SpGEMM_Benchmarks
- Kokkos 2.50 is used for below experiments. The KokkosKernels algorithms described here are released as part of Kokkos Kernels version 2.60.
- April 24, 2018: Kokkos::deep_copy has a minor bug in Kokkos 2.60 (https://github.com/kokkos/kokkos/issues/1583). Use Kokkos 2.50 until the next Kokkos release.
This benchmark includes comparison of
- KokkosKernels methods
- KKSpGEMM (default algorithm in KokkosKernels)
- KKMEM
- KKDENSE
- MKL methods: (intel-18.0.128)
- MKL-INS: mkl-inspector executor.
- MKL7: two-phase mkl with no sorting option:7
- MKL8: two-phase mkl with output sorting option:8
The comparison is performed for both KNL's cache mode, and flat ddr memory. All experiments use quadrant mode that has single NUMA domain. All runtimes correspond to the runtime of "NoReuse" case where both symbolic and numeric phases are executed.
-
Setting up and replicating results on KNLs: Explains how the experiments are compiled and run with cache-mode.
Same procedure can be followed to run on flat-ddr. Only changes required are:
- Node-allocation: allocate node in flat memory mode.
- Run with "numactl --membind 0 executable ..." to skip the use of MCDRAM.
-
KNL DDR RAW TABLE: gives a table including the runtimes of the 6 methods on 83 multiplications. For each matrix, table gives the best runtime of the method among different number of threads. Last 6 column gives the number of threads that the method achieved the best performance. For example, all methods achieve the best runtime for audikw_1 with 128 threads except MKL8 on DDR.
-
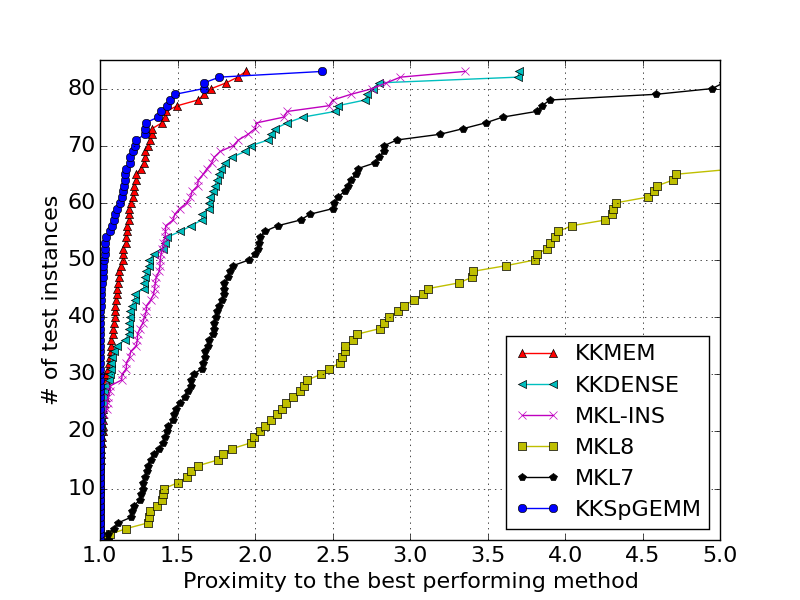
KNL DDR Performance Profile: gives the performance profiles of the algorithms for KNL's with flat ddr. For a given x, the y value indicates the number of problem cases, for which a method is less than x times slower than the best result achieved among the compared methods for each individual problem. The max value of y at x=1 is the number of problem cases for which a method achieved the best performance. The x value for which y=83 is the largest slowdown a method showed over any problem, compared with the best observed performance for that problem over all methods.
- KNL CACHE MODE - RAW TABLE: gives the same table as above for cache-mode.
-
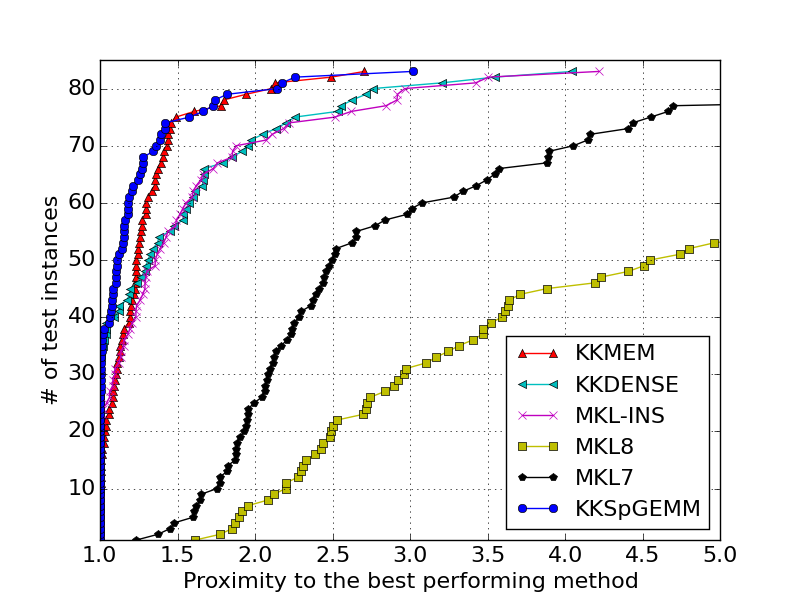
KNL CACHE MODE - Performance Profile: gives the performance profiles of the algorithms for KNL's with cache mode.
