Here we provide the implementation for the paper Exposing Outlier Exposure: What Can Be Learned From Few, One, and Zero Outlier Images. The implementation is based on PyTorch 1.12.0 and Python 3.10. The code is tested on Linux only.
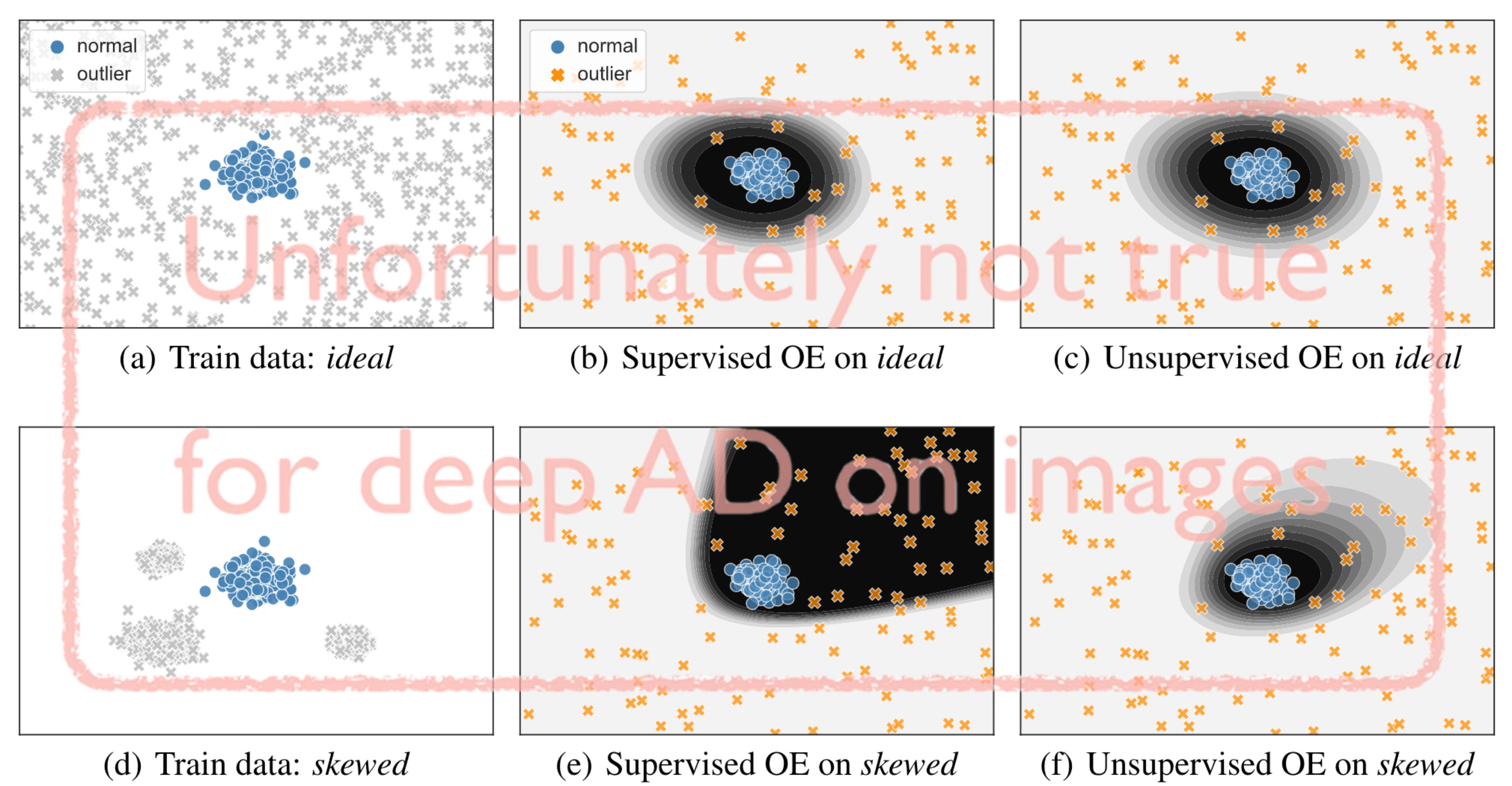
Abstract Due to the intractability of characterizing everything that looks unlike the normal data, anomaly detection (AD) is traditionally treated as an unsupervised problem utilizing only normal samples. However, it has recently been found that unsupervised image AD can be drastically improved through the utilization of huge corpora of random images to represent anomalousness; a technique which is known as Outlier Exposure. In this paper we show that specialized AD learning methods are unnecessary for state-of-the-art performance, and furthermore one can achieve strong performance with just a small collection of Outlier Exposure data, contradicting common assumptions in the field of AD. We find that standard classifiers and semi-supervised one-class methods trained to discern between normal samples and relatively few random natural images are able to outperform the current state of the art on an established AD benchmark with ImageNet. Further experiments reveal that even one well-chosen outlier sample is sufficient to achieve decent performance on this benchmark (79.3% AUC). We investigate this phenomenon and find that one-class methods are more robust to the choice of training outliers, indicating that there are scenarios where these are still more useful than standard classifiers. Additionally, we include experiments that delineate the scenarios where our results hold. Lastly, no training samples are necessary when one uses the representations learned by CLIP, a recent foundation model, which achieves state-of-the-art AD results on CIFAR-10 and ImageNet in a zero-shot setting.
A PDF of our TMLR paper is available at: https://openreview.net/forum?id=3v78awEzyB.
If you use our work, please also cite the paper:
@article{
liznerski2022exposing,
title={Exposing Outlier Exposure: What Can Be Learned From Few, One, and Zero Outlier Images},
author={Philipp Liznerski and Lukas Ruff and Robert A. Vandermeulen and Billy Joe Franks and Klaus-Robert M{\"u}ller and Marius Kloft},
journal={Transactions on Machine Learning Research},
