![]()
![]()
Pointcept is a powerful and flexible codebase for point cloud perception research. It is also an official implementation of the following paper:
-
Point Transformer V3: Simpler, Faster, Stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, Hengshuang Zhao
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2024 - Oral
[ Backbone ] [PTv3] - [ arXiv ] [ Bib ] [ Project ] → here -
OA-CNNs: Omni-Adaptive Sparse CNNs for 3D Semantic Segmentation
Bohao Peng, Xiaoyang Wu, Li Jiang, Yukang Chen, Hengshuang Zhao, Zhuotao Tian, Jiaya Jia
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2024
[ Backbone ] [ OA-CNNs ] - [ arXiv ] [ Bib ] → here -
PonderV2: Pave the Way for 3D Foundation Model with A Universal Pre-training Paradigm
Haoyi Zhu*, Honghui Yang*, Xiaoyang Wu*, Di Huang*, Sha Zhang, Xianglong He, Tong He, Hengshuang Zhao, Chunhua Shen, Yu Qiao, Wanli Ouyang
arXiv Preprint 2023
[ Pretrain ] [PonderV2] - [ arXiv ] [ Bib ] [ Project ] → here -
Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training
Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, Hengshuang Zhao
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2024
[ Pretrain ] [PPT] - [ arXiv ] [ Bib ] → here -
Masked Scene Contrast: A Scalable Framework for Unsupervised 3D Representation Learning
Xiaoyang Wu, Xin Wen, Xihui Liu, Hengshuang Zhao
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2023
[ Pretrain ] [ MSC ] - [ arXiv ] [ Bib ] → here -
Learning Context-aware Classifier for Semantic Segmentation (3D Part)
Zhuotao Tian, Jiequan Cui, Li Jiang, Xiaojuan Qi, Xin Lai, Yixin Chen, Shu Liu, Jiaya Jia
AAAI Conference on Artificial Intelligence (AAAI) 2023 - Oral
[ SemSeg ] [ CAC ] - [ arXiv ] [ Bib ] [ 2D Part ] → here -
Point Transformer V2: Grouped Vector Attention and Partition-based Pooling
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, Hengshuang Zhao
Conference on Neural Information Processing Systems (NeurIPS) 2022
[ Backbone ] [ PTv2 ] - [ arXiv ] [ Bib ] → here -
Point Transformer
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip Torr, Vladlen Koltun
IEEE International Conference on Computer Vision (ICCV) 2021 - Oral
[ Backbone ] [ PTv1 ] - [ arXiv ] [ Bib ] → here
Additionally, Pointcept integrates the following excellent work (contain above):
Backbone:
MinkUNet (here),
SpUNet (here),
SPVCNN (here),
OACNNs (here),
PTv1 (here),
PTv2 (here),
PTv3 (here),
StratifiedFormer (here),
OctFormer (here),
Swin3D (here);
Semantic Segmentation:
Mix3d (here),
CAC (here);
Instance Segmentation:
PointGroup (here);
Pre-training:
PointContrast (here),
Contrastive Scene Contexts (here),
Masked Scene Contrast (here),
Point Prompt Training (here);
Datasets:
ScanNet (here),
ScanNet200 (here),
ScanNet++ (here),
S3DIS (here),
Matterport3D (here),
ArkitScene,
Structured3D (here),
SemanticKITTI (here),
nuScenes (here),
ModelNet40 (here),
Waymo (here).
- May, 2024: In v1.5.2, we redesigned the default structure for each dataset for better performance. Please re-preprocess datasets or download our preprocessed datasets from here.
- Apr, 2024: PTv3 is selected as one of the 90 Oral papers (3.3% accepted papers, 0.78% submissions) by CVPR'24!
- Mar, 2024: We release code for OA-CNNs, accepted by CVPR'24. Issue related to OA-CNNs can @Pbihao.
- Feb, 2024: PTv3 and PPT are accepted by CVPR'24, another two papers by our Pointcept team have also been accepted by CVPR'24 🎉🎉🎉. We will make them publicly available soon!
- Dec, 2023: PTv3 is released on arXiv, and the code is available in Pointcept. PTv3 is an efficient backbone model that achieves SOTA performances across indoor and outdoor scenarios.
- Aug, 2023: PPT is released on arXiv. PPT presents a multi-dataset pre-training framework that achieves SOTA performance in both indoor and outdoor scenarios. It is compatible with various existing pre-training frameworks and backbones. A pre-release version of the code is accessible; for those interested, please feel free to contact me directly for access.
- Mar, 2023: We released our codebase, Pointcept, a highly potent tool for point cloud representation learning and perception. We welcome new work to join the Pointcept family and highly recommend reading Quick Start before starting your trail.
- Feb, 2023: MSC and CeCo accepted by CVPR 2023. MSC is a highly efficient and effective pretraining framework that facilitates cross-dataset large-scale pretraining, while CeCo is a segmentation method specifically designed for long-tail datasets. Both approaches are compatible with all existing backbone models in our codebase, and we will soon make the code available for public use.
- Jan, 2023: CAC, oral work of AAAI 2023, has expanded its 3D result with the incorporation of Pointcept. This addition will allow CAC to serve as a pluggable segmentor within our codebase.
- Sep, 2022: PTv2 accepted by NeurIPS 2022. It is a continuation of the Point Transformer. The proposed GVA theory can apply to most existing attention mechanisms, while Grid Pooling is also a practical addition to existing pooling methods.
If you find Pointcept useful to your research, please cite our work as encouragement. (੭ˊ꒳ˋ)੭✧
@misc{pointcept2023,
title={Pointcept: A Codebase for Point Cloud Perception Research},
author={Pointcept Contributors},
howpublished = {\url{https://github.com/Pointcept/Pointcept}},
year={2023}
}
- Ubuntu: 18.04 and above.
- CUDA: 11.3 and above.
