
-
- 11.1. Activate Pre-commit
- 11.2. Environment Variables
- 11.3. Github Action Secrets
- 11.4. GCP Setup
- 11.5. Environment Setup
- 11.6. Prefect Setup
- 11.7. Setup Storage
- 11.8. Deployment and Testing
Ever wondered which type of photos are downloaded the most often? Look no further. This project aims to deliver the answer to this question.
This Project is a Data Enginering Project about collecting photo metadata and actual photos from the Unsplash Photo Platform. Unsplash offers photos for download under a free licensing model.
The Project is mostly written in Python, uses Prefect for Data Orchestration and Google Cloud Storage and Google BigQuery as main storage technologies. The Jobs are scheduled either daily or in 10-60 minute intervals and are executed trough Google Cloud Runs.
Last Update on 17th October, 2023
- 243.000 Photos (~712 GiB)
- 243.000 Metadata Photo entries
- including Views, Likes, Downloads, EXIF, Location, User
- Unsplash Platform Stats
- including number of total photos/views/downloads on platform, daily new photos, daily new photographers etc.
Just the EL part of ELT is done in this project.
Google Cloud Storage is used as initial, immutable raw data layer (E).
BigQuery is used for two purposes:
- to log which photos have already been requested. This logs are checked in each run, so the same image won't get requested twice.
- to serve as intermediata storage (
L). The actual data requires further processing and transformation (T) to be suitable for data analysis.
The following diagram describes the flow of data from different API endpoints to different storages.
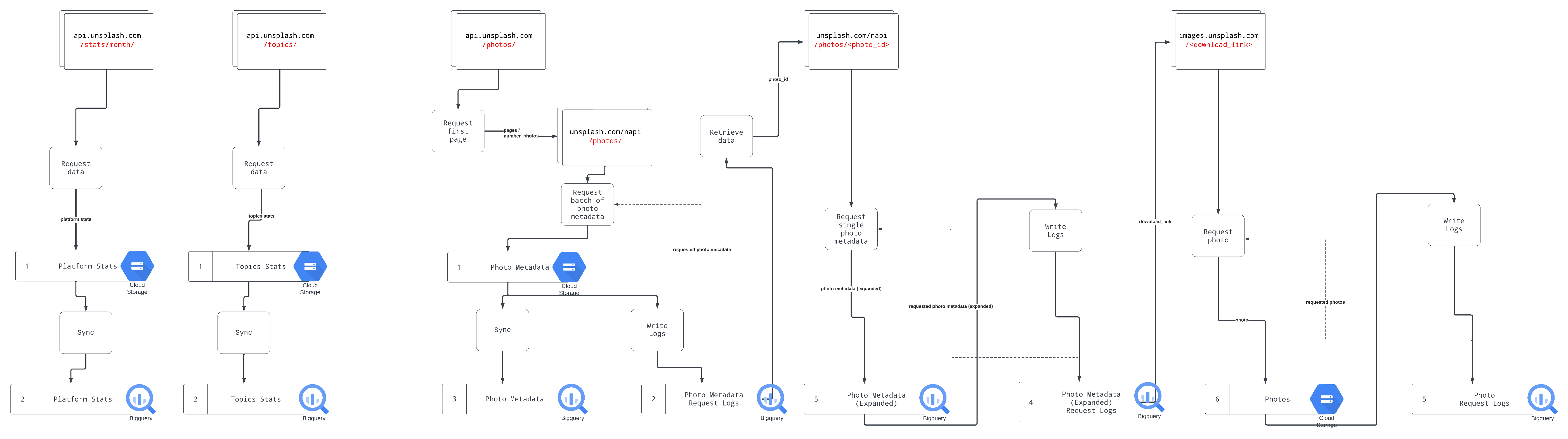
A scrollable/zoomable version can be found here (Lucid account required)
The most important table is photo-editorial-metadata-expanded which contains Photo metadata from the Editorial section of Unsplash.
Editorial photos can only be used in editorial projects such as: news related materials (newspaper and magazine articles, TV news), blogs and educational materials.