year={2022},
url={https://openreview.net/forum?id=3v78awEzyB}
}
We recommend to use a virtual environment (via virtualenv or conda) to install eoe.
virtualenv:
virtualenv -p python3 eoe/data/venv
source eoe/data/venv/bin/activate
pip install -e eoe/src
conda:
conda create -n eoe python=3.10
conda activate eoe
python -m pip install -e eoe/src
Datasets:
Apart from ImageNet-30, ImageNet-22K, and 80MTI images, all datasets are automatically downloaded once requested.
The ImageNet-30 AD benchmark dataset can be downloaded from https://github.com/hendrycks/ss-ood, which is the data repository of the paper that introduced the benchmark.
It needs to be placed in eoe/data/datasets/imagenet_ad/train and eoe/data/datasets/imagenet_ad/test, respectively.
eoe/ refers to the root directory of this repository.
The ImageNet-22K dataset can be downloaded from https://image-net.org/, which requires a registration.
It needs to be placed in eoe/data/datasets/imagenet22k/fall11_whole_extracted.
The 80MTI dataset has been withdrawn since it contains offensive images (https://groups.csail.mit.edu/vision/TinyImages/). We also encourage to not use this for further research but decided to use it for our experiments to be comparable with previous work.
There are several pre-configured runners available.
All runners download datasets to eoe/data/datasets and log results at eoe/data/results.
As before, eoe/ refers to the root directory of this repository.
The following scripts iterate over all classes of a given dataset and perform each multiple trainings with different random seeds. Per default, the scripts train HSC for the one vs. rest benchmark (i.e., treat the current class as normal) and use the hyperparameters reported in the paper.
Train with dataset {DS}:
python eoe/src/eoe/main/train_{DS}.py
For example, with ImageNet-30:
python eoe/src/eoe/main/train_imagenet.py
There are several parameters that configure the training. Have a look at them with:
python eoe/src/eoe/main/train_imagenet.py -h
For example, you can train and evaluate BCE with the leave-one-class-out benchmark for just two random seeds for each anomalous class by executing:
python eoe/src/eoe/main/train_imagenet.py -o bce --ad-mode loo --it 2
In principle, the scripts all execute the same code. They just differ in their default configuration.