- PyTorch: 1.10.0 and above.
conda create -n pointcept python=3.8 -y
conda activate pointcept
conda install ninja -y
# Choose version you want here: https://pytorch.org/get-started/previous-versions/
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch -y
conda install h5py pyyaml -c anaconda -y
conda install sharedarray tensorboard tensorboardx yapf addict einops scipy plyfile termcolor timm -c conda-forge -y
conda install pytorch-cluster pytorch-scatter pytorch-sparse -c pyg -y
pip install torch-geometric
# spconv (SparseUNet)
# refer https://github.com/traveller59/spconv
pip install spconv-cu113
# PPT (clip)
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git
# PTv1 & PTv2 or precise eval
cd libs/pointops
# usual
python setup.py install
# docker & multi GPU arch
TORCH_CUDA_ARCH_LIST="ARCH LIST" python setup.py install
# e.g. 7.5: RTX 3000; 8.0: a100 More available in: https://developer.nvidia.com/cuda-gpus
TORCH_CUDA_ARCH_LIST="7.5 8.0" python setup.py install
cd ../..
# Open3D (visualization, optional)
pip install open3dThe preprocessing supports semantic and instance segmentation for both ScanNet20, ScanNet200, and ScanNet Data Efficient.
-
Download the ScanNet v2 dataset.
-
Run preprocessing code for raw ScanNet as follows:
# RAW_SCANNET_DIR: the directory of downloaded ScanNet v2 raw dataset. # PROCESSED_SCANNET_DIR: the directory of the processed ScanNet dataset (output dir). python pointcept/datasets/preprocessing/scannet/preprocess_scannet.py --dataset_root ${RAW_SCANNET_DIR} --output_root ${PROCESSED_SCANNET_DIR}
-
(Optional) Download ScanNet Data Efficient files:
# download-scannet.py is the official download script # or follow instructions here: https://kaldir.vc.in.tum.de/scannet_benchmark/data_efficient/documentation#download python download-scannet.py --data_efficient -o ${RAW_SCANNET_DIR} # unzip downloads cd ${RAW_SCANNET_DIR}/tasks unzip limited-annotation-points.zip unzip limited-reconstruction-scenes.zip # copy files to processed dataset folder mkdir ${PROCESSED_SCANNET_DIR}/tasks cp -r ${RAW_SCANNET_DIR}/tasks/points ${PROCESSED_SCANNET_DIR}/tasks cp -r ${RAW_SCANNET_DIR}/tasks/scenes ${PROCESSED_SCANNET_DIR}/tasks
-
(Alternative) Our preprocess data can be directly downloaded [here], please agree the official license before download it.
-
Link processed dataset to codebase:
# PROCESSED_SCANNET_DIR: the directory of the processed ScanNet dataset. mkdir data ln -s ${PROCESSED_SCANNET_DIR} ${CODEBASE_DIR}/data/scannet
- Download the ScanNet++ dataset.
- Run preprocessing code for raw ScanNet++ as follows:
# RAW_SCANNETPP_DIR: the directory of downloaded ScanNet++ raw dataset. # PROCESSED_SCANNETPP_DIR: the directory of the processed ScanNet++ dataset (output dir). # NUM_WORKERS: the number of workers for parallel preprocessing. python pointcept/datasets/preprocessing/scannetpp/preprocess_scannetpp.py --dataset_root ${RAW_SCANNETPP_DIR} --output_root ${PROCESSED_SCANNETPP_DIR} --num_workers ${NUM_WORKERS}
- Sampling and chunking large point cloud data in train/val split as follows (only used for training):
# PROCESSED_SCANNETPP_DIR: the directory of the processed ScanNet++ dataset (output dir). # NUM_WORKERS: the number of workers for parallel preprocessing. python pointcept/datasets/preprocessing/sampling_chunking_data.py --dataset_root ${PROCESSED_SCANNETPP_DIR} --grid_size 0.01 --chunk_range 6 6 --chunk_stride 3 3 --split train --num_workers ${NUM_WORKERS} python pointcept/datasets/preprocessing/sampling_chunking_data.py --dataset_root ${PROCESSED_SCANNETPP_DIR} --grid_size 0.01 --chunk_range 6 6 --chunk_stride 3 3 --split val --num_workers ${NUM_WORKERS}
- (Alternative) Our preprocess data can be directly downloaded [here], please agree the official license before download it.
- Link processed dataset to codebase:
# PROCESSED_SCANNETPP_DIR: the directory of the processed ScanNet dataset. mkdir data ln -s ${PROCESSED_SCANNETPP_DIR} ${CODEBASE_DIR}/data/scannetpp
-
Download S3DIS data by filling this Google form. Download the
Stanford3dDataset_v1.2.zipfile and unzip it. -
Fix error in
Area_5/office_19/Annotations/ceilingLine 323474 (103.0�0000 => 103.000000). -
(Optional) Download Full 2D-3D S3DIS dataset (no XYZ) from here for parsing normal.
-
Run preprocessing code for S3DIS as follows:
# S3DIS_DIR: the directory of downloaded Stanford3dDataset_v1.2 dataset. # RAW_S3DIS_DIR: the directory of Stanford2d3dDataset_noXYZ dataset. (optional, for parsing normal) # PROCESSED_S3DIS_DIR: the directory of processed S3DIS dataset (output dir). # S3DIS without aligned angle python pointcept/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root ${S3DIS_DIR} --output_root ${PROCESSED_S3DIS_DIR} # S3DIS with aligned angle python pointcept/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root ${S3DIS_DIR} --output_root ${PROCESSED_S3DIS_DIR} --align_angle # S3DIS with normal vector (recommended, normal is helpful) python pointcept/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root ${S3DIS_DIR} --output_root ${PROCESSED_S3DIS_DIR} --raw_root ${RAW_S3DIS_DIR} --parse_normal python pointcept/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root ${S3DIS_DIR} --output_root ${PROCESSED_S3DIS_DIR} --raw_root ${RAW_S3DIS_DIR} --align_angle --parse_normal
-
(Alternative) Our preprocess data can also be downloaded [here] (with normal vector and aligned angle), please agree with the official license before downloading it.
