
Este taller está basado en los Workshops de pgRouting de los FOSS4G sin los cuales hubiera sido imposible aprender a usar pgRouting. Gracias!
pgRouting es una extensión para PostgreSQL/PostGIS que añade funcionalidades para ánalisis de redes y planificación de rutas. Esto nos permite realizar cálculos de rutas óptimas, áreas de servicio e iscocronas (con la ayuda de QGIS), desde la propia base de datos con los beneficios que esto conlleva:
- Los datos pueden ser modificados desde diversos tipos de clientes:
- SIG de Escritorio (QGIS, gvSIG, uDig, etc)
- Aplicaciones web
- Dispositivos móviles
- Las modificaciones de los datos pueden reflejarse de forma inmediata en el motor de enrutamiento.
- Los parámetros de costo de desplazamiento por la red puede calcularse de forma dinámica usando SQL, permitiendo utilizar atributos de diferentes campos o tablas (por ejemplo, la velocidad máxima permitida en una carretera).
La librería pgRouting contiene los siguientes algoritmos:
- Algoritmo de Dijkstra
- Algoritmo de Johnson
- Algoritmo de Floyd-Warshall
- Algoritmo A*
- Algoritmos bidireccionales: Dijkstra y A* bidireccionales
- Problema del viajante
- Distancia manejando
- Camino más corto con restricción de giros
- Etc.
pgRouting es una librería de código abierto disponible con la licencia GPLv2 y soportada y mantenida por Georepublic, iMaptools y una amplica comunidad de usarios.
Una de las principales desarrolladoras es Vicky Vergara
Los archivos para el taller los podemos descargar desde aquí
La estructura básica que necesitamos para empezar a trabajar con PgRouting es una capa de líneas (o tabla de base de datos) con una buena calidad topológica (que no tenga lineas desconectadas). Si queremos hacer cálculos en función del tiempo de desplazamiento necestaremos además un campo que contenga la velocidad máxima permitida en la vía y longitud de la linea (en metros). Si además queremos tener en cuenta el sentido de circulación necesitamos un atributo que nos indique el sentido de circulación o si la vía es de doble sentido.
Además de la "capa" de líneas necesitamos una capa de nodos de la red. Estos nodos definen las conexiones entre calles y carreteras. La capa de lineas tiene que contener para cada segmento de la red cuál es el nodo de origen y el nodo de destino que conecta. Así que finalmente la capa de lineas tiene que contener dos atributos más, nodo de origen y nodo de estino (source y target).
Una de las fuentes de datos con la que podemos trabajar es OpenStreetMap. Para ello necesitamos dos cosas:
- Descargar los datos de OSM desde:
- https://www.openstreetmap.org (nos ubicamos el en el área de interés y luego hacemos click en Overpass API)
- Descargamos los conglomerados a nivel subregión, país o ciudad desde https://download.geofabrik.de
- Instalar osm2pgrouting
osm2pgrouting nos va a permitir generar toda la estructura de base de datos que necesitamos para pgRouting de forma sencilla y rápida. El único incoveniente es que si queremos procesar conjuntos de datos muy grandes (por ejemplo, todo un estado de México o el país completo) vamos a necesitar hacerlo por partes (eliminando el parámetro --clean) o contar con un servidor con una cantidad enorme de memoria RAM.
El ejemplo que aparece a continuación exportaría a nuestra base de datos PostgreSQL de nombre ruteo, el archivo que descargamos "tu_archivo_osm_xml.osm" usando la configuración en el archivo de configuración mapconfig.xml.
osm2pgrouting --f tu_archivo_osm_xml.osm --conf mapconfig.xml --dbname ruteo --username postgres --cleanA continuación se muestra la ayuda de osm2pgrouting:
osm2pgrouting --help
Allowed options:
Help:
--help Produce help message for this version.
-v [ --version ] Print version string
General:
-f [ --file ] arg REQUIRED: Name of the osm file.
-c [ --conf ] arg (=/usr/share/osm2pgrouting/mapconfig.xml)
Name of the configuration xml file.
--schema arg Database sch2pgrouting -f map.osm -c mapconfig_for_cars_mod.xml -d gislocal -p 5433 --schema ruteoamg -U gisadmin -W privacidad% --clean --chunk 20000ema to put tables.
blank: defaults ´to default schema
dictated by PostgreSQL
search_path.
--prefix arg Prefix added at the beginning of the
table names.
--suffix arg Suffix added at the end of the table
names.
--addnodes Import the osm_nodes, osm_ways &
osm_relations tables.
--attributes Include attributes information.
--tags Include tag information.
--chunk arg (=20000) Exporting chunk size.
--clean Drop previously created tables.
--no-index Do not create indexes (Use when indexes
are already created)
Database options:
-d [ --dbname ] arg Name of your database (Required).
-U [ --username ] arg Name of the user, which have write access to
the database.
-h [ --host ] arg (=localhost) Host of your postgresql database.
-p [ --port ] arg (=5432) db_port of your database.
-W [ --password ] arg Password for database access.El parámetro --conf nos permite utilizar un archivo de configuración para osm2pgrouting que va a definir que tipos de carreteras o vías queremos utilizar y cual es la velocidad de desplazamiento en cada tipo de vía. Por defecto vamos a encontrar 3 configuraciones en la carpeta /usr/share/osm2pgrouting/:
- Para bicicletas
- Para automóviles
- Para peatones
Si queremos podemos modificar los archivos de coniguración para que se adapte a nuestras necesidades, qué tipo de vías vamos a importar (definido por los tipos de vías de OSM) y la velocidad máxima a utilizar paraa cada tipo de vía.
