Semantic Segmentation
Computer-Vision-Research-Project (GitHub)
• Computer-Vision-Research-Project (Wiki)
• LVSN (Research Laboratory)
• Institut intelligence et données (IID) (research Institute)
• Sentinelle Nord (Project)
• J-F Lalonde Group (Team)
• Algorithmic Photography (Course)
isabelleysseric (GitHub)
• isabelleysseric.com (Portfolio)
• isabelleysseric (LinkedIn)
Figure – Semantic Segmentation.

Semantic segmentation or image segmentation consists in classifying each pixel of the image according to the category to which it belongs.
- Semantic Segmentation: It involves arranging the pixels in an image based on semantic classes. It assigns a class label to each pixel
- Instance Segmentation: It involves classifying pixels based on the instances of an object (as opposed to object classes). It detects and segments each object instance.
-
Panoptic Segmentation: It involves as a combination of semantic and instance segmentation. It detects and segments each object instance while assigning a class label to each pixel.

Figure – Types of segmentation.
The convolutional neural network architecture consists of stacking several blocks:
-
Convolution layer (CONV) which processes the data and it used to extract the various features from the input images with kernel (filter);
-
Pooling layer (POOL), which compresses the information by reducing the size of the of the convolved feature map (sub-sampling);
-
Dropout layer (ReLU, Sigmoïde, TanH, Softmax), it served to cancel the contribution of certain neurons;
-
Fully connected (FC) layer, it's the last few layers and it used to connect the neurons between two different layers;
-
Loss layer (LOSS).
Figure – Standard architecture of a convolutional network.

-
LeNet (1998): is a CNN structure proposed by LeCun and it's a simple CNN.
-
AlexNet (2012): It's designed by Alex Krizhevsky in collaboration with Ilya Sutskever and Geoffrey Hinton. AlexNet contained eight layers: the first five were convolutional layers, some of them followed by max-pooling layers, and the last three were fully connected layers. AlexNet is considered one of the most influential papers published in computer vision, having spurred many more papers published employing CNNs and GPUs to accelerate deep learning.[0]
-
U-Net (2015): (medical field) It's a CNN that was developped for biomedial image segmentation in and its architecture was modified and extended to work with fewer training images and to yield more precise segmentations. It performs upsampling operations, so it can be thought of as an encoder (left part) followed by a decoder (right part)
-
ResNet (2015): It's a Residual Neural Network and it's the first working very deep feedforward neural network with hundreds of layers, much deeper than previous neural networks.
-
VGG (2014) is a Very Deep Convolutional Networks (VGGNet) for Large-Scale Image Recognition
-
SqueezeNet (2016): The “fire” module in SqueezeNet, consisting of a squeeze and an expand.
-
Inception (2015) or GoogleNet is a famous ConvNet trained on Imagenet.
-
Xception (2016) is an extension of the Inception architecture which replaces the standard Inception modules with depthwise separable convolutions.
Figure – U-Net architecture.

-
FCN is a Fully Convolutional Network (FCN) is a Convolutional Neural Network (CNN) with no fully connected layers that have been replaced by convolutional layers with 1 x 1 kernel. It only performs convolution operations (and downsampling or oversampling).
Problem: The problem in FCNs is that by propagating through several alternating convolution and clustering layers, the resolution of the output feature maps is undersampled and therefore direct FCN predictions are generally low resolution, resulting in relatively fuzzy object boundaries. -
Fast R-CNN is a Fast Region-based Convolutional Network method for object detection;
-
Faster R-CNN is an RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position for Real-Time Object Detection;
-
Mask R-CNN: it's Faster R-CNN + FCN. It's a high-quality segmentation mask for each instance;
-
[Mesh R-CNN] it's a Mask R-CNN + Mesh. It'a augments Mask R-CNN with a mesh prediction branch that outputs meshes.
-
DeepLab: FCN + Convolution atreuse pour le sur-échantillonnage.
-
**Deeplab (Deeplabv1)** in 2014-> FCN + Convolution atreuse
Challenge 1: Reduced Feature Resolution
Challenge 2: Reduced location accuracy due to DCNN invariance -
**Deeplab (Deeplabv2)** in 2016 -> FCN + Atrous Convolution + Atrous Spatial Pyramid Pooling (ASPP) Challenge: existence of objects at several scales
-
Deeplab (Deeplabv3) in 2017 -> FCN + Separable Atrous Convolution + Deep Separable Convolution to increase computational efficiency.
Challenge: Capture sharper object boundaries by gradually recovering spatial information. -
HoHoNet (2020): It's a versatile and efficient framework for holistic understanding of an indoor 360-degree panorama using a Latent Horizontal Feature (LHFeat). On the tasks of layout estimation and semantic segmentation, HoHoNet achieves results on par with current state-of-the-art. .
-