-
Link processed dataset to codebase.
# PROCESSED_S3DIS_DIR: the directory of processed S3DIS dataset. mkdir data ln -s ${PROCESSED_S3DIS_DIR} ${CODEBASE_DIR}/data/s3dis
- Download Structured3D panorama related and perspective (full) related zip files by filling this Google form (no need to unzip them).
- Organize all downloaded zip file in one folder (
${STRUCT3D_DIR}). - Run preprocessing code for Structured3D as follows:
# STRUCT3D_DIR: the directory of downloaded Structured3D dataset. # PROCESSED_STRUCT3D_DIR: the directory of processed Structured3D dataset (output dir). # NUM_WORKERS: Number for workers for preprocessing, default same as cpu count (might OOM). export PYTHONPATH=./ python pointcept/datasets/preprocessing/structured3d/preprocess_structured3d.py --dataset_root ${STRUCT3D_DIR} --output_root ${PROCESSED_STRUCT3D_DIR} --num_workers ${NUM_WORKERS} --grid_size 0.01 --fuse_prsp --fuse_pano
Following the instruction of Swin3D, we keep 25 categories with frequencies of more than 0.001, out of the original 40 categories.
-
(Alternative) Our preprocess data can also be downloaded [here] (with perspective views and panorama view, 471.7G after unzipping), please agree the official license before download it.
-
Link processed dataset to codebase.
# PROCESSED_STRUCT3D_DIR: the directory of processed Structured3D dataset (output dir). mkdir data ln -s ${PROCESSED_STRUCT3D_DIR} ${CODEBASE_DIR}/data/structured3d
- Follow this page to request access to the dataset.
- Download the "region_segmentation" type, which represents the division of a scene into individual rooms.
# download-mp.py is the official download script # MATTERPORT3D_DIR: the directory of downloaded Matterport3D dataset. python download-mp.py -o {MATTERPORT3D_DIR} --type region_segmentations
- Unzip the region_segmentations data
# MATTERPORT3D_DIR: the directory of downloaded Matterport3D dataset. python pointcept/datasets/preprocessing/matterport3d/unzip_matterport3d_region_segmentation.py --dataset_root {MATTERPORT3D_DIR} - Run preprocessing code for Matterport3D as follows:
# MATTERPORT3D_DIR: the directory of downloaded Matterport3D dataset. # PROCESSED_MATTERPORT3D_DIR: the directory of processed Matterport3D dataset (output dir). # NUM_WORKERS: the number of workers for this preprocessing. python pointcept/datasets/preprocessing/matterport3d/preprocess_matterport3d_mesh.py --dataset_root ${MATTERPORT3D_DIR} --output_root ${PROCESSED_MATTERPORT3D_DIR} --num_workers ${NUM_WORKERS}
- Link processed dataset to codebase.
# PROCESSED_MATTERPORT3D_DIR: the directory of processed Matterport3D dataset (output dir). mkdir data ln -s ${PROCESSED_MATTERPORT3D_DIR} ${CODEBASE_DIR}/data/matterport3d
Following the instruction of OpenRooms, we remapped Matterport3D's categories to ScanNet 20 semantic categories with the addition of a ceiling category.
- (Alternative) Our preprocess data can also be downloaded here, please agree the official license before download it.
- Download SemanticKITTI dataset.
- Link dataset to codebase.
# SEMANTIC_KITTI_DIR: the directory of SemanticKITTI dataset. # |- SEMANTIC_KITTI_DIR # |- dataset # |- sequences # |- 00 # |- 01 # |- ... mkdir -p data ln -s ${SEMANTIC_KITTI_DIR} ${CODEBASE_DIR}/data/semantic_kitti
-
Download the official NuScene dataset (with Lidar Segmentation) and organize the downloaded files as follows:
NUSCENES_DIR │── samples │── sweeps │── lidarseg ... │── v1.0-trainval │── v1.0-test
-
Run information preprocessing code (modified from OpenPCDet) for nuScenes as follows:
# NUSCENES_DIR: the directory of downloaded nuScenes dataset. # PROCESSED_NUSCENES_DIR: the directory of processed nuScenes dataset (output dir). # MAX_SWEEPS: Max number of sweeps. Default: 10. pip install nuscenes-devkit pyquaternion python pointcept/datasets/preprocessing/nuscenes/preprocess_nuscenes_info.py --dataset_root ${NUSCENES_DIR} --output_root ${PROCESSED_NUSCENES_DIR} --max_sweeps ${MAX_SWEEPS} --with_camera
-
(Alternative) Our preprocess nuScenes information data can also be downloaded [here] (only processed information, still need to download raw dataset and link to the folder), please agree the official license before download it.
-
Link raw dataset to processed NuScene dataset folder:
# NUSCENES_DIR: the directory of downloaded nuScenes dataset. # PROCESSED_NUSCENES_DIR: the directory of processed nuScenes dataset (output dir). ln -s ${NUSCENES_DIR} {PROCESSED_NUSCENES_DIR}/raw
then the processed nuscenes folder is organized as follows:
nuscene |── raw │── samples │── sweeps │── lidarseg ... │── v1.0-trainval │── v1.0-test |── info
-
Link processed dataset to codebase.