Pros:
- Los datos están más actualizados que otras fuentes de información en México y se manejan como un único conjunto de datos (no son dos capas de información separadas como en el caso de INEGI, una para carreteras y otra para calles).
- La información está en algunos casos más actualizada.
- Las líneas cuentan con todos los atributos necesarios para pgRouting
- Los nodos de conexión de la red siguen reglas precisas de manera que aunque dos lineas se crucen puede no existir un nodo de conexión porque sea un paso a desnivel, un tunel o un puente.
- En general facilita enormemente la creación de una red "ruteable"
Contras:
- Puede que los datos en tu región no estén tan completos o actualizados como desearías
- La herramienta osm2pgrouting puede consumir enormes cantidades de memoría por lo que necesitamos hacer importaciones "incrementales" si queremos trabajar en regiones muy grandes (también podemos utilizar un servidor en la nube con mucha RAM para hacer el proceso y una vez creada la red descargarla a un servidor con menos memoria RAM o un PC).
La Red Nacional de Caminos de INEGI soporta el estándar internacional ISO 14825:2011 Intelligent Transport Systems_Geographic Data Files_GDF5.0, la cual integra los elementos necesarios para ruteo, ya tiene el formato necesario para pgRouting:
- Capa red_vial: Contiene las carreteras. Tiene como atributos VELOCIDAD, UNION_INI (nodo de inicio) y UNION_FIN (nodo de destino) y LONGITUD.
- Capa union: Puntos que representan los nodos (uniones) de los segmentos de la red de caminos.Tiene el atributo ID_UNION que es el identificador que está almacenado en los campos UNION_INI y UNION_FIN de la capa. red_vial
- Localidad: Localidades de México (puntual). Muchas de las localidades tiene las mismas coordenadas que los puntos de la capa de unión.
Pros:
- Ya viene preparada para ruteo con lo que simplifca mucho la creación de la red
Contras:
- La capa red_vial no incluye la mayoría de las calles de los núcleos urbanos, solo algunas de las vías principales que las cruzan.
Para agilizar el taller no vamos a realizar la instalación de PostgreSQL, PostGIS y pgRouting. Utilizaremos una base de datos en un servidor remoto. Para conectar al servidor vamos a usar pgAdmin4.
IP del Servidor: xx.xx.xx.xx
Los datos están en los schemas ruteoinegi y ruteoamg.
Pueden descargar la base de datos completa desde aquí, es un dump con todos los datos del taller.
NOTA:
- Muchas de las funciones de pgRouting incluyen parámetros del tipo sql::text, es decir una consulta sql como una cadena de texto. Esto puede parecer algo confuso al principio pero permite gran flexibilidad ya que el usuario puede pasar cualquier sentencia
SELECTcomo argumento para una función siempre que el resultado de dichoSELECTcontenga el número de atributos requerido y los nombres de atributos correctos. - La mayoría de los algoritmos de pgRouting no necesitan la geometría de la red.
- La mayoría de los algoritmos de pgRouting no retornan una geometría, si no una lista ordenada de nodos o segmentos.
El algoritmo de Dijkstra fue el primer algorimto implementado en pgRouting. Solo requiere los atributos , ìd , source y target y cost. Podemos especificar si el grafo es dirigido o no dirigido (tendrá en cuenta el sentido de las vias o no).
Resumen de signaturas
pgr_dijkstra(edges_sql, start_vid, end_vid)
pgr_dijkstra(edges_sql, start_vid, end_vid [, directed])
pgr_dijkstra(edges_sql, start_vid, end_vids [, directed])
pgr_dijkstra(edges_sql, start_vids, end_vid [, directed])
pgr_dijkstra(edges_sql, start_vids, end_vids [, directed])
RETURNS SET OF (seq, path_seq [, start_vid] [, end_vid], node, edge, cost, agg_cost)
OR EMPTY SETLa primera opción es un origen y un destino, la segunda es igual pero dirigida, la tercera un origen y muchos destinos (1:n), la cuarta muchos orígenes y un destino (n:1) y la última es muchos origens y muchos destinos (n:m).
Como comentamos en la nota anterior uno de los parámetros es un SELECT que se lo pasamos a la función como una cadena de texto. También hay que dar un alias al parámetro length_m para que la función entienda que es el costo. El costo puede ser cualquier atributo, en este caso usamos el atributo length_m pero podría ser tiempo en segundos (la ruta más rápida) o cualquier atributo que represente el costo de desplazamiento por la red. Después del SELECT tenemos los IDs de los nodos entre los que queremos calcular la ruta más corta. Finalmente tenemos el parámetro directed que nos indica si queremos que la ruta tenga en cuenta el sentido de circulación o no.
SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
length_m AS cost
FROM ruteoamg.ways',
79012, 35280,
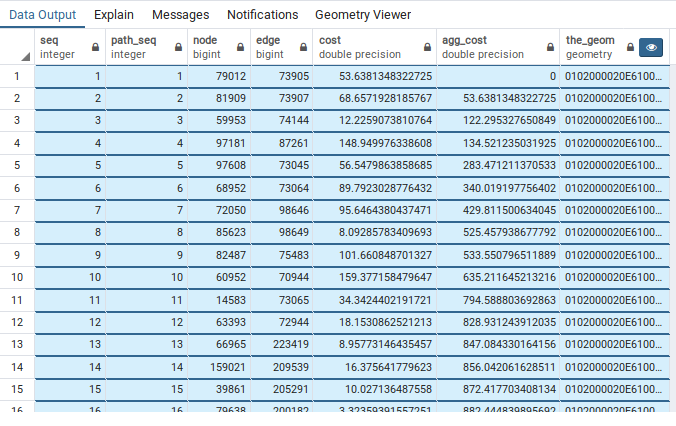
directed := false)El resultado de la consulta es una tabla con las columnas:
seq: Identificador únicopath_seq: Secuencia dentro de la rutastart_vid: Nodo de inicio de la ruta.node: Nodo por el que pasa la rutaedge: Segmento de la redcost: Costo de desplazamiento por el segmentoagg_cost: Costo agregado para cada paso de la ruta
Como la función pgr_dijkstra no retorna las geometrías vamos a generar una consulta que nos permita obtener las geometrías de la red para poder visualizar la ruta. En este caso estamos trayendo las geometrías de los segmentos de la red que están en la tabla ruteoamg.ways mediante un join entre el id del segmento, edge, retornado por la función pgr_dijkstra y la llave primaria de la tabla ruteoamg.ways, gid.
WITH ruta as (SELECT * FROM pgr_dijkstra(
'SELECT gid as id,
source,
target,
length_m AS cost
FROM ruteoamg.ways',
79012, 35280,
directed := false))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid ;Podemos visualizar el resultado de la consulta directamente en pgAdmin4 haciendo clic en el botón con un ojo. También podriamo visualizarlo en QGIS.

En este caso vamos especificar varios orígenes y un destino:
- Los orígenes son los nodos: 3443 y 29539
- Para el costo vamos a volver a utilizar el atributo length_m
Para pasarle los origenes a la función pgr_dijkstra tenemos que usar un ARRAY (arreglo: conjunto de elementos del mismo tipo).
SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
length_m AS cost
FROM ruteoamg.ways',
ARRAY[3443, 29539], 35280,
directed := false)WITH ruta as (SELECT * FROM pgr_dijkstra(
'SELECT gid as id,
source,
target,
length_m AS cost
FROM ruteoamg.ways',
ARRAY[3443, 29539], 35280,
directed := false))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid;En este caso vamos especificar un origen y varios destinos:
- El origen es el nodos: 67272
- Los nodos de destino son: 1017 y 55134
- Para el costo vamos a utilizar el tiempo de desplazamiento suponiendo una velocidad constante de 20 km/h (5.56 m/s).
v = 5.56 m/syt=d/v
SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
length_m / 5.56 AS cost
FROM ruteoamg.ways',
67272, ARRAY[1017, 55134],
directed := false)WITH ruta as (SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
length_m / 5.56 AS cost
FROM ruteoamg.ways',
67272, ARRAY[1017, 55134],
directed := false))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid;¿Qué ocurre si cambiamos el parámetro de dirigido a no dirigido (directed:=false)?¿En qué unidades estamos midiendo el costo de desplazamiento en este último ejercicio?
En este caso vamos especificar varios origenes y varios destinos:
- El origen es el nodos: 67272 y 133535 (Hoteles recomendados)
- Los nodos de destino son: 1017 y 55134 (Sedes del evento QGIS RNU 2019 - CUCSH y CUAAD)
- Para el costo vamos a utilizar el tiempo de desplazamiento suponiendo una velocidad constante de 20 km/h (5.56 m/s)
v = 5.56 m/syt=d/v, pero en este caso vamos a obtener el tiempo en minutos.
SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
length_m / 5.56 / 60 AS cost
FROM ruteoamg.ways',
ARRAY[67272, 133535], ARRAY[1017, 55134],
directed := false)WITH ruta as (SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
length_m / 5.56 / 60 AS cost
FROM ruteoamg.ways',
ARRAY[67272, 133535], ARRAY[1017, 55134],
directed := false))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid;NOTA: Si inspeccionamos el resultado de la consulta, veremos que hay algunas filas que tiene edge=-1, estas filas nos indican el costo total de cada ruta:
- De 67272 a 1017 tardaremos 9.33 minutos.
- De 67272 a 55134 tardaremos 27.91 minutos.
- De 133535 a 1017 tardaremos 14.60 minutos.
- De 133535 a 32.70 tardaremos 32.70 miuntos.
Si lo que queremos es calcular el costo total de desplazamiento, sin necesidad de buscar en los resultados de pgr_dijkstra podemos utilizar pgr_dijkstraCost que nos arrojará resultados más compactos.
Resumen de signaturas
pgr_dijkstraCost(edges_sql, start_vid, end_vid)
pgr_dijkstraCost(edges_sql, start_vid, end_vid [, directed])
pgr_dijkstraCost(edges_sql, start_vid, end_vids [, directed])
pgr_dijkstraCost(edges_sql, start_vids, end_vid [, directed])
pgr_dijkstraCost(edges_sql, start_vids, end_vids [, directed])
RETURNS SET OF (start_vid, end_vid, agg_cost)
OR EMPTY SETSELECT * FROM pgr_dijkstraCost('SELECT gid as id,
source,
target,
length_m / 5.56 / 60 AS cost
FROM ruteoamg.ways',
ARRAY[67272, 133535], ARRAY[1017, 55134],
directed := false)3.2.2 Ejercicio 6 - Resumen de los costos totales por origen entre varios orígenes y varios destinos
En este caso tenemos que utilizar la clausula GROUP BY para obtener los resultados agrupados para cada origen.