For training CLIP-based models, there are again pre-configured runners. They have the same parameters but, as before, a different default configuration.
Train with dataset {DS}:
python eoe/src/eoe/main/train_clip_{DS}.py
For each class (here we use class "5" which would, e.g., correspond to "dog" on CIFAR-10 and to "barn" on ImageNet-30), we can find "best" single OE samples for HSC via the following scripts:
For CIFAR-10 with 80MTI as OE:
python eoe/src/eoe/main/evolve_oe_cifar.py --classes 5
For ImageNet-30 with ImageNet-22K (ImageNet-1K removed) as OE:
python eoe/src/eoe/main/evolve_oe_imagenet.py --classes 5
We change the optimization target from finding the best to finding the worst via --ev-minimize-fitness, like:
python eoe/src/eoe/main/evolve_oe_imagenet.py --classes 5 --ev-minimize-fitness
For finding optimal OE samples in the filtered setting (either low-pass or high-pass-filtered, see Appendix B in the paper), we use the same scripts as before but change the --ms-mode parameter.
For low-pass-filtered CIFAR-10 with 80MTI as OE:
python eoe/src/eoe/main/evolve_oe_cifar.py --classes 5 --ms-mode lpf+train_oe lpf+train_nominal lpf+test_nominal lpf+test_anomalous --magnitude 14
For high-pass-filtered CIFAR-10 with 80MTI as OE:
python eoe/src/eoe/main/evolve_oe_cifar.py --classes 5 --ms-mode hpf+train_oe hpf+train_nominal hpf+test_nominal hpf+test_anomalous --magnitude 14
Similar for ImageNet-30, where we use evolve_oe_imagenet.py instead.
For using pure random search instead of an evolutionary algorithm to find optimal OE samples, we use the following script:
python eoe/src/eoe/main/random_oe_imagenet.py --classes 5
We use random_oe_cifar.py for CIFAR-10 instead.
For changing the class, objective, optimization target, or filter setting, we change the same parameters as before.
To train on (low or high-pass) filtered datasets for varying amount of Outlier Exposure and magnitudes of filters (like in Appendix C in the paper), we use the following scripts. For a particular number of OE samples (here we use 16), we execute:
For low-pass-filtered CIFAR-10 with 80MTI as OE:
python eoe/src/eoe/main/multiscale_cifar.py --oe-size 16 --ms-mode lpf+train_oe lpf+train_nominal lpf+test_nominal lpf+test_anomalous --magnitudes 0 1 2 4 8 12 14 15
Similar for ImageNet-30, where we use multiscale_imagenet.py instead.
All results are automatically logged in a newly created folder in eoe/data/results/.
The folder will have an auto-generated name starting with log_{YYYYMMDDHHMMSS}_, where {YYYYMMDDHHMMSS} is the current datetime (e.g., 20220128000000).
AD Experiments
In this folder you can find all results, most importantly, a results.json file that contains the recorded class-wise AUC scores along with some statistics like the standard deviation.
There also plots for the AUC curves, some image batches of the train and validation loader, and network snapshots.
You can find a precise enumeration below.
eoe/data/results/log_{YYYYMMDDHHMMSS}_{COMMENT}
├── snapshots
│ ├── snapshot_cls{i}_it{j}.pt # snapshot of the model and optimizer for class {i} and the {j}-th random seed
│ ├── ...
│ └── ...
├── eval_cls{i}-{clsname}_prc.pdf # test precision-recall curve of cls {i} with a plot for each random seed and the legend showing the average precision
├── ...
├── eval_cls{i}-{clsname}_preview.png # an image showing random images retrived from the test dataloader; first row for normal and second row for anomalous; with the number of samples printed on the left
├── ...
├── eval_cls{i}-{clsname}_roc.pdf # test receiver-operator-characteristic of cls {i} with a plot for each random seedd and the legend showing the AUC
├── ...