# PROCESSED_NUSCENES_DIR: the directory of processed nuScenes dataset (output dir). mkdir data ln -s ${PROCESSED_NUSCENES_DIR} ${CODEBASE_DIR}/data/nuscenes
-
Download the official Waymo dataset (v1.4.3) and organize the downloaded files as follows:
WAYMO_RAW_DIR │── training │── validation │── testing
-
Install the following dependence:
# If shows "No matching distribution found", download whl directly from Pypi and install the package. conda create -n waymo python=3.10 -y conda activate waymo pip install waymo-open-dataset-tf-2-12-0 -
Run the preprocessing code as follows:
# WAYMO_DIR: the directory of the downloaded Waymo dataset. # PROCESSED_WAYMO_DIR: the directory of the processed Waymo dataset (output dir). # NUM_WORKERS: num workers for preprocessing python pointcept/datasets/preprocessing/waymo/preprocess_waymo.py --dataset_root ${WAYMO_DIR} --output_root ${PROCESSED_WAYMO_DIR} --splits training validation --num_workers ${NUM_WORKERS}
-
Link processed dataset to the codebase.
# PROCESSED_WAYMO_DIR: the directory of the processed Waymo dataset (output dir). mkdir data ln -s ${PROCESSED_WAYMO_DIR} ${CODEBASE_DIR}/data/waymo
- Download modelnet40_normal_resampled.zip and unzip
- Link dataset to the codebase.
mkdir -p data ln -s ${MODELNET_DIR} ${CODEBASE_DIR}/data/modelnet40_normal_resampled
Train from scratch. The training processing is based on configs in configs folder.
The training script will generate an experiment folder in exp folder and backup essential code in the experiment folder.
Training config, log, tensorboard, and checkpoints will also be saved into the experiment folder during the training process.
export CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES}
# Script (Recommended)
sh scripts/train.sh -p ${INTERPRETER_PATH} -g ${NUM_GPU} -d ${DATASET_NAME} -c ${CONFIG_NAME} -n ${EXP_NAME}
# Direct
export PYTHONPATH=./
python tools/train.py --config-file ${CONFIG_PATH} --num-gpus ${NUM_GPU} --options save_path=${SAVE_PATH}For example:
# By script (Recommended)
# -p is default set as python and can be ignored
sh scripts/train.sh -p python -d scannet -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# Direct
export PYTHONPATH=./
python tools/train.py --config-file configs/scannet/semseg-pt-v2m2-0-base.py --options save_path=exp/scannet/semseg-pt-v2m2-0-baseResume training from checkpoint. If the training process is interrupted by accident, the following script can resume training from a given checkpoint.
export CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES}
# Script (Recommended)
# simply add "-r true"
sh scripts/train.sh -p ${INTERPRETER_PATH} -g ${NUM_GPU} -d ${DATASET_NAME} -c ${CONFIG_NAME} -n ${EXP_NAME} -r true
# Direct
export PYTHONPATH=./
python tools/train.py --config-file ${CONFIG_PATH} --num-gpus ${NUM_GPU} --options save_path=${SAVE_PATH} resume=True weight=${CHECKPOINT_PATH}During training, model evaluation is performed on point clouds after grid sampling (voxelization), providing an initial assessment of model performance. However, to obtain precise evaluation results, testing is essential. The testing process involves subsampling a dense point cloud into a sequence of voxelized point clouds, ensuring comprehensive coverage of all points. These sub-results are then predicted and collected to form a complete prediction of the entire point cloud. This approach yields higher evaluation results compared to simply mapping/interpolating the prediction. In addition, our testing code supports TTA (test time augmentation) testing, which further enhances the stability of evaluation performance.
# By script (Based on experiment folder created by training script)
sh scripts/test.sh -p ${INTERPRETER_PATH} -g ${NUM_GPU} -d ${DATASET_NAME} -n ${EXP_NAME} -w ${CHECKPOINT_NAME}
# Direct
export PYTHONPATH=./
python tools/test.py --config-file ${CONFIG_PATH} --num-gpus ${NUM_GPU} --options save_path=${SAVE_PATH} weight=${CHECKPOINT_PATH}For example:
# By script (Based on experiment folder created by training script)
# -p is default set as python and can be ignored
# -w is default set as model_best and can be ignored
sh scripts/test.sh -p python -d scannet -n semseg-pt-v2m2-0-base -w model_best
# Direct
export PYTHONPATH=./
python tools/test.py --config-file configs/scannet/semseg-pt-v2m2-0-base.py --options save_path=exp/scannet/semseg-pt-v2m2-0-base weight=exp/scannet/semseg-pt-v2m2-0-base/model/model_best.pthThe TTA can be disabled by replace data.test.test_cfg.aug_transform = [...] with:
data = dict(
train = dict(...),
val = dict(...),
test = dict(
...,
test_cfg = dict(
...,
aug_transform = [
[dict(type="RandomRotateTargetAngle", angle=[0], axis="z", center=[0, 0, 0], p=1)]
]
)
)
)Offset is the separator of point clouds in batch data, and it is similar to the concept of Batch in PyG.
