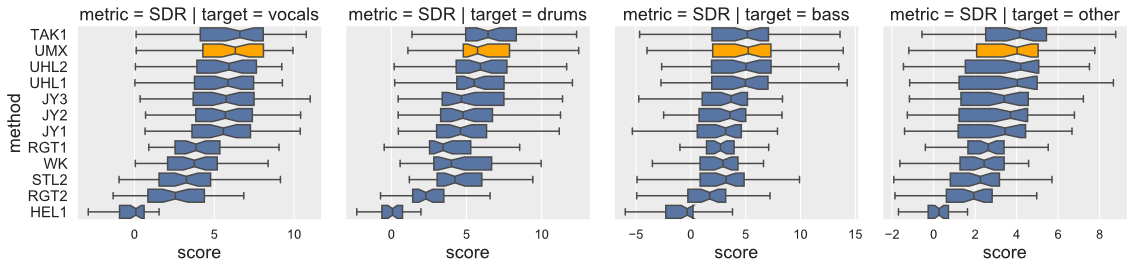
Note that
- [
STL1,TAK2,TAK3,TAU1,UHL3,UMXHQ] were omitted as they were not trained on only MUSDB18. - [
HEL1,TAK1,UHL1,UHL2] are not open-source.
| target | SDR | SIR | SAR | ISR | SDR | SIR | SAR | ISR |
|---|---|---|---|---|---|---|---|---|
model |
UMX | UMX | UMX | UMX | UMXHQ | UMXHQ | UMXHQ | UMXHQ |
| vocals | 6.32 | 13.33 | 6.52 | 11.93 | 6.25 | 12.95 | 6.50 | 12.70 |
| bass | 5.23 | 10.93 | 6.34 | 9.23 | 5.07 | 10.35 | 6.02 | 9.71 |
| drums | 5.73 | 11.12 | 6.02 | 10.51 | 6.04 | 11.65 | 5.93 | 11.17 |
| other | 4.02 | 6.59 | 4.74 | 9.31 | 4.28 | 7.10 | 4.62 | 8.78 |
Details on the training is provided in a separate document here.
Details on how open-unmix can be extended or improved for future research on music separation is described in a separate document here.
we favored simplicity over performance to promote clearness of the code. The rationale is to have open-unmix serve as a baseline for future research while performance still meets current state-of-the-art (See Evaluation). The results are comparable/better to those of UHL1/UHL2 which obtained the best performance over all systems trained on MUSDB18 in the SiSEC 2018 Evaluation campaign.
We designed the code to allow researchers to reproduce existing results, quickly develop new architectures and add own user data for training and testing. We favored framework specifics implementations instead of having a monolithic repository with common code for all frameworks.
open-unmix is a community focused project, we therefore encourage the community to submit bug-fixes and requests for technical support through github issues. For more details of how to contribute, please follow our CONTRIBUTING.md. For help and support, please use the gitter chat or the google groups forums.
Fabian-Robert Stöter, Antoine Liutkus, Inria and LIRMM, Montpellier, France
If you use open-unmix for your research – Cite Open-Unmix
@article{stoter19,
author={F.-R. St\\"oter and S. Uhlich and A. Liutkus and Y. Mitsufuji},
title={Open-Unmix - A Reference Implementation for Music Source Separation},
journal={Journal of Open Source Software},
year=2019,
doi = {10.21105/joss.01667},
url = {https://doi.org/10.21105/joss.01667}
}If you use the MUSDB dataset for your research - Cite the MUSDB18 Dataset
@misc{MUSDB18,
author = {Rafii, Zafar and
Liutkus, Antoine and
Fabian-Robert St{\"o}ter and
Mimilakis, Stylianos Ioannis and
Bittner, Rachel},
title = {The {MUSDB18} corpus for music separation},
month = dec,
year = 2017,
doi = {10.5281/zenodo.1117372},
url = {https://doi.org/10.5281/zenodo.1117372}
}If compare your results with SiSEC 2018 Participants - Cite the SiSEC 2018 LVA/ICA Paper
@inproceedings{SiSEC18,
author="St{\"o}ter, Fabian-Robert and Liutkus, Antoine and Ito, Nobutaka",
title="The 2018 Signal Separation Evaluation Campaign",
booktitle="Latent Variable Analysis and Signal Separation:
14th International Conference, LVA/ICA 2018, Surrey, UK",
year="2018",
pages="293--305"
}MIT
![]()