├── eval_cls{i}_it{j}.json # dictionary of test sample indices to anomaly scores for cls {i} and the {j}-th random seed
├── ...
├── eval_prc.pdf # test precision-recall curve over all classes
├── eval_roc.pdf # test receiver-operator-characteristic over all classes
├── logtxt.txt # contains all computed metrics in the form of human-readable text
├── print.txt # a log containing most of the printed messages
├── results.json # contains all computed metrics in the form of computer-readable json lines
├── setup.json # contains the configuration of the experiment in computer-readable format
├── src.tar.gz # contains the complete code that was used for the experiment
├── warnings.txt # contains a log of certain EOE warnings
├── ...
├── training_cls{i}-{clsname}_preview.png
├── ...
├── training_cls{i}-{clsname}_roc.pdf
└── ...
There is also a tensorboard logfile that contains most of the logged data.
Evolutionary Experiments
For experiments finding optimal single OE samples, there are images showing the optimal samples of each generation, an evolution.json file that contains the full genealogical tree (i.e., all samples, their fitness, and genealogical trees), and a figure for the best and worst overall samples in the subfolder final.
eoe/data/results/log_{YYYYMMDDHHMMSS}_{COMMENT}
├── final
│ ├── best.png # showing the overall best-performing OE samples with fitness (i.e., mean test AUC) printed on the left
│ ├── best_raw.png # showing the overall best-performing OE samples
│ ├── worst.png # showing the overall worst-performing OE samples with fitness (i.e., mean test AUC) printed on the left
│ └── worst_raw.png # showing the overall worst-performing OE samples
├── final-transformed
│ ├── ... # the same as above but with the OE samples being shown with filters applied if filters were used during the experiment
│ └── ...
├── individuals
│ ├── gen{GEN}_ind{IND}_fit{FIT}.png # an image of the {IND}-th OE sample of the {GEN}-th generation with the fitness {FIT} (i.e., mean test AUC)
│ └── ...
├── log_{YYYYMMDDHHMMSS}_ # the log directory (as explained above) of the training for the first OE sample
│ ├── ...
│ └── ...
├── mating
│ ├── gen{GEN}.png # an image visualizing which samples of the {GEN-1}-th generation mated to produce which samples of the {GEN}-th generation
│ └── ...
├── mutation
│ ├── gen{GEN}.png # an image visualizing which samples of the {GEN-1}-th generation mutated to which samples of the {GEN}-th generation
│ └── ...
├── raw_gen
│ ├── gen{GEN}.png # an overview containing all images of the {GEN}-th generation
│ └── ...
├── selection
│ ├── gen{GEN}.png # an image visualizing which samples of the {GEN-1}-th generation were selected for the {GEN}-th generation
│ └── ...
├── selection
│ ├── ...
│ └── ...
├── avg_fit.pdf # plots the average fitness of each generation
├── evolution.json # contains the full genealogical tree (i.e., all OE samples, their fitness and relation)
├── gen{GEN}.png # an overview containing all images of the {GEN}-th generation with fitness printed on the left
├── ...
├── max_fit.pdf # plots the max fitness of each generation
└── ...
There is also a tensorboard logfile that contains most of the logged data.
We also support training with custom datasets and models.
Please use either eoe/src/eoe/main/train_custom.py or eoe/src/eoe/main/evolve_oe_custom.py for custom data.
The code looks for the data in eoe/data/datasets/custom/ and expects the folder to be of the form specified in (1), which follows the
one-vs-rest approach, or of the form specified in (2), which follows the general AD approach.
The data is expected to be contained in class folders. We distinguish between
(1) the one-vs-rest (ovr) approach where one class is considered normal
and is tested against all other classes being anomalous
(2) the general approach where each class folder contains a normal data folder and an anomalous data folder.
The default is (2). You can change it to (1) with --custom-dataset-ovr.