A visual illustration of batch and offset is as follows:
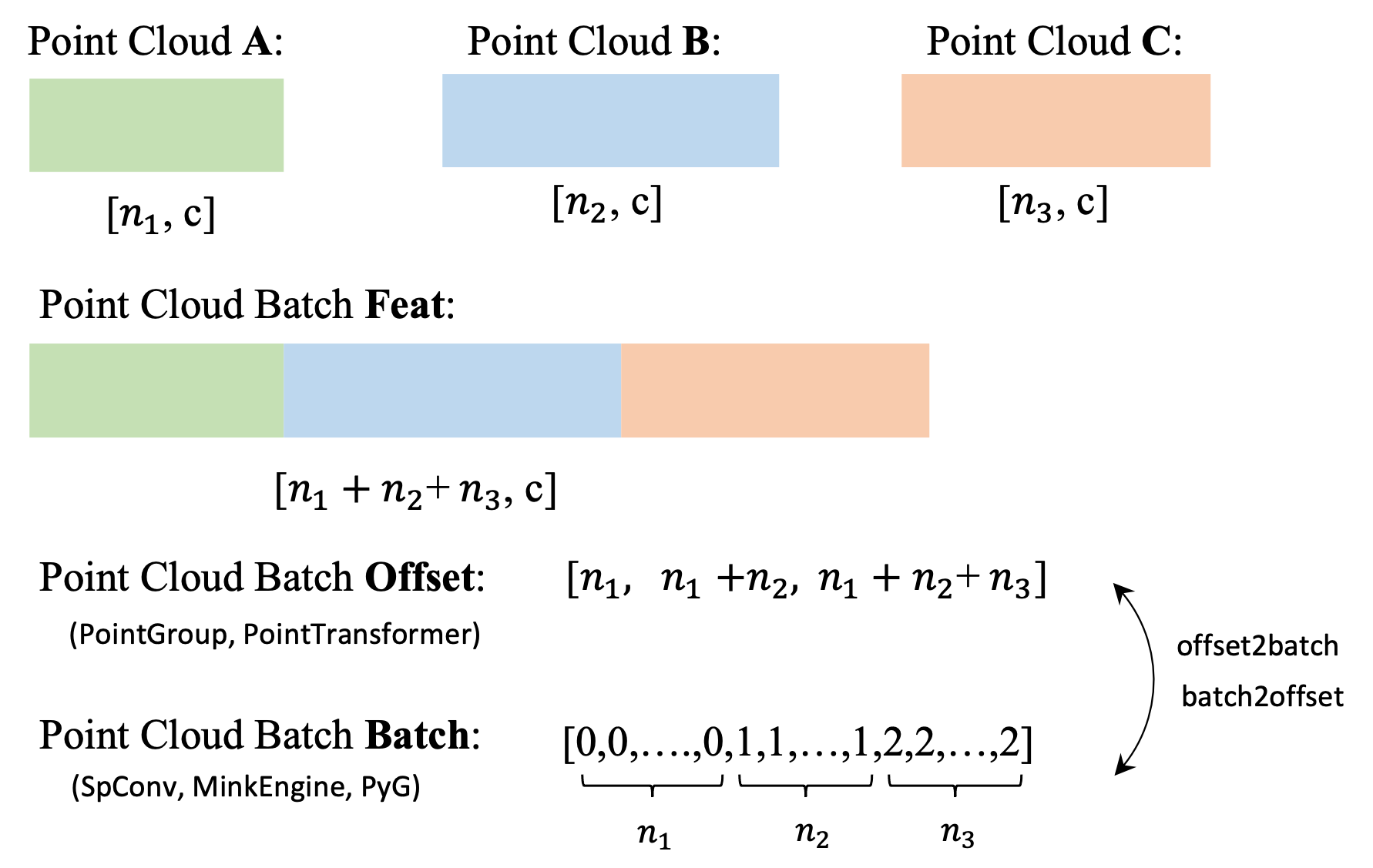
Pointcept provides SparseUNet implemented by SpConv and MinkowskiEngine. The SpConv version is recommended since SpConv is easy to install and faster than MinkowskiEngine. Meanwhile, SpConv is also widely applied in outdoor perception.
- SpConv (recommend)
The SpConv version SparseUNet in the codebase was fully rewrite from MinkowskiEngine version, example running script is as follows:
# ScanNet val
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# S3DIS (with normal)
sh scripts/train.sh -g 4 -d s3dis -c semseg-spunet-v1m1-0-cn-base -n semseg-spunet-v1m1-0-cn-base
# SemanticKITTI
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# nuScenes
sh scripts/train.sh -g 4 -d nuscenes -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# ModelNet40
sh scripts/train.sh -g 2 -d modelnet40 -c cls-spunet-v1m1-0-base -n cls-spunet-v1m1-0-base
# ScanNet Data Efficient
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-la20 -n semseg-spunet-v1m1-2-efficient-la20
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-la50 -n semseg-spunet-v1m1-2-efficient-la50
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-la100 -n semseg-spunet-v1m1-2-efficient-la100
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-la200 -n semseg-spunet-v1m1-2-efficient-la200
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-lr1 -n semseg-spunet-v1m1-2-efficient-lr1
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-lr5 -n semseg-spunet-v1m1-2-efficient-lr5
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-lr10 -n semseg-spunet-v1m1-2-efficient-lr10
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-lr20 -n semseg-spunet-v1m1-2-efficient-lr20
# Profile model run time
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-0-enable-profiler -n semseg-spunet-v1m1-0-enable-profiler- MinkowskiEngine
The MinkowskiEngine version SparseUNet in the codebase was modified from the original MinkowskiEngine repo, and example running scripts are as follows:
- Install MinkowskiEngine, refer https://github.com/NVIDIA/MinkowskiEngine
- Training with the following example scripts:
# Uncomment "# from .sparse_unet import *" in "pointcept/models/__init__.py"
# Uncomment "# from .mink_unet import *" in "pointcept/models/sparse_unet/__init__.py"
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-minkunet34c-0-base -n semseg-minkunet34c-0-base
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-minkunet34c-0-base -n semseg-minkunet34c-0-base
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-minkunet34c-0-base -n semseg-minkunet34c-0-base
# SemanticKITTI
sh scripts/train.sh -g 2 -d semantic_kitti -c semseg-minkunet34c-0-base -n semseg-minkunet34c-0-baseIntroducing Omni-Adaptive 3D CNNs (OA-CNNs), a family of networks that integrates a lightweight module to greatly enhance the adaptivity of sparse CNNs at minimal computational cost. Without any self-attention modules, OA-CNNs favorably surpass point transformers in terms of accuracy in both indoor and outdoor scenes, with much less latency and memory cost. Issue related to OA-CNNs can @Pbihao.
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-oacnns-v1m1-0-base -n semseg-oacnns-v1m1-0-base- PTv3
PTv3 is an efficient backbone model that achieves SOTA performances across indoor and outdoor scenarios. The full PTv3 relies on FlashAttention, while FlashAttention relies on CUDA 11.6 and above, make sure your local Pointcept environment satisfies the requirements.