SELECT start_vid, sum(agg_cost) as tiempo_total
FROM pgr_dijkstraCost('SELECT gid as id,
source,
target,
length_m / 5.56 / 60 AS cost
FROM ruteoamg.ways',
ARRAY[67272, 133535], ARRAY[1017, 55134],
directed := false)
GROUP BY start_vid
ORDER BY start_vid;¿En cuál de los dos hoteles conviene más hospedarse?
Una consulta para ruteo de vehículos es diferente a una para peatones:
- Los segmentos de la red de carreteras suelen considerarse "dirigidos" (pueden tener limitaciones en cuanto al sentido en el que pueden recorrerse)
- El costo puede ser:
- Distancia
- Tiempo
- Dinero
- Emisiones de CO2
- Desgaste del vehículo, etc.
- El atributo reverse_cost debe tenerse en cuenta en vias de doble sentido
- El costo tiene que tener las mismas unidades que el atributo cost
- cost y reverse_cost pueden ser diferentes (Esto es debido a que existen vias de sentido único)
Dependiendo de la geometría, la forma válida:
- segmento (origen, destino) (
cost >= 0yreverse_cost< 0) - segmento (destino, origen) (
cost < 0yreverse_cost>= 0)
De manera que un "sentido contrario" se indica mediante un valor negativo y no es insertado en el grafo para su procesamiento.
Para vías de doble sentido cost >= 0 y reverse_cost >= 0 y sus valores pueden ser diferentes. Por ejemplo, es más rápido ir cuesta abajo en una carretera en pendiente. En general cost y reverse_cost no tienen porque ser distancias, en realidad pueden ser casi cualquier cosa, por ejemplo: tiempo, pendiente, superficie, tipo de carretera, o una combinación de varios parámetros.
Desde el Hotel Portobello al CUCSH:
- El vehículo va desde el nodo 67272 al nodo 1017
- Usaremos los atributos
costyreverse_costque están en grados.
SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
cost,
reverse_cost
FROM ruteoamg.ways',
67272, 1017,
directed := true);WITH ruta as (SELECT * FROM pgr_dijkstra(
'SELECT gid as id,
source,
target,
cost,
reverse_cost
FROM ruteoamg.ways',
67272, 1017,
directed := true))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid;Desde el CUCSH al Hotel Portobello:
- El vehículo va desde el nodo 1017 al nodo 67272
- Usaremos los atributos
costyreverse_costque están en grados.
SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
cost,
reverse_cost
FROM ruteoamg.ways',
1017, 67272,
directed := true);WITH ruta as (SELECT * FROM pgr_dijkstra(
'SELECT gid as id,
source,
target,
cost,
reverse_cost
FROM ruteoamg.ways',
1017, 67272,
directed := true))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid;En un grafo dirigido las rutas de ida y retorno son casi siempre diferentes.
Desde el CUCSH al Hotel Portobello:
- El vehículo va desde el nodo 1017 al nodo 67272
- El costo es
$1000 por hora - Usaremos los atributos
cost_syreverse_cost_sque están en segundos. - La duración del viaje en horas es
cost_s / 3600 - El costo del viaje en pesos es
cost_s * 1000 / 3600
Los atributos cost_s y reverse_cost_s se calculan usando la longitud de un segmento de la red y los atributos maxspeed_forward y maxspeed_backward (velocidad máxima y velocidad máxima hacia atrás). Estas velocidades vienen definidas en el archivo de configuración que utilizamos junto con osm2pgrouting para importar los datos a nuestra base de datos.
SELECT * FROM pgr_dijkstra('SELECT gid as id,
source,
target,
cost_s * 1000 / 3600 as cost,
reverse_cost_s * 1000 / 3600 as reverse_cost
FROM ruteoamg.ways',
1017, 67272,
directed := true);WITH ruta as (SELECT * FROM pgr_dijkstra(
'SELECT gid as id,
source,
target,
cost_s * 1000 / 3600 as cost,
reverse_cost_s * 1000 / 3600 as reverse_cost
FROM ruteoamg.ways',
1017, 67272,
directed := true))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid;Como podemos observar las rutas son idénticas y los costos son directamente proporcionales.
Cuando usamos datos de OSM importados a través de la herramienta osm2pgrouting, se crean algunas tablas adicionales, una de ellas se llama configuration. Esta tabla contiene los parámetros de importación que definimos en el archivo mapconfig_for_cars_mod.xml. Vamos a explorar los tag_id (identificador de etiqueta) de red.
SELECT tag_id, tag_key, tag_value
FROM ruteoamg.configuration
ORDER BY tag_id;SELECT *
FROM ruteoamg.configuration;Para modificar el comportamiento de los algoritmos vamos añadir una columna llamada penalty a la tabla ruteoamg.configuration y usarla para recalcular el costo de desplzamiento en función de unos criterios definidos por nosotros mismos. A continuación mostramos algunos ejemplos:
ALTER TABLE ruteoamg.configuration ADD COLUMN penalty FLOAT;
-- Sin penalización
UPDATE ruteoamg.configuration SET penalty=1;Ahora al calcular la ruta vamos a traer el atributo penalty haciendo un join con la tabla ruteoamg.configuration usando el campo tag_id que también está en la tabla ruteoamg.ways
WITH ruta as (SELECT * FROM pgr_dijkstra('
SELECT gid AS id,
source,
target,
cost_s * penalty AS cost,
reverse_cost_s * penalty AS reverse_cost
FROM ruteoamg.ways JOIN ruteoamg.configuration
USING (tag_id)',
1017, 67272,
directed := true))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid;Vamos a cambiar los valores de penalty para que algunos tipos de vía no sea utilizados:
--- Vamos a modificar el penalty de las vías primarias
UPDATE ruteoamg.configuration SET penalty=100 WHERE tag_value = 'primary';Ahora volvemos a calcular la ruta:
WITH ruta as (SELECT * FROM pgr_dijkstra('
SELECT gid AS id,
source,
target,
cost_s * penalty AS cost,
reverse_cost_s * penalty AS reverse_cost
FROM ruteoamg.ways JOIN ruteoamg.configuration
USING (tag_id)',
1017, 67272,
directed := true))
SELECT ruta.*, b.the_geom
FROM ruta
LEFT JOIN ruteoamg.ways b ON ruta.edge = b.gid;¿Qué ha cambiado con respecto al ejercicio 9?