For (1) the data folders have to follow this structure:
eoe/data/datasets/custom/train/dog/xxx.png
eoe/data/datasets/custom/train/dog/xxy.png
eoe/data/datasets/custom/train/dog/xxz.png
eoe/data/datasets/custom/train/cat/123.png
eoe/data/datasets/custom/train/cat/nsdf3.png
eoe/data/datasets/custom/train/cat/asd932_.png
For (2):
eoe/data/datasets/custom/train/hazelnut/normal/xxx.png
eoe/data/datasets/custom/train/hazelnut/normal/xxy.png
eoe/data/datasets/custom/train/hazelnut/normal/xxz.png
eoe/data/datasets/custom/train/hazelnut/anomalous/xxa.png -- may be used during training as OE with --oe-dataset custom
eoe/data/datasets/custom/train/screw/normal/123.png
eoe/data/datasets/custom/train/screw/normal/nsdf3.png
eoe/data/datasets/custom/train/screw/anomalous/asd932_.png -- may be used during training as OE with --oe-dataset custom
The same holds for the test set, where "/train/" has to be replaced by "/test/", and in (2) the anomalies are not used as OE but as ground-truth anomalies for testing.
For full customizability, we provide separate scripts for training and inference with custom models and data.
Use eoe/src/eoe/main/train_only_custom.py for training.
This script defines additional arguments:
- --custom-dataset-path: A path to the custom dataset's training data directory. The directory has to contain a folder named 'normal' for normal training samples. Additionally, it can contain a folder named 'anomalous' for anomalous training samples, which are used if -oe is set to "custom". Both these folder have to contain images only.
- --log-path: A path to a directory where results are to be logged (see Log Data).
- --custom-model-name: The class name of any model implemented in
xad.models.custom. - [--custom-model-snapshot, optional]: The snapshot can either be: (1) A state_dict of the feature model specified with --custom-model-name. In this case, the feature model gets initialized with those weights. (2) a snapshot that is automatically logged via previous EOE experiments. In this case, the states of the model, optimizer, scheduler, and epoch are loaded. EOE continues training.
- [--custom-model-add-prediction-head, optional]: Adds a randomly-initialized prediction head with either 256 output neurons (HSC, ...) or 1 neuron (BCE, focal, ...) to the model.
- [--custom-model-freeze, optional]: Freezes gradients for a part of the model, depending on the implementation of the model's self.freeze_parts() method. Per default, if argument is set, freezes the entire feature extraction module.
For inference, use eoe/src/eoe/main/inference_custom.py. Similar to training, the script defines additional arguments:
- --custom-dataset-path: A path to the custom dataset's test data directory. The directory has to contain at least one of the following folders: (1) 'normal' for normal test samples, (2) 'anomalous' for anomalous test samples, and (3) 'unlabeled' for unlabeled test samples. One of these folders needs to be non-empty. If both (1) and (2) contain each at least one image, an AuROC will be computed for (1) vs (2). All folders have to contain images only.
- --log-path: A path to a directory where results are to be logged (see Log Data).
- --custom-model-snapshot: The path to a snapshot that was automatically logged via previous EOE experiments.
- --custom-model-name: The class name of any model implemented in
xad.models.custom. - [--custom-model-add-prediction-head, optional]: Adds a randomly-initialized prediction head with either 256 output neurons (HSC, ...) or 1 neuron (BCE, focal, ...) to the model.
All models that are in the package xad.models.custom and inherit xad.models.custom_base.CustomNet become available for training and inference.
Per default, any CustomNet extracts features using its self.feature_model module---which needs to be set for any CustomNet---,passes those through a prediction head if --custom-model-add-prediction-head is True, and returns the outcome.
You can manually redefine the data transformation pipeline. The default one for training resizes all images to 256x256, applies mild random color jitter, random horizontal flips, random crop to 224x224, transfroms the images to PyTorch tensors, and standardizes the data with an automatically extracted mean and std of the training data. The mean and std are stored in the model snapshot and will be reused for inference.
If you find any bugs, have questions, need help modifying EOE, or want to get in touch in general, feel free to write us an email!