If you can not upgrade your local environment to satisfy the requirements (CUDA >= 11.6), then you can disable FlashAttention by setting the model parameter enable_flash to false and reducing the enc_patch_size and dec_patch_size to a level (e.g. 128).
FlashAttention force disables RPE and forces the accuracy reduced to fp16. If you require these features, please disable enable_flash and adjust enable_rpe, upcast_attention andupcast_softmax.
Detailed instructions and experiment records (containing weights) are available on the project repository. Example running scripts are as follows:
# Scratched ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# PPT joint training (ScanNet + Structured3D) and evaluate in ScanNet
sh scripts/train.sh -g 8 -d scannet -c semseg-pt-v3m1-1-ppt-extreme -n semseg-pt-v3m1-1-ppt-extreme
# Scratched ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# Fine-tuning from PPT joint training (ScanNet + Structured3D) with ScanNet200
# PTV3_PPT_WEIGHT_PATH: Path to model weight trained by PPT multi-dataset joint training
# e.g. exp/scannet/semseg-pt-v3m1-1-ppt-extreme/model/model_best.pth
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v3m1-1-ppt-ft -n semseg-pt-v3m1-1-ppt-ft -w ${PTV3_PPT_WEIGHT_PATH}
# Scratched ScanNet++
sh scripts/train.sh -g 4 -d scannetpp -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# Scratched ScanNet++ test
sh scripts/train.sh -g 4 -d scannetpp -c semseg-pt-v3m1-1-submit -n semseg-pt-v3m1-1-submit
# Scratched S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# an example for disbale flash_attention and enable rpe.
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v3m1-1-rpe -n semseg-pt-v3m1-0-rpe
# PPT joint training (ScanNet + S3DIS + Structured3D) and evaluate in ScanNet
sh scripts/train.sh -g 8 -d s3dis -c semseg-pt-v3m1-1-ppt-extreme -n semseg-pt-v3m1-1-ppt-extreme
# S3DIS 6-fold cross validation
# 1. The default configs are evaluated on Area_5, modify the "data.train.split", "data.val.split", and "data.test.split" to make the config evaluated on Area_1 ~ Area_6 respectively.
# 2. Train and evaluate the model on each split of areas and gather result files located in "exp/s3dis/EXP_NAME/result/Area_x.pth" in one single folder, noted as RECORD_FOLDER.
# 3. Run the following script to get S3DIS 6-fold cross validation performance:
export PYTHONPATH=./
python tools/test_s3dis_6fold.py --record_root ${RECORD_FOLDER}
# Scratched nuScenes
sh scripts/train.sh -g 4 -d nuscenes -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# Scratched Waymo
sh scripts/train.sh -g 4 -d waymo -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# More configs and exp records for PTv3 will be available soon.Indoor semantic segmentation
| Model | Benchmark | Additional Data | Num GPUs | Val mIoU | Config | Tensorboard | Exp Record |
|---|---|---|---|---|---|---|---|
| PTv3 | ScanNet | ✗ | 4 | 77.6% | link | link | link |
| PTv3 + PPT | ScanNet | ✓ | 8 | 78.5% | link | link | link |
| PTv3 | ScanNet200 | ✗ | 4 | 35.3% | link | link | link |
| PTv3 + PPT | ScanNet200 | ✓ (f.t.) | 4 | ||||
| PTv3 | S3DIS (Area5) | ✗ | 4 | 73.6% | link | link | link |
| PTv3 + PPT | S3DIS (Area5) | ✓ | 8 | 75.4% | link | link | link |
Outdoor semantic segmentation
| Model | Benchmark | Additional Data | Num GPUs | Val mIoU | Config | Tensorboard | Exp Record |
|---|---|---|---|---|---|---|---|
| PTv3 | nuScenes | ✗ | 4 | 80.3 | link | link | link |
| PTv3 + PPT | nuScenes | ✓ | 8 | ||||
| PTv3 | SemanticKITTI | ✗ | 4 | ||||
| PTv3 + PPT | SemanticKITTI | ✓ | 8 | ||||
| PTv3 | Waymo | ✗ | 4 | 71.2 | link | link | link (log only) |
| PTv3 + PPT | Waymo | ✓ | 8 |
*Released model weights are trained for v1.5.1, weights for v1.5.2 and later is still ongoing.
- PTv2 mode2
The original PTv2 was trained on 4 * RTX a6000 (48G memory). Even enabling AMP, the memory cost of the original PTv2 is slightly larger than 24G. Considering GPUs with 24G memory are much more accessible, I tuned the PTv2 on the latest Pointcept and made it runnable on 4 * RTX 3090 machines.
PTv2 Mode2 enables AMP and disables Position Encoding Multiplier & Grouped Linear. During our further research, we found that precise coordinates are not necessary for point cloud understanding (Replacing precise coordinates with grid coordinates doesn't influence the performance. Also, SparseUNet is an example). As for Grouped Linear, my implementation of Grouped Linear seems to cost more memory than the Linear layer provided by PyTorch. Benefiting from the codebase and better parameter tuning, we also relieve the overfitting problem. The reproducing performance is even better than the results reported in our paper.