Las isocronas son iso-lineas que unen puntos con el mismo tiempo de deslazamiento respecto a un origen. Para este ejercicio vamos a usar la Red Nacional de Caminos de INEGI que ya está precargada en la base de datos, una capa de hospitales públicos generada a partir de datos de la Secretaría de Salud (Catálogo de Clave Única de Establecimientos de Salud - CLUES), y la función de pgRouting pgr_drivingDistance.
La función pgr_drivingDistance calcula la distancia manejando desde uno o varios nodos iniciales. Usando el algoritmo de Dijkstra extrae todos los nodos que tengan un costo de desplazamiento igual o menor al valor distance, este parámetro puede ser en unidades de tiempo o distancia (las mismas que el parámetro de costo que vayamos a utilizar).
Sumario de Signaturas
pgr_drivingDistance(edges_sql, start_vid, distance) -- Un único nodo de origen
pgr_drivingDistance(edges_sql, start_vid, distance, directed) -- Un único nodo de origen dirigido
pgr_drivingDistance(edges_sql, start_vids, distance, directed, equicost) -- Varios nodos de origen
RETURNS SET OF (seq, [start_vid,] node, edge, cost, agg_cost)El algoritmo retorna una sequencia, el nodo de inicio start_vid,, el nodo actual de la ruta node, el segmento recorrido edge para llegar al nodo actual, el costo y el costo acumulado desde start_vid a node.
Para calcular el parámetro de costo cost_s en la RNC de INEGI podemos utilizar los atributos longitud y velocidad, donde cost_s = longitud / (velocidad * 1000 / 3600) para obtener el costo en segundos.
ALTER TABLE ruteoinegi.red_vial ADD COLUMN cost_s FLOAT;UPDATE ruteoinegi.red_vial
SET cost_s = longitud / (velocidad * 1000 / 3600);Para este ejericio vamos a calcular la distancia de manejo desde el Hospital General Regional 46 del IMSS (id_union = 635443) y distance = 3600 (en segundos). En parmetro de id_union lo hemos calculado previamente asignando el nodo más cercano de la RNC a todos los hospitales. Si observamos la tabla ruteoinegi.red_vial veremos que tiene dos atributos id_union y distancia, este segundo atributo nos indica la distancia lineal entre el punto donde está ubicado un hospital y el nodo más cercano de la red, que podemos encontrar en la tabla ruteoinegi.union.
Para realizar este proceso hemos utilizado la consulta que aparece a continuación. En ella para cada hospital calculamos cual es el nodo de la red (tabla ruteoinegi.union) más cercano a cada hospital y la distancia a la que se encuentra. El atributo de la distancia nos da una idea de lo correcto que puede ser el cálculo de una ruta para cada hospital. Esto es necesario ya que la RNC, como ya habíamos comentado, no cuenta con toda la red de calles en las zonas urbanas y tampoco están algunos caminos/terracerías de zonas rurales. Este proceso de encontrar el nodo más cercano de la red lo vamos a tener que realizar siempre ya que para los parámetros de start_vid y end_vid de los diferentes algoritmos siempre tenemos que utilizar las IDs de los nodos de la red (en este caso es el atributo id_union)
WITH foo as (
SELECT
hospitales.id,
closest_node.id_union,
closest_node.dist
FROM ruteoinegi.hospitales
CROSS JOIN LATERAL -- Este CROSS JOIN lateral funciona como un bucle "for each"
(SELECT
id_union,
ST_Distance("union".geom, hospitales.geom) as dist
FROM ruteoinegi."union"
ORDER BY ST_Distance("union".geom, hospitales.geom)
LIMIT 1 -- Este limit 1 hace que solo obtengamos el nodo más cercano de la red
) AS closest_node)
UPDATE ruteoinegi.hospitales -- Finalmente actualizamos la capa de hospitales
SET id_union = foo.id_union,
distancia = foo.dist
FROM foo
WHERE hospitales.id = foo.idAhora ya estamos listos para usar el algoritmo pgr_drivingDistance, a partir del que luego podemos generar las isocronas (utilizando QGIS).
SELECT subquery.seq,
subquery.node,
subquery.edge,
subquery.cost,
subquery.aggcost,
st_transform(pt.geom,4326) as geom -- Reproyectamos a epsg:4326 para poder ver el resultado en pgAdmin4
FROM pgr_drivingDistance('SELECT
id_red as id,
union_ini AS source,
union_fin AS target,
cost_s AS cost
FROM ruteoinegi.red_vial', 635443, 3600, false)
subquery(seq, node, edge, cost, aggcost)
JOIN ruteoinegi.union pt ON subquery.node = pt.id_union;Para generar la distancias de manejo desde varios orígenes tenemos que volver a utilizar un ARRAY. En este caso concreto vamos a extraer todos los id_union desde la tabla ruteoinegi.hospitales y pasárselos a pgr_drivingDistance. Para que podamos generar las isocronas de todos los hospitales en conjunto tenemos que hacer dos procesos, primero calculamos la distancia de manejo desde cada hospital y posteriormente agrupamos los resulados por nodo (y geometría) y nos quedamos con el costo agregado mínimo que nos va a representar el tiempo mínimo desde ese nodo a un hospital.
