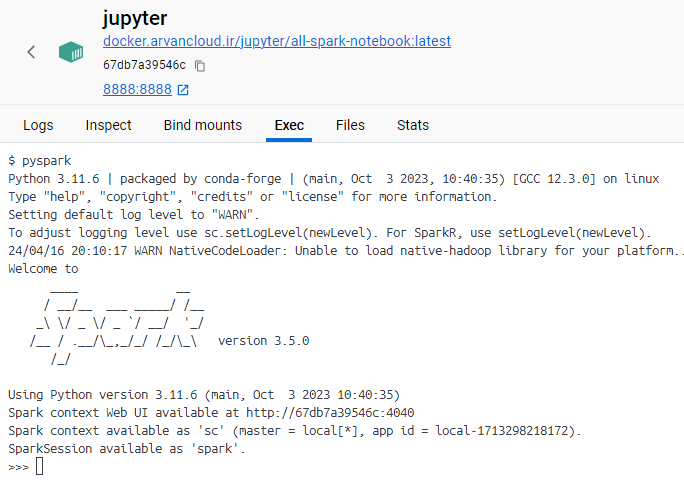
![]()
Install Spark On Kubernetes via helm chart
The control-plane & worker nodes addresses are :
192.168.56.115
192.168.56.116
192.168.56.117
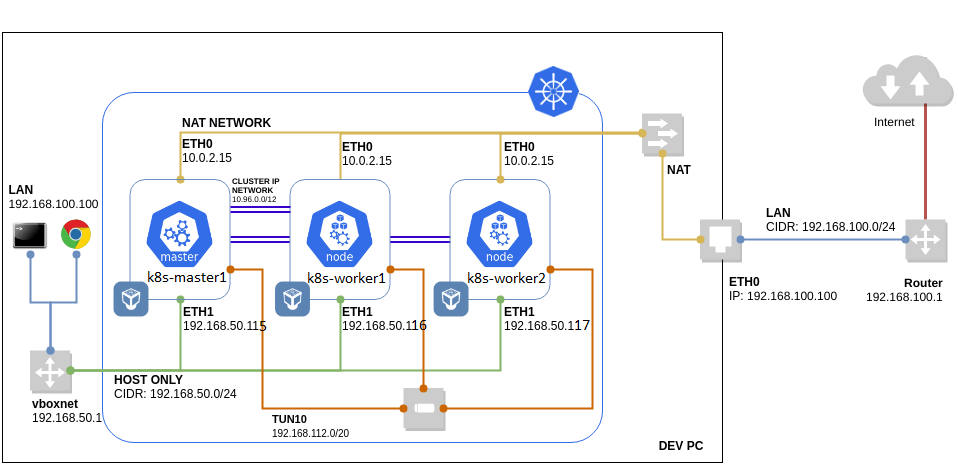
Kubernetes cluster nodes :

you can install helm via the link helm :
The Steps :
you can install helm chart via the link helm chart :
Important: the spark version of helm chart must be the same as the PySpark version of jupyter
- Install spark via helm chart (bitnami) :

$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm search repo bitnami
$ helm install kayvan-release bitnami/spark --version 8.7.2
- Deploy Jupyter workloads :
jupyter.yaml :
apiVersion: apps/v1
kind: Deployment
metadata:
name: jupiter-spark
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: spark
template:
metadata:
labels:
app: spark
spec:
containers:
- name: jupiter-spark-container
image: docker.arvancloud.ir/jupyter/all-spark-notebook
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8888
env:
- name: JUPYTER_ENABLE_LAB
value: "yes"
---
apiVersion: v1
kind: Service
metadata:
name: jupiter-spark-svc
namespace: default
spec:
type: NodePort
selector:
app: spark
ports:
- port: 8888
targetPort: 8888
nodePort: 30001
