A data pipeline for analyzing Open edX data. This is a batch analysis engine that is capable of running complex data processing workflows.
The data pipeline takes large amounts of raw data, analyzes it and produces higher value outputs that are used by various downstream tools.
The primary consumer of this data is Open edX Insights.
It is also used to generate a variety of packaged outputs for research, business intelligence and other reporting.
It gathers input from a variety of sources including (but not limited to):
- Tracking log files - This is the primary data source.
- LMS database
- Otto database
- LMS APIs (course blocks, course listings)
It outputs to:
- S3 - CSV reports, packaged exports
- MySQL - This is known as the "result store" and is consumed by Insights
- Elasticsearch - This is also used by Insights
- Vertica - This is used for business intelligence and reporting purposes
This tool uses spotify/luigi as the core of the workflow engine.
Data transformation and analysis is performed with the assistance of the following third party tools (among others):
The data pipeline is designed to be invoked on a periodic basis by an external scheduler. This can be cron, jenkins or any other system that can periodically run shell commands.
Here is a simplified, high level, view of the architecture:
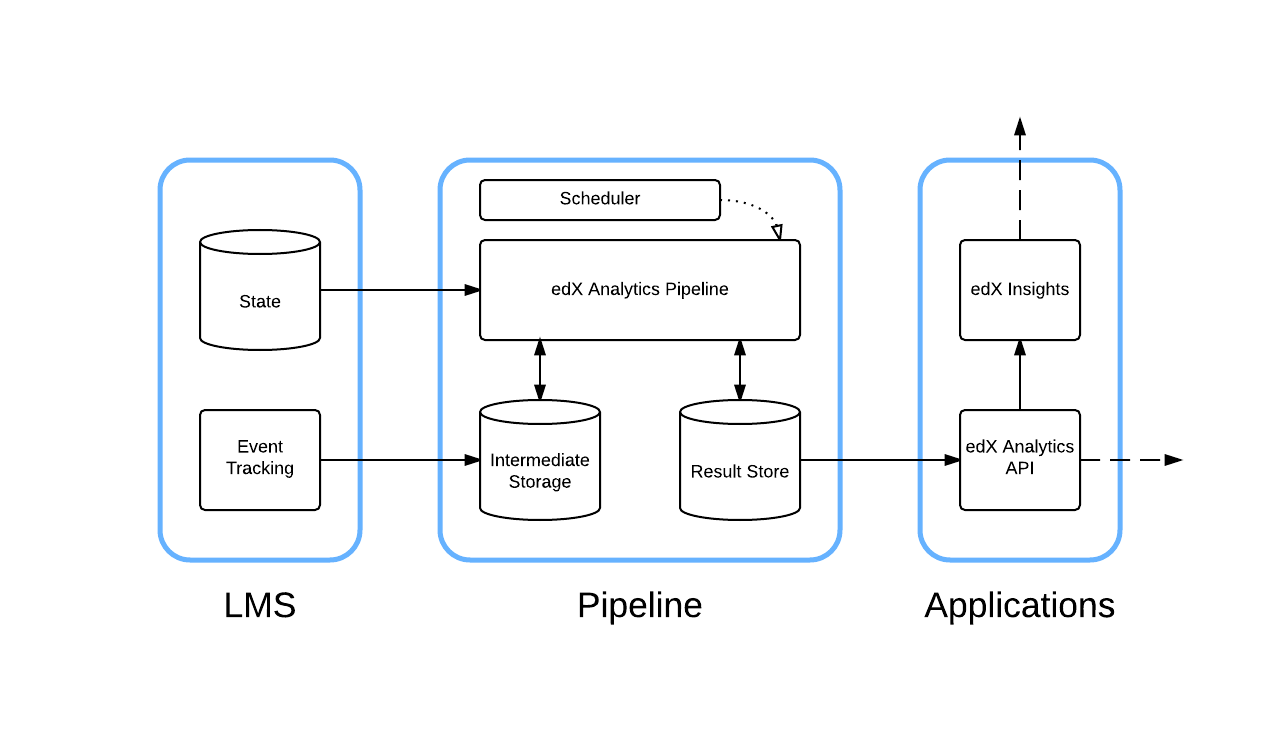
We call this environment the "analyticstack". It contains many of the services needed to develop new features for Insights and the data pipeline.
A few of the services included are:
- LMS (edx-platform)
- Studio (edx-platform)
- Insights (edx-analytics-dashboard)
- Analytics API (edx-analytics-data-api)
We currently have a separate development from the core edx-platform devstack because the data pipeline depends on several services that dramatically increase the footprint of the virtual machine. Given that a small fraction of Open edX contributors are looking to develop features that leverage the data pipeline, we chose to build a variant of the devstack that includes them. In the future we hope to adopt OEP-5 which would allow developers to mix and match the services they are using for development at a much more granular level. In the meantime, you will need to do some juggling if you are also running a traditional Open edX devstack to ensure that both it and the analyticstack are not trying to run at the same time (they compete for the same ports).
If you are running a generic Open edX devstack, navigate to the directory that contains the Vagrantfile for it and run vagrant halt.
Please follow the analyticstack installation guide.
For small installations, you may want to use our single instance installation guide.
For larger installations, we do not have a similarly detailed guide, you can start with our installation guide.
Contributions are very welcome, but for legal reasons, you must submit a signed individual contributor's agreement before we can accept your contribution. See our CONTRIBUTING file for more information -- it also contains guidelines for how to maintain high code quality, which will make your contribution more likely to be accepted.