WITH ruteo as (
SELECT subquery.seq,
subquery.start_v,
subquery.node,
subquery.edge,
subquery.cost,
subquery.aggcost,
pt.geom
FROM pgr_drivingDistance('SELECT
id_red as id,
union_ini AS source,
union_fin AS target,
cost_s AS cost
FROM ruteoinegi.red_vial',
array(SELECT id_union FROM ruteoinegi.hospitales), 1800, false)
subquery(seq, start_v, node, edge, cost, aggcost)
JOIN ruteoinegi.union pt ON subquery.node = pt.id_union)
SELECT node, geom, min(aggcost) AS aggcost
FROM ruteo
GROUP By node, geom;Para generar las isocronas necesitamos el resultado del ejercicio anterior, podemos crear la tabla usando:
CREATE TABLE public."elnombrequetuquieras" as (
WITH ruteo as (
SELECT subquery.seq,
subquery.start_v,
subquery.node,
subquery.edge,
subquery.cost,
subquery.aggcost,
pt.geom
FROM pgr_drivingDistance('SELECT
id_red as id,
union_ini AS source,
union_fin AS target,
cost_s AS cost
FROM ruteoinegi.red_vial',
array(SELECT id_union FROM ruteoinegi.hospitales), 1800, false)
subquery(seq, start_v, node, edge, cost, aggcost)
JOIN ruteoinegi.union pt ON subquery.node = pt.id_union)
SELECT node, geom, min(aggcost) AS aggcost
FROM ruteo
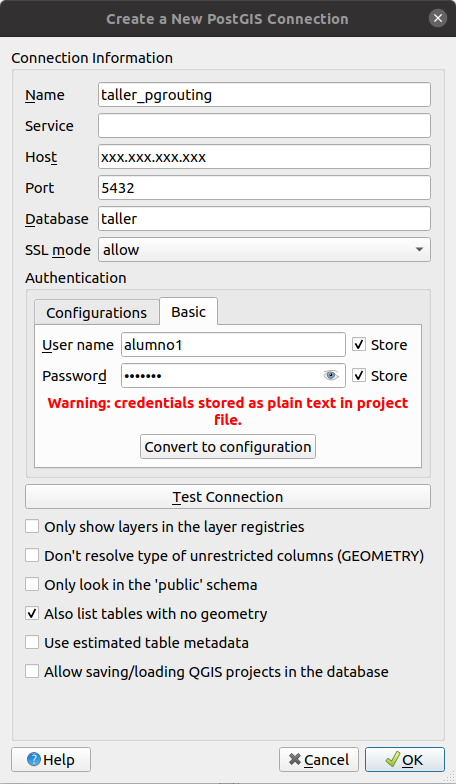
GROUP By node, geo);Esto creará la tabla "elnombrequetuquieras" en el schema public. Para los siguientes pasos vamos a necesitar QGIS así que a continuación vamos a configurar la conexión a la base de datos dentro de QGIS.
Para ello vamos al menú panel del navegador y en PostGIS creamos nueva conexión haciendo clic con el botón derecho.
Ahora podemos cargar la tabla que acabamos de crear que estará en el schema public.

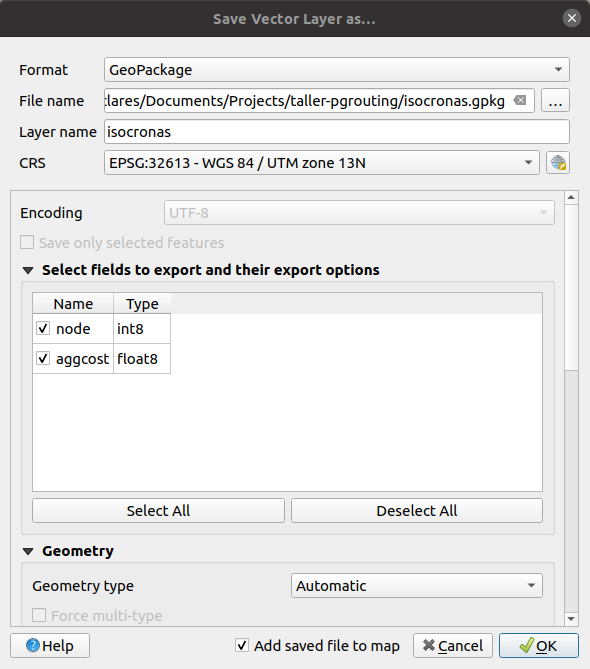
Una vez cargada la capa vamos a exportar a un archivo local para poder trabajar con mayor comodidad sin depender de la conexión. Para ello hacemos clic con el botón derecho sobre la capa y la guardamos como un geopackage.