Example running scripts are as follows:
# ptv2m2: PTv2 mode2, disable PEM & Grouped Linear, GPU memory cost < 24G (recommend)
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v2m2-3-lovasz -n semseg-pt-v2m2-3-lovasz
# ScanNet test
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v2m2-1-submit -n semseg-pt-v2m2-1-submit
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# ScanNet++
sh scripts/train.sh -g 4 -d scannetpp -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# ScanNet++ test
sh scripts/train.sh -g 4 -d scannetpp -c semseg-pt-v2m2-1-submit -n semseg-pt-v2m2-1-submit
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# SemanticKITTI
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# nuScenes
sh scripts/train.sh -g 4 -d nuscenes -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base- PTv2 mode1
PTv2 mode1 is the original PTv2 we reported in our paper, example running scripts are as follows:
# ptv2m1: PTv2 mode1, Original PTv2, GPU memory cost > 24G
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v2m1-0-base -n semseg-pt-v2m1-0-base
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v2m1-0-base -n semseg-pt-v2m1-0-base
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v2m1-0-base -n semseg-pt-v2m1-0-base- PTv1
The original PTv1 is also available in our Pointcept codebase. I haven't run PTv1 for a long time, but I have ensured that the example running script works well.
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v1-0-base -n semseg-pt-v1-0-base
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v1-0-base -n semseg-pt-v1-0-base
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v1-0-base -n semseg-pt-v1-0-base- Additional requirements:
pip install torch-points3d
# Fix dependence, caused by installing torch-points3d
pip uninstall SharedArray
pip install SharedArray==3.2.1
cd libs/pointops2
python setup.py install
cd ../..- Uncomment
# from .stratified_transformer import *inpointcept/models/__init__.py. - Refer Optional Installation to install dependence.
- Training with the following example scripts:
# stv1m1: Stratified Transformer mode1, Modified from the original Stratified Transformer code.
# PTv2m2: Stratified Transformer mode2, My rewrite version (recommend).
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-st-v1m2-0-refined -n semseg-st-v1m2-0-refined
sh scripts/train.sh -g 4 -d scannet -c semseg-st-v1m1-0-origin -n semseg-st-v1m1-0-origin
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-st-v1m2-0-refined -n semseg-st-v1m2-0-refined
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-st-v1m2-0-refined -n semseg-st-v1m2-0-refinedSPVCNN is a baseline model of SPVNAS, it is also a practical baseline for outdoor datasets.
- Install torchsparse:
# refer https://github.com/mit-han-lab/torchsparse
# install method without sudo apt install
conda install google-sparsehash -c bioconda
export C_INCLUDE_PATH=${CONDA_PREFIX}/include:$C_INCLUDE_PATH
export CPLUS_INCLUDE_PATH=${CONDA_PREFIX}/include:CPLUS_INCLUDE_PATH
pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git- Training with the following example scripts:
# SemanticKITTI
sh scripts/train.sh -g 2 -d semantic_kitti -c semseg-spvcnn-v1m1-0-base -n semseg-spvcnn-v1m1-0-baseOctFormer from OctFormer: Octree-based Transformers for 3D Point Clouds.
- Additional requirements:
cd libs
git clone https://github.com/octree-nn/dwconv.git
pip install ./dwconv
pip install ocnn- Uncomment
# from .octformer import *inpointcept/models/__init__.py. - Training with the following example scripts:
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-octformer-v1m1-0-base -n semseg-octformer-v1m1-0-baseSwin3D from Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding.
- Additional requirements:
# 1. Install MinkEngine v0.5.4, follow readme in https://github.com/NVIDIA/MinkowskiEngine;
# 2. Install Swin3D, mainly for cuda operation:
cd libs
git clone https://github.com/microsoft/Swin3D.git
cd Swin3D
pip install ./- Uncomment
# from .swin3d import *inpointcept/models/__init__.py. - Pre-Training with the following example scripts (Structured3D preprocessing refer here):
# Structured3D + Swin-S
sh scripts/train.sh -g 4 -d structured3d -c semseg-swin3d-v1m1-0-small -n semseg-swin3d-v1m1-0-small
# Structured3D + Swin-L
sh scripts/train.sh -g 4 -d structured3d -c semseg-swin3d-v1m1-1-large -n semseg-swin3d-v1m1-1-large
# Addition
# Structured3D + SpUNet
sh scripts/train.sh -g 4 -d structured3d -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# Structured3D + PTv2
sh scripts/train.sh -g 4 -d structured3d -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base- Fine-tuning with the following example scripts:
# ScanNet + Swin-S
sh scripts/train.sh -g 4 -d scannet -w exp/structured3d/semseg-swin3d-v1m1-1-large/model/model_last.pth -c semseg-swin3d-v1m1-0-small -n semseg-swin3d-v1m1-0-small
# ScanNet + Swin-L
sh scripts/train.sh -g 4 -d scannet -w exp/structured3d/semseg-swin3d-v1m1-1-large/model/model_last.pth -c semseg-swin3d-v1m1-1-large -n semseg-swin3d-v1m1-1-large
# S3DIS + Swin-S (here we provide config support S3DIS normal vector)
sh scripts/train.sh -g 4 -d s3dis -w exp/structured3d/semseg-swin3d-v1m1-1-large/model/model_last.pth -c semseg-swin3d-v1m1-0-small -n semseg-swin3d-v1m1-0-small
# S3DIS + Swin-L (here we provide config support S3DIS normal vector)
sh scripts/train.sh -g 4 -d s3dis -w exp/structured3d/semseg-swin3d-v1m1-1-large/model/model_last.pth -c semseg-swin3d-v1m1-1-large -n semseg-swin3d-v1m1-1-largeContext-Aware Classifier is a segmentor that can further boost the performance of each backbone, as a replacement for Default Segmentor. Training with the following example scripts:
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-cac-v1m1-0-spunet-base -n semseg-cac-v1m1-0-spunet-base
sh scripts/train.sh -g 4 -d scannet -c semseg-cac-v1m1-1-spunet-lovasz -n semseg-cac-v1m1-1-spunet-lovasz
sh scripts/train.sh -g 4 -d scannet -c semseg-cac-v1m1-2-ptv2-lovasz -n semseg-cac-v1m1-2-ptv2-lovasz
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-cac-v1m1-0-spunet-base -n semseg-cac-v1m1-0-spunet-base
sh scripts/train.sh -g 4 -d scannet200 -c semseg-cac-v1m1-1-spunet-lovasz -n semseg-cac-v1m1-1-spunet-lovasz
sh scripts/train.sh -g 4 -d scannet200 -c semseg-cac-v1m1-2-ptv2-lovasz -n semseg-cac-v1m1-2-ptv2-lovaszPointGroup is a baseline framework for point cloud instance segmentation.