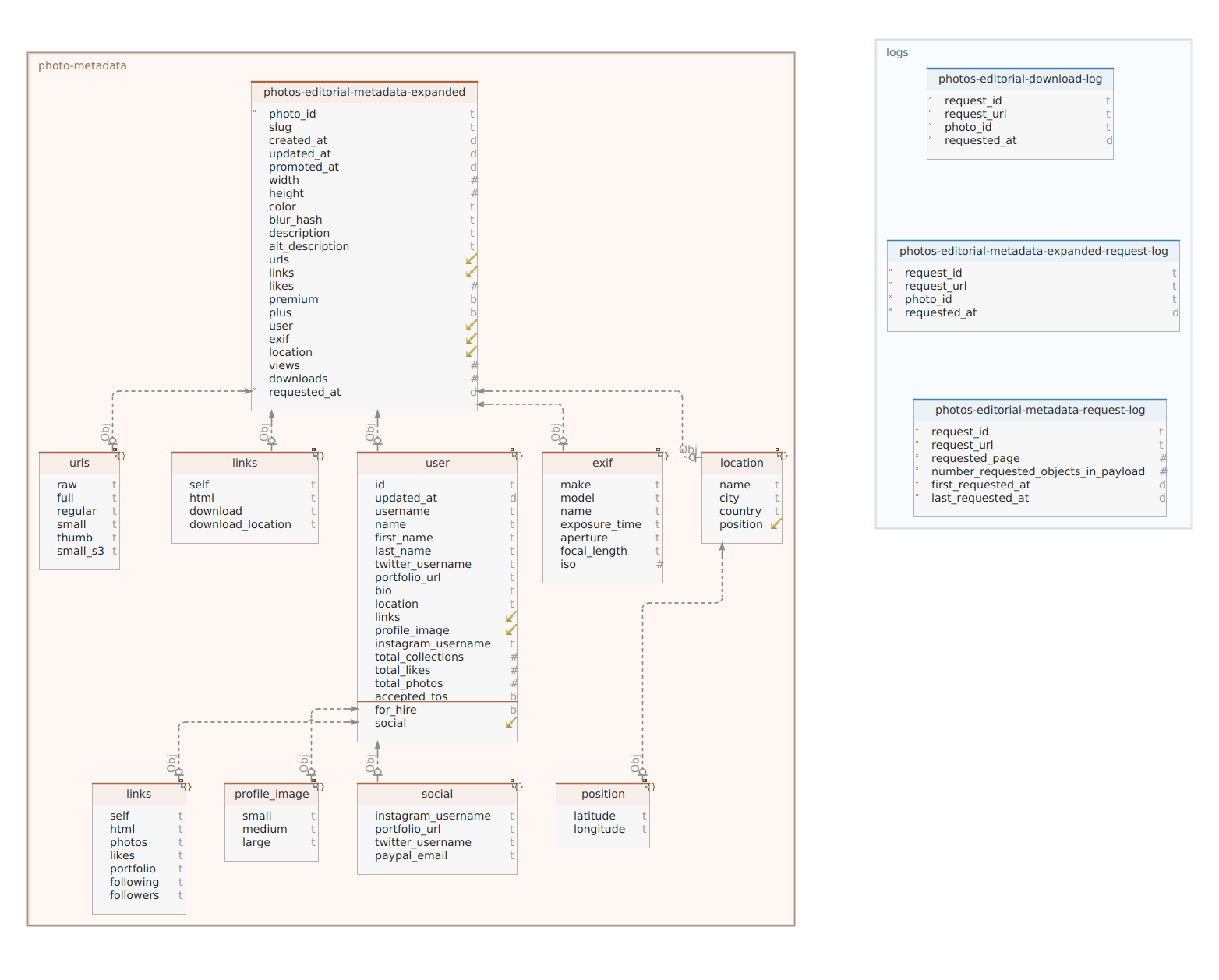
Additional tables not shown in this diagram as they are external tables syncing data from Google Cloud Storage to Big Query and are not being picked up by ERM modeling software are:
{kind=link}
{kind=link}
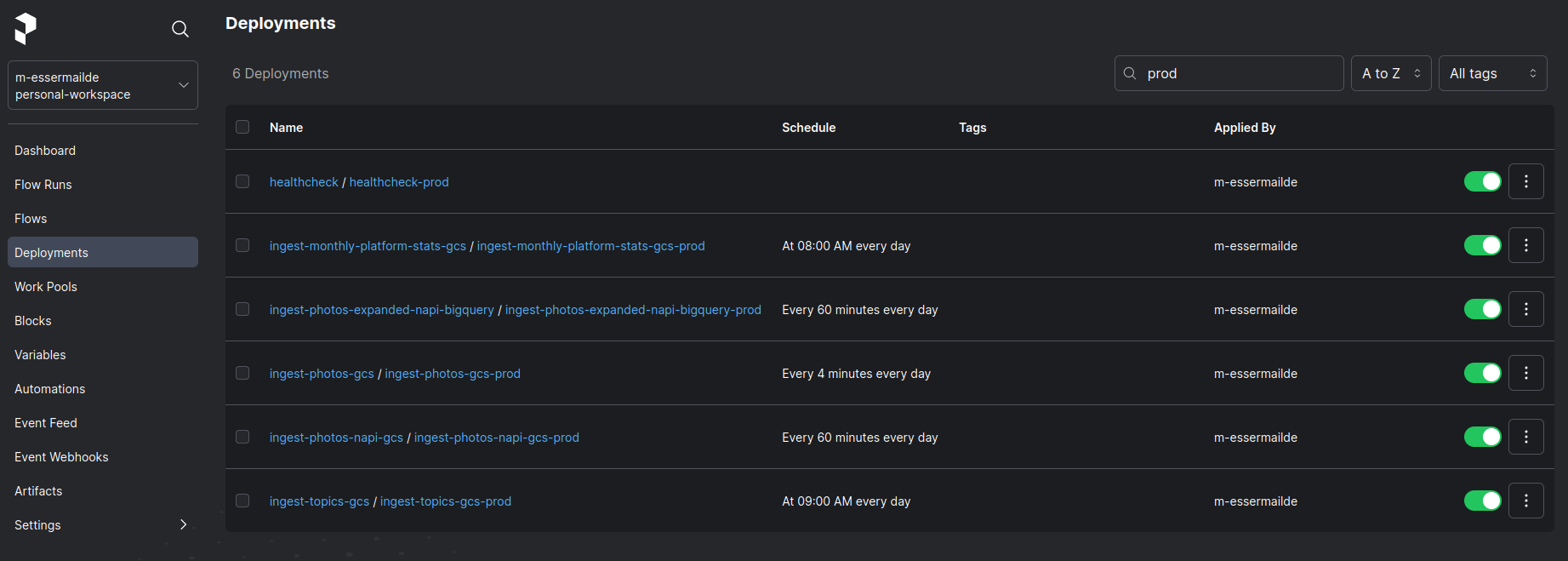
The Data Pipeline consist of 5 different Flows. A Flow in the context of Prefect is comparable to an ETL Job.
Storage
Compute
Orchestration
Languages
- Python
- Bash
- SQL
If you want to reproduce some of this code or copy and paste parts of it, feel free to do so.
If you want to build on this projects, here are the prerequisites
- A Google account (to create ressources in GCP)
- A Prefect account (with access to the Prefect Cloud)
- Expects the following Git branches. See Git Branching Strategy:
- master
- develop
- test
{kind=link}
These are the main folders (and their their descrptions) of this Github repo. In case some folders are not visible, then they are not meant to be shared (see .gitignore)
hint: tree -L 2 -d -A
.
└── .github --> Github actions (e.g. CI)
├── data --> Data in different stages (raw, staged, final)
│ ├── 00_raw --> Immutable, raw data
│ ├── 01_staged --> Processed data
│ └── 02_final --> Data which can be served (ML, Analytics)
├── docs
│ └── images --> Images used in this Readme.md
├── images --> Docker Images (which are used across flows)
├── make --> Makefiles for setting up ressources and environment
├── output --> Deliverables in form of reports or models
│ ├── models
│ └── reports
├── references --> Data dictionaries, manuals, and all other explanatory materials
├── src --> Source code (Python)
│ ├── blocks --> Prefect Blocks
│ ├── etl --> Collection of common Extraction, Transformation and Loading functions used
│ ├── prefect --> Prefect Flows
│ └── scripts --> Python and Bash utility scripts
├── tests --> Unit tests