---
apiVersion: v1
kind: Service
metadata:
name: jupiter-spark-driver-headless
spec:
clusterIP: None
selector:
app: sparkkubectl apply -f jupyter.yaml
the installed pods :
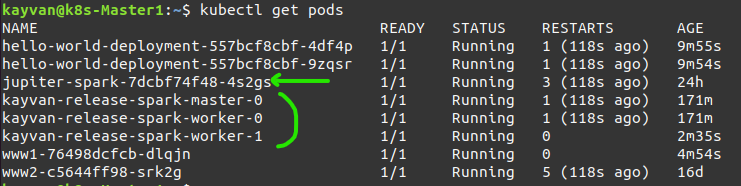
and Services (headless for statefull) :
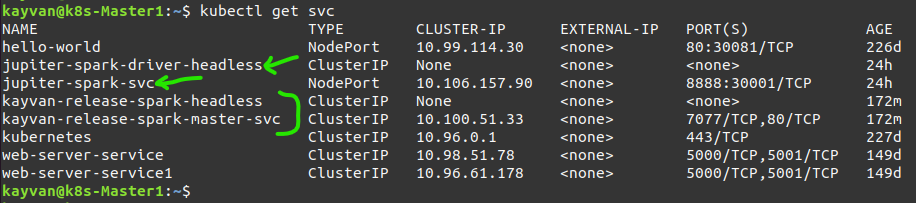
Note: spark master url address is :
spark://kayvan-release-spark-master-0.kayvan-release-spark-headless.default.svc.cluster.local:7077
- Open jupyter notebook and write some python codes based on pyspark and press shift + enter keys on each block to execute:
#import os
#os.environ['PYSPARK_SUBMIT_ARGS']='pyspark-shell'
#os.environ['PYSPARK_PYTHON']='/opt/bitnami/python/bin/python'
#os.environ['PYSPARK_DRIVER_PYTHON']='/opt/bitnami/python/bin/python'
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("spark://kayvan-release-spark-master-0.kayvan-release-spark-headless.default.svc.cluster.local:7077")\
.appName("Mahla").config('spark.driver.host', socket.gethostbyname(socket.gethostname()))\
.getOrCreate()note:
socket.gethostbyname(socket.gethostname()) ---> returns the jupyter pod's ip address
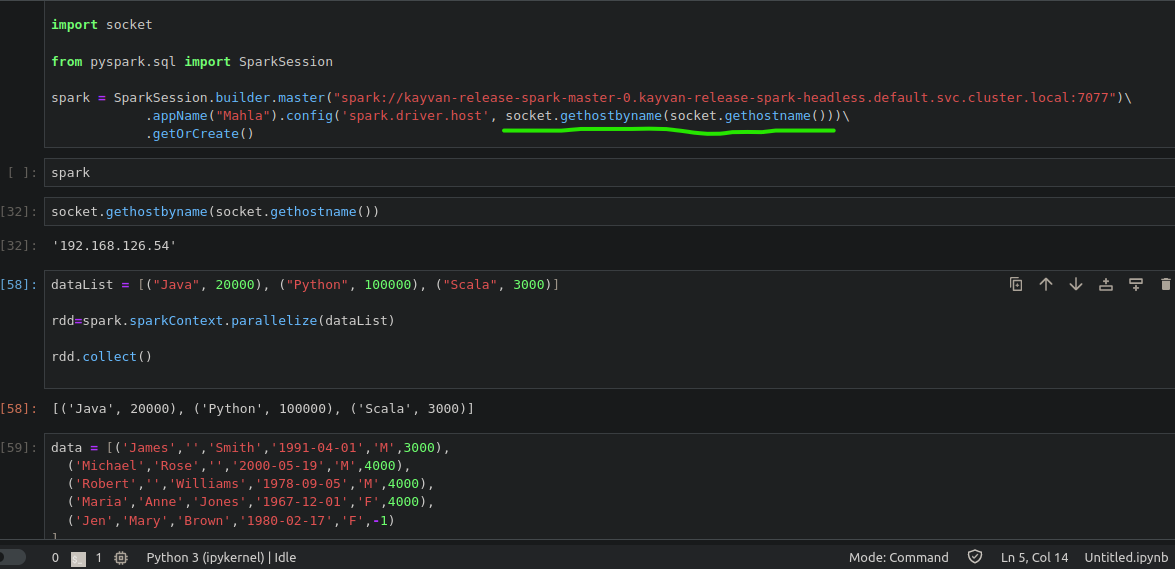
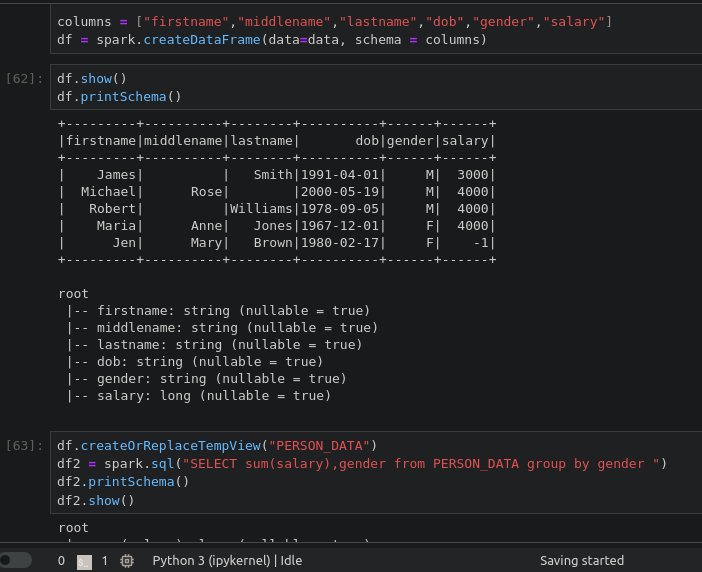
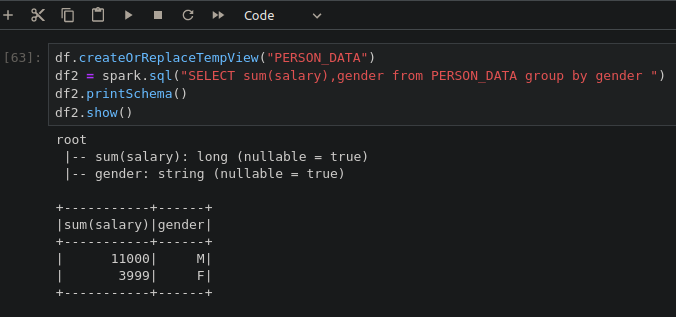