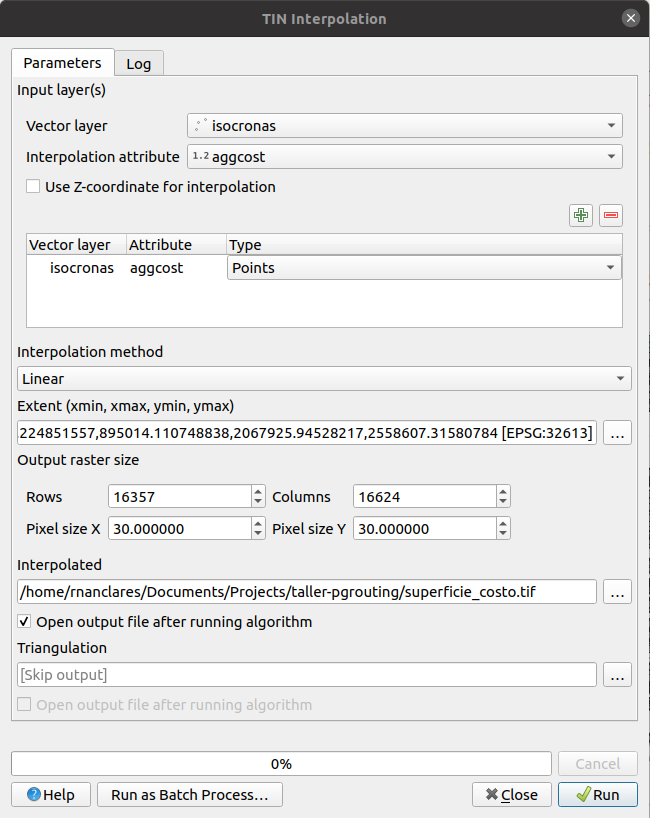
Para siguiente paso vamos a interpolar sobre la capa de puntos y generar una superficie de costo continua. Podemos utilizar la herramienta para generar TINs desde la caja de herramientas.
 Configuramos la herramienta como se ve en la imagen.
Configuramos la herramienta como se ve en la imagen.
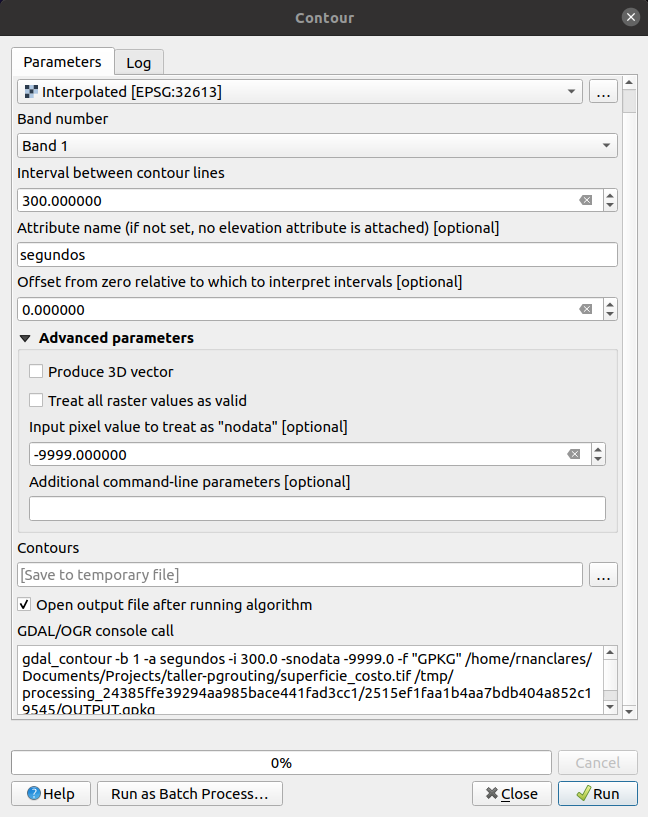
 El siguiente paso es generar las isolineas, en este caso, isocronas. Para ello vamos a usar la herramienta de
El siguiente paso es generar las isolineas, en este caso, isocronas. Para ello vamos a usar la herramienta de Curvas de nivel (Contours) y la vamos a configurar como aparecen en la siguiente imagen.
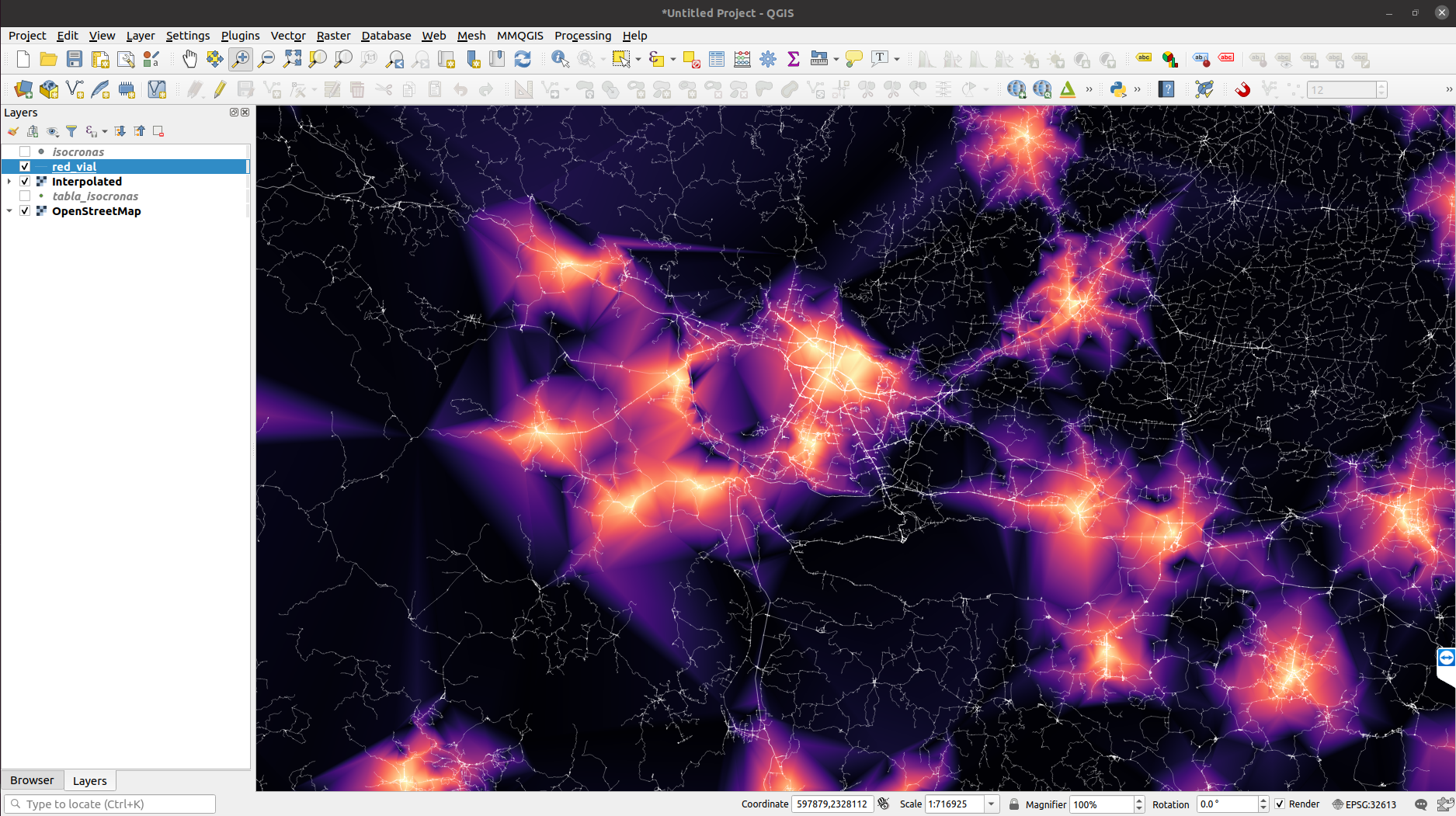
El resultado final con un poco de diseño.
Una de las capacidades más notables de pgRouting es la posibilidad de realizar operaciones con grandes cantidades de datos de forma extremadamente rápida. Por ejemplo, podemos contestar preguntas del tipo: ¿Cuáles centros de salud son los más cercanos a cada la localidad de Jalisco?¿Cuáles son los 3 hospitales más cercanos a cada centro de salud? ¿Cuáles localidades se encuentran a más de 30 minutos de una escuela?¿Cuál es la accesibilidad de las escuelas de todo un estado?¿Qué zonas de un estado tienen poca accesibilidad a un servicio (escuelas, centros de salud, taquerías, etc).
En este ejercicio vamos a utilizar la función pgr_dijkstraCost para analizar cuáles son los tres hospitales más cercanos a cada localidad de Jalisco. Para ello vamos a usar las tablas ruteoinegi.hospitales y ruteoinegi.locpob. De nuevo vamos a utilizar arreglos (ARRAY) para definir los parametros de los nodos de origen y destino del algoritmo pgr_dijkstraCost. Esto nos va a permitir analizar 10972 localidades contra 92 hospitales en unos