Figure – Deeplab & HoHoNet models.
- 2D datatset
-
3D dataset for panoramic images
-
Zillow dataset[1]
The Zillow Indoor Dataset (ZInD) provides extensive visual data that covers a real world distribution of unfurnished residential homes.
It consists of primary 360º panoramas with annotated room layouts, windows, doors, and openings (W/D/O), merged rooms, secondary localized panoramas, and final 2D floor plans.
- Panoramic Video Panoptic Segmentation Dataset
-
Matterport3D dataset[2]
-
Stanford2D3D dataset[3]
-
Zillow dataset[1]
The Zillow Indoor Dataset (ZInD) provides extensive visual data that covers a real world distribution of unfurnished residential homes.
It consists of primary 360º panoramas with annotated room layouts, windows, doors, and openings (W/D/O), merged rooms, secondary localized panoramas, and final 2D floor plans.
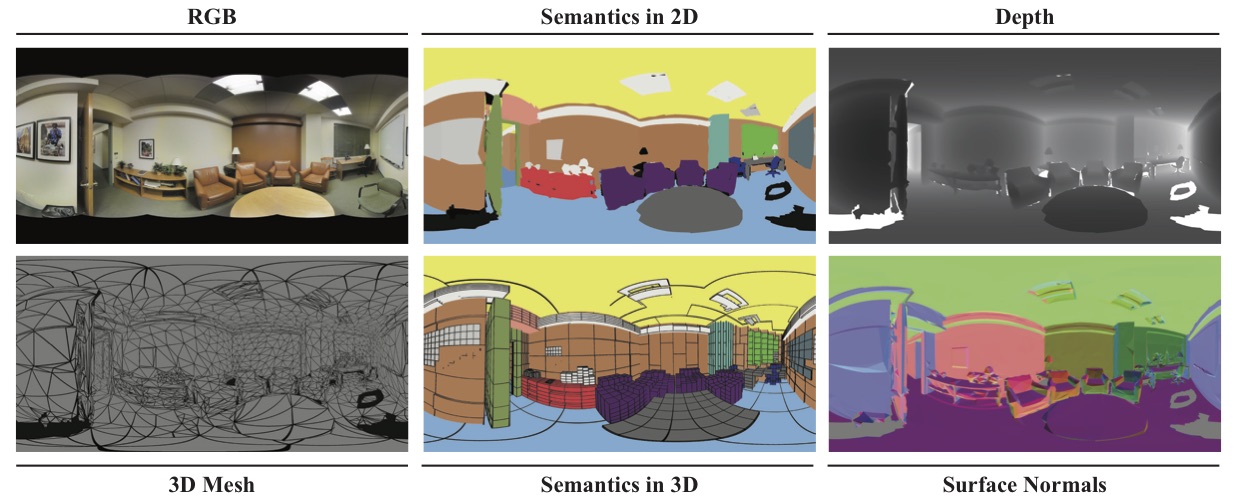
Figure – Stanford 2D3D dataset.
[1] Article Zillow Indoor Dataset: Annotated Floor Plans With 360o Panoramas and 3D Room Layouts from the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2021) and the Zillow dataset.
[2] Article Matterport3D: Learning from RGB-D Data in Indoor Environments from International Conference on 3D Vision (3DV 2017) and the Mattrport3D dataset.
[3] Website for the information and Stanford 2D3D dataset
[4] Article Semantic Segmentation — Popular Architectures writes by Priya Dwivedi on Towards Data Science
[0] Article from Wikipedia on AlexNet
[00] Article from Wikipedia on ResNet architecture