prefect.yaml: Deployment steps and configuration.pre-commit-config.yaml: Pre-commit hooks which are run before each commitMakefile: Settings for Makefile (which are stored in foldermake/*)pyproject.toml&poetry.lock: Python dependencies
Install Pre-commit hooks (for code formatting, import statement checks before committing)
pre-commit install
Define values in base.env (not part of this repository)
For reference check base.env.example which contains all major variables required for this project
Add the following Secrets as Action secrets to your Github repository:
PREFECT_API_KEYPREFECT_API_URL
See https://docs.prefect.io/latest/api-ref/rest-api/#finding-your-prefect-cloud-details
Run make setup-gcp to setup up the Google Cloud Project
If this doesn't work, run the commands from 00_setup_gcp.mk command by command in the following order:
make create-gcp-projectmake set-default-gcp-projectmake link-project-to-billing-accountmake create-deployment-service-accountmake create-deployment-service-account-key-filemake enable-gcp-servicesmake bind-iam-policies-to-deployment-service-accountmake set-deployment-service-account-as-default
necessary everytime you start working on the project
make env-initto prepare ENV environment variablemake dev-initto setup development environment
As mentioned above, this project requires a Prefect account and access to the Prefect Cloud
make setup-prefect
Setup the storage infrastructure by running
make create-gcs-buckets
Start on develop
- Write Tasks and Flows
- If necessary write Unit Tests
- Run
make run-unit-tests
Move on to test
- Merge with
develop - Deploy Flow by running
make deploy-flow - Run integration test trough a manual Flow run
- Sync with Bigquery (using existing Flow if you want to sync GCS and Bigquery using a Push pattern)
Move on prod
- Merge with
test - Deploy Flow by running
make deploy-flow