- Additional requirements:
conda install -c bioconda google-sparsehash
cd libs/pointgroup_ops
python setup.py install --include_dirs=${CONDA_PREFIX}/include
cd ../..- Uncomment
# from .point_group import *inpointcept/models/__init__.py. - Training with the following example scripts:
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c insseg-pointgroup-v1m1-0-spunet-base -n insseg-pointgroup-v1m1-0-spunet-base
# S3DIS
sh scripts/train.sh -g 4 -d scannet -c insseg-pointgroup-v1m1-0-spunet-base -n insseg-pointgroup-v1m1-0-spunet-base- Pre-training with the following example scripts:
# ScanNet
sh scripts/train.sh -g 8 -d scannet -c pretrain-msc-v1m1-0-spunet-base -n pretrain-msc-v1m1-0-spunet-base- Fine-tuning with the following example scripts:
enable PointGroup (here) before fine-tuning on instance segmentation task.
# ScanNet20 Semantic Segmentation
sh scripts/train.sh -g 8 -d scannet -w exp/scannet/pretrain-msc-v1m1-0-spunet-base/model/model_last.pth -c semseg-spunet-v1m1-4-ft -n semseg-msc-v1m1-0f-spunet-base
# ScanNet20 Instance Segmentation (enable PointGroup before running the script)
sh scripts/train.sh -g 4 -d scannet -w exp/scannet/pretrain-msc-v1m1-0-spunet-base/model/model_last.pth -c insseg-pointgroup-v1m1-0-spunet-base -n insseg-msc-v1m1-0f-pointgroup-spunet-basePPT presents a multi-dataset pre-training framework, and it is compatible with various existing pre-training frameworks and backbones.
- PPT supervised joint training with the following example scripts:
# ScanNet + Structured3d, validate on ScanNet (S3DIS might cause long data time, w/o S3DIS for a quick validation) >= 3090 * 8
sh scripts/train.sh -g 8 -d scannet -c semseg-ppt-v1m1-0-sc-st-spunet -n semseg-ppt-v1m1-0-sc-st-spunet
sh scripts/train.sh -g 8 -d scannet -c semseg-ppt-v1m1-1-sc-st-spunet-submit -n semseg-ppt-v1m1-1-sc-st-spunet-submit
# ScanNet + S3DIS + Structured3d, validate on S3DIS (>= a100 * 8)
sh scripts/train.sh -g 8 -d s3dis -c semseg-ppt-v1m1-0-s3-sc-st-spunet -n semseg-ppt-v1m1-0-s3-sc-st-spunet
# SemanticKITTI + nuScenes + Waymo, validate on SemanticKITTI (bs12 >= 3090 * 4 >= 3090 * 8, v1m1-0 is still on tuning)
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-ppt-v1m1-0-nu-sk-wa-spunet -n semseg-ppt-v1m1-0-nu-sk-wa-spunet
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-ppt-v1m2-0-sk-nu-wa-spunet -n semseg-ppt-v1m2-0-sk-nu-wa-spunet
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-ppt-v1m2-1-sk-nu-wa-spunet-submit -n semseg-ppt-v1m2-1-sk-nu-wa-spunet-submit
# SemanticKITTI + nuScenes + Waymo, validate on nuScenes (bs12 >= 3090 * 4; bs24 >= 3090 * 8, v1m1-0 is still on tuning))
sh scripts/train.sh -g 4 -d nuscenes -c semseg-ppt-v1m1-0-nu-sk-wa-spunet -n semseg-ppt-v1m1-0-nu-sk-wa-spunet
sh scripts/train.sh -g 4 -d nuscenes -c semseg-ppt-v1m2-0-nu-sk-wa-spunet -n semseg-ppt-v1m2-0-nu-sk-wa-spunet
sh scripts/train.sh -g 4 -d nuscenes -c semseg-ppt-v1m2-1-nu-sk-wa-spunet-submit -n semseg-ppt-v1m2-1-nu-sk-wa-spunet-submit- Preprocess and link ScanNet-Pair dataset (pair-wise matching with ScanNet raw RGB-D frame, ~1.5T):
# RAW_SCANNET_DIR: the directory of downloaded ScanNet v2 raw dataset.
# PROCESSED_SCANNET_PAIR_DIR: the directory of processed ScanNet pair dataset (output dir).
python pointcept/datasets/preprocessing/scannet/scannet_pair/preprocess.py --dataset_root ${RAW_SCANNET_DIR} --output_root ${PROCESSED_SCANNET_PAIR_DIR}
ln -s ${PROCESSED_SCANNET_PAIR_DIR} ${CODEBASE_DIR}/data/scannet- Pre-training with the following example scripts:
# ScanNet
sh scripts/train.sh -g 8 -d scannet -c pretrain-msc-v1m1-1-spunet-pointcontrast -n pretrain-msc-v1m1-1-spunet-pointcontrast- Fine-tuning refer MSC.
- Preprocess and link ScanNet-Pair dataset (refer PointContrast):
- Pre-training with the following example scripts:
# ScanNet
sh scripts/train.sh -g 8 -d scannet -c pretrain-msc-v1m2-0-spunet-csc -n pretrain-msc-v1m2-0-spunet-csc- Fine-tuning refer MSC.
Pointcept is designed by Xiaoyang, named by Yixing and the logo is created by Yuechen. It is derived from Hengshuang's Semseg and inspirited by several repos, e.g., MinkowskiEngine, pointnet2, mmcv, and Detectron2.