Above experiments are run using the below environment variable.
export OMP_PROC_BIND=spread
Most methods achieve their best performance using this configuration in most of the datasets. However, this configuration uses 256 threads on 68 cores of KNL (or 128 threads on 68 cores) with either 3 or 4 threads running each core when used without a processor masking. Below we run another benchmark using MPI masking by adding mpirun -np 1 -map-by socket:PE=64 before the executable. This limits only the use of 64 cores. We observe similar results as above.
- KNL DDR MODE - Performance Profile with MPI Processor Masking

- KNL CACHE MODE - Performance Profile with MPI Processor Masking
This benchmark includes comparison of
- KokkosKernels methods
- KKSpGEMM (default algorithm in KokkosKernels)
- KKMEM
- KKDENSE
- viennaCL OpenMP spgemm methods (v. 1.7.1).
All runtimes correspond to the runtime of "NoReuse" case where both symbolic and numeric phases are executed.
- Setting up and replicating results on Power8 CPUs: Explains how the experiments are compiled and run.
-
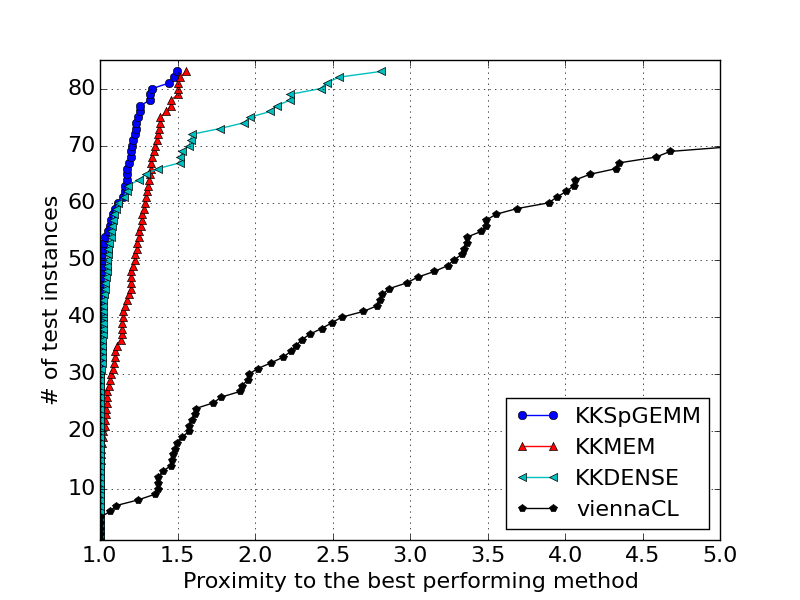
Power8 RAW TABLE: gives a table including the runtimes of the 6 methods on 83 multiplications for Power8.
-
Power8 Performance Profile: gives the performance profiles of the algorithms for Power8.
This benchmark includes comparison of
- KokkosKernels methods
- KKSpGEMM (default algorithm in KokkosKernels)
- KKMEM
- KKLP
- viennaCL Cuda Implementation (v. 1.7.1)
- cuSPARSE (cuda-8)
- Nsparse: (v-1.2 July, 2017)
All runtimes correspond to the runtime of "NoReuse" case where both symbolic and numeric phases are executed.
- Setting up and replicating results on P100 GPUs: Explains how the experiments are compiled and run with P100 GPUs.
-
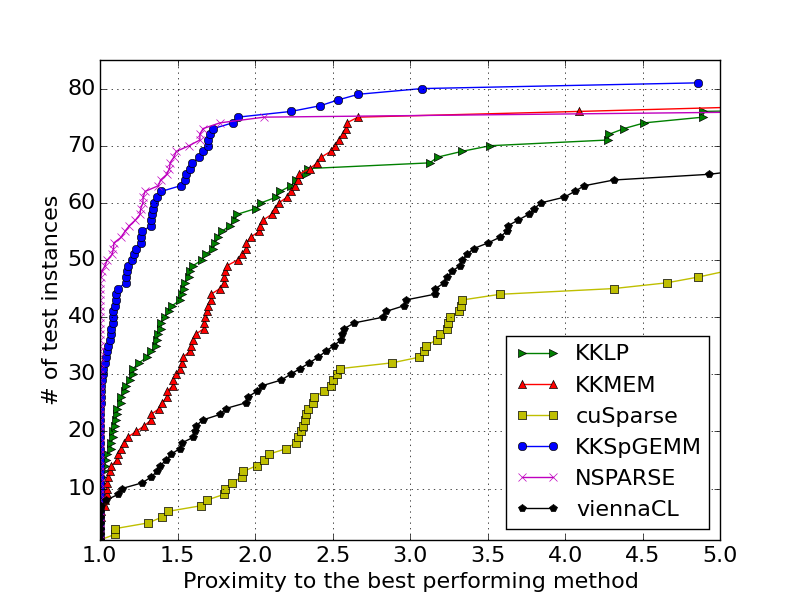
P100 RAW TABLE: gives a table including the runtimes of the 6 methods on 81 multiplications.