pocos minutos (¡Más de 1,000,000 de combinacines posibles!). El tiempo de ejecución de la consulta es de 13 minutos 44 segundos en nuestro servidor. ¡¡¡Nada mal!!! Para no emplear demasiado tiempo vamos a limitar el número de localidades a analizar añadiendo un pequeño filtro al arreglo y seleccionando las localidaes con id<1000.
CREATE TABLE ruteoinegi.localidadesVShospitales as (SELECT *
FROM pgr_dijkstraCost(
'SELECT id,
union_ini as source,
union_fin as target,
cost_s as cost
FROM ruteoinegi.red_vial',
array(SELECT id_union FROM ruteoinegi.locpob WHERE id<1000),
array(SELECT id_union FROM ruteoinegi.hospitales),
directed := false));Ahora vamos a seleccionar solo los tres hospitales más cercanos a cada localidad.
CREATE TABLE ruteoinegi.locpobvshospitalesrank as ( SELECT foo.* FROM (
SELECT localidadesVShospitales.*, rank() over (partition BY start_vid ORDER BY agg_cost asc)
FROM ruteoinegi.localidadesVShospitales) foo WHERE RANK <= 3);El resultado de esta consulta es el costo de desplazamiento acumulado agg_cost desde cada localidad start_vid a todos los hospitales end_vid. Podemos mejorar la visualización de los resultados añadiendo los nombres de las localidades, los nombres de los hospitales y generando una linea usando st_makeline en caso de que queramos crear un mapa.
CREATE TABLE ruteoinegi.matriz_locpobVShospitales as (
SELECT row_number() over (order by a.start_vid) as id, a.start_vid as nodo_inicio, b.nom_loc as localidad,
a.end_vid as nodo_fin, c."nombre de la unidad" as hospital,
c."nombre de tipologia" as tipologia_hosp, a."agg_cost" / 60 as tiempo_minutos, a."rank",
st_makeline(b.geom,c.geom)
FROM ruteoinegi.locpobvshospitalesrank a
LEFT JOIN ruteoinegi.locpob b ON a.start_vid = b.id_union
LEFT JOIN ruteoinegi.hospitales c ON a.end_vid = c.id_union);