enjoying from sending python codes to spark cluster on kubernetes via jupyter.
Note: of course you can work with pyspark single node installed on jupyter without kubernetes and when you will be sure that the code is correct, then send it via spark-submit or like above code to spark cluster on kubernetes.
docker-compose.yml :
version: '3.6'
services:
spark-master:
container_name: spark
image: docker.arvancloud.ir/bitnami/spark:3.5.0
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- SPARK_USER=root
- PYSPARK_PYTHON=/opt/bitnami/python/bin/python3
ports:
- 127.0.0.1:8081:8080
- 127.0.0.1:7077:7077
networks:
- spark-network
spark-worker:
image: docker.arvancloud.ir/bitnami/spark:3.5.0
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark:7077
- SPARK_WORKER_MEMORY=2G
- SPARK_WORKER_CORES=2
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- SPARK_USER=root
- PYSPARK_PYTHON=/opt/bitnami/python/bin/python3
networks:
- spark-network
jupyter:
image: docker.arvancloud.ir/jupyter/all-spark-notebook:latest
container_name: jupyter
ports:
- "8888:8888"
environment:
- JUPYTER_ENABLE_LAB=yes
networks:
- spark-network
depends_on:
- spark-master
networks:
spark-network:run in cmd :
docker-compose up --scale spark-worker=2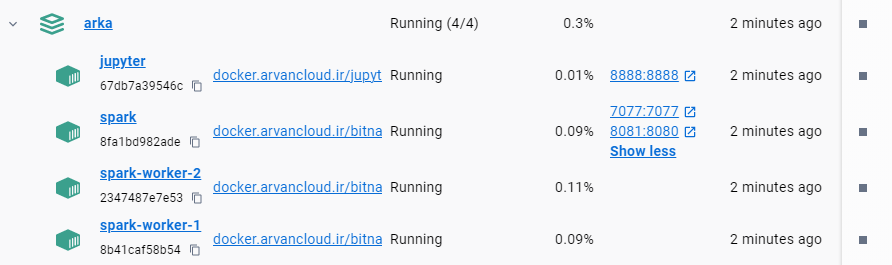
Copy csv file to inside spark worker container :
docker cp file.csv spark-worker-1:/opt/file
docker cp file.csv spark-worker-2:/opt/fileOpen jupyter notebook and write some python codes based on pyspark and press shift + enter keys on each block to execute:
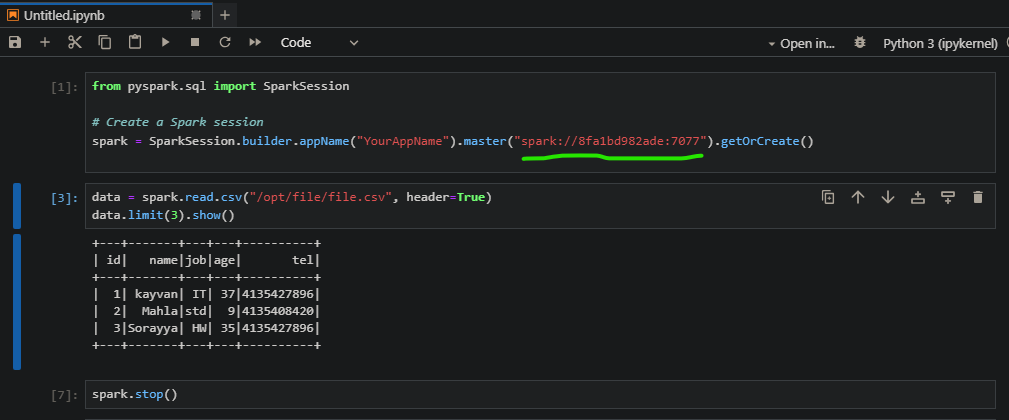
from pyspark.sql import SparkSession
# Create a Spark session
spark = SparkSession.builder.appName("YourAppName").master("spark://8fa1bd982ade:7077").getOrCreate()data = spark.read.csv("/opt/file/file.csv", header=True)
data.limit(3).show()spark.stop()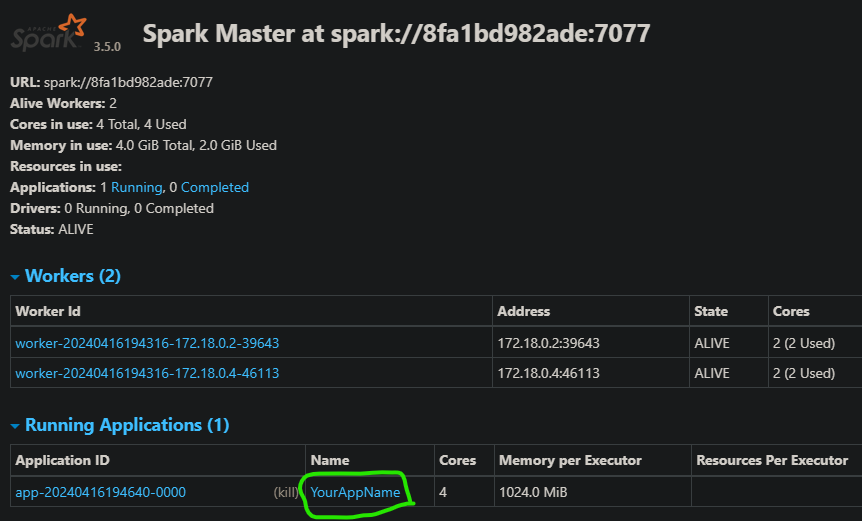
Note again: you can work with pyspark single node installed on jupyter without spark cluster and when you will be sure that the code is correct, then send it via spark-submit or like above code to spark cluster on docker desktop.
Copy csv file to inside jupyter container :
docker cp file.csv jupyter:/opt/filefrom pyspark.sql import SparkSession
# Create a Spark session
spark = SparkSession.builder.appName("YourAppName").getOrCreate()
data = spark.read.csv("/opt/file/file.csv", header=True)
data.limit(3).show()
spark.stop()and also you can practice on single node pyspark in jupyter :