Adaptasi dari:
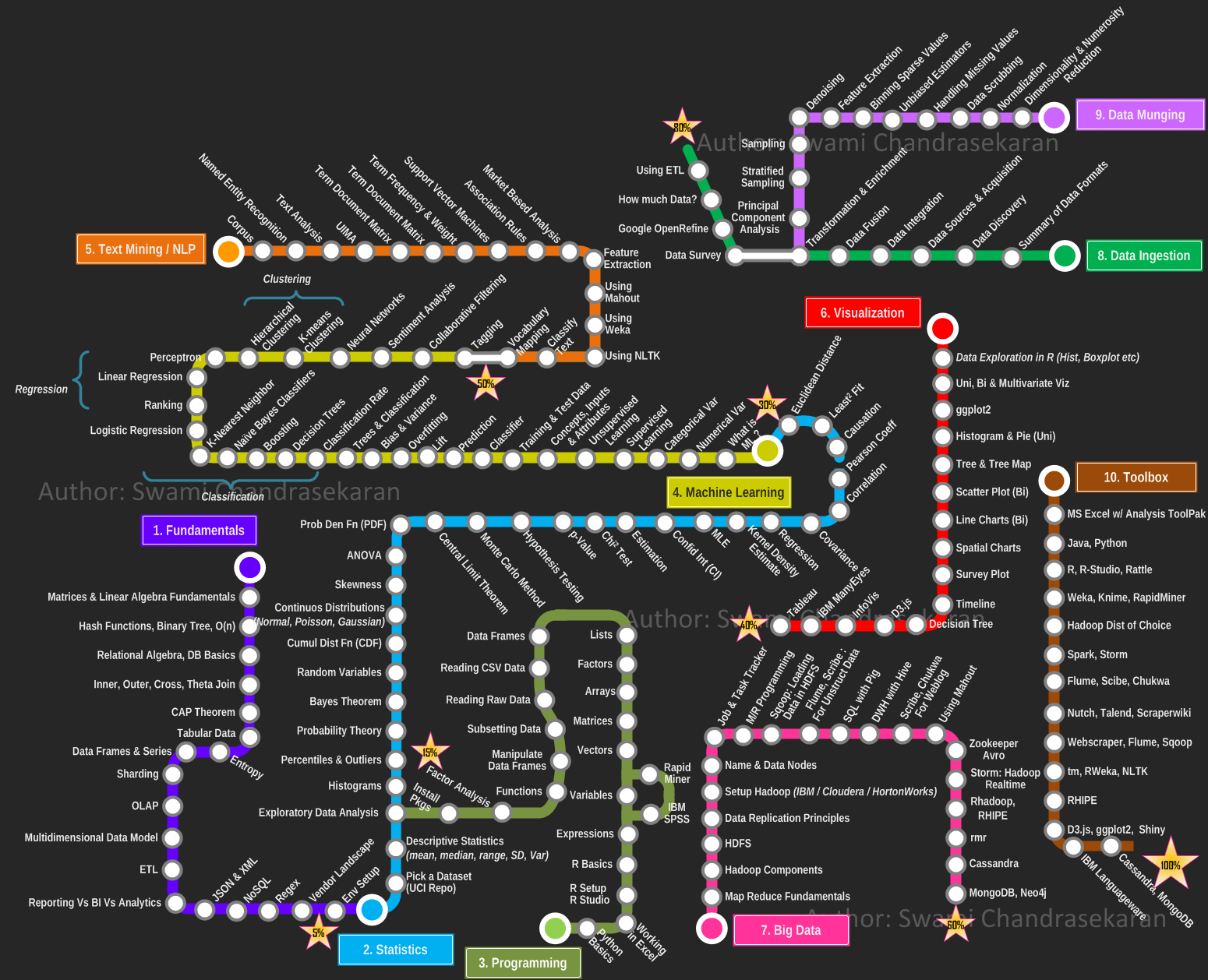
- Draft Kurikulum iData1011
- Daftar Isi
- Normalization memiliki arti mentransformasikan data, yakni mengubah data ke bentuk lain untuk pemrosesan data yang memungkinkan menjadi lebih efektif. Tujuan utama Normalization adalah meminimalkan bahkan mengecualikan data-data yang bersifat ganda atau duplikat. Hal ini cukup penting karena menjadi permasalahan apabila menyimpan data dalam database relasional, dimana menyimpan data identik di lebih dari satu tempat.
- Penggunaan Normalization memiliki beberapa keuntungan, yaitu :
-
- Penerapan algoritma menjadi lebih mudah.
-
- Algoritma data menjadi lebih efektif dan efisien.
-
- Dapat dipahami semua orang.
-
- Data dapat diekstraksi lebih cepat.
-
- Memungkinkan untuk menganalisis data dengan cara tertentu.
-
- Teknik umum Normalization adalah sebagai berikut :
-
- Min-Max Normalization ⇒ x_new = (x - min(x))/(max(x)-min(x))
-
- Mean-Standard Deviation Normalization ⇒ x_new = (x - mean(x))/std(x)
-
- Softmax Normalization ⇒ (1+exp((mean(x)-x)/std(x)))^-1
-
Dimensionality Reduction
- Dimensionality reduction adalah proses pengurangan jumlah variabel atau atribut acak yang mengubah atau memproyeksikan data asli ke ruang yang lebih kecil.
- Beberapa teknik yang mungkin, diantaranya sebagai berikut :
-
- Principal Component Analysis. Merupakan teknik pengurangan fitur yang paling umum. Dalam teknik ini dapat menentukan jumlah komponen utama yang sesuai.
-
- Linear Discriminant Analysis. Ialah teknik lain dengan cara kerja serupa, yaitu dengan memilih jumlah vektor eigen yang sesuai.
-
- Autoencoders. Merupakan teknik pengurangan dimensi berbasis Neural Networks.
-
- Manifold Learning. Adalah teknik yang menggunakan reduksi dimensi non-linier.
-
- Terdapat beberapa teknik lain untuk reduksi fitur dengan berdasarkan fitur yang dipilih sesuai dengan kepentingannya masing-masing, yaitu : sequential forward selection, feature importance estimation based on Random forests or decision trees or any ensemble methods, Relief Algorithm, mutual information, information gain, dan lain-lain. Numerosity Reduction
- Numerosity Reduction adalah teknik reduksi data yang menggantikan data asli dengan bentuk representasi data yang lebih kecil. Terdapat dua teknik untuk Numerosity Reduction, yaitu :
-
- Parametric Methods, data direpresentasikan menggunakan model untuk mengestimasi data, sehingga hanya parameter data yang perlu disimpan, bukan data aktualnya. Terdapat dua model, diantaranya : Regression, dapat berupa linier sederhana dan linier berganda. Dan Log-Linear, dapat digunakan untuk memperkirakan probabilitas setiap titik data dalam ruang multidimensi untuk sekumpulan atribut terpisah, memungkinkan ruang data dimensi lebih tinggi dibangun dari atribut berdimensi lebih rendah.
-
- Non-Parametric Methods, metode ini digunakan untuk menyimpan representasi data yang dikurangi meliputi Histogram, Clustering, Sampling, dan Data Cube Aggregation.
-