-
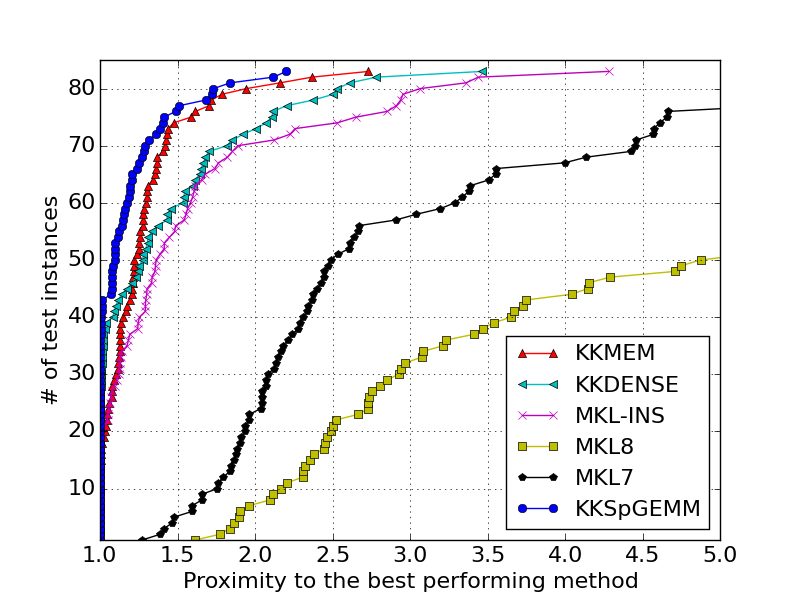
P100 Performance Profile: gives the performance profiles of the algorithms for P100 GPUs.
-
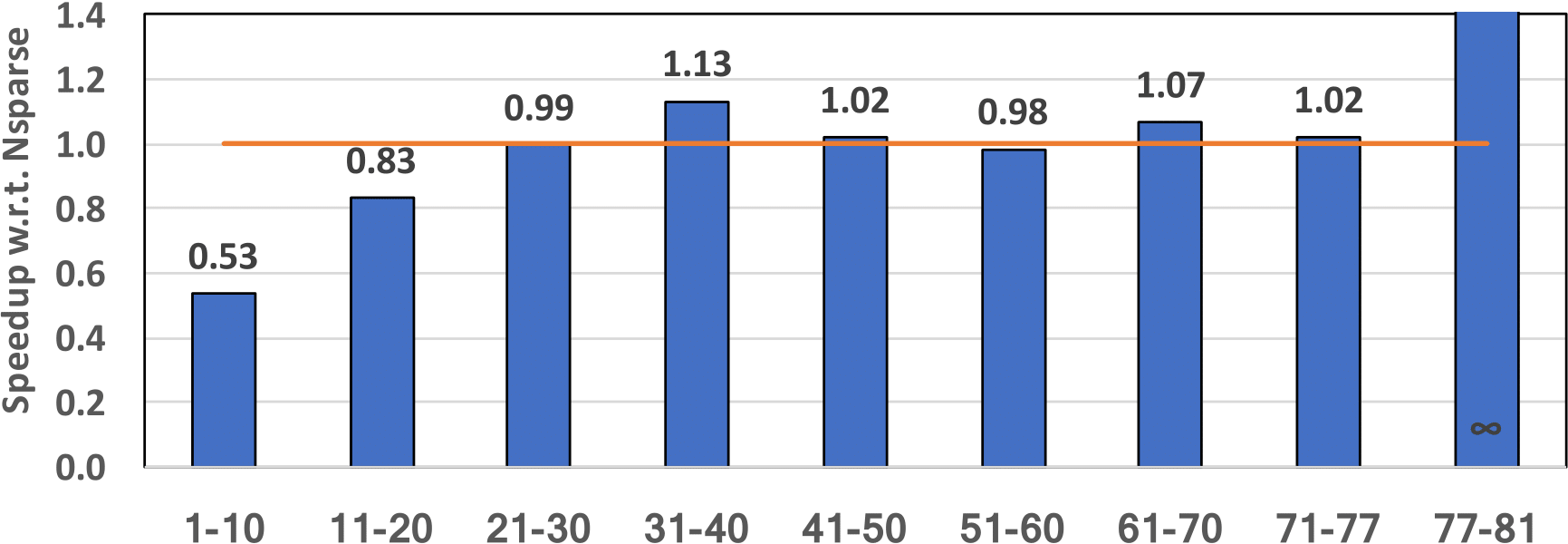
KKSPGEMM Speedup w.r.t. Nsparse: gives the speedup of KKSPGEMM w.r.t. Nsparse. Each bar shows the geometric mean of the 10 multiplications that are sorted